

چکیده
:
محیط از طریق خاک، آب و هوا و غیره بر کشاورزی تأثیر می گذارد.و کشاورزی به صورت محلی در سطح مزرعه و از طریق تأثیر آن بر تغییرات آب و هوا بر محیط زیست تأثیر می گذارد. بنابراین، قرار دادن کشاورزی در محیط فضایی آن برای کشاورزان و سیاست گذاران مهم است. در کشورهای اتحادیه اروپا داده های دقیق مزرعه را برای درک عملکرد فنی و مالی مزارع جمع آوری می کند. شبکه داده های حسابداری مزرعه با این حال، دانش از بافت فضایی-محیطی این مزارع در مقیاس ناخالص گزارش شده است. در این مقاله، دادههای حسابداری مزرعه ایرلندی با استفاده از تطبیق آدرس با پایگاه داده آدرس ملی ارجاع جغرافیایی میشوند. تحلیلی از توزیع جغرافیایی مزارع بررسی، که از طریق یک طرح جفت رتبه بندی شده جدید مختصات نشان داده شده است. در مقایسه با توزیع ملی مزارع، روندی را در مکان مزارع بررسی نشان می دهد که منجر به تفاوت آماری در متغیرهای اقلیمی مرتبط با مزرعه می شود. مزارع مورد بررسی دارای مقادیر تابش خورشیدی انباشته به طور قابل توجهی بالاتر از میانگین ملی هستند. در نتیجه، بررسی ممکن است از نظر فضایی نشان دهنده الگوی محیط x سیستم مزرعه نباشد. این میتواند ملاحظات مهمی در هنگام استفاده از دادههای FADN در مدلسازی تأثیرات تغییر اقلیم بر عملکرد کشاورزی-اقتصادی داشته باشد.
کلید واژه ها:
FADN ; کشاورزی – محیط زیست ; تطبیق آدرس ؛ کشاورزی
1. مقدمه
محیط زیست از طریق خاک، آب و هوا، در دسترس بودن آب و غیره بر تولیدات کشاورزی تأثیر میگذارد و کشاورزی از طریق تأثیر محلی بر چشمانداز، آب، تغذیه خاک و تنوع زیستی و به طور گستردهتر از طریق تأثیر آن بر تغییرات آب و هوا، بر محیطزیست تأثیر میگذارد. بنابراین، قرار دادن کشاورزی در محیط فضایی آن در تصمیم گیری کشاورزان، سیاست گذاران و سایر ذینفعان بسیار مهم است.
در دسترس بودن داده های مزرعه بسیار خوب است، به ویژه در کشورهای اروپایی، زیرا جمع آوری داده ها در شبکه داده های حسابداری مزرعه (FADN) یک الزام اجباری سیاست کشاورزی مشترک اتحادیه اروپا است. در داخل اتحادیه اروپا، کشورها داده های دقیق مزرعه را برای درک عملکرد فنی و مالی مزارع جمع آوری می کنند. شبکه داده های حسابداری مزرعه برای جمع آوری جزئیات مدیریت مزرعه، داده های مالی و فنی به نمایندگی از شرکت های بزرگ کشاورزی طراحی شده است. رویکرد آن در جمع آوری و انتشار داده ها همیشه بر اساس بخش کشاورزی و نوع شرکت بوده است. داده ها که در سطح ملی نماینده هستند، در درجه اول برای مقایسه عملکرد مالی مزارع در کشورهای مختلف استفاده می شود.
با این حال، اطلاعات نسبتاً محدودی از نظر مکانی (فقط سطح NUTS 3) در دسترس بوده است. ارجاع جغرافیایی داده ها ظرفیت بهبود درک تعامل بین محیط زیست و کشاورزی را دارد. کوکیچ و همکاران (2007) تعدادی از مزایای ارجاع جغرافیایی داده های مزرعه را شناسایی کرد [ 1 ].
-
توانایی زمینبندی مدلهای حقیقت بر اساس دادههای ماهوارهای برای مدیریت منابع طبیعی.
-
بهبود اندازه گیری انتشار گازهای گلخانه ای مانند ترسیب کربن و انتشارات حاصل از کشاورزی.
-
ظرفیت افزایش یافته برای تولید تخمین های منطقه کوچک که منعکس کننده ناهمگونی درون و بین مناظر است.
-
توانایی انجام تجزیه و تحلیل اقتصادی تغییرات در شیوه های مدیریت زمین بر اساس قابلیت اطمینان تامین آب و بارندگی.
-
روش های بهبود یافته برای ارائه پیش بینی های تولید با کیفیت بالاتر و به موقع تر از طریق ظرفیت تجزیه و تحلیل علائم طیفی محصولات و مراتع با استفاده از تصاویر ماهواره ای.
-
درک بهتر از اثرات اقتصادی حملات آفات و بیماری ها در مزارع با استفاده از داده های مکانی با وضوح بهتر برای بهبود ارزیابی گزینه های مدیریت پس از حمله.
-
کاهش تعداد متغیرهایی که باید در نظرسنجیها جمعآوری شوند، که منجر به کاهش بار پاسخ میشود.
کوربت (1996) استدلال میکند که مدلسازی در چارچوب GIS مکانیزمی را برای ادغام مقیاسهای بسیاری از دادههای توسعهیافته در تحقیقات کشاورزی و برای تحقیقات کشاورزی ارائه میدهد، جایی که یک پایگاه داده مکانی (و زمانی) دقیق توصیف اکوسیستمهای کشاورزی را ممکن میسازد و برای منابع کارآمد حیاتی است. تخصیص در تحقیقات کشاورزی او خاطرنشان می کند که از آنجایی که اکوسیستم های کشاورزی موجودیت های پیچیده ای هستند، یک خصوصیات پویا به داده های بیوفیزیکی و اجتماعی-اقتصادی نیاز دارد [ 2 ].
در جایی که دادههای نظرسنجی مزرعه حاوی دادههای ارجاعشده جغرافیایی است، پیوند دادههای محیطی با دادههای تولید مزرعه از نظر فنی ساده است. کوکیچ و همکاران (2007) روشی را برای جمع آوری داده های مکانی توصیف می کند. بسیاری از نظرسنجی ها، به ویژه در موقعیت های توسعه، حاوی داده های ارجاع جغرافیایی هستند [ 3 ].
با این حال، حتی در جایی که داده های آدرس پستی یا مزرعه در دسترس است، ممکن است چالش های فنی در رابطه با مزارع ارجاع جغرافیایی وجود داشته باشد. این به دلیل این واقعیت است که ارجاعات شبکه منفرد ممکن است لزوماً موقعیت مکانی مزرعه را نشان ندهند، به دلیل چند بسته یا اندازه بزرگ [ 4 ]. همچنین میتواند چالشهایی در محرمانگی دادههای رابطه وجود داشته باشد، که مانع از اشتراک دادهها بین آژانس جمعآوری دادههای نظرسنجی مزرعه و محققانی که دادههای مکانی را نگهداری میکنند، میشود.
در حال حاضر دانش ویژگیهای فضایی-محیطی مزارع در دادههای پیمایش بسیار ضعیف است زیرا موقعیت مکانی مزارع در این بررسیها بسیار محدود است. تنها اطلاعات جغرافیایی جمع آوری شده آدرس خبرنگار بود. ارائه نتایج بر اساس بخشی، الزامات گزارش دهی ملی FADN را برآورده می کند و همچنین محرمانه بودن خبرنگاران را تضمین می کند [ 5 ]. تا کنون این اهداف محرمانه ارتباط داده های فضایی-محیطی را با این حساب مزرعه و داده های مدیریتی محدود کرده است.
با این حال، در نظر گرفته شده است که بررسیهای آینده اتحادیه اروپا مانند FADN و بررسی ساختارهای مزرعه در جایی که نقطه ارجاع جغرافیایی، خانه مزرعه باشد، ارجاع جغرافیایی داده شود [ 6 ]. با این حال، برای اینکه بتوانیم تجزیه و تحلیل بهرهوری مزرعه را به عنوان تابعی از ویژگیهای محیطی انجام دهیم، ترکیب دادههای مکانی و زمانی برای به دست آوردن تغییرات مکانی و زمانی مفید است. در حالی که با گذشت زمان، این داده ها در دسترس خواهند بود، اکنون مفید است که مکانیسم های جایگزین برای ارجاع جغرافیایی داده های بررسی مزرعه تاریخی را بررسی کنیم.
در این مقاله یک روش تطبیق آدرس برای دادههای بررسی مزرعه مرجع جغرافیایی استفاده میشود. ایرلند به عنوان یک مطالعه موردی انتخاب خوبی است زیرا سیستمهای مزرعه غالب عمدتاً سیستمهای حیوانی مبتنی بر مرتع هستند و به دلیل اینکه ارجاع جغرافیایی آدرسها چالشهای خاصی را ایجاد میکند که در بخش 2.1 بیان شده است. به عنوان یک سیستم شبانی، محیط محلی به ویژه با خروجی مرتبط است. کشاورزی در ایرلند نیز به عنوان نسبتی از اندازه اقتصاد در اتحادیه اروپا یکی از بزرگترین ها است و بنابراین تأثیرات زیست محیطی احتمالاً مهم تر است. داده های مورد استفاده در این مقاله، نوع ایرلندی FADN، بررسی مزرعه ملی Teagasc (NFS) از سال 2008 است [ 7 ].
از زمان استقرار روش NFS در اوایل دهه 1970، پیشرفتهای عمدهای در ژئو انفورماتیک رخ داده است به طوری که اکثر دادههای کشاورزی-محیطی اکنون دارای یک عنصر فضایی هستند و اطلاعات به صورت مکانی با پایگاههای اطلاعات جغرافیایی بزرگ مدیریت میشوند. در دهه گذشته استفاده از تحلیل صریح ژئو فضایی در اقتصاد کشاورزی اهمیت پیدا کرده است [ 8 ].
فعال کردن فضایی به گذشته نگر NFS به سوابق جمع آوری شده اجازه می دهد تا راحت تر در این محیط جدید جغرافیایی استفاده شوند. تخصیص هر خبرنگار مزرعه در NFS با مختصات جغرافیایی امکان تخصیص دادهها را به هر مزرعه از منابع جغرافیایی یا نقشهای [ 9 ] میدهد (به عنوان مثال، محاسبه فاصله واقعی جاده تا نزدیکترین بازار برای همه مزارع گوشت گاو در NFS. ). با NFS فعال شده از نظر جغرافیایی، می توان رکوردهای آب و هوای تاریخی را به هر مزرعه نسبت داد یا مشاهده کرد که چگونه تصمیمات سال به سال تحت تأثیر آب و هوا قرار می گیرد. تلاشهایی در اروپا برای کاهش مقیاس حسابهای ملی و منطقهای منتشر شده برای ارائه یک FADN فضایی ersatz انجام شده است [ 10]، این مقاله اولین نمونه از سیستم حسابداری مزرعه ملی است که به طور کامل ارجاع و تحلیل جغرافیایی شده است.
یک برنامه قبلی Teagasc در تطبیق آدرسها با Districts و پیوند دادن نمونههای خاک مزرعه به نقشههای ED از طریق آدرسهای متصل به نمونه موفق بود [ 11 ]. همچنین تعدادی از شرکت ها در ایرلند وجود دارند که تطبیق را با پایگاه داده آدرس ملی، GeoDirectory، به عنوان یک سرویس ارائه می دهند (به بخش 3.1 مراجعه کنید ). با این حال، در حالی که این خدمات برای فروش در دسترس هستند، الگوریتم های آنها برای اهداف تحقیقاتی در دسترس نیست. در این مقاله ارجاع جغرافیایی آدرسها به طور خاص در شبکه داده حسابداری مزرعه ایرلندی توضیح داده شده و چالشهای خاص سیستم آدرس ایرلندی تشریح شده است.
به کارگیری این روش دارای تعدادی چالش است زیرا ایرلند سیستم کدهای پستی (زیپ) ندارد. علاوه بر این، در رابطه با نام مکان ها که ممکن است به زبان انگلیسی یا ایرلندی یا ترکیبی باشد، اغلب با املای هماهنگ و با نام مکان های غیر منحصر به فرد، پیچیدگی هایی وجود دارد. روش متداول مبتنی بر SQL نشان داده شده در این مقاله بر این مشکلات غلبه می کند.
هدف اصلی NFS ارائه تصویری نماینده ملی از خروجی ها و نتایج مزرعه برای سیستم های کشاورزی مختلف است که در نظر گرفته نشده است که از نظر جغرافیایی نماینده باشد. در نتیجه این بررسی ممکن است همه مناطق کشاورزی-اقلیمی در کشور را نشان ندهد و لزوماً ممکن است از نظر فضایی نماینده توزیع محیط x سیستم مزرعه نباشد. در این مقاله بازنمایی جغرافیایی داده ها با توجه به اقلیم ارزیابی می شود. این مهم است؛ داده های FADN اغلب به عنوان مبنایی برای مطالعات تأثیر تغییرات آب و هوایی آینده بر کشاورزی استفاده می شود [ 12 ]]. اگر نمونه FADN به طور قابل توجهی از نظر زیست محیطی با میانگین مزرعه در هر گزارش ملی مشخص متفاوت باشد (به عنوان مثال ایرلند در این مقاله)، این پیشبینیها از تغییرات آب و هوایی در تولید مزرعه میتواند در مقیاس ملی ناهنجار باشد (احتمال کمتری برای داشتن یک تاثیر زمانی که در مقیاس منطقه ای اروپا تحلیل می شود [ 13 ]).
2. چالش های فنی
2.1. ارجاع جغرافیایی
چالش قابل توجهی در ارجاع جغرافیایی داده های نظرسنجی مزرعه در ایرلند وجود دارد. اولاً، این کشور (برخلاف اکثر کشورهای اروپایی دیگر) کد پستی ندارد و در عین حال به دلایل زبانی، فرهنگی و اندازه گیری درجه قابل توجهی از عدم قطعیت در رابطه با نام مکان ها با تفاوت های مکرر در املاء و تکرار گاه به گاه وجود دارد. نام. کدگذاری جغرافیایی آینده داده های FADN در سراسر اروپا احتمالاً بر اساس شناسایی بسته است که وابستگی به تطبیق آدرس را کاهش می دهد.
تاریخچه نامشناسی ایرلندی داستانی پیچیده از نامهای محلی است که در برابر تحمیل استانداردها توسط مقامات مختلف باقی ماندهاند. تخصیص یا شناسایی رسمی نام مکان ها (در An Coimisiún Logainmneacha) بر اساس توسعه تاریخی واحدهای اداری است [ 14 ]. در عمل آدرس های ایرلندی طیف گسترده ای از اشکال دارند. در روستاهای ایرلند، آنها تمایل دارند با نوع زیر مطابقت داشته باشند:
-
نام متصدی/نام ساختمان،
-
محل،
-
سرزمین شهر،
-
شهر،
-
شهرستان.
از آنجایی که محله/شهرستان دارای تعداد زیادی خانوار است. اگر خانواده شماره خیابان نداشته باشد (همانطور که در اکثر مناطق روستایی وجود دارد)، آدرس داده شده به طور منحصر به فرد یک ساختمان/خانه در روستایی ایرلند را مشخص نمی کند. در عمل عملکرد موفقیت آمیز خدمات پستی به دانش کارمند پست محلی در مورد نام سرنشینان بستگی دارد.
رجیستری “رسمی” آدرس ها که توسط سرویس پستی نگهداری می شود GeoDirectory است که تلاش می کند ساختاری را بر آدرس ها تحمیل کند. هر سیستم از سیستم آدرس اداره مرکزی آمار/بررسی مهمات ایرلند استفاده می کند که در چهار بخش است:
-
شماره ساختمان/خیابان/محل، شهرک/شهرک، شهرک/شهرستان، شهرستان
-
به عنوان مثال: مرکز تحقیقات Teagasc، Malahide Rd، Kinsealy، Co. Dublin
با این حال، نمونههایی از فرمهای آدرس جایگزین رایج برای یک مکان عبارتند از:
-
Teagasc، Kinsealy، Malahide، Co. Dublin
-
Teagasc، Kinsaley ، Malahide، Co. Dublin
-
Teagasc، Mullach Ide، Baile Atha Cliath (نسخه ایرلندی)
همه این آدرس ها “رسمی” و صحیح هستند. در بالای این تغییرات رسمی، غلط املایی تصادفی، املای جایگزین محاوره ای و معکوس وجود دارد. با این قید، یک سیستم آدرس دهی رسمی تر مفید خواهد بود و GeoDirectory سعی در ارائه آن داشت.
بررسی مزرعه ملی Teagasc (NFS) مورد استفاده در این مطالعه از کدگذاری آدرسی مشابه GeoDirectory استفاده میکند که کار را نسبتاً آسانتر میکند. همچنین، از آنجایی که استفاده از نامهای ایرلندی محلات که بیشتر به انگلیسی در مجموعه NFS اشاره میشود، گسترده نبود و بنابراین خودکارسازی جایگزین نامهای مکان انگلیسی/ایرلندی ضروری نبود.
به منظور پیوند دادههای محیطی محلی به دادههای مالی در NFS، یک چالش در این مقاله شناسایی مکان آدرسها در NFS به نقاط داده در GeoDirectory است.
2.2. نمونه برداری جغرافیایی
پس از شناسایی آدرس ها، تعدادی از منابع بالقوه مسائل نمونه جغرافیایی باقی می ماند – تمایل NFS به نمونه برداری در مناطق خاص به جای تصادفی در سراسر کشور. اینها دلایل متعددی را شامل می شوند.
-
اولاً، کشاورزی کاربرد اصلی زمین در تمام فضای فیزیکی نیست. سایر کاربری ها و پوشش اراضی شامل ساختمان ها، راه ها، آب، زمین های نامناسب برای کشاورزی مانند ارتفاع بالاتر، باتلاق و کیفیت پایین زمین و غیره است.
-
دلیل دوم این است که داده های بررسی مزرعه مورد استفاده، نمونه آن را از نظر جغرافیایی بهینه نمی کند. بلکه هدف از نمونه برداری به حداکثر رساندن حجم خروجی است. همچنین انواع خاصی از مزارع مانند مزارع کوچکتر، و مزارع با انواع خاصی از شرکت ها مانند مزارع پرورش خوک، مرغ و باغبانی را نادیده می گیرد. اگر الگوی فضایی انواع مزارع از نظر فضایی غیر تصادفی باشد، در آن صورت یک سوگیری جغرافیایی مشاهده می شود.
-
دلیل بالقوه سوم ممکن است ناشی از الگوی فضایی جمعآوران داده باشد، که اگرچه به صورت مکانی توزیع شده است از نظر مکانی غیر تصادفی است، که ممکن است به دلیل زمان صرف شده برای رسیدن به مقصد منجر به سوگیری عدم پاسخ شود.
بنابراین یک چالش مقایسه توزیع جغرافیایی مزارع در بررسی با مزارع در کشور است.
3. داده ها
مقایسه بازنمایی فضایی داده های مالی و داده های زیست محیطی به 3 منبع داده نیاز دارد:
-
GeoDirectory حاوی آدرس ها و مختصات جغرافیایی
-
بررسی مزرعه ملی Teagasc حاوی اطلاعات مالی و فنی مزرعه فضایی است
-
داده های محیطی فضایی
3.1. ژئودایرکتوری
GeoDirectory (GD) پایگاه داده ای است که بر اساس پایگاه داده OSi مکان های ساختمان در مقابل پایگاه داده خدمات پستی ایرلند (An Post) آدرس های تحویل ایجاد شده است. در ابتدا در سال 2003 منتشر شد و تنها در سال 2006 پس از اضافه شدن ساختمان های جدید و حذف خطاها به یک پایگاه داده ملی کامل تبدیل شد [ 15 ]. اکنون هر سه ماه یکبار در سطوح مختلف دقت به روز می شود. پایگاه داده مورد استفاده در این پروژه Q1 2007 بود. پایگاه داده با جداول و فیلدهایی ارائه می شود که هر آدرس را به یک ساختمان و هر ساختمان را به موقعیت جغرافیایی 6 شکلی (با دقت 1 متر) در مختصات شبکه ملی ایرلندی (ING) اختصاص می دهد.
3.2. بررسی مزرعه ملی Teagasc
نظرسنجی ملی مزرعه Teagasc نمونه ایرلندی شبکه داده حسابداری مزرعه اتحادیه اروپا است و از اوایل دهه 1970 به شکل فعلی جمع آوری شده است. این بررسی شامل تقریباً 1100 مزرعه است و به عنوان یک مجموعه داده پانل جمع آوری شده است و مزارع به طور متوسط حدود 6 سال در نظرسنجی باقی می مانند. این نمونه حجم وسیعی از تولید مزرعه در ایرلند را نشان میدهد، اما شامل عملیات مزرعه بسیار کوچک یا انواع خاصی از شرکتها مانند شرکتهای خوک، طیور یا باغبانی نمیشود.
یک بررسی جداگانه، بررسی ساختار مزرعه، که حجم نمونه بزرگتری دارد، اما با اطلاعات فنی و مالی کمتر، توسط اداره مرکزی آمار (CSO) انجام شده است، برای تولید وزنها به منظور تخمین توزیع مزرعه استفاده میشود. جمعیت برای سیستم ها و اندازه های عمده مزارع.
نمونه هر ساله به روز می شود تا مزارعی را تامین کند که به دلایل مختلف از نظرسنجی خارج شده اند. مزارع بر اساس نوع شناسی به سلول ها بر اساس اندازه/سیستم تقسیم می شوند. روش طبقهبندی مزارع به سیستمهای کشاورزی، همانطور که در گزارش ملی مزرعه استفاده میشود، بر اساس گونهشناسی مزرعه اتحادیه اروپا است که در تصمیم 78/463 کمیسیون و اصلاحات بعدی آن [ 16 ] تعیین شده است. روش مورد استفاده قبل از سال 2011 یک حاشیه ناخالص استاندارد (SGM) را به هر نوع حیوان مزرعه و هر هکتار محصول اختصاص می دهد. سپس مزارع بر اساس نسبت کل SGM مزرعه که از شرکت های اصلی که سیستم ها نامگذاری شده اند به گروه هایی به نام انواع خاص و انواع اصلی طبقه بندی می شوند.
به عنوان مهمترین منبع داده در مورد تصمیمات مالی در مزارع ایرلندی، محرمانه بودن بسیار مهم است. در نتیجه، مختصات تولید شده توسط این کار با آدرسهایی در پایگاه داده NFS ذخیره میشود و برای محققان صادر نخواهد شد. در عوض، متغیرهای محیطی با مختصات مرتبط هستند و برای اهداف تحقیقاتی در مجموعه داده گنجانده می شوند. نقشه های منتشر شده نیز باید تعمیم داده شوند تا از شناسایی سهوی جلوگیری شود. علاوه بر این، ویژگیهای محیطی مشتقشده بهصورت فضایی، اگر منجر به شناسایی بالقوه یک خبرنگار شود، نباید استخراج شود [ 17 ، 18 ].
3.3. داده های محیطی مکانی
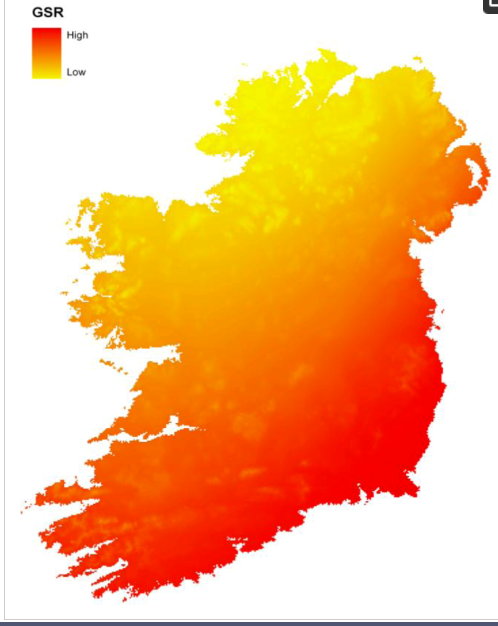
برای اهداف آزمایشی در این مقاله، بازنمایی فضایی NFS در برابر دادههای آبوهوا با استفاده از دادههای آب و هوای تاریخی تولید شده توسط ICARUS، دانشگاه ملی ایرلند Maynooth، بر اساس میانگینهای سال 30 (1960-1991) از ایستگاههای هواشناسی ایرلندی آزمایش میشود [ 19 ]. مدل ها در مقیاس سلول شبکه ای 1 کیلومتری برای کل کشور ساخته شده اند. مجموعه دادههای مورد استفاده میانگین تجمعی تابش خورشیدی جهانی ماه می-اکتبر (میانگین 40 سال) در واقع میانگین 30 سال مورد نظر از میزان کل تابش خورشید بر روی زمین در طول ماههای تابستان است که بر حسب kJ/m2 اندازهگیری شده است . همانطور که در شکل 1 نشان داده شده است، سطح انتخاب شده، نقشه میانگین سالانه 40 سال انباشته شده تابش خورشیدی بود .

شکل 1. شماتیک توزیع جغرافیایی متوسط انباشته تابستان (مه تا اکتبر) تابش خورشیدی جهانی را نشان می دهد.
4. روش شناسی
سه بخش برای مشکل فعال کردن فضایی بررسی مزرعه برای تخصیص ویژگی های زیست محیطی وجود دارد:
-
تطبیق آدرسها در NFS با آدرسهای احتمالی در GD.
-
تخصیص یک نقطه جغرافیایی که نشان دهنده آدرس های GD منطبق است که با احتمالات تطبیق یک به چند سروکار دارد و عنصر محرمانه بودن داده ها را حفظ می کند.
-
نسبت دادن نمونه ای نماینده از ویژگی محیطی به نقطه.
4.1. تطبیق آدرس
اولین کار مورد نیاز تطبیق آدرس های NFS با آدرس های GD و مختصات GIS حاصله است. از آنجایی که ترتیب پیچیدگی بسیار زیاد است، الگوریتم ابتدا روی یک نمونه آزمایشی از 51 آدرس آزمایش شد. اینها به صورت دستی بررسی شدند و با GD مطابقت داشتند. 51 آدرس با استفاده از Access SQL مطابقت داده شدند. به منظور کنار آمدن با املای جایگزین و آدرس کوتاهی که قبلاً شناسایی شده بود، اسکریپت ها به گونه ای نوشته شدند که با دو حرف اول (ابتدایی) و دو حرف آخر یک محله و شهر تطابق مثبت داشته باشند یا با پنج حرف اول یا پنج حرف آخر مطابقت داشته باشند. محل به شهر – مطابق با شهرستان. از عدد پنج برای شناسایی نامهای بالی* (بالی نسخه انگلیسی baile، کلمه ایرلندی به معنی شهر) استفاده میشود.* نام شهر که باید مشخص شود ( شهر در زمینه نام مکان ایرلندی مالکیت دارد و بنابراین اغلب با “s” قبل از آن قرار می گیرد، به عنوان مثال، Abbotstown).
این منجر به تطبیق خودکار 44 مورد از 51 رکورد NFS شد – سه رکورد دیگر را میتوان به صورت دستی تطبیق داد (نامها بسیار متفاوت بودند اما قابل تشخیص بودند) و چهار نقطه باقیمانده به صورت دستی با محتملترین آدرس(ها) مطابقت داده میشوند. رکوردهای NFS با دستههای آدرسهای GD از 1 تا 45 خانه مطابقت داده شد.
پس از این آزمایش، ما به فعال سازی جغرافیایی کل پایگاه داده آدرس NFS 2007 پرداختیم. فهرست کامل ارائه شده شامل 1350 رکورد بود. بررسی دقیق این فهرست تعدادی از مسائل مربوط به جمعآوری دادهها را نشان داد، مانند فرمتهای مختلف نام شهرستان: Dublin یا Co Dublin یا Co. Dublin. این مسائل و موارد دیگر میتوانست در SQL حل شود، اما تصمیم گرفته شد که یک پاکسازی اولیه آدرسهای ورودی در MS Excel انجام شود. قوانین اصلاح و به آن اضافه شد. یک منبع رایج سردرگمی در این مجموعه، تعویض عناصر آدرس بود. بنابراین قوانین باید برای گنجاندن این جابجایی ها گسترش می یافتند. مجموعه قوانین اضافی که با دو حرف اول سه عنصر آدرس اول مطابقت داشت نیز معرفی شد.
بررسی دقیق زیرمجموعه ای از مجموعه بی همتا نشان داد که منابع سردرگمی بسیار زیاد است و گنجاندن آنها به عنوان قوانین SQL و اجرا بر روی کل پایگاه داده بیشتر از بررسی دستی طول می کشد. بنابراین اسامی باقی مانده به صورت دستی بررسی و مطابقت داده شد. حتی با تطبیق دستی، آدرس 85 با هیچ اطمینانی قابل شناسایی نیست و در تجزیه و تحلیل بعدی گنجانده نشده است.
4.2. مکان یابی جغرافیایی
اکثر آدرسهای NFS با چندین نقطه ساختمان مطابقت دارند، بنابراین روشی برای نسبت دادن یک نقطه به آدرس NFS، با این فرض که در تطابق یک به چند، یکی از خانهها خانه مزرعه واقعی است، مورد نیاز است.
به دلیل وضوح ذاتی در مجموعه داده های محیطی، نیازی به دقت بیشتر از 1 کیلومتر نیست زیرا مدل های آب و هوایی دارای اندازه سلولی 1 کیلومتری هستند و نکته ای که باید در نظر داشت این است که نقطه GD به خانه مزرعه اختصاص داده می شود نه مزرعه. بحث در بخش 1 را ببینید.
هنگام تلاش برای ارزیابی محرک های زیست محیطی عملکرد مزرعه برای یک مزرعه فردی ، نسبت دادن مکان آن به یک نقطه انتخاب ضعیفی است – مزارع مناطقی هستند که حتی در درون خودشان نیز بسیار متفاوت هستند. با این حال، برای این مطالعه، بررسی توزیع فضایی مزارع در سطح کشور، امتیاز کافی است.
همانطور که در بالا ذکر شد به طور بالقوه بسیاری از خانوارهای ممکن وجود دارند که می توانند آدرس NFS را به دلایل ذکر شده در بالا نشان دهند. برای اهداف ما مرکز جغرافیایی هر خوشه به عنوان مکان نماینده انتخاب می شود.
4.3. نمونه برداری جغرافیایی
یکی از اهداف این مقاله، آزمون نمونه جغرافیایی داده های بررسی مزرعه است. به عبارت دیگر؛ برای اینکه ببینیم آیا پراکندگی فضایی مزارع نمونه برداری معادل پراکندگی فضایی مزارع واقعی است یا خیر. یکی از راههای بالقوه برای انجام این کار، تقسیم کشور به شبکهها و آزمایش توزیع مزارع در سراسر شبکهها نسبت به توزیع واقعی آدرسهای مزرعه است. اما از آنجایی که نظرسنجی نمونه ای در حدود 1 درصد است، این روش به دلیل کمیاب بودن داده ها امکان پذیر نیست.
یک روش جایگزین برای ارزیابی هر روند، در نظر گرفتن یک جمعیت توزیع شده یکنواخت در یک مربع یا متوازی الاضلاع است، همانطور که در مورد مختصات بیان شده در شبکه ملی ایرلندی وجود دارد. اگر مختصات x در برابر مختصات y به ترتیب رتبهبندی رسم شوند، در یک جمعیت به طور مساوی، نتیجه یک نمودار خط مورب مستقیم است. در این مورد، یک تصویر گرافیکی از روندها برای یک جمعیت جایگزین، انحراف از این خط خواهد بود (به بخش 5.2 مراجعه کنید ).
بنابراین مختصات فضایی x و y بهعنوان جفتهای نمونه منطبق در نظر گرفته میشوند و بهعنوان معادل نمودارهای pp ترسیم میشوند، یعنی در عمل، مختصات x و مختصات y مزارع نمونه بهطور مستقل از حداقل تا حداکثر مرتبسازی میشوند و رتبهبندیشده به صورت جفت شده و ترسیم شده است.
اما خشکی کشور تنها زیرمجموعه ای از شبکه ملی است و شکلی نامنظم دارد و در نتیجه متوازی الاضلاع نیست. بنابراین یک طرح جفت رتبه بندی شده از نقاط تصادفی روی زمین کاملاً یک خط مستقیم نیست. با این وجود، در صورت انحراف از این خط، روندهای جغرافیایی همچنان قابل مشاهده است. با مقایسه کرت برای مزارع نمونه برداری شده، فاصله بین دو کرت نشان دهنده روندهای جغرافیایی است.
این رویکرد مشابهی با آزمونهای رتبهبندی غیرپارامتری تفاوت دارد. مقایسه با آزمون کولموگروف-اسمیرنوف برای بررسی مشابه بودن دو نمونه، که در آن نقاط داده ترکیب و رتبه بندی شده و حداکثر اختلاف تجمعی محاسبه می شود.
مزیت این روش این است که می توان از آن برای مقایسه توزیع ها با اندازه های زیرین مختلف استفاده کرد. بنابراین برای مثال حدود 120000 مزرعه در جمعیت وجود دارد، اما در نمونه ما فقط 1350 مزرعه وجود دارد. با این وجود، مختصات x و y را می توان رسم کرد و با یکدیگر مقایسه کرد. در حال حاضر ما روشی برای آزمایش خواص آماری این مقایسه ایجاد نکردهایم و بنابراین در موقعیتی نیستیم که اهمیت آماری تفاوت را آزمایش کنیم.
5. نتایج
درجه تأثیر، همانطور که در زیر ذکر شد، در الگوریتم تطبیق کمتر از وضوح داده های آب و هوایی (1 کیلومتر سلول مربع) است و بنابراین می توان از آن برای هدف ما برای آزمایش نمونه NFS جغرافیایی با توجه به متغیرهای کشاورزی-اقلیمی استفاده کرد. . در این بخش بازنمایی فضایی-محیطی مورد آزمایش قرار گرفته است. برای انجام این کار، الگوی فضایی نقاط NFS مرجع جغرافیایی با مجموعه داده های ملی جغرافیایی و محیطی مقایسه می شود.
5.1. ارزیابی ارجاع جغرافیایی
با استفاده از روش تشریح شده در بخش 4 ، تجزیه و تحلیل آزمایشی گسترش یافته و قوانین را به صورت متوالی اجرا می کند. تطبیق 1350 آدرس با پایگاه داده بیش از 1.5 میلیون و در نتیجه تقریباً 1000 تطابق مثبت. این تطابقهای مثبت گاهی اوقات شامل موارد مثبت کاذب میشدند، اما حذف آنها با دست آسان است.
در شکل 2 ، درصد آدرس های NFS که به طور خودکار با تعداد معینی از ساختمان ها در GD مطابقت دارند، گزارش شده است. می بینیم که تنها 6 درصد از آدرس های NFS به صورت یک به یک با ساختمان GD مطابقت دارند، بقیه با طیف وسیعی از ساختمان ها مطابقت دارند، با آدرس های NFS که به طور متوسط با 10 ساختمان GD مطابقت دارند. لازم به ذکر است که این یک “خطا” نیست زیرا همه 10 ساختمان در GD دقیقاً آدرس یکسانی دارند.
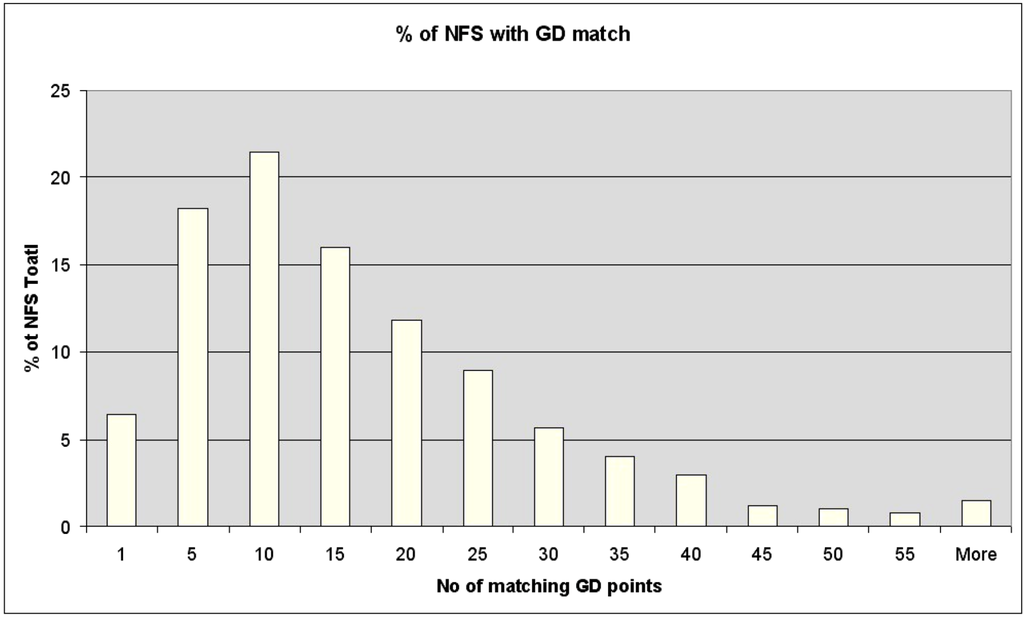
شکل 2. درصد هیستوگرام فرکانس آدرس های بررسی ملی مزرعه (NFS) که با مجموعه ای از خانه ها با اندازه معین مطابقت دارد.
هیستوگرام فرکانس در شکل 3 توزیع 1 اندازه خوشه انحراف استاندارد را نشان می دهد. میانگین خوشه ساختمان های GD مرتبط با آدرس NFS دارای انحراف استاندارد از میانگین 475 متر است. این بدان معناست که روش کدگذاری خودکار جغرافیایی که در اینجا توضیح داده شده است، دقت ذاتی 1 کیلومتر دارد. این برای مطالعات محیطی/اقلیمی در حال انجام کافی است.
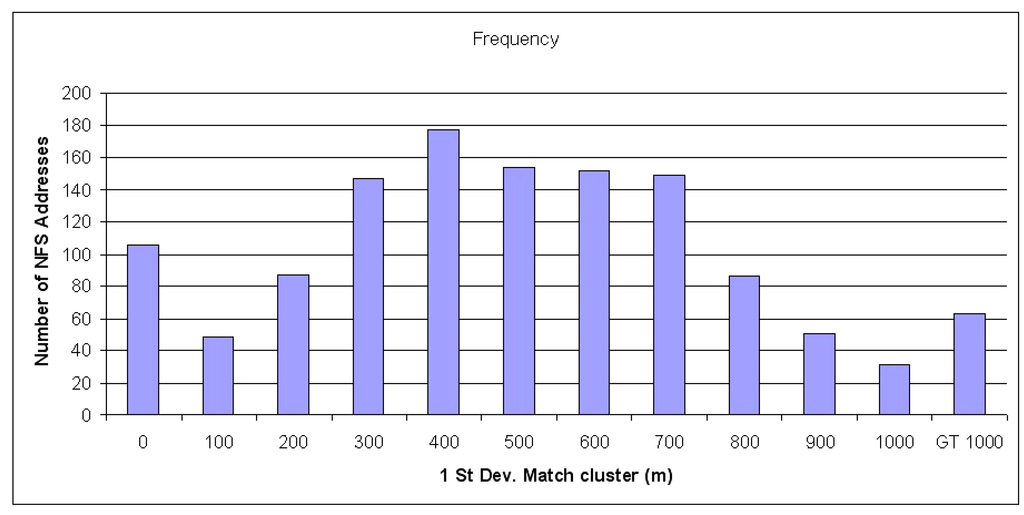
شکل 3. هیستوگرام فرکانس نشان دهنده اندازه 1 انحراف استاندارد از میانگین جغرافیایی هر خوشه ساختمانی است.
5.2. ارزیابی نمونه گیری جغرافیایی
برای بررسی توزیع جغرافیایی مزارع NFS، الگوی فضایی مزارع NFS را با توزیع واقعی مزارع، مزارع غیر NFS مقایسه میکنیم. داده ها به روش زیر ایجاد شدند:
-
یک توزیع جغرافیایی ملی با انتخاب تصادفی 1000 نقطه در سراسر جمهوری ایرلند ایجاد شد (این مجموعه داده ملی است).
-
این کار برای دو مجموعه داده دیگر ( نقاط NFS و مجموعه کنترل کشاورزی NON-nfs ) نیز انجام می شود.
-
نقاط آدرس برای مزارع غیر NFS با گرفتن داده ها از سرشماری CSO کشاورزی 2000 در سطح منطقه ایجاد شد، نشان دادن تعداد کشاورزان و اندازه متوسط مزرعه در آزمایش ویژگی های فضایی NFS (CSO، 2002). مرکز برای همه مناطق محاسبه شد. تمام ولسوالیهای دارای امتیاز NFS در آنها (حدود 900) حذف شدند و همچنین تمام ولسوالیهایی که طبق سرشماری CSO از کشاورزی 2000، کشاورز نداشتند نیز حذف شدند. این باعث شد تا 1900 نقطه (مرکز ناحیه) به عنوان مزارع ساختگی عمل کنند – مجموعه غیر nfs . این مجموعه نمونه از نظر جغرافیایی وزن دارد اما به جمعیت کشاورزان وزن داده نمی شود.
بررسی نمونه جغرافیایی احتمالی در شکل 4 تفاوت بین مجموعه NFS، غیر nfs و مجموعه ملی را نشان می دهد. نمودار همانطور که در بخش 4 در بالا ذکر شد ایجاد می شود – مختصات x و y نمونه های مختلف به طور مستقل از پایین ترین تا بالاترین رتبه بندی می شوند – تا اینکه جفت رتبه بندی شده مربوطه ترسیم شود.
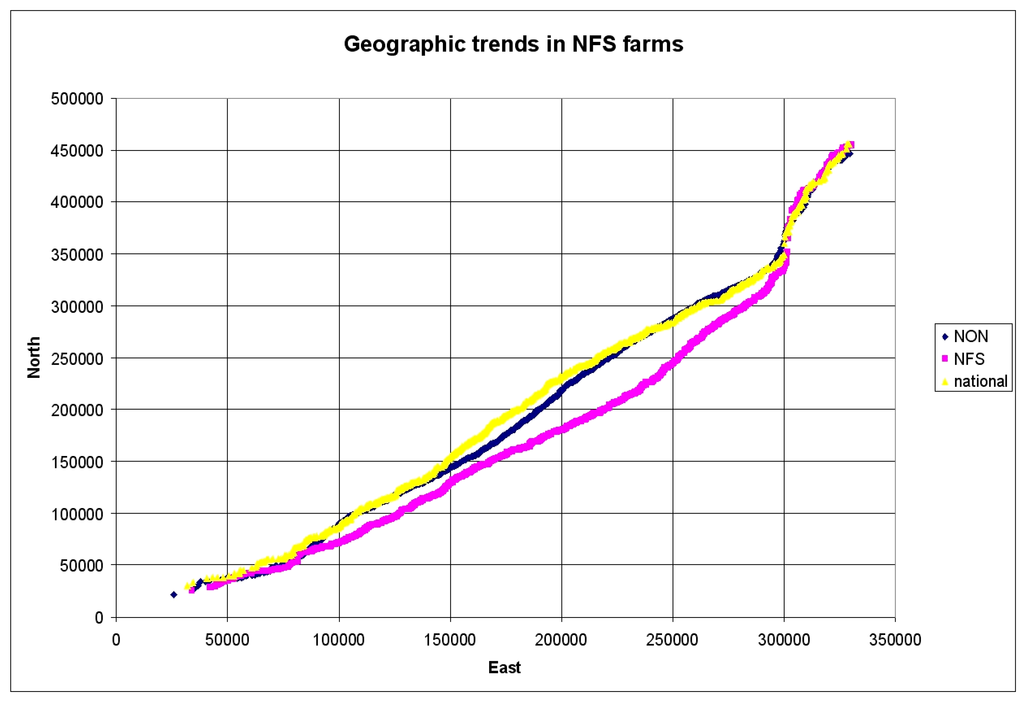
شکل 4. توزیع فضایی مجموعه نقطه ملی، مجموعه نقطه NFS و مجموعه نقطه NON.
این طرح باید به دقت تفسیر شود. همانطور که مشاهده می شود مجموعه تصادفی ملی (زرد) توزیع فضایی بسیار مشابهی با نقاط مزرعه NON NFS (آبی) دارد. نقاط صورتی NFS کاملا متفاوت هستند. طرح به صورت افزایش شرق از چپ به راست و افزایش شمال از پایین به بالا خوانده می شود. بنابراین پیچ خوردگی در ربع بالا سمت راست ناشی از کمبود نقاط در ایرلند شمالی است و به عنوان بالای 350000 نیوتن تفسیر می شود که نقاط نمونه به سمت غرب گرایش دارند (کانتی دونگال). این باید به تفسیر نقاط داده NFS کمک کند. میتوانیم ببینیم، همانطور که رنگ صورتی در زیر روند ملی برآمده است، که گرایش GNFS هم به سمت شرق و هم به سمت جنوب بیشتر از مجموعههای ملی و غیر nfs است.
به منظور آزمایش بازنمایی فضایی-محیطی این بررسی، ما نقاط داده خود را از تطابق NFS-GD به داده های محیطی مرتبط می کنیم. آزمایشی در مورد استفاده از نقاط NFS برای استخراج اطلاعات آب و هوا نیز انجام شد. سطوح آب و هوایی همانطور که در بالا ذکر شد استفاده شد. ما از یک سطح درونیابی شده بر اساس داده های روند ایستگاه آب و هوا در برابر داده های ارتفاعی می گیریم. برای هر NFS مقدار سلول منطبق 1 کیلومتر به نقطه NFS نسبت داده شد زیرا سطوح دقت یکسان است. در این مورد که ما به روند علاقه مندیم، مقادیر واقعی بی اهمیت هستند. سطوح بالای GSR در جنوب شرق و سطوح پایین تر در شمال غرب کشور. شکل 5توزیع مقادیر میانگین سالانه GSR تابستانی انباشته شده را برای سه مجموعه تست ملی، NON-NFS و NFS نشان می دهد. در این مورد مجموعه ملی مقادیر تمام سلولهای شبکه در نقشه بازگشت سرمایه (هر چهارمین مقدار، در مجموع 5240) است.

شکل 5. توزیع تابش جهانی خورشید.
می بینیم که توزیع مزارع ساختگی غیر NFS تقریباً با توزیع ملی مطابقت دارد. توزیع مجموعه NFS کاملاً متفاوت است و به سمت مقادیر بالاتر منحرف می شود.
آیا انحراف قابل توجه است؟ نمونهها در اینجا در مقایسه با نمونه ملی (1260 تا 5200) بسیار بزرگ هستند و بنابراین آزمایشهای مبتنی بر میانگین میتواند تصور اشتباهی را ایجاد کند. بررسی نمودارها ما را به این فرضیه می کشاند که توزیع استاندارد مقادیر GSR در نمونه NFS به طور قابل توجهی با مجموعه ملی متفاوت است. برای آزمایش، یک F-Test دو طرفه برای هر دو مجموعه نمونه ملی در مقابل غیر NFS و مجموعه نمونه ملی در مقابل NFS اعمال شد.
برای نقاط NON-NFS ( جدول 1 ): به طور رسمی فرضیه صفر σ NAT = σ NON و فرضیه جایگزین σ NAT ≠ σ NON است.

جدول 1. خلاصه آزمون F دو طرفه برای مجموعه های ملی/غیر NFS.
مقدار F (038/1) کمتر از مقدار بحرانی f (077/1 در حد اطمینان 95 درصد) است، بنابراین فرضیه صفر رد نمیشود و میتوان گفت انحراف معیار هر دو یکسان است. بنابراین، مجموعه نمونه NON-NFS یک نمونه قابل اعتماد از داده های آب و هوای ملی مورد بررسی است.
برای نقاط NFS ( جدول 2 ): به طور رسمی فرضیه صفر σ NAT = σ NFS و فرضیه جایگزین σ NAT ≠ σ NFS است.
جدول 2. خلاصه آزمون F دو طرفه برای مجموعه های ملی/NFS.
در این مورد، مقدار F (173/1) از مقدار بحرانی (09/1 در اطمینان 95 درصد) بیشتر است، بنابراین فرضیه صفر به نفع جایگزین رد می شود، که انحراف استاندارد نمونه NFS به طور قابل توجهی با نمونه ملی متفاوت است.
یک آزمون ناپارامتریک برای آزمایش این فرضیه استفاده شد که از بین دو نمونه، متغیر آب و هوا NFS دارای مقادیر قابل توجهی بالاتر از نمونه ملی است. آزمون Mann-Whitney U هیچ فرضی در مورد توزیع داده ها ندارد (به غیر از فرضیه صفر که توزیع ها یکسان هستند) و در آزمون دو نمونه رتبه بندی شده و رتبه بندی مقایسه می شوند. آمار U معیاری است که نشان می دهد رتبه ها چقدر متفاوت هستند. در آزمون U فرضیه صفر این است که نمونه ها یکسان هستند – نتایج به کارگیری این آزمون این است که نمونه NFS GSR با مجموعه ملی با P <0.001 (آزمون دو طرفه) تفاوت معنی داری دارد.
تفاوت در ویژگی های مزرعه بین مجموعه داده های NFS و غیر NFS نیز مشهود است، با نگاه کردن به ویژگی های مزرعه مناطق دارای نقاط NFS و مقایسه با آن هایی که فاقد آن هستند. میانگین اندازه مزرعه با بسیاری از متغیرهای اقتصادی دیگر کوواریانس است و بنابراین به عنوان متغیر آزمون انتخاب شد. شکل 6 هیستوگرام فرکانس اندازه متوسط مزرعه را در مناطق NFS و NON NFS Farm Districts نشان می دهد. همانطور که می بینیم توزیع ها مشابه هستند (اگرچه NFS یک انحراف جزئی به سمت مزارع بزرگتر دارد). این غیرمنتظره نیست زیرا انتخاب مزارع با داده های سرشماری CSO مطابقت دارد.

شکل 6. هیستوگرام فرکانس اندازه متوسط مزرعه در مناطق NFS و NON NFS Districts.
6. بحث
مجموعه داده NFS یک روند جغرافیایی به سمت جنوب شرق کشور را نشان می دهد. این غیرمنتظره نیست زیرا NFS برای ارائه نمونه ملی نماینده شرکت های اصلی مزرعه طراحی شده است. در ایرلند این شرکت ها خود از نظر جغرافیایی مغرضانه و محلی هستند. به طرز خام خاک ورزی در جنوب و شرق ایرلند، لبنیات در جنوب و گوشت گاو در سطح ملی است. بنابراین انتظار می رود که هر سیستم نمونه برداری طبقه بندی شده در این بخش ها از نظر فضایی به سمت جنوب شرقی سوگیری داشته باشد. داده های اقلیمی و زیست محیطی نیز از نظر جغرافیایی وزن دارند. دوباره با یک محور SE/NW. طبیعتاً این دو واقعیت مکمل یکدیگر هستند، زیرا شرکتها در مکانهای مناسب از نظر محیطی رخ میدهند.
با این حال، تجزیه و تحلیل بیشتر GSR نشان می دهد که مزارع در NFS “از نظر زیست محیطی مورد علاقه” هستند و شرایط محیطی کل کشاورزی ایرلند را به طور کامل مشخص نمی کنند. برای نشان دادن این نکته یک آزمایش نهایی بر روی مجموعه داده GSR انجام شده است. به جای مجموعه ای از نقاط توزیع شده به طور تصادفی، ما یک نمونه تصادفی از نقاط ایجاد کرده ایم (979 = n)، که برای تراکم جمعیت کشاورزی از ارقام CSO وزن شده است (هر چه مزارع در یک منطقه بیشتر باشد، شانس وقوع یک نقطه تصادفی بالاتر است). یک هیستوگرام درصد فرکانس اندازهگیری GSR برای هر یک از نقاط دارای وزن جمعیت (pop) همراه با مجموعه NFS معادلی که قبلاً دیدهایم رسم میشود. شکل 7تفاوت بین دو نمونه را نشان می دهد و تجزیه و تحلیل دو نمونه تفاوت معنی داری بین میانگین ها را نشان می دهد.
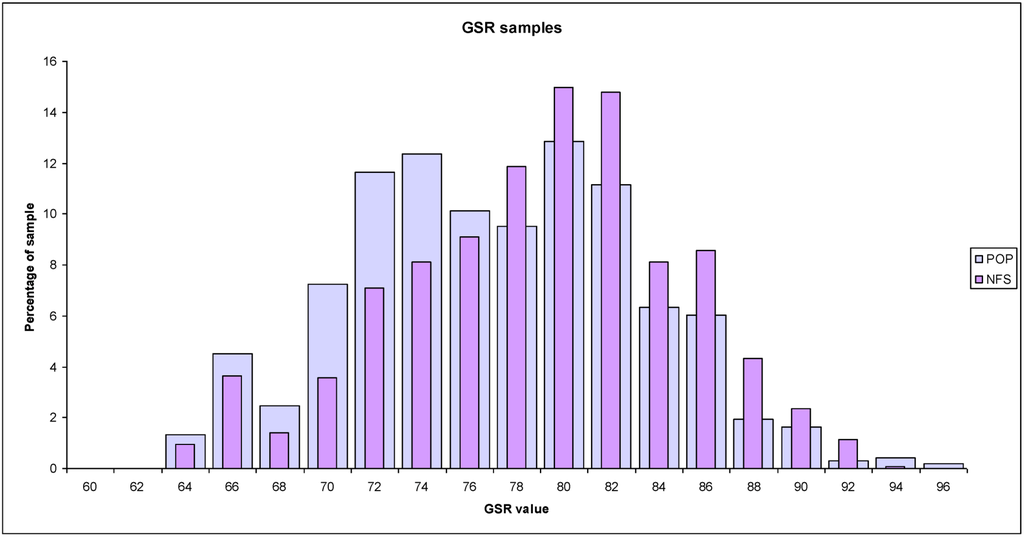
شکل 7. هیستوگرام فراوانی مقادیر GSR مرتبط برای مجموعه داده NFS و یک مجموعه داده جمعیت کشاورزی تصادفی وزن دار.
8. نتیجه گیری
در این مقاله، خانوارهای کشاورز در نمونه ایرلندی شبکه داده حسابداری مزرعه (FADN) ارجاع جغرافیایی شدند. با آزمایش تفاوت های آماری در متغیرهای کشاورزی-اقلیمی همانطور که توسط NFS نمونه برداری شد، تفاوت قابل توجهی بین نمونه و توزیع زیربنایی مشاهده می کنیم.
بررسی ملی مزرعه، به عنوان بخشی از FADN، برای نمایش دقیق سیستم های مزرعه طراحی شده است. ارجاع جغرافیایی دادههای بررسی مزرعه، تجزیه و تحلیلهای آتی توزیع بین دادههای بازده مزرعه و هزینه و ویژگیهای محیطی را امکانپذیر میسازد. با این حال، همانطور که در اینجا نشان دادیم که در مورد ایرلند، جغرافیای مزرعه را به طور کامل نشان نمیدهد و دادهها ممکن است برخی از تحلیلها را که در آن ترکیبهای خاصی از متغیرهای محیطی و متغیرهای مزرعه به دلیل ماهیت نمونه وجود ندارد، محدود کند. اگر از داده های FADN در سطح ملی برای پیش بینی اثرات تولید و کشاورزی-اقتصادی تحت سناریوهای مختلف تغییرات آب و هوایی استفاده شود، این می تواند پیامدهایی داشته باشد.
اگر مدل فرض کند که نمونه FADN نمونه ای نماینده از جغرافیاهای مختلف کشاورزی و زیست محیطی در منطقه است، این مسئله همچنین می تواند بر روی آن دسته از تکنیک های کاهش مقیاس که بر ایجاد کوواریانس فضایی داده های FDAN منطقه ای با استفاده از زمین و داده های زیست محیطی منطقه ای تکیه دارند، تأثیر بگذارد.
همانطور که سیستم FADN اروپایی به سمت معرفی یک عنصر جغرافیایی در گزارش خود حرکت می کند، ممکن است لازم باشد که استراتژی های نمونه گیری فعلی را تطبیق دهیم تا اطمینان حاصل شود که نمونه انتخاب شده به طور مساوی جغرافیا (اعم از اروپایی و ملی) و همچنین عملکرد سیستم ها را نشان می دهد. نمی توان فرض کرد که یک نمونه 1٪ از سیستم های مزارع اروپایی، جغرافیای محیطی کامل کشاورزی اروپا را نشان می دهد. تطبیق آدرس گذشتهنگر مهم دادههای بررسی تاریخی FADN تضمین میکند که بررسیهای موجود با نظرسنجیهای آینده که حاوی اطلاعات جغرافیایی دقیق هستند، کاملاً سازگار هستند.
منابع
- کوکیچ، پ. لاوسون، ک. دیویدسون، ا. الیستون، ال. جمع آوری داده های جغرافیایی مرجع در بررسی های مزرعه. در مجموعه مقالات سومین کنفرانس بینالمللی بررسیهای استقرار (ICES-III)، مونترال، QB، کانادا، 18 تا 21 ژوئن 2007.
- Corbett, JD چهره در حال تغییر ویژگیهای اکوسیستم کشاورزی: مدلها و دادههای فضایی، مبنایی برای مشخصهسازی قوی اکوسیستم کشاورزی. در مجموعه مقالات سومین کنفرانس بین المللی یکپارچه سازی GIS و مدلسازی محیطی، سانتافه، NM، ایالات متحده آمریکا، 21-26 ژانویه 1996.
- حسن، RM; کوربت، جی دی. Njoroge، K. فصل 4. ترکیب داده های بررسی جغرافیایی ارجاع شده با ویژگی های اقلیمی کشاورزی برای مشخص کردن سیستم های تولید ذرت در کنیا. در توسعه و انتقال فناوری ذرت: یک برنامه GIS برای برنامه ریزی تحقیقاتی در کنیا . حسن، RM، اد. CAB International: Wallingford; UK/CIMMYT: ادو. مکزیک؛ مکزیک/KARI: نایروبی، کنیا، 1998; صص 43-68. [ Google Scholar ]
- دور، پی. Froggatt، AEA بهترین مزارع مرجع جغرافیایی چگونه است؟ مطالعه موردی از کورنوال، انگلستان. قبلی دامپزشک پزشکی 2002 ، 56 ، 51-62. [ Google Scholar ] [ CrossRef ]
- FADN. شبکه داده های حسابداری مزرعه از روش شناسی A تا Z. در دسترس آنلاین: http://ec.europa.eu/agriculture/rica//pdf/site_en.pdf (در 1 اکتبر 2010 قابل دسترسی است).
- Charlier, H. بررسیهای ساختار مزرعه اتحادیه اروپا از سال 2010 به بعد. در مجموعه مقالات چهارمین کنفرانس بین المللی آمار کشاورزی (ICAS-IV)، پکن، چین، 22 تا 24 اکتبر 2007.
- کانولی، ال. Kinsella، A.; کوینلان، جی. موران، بی. بررسی ملی مزرعه 2008 ; Teagasc: Carlow، ایرلند، 2008. [ Google Scholar ]
- هالووی، جی. لاکومب، دی. LeSage، JP مسائل اقتصادسنجی فضایی برای مدلسازی زیستاقتصادی و کاربری زمین. جی. آگر. اقتصاد 2007 ، 58 ، 549-588. [ Google Scholar ] [ CrossRef ]
- فایس، ع. نینو، پ. Giampaolo، A. ادغام داده های خرد اقتصادی و ژئوفیزیکی برای تجزیه و تحلیل کشاورزی-محیطی، ارجاع جغرافیایی داده های Fadn: مطالعه موردی در ایتالیا. در مجموعه مقالات یازدهمین سمینار انجمن اروپایی اقتصاددانان کشاورزی (EAAE)، کپنهاگ، دانمارک، 2 تا 4 مارس 2005.
- Cantelaube، P. Jayt، PA; کاره، اف. بامپس، سی. زاخاروف، ص. کاهش مقیاس جغرافیایی خروجی های ارائه شده توسط یک مدل مزرعه اقتصادی کالیبره شده در سطح منطقه ای. کاربری اراضی Pol. 2012 ، 29 ، 35-44. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کولتر، BS; مک دونالد، ای. مورفی، ما؛ لی، جی. داده های زیست محیطی بصری در مورد خاک و کاربری زمین. در پایان گزارش پروژه ; شماره 4496; تیگاسک: کارلو، ایرلند، می 1999; پ. 46. [ Google Scholar ]
- کلاین، تی. Calanca، P. هولزکمپر، آ. لمان، ن. روش، ا. Fuhrer, J. استفاده از داده های حسابداری مزرعه برای کالیبره کردن یک مدل محصول برای مطالعات تأثیر آب و هوا. Agr. سیستم 2012 ، 111 ، 23-33. [ Google Scholar ]
- ریدزما، پی. اورت، اف. Lansink، AO; لیمانز، آر. سازگاری با تغییرات آب و هوا و تنوع آب و هوا در کشاورزی اروپا: اهمیت پاسخهای سطح مزرعه. یورو جی. آگرون. 2010 ، 32 ، 91-102. [ Google Scholar ] [ CrossRef ]
- Ordnance Survey Ireland Act, 2001 (شماره 43 از 2001) ; کتاب اساسنامه ایرلند، دفتر دادستان کل: دوبلین، ایرلند، 2001.
- فاهی، دی. Finch, F. GeoDirectory Technical Guide ; An Post GeoDirectory Limited: دوبلین، ایرلند. در دسترس آنلاین: http://www.geodirectory.ie/Downloads.aspx (در 1 ژوئیه 2009 قابل دسترسی است).
- جوامع اروپایی، تصمیم کمیسیون 7 ژوئن 1985 در مورد ایجاد یک گونه شناسی جامعه برای مزارع کشاورزی (85/377/EEC) . مجله رسمی L220; 17 اوت 1985.
- VanWey، LK; ریندفوس، RR; گاتمن، نماینده مجلس؛ انتویسل، بی. Balk، DL محرمانه بودن و دادههای صریح فضایی: نگرانیها و چالشها. Proc. Natl. آکادمی علمی ایالات متحده 2005 ، 102 ، 15337-15342. [ Google Scholar ]
- آلن، آر. Hanuschak., G. مسائل مربوط به سیاست مرتبط با استفاده از سیستم های اطلاعات جغرافیایی در سرویس ملی آمار کشاورزی ایالات متحده. در مجموعه مقالات کمیسیون آماری کمیسیون اقتصادی اروپا کنفرانس آماردانان اروپایی، اتاوا، ON، کانادا، 5-7 اکتبر 1998.
- سوینی، جی. بریتون، تی. بیرن، سی. چارلتون، آر. Emblow، C. روآن، اف. هولدن، ن. جونز، ام. دانلی، آ. مور، اس. و همکاران سناریوها و اثرات تغییرات آب و هوا برای ایرلند . آژانس حفاظت از محیط زیست: دوبلین، ایرلند، 2006. [ Google Scholar ]
© 2013 توسط نویسندگان; دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (http://creativecommons.org/licenses/by/3.0/) توزیع شده است.
بدون نظر