

چکیده
:
با توجه به اهمیت مسائل فضایی در برنامه ریزی حمل و نقل، هدف اصلی این مطالعه تحلیل نتایج حاصل از رویکردهای مختلف مدل های رگرسیون فضایی بود. در مورد خود همبستگی فضایی، الگوهای وابستگی فضایی باید در مدلها گنجانده شوند، زیرا این وابستگی ممکن است بر قدرت پیشبینی این مدلها تأثیر بگذارد. نتایج بهدستآمده با مدلهای رگرسیون فضایی نیز با نتایج یک مدل رگرسیون خطی چندگانه که معمولاً در تخمینهای تولید سفر استفاده میشود، مقایسه شد. یافتهها از این فرضیه حمایت میکنند که گنجاندن اثرات فضایی در مدلهای رگرسیون مهم است، زیرا بهترین نتایج با مدلهای جایگزین (مدلهای رگرسیون فضایی یا مدلهایی با متغیرهای فضایی شامل) به دست آمد.
کلید واژه ها:
برنامه ریزی حمل و نقل ؛ تقاضای حمل و نقل ؛ وابستگی فضایی ؛ رگرسیون فضایی
1. مقدمه
روابط فضایی نقش مهمی در حمل و نقل ایفا می کند. اگرچه، مطالعات زیادی بر روی معرفی صریح مسائل فضایی در مدلسازی برنامهریزی حملونقل متمرکز نشدهاند. بنابراین، به عنوان کمک به این زمینه، هدف این مطالعه تحلیل نتایج بهدستآمده از رویکردهای مختلف مدلهای رگرسیون فضایی است. در مرحله بعد، نتایج این مدلهای فضایی نیز با نتایج یک مدل رگرسیون خطی چندگانه که معمولاً در تخمینهای تولید سفر استفاده میشود، مقایسه میشود. بنابراین سوال اصلی تحقیق این مطالعه این بود که آیا گنجاندن متغیرهای فضایی مدلهای تقاضای حمل و نقل را بهبود میبخشد یا خیر. بسیاری از محققان قبلاً در مورد اهمیت در نظر گرفتن اثرات فضایی در تحلیل های شهری و حمل و نقل بحث کرده اند. پائز و اسکات [ 1برای مثال، تکنیک ها و نمونه هایی از کاربردها را بررسی کرده اند که نشان می دهد چگونه می توان از آمار فضایی در حمل و نقل شهری و برنامه ریزی کاربری زمین استفاده کرد. هدف از آن مطالعه بحث در مورد برخی از مسائل فنی عمده در تحلیل فضایی ( به عنوان مثال ، تداعی فضایی، ناهمگنی و مسئله واحد مساحتی قابل تغییر) بود و نویسندگان یک روند امیدوارکننده را برای استفاده از روشهای آماری فضایی پیچیده در تحلیلهای شهری نشان دادند. . همانطور که اخیراً توسط وانگ و همکاران مورد بحث قرار گرفته است، این موضوعات هنوز به موقع هستند . [ 2 ].
وابستگی فضایی و تأثیرات آن بر مدلهای تقاضای حملونقل، که تمرکز این مطالعه است، بدون شک از جمله موضوعاتی است که در مورد تحلیل فضایی هنوز به طور کامل در برنامهریزی حملونقل مورد بررسی قرار نگرفته است. این را می توان در جدول 1 مشاهده کرد که در آن مروری بر مطالعات انجام شده در سه دهه گذشته در مورد اثرات فضایی بر حمل و نقل و تحلیل شهری خلاصه شده است. جدول به گونه ای سازماندهی شده است که مراجع در ستون مرکزی نشان داده شده اند، مسائل تحلیلی فضایی بررسی شده در سمت چپ جدول و زمینه های کاربردی در سمت راست جدول فهرست شده اند. با توجه به مسائل تحلیلی فضایی، اکثر مطالعات انتخاب شده بر روی مسائل تداعی فضایی ( یعنی، وابستگی فضایی یا خودهمبستگی فضایی). با توجه به کاربردها، تنها تعداد کمی از آنها به تجزیه و تحلیل تقاضای حمل و نقل پرداختند. شایان ذکر است که تقریباً همه مطالعات به یک نتیجه مشترک رسیده اند: گنجاندن اثرات فضایی نتایج تجزیه و تحلیل را بهبود بخشید. این واقعاً تعجبآور نیست، اما توجه را به این واقعیت جلب میکند که بسیاری از مطالعاتی که در جدول 1 فهرست نشدهاند، هنوز به صراحت عناصر تحلیل فضایی را در تحلیلهای خود لحاظ نمیکنند.
برای مثال، مدلهای رگرسیون معمولاً در مرحله تولید سفر در برنامهریزی حملونقل استفاده میشوند. آنها ابزارهای آماری هستند که روابط موجود بین دو یا چند متغیر را بررسی می کنند، به طوری که یکی از آنها می تواند توسط دیگری توضیح داده شود (و بنابراین می توان ارزش آن را تخمین زد). با این حال، در حضور یک خود همبستگی فضایی قابل توجه، تخمین مدل باید ساختار فضایی داده ها را در نظر گرفته و ترکیب کند. رگرسیون های فضایی، یا تحلیل های رگرسیونی که وابستگی فضایی موجود داده ها را در بر می گیرد، احتمالاً قدرت پیش بینی مدل های رگرسیون را بهبود می بخشد.
بولدوک و همکاران [ 3 ، 4 ، 5 ]، حیدر و میلر [ 6 ]، وانگ [ 7 ]، چادو و پروکوپنکو [ 8 ]، کاوامورا و ماهاجان [ 9 ]، ویچینسان و همکاران. [ 10 ]، ژو و کوکلمن [ 11 ]، ریبیرو و آنتونس [ 12 ]، چالرمپونگ [ 13 ]، هاکنی و همکاران. [ 14 ، 15 ] و نواک و همکاران. [ 16] نمونه هایی از کاربردهای رگرسیون فضایی، برخی از آنها در برنامه ریزی شهری و حمل و نقل را ارائه می دهد. به طور کلی، مدلهای فضایی آزمایششده برازش بهتری با دادههای واقعی نسبت به مدلهای غیرمکانی مربوطه داشتند.

جدول 1. کاربردهای آمار فضایی در تحلیل حمل و نقل.
این مطالعه بر روی نتایج فاز تولید سفر مدل چهار مرحله ای ( یعنی تولید سفر، توزیع سفر، انتخاب حالت حمل و نقل و انتخاب مسیر) تمرکز دارد. بنابراین، هدف آن کمک به ارزیابی مزایای استفاده از ابزارهای آمار مکانی در تجزیه و تحلیل تقاضا برای حمل و نقل و برنامه ریزی حمل و نقل پایدار است.
لوپس و رودریگز داسیلوا [ 32] تاثیرات معرفی شاخص های جهانی و محلی وابستگی فضایی در مدل های پیش بینی تقاضا را ارزیابی کرد. مدلهای دارای ویژگیهای فضایی، که مدلهای «جایگزین» نامیده میشوند، با مدلهای «سنتی» مقایسه شدند که در آن متغیرها به لحاظ فضایی مورد بررسی قرار نگرفتند. این روش در شهر پورتو آلگره، پایتخت ایالت ریو گراند دو سول، برزیل به کار گرفته شد. دادههای تحلیلها از نظرسنجیهای مبدا-مقصد (OD) بدست آمده از طریق مصاحبههای خانگی (که از این پس EDOM نامیده میشود، که مخفف مصاحبههای خانگی در پرتغالی است) در دو سال متمایز (1974 و 1986) به دست آمده است. مجموعه داده 1974 برای کالیبراسیون و تنظیم مدل ها استفاده شد. مجموعه داده 1986 اطلاعات مورد نیاز برای تجزیه و تحلیل تخمین ها را بر اساس مدل های 1974 ارائه کرد. چندین مدل مورد آزمایش قرار گرفت و کارآمدترین آنها مدلی بود که در آن متغیرهای فضایی جهانی و محلی معرفی شدند. این سالها به این دلیل انتخاب شدند که مجموعه دادههای موجود در شهر پورتو آلگره هستند.
در این مطالعه، ما مطالعات قبلی خود را با تجزیه و تحلیل نتایج بهدستآمده با مدلی که به بهترین وجه با مجموعه دادههای 1974 تنظیم شده بود، توسعه دادیم. مدل به اصطلاح AGL74 که مخفف مدل جایگزین، جهانی و محلی برای سال 1974 است، یک مدل رگرسیون چندگانه بود که به دلیل متغیرهای فضایی که نشان دهنده وابستگی فضایی جهانی و محلی بود، نام “جایگزین” را دریافت کرد. علاوه بر مدل AGL74، ما از مجموعه دادههای مشابه پورتو آلگره برای تجزیه و تحلیل نتایج مدلهای رگرسیون جایگزین زیر استفاده کردیم که اثرات فضایی جهانی را در نظر میگیرند: مدل خودکار رگرسیون فضایی و مدل خطای فضایی (Anselin [ 33 ] و Fotheringham et . همکاران [ 34 ]).
عملکرد مدلها نیز با دادههای یک بررسی مبدا-مقصد جدیدتر در مراحل اعتبارسنجی و پیشبینی آزمایش شد. این دادهها که از طریق مصاحبههای خانگی در سال 2003 بهدست آمدند (EDOM، 2003)، در زمان انجام مطالعات قبلی در دسترس نبودند. بنابراین، در این مقاله نتایج بهدستآمده با اجرای مدلهای جایگزین کالیبرهشده با مجموعه دادههای 1974 و 2003 را ارائه کردیم. علاوه بر این، ما تجزیه و تحلیلهای مقایسهای را با نتایج مدلهای سنتی انجام دادیم که با مجموعه دادههای مشابه کالیبره شدند.
دو موضوع مرتبط با این مطالعه در یک مرور ادبیات مختصر درست پس از این مقدمه مورد بحث قرار گرفت. در ابتدا، ابزارهای تجزیه و تحلیل داده های فضایی اکتشافی (ESDA، همانطور که توسط Anselin [ 35 ] توضیح داده شد) در بخش 2 مورد بحث قرار گرفت . این ابزارها برای تولید شاخصهایی که به عنوان متغیرهای فضایی در مدلهای جایگزین معرفی شدهاند، خدمت کردند. آنها همچنین در تجزیه و تحلیل نتایج مدل ها ضروری بودند. سپس، ابزارهای تحلیل دادههای مکانی تأییدی (CSDA) نیز در بخش 2 مورد بررسی قرار گرفتند . ما به طور خاص بر روی رگرسیون فضایی تمرکز کردیم، به شرح زیر: ابتدا یک نمای کلی از موضوع ارائه کردهایم و متعاقباً ساختار مدلهایی را که برای استفاده انتخاب کردهایم ارائه کردیم. در بخش 3، ما جزئیات روش مورد استفاده در مطالعه را ارائه دادیم و به دنبال آن تجزیه و تحلیل نتایج برنامه خود را در بخش 4 و نتایج اصلی مطالعه در بخش 5 ارائه کردیم .
2. ابزارهای تجزیه و تحلیل داده های مکانی اکتشافی و تاییدی
ابزارهای تجزیه و تحلیل داده های مکانی اکتشافی (ESDA) را می توان برای موارد زیر مورد استفاده قرار داد: ( 1 ) تجسم و توصیف توزیع های فضایی. ( ii ) استانداردهای ارتباط فضایی (تراکمها یا خوشههای فضایی) را شناسایی کند. ( iii ) مشاهدات غیر معمول (مقادیر شدید یا نقاط پرت) را شناسایی کنید. و ( IV ) وجود ناپایداری های فضایی (غیر ایستایی) را شناسایی کنید. روش های ESDA توصیفی هستند و تاییدی نیستند. بنابراین، قرار نیست از آنها برای تشخیص الگوها، بسط فرضیه ها و تخمین مدل های فضایی استفاده شود (Anselin [ 35 ]).
خودهمبستگی فضایی از جمله تحلیل هایی است که با ابزار ESDA انجام شده است. مقدار خودهمبستگی مکانی می تواند نشان دهد که چقدر مقدار یک متغیر در یک منطقه به مقادیر همان متغیر در مکان های همسایگی وابسته است. برای مثال، شاخص موران از طریق مقادیری که از ۱- تا ۱+ متفاوت است، نشان میدهد که هر ناحیه چقدر به همسایه نزدیک خود در رابطه با یک متغیر خاص شباهت دارد. در حالی که صفر به معنای عدم وجود خودهمبستگی فضایی است، مقادیر نزدیک به 1- یا 1+ به ترتیب نشان دهنده وجود همبستگی منفی یا مثبت است. در نتیجه، با اجازه دادن به شناسایی توزیعهای غیر تصادفی متغیرها، I موران میتواند در تحلیلها در مراحل اولیه مدلسازی حملونقل، زمانی که معادلات رگرسیون به طور گسترده در مدل چهار مرحلهای استفاده میشود، مفید باشد.
نمودار پراکندگی موران می تواند برای به دست آوردن متغیرهای فضایی جهانی (یا شاخص های جهانی وابستگی فضایی) استفاده شود. این یک نمودار دو بعدی است که به چهار ربع تقسیم شده است که در آن مقادیر نرمال شده متغیر تحلیل (Z) با میانگین مقادیر در مناطق مجاور (W z ) مقایسه می شود. مقدار I موران معادل ضریبی است که شیب (α) خط رگرسیون Wz در Z را نشان میدهد.
-
Q1 (مقدار مثبت برای منطقه و مقدار مثبت برای میانگین مقادیر در مناطق همسایه) و Q2 (مقدار منفی برای منطقه و مقدار منفی برای میانگین مقادیر در مناطق همسایه). این نشان دهنده نقاط ارتباط فضایی مثبت است، به این معنی که یک منطقه دارای مناطق همسایه با مقادیر مشابه است. به ترتیب High-High و Low-Low نیز نامیده می شود.
-
Q3 (مقدار منفی برای منطقه و مقدار مثبت برای میانگین مقادیر در مناطق همسایه) و Q4 (مقدار مثبت برای منطقه و مقدار منفی برای میانگین مقادیر در مناطق همسایه). این نشان دهنده نقاط ارتباط فضایی منفی است، به این معنی که یک منطقه دارای مقادیر متمایز از همسایگان خود است. به ترتیب Low-High و High-Low نیز نامیده می شود.
مقادیر Scatterplot موران را می توان در به اصطلاح Box Maps نیز ارائه کرد. در چنین نقشه ای، هر چند ضلعی بر اساس ربعی که در نمودار پراکندگی به آن تعلق دارد، طبقه بندی می شود. در حالی که شاخص های جهانی، مانند موران I، یک مقدار منحصر به فرد را به عنوان معیار ارتباط فضایی داده ها ارائه می دهند، شاخص های محلی برای هر منطقه یک مقدار خاص تولید می کنند. آنها امکان شناسایی مناطق را با: مقادیر مشخصه های مشابه (خوشه ها)، نقاط پرت، و بیشتر از یک رژیم فضایی فراهم می کنند. Anselin [ 35 ] از آنها به عنوان آمار LISA (شاخص های محلی انجمن فضایی) یاد می کند.
اهمیت آماری شاخص های محلی موران را می توان به صورت زیر محاسبه کرد. این فرآیند با محاسبه شاخص ها برای هر منطقه شروع می شود. سپس مقادیر تمام نواحی به طور تصادفی جابجا می شوند تا زمانی که یک توزیع شبه به دست آید، که پارامترهای قابل توجهی را می توان برای آن محاسبه کرد. در این مورد، نقشه LISA و نقشه موران مناطقی را نشان میدهند که همبستگی محلی به طور قابل توجهی متفاوت از بقیه دادهها هستند. آنها مناطقی با پویایی فضایی خاص خود هستند (به عنوان مثال ، جیب های غیر ایستایی محلی) که نیاز به تجزیه و تحلیل دقیق دارند. خودهمبستگی های قابل توجه در سطح 5 درصد نشان دهنده مناطق بسیار مشابه در مقایسه با همسایگان خود است.
متغیرهای فضایی از طریق آمار موران محلی به مدلهای تقاضای حملونقل در مطالعه حاضر معرفی شدند. آنها به عنوان شاخص های محلی وابستگی فضایی به دست آمدند و متغیرهای فضایی محلی را تعیین کردند. شاخصها و ابزارهای ESDA نیز در ارزیابی عملکرد مدلها بسیار مفید بودند، زیرا میتوان از آنها در تجزیه و تحلیل توزیع فضایی خطاهای تخمین استفاده کرد.
ابزارهای تجزیه و تحلیل داده های مکانی تاییدی (CSDA) فرآیندهای کمی مدل سازی، برآورد و اعتبار سنجی لازم برای تجزیه و تحلیل اجزای فضایی را گروه بندی می کند. در این گروه میتوان به «ابزار» موجود برای آمار فضایی و اقتصادسنجی فضایی بهعنوان رگرسیون فضایی یا معرفی شاخصهای خودهمبستگی مکانی بهعنوان متغیرهای فضایی در مدلهای رگرسیونی اشاره کرد.
به طور معمول، هنگام انجام تحلیل رگرسیون، هدف یافتن تناسب خوبی بین مقادیر پیشبینیشده و مشاهدهشده متغیر وابسته در مدل است. علاوه بر این، یافتن اینکه کدام یک از متغیرها به طور قابل توجهی در رابطه خطی نقش دارند، مهم است. فرضیه استاندارد این است که مشاهدات همبستگی ندارند و به این ترتیب، باقیمانده ε iمدلی که از توزیع نرمال با میانگین صفر و واریانس ثابت پیروی می کند، مستقل و با متغیر وابسته همبستگی ندارند. با این حال، در مورد داده هایی که از نظر مکانی وابسته هستند، بسیار بعید است که فرضیه استاندارد مشاهدات غیرهمبسته درست باشد. در رایجترین حالت، باقیماندهها به نمایش خودهمبستگی فضایی در دادهها ادامه میدهند که میتواند در تفاوتهای منطقهای سیستماتیک، یا حتی از طریق یک روند فضایی پیوسته آشکار شود.
تجزیه و تحلیل رگرسیون داده های مکانی، قدرت پیش بینی یک مدل را با ترکیب وابستگی فضایی بین داده ها در مدل بهبود می بخشد. در ابتدا، یک تحلیل اکتشافی باید با هدف شناسایی ساختار وابستگی در داده ها انجام شود. این برای تعریف نحوه گنجاندن این وابستگی در مدل رگرسیون بسیار مهم است. دو نوع اساسی از رگرسیون فضایی امکان ترکیب اثرات فضایی را فراهم می کند: آنهایی که به شکل جهانی و آنهایی که از شکل محلی هستند (Anselin [ 33 ] و Fotheringham و همکاران [ 34 ]). مدلهای جهانی ساختار فضایی را از طریق یک پارامتر منحصر به فرد که به مدل رگرسیون سنتی اضافه میشود، ثبت میکنند. ساده ترین مدل های رگرسیون فضایی، که به طور رسمی توسط Anselin ارائه شده است [33 ]، مدل خود رگرسیون فضایی (SAR) یا مدل تأخیر فضایی و مدل رگرسیون خودکار شرطی (CAR) یا مدل خطای فضایی هستند.
2.1. SAR (خودرورگرسیون فضایی)
در مدل SAR (یا LAG، همانطور که در این مطالعه نامیده می شود) خودهمبستگی فضایی نادیده گرفته شده به متغیر Y نسبت داده می شود. وابستگی فضایی با افزودن یک عبارت جدید در قالب یک رابطه فضایی به متغیر وابسته در مدل رگرسیون خطی گنجانده شده است. به طور رسمی، Anselin [ 33 ] مدل SAR را با معادله (1) معرفی کرد. فرضیه صفر برای عدم وجود خودهمبستگی این است که ρ = 0. ایده اصلی این است که خودهمبستگی فضایی را به عنوان جزئی از مدل ترکیب کنیم.
Y = ρWY + Xβ + ε
جایی که: Y = متغیر وابسته; X = متغیر مستقل. β = ضرایب رگرسیون. ε = خطاهای تصادفی با میانگین صفر و واریانس σ 2 ; W = ماتریس مجاورت یا ماتریس وزنی فضایی. ρ = ضریب خودرگرسیون فضایی.
طبق گفته گتیس و گریفیث [ 37 ]، این مدلها به یک یا چند ماتریس ساختاری فضایی وابسته هستند که خود همبستگی فضایی را در دادههای جغرافیایی ارجاع داده شده که پارامترهای مدل از آن تخمین زده میشوند، محاسبه میکنند. همان نویسندگان همچنین اشاره کردند که مدلهای خودرگرسیون فضایی تقریباً به طور انحصاری نرمال بودن را فرض میکنند و ماهیت غیرخطی دارند. به این ترتیب، برای این مدلها، استفاده از روشهای تخمین حداقل مربعات معمولی (OLS) برای توسعه و آزمایش مدل نامناسب است. علاوه بر این، این مدلها معیارهای جهانی وابستگی فضایی را ارائه میکنند، اما مشارکتهای فضایی و غیرفضایی فردی اجزا را نشان نمیدهند.
2.2. ماشین (خودرو رگرسیون شرطی)
در نوع دوم مدل رگرسیون فضایی با پارامترهای سراسری که به آن مدل خطای فضایی نیز گفته می شود، اثرات مکانی به عنوان یک نویز یا اختلال در نظر گرفته می شود، یعنی عاملی که باید حذف شود. در این حالت، اثرات خودهمبستگی مکانی با عبارت خطای ε مرتبط است و مدل را می توان با رابطه (2) بیان کرد. فرضیه صفر برای عدم وجود خودهمبستگی این است که λ = 0، یعنی عبارت خطا از نظر مکانی همبستگی ندارد.
Y = Xβ + ε , ε = λWe + ξ
جایی که: Wε = خطاهایی با اثرات فضایی. ξ = خطاهای تصادفی با میانگین صفر و واریانس σ 2 ; λ = ضریب خودرگرسیون.
2.3. مدل هایی با شاخص های محلی و جهانی وابستگی فضایی
روش دیگر در نظر گرفتن وابستگی فضایی در مدلهای رگرسیونی که در پژوهش حاضر مدل حمل و نقل جایگزین نامیده میشود، معرفی شاخصهای خودهمبستگی مکانی (جهانی و محلی) به عنوان متغیر است. آنها به متغیرهای سنتی در مدل رگرسیون چندگانه یا مدل سنتی (همانطور که توسط لوپس و رودریگز داسیلوا [ 32 ] پیشنهاد شدهاند) اضافه میشوند. به این ترتیب، متغیرهای فضایی جهانی و محلی از طریق تحلیل فضایی متغیرهای اجتماعی-اقتصادی با استفاده از ابزارهای ESDA از طریق بسته های کامپیوتری آمار مکانی تعریف و به دست می آیند.
متغیرهای فضایی جهانی، متغیرهای باینری (ساختگی) هستند که به ربع های موران Scatterplot (نشانگر جهانی) مرتبط هستند. برای یک متغیر مستقل “X”، سه متغیر (X_Q1، X_Q2 و X_Q3) برای نمایش رژیم فضایی هر منطقه تحلیل ترافیک (TAZ) تعریف شدهاند. برای تعریف متغیرهای مکانی محلی (LISA_X)، شاخص های LISA در نظر گرفته شده است. در وجود وابستگی فضایی مؤثر بر نتایج مدلهای سنتی، لوپس و رودریگز داسیلوا [ 32 ] نشان دادند که مدلهای جایگزین کارآمدتر از مدلهای رگرسیون فضایی جهانی (SAR و CAR) در پیشبینی تولیدات سفرهای خانگی هستند. (HBTP) برای داده های پورتو آلگره.
مدلهای جایگزین همچنین به تحلیلهای دقیقی از اهمیت متغیرهای گنجانده شده نیاز دارند تا از اضافه شدن متغیرهای غیر ضروری جلوگیری شود. علاوه بر ابزارهای موجود در بسته نرم افزاری GIS-T، از روش رگرسیون گام به گام رو به جلو برای تحلیل تغییرات ایجاد شده در مدل ها با گنجاندن متغیرهای فضایی استفاده شد. این فرآیند به طور مفصل در بخش 4.3 و بخش 4.8 ارائه شده است. به طور خلاصه، روش بررسی میکند که آیا افزودن یک متغیر جدید به مدل باعث افزایش قابلتوجهی در R-squared تنظیمشده میشود یا خیر. با این حال، این روش ارزیابی نتایج مدل توسط تحلیلگران را رد نمی کند، زیرا در برخی موارد ابزارهای مورد استفاده ممکن است قادر به شناسایی مشکلات چند خطی نباشند. با این حال، این رویکرد امکان استفاده از تکنیکهای رگرسیون خطی سنتی را فراهم میکند و در عین حال اطمینان میدهد که باقیماندههای رگرسیون بر اساس مفروضات مدل مورد نیاز، مانند خطاهای نامرتبط رفتار میکنند.
2.4. ارزیابی مدل های فضایی
تجزیه و تحلیل بصری باقیمانده ها در یک نمودار، گام مهمی برای ارزیابی تنظیم یک رگرسیون است. با توجه به اینکه غلظت بالای مقادیر مثبت یا منفی در بخشی از نقشه، نشانگر خوبی از وجود خود همبستگی فضایی است، نگاشت باقیمانده نیز مفید است. شاخص موران I از باقیمانده ها معمولاً به عنوان یک آزمون کمی استفاده می شود.
مقادیر حداکثر احتمال وزن شده با تفاوت در تعداد پارامترهای برآورد شده معمولاً برای انتخاب مدل های رگرسیون استفاده می شود. در مدلهای با ساختار وابستگی (مکانی یا زمانی)، ارزیابی تعدیل با تعداد پارامترها جریمه میشود. معمولاً، مقایسه مدلها از log-likelihood استفاده میکند که نشاندهنده بهترین تنظیم برای دادههای مشاهدهشده است. معیار اطلاعات آکایک در معادله (3) بیان شده است. بهترین مدل مدلی است که کمترین مقدار AIC را داشته باشد. بسیاری از معیارهای اطلاعاتی دیگر در بسته های GIS با آمار مکانی، از طریق ابزار CSDA در دسترس هستند. بسیاری از آنها تغییرات AIC، با تغییرات در جریمه پارامترها یا مشاهدات هستند.
AIC = -2 × LIK + 2 k
جایی که: LIK = log-likelihood; k = تعداد ضرایب رگرسیون.
3. روش
بیشتر رویهها در یک محیط GIS، با استفاده اضافی از بسته نرمافزار GeoDA [ 37 ]، با توجه به اینکه حاوی ابزارهای ESDA و CSDA (مثلاً مدلسازی رگرسیون فضایی) است که میتواند برای به دست آوردن متغیرهای مکانی و برای کالیبراسیون استفاده شود، انجام شد. از مدل ها
کالیبراسیون و اعتبارسنجی مدلها بر اساس دادههای دو نظرسنجی مبدا و مقصد انجام شده در شهر پورتو آلگره برزیل در سالهای 1974 و 2003 به شرح زیر است.
-
“سال پایه” – مجموعه داده 1974 (EDOM 74) برای کالیبراسیون و همچنین برای بررسی عملکرد بهترین مدل های تقاضا استفاده شد. آنها می توانند مدل های سنتی یا جایگزین باشند. در حالی که اولی به روشهای سنتی متکی بود، دومی از متغیرهایی استفاده کرد که درجه وابستگی فضایی را در بر میگرفت. اما در هر دو مورد، از آنها برای پیش بینی تقاضای حمل و نقل استفاده شد.
-
“سال هدف” – از آنجایی که سال 2003 به عنوان سال پیش بینی در نظر گرفته شد، مجموعه داده EDOM 2003 برای مقایسه با تخمین سفرهای آینده استفاده شد که از طریق استفاده از مدل های سنتی و جایگزین به دست آمد. مجموعه داده حاوی اطلاعات آخرین نظرسنجی OD بود و از طریق مصاحبه خانوار به دست آمد. آن پایگاه داده، که در اینجا برای اندازه گیری عملکرد مدل استفاده شد، برای مطالعات قبلی لوپس و رودریگ داسیلوا [ 32 ] در دسترس نبود.
خوب بودن برازش مدلها از طریق آزمونهای آماری، مانند Adjusted R-Squared و AIC (معیار اطلاعات Akaike)، در میان سایر موارد مورد ارزیابی قرار گرفت. قدرت پیش بینی با برخی از معیارهای عملکرد، مانند MRE (میانگین خطای نسبی) و Moran’s I برای خطاها ارزیابی شد. برای متغیرها، معناداری (t-Student)، وجود چند خطی (شماره شرط همخطی چندگانه)، و شرایط خودهمبستگی فضایی مورد تجزیه و تحلیل قرار گرفت. مقادیر خودهمبستگی فضایی نیز برای باقیمانده ها مورد بررسی قرار گرفت. آنها همچنین برای تأیید شرایط توزیع نرمال و هموسداستیسیته آزمایش شدند.
روش اعمال شده را می توان در چهار مرحله خلاصه کرد. ابتدا، کارایی مدلهای جایگزین مورد مطالعه در اینجا از طریق مقایسه نتایج آنها با نتایج ارائه شده توسط مدل رگرسیون چندگانه به نام T74 مورد تجزیه و تحلیل قرار گرفت. مدل T74 به بهترین وجه با داده های سال 1974 مطابقت دارد، اما هیچ اطلاعاتی در مورد توزیع مکانی داده ها را شامل نمی شود. مرحله دوم استفاده از بهترین مدل جایگزین برای تخمین سفرهای آینده بود. مجموعه داده نظرسنجی OD در سال 2003 اطلاعات واقعی را برای مقایسه با برآوردهای تولید شده با مدل T74 برای همان سال ارائه کرد. در مرحله سوم، مدل های جدید برای سال 2003 با استفاده از همان ساختار مدل های تنظیم شده برای سال 1974 کالیبره شدند. با توجه به بازه زمانی نزدیک به 30 سال، تغییراتی در روابط بین متغیرها قابل انتظار بود. از این رو، هر گونه تغییر در ضرایب متغیرها به دقت مورد تجزیه و تحلیل قرار گرفت. این مرحله همچنین به منظور یافتن این بود که کدام یک از مدل های آزمایش شده برای سال 1974 بهترین برازش را با داده های سال 2003 دارد.
آخرین گام، یافتن مهمترین متغیرها برای سال 2003 و مدلی بود که بهترین تعدیل را با دادههای واقعی داشته باشد، بر اساس این فرض که معرفی شاخصهای مکانی عملکرد مدل را بهبود میبخشد. علاوه بر ابزارهای موجود در بسته نرم افزاری GIS-T، از روش رگرسیون گام به گام رو به جلو نیز برای تحلیل تغییرات ایجاد شده در مدل ها با گنجاندن متغیرهای فضایی استفاده شد.
لازم به ذکر است که تمرکز مطالعه به مرحله تولیدات سفر در منزل (HBTP) محدود شده است که تنها بخشی از اولین مرحله از روش مدل چهار مرحله ای یا برنامه ریزی حمل و نقل شهری (UTP) است. همچنین، سفرها بر اساس حالت یا هدف از هم جدا نشدند، زیرا این اطلاعات در مجموعه داده سال پایه در دسترس نبود. از این رو، روش پیشنهادی قصد ندارد به بحث در مورد موضوع پایان دهد. برعکس، ایده این است که تحقیقات در مورد استفاده از ابزارها و تکنیکهای تحلیل فضایی در برنامهریزی حملونقل را تقویت کنیم، همانطور که وانگ و همکارانش پیشنهاد کردند. [ 2 ].
4. نتایج و بحث
نتایج در این بخش به همان ترتیبی که مدلها ساخته شدند، با متغیرهای معمولی و مجموعه دادههای 1974 شروع میشوند، ارائه میشوند.
4.1. رگرسیون چندگانه-مدل سنتی با مجموعه داده 1974 (T74)
نتایج اصلی مدل T74، که مدل رگرسیون چندگانه بود که در ابتدا با مجموعه داده 1974 با برنامه کامپیوتری GeoDA تنظیم شد، در جدول 2 خلاصه شده است. مقادیر استاندارد شده جمعیت (POPst) و ناوگان خودرو (CARst) به عنوان متغیرهای مستقل استفاده شد. آنها قبلاً به عنوان مهمترین متغیرهای توضیحی سنتی برای HBTP در سال 1974 توسط Lopes و Rodrigues da Silva [ 32 ] که جزئیات انتخاب و استانداردسازی این متغیرها را نیز مورد بحث قرار دادند، تعیین شده بودند. مدل به خوبی واریانس متغیر وابسته (HBTP) را توضیح میدهد، همانطور که با مقدار R-squared تنظیم شده 0.91 نشان داده شده است. همچنین آزمون t Student نشان داد که تمامی پارامترهای مدل در سطح معنی داری 5 درصد معنادار هستند.
GeoDA همچنین شماره شرط چند خطی را به عنوان شاخص احتمالی چند خطی بودن ارائه می دهد. مقادیر بالای 30 نشان می دهد که متغیرها همبستگی بالایی دارند. در آن صورت، اطلاعات به دست آمده در صورتی که متغیرها به طور جداگانه مورد بررسی قرار گیرند ممکن است برای تجزیه و تحلیل کافی نباشد. عدد شرط چند خطی به دست آمده برابر با 2.309 بود. بنابراین، هیچ نشانه ای مبنی بر همبستگی متغیرهای مستقل وجود نداشت. یکی دیگر از شواهد چند خطی بودن تفاوت قابل توجهی بین مقادیر R-squared و R-squared تعدیل شده بود که همچنین یافت نشد.
تجزیه و تحلیل نرمال بودن باقیمانده ها از طریق آزمون Jarque-Bera مورد بررسی قرار گرفت. برای مدل T74 مقدار این آمار برابر با 27.52 بود که نشان می دهد فرضیه توزیع نرمال در سطح معنی داری 5 درصد رد شده است. مقادیر آمار مربوط به همسویی بودن آزمون خطا متناقض بود. در حالی که آزمون های بروش-پاگان و وایت فرضیه همسویی بودن را رد کردند، آزمون کوئنکر-باست این فرضیه را در همه موارد برای سطح معنی داری 5 درصد رد نکرد. به گفته گرین [ 38 ]، در غیاب نرمال بودن، شواهدی وجود دارد که نشان میدهد آزمون کوئنکر-باست آزمون قویتری برای همسویی بودن ارائه میدهد. به این ترتیب نمی توان فرضیه همسویی را رد کرد.
گام بعدی تحلیل مدل، جستجوی وابستگی فضایی با مشاهده آمارهای زیر بود: ضریب لاگرانژ (خطا)، ضریب لاگرانژ قوی (خطا)، ضریب لاگرانژ (SARMA)، ضریب لاگرانژ (تاخیر)، ضرب کننده قوی لاگرانژ (خطا) تاخیر) و Moran’s I (خطا). از این آمار، تنها ضریب لاگرانژ قوی (تاخر) معنی دار در نظر گرفته نشد. بنابراین، فرضیه وجود خودهمبستگی فضایی رد نشد. اهمیت آماری ضریب لاگرانژ (خطا) مشخصه یک مدل خطای فضایی (ERR74) را پیشنهاد می کند که در جدول 2 ارائه شده و در ترتیب مورد بحث قرار گرفته است. آنسلین [ 36] نشان میدهد که نسخههای قوی آمار تنها در صورتی در نظر گرفته میشوند که نسخههای استاندارد (LM-Lag یا LM-Error) قابل توجه باشند. اگر فرم استاندارد قابل توجه باشد اما فرم قوی نباشد، مشکلات تعیین نادرست وجود دارد.
جدول 2. خلاصه مدل های مورد مطالعه و نتایج برآورد برای HBTP.
4.2. مدل رگرسیون مکانی-خطای مکانی با مجموعه داده 1974 (ERR74)
در مدل ERR74 مقدار تخمینی λ که ضریب خودرگرسیون مکانی است 0.645 بود. آزمون z λ را به عنوان بسیار معنی دار و همچنین سایر پارامترهای مدل را نشان داد. مقدار لگاریتم درستنمایی (LIK) یافت شده برای این مدل برابر با 01/787- بود که در مقایسه با مقدار 34/802- که برای مدل T74 به دست آمده بود، بهبود کمی داشت. تغییرات دیگر به نفع مدل ERR74 در مقادیر آمار AIC و SC (معیار شوارتز) از 1610.68 (مدل T74) تا 1580.02 (مدل ERR74) و 1618.18 (مدل T74) تا 1587.52 (مدل ER74) یافت شد. . این نتایج نشان می دهد که مدل ERR74 بهتر از مدل T74 با داده های سال 1974 تنظیم شده است. با این حال، آزمون بروش-پاگان فرضیه همسویی بودن را رد کرد و آزمون نسبت احتمال وجود وابستگی فضایی را پیشنهاد کرد.
4.3. مدل رگرسیون چندگانه – مدل جهانی محلی جایگزین با مجموعه داده 1974 (AGL74)
گام بعدی شامل تنظیم یک مدل با شاخصهای محلی و جهانی وابستگی فضایی به عنوان متغیرهای فضایی بود. مدلی از این نوع، به نام AGL، مدلی بود که در مطالعه قبلی انجام شده توسط لوپس و رودریگز داسیلوا [ 32 ]، با داده های سال 1974 به بهترین وجه برازش داشت. متغیرهای فضایی شامل: LISA_DPOPst و LISA_DHHst، که به ترتیب نشاندهنده شاخصهای محلی استاندارد شده وابستگی مکانی برای متغیرهای تراکم جمعیت (DPOP) و تراکم خانوارها (DHH) هستند. و همچنین متغیر DFLEET_Q2، که یک نمایش باینری است که به ربع Low-Low نمودار پراکندگی موران برای چگالی متغیر ناوگان خودرو مرتبط است. R-squared تنظیم شده برای مدل AGL74 0.95 بود ( جدول 2 ).
آزمون t Student نشان داد که تمامی پارامترهای مدل AGL74 در سطح 05/0 معنی دار بودند. عدد شرط چند خطی 9.047 بود که نشان میدهد متغیرهای مستقل همبستگی بالایی ندارند. آزمون Jarque-Bera فرضیه توزیع نرمال باقیمانده ها را رد نکرد و آزمون های Breusch-Pagan و Koenker-Basett فرضیه واریانس ثابت برای خطاها را رد نکردند.
علاوه بر این، افزایش در مقدار لگاریتم درستنمایی (LIK) به -773.2 و کاهش در مقادیر آمار AIC و SC به ترتیب به 1558.4 و 1573.4 مشاهده شد. این مقادیر نشان دهنده برتری مدل AGL74 در مقایسه با مدل های قبلی تنظیم شده T74 و ERR74 است. همانطور که می توان با نتایج مورد بحث تا کنون پیش بینی کرد، فرضیه خودهمبستگی فضایی باقیمانده ها رد شد. برتری مدل AGL را می توان با تجزیه و تحلیل بصری شکل 1 نیز تأیید کرد که در آن نقشه های موران با پراکندگی باقیمانده های سه مدل آزمایش شده نشان داده شده است.
4.4. اعتبار سنجی مدل جهانی محلی جایگزین (AGL74)
دنباله این مطالعه استفاده از مدل AGL74 برای برآوردهای آینده بود. سپس مجموعه داده بررسی OD سال 2003 برای بررسی عملکرد مدل مورد استفاده قرار گرفت. این مقادیر واقعی نیز با برآوردهای به دست آمده با مدل T74 مقایسه شد. مقادیر HBTP برآورد شده با دو مدل برای سال 2003 به طور قابل توجهی پایین تر بود. آنها 59٪ (مدل AGL74) و 55٪ (مدل T74) را از آنچه در واقعیت مشاهده شده بودند نشان دادند (EDOM 2003). این نتایج ممکن است نشان دهد که ضرایب متغیرها در دو مدل تنظیم شده برای سال 1974، پدیده مورد تجزیه و تحلیل را دست کم می گیرند. مقادیر بالای خطاها در برآوردهای سال 2003 را می توان با تجزیه و تحلیل شکل 2 تأیید کرد.، که در آن خوشههایی از مناطق با مقادیر باقیمانده زیاد-بالا (مقادیر بالا احاطه شده با مقادیر بالا) یافت شد. این امر به دو صورت میتواند ناشی از پویایی توسعه شهری باشد: از طریق تغییر در روابط بین متغیرهای مختلف تأثیرگذار بر پدیدههای مورد مطالعه و همچنین از طریق تغییر در الگوهای فضایی در آن دوره نزدیک به 30 سال. نقشههای موضوعی شکل 3 تغییرات الگوهای فضایی تولیدات سفرهای خانگی را نشان میدهد که در واقع از سال 1974 تا 2003 رخ داده است. در حالی که در سال 1974 مناطق با بیشترین تعداد سفرها عمدتاً در اطراف CBD متمرکز بودند، در سال 2003 آنها در سراسر جهان توزیع شدند. بخش های شرقی، جنوب غربی و جنوب شرقی شهر.
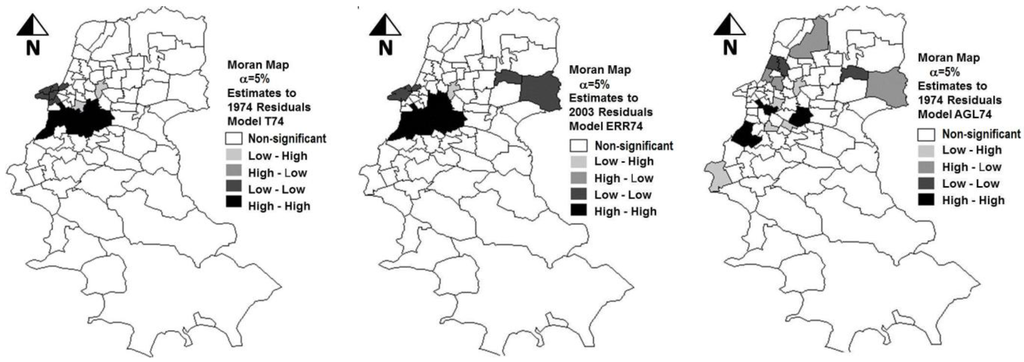
شکل 1. توزیع فضایی باقیمانده های برآوردهای به دست آمده با مدل های T74، ERR74 و AGL74 در مقایسه با داده های واقعی سال 1974 (α = 5٪؛ فاز کالیبراسیون).
4.5. مدل رگرسیون چندگانه- سنتی با مجموعه داده 2003 (T03)
رویکرد مدلسازی سنتی که برای مجموعه دادههای 1974 اعمال شد و در بخش 4.1 شرح داده شد ، همچنین برای ساخت مدل T03 با مجموعه دادههای 2003 استفاده شد (همانطور که در قسمت سمت راست جدول 2 نشان داده شده است.). با این حال، مقایسه ضرایب دو مدل، تفاوت های زیادی را در مقادیر نشان داده است. تفاوت قابل توجهی برای متغیر POPst (3.4 برابر بیشتر برای T03 نسبت به T74) و برای مدت ثابت مدل (1.8 برابر بیشتر برای T03 نسبت به T74) وجود دارد. متغیر FLEETst که دومین متغیر سنتی موجود در مدل بود، با این حال، از نظر بزرگی مقادیر مشابهی برای هر دو مدل داشت. با توجه به اینکه مقادیر متغیرها در هر دو دوره استاندارد شده بودند، این نتایج نشان می دهد که تأثیر جمعیت (POPst) بر تقاضای حمل و نقل در سال 2003 بیشتر از سال 1974 بود، در حالی که تأثیر ناوگان اتومبیل (FLEETst) تقریباً یکسان بود. در هر دو دوره زمانی
همانطور که در جدول 2 مشاهده می شودمقدار R-squared تعدیل شده مدل T03 برابر با 0.97 بود. این نشانه ای است که واریانس متغیر وابسته HBTP به طور رضایت بخشی توسط مدل گرفته شده است. آزمون t Student نشان داد که تمامی پارامترهای مدل T03 در سطح 05/0 از نظر آماری معنی دار هستند. عدد شرط چند خطی 2.975 بود که نشان می دهد متغیرهای مستقل همبستگی بالایی ندارند. همان آزمون های مورد استفاده برای تجزیه و تحلیل خطاهای مدل های دیگر نیز برای مدل T03 اعمال شد. نتایج این آزمونها تأیید کرد که فرضیههای توزیع نرمال و همسیداستیتی در سطح 5 درصد معنیداری رد نشدند. از آنجایی که فرضیه عدم وجود خودهمبستگی فضایی رد شد، فرمولبندی مدلهای فضایی نشان داده شد. یک مدل تاخیر مکانی و یک مدل خطای فضایی دیگر، به ترتیب LAG03 و ERR03،جدول 2 ).
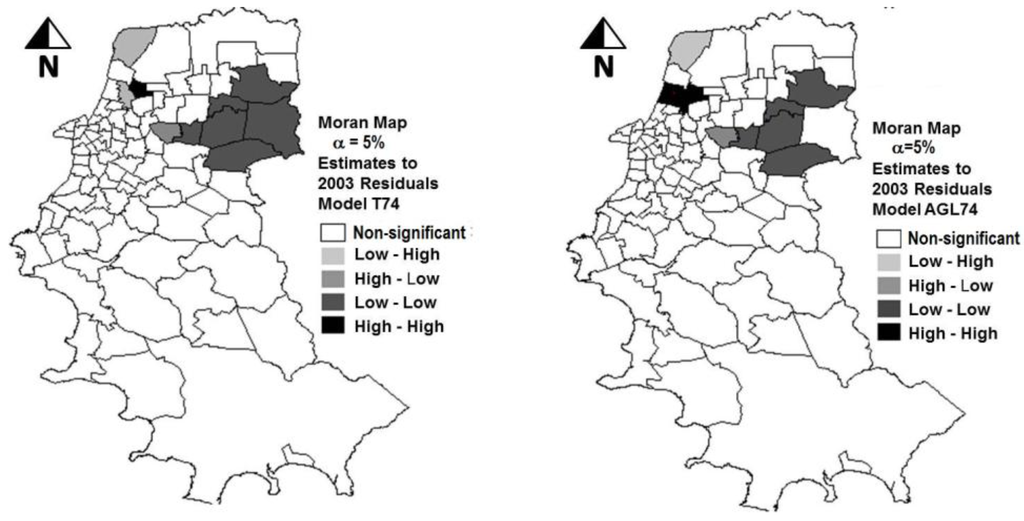
شکل 2. توزیع فضایی باقیماندههای تخمینهای بهدستآمده با مدلهای T74 و AGL74 در مقایسه با دادههای واقعی سال 2003 (α = 5٪؛ مرحله اعتبارسنجی).
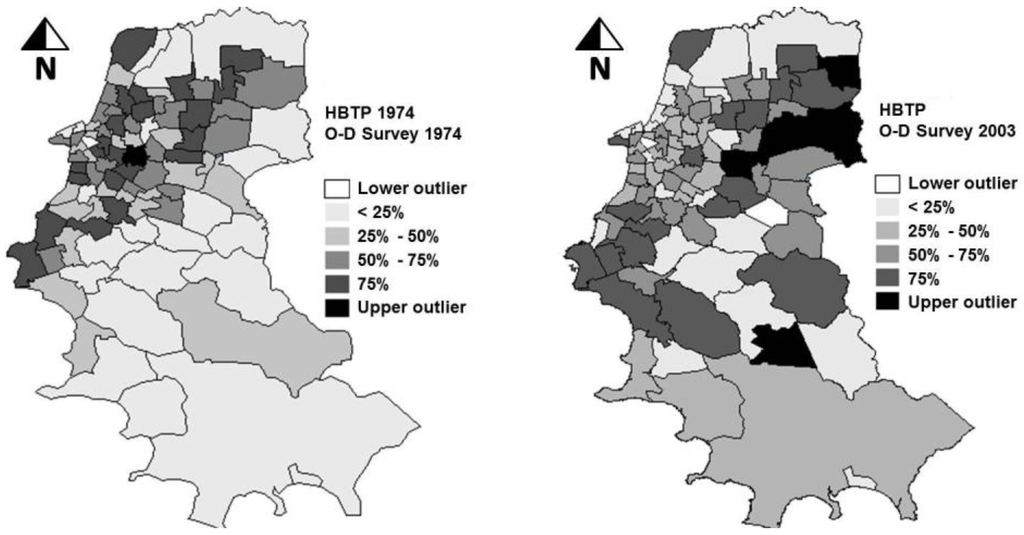
شکل 3. توزیع فضایی تولیدات HBTP در سفرهای خانگی در سال 1974 و 2003. نقشه بر اساس نمودار جعبه با نقاط پرت بالا و پایین 1.5 برابر محدوده بین چارکی.
4.6. مدل رگرسیون مکانی-خودرگرسیون مکانی با مجموعه داده 2003 (LAG03)
مقدار تخمینی ضریب خودرگرسیون فضایی (λ) برای مدل LAG03 0.084 بود. آزمون z λ و سایر پارامترهای مدل را معنی دار نشان داده است. علاوه بر این، آزمون بروش-پاگان فرضیه واریانس ثابت را برای باقیماندهها رد کرد و احتمال ورود به سیستم (LIK) فرضیه عدم وجود خودهمبستگی فضایی را رد کرد. بنابراین، نتایج نشان داد که این مدل (LAG03) برای تکرار داده های 2003 مناسب نیست.
4.7. مدل رگرسیون مکانی-خطای مکانی با مجموعه داده 2003 (ERR03)
برای مدل ERR03، مقدار λ (W_HBPT) 0.457 و سایر پارامترهای برآورد شده با آزمون z معنی دار نشان داده شد. فرضیه همبستگی و عدم وجود خودهمبستگی فضایی به ترتیب با آزمون بروش-پاگان و با لاگ احتمال (LIK) رد شد. در نتیجه مدل ERR03 نیز برای اهداف این مطالعه پذیرفته نشد.
4.8. رگرسیون چندگانه-مدل جهانی محلی جایگزین با مجموعه داده 2003 (AGL03)
گام بعدی افزودن شاخص های محلی و جهانی وابستگی فضایی به عنوان متغیرهای مستقل بود، به همان روشی که برای مجموعه داده 1974 انجام شد (همانطور که در بخش 4.3 بحث شد )، که منجر به مدل AGL03 ( جدول 2 ) شد. به استثنای ضرایب برآورد شده برای LISA_DPOPst و LISA_DHHst، همه پارامترهای دیگر در سطح معنی داری 5٪ معنی دار بودند. مقدار R-squared تعدیلشده بهدستآمده برابر با 98/0 بود و مفروضات نرمال بودن و همسیداستیک بودن خطاها در سطح 5 درصد معنیداری رد نشد. عدد شرط چند خطی 9.386 بود که نشان میدهد متغیرهای مستقل همبستگی بالایی ندارند. فرضیه خودهمبستگی فضایی رد شد.
خلاصه ای از ویژگی های مدل ها و نتایج آزمون های آماری مربوطه در جدول 2 ارائه شده است. بهترین نتایج برجسته شده است. با توجه به اینکه مدل AGL03 بالاترین مقدار LIK و کمترین مقادیر AIC و SC را ارائه کرد، این مدل از نظر کیفیت تنظیم بهتر از سه تلاش دیگر با مجموعه داده 2003 است. همانطور که در مورد مجموعه داده 1974، گنجاندن متغیرهای مکانی و تنظیم بعدی توسط حداقل مربعات معمولی منجر به کیفیت بهتر تعدیل نیز برای مجموعه داده 2003 شد.
همانطور که قبلاً بحث شد، ایده کالیبره کردن مدل ها با مجموعه داده 2003 اما با در نظر گرفتن همان متغیرهای مدل تنظیم شده با مجموعه داده 1974، تعیین تأثیر ساختار مدل بر ضرایب و عملکرد آن بود. با این حال، با وجود نتایج خوب مدل AGL03، دو متغیر از سه متغیر فضایی گنجانده شده معنیدار نبودند. این امر نیاز به تحقیقات بیشتر را به منظور جستجوی متغیرهای اضافی که می تواند داده های سال 2003 را بهتر نشان دهد، پیشنهاد می کند. بنابراین، مدلی برای سال 2003 نیز با استفاده از یک الگوریتم گام به گام ساخته شد، مشابه آنچه که با مجموعه داده 1974 انجام شد و منجر به مدل AGL74 شد.
4.9. مدل جهانی جایگزین با مجموعه داده 2003 (AG03)
آخرین مدل آزمایش شده یک مدل رگرسیون چندگانه شامل شاخص های جهانی وابستگی فضایی به عنوان متغیرهای اکتشافی بود. جستجو برای بهترین مدل با 18 متغیر کاندید آغاز شد. 6 متغیر سنتی، سه متغیر محلی وابستگی مکانی و 9 متغیر جهانی وابستگی مکانی بودند. این فرآیند منجر به مدلی به نام AG03 شد که در جدول 3 ارائه شده است. پس از استفاده از روش رگرسیون گام به گام رو به جلو، شاخص جهانی وابستگی فضایی (DPOP_Q2) نیز معنادار یافت شد. بنابراین، علاوه بر متغیرهای سنتی POPst، FLEETst و HHst در مدل گنجانده شد. متغیرهای سنتی به ترتیب مقادیر استاندارد شده جمعیت، ناوگان خودرو و خانوارها را در هر TAZ نشان می دهند. متغیر فضایی DPOP_Q2 TAZ ها را با مقادیر تراکم جمعیت در ربع 2 نشان می دهد ( به عنوان مثال ، مقادیر کم-پایین در نمودار پراکندگی موران)، که نشانگر ارتباط فضایی جهانی است. همانطور که در جدول 3 مشاهده می شود، این مدل در تمام تست ها به طور رضایت بخشی عمل کرد . همچنین، مقادیر LIK، AIC و SC، و همچنین MRE، بهتر از مقادیر یافت شده برای مدل قبلی تنظیم شده AGL03 بود.
جدول 3. خلاصه ای از بهترین مدل تنظیم شده برای HBTP هنگام در نظر گرفتن داده های 2003.
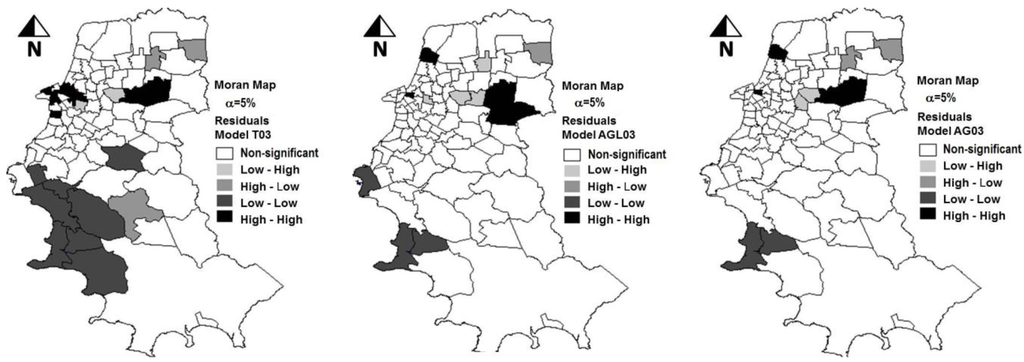
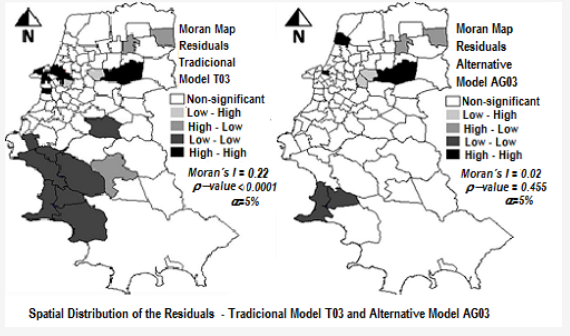
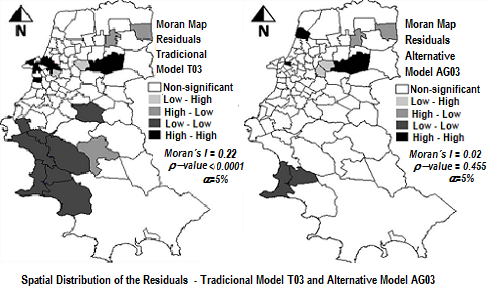
شکل 4. توزیع فضایی باقیمانده های برآوردهای به دست آمده با مدل های T03، AGL03 و AG03 در مقایسه با داده های واقعی سال 2003 (α = 5٪).
بنابراین، این مطالعه این فرض را تایید کرد که گنجاندن شاخصهای وابستگی مکانی در بین متغیرها میتواند قدرت پیشبینی مدل را بهبود بخشد. نقشه های موران در شکل 4 ، که مناطق با گروه بندی قابل توجه مقادیر بالا یا پایین باقیمانده های تخمینی را نشان می دهد، همچنین برتری مدل های جایگزین AGL03 و AG03 را در مقایسه با مدل سنتی T03 نشان می دهد. مدل T03 چندین منطقه را نشان میدهد که در مناطقی با مقادیر مطلق باقیماندهها گروهبندی شدهاند، که نشاندهنده تمایل به دست کم گرفتن یا دستکمگرفتن تعداد سفرها در مناطق خاص است.
5. نتیجه گیری ها
نتایج کاربرد در شهر پورتو آلگره نشان داد که مدلهای جایگزین ( یعنی مدلهای رگرسیون فضایی یا مدلهای رگرسیون شامل متغیرهای فضایی) بهتر از مدلهای سنتی عمل میکنند. بنابراین، اثرات وابستگی مکانی در مدلهای رگرسیونی مهم است و باید به صراحت مورد توجه قرار گیرد. این در مدل های ساخته شده با استفاده از مجموعه داده های 1974 و 2003 مشاهده شد.
مدلهای AGL مدلهای رگرسیون چندگانه هستند که شامل متغیرهای فضایی (هم جهانی و هم محلی) به عنوان متغیرهای مستقل هستند. AGL74 مدلی بود که بهترین برازش را با داده های سال 1974 داشت. به طور مشابه، AGL03 در ابتدا مدلی بود که بهترین نتایج را برای مجموعه داده 2003 نشان داد. با این حال، پس از آن، بررسی مهم ترین متغیرها برای سال 2003 منجر به توسعه مدل AG03 شد که بهترین گزینه تنظیم شده برای مجموعه داده 2003 شد. از این رو، گنجاندن متغیرهای فضایی، مانند شاخصهای جهانی و محلی وابستگی فضایی، در مشخصات مدل و تعدیل بعدی توسط حداقل مربعات معمولی بهترین جایگزین در مورد مورد تجزیه و تحلیل بود. همچنین به گفته گتیس و گریفیث [ 37]، این رویکرد نتایج را مستقیماً با روش های آماری سنتی تر مقایسه می کند.
با این حال، پیشبینیهای بلندمدت در شهرهای با رشد سریع، مانند موردی که در اینجا مورد بحث قرار گرفت، ممکن است به خوبی توسط مدلها نمایش داده نشود. تغییرات قابل توجه مشاهده شده در تنظیمات شهری پورتو آلگره مطمئناً یکی از دلایلی است که نشان می دهد نتایج به دست آمده با مدل AGL74 فقط اندکی بهتر (و نه به طور قابل توجهی) از نتایج به دست آمده با سایر مدل ها بود. ما معتقدیم که در نظر گرفتن اثرات ناشی از پویایی توسعه شهری در مدل سازی تقاضای حمل و نقل می تواند نتایج را بیشتر بهبود بخشد.
مقایسه ضرایب مدلهای تعدیلشده برای سال 2003 با ضرایب تعدیلشده برای سال 1974، تغییرات قابلتوجهی را در روابط متغیرها در آن دوره نزدیک به سه دهه نشان میدهد. به عنوان مثال، وزن جمعیت که یک متغیر توضیحی برای تولیدات سفرهای خانگی است، در سال 2003 بسیار بیشتر از سال 1974 بود. همچنین تغییراتی در الگوهای فضایی سفرها در دوره های مختلف وجود داشت. تحلیلهای آنها ممکن است به درک بهتر پویایی توسعه شهری، برای بهبود مدلهای مورد بحث در اینجا کمک کند.
منابع
- پائز، آ. Scott، DM آمار فضایی برای تحلیل شهری: مروری بر تکنیک ها با مثال. جئوژورنال 2004 ، 61 ، 53-67. [ Google Scholar ] [ CrossRef ]
- وانگ، سی. قدوس، م. رایلی، تی. انوک، م. دیویسون، ال. مدل های فضایی در حمل و نقل: بررسی و ارزیابی مسائل روش شناختی. در مجموعه مقالات نود و یکمین نشست سالانه هیئت تحقیقات حمل و نقل، واشنگتن، دی سی، ایالات متحده آمریکا، 22 تا 26 ژانویه 2012.
- بولدوک، دی. Dagenais، MG; Gaudry، MJI خطاهای همبسته فضایی در مدلهای مبدا-مقصد: مشخصات جدیدی که برای انتخاب حالت جمعی اعمال میشود. ترانسپ Res. قسمت ب 1989 ، 23 ، 361-372. [ Google Scholar ] [ CrossRef ]
- بولدوک، دی. لافریر، آر. سانتاروسا، G. مولفه های خطای خودبازگشت فضایی در مدل های جریان سفر. Reg. علمی اقتصاد شهری 1992 ، 22 ، 371-385. [ Google Scholar ] [ CrossRef ]
- بولدوک، دی. لافریر، آر. سانتاروسا، G. مولفه های خطای خودرگرسیون فضایی در مدل های جریان سفر: یک کاربرد برای انتخاب حالت جمع. در جهت های جدید در اقتصاد سنجی فضایی ; Anselin, L., Florax, RJGM, Eds. Springer-Verlag: برلین، آلمان، 1995; صص 96-108. [ Google Scholar ]
- حیدر، م. میلر، EJ اثرات زیرساختهای حملونقل و مکان بر ارزشهای املاک مسکونی: کاربرد تکنیکهای خودرگرسیون فضایی. ترانسپ Res. ضبط 2000 ، 1722 ، 1-8. [ Google Scholar ] [ CrossRef ]
- وانگ، FH تغییرات درون شهری رفت و آمد را با نزدیکی شغل و ویژگی های کارگران توضیح می دهد. محیط زیست برنامه ریزی کنید. B 2001 , 28 , 169-182. [ Google Scholar ] [ CrossRef ]
- چادو، سی. پروکوپنکو، اس. مدل سازی تصمیمات حالت حمل و نقل با استفاده از مدل های رگرسیون لجستیک سلسله مراتبی با اثرات فضایی و خوشه ای. آمار مدل. 2008 ، 8 ، 315-345. [ Google Scholar ] [ CrossRef ]
- کاوامورا، ک. ماهاجان، اس. تحلیل لذتگرایانه تأثیرات حجم ترافیک بر ارزشهای دارایی. ترانسپ Res. ضبط 2005 ، 1924 ، 69-75. [ Google Scholar ] [ CrossRef ]
- ویچینسان، وی. پائز، آ. کاوایی، ک. میاموتو، ک. روش درونیابی فضایی غیر ساکن برای توسعه مدل شهری. ترانسپ Res. ضبط 2006 ، 1977 ، 103-111. [ Google Scholar ] [ CrossRef ]
- ژو، بی. Kockelman، KM ریزشبیهسازی توسعه زمین مسکونی و انتخاب مکان خانگی: مناقصه برای زمین در آستین، تگزاس. در مجموعه مقالات هشتاد و هفتمین نشست سالانه هیئت تحقیقات حمل و نقل، واشنگتن، دی سی، ایالات متحده آمریکا، 13 تا 17 ژانویه 2008.
- ریبیرو، آ. Antunes، دسترسی AP و توسعه در مناطق بدون هزینه پرتغال: تحلیل رگرسیون فضایی. در مجموعه مقالات کنفرانس حمل و نقل اروپا، Noordwijkerhout، هلند، 5-7 اکتبر 2009.
- Chalermpong، S. حمل و نقل ریلی و استفاده از زمین مسکونی در کشورهای در حال توسعه: مطالعه لذتبخش قیمتهای املاک مسکونی در بانکوک، تایلند. در مجموعه مقالات هشتاد و ششمین نشست سالانه هیئت تحقیقات حمل و نقل، واشنگتن، دی سی، ایالات متحده آمریکا، 21 تا 25 ژانویه 2007.
- هاکنی، جی. برنارد، ام. بیندرا، اس. Axhausen، KW سرعت های جاده را با مدل های رگرسیون فاصله مکانی و خطای مکانی توضیح می دهد. مجموعه مقالات هشتاد و ششمین نشست سالانه هیئت تحقیقات حمل و نقل ، واشنگتن، دی سی، ایالات متحده آمریکا، 21 تا 25 ژانویه 2007.
- هاکنی، جی. برنارد، ام. بیندرا، اس. Axhausen، KW پیش بینی سرعت سیستم جاده با استفاده از متغیرهای ساختار فضایی و ویژگی های شبکه. جی. جئوگر. سیستم 2007 ، 9 ، 397-417. [ Google Scholar ] [ CrossRef ]
- نواک، دی سی؛ هاجدون، سی. گوا، اف. Aultman-Hall، L. مدل های تولید بار در سراسر کشور: یک رویکرد رگرسیون فضایی. شبکه تف کردن اقتصاد 2011 ، 11 ، 23-41. [ Google Scholar ] [ CrossRef ]
- بندر، بی. Hwang، H. Hedonic قیمت مسکن و مراکز اشتغال ثانویه. J. شهری اقتصاد. 1985 ، 17 ، 90-107. [ Google Scholar ] [ CrossRef ]
- Eom، JK; پارک، ام اس؛ هیو، تی. هانتسینگر، LF بهبود پیشبینی میانگین ترافیک روزانه سالانه برای تأسیسات غیرآزادراهی با استفاده از یک روش آماری فضایی. ترانسپ Res. ضبط 2006 ، 1968 ، 20-29. [ Google Scholar ]
- وانگ، ایکس. Kockelman، KM پیش بینی داده های شبکه: درون یابی فضایی تعداد ترافیک با استفاده از داده های تگزاس. در مجموعه مقالات هشتاد و هشتمین نشست سالانه هیئت تحقیقات حمل و نقل، واشنگتن، دی سی، ایالات متحده آمریکا، 11 تا 15 ژانویه 2009.
- بات، سی. ژائو، HM تجزیه و تحلیل فضایی تولید توقف فعالیت. ترانسپ Res. قسمت B 2002 ، 36 ، 557-575. [ Google Scholar ] [ CrossRef ]
- Kwan، MP تصویرسازی تعاملی جغرافیایی الگوهای فعالیت سفر با استفاده از سیستم های اطلاعات جغرافیایی سه بعدی: یک کاوش روش شناختی با مجموعه داده بزرگ. ترانسپ Res. قسمت C 2000 ، 8 ، 185-203. [ Google Scholar ] [ CrossRef ]
- استینبرگن، تی. دوفایس، تی. توماس، آی. Flahaut، B. مکان یابی درون شهری و خوشه بندی تصادفات جاده ای با استفاده از GIS: یک مثال بلژیکی. بین المللی جی. جئوگر. Inf. علمی 2004 ، 18 ، 169-181. [ Google Scholar ] [ CrossRef ]
- لی، ال. Zhang، Y. یک رویکرد بیزی مبتنی بر GIS برای شناسایی بخشهای خطرناک جاده برای تصادفات ترافیکی. در مجموعه مقالات هشتاد و ششمین نشست سالانه هیئت تحقیقات حمل و نقل، واشنگتن، دی سی، ایالات متحده آمریکا، 21 تا 25 ژانویه 2007.
- Gundogdu، IB; ساری، ف. Esen, O. یک رویکرد جدید برای نقشه برداری اطلاعات تصادفات ترافیکی توسط سیستم اطلاعات جغرافیایی. در مجموعه مقالات هفته کاری FIG 2008، استکهلم، سوئد، 14-19 ژوئن 2008.
- خان، جی. سانتیاگو-شاپارو، KR؛ Qin، X. Noyce، کاربرد DA و ادغام تجزیه و تحلیل داده های شبکه، توابع k شبکه و GIS برای مطالعه خرابی های مرتبط با یخ. در مجموعه مقالات هشتاد و هشتمین نشست سالانه هیئت تحقیقات حمل و نقل، واشنگتن، دی سی، ایالات متحده آمریکا، 11 تا 15 ژانویه 2009.
- گوا، اف. وانگ، ایکس. Abdel-Aty، MA، تحلیل ایمنی تقاطع علامتدار سطح راهرو با استفاده از مدلهای فضایی بیزی. در مجموعه مقالات هشتاد و هشتمین نشست سالانه هیئت تحقیقات حمل و نقل، واشنگتن، دی سی، ایالات متحده آمریکا، 11 تا 15 ژانویه 2009.
- پائز، آ. لوپز، FA; رویز، م. مورنسی، ج. توسعه شاخصی برای ارزیابی تناسب فضایی مدلهای انتخاب گسسته. ترانسپ Res. قسمت B. 2013 ، 56 ، 217-233. [ Google Scholar ] [ CrossRef ]
- ویکتوریا، آی سی; پروزی، جی. والتون، سی ام. Prozzi، J. مناطق تمرکز عدالت زیست محیطی برای ارزیابی اثرات پروژه حمل و نقل. ترانسپ Res. ضبط 2006 ، 1983 ، 75-80. [ Google Scholar ]
- ایبیاس، ا. کوردرا، آر. دل اولیو، ال. کاپولا، پی. دومینگوئز، الف. مدل سازی تعاملات ارزش های حمل و نقل و املاک در سیستم های شهری. J. Transp. Geogr. 2012 ، 24 ، 370-382. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- افتیمیو، دی. آنتونیو، سی. چگونه زیرساختها و سیاستهای حملونقل بر قیمت و اجاره خانه تأثیر میگذارند؟ شواهدی از آتن، یونان. ترانسپ Res. قسمت A 2013 ، 52 ، 1-22. [ Google Scholar ]
- هورنر، مگاوات؛ موری، AT رفت و آمد اضافی و مشکل واحد منطقه ای قابل تغییر. مطالعه شهری. 2002 ، 39 ، 131-139. [ Google Scholar ] [ CrossRef ]
- لوپس، اس بی؛ رودریگ داسیلوا، AN یک مطالعه ارزیابی وابستگی فضایی در مدلهای تقاضای حملونقل. در مجموعه مقالات سیزدهمین کنفرانس پان آمریکایی مهندسی ترافیک و حمل و نقل، آلبانی، نیویورک، ایالات متحده آمریکا، 27-29 سپتامبر 2004.
- Anselin, L. Under the hood: مسائلی در مشخصات و تفسیر مدل های رگرسیون فضایی. کشاورزی. اقتصاد 2002 ، 17 ، 247-267. [ Google Scholar ] [ CrossRef ]
- Fotheringham، AS; براندون، سی. چارلتون، ام. جغرافیای کمی: دیدگاههای تحلیل دادههای فضایی . Sage: لندن، بریتانیا، 2000. [ Google Scholar ]
- Anselin, L. The Moran Scatterplot به عنوان یک ابزار ESDA برای ارزیابی ناپایداری محلی در انجمن فضایی. در دیدگاه های تحلیلی فضایی GIS ; Fischer, M., Scholten, H., Unwin, D., Eds. تیلور و فرانسیس: لندن، بریتانیا، 1996; صص 111-125. [ Google Scholar ]
- راهنمای کاربر Anselin, L. GeoDa™ 0.9. در دسترس آنلاین: https://geodacenter.org/downloads/pdfs/geoda093.pdf (دسترسی در 31 دسامبر 2013).
- گتیس، ع. گریفیث، DA فیلترینگ فضایی مقایسه ای در تحلیل رگرسیون. Geogr. مقعدی 2002 ، 34 ، 130-140. [ Google Scholar ] [ CrossRef ]
- گرین، تحلیل اقتصاد سنجی WH ; Prentice Hall: Upper Saddle River، نیوجرسی، ایالات متحده آمریکا، 2003. [ Google Scholar ]
© 2014 توسط نویسندگان; دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (http://creativecommons.org/licenses/by/3.0/) توزیع شده است.
بدون نظر