

خلاصه
:در پایش بیماری های فضایی، مناطق جغرافیایی با تعداد زیادی از موارد بیماری باید شناسایی شود تا بتوان تحقیقات هدفمند را دنبال کرد. مناطق جغرافیایی با نرخ بیماری بالا، خوشه بیماری نامیده می شوند و آزمایش های تشخیص خوشه آماری برای شناسایی مناطق جغرافیایی با نرخ بیماری بالاتر از حد انتظار به تنهایی استفاده می شود. در برخی شرایط، رویدادهای مرتبط با بیماری به جای افراد مورد توجه نظارت جغرافیایی هستند، و روشهای شناسایی خوشههای رویدادهای مرتبط با بیماری، روشهای تشخیص خوشه رویداد نامیده میشوند. در این مقاله، ما سه فرض توزیعی را برای رویدادهای تشخیص خوشه بررسی میکنیم: پواسون مرکب، نرمال تقریبی و ابر هندسی چندگانه (دقیق). روش ها در انتخاب فرض توزیعی برای رویدادهای مرتبط بالقوه چندگانه برای هر فرد متفاوت است. این روشها در ارائههای بخش اورژانس (ED) توسط کودکان و جوانان (سن کمتر از 18 سال) به دلیل مصرف مواد در استان آلبرتا، کانادا، طی 1 آوریل 2007 تا 31 مارس 2008 نشان داده شدهاند. مطالعات شبیهسازی برای بررسی نوع انجام شده است. خطای I و قدرت روش های خوشه بندی.
خوشه رویداد فضایی ; تشخیص خوشه ; توزیع پواسون مرکب ; توزیع نرمال تقریبی توزیع بیش هندسی چندگانه ; نظارت ؛ مصرف مواد
1. معرفی
در نظارت بر بیماری، از روش های آماری می توان برای شناسایی مناطق جغرافیایی استفاده کرد که از نظر آماری تعداد موارد بیماری بیش از حد انتظار است. این مناطق جغرافیایی با تجمع بیماری را خوشه می گویند. یک خوشه جغرافیایی به عنوان یک منطقه محدود در منطقه مورد مطالعه کلی با افزایش قابل توجهی در بروز یک بیماری تعریف می شود (یک خوشه نقطه داغ؛ به لاوسون [ 1 ] مراجعه کنید.]، پ. 104). در برخی شرایط، بروز یا شیوع بیماری ممکن است بیشترین یا تنها ویژگی مرتبط برای تجزیه و تحلیل نباشد، و تجزیه و تحلیل رویدادهای مربوط به افراد مبتلا ممکن است مناسب تر باشد. به عنوان مثال، هنگام بررسی ارائه خدمات بهداشتی از طریق بخشهای اورژانس (ED)، تعداد ارائهها به ED میتواند بیشتر از تعداد افراد متمایز مشاهده شده در ED مرتبط باشد. اگر افراد زیادی وجود داشته باشند که چندین ارائه داشته باشند، تجزیه و تحلیل صرفاً بر اساس تعداد افراد، و نه تعداد ارائهها، تنها میتواند خوشههایی را با تعداد افراد اضافی شناسایی کند نه خوشههایی با ارائههای اضافی. نادیده گرفتن ارائه ها از شناسایی خوشه هایی جلوگیری می کند که در آن ارائه های بیشتری، اما نه لزوماً تعداد بیشتری از افراد، بیش از حد انتظار انجام می شود.
واحدهای جغرافیایی تجزیه و تحلیل عموماً مناطق اداری هستند که تعداد موارد و جمعیت برای آنها در دسترس است. روش های مختلفی از آزمون های آماری برای مکان یابی و شناسایی خوشه های موارد بیماری در مناطق جغرافیایی پیشنهاد شده است. Besag و Newell [ 2 ] این آزمونهای آماری تشخیص خوشهای را بهعنوان عمومی (همچنین غیرمتمرکز) و متمرکز طبقهبندی کردند. تستهای عمومی هر خوشهای را با تعداد بیش از حد موارد شناسایی میکنند، در حالی که تستهای متمرکز مناطقی از موارد اضافی را در نزدیکی عوامل ایجادکننده احتمالی، مانند آلایندههای محیطی شناسایی میکنند. تعدادی آزمایش مختلف وجود دارد که می تواند خوشه هایی از موارد را تشخیص دهد که منطقه جغرافیایی دارای اندازه های جمعیتی متنوع است (به عنوان مثال، [ 2-5 را ببینید]). هنگامی که رویدادهای مرتبط با بیماری مورد توجه هستند، روشهایی برای تطبیق با احتمال رویدادهای متعدد و مرتبط برای هر فرد مورد نیاز است. آزمایشهای تشخیص خوشههای رویدادها (از این پس، تشخیص خوشه رویداد) یک حوزه تحقیقاتی نسبتاً جدید است و چند رویکرد پیشنهاد شده است. Rosychuk، Huston و Prasad [ 6 ] یک آزمون خوشهبندی رویداد ارائه کردند که از نظر روحی شبیه به استراتژی Besag و Newell [ 2 ] است، که در آن نواحی ترکیب میشوند تا حداقل تعداد معینی از رویدادهای مرتبط با بیماری را در بر گیرند. در رویکرد آنها، احتمال مشاهده تعداد رویدادها بر اساس توزیع پواسون مرکب است و احتمالات مربوطه از طریق یک رابطه بازگشتی به دست میآیند. بر اساس این اثر، ترابی و روزیچوک [ 7] استفاده از یک توزیع نرمال تقریبی را برای توزیع پواسون ترکیبی پیشنهاد کردند و Rosychuk و Stuber [ 8 ] یک آزمایش دقیق بر اساس توزیع ابر هندسی چندگانه ارائه کردند.
ما عملکرد سه رویکرد را برای شناسایی خوشههای جغرافیایی رویدادها ارزیابی میکنیم. بخش 2 آزمایش ها را با جزئیات شرح می دهد و بخش 3 روش های موجود در مجموعه داده های ارائه ED را که توسط کودکان و جوانان برای مصرف مواد ساخته شده است، نشان می دهد. نتایج یک مطالعه شبیه سازی در بخش 4 ارائه شده است و خلاصه ای از یافته ها در بخش 5 ارائه شده است.
2. مواد و روشها
ابتدا تعدادی نماد را معرفی می کنیم که برای همه روش ها استفاده می شود. ما یک منطقه مطالعاتی جغرافیایی را در نظر می گیریم که به مناطق اداری مجزا تقسیم شده است که سلول نامیده می شود . یک رابطه فضایی خام بین سلول ها با محاسبه فواصل زوجی بین مرکز سلول مشخص می شود. برای سلول i، i = 1، ⋯، I ، سلول های باقیمانده در فاصله فزاینده از مرکز سلول مرتب می شوند. به طور خاص ، اجازه میدهیم سلول i p نزدیکترین سلول به سلول i باشد . برای راحتی، i 0 = را تعریف می کنیممن _ جمعیت سلول i با کل جمعیت با n i نشان داده می شودنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونت. برای خوشهبندی رویداد، ما این فرضیه صفر را آزمایش میکنیم که احتمال دارد هر فرد مستقل از افراد دیگر و محل سکونت، رویدادهایی را به یک اندازه داشته باشد. رد فرضیه صفر نشان می دهد که تعداد رویدادها بیشتر از انتظار توزیع رویداد است. برای سلول i ، اجازه دهید C ix ، x < ∞ متغیر تصادفی باشد که تعداد موارد با دقیقاً x رویداد را نشان می دهد (مقدار مشاهده شده c ix ). تعداد کل موارد با حداقل یک رویداد در سلول i C i = ∑ x C ix و متغیر تصادفی V i = ∑ است.x xC ix تعداد رویدادها را نشان می دهد (مقدار مشاهده شده v i ). ما فرض می کنیم که C i و V i متناهی هستند، و سپس، نوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتو نوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتتعداد کل موارد و رویدادها را برای کل منطقه به ترتیب با مقادیر مشاهده شده c و v نشان دهید .
هر سلول به طور جداگانه آزمایش می شود، شبیه به روش Besag و Newell [ 2 ]. آمار آزمون بر اساس تعداد سلولهایی است که باید ترکیب شوند تا نزدیکترین رویدادهای k ∗ را شامل شود، جایی که k ∗ یک عدد طبیعی است. برای سلول i ، آمار آزمون به صورت زیر تعریف می شود:
تعداد رویدادها در سلول های ترکیبی را می توان به عنوان مجموع یک متغیر تصادفی از تعداد رویدادها در نظر گرفت. برای سلول i ، فرض کنید تعداد موارد و جمعیت در l نزدیکترین همسایه آن، نوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتو نوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونت، به ترتیب. تعداد کل رویدادها برای افراد n il را می توان به صورت زیر نوشت:
که در آن Y j یک متغیر تصادفی است که تعداد رویدادهای j- th ( j = 1, …, C il ) فرد را نشان می دهد.
2.1. توزیع پواسون مرکب
رویکرد مرکب پواسون (CP) زمانی که به تعداد رویدادهای یک سلول و همسایه آن به عنوان مجموع تصادفی متغیرهای تصادفی فکر می کنیم، انتخاب طبیعی است (روزیچوک و همکاران [ 6 ]). از آنجایی که هر مورد حداقل یک رویداد و به طور بالقوه بسیاری از رویدادها دارد، سطح اهمیت هر سلول با این فرض تعیین می شود که تعداد رویدادها در سلول های ترکیبی V il دارای توزیع پواسون مرکب است در حالی که C il دارای توزیع پواسون است. بنابراین، V il در معادله (2) دارای توزیع پواسون مرکب تحت فرض صفر است و از رابطه (1) سطح معناداری می شود:
که در آن P il ( z ) = P r ( V il = z ). توجه داشته باشید که احتمال P il ( z ) در رابطه (3) را می توان از طریق یک رابطه بازگشتی به دست آورد (برای مثال رجوع کنید به راس [ 9 ]، ص 156) که در آن:
احتمال Q ( x ) = Pr ( Yj = x ) ممکن است توسط محقق شناخته شود، و λ il = n il C /N میانگین پواسون است. ما عملا استفاده می کنیم λˆمن l=nمن lج / نλ^منل=�منلج/نبا جایگزینی متغیر تصادفی با متغیری که مشاهده می شود. روزیچوک و همکاران [ 6 ] از Q ( x ) = c x /c استفاده کرد که c x تعداد موارد دقیقاً x رویداد است.
اگر توزیع جمعیت در منطقه اداری بر اساس ویژگیهای کلیدی، مانند جنسیت و سن متفاوت باشد، و این ویژگیها هم از جمعیت و هم از دادههای موردی در دسترس باشد، آنگاه میتوان این ویژگیها را به آزمون اضافه کرد تا برای توزیع جمعیت متغیر تنظیم شود. . فرض کنید C •s متغیر تصادفی باشد (مقدار مشاهده شده c •s ) که تعداد موارد در لایه s را نشان می دهد ( s = 1, ⋯, S, S > 1) و n •s کل جمعیت متناظر در کل منطقه باشد. . برای سلول i ، اجازه دهید n isl و C isl باشدبه ترتیب تعداد جمعیت و موارد قشر s و l نزدیکترین همسایه آن باشد. متغیر تصادفی C isl (مقدار مشاهده شده c isl ) از توزیع پواسون با میانگین λ isl = n isl C •s /n •s پیروی می کند و:
تعداد کل رویدادها برای موارد C il است. V il از توزیع پواسون مرکب پیروی می کند، با Yjs برابر با تعداد رویدادهای فرد j- ام در لایه s، j = 1، ⋯، C isl با احتمال Q s ( x ) = Pr ( Y js = x ) برای همه j و رویدادهای x ≥ 1. بنابراین، احتمالات مورد نیاز را می توان از معادلات (4) و (5) با کمک Q تعیین کرد.x ) = Q 1 ( x ) λ i 1 l / λ il + · ⋯ · + Q S ( x ) λ iSl /λ il ، و آزمون معنی داری مربوطه را می توان با رابطه (3) بدست آورد .
2.2. توزیع نرمال تقریبی
هنگامی که اندازه جمعیت بزرگ است، ممکن است تعداد نسبتا زیادی رویداد وجود داشته باشد که می تواند باعث کند محاسبه رابطه بازگشتی معادلات (4) و (5) شود. زمانی که لایه هایی با اطلاعات کمکی داشته باشیم، زمان محاسبه افزایش می یابد. استفاده از یک رویکرد نرمال تقریبی (AN) (ترابی و روزیچوک [ 7 ]) جایگزینی برای رویکرد CP ارائه می دهد. یعنی تعداد کل رویدادها برای افراد n ilVمن l=∑سیمن lj = 1Yj�منل=∑�=1سیمنل��در رابطه (2) دارای توزیع نرمال با میانگین μ il و واریانس است σ2من lσمنل2، و می توانیم میانگین و واریانس V il را به صورت زیر بنویسیم :
و:
که در آن Q ( x ) = Pr ( Yj = x ) در بخش 2.1 مورد بحث قرار گرفته است. بنابراین سطح معنی داری به صورت زیر می شود:
که در آن Φ( · ) توزیع نرمال استاندارد تجمعی است. سطح معناداری در معادله (9) را می توان با استفاده از تخمین ها محاسبه کرد μˆمن lμ^منلو σˆ2من lσ^منل2از پارامترهای میانگین μ il و واریانس σ2من lσمنل2. در نتیجه،
و:
با v∗من=∑ایکسایکس2جمن x�من*=∑ایکسایکس2جمنایکسو v∗=∑منv∗من�*=∑من�من*.
هنگامی که اقشار در تحلیل گنجانده می شوند، V il در رابطه (6) دارای توزیع نرمال با میانگین است μمن l=∑اسs = 1μمن s lμمنل=∑س=1اسμمنسلو واریانس σ2من l=∑اسs = 1σ2من s lσمنل2=∑س=1اسσمنسل2، جایی که μ isl و σ2من s lσمنسل2را می توان به ترتیب از معادلات (7) و (8) با λ isl = n isl C •s / n •s تعریف شده در بالا بدست آورد. بنابراین می توان آزمون معناداری مشابه رابطه (9) بدست آورد. به طور خاص، برای هر دو روش CP و AN، Qs ( x ) را می توان با c •sx /c •s تخمین زد ، که در آن c •sx تعداد موارد با دقیقاً x رویداد در لایه s است.
2.3. توزیع بیش از حد هندسی چندگانه
برای یک رویکرد دقیق، Rosychuk و Stuber [ 8 ] فرکانس های رویداد را به عنوان کلاس در نظر گرفتند، و افراد بدون جایگزینی از کلاس ها نمونه برداری می شوند. این رویکرد منجر به توزیع بیش هندسی چندگانه می شود. احتمال مشاهده x وقایع در میان نمونه ای از m افراد به صورت زیر است:
جایی که سی∙ y=∑منi = 1سیمن yسی•�=∑من=1منسیمن�تعداد کل موارد در کل منطقه مورد مطالعه با دقیقاً y رویداد است و { r y } اعداد صحیح غیر منفی از مجموعه هستند آآبا:
سطح معنی داری برای سلول آزمایش شده i می شود:
از این پس، ما به این رویکرد به عنوان آزمون رویداد دقیق (EE) اشاره می کنیم. در موقعیتهای عملی، متغیرهای تصادفی با مقادیر مشاهدهشده مربوطه جایگزین میشوند و تعداد مورد انتظار رویدادها n il v/N مفید است. علاوه بر این، فرض کنید که V است تعداد رویدادهای سلول i برای اقشار است ، و تعداد رویدادها در سلول i است. Vمن=∑اسs = 1Vمن _=∑اسs = 1∑Yz= 1zسیمن z _�من=∑س=1اس�منس=∑س=1اس∑�=1��سیمنس�، با C isx به عنوان متغیر تصادفی نشان دهنده تعداد موارد در سلول i است که دقیقاً x رویداد دارند. هنگامی که اقشار در نظر گرفته می شوند، آمار آزمون در رابطه (1) اعمال می شود و یک آزمون معناداری مشابه با رابطه (13) با احتمال مربوطه بیان شده در رابطه (12) به دست می آید .
2.4. انتخاب اندازه خوشه
تستهای تشخیص خوشه رویداد که شرح داده شد، همگی به انتخاب اندازه خوشه، k * بستگی دارند ، که معلوم نیست. انتخاب k ∗ بسیار مهم است زیرا انتخاب خیلی بزرگ یا خیلی کوچک ممکن است منجر به از دست دادن خوشه شود. Le، Petkau و Rosychuk [ 10 ] یک الگوریتم آزمایشی را توصیه میکنند که دارای چندین اندازه خوشه خاص سلولی است که به جمعیت سلول و همسایگان آن بستگی دارد. ما شرحی از الگوریتم را در زمینه تست های مختلف ارائه می دهیم.
اجازه دهید ک∗من 0کمن0*، ک∗من 1کمن1*و ک∗من 2کمن2*اندازه های خوشه رویداد انتخاب شده برای سلول i، i = 1، ⋯، I باشد. به روشی مشابه با آنالیز متوالی، سلول i در آن آزمایش می شود ک∗من 0کمن0*، ک∗من 1کمن1*، ک∗من 2کمن2*به ترتیب تنها در صورتی که اندازه خوشه قبلی نتواند به اهمیت برسد. اجازه دهید ک∗من w– 1کمن�*–1صدک 100 (1 – α) توزیع احتمال رویدادها f ( · ) با جمعیت از سلول و تا w نزدیکترین همسایگان آن باشد. اندازه خوشه رویداد ک∗من wکمن�*کوچکترین عدد صحیح است که به صورت زیر تعریف می شود:
اندازه خوشه برابر با ک∗من wکمن�*به عنوان حداقل تعداد رویدادهایی که باید مشاهده شود تا باعث شود سلول i و نزدیکترین همسایگان w آن در سطح α قابل توجه باشند، تفسیر می شود. f ( · ) در معادله (14) با توزیع مناسب روش خاص مورد استفاده جایگزین می شود. برای روش EE، اندازه خوشه رویداد به صورت زیر تعریف می شود:
جایی که M ( x, n iz ) در معادله (12) تعریف شده است .
3. کاربرد به داده های استفاده از مواد
برای نشان دادن رفتار در بین سه روش، ما بر ارائههای ED توسط کودکان و نوجوانان (سن کمتر از 18 سال) برای مصرف مواد در استان غربی کانادا از آلبرتا از 1 آوریل 2007 تا 31 مارس 2008 تمرکز میکنیم. آلبرتا دارای جمعیتی بالغ بر بیش از 3.5 میلیون [ 11 ] و 661848 کیلومتر مربع را پوشش می دهد [ 12 ] . شهر پایتخت، ادمونتون، در نزدیکی مرکز جغرافیایی استان واقع شده است و ادمونتون و کلگری دو منطقه اصلی شهری هستند که هر کدام بیش از یک میلیون نفر جمعیت دارند. مرز جنوب غربی استان دارای رشته کوه های راکی است و نواحی شمالی آن جنگلی و کم جمعیت است.
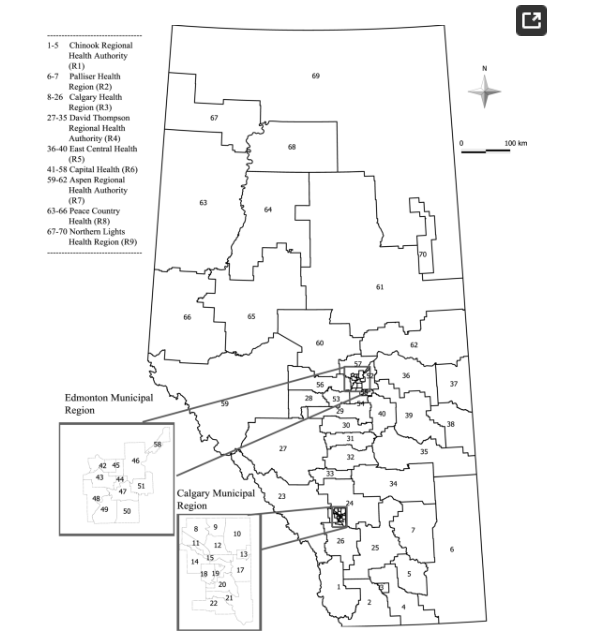
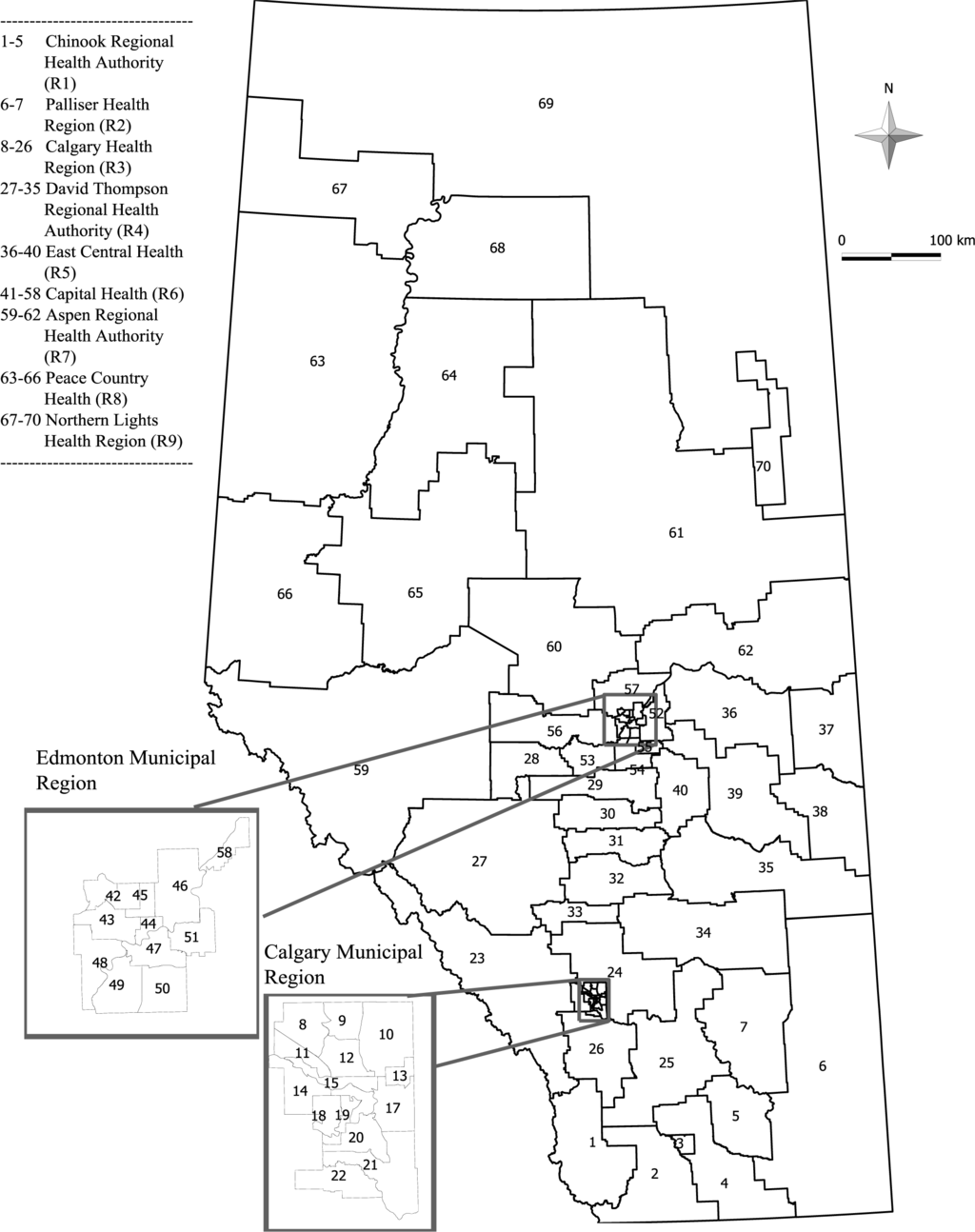
دادهها از پایگاههای اطلاعاتی اداری استانی مبتنی بر جمعیت که شامل همه ارائههای ED در آلبرتا است، استخراج شد. هر ارائه ED در طول دوره مطالعه به عنوان یک رویداد در نظر گرفته می شود. یک مورد به عنوان فردی تعریف می شود که حداقل یک مورد ED برای مصرف مواد در طول دوره مطالعه داشته باشد. از آنجایی که تفاوت های شناخته شده ای بین کودکان و نوجوانان و مردان و زنان [ 13 ] وجود دارد، ما داده ها را بر اساس جنسیت (مرد یا زن) و گروه سنی (0-14، 15-17 سال) طبقه بندی کردیم. استان آلبرتا ( شکل 1 ) به I تقسیم می شود= 70 سازمان بهداشتی زیر منطقه ای (sRHAs) با اندازه های مختلف جمعیت. صدک 25، میانه و صدک 75 اندازه جمعیت sRHA به ترتیب 5704، 10832 و 18027 ساکن هستند و از 2225 تا 31828 متغیر است. تعداد کل کودکان و نوجوانان 862771= N در جمعیت و کل موارد 1232= c بود . اکثر افراد سه یا کمتر ارائه داشتند: یک (1128)، دو (83) یا سه (17). دامنه ارائه ها از یک تا پنج بود. برای هر sRHA، میانگین تعداد موارد 14 (محدوده صفر تا 52)، و تعداد متوسط رویدادها 15.5 (محدوده صفر تا 59) بود [ 13 ].
ما w را حداکثر دو برای برنامه خود انتخاب کردیم و از بسته های نرم افزاری آماری hyperev [ 14 ] و R [ 15 ] برای به دست آوردن نتایج استفاده کردیم. خوشه های آماری معنی دار ( p -value <0.05) در جدول 1 به همراه اندازه خوشه رویداد k * ، آمار آزمون l ، تعداد رویدادهای مشاهده شده v il ، تعداد رویدادهای مورد انتظار ( E il ) و p ارائه شده است. -ارزش.
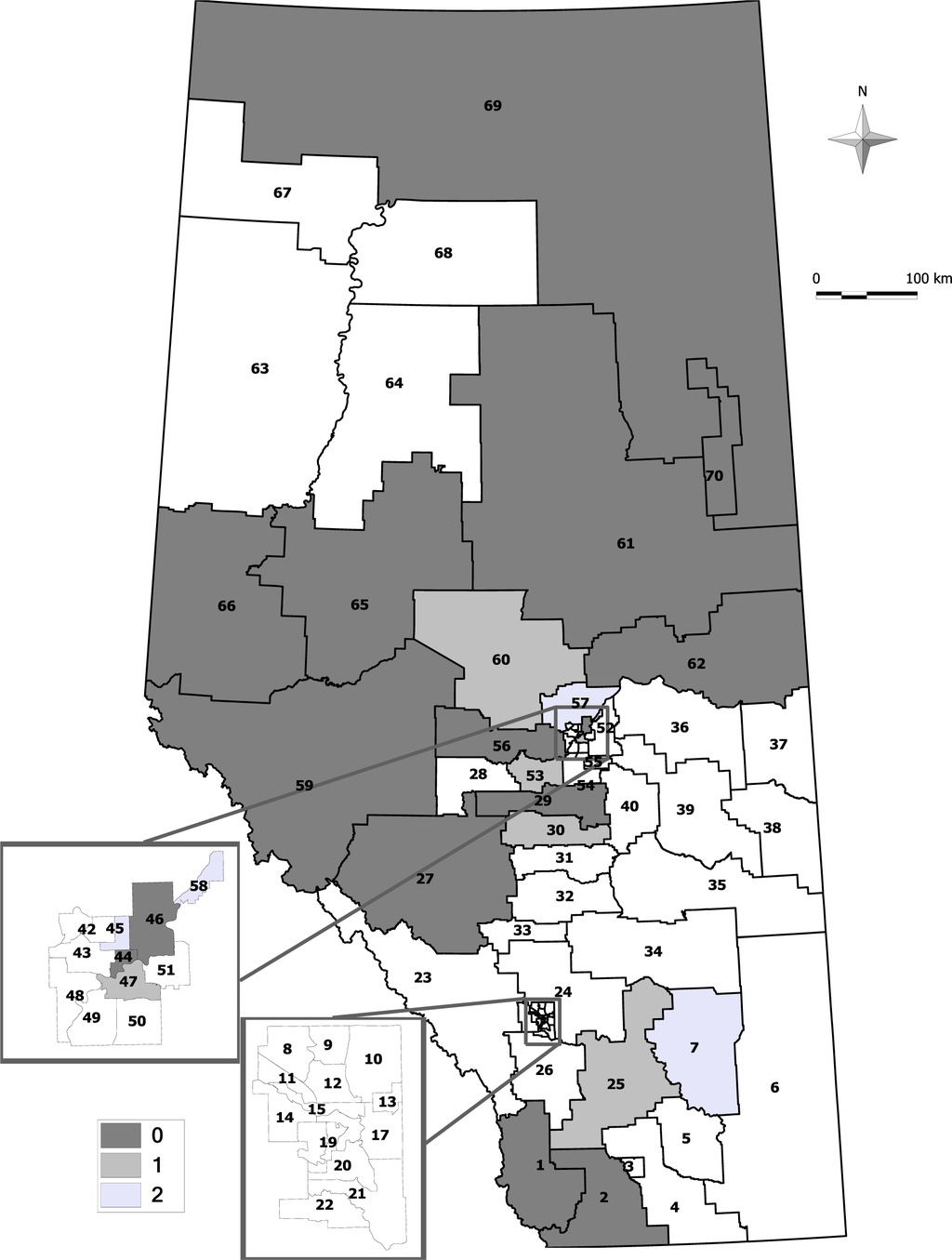
تقریباً هر سه روش، مناطق جغرافیایی در نواحی شمال شرق و جنوب غرب استان را بهعنوان خوشههای آماری معنیدار در طول دوره مورد مطالعه شناسایی کردند. تعداد کمی از sRHA های مشابه در منطقه شهرداری ادمونتون به عنوان خوشه های ارائه ED شناسایی شدند، اما هیچ یک از sRHA ها به عنوان یک خوشه قابل توجه در منطقه شهرداری کلگری شناسایی نشدند. چند منطقه جغرافیایی در جنوب بهعنوان خوشههای بالقوه تک سلولی در بین هر سه روش شناسایی شدند، و چند sRHA مختلف دیگر به عنوان خوشههایی از هر رویکرد شناسایی شدند (شکلهای 2-4 را ببینید ) .
چند sRHA نتایج متفاوتی در بین سه روش داشتند. اینها احتمالاً به این دلیل است که رویکردهای CP و EE دارای 95٪ دنباله کمتری نسبت به رویکرد AN هستند. اگر اندازههای خوشه متفاوت باشد، ممکن است موارد کاملاً کافی برای برآورده کردن اهمیت آماری مشاهده نشود و ممکن است نیاز به ترکیب تعداد متفاوتی از سلولها باشد. به عنوان مثال، sRHA 25 به عنوان یک خوشه مهم با اولین نزدیکترین همسایه آن برای رویکردهای CP و EE ترکیب شده است، اما از نظر آماری برای رویکرد AN معنیدار نیست. توالی اندازه های خوشه ( ک∗من 0کمن0*، ک∗من 1کمن1*) آزمایش شده برای رویکردهای CP، AN و EE به ترتیب (14، 42)، (15، 45) و (14، 44) هستند. 13 رویداد در sRHA 25 (< ک∗من 0کمن0*برای همه رویکردها)، و این عدد مشاهده شده نیاز به آزمایش دارد ک∗من 1کمن1*. اولین نزدیکترین همسایه sRHA 25 sRHA 26 است و شامل 31 رویداد است. در ترکیب، این دو sRHA دارای 44 رویداد هستند و این موارد بیشتر است ک∗من 1کمن1*برای رویکردهای CP و EE. با رویکرد AN، ک∗من 1کمن1*= 45، و چون 44 < 45، آزمایش بعدی برای آن رخ می دهد ک∗من 2کمن2*= 88. ادامه ترکیب همسایگان تا زمانی که حداقل 88 رویداد مشاهده شود، l = 4 همسایه باید ترکیب شوند (sRHAs 26 (31 رویداد)، 21 (19 رویداد)، 17 (14 رویداد)، و 22 (20 رویداد)) و این ترکیب از sRHA ها دارای 97 رویداد مشاهده شده است (>88). با تعداد همسایگان بیشتر (و اندازه ترکیبی بزرگتر)، sRHA های ترکیبی رویدادهای کافی برای شناسایی به عنوان یک خوشه آماری معنی دار را ندارند و p -value کمتر از 0.05 است.
توجه به این نکته حائز اهمیت است که صرفاً داشتن تعداد مشاهده شده از رویدادها بالاتر از تعداد مورد انتظار رویدادها، تضمین کننده اهمیت آماری نیست. با الگوریتم اندازه خوشه، اگر تعداد رویدادهای مشاهده شده حداقل به اندازه ک∗من wکمن�*و l ≤ w است. به عنوان مثال در رویکردهای AN و EE، sRHA 60 نیاز به داشتن حداقل 83 رویداد زمانی که با دو همسایه نزدیک خود ( w = 2) ترکیب میشد تا از نظر آماری معنیدار باشد. برای دستیابی به حداقل 83 رویداد، l = 3 نزدیکترین همسایه آن باید با آن ترکیب می شد. اگرچه تعداد رویدادهای مشاهده شده 100 و تعداد مورد انتظار رویدادها در 91.26 کوچکتر بود، این افزایش به اندازه کافی بزرگ نبود که جمعیت های ترکیبی به عنوان یک خوشه آماری معنی دار شناسایی شوند.
4. مطالعات شبیه سازی
ما خطای نوع I و قدرت تستهای رویکردهای CP، AN و EE را از طریق مطالعات شبیهسازی بررسی میکنیم. این مطالعات از سلول های آلبرتا و روابط جغرافیایی آنها استفاده می کند. جمعیت سلولی جمعیت آلبرتا برای سال مالی 2007/2008 یا همان جمعیت (1000، 5000، یا 8000) در هر سلول تنظیم شده است.
4.1. مقایسه خطای نوع اول
پنج تنظیم برای احتمال رویدادهای متعدد در هر مورد در نظر گرفته شد ( جدول 2 ) با میانگین و چولگی متفاوت برای راحتی انتخاب شد. تنظیم S5 بر اساس برنامه مصرف مواد ما است. نرخ رویدادها دو رویداد به ازای هر 1000 نفر جمعیت تعیین شد. به این معنا که تعداد کل رویدادها در هر مجموعه داده شبیهسازیشده، به ترتیب 140، 700، 1120 و 1354 برای تنظیمات با 1000، 5000 و 8000 در هر سلول و جمعیت آلبرتا خواهد بود. با احتمالات چندگانه رویداد برای سناریوهای S1-S5 از جدول 2 و نرخ رویداد خام، مجموعه داده های شبیه سازی شده با تخصیص تصادفی c • 1 ، c • 2 ایجاد می شوند.، ⋯، موارد بر اساس نسبت هر سلول از کل جمعیت. برای هر تنظیم شبیه سازی، ما 1000 مجموعه داده تولید کردیم و رویکردهای CP، AN و EE را برای هر مجموعه داده اعمال کردیم. اندازه های خوشه را به دست آوردیم ک∗من 0کمن0*برای هر رویکرد و هر سلول را فقط یک بار آزمایش کرد تا امکان مقایسه واضح را فراهم کند. ما سطح اهمیت موثر α * را برای هر سناریو ( جدول 3 ) بر اساس اندازه خوشه ارائه می کنیم و تعداد شبیه سازی هایی را ارائه می دهیم که حداقل یک خوشه با انحرافات استاندارد مربوطه (SDs) شناسایی شده است.
برای سناریوهایی با جمعیت سلولی ثابت، α ∗ و SD در بین سه روش یکسان هستند. این نتیجه قابل انتظار است، زیرا اندازههای خوشه احتمالاً در سراسر رویکردها یکسان هستند و تعداد رویدادها در هر سلول در طول شبیهسازیها کاملاً پایدار خواهد بود. در تمام سناریوها، سطوح معناداری موثر نزدیک به 0.05 است. سطوح معنیداری مؤثر برای وضعیت سلولی غیرثابت، جایی که جمعیت آلبرتا استفاده شد، نزدیکتر به 0.05 است. برای این وضعیت داده، به نظر می رسد رویکرد EE برای اکثر سناریوهای در نظر گرفته شده اندکی بهتر از رویکردهای CP و AN عمل می کند. همه نتایج نشان میدهند که میزان تشخیص خوشههای کاذب نزدیک به آنچه در سطح معنیداری مورد انتظار است است.
در عمل، کاربران این روشها احتمالاً مجموعه دادههایی خواهند داشت که اندازههای جمعیت غیر ثابتی دارند، اگرچه اندازهها ممکن است به اندازه جمعیت آلبرتا متفاوت نباشد. نتایج نشان میدهد که رویکرد EE ممکن است گزینه بهتری برای در نظر گرفتن باشد، اگرچه الزامات محاسباتی آن ممکن است نگرانکننده باشد اگر اندازه جمعیت زیاد باشد و تعداد رویدادها زیاد باشد. رویکردهای CP و AN ممکن است مزایای محاسباتی داشته باشند که ممکن است از مزیت خطای نوع I رویکرد EE پیشی بگیرد.
4.2. مقایسه قدرت
به منظور انجام مقایسه قدرت بین سه روش تشخیص خوشه رویداد، ما دو مورد از sRHA ها را به عنوان خوشه های واقعی انتخاب کردیم: sRHA 25 (در یک منطقه روستایی) و sRHA 44 (در یک منطقه شهری). با استفاده از مجموعه داده های شبیه سازی شده از بخش 4.1، تعداد رویدادها را در sRHAs 25 و 44 افزایش دادیم تا خوشه های واقعی ایجاد کنیم. رویدادها در sRHA های 25 و 44 به ترتیب در دو و 1.5 ضرب شدند و اگر ضرب منجر به تعداد کسری از رویدادها شود از سقف استفاده می شود. این رویکرد شبیهسازی امکان توزیع متفاوت رویدادها را در خوشههای واقعی نسبت به بقیه سلولها فراهم کرد. نرخ 1.5 برابر بیشتر از نرخ کلی معیاری است که معمولاً برای مناطق شهری استفاده می شود.
جدول 4 نتایج تحلیل توان را نشان می دهد. برای اندازه جمعیت سلولی ثابت، هر دو رویکرد CP و EE قدرت بالاتری دارند، در حالی که قدرت آزمون AN کم است. همه تست ها برای خوشه واقعی که نرخ بالاتری دارد بهتر عمل می کنند. به طور خاص، روش AN تقریباً همیشه sRHA 25 را برای سناریوی جمعیت آلبرتا شناسایی می کند و تقریباً همیشه در شناسایی sRHA 44 ناموفق است. فقط کمی بهتر عمل می کند.
5. بحث
ادبیات تشخیص خوشه آماری بر تشخیص خوشههای بیماری تمرکز دارد و روشهای نسبتا کمی برای بررسی خوشههای رویدادهای مرتبط با بیماری، که در آن موارد بیمار ممکن است چندین رویداد مرتبط با بیماری داشته باشند، معرفی شدهاند. ما مقایسه ای از سه روش مختلف تشخیص خوشه رویداد ارائه کرده ایم. هر روش از یک طرح آزمایش کلی با مفروضات توزیعی متفاوت پیروی می کند: ترکیب پواسون (CP)، نرمال تقریبی (AN) و ابر هندسی چندگانه (دقیق، EE). ما از یک الگوریتم آزمایشی استفاده کردیم که برای هر روش تطبیق داده شده است. معاینه ما شامل تجزیه و تحلیل ارائه های ED برای مصرف مواد در آلبرتا و یک مطالعه شبیه سازی بود.
روش CP 23 خوشه بالقوه از ارائه ED را برای مصرف مواد در کودکان و جوانان آلبرتا در طول سال مالی 2007/2008 شناسایی کرد. خوشههای بالقوه به تنهایی یا زمانی که با تعداد کمی از نزدیکترین همسایگان ترکیب میشوند، بهعنوان خوشهها شناسایی شدند. دو روش دیگر خوشههای بالقوه کمی کمتر را شناسایی کردند و این نتیجه ممکن است به احتمال در دنباله توزیعهای مربوطه مرتبط باشد. بر اساس این کاربرد، روش CP تعداد بیشتری از خوشههای بالقوه را ارائه میکند، اگرچه هنوز مشخص نشده است که آیا این خوشههای بالقوه واقعی هستند یا ساختگی (مثلاً به دلیل سایر عوامل بالقوه که با sRHA متفاوت هستند، اما برای آن تنظیم نشدهاند. تجزیه و تحلیل). در خوشه های واقعی، مناطق شناسایی شده در مناطق کمتر شهری ممکن است نشان دهنده مصرف بیشتر مواد یا در دسترس بودن کمتر سایر خدمات بهداشتی باشد. در مناطق کمتر شهری، افراد ممکن است از نظر جغرافیایی به خدمات یا برنامه های بهداشتی نزدیک نباشند و ممکن است برای مراقبت از ED مراجعه کنند. به ویژه در ناحیه شمال غربی استان، گستره جغرافیایی وسیع و جمعیت نسبتاً کمی وجود دارد. تحقیقات بیشتر برای تعیین علل بالقوه تعداد به ظاهر بالای ارائه ED برای مصرف مواد مورد نیاز است.
ما مطالعات شبیه سازی را برای بررسی احتمال تشخیص کاذب خوشه ها انجام دادیم. مطالعات شبیهسازی توزیعهای احتمال رویداد و اندازه سلولهای متفاوتی داشتند که یا همه یکسان بودند یا جمعیت آلبرتا را دنبال میکردند. هر سه رویکرد دارای سطوح معنی داری موثر نزدیک به سطح تعیین شده 05/0 بودند. به نظر میرسید که روشها برای تنظیم جمعیت سلولی غیر ثابت به 0.05 نزدیکتر باشند، و در آن تنظیم، رویکرد EE سطوح معنیداری مؤثری داشت که در مقایسه با سایر رویکردها برای اکثر سناریوها، نزدیکترین سطوح به 0.05 بود.
ما همچنین از این مطالعات شبیهسازی برای انجام یک بررسی توان با استفاده از دو خوشه واقعی تک سلولی استفاده کردیم. در همه شرایط، رویکردهای CP و EE بهتر از رویکرد AN بودند. رویکرد AN به اندازه جمعیت سلولی بسیار حساس بود و زمانی که اندازه جمعیت بزرگتر بود و خوشه واقعی دو برابر نرخ رویدادها را داشت، عملکرد خوبی داشت. رویکرد AN برای یافتن خوشههایی با نرخهای بالا در مقایسه با پسزمینه بهترین مناسب است. رویکردهای CP و EE نیز برای اندازههای جمعیت بالاتر و نرخهای بالاتر بهتر عمل کردند. رویکرد EE کمی بهتر از رویکرد CP بود، اما از نظر محاسباتی فشردهتر و سود آن نسبتاً کم است. بر اساس این نتایج، رویکرد CP برای استفاده توصیه میشود و مانند همه روشهای خوشهبندی،
همه روشها از الگوریتمهای آزمایش اندازه خوشه مشابه استفاده میکردند. یکی از مزایای این رویکرد این است که اندازه های خوشه می تواند برای هر سلول آزمایش شده خاص باشد، که برای مناطق جغرافیایی با اندازه های جمعیت متنوع مهم است. یک اشکال رویکرد این است که هر سلول ممکن است به طور بالقوه در چندین اندازه آزمایش شود، بنابراین مشکل آزمایش چندگانه افزایش می یابد. البته اشاره میشود که شبیهسازیهای مونت کارلو برای p-value کلی از الگوریتم آزمایش یکسانی استفاده میکنند، و بنابراین، p کلیمقدار برای آزمایش های متعدد تنظیم می شود. یکی دیگر از مزایای الگوریتم تست این است که به حداقل اندازه خوشه اجازه می دهد تا به اهمیت آماری دست یابد. برای توزیع های گسسته، این حداقل ممکن است عددی را ارائه دهد که کمتر از سطح معناداری 0.05 مورد نظر باشد. با برخی تفاوتها در توزیعهای انتخاب شده، مقداری تغییرپذیری در نزدیکی 0.05 p -values وجود دارد.
این روش ها از فواصل زوجی و سفارش نزدیکترین همسایه استفاده می کنند. بیشتر محاسبات فقط مربوط به چند همسایه اول بود. این جنبه مزایایی را به وجود میآورد به این معنا که فاصلهها لازم نیست دقیقاً شناخته شوند و مطالعات شبیهسازی برای سایر جغرافیاها، جایی که نزدیکترین همسایه سفارشدهنده یکسان بود، قابل استفاده است. این جنبهها نتایج شبیهسازی ما را به سایر مناطق جغرافیایی قابل تعمیمتر میسازد.
محدودیتهای مطالعه ما شامل لزوم انتخاب اندازه خوشه (یا حداکثر تعداد اندازههای خوشه برای آزمایش) و تعیین سناریوها برای مطالعه شبیهسازی ما است. الگوریتم آزمایش به اندازههای خوشه اجازه میدهد تا حساسیت کمتری نسبت به انتخاب کاربر داشته باشند، اما همچنان کاربر را ملزم میکند که حداکثر تعداد سلولها را برای ترکیب به عنوان بخشی از انتخاب اندازههای خوشه آزمایششده تعیین کند. این انتخاب باعث میشود که مقایسه نتایج حاصل از روشهای مختلف کمی آسانتر باشد، زیرا اندازههای خوشههای آزمایش شده ممکن است در بین سه روش متفاوت باشد. همچنین ارائه سناریوهایی برای مطالعه شبیه سازی که با هر موقعیت داده واقعی مطابقت دارد، دشوار است. سناریوهای معدود ارائه شده، طعم رفتار روش ها را در شرایط مختلف ارائه می دهند، و عملکرد ممکن است برای یک موقعیت داده خاص گویا نباشد.
مطالعه ما به کاربران بالقوه این سه روش تشخیص خوشه ای رویدادها راهنمایی می کند. در غیاب مفروضات توزیعی قوی، روش EE ممکن است بهترین روش برای کاربران باشد. تجزیه و تحلیل حساسیت همچنین می تواند با سایر توزیع ها انجام شود و احتمالاً نتایج مشابهی را نشان می دهد. از نظر نظارت بهداشتی و خط مشی، حداقل یکی از این روش ها می تواند به عنوان بخشی از برنامه نظارت معمولی رویدادهای مرتبط با سلامت، مانند ارائه های ED، گنجانده شود. اگر یک منطقه جغرافیایی رویدادهای بالاتر از حد انتظار داشته باشد، می توان آن را برای تحقیقات بیشتر و/یا مداخله هدف قرار داد.
منابع
- Lawson, AB Statistical Methods in Spatial Epidemiology ; John Wiley & Sons, Ltd.: Chichester, UK, 2001. [ Google Scholar ]
- بساج، ج. نیول، جی. تشخیص خوشه ها در بیماری های نادر. JR Stat. Soc. سر. A. 1991 , 154 , 143-155. [ Google Scholar ]
- کولدورف، ام. Nagarwalla، N. خوشه بیماری فضایی: تشخیص و استنتاج. آمار. پزشکی 1995 ، 14 ، 269-286. [ Google Scholar ]
- Tango, T. دسته ای از تست ها برای تشخیص خوشه بندی “عمومی” و “متمرکز” بیماری های نادر. آمار پزشکی 1995 ، 14 ، 2323-2334. [ Google Scholar ]
- Tango, T. آزمونی برای خوشهبندی بیماریهای فضایی که برای آزمایشهای چندگانه تنظیم شده است. آمار پزشکی 2000 ، 19 ، 191-204. [ Google Scholar ]
- Rosychuk، RJ; هیوستون، سی. Prasad، NGN تشخیص خوشه رویداد فضایی با استفاده از توزیع سم مرکب. بیومتریک 2006 ، 62 ، 465-470. [ Google Scholar ]
- ترابی، م. Rosychuk، RJ تشخیص خوشه رویداد فضایی با استفاده از توزیع نرمال تقریبی. بین المللی J. Health Geogr. 2008 . [ Google Scholar ] [ CrossRef ]
- Rosychuk، RJ; Stuber, JL یک آزمایش دقیق برای تشخیص تجمعات جغرافیایی رویدادها. بین المللی J. Health Geogr. 2010 . [ Google Scholar ] [ CrossRef ]
- Ross, SM Introduction to Probability Models , 8th ed.; انتشارات آکادمیک: سن دیگو، کالیفرنیا، ایالات متحده آمریکا، 2003. [ Google Scholar ]
- Le، ND; پتکائو، ای جی؛ Rosychuk، RJ نظارت بر خوشه های نزدیک به منابع نقطه ای. آمار پزشکی 1996 ، 15 ، 727-740. [ Google Scholar ]
- شمارش جمعیت و مسکن، برای کانادا، استانها و مناطق، سرشماریهای 2011 و 2006، آمار کانادا ، در دسترس آنلاین: http://www12.statcan.gc.ca/census-recensement/2011/dp-pd/hlt-fst/pd -pl/Table-Tableau.cfm?LANG=Eng&T=101&S=50&O=A در 7 ژانویه 2015 مشاهده شد.
- آمار کانادا ، در دسترس آنلاین: http://www.statcan.gc.ca/tables-tableaux/sum-som/l01/cst01/phys01-eng.htm در 7 ژانویه 2015 قابل دسترسی است.
- نیوتن، ع. Rosychuk، RJ; علی، س. کاوترپ، دی. کوران، جی. دونگ، ک. اسلمپ، ام. Urichuk, L. The Emergency Department Compass: Children’s Mental Health , موجود آنلاین: http://www.EDCompass.net در 15 مه 2013 قابل دسترسی است.
- Rosychuk، RJ Hyperev: برنامه تشخیص خوشه ای بیماری های آماری . Rosychuk: Edmonton، AB، Canada، 2007. [ Google Scholar ]
- تیم اصلی R. R: زبان و محیطی برای محاسبات آماری . بنیاد R برای محاسبات آماری: وین، استرالیا، 2013. [ Google Scholar ]



© 2015 توسط نویسندگان; دارنده مجوز MDPI، بازل، سوئیس این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر