1. معرفی
محاسبه شباهت مفاهیم در ساختار بازنمایی دانش، سنگ بنای بسیاری از وظایف پیشرفته در علم اطلاعات جغرافیایی (GIScience)، بازیابی اطلاعات جغرافیایی، تجزیه و تحلیل جغرافیایی، پردازش زبان طبیعی و هوش مصنوعی است. در این مقاله، ما شباهت شبکه و اقدامات شباهت واژگانی را در یک معیار ترکیبی ترکیب میکنیم تا شباهت مفاهیم جغرافیایی را در ساختارهای مبتنی بر نمودار که دانش جغرافیایی را نشان میدهند، محاسبه کنیم، و بهطور تجربی نشان میدهیم که هر دو جنبه شباهت عملکرد را افزایش میدهند. نمودارها به دلیل سادگی و تبعیت از شهود معنایی انسان، محبوبترین ساختار بازنمایی دانش در 30 سال گذشته بودهاند [ 1 ]]. طیف گستردهای از پایگاههای دانش جغرافیایی به نوعی از نمایش مبتنی بر نمودار متکی هستند، از روزنامهها، پایگاههای داده جغرافیایی، رسانههای اجتماعی مبتنی بر مکان و ویکیها، تا ابر دادههای باز مرتبط که از تحقیقات وب معنایی [ 2 ] پدید آمده است ( http ://lod-cloud.net ).
در هسته، این ساختارها را می توان به عنوان نمودارهای دانش جغرافیایی (GKGs) مشاهده کرد. در این مقاله، ما یک GKG را به عنوان یک مصنوع بازنمایی که حاوی مفاهیم جغرافیایی، روابط متقابل آنها و توصیفات واژگانی آنها است، تعریف می کنیم. GKG ها لزوماً محدودیت های رسمی برای مفاهیم و روابط خود قائل نیستند. لطفاً توجه داشته باشید که GKG یک اصطلاح کلی است که به نمودار دانش Google اشاره نمی کند ( http://googleblog.blogspot.com/2012/05/introducing-knowledge-graph-things-not.html). به طور رسمی، یک GKG یک گراف جهت دار است که رئوس آن با مفاهیم مطابقت دارد و یال های آن روابط هستند. توصیفات لغوی مفاهیم با رئوس همراه است. از این رو، چنین ساختارهای بازنمایی دانش در همه جا وجود دارند: حتی وب سایت ها را می توان به عنوان GKG مشاهده کرد، که در آن هر صفحه یک مفهوم است، و لینک ها نشان دهنده یک رابطه عمومی و نامشخص هستند. فرمالیسمهای منطقی پیچیدهتر، مانند گرافهای مفهومی و هستیشناسی، همچنان حاوی GKG هستند.
به طور سنتی، مصنوعات بازنمایی دانش توسط متخصصان برای اهداف علمی یا مهندسی خاص ساخته میشدند، مانند پایگاه داده واژگانی WordNet [ 3 ] و پروژه هوش مصنوعی Cyc ( http://www.cyc.com ). با ظهور و پیچیدگی اطلاعات جغرافیایی داوطلبانه (VGI) [ 4 ]، GKGها اغلب با پوشش و کیفیت بسیار متغیر مشخص می شوند [ 5 ]. GeoNames ( http://www.geonames.org) را می توان به عنوان یک GKG مشاهده کرد، که در آن ورودی های روزنامه مفاهیمی هستند که از طریق روابط سلسله مراتبی و روابط دیگر به هم متصل می شوند. GKGها در نمودار هایپرپیوندی مقالات ویکیپدیا، و همچنین در پروژههای نقشهبرداری، مانند OpenStreetMap، که بر دادههای برداری مکانی تمرکز دارد، یافت میشوند ( شکل 1 را ببینید ).
در زمینه چنین نمودارهای بازنمایی دانش، با توجه به دو مفهوم در یک GKG (یا در GKG های مختلف)، یک معیار تشابه معنایی با هدف کمی کردن شباهت آنها به عنوان یک عدد واقعی، معمولاً در بازه ∈ [0، 1] نرمال می شود. به طور معمول، محاسبه شباهت معنایی به خودی خود یک هدف نیست، بلکه یک کار میانی است که برای فعال کردن سایر وظایف ضروری است. به عنوان مثال، در یک GKG معین، مفاهیم “رودخانه” و “کانال” ممکن است 0.75 شباهت داشته باشند، در حالی که “رودخانه” و “رستوران” فقط 0.05 امتیاز دارند. اگر معیاری به میزان کافی از قضاوت انسان تقلید کند، این مقادیر شباهت را می توان برای آرامش پرس و جو در بازیابی اطلاعات جغرافیایی، از جمله کانال های موجود در نتایج برای یک جستار با هدف رودخانه ها، و همچنین برای تراز مفهومی استفاده کرد.6 ، 7 ].
در کار قبلی خود، ما کاربرد معیارهای شباهت مبتنی بر شبکه و واژگانی را برای محاسبه شباهت معنایی مفاهیم جغرافیایی، در زمینه یک شبکه معنایی جمعسپاری بررسی کردیم [ 8-10 ] . سهم اصلی این مقاله از چندین جنبه بر این مجموعه کار استوار است و آن را گسترش می دهد. ابتدا، ما یک معیار تشابه معنایی ترکیبی، معیار شباهت واژگانی شبکه (NLS)، که دو ستون تشابه مفاهیم را در GKGها ترکیب میکند، ابداع میکنیم. ما ستون اول را به عنوان مکان توپولوژیکی مفهوم تعریف می کنیم، روابط ساختاری آن با مفاهیم دیگر. رکن دوم مبتنی بر تشابه معنایی تعاریف واژگانی مفاهیم است که به زبان طبیعی بیان شده است. NLS معیارهای شباهت واژگانی و شبکه ای را ترکیب می کند، و هر دو جنبه به افزایش معقولیت شناختی اندازه گیری کمک می کنند، به عنوان مثال ، توانایی اندازه گیری برای تقلید از قضاوت های انسانی. تا آنجا که ما می دانیم، NLS اولین رویکرد به شباهت معنایی است که این دو جنبه را با هم ترکیب می کند.
دوم، معقول بودن شناختی NLS به طور کامل در یک GKG دنیای واقعی، شبکه معنایی OpenStreetMap (OSM) [ 5 ]، که شامل حدود 5000 مفهوم استخراج شده از پروژه جمع سپاری OpenStreetMap است، ارزیابی می شود. این GKG امکان ارزیابی دقیق NLS را در زمینه یک مصنوع بازنمایی دانش جغرافیایی فراهم میکند و امکان بحث انتقادی در مورد محدودیتهای شبکه و اقدامات شباهت واژگانی را فراهم میکند. به عنوان حقیقت پایه، این ارزیابی از مجموعه دادههای مرتبط با جغرافیا و شباهت (GeReSiD) [ 10 ] استفاده میکند و ارزیابی قابلاعتمادتر و گستردهتری را ارائه میکند و امکان مقایسه دقیق معیارها را فراهم میکند. این نتایج با نتایج بهدستآمده با مجموعه داده مورد استفاده برای ارزیابی اندازهگیری شباهت فاصله انطباق (MDSM) [ 11 ] مقایسه میشوند.]. نتایج تجربی این مطالعه ارزیابی معقولپذیری شناختی مقیاسهای واژگانی و شبکهای را بیشتر میکند و معقولپذیری شناختی بالای NLS را تأیید میکند، که به طور مداوم از معیارهای شبکه و واژگانی بهتر عمل میکند.
ادامه این مقاله به شرح زیر سازماندهی شده است. بخش 2 ادبیات مرتبط در مورد شباهت معنایی را بررسی می کند. بخش 3 NLS، معیار ترکیبی پیشنهادی شباهت معنایی را تشریح میکند. پس از آن، یک ارزیابی تجربی دقیق از اندازه گیری ارائه شده و مورد بحث قرار می گیرد (بخش 4). ما با یک خلاصه و بحث در مورد مسیرهای تحقیقات آتی (بخش 5) نتیجه گیری می کنیم.
2. پس زمینه
تشابه معنایی نوع خاصی از ارتباط معنایی است که بر اساس روابط فرعی ( a ) است [ 10 ]. به عنوان مثال، “سوخت” از نظر معنایی با “ماشین” مرتبط است، در حالی که “اتوبوس” از نظر معنایی مرتبط و شبیه به “ماشین” است. با توجه به ماهیت بنیادی تشابه معنایی، ارائه تعریفی بدون دایره بودن مشکل است و اصطلاحات متعددی برای بحث در مورد آن به کار رفته است. “فاصله معنایی” برای اشاره به فاصله بین دو مفهوم ارائه شده در یک مدل معنایی هندسی استفاده می شود [ 12 ]]. بسته به اینکه چه ویژگی ها و روابطی در نظر گرفته می شود، شباهت معنایی را می توان به صورت معکوس با فاصله معنایی محاسبه کرد. علاوه بر این، اصطلاح “تداعی معنایی” برای تعریف ارتباط معنایی، به ویژه در فرآیندهای بازیابی حافظه انسانی استفاده می شود. از سوی دیگر، “شباهت تاکسونومیکال” معادل تشابه معنایی است [ 13 ]. در یک GKG، مفاهیم از طریق روابطی که ارتباط معنایی کلی آنها را بیان می کند، به هم متصل می شوند.
در زمینه علم GIS، معیارهای تشابه و ارتباط معنایی به طور گسترده در بازیابی اطلاعات جغرافیایی، داده کاوی و ژئومعناشناسی استفاده می شود [ 6 ، 14 ]. معیارهای خاصی از شباهت معنایی متناسب با مفاهیم جغرافیایی پدید آمده است [ 15 ]. رودریگز و اگنهوفر [ 11 ] با انتخاب زیرمجموعهای از ویژگیها بر اساس نیازهای کاربر، مدل نسبت Tversky را با در نظر گرفتن زمینه به صراحت در نظر گرفتهاند. یانوویچ و همکاران [ 14] یک معیار تشابه برای مفاهیم جغرافیایی بر اساس منطق توصیف (DL)، خانواده ای از زبان های وب معنایی ایجاد کرده اند. چنین معیارهایی را فقط می توان برای مفاهیمی که در فرمالیسم های خاص بیان شده اند، مانند DL اعمال کرد. از این رو، در زمینه GKGs، این اقدامات به طور مستقیم قابل اجرا نیستند و رویکردهای متفاوتی مورد نیاز است.
2.1. اقدامات شباهت شبکه
این بخش تکنیک های موجود را برای محاسبه شباهت رئوس در نمودارها، اولین مؤلفه NLS، توضیح می دهد. این رویکردها برای تشابه مبتنی بر نوعی از فاصله ساختاری بین گرهها هستند، مانند شمارش لبهها، گاهی اوقات پارامترهای اضافی را برای وزن دادن به مسیرها اضافه میکنند [ 16 ]]. چنین تکنیکهای مبتنی بر شبکه برای شبکههای معنایی کاملاً تعریفشده و تولید شده توسط متخصصان که در آنها لبهها در برخی از معنایشناسی رسمی، مانند WordNet بیان میشوند، اعمال شدهاند. با این حال، GKG هایی که ما روی آنها تمرکز می کنیم، چنین ساختار معنایی غنی را ارائه نمی دهند، اما دانش را در قالب نمودارهای ساده اشیاء به هم پیوسته رمزگذاری می کنند. با توجه به محبوبیت شبکهها در بسیاری از زمینهها، الگوریتمهای متعددی برای شناسایی اشیاء مشابه بهطور انحصاری بر روی الگوهای پیوندشان در نمودارها پدید آمدهاند که به طور صریح روابط را رسمیت نمیدهند.
اسمال [ 17 ] الگوریتم اصلی «هم-استناد» را ابداع کرد. با توجه به نموداری که مقالات علمی و ارجاعات متقابل آنها را نشان می دهد، این معیار شباهت بین دو مقاله داده شده را بر اساس فراوانی استناد آنها با هم مدل می کند. Jeh و Widom [ 18 ] با گسترش استناد همزمان به یک فرم بازگشتی، SimRank را ایجاد کردند، رویکردی برای محاسبه شباهت رئوس در نمودارهای جهت دار. شهود دایره ای زیربنایی این است که دو شی را می توان مشابه در نظر گرفت اگر توسط اشیاء مشابه ارجاع داده شوند. الگوریتم P-Rank [ 19 ] با در نظر گرفتن پیوندهای خروجی، استناد مشترک را بیشتر گسترش می دهد. الگوریتمهای شباهت شبکه قبلی، مانند استناد اولیه [ 17 ]، Coupling [ 20] و Amsler [ 21 ]، موارد خاصی از P-Rank هستند. در کار قبلی ما نشان دادیم که وقتی برای مفاهیم جغرافیایی اعمال میشود، SimRank و P-Rank نسبت به سایر معیارهای شبکه به معقولیت بالاتری دست پیدا میکنند [ 8 ].
2.2. معیارهای تشابه واژگانی
هدف کلی معیارهای تشابه واژگانی، کمی کردن شباهت دو واحد واژگانی است، معمولاً به عنوان یک عدد واقعی. یک واحد واژگانی می تواند یک کلمه منفرد، یک کلمه مرکب یا بخشی از متن باشد [ 22 ]. رویکردهای محاسبه شباهت معنایی کلمات منفرد (در مقابل موجودیت های معنایی بزرگتر) را می توان به دو خانواده اصلی طبقه بندی کرد: دانش محور و پیکره محور. تکنیک های مبتنی بر دانش از مصنوعات دستی به عنوان منبع دانش مفهومی استفاده می کنند. تحت یک فرض ساختارگرا، بیشتر این تکنیکها روابطی را مشاهده میکنند که اصطلاحات را به هم پیوند میدهند، مثلاً با این فرض که فاصله هستیشناختی با شباهت معنایی نسبت معکوس دارد [ 23 ]. WordNet [ 3] برای محاسبه شباهت واژگانی با روشهای مختلف استفاده شده است، همانطور که در جدول 1 نشان داده شده است [ 24-30 ] . این معیارها بسته به زمینه، معقولیت متفاوتی به دست میآورند و میتوانند در مجموعههایی برای به دست آوردن معقولیت بالاتر [ 31 ] ترکیب شوند. از سوی دیگر، تکنیک های مبتنی بر پیکره نیازی به روابط صریح بین اصطلاحات ندارند و شباهت معنایی دو عبارت را بر اساس همزمانی آنها در مجموعه بزرگی از اسناد متنی محاسبه می کنند [ 32 ، 33 ].
شباهت معنایی را می توان بین بخش هایی از متون، در یک مسئله زبانی به نام “تشخیص پارافراسی” محاسبه کرد. به عنوان مثال، جمله “هر سفر به ایتالیا باید شامل بازدید از توسکانی برای آزمایش شراب آنها باشد” شباهت معنایی بالایی دارد و عبارتی است از “حتماً در هنگام بازدید از ایتالیا تجربه مزه شراب توسکانی را در نظر بگیرید”. برای مقابله با این موضوع، Corley و Mihalcea [ 34 ] یک تکنیک کیسه ای از کلمات مبتنی بر دانش را برای بازنویسی تشخیص توسعه دادند که بر برخی از معیارهای WordNet متکی است. در کار قبلی خود، ما یک معیار تشابه را برای تعاریف واژگانی توسعه دادیم [ 9 ]. از نظر دقت، معیارهای مبتنی بر دانش عموماً از معیارهای مبتنی بر پیکره بهتر عمل می کنند [ 35 ]]. اگرچه معیارهای تشابه معنایی متعددی وجود دارد، تا جایی که ما می دانیم، هیچ معیار ترکیبی که شباهت شبکه و واژگانی را برای GKG ها ترکیب کند، پیشنهاد نشده است. بخش بعدی NLS، رویکرد ما برای پر کردن این شکاف دانش را تشریح میکند.
3. معیار شباهت واژگانی شبکه
مشکل کلی که معیار شباهت واژگانی شبکه (NLS) در حل آن است، کمی کردن شباهت معنایی در یک GKG است. به طور رسمی، یک GKG یک گراف برچسبدار G ( V، E، L )، با مجموعهای از رئوس V (مفاهیم)، مجموعهای از یالهای جهتدار E (روابط) و مجموعهای از برچسبها L (تعریفهای لغوی) است. یک تابع برچسب گذاری V → L رئوس را با برچسب ها مرتبط می کند. یک برچسب l ∈ L حاوی بخشی از متن است و می تواند خالی باشد. یک یال جهت دار e ∈ E دو گره e = { u, v } را به هم مرتبط می کند، جایی که u، v∈ V. _ با توجه به دو مفهوم a و b ∈ V ، هدف یک معیار تشابه معنایی محاسبه امتیاز شباهت s ( a, b ) ∈ ℜ است. برای سهولت در تفسیر آنها، نمرات در بازه ∈ [0، 1] نرمال می شوند. توجه به این نکته مهم است که نمرات شباهت به صورت مجزا معنی دار نیستند، اما در مقایسه با سایر مفاهیم، اطلاعات مفیدی را منتقل می کنند.
به منظور محاسبه شباهت معنایی در GKG ها ، NLS بر دو پایه استوار است: شبکه شباهت شبکه و شباهت واژگانی lex . شباهت شبکه دو مفهوم از موقعیت توپولوژیکی آنها در نمودار با مشاهده ساختار پیوند G استخراج شده است. از سوی دیگر، شباهت واژگانی بر روی برچسبها در L متمرکز استکه شامل بخش هایی از متن است که مفاهیم را توصیف می کند. بنابراین می توان از تکنیک های پردازش زبان طبیعی برای اندازه گیری شباهت معنایی بخش های متن استفاده کرد. این دو دیدگاه در مورد شباهت مفهومی متقابل نیستند و NLS آنها را مکمل یکدیگر می داند. NLS باید به عنوان یک چارچوب کلی برای محاسبه شباهت معنایی، ترکیبی از جنبه های مکمل شباهت در GKG ها دیده شود.
3.1. شباهت شبکه (s net )
تابع شباهت شبکه s net ( a, b ) با هدف کمی کردن شباهت ساختاری رئوس در نمودار G است. از آنجایی که GKGها معناشناسی رسمی روابط بین مفاهیم را رمزگذاری نمی کنند، معیارهای مناسب باید لبه ها را به عنوان شاخص های ارتباط کلی در نظر بگیرند. اگر a یا b به گره های دیگر متصل نباشد، s net ( a, b ) نامشخص است و NLS فقط به s lex ( a, b ) متکی است .). بر اساس کار قبلی در مورد معقول بودن شناختی معیارهای هماستنادی در زمینه نمودارهای مفهومی، ما شش معیار شباهت شبکه پیشرفته را اتخاذ میکنیم [ 8 ]. به طور خاص، ما P-Rank، یک الگوریتم هم استنادی عمومی [ 19 ] را در نظر می گیریم. همانطور که در بخش 2.1 بحث شد، پارامترهای مختلف، P-Rank معادل الگوریتم های قبلی است، از جمله Co-citation [ 17 ]، Amsler [ 21 ]، Coupling [ 20 ] و SimRank [ 18 ] و rvs-SimRank [ 19 ]. در این زمینه، ما یک فرمول از P-Rank در جبر خطی [ 8 ] را اتخاذ می کنیم، و در مورد معنی و تاثیر پارامترهای آن ( K، λ و C ) به تفصیل بحث می کنیم.).
P-Rank یک معیار بازگشتی از شباهت است که بر اساس ترکیب دو فرض بازگشتی است: (1) دو موجودیت مشابه هستند اگر توسط موجودیت های مشابه ارجاع داده شوند. و (2) دو موجودیت مشابه هستند اگر به نهادهای مشابه ارجاع دهند. P-Rank به صورت تکراری محاسبه می شود، با انتخاب تعدادی تکرار K ∈ [1, ∞). هر چه K بالاتر باشد ، تقریب جواب نظری به رتبه P بهتر است. در این زمینه، C ضریب فروپاشی P-Rank ∈ (0، 1) است. ضریب λ ثابت تعادل درون-خارجی P-Rank در بازه [0، 1] است. وقتی λ = 1، فقط لینک های ورودی در نظر گرفته می شوند و زمانی که λ= 0، فقط پیوندهای خروجی در محاسبه گنجانده شده است. بنابراین net را به صورت زیر تعریف می کنیم :
که در آن K تکرارهای حداکثر P-Rank است ( K ∈ [1, ∞)). ماتریس Rk یک ماتریس امتیاز P-Rank در تکرار k است. ماتریس T i یک ماتریس انتقالی از G است که بر روی I ( a ) ساخته شده است. علاوه بر این، T o ماتریس انتقال G است که روی O ( a ) ساخته شده است، و Θ یک ماتریس مورب است، به طوری که ∀ k ، زمانی که a = b ، Θ( a, b ) + R k ( a, b ) = 1. تمام تکرارهای P-Rank با k> 0 را می توان به عنوان یک سری تکرار همگرا به نمره شباهت نظری بیان کرد. بر اساس بهینه سازی ابداع شده توسط یو و همکاران. [ 36 ]، پیچیدگی محاسباتی این معیار دارای کران بالای O ( n 3 + Kn 2 ) است.
3.2. شباهت واژگانی (s lex )
هدف تابع شباهت s lex ( a, b ) کمی کردن شباهت معنایی دو بخش متن l a و l b ∈ L است که تعریف لغوی گرههای a و b را در یک GKG نشان میدهند. هر مفهوم با مجموعه ای از اصطلاحات تعریفی مرتبط است که مفهوم را توصیف می کند. اگر l a یا l b خالی باشد، lex s ( a, b ) نامشخص است و NLS باید فقط بر s تکیه کند.خالص . به منظور محاسبه lex بین دو بخش از متن، تکنیک مبتنی بر دانش را که در کار قبلی خود توسعه دادیم [ 9 ] اتخاذ می کنیم. شهود اساسی پشت این معیار تشابه واژگانی این است که اصطلاحات مشابه با استفاده از اصطلاحات مشابه توصیف می شوند. این اندازه گیری کیسه کلمات شباهت معنایی دو عبارت s ( a, b ) را بر اساس پارامترهای ورودی { POS, C, simt , sim v } محاسبه می کند: یک فیلتر بخشی از گفتار (POS) که شامل مجموعه ای از تگ های POS (به عنوان مثال، اسم ها و افعال). یک پیکره C ؛ تابع شباهت اصطلاح sim t ; و یک تابع شباهت برداری sim v. چهار مرحله الگوریتم شباهت به شرح زیر است:
-
با توجه به دو مفهوم a و b ، اصطلاحات آنها را در برچسبهای l a و l b علامتگذاری کنید و POS تگ کنید.
-
بردارهای معنایی بسازید آ→�→و ب→�→، بر اساس اصطلاحات تعریفی دارای POS موجود در فیلتر POS. برای هر عبارت تعریفی t ، وزنهای w t را از جسم C بازیابی کنید. یک رویکرد رایج برای محاسبه وزن عبارات تعریفی عبارت فرکانس معکوس سند فرکانس (TF-IDF) است. انتظار میرود که یک عبارت نسبتاً نادر در جسم C وزن بیشتری نسبت به عبارت متداول داشته باشد.
-
ماتریس های M ab و M ba را بسازید . هر سلول از این ماتریسهای شباهت دارای یک امتیاز شباهت اصطلاح sim t ( t ai , t bj ) است. در اصل، هر معیار تشابه معنایی اصطلاح به ترم ممکن است به عنوان sim t اتخاذ شود (برای مثال، جدول 1 را ببینید).
-
امتیاز شباهت s lex ( a, b ) را از ماتریسهای شباهت با استفاده از شباهت برداری sim v ، بر اساس تکنیکهای تشخیص بازنویسی، مانند تکنیکهای Corley و Mihalcea [ 34 ] یا فرناندو و استیونسون [ 37 ] محاسبه کنید.
پس از ساختن بردارهای معنایی آ→�→و ب→�→و ماتریس های M ab و Mba ، شباهت بردار به بردار sim v در مرحله 4 سزاوار توجه ویژه است . اول، یک معیار تشابه نامتقارن بردارهای معنایی من _متر“v(آ→،ب→)���′�(�→,�→)می توان به صورت زیر رسمیت داد:
که در آن تابع ŝ یک امتیاز شباهت بین یک عبارت تعریفی و یک بردار معنایی را بر اساس یک ماتریس شباهت برمی گرداند. دو تابع را می توان به عنوان ŝ پذیرفت : یا ŝ com (بر اساس Corley و Mihalcea [ 34 ]) یا ŝ fes (بر اساس فرناندو و استیونسون [ 37 ]). در نهایت، اندازه گیری متقارن s lex ∈ [0, 1] را می توان به راحتی از من _متر“vسمنمتر“�به عنوان میانگین من _متر“v( الف ، ب )سمنمتر“�(آ،ب)و من _متر“v( ب ، الف )سمنمتر“�(ب،آ). این رویکرد مبتنی بر دانش با تکیه بر بردارهای معنایی، محاسبه شباهت واژگانی در NLS را ممکن میسازد. از نظر پیچیدگی محاسباتی، کران بالای این معیار O ( n 3 ) است. همانطور که در بخش بعدی نشان داده شده است، برای به دست آوردن یک معیار قابل قبول تر از شباهت در GKG ها، این جزء تشابه معنایی را می توان با شباهت شبکه ترکیب کرد.
3.3. شباهت ترکیبی (s hyb )
به طور کلی، محدودیت های رویکردهای محاسباتی برای یک مسئله مشابه را می توان با ترکیب آنها در یک اندازه گیری ترکیبی مناسب برطرف کرد. در یک GKG، برخی از مفاهیم ممکن است در ناحیهای از شبکه با اتصال متراکم قرار گیرند، در حالی که دارای برچسبهای ترسیمی هستند. در مقابل، سایر مفاهیم می توانند پیوند ضعیفی داشته باشند، اما برچسب های واژگانی غنی تری دارند. این پدیده مرزهای بالایی را برای شباهت واژگانی و شبکه ای تعیین می کند و معقولیت شناختی کلی معیارهای شباهت را محدود می کند.
با در نظر گرفتن دو مفهوم a و b در نمودار G ، یک معیار شباهت شبکه s net ( a, b ) و یک معیار شباهت واژگانی s lex ( a, b ) را تعریف کرده ایم. هر دو معیار شباهت مفهومی را با یک عدد واقعی در بازه ℜ ∈ [0، 1] کمی می کنند، که در آن 0 به معنای حداقل شباهت و 1 حداکثر شباهت است. برای به دست آوردن یک معیار ترکیبی از شباهت s hyb ( a, b )، ما دو استراتژی ترکیبی را تعریف می کنیم: ترکیب امتیاز ( s sc ) و ترکیب رتبه ( s rk ). ترکیب امتیازs sc از ترکیب نمره خطی شباهت های شبکه و واژگانی تشکیل شده است که با یک عامل ترکیبی α ∈ [0, 1] وزن می شود:
از سوی دیگر، ترکیب رتبه s rk ، ترکیب خطی رتبه بندی جفت است که بر اساس کاردینالیته مجموعه جفت نرمال شده است:
که در آن rk یک تابع رتبه بندی است، P مجموعه ای از جفت های مفهومی و α عامل ترکیبی است. در حالی که s sc یک تابع پیوسته است، s rk گسسته است. به عنوان مثال، در یک مجموعه P متشکل از ده جفت، یک جفت از مفاهیم ( a, b ) می تواند s net = 0.7 داشته باشد که در نتیجه rk ( s net ) = 3 در مجموعه زوج است. نمره واژگانی s lex = 0.45 ممکن است با rk ( s lex ) = 8 مطابقت داشته باشد. با ثابت کردن مقدار α به 0.5، ترکیب نمره s است.sc = 0.57. ترکیب رتبه برابر با rk comb = 5.5 است. بنابراین، s rk = 0.5. بخش بعدی یک ارزیابی تجربی از NLS در یک سناریوی دنیای واقعی را توصیف میکند.
4. ارزیابی
در این بخش، NLS در یک سناریوی واقعی ارزیابی می شود. هدف اصلی این ارزیابی اعتبار شهود زیربنایی NLS است: ماهیت مکمل شبکه و شباهت واژگانی در GKGs. این نتایج تجربی نشان میدهد که معیار ترکیبی میتواند بر محدودیتهای معیارهای شبکهای و واژگانی غلبه کند. به عنوان حقیقت اصلی، ما شبکه معنایی OSM، یک GKG و مجموعه داده مربوطه از قضاوتهای مشابهت تولید شده توسط انسان را انتخاب کردیم که در بخش بعدی توضیح داده شد. در ارزیابی، ما نشان میدهیم که معیارهای تشابه مبتنی بر WordNet برای محاسبه شباهت معنایی در زمینه کافی نیست، و عملکرد دو مؤلفه NLS را به تفصیل تجزیه و تحلیل میکنیم و معقولیت برتر معیار ترکیبی را ارزیابی میکنیم.11 ] برای ارزیابی معیار تشابه فاصله (MDSM)، معیار تشابه برای مفاهیم جغرافیایی.
4.1. حقیقت زمینی
به عنوان یک بستر آزمایشی ارزیابی برای NLS، ما یک GKG، شبکه معنایی OSM [ 8 ] را انتخاب کردیم. این GKG حاوی یک نمایش ماشینخوان از مفاهیم جغرافیایی است که از پروژه نقشهکشی OpenStreetMap استخراج شده است. به عنوان مثال، کانال مفهومی با یک راس مرتبط با مفاهیم آبراه و رودخانه نشان داده می شود ( http://github.com/ucd-spatial/OsmSemanticNetwork ). تا به امروز، این شبکه شامل حدود 5000 مفهوم جغرافیایی است که توسط 19000 یال به هم مرتبط شده اند. شبکه معنایی OSM انتخاب مناسبی است، زیرا از یک نمودار شامل مفاهیم به هم پیوسته تشکیل شده است و مفاهیم آن با توضیحات لغوی مرتبط است. برای ارزیابی NLS، ما رویکرد شناختی-قابلیت پذیری را اتخاذ کردیم، قضاوت های شباهت ایجاد شده توسط اندازه گیری با قضاوت های به دست آمده از افراد انسانی مقایسه می شود.
به عنوان مجموعهای از قضاوتهای روانشناختی انسان، مجموعه دادههای مرتبط با جغرافیا و شباهت (GeReSiD) ( http://github.com/ucd-spatial/Datasets ) [ 10 ] را انتخاب کردیم. این مجموعه داده مجموعهای از نمرات تشابه تولید شده توسط انسان را در 50 جفت مفهومی که توسط 203 آزمودنی انسانی رتبهبندی شدهاند، ارائه میکند و سپس به عنوان Hrk رتبهبندی میشود و در مجموع 97 مفهوم را پوشش میدهد. از آنجایی که ارتباط معنایی خارج از محدوده این مطالعه است، ما فقط قضاوت های مشابهت معنایی را در نظر گرفتیم. به دنبال رسنیک [ 16 ]، ما حد بالایی برای معقول بودن شناختی یک اندازه گیری قابل محاسبه را بالاترین همبستگی به دست آمده توسط یک ارزیاب انسانی با میانگین مجموعه داده در نظر می گیریم (Spearman’s ρ= 0.93). به عبارت دیگر، این کران بالا نشاندهنده بهترین نتایج تجربی است که آزمودنیهای انسانی هنگام رتبهبندی شباهت جفتهای مفهومی به دست آوردهاند. جدول 2 شامل تمام 50 جفت مفهومی با امتیاز شباهت و رتبه بندی شده توسط آزمودنی های انسانی است که در بخش های بعدی به عنوان حقیقت پایه استفاده شده است.
4.2. آزمایش مبتنی بر WordNet
هدف این آزمایش بررسی معقول بودن شناختی معیارهای شباهت مبتنی بر WordNet در صورت اعمال مستقیم به مفاهیم موجود در GeReSiD است. به منظور ارزیابی معیارهای شباهت WordNet به طور مستقیم بر روی مفاهیم، 97 مفهوم OpenStreetMap موجود در GeReSiD به صورت دستی به synset های WordNet مربوطه نگاشت شدند. ده معیار مبتنی بر WordNet، که در جدول 1 خلاصه شده است، بر روی 50 جفت محاسبه شد. همبستگیهای حاصل از این نمرات شباهت با نمرات انسانی GeReSiD، همبستگیهایی را با شباهت انسانی در محدوده [0.53، 0.18] به دست میآورد. در حالی که برخی از معیارها معقولیت نسبتاً بالایی به دست آوردند (به عنوان مثال، hso، ρ= 0.53)، دیگران منجر به همبستگی ضعیف شدند که معقولیت شناختی بسیار پایینی را نشان دادند. نتایج آماری معنی دار در p <0.05 نشان می دهد ρ در فاصله [0.33، 0.53]. معیارهای عملکرد برتر hso، بردار و بردار هستند که ρ∈ [ 0.43، 0.53] را به دست می آورند. سایر معیارها قابلیت شناختی قابل توجهی پایین تری را به دست می آورند ( ρ < 0.34)، که نشان دهنده عدم همگرایی نسبت به مجموعه داده های تولید شده توسط انسان است. این آزمایش ناکافی بودن معیارهای مبتنی بر WordNet را نشان میدهد که مستقیماً در این GKG اعمال میشود و نیاز به اندازهگیری قابل قبولتر است.
4.3. ارزیابی شباهت شبکه
این بخش در مورد ارزیابی انجام شده برای ارزیابی مؤلفه شبکه شبکه NLS گزارش می دهد . به منظور ارزیابی معقول بودن شناختی معیارهای هماستنادی اعمال شده در GKGها، آزمایشی به دنبال و گسترش رویکردی که ما در [ 8 ] اتخاذ کردیم، تنظیم شد. نمرات ایجاد شده توسط الگوریتم های استنادی مشترک با نمرات شباهت 50 جفت موجود در GeReSiD مقایسه شد و معقول بودن شناختی آنها ارزیابی شد.
راه اندازی آزمایش شبکه
همانطور که در بخش 3.1 بحث شد، الگوریتم هم استنادی بازگشتی P-Rank شامل تعدادی از الگوریتمهای هماستنادی [ 19 ]، از جمله، Coupling [ 20 ]، Amsler [ 21 ] و SimRank [ 18 ] است. برای بررسی عملکرد این معیارهای شباهت شبکه، پارامترهای P-Rank زیر انتخاب شدند:
-
λ (رتبه P-Rank in-out link تعادل): 11 سطح مجزای مساوی ∈ [0، 1].
-
C (ثابت فروپاشی P-Rank): نه سطح مجزا با فاصله مساوی ∈ [0.1، 0.9]. C = 0.95 نیز گنجانده شد که مقدار بهینه برای دامنه [ 8 ] است.
-
K (تکرار رتبه P): 40 تکرار رتبه P.
این پارامترها منجر به 4400 ترکیب منحصر به فرد از λ، C و K شد. سپس نمرات شباهت برای 50 جفت مفهومی در GeReSiD، با استفاده از P-Rank برای همه 4400 ترکیب به دست آمد. 4400 مجموعه از نمرات شباهت حاصل، متعاقباً با نمرات شباهت GeReSiD مقایسه شد. ضریب همبستگی رتبه اسپیرمن ρ تصحیح شده برای ارزیابی همبستگی بین نمرات ماشین و انسان، در رتبهبندی 50 جفت بدون کراوات استفاده شد.
نتایج آزمایش شبکه
این آزمایش منجر به 4400 همبستگی بین نمرات شباهت هماستنادی در شبکه معنایی OSM و نمرات شباهت متناظر در GeReSiD شد که در همه موارد 01/ 0p < بود. همه آزمونهای همبستگی بر روی 50 جفت مفهومی، با تعداد پیوندهای متفاوت از صفر تا نه، به طور متوسط 2.3 انجام شد. به منظور شناسایی روندهای کلی در نتایج، همبستگی ها توسط سه پارامتر P-Rank گروه بندی می شوند. با افزایش K ، نمرات شباهت به ارزش نظری مجانبی P-Rank نزدیکتر میشوند. در نتایج، همبستگی ها به سرعت با K ∈ [1، 10] همگرا می شوند، به دنبال آن کاهش آهسته در بازه [11، 20]، با K > 20، همبستگی ها در اطراف میانگین پایدار می مانند.ρ = 0.62، با انحراف استاندارد ( SD ) برابر با 0.1.
ثابت C تعیین می کند که شباهت با چه سرعتی در طول تکرارها کاهش می یابد. وقتی C → 0، پوسیدگی سریع است، در حالی که C → 1 حاکی از فروپاشی آهسته است. برای همه مقادیر C ، میانگین همبستگی در محدوده [0.55، 0.62] با SD = 0.11 باقی می ماند. مقادیر پایین C ([0.1، 0.4]) با کمترین احتمال پذیری در آزمایش مطابقت دارد ( ρ <0.65). بهترین نتایج زمانی به دست می آید که C∈ [0.5، 0.9]، با پیک در C = 0.8 ( ρ = 0.62) و افت زمانی که C = 0.95 باشد. سومین پارامتری که بر نتایج P-Rank تأثیر می گذارد λ است، تعادل بین پیوندهای درونی و بیرونی در شبکه معنایی. وقتی λ = 0، فقط پیوندهای بیرونی در نظر گرفته می شوند، در حالی که λ = 1 فقط پیوندهای درونی را شامل می شود.
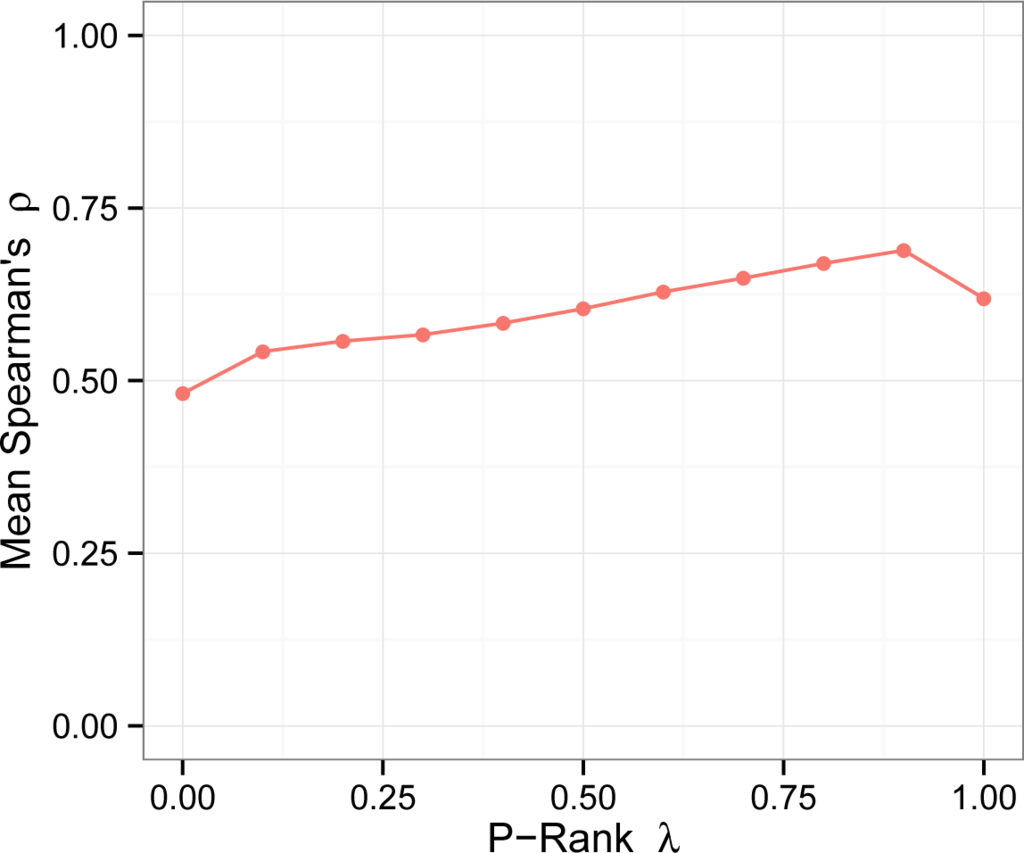
شکل 2 تأثیر λ را بر معقول بودن شناختی رتبه P نشان می دهد. هر نقطه در نمودار نشان دهنده میانگین 410 همبستگی است که در محدوده [0.48، 0.65] قرار می گیرد، با انحراف معیار ≈ 0.1. عملکرد الگوریتمها با حرکت λ از صفر به 0.9، با پیک در λ = 0.9 (میانگین ρ = 0.69) به طور پیوسته بهبود مییابد. هنگامی که λ = 1، عملکرد به طور ناگهانی کاهش می یابد ( ρ = 0.63)، که نشان می دهد که لینک های بیرونی اطلاعات مفیدی را ارائه می دهند. از این رو، با تمرکز بر بهترین تقریب ها برای ارزش نظری P-Rank ( K = 40)، قابل قبول ترین نتایج در برابر GeReSiD در فواصل C∈ [ 0.5, 0.8] قرار دارند،λ ∈ [0.8، 0.9]. در این منطقه، میانگین همبستگی با رتبه های انسانی به 73/0 = ρ می رسد. جدول 3 نتایج این ارزیابی را خلاصه میکند و قابلیت شناختی الگوریتمهای شبکه s را در برابر GeReSiD، از جمله نتایج با مجموعه داده ارزیابی MDSM از [ 8 ] مقایسه میکند.
مقایسه داده های شبکه
اگرچه نتایج GeReSiD مطابقت قابلتوجهی با مجموعه داده ارزیابی MDSM نشان میدهد، تفاوتهایی بین دو مجموعه داده وجود دارد. عملکرد بهینه P-Rank در GeReSiD با پارامترهای C = 0.8، λ = 0.9 به دست می آید. در مقابل، مجموعه داده ارزیابی MDSM زمانی بهترین تقریب است که C = 0.9، λ = 1، مربوط به الگوریتم SimRank است. زمانی که λ = 1 در GeReSiD، که در مجموعه داده ارزیابی MDSM رخ نمیدهد، احتمال P-Rank ناگهان کاهش مییابد . این تفاوت به دلیل مشکل اطلاعات محدودی است که SimRank را تحت تأثیر قرار می دهد، همانطور که Zhao و همکارانش. [ 19] با اشاره به. از آنجایی که SimRank فقط به پیوندهای درونی متکی است، رئوس هایی که فقط پیوندهای بیرونی دارند نمی توانند امتیاز شباهت به دست آورند. پوشش متفاوت در دو مجموعه داده نیز می تواند به توضیح این تفاوت ها کمک کند. در حالی که مجموعه داده ارزیابی MDSM شامل 29 مفهوم است، GeReSiD 97 مفهوم OpenStreetMap را پوشش می دهد، از جمله مفاهیم بیشتری که تحت تأثیر مشکل اطلاعات محدود قرار گرفته اند.
محدودیت شباهت شبکه
اگرچه پارامترهای بهینه منجر به همبستگی قوی برای شباهت ( ρ ≈ 0.7) می شود، ارزیابی مواردی که در آن معیارهای شباهت شبکه اختلاف قابل توجهی با رتبه بندی های تولید شده توسط انسان نشان می دهد، سودمند است. هنگامی که K = 40، C = 0.8 و λ = 0.9، جفت مفهومی < مرکز هنری، دفتر تغییرات > در مجموعه 50 جفتی توسط افراد انسانی در رتبه 35 قرار می گیرد، در حالی که این جفت با رتبه P در رتبه ششم قرار می گیرد. این شکاف گسترده به دلیل شباهت ساختاری بالای این دو مفهوم است که هر دو با امکانات کلیدی مرتبط هستند .و با مفاهیم دیگری که ممکن است به الگوریتم کمک کند شباهت معنایی آنها را کاهش دهد، پیوند متراکمی ندارند. مورد مخالف با دو جفت < شهر، ایستگاه راهآهن > و < آیتم میراث، دره > به وجود میآید که به ترتیب در رتبههای 27 و 28 توسط سوژههای انسانی و رتبههای 44 و 45 با رتبه P قرار دارند. این روابط ضعیف توسط ساختار پیوند در شبکه معنایی OSM ضبط نمیشوند و بنابراین، P-Rank هیچ شباهتی بین جفتها پیدا نمیکند.
4.4. ارزیابی تشابه واژگانی
این بخش ارزیابیهایی را که در مورد مولفه شباهت واژگانی NLS انجام دادهایم، که در بخش 3.2 مشخص شده است، با استفاده از GeReSiD به عنوان حقیقت پایه مورد بحث قرار میدهد. این رویکرد شامل استخراج بازنمایی های برداری از تعاریف واژگانی و سپس مقایسه آنها با استفاده از معیارهای تشابه معنایی اصطلاح به اصطلاح است. معیار کلی تشابه برچسب به برچسب متعاقباً با ترکیب عبارت ماتریس شباهت با استفاده از تکنیکهای تشخیص ترجمه به دست میآید.
تنظیم آزمایش واژگانی
این آزمایش شامل مجموعه ای از 180 ترکیب از چهار پارامتر ورودی تکنیک { POS, C, sim t , sim v } است که در جدول 4 به تفصیل شرح داده شده است. تمام رتبهبندیهای ایجاد شده در این مرحله هیچ پیوندی نداشتند و با استفاده از ρ Spearman با GeReSiD مقایسه شدند .
نتایج آزمایش واژگانی
نتایج در جدول 5 خلاصه شده است که برای هر پارامتر میانه، چارک و حداکثر ρ را گزارش می کند. از آنجایی که توزیع ρ برای پارامترهای الگوریتم تمایل زیادی به انحراف دارد، ما میانه را اتخاذ می کنیم. ρ˜�˜به عنوان یک برآوردگر قوی از تمایل مرکزی، چارک های 25% و 75% را برای هر پارامتر گزارش می کند. همانطور که قبلاً در رابطه با نتایج در [ 9 ] ذکر شد، افعال استفاده شده به صورت مجزا (POS = VB ) همبستگی با مجموعه داده های انسانی را نشان نمی دهند، در نتیجه ρ∈ [0.01، 0.16]، با p > 0.1. مسائل مشابهی برای اندازه گیری بردار به بردار fes اعمال می شود که به دست آمدρ˜= 0.26�˜=0.26، با p > 0.05. از این رو، این نتایج غیر معنی دار از تجزیه و تحلیل حذف شدند. برای همه موارد دیگر، همبستگی ها از نظر آماری با 001/0 > P معنی دار بود.
به طور کلی، مؤلفه لغوی رویکرد NLS برای محاسبه شباهت معنایی در یک GKG یک میانه به دست میآورد. ρ˜= 0.61�˜=0.61، با کران بالایی ρ = 0.74 است. چهار پارامتری که بر نتایج الگوریتم تأثیر می گذارند عبارتند از { POS, C, sim t , sim v }. اندازه گیری بردار به برداری sim v استراتژی محاسبه شباهت بردارهای معنایی را تعیین می کند. در حالی که fes قابل قبولی شناختی رضایت بخشی را نشان نداد، com نتایج معقول تری به دست آورد. فیلتر POS عباراتی را انتخاب می کند که در بردارهای معنایی گنجانده شوند. به استثنای تجزیه و تحلیل افعال به صورت مجزا ( VB )، NN و NN VB معقول شناختی بسیار نزدیکی را نشان می دهند. (ρ˜= 0.61 )(�˜=0.61). پیکره متن C برای تعیین وزن معنایی به اصطلاحات استفاده می شود. معقول بودن شناختی به دست آمده توسط مجموعه های ویکی Null و OSM تا حد زیادی قابل مقایسه است. (ρ˜= 0.58 )(�˜=0.58). در مقابل، مجموعه استخراج شده از ایرلندی ایندیپندنت، که حاوی داستان های خبری است، از سایر مجموعه ها بهتر عمل می کند و در نتیجه معقولیت شناختی بالاتری به همراه دارد. (ρ˜= 0.64 )(�˜=0.64)، نشان می دهد که پیکره غیر اختصاصی از محاسبات بهتر از پیکره دامنه خاص پشتیبانی می کند.
پارامتر چهارم که تاثیر زیادی بر نتایج دارد، اندازه گیری ترم به ترم sim t است. اندازه گیری بردار، مسیر، lch و hso در ردیف بالا، با کران بالا ρ ≥0.7 و یک میانه ρ˜> 0.6�˜>0.6. همه معیارهای دیگر به روشی کمتر رضایتبخش عمل میکنند، با میانه پایینتر در بازه [0.48، 0.6] و کران بالایی ρ∈ [0.56، 0.66]. پس از خوشه بالای این چهار معیار ترم به مدت، عملکرد بهطور مشهودی کاهش مییابد و با لین به حداقل میرسد (میانگین ≈ 0.47، کران بالا ≈ 0.55). سایر معیارها ( wup، res، lesk، vectorp و jcn ) بین چهار معیار برتر قرار میگیرند و به نتایج متوسط میرسند. اندازهگیریهای تشابه واژگانی ، lex از معیارهای مبتنی بر WordNet با کران بالایی ρ = 0.74 بهتر عمل میکند. بهترین عملکرد با پارامترهای زیر حاصل می شود: POS = NN، C = Irish Indep، sim v= com، sim t = { بردار، مسیر، lch، hso }). در چنین مواردی، معقول شناختی ρ در بازه [0.61، 0.74] قرار میگیرد که یک همبستگی قوی آماری معنیدار را با GeReSiD نشان میدهد.
مقایسه داده های واژگانی
جدول 5 شامل میانه است ρˆ�^که با مجموعه داده ارزیابی MDSM در [ 9 ] به دست آوردیم. معقول شناختی به دست آمده در این دو ارزیابی، روندهای مشترک، اما همچنین واگرایی برای پارامترهای خاص را نشان می دهد. این واقعیت با ارزیابی شباهت شبکه سازگار است، که در آن رویکردهای استنادی مشترک در مجموعه داده ارزیابی MDSM بهتر از GeReSiD عمل کردند. این تفاوت بیشتر به دلیل ساختار و پوشش مجموعه داده ارزیابی MDSM (29 مفهوم ساختار یافته در پنج مجموعه) و GeReSiD (97 مفهوم در یک مجموعه) است. در حالی که روند کلی در دو آزمایش در مورد شباهت واژگانی سازگار است، تأثیر پارامترهای فردی { POS، C، sim t ، sim v } متفاوت است.
به طور خاص، sim t تأثیر عمده ای بر معقول بودن شناختی الگوریتم دارد. تنوع بالایی را می توان بین دو آزمایش مشاهده کرد، که در ادبیات مشابهت معنایی غیر معمول نیست. در مطالعهای توسط بودانیتسکی و هیرست [ 38 ]، اندازهگیریهای jcn، hso، lin، lch و lesk قابلیتهای شناختی بسیار متفاوتی را در برابر دو مجموعه دادههای شباهت معروف به دست میآورند. معیارهایی که به بالاترین عملکرد کلی می رسند عبارتند از lch، مسیر، بردار و hso، با کران های بالایی در محدوده [0.72، 0.75]. سایر معیارها رتبه پایین تری دارند و در بازه [0.62، 0.69] سقوط می کنند. ممکن است توجه داشته باشید که اگرچه معیارهای پیچیدهتر میتوانند نتایج بهینه را در زمینههای خاص به دست آورند، سادهترین معیارهای مبتنی بر مسیر، مانند path و lch ، تمایل دارند که در بین دو مجموعه داده با اطمینان بیشتری عمل کنند.
محدودیت های تشابه واژگانی
اگرچه s lex می تواند به معقولیت بالایی برسد، موارد خاص اختلاف زیادی با قضاوت های شباهت تولید شده توسط انسان در مجموعه 50 جفت مفهومی در GeReSiD نشان می دهد. با تمرکز بر بهترین حالت (POS = NN، C = Irish Indep، sim v = com، sim t = بردار ، با ρ = 0.74)، می توان مشاهده کرد که جفت < دریا، جزیره> توسط افراد انسانی در رتبه 24 و از نظر الگوریتم رتبه هشتم را دارد. تعاریف این دو مفهوم دارای همپوشانی واژگانی زیادی هستند، اما ارتباط زیادی با یکدیگر دارند (هشتم در رتبه بندی همبستگی) و مشابه نیستند. در این مورد، الگوریتم ارتباط را با شباهت اشتباه می گیرد.
علاوه بر این، < میدان نبرد، بنای تاریخی > توسط سوژه های انسانی در رتبه 10 و از نظر الگوریتم تنها 36 ام است. برچسبهای مفاهیم تنها یک اصطلاح مشترک دارند ( نظامی ) و سایر اصطلاحات شباهت آنها را افزایش نمیدهد. به طور مشابه، شباهت < کاربری صنعتی زمین، دفن زباله > دست کم گرفته می شود، زیرا توسط انسان در رتبه 21 و توسط الگوریتم رتبه 47 قرار دارد. دلیل این عدم تطابق گسترده در این واقعیت نهفته است که برچسب محل دفن زباله بسیار کوتاه است («جایی که زباله جمعآوری، طبقهبندی یا پوشانده میشود») و حاوی عباراتی نیست که به الگوریتم اجازه دهد تا درجهای از شباهت را با زمینه دریافت کند. تولید صنعتی و فرآوری زباله با ترکیب s net می توان بر این محدودیت ها غلبه کردو lex به یک اندازه گیری ترکیبی، همانطور که در بخش بعدی نشان داده شده است.
4.5. ارزیابی تشابه ترکیبی
همانطور که در بخش 3.3 بیان شد، دو روش را می توان برای ترکیب s net و s lex در یک اندازه گیری ترکیبی استفاده کرد: ترکیب امتیاز s sc و ترکیب رتبه s rk . این بخش یک ارزیابی تجربی از این دو تکنیک ترکیبی را توصیف میکند و نشان میدهد که معقولپذیری شناختی چنین معیارهای ترکیبی به طور کلی بالاتر از شبکههای فردی و معیارهای واژگانی است و از شهود پشت NLS پشتیبانی میکند.
راه اندازی آزمایش ترکیبی
برای بررسی اثربخشی روشهای ترکیب امتیاز و رتبه، یک آزمایش معقولپذیری شناختی با استفاده از GeReSiD تنظیم شد. معقول ترین موارد برای شبکه s net و معیارهای لغوی lex انتخاب شدند، بر اساس نتایج تجربی نشان داده شده در بخش های 4.3 و 4.4. از آنجایی که ما علاقه مند به ارزیابی این هستیم که آیا روش های ترکیبی قادر به بهبود نتایج در بالای محدوده هستند، انتخاب به 30 مورد برتر برای هر دو رویکرد، به عنوان نمونه ای نماینده از شبکه و معیارهای واژگانی محدود می شود. این موارد برتر آماری پرت نیستند، اما به طور دقیق روندهای کلی در شواهد تجربی جمع آوری شده در آزمایش های فوق الذکر را منعکس می کنند. آزمایش با پارامترهای ورودی زیر تنظیم شد:
-
روش های ترکیبی: ترکیب امتیاز s sc و ترکیب رتبه s rk .
-
ضریب ترکیبی α : ده سطح مجزای مساوی ∈ [0، 1]. وقتی α = 0، فقط معیار واژگانی در نظر گرفته می شود. از طرف دیگر α = 1 مربوط به اندازه گیری شبکه است.
-
شبکه شباهت شبکه : 30 مورد از نظر شناختی قابل قبول در مقایسه با GeReSiD.
-
lex شباهت واژگانی : 30 مورد از نظر شناختی قابل قبول در مقایسه با GeReSiD.
برای هر مقدار α , هر مورد s net و s lex از طریق s sc و s rk ترکیب شدند . این منجر به معقولپذیری شناختی 18000 معیار ترکیبی در 50 جفت مفهومی GeReSiD، با p <0.001 برای همه آزمونهای همبستگی اسپیرمن، بدون هیچ ارتباطی در رتبهبندی شد. یک معیار ترکیبی در صورتی موفق در نظر گرفته میشود که از هر دو مؤلفهاش net و lex عملکرد بهتری داشته باشد ، یعنی معقولپذیری شناختی معیار ترکیبی به شدت بیشتر از شباهت شبکهای و واژگانی، به طور رسمی ρ hyb باشد.> ρ خالص ∧ ρ hyb > ρ lex . اگر معیار ترکیبی کمتر یا برابر هر یک از اجزای آن باشد، شکست خورده است.
نتایج آزمایش ترکیبی
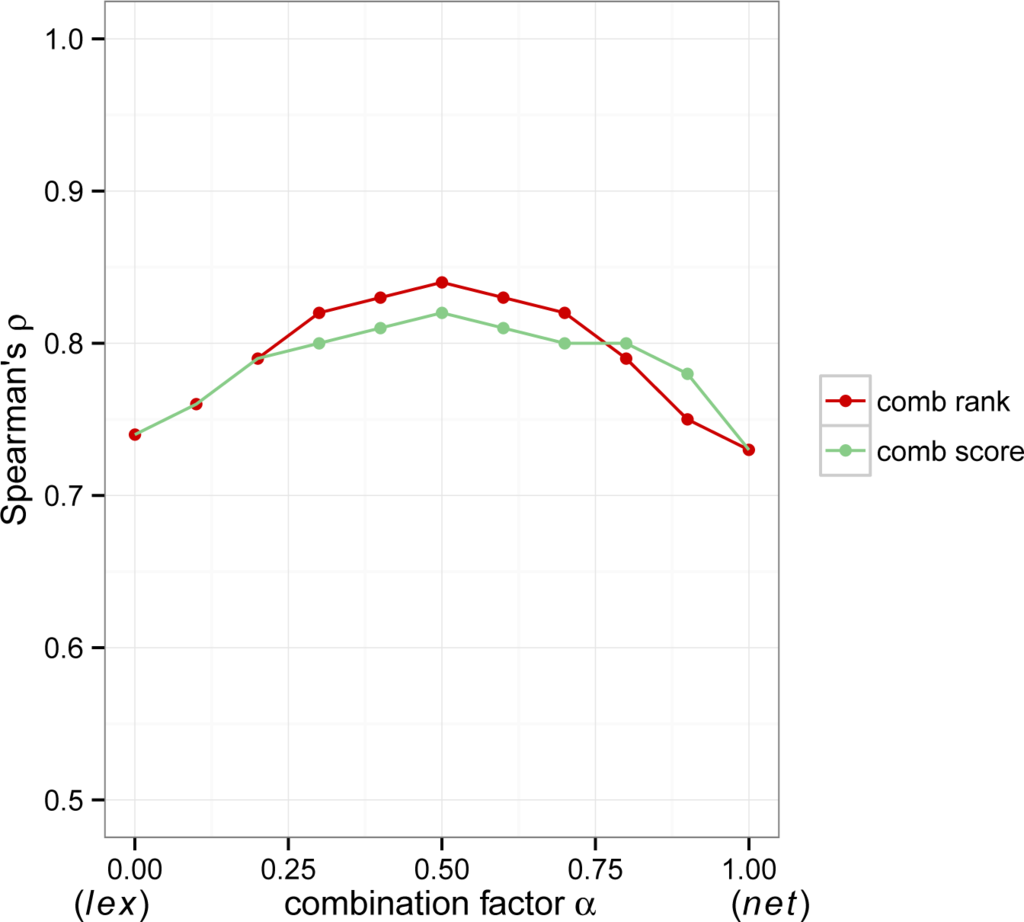
الگوهای واضحی از نتایج آزمایش ظاهر می شوند. معیارهای ترکیبی، ترکیب شبکه و شباهت واژگانی، برتری ثابتی را نسبت به شبکه و اجزای واژگانی خود نشان میدهند. ترکیب رتبهبندی s rk به طور مداوم بهتر از ترکیب امتیاز s sc عمل میکند و قابلیت قبولی و میزان موفقیت بالاتری را به دست میآورد. جدول 6 نتایج آزمایش را خلاصه می کند، کران بالایی ρ بدست آمده با معیارهای نت و lex به صورت مجزا و hyb در هنگام ترکیب را در مقابل هم قرار می دهد. معقولپذیری شناختی معیارهای ترکیبی به طور قابلتوجهی بیشتر از معیارهای فردی است، با اوج در ρ .= 0.84 وقتی α = 0.5. این شواهد تجربی نشان میدهد که مقدار بهینه α در بازه [0.4، 0.6] کاهش مییابد و اطلاعات را به طور یکنواخت از شبکه و اجزای واژگانی میگیرد.
نرخ موفقیت، که به صورت درصد بیان میشود، نشان میدهد که در چند مورد یک معیار ترکیبی از هر دو معیار فردی بهتر عمل کرده است. همانطور که در جدول 6 می توان متوجه شد ، زمانی که α ∈ [0.4، 0.6]، میزان موفقیت بسیار بالا است، در فاصله [87.5٪، 100٪]. به طور خاص، ترکیب رتبه بندی s rk از تمام معیارهای فردی (100٪) بهتر عمل می کند. نرخ موفقیت بالا نیز زمانی قابل مشاهده است که α ∈ (0، 0.4)، با میانگین میزان موفقیت 82.9٪. در انتهای دیگر طیف ( α ∈ (0.6، 1))، میانگین میزان موفقیت 75٪ است. در هیچ یک از موارد مورد بررسی، یک معیار ترکیبی کمتر از هر دو جزء آن نبود.
میزان موفقیت گزارش شده در جدول 6 نشان می دهد که، به طور کلی، هر دو مؤلفه به شدت در معقول بودن شناختی NLS نقش دارند. به طور خاص، هنگام استفاده از ترکیب رتبه بندی s rk با مقادیر بهینه α ، اندازه گیری های ترکیبی موفقیت بیش از 89٪ را به دست می آورند. عملکرد NLS در شکل 3 نشان داده شده است ، که تاثیر α بر معقول بودن شناختی را برجسته می کند و از دو تکنیک ترکیبی ( s sc و srk ) استفاده می کند . منحنیهای زنگولهای تقریباً متقارن در شکل، مزایای معیارهای ترکیبی را نشان میدهند ( α∈ (0، 1)) روی معیارهای فردی، در منتهی الیه محور افقی ( α = 0 مربوط به معیارهای لغوی، α = 1 به معیارهای شبکه است).
محدودیت های شباهت ترکیبی
با در نظر گرفتن بهترین معیارهای ترکیبی ( α = 0.5)، می توان تغییرات را با توجه به رتبه بندی های ایجاد شده توسط معیارهای فردی مشاهده کرد. تنها در یک مورد، معیارهای ترکیبی نسبت به معیارهای قبلی، رتبه بندی < دریا، جزیره > پنجم، بهبود نمی یابند ( برای مقایسه با رتبه بندی انسان به جدول 2 مراجعه کنید). در تمام موارد دیگری که در بالا مورد بحث قرار گرفت، معیارهای ترکیبی رتبهبندیهای معقولتری از نظر شناختی ارائه میدهند: < مرکز هنری، دفتر تغییرات > (15)، < شهر، ایستگاه راهآهن > (19)، < موارد میراث، دره > (28)، < میدان جنگ، بنای تاریخی > (بیست و نهم)، و < کاربری صنعتی، دفن زباله> (چهل و چهارم). به طور خلاصه، معیارهای ترکیبی نمی توانند به طور کامل بر محدودیت های ذاتی منبع داده غلبه کنند، اما به طور متوسط موفق می شوند رتبه بندی را به قضاوت های انسانی نزدیک تر کنند. بر اساس این مجموعه از شواهد تجربی، رویکرد ترکیبی مناسبترین روش برای محاسبه شباهت معنایی در GKG است.
5. نتیجه گیری ها
در این مقاله، اندازهگیری شباهت واژگانی شبکه (NLS) را توصیف کردیم، معیاری که برای به تصویر کشیدن شباهت مفاهیم در GKGها، ساختارهای بازنمایی دانش که برای نمایش مفاهیم و روابط آنها استفاده میشود، طراحی شده است. ارزیابی در شبکه معنایی OSM، مزایای ترکیب شباهت شبکه و شباهت واژگانی را در یک معیار ترکیبی تأیید کرد، و معقولپذیری شناختی بالاتری به دست آورد. در مقایسه با کرانهای بالایی برای اندازههای شبکه ( 73/0 = ρ ) و معیارهای لغوی ( 74/0= ρ )، معیارهای ترکیبی به کران بالایی بسیار بالاتری میرسند ( 84/0 = ρ ). به منظور ارائه رهنمودهای عملی، جدول 7 نتایج بهینه شبکه، معیارهای لغوی و ترکیبی را خلاصه می کند.
اگرچه NLS از قابلیت شناختی بالایی برخوردار است، با غلبه بر مسائل ذاتی شباهتهای واژگانی و شبکه، برخی از محدودیتها باقی مانده است که باید در تحقیقات آینده مورد توجه قرار گیرند. شبکه اندازهگیریهای شبکه که در این مطالعه گنجاندهایم پیچیدگی مکعبی دارند و بهینهسازی مکانی-زمانی قابل توجهی برای اعمال آنها در GKGهای بزرگ مورد نیاز است [ 39 ]. در رابطه با s lex ، تکنیکهای تشخیص پارافراسی مورد استفاده در مؤلفه واژگانی به بهینهسازی نیاز دارند تا در مقیاس بسیار بزرگ قابل اجرا باشند. علاوه بر این، WordNet محدودیت هایی در پوشش و سوگیری دارد. روشی که در s lex توضیح داده شده استاز یک مدل کیسه ای از کلمات برای اصطلاحات در توصیفات واژگانی استفاده می کند. با این حال، در بسیاری از موارد، مهمترین اصطلاحات معمولاً در ابتدای توضیحات قرار می گیرند و در نظر گرفتن ترتیب اصطلاح ممکن است نتایج را بهبود بخشد، به خصوص در مواردی که تعاریف لغوی بسیار طولانی و پر سر و صدا وجود دارد. علاوه بر این، اقدامات کاملاً مبتنی بر پیکره را می توان در s lex برای غلبه بر NLS به منظور افزایش پوشش آن، به قیمت کمی دقت، استفاده کرد.
از دیدگاه شناختی تر، محدودیت اصلی NLS در فقدان زمینه دقیق برای محاسبه معیار شباهت نهفته است، همانطور که توسط Keßler [ 40 ] نشان داده شده است. سایر محدودیتها بر ارزیابی معقولپذیری شناختی تأثیر میگذارند که در بخش 4 پذیرفته شدهایم. سوژههای انسانی شباهت معنایی را به طور شهودی درک میکنند، اما ترجمه قضاوت شباهت به یک عدد گسسته میتواند بسیار ذهنی باشد، و توافق بین ارزیابیکنندهها و تعمیمپذیری را محدود میکند. نتایج [ 41 ]. در این مقاله، ما NLS را در مورد توانایی آن در شبیهسازی قضاوتهای انسانی در کل محدوده شباهت معنایی، یعنی از مفاهیم بسیار مشابه تا مفاهیم بسیار متفاوت ارزیابی کردیم. با این حال، بسیاری از برنامه های مشابه به طور خاص به برنامه های برتر نیاز دارند.k شبیه ترین مفاهیم به یک مفهوم معین، به جای مفاهیم کم مشابه. با توجه به اینکه هیچ ارزیابی معقول شناختی به طور کامل قابل تعمیم نیست، شواهد قوی تنها با بررسی متقاطع ارزیابی های مختلف قابل ایجاد است. به عنوان مثال، ارزیابیهای غیرمستقیم تکمیلی میتوانند بر وظایف خاص مبتنی بر شباهت، مانند ابهامزدایی از معنای کلمه و بازیابی اطلاعات تمرکز کنند. رویکرد تشابه معنایی اتخاذ شده در NLS را می توان به اندازه گیری های محاسباتی ارتباط، که کاربرد وسیعی دارند، گسترش داد [ 38 ].
ارزیابی ما بر روی شبکه معنایی OSM به عنوان یک GKG متمرکز شد. در حالی که این شبکه معنایی ویژگی های معمولی GKG ها را نشان می دهد [ 8 ]، به یک دامنه بسیار خاص محدود می شود. سایر GKG های مناسب برای ارزیابی NLS ممکن است YAGO، DBpedia و سایر مجموعه داده های باز پیوند داده شده باشند [ 5]. علاوه بر این، مجموعه متن کلی که ما استفاده کردیم یک سوگیری منطقهای را نشان میدهد و مجموعههای بزرگتر و جهانیتر ممکن است نتایج را بیشتر بهبود بخشد. با این حال، ارزیابیهای معقولپذیری شناختی بر روی GKGهای بزرگ و مستقل از دامنه طراحی دشوار است و باید یک مبادله بین ویژگی دامنه و قابلیت اطمینان نتیجه در نظر گرفته شود. این کار آینده نقش NLS را به عنوان یک رویکرد کلی برای مقابله با چالش محاسبه شباهت معنایی، در GKGهای همه جا، که به طور فزاینده ای حاوی دانش ارزشمندی است که مجموعه داده های جغرافیایی سنتی را تکمیل می کند، تقویت می کند.





بدون نظر