

خلاصه
برنامه ریزی و مدیریت شهری پایدار نیازمند مدل های قابل اعتماد تغییر زمین است که می تواند برای بهبود تصمیم گیری استفاده شود. هدف از این مطالعه آزمایش یک مدل اتوماتای تصادفی جنگل سلولی (RF-CA)، که ترکیبی از مدلهای جنگل تصادفی (RF) و اتوماتای سلولی (CA) است. شبیهسازی کاپا (KSimulation)، رقم شایستگی، و مؤلفههای آمار توافق و عدم توافق برای اعتبارسنجی مدل RF-CA استفاده شد. علاوه بر این، مدل RF-CA با مدلهای خودکار سلولی ماشین بردار پشتیبان (SVM-CA) و مدلهای اتوماتای سلولی رگرسیون لجستیک (LR-CA) مقایسه شد. نتایج نشان میدهد که مدل RF-CA بهتر از مدلهای SVM-CA و LR-CA عمل میکند. مدل RF-CA دارای دقت شبیهسازی کاپا (KSimulation) 0.51 (با رقم آمار شایستگی 47٪) بود، در حالی که مدلهای SVM-CA و LR-CA دارای دقت KSimulation 0 بودند. 39 و -0.22 (با رقم آمار شایستگی 39% و 6%) به ترتیب. به طور کلی، مدل RF-CA در تخصیص تغییرات «غیر ساختهشده به ساختهشده» که توسط مؤلفههای «غیر ساختهشده به ساختهشده» در توافق 15 درصد منعکس میشود، نسبتاً دقیق بود. عملکرد مدل RF-CA به نقشههای پتانسیل انتقال RF نسبتاً دقیق نسبت داده شد. بنابراین، این مطالعه پتانسیل مدل RF-CA را برای شبیهسازی رشد شهری برجسته میکند.
کلید واژه ها:
رشد شهری ؛ مدل های تغییر زمین ; جنگل تصادفی ; اتوماتای سلولی ; شبیه سازی کاپا
چکیده گرافیکی
1. معرفی
مدلهای تغییر زمین شهری برای تحلیل نیروهای محرک تغییرات کاربری/پوشش زمین و شبیهسازی سناریوهای رشد شهری «چه میشد» مهم هستند [ 1 ، 2 ، 3 ]. این امر به ویژه در کشورهای در حال توسعه که رشد سریع شهری را تجربه می کنند بسیار مهم است [ 4 ، 5 ، 6 ]. تخمین زده می شود که تا سال 2050 بیش از سه میلیارد نفر در مناطق شهری زندگی خواهند کرد که 80 درصد از آنها ساکنان شهرهای کشورهای در حال توسعه خواهند بود [ 7 ، 8 ]. طبق گزارش سازمان ملل متحد [ 7پیش بینی می شود جمعیت شهری در آسیا از 1.8 میلیارد در سال 2010 به 3.4 میلیارد در سال 2050 افزایش یابد، در حالی که پیش بینی می شود جمعیت شهری در آفریقا از 0.8 میلیارد در سال 2010 به 1.2 میلیارد در سال 2050 افزایش یابد. انتظار می رود شهرنشینی سریع باعث افزایش غیررسمی شود. سکونت گاه ها، اپیدمی ها و تخریب محیط زیست [ 9 ، 10 ]. بنابراین، برنامه ریزان شهری و سیاست گذاران نیازمند مدل های قابل اعتماد تغییر زمین هستند که می توانند برای شبیه سازی سناریوهای مختلف رشد یا توسعه شهری استفاده شوند [ 3 ، 11 ].
دهههای گذشته شاهد توسعه و کاربرد بسیاری از مدلهای تغییر زمین شهری مبتنی بر اتوماتای سلولی (CA) بودهاند [ 12 ، 13 ، 14 ، 15 ، 16 ، 17 ، 18 ، 19 ، 20 ]. اتوماتای سلولی (CA) مدلهای دینامیکی از پایین به بالا و گسسته هستند که در ابتدا توسط اولام و فون نویمان در دهه 1940 به منظور درک رفتار سیستمهای پیچیده مفهومسازی شدند [ 21 ]. مدل CA شامل فضای سلول، حالات سلولی، همسایگی ها، مراحل زمانی و قوانین انتقال است [ 22 ]]. فضا را می توان به عنوان شبکه ای از سلول ها نشان داد، در حالی که یک همسایگی به عنوان مجموعه ای از سلول ها بر اساس مجاورت تعریف می شود [ 21 ، 22 ]. هر سلول می تواند یکی از حالت های گسسته i را در هر زمان فرض کند [ 23 ، 24 ]. زمان در مراحل مجزا پیش میرود و همه سلولها به طور همزمان به عنوان تابعی از حالت خود، همراه با وضعیت سلولهای مجاور طبق قوانین انتقال مشخص، حالت خود را تغییر میدهند [ 25 ]. قوانین انتقال اجزای کلیدی CA هستند زیرا آنها فرآیندهای سیستم در حال مدلسازی را نشان میدهند [ 26]. توابع فاصله در یک همسایگی اعمال می شوند تا جذابیت یا دافعه بودن وابسته به فضایی یک حالت سلولی بر دیگری را در نظر بگیرند [ 27 ]. مدل CA، تغییرات کاربری/پوشش زمین در آینده را بر اساس برون یابی کاربری/پوشش زمین گذشته شبیه سازی می کند.
مدل های اتوماتای سلولی (CA) به طور قابل توجهی به مدل سازی رشد شهری کمک کرده اند [ 2 ، 12 ، 22 ، 24 ، 28 ، 29 ]. با این حال، مطالعات قبلی محدودیتهای مربوط به تعریف قوانین انتقال یا پتانسیل انتقال را برجسته کردهاند [ 1 ، 30 ، 31 ، 32 ]. ایستمن و همکاران در تحلیل تطبیقی دوازده مدل پتانسیل انتقال تجربی . [ 1] نشان داد که یازده مدل، از جمله ارزیابی چند معیاره رایج (MCE)، رگرسیون لجستیک (LR) و وزن شواهد (WoE)، عملکرد ضعیفی داشتند. این به این دلیل است که بیشتر مدلهای پتانسیل انتقال به صورت خطی تعریف میشوند [ 33 ]. در نتیجه، مدلهای بالقوه انتقال در دریافت الگوها و فرآیندهای تغییر کاربری/پوشش زمین که اغلب با غیرخطی بودن، پیچیدگی، ظهور و خودسازماندهی مشخص میشوند ، شکست میخورند . به منظور غلبه بر محدودیت های مدل های خطی، لی و یه [ 35] یک مدل CA شبکه عصبی را برای مدیریت روابط پیچیده در سیستم های شهری توسعه داد. اگرچه گزارش شده است که شبکههای عصبی مدلسازی تغییر زمین را بهبود میبخشند، اما کالیبره کردن آنها دشوار است و تمایل دارند بیش از حد برازش کنند [ 35 ]. علاوه بر این، یانگ و همکاران. [ 33 ] یک مدل خودکار ماشین سلولی بردار پشتیبان (SVM-CA) را در شهر شنژن اعمال کرد. نویسندگان گزارش دادند که مدل SVM-CA به دقت بالاتری دست یافت و بر محدودیت های شبکه های عصبی غلبه کرد. با این حال، SVM ها به موارد پرت حساس هستند [ 36 ] و عموماً به زمان آموزش بیشتری نیاز دارند، به خصوص اگر مجموعه داده دارای ویژگی های زیادی باشد.
مدل های تغییر زمین شهری قابل اعتماد یک نیاز کلیدی برای برنامه ریزی رشد شهری پایدار است [ 11 ، 37 ]. در حالی که محققان دیگر اخیراً مدلهای تغییر زمین را با استفاده از رگرسیون لجستیک خودکار و مدلهای خطوط رگرسیون تطبیقی چند متغیره بهبود دادهاند [ 38 ، 39 ، 40 ]، هنوز نیاز به آزمایش مدلهای غیرخطی دیگر وجود دارد. جنگل تصادفی (RF) یک مدل مجموعه (مجموعه) است [ 41 ]، که از کیسهبندی (نمونهگیری جمعآوری شده بوت استرپ) برای ساختن بسیاری از درختهای تصمیم فردی برای پیشبینی یا طبقهبندی نهایی استفاده میکند [ 42 ]. این الگوریتم از یک زیرمجموعه تصادفی از متغیرهای پیش بینی کننده برای تقسیم داده های مشاهده به زیر مجموعه های همگن استفاده می کند [ 42]. علاوه بر این، مدل RF از دادههای نمونه خارج از کیسه (OOB) استفاده میکند که از دادههایی که در نمونه بوت استرپ نیستند برای ارزیابی عملکرد [ 42 ] مشتق شدهاند. مزایای مدل های RF عبارتند از: (1) آنها می توانند یک پایگاه داده بزرگ را مدیریت کنند (به عنوان مثال، هزاران متغیر عددی و دسته بندی ورودی). (ii) در مقایسه با دیگر طبقهبندیکنندههای یادگیری ماشین (به عنوان مثال، شبکه عصبی مصنوعی، SVM، تقویت) به زمان آموزش کمتری نیاز دارند. (iii) آنها فاقد فرضیات توزیع نرمال هستند. (IV) آنها در برخورد با نویزهای پرت و سر و صدا قوی هستند. و (v) هر متغیر ورودی را در یک اندازه گیری اهمیت کمیت می کنند [ 43]. در حالی که، مدل RF با موفقیت برای طبقهبندی تصاویر سنجش از دور استفاده شده است، طبق دانش ما، مدل RF برای مدلسازی پتانسیل انتقال و شبیهسازی رشد شهری آزمایش نشده است.
هدف از این مطالعه آزمایش مدل تغییر زمین شهری تصادفی اتوماتای جنگلی سلولی (RF-CA) در استان شهری هراره، زیمبابوه است. مدل RF-CA اعمال شده در این مطالعه، مدلهای RF و CA را به منظور آزمایش اثربخشی مدل RF-CA برای شبیهسازی رشد شهری ادغام میکند. ابتدا، نرخهای انتقال چند مرحلهای را از نقشههای کاربری/پوشش زمین (1984، 2002 و 2008) محاسبه کردیم. دوم، مدل RF برای محاسبه نقشههای پتانسیل انتقال استفاده شد. سوم، ما استفاده/پوشش زمین را تا سال 2013 با استفاده از نرخهای انتقال چند مرحلهای و یک نقشه پتانسیل انتقال بر اساس مدل CA شبیهسازی کردیم. چهارم، شبیهسازی کاپا (KSimulation)، رقم شایستگی، و مؤلفههای آمار توافق و عدم توافق برای اعتبارسنجی مدل RF-CA استفاده شد. علاوه بر این، ما مدلهای SVM-CA و رگرسیون لجستیک سلولی اتوماتای (LR-CA)را به منظور مقایسه عملکرد با مدل RF-CA اعمال کردیم. این به این دلیل است که مدل های LR-CA و SVM-CA برخی از مدل های متداول تغییر زمین هستند.
2. پیاده سازی مدل RF-CA
2.1. منطقه و داده های مطالعه
استان کلانشهر حراره بین 17 درجه و 40 دقیقه تا 18 درجه دقیقه جنوبی و بین 30 درجه و 55 دقیقه تا 31 درجه و 15 دقیقه شرقی امتداد دارد و مساحتی در حدود 942 کیلومتر مربع را در بر می گیرد ( شکل 1 ). این استان شهری از مناطق شهری هراره، روستایی هراره، چیتونگویزا و اپورث تشکیل شده است. منطقه شهری هراره شامل شهر حراره، پایتخت زیمبابوه است. ساختار فضایی شهر حراره با یک شبکه جاده شعاعی با منطقه تجاری مرکزی (CBD) در هسته آن، و مناطق صنعتی در شرق و جنوب مشخص می شود [ 44 ]. در شمال و شمال شرقی مناطق مسکونی کم تراکم در مساحتی حدود 1000 متر مربع قرار دارند .یا بیشتر، در حالی که در منتهی الیه شرق، جنوب، جنوب غربی و غرب مناطق مسکونی با تراکم بالا در مساحتی حدود 300 متر مربع قرار دارند [ 44 ] . علاوه بر این، برخی از مناطق مسکونی با تراکم متوسط بین 800 متر مربع و 1000 متر مربع در بخش جنوبی شهر حراره یافت می شود. شهر Chitungwiza (در منطقه Chitungwiza) تقریباً در 25 کیلومتری جنوب شهر هراره واقع شده است. این شهر توسط دولت استعماری به منظور اختصاص مناطق مسکونی برای آفریقایی ها دور از شهر هراره [ 45 ] توسعه یافت.]. اگرچه شهر چیتونگویزا دارای شرکت های تجاری و صنعتی است، اکثر ساکنان آن در شهر حراره کار می کنند. منطقه Epworth، که در جنوب شرقی شهر هراره واقع شده است، یک سکونتگاه شهری بدون برنامه و غیررسمی است که توسط پناهندگان جنگی در طول مبارزات آزادیبخش در دهه 1970 شکل گرفت [ 9 ].
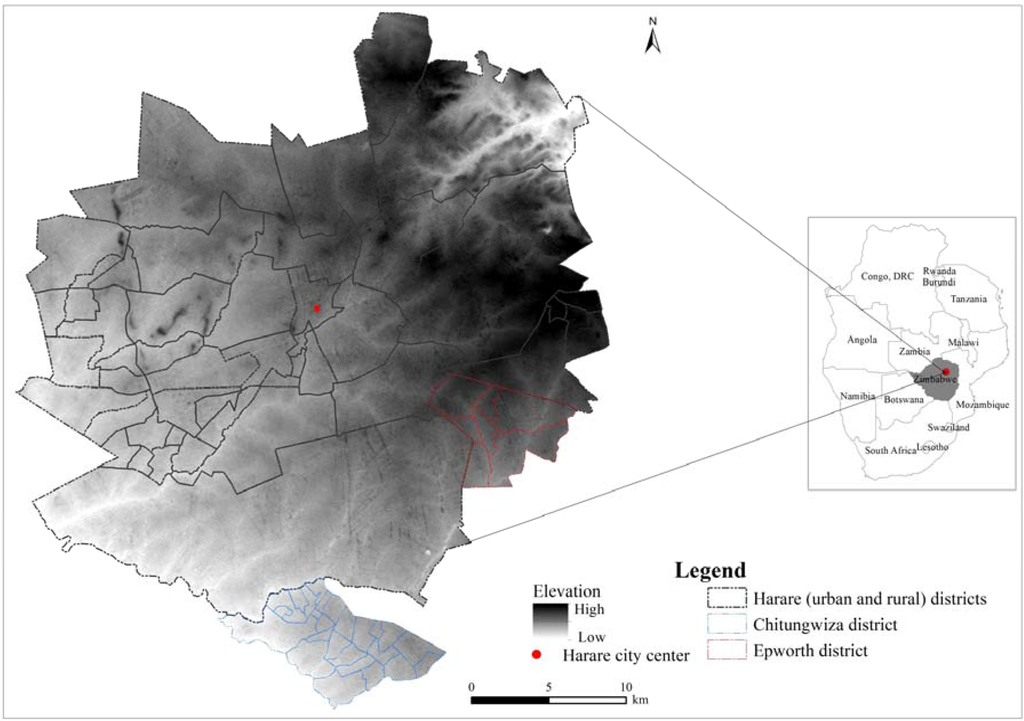
شکل 1. موقعیت استان شهری هراره، زیمبابوه.
با توجه به Colquhoun [ 46 ] و Mutizwa-Mangiza [ 47 ]، جمعیت استان شهری هراره پس از استقلال در سال 1980، زمانی که کنترل مهاجرت حذف شد، به طور قابل توجهی افزایش یافت. جمعیت در ناحیه شهری هراره از حدود 642191 نفر در سال 1982 به 1435784 نفر در سال 2012 افزایش یافت، در حالی که جمعیت منطقه روستایی هراره از 16173 به 23023 در مدت مشابه افزایش یافت [ 10 ، 48 ]. با این حال، جمعیت شهر چیتونگویزا به طور تصاعدی از حدود 15000 نفر در سال 1969 به 354472 نفر در سال 2012 افزایش یافت [ 45 ، 48 ]. افزایش جمعیت عمدتاً توسط افرادی انجام شد که در طول مبارزات آزادیبخش در دهه 1970 از مناطق روستایی مهاجرت کردند.9 ]. جمعیت ناحیه اپورث نیز پس از استقلال به سرعت افزایش یافت، زیرا افرادی که نمی توانستند در شهر هراره اسکان پیدا کنند، به پناهجویان جنگی پیوستند [ 45 ]. در حال حاضر، جمعیت ناحیه اپورث 161840 نفر برآورد شده است [ 48 ]. با توجه به این رشد سریع جمعیت و شهرنشینی متعاقب آن [ 49 ]، ما استان شهری هراره را برای آزمایش مدل RF-CA انتخاب کردیم. علاوه بر این، استان کلان شهر هراره با الگوهای رشد شهری مانند توسعه، پر کردن و توسعه جهشی مشخص می شود که در شهرهای دیگر در جنوب صحرای آفریقا نیز مشاهده می شود [ 17 ].
ما از نقشه های کاربری/پوشش زمین و عوامل محرک برای توسعه مدل RF-CA ( جدول 1 ) برای استان شهری هراره ( جدول 1 و شکل 2 ) استفاده کردیم. نقشههای کاربری/پوشش زمین از تصاویر Landsat برای سالهای 1984، 2002، 2008، 2013 طبقهبندی شدند و با استفاده از دادههای مرجع سالگرد و نزدیک به سالگرد اعتبارسنجی شدند [ 49 ]. سطوح دقت کلی برای چهار تاریخ از 86٪ تا 93٪ [ 49 ] متغیر است. جدول 2شرحی از طبقات کاربری/پوشش زمین ارائه می دهد. جادههای اصلی دورههای «1984-2002» و «2002-2008» از نقشههای خیابان هراره در مقیاس 1:30000 که توسط اداره کل نقشهبرداری (زیمبابوه) در سالهای 1989 و 2005 منتشر شد، دیجیتالی شدند. علاوه بر این، مراکز صنعتی بزرگ و مرکز شهر نیز از نقشههای خیابان هراره در مقیاس 1:30000 دیجیتالی شدند. ارتفاع از ASTERGDEM استخراج شد، در حالی که داده های تراکم جمعیت از اداره آمار زیمبابوه [ 48 ] به دست آمد.]. ما از مناطق ساخته شده (استخراج شده از نقشه های پوشش زمین 1984 و 2002)، جاده های اصلی، مراکز صنعتی عمده و داده های مرکز شهر برای محاسبه «فاصله تا مناطق ساخته شده»، «فاصله تا جاده های اصلی»، «فاصله تا» استفاده کردیم. مناطق صنعتی عمده» و «فاصله تا مرکز شهر» با استفاده از روشهای فاصله اقلیدسی موجود در ArcGIS 10.2 ( جدول 1 و شکل 3 ). ما «فاصله تا مناطق مسکونی» را برای سالهای 1984 و 2002، و «فاصله تا جادههای اصلی» را برای دورههای «1984–2002» و «2002–2008» محاسبه کردیم، زیرا مناطق ساختهشده و جادهها عوامل محرک پویایی هستند که تغییر میکنند. زمان. علاوه بر این، ما از “فاصله تا مناطق ساخته شده” به عنوان عامل محرک استفاده کردیم زیرا شکل شهری قبلی بر الگوهای شهری آینده تأثیر می گذارد [ 26 ]]. در نهایت، تمام عوامل محرک به منظور مطابقت با وضوح فضایی نقشه های کاربری/پوشش زمین مشتق شده از Landsat به وضوح فضایی 30 × 30 متر نمونه برداری شدند ( شکل 2 ).

جدول 1. داده های ورودی برای کالیبراسیون و شبیه سازی تغییر کاربری/پوشش زمین.
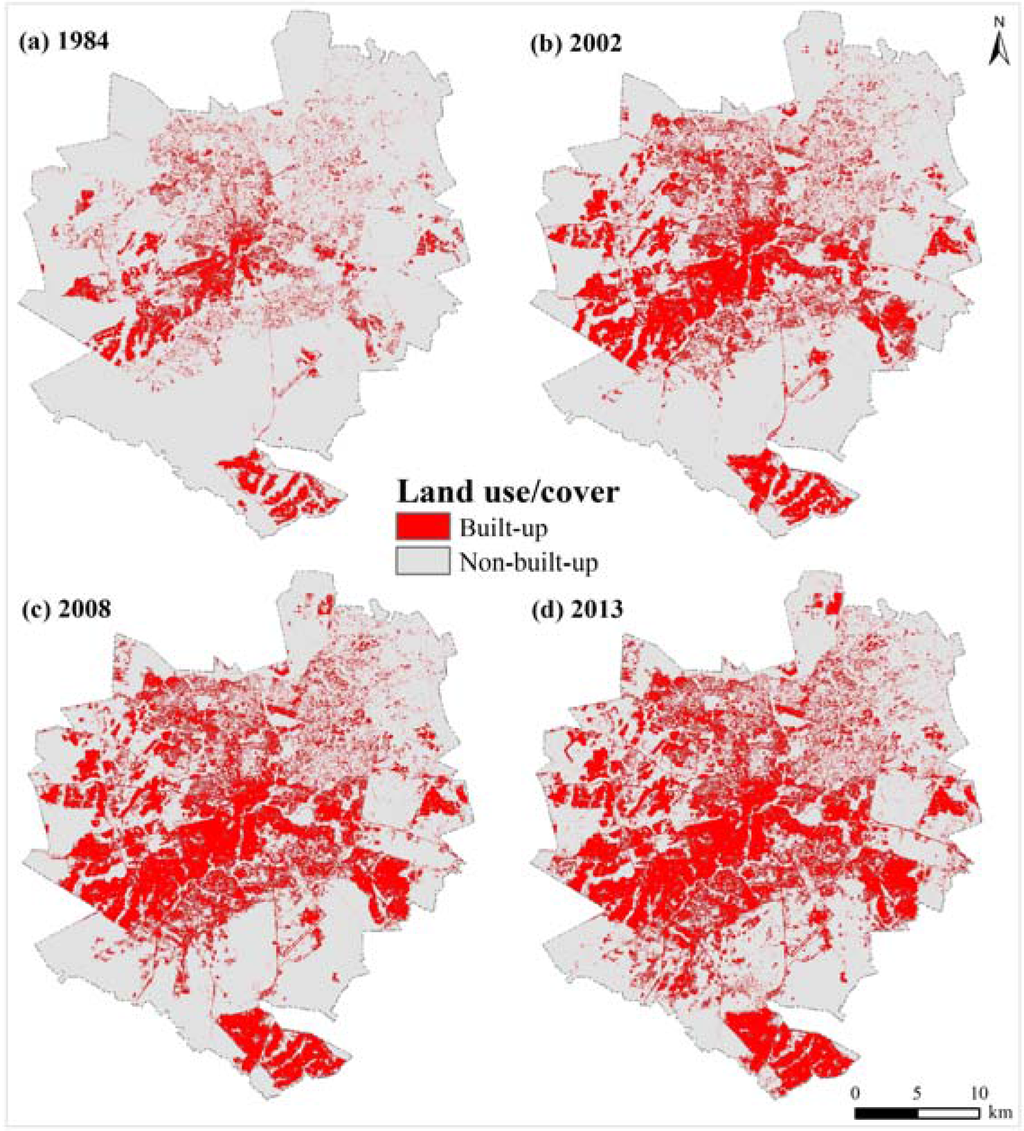
شکل 2. کاربری /پوشش زمین برای ( الف ) 1984، ( ب ) 2002، ( ج ) 2008 و ( د ) 2013.
جدول 2. طبقات کاربری/پوشش زمین.
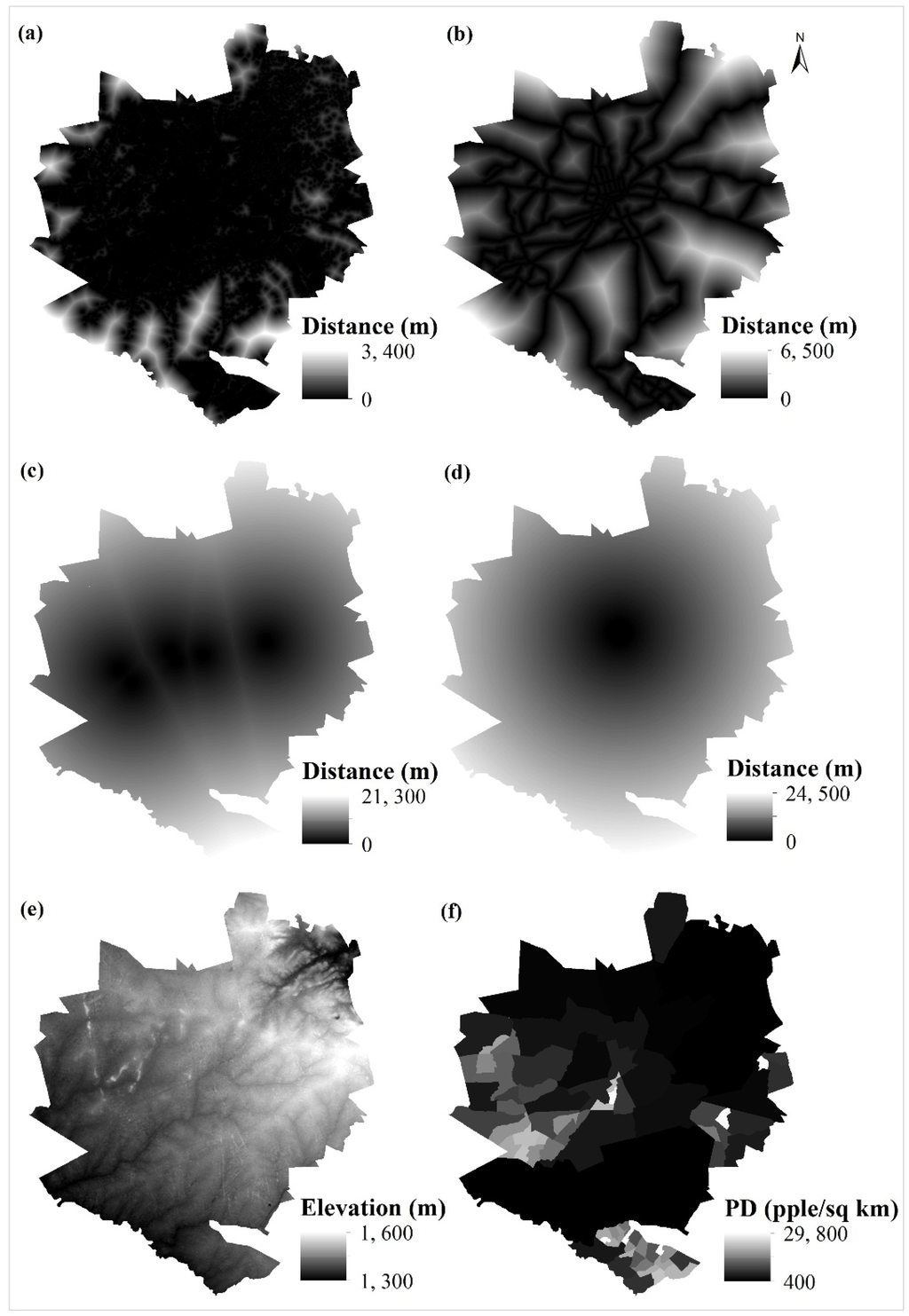
شکل 3. عوامل محرک انتخابی مورد استفاده برای محاسبه نقشه های پتانسیل انتقال: ( الف ) فاصله تا مناطق ساخته شده (2002). ( ب ) فاصله تا جاده های اصلی (2002). ج ) فاصله تا مراکز صنعتی عمده؛ ( د ) فاصله تا مرکز شهر؛ ( ه ) ارتفاع؛ و ( f ) تراکم جمعیت (2002).
2.2. کالیبراسیون و شبیه سازی مدل
ما از روشهای زیر برای پیادهسازی مدل RF-CA استفاده کردیم: (1) محاسبه نرخهای انتقال. (2) مدل سازی پتانسیل انتقال. و (3) شبیه سازی CA، و همچنین اعتبار سنجی مدل ( شکل 4 ). یادگیری ماشین و الگوریتمهای آماری موجود در R برای مدلسازی پتانسیل انتقال استفاده شد، در حالی که توابع موجود در Dinamica EGO برای محاسبه نرخ انتقال و شبیهسازی تغییرات کاربری/پوشش زمین استفاده شد. R یک نرم افزار آماری و گرافیکی کامپیوتری رایگان و متن باز است [ 50 ]، در حالی که Dinamica EGO (محیط زیست برای اشیاء پردازش جغرافیایی) نرم افزار رایگانی است که توسط Soares-Filho و همکاران توسعه داده شده است. [ 51]. Dinamica EGO متشکل از یک پلت فرم پیچیده برای توسعه مدلهای فضایی پویا است که شامل تکرارهای تودرتو، انتقالهای چند مرحلهای، بازخوردهای پویا و رویکردهای چند مقیاسی است [ 51 ].
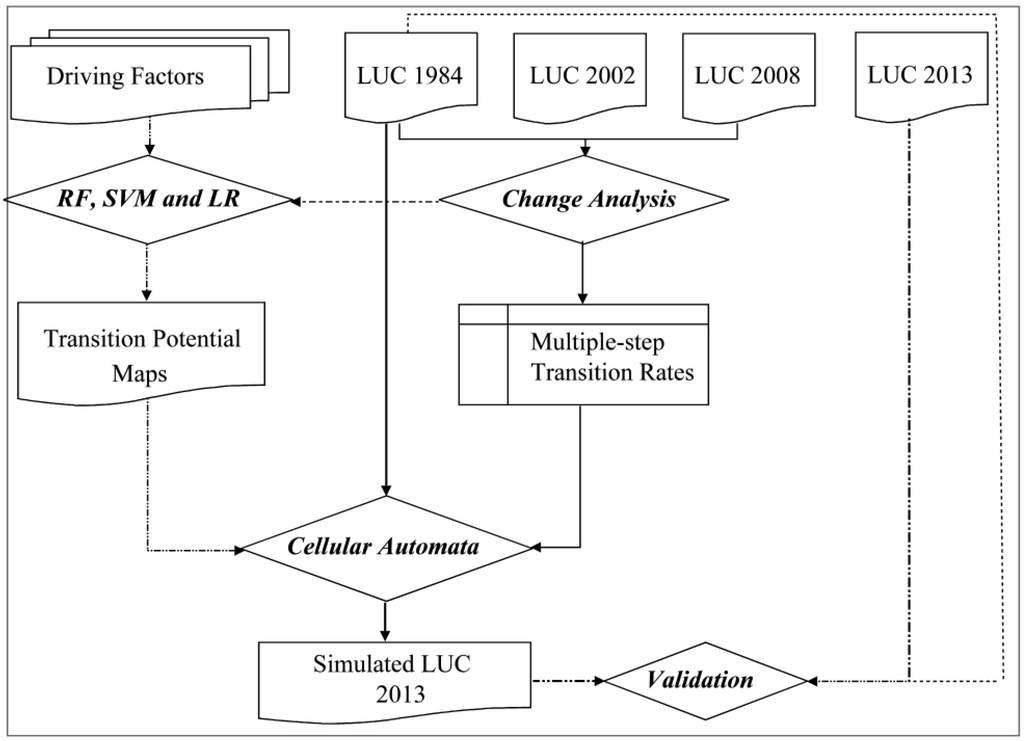
شکل 4. مدل اتوماتای سلولی تصادفی جنگلی (RF-CA). توجه LUC به کاربری/پوشش زمین اشاره دارد.
2.2.1. محاسبه نرخ گذار
ما از نقشههای کاربری/پوشش زمین برای سالهای 1984، 2002 و 2008 ( شکل 2 ) برای محاسبه نرخهای انتقال تک مرحلهای و چند مرحلهای در Dinamica EGO استفاده کردیم. نرخهای انتقال تک مرحلهای به نرخهای کل مطلق محاسبهشده برای یک دوره معین (مثلاً 16 سال) اشاره دارد، در حالی که نرخهای انتقال چند مرحلهای به نرخهای انتقالی اشاره دارد که در یک مرحله زمانی سالانه محاسبه میشوند. نرخ انتقال تک مرحله ای و انتقال چند مرحله ای بر اساس الگوریتم های شناخته شده موجود در Dinamica EGO [ 52 ] محاسبه می شود. جدول 3a نشان می دهد که نرخ های انتقال برای دوره های “1984-2002″، “2002-2008” (کالیبراسیون) و “2008-2013” (اعتبارسنجی) متفاوت و در نتیجه غیر ثابت هستند. بنابراین، ما اثربخشی نرخ انتقال تک مرحلهای و چند مرحلهای را در طول اجرای کالیبراسیون CA آزمایش کردیم. نتایج کالیبراسیون اولیه نشان داد که نرخ انتقال چند مرحلهای «1984-2008» و نرخهای انتقال چند مرحلهای ترکیبی «1984-2002»، «2002-2008» و «1984-2008» بهترین دقت شبیهسازی را داشتند ( جدول 3). ب). با این حال، ترکیب نرخهای انتقال چند مرحلهای «1984-2002»، «2002-2008» و «1984-2008» ( جدول 3)ب) دقت تخصیص فضایی بهتری ایجاد کرد. این به این دلیل است که نرخهای انتقال چند مرحلهای «1984–2002» و «2002–2008» مقدار تغییرات «غیر ساختهشده به ساختهشده» را اختصاص میدهند، در حالی که نرخ انتقال چند مرحلهای «1984-2008» تنظیم میشود. یا تخصیص تغییرات “غیر ساخته شده به ساخته شده” را تعدیل کرده است. در نتیجه، برآورد بیش از حد یا دست کم گرفتن در طول شبیه سازی به حداقل رسید. بنابراین، سه نرخ انتقال چند مرحلهای از دورههای “1984-2002″، “2002-2008” و “1984-2008” برای اجرای نهایی شبیهسازی CA انتخاب شدند ( جدول 3 a). لازم به ذکر است که استفاده از سه نرخ گذار چند مرحله ای از دوره های “1984-2002″، “2002-2008” و “1984-2008” به تحقیقات بیشتر در سایر مناظر شهری به منظور آزمایش اثربخشی نیاز دارد.
جدول 3. ( الف ) نرخ انتقال تک مرحله ای و چند مرحله ای (%). ( ب ) دقت شبیه سازی بر اساس نرخ انتقال تک مرحله ای و چند مرحله ای (%).
2.2.2. مدل سازی پتانسیل انتقال
ما بین سالهای 1984 تا 2008 از 3000 نقطه آموزشی بهطور تصادفی از مناطق «غیر ساختهشده به ساختهشده» و «بدون تغییر» (یعنی پایداری ساختهشده و غیرساختشده) نمونهبرداری کردیم تا مدل RF را توسعه دهیم. بر اساس بسته تصادفی Forest [ 53 ] موجود در R. همه عوامل محرک ( جدول 1 ) برای توسعه مدل پس از آزمایش چند خطی نشان داد که آنها زیر مقدار آستانه 0.7 [ 54 ] هستند، و بنابراین اضافی نیستند، استفاده شدند. پس از بررسی چند خطی بودن، ما به طور تصادفی 70٪ از نقاط آموزشی را برای توسعه مدل انتخاب کردیم، در حالی که 30٪ برای اعتبارسنجی متقاطع استفاده شد.
به منظور دستیابی به عملکرد بهینه مدل، پارامترهای مدل RF را تنظیم کردیم. الگوریتم RF متغیرهای ورودی را بر اساس تصمیمات دودویی به گروههای مستقل تقسیم میکند تا درختهای بزرگ و پیچیده اولیه را تولید کند. با این حال، درختان بزرگ تمایل دارند که داده های آموزشی را بیش از حد مناسب کنند و در نتیجه پیش بینی ضعیفی دارند. بنابراین، ما پارامترهای مدل RF را با تغییر تعداد متغیرهای ورودی انتخاب شده در هر تقسیم گره و تعداد کل درختان موجود در مدل (25، 50، 100، و 500) تنظیم کردیم. پس از کالیبراسیون، از 100 درخت برای ساخت مدل نهایی RF و سپس محاسبه نقشه پتانسیل انتقال “غیر ساخته شده به ساخته شده” استفاده شد.
ما همچنین مدل های SVM و LR را به منظور مقایسه عملکرد با مدل RF توسعه دادیم. SVMها تکنیک های یادگیری ماشینی هستند که بر اساس تئوری یادگیری آماری [ 55 ، 56 ] هستند. این تکنیک توسط Boser و همکاران معرفی شد. ، [ 55 ] و Vapnik [ 56 ] برای حل مسائل طبقه بندی و رگرسیون با ساخت ابرصفحه ها در یک فضای چند بعدی. به طور کلی، SVM ها مرز تصمیم گیری را از بین تعداد نامتناهی بالقوه انتخاب می کنند، و بیشترین حاشیه را بین نزدیک ترین نقاط داده به ابر صفحه، که به عنوان “بردارهای پشتیبان” نامیده می شوند، باقی می گذارند [ 57 ].]. SVM از یک تابع هسته برای تبدیل داده های آموزشی به فضای ویژگی های بعدی بالاتر برای مسائل طبقه بندی غیرخطی استفاده می کند [ 57 ]. برای مدل SVM در این مطالعه، ما یک تابع پایه شعاعی را به عنوان هسته SVM با استفاده از بسته e071 موجود در R [ 58 ] انتخاب کردیم.
تکنیک LR رابطه بین یک متغیر وابسته و یک یا چند متغیر مستقل (که ممکن است مقوله ای یا پیوسته باشند) را مدل می کند. مدل LR را می توان به صورت زیر بیان کرد:
پ( Y∣∣∣ایکس) =هβo+β1ایکس1 +هβo+β1ایکسپ(�|ایکس)=ه��+�1ایکس1+ه��+�1ایکس
که در آن: P( Y | X ) احتمال متغیر وابسته Y است که X داده می شود (یعنی احتمال شهری شدن یک سلول). X نشان دهنده متغیرهای مستقل مانند فاصله تا جاده ها است. β o ثابتی است که باید تخمین زده شود. و β 1 ضریبی است که برای هر متغیر مستقل X تخمین زده می شود . برای مدل LR در این مطالعه، از مدل خطی تعمیم یافته (GLM) موجود در R [ 50 ] استفاده کردیم.
2.2.3. شبیه سازی بر اساس مدل CA
سه مجموعه داده، (1) نقشه کاربری/پوشش اولیه زمین (1984). (2) نقشه های بالقوه انتقال (1984-2008). و (3) نرخهای انتقال چند حالته «1984-2002»، «2002-2008» و «1984-2008» برای شبیهسازی کاربری/پوشش زمین تا سال 2013 بر اساس توابع CA انتقال توسعهدهنده و پچر مورد استفاده قرار گرفتند. تابع انتقال گسترش دهنده وصله های کلاس کاربری/پوشش زمین قبلی را گسترش یا منقبض می کند، در حالی که تابع انتقال پچر وصله های جدید را تشکیل می دهد [ 51 ]. توابع انتقال گسترش دهنده و پچر از یک مکانیسم تخصیص تشکیل شده است که مسئول شناسایی سلول هایی با بالاترین پتانسیل انتقال برای هر انتقال است [ 51 ]. به عنوان مثال، تابع انتقال توسعه دهنده، انتقال از حالت i (غیر ساخته شده) به حالت را انجام می دهد.j (ساخته شده) فقط در سلول های همسایه حالت j به منظور گسترش یا انقباض استفاده از زمین/تکه ها. سپس تابع patcher انتقال از حالت i به حالت j را فقط در سلول های همسایه با حالت هایی غیر از j انجام می دهد [ 51 ]. به منظور شبیه سازی تغییرات کاربری/پوشش زمین، هر دو تابع انتقال از مکانیزم انتخاب تصادفی [ 51 ] استفاده می کنند.
اندازه وصلههای کاربری/پوشش زمین جدید بر اساس یک تابع احتمال لگ نرمال تنظیم میشوند که پارامترهای آن با میانگین اندازه پچ (MPS)، واریانس اندازه وصله (VAR) و ایزومتریک (ISO) [ 59 ] تعریف میشوند. پارامترها را می توان برای تولید الگوهای فضایی مختلف کاربری/پوشش تغییر داد. برای این مطالعه، مدل CA را با تغییر پارامترهای توابع انتقال گسترش دهنده و پچر با استفاده از آزمون و خطا کالیبره کردیم. سال شبیه سازی اولیه 1984 بود، در حالی که سال پایانی 2013 (یعنی سال مشاهده شده یا مرجع) بود. در نتیجه، مدل CA بیست و نه تکرار در یک مرحله زمانی سالانه داشت.
3. نتایج و بحث
3.1. ارزیابی خوب بودن تناسب نقشههای بالقوه انتقال
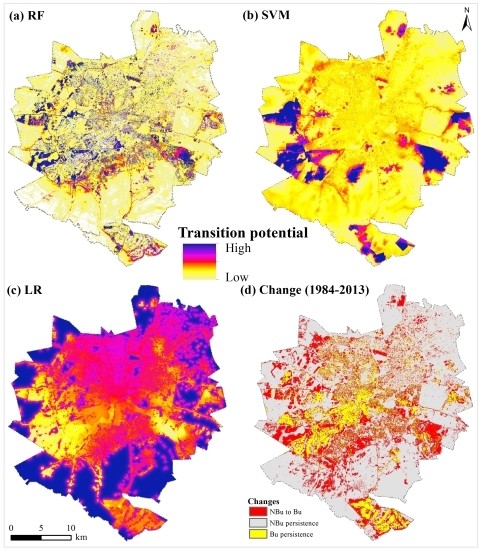
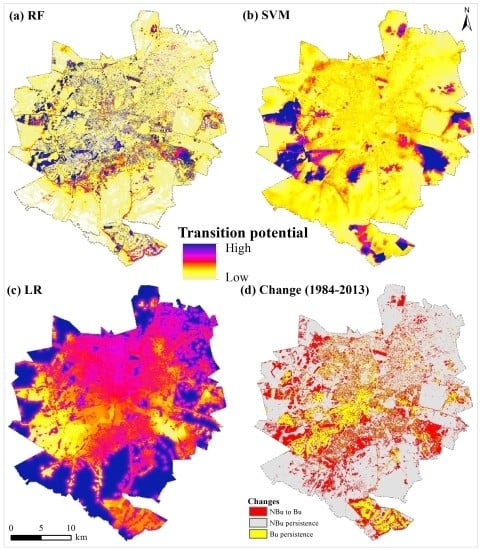
شکل 5 a-c نقشههای پتانسیل انتقال «غیر ساختهشده به ساختهشده» را نشان میدهد – محاسبهشده با استفاده از مدلهای RF، SVM و LR – در حالی که شکل 5 د تغییرات کاربری/پوشش زمین را نشان میدهد که بین سالهای 1984 و 2013 رخ داده است. تجزیه و تحلیل بصری نشان داد که مدل RF یک نقشه پتانسیل انتقال نسبتاً دقیق در مقایسه با مدلهای SVM و LR ایجاد کرد. بهویژه، مدل RF در پیشبینی توسعههای پرکننده جدید و مناطق ساختهشده در نزدیکی مناطق ساختهشده قبلی (از سالهای 1984 و 2002) ماهر بود. توسعه Infill به رشد نواحی تازه توسعه یافته در مناطق شهری دوره قبلی (یعنی 1984 و 2002) اشاره دارد، در حالی که توسعه به گسترش مناطق ساخته شده در مناطق شهری اشاره دارد [ 60 ]]. در مقابل، مدل SVM تغییرات “غیر ساخته شده به ساخته شده” را بیش از حد برآورد کرد ( شکل 5 ب). در نتیجه، نقشه پتانسیل انتقال SVM با الگوهای تغییر مشاهده شده “غیر ساخته شده به ساخته شده” مطابقت ندارد ( شکل 5 b,d). این نشان میدهد که پیشبینی نواحی تازهساختهشده تحت تأثیر انباشتگی (یعنی سوگیری صحت نسبت به مناطق با انتقال بالا) به دلیل تطبیق بیش از حد [ 61 ] قرار میگیرد. شکل 5 ج نشان می دهد که مدل LR ضعیف عمل کرده است. این امر با وقوع مناطق با پتانسیل انتقال بالا در مناطق “غیر ساخته شده” پایدار منعکس می شود ( شکل 5 ). به طور کلی، همه مدل ها در پیش بینی تحولات جهشی برنامه ریزی نشده، به ویژه در قسمت جنوب غربی منطقه مورد مطالعه شکست می خورند.شکل 5 د). توسعههای جهشی نواحی تازه ساختهشدهای هستند که از قطعات غیرساختشده خارج از مناطق ساختهشده شهری موجود و غیر مرتبط با آنها تبدیل میشوند [ 60 ]. مطالعات قبلی نشان داد که مدلهای آماری یا یادگیری ماشینی موقعیت وصلههای جدیدی را که به مناطق ساختهشده موجود [ 62 ] متصل نیستند، به دلیل ناپایداری مکانی یا زمانی [ 63 ] کمتر پیشبینی میکنند.
ما ابتدا منطقه زیر منحنی (AUC) را برای آماره مشخصه عملیاتی نسبی (ROC) تجزیه و تحلیل کردیم تا خوب بودن برازش نقشههای پتانسیل انتقال را ارزیابی کنیم [ 64 ]. بر اساس آمار ROC، اندازه گیری با قدرت پیش بینی کامل مقدار 1.0 را به دست می دهد، در حالی که اندازه گیری بدون توان (تصادفی) مقدار 0.5 را به دست می دهد [ 1 ]. مقادیر کمتر از 0.5 (مدل تهی) معیاری را نشان می دهد که به طور سیستماتیک نادرست است [ 1 ]. آمار AUC ROC – که قدرت در دسترس بودن کلی تشخیصی را خلاصه می کند – برای مدل RF 0.77، برای مدل SVM 0.75 و برای مدل LR 0.7 بود. با این حال، شکل 5a-c نشان می دهد که آمار AUC اطلاعات کافی برای ارزیابی عملکرد مدل در این مطالعه ارائه نمی دهد. مطالعات قبلی نشان داد که آمار AUC می تواند به طور بالقوه گمراه کننده باشد [ 65 ، 66 ] زیرا شامل مناطق پایدار در اعتبارسنجی مدل [ 1 ] است. بنابراین، Pontius و Si [ 67 ] تفسیر منحنی ROC و همچنین استفاده از آماره مشخصه عملیاتی کل (TOC) را برای ارزیابی خوب بودن برازش نقشههای پتانسیل انتقال توصیه میکنند. آمار TOC بر روی آمار رایج ROC بسط مییابد [ 67]. بنابراین، آمار TOC اطلاعات بیشتری را در مقایسه با آماره ROC ارائه می دهد که برای ارزیابی خوب بودن برازش نقشه های پتانسیل انتقال مفید است. به عنوان مثال، آمار ROC فقط دو نسبت را نشان می دهد، hits/(Hits plus misss) و false alarms/(false alarms به اضافه رد صحیح)، در حالی که آمار TOC هر چهار ورودی را در ماتریس نشان می دهد: hits، misss، false alarms و correct. ردها [ 67 ]. علاوه بر این، آمار TOC بصری تر است زیرا نتایج را بر اساس واحدهای واقعی در جدول احتمالی (به عنوان مثال، کیلومتر مربع) به جای یک آمار بدون واحد مانند AUC ارائه می دهد [ 67 ]. جزئیات بیشتر در مورد آمار TOC را می توان در Pontius و Si [ 67 ] یافت.
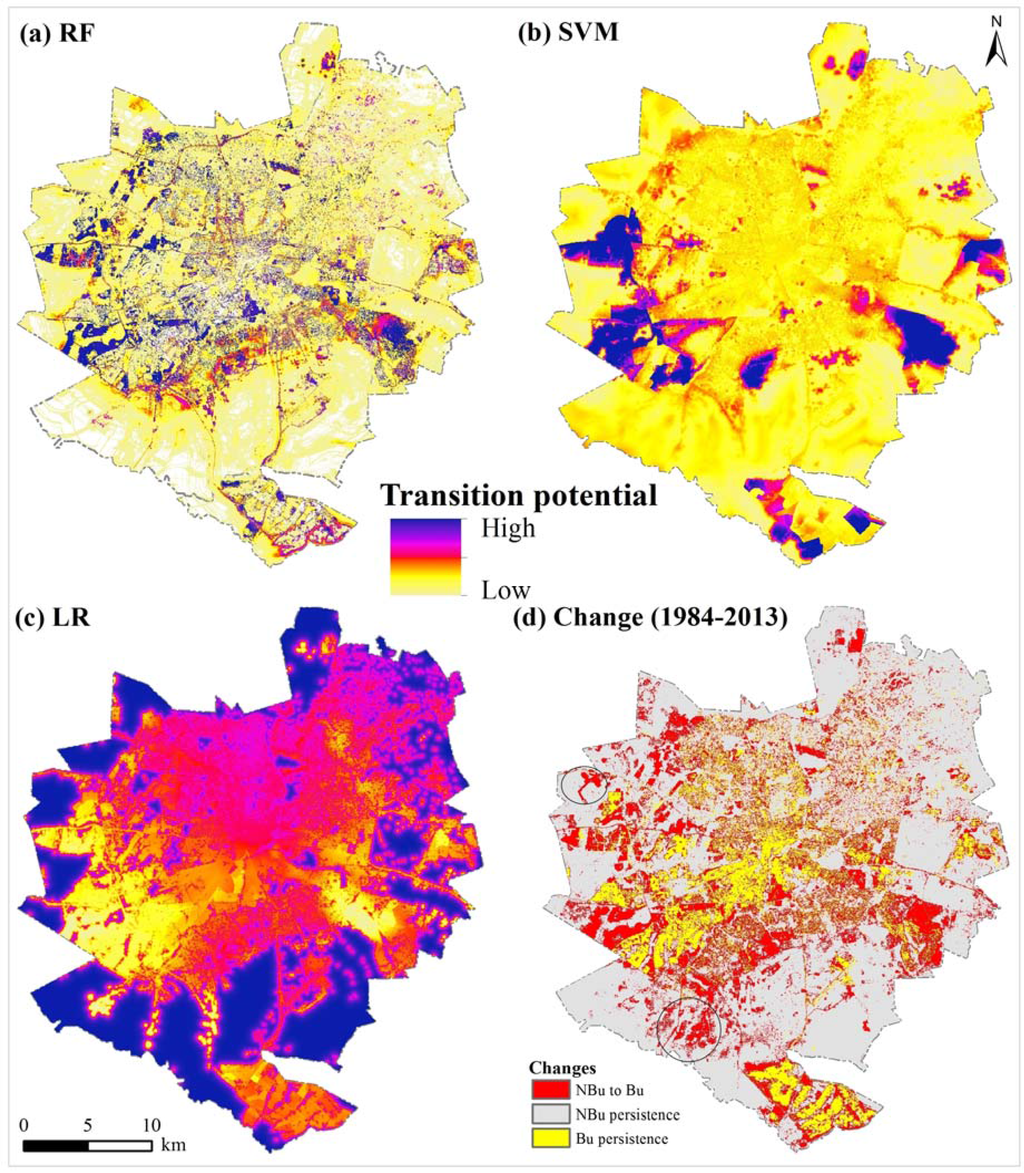
شکل 5. ( الف ) نقشه پتانسیل انتقال RF. ( ب ) نقشه پتانسیل انتقال SVM. ( ج ) نقشه پتانسیل انتقال LR. و ( د ) تغییرات کاربری/پوشش زمین بین سالهای 1984 و 2013 (توجه داشته باشید دایرههای سیاه تحولات جهشی را در بخشهای جنوب غربی و غربی منطقه مورد مطالعه نشان میدهند). توجه داشته باشید NBu نمایانگر مناطق غیر ساخته شده است، در حالی که Bu نشان دهنده مناطق ساخته شده است.
شکل 6 a-c نمودارهای TOC را برای همه مدل ها نشان می دهد. ما اعتبار مدل خود را بر روی عدد آستانه بیستم متمرکز کردیم که نشان دهنده 28.8٪ یا 182 کیلومتر مربع از تغییرات “غیر ساخته شده تا ساخته شده” بین سال های 1984 و 2008 است. شکل 6 a نشان می دهد که منحنی ROC برای مدل RF بالاتر از مدل یکنواخت در عدد آستانه 20 مشاهده شده است. این نشان می دهد که مدل RF در پیش بینی تخصیص فضایی تغییرات “غیر ساخته شده به ساخته شده” بهتر از مدل یکنواخت است. منحنی ROC برای مدل SVM ( شکل 6 ب) نیز بالاتر از مدل ROC یکنواخت در عدد آستانه بیستم مشاهده شده است. با این حال، منحنی ROC برای مدل SVM ( شکل 6ب) به مدل یکنواخت نزدیک است، که نشان دهنده کاهش دقت تخصیص برای تغییرات “غیر ساخته شده به ساخته شده” است. روند مشابهی با منحنی ROC مدل LR مشاهده می شود ( شکل 6 c)، که بسیار نزدیکتر به مدل یکنواخت است. این نشان می دهد که مدل LR در پیش بینی تخصیص تغییرات “غیر ساخته شده به ساخته شده” دقت کمتری دارد. نتایج ما با وانگ و همکاران همخوانی دارد. [ 68 ]، که اشاره کرد که مدل LR در مدلسازی توسعههای کاربری آرام یا سریع زمین دقت کمتری دارد. علاوه بر این، رودریگز-گالیانو و همکاران در یک مطالعه بر روی مدلسازی پیشبینی مکانهای طلای بالقوه. [ 69 ] نشان داد که مدلهای LR مکانهای بالقوه طلا را بیش از حد تخمین میزنند. مهمتر از آن رودریگز-گالیانوو همکاران [ 69 ] به این نتیجه رسیدند که مدلهای RF بهتر از مدلهای LR عمل میکنند، که با نتایج ما نیز سازگار است. با این وجود، هر سه مدل در پیش بینی تخصیص پایداری غیر ساخته شده بهتر از مدل یکنواخت هستند. این با مقدار رد صحیح منعکس می شود، که تقریباً برای همه مدل ها مشابه است ( شکل 6 a-c). از آنجایی که دوام ساخته شده و غیر ساخته شده تقریباً 68٪ از منطقه مورد مطالعه را تشکیل می دهد، همه مدل ها دارای AUC نسبتاً بالایی هستند. شکل 6 a-c نشان می دهد که مدل RF نسبت به مدل های SVM و LR تعداد ضربه های بیشتر و خطاها و آلارم های کاذب کمتری دارد. به عنوان مثال، مدل RF تقریباً 33.1 کیلومتر مربع داشتدر مقایسه با 37.5 کیلومتر مربع از تغییرات مشاهده شده بین سالهای 2008 و 2013 (دوره اعتبارسنجی) تعداد بازدیدها (یعنی بهدرستی پیشبینیشده تغییرات «غیر ساختهشده به ساختهشده» بود). برعکس، مدل های SVM و LR تقریباً 23.5 کیلومتر مربع و 15.7 کیلومتر مربع داشتند .به ترتیب بازدید می کند. در نتیجه، مدل RF در پیشبینی تخصیص فضایی تغییرات «غیر ساختهشده به ساختهشده» بهتر از مدلهای SVM و LR بود. این به این دلیل است که مدل RF می تواند رابطه غیرخطی بین عوامل محرک وابسته و توضیحی را مدیریت کند. بنابراین، مدل RF برای پیشبینی رشد شهری بر اساس عوامل محرک عددی و طبقهای مورد استفاده در این مطالعه مناسب بود. علاوه بر این، مدل RF کمتر تحت تأثیر بیش از حد قرار گرفت. در نتیجه، پیشبینی مناطق ساختهشده جدید تحت تأثیر کلوخه قرار نگرفت.
3.2. اعتبارسنجی مدل RF-CA
شکل 7 نقشه های کاربری/پوشش مشاهده شده و شبیه سازی شده برای منطقه مورد مطالعه را نشان می دهد. تحلیل بصری نشان میدهد که مدل RF-CA بهترین مطابقت را بین نقشههای کاربری/پوشش زمین مشاهدهشده و شبیهسازیشده برای سال 2013 داشت ( شکل 7 ب). این نشان میدهد که مدل RF-CA در تخصیص تغییرات «غیر ساختهشده به ساختهشده» و همچنین شبیهسازی الگوهای توسعهی پرکننده و توسعهدهی در منطقه مورد مطالعه دقیق بود. شکل 7 ج نشان می دهد که الگوهای ساخته شده شبیه سازی شده با الگوهای ساخته شده مشاهده شده مطابقت ندارند. این نشان میدهد که در حالی که مدل SVM-CA از نظر کمیت از دقت شبیهسازی نسبتاً بالایی برخوردار است، تخصیص فضایی تغییرات «غیر ساختهشده به ساختهشده» به دلیل برازش بیش از حد مشاهدهشده در طول کالیبراسیون مدل SVM ضعیف بود.شکل 5 ب). در نتیجه، مدل SVM-CA در شبیه سازی الگوهای ساخته شده مشابه با الگوهای ساخته شده مشاهده شده مشکل داشت. علاوه بر این، مدل LR-CA تطابق ضعیف بین نقشه کاربری/پوشش زمین مشاهده شده و شبیه سازی شده را نشان می دهد ( شکل 7 د). این نشان می دهد که مدل LR-CA در تخصیص تغییرات “غیر ساخته شده به ساخته شده” شکست خورده است. نتایج ما با برخی از مطالعات مطابقت دارد که نشان داد مدلهای رگرسیون لجستیک-CA برای شبیهسازی تغییرات کاربری زمین شهری ضعیف عمل میکنند [ 33 ]. توجه داشته باشید که همه مدلهای شبیهسازی (RF-CA، SVM-CA و LR-CA) نتوانستند مناطق ساختهشده جدید غیرمرتبط را شبیهسازی کنند. این به این دلیل است که همه مدلهای پتانسیل انتقال (RF، SVM و LR) در پیشبینی پیشرفتهای جهشی شکست خوردهاند ( شکل 5 ).

شکل 6. ( الف ) کل مشخصه عملیاتی (TOC) برای مدل RF. ( ب ) کل مشخصه عملیاتی (TOC) برای مدل SVM. ( ج ) کل مشخصه عملیاتی (TOC) برای مدل LR.
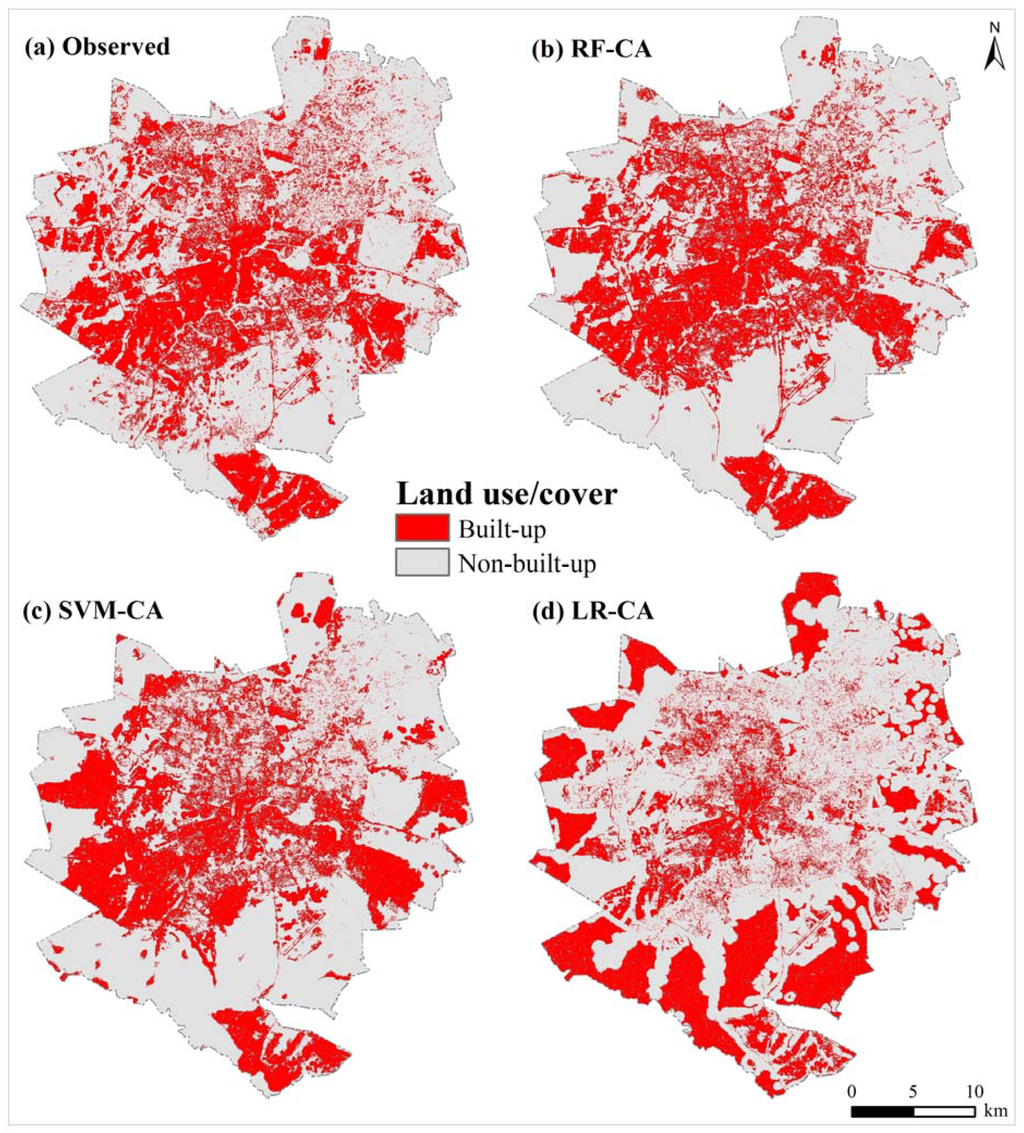
شکل 7. مقایسه نقشههای کاربری/پوشش اراضی مشاهده شده با شبیهسازیشده برای سال 2013: ( الف ) نقشه کاربری/پوشش اراضی مشاهدهشده. ( ب ) نقشه کاربری/پوشش زمین شبیه سازی شده RF-CA. ( ج ) نقشه کاربری/پوشش زمین شبیه سازی شده SVM-CA. و ( د ) نقشه کاربری/پوشش زمین شبیه سازی شده LR-CA.
برای اعتبار سنجی مدل کمی، از نقشه کاربری/پوشش زمین مشاهده شده (اولیه) برای سال 1984، نقشه کاربری/پوشش اراضی مشاهده شده (مرجع) برای سال 2013، و نقشه کاربری/پوشش زمین شبیه سازی شده برای سال 2013 استفاده کردیم. شبیه سازی کاپا (KSimulation) ، انتقال کاپا (KTransition)، انتقال کاپا (KTranslocation)، و رقم آمار شایستگی برای اعتبارسنجی مدل RF-CA [ 70 ، 71 ، 72 ، 73 ] استفاده شد. KSimulation توافق بین انتقال کاربری/پوشش زمین شبیهسازی شده و انتقال کاربری اراضی/پوشش مرجع را بیان میکند، در حالی که KTranslocation میزان توافق انتقالها را از نظر تخصیصها اندازهگیری میکند [ 70 ، 71 ، 72 ]]. KTransition توافق را از نظر کمیت انتقال های ساخته شده و غیر ساخته شده نشان می دهد، در حالی که شکل شایستگی توافق بین تغییرات مشاهده شده و شبیه سازی شده را بیان می کند [ 70 ، 71 ، 72 ]. آمار KSimulation، KTransition و KTranslocation در نرم افزار Map Comparison Kit [ 70 ] موجود است. جزئیات بیشتر در مورد آمار KSimulation، KTransition و KTranslocation را می توان در [ 70 ، 71 ] یافت، در حالی که جزئیات شکل شایستگی در [ 73 ] موجود است.
جدول 4 آمار اعتبارسنجی را بر اساس KSimulation، KTranslocation، KTransition و رقم شایستگی نشان می دهد. امتیاز کلی KSimulation برای مدل RF-CA نشان می دهد که تغییرات “غیر ساخته شده به ساخته شده” به درستی شبیه سازی شده اند. تجزیه و تحلیل بیشتر نشان می دهد که مدل RF-CA به درستی تخصیص و مقدار تغییرات “غیر ساخته شده به ساخته شده” را شبیه سازی کرده است. این با KTranslocation و KTransition بالا منعکس شده است ( جدول 4 ). امتیاز کلی KSimulation برای مدل SVM-CA 0.12 کمتر از مدل RF-CA بود. KTranslocation برای مدل SVM-CA کمتر از مدل RF-CA بود، که نشان میدهد مدل SVM-CA تخصیص تغییرات «غیر ساختهشده به ساختهشده» را ضعیف شبیهسازی کرده است ( جدول 4).). برخلاف مدلهای RF-CA و SVM-CA، امتیاز کلی KSimulation برای مدل LR-CA بسیار پایین بود. واضح است که مدل LR-CA در شبیه سازی تغییرات “غیر ساخته شده به ساخته شده” شکست خورد. KTranslocation پایین 0.22- نشان می دهد که مدل LR-CA نمی تواند تغییرات “غیر ساخته شده به ساخته شده” را در طول شبیه سازی اختصاص دهد. بیشتر خطاهای تخصیص برای مدل LR-CA به عملکرد ضعیف مدل LR نسبت داده می شود. به طور کلی، مدل RF-CA بالاترین دقت را داشت، همانطور که با رقم بالای شایستگی (تقریباً 47٪) نشان داده شده است. مطالعه ای توسط پونتیوس و همکاران. [ 72] نشان داد که رقم شایستگی مشاهده شده در سایر مدل های تغییر زمین از 1% تا 59% متغیر است. بنابراین، دقت مدل RF-CA نسبتاً بالا است زیرا رقم شایستگی در محدوده بالایی از مدلهای تغییر زمین مشاهده شده قبلی است [ 73 ].
جالب است بدانید که KTransition برای همه مدلهای شبیهسازی بسیار بالا بود (۹۸٪ تا ۹۹٪)، زیرا نرخهای انتقال چند مرحلهای مشابه در طول شبیهسازی CA استفاده شد ( جدول 3 a). مقایسه کمی نقشههای کاربری/پوشش زمین مشاهدهشده و شبیهسازیشده نشان میدهد که کلاس ساختهشده مشاهدهشده ۳۳۸.۳ کیلومتر مربع بود ، در حالی که کلاس شبیهسازیشده مربوطه ۳۴۰.۳ کیلومترمربع برای مدل RF-CA بود. در مقابل، کلاس غیر ساخته شده مشاهده شده 601.9 کیلومتر مربع بود ، در حالی که کلاس شبیه سازی شده مربوطه 599.9 کیلومتر مربع بود . برای مدل SVM-CA، کلاس ساخته شده مشاهده شده 338.3 کیلومتر مربع بود ، در حالی که کلاس شبیه سازی شده مربوطه 332.9 کیلومتر مربع بود .. با این حال، کلاس غیر ساخته شده مشاهده شده 601.9 کیلومتر مربع بود ، در حالی که کلاس شبیه سازی شده مربوطه 607.4 کیلومتر مربع بود . برای مدل LR-CA، کلاس ساخته شده مشاهده شده 338.3 کیلومتر مربع بود ، در حالی که کلاس شبیه سازی شده مربوطه 340.3 کیلومتر مربع بود . در مقابل، کلاس غیر ساخته شده مشاهده شده 601.9 کیلومتر مربع بود ، در حالی که کلاس شبیه سازی شده مربوطه 599.9 کیلومتر مربع بود . این نتایج نشان میدهد که همه مدلهای شبیهسازی برای شبیهسازی مقدار کاربری/پوشش زمین نسبتاً دقیق بودند.
جدول 4. آمار اعتبارسنجی برای همه مدل های شبیه سازی.
3.3. تحلیل مولفه های توافق و عدم توافق
آمار KSimulation اندازه گیری کمی از دقت شبیه سازی را ارائه می دهد. با این حال، KSimulation مؤلفه های توافق و عدم توافق بین نقشه های کاربری/پوشش اراضی مشاهده شده و شبیه سازی شده را ارائه نمی دهد. بنابراین، ما اجزای توافق و عدم توافق را برای مدلهای RF-CA، SVM-CA و LR-CA تجزیه و تحلیل کردیم. شکل 8a-c مؤلفه های موافقت و مخالفت را بر اساس همپوشانی نقشه های اولیه (1984)، مشاهده شده (2013) و شبیه سازی شده کاربری/پوشش زمین (2013) برای همه مدل ها نشان می دهد. اجزای توافق و عدم توافق اطلاعاتی مانند: (1) تغییر مشاهده شده به درستی شبیه سازی شده به عنوان تغییر (بازدید) را نشان می دهد. (2) تداوم مشاهده شده (یعنی ساخته شده و غیر ساخته شده) که به درستی به عنوان پایداری شبیه سازی شده است (موفقیت های تهی). (3) تغییر مشاهده شده به اشتباه به عنوان تداوم شبیه سازی شده است. و (4) تداوم مشاهده شده به اشتباه به عنوان تغییر شبیه سازی شده است (آژارهای نادرست).

شکل 8. اجزای توافق و عدم توافق برای: ( الف ) نقشه کاربری/پوشش زمین شبیه سازی شده RF-CA. ( ب ) نقشه کاربری/پوشش زمین شبیه سازی شده SVM-CA. و ( ج ) نقشه کاربری/پوشش زمین شبیه سازی شده LR-CA.
برای مدل RF-CA، تداوم غیر ساخته شده بیشترین مولفه های توافق را داشت که تقریباً 55 درصد از منطقه مورد مطالعه را تشکیل می داد ( شکل 8 a و شکل 9 ). این به این دلیل است که پایداری غیرساختشده حدود 68 درصد از منطقه مورد مطالعه را بین سالهای 1984 و 2008 اشغال کرده است. دومین مؤلفه بزرگ توافق، تغییرات «بدون ساختهشده به ساختهشده» است که تقریباً 15 درصد از منطقه مورد مطالعه را تشکیل میدهد. ، در حالی که پایداری ساخته شده با تقریباً 13٪ کوچکترین اجزای توافق را داشت ( شکل 8 الف و شکل 9 ). بزرگترین مؤلفههای عدم توافق، خطاها (یعنی تغییر مشاهدهشده شبیهسازی شده به عنوان تداوم در 9٪) و هشدارهای نادرست (تداوم مشاهده شده شبیهسازی شده به عنوان تغییر در 8٪) بودند. شکل 8a نشان می دهد که مدل RF-CA نسبتاً خوب عمل کرده است. با این حال، تجزیه و تحلیل بیشتر نشان می دهد ( شکل 9 ) که ترکیب اشتباهات و هشدارهای اشتباه (17٪) کمی بیشتر از ضربه ها (15٪) است. برای مدل SVM-CA، پایداری غیر ساخته شده با تقریباً 54% بیشترین مولفه توافق را داشت، به دنبال آن تغییرات “غیر ساخته شده به ساخته شده” و ماندگاری ساخته شده با تقریبا 13٪ ( شکل 8) ب و شکل 9). بزرگترین مؤلفههای عدم توافق، خطاها (یعنی تغییر مشاهدهشده شبیهسازی شده به عنوان تداوم در 10٪) و هشدارهای نادرست (تداوم مشاهده شده شبیهسازی شده به عنوان تغییر در 10٪) بودند. ترکیبی از خطاها و آلارم های کاذب (20٪) برای مدل SVM-CA بیشتر از ضربه ها (13٪) است. با این حال، برای مدل LR-CA، پایداری غیر ساخته شده با تقریباً 43 درصد، بیشترین مولفه توافق را داشت ( شکل 8 ج و شکل 9 ). دومین مؤلفه بزرگ توافق، پایداری ایجاد شده (با تقریباً 13 درصد) بود، در حالی که تغییرات «غیر ساختهشده به ساختهشده» کوچکترین مؤلفههای توافق را تنها با 2 درصد داشتند ( شکل 8 ج و شکل 9).). بزرگترین مؤلفه های عدم توافق، خطاها (یعنی تغییر مشاهده شده شبیه سازی شده به عنوان تداوم در 21٪) و هشدارهای نادرست (تداوم مشاهده شده شبیه سازی شده به عنوان تغییر در 21٪)، از این رو دقت شبیه سازی ضعیف آن بود ( جدول 4 ).
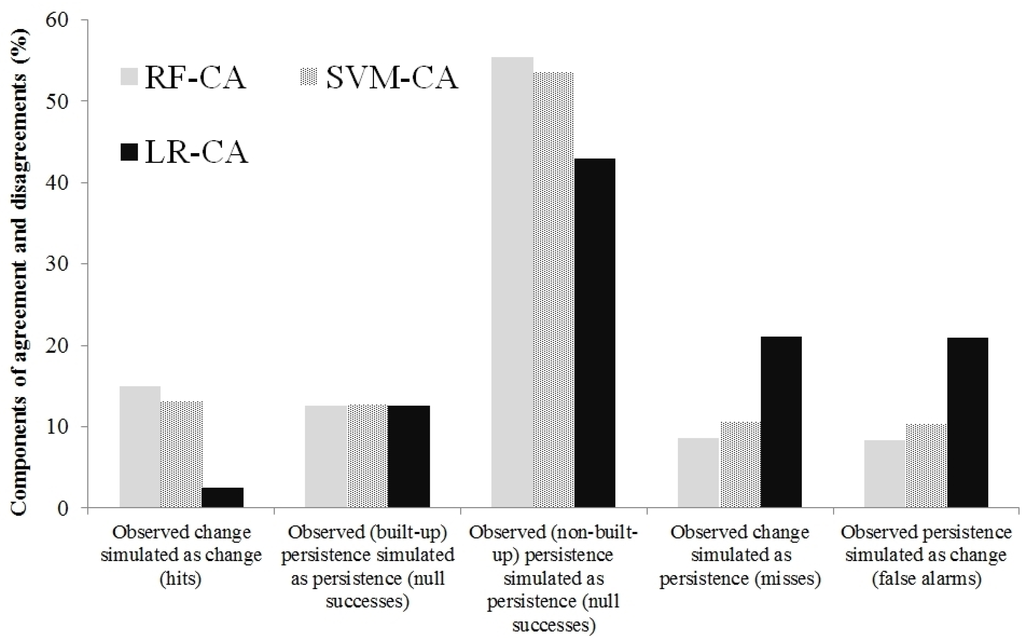
شکل 9. مولفه های موافقت و مخالفت به صورت درصد بیان شده است.
نتایج شبیه سازی نشان می دهد که مدل RF-CA به طور قابل ملاحظه ای دقیق تر از مدل های SVM-CA و LR-CA بود. این به این دلیل است که مدل RF در مدلسازی نتایج نامتعادل زمین، یعنی ترکیبی از پیشرفتهای سریع و کند رشد شهری، که در دورههای “1984-2002” و “2002-2008” رخ داد، بهتر بود. به عنوان مثال، نرخ تغییر “بدون ساخته به ساخته شده” بین سال های 1984 و 2002 تقریباً 114.4 کیلومتر مربع بود ، در حالی که تغییر “بدون ساخته به ساخته شده” به 69.8 کیلومتر مربع بین سال های 2002 و 2002 کاهش یافت. 2008 [ 49 ]. به گفته وانگ و همکاران. [ 68]، زمانی که فرآیندهای تغییر سریع یا آهسته زمین منجر به نتایج بسیار نامتعادل زمین می شود، مدل های LR توصیه نمی شوند. همچنین مهم است که توجه داشته باشید که تعداد پیکسل های آموزشی برای تغییر “غیر ساخته شده به ساخته شده” کمتر از مناطق پایدار کاربری/پوشش زمین (ساخت و غیر ساخته شده) بود. در نتیجه نمونههای آموزشی نامتعادل، مدل LR نتوانست تعمیم یابد و منجر به خطاهای بزرگ میشود. نتایج ما نشان میدهد که مدل SVM نیز تحت تأثیر بیشبرازش قرار گرفت و از این رو مدل SVM-CA دقت پایینتری نسبت به مدل RF-CA دارد.
این مطالعه بینش های مهمی را که ممکن است برای بهبود مدل های تغییر زمین مورد استفاده قرار گیرد، برجسته می کند. ابتدا، مدل RF-CA از نرخهای انتقال چند مرحلهای استفاده کرد – از دورههای “1984-2002″، “2002-2008” و “1984-2008” – که از سه نقشه کاربری/پوشش زمین (1984، 2002 و 1984) محاسبه شدند. 2008). این مهم است زیرا تغییرات کاربری/پوشش زمین، به ویژه در یک دوره زمانی بیست و نه ساله، از تغییرات غیرخطی پیروی میکند که بسیار پیچیدهتر از آن هستند که تنها با دو تاریخ مشاهده نشان داده شوند [ 74 ، 75 ].]. بنابراین، نرخهای انتقال چند مرحلهای سه دوره، تخصیص فضایی تغییرات «غیر ساختهشده به ساختهشده» را بهبود بخشید. دوم، ما از فاکتورهای محرک زمانی “فاصله نسبت به ساخت قبلی” (1984 و 2002) و “فاصله تا جاده های اصلی” (دوره های 1984-2002 و 2002-2008) برای بهبود تخصیص فضایی “غیر ساخته شده تا ایجاد شده» تغییرات در چارچوب مدل CA. سوم، ما از مدل RF استفاده کردیم که با رابطه غیرخطی بین تغییرات “غیر ساخته شده به ساخته شده” و عوامل محرک بر اساس یادگیری مطابقت دارد. نتایج نشان می دهد که نقشه پتانسیل انتقال RF ( شکل 5الف) الگوهای رشد شهری نسبتاً دقیقی مانند توسعه توسعه و پر کردن را نشان می دهد. در نتیجه، مدل RF-CA در تخصیص تغییرات “غیر ساخته شده به ساخته شده” بهتر از مدل های SVM-CA و LR-CA بود. چهارم، در حالی که مدل RF نمی تواند اثرات عوامل محرک را بر تغییرات “غیر ساخته شده به ساخته شده” تجزیه و تحلیل کند، اهمیت متغیر محاسبه شد. شکل 10 نشان می دهد که فاکتورهای محرک “فاصله تا ساخته شده قبلی” بیشترین اهمیت را دارند و به دنبال آن “فاصله تا مرکز شهر” در منطقه مورد مطالعه قرار دارند. نتایج ما با مطالعه قبلی همخوانی دارد [ 11]، که نشان داد زمین شهری در یک محله 1 کیلومتری و دسترسی به مرکز شهر تاثیرگذارترین متغیرها برای مدلسازی الگوهای فضایی رشد شهری در آفریقا بودند. پنجم، مدل RF-CA مزایای هر دو مدل RF و مدل CA پویا تصادفی صریح فضایی موجود در Dinamica EGO را ترکیب می کند. برای مثال، مدل RF یک رابطه غیرخطی بین تغییرات کاربری/پوشش زمین و عوامل محرک به منظور تولید یک نقشه پتانسیل انتقال ایجاد میکند. سپس مدل CA از توابع گسترش وصله و لبه برای تخصیص پیکسلهای تغییر بر اساس نقشه پتانسیل انتقال RF و نرخهای انتقال چند مرحلهای استفاده میکند [ 1 ، 59]. علاوه بر این، مدل CA همچنین دارای یک پارامتر مقدار اشباع است که نرخ های انتقال چند مرحله ای را بر اساس تحلیل دینامیکی بازخوردها تغییر می دهد [ 52 ، 59 ]. از آنجایی که همسایگی در مدل CA در طول هر شبیه سازی به روز می شود، تخصیص فضایی پیکسل ها با توجه به یک نقشه پتانسیل انتقال نسبتاً دقیق بهبود می یابد. آخرین اما نه کم اهمیت ترین، هر دو مدل پتانسیل انتقال RF و مدل شبیه سازی RF-CA با استفاده از آمار اعتبار سنجی توصیه شده توسط کارشناسان مدل سازی تغییر زمین [ 65 ، 66 ، 67 ، 70 ، 71 ] تایید شده اند.]. این مهم است زیرا آمار اعتبار سنجی قابل اعتماد و اطلاعاتی بینش های ارزشمندی را در مورد خطاهای مدل سازی و شبیه سازی ارائه می دهد که ممکن است به محققان در بهبود مدل های تغییر زمین کمک کند.
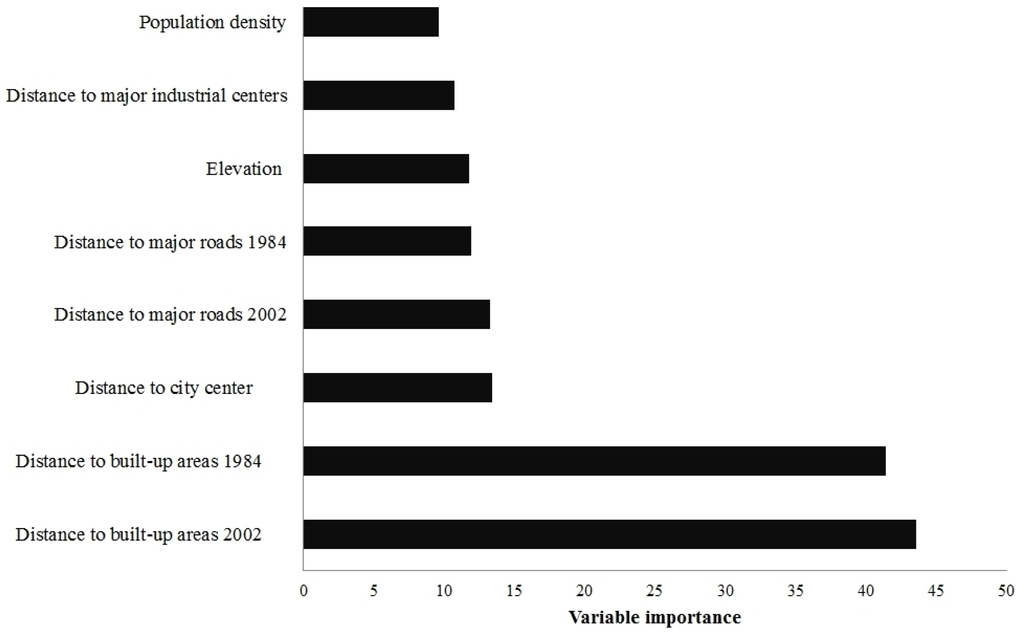
شکل 10. اهمیت متغیر برای تغییرات “غیر ساخته شده به ساخته شده” بر اساس دقت کاهش میانگین.
در حالی که این مطالعه بینش های مهمی را برجسته کرده است که می تواند برای بهبود مدل های تغییر زمین شهری مورد استفاده قرار گیرد، تعدادی محدودیت وجود دارد که نیاز به مطالعه بیشتر دارد. اول، ترکیب اشتباهات و آلارمهای کاذب کمی بیشتر از ضربهها هستند، زیرا مدل RF-CA در شبیهسازی تحولات جهشی برنامهریزی نشده در بخش جنوب غربی منطقه مورد مطالعه شکست خورده است ( شکل 3 د). دوم، عدم ادغام دادههای اجتماعی-اقتصادی صریح فضایی (مانند طرحهای توسعه مسکن، سطح درآمد و غیره ) به دلیل در دسترس نبودن دادهها [ 30 ]] به این معنی است که برخی از تغییرات “غیر ساخته شده به ساخته شده” پیش بینی نمی شوند و بنابراین نمی توان به درستی شبیه سازی کرد. علاوه بر این، مسائل مربوط به غیر ایستایی باید با استفاده از دادههای کاربری/پوشش زمانی بیشتر (به عنوان مثال، در فواصل زمانی پنج ساله) یا ترکیب مدلهای RF-CA با سایر مدلهای تغییر زمین مورد بررسی قرار گیرد. سوم، ما فقط از کلاس های ساخته شده و غیر ساخته شده برای شبیه سازی رشد شهری استفاده کردیم، که الگوهای کاربری/پوشش زمین و فرآیندهای رشد شهری [ 76 ] را در منطقه مورد مطالعه ساده می کند. این به این دلیل است که دادههای ورودی اولیه کاربری/پوشش زمین فقط شامل کلاسهای ساختهشده، غیرساختشده و آب است. بنابراین، مطالعات بیشتر باید مدل RF-CA را با استفاده از چندین کلاس کاربری/پوشش زمین آزمایش کند.
4. نتیجه گیری
هدف از این مطالعه آزمایش مدل تغییر زمین RF-CA برای استان شهری هراره بود. به منظور پیادهسازی مدل RF-CA، نرخهای انتقال چند مرحلهای را محاسبه کردیم و مدلسازی پتانسیل انتقال و شبیهسازی CA و همچنین اعتبارسنجی مدل را انجام دادیم. علاوه بر این، مدلهای SVM-CA و LR-CA را به منظور مقایسه عملکرد با مدل RF-CA اعمال کردیم.
نتایج شبیه سازی نشان می دهد که مدل RF-CA بهتر از مدل های SVM-CA و LR-CA عمل می کند. مدل RF-CA دقت شبیهسازی بالایی داشت، در حالی که مدلهای SVM-CA و LR-CA دقت شبیهسازی پایینتری داشتند. عملکرد مدل RF-CA به نقشههای پتانسیل انتقال RF نسبتاً دقیق نسبت داده شد. به طور کلی، مدل RF-CA در تخصیص تغییرات «غیر ساختهشده به ساختهشده» و همچنین شبیهسازی الگوهای ساختهشده مانند توسعههای توسعه و تکمیل نسبتاً دقیق بود. برای مدل RF-CA، تداوم غیر ساختهشده بیشترین مولفههای توافق را داشت، در حالی که دومین مؤلفه بزرگ توافق، تغییرات «غیر ساختهشده به ساختهشده» بود. نتایج مدلسازی و شبیهسازی ارائهشده در این مقاله، با وجود مطالعه موردی خاص، یک کاوش اولیه از مدل RF-CA برای مدلسازی تغییر زمین ارائه میکند.
منابع
- ایستمن، جی آر. سولورزانو، لس آنجلس؛ ون فوسن، ME مدل سازی پتانسیل انتقال برای تغییر پوشش زمین. در GIS، تحلیل فضایی و مدل سازی ; Maguire, DJ, Batty, M., Goodchild, MF, Eds. ESRI Press: کالیفرنیا، انگلستان، 2005; صص 357-385. [ Google Scholar ]
- Torrens, PM شبیه سازی پراکندگی. ان دانشیار صبح. Geogr. 2008 ، 96 ، 248-275. [ Google Scholar ]
- چنگ، جی. Masser, I. درک فرآیندهای مکانی و زمانی رشد شهری: مدل سازی اتوماتای سلولی. محیط زیست برنامه ریزی کنید. B 2004 ، 31 ، 167-194. [ Google Scholar ]
- گریفیث، پی. هاسترت، پ. گروبنر، او. ون در لیندن، اس. نقشه برداری رشد کلان شهر با داده های چندحسی. سنسور از راه دور محیط. 2010 ، 114 ، 426-439. [ Google Scholar ]
- Pacione, M. توسعه شهری پایدار در بریتانیا: لفاظی یا واقعیت؟ جغرافیا 2007 ، 92 ، 246-263. [ Google Scholar ]
- لوپز، ای. بوکو، جی. مندوزا، م. Duhau، E. پیش بینی پوشش زمین و استفاده از زمین در حاشیه شهری – مطالعه موردی در شهر مورلیا، مکزیک. Landsc. طرح شهری. 2001 ، 55 ، 271-285. [ Google Scholar ]
- سازمان ملل. چشم انداز شهرنشینی جهان: بازبینی 2011 . 2012. در دسترس آنلاین: http://esa.un.org/unpd/wup/index.htm (در 25 ژوئیه 2012 قابل دسترسی است).
- ماسر، I. مدیریت آینده شهری ما: نقش سنجش از دور و سیستم های اطلاعات جغرافیایی. Habitat Int. 2001 ، 25 ، 503-512. [ Google Scholar ]
- براون، الف. شهرهایی برای فقرای شهری در زیمبابوه: فضای شهری به عنوان منبعی برای توسعه پایدار. توسعه دهنده تمرین کنید. 2001 ، 11 ، 263-281. [ Google Scholar ]
- راکودی، سی. هراره – وارث شهر مهاجرنشین-استعماری: تغییر یا تداوم؟ جان وایلی و پسران: چیچستر، بریتانیا، 1995. [ Google Scholar ]
- لینارد، سی. تاتم، ای جی. گیلبرت، ام. مدل سازی الگوهای فضایی رشد شهری در آفریقا. Appl. Geogr. 2013 ، 44 ، 23-32. [ Google Scholar ]
- کلارک، کی سی; هاپن، اس. Gaydos, L. یک مدل خودکار سلولی خود اصلاح شونده شهرنشینی تاریخی در منطقه خلیج سان فرانسیسکو. محیط زیست برنامه ریزی کنید. B 1997 ، 24 ، 247-261. [ Google Scholar ]
- Batty، M. تکامل شهری روی دسکتاپ: شبیه سازی با استفاده از اتوماتای سلولی توسعه یافته. محیط زیست برنامه ریزی کنید. B 1998 ، 30 ، 1943-1967. [ Google Scholar ]
- لی، ایکس. Yeh, AG کالیبراسیون اتوماتای سلولی با استفاده از شبکه های عصبی برای شبیه سازی سیستم های پیچیده شهری. محیط زیست برنامه ریزی کنید. A 2001 , 33 , 1445-1462. [ Google Scholar ]
- پیجانوفسکی، ق.م. پیتادیا، اس. شلیتو، BA; الکساندریدیس، ک. کالیبراسیون یک مدل تغییر مبتنی بر شبکه عصبی برای دو منطقه شهری در غرب میانه بالایی ایالات متحده. بین المللی جی. جئوگر. Inf. علمی 2005 ، 19 ، 197-215. [ Google Scholar ]
- چونیانگ، اچ. اوکادا.، ن. ژانگ، او. شیعه، ص. Zhang، J. مدلسازی سناریوهای گسترش شهری با جفت کردن مدل اتوماتای سلولی و مدل پویا سیستم در پکن، چین. Appl. Geogr. 2006 ، 26 ، 323-345. [ Google Scholar ]
- Mundia، CN; Aniya, M. مدلسازی رشد شهری شهر نایروبی با استفاده از اتوماتای سلولی و سیستمهای اطلاعات جغرافیایی. Geogr. کشیش Jpn. 2007 ، 80 ، 777-788. [ Google Scholar ]
- شان، جی. الخدر، س. وانگ، جی. الگوریتم ژنتیک برای کالیبراسیون اتوماتای سلولی مدلسازی رشد شهری. فتوگرام مهندس Remote Sens. 2008 ، 74 ، 1267-1277. [ Google Scholar ]
- بله، پیش از این؛ Li، X. اتوماتای سلولی و GIS برای برنامه ریزی شهری. در کتابچه راهنمای سیستم های اطلاعات جغرافیایی ; مدن، ام.، اد. انجمن آمریکایی فتوگرامتری و سنجش از دور: Bethesda، MD، ایالات متحده آمریکا، 2009; صص 591-619. [ Google Scholar ]
- الاحمدی، ک. ببینید، L. هپنستال، ا. هاگ، جی. کالیبراسیون یک مدل اتوماتای سلولی فازی دینامیک شهری در عربستان سعودی. Ecol. مجتمع. 2009 ، 6 ، 80-101. [ Google Scholar ]
- مورنو، ن. وانگ، اف. Marceau, DJ رویکرد مبتنی بر شی جغرافیایی در مدلسازی اتوماتای سلولی. فتوگرام مهندس Remote Sens. 2010 ، 76 ، 183-191. [ Google Scholar ]
- وایت، آر. انگلن، جی. اتوماتای سلولی به عنوان اساس مدلسازی منطقهای پویا یکپارچه. محیط زیست برنامه ریزی کنید. B 1997 ، 24 ، 235-246. [ Google Scholar ]
- Tobler، W. جغرافیای سلولی. در فلسفه در جغرافیا ; Gale, S., Olsson, G., Eds. Dordrecht Reidel: Dordrecht, The Netherlands, 1979; صص 379-386. [ Google Scholar ]
- Couclelis، H. جهان های سلولی: چارچوبی برای مدل سازی دینامیک میکرو کلان. محیط زیست برنامه ریزی کنید. A 1985 , 17 , 585-596. [ Google Scholar ]
- انگلن، جی. وایت، آر. اولجی، آی. درازان، ص. استفاده از اتوماتای سلولی برای مدلسازی یکپارچه سیستمهای اجتماعی-محیطی. محیط زیست نظارت کنید. ارزیابی کنید. 1995 ، 34 ، 203-214. [ Google Scholar ]
- لیو، ی. مدلسازی توسعه شهری با سیستم های اطلاعات جغرافیایی و اتوماتای سلولی . CRC Press, Taylor & Francis Group: Boca Raton, FL, USA, 2009; پ. 188. [ Google Scholar ]
- Soares-Filho، BS; Cerqueira، GC; Pennachin، CL مدل سازی احتمالات انتقال فضایی پویایی چشم انداز در یک مرز استعمار آمازون BioScience 2002 ، 51 ، 1059-1067. [ Google Scholar ]
- باتی، م. Xie، Y. رشد شهری با استفاده از مدلهای اتوماتای سلولی. در GIS، تحلیل فضایی و مدل سازی ; Maguire, DJ, Batty, M., Goodchild, MF, Eds. ESRI Press: Redlands, CA, USA, 2005; صص 151-172. [ Google Scholar ]
- وو، اف. Webster, CJ شبیه سازی توسعه زمین از طریق ادغام اتوماتای سلولی و ارزیابی چند معیاره. محیط زیست برنامه ریزی کنید. B 1998 ، 25 ، 103-126. [ Google Scholar ]
- وربورگ، پی. دی نیس، تی. ریتسما ون اک، جی. ویسر، اچ. دی جونگ، ک. روشی برای تجزیه و تحلیل ویژگی های همسایگی الگوهای کاربری زمین. محاسبه کنید. محیط زیست سیستم شهری 2004 ، 28 ، 667-690. [ Google Scholar ]
- لیو، ایکس. لی، ایکس. شی، ایکس. وو، اس. لیو، تی. شبیه سازی توسعه شهری پیچیده با استفاده از اتوماتای سلولی غیرخطی مبتنی بر هسته. Ecol. مدل. 2008 ، 211 ، 169-181. [ Google Scholar ]
- لیو، ی. فنگ، ی. Pontius, R. شبیه سازی فضایی صریح رشد شهری از طریق الگوریتم ژنتیک خودسازگار و مدل سازی اتوماتای سلولی. Land 2014 , 3 , 719-738. [ Google Scholar ]
- یانگ، کیو. لی، ایکس. Shi, X. اتوماتای سلولی برای شبیهسازی تغییرات کاربری زمین بر اساس ماشینهای بردار پشتیبان. محاسبه کنید. Geosci. 2008 ، 34 ، 592-602. [ Google Scholar ]
- Torrens, PM چگونه مدل های سلولی سیستم های شهری کار می کنند (1. نظریه) ; CASA Working Paper Series (28); مرکز تجزیه و تحلیل فضایی پیشرفته (UCL): لندن، بریتانیا، 2000. در دسترس آنلاین: http://www.casa.ucl.ac.uk/working_papers/paper28.pdf (در 17 اوت 2009 قابل دسترسی است).
- لی، ایکس. بله، الف. اتوماتای سلولی مبتنی بر شبکه عصبی برای شبیه سازی تغییرات کاربری چندگانه با استفاده از GIS. بین المللی جی. جئوگر. Inf. علمی 2002 ، 16 ، 323-343. [ Google Scholar ]
- رسلر، ال. شائو، ی. تامبک، دی. Malanson، G. پیش بینی نقش عملکردی و وقوع کاج سفید پوست (Pinus albicaulis) در درختان آلپ: دقت مدل و اهمیت متغیر. ان دانشیار صبح. Geogr. 2014 ، 104 ، 1-20. [ Google Scholar ]
- کوکاباس، وی. Dragicevic، S. ارزیابی رفتار مدل اتوماتای سلولی با استفاده از رویکرد تحلیل حساسیت. محاسبه کنید. محیط زیست Urban 2006 , 30 , 921-953. [ Google Scholar ]
- لین، YP; چو، اچ جی; وو، سی اف. Verburg، PH توانایی پیشبینی رگرسیون لجستیک، رگرسیون لجستیک خودکار و مدلهای شبکه عصبی در مدلسازی تجربی تغییر کاربری زمین – مطالعه موردی. بین المللی جی. جئوگر. Inf. علمی 2011 ، 25 ، 65-87. [ Google Scholar ]
- طیبی، ع. پیجانوفسکی، ق.م. لیندرمن، ام. Gratton, C. مقایسه سه مدل پارامتری جهانی و ناپارامتریک محلی برای شبیهسازی تغییر کاربری اراضی در مناطق مختلف جهان. محیط زیست مدل نرم افزار 2014 ، 59 ، 202-221. [ Google Scholar ]
- طیبی، ع. Pijanowski، BC مدلسازی چندین تغییر کاربری زمین با استفاده از ANN، CART و MARS: مقایسه معاوضه در خوبی تناسب و قدرت توضیحی ابزارهای دادهکاوی. بین المللی J. Appl. زمین Obs. Geoinf. 2014 ، 28 ، 102-116. [ Google Scholar ]
- بریمن، L. جنگل های تصادفی. ماخ فرا گرفتن. 2001 ، 45 ، 5-32. [ Google Scholar ]
- ملور، ا. هیوود، ا. استون، سی. جونز، اس. عملکرد جنگلهای تصادفی در یک محیط عملیاتی برای طبقهبندی جنگلهای اسکلروفیل در مساحت وسیع. Remote Sens. 2013 ، 5 ، 2838–2856. [ Google Scholar ]
- رودریگز-گالیانو، وی اف. چیکا اولمو، م. آبارکا هرناندز، اف. اتکینسون، PM؛ Jeganathan، C. طبقهبندی تصادفی جنگلهای پوشش زمین مدیترانه با استفاده از تصاویر چند فصلی و بافت چند فصلی. سنسور از راه دور محیط. 2012 ، 121 ، 93-107. [ Google Scholar ]
- گامانیا، آر. دی مایر، پ. د داپر، ام. تشخیص تغییر شی گرا برای شهر هراره، زیمبابوه. سیستم خبره Appl. 2009 ، 36 ، 571-588. [ Google Scholar ]
- زینیاما، ال. تیورا، دی. Cumming, S. Harare: The Growth and Problems of the City ; Zinyama, L., Tevera, D., Cumming, S., Eds. انتشارات دانشگاه زیمبابوه: هراره، زیمباوه، 1993. [ Google Scholar ]
- Colquhoun, S. مشکلات موجود پیش روی شورای شهر حراره. در حراره: رشد و مشکلات شهر . Zinyama, L., Tevera, D., Cumming, S., Eds. انتشارات دانشگاه زیمبابوه: حراره، زیمباوه، 1993; صص 33-41. [ Google Scholar ]
- Mutizwa-Mangiza، ND مراکز شهری در زیمبابوه: تغییرات بین سرشماری، 1962-1982. جغرافیا 1986 ، 71 ، 148-151. [ Google Scholar ]
- ZimStats (آژانس ملی آمار زیمبابوه). سرشماری 2012: گزارش مقدماتی ; ZimStats (آژانس ملی آمار زیمبابوه): هراره، زیمباوه، 2012. [ Google Scholar ]
- کاموسوکو، سی. گامبا، جی. موراکامی، اچ. نظارت بر رشد فضایی شهری در استان شهری هراره، زیمبابوه. ARS 2013 ، 2 ، 322-331. [ Google Scholar ]
- تیم اصلی توسعه R. R: زبان و محیطی برای محاسبات آماری . بنیاد R برای محاسبات آماری. 2005. موجود آنلاین: http://r-project.kr/sites/default/files/2%EA%B0%95%EA%B0%95%EC%A2%8C%EC%86%8C%EA%B0 %9C_%EC%8B%A0%EC%A2%85%ED%99%94.pdf (در 3 آوریل 2014 قابل دسترسی است).
- Soares-Filho، BS; رودریگز، هو. Costa، WLS مدلسازی دینامیک محیطی با Dinamica EGO . 2009. در دسترس آنلاین: http://www.csr.ufmg.br/dinamica/ (در 3 اوت 2009 قابل دسترسی است).
- سوآرس فیلهو، بی. آلنکار، ا. نپستاد، دی. سرکیرا، جی. ورا دیاز، م. ریورو، اس. سولورزانو، ال. وول، ای. شبیه سازی واکنش تغییرات پوشش زمین به آسفالت جاده و حکمرانی در امتداد بزرگراه اصلی آمازون: کریدور Santarem-Cuiaba. گلوب. چانگ. Biol. 2004 ، 10 ، 745-764. [ Google Scholar ]
- لیاو، ا. وینر، ام. طبقه بندی و رگرسیون توسط جنگل تصادفی. R News 2002 , 2 , 18-22. [ Google Scholar ]
- Dormann، CF; الیت، جی. باچر، اس. بوخمن، سی. کارل، جی. کاره، جی. مارکوز، جی آر جی؛ گروبر، بی. لافورکید، بی. لیتائو، پی جی. و همکاران هم خطی: مروری بر روش های مقابله با آن و یک مطالعه شبیه سازی که عملکرد آنها را ارزیابی می کند. اکوگرافی 2013 ، 36 ، 27-46. [ Google Scholar ]
- Boser، BE; Guyon، IM; Vapnik، VN یک الگوریتم آموزشی برای طبقهبندیکننده حاشیه بهینه. مجموعه مقالات پنجمین کارگاه سالانه نظریه یادگیری محاسباتی ; ACM، 1992; صص 144-152. در دسترس آنلاین: http://dl.acm.org/citation.cfm?id=130401 (در 22 فوریه 2014 قابل دسترسی است).
- Vapnik، VN ماهیت نظریه یادگیری آماری . Springer: نیویورک، نیویورک، ایالات متحده آمریکا، 2000. [ Google Scholar ]
- واتاناچاتوراپورن، پ. آرورا، MK; طبقهبندی چند منبع Varshney، PK با استفاده از ماشینهای بردار پشتیبان: مقایسه تجربی با طبقهبندیکننده درخت تصمیم و شبکه عصبی. فتوگرام مهندس Remote Sens. 2008 , 74 , 239-246. [ Google Scholar ]
- هورنیک، ک. مایر، دی. Karatzoglou, A. پشتیبان ماشین های بردار در R. J. Stat. نرم افزار 2006 ، 15 ، 1-28. [ Google Scholar ]
- سوآرس فیلهو، بی. کوتینیو سرکیرا، جی. Lopes Pennachin، C. DINAMICA: یک مدل اتوماتای سلولی تصادفی که برای شبیه سازی پویایی چشم انداز در مرز استعمار آمازون طراحی شده است. Ecol. مدل. 2002 ، 154 ، 217-235. [ Google Scholar ]
- یو، دبلیو. لیو، ی. فن، ص. اندازه گیری پراکندگی شهری و عوامل آن در شهرهای بزرگ چین: مورد هانگژو. سیاست کاربری زمین 2013 ، 31 ، 358-370. [ Google Scholar ]
- Meentemeyer, R.; تانگ، دبلیو. دورنینگ، ام. ووگلر، جی. کانیف، ن. Shoemaker، D. FUTURES: شبیهسازیهای چندسطحی ساختار منظر شهری-روستایی نوظهور با استفاده از الگوریتم رشد تصادفی تکهای. ان دانشیار صبح. Geogr. 2013 ، 103 ، 785-807. [ Google Scholar ]
- پونتیوس، آر جی، جونیور؛ Malanson, J. مقایسه ساختار و دقت دو مدل تغییر زمین. بین المللی جی. جئوگر. Inf. علمی 2005 ، 19 ، 243-265. [ Google Scholar ]
- مدل سازی وضعیت تغییر زمین. در پیشبرد مدلسازی تغییر زمین: فرصتها و الزامات پژوهشی . انتشارات آکادمی ملی: واشنگتن، دی سی، ایالات متحده آمریکا، 2014.
- پونتیوس، آر جی، جونیور؛ Schneider, L. اعتبارسنجی مدل تغییر کاربری زمین با روش ROC. کشاورزی اکوسیست. محیط زیست 2001 ، 85 ، 239-248. [ Google Scholar ]
- ماس، جی. سوآرس فیلهو، بی. پونتیوس، آر. فارفان گوتی یرز، م. Rodrigues, H. مجموعه ای از ابزارها برای تجزیه و تحلیل ROC مدل های فضایی. ISPRS Int. J. Geo-Inf. 2013 ، 2 ، 869-887. [ Google Scholar ]
- پونتیوس، آر.، جونیور؛ Parmentier، B. توصیه هایی برای استفاده از مشخصه عملیاتی نسبی (ROC). Landsc. Ecol. 2014 ، 29 ، 367-382. [ Google Scholar ]
- پونتیوس، آر.، جونیور؛ Si، K. مشخصه عملیاتی کل برای اندازه گیری توانایی تشخیصی برای چند آستانه. بین المللی جی. جئوگر. Inf. علمی 2014 ، 28 ، 570-583. [ Google Scholar ]
- وانگ، ن. براون، DG; آن، ال. یانگ، اس. Ligmsnn-Zielinsak، A. عملکرد مقایسه ای رگرسیون لجستیک و تجزیه و تحلیل بقا برای تشخیص پیش بینی های فضایی تغییر کاربری زمین. بین المللی جی. جئوگر. Inf. علمی 2013 ، 27 ، 1960-1982. [ Google Scholar ]
- رودریگز-گالیانو، وی اف. چیکا اولمو، م. Chica-Rivas، M. مدلسازی پیشبینی پتانسیل طلا با ادغام اطلاعات چند منبعی بر اساس جنگل تصادفی: مطالعه موردی در منطقه Rodalquilar، جنوب اسپانیا. بین المللی جی. جئوگر. Inf. علمی 2014 ، 28 ، 1336-1354. [ Google Scholar ]
- ویسر، اچ. de Nijs, T. کیت مقایسه نقشه. محیط زیست مدل نرم افزار 2006 ، 21 ، 346-358. [ Google Scholar ]
- Vliet، J. برگت، آ.ک. Hagen-Zanker، A. بازدید مجدد از کاپا برای توضیح تغییر در ارزیابی دقت مدلهای تغییر کاربری زمین. Ecol. مدل. 2011 ، 222 ، 1367–1375. [ Google Scholar ]
- پونتیوس، آر جی، جونیور؛ واکر، آر. یائو کومه، آر. آریما، ای. آلدریچ، اس. کالداس، ام. ورگارا، دی. ارزیابی دقت برای یک مدل شبیهسازی جنگلزدایی آمازون. ان دانشیار صبح. Geogr. 2007 ، 97 ، 677-695. [ Google Scholar ]
- پونتیوس، آر جی، جونیور؛ بوئرسما، دبلیو. کاستلا، جی سی. کلارک، ک. دی نیس، تی. دیتزل، سی. دوان، ز. فوتسینگ، ای. گلدشتاین، ن. کوک، ک. و همکاران مقایسه نقشه های ورودی، خروجی و اعتبارسنجی برای چندین مدل تغییر زمین. ان علمی منطقه ای 2008 ، 42 ، 11-37. [ Google Scholar ]
- مرتنز، بی. لامبین، E. مسیرهای تغییر پوشش زمین در جنوب کامرون. ان دانشیار صبح. Geogr. 2000 ، 90 ، 467-494. [ Google Scholar ]
- بریمو، ا. Vlek، P. مسیرهای تغییر پوشش زمین در شمال غنا. محیط زیست مدیریت 2005 ، 36 ، 356-373. [ Google Scholar ]
- دیتزل، سی. کلارک، ک. تأثیر تفکیک دستههای کاربری زمین در اتوماتای سلولی در طول کالیبراسیون و پیشبینی مدل. محاسبه کنید. محیط زیست سیستم شهری 2006 ، 30 ، 78-101. [ Google Scholar ]
© 2015 توسط نویسندگان; دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر