1. معرفی
خوانایی نقشه ها مهم است. به طور سنتی، نقشهنگاران مسئول اطمینان از خوانایی نقشهها بودند. با این حال، به دلیل انقلاب دیجیتال کارتوگرافی، به ویژه استفاده از اینترنت، بسیاری از نقشه ها توسط نقشه نگاران کنترل نمی شوند. بنابراین، امکان اندازهگیری خوانایی نقشه به صورت تحلیلی مهم است: آیا میتوان معیار یا ترکیبی از معیارها را تعریف کرد که خوانایی نقشه را توصیف کند؟
معیارهای خوانایی نقشه دو کاربرد اصلی دارند. اولین کاربرد مربوط به مشخصات مجموعه داده است، که در آن تولیدکنندگان اغلب آستانه های اندازه گیری را تعیین می کنند، مانند حداقل اندازه یک شی و حداقل عرض خط. کاربرد دوم، راه اندازی، کنترل و ارزیابی فرآیند تعمیم خودکار است. اگرچه معیارهای خوانایی به طور مکرر اعمال می شوند، مطالعات نسبتا کمی از کاربران درک کاربرد آنها را ارتقا داده اند. در این مطالعه، ما تعداد گستردهای از معیارهای خوانایی را محاسبه کرده و کاربرد این معیارها را در یک مطالعه کاربر ارزیابی میکنیم. هدف از ارزیابی دو جنبه است. ابتدا، هدف ارزیابی تعیین این است که کدام معیارها برای توضیح خوانایی نقشه مفید هستند. از آنجایی که یک نقشه یک موجودیت پیچیده است، بعید است که یک اندازه گیری واحد خوانایی کامل آن را توضیح دهد. ما باید معیارها را به عنوان فرمول خوانایی وزنی ترکیب کنیم. بنابراین، هدف دوم ما مقایسه سه روش ترکیبی از اقدامات برای توصیف خوانایی نقشه است. به طور خاص، هدف این مطالعه ارزیابی استفاده از اقدامات، به جای توسعه اقدامات جدید است. مقاله بصورت زیر مرتب شده است. ابتدا، پیشینه تحقیقات قبلی در معیارهای خوانایی ارائه شده است. که دربخش 3 ، روششناسی را شامل جزئیات نمونههای نقشه، روش آزمون کاربر، شرکتکنندگان در آزمون کاربر، و معیارهای خوانایی و ترکیبات توصیف میکنیم. بخش 4 نتایج آزمون کاربر و ارزیابی معیارهای منفرد و ترکیبی را ارائه میکند. مقاله با بحث و نتیجه گیری به پایان می رسد.
2. مطالعات مرتبط
2.1. زمینه
خوانایی نقشه یک اصطلاح گسترده است. در این مطالعه، ما یک تست کاربر انجام دادیم که در آن از تعریف زیر استفاده کردیم: خوانایی نقشه بر امکان تشخیص نمادهای نقشه (جدا کردن نمادهای فردی و جدا کردن نمادها از پس زمینه) و بر سهولت خواندن، تفسیر و درک یک نقشه تمرکز دارد. نقشه
توسعه معیارهای تحلیلی خوانایی نقشه در مقایسه با تجزیه و تحلیل متن نوشته شده، یک زمینه تحقیقاتی نسبتاً جدید است. در قرن 19، شرمن [ 1 ] پیشنهاد کرد که خوانایی تحت تأثیر طول و سازمان جملات و همچنین انتخاب کلمات است. فرمول های خوانایی در دهه 1920 معرفی شدند. از این فرمول ها برای پیش بینی سختی یک متن بر اساس محتوای آن استفاده می شد. گری و لیری [ 2 ، 3برای مثال، بیش از 200 عنصر محتوا، سبک، قالب و ویژگی های سازمان را بررسی کرد. تا سال 1981، بیش از 200 فرمول خوانایی منتشر شد. این فرمولها توسط تستهای کاربر تایید شدهاند، که به عنوان مثال بر روی خوانندگی، تداوم خواندن و کارایی خواندن تمرکز کردهاند [ 3 ]. سوال واضح این است که آیا معیارهای منفرد یا ترکیبی از معیارها، مشابه آنچه برای تعیین خوانایی متن استفاده میشود، برای پیشبینی خوانایی نقشه مفید هستند؟
2.2. اقدامات خوانایی
در علم نقشه برداری و بینایی، پیچیدگی بصری شناسایی و کاهش یافته است. پیچیدگی بصری را می توان به عنوان حالتی تعریف کرد که در آن موارد اضافی، یا نمایش یا سازماندهی آنها، منجر به تنزل عملکرد کاربر می شود [ 4 ]. این تعریف نشان میدهد که عواملی مانند میزان پیچیدگی اطلاعات / شی (“اقلام اضافی”)، وضوح گرافیکی (“نمایش”) و توزیع فضایی (“سازمان”) اشیاء نقشه، میزان خوانایی نقشه را تعیین میکنند. . در ادبیات نقشه کشی، تعداد قابل توجهی از اقدامات پیشنهاد شده است:
-
مقدار اطلاعات : تعداد اشیا (به عنوان مثال، [ 5 ، 6 ، 7 ]). تعداد اشیاء از یک نوع خاص [ 8 ، 9 ]؛ تعداد رئوس [ 10 , 11 , 12 ]; تعداد گره ها، پیوندها و مناطق [ 11 ، 12 ]؛ طول کل پیوندها [ 12 ]; و فضای اشغال شده [ 7 ، 13 ].
-
توزیع فضایی : توزیع اشیاء [ 11 ]; تقارن و سازماندهی شیء [ 7 ]; اندازه گیری آنتروپی برای اشیاء و نقاط [ 14 ، 15 ]؛ همگنی و تعداد همسایگان [ 15 ]; چگالی اجسام [ 16 ]; و اقدامات تراکم [ 17 ].
-
پیچیدگی شی : سینوسی [ 18 ، 19 ]; زاویه دید کل [ 7 ]; و اتصال خط [ 12 ، 20 ].
-
وضوح گرافیکی : حداقل اندازه نقاط (روی کاغذ و روی صفحه نمایش)؛ حداقل عرض خطوط؛ و حداقل تفکیک اشیا (به عنوان مثال، [ 21 ] را ببینید). اقدامات اضافی شامل جنبه های رنگ ها (به عنوان مثال، کنتراست) اشیاء تجسم شده است [ 7 ، 22 ].
معیارهای فوق عمدتاً برای نقشه های برداری استفاده می شوند. برای نقشه های شطرنجی، انواع دیگری از معیارهای پیچیدگی استفاده می شود. به عنوان مثال، Fairbairn [ 12 ] نشان داد که فشرده سازی تصویر یک معیار معتبر برای پیچیدگی ساختاری نقشه های شطرنجی است. این نتیجه توسط Jégou و Deblonde [ 23 ] که، در میان دیگران، از یک نمایش چهار درختی از نقشه شطرنجی استفاده کردند، گسترش یافته است. سپس پیچیدگی تصویر با استفاده از ساختار درخت و تفاوت ارزش رنگ پیکسل های مجاور تخمین زده می شود.
برخی از مطالعات در مورد ترکیبی از اقدامات برای پیچیدگی نقشه انجام شده است. Fairbairn [ 12 ] استدلال کرد که استفاده از معیارهای ترکیبی برای توصیف پیچیدگی نقشه های برداری سودمند است. روزنهولتز و همکاران [ 4 ] و روزنهولتز و همکاران. [ 24 ] سه معیار برای توصیف ویژگیهای تجسم ارائه کرد: اولی پیچیدگی بصری را بر اساس رنگ، کنتراست و جهتگیری توصیف میکند. دومی مجموع وزنی آنتروپی ها را محاسبه می کند. و سومی تراکم پیکسل های لبه را نشان می دهد.
خوانایی نقشه ها به طور کلی با حواس پرتی تصاویر مرتبط است. در علم بینایی، مطالعات متعددی در رابطه با عوامل موثر در جستجوی تصویر انجام شده است. محققان (با استفاده از اصطلاحات میدانی خاص) و دیگران بررسی کرده اند که کدام عوامل حواس پرت (اشیاء فضایی ناخواسته) بر جستجوی یک هدف خاص تأثیر می گذارند. او و همکاران [ 25 ] به این نتیجه رسیدند که بدون حواسپرتی، ادراک اشیاء فضایی با وضوح بصری محدود میشود. با این حال، هنگامی که چندین شی ارائه می شود، ادراک به توانایی فرآیندهای توجه برای جداسازی اشیا بستگی دارد. برای هدایت توجه فرد، هدف باید با عوامل حواس پرتی متفاوت باشد. نمونه هایی از این تفاوت ها می تواند رنگ، جهت و اندازه باشد [ 26]. در محدوده این مقاله، میتوان گفت که علم بصری دریافته است که شناسایی و جستجوی اشیاء نقشه به محیط اطراف اشیاء نقشه بستگی دارد. اگر اشیاء مشابه زیادی در این نزدیکی وجود داشته باشد، این فرآیند شناسایی/جستجو کاهش می یابد، که بر خوانایی نقشه تأثیر می گذارد ( ر.ک. [ 5 ]).
2.3. تستهای کاربردپذیری معیارهای خوانایی
معکدیه و سارتر [ 27 ] بررسی گسترده ای از روش شناسی برای اندازه گیری خوانایی (که نشان دهنده سطح درهم و برهمی است ) در گرافیک ها و تصاویر ارائه کردند. در نتیجه گیری، نویسندگان بیان می کنند که اندازه گیری خوانایی نیاز به توصیف نمایش و/یا ارزیابی ذهنی و ارزیابی عملکرد خوانایی با استفاده از معیارهای نتیجه عملکرد دارد. فیلیپس و نویز [ 5] پیچیدگی پایه توپوگرافی نقشه های زمین شناسی را آزمایش کرد. هدف از این مطالعه پیشنهاد روشهایی برای بهبود نقشههای زمینشناسی 1:50000 بود. در این آزمون، پنج نسخه از یک نقشه با پایه های توپوگرافی متفاوت از نظر خوانایی نقشه مقایسه شد. نویسندگان دریافتند که مقدار اطلاعات روی نقشه نشان دهنده خوانایی نقشه است. نتایج از این ایده حمایت میکند که اشیاء نزدیک به هم با سبک نماد یا رنگ یکسان تمایل به ایجاد درهم و برهم دارند. روزنهولتز و همکاران [ 24 ] سه معیار خوانایی نقشه شطرنجی را آزمایش کرد، به عنوان مثال، ازدحام ویژگی ها، آنتروپی زیر باند و چگالی لبه، در وظایف جستجوی نقشه. کارهای جستجو بر روی نقشه های دیجیتال انجام شد. بین میانگین لاگ (زمان واکنش) و معیارهای خوانایی همبستگی معنیداری وجود داشت. در آزمایش دوم، از چهار کاربر خواسته شد تا یک هدف نمایش داده شده یک ثانیه ای (روی نقشه) را شناسایی کرده و جهت آن را نشان دهند. آستانه های کنتراست در رابطه با معیارهای خوانایی مورد مطالعه قرار گرفتند و همبستگی معنی داری مشاهده شد. در آزمایش سوم، تنوع رنگ مورد مطالعه قرار گرفت. هجده نقشه با رنگ های مختلف ایجاد شد. از چهار کاربر خواسته شد تا در اسرع وقت یک هدف خاص را روی نقشه ها پیدا کنند. اشاره شد که زمان واکنش برای نقشه هایی با محدوده رنگ بزرگتر طولانی تر بود. لورنز و همکاران [ 28] همچنین از معیارهای خوانایی نقشه شطرنجی استفاده کرد که بر اساس برجستگی و رنگ بود. نویسندگان دریافتند که تراکم رنگ کم به علاوه برجستگی بالا باعث به هم ریختگی می شود. استیگمار و هری [ 29 ] 17 معیار از میزان اطلاعات، توزیع فضایی و پیچیدگی شی را ارزیابی کردند. با 12 شرکت کننده آزمون در مورد خوانایی تعدادی از نقشه های آزمایشی مصاحبه شد و از آنها خواسته شد تا نقشه ها را بر اساس خوانایی درک شده رتبه بندی کنند. نتایج نشان داد که برخی از معیارهای میزان اطلاعات و توزیع فضایی به خوبی با نظرات شرکت کنندگان مطابقت دارد. معیارهای پیچیدگی شی مطابقت یکسانی را نشان ندادند.
2.4. معیارهای خوانایی در مشخصات مجموعه داده و تعمیم کارتوگرافی
معیارهای خوانایی نقشه در مشخصات دادهها برای وضوحهای گرافیکی استفاده میشوند (به عنوان مثال، [ 30 ، 31 ])، اما سایر دستههای اندازهگیری هنوز به توصیههای مشابهی برای تولید نقشه منجر نشدهاند. برای مثال، قوانین کمی در مورد زاویهای بودن کل یک خط یا حداکثر تعداد رئوس در یک منطقه نقشه وجود دارد. علاوه بر این، طبق دانش نویسندگان، هیچ مشخصات نقشه شامل ترکیبی از اندازه گیری ها نیست.
استوتر و همکاران [ 32 ] مشخصات نقشه را به طور جامع برای تعمیم خودکار نقشه مورد مطالعه قرار داد (به عنوان مثال ، انتخاب و نمایش ساده جزئیات متناسب با مقیاس و/یا هدف یک نقشه [ 17 ]). در نتایج خود، نویسندگان معیارهای گرافیکی را هم برای اشیاء منفرد و هم برای گروههایی از اشیاء فهرست کردند. با این حال، معیارهایی که خوانایی نقشه را هدف قرار می دهند در مشخصات گم شده بودند. بسیاری از مطالعات دیگر در زمینه تعمیم، هم معیارهای خوانایی نقشه را توسعه داده و هم از آنها استفاده کرده اند، به ویژه در زمینه ارزیابی. کارهای اولیه توسط مک مستر و شی [ 19]. این نویسندگان استفاده از ارزیابی کارتومتری، به عنوان مثال، معیارهای چگالی، توزیع و شکل را برای تحریک تعمیم پیشنهاد کردند. مطالعات جامع تری انجام شده است، به عنوان مثال، پروژه AGENT [ 17 ]. در این پروژه، چندین معیار خوانایی هر دو و گروههای شی (نزدیکی، موازی، ازدحام، و غیره ) توسعه داده شد (به عنوان مثال، [ 33 ، 34 ] برای خلاصهها و [ 17 ] برای شرح مفصل را ببینید). مرورهای اخیر ارزیابی تعمیم، که در آن معیارهای خوانایی یک جزء هستند، در [ 35 ، 36 ] آورده شده است.
اکثر معیارهای خوانایی نقشه به صورت هندسی جهت گیری شده اند، به عنوان مثال، بر اساس مقدار و توزیع اطلاعات. این روند با اکثر تحقیقات در مورد تعمیم خودکار که بر روی هندسه ها متمرکز شده است، سازگار است. برویر و نویسندگان همکار [ 37 ، 38] به طور مهمی پیشنهاد کرد که ما نباید از اهمیت سبک نماد غافل شویم. علاوه بر بهبود کیفیت کارتوگرافی، گنجاندن تغییرات سبک نماد میتواند کار نگهداری پایگاههای داده در مقیاس چندگانه را نیز کاهش دهد. یک مثال عملی از کاهش نیاز به تعمیم هندسی با تغییر سبک نمادها توسط سازمان ملی زمین شناسی سوئد ارائه شده است. این نظرسنجی از بخش خارجی تا حدی شفاف نمادهای جاده در نقشههای کوچک مقیاس استفاده کرده است تا نیاز به حرکت را کاهش دهد، به عنوان مثال، دور کردن اشیاء ساختمانی از اشیاء جاده. علاوه بر این، راث و همکاران. [ 39 ] پیشنهاد کرد که عملگرهای تعمیم سنتی که بر هندسه متمرکز هستند (به عنوان مثال، [ 40 ] را ببینید]) باید با عملگرهای جدیدی گسترش یابد که بر تغییرات در سبک نمادها تمرکز دارند. نویسندگان یک عملگر جدید به نام نماد را معرفی می کنند که شامل، به عنوان مثال، تنظیم رنگ، تنظیم نماد و تنظیم الگو است. برای راه اندازی و کنترل عملگرهای تعمیم جدید، به معیارهای خوانایی نیاز داریم که بر سبک های نماد تمرکز دارند. تعریف معیارهای خوانایی سبک نمادها به دلیل رسمی شدن مشکل است. برای مثال، معیارهای رنگ باید شامل قوانین معنایی (اگر مضامین مرتبط هستند، پس باید رنگهای مشابه داشته باشند)، قواعد کنتراست (تصویر پشتیبانی/زمین در نقشه) و قوانین مرسوم (مثلاً آب آبی است) [ 41 ].
2.5. جنبه های معنایی معیارهای خوانایی
لازم به ذکر است که بیشتر معیارهای خوانایی در ادبیات (و همچنین در این مطالعه) به مولفه نحوی و نه مؤلفه معنایی خوانایی نقشه مربوط می شود. معناشناسی با معنای درک شده از نمادهای نقشه مرتبط است و بنابراین اندازه گیری آن دشوار است. استدلال شده است (به عنوان مثال، [ 42 ]) که اندازه گیری خوانایی یک نقشه ممکن نیست، زیرا امکان اندازه گیری کامل جنبه های معنایی وجود ندارد. برخی از بخشهای اطلاعات در واقع در نقشه ارائه نمیشوند، بلکه از دانش و هوش قبلی خواننده مشتق شدهاند. این بیانیه همچنین توسط مطالعات علوم بصری پشتیبانی می شود. نیدر و زلینسکی [ 43]، برای مثال، یک آزمایش کاربر از زمان های جستجو به عنوان تابعی از درهم ریختگی در تصاویر (تعداد ساختمان ها در صحنه) انجام داد. نویسندگان دریافتند که توصیفات سطح پایین صحنه (مشابه برخی از اقداماتی که در 3.5 در زیر توضیح داده شده است) نمی تواند زمان جستجو را به طور کامل توضیح دهد. بنابراین، آنها نتیجه می گیرند که جنبه های مفهومی نیز ممکن است در تعیین اثرات درهم و برهمی بر جستجو مهم باشد. ما همچنین متقاعد شدهایم که سطح معنایی بر خوانایی تأثیر میگذارد، اما دیدگاهی عملگرایانه داریم. اگر بتوانیم نشان دهیم که معیارهای نحوی برای بهبود خوانایی نقشه مفید هستند (مثلاً با کنترل فرآیند تعمیم نقشه)، در این صورت باید از این معیارها استفاده کرد، حتی اگر تمام حقیقت را ارائه ندهند.
همانطور که در بالا توضیح داده شد، تحقیقات زیادی بر روی تعریف معیارهای خوانایی نقشه متمرکز شده است. با این حال، نظرسنجیهای جامع کاربر که کاربرد این اقدامات را هدف قرار دهد، وجود ندارد. چنین مطالعاتی برای تعیین معیارهای خوانایی یا معیارهای ترکیبی باید در مشخصات نقشه گنجانده شود و برای راه اندازی و کنترل فرآیند تعمیم خودکار نقشه استفاده شود مفید است. ما استدلال می کنیم که چنین اقداماتی به ویژه برای تعمیم خودکار در خدمات نقشه بر اساس داده های تولید شده توسط کاربر، مانند OpenStreetMap [ 44 ] مهم هستند. کاربر این سرویسها نمیتواند انتظار همان سطح دقت و کامل بودن موقعیت را داشته باشد که هنگام استفاده از سرویسهای NMA ( ر.ک. [ 45 ])، اما خوانایی نقشه بالایی را انتظار دارند.
3. مواد و روشها
3.1. مروری بر روش
این مطالعه محاسبه خودکار خوانایی نقشه و خوانایی درک شده را مقایسه می کند. این روش شامل شش مرحله اصلی است.
-
تعدادی نمونه نقشه ایجاد شد.
-
یک آزمایش کاربر با استفاده از این نمونه های نقشه انجام شد.
-
معیارهای خوانایی تحلیلی انتخاب شدند.
-
ترکیبات معیارهای خوانایی انتخاب شدند.
-
ارزیابی این که چگونه معیارهای خوانایی منفرد می توانند خوانایی نقشه را توصیف کنند، انجام شد.
-
ارزیابی اینکه چگونه ترکیبات معیارهای خوانایی می توانند خوانایی نقشه را توصیف کنند، انجام شد.
در ادامه این بخش، چهار مرحله اول را شرح می دهیم. دو مرحله آخر در بخش نتایج آورده شده است.
3.2. مواد – ایجاد نمونه های نقشه
ما تصمیم گرفتیم که تمام نمونه های نقشه به دو دلیل از نقشه های توپوگرافی استخراج شوند. اول اینکه نقشه های توپوگرافی رایج ترین نقشه ها هستند و همچنین پایه سایر نقشه ها (مانند نقشه های موضوعی) هستند. دوم، این مطالعه با هدف ارزیابی کاربرد معیارهای خوانایی نحوی است. بنابراین، ما ترجیح دادیم از نمونههای نقشه حاوی انواع ویژگیهایی استفاده کنیم که برای اکثر شرکتکنندگان شناخته شده است. اگر انواع ویژگی های ناشناخته در نقشه وجود داشته باشد، این خطر وجود دارد که این نوع ویژگی بر درک شرکت کننده از خوانایی نقشه تأثیر بگذارد. به عبارت دیگر، ما می خواهیم از موقعیتی اجتناب کنیم که در آن کاستی های شرکت کننده در درک معنایی بر قضاوت آنها از محتوای نحوی تأثیر بگذارد.
اندازه نمونه نقشه ایده آل توسط دو جنبه متضاد کنترل می شود. جنبه اول این است که نمونه های نقشه باید تا حد امکان بزرگ باشند. استفاده از نمونه های کوچک نقشه، محیطی غیرطبیعی را برای شرکت کنندگان فراهم می کند. با این حال، نمونه های نقشه باید همگن باشند تا نتایج قابل اعتمادی تولید شود. اگر نمونه های نقشه همگن نباشند، ارزیابی اینکه چه شرایطی بر خوانایی درک شده توسط کاربر از یک نقشه تأثیر می گذارد دشوار است. علاوه بر این، از آنجایی که معیارهای خوانایی بر اساس کل نمونه نقشه هستند، ارزیابی کاربرد آنها در صورتی که فقط قسمت هایی از نمونه نقشه غیرقابل خواندن باشد مشکل ساز است.
بر اساس این ملاحظات، نمونههای نقشه را از پایگاه داده نقشه توپوگرافی که در مجاورت هلسینبورگ، سوئد قرار دارد، استخراج کردیم. پایگاه داده نقشه از لایه هایی در محدوده مقیاس 1:10000-1:50000 (از بررسی ملی زمین سوئد و شهرداری هلسینگبورگ) تشکیل شده است. ابتدا 60 منطقه نقشه انتخاب شدند: 30 منطقه در مقیاس 1:10000 و سایر مناطق در مقیاس 1:50000. مناطق نقشه به گونه ای انتخاب شدند که مناطق نسبتاً همگنی را ارائه کردند که با اندازه نقشه نسبتاً کوچک (3×2 سانتی متر) به دست آمد. مناطق نقشه معمولی ترین نوع مناطق را در نقشه نشان می دهند (به عنوان مثال، مناطق شهری، مناطق تفریحی، مناطق صنعتی، و مناطق روستایی) و خوانایی نقشه متغیر را نشان می دهند. ما نمونه های نقشه را به دسته های زیر طبقه بندی کردیم: متراکم(اگر نمونه نقشه دارای برداشت اطلاعاتی به طور کلی متراکم باشد)؛ پراکنده ; بسیاری از انواع شی ؛ چند نوع شی ; خطوط متراکم (زیر مناطق حاوی اشیاء خط متراکم هستند). اشیاء نقطه متراکم (زیر مناطق حاوی اشیاء نقطه متراکم هستند). و ساختمان های متراکم .
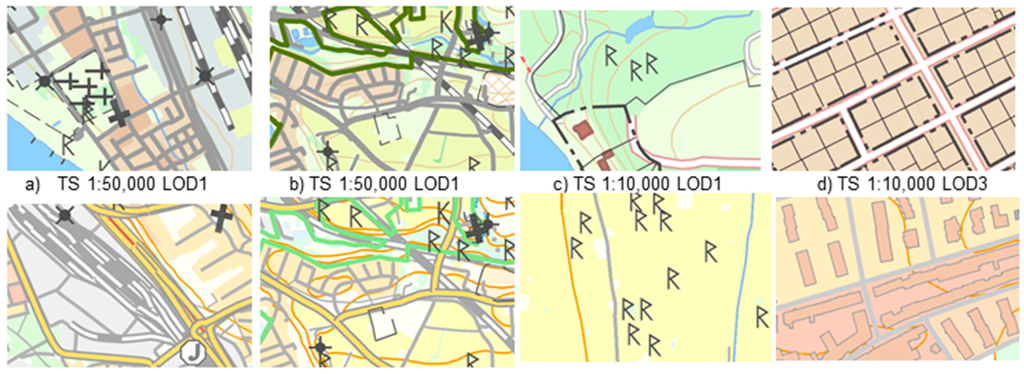
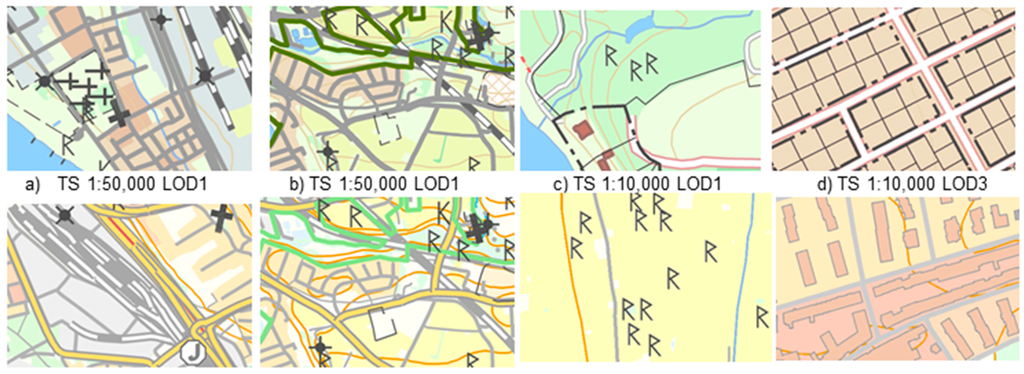
نقشهها برای هر 60 منطقه با استفاده از سه سطح جزئیات (LOD 1-3، جدول 1 را برای جزئیات در مورد اطلاعات نقشه در هر LOD ببینید) با انتخاب لایههای داده با وضوحهای مختلف گردآوری شدند. برای انجام ارزیابی مقیاسهای وضوح گرافیکی، نقشهها با دو سبک نماد متفاوت ارائه شدند. اولین سبک نماد، TS، (نگاه کنید به شکل 1 a-d) یک سبک سوئدی “سنتی” است که اغلب برای نقشه های کاغذی و برای نقشه های دیجیتالی با ظاهر سنتی استفاده می شود. دومین سبک نماد، NS، ( شکل 1 e–h را ببینید) یک سبک کم رنگ است که توسط سازمان ملی زمین سروی سوئد برای نگاشت پسزمینه توسعه یافته است.
جدول 1. اطلاعات نقشه موجود در سه سطح جزئیات (LOD) نمونه های نقشه. LODها محصولات استاندارد نیستند، بلکه مجموعهای از لایههای داده هستند که متناسب با هدف این مطالعه انتخاب شدهاند. دادههای نقطهای به صورت پررنگ ، دادههای خط به صورت مورب و دادههای چندضلعی با فونت معمولی هستند.
شکل 1. هشت نمونه نقشه ( a – h ) مورد استفاده در مطالعه. نقشه ها با دو سبک نماد (NS و TS) در دو مقیاس (1:50000 و 1:10000) و در سه سطح جزئیات ((LOD) 1-3) ارائه شده اند. نقشه های b و f فقط در سبک نمادها متفاوت هستند.
3.3. شرکت کنندگان در مطالعه کاربر
ما به دنبال کاربران باتجربه نقشه یا کسانی که در GIS درگیر هستند به عنوان شرکت کنندگان در آزمون جستجو کردیم. بنابراین دستههای کاربران هدف، متخصصان GIS و جغرافیا، دانشآموزان GIS و جغرافیا، و متخصصانی که از نقشهها در کار خود استفاده میکنند (مثلاً نقشهبرداران) بودند. از میان شرکت کنندگان، 47 درصد زن و 53 درصد مرد بودند. میانگین سنی تقریباً 30 سال بود (اگرچه سن شرکت کنندگان از کمتر از 20 تا بزرگتر از 70 سال متغیر بود). نیمی (51٪) از شرکت کنندگان دانش آموزان، 23٪ معلمان یا محققین، و 26٪ “دیگران” بودند. 47 درصد از شرکت کنندگان دانش آموزان صرب بودند. آخرین گروه تنها گروهی بود که بررسی را به عنوان بخشی از یک آزمایشگاه تکمیل کرد ( یعنی، آنها داوطلب شرکت نکردند). همه شرکت کنندگان دیگر به صورت داوطلبانه پاسخ دادند. آنها با استفاده از لیست های ایمیل برای حرفه ای ها در دسته های کاربران هدف دعوت شدند. به طور کلی، 37٪ از شرکت کنندگان از سوئد، 56٪ از صربستان و 7٪ از کشورهای دیگر بودند. بیش از یک چهارم از شرکت کنندگان (27٪) هر روز از نقشه استفاده می کردند، 59٪ هر هفته از نقشه استفاده می کردند، 13٪ هر ماه از نقشه استفاده می کردند و 1٪ ادعا می کردند که هرگز از نقشه استفاده نمی کردند.
3.4. رویه مطالعه کاربر
آزمون کاربر به عنوان یک پرسشنامه توزیع شده در وب طراحی شد. برای آزمایش تمام 350 نمونه نقشه بدون خسته کردن شرکتکنندگان، هفت آزمایش با 50 نمونه نقشه ایجاد کردیم. اکثر نمونه های نقشه در بیش از یک بخش از آزمون استفاده شدند (به زیر مراجعه کنید). نمونه های نقشه به صورت تصادفی در آزمون ها نمایش داده شدند. جدا از نقشه های مختلف، هفت تست یکسان بودند. آزمون ها به ترتیبی که شرکت کنندگان صفحه وب آزمون را باز کردند داده شد ( یعنی به شرکت کننده 1 آزمون 1 داده شد، شرکت 2 با آزمون 2، …، شرکت 8 آزمون 1 و غیره داده شد ). زبان آزمون انگلیسی بود، همانطور که از شرکت کنندگان ملیت های مختلف انتظار داشتیم.
در صفحه اول مقدمه ای ارائه شد که در آن شرکت کنندگان از هدف آزمون و همچنین روند آزمون مطلع شدند. ما همچنین تعریفی از خوانایی نقشه ارائه کردیم (به بخش 2.1 بالا مراجعه کنید). پس از آن چند سوال پروفایل شخصی و خود آزمون اصلی دنبال شد. آزمون اصلی شامل پنج بخش بود:
-
ارزیابی خوانایی 17 نمونه نقشه (به پیوست A مراجعه کنید )،
-
رتبه خوانایی 10 × 4 نمونه نقشه،
-
ارزیابی خوانایی 17 نمونه نقشه،
-
وظیفه نقشه (برای 10 نمونه نقشه)، و
-
ارزیابی خوانایی 16 نمونه نقشه.
آزمون با یک جعبه نظر به پایان رسید که در آن از شرکت کنندگان خواسته شد تا در صورت داشتن نظرات، نظرات خود را روی نمونه نقشه یا آزمون بنویسند. کل آزمون تقریباً 20 دقیقه طول کشید تا تکمیل شود.
ارزیابیهای خوانایی بخشهای آزمایشی 1 و 3 شامل 17 صفحه و بخش آزمون 5 16 صفحه بود که در هر صفحه یک نمونه نقشه وجود داشت. تعریف «خوانایی» در صفحه اول ارائه شد ( به بخش 2.1 مراجعه کنیدو از شرکتکننده خواسته شد که «خوانایی» نمونه نقشه را بهعنوان «خواندن بسیار دشوار»، «خواندن دشوار»، «آسان خواندن» یا «خواندن بسیار آسان» ارزیابی کند. رتبهبندی خوانایی (بخش دوم آزمون) شامل 10 صفحه با چهار نمونه نقشه در هر صفحه بود. نمونه نقشه های مورد استفاده در این بخش از آزمون منتخبی از 50 نقشه مورد استفاده در ارزیابی خوانایی (قسمت های 1، 3 و 5) بود. از شرکت کنندگان خواسته شد تا نمونه های نقشه را با هم مقایسه کرده و با توجه به خوانایی آنها ترتیب دهند. ما از دنباله های این قسمت برای مقایسه ترتیب نقشه های مشابه در ارزیابی خوانایی استفاده کردیم. کار نقشه (بخش چهارم) شامل 10 صفحه بود که در هر صفحه یک نمونه نقشه وجود داشت. از شرکت کنندگان خواسته شد که تعداد ساختمان ها یا بقایای باستانی را روی نقشه بشمارند و تعداد آنها را یادداشت کنند. نمونه های نقشه در این بخش از آزمون از یک مجموعه 28 نقشه ای گرفته شده است که در وظایف نقشه در هر هفت نسخه از آزمون ها استفاده شده است. هر دو رتبهبندی و ارزیابی نمونههای نقشه یکسان برای تعیین اینکه آیا شرکتکنندگان در قضاوت خوانایی نقشه سازگار هستند یا خیر، گنجانده شد. هدف از کار نقشه مقایسه عملکرد شرکت کنندگان با پاسخ های آنها در ارزیابی خوانایی بود.
پس از حذف برخی موارد پرت (به عنوان مثال، زمانی که شرکتکننده تمام نمونههای نقشه را به عنوان «خواندن بسیار آسان» ارزیابی کرد)، 214 شرکتکننده در آزمون قرار گرفتند. برخی از شرکت کنندگان (18) کل آزمون را کامل نکردند، اما ما از نتایج سوالاتی که آنها تکمیل کردند استفاده کرده ایم. ما استدلال می کنیم که این شرکت کنندگان ممکن است برای تکمیل کل آزمون وقت نداشته باشند یا ممکن است قطع شده باشند. از آنجایی که پاسخ های آنها جدی به نظر می رسد، ما تصمیم گرفتیم که سؤالات پاسخ آنها را نیز درج کنیم. یک تمایل جزئی وجود دارد که این افراد نمونه های نقشه را دشوارتر از بقیه شرکت کنندگان نشان می دهند.
به دلیل شکل آزمون – یک پرسشنامه توزیع شده در وب – اندازه نمونه های نقشه ممکن است برای شرکت کنندگان بر اساس اندازه و وضوح صفحه نمایش رایانه آنها متفاوت به نظر برسد. نمونه های نقشه برای یک صفحه نمایش 19 اینچی با وضوح 1280 × 1024 پیکسل طراحی شده اند که در آن نمونه های نقشه در مقیاس های اصلی خود (1:50000 و 1:10000) (3×2 سانتی متر) نمایش داده می شوند. برای محاسبه اندازه نمونه های نقشه ارزیابی شده توسط شرکت کنندگان، از آنها خواسته شد که اندازه و وضوح صفحه نمایش خود را ارائه دهند. با این حال، هنگام ارزیابی نتایج با مقایسه مقادیر خوانایی درک شده (به بخش بعدی مراجعه کنید)، هیچ تفاوتی در خوانایی درک شده توسط شرکتکنندگان با استفاده از اندازهها یا وضوحهای مختلف صفحه نمایش پیدا نکردیم. بنابراین تمام داده ها با هم ارزیابی شدند.
3.5. اقدامات خوانایی
در این مطالعه از معیارهای خوانایی تحلیلی تعریف شده برای انواع مختلف اطلاعات در نقشه استفاده شد. بر اساس ویژگی های هندسی آنها، ما چهار نوع اطلاعات زیر را تعریف کردیم ( ر.ک. [ 46 ]):
-
اشیاء جزئی متشکل از اشیاء نقطه، خط و مساحت مستقل و کوچک.
-
شبکه های خطی متشکل از اشیاء خطی که شبکه ها را تشکیل می دهند (مانند جاده ها، رودخانه ها و مرزها).
-
اشیاء تسلیتی متشکل از اشیاء منطقه ای که پارتیشن ها را تشکیل می دهند، مانند کاربری زمین. و
-
داده های میدانی متشکل از خطوط کانتور.
اندازهگیریها به دستههای زیر تعلق دارند : مقدار اطلاعات، توزیع فضایی، پیچیدگی شی و وضوح گرافیکی ( به بخش 2 مراجعه کنید ). اقدامات در جدول 2 فهرست شده و در بخش آتی شرح داده شده است. تمام معیارها برای هر نمونه نقشه محاسبه شد. انتخاب بر اساس جستجوی ادبیات و تجربه قبلی بود [ 29 ، 47 ]. در آزمون، ما خود را به معیارهای مبتنی بر برداری محدود کردیم، به عنوان مثال ، از معیارهای پیچیدگی مبتنی بر شطرنجی استفاده نکردیم (مثلاً [ 12 ، 23 ]).
جدول 2. اندازه گیری ها و کاربرد آنها در انواع اطلاعات (ردیف ها) و انواع اندازه گیری ها (ستون ها).
معیارهای خوانایی مورد استفاده در حالت ایده آل باید بر اساس نمایش بصری داده ها تعریف شوند. بنابراین، نقاط ناچیز در اشیا (از منظر بصری) با الگوریتم داگلاس و پوکر [ 48 ] با استفاده از آستانه 1.0 متر حذف شدند.
3.5.2. اقدامات توزیع فضایی
* توزیع فضایی اشیاء ( Hمناسد _ اُ ب ج)(����_���)نسخه نرمال شده اندازه گیری هندسی لی و هوانگ [ 15 ] است (به کار قبلی سوخوف [ 49 ، 50 ] مراجعه کنید). اندازه گیری بر اساس سلول های ورونوی اشیاء است و به عنوان آنتروپی زیر تعریف می شود ( ر.ک. [ 51 ]):
که در آن p i نسبت بین مساحت سلول ورونوی i و مساحت نقشه است و n تعداد اشیا است.
* توزیع فضایی رئوس ( HمناسD _ Ve r)(����_���)شبیه توزیع فضایی اشیاء است. این بر اساس نمودار ورونوی از رئوس است:
که در آن p i اندازه نسبی سلول ورونوی i است، و k تعداد رئوس است.
* مقدار مجاورت ( PV ) تعیین می کند که آیا اجسام مجزا خیلی به هم نزدیک هستند یا خیر:
که در آن n تعداد اشیاء ناهمگون است. اندازه بافر بر اساس اندازه نماد و حداقل فاصله 0.3 میلی متری بین نمادهای اشیاء است. توجه داشته باشید که این معیار فقط به اشیاء مجزا می پردازد. اشیایی که متصل هستند نباید به مقدار مجاورت اضافه شوند.
* نشانگر مجاورت به عنوان تعداد جفت شی تعریف می شود که کوتاه ترین فاصله بین اشیا کمتر از مقدار آستانه تعیین شده (0.2 میلی متر) باشد. اشیاء در جفت باید از هم جدا باشند. این اندازه گیری برای فواصل بین اشیاء جزئی مختلف، بین اشیاء و خطوط جزئی و بین اشیاء مختلف مبتنی بر میدان محاسبه می شود.
3.5.3. اندازه گیری پیچیدگی شی
* اندازه شی منعکس کننده توزیع اندازه شی است. در بسیاری از موارد، علاقه به اندازه کوچکترین جسم نیست، بلکه این است که آیا اشیاء کوچک زیادی وجود دارد یا خیر. بنابراین، ما همه اشیاء را بر اساس اندازه فهرست می کنیم و از اندازه شی صدک 30 درصد استفاده می کنیم ( یعنی 30 درصد از اشیاء کوچکتر از اندازه اندازه گیری هستند).
* طول پاره خط به تمام بخش های خط در اشیاء خط و ناحیه مربوط می شود و توزیع طول پاره خط همه این بخش ها را منعکس می کند. در این مطالعه، ما از مقدار صدک 10% به عنوان اندازه گیری طول پاره خط استفاده می کنیم.
3.5.4. اقدامات تفکیک گرافیکی
در مطالعات کاربر، از پایگاه داده نقشه توپوگرافی برای تولید نمونه نقشه استفاده کردیم. بنابراین، پایگاه داده با رعایت محدودیتهای استاندارد حداقل اندازه اشیا و غیره جمعآوری شد. بنابراین، اندازهگیری وضوح گرافیکی را به رنگها، بهویژه معیارهای تفاوت روشنایی و تفاوت رنگ محدود کردیم . هر دو فقط به یک رنگ در هر شی اشاره دارند. اگر یک شی چند رنگ باشد، از غالب ترین رنگ استفاده می شود. معیارها بر اساس رنگهای بیان شده در سیستم RGB هستند، جایی که هر جزء ( قرمز ، سبز و آبی ) با مقداری بین 0 تا 255 تعریف میشود.
* اختلاف روشنایی (Δ br ) به عنوان تفاوت مطلق در روشنایی ( br 1 ، br 2 ) برای دو جسم همسایه تعریف می شود ( ر.ک. [ 52 ]):
* تفاوت رنگ (Δ h ) با ( ر.ک. [ 52 ]) به دست می آید:
فرمول های روشنایی و تفاوت رنگ برای روابط همسایگی تک تعریف شده است. در این مطالعه، ما از مقادیر میانگین برای همه روابط همسایگی برای توصیف تفاوت در روشنایی و رنگ در نقشه استفاده کردیم. ما اقداماتی را برای انواع مختلف اطلاعات به شرح زیر اعمال کردیم:
-
اشیاء جزئی – هر جفت ممکن از اشیاء فرعی غیر متمایز و اشیاء تسلط یک رابطه همسایگی را تشکیل می دهد.
-
شبکههای خطی- هر جفت ممکن از اشیاء شبکه خط غیرمتشکل و آبجکتهای تسلیمی یک رابطه همسایگی را تشکیل میدهند. و
-
Tesselations ناحیه – همسایه ها به سادگی اشیاء چند ضلعی همسایه هستند.
3.5.5. اجرای اقدامات تحلیلی
اقدامات در یک برنامه جاوا بر اساس بسته های منبع باز JTS Topology Suite (JTS; [ 53 ]) و پلت فرم OpenJUMP [ 54 ] اجرا شد. برای ایجاد مناطق Voronoi (برای ارزیابی توزیع فضایی نقاط و اشیاء)، از برنامه c مثلث [ 55 ، 56 ] استفاده کردیم.
3.6. روش های ترکیبی
هدف دوم ارزیابی، مقایسه روش های ترکیبی برای یافتن مناسب ترین گزینه است. اولین کار انتخاب روش های ترکیبی برای مقایسه بود.
یک رویکرد متداول برای ترکیب، تنظیم تعدادی از معیارها است که همه باید برآورده شوند. در این تحقیق ملاک خوانایی نقشه این است که معیارهای خوانایی نقشه کمتر از یک آستانه خاص باشد. برای آزمایش این رویکرد، ارزیابی آستانه را به عنوان یکی از روشهای ترکیبی در نظر گرفتیم. یکی دیگر از رویکردهای مرکب رایج که مایل به ارزیابی آن هستیم، ترکیب خطی معیارها است. بنابراین، ما روش ترکیبی رگرسیون خطی چندگانه را وارد کردیم .
رگرسیون خطی چندگانه مستلزم آن است که نمونههای نقشه مورد استفاده برای ایجاد رابطه رگرسیون دارای یک مقدار عددی باشند که خوانایی نقشه (به عنوان مقادیر خوانایی درک شده ما) را توصیف کند. می توان موقعیتی را پیش بینی کرد که در آن نمونه های نقشه به عنوان قابل خواندن یا ناخوانا طبقه بندی می شوند. در چنین حالتی، رگرسیون خطی چندگانه سنتی امکان پذیر نیست. یکی از روش های ترکیبی که می تواند از چنین مجموعه آموزشی استفاده کند، ماشین بردار پشتیبانی است (SVM؛ [ 57 ]). در این مطالعه، میخواهیم تعیین کنیم که آیا با استفاده از یک مجموعه آموزشی فقط بر اساس یک طبقهبندی (به جای مقادیر خوانایی درک شده) اطلاعات را از دست میدهیم یا خیر. بنابراین، ما SVM را در مطالعه خود قرار دادیم.
ماشین بردار پشتیبانی
ماشینهای بردار پشتیبان (SVM) یک تکنیک یادگیری تحت نظارت هستند. SVM اولین بار در دهه 1970 [ 57 ] توسعه یافت اما تا دهه 1990 توجه زیادی به آن نشد. SVM ها برای مشکلات طبقه بندی در تشخیص الگو و ردیابی شی مورد استفاده قرار گرفته اند. در ابتدا، SVM ها برای استفاده فقط برای دو کلاس طراحی شده بودند. با این حال، در حال حاضر، چندین رویکرد برای طبقه بندی چند طبقه ارائه شده است.
SVM ها یک ابر صفحه تقسیم کننده را بر اساس ویژگی های نمونه های آموزشی می سازند. فاصله از هایپرپلین تا نزدیکترین نقاط داده آموزشی (هر کلاس) باید حداکثر باشد. برای یافتن این ابر صفحه، به اصطلاح بردارهای پشتیبانی استفاده می شود ( شکل 2 را ببینید ). همه نمونه های آموزشی نیازی به کمک به هایپرپلن ندارند. با این حال، برای بسیاری از نمونه های داده، جداسازی کامل داده ها با مرزهای خطی امکان پذیر نیست. در این موارد، معیارهای هزینه برای “جریمه کردن” برخی از نقاط داده ای که با مرز خطی تناسب ندارند، معرفی می شوند ( ر.ک. [ 58 ]). هنگامی که یک رویکرد خطی مناسب نیست، SVMها میتوانند از یک طبقهبندی غیرخطی استفاده کنند، که بردارهای ویژگی را در فضایی با ابعاد بالاتر ترسیم میکند، جایی که ممکن است راحتتر از هم جدا شوند.59 ].
شکل 2. یک ابر صفحه دو کلاس را در یک فضای دو بعدی ( x و y ) جدا می کند.
4. نتیجه
4.1. خوانایی نقشه درک شده
پاسخ های آزمون بر اساس تکلیف آزمون جمع آوری و گروه بندی شدند. پاسخهای ارزیابی خوانایی (بخشهای آزمایشی 1، 3 و 5) به مقادیر عددی 1 تا 4 تبدیل شد، که مطابق با ارزیابیهای خوانایی انجامشده توسط شرکتکنندگان (1 برای “خواندن بسیار دشوار”، 2 برای “خواندن مشکل است” “، و غیره ). برای هر نمونه نقشه، میانگین مقادیر عددی خوانایی محاسبه شد. این مقدار به عنوان مقدار خوانایی درک شده نشان داده می شود . در ارزیابی معیارهای منفرد از مقادیر خوانایی درک شده استفاده شد.
برای ارزیابی اندازهگیریها، نمونههای نقشه را به عنوان قابل خواندن یا غیرقابل خواندن نیز دستهبندی کردیم ( جدول 3 ). در این طبقه بندی، ما از میانگین مقدار خوانایی درک شده 2.5 به عنوان مقدار آستانه استفاده کردیم. این یک آستانه معقول است زیرا شرکتکنندگان این نمونههای نقشه را بهعنوان «خواندن بسیار دشوار» یا «خواندن دشوار» بیشتر از «آسان خواندن» یا «خواندن بسیار آسان» ارزیابی کردند.
پاسخها بین گروههای مختلف شرکتکنندگان کاملاً ثابت بود. اگر پاسخهای فقط دانشآموزان صربستان را با پاسخهای کل گروه مقایسه کنیم، 6 درصد عدم تطابق در طبقهبندی در نمونههای نقشه خواندنی/غیرخوانا وجود دارد.
جدول 3. تعداد نمونه های نقشه خوانا و ناخوانا.
نمونه هایی از مقادیر خوانایی درک شده، انحراف استاندارد مقادیر خوانایی درک شده و کلاس های خوانایی درک شده برای نمونه های نقشه نشان داده شده در شکل 1 a-h در جدول 4 فهرست شده است.
جدول 4. نمونه هایی از مقادیر خوانایی درک شده (PRV)، انحراف استاندارد مقادیر خوانایی درک شده (Std) و طبقه بندی خوانایی برای هشت نمونه نقشه نشان داده شده در شکل 1 . لازم به ذکر است که نقشه های b و f فقط در سبک نمادها متفاوت هستند. بنابراین، نقشه با سبک سنتی (TS) خواناتر از نقشه با سبک کم رنگ (NS) در نظر گرفته می شود.
نتایج رتبهبندی خوانایی (بخش دوم آزمون) بهعنوان دنبالهای مرتب از نقشهها از خواناییترین تا کمخوانترین مرتبسازی شد. میانگین رتبه بندی همه شرکت کنندگان برای هر دنباله محاسبه شد. این دنباله با ترتیب نقشه های مشابه داده شده توسط مقادیر خوانایی درک شده مقایسه شد. توالی ها فقط در چند مورد متفاوت بودند. از این رو، ارزیابیهای خوانایی زمانی که شرکتکنندگان خوانایی یک نقشه را در یک زمان و زمانی که تعدادی از نقشهها را با هم ارزیابی کردند، بسیار مشابه بود. این نتیجه قابلیت اطمینان مقادیر خوانایی درک شده را تایید می کند.
نتایج کار نقشه (4)، شمارش تعداد ساختمان ها یا بقایای باستانی روی نقشه ها، به تعداد پاسخ های صحیح و نادرست برای هر نقشه تبدیل شد. نتایج نشان داد نسبت نسبتاً کمی از اشیاء نقشه به درستی شمارش شده است. با این حال، بیشتر اوقات خطا فقط یک یا دو شی بود. همچنین میتوان اشاره کرد که اکثر نمونههای نقشه مورد استفاده در این بخش از آزمون بهعنوان غیرقابل خواندن (“خواندن بسیار دشوار” و “خواندن دشوار”) در ارزیابی خوانایی تلقی میشوند.
4.2. همبستگی معیارهای منفرد خوانایی نقشه
هدف از ارزیابی معیارهای منفرد، شناسایی معیارهایی است که همبستگی خوبی با خوانایی درک شده از آزمون کاربر نشان دادند. این با مقایسه مقادیر محاسبه شده هر اندازه گیری با مقدار خوانایی درک شده انجام شد. تمام نمونه های نقشه در ارزیابی معیارهای وضوح گرافیکی استفاده شد. برای سایر انواع اندازهگیریها، ما فقط از نمونههای نقشه TS استفاده کردیم، زیرا این سبک نماد خواناتر بود (در ادامه در این بخش بحث خواهد شد).
ارزیابی با تنظیم فرمول رگرسیون از فرم انجام می شود:
که در آن x مقدار خوانایی درک شده، y مقدار اندازه گیری، و α و β پارامترهای رگرسیون هستند. تعداد مقادیر خوانایی درک شده که می توان با اندازه گیری توضیح داد با R محاسبه می شود :
جایی که
-
y i یک مقدار خوانایی درک شده است.
-
yˆمن�^�تخمینی از مقدار خوانایی بر اساس مقدار اندازه گیری با استفاده از رگرسیون است (معادله (6)).
-
y¯�¯مقدار میانگین تمام مقادیر خوانایی درک شده است.
ما همچنین آزمایش کردیم که آیا مقادیر خوانایی درک شده مستقل از معیارهای منفرد هستند یا خیر. ابتدا، ما این فرضیه صفر را معرفی کردیم که مقادیر خوانایی مستقل از اندازه گیری منفرد هستند و یک آزمون آماری دو طرفه را با محاسبه مقدار p انجام دادیم . p – value احتمال به دست آوردن مقادیر یکسان در فرضیه صفر و در مواد داده است. در عمل، اینکه آیا پارامتر رگرسیون β برابر با صفر است، آزمایش می شود ( یعنی مقادیر خوانایی درک شده مستقل از مقادیر اندازه گیری ها هستند). اگر مقدار p کمتر از 0.01 باشد، استدلال قوی علیه فرضیه صفر وجود دارد.
4.2.1. نتیجه
نتیجه ارزیابی اقدامات واحد در جدول 5 ارائه شده است . به طور کلی، اندازهگیریهای مقدار اطلاعات دارای بالاترین مقدار R بوده و خوانایی نقشهها را به بهترین شکل توضیح میدهند. دومین دسته بهترین مقیاس توزیع فضایی بود. اندازه گیری پیچیدگی شی و وضوح گرافیکی نمی تواند خوانایی نقشه را توضیح دهد.
جدول 5. ارزیابی اقدامات واحد. توجه داشته باشید که در برخی موارد، اندازه برای نمونه نقشه برابر با صفر است (به عنوان مثال، اندازه گیری توزیع فضایی اشیاء زمانی که هیچ شی جزئی وجود نداشته باشد صفر است). سپس این نمونه ها برای ارزیابی این معیار خاص حذف می شوند.
4.2.2. بحث
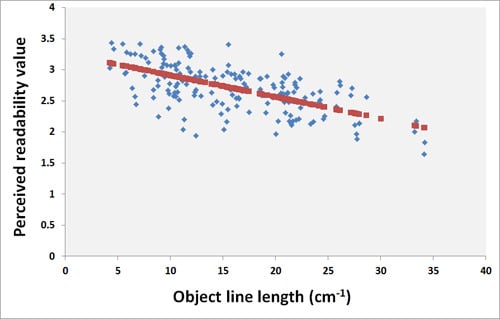
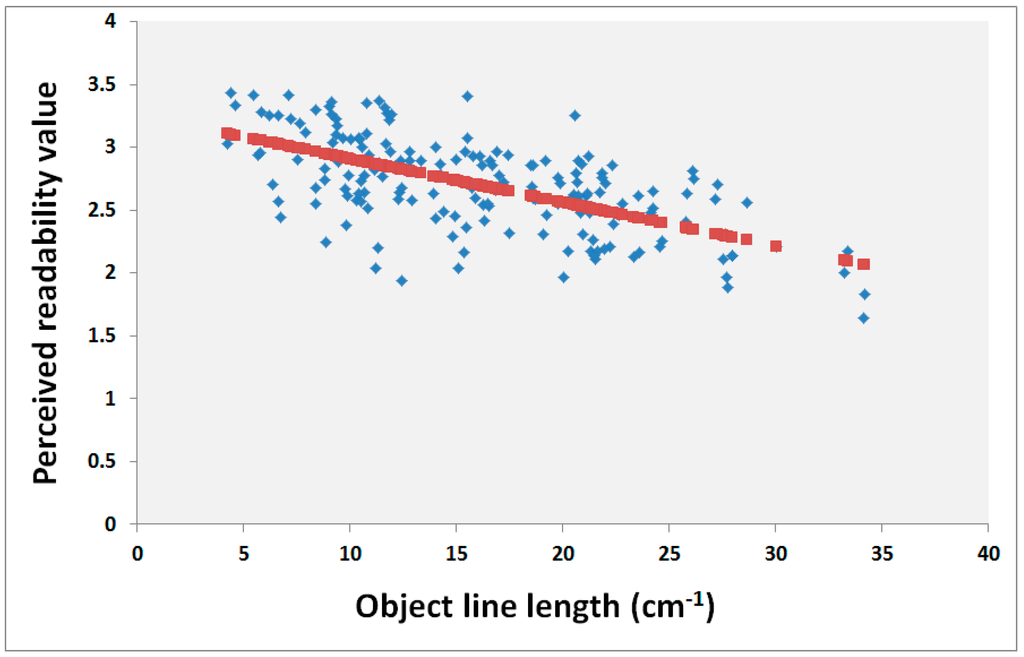
بر اساس p -values، میتوانیم این فرضیه صفر را رد کنیم که مقادیر خوانایی درک شده مستقل از مقادیر مقدار اطلاعات هستند. این یافته های قبلی فیلیپس و نویز [ 5 ]، روزنهولتز و همکاران را تایید می کند. [ 24 ]، و استیگمار و هری [ 29 ]. با این حال، حتی اگر مقادیر خوانایی درک شده به مقادیر اندازه گیری شده بستگی داشته باشد، درجه توضیح پایین است ( R– ارزش ها نسبتاً کوچک هستند؛ نمی توان خوانایی را تنها با اندازه گیری مقدار اطلاعات توضیح داد. این بیانیه را می توان با بهترین معیار کلی – طول خط شی نشان داد. برای این اندازه گیری رابطه رگرسیون زیر به دست آمد:
از شکل 3 ، میتوانیم ببینیم که نمونههای نقشه با طول خط شی طولانی معمولاً خوانایی درک پایینی دارند. با این حال، مورد مخالف آنچنان واضح نیست. نقشه ای با طول خط شی کوتاه می تواند خوانایی درک شده کمی داشته باشد. مشکل در خواندن این نقشه ها ممکن است ناشی از ویژگی های دیگر نقشه باشد (به عنوان مثال، به هم ریختگی توسط اشیاء نقطه ای). به طور خاص، امکان شناسایی رابطه بین خوانایی نقشه و یک اندازه گیری واحد وجود ندارد. بنابراین، تعریف خوانایی بر اساس ترکیب معیارها مورد نیاز است.
پیچیدگی شی و وضوح گرافیکی ممکن است خوانایی درک شده را به خوبی توضیح دهد زیرا داده های کارتوگرافی وضوح و سبک نماد مناسب برای مقیاس مورد استفاده بودند. اگر از دادههای بسیار دقیقتری در نقشههای هم مقیاس استفاده میکردیم، این نوع اندازهگیری ممکن بود اهمیت بیشتری داشته باشد.
شکل 3. رابطه بین مقدار خوانایی درک شده و طول خط شی.
4.2.3. ارزیابی میزان روشنایی و رنگ
از معیارهای رنگی در این مطالعه برای مقایسه سبک نماد رنگ پریده (NS) با سبک سنتی (TS) استفاده شد. ارزیابی نشان داد که خواندن نمونههای نقشه NS دشوارتر از نمونههای TS بود ( جدول 3 ). اندازه گیری های رنگی برای اشیاء tessellation در نقشه های NS بود Δ b r====∆��== 8 (میانگین تفاوت در روشنایی برای تمام اشیاء تسلیت و نمونه های نقشه) و Δ h====∆ℎ== 35 (میانگین تفاوت در رنگ برای همه اشیاء و نمونه های نقشه). مقادیر مربوطه برای نقشه های TS بود Δ b r====∆��== 15 و Δ h====∆ℎ== 52.
تفاوت در مقادیر درک شده خوانایی (برای نقشههای همان منطقه اما با سبکهای نماد متفاوت) به ویژه برای نقشههایی که فقط حاوی اطلاعات کاربری زمین هستند، زیاد است. نقشه های نشان داده شده در شکل 4 دارای مقادیر خوانایی 1.9 (NS) و 3.0 (TS) بودند. برای این نقشهها، اندازههای رنگی برای اشیاء تسلیت بود Δ b r¯¯¯¯¯¯∆��¯= 7 و Δ h¯¯¯¯¯∆ساعت¯= 28 برای نقشه NS و Δ b r¯¯¯¯¯¯∆ب�¯= 25 و Δ h¯¯¯¯¯∆ساعت¯= 84 برای نقشه TS.
شکل 4. همان منطقه نقشه با سبک های مختلف نماد. نمونه نقشه TS ( راست ) خواناتر از نمونه نقشه NS ( سمت چپ ) بود.
4.3. ارزیابی ترکیبات اندازه گیری ها
4.3.1. انتخاب اقدامات در کامپوزیت ها
انتخاب اقدامات برای کامپوزیت ها بر اساس معیارهای زیر انجام شد:
- (1)
-
اندازهگیریهای تا حد امکان از دستهها (به عنوان مثال ، مقدار اطلاعات، توزیع فضایی، پیچیدگی شی و رنگ) باید گنجانده شود.
- (2)
-
تنها معیارهایی که میتوانیم فرضیههای صفر را رد کنیم مبنی بر اینکه مقدار خوانایی درکشده مستقل از اندازهگیری است را رد کنیم (به عنوان مثال ، p-value باید کمتر از 0.01 در جدول 5 باشد).
- (3)
-
همبستگی بین معیارها نباید خیلی زیاد باشد.
از آنجایی که معیارهای مقدار اطلاعات به بهترین وجه خوانایی درک شده را توضیح می دهند ( جدول 5 را ببینید)، تصمیم گرفتیم دو معیار را از این دسته انتخاب کنیم. سه کاندیدای برتر عبارتند از طول خط شی , تعداد رئوس و تعداد انواع شی . دومین دسته بهترین توزیع مکانی بود. بهترین نامزد نشانگر مجاورت است . همه این معیارها برای همه اشیا تعریف شده اند ( جدول 5 را ببینید). هیچ معیاری در دسته بندی پیچیدگی شی و وضوح گرافیکی وجود ندارد که معیار دوم را برآورده کند.
ما همبستگی بین چهار معیار نامزد را با استفاده از فرمول همبستگی زیر بررسی کردیم:
که در آن m 1 و m 2 دو معیار هستند، n m تعداد نمونه های نقشه، m 1 j مقدار اندازه گیری 1 برای نمونه نقشه j است، و متر¯¯¯1متر¯1مقدار میانگین اندازه گیری 1 برای همه نمونه های نقشه است. این ضریب برای همبستگی کامل برابر با 1 و برای عدم همبستگی 0 است.
جدول 6 مقادیر ضریب همبستگی را برای چهار معیار کاندید ارائه می دهد. همبستگی بالایی بین معیارهای توصیف کننده میزان اطلاعات یافت شد. به عنوان مثال، همبستگی بین تعداد رئوس و طول خط شی 0.92 بود. بر اساس این مقادیر همبستگی، تصمیم گرفتیم از اندازه گیری تعداد رئوس استفاده نکنیم . فهرست نهایی اقدامات این بود:
-
m 1 = طول خط شی (همه اشیاء)
-
m 2 = تعداد انواع شی (همه اشیا)
-
m 3 = مجاورت (همه اشیاء).
جدول 6. همبستگی (معادله (10)) بین معیارها. محاسبات بر اساس 175 نمونه نقشه TS است.
4.3.2. مرکب I: ارزیابی آستانه
برای محاسبه مقدار آستانه برای هر اندازه گیری، از روابط رگرسیون محاسبه شده در بخش 4.2 استفاده کردیم . محاسبات مقدار آستانه بر اساس جایی بود که خط رگرسیون آستانه یک نقشه قابل خواندن را قطع می کند (به عنوان مثال ، زمانی که y = 2.5 در معادله (6)؛ طبقه بندی نقشه های قابل خواندن در بخش 4.1 را ببینید). با استفاده از این رویکرد، مقدار آستانه 21.7 سانتیمتر بر 1 برای طول خط شی بهدست میآوریم. مطابق شکل 3، این مقادیر بسیاری از نمونه های نقشه را به عنوان غیرقابل خواندن طبقه بندی می کنند (که در مورد دو معیار دیگر نیز صادق است). ما چند آزمایش از مقادیر مختلف انجام دادیم و دریافتیم که افزایش 10٪ از مقادیر آستانه در صورت لزوم ( به عنوان مثال ، بسیاری از نمونههای نقشه طبقهبندی شده صحیح را ارائه دادیم). بنابراین، مقادیر آستانه ( Ti ) به صورت زیر تعریف می شود:
که α j و β j پارامترهای رگرسیون تخمین زده شده برای اندازه گیری j هستند ( معادله (6) را ببینید).
جدول 7 حاوی مقادیر آستانه تخمینی است. این جدول همچنین حاوی اطلاعاتی در مورد تعداد نقشه هایی است که بر اساس هر اندازه گیری به عنوان ناخوانا طبقه بندی شده اند. تعداد کل نمونههای نقشهای که حداقل یکی از مقادیر آستانه را برآورده نمیکردند 39 بود که باید با تعداد کل نمونههای نقشه که در آزمون کاربر غیرقابل خواندن درک شدند مقایسه شود (49).
جدول 7. مقادیر آستانه برای طبقه بندی یک نمونه نقشه به عنوان غیرقابل خواندن.
4.3.3. مرکب II: رگرسیون خطی چندگانه
روش ترکیبی رگرسیون خطی چندگانه برای بررسی اینکه آیا یک ترکیب خطی از چندین معیار میتواند خوانایی نمونههای نقشه را توصیف کند، گنجانده شد. از فرمول رگرسیون زیر استفاده شد:
جایی که
پس از تعیین پارامترها، از پارامترهای رگرسیون برای طبقه بندی نمونه های نقشه استفاده شد. این طبقه بندی با اعمال معادله (11) برای همه نمونه های نقشه انجام شد. اگر مقدار تخمینی کمتر از 2.5 بود، نمونه نقشه به عنوان غیرقابل خواندن طبقه بندی می شد. محاسبات برای رگرسیون خطی چندگانه توسط اسکریپت Matlab انجام شد.
4.3.4. کامپوزیت III: ماشین بردار پشتیبانی
در این مطالعه از رویکرد خطی SVMها استفاده کردیم که در آن دو کلاس (غیرقابل خواندن و خواندنی) در دسترس بود، یعنی از تنظیماتی مشابه شکل 2 استفاده کردیم . ما از تمام نمونه های نقشه به عنوان یک مجموعه آموزشی استفاده کردیم. برای محاسبات، ما از ابزار SVM در جعبه ابزار بیوانفورماتیک در Matlab [ 60 ] به همراه اسکریپت های شخصی Matlab استفاده کردیم.
4.3.5. نتایج کامپوزیت های اندازه گیری
جدول 8 نتیجه ترکیبات اندازه گیری را نشان می دهد. توجه داشته باشید که ما از همان نمونههای نقشه برای آموزش و آزمایش روشهای ترکیبی استفاده کردیم (مثلاً همان نمونههای نقشه برای تعیین پارامترهای رگرسیون که بعداً برای ارزیابی استفاده میشوند). با انجام این کار، مقدار نمونه های نقشه به درستی طبقه بندی شده را بیش از حد برآورد می کنیم. برای روشهای ترکیبی، رگرسیون خطی چندگانه و ماشین بردار پشتیبان، آزمایشهای متعددی انجام دادیم که در آنها نمونههای نقشه را به دو بخش تقسیم کردیم، به عنوان مثال ۱۴۵ نمونه نقشه برای آموزش و ۳۰ نمونه برای ارزیابی. به طور معمول، تعداد نمونه های نقشه به درستی طبقه بندی شده تقریباً 2٪ تا 5٪ کمتر از نشان داده شده در جدول 8 است .. با این حال، انتخاب تصادفی نمونههای نقشه در هر دسته به طور قابلتوجهی بر نتایج تأثیر میگذارد (یک ارزیابی میتواند بین 65 تا 95 درصد نمونههای نقشه بهدرستی طبقهبندی شده متفاوت باشد). بنابراین، مقایسه روش های ترکیبی که هدف اصلی این مطالعه بود، ساده نیست. از این رو، ما تمام نمونه های نقشه را هم در مجموعه داده های آموزشی و هم در ارزیابی گنجانده ایم.
جدول 8. درصد نمونه های نقشه به درستی طبقه بندی شده برای هر روش ترکیبی با استفاده از معیارهای m 1 = طول خط شی، m 2 = تعداد انواع شی و m 3 = نشانگر مجاورت.
در مطالب تکمیلی، نتایج سه روش ترکیبی برای هر نمونه نقشه ذکر شده است. از این فهرست میتوان نتیجه گرفت که تفاوتهای جزئی بین روشهای طبقهبندی نمونههای خواندنی و ناخوانا وجود دارد.
5. بحث
5.1. تست های کاربر
فرآیند اکتساب داده ها، به عنوان مثال، تست کاربر، مهم است. در این مطالعه از آزمون توزیع شده تحت وب استفاده کردیم که تعداد زیادی شرکت کننده را در اختیار ما قرار داد. این مطالب گسترده هنگام انجام ارزیابی های توصیف شده ارزشمند بوده است. با این حال، هر روشی دارای معایبی است. یکی از معایب آزمون کاربر ما این است که ما قادر به مشاهده یا صحبت با شرکت کنندگان در طول آزمون نبودیم. در پایان آزمون، یک جعبه نظر ارائه کردیم که شرکت کنندگان می توانستند در مورد آزمون یا نقشه ها نظر بدهند. با این حال، تنها تعداد کمی از شرکت کنندگان از این ویژگی استفاده کردند. بنابراین، ما از نگرش اکثر شرکت کنندگان نسبت به نقشه ها اطلاعی نداریم که ممکن است داده های کیفی ارزشمندی را ارائه کرده باشد. یکی دیگر از معایب تستهای کاربر بر اساس قضاوت این است که ممکن است متفاوت از آنچه در زندگی واقعی پاسخ میدهند [ 61 ]]. بنابراین، در مطالعات آتی، گنجاندن سایر روشهای تست کاربر برای انعکاس جنبههای مختلف عملکرد شرکتکنندگان مهم است.
در مطالعات کاربر، شرکتکنندگان را به هفت گروه تقسیم کردیم که گروهها نقشههای مختلف را مطالعه کردند. اگر تعصباتی بین گروهها وجود داشته باشد، این امر به طور بالقوه بر طبقهبندی نمونههای نقشه تأثیر میگذارد، به خصوص که ما از یک مقدار آستانه واحد برای تمایز بین نقشههای قابل خواندن و غیرقابل خواندن استفاده کردیم. این شرایط احتمالاً دلیل طبقهبندی متفاوت نقشههای به ظاهر مشابه هستند (به عنوان مثال، نمونههای نقشه Trad10_GL1_04، Trad10_GL2_04 و Trad10_GL3_04 را در مطالب تکمیلی ببینید).
در آزمون کاربر، از مقیاس چهار پاسخ ممکن استفاده کردیم که بعداً دو مورد را به عنوان نقشه های خواندنی و دو مورد دیگر را به عنوان نقشه های غیرقابل خواندن طبقه بندی کردیم. به این ترتیب کاربر را مجبور کردیم که تصمیم بگیرد نقشه خوانا است یا خیر. اجبار کاربر به پاسخ دادن بدون انتخاب خنثی قابل بحث است، و ما می دانیم که انتخاب ما برای حذف یک انتخاب خنثی ممکن است نتایج ما را سوگیر کند. علاوه بر این، ما از مقدار میانگین همه پاسخ ها برای تصمیم گیری در مورد اینکه آیا نقشه قابل خواندن یا غیرقابل خواندن است استفاده کردیم. ما همچنین با استفاده از مقادیر میانه آزمایش کردیم. تفاوت بین این اقدامات نسبتاً کم بود. پنج نمونه نقشه قابل خواندن (با استفاده از مقادیر میانگین) که با استفاده از میانهها به عنوان غیرقابل خواندن طبقهبندی شدهاند، و همین مقدار در جهت دیگر به اشتباه طبقهبندی شده است. همه نمونههای نقشهای که با استفاده از میانگین و میانهها به طور متفاوت طبقهبندی شدهاند، مقدار خوانایی درک شده بین 2.41 و 2.58 داشتند. در مطالعه ما ترجیح دادیم از مقدار میانگین استفاده کنیم زیرا امکان استفاده از رگرسیون خطی چندگانه استاندارد را با مقادیر خوانایی درک شده (میانگین) به عنوان متغیر وابسته به ما میدهد.رجوع کنید به معادله (11)).
5.2. ترکیبات اندازه گیری ها
هیچ تفاوت عمده ای بین نتایج سه روش ترکیبی وجود ندارد ( جدول 8). درصد نقشه هایی که به درستی طبقه بندی شده اند عمدتاً به توانایی یا ناتوانی اقدامات در توضیح خوانایی بستگی دارد. با این حال، چند نکته وجود دارد که باید به آنها توجه کنیم. ارزیابی آستانه جذاب است زیرا از نظر مفهومی آسان و منطقی است. اگر تمام محدودیت های آستانه برآورده شوند، نقشه به سادگی به عنوان قابل خواندن طبقه بندی می شود. چالش این روش تعیین آستانه است. در این مطالعه، مقادیر آستانه را بر اساس یک فرمول مشترک برای همه معیارها تنظیم کردیم (معادله (10)). ما مقادیر آستانه را از طریق اصلاحات دستی آزمایش کردیم تا نتیجه بهتری به دست آوریم، اما ترجیح دادیم در ارزیابی با معادله (10) ادامه دهیم. در اصل، نوشتن یک روال بهینه سازی برای تعریف مقادیر آستانه بهینه (طبق نمونه های نقشه) نیز امکان پذیر است.
نتایج رگرسیون خطی چندگانه (MLR) و ماشین بردار پشتیبان (SVM) مشابه هستند ( جدول 8 ). روش های شناخته شده ای برای تعیین پارامترهای رگرسیون در MLR و هایپرپلن ها در SVM وجود دارد. یکی از مزیت های SVM توانایی آن در مدیریت شرایطی است که در آن مجموعه داده های آموزشی فقط اطلاعاتی در مورد خواندن یا غیرقابل خواندن نمونه های نقشه آموزشی دارند (یک MLR استاندارد به مقادیر خوانایی عددی نیاز دارد). علاوه بر این، روش MLR به احتمال زیاد برای نقاط پرت در داده های آزمایش حساس تر است، که می تواند نمونه های نقشه با مقادیر اندازه گیری غیر معمول باشد.
ما همچنین آزمایش هایی را با شبکه عصبی مصنوعی ARTMAP Biased [ 62 ، 63 ] انجام دادیم. Biased ARTMAP یک طبقهبندی یادگیری بدون نظارت است (خوشهبندی نمونههای نقشه در فضای اندازهگیری) و به دنبال آن طبقهبندی نظارت شده (تعیین اینکه آیا هر خوشه نمونه نقشه شامل نمونههای نقشه قابل خواندن یا غیرقابل خواندن است). با این حال، استفاده از ARTMAP بایاس نتایج بسیار بدتری نسبت به سایر روشهای ترکیبی ایجاد کرد، احتمالاً به این دلیل که ARTMAP بایاس و روشهای مشابه، به خوشههایی در دادههای ورودی متکی هستند. با این حال، نمونههای نقشه خواندنی/غیرخواندنی، خوشههایی را در فضای اندازهگیری تشکیل نمیدهند ( شکل 2 ) بلکه خوانایی درک شده را با مقادیر آستانه تعیین میکنند.
5.3. ارزیابی مطالعه
در مطالعه ترکیبی ما ( جدول 8 )، تقریباً 80 درصد از نمونههای نقشه بر اساس سه بهترین معیار موجود به درستی طبقهبندی شدند. دقت احتمالاً توسط عوامل زیر محدود شده است:
- (1)
-
معیارهای خوانایی ناکافی هستند.
- (2)
-
طراحی نماد خوب نبود.
- (3)
-
از بهترین روش های کامپوزیت استفاده نشد.
- (4)
-
ما باید جنبه های معنایی نقشه خوانی را در نظر بگیریم.
- (5)
-
ما باید به جای طبقه بندی واضح از طبقه بندی فازی استفاده می کردیم.
در زیر بحث کوتاهی در مورد هر یک از این عوامل بیان شده است.
می توان استدلال کرد که ما تمام اقدامات مربوطه را در این مطالعه گنجانده ایم. با این حال، معیارهای مبتنی بر شطرنجی (به عنوان مثال، [ 12 ، 23 ]) و معیارهای پیچیدگی و وضوح گرافیکی (به عنوان مثال، [ 17 ] توسعه یافته) وجود ندارند. البته، ممکن است هنوز نیاز به توسعه اقدامات جدیدی داشته باشیم که در ادبیات وجود ندارد. اگر نمونههای نقشهای را مطالعه کنیم که بهعنوان غیرقابل خواندن (توسط شرکتکنندگان) اما بهعنوان خوانا طبقهبندی شدهاند (بر اساس معیارها)، نمونههایی را با مناطقی از خطوط متراکم (بالاترین خطوط راهآهن) و اشیاء نقطهای ( ر.ک. شکل 5 ) پیدا میکنیم.و مواد تکمیلی). در اینجا، ما به اقدامات بهتری برای گنجاندن این ویژگی ها نیاز داریم. همچنین ممکن است استدلال شود که مشکل خوانایی این نقشه ها مربوط به هندسه نیست، بلکه به سبک نماد مربوط می شود. از این رو، معیارهای خوانایی لازم است که سبک نماد را بهتر ثبت کند. همچنین ممکن است نقشههای شکل 5 غیرقابل خواندن تلقی شوند، زیرا چندین شیء مشابه در یک همسایگی وجود دارد که جستجوی یک شی فضایی را پیچیده میکند (به عنوان مثال، [ 5 ، 26 ] را ببینید).
طراحی نمادها مطمئناً یک جنبه مهم خوانایی نقشه است. در نتیجه ما نشان دادیم که نمونههای نقشه شامل مرزهای کاداستر اغلب به عنوان غیرقابل خواندن طبقهبندی میشوند. این امر به ویژه برای املاک کوچک مانند نقشه سمت راست در شکل 5 صادق است. در این حالت نماد نقشه انتخاب شده برای مرز کاداستر برای اندازه واحدهای کاداستر مناسب نیست.
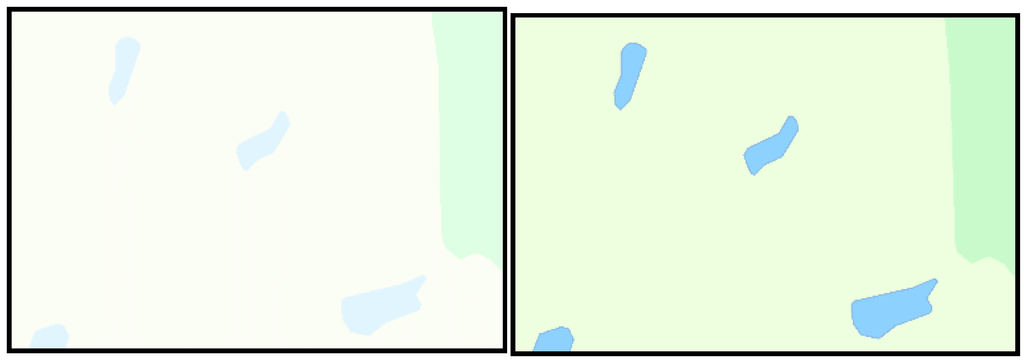
شکل 5. نقشه هایی که اغلب به اشتباه به عنوان خوانا طبقه بندی می شدند: ( سمت چپ ) نقشه هایی با خطوط متراکم، ( وسط ) نقشه هایی با نمادهای متراکم/همپوشانی و ( راست ) نقشه با انواع نمادهای بد (مرزهای کاداستر).
یک جهت تحقیق جالب، شناسایی الگویی بین نقشههای طبقهبندی اشتباه و ویژگیهای نمونههای نقشه است ( مطالب تکمیلی را رجوع کنید ). ما روابط بین طبقهبندی بین نمونههای نقشه و نتایج مطالعه را بررسی کردیم. آزمون χ 2 (با 5% اهمیت) نشان میدهد که نمونههای نقشهای که متراکم هستند و خطوط متراکم دارند، احتمالاً به اشتباه طبقهبندی میشوند (نسبت به نمونههای نقشه به طور کلی)، اما به سختی میتوان نتیجهگیری روشنی داشت. اگر میتوانستیم از دستهبندی دقیقتری از ویژگیهای نمونههای نقشه استفاده میکردیم، شاید میتوانستیم نمونههای نقشه را در شکل 5 شناسایی کنیم . با این حال، طبقه بندی ما (که قبل از تجزیه و تحلیل رخ داد) بسیار گسترده بود.
میتوان نتیجه گرفت که سه روش ترکیبی مورد استفاده علیرغم مبانی متفاوت روشها، نتایج مشابهی ارائه کردند. همچنین میتوان نتیجه گرفت که روشهای ترکیبی مبتنی بر خوشهبندی در فضای اندازهگیری، مانند Biased ARTMAP [ 62 ، 63 ]، مناسب نیستند. این که آیا روشهای ترکیبی دیگری وجود دارد که میتواند نتایج قابل ملاحظهای بهتری ارائه دهد، تا آنجا که نویسندگان میدانند، چندان محتمل نیست.
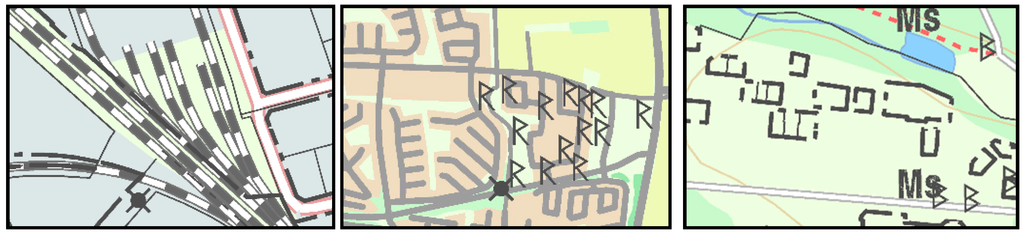
معیارهای خوانایی در این مطالعه در سطح نحوی ( ر.ک. بخش 2.5 ) هستند، یعنی پیچیدگی گرافیکی را اندازه گیری می کنند. با مطالعه نمونه های نمونه نقشه های طبقه بندی شده اشتباه می توان موارد زیر را مشاهده کرد. نمونههای نقشهای که بهعنوان قابل خواندن درک میشوند اما بهعنوان ناخوانا طبقهبندی میشوند، اغلب یک الگوی جغرافیایی مشترک را پوشش میدهند ( شکل 6 و مطالب تکمیلی). برای نمونههای نقشهای که مناطق جغرافیایی غیرمعمولتری را پوشش میدهند، وضعیت اغلب برعکس است: نمونههای نقشه بهعنوان غیرقابل خواندن درک میشوند اما بهعنوان قابل خواندن طبقهبندی میشوند ( شکل 6 و مطالب تکمیلی). از این رو، به نظر می رسد که توانایی نقشه خوان در تفسیر نقشه در یک زمینه جغرافیایی مهم است .، هنگام مطالعه نقشه خوانی نمی توانیم از جنبه های معنایی نمونه های نقشه غافل شویم. این نتیجه نشان داده شده است حتی اگر ما عمداً مناطق نقشه ای را انتخاب کنیم که دارای ویژگی های جغرافیایی عجیب و غریب نباشد ( به بخش 3.2 مراجعه کنید ). می توان استدلال کرد که این نتیجه یک نتیجه آشکار است، به عنوان مثال، به خوبی ثابت شده است که خوانایی تصاویر به طور کلی تحت تأثیر درک زمینه است [ 43 ].
شکل 6. دو نقشه در بالا قابل خواندن هستند اما به عنوان ناخوانا طبقه بندی می شوند. هر دو شامل یک الگوی جغرافیایی مشترک هستند. دو نقشه در پایین به عنوان غیرقابل خواندن درک می شوند اما به عنوان قابل خواندن طبقه بندی می شوند. هر دو الگوی جغرافیایی غیرعادی تری را پوشش می دهند.
در نهایت، در مطالعه خود، تمام نمونههای نقشه را به عنوان خوانا یا ناخوانا طبقهبندی کردیم. با مطالعه مقادیر خوانایی درک شده برای نمونههای نقشه طبقهبندیشده اشتباه ( ر.ک. مطالب تکمیلی)، میتوان نتیجه گرفت که بسیاری از نمونههای نقشه طبقهبندیشده اشتباه، مقدار خوانایی درک شده نزدیک به آستانه دارند (همانطور که در بخش 4.1 توضیح داده شد ، ما از مقدار خوانایی درک شده 2.5 استفاده کردیم. آستانه). می توان آزمایش کرد تا ببیند آیا استفاده از یک طرح طبقه بندی فازی نتایج را بهبود می بخشد، اما این هدف خارج از محدوده مقاله ما است.
6. نتیجه گیری
در این مطالعه، ما معیارهای منفرد خوانایی نقشه و روشهایی را برای توصیف خوانایی توسط ترکیب معیارها ارزیابی کردیم. در ارزیابی معیارهای منفرد، متوجه شدیم که اندازهگیریهای مقدار اطلاعات با خوانایی نقشه درک شده مرتبط است که نتایج فیلیپس و نویز [ 5 ]، روزنهولتز و همکاران را تأیید میکند. [ 24 ] و استیگمار و هری [ 29 ]. بهترین همبستگی با طول خط شی، تعداد انواع شی و تعداد رئوس داده شد. برای معیارهای توزیع فضایی، نشانگر مجاورت و ارزش مجاورتبهترین نتایج را نشان داد. ما نمیتوانیم این فرضیه را رد کنیم که مقدار خوانایی درک شده مستقل از معیارهای پیچیدگی شی یا وضوح گرافیکی است. با این حال، نمونههای نقشه مورد استفاده در آزمونها همگی از قوانین اساسی پیچیدگی شی (سطح تعمیم مناسب) و وضوح گرافیکی (سبک نماد مناسب) پیروی میکنند. در نهایت، به نظر می رسد که مطالعه ما فاقد معیارهای مناسب برای شناسایی نقشه های غیرقابل خواندن به دلیل خطوط متراکم و نمادهای متراکم/همپوشانی است.
نتایج نشان میدهد که استفاده از کامپوزیتهای اندازهگیری برای توصیف خوانایی نقشه بهتر از معیارهای منفرد است. با استفاده از بهترین اندازهگیری طول خط شیء ، میتوانیم به درستی تقریباً ۷۵ درصد از نمونههای نقشه را بهعنوان قابل خواندن/غیرخواندن طبقهبندی کنیم. وقتی دو معیار دیگر اضافه کردیم، تعداد انواع شی و نشانگر مجاورت،مقدار نمونه های طبقه بندی شده به درستی به حدود 80 درصد افزایش یافت. ما نتوانستیم هیچ تفاوت عمده ای را در سه روش ترکیبی که ارزیابی کردیم شناسایی کنیم. با این حال، میتوان نتیجه گرفت که روش ارزیابی آستانه به کار بیشتری برای بهینهسازی مقادیر آستانه نیاز دارد. ما همچنین میتوانیم نتیجه بگیریم که ماشین بردار پشتیبان روش مناسبی است زیرا فقط به یک مجموعه داده آزمایشی نیاز دارد که در آن هر نقشه به عنوان قابل خواندن یا غیرقابل خواندن طبقهبندی میشود (در حالی که روش رگرسیون خطی چندگانه به مقادیر خوانایی عددی نیاز دارد).
با مطالعه نمونههای نقشهای که با روشهای ترکیبی به درستی طبقهبندی نشدهاند، میتوان به موارد زیر نتیجهگیری کرد. به نظر می رسد توانایی نقشه خوان برای درک بافت جغرافیایی (که در نمونه های نقشه نشان داده شده است) بر توانایی او در خواندن نقشه تأثیر می گذارد. یعنی ما نمی توانیم خوانایی نقشه را با پیچیدگی گرافیکی نقشه به طور کامل توضیح دهیم.
یک توصیه عملی، بر اساس این مطالعه، این است که تولیدکنندگان نقشه نباید تنها از معیارهای خوانایی وضوح گرافیکی در مشخصات نقشه خود استفاده کنند. تولیدکنندگان باید این اقدامات را با معیارهای مقدار اطلاعات، مانند طول خط شی تکمیل کنند. علاوه بر این، فرآیند تعمیم نقشه باید با معیارهای خوانایی برای مقدار اطلاعات و احتمالاً توزیع فضایی (که گاهی اوقات قبلاً در نظر گرفته می شود) راه اندازی و کنترل شود.
مقایسه ما از دو سبک نماد (به TS و NS، رجوع کنید به بخش 3.2 و شکل 4 ) نشان می دهد که سبک کم رنگ نسبت به سبک سنتی خوانایی کمتری دارد. تفاوت رنگ در این دو سبک نیز به خوبی با معیارهای رنگ و روشنایی مشخص می شود. این نتیجه در زمینه نگاشت پس زمینه در وب جالب است. خدمات تجاری (Google Maps، Bing Maps و غیره ).) برای مدت طولانی از رنگ های کم رنگ استفاده کرده اند زیرا به کاربران اجازه می دهند اطلاعات موضوعی خود را در بالای نقشه ها اضافه کنند. در سالهای اخیر، بسیاری از آژانسهای ملی نقشهبرداری نیز خدماتی را با رنگهای کمرنگ برای پشتیبانی از افزودن اطلاعات موضوعی ارائه کردهاند. این پیشرفت در کل مثبت است، اما باید مراقب بود که خوانایی نقشه ها از دست نرود. طبق یافته های ما، از دست دادن خوانایی یک خطر است.





بدون نظر