

خلاصه
دادههای رسانههای اجتماعی بهعنوان منبع جدیدی برای شناسایی و نظارت بر رویدادهای بلایای طبیعی پدیدار شدهاند. تعدادی از مطالعات اخیر نشان دادهاند که میتوان از جریانهای داده رسانههای اجتماعی برای استخراج دادههای عملی برای واکنش اضطراری و عملیات امدادی استفاده کرد. با این حال، هیچ تلاشی برای طبقهبندی دادههای رسانههای اجتماعی در مراحل مدیریت بلایا (کاهش، آمادگی، واکنش اضطراری و بازیابی) صورت نگرفته است، که برای دههها به عنوان یک مرجع مشترک برای محققان بلایا و مدیران اضطراری برای سازماندهی اطلاعات و سادهسازی استفاده شده است. اولویت ها و فعالیت ها در طول یک فاجعه. این مقاله با بررسی دستی بیش از 10 مورد، تلاش اولیه ای را برای کدگذاری پیام های رسانه های اجتماعی در موضوعات مختلف در مراحل مختلف فاجعه در طول یک بحران بحرانی زمانی انجام می دهد. 000 توییت ایجاد شده در طی یک بلایای طبیعی و ارجاع به یافته های ادبیات مربوطه و رویه های رسمی دولتی که شامل مراحل مختلف فاجعه است. علاوه بر این، یک طبقهبندی بر اساس رگرسیون لجستیک برای استخراج خودکار و طبقهبندی پیامهای رسانههای اجتماعی به دستههای موضوعی مختلف در طول مراحل مختلف فاجعه، آموزش داده شده و استفاده میشود. نتایج طبقهبندی برای مدیران اضطراری ضروری و مفید است تا انتقال بین مراحل مدیریت بلایا را شناسایی کنند، که زمانبندی آن معمولاً ناشناخته است و در رویدادهای بلایا متفاوت است، به طوری که آنها میتوانند به سرعت و کارآمد در جوامع آسیبدیده اقدام کنند. اطلاعات تولید شده از طبقه بندی همچنین می تواند توسط جوامع تحقیقاتی علوم اجتماعی برای مطالعه جنبه های مختلف آمادگی، پاسخ، تاثیر و بازیابی استفاده شود.
کلید واژه ها:
رسانه های اجتماعی ؛ فاجعه ؛ متن کاوی ; داده کاوی ; هماهنگی بلایا تسکین فاجعه
1. معرفی
برای چندین دهه، محققان بلایا و مدیران اضطراری معمولاً برای درک و مدیریت بلایا بر یک طبقهبندی چهار مرحلهای (کاهش، آمادگی، واکنش و بازیابی) تکیه کردهاند [ 1 ]. طبقه بندی چارچوب مشترکی را برای پژوهشگران فراهم می کند تا یافته های تحقیق را سازماندهی، مقایسه و به اشتراک بگذارند. این به عنوان یک مرجع زمانی برای پزشکان برای پیشبینی چالشها و آسیبها، اولویتبندی عملکردها، و سادهسازی فعالیتها در طول دوره مدیریت بلایا عمل میکند [ 2 ، 3 ]. اگرچه پذیرفته شده است که داده های منبع عمومی می توانند در تمام مراحل مدیریت بلایا کمک کنند [ 4 ]و کاوی رسانه های اجتماعی برای واکنش و هماهنگی در بلایا سطح فزاینده ای از توجه جامعه پژوهشی را به خود جلب کرده است (به عنوان مثال، [ 5 ، 6 ، 7 ، 8 ، 9 ، 10 ، 11 ، 12 ]، هیچ تلاشی به این موضوع اختصاص داده نشده است. شناسایی و طبقهبندی اطلاعات از رسانههای اجتماعی به این مراحل که معمولاً توسط محققان و پزشکان ارجاع میشوند.
استفاده از دادههای رسانههای اجتماعی مزایای متعددی نسبت به روشهای سنتی جمعآوری دادهها برای درک مراحل متعدد مدیریت بلایا دارد. پیش از این، روشهایی مانند تماسهای تلفنی، مشاهدات مستقیم یا مصاحبههای شخصی، معمولاً توسط پاسخدهندگان بلایا و ارزیابیکنندگان آسیب برای به دست آوردن آگاهی موقعیتی و بررسی جمعیتهای آسیبدیده انجام میشد. یک بررسی اجتماعی معمولی در سطح شهر نیازمند سالها سرمایه گذاری اختصاصی در منابع برای موفقیت است [ 9 ]. حتی با تحقیقات در سطح ابتدایی، دادههای رسانههای اجتماعی عکسهای فوری جالبی از جامعه انسانی در مقیاس کلان با چابکی ارائه کردهاند که تنها با نظرسنجیهای سنتی میتوان رویای آن را دید [ 13 ].]. علاوه بر این، زمان انتقال بین مراحل مختلف فاجعه معمولاً ناشناخته است. چهار مرحله مدیریت بلایا همیشه به صورت مجزا یا با این ترتیب دقیق اتفاق نمی افتد. اغلب مراحل چرخه با هم همپوشانی دارند و طول هر فاز تا حد زیادی به شدت فاجعه بستگی دارد [ 14 ]. دادههای رسانههای اجتماعی میتوانند اطلاعات «زمان واقعی» را برای مدیران اضطراری فراهم کنند تا انتقالها را درک کنند و تصمیمهای مؤثری را از طریق مراحل متعدد مدیریت بلایا اتخاذ کنند.
دسته بندی های محتوایی (یا موضوعات) تعریف شده در مطالعات قبلی [ 5 ، 10 ، 11 ، 15 ] بیشتر بر روی “داده های عملی” درگیر در مراحل واکنش به بلایا تمرکز دارند، در حالی که اطلاعات مفیدی که می توانند قبل و بعد از یک رویداد فاجعه پست شوند عبارتند از مورد بحث و بررسی قرار نگرفته است. Vieweg [ 14 ] فهرست کاملی از دسته بندی ها را برای کدگذاری پیام رسانه های اجتماعی از جمله احتیاط، توصیه، مرگ و میر، جراحت، پیشنهادات کمک، گمشده و اطلاعات عمومی جمعیت تعریف کرد. سایر محققان [ 10 ، 11 ] بسته به هدف مطالعه، پیام ها را به دسته های کمتری تقسیم کردند. عمران و همکاران [ 10]، به عنوان مثال، توییتها را در طول یک بلای طبیعی به چندین دسته از قبیل احتیاط و توصیه، تلفات و خسارت، اهدا و پیشنهاد، و منبع اطلاعات استخراج کرد. پوروهیت و همکاران [ 11 ] پیامهایی را که به دستههای درخواست و پیشنهاد (منابع یا خدمات داوطلبانه) تعلق دارند، بررسی کرد. در این طرحوارههای کدگذاری، اطلاعات مربوط به زمان، چگونگی و مکان برای آماده شدن برای فاجعه، به عنوان مثال، و بازیابی پس از فاجعه به طور کامل در نظر گرفته نشده و کمتر شناخته شده است.
هدف این مقاله بررسی ماهیت محتوای توییت تولید شده در بازه زمانی یک فاجعه، و تعریف فهرستی از دسته بندی محتوا با در نظر گرفتن اطلاعات درگیر در مراحل بلایا از جمله آمادگی، واکنش اضطراری و بازیابی است. در کار ما، توییتها به 47 موضوع تفکیک شدهاند که تا آنجا که میدانیم، دقیقترین و کاملترین طرح کدگذاری برای دستهبندی رسانههای اجتماعی به مضامین مختلف است. طرح کدگذاری می تواند به طور بالقوه برای استخراج رسانه های اجتماعی به طور موثر در طول مراحل مختلف فاجعه و به دست آوردن تصویر بهتری از محیط پیچیده در زمان بحران مفید باشد. ما همچنین کلمات کلیدی و موضوعاتی را برای تأثیر بلایا شناسایی کردیم که اغلب برای واکنش اضطراری و بازیابی مفید است. علاوه بر این، لیستی از کلمات کلیدی مرتبط با پیام های هر کلاس به صورت دستی برای هر دسته استخراج شده و به عنوان مبنایی برای تحقیقات مشابه در آینده ارائه می شود. این کلمات کلیدی را می توان به عنوان مرجعی برای سایر محققانی که روش تطبیق الگوی متن را برای استخراج توییت هایی که به یک دسته خاص تعلق دارند، استفاده می کنند. این مقاله همچنین چارچوبی را معرفی می کند که می تواند داده های رسانه های اجتماعی را برای تجزیه و تحلیل فاجعه در مراحل مختلف پردازش و استخراج کند. با استفاده از این چارچوب، توییت های مرتبط برای هر دسته را می توان از داده های خام استخراج کرد. این مقاله همچنین چارچوبی را معرفی می کند که می تواند داده های رسانه های اجتماعی را برای تجزیه و تحلیل فاجعه در مراحل مختلف پردازش و استخراج کند. با استفاده از این چارچوب، توییت های مرتبط برای هر دسته را می توان از داده های خام استخراج کرد. این مقاله همچنین چارچوبی را معرفی می کند که می تواند داده های رسانه های اجتماعی را برای تجزیه و تحلیل فاجعه در مراحل مختلف پردازش و استخراج کند. با استفاده از این چارچوب، توییت های مرتبط برای هر دسته را می توان از داده های خام استخراج کرد.
بخش بعدی این مقاله مروری کلی بر تحقیق در مورد استفاده از رسانه های اجتماعی در یک فاجعه است تا زمینه وسیع تری را برای مطالعه تجربی ما فراهم کند و به دنبال آن بخش سوم روش شناسی تهیه و استخراج توییت ها برای تجزیه و تحلیل بلایا را شرح می دهد. بخش چهارم نحوه اعمال نتایج طبقه بندی را برای تجزیه و تحلیل بلایا نشان می دهد. این مقاله با بحث در مورد مسائل، چالش ها و جهت گیری های تحقیقاتی آینده استفاده از داده های رسانه های اجتماعی برای تجزیه و تحلیل و مطالعه بلایا به پایان می رسد.
2. آثار مرتبط
اخیراً، بسیاری از مطالعات از داده های رسانه های اجتماعی برای درک جنبه های مختلف رفتار انسان، محیط فیزیکی و پدیده های اجتماعی استفاده کرده اند. مطالعات استفاده از رسانه های اجتماعی برای تجزیه و تحلیل مربوط به فاجعه بر حوزه های زیر متمرکز است: (1) آگاهی موقعیتی و کدگذاری پیام رسانه های اجتماعی در طول یک فاجعه. (2) تشخیص رویداد و ردیابی احساسات؛ (3) واکنش در بلایا و هماهنگی امداد. و (4) ارزیابی خسارت.
2.1. آگاهی موقعیتی و کدگذاری پیام
طبق نظر Viewveg و همکاران. [ 5]، آگاهی موقعیتی (SA) “وضعیت ایده آل درک آنچه در یک رویداد اتفاق می افتد با بسیاری از بازیگران و سایر بخش های متحرک، به ویژه با توجه به نیازهای عملیات فرماندهی و کنترل را توصیف می کند.” ساده تر، دانستن آنچه در جوامع آسیب دیده در طول یک رویداد اتفاق می افتد. در کار خود، ما آگاهی موقعیت جغرافیایی (GSA) را به عنوان دانستن آنچه در فضا اتفاق می افتد تعریف می کنیم. کاربرانی که خدمات مکان را در دستگاههای تلفن همراه هوشمند فعال کردهاند، میتوانند محتوا (مثلاً پیامهای متنی یا عکس) را با مکانهایی که معمولاً به صورت یک جفت مختصات (طول و عرض جغرافیایی) نشان داده میشوند، پست کنند. در نتیجه، کاربران میتوانند اطلاعاتی را در مورد رویدادهایی گزارش کنند (مثلاً جادههای سیلزده، بسته شدن پلها، پناهگاهها، یا مکانهای اهدایی) که در مکانهایی که این رویدادها در طی یک فاجعه رخ دادهاند و تجربه کردهاند.
از آنجایی که پیامهایی که از طریق شبکه رسانههای اجتماعی پخش و به اشتراک گذاشته میشوند بسیار متنوع هستند، قبل از اینکه بتوانیم از آنها برای تولید نقشه بحران یا استخراج «دادههای عملی» بهعنوان اطلاعاتی که به آگاهی موقعیتی کمک میکند استفاده کنیم، به یک طرح کدگذاری برای تفکیک پیامها به دستههای مختلف نیاز است. . در طول طوفان بوفا، داوطلبان از طریق PyBossa، یک پلت فرم وظیفهای کوچک، توییتها را به صورت دستی در مضامین مختلف، مانند خودروی آسیبدیده، سیل، و غیره حاشیهنویسی کردند و سپس نقشه بحران برای استفاده توسط سازمانهای بشردوستانه تولید شد [ 16 ] . چند تلاش [ 15] برای کشف و توضیح اطلاعاتی که کاربران توییتر در هنگام شرایط اضطراری جمعی با آنها ارتباط برقرار می کنند ساخته شده اند. اطلاعات مربوط به تلفات و خسارت، تلاشهای اهدایی و هشدارها بیشتر برای بهبود آگاهی موقعیتی در طول یک رویداد حساس زمانی مورد استفاده و استخراج قرار میگیرند. در نتیجه، پیامها معمولاً در این دستههای اصلی دستهبندی میشوند. عمران و همکاران [ 10 ]، برای مثال، توییت های منتشر شده در طول یک بلای طبیعی را به چندین دسته از جمله احتیاط و توصیه، تلفات و خسارت، اهدا و پیشنهاد، و منبع اطلاعات استخراج کرد. دسته بندی محتوا (یا موضوعات) تعریف شده در آن مطالعات [ 5 ، 10 ، 15]، برای کاوش و استخراج داده های عملی درگیر در مراحل واکنش و بازیابی بلایا بسیار مفید هستند. با این حال، اطلاعات مفیدی که می تواند قبل یا بعد از یک رویداد فاجعه بار ارسال شود، ممکن است توسط این طرح های کدگذاری فاش نشود.
2.2. تشخیص و ردیابی رویداد
شبکه کاربران رسانه های اجتماعی یک شبکه کم هزینه و موثر «حسگر جغرافیایی» برای اطلاعات ارائه شده در نظر گرفته می شود. به عنوان مثال، توییتر بیش از 190 میلیون کاربر ثبت شده دارد و روزانه 55 میلیون توییت ارسال می شود. به عنوان مثال، پرواز 214 آسیانا از سئول، کره هنگام فرود در فرودگاه بین المللی سانفرانسیسکو در 6 ژوئیه 2013 سقوط کرد. اخبار سقوط به سرعت در اینترنت از طریق رسانه های اجتماعی پخش شد. با ارسال توئیتهایی از داستانهای خود توسط شاهدان عینی، ارسال تصاویری از تودههای دود بر فراز خلیج و بارگذاری ویدئویی از فرار مسافران از هواپیمای در حال سوختن در اینترنت، این رویداد به سرعت در سطح جهانی مورد تایید قرار گرفت.
در نتیجه دسترسی سریع یا حتی فوری اطلاعات در رسانه های اجتماعی، داده ها به طور گسترده برای تشخیص رویدادهای مهم استفاده می شوند. ساکاکی و همکاران [ 17 ]، برای مثال، تعامل بلادرنگ رویدادها، مانند زلزله و توییتر را بررسی کرد. تحقیقات آنها یک مدل مکانی-زمانی احتمالی برای رویداد هدف تولید کرد که می تواند مرکز و مسیر مکان رویداد را پیدا کند. سیگنورینی و همکاران [ 18] استفاده از توییتها را برای (1) ردیابی احساسات عمومی در حال تحول سریع در رابطه با آنفولانزای خوکی بررسی کرد. و (2) ردیابی و اندازه گیری فعالیت واقعی بیماری. این کار همچنین نشان داد که توییتر می تواند به عنوان معیاری برای منافع عمومی یا نگرانی در مورد رویدادهای مرتبط با سلامت مورد استفاده قرار گیرد و تخمین های بیماری شبه آنفولانزا که از کاربران توییتر به دست آمده است، به طور دقیق سطوح بیماری گزارش شده را دنبال می کند. کنت و کاپلو [ 19 ] داده های تولید شده توسط کاربر استخراج شده از چندین شبکه اجتماعی را در طول یک آتش سوزی جمع آوری و ترکیب کردند. تجزیه و تحلیل رگرسیون برای شناسایی ویژگی های جمعیت شناختی مربوطه استفاده شد که منعکس کننده بخشی از جامعه آسیب دیده است که داوطلبانه داده های معناداری در مورد آتش سوزی ارائه می دهد. مندل و همکاران با استفاده از طوفان ایرنه به عنوان مثال . [ 20] به این نتیجه رسید که تعداد پیامهای توییتر با اوج رویداد، سطح نگرانی بستگی به موقعیت مکانی و جنسیت دارد، و زنان بیشتر از مردان در طول بحران ابراز نگرانی میکنند.
2.3. واکنش و امداد در بلایا
در طول یک فاجعه، شهروندان آسیبدیده قبل از رسیدن اولین پاسخدهندگان روی زمین هستند و با ارائه بهروزرسانیهای نزدیک به زمان واقعی، به مشارکتکنندگان و توزیعکنندگان فعال اطلاعات تبدیل میشوند [ 21 ]. در واقع، به طور گسترده ای پذیرفته شده است که پاسخ دهندگان کمک های بشردوستانه و امداد در بلایا (HADR) می توانند بینش های ارزشمند و آگاهی موقعیتی را با نظارت بر فیدهای مبتنی بر رسانه های اجتماعی به دست آورند، که از آن داده های تاکتیکی و عملی را می توان از متن استخراج کرد [ 15 ]. در نتیجه، سطح فزاینده ای از توجه توسط استخراج داده های رسانه های اجتماعی برای پاسخ به بلایا و امدادرسانی از جامعه تحقیقاتی به خود جلب شده است [ 6 ، 10 ، 12 ، 21 .]. کومار و همکاران با هدف کمک به پاسخدهندگان HADR برای ردیابی، تجزیه و تحلیل و نظارت بر توییتها و کمک به اولین پاسخدهندگان به آگاهی موقعیتی بلافاصله پس از یک فاجعه یا بحران کمک میکنند . [ 6 ] ابزاری با قابلیتهای تحلیلی و تجسمی دادهها، مانند روند نزدیک به زمان واقعی، کاهش دادهها و بررسی تاریخی ارائه کرد. گائو و همکاران [ 22 ] مزایا و معایب رسانههای اجتماعی را که برای هماهنگی کمکرسانی به بلایا اعمال میشود، تشریح کرد و چالشهای تبدیل چنین دادههای جمعسپاری را به ابزار مفیدی که میتواند به طور مؤثر فرآیند امداد را در هماهنگی، دقت و امنیت تسهیل کند، مورد بحث قرار داد.
یافتههای اخیر همچنین نشان میدهد که دادههای عملی را میتوان از رسانههای اجتماعی استخراج کرد تا به واکنشگران اضطراری کمک کند تا سریع و کارآمد عمل کنند. اشکتراب و همکاران [ 12 ]، برای مثال، Tweedr، یک ابزار استخراج توییتر را معرفی کرد که اطلاعات عملی را برای امدادگران در هنگام بلایای طبیعی استخراج میکند. خط لوله Tweedr از سه بخش اصلی تشکیل شده است: طبقه بندی، خوشه بندی و استخراج. پوروهیت و همکاران [ 11 ] روشهای یادگیری ماشینی را برای شناسایی و مطابقت خودکار نیازها و پیشنهادات ارائه شده از طریق رسانههای اجتماعی برای اقلام و خدمات، مانند سرپناه، پول، لباس و غیره ارائه کرد.
2.4. ارزیابی خسارت
در مواقع اضطراری در مناطق شهری، ارزیابی آسیب به افراد، اموال و محیط زیست به منظور هماهنگی تخلیه و عملیات امدادی بسیار مهم است. سنجش از دور که قادر به جمع آوری مقادیر انبوهی از داده های مکانی-زمانی پویا و جغرافیایی توزیع شده روزانه است، اغلب برای ارزیابی بلایا استفاده می شود. با این حال، علیرغم تعداد کلان دادههای موجود، شکافها اغلب به دلیل محدودیتهای خاص ابزارها یا پلتفرمهای حامل آنها وجود دارد. چندین تلاش [ 23 ، 24 ، 25بنابراین، برای نشان دادن اینکه چگونه دادههای جغرافیایی داوطلبانه (VGI) میتواند برای تقویت دادهها و روشهای سنجش از دور سنتی برای تخمین گستردگی سیل و شناسایی جادههای آسیبدیده در طول یک فاجعه سیل استفاده شود، ساختهاند. در این کار، انواع دادههای غیرمعتبر و چند منبعی، مانند توییتها، عکسهای مکانیابی شده از موتور جستجوی Google، دادههای ترافیک از دوربینها، OpenStreetMap، ویدئوها از یوتیوب و اخبار، جمعآوری میشوند تا آسیب زیرساختهای حملونقل را ارزیابی کنند. و تخمینی از پیشرفت و رکود رویداد سیل بسازید.
به طور خلاصه، کاربردهای استفاده از پیامهای رسانههای اجتماعی برای شناسایی و ردیابی رویدادها، کاوش در افکار عمومی یا احساسات نسبت به یک رویداد فاجعهبار، و حتی استخراج اطلاعات عملی برای حمایت از واکنش و امداد رسانی به بلایا به شدت بررسی و نشان داده شده است. هدف این مقاله، با این حال، کمک به دستیابی به آگاهی موقعیتی دقیق تر از یک رویداد فاجعه برای پاسخ دهندگان HADR و کشف الگوی مکانی-زمانی رفتارها و واکنش های افراد با کدگذاری و جداسازی پیام های داده های رسانه های اجتماعی در دسته های دقیق در طول مراحل مختلف فاجعه است. و آنها را در مکان و زمان ترسیم کنید. با در نظر گرفتن ماهیت محتوای توییت تولید شده در طول کل بازه زمانی یک فاجعه، این مقاله فهرستی از دستههای پیام را تعریف میکند که در هر مرحله فاجعه نقش دارند. با ترسیم موقعیت جغرافیایی توییتهای یک دسته خاص، میتوانیم رویدادهای «محلی» (مثلاً مناطق سیلزده) را بفهمیم. چارچوبی برای تفکیک پیام های رسانه های اجتماعی به این دسته ها برای تجزیه و تحلیل بلایا در مراحل مختلف نیز معرفی شده است. در این چارچوب، توییتهای مرتبط برای هر دسته را میتوان از دادههای خام بر اساس کلمات کلیدی از پیش تعریفشده و توییتهای حاشیهنویسی دستی که برای آموزش و ساخت مدلهای طبقهبندی استفاده میشوند، دستهبندی کرد.
3. روش شناسی
3.1. داده ها
طوفان سندی که در 29 اکتبر 2012 شمال غربی ایالات متحده را درنوردید، به عنوان مطالعه موردی انتخاب شد و مرکز شهر نیویورک به عنوان منطقه مورد مطالعه انتخاب شد. از آنجایی که هدف این مقاله ایجاد آگاهی موقعیت جغرافیایی است، تنها توییت هایی با برچسب های جغرافیایی مورد بررسی قرار می گیرند. برای بازیابی همه پیامهای برچسبگذاریشده جغرافیایی ارسال شده در توییتر در طول 10 اکتبر و 27 نوامبر 2012، از Gnip ( http://gnip.com/ )، یک جستجوی جغرافیایی با مرز منطقه مطالعه انتخابی ارسال کردیم. در مجموع 1763141 توییت جمع آوری شد. علاوه بر محتوای متن پیام، هر توییت شامل ابردادههایی مانند مهر زمانی ارسال، برچسب جغرافیایی (موقعیت مکانی) و اطلاعات نمایه نویسنده است که شامل مکان نویسنده، توضیحات نمایه، تعداد توییتها، تعداد فالوورها و دوستان است. و غیره.
3.2. دسته ها و کلمات کلیدی توییت در مراحل مختلف بلایا
مدیریت اضطراری معمولاً شامل چهار مرحله است: کاهش، آمادگی، پاسخ و بازیابی [ 1 ]]. با این حال، کاهش در این کار گنجانده نشده است زیرا به اقدامات یا فعالیت های بلند مدت برای جلوگیری از بلایای آینده یا به حداقل رساندن اثرات آنها مربوط می شود. مثالها شامل هر اقدامی است که از وقوع یک فاجعه جلوگیری میکند، احتمال وقوع فاجعه را کاهش میدهد، یا اثرات مخرب یک فاجعه را کاهش میدهد، به عنوان مثال، عوارض ساختمانی یا بالا بردن ساختمان برای یک طوفان بالقوه. بنابراین، این مقاله بر سه مرحله دیگر تمرکز دارد. ما همچنین توییتهایی را در مورد تأثیر شناسایی کردیم که برای واکنش به بلایا بسیار مهم است. در طول یک فاجعه، تنها برخی از پیام های ارسال شده توسط کاربران توییتر به آگاهی موقعیت کمک می کند. بنابراین، قبل از استخراج اطلاعات مفید از داده های عظیم رسانه های اجتماعی برای تجزیه و تحلیل فاجعه، ابتدا باید پیام هایی را که به فاجعه بی ربط هستند فیلتر کنیم. ما با فهرست کردن همه هشتگها از دادههای جمعآوریشده با استفاده از برنامهای که با استفاده از جاوا توسعه دادهایم، شروع میکنیم، که میتواند به طور خودکار هشتگهای توییتها را استخراج کند و تعداد کلمات هر هشتگ را شمارش کند. هشتگ های برتر مربوط به طوفان سندی سپس انتخاب و به شرح زیر ارائه می شوند:
beprep, blackoutnyc, breakingstorm, franken-storm, frankenstorm, frankenstormsupplies, hurricane, hurricaneny, hurricanenyc, hurricaneprep, hurricanepreparation, hurricanerelief, hurricanes, hurricanesandy, hurricanesandyaftermath, hurricanesandyproblems, hurricanesandysuppprt, newyorkhurricane, newyorksandy, njpower, nychurricane, nycsandy, nycsandyneeds, nycstorm, nyhurricane, nysandy, nystorm, sandy, sandyaftermath, sandyaid, sandycommute, sandyhelp, sandyhuracan, sandyinny, sandyisknockingatmydoor, sandylove, sandyny, sandynyc, sandyprep, sandypreparation, sandyproblems, sandy regep sandy reparation, sandyproblems, sandy regeng sandystory, sandyuracan, sandyinny طوفان، ابرطوفان، ابرطوفان
سپس با استفاده از آن هشتگ ها، پیام هایی را که مربوط به فاجعه نیستند فیلتر می کنیم. اگر توییتی حاوی هیچ کلمه کلیدی هشتگ از پیش تعریف شده ای در پیام ها یا هشتگ ها نباشد، در تجزیه و تحلیل زیر حذف می شود. از آنجایی که لیست کلمات کلیدی شامل برخی از کلیدواژه های رایج مرتبط با طوفان ها مانند “شنی”، “طوفان”، “طوفان” و “سوپر طوفان” است و این کلمات کلیدی علاوه بر هشتگ ها برای مطابقت با پیام های متنی توییت ها استفاده می شود، فیلتر میتوانیم بیشتر توییتهایی را که به طوفان سندی اشاره میکنند را برای مطالعه بیشتر نگه داریم. پس از انجام این فیلتر، 38224 توییت برای تجزیه و تحلیل مرحله بعدی گنجانده شده است.
هنگامی که توییت های مربوطه را به دست آوردیم، باید پیام ها را در دسته های مختلف در هر مرحله فاجعه تعیین و جدا کنیم. انتظار می رود که کاربران دسته های مختلفی از پیام ها را در مراحل مختلف فاجعه ارسال کنند. به عنوان مثال، مردم پیام هایی در مورد چگونگی آماده شدن برای طوفان آینده در مرحله آمادگی ارسال می کنند. به منظور تعیین دستهبندی پیامها برای مراحل مختلف فاجعه، از یک رویکرد پایین به بالا برای توسعه طرح کدگذاری استفاده میکنیم. ابتدا یک طرح کد نویسی خالی ایجاد می شود. سپس 2000 پیام مرتبط را نمونه برداری می کنیم، به صورت دستی ویژگی های هر پیام را بررسی می کنیم و اجازه می دهیم طرح از مجموعه داده ها رشد کند. علاوه بر این، در حین توسعه طرحهای کدگذاری، به ادبیات مرتبط با مدیریت بلایا نیز اشاره میکنیم [ 5 ، 10 ،14 ] و رویه های رسمی دولت برای مراحل مختلف فاجعه [ 2 ، 3 ]. برای اینکه تا حد امکان همه دستههای مختلف را به تصویر بکشیم، فرآیند نمونهگیری و بررسی توییت را دو بار دیگر تکرار میکنیم تا زمانی که دسته جدیدی از مجموعه دادههای نمونهگیری کشف نشود. بنابراین، بیش از 6000 توییت به صورت دستی در طول این فرآیند مورد بررسی قرار می گیرند تا طرح واره کدگذاری توسعه یابد. علاوه بر این، ما در طول فرآیند حاشیه نویسی که بیش از 10000 توییت بررسی می شود، به تنظیم طرح واره ادامه می دهیم.
در نهایت، 47 دسته پیام ایجاد می شود و 8، 6، 20 و 13 زیرمجموعه به ترتیب برای چهار دسته اصلی آمادگی، پاسخ، تأثیر و بازیابی تعریف شده است ( جدول 1 ). پیوست 1 شامل نمونه های پیام برای هر زیر مجموعه است. استفاده از هشتگ ها می تواند به فیلتر کردن بیشتر داده های نامربوط کمک کند. با این حال، هنوز توییت های زیادی وجود دارد که شامل هشتگ ها و کلمات کلیدی از پیش تعریف شده در متن است، اما به آگاهی موقعیت کمک نمی کند. بنابراین، دسته «سایر» برای توصیف چنین نوع پیامهایی تعریف میشود. با بررسی متن، کلمات و الگوی جمله استفاده شده در هر پیام، کلمات کلیدی را نیز به صورت دستی استخراج می کنیم که می توانند با دسته های مختلف مرتبط باشند ( جدول 1).). اگر بخواهند از روشهای مبتنی بر مطابقت الگوی متن برای استخراج توییتهای مرتبط با یک دسته خاص استفاده کنند، چنین کلمات کلیدی میتوانند به عنوان مرجع خوبی برای سایر محققان عمل کنند.

جدول 1. توییت کردن کلاس ها و کلمات کلیدی در طول فاز فاجعه مختلف.
3.3. حاشیه نویسی داده ها
پس از تعریف طرحواره کدگذاری، زیرمجموعهای از توییتها (5000) به صورت تصادفی نمونهبرداری شده و به صورت دستی در مضامین مختلف حاشیهنویسی میشوند. در طول فرآیند حاشیه نویسی اولیه، متوجه می شویم که بیشتر توییت ها به عنوان دسته های دیگر حاشیه نویسی می شوند و برخی از دسته ها فقط حاوی تعداد بسیار کمی توییت هستند. برای اطمینان از اینکه ما توییتهای کافی برای ساخت یک مدل طبقهبندی برای دستههای از پیش تعریفشده داریم، توییتهای بیشتری از هر دسته باید در مجموعههای نمونهگیری گنجانده شود که سپس برای فرآیندهای آموزشی و اعتبارسنجی مدل بعدی استفاده میشود. بنابراین، یک برنامه خودکار با استفاده از رویکرد تطبیق متن ساده برای دستهبندی توییتهای باقیمانده در مضامین مختلف ایجاد شده است. یک توییت در صورتی به دسته خاصی نسبت داده می شود که حاوی کلمات کلیدی مرتبط تعریف شده در آن باشدجدول 1 . توییتهای هر دسته اولیه به جز دستههای دیگر را بررسی میکنیم و آنهایی را که از دستههای واقعی آنها مطمئن هستیم، حاشیهنویسی میکنیم، که سپس به مجموعههای نمونهگیری اضافه میشوند. به منظور کاهش توییتهای تکراری در طبقهبندیکننده، همه ریتوییتها کنار گذاشته میشوند. در پایان، 8807 توییت برای آموزش و آزمایش طبقهبندی کننده چند برچسبی قرار داده شده است که در بخش بعدی ارائه خواهد شد.
3.4. پیش پردازش و طبقه بندی داده ها
چندین الگوریتم طبقهبندی کلاسیک برای متن کاوی آزمایش و مقایسه میشوند، از جمله K-نزدیکترین همسایه (KNN)، بیز ساده و رگرسیون لجستیک. این الگوریتمها همگی در Apache Mahout [ 26 ]، یک بسته یادگیری ماشینی منبع باز پیادهسازی شدهاند. برای آمادهسازی توییتها برای فرآیند آموزش، مجموعهای از عملیات پیشپردازش متن استاندارد انجام میشود. برای هر ورودی توییت، ابتدا همه غیرکلمات (نقاط نگارشی، کاراکترهای خاص، URL ها، احساسات و فضای خالی) را حذف می کنیم. سپس Apache Lucene ( https://lucene.apache.org/ )، یک کتابخانه نرمافزاری بازیابی اطلاعات منبع باز، برای توکن کردن (جدا کردن) متن باقیمانده به تک کلمات و توقف کلمات (مانند a، an و، هستند، به عنوان و غیره) حذف می شوند. با استفاده از بقیه نشانهها، میتوانیم مجموعهای از یونیگرامهای استاندارد را تولید کنیم که هر یونیگرام مربوط به دنبالهای از یک توکن (کلمه) است. این یونیگرام ها به نوبه خود می توانند برای ایجاد یک بردار ویژگی یونیگرام برای آموزش طبقه بندی کننده ها استفاده شوند. پس از آزمایشهای گسترده با الگوریتمهای متن کاوی مختلف، متوجه شدیم که رگرسیون لجستیک از سایر الگوریتمها برای وظایف طبقهبندی ما بهتر عمل میکند و بنابراین برای طبقهبندی پیامها در دستههای مختلف انتخاب میشود.
3.5. نتایج تجربی
اعتبارسنجی متقاطع ده برابری برای آزمایش طبقهبندیکننده انجام میشود. در طول تست طبقهبندی اولیه، متوجه میشویم که طبقهبندیکننده تولید شده چندین کلاس را به دلیل شباهت موضوعی و عدم تعادل در مجموعههای آموزشی اختصاص داده شده به هر دسته اشتباه گرفته است. برای پرداختن به این موضوع، دسته های مشابه را با هم ترکیب می کنیم. جدول 2ستون 1 و 5 دسته های ادغام شده و زیرمجموعه های مربوط به آنها را نشان می دهد. تعداد پیام های حاشیه نویسی شده برای هر دسته در ستون آخر نمایش داده می شود. علاوه بر این، ما همچنین چندین دسته را با نمونههای آموزشی کمتر از آستانه از پیش تعریفشده (مثلاً 20) کنار میگذاریم، زیرا نمیتوانیم کلاسکننده را آموزش دهیم که بهطور دقیق توییتها را به آن دستهها بر اساس اندازه کوچک مجموعه آموزشی اختصاص دهد. به عنوان مثال میتوان به آمادهسازی.طرحها، آمادهسازی.نکات، بازیابی.مدرسه، بازیابی.بازیابی، بازیابی.مسکن، بازیابی.تعمیر، بازیابی. سهام، بازیابی.برنامهها.نیرو، بازیابی.کاربردها.گاز و ضربه.
جدول 2. دقت، یادآوری، و امتیاز F1 برای وظایف طبقه بندی مختلف.
چندین اندازه گیری دقت برای ارزیابی عملکرد طبقه بندی پیام استفاده می شود، از جمله دقت (p)، یادآوری (r) و امتیاز F1. دقت درصدی از توییتهای پیشبینیشده درست برای یک کلاس به کل توییتهای پیشبینیشده برای آن کلاس در نمونههای آزمایشی است. یادآوری نسبتی از درصد توییتهای پیشبینیشده درست برای یک کلاس به تعداد کل توییتهای آن کلاس در نمونههای آزمایشی است. امتیاز F1 که به عنوان میانگین وزنی دقت و یادآوری شناخته می شود، به بهترین مقدار خود در 1 و بدترین امتیاز در 0 می رسد.
پس از اعتبارسنجی متقاطع 10 برابری، طبقه بندی کننده به دقت کلی 0.647، فراخوانی 0.711 و امتیاز F1 0.664 دست یافت. جدول 2عملکرد طبقه بندی کننده را برای طبقه بندی هر دسته نشان می دهد. بر اساس نتایج، می توان مشاهده کرد که طبقه بندی کننده در اکثر دسته بندی ها عملکرد خوبی دارد، همانطور که با مقدار نسبتاً بالایی برای هر شاخص ارزیابی نشان داده شده است. به خصوص، سه دسته برتر، از جمله بازیابی. امداد، ضربه. ابزارها. گاز، آماده سازی هستند، دقت بالای 0.9 را به دست می آورند. چندین دسته، Recovery.Rebuild، Response.Rescue و readyness.Eventmonitoring، با دسته بندی اشتباه اکثر پیام ها برجسته می شوند، به خصوص دسته بازیابی.بازسازی، که در آن هیچ یک از پیام ها به درستی اختصاص داده نشده اند. دلیل این امر این است که ما داده های آموزشی کافی برای آن دسته ها نداریم ( جدول 2). حدود دو سوم پیامهای تأثیر.تجاری و بازیابی.کسب و کار به درستی دستهبندی نشدهاند.
ما همچنین برای آزمایش همبستگی بین عملکرد و شیوع یک دسته، شیوع هر دسته را محاسبه کردیم ( شکل 1 ). نتایج بیشتر اثرات یک مجموعه آموزشی نامتعادل و مثالهای همپوشانی را نشان میدهد. به طور کلی، دقت بهتری برای طبقهبندی دستهبندی زمانی به دست میآید که شیوع دسته بالاتر باشد. در واقع، اگر شیوع یک دسته بیش از 5 درصد باشد، دقت طبقهبندی دستهبندی میتواند بیش از 80 درصد باشد، با یک استثنا برای مقوله تأثیر. دلیل این امر این است که بسیاری از محتوای حاصل از Impact.business و Recovery.business با هم تداخل دارند.
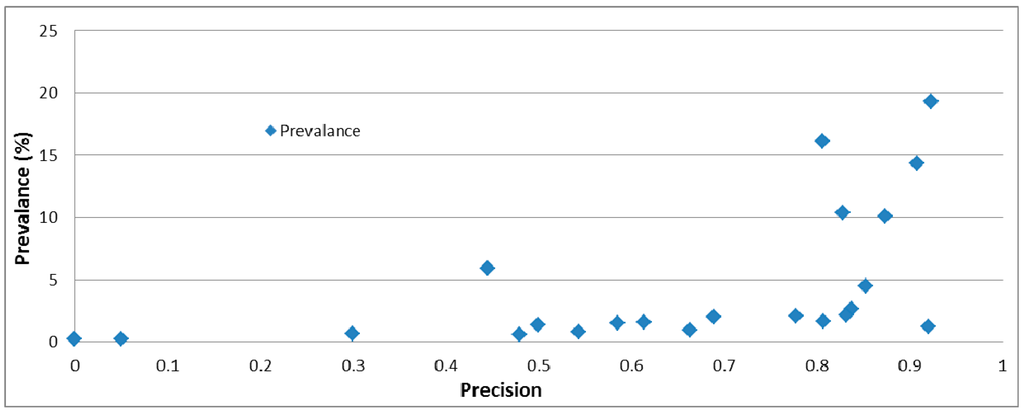
شکل 1. همبستگی بین دقت و شیوع یک دسته.
4. تجزیه و تحلیل وضعیت بلایا
با مطالعه توزيع فضاي زماني پيام ها، مي توان رفتارها و واكنش هاي شهروندان را نسبت به يك حادثه فاجعه آميز درك كرد. در این بخش، نتایج پیشبینیشده را برای بررسی الگوهای مکانی-زمانی موضوعات مختلف اعمال میکنیم. ما در مورد اینکه چگونه موضوعات در طول زمان تغییر کرده اند و موضوعات در کجا توزیع شده اند، گزارش می دهیم.
4.1. روند موضوع در طول زمان
از آنجایی که کاربران توییتر احتمالاً انواع مختلفی از پیامها را ارسال میکنند، از موضوعات مرتبط با آمادگی در طول مراحل اولیه یک فاجعه به بازیابی محتوای مرتبط پس از یک بحران، ما موضوعات را در مراحل مختلف فاجعه در طول زمان مقایسه میکنیم.
شکل 2 روند زمانی موضوعات را در مراحل مختلف فاجعه نشان می دهد. می توان مشاهده کرد که قبل از 24 اکتبر و بعد از 21 نوامبر، فقط توییت های محدودی مربوط به فاجعه هستند. چند روز قبل از وقوع طوفان سندی در نیویورک، رسانه های خبری به طور گسترده گزارش دادند که باد، باران و سیل در طول شب 29 اکتبر شهر را درنوردیده است. ما شاهد افزایش توییتهای مربوط به آمادگی بودیم که در 28 اکتبر، روزی که پرزیدنت اوباما اعلامیه اضطراری برای نیویورک صادر کرد، به اوج خود رسید. با هشدار رسانه ها، شهروندان شروع به آماده شدن برای طوفان آینده کردند. چنین اقداماتی با گزارش های خرید مواد غذایی، شارژ تلفن همراه، دریافت کیت ابزار اضطراری، خرید شمع، چراغ قوه و ژنراتور برای قطع برق، تخلیه و غیره منعکس می شود.، در توییتر. قبل از فاجعه، میتوانیم ببینیم که آمادگی در میان همه موضوعات قبل از 29 اکتبر غالب بود. توجه داشته باشید که توییتهای زیادی درباره موضوعات مرتبط با پاسخ در دستههای مسکن و نجات وجود ندارد، که در 29 نوامبر به اوج خود رسید و بیشتر در 29 اکتبر و 1 نوامبر پخش شد.
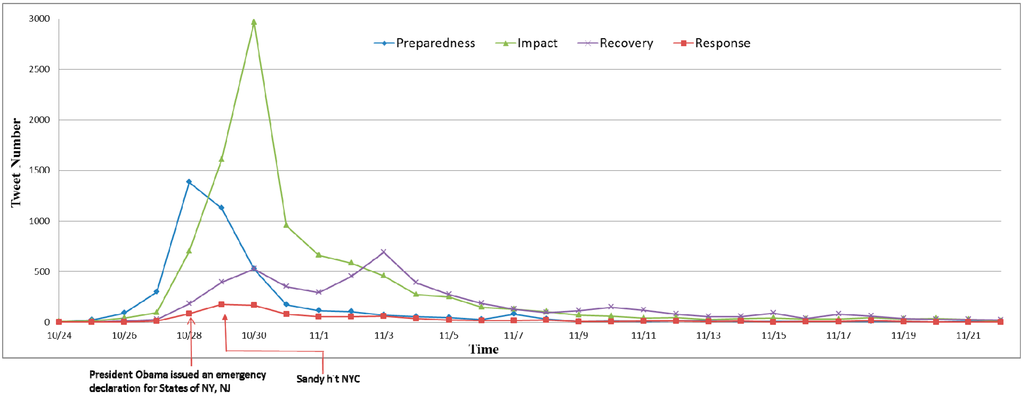
شکل 2. تعداد توییت در مراحل مختلف فاجعه در طول زمان.
تأثیر فاجعه توسط دادههای رسانههای اجتماعی ثبت شده است، جایی که بخش بزرگی از توییتها مربوط به دستههای تأثیر از ۲۹ اکتبر تا ۳ نوامبر است. موضوع تأثیر در 30 اکتبر، روز پس از اینکه سندی از نیویورک دور شد، به حداکثر خود می رسد. از سوی دیگر، زمانی که طوفان از بین رفت، می توان مشاهده کرد که تعداد فزاینده ای از توییت ها مربوط به موضوعات بازیابی است، به خصوص پس از 2 نوامبر، زمانی که بازیابی موضوع اصلی مربوط به فاجعه بود و پیام های مربوط به سایر موضوعات فاجعه در حال کاهش بود. .
تعداد توییتهای مربوط به بازیابی فاجعهها چندین اوج داشت. اولین مورد در 30 اکتبر، یک روز پس از حمله سندی به منطقه بود. بسیاری از مردم پیام هایی در مورد بازگشت به خانه و بازگشت به محل کار ارسال کردند. بزرگترین اوج در 3 نوامبر ظاهر شد، اولین شنبه پس از سندی، زمانی که بسیاری از مردم بیرون رفتند تا برای امداد رسانی در بلایای طبیعی کمک مالی کنند و داوطلبانه وقت خود را برای کمک به جوامع در پاکسازی آشفتگی ها صرف کنند. اوج کوچکی در شنبه بعدی، 10 نوامبر ظاهر شد. این توییتها همچنین مربوط به کار داوطلبانه و کمک به بهبودی جوامع بود.
4.2. موضوعات در فضا
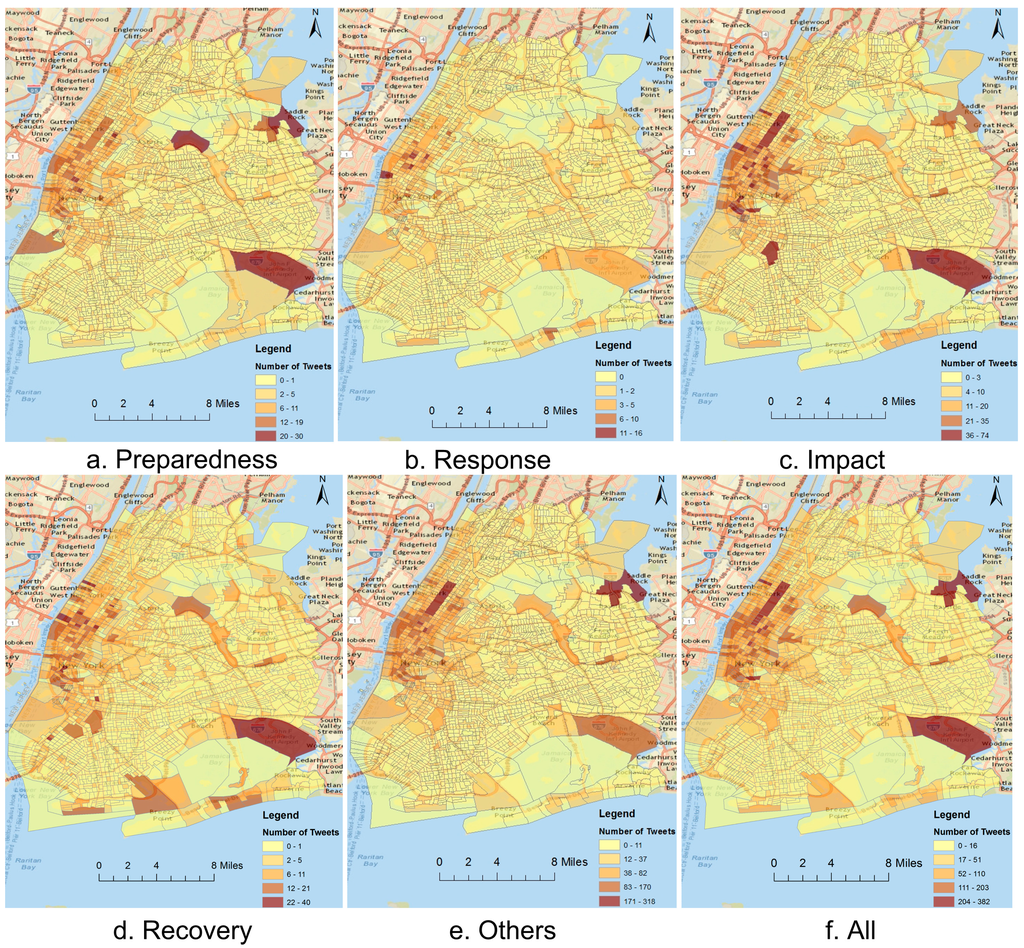
ما می توانیم رفتارهای اجتماعی آنلاین شهروندان را با نقشه برداری و تجسم توییت های یک موضوع خاص (مانند پاسخ در طول طوفان سندی) بررسی کنیم. شکل 3توزیع جغرافیایی توییت ها را برای موضوعات مختلف بر اساس سرشماری در سه مرحله فاجعه نشان می دهد. می توان مشاهده کرد که مکان های مختلفی وجود دارد که کاربران به طور فعال ترین اطلاعات را در مورد فاجعه ارسال می کنند. به عنوان مثال، بیشتر توییتها از جوامع منهتن پایین، شهرهایی در منطقه طوفانهای ساحلی مانند هوبوکن، که در ساحل رودخانه هادسون قرار دارد، و بروکلین در ساحل رودخانه شرقی ارسال شدهاند. این مکان ها توسط طوفان و بادهای شدید مرتبط با طوفان سندی ویران شدند. چنین الگوهایی نشان میدهد که کاربران توییتر در محلههای آسیبدیده به احتمال زیاد دادههای معناداری درباره فاجعه ارائه میکنند.
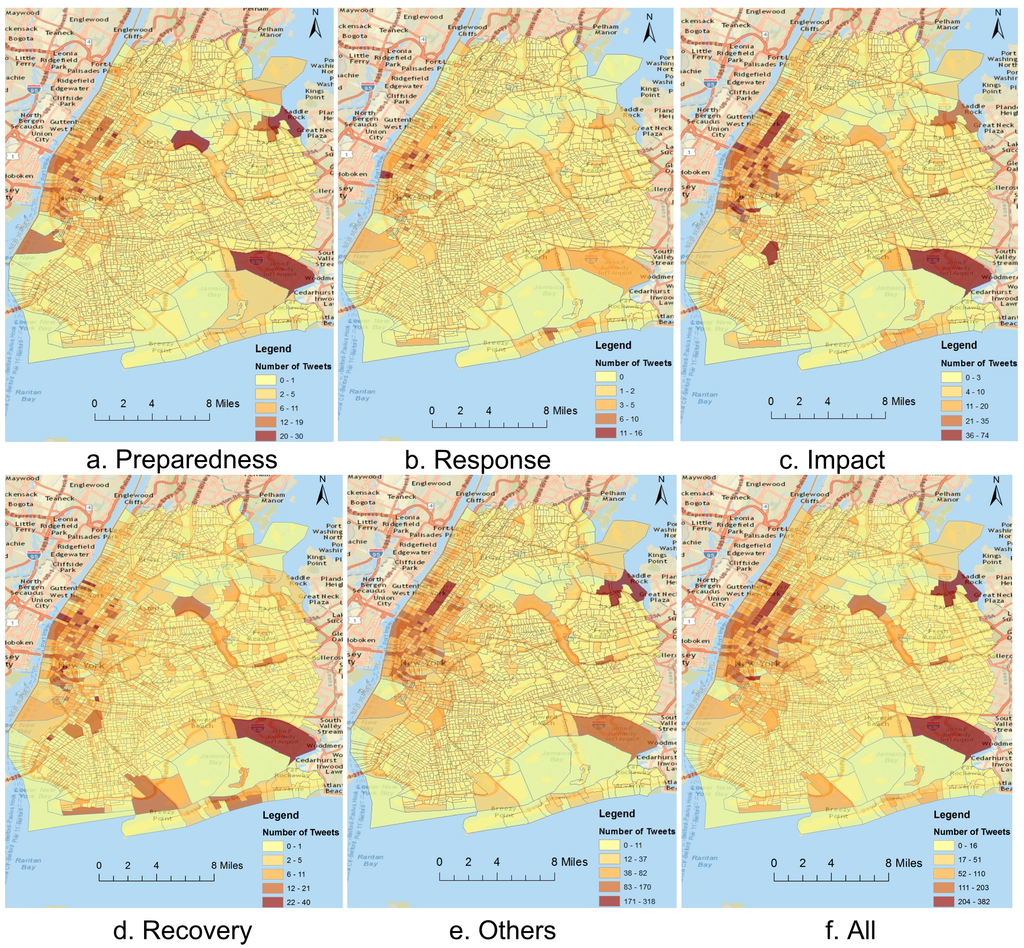
شکل 3. توزیع جغرافیایی توییت های مرتبط با فاجعه در مراحل مختلف فاجعه.
علاوه بر این، تعداد زیادی توییت از بسیاری از جوامع داخلی در منهتن وجود دارد ( شکل 3 f). تراکم بالای جمعیت و دسترسی به برق و اینترنت در منهتن ممکن است به توییتهای گسترده در این جوامع کمک کند [ 27 ]. بسیاری از مناطق عمومی، مانند پارک مرکزی، فرودگاه بین المللی جان اف کندی، و فرودگاه لاگاردیا، تعداد زیادی توییت را ثبت می کنند. مشاهده می شود که توییت های زیادی از فرودگاه طی مراحل مختلف ارسال می شود. این به این دلیل است که مردم اطلاعات مربوط به ترک نیویورک را قبل از طوفان ارسال میکنند (آمادگی؛ شکل 3 الف)، خسارتهای فرودگاه یا لغو پروازها را بهطور نامحدود پس از سندی گزارش میکنند (تصویر، شکل 3)ج)، و اخبار مربوط به عملکرد عادی فرودگاه، بازگشت به شهر یا پرواز از شهر را به اشتراک بگذارید (بازیابی؛ شکل 3 د). تعداد بسیار زیادی توییت از منطقه خلیج تراس (گوشه شمال شرقی منطقه مورد مطالعه) ارسال می شود. این به این دلیل است که ما توییتهای ارسال شده از Foursquare را درج میکنیم، که در آن کاربران میتوانند به مکانهای مختلف مراجعه کنند و این ورود را با دوستان خود در Foursquare و دیگر سایتهای رسانههای اجتماعی مانند توییتر به اشتراک بگذارند. ما متوجه شدهایم که تعداد زیادی اعلام حضور در «آخرین طوفان فرانک – طوفان سندی ( https://foursquare.com/frankenstorm_ny )» با عکسها، بهروزرسانیها و نکاتی که بین کاربران منطقه خلیج تراس به اشتراک گذاشته شده بود، انجام شد.
واضح است که بسیاری از توییتهای دستهبندی Impact از پارکهای عمومی (مثلاً پارک مرکزی) تولید میشوند، زیرا مردم شاهد عکسهای درختان افتاده و ارسال آن بوده و بسته شدن این پارکها را گزارش کردهاند ( شکل 3 ج). نواحی سرشماری در امتداد ساحل رودخانه هادسون، به ویژه مناطق نزدیک به تونل لینکلن، و تونل هلند، دارای تعداد زیادی توییت از هر دو تأثیر ( شکل 3 ج) و بازیابی ( شکل 3 د) هستند. این امر به این دلیل است که بسیاری از افراد با بازدید یا گذر از این مناطق، اطلاعات مربوط به موج یا محو شدن آب و بسته شدن یا باز شدن تونل ها و غیره را گزارش می دهند.
5. نتیجه گیری ها
پیامهای رسانههای اجتماعی سرشار از محتوا هستند و بسیاری از جنبههای زندگی، تجربیات، رفتارها و واکنشها به یک موضوع یا رویداد خاص را به تصویر میکشند و منعکس میکنند. بنابراین، این پیامها میتوانند برای نظارت و ردیابی رویدادهای ژئوپلیتیک و بلایا، پشتیبانی از واکنش و هماهنگی اضطراری، و به عنوان معیاری برای منافع عمومی یا نگرانی در مورد رویدادها مورد استفاده قرار گیرند. این کار یک طرح کدگذاری برای تفکیک پیام های رسانه های اجتماعی به مضامین مختلف در مراحل مختلف فاجعه ارائه می دهد. تعدادی از تکنیکهای استاندارد متن کاوی به طور آزمایشی برای طبقهبندی توییتهای جمعآوریشده در طول یک فاجعه، طوفان سندی در سال ۲۰۱۲ استفاده میشوند. یک طبقهبندی رگرسیون لجستیک برای آموزش و دستهبندی خودکار پیامها در دستههای از پیش تعریفشده ما انتخاب شده است.
طبقه بندی کننده می تواند به طور متوسط به دقت کلی 0.647 دست یابد. همانطور که در بخش 3.3 معرفی شد، چند دسته که اندازه نمونه آنها بسیار کوچک است (کمتر از 20 توییت) برای آموزش طبقه بندی کننده کنار گذاشته می شوند. علاوه بر این، چند موضوع که شامل نمونههای بسیار کوچک (کمتر از 20 توییت) برای آموزش طبقهبندی کننده هستند، کنار گذاشته میشوند (preparedness.plans). برخی از دسته های موضوعات مشابه ترکیب شده اند. در آینده، یک مدل طبقهبندی پیچیدهتر که بتواند دادههای نامتعادل را مدیریت کند، ممکن است برای افزایش دقت طبقهبندی توسعه یابد. ترکیبهای مختلف تمهای مشابه نیز ممکن است برای به دست آوردن دقت بهتر آزمایش شوند. علاوه بر این، اطلاعات عملی باید برای هر مرحله فاجعه به جای مرحله واکنش استخراج شود. به عنوان مثال، میتوانیم فروشگاههای باز موجود برای ذخیرهسازی ملزومات بلایای طبیعی و بازیابی منابع روزانه قبل و بعد از بلایا را استخراج کنیم، که در مطالعات قبلی کمتر مورد بررسی قرار گرفتهاند.
در این کار، ما از داده های طوفان سندی برای آموزش و اعتبار سنجی طبقه بندی کننده استفاده کردیم. در آینده، دادههای مربوط به رویدادهای مخاطره طبیعی شدید، بهویژه رویدادهای مرتبط با طوفان، باید برای ایجاد یک طبقهبندی مشترک بررسی و ادغام شوند تا بتوان از آن برای دستهبندی خودکار توییتها در دستههای مختلف در طول یک فاجعه استفاده کرد. چنین طبقهبندیکننده معمولی میتواند با نظارت بر رویدادهای بعدی در حین پخش توییتها و استخراج اطلاعات مفید، به پشتیبانی از مدیریت بلادرنگ و تجزیه و تحلیل بلایا کمک کند.
این مقاله یک طرح کدگذاری جدید برای دستهبندی توییتها در مضامین مختلف برای ایجاد آگاهی موقعیت جغرافیایی و چارچوبی ارائه میکند که میتواند برای جدا کردن توییتها در آن دستهها اعمال شود. بنابراین، تنها تحلیل اولیه بر روی نتایج طبقهبندی انجام میشود و تلاش زیادی برای تجزیه و تحلیل الگوهای مکانی-زمانی زیرمجموعهای خاص از دستهها (مثلاً قطع برق) و درک محرکهای این الگوها با پیوند دادن طبقهبندی انجام میشود. نتایج با سایر داده های GIS، مانند اطلاعات جمعیت شناختی و اجتماعی-اقتصادی.
علیرغم فرصت ها و امکاناتی که محققان و متخصصان در استفاده از رسانه های اجتماعی برای بلایا متصور بودند، نگرانی های متعددی در مورد کیفیت اطلاعات داده های رسانه های اجتماعی مطرح شده است [ 28 ، 29 ]. به عنوان مثال، مشخص شده است که گروههای خاصی (به عنوان مثال ، کم درآمد، تحصیلات پایین و سالمندان) ممکن است فاقد ابزار، مهارتها و انگیزههای دسترسی به رسانههای اجتماعی باشند و بنابراین ممکن است کمتر احتمال دارد اطلاعات مربوط به فاجعه را از طریق رسانههای اجتماعی ارسال کنند. 27]. علاوه بر این، مناطق خاصی ممکن است به شدت توسط فاجعه آسیب ببینند، که منجر به مشارکت بسیار کم در استفاده از رسانه های اجتماعی پس از فاجعه می شود. در نتیجه، اطلاعات آگاهی موقعیتی استخراجشده از دادههای رسانههای اجتماعی ممکن است مغرضانه باشد و نیازهای جوامعی که به طور قابلتوجهی تحتتاثیر قرار گرفتهاند دست کم گرفته شود. بنابراین، نابرابری اجتماعی و مکانی زمانی در استفاده از دادههای رسانههای اجتماعی باید به طور کامل در نظر گرفته شود تا بتوان از این دادهها برای پیشبینی آسیب، بررسی جمعیتهای تحت تأثیر و اولویتبندی فعالیتها در طول دوره مدیریت بلایا استفاده کرد. به جای استفاده از رسانه های اجتماعی به عنوان یک منبع اطلاعاتی مستقل، مطالعات قبلی [ 25 ، 30 ]] پیشنهاد کرد که دادههای معتبر (مثلاً دادههای سنجش از راه دور) باید برای افزایش شناسایی پیامهای مرتبط از رسانههای اجتماعی ترکیب شوند.
منابع
- نیل، DM در حال بررسی مجدد مراحل فاجعه. بین المللی J. Mass Emerg. بلایا 1997 ، 15 ، 239-264. [ Google Scholar ]
- وزارت آموزش و پرورش آمریکا راهنمای اقدام برای مدیریت اضطراری در مؤسسات آموزش عالی. 2010. در دسترس آنلاین: http://rems.ed.gov/docs/rems_ActionGuide.pdf (در 7 ژوئن 2015 قابل دسترسی است). [ Google Scholar ]
- FEMA 1998 Animals in Disaster: Module Awareness and Preparedness. در دسترس آنلاین: http://training.fema.gov/EMIWeb/downloads/is10comp.pdf (در 7 ژوئن 2015 قابل دسترسی است).
- Pu، C. Kitsuregawa، M. داده های بزرگ و مدیریت بلایا: گزارشی از کارگاه مشترک JST/NSF. موسسه فناوری جورجیا، CERCS . 2013. در دسترس آنلاین: https://grait-dm.gatech.edu/wp-content/uploads/2014/03/BigDataAndDisaster-v34.pdf (در 7 ژوئن 2015 قابل دسترسی است).
- Vieweg, S.; هیوز، آل. استاربرد، ک. Palen, L. میکروبلاگینگ در طول دو رویداد مخاطره طبیعی: آنچه توییتر ممکن است به آگاهی موقعیتی کمک کند. در مجموعه مقالات کنفرانس SIGCHI 2010 در مورد عوامل انسانی در سیستم های محاسباتی، آتلانتا، GA، ایالات متحده آمریکا، 10-15 آوریل 2010.
- کومار، اس. باربیر، جی. عباسی، م. Liu, H. TweetTracker: ابزار تحلیلی برای امداد بشردوستانه و بلایای طبیعی. در مجموعه مقالات پنجمین کنفرانس بین المللی وبلاگ ها و رسانه های اجتماعی، ICWSM، بارسلونا، اسپانیا، 17-21 ژوئیه 2011.
- بلانچارد، اچ. کاروین، ا. ویتاکر، من. فیتزجرالد، ام. هارمن، دبلیو. همفری، بی. کاغذ سفید: موردی برای ادغام واکنش به بحران با رسانه های اجتماعی . صلیب سرخ آمریکا: واشنگتن، دی سی، ایالات متحده آمریکا، 2012. [ Google Scholar ]
- کامرون، MA; پاور، آر. رابینسون، بی. یین، جی. آگاهی از وضعیت اضطراری از توییتر برای مدیریت بحران. در مجموعه مقالات بیست و یکمین کنفرانس بین المللی همراه در شبکه جهانی وب، لیون، فرانسه، 16 تا 20 آوریل 2012.
- ساویج، م. دیوین، اف. کانینگهام، ن. تیلور، ام. لی، ی. هجلبرکه، جی. روکس، BL; فریدمن، اس. مایلز، الف. مدل جدیدی از طبقه اجتماعی؟ یافتههای آزمایش نظرسنجی کلاسی بریتانیای بزرگ بیبیسی. جامعه شناسی 2013 ، 47 ، 219-250. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- عمران، م. الباسونی، اس. کاستیو، سی. دیاز، اف. Meier, P. استخراج عملی اطلاعات مربوط به فاجعه از رسانه های اجتماعی. در مجموعه مقالات بیست و دومین کنفرانس بین المللی در مورد همنشین وب جهانی، ریودوژانیرو، برزیل، 13 تا 17 مه 2013.
- پوروهیت، اچ. کاستیو، سی. دیاز، اف. شث، ا. Meier, P. هماهنگی امداد اضطراری در رسانه های اجتماعی: مطابقت خودکار درخواست ها و پیشنهادات منابع. اولین دوشنبه 2013 19 . [ Google Scholar ] [ CrossRef ]
- اشکتراب، ز. براون، سی. ناندی، م. Culotta، A. Tweedr: استخراج توییتر برای اطلاع رسانی واکنش به بلایا. در مجموعه مقالات یازدهمین کنفرانس بین المللی ISCRAM، پارک دانشگاه، PA، ایالات متحده آمریکا، 18-21 مه 2014.
- هوانگ، Q. Xu, C. چارچوب داده محور برای بایگانی و کاوش داده های رسانه های اجتماعی. ان GIS 2014 ، 20 ، 265-277. [ Google Scholar ]
- وارفیلد، سی. چرخه مدیریت بلایا. 2008. در دسترس آنلاین: http://www.gdrc.org/uem/disasters/1-dm_cycle.html (در 7 ژوئن 2015 قابل دسترسی است).
- Vieweg, S. Situational Awareness in Mass Emergency: A Behavioral and Linguistic Analysis of Microblogged Communications. دکتری پایان نامه، دانشگاه کلرادو در بولدر، بولدر، CO، ایالات متحده آمریکا، 2012. [ Google Scholar ]
- مایر، پی. واکنش فاجعه دیجیتال به طوفان پابلو. در دسترس آنلاین: http://voices.nationalgeographic.com/2012/12/19/digital-disaster-response/ (در 7 ژوئن 2015 قابل دسترسی است).
- ساکاکی، ت. اوکازاکی، م. Matsuo, Y. زلزله کاربران توییتر را می لرزاند: تشخیص رویداد در زمان واقعی توسط حسگرهای اجتماعی. در مجموعه مقالات نوزدهمین کنفرانس بین المللی وب جهانی، رالی، NC، ایالات متحده، 26-30 آوریل 2010.
- سیگنورینی، آ. Segre, AM; Polgreen, PM استفاده از توییتر برای ردیابی سطوح فعالیت بیماری و نگرانی عمومی در ایالات متحده در طول همهگیری آنفولانزای H1N1. PLoS ONE 2011 , 6 . [ Google Scholar ] [ CrossRef ] [ PubMed ]
- کنت، جی دی. Capello, HT, Jr. الگوهای فضایی و شاخصهای جمعیت شناختی محتوای مؤثر رسانههای اجتماعی در طول آتشسوزی Horsethief Canyon در سال 2012. Cartogr. Geogr. Inf. علمی 2013 ، 40 ، 78-89. [ Google Scholar ] [ CrossRef ]
- مندل، بی. کولوتا، ا. بولهانیس، ج. استارک، دی. لوئیس، بی. رودریگ، جی. تجزیه و تحلیل جمعیت شناختی احساسات آنلاین در طول طوفان ایرن. در مجموعه مقالات دومین کارگاه زبان در رسانه های اجتماعی، آتلانتا، GA، ایالات متحده آمریکا، 13 ژوئن 2012.
- اسپینسانتی، ال. Ostermann, F. تجزیه و تحلیل خودکار زمینه جغرافیایی برای اطلاعات داوطلبانه. Appl. Geogr. 2013 ، 43 ، 36-44. [ Google Scholar ] [ CrossRef ]
- گائو، اچ. باربیر، جی. گولزبی، آر. استفاده از قدرت جمعسپاری رسانههای اجتماعی برای امدادرسانی به بلایا. IEEE Intell. سیستم 2011 ، 26 ، 10-14. [ Google Scholar ] [ CrossRef ]
- اشنبله، ای. سروون، جی. بهبود ارزیابی سیل سنجش از دور با استفاده از داده های جغرافیایی داوطلبانه. نات سیستم خطرات زمین. علمی 2013 ، 13 ، 669-677. [ Google Scholar ] [ CrossRef ]
- اشنبله، ای. سروون، جی. کومار، اس. واترز، N. برآورد زمان واقعی سیل های کلگری با استفاده از داده های سنجش از دور محدود. آب 2014 ، 6 ، 381-398. [ Google Scholar ] [ CrossRef ]
- اشنبله، ای. اکسندین، سی. سروون، جی. فریرا، سی ام. Waters, N. استفاده از منابع غیر معتبر در مواقع اضطراری در مناطق شهری. در رویکردهای محاسباتی برای محیط های شهری ; Springer: برلین، آلمان، 2015; صص 337-361. [ Google Scholar ]
- اوون، اس. آنیل، آر. دانینگ، تی. فریدمن، ای. ماهوت در عمل ; Manning Publications Co.: Greenwich, CT, USA, 2011. [ Google Scholar ]
- شیائو، ی. هوانگ، Q. Wu, K. درک داده های رسانه های اجتماعی برای مدیریت بلایا. نات خطرات 2015 . [ Google Scholar ] [ CrossRef ]
- اوه، او. Kwon، KH; رائو، منابع انسانی اکتشاف رسانه های اجتماعی در رویدادهای شدید: نظریه شایعه و توییتر در طول زلزله هائیتی 2010. در مجموعه مقالات ICIS 2010، سنت لوئیس، MO، ایالات متحده آمریکا، 10-20 اوت 2010.
- Goodchild، MF; Li, L. اطمینان از کیفیت اطلاعات جغرافیایی داوطلبانه. تف کردن آمار 2012 ، 1 ، 110-120. [ Google Scholar ] [ CrossRef ]
- دی آلبوکرک، جی پی; هرفورت، بی. برنینگ، آ. Zipf، A. یک رویکرد جغرافیایی برای ترکیب رسانه های اجتماعی و داده های معتبر به منظور شناسایی اطلاعات مفید برای مدیریت بلایا. بین المللی جی. جئوگر. Inf. علمی 2015 ، 29 ، 667-689. [ Google Scholar ] [ CrossRef ]
© 2015 توسط نویسندگان; دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر