

خلاصه
سوابق فضایی گونهها معمولاً اشتباه شناسایی میشوند، که میتواند توزیع پیشبینیشده یک گونه بهدستآمده از مدل توزیع گونه (SDM) را تغییر دهد. آزمایشهایی برای پیشبینی توزیع گونههای واقعی و شبیهسازیشده با استفاده از MaxEnt و دادههای فقط حضوری «آلوده» با نرخهای متفاوت خطای شناسایی اشتباه انجام شد. علاوه بر این، تفاوت بین طاقچه های هدف و گونه های آلوده متفاوت بود. نتایج نشان میدهد که خطاهای شناسایی نادرست گونهها ممکن است باعث انقباض یا گسترش توزیع پیشبینیشده یک گونه شود در حالی که توزیع پیشبینیشده را به سمت گونههای آلوده تغییر میدهد. علاوه بر این، بزرگی اثرات به طور مثبت با فاصله اکولوژیکی بین سولههای گونه و اندازه میزان خطا مرتبط بود. انتقادی، بزرگی اثرات حتی در هنگام استفاده از نرخ های خطای کوچک، کوچکتر از میانگین نرخ های معمول گزارش شده در ادبیات، قابل توجه بود، که ممکن است هنگام استفاده از یک روش ارزیابی استاندارد، مانند ناحیه زیر منحنی مشخصه عملکرد گیرنده، مورد توجه قرار نگیرد. در نهایت، اثرات ذکر شده بر کاربردهای عملی که از SDM ها برای شناسایی حوزه های اولویت دار استفاده می کنند، که معمولاً برای اهداف مختلفی مانند مدیریت انتخاب می شوند، تأثیر منفی نشان دادند. نتایج نشان میدهد که شناسایی نادرست گونهها نباید در مدلسازی توزیع گونهها نادیده گرفته شود. نشان داده شد که اثرات ذکر شده بر کاربردهای عملی که از SDM ها برای شناسایی حوزه های اولویت دار استفاده می کنند که معمولاً برای اهداف مختلفی مانند مدیریت انتخاب می شوند، تأثیر منفی می گذارد. نتایج نشان میدهد که شناسایی نادرست گونهها نباید در مدلسازی توزیع گونهها نادیده گرفته شود. نشان داده شد که اثرات ذکر شده بر کاربردهای عملی که از SDM ها برای شناسایی حوزه های اولویت دار استفاده می کنند که معمولاً برای اهداف مختلفی مانند مدیریت انتخاب می شوند، تأثیر منفی می گذارد. نتایج نشان میدهد که شناسایی نادرست گونهها نباید در مدلسازی توزیع گونهها نادیده گرفته شود.
کلید واژه ها:
شناسایی اشتباه گونه ها خطای مثبت کاذب ؛ فقط حضوری MaxEnt
1. معرفی
الگوهای فضایی حضور گونهها برای مدت طولانی موضوع محوری در رشتههای مختلف مانند اکولوژی، جغرافیای زیستی، تکامل و مدیریت بوده است. بنابراین، علاقه زیادی به پیشبینی توزیع گونهها وجود دارد، که روشهایی برای آن توسعه یافتهاند، از جمله چندین رویکرد مدلسازی که به طور گسترده به عنوان مدلهای توزیع گونهها (SDMs) شناخته میشوند [ 1 ، 2 ]. به طور معمول، SDM ها رکوردهای فضایی محدود از حضور یا فراوانی یک گونه را به متغیرهای محیطی (مانند دما) که توزیع آن را کنترل می کنند، مرتبط می کنند. روابط ایجاد شده ممکن است برای پیش بینی حضور گونه در مناطق بررسی نشده استفاده شود [ 3 ].
خطا و عدم قطعیت در تحلیل مبتنی بر SDM فراوان است. باری و الیت [ 4 ] منابع خطا و عدم قطعیت تعبیه شده در SDM ها را به دو دسته اصلی طبقه بندی می کنند: نقص در داده ها و کمبودهای معرفی شده توسط مشخصات مدل. در دسته اول، مشکلات رایج شامل متغیرهای گمشده [ 4 ]، حجم نمونه کوچک [ 5 ، 6 ]، نمونههای مغرضانه [ 7 ]، سوابق گونهای نادرست [ 6 ]، عدم وجود سوابق غیبت [ 8 ] و عدم توافق بین مقیاس است. (دانه/وسعت) دادههای گونه و تنظیم مدلسازی [ 1 ، 6 ، 9]. دسته دوم شامل تناقضات احتمالی بین مدل استفاده شده و مدل واقعی (به عنوان مثال، اگر مدل استفاده شده خطی است و رابطه واقعی بین حضور گونه ها و متغیرها درجه دوم است) و رویکرد مدل سازی (به عنوان مثال، پوشش، مبتنی بر فاصله، و رگرسیون) [ 4 ].
در این مقاله، توجه به کمبودهای دادهها، یعنی دادههای گونهای معطوف شده است. کیفیت داده های گونه ها اغلب به دلایل مختلف به خطر می افتد. به عنوان مثال، مجموعه دادههای رایج مورد استفاده، مانند مجموعههای بهدستآمده از موزهها، گیاهان دارویی، و اطلسها، اغلب فقط شامل سوابق حضور هستند (به عنوان مثال، مرجع فضایی جایی که گونهها شناسایی شدهاند)، که اغلب ناشی از گردآوریهای موردی از سوابق جمعآوریشده گهگاه بدون اطلاعات در مورد غیبت گونه ها و تلاش های بررسی. مورد دوم مرتبط است زیرا مناطقی که به راحتی قابل دسترسی هستند (مثلاً جاده های نزدیک) اغلب بیشتر از مناطق دور افتاده مورد بررسی قرار می گیرند که منجر به نمونه هایی با سوگیری فضایی می شود [ 8 ، 10 ].
انواعی از اثرات کمبود دادههای گونهها بر SDMs مورد مطالعه قرار گرفتهاند و طیف وسیعی از راهحلهای کاهش پیشنهاد شدهاند. برای مثال، روشهای مدلسازی توسعه یافتهاند که از دادههای فقط حضوری استفاده میکنند [ 11 ]. تأثیر حجم نمونه محدود در مدل سازی مورد مطالعه قرار گرفته است [ 5 ، 12 ]. و راهحلهایی برای مشکل سوابق گونههای نادرست قرار گرفتهاند [ 13 ]، تلاش نمونهگیری ناهموار [ 14 ، 15 ، 16 ]، خودهمبستگی فضایی [ 17 ، 18 ، 19 ، 20 ] و مقیاسها [ 21 ، 22 ]]. با این حال، تمام کمبودها در مجموعه داده های گونه ها به طور کامل مورد مطالعه قرار نگرفته است. یکی از مشکلات کلیدی که توجه کمی را به خود جلب کرده اما ممکن است رایج باشد، شناسایی نادرست گونه ها است. شناسایی نادرست گونه نوع خاصی از خطای مثبت کاذب است که زمانی رخ می دهد که گونه ای در مکانی که در واقع وجود ندارد، ثبت شود. نمونه ای از خطای مثبت کاذب به غیر از شناسایی نادرست گونه، شمارش دوبار افراد است (به عنوان مثال، زمانی که از شمارش نقاط شنیداری برای تشخیص پرندگان استفاده می شود [ 23 ]). در اینجا، نگرانی زمانی است که یک گونه به سادگی شناسایی نشده است.
خطاهای مثبت کاذب، به طور کلی، تا حد زیادی نادیده گرفته شده اند [ 24 ]. یکی از دلایلی که معمولاً اشتباهات مثبت کاذب نادیده گرفته می شوند این است که این تمایل وجود دارد که باور شود آنها کوچک هستند و بنابراین تأثیر ناچیزی دارند. با این حال، این همیشه درست نیست. با توجه به شناسایی نادرست گونه ها، میزان خطای قابل توجهی در ادبیات گزارش شده است. به عنوان مثال، ~7٪ برای گیاهان [ 25 ]، ~20٪ برای کوسه ها [ 26 ]، 23٪ برای شاهین ها [ 27 ]، ~27٪ برای صدف های آب شیرین [ 28 ]، و ~70٪ برای مگس های دزد [ 29]]. بزرگی مشکل شناسایی نادرست گونه ها به عنوان تابعی از عوامل متعددی متفاوت است، یعنی سطح تخصص نقشه بردار و گونه های درگیر. به عنوان مثال، در مطالعه ای که به علل شناسایی نادرست گونه ها در پایش پوشش گیاهی پرداخته است، اسکات و هالام [ 30 ] به طور متوسط نرخ شناسایی نادرست 2.7٪ تا 25.6٪ بسته به تخصص نقشه برداران را یافتند. علاوه بر این، اسکات و هالام [ 30 ] نرخ شناسایی نادرست بالایی (به عنوان مثال، بیش از 14٪) برای دسته های خاص گیاهان، مانند گیاهان پایین تر و درختان خاص پیدا کردند.
یک نمونه نادر از مطالعه ای که به اثرات شناسایی نادرست گونه ها بر تحقیقات با استفاده از SDM ها پرداخته است، مطالعه Ensing و همکاران است. [ 31 ] در مطالعه ای که توزیع بالقوه یک گونه مهاجم در آمریکای شمالی را پیش بینی کرد. انسینگ و همکاران [ 31 ] دریافت که توزیع گونهای که با استفاده از تمام سوابق حضور موجود (احتمالاً از جمله شناسایی اشتباه) مدلسازی شده است، به طور قابلتوجهی بزرگتر از آن است که فقط بر اساس رکوردهایی که از نظر طبقهبندی «معتبر» در نظر گرفته میشوند. نتیجهگیری مشابهی توسط مولیناری-جوبین و همکاران گرفته شده است. [ 32] با استفاده از داده های قابل اعتماد و غیر قابل اعتماد برای پیش بینی توزیع سیاهگوش اوراسیا در آلپ با مدل سازی اشغال سایت.
با این حال، اثرات شناسایی نادرست گونه ها در مطالعات با استفاده از SDMs هنوز به طور کامل قابل درک است. یک مسئله کلیدی این است که آیا شناسایی اشتباه انجام شده خودسرانه است یا سیستماتیک. شناسایی نادرست خودسرانه در اینجا به خطاهایی اشاره دارد که فاقد الگوی واضح هستند، به ویژه زمانی که منبع خطا متفاوت است. به عنوان مثال، حضور فرضی یک گونه ممکن است شامل سردرگمی با چندین گونه باشد که توسط نقشه برداران مختلف با تخصص های مختلف ثبت شده و از روش های متناقض پیروی می کند [ 31 ، 32]. شناسایی اشتباه سیستماتیک به اشتباه سیستماتیک یک گونه با گونه دیگر اشاره دارد. شناسایی نادرست گونههای سیستماتیک میتواند به خصوص زمانی اتفاق بیفتد که دو گونه از نظر مورفولوژیکی مشابه و همدل باشند. به عنوان مثال، شناسایی نادرست مارلین سفید ( Tetrapturus albidus ) برای مدت طولانی با نیزهماهیهای گرد از نظر مورفولوژیکی مشابه و همدل ( T. georgii ) رخ داده است. در نتیجه، این دو گونه به طور ناآگاهانه ارزیابی و به عنوان یک گروه گونه مدیریت شدند [ 33 ].
هنگامی که شناسایی نادرست گونهها رخ میدهد، دادههای مکانی گونههای شناساییشده به طور سیستماتیک دادههای مکانی گونههای مورد علاقه را “آلوده میکنند”. انتظار می رود که اثرات داده های آلوده در مدل سازی مربوط به توزیع گونه های اشتباه گرفته شود. به عنوان مثال، اگر گونه آلوده کننده توزیع گسترده تری نسبت به گونه مورد علاقه داشته باشد، گنجاندن اشتباه آن در مجموعه داده ها، توزیع پیش بینی شده گونه مورد نظر را گسترش می دهد، همانطور که Ensing و همکارانش. [ 31 ] و مولیناری جوبین و همکاران. [ 32] نتیجه گیری. اما اگر گونه آلوده کننده پراکنش محدودتری نسبت به گونه مورد نظر داشته باشد، احتمالاً اثر معکوس خواهد داشت. در نهایت، انتظار می رود پیش بینی های SDM به سمت توزیع گونه های آلوده تغییر کند. علاوه بر این، انتظار میرود که بزرگی تأثیرات به عنوان تابعی از میزان شناسایی نادرست گونهها از تأثیر بالقوه ناچیز در صورتی که شناسایی نادرست نادر است تا بزرگ باشد، اگر شناسایی اشتباه رایج باشد، متفاوت باشد. موضوع اخیر به تفصیل مورد بررسی قرار نگرفته است. به عنوان مثال، نتایج Ensing، و همکاران. [ 31 ] و مولیناری جوبین و همکاران. [ 32] بر اساس داده هایی با نرخ ناشناخته شناسایی نادرست گونه ها بود. این مقاله بر اثرات شناسایی نادرست گونههای سیستماتیک نرخ متغیر بر پیشبینی SDM حضور گونهها با استفاده از دادههای فقط حضوری تمرکز دارد.
2. مواد و روش ها
برای بررسی اثرات خطای شناسایی نادرست گونهها بر مدلسازی توزیع گونهها، مجموعهای از تحلیلها انجام شد. تجزیه و تحلیل ها بر روی اثرات خطای شناسایی نادرست بر توزیع پیش بینی شده یک گونه مورد علاقه و تأثیر بالقوه آن بر کاربردهای عملی که از SDM ها برای انتخاب مناطق برای اهداف مختلف مانند مدیریت گونه های در خطر انقراض استفاده می کنند، متمرکز شدند. به طور خاص، چهار تجزیه و تحلیل انجام شد که در آنها نتایج مدلسازی بهدستآمده با دادههایی که بهعنوان استاندارد طلا در نظر گرفته شدند ( یعنی، بدون خطا) با نتایج به دست آمده با داده های آلوده به خطای شناسایی اشتباه مقایسه شد. برای اطمینان از اینکه خطای شناسایی نادرست می تواند به طور دقیق شناخته و مشخص شود تا بتوان یک ارزیابی دقیق از اثرات شناسایی نادرست گونه ها در مدل سازی مجموعه ای از مجموعه داده های شبیه سازی شده را انجام داد، اما یک مجموعه داده واقعی نیز برای ارائه یک مطالعه موردی گویا از اهمیت استفاده شد. موضوع. شش نرخ، r ، از شناسایی نادرست گونه (آلودگی) استفاده شد: 1، 2، 4، 8، 16، و 32٪. همه در محدوده مقادیر گزارش شده در ادبیات ذکر شده در بالا هستند. تمام آنالیزها با استفاده از مدل توزیع گونهای که به طور گسترده استفاده میشود انجام شد: حداکثر آنتروپی (MaxEnt) [ 11 ].
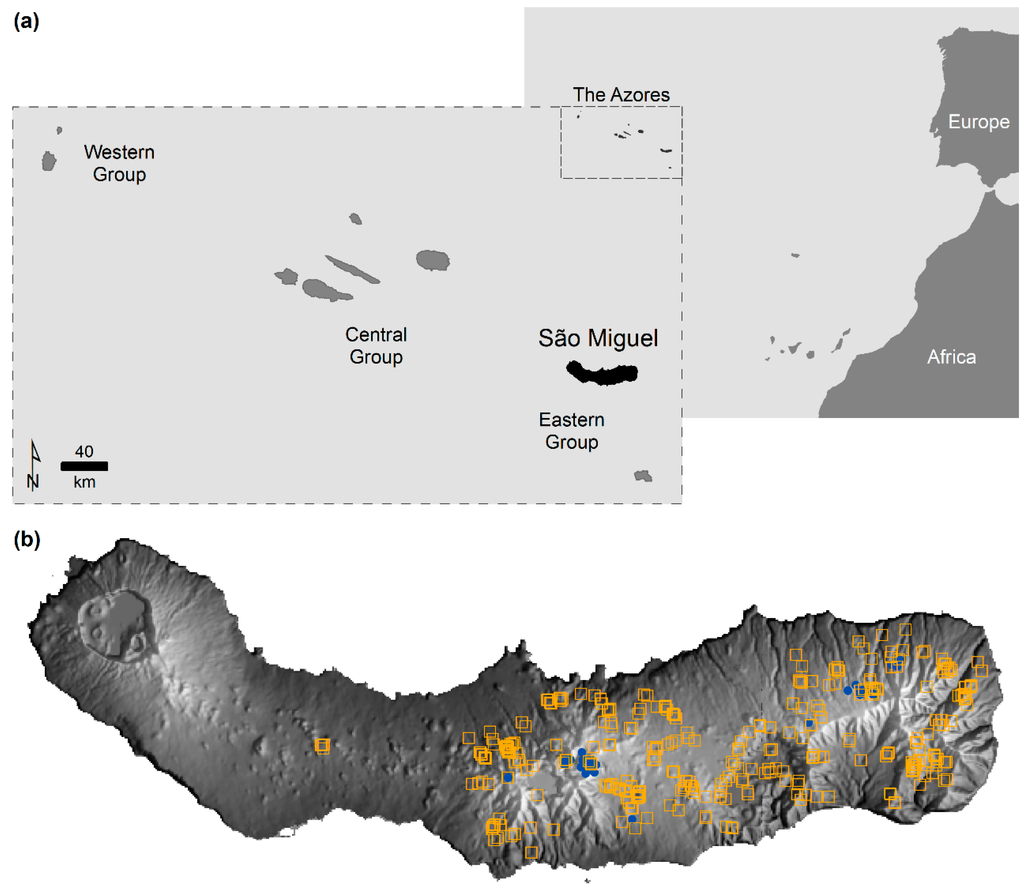
شکل 1. منطقه مورد مطالعه و داده های گونه مورد استفاده: ( الف ) جزیره سائو میگل در آزور، پرتغال. و ( ب ) محل حضور Cyathea cooperi (مربع های نارنجی) و C. medullaris (نقاط آبی) در سائو میگل بین سپتامبر 2011 و مه 2012 ثبت شده است. تن های تیره برای شرایط مخالف
2.1. داده های واقعی
داده های واقعی مورد استفاده در این مطالعه مربوط به جزیره سائو میگل در آزور (پرتغال) است. آزور مجمع الجزایری با منشا آتشفشانی است که در اقیانوس اطلس شمالی، در حدود 1500 کیلومتری غرب سرزمین اصلی پرتغال واقع شده است ( شکل 1 a). آب و هوای آزور معتدل اقیانوسی با میانگین دمای سالانه 17 درجه سانتی گراد در سطح دریا است که با افزایش ارتفاع کاهش می یابد. رطوبت نسبی زیاد است و میزان بارندگی از 1000 تا 3000 میلی متر در سال متغیر است که با افزایش ارتفاع و از شرق به غرب افزایش می یابد [ 34 ، 35 ]. سائو میگل بزرگترین جزیره (745 کیلومتر مربع ) است و بلندترین قله آن به ارتفاع 1103 متر در شرق قرار دارد ( شکل 1 ب).
دادههای واقعی گونههای مورد استفاده در یک بررسی میدانی که بین سپتامبر 2011 و مه 2012 در سرتاسر سائو میگل انجام شد، جمعآوری شد تا دانش در مورد حضور سرخسهای درختی که با آزور بیگانه هستند، افزایش یابد. حضور سرخس های درختی در بررسی های میدانی انجام شده با ماشین و پیاده تشخیص داده شد. بنابراین، مجموعه دادههای گونهها ناشی از گردآوریهای موردی از سوابق جمعآوریشده گهگاه بدون اطلاعات در مورد غیبت گونهها و تلاشهای پیمایشی است.
گونه مورد علاقه (که از این پس به عنوان گونه هدف نامیده می شود) Cyathea cooperi (351 فرد ثبت شده) است. C. cooperi یک سرخس درختی است که به دلیل تهاجمی بودنش مشکل ساز در نظر گرفته می شود [ 36 ] و یکی از 100 گونه مهاجم بیگانه برتر با اولویت مدیریت در ماکارونزی اروپایی است [ 34 ]. C. cooperi را می توان با C. medullaris اشتباه گرفت که برای اولین بار در آزور در بررسی 2011/2012 (32 رکورد) شناسایی شد. این دو گونه از نظر مورفولوژیکی مشابه هستند، با 141 رکورد دیگر که فقط با عنوان Cyathea sp. چون گونه دقیق آنها مشخص نبود. در نهایت، نمونه هایی از گونه های دیگر سرخس درختی،Dicksonia antartica به دست آمد (59 نفر ثبت شدند) که می تواند در مدل سازی مفید باشد.
حضور C. medullaris مطالعات گذشته در مورد حضور C. cooperi در سائو میگل را مورد تردید قرار می دهد زیرا شناسایی اشتباه ممکن است از نظر تاریخی اتفاق افتاده باشد. این وضعیت بهویژه به دلیل تعداد بالای نمونههای شناساییشده به عنوان C. medullaris در یک جمعیت ظاهراً خود حمایتکننده امکانپذیر است، که احتمال اینکه اخیراً معرفی شده باشد را بعید میسازد. حضور C. cooperi در طیف وسیعی از محیطها ثبت شد در حالی که C. medullaris از نظر جغرافیایی کمتر پراکنده بود. به طور خاص، C. medullaris عمدتا در ارتفاع بالا مشاهده شد در حالی که C. cooperi در تمام ارتفاعات مشاهده شد ( شکل 1).ب). توجه داشته باشید که هیچ تضمینی وجود ندارد که مجموعه داده های C. cooperi و C. medullaris عاری از خطای شناسایی اشتباه باشند. همه نمونههایی که شناسایی آنها دشوار بود، بهعنوان Cyathea sp برچسبگذاری شدند. اما ممکن است اشتباهاتی رخ داده باشد. به دلایل عملی، در این مقاله از این مجموعه داده ها به گونه ای استفاده شد که گویی هیچ خطایی وجود ندارد.
متغیرهای محیطی برای مدلسازی توزیع سرخس درختی انتخاب شدند. داده های آب و هوایی از مدل “Clima Insular à Escala Local” (CIELO) [ 37 ] به دست آمد. CIELO متغیرهای آب و هوایی در مقیاس محلی را با استفاده از دادههای ایستگاههای هواشناسی ساحلی همدیدی مدلسازی میکند و در قالب شطرنجی با وضوح مکانی 100 متر در دسترس است (جزئیات در [ 38 یافت میشود.]). به طور خاص، از شش متغیر اقلیمی زیر استفاده شد: بارش (mm) و میانگین حداکثر دمای (درجه سانتی گراد) گرم ترین سه ماهه، بارش (mm) و میانگین حداقل دمای (درجه سانتی گراد) سردترین سه ماهه، و میانگین سالانه حداقل و حداکثر رطوبت نسبی (%). این دادهها بهعنوان متغیرهای پایه آب و هوایی از نوع شناخته شدهای که بر توزیع گونههای گیاهی تأثیر میگذارند، استفاده شد. علاوه بر این، مجموعه ای از متغیرهای توپوگرافی در یک سیستم اطلاعات جغرافیایی (ESRI ArcGIS 9.3) بر اساس یک مدل ارتفاع رقومی موجود در پایگاه داده CIELO مشتق شد: شیب (٪)، سایه کوه زمستانی، سایه تپه تابستانی، و انحنا. Hillshade شبیه سازی شرایط نوری روی سطح است که توسط توپوگرافی و موقعیت خورشید دیکته می شود ( انقلاب زمستانی و تابستانی در نظر گرفته شد). انحنا دومین مشتق سطح است، بنابراین نواحی مسطح، محدب و مقعر را برجسته می کند. این متغیرها به عنوان شاخصهای شرایط محیطی محلی شناخته شده برای تأثیر بر توزیع گونههای گیاهی که برای این مطالعه در دسترس نبودند، مانند آب موجود در خاک و تابش تابش استفاده شد.
2.2. داده های شبیه سازی شده
مجموعه دادههای گونههای واقعی معمولاً بهطور خاص در رابطه با مسائلی مانند کیفیت دادهها و سوگیری نمونهگیری دارای نقص هستند. از این رو، برای نشان دادن بیشتر اهمیت شناسایی نادرست گونهها در پیشبینیهای SDMs، دادههای گونههای شبیهسازیشده با ویژگیهای کاملاً تعریفشده تولید شدند. گونههای هدف و گونههای آلوده بهعنوان در تعادل با محیط شبیهسازی شدند، یعنی گونهها در همه مکانهایی که از نظر اکولوژیکی مناسب هستند، تعریف شدند، بنابراین فرض تعادل اکثر SDMها برآورده شد [1 ، 3 ] .
تناسب زیست محیطی برای حضور هر دو هدف شبیه سازی شده و گونه های آلوده برای هر مکان از جزیره محاسبه شد. یک مکان در اینجا به عنوان یک سلول شطرنجی i از داده های محیطی استفاده شده تعریف می شود. تناسب زیست محیطی به طور مشابه در Varela و همکاران تعریف شد . [ 16 ]، یعنی به عنوان تابعی از پاسخ گونه به برهمکنش ضربی دو متغیر محیطی: بارش (P) و دما (T). به طور خاص، پاسخ گونهها به هر متغیر با استفاده از منحنیهای نرمال (میانگین μ و انحراف استاندارد σ) و تناسب محیطی در مکان i (S i) تعریف شد.) به عنوان حاصل ضرب آن دو پاسخ تعریف شد که ممکن است به صورت S i = P i T i بیان شود .
برای گونههای هدف شبیهسازیشده، μ و σ از P (μP , σP ) و T (μT , σT ) به ترتیب برابر با میانگین و انحراف استاندارد بارش و میانگین حداکثر دمای گرمترین فصل تعریف شد. (در بالا معرفی شد) از کل مجمع الجزایر آزور. بنابراین، μ P = 314.77، σ P = 162.90، μ T = 21.83، و σ T = 1.79.
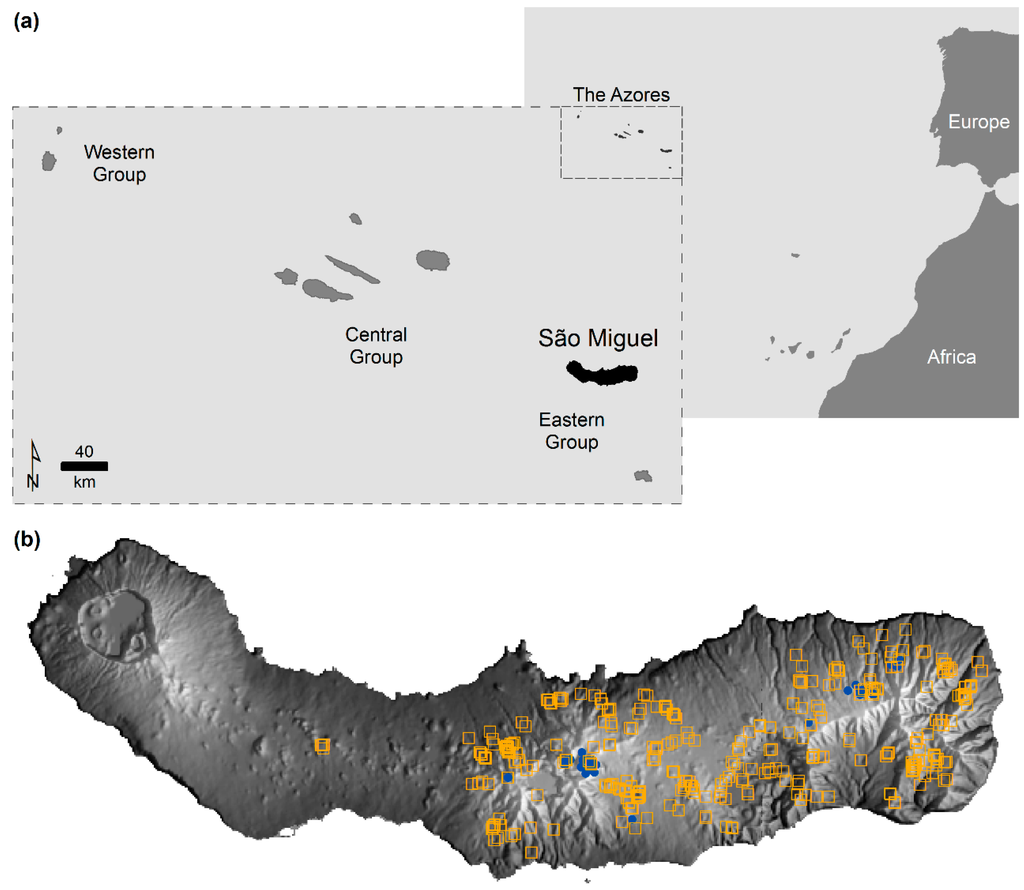
برای گونههای آلودهکننده شبیهسازیشده، میانگین و انحراف استاندارد P و T در واحدهای انحراف استاندارد در رابطه با گونههای هدف شبیهسازیشده تعریفشده در بالا متفاوت است. به طور خاص، یک گونه آلوده کننده خاص در پنج سناریو (سناریوهای I-V) شبیهسازی شد، زیرا انتظار میرود تأثیر شناسایی نادرست گونهها به تفاوت اکولوژیکی بین سولههای گونهای که اشتباه گرفته شده است بستگی داشته باشد. شکل 2میانگین و انحراف معیار P و T و طاقچه حاصل را برای هدف شبیه سازی شده و گونه های آلوده در تمام سناریوها نشان می دهد. به طور خاص، طاقچه گونه های آلوده کننده شبیه سازی شده نسبت به گونه هدف شبیه سازی شده به صورت گسترده تر (سناریوهای I و III) و باریکتر (سناریوهای II و V) تعریف شد. هر دو گونه در سناریوی IV وسعت طاقچه یکسانی دارند. علاوه بر این، سناریوهای III، IV و V گونههای آلودهکننده شبیهسازیشده را با تغییر در حالت بهینه تعریف میکنند و شرایط محیطی خنکتر و مرطوبتر را نسبت به گونههای هدف شبیهسازی شده ترجیح میدهند. در نتیجه سناریوهای تعریفشده، انتظار میرفت که جایگاه هدف شبیهسازیشده و گونههای آلوده از هم جدا شوند. فاصله Bhattacharyya [ 39] برای اندازهگیری واگرایی بین سولهها استفاده شد، که در تمام سناریوها افزایش یافت – فاصله Bhattacharyya بین طاقچه هدف شبیهسازی شده و گونههای آلوده سناریوهای I-V 3.5 × 10-3، 9.4 × 10-3، 34.6 × بود . 10-3 ، 95.7 × 10-3 ، و 138.8 × 10-3 به ترتیب.

شکل 2. طاقچه اکولوژیکی هدف شبیه سازی شده و گونه های آلوده در پنج سناریو (بیضی ها مناطق احتمال 95 درصد را نشان می دهند). طاقچه گونه هدف به عنوان برهمکنش ضربی بارش (P) و دما (T) تعریف شد. پاسخ گونه های هدف به P و T با استفاده از منحنی های نرمال تعریف شد که در آن میانگین μ و انحراف استاندارد σ P (μP , σ P ) و T (μT , σT ) 314.77 و 162.90 و 21.83 و 1.79 است. ، به ترتیب. برای گونههای آلودهکننده شبیهسازیشده، μ و σ از P و T در واحدهای انحراف استاندارد در رابطه با گونههای هدف شبیهسازیشده، همانطور که در هر سناریو نشان داده شده است، متفاوت بودند (برای مثال، منحنی نرمال P در سناریوی III از مقدار میانگین μP استفاده کرد .+ σ P و انحراف استاندارد 2σ P ).
تناسب زیست محیطی گونه های شبیه سازی شده در بالا برای ایجاد یک نمونه حضوری برای هر گونه، مورد نیاز برای مدل سازی با MaxEnt استفاده شد. در مجموع 1000 رکورد (مکان) برای هر گونه نمونه برداری شد. مکان ها از طریق نمونه گیری تصادفی وزنی و با استفاده از تناسب محیطی مکان ها انتخاب شدند (S i) به عنوان اوزان. بنابراین، مکانهای با تناسب بالا برای گونه، شانس بیشتری برای انتخاب داشتند و از این رو، نمونهها ترجیحات اکولوژیکی گونه را نشان میدادند. علاوه بر این، از همان استراتژی برای ایجاد یک نمونه آزمایشی به منظور تخمین دقت پیشبینی نتایج MaxEnt در حین استفاده از دادههای شبیهسازی شده استفاده شد. با این حال، در اینجا فرصتی برای تولید دادهها برای غیاب و همچنین حضور وجود داشت که امکان محاسبه معیارهای دقت استاندارد مانند مساحت زیر منحنی مشخصه عملکرد گیرنده (AUC) را فراهم میکرد [40 ] . در مجموع 1000 حضور و 1000 غیبت به همان روشی که در بالا ذکر شد، ایجاد شد، اما با استفاده از معکوس تناسب محیطی (1-Si ) به عنوان وزن برای تولید غیبت ها ( یعنی، مکان هایی با تناسب زیست محیطی پایین برای گونه ها شانس بیشتری برای انتخاب داشتند).
2.3. رویه های مدل سازی
MaxEnt (نسخه 3.3.3k؛ [ 41 ]) در این مطالعه استفاده شد زیرا یکی از محبوب ترین روش ها برای مدل سازی توزیع گونه ها است. MaxEnt توزیع فضایی گونه حداکثر آنتروپی ( یعنی نزدیکترین به یکنواخت) را مشروط به مجموعه ای از محدودیت های تعیین شده توسط داده های گونه در حال استفاده می یابد [ 11 ]، که معادل به حداقل رساندن آنتروپی نسبی در فضای محیطی است. چگالی احتمال برآورد شده از داده های حضور و آنچه از چشم انداز، یا از نمونه ای از آن، به نام پس زمینه [ 42 ] تخمین زده شده است.
مقادیر پیش فرض پارامترهای MaxEnt به جز انواع ویژگی و فرمت خروجی استفاده شد. اصطلاح «ویژگی» به مجموعه گستردهای از تبدیلهای متغیرهای محیطی اصلی مورد استفاده، مانند حاصلضرب همه ترکیبهای زوجی ممکن از متغیرها اشاره دارد [ 42 ]. فقط از نوع ویژگی “لولا” استفاده شد زیرا به تنهایی نتایجی مشابه با سایر انواع ویژگی های موجود در نرم افزار ایجاد می کند [ 43 ]. قالب خروجی خام استفاده شد و به عنوان احتمال نسبی یا شاخص مناسب بودن در مکانی برای حضور یک گونه تفسیر شد [ 44 ، 45 ، 46]. علاوه بر این، یک پسزمینه «گروه هدف» در مورد دادههای واقعی برای رسیدگی به سوگیری نمونه تعریف شد. گروه هدف در نظر گرفته شده سرخس های درختی شناسایی شده در جزیره، از جمله C. cooperi ، C. medullaris ، Cyathea sp. و D. antartica بودند . هدف یک پسزمینه «گروه هدف» گنجاندن سوگیری فضایی در پسزمینه بهصورتی است که در دادههای فقط حضوری تعبیه شده است، به طوری که هر دو به شیوهای مشابه سوگیری فضایی شوند. این روش پتانسیل پیشبینیهای MaxEn را کاهش میدهد تا شبیه به تعصب فضایی موجود در دادههای گونه باشد [ 43 ، 47]]. در مجموع 10000 رکورد (موقعیت) در سراسر جزیره از طریق یک نمونهگیری تصادفی وزنی با استفاده از فاصله معکوس از مکان تا نزدیکترین حضور سرخس درختی شناساییشده در بررسی میدانی به عنوان وزنهای احتمالی انتخاب شدند. به این ترتیب، مکانهایی که به مکانهای نمونهگیری نزدیکتر هستند، بیشتر انتخاب میشوند و در نتیجه بیشتر در پسزمینه نمایش داده میشوند.
MaxEnt در مراحل بوت استرپ استفاده شد. بوت استرپینگ امکان محاسبه معیارهای واریانس مانند فواصل اطمینان مفید برای منعکس کردن عدم قطعیت مورد انتظار تخمین های تولید شده بر اساس نمونه های میدانی را فراهم می کند. تعداد تکرارهای بوت استرپ مورد استفاده با گونه واقعی و شبیه سازی شده به ترتیب 250 و 500 بود. هر یک از بوت استرپ 200 رکورد را به طور تصادفی از نمونه گونه ها تکرار می کند تا یک نمونه بوت استرپ با نرخ شناسایی نادرست گونه خاص، r ایجاد کند . اول، نمونه بوت استرپ شامل خطا ( r = 0%) نبود ، یعنی نمونه های بوت استرپ به طور تصادفی 200 رکورد را از هر دو C. cooperi انتخاب کردند.مجموعه داده یا نمونه تعریف شده برای گونه هدف شبیه سازی شده. سپس، نمونههای راهاندازی شامل افزایش نرخ خطا، از 1٪ به 32٪ بود. به عنوان مثال، هر نمونه بوت استرپ با 1% خطا شامل 198 رکورد تصادفی از گونه های هدف و دو رکورد تصادفی از گونه های آلوده کننده بود. بنابراین، در مورد داده های واقعی، رکوردهای تصادفی انتخاب شده از مجموعه داده C. cooperi با رکوردهایی که به طور تصادفی از مجموعه داده C. medullaris انتخاب شده بودند، آلوده شدند . با این حال، در اینجا، بررسی نرخ 32٪ امکان پذیر نبود زیرا رکورد هر گونه می تواند تنها یک بار در هر تکرار انتخاب شود تا از تکرار جلوگیری شود، و حداقل 64 رکورد از C. medullaris.مورد نیاز بود در حالی که فقط 32 رکورد دارد. در مورد داده های شبیه سازی شده، بوت استرپینگ در هر سناریو اعمال شد، به این معنی که رکوردهای تصادفی انتخاب شده از نمونه تعریف شده برای گونه های هدف شبیه سازی شده، با رکوردهایی که به طور تصادفی از نمونه گونه های آلوده کننده شبیه سازی شده در سناریوی مربوطه تعریف شده بودند، آلوده شدند.
در نهایت، پیشبینیهایی برای گونههای آلوده تولید شد که معادل ضریب خطای 100 درصدی است. در مورد دادههای واقعی، یک روش راهاندازی در اینجا اعمال نشد زیرا مجموعه داده C. medullaris تنها 32 رکورد دارد که به طور همزمان برای تولید مدلی برای پیشبینی حضور C. medullaris در سراسر جزیره استفاده شد. در مورد دادههای شبیهسازیشده، پیشبینیها برای گونههای آلوده تعریفشده در هر سناریو در یک روش راهاندازی مشابه آنچه در بالا توضیح داده شد، با نمونههای بوت استرپ با اندازه 200 بهطور تصادفی تنها از نمونه گونههای آلوده تعریفشده در سناریوی مربوطه محاسبه شد. .
هر روش بوت استرپینگ 250 یا 500 خروجی MaxEnt ایجاد می کرد که باید خلاصه می شد. به هر مکان i در جزیره، مقدار میانگین پیشبینیهای محاسبهشده در روشهای راهاندازی برای گونههای واقعی و شبیهسازی شده اختصاص داده شد. میانگین پیشبینیها برای تجزیه و تحلیل بیشتر نگهداری میشوند و از این پس به سادگی «پیشبینی» نامیده میشوند. فواصل اطمینان 95 درصد در اطراف پیش بینی ها نیز برای هر مکان محاسبه شد. علاوه بر این، پیش بینی ها به ترتیب بزرگی رتبه بندی شدند. بنابراین، نتایج مدلسازی را میتوان به دو روش مختلف بر اساس ارزش پیشبینیها یا ترتیب رتبهبندی نسبی آنها مورد استفاده قرار داد. این دو روش متمایز برای نمایش خروجی های SDM معمولاً در برنامه های کاربردی دنیای واقعی در نظر گرفته می شوند [ 48 ،49 ]. جدول 1 تعاریف مدلسازی اعمال شده را خلاصه می کند.

جدول 1. خلاصه ای از تنظیمات مدل سازی انجام شده با MaxEnt.
در نهایت، دقت پیشبینیهای تولید شده با استفاده از دادههای شبیهسازی شده از طریق محاسبه AUC اندازهگیری شد که به طور گسترده استفاده میشود. به طور خاص، برای هر سناریو و میزان خطا، 50 حضور و 50 عدم حضور به طور تصادفی 100 بار از نمونه آزمایشی برای محاسبه 100 مقدار AUC با استفاده از بسته R PresenceAbsence [50 ] نمونه برداری شد. میانگین 100 مقدار AUC برای هر سناریو و میزان خطا محاسبه شد و از این پس به عنوان مقادیر AUC نامیده می شود.
2.4. تجزیه و تحلیل می کند
دو تحلیل (A و B) برای درک ماهیت اثرات شناسایی نادرست گونهها بر پیشبینیهای MaxEnt انجام شد. دو تحلیل دیگر (C و D) برای ارزیابی میزان تأثیرات و تأثیرات بالقوه آنها در کاربردهای عملی انجام شد. چهار تجزیه و تحلیل ( جدول 2 ) برای نتایج به دست آمده با داده های واقعی و شبیه سازی شده انجام شد.
جدول 2. خلاصه تجزیه و تحلیل های انجام شده برای بررسی تأثیر شناسایی نادرست بر پیش بینی های MaxEnt.
فرکانس نسبی مقادیر پیشبینیشده تولید شده توسط MaxEnt در سراسر جزیره در تجزیه و تحلیل A مورد بررسی قرار گرفت. مقایسه بین فرکانس نسبی مقادیر پیشبینیشده تولید شده با دادههای آلوده و بدون آن، به درک این امکان میدهد که آیا شناسایی نادرست گونهها باعث انقباض یا گسترش پیشبینیشده شده است یا خیر. توزیع گونه های مورد نظر به طور خاص، زمانی که انقباض رخ می دهد، انتظار می رود فرکانس نسبی مقادیر پیش بینی پایین به بهای کاهش فراوانی مقادیر پیش بینی بالا افزایش یابد. با گسترش برعکس اتفاق می افتد. بنابراین، تخمینهای چگالی هسته گاوسی مقادیر پیشبینی با استفاده از بسته R ggplot2 [ 52] محاسبه شد.]؛ تخمین تراکم هسته نزدیک به هیستوگرام است اما خوانایی و تفسیر را تسهیل می کند.
جهت اثرات انقباض یا انبساط در تجزیه و تحلیل B مورد تجزیه و تحلیل قرار گرفت، یعنی اینکه آیا شناسایی نادرست گونهها پیشبینیهای MaxEnt از حضور گونهها را به سمت توزیع گونههای آلوده تغییر داده است یا خیر. Schoener’s D [ 53 , 54 ] برای مقایسه پیشبینیهای تولید شده با استفاده از دادههای آلوده (1%≤ r≤32 %) با پیشبینیهای تولید شده با استفاده از مجموعه دادههای استاندارد طلا ( r = 0%) و گونههای آلوده ( r = r) استفاده شد. 100 درصد. محاسبه D شوئنر بر اساس مقادیر پیشبینی نرمال شده است (همه پیشبینیها باید مجموع 1 باشند) و ممکن است به صورت D = 1 − 1/2∑|p Xi بیان شود.− p Yi |، که در آن p Xi و p Yi مقادیر پیشبینی نرمال شده در محل i خروجیهای SDM در حال مقایسه هستند. بنابراین، D شونر بین 0 و 1 قرار دارد و معیاری از شباهت دو خروجی مدل سازی در فضای جغرافیایی را ارائه می دهد.
خروجیهای MaxEnt تولید شده با استفاده از دادههای آلوده (1% ≤ r≤ 32%)، در تحلیل C مجدداً در فضای جغرافیایی با خروجیهای MaxEnt تولید شده با استفاده از مجموعه دادههای استاندارد طلا مقایسه شدند ( r = 0%). با این حال، تجزیه و تحلیل C معیاری از بزرگی اثرات شناسایی شده در تجزیه و تحلیل های قبلی را ارائه می دهد. تفاوت بین پیشبینیهای بهدستآمده با و بدون دادههای آلوده برای یک مکان معین i ناچیز در نظر گرفته میشود، اگر فاصلههای اطمینان 95 درصدی پیشبینیها همپوشانی داشته باشند. نسبت مکان های سائو میگل که پیش بینی های آن به طور قابل توجهی متفاوت بود محاسبه شد.
در نهایت، اثرات بالقوه شناسایی نادرست گونهها بر کاربردهای عملی مانند مدیریت در تجزیه و تحلیل D در نظر گرفته شد. به طور خاص، این تجزیه و تحلیل تنها بر مکانهایی متمرکز بود که در دهکهای بالا رتبهبندی شدند ( یعنی، 10٪، به عنوان مثال، به عنوان مثال، به عنوان مکان هایی با ارزش های پیش بینی نسبتا بالاتر معمولا هدف قرار می گیرند، مانند برای نظارت بر تهاجمات اولیه گونه های بیگانه. از این پس به چنین مکان هایی به عنوان مناطق اولویت دار گفته می شود. خطاهای حذف و کمیسیون مرتکب شده توسط MaxEnt در تعریف مناطق اولویت از طریق مقایسه مکان مناطق اولویت تعریف شده با و بدون داده های آلوده محاسبه شد. خطای حذف نسبت مکانهایی است که به عنوان مناطق اولویتدار با استفاده از مجموعه دادههای استاندارد طلایی تعریف شدهاند، اما نه در هنگام استفاده از دادههای آلوده. خطای کمیسیون نسبت مکانهایی است که به عنوان مناطق اولویتدار با استفاده از دادههای آلوده تعریف شدهاند، اما نه در هنگام استفاده از مجموعه داده استاندارد طلایی.
3. نتایج
نتایج تحلیلهای انجامشده نشان میدهد که استفاده از دادههای مکانی یک گونه آلوده به سوابق گونههای دیگر، توزیع پیشبینیشده مورد علاقه را تغییر داده است. تجزیه و تحلیل A نشان میدهد که توزیع پیشبینیشده گونههای هدف یا منقبض یا گسترش مییابد، زیرا برآوردهای تراکم محاسبهشده به سمت مقادیر پیشبینی پایینتر یا بالاتر تغییر میکنند ( شکل 3) .). اندازه اثرات مشاهده شده، همانطور که انتظار می رفت، به طور مثبت با اندازه نرخ شناسایی نادرست مرتبط بود، در حالی که نوع اثر مشاهده شده – انقباض یا گسترش – وابسته به توزیع گونه های آلوده بود. انقباض تنها زمانی رخ میدهد که گونههای آلوده کننده کمتر از گونههای هدف پراکنده باشند، در حالی که، برعکس، زمانی که گونههای آلودهکننده پراکندهتر از گونههای هدف بودند، انبساط تمایل داشت. چند نمونه از نتایج مشهود است. با توجه به دادههای واقعی، توزیع پیشبینیشده گونههای هدف C. cooperi هنگام مدلسازی با رکوردهای آلوده کننده C. medullaris ( شکل 3 a)، که توزیع محدودی در سائو میگل دارد، کاهش یافت. شکل 3a نشان می دهد که فرکانس نسبی مقادیر پیش بینی بالا کاهش می یابد در حالی که فرکانس نسبی مقادیر پایین به عنوان تابعی از میزان خطا افزایش می یابد. با توجه به داده های شبیه سازی شده، نتایج مشابهی مشاهده شد، به عنوان مثال، در سناریوی II ( شکل 3 ج)، که در آن طاقچه گونه های آلوده به عنوان باریک نسبت به گونه هدف تعریف شد. برعکس، در سناریوهای I و III، که در آن گونههای آلوده، جایگاه وسیعتری نسبت به گونههای هدف داشتند، توزیع پیشبینیشده گونههای هدف گسترش یافت. شکل 3 b,d نشان می دهد که فراوانی نسبی مقادیر پیش بینی بالا در سناریوی I و III به عنوان تابعی از میزان شناسایی اشتباه افزایش یافته است.
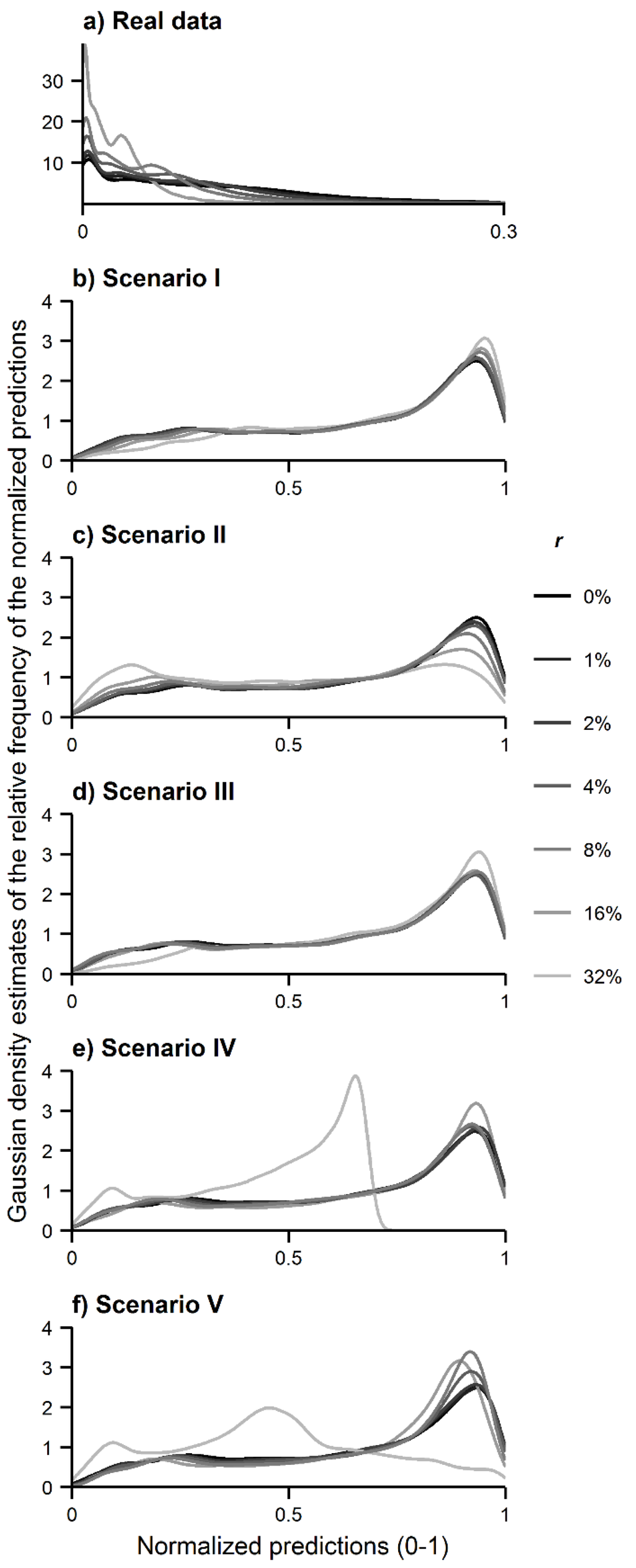
شکل 3. تخمین تراکم هسته گاوسی از پیش بینی های MaxEnt: ( الف ) داده های واقعی. ( ب ) داده های شبیه سازی شده در سناریوی I. ( ج ) داده های شبیه سازی شده در سناریوی II. ( د ) داده های شبیه سازی شده در سناریوی III. ( ه ) داده های شبیه سازی شده در سناریوی IV. و ( f ) داده های شبیه سازی شده در سناریوی V.
تجزیه و تحلیل دوم انجام شده، آنالیز B، بر جهت اثرات انقباض و انبساط شناسایی شده متمرکز شده است و نشان می دهد که توزیع پیش بینی شده گونه های هدف به سمت توزیع گونه های آلوده منقبض یا گسترش یافته است. شکل 4 نشان میدهد که توزیع پیشبینیشده گونههای هدف به تدریج به سمت توزیع گونههای آلوده منتقل شد، زیرا نرخ شناسایی نادرست افزایش یافت. به طور خاص، Schoener’s D نشان داد که خروجیهای MaxEnt همانطور که انتظار میرفت کمتر شبیه به خروجیهای تولید شده با استفاده از مجموعه دادههای استاندارد طلا شدند، و بیشتر شبیه خروجیهای تولید شده برای گونههای آلوده شدند. برای مثال، در مورد سرخس درختی، شکل 4a نشان می دهد که شباهت بین خروجی MaxEnt به دست آمده با r = 1٪ و به دست آمده با مجموعه داده های استاندارد طلا ( r = 0٪) بسیار زیاد است ( D ~1 Schoener ). با افزایش مقدار r ، مقدار D شونر کاهش یافت. این است که، توزیع C. cooperi پیش بینی شده با افزایش نرخ خطا به تدریج از توزیع واقعی گونه متفاوت است. در مقابل، در شکل 4 ب، شباهت بین خروجی MaxEnt به دست آمده با استفاده از r = 1٪ و به دست آمده برای گونه های آلوده ( r = 100٪) بسیار کم بود (Schoener’s D~0.3)، اما با افزایش مقادیر r افزایش یافت . این بدان معنی است که استفاده از سوابق شناسایی نادرست باعث شد که توزیع پیشبینیشده C. cooperi بیشتر شبیه پراکنش گونههای آلوده کننده C. medullaris شود . این روندهای مشاهده شده در شکل 4 به طور کلی در میان داده های واقعی و سناریوهای داده های شبیه سازی شده سازگار بودند. تأثیر طاقچه گونه، در زمینه تحلیل B، بی ربط بود، زیرا انتظار می رفت فاصله اکولوژیکی بین سوله های هدف و گونه های آلوده، صرفاً بزرگی مقادیر D شونر را تغییر دهد . در همه موارد ، دی شونرنشان داد که توزیع پیشبینیشده به سمت توزیع گونههای آلوده منتقل شده است که هدف تجزیه و تحلیل را برآورده میکند.
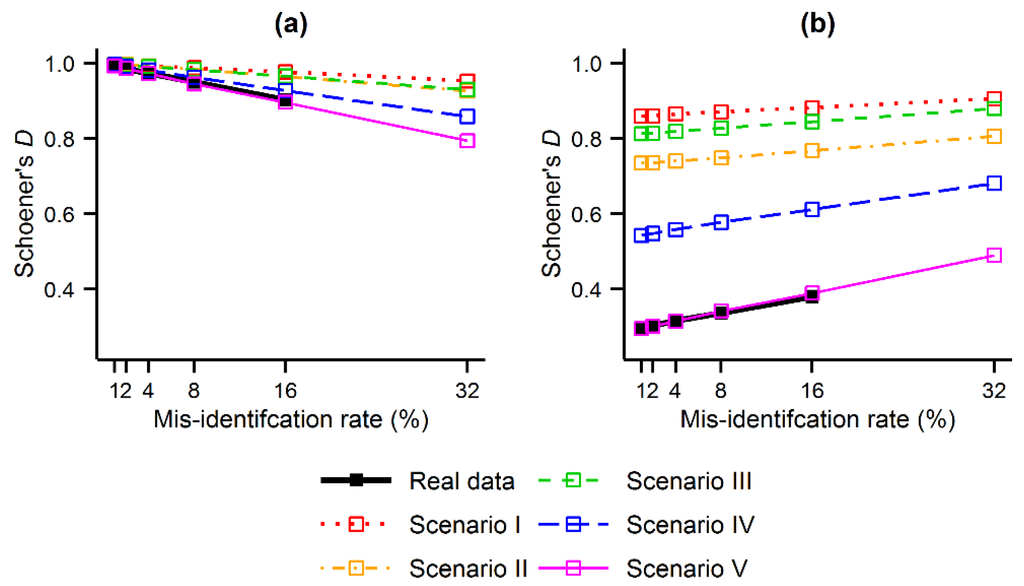
شکل 4. شباهت (Schoener’s D ) بین خروجی های MaxEnt تولید شده با و بدون داده های آلوده: ( الف ) مقایسه بین خروجی های آلوده (1% ≤ r ≤ 32%) و خروجی های تولید شده با استفاده از مجموعه داده های استاندارد طلا ( r = 0% ) و ( ب ) مقایسه بین خروجی های آلوده (1٪ ≤ r ≤ 32٪) و آنهایی که با استفاده از گونه های آلوده ( r = 100٪) تولید می شوند.
اثرات شناسایی شده در تجزیه و تحلیل A و B به صورت بصری در نقشه های تولید شده توسط MaxEnt مشهود است و برخی از نمونه ها در شکل 5 نشان داده شده است . با توجه به داده های واقعی، که در آن گونه های آلوده به طور گسترده ای کمتر از گونه های هدف توزیع شده بودند، استفاده از داده های آلوده MaxEnt را به تولید مقادیر پیش بینی کمتری از حضور گونه های هدف در سراسر جزیره سوق داد. یعنی توزیع پیشبینیشده C. cooperi کاهش یافت ( شکل 5 a,b). علاوه بر این، مکانهای سائو میگل که مقادیر پیشبینی نسبتاً بالاتری را در شکل 5 ب نشان میدهند ( r = 16%)، که با یک فلش مشخص شدهاند، با مکانهای ارزش پیشبینی بالاتر برای گونههای آلوده مطابقت دارد.C. medullaris ( شکل 5 ج). این بدان معنی است که سوابق شناسایی نادرست پیش بینی حضور C. cooperi را به سمت C. medullaris تغییر داده است . اثرات مشابهی در نتایج به دست آمده با داده های شبیه سازی شده قابل مشاهده بود. با این حال، دادههای شبیهسازیشده نیز امکان ارزیابی سناریوهایی را فراهم میآورد که در آن جایگاه گونههای آلوده گستردهتر از گونههای هدف بود. در این وضعیت، توزیع پیشبینیشده گونههای هدف گسترش مییابد ( شکل 5 d,e)، بهویژه در مناطق در ارتفاع در سناریوهای III-V، زیرا توزیع گونههای آلوده برای شامل چنین محیطهایی شبیهسازی شده است ( شکل 2 و شکل 5 f) . .

شکل 5. چند نمونه از پیش بینی حضور گونه های واقعی و شبیه سازی شده تولید شده توسط MaxEnt: ( الف ) پیش بینی های حضور C. cooperi که با استفاده از مجموعه داده های استاندارد طلا تولید شده است ( r = 0%). ( ب ) پیش بینی حضور C. cooperi تولید شده با استفاده از داده های آلوده ( r = 16٪). ( ج ) پیش بینی حضور گونه های آلوده کننده C. medullaris ( r = 100%). ( د ) پیش بینی حضور گونه های هدف شبیه سازی شده با استفاده از مجموعه داده های استاندارد طلا ( r = 0%). ( ه) پیش بینی حضور گونه های هدف شبیه سازی شده با استفاده از داده های آلوده در سناریوی III ( r = 16%). و ( f ) پیش بینی حضور گونه های آلوده کننده شبیه سازی شده در سناریوی III ( r = 100%). نکات: مقیاس خاکستری از سیاه (مقادیر پیشبینی بالا) تا سفید (مقادیر پیشبینی کم). فلشهای سیاه در قسمتهای (ب) و (ج) ناحیهای را برجسته میکنند که در آن تأثیر توزیع گونههای آلوده بر گونههای هدف به ویژه هنگام استفاده از دادههای آلوده مورد توجه قرار میگیرد.
بزرگی اثرات انقباض و انبساط نشان داده شده در بالا در تجزیه و تحلیل C ارزیابی شد. نسبت پیشبینیها ( به عنوان مثال ، مکانها) که در هنگام استفاده از مجموعه داده استاندارد طلا و دادههای آلوده به طور قابلتوجهی متفاوت بودند، همانطور که انتظار میرفت، با اندازه نرخ شناسایی نادرست ( شکل 6 ). با این حال، اثرات بسیار واضح بود زیرا افزایش کوچک نرخ شناسایی نادرست باعث شد که بخش بزرگی از پیشبینیها به طور قابل توجهی در سائو میگل متفاوت باشند. به عنوان مثال، 1% از رکوردهای شناسایی نادرست مورد استفاده برای مدل سازی توزیع C. cooperi به طور قابل توجهی پیش بینی های MaxEnt را تنها در 1% از مکان های جزیره تغییر دادند ( شکل 6 ب). افزایش rبه 4 و 16 درصد نسبت تفاوت های معنی دار به ترتیب به 24 و 77 درصد از مکان ها افزایش یافت ( شکل 6 ج، د). نتایج بهدستآمده با گونههای شبیهسازیشده مشابه بود، و همچنین امکان ارزیابی تأثیر طاقچه گونههای آلوده را فراهم کرد. نسبت تفاوت های قابل توجه مشاهده شده در پیش بینی های MaxEnt نسبت به سناریوهای I-V افزایش یافته است ( شکل 6 a). یعنی، نسبت پیشبینیهایی که هنگام استفاده از دادههای آلوده به طور قابلتوجهی متفاوت بودند، به دنبال افزایش فاصله اکولوژیکی مشاهدهشده بین سولههای هدف شبیهسازیشده و گونههای آلوده در سناریوهای I-V، افزایش یافت.

شکل 6. میزان تأثیرات ناشی از شناسایی نادرست گونهها بر پیشبینیهای MaxEnt: ( الف ) نسبت پیشبینیهایی که در نرخهای مختلف شناسایی نادرست برای گونههای واقعی و شبیهسازیشده بهطور قابلتوجهی متفاوت بودند. ( ب ) مکان پیشبینیهایی که بهطور قابلتوجهی (به رنگ سیاه) برای C. cooperi با استفاده از نرخ شناسایی نادرست 1% تغییر کردند. ( ج ) محل پیشبینیهایی که بهطور قابلتوجهی (به رنگ سیاه) برای C. cooperi با استفاده از نرخ شناسایی نادرست 4% تغییر کردند. و ( د ) مکان پیش بینی هایی که به طور قابل توجهی (در رنگ سیاه) برای C. cooperi با استفاده از نرخ شناسایی اشتباه 16٪ تغییر کرد.
آخرین تجزیه و تحلیل انجام شده، تجزیه و تحلیل D، بر تأثیر بالقوه ای متمرکز بود که اثرات شناسایی شده در بالا ممکن است بر کاربردهای عملی داشته باشد. شکل 7نشان میدهد که اشتباهات حذفی و کمیسیونی که هنگام تعریف حوزههای اولویتدار، به عنوان مثال مفید برای مدیریت زیستمحیطی، صورت میگیرد، با افزایش نرخ شناسایی اشتباه، به تدریج افزایش مییابد. مکانهای با احتمال نسبی بالای حضور گونهها به اشتباه از مجموعه مناطق اولویتدار در هنگام استفاده از دادههای آلوده حذف شدند (خطاهای حذف)، در حالی که مکانهایی با احتمال نسبی کم حضور گونهها به اشتباه در مجموعه مناطق اولویتدار در هنگام آلوده گنجانده شدند. داده ها استفاده شد (خطاهای کمیسیون). علاوه بر این، نتایج همچنین نشان داد که اندازه و محل خطاهای حذف و سفارش به پراکنش گونه های اشتباه گرفته شده بستگی دارد. با توجه به داده های شبیه سازی شده، اندازه خطاها ارتباط مثبتی با فاصله اکولوژیکی بین سولههای هدف و گونههای آلوده داشت. به طور خاص، خطاها از سناریوهای I-V افزایش یافته است (شکل 7 الف)، که مربوط به افزایش فاصله اکولوژیکی بین سوله ها است. محل خطاها با ترجیحات اکولوژیکی گونه مرتبط بود. خطاهای حذف در مکانهایی که گونههای هدف ترجیح میدهند ظاهر میشوند، اما گونههای آلوده کننده ظاهر نمیشوند و خطاهای سفارش در شرایط مخالف ظاهر میشوند. به عنوان مثال، شکل 7 b-d، محل خطاهای حذف و اشتباه را نشان می دهد که در حین تعریف مناطق اولویت دار برای C. cooperi با داده های ناقص انجام شده است. با افزایش میزان شناسایی نادرست، پیشبینیهای رتبهبندی بالاتر به تدریج در بخش داخلی سائو میگل، جایی که C. medullaris ظاهر شد.رخ می دهد. این اشتباهات کمیسیون به قیمت خطاهای حذفی که در جاهای دیگر واقع شده اند رخ داده است. توجه داشته باشید که داده های واقعی مورد استفاده موردی است که در آن طاقچه گونه های آلوده نسبت به گونه های مورد نظر توزیع کمتری دارد و بنابراین، توزیع پیش بینی شده C. cooperi منقبض شده است ( شکل 3 a). در نتیجه، محل خطاهای حذف و سفارش منعکس کننده انقباض توزیع گونه های گسترده تر به سمت محیط های باریک مرتبط با سوابق گونه های آلوده است.
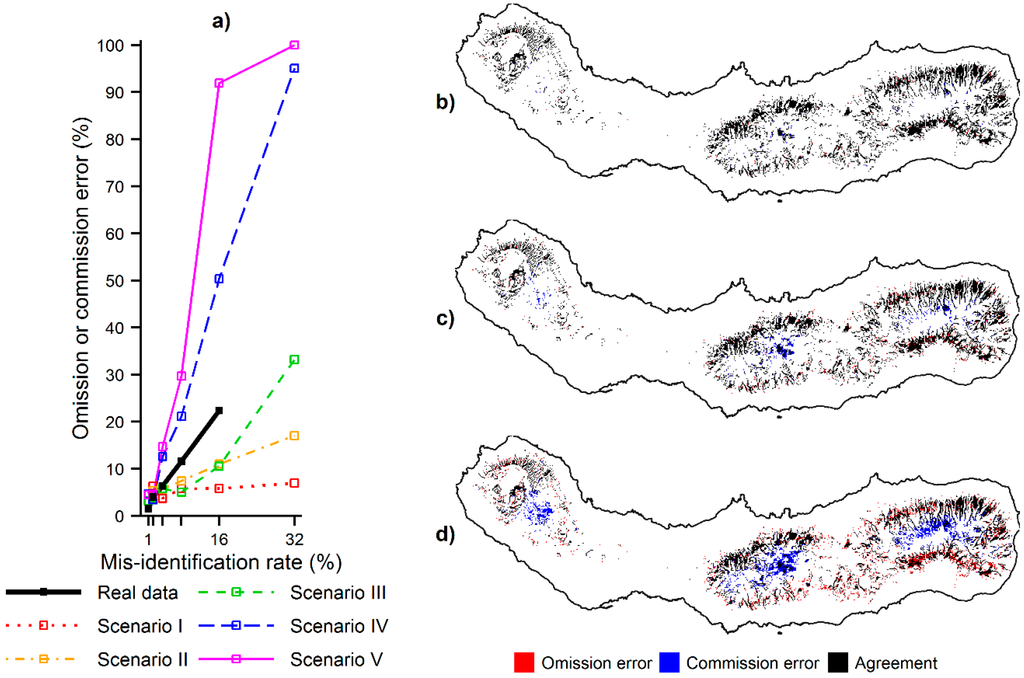
شکل 7. خطاهای حذف و کمیسیون مرتکب شده توسط MaxEnt در هنگام تعریف مناطق اولویت دار با استفاده از داده های آلوده: ( الف ) حذف یا خطای کمیسیون با نرخ های مختلف شناسایی اشتباه برای گونه های واقعی و شبیه سازی شده انجام شده است. ( ب ) محل خطاهای حذف و کمیسیون مرتکب شده برای C. cooperi با استفاده از نرخ شناسایی نادرست 1٪. ( ج ) محل اشتباهات حذفی و کمیسیون مرتکب شده برای C. cooperi با استفاده از نرخ شناسایی اشتباه 4%؛ و ( د ) محل حذف و اشتباهات انجام شده برای C. cooperiبا استفاده از نرخ شناسایی نادرست 16٪. توجه: مناطق اولویتی که با استفاده از داده های آلوده به درستی تعریف شده اند در قسمت های (ب)، (ج) و (د) با رنگ مشکی نشان داده شده اند.
در نهایت، اثرات خطای شناسایی نادرست شناسایی و اندازهگیری شده در تجزیه و تحلیل AD در مقادیر AUC محاسبهشده با استفاده از دادههای شبیهسازی شده کمتر آشکار بود. اگر چه مقادیر AUC با افزایش نرخ خطا، همانطور که انتظار میرفت، تمایل به کاهش داشت، مقادیر AUC تا زمانی که r بزرگ بود ثابت بودند. تنها زمانی که میزان خطا در سناریوهای IV و V 16% بود، مقادیر AUC به وضوح شروع به کاهش کردند ( شکل 8 ).
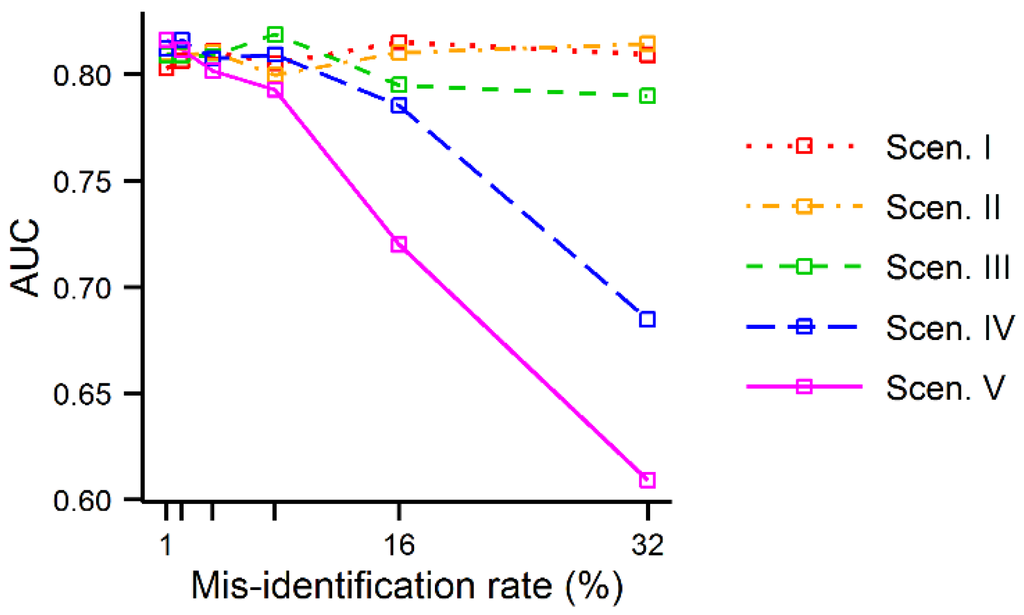
شکل 8. مقادیر AUC خروجی های MaxEnt تولید شده با استفاده از داده های شبیه سازی شده به عنوان تابعی از میزان خطای شناسایی اشتباه.
4. بحث
شناسایی نادرست سیستماتیک گونهها و در نتیجه تولید مجموعه دادههای فضایی آلوده تأثیر منفی بر مدلسازی توزیع گونهها دارد. خطاهای شناسایی نادرست گونهها ممکن است باعث تغییر توزیع پیشبینیشده گونههای هدف شود و در عین حال توزیع پیشبینیشده را به سمت گونههای آلوده تغییر دهد. بزرگی و جهت تغییرات به طور مثبت با نرخ شناسایی نادرست و تفاوت اکولوژیکی بین توزیع گونه های اشتباه مرتبط است.
گسترش توزیع پیشبینیشده یک گونه ناشی از خطاهای شناسایی نادرست قبلاً در ادبیات گزارش شده است [ 31 ، 32 ]. در اینجا، با این حال، بدیهی است که انقباض می تواند رخ دهد اگر گونه آلوده به طور گسترده ای کمتر از گونه هدف پراکنده باشد. به عنوان مثال، تجزیه و تحلیل A اثرات انقباض در نتایج MaxEnt تولید شده با داده های واقعی را نشان داد ( شکل 3 a)، که در آن گونه های آلوده به طور گسترده ای کمتر از گونه های هدف توزیع شده بودند ( شکل 1) .ب). بنابراین انتظار میرود که خطای سیستماتیک شناسایی نادرست گونهها اغلب میتواند باعث کاهش توزیع پیشبینیشده گونههای هدف شود، زیرا گونههای آلودهکننده کمتر پراکنده ممکن است گونههای کمیاب و ناآشنا باشند و از این رو، بیشتر از گونههای شناختهشده مستعد شناسایی نادرست باشند. .
اگرچه اثرات شناسایی نادرست گونه ها که در بالا ذکر شد ممکن است تعجب آور نباشد، بزرگی آنها ممکن است بیشتر از حد انتظار باشد. حتی نرخ های نادرست شناسایی پایین، کوچکتر از میانگین نرخ های گزارش شده در ادبیات (به عنوان مثال، 6.8٪ برای گیاهان در Archaux، و همکاران [ 25 ])، ممکن است با تغییرات مشخص در خروجی SDM ها مطابقت داشته باشد ( شکل 6 ). نگرانکننده است، نرخ شناسایی نادرست گونهها در مجموعه دادههای گونهها ممکن است کم نباشد. به عنوان مثال، نرخ شناسایی نادرست گونه حدود 70٪ در Meier و Dikow [ 29] گزارش شده است.] برای مگس دزد. نتایج ارائهشده در این مقاله نشان میدهد که نرخ شناسایی نادرست با چنین اندازهای ممکن است تأثیر بسیار زیادی بر پیشبینیهای SDMs داشته باشد. علاوه بر این، تأثیر خطای شناسایی نادرست بر پیشبینیهای SDM ممکن است در حین ارزیابی دقت آنها تا حد زیادی مورد توجه قرار نگیرد. نتایج بهدستآمده با دادههای شبیهسازیشده نشان میدهد که اندازهگیری مانند AUC ممکن است هیچ مشکلی را در پیشبینیها نشان ندهد، حتی اگر مجموعه داده آزمایشی مورد استفاده مانند این مطالعه بدون خطا باشد. بنابراین، شناسایی نادرست گونهها که در این مقاله به آن پرداخته میشود، میتواند منبع خطای خطرناکی در مدلسازی توزیع گونهها باشد، زیرا ممکن است پس از استفاده از مجموعه دادههای گونهای بدون خطا، هیچ وسیلهای برای تشخیص آن وجود نداشته باشد.
شاید یافته اصلی این مطالعه این باشد که وقوع خطاهای شناسایی نادرست در دادههای گونهها ممکن است هدف پشت کاربرد SDMs را به خطر بیندازد. برای مثال، اگر پیشبینیهای SDMs بهعنوان تخمینی از احتمال [ 45 ] در نظر گرفته شود، نرخهای کوچک خطای شناسایی نادرست ممکن است بهطور قابلتوجهی مقادیر پیشبینی تولید شده را تغییر دهد، که منجر به تخمینهای اشتباه احتمال حضور گونهها در بیشتر منطقه مورد مطالعه میشود. . این در نتایج آنالیز C در بالا مشهود بود ( شکل 6). از طرف دیگر، پیشبینیهای SDMs ممکن است به صورت ترتیبی در نظر گرفته شوند، که برای شناسایی مناطق با احتمال نسبتاً بالاتر حضور گونه کافی است. در این مورد، SDM ها برای حل یک مشکل ساده تر، که رتبه بندی مکان ها بر اساس احتمال یک گونه است، مورد نیاز است. مورد دوم تمرکز تجزیه و تحلیل D بود، که نشان داد شناسایی نادرست سیستماتیک ممکن است بر رتبه پیشبینیها و در نتیجه بر شناسایی حوزههای اولویت تأثیر منفی بگذارد ( شکل 7 ). به طور بحرانی، اشتباهات شناسایی نادرست ممکن است باعث شود که مناطق اولویت شامل مکانهایی شوند که احتمال وقوع این گونه وجود ندارد، در نتیجه تلاشها و منابع هدر میرود و به مکانهایی که احتمال وقوع گونهها وجود دارد مشرف میشوند، بنابراین احتمالاً اثربخشی اقدامات مدیریتی را به خطر میاندازد.
محل خطاها و خطاهای مرتکب در هنگام تعریف مناطق اولویت دار مربوط به جهت اثرات انقباض یا انبساط ذکر شده در بالا است. مورد دوم تمرکز تجزیه و تحلیل B بود که نشان داد توزیع پیشبینیشده گونههای هدف به سمت توزیع گونههای آلوده منتقل شد ( شکل 4 ). در نتیجه، مناطقی که به اشتباه به عنوان مناطق اولویت شناسایی شده اند (خطای کمیسیون) تمایل دارند در مکان های نزدیک به محیط های ایده آل برای گونه های آلوده ظاهر شوند. از طرف دیگر، مکان هایی که ارزش توجه دارند، در سراسر مناطق مرتبط با محیط های ترجیح داده شده توسط گونه های هدف نادیده گرفته می شوند (خطای حذف). این امر به عنوان مثال در شکل 7 مشهود استd، که نشان می دهد که خطاهای کمیسیون مناطق اولویت تعریف شده برای C. cooperi در ارتفاع، در داخل جزیره، جایی که گونه آلوده کننده C. medullaris شناسایی شد، ظاهر شد ( شکل 1 ب).
چهار تجزیه و تحلیل انجام شده با دادههای واقعی و شبیهسازی شده نشان میدهد که وقوع خطاهای شناسایی نادرست سیستماتیک در دادههای گونهها انتظار میرود پیشبینی SDMs را در شرایط مختلف کاهش دهد. مجموعه داده واقعی یک موقعیت معمولی را نشان می دهد که در آن گونه ها در تعادل نبودند و نمونه از نظر مکانی سوگیری داشت، در حالی که مجموعه داده شبیه سازی شده وضعیتی را نشان می داد که در آن گونه ها در تعادل و نمونه بی طرف بودند.
برخی از راه حل ها برای مشکل خطای شناسایی نادرست ممکن است با اشکالات قوی استفاده شوند. به عنوان مثال، اگر اطلاعاتی در مورد قابلیت اطمینان منبع داده یا اطمینان از برچسبگذاری در دسترس باشد، فقط موارد با اطمینان بالا ممکن است مانند Ensing و همکاران در نظر گرفته شوند. [ 31 ] و مولیناری جوبین و همکاران. [ 32 ]. با این حال، موارد با اطمینان بالا ممکن است شامل خطای شناسایی نادرست نیز باشد، یا مواردی را که شناسایی آنها دشوار است اما به درستی شناسایی شده اند را حذف کند. این امر به ویژه زمانی صادق است که گونه ها فقط توسط افراد شناسایی شوند ( به عنوان مثال، بدون هیچ گونه کمکی مانند تجزیه و تحلیل ژنتیکی)، که شناسایی گونه ها را در برابر خطاهای انسانی آسیب پذیر می کند. به عنوان مثال، یک نقشه بردار ممکن است ناخواسته یک مورد را با اطمینان زیاد به اشتباه شناسایی کند و بالعکس . در واقع، تخصص گیاه شناسان درگیر در شناسایی گونه ها به عنوان یکی از دلایل مرتبط با شناسایی نادرست گونه ها نام برده شده است [ 25 ، 28 ، 30 ]. بنابراین، دادههای بهدستآمده در شرایطی مانند چارچوب نوظهور علم شهروندی [ 55 ] نیاز به بررسی دقیق دارند زیرا نقشهبرداران با سطوح مهارت بسیار متغیر اغلب درگیر هستند [ 56 ]. روش دیگر، تجزیه و تحلیل پرت ممکن است به عنوان ابزاری برای تشخیص و حذف سوابق مشکوک استفاده شود [ 57]]. با این حال، موارد پرت ممکن است با سوابق گونه های مورد علاقه مطابقت داشته باشند. به عنوان مثال، نقاط پرت ممکن است با افراد در خط مقدم تهاجم مطابقت داشته باشند و بنابراین اطلاعات مهمی را ارائه می دهند که باید در نظر گرفته شوند [ 58 ]. توجه داشته باشید که رکوردهایی که در میان رکوردهای جمع آوری شده در مناطق مورد علاقه (مثلاً یک جزیره) دیده می شوند، ممکن است بسیار شبیه به رکوردهای گونه های جمع آوری شده در یک منطقه بزرگتر باشند. بنابراین، مهم است که طیف وسیعی از شرایط محیطی شناخته شده برای استفاده توسط گونه را در نظر بگیریم [ 59 ]. با این حال، این کافی نیست، اگر گونه ای به مناطق جدیدی معرفی شود که در آن هیچ محدودیتی نداشته باشد [ 60]]، مانند شکار و رقابت، و در نتیجه فرصت استفاده از محیط های جدید را دارد. تغییر رویکرد مدلسازی نیز یک امکان است و بنابراین ممکن است مدلهای اشغال در نظر گرفته شود. این نوع مدل امکان خطاهای شناسایی نادرست [ 24 ] را فراهم می کند، اما در داده ها مانند چندین بررسی در طول زمان، که ممکن است از نظر لجستیکی امکان پذیر نباشد یا در صورت استفاده از پایگاه های اطلاعاتی تنوع زیستی قابل اجرا نباشد [ 8 ، 10 ] نیاز است. بنابراین مطالعه حاضر نشان میدهد که سرمایهگذاری روی کیفیت باید یک نگرانی مداوم با توجه به جمعآوری دادهها باشد.
5. نتیجه گیری ها
علیرغم پیشرفتهای اخیر در روششناسی برای مدلسازی توزیع گونهها، مانند SDMهایی که از دادههای فقط حضوری استفاده میکنند و قادر به جبران سوگیری نمونهگیری هستند، نتایج نیازمند شناسایی دقیق گونهها هستند. خطاهای سیستماتیک شناسایی نادرست گونهها بر مدلسازی توزیع گونهها تأثیر منفی میگذارد، زیرا ممکن است برای تغییر توزیع پیشبینیشده یک گونه عمل کنند. به طور خاص، شناسایی نادرست ممکن است باعث کاهش یا گسترش توزیع پیشبینیشده به سمت گونههای آلوده شود. بنابراین، شناسایی نادرست گونه ها ممکن است خروجی SDM ها را به طور اساسی تغییر دهد. این مشکل ممکن است در حین ارزیابی دقت پیشبینیها با استفاده از روشهای رایج مانند AUC تا حد زیادی مورد توجه قرار نگیرد و بنابراین بر برنامههای کاربردی منفی که از تحلیلهای مبتنی بر SDMs استفاده میکنند، تأثیر بگذارد. از این رو،61 ] و Cayuela، و همکاران. [ 62 ]. به طور خاص، این مقاله تاکید می کند که شناسایی نادرست گونه ها نباید در مدل سازی توزیع گونه ها نادیده گرفته شود.
منابع
- گیسان، ع. Thuiller، W. پیشبینی توزیع گونهها: ارائه بیش از مدلهای زیستگاه ساده. Ecol. Lett. 2005 ، 8 ، 993-1009. [ Google Scholar ] [ CrossRef ]
- الیت، جی. مدلهای توزیع گونههای Leathwick، JR: توضیح و پیشبینی اکولوژیکی در سرعت و زمان آنو. کشیش اکول. Evolut. سیستم 2009 ، 40 ، 677-697. [ Google Scholar ] [ CrossRef ]
- گیسان، ع. Zimmermann، NE مدلهای توزیع زیستگاه پیشبینیکننده در اکولوژی. Ecol. مدل. 2000 ، 135 ، 147-186. [ Google Scholar ] [ CrossRef ]
- بری، اس. الیت، جی. خطا و عدم قطعیت در مدلهای زیستگاه. J. Appl. Ecol. 2006 ، 43 ، 413-423. [ Google Scholar ] [ CrossRef ]
- یانیز-آرناس، سی. چه گوارا، آر. مارتینز مایر، ای. ماندوجانو، اس. Lobo، JM پیش بینی فراوانی گونه ها از داده های وقوع: اثرات اندازه نمونه و سوگیری. Ecol. مدل. 2014 ، 294 ، 36-41. [ Google Scholar ] [ CrossRef ]
- مودری، وی. Šímová، P. تأثیر دقت موقعیت، اندازه نمونه و مقیاس در مدلسازی توزیع گونهها: مروری. بین المللی جی. جئوگر. Inf. علمی 2012 ، 26 ، 2083-2095. [ Google Scholar ] [ CrossRef ]
- Syfert، MM; اسمیت، ام جی. Coomes, DA اثرات سوگیری نمونهگیری و پیچیدگی مدل بر عملکرد پیشبینی مدلهای توزیع گونههای حداکثر. PLoS ONE 2013 , 8 . [ Google Scholar ] [ CrossRef ]
- هورتال، جی. لوبو، جی.ام. Jiménez-Valverde، A. محدودیت های پایگاه داده های تنوع زیستی: مطالعه موردی در مورد تنوع گیاهی در تنریف، جزایر قناری. حفظ کنید. Biol. 2007 ، 21 ، 853-863. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- گیسان، ع. گراهام، CH; الیت، جی. Huettmann، F. گروه مدل سازی توزیع گونه های NCEAS. حساسیت مدل های توزیع گونه های پیش بینی کننده به تغییر در اندازه دانه غواصان. توزیع کنید. 2007 ، 13 ، 332-340. [ Google Scholar ] [ CrossRef ]
- گراهام، CH; فریر، اس. هوتمن، اف. موریتز، سی. پترسون، AT تحولات جدید در انفورماتیک مبتنی بر موزه و کاربردها در تجزیه و تحلیل تنوع زیستی. روند. Ecol. تکامل. 2004 ، 19 ، 497-503. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- فیلیپس، اس جی. اندرسون، آر.پی. Schapire، RE مدلسازی حداکثر آنتروپی توزیعهای جغرافیایی گونهها. Ecol. مدل. 2006 ، 190 ، 231-259. [ Google Scholar ] [ CrossRef ]
- Hanberry، BB; او، HS; دی، دی سی اندازه های نمونه و معیارهای مقایسه مدل برای مدل های توزیع گونه ها. Ecol. مدل. 2012 ، 227 ، 29-33. [ Google Scholar ] [ CrossRef ]
- هفلی، تی جی; Baasch، DM; تایر، ای جی. Blankenship، EE تصحیح خطاهای مکان برای مدل های توزیع گونه های فقط حضوری. روش. Ecol. Evolut. 2014 ، 5 ، 207-214. [ Google Scholar ] [ CrossRef ]
- کرامر-شادت، اس. نیدبالا، ج. Pilgrim, JD; شرودر، بی. لیندنبورن، جی. راینفلدر، وی. استیلفرید، ام. هکمن، آی. شارف، AK; اوگری، DM; و همکاران اهمیت تصحیح برای سوگیری نمونهگیری در مدلهای توزیع گونههای حداکثر. غواصان. توزیع کنید. 2013 ، 19 ، 1366–1379. [ Google Scholar ] [ CrossRef ]
- بوریا، RA; اولسون، LE; گودمن، اس ام. اندرسون، RP فیلتر فضایی برای کاهش سوگیری نمونهبرداری میتواند عملکرد مدلهای طاقچه اکولوژیکی را بهبود بخشد. Ecol. مدل. 2014 ، 275 ، 73-77. [ Google Scholar ] [ CrossRef ]
- وارلا، اس. اندرسون، آر.پی. گارسیا والدس، آر. Fernández-González، F. فیلترهای محیطی اثرات سوگیری نمونهبرداری را کاهش میدهند و پیشبینیهای مدلهای طاقچه اکولوژیکی را بهبود میبخشند. اکوگرافی 2014 ، 37 ، 1084-1091. [ Google Scholar ] [ CrossRef ]
- Dormann، CF; مک فرسون، جی.ام. Araújo، MB; بیوند، ر. بولیگر، جی. کارل، جی. دیویس، آر جی. هیرزل، ا. جتز، دبلیو. بوسیدن، WD; و همکاران روشهایی برای محاسبه خودهمبستگی فضایی در تجزیه و تحلیل دادههای توزیع گونهها: مروری. اکوگرافی 2007 ، 30 ، 609-628. [ Google Scholar ] [ CrossRef ]
- سانتیکا، تی. هاچینسون، MF اثر فرم پاسخ گونه بر پیش بینی و استنتاج مدل توزیع گونه. Ecol. مدل. 2009 ، 220 ، 2365-2379. [ Google Scholar ] [ CrossRef ]
- واکلاویک، تی. کوپفر، جی. Meentemeyer، RK حسابداری برای خودهمبستگی فضایی چند مقیاسی عملکرد مدلسازی توزیع گونههای مهاجم (iSDM) را بهبود میبخشد. J. Biogeogr. 2012 ، 39 ، 42-55. [ Google Scholar ] [ CrossRef ]
- دی اولیویرا، جی. Rangel، TF; لیما-ریبیرو، ام اس؛ وحشتناک، LC; Diniz-Filho، JAF ارزیابی، تقسیمبندی و نقشهبرداری مؤلفه خودهمبستگی فضایی در مدلسازی طاقچه بومشناختی: رویکردی جدید بر اساس سوابق مساوی از نظر محیطی. اکوگرافی 2014 ، 37 ، 637-647. [ Google Scholar ] [ CrossRef ]
- مایر، CB; Thuiller, W. دقت عملکردهای انتخاب منبع در مقیاس های فضایی. غواصان. توزیع کنید. 2006 ، 12 ، 288-297. [ Google Scholar ] [ CrossRef ]
- فرناندز، آر. ویسنته، جی. جورج، دی. آلوز، پی. Thuiller، W. Honrado, J. یک رویکرد کاهش مقیاس جدید برای پیشبینی تهاجمات گیاهی و بهبود اقدامات حفاظتی محلی. Biol. تهاجم. 2014 ، 16 ، 2577-2590. [ Google Scholar ] [ CrossRef ]
- آلدرج، مگاوات؛ پاسیفیچی، ک. سیمونز، TR; پولاک، KH یک ارزیابی میدانی جدید از اثربخشی نمونه برداری از راه دور و ناظر مستقل برای تخمین احتمالات تشخیص پرندگان شنیداری. J. Appl. Ecol. 2008 ، 45 ، 1349-1356. [ Google Scholar ] [ CrossRef ]
- بیلی، LL; مکنزی، دی. Nichols، JD پیشرفتها و کاربردهای مدلهای اشغال. روش. Ecol. Evolut. 2013 ، 5 ، 1269-1279. [ Google Scholar ] [ CrossRef ]
- آرشو، اف. گوسلین، اف. برگس، ال. شوالیه، آر. تأثیر زمان نمونهبرداری، غنای گونهای و مشاهدهگر بر جامعیت سرشماریهای گیاهی. J. Veg. علمی 2006 ، 17 ، 299-306. [ Google Scholar ] [ CrossRef ]
- تیلت، بی جی; فیلد، آی سی; برادشاو، CJA; جانسون، جی. Buckworth، RC; میکان، ام جی; Ovenden, JR دقت شناسایی گونه ها توسط ناظران ماهیگیری در یک ماهیگیری کوسه شمال استرالیا. ماهی. Res. 2012 ، 127-128 ، 109-115. [ Google Scholar ] [ CrossRef ]
- هال، جی.ام. ماهی، AM; کین، جی جی. موری، اس آر. Sacks, BN; هال، AC تخمین خطای شناسایی گونه: پیامدهایی برای شمارش مهاجرت و تخمین روند رپتور. جی. وایلدل. مدیریت 2010 ، 74 ، 1326-1334. [ Google Scholar ] [ CrossRef ]
- شی، CP; پیترسون، جی تی. ویسنیفسکی، جی.ام. جانسون، NA شناسایی نادرست گونه های صدف آب شیرین (Bivalvia: Unionidae): عوامل کمک کننده، پیامدهای مدیریتی، و راه حل های بالقوه. جی. نورث. صبح. بنتول. Soc. 2011 ، 30 ، 446-458. [ Google Scholar ] [ CrossRef ]
- مایر، آر. Dikow, T. اهمیت پایگاههای داده نمونه از ویرایشهای طبقهبندی برای تخمین و نقشهبرداری تنوع گونههای جهانی بیمهرگان و بازگرداندن دادههای نمونه قابل اعتماد. حفظ کنید. Biol. 2004 ، 18 ، 478-488. [ Google Scholar ] [ CrossRef ]
- اسکات، WA; هالام، سی. ارزیابی نرخ شناسایی نادرست گونه ها از طریق تضمین کیفیت نظارت بر پوشش گیاهی. بوم گیاهی. 2003 ، 165 ، 101-115. [ Google Scholar ] [ CrossRef ]
- Ensing، DJ; موفات، م. Pither, J. خطاهای شناسایی طبقهبندی پیشبینیهای مدل طاقچه اکولوژیکی گمراهکننده یک تاج شاهین مهاجم را ایجاد میکند. گیاه شناسی 2012 ، 91 ، 137-147. [ Google Scholar ] [ CrossRef ]
- مولیناری جوبین، ع. کری، ام. ماربوتین، ای. مولیناری، پ. کورن، آی. فوکسجگر، سی. برایتنموزر-وورستن، سی. وولفل، اس. فاصل، م. کوس، آی. و همکاران پایش در حضور شناسایی نادرست گونه: مورد سیاهگوش اوراسیا در آلپ. انیمیشن. حفظ کنید. 2012 ، 15 ، 266-273. [ Google Scholar ] [ CrossRef ]
- بیرکرچر، ال. آروچا، اف. بارسه، ا. پرنس، ای. رسترپو، وی. سرافی، ج. Shivji, M. اثرات شناسایی نادرست گونهها بر ارزیابی جمعیت مارلین tetrapturus albidus سفید بیش از حد صید شده و نیزه ماهی T. georgii . به خطر انداختن. گونه Res. 2009 ، 9 ، 81-90. [ Google Scholar ] [ CrossRef ]
- سیلوا، ال. اوجدا-لند، ای. رودریگز-لوئنگو، فلور و جانوران مهاجم زمینی JL ماکارونیزیا. 100 برتر در آزور، مادیرا و قناری. ARENA: Ponta Delgada، پرتغال، 2008. [ Google Scholar ]
- بورخس، PAV؛ Amorim, IR; کونا، آر. گابریل، ر. مارتینز، AF; سیلوا، ال. کاستا، آ. ویرا، وی. آزور. در دایره المعارف جزایر ; Gillespie, RG, Clague, DA, Eds. انتشارات دانشگاه کالیفرنیا: اوکلند، کالیفرنیا، ایالات متحده آمریکا، 2009; صص 70-75. [ Google Scholar ]
- رابینسون، آرسی شفیلد، ای. شارپ، JM مشکل سرخس: تأثیر و مدیریت آنها. در بوم شناسی سرخس ; Mehltreter، K.، Walker، LR، Sharpe، JM، Eds. انتشارات دانشگاه کمبریج: کمبریج، انگلستان، 2010; صص 255-322. [ Google Scholar ]
- آزودو، ای بی. پریرا، LS; ایتیر، ب. مدلسازی آب و هوای محلی در محیطهای جزیره: کاربردهای تعادل آب. کشاورزی مدیریت آب. 1999 ، 40 ، 393-403. [ Google Scholar ] [ CrossRef ]
- Projectos Climaat e Climarcost. در دسترس آنلاین: www.climaat.angra.uac.pt (دسترسی در 10 نوامبر 2015).
- تئودوریدیس، اس. Koutroumbas, K. Pattern Recognition , 4th ed.; انتشارات آکادمیک: برلینگتون، MA، ایالات متحده آمریکا، 2009. [ Google Scholar ]
- فیلدینگ، ق. Bell, JF مروری بر روشهای ارزیابی خطاهای پیشبینی در مدلهای حضور/غیاب حفاظتی. محیط زیست حفظ کنید. 1997 ، 24 ، 38-49. [ Google Scholar ] [ CrossRef ]
- نرم افزار Maxent برای مدل سازی زیستگاه گونه ها. در دسترس آنلاین: http://www.cs.princeton.edu/~schapire/maxent (در 10 نوامبر 2015 قابل دسترسی است).
- الیت، جی. فیلیپس، اس جی. هستی، تی. دودیک، م. Chee، YE; Yates, CJ توضیح آماری maxent برای بوم شناسان. غواصان. توزیع کنید. 2011 ، 17 ، 43-57. [ Google Scholar ] [ CrossRef ]
- فیلیپس، اس جی. Dudík، M. مدل سازی توزیع گونه ها با Maxent: الحاقات جدید و ارزیابی جامع. اکوگرافی 2008 ، 31 ، 161-175. [ Google Scholar ] [ CrossRef ]
- رویل، جی. چندلر، RB; یاکولیک، سی. نیکولز، JD تحلیل احتمال وقوع گونهها از دادههای حضوری برای مدلسازی توزیع گونهها. روش. Ecol. Evolut. 2012 ، 3 ، 545-554. [ Google Scholar ] [ CrossRef ]
- فیلیپس، اس جی. Elith, J. در مورد تخمین احتمال حضور از داده های استفاده-در دسترس بودن یا حضور-پس زمینه. اکولوژی 2013 ، 94 ، 1409-1419. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Yackulic، CB; چندلر، آر. Zipkin، EF; رویل، جی. نیکولز، جی دی. کمپبل گرانت، EH; Veran, S. مدل سازی فقط حضوری با استفاده از Maxent: چه زمانی می توانیم به استنتاج ها اعتماد کنیم؟ روش. Ecol. Evolut. 2013 ، 4 ، 236-243. [ Google Scholar ] [ CrossRef ]
- مرو، سی. اسمیت، ام جی. Silander، JA راهنمای عملی Maxent برای مدلسازی توزیع گونهها: چه کاری انجام میدهد و چرا ورودیها و تنظیمات اهمیت دارند. اکوگرافی 2013 ، 36 ، 1058-1069. [ Google Scholar ] [ CrossRef ]
- استرابه، دی. ماتیسن، ای. پیشبینی توزیع بالقوه طوطیهای تهاجمی گردن حلقهای Psittacula krameri در شمال بلژیک با استفاده از رویکرد مدلسازی طاقچه اکولوژیکی. Biol. تهاجم. 2009 ، 11 ، 497-513. [ Google Scholar ] [ CrossRef ]
- کاستا، اچ. آراندا، SC; لورنسو، پی. مدیروس، وی. د آزودو، EB; Silva، L. پیشبینی جایگزینی موفق مهاجمان جنگلی توسط گونههای بومی با استفاده از مدلهای توزیع گونهها: مورد Pittosporum undulatum و Morella faya در آزور. برای. Ecol. مدیریت 2012 ، 279 ، 90-96. [ Google Scholar ] [ CrossRef ]
- فریمن، EA؛ Moisen, G. PresenceAbsence: یک بسته R برای تجزیه و تحلیل عدم حضور. J. Stat. نرم افزار 2008 ، 23 ، 1-31. [ Google Scholar ] [ CrossRef ]
- سیلورمن، تخمین چگالی BW برای آمار و تجزیه و تحلیل داده ها . چپمن و هال: لندن، انگلستان، 1986; جلد 26. [ Google Scholar ]
- Wickham, H. ggplot2: گرافیک زیبا برای تجزیه و تحلیل داده ها . Springer: New York, NY, USA, 2009; پ. 212. [ Google Scholar ]
- Schoener, TW The Anolis Lizards of Bimini: پارتیشن بندی منابع در یک جانوران پیچیده. اکولوژی 1968 ، 49 ، 704-726. [ Google Scholar ] [ CrossRef ]
- وارن، دی.ال. گلر، RE; تورلی، م. فانک، دی. هم ارزی جایگاه محیطی در مقابل محافظه کاری: رویکردهای کمی برای تکامل جایگاه. تکامل 2008 ، 62 ، 2868-2883. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- کرال، ا. نیومن، جی. یارنویچ، سی. استولگرن، تی. والر، دی. Graham, J. بهبود و یکپارچه سازی داده ها در مورد گونه های مهاجم جمع آوری شده توسط شهروندان دانشمندان. Biol. تهاجم. 2010 ، 12 ، 3419-3428. [ Google Scholar ] [ CrossRef ]
- فیتزپاتریک، ام سی؛ پریسر، EL; الیسون، AM; Elkinton، تعصب JS Observer و تشخیص جمعیت های کم تراکم. Ecol. Appl. 2009 ، 19 ، 1673-1679. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- سولی-گاردیا، م. رادوساولیویچ، آ. ریورا، جی ال. اندرسون، RP اثر مکانهای حاشیهای فضایی در مدلسازی سولهها و توزیعهای گونهها. J. Biogeogr. 2014 ، 41 ، 1390-1401. [ Google Scholar ] [ CrossRef ]
- واکلاویک، تی. Meentemeyer، RK Equilibrium یا نه؟ مدلسازی توزیع پتانسیل گونههای مهاجم در مراحل مختلف تهاجم غواصان. توزیع کنید. 2012 ، 18 ، 73-83. [ Google Scholar ] [ CrossRef ]
- برونیمن، او. Guisan، A. پیش بینی تهاجمات بیولوژیکی فعلی و آینده: هر دو محدوده بومی و مورد تهاجم اهمیت دارند. Biol. Lett. 2008 ، 4 ، 585-589. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- جیمنز والورده، آ. پترسون، AT; سوبرون، جی. اورتون، جی.ام. آراگون، پی. Lobo, JM استفاده از مدل های طاقچه در ارزیابی خطر گونه های مهاجم. Biol. تهاجم. 2011 ، 13 ، 2785-2797. [ Google Scholar ] [ CrossRef ]
- Lobo، JM مدل های توزیع پیچیده تر یا داده های نماینده بیشتر؟ تنوع زیستی آگاه کردن. 2008 ، 5 ، 14-19. [ Google Scholar ] [ CrossRef ]
- کایولا، ال. گولیچر، دی جی؛ نیوتن، AC; کلب، م. د آلبورک، FS; آرتس، EJMM؛ Alkemade، JRM; پرز، AM مدلسازی توزیع گونهها در مناطق استوایی: مشکلات، پتانسیلها و نقش دادههای بیولوژیکی برای حفاظت از گونههای موثر. تروپ حفظ کنید. علمی 2009 ، 2 ، 319-352. [ Google Scholar ]
© 2015 توسط نویسندگان; دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (http://creativecommons.org/licenses/by/4.0/) توزیع شده است
بدون نظر