1. معرفی
بازار مسکن به عنوان بازاری تعریف میشود که در آن خدمات مسکن با مکانیسم عرضه و تقاضا تخصیص مییابد و میتواند تحت تأثیر متغیرهای کلان اقتصادی، تفاوتهای فضایی، ویژگیهای ساختار جامعه و امکانات محیطی قرار گیرد [1 ، 2 ] . تغییر قیمت مسکن هم برای ساکنان و هم برای دولتها نگرانکننده بوده است، زیرا بر شرایط اجتماعی-اقتصادی تأثیر میگذارد و تأثیر بیشتری بر ثبات اقتصاد ملی دارد [ 2 ]. بنابراین، موضوع پیشبینی قیمت مسکن اخیراً مورد توجه تحقیقات در زمینه اطلاعات جغرافیایی قرار گرفته است [ 3 ، 4 ، 5 ، 6 ].
قیمت مسکن معمولاً از طریق ایجاد یک مدل رگرسیونی پیشبینی میشود که از پارامترهای قیمت مسکن (به عنوان مثال، ویژگیهای ساختاری و همسایگی املاک و مستغلات) استفاده میکند [ 7 ، 8 ]. بسیاری از نویسندگان برای پیشبینی قیمت مسکن بر مدل لذتگرا تمرکز کردهاند و مدلهای لذتگرایانه مختلف در اقتصاد املاک و مستغلات مقایسه شدهاند [ 9 ، 10 ، 11 ]. اگرچه مدلهای رگرسیون لذتگرا به طور گسترده پذیرفته شدهاند، وجود وابستگی فضایی برای کارایی و بیطرف بودن مدل OLS در مدلهای لذتگرای سنتی مضر است. موقعیت مکانی یک عامل مهم در قیمت مسکن است [ 10 ]. قیمت املاک و مستغلات از نظر مکانی ناهمگن است [ 12]. بنابراین، مدلهای اقتصاد فضایی برای رفع این مسائل پیشنهاد شدهاند. LeSage و Pace بررسی گسترده ای از این روش ها ارائه می دهند [ 13 ، 14 ]. گودمن و تیبودو مفهوم مدلسازی خطی سلسله مراتبی را معرفی میکنند که در آن ویژگیهای مسکن، ویژگیهای محله و بازارهای فرعی برای تأثیرگذاری بر قیمت مسکن با هم تعامل دارند [ 15 ]. Brunsdon و Fotheringham یک رگرسیون با وزن جغرافیایی را به عنوان یک تکنیک مدلسازی تغییرات محلی برای کشف ناایستایی فضایی پیشنهاد میکنند [ 6 ، 7 ].
با فرض اینکه تعداد نمونههای خانه محدود است، محققان هنوز باید تعیین کنند که چگونه میتوانند با استفاده از متغیرهای توضیحی برای خانههایی که قیمت آنها نامعلوم است، تناسب قیمت مسکن را افزایش دهند. یادگیری نیمه نظارت شده یک رویکرد کارآمد است که تلاش می کند تا داده های بدون قیمت را با استفاده از چند یادگیرنده ادغام کند تا به یک تعمیم قوی دست یابد، و برخی از مطالعات از مدل های رگرسیون نیمه نظارت شده برای پرداختن به این موضوع استفاده کرده اند [ 16 , 17 , 18 , 19 , 20]. با این حال، زمانی که روشهای رگرسیون نیمه نظارت شده سنتی برای دادههای مکانی اعمال میشوند، فرآیندها در فضا ثابت فرض میشوند، که دقیق نیست. برای داده های قیمت مسکن، فرض ثبات در فضا به طور کلی غیر واقعی است، زیرا پارامترهای قیمت مسکن در یک منطقه مورد مطالعه متفاوت است [ 21 ].
در شناخت چالشهای فوق، این تحقیق یک رویکرد رگرسیون نیمه نظارتی گسترده را برای استفاده کامل از مزایای هر دو روش رگرسیون وزندار جغرافیایی و روشهای یادگیری نیمه نظارت شده برای افزایش تناسب با توجه به دادههای قیمت مسکن پیشنهاد میکند.
ادامه این مقاله به شرح زیر سازماندهی شده است. در بخش 2 ، مطالعات مرتبط به اختصار بررسی شده است. در بخش 3 ، داده های تجربی و رویکرد پیشنهادی معرفی می شوند. بخش 4 نتایج تجربی را شرح می دهد. بخش 5 نکات پایانی را ارائه می دهد.
2. بررسی ادبیات
اصطلاح لذتگرا برای توصیف «اهمیت نسبی مؤلفههای مختلف در میان سایر مؤلفهها در ساختن شاخص سودمندی و مطلوبیت» استفاده میشود [ 22 ]. مدل قیمت لذتگرا مبتنی بر این فرضیه لذتگرایانه است که کالاها برای ویژگیها یا ویژگیهای مفید ارزشگذاری میشوند [ 23 ]. اگر قیمتهای این ویژگیها مشخص باشد، یا بتوان آن را تخمین زد، و ترکیب ویژگیهای یک کالای متمایز خاص نیز شناخته شده باشد، روش لذتشناسی چارچوبی برای تخمین ارزش ارائه میکند [24 ] . مدل لذتگرا، خانهها را کالایی ترکیبی میداند که از ویژگیهای ساختاری (سن خانه، تعداد اتاق خواب، وجود گاراژ و غیره) تشکیل شده است.با ویژگی های مکانی که بین املاک (پیوندهای حمل و نقل خوب، دسترسی به مغازه ها و خدمات، نزدیکی به مرکز شهر و غیره ) و با ویژگی های محله (تراکم جمعیت، بیکاری، معیارهای استرس اجتماعی و غیره ) متفاوت است. قیمت یک ملک به عنوان تحقق مقادیر این ویژگی ها در نظر گرفته می شود [ 25 ].
مدل پارامتری شرطی که رگرسیون وزندار جغرافیایی (GWR) نامیده میشود، یک مدل بهصراحت محلی است و مشکلاتی را که در زمینه مدلسازی گسسته ناهمگنی و رگرسیون چندجملهای مورد بحث قرار گرفتهاند دور میزند [ 6 ، 7 ]. GWR به طور ضمنی توابع و مدل های قیمت را در حال تغییر مداوم فرض می کند. یک مزیت قوی GWR انعطاف پذیری آن است و تابع قیمت نیازی به فرض قبلی در مورد فرآیند تعیین قیمت و تغییرات فضایی آن ندارد [ 26 ، 27 ]. لو، بی و همکارانمدل GWR را با استفاده از آن با معیارهای فاصله غیر اقلیدسی جایگزین (غیر ED) بررسی می کند. یک مطالعه موردی از مجموعه داده قیمت خانه لندن با متغیرهای مستقل لذتگرا همراه است، که در آن مدلهای GWR با معیارهای فاصله اقلیدسی (ED)، فاصله شبکه جادهای و معیارهای زمان سفر کالیبره میشوند. نتایج نشان میدهد که GWR کالیبرهشده با یک متریک غیر اقلیدسی نه تنها میتواند تناسب مدل را بهبود بخشد، بلکه بینشهای اضافی و مفیدی را در مورد ماهیت روابط متغیر در مجموعه داده قیمت خانه ارائه میکند [4 ] . یک مدل خودرگرسیون با وزن جغرافیایی و زمانی (GTWAR) توسعه داده شده است تا اثرات غیر ثابت و همبسته خودکار را به طور همزمان محاسبه کند و یک چارچوب حداقل مربعات دو مرحله ای را برای برآورد این مدل فرموله کند [5 ] .
با این حال، مدل GWR فرض میکند که همه متغیرهای توضیحی در فضا تغییر میکنند و اثرات کلی اغلب نادیده گرفته میشوند. مدل رگرسیون جغرافیایی وزنی مخلوط (MGWR) برای بررسی اثرات فضایی-ایستا و غیر ثابت پیشنهاد شده است. با مثالهای تجربی MGWR نشان داده میشود که تنوع فضایی قابلتوجهی در برخی از پارامترهای برآورد شده وجود دارد، در حالی که اثرات جهانی شواهدی را برای پیوندهای مبتنی بر سیاست و یک بازار مسکن مرتبط اقتصادی ارائه میکنند [ 28 ]
علاقه قابل توجهی به روش های غیر متعارف در ارزیابی املاک و مستغلات اختصاص یافته است. متداول ترین روش های مورد مطالعه، رویکردهای مبتنی بر شبکه عصبی هستند. جذابیت روش های مبتنی بر شبکه عصبی در این است که آنها به فرضیات مربوط به داده ها وابسته نیستند [ 29 ]. شبکههای عصبی برای مدلسازی نادرست و به ویژه ویژگیهای مختلف در نحوه اندازهگیری متغیرهای توضیحی مختلف قویتر هستند [ 30 ]. یک چارچوب منطق فازی نیز به عنوان جایگزینی برای رویکردهای مرسوم ارزیابی دارایی پیشنهاد شده است [ 29 ، 31 ]. کوشان، اچ و همکاران.دادههای سطح خانوار را در مدلهای لذتگرا به منظور اندازهگیری ناهمگونی قیمتهای ضمنی در رابطه با نوع خانوار، سن، میزان تحصیلات و درآمد معرفی کنید [ 32 ].
در زمینه یادگیری نیمه نظارتی، برچسبگذاری شده نمونههای آموزشی شناخته شده از قبل و بدون برچسب نمونههای آموزشی ناشناخته را مشخص میکند. در این مقاله، «دادههای برچسبدار» به نمونه قیمتهای شناخته شده مسکن و «دادههای بدون برچسب» به متغیرهای توضیحی خانههایی که قیمت آنها نامشخص است، اشاره دارد. برفلد و همکاران یک الگوریتم رگرسیون حداقل مربعات همتنظیم شده (coRLSR) برای مدیریت مجموعههای بزرگتری از نمونههای بدون برچسب بر اساس چارچوب یادگیری مشترک ایجاد کرد، و آزمایشها کاهش قابلتوجه خطا و بهبود زمان اجرا زیادی را برای تقریب نیمه پارامتریک نشان دادند [17 ]]. ژو و لی مکانیسم آموزش مشترک را برای یک رگرسیون KNN اعمال کردند. دو مدل رگرسیون KNN مختلف استفاده شده است. هر مدل دادههای بدون برچسب را برای رگرسیور دیگر برچسبگذاری میکند، بهویژه در مواردی که اطمینان برچسبگذاری بر اساس تأثیر برچسبگذاری نمونههای بدون برچسب روی دادههای برچسبدار پیشبینی میشود [ 18 ، 19 ].
3. داده ها و روش ها
3.1. داده های مورد استفاده در آزمایش ها
یک مطالعه موردی با استفاده از داده های قیمت مسکن مشاهده شده در پکن، چین انجام شده است. پکن یکی از توسعهیافتهترین شهرها و مرکز اقتصادی چین است که 71.3 درصد از تولید ناخالص داخلی آن را صنایع ثالث تشکیل میدهند. این شهر را به اولین شهر پسا صنعتی در سرزمین اصلی چین تبدیل می کند. همراه با روند اصلاحات، هم رونق اقتصادی و هم شهرنشینی سریع تقاضا برای مسکن در شهر را افزایش داده است. افزایش تقاضا برای مسکن با افزایش قیمت ها و اجاره بها همراه بود [ 33 ].
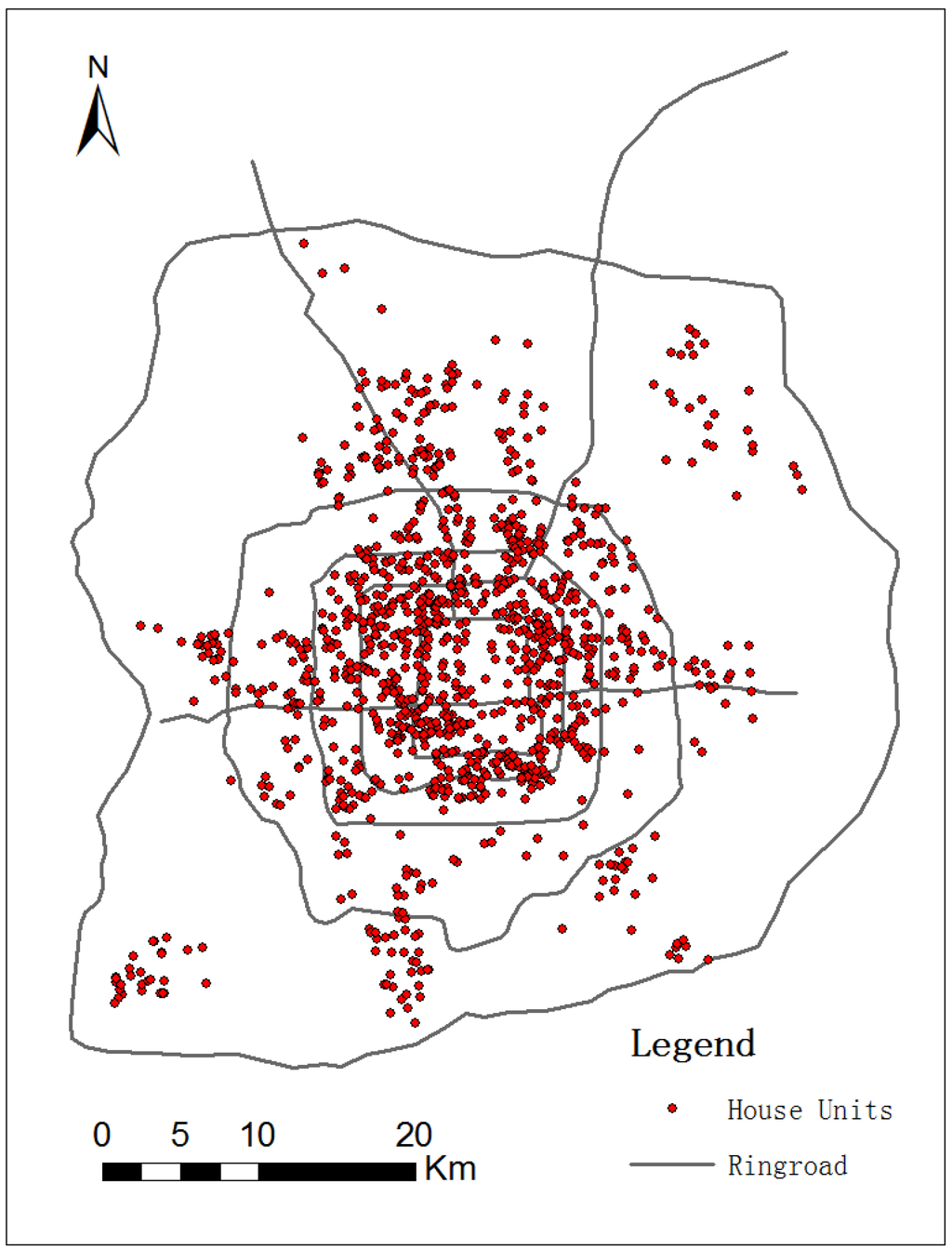
مروری بر متغیرهای قیمت مسکن در جدول 1 نشان داده شده است . در مجموع 1350 خانه مسکونی در این مطالعه گنجانده شده است و موقعیت جغرافیایی آنها در شکل 1 نشان داده شده است . داده های مطالعه توسط اداره ملی آمار ارائه شده است و متغیرهای ساختاری، محله ای و زمانی برای توضیح قیمت مسکن در این مطالعه استخراج شده است.
متغیر وابسته (lnp) قیمت فروش خانه با تغییر لگاریتمی با واحد قیمت RMB است. ویژگی های ساختاری هر خانه با پنج متغیر توضیح داده شده است. مساحت کل طبقه خانه، با واحد مساحت متر مربع ، به صورت لگاریتمی به lnarea_total تبدیل می شود. تعداد اتاق های حمام به صورت nbath بیان می شود. هزینه مدیریت ملک، با واحد کارمزد RMB/ m2، به صورت لگاریتمی به عنوان lnpfee تبدیل می شود. نسبت خانه ها به صورت لگاریتمی به صورت lnplotratio تبدیل می شود. علاوه بر این، نسبت سبز به صورت لگاریتمی به عنوان lngratio تبدیل می شود. محله هر خانه توسط شبکه خیابان های شهری پکن توصیف می شود که اسکلت ساختاری شهر را مشخص می کند و به طور مستقیم بر حمل و نقل و عملکرد اقتصادی شهر تأثیر می گذارد. متغیر زمانی، سن ساختمان در زمان فروش (سن) است.
جدول 1. متغیرهای مورد استفاده برای پیش بینی قیمت مسکن در پکن، چین.
شکل 1. نقشه منطقه مورد مطالعه.
3.2. مواد و روش ها
3.2.1. مدل رگرسیون دارای وزن جغرافیایی
GWR یک تکنیک غیر ثابت است که روابط متغیر فضایی بین متغیرهای مستقل و وابسته را مدل میکند [ 3 ، 4 ، 5 ، 34 ]. مدل GWR را می توان به صورت زیر بیان کرد:
جایی که مختصات نقطه است منمندر فضا به صورت بیان می شود (تومن،vمن)(تومن،�من); β0(تومن،vمن)�0(تومن،�من)نشان دهنده مقدار رهگیری است. و βک(تومن،vمن)�ک(تومن،�من)مجموعه ای از مقادیر را برای عدد نشان می دهد پپپارامترها در نقطه منمن. خطای تصادفی که با توزیع نرمال مطابقت دارد، به عنوان نشان داده می شود εمن�من، εمن∼ N( 0 ,σ2)�من∼ن(0،�2). هیچ ارتباطی در خطای تصادفی بین نقاط مختلف وجود ندارد: Cov (εمن،εj) =0 ( i ≠ j )Cov(�من،��)=0(من≠�). پارامتر رگرسیون β^من�^مندر نقطه منمنمی توان با استفاده از مدل حداقل مربعات به دست آورد.
مقدار مناسب yˆ�^است:
که در آن ماتریس وزن دبلیومندبلیومنبر اساس فواصل بین نقطه رگرسیون i و نقاط داده اطراف آن است. دو نوع ماتریس وزنی استفاده می شود، هسته های ثابت و تطبیقی. در یک تابع هسته ثابت، یک پهنای باند هسته فضایی بهینه محاسبه و در منطقه مورد مطالعه اعمال می شود. متداول ترین تابع وزن ثابت تابع گاوسی است:
جایی که ساعتساعتیک پارامتر غیرمنفی است که به عنوان پهنای باند شناخته میشود و با فاصله بین مکانهای i و j یک کاهش تأثیر ایجاد میکند .
وزن تطبیقی که معمولاً استفاده می شود تابع دو مربع است که پهنای باند مختلف را در مکان i نشان می دهد .
اگر مقدار پیش بینی شده از yمن��از GWR با نشان داده می شود yˆمن( h )�^�(ℎ)، مجموع مربع خطا را می توان به صورت زیر نوشت:
پهنای باند به طور خودکار با یک تکنیک بهینهسازی با کمینه کردن معادله (6) از نظر آمار برازش به دست میآید.
3.2.2. پارادایم یادگیری مشترک
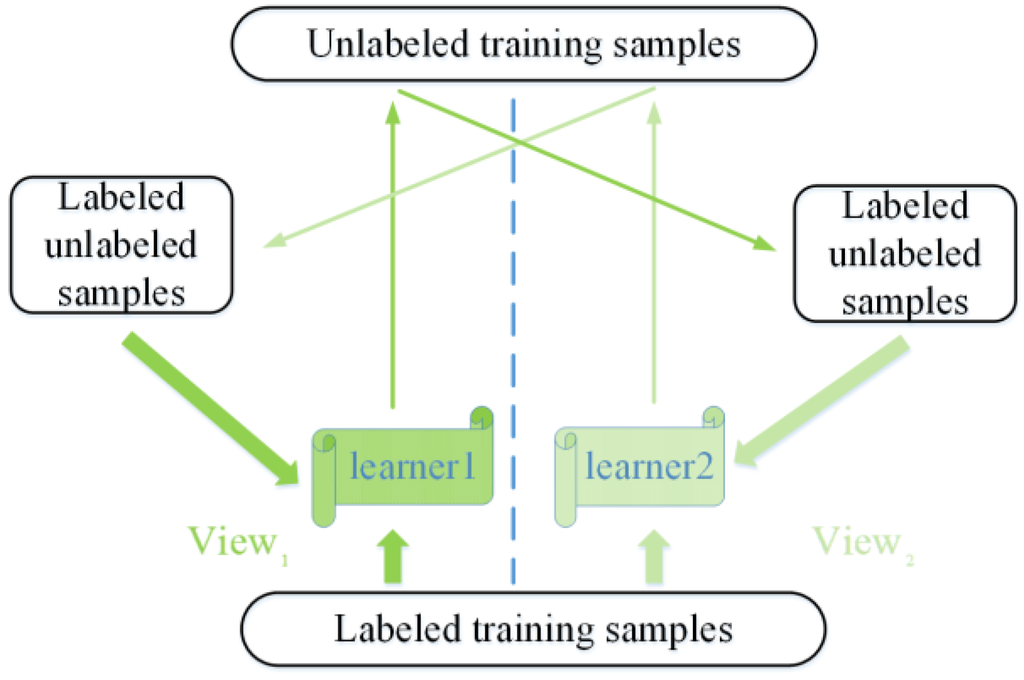
پارادایم آموزش مشترک یکی از برجسته ترین رویکردهای نیمه نظارتی است. این اولین بار توسط بلوم و میچل پیشنهاد شد، دو طبقهبندی کننده را به طور جداگانه بر روی دو نمای متفاوت آموزش میدهد، به عنوان مثال، دو مجموعه مستقل از ویژگیها، و از پیشبینی هر طبقهبندی کننده بر روی نمونههای بدون برچسب برای بهبود مجموعه آموزشی دیگری استفاده میکند [16 ] . همانطور که در شکل 2 نشان داده شده است، الگوریتم استاندارد آموزش مشترک مستلزم آن است که ویژگی ها به طور طبیعی به دو مجموعه تقسیم شوند، که هر یک برای یادگیری کافی است و به صورت شرطی مستقل از دیگری با توجه به برچسب کلاس [35 ] .
شکل 2. فلوچارت پارادایم یادگیری مشارکتی.
گلدمن و ژو الگوریتم آموزش مشترک را به گونه ای گسترش دادند که نیاز به دو نما ندارد، بلکه به دو الگوریتم یادگیری ویژه متفاوت نیاز دارد [ 36 ]. ژو و لی پیشنهاد کردند که از سه طبقهبندی کننده به نام آموزش سهگانه برای توضیح دادههای بدون برچسب استفاده شود. در فرآیند آنها، یک مثال بدون برچسب برچسب گذاری می شود و برای آموزش یک طبقه بندی کننده استفاده می شود که آیا دو طبقه بندی دیگر در مورد برچسب گذاری آن توافق دارند یا خیر [ 37 ]. لی و ژو این ایده را با ادغام طبقهبندیکنندههای بیشتر در فرآیند آموزش گسترش دادند [ 38 ].
3.2.3. رویکرد رگرسیون وزندار جغرافیایی
اجازه دهید L = { (ایکس1،y1) ، ⋯ ، (ایکس| L |،y| L |) }�={(�1,�1),⋯,(�|�|,�|�|)}مجموعه نمونه قیمت مسکن را نشان می دهد که در آن نمونه i-ام است ایکسمن��با ویژگی های d توصیف می شود، yمن��ارزش قیمت مسکن است و | L ||�|تعداد نمونه های با ارزش واقعی است. اجازه دهید U مجموعه داده بدون مقدار واقعی را نشان دهد، که در آن موارد نیز با ویژگی های d توصیف می شوند که مقادیر واقعی آنها ناشناخته است، و | U||�|تعداد نمونه های بدون ارزش واقعی است. روش به شرح زیر است:
1 راه اندازی: ایجاد رگرسیون رگرسیون وزنی جغرافیایی (COGWR) با هسته گاوس تطبیقی آر1�1و رگرسیور COGWR هسته دو مربعی تطبیقی آر2�2با نمونه های برچسب دار L. به طور تصادفی تعداد کمی از نمونه های بدون برچسب را انتخاب کنید و یک مخزن داده بدون برچسب P بسازید.
2 نمونه های بدون برچسب را جذب کنید: در هر دور، یک رکورد r بدون برچسب را از مخزن داده بدون برچسب P انتخاب کنید.
- (1)
-
مقدار پیش بینی شده را تعیین کنید yrˆ��^رکورد بدون مقدار واقعی با استفاده از رگرسیون COGWR آر1�1و رکورد را به رگرسیون COGWR اضافه کنید آر1“�1′. اگر آر2�2از آر1“�1′نسبت به نسخه اصلی کاهش می یابد آر2�2با استفاده از معادله (2)، این رکورد توسط رگرسیون جذب می شود آر2“�2“.
خوب بودن r را می توان با استفاده از معیار نشان داده شده در رابطه (7) ارزیابی کرد.
اگر ارزش از ΔrΔ�مثبت است، سپس استفاده می شود (ایکسr،yˆr)(ایکس�،�^�)سودمند است.
- (2)
-
در غیر این صورت، مقدار پیش بینی شده را تعیین کنید yrˆ��^رکورد بدون مقدار واقعی با استفاده از رگرسیون COGWR آر2آر2و رکورد را به رگرسیون COGWR اضافه کنید آر2“آر2“. اگر آر2آر2از آر2“آر2“نسبت به نسخه اصلی کاهش می یابد آر2 آر2، این رکورد توسط رگرسیون جذب می شود.
خوب بودن r را می توان با استفاده از معیار نشان داده شده در رابطه (8) ارزیابی کرد.
اگر ارزش از ΔrΔ�مثبت است، سپس استفاده می شود (ایکسr،yˆr)(ایکس�،�^�)سودمند است.
- (3)
-
اگر رکورد بدون برچسب توسط هیچ یک از رگرسیون ها جذب نشود آر1آر1نه واپسگرا آر2 آر2، سپس تکرار را پایان دهید.
3 پیش بینی: مقدار میانگین رگرسیور را محاسبه کنید آر1آر1و واپسگرا آر2آر2.
نمودار جریان رویکرد COGWR در شکل 3 نشان داده شده است .
شکل 3. نمودار جریان الگوریتم رگرسیون وزنی جغرافیایی (COGWR) آموزش مشترک.
4. نتایج تجربی و مقایسه
در این بخش، مدل GWR با استفاده از توابع هسته گاوسی برای در نظر گرفتن ناهمگونی فضایی دادههای قیمت مسکن برای اعتبارسنجی قابلیت اطمینان پیشبینیهای قیمت مسکن در پکن اتخاذ شد. در مرحله دوم، داده های قیمت مسکن با استفاده از روش های GWR و COGWR تجزیه و تحلیل شد.
4.1. نتایج مدل GWR
در مدلهای رگرسیون خطی، همخطی قوی بین متغیرهای توضیحی میتواند واریانس ضرایب رگرسیون برآورد شده را افزایش داده و منجر به نتایج گمراهکننده در مورد روابط در پدیده مورد مطالعه شود. در تنظیم رگرسیون خطی محلی، این می تواند منجر به الگوهای ضرایب نادقیق با علائم ضد شهودی در بخش های قابل توجهی از منطقه مورد مطالعه شود [ 39 ]. به عنوان مثال، ویلر نشان میدهد که همخطی میتواند دقت ضریب را در GWR کاهش دهد و منجر به نشانههای ضد شهودی برای برخی از ضرایب رگرسیون در برخی مکانها در منطقه مورد مطالعه شود [ 40 ].
در این مطالعه، چند خطی بودن با استفاده از ابزارهای تشخیصی عامل تورم واریانس (VIF)، شاخص وضعیت و نسبتهای واریانس-تجزیه تشخیص داده میشود. مقادیر VIF شاخصی برای شدت چند خطی بودن هستند و متغیرهایی با مقادیر VIF بیشتر از 10 باید حذف شوند. Belsley پیشنهاد می کند که از شاخص های شرایط بزرگتر یا مساوی 30 و نسبت های واریانس بیشتر از 0.50 برای هر جزء واریانس به عنوان نشانه ای از هم خطی در یک مدل رگرسیونی استفاده شود [41 ] . در این تحقیق مقادیر VIF متغیرهای کمکی توضیحی کمتر از 10 و شاخص وضعیت همه متغیرهای کمکی توضیحی و فاصله کمتر از 30 است.
مشخص است که یک پهنای باند تطبیقی در عمل در مقایسه با پهنای باند از پیش تعریف شده و ثابت بسیار مناسب است [ 27 ، 29 ]. در این آزمایش، تابع هسته گاوس تطبیقی پذیرفته شده است. مدل GWR آزمایش شده است و نتایج در جدول 2 نشان داده شده است [ 27 ، 42 ، 43 ]. آمار نشان می دهد که قیمت مسکن در پکن را می توان با استفاده از متغیرهای توضیحی مدل کرد. تقریباً 70.1 درصد از تغییرات قیمت مسکن را می توان با توجه به مدل توضیح داد آر2 آر2. علائم همه پارامترهای بین چارک پایین (LQ) و چارک بالا (UQ) در جدول 2 نشان داده شده است . آمار توصیفی برای ضرایب پارامتر محلی تولید شده توسط GWR، واریانس زیادی را در مقادیر پارامتر نشان میدهد، که نشاندهنده وجود ناپایداری مکانی در روابط بین قیمت مسکن و متغیرهای توضیحی است. متراژ طبقات، تعداد حمام ها و قدمت ساختمان در زمان فروش دارای مقادیر پارامتر مثبت هستند، در حالی که حق الزحمه مدیریت املاک، نسبت قطعه خانه ها، نسبت سبز و جاده کمربندی دارای مقادیر پارامترهای منفی و مثبت هستند.
جدول 2. آمار برآورد پارامتر مدل GWR. LQ، چارک پایین. UQ، چارک بالایی.
برای آزمون عدم ایستایی، آزمون F پیشنهاد شده توسط Leung و همکاران. (2000) انجام شد [ 42 ]. جدول 3 واریانس ها، مقادیر آماره F ضرایب رگرسیون و مقادیر p مربوط به آنها را فهرست می کند . این مقادیر از نظر آماری معنی دار در سطح 5٪ با ستاره “*” مشخص می شوند. می توان دریافت که تنها یک متغیر تغییرات فضایی غیر قابل توجهی را در GWR نشان می دهد: تعداد اتاق های حمام (nbath). متغیرهای باقیمانده تغییرات فضایی قابل توجهی را نشان می دهند.
جدول 3. نتایج آزمون غیر ایستایی برای مدل های GWR.
یکی از ویژگیهای مهم تکنیک مبتنی بر GWR این است که تخمینهای پارامتر محلی که نشاندهنده روابط محلی هستند، قابل نقشهبرداری هستند و بنابراین امکان تحلیل بصری را فراهم میکنند. با در نظر گرفتن ضرایب مساحت طبقه با تغییر لگاریتمی به عنوان مثال، میتوانیم آنها را در چندین بازه گروهبندی کنیم و هر بازه را رنگ کنیم تا الگوهای تغییرات فضایی این متغیر را تجسم کنیم. همانطور که در شکل 4 نشان داده شده است، مشاهده می شود که قیمت مسکن تحت تأثیر مساحت طبقه است. در بخش مرکزی پکن، تعداد زیادی خانه با اندازه کوچک مسکونی ساخته شده است. دلیل آن این است که منطقه مرکزی پکن در زمانهای قبلی برنامهریزی شده بود و دیگر نمیتوان از زمین برای ساخت خانه استفاده کرد. در سالهای اخیر، با توسعه سریع اقتصاد و پیشرفت سریع شهرنشینی، جنبش گستردهای از گسترش شهری در سراسر کشور پدیدار شده است و خانههای بزرگی در بخش خارجی پکن ساخته میشوند.
شکل 4. تغییرات فضایی ضریب سطح زمین به صورت لگاریتمی = تبدیل شده.
4.2. مقایسه COGWR با مدل GWR
در این مقاله، یک رویکرد رگرسیون نیمه نظارت کارآمد برای پیشبینی قیمت مسکن معرفی کردهایم. یک روال رایج در ارزیابی الگوریتم های نیمه نظارت شده اتخاذ شده است [ 18 ، 19]. در جزئیات، قطعات مسکونی به طور تصادفی به مجموعه دادههای برچسبدار/بدون برچسب/آزمایش با توجه به نسبتهای خاص تقسیم میشوند. حدود 25 درصد از داده ها به عنوان نمونه های آزمایشی نگهداری می شوند، در حالی که 75 درصد بقیه داده ها به عنوان مجموعه داده های آموزشی استفاده می شود. در مجموعه آموزشی، داده های برچسب دار و بدون برچسب تحت نرخ های مختلف برچسب شامل 10، 20، 30، 40 و 50 درصد تقسیم بندی می شوند. پنجاه اجرا از آزمایش انجام شده است. در هر اجرا، مقادیر RSS (مجموع باقیمانده مربعات)، MSE (میانگین مربعات خطا) و مقادیر AIC ثبت می شود. در آزمایشها، حداکثر تعداد تکرارها روی 50 تنظیم میشود و اندازه استخری که در فرآیند یادگیری استفاده میشود 50 است. از آنجایی که فرآیند یادگیری ممکن است قبل از رسیدن به حداکثر تعداد تکرار متوقف شود، از مقادیر نهایی RSS، MSE و AIC در محاسبه میانگین RSS استفاده می شود.
بررسی اینکه آیا مدل COGWR به طور قابل توجهی بهتر از مدل های GWR عمل می کند، ضروری است. بهبود مقادیر RSS، MSE و AIC بین COGWR و GWR در جدول 4 نشان داده شده است .
جدول 4. بهبود بین مدل های COGWR و GWR.
ابتدا، RSS و MSE را بین COGWR و GWR مقایسه کردیم. همه رگرسیورهای COGWR (توابع هسته گاوس و دو مربع) عملکرد بهتری نسبت به رگرسیورهای GWR در نرخ برچسب 10٪، 20٪ و 30٪ دارند. به عنوان مثال، در مقایسه با رگرسیورهای GWR، بهبود RSS به دست آمده توسط رگرسیورهای COGWR به ترتیب (3.242، 2.216)، (3.375، 2.801) و (3.551، 2.909) بود. با این حال، برای نرخ برچسب 40٪ و 50٪، هیچ بهبود قابل توجهی در مقایسه با رگرسیون GWR مشاهده نشد. به عنوان مثال، بهبود RSS محاسبه شده با استفاده از رگرسیون COGWR به ترتیب (144/0-، 101/0) و (314/0-، 633/1-) بود.
دوم، ما مقادیر AIC را بین مدلهای COGWR و GWR مقایسه کردیم و مشخص کردیم که آیا مدل COGWR به طور قابلتوجهی قابل اعتمادتر از مدلهای GWR است. به گفته فاثرینگهام و بو وو [ 5 ، 44]، یک تفاوت “جدی” بین دو مدل به طور کلی به عنوان تفاوتی در نظر گرفته می شود که در آن تفاوت در مقادیر AIC بین مدل ها بیشتر از سه باشد. هنگامی که نرخ برچسب گذاری شده 10٪، 20٪ یا 30٪ است، پیشرفت های قابل توجهی با استفاده از COGWR در مقایسه با GWR حاصل می شود. به عنوان مثال، زمانی که نرخ برچسب 10٪، 20٪ و 30٪ است، تفاوت بین مدل های COGWR و GWR به ترتیب (23.716، 18.645)، (36.479، 21.328) و (41.921، 22.899) بود. با این حال، هیچ بهبود قابل توجهی با استفاده از COGWR هنگامی که نرخ برچسب گذاری شده 40٪ یا 50٪ است به دست نمی آید. زمانی که نرخ برچسبگذاری شده 40% و 50% باشد، تفاوت بین COGWR و GWR به ترتیب (2.892-، 2.204) و (-4.812، -16.641) است.
با افزایش نرخ برچسب، به نظر میرسد که بهبود تناسب حاصل از بهرهبرداری از دادههای قیمت مسکن بدون برچسب در حال کاهش است. این عجیب نیست، زیرا از عملکرد برچسبگذاری میتوان دریافت که رگرسیونهای اولیه GWR زمانی که دادههای قیمت خانه برچسبدار بیشتری در دسترس هستند، قوی میشوند و بنابراین، بهبود آنها دشوارتر است.
5. نتیجه گیری ها
روشهای رگرسیون نیمهنظارتشده سنتی را نمیتوان مستقیماً برای دادههای مکانی اعمال کرد، زیرا فرض ثبات در فضا عموماً غیر واقعی است. این مقاله رویکردهای جدید GWR آموزشی مشترک را معرفی میکند که به طور کامل از مزایای رگرسیون جغرافیایی و یادگیرندگان نیمهنظارتی برای افزایش تناسب با توجه به ویژگیهای ساختاری، مکان و محله خانه بدون برچسب و دادههای جغرافیایی استفاده میکند.
مدل COGWR، که به طور کامل از جنبههای مثبت هر دو روش رگرسیون وزندار جغرافیایی (GWR) و الگوی یادگیری نیمه نظارتی استفاده میکند، پیادهسازی شد و نتایج نشان میدهد که وقتی مقدار دادههای برچسبگذاری شده کم باشد، روش COGWR به طور قابلتوجهی باعث بهبود عملکرد میشود. عملکرد روش GWR این روش با جذب داده های بدون برچسب، مناطق داده پراکنده را به مناطق داده متراکم تبدیل می کند. بنابراین، استحکام رگرسیورها افزایش می یابد. این نشان میدهد که ترکیب دادههای بدون قیمت در یک مدل GWR میتواند نتایج معنیداری داشته باشد. هنگامی که نرخ برچسب دادههای قیمت مسکن افزایش مییابد، سود حاصل از جذب دادههای بدون برچسب کاهش مییابد زیرا پسروندههای آموزشدیده بر روی نمونههای آموزشی برچسبگذاری شده قویتر میشوند و بنابراین بهبود آن دشوارتر میشود.
این مطالعه تلاشی سودمند در تحقیق ژئو اطلاعات و اقتصاد املاک و مستغلات است. این مرجع هم به تصمیم گیری و هم به تحقیقات نظری ارائه می دهد. تنوع فضایی ضرایب رگرسیون برای تصمیم گیرندگان محلی [ 12 ] از اهمیت بالایی برخوردار است. هنگامی که مقدار داده های قیمت مسکن محدود است، رویکرد COGWR ابزار مفیدی برای متخصصان املاک است تا به طور کامل از داده های بدون قیمت با متغیرهای توضیحی بهره برداری کنند.
برخی محدودیت ها هنوز در مطالعه ما باقی مانده است و کار بیشتری لازم است. در این مقاله، همه متغیرهای توضیحی در فضا تغییر نمیکنند، و رویکرد رگرسیون جغرافیایی وزندار مخلوط (MGWR) باید برای جلوگیری از محدودیتهای اثرات ثابت با کاوش اثرات فضایی-ایستا و غیر ثابت در آینده بررسی شود [12 ] . ناهمگونی مکانی-زمانی در دادههای املاک و مستغلات غالب است و یک GWR نیمه نظارت موقت هنوز باید دنبال شود.





بدون نظر