


خلاصه
مرکز تحقیقاتی GFZ آلمان برای علوم زمین آزمایشگاه ملی علوم زمین در آلمان است. به عنوان بخشی از انجمن هلمهولتز، ارائه و حفظ زیرساخت های علمی در مقیاس بزرگ بخشی ضروری از فعالیت های GFZ است. این شامل تولید حجم و تعداد قابل توجهی از داده های تحقیقاتی است که متعاقباً به منابع منبع برای انتشار داده ها تبدیل می شود. توسعه و نگهداری سیستم های داده یکی از اجزای کلیدی خدمات داده های GFZ برای پشتیبانی از تحقیقات پیشرفته است. یک چالش نه تنها در تنوع موضوعات و جوامع علمی، بلکه در انواع و جلوههای مختلف نحوه مدیریت دادهها توسط گروههای تحقیقاتی و دانشمندان فردی نهفته است. مخزن داده های GFZ Data Services یک زیرساخت فناوری اطلاعات انعطاف پذیر برای ذخیره سازی و انتشار داده ها فراهم می کند. از جمله ضرب شناسه های دیجیتالی شی (DOI). این به عنوان یک سیستم ماژولار از چندین مؤلفه نرم افزار مستقل ساخته شده است که از طریق رابط های برنامه نویسی کاربردی (API) ارائه شده توسط چارچوب eSciDoc به یکدیگر متصل شده اند. نرم افزارهای کاربردی اصلی عبارتند از panMetaDocs برای مدیریت داده ها و DOIDB برای ثبت و تعدیل فعالیت های انتشارات داده ها. تا جایی که امکان داشت، راه حل های نرم افزاری موجود یکپارچه یا تطبیق داده شدند. خلاصه ای از تجربیات ما در راه اندازی این سرویس ارائه شده است. دادهها از طریق صفحات فرود جامع و اسناد تکمیلی، مانند مقالات مجلات یا گزارشهای داده توصیف میشوند، بنابراین قابلیت استفاده علمی سرویس را افزایش میدهند. این به عنوان یک سیستم ماژولار از چندین مؤلفه نرم افزار مستقل ساخته شده است که از طریق رابط های برنامه نویسی کاربردی (API) ارائه شده توسط چارچوب eSciDoc به یکدیگر متصل شده اند. نرم افزارهای کاربردی اصلی عبارتند از panMetaDocs برای مدیریت داده ها و DOIDB برای ثبت و تعدیل فعالیت های انتشارات داده ها. تا جایی که امکان داشت، راه حل های نرم افزاری موجود یکپارچه یا تطبیق داده شدند. خلاصه ای از تجربیات ما در راه اندازی این سرویس ارائه شده است. دادهها از طریق صفحات فرود جامع و اسناد تکمیلی، مانند مقالات مجلات یا گزارشهای داده توصیف میشوند، بنابراین قابلیت استفاده علمی سرویس را افزایش میدهند. این به عنوان یک سیستم ماژولار از چندین مؤلفه نرم افزار مستقل ساخته شده است که از طریق رابط های برنامه نویسی کاربردی (API) ارائه شده توسط چارچوب eSciDoc به هم مرتبط شده اند. نرم افزارهای کاربردی اصلی عبارتند از panMetaDocs برای مدیریت داده ها و DOIDB برای ثبت و تعدیل فعالیت های انتشارات داده ها. تا جایی که امکان داشت، راه حل های نرم افزاری موجود یکپارچه یا تطبیق داده شدند. خلاصه ای از تجربیات ما در راه اندازی این سرویس ارائه شده است. دادهها از طریق صفحات فرود جامع و اسناد تکمیلی، مانند مقالات مجلات یا گزارشهای داده توصیف میشوند، بنابراین قابلیت استفاده علمی سرویس را افزایش میدهند. نرم افزارهای کاربردی اصلی عبارتند از panMetaDocs برای مدیریت داده ها و DOIDB برای ثبت و تعدیل فعالیت های انتشارات داده ها. تا جایی که امکان داشت، راه حل های نرم افزاری موجود یکپارچه یا تطبیق داده شدند. خلاصه ای از تجربیات ما در راه اندازی این سرویس ارائه شده است. دادهها از طریق صفحات فرود جامع و اسناد تکمیلی، مانند مقالات مجلات یا گزارشهای داده توصیف میشوند، بنابراین قابلیت استفاده علمی سرویس را افزایش میدهند. نرم افزارهای کاربردی اصلی عبارتند از panMetaDocs برای مدیریت داده ها و DOIDB برای ثبت و تعدیل فعالیت های انتشارات داده ها. تا جایی که امکان داشت، راه حل های نرم افزاری موجود یکپارچه یا تطبیق داده شدند. خلاصه ای از تجربیات ما در راه اندازی این سرویس ارائه شده است. دادهها از طریق صفحات فرود جامع و اسناد تکمیلی، مانند مقالات مجلات یا گزارشهای داده توصیف میشوند، بنابراین قابلیت استفاده علمی سرویس را افزایش میدهند.
کلید واژه ها:
انتشار داده ها ; مدیریت داده ها ؛ شناسه دائمی ; مخزن نهادی
1. معرفی
دسترسی آزاد و آزاد به داده های تحقیقاتی به عنوان یک موضوع کلیدی توسط جامعه علمی، توسط آژانس های تحقیقاتی و دولت ها شناسایی شده است (به عنوان مثال، بیانیه برلین، بیانیه وزیران علوم G8، اجرای اتحادیه اروپا منشور داده های باز G8، دستور کار دیجیتالی فدرال دولت آلمان [ 1 ، 2 ، 3 ، 4 ]). در نتیجه، یک تحول مشترک پویا از دستورالعمل های ملی و بین المللی در مورد مدیریت و دسترسی آزاد به داده های تحقیقاتی وجود دارد (به عنوان مثال، بیانیه برلین، اعلامیه OECD، دستورالعمل های INSPIRE [1، 5 ، 6 ] ) .]). به موازات آن، جامعه علمی مدلهای فنی و مفهومی را توسعه داد تا دادههای تحقیق را قابل استناد و قابل استفاده برای دیگران کند. در این زمینه، شناسه های دیجیتالی شی (DOI) به عنوان سیستم شناسه پیشرو برای انتشارات متن و داده ظاهر شده اند [ 7 ].
ذخیره سازی در مخازن مناسب و خاص، بخش اساسی تضمین دسترسی و حفظ طولانی مدت این داده ها است. برای اینکه دادهها قابل استفاده مجدد باشند، باید با یک توصیف جامع همراه با متادیتاهای استاندارد شده و خاص رشتهای همراه باشند تا کشف دادهها را بهبود بخشد و استفاده مجدد و درک را تسهیل کند. ناشران، ناشران دادهها و دانشمندان حوزه خود را متعهد به دستورالعملهایی در مورد نحوه جاسازی پیوندها به مجموعه دادهها در نشریات، و پیوندهای متناظر از امکانات داده به مجلات، از طریق شناسههای دائمی کردهاند. مجموعه دادهها در حالت ایدهآل باید توسط شناسههای ثابت و منحصربهفرد جهانی، مانند شناسههای دیجیتالی شی (DOI) ارجاع داده شوند [ 7]]. این مقاله عمدتاً متوجه متصدیان داده، مدیران مخزن و دانشمندان داده است، اما ممکن است برای محققان، بهویژه بخشهای مربوط به صفحات فرود و توضیحات دادهها نیز جالب باشد (بخش 3، بخش 4 و بخش 5 ) . پس از یک بررسی کلی، طراحی و عملکرد هر یک از اجزای نرم افزار (eSciDoc، panMetaDocs، DOIDB) را توضیح می دهیم، مروری کوتاه بر فرمت های مختلف برای انتشار داده ها، معرفی ویرایشگر ابرداده، نمونه هایی از صفحات فرود DOI، مجوزهای اجزای نرم افزار، و با بخش بحث و چشم انداز نتیجه گیری کنید.
مرکز هلمهولتز پوتسدام GFZ مرکز تحقیقاتی آلمان برای علوم زمین آزمایشگاه ملی علوم زمین در آلمان و عضو انجمن هلمهولتز، بزرگترین سازمان تحقیقاتی آلمان است. تمرکز GFZ مطالعه تاریخچه زمین و ویژگی های آن، فرآیندهای رخ داده در سطح و درون آن، و همچنین تعاملات بین ژئوسفر، هیدروسفر، جو و زیست کره است. داده های تحقیقاتی به دست آمده همه رشته های علم زمین را پوشش می دهد. آنها از مجموعه دادههای دینامیکی بزرگ مشتقشده از شبکههای لرزهای، مغناطیسی یا ژئودزیکی جهانی با جمعآوری دادههای بیدرنگ یا دادههای ایستگاه اقلیمی، تا محصولات ماهوارهای سنجش از راه دور، تا نتایج مدلهای مختلف، تا تحلیلهای ژئوشیمیایی از آزمایشگاههای مختلف و مشاهدات میدانی را شامل میشوند. . در علوم زمین، مدیریت کلی و مدیریت داده ها چالش برانگیز است. اندازه مجموعه داده ها از نسبتاً کوچک تا بسیار بزرگ متفاوت است. راهحلهای نرمافزاری مختلفی برای پردازش دادهها و تعداد زیادی فرمت فایل و طرحوارههای فراداده وجود دارد. اغلب به دست آوردن داده ها گران است و اغلب داده های تحقیق یک پدیده طبیعی را ثبت می کنند که فقط یک بار قابل مشاهده است. همه این داده ها داده های ارزشمندی هستند و شایسته است برای نسل های آینده دانشمندان حفظ شوند.8 ].
به عنوان بخشی از تحقیقات علمی، حجم و تعداد قابل توجهی از داده های تحقیقاتی تولید می شود و متعاقباً به منابع منبع برای انتشارات تبدیل می شود. توسعه و نگهداری سیستم های داده یک ستون اساسی از فعالیت های GFZ برای حمایت از تحقیقات پیشرفته است. مجموعه دادههای دینامیکی بزرگ از شبکههای نظارتی جهانی جریانهای دادهای در زمان واقعی یا نزدیک به زمان واقعی تولید میکنند که به مخازن دادهها وارد میشوند و از طریق پورتالهای دادهای با موضوع بینالمللی قابل دسترسی هستند. نمونه هایی در GFZ برای این کار سیستم هایی مانند GEOFON، سرویس های GNSS، INTERMAGNET و بسیاری دیگر هستند. GEOFON [ 9 ] یک شبکه جهانی پایش لرزه ای و یک مرکز داده و آرشیو بین المللی را اداره می کند که دسترسی بلادرنگ به داده های زلزله شناسی را تسهیل می کند. به عنوان بخشی از خدمات بین المللی GNSS IGS [10 ]، GFZ حدود 30 ایستگاه مرجع چند GNSS توزیع شده در سطح جهانی را اداره می کند و یک مرکز تجزیه و تحلیل برای داده های GNSS را میزبانی می کند. 18 رصدخانه مغناطیسی GFZ و شرکای همکاری بخشی از شبکه بین المللی رصدخانه مغناطیسی بلادرنگ INTERMAGNET [ 11 ] است. علاوه بر چنین دادههایی از شبکههای نظارتی، یک «دم دراز» از دادههای تحقیقاتی بسیار مشخص و بسیار متغیر از دانشمندان یا گروههای تحقیقاتی فردی وجود دارد که باید سرپرستی و منتشر شوند.
GFZ Data Services نقطه خدمات مرکزی برای داده های تحقیقاتی است، به ویژه برای انتشار و بایگانی داده ها. خدمات داده GFZ برای خدمت به نیازهای مدیریت داده محققان، پس از مشاوره های گسترده با ذینفعان مربوطه، طراحی شده است. علاوه بر این، GFZ Data Services یک مخزن داده ایجاد و نگهداری می کند و انتشار مجموعه داده ها و محصولات داده را در ارتباط با ثبت DOI ارائه می دهد. ثبت DOI همچنین به عنوان یک سرویس به مخازن دیگر در GFZ، به عنوان مثال، GEOFON ارائه می شود. مجموعه داده های منتشر شده در GFZ طیف کاملی از انتشارات داده را پوشش می دهد همانطور که در Katz and Strasser (2015) [ 12] توضیح داده شده است.]: داده ها ممکن است به عنوان مواد تکمیلی برای مقالات مجلات، با یک مقاله توصیفی در یکی از “مجله های داده” جدید، یا به عنوان نهادهای مستقل منتشر شوند. برای ارائه قالبی برای توصیف گسترده مجموعه دادههای منتشر شده مستقل، GFZ Data Services مجموعهای از گزارشهای داده را در سال 2011 راهاندازی کرد. این طیف وسیعی از مشتریان انتشار دادهها نیازمند این است که سیستم بتواند طرحوارههای مختلف ابرداده را مدیریت کند و انعطافپذیر و دقیق ارائه دهد. مدیریت حقوق دسترسی به سیستم و دارایی های آن.
به ویژه با توجه به افزایش انتظارات و درخواستها برای دسترسی آزاد به دادههای تحقیقاتی، حفظ و نگهداری مجموعه دادههای تحقیقاتی و نگهداری نرمافزارهای سفارشی دادهها فراتر از طول عمر و تأمین مالی یک پروژه، وظایف کلیدی برای خدمات دادههای GFZ هستند. برای پاسخگویی به این نیازها، مخزن خدمات داده GFZ به عنوان یک سیستم ماژولار ساخته شد تا امکان سازگاری آسان با نیازهای متغیر را فراهم کند، تا بتواند تنوع بالایی در انواع داده ها را مدیریت کند، و همچنین برای طیف گسترده ای از رشته های علم زمین شناسی موجود مناسب باشد. در GFZ تا جایی که امکان داشت، راه حل های نرم افزاری موجود و اثبات شده یکپارچه یا تطبیق داده شدند. این بسته تقریباً شامل چارچوب eSciDoc، مخزن ضروری در پایه، panMetaDocs به عنوان برنامه کاربردی برای انتشار مجموعه دادهها است. و DOIDB به عنوان تسهیلاتی برای ثبت DOI و ابرداده. این رویکرد ماژولار همچنین به ما اجازه میدهد تا بخشهایی از سرویس را در طول زمان بدون نیاز به مهندسی مجدد کامل سیستم تغییر دهیم (نگاه کنید بهشکل 1 برای ساختار کلی مخزن خدمات داده GFZ). سرویسهای انتشار دادهها از نزدیک به PubMan، برنامهای برای انتشار متنی [ 13 ] که همچنین بر اساس eSciDoc است و بنابراین بخشی از خدمات چاپ و نشر به خوبی تثبیت شده کتابخانه GFZ است، مرتبط هستند. این کتابخانه همچنین به عنوان کتابخانه مرکزی برای چهار موسسه تحقیقاتی در پوتسدام (کتابخانه Wissenschaftspark Albert Einstein Potsdam) عمل می کند.
خط مشی سرپرستی خدمات داده GFZ بر اساس جداسازی نگرانی ها بین پروژه تحقیقاتی و مؤسسه حافظه (به عنوان مثال، کتابخانه) است. در این مفهوم، پیوستار گزینش داده از تولید داده از طریق ذخیره سازی داده تا دسترسی به داده ها به چهار “حوزه مسئولیت” تقسیم می شود [ 14 ، 15 ]]. این “حوزه های مسئولیت” در مدیریت داده های تحقیقاتی به تعیین مسئولیت های بازیگران درگیر کمک می کند. آنها همچنین زمینه دانش مشترک در مورد دادهها را ترسیم میکنند و به این ترتیب، به تعیین جزئیات توصیفی فرادادهها کمک میکنند تا امکان استفاده مجدد از دادههای تحقیق فراهم شود و در چه مرحلهای باید فرادادههای متنی ضمنی در ابردادههای ذخیرهشده کدگذاری شوند. . سرویسهای داده GFZ در حوزههای «مداوم» و «دسترسی» کار میکنند و با محققان برای انتقال دادههایشان به دامنه «دائم» برای انتشار و بایگانی کار میکنند. جزئیات بیشتر در مورد نحوه پیادهسازی دامنههای سرپرستی بر اساس eSciDoc را میتوان در کلمپ و همکاران یافت . (2015) [ 14 ].
2. اجزای نرم افزار برای انتشار داده ها
سیستم ما برای انتشار داده ها از چهار جزء نرم افزاری استفاده می کند که به صورت مدولار ترکیب شده اند. ما مقالات تحقیقاتی، مجموعه دادهها و ابردادههای مرتبط را با مؤلفههای نرمافزار مبتنی بر وب PubMan برای مقالات و panMetaDocs برای مجموعههای داده جمعآوری میکنیم. ذخیره سازی این اشیاء دیجیتال توسط یک میان افزار مخزن eSciDoc انجام می شود. DOIDB، مؤلفه چهارم ما، از طریق سرویس ثبت DataCite DOI در کتابخانه ملی علم و فناوری آلمان (TIB Hannover) برای برش DOI های مجموعه داده استفاده می کند و به عنوان پورتال ابرداده برای مجموعه داده های منتشر شده از طریق سرویس های داده GFZ عمل می کند. اجزای نرم افزار از طریق وب سرویس ها جفت می شوند. علاوه بر این، ابرداده ها را می توان از هر مؤلفه در پورتال های فراداده فراگیر، به عنوان مثال، B2FIND یا Earth Cube، جمع آوری کرد.16 ].
شکل 1 ساختار سیستم انتشار در GFZ را نشان می دهد. فلش ها جریان داده یا فراداده و پروتکل های مورد استفاده را نشان می دهد. eSciDoc، به عنوان یک میان افزار، رابط کاربری گرافیکی ارائه نمی دهد. این یک رابط انتقال حالت نمایشی (REST) دارد [ 17] و کل عملکرد آن از طریق نقاط پایانی وب سرویس ارائه می شود. برنامه های کاربردی PubMan و panMetaDocs رابط های کاربری گرافیکی را برای حاشیه نویسی فایل های داده با ابرداده و ذخیره داده ها و ابرداده ها در eSciDoc با استفاده از سرویس های وب eSciDoc ارائه می دهند. انتشار داده توسط GFZ، به عنوان یک عامل انتشار DataCite، برای سیستم های داده خارج از چارچوب eSciDoc نیز در دسترس است. این نشریات ممکن است از طریق DOIDB ثبت شوند. برای نظارت و تعدیل ثبت DOI از سیستم های داده GFZ، کد منبع فروشگاه فراداده DataCite را تغییر دادیم تا به عنوان یک پروکسی برای زیرساخت ثبت DataCite DOI عمل کند و نرم افزار را به عنوان DOIDB منتشر کردیم. عملکرد DOIDB در ادامه این مقاله با جزئیات بیشتری مورد بحث قرار خواهد گرفت. ابرداده می تواند توسط پورتال ها برای پیمایش مجموعه داده ها و انتشارات استفاده شود، برای نشان دادن یک نمای کلی از محتوا، و ارائه لینک به صفحات فرود. صفحات فرود داده ها و انتشارات را با جزئیات بیشتر توصیف می کنند، حاوی پیوندهایی به مطالب مرتبط هستند و فایل هایی را برای دانلود ارائه می دهند.
تمامی اجزای نرم افزار مبتنی بر راه حل های نرم افزاری رایگان و متن باز هستند و متناسب با نیازهای خاص ما اصلاح شده اند. به طور خاص، ما panMetaWorks [ 18 ] را برای استفاده از eSciDoc برای ذخیره سازی داده ها، به جای یک سیستم فایل، اصلاح کردیم و نرم افزار تازه مشتق شده را به عنوان panMetaDocs منتشر کردیم [ 19 ، 20 ]. این راه حل نرم افزاری نیز در این مقاله با جزئیات بیشتر توضیح داده خواهد شد.
گردش کار انتشار داده ها امکان داشتن یک حالت میانی را ارائه می دهد که طی آن مجموعه داده ها و ابرداده ها هنوز در حوزه عمومی منتشر نشده اند، اما در عین حال به طور کامل در دسترس هستند، به عنوان مثال، بازبینان یک مقاله مجله در مورد مجموعه داده ها. این حالت میانی همچنین برای هماهنگ کردن جزئیات مربوط به مجموعه داده ها و ابرداده ها با ایجاد کننده داده استفاده می شود.
2.1. eSciDoc- پیاده سازی eSciDoc به عنوان زیرساخت مخزن در GFZ
eSciDoc به طور مشترک توسط انجمن Max Planck و FIZ Karlsruhe-Leibniz Institute for Information Infrastructure توسعه داده شد. توسعه eSciDoc که توسط وزارت آموزش و تحقیقات فدرال آلمان (BMBF) تامین می شود، با الهام از نیاز به ایجاد چارچوبی برای محیط های تحقیقاتی مجازی برای سازمان های تحقیقاتی چند رشته ای ساخته شده است. eSciDoc یک میان افزار برای برنامه های کاربردی تحقیقاتی مبتنی بر اینترنت است [ 21 ]. این توابع معمولاً برای مونتاژ و انتشار فایل های باینری مانند ایجاد، خواندن، به روز رسانی و حذف استفاده می شود. علاوه بر این خدمات اساسی، eSciDoc طیف وسیعی از خدمات اضافی را ارائه می دهد که یکی از آنها احراز هویت و مجوز کاربران است.
در GFZ ما eSciDoc را به عنوان میان افزار ذخیره سازی نهادی برای انتشارات داده های متنی و پژوهشی ایجاد کردیم. همانطور که در مقدمه ذکر شد، این کار عمدتاً با هدف سادهسازی مدیریت دادهها با ارائه یک زیرساخت ذخیرهسازی مشترک در GFZ انجام شد که مستقل از راهحلهای مدیریت داده خاص پروژه تحقیقاتی است. نرم افزارهای خاص پروژه را فقط می توان در زمانی که یک پروژه تحقیقاتی فعال است نگهداری کرد. پس از پایان یک پروژه تحقیقاتی، نگهداری ده ها نمونه نرم افزاری خاص پروژه برای اطمینان از دسترسی مداوم به داده های ذخیره شده، غیر قابل دوام می شود. eSciDoc این چالش نگهداری و دسترسی را با جدا کردن برنامههای مدیریت داده از ذخیرهسازی دادهها با ارائه یک رابط برنامهنویسی کاربردی (API) به یک زیرساخت ذخیرهسازی داده مشترک، برطرف میکند.
در برنامه های خود از «اقلام» eSciDoc استفاده می کنیم، که موجودیت های اصلی مدل اطلاعاتی eSciDoc هستند. مدل محتوای eSciDoc همچنین اجازه می دهد تا داده ها در بیش از یک فرم نمایشی که توسط بیش از یک طرحواره ابرداده توصیف شده است، ذخیره شوند [ 14 ، 19 ]. موارد eSciDoc همچنین ممکن است از چندین فایل تشکیل شده باشند که باز هم میتوانند با تعداد دلخواه رکوردهای فراداده توصیف شوند. به روز رسانی یک مورد eSciDoc به طور خودکار نسخه جدیدی از مورد را ایجاد می کند.
تمام حقوق دسترسی برای اشیاء داده ای که از طریق eSciDoc اداره می شوند، از جمله فرآیند انتشار، در eSciDoc تعریف شده اند. با تنظیم حقوق دسترسی مناسب، سیستم اجازه می دهد تا مجموعه داده ها را به عنوان خصوصی، به اشتراک گذاشته شده در گروه ها، یا منتشر شده و قابل دسترسی برای عموم اعلام کند. این برای همه برنامههایی که از طریق eSciDoc به اشیاء داده دسترسی دارند، به عنوان مثال، panMetaDocs و PubMan اعمال میشود. فایلهای منتشر شده میتوانند به صورت عمومی در دسترس باشند، یا میتوانند به احراز هویت و مجوز کاربر نیاز داشته باشند. مورد دوم ممکن است در مورد دوره های تحریم انتشار داده ها، یا برای محافظت در برابر دانلود تصادفی مجموعه داده های بسیار بزرگ اعمال شود. پروتکل های احراز هویت پشتیبانی شده عبارتند از پروتکل دسترسی به دایرکتوری سبک وزن (LDAP)، Shibboleth و OpenID [ 22 ، 23 ، 24]. سیستم در GFZ Data Services از LDAP استفاده می کند تا بتواند از اطلاعات کاربر نگهداری شده توسط تسهیلات مدیریت هویت متمرکز پشتیبانی شده در GFZ استفاده مجدد کند. از آنجایی که این امر دسترسی به سیستم را برای کارمندان GFZ محدود میکند، ما همچنین راهحلهای خود را برای قرار دادن مجموعههای داده در معرض بازبینهای خارجی و روشهای جمعآوری ابرداده از دانشمندان خارجی در ادامه این مقاله شرح میدهیم.
2.2. panMetaDocs – داده های تحقیق را توصیف و منتشر کنید
panMetaWorks، که panMetaDocs [ 25 ] از آن مشتق شده است، یک بستر مبتنی بر وب، مشترک، ابرداده و تبادل داده برای پروژه های تحقیقاتی توزیع شده است که توسط Robert Huber در PANGEA [ 18 ] توسعه یافته است.]. هدف این بود که یک رابط کاربری گرافیکی با کاربری آسان، ارائه یک ویرایشگر فراداده غنی، و تسهیل انتشار فراداده از طریق واسط های Really Simple Syndication (RSS) و OAI-PMH ارائه شود. دسترسی به دادهها و ابردادهها را میتوان برای هر محقق خصوصی تنظیم کرد، در یک گروه پروژه به اشتراک گذاشت یا در اینترنت در دسترس عموم قرار داد. در شرایطی که پردازش دادهها بین چندین گروه توزیع میشود، رابط OAI-PMH panMetaWorks جمعآوری ابردادهها را در فهرست دادههای مرکزی موسسه یا پروژه امکانپذیر میسازد.
از آنجایی که panMetaWorks مجموعهای غنی از ویژگیها را ارائه کرد که برای پروژههای تحقیقاتی در GFZ مفید بود، تصمیم گرفتیم که panMetaWorks را با نیازهای خود تطبیق دهیم. ما اجازه استفاده مجدد از کد منبع panMetaWorks را گرفتیم و آن را برای استفاده از eSciDoc API برای ذخیره سازی داده ها و احراز هویت کاربر و تسهیل مدیریت فراداده های مختلف تغییر دادیم. نصبهای panMetaDocs قادر به ذخیره ابردادهها در قالبهای مختلف و طرحوارههای رایج مانند Dublin Core، DataCite [ 26 ]، نمایه INSPIRE ISO19139 [ 27 ] و NASA GCMD DIF [ 28] هستند.]. ذخیره ابرداده در قالب های متعدد با یک آیتم eSciDoc امکان توصیف مجموعه داده ها را در جنبه های بیشتری نسبت به مواردی که تنها توسط یک مخرج مشترک ارائه می شود، می دهد. این برای رسیدگی به طیف گسترده ای از داده های تولید شده در GFZ مورد نیاز است. علاوه بر این، سوابق فراداده را می توان در طول زمان غنی کرد زیرا شی داده از یک دامنه مسئولیت به حوزه دیگر منتقل می شود [ 14]]. با شروع از پایه کد panMetaWorks، ویرایشگر ابرداده را اصلاح کردیم و رابط کاربری را از HTML4 به HTML5 تغییر دادیم. ویرایشگر ابرداده اکنون یک برنامه جاوا اسکریپت است که از چارچوب Sencha ExtJS برای ارائه عناصر رابط کاربری گرافیکی، تجزیه زبان نشانه گذاری توسعه پذیر (XML) و تولید XML استفاده می کند. عملکرد ویرایشگر فراداده در ادامه این مقاله با جزئیات بیشتر توضیح داده خواهد شد. برای اجازه دادن به اشتراک گذاری داده ها بین شرکای پروژه، نمونه های panMetaDocs واسط های خاص خود را برای انتشار فراداده دارند تا قوانین دسترسی eSciDoc را دور بزنند که اجازه انتشار ابرداده مجموعه داده های منتشر نشده را نمی دهد.
برای اعطای دسترسی بازبینان به مجموعه داده منتشر نشده مستقل از سیستم احراز هویت eSciDoc، ما یک پیوند موقت مرموز ایجاد می کنیم که منجر به پیش نمایش صفحه فرود آینده می شود. پیشنمایش شامل تمام دادهها و ابردادهها با DOI صحیح آینده است که ممکن است در طول بررسی همتا ارزیابی شوند و استناد صحیح را میتوان از قبل به فهرست مرجع مقاله اضافه کرد. علاوه بر این، پیوند بررسی برای نشان دادن پیش نمایشی از مجموعه داده های دانشمندان در طول فرآیند انتشار مفید بود. برای جلوگیری از استفاده دانشمندان از DOI قبل از ثبت آن، صفحه پیش نمایش حاوی یادداشتی است که مجموعه داده در حال حاضر در دست بررسی است.
2.3. DOIDB—یک نماینده ضربکاری DOI Proxy
GFZ در چارچوب پروژه “انتشار و استناد به داده های علمی اولیه” (STD-DOI) به یک “عامل انتشار” برای انتشار داده ها تبدیل شد [ 29 ، 30]. در این پیشرو برای DataCite، سازمان بینالمللی که خدمات DOI را برای انتشار دادهها امروز اجرا میکند، کتابخانه ملی علم و فناوری آلمان (TIB Hannover)، انتشار و ذخیرهسازی دادهها را به «عاملهای انتشاراتی» واگذار کرد که انتشارات دادههای خود را در DOI ثبت کردند. خدمات ثبت نام در TIB Hannover. در حالی که سایر شرکای پروژه در STD-DOI مخازن داده واحد را اداره می کردند، GFZ مجبور بود تعدادی از مخازن از قبل موجود (مثلا GEOFON) را برای استفاده از این سرویس یکپارچه کند. برای ثبت و تعدیل ثبتهای DOI در GFZ، ما یک سرویس پروکسی ثبت DOI ایجاد کردیم که آن را DOIDB نامیدیم.
با تاسیس DataCite TIB هانوفر به یک “عامل تخصیص” DataCite تبدیل شد. سرویس ثبت DOI آن برای انتشارات داده تعدادی به روز رسانی فنی را دریافت کرد که یکی از آنها ذخیره ابرداده و سرویس DOI minting است. در اکتبر 2010، DataCite کد منبع مؤلفه جدید به نام DataCite Metadata Store (MDS) را در GitHub منتشر کرد. علاوه بر ثبت DOI، MDS دارای مؤلفه ای برای جستجوی مجموعه داده ها بر اساس ویژگی های فراداده است و مؤلفه ای را برای انتشار فهرست فراداده خود از طریق رابط OAI-PMH فراهم می کند. MDS همچنین حساب های ثبت DOI را برای مراکز داده مرتبط با استفاده از این سرویس برای برش DOI های مجموعه داده مدیریت می کند.
تغییرات در DataCite API در سطح مرکزی همچنین تغییراتی را در DOIDB ما ایجاد کرد. به جای تغییر نرم افزار اصلی در GFZ، تصمیم گرفتیم از DataCite MDS مجدد استفاده کنیم و آن را با تغییرات جزئی تطبیق دهیم [ 31 ]. مانند عملکرد قبلی خود، DOIDB جدید به عنوان یک سرویس پروکسی بین سیستم های داده GFZ و فروشگاه ابرداده DataCite عمل می کند. علاوه بر طرحواره ابرداده DataCite [ 32 ]، DOIDB دو طرحواره اضافی خاص برای علوم زمین را می پذیرد (ISO19139 [ 27 ] و NASA GCMD DIF [ 28 ]). ما کد منبع DOIDB را در GitHub منتشر کردیم [ 33 , 34 , 35] و ما از مکانیسمهای git برای همگام شدن با پیشرفتهای فعلی در پایه کد اصلی DataCite استفاده میکنیم.
3. قالب های انتشار داده ها
دادههای تحقیقاتی با کیفیت بالا باید با ابرداده همراه باشد تا اطمینان حاصل شود که قالبهای داده مستند و قابل درک هستند تا امکان استفاده مجدد توسط دیگران فراهم شود. با فرض کسب و پردازش علمی صحیح و دقیق یک مجموعه داده، دانشمندان، مخزن داده یا ناشر باید اطمینان حاصل کنند که مجموعه داده نه تنها با ابرداده استاندارد شده برای کشف داده ها همراه است، بلکه با توصیف کافی و مناسب برای داده ها نیز همراه است. استفاده مجدد ( به عنوان مثال ، ابرداده ساختاری [ 36 ]).
مکمل های داده به مقالات علمی بیشترین تعداد انتشارات داده را در GFZ تاکنون تشکیل می دهند. این به طور فزاینده ای توسط ناشران پذیرفته شده و حتی تبلیغ می شود که داده های تکمیلی یک مقاله را در یک مخزن داده های خاص رشته یا سازمانی ذخیره کنند، و مستقیماً به مقاله پیوست نشده باشند [7 ]]. مزیت استفاده از مخزن داده با دسترسی باز مانند آنچه در اینجا توضیح داده شده است، این است که مجموعه داده ها به صورت رایگان در دسترس هستند حتی زمانی که مجله یک مجله با دسترسی آزاد نیست. علاوه بر این، اگر مجله به ناشر دیگری منتقل شود، مکمل ها گم نمی شوند، همانطور که در گذشته اتفاق افتاده است. ما به دانشمندان توصیه می کنیم که دست نوشته های خود را به یک مجله بفرستند و مجموعه داده های تکمیلی را در مخزن داده های GFZ منتشر کنند. از لحاظ فنی، ما از panMetaDocs برای ورود داده ها و ابرداده ها به eSciDoc استفاده می کنیم. در مورد دادههای همراه با انتشار، مجموعه داده ممکن است همزمان با مقالات علمی منتشر شود (اگر دادهها قبلاً منتشر نشده باشند)، هر دو بخش دارای ارجاع متقابل هستند، و مجموعه داده باید برای همتایان قابل دسترسی باشد. -فرایند بررسی در این مورد، ما پیوندهای دسترسی موقت را برای فرآیند بررسی، همانطور که در توضیح داده شده است، ارائه می دهیمبخش 2.2 ، و DOI را در مرحله بعد ثبت کنید تا با انتشار مقاله همزمان باشد.
گزارشهای دادهای که در GFZ منتشر شدهاند، ثابت کردهاند که قالبهای انتشار مناسبی برای توصیف جامع مجموعه دادههای منتشر شده، بهویژه برای مجموعه دادههای منتشر شده مستقل هستند. این انتشارات داده ها در یک فرآیند بررسی داخلی بررسی می شوند و در صورت امکان در قالب استاندارد منتشر می شوند. گزارش داده ها همراه با مجموعه داده ها منتشر می شود. در این مورد، ما از PubMan و panMetaDocs به طور مستقل برای قرار دادن یک دست نوشته و داده های تحقیق در eSciDoc و انتشار هر دو موجودیت استفاده می کنیم. نسخه خطی و مجموعه داده هر دو DOIهای فردی را دریافت می کنند که از طریق ابرداده DataCite به آنها ارجاع داده می شود.
برای مجموعه دادههای بزرگی که در مراکز داده بینالمللی ذخیره میشوند، یا خیلی بزرگ هستند که از طریق صفحه فرود قابل دسترسی نیستند، نمونههای panMetaDocs را ارائه میکنیم که فقط ابردادهها را جمعآوری میکنند تا برای صفحه فرود DOI استفاده شوند. در این مورد، لینک های دانلود فایل های داده ممکن است به یک سرور خارجی هدایت شوند.
با توجه به تنوع رشته های تحقیقاتی در GFZ، چارچوب مخزن مبتنی بر فایل برای ذخیره داده ها در هر قالبی به محض ارائه آنها به عنوان فایل های جداگانه باز است. با این وجود، دانشمندان تشویق میشوند تا فایلها را در قالبهایی که برای نگهداری توسط کتابخانه کنگره توصیه میشود، واریز کنند [ 37 ]. در موارد استثنایی، فرمت های فایل رایج در جامعه مربوطه پذیرفته می شود.
4. رابط کاربری برای ارزیابی فراداده
برای پر کردن طرحواره های ابرداده با اطلاعات ارزشمند، هم از اطلاعات استاتیک تولید شده از بافت پروژه و هم اطلاعات پویا وارد شده توسط دانشمندان استفاده می شود. جداسازی در محتوای ایستا و پویا برای تولید فرمهایی با کاربری آسان لازم است که کاربران را با اجبار به وارد کردن مکرر اطلاعات یکسان آزار نمیدهد.
شکل 2 رابط کاربری گرافیکی (GUI) ویرایشگر فراداده جاوا اسکریپت [ 38] را نشان می دهد.] که برای ایجاد ابرداده استاندارد شده برای کشف داده ها، که پایه ثبت DOI است، توسعه یافته است. دانشمند ممکن است متادیتا را در فرم وارد کند، یک فایل XML را در درایو محلی خود ذخیره کند، فایل های XML را در ویرایشگر بارگذاری کند و نسخه نهایی را به سرویس داده های GFZ ارسال کند. در اینجا، عملکردهای اضافی، مانند ثبت DOI و همگام سازی با panMetaDocs و eSciDoc، پس از بررسی فراداده امکان پذیر است. ویرایشگر ابرداده یک برنامه مستقل است که می تواند بدون panMetaDocs یا eSciDoc استفاده شود. این امکان ارسال ابرداده توسط خود دانشمندان را فراهم می کند. علاوه بر این، کاربران خارجی، به عنوان مثال، شرکای پروژه، به راهی برای ارائه ابرداده بدون ورود به سیستم eSciDoc نیاز داشتند.
برای افزایش قابلیت استفاده ویرایشگر فراداده، فیلدهای ابرداده نشان داده شده در رابط کاربری گرافیکی با هدف قابل استفاده بودن و قابل فهم بودن برای دانشمندان است. این شامل عدم درخواست ورود دستی برای اطلاعاتی است که ممکن است به طور خودکار بازیابی شوند، به عنوان مثال، URL یک مجوز Creative Commons خاص، اما همچنین تغییر نام برخی از فیلدها در زبان “علمی”، به عنوان مثال، “سازندگان” DataCite “نویسندگان” نامیده می شوند. “. این انطباق فقط در رابط کاربری گرافیکی انجام شد. پایگاه داده خود شرایط مورد نیاز را طبق استانداردهای ابرداده پشتیبانی شده حفظ می کند. برای جلوگیری از خطاهای تایپی، از منوهای کشویی استفاده می شود و توضیحات مربوط به ورودی های احتمالی از طریق پنجره های بازشو ارائه می شود ( شکل 2 را ببینید.). مستندات کامل فیلدهای فراداده و استفاده از ویرایشگر فراداده برای دانلود در بخش راهنما موجود است. به عنوان یک سرویس اضافی، ویرایشگر ابرداده مجهز به یک ابزار نگاشت تعاملی است که از طریق آن میتوان مختصات جغرافیایی را از نقشه بازیابی کرد و بهطور خودکار در فیلدهای فوقداده مربوطه وارد کرد، اما همچنین به عنوان بازخورد بصری برای مختصات وارد شده به صورت دستی عمل میکند که بلافاصله در صفحه نمایش داده میشوند. نقشه. چندین ورودی جغرافیایی به عنوان جعبه یا نقطه امکان پذیر است.
5. صفحات فرود – ارائه مجموعه های داده ویژه رشته
شکل 3 یک صفحه فرود DOI را نشان می دهد که توسط تبدیل صفحه سبک XSLT از یک آیتم eSciDoc حاوی ابرداده تولید شده با panMetaDocs ایجاد شده است. از آنجایی که هر طرحواره ابرداده نقاط قوت و ضعف خود را دارد، ارائه بصری در یک مرورگر اینترنتی ترکیبی از اطلاعات ارائه شده از eSciDoc و از اطلاعات پراکنده شده در طرحواره های ابرداده مختلف است. اطلاعات مربوط به محدودیتهای دانلود برای تحریم در eSciDoc ذخیره میشد، اطلاعات تماس و پوشش مکانی در طرح ISO19139 [ 27 ] و کلیدواژههای علمی از طرح ناسا GCMD DIF [ 28 ] میآیند. علاوه بر این، طرحواره فراداده DataCite [ 32] برای پیوند به انواع مختلف انتشارات استفاده شد. اطلاعات استنادی نشریات مرتبط (که فقط با DOI در فرم فراداده وارد شده است) در زمان نمایش در مرورگر با استفاده از جاوا اسکریپت از DataCite و Crossref دانلود می شود.
ارائه واضح و کاربرپسند مجموعههای داده چالشی اضافی برای ایجاد صفحات فرود است، زیرا دادههای تولید شده نه تنها در قالبهای فایل، بلکه بهویژه در فرادادههای خاص حوزه تحقیق برای استفاده مجدد متفاوت است. این امر بهویژه برای دادههای بسیار متنوع GFZ رشتههای علمی مختلف مرتبط است و منجر به توسعه صفحات فرود DOI ویژه رشته شد. این امر عمدتاً با کاهش اطلاعات به عناصر مربوطه برای هر رشته به دست می آید و قابلیت استفاده و استفاده مجدد از مجموعه داده های منتشر شده را بهبود می بخشد. یک مدل گرانشی جهانی منتشر شده از طریق مرکز بینالمللی مدلهای زمین جهانی [ 39 ]، به عنوان مثال، نیازی به نقشه ندارد ( شکل 4)در حالی که نقشههایی با جعبههای محدودکننده متعدد برای ارائه کمپینهای پرواز فراطیفی با مشاهدات میدانی مرتبط در برنامه نقشهبرداری و تحلیل محیطی آلمان ضروری هستند (EnMAP [ 40 ]، شکل 4 ). با این وجود، ابرداده استاندارد شده برای کشف داده ها همیشه جمع آوری شده و برای دانلود و مشاهده درون خطی در صفحه فرود در دسترس است ( شکل 3 ج).
مزیت اضافی داشتن انواع مختلف صفحات فرود، امکان ایجاد طرح های خاص پروژه برای پروژه های مشترک بزرگ بین GFZ و شرکای خارجی است ( شکل 4 ). با تولید اسکریپتهایی برای ارائه دادهها به روشی خاص، امکان انتخاب رندر HTML در زمان برش DOI وجود دارد.
6. مجوزها و عملکرد پشته نرم افزار
بسته به مخاطبان هدف یک اثر فکری، میتوان آن را تحت مجوزی منتشر کرد که محدودیتهایی برای استفاده مجدد تعیین میکند یا هیچ محدودیتی برای برنامههای آینده تعیین نمیکند. مجوزهای موجود برای نرم افزار می توانند شرایط مجوز برای نرم افزارهای مشتق شده را تعیین کنند. بنابراین، هنگام ترکیب اجزای مختلف نرمافزار، باید دقت ویژهای برای رعایت مجوزهای اعمال شده توسط هر یک از نویسندگان اصلی انجام شود. در مورد ما میان افزار eSciDoc از “مجوز توسعه و توزیع مشترک” در نسخه 1.0 استفاده می کند که توسط برنامه PubMan نیز استفاده می شود. DOIDB و panMetaDocs تحت “مجوز آپاچی” در نسخه 2.0 منتشر شده اند. ویرایشگر فراداده از “مجوز عمومی عمومی گنو” در نسخه 3.0 استفاده می کند که از چارچوب Sencha EXTJS سرچشمه می گیرد و در مورد ما محدودترین مجوز است.
برای تخمین عملکرد کل پشته نرم افزار، باید به DOIDB و میان افزار eSciDoc و برنامه های آنها به طور جداگانه نگاه کنیم. DOIDB به عنوان یک پروکسی برای زیرساخت DataCite عمل می کند و زمان لازم برای پردازش تماس های ثبت نام نشان دهنده زمان پاسخگویی زیرساخت DataCite است. در مورد ما ثبت نام های DOIDB به ترتیب 1.2 تا 1.5 ثانیه طول می کشد و تفاوت معنی داری بین ثبت مستقیم در DataCite و ثبت از طریق DOIDB ما وجود ندارد. اجزای جستجو و انتشار به صورت محلی بدون ارتباط با زیرساخت های خارجی عمل می کنند و زمان پاسخگویی معمولاً به ترتیب کسری از ثانیه است.
میانافزار eSciDoc ذخیرهسازی مرکزی برای چندین برنامه است که از eSciDoc REST API برای ذخیره دادهها و ابردادهها استفاده میکنند. هیچ زیرساخت خارجی برای ذخیره داده یا ابرداده وجود ندارد. در صورت بروز مشکل در عملکرد، انتقال برنامههایی که از eSciDoc به عنوان پشتیبان داده استفاده میکنند به میزبانی متفاوت و سریعتر بسیار آسان است. با این حال، میانافزار eSciDoc قابل تکرار نیست و باید در یک محیط نسبتاً سریع راهاندازی شود. مجموعه ما در حال حاضر شامل تقریباً 28000 مورد eSciDoc است و عملیات خواندن برای دانلود فراداده یک مورد معمولاً حدود یک ثانیه طول می کشد. پشته نرم افزار ما اجازه می دهد تا فایل ها را تا 100 مگابایت ذخیره کند، که محدودیتی است که توسط محیط اجرای PHP panMetaDocs تعیین شده است. بزرگترین فایلی که ذخیره می کنیم 2.8 گیگابایت حجم دارد و از طریق یک برنامه جاوا آپلود شده است.
7. بحث، درس های آموخته شده، و کار آینده
زیرساخت انتشار ارائه شده در این مقاله شامل یک مرکز ذخیرهسازی مرکزی برای دادهها و ابردادهها (eSciDoc)، برنامههای کاربردی برای آپلود دادهها و ابردادهها در مرکز ذخیرهسازی (PubMan، panMetaDocs) و یک برنامه کاربردی برای ثبت ثبتهای DOI و ابردادههای مرتبط (DOIDB) است. . این زیرساخت انتشار به شکل مدولار ساخته شده است تا امکان مبادله اجزای منفرد را بدون تأثیرات جزئی بر وضعیت عملیاتی سیستم فراهم کند. با این حال، eSciDoc به عنوان ذخیرهسازی مرکزی نقشی محوری در سیستم ایفا میکند و همه برنامههایی که از آن برای ذخیرهسازی دادهها استفاده میکنند باید با eSciDoc API سازگار باشند. این مهم زمانی است که تغییراتی در API eSciDoc در طول بهروزرسانی نسخه ایجاد میشود.
برای به حداقل رساندن هزینه های تعمیر و نگهداری، ما به دنبال جلوگیری از توسعه نرم افزار سفارشی و خطر قفل شدن فروشنده بودیم، اما به دنبال استفاده مجدد از اجزای رایگان و منبع باز موجود توسعه یافته توسط جامعه مدیریت دیجیتال بودیم. سیستم انتشار حاصل از اجزای نرم افزاری از قبل موجود تشکیل شده است که از قبل با اکثر نیازهای ما مطابقت داشته و نیاز به تطبیق کمی داشت.
درجه خاصی از افزونگی در نحوه ذخیره ابرداده ها در هر یک از مؤلفه ها وجود دارد، که در eSciDoc، در DOIDB و نمونه های panMetaDocs مربوطه است. با این حال، هر ذخیره ابرداده در مؤلفههای نرمافزار هدف خاصی را دنبال میکند: eSciDoc دادهها و ابردادههای مربوط به موارد را ذخیره میکند، DOIDB ابردادههای GFZ DOI را ذخیره میکند و panMetaDocs یک کپی از ابرداده نمونه مربوطه را برای دور زدن مدیریت حقوق دسترسی جهانی ذخیره میکند. eSciDoc به نفع دسترسی مبتنی بر پروژه به ابرداده داده های منتشر نشده است.
واگذاری احراز هویت کاربر به GFZ LDAP ما را از مدیریت حسابهای کاربری با استفاده مجدد از اطلاعاتی که قبلاً توسط مدیریت هویت سرویسهای فناوری اطلاعات GFZ ارائه شده بود نجات داد. نقطه ضعف استفاده از LDAP این است که مدیریت کاربر زیرساخت eSciDoc و تمام برنامه های کاربردی متصل به eSciDoc را به کاربران در GFZ مرتبط می کند در حالی که گنجاندن کاربران خارجی را دشوار می کند. در برخی موارد، دسترسی خارجی به دادهها مورد نیاز است، چه در همکاریهای پروژه و چه در فرآیند بررسی همتا که شامل دادهها میشود. برای اجازه دادن به بازبینان برای دسترسی به داده ها، می توان یک پیوند موقت ایجاد کرد تا امکان دسترسی به داده های منتشر نشده را فراهم کند. با این حال، مشکل همچنان ادامه دارد و مدیریت حسابهای کاربری خارجی در eSciDoc زمانی که LDAP مکانیسم اصلی احراز هویت است، دشوار است. در زمان اجرای eSciDoc در GFZ، اطلاعات حساب کاربری فقط از طریق LDAP در دسترس بود. برای نصبهای جدید، توصیه میکنیم از فناوریهایی برای احراز هویت فدرال استفاده کنید، مانند OpenID و Shibboleth [23 ، 24 ].
PHP برای برنامه های کاربردی کلاینت eSciDoc انتخاب شد زیرا به نظر می رسید در مقایسه با زبان های برنامه نویسی مانند جاوا برای محققان در پروژه ها استفاده از آن آسان تر باشد. امروز احتمالاً پایتون را به دلیل محدودیت ورودی کم و فهرست غنی از کتابخانههای کد علمی توصیه میکنیم. مدیریت جریان های بزرگ داده در PHP یک مورد استفاده عجیب و غریب برای این زبان برنامه نویسی است. PHP برای تحویل سریع وب سایت ها طراحی شده است و اندازه فایل های بزرگ مشکل ساز است. در حالی که تغییر پارامترهای مدیریت حافظه در زمان اجرا PHP به حل این مشکل کمک می کند، محیط اجرای PHP حداکثر مدت زمان آپلود را محدود می کند. مشخص شد که این مشکل ساز است زیرا مدت زمان مورد نیاز برای آپلود داده ها از قبل تخمین زده نمی شود. یک امکان برای مدیریت داده های بزرگ، ذخیره ابرداده XML در داخل eSciDoc و ذخیره یک مرجع (URL) به داده های باینری در یک سرور خارجی است. این رویکرد از آپلودهای بزرگ در eSciDoc جلوگیری می کند، اما کنترل دسترسی eSciDocs به داده های باینری را نیز دور می زند.
در حالی که صفحات فرود خاص جامعه یک الزام در پروژه های فدرال هستند، حفظ حضور وب آنها در دوره های زمانی طولانی نیز به منابع اضافی برای نگهداری زیرساخت های اساسی نیاز دارد. این باید به دقت بررسی شود، اگرچه ما معتقدیم که XML Stylesheet Transformation (XSLT) میتواند نیازهای تعمیر و نگهداری را با ارائه مکانیزمی مستقل از پلتفرم سختافزار و زبان برنامهنویسی برای تولید صفحات وب برای ارائه داده به حداقل برساند.
در حال حاضر، ویرایشگر فراداده panMetaDocs برای ورود پوششهای فضایی کمک میکند. این فرم همچنین میتواند از طریق APIهای DataCite، Crossref و ORCID برای پر کردن شناسههای صحیح با جستجوی تعاملی برای مجموعه دادههای مرتبط، مقالات مرتبط و نویسندگان پشتیبانی کند. این به محققان کمک می کند تا مجموعه داده های خود را به داده ها، دست نوشته ها و نویسندگان مرتبط مرتبط کنند. علاوه بر این، تقاضا برای پسوندهای خاص حوزه تحقیق یا اصلاحات ویرایشگر ابرداده وجود دارد. این امکان وجود دارد که ابرداده را برای برنامه های داده مرتبط باز کرده و از این طریق ارتباط ماشین به ماشین را فعال کنید. نگاشتی از طرحواره ابرداده DataCite به چارچوب شرح منابع (RDF) وجود دارد و چنین نگاشتهایی برای فراداده ISO19139 [ 44 ، 45] نیز موجود است.]. ما از اصطلاحات اصطلاحنامه چند زبانه GEMET استفاده می کنیم که برای فراداده INSPIRE [ 27 ] استفاده می شود. علاوه بر این، ما کلمات کلیدی علمی را از ناسا GCMD DIF [ 28 ] به ابرداده ها اعمال می کنیم. هر دو لیست واژگان بسیار محبوب هستند و یافتن داده های مرتبط را آسان تر می کنند.
8. نتیجه گیری
بر اساس مفهوم “حوزه های مسئولیت” [ 15]، ما زیرساختی برای نگهداری و انتشار داده ها ایجاد کردیم که مقیاس پذیر و سازگار با نیازهای دائمی در حال تغییر پروژه های تحقیقاتی در یک مرکز تحقیقاتی ملی است. ماهیت ماژولار سیستم و معماری سرویس گرا آن به ما این امکان را می دهد که بخش های بزرگی از سیستم را بدون تغییر نگه داریم، در حالی که اجزای جدید را اضافه کرده و در صورت نیاز اجزای منسوخ را از رده خارج کنیم. اجزای نرم افزار تا زمانی که جایگزین آن و اجزای مشتری ما یک API مشترک دارند، ممکن است مبادله شوند. استفاده از یک میانافزار آگنوستیک محتوا برای مدیریت ذخیرهسازی دادهها به ما امکان میدهد تا هر نوع فایلی را که توسط هر طرح ابردادهای توصیف شده است، پردازش کنیم، از جمله با طرحوارههای متعدد همزمان، در قالبهای نمایشی متعدد، یا ذخیرهسازی خارج از سیستم. تمامی اجزای نرم افزار مبتنی بر نرم افزار رایگان و متن باز هستند،
ارائه یک API مشترک به پروژه ها اجازه می دهد تا سیستم های داده خود را مستقل از سیستم مدیریت داده های سازمانی توسعه دهند. برای انتقال داده ها به “دامنه دائمی”، سیستم های مستقل باید بتوانند با API مشترک ارتباط برقرار کنند. داده های ذخیره شده ایمن هستند و توسط کتابخانه نگهداری می شوند، حتی اگر تعمیر و نگهداری نرم افزار خاص پروژه ممکن است یک روز ادامه پیدا نکند. از دیدگاه سازمانی، این تفکیک نگرانی ها به “حوزه های مسئولیت” [ 14]] این مزیت را دارد که تخصیص منابع برای توسعه و نگهداری سیستم و تعیین منابع تأمین مالی این منابع آسان تر می شود. در حالی که ممکن است نگهداری نرم افزار از پروژه های تکمیل شده دشوار به نظر برسد، ممکن است دیگر در سناریوی ارائه شده لازم نباشد. تمام دادهها و ابردادهها باید به «دامنه دائمی» که توسط «موسسه حافظه» اداره میشود، منتقل میشد و در آنجا مدیریت و در دسترس باقی میماند.
الگوی ارائه شده در این مقاله با مفاهیم کنونی نگهداری داده های تحقیقاتی و حفظ دیجیتال بلند مدت مطابقت دارد. معماری مدولار و خدمات گرا آن را می توان با نیازهای در حال تغییر مدیریت داده در پروژه های تحقیقاتی تطبیق داد، در حالی که در عین حال ذخیره سازی داده های هسته ای و زیرساخت دسترسی پایدار را حفظ می کند که با سرعت بسیار کمتری توسعه می یابد. بنابراین، این الگو ممکن است به عنوان طرحی برای سایر مؤسسات در نظر گرفته شود که سیستمی در سطح سازمانی برای جمع آوری داده های تحقیقاتی پیاده سازی کنند.
منابع
- اعلامیه برلین در مورد دسترسی آزاد به دانش در علوم و علوم انسانی. در دسترس آنلاین: http://openaccess.mpg.de/Berlin-Declaration (در 24 فوریه 2016 قابل دسترسی است).
- وزرای علوم G8 بیانیه وزرای علوم G8 در دسترس آنلاین: https://www.gov.uk/government/news/g8-science-ministers-statement (دسترسی در 10 ژوئن 2015).
- کمیسیون اروپایی. اجرای اتحادیه اروپا منشور داده های باز G8. در دسترس آنلاین: http://ec.europa.eu/information_society/newsroom/cf/dae/document.cfm?doc_id=3489 (دسترسی در 10 ژوئن 2015).
- وزارت امور اقتصادی و انرژی فدرال، وزارت کشور فدرال و وزارت حمل و نقل و زیرساخت دیجیتال فدرال. دستور کار دیجیتال 2014-2017 دولت فدرال آلمان. در دسترس آنلاین: http://www.digitale-agenda.de/Content/DE/_Anlagen/2014/08/2014-08-20-digitale-agenda-engl.pdf?__blob=publicationFile&v=6 (دسترسی در 10 ژوئن 2015 ).
- سازمان توسعه و همکاری اقتصادی (OECD). اعلامیه دسترسی به داده های تحقیق از محل بودجه عمومی. در دسترس آنلاین: http://acts.oecd.org/Instruments/ShowInstrumentView.aspx?InstrumentID=157 (در 26 نوامبر 2015 قابل دسترسی است).
- پارلمان اروپا، شورای اتحادیه اروپا. دستورالعمل 2007/2/EC پارلمان اروپا و شورای 14 مارس 2007 مبنی بر ایجاد زیرساختی برای اطلاعات مکانی در جامعه اروپا (INSPIRE). در دسترس آنلاین: http://eur-lex.europa.eu/legal-content/EN/ALL/?uri=CELEX:32007L0002 (در 28 نوامبر 2015 قابل دسترسی است).
- ائتلاف در انتشار داده ها در علوم زمین و فضایی. بیانیه تعهد ناشران علوم زمین و فضا و تأسیسات داده. در دسترس آنلاین: http://www.copdess.org/statement-of-commitment/ (دسترسی در 5 ژوئیه 2015).
- کلمپ، جی. Geowissenschaften. در Langzeitarchivierung von Forschungsdaten—Eine Bestandsaufnahme ; Neuroth, H., Strathmann, S., Oßwald, A., Scheffel, R., Klump, J., Ludwig, J., Eds. Verlag Werner Hülsbusch: Boizenburg، آلمان، 2012; صص 179-194. [ Google Scholar ]
- برنامه GEOFON، GFZ Potsdam. در دسترس آنلاین: http://geofon.gfz-potsdam.de (دسترسی در 30 نوامبر 2015).
- سرویس بین المللی GNSS IGS (خدمات بین المللی GPS سابق). در دسترس آنلاین: https://igscb.jpl.nasa.gov (دسترسی در 30 نوامبر 2015).
- شبکه بین المللی رصدخانه مغناطیسی بلادرنگ در دسترس آنلاین: http://www.intermagnet.org (دسترسی در 30 نوامبر 2015).
- کراتز، جی. Strasser, C. انتشار داده ها اجماع و مناقشه ; F1000Research: لندن، بریتانیا، 2014. [ Google Scholar ]
- پایگاه انتشارات GFZ. در دسترس آنلاین: http://gfzpublic.gfz-potsdam.de (دسترسی در 30 نوامبر 2015).
- کلمپ، جی. اولبریخت، دی. Conze, R. بررسی گذشته عمیق وب – استراتژی های مهاجرت برای محتوای وب برنامه حفاری عمیق قاره آلمان. GeoRes. J. 2015 ، 6 ، 98-105. [ Google Scholar ] [ CrossRef ]
- ترلوار، ا. Groenewegen، D.; هاربو-ری، سی. پیوستار مدیریت داده – مدیریت اشیاء داده در مخازن سازمانی. D-Lib Mag. 2007 ، 13 . [ Google Scholar ] [ CrossRef ]
- دواراکوندا، ر. پالانیسامی، جی. گرین، جی. Wilson, B. به اشتراک گذاری و بازیابی داده ها با استفاده از OAI-PMH. علوم زمین Inf. 2011 ، 4 ، 1-5. [ Google Scholar ] [ CrossRef ]
- فیلدینگ، سبک های معماری RT و طراحی معماری های نرم افزاری مبتنی بر شبکه. دکتری پایان نامه، دانشگاه کالیفرنیا، ایروین، کالیفرنیا، ایالات متحده آمریکا، 2000. [ Google Scholar ]
- Huber, R. panMetaWorks—PangaWiki. در دسترس آنلاین: http://wiki.pangaea.de/wiki/Panmetaworks (دسترسی در 9 ژوئیه 2015).
- اولبریخت، دی. Klump, J. panMetaDocs – ابزاری برای جمع آوری و مدیریت اشیاء دیجیتال در یک محیط تحقیقاتی علمی. در مجموعه مقالات مجمع عمومی اتحادیه علوم زمین اروپا، وین، اتریش، 3 تا 8 آوریل 2011.
- اولبریخت، دی. کلمپ، جی. Bertelmann, R. انتشار مجموعه داده ها با eSciDoc و panMetaDocs. در مجموعه مقالات مجمع عمومی اتحادیه علوم زمین اروپا، وین، اتریش، 22-27 آوریل 2012.
- رزم، م. شویختنبرگ، اف. واگنر، اس. Hoppe، M. eSciDoc زیرساخت: چارچوب تحقیق الکترونیکی مبتنی بر فدورا. در مجموعه مقالات کنفرانس اروپایی کتابخانه های دیجیتال، کورفو، یونان، 27 سپتامبر تا 2 اکتبر 2009. ص 227-238.
- جامعه اینترنت پروتکل دسترسی به دایرکتوری سبک وزن (LDAP): نقشه راه مشخصات فنی. در دسترس آنلاین: https://tools.ietf.org/html/rfc4510 (در 9 ژوئیه 2015 قابل دسترسی است).
- بنیاد OpenID. مشخصات و اطلاعات توسعه دهنده در دسترس آنلاین: http://openid.net/developers/specs/ (در 9 ژوئیه 2015 قابل دسترسی است).
- کنسرسیوم Shibboleth. Shibboleth چیست. در دسترس آنلاین: http://shibboleth.net/about/ (در 9 ژوئیه 2015 قابل دسترسی است).
- مخزن کد منبع panMetaDocs. در دسترس آنلاین: http://panmetadocs.sf.net (در 29 نوامبر 2015 قابل دسترسی است).
- استار، جی. Gastl, A. IsCitedBy: یک طرح ابرداده برای DataCite. D-Lib Mag. 2007 ، 17 . [ Google Scholar ] [ CrossRef ]
- فراداده های تیم پیش نویس و مرکز تحقیقات مشترک کمیسیون اروپا. قوانین اجرای فراداده INSPIRE: دستورالعمل های فنی بر اساس EN ISO 19115 و EN ISO 19119 . مرکز تحقیقات مشترک کمیسیون اروپا: بروکسل، بلژیک، 2010; در دسترس آنلاین: http://inspire.ec.europa.eu/documents/Metadata/INSPIRE_MD_IR_and_ISO_v1_2_20100616.pdf (در 20 فوریه 2016 دسترسی پیدا کرد).
- اداره ملی هوانوردی و فضایی – فهرست اصلی تغییر جهانی. فرمت تبادل دایرکتوری (DIF) راهنمای نویسنده. در دسترس آنلاین: http://gcmd.nasa.gov/add/difguide/ (در 28 نوامبر 2015 قابل دسترسی است).
- کلمپ، جی. هوبر، آر. Diepenbroek، M. DOI برای دادههای علوم زمین – چگونه شیوههای اولیه ادراکات فعلی را شکل میدهند. علوم زمین Inf. 2016 ، 9 ، 123-136. [ Google Scholar ] [ CrossRef ]
- کلمپ، جی. برتلمن، آر. بریس، جی. دیپنبروک، ام. گروب، اچ. هاک، اچ. لاوتنشلاگر، ام. شیندلر، یو. سنس، من. Wächter, J. انتشار داده در ابتکار دسترسی آزاد. اطلاعات علمی J. 2006 ، 5 ، 79-83. [ Google Scholar ] [ CrossRef ]
- کلمپ، جی. Ulbricht, D. استفاده مجدد از ذخیره ابرداده DataCite به عنوان پروکسی ثبت DOI و رجیستری IGSN. در مجموعه مقالات اتحادیه ژئوفیزیک آمریکا، سانفرانسیسکو، کالیفرنیا، ایالات متحده آمریکا، 3 تا 7 دسامبر 2012.
- گروه کاری فراداده DataCite. طرحواره فراداده DataCite برای انتشار و استناد به داده های تحقیق ، نسخه 3.1. DataCite: لندن، بریتانیا، 2015. [ Google Scholar ] [ CrossRef ]
- DOIDB Store GitHub Repository. در دسترس آنلاین: https://github.com/ulbricht/mds/tree/doidb (در 29 نوامبر 2015 قابل دسترسی است).
- جستجوی DOIDB مخزن GitHub. در دسترس آنلاین: https://github.com/ulbricht/search/tree/doidb (در 29 نوامبر 2015 قابل دسترسی است).
- مخزن DOIDB OAI-PMH GitHub. در دسترس آنلاین: https://github.com/ulbricht/oaip/tree/doidb (دسترسی در 29 نوامبر 2015).
- سازمان ملی استاندارد اطلاعات. درک متادیتا ؛ NISO Press: Bethesda، MD، USA، 2004. [ Google Scholar ]
- کتابخانه کنگره. بیانیه فرمت های توصیه شده در دسترس آنلاین: http://www.loc.gov/preservation/resources/rfs/ (در 24 فوریه 2016 قابل دسترسی است).
- ویرایشگر متادیتا برای مخزن گیت هاب panMetaDocs. در دسترس آنلاین: https://github.com/ulbricht/pmdmeta (در 29 نوامبر 2015 قابل دسترسی است).
- بارتلمز، اف. کوهلر، مرکز بینالمللی مدلهای زمین جهانی (ICGEM). در مجله Geodesy: The Geodesist’s Handbook 2012 ; دروز، اچ.، اد. Springer: برلین، آلمان، 2012; ص 932-934. [ Google Scholar ]
- گوانتر، ال. کافمن، اچ. سگل، ک. فورستر، اس. روگاس، سی. چابریلات، س. کوستر، تی. هالشتاین، ا. راسنر، جی. چلبیک، سی. و همکاران ماموریت طیفسنجی تصویربرداری فضایی EnMAP برای رصد زمین. Remote Sens. 2015 , 7 , 8830–8857. [ Google Scholar ] [ CrossRef ]
- لورنز، اچ. روزبرگ، ج.-ای. جوهلین، سی. بجلم، ال. المکویست، بی. برتت، تی. Conze، R.; جی، دی جی. کلونوسکا، آی. پاسکال، سی. و همکاران COSC-1 گزارش عملیاتی – مجموعه داده های عملیاتی ; خدمات داده GFZ: پوتسدام، آلمان، 2015; در دسترس آنلاین: http://doi.org/10.1594/GFZ.SDDB.ICDP.5054.2015 (دسترسی در 20 فوریه 2016).
- فورسته، سی. بروینسما، اس. ابریکوسوف، او. Lemoine, J.-M.; مارتی، جی سی. فلچتنر، اف. بالمینو، جی. بارتلمز، اف. Biancale، R. EIGEN-6C4 آخرین مدل میدان گرانشی جهانی ترکیبی شامل دادههای GOCE تا درجه و سفارش 2190 GFZ Potsdam و GRGS Toulouse . خدمات داده GFZ: پوتسدام، آلمان، 2015; در دسترس آنلاین: http://doi.org/10.5880/icgem.2015.1 (دسترسی در 20 فوریه 2016).
- نویمان، سی. ویس، جی. Itzerott, S. Döberitzer Heide 2008/2009—یک کمپین پرواز مقدماتی EnMAP ; خدمات داده GFZ: پوتسدام، آلمان، 2015; در دسترس آنلاین: http://doi.org/10.5880/enmap.2015.001 (دسترسی در 20 فوریه 2016).
- DataCite Ontology GitHub Repository. در دسترس آنلاین: http://github.com/datacite/ontology (دسترسی در 17 ژانویه 2016).
- OWL نمایندگی ISO 19115 (اطلاعات جغرافیایی-فراداده). در دسترس آنلاین: http://def.seegrid.csiro.au/isotc211/iso19115/2003/metadata (در 24 فوریه 2016 در دسترس است).
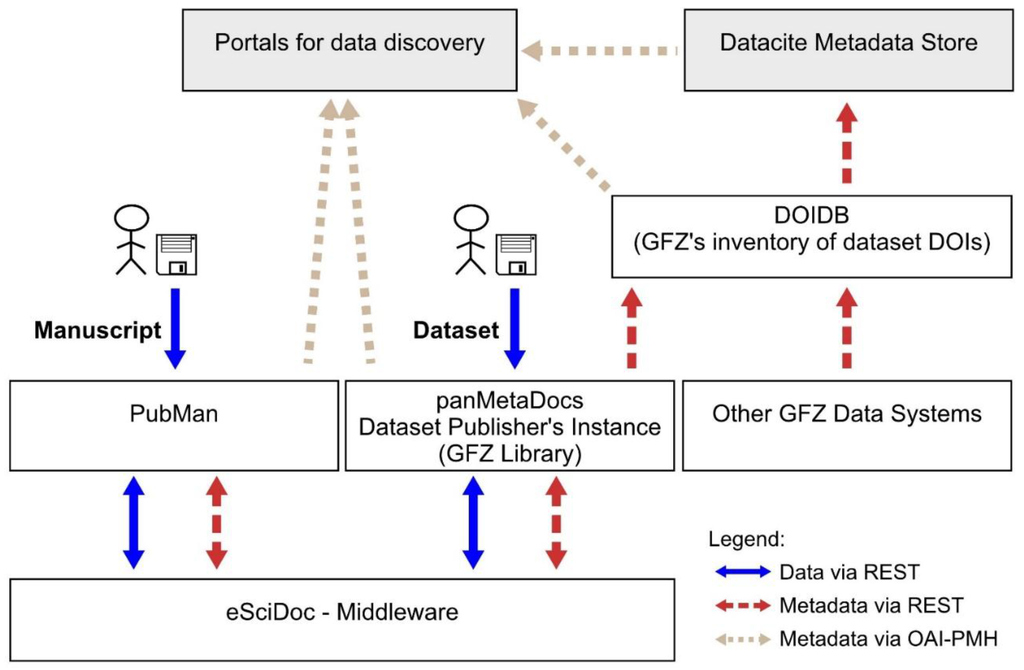
شکل 1. تصویری از معماری سیستم مجموعه نرم افزار مدولار برای مخزن سرویس های داده GFZ. جعبه های خاکستری نشان دهنده سیستم های موجود در حوزه عمومی است.
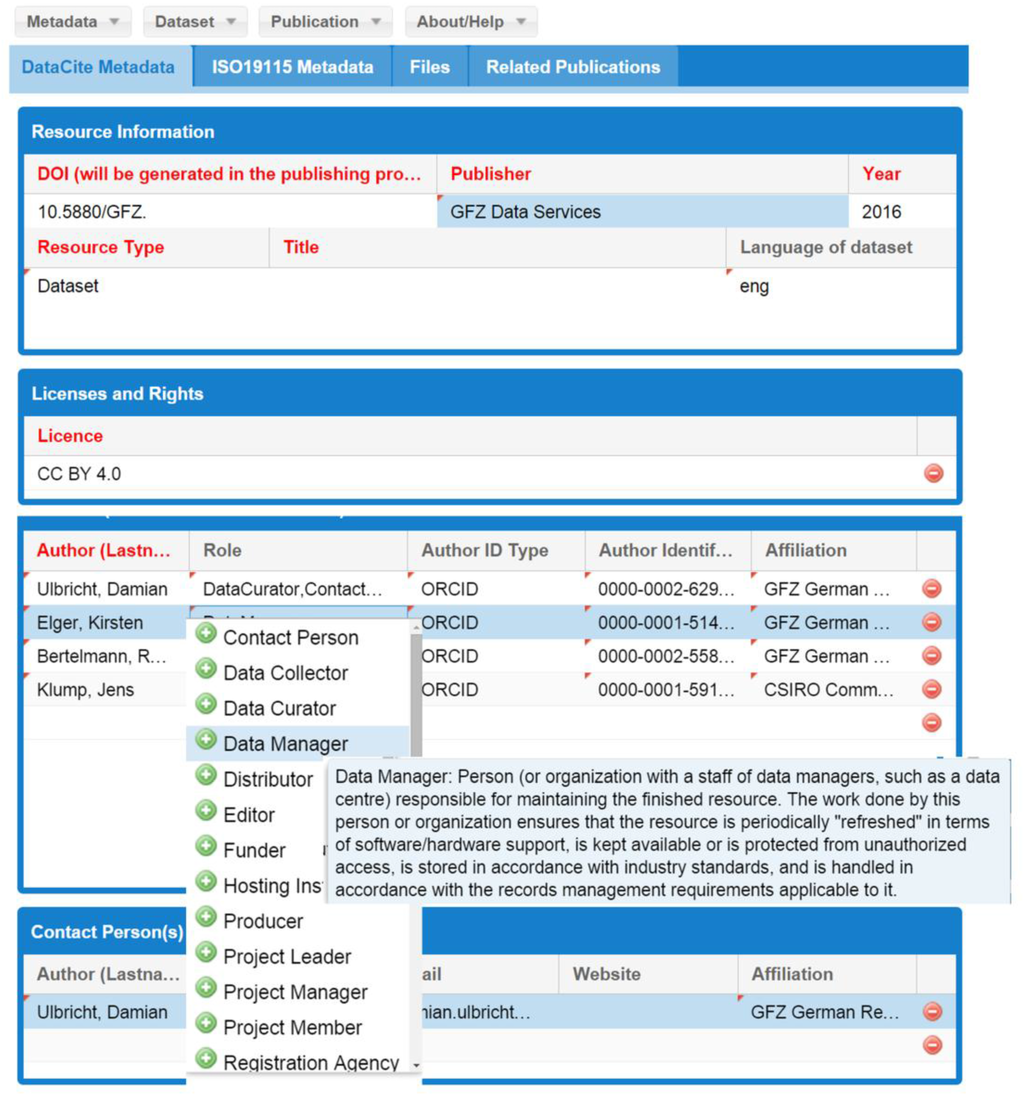
شکل 2. استخراج از رابط کاربری گرافیکی (GUI) ویرایشگر فراداده مبتنی بر جاوا اسکریپت برای مجموعه ثبت فراداده و شناسه های شی دیجیتال (DOI)، بر اساس طرحواره ابرداده DataCite 3.1 [32] و تکمیل شده توسط فیلدهای موضوعی خاص . همانطور که برای داده های GFZ مورد نیاز است. فیلدهای فراداده اجباری و توصیه شده دارای کد رنگی هستند (حروف قرمز = فیلدهای اجباری). در صورت امکان، لیست های اسمی و توضیحات در پنجره های پاپ آپ اجرا می شد.

شکل 3. یک صفحه فرود DOI که توسط تبدیل صفحه سبک XSLT یک مورد eSciDoc ایجاد شده است (مثالی از برنامه بین المللی حفاری قاره ای [ 41 ]). اطلاعات مربوط به فایلهای داده، مخاطبین، و محدودیتهای دانلود ( A )، مقالات مرتبط و مجموعه دادههای پیوندی ( B ) و لینکهای دانلود برای ابرداده در طرحوارههای ابرداده مختلف ( C ) مشخص شده است. در این مثال، فایلهای داده تا حدی دسترسی باز هستند و مستقیماً از طریق صفحه فرود قابل دانلود هستند (اندازه فایل نشان داده شده است)، در حالی که سایر فایلهای داده دسترسی محدودی برای یک دوره تحریم تعریف شده دارند (با علامت قرمز R). داده های نقشه © OpenStreetMap مشارکت کنندگان هستند و تحت مجوز CC-BY-SA منتشر شده اند.

شکل 4. صفحات فرود مخصوص رشته های مختلف که داده های منتشر شده از طریق سرویس های داده GFZ را توصیف می کنند. نمونه ای برای سرویس انتشار مدل های گرانشی جهانی ICGEM، مرکز بین المللی مدل های زمین جهانی [ 42 ]، ( سمت چپ ). صفحه فرود ویژه پروژه برای داده های هوابرد ابرطیفی در برنامه نقشه برداری و تحلیل محیطی آلمان (EnMAP) [ 43 ]، ( راست ). شکل 3 را برای طرح استاندارد GFZ ببینید . داده های نقشه © OpenStreetMap مشارکت کنندگان هستند و تحت مجوز CC-BY-SA منتشر شده اند.
© 2016 توسط نویسندگان؛ دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons by Attribution (CC-BY) (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر