

خلاصه
توسعه فزاینده اطلاعات جغرافیایی داوطلبانه (VGI) و نقش بالقوه آن در مطالعات GIScience سوالاتی را در مورد کیفیت داده های حاصل ایجاد می کند. چندین مطالعه به کیفیت VGI از دیدگاه های مختلف مانند کامل بودن، دقت موقعیتی، ثبات و غیره می پردازند. آنها عمدتاً در مورد ناهمگونی کیفیت داده اتفاق نظر دارند. مشکل ممکن است به دلیل فقدان رویه های استاندارد برای جمع آوری داده ها و عدم وجود بازخورد کنترل کیفیت برای شرکت کنندگان داوطلب باشد. در تحقیق خود، ما با کیفیت داده ها از منظر طبقه بندی سروکار داریم. مخصوصاً در پروژههای نقشه برداری VGI، تخصص محدود شرکتکنندگان و تعریف غیر دقیق ویژگیهای جغرافیایی منجر به کلاسهای همپوشانی مفهومی میشود، جایی که یک موجودیت به طور منطقی میتواند به چندین کلاس تعلق داشته باشد، مثلاً دریاچه یا برکه ، پارک یا باغ ، مرداب یا باتلاق . و غیره. معمولاً ویژگی های کمی و/یا کیفی وجود دارد که بین طبقات تمایز قائل می شود. با این وجود، این ویژگی ها ممکن است برای شرکت کنندگان غیرمتخصص قابل تشخیص نباشد. در کار قبلی، ما رویکرد طبقهبندی مبتنی بر قانون را توسعه دادیم که شرکتکنندگان را به مناسبترین کلاسها راهنمایی میکند. به عنوان مثال، ما به همپوشانی مفهومی برخی از طبقات مرتبط با علف می پردازیم. برای یک مجموعه داده معین، رویکرد ما توصیهشدهترین کلاسها را برای هر موجودیت ارائه میکند. در این مقاله، ما اعتبار رویکرد خود را ارائه می دهیم. ما یک برنامه مبتنی بر وب به نام Grass&Green پیاده سازی می کنیمکه توصیه هایی را برای اعتبارسنجی جمع سپاری ارائه می دهد. یافته ها کاربرد رویکرد پیشنهادی را نشان می دهد. در چهار ماه، این برنامه 212 شرکت کننده از بیش از 35 کشور را جذب کرد که 2865 نهاد را بررسی کردند. نتایج نشان میدهد که 89 درصد مشارکتها به طور کامل یا جزئی با توصیههای ما موافق هستند. سپس یک تجزیه و تحلیل دقیق انجام دادیم که پتانسیل این طبقه بندی داده های پیشرفته را نشان می دهد. این تحقیق توسعه برنامه های کاربردی سفارشی شده را تشویق می کند که یک ویژگی جغرافیایی خاص را هدف قرار می دهند.
کلید واژه ها:
اطلاعات جغرافیایی داوطلبانه (VGI) ; طبقه بندی ; کیفیت داده های مکانی ؛ OpenStreetMap (OSM)
1. معرفی
انقلابهای وب و اطلاعات، افزایش در دسترس بودن دستگاههای سنجش مکان، و فناوریهای ارتباطی پیشرفته، تکامل محتوای جغرافیایی رایگان را تسهیل میکنند که به اطلاعات جغرافیایی داوطلبانه (VGI) معروف است [1 ] . به طور خاص، ما نگران قالب VGI هستیم که در آن مردم بدون توجه به تجربه جغرافیایی قبلی خود در فرآیندهای نقشه برداری شرکت می کنند. در گذشته، این فرآیندها منحصراً توسط نقشهبرداران در آژانسهای نقشهبرداری و در سازمانهای تخصصی انجام میشد. از جمله، OpenStreetMap (OSM) ( http://openstreetmap.org/ )، Wikimapia ( http://www.wikimapia.org/ )، و Google Map Maker ( https://www.google.com/mapmaker )) نمونه هایی از پروژه های نقشه برداری مبتنی بر VGI هستند. با گسترش جمعسپاری، شرکتکنندگان حجم عظیمی از دادههای جغرافیایی رایگان را توسعه دادهاند که در برنامههای مختلف مورد استفاده قرار گرفتهاند. به عنوان مثال، VGI به عنوان یک منبع داده بالقوه برای کاربردهای نقشه برداری محیطی [ 2 ، 3 ]، مدیریت بحران [ 4 ، 5 ]، برنامه ریزی شهری [ 6 ، 7 ]، ارائه نقشه [ 8 ] و خدمات مبتنی بر مکان (LBS) عمل می کند. ) [ 7 ، 9 ]. با این حال، در هر برنامه، کیفیت داده ها یک موضوع نگران کننده است. چندین مطالعه به این نتیجه رسیده اند که کیفیت VGI ناهمگن است [ 10]. این یافته بر کاربرد VGI به عنوان یک منبع مکمل یا به عنوان جایگزینی برای منابع داده معتبر تأثیر می گذارد [ 11 ، 12 ، 13 ، 14 ].
به طور کلی، VGI – به عنوان داده های مکانی – دارای معیارهای متعددی از کیفیت داده ها مانند: کامل بودن، اصل و نسب، سازگاری منطقی، دقت موقعیتی، و دقت معنایی (ویژگی) است [15 ] . در تحقیق خود، ما به دقت ویژگی توجه داریم. به طور خاص، ما کیفیت داده ها را از نظر طبقه بندی بررسی می کنیم، به عنوان مثال ، آیا یک قطعه زمین پوشیده از چمن به عنوان پارک ، باغ یا جنگل طبقه بندی می شود ، اگر یک آب منطقه ای متعلق به کلاس دریاچه ، حوضچه یا مخزن و غیره باشد.. در پروژه های VGI، طبقه بندی داده ها عمدتا بر اساس شناخت شرکت کنندگان است. از یک طرف، طبقه بندی مناسب به ویژگی های کمی (مثلاً اندازه، مساحت) و/یا کیفی (مثلاً زمینه) بستگی دارد. با این حال، این ویژگی ها، که بین کلاس ها تمایز قائل می شود، ممکن است توسط شرکت کنندگان مشاهده نشود. علاوه بر این، روشهای غیر استاندارد جمعآوری دادهها و تخصص محدود شرکتکنندگان ممکن است منجر به طبقهبندی ناهمگن دادهها شود. از سوی دیگر، تعریف غیر دقیق ویژگیهای جغرافیایی – در برخی موارد – به طبقات همپوشانی مفهومی منجر میشود. بنابراین، یک موجودیت معین ممکن است به عنوان دریاچه یا برکه ، پارک یا باغ ، مرداب یا باتلاق طبقه بندی شود.و به طور قابل قبولی می تواند به چندین کلاس تعلق داشته باشد، اما فقط جزئیات کوچک ممکن است بین مناسب ترین کلاس تمایز قائل شود [ 16 ، 17 ].
برای مقابله با مشکلات فوق الذکر، ما رویکرد طبقه بندی مبتنی بر قانون را در کار قبلی خود پیشنهاد می کنیم [ 16 ، 17 ]. این رویکرد ویژگی های کیفی متمایز کلاس های خاص را می آموزد و آنها را در قوانین پیش بینی رمزگذاری می کند. پس از آن، قوانین استخراج شده در یک طبقه بندی سازماندهی می شوند که برای هدایت شرکت کنندگان به سمت مناسب ترین کلاس ها عمل می کند. در این مقاله، ما اعتبار یابی جمع سپاری را به عنوان یکی از سناریوهای اجرای ممکن رویکرد خود پیشنهاد می کنیم. در این سناریو، مجموعهای از موجودیتهای مرتبط با کلاسهای توصیهشده خود را به منظور اعتبارسنجی به جمعیت ارائه میکنیم.
در این مقاله، ما برنامه Grass&Green ( http://www.opensciencemap.org/quality ) را ارائه می کنیم: یک برنامه وب که به چالش همپوشانی مفهومی برخی از کلاس های مرتبط با چمن می پردازد. ما از داده های پروژه OSM، به ویژه مجموعه داده های آلمان استفاده کردیم. با این حال، نتایج به کل نقشهبرداران OSM و همچنین شرکتکنندگان عمومی ارائه شد. ما کلاس های باغ ، چمن ، جنگل ، پارک و علفزار را انتخاب کردیمبه عنوان نمونه ای از مسئله همپوشانی مفهومی. این انتخاب بر اساس دلایل زیر است: (1) در مجموعه داده های مورد استفاده، آنها رایج ترین طبقات مربوط به چمن در محدوده شهر هستند (حوزه جغرافیایی تحقیق ما). و (ii) برای افراد غیرمتخصص، همپوشانی مفهومی بین این طبقات وجود دارد، زیرا آنها با مفهوم جهانی چمن مرتبط هستند اما با تفاوتهای ظریفتری. ما برنامه را برای اعتبارسنجی کار قبلی خود در [ 16 ، 17 ] راه اندازی کردیم. به شرکت کنندگان اجازه داده شد تا موافقت/مخالفت خود را با کلاس های پیشنهادی اعلام کنند. علاوه بر این، شرکت کنندگان تشویق شدند تا بازخورد و نظرات خود را برای ما ارسال کنند. ما برنامه را در دفتر خاطرات OSM اعلام کردیم [ 18] و سایر وبلاگ های رسانه های اجتماعی. در چهار ماه، این برنامه 212 شرکت کننده از بیش از 35 کشور را جذب کرد. در این دوره، شرکت کنندگان 2865 نهاد را بررسی کردند. یافته ها نشان دهنده کاربردی بودن رویکرد پیشنهادی است. حدود 89٪ از مشارکت ها به طور کامل یا جزئی با کلاس های توصیه شده ما مطابقت دارد. علاوه بر این، بررسی دقیق نتایج، طبقهبندی پیشرفته موجودیتهای هدف را نشان میدهد. ما بازخورد مثبتی از شرکتکنندگان دریافت کردیم، که گسترش کاربرد رویکرد پیشنهادی را در مکانهای مختلف تشویق میکند. علاوه بر این، یافتههای این کار، انگیزه توسعه برنامههای کاربردی سفارشیسازیشدهتری را ایجاد میکند که یک ویژگی جغرافیایی خاص را مدیریت میکنند تا کیفیت دادههای مجموعه دادههای جغرافیایی داوطلبانه را افزایش دهند.
این مقاله به شرح زیر سازماندهی شده است. بخش 2 یک نمای کلی در مورد کارهای مرتبط ارائه می دهد. دلایل طبقهبندی مشکلدار دادهها در پروژههای VGI، از جمله طبقهبندی ذهنی، ناهمگونی شرکتکنندگان، و کلاسهای همپوشانی مفهومی در بخش 3 مورد بحث قرار گرفتهاند . خلاصه ای از رویکرد پیشنهادی ما در بخش 4 ارائه شده است . برنامه Grass&Green در بخش 5 ارائه شده است که شامل: توضیحات، معماری مفهومی، و متدولوژی های اعلام است. بخش 6 نتایج را از دیدگاه های مختلف نشان می دهد. چشم اندازی از رویکرد پیشنهادی با توجه به افزایش کیفیت داده ها در بخش 7 ارائه شده است. بخش 8 مقاله را به پایان می رساند و برخی از جهت گیری های تحقیقاتی آینده را برجسته می کند.
2. کارهای مرتبط
با افزایش در دسترس بودن منابع VGI، کیفیت داده های حاصل به عنوان یک موضوع نگران کننده در GIScience مطرح شده است [ 10 ، 12 ، 14 ]. بیشتر تحقیقات پروژه OSM را به عنوان برجسته ترین پروژه نقشه برداری VGI هدف قرار داده اند. هدف این پروژه ایجاد یک نقشه دیجیتالی رایگان جهان است که توسط همه قابل ویرایش و قابل دستیابی است [ 8 ]. در حال حاضر، دادههای OSM بیشتر جهان را پوشش میدهد و طبق وبسایت OSMstats [ 19 ]، این پروژه در 10 آوریل 2016 بیش از 2500000 کاربر ثبتشده دارد. چندین مطالعه تحقیقاتی به کیفیت از دیدگاه های مختلف مانند ارزیابی داده های حاصل پرداخته اند ( بخش 2.1).و توسعه رویکردها و روششناسی برای افزایش کیفیت دادهها ( بخش 2.2 ). تحقیقات دیگر بر طبقه بندی داده ها در محتوای جغرافیایی تولید شده توسط کاربر متمرکز شده است ( بخش 2.3 ).
2.1. ارزیابی کیفیت VGI
به طور کلی، داده های جغرافیایی-مکانی یا با مقایسه با یک منبع داده معتبر یا با تجزیه و تحلیل ویژگی های ذاتی داده ها ارزیابی می شوند. ارزیابی بر اساس معیارهای استاندارد کیفیت داده های مکانی توسعه یافته در ISO/TC 211 [ 20 ، 21 ] انجام می شود. دادههای OSM با دادههای معتبر در بریتانیا، آلمان، کانادا و فرانسه مقایسه میشوند [ 22 ، 23 ، 24 ، 25 ، 26 ، 27 ]. با تکامل VGI، نویسندگان در [ 13] استدلال می کنند که در ارزیابی داده های VGI سه بعد وجود دارد: ابعاد جمع سپاری، اجتماعی و ابعاد جغرافیایی. از این رو، ویژگی های ذاتی داده ها مانند شهرت مشارکت کنندگان، تاریخچه ویرایش و تکامل داده ها برای ارزیابی کیفیت داده ها تجزیه و تحلیل شده است [ 28 ، 29 ، 30 ، 31 ، 32 ، 33 ، 34 ، 35 ]. محققان معیارهای کیفی مختلفی مانند دقت موقعیتی، کامل بودن و دقت موضوعی را با توجه به ویژگیهای مختلف جغرافیایی مانند شبکههای جادهای، ساختمانها و ویژگیهای کاربری زمین بررسی کردهاند. دیدگاه دیگری از ارزیابی کیفیت در [ 36] ارائه شده است]، که در آن کیفیت داده با هدف استفاده مرتبط است. در [ 37 ]، نویسندگان چارچوبی را برای ارزیابی مفهومی کیفیت داده ها ارائه کردند.
اکثر تحقیقات به این نتیجه رسیدند که VGI یک منبع داده بالقوه ارزشمند است، به ویژه در مکان های شهری [ 38 ]. با این وجود، آنها عمدتاً در مورد کیفیت ناهمگن داده ها با توجه به معیارهای مختلف کیفیت توافق دارند [ 12 ، 13 ].
2.2. افزایش کیفیت VGI: رویکردها و روش ها
چندین عامل اقتصادی و فرهنگی بر کیفیت داده ها در پروژه های نقشه برداری VGI تأثیر می گذارد [ 35 ، 39 ]. طبق دانش ما، تنها تعداد محدودی از مطالعات تحقیقاتی مربوط به افزایش کیفیت داده ها در پروژه های نقشه برداری مبتنی بر VGI وجود دارد.
در [ 40 ، 41 ]، نویسندگان استدلال می کنند که رابط های انسانی بصری می توانند در تولید داده های با کیفیت بالا نقش داشته باشند. کار در [ 42 ] ترکیب OSM و داده های معتبر را تشویق می کند تا یک منبع داده باز یکپارچه ایجاد کند در حالی که [ 43 ] یک راه حل معنایی ارائه می دهد که به مشارکت کنندگان در طول فرآیند ویرایش به سمت بهبود کیفیت داده ها کمک می کند تا بر بین فرهنگی و چند-فرهنگی غلبه کنند. مشکلات زبان علاوه بر این، [ 11 ، 44 ] در مورد استفاده از یادگیری برای افزایش طبقه بندی داده های پروژه های VGI بحث کردند. در [ 16 ، 17]، ما رویکرد طبقهبندی مبتنی بر قانون را ارائه کردیم که برای ایجاد کلاسهای توصیهشده برای بهبود کیفیت طبقهبندی عمل کرد. به عنوان یک جایگزین، “Gamification” به عنوان روش دیگری برای افزایش کیفیت VGI ارائه شده است [ 45 ].
به طور خاص برای پروژه OSM، OSMRec یک ابزار توصیه ارائه شده در [ 46 ] است. این یک ابزار افزونه ویرایشگر برای حاشیه نویسی خودکار موجودات فضایی در پروژه OSM است [ 47 ]. علاوه بر این، OSM Inspector [ 48 ]، KeepRight [ 49 ]، MapRoulette [ 50 ] و MapDust [ 51 ] نمونههایی از برنامههای وب هستند که برای افزایش کیفیت دادههای پروژه توسعه یافتهاند. این برنامه ها یا برای یک ویژگی خاص در یک مکان خاص مانند NOVAM سفارشی شده اند [ 52]، که ویژگی های ایستگاه اتوبوس را در بریتانیا مدیریت می کند، یا به طور کلی برای چندین ویژگی در مکان های مختلف توسعه یافته اند. این برنامهها نقش مشارکتکنندگان را برای ارتقای کیفیت دادهها از طریق تجدیدنظر در جمعسپاری تشویق میکنند.
2.3. طبقه بندی داده های انسان محور
تحقیقات دیگر به ویژه بر طبقه بندی داده ها در محتوای جغرافیایی-مکانی تولید شده توسط کاربر متمرکز شده است. در VGI، طبقه بندی داده ها انسان محور است. داده ها بر اساس ادراکات فردی به جای یک مدل از پیش تعریف شده طبقه بندی می شوند، همانطور که در طبقه بندی داده های حرفه ای وجود دارد. نویسندگان در [ 53 ] اشکال مختلفی از عدم قطعیت داده های مکانی را ارائه کردند که بر دقت طبقه بندی و دانه بندی تأثیر می گذارد. در [ 44 ]، نویسندگان طبقه بندی قابل قبول و مبهم در VGI را تجزیه و تحلیل کردند. با این وجود، تحقیق در [ 54 ] توانایی عموم را برای طبقهبندی دقیق ویژگیهای پوشش زمین زمانی که عکسهای هوایی و زمینی به آنها ارائه میشود، نتیجهگیری میکند. کار [ 55] تأثیرات فرهنگی، زبانشناسی و منطقهای را بر طبقهبندی دادهها مورد مطالعه قرار داد در حالی که نویسندگان [ 56 ] کیفیت طبقهبندی کاربری زمین و ویژگیهای پوشش زمین در VGI را با توجه به مشارکتکنندگان و دادههای ارائهشده بررسی کردند.
نویسندگان [ 57 ] Geo-Wiki ( http://www.geo-wiki.org/ ) (یک برنامه کاربردی وب جمع سپاری) را برای اعتبارسنجی و ارتقای طبقه بندی داده های پوشش زمین جهانی توسعه داده اند. Geo-Wiki همچنین با هدف توسعه یک نقشه جهانی ترکیبی پوشش زمین از منابع داده های مختلف، که در آن منابع داده معتبر با منابع باز تقویت می شوند و قدرت جمع سپاری برای اعتبار سنجی استفاده می شود.
در [ 58 ]، نویسندگان فرآیند حاشیه نویسی در پروژه OSM را مطالعه کردند. آنها مشکل استفاده از طبقه بندی داده های OSM و تأثیرات آن بر طبقه بندی داده ها را شناسایی کردند. از یک نقطه نظر خاص، ماهیت بین فرهنگی پروژه OSM منجر به طبقه بندی داده های ناهمگن از ویژگی های جغرافیایی یکسان و در نتیجه استفاده محدود از داده ها می شود. با این حال، راه حل های معنایی برای غلبه بر این مشکل استفاده شده است [ 59 ، 60 ].
با این وجود، تحقیق در [ 24 ، 26 ] دقت طبقه بندی کاربری و ویژگی های پوشش زمین را در پروژه OSM ارزیابی کرده است. آنها کیفیت قابل توجه داده و استفاده بالقوه از VGI را به عنوان منبع داده مکمل این ویژگی ها برجسته کردند.
3. فراتر از طبقه بندی داده ها در پروژه های VGI: مورد OpenStreetMap
چندین مطالعه تحقیقاتی بر اهمیت منابع VGI تاکید کرده اند. با این حال، آنها همچنین طبقه بندی داده های مشکل ساز خود را برجسته می کنند: در اکثر برنامه ها، طبقه بندی داده های نادقیق منجر به نتایج نادرست یا ناقص می شود. داده ها چگونه طبقه بندی می شوند؟ آیا داده ها از یک مدل طبقه بندی دقیق پیروی می کنند؟ چگونه می توانیم طبقه بندی داده ها را تأیید کنیم؟ طبقه بندی داده ها در کدام سطح دانه بندی کامل است؟ همه اینها مسائل مهمی هستند که بر استفاده مؤثر از منابع VGI تأثیر میگذارند. بنابراین، این بخش بینشی از چالش های طبقه بندی در پروژه های VGI می دهد. در این مقاله، دادههای OSM را تحلیل کردیم. تأثیر مکانیسم مشارکت و مدلهای داده مورد استفاده بر کیفیت داده در بخش 3.1 ارائه شده است. در هر پروژه VGI، شرکت کنندگان نقش اصلی را در فرآیند جمع آوری داده ها ایفا می کنند. بنابراین، جوامع OSM و تأثیر آنها بر طبقه بندی داده ها در بخش 3.2 مورد بررسی قرار می گیرند ، در حالی که بخش 3.3 مشکلات کلی طبقه بندی داده های جغرافیایی را مورد بحث قرار می دهد.
3.1. طبقه بندی بر اساس برچسب ها ( کلید = مقدار )
در OSM، مشارکتها توسط شرکتکنندگان به شرح زیر انجام میشود: شرکتکنندگان ویژگیهای جغرافیایی را از تصاویر ماهوارهای ارائه شده (مثلاً تصاویر هوایی بینگ)، با استفاده از یکی از ویرایشگرهای OSM (مثلاً ویرایشگر iD) مشخص میکنند. ویژگی ها به عنوان موجودیت ها با استفاده از مدل های داده مناسب نشان داده می شوند: نقطه (ویژگی های 0-D)، راه (ویژگی های خطی)، و رابطه (ویژگی های پیچیده). پس از آن، شرکت کنندگان آزادند تا موجودیت ارائه شده را با استفاده از برچسب ها توصیف و طبقه بندی کنند. هنگامی که یک برچسب دارای قالب کلید = مقدار باشد ، کلید دیدگاه طبقه بندی را توصیف می کند و مقدار آن برچسب کلاس است. مثلاً برچسب طبیعی = آبپوشش طبیعی یک موجود را به عنوان یک بدنه آبی توصیف می کند، در حالی که یک برچسب اضافی، به عنوان مثال، آب = دریاچه ، برای بیان طبقه بندی دقیق مورد نیاز است.
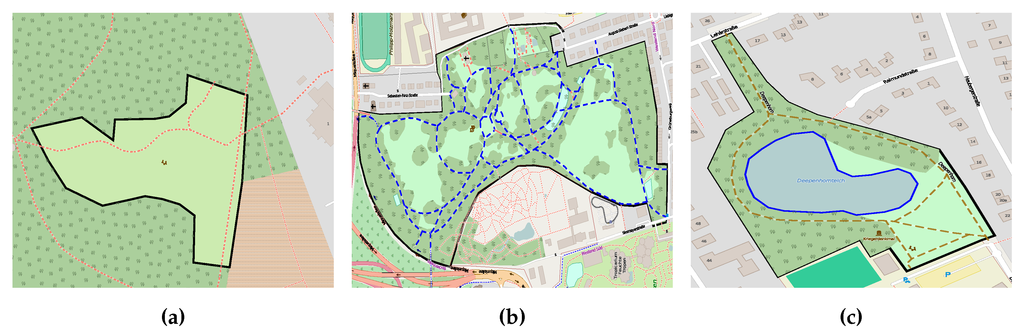
پروژه OSM برچسب های توصیه شده و روش های مناسب برای نگاشت ویژگی های مختلف جغرافیایی را در صفحات ویکی خود ارائه می دهد ( http://wiki.openstreetmap.org/wiki/Map_Features ). با این حال، فقدان مکانیسمهای بررسی یکپارچگی و مکانیسمهای مشارکت رایگان کامل منجر به طبقهبندی مشکلساز میشود. به عنوان مثال، یک موجودیت را نمی توان بدون برچسب یا تگ بی نهایت نسبت داد و حتی تکرار برچسب ها ممکن است، به عنوان مثال، طبیعی = آب و natural_1 = شن . اگرچه این مکانیسمهای انعطافپذیر به شرکتکنندگان اجازه میدهد تا کلاسهای جدیدی را راهاندازی کنند، اما چالشهای مختلفی را در طول پردازش و تمیز کردن دادهها ایجاد میکنند. شکل 1یک مثال طبقه بندی مشکل ساز از زمانی که موجودیت مشخص شده به کلاس های متضاد نسبت داده می شود را نشان می دهد.
3.2. طبقه بندی ذهنی
پروژه های نقشه برداری VGI توسط قدرت جمعیت اجرا می شود. کمک ها از دانش محلی شرکت کنندگان می آید. آنها آزادند مشاهدات خود را به یک ویژگی جغرافیایی مشروح با توضیحات/ردهبندی/طبقهبندی ترجمه کنند. از آنجایی که انسان مشاهدات را متفاوت تفسیر میکند، ممکن است ویژگیهای جغرافیایی را متفاوت درک کنند. یک موجودیت خاص ممکن است توسط یک شرکتکننده به عنوان رستوران طبقهبندی شود ، اما ممکن است توسط دیگران به عنوان یک کافه طبقهبندی شود . آیا یک حجم آبی به اندازه کافی بزرگ است که به عنوان دریاچه طبقه بندی شود یا آنقدر کوچک است که به طور مناسب به عنوان یک برکه طبقه بندی شود . این طبقه بندی ها به جنبه های عقلانی و فردی بستگی دارد. این واقعیت منجر به طبقه بندی ذهنی می شود.
در پروژه OSM، شرکت کنندگان تجربه نقشه برداری و نقشه برداری نابرابر دارند. آنها از فرهنگ های مختلف آمده اند. و سوابق تحصیلی و علایق مختلفی دارند. بنابراین، شرکتکنندگان ناهمگن، طبقهبندی مشکلساز را تقویت میکنند. طبقه بندی ناقص و ناسازگار نمونه هایی از مشکلات مربوط به طبقه بندی ذهنی است.
-
طبقهبندی ناقص: دانش محلی محدود یک شرکتکننده یا مشاهدات درک شده نامشخص از تصاویر ماهوارهای ارائهشده بر جزئیات طبقهبندی تأثیر میگذارد. در یک مطالعه آزمایشی بر روی مجموعه داده های OSM آلمان (مه 2015)، ما 225933 نهاد مرتبط با کلاس های بدنه آب را پیدا کردیم. تنها 20 درصد از این نهادها دارای کلاس های ظریف تری مانند دریاچه ، فاضلاب و غیره هستند . ما حدود 10،520،418 ساختمان طبقهبندینشده را شناسایی کردیم که طبقهبندی درشتتری به عنوان ساختمان دارند در حالی که سایر نهادهای ساختمانی به کلاسهای ظریفتری مانند مسکونی ، صنعتی و غیره طبقهبندی میشوند .
-
طبقهبندی ناسازگار: وقتی شرکتکنندگان یک ویژگی خاص را متفاوت تفسیر میکنند، آن را به کلاسهای متضاد یا یک کلاس مبهم اختصاص میدهند. در طول بررسیهایمان، متوجه شدیم که برخی از نهادها به کلاسهای متضاد اختصاص داده شدهاند. برخی از نهادها به عنوان چمنزار ( به عنوان مثال ، زمین چمن) و تالاب ( به عنوان مثال ، بدنه آبی) طبقه بندی می شوند. شکل 1 مثال واضحی از ناسازگاری طبقه بندی را نشان می دهد، زمانی که موجودیت داده شده بر اساس کلاس های زمین ، مدرسه و ساحل طبقه بندی می شود .
3.3. کلاس های همپوشانی مفهومی
به طور کلی، داده های مکانی مستعد اشکال مختلف عدم قطعیت هستند: احتمال، ابهام و ابهام. مشکل ممکن است مربوط به این باشد که آیا یک ویژگی جغرافیایی خوب یا ضعیف تعریف شده است [ 53 ]. در [ 61 ، 62 ]، نویسندگان عدم قطعیت داده های مکانی را با کیفیت VGI مرتبط می کنند. به طور خاص، تعاریف ضعیف منجر به ایجاد مرزهای واضح بین کلاس های مشابه می شود. بنابراین، یک موجودیت خاص به طور قابل قبولی می تواند به چندین کلاس همپوشانی با درجات مختلف دقت تعلق داشته باشد. با این وجود، معمولاً ویژگی های کیفی و/یا کمی وجود دارد که می تواند بین این طبقات تمایز قائل شود.
از جمله ویژگیهای بدنههای آبی، مربوط به چمن و تالاب نمونههایی از ویژگیها با تعاریف غیر دقیق هستند و از این رو، آنها شامل طبقات همپوشانی هستند. شکل 2 کلاس های همپوشانی مفهومی را در ویژگی های مربوط به چمن و بدنه آب، با توجه به توصیه های داده شده در OSM Wiki نشان می دهد. جدول 1 نقشه برداری بین تگ های OSM و کلاس های مربوط به آنها را توضیح می دهد. در پروژه OSM، یک کلاس واحد را می توان با برچسب های مختلف توصیف کرد. با این حال، ما رایج ترین برچسب گذاری را بررسی می کنیم. همپوشانی بین طبقات در شکل بر اساس اشتراک یک مفهوم خاص یا ویژگی های مشترک است. علاوه بر این، اندازه همپوشانی نشان دهنده میزان شباهت مفهومی است.
به عنوان مثال، پارک ، تفریح و باغ طبقات همپوشانی در شکل 2 الف هستند: آنها ویژگی های مشترک استفاده برای سرگرمی و سرگرمی را دارند. کلاسهای پارک ، باغ با کلید اوقات فراغت طبقهبندی میشوند ، در حالی که کلاس تفریحی با کلید کاربری زمین توصیف میشود . با این حال، موجودیتهای تفریحی به احتمال زیاد به فعالیتهای خاصی (به عنوان مثال، فعالیتهای ورزشی یا اجتماعی) مرتبط هستند، موجودیتهای باغ بیشتر از سایرین با گل و گیاه کشت میشوند و پارک .موجودیت ها به طور کلی بزرگتر از باغ و تفریح هستند و ممکن است هر دوی آنها را نیز شامل شوند. شکل 2 ب نمونه دیگری از همپوشانی طبقات مربوط به ویژگی های بدنه آبی را نشان می دهد. هنگامی که یک آب راکد و طبیعی است، میتوان آن را به عنوان دریاچه (اگر بزرگ باشد) یا برکه (اگر کوچک باشد) طبقهبندی کرد، اما زمانی که ساخته دست بشر باشد بهطور مناسبتری به عنوان مخزن طبقهبندی میشود . طبقات دیگر مانند مرداب و باتلاق هر دو منطقه ای را توصیف می کنند که به طور دائم یا فصلی از آب اشباع شده است. در دادههای OSM، هر دو با کلید تالاب توصیف شدهاند . فقط نوع پوشش گیاهی بین طبقات متمایز می شود: مردابزمانی که پوشش گیاهی چوبی و مردابی است و زمانی که پوشش گیاهی غیرچوبی و زیستگاه های باز.
بحث های قبلی دلایل طبقه بندی مشکل ساز در پروژه های VGI را خلاصه می کند. بخش 3.1 و بخش 3.2 مشکل را از ماهیت پروژه های VGI استدلال می کنند، در حالی که بخش 3.3 مشکل را از منظر عدم قطعیت داده های مکانی مورد بحث قرار می دهد. این مشکلات طبقهبندی نه تنها بر کیفیت دادهها تأثیر میگذارد، بلکه توسعه برنامههای کاربردی عمومی را نیز محدود میکند، بهعنوان مثال، برنامههای کاربردی ارائه و تجسم جهانی. علاوه بر این، کیفیت داده های مشکل ساز، کاربرد منابع VGI را برای انواع خاصی از برنامه ها تعیین می کند.
4. رویکرد طبقه بندی مبتنی بر قانون
در [ 16 ، 17 ]، ما با توسعه رویکرد طبقه بندی مبتنی بر قانون، به طبقه بندی پرداختیم. در پروژه های VGI، مفهوم سازی مشارکت کنندگان از ویژگی های جغرافیایی بر طبقه بندی داده ها تأثیر می گذارد. از دیدگاه شناختی انسان، افراد احتمالاً ویژگی های کیفی یک ویژگی معین را بررسی می کنند تا آن را به طور مناسب طبقه بندی کنند. علاوه بر این، انسان ها به طور ضمنی بین طبقات مشابه تضاد دارند تا طبقه خاصی را به جای طبقه های دیگر استنتاج کنند. به عنوان مثال، ما بین پارک و جنگل تضاد داریمکلاس ها با بررسی پوشش درختان، در دسترس بودن امکانات تفریحی و سرگرمی، و دسترسی عابران پیاده. از این رو، رویکرد ما از ویژگیهای کیفی و مقایسه برای تمایز بین کلاسهای مشابه استفاده میکند. برای موجودیتهای خاص کلاسهای همپوشانی، ما یک مکانیسم یادگیری ماشین را برای استخراج ویژگیهای توپولوژیکی کیفی متمایز که هر کلاس را شناسایی میکنند، اعمال میکنیم. این ویژگی ها برای توسعه یک طبقه بندی کننده فرموله و سازماندهی شده اند. سپس، این رویکرد از طبقهبندیکننده توسعهیافته برای طبقهبندی مجدد موجودیتها استفاده میکند و دوباره آنها را برای اعتبارسنجی جمعسپاری ارائه میکند. در این رویکرد، ما فرض می کنیم که نهادهای یکسان باید به طور مشابه در یک کشور طبقه بندی شوند ( یعنی، طبقه بندی موضعی). بنابراین، یادگیری از دادههای هند و بهکارگیری دانش استخراجشده بر روی دادههای آلمان ممکن است منجر به طبقهبندی مشکلساز دیگری به دلیل فرهنگها و مفاهیم مختلف شود. برای جزئیات بیشتر، [ 17 ] را ببینید.
شکل 3 ساختار مفهومی رویکرد طبقه بندی مبتنی بر قانون را نشان می دهد. برای مثال، ما رویکرد را در یک مطالعه موردی نشان میدهیم. ما از مجموعه داده های OSM آلمان استفاده می کنیم و طبقه بندی برخی از طبقات مرتبط با چمن را هدف قرار می دهیم: چمن ، باغ ، جنگل ، پارک و چمنزار . انتخاب مجموعه داده آلمان به دلایل زیر است: (الف) در آلمان، یک جامعه نقشهبردار فعال در پروژه OSM وجود دارد. (ب) چندین مطالعه کیفیت بالای داده ها را به ویژه در مناطق شهری تأیید کردند. و (ج) واردات انبوه زیادی از داده ها وجود ندارد. شکل 3این رویکرد را به سه مرحله تقسیم می کند: مراحل پردازش داده، یادگیری و مراحل اعتبار سنجی.
- (1)
-
پردازش داده ها :از مجموعه داده های OSM آلمان، موجودیت های کلاس های هدف را استخراج کردیم. نهادها از پرجمعیت ترین شهرها استخراج می شوند تا از داده هایی با کیفیت بالا اطمینان حاصل شود. ما نگران نهادهای منطقه هستیم. بنابراین، برای درک ویژگیهای کیفی کلاسها، ما هر موجودیت جداگانه را به صورت توپولوژیکی بررسی کردیم. ما یک الگوریتم خودکار را با استفاده از مدل 9-تقاطع (9IM) برای انجام بررسی توسعه دادیم [ 63 ]. هدف این تحقیق یافتن روابط توپولوژیکی مشترک بین جفت موجودیت است. این روابط به طور بالقوه برای تمایز بین کلاس های مشابه مفید هستند. برای مثال، رابطه بین جفت موجودیت ( E1، E2)، چه زمانی E1نشان دهنده ویژگی هدف (به عنوان مثال، موجودیت پارک ) و E2نوع دیگری از ویژگی های نزدیک به است E1(به عنوان مثال، زمین بازی، بدنه های آبی، و غیره ).
- (2)
-
یادگیری :هدف مرحله یادگیری، ایجاد طبقهبندیکنندهای است که بتواند به طور بالقوه بین کلاسهای مشابه تمایز قائل شود. ما یک مکانیسم داده کاوی طبقه بندی انجمنی [ 64 ] را برای انجام وظیفه یادگیری اعمال می کنیم. این رویکرد استخراج از قانون تداعی برای ساختن سیستم طبقه بندی استفاده می کند [ 64 ]. ابتدا مجموعه ای از قوانین پیش بینی را استخراج می کنیم که هر کلاس را توصیف می کند و سپس این قوانین در طبقه بندی کننده رتبه بندی و سازماندهی شدند. در طی فرآیند طبقه بندی، یک موجودیت معین با کل مجموعه قوانین استخراج شده مطابقت داده می شود. قوانین منطبق بر اساس معیارهای اطمینان آنها به ترتیب نزولی رتبه بندی می شوند. به دلیل مشکل همپوشانی (به بخش 3 مراجعه کنید)، طبقهبندیکننده توسعهیافته طوری پیکربندی شده است که به جای انتخاب یک کلاس، دو کلاس مناسب را ارائه دهد.
- (3)
-
اعتبارسنجی :با توجه به ماهیت VGI، رویکرد پیشنهادی از جمعسپاری برای اعتبار بخشیدن به طبقهبندی استفاده میکند. موجودیت ها با استفاده از طبقه بندی کننده توسعه یافته مجدداً طبقه بندی می شوند. سپس مجدداً به منظور بازنگری در کلاس های توصیه شده به عموم ارائه می شود. مرحله اعتبار سنجی دارای عملکردهای متعددی است: (الف) طبقه بندی نهادهای هدف را با تجدید نظر در جمع سپاری افزایش/تضمین می کند. (ب) درک عمومی از طبقات هدف. و (ج) پاسخ شرکت کنندگان به توصیه های ارائه شده را بیابد.
فاز اول و دوم با جزئیات بیشتر در کار قبلی ارائه شده است [ 16 ، 17 ]، در حالی که این مقاله بر فاز سوم تمرکز دارد، جایی که اجرای مرحله اعتبار سنجی در بخش بعدی ارائه شده است.
5. Grass&Green: برنامه تضمین کیفیت سفارشی
به عنوان اعتبار سنجی رویکرد طبقه بندی مبتنی بر قانون، ما یک برنامه وب به نام Grass&Green را توسعه دادیم . ما یک معماری مبتنی بر وب را برای دستیابی به تعداد زیادی از شرکت کنندگان اتخاذ کردیم. این برنامه در آگوست 2015 راه اندازی شد و شرکت کنندگان عمومی و نقشه برداران OSM را نیز هدف قرار داد. برنامه بر روی یک سرور اوبونتو [ 65 ] به عنوان یک زیرشاخه از پروژه OpenScienceMap (OScieM) میزبانی می شود [ 66 ].
شرح برنامه در بخش 5.1 ارائه شده است . بخش 5.2 معماری برنامه و اجزای آن را نشان می دهد، در حالی که کانال های مورد استفاده برای جذب شرکت کنندگان در بخش 5.3 مورد بحث قرار گرفته است .
5.1. توضیحات برنامه
شکل 4 ، شکل 5 و شکل 6 رابط کاربری (UI) برنامه را نشان می دهد. قابلیت استفاده از رابط و سهولت استفاده برای ما برای دستیابی به اهداف برنامه و شبیه سازی ماهیت پروژه های VGI نگران کننده است. قبل از ورود به سیستم، Grass&Green دستورالعمل استفاده را به شرکت کننده ارائه می دهد. از آنجایی که ما مستقیماً در پروژه OSM مشارکت می کنیم، شرکت کنندگان باید یک حساب کاربری OSM داشته باشند. این برنامه به کاربران غیر OSM اجازه می دهد تا برای یک حساب ثبت نام کنند ( شکل 4 را ببینید ).
برای شرکت کنندگان غیرمتخصص، برنامه دارای منویی به نام “راهنما” است که توضیحات کلاس را معرفی می کند. توضیحات به صورت بصری و به صورت متن از منابع متعدد ارائه شده است: Wikipedia، OSM Wiki، و WordNet [ 67 ] ( شکل 5 را ببینید ).
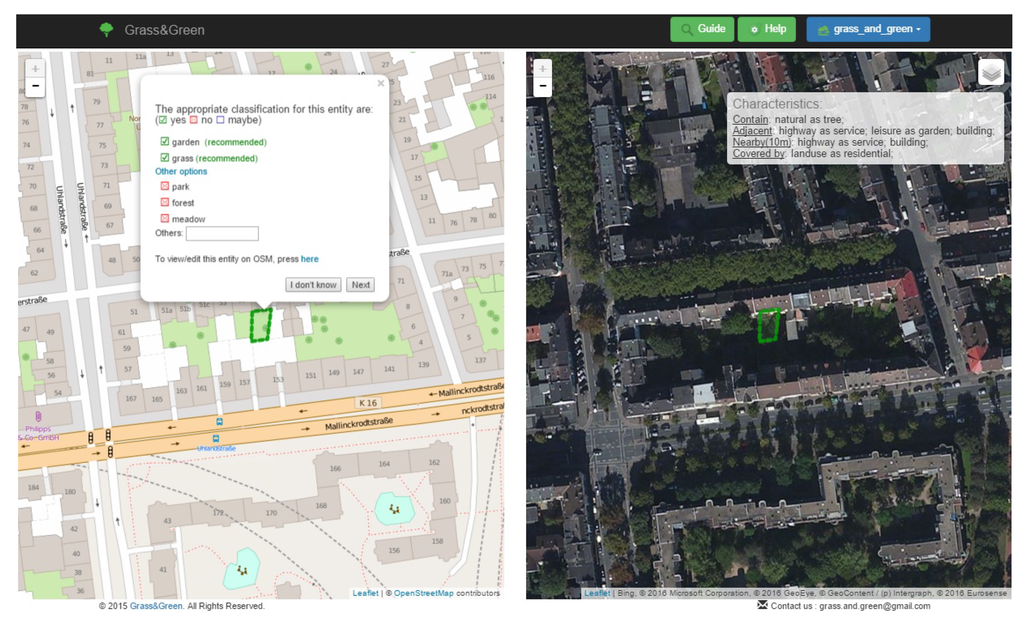
پس از ورود، برنامه به طور تصادفی موجودیت ها را به شرکت کننده نشان می دهد. شکل 6 رابط ساده فرآیند تجدید نظر را نشان می دهد. در سمت راست، موجودیت داده شده مشخص شده و با تصاویر ماهوارهای Bing، که یک ارائهدهنده تصویر هوایی است، همپوشانی دارد. علاوه بر این، توضیحات کیفی توپولوژیکی موجودیت به صورت متن ارائه شده است. برای مثال، موجودیت داده شده در شکل 6 شامل درختانی است که در مجاورت یک ساختمان، یک باغ و یک راه خدماتی قرار دارند و توسطیک منطقه مسکونی در سمت چپ، موجودیت مشخص شده و با نقشه پایه OSM همپوشانی دارد. بر روی نهاد، یک پیام پاپ آپ کلاس های توصیه شده (که به عنوان توصیه شده علامت گذاری شده اند) و کلاس های دیگر را نیز نشان می دهد. اعتبار سنجی منعطف است، شبیه به مکانیسم مشارکت پروژه OSM. شرکتکننده میتواند بین گزینههای «بله»، «نه» و «شاید» از کلاسهای ارائه شده انتخاب کند. شرکتکننده میتواند توصیههای ما را لغو انتخاب کند و کلاسهای دیگر را انتخاب کند یا کلاس جدیدی اضافه کند (در صورت نیاز). گزینه های بیشتری مانند مشاهده و ویرایش موجودیت مستقیماً از طریق رابط های پروژه OSM برای شرکت کننده ارائه شده است. در هر دو نقشه، یک گزینه بزرگنمایی/کوچک کردن ارائه شده است تا شرکت کنندگان بتوانند زمینه جغرافیایی را کشف کنند.
علاوه بر این، منوی “Help” در صورت نیاز دستورالعملها را در هر زمان به شرکتکنندگان ارائه میدهد. در پایین، یک آدرس ایمیل تماس برای بازخورد بیشتر و نظرات شرکت کنندگان علاقه مند داده شده است. در هر نقطه، شرکت کنندگان مجاز به خروج یا بستن برنامه برای خروج از فرآیند اعتبار سنجی هستند.
5.2. معماری اپلیکیشن
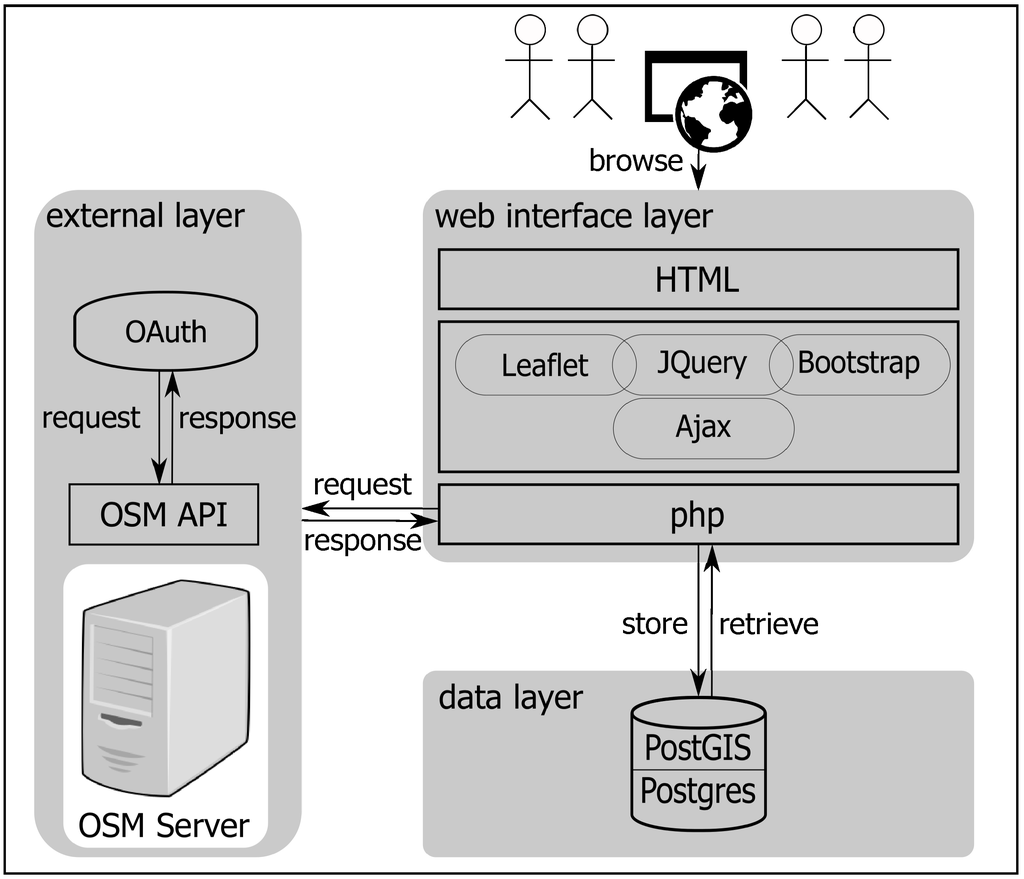
به عنوان یک برنامه مبتنی بر وب، Grass&Green از اجزای جلویی و انتهایی تشکیل شده است. اجزای جلویی قابلیت استفاده و تجسم را در UI مانند مولفه برگه [ 68 ]، چارچوب Bootstrap [ 69 ] و کتابخانه JQuery [ 70 ] کنترل میکنند، در حالی که مؤلفههای backend مسئول انجام ارتباطات کارآمد و قابل اعتماد هستند. در میان لایه های کاربردی شکل 7 نشان می دهد که چگونه برنامه از سه لایه تشکیل شده است: لایه رابط، لایه داده و لایه خارجی.
با استفاده از هر مرورگر اینترنتی، شرکت کنندگان می توانند به لایه رابط دسترسی داشته باشند. ابتدا، شرکتکنندگان با استفاده از استاندارد باز مجوز OAuth [ 71 ] به برنامه وارد میشوند، که به آنها اجازه میدهد به یک وبسایت شخص ثالث – در این مورد، پروژه OSM – به روشی امن و بدون افشای رمز عبور خود متصل شوند. پس از ورود موفقیت آمیز، لایه رابط، با استفاده از AJAX و PHP، شروع به فراخوانی داده ها از لایه داده برای فرآیند اعتبار سنجی می کند. با استفاده از توابع php، برنامه نتایج اعتبارسنجی و مشارکت های شرکت کننده را کنترل می کند. لایه داده شامل مجموعه داده های توسعه یافته توسط رویکرد پیشنهادی در [ 17]. در مجموعه داده ها، هر موجودیت با ویژگی های کیفی توپولوژیکی، هندسه آن و دو کلاس توصیه شده مرتبط است. مجموعه داده در پایگاه داده Postgres با پسوند postGIS ذخیره می شود تا هندسه موجودیت ها را مدیریت کند. به عنوان یک لایه خارجی، سرور OSM از طریق رابط برنامه کاربردی OSM (API) قابل دسترسی است. ما از حساب کاربری OSM به عنوان مرجعی برای تجربه شرکت کنندگان و منشاء جغرافیایی آنها استفاده کردیم. در طول اعتبارسنجی، شرکت کنندگان گزینه هایی برای ویرایش/مشاهده موجودیت های ارائه شده توسط ویرایشگران/بینندگان OSM دارند. علاوه بر این، لایه رابط، OSM API را برای به روز رسانی موجودیت ها پس از فرآیند اعتبار سنجی فراخوانی می کند.
5.3. روشهای اعلام و شرکتکنندگان هدف
شرکت کنندگان قدرت هر پروژه VGI هستند. بنابراین، جذب و تشویق شرکت کنندگان به مشارکت یکی از چالش های استقرار است. هدف جذب تعداد زیادی از شرکت کنندگان است: نقشه برداران OSM و شرکت کنندگان عمومی نیز. ما از قدرت جمعیت برای جذب شرکت کنندگان با استفاده از کانال های زیر استفاده کرده ایم:
-
خاطرات OSM:ما راهاندازی و اهداف برنامه را به صورت محلی به نقشهبرداران OSM از طریق دفتر خاطرات پروژه ( https://www.openstreetmap.org/user/grass_and_green/diary ) اعلام کردیم. خاطرات OSM برای همه عمومی است.
-
رسانه های اجتماعی:ما دو صفحه برای این پروژه ایجاد کردیم: یکی در توییتر ( https://twitter.com/grass_and_green ) و دیگری در فیس بوک ( https://www.facebook.com/grassANDgreen/ ) تا از قدرت رسانه های اجتماعی برای جذب استفاده کنیم. شرکت کنندگان عمومی ما به ندرت اخبار برنامه را ارسال کردیم و از شرکت کنندگان در صفحات پروژه تشکر کردیم.
-
دیگران:لیست های پستی و بروشورهای مبتنی بر کاغذ نیز برای هدف قرار دادن سایر محققان و دانشجویان نیز استفاده می شود.
6. نتایج
در این بخش، ما نتایجی را که توسط برنامه از دیدگاههای مختلف بهدست آمده است، مورد بحث قرار میدهیم: الگوهای مشارکتکننده و مشارکت ( بخش 6.1 )، پاسخهای شرکتکننده به توصیهها ( بخش 6.2 )، و طبقهبندی دادههای افزایشیافته بالقوه ( بخش 6.3 ). علاوه بر این، ما بازخورد شرکتکنندگان را نیز تحلیل کردیم ( بخش 6.4 ). نتایج ارائه شده نشان دهنده مشارکت در یک دوره چهار ماهه از 28 اوت تا 28 دسامبر 2015 است.
6.1. الگوهای مشارکت و مشارکت
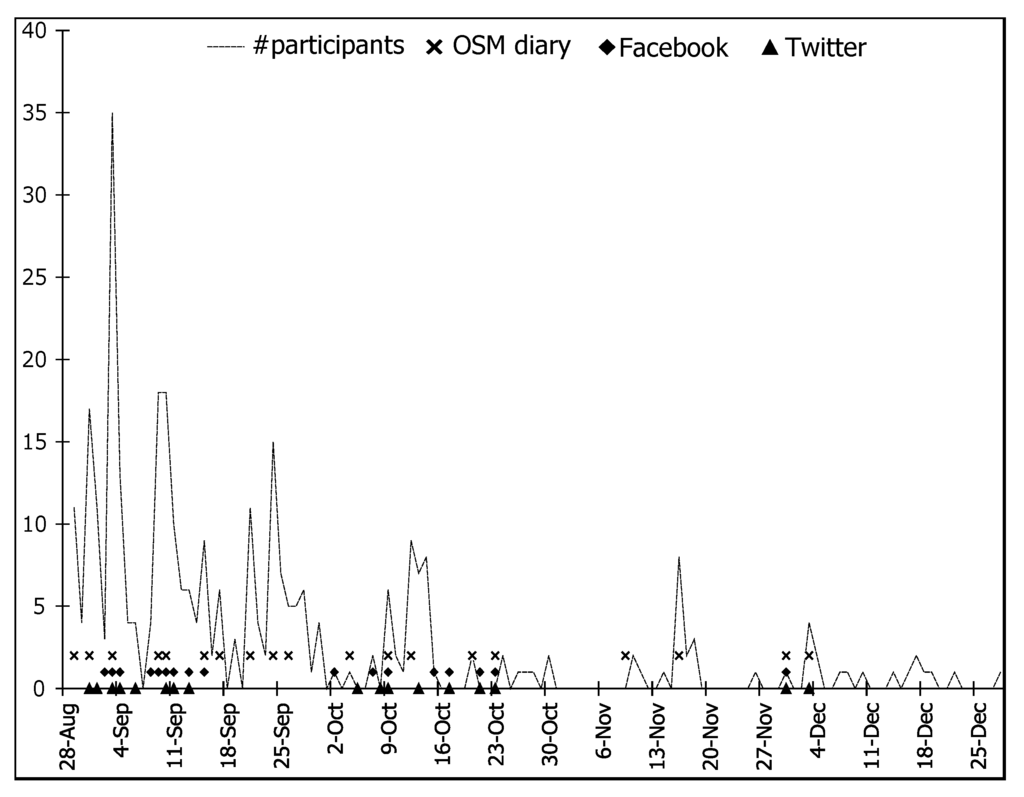
با در نظر گرفتن اینکه ما از رویکردهای اعلامی ساده استفاده کردیم، شکل 8 ، شکل 9 و شکل 10 بینشی را در مورد الگوهای شرکت کنندگان و مشارکت ها ارائه می دهد. این برنامه 212 شرکت کننده را جذب کرد: 163 شرکت کننده دارای منشأ مشخصی از مکان از 35 کشور مختلف هستند در حالی که بقیه از مکان های ناشناخته هستند. شکل 8 الف نشان می دهد که 46 نفر (حدود 28%) از 163 شرکت کننده از آلمان هستند. علاوه بر این، شرکت کنندگان طبقه بندی 2865 نهاد را بررسی کردند. 1060 مورد از این نهادها توسط شرکت کنندگان مرتبط با آلمان بررسی شده است، همانطور که در شکل 8 نشان داده شده است.b، که مربوط به مجموعه داده های مورد استفاده در اینجا است. بقیه نهادها توسط شرکت کنندگان از مکان های مختلف بررسی شده است.
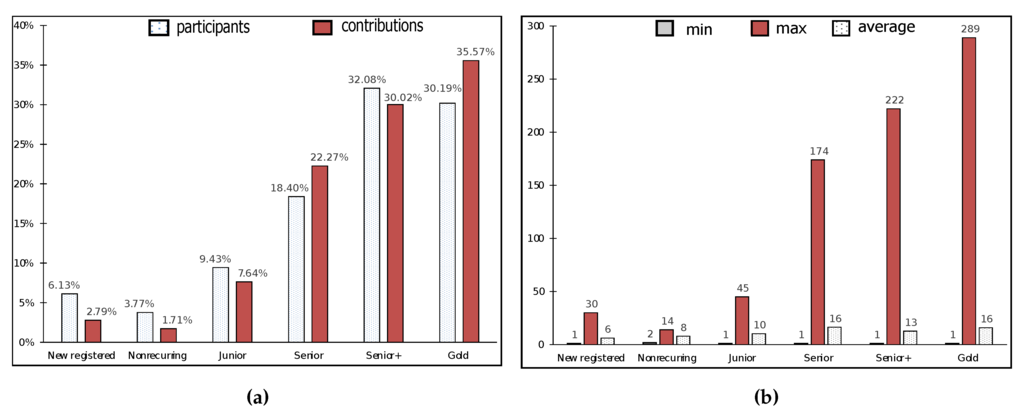
از سوی دیگر، شرکت کنندگان سطوح مختلفی از آشنایی با پروژه OSM، و در نتیجه، سطوح متفاوتی از مشارکت را دارند، همانطور که در شکل 9 نشان داده شده است . ما شرکتکنندگان را بر اساس طرح طبقهبندی پیشنهادی در [ 30 ]، بر اساس Changsets گروهبندی میکنیم. هنگامی که Changesets تعداد تغییراتی را که نقشهبردار انجام داده از جمله عملیات افزودن، حذف و بهروزرسانی را نشان میدهد.
شکل 9 الف توزیع شرکت کنندگان و مشارکت در هر گروه را به شرح زیر نشان می دهد: 30.19٪ طلا >=2000)، 32.08٪ ارشد +(500 <=تغییرات < 2000)، 18.4% ارشد (100 <=تغییرات < 500)، 9.43% جونیور (10 <=تغییرات < 100)، 3.77٪ غیر تکراری (1 < تغییرات < 10)، و 6.13٪ ثبت شده جدید (تغییرها) <=1). در Grass&Green ، حدود 65% از مشارکتها از سالمندان است +و Gold mappers که قابلیت اطمینان را به نتایج به دست آمده می افزاید. شکل 9 ب، حداقل و حداکثر مشارکت شرکت کنندگان در هر گروه، علاوه بر میانگین مشارکت در هر شرکت کننده را نشان می دهد. این رقم بیانگر آن است که هرچه تجربه و آشنایی یک شرکت کننده با پروژه OSM بیشتر باشد، نگرانی و مشارکت آنها بیشتر است. شکل 9 ب نشان می دهد که شرکت کنندگان از طلا ، ارشد +گروههای ارشد و جوان بهطور متوسط بین 11 تا 16 نهاد/شرکتکننده را مورد بررسی قرار دادند، در حالی که شرکتکنندگان از گروههای غیر تکراری و ثبتشده جدید بهطور میانگین بین 6 تا 8 نهاد/شرکتکننده را بررسی کردند. این یافته برخی نگرانیهای شدید از مشارکتهای فردی 289، 222 و 174 نهاد از شرکتکنندگان متعلق به Gold ، Senior و Senior را نشان میدهد. +گروه ها به ترتیب
شکل 10 الگوهای مشارکت را نسبت به روش های اعلام استفاده شده نشان می دهد. پس از دو هفته، تعداد شرکت کنندگان اکثراً کمتر از ده نفر در روز است. شکل نشان می دهد که تعداد شرکت کنندگان با گذشت زمان کاهش می یابد و با استفاده از روش جذب، به ویژه دفترچه خاطرات OSM افزایش می یابد.
6.2. پاسخ های شرکت کنندگان
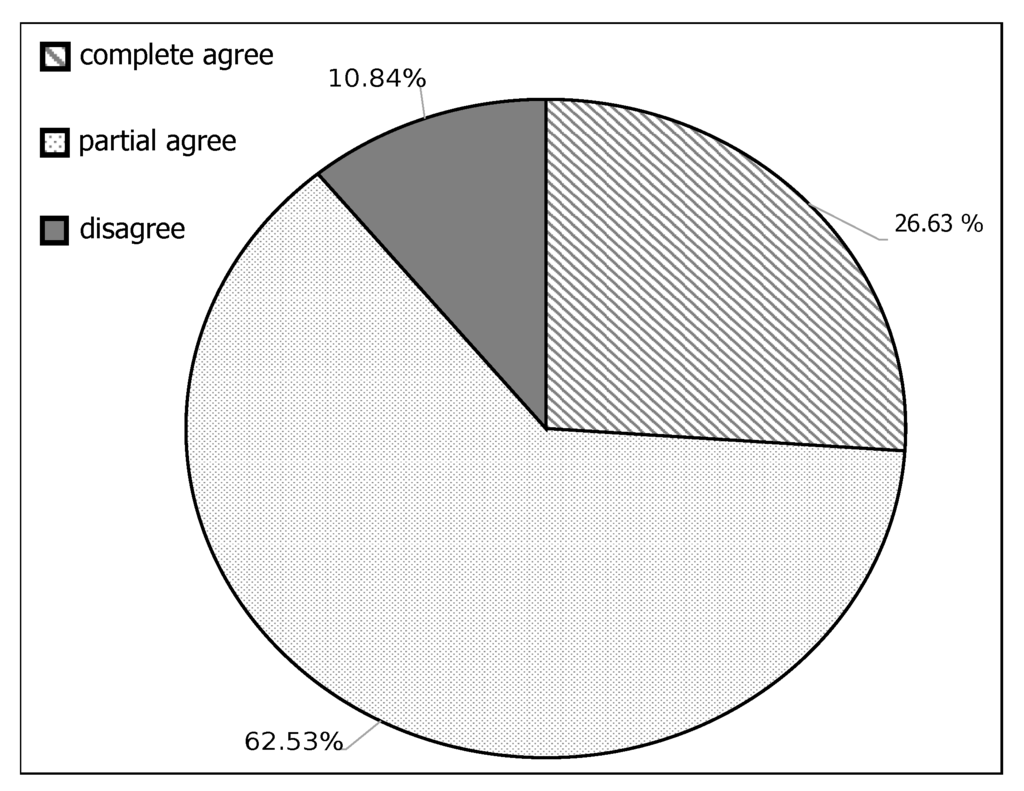
شرکت کنندگان 2865 نهاد را بررسی کردند. در طول اعتبارسنجی، زمانی که شرکتکننده از طبقهبندی خاصی مطمئن نیست، میتواند گزینه «نمیدانم» را انتخاب کند. برای 586 نهاد، زمانی که واریانس بین کلاسها توسط شرکتکنندگان شناسایی نشد، گزینه «نمیدانم» را دریافت کردیم. در این موارد، نهادها در پروژه OSM به روز نشده اند و از تجزیه و تحلیل ما نیز حذف شده اند. برای بقیه 2279 نهاد، نظر یک شرکت کننده را دریافت کردیم. همانطور که قبلا توضیح داده شد (به بخش 5.1 مراجعه کنید )، شرکت کننده انعطاف کاملی برای انطباق کلاس های توصیه شده ما دارد که منجر به سه سطح توافق شرکت کننده می شود:
-
توافق کامل : زمانی که یک شرکت کننده با هر دو کلاس توصیه شده موافق است و آنها را با گزینه “بله” علامت گذاری می کند.
-
توافق جزئی : زمانی که یک شرکتکننده فقط با یکی از کلاسهای پیشنهادی موافقت میکند و دیگری را با گزینه «نه» یا «شاید» علامتگذاری میکند.
-
اختلاف نظر : زمانی که یک شرکتکننده با هیچ یک از کلاسهای پیشنهادی موافق نیست و هر دو را با گزینه «نه» یا «شاید» علامتگذاری میکند.
شکل 11 موافقت شرکت کنندگان با کلاس های پیشنهادی را به شرح زیر نشان می دهد: 10.84% مخالف، 26.89% کاملا موافق و 62.53% تا حدی موافق هستند. می توان نتیجه گرفت که حدود 89 درصد از شرکت کنندگان با کلاس های توصیه شده توافق کامل/جزئی دارند. یافتهها نشاندهنده موفقیت طبقهبندیکننده توسعهیافته برای تمایز بین کلاسهای هدف است. علاوه بر این، پاسخ ها و مشارکت حاکی از امکان سنجی رویکرد پیشنهادی نیز می باشد.
6.3. کیفیت طبقه بندی داده های پیشرفته
برای درک تأثیر رویکرد ما بر کیفیت طبقهبندی دادهها، مشارکتها را با جزئیات بیشتری تحلیل کردیم. ما طبقه بندی موجودیت ها را قبل و بعد از اعتبارسنجی با توجه به کلاس های توصیه شده بررسی کردیم. جدول 2 و جدول 3 دو دیدگاه متفاوت از نتایج ارائه می دهند.
جدول 2 طبقه بندی موجودیت ها را قبل و بعد از اعتبارسنجی با توجه به کلاس های توصیه شده و نظرات شرکت کنندگان مقایسه می کند. در طول دوره مشخص شده، شرکت کنندگان 2279 نهاد را اعتبارسنجی کردند. این نهادها قبلاً به شرح زیر طبقه بندی می شدند: 412 باغ ، 1136 چمن و 731 پارک . در تجزیه و تحلیل، بررسی می کنیم که آیا طبقه بندی قبلی توسط رویکرد ما توصیه می شود یا خیر. از دیدگاه شناختی، در این تحلیل، پاسخ «شاید» را بیشتر به «بله» نزدیک میکنیم تا «نه». یافته ها حاکی از آن است که شرکت کنندگان 9/75 درصد، 2/89 درصد و 2/85 درصد از توصیه های باغ ، چمن و پارک را پذیرفتند.نهادها به ترتیب شرکتکنندگان طبقهبندی بخش بزرگی از موجودیتهای ارائهشده، و همچنین تصحیح سایر موجودیتهای بالقوه اشتباه طبقهبندی شده را تأیید کردند (اعداد پررنگ در ستونهای 3 و 4 جدول 2 ). به طور کلی حدود 85.5 درصد از توصیه های ارائه شده را پذیرفتند.
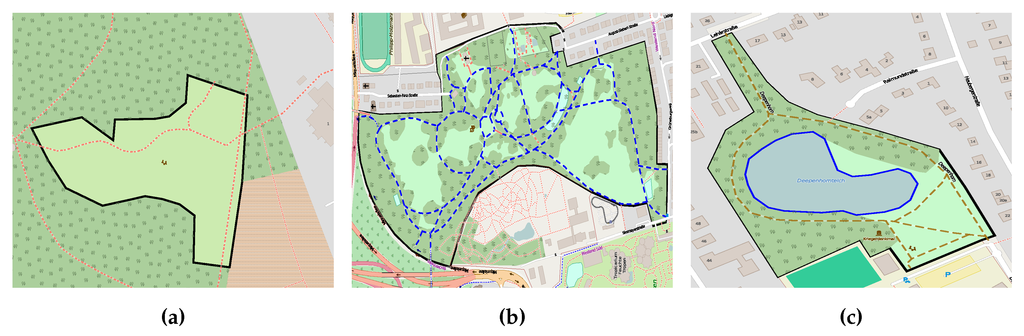
در تجزیه و تحلیل دیگری، جدول 3 بینشی در مورد کلاس ها با توجه به توصیه ها و نظرات شرکت کنندگان پس از فرآیند اعتبار سنجی ارائه می دهد. در طول فرآیند اعتبار سنجی، کلاس جنگل برای 748 نهاد به عنوان توصیه اول یا دوم توصیه شد. برای 184 از 748 نهاد، شرکتکنندگان در مورد کلاسهای پیشنهادی بالقوه زمانی که کلاس جنگل قبلاً به هیچ یک از نهادهای ارائهشده اختصاص داده نشده بود، توافق کردند. در مورد کلاس meadow نیز همین اتفاق افتاد (اعداد پررنگ در جدول 3 ). علاوه بر این، نهادهایی که به طور بالقوه کلاس های باغ ، چمن و پارک را پذیرفته اندهمانطور که در مقایسه با جدول 2 نشان داده شده است، بیشتر از موجودیت های ارائه شده در هر کلاس هستند . از یک طرف، این یافته ممکن است نشان دهنده اصلاح بالقوه موجودیت های طبقه بندی شده اشتباه باشد. از سوی دیگر، نتایج کلی در جدول 3 طبقه بندی همپوشانی مفهومی را اثبات کرد و معقول بودن طبقات چندگانه را همانطور که در شکل 12 نشان داده شده است نشان داد .
از طریق بررسی دستی، مواردی را شناسایی کردیم که موجودیتها میتوانند به شدت به کلاسهای مختلف تعلق داشته باشند. با توجه به اعتبار سنجی شرکت کنندگان، ما موجودیت های متعددی با دو کلاس معتبر پیدا کردیم. از جمله، 37 نهاد به عنوان پارک / جنگل ، 24 نهاد به عنوان پارک / باغ ، و دو نهاد به عنوان پارک / علفزار . شکل 12 برخی از این مثال ها را زمانی که موجودیت داده شده در شکل 12 a در یک منطقه جنگلی و در مجاورت یک حیاط مزرعه قرار دارد، نشان می دهد. با این حال، موجودیت دارای یک زمین بازی است ( به عنوان مثال، امکانات تفریحی) و توسط پیاده راه (خطوط قرمز شکسته) سنگفرش شده است. بنابراین، توصیه و تایید می شود که به عنوان پارک / علفزار طبقه بندی شود ، در حالی که موجودیت های ارائه شده در شکل 12 b,c به عنوان پارک / جنگل توصیه و تایید شده اند . آنها تا حدی توسط درختان سنگین و گیاهان چوبی (مناطق سبز تیره) پوشیده شده اند. علاوه بر این، آنها حاوی آب (که با یک خط آبی مشخص شده اند) و راه های چرخشی (خطوط آبی چین دار) هستند.
شکل 13 به صورت بصری پتانسیل طبقه بندی داده های پیشرفته را نشان می دهد. شکل سه سناریوی مشارکت را نشان می دهد: تأیید، تصحیح و ناآگاهی. شکل 13 a سناریوی تایید را در زمانی که موجودیت مشخص شده به عنوان پارک طبقه بندی می شود، نشان می دهد . این رویکرد پارک و چمن را به عنوان کلاس های توصیه شده پیشنهاد می کند. در طول اعتبارسنجی، یک شرکتکننده فقط کلاس پارک را انتخاب کرد . شکل 13 ب سناریوی اصلاحی را نشان می دهد که موجودیت داده شده به عنوان پارک طبقه بندی می شود و رویکرد کلاس های علفزار و چمن را توصیه می کند . در طول اعتبارسنجی، یک شرکتکننده آن را به عنوان یک طبقهبندی کردچمنزار . شکل 13 ج سناریوی ناآگاهی را در زمانی که موجودیت مشخص شده به عنوان چمن طبقه بندی شده است، نشان می دهد . این رویکرد کلاس های باغ و چمن را توصیه می کند . با این حال، یکی از شرکتکنندگان تصمیم گرفت آن را به عنوان علفزار طبقهبندی کند ، که انتخاب نامناسبی بود.
در سناریوی اول، موجودیت داده شده دارای ویژگی های اوقات فراغت است و شرکت کننده به توصیه های ما عمل کرده و طبقه بندی آن را به عنوان پارک تایید کرده است . موجودیت در سناریوی دوم شامل هیچ ویژگی دیگری نیست، در یک منطقه جنگلی واقع شده است، و نام “Gerlach-Wiese” دارد، که در آن wiese (آلمانی) = مراتع (انگلیسی) است. به عنوان پارک طبقه بندی شده بود ، اما یکی از شرکت کنندگان توصیه های ما را دنبال کرد و آن را به مراتع به روز کرد . در سناریوی سوم، موجودیت با ساختمانهایی احاطه شده است و طبق توصیههای ما، احتمال باغ بودن آن بیشتر است. با این حال، شرکت کننده آن را به عنوان چمنزار طبقه بندی کرد، که کلاس نامناسبی بود. آخرین سناریو طبقه بندی داده ها را افزایش نمی دهد، اما ادراکات فردی را منعکس می کند. این سناریو همچنین ممکن است زمانی اتفاق بیفتد که توصیههای ما اشتباه باشد یا واقعیت را منعکس نکند. در چنین مواردی، اعتبارسنجی های متعدد می تواند راه حل مناسبی باشد.
6.4. بازخورد شرکت کنندگان
به شرکت کنندگان اجازه داده شد با ما تماس بگیرند و نظرات و بازخوردهای خود را از طریق ایمیل یا نظر دادن در مورد پست های ما بیان کنند. بازخورد مثبت و منفی نیز دریافت کردیم. با توجه به بازخورد مثبت، شرکتکنندگان احترام گذاشتند و با عبارات مختلفی ما را تشویق کردند: «خدمات عالی، برنامههایی برای توسعه دارید؟»، «اگر قصد دارید بلژیک را هم شامل کنید، چیزهای بسیار عجیبی خواهید دید»، «فقط عالی. متشکرم، “این واقعاً موضوع خوبی است!”، و غیره. برعکس، برخی از افراد برای ما بازخورد منفی یا بهبودی ارسال کردند، مانند: “سوالات شما یک سوگیری پاسخ بسیار قوی ایجاد می کند”، “ارجاع به ویکی پدیا و تعاریف از فرهنگ لغت کاملا اشتباه است زیرا OSM از زبان طبیعی برای توصیف اشیا استفاده نمی کند”، برای اینکه بتوان از این ابزار به درستی استفاده کرد، باید اجماع واضحی در مورد معنای دقیق وجود داشته باشد.» و غیره . ما از همه شرکت کنندگان برای مشارکت و بازخوردشان تشکر می کنیم. کل بازخورد برای گسترش برنامه در نظر گرفته خواهد شد.
7. بحث
در گذشته، نقشه برداری وظیفه انحصاری نقشه برداران و افراد آموزش دیده بود. با این وجود، خطاها و دقت نقشه ها حتی در تولید حرفه ای نیز موضوعی نگران کننده بود. در واقع، به دلیل ابهام داده های جغرافیایی و تحولات زمانی داده ها، نقشه دقیقی وجود ندارد [ 72 ، 73 ، 74]]. با در دسترس بودن فناوری های جدید، VGI به منبع بالقوه داده های جغرافیایی تبدیل شده است. به ویژه، VGI فرآیند نقشه برداری را زمانی که عموم مردم در فرآیند جمع آوری داده ها شرکت می کنند، تسهیل می کند. با این حال، در VGI، عوامل دیگری بر دقت دادههای حاصل تأثیر میگذارند، مانند: ویژگیهای ناهمگن شرکتکنندگان، فقدان تخصص، و مکانیسمهای مشارکت انعطافپذیر. به طور خاص، اکثر منابع VGI دارای مسائل ذاتی مانند طبقه بندی داده های مشکل ساز هستند که یا ناسازگار یا ناقص است. برای ارائه خدمات قابل اعتماد نیاز به داده هایی با کیفیت تضمین شده است. مفهوم خدمات جغرافیایی داوطلبانه (VGS) در [ 75 ] معرفی شده است. با این حال، هنوز نیاز به منابع داده قابل اعتماد وجود دارد [ 76 ].
VGI بر اساس قدرت جمع سپاری است. از دیدگاه ما، به منظور بهره برداری از جمعیت برای ارائه اطلاعات ارزشمند، شرکت کنندگان باید در مورد کیفیت داده های مورد نیاز راهنمایی و/یا به خوبی آموزش داده شوند. بنابراین، ما رویکرد طبقهبندی مبتنی بر قانون را در [ 16 ، 17] پیشنهاد کردیم]. هدف این رویکرد پر کردن شکاف بین نیاز به مکانیسمهای مشارکت انعطافپذیر، عدم قطعیت دادههای مکانی، و ادراکات مختلف شرکتکنندگان است. با افزایش تکامل منابع VGI، یادگیری ماشین، به ویژه داده کاوی، می تواند نقشی حیاتی در تضمین کیفیت داده ایفا کند. در رویکرد خود، ما مکانیسمهای داده کاوی را برای ایجاد یک طبقهبندی که میتواند بین کلاسهای مشابه تمایز قائل شود، اعمال کردیم. پس از آن، طبقهبندیکننده توسعهیافته برای هدایت شرکتکنندگان به سمت طبقهبندی دقیقتر استفاده میشود.
برای افزایش کیفیت داده، استفاده از جمعسپاری یکی از امکانهایی است که قبلاً به عنوان یک بعد برای اطمینان از کیفیت داده تشویق شده بود [ 13 ]. در این مقاله، ما بهرهبرداری از جمعیت را تشویق میکنیم اما به شیوهای هدایتشده. در جمع سپاری، شرکت کنندگان مایل به مشارکت هستند. با این حال، آنها به طور کلی به هدف هدف اهمیت نمی دهند. برای مثال، ما تعاملات شرکتکنندگان را در طول مشارکت آنها در Grass&Green ردیابی کردیمتا دریابند که آیا توضیحات ارائه شده را به دقت بررسی کرده اند یا خیر. ما متوجه شدیم که تنها 80 نفر از 212 شرکت کننده، توضیحات داده شده را در منوی “راهنما” بررسی کردند. همین وضعیت در پروژه OSM رخ می دهد که در آن اکثر شرکت کنندگان بدون صرف زمان کافی برای خواندن پیشنهادات و توصیه های ارائه شده در صفحات OSM Wiki مشارکت می کنند.
کاربرد ارائه شده در این مقاله امکان سنجی رویکرد پیشنهادی را نشان می دهد. علاوه بر این، توسعه برنامه های کاربردی سفارشی شده برای یک ویژگی جغرافیایی خاص را تشویق می کند. به عنوان مثال، در مورد پروژه OSM، چندین برنامه کاربردی و خدمات برای بررسی و بهبود شبکه های جاده ای در مکان های مختلف توسعه یافته است. در نتیجه، OSM اطلاعات قابل اعتماد و دقیق تری در مورد جاده ها نسبت به منابع داده معتبر در برخی مکان ها ارائه می دهد. در Grass & Green، ما یک برنامه کاربردی ساده برای تأیید رویکرد خود ایجاد کردیم. معدود اشکالات درک شده را می توان با ماژول های هوشمند برطرف کرد. توسعه رابط های بصری و تعاملی برای پروژه های نقشه برداری مبتنی بر VGI یکی از امکان های غلبه بر چالش های طبقه بندی خواهد بود. به عنوان مثال، با مذاکره یا مثال زدن، یک رابط هوشمند ممکن است بتواند شرکت کنندگان را به سمت طبقه بندی دقیق تر و دقیق تر سوق دهد.
از منظر شناختی، درک درک انسان از ویژگی های جغرافیایی مورد نیاز است، زیرا آنها موتور پروژه های نقشه برداری VGI هستند. تنوع فرهنگ ها و علایق شرکت کنندگان دارای عملکرد دوگانه است: غنی سازی منبع داده و تضمین کیفیت داده ها. در Grass & Green، ما با تمرکز بر مفاهیم و بررسی بازنمایی کیفی کلاس ها با تنوع شرکت کنندگان کنار آمدیم. بنابراین، ما از کلاسها، تعاریف و توضیحات ویکیپدیا و دیکشنریها استفاده کردیم. تکنیکهای اکتساب شناختی و نمایش دادههای کافی نیز برای تشویق شرکتکنندگان به تولید دادههای دقیقتر مورد نیاز است. علاوه بر این، مشکلات طبقه بندی را می توان با استفاده از هستی شناسی جغرافیایی-فضایی حل کرد. نیاز به هستی شناسی ژئو فضایی قبلا برای درک بهتر فضا و ساختن کاربردهای GIS کارآمدتر مورد بحث قرار گرفته است [ 77 ].
رویکرد توسعهیافته مبتنی بر پایههای قوی است، و بنابراین میتوان آن را برای سایر ویژگیهای جغرافیایی و مکانهای دیگر نیز پیکربندی کرد. اول، این رویکرد مبتنی بر بررسی توپولوژیکی ویژگیهای هدف با توجه به زمینه آنها است. بنابراین، می توان آن را برای سایر ویژگی های جغرافیایی منطقه (به عنوان مثال، ویژگی های بدنه آبی) اعمال کرد. دوم، رویکرد بر اساس فرض طبقه بندی محلی ساخته شده است. بنابراین، در یک کشور خاص، این رویکرد ممکن است برای غنیسازی طبقهبندی دادهها در مناطق غیر شهری، پس از یادگیری از دادههای مناطق شهری، در صورت در دسترس بودن مورد استفاده قرار گیرد. در مقابل، این رویکرد محدودیت هایی نیز دارد. اولا، طبقه بندی کننده به در دسترس بودن مقادیر زیادی از داده ها بستگی داردبه منظور استخراج دانش قابل اعتماد ثانیاً، یادگیری از دادههای با کیفیت مشکلساز ممکن است باعث عدم اطمینان در طبقهبندیکننده توسعهیافته شود، و از این رو، بررسی دقیق کیفیت دادههای آموزشی مورد استفاده مورد نیاز است.
8. نتیجه گیری
VGI می تواند به عنوان یک منبع داده مکمل برای داده های معتبر و یک عنصر مهم در زیرساخت داده های جغرافیایی-مکانی عمل کند. با این وجود، کیفیت داده های ناهمگون، کاربرد این منبع امیدوارکننده را محدود می کند. به طور خاص، این تحقیق به طبقهبندی مشکلساز VGI میپردازد، جایی که طبقهبندی دادهها به ترجیحات و ادراکات فردی بستگی دارد. در کار قبلی، ما رویکرد طبقهبندی مبتنی بر قانون را توسعه دادیم که از مکانیسمهای یادگیری ماشین برای مدیریت چالشهای طبقهبندی در پروژههای VGI استفاده میکند. این رویکرد از در دسترس بودن داده ها برای یادگیری ویژگی های متمایز استفاده می کند که می تواند به تمایز بین کلاس های مشابه کمک کند. ویژگی های آموخته شده پس از آن برای ایجاد یک طبقه بندی کننده، که قادر به تمایز بین کلاس های مشابه بود، استفاده شد.
به عنوان اعتبار سنجی رویکرد، ما یک برنامه کاربردی مبتنی بر وب به نام Grass&Green ایجاد کردیم. برنامه به کلاس های همپوشانی برخی از موجودیت های مرتبط با علف می پردازد. برای یک مجموعه داده معین، برنامه از طبقهبندی مبتنی بر قانون استفاده کرد و کلاسهای توصیهشده را برای اعتبارسنجی عمومی ارائه کرد. یافتهها نشاندهنده امکانسنجی رویکرد پیشنهادی و موفقیت کاربرد نیز هستند. با استفاده از روش های ساده اعلام، توجه 212 شرکت کننده از بیش از 35 زمینه فرهنگی مختلف را به خود جلب کردیم. حدود 89 درصد از مشارکت ها با توصیه های ما موافق هستند. تجزیه و تحلیل مشارکت ها افزایش بالقوه طبقه بندی داده ها را نشان می دهد. بازخورد شرکتکنندگان به کارگیری رویکرد ما در سایر مجموعههای داده را تشویق کرده است. نتایج توسعه برنامه های کاربردی سفارشی تر را برای اطمینان از کیفیت طبقه بندی یک ویژگی خاص تحریک می کند. در کارهای آینده، ما قصد داریم مکانیزم های شناختی و تعاملی اکتساب داده ها را طراحی کنیم. علاوه بر این، ما میخواهیم از ماهیت VGI و شرکتکنندگان به منظور توسعه تفسیر شهودی دادهها استفاده کنیم.
منابع
- Goodchild، MF Citizens به عنوان حسگر: دنیای جغرافیای داوطلبانه. ژئوژورنال 2007 ، 69 ، 211-221. [ Google Scholar ] [ CrossRef ]
- گوویا، سی. Fonseca، A. رویکردهای جدید برای نظارت بر محیط زیست: استفاده از فناوری اطلاعات و ارتباطات برای کشف اطلاعات جغرافیایی داوطلبانه. جئوژورنال 2008 ، 72 ، 185-197. [ Google Scholar ] [ CrossRef ]
- مونی، پی. Corcoran, P. آیا اطلاعات جغرافیایی داوطلبانه می تواند در eEnvironment و SDI شرکت کند؟ در سیستم های نرم افزاری محیطی. چارچوب های محیط الکترونیکی ; Springer: برلین، آلمان، 2011; صص 115-122. [ Google Scholar ]
- روشه، اس. پروپک-زیمرمن، ای. Mericskay، B. GeoWeb و مدیریت بحران: مسائل و دیدگاههای اطلاعات جغرافیایی داوطلبانه. جئوژورنال 2013 ، 78 ، 21-40. [ Google Scholar ] [ CrossRef ]
- زوک، م. گراهام، ام. شلتون، تی. گورمن، اس. داوطلبانه اطلاعات جغرافیایی و امداد رسانی به منابع جمعی: مطالعه موردی زلزله هائیتی. پزشکی جهانی سیاست سلامت 2010 ، 2 ، 7-33. [ Google Scholar ] [ CrossRef ]
- فوث، م. باجراچاریا، بی. براون، آر. هرن، جی. زندگی دوم شهرسازی؟ استفاده از ابزار NeoGeography برای تعامل با جامعه. J. Locat. سرویس مبتنی بر 2009 ، 3 ، 97-117. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- مونی، پی. سان، اچ. Yan, L. VGI به عنوان یک منبع داده بهروزرسانی پویا در خدمات مبتنی بر مکان در محیطهای شهری. در مجموعه مقالات دومین کارگاه بین المللی در جمع سپاری همه جا حاضر: UbiCrowd’11، پکن، چین، 17-21 سپتامبر 2011.
- هاکلی، م. Weber, P. OpenStreetMap: نقشه های خیابانی تولید شده توسط کاربر. IEEE Pervasive Computing 2008 ، 7 ، 12-18. [ Google Scholar ] [ CrossRef ]
- ساولیف، آ. خو، اس. یانوویچ، ک. مولیگان، سی. تاچر، جی. Luo, W. خدمات جغرافیایی داوطلبانه: توسعه یک سرویس مبتنی بر مکان مبتنی بر داده های مرتبط. در مجموعه مقالات اولین کارگاه بین المللی ACM SIGSPATIAL در مورد معناشناسی و هستی شناسی فضایی، شیکاگو، IL، ایالات متحده، 1 نوامبر 2011. صص 25-31.
- الوود، اس. Goodchild، MF; Sui، DZ تحقیق داوطلبانه اطلاعات جغرافیایی: داده های فضایی، تحقیقات جغرافیایی، و عملکرد اجتماعی جدید. ان دانشیار صبح. Geogr. 2012 ، 102 ، 571-590. [ Google Scholar ] [ CrossRef ]
- علی، ال. Schmid, F. تضمین کیفیت داده برای اطلاعات جغرافیایی داوطلبانه. در علم اطلاعات جغرافیایی ; Springer: وین، اتریش، 2014; صص 126-141. [ Google Scholar ]
- دیویلر، آر. استین، ا. Bédard، Y.; کریسمن، ن. فیشر، پی. Shi, W. سی سال تحقیق در مورد کیفیت داده های مکانی: دستاوردها، شکست ها و فرصت ها. ترانس. GIS 2010 ، 14 ، 387-400. [ Google Scholar ] [ CrossRef ]
- Goodchild، MF; Li, L. اطمینان از کیفیت اطلاعات جغرافیایی داوطلبانه. تف کردن آمار 2012 ، 1 ، 110-120. [ Google Scholar ] [ CrossRef ]
- Goodchild، MF ادعا و قدرت: علم محتوای جغرافیایی تولید شده توسط کاربر. در مجموعه مقالات همایش برای شصتمین زادروز اندرو یو. فرانک، وین، ایتالیا، 30 ژوئن تا 1 ژوئیه 2008.
- گوپتیل، SC; موریسون، JL عناصر کیفیت داده های مکانی ; الزویر: آمستردام، هلند، 2013. [ Google Scholar ]
- علی، ال. اشمید، اف. فالومیر، ز. Freksa, C. به سمت طبقه بندی مبتنی بر قانون برای اطلاعات جغرافیایی داوطلبانه. ISPRS Ann. فتوگرام حسگر از راه دور اسپات. Inf. علمی 2015 ، II-3/W5 ، 211-217. [ Google Scholar ] [ CrossRef ]
- علی، ال. فالومیر، ز. اشمید، اف. Freksa, C. طبقهبندی انسانی مبتنی بر قوانین اطلاعات جغرافیایی داوطلبانه. ISPRS J. Photogramm and Remote Sens. 2016 ، در دست چاپ. [ Google Scholar ]
- خاطرات کاربران OSM. در دسترس آنلاین: https://www.openstreetmap.org/diary (در 24 مه 2016 قابل دسترسی است).
- OSMstats. در دسترس آنلاین: http://osmstats.neis-one.org/ (دسترسی در 24 مه 2016).
- stensen, OM; اسمیتز، PC ISO/TC211: استانداردسازی اطلاعات جغرافیایی و ژئو انفورماتیک. در مجموعه مقالات سمپوزیوم بین المللی زمین شناسی و سنجش از دور IEEE 2002، IGARSS’02، تورنتو، ON، کانادا، 24-28 ژوئن 2002. جلد 1، ص 261-263.
- ISO/TC211. در دسترس آنلاین: http://www.isotc211.org/ (دسترسی در 24 مه 2016).
- Haklay, M. اطلاعات جغرافیایی داوطلبانه چقدر خوب است؟ مطالعه تطبیقی مجموعه دادههای OpenStreetMap و Ordnance Survey. محیط زیست طرح. B طرح. دس 2010 ، 37 ، 682-703. [ Google Scholar ] [ CrossRef ]
- لودویگ، آی. ووس، ا. Krause-Traudes، M. مقایسه شبکه های خیابانی Navteq و OSM در آلمان. در پیشرفت علم اطلاعات جغرافیایی برای جهانی در حال تغییر . Springer: Berlin, Gernany, 2011; صص 65-84. [ Google Scholar ]
- ارسنجانی، ج. مونی، پی. Zipf، A.; Schauss, A. ارزیابی کیفیت اطلاعات استفاده از زمین از OpenStreetMap در مقابل مجموعه دادههای معتبر. در OpenStreetMap در GIScience ; Springer: برلین، آلمان، 2015; صص 37-58. [ Google Scholar ]
- دورن، اچ. تورنروس، تی. Zipf، A. ارزیابی کیفیت VGI با استفاده از دادههای معتبر – مقایسه با دادههای کاربری زمین در جنوب آلمان. ISPRS Int. J. Geo-Inf. 2015 ، 4 ، 1657-1671. [ Google Scholar ] [ CrossRef ]
- واز، ای. جوکار ارسنجانی، جی. نقشه برداری جمع سپاری استفاده از زمین در محیط های متراکم شهری: ارزیابی تورنتو. می توان. Geogr. 2015 . [ Google Scholar ] [ CrossRef ]
- گیرس، جی اف. Touya, G. ارزیابی کیفیت مجموعه داده OpenStreetMap فرانسه. ترانس. GIS 2010 ، 14 ، 435-459. [ Google Scholar ] [ CrossRef ]
- Flanagin، AJ; Metzger, MJ اعتبار اطلاعات جغرافیایی داوطلبانه. جئوژورنال 2008 ، 72 ، 137-148. [ Google Scholar ] [ CrossRef ]
- بیشر، م. کوهن، دبلیو. اطلاعات مکانی از پایین به بالا: موضوع اعتماد و معناشناسی. در جامعه اطلاعاتی اروپا ; Springer: برلین، آلمان، 2007; صص 365-387. [ Google Scholar ]
- نیس، پ. Zipf، A. تجزیه و تحلیل فعالیت مشارکت کننده یک پروژه داوطلبانه اطلاعات جغرافیایی: مورد OpenStreetMap. ISPRS Int. J. Geo-Inf. 2012 ، 1 ، 146-165. [ Google Scholar ] [ CrossRef ]
- نیس، پ. زیلسترا، دی. Zipf، A. تکامل شبکه خیابانی نقشههای crowdsourced: OpenStreetMap در آلمان 2007-2011. اینترنت آینده 2011 ، 4 ، 1-21. [ Google Scholar ] [ CrossRef ]
- کسلر، سی. de Groot، RTA Trust به عنوان معیاری برای کیفیت اطلاعات جغرافیایی داوطلبانه در مورد OpenStreetMap. در علم اطلاعات جغرافیایی در قلب اروپا ; Springer: برلین، آلمان، 2013; ص 21-37. [ Google Scholar ]
- کسلر، سی. ترام، جی. Kauppinen، T. پیگیری فرآیندهای ویرایش در اطلاعات جغرافیایی داوطلبانه: مورد OpenStreetMap. در مجموعه مقالات کارگاه شناسایی اشیاء، فرآیندها و رویدادها در داده های توزیع شده مکانی-زمانی (IOPE 2011)، بلفاست، ME، ایالات متحده آمریکا، 12-16 سپتامبر 2016.
- D’Antonio، F. فوگلیارونی، پ. تاریخچه ویرایش Kauppinen، T. VGI قابلیت اطمینان داده ها و شهرت کاربر را نشان می دهد. در مجموعه مقالات هفدهمین کنفرانس AGILE در علم اطلاعات جغرافیایی، اتصال اروپای دیجیتال از طریق مکان و مکان، کاستلون، اسپانیا، 3 تا 6 ژوئن 2014.
- نیس، پ. زیلسترا، دی. Zipf، A. مقایسه مشارکت داوطلبانه اطلاعات جغرافیایی و توسعه جامعه برای مناطق منتخب جهان. اینترنت آینده 2013 ، 5 ، 282-300. [ Google Scholar ] [ CrossRef ]
- بالاتوره، آ. Zipf، A. چارچوب کیفیت مفهومی برای اطلاعات جغرافیایی داوطلبانه. در مجموعه مقالات دوازدهمین کنفرانس بین المللی نظریه اطلاعات مکانی COSIT 2015، سانتافه، NM، ایالات متحده، 12-16 اکتبر 2015; صص 89-107.
- بارون، سی. نیس، پ. Zipf، A. چارچوبی جامع برای تحلیل کیفی OpenStreetMap ذاتی. ترانس. GIS 2014 ، 18 ، 877-895. [ Google Scholar ] [ CrossRef ]
- هچت، بی. استفنز، ام. داستان شهرها: تعصبات شهری در اطلاعات جغرافیایی داوطلبانه. در مجموعه مقالات هشتمین کنفرانس بین المللی وبلاگ ها و رسانه های اجتماعی (ICWSM)، آکسفورد، انگلستان، 27-29 مه 2014.
- کواترون، جی. مشهدی، ع. Capra, L. Mind the map: تأثیر فرهنگ و ثروت اقتصادی بر رفتارهای نقشه برداری جمعیت. در مجموعه مقالات هفدهمین کنفرانس ACM در زمینه کار تعاونی و محاسبات اجتماعی با پشتیبانی رایانه، بالتیمور، MD، ایالات متحده، 15 تا 19 فوریه 2014. ص 934-944.
- اشمید، اف. کوتز، او. فرومبرگر، ال. کاوپینن، تی. Cai, C. رابط های بصری و طبیعی برای طبقه بندی داده های مکانی. در مجموعه مقالات کارگاه تحقیقات کسب دانش مرتبط با مکان (P-KAR)، کلستر سیون، آلمان، 31 اوت 2012.
- اشمید، اف. فرومبرگر، ال. کای، سی. Dylla, F. Lowering the barrier: چگونه الگوی What-You-See-Is-What-You-Map مردم را قادر می سازد تا اطلاعات جغرافیایی داوطلبانه را به اشتراک بگذارند. در مجموعه مقالات چهارمین سمپوزیوم سالانه محاسبات برای توسعه، کیپ تاون، آفریقای جنوبی، 6-7 دسامبر 2013. صص 8-18.
- پورعبدالله، ع. مورلی، جی. فلدمن، اس. جکسون، ام. به سوی نقشه خیابان باز معتبر: تلفیق شبکه جاده ای نقشه های ملی OSM و OS OpenData. ISPRS Int. J. Geo-Inf. 2013 ، 2 ، 704-728. [ Google Scholar ] [ CrossRef ]
- واندکاستیل، ا. Devillers, R. بهبود کیفیت داده های جغرافیایی داوطلبانه با استفاده از اندازه گیری های تشابه معنایی. ISPRS-Int. قوس. فتوگرام حسگر از راه دور اسپات. Inf. علمی 2013 ، 1 ، 143-148. [ Google Scholar ] [ CrossRef ]
- علی، ال. اشمید، اف. السلمان، ر. Kauppinen، T. ابهام و معقولیت: مدیریت کیفیت طبقه بندی در اطلاعات جغرافیایی داوطلبانه. در مجموعه مقالات بیست و دومین کنفرانس بین المللی ACM SIGSPATIAL در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، دالاس، تگزاس، ایالات متحده آمریکا، 4 تا 7 نوامبر 2014. صص 143-152.
- یاننکو، او. Schlieder, C. اصول بازی برای افزایش کیفیت مجموعه داده های تولید شده توسط کاربر. در Proceedings of the AGILE، کارگاه Geogames Geoplay، Castellon، اسپانیا، 3-6 ژوئن 2014. صص 1-5.
- کاراگیاناکیس، ن. جیانوپولوس، جی. اسکوتاس، دی. ابزار Athanasiou، S. OSMRec برای توصیه خودکار دستهها در موجودیتهای فضایی در OpenStreetMap. در مجموعه مقالات نهمین کنفرانس ACM در سیستم های توصیه کننده، وین، اتریش، 16-20 سپتامبر 2015. صص 337-338.
- پلاگین OSMRec. در دسترس آنلاین: https://github.com/GeoKnow/OSMRec (در 24 مه 2016 قابل دسترسی است).
- بازرس OSM. در دسترس آنلاین: http://tools.geofabrik.de/osmi/ (در 24 مه 2016 قابل دسترسی است).
- نگه داشتن راست. در دسترس آنلاین: http://keepright.ipax.at/ (دسترسی در 24 مه 2016).
- رولت نقشه. در دسترس آنلاین: http://maproulette.org/ (در 24 مه 2016 قابل دسترسی است).
- گرد و غبار نقشه. در دسترس آنلاین: http://www.mapdust.com/ (در 24 مه 2016 قابل دسترسی است).
- NOVAM. در دسترس آنلاین: http://b3e.net/novam/ (در 24 مه 2016 قابل دسترسی است).
- مدل های فیشر، PF عدم قطعیت در داده های مکانی. جغرافیا. Inf. سیستم 1999 ، 1 ، 191-205. [ Google Scholar ]
- اسپارکس، ک. کلیپل، ا. والگرون، JO; Mark, D. Citizen Science طبقه بندی پوشش زمین بر اساس تصاویر زمینی و هوایی. در نظریه اطلاعات مکانی ; Springer: برلین، آلمان، 2015; صص 289-305. [ Google Scholar ]
- کلیپل، ا. اسپارکس، ک. والگرون، JO دامها و پتانسیلهای علم جمعی: متاآنالیز تأثیرات زمینهای. ISPRS Ann. فتوگرام حسگر از راه دور اسپات. Inf. علمی 2015 ، II-3/W5 ، 325-331. [ Google Scholar ] [ CrossRef ]
- فودی، جی. ببینید، L. فریتز، اس. ون در ولده، م. پرگر، سی. شیل، سی. بوید، دی. Comber، A. نقشه برداری دقیق ویژگی از اطلاعات جغرافیایی داوطلبانه: مسائل کمیت و کیفیت داوطلب. کارتوگر. J. 2014 ، 52 ، 1-9. [ Google Scholar ] [ CrossRef ]
- فریتز، اس. مک کالوم، آی. شیل، سی. پرگر، سی. ببینید، L. شپاچنکو، دی. ون در ولده، م. کراکسنر، اف. Obersteiner, M. Geo-Wiki: یک پلت فرم آنلاین برای بهبود پوشش جهانی زمین. محیط زیست مدل. نرم افزار 2012 ، 31 ، 110-123. [ Google Scholar ] [ CrossRef ]
- مونی، پی. Corcoran, P. فرآیند حاشیه نویسی در OpenStreetMap. ترانس. GIS 2012 ، 16 ، 561-579. [ Google Scholar ] [ CrossRef ]
- بالاتوره، آ. برتولتو، ام. استخراج دانش جغرافیایی ویلسون، دی سی و تشابه معنایی در OpenStreetMap. بدانید. Inf. سیستم 2013 ، 37 ، 61-81. [ Google Scholar ] [ CrossRef ]
- باگلاتزی، ع. کوکلا، م. Kavouras, M. معنایی سازی OpenStreetMap. در مجموعه مقالات پنجمین کارگاه بین المللی Terra Cognita، بوستون، MA، ایالات متحده آمریکا، 12 نوامبر 2012; صص 39-50.
- کامبر، ای جی. فیشر، پی. هاروی، اف. گهگان، م. Wadsworth، R. استفاده از فراداده برای پیوند عدم قطعیت و ارزیابی کیفیت داده ها. در مجموعه مقالات دوازدهمین سمپوزیوم بین المللی در مورد مدیریت داده های فضایی، وین، اتریش، 12-14 ژوئیه 2006; صص 279-292.
- گریرا، جی. Bédard، Y.; Roche, S. عدم قطعیت داده های فضایی در دنیای VGI: رفتن از مصرف کننده به تولید کننده. Geomatica 2010 ، 64 ، 61-72. [ Google Scholar ]
- Egenhofer، MJ; آل طه، ک.ک. استدلال درباره تغییرات تدریجی روابط توپولوژیکی. در مجموعه مقالات کنفرانس بین المللی GIS-از فضا تا قلمرو: نظریه ها و روش های استدلال مکانی-زمانی، پیزا، ایتالیا، 21-23 سپتامبر 1992; صص 196-219.
- ثبتاه، اف. بررسی معادن طبقه بندی انجمنی. بدانید. مهندس Rev. 2007 , 22 , 37-65. [ Google Scholar ] [ CrossRef ]
- سرور اوبونتو در دسترس آنلاین: http://www.ubuntu.com/server (در 24 مه 2016 قابل دسترسی است).
- OpenScienceMap. در دسترس آنلاین: http://www.opensciencemap.org/ (دسترسی در 24 مه 2016).
- ورد نت. در دسترس آنلاین: https://wordnet.princeton.edu/ (دسترسی در 24 مه 2016).
- جزوه در دسترس آنلاین: http://leafletjs.com/ (در 1 ژوئن 2016 قابل دسترسی است).
- بوت استرپ در دسترس آنلاین: http://getbootstrap.com/ (در 1 ژوئن 2016 قابل دسترسی است).
- جی کوئری. در دسترس آنلاین: https://jquery.com/ (در 1 ژوئن 2016 قابل دسترسی است).
- OAuth. در دسترس آنلاین: http://oauth.net/ (در 1 ژوئن 2016 قابل دسترسی است).
- Crone، GR Maps و سازندگان آنها: مقدمه ای بر تاریخچه نقشه برداری . کتابخانه دانشگاه هاچینسون: لندن، بریتانیا، 1966. [ Google Scholar ]
- Goodchild، MF; Gopal, S. The Accuracy of Spatial Databases ; CRC Press: Boca Raton، FL، USA، 1989. [ Google Scholar ]
- Goodchild، مدل های داده MF و کیفیت داده: مشکلات و چشم اندازها. در دسترس آنلاین: http://www.geog.ucsb.edu/ good/papers/192.pdf (در 1 ژوئن 2016 قابل دسترسی است).
- تاچر، جی. از اطلاعات جغرافیایی داوطلبانه تا خدمات جغرافیایی داوطلبانه. در جمع سپاری دانش جغرافیایی ; Springer: برلین، آلمان، 2013; صص 161-173. [ Google Scholar ]
- پارکر، سی جی; می، آ. میچل، وی. باروز، الف. گرفتن اطلاعات داوطلبانه برای طراحی خدمات فراگیر: مزایا و چالش های بالقوه. دس J. 2013 , 16 , 197-218. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- فرانک، AU هستی شناسی فضایی: دیدگاه اطلاعات جغرافیایی. در استدلال مکانی و زمانی ; Springer: برلین، آلمان، 1997; صص 135-153. [ Google Scholar ]
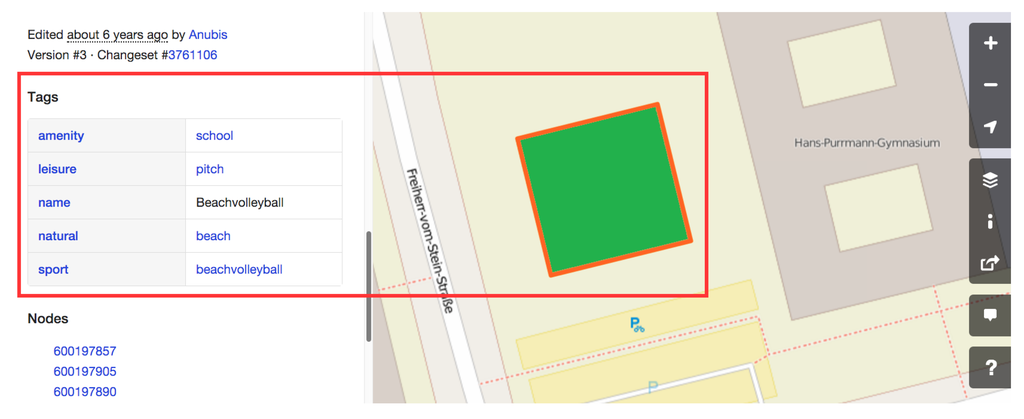
شکل 1. نمونه ای از طبقه بندی مشکل ساز در پروژه OSM: موجودیت برجسته شده به عنوان زمین ، مدرسه و ساحل طبقه بندی می شود ، در حالی که در واقع یک زمین بازی والیبال ساحلی در یک مدرسه است.
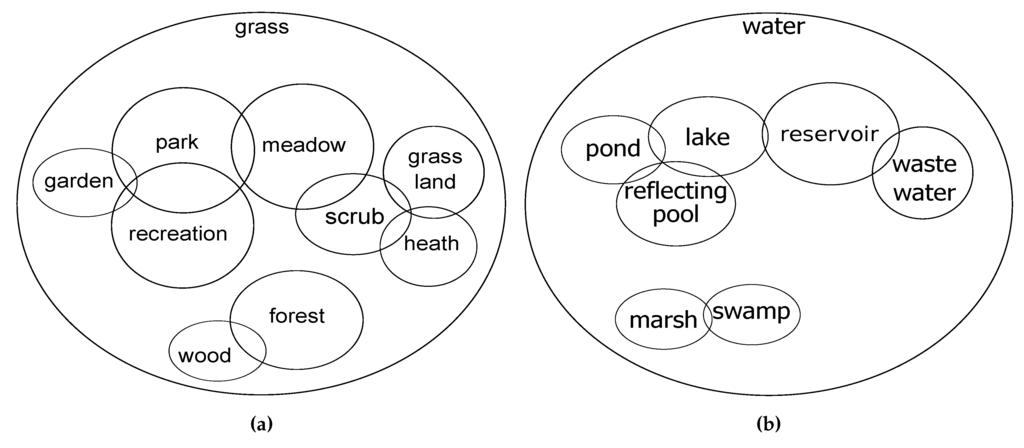
شکل 2. طبقات همپوشانی مفهومی به دلیل توضیحات داده شده در ویکی OSM. نمونه هایی از ( الف ) طبقات مرتبط با چمن همپوشانی، ( ب ) طبقات مرتبط با آب همپوشانی دارند.
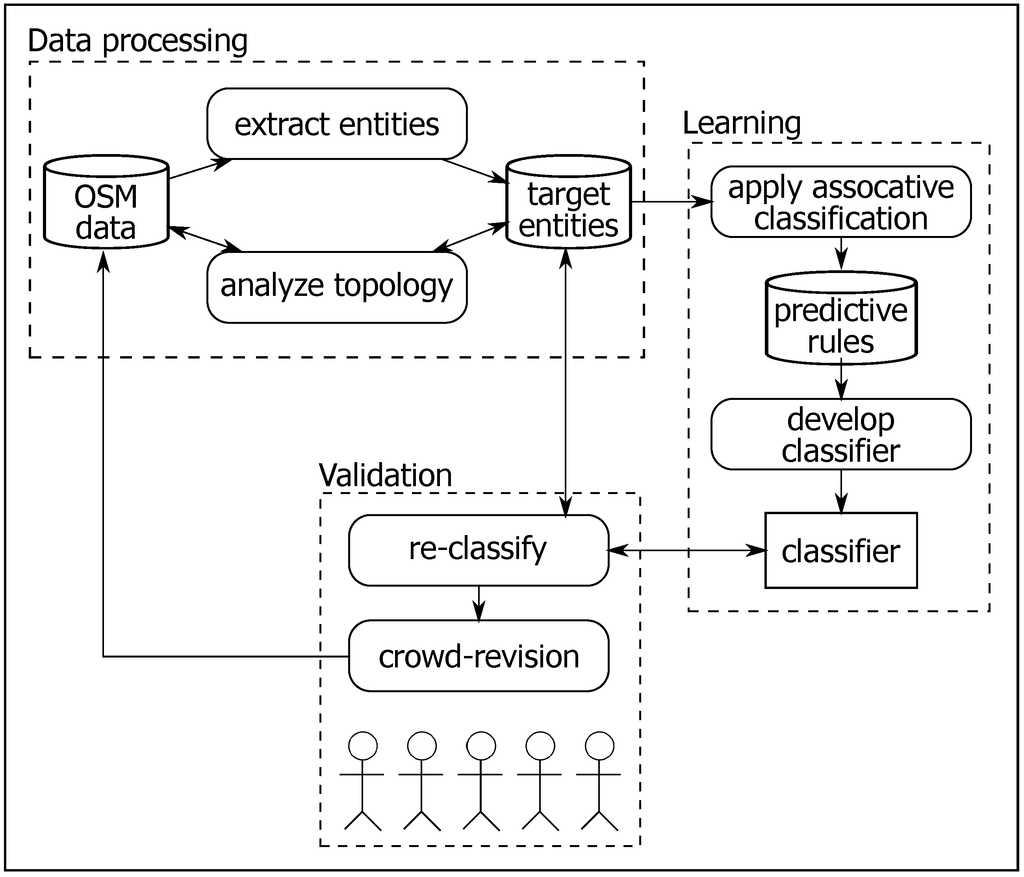
شکل 3. ساختار مفهومی رویکرد طبقه بندی مبتنی بر قانون.
شکل 4. دستورالعمل های برنامه و گزینه های ورود کاربر OSM.

شکل 5. توضیحات متنی و تصویری کلاس های هدف.
شکل 6. واسط اعتبارسنجی برای موجودیت های ارائه شده.
شکل 7. ساختار برنامه Grass &Green .

شکل 8. الگوهای مشارکت و مشارکت با توجه به خاستگاه جغرافیایی شرکت کننده. ( الف ) توزیع منابع جغرافیایی شرکتکنندگان، ( ب ) مشارکتها نسبت به مبداهای جغرافیایی شرکتکننده.
شکل 9. مشارکت کنندگان و مشارکت های مربوط به تجربه شرکت کننده. ( الف ) توزیع شرکتکنندگان و مشارکتها در هر گروه، ( ب ) نگرانیهای شرکتکنندگان در هر گروه.
شکل 10. تعداد شرکت کنندگان در روز نسبت به روش های اعلامی.
شکل 11. توافق شرکت کننده با کلاس های توصیه شده.
شکل 12. تصاویر بصری موجودیت هایی که به طور قابل قبولی به کلاس های همپوشانی مفهومی تعلق دارند. موجودیت های داده شده ( که با خطوط سیاه مشخص شده اند ) توسط شرکت کنندگان تأیید می شوند. ( الف ) یک موجودیت برای طبقهبندی بهعنوان پارک / چمنزار اعتبارسنجی میشود ، ( ب ) یک موجودیت برای طبقهبندی بهعنوان پارک / جنگل تأیید میشود ، ( ج ) یک موجودیت اعتبار برای طبقهبندی بهعنوان پارک / جنگل تأیید میشود .

شکل 13. بررسی بصری مشارکت های شرکت کنندگان در مقایسه با توصیه های ارائه شده توسط رویکرد ما و طبقه بندی داده های پیشرفته حاصل. ( الف ) یک شرکتکننده از توصیه ما پیروی کرد و طبقهبندی نهاد را بهعنوان پارک تأیید کرد ، ( ب ) یک شرکتکننده از توصیه ما پیروی کرد و طبقهبندی نهاد را از پارکی به علفزار اصلاح کرد ، ( ج ) یک شرکتکننده کلاس باغ پیشنهادی ما را نادیده گرفت و نهاد را بهعنوان اشتباه طبقهبندی کرد. چمنزار .

جدول 1. نقشه برداری بین برچسب های OSM و برخی از کلاس های همپوشانی مرتبط با چمن و آب.
جدول 2. نهادهای طبقه بندی شده قبل و بعد از اعتبارسنجی با توجه به کلاس های توصیه شده و نظرات شرکت کنندگان.
جدول 3. کلاس ها با توجه به توصیه ها و پاسخ های شرکت کنندگان پس از اعتبار سنجی.
© 2016 توسط نویسندگان؛ دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (CC-BY) (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر