1. معرفی
تخمین و پیشبینی زمان سفر به دلیل عدم قطعیت ذاتی سفر در شبکههای جادهای شهری متراکم و عدم قطعیت ناشی از جمعآوری دادهها با وسایل نقلیه کاوشگر مجهز به GPS چالش برانگیز است. عدم قطعیت توسط نوسانات در ترافیک ایجاد می شود و تحت تأثیر بسیاری از عوامل دیگر، مانند تقاضای ترافیک (به عنوان مثال، به دلیل ویژگی های جمعیت، اثرات فصلی، لحظه لحظه، رفتار راننده، در دسترس بودن اطلاعات ترافیک، و پاسخ های کاربر)، کنترل ترافیک (مثلاً ، به دلیل تصادفات، کار جاده، و هندسه جاده)، شرایط آب و هوایی (به عنوان مثال، به دلیل دما، باران، برف و باد)، ورود و خروج تصادفی در تقاطع های علامت دار [ 1] و جهت حرکت جریان های ترافیکی. این نوسانات تصادفی اغلب پیچیده و پیش بینی آن دشوار است. درک این نوسانات به ویژه هنگام توسعه الگوریتم های پیش بینی دقیق تر ضروری است. در همین حال، به دلیل فرکانس پایین [ 2 ، 3 ، 4 ] اکتساب داده های GPS وسیله نقلیه کاوشگر و محدودیت منطقه ای مناطق رانندگی، اطلاعات مسیر جمع آوری شده توسط GPS خودروهای کاوشگر نمی تواند کل شبکه جاده شهری را پوشش دهد. بنابراین، داده های جمع آوری شده پراکنده هستند [ 5 ، 6 ]. تخمین و پیشبینی زمان سفر لینک با استفاده از دادههای پراکنده چالشی است که برای تخمین و پیشبینی دقیق زمان سفر باید حل شود.
مطابق با نیازهای پیشبینی زمان سفر، روشهای پیشبینی بسیاری پیشنهاد شدهاند، از جمله روشهای آماری و رگرسیونی [ 7 ، 8 ، 9 ]، میانگین تاریخی و هموارسازی [ 10 ، 11 ، 12 ]، یادگیری ماشینی متنوع [ 13 ، 14 ]، و روش های مبتنی بر نظریه جریان ترافیک [ 15 ]. در میان این روشها، مدل میانگین متحرک یکپارچه خودرگرسیون (ARIMA) به تدریج در حال تبدیل شدن به معیاری برای ارزیابی مدلهای پیشبینی جدید توسعهیافته است [ 16 ]. مدل ARIMA [ 7 ، 17] به طور کلی ساختار مدل خاصی را برای داده ها فرض می کند و پارامترهای قابل تفسیر را با ساختار مدل ساده ارائه می دهد. این مدل زمانی که جریان ترافیک الگوهای تغییر منظم را نشان می دهد، بهتر می تواند زمان سفر را پیش بینی کند. یکی دیگر از روشهای پیشبینی مؤثر، الگوریتمهای یادگیری ماشینی است که بهطور گسترده در پیشبینی ترافیک نیز کاربرد دارند. کاربردهای موفق شامل ماشین های بردار پشتیبان (SVM) [ 13 ، 18 ]، شبکه های عصبی [ 14 ، 19 ] و تکنیک های ترکیبی و مجموعه ای [ 13 ، 20] است.]. برخلاف مدلهای آماری موجود، در یادگیری ماشینی، لازم نیست فرض کنیم که دادهها ساختار خاصی دارند. این ساختار می تواند ناشناخته باشد. الگوریتم های یادگیری ماشینی می توانند ساختار مدل بالقوه داده ها را به تصویر بکشند [ 21 ]. با این حال، یک نقطه ضعف مهم این رویکرد، عدم تفسیرپذیری است که کاربرد این مدل را محدود میکند.
در سالهای اخیر، الگوریتمهای مجموعه برای حل مسائل پیشبینی و طبقهبندی در بسیاری از زمینههای مختلف با دستاوردهای خاص مهم شدهاند [ 22 ]. در بین تمامی الگوریتمهای مجموعه، الگوریتمهای مجموعهای مبتنی بر درخت یکی از مهمترین روشها هستند. روشهای مبتنی بر درخت به جای برازش یک مدل واحد، چندین مدل تک درختی را برای به دست آوردن عملکرد پیشبینی بهینه ترکیب میکنند. این رویکرد پیشبینیهای بهتری را تولید میکند و ممکن است به سیاستگذاران کمک کند تا رابطه بین ترافیک و عوامل مؤثر بر آن را بهتر درک کنند. علاوه بر این، الگوریتمهای مجموعه مبتنی بر درخت به پیش پردازش داده کمتری نیاز دارند و تناسب بهتری با روابط غیرخطی ارائه میدهند. این مزایا رویکرد مبتنی بر درخت را به انتخاب خوبی در هنگام پرداختن به تحلیل ترافیک تبدیل می کند.
با این حال، تحقیقات محدودی در مورد استفاده از الگوریتم های درختی در زمینه حمل و نقل وجود دارد. هامنر [ 23 ] از الگوریتم جنگل تصادفی برای پیش بینی زمان سفر استفاده کرد و نشان داد که مدل پیشنهادی از نظر دقت پیش بینی از سایر مدل ها بهتر عمل می کند. وانگ [ 24 ] از درخت تصمیم گیری مجموعه ای برای پیش بینی تأثیر آب و هوا بر ظرفیت فرودگاه استفاده کرد و نشان داد که عملکرد آن بهتر از الگوریتم SVM است. احمد و عبدالآتی [ 25 ] خطرات حمل و نقل را با استفاده از داده های به دست آمده از حسگرهای مختلف شناسایی کردند. نتایج نشان داد که روش تقویت گرادیان تصادفی نسبت به روش های آماری سنتی برتری دارد. به همین ترتیب، چانگ [ 26] یک درخت رگرسیون گرادیان را برای مطالعه وقوع تصادف اعمال کرد. این دو مطالعه اخیر از یک الگوریتم تقویت کننده برای رسیدگی به مشکلات طبقه بندی و پیش بینی به جای پیش بینی زمان سفر استفاده کردند. Yanru Zhang [ 27 ] از یک روش افزایش گرادیان برای بهبود پیشبینی زمان سفر با در نظر گرفتن زمان واقعی سفر استفاده کرد، اما اطلاعات حاصل از دادههای زمان سفر تاریخی و همبستگی مکانی-زمانی بین هدف و پیوندهای مجاور را نادیده گرفت. علاوه بر این، این رویکرد نمی تواند به طور موثر زمان سفر پیوند را در شرایط داده پراکنده پیش بینی کند. تحقیقات موجود اثربخشی و کارایی الگوریتمهای مبتنی بر درخت را نشان میدهد. با این وجود، تحقیقات کمی در مورد استفاده از درختان تقویت کننده گرادیان برای پیش بینی زمان سفر وجود دارد.
برای پر کردن این شکاف، تحقیق ما یک الگوریتم مجموعهای مبتنی بر درخت را برای پیشبینی زمان سفر پیوند شهری با در نظر گرفتن متغیرهای ورودی مرتبط به دست آمده از زمان سفر تاریخی و زمان واقعی سفر ارائه میکند. در همان زمان، ما همبستگی مکانی-زمانی بین پیوندهای هدف و مجاور را هنگام محاسبه زمان سفر پیوند شهری در نظر می گیریم. الگوریتم پیشنهادی ما از مدل درخت رگرسیون با گرادیان مکانی-زمانی تقویتشده (STGBRT) از یادگیری ماشین برای پیشبینی زمان سفر پیوند بهرهبرداری میکند. مدل STGBRT الگوهای اساسی در داده های زمان سفر را برای افزایش دقت و تفسیرپذیری مدل آشکار می کند. بر خلاف سایر مدل های مبتنی بر درخت، رویکرد درختی تقویت کننده گرادیان وزن کمتری را به درختانی اختصاص میدهد که طبقهبندیهای نادرست تولید شده توسط مدل درخت رگرسیون را ایجاد میکنند و در عین حال ترکیبی بهینه از درختان را شناسایی میکنند. روش تقویت گرادیان پتانسیل ارائه پیشبینیهای دقیقتری را نسبت به الگوریتمهای جنگل تصادفی دارد.
مقاله به شرح زیر است. در بخش 2 ، شرح مفصلی از روش های درخت رگرسیون منفرد و درخت رگرسیون تقویت شده با گرادیان ارائه شده است. در بخش 3 ، استانداردسازی اندازه گیری و همبستگی بین هدف و پیوندهای مجاور توضیح داده شده است. در بخش 4 ، آزمایش خود را توصیف می کنیم، از جمله داده هایی که استفاده کردیم، کاربرد مدل خود و مقایسه مدل خود با دیگران. بحث در مورد نتایج و برخی از نتیجه گیری ها در پایان بیان شده است.
2. روش شناسی
الگوریتمهای مجموعه مبتنی بر چندین مدل پایه، مانند شبکههای عصبی، جنگلهای تصادفی، درختهای تصمیمگیری و k-نزدیکترین همسایهها، میتوانند دقت بالاتری در تخمین و پیشبینی به دست آورند. در یک الگوریتم مجموعه، هر مدل پایه می تواند راه حلی برای یک مسئله ارائه دهد. این پیشبینیها به نوعی ترکیب میشوند، مانند وزندهی یا میانگینگیری، برای تولید خروجی نهایی. به طور کلی، دقت پیشبینی یک مدل گروهی از مدلهای پایه موجود در مدل مجموعه برتر است [ 28] .]. پیش بینی مدل های مجموعه را می توان از مثال زیر فهمید. به عنوان مثال، ما معمولاً هنگام تصمیم گیری نظرات دیگران را جویا می شویم. هر فردی بر اساس تجربه خود راه حلی برای مشکل ارائه می دهد. با سنجش همه جانبه همه نظرات می توانیم تصمیم دقیق تری بگیریم. الگوریتمهای مجموعه با تصحیح اشتباهات در هر مدل پایه، خطاهای تصمیمگیری را کاهش میدهند.
از میان مدلهای پایه ممکن، درختهای تصمیم که درختهای رگرسیون نیز نامیده میشوند، از متداولترین رویکردها هستند. در تحقیقات عملیاتی، درختهای تصمیم به شناسایی استراتژی برای رسیدن به هدف کمک میکنند و همچنین ابزاری محبوب در یادگیری ماشین هستند. درخت تصمیم یک ساختار فلوچارت مانند است که در آن هر گره داخلی یک “آزمون” انجام شده بر روی یک ویژگی را نشان می دهد (به عنوان مثال، اینکه آیا یک سکه به سمت بالا می آید یا دم). هر شاخه نشان دهنده نتیجه آزمون و هر گره برگ نشان دهنده یک برچسب کلاس است. مسیرهای ریشه تا برگ نشان دهنده قوانین طبقه بندی هستند. الگوریتمهای درخت تصمیم دارای ویژگیهای جذاب بسیاری مانند زمان و پیچیدگی کم، پردازش سریع پیشبینی و نمایش ساده هستند. در عین حال دارای معایبی از جمله برازش بیش از حد هستند. الگوریتمهای مجموعهای مبتنی بر درخت، درختهای منفرد زیادی را ایجاد میکنند و نتایج هر درخت را برای نتایج دقیقتر ترکیب میکنند. به طور کلی، دو نوع الگوریتم مجموعه بر اساس درختان وجود دارد، روش جنگل تصادفی و الگوریتم درخت رگرسیون تقویتشده با گرادیان.29 ]. در این دو الگوریتم از یک درخت رگرسیون منفرد به عنوان مدل پایه استفاده شده است. بخش 2.1 به طور خلاصه توضیح می دهد که درختان رگرسیون منفرد چگونه کار می کنند و روند ساخت یک درخت رگرسیون تقویت شده با گرادیان (GBRT) را نشان می دهد.
2.1. درخت رگرسیون منفرد
مانند تمام تکنیک های رگرسیون، ما وجود یک متغیر خروجی واحد (پاسخ) و یک یا چند متغیر ورودی را فرض می کنیم. روش رگرسیون عمومی درخت سازی به متغیرهای ورودی اجازه می دهد تا مخلوطی از متغیرهای پیوسته و طبقه ای باشند. درخت رگرسیون را می توان گونه ای از درخت های تصمیم در نظر گرفت که به جای استفاده برای کارهای طبقه بندی، برای تقریب توابع با ارزش واقعی طراحی شده اند. درخت رگرسیون از طریق فرآیندی به نام پارتیشن بندی بازگشتی باینری ساخته می شود [ 30]. این یک فرآیند تکراری برای تقسیم داده ها به پارتیشن ها و سپس تقسیم بیشتر پارتیشن ها در هر یک از شاخه ها است. در ابتدا، تمام رکوردهای یک مجموعه آموزشی با هم در یک گروه واحد هستند. سپس الگوریتم سعی می کند داده ها را با استفاده از هر تقسیم باینری ممکن در هر فیلد تقسیم کند. الگوریتم تقسیمی را انتخاب می کند که داده ها را به دو قسمت تقسیم می کند به طوری که مجموع انحرافات مجذور از میانگین در قسمت های جداگانه را به حداقل می رساند. سپس این تقسیم یا پارتیشن بندی برای هر یک از شاخه های جدید اعمال می شود. این فرآیند تا زمانی ادامه می یابد که هر گره به حداقل اندازه گره تعیین شده توسط کاربر برسد و به یک گره ترمینال تبدیل شود.
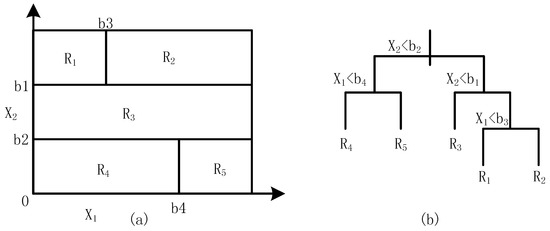
یک درخت رگرسیون واحد [ 27 ] را می توان به صورت زیر توصیف کرد. همانطور که در شکل 1 الف نشان داده شده است، پانل سمت چپ با توجه به دو متغیر X1 و X2 با استفاده از چهار نقطه تقسیم b1، b2، b3 و b4 به پنج منطقه، {R1، R2، R3، R4، و R5} تقسیم شده است. اندازه درخت رگرسیون در شکل 1 تعداد کل گره های انتهایی است زیرا درخت به پنج ناحیه مختلف تقسیم شده است که برابر با تعداد گره های انتهایی درخت است. پانل سمت راست شکل 1 یک نمایش درخت باینری از همان مدل است که پنج ناحیه تقسیم شده مختلف را بیان می کند.
اکنون، یک سوال کلی از همان نوع مثال نشان داده شده در شکل 1 در نظر می گیریم که شامل ورودی های p با یک خروجی مربوط به ورودی مسئله رگرسیون است. به عنوان مثال، ما n مشاهده داریم و هر مشاهده به صورت نشان داده می شود yمن،ایکسمن 1،ایکسمن 2،ایکسمن 3, … ,ایکسمن ج, … ,ایکسمن ص�من،ایکسمن1،ایکسمن2،ایکسمن3،…،ایکسمن�،…،ایکسمنپبرای i = 1، 2، …، n. برای پیش بینی زمان سفر، yمن�منمتغیر وابسته است و به عنوان زمان سفر پیش بینی شده مربوط به مشاهده من در نظر گرفته می شود . ایکسمن 1،ایکسمن 2،ایکسمن 3, … ,ایکسمن ج, … ,ایکسمن صایکسمن1،ایکسمن2،ایکسمن3،…،ایکسمن�،…،ایکسمنپمتغیرهای مستقل مربوط به پیش بینی زمان سفر هستند، مانند زمان سفر تاریخی، زمان سفر در زمان واقعی، حجم ترافیک، لحظه زمانی و آب و هوا یا سایر عوامل خارجی. اجازه دهید فرض کنیم که فضای ویژگی به m مناطق R 1 ، R 2 ، …، Rm تقسیم شده است که نشان دهنده مناطق مختلف شرایط ترافیکی مختلف است. بنابراین، وضعیت ترافیک توسط یک پارامتر ورودی به دسته های مختلف تقسیم می شود و مدل مربوطه برای هر نوع متغیر وابسته ایجاد می شود. به طور کلی، مقدار مورد انتظار در هر ناحیه از متغیر وابسته به عنوان یک Cm ثابت در نظر گرفته می شود. این یک مقدار بهینه مورد انتظار است که امیدواریم با استفاده از متغیرهای مستقل به دست آوریم. اگر معیار بهینگی به حداقل رساندن مجموع مجذورات انحراف باشد ، آنگاه مقدار بهینه C m میانگین مقادیر y i در مساحت Rm است [ 31 ]. همانطور که در شکل 1 الف نشان داده شده است، ما مقادیر متفاوتی را در ناحیه Rm برآورد کردیم . در این تحقیق، ما از الگوریتم حریص [ 32 ، 33 ] برای تعیین بهترین متغیرهای تقسیم و نقاط تقسیم استفاده می کنیم. درخت رگرسیون منفرد مدل پایه برای درخت رگرسیون تقویتشده با گرادیان است.
2.2. درخت رگرسیون تقویتشده با گرادیان
ایده تقویت گرادیان از مشاهدات انجام شده توسط لئو بریمن [ 34 ] سرچشمه می گیرد که تقویت را می توان به عنوان یک الگوریتم بهینه سازی بر روی یک تابع هزینه مناسب تفسیر کرد. الگوریتم های رگرسیون تقویت گرادیان صریح متعاقبا توسط جروم اچ فریدمن [ 35 ، 36 ] توسعه یافت. میسون و همکاران [ 37] دیدگاه انتزاعی الگوریتم های تقویت کننده را به عنوان الگوریتم های شیب نزولی تابعی تکراری معرفی کرد. یعنی، آنها الگوریتمهایی هستند که با انتخاب مکرر یک تابع (فرضیه ضعیف) که شیب را به پایین نشان میدهد، یک تابع هزینه را در فضای تابع بهینه میکنند. این دیدگاه شیب عملکردی تقویت منجر به توسعه الگوریتمهای تقویت در بسیاری از حوزههای یادگیری ماشین و آمار فراتر از رگرسیون و طبقهبندی شده است. تقویت درخت گرادیان که روش درخت رگرسیون تقویتشده گرادیان (GBRT) نیز نامیده میشود، یک تعمیم از تقویت اعمال شده برای توابع از دست دادن قابل تمایز دلخواه است. تقویت گرادیان یک تکنیک یادگیری ماشینی برای مشکلات رگرسیون و طبقهبندی است که یک مدل پیشبینی را در قالب مجموعهای از مدلهای پیشبینی ضعیف، معمولاً درختهای تصمیم، تولید میکند.
فریدمن [ 35 ] بهبودی در روش تقویت گرادیان با استفاده از درختان رگرسیون اندازه ثابت به عنوان مدل پایه ارائه کرد. مدل اصلاح شده کیفیت مدل تقویت کننده گرادیان را بهبود می بخشد [ 37 ]. در این مطالعه، یک مدل درخت رگرسیون تقویتشده با گرادیان، مدل درخت رگرسیون شیب تقویتشده مکانی-زمانی (STGBRT)، برای پیشبینی زمان سفر پیشنهاد شدهاست. این مدل همبستگی های مکانی-زمانی بین پیوندهای هدف و مجاور را در نظر می گیرد. با فرض اینکه تعداد برگهای هر درخت J باشد ، فضای درخت m را میتوان به زیرفضاهای J جدا از هم تقسیم کرد ، مانند R 1m , R 2m , …, R Jmو مقدار پیشبینیشده برای زیرفضای R Jm ثابت b jm است . بنابراین، درخت رگرسیون را می توان با معادلات (1) و (2) بیان کرد:
برای به حداقل رساندن تابع تلفات مدل STGBRT، از شیبدارترین روش فرود استفاده میکنیم، که یکی از سادهترین روشهای کمینهسازی عددی پرکاربرد است. اف(ایکسمن)اف(ایکسمن)، بودن
جایی که f0( x )�0(ایکس)یک حدس اولیه است، M نشان دهنده شاخص درخت است، و {fمتر(ایکسمن) }م1 {�متر(ایکسمن)}1متوابع افزایشی هستند که با روش بهینه سازی [ 35 ] تعریف می شوند. با استفاده از روش شیب دارترین نزول، معادله زیر وجود دارد
گرادیان فعلی gمتر�متر، بر اساس رابطه (5) [ 35 ]، بر اساس دنباله مراحل قبل محاسبه می شود. افزایشی را تعریف می کند. در معادله (5)، f(ایکسمن)�(ایکسمن)تخمین یا تقریبی از مشاهده است yمن�منکه با متغیرهای “ورودی” یا “تبیینی” مطابقت دارد، x = { ایکس1, … ,ایکسn}ایکس ={ایکس1،…،ایکس�}،
ضریب ρمتر�متردر رابطه (4) مطابق رابطه (6) آورده شده است:
مدل مطابق با معادله (7) به روز می شود:
روش درخت رگرسیون تقویتشده با گرادیان، مدل جدیدی را در جهت کاهش باقیمانده ایجاد میکند و با به حداقل رساندن انتظارات تابع ضرر مطابق با معادلات (5)- (7) مدل را بهروزرسانی میکند. این مرحله مهمترین بخش تقویت گرادیان است. به طور کلی، مدل برازش می تواند خطای آموزشی خود را با افزایش تعداد درختان پایه در مدل کاهش دهد. با این حال، اگر مدل بیش از حد به داده های آموزشی نزدیک باشد، توانایی تعمیم مدل برازش را نیز کاهش می دهد. با افزایش تعداد تکرارها، مدل پیچیده می شود، بنابراین نوسانات جزئی در داده ها اغراق آمیز می شود. این پیچیدگی افزوده باعث عملکرد ضعیف پیشبینی دادههای تست میشود. در نتیجه، تعیین تعداد بهینه تکرار برای مدل ضروری است تا خطاهای احتمالی پیشبینی به حداقل برسد. همچنین می توان با کنترل تعداد تکرارها، تعداد درختان اصلی و نرخ یادگیری از پدیده بیش از حد برازش جلوگیری کرد. مدل STGBRT به طور استراتژیک باعث می شود هر مدل پایه به حداقل ضرر برسد. از استراتژی نمونه گیری مرحله ای استفاده می کند که به نمونه های نامطلوب توجه بیشتری می کند. این ویژگی آن را از مدل جنگل تصادفی که هر مدل را با استفاده از نمونهگیری تصادفی یا نمونهبرداری با احتمال مساوی آموزش میدهد متمایز میکند. بنابراین، عملکرد مدل STGBRT تحت تأثیر تعداد درختان و نرخ یادگیری است. عملکرد بهینه مدل را می توان با انتخاب دقیق بهترین ترکیب از این پارامترها به دست آورد. مدل STGBRT به طور استراتژیک باعث می شود هر مدل پایه به حداقل ضرر برسد. از استراتژی نمونه گیری مرحله ای استفاده می کند که به نمونه های نامطلوب توجه بیشتری می کند. این ویژگی آن را از مدل جنگل تصادفی که هر مدل را با استفاده از نمونهگیری تصادفی یا نمونهبرداری با احتمال مساوی آموزش میدهد متمایز میکند. بنابراین، عملکرد مدل STGBRT تحت تأثیر تعداد درختان و نرخ یادگیری است. عملکرد بهینه مدل را می توان با انتخاب دقیق بهترین ترکیب از این پارامترها به دست آورد. مدل STGBRT به طور استراتژیک باعث می شود هر مدل پایه به حداقل ضرر برسد. از استراتژی نمونه گیری مرحله ای استفاده می کند که به نمونه های نامطلوب توجه بیشتری می کند. این ویژگی آن را از مدل جنگل تصادفی که هر مدل را با استفاده از نمونهگیری تصادفی یا نمونهبرداری با احتمال مساوی آموزش میدهد متمایز میکند. بنابراین، عملکرد مدل STGBRT تحت تأثیر تعداد درختان و نرخ یادگیری است. عملکرد بهینه مدل را می توان با انتخاب دقیق بهترین ترکیب از این پارامترها به دست آورد. عملکرد مدل STGBRT تحت تأثیر تعداد درختان و نرخ یادگیری است. عملکرد بهینه مدل را می توان با انتخاب دقیق بهترین ترکیب از این پارامترها به دست آورد. عملکرد مدل STGBRT تحت تأثیر تعداد درختان و نرخ یادگیری است. عملکرد بهینه مدل را می توان با انتخاب دقیق بهترین ترکیب از این پارامترها به دست آورد.38 ].
3. اندازه گیری و همبستگی در فضا و زمان
3.1. همبستگی فضایی
بسیاری از شاخص ها برای اندازه گیری کمی همبستگی بین داده های مکانی و زمانی طراحی شده اند و بیشتر این شاخص ها بر اساس ضریب پیرسون [ 39 ] است. در آمار، ضریب همبستگی پیرسون (که به آن PCC یا پیرسون گفته میشود) معیاری از همبستگی خطی بین دو متغیر X و Y است و مقداری بین -1 و +1 میگیرد. اگر مقدار 1 باشد، نشان دهنده یک همبستگی مثبت کامل است. در حالی که 0 نشان دهنده عدم همبستگی و -1 نشان دهنده همبستگی منفی کامل است. این به طور گسترده ای در علوم به عنوان معیار درجه وابستگی خطی بین دو متغیر استفاده می شود و توسط کارل پیرسون توسعه داده شد. با توجه به دو متغیر X و Yضریب همبستگی پیرسون به صورت زیر تعریف می شود:
جایی که μایکس�ایکسو μY��به ترتیب میانگین متغیرهای X و Y هستند . به همین ترتیب، σایکس�ایکسو σY��انحراف استاندارد مربوط به متغیرهای X و Y هستند . ضریب همبستگی فضایی بین یک پیوند هدف و یک پیوند مجاور را می توان با توجه به رابطه (8) محاسبه کرد.
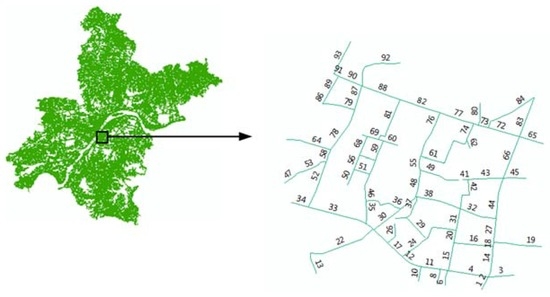
نمودار شماتیک در بخش 4.1 جریان ترافیک را نشان می دهد، که در آن پیوند 82 یک پیوند هدف، پیوند 88 یک پیوند بالادست، و پیوند 77 یک پیوند پایین دست است. در این تحقیق گام زمانی 30 دقیقه تعیین شد. بنابراین، ما سرعت مورد انتظار مرتبط با پیوندهای مربوطه را در یک جهت معین هر 30 دقیقه استخراج کردیم. جدول 1 همبستگی های زوجی بین پیوندهای منفرد در زیرمجموعه ای از شبکه را طبق رابطه (8) نشان می دهد. همانطور که از جدول 1 می توان استنباط کردضریب همبستگی سرعت مورد انتظار در جهت معین و برای زمان متفاوت بین هر دو لینک برای لینک های 82، 77 و 88 به طور معنی داری در سطح اطمینان 0.01 (دو دنباله) همبستگی دارد. ضرایب همبستگی برای سرعت در روزهای مختلف مقادیر متفاوتی دارند و در روز متفاوت هستند. شکل 2 نمودار خطی است که رابطه سرعت مورد انتظار بین لینک های 77، 82 و پیوند مجاور 88 را از دوشنبه تا جمعه منعکس می کند. همانطور که در نمودار خطی مشاهده می شود، سرعت مورد انتظار برای لینک 82 با افزایش سرعت مورد انتظار پیوند مجاور 88 افزایش می یابد که نشان دهنده یک همبستگی مثبت است. همچنین در شکل 2 مشاهده می شود که سرعت مورد انتظار لینک های 77، 82 و 88 دارای الگوی ریتمیک است. در نتیجه، هر دو جدول 1 وشکل 2 همبستگی های فضایی پویا بین یک پیوند هدف و یک پیوند مجاور را نشان می دهد. بنابراین، ما اطلاعات پیوند مجاور را به عنوان ورودی مدل برای پیشبینی زمان سفر پیوند هدف انتخاب کردیم.
3.2. همبستگی زمانی
تابع همبستگی زمانی (TACF) [ 40 ] دو سری زمانی را به عنوان یک فرآیند تصادفی دو متغیره در نظر می گیرد و ضرایب کوواریانس بین هر سری را در تاخیرهای مشخص اندازه گیری می کند. به عنوان مثال، اگر یک سری زمانی در زمان t برای متغیر X وجود داشته باشد ، در این صورت سری زمانی دیگری در زمان تاخیر k مطابق با متغیر X در زمان tk وجود دارد . سپس ضریب همبستگی این دو سری زمانی مربوط به X را می توان به صورت معادله زیر نشان داد:
جایی که μ�میانگین متغیر X و استσایکس�ایکسانحراف استاندارد متناظر متغیر X است.
در واقع، یک ضریب خودهمبستگی زمانی را می توان به سادگی با در نظر گرفتن همبستگی یک متغیر با مشخصات تاخیری خود اندازه گیری کرد. بنابراین، خود همبستگی زمانی با اصلاح PCC اندازهگیری شد تا این مشخصات تأخیر را شامل شود. تفاوت زمانی متغیر X بین زمان t و زمان t-k مطابق با رابطه (9) اندازه گیری می شود. اگر فرآیند ثابت است، پس σایکس 2�ایکس 2را می توان به عنوان انحراف x استفاده کرد و در طول زمان ثابت فرض می شود. جدول 2 خودهمبستگی زمانی پیوند 82 را در زمانهای تاخیر مختلف مربوط به زمان t نشان میدهد .
4. آزمایش
برخلاف روشهای برآورد، هدف از پیشبینی زمان سفر، پیشبینی زمان سفر برای یک مسیر است که در یک لحظه خاص شروع میشود، با استفاده از زمان سفر تاریخی و فعلی برای آن مسیر. یک پیش بینی در حال حاضر یا در آینده انجام می شود [ 41 ]. برای این منظور از داده های ترافیکی پیوندهای هدف و مجاور از داده های گذشته و فعلی همانطور که در شکل 3 نشان داده شده است استفاده شد.، که یک نمودار شماتیک از پیش بینی زمان سفر را بر اساس داده های گذشته همراه با داده های فعلی نشان می دهد. بنابراین، هم دادههای ترافیک بلادرنگ و هم دادههای بزرگ که شرایط ترافیک تاریخی را منعکس میکنند، به پیشبینی زمان سفر کمک میکنند. داده های ترافیک در زمان واقعی با دقت بیشتری وضعیت ترافیک فعلی را منعکس می کند. پیش بینی زمان سفر، همبستگی متغیرهای مختلف را با اطلاعات ترافیک موجود مدل می کند. در نتیجه، هرچه اطلاعاتی که استخراج میکنیم جامعتر باشد، نتایج پیشبینی زمان سفر دقیقتر خواهد بود. با توجه به اینکه مشخصه های ترافیکی یک پدیده پیچیده است که شامل ویژگی های غیر خطی و آشفته است، ایجاد یک معادله دقیق برای بیان رابطه بین ویژگی های مختلف اغلب دشوار است. رویکردهای داده محور یک حوزه امیدوارکننده در مدلسازی و پیشبینی ترافیک هستند.
4.1. توصیف و آماده سازی داده ها
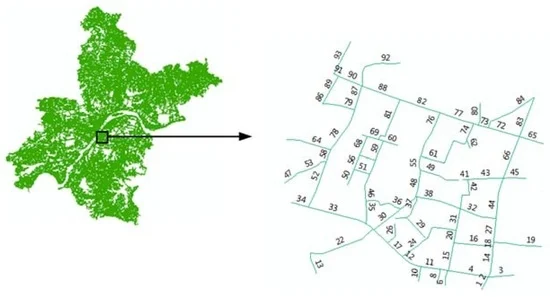
وسایل نقلیه کاوشگر مجهز به GPS به عنوان حسگرهای ترافیک سیار برای جمع آوری داده های ترافیکی شبکه استفاده می شود. در تحقیق ما، دادههای خودروی کاوشگر تاریخی و بیدرنگ ارائهشده توسط یک شرکت بخش خصوصی استفاده میشود. پایگاه داده Oracle حاوی داده های خودروی کاوشگر از سیستم حمل و نقل هوشمند (ITS) در ووهان چین به دست آمده است. وسایل نقلیه کاوشگر اطلاعاتی مانند سرعت های لحظه ای، مهرهای زمانی، مختصات طول و عرض جغرافیایی و سرفصل های قطب نما را جمع آوری می کنند. منعکس کننده وضعیت جاری ترافیک شهری، که نقش مهمی در تخمین و پیشبینی زمان سفر در زمان واقعی یا نزدیک به زمان واقعی دارد. تحقیق ما از دادههای زمان سفر از وسایل نقلیه کاوشگر که در شبکه جادهای محلی شهر ووهان کار میکنند برای پیشبینی زمان سفر استفاده کرد. جدول 3اطلاعات مکان را برای جاده های محلی انتخاب شده در شبکه جاده ای ووهان نشان می دهد. این داده ها شامل شماره بخش، مختصات جغرافیایی شروع، مختصات جغرافیایی پایانی و طول هر بخش است. شکل 4 جاده های محلی در شبکه جاده ای ووهان را نشان می دهد.
با توجه به اثر خطای موقعیت یابی GPS [ 42 ]، نقاط GPS تمایل دارند از جاده واقعی سفر وسیله نقلیه کاوشگر منحرف شوند. بنابراین، نقاط GPS که از شبکه جاده منحرف می شوند، باید ابتدا با توجه به مسیر عبور وسیله نقلیه کاوشگر به جاده پیش بینی شوند. سپس زمان سفر لینک یک وسیله نقلیه کاوشگر با استفاده از این نقاط مطابق با نقشه محاسبه می شود. در تحقیق ما، مسیرهای وسیله نقلیه کاوشگر با استفاده از الگوریتم تطبیق نقشه [ 43 ، 44 ، 45 ، 46 ] تنظیم شد. ما زمان سفر و سرعت متوسط وسایل نقلیه کاوشگر را که از پیوندهای هدف عبور می کنند، با در نظر گرفتن حالات وسایل نقلیه کاوشگر در تقاطع ها محاسبه کردیم [ 47 ، 48 ،49 ]. ما ویژگیهای پیوندها را از مقادیر انبوه دادههای آماری زمان سفر جمعآوریشده توسط وسایل نقلیه کاوشگر که از پیوند هدف عبور میکنند استخراج کردیم. دادههای آماری بهدستآمده شامل شناسه پیوند، شناسه ورودی نقطه پایانی، شناسه نقطه پایانی خروجی، شناسه وسیله نقلیه کاوشگر، لحظه ورود خودروی کاوشگر به لینک، زمان سفر خودروی کاوشگر که از این لینک عبور میکند، و میانگین سرعت خودروی کاوشگر که از این لینک عبور میکند، میباشد. پیوند، همانطور که در جدول 4 نشان داده شده است . تحقیقات موجود نشان داده است که مسیرهای وسایل نقلیه کاوشگر الگوهای ترافیکی مشابهی را در یک چرخه هفتگی نشان می دهند [ 50 , 51 , 52 , 53]. بنابراین، ما ویژگی های بین پیوندهای هدف و بالادست را به عنوان ویژگی های تاریخی با توجه به چرخه هفتگی استخراج کردیم. در همین حال، به دلیل کمیاب بودن اطلاعات سفر، داده های دسترسی به فواصل زمانی 30 دقیقه ای جمع آوری شدند. بنابراین، یک روز به 48 بازه زمانی تقسیم شد و ویژگی های ورودی از این اطلاعات برای پیش بینی زمان سفر در آینده استخراج شد. شکل 5 نمودار شماتیک جریان ترافیک در یک شبکه جاده جزئی از شکل 4 است.که شامل شماره جاده و جهت ترافیک می شود. در تحقیق خود، ما از مدل خود برای پیشبینی زمان سفر برای پیوند 82 با استفاده از همبستگیهای مکانی-زمانی مشاهدهشده در بین پیوند 82، پیوند 88 و پیوند 77 استفاده میکنیم. ما ویژگیهای همبستگی مکانی-زمانی را از دادههای بزرگ که منعکسکننده شرایط ترافیکی تاریخی جمعآوریشده توسط وسایل نقلیه کاوشگر از ژانویه تا می، 2014. سپس، داده های یازده هفته ای که دوره 5 می 2014 تا 20 ژوئیه 2014 را پوشش می دهد، به عنوان داده های آموزشی برای مدل STGBRT در نظر گرفته شد. در نهایت، یک هفته داده از 21 جولای 2014 (دوشنبه) تا 25 جولای 2014 (جمعه) به عنوان داده های آزمون برای تأیید اعتبار مدل در نظر گرفته شد.
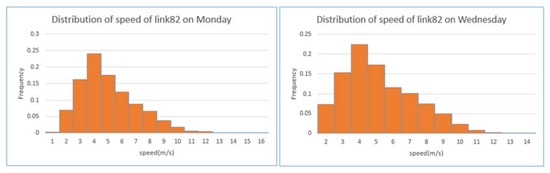
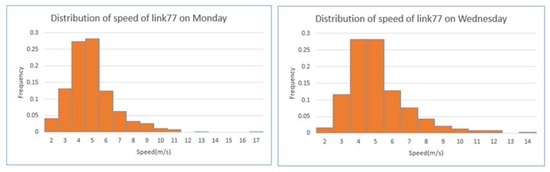
جدول 5 ، جدول 6 و جدول 7 اطلاعات زمان سفر را از وسایل نقلیه کاوشگر که در همان جهت از ژانویه تا می 2014 حرکت می کنند، از نظر آمار توصیفی، از جمله میانگین، خلاصه می کنند. انحراف استاندارد (SD)؛ صدک های 25، 50 و 75; و حداقل (Min) و حداکثر (Max) مشاهدات. اطلاعات زمان سفر بر حسب ثانیه ثبت شد. از این سه جدول می توان استنباط کرد که چارک های سرعت برای یک پیوند برای هر روز مشابه است و تفاوت های روز به روز اندک است. در مقابل، تفاوت زیادی در سرعت در بین لینک های مختلف وجود دارد. شکل 6 ، شکل 7 و شکل 8توزیع سرعت های مشاهده شده را از لینک 88، لینک 82 و لینک 77 به ترتیب در روزهای دوشنبه و چهارشنبه نشان می دهد. دو هیستوگرام از یک پیوند، الگوهای مشابهی را با توزیع تقریباً نرمال نشان میدهند، اگر مقادیر غیرعادی نادیده گرفته شوند. با این حال، توزیع سرعت سفر تفاوت های جزئی را در بین پیوندهای مختلف نشان می دهد.
همانطور که در جدول 2 نشان داده شده است، با توجه به فاصله زمانی در لحظه جاری، خودهمبستگی زمانی در یک دوره زمانی سه مرحله ای در سطح اطمینان 0.01 در هنگام استفاده از آزمون دو طرفه معنی دار است. ضریب همبستگی با افزایش زمان تاخیر کاهش می یابد. هیچ ارتباطی برای تاخیرهای بیشتر از سه مرحله زمانی وجود ندارد. در نتیجه، بررسی خودهمبستگی زمانی خارج از یک دوره سه مرحله زمانی غیر ضروری است. بنابراین، ما اطلاعات جمع آوری شده در دو مرحله زمانی قبل از زمان فعلی را به عنوان ورودی مدل هنگام پیش بینی زمان سفر انتخاب کردیم. همانطور که در جدول 8 نشان داده شده است، چندین متغیر مکانی-زمانی را که مربوط به زمان سفر هستند به عنوان ورودی و خروجی مدل خود انتخاب کردیم.. 17 ستون اول متغیرهای ورودی مدل و ستون آخر متغیر خروجی است که تابعی از ورودی ها است. خروجی مدل زمان سفر واقعی در زمان تأخیر t است که با tarRTT t نشان داده می شود و 17 متغیر ورودی که برای پیش بینی زمان سفر در زمان تأخیر t استفاده شده است به شرح زیر است: روز هفته، زمان روز، tarHTT t-1 ، tarHTT t-2 ، ΔtarHTT t-1 ، tarRTT t-1 ، tarRTT t-2، ΔtarRTT t-1 ، UpHTT t-1 ، UpHTT t-2 ، UpRTT t-1 ، UpRTT t-2،، DoHTT t-1 ، DoHTT t-2 ، ΔUpHTT t-1 ، ΔUpRTT t-1 و ΔDoHTT t-1 . روزهای هفته از یک تا پنج نمایه می شوند که نشان دهنده دوشنبه تا جمعه است. زمان روز با مراحل زمانی 30 دقیقه ای نشان داده می شود که از 1 تا 48 نمایه شده است . ΔtarHTT t-1 نرخ رشد زمان سفر تاریخی برای یک پیوند در دو بار متوالی است، همانطور که طبق رابطه (10) محاسبه می شود.tarRTT t-1 و tarRTT t-2 دو آخرین مشاهدات زمان سفر واقعی برای پیوند هدف در زمانهای t-1 و t-2 هستند . ΔtarRTT t-1 نرخ رشد زمان سفر واقعی برای پیوند بین دو مرحله زمانی متوالی است و طبق رابطه (11) محاسبه می شود. به همین ترتیب، UpHTT t-1 و UpHTT t-2 دو آخرین مشاهدات زمان سفر تاریخی پیوندهای بالادست در زمان های t-1 و t-2 هستند . UpRTT t-1 و UpRTT t-2دو آخرین مشاهدات زمان سفر واقعی از یک پیوند بالادست در زمانهای t-1 و t-2 هستند. DoHTT t-1 و DoHTT t-2 دو آخرین مشاهدات زمان سفر تاریخی یک پیوند پایین دست در زمان های t-1 و t-2 هستند . به طور مشابه، ΔUpHTT t-1 ، ΔUpRTT t-1 ، و ΔDoHTT t-1نرخ رشد زمان سفر تاریخی برای یک پیوند بالادستی، نرخ رشد زمان واقعی سفر برای یک پیوند بالادستی و نرخ رشد زمان سفر تاریخی برای پیوند پایین دستی بین دو مرحله زمانی متوالی است. این متغیرها بر اساس معادلات (12-14) محاسبه شدند. با توجه به فرکانس پایین اکتساب داده های GPS وسیله نقلیه کاوشگر و محدودیت های منطقه ای مناطق رانندگی، اطلاعات مسیر جمع آوری شده توسط یک واحد GPS وسیله نقلیه کاوشگر نمی تواند کل شبکه جاده های شهری را پوشش دهد. بنابراین، داده های جمع آوری شده پراکنده هستند [ 5 ، 6]. از طریق تجزیه و تحلیل، متوجه شدیم که دادههای ما فاقد اطلاعات کافی برای سفر با وسیله نقلیه در بازه زمانی بین نیمهشب و ۵ صبح هستند، در مقابل، دادههای سایر دورههای زمانی نسبتاً فراوان بودند. بنابراین، دادههای ترافیک روزانه را برای دوره از ساعت 6 صبح و نیمه شب هر روز به عنوان دوره زمانی تحقیق انتخاب میکنیم. برای دادههای بیدرنگ از دست رفته در برخی بازههای زمانی آزمایشی، از اطلاعات سفر از دادههای بزرگ که شرایط ترافیک تاریخی مربوط به دوره زمانی را منعکس میکند برای جبران دادههای بیدرنگ از دست رفته استفاده کردیم.
4.2. نرم افزار مدل
برای به دست آوردن مدل بهینه، درک تأثیر ترکیبات پارامترهای مختلف بر عملکرد مدل بسیار مهم است. با در نظر گرفتن اطلاعات ورودی، پارامترهای ترکیبی بهینه مدل را برای دستیابی به خطای پیشبینی کمتر به دست آوردیم. این بخش نشان می دهد که چگونه عملکرد برای انتخاب های مختلف پارامترها متفاوت است. اینها شامل تعداد درخت N و نرخ یادگیری lr میشدکه هنگام استخراج ویژگیهای مکانی-زمانی از پنج ماه اطلاعات زمان سفر جمعآوریشده بین ژانویه و مه 2014 استفاده شد. پنج روز بعد از داده های جمع آوری شده از دوشنبه، 21 ژوئیه 2014، تا جمعه، 25 ژوئیه 2014 به عنوان داده های آزمون در نظر گرفته شد. ما درخت رگرسیون شیب-زمانی تقویتشده مکانی (STGBRT) را با استفاده از تعداد درختهای مختلف (1-5000) و نرخهای یادگیری مختلف (0.01-1) به دادههای آموزشی منعکسکننده ویژگیهای مکانی-زمانی وسیله نقلیه استخراجشده از شبکه جادههای شهری برازش دادیم. برای ارزیابی عملکرد یک مدل STGBRT که پارامترهای مختلف را ترکیب می کند، میانگین درصد مطلق خطا (MAPE) را به عنوان یک شاخص معرفی کردیم. تعریف MAPE به شرح زیر است:
جایی که تیp v ، iتیپ�،مننشان دهنده پیش بینی زمان سفر لینک برای وسیله نقلیه کاوشگر است که در زمان آینده به پیوند هدف سفر می کند و تیt r u e , iتیتی�توه،منزمان سفر لینک واقعی است.
برای مطالعه تأثیر تعداد درختان و میزان یادگیری بر دقت پیشبینی، آزمایشهایی را با استفاده از تعداد درختان مختلف انجام دادیم. شکل 9 و شکل 10 تأثیر پارامترهای مختلف از جمله تعداد درختان ( N ) و نرخ یادگیری ( lr ) را بر روی خطاهای پیشبینی زمان سفر پیوند با استفاده از MAPE نشان میدهند. در اینجا، پارامتر N تعداد درختان اصلی در مدل STGBRT و lr را نشان می دهدمیزان یادگیری را نشان می دهد. از لحاظ نظری، دقت پیشبینی بالاتری را میتوان با افزایش تعداد درختان در مدل به دست آورد. با این حال، هنگامی که درختان بیش از حد وجود دارد، ممکن است بیش از حد برازش ایجاد شود. این تطابق بیش از حد بر دقت پیشبینی مدل زمانی که برای کاوش دادههای زمان سفر وسیله نقلیه که در مجموعه داده آموزشی گنجانده نشدهاند، اعمال میشود. در همان زمان، زمان محاسبات مدل با تعداد درختان اصلی موجود در مدل افزایش خواهد یافت. شکل 9 رابطه بین MAPE و N را تحت نرخ های مختلف یادگیری ترسیم می کند. پانل پایینی شکل 9بخشی از پانل بالایی را با جزئیات بیشتر نشان می دهد. همانطور که نشان داده شده است، MAPE با افزایش تعداد درختان رگرسیون، تا مقدار معینی کاهش می یابد. شیب منحنی های رسم شده با نرخ های مختلف یادگیری متفاوت است، lr . منحنی برای lr = 0.01 کمترین شیب را دارد زیرا سهم دقت پیشبینی هر درخت با نرخ یادگیری کوچک محدود میشود. با N = 300 به حداقل می رسد. منحنی های مربوط به نرخ های یادگیری بالاتر با سرعت بیشتری کاهش می یابند و با استفاده از درختان اصلی به سرعت به حداقل MAPE می رسند. به عنوان مثال، منحنی با lr = 0.5 و lr = 1 به ترتیب در N = 10 و N = 50 به حداقل می رسد . همانطور که می بینیم ازشکل 9 ، نرخ های یادگیری بالاتر مانند lr = 1، lr = 0.5، lr = 0.25، و lr = 0.2 بهترین عملکرد پیش بینی شده را با درختان رگرسیون نسبتا کمی به دست می آورند. اگر تعداد درختان رگرسیون از حدی فراتر رود، درختان بیش از حد ممکن است منجر به بیش از حد برازش شوند. در نتیجه، میتوانیم با استفاده از درختان کافی، دقت پیشبینی را تضمین کنیم و در عین حال از تطبیق بیش از حد درختان با تعداد مناسب جلوگیری کنیم.
شکل 10 اثر نرخ یادگیری بر MAPE را نشان می دهد. MAPE با نرخ یادگیری متفاوت است به شرطی که تعداد درختان رگرسیون ثابت نگه داشته شود. پانل پایینی شکل 10 بخشی از پانل بالایی را با جزئیات بیشتر نشان می دهد. نرخ یادگیری برای تنظیم تأثیر هر درخت بر دقت پیشبینی مدل استفاده میشود. مقدار نرخ یادگیری از 0 تا 1 متغیر است. به طور کلی، مقادیر کوچکتر سهم هر درخت را در دقت مدل محدود می کند. معمولاً هنگام پیشبینی زمان سفر پیوند با نرخهای یادگیری کمتر، تکرارهای بیشتری لازم است. مقدار بهینه lrبا تعداد درختان مجموعه متفاوت است. اگر تعداد درختان رگرسیون 200 یا کمتر باشد، MAPE برای زمان سفر پیش بینی شده با افزایش نرخ یادگیری کاهش می یابد. در این حالت، MAPE با افزایش تعداد درختان رگرسیون در همان نرخ یادگیری کاهش می یابد. MAPE زمانی به حداقل می رسد که نرخ یادگیری برابر با 0.01 باشد و تعداد درختان رگرسیون از 200 بیشتر شود. با در نظر گرفتن N = 500 در شکل 10 به عنوان مثال، MAPE زمانی به حداقل می رسد که lr = 0.01 باشد.، در حالی که خطا با نرخ یادگیری افزایش می یابد. این نتیجه به این دلیل رخ می دهد که تعداد درختان رگرسیون کافی است. این مدل با نرخ یادگیری کوچکتر 0.01 به بالاترین دقت خود می رسد. نرخ یادگیری بالاتر منجر به عملکرد پیش بینی ضعیف تحت این شرایط شد.
شکل 11فلوچارتی را نشان میدهد که نحوه پیشبینی مدل GBRT زمان سفر پیوند را در حالی که اطلاعات مربوط به همبستگیهای مکانی-زمانی را شامل میشود، نشان میدهد. بر اساس نتایج تجربی ما، می توانیم نتایج زیر را بدست آوریم. (1) نرخ یادگیری کوچکتر با درختان رگرسیون پایه بیشتر در مدل برای دقت پیشبینی، نسبت به نرخ یادگیری بزرگتر با درختان رگرسیون پایه کمتر برتری دارد. نرخ یادگیری کوچکتر سهم هر درخت را در دقت پیشبینی مدل کاهش میدهد و عملکرد پیشبینی بهینه را با نتایج پیشبینی مطمئنتر به دست میآورد. (2) لازم است بین دقت پیشبینی و زمان محاسباتی تعادل پیدا شود. یک نرخ یادگیری کوچک همراه با تعداد بیشتری از درختان رگرسیون پایه به زمان محاسباتی بیشتری برای رسیدن به عملکرد یکسان نیاز دارد. در حالی که دقت پیشبینی کمتر به زمان محاسبات کمتری نیاز دارد. در آزمایش ما، MAPE زمانی به حداقل رسید که نرخ یادگیری 0.01 و تعداد درختان رگرسیون 500 بود. در نتیجه، ما مدل STGBRT را با استفاده از آن پارامترها برای پیشبینی دقیق زمان سفر پیوند آموزش دادیم.
4.3. مقایسه مدل ها
برای آزمایش عملکرد روش درخت رگرسیون شیب-زمانی تقویتشده (STGBRT)، عملکرد پیشبینیکننده STGBRT را با میانگین متحرک یکپارچه خودرگرسیون [12]، جنگل تصادفی [ 54 ] و تقویت گرادیان [ 27] مقایسه کردیم.] روش ها بر حسب درصد خطای مطلق آنها (MAPE). روش تقویت گرادیان (GBM) همبستگی زمانی یک پیوند هدف را بدون توجه به تأثیر همبستگی فضایی یا کلان داده که شرایط ترافیکی تاریخی را در تخمین زمان سفر پیوند توصیف میکند، در نظر میگیرد. مدل میانگین متحرک یکپارچه اتورگرسیو (ARIMA) تعمیم مدل میانگین متحرک اتورگرسیو (ARMA) است و یکی از شناخته شده ترین روش ها برای پیش بینی پارامتر ترافیک است. این مدل برای درک بهتر دادهها یا پیشبینی نقاط آینده در سریهای زمانی به دادههای سری زمانی برازش داده میشود. ARIMA در مواردی استفاده می شود که داده ها شواهدی از غیر ثابت بودن را نشان می دهند. سری های زمانی غیر ثابت را به سری های زمانی ثابت تبدیل می کند. مدل با استفاده از متغیر وابسته، مقدار تاخیر آن، ساخته شده است. و مقدار فعلی خطای تصادفی؛ پیش بینی های ARIMA بر اساس رگرسیون داده های فعلی و گذشته است. مدلهای غیرفصلی ARIMA معمولاً به صورت ARIMA (p, d, q) نشان داده میشوند که در آن پارامترهای p, d و q اعداد صحیح غیر منفی هستند، p مرتبه مدل خودرگرسیون، d درجه تفاضل و q است. ترتیب مدل میانگین متحرک بهینه سازی مدل ARIMA شامل انتخاب سفارش و تخمین پارامتر است. اطلاعات دقیق در زمینه پیشینه نظری زیربنای ARIMA، و مراحل مربوط به برازش یک مدل ARIMA را می توان در ادبیات پیدا کرد [ d درجه تفاضل و q ترتیب مدل میانگین متحرک است. بهینه سازی مدل ARIMA شامل انتخاب سفارش و تخمین پارامتر است. اطلاعات دقیق در زمینه پیشینه نظری زیربنای ARIMA، و مراحل مربوط به برازش یک مدل ARIMA را می توان در ادبیات پیدا کرد [ d درجه تفاضل و q ترتیب مدل میانگین متحرک است. بهینه سازی مدل ARIMA شامل انتخاب سفارش و تخمین پارامتر است. اطلاعات دقیق در زمینه پیشینه نظری زیربنای ARIMA، و مراحل مربوط به برازش یک مدل ARIMA را می توان در ادبیات پیدا کرد [55 ]. روش جنگل تصادفی (RF) یکی دیگر از روشهای گروهی پرکاربرد است که بسط آن توسط لئو بریمن [ 54 ] توسعه داده شد و با روش درخت رگرسیون تقویتشده گرادیان متفاوت است.
برای مقایسه این چهار روش برای پیشبینی زمان سفر لینک، دادههای آماری جمعآوریشده توسط وسایل نقلیه کاوشگر که از شبکه جادهای منطقهای در ووهان در روزهای هفته، دوشنبه تا جمعه، بهجز تعطیلات، از ژانویه تا مه 2014 عبور میکنند، جمعآوری کردیم. ویژگیهای مکانی و زمانی پیوندها را در داخل استخراج کردیم. شبکه. داده های 21 ژوئیه 2014 تا 22 ژوئیه 2014 به عنوان داده های آزمون برای مقایسه عملکرد پیش بینی در بین چهار مدل (STGBRT، GBM، RF، و ARIMA) استفاده شد. دقت پیشبینی این چهار مدل بر اساس پیشبینیهای آنها یک و دو مرحله زمانی (یعنی 30 و 60 دقیقه) پس از زمان کنونی مقایسه شد. آزمایش مورد بحث در بخش 4.2نشان داد که MAPE مدل STGBRT زمانی به حداقل مقدار دست یافت که نرخ یادگیری روی 01/0 و تعداد درخت های رگرسیون پایه 500 تنظیم شد. به ترتیب. برای GBM و ARIMA، ما ترکیبات مختلفی از متغیرها را در طول فرآیند آموزش آزمایش کردیم و پارامترهایی را انتخاب کردیم که حداقل مقادیر MAPE را به دست آوردند.
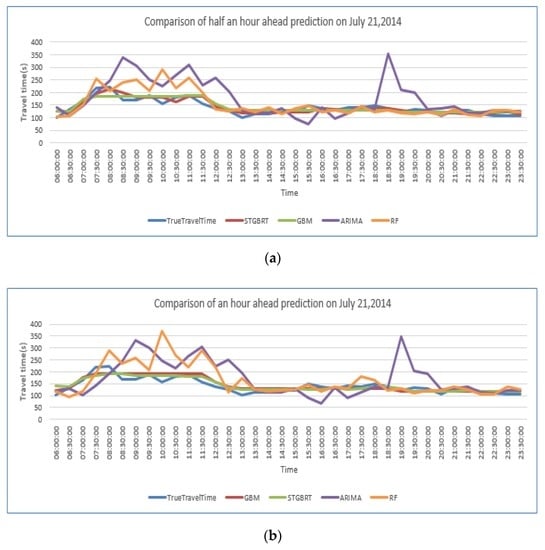
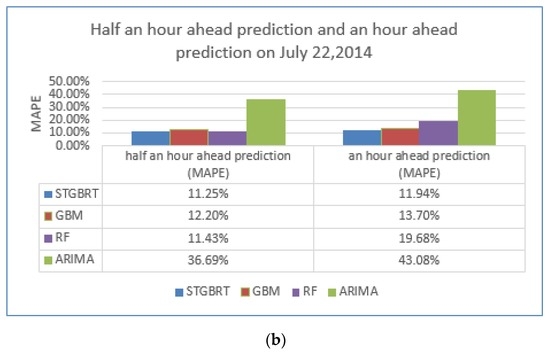
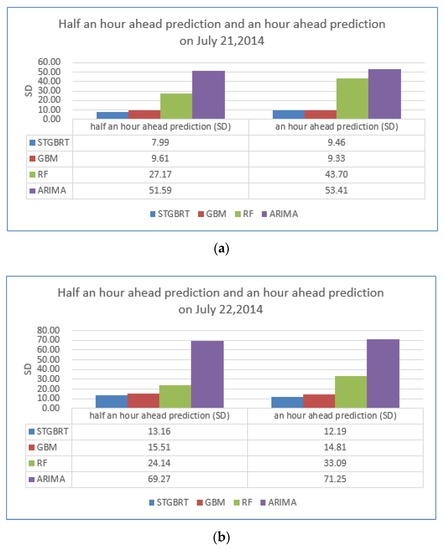
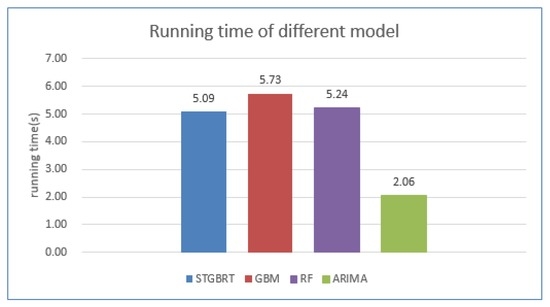
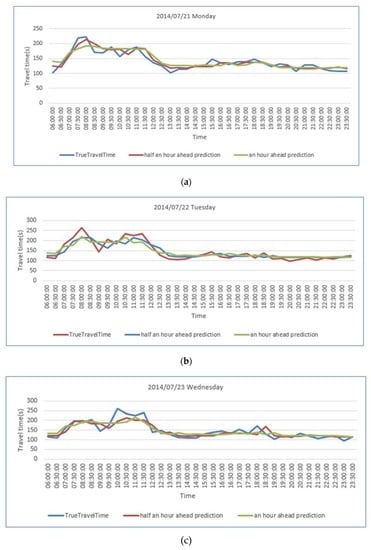
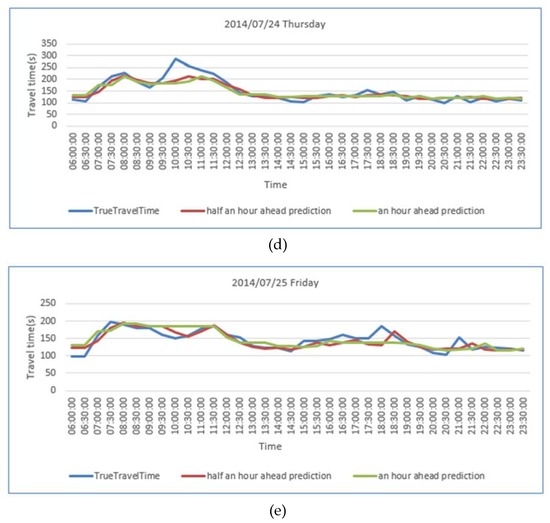
ما از دادههای بزرگ ترافیکی که بیانگر شرایط ترافیکی تاریخی از ژانویه تا مه در سال 2014 بود و دادههای واقعی بهدستآمده از 11 هفته بین 5 مه 2014 و 20 ژوئیه 2014 به عنوان دادههای آموزشی استفاده کردیم. ما از داده های دو روزه (21 و 22 ژوئیه 2014) به عنوان داده های آزمایشی برای مقایسه عملکرد پیش بینی بین STGBRT، GBM و ARIMA استفاده کردیم. نمودارهای خطی در شکل 12 و شکل 13تفاوت بین پیش بینی های انجام شده 30 دقیقه و یک ساعت جلوتر از چهار مدل به ترتیب در 21 ژوئیه 2014 و 22 جولای 2014 را نشان می دهد. خط آبی در دو شکل نشاندهنده زمان سفر واقعی پیوند است، در حالی که خط قرمز نشاندهنده نتایج پیشبینی از مدل STGBRT، خط سبز نشاندهنده نتایج پیشبینی از GBM، خط نارنجی نشاندهنده پیشبینی از RM و خط بنفش نشاندهنده پیشبینی نتایج از GBM است. نتایج پیشبینی از مدل ARIMA. همانطور که نشان داده شده است، مدل STGBRT و مدل GBM بیشترین تناسب را با زمان سفر لینک واقعی دارند. ARIMA کمترین تطابق را با زمان سفر پیوند واقعی در بین چهار مدل ارائه کرد. تحت شرایط یکسان، پیشبینیهای STGBRT از روش جنگل تصادفی در آزمایشهای ما بهتر است، همانطور که در شکل 12 ، شکل 13 نشان داده شده است.و شکل 14 . شکل 14 مقایسه ای از مقادیر MAPE را برای عملکرد این چهار مدل برای پیش بینی های انجام شده 30 دقیقه و یک ساعت جلوتر نشان می دهد. همانطور که در شکل 14 نشان داده شده است ، نتایج پیشبینی STGBRT از سه مدل دیگر بهتر بود. MAPE برای STGBRT (7.43٪) نسبت به مقادیر MAPE مربوط به پیش بینی های نیم ساعته برای GBM، RF و ARIMA که به ترتیب 9.37٪، 15.83٪ و 33.79٪ بود، برتر بود. در همان زمان، عملکرد پیشبینی نیم ساعته STGBRT نسبت به پیشبینی یک ساعته (9.49 درصد) مقدار MAPE بهطور قابلتوجهی (7.43 درصد) بهتر بود. شکل 15انحراف استاندارد پیشبینیهای انجام شده 30 دقیقه و یک ساعت جلوتر توسط چهار مدل برای 21 جولای 2014 و 22 جولای 2014 را نشان میدهد . شکل 16 عملکرد محاسباتی مدل های مختلف را در شرایط یکسان نشان می دهد، یعنی با استفاده از داده های آموزشی و پیش بینی یکسان. شکل نشان می دهد که STGBRT، GBM، و RF به مقادیر مشابهی از زمان محاسباتی نیاز دارند: به ترتیب 5.09 ثانیه، 5.73 ثانیه و 5.24 ثانیه. مدل ARIMA به کمترین زمان محاسباتی نیاز دارد. با این حال، عملکرد پیشبینی ضعیفی در مقایسه با سه مدل دیگر داشت، همانطور که در شکل 14 نشان داده شده است.. آزمایش Wilcoxon نشان داد که تفاوتهای بین زمان سفر پیوند واقعی و نتایج مدلهای STGBRT، GBM و RF بهجز پیشبینیهایی که یک ساعت جلوتر توسط مدل RF برای 21 ژوئیه 2014 انجام شد، به طور متقارن در حدود صفر توزیع شدهاند. با این حال، تفاوتها بین زمان سفر پیوند واقعی و مقادیر پیشبینیشده از ARIMA بهجز پیشبینیهایی که یک ساعت جلوتر برای 22 ژوئیه 2014 انجام شده است، به طور متقارن در حدود صفر توزیع نمیشوند. بنابراین، مدلهای STGBRT، GBM، و RF پیشبینیهای بهتری نسبت به مدل ARIMA ارائه میدهند. شکل 17 پنج روز (دوشنبه، 21 ژوئیه 2014 تا جمعه، 25 ژوئیه 2014) زمان پیش بینی شده سفر لینک را از مدل STGBRT نشان می دهد. خط آبی نشان دهنده زمان سفر لینک واقعی و خط قرمز نشان دهنده زمان سفر لینک پیش بینی شده است. جدول 9مقادیر MAPE را برای پیش بینی زمان سفر به دست آمده از مدل STGBRT از دوشنبه تا جمعه نشان می دهد. مدل STGBRT دارای مقادیر MAPE بالایی بود. شکل 17 روندهای کلی را نشان می دهد و همچنین اینکه مدل ها تا چه اندازه تغییرات ناگهانی در زمان سفر را به خوبی ثبت کرده اند. به عنوان مثال، در 21 ژوئیه 2014 (پانل بالای شکل 17 )، مدل STGBRT تغییرات را بهویژه در ساعات شلوغی صبحگاهی که احتمال وقوع ازدحام وجود دارد، به خوبی ثبت کرد. از نظر تئوری، مدل STGBRT میتواند تعاملات پیچیده بین متغیرهای ورودی را مدیریت کند و میتواند روابط غیرخطی پیچیده موجود در سیستمهای ترافیک پویا را برای عملکرد پیشبینی برتر مطابقت دهد.
5. بحث و نتیجه گیری
مدل GBRT دارای ویژگی هایی است که آن را از روش های مجموعه سنتی متمایز می کند، مانند رویکردهای جنگل تصادفی و درختان کیسه ای و همچنین رویکردهای آماری کلاسیک. مدل GBRT درختان را به طور متوالی با تنظیم وزن توزیع داده های آموزشی در جهت “تندترین نزول” رشد می دهد تا عملکرد تلفات را به حداقل برساند. این سوگیری مدل را از طریق مدل سازی گام به گام رو به جلو کاهش می دهد و از طریق میانگین گیری واریانس را کاهش می دهد. با این حال، روش پیشنهادی ما، مدل پیشبینی زمان سفر مبتنی بر STGBRT، مزایای قابلتوجهی نسبت به مدل سنتی GBRT دارد. روش پیشنهادی نه تنها از روش “شیبترین نزول” استفاده میکند، بلکه همبستگی مکانی-زمانی بین پیوند هدف و پیوندهای مجاور در دادههای آموزشی را نیز در بر میگیرد. بنابراین، عملکرد بالاتری نسبت به GBM، ARIMA،
تا آنجا که نویسندگان میدانند، مطالعات کمی وجود دارد که روش STGBRT را در زمینه پیشبینی زمان سفر مورد بحث قرار میدهد و کار کمی روی کاربرد روش STGBRT برای تخمین زمان سفر پیوند شهری انجام شده است. مدل STGBRT میتواند ناپیوستگیهای ناگهانی را که یکی از مشخصههای مهم جریانهای ترافیکی است، ثبت کند، با توجه به اینکه ترافیک به سرعت از بدون تراکم به شلوغ و بالعکس تغییر میکند. مهمتر از آن، مدل STGBRT ویژگیهای مکانی-زمانی ترافیک، نه تنها جریانهای ترافیک فعلی، بلکه در رابطه با دادههای ترافیک تاریخی را نیز در نظر میگیرد. این نه تنها ویژگی های ترافیک لینک هدف را در نظر می گیرد، بلکه از اطلاعات ویژگی های پیوند ترافیک مجاور نیز بهره برداری می کند. برخلاف الگوریتمهای یادگیری ماشین سنتی که اغلب به عنوان «جعبههای سیاه» در نظر گرفته میشوند. تعداد درختان رگرسیون پایه و نرخ یادگیری در STGBRT پارامترهایی هستند که قابل تجزیه و تحلیل و تنظیم هستند. در مقایسه با روشهای GBM و ARIMA، روش STGBRT ویژگیهای مکانی-زمانی را در نظر میگیرد و نسبت به مدلهای آماری معمولی برتری دارد.
بهینه سازی پارامتر یک جنبه مهم برای پیش بینی زمان سفر لینک با استفاده از مدل STGBRT است. درست مانند بهینه سازی مدل، عملکرد مدل STGBRT به طور قابل ملاحظه ای تحت تأثیر پارامترهای آن، از جمله تعداد درختان رگرسیون، نرخ یادگیری، و پیچیدگی درخت است. بنابراین لازم است ترکیب بهینه متغیرها هنگام استفاده از مدل STGBRT پیدا شود. زمان محاسبه یکی دیگر از مسائل مهم در افزایش تعداد و پیچیدگی درختان رگرسیون است. در نتیجه، باید افزایش زمان محاسبه را با دقت مدل سنجید.
مدل STGBRT دارای مزایای مشخصی از نظر پیشبینی زمان سفر جریان آزاد است. با توجه به توسعه این فناوری های پیشرفته، این امکان برای ما وجود دارد که مقادیر زیادی از داده های ترافیکی مختلف را از حسگرهای جاده، تلفن های هوشمند و دستگاه های GPS جمع آوری کنیم. با گذشت زمان، اطلاعات ترافیکی بیشتری را می توان جمع آوری کرد و برای مطالعه پدیده های ترافیکی استفاده کرد. بنابراین، پیدا کردن مدلی که بتواند روابط پیچیده را هنگام ترکیب داده های بزرگ ناهمگن نشان دهد، بسیار مهم است. مدل STGBRT میتواند به روابط غیرخطی پیچیده رسیدگی کند و آن را به یک الگوریتم امیدوارکننده برای پیشبینی زمان سفر تبدیل کند. دقت روش مدلسازی پیشنهادی به اندازهای است که میتوان آن را در سیستمهای حملونقل هوشمند برای پیشبینی زمان سفر لینک یا پیشبینی زمان سفر در زمان واقعی اعمال کرد. همچنین می توان آن را به پیش بینی جریان ترافیک تعمیم داد. با این حال، این مدل در حال حاضر فقط همبستگی های فضایی مرتبه اول پیوندهای هدف را در نظر می گیرد. تحقیقات بیشتر سطوح مرتبه دوم و بالاتری از همبستگی را برای ثبت دقیق تر پویایی ترافیک ترکیب می کند. مسئله دیگری که باید به آن توجه شود کمبود داده است. وقتی دادههای ترافیکی تاریخی و بیدرنگ برای یک زمان وجود ندارد، این مدل نمیتواند سفر پیوند را پیشبینی کند. این مشکل موضوع مهمی است که در آینده به بررسی آن خواهیم پرداخت. نتایج تجربی ما بر اساس بخشهای جادهای خاص است. ما در آینده آزمایشات خود را به سایر بخش های جاده گسترش خواهیم داد. تحقیقات بیشتر سطوح مرتبه دوم و بالاتری از همبستگی را برای ثبت دقیق تر پویایی ترافیک ترکیب می کند. مسئله دیگری که باید به آن توجه شود کمبود داده است. وقتی دادههای ترافیکی تاریخی و بیدرنگ برای یک زمان وجود ندارد، این مدل نمیتواند سفر پیوند را پیشبینی کند. این مشکل موضوع مهمی است که در آینده به بررسی آن خواهیم پرداخت. نتایج تجربی ما بر اساس بخشهای جادهای خاص است. ما در آینده آزمایشات خود را به سایر بخش های جاده گسترش خواهیم داد. تحقیقات بیشتر سطوح مرتبه دوم و بالاتری از همبستگی را برای ثبت دقیق تر پویایی ترافیک ترکیب می کند. مسئله دیگری که باید به آن توجه شود کمبود داده است. وقتی دادههای ترافیکی تاریخی و بیدرنگ برای یک زمان وجود ندارد، این مدل نمیتواند سفر پیوند را پیشبینی کند. این مشکل موضوع مهمی است که در آینده به بررسی آن خواهیم پرداخت. نتایج تجربی ما بر اساس بخشهای جادهای خاص است. ما در آینده آزمایشات خود را به سایر بخش های جاده گسترش خواهیم داد. نتایج تجربی ما بر اساس بخشهای جادهای خاص است. ما در آینده آزمایشات خود را به سایر بخش های جاده گسترش خواهیم داد. نتایج تجربی ما بر اساس بخشهای جادهای خاص است. ما در آینده آزمایشات خود را به سایر بخش های جاده گسترش خواهیم داد.












بدون نظر