1. معرفی
نقشه ها به طور گسترده در تحقیقات علمی مورد استفاده قرار می گیرند. با این حال، دقت آنها می تواند بسیار مهم باشد، زیرا اثر خطای نقشه در طیف وسیعی از برنامه ها چشمگیر است (به عنوان مثال، [ 1 ]). به عنوان مثال، ارزش تخمینی خدمات اکوسیستم برای ایالات متحده که با استفاده از پایگاه ملی پوشش زمین (2006) تعیین می شود، پس از تعدیل برای خطای شناخته شده در نقشه های مورد استفاده، از 1118 میلیارد دلار در سال به 600 میلیارد دلار در سال تغییر می کند [2 ] . بنابراین ضروری است که نقشه ها تا حد امکان دقیق باشند و اطلاعات دقت به طور مفید به کاربران نقشه منتقل شود.
یکی از منابع اولیه خطا در نقشه برداری، داده های مرجعی است که برای ساختن نقشه استفاده می شود. به عنوان مثال، معمولاً فرض می شود که مجموعه داده مرجع مورد استفاده از یک منبع معتبر است و می تواند به عنوان یک استاندارد طلا در نظر گرفته شود. با این حال، اغلب بعید است که درست باشد. علاوه بر این، ممکن است نگرانی های دیگری در مورد داده های مرجع وجود داشته باشد. برای مثال، این دادهها ممکن است از نمونههایی تولید شده باشند که کوچک، مغرضانه و غیرنماینده هستند. علاوه بر این، در برخی از پایگاه های داده بزرگ بین المللی، مسائل نمونه گیری ممکن است از منطقه ای به منطقه دیگر متفاوت باشد (به عنوان مثال، به دلیل سیاست های مختلف جمع آوری داده های ملی). پایگاه داده ها همچنین ممکن است حاوی خطاهایی با ماهیت و بزرگی های مختلف مانند برچسب زدن اشتباه ناشی از سردرگمی بین کلاس ها باشد [ 3]]، که ممکن است به صورت منطقه ای نیز متفاوت باشد، اگر، برای مثال، مهارت ها و تخصص گردآورندگان داده ها متفاوت باشد. این منابع مختلف خطا (مثلاً موارد با برچسب اشتباه) و عدم قطعیت (مثلاً عضویت در کلاس مبهم) ممکن است نقشه برداری را کاهش دهند و تأثیر ممکن است بین روش های نگاشت متفاوت باشد. در نتیجه، دانستن حساسیت روشهای نگاشت به خطا در دادههای مورد استفاده برای تولید آنها بسیار مهم است. هدف این مقاله بررسی حساسیت روش های نقشه برداری به خطا و عدم قطعیت در مجموعه داده های مرجع مورد استفاده در استخراج نقشه است. بر روی نقشه برداری موضوعی مانند نقشه های توزیع گونه ها و پوشش زمین تمرکز دارد.
2. کیفیت داده های مرجع و نقشه برداری
گاهی اوقات ممکن است داده های مرجع از پایگاه های داده ای که داده ها را از منابع مختلف گرد هم می آورند، بدست آورید. در حالی که این مفید است، ممکن است طیف وسیعی از مشکلات با چنین منابعی نیز وجود داشته باشد. یک مسئله کلیدی این است که داده های ارائه شده ممکن است با استفاده از روش های بسیار متفاوتی به دست آمده باشند. برای مثال، ممکن است از طرحهای نمونه متفاوتی استفاده شده باشد، و اگر این تنوع در تحلیلهای بعدی مورد توجه قرار نگیرد، میتواند مشکلاتی را ایجاد کند (مثلاً نمونههای نامتعادل و غیره). کیفیت برچسب گذاری موارد در پایگاه داده نیز ممکن است متفاوت باشد. این یک نگرانی عمده در برنامه های کاربردی رایج مانند نقشه برداری پوشش زمین از داده های سنجش از راه دور است زیرا مجموعه داده مرجع معمولاً به گونه ای استفاده می شود که گویی کامل است اما حتی یک انحراف کوچک نیز می تواند مشکل ساز باشد. به عنوان مثال، در ارزیابی دقت نقشه ها یا تخمین وسعت سطح طبقه از آنها،4 ]. در اینجا، تمرکز بر روی داده های مرجع مورد استفاده در تولید نقشه است (به عنوان مثال، آموزش طبقه بندی تصویر نظارت شده) زیرا کیفیت مرحله آموزش می تواند تأثیر قابل توجهی بر کیفیت نقشه پوشش زمین به دست آمده داشته باشد.
دقت نقشه های پوشش زمین به دست آمده از سنجش از دور اغلب به عنوان ناکافی در نظر گرفته می شود (به عنوان مثال، [ 5 ]). دلایل مختلفی را می توان برای توضیح این وضعیت ارائه کرد [ 6 ]، که تحقیقات قابل توجهی را برای رسیدگی به منابع بالقوه خطا از توسعه حسگرهای جدید تا تولید تکنیک های جدید تجزیه و تحلیل تصویر هدایت کرده است. با وجود این پیشرفت های مختلف، هنوز هم گاهی اوقات برای بسیاری از کاربران چالشی است که از داده های سنجش از راه دور نقشه پوشش زمین را با دقت کافی انجام دهند. یکی از دلایل این وضعیت فراتر از مسائل مرتبط با سنجش از دور و با داده های مرجع زمینی است که در طبقه بندی تصاویر دیجیتال نظارت شده مرکزی هستند.
داده های مرجع زمینی نقش اساسی در طبقه بندی تصاویر نظارت شده ایفا می کنند. معمولاً فرض می شود که مجموعه داده زمینی مورد استفاده کامل است (یعنی حقیقت پایه) اما در واقعیت معمولاً ناقص است. مجموعه های داده مانند تسهیلات جهانی اطلاعات تنوع زیستی (GBIF، [ 7]) برای مثال، اطلاعات ارزشمندی را در مورد مشاهدات گونه ها نگهداری کنید که می تواند برای کمک به نقشه برداری گونه ها به طور مستقیم یا از داده های سنجش از راه دور استفاده شود. با این حال، داده های موجود در پایگاه داده بسیار متغیر هستند. این محتویات شامل دادههای جمعآوریشده از بسیاری از منابع، از سرشماریهای معتبر، سیستماتیک و بررسیهای میدانی تا مشاهدات تصادفی ارائهشده توسط «دانشمندان شهروند» است. استانداردسازی داده ها از نظر عواملی مانند تلاش نمونه گیری یا کیفیت برچسب گذاری، یک چالش است. برای مثال، برچسبگذاری اشتباه یک خطای رایج در دادههای زمینی است، حتی آنهایی که توسط منابع معتبر به دست میآیند [ 3]. این خطا ممکن است به طرق مختلف، از اشتباهات تایپی یا رونویسی ساده گرفته تا ابهام در عضویت در کلاس ایجاد شود، و بزرگی آن می تواند زیاد باشد. برای مثال، مفسرهای خبره عکس هوایی معمولاً ممکن است در 30% موارد [ 8 ] بر روی برچسب کلاس اختلاف نظر داشته باشند، با این حال چنین داده هایی به طور گسترده به عنوان داده های زمینی برای پشتیبانی از طبقه بندی نظارت شده داده های سنسور از راه دور ماهواره ای استفاده می شود. به طور مشابه، دقت شناسایی گونه ها در میدان می تواند بسیار متفاوت باشد، بسته به مهارت و تخصص نقشه بردار [ 3 ، 9 ]. این نوع موضوع ممکن است در رابطه با استفاده از داوطلبان به عنوان منبع داده نگرانی خاصی باشد. پتانسیل قابل توجهی برای اطلاعات جغرافیایی داوطلبانه و مشارکت شهروندان وجود دارد [ 10، 11 ] در ارائه داده های مرجع زمینی، به ویژه در کمک به کسب به موقع داده ها در مناطق وسیع، اما همچنین نگرانی های اساسی مرتبط با کیفیت داده ها، که می تواند مانع استفاده از آن شود [12 ] .
مشخص است که خطاهای داده های زمینی می توانند ارزیابی طبقه بندی یا دقت نقشه را به طور قابل ملاحظه ای کاهش دهند [ 13 ، 14 ]، حتی اگر مقدار خطا کم باشد [ 4 ]. اثرات خطای داده های زمینی بر آموزش یک طبقه بندی کننده نظارت شده کمتر تعریف شده است، اگرچه ادبیات رو به رشد طیفی از مسائل و نگرانی ها را برجسته می کند (به عنوان مثال، [ 15 ]).
ممکن است انتظار می رود موارد آموزشی با برچسب نادرست به طرق مختلف بر مرحله آموزش طبقه بندی نظارت شده تأثیر بگذارد. موارد با برچسب اشتباه را می توان به عنوان یک نوع نویز در نظر گرفت و مشخص است که نویز می تواند اثرات منفی و مثبت بر یک طبقه بندی داشته باشد (به عنوان مثال، [ 16 ، 17 ]). تأثیر نیز در رابطه با جنبه های کلیدی ماهیت خطا متفاوت خواهد بود. برای مثال، اثرات برچسبگذاری نادرست بین نمونههایی که در آن برچسبگذاری اشتباه به طور نسبتاً یکنواختی از طریق دادهها پخش میشود و مواردی که برچسبگذاری اشتباه ممکن است فقط بر زیر مجموعه کوچکی از کلاسهای درگیر متمرکز شده باشد، متفاوت است [16] .]. اهمیت این نوع موضوع نیز بین کاربران و استفاده برنامه ریزی شده آنها از نقشه موضوعی متفاوت خواهد بود. برای هر مورد استفاده خاص، برخی از خطاها حیاتی تر از بقیه خواهند بود [ 18 ]. بهعنوان یک نقطه شروع کلی، انتظار میرود موارد برچسبگذاری نادرست در یک مجموعه داده زمینی، آمار آموزش و در نهایت دقت طبقهبندی تصویر دیجیتال نظارت شده را کاهش دهد. با این حال، اثرات خاص موارد با برچسب اشتباه به جزئیات رویکرد طبقهبندی اتخاذ شده بستگی دارد. برای مثال، طبقهبندیکنندهها میتوانند در نحوه استفاده از یک مجموعه آموزشی بسیار متفاوت باشند (به عنوان مثال، برخی بر ویژگیهای آماری خلاصه مانند مرکز کلاس تمرکز میکنند در حالی که دیگران مستقیماً بر زیر مجموعههایی از موارد فردی موجود متکی هستند) [ 16 ، 19 ،20 ، 21 ، 22 ] و بنابراین انتظار می رود حساسیت آنها نسبت به برچسب گذاری اشتباه متفاوت باشد. علاوه بر این، روشهای مختلفی وجود دارد که ممکن است برای کاهش اثرات برچسبگذاری نادرست در تجزیه و تحلیل طبقهبندی اتخاذ شود.
فرض بر این است که بزرگی اثر موارد آموزشی با برچسب اشتباه تابعی از بزرگی خطا، ماهیت خطا و طبقهبندی کننده مورد استفاده خواهد بود. در اینجا، توجه ویژه ای به طبقه بندی توسط ماشین بردار پشتیبان (SVM) می شود، که به یک طبقه بندی محبوب برای تولید نقشه های پوشش زمین از داده های سنجش از دور تبدیل شده است. مطالعات مقایسه ای متعدد نشان داده اند که SVM قادر است نقشه های پوشش زمین را با دقت بیشتری نسبت به مجموعه ای از روش های جایگزین مورد استفاده توسط جامعه سنجش از دور تولید کند [ 23 , 24 , 25]. در حالی که طبقهبندی توسط SVM میتواند به مجموعههای آموزشی نامتعادل حساس باشد، که در آن کلاسها به طور نابرابر نمایش داده میشوند، ابزارهایی برای رسیدگی به این موضوع در دسترس است و از این رو دانش فراوانی نسبی کلاس و نگرانیهای نمونهگیری میتواند به طور سازنده برای تسهیل نقشهبرداری دقیق استفاده شود [26 ] . همچنین ادعا شده است که SVM دارای طیف وسیعی از ویژگی ها است که آن را برای استفاده در نقشه برداری پوشش زمین از داده های سنجش از دور جذاب می کند. به طور خاص، ادعا شده است که SVM نسبت به اثر هیوز حساس نیست [ 27 ]، تنها به یک مجموعه آموزشی کوچک نیاز دارد [ 28 ، 29 ]، و به خطا در مجموعه آموزشی حساس نیست [ 30]]. ادعای اول، در مورد آزادی از اثر هیوز، نادرست است [ 31 ]. ادعای دوم، در مورد پتانسیل طبقه بندی دقیق از مجموعه های آموزشی کوچک، نشان داده شده است، اما موارد آموزشی باید با دقت جمع آوری شوند تا این پتانسیل برآورده شود [ 32 ]. تمرکز این مقاله بر ویژگی نهایی است که ادعا می شود: یعنی حساسیت کم SVM به خطا در مجموعه داده آموزشی. ادبیات شامل مطالعاتی است که نشان میدهد دقت طبقهبندی توسط SVM میتواند تحتتاثیر خطا در مجموعه آموزشی [ 33 ، 34 ] قرار گیرد، و این موضوع در این مقاله از دیدگاه سنجش از دور بررسی میشود.
در اینجا، تأثیر دادههای آموزشی با نوع متغیر و میزان خطای برچسبگذاری نادرست بر دقت طبقهبندی SVM بررسی میشود. برای زمینه، یک ارزیابی مقایسهای نیز نسبت به طبقهبندیکننده آماری مرسوم، تحلیل تفکیککننده، ماشین بردار مربوط (RVM) و رگرسیون لجستیک چندجملهای پراکنده (SMLR) انجام میشود، که مانند SVM، پتانسیل طبقهبندی دقیق را ارائه میدهد. مجموعه های آموزشی کوچک [ 35]. تمرکز اصلی بر روی تأثیرات ناشی از ماهیت و بزرگی برچسبگذاری اشتباه است. در اینجا دو نوع خطای برچسب گذاری اشتباه در نظر گرفته می شود. اولی خطای تصادفی است که در مطالعات دیگر مورد بررسی قرار گرفته است، اما دومی خطای مربوط به کلاس های مشابه است. مورد دوم از اهمیت ویژه ای برخوردار است زیرا در بسیاری از موارد انتظار نمی رود که خطا تصادفی باشد، بلکه شامل سردرگمی بین کلاس های نسبتاً مشابه است. به عنوان مثال، در بسیاری از مطالعات برخی از طبقات پوشش زمین به گونه ای تعریف شده اند که مکان های روی زمین که بسیار شبیه به هم هستند متعلق به طبقات مختلف هستند. به عنوان مثال، جنگل کلاس اغلب با استفاده از متغیری مانند درصد تاج پوشش [ 36] تعریف می شود.]. دو سایت روی زمین که از یک گونه تشکیل شدهاند و شرایط محیطی مشابهی دارند، میتوانند به طبقات کاملاً متفاوتی تعلق داشته باشند، به دلیل تفاوتهای جزئی در پوشش تاج پوشششان، اگر نزدیک به مقدار آستانه مورد استفاده در تعریف طبقات باشد. در نتیجه، خطا به طور نامتناسبی بر مواردی تأثیر می گذارد که انتظار می رود هم از نظر زمینی و هم از نظر طیفی مشابه باشند.
این مقاله به طور خلاصه عدم تعادل در پایگاههای داده را برجسته میکند، که اغلب به نمونهگیری مربوط میشود، که ممکن است قبل از تمرکز، با جزئیات بیشتر، بر روی اثرات موارد آموزشی برچسبگذاری نادرست بر دقت نقشه، نیاز به توجه قبل از طبقهبندی داشته باشد.
3. تنوع در نمونه گیری
در بسیاری از مطالعات نقشه برداری، داده های موجود به سادگی بدون تطبیق صریح برای ماهیت دقیق آنها استفاده می شود. برای مثال، در نقشهبرداری پوشش زمین از دادههای سنجش از راه دور، معمول است که نسبتی از دادههای مرجع موجود برای آموزش یک طبقهبندیکننده و بقیه برای اعتبارسنجی استفاده شود. با این حال، در برخی از مجموعه های داده ممکن است مشکلاتی با چنین رویکردی وجود داشته باشد. یکی از مشکلات پایگاه های داده بزرگ بین المللی این است که داده های ارائه شده ممکن است با روش های بسیار متفاوتی به دست آمده باشند. به طور بحرانی، برای مثال، تلاش نمونه گیری ممکن است بسیار متفاوت باشد. این میتواند منجر به مشکلات اساسی شود، بهعنوان مثال، نمونهبرداری در برخی از مناطق فشردهتر از مناطق دیگر است، که منجر به ایجاد مجموعه دادههایی میشود که در صورت متفاوت بودن توزیعهای جغرافیایی طبقات، از نظر ترکیب کلاسها به طور مصنوعی نامتعادل هستند.26 ] و عدم در نظر گرفتن تغییرات نمونه ممکن است مانع استفاده از طبقهبندیکنندههای پیشرفته یادگیری ماشین شود. در این بخش هدف این است که به سادگی بزرگی مشکلات نمونه برداری را با استفاده از یک پایگاه داده اصلی به عنوان مثال نشان دهیم.
منبع مهم و به طور فزاینده ای مورد استفاده برای مشاهدات میدانی گونه ها GBIF [ 7 ] است. دادههای GBIF شامل طیف وسیعی از مشاهدات وقوع گونهها است که با طیف گستردهای از روشهای نمونهگیری جمعآوری شدهاند. علاوه بر این، ممکن است تفاوتهایی در روشهای مورد استفاده برای مشاهده و ثبت وقوع در هر تاکسون وجود داشته باشد. قطعهها، و کرتهای درون ترانسکتها، در سرشماریهای گیاهی رایج هستند، در حالی که ترانسکتها، شمارش نقاط و تلههای زنده در مورد حیوانات ترجیح داده میشوند. علاوه بر این، عواملی مانند طرحهای ملی پایش تنوع زیستی، طرحهای تامین مالی، اکوسیستمهای کانونی و دسترسی به مناطق دورافتاده برای افزودن منابع بیشتری از تنوع، بهویژه در مقیاسهای چند ملیتی عمل میکنند [37] .]. بدون شک، همه آن منابع تنوع ترکیبی منجر به نمونهبرداری غیرهمگن میشود و این پیامدهای مهمی نه تنها برای توسعه مدلهای توزیع دقیق گونهها، بلکه مهمتر از آن، برای تصمیمگیریهای حفاظتی و مدیریتی که توسط نقشههای مشتق شده از پراکنش گونهها مشخص میشود، دارد.
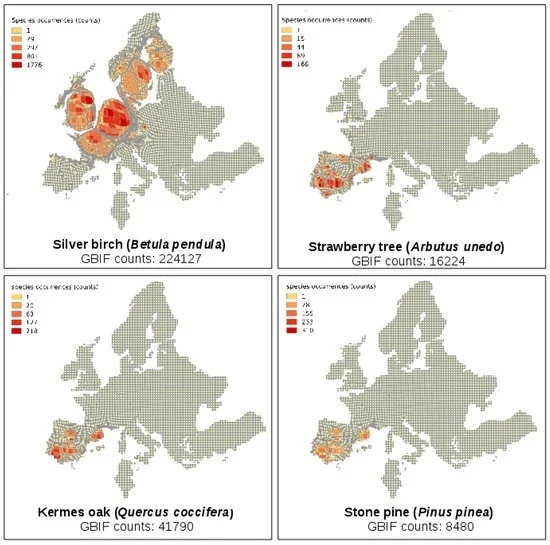
در اینجا، کارتوگرام ها برای تسهیل تجسم عدم قطعیت فضایی در نتایج با تغییر اندازه چند ضلعی ها بر اساس تراکم اطلاعات موجود (به عنوان مثال، تعداد مشاهدات، تلاش نمونه برداری، و غیره) استفاده می شود، بنابراین تنوع در تلاش نمونه گیری را نشان می دهد. و اتفاقات در بررسی های میدانی. با استفاده از این رویکرد، نقشههایی که تفاوتها در تلاش نمونهبرداری (تعداد تاریخهای مختلف بررسی در پایگاه داده) و وقوع (شمارش مشاهدات) را برای مجموعهای از گونههای گیاهی در یک شبکه با اندازه مساوی از اروپا نشان میدهند، تولید شد (شکل 1 ) . کارتوگرام ها با استفاده از نرم افزار رایگان و متن باز ScapeToad ( http://scapetoad.choros.ch/ ) توسعه یافته اند.
کارتوگرام ها بر اساس دو معیار، تعداد بررسی های میدانی (پراکسی: تاریخ) و تعداد مشاهدات در هر سلول شبکه تولید شدند. اندازه خطا با اندازه ای که سلول شبکه باید بر حسب منطقه فضایی واقعی که پوشش می دهد داشته باشد، بیش از نسبت واقعی، همانطور که توسط تعداد مشاهدات/منطقه محاسبه می شود، داده می شود. عدم قطعیت در مقیاس سلول شبکه ای نشان داده می شود و مربوط به تغییر شکل اندازه سلول اصلی است، یعنی سلول های بزرگتر از اندازه اصلی خود به استراتژی هایی نیاز دارند تا اثر نمونه برداری بیش از حد بر محصولات مشتق شده از داده های GBIF را کاهش دهند، در حالی که سلول ها به عنوان نمایش داده می شوند. کوچکتر از اندازه اصلی آنها به تلاش های نمونه برداری بیشتری نیاز داشت. به طور بحرانی، روشهایی برای توضیح تفاوتها در تلاش نمونهگیری و رخدادها (به عنوان مثال، [ 26]) ممکن است برای تقویت یک فعالیت نقشه برداری استفاده شود.
4. موارد آموزشی با برچسب اشتباه
اثر موارد برچسب گذاری اشتباه در مجموعه داده های آموزشی با استفاده از مجموعه ای از طبقه بندی کننده ها مورد بررسی قرار گرفت. مجموعه طبقهبندیکنندههای مورد استفاده شامل معاصر بود. رویکردهای پیشرفته مانند SVM، RVM، و SMLR، همراه با یک طبقهبندی آماری مرسوم، تجزیه و تحلیل متمایز (DA)، به عنوان یک معیار. مجموعه های آموزشی با ماهیت متفاوت تولید شد و جنبه های کلیدی طراحی مطالعه و نتایج در بخش های فرعی زیر ارائه شده است.
4.1. داده ها و روش ها
مجموعه ای از طبقه بندی های نظارت شده با استفاده از داده های نقشه برداری موضوعی هوابرد (ATM) به دست آمده برای یک سایت آزمایشی در نزدیکی Feltwell در بریتانیا انجام شد. این یک سایت آزمایشی از نظر توپوگرافی مسطح است که عمدتاً از مزارع کشاورزی بزرگی تشکیل شده است که هر یک از آنها با یک نوع محصول در زمان جمعآوری دادههای ATM کاشته شدهاند (شکل 2 )). ATM یک سیستم اسکن چندطیفی استاندارد است که داده ها را در 11 باند موج طیفی به دست می آورد. در اینجا، وضوح فضایی تصاویر بسیار کوچکتر از اندازه میدان معمولی بود، و جنبه های مشکل پیکسل های مختلط را کاهش داد و بنابراین پتانسیل عضویت در کلاس مبهم را کاهش داد. نمونههایی از دادهها با استفاده از طیفی از طبقهبندیکنندهها، از طبقهبندیکنندههای آماری معمولی گرفته تا روشهای یادگیری ماشین معاصر، به مجموعهای از طبقهبندیهای تصویری نظارتشده وارد شدند.
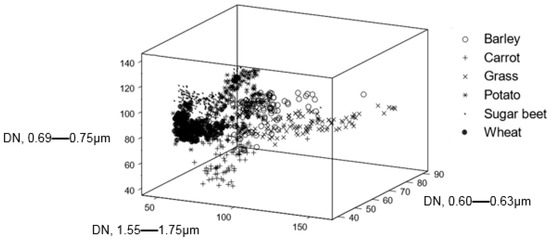
برای سادهسازی تحلیلها و کمک به دستیابی به دادههای آموزشی کافی، فقط دادههای بهدستآمده در سه باند موج، آنهایی که در 0.60-0.63، 0.69-0.75، و 1.55-1.75 میکرومتر قرار دارند، که در مطالعات قبلی شناسایی شده بودند (به عنوان مثال، [38 ] ]) به عنوان ارائه درجه بالایی از تفکیک پذیری کلاس، استفاده شد. در اینجا، توجه بر شش طبقه محصول که در زمان جمع آوری داده های خودپرداز بر منطقه غالب بودند متمرکز شد: چغندرقند (S)، گندم (W)، جو (B)، هویج (C)، سیب زمینی (P)، و علف. (G). به دنبال اکتشافی 30p که به طور گسترده استفاده می شود، که p تعداد متغیرهای متمایزکننده است که اغلب با طبقه بندی کننده های آماری استفاده می شود [ 39]]، یک مجموعه آموزشی شامل حداقل 90 مورد برای هر کلاس مورد نیاز بود. در اینجا، در مجموع 100 پیکسل از هر کلاس به طور تصادفی از داده های ATM به دست آمد و برای تشکیل یک مجموعه آموزشی ( n = 600) استفاده شد. این مجموعه آموزشی اولیه متعادل است، با هر کلاس به طور مساوی، و کامل یا بدون خطا در نظر گرفته شد. مکان شش کلاس در فضای ویژگی سه باند موج برای این داده های آموزشی در شکل 3 نشان داده شده است .
داده های ATM با استفاده از SVM، RVM، و SMLR و همچنین تجزیه و تحلیل متمایز درجه دوم استاندارد طبقه بندی شدند. دومی یک طبقهبندی آماری استاندارد است که از آمار خلاصه برای هر کلاس به دست آمده از دادههای آموزشی استفاده میکند، در حالی که سه طبقهبندیکننده دیگر از موارد آموزشی موجود بهطور متفاوتی استفاده میکنند. جزئیات در مورد الگوریتم ها در زیر آورده شده است، اما توجه به این نکته مهم است که SVM، RVM، و SMLR بر روی موارد مختلف در مجموعه آموزشی [ 35 ] تمرکز می کنند، که هر کدام معمولاً از زیر مجموعه ای از تمام موارد موجود استفاده می کنند. زیر مجموعه استفاده شده ممکن است بین طبقه بندی کننده ها تفاوت زیادی داشته باشد. برای مثال، RVM و SVM هر دو ممکن است از موارد آموزشی نسبتاً غیر معمول استفاده کنند، اما از مکانهای مشخصی از فضای ویژگی ترسیم شدهاند [ 35]]. برای یافتن مقادیر بهینه پارامترهای تعریفشده توسط کاربر ( جدول 1 ) برای دادههای آموزش بدون خطا با الگوریتمهای مختلف، از اعتبارسنجی متقابل 5 برابری با SVM و روش آزمون و خطا با RVM و SMLR استفاده شد. این مقادیر در سراسر استفاده شد.
یک سری از طبقه بندی ها با استفاده از مجموعه های آموزشی با کیفیت متغیر انجام شد. در هر طبقه بندی اندازه مجموعه آموزشی ثابت بود. مجموعه دادههای آموزشی اولیه بدون خطا در نظر گرفته شد و مجموعهای از مجموعههای آموزشی با کیفیت متغیر از آن با تخریب کنترلشده به دنبال دو استراتژی به دست آمد. در هر دو استراتژی، برچسب کلاس برای موارد آموزشی که نزدیکترین نقطه به موقعیت مرزی بین دو کلاس در فضای ویژگی قرار دارند، از مجموعه فاصلههای Mahalanobis تا مرکز کلاس برای هر مورد شناسایی شده است [ 22]، تغییر یافت. بنابراین، تمرکز بر ناحیه مرزی بین طبقات در فضای ویژگی است که احتمالاً بردارهای پشتیبانی را ارائه می دهد. به طور خاص، تفاوت بین فاصله Mahalanobis تا دو کلاس طیفی نزدیک به عنوان یک ابزار ساده برای شناسایی موارد مرزی که بین طبقات قرار دارند استفاده شد [ 22]]. موارد آموزشی برای هر کلاس بر اساس تفاوت در این فاصله مرتب شدند و درصدی از موارد با کمترین فاصله مجدداً برچسب زدند تا مجموعه های آموزشی ناقص را تشکیل دهند. در استراتژی اول، برچسب کلاس از کلاس واقعی به طبقه دوم محتمل ترین عضویت تغییر یافت و بنابراین خطا بین کلاس های نسبتا مشابه است. در استراتژی دوم، برچسب از کلاس واقعی به کلاسی که به طور تصادفی انتخاب شده بود، تغییر یافت. هر دو استراتژی برای تشکیل مجموعهای از مجموعههای آموزشی مورد استفاده قرار گرفتند که در آنها میزان موارد برچسبگذاری نادرست 5، 10 و 20 درصد از کل اندازه مجموعه آموزشی بود. بنابراین، در سرتاسر، به جای مواردی که به طور تصادفی انتخاب شده اند، تمرکز بر روی برچسب گذاری نادرست مواردی است که ممکن است به عنوان موارد مرزی در نظر گرفته شود.
دقت هر طبقهبندی با استفاده از یک مجموعه آزمایشی واحد ارزیابی شد. این مجموعه آزمون با استفاده از نمونه گیری تصادفی طبقه ای با 75 مورد در هر کلاس ( n = 450) تشکیل شد . توجه داشته باشید که این اندازه مجموعه آزمایشی از پیشنهاد پرکاربرد که حداقل 50 مورد در هر کلاس استفاده می شود، فراتر است. دقت هر طبقهبندی به عنوان نسبت موارد بهدرستی تخصیص یافته از ماتریس سردرگمی ارزیابی و بیان شد. اهمیت آماری تفاوت ها در میزان دقت کلی تخمین زده شده طبقه بندی ها نیز با استفاده از آزمون مک نمار در سطح اطمینان 95 درصد ارزیابی شد [ 40]]. علاوه بر این، برای تشخیص نیاز به تطبیق برای طرح نمونه مورد استفاده، برای کلاسهای جداگانه، از فاصله اطمینان حول تخمینهای دقت بهدستآمده برای ارزیابی اهمیت آماری تفاوتها در دقت استفاده شد [41 ] .
4.2. طبقه بندی کننده ها
چهار الگوریتم طبقه بندی استفاده شد: تجزیه و تحلیل متمایز، SVM، RVM، و SMLR. جزئیات برجسته هر یک از طبقه بندی کننده ها در زیر ارائه شده است. این بحث تا حدی از مقاله قبلی [ 35 ] که جزئیات کامل تری در مورد SVM، RVM و SMLR نیز ارائه می دهد، استوار است. در بحث در مورد الگوریتم های طبقه بندی مختلف، مجموعه داده های آموزشی (ایکسمن، yمن) ،(��, ��)، i = 1، …، n ، داشتن n تعداد نمونه، که در آن x =[ایکس1، ایکس2, … , ایکسf]تی∈ آرf�=[x1, x2, …, xf]T∈ �fبردار ورودی با ویژگی های طیفی f است وy = [y1، y2, … , yq]تی∈ آرq�= [�1, �2,…, ��]T∈ ��بردار کلاس با کلاس های q است ، استفاده می شود.
4.2.1. تجزیه و تحلیل تشخیصی
تجزیه و تحلیل تمایز به طور گسترده ای در طبقه بندی داده های سنجش از دور استفاده می شود [ 42 ، 43 ]. این یک طبقهبندیکننده آماری متعارف است که هر مورد را به کلاسی اختصاص میدهد که با آن بالاترین احتمال عضویت پسینی را نشان میدهد. دومی ممکن است از
جایی که L ( c | x ) � (�|�)احتمال عقبی مورد x متعلق به کلاس c است ، p ( x | c )�(�|�)احتمال معمولی است (احتمال اینکه مورد x عضوی از کلاس c باشد با توجه به فاصله آن از مرکز کلاس c )، Pc احتمال پیشینی برای کلاس c است و q تعداد کل کلاس ها است. احتمال تیپیکیت از فاصله Mahalanobis، D ، بین یک مورد و مرکز یک کلاس از محاسبه می شود.
جایی که ایکسfایکس�بردار داده برای پیکسل است، vج�جماتریس واریانس کوواریانس برای کلاس c است و توجتوجبردار میانگین برای کلاس c [ 39 ] است.
4.2.2. SVM
هدف SVM تعیین مکان مرزهای کلاس است که جداسازی بهینه کلاس ها [ 44 ] را بر اساس تئوری یادگیری آماری ایجاد می کند. برای یک مسئله طبقه بندی خطی دو کلاسه قابل جداسازی، SVM مرزهای تصمیم خطی را انتخاب می کند که بیشترین حاشیه را بین دو کلاس فراهم می کند، جایی که حاشیه به عنوان مجموع فواصل تا ابر صفحه از نزدیکترین نقاط دو کلاس تعریف می شود. 44]. SVM از یک روش استاندارد بهینهسازی برنامهنویسی درجه دوم برای حل مشکل به حداکثر رساندن حاشیه بین دو کلاس استفاده میکند و موارد کلاس نزدیکترین به ابر صفحه مورد استفاده برای اندازهگیری حاشیه، «بردارهای پشتیبانی» نامیده میشوند. این بردارهای حمایتی، که بخش کوچکی از کل مجموعه آموزشی هستند، ماهیت غیر معمولی دارند و در منطقه مرزی بین کلاسها قرار دارند [ 32 ، 35 ].
در مورد کلاسهای غیرقابل تفکیک خطی، SVM ابر صفحهای را انتخاب میکند که حاشیه را به حداکثر میرساند، در حالی که در عین حال مقداری متناسب با تعداد خطاهای طبقهبندی اشتباه را به حداقل میرساند. یک متغیر slack برای رفع محدودیت معرفی شده است که همه موارد آموزشی یک کلاس معین در یک سمت ابر صفحه بهینه قرار دارند و مبادله بین حاشیه و خطای طبقهبندی اشتباه توسط یک ثابت C مثبت تعریف شده توسط کاربر کنترل میشود (یک پارامتر منظمسازی ) . ) به طوری که ∞ > C > 0 [ 27 ].
برای رسیدگی به مرزهای تصمیم گیری غیرخطی با SVM، رویکردی برای نمایش داده های ورودی بر روی یک فضای ویژگی با ابعاد بالا از طریق نگاشت غیرخطی توسط [ 45 ] پیشنهاد شد. این رویکرد اجازه می دهد تا یک مسئله طبقه بندی خطی در فضای ویژگی جدید قاب شود. چالش اصلی در حل مسائل SVM در این فضای ویژگی با ابعاد بالا، هزینه محاسباتی هنگفت است. برای مقابله با این فضای ویژگی با ابعاد بالا و کاهش هزینه محاسباتی، استفاده از یک تابع هسته که قضیه مرسر را برآورده می کند، توسط [ 27 ] پیشنهاد شد. یک تابع هسته به صورت تعریف شده است ک(ایکسمن، ایکسj) = Φ ( ایکسمن) . Φ (ایکسj)ک(ایکسمن، ایکس�)= Φ(ایکسمن).Φ(ایکس�)و فضای فرضیه برای SVM با استفاده از یک تابع هسته می تواند به صورت زیر تعریف شود:
جایی که λمن�منضریب لاگرانژ است. بحث بیشتر و دقیق تر در مورد SVM را می توان در [ 44 ] و [ 45 ] یافت. تحلیلهای SVM گزارششده در این مقاله با آنهایی که در یک مطالعه قبلی گزارش شدهاند [ 46 ] متفاوت است، با همه تحلیلها عمدتاً بهگونهای که اطلاعاتی درباره ویژگیهای اضافی، اما قبلاً ثبتنشده، مانند تعداد بردارهای پشتیبانی، بهدست آید.
4.2.3. RVM
RVM، همچنین یک الگوریتم یادگیری ماشین مبتنی بر هسته، بر اساس یک فرمول بیزی از یک مدل خطی با پیشین مناسب است [ 47 ]. RVM یک همتای احتمالی برای SVM در نظر گرفته می شود و به طور موثر به عنوان جایگزینی برای SVM برای طبقه بندی تصاویر سنجش از دور استفاده می شود [ 48 ، 49 ، 50 ]. RVM بر اساس یک پیشین سلسله مراتبی است، که در آن یک پیشین گاوسی مستقل بر روی پارامترهای وزن تعریف می شود و یک پیشین گامای مستقل برای پارامترهای واریانس در سطح اول و دوم به ترتیب استفاده می شود [47 ] . این منجر به یک student-t کلی قبل از پارامترهای وزن می شود، که منجر به یک راه حل پراکنده می شود [ 47]]. توانایی استفاده از هسته های غیر مرسر، خروجی احتمالی و عدم نیاز به تعریف پارامتر تنظیم ( C ) برخی از مزایای کلیدی RVM نسبت به SVM است [ 35 ]. در یک طبقهبندی دو کلاسه توسط RVM، هدف اساساً پیشبینی احتمال بعدی عضویت برای یکی از کلاسها برای یک ورودی داده شده است. سپس ممکن است یک مورد به کلاسی که بیشترین احتمال عضویت در آن را دارد اختصاص داده شود. با استفاده از توزیع برنولی، تابع احتمال برای آنالیز به صورت زیر خواهد بود:
برای به دست آوردن از روش تکراری استفاده می شود p ( y | g ) پ (�|�). اجازه دهید α∗من�من*بیانگر حداکثر تخمین پسینی ابرپارامتر است αمن�من. حداکثر برآورد پسینی وزن ها (gمA P)(�مآپ)می توان با به حداکثر رساندن تابع هدف زیر به دست آورد:
اولین جمله جمع در معادله (5) با احتمال برچسب های کلاس و جمله دوم مربوط به پارامترهای قبلی است. gمن�من. گرادیان تابع f نسبت به g برای حل معادله (5) و فقط موارد آموزشی که ضرایب غیر صفر دارند محاسبه می شود. gمن�منکه بردارهای مرتبط نامیده می شوند، به تولید یک تابع تصمیم کمک می کنند.
یک فرآیند تکراری، که در آن فراپارامترها αمن�منمربوط به هر وزن به روز می شود، برای یافتن مجموعه اوزان با حداکثر کردن مقدار معادله (5) استفاده می شود. در طول فرآیند آموزش RVM، هایپرپارامتر αمن�منبرای تعداد زیادی از موارد تمرینی ارزش بسیار زیادی به دست می آورد و وزن های مربوطه به صفر کاهش می یابد. این فرآیند بیشتر موارد آموزشی را به مشکل طبقه بندی بی ربط می کند و منجر به استفاده از زیر مجموعه ای از موارد آموزشی مفید برای طبقه بندی نهایی می شود. مانند SVM، این موارد آموزشی مفید معمولا غیر معمول هستند، اما بر خلاف SVM، ماهیت ضد مرزی نیز دارند [ 35 ، 47 ]. جزئیات بیشتر در مورد RVM در [ 47 ] ارائه شده است.
4.2.4. SMLR
الگوریتم رگرسیون لجستیک چند جمله ای پراکنده (SMLR؛ [ 51 ]) یک طبقه بندی کننده چند طبقه ای بر اساس رگرسیون لجستیک چند جمله ای است. این طبقهبندیکننده تنک بودن را با استفاده از یک لاپلاسی قبل از وزنهای ترکیب خطی توابع اعمال میکند. قبلی لاپلاسین وزنه های بزرگ کمی را پشتیبانی می کند در حالی که بیشتر وزن های دیگر دقیقاً صفر هستند.
اگر wج�جبردار وزن مربوط به کلاس c است ، پس احتمال اینکه یک مورد آموزشی داده شده x متعلق به کلاس باشد را می توان با
معمولاً از یک روش تخمین حداکثر درستنمایی برای به دست آوردن مولفه های استفاده می شود w�از داده های آموزشی با به حداکثر رساندن تابع log-relihood [ 52 ] تعریف شده به صورت:
برای دستیابی به پراکندگی در طول فرآیند آموزش، SMLR از یک پیشین لاپلاسی استفاده می کند (ل1)(ل1)و برای تخمین w ، از یک معیار حداکثر پسینی (MAP) همانطور که توسط [ 39 ] پیشنهاد شده است استفاده می شود:
جایی که l a p ( w )لآپ(�)یک لاپلاسی قبل از w است و می توان آن را به صورت تعریف کرد l a p ( w ) α e x p ( – β ∥ w ∥1)لآپ(�) � هایکسپ (–� “�“1)، با β�یک پارامتر تعریف شده توسط کاربر که سطح پراکندگی را کنترل می کند. جزئیات بیشتر را می توان در [ 51 ] یافت .
4.3. نتایج و بحث
طبقهبندیهای مبتنی بر مجموعه آموزشی اصلی، که فرض میشد بدون خطا باشد، نشان داد که طبقهبندی SVM (11/89%) کمی دقیقتر از همه طبقهبندیهای دیگر بود. دقت طبقهبندی از تجزیه و تحلیل متمایز، RVM و SMLR به ترتیب 88/88 درصد، 0/88 درصد و 67/88 درصد بود. این نتیجه با بحث های موجود در ادبیات سازگار است و پتانسیل طبقه بندی مبتنی بر SVM را تایید می کند که به طور گسترده در ادبیات گزارش شده است. ماتریس های سردرگمی برای طبقه بندی های به دست آمده با استفاده از مجموعه آموزشی بدون خطا در جدول 2 نشان داده شده است . با این حال، در اینجا تمرکز بر تأثیر موارد آموزشی با برچسب اشتباه بر دقت طبقهبندی است.
طبقه بندی با استفاده از هر مجموعه آموزشی و طبقه بندی انجام شد. دقتی که با آن موارد مجموعه آزمایشی با استفاده از هر طبقهبندیکننده و مجموعه آموزشی طبقهبندی شدند، به ترتیب در جدول 3 و جدول 4 برای سناریوهای مربوط به برچسبگذاری اشتباه به یک کلاس تصادفی و یک کلاس مشابه خلاصه شدهاند. نتایج کلیدی هر یک در ماتریس های سردرگمی برای SVM ( جدول 5 و جدول 6 )، RVM ( جدول 7 و جدول 8 )، SMLR ( جدول 9 و جدول 10 )، و تجزیه و تحلیل متمایز ( جدول 11 و جدول 12 ) خلاصه شده است.
بدیهی است که خطای داده های زمینی، دقت طبقه بندی های به دست آمده از هر طبقه بندی کننده را کاهش می دهد. با این حال، میزان تأثیر بین دو استراتژی مورد استفاده برای برچسب زدن اشتباه موارد آموزشی متفاوت بود. با مجموعههای آموزشی که حاوی مواردی بودند که بهطور تصادفی برچسبگذاری شده بودند، دقت طبقهبندی کمترین کاهش یافت، 1.11٪، برای تجزیه و تحلیل متمایز، و بیشتر، 4.22٪، برای SVM، زیرا مقدار موارد با برچسب اشتباه به 20٪ افزایش یافت. مجموعه آموزشی ( جدول 3 و جدول 5). با SVM، زمانی که تنها 5% و 10% مجموعه آموزشی دارای برچسب اشتباه بودند، تاثیر موارد با برچسب اشتباه بسیار کم بود، اما زمانی که 20% موارد آموزشی به اشتباه برچسبگذاری شدند، دقت کاهش یافت. همچنین مشهود بود که SVM از دقیقترین طبقهبندی زمانی که از دادههای آموزشی بدون خطا استفاده میشد، به کمترین دقت در زمانی که 20 درصد موارد آموزشی به اشتباه برچسبگذاری شده بودند تغییر کرد (جدول 3 ). نتایج نشان میدهد که تجزیه و تحلیل تمایز، که از آمار خلاصه کلی بهدستآمده از موارد آموزشی استفاده میکند، متحملترین مجموعه طبقهبندیکنندههای بررسیشده برای موارد نامگذاری اشتباه بود.
با مجموعههای آموزشی که در آنها موارد به اشتباه به یک کلاس مشابه برچسبگذاری شده بودند، تأثیر برچسبگذاری اشتباه روی طبقهبندیهای هر چهار طبقهبندی بیشتر از زمانی بود که از برچسبهای تصادفی استفاده شده بود. مجدداً دقت طبقهبندیهای بهدستآمده از همه طبقهبندیکنندهها با افزایش نسبت مواردی که در مجموعه آموزشی به اشتباه برچسبگذاری شدهاند، کاهش مییابد و بیشترین تأثیر برای SVM بود ( جدول 4) .). با SVM، دقت تا 8.00% کاهش یافت زیرا درصد مجموعه آموزشی با برچسب اشتباه به 20% افزایش یافت، در حالی که کاهش متناظر برای تجزیه و تحلیل متمایز کمترین میزان در 3.11% بود. علاوه بر این، برای طبقهبندیهای بهدستآمده با مجموعه آموزشی حاوی 20٪ موارد با برچسب اشتباه، دقت طبقهبندی SVM (81.11٪) کمتر از تجزیه و تحلیل متمایز (83.77٪) بود. همانطور که در مورد مواردی که به طور تصادفی برچسب اشتباهی داشتند، SVM از دقیقترین طبقهبندی زمانی که مجموعه آموزشی بدون خطا بود به کمترین طبقهبندی زمانی که 20% موارد آموزشی برچسب اشتباه داشتند تغییر کرد.
نتایج SVM به ویژه با توجه به ادعای قبلی در مورد عدم حساسیت نسبی آن به خطای داده های آموزشی، از اهمیت ویژه ای برخوردار است. شایان ذکر است که وقتی برچسبگذاری نادرست شامل انتخاب کلاس تصادفی بود، تفاوت بین دقت طبقهبندی با نه و با 20% موارد برچسبگذاری اشتباه از نظر آماری معنیدار بود. وقتی برچسبگذاری نادرست شامل کلاسهای مشابه بود، دقت طبقهبندیهای بهدستآمده با موارد آموزشی با برچسب اشتباه 5، 10، و 20 درصد، همه بهطور قابلتوجهی (در سطح اطمینان 95 درصد) با آنچه در زمانی که هیچ مورد با برچسب اشتباهی وجود نداشت، متفاوت بود. این نشان میدهد که SVM به خطای دادههای آموزشی حساس است، بهویژه اگر برچسبگذاری نادرست شامل مواردی باشد که در منطقه مرزی بین کلاس واقعی و برچسب اشتباه قرار دارند. همچنین مشهود بود که اثرات بین کلاسها متفاوت بوده و میتواند نسبتاً بزرگ باشد. به عنوان مثال، دقت تولید کننده برای کلاس چمن از 98.67٪ به 84.00٪ کاهش یافته است، زمانی که 20٪ موارد آموزشی به اشتباه به مشابه ترین کلاس برچسب خورده بودند.جدول 6 ). به طور مشابه، برای کلاس جو دقت از 90.67٪ به 72.00٪ کاهش یافت، زمانی که 20٪ موارد آموزشی به اشتباه به مشابه ترین کلاس برچسب گذاری شدند ( جدول 6) .). این تفاوت در دقت تولیدکننده نیز در سطح اطمینان 95 درصد معنی دار بود. البته باید توجه داشت که وجود موارد آموزشی با برچسب اشتباه گاهی اوقات میتواند دقت طبقهبندی کلاسهای فردی را افزایش دهد، که با SVM برای کلاس گندم مشهود بود، که در زمانی که 20 درصد آموزش، دقت 5.33 درصد افزایش یافت. موارد به اشتباه به مشابه ترین کلاس برچسب گذاری شدند. با توجه به کلاس های فردی، همچنین مشهود بود که وجود موارد آموزشی با برچسب اشتباه باعث حذف و اشتباهات مختلف در طبقه بندی های به دست آمده از چهار طبقه بندی شده است. به عنوان مثال، با SVM بیشترین خطای کمیسیون مربوط به چمن بود (بالاترین کل ردیف را در جدول 5 دارد.) زمانی که خطاها تصادفی بودند اما در گندم زمانی که خطاها با مشابه ترین کلاس بودند ( جدول 6 ). بزرگی خطاهای حذف و کارمزد مرتبط با طبقات بین طبقهبندیهای چهار طبقهبندی متفاوت بود، اگرچه طبقه گندم اغلب با خطاهای کارمزد بالا همراه بود ( جدول 5 ، جدول 6 ، جدول 7 ، جدول 8 ، جدول 9 ، جدول 10) . ، جدول 11 و جدول 12). ارزیابی کاملتر از تأثیرات این خطاها بر روی نقشههای پوشش زمین باید نمونه طبقهبندیشده مورد استفاده در تشکیل ماتریسهای سردرگمی را در نظر بگیرد، زیرا کلاسها در واقع به وفور در محل آزمایش متفاوت هستند. به طور اساسی، اثرات موارد آموزشی با برچسب اشتباه بین طبقه بندی ها متفاوت است، با طبقه بندی کننده و نوع خطا متفاوت است، و از این رو تأثیرات به نیازهای کاربر نهایی خاص بستگی دارد.
همچنین مشهود بود که تعداد بردارهای پشتیبانی مورد استفاده در طبقهبندیها با نسبت موارد آموزشی با برچسب اشتباه افزایش مییابد. در طبقه بندی با داده های آموزشی بدون خطا، در مجموع از 203 بردار پشتیبانی استفاده شد. بنابراین، این SVM تنها از یک سوم داده های آموزشی موجود استفاده می کند. با این حال، تعداد بردارهای پشتیبانی استفاده شده به ترتیب به 218، 236 و 266 برای طبقهبندی با استفاده از مجموعههای آموزشی حاوی موارد 5، 10 و 20 درصد بهطور تصادفی با برچسب اشتباه افزایش یافت. با برچسب گذاری اشتباه موارد آموزشی به یک کلاس مشابه، تعداد بردارهای پشتیبانی کمتر افزایش یافت و به 218 مورد رسید، در حالی که درصد موارد برچسب گذاری اشتباه 20٪ بود. بنابراین، برچسب زدن اشتباه نه تنها به طور کلی برای کاهش دقت طبقه بندی عمل می کند. نیاز به افزایش بردارهای پشتیبانی داشت، اندکی پتانسیل طبقه بندی دقیق از مجموعه های آموزشی کوچک را کاهش می دهد. بدیهی است که طبقهبندیهای RVM و SMLR از موارد آموزشی کمتری استفاده میکنند: معمولاً فقط 98-36 مورد آموزشی مورد نیاز است. علاوه بر این، تعداد موارد آموزشی مورد استفاده گاهی اوقات با درصد بیشتری از موارد با برچسب اشتباه کمتر بود، به ویژه برای RVM.
نتایج نشان میدهد که طبقهبندی توسط SVM، بر خلاف برخی پیشنهادات در ادبیات (به عنوان مثال، [ 30 ])، به خطای برچسبگذاری اشتباه حساس است، در واقع بیشتر از یک طبقهبندی آماری معمولی مانند تجزیه و تحلیل متمایز. در اینجا، باید تاکید کرد که تفاوت اصلی در نتیجه گیری با سایر کارها به این دلیل است که تمرکز در اینجا بر روی برچسب گذاری نادرست موارد در مناطق مرزی فضای ویژگی است که معمولاً بردارهای پشتیبانی از آن استخراج می شوند. با این حال، این تمرکز به ویژه در صورتی مهم است که به دنبال بهرهبرداری از پتانسیل طبقهبندی دقیق توسط یک SVM با مجموعههای آموزشی کوچک بهعنوان مفیدترین موارد آموزشی از مناطق مرزی باشد [32 ، 35 ]]. اگر مجموعههای آموزشی کوچک متمرکز بر بردارهای حمایت نامزد به طور مؤثر در تحلیلها استفاده شوند، بدیهی است که از برچسبگذاری نادرست باید اجتناب شود تا تأثیر منفی بر دقت طبقهبندی حاصل نداشته باشد. این موضوع به ویژه مهم است زیرا مواردی که در فضای ویژگی نزدیک به هم قرار دارند اما متعلق به طبقات مختلف هستند ممکن است شباهت هایی داشته باشند که می تواند منجر به برچسب زدن اشتباه شود (به عنوان مثال، طبقاتی از پوشش گیاهی که بر اساس متغیری مانند درصد پوشش تاج پوشش تعریف می شوند). همچنین توجه داشته باشید که نتایج برای SVM مشابه نتایج گزارش شده در [ 46 ] بود، که در آن پارامترهای الگوریتم برای هر تحلیل بهینه شده بودند و بنابراین تابعی از رویکرد اتخاذ شده در اینجا نیستند.
5. نتیجه گیری ها
مجموعه داده های مرجع مورد استفاده در تولید نقشه معمولاً به نوعی ناقص هستند. در این مقاله تاکید شده است که دادههای مرجع ممکن است ماهیت ناهمگونی در رابطه با موضوعاتی مانند تلاش نمونهگیری داشته باشند و ممکن است حاوی خطاهایی مانند برچسبگذاری اشتباه باشند. می توان انتظار داشت که این نواقص تأثیر منفی بر پروژه نقشه برداری داشته باشد. این به ویژه در مورد استفاده از طبقه بندی کننده های معاصر مانند تکنیک های یادگیری ماشین مانند SVM صادق است. برای مثال، نمونههای آموزشی نامتعادل میتوانند بر SVM تأثیر بگذارند، اما اگر ماهیت نمونههای کمکشده به یک مجموعه داده مرجع شناخته شده باشد، ممکن است مشکل کاهش یابد. نامگذاری اشتباه پیشنهاد شده است که موضوع کمتری باشد (به عنوان مثال، [ 30])، اما در اینجا تمرکز خاصی داده شد. در اینجا، نشان داده شد که کیفیت مجموعه دادهها، از نظر دقت برچسبگذاری طبقاتی، در تولید نقشههای پوشش زمین از دادههای سنجش از دور مهم است. دادههای آموزشی اغلب به گونهای استفاده میشوند که گویی بدون خطا، اما بعید است که چنین باشد. خطا ممکن است از منابع مختلفی ناشی شود، نه فقط از خطاهای ساده و تصادفی. در بسیاری از موارد خطا ممکن است شامل کلاس های نسبتا مشابه باشد و در ناحیه مرزی بین کلاس ها در فضای ویژگی متمرکز شود. نشان داده شد که موارد آموزشی با برچسب نادرست که از مکانهای مرزی کشیده شدهاند، میتوانند دقت طبقهبندیکنندههای تصویری نظارتشده بهطور گسترده مورد استفاده را کاهش دهند. به طور خاص، مشهود بود که بزرگی اثر تابعی از تعداد موارد برچسبگذاری نادرست، ماهیت برچسبگذاری اشتباه، و طبقهبندیکننده استفادهشده است.
به طور بحرانی، نتایج ارائه شده نشان میدهد که SVM، بر خلاف برخی بحثها در ادبیات، به موارد آموزشی برچسبگذاری نادرست حساس است، که نیاز به در نظر گرفتن تأثیر کیفیت دادههای آموزشی بر طبقهبندی توسط SVM را برجسته میکند. نتایج کلیدی ناشی از نتایج تحلیل های انجام شده عبارت بودند از:
-
دادههای آموزشی برچسبگذاری نادرست معمولاً دقت طبقهبندی تصویر و بهویژه برای SVM را کاهش میدهند.
-
اثرات آموزش با برچسب غلط زمانی بیشتر بود که برچسب گذاری اشتباه در یک کلاس مشابه بود تا کلاسی که به طور تصادفی انتخاب شده بود.
-
اثرات خطای داده های آموزشی بین کلاس های درگیر متفاوت بود.
-
تعداد بردارهای پشتیبانی مورد نیاز برای یک طبقه بندی با خطای داده های آموزشی افزایش یافت.
-
SVM از دقیقترین به کمترین دقت در بین چهار طبقهبندیکننده بررسیشده تغییر کرد زیرا خطای دادههای آموزشی از 0٪ به 20٪ افزایش یافت.
با آگاهی از کیفیت دادههای آموزشی، باید امکان تنظیم تجزیه و تحلیل طبقهبندی برای کاهش اثرات منفی مرتبط با موارد برچسبگذاری نادرست وجود داشته باشد. برای مثال، اگر نگرانیهایی در مورد موارد آموزشی نسبتاً شدید طیفی وجود داشته باشد که در ناحیه مرزی بین کلاسها در فضای ویژگی وجود داشته باشد (مثلاً ممکن است شباهت واقعی بین موارد روی زمین وجود داشته باشد، زیرا آنها با یکدیگر در سطح هستند و بنابراین طیفی نیز هستند. مشابه)، در برخی موارد میتوان این موارد را نادیده گرفت یا میتوانیم از طبقهبندیکنندهای استفاده کنیم که بر اساس توصیف کلی کلاسها باشد و بنابراین کمتر تحت تأثیر موارد آموزشی فردی باشد.




بدون نظر