

خلاصه
تغییر تنوع زیستی جهانی نیاز به روش های نظارت استاندارد را ایجاد می کند. مدلسازی و نقشهبرداری الگوهای فضایی ترکیب جامعه با استفاده از دادههای سنجش از راه دور با ابعاد بالا، نیازمند روشهای مناسب برای چنین مجموعههای دادهای است. مدلسازی عدم تشابه تعمیمیافته پراکنده برای مقابله با مجموعه دادههای با ابعاد بالا، مانند دادههای سنجش از دور سری زمانی یا فراطیفی طراحی شده است. در این دست نوشته ما sgdm را ارائه می دهیمیک بسته R برای انجام مدلسازی عدم تشابه تعمیمیافته پراکنده (SGDM). این بسته شامل برخی ابزارهای کلی است که هم به مدلسازی عدم تشابه تعمیمیافته و هم به مدلسازی عدم شباهت تعمیمیافته پراکنده، قابلیتهایی را اضافه میکند. همچنین شامل یک مجموعه داده نمونه است که امکان استفاده از SGDM را برای نقشه برداری از الگوهای فضایی جوامع درختی در منطقه ای از پوشش گیاهی طبیعی در سرادوی برزیل فراهم می کند.
کلید واژه ها:
درختان سرادو ; گردش مالی جامعه ؛ داده های با ابعاد بالا ؛ سنجش از دور فراطیفی ; مدلسازی عدم تشابه تعمیم یافته ; تجزیه و تحلیل مولفه های متعارف پراکنده ; بسته R
1. معرفی
تغییر تنوع زیستی جهانی ممکن است منجر به کاهش و تغییر در عملکرد اکوسیستم و ارائه خدمات شود [ 1 ]، که نیاز به روشهای استاندارد شده را نشان میدهد که قادر به استخراج اطلاعات مفید از مشاهدات بیولوژیکی درجا برای استفاده از نظارت بر تنوع زیستی جهانی است [ 2 ، 3 ]. به طور خاص، توصیف ترکیب و گردش جامعه گونه ها بسیار مرتبط است، زیرا آنها مستقیماً به عملکرد اکوسیستم مربوط می شوند [ 4 ، 5]]. مدلسازی تنوع زیستی در سطح جامعه دارای چندین مزیت در رابطه با مدلسازی گونههای فردی است، زیرا امکان ترکیب گونههای کمیاب را از طریق تشخیص الگوهای مشترک واکنشهای محیطی در بین گونهها فراهم میکند، در حالی که به طور مستقیم ترکیب و گردش جامعه را پیشبینی میکند [6 ، 7 ] . علاوه بر این، از مشکلات انباشتن مدلهای گونههای فردی با قدرتهای توضیحی متفاوت، که به طور کلی منجر به استنتاج مغرضانه میشود، اجتناب میکند [ 8 ]. دو رویکرد اصلی مورد استفاده برای مدلسازی جوامع گونهها، رویکردهایی هستند که بر اساس ترتیب دادهها، مانند تجزیه و تحلیل همبستگی متعارف [ 5 ]، یا از طریق معیارهای عدم تشابه [ 9 ، 10] است.]. مدلسازی عدم تشابه تعمیم یافته (GDM) یک تکنیک آماری مبتنی بر عدم تشابه به خوبی تثبیت شده برای تجزیه و تحلیل و پیش بینی تغییرات بیولوژیکی به عنوان تابعی از محیط است [ 10 ]. این به طور خاص به عدم شباهت در ترکیب یک جامعه بیولوژیکی (به عنوان مثال، تفاوت در گونه ها یا صفات) بین جفت مکان ها با تفاوت های محیطی مربوطه که توسط پیش بینی ها توضیح داده شده است، مربوط می شود. این از طریق یک ترکیب خطی از توابع پایه I-Spline (یکنواخت) انجام می شود، با این فرض که افزایش جدایی مکان ها در امتداد یک گرادیان محیطی تنها می تواند منجر به افزایش عدم تشابه ترکیبی شود [10 ]]. پیشبینیهای عدم تشابه تولید شده توسط GDM را میتوان برای تجسم الگوی فضایی در تغییر ترکیبی جامعه از طریق ترتیببندی غیرخطی بعدی استفاده کرد. بنابراین GDM ابزار مفیدی برای ارزیابی تغییرات تنوع زیستی در مناطق وسیع است، اگرچه پتانسیل آن برای استفاده گسترده بستگی به در دسترس بودن دادههای زیست محیطی با کیفیت بالا استاندارد دارد.
داده های سنجش از دور به ویژه برای توصیف جهانی و سیستماتیک فرآیندهای اکولوژیکی و محیط مناسب هستند [ 11 ، 12 ]. محصولات داده سنجش از دور، مانند سریهای زمانی طولانی دادههای ماهوارهای نوری، یا تصاویر فراطیفی فضایی، امکان توصیف سطح زمین را با کیفیت و جزئیات بیسابقهای فراهم میکنند [13 ، 14 ] . این به بوم شناسان فرصت های بزرگی برای استفاده از آنها در ارزیابی های تنوع زیستی می دهد [ 15 ، 16 ]. با این حال، انتخاب متغیرهای سنجش از دور مناسب برای مدلسازی تنوع زیستی، حوزهای از تحقیقات در حال انجام است [ 17]]. در حالی که استفاده از اطلاعات مستمر سنجش از دور، مانند شاخص های طیفی یا داده های سری زمانی، برای توصیف توزیع گونه ها مفید است [ 18 ، 19 ]، ماهیت بسیار بعدی (و بالقوه چند خطی) این داده ها چالش هایی را برای تجزیه و تحلیل [ 20 ]، که معمولاً منجر به از دست دادن عملکرد مدل و تعمیم می شود.
اخیراً یک پیشرفت روششناختی ایجاد شده است که امکان برازش دادههای با ابعاد بالا در GDM را فراهم میکند. این افزایش، مدلسازی عدم تشابه تعمیمیافته پراکنده (SGDM) [ 21 ] نامیده میشود و یک رویکرد دو مرحلهای است که شامل کاهش اولیه دادههای محیطی (یعنی متغیرهای پیشبینیکننده) با استفاده از تحلیل همبستگی متعارف پراکنده (SCCA) است [22] .]، و سپس برازش فضای محیطی تبدیل شده با یک مدل GDM. SCCA شکلی از تجزیه و تحلیل همبستگی متعارف جریمهشده است، بنابراین ماتریس دادههای بیولوژیکی و محیطی را به منظور به حداکثر رساندن همبستگی بین هر دو تغییر میدهد. جریمه در SCCA از طریق تابع جریمه L1 (کند) انجام می شود که برای مقابله با مجموعه داده های چند بعدی و چند خطی طراحی شده است [ 23 ، 24]. SCCA داده های با ابعاد بالا را کاهش می دهد در حالی که به طور همزمان امکان استخراج اطلاعات محیطی مربوط به تنوع داده های جامعه را فراهم می کند. برای اجرای یک SCCA، لازم است پارامتر جریمه برای هر یک از ماتریس های داده های محیطی و جامعه اعمال شود. در SGDM، پارامترسازی به روش جستجوی شبکه اکتشافی انجام میشود، به منظور به حداقل رساندن باقیماندهها (به شکل خطای میانگین مربعات ریشه اعتبار متقابل؛ RMSE) در تفاوتهای پیشبینیشده یک مدل GDM [21 ] .
SGDM برای انجام مدلسازی عدم تشابه تعمیمیافته با دادههای سنجش از دور با ابعاد بالا مفید است [ 21 ]. در حالی که رویکرد مدلسازی GDM در بسته gdm R پیادهسازی شده و از مخزن CRAN در دسترس است [ 25 ، 26 ]، هنوز هیچ پیادهسازی SGDM در دسترس بومشناسان و محققان محیطزیست وجود ندارد. در زمان افزایش دسترسی به دادههای سنجش از دور، و در نتیجه افزایش ابعاد، بسیار مهم است که ابزارهای مفیدی که قادر به مقابله با این دادهها هستند در دسترس جامعه اکولوژیستهای جهانی باشد. در مقاله فعلی، هدف ما پر کردن این شکاف و ارائه sgdm استیک بسته R برای انجام مدلسازی عدم تشابه تعمیمیافته پراکنده، شامل برخی ابزارهای اضافی مناسب برای SGDM و GDM.
2. توضیحات بسته کلی sgdm
بسته sgdm از GitHub ( https://github.com/sparsegdm/sgdm_package ) در دسترس است و برای اجرا به نصب چند بسته R دیگر بستگی دارد. یعنی به بسته gdm [ 25 ] برای اجرای مدل GDM، بسته PMA [ 27 ] برای اجرای SCCA، و بسته گیاهخواری [ 28 ] برای چندین عملیات داخلی نیاز دارد. توابع برای نگاشت صریح فضایی نتایج مدل بیشتر به نصب بسته های رستر [ 29 ] و yalmpute [ 30 ] نیاز دارند. sgdm _بسته را می توان مستقیماً با استفاده از دستورات زیر در R نصب و بارگذاری کرد:
-
R> # نصب بسته از GitHub
-
R> devtools::install_github(“sparsegdm/sgdm_package”)
-
R> در حال بارگیری بسته
-
R> کتابخانه (sgdm)
این بسته شامل نه تابع و سه مجموعه داده نمونه است. در شکل 1 ما تمام توابع و مجموعه داده ها و همچنین یک گردش کار ممکن برای استخراج یک نقشه شطرنجی از جوامع درختی Cerrado را بر اساس مجموعه داده های نمونه ارائه می کنیم.
مجموعه داده های ارائه شده با بسته شامل یک مجموعه داده بیولوژیکی و یک مجموعه داده پیش بینی کننده (هر دو به عنوان چارچوب داده)، و همچنین یک نقشه پیش بینی به عنوان شی شطرنجی ( شکل 2 ) است. مجموعه داده بیولوژیکی درختان از 30 مشاهده با مقادیر فراوانی برای 48 خانواده درختی مختلف در منطقه ای از پوشش گیاهی طبیعی در سرادوی برزیل تشکیل شده است. طیف _مجموعه داده پیشبینیکننده از همان 30 مشاهدات تشکیل شده است، با مقادیر بازتاب برای 83 باند طیفی باریک که بخشهای مادون قرمز مرئی، نزدیک و موج کوتاه طیف الکترومغناطیسی را پوشش میدهند. این طیف ها از تصاویر فراطیفی هایپریون فضایی که در 27 ژوئن 2014 پس از پیش پردازش و غربالگری با کیفیت به دست آمد، استخراج شده اند. هر دو مجموعه داده شامل یک ستون ID و دومی نیز شامل دو ستون مختصات جغرافیایی (X و Y) است. نقشه پیشبینی تصویر طیفی زیرمجموعهای (100 × 100 پیکسل) از تصویر Hyperion مربوطه را تشکیل میدهد.
3. اجرای یک مدل SGDM در بسته sgdm
برای اجرای یک مدل SGDM در بسته sgdm ، لازم است SCCA داخلی را پارامتر کنیم، که شامل تعریف مقادیر جریمه برای اعمال تبدیل متعارف مبتنی بر کمند برای ماتریسهای بیولوژیکی و محیطی است. این کار از طریق جستجوی شبکه اکتشافی با آزمایش ترکیبی از جفت پارامترها با استفاده از تابع sgdm.param انجام می شود . در جستجوی شبکه، تمام جفتهای پارامتر ممکن در یک اعتبارسنجی متقابل پنج برابری آزمایش میشوند و با حداقل کردن ریشه میانگین مربعات خطا (RMSE) بین تفاوتهای پیشبینیشده و مشاهدهشده بین جفتهای نمونه بهینهسازی میشوند. مقادیر جریمه مورد آزمایش می تواند از 0 (جریمه قوی) تا 1 (جریمه ضعیف) متغیر باشد. همانطور که توسط Leitão و همکاران توضیح داده شده است. [ 21]، از سطوح بالای جریمه (مقادیر جریمه پایین) باید اجتناب شود تا از ارتباط قوی بین پیش بینی تبدیل شده و داده های بیولوژیکی اطمینان حاصل شود. به دنبال این توصیه، مقادیر جریمه پیشفرض (برای هر دو ماتریس داده) در بسته sgdm از 0.6 تا 1 در مراحل 0.1 متغیر است، اگرچه این مقادیر را میتوان به صورت دستی پیکربندی کرد تا بهتر با نیازهای کاربر مطابقت داشته باشد (برای مثال، مجموعه دادههایی با ابعاد بالاتر ممکن است به سطوح بالاتری از مجازات نیاز دارند). تابع sgdm.param همچنین به تعریف تعداد مؤلفه هایی که باید در SCCA استخراج شوند، متریک فاصله مورد استفاده در مدل های GDM و استفاده اختیاری از فاصله جغرافیایی به عنوان متغیر در مدل GDM نیاز دارد. همانطور که در شرح روش پیشنهاد شده است [ 21]، در ابتدا باید از حداکثر تعداد ممکن اجزا (یعنی تعداد نمونه) استفاده شود تا بعداً به مقادیر معنی دار آماری کاهش یابد. اگرچه این گزینه در اینجا موجود است، استفاده از فاصله جغرافیایی به عنوان یک متغیر با SGDM آزمایش نشده باقی می ماند. توجه داشته باشید که اجرای فعلی این تابع فقط به دادههای فراوانی بیولوژیکی اجازه میدهد که به عنوان فرمت 1 در بسته gdm [ 25 ] توضیح داده شده است. تابع پارامترسازی مدل SGDM توسط:
-
R> # SGDM را پارامتر کنید
-
R> sgdm.gs <− sgdm.param(predData = طیف، bioData = درختان، k = 30)
تابع sgdm.param یک ماتریس عملکرد با مقادیر RMSE برای هر جفت پارامتر تست شده در مدل SGDM ارائه می دهد ( شکل 3 ). در این مورد، بهترین مدل مربوط به استفاده از مقدار جریمه 0.7 در هر دو ماتریس زیستمحیطی و بیولوژیکی است که منجر به مقدار RMSE 0.114 میشود.
برای اجرای بهترین مدل SGDM (به دنبال مرحله پارامترسازی)، این ماتریس می تواند به تابع sgdm.best وارد شود :
-
R> # بازیابی و ساخت بهترین مدل SGDM
-
R> sgdm.model <− sgdm.best (perf.matrix = sgdm.gs، predData = طیف، bioData = درختان، خروجی = ”m”، k = 30)
مرحله قبلی یک مدل GDM با 30 متغیر پیشبینیکننده، یعنی 30 مؤلفه متعارف تولید شده در SCCA (با مقادیر جریمه 0.7 برای هر دو ماتریس) ایجاد کرد و 73.36٪ از انحراف (مطابق با عملکرد برازش مدل) را توضیح داد. با بررسی مدل GDM (با تابع summary.gdm بسته gdm )، می توان تأیید کرد که هر متغیر پیش بینی کننده به طور مؤثر در مدل استفاده نشده است. در واقع، در مثال داده شده، تنها 12 متغیر حداقل یک ضریب غیر صفر داشتند.
از طرف دیگر، تابع sgdm.best همچنین به کاربر این امکان را می دهد که اجزای متعارف پراکنده یا بردارهای متعارف مربوطه را با تنظیم آرگومان خروجی به ترتیب روی ” c ” یا ” v ” بازیابی کند. کد زیر کد لازم برای بازیابی مولفه ها و بردارهای متعارف پراکنده حاصل را با استفاده از داده های مثال نشان می دهد:
-
R> # بازیابی اجزای متعارف پراکنده مربوط به بهترین مدل GDM
-
R> sgdm.sccbest <− sgdm.best(perf.matrix = sgdm.gs، predData = طیف، bioData = درختان، خروجی = ”c”، k = 30)
-
R> # بازیابی بردارهای متعارف پراکنده مربوط به بهترین مدل GDM
-
R> sgdm.vbest <− sgdm.best(perf.matrix = sgdm.gs، predData = طیف، bioData = درختان، خروجی = ”v”، k = 30)
تبدیل متعارف انتخاب شده همچنین می تواند در نقشه پیش بینی اعمال شود تا امکان پیش بینی فضایی مدل SGDM فراهم شود. این کار را می توان با تابع predData.transform ، مطابق شکل زیر انجام داد.
-
R> # اعمال تبدیل SCCA بر روی نقشه پیش بینی
-
R> component.image <− predData.transform(predData = spectral.image, v = sgdm.vbest)
مراحل زیر از رویکرد SGDM به ساده سازی مدل به دنبال آزمون معناداری [ 21 ] مربوط می شود. توابع ارائه شده برای انجام این کار مختص SGDM نیستند، بلکه به طور کلی برای GDM مفید هستند.
4. ابزارهای اضافی مفید برای GDM و SGDM
علاوه بر توابع خاص که در بالا توضیح داده شد، بسته sgdm همچنین برخی از توابع کلی را ارائه می دهد که عملکرد را به SGDM و GDM اضافه می کند. سهم افت متغیر یک مدل GDM را می توان از طریق تابع gdm.varcont محاسبه کرد، که هر متغیر منفرد را به یکباره حذف می کند و ضرر مربوطه را در انحراف مدل محاسبه می کند. اهمیت مشارکتهای متغیر را میتوان با تابع gdm.varsig بررسی کرد ، زیرا اینها در برابر تصادفی بودن از طریق جایگشتهای ماتریس دادههای بیولوژیکی آزمایش میشوند [ 10 ]. سطح معنی داری که مشارکت های متغیر در آن آزمایش می شوند، روی p تنظیم می شود< 0.05 در هر پیش فرض، اگرچه می توان آن را به صورت دستی تعریف کرد. این تابع یک بردار با طول یکسان با تعداد متغیرها ارائه میکند، با مقادیر منطقی که نشان میدهد آیا سهم متغیرها قابل توجه است یا خیر—همه متغیرهای بدون مشارکت به طور خودکار به عنوان غیر معنیدار اختصاص داده میشوند. پس از آزمون معناداری، مدل ها را می توان با حذف متغیرهای غیر معنی دار با استفاده از تابع data.reduce ساده کرد . کد زیر نمونهای از مشارکت متغیرها و بررسیهای معنیداری است، و به دنبال آن متغیرهای غیر مهم حذف میشوند و مدل نهایی (کاهششده) با استفاده از دادههای نمونه بازیابی میشود.
-
R> # ترکیب جفت دادههای سایت برای بررسی سهم متغیر مدل GDM
-
R> spData.sccbest <− gdm:: formatsitepair(bioData = درختان، bioFormat = 1، dist = “bray”، فراوانی = TRUE، siteColumn = “Plot_ID”، XColumn = “X”، YColumn = “Y”، predData = sgdm.sccbest)
-
R> # بررسی سهم افت متغیر SGDM
-
R> gdm.varcont(spData = spData.sccbest)
-
R> # بررسی اهمیت مشارکت های متغیر
-
R> sigtest.sgdm <− gdm.varsig(predData = sgdm.sccbest، bioData = درختان)
-
R> # به استثنای متغیرهای غیر معنی دار
-
R> sgdm.sccbest.red <− data.reduce(data = sgdm.sccbest، datatype = “pred”، sigtest = sigtest.sgdm)
-
R> # ترکیب جفت داده های سایت برای ورودی در GDM
-
R> spData.sccbest.red <− gdm:: formatsitepair(bioData = درختان، bioFormat = 1، dist = “bray”، فراوانی = TRUE، siteColumn = “Plot_ID”، XColumn = “X”، YColumn = “Y”، predData = sgdm.sccbest.red)
-
R> # مدل نهایی SGDM
-
R> sgdm.model.red <− gdm:: gdm(data = spData.sccbest.red)
در این مورد، کاهش مدل منجر به یک مدل نهایی GDM با شش متغیر پیشبینی میشود که 70.09 درصد از انحراف را در دادهها توضیح میدهد. مدل برازش شده و I-splines مربوطه را می توان با استفاده از تابع plot.gdm بسته gdm رسم کرد ( شکل 4 ).
برای بازرسی بیشتر از نتایج مدل نهایی، تفاوت های پیش بینی شده را می توان در برابر تفاوت های مشاهده شده بین تمام جفت های سایت رسم کرد ( شکل 5 ). این بینش خوبی در مورد توزیع مقادیر عدم تشابه و همچنین پیشبینیهای مدل میدهد.
این بسته همچنین شامل دو قابلیت برای اعتبارسنجی مدل GDM است. یعنی تابع gdm.cv که اعتبارسنجی متقابل مدل n برابری را انجام میدهد و تابع gdm.validate که اعتبار مدل را با استفاده از یک مجموعه داده مستقل انجام میدهد. این تابع می تواند هم RMSE و هم r-square (محاسبه شده بر اساس مجذور ضریب همبستگی پیرسون) را محاسبه کند. به عنوان مثال، اعتبارسنجی متقابل GDM را می توان با استفاده از موارد زیر انجام داد:
-
R> # 10 برابر اعتبار متقابل مدل نهایی SGDM
-
R> gdm.cv(spData = spData.sccabest.red، nfolds = 10، عملکرد = “r2”)
در این مثال، مدل نهایی (کاهش یافته) یک r مربع اعتبار متقاطع 64.34٪ ارائه کرد. از سوی دیگر، با مقایسه آن با یک مدل GDM ساخته شده با باندهای طیفی اصلی (4 از 83؛ بدون تبدیل قبلی SCCA)، می توان مشاهده کرد که دومی منجر به عملکرد تایید متقابل ضعیف تری می شود (r -مربع 53.38٪.
الگوهای ترکیب اصلی جامعه را می توان در امتداد محورهای اصلی تغییر بین تفاوت های پیش بینی شده بین همه جفت سایت ها از طریق اعمال تبدیل مقیاس بندی چند بعدی غیر متریک (NMDS) ترسیم کرد [10 ] . این تبدیل در تابع gdm.map بسته sgdm پیاده سازی شده است که از تابع monoMDS پیاده سازی شده در بسته وگان استفاده می کند . این نیاز به تعریف تعداد محورهای NMDS برای استخراج دارد، که می تواند به صورت دستی یا خودکار بر اساس مقادیر تنش NMDS انجام شود [ 31 ]:
-
R> # ترکیب جامعه نقشه برداری
-
R> map.sitepairs <− gdm.map(spData = spData.sccabest.red، model = sgdm.model.red)
در این مثال، تعداد مؤلفههای NMDS بهطور خودکار تنظیم شد (با استفاده از آستانه مقدار تنش پیشفرض 0.1)، که منجر به هشت مؤلفه شد. این هشت مولفه بیشتر واریانس در ساختار جامعه درختی موجود در منطقه مورد مطالعه را خلاصه کردند.
پیشبینیهای مدل را میتوان به کل منطقه مورد مطالعه تعمیم داد، همانطور که توسط نقشه پیشبینیکننده توضیح داده شده است. از آنجایی که اجرای یک NMDS بر روی تفاوتهای بین تمام جفتهای ممکن پیکسلهای تصویر [ 10 ] غیرممکن است، میتوان پیکسلها را از جفتهای نمونه از طریق یک knn-imputation به محورهای NMDS اختصاص داد [ 32 ]. این امر مستلزم کاهش نقشه مؤلفه متعارف (به دست آمده از تابع predData.transform ) به اجزای مهم با استفاده از تابع data.reduce است . در نهایت، هنگامی که یک تصویر پیشبینی (مثلاً نقشه مولفههای مهم) را به عنوان آرگومان در gdm.map اضافه کنید .تابع، این پیکسل های تصویر را در امتداد محورهای NMDS، همانطور که برای جفت های نمونه محاسبه می شود، اختصاص می دهد. این روش منجر به نقشه برداری فضایی صریح از الگوهای ترکیب جامعه در سراسر منطقه مورد مطالعه می شود. یک مثال نقشه برداری در زیر آورده شده است:
-
R> # کاهش نقشه مؤلفه متعارف به مؤلفه های مهم
-
R> component.image.red <− data.reduce(data = component.image، datatype = “pred”، igtest = sigtest.sgdm)
-
R> # نگاشت ترکیب جامعه در فضا
-
R> map.image <− gdm.map(spData = spData.sccabest.red، predMap = component.image.red، model = sgdm.model.red، k = 8)
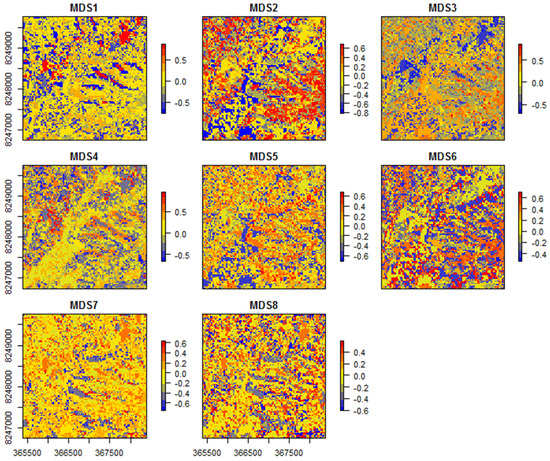
در این مثال آخر، الگوهای اصلی انتقال جامعه، مطابق با هشت دستور NMDS پیشبینیهای مدل SGDM ترسیم شدهاند ( شکل 6 ).
با بررسی نقشه های حاصل می توان مشاهده کرد که جنبه های مختلف انتقال جامعه توسط محورهای مختلف NMDS به تصویر کشیده شده است. به عنوان مثال، محور اول بیشتر نشان دهنده گردش گونه ها در مناطق معمولی ساوانا (آبی به قرمز) است، در حالی که محور دوم بیشتر نشان دهنده گردش بین مناطق جنگلی (آبی) و ساوانا (قرمز) است. با این حال، محور سوم عمدتاً چرخش گونهها را بین سازندهای ساوانای پراکنده (آبی) و متراکمتر (قرمز) نشان میدهد – این استنتاج را میتوان برای همه محورهای حاصل انجام داد. بررسی متقاطع محورهای NDMS حاصل با جامعه گونه های مربوطه (برای نمونه ها) بینش های بیشتری را برای استنتاج معقول الگوهای فضایی مدل شده ارائه می دهد. در این مطالعه موردی، تنوع طبقهبندی بالای درخت Cerrado در تعداد نسبتاً زیادی محورهای NMDS حاصل به خوبی نشان داده شده است.
5. بحث
بسته sgdm امکان استفاده از دادههای با ابعاد بالا، مانند دادههای سنجش از دور فراطیفی یا سری زمانی، را در چارچوب مدلسازی GDM برای نقشهبرداری الگوهای فضایی جوامع گونهای در مناطق بزرگ فراهم میکند . در واقع، در مطالعه موردی نشاندادهشده، ما از یک تصویر فراطیفی از سنسور ماهوارهای Hyperion برای نقشهبرداری موفقیتآمیز انتقال جامعه درختی در سرادو برزیل استفاده کردیم. مدل حاصل شامل شش متغیر مهم (مولفههای متعارف) بود که از 83 باند طیفی اصلی متراکم شدند و در نتیجه منجر به بهبود قابلتوجهی در عملکرد مدل پیشبینیکننده (متقابل تایید شده) مربوطه شد.
بر خلاف خود مدل GDM (که قطعی است)، رویکرد SGDM یک رویکرد احتمالی است، زیرا پارامترسازی آن به جستجوی شبکه اکتشافی بر اساس یک روش اعتبار سنجی متقابل بستگی دارد [21 ] . این به این معنی است که چندین اجرا از مدل SGDM بر روی دادههای یکسان ممکن است به پارامترهای مدل کمی متفاوت منجر شود، با عملکردهای مدل متفاوت و الگوهای پیشبینیشده، که ممکن است باعث بیثباتی در پارامترسازی مدل شود. ما دریافتیم که با تنظیم پارامترهای پیشفرض روی جریمهسازی متوسط تا ضعیف (از 0.6 تا 1)، همانطور که در شرح روش توصیه میشود [ 21]]، انتخاب پارامتر به دست آمده قوی بود. با این حال، این موضوع به طور عمیق مورد تجزیه و تحلیل قرار نگرفته است و نیاز به تحقیقات بیشتری دارد. علاوه بر این، بهترین جفت پارامتر جریمه کاملاً به دادهها وابسته است و جفتهای پارامتر کاندید برای آزمایش در جستجوی شبکه ممکن است نیاز به تطبیق با مجموعه دادههای مورد استفاده داشته باشند. در واقع، مجموعه دادههایی با ابعاد بسیار بالا ممکن است به سطوح بالاتری از جریمه (مقادیر پارامتر پایینتر) نسبت به آنهایی با ابعاد پایینتر نیاز داشته باشند.
نگاشت الگوهای فضایی ترکیب جامعه با استفاده از یک تصویر طیفی بر روی یک منطقه جغرافیایی بزرگ ساده و سرراست نیست. در حالت ایدهآل، تفاوتهای بین تمام جفتهای پیکسل تصویر از مدل GDM یا SGDM پیشبینی میشود و سپس با استفاده از NMDS تبدیل میشود. با این حال، برای مناطق بزرگ (یعنی میلیون ها پیکسل) این مراحل به دلیل منابع محاسباتی مورد نیاز غیرممکن است [ 10 ، 21 ]. در اجرای بسته فعلی یک رویکرد جایگزین پیشنهاد شد، که در آن پیکسلهای تصویر از طریق یک رویکرد انتساب نزدیکترین همسایه به محورهای NMDS اختصاص داده میشوند [ 32]. این نقشه ای از پیکسل ها با جوامع مشابه ارائه می دهد که گردش جامعه را در فضا، با شرایط محیطی متفاوت نشان می دهد. یک رویکرد جایگزین، که در حال حاضر در بسته sgdm پیادهسازی نشده است ، بازگشت به رویکرد رگرسیون برای تخصیص پیکسلهای تصویر در امتداد محورهای NMDS است.
6. نتیجه گیری
بسته ارائه شده در این مطالعه یک پیاده سازی در حال اجرا از رویکرد روش شناختی SGDM است و به صورت آنلاین (در GitHub) تحت مجوز Creative Commons برای استفاده عمومی در دسترس است. بنابراین، این نسخه امکان مدلسازی و نقشهبرداری گردش مالی در ساختار جامعه را در مناطق بزرگ جغرافیایی با تسهیل استفاده از دادههای با ابعاد بالا از نسلهای جدید ماهوارههای رصد زمین موجود و آینده در چارچوب GDM فراهم میکند.
منابع
- Chapin، FS، III; زاوالتا، ES; Eviner، VT; نایلور، RL; Vitousek، PM; رینولدز، اچ ال. هوپر، DU; لاورل، اس. سالا، OE; Hobbie, SE; و همکاران پیامدهای تغییر تنوع زیستی طبیعت 2000 ، 405 ، 234-242. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- پریرا، اچ ام. ناوارو، ال.ام. مارتینز، IS تغییر تنوع زیستی جهانی: بد، خوب و ناشناخته. آنو. کشیش محیط زیست. منبع. 2012 ، 37 ، 25-50. [ Google Scholar ] [ CrossRef ]
- Ferrier, S. استخراج ارزش بیشتر از مشاهدات تغییر تنوع زیستی از طریق مدل سازی یکپارچه. BioScience 2011 ، 61 ، 96-97. [ Google Scholar ] [ CrossRef ]
- هوپر، DU; چاپین، FS; ایول، جی جی. هکتور، ا. اینچاوستی، پ. لاورل، اس. لاتون، جی اچ. Lodge, DM; لورو، ام. نعیم، س. و همکاران اثرات تنوع زیستی بر عملکرد اکوسیستم: اجماع دانش فعلی Ecol. مونوگر. 2005 ، 75 ، 3-35. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لژاندر، پ. بورکارد، دی. Peres-Neto، PR تجزیه و تحلیل تنوع بتا: تقسیم بندی تغییرات فضایی داده های ترکیب جامعه. Ecol. مونوگر. 2005 ، 75 ، 435-450. [ Google Scholar ] [ CrossRef ]
- گیسان، ع. ویس، SB; Weiss، AD GLM در مقابل مدل سازی فضایی CCA توزیع گونه های گیاهی. بوم گیاهی. 1999 ، 143 ، 107-122. [ Google Scholar ] [ CrossRef ]
- فریر، اس. گیسان، الف. مدلسازی فضایی تنوع زیستی در سطح جامعه. J. Appl. Ecol. 2006 ، 43 ، 393-404. [ Google Scholar ] [ CrossRef ]
- گیسان، ع. Rahbek، C. SESAM – چارچوب جدیدی که مدلهای توزیع کلان اکولوژیکی و گونهها را برای پیشبینی الگوهای مکانی-زمانی مجموعههای گونهها ادغام میکند. J. Biogeogr. 2011 ، 38 ، 1433-1444. [ Google Scholar ] [ CrossRef ]
- دی کاسرس، ام. لژاندر، پ. او، F. اندازه گیری های عدم تشابه و ساختار اندازه جوامع بوم شناختی. روش ها Ecol. Evolut. 2013 ، 4 ، 1167-1177. [ Google Scholar ] [ CrossRef ]
- فریر، اس. مانیون، جی. الیت، جی. ریچاردسون، ک. استفاده از مدلسازی عدم تشابه تعمیمیافته برای تحلیل و پیشبینی الگوهای تنوع بتا در ارزیابی تنوع زیستی منطقهای. غواصان. توزیع کنید. 2007 ، 13 ، 252-264. [ Google Scholar ] [ CrossRef ]
- کر، جی تی؛ Ostrovsky، M. از فضا تا گونه: کاربردهای اکولوژیکی برای سنجش از دور. Trends Ecol. Evolut. 2003 ، 18 ، 299-305. [ Google Scholar ] [ CrossRef ]
- جتز، دبلیو. کاوندر-بارز، جی. پاولیک، آر. شیمل، دی. دیویس، FW; آسنر، GP; گورالنیک، آر. کاتگ، جی. لاتیمر، AM; مورکرافت، پی. و همکاران نظارت بر تنوع عملکردی گیاه از فضا نات Plants 2016 , 2 , 16024. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Wulder، MA; سفید، JC; لاولند، TR; Woodcock، CE; بلوارد، ع. کوهن، WB; Fosnight، EA؛ شاو، جی. ماسک، جی جی. روی، DP آرشیو جهانی لندست: وضعیت، تثبیت و جهت. سنسور از راه دور محیط. 2015 . [ Google Scholar ] [ CrossRef ]
- گوانتر، ال. کافمن، اچ. سگل، ک. چابریلات، س. فورستر، اس. روگاس، سی. کوستر، تی. هالشتاین، ا. راسنر، جی. چلبیک، سی. و همکاران ماموریت طیفسنجی تصویربرداری فضایی EnMAP برای رصد زمین. Remote Sens. 2015 ، 7 ، 8830–8857. [ Google Scholar ] [ CrossRef ]
- لاوش، آ. بنهر، ال. بکمن، ام. بوهم، سی. فیلهاور، اچ. هکر، JM; هیوریچ، ام. یونگ، آ. کلنکه، آر. نیومن، سی. و همکاران پیوند رصد زمین و تنوع زیستی طبقهبندی، ساختاری و عملکردی: دیدگاههای محلی به اکوسیستم Ecol. اندیک. 2016 ، 70 ، 317-339. [ Google Scholar ] [ CrossRef ]
- کندی، RE; آندرفوئه، اس. کوهن، WB; گومز، سی. گریفیث، پی. هایس، م. هیلی، SP; هلمر، EH; هاسترت، پ. لیون، مگابایت؛ و همکاران ارائه دیدگاه اکولوژیکی از تغییر به سنجش از دور مبتنی بر لندست. جلو. Ecol. محیط زیست 2014 ، 12 ، 339-346. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- سیم، AF؛ Meentemeyer، RK; لیتائو، پی جی. Václavík، T. مدلسازی توزیعهای گونهها با دادههای سنجش از دور: پل زدن دیدگاههای انضباطی. J. Biogeogr. 2013 ، 40 ، 2226-2227. [ Google Scholar ] [ CrossRef ]
- پروینن، م. Zimmermann، NE; Heikkinen، RK; Luoto، M. استفاده از داده های سنجش از دور مستمر طبقه بندی نشده برای بهبود مدل های توزیع گونه های گیاهی در فهرست قرمز. تنوع زیستی حفظ کنید. 2013 ، 22 ، 1731-1754. [ Google Scholar ] [ CrossRef ]
- سیم، AF؛ کلاین، دی. مورا، اف. Dech, S. مقایسه مناسب بودن داده های طبقه بندی شده پوشش زمین و متغیرهای سنجش از دور برای مدل سازی الگوهای توزیع گیاهان. Ecol. مدل. 2014 ، 272 ، 129-140. [ Google Scholar ] [ CrossRef ]
- Dormann، CF; الیت، جی. باچر، اس. بوخمن، سی. کارل، جی. کاره، جی. مارکوز، جی آر جی؛ گروبر، بی. لافورکید، بی. لیتائو، پی جی. و همکاران هم خطی: مروری بر روش های مقابله با آن و یک مطالعه شبیه سازی که عملکرد آنها را ارزیابی می کند. اکوگرافی 2013 ، 36 ، 27-46. [ Google Scholar ] [ CrossRef ]
- لیتائو، پی جی. شویدر، ام. سوس، اس. کاتری، من. میلتون، ای جی; موریرا، اف. آزبورن، PE; پینتو، ام جی. وان در لیندن، اس. Hostert، P. نگاشت تنوع بتا از فضا: مدلسازی ناهمسانی تعمیم یافته پراکنده (SGDM) برای تجزیه و تحلیل داده های با ابعاد بالا. روش ها Ecol. Evolut. 2015 ، 6 ، 764-771. [ Google Scholar ] [ CrossRef ]
- ویتن، دی.ام. طبشیرانی، ر. Hastie, T. تجزیه ماتریس جریمه شده، با کاربردهایی برای اجزای اصلی پراکنده و تجزیه و تحلیل همبستگی متعارف. آمار زیستی 2009 ، 10 ، 515-534. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- تبشیرانی، آر. انقباض و انتخاب رگرسیون از طریق کمند. JR Stat. Soc. 1996 ، 58 ، 267-288. [ Google Scholar ]
- رینکینگ، بی. شرودر، ب. محدودیت برای انجام: منظم کردن مدلهای زیستگاه. Ecol. مدل. 2006 ، 193 ، 675-690. [ Google Scholar ] [ CrossRef ]
- مانیون، جی. لیسک، ام. فریر، اس. نیتو-لوژیلد، دی. فیتزپاتریک، MC GDM: توابع برای مدلسازی عدم تشابه تعمیم یافته. پکیج R نسخه 1.2.3. در دسترس آنلاین: http://CRAN.R-project.org/package=gdm (در 18 ژانویه 2017 قابل دسترسی است).
- R Development Core Team R. A Language and Environment for Statistical Computing, 3.2.2 ; بنیاد R برای محاسبات آماری: وین، اتریش، 2016. [ Google Scholar ]
- ویتن، دی. طبشیرانی، ر. گراس، اس. نراسیمهان، B. PMA: تجزیه و تحلیل چند متغیره مجازات. بسته R نسخه 1.0.9. در دسترس آنلاین: http://CRAN.R-project.org/package=PMA (در 18 ژانویه 2017 قابل دسترسی است).
- وگان: بسته اکولوژی جامعه; بسته R نسخه 2.3-5. در دسترس آنلاین: http://CRAN.R-project.org/package=vegan (در 18 ژانویه 2017 قابل دسترسی است).
- Hijmans، RJ Raster: تجزیه و تحلیل داده های جغرافیایی و مدل سازی; بسته R نسخه 2.5-8. در دسترس آنلاین: http://CRAN.R-project.org/package=raster (در 18 ژانویه 2017 قابل دسترسی است).
- کروکستون، NL; Finley، AO yaImpute: یک بسته R برای انتساب kNN. J. Stat. نرم افزار 2008 ، 23 ، 1-16. [ Google Scholar ] [ CrossRef ]
- Clarke، KR تحلیل های چند متغیره ناپارامتریک تغییرات در ساختار جامعه. اوست جی. اکول. 1993 ، 18 ، 117-143. [ Google Scholar ] [ CrossRef ]
- تسلر، اس. روکولاینن، ک. تومیستو، اچ. Tomppo، E. نقشهبرداری تدریجی تغییرات گلشناسی در مقیاس چشمانداز در جنگلهای بارانی اولیه آمازون با ترکیب تنظیم و سنجش از دور. گلوب. Ecol. Biogeogr. 2005 ، 14 ، 315-325. [ Google Scholar ] [ CrossRef ]
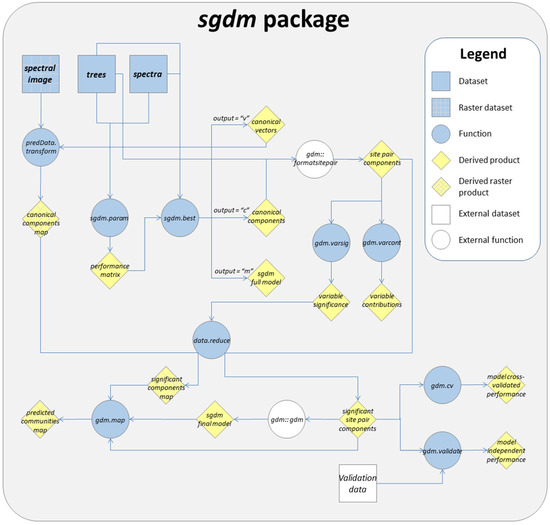
شکل 1. گردش کار گویا برای استخراج یک نقشه شطرنجی از جوامع درختی Cerrado در بسته sgdm .
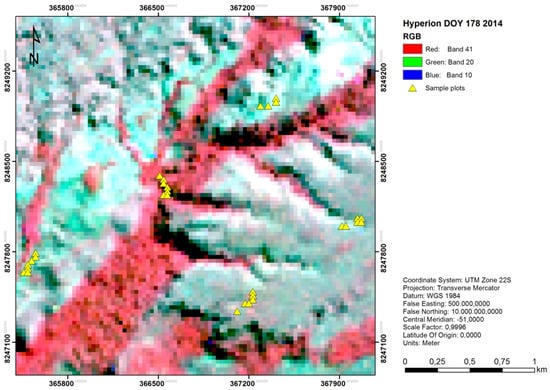
شکل 2. ترکیب RGB رنگ نادرست نقشه پیشبینی تصویر طیفی : زیرمجموعهای از تصویر فراطیفی Hyperion که منطقهای از پوشش گیاهی طبیعی در سرادوی برزیل را پوشش میدهد، که در 27 ژوئن 2014 به دست آمد (DOY 178). مثلث های زرد پوشانده شده نشان دهنده مکان های نمونه هستند که هر دو مجموعه داده های بیولوژیکی ( درختان ) و پیش بینی کننده ( طیف ) برای آنها مشتق شده اند.

شکل 3. نمایش ماتریس عملکرد با مقادیر ریشه مدل میانگین مربعات خطا (RMSE) برای هر جفت پارامتر. در محور x مقادیر جریمه برای ماتریس محیطی (از 0.6 تا 1) و در محور y برای ماتریس بیولوژیکی (همچنین از 0.6 تا 1) وجود دارد.
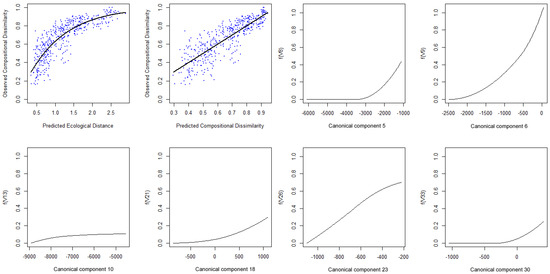
شکل 4. نمودار مدل سازی عدم تشابه تعمیم یافته برازش شده (GDM) و I-splines مربوطه.

شکل 5. نمودار تفاوت های مشاهده شده در مقابل پیش بینی شده مدل نهایی.

شکل 6. نمودارهای هشت محور مقیاسبندی چند بعدی غیر متریک (NMDS) که نشاندهنده انتقال جامعه درختی در منطقه مورد مطالعه، با توجه به پیشبینی مدلسازی ناهمسانی تعمیمیافته پراکنده (SGDM) است.
© 2017 توسط نویسندگان؛ دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (CC-BY) (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر