1. معرفی
انتخاب ویژگی یک مرحله مهم در فرآیند طبقه بندی در نظر گرفته می شود زیرا عملکرد طبقه بندی کننده را بهبود می بخشد و پیچیدگی محاسبات را با حذف اطلاعات اضافی کاهش می دهد [ 1 ]. انتخاب ویژگی به طور گسترده در طبقه بندی تصاویر سنجش از دور به طور کلی [ 2 ، 3 ]، و برای داده های فراطیفی به طور خاص [ 4 ، 5 ] استفاده شده است. با فضای ویژگی توسعه یافته مشتق شده از اشیاء قطعه بندی شده (به عنوان مثال، مجموعه ویژگی های طیفی گسترده در هر شی، ویژگی های شکل، یا ویژگی های بافتی) [ 6 ، 7]]، طبقه بندی مبتنی بر شی ممکن است پیچیدگی طبقه بندی و تقاضا برای قدرت محاسباتی را افزایش دهد. یک چالش دیگر، اجتناب از مرحله زمانبر محاسبه همه ویژگیهای موجود و فرآیند ذهنی انتخاب ویژگی مصنوعی هنگام تعیین ویژگیهای بهینه، علاوه بر برخی دیگر از مسائل خاص تجزیه و تحلیل تصویر مبتنی بر شی (مانند مقیاس شی و اندازه مجموعه آموزشی) است. 8 ، 9 ].
تحقیقات قبلی به طور فزاینده ای چندین روش انتخاب ویژگی پیشرفته را برای تجزیه و تحلیل تصویر مبتنی بر شی به کار برده اند. دورو و همکاران [ 10 ] انتخاب ویژگی را با محاسبه امتیاز اهمیت متغیر با استفاده از روش جنگل تصادفی اجرا کرد. Stumpf and Kerle [ 11 ] و Puissant و همکاران. [ 12 ] یک حذف تکراری به عقب را اجرا کرد که به موجب آن کمترین اهمیت 20 درصد از متغیرها، با توجه به رتبه بندی متغیر حاصل از روش جنگل تصادفی، در هر تکرار حذف شدند تا زیر مجموعه ویژگی بهینه تعیین شود. قاعده تقسیم برای درخت تصمیم قبلاً به عنوان معیار انتخاب ویژگی استفاده می شد [ 13] و در چندین مطالعه برای آموزش مدل درخت تصمیم استفاده شده است، در حالی که طبقهبندیکنندههای درخت تصمیم به طور گسترده برای تجزیه و تحلیل تصویر مبتنی بر شی استفاده میشوند [ 14 ، 15 ]. به عنوان مثال، ویرا و همکاران. [ 16 ] از بالاترین معیار افزایش اطلاعات نرمال شده برای انتخاب ویژگی استفاده کرد و سپس بهترین مدل را با استفاده از ارزیابی اعتبار متقابل انتخاب کرد، در حالی که Peña-Barragán و همکاران. [ 17 ] از معیار آماری کای اسکوئر ( χ2 ) به عنوان قانون تصمیم گیری استفاده کرد. علاوه بر این، یو و همکاران. [ 18 ] و ما و همکاران. [ 9 ] از روش انتخاب ویژگی مبتنی بر همبستگی (CFS) برای اجرای کاهش ابعاد ویژگیهای شی قبل از طبقهبندی استفاده کرد. نواک و همکاران [2 ] از چهار الگوریتم انتخاب ویژگی پیشرفته برای شناسایی مرتبطترین ویژگیها برای طبقهبندی یک تصویر با وضوح بالا استفاده کرد، اما این روشها و عملکرد مربوطه آنها را نسبت به یکدیگر ارزیابی نکرد.
مطالعات ذکر شده در بالا به طور مداوم در مورد مزیت (به عنوان مثال، کاهش پیچیدگی یا بهبود دقت) انتخاب ویژگی قبلی در طبقهبندی مبتنی بر شی اتفاق نظر دارند، اما همه مطالعات ذکر شده در واقع به دلیل برخی مبهم بودن در طبقهبندی مبتنی بر شی، بهبود دقت را به دست نیاوردند. به عنوان مثال، استفاده گسترده از طبقهبندیکنندههای فازی و بهویژه انتخاب و پارامترسازی روشهای تقسیمبندی به این صورت). علاوه بر این، تحقیقات قبلی برای سایر دادههای با ابعاد بالا (مانند دادههای فراطیفی) نشان داد که بخشهایی از این عدم قطعیت ممکن است به اثرات ترکیبهای خاصی از روشهای انتخاب ویژگی با روشهای طبقهبندی نظارت شده مختلف مرتبط باشد [5 ، 19 ]]. برخی از مطالعات ادعا کردند که طبقهبندیکنندههای SVM نسبت به ابعاد مجموعه داده حساس نیستند [ 4 ، 20 ، 21 ]، در حالی که وستون و همکاران. [ 22 ] و Guyon و همکاران. [ 23] افزایش دقت طبقه بندی را از طریق کاهش ابعاد مشاهده کرد. از این یافتههای تا حدی متناقض، ممکن است نتیجه بگیریم که انتخاب ویژگی عمدتاً به عنوان دارای اثرات مثبت بر دقت طبقهبندی در نظر گرفته میشود، اما ممکن است باعث درجهای از عدم قطعیت، به ویژه در طبقهبندیهای مبتنی بر SVM شود. به طور مشابه، مطالعات بر روی طبقهبندیکنندههای RF نیز ابهاماتی را در مورد تأثیرات انتخاب ویژگی برای طبقهبندی مبتنی بر شی ایجاد میکند. این مهم است زیرا، در کنار SVM، روشهای RF در طبقهبندی مبتنی بر شی محبوبیت پیدا کردهاند [ 11 ، 12 ]. برای مثال، دورو و همکاران. [ 24 ] ثابت کرد که RF با انتخاب ویژگی قبلی بهتر از بدون انتخاب ویژگی عمل می کند، اما لی و همکاران. [ 19] پیشنهاد کرد که RF یک روش طبقهبندی مبتنی بر شی پایدار با و بدون انتخاب ویژگی قبلی است. در واقع لی و همکاران [ 19 ] هرگز تفاوت آماری معنیداری در دقت طبقهبندی بین زیرمجموعههای ویژگی انتخابی و همه ویژگیها مشاهده نشد. بنابراین، به نظر میرسد که انتخاب ویژگی در طبقهبندی مبتنی بر شی، یک شکاف تحقیقاتی را نشان میدهد: در مورد اثرات کلی ترکیب روشهای انتخاب ویژگی و طبقهبندی مبتنی بر شی، اتفاق نظر مشترکی وجود ندارد.
فرآیندهای تقسیمبندی تصویر برای ترسیم کشاورزی از تصاویر وسایل نقلیه هوایی بدون سرنشین (UAV) برای چندین سال مورد استفاده عملیاتی قرار گرفتهاند، به عنوان مثال، برای کشاورزی دقیق [ 25 ، 26]]. تصاویر پهپاد معمولاً با سایر تصاویر متفاوت است (معمولاً فقط باندهای RGB، وضوح فضایی بسیار بالا، تفاوت های رادیومتریک). علاوه بر این، به دلیل قوانین و مقررات، پهپادها عمدتاً در مناطق بدون حضور انسان (بدون مناطق شهری) و در جاهایی که کنترل بصری امکان پذیر است (مناطق باز) پرواز می کنند – این منجر به کاربرد فراوانی در مناطق کشاورزی در مقایسه با سایرین می شود. متعاقباً، توانایی نقشهبرداری مناطق کشاورزی با وضوح فضایی بالا، نظارت بر کشاورزی را تشویق میکند، تصاویر پهپاد را با روشهای مبتنی بر شی ترکیب میکند، که به درک اساسی روشهای طبقهبندی مبتنی بر شی موجود کمک میکند.
هدف این مطالعه، تحلیل عدم قطعیت روشهای مختلف انتخاب ویژگی برای طبقهبندی مبتنی بر شی، به جای ارزیابی مشابه برای روش هر پیکسل است. بر اساس ارزیابی قبلی روش های طبقه بندی برای مناطق کشاورزی با استفاده از تصاویر با وضوح بالا [ 19 ، 24]]، این مطالعه اکنون به طور خاص بر ارزیابی تأثیر ابعاد ویژگی و اندازه مجموعه آموزشی بر طبقهبندیکنندههای SVM و RF برای روشهای مختلف انتخاب ویژگی، از جمله روش فیلتر، پوششها، و روشهای تعبیهشده متمرکز است. استراتژی ارزیابی با دقت طراحی شده بینش جدیدی را در مورد تأثیر روشهای مختلف انتخاب ویژگی ارائه میکند و روشهای آماری مورد استفاده در تشخیص تفاوتهای قابل توجه در دقت طبقهبندی متوسط کمک میکنند. طبق دانش ما، این مطالعه اولین ارزیابی سیستماتیک روشهای انتخاب ویژگی پیشرفته در ترکیب با طبقهبندیکنندههای SVM و RF در مورد طبقهبندی مبتنی بر شی است.
2. روش ها
2.1. محدوده مطالعه و مجموعه داده ها
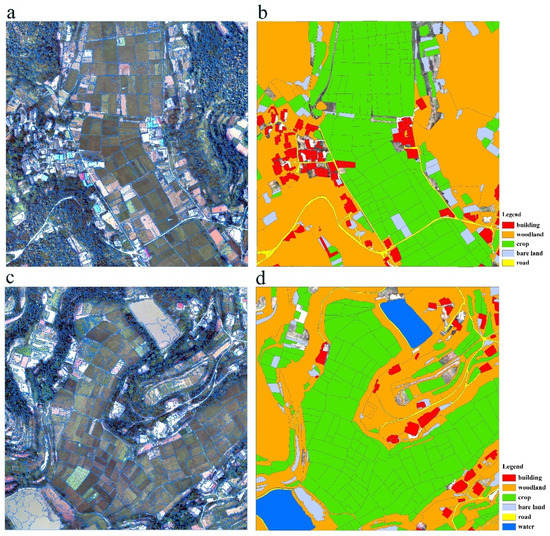
این مطالعه در حومه شرقی شهر دیانگ، که در حوزه سیچوان چین واقع شده است، انجام شد. این سایت تقریباً 10×5 کیلومتر مربع وسعت دارد و انواع پوشش زمین معمولاً کشاورزی هستند. در منطقه مورد مطالعه، یک مجموعه داده پهپاد که تقریباً 10×5 کیلومتر مربع را پوشش میدهد با دوربین Canon 5D 2 در ارتفاع حدود 750 متر در آگوست 2011 به دست آمد. پس از آن یک نقشه دیجیتال ارتوفتو (DOM)، دو نقشه استاندارد تهیه شد. صفحات 500 × 500 متر (0.2 متر وضوح فضایی و باندهای RGB) با استفاده از نرم افزار فتوگرامتری دیجیتال [ 27 ] تولید شد. برای ارزیابی روشهای انتخاب ویژگی، هر دو برگه استاندارد نقشه را به عنوان مناطق مطالعه انتخاب کردیم تا نتایج را افزایش دهیم. منطقه مطالعه 1 ( شکل 1الف) عمدتاً شامل زمین های زراعی (38٪) و زمین های جنگلی (43٪) است و همچنین شامل 6٪ ساختمان، 5٪ زمین های بایر و 2٪ جاده است ( شکل 1 ب). منطقه مورد مطالعه 2 ( شکل 1 ج) عمدتاً شامل زمین های زراعی (45٪) و زمین های جنگلی (37٪) است، و همچنین شامل 5٪ آب، 4٪ ساختمان، 4٪ زمین بایر و 1٪ جاده است (شکل 1 د ) . تمام درصدهای کلاس های موضوعی با استفاده از یک لایه مرجع برگرفته از تفسیر دستی محاسبه شد (نگاه کنید به شکل 1 ب، د).
2.2. تقسیم بندی و ویژگی ها
الگوریتم تقسیم بندی چند وضوح [ 28 ] پیاده سازی شده در بسته نرم افزاری eCognition (Trimble Geospatial) برای تولید اشیا استفاده شد. وزن رنگ و شکل به ترتیب 0.9/0.1 تنظیم شد، در حالی که وزن صافی/فشردگی روی 0.5/0.5 (تنظیمات استاندارد) تنظیم شد. تصویر (که هر سه باند به طور مساوی وزن داشتند) در یک پارامتر مقیاس متوسط (آستانه همگنی) 100 قطعه بندی شد که بر اساس ارزیابی طبقه بندی قبلی از نظر پارامترهای مقیاس تقسیم بندی خاص تعیین شد [19 ] . 32 ویژگی در eCognition برای هر شی محاسبه شد، از جمله ویژگیهای طیفی، بافت و شکل، تا متعاقباً در الگوریتمهای انتخاب ویژگی پیادهسازی شوند.
جزئیات ویژگی های انتخاب شده در جدول 1 آورده شده است . ویژگی های طیفی شامل میانگین و انحراف استاندارد طیف جسم، به همراه حداکثر اختلاف و روشنایی ویژگی است. اندازهگیریهای شکل شامل ویژگیهای هندسی ارائهشده توسط هر جسم تقسیمبندی شده، مانند مساحت، عدم تقارن، شاخص مرزی، فشردگی، چگالی، تناسب بیضی، جهت اصلی، تناسب مستطیلی، شاخص شکل و گردی است. ویژگیهای بافت این مطالعه بر اساس تحلیل هارالیک (ماتریس هموقوع سطح خاکستری (GLCM) و بردار اختلاف سطح خاکستری (GLDV)) است و به همه جهات، یعنی زاویه 2 لحظه، کنتراست، همبستگی وابسته است. ، عدم تشابه، آنتروپی، میانگین و انحراف معیار.
2.3. الگوریتم های انتخاب ویژگی
در این مطالعه، ما هشت روش انتخاب ویژگی شامل پنج روش فیلتر (نسبت به دست آوردن، Chi-square، SVM-RFE، CFS و Relief-F)، دو روش پوشش (پوشش RF و بسته بندی SVM) و یک روش تعبیه شده را اجرا کردیم. (RF). ما روش ها را با تقسیم آنها به دو دسته با توجه به نتایج انتخاب ویژگی (رتبه بندی اهمیت ویژگی و زیر مجموعه ویژگی) ارزیابی کردیم. تمام روش های انتخاب ویژگی با استفاده از نسخه 3.7.9 WEKA [ 29 ] یا نسخه 3.1.1 R در یک پلتفرم C# ادغام شدند تا به طور خودکار اجرا شوند.
(1) نسبت سود
نسبت بهره گسترشی از اندازه گیری به دست آوردن اطلاعات است، که تلاش می کند بر این سوگیری غلبه کند که معیار افزایش اطلاعات مستعد انتخاب ویژگی هایی با تعداد زیادی مقادیر است [ 13 ]. بنابراین، اندازه گیری به دست آوردن اطلاعات به عنوان معیار انتخاب ویژگی درخت تصمیم استفاده می شود و با محاسبه تفاوت بین نیاز اطلاعات مورد انتظار، طبقه بندی یک تاپل در چند تا، و نیاز اطلاعات جدید برای ویژگی A پس از پارتیشن بندی به دست می آید . اندازه گیری نیاز اطلاعات مورد انتظار توسط [ 13 ] ارائه شده است.
که در آن m تعداد کلاس های متمایز است. پمنپمنبا محاسبه نسبت تعلق به کلاس، احتمال را نشان می دهد سیمنسیمندر تاپل های D. نیاز اطلاعات جدید برای ویژگی A با اندازه گیری می شود
که در آن v نشان می دهد که D به v پارتیشن یا زیر مجموعه تقسیم شده است، {D1،D2، ⋯ ،Dv}{�1،�2،⋯،��}. بنابراین، اندازه گیری افزایش اطلاعات Gain( A ) برای ویژگی A را می توان با فرمول محاسبه کرد.
سپس، یک تابع ‘اطلاعات تقسیم شده’ برای عادی سازی اندازه گیری به دست آوردن اطلاعات استفاده شد سود ( الف )کسب کردن(آ). تابع اطلاعات تقسیم شده توسط
در نهایت، نسبت بهره به عنوان معیار افزایش اطلاعات محاسبه می شود سود ( الف )کسب کردن(آ)تقسیم بر مقیاس اطلاعات تقسیم شده اسp l i t In fo ( الف )اسپلمنتیمن���(آ)، به این معنا که
هر چه نسبت بهره به دست آمده بزرگتر باشد، ویژگی های نمایش داده شده اهمیت بیشتری دارند.
(2) ارزیابی ویژگی Chi-square
روش مجذور کای می تواند آزمون های مقایسه استقلال [ 30 ] را اجرا کند. برای انتخاب ویژگی، از ارزیابی ویژگیهای مجذور کای برای ارزیابی ارزش یک ویژگی با محاسبه نمره کای دو کلاسها استفاده شد تا فهرست رتبهبندی همه ویژگیها به دست آید. گسسته سازی برای ویژگی های عددی (گسسته ساختن آنها) به منظور استفاده از آماره مجذور کای برای یافتن تناقضات در داده ها استفاده شد [ 31 ]. نمره خی دو یک ویژگی با استفاده از فرمول زیر محاسبه شد.
که در آن c تعداد کلاس ها است. r تعداد فواصل گسسته برای یک ویژگی خاص است، و nمن ج�من�فرکانس مشاهده شده نمونه ها در بازه i و کلاس j است. اگر nمن�من= ∑جj = 1nمن ج∑�=1ج�من�تعداد نمونه ها را در بازه i برای یک ویژگی نشان می دهد. nj��= ∑ri = 1nمن ج∑من=1��من�شماره نمونه های کلاس j را نشان می دهد . n تعداد کل نمونه ها است. سپس μمن ج=nمن⋅nj/ n�من�=�من⋅��/�فرکانس مورد انتظار را نشان می دهد nمن ج�من�.
(3) حذف ویژگی بازگشتی SVM (SVM-RFE)
SVM-RFE یک روش تکراری برای حذف ویژگی های عقب مانده است که از تابع هزینه استفاده می کند. جی= ( 1/2 ) _ _∥ w ∥2جی=(1/2)“�“2به عنوان معیار رتبه بندی و SVM به عنوان طبقه بندی کننده پایه [ 23 ]. ما در اینجا قصد داریم یک لیست رتبه بندی ویژگی را برای مقایسه با سایر مدل های فیلتر استخراج کنیم، بنابراین ویژگی با کمترین امتیاز رتبه بندی به جای حذف ویژگی های بیشتر، یکی یکی حذف شد. طرح کلی الگوریتم به شرح زیر است: ابتدا طبقه بندی کننده SVM با استفاده از اشیاء آموزشی برای بهینه سازی وزن ها آموزش داده شد. wمن�منبا توجه به جیجی، جایی که wمن�منمولفه i مربوط به w را نشان می دهد. ثانیاً، همه ویژگی ها با استفاده از معیار رتبه بندی رتبه بندی شدند (wمن)2(�من)2(مربع وزن محاسبه شده توسط SVM). در نهایت، ویژگی با کوچکترین معیار در هر مرحله تکراری حذف شد تا لیست رتبه بندی همه ویژگی ها ایجاد شود.
(4) Relief-F
Relief-F الگوریتم دیگری است که ارزش یک ویژگی را ارزیابی می کند و عملکرد برتر را برای بسیاری از کاربردهای ارزیابی کیفیت ویژگی ارائه کرده است [ 32 ]. روش Relief-F از نمونههای آموزشی بهطور تصادفی از دادهها با مقادیر ویژگی و مقدار کلاس برای محاسبه بردار وزن w که کیفیت همه ویژگیها را نشان میدهد، استفاده میکند [ 33 ]. وزن به عنوان معیار ارزیابی ویژگی روش Relief-F بر اساس احتمال چنین ویژگی برای تمایز بین طبقات محاسبه شد، که به موجب آن وزن مورد انتظار بزرگتر نشان دهنده ارتباط افزایش یافته ویژگی برای کلاس ها است [32 ] . ابتدا، همه وزنهای w[A] روی صفر تنظیم میشوند و سپس یک نمونه بهطور تصادفی انتخاب میشودRi برای جستجوی نزدیکترین ضربه H و نزدیکترین ضربه M استفاده می شود . تخمین کیفیت w[A] زمانی کاهش یافت که جداسازی دو نمونه با یک کلاس با استفاده از ویژگی A مطلوب نباشد . در مقابل، برآورد کیفیت w[A] زمانی افزایش یافت که ویژگی A فعال شد تا دو نمونه را در مقادیر کلاسهای مختلف متمایز کند. در این مطالعه ما Relief-F را در محیط WEKA اجرا کردیم [ 29 ].
(5) جنگل تصادفی
رویکرد ارزیابی ویژگی مبتنی بر جنگل تصادفی به عنوان یک روش تعبیه شده [ 5 ] شناخته میشود و با محاسبه میانگین کاهش دقت طبقهبندی برای دادههای خارج از کیسه (OOB) از نمونهگیری راهانداز، یک معیار اهمیت متغیر برای هر ویژگی ارائه میکند [ 34 ] . با فرض نمونه های بوت استرپ b = 1، …، B، میانگین کاهش دقت طبقه بندی D¯¯¯j�¯�برای متغیر ایکسjایکس�همانطور که معیار اهمیت توسط
جایی که آرo o bبآرب��بنشان دهنده دقت طبقه بندی برای داده های OOB است ℓo o bبℓب��ببا استفاده از مدل طبقه بندی تیبتیب; و آرo o bb jآرب���بدقت طبقه بندی برای داده های OOB است ℓo o bb jℓب���بمقادیر متغیر را تغییر داد ایکسjایکس�که در ℓo o bبℓب��ب( j = 1، …، N ). در نهایت، یک امتیاز z از متغیر ایکسjایکس�نشان دهنده معیار اهمیت متغیر را می توان با استفاده از فرمول محاسبه کرد zj=D¯¯¯jسj/ب√��=�¯�س�/ب، پس از انحراف معیار سjس�کاهش دقت طبقه بندی محاسبه می شود. در این کار، روش ارزیابی ویژگی به طور خودکار با استفاده از بسته R “RRF” انجام شد.
(6) انتخاب ویژگی مبتنی بر همبستگی
برخلاف روشهای ارزیابی ویژگی که در بالا ذکر شد، یک زیرمجموعه ویژگی به سادگی با استفاده از الگوریتم فیلتر انتخاب ویژگی مبتنی بر همبستگی (CFS) ارزیابی شد. CFS ارزش مجموعهای از ویژگیها را با استفاده از یک تابع ارزیابی اکتشافی بر اساس همبستگی ویژگیها ارزیابی کرد و هال و هولمز [35 ] ادعا کردند که زیرمجموعهای برتر از ویژگیها باید با کلاسهایی که به شدت با یکدیگر مرتبط نیستند همبستگی داشته باشند. بنابراین، معیار یک زیر مجموعه را می توان با استفاده از فرمول زیر ارزیابی کرد
جایی که f نشان دهنده ویژگی است. c کلاس است. r¯ج ج�¯ج�نشان دهنده همبستگی میانگین ویژگی با کلاس ها است. r¯ff�¯��میانگین همبستگی ویژگی را نشان می دهد. و ککتعداد صفات موجود در زیر مجموعه را نشان می دهد. علاوه بر این، بهترین جستجوی اول برای کاوش فضای ویژگی مورد استفاده قرار گرفت و پنج زیرمجموعه متوالی کاملاً توسعهیافته بدون بهبود، برای جلوگیری از جستجوی کل فضای زیر مجموعه ویژگی، معیار توقف قرار گرفتند. در این تحقیق از بسته WEKA برای پیاده سازی این الگوریتم انتخاب ویژگی استفاده شد.
(7) لفاف RF/SVM
به طور کلی، روشهای wrapper برای ارزیابی زیرمجموعههای زیرمجموعه متغیرها، برای شناسایی بهترین زیرمجموعه ویژگی [ 36 ] استفاده شد. یک طرح یادگیری برای روشهای wrapper برای ارزیابی مجموعههای ویژگیها اجرا شد و دقت طرح یادگیری با استفاده از اعتبارسنجی متقاطع برای شناسایی بهترین زیرمجموعه برآورد شد [ 37 ]. پس از آن، مجموعهای از ویژگیها که بالاترین دقت را با اعتبارسنجی متقاطع تولید میکنند، به عنوان زیرمجموعه ویژگی بهینه شناسایی شدند. بسیاری از مطالعات قبلی ترجیح میدهند SVM را بهعنوان طرح یادگیری به دلیل برتری آن در مقایسه با سایر طبقهبندیکنندهها [ 12 ، 38 ] انتخاب کنند، اما طبقهبندیکننده RF نیز اخیراً مورد استفاده قرار گرفته است [ 39]]. از آنجایی که طبقهبندیکنندههای RF و SVM بهعنوان تکنیکهای طبقهبندی آزمایششده در این مطالعه مورد استفاده قرار گرفتند (به بخش 2.4 مراجعه کنید)، ما دو روش پوششی را آزمایش کردیم و طرحهای یادگیری به ترتیب روی طبقهبندیکنندههای RF و SVM تنظیم شدند تا به بهترین عملکرد طبقهبندی ممکن برای ویژگی دست پیدا کنیم. انتخاب. برای روش بسته بندی SVM، ما الگوریتم حداقل بهینه سازی متوالی جان پلات [ 40 ] را پیاده سازی کردیم و طبقه بندی کننده بردار پشتیبانی را با پارامترهای پیش فرض در بسته طبقه بندی کننده WEKA آموزش دادیم. برای روش RF wrapper، ما الگوریتم جنگل تصادفی را با استفاده از پارامترهای پیشفرض در بسته طبقهبندی کننده WEKA پیادهسازی کردیم. برای هر دو روش، استراتژی wrapper در بسته انتخاب ویژگی WEKA انجام شد.
2.4. روش طبقه بندی
2.4.1. نمونه گیری و اعتبار سنجی
همه اشیاء بخشبندی شده ابتدا با یک قانون نسبت همپوشانی مبتنی بر GIS بین لایه تقسیمبندی شده و لایه مرجع [ 19 ] برچسبگذاری شدند، که بیان میکند که یک شی به کلاسی اختصاص داده میشود که بیش از 50 درصد از چند ضلعی مرجع را پوشش میدهد، و از این رو نمونهگیری تصادفی طبقهای انجام شد. قابل انجام است. پس از آن، نسبت مجموعه آموزشی 30 درصد نمونهگیری برای هر قشر استفاده شد تا بهطور تصادفی اشیاء آموزشی برای ساخت مدل طبقهبندی به دست آید. سپس، هر دو طبقهبندیکننده نظارتشده (به بخش 2.4.2 بعدی مراجعه کنید ) با استفاده از این اشیاء نمونهگیری اعمال شدند. یک روش ارزیابی دقت مبتنی بر چند ضلعی باید در طبقه بندی مبتنی بر شی به دلیل عدم قطعیت اشیاء قطعه بندی شده استفاده شود [ 41]، و بنابراین ما از چند ضلعی های مرجع به عنوان نمونه های اعتبار سنجی برای ایجاد ماتریس سردرگمی با محاسبه صحیح ناحیه بخشی از شی طبقه بندی شده بین اشیاء طبقه بندی شده و چند ضلعی های مرجع استفاده کردیم.
2.4.2. تکنیک های طبقه بندی
با توجه به مقایسه سیستماتیک قبلی ما [ 19 ]، جنگل تصادفی (RF) و ماشینهای بردار پشتیبان (SVM) برای طبقهبندی GEOBIA بسیار مناسب هستند و تمایل کلی مورد انتظار کاهش دقت کلی با افزایش مقیاس تقسیمبندی تایید میشود. بنابراین، طبقهبندیکنندههای RF و SVM برای ارزیابی عملکرد روشهای مختلف انتخاب ویژگی مورد استفاده قرار گرفتند.
(1) طبقه بندی RF
RF چندین درخت طبقه بندی را به عنوان یک طبقه بندی گروه جدید ترکیب می کند و به دلیل عملکرد برتر خود به طور گسترده در زمینه طبقه بندی سنجش از دور استفاده شده است [ 9 ، 11 ، 12 ، 42 ، 43 ]. روش بسته بندی برای تولید مجموعه داده آموزشی برای رشد هر درخت استفاده می شود. اشیاء بدون برچسب با اختصاص دادن آنها به کلاسی که بیشترین رای داده شده است طبقه بندی می شوند. طبقهبندیکننده RF برای ساخت مدل پیشبینی به دو پارامتر نیاز دارد: تعداد درختهای تصمیم و تعداد متغیرهایی که در هر تقسیم برای رشد درخت استفاده میشوند. تعداد 479 درخت برای این مطالعه انتخاب شد (که به نظر می رسد یک مقدار منظم برای طبقه بندی کننده RF با توجه به رودریگز-گالیانو و همکاران.44 ])، و از یک متغیر تقسیم تصادفی منفرد برای رشد درختان استفاده شد. بسته “randomForest” در R برای تحقق طبقه بندی کننده RF استفاده شد.
(2) طبقه بندی SVM
ماشین بردار پشتیبان، که یک طبقهبندی کننده یادگیری آماری نظارت شده غیرپارامتری است، در طبقهبندی سنجش از دور محبوبیت فزایندهای پیدا کرده است [ 4 ، 45 ، 46 ]. در این مطالعه، بسته R ‘e1071’، که کتابخانه LIBSVM را یکپارچه می کند [ 47 ، 48]، برای اجرای الگوریتم SVM با استفاده از هسته تابع پایه شعاعی (RBF) پیادهسازی شد، در حالی که ترفند هسته ممکن است عملکرد طبقهبندی را در مقایسه با SVMهای خطی بهبود بخشد. سپس، از روش جستجوی شبکه ای برای یافتن بهترین جفت پارامتر (پارامتر جریمه C و پارامتر هسته γ) استفاده شد که در آن بهترین دقت اعتبارسنجی متقاطع مشاهده می شود. بنابراین، عدم قطعیت ناشی از پارامترهای طبقهبندی کننده SVM ممکن است با استفاده از بهترین نتیجه طبقهبندی اجتناب شود. یک شبکه درشت متشکل از یک فضای پارامتر دو بعدی (تابع fun = 2 d است ، که در آن d = -4، -1.5، -1، …، 4 برای C، و d = -4، -3.5، -3 است. , …, 1 برای γ) برای هر طبقه بندی برای سرعت بخشیدن به فرآیند جستجوی شبکه استفاده شد.
2.5. استنتاج آماری
در این مطالعه، از آزمون t دو دنباله برای تعیین اینکه آیا دو میانگین جامعه مشتق شده با استفاده از همه ویژگی ها و آنهایی که از ویژگی های انتخاب شده به دست آمده اند، برابر هستند یا خیر استفاده می شود. پس از ارزیابی بصری الگوی تغییر دقت طبقهبندی با تعداد متفاوتی از ویژگیهای به دست آمده از پنج روش ارزیابی ویژگی، اهمیت، آزمون t دو دنباله برای دو گروه دقت (به ترتیب ده دقت مستقل برای هر گروه) اعمال شد. با استفاده از همه ویژگیها و فهرست رتبهبندی ویژگیها با استفاده از پنج روش ارزیابی ویژگی-اهمیت-ارزیابی، برای یافتن کمترین تعداد ویژگیهای لازم برای دستیابی به دقت نسبی با آنچه که با استفاده از همه ویژگیها به دست میآید، تولید شده است. برای سه روش ارزیابی ویژگی – زیر مجموعه – از t دو دنباله استفاده کردیم-تست برای تعیین اینکه آیا زیرمجموعه ویژگی بهینه می تواند عملکرد طبقه بندی را به طور قابل توجهی بهبود بخشد در مقایسه با آنچه که با استفاده از همه ویژگی ها برای اندازه مجموعه آموزشی متفاوت بدست می آید یا خیر. در نهایت، ده بهترین دقت ویژگی های انتخاب شده با دقت به دست آمده با استفاده از همه ویژگی ها مقایسه شد. به طور کلی، اگر قدر مطلق آماره آزمون بیشتر از مقدار بحرانی 1.96 باشد، فرض صفر را رد می کنیم و نتیجه می گیریم که میانگین دو جامعه در سطح معنی داری 0.05 متفاوت است.
3. نتایج و بحث
این مطالعه تنها روشهای انتخاب ویژگی را به جای تحلیل اهمیت ویژگیهای فردی ارزیابی میکند، زیرا مطالعات قبلی ما [ 9] برخی ویژگی های مهم خاص برای استخراج اطلاعات کشاورزی را تعیین کرد. مقایسه روشهای انتخاب ویژگی برای طبقهبندی مبتنی بر شی، به دلیل انواع مختلف نتایج بهدستآمده از فرآیند انتخاب ویژگی (به عنوان مثال، فهرست ویژگیهای رتبهبندیشده و زیر مجموعه ویژگیهای بهینه)، از جمله تجزیه و تحلیل، در این مطالعه به دو بخش تقسیم شد. روشهای ارزیابی اهمیت ویژگی و روشهای ارزیابی زیر مجموعه ویژگیها. با توجه به روشهای ارزیابی ویژگی، اهمیت، از پنج الگوریتم (نسبت به دست آوردن، Chi-square، SVM-RFE، Relief-F و Random Forest) برای به دست آوردن فهرست رتبهبندی ویژگیها استفاده شد و سپس هر ویژگی به صورت جداگانه برای طبقهبندی اضافه شد. با توجه به لیست رتبه بندی در مورد روشهای ارزیابی ویژگی-زیر مجموعه، زیر مجموعه ویژگی بهینه از سه الگوریتم انتخاب ویژگی (CFS،
3.1. ارزیابی ویژگی-اهمیت-روش های ارزیابی
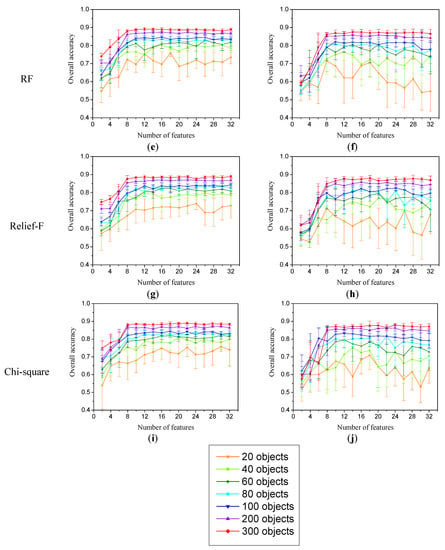
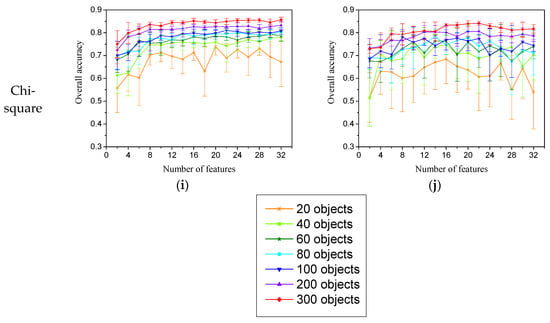
شکل 2 و شکل 3الگوهای تغییر دقت طبقهبندی را برای هر دو طبقهبندی کننده در هر دو ناحیه نشان میدهد، زیرا تعداد ویژگیهای متفاوتی استفاده شده و اندازه مجموعه آموزشی متفاوت است. میانگین دقت کلی ده تکرار طبقهبندی با تعداد مشخصی از ویژگیها و اندازه مجموعه آموزشی یکسان برای روشهای مختلف ارزیابی ویژگی-اهمیت- ارزیابی محاسبه شد. میانگین دقت کلی در ابتدا با افزایش تعداد ویژگیهای مورد استفاده به سرعت افزایش یافت. پس از رسیدن به یک آستانه مشخص، دقت طبقه بندی ثابت باقی می ماند، حتی اگر ویژگی های بیشتری اضافه شود. علاوه بر این، عملکرد طبقهبندی کمی متفاوت بین هر دو طبقهبندی کننده برای اندازههای مختلف مجموعه آموزشی، حتی استفاده از روشهای مختلف انتخاب ویژگی مشاهده شد. برای منطقه 1، زمانی که اندازه مجموعه آموزشی کمتر از 60 شی بود،شکل 2 )، که مطابق با یافته های قبلی برای مطالعات داده های فراطیفی [ 5 ] است. الگوی مشابهی نیز در منطقه 2 مشاهده شد ( شکل 3 ). با این حال، برای هر دو منطقه، طبقهبندیکننده RF به طور کلی بهتر از طبقهبندیکننده SVM عمل میکند، و دقت طبقهبندی با تغییر ویژگیها در هنگام استفاده از اندازههای مجموعه آموزشی کوچک نسبتاً پایدار بود. بنابراین، بیشتر مشهود بود که طبقهبندیکننده RF نسبت به طبقهبندیکننده SVM به تأثیر ابعاد دادهها حساسیت کمتری دارد، حتی اگر از یک مجموعه آموزشی کوچک استفاده شده باشد، و لی و همکاران. [ 19] ثابت کرد که هر یک از طبقهبندیکنندهها را میتوان با نمونههای آموزشی محدود استفاده کرد. همچنین باید توجه داشت که نتایج ما با یافتههای اولیه مبنی بر اینکه SVM نسبت به اثر هیوز حساس نیست، مطابقت ندارد، اما مطابق با پال و فودی [5 ] است که مشخص کردند طبقهبندی SVM تحت تأثیر تعداد ویژگیهای مورد استفاده قرار میگیرد. ما فرض کردیم که ویژگیهای اضافی میتواند کمبود نمونههای آموزشی برای طبقهبندی کننده RF را جبران کند و SVM مستعد اثر هیوز برای طبقهبندی مبتنی بر شی با فقدان نمونههای آموزشی بدون توجه به استفاده از ویژگیهای اضافی است.
میتوانیم توجه کنیم که نتایج بهطور چشمگیری بین چندین اندازه مجموعه آموزشی متفاوت بود، اما عملکردهای کمی متفاوت هنوز بین الگوریتمهای انتخاب ویژگی با توجه به محدودیتهای ویژگیها مشاهده شد. به عنوان مثال، عملکرد هنگام استفاده از تعداد کمی از ویژگیها به شدت به روشهای ارزیابی ویژگی-اهمیت-وابستگی بستگی دارد، در حالی که روشهای مختلف انتخاب ویژگی احتمالاً مستلزم فهرست رتبهبندی متفاوتی از ویژگیها هستند، حتی زمانی که از همان اندازه مجموعه آموزشی استفاده میشود [37 ] . برای مقایسه تفاوت معنیداری آماری بین میانگین دقتهای تولید شده با استفاده از تمام ویژگیها و مواردی که از فهرست رتبهبندی ویژگیها به دست آمدهاند، از آزمون t دو دنباله استفاده شد ( جدول 2) .) برای به دست آوردن یک نتیجه گیری درست. جدول 2نتایج آزمونهای معنیداری آماری را نشان میدهد که با استفاده از اندازه مجموعه آموزشی 300 شی برای ناحیه 1 به دست آمده است، که احتمالاً بر اساس تحلیل قبلی نسبت به اثر هیوز (بعدی دادهها) حساس نیست. نتایج نشان میدهد که کارایی روشهای انتخاب ویژگی زمانی که تعداد کمی از ویژگیها استفاده میشد متفاوت بود، زیرا دقت قابل مقایسه با یک مجموعه کامل از ویژگیها با نیاز به تعداد متفاوتی از ویژگیها به دست آمد و همچنین عملکرد متفاوتی در یک کوچک مشاهده شد. تعداد ویژگی های هر الگوریتم حتی با استفاده از طبقه بندی کننده یکسان. برای هر دو طبقهبندیکننده، نسبت بهره و SVM-RFE بهتر از سایر روشهای ارزیابی اهمیت ویژگیها بودند، زیرا مقادیر آماری پایینتری در هنگام استفاده از تعداد کمی از ویژگیها بهدست میآیند (جدول 2) .). با این حال، با توجه به کارایی انتخاب ویژگی برای طبقهبندی کننده RF، مشهود بود که SVM-RFE و Chi-square هر دو روشهای انتخاب ویژگی مناسب هستند. هنگامی که تعداد کمتری از ویژگی ها (8 ویژگی) در مقایسه با سه الگوریتم دیگر ( جدول 2 ) استفاده شد، تفاوت ها کاهش یافت. برای طبقهبندیکننده SVM، هر پنج روش ارزیابی اهمیت-ویژگی با استفاده از هشت ویژگی به دقت قابل مقایسه با مجموعه کامل ویژگیها دست یافتند ( جدول 2 ). این نتایج مشابه نتایج Ghosh & Joshi [ 49] است]، که ثابت کرد که دقت می تواند اشباع شود و پس از گنجاندن ده متغیر اول هنگام استفاده از تکنیک RFE با متغیرهای تبدیل (به عنوان مثال، جزء اصلی) هیچ تغییری نشان نمی دهد. بنابراین، به نظر می رسد که روش SVM-RFE ممکن است برای طبقه بندی کننده RF مناسب باشد، در حالی که نسبت Gain و SVM-RFE هر دو برای طبقه بندی کننده SVM مناسب هستند.
3.2. ارزیابی برای روشهای ارزیابی ویژگی-زیر مجموعه
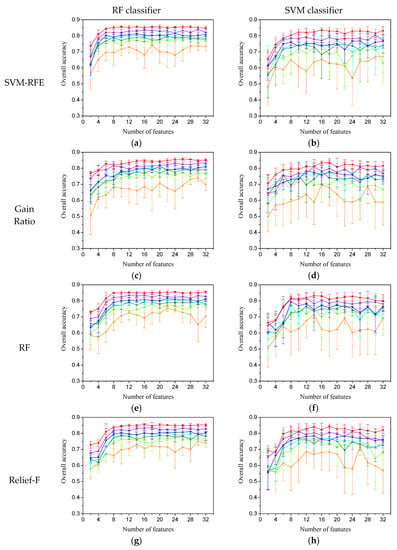
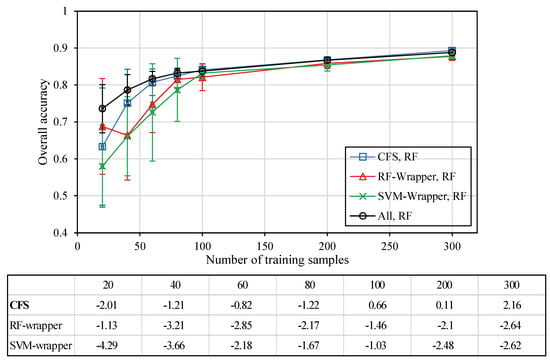
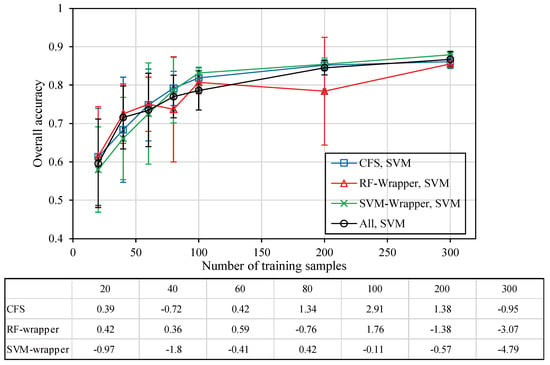
میانگین منحنی های دقت کلی و خطاهای استاندارد برای سه روش ارزیابی ویژگی-زیر مجموعه در شکل 4 و شکل 5 گزارش شده است . صرف نظر از استراتژیهای ترکیبی بین روشهای انتخاب ویژگی و الگوریتمهای طبقهبندی بکار گرفته شده، این نتایج مطابق با این واقعیت است که میانگین دقت افزایش مییابد و خطای استاندارد همراه با افزایش اندازه مجموعه آموزشی کاهش مییابد [9 ] . علاوه بر این، تفاوت آماری معنیدار بین دقت کلی حاصل از سه روش ارزیابی ویژگی-زیر مجموعه-ارزیابی و آنچه که با استفاده از همه ویژگیها ایجاد شده است با استفاده از تی دو دنباله ارزیابی شد .-روش آزمون. برای طبقهبندیکننده RF، نتایج نشان داد که عملکرد طبقهبندی با استفاده از ویژگیهای انتخابشده CFS در اکثر موارد بهطور معنیداری شبیه به آن چیزی است که با استفاده از همه ویژگیها به دست میآید، در حالی که تأثیر منفی معنیدار آماری انتخاب ویژگی اغلب برای هر دو روش پوشش مشاهده شد (شکل 4) . ). میتوان آن را به حساسیت RF به نمونههای آموزشی محدود نسبت داد، زیرا این روش از حجم نمونه بزرگتر سود میبرد [ 50 ]. برای طبقهبندی کننده SVM، نتایج نشان داد که معمولاً هیچ تفاوت آماری معنیداری در دقت کلی بین استفاده از ویژگیهای انتخاب شده با سه روش ارزیابی ویژگی-زیر مجموعه-ارزیابی و مجموعه ویژگی کامل وجود ندارد (شکل 5) .، به ویژه برای اندازه مجموعه آموزشی کوچک، از آنجایی که ترکیب بردارهای پشتیبان را نمی توان به طور قابل توجهی با افزودن نمونه های آموزشی بیشتر برای گستره ابر صفحه جداکننده تغییر داد [ 51 ]. بنابراین، به نظر میرسد طبقهبندیکننده SVM از سه روش ارزیابی ویژگی-زیر مجموعه-ارزیابی بهره میبرد، حتی اگر هیچ بهبودی در دقت آماری معنیداری رخ نداده باشد، زیرا ویژگیهای کاهشیافته با این وجود قادر به بهبود کارایی فرآیند طبقهبندی بودند.
3.3. ارزیابی جامع برای همه روشهای انتخاب ویژگی
به منظور ارزیابی تمامی روشهای انتخاب ویژگی در نظر گرفته شده در این مطالعه، تفاوت معنیدار آماری بین بهترین دقت بهدستآمده با استفاده از ویژگیهای انتخابشده و حاصل از مجموعه ویژگیهای کامل با استفاده از آزمون t دو دنباله و همچنین ارزیابی ارزیابی شد . از پاسخ های همه روش های انتخاب ویژگی در نظر گرفته شده و هر دو طبقه بندی کننده در برابر پارامتر اندازه مجموعه آموزشی ( جدول 3). از نظر سه رویکرد ارزیابی ویژگی – زیرمجموعه – ارزیابی، تنها یک زیرمجموعه ویژگی بهینه را میتوان برای نمونهگیری منفرد به دست آورد، در حالی که مجموعهای از زیرمجموعههای ویژگی احتمالاً از فهرست ویژگیهای رتبهبندی شده برای روشهای ارزیابی اهمیت ویژگی مشتق میشوند. بنابراین ما در نظر گرفتیم که بهترین دقت طبقهبندی از این زیرمجموعه ویژگی بهینه برای رویکردهای ارزیابی ویژگی – زیر مجموعه – به دست آمد. در جدول 3اعداد اعشاری ممکن است برای این سه رویکرد ارزیابی ویژگی-زیرمجموعه در پرانتز قرار گیرند، زیرا تعداد ویژگی ها در اینجا با میانگین تعداد ویژگی های انتخاب شده بر اساس ده تکرار طبقه بندی نشان داده می شود. به دلیل تغییر نمونههای آموزشی، تعداد ویژگیهای بهینه لزوماً برای هر تکرار طبقهبندی سازگار نبود.
با توجه به مقایسه بین دو نوع نتیجه انتخاب ویژگی، ویژگیهای به دست آمده از ارزیابی اهمیت ویژگی همیشه تأثیر مثبتی بر عملکرد طبقهبندی مبتنی بر شی داشت، هر طبقهبندیکننده که استفاده میشد، در حالی که تأثیر منفی اغلب برای یک طبقهبندی مشاهده شد. زیر مجموعه ویژگی که از دو روش wrapper مشتق شده است. به نظر میرسد که روشهای wrapper برتری را برای طبقهبندی مبتنی بر شی، که در دادههای ابرطیفی هر پیکسل ادعا میشود، حفظ نمیکنند [ 37 ، 52 ، 53 .]. علاوه بر این، سه روش ارزیابی ویژگی-زیر مجموعه-از تعداد کمی از ویژگی ها به عنوان زیرمجموعه ویژگی بهینه استفاده می کنند، به ویژه برای هر دو روش بسته بندی، در حالی که سایر روش های ارزیابی اهمیت-ویژگی ثابت کردند که تعداد نسبتاً زیادی از ویژگی ها احتمالاً به دست می آیند. بهترین دقت طبقه بندی ( جدول 3 ). ما فرض میکنیم که این مربوط به تخمین بیش از حد عملکرد طبقهبندیکننده است، به دلیل اعتبارسنجی متقاطع مبتنی بر نقطه در فرآیند روش wrapper [ 54 ، 55 ]، به طوری که بهترین دقت بیشتر برای تعداد کمتری به دست آمد. ویژگی ها، به خصوص زمانی که طرح یادگیری روش wrapper یک طبقه بندی کننده RF بود. دنبال کردن جانسون [ 56]، همچنین این موضوع را با استفاده از یک روش ارزیابی دقت مبتنی بر نقطه برای اعتبار سنجی متقابل انتخاب ویژگی مبتنی بر پوشش در یک طبقهبندی مبتنی بر شی ارائه کردیم، زیرا شی قطعهبندی شده لزوماً بهعنوان یک کلاس نشان داده نمیشود زیرا احتمال وقوع اشیاء مخلوط [ 9 ]. در یک مطالعه آینده، ما یک روش ارزیابی دقت مبتنی بر چند ضلعی را توصیه میکنیم که برای اعتبارسنجی متقابل در فرآیند انتخاب ویژگی مبتنی بر لفاف استفاده شود.
از سوی دیگر، بهترین دقت طبقه بندی از ویژگی های رتبه بندی شده ایجاد شد. این به طور قابل توجهی بهتر از آن است که از مجموعه ویژگی های کامل مشتق شده است و نشان می دهد که انتخاب ویژگی دارای پتانسیل بهبود طبقه بندی مبتنی بر شی است، حتی اگر دقت طبقه بندی با استفاده از روش های ارزیابی ویژگی-زیر مجموعه برتری نسبت به مواردی که با استفاده از همه ویژگی ها به دست می آیند، ندارد. به دلیل ویژگی های محدود تعیین شده بنابراین، به نظر میرسد که روشهای ارزیابی اهمیت ویژگی برای طبقهبندی مبتنی بر شی مناسبتر هستند و روشهای wrapper برای استفاده از اعتبارسنجی متقاطع مبتنی بر چند ضلعی ضروری هستند.
برای روشهای ارزیابی اهمیت-ویژگی، طبقهبندیکننده RF به طور قابلتوجهی از روشهای انتخاب ویژگی RF و SVM-RFE بهرهمند شد، در حالی که هیچ بهبود قابلتوجهی برای هر دو روش دیگر (نسبت به دست آوردن و Relief-F) مشاهده نشد (جدول 3 )). برعکس، طبقهبندیکننده SVM میتواند بیشترین پیشرفت را از هر پنج روش ارزیابی ویژگی-اهمیت-ارزیابی به دست آورد. علاوه بر این، اگر هدف بهینهسازی دقت طبقهبندی مبتنی بر شی باشد، ممکن است استفاده از روشهای ارزیابی ویژگی-اهمیت-ارزیابی را پیشنهاد کنیم، در حالی که روشهای ارزیابی ویژگی-زیر مجموعه به طور قابل توجهی دقت طبقهبندی را در هیچ موردی بهبود ندادند. علاوه بر این، آزمایش ما (با استفاده از حداکثر 32) نشان داد که تعداد بهینه ویژگی های ورودی برای به دست آوردن بهترین طبقه بندی بین 15-25 ویژگی برای طبقه بندی کننده RF است. با این حال، در بیشتر مواردی که از روشهای ارزیابی ویژگی-اهمیت-ارزیابی در ترکیب با طبقهبندی کننده SVM استفاده میکردند، نتایج نشان داد که مجموعههای ویژگی نسبتاً کوچک (10-20) بهترین دقت را به دست آوردند.
4. نتیجه گیری
در این مطالعه، چندین روش انتخاب ویژگی پیشرفته برای طبقهبندی مبتنی بر شی مناطق کشاورزی با استفاده از تصاویر پهپاد و طبقهبندیکنندههای RF و SVM مورد ارزیابی قرار گرفت. یک نتیجهگیری اصلی این است که طبقهبندیکننده RF نسبتاً به ابعاد دادهها حساس نیست و طبقهبندیکننده SVM از تجزیه و تحلیل انتخاب ویژگی در مورد دقت، بهویژه برای اندازههای مجموعه آموزشی کوچک سود بیشتری میبرد. علاوه بر این، SVM به راحتی تحت تأثیر تعداد ویژگی های ورودی، یعنی پدیده هیوز، زمانی که از نمونه های آموزشی کوچک استفاده می شود، قرار می گیرد.
نتایج همچنین نشان می دهد که انتخاب یک روش انتخاب ویژگی مناسب بسیار مهم است زیرا عملکرد در اکثر موارد بسیار متفاوت است. به عنوان مثال، با روشهای ارزشیابی-اهمیت-ویژگی، ابتدا دقت قابل مقایسه با استفاده از تعداد ویژگیهای مختلف به دست آمد، در حالی که دقتهای طبقهبندی مختلف با همان تعداد ویژگی به دست آمد ( جدول 1 ). برای طبقهبندی RF با استفاده از هر دو روش لفاف، کاهش آماری معنیداری در دقت مشاهده شد که عمدتاً مستقل از اندازه مجموعه تمرینی بود ( شکل 4) .). بنابراین، CFS ممکن است یک روش ارزیابی ویژگی – زیرمجموعه – ارزیابی مناسب باشد، زیرا مجموعه دادههای کاهشیافته میتواند دقت طبقهبندی مشابهی را در مقایسه با آنچه از مجموعه ویژگیهای کامل به دست میآید به دست آورد. در نهایت، نتایج روشهای ارزیابی اهمیت ویژگی نشان میدهد که طبقهبندی مبتنی بر شی میتواند از انجام تحلیل انتخاب ویژگی قبل از طبقهبندی سود ببرد، اما ممکن است پیشبینی شود که اعتبارسنجی متقاطع مبتنی بر چند ضلعی میتواند حتی برای بهبود بیشتر ویژگی مناسبتر باشد. انتخاب برای طبقه بندی مبتنی بر شی برای روش wrapper.
برای روش طبقهبندی با استفاده از روشهای ارزیابی اهمیت ویژگی، 15 تا 25 ویژگی ورودی احتمالاً بهترین نتایج طبقهبندی را برای طبقهبندی کننده RF در بیشتر موارد ایجاد میکنند. برای طبقهبندیکننده SVM، 10 تا 20 ویژگی ورودی معمولاً بهترین نتایج را ایجاد میکنند، بسته به الگوریتم انتخاب ویژگی و اندازه مجموعه آموزشی. ایده در مورد روش لفاف در مطالعات قبلی اثبات نشده است، و بنابراین نویسندگان امیدوارند که این یافتهها از پیشرفت و بلوغ بیشتر روشهای طبقهبندی OBIA پشتیبانی کند. بنابراین در کار آینده، ما انتظار داریم که روشهای wrapper با اعتبار متقاطع مبتنی بر چند ضلعی ممکن است عملکرد روشهای wrapper را در طبقهبندی مبتنی بر شی بهبود بخشد.




بدون نظر