1. معرفی
توسعه سریع فناوری اطلاعات و ارتباطات (ICT) منجر به گسترش مجموعهای از دادههای تحرک بسیار شخصی شده استخراج شده از پستهای رسانههای اجتماعی شده است. سرویسهای رسانههای اجتماعی، بهویژه پلتفرمهای میکروبلاگینگ مانند توییتر، اشتراکگذاری افکار خود در مورد رویدادهای لحظهای را برای افراد آسانتر میکنند و اطلاعاتی را ارائه میدهند که میتواند توسط محققان برای اهداف مختلف استخراج و استفاده شود. از سال 2007 تا 2013، تعداد کل توییت های روزانه از پنج هزار به 500 میلیون در سراسر جهان افزایش یافت .]. افزایش تعداد توییت ها و محتوای جغرافیایی فراوانی که در توییت ها تعبیه شده است، توییتر را به منبعی عالی برای مطالعات تحرک جغرافیایی تبدیل کرده است. دادههای توییتر برای محققان جغرافیایی که برای جمعآوری اطلاعات رویدادهای جغرافیایی تلاش میکنند که میتواند زودگذر و پویا باشد، نعمت بزرگی بوده است.
چندین ویژگی کلیدی توییتر آن را در نظارت بر چگونگی پیشرفت رویدادها ارزشمند می کند. ابتدا، پلتفرم توییتر به کاربران امکان می دهد در هر زمان و در هر مکانی درباره آنچه اتفاق می افتد توییت کنند. دوم، کاربرانی که بهعنوان حسگرهای اجتماعی عمل میکنند، دائماً اطلاعات بلادرنگ یا نزدیک به زمان واقعی را به عموم گزارش میدهند. ویژگی ریتوییت (پست مجدد توییت شخص دیگری) به انتشار اطلاعات بیشتر و سریعتر کمک می کند. ثالثاً، توییتهای ارجاعشده جغرافیایی نیز توصیفهای صریح زمانی-مکانی رویدادها را ارائه میکنند. چهارم، پایگاه کاربران بزرگ (اعم از افراد و سازمان ها) و توزیع جغرافیایی گسترده کاربران، پوشش گسترده ای از رویدادها را در سراسر جهان ارائه می دهد. این ویژگی ها تعداد فزاینده ای از محققین را جذب کرده است که از داده های توییتر برای بررسی فعالیت های انسانی شهری و الگوهای تحرک استفاده می کنند [ 2]، 3 ، 4 ].
علیرغم مزایای توییتر در تحقیقات جغرافیایی، ناهمگونی داده ها و اندازه کلان داده استخراج اطلاعات مفید از داده های توییتر را چالش برانگیز می کند [ 5 ]. پیامهای کاربران به موضوعات و احساسات، علایق شخصی و فعالیتهای مختلف میپردازد. توییت ها همچنین از اختصارات و عبارات یا کلمات غیر معمول استفاده می کنند. استخراج اطلاعات ثابت در مورد رویدادها به دلیل محتوای فراوان و متنوع دشوار است. برخی رویدادهای مهم میتوانند تعداد زیادی پست را در مدت زمان بسیار کوتاهی ایجاد کنند و مدیریت کارآمد حجم دادههای بزرگ در برنامههای حساس به زمان را دشوار میکنند. در سالهای اخیر، سیستمها و الگوریتمهای زیادی برای رسیدگی به این چالشها توسعه یافتهاند [ 6]، از جمله رویکردهایی که توزیع فضایی توییتهای دارای برچسب جغرافیایی را تحلیل میکنند، مانند خوشهبندی جغرافیایی یا اسکنهای زمانی- مکانی [ 7 ]. بیشتر مطالعات قبلی بر روی توسعه الگوریتم هایی برای تشخیص رویداد تمرکز دارند. توجه کمتری به تجزیه و تحلیل تکامل مکانی-زمانی رویدادهای شناسایی شده شده است. یافتن الگوها و توالی رویدادها در وضعیت شار رویداد پیوسته ضروری می شود [ 8 ]. پرسشهایی مانند زمان و مکان شکلگیری رویدادها و اینکه رویدادها چگونه تکامل توییتها را در مکان و زمان دیکته میکنند، کمتر مستند شدهاند.
در این مقاله، ما یک رویکرد سیستماتیک برای برداشت، پردازش و تجزیه و تحلیل دادههای رسانههای اجتماعی به منظور ترسیم تکامل مکانی و زمانی رویدادها ارائه میکنیم.
رویکرد ما سه کمک منحصر به فرد به ادبیات ارائه می دهد. اول، این مطالعه از جریان داده های توییتر در زمان واقعی استفاده می کند. برخلاف روشهایی مانند اسکنهای مکانی-زمانی که عمدتاً برای فرآیندهای دستهای استفاده میشوند، این مطالعه از دو پنجره متحرک برای شناسایی مؤثر رویدادهای زمان واقعی بالقوه در منطقه مورد مطالعه استفاده میکند. دوم، رویکرد پیشنهادی همچنین رویدادهای منطقهای و محلی را بر اساس ویژگیهایی از ابعاد مختلف توییتها به طور همزمان کشف میکند. سوم، ما همچنین تکامل مکانی-زمانی و پویایی رویدادهای طبیعی و اجتماعی را بررسی می کنیم.
در این مطالعه، ما یک رویکرد کارآمد مبتنی بر یادگیری ماشین و تجسم جغرافیایی را با استفاده از ابعاد مختلف توییتها (اطلاعات پیام، نویسنده، زمان و مکان)، برای شناسایی تکامل رویدادها، از جمله رویدادهای برنامهریزیشده (مانند جشنوارهها یا ورزش) توسعه میدهیم. و حوادث اتفاقی (مثلاً بلایا یا حوادث). ما مسیر رویدادها را در فضا و زمان دنبال می کنیم. ما این روش را با دو مطالعه موردی نشان میدهیم که الگوهای حرکت زمانی رویدادها را در شهر نیویورک-واشنگتن، منطقه دی سی تحلیل میکنند. با ترکیب ابعاد چندگانه دادههای توییتر، این مقاله روشی را برای ایجاد مسیرهای مکانی و زمانی رویدادها با استخراج دادههای داوطلبانه از پلتفرمهای رسانههای اجتماعی ارائه میکند.
2. کارهای مرتبط
تجزیه و تحلیل داده های رسانه های اجتماعی برای به دست آوردن اطلاعات مکانی و دانش مربوط به رویداد توجه فزاینده ای را به خود جلب کرده است [ 9 ، 10 ، 11 ]. داده های رسانه های اجتماعی یک فرصت بی سابقه برای مطالعه پویایی های زمانی در زمان واقعی و در مقیاس های چندگانه ارائه می دهد [ 8 ]. با این حال، به دلیل ماهیت پر سر و صدا و پیچیده پیامهای رسانههای اجتماعی، استخراج اطلاعات معنادار بیاهمیت است. به عنوان مثال، بیش از 200 میلیون توییت در سال 2011 هر روز پست می شد [ 12 ]. اطلاعات مهم شهری اغلب در مخزن بزرگی از داده های نامربوط دفن می شوند. استخراج اطلاعات معنی دار بدون تجزیه و تحلیل متن هوشمند و استراتژی های کارآمد عملا غیرممکن است [ 12].
برای تسهیل استخراج چنین دادههایی، مطالعات اخیر روشهایی را برای ثبت الگوهای مکانی-زمانی فعالیتهای انسانی و رویدادهای شهری از دادههای توییتر توسعه دادهاند [ 6 ، 13 ]. روش های تشخیص رویداد در این مطالعات را می توان تا حد زیادی به عنوان هدفمند یا عمومی طبقه بندی کرد. تشخیص رویداد هدفمند معمولاً بر روی انواع خاصی از رویدادها بر اساس مجموعه ای از کلمات یا هشتگ ها تمرکز می کند، مانند زلزله [ 14 ]، اپیدمی های آنفولانزا [ 15 ] و بازی های ورزشی [ 16 ، 17]]. توییتهایی که حاوی کلمات کلیدی یا هشتگهای خاصی هستند، مانند «زلزله» یا «NFL» میتوانند برای شناسایی دقیق رویدادهای مرتبط با موضوع مورد علاقه استفاده شوند. با این حال، مجموعه کلمات کلیدی ممکن است ذهنی باشد و بسیاری از توییت های دیگر مرتبط با رویدادها را حذف کند. همچنین ممکن است برای انتخاب کلمات مناسب برای ردیابی به تجربه قبلی رویداد نیاز باشد [ 7 ]. برخی از مطالعات اخیر الگوریتم هایی را برای مقابله با این موضوع ایجاد کرده اند. سیستم TEDAS برای کشف جرم و حوادث مرتبط با فاجعه (CDE) توسعه یافته است. این مطالعه به صورت دستی مجموعه ای از کلمات کلیدی مرتبط با CDE را به عنوان دانه تنظیم کرد و سپس یک الگوریتم اصلاح شده تکراری را برای استخراج کلمات کلیدی مرتبط جدید اعمال کرد [ 4 ]. لیلوی و همکاران (2017) میزان ارتباط پیام های توییتر را با یک رویداد خاص مورد علاقه ارزیابی کرد [18 ]. وانگ و همکاران (2012) از یک رویکرد برچسب گذاری نقش معنایی برای هدف قرار دادن توییت های مرتبط با جرم استفاده کرد [ 19 ].
در مقابل، تشخیص رویداد عمومی بر موضوعات نوظهوری تمرکز میکند که توجه جمعیت زیادی را به خود جلب میکند (مثلاً یک طوفان یا جشنواره ملی) یا حوادث محلی که به سرعت در زمان و در مکان متراکم اتفاق میافتند (مثلاً تصادفات رانندگی یا رژه). روش های مختلفی برای تشخیص این رویدادهای عمومی استفاده شده است. روشهای تشخیص مبتنی بر محتوا از تکنیکهای محوری سند یا محور محوری استفاده میکنند [ 20 ، 21]. Document-pivots معمولاً از تکنیک های خوشه بندی برای یک ماتریس سند-ترم برای شناسایی یک موضوع در یک مجموعه بزرگ استفاده می کند. تکنیکهای محور محوری بر روی ویژگیهای n-gram کار میکنند، با هدف شناسایی عبارات نماینده برای رویداد مورد نظر. بسیاری از تکنیکهای داده کاوی در این دو رویکرد استفاده شدهاند، از جمله تکنیکهای خوشهبندی سلسله مراتبی مبتنی بر فواصل زوجی [ 21 ]، تجزیه و تحلیل موجک فرکانسهای کلمه برای به دست آوردن ویژگیهایی برای هر کلمه [ 22 ]، و هش حساس محلی (LSH) برای کشف رویدادهای احتمالی. [ 23 ]. برای تشخیص مبتنی بر مختصات، مجاورت فضایی به طور گسترده ای برای آماده سازی توییت های نامزد برای رویدادهای محلی استفاده شده است [ 3 ، 24]]. DBSCAN همچنین برای کشف خوشه هایی با شکل دلخواه استفاده شده است [ 25 ]. نقاط داغ شناسایی شده احتمالاً با رویدادهای خاصی مرتبط هستند.
آمار اسکن فضا-زمان برای جستجوی دستههایی از توییتها در فضا و زمان، صرف نظر از محتوای توییت، استفاده شده است. این روش می تواند رویدادهای مختلف را حتی در مدت زمان نسبتاً کوتاهی از جمع آوری داده ها شناسایی کند [ 7 ]. از الگوهای زمانی توییت ها نیز می توان برای تشخیص رویدادها استفاده کرد. رویدادها معمولاً انبوهی از ویژگیها را در جریانهای توییتر نشان میدهند، مانند افزایش ناگهانی کلمات کلیدی خاص [ 20 ]. لی از تکنیک پنجره کشویی برای تشخیص تغییرات زمینه استفاده کرد و جریان های پیام را بر این اساس وزن کرد [ 26 ]. بوچر و لی از تکنیکهای خوشهبندی مبتنی بر چگالی در توییتهایی که در یک بازه زمانی کشویی گرفته شدهاند برای شناسایی رویدادهای احتمالی استفاده کردند [ 24 ].
بسیاری از روشهای مورد استفاده برای استخراج رویدادها، مانند روش اسکن فضا-زمان، مبتنی بر تکنیکهای خوشهبندی مکان هستند. این تکنیک ها در زمینه تشخیص رویداد گذشته نگر (RED) موثر هستند، زیرا مجموعه داده های تاریخی معمولاً حاوی مختصات نقطه غنی هستند. با این حال، ما به رویکردهایی برای مقابله با چالش تشخیص رویداد جدید (NED) از جریانهای زمان واقعی نیاز داریم. روشهای قبلی که با NED مقابله میکنند، مانند خوشهبندی سلسله مراتبی، از نظر محاسباتی فشرده و کند هستند. روشهای سبک و کارآمد برای پردازش دادههای توییت بلادرنگ مورد نیاز است.
بسیاری از مطالعات بر روی تکنیکهای تشخیص رویداد تمرکز دارند، اما تعداد کمتری از آنها به بررسی تکامل مکانی-زمانی این رویدادها میپردازند. داده های رسانه های اجتماعی ممکن است معنای معنایی، اطلاعات پس زمینه و احساسات را در محتوا جاسازی کنند. گاهی اوقات این محتوا به صورت مکان دقیق از جایی که این توییتها پست شدهاند یا به عنوان نامهای این مکانها دارای برچسب جغرافیایی میشوند [ 9 ]. مطالعات گزارش کردهاند که درصد توئیتهای دارای برچسب جغرافیایی دقیق ممکن است بسته به رویداد، زمان و مکان متفاوت باشد و تقریباً از 0.5٪ تا 5.0٪ از کل مجموعه دادهها متغیر باشد [9 ، 27 ، 28 ]]. اگرچه درصد کلی توییتهای برچسبگذاریشده جغرافیایی زیاد نیست، اما هنوز هم میتوان رویدادهای برچسبگذاریشده جغرافیایی را از توییتها در سطح جمعآوری، بهویژه در مقیاس منطقهای تشخیص داد. اطلاعات معنایی و مکانی در مقیاس های منطقه ای فرصت خوبی برای تجزیه و تحلیل تحول مکانی- زمانی رویدادها فراهم می کند. احساسات تعبیه شده در توییتها همچنین میتواند نگرشها و احساسات عمومی را در حین توسعه رویداد دنبال کند. چند مطالعه جغرافیایی پیشرفت رویدادها را با برداشت و تجزیه و تحلیل اطلاعات مکانی از محتوای رسانههای اجتماعی بررسی کردهاند. این مطالعات پیشرفت بلایای طبیعی مانند آتش سوزی [ 29 ] و زلزله [ 30] را بررسی کرده اند.]. تجزیه و تحلیل فضایی و زمانی محتوای توییتر نیز برای ردیابی شیوع و توزیع بیماری استفاده شده است [ 31 ، 32 ].
هدف این مطالعه ابتدا ایجاد یک رویکرد کارآمد برای اسکن سریع ابعاد چندگانه توییتها برای ثبت رویدادهای زمان واقعی و منطقهای، از جمله رویدادهای برنامهریزیشده (مانند جشنوارهها یا ورزش) و تصادفی (مثلاً بلایا یا حوادث) و فرمولبندی تصاویر موضوعی این رویدادها است. در نقاط مبدأ خود دوم، ما مسیرهای مکانی و زمانی رویدادهای فرموله شده را ردیابی می کنیم تا ویژگی های مکانی-زمانی آن رویدادهای منطقه ای شناسایی شده را بررسی کنیم و واکنش مردم به این رویدادها را بررسی کنیم.
3. روش ها
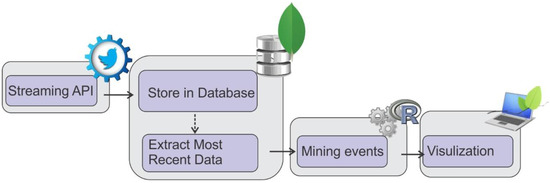
شکل 1 جریان کلی فرآیند داده را نشان می دهد. دادههای توییتر بلادرنگ منتشر شده از طریق رابط برنامهنویسی جریانی (API) به عنوان اسناد MongoDB جمعآوری و تجزیه میشوند. سپس، اطلاعات مکانی-زمانی از سند MongoDB برای فرآیند تشخیص الگو خوانده می شود. مدل محاسباتی برای تشخیص الگو به زبان R ساخته شد. برای تجسم نتایج از برگه و R استفاده شد.
3.1. جمع آوری داده ها
داده های مورد استفاده در این مطالعه از طریق API جریان توییتر در زمان واقعی به سیستم ما منتقل شد. Geo API توییتر به کاربران این امکان را میدهد که پستهای توییتی را که در یک منطقه جغرافیایی تعریف شده توسط یک کادر محدود قرار دارند، جمعآوری کنند. در این مطالعه، ما یک کادر مرزی ترسیم می کنیم که مناطق شهری از نیویورک تا واشنگتن دی سی را پوشش می دهد. این منطقه نه تنها یکی از مناطقی است که بیشترین جمعیت کاربر توییتر را دارد، بلکه دارای شهرهایی با موقعیت اجتماعی-اقتصادی متمایز و برجسته است. واشنگتن دی سی پایتخت ایالات متحده است و شهر نیویورک یک شهر جهانی با نقش تعیین کننده در اقتصاد جهانی است. داده ها با استفاده از یک ساختار ارزش کلیدی استاندارد منتشر می شوند. اطلاعات جغرافیایی بسیار ارزشمندی را می توان با استفاده از این ساختار استخراج کرد، مانند پروفایل های کاربر و موقعیت جغرافیایی توییت ها. توییتهای جمعآوریشده از Geo API حداقل یک نوع داده مکان دارند، مانند محتوای مکان، مناطق زمانی، نام مکانها و اندازهگیریهای سیستم موقعیتیابی جهانی (GPS). اطلاعات GPS دقیق ترین اطلاعات نقطه ای را از جایی که یک توییت پست شده است، ارائه می دهد. میانه خطای افقی تخمین زده شده برای GPS در تلفن های هوشمند حدود 5-8.5 متر است.33]. از آنجایی که اکثر توییت ها از GPS برای نشان دادن مکان خود استفاده می کردند، ما فقط از توییت هایی با اطلاعات GPS استفاده می کردیم. در این مطالعه، پیام توییت واقعی، مکان ارسال و زمان پست تجزیه و تحلیل شد. هر توییت تجزیهشده را میتوان با عبارت زیر نشان داد: tw = (id; uid; twtxt; twtime; twloc) که در آن id شناسه توییت است، uid شناسه کاربر، twtxt پیام توییت، twtime مهر زمانی و twloc مکان جغرافیایی است. اطلاعات هر توییت تجزیه شده به عنوان یک سند MongoDB ذخیره شد. MongoDB از پرس و جوهای متنی (غیر مکانی) و همچنین پرس و جوهای فضایی پشتیبانی می کند. به منظور بهبود عملکرد پرس و جو MongoDB، دو شاخص ایجاد شده است، یکی برای شناسه غیرمکانی و دیگری شاخص فضایی برای twloc فضایی. برای شاخص فضایی، روابط جغرافیایی نسبی توییت ها را می توان برای نشان دادن توییت های نزدیک ایجاد کرد.
3.2. پیش پردازش داده ها
در این مرحله، توییتها با حذف توییتهای غیر انگلیسی، کاراکترهای خاص، کلمات توقف، جایگزینی حروف بزرگ با حروف کوچک و توکن کردن هر توییت به کلمات جداگانه، پاک و فیلتر شدند. کلمات توقف از لیست SMART در بسته R tm بازیابی شد. ما همچنین کلمات محبوب دیگری را در منطقه مورد مطالعه بر اساس توییتهای تاریخی شناسایی کردیم، مانند «احساس»، «ساعت» و «دوست» که در بستههای کلمات توقف گنجانده نشدهاند. این کلمات در فرآیند تشخیص کاربرد کمتری دارند و از این رو از مجموعه حذف شدند. ما از جعبه ابزار MC برای توکن کردن یک سند در فضای برداری استفاده کردیم. MC toolkit یک برنامه مبتنی بر C++ است که مدلهای فضای برداری را از اسناد متنی با استفاده از پیادهسازی چند رشتهای ایجاد میکند که میتواند به طور موثر مجموعههای اسناد بسیار بزرگ را پردازش کند [ 34 ]. فرض کنید تیمنتیمنداده های توییت در حال پردازش است، و جمنجمنمحتوای آن است تیمنتیمن. نتیجه پیش پردازش تقسیم می شود جمنجمندر اطراف فضاهای خالی برای ایجاد مجموعه ای از کلمات دبلیومندبلیومن. عبارت جمن= ” So t h i s i s h a p p e n i n g . u f c 205 ”جمن=”اس� تیساعتمنس منس ساعتآپپه�من��. تو�ج205”تبدیل خواهد شد به دبلیومن = { “ اتفاق می افتد ” , “ u f c 205 ” }دبلیومن ={“اتفاق می افتد”، “تو�ج205”}.
3.3. ماژول ساخت لایه
بر اساس مهرهای زمانی، توییتها در یک بازه زمانی یک ساعته ابتدا استخراج و به سازنده لایه ارسال شدند. سازنده هر توییت t را به شماره توکن، شماره کاربر و شماره مختصات خود، یعنی یک تاپل شماره توکن Pwn = ( w , n )، یک توکن کاربر تاپل P wu = ( w , u ) و یک توکن نگاشت کرد. تاپل مختصات P wc = ( w , C )، که در آن n تعداد هر توکن w است ، u تعداد کاربرانی است که توکن w را ذکر کرده اند.و C لیستی از جفت مختصات ( lat ، lon ) در ناحیه مورد مطالعه مرتبط با w است . سازنده همچنین فرکانس f(w) هر نشانه و فرکانس کاربر f(u) را برای هر نشانه w در پیکره محاسبه کرد. توکن هایی با فرکانس کمتر از سه w“∈ تی { f( w ) < 3 }�”∈ تی{�(�)<3}و نشانه هایی که فقط توسط یک کاربر ذکر شده است w“∈ تی { f( تو ) < 2 }�”∈ تی{�(تو)<2}مستثنی شدند. این کلمات بخش بزرگی از کل کلمات را تشکیل می دهند، اما به احتمال زیاد نویز هستند و به ندرت با رویدادهای احتمالی مرتبط هستند. بنابراین ما این نشانهها را دور میاندازیم و بقیه توکنها را در جداول هش کلید-مقدار کپسوله میکنیم. کلیدها نشانه هستند، مقادیر فرکانس نشانه، شماره کاربر و لیست مختصات مرتبط با هر نشانه هستند. نتایج این مرحله شامل سه مجموعه هش است که کلیدها توکن های حاصل هستند w�در حالی که مقادیر مربوط به P wu ، P wn و P wc برای هستندw�. یک لایه لیستی است که از سه مجموعه هش تشکیل شده است.
برای یافتن نشانههایی که به طور بالقوه به رویدادها مرتبط هستند، از تکنیکهای تشخیص کلمات انفجاری استفاده کردیم. کلمات انفجاری نوکهایی در فرکانس توییتها در طول طیف زمانی هستند. تشخیص رویداد بر اساس کلمات انفجاری شبیه به تشخیص روند است [ 24 ]. بهجای استفاده از روشهای سنتی برای تشخیص کلمات انفجاری، ما دو جفت پنجره زمانی شناور برای آشکارسازی بهتر رویدادها طراحی کردیم. اولین جفت پنجره نشانه هایی را که در یک ساعت اخیر رخ داده اند مقایسه می کند دبلیودساعتدبلیوساعتدبا همان نشانه هایی که در چهار ساعت گذشته رخ داد دبلیودh − 4دبلیوساعت-4دبه دبلیودh − 1دبلیوساعت-1د. جفت پنجره دوم نشانه هایی را که در یک ساعت اخیر رخ داده اند مقایسه می کند دبلیودساعتدبلیوساعتدبا همان نشانه هایی که یک هفته پیش در همان زمان رخ داد دبلیود– 7ساعتدبلیوساعتد-7. سیستم دو صف برای ذخیره داده ها در دو جفت پنجره زمانی نگه می دارد. هر صف شامل پنج جزء مربوط به پنج جدول برای هر ساعت است ( شکل 2 ). هنگامی که سیستم برای اولین بار راه اندازی می شود، ده جزء به یکباره محاسبه می شوند (که با بلوک های رنگی در شکل 2 نشان داده شده اند ). در ساعات بعدی، تنها دو جزء (آخرین ساعت و ساعت مشابه یک هفته پیش) به ترتیب به صفهای پنجره زمانی فشار داده میشوند. قدیمی ترین مولفه ها از صف ها بیرون می آیند. بقیه در صف نگه داشته می شوند (که با رنگ b/w در شکل 2 نشان داده شده است ). طراحی پنجره متحرک تا حد زیادی تقاضای محاسباتی را کاهش می دهد. تنها دو مؤلفه از هر ده مؤلفه باید هر ساعت به روز شود. توکنها در یک ساعت اخیر دبلیودساعتدبلیوساعتدبه عنوان لایه مرجع RL مشخص می شوند . ویژگی های طبقه بندی بر اساس لایه مرجع تهیه می شود. ویژگی طبقه بندی در بخش بعدی معرفی خواهد شد.
3.4. ماژول آماده سازی ویژگی
هنگامی که ده لایه ساخته شد، ویژگی های طبقه بندی برای شناسایی رویدادهای منطقه ای و محلی آماده می شود. توکن ها دبلیوآر افدبلیوآرافدر لایه مرجع RL به عنوان مشاهدات استفاده می شود. به عبارت دیگر، ویژگیها فقط برای توکنهای موجود در RL محاسبه میشوند . توکن هایی که در لایه های دیگر وجود دارند اما در RL نیستند محاسبه نمی شوند.
توکن های مربوط به رویدادها معمولاً چهار ویژگی دارند. اول، کلمات مرتبط با رویدادهای مهم تمایل دارند که افزایش ناگهانی بیشتری در فراوانی داشته باشند. دوم، توکن هایی که توسط بسیاری از افراد توییت می شوند، تمایل دارند رویدادهای منطقه ای را نشان دهند. سوم، رویدادهای منطقه ای تمایل دارند با افزایش ناگهانی توکن ها از یک منطقه جغرافیایی گسترده همراه باشند. چهارم، توکنهایی که در یک منطقه کوچک در مدت زمان کوتاهی متمرکز میشوند ممکن است حاکی از رویدادهای محلی باشند.
برای ثبت اولین مشخصه، فرکانس را محاسبه کردیم افwاف�برای هر نشانه wمن�من∈ دبلیوآر افدبلیوآرافدر ده لایه برای تنظیم تعداد کل توییت ها در زمان های مختلف، توکن را تقسیم کردیم افwاف�با تعداد کل توییت در پنجره زمان برای دریافت فرکانس رمز تنظیم شده زمان.
این احتمال وجود دارد که توییت های مشابه تنها توسط یک فرد یا ماشین بارها در مدت زمان کوتاهی توییت شود. سهم کلمات کلیدی در چنین توییت هایی باید کاهش یابد. به همین دلیل، مانند فرکانس توکن، اعداد کاربران را محاسبه کردیم افتوافتوبرای ده لایه نیز. اعداد کاربر نشان دهنده محبوبیت کلمات کلیدی در بین کاربران مختلف است.
برای محاسبه ویژگی سوم، تعداد مختصات را محاسبه کردیم افجافجکه با توکن مرتبط هستند wمن�من∈ دبلیوآر افدبلیوآرافدر ده لایه توکن هایی که به طور گسترده ذکر می شوند به احتمال زیاد با یک رویداد منطقه ای مرتبط هستند.
رویدادهای محلی ممکن است حاوی پیامهایی باشد که به شدت گزارش شده است. ما از تکنیک DBSCAN برای محاسبه خوشه های محلی استفاده کردیم. DBSCAN یک الگوریتم خوشه بندی است که نقاط نزدیک به هم را گروه بندی می کند. DBSCAN برای محاسبه به دو پارامتر نیاز دارد: حداقل تعداد نقاط و حداکثر شعاع در اطراف یکی از اعضای خود (seed). نقاطی در شعاع یک نقطه داده شده، که شرایط دانه را برآورده می کنند، به صورت بازگشتی به عنوان اعضای خوشه انتخاب می شوند [ 35]. ما از بسته “fpc” در R برای انجام تجزیه و تحلیل DBSCAN استفاده کردیم. ما توکن ها را با مختصات جغرافیایی اسکن کردیم و با مشاهده اندازه و میانگین نقاط برای رویدادهای محلی، دو پارامتر را تعیین کردیم. ما از شعاع جستجو eps = 0.0007 و حداقل امتیاز MinPts = 3 در این مطالعه استفاده کردیم. تعداد خوشه ها و تعداد کل نقاط در خوشه ها به عنوان ویژگی استفاده شد.
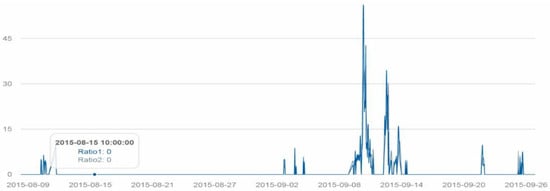
رویدادها معمولاً زمانی رخ میدهند که تعداد کاربران، پوشش جغرافیایی و تعداد توکنها تغییر ناگهانی داشته باشند. ما نسبت ویژگی ها (یعنی ویژگی ها) را محاسبه کردیم افwاف�، افتوافتو، افجافجمحاسبه شده در بالا) برای ثبت تغییر ناگهانی. ما دو گروه از نسبت ها را محاسبه کردیم: (1) نسبت ویژگی ها بین آخرین ساعت h i و یک هفته قبل و (2) نسبت ویژگی ها بین پنج ساعت گذشته h i – h i- 4 و یک هفته پیش. نسبت بالاتر نشان دهنده شانس بالاتری است که کلمه کلیدی به یک رویداد مرتبط است.
مواردی وجود دارد که علامت خاصی w در لایه مرجع ( L R ) ظاهر می شود اما هفت روز زودتر در لایه رخ نمی دهد ( L d- 7 ). برای محاسبه نسبت برای این مورد، مسئله «تقسیم بر صفر» را خواهیم داشت. توکن ها در این موارد را می توان بیشتر به سناریوهای S 1 و S 2 تقسیم کرد . S 1 حاوی کلمات تصادفی (مثلاً کلمات خاص یا کلمات غلط املایی) در L R است اما در L d- 7 نیست . این کلمات در L R بسامد پایینی دارند و بعید است که با رویدادها مرتبط باشند.S 2 حاوی کلمات انفجاری است که در L d- 7 وجود ندارند ، اما اغلب در L R وجود دارند . این کلمات به احتمال زیاد کلمات مرتبط با رویداد هستند. ما صدک 60 تا 80 را آزمایش کردیم و نتایج تفاوت قابل توجهی نداشت. بنابراین ما از صدک 70 فراوانی کلمه به عنوان برش برای تشخیص این دو سناریو استفاده کردیم. به کلمات در S 1 نسبت صفر اختصاص داده می شود و نسبت کلمات در S 2 متناسب با فراوانی کلمه در L R خواهد بود که در معادله زیر نشان داده شده است:
که در آن R نسبت وقوع کلمه بین لایه مرجع ( LR ) و لایه هفت روز پیش ( L d- 7 ) را نشان می دهد، و اف( w )اف(�)فرکانس کلمه w را محاسبه می کند. تابع چندک، چندک های نمونه مربوط به احتمالات داده شده را 0.7 محاسبه می کند.
3.5. ماژول طبقه بندی
برای تهیه مجموعه داده آموزشی، ما به صورت دستی 8167 توکن را در روزهای متوالی در آگوست 2015 نمونه برداری و کدگذاری کردیم. بر اساس پیش آزمون الگوریتم های مختلف از جمله kNN، SVM، Naive Bayes، و جنگل تصادفی (RF)، الگوریتم RF را پیدا کردیم. بالاترین دقت را در عملکرد طبقه بندی ایجاد کرد. طبقهبندیکننده RF چندین درخت تصمیم را در فرآیند آموزش برای پیشبینی یک متغیر نتیجه تولید میکند. برای طبقه بندی یک مشاهده جدید، جنگل تصادفی متغیرها را در هر یک از درختان جنگل قرار می دهد. هر درخت یک نتیجه طبقه بندی تولید می کند. سپس جنگل رده بندی را با بیشترین رای به عنوان طبقه بندی نهایی انتخاب می کند. ما از بسته “randomForest” در R برای انجام تجزیه و تحلیل RF استفاده کردیم. در مدل ما، 200 درخت را رشد دادیم تا متغیرهای ورودی را طبقه بندی کنیم.h i و h i تا h i- 4 به ترتیب (4 ویژگی)، فرکانس کاربر تنظیم شده با زمان و نسبت فرکانس کاربر در بازه زمانی h i و h i تا h i- 4 به ترتیب (4 ویژگی)، مختصات تنظیم شده زمان فرکانس و نسبت فرکانس مختصات در بازه زمانی h i تا h i- 4به ترتیب (4 ویژگی)، و تعداد خوشه ها و تعداد کل نقاط در خوشه ها (2 ویژگی). نتایج مدل کلاسهای دوتایی بود که نشان میداد آیا یک نشانه به یک کلاس رویداد تعلق دارد یا خیر. این مدل همچنین یک امتیاز احتمال ایجاد میکند که نشان میدهد چقدر احتمال دارد که نشانه با یک رویداد مرتبط باشد. ما توکن هایی با امتیاز احتمالی بیشتر از 90 درصد را به عنوان نامزدهای مرتبط با رویداد انتخاب کردیم.
بر اساس مدل آموزش دیده، هر نشانه در مجموعه هش به عنوان مرتبط با رویداد یا غیر مرتبط با رویداد برچسب گذاری شد. ما یک رویداد بالقوه را بهعنوان یک کلید-مقدار PE = (Ke , Ve) تعریف میکنیم که در آن Ke مجموعهای از توکنهایی است که بهعنوان مرتبط با رویداد طبقهبندی میشوند و V مجموعهای از توییتها است. ما از یک شاخص ارتباط بین نشانهها در یک ماتریس سند اصطلاح برای یافتن نشانههایی استفاده کردیم که به یک رویداد در مجموعه Ke مرتبط هستند.. شاخص ارتباط نشان دهنده همبستگی بین یک جفت عبارت در بین تمام توییتهای موجود در اسناد است. یک شاخص ارتباط بالا نشان دهنده احتمال زیاد وجود دو کلمه در توییت ها است. به عنوان مثال، اگر نشانههای مرتبط با کلمه «NYFW» (هفته مد نیویورک) را با شاخص ارتباطی بیشتر از 0.4 پیدا کنیم، میتوانیم کلمه کلیدی «مد» را تشخیص دهیم. تمام توییت های مرتبط با این کلمات کلیدی در مجموعه Ve قرار می گیرند . توییت هایی که حاوی مختصات جغرافیایی هستند برای تجزیه و تحلیل الگوی بیشتر در یک Shapefile آماده و ذخیره می شوند.
3.6. تکامل مکانی- زمانی رویدادها
در ماژول تجزیه و تحلیل رویداد، ما عمدتا به ویژگی های زمانی، مکانی و احساسی یک رویداد نگاه می کنیم. برای ویژگیهای زمانی، ما طیف زمانی را برای یک رویداد منحصربهفرد تحلیل کردیم و تشخیص دادیم که این رویداد چه زمانی شروع میشود، به پایان میرسد یا به زمان اصلی میرسد. برای ویژگیهای فضایی، تکامل الگوی فضایی در طول رویداد مورد بررسی قرار گرفت. خطوط کانتور برای نمایش تراکم توییت ها ایجاد شد. از آنجا که مراکز شهرها معمولاً مکانهایی هستند که بیشتر توییتها متمرکز میشوند، ما از حوضه آبریز شناور (FCA) برای کاهش وزن توییتها در مناطق پراکنده استفاده کردیم. به طور خاص، ما یک بافر با 0.05 درجه در اطراف هر توییت مرتبط ترسیم کردیم تا یک پنجره فیلتر تعریف کنیم. وزن هر توییت مربوط به رویداد با تمام توییتهای داخل پنجره فیلتر رابطه معکوس دارد. ما چگالی هسته را بر اساس وزن هر توییت در منطقه مورد مطالعه محاسبه کردیم. فضاهای تراکم هسته با گذشت زمان مورد بررسی قرار گرفت. برای ویژگیهای معنایی، عبارات رایج را تجزیه و تحلیل کردیم و ابرهای کلمه مرتبط با هر رویداد را ایجاد کردیم. منابع واژگانی انگلیسی SentiWordNet 3.0 برای استنتاج احساسات توییتهای مربوط به رویداد استفاده شد. SentiWordNet به صورت عمومی برای پشتیبانی از طبقه بندی احساسات و برنامه های کاربردی نظر کاوی در دسترس است [36 ]. پایگاه داده پسزمینه WordNet شامل مجموعهای غنی از اسمها، افعال، صفتها و قیدها در مفاهیم مختلف شناختی و امتیازات احساسی است. ما احساسات هر توییت را محاسبه کردیم و آنها را در یک پنجره ساعتی جمع کردیم. نمرات مثبت یا منفی به ترتیب نشان دهنده احساسات مثبت یا منفی هستند. نمره صفر به معنای احساس خنثی است. شکل 3 روش های مورد استفاده در این مطالعه را خلاصه می کند.
4. نتایج
در بخشهای بعدی، دو رویداد (طبیعی و اجتماعی) را انتخاب میکنیم که با روش ارائهشده شناسایی شدهاند تا ابعاد مکانی، زمانی و احساسی رویدادها را نشان دهیم.
4.1. بارش شدید
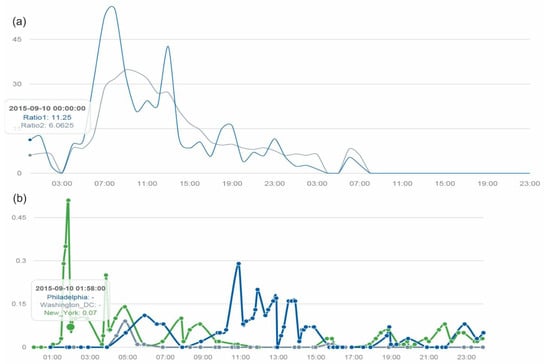
وقتی توییتهایی را در سیستم پخش کردیم و تجزیه و تحلیل رویدادها را در حدود 9 تا 10 سپتامبر انجام دادیم، متوجه شدیم که تعدادی از توییتها به هوای بارانی اشاره کردهاند. پس از جمعآوری دادهها برای یک ماه کامل، به گذشته نگاه کردیم و در 10 سپتامبر در توییتهای مربوط به بارندگی افزایش چشمگیری پیدا کردیم ( شکل 4 ). ما از تابع ارتباط برای جستجوی کلمات کلیدی استفاده کردیم که به شدت با “باران” مرتبط هستند. کلیدواژههای «تر»، «ریختن»، «سیل» و «چتر» شناسایی شدند.
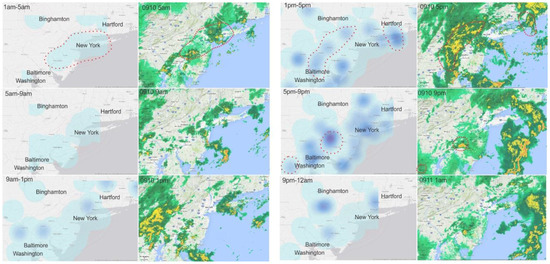
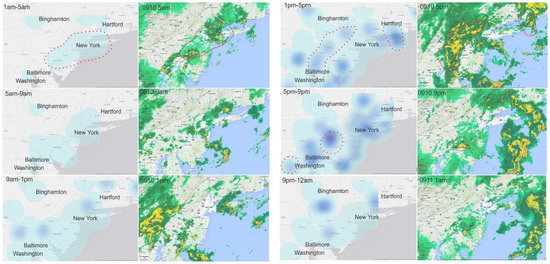
ما توزیع فضایی کلمات کلیدی در مورد باران و نقشه ابر زمان واقعی را در منطقه مورد مطالعه مقایسه کردیم. تخمین چگالی هسته بر اساس وزن توییتهای مرتبط با باران تنظیم شده توسط تعداد کل توییتها، یک الگوی فضایی معقول را نشان داد. ما توییتها را به مدت چهار ساعت جمعآوری کردیم تا تعداد توییتها را با مختصات جغرافیایی برای تجسم افزایش دهیم. اگرچه مقداری اختلاف وجود داشت، نقشه چگالی هسته توییتهای مربوط به باران با نقشه ابری مطابقت داشت. به عنوان مثال، در ساعت 5 صبح، توزیع و جهت توئیت های مربوط به باران تا حد زیادی از توزیع ابر پیروی می کند. مناطق با تراکم هسته قوی در شکل 5 تا حد زیادی با مناطقی که ابرهای سنگین توزیع شده اند مطابقت دارد.
به طور موقت، توییت هایی درباره باران در نیمه شب 10 سپتامبر منتشر شد. توییتهای مربوط به باران حوالی ساعت 4 صبح افزایش یافت و در حدود ساعت 8 صبح به بالاترین حد خود رسید. دومین اوج در حدود ساعت 12 بعد از ظهر تا 1 بعد از ظهر رخ داد و سپس میزان توئیتهای مرتبط با باران کاهش یافت. حوالی ساعت 5 تا 8 بعدازظهر، یک موج کوچک دیگر در توییتهای مرتبط با باران وجود داشت تا اینکه رویداد باران در ساعت 8 صبح، 11 سپتامبر به پایان رسید. ما همچنین سطوح بارندگی را در سه شهر بزرگ (فیلادلفیا، واشنگتن دی سی و شهر نیویورک) در منطقه مورد مطالعه رسم کردیم. ما دریافتیم که شدت توییتهای مرتبط با باران با منحنی بارش مطابقت ندارد. توییتهای بیشتری در زمانهایی که نیاز به حملونقل بیشتر در فضای باز بود (ساعت اوج حملونقل صبح، ظهر و بعدازظهر) پست میشد.شکل 6 ).
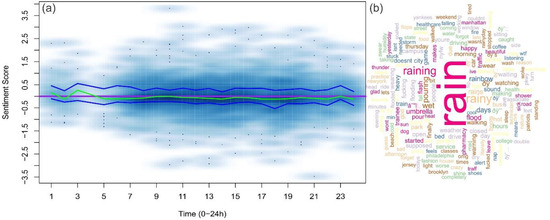
شکل 7 کلمه ابر رویداد باران را نشان می دهد. ما امتیازات احساسات را برای هر توییت مرتبط با باران در 10 سپتامبر محاسبه کردیم. توزیع امتیاز توسط نمودار پراکندگی هموار نشان داده شد. خط بنفش نشان دهنده احساسات کاملاً خنثی است در حالی که منحنی سبز نشان دهنده احساسات میانه در هر ساعت است. دو منحنی آبی که به دور منحنی سبز پیچیده شدهاند، چارک پایینتر و ربع بالاتر احساسات هستند. به طور کلی، میانگین نمرات احساسات کمی زیر صفر بود که نشان دهنده یک احساسات منفی خفیف است. با این حال، منحنیهای چارکهای پایینتر و بالاتر در دو طرف احساس خنثی تقسیم میشوند که نشاندهنده احساسات متفاوتی درباره باران است. نگاه دقیق تر به توییت ها احساسات متناقضی را نشان می دهد: “من عاشق باران هستم!!!!! من عاشق چکمه های بارانی هستم!!!!!!!” در مقابل “این باران فقط آزاردهنده است.”
4.2. دیدار پاپ فرانسیس
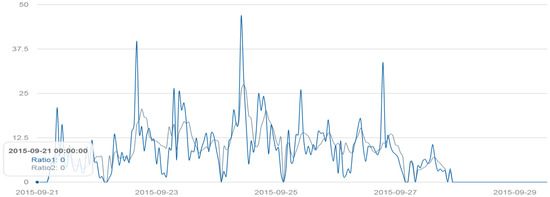
پاپ فرانسیس برای اولین بار از 22 سپتامبر 2015 تا 27 سپتامبر 2015 از ایالات متحده بازدید کرد. این یک رویداد اجتماعی مهم بود که توییت های زیادی را به خود جلب کرد. پاپ فرانسیس عمدتاً به سه شهر در ایالات متحده سفر کرد: واشنگتن، دی سی، شهر نیویورک و فیلادلفیا. ما نقاط داغ توییت را در طول بازدید او تجزیه و تحلیل کردیم. قبل از سفر پاپ به ایالات متحده، توییتهای بسیاری از دیسی و فیلادلفیا نشان میداد که مردم درباره رویداد آینده بحث میکنند. در 22 تا 23 سپتامبر، توییتهای مربوط به پاپ در دی سی، جایی که پاپ برای اولین بار از آنجا بازدید کرد، متمرکز شد. نقطه کانونی توییت در 24 ام به نیویورک منتقل شد، زیرا پاپ به آنجا پرواز کرد. نقطه داغ دوباره در 26th به فیلادلفیا مهاجرت کرد و در 27th هنگامی که پاپ سفر خود به ایالات متحده را به پایان رساند به اوج خود رسید. حرکت توییت ها تا حد زیادی با برنامه سفر پاپ مطابقت داشت (شکل 8 ).
به طور موقت، دیدار پاپ الگوی جالبی را نشان داد. بحث در مورد سفر پاپ فرانسیس در 21 سپتامبر آغاز شد. دو اوج عمده در توییت ها در طول این بازدید وجود داشت. اولین اوج بزرگ در 22 سپتامبر حول و حوش ساعت 4 بعد از ظهر، زمانی که پاپ وارد دی سی شد، رخ داد. دومین اوج در 24 سپتامبر در ساعت 10 صبح هنگام سخنرانی پاپ در مجلس سنا و مجلس نمایندگان رخ داد. در طول بازدید شش روزه، بحث در توییتر در مورد این رویداد در صبح فشرده تر بود اما در اوایل بعدازظهر کمتر فشرده بود. این واقعیت همچنین با برنامه های فعالیت پاپ مطابقت دارد. بحث در مورد بازدیدها در حدود 27 سپتامبر در ساعت 11 شب پایان یافت ( شکل 9 ).
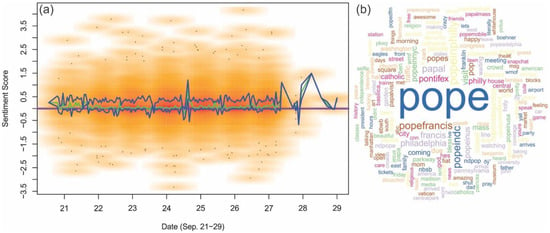
شکل 10 کلیدواژه های اصلی توییت های مردم در مورد دیدار پاپ را نشان می دهد. تحلیل احساسات نیز برای این رویداد اعمال شد. برخلاف رویداد باران، میانگین کلی نمرات احساسات بالای صفر بود در حالی که چارک پایین احساس نزدیک به صفر بود. این توزیع نشان دهنده یک روند کلی مثبت است. این رقم نیز نشان دهنده مدت زمان این رویداد است. پس از 28 سپتامبر، توئیت های مربوط به این رویداد بسیار کمتر از روزهای گذشته بود.
5. بحث و نتیجه گیری
پارکس و تریفت (1980) استدلال می کنند که زندگی شهری دارای یک الگوی ریتمیک است که توسط توزیع فضایی امکانات و رویدادها و در دسترس بودن زمانی آنها شکل می گیرد [ 37 ، 38 ]. اکنون محققان می توانند از داده های توییتر برای قابل مشاهده کردن این الگوهای ریتمیک نامرئی استفاده کنند. با نمایش داده های چند روزه، الگوی ریتمیک حتی بیشتر قابل مشاهده می شود. ما نشان میدهیم که چگونه از حداکثر دادههای توییت برای شناسایی رویدادهای مهم و شروع به شناسایی جزر و مد زندگی شهری استفاده کنیم. دادههای توییتر پنجرهای منحصربهفرد به الگوهای مکانی و زمانی منحصربهفرد شهری ارائه میدهند.
در این مطالعه، ما یک رویکرد نوآورانه برای شناسایی توییتهای مرتبط با رویداد با تجزیه و تحلیل دادههای پخش زنده توییتر پیشنهاد میکنیم. این رویکرد به ما امکان میدهد توییتهای جریانی را که تقریباً یک ساعت قبل از جمعآوری پست شدهاند، تجزیه و تحلیل کنیم. ویژگی بارز این رویکرد این است که هیچ دانش قبلی در مورد رویدادها را فرض نمی کند. درعوض، دانشی را در مورد مکان ها به عنوان پروفایل های ریتمیک ایجاد می کند. هیچ کلمه کلیدی قبلی برای محدود کردن دامنه رویدادها استفاده نشده است. این سیستم فقط به جریان توییت ها متکی است. برای استنتاج رویدادها به دانش دیگری مانند اخبار یا داده های GIS نیازی نیست. از این رو، اگرچه مطالعه موردی در منطقه واشنگتن دی سی-نیویورک انجام شد، اما میتوان آن را در سایر مناطق جغرافیایی اعمال کرد. با استخراج ویژگی های آموزشی از توییت ها (پیام ها، کاربران، مُهرهای زمانی، مختصات جغرافیایی)، این سیستم می تواند توسعه مکانی – زمانی رویدادهای منطقه ای را در زمان واقعی کشف کند. از آنجا که ما از ساختارهای پنجره کشویی و هش استفاده کردیم، آنها می توانند به سرعت کلمات کلیدی مرتبط با رویدادهای احتمالی را استخراج کنند. از کلمات کلیدی به عنوان واحد تحلیل استفاده شد. با اعمال توابع ارتباط، میتوانیم مجموعهای از کلمات کلیدی را پیدا کنیم که ارتباط نزدیکی با یک رویداد دارند و سپس توییتهای مرتبط را از مجموعه استخراج کنیم.
ما نشان میدهیم که چگونه این رویکرد میتواند الگوهای مکانی-زمانی دو رویداد را شناسایی کند: یک رویداد طبیعی و یک رویداد اجتماعی. این دو رویداد دارای مدت زمان و پوشش جغرافیایی متفاوتی هستند. این رویداد بارانی یک روز طول کشید، در حالی که رویداد دیدار پاپ یک هفته طول کشید. ما به راحتی توانستیم شروع، پایان و اوج این رویدادها را تشخیص دهیم. هنگامی که به الگوهای زمانی-مکانی نگاه می کنیم، توزیع توییت های مربوط به باران به طور کلی با نقشه ابر ماهواره ای مطابقت دارد در حالی که توییت های رویدادهای مربوط به پاپ، برنامه سفر را منعکس می کند. علاوه بر این، این تجزیه و تحلیل احساسات مردم را نسبت به رویدادها منعکس می کند. چنین تحلیلی با افزودن ادراکات انسانی به داده های GIS سنتی، اطلاعات جغرافیایی را غنی می کند.
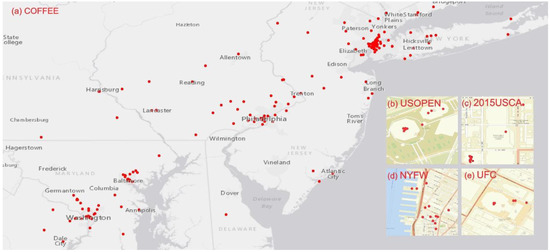
با استفاده از ویژگیها از هر دو بعد زمانی و مکانی، روش پیشنهادی میتواند رویدادهای منطقهای و محلی را به تصویر بکشد. تعداد و نسبتهای کاربران، توکنها و همچنین پوشش جغرافیایی توکنها سرنخهایی را ارائه میدهند که رویداد منطقهای است، در حالی که اندازه و اعداد خوشه نشانههایی از محلی بودن رویدادها را ارائه میدهند. تجزیه و تحلیل به کشف اطلاعات جغرافیایی در مقیاس های مختلف کمک می کند. شکل 11تصاویری از رویدادهای منطقه ای و محلی استخراج شده و توزیع فضایی آنها را نشان می دهد. به عنوان مثال، ما فهمیدیم که 29 سپتامبر روز ملی قهوه است. توییتها حاوی نشانههایی «قهوه» بودند که در منطقه مورد مطالعه پخش شده بودند. بسیاری از مردم به قهوه رایگان از Dunkin Donuts اشاره کردند (به عنوان مثال، “هیچ چیز من را شادتر از قهوه رایگان @DunkinDonuts #CoffeeDay نمی کند”). ما همچنین توانستیم رویدادهای محلی را شناسایی کنیم، مانند کنفرانس ایالات متحده در مورد ایدز (USCA) در 10 سپتامبر در واشنگتن دی سی، مسابقات قهرمانی تنیس آزاد ایالات متحده (USOPEN) در استادیوم آرتور اش در 2 سپتامبر 2015، هفته مد نیویورک در 10 سپتامبر 2015، و رویداد هنرهای رزمی ترکیبی UFC 205 در 12 نوامبر 2016. نشانههای خوشهای و انفجاری برای این رویدادهای محلی مشاهده شد.
این یک مطالعه اکتشافی است که رویدادها را از توییت های منتشر شده در یک پنجره یک ساعته اخیر استخراج می کند. ما چندین محدودیت را در این مطالعه تصدیق می کنیم. اول، به دلیل نسبت پایین توییتهای دارای برچسب جغرافیایی، حتی اگر میتوانیم رویدادهای محلی معنیدار را استخراج کنیم، فقط رویدادهای محلی اصلی را میتوان آشکار کرد، به خصوص در زمان واقعی. دوم، ما از تک تک کلمات به عنوان واحد تحلیل استفاده کردیم. رویدادهایی که با عبارات توصیف می شوند ممکن است با استفاده از این رویکرد به خوبی ثبت نشوند. در مطالعات آینده، ما قصد داریم رویدادهای استخراج شده را با اطلاعات گزارش شده از رسانه های سنتی مقایسه کنیم و ارتباط رویدادهای کشف شده از توییت ها را ارزیابی کنیم. همچنین قصد داریم این مطالعه را به دو صورت گسترش دهیم. در این مطالعه ما فقط توکنهای فردی را در نظر میگیریم و مدل بر اساس این توکنها آموزش داده شد. ما قصد داریم یک دنباله پیوسته از n مورد (n-گرم) را برای نمایش بهتر عبارات طولانی تر ترکیب کنیم. دوم، کلمات کلیدی مرتبط با رویداد شناسایی شده هیچ ویژگی اضافی در رویکرد فعلی ندارند. ما از اهمیت نسبی اطلاعات استخراج شده از توییت ها اطلاعی نداریم. ما قصد داریم رتبه بندی اهمیت رویدادهای شناسایی شده و همچنین نوع رویداد (به عنوان مثال، ورزش) را در کار آینده خود کشف کنیم.





بدون نظر