

خلاصه
تجزیه و تحلیل داده های بزرگ جغرافیایی (GBDA) برای کاربردهای محدودیت زمانی مانند واکنش به بلایا بسیار مهم است. با این حال، تجزیه و تحلیل محدودیت زمانی هنوز یک کار پیش پا افتاده در محیط محاسبات ابری نیست. پردازش پرس و جو فضایی (SQP) برای GBDA محاسباتی فشرده و ضروری است و الگوریتمهای جستجوی محدوده مکانی، جستوجو و نزدیکترین همسایه بدون استفاده از چارچوبهای مورد علاقه MapReduce مقیاسپذیر نیستند. الگوریتمهای SQP موازی (PSQPAs) در پردازش پیچی به دام افتادهاند، که یک موضوع شناخته شده در علم زمین است. برای ارضای GBDA با زمان محدود، ما یک رویکرد SQP الاستیک را در این مقاله پیشنهاد میکنیم. ابتدا Spark برای پیاده سازی PSQPA ها استفاده می شود. دوم، خوشههای سیستم عامل هسته (CoreOS) تحت مدیریت کوبرنتیس، ظروف Docker خودترمیمی را برای اجرای خوشههای Spark در فضای ابری فراهم میکنند. PSQPA های مبتنی بر Spark به کانتینرهای Docker ارسال می شوند، جایی که نمونه های اصلی Spark در آن قرار دارند. در نهایت، مقیاسکننده خودکار غلاف افقی (HPA) کانتینرهای Docker را برای پشتیبانی از منابع محاسباتی بر حسب تقاضا، کوچک و بزرگ میکند. همراه با یک گروه مقیاس خودکار از نمونه های مجازی، HPA به یافتن هر یک از پنج همسایه نزدیک برای 46139532 شی پرس و جو از 834158 شی داده مکانی در کمتر از 300 ثانیه کمک می کند. آزمایشهای انجامشده روی ابر OpenStack نشان میدهد که ظروف مقیاسبندی خودکار میتوانند GBDA محدودیت زمانی را در ابرها برآورده کنند. HPA به یافتن هر یک از پنج همسایه نزدیک برای 46139532 شی پرس و جو از 834158 شی داده مکانی در کمتر از 300 ثانیه کمک می کند. آزمایشهای انجامشده روی ابر OpenStack نشان میدهد که ظروف مقیاسبندی خودکار میتوانند GBDA محدودیت زمانی را در ابرها برآورده کنند. HPA به یافتن هر یک از پنج همسایه نزدیک برای 46139532 شی پرس و جو از 834158 شی داده مکانی در کمتر از 300 ثانیه کمک می کند. آزمایشهای انجامشده روی ابر OpenStack نشان میدهد که ظروف مقیاسبندی خودکار میتوانند GBDA محدودیت زمانی را در ابرها برآورده کنند.
کلید واژه ها:
خاصیت ارتجاعی ؛ پردازش پرس و جو فضایی ; جرقه ؛ ظرف ; کوبرنتیس _ OpenStack
1. معرفی
با توجه به حجم مجموعه دادههای فضایی جمعآوریشده از حسگرهای همه جا حاضر بیش از ظرفیت زیرساختهای فعلی، جهت جدیدی به نام دادههای بزرگ جغرافیایی (GBD) توجه زیادی را از دانشگاه و صنعت در سالهای اخیر به خود جلب کرده است [1 ، 2 ] . تجزیه و تحلیل مجموعه دادههای فضایی میتواند برای بسیاری از کاربردهای اجتماعی مانند برنامهریزی و مدیریت حملونقل، واکنش به بلایا و تحقیقات تغییرات آب و هوایی ارزشمند باشد [ 3 ]. با این حال، پردازش کارآمد آنها هنوز یک کار چالش برانگیز است، به ویژه زمانی که به دست آوردن نتایج به موقع برای پاسخ های اضطراری مقدماتی است [ 4 ، 5 ].
صرف نظر از منبع داده، پردازش پرس و جو فضایی موازی (SQP) برای تجزیه و تحلیل GBD ضروری است و برای اکثر پایگاه های داده فضایی ضروری است [ 6 ، 7 ]. از آنجایی که یک موازی مبتنی بر GPU (واحد پردازش گرافیکی) به تلاش قابل توجهی در طراحی مجدد الگوریتمهای مرتبط نیاز دارد، تحقیقات پیشرفته SQP موازی (PSQP) را برای مدیریت دادههای فضایی بزرگ در محیط محاسبات ابری هدایت میکند [8 ، 9 ] . برای مثال، ژونگ و همکاران. [ 9] چندین عملگر جستجوی فضایی مبتنی بر MapReduce را برای الگوریتمهای SQP موازی (PSQPA) پیادهسازی کرد. اگرچه PSQPA های مبتنی بر MapReduce با مقیاس پذیری بهبود یافته عملکرد خوبی دارند، کارایی PSQPA ها به سیستم دارایی مبتنی بر Hadoop بستگی دارد. علاوه بر این، الگوریتمهای مبتنی بر MapReduce مورد استفاده در Hadoop از هزینههای ورودی/خروجی دیسک متراکم (I/O) و ارتباطات شبکه رنج میبرند و بنابراین برای تجزیه و تحلیل به موقع دادهها نامناسب هستند [ 10 ]. برای دستیابی به عملکرد بالاتر، You et al. [ 8 ] یک سیستم نمونه اولیه به نام SpatialSpark را بر اساس Spark برای جستارهای فضایی در مقیاس بزرگ در رایانش ابری طراحی کرد. Spark یک مدل محاسباتی پیشرفته (CM) مشابه اما متفاوت از Hadoop MapReduce است. از طریق انتقال تبدیل به مجموعه داده های درون حافظه با انتزاع مجموعه داده های توزیع شده انعطاف پذیر (RDDs) [11 ]، Spark در سال های اخیر به الگوی پیشرو در تحلیل داده های بزرگ در حافظه تبدیل شده است [ 12 ]. ماهیت توسعه پذیر RDD ها چارچوب های مفیدی مانند GeoSpark و LocationSpark را برای پردازش کارآمد داده های فضایی بزرگ پرورش می دهد [ 13 ، 14 ]. مدل محاسباتی پتانسیل را برای محاسبات GBD با کارایی بالا در 207 گره متشکل از یک خوشه Hadoop در ابر آمازون EC2 نشان داده است، همانطور که در [ 12 گزارش شده است.]. با این حال، اشیاء هندسی چند بعدی هستند و محاسبه هندسه در مجموعه دادههای فضایی بزرگ به شدت منابع محدود محاسباتی را کاهش میدهد. علاوه بر این، محیط محاسبات ابری دارای محدودیت فقط برای کاربران ابر خصوصی محدودیت «قفل کردن فروشنده» را ایجاد می کند. علاوه بر این، حتی ساختن شاخصهای فضایی پیچیده و جداسازی فضایی مجموعههای داده عظیم، پردازش پیچ ناشی از اندازه یا چگالی اجسام هندسی ممکن است تأخیر طولانی ایجاد کند [15 ] .
رایانش ابری به عنوان یک پارادایم با وعده فراهم کردن منابع محاسباتی از لحاظ نظری بی نهایت برای برنامه های کاربردی ابری ظهور کرد. کشش، یکی از ویژگی های اصلی رایانش ابری، نشان دهنده قابلیت افزایش و کاهش تعداد منابع تخصیص یافته برای برنامه های کاربردی در صورت تقاضا است [ 16 ]. هم کشش عمودی و هم افقی باعث بهبود عملکرد برنامه ها و کاهش هزینه می شود [ 17]. الاستیسیته عمودی به این معنی است که منبع محاسباتی یک سرور مجازی منفرد مانند حافظه و واحدهای پردازش مرکزی مجازی (VCPU) میتواند برحسب تقاضا، کم و زیاد شود، در حالی که کشش افقی به معنای توانایی در مقیاسبندی منابع مجازی در صورت تقاضا است. پارادایم «پرداخت در صورت تمایل» کاربران را تشویق میکند تا با تخلیه سرمایهگذاری زیرساختها، هزینهها را کاهش دهند. با این حال، شناسایی مقدار مناسب منابع مجازی برای استفاده برای کاربران ابری کار دشواری است و ارائه دهندگان خدمات ابری اغلب نمی توانند قراردادهای قرارداد سطح سرویس (SLA) را برای کاربران ابری برآورده کنند [18 ] . تکنیک های مقیاس خودکار متنوع برای کاربردهای الاستیک در ابرها پیشنهاد شده است [ 19]. با این حال، برخی تحقیقات علوم زمین وجود دارد که از فناوری های مقیاس خودکار در محیط محاسبات ابری استفاده می کند [ 20 ].
هدف این مقاله بررسی استراتژی های مقیاس خودکار برای پشتیبانی از پردازش پرس و جو فضایی با محدودیت زمانی در ابرها است. تا جایی که می دانیم، می توانیم یک اثر واحد پیدا کنیم که کمی شبیه به کار ما باشد [ 20 ]. آنها پیشنهاد کردند از گروه های مقیاس خودکار در ابرهای OpenStack با Heat برای تعریف قوانین اضافه کردن یا حذف ماشین های مجازی (VM) در صورت تقاضا استفاده شود. ما بر روی ظروف مقیاس خودکار افقی تمرکز می کنیم که برای برنامه های ابری ارزشمندتر است. در مقایسه با مجازی سازی مبتنی بر Hypervisor، مجازی سازی مبتنی بر کانتینر جایگزینی برای ارائه محیط های ایزوله برای برنامه ها در نظر گرفته شده است [ 21]]. کانتینرهای برنامه را می توان به عنوان ماشین های مجازی سبک وزن در نظر گرفت که هسته یکسانی از سیستم عامل اصلی دارند. برنامههایی که در داخل ماشینهای مجازی مبتنی بر هایپروایزر سنتی اجرا میشوند، به ظرفیت زمانبندی سیستمعامل (OS)، که سطح بیشتری از انتزاع را معرفی میکند، بستگی دارد . ماشین های مجازی مقیاس خودکار افقی اغلب چندین دقیقه طول می کشد تا خوشه های محاسباتی مجازی بسازند، که ممکن است برای کارهای محاسباتی با محدودیت زمانی نامناسب باشند. در واقع، کارایی PSQPA ها نه تنها با حجم داده ها تعیین می شود، بلکه با پارامترهای داخلی و CM های زیربنایی نیز بسیار مرتبط است. برای کاهش هزینه های زمانی PSQPA ها، ابتدا پیاده سازی PSQPA های مبتنی بر Spark را معرفی می کنیم و پارامترهایی را که بر کارایی PSQPA ها تأثیر می گذارند در بخش 2 شناسایی می کنیم.. پس از معرفی Docker برای مدیریت کانتینر در یک گره محاسباتی، مدیریت کانتینر مبتنی بر Kubernetes و زمانبندی برای مقیاس خودکار کانتینرها در گرههای محاسبات ابری را شرح میدهیم. سپس، برخی از استراتژی های مقیاس خودکار و یک مورد پردازش پرس و جو فضایی در بخش 3 آورده شده است . آزمایش ها و نتایج در بخش 4 و به دنبال آن بحث در بخش 5 شرح داده شده است . در نهایت، ما کارهای آینده خود را در بخش 6 نتیجه گیری و ذکر می کنیم .
2. SQPAهای موازی با استفاده از Spark CM
اجازه دهید D و Q به ترتیب یک مجموعه شی داده و یک مجموعه شی پرس و جو باشند. جستجوی محدوده مکانی (SRQ) جستجوی اشیاء داده D مربوط به اشیاء پرس و جو از Q را در فاصله معینی نشان می دهد. پرس و جوی نزدیکترین همسایه (NNQ) نزدیکترین اشیاء داده به یک شی پرس و جو داده شده را جستجو می کند. پرس و جو “نزدیک ترین هتل ها را نزدیک به یک فضای داده شده بیابید” نمونه ای از NNQ است، که در آن هتل ها اشیاء داده و فضا شی مورد نظر است. پرس و جو پیوستن فضایی (SJQ) جفت اشیاء را از دو مجموعه داده بر اساس روابط فضایی آنها ترکیب می کند [ 23]. قبل از شناسایی پارامترهای موثر بر کارایی PSQPAهای مبتنی بر اسپارک، به طور مختصر پیاده سازی و اجرای آنها را معرفی می کنیم.
2.1. PSQPA با استفاده از Spark CM
شکل 1 اجرای الگوریتم SRQ مبتنی بر Spark (SSRQA) را نشان می دهد. ابتدا، اشیاء داده های مکانی در گره های توزیع شده پارتیشن بندی و ذخیره می شوند. سپس، اشیاء پرس و جو به گره هایی که پارتیشن ها در آن قرار دارند پخش می شوند. در این گره ها، هر شی پرس و جو برای تطبیق اشیاء داده با انجام محاسبات محمولی محدوده فضایی استفاده می شود. ما از GeoSpark برای پردازش دادههای فضایی در مقیاس بزرگ در این کار استفاده میکنیم، که یک بسته نرمافزاری است که عملیات هندسی اولیه را ارائه میدهد. پخش فعال با بیت تورنت رویکرد اصلی Spark Master برای به اشتراک گذاشتن اشیاء تغییرناپذیر با Spark Workers است [ 10]]. به اشتراک گذاری داده ها، که حجم آنها از اندازه پشته ماشین مجازی جاوا (JVM) در نمونه های اصلی Spark تجاوز نمی کند، کارآمد است. پیاده سازی یک SSRQA ساده تنها شامل یک تبدیل نقشه برداری است.
یک الگوریتم NNQ مبتنی بر جرقه (SNNQA) به شرح زیر اجرا می شود. اگر فرض کنیم که اشیاء پرس و جو کوچک هستند و اشیاء داده بزرگ هستند، اشیاء پرس و جو می توانند به گره های محاسباتی که در آن اشیاء داده پارتیشن بندی شده در آن قرار دارند، پخش شوند. در این گرهها، کارگران Spark محاسبات محمول فضایی را با استفاده از اشیاء دادههای مکانی محلی اجرا میکنند. فرض بر این است که اشیاء پرس و جو برای به اشتراک گذاشتن خیلی بزرگ هستند، در حالی که اشیاء داده نسبتا کوچک هستند. سپس میتوانیم اشیاء داده را به صورت فضایی به شبکهها تقسیم کنیم و در صورت لزوم، یک شاخص برای آنها بسازیم [ 24]]. سپس شبکهها را میتوان به گرههای محاسباتی که در آن اشیاء پرس و جو قرار دارند، پخش کرد. اگر هم اشیاء داده و هم اشیاء پرس و جو خیلی بزرگ هستند که نمیتوان آنها را به اشتراک گذاشت، باز هم میتوان اشیاء پرس و جو را به تکههایی تقسیم کرد و الگوریتمهای مشابه را با تکههای مختلف به عنوان ورودی ارسال کرد. پیاده سازی یک SNNQA ساده تنها شامل یک تبدیل نقشه برداری است. از آنجایی که جریان اجرای یک SNNQA تقریباً مشابه جریان یک SSRQA است، برای صرفه جویی در فضا، نمودار شماتیک را در اینجا حذف می کنیم.
شکل 2 یک الگوریتم SJQ مبتنی بر Spark (SSJQA) را نشان می دهد که به صورت زیر اجرا می شود. پس از بارگذاری مجموعههای داده در گرههای محاسباتی، یک موتور اسپارک آنها را با توجه به موقعیت مکانی تقریبی آنها، مانند حداقل مستطیل مستطیل مرزی (MBR) به شبکههایی تقسیم میکند. در مرحله بعد، موتور Spark به مجموعه داده ها بر اساس شناسه شبکه آنها می پیوندد [ 25 ]. برای آن دسته از اشیاء فضایی که شناسه شبکه یکسانی دارند، همپوشانی فضایی که محاسبات را محمول میکند در همان گرههای محاسباتی ارزیابی میشود. اگر دو نوع شی با هم همپوشانی داشته باشند، در نتایج نهایی باقی می مانند. در نهایت، نتایج توسط مستطیل هایی با حذف اشیاء تکراری گروه بندی می شوند. پیاده سازی یک SSJQA ممکن است شامل چندین تبدیل، پیوند، نقشه برداری و فیلتر باشد.
2.2. شناسایی عوامل موثر بر کارایی PSQPAهای مبتنی بر جرقه
از آنجایی که روش عملی برای پرس و جوی کارآمد در برابر داده های فضایی بزرگ، به کارگیری استراتژی تقسیم و غلبه [ 9 ، 26 ] است، اکثر PSQPA های مبتنی بر MapReduce از انواع خاصی از منحنی های پرکننده فضا، مانند منحنی پرکننده فضا هیلبرت، برای نگاشت MBR ها استفاده می کنند. شبکه های مبتنی بر همبستگی فضایی برای بهینه سازی کارایی [ 27 ، 28 ]. ما به سادگی تعداد شبکه های p را بررسی می کنیمبه عنوان یکی از پارامترهای داخلی PSQPA های مبتنی بر Spark. ما به طور انحصاری بر SNNQA تمرکز می کنیم. از آنجایی که یک SSRQA را می توان به عنوان یک مورد ساده از SNNQAها مشاهده کرد، محدوده فضایی محمولات SSRQAهایی است که می توانند در یک تبدیل نقشه برداری واحد پیچیده شوند. SNNQAs. SSJQA ها پیچیده تر از SNNQA هستند. واحدهای اساسی که این پیچیدگی را تشکیل می دهند، اتصالات چند راهه هستند. اگرچه اتصال ها اجتناب ناپذیر و وقت گیر هستند، نقشه برداری عملیات طرح ریزی مجموعه داده های همبسته فضایی در شبکه های یکسان معمولاً در مراحل فیلتر و پالایش استفاده می شود [ 28]]. از دیدگاه Spark CM، تعداد شبکهها تعداد وظایفی را که باید اجرا شوند تعیین میکند، که میتواند مستقیماً بر کارایی PSQPA تأثیر بگذارد. عملیات طرح ریزی فقط هزینه ارتباطات شبکه را تعیین می کند. از آنجایی که مدل های هزینه ساخت برای ارتباطات شبکه پیچیده است، ما تعداد شبکه ها را به عنوان پارامترهای داخلی PSQPA ها شناسایی می کنیم. هدف ما ارزیابی رابطه بین تعداد شبکهها و زمان اجرای PSQPA است که ممکن است برای سیستمهای خودسازگار مفید باشد. در این مقاله، ما به طور انحصاری از یک مدل مستقل Spark استفاده میکنیم، زیرا پیکربندی یک خوشه Spark بدون استفاده از چارچوبهای دیگر در یک محیط محاسبات ابری آسان است. علاوه بر این، مدل مستقل، همانطور که در کار قبلی ما نشان داده شد، قابلیت اطمینان خوبی را نشان میدهد. پارامترهای مدل مستقل Spark عبارتند از: درایور-هسته، درایور-حافظه، مجری-حافظه، هسته-هسته-اجرایی- هسته ها و هسته های اجرایی. دو پارامتر اول مربوط به برنامه است و توسط کاربران برای تنظیم منابع مورد نیاز برای نمونه های اصلی Spark تعریف شده است. سه پارامتر آخر برای تنظیم منابع مورد نیاز برای هر یک از نمونه های Spark worker استفاده می شود. از آنجایی که ارزش هستههای مجری کل انتظار کاربرانی است که حجم زیادی از دادههای فضایی را مدیریت میکنند، تأثیرگذار دیگری در نظر گرفته میشود. علاوه بر این، کارگران اسپارک که روی کانتینرها کار می کنند، برای منابع موجود با یکدیگر رقابت می کنند. بنابراین، ما Executor-Memory و Executor-cores را به عنوان پارامتر در نظر نمی گیریم. پارامتر احتمالی دیگر SNNQAs خواهد بود دو پارامتر اول مربوط به برنامه است و توسط کاربران برای تنظیم منابع مورد نیاز برای نمونه های اصلی Spark تعریف شده است. سه پارامتر آخر برای تنظیم منابع مورد نیاز برای هر یک از نمونه های Spark worker استفاده می شود. از آنجایی که ارزش هستههای مجری کل انتظار کاربرانی است که حجم زیادی از دادههای فضایی را مدیریت میکنند، تأثیرگذار دیگری در نظر گرفته میشود. علاوه بر این، کارگران اسپارک که روی کانتینرها کار می کنند، برای منابع موجود با یکدیگر رقابت می کنند. بنابراین، ما Executor-Memory و Executor-cores را به عنوان پارامتر در نظر نمی گیریم. پارامتر احتمالی دیگر SNNQAs خواهد بود دو پارامتر اول مربوط به برنامه است و توسط کاربران برای تنظیم منابع مورد نیاز برای نمونه های اصلی Spark تعریف شده است. سه پارامتر آخر برای تنظیم منابع مورد نیاز برای هر یک از نمونه های Spark worker استفاده می شود. از آنجایی که ارزش هستههای مجری کل انتظار کاربرانی است که حجم زیادی از دادههای فضایی را مدیریت میکنند، تأثیرگذار دیگری در نظر گرفته میشود. علاوه بر این، کارگران اسپارک که روی کانتینرها کار می کنند، برای منابع موجود با یکدیگر رقابت می کنند. بنابراین، ما Executor-Memory و Executor-cores را به عنوان پارامتر در نظر نمی گیریم. پارامتر احتمالی دیگر SNNQAs خواهد بود از آنجایی که ارزش هستههای مجری کل انتظار کاربرانی است که حجم زیادی از دادههای فضایی را مدیریت میکنند، تأثیرگذار دیگری در نظر گرفته میشود. علاوه بر این، کارگران اسپارک که روی کانتینرها کار می کنند، برای منابع موجود با یکدیگر رقابت می کنند. بنابراین، ما Executor-Memory و Executor-cores را به عنوان پارامتر در نظر نمی گیریم. پارامتر احتمالی دیگر SNNQAs خواهد بود از آنجایی که ارزش هستههای مجری کل انتظار کاربرانی است که حجم زیادی از دادههای فضایی را مدیریت میکنند، تأثیرگذار دیگری در نظر گرفته میشود. علاوه بر این، کارگران اسپارک که روی کانتینرها کار می کنند، برای منابع موجود با یکدیگر رقابت می کنند. بنابراین، ما Executor-Memory و Executor-cores را به عنوان پارامتر در نظر نمی گیریم. پارامتر احتمالی دیگر SNNQAs خواهد بودپارامتر k که تعداد مورد نظر اشیاء کوئری نزدیکترین همسایه را مشخص می کند.
3. ظروف مقیاس خودکار افقی برای پردازش پرس و جو فضایی الاستیک
3.1. Docker with Kubernetes Orchestration for Clustering Containers
سیستم تست ما مبتنی بر Docker است، که یک پروژه منبع باز برای خودکار کردن استقرار برنامه های کاربردی کانتینری در یک محیط لینوکس است [ 29]]. داکر چارچوبی است که چرخه حیات کانتینرهای برنامه را مدیریت می کند. یک برنامه کاربردی و وابستگی های آن در یک تصویر گنجانده شده است. یک تصویر Docker را می توان از یک تصویر اصلی و سایر تصاویر موجود ساخت. تصویر اصلی یک حداقل سیستم عامل مانند سیستم عامل سازمانی اجتماعی (CentOS)، Rancheros یا CoreOS است. برنامه ها و یک تصویر اصلی در یک تصویر تک لایه ترکیب می شوند. ذخیره سازی لایه به لایه به اشتراک گذاری و به روز رسانی اجزای برنامه را با حداقل هزینه تسهیل می کند. از دیدگاه داکر، کانتینر واحد مدیریت پایه ای است که یک برنامه کاربردی در آن اجرا می شود. کانتینرهای Docker به جای استفاده از کپی دیگر، سیستم عامل اصلی را با سایر کانتینرها به اشتراک می گذارند. شکل 3نشان می دهد که چگونه کلاینت های Docker به میزبان Docker دستور می دهند تا کانتینرهایی را برای اجرای برنامه های کاربردی با تصاویر مشخص شده راه اندازی کند. رجیستری تصویر Docker گالری اختصاصی برای ذخیره تصاویر است. ما از یک رجیستری تصویر خصوصی برای ذخیره تصاویر Spark-master و Spark-worker در تست های خود استفاده می کنیم.
Docker اجرای برنامه ها را در یک میزبان تسهیل می کند. برای ساخت خوشه های محاسباتی با استفاده از کانتینرها، ابزارهای سطح بالاتری مانند Docker Swarm و Kubernetes ضروری هستند [ 30 ، 31 ]. Docker Swarm یک سیستم ارکستراسیون کانتینری بومی Docker برای محاسبات خوشه ای است. از آنجایی که در استقرار ساده و انعطاف پذیر است، به طور گسترده در ابرهای OpenStack برای تجزیه و تحلیل داده ها استفاده شده است [ 32]]. با این حال، کانتینرها در میزبان های مختلف نمی توانند بدون استفاده از شبکه همپوشانی ناپایدار فعلی Docker با یکدیگر تعامل داشته باشند. علاوه بر این، در زمان نگارش این مقاله، بسیاری از قابلیتهای پیشرفته مانند خود ترمیم و مقیاسبندی خودکار توسط Docker Swarm پشتیبانی نمیشوند. Kubernetes یکی دیگر از پروژه های منبع باز است. در ژوئن 2014 منتشر شد و از نیاز به مدیریت میلیاردها کانتینر در زیرساخت ناشی می شود. Kubernetes، که پیچیده تر از Docker Swarm است، برای چندین دهه توسط گوگل استفاده می شود. پیچیدگیها مزایای بیشماری را برای کاربردهای کانتینری مانند ظروف در دسترس بودن بالا، خود ترمیمشوندگی و پوستهبندی خودکار با نظارت خوشهای ریز به همراه دارد. شکل 4نشان می دهد که چگونه Kubernetes معماری master-slave را برای مدیریت کانتینرها در مینیون ها تطبیق می دهد. Kubelet و Kube-proxy در حال اجرا بر روی مینیون، به ترتیب اجزایی برای انتشار بارهای کاری در حال تغییر به پادها و مسیریابی دسترسی خدمات محور به پادها هستند. در اینجا هر pod یک گروه منطقی از کانتینرها است که روی یک برنامه اجرا می شوند. سرور Application Programming Interface (API) گالری خدمات اصلی و یک نقطه دسترسی برای Kubectl (یک رابط خط فرمان برای اجرای دستورات در برابر خوشه های Kubernetes) برای پرس و جو و تعریف بارهای کاری خوشه است. Kube-scheduler و Kube-controller-manager به ترتیب با سرور API برای زمانبندی بارهای کاری در قالب پادها کار میکنند و به ترتیب پادهای مشخص شده در Minions اجرا میشوند. به دلیل سادگی، آنها در شکل 4 نشان داده نشده اند.
3.2. ظروف مقیاس خودکار افقی برای پردازش پرس و جو فضایی الاستیک
برای بررسی پردازش پرس و جوی فضایی الاستیک در یک محیط محاسبات ابری، فرض میکنیم که هستههای C، نمونههای حداکثر I و M گیگابایت حافظه اجارهای برای مستاجر وجود دارد. شکل 5منابع محاسباتی را نشان می دهد که به شرح زیر استفاده می شود. قسمت سمت چپ از یک خوشه پایدار تشکیل شده است که در آن استاد Kubernetes کانتینرها را روی تعداد ثابتی از گره های مینیون مدیریت می کند. مقیاس خودکار غلاف افقی (HPA) افزونه ای برای Kubernetes است که به طور خودکار تعداد پادها را در مینیون ها افزایش و/یا کاهش می دهد. برای ایجاد یک خوشه Spark قوی در بالای Kubernetes، کاربران می توانند از Kubernetes درخواست کنند تا یک کنترل کننده تکرار ایجاد کند تا مطمئن شوند که یک و تنها یک Pod که تصویر Spark-master را اجرا می کند. Kubernetes به کاربران اجازه می دهد تا به صراحت سهمیه های منابع را برای پادها تعریف کنند. بنابراین، یک پاد که حافظه و هستههای کافی داشته باشد منحصراً توسط نمونه Spark-master استفاده میشود. سپس، HPA یک گروه مقیاس خودکار از کانتینرها را برای نمونه های Spark-worker بر اساس برخی استراتژی های مقیاس خودکار ایجاد می کند. سرانجام، Spark-workers با استفاده از سرویس Kubernetes برای ساخت خوشه Spark الاستیک به نمونه های Spark-master متصل می شوند. سرویس های Kubernetes گروه های منطقی از pods هستند. آنها برای مسیریابی ترافیک ورودی به غلاف های پس زمینه استفاده می شوند. سه پارامتر به طور عمده برای تعریف استراتژی های مقیاس خودکار استفاده می شود. پارامترهای minReplicas و maxReplicas به ترتیب حداقل و حداکثر تعداد پادهای مجاز را اعلام می کنند. Kubernetes میانگین حسابی استفاده از CPU پادها را با مقدار هدف که توسط پارامتر درصد هدف تعریف شده است محاسبه می کند و در صورت لزوم تعداد پادهای مجاز را تنظیم می کند. قسمت سمت راست شامل یک گروه مقیاسبندی خودکار است که در آن ماشینهای مجازی (VMs) با توجه به خطمشیهای تعریفشده در قالبهای Heat مقیاسبندی میشوند. ویژگی های حداقل و حداکثر اندازه یک گروه مقیاس خودکار برای تعریف آستانه نمونه های مجاز برای کاربران ابری استفاده می شود. برای مقیاس افقی ظروف Docker در یک گروه مقیاس خودکار، لازمه اولیه این است که ماشین های مجازی بتوانند به طور خودکار به خوشه Kubernetes بپیوندند. خوشبختانه، فایلهای پیکربندی ابری OpenStack را میتوان در این زمینه استفاده کرد [33 ]. بارگذاری سرویسهای kube-proxy و kubelet در گرههای مینیون میتواند به صورت خودکار در بوت ماشینهای مجازی انجام شود.
این استراتژی تجربی پیشنهادی منابع محاسباتی را به دو بخش تقسیم میکند و راهی برای توزیع کانتینرها بر روی تمام گرهها ارائه میکند. با جداسازی Spark-master و Spark-workers در کانتینرها و استفاده از HPA برای توزیع بار کاری، میتوانیم خوشههای Spark خود ترمیم شونده را برای پردازش حجم عظیمی از مجموعه دادههای فضایی بسازیم. آزمایش ها و نتایج در بخش 4 ارائه شده است .
4. آزمایش ها و نتایج
4.1. مجموعه داده های فضایی برای یک مورد پردازش پرس و جو فضایی
در این مقاله، مفهوم مجموعه دادههای فضایی را برای درک بهتر الگوهای تحرک انسان در مناطق شهری معرفی میکنیم. به منظور انجام این تحلیل، که برای برنامه ریزان شهری اساسی است، داده های مسیر از دستگاه های ارزان قیمت مجهز به GPS، مانند تاکسی ها جمع آوری می شود. داده های سفر تاکسی به طور گسترده برای استخراج الگوهای جریان ترافیک استفاده می شود، همانطور که در [ 34 ، 35 توضیح داده شده است.]. برای مثال، طرح دادههای باز نیویورک پورتالی برای انتشار دادههای عمومی دیجیتال خود برای تجمیع در سطح شهر، طبق قوانین محلی ایجاد کرده است. علاوه بر این، کمیسیون تاکسی و لیموزین شهر نیویورک از سال 2009 مجموعه داده های سفر تاکسی را به پورتال منتشر کرده است. در سال 2015، در مجموع 11534883 ردیف داده سفر تاکسی سبز ثبت شد. این سوابق شامل ضبط صحرایی، تاریخ تحویل و تحویل، زمان، مکان، مسافت، نوع پرداخت و تعداد مسافران گزارش شده توسط راننده است. از آنجایی که مکانهای انتقال و رها کردن فقط جفت مختصات جغرافیایی هستند، مجموعههای دادههای مکانی اضافی که شامل نوع کاربری زمین (LUT) میشود، مورد نیاز است. ما یک مجموعه داده به نام NYC MapPluto Tax Lot از اداره برنامه ریزی شهر نیویورک جمع آوری کردیم. فیلدهای مجموعه داده شامل LandUse، XCoord، و YCoord، که دسته بندی کاربری زمین مانند ساختمان خانوادگی، ساختمان های تجاری و اداری، صنعتی و تولیدی و موقعیت تقریبی زمین ها را توصیف می کند. مجموعه داده Tax Lot شامل 834158 رکورد است. مکان تحویل مشتری تاکسی در نزدیکی ساختمان خانواده و محل تحویل در نزدیکی یک ساختمان تجاری و اداری در ساعات شلوغی، نشان میدهد که درخواست تاکسی فرد ممکن است مربوط به کار باشد. ما مجموعه داده ها را با SNNQAهایی که قبلا ذکر شد بررسی می کنیم. خوانندگان می توانند مجموعه داده ها را با استفاده از پیوندهای زیر بیابند: نشان می دهد که درخواست تاکسی فرد ممکن است مربوط به کار باشد. ما مجموعه داده ها را با SNNQAهایی که قبلا ذکر شد بررسی می کنیم. خوانندگان می توانند مجموعه داده ها را با استفاده از پیوندهای زیر بیابند: نشان می دهد که درخواست تاکسی فرد ممکن است مربوط به کار باشد. ما مجموعه داده ها را با SNNQAهایی که قبلا ذکر شد بررسی می کنیم. خوانندگان می توانند مجموعه داده ها را با استفاده از پیوندهای زیر بیابند:https://data.cityofnewyork.us/Transportation/2015-Green-Taxi-Trip-Data/n4kn-dy2y و http://www1.nyc.gov/site/planning/data-maps/open-data.page ( آخرین تاریخ دسترسی: 2017/2/8)
4.2. Cloud Computing Environemt
شش ماشین برای راه اندازی ابر OpenStack ما استفاده می شود. نسخه Liberty OpenStack که در اکتبر 2015 برای عموم منتشر شد، انتخاب شد. همانطور که در جدول 1 نشان داده شده است، گره کنترلر یک رایانه شخصی کالایی است که مجهز به 1 پردازنده، 4 هسته، 4 گیگابایت حافظه و دیسک 500 گیگابایتی است که سرویس هویت کیستون، سرویس تله متری، سرویس شبکه نوترون و سرویس Glance روی آن اجرا می شود. عامل های پل لینوکس نوترون که روی گره های محاسباتی اجرا می شوند به یکدیگر متصل می شوند تا برای نمونه های مجازی شبکه سازی کنند. ما از چهار سرور Dell PowerEdge M610 برای ساخت کلاسترهای گره های محاسباتی استفاده می کنیم که یکی از آنها دارای دو CPU فیزیکی، 24 هسته، 92 گیگابایت حافظه اصلی و یک دیسک 160 گیگابایتی است و سه مورد از آنها دارای دو CPU فیزیکی، 24 هسته هستند. 48 گیگابایت حافظه اصلی و یک دیسک 500 گیگابایتی. گره ذخیره سازی بلوک یک ایستگاه کاری HP Z220 است که با دو پردازنده فیزیکی، 8 هسته، 32 گیگابایت حافظه اصلی و دیسک 3 ترابایتی پیکربندی شده است. سرویسهای Cinder در ایستگاه کاری HP از سیستم فایل شبکه (NFS) برای ارائه نمونه مجازی با فضای ذخیرهسازی استفاده میکنند. برای شبیهسازی زیرساخت شبکه پیچیده، به گرههای محاسباتی اجازه میدهیم دو زیرشبکه مختلف را طی کنند. از دستگاه های شبکه 1000 مگابیت بر ثانیه برای پل زدن دو زیرشبکه استفاده می شود. همه گره ها در محیط محاسبات ابری یک سیستم عامل اوبونتو 14.04.4 LTS 64 بیتی را تطبیق می دهند. همه بستههای مورد نیاز که از OpenStack ابری پشتیبانی میکنند با بسته اصلی خود نصب میشوند. به طور خاص، RabbitMQ 3.5.4 برای هماهنگی عملیات و اطلاعات وضعیت در بین سرویس ها استفاده می شود. MariaDB 5.5.52 برای خدمات ذخیره داده استفاده می شود. libvirt KVM و Linux Bridge برای ارائه مجازی سازی پلت فرم و شبکه سازی برای نمونه های مجازی استفاده می شوند. ما منحصراً از مکانیزم vxlan برای ارائه شبکه با نمونه های مجازی استفاده می کنیم.
4.3. نتیجه
4.3.1. مقایسه SNNQA با استفاده از ASVI و ASVC
برای آزمایش کارایی SQP با استفاده از ASVI و ASVC، دو خوشه با استفاده از دو قالب OpenStack Heat میسازیم. همانطور که در جدول 2 نشان داده شده است ، تنها تفاوت بین خوشه ها، تصویر و نرم افزار استفاده شده است. این دو خوشه می توانند در این زمینه قابل مقایسه باشند، زیرا استقرار نمونه هایی که در آنها گره های محاسباتی می توانند دقیقاً با استفاده از ویژگی OS::Nova::Server Availability zone در قالب های Heat مشخص شوند. در خوشه اوبونتو، گره دارای 4 VCPU و 8 گیگابایت حافظه میزبان نمونه اصلی Spark است، در حالی که چهار نمونه دیگر میزبان نمونههای Spark worker هستند. در خوشه CoreOS، گره های نگهدارنده هر نوع جزء Spark در زمان اجرا تعیین می شوند. به طور دقیق تر، نرم افزارها و نسخه های آنها در جدول 3 آمده است .
با فرض ناچیز بودن زمان راهاندازی خوشهها، ابتدا کارایی SNNQAs را در دو خوشه آزمایش میکنیم. از آنجایی که لازم است تصویر اوبونتو از قبل مشخص شود، تعداد کارگران Spark در حال اجرا در هر نمونه مجازی هنگام استفاده از ASVI یکسان است. همانطور که در شکل 6 نشان داده شده است ، کارایی SNNQAها با استفاده از دو استراتژی مقیاس بندی خودکار در ابر OpenStack بسیار متفاوت است. وقتی p = 3000 و k= 5، 3000 شبکه وجود دارد که روی آنها اشیاء داده های مکانی ذخیره می شوند، و هر شی پرس و جو پنج شیء داده مکانی را نزدیکترین در شبکه ها جستجو می کند. میانگین زمان اجرا زمانی ثبت میشود که هر ارسال SNNQA 10 بار با پارامتر total-executor-cores روی 6 اجرا شود. مشاهده می کنیم که افزایش تعداد کارگران Spark کارایی بهتر الگوریتم ها را تضمین نمی کند. به عنوان مثال، هنگامی که 12 کارگر Spark وجود دارد، میانگین زمان اجرای SNNQA با استفاده از استراتژی ASVI 235.84 ثانیه است. دوبرابر کردن تعداد کارگران اسپارک به 24، میانگین زمان اجرای SNNQA را با استفاده از استراتژی ASVI (SNNQA-ASVI) به نزدیک به 400 ثانیه افزایش می دهد و زمانی که تعداد کارگران Spark به 32 افزایش می یابد، میانگین زمان اجرای SNNQA- ASVI به 281.18 ثانیه سقوط می کند. سپس، وقتی تعداد کارگران اسپارک را به 36 نفر افزایش دادیم، میانگین هزینه زمانی SNNQA-ASVI به 420 ثانیه افزایش می یابد. تنوع کارایی بالا SNNQA-ASVI احتمالاً به دلیل دو عامل است. (1) اختلال عملکرد نمونه های مجازی و (2) عدم قطعیت تعداد کارگران Spark تغییرات SNNQA را با استفاده از ASVI معرفی می کند. ما متوجه می شویم که کارگران Spark اغلب در آزمایشات گم می شوند. وظایف محاسباتی فشرده که بر روی هر Spark Worker اجرا میشوند، به منابع حافظه زیادی نیاز دارند، که ممکن است ارتباط بین کارگران Spark و نمونه Master Spark را مختل کند. علاوه بر این، هیچ مکانیزم خوددرمانی برای کارگران Spark در این زمینه وجود ندارد. زمانی که کمتر از 28 کانتینر داکر به الگوریتم داده شود، زمان اجرا همیشه کمتر از 270 ثانیه است. همانطور که نتایج در تنوع کارایی بالا SNNQA-ASVI احتمالاً به دلیل دو عامل است. (1) اختلال عملکرد نمونه های مجازی و (2) عدم قطعیت تعداد کارگران Spark تغییرات SNNQA را با استفاده از ASVI معرفی می کند. ما متوجه می شویم که کارگران Spark اغلب در آزمایشات گم می شوند. وظایف محاسباتی فشرده که بر روی هر Spark Worker اجرا میشوند، به منابع حافظه زیادی نیاز دارند، که ممکن است ارتباط بین کارگران Spark و نمونه Master Spark را مختل کند. علاوه بر این، هیچ مکانیزم خوددرمانی برای کارگران Spark در این زمینه وجود ندارد. زمانی که کمتر از 28 کانتینر داکر به الگوریتم داده شود، زمان اجرا همیشه کمتر از 270 ثانیه است. همانطور که نتایج در تنوع کارایی بالا SNNQA-ASVI احتمالاً به دلیل دو عامل است. (1) اختلال عملکرد نمونه های مجازی و (2) عدم قطعیت تعداد کارگران Spark تغییرات SNNQA را با استفاده از ASVI معرفی می کند. ما متوجه می شویم که کارگران Spark اغلب در آزمایشات گم می شوند. وظایف محاسباتی فشرده که بر روی هر Spark Worker اجرا میشوند، به منابع حافظه زیادی نیاز دارند، که ممکن است ارتباط بین کارگران Spark و نمونه Master Spark را مختل کند. علاوه بر این، هیچ مکانیزم خوددرمانی برای کارگران Spark در این زمینه وجود ندارد. زمانی که کمتر از 28 کانتینر داکر به الگوریتم داده شود، زمان اجرا همیشه کمتر از 270 ثانیه است. همانطور که نتایج در ما متوجه می شویم که کارگران Spark اغلب در آزمایشات گم می شوند. وظایف محاسباتی فشرده که بر روی هر Spark Worker اجرا میشوند، به منابع حافظه زیادی نیاز دارند، که ممکن است ارتباط بین کارگران Spark و نمونه Master Spark را مختل کند. علاوه بر این، هیچ مکانیزم خوددرمانی برای کارگران Spark در این زمینه وجود ندارد. زمانی که کمتر از 28 کانتینر داکر به الگوریتم داده شود، زمان اجرا همیشه کمتر از 270 ثانیه است. همانطور که نتایج در ما متوجه می شویم که کارگران Spark اغلب در آزمایشات گم می شوند. وظایف محاسباتی فشرده که بر روی هر Spark Worker اجرا میشوند، به منابع حافظه زیادی نیاز دارند، که ممکن است ارتباط بین کارگران Spark و نمونه Master Spark را مختل کند. علاوه بر این، هیچ مکانیزم خوددرمانی برای کارگران Spark در این زمینه وجود ندارد. زمانی که کمتر از 28 کانتینر داکر به الگوریتم داده شود، زمان اجرا همیشه کمتر از 270 ثانیه است. همانطور که نتایج در زمان اجرا همیشه کمتر از 270 ثانیه است. همانطور که نتایج در زمان اجرا همیشه کمتر از 270 ثانیه است. همانطور که نتایج درشکل 6 نشان می دهد که وقتی 24 کانتینر داکر داده می شود، میانگین زمان اجرا 269.91 ثانیه است. زمانی که تعداد کانتینرهای داکر به 20 عدد محدود شود، میانگین زمان اجرا به 250.31 ثانیه کاهش می یابد. هزینه زمانی SNNQAها، با استفاده از دو استراتژی، زمانی که تعداد کارگران Spark بیش از 32 نفر باشد، به سرعت افزایش مییابد. این نتایج نشان میدهد که اگر تعداد کانتینر Docker کوچکتر از 32 باشد، SNNQAs با استفاده از ASVC میتوانند قوی باشند.
برای بررسی اثربخشی شاخص بر SNNQAs، آزمایش دوم را به شرح زیر انجام میدهیم. هنگام استفاده از ASVI و 20 اسپارک، الگوریتم های KNN مبتنی بر Spark با استفاده از شاخص Sort-Tile-Recursive Tree (SKNN-STRtree) در حدود 297.92 ثانیه تکمیل می شود، همانطور که در شکل 7 نشان داده شده است . همانطور که در شکل 6 نشان داده شده است، الگوریتم های KNN مبتنی بر Spark بدون شاخص STRtree در حدود 284.89 ثانیه تکمیل می شوند.. این نتایج نشان میدهد که استفاده از شاخص، زمان اجرای SNNQAs با استفاده از استراتژیهای ASVI را کاهش نمیدهد. دلیل ممکن است این باشد که تعداد اشیاء داده در شبکه ها زیاد نیست. بنابراین نمایه سازی در این زمینه ممکن است ضروری نباشد. شماره شبکه، میانگین تعداد اشیایی را که توسط هر Spark Worker پردازش میشود، تعیین میکند. وقتی تعداد شبکه کوچک است، تعداد اشیاء زیاد است. هر Spark Worker حافظه بیشتری مصرف می کند و مقدار زمان صرف شده برای اجرای محاسبات محمول فضایی را افزایش می دهد. وقتی تعداد شبکه زیاد باشد، تعداد اشیا کم است. هنگام استفاده از ASVC، الگوریتمهای K Nearest Neighbor (KNN) مبتنی بر Spark با استفاده از شاخص STRtree در کمتر از 300 ثانیه در صورت کار با 20 تا 28 کانتینر کامل میشوند. این نتایج نشان می دهد که SNNQA با شاخص STRtree با استفاده از ASVC می تواند قوی باشد اگر تعداد کانتینر کوچکتر از 28 باشد، و هنگام دادن بیش از 28 کانتینر به کارگران Spark، هزینه های SKNN-STRtree بدیهی است افزایش می یابد. این نتایج نشان میدهد که خوشه CoreOS ممکن است برای Kubernetes برای مقیاسبندی خودکار بسیاری از کانتینرها بسیار کوچک باشد. ما همچنین متوجه شدیم که کارایی SKNN-STRtree هنگام استفاده از استراتژی ASVI متفاوت است. این نتایج مشابه نشان می دهد که، صرف نظر از اینکه آیا از نمایه سازی استفاده می شود یا نه، کارایی SNNQAs با استفاده از استراتژی ASVI در ابرها بسیار متغیر است. تعداد دیمون های کارگر Spark که در نمونه های مجازی اجرا می شوند متفاوت است. دیمون های Spark که در هر نمونه مجازی مستقر هستند به دلایل زیادی مستعد از کار افتادن هستند. کارهای فشرده داده مقدار زیادی از حافظه یک نمونه Spark worker را مصرف می کنند، که ممکن است منجر به خطای «خارج از حافظه» شود. علاوه بر این، شبکهسازی در فضای ابری معمولاً ناپایدار است و شبکهسازی بین کارگران Spark و استاد Spark گاهی اوقات ممکن است از بین برود. مشاهده می کنیم که دیمون های کارگر Spark اغلب در طول آزمایش ها شکست می خورند. بنابراین، ما تحقیقات باقی مانده خود را در این مقاله منحصراً بر روی استراتژی های ASVC متمرکز می کنیم.
4.3.2. SNNQA با استفاده از ASVC
برای درک اینکه چگونه پارامتر p بر کارایی SNNQA ها تأثیر می گذارد، آزمایش سوم را به شرح زیر انجام می دهیم. هر ارسال SNNQA با استفاده از ASVC 10 بار با پارامتر total-executor-cores روی شش تنظیم شده است و میانگین زمان اجرا ثبت می شود. همانطور که در شکل 8 نشان داده شده است، زمانی که کمتر از 32 کانتینر داکر نسبت به کارگران Spark وجود دارد، SNNQA ها در کمتر از 300 ثانیه تکمیل می شوند. هنگام تنظیم p = 3000، k = 5، و استفاده از 20 کانتینر Docker، حداقل زمان اجرای SNNQAs حدود 250 ثانیه است. هنگام تنظیم p = 2500، k= 5 و با استفاده از 20 کانتینر داکر، میانگین حداقل زمان اجرای SNNQAها حدود 270 ثانیه است. هنگام تنظیم p = 2000، k = 5 و استفاده از 20 کانتینر Docker، میانگین حداقل زمان اجرای SNNQAs حدود 271 ثانیه است. ما دریافتیم که کاهش مقدار پارامتر p زمان اجرای SNNQAs را در این زمینه افزایش میدهد. به عنوان مثال، هنگام تنظیم p = 1500، k = 5، و استفاده از 20 کانتینر Docker، حداقل زمان اجرای SNNQAs به طور متوسط حدود 330 ثانیه است. هنگام تنظیم p = 1000، k= 5، و با استفاده از 20 کانتینر داکر، میانگین حداقل زمان اجرای SNNQAs حدود 437 ثانیه است. نتایج نشان داد که Spark برای انجام کارهای کوچک موازی مناسب تر است. همانطور که قبلا بحث شد، پارامتر p تعداد وظایف موازی را در هر مرحله از زنجیره های تبدیل اسپارک کنترل می کند. زمانی که پارامتر pکوچک است، تعداد اشیاء فضایی پردازش شده توسط هر مجری Spark زیاد خواهد بود و پس از آن تأخیر الگوریتم ها افزایش می یابد. ما به صراحت بیان نمیکنیم که کدام پیکربندی در این مقاله بهترین است، اما منحنیهای میانگین زمان اجرای SNNQA با استفاده از ASVC زمانی که تعداد کانتینر Docker کمتر از 32 باشد، سازگاری زیادی نشان میدهند. آزمایش ما نشان میدهد که کارگران Spark روی همان کار میکنند. میزبان با هزینه کم با یکدیگر ارتباط برقرار می کنند. بنابراین عملکرد SNNQA قابل اعتماد است. مشاهده میکنیم که وقتی بیش از 32 کانتینر Docker به کارگران Spark داده میشود، هزینه اجرای SNNQAها افزایش مییابد، عمدتاً به این دلیل که Kubernetes نمیتواند تعداد مورد نیاز کانتینرها را در خوشههای کوچک CoreOS حفظ کند.
k یک پارامتر مهم برای SNNQA ها است و طبق آزمایشات ما، الگوی مشابهی را با مشاهده پارامتر p نشان می دهد . به منظور صرفه جویی در فضا، نتایج در این مقاله به تصویر کشیده نشده است. ما ترجیح میدهیم کارایی SNNQAها را با استفاده از ASVC در خوشههای بزرگ بدانیم. بنابراین، آزمایش چهارم را به شرح زیر انجام می دهیم. یک خوشه CoreOS با 19 نمونه مجازی ساخته شده است که در آن یک نمونه دارای چهار VCPU و 8 گیگابایت رم است و نمونه های دیگر هر کدام دو VCPU و 4 گیگابایت رم دارند. میانگین زمان اجرا برای هر یک از 10 مورد ارسالی ثبت می شود. همانطور که در جدول 4 نشان داده شده است، هنگام تنظیم پارامتر total-executor-cores روی شش، SNNQAها با پارامترهای مختلف در کمتر از 300 ثانیه تکمیل می شوند. میانگین زمان اجرای SNNQAها از 259.53 ثانیه تا 288.50 ثانیه است. هنگام ارائه 90 کانتینر داکر با کارگران Spark، میانگین زمان اجرای SNNQAs حدود 259.53 ثانیه است. نتایج بحث قبلی ما را تأیید کردند. در یک خوشه کوچک Kubernetes، تعداد زیادی از کانتینرهای Docker ممکن است تکمیل بالاتری را برای سیستم عامل اصلی ایجاد کنند، که دلیل اصلی کاهش کارایی SNNQAs است. اگرچه Kubernetes مقیاس خودکار صدها و حتی هزاران کانتینر را در چند ثانیه امکانپذیر میکند، پیشنهاد میکنیم از تعداد زیادی از کانتینرهای Docker در کلاسترهای کوچک استفاده نکنید تا از بارگذاری بیش از حد جلوگیری شود.
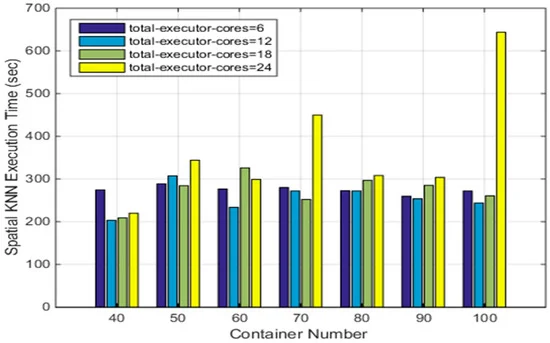
از آنجایی که خوشه CoreOS در مجموع 40 هسته دارد، مقدار پارامتر “total-executor-cores” در تست های بالا می تواند بزرگتر از شش باشد. برای درک تأثیر عدد ظرف داکر بر کارایی SNNQA با استفاده از هستههای بیشتر، آزمایش پنجم خود را به شرح زیر انجام میدهیم. هر ارسال یک SNNQA با استفاده از ASVI 10 بار با p = 3000 و k = 5 اجرا می شود و میانگین زمان اجرا ثبت می شود. همانطور که در شکل 9 نشان داده شده است، زمانی که مقدار هسته های مجری کل از 6 تا 18 باشد، میانگین زمان اجرا حدود 300 ثانیه است. حتی زمانی که عدد کانتینر داکر روی 100 تنظیم شده باشد، هزینه زمانی هرگز از 300 ثانیه تجاوز نمی کند. با این حال، زمانی که 24 هسته مجری کل وجود داشته باشد، عملکرد متفاوت است. به عنوان مثال، هنگام دادن 50 کانتینر داکر به کارگران اسپارک، میانگین زمان اجرا 343.92 ثانیه است. با افزایش تعداد کانتینرهای Docker داده شده به کارگران Spark به 70، میانگین زمان اجرا به بیش از 400 ثانیه افزایش می یابد. افزایش بیشتر این تعداد کانتینرهای Docker به 90 عدد، میانگین زمان اجرا را به حدود 300 ثانیه کاهش می دهد. این نتایج نشان میدهد که تعداد کانتینر و کل هستههای اجرایی مورد استفاده توسط کارگران Spark، عوامل تعیینکننده برای عملکرد SNNQAs هستند. زمانی که 40 کانتینر Docker برای کارگران Spark میدهید و هستههای مجری کل را روی 12 تنظیم میکنید، میانگین زمان اجرای SNNQAs 203.33 ثانیه است. استفاده از همان تعداد کانتینرهای Docker برای کارگران Spark اما افزایش تعداد هسته مجری کل به 18، میانگین زمان اجرای SNNQAs را به 208.93 ثانیه افزایش می دهد. این نتایج نشان میدهد که اگر تعداد نسبتاً کمی از کانتینرهای Docker با هستههای مجری کل متوسط برای کارگران Spark انتخاب کنیم، قابلیت اطمینان عملکرد و کارایی SNNQAs افزایش مییابد. توجه به این نکته مهم است که هزینه زمانی SNNQA ها در هنگام دادن شش، ۱۲ و ۱۸ هسته به کارگران Spark نزدیک به ۳۰۰ ثانیه است. مشاهده می کنیم که عملکرد کلی SNNQA با استفاده از 12 هسته قوی تر از عملکرد با استفاده از 6 و 18 هسته است. پارامتر total-executor-cores آستانه بالایی است که نشان دهنده حداکثر تعداد هسته هایی است که کانتینرهای Spark Worker می توانند مصرف کنند. همانطور که هسته های بیشتری به کارگران Spark داده می شود، تعداد شانس های هر Spark Worker برای اجرای وظایف افزایش می یابد، اما مقدار بزرگتر پارامتر همچنین وظایف زمان بندی بیشتری را برای زمانبندی Kubernetes معرفی می کند. این وضعیت زمانی واضح است که از تعداد بیشتری از کانتینرهای Docker استفاده می کنیم زیرا Kubernetes زمان بیشتری را برای اطمینان از آماده بودن تعداد مشخص شده از کانتینرهای Docker نیاز دارد. هر چه تعداد کل هسته های اجرایی مورد استفاده توسط Spark Workers بیشتر باشد، میزان رقابتی که بین کانتینرهایی که دیمون های Spark Worker را اجرا می کنند بیشتر می شود. Kubernetes زمان بیشتری را برای برنامه ریزی مجدد کارگران Spark خراب شده نیاز دارد، که در این شرایط باعث می شود نمونه Master Spark وظایف ناموفق را مجددا برنامه ریزی کند.
4.3.3. SNNQA با استفاده از استراتژی های مختلف ASVC
برای بررسی کارایی SNNQAs با استفاده از استراتژی های مختلف مقیاس خودکار، آزمایش ششم را به شرح زیر انجام می دهیم. یک پلاگین Heapster برای جمع آوری معیارهای بار کاری CPU از دیمون های kubelet استفاده می شود. هر ارسال الگوریتم 10 بار اجرا می شود و میانگین زمان اجرا ثبت می شود. همانطور که در جدول 5 نشان داده شده است، زمانی که MinReplicas، MaxReplica و TargetPercentage به ترتیب روی 1٪، 40٪ و 50٪ تنظیم می شوند، میانگین زمان اجرای SNNQAs 303.49 ثانیه است. زمانی که مقادیر پارامترهای MinReplicas، MaxReplica و TargetPercentage به ترتیب 10، 40 و 50 درصد باشند، میانگین زمان اجرای SNNQAs 247.68 ثانیه است. این نتایج نشان میدهد که حداقل تعداد کپیهای کارگران Spark تضمینشده توسط Kubernetes تأثیر خاصی بر کارایی SNNQAs دارد، اما همانطور که در آزمایش ما مشاهده شد، تأثیر مشخص نیست. به عنوان مثال، وقتی مقادیر MinReplicas، MaxReplica و TargetPercentage را به ترتیب روی 1٪، 40٪ و 80٪ قرار می دهیم، میانگین زمان اجرای SNNQAs 272.56 ثانیه است. هنگامی که مقادیر پارامترهای MinReplicas، MaxReplica و TargetPercentage به ترتیب 10%، 40% و 80% هستند، میانگین زمان اجرا 249.89 ثانیه است. مشاهده می کنیم که وقتی مقدار پارامتر MinReplicas را روی 10٪، 20٪ و 30٪ قرار می دهیم، به دلیل دو عامل، تعداد کانتینرها هرگز به 40 نمی رسد. اولین دلیل این است که Kubernetes Master نمی تواند میانگین بار کاری CPU را در مدت زمان بسیار کوتاه هر ارسال محاسبه کند. دلیل دوم این است که پلاگین Heapster ممکن است نتواند معیارهای کانتینرها را جمع آوری کند. هدف ما، در آینده نزدیک، یافتن جایگزین هایی است که نظارت بر زمان واقعی را برای Kubernetes فراهم می کند. اگرچه هنوز در استراتژیهای مقیاسبندی خودکار نقصهایی وجود دارد، اما مشاهده میکنیم که هنگام تنظیم مقدار MinReplicas روی 1٪، یک HPA در همه آزمایشها به خوبی کار میکند. و 30 درصد به دلیل دو عامل. اولین دلیل این است که Kubernetes Master نمی تواند میانگین بار کاری CPU را در مدت زمان بسیار کوتاه هر ارسال محاسبه کند. دلیل دوم این است که پلاگین Heapster ممکن است نتواند معیارهای کانتینرها را جمع آوری کند. هدف ما، در آینده نزدیک، یافتن جایگزین هایی است که نظارت بر زمان واقعی را برای Kubernetes فراهم می کند. اگرچه هنوز در استراتژیهای مقیاسبندی خودکار نقصهایی وجود دارد، اما مشاهده میکنیم که هنگام تنظیم مقدار MinReplicas روی 1٪، یک HPA در همه آزمایشها به خوبی کار میکند. و 30 درصد به دلیل دو عامل. اولین دلیل این است که Kubernetes Master نمی تواند میانگین بار کاری CPU را در مدت زمان بسیار کوتاه هر ارسال محاسبه کند. دلیل دوم این است که پلاگین Heapster ممکن است نتواند معیارهای کانتینرها را جمع آوری کند. هدف ما، در آینده نزدیک، یافتن جایگزین هایی است که نظارت بر زمان واقعی را برای Kubernetes فراهم می کند. اگرچه هنوز در استراتژیهای مقیاسبندی خودکار نقصهایی وجود دارد، اما مشاهده میکنیم که هنگام تنظیم مقدار MinReplicas روی 1٪، یک HPA در همه آزمایشها به خوبی کار میکند. یافتن جایگزین هایی است که نظارت در زمان واقعی را برای Kubernetes فراهم می کند. اگرچه هنوز در استراتژیهای مقیاسبندی خودکار نقصهایی وجود دارد، اما مشاهده میکنیم که هنگام تنظیم مقدار MinReplicas روی 1٪، یک HPA در همه آزمایشها به خوبی کار میکند. یافتن جایگزین هایی است که نظارت در زمان واقعی را برای Kubernetes فراهم می کند. اگرچه هنوز در استراتژیهای مقیاسبندی خودکار نقصهایی وجود دارد، اما مشاهده میکنیم که هنگام تنظیم مقدار MinReplicas روی 1٪، یک HPA در همه آزمایشها به خوبی کار میکند.
4.3.4. SNNQAها با استفاده از ASVC در یک گروه مقیاسبندی خودکار
برای بررسی کارایی SNNQAs با استفاده از HPA همراه با یک گروه مقیاسبندی خودکار، آزمایش هفتم را به شرح زیر انجام میدهیم. ابتدا از یک الگوی Heat برای نمایش حداقل، مطلوب و حداکثر تعداد نمونه های CoreOS استفاده می شود که به ترتیب باید 5، 5 و 10 باشد. هر نمونه CoreOS دارای دو VCPU و 4 گیگابایت رم است. در مرحله بعد، زمانی که نرخ استفاده از CPU بالای 80 درصد است و حدود 1 دقیقه طول میکشد، گروه مقیاسبندی خودکار را مجبور میکنیم تا کوچک شوند. دوم، از یک الگوی Kubernetes برای نشان دادن مقادیر حداقل و حداکثر کپی از کارگران Spark استفاده می شود که به ترتیب باید 1 و 200 باشد. پارامتر TargetPercentage روی 80% تنظیم شده است. در نهایت، SNNQAها با استفاده از پارامترهای: total-executor-cores = 18، p = 3000، و k به گروه مقیاس خودکار ارسال می شوند.= 5. هر ارسال SNNQAs پنج بار اجرا می شود و میانگین زمان اجرا ثبت می شود. همانطور که در شکل 10 نشان داده شده است، افزایش تعداد اشیاء پرس و جو به طور یکنواخت زمان اجرای SNNQAها را با استفاده از نمایشگرهای HPA در زمانی که گروه مقیاس خودکار استفاده نمی شود، افزایش می دهد. یافتن پنج نزدیکترین همسایه از 834158 شی داده مکانی برای هر یک از 34604649 شی پرس و جو تقریباً 660.64 ثانیه طول کشید، در حالی که زمان اجرای استفاده از HPA همراه با گروه مقیاس خودکار عملکرد عالی را به همراه دارد. تمام اجراها در کمتر از 300 ثانیه کامل می شوند. نتایج نشان می دهد که HPA همراه با گروه مقیاس خودکار برای تجزیه و تحلیل داده های بزرگ فضایی قابل اعتماد مفید است. پیشنهاد می شود که تحقیقات آینده به سمت پیکربندی خودکار این پارامترها هدایت شود.
5. بحث
کشش یکی از مشخصه های اصلی رایانش ابری است، به این معنی که منابع محاسباتی را می توان به صورت پویا و بر حسب تقاضا با توجه به حجم کار فعلی برنامه ها افزایش یا کاهش داد [17] .]. راهحلهای کنونی مستقیماً از گروههای مقیاس خودکار برای تولید ماشینهای مجازی استفاده میکنند که در آنها از یک ماشین مجازی اختصاصی برای اجرای دیمونهای اصلی Spark و سایر ماشینهای مجازی برای اجرای دیمونهای Spark worker استفاده میشود. از آنجایی که تغییر عملکرد ماشینهای مجازی که دیمونهای اصلی Spark را اجرا میکنند میتواند بر وظایف زمانبندی موتور اسپارک تأثیر بگذارد، ممکن است احتمال کمتری برای ساخت مدلهای رگرسیون مفید برای تخمین زمان اجرای PSQPAهای مبتنی بر Spark وجود داشته باشد. علاوه بر این، دیمونهای Spark master و worker که روی ماشینهای مجازی کار میکنند، میتوانند بدون استفاده از مکانیزم بازیابی اضافی از کار بیفتند. بعلاوه، ظرفیت ماشین مجازی اختصاصی بیش از حد یا کمتر تامین می شود، چه رسد به منابع محاسباتی که به طور موثر استفاده نمی شود. همانطور که در شکل 6 نشان داده شده است، هنگام استفاده از استراتژی های ASVI، کارایی SNNQAs بسیار متغیر است. از آنجایی که هر شبح کاری اسپارک تعداد ثابتی از منابع حافظه را در ماشین های مجازی اوبونتو مصرف می کند، نمی توانیم مقدار زیادی را برای تعداد کارگران اسپارک که روی همان ماشین مجازی کار می کنند، تعیین کنیم. در طول آزمایش ما مشاهده کردیم که شیاطین کارگر Spark اغلب گم می شوند. این ممکن است با پروتکل Netty مبتنی بر پروتکل کنترل انتقال (TCP) که برای دریافت دستورات از Spark master و انتقال داده ها بین کارگران Spark استفاده می شود، مرتبط باشد. اگر اتصال قطع شود، کارگران Spark از خدمات خارج می شوند. علاوه بر این، فضای محدود حافظه مجریهای Spark نمیتواند نیاز محاسباتی را هنگام مدیریت دادههای بیش از حد یا بسیاری از اشیاء پرس و جو برآورده کند. رابطه بین تعداد دیمون های کارگر Spark که روی ماشین های مجازی اجرا می شوند و زمان اجرای SNNQA نامحدود است. برای ارضای تجزیه و تحلیل داده های محدود به زمان، عدم قطعیت باید حذف شود. تنوع عملکرد ماشین های مجازی و فقدان مکانیزم خود ترمیمی برای کارگران Spark که روی ماشین های مجازی کار می کنند، ما را از استفاده از استراتژی ASVI منع می کند، در حالی که عملکرد کلی SNNQA با استفاده از ASVC پایدارتر از استراتژی های ASVC است. اگر کمتر از 28 کانتینر داکر را در این زمینه ارائه دهیم، هزینه های زمانی SNNQAها می تواند در کمتر از 280 ثانیه تکمیل شود. ما متوجه میشویم که هنگام استفاده از بیش از 32 کانتینر برای کارگران Spark و استراتژی ASVC، هزینه زمان به سرعت افزایش مییابد. دلیل ممکن است به شدت با بار هسته برای فرآیندهای سوئیچینگ مرتبط باشد و تکمیل بین پادهای Kubernetes زیاد خواهد بود. از آنجایی که Kubernetes یک خط مشی بهینه سازی ضمنی را تطبیق می دهد که همیشه سعی می کند به وضعیت مشخص شده مطابق با منبع موجود فعلی دست یابد، زمانبندی زمان بیشتری را برای تخصیص مجدد کانتینرهای شکست خورده به گره های مناسب نیاز دارد. در مقایسه با ماشینهای مجازی، کانتینرهای لینوکس عملکرد برابر یا بهتری را تحت بارهای کاری مختلف نشان میدهند.همانطور که در شکل 8 نشان داده شده است، SNNQA با استفاده از استراتژی های ASVI در کمتر از 300 ثانیه تکمیل می شود، زمانی که کمتر از 32 کانتینر برای کارگران Spark استفاده می شود. به غیر از ظروف خود ترمیم شونده، Kubernetes با استفاده از HPA، ظروف مقیاس بندی خودکار را برای تمام گره های محاسباتی موجود تسهیل می کند. ما همچنین رابطه بین زمان اجرای SNNQAها و تعداد کانتینرها در خوشههای بزرگ را بررسی میکنیم. شکل 9نشان میدهد که تعداد کمی از کانتینرها با تعداد متوسطی از هستههای مجری کل استفاده شده توسط Spark، منجر به اجرای قوی SNNQAs میشود. این رابطه زمانی قطعی است که مجموع هسته های اجرایی از تعداد هسته های مجازی تمام ماشین های مجازی موجود بیشتر نباشد. در نهایت، امکان سنجی یک HPA همراه با یک گروه پوسته پوسته شدن خودکار برای تهیه الاستیک ظروف به روشی بزرگ را بررسی می کنیم. نتایج، همانطور که در شکل 10 نشان داده شده است، نشان می دهد که یک HPA همراه با یک گروه مقیاس خودکار برای پیش بینی SQP در یک محیط محاسبات ابری مفید است. اگرچه با استفاده از HPA می توان کارایی فوق العاده ای به دست آورد، اما مشاهده می کنیم که پلاگین Heapster گاهی اوقات نمی تواند معیارهای CPU را جمع آوری کند، که ممکن است بر استراتژی های مقیاس خودکار کانتینر تأثیر بگذارد. کمبود دیگر این است که اجزای Spark که در کانتینرهای Docker اجرا می شوند، راه ساده ای برای اشتراک گذاری داده ها و بسته های نرم افزاری ندارند. ما از تصویر حجمی NFS برای به اشتراک گذاری داده ها بین Kubernetes Pods استفاده می کنیم، که ممکن است بر کل زمان اجرای SNNQA تأثیر بگذارد. این یک حوزه تحقیقات آینده است.
6. نتیجه گیری
در این مقاله، ما یک رویکرد پردازش پرس و جو فضایی الاستیک در یک محیط محاسبات ابری OpenStack با استفاده از ظروف Docker مدیریت شده توسط Kubernetes برای مقیاس خودکار یک موتور محاسباتی Apache Spark پیشنهاد کردیم. با استفاده از مکانیزم خود درمانی و مقیاس خودکار Kubernetes و استفاده از الگوی محاسباتی درون حافظه Spark، میتوانیم یک محیط محاسباتی خوشهای الاستیک برای پردازش پرس و جوی فضایی در یک محیط رایانش ابری بسازیم. برای ارضای تجزیه و تحلیل داده های محدود به زمان، پیاده سازی الگوریتم های پردازش پرس و جو فضایی مبتنی بر Spark (SQPAs) را در این مقاله معرفی می کنیم و سپس سه عامل را شناسایی می کنیم که بر زمان اجرای SQPA ها تأثیر می گذارد. اولین عامل پارامترهای داخلی SQPA ها است که شامل تعداد گرید p استکه برای گروه بندی مجموعه داده های همبستگی فضایی استفاده می شود. از آنجایی که موتور اسپارک برای انجام کارهای بزرگ اما نسبتاً کوچک مناسب است، ما استفاده از مقدار زیادی از پارامتر p را پیشنهاد کردیم.و با در نظر گرفتن حجم مجموعه داده های فضایی و منبع محاسباتی زیربنایی. عامل دوم، پارامترهای مدل محاسباتی اسپارک مانند هستههای مجری کل است. به عنوان مثال، تعداد نامناسبی از مجموع هستههای اجرایی مورد استفاده توسط موتور اسپارک باعث تکمیل شدید بین کانتینرها میشود. ما استفاده از تعداد کمی از کانتینرها با تعداد متوسطی از کل هستههای اجرایی را برای پردازش پرس و جو فضایی قابل اعتماد دادههای فضایی بزرگ پیشنهاد کردیم. آخرین عامل پارامترهای مورد استفاده برای تعریف استراتژی های مقیاس خودکار است. به عنوان مثال، پارامترهای MinReplicas، MaxReplica و Targetpercentage بر زمان اجرای SQPA تأثیر میگذارند. آزمایشها و آزمایشهای انجامشده بر روی یک پلتفرم رایانش ابری OpenStack نشاندهنده شانسی برای SQPAهای با زمان محدود است. با در نظر گرفتن پارامترها،
منابع
- لی، جی جی; کانگ، ام. داده های بزرگ جغرافیایی: چالش ها و فرصت ها. بیگ دیتا Res. 2015 ، 2 ، 74-81. [ Google Scholar ] [ CrossRef ]
- یانگ، سی. هوانگ، Q. لی، ز. لیو، ک. Hu, F. داده های بزرگ و رایانش ابری: فرصت ها و چالش های نوآوری. بین المللی جی دیجیت. زمین 2017 ، 10 ، 13-53. [ Google Scholar ] [ CrossRef ]
- لی، اس. دراگیسویچ، اس. کاسترو، FA; سستر، ام. زمستان، اس. کولتکین، ا. پتیت، سی. جیانگ، بی. هاورث، جی. استاین، الف. نظریه و روشهای مدیریت دادههای بزرگ جغرافیایی: بررسی و چالشهای تحقیق. ISPRS J. Photogramm. Remote Sens. 2016 ، 115 ، 119-133. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لی، ز. یانگ، سی. لیو، ک. هو، اف. جین، بی. مقیاسپذیری خودکار در ابر برای فرآیند کارآمد دادههای بزرگ مکانی. ISPRS Int. J. Geo-Inf. 2016 ، 5 ، 173. [ Google Scholar ] [ CrossRef ]
- یانگ، سی. گودچایلد، م. هوانگ، Q. نبرت، دی. راسکین، آر. خو، ی. بامباکوس، ام. Fay, D. محاسبات ابری فضایی: علوم زمین فضایی چگونه می تواند از محاسبات ابری استفاده کند و به شکل گیری آن کمک کند؟ بین المللی جی دیجیت. زمین 2011 ، 4 ، 305-329. [ Google Scholar ] [ CrossRef ]
- آجی، ع. Wang, F. پردازش پرس و جو فضایی با کارایی بالا برای داده های علمی در مقیاس بزرگ. در مجموعه مقالات سمپوزیوم دکترای SIGMOD/PODS 2012، Scottsdale، AZ، ایالات متحده، می 2012 . ACM: نیویورک، نیویورک، ایالات متحده آمریکا، 2012; صص 9-14. [ Google Scholar ]
- Orenstein، JA پردازش پرس و جو فضایی در یک سیستم پایگاه داده شی گرا. در ACM SIGMOD Record ; ACM: نیویورک، نیویورک، ایالات متحده آمریکا، 1986; جلد 15، ص 326–336. [ Google Scholar ]
- شما، اس. ژانگ، جی. Gruenwald, L. پردازش پرس و جو پیوستن فضایی در مقیاس بزرگ در ابر. در مجموعه مقالات سی و یکمین کنفرانس بین المللی IEEE در کارگاه های مهندسی داده (ICDEW)، سئول، کره، 13 تا 17 آوریل 2015 در سال 2015. صص 34-41.
- ژونگ، ی. هان، جی. ژانگ، تی. لی، ز. نیش، جی. Chen, G. به سمت پردازش پرس و جو فضایی موازی برای داده های فضایی بزرگ. در مجموعه مقالات بیست و ششمین سمپوزیوم بین المللی پردازش موازی و توزیع شده IEEE 2012، کارگاه ها و انجمن دکتری (IPDPSW)، شانگهای، چین، 21 تا 25 مه 2012. ص 2085–2094.
- هوانگ، دبلیو. منگ، ال. ژانگ، دی. Zhang، W. پردازش موازی در حافظه داده های عظیم سنجش از راه دور با استفاده از یک جرقه آپاچی در مدل نخ هادوپ. IEEE J.Sel. بالا. Appl. زمین Obs. Remote Sens. 2016 ، 10 ، 3-19. [ Google Scholar ] [ CrossRef ]
- زهاریا، م. چاودری، ام. داس، تی. دیو، ا. ما، جی. مک کاولی، ام. فرانکلین، ام جی; شنکر، اس. Stoica، I. مجموعه داده های توزیع شده انعطاف پذیر: یک انتزاع مقاوم در برابر خطا برای محاسبات خوشه ای در حافظه. در مجموعه مقالات نهمین کنفرانس USENIX در مورد طراحی و پیاده سازی سیستم های شبکه ای، سن خوزه، کالیفرنیا، ایالات متحده، آوریل 2012 . انجمن USENIX: برکلی، کالیفرنیا، ایالات متحده آمریکا، 2012; پ. 2. [ Google Scholar ]
- زهاریا، م. Xin، RS; وندل، پی. داس، تی. آرمبراست، ام. دیو، ا. منگ، ایکس. روزن، جی. ونکاتارامان، س. فرانکلین، ام جی آپاچی اسپارک: موتور یکپارچه برای پردازش کلان داده. اشتراک. ACM 2016 ، 59 ، 56-65. [ Google Scholar ] [ CrossRef ]
- یو، جی. وو، جی. Sarwat، M. Geospark: یک چارچوب محاسباتی خوشه ای برای پردازش داده های فضایی در مقیاس بزرگ. در مجموعه مقالات بیست و سومین کنفرانس بین المللی SIGSPATIAL در زمینه پیشرفت در سیستم های اطلاعات جغرافیایی ; ACM: نیویورک، نیویورک، ایالات متحده آمریکا، 2015; پ. 70. [ Google Scholar ]
- تانگ، م. یو، ی. ملوهی، QM; اوزانی، م. Aref, WG Locationspark: یک سیستم مدیریت داده در حافظه توزیع شده برای داده های فضایی بزرگ. Proc. VLDB Enddow. 2016 ، 9 ، 1565-1568. [ Google Scholar ] [ CrossRef ]
- ری، اس. سیمیون، بی. براون، AD; جانسون، R. اتصال فضایی موازی در حافظه مقاوم در برابر انحراف. در مجموعه مقالات بیست و ششمین کنفرانس بین المللی مدیریت پایگاه های علمی و آماری ; ACM: نیویورک، نیویورک، ایالات متحده آمریکا، 2014; پ. 6. [ Google Scholar ]
- هربست، NR; کونف، اس. Reussner, R. Elasticity in cloud computing: چیست و چه نیست. در مجموعه مقالات دهمین کنفرانس بین المللی محاسبات خودکار (ICAC 13)، سن خوزه، کالیفرنیا، ایالات متحده آمریکا، 26-28 ژوئن 2013. ص 23-27.
- گالانته، جی. دی بونا، LCE; موری، AR; شولزه، بی. دا روزا ریگی، آر. تجزیه و تحلیل کشش ابرهای عمومی در اجرای برنامه های علمی: یک بررسی. J. Grid Comput. 2016 ، 14 ، 193-216. [ Google Scholar ] [ CrossRef ]
- لایتنر، پی. Cito, J. الگوهای در هرج و مرج – مطالعه تغییرات عملکرد و قابلیت پیش بینی در ابرهای عمومی IAAS. ACM Trans. فناوری اینترنت (TOIT) 2016 ، 16 ، 15. [ Google Scholar ] [ CrossRef ]
- لوریدو بوتران، تی. میگل آلونسو، جی. Lozano, JA مروری بر تکنیک های مقیاس خودکار برای کاربردهای الاستیک در محیط های ابری. J. Grid Comput. 2014 ، 12 ، 559-592. [ Google Scholar ] [ CrossRef ]
- کانگ، اس. لی، ک. مقیاس خودکار پردازش تصویر مبتنی بر جغرافیا در یک محیط محاسبات ابری باز. Remote Sens. 2016 , 8 , 662. [ Google Scholar ] [ CrossRef ]
- سولتز، اس. پوتزل، اچ. فیوچینسکی، من؛ باویر، ا. Peterson, L. مجازی سازی سیستم عامل مبتنی بر کانتینر: یک جایگزین مقیاس پذیر و با کارایی بالا برای هایپروایزرها. در بررسی سیستم عامل ACM SIGOPS ; ACM: نیویورک، نیویورک، ایالات متحده آمریکا، 2007; ص 275-287. [ Google Scholar ]
- فلتر، دبلیو. فریرا، آ. راجامونی، آر. Rubio, J. مقایسه عملکرد به روز شده ماشین های مجازی و ظروف لینوکس. در مجموعه مقالات سمپوزیوم بین المللی IEEE 2015 در تجزیه و تحلیل عملکرد سیستم ها و نرم افزارها (ISPASS)، فیلادلفیا، PA، ایالات متحده آمریکا، 29 تا 31 مارس 2015؛ صص 171-172.
- برینخوف، تی. کریگل، اچ.-پی. سیگر، ب. پردازش کارآمد اتصالات فضایی با استفاده از درختان R. ACM: نیویورک، نیویورک، ایالات متحده آمریکا، 1993; جلد 22. [ Google Scholar ]
- آکدوگان، ا. Demiryurek، U. بنایی کاشانی، ف. شهابی، سی. پردازش پرس و جو مکانی مبتنی بر ورونوی با mapreduce. در مجموعه مقالات دومین کنفرانس بین المللی IEEE در سال 2010 درباره فناوری و علم رایانش ابری (CloudCom)، ایندیاناپولیس، IN، ایالات متحده آمریکا، 30 نوامبر تا 3 دسامبر 2010. صص 9-16.
- برینخوف، تی. کریگل، اچ.-پی. اشنایدر، آر. سیگر، ب. پردازش چند مرحله ای اتصالات فضایی . ACM: نیویورک، نیویورک، ایالات متحده آمریکا، 1994; جلد 23. [ Google Scholar ]
- تره فرنگی.؛ گانتی، RK; سریواتسا، م. لیو، ال. پردازش پرس و جو فضایی کارآمد برای داده های بزرگ. در مجموعه مقالات بیست و دومین کنفرانس بین المللی ACM SIGSPATIAL در زمینه پیشرفت در سیستم های اطلاعات جغرافیایی ; ACM: نیویورک، نیویورک، ایالات متحده آمریکا، 2014; صص 469-472. [ Google Scholar ]
- چن، اچ.-ال. چانگ، Y.-I. همسایه یابی بر اساس منحنی های پرکننده فضا. Inf. سیستم 2005 ، 30 ، 205-226. [ Google Scholar ] [ CrossRef ]
- گوپتا، اچ. چاودا، بی. نگی، س. فاروکی، TA; Subramaniam، LV; Mohania, M. پردازش اتصالات فضایی چند طرفه در کاهش نقشه. در مجموعه مقالات شانزدهمین کنفرانس بین المللی گسترش فناوری پایگاه داده ; ACM: نیویورک، نیویورک، ایالات متحده آمریکا، 2013; صص 113-124. [ Google Scholar ]
- Mouat، A. استفاده از Docker: توسعه و استقرار نرم افزار با کانتینرها . O’Reilly Media, Inc.: Sebastopol, CA, USA, 2015. [ Google Scholar ]
- پینل، آر. Holzschuher، F. مدیریت خوشه Pfitzer، F. Docker برای نتایج بررسی ابری و راه حل خود. J. Grid Comput. 2016 ، 14 ، 265-282. [ Google Scholar ] [ CrossRef ]
- برنز، بی. گرانت، بی. اوپنهایمر، دی. بروور، ای. ویلکس، جی. بورگ، امگا و کوبرنتس. اشتراک. ACM 2016 ، 59 ، 50–57. [ Google Scholar ] [ CrossRef ]
- یانسن، سی. ویت، ام. کرفتینگ، دی. بکارگیری ازدحام داکر در پشته باز برای تجزیه و تحلیل زیست پزشکی. در مجموعه مقالات کنفرانس بین المللی علوم محاسباتی و کاربردهای آن ; Springer: برلین، آلمان، 2016; صص 303-318. [ Google Scholar ]
- جکسون، ک. دسته، سی. Sigler, E. Openstack Cloud Computing Cookbook ; Packt Publishing Ltd.: Birmingham, UK, 2015. [ Google Scholar ]
- لیو، ی. کانگ، سی. گائو، اس. شیائو، ی. Tian, Y. درک الگوهای سفر درون شهری از داده های مسیر تاکسی. جی. جئوگر. سیستم 2012 ، 14 ، 463-483. [ Google Scholar ] [ CrossRef ]
- لیو، ایکس. گونگ، ال. گونگ، ی. لیو، ی. افشای الگوهای سفر و ساختار شهر با دادههای سفر تاکسی. J. Transp. Geogr. 2015 ، 43 ، 78-90. [ Google Scholar ] [ CrossRef ]
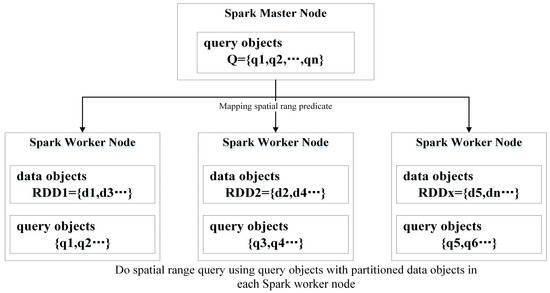
شکل 1. جریان اجرای الگوریتم های جستجوی محدوده فضایی مبتنی بر Spark (SRQ). اشیاء داده های فضایی پارتیشن بندی شده، مجموعه داده های توزیع شده انعطاف پذیر مکانی (RDDs) هستند. مجریان اسپارک در گرههای کارگر اسپارک، پس از دریافت وظایف تبدیل نقشهبرداری از نمونه Spark Master، محاسبات محمولی محدوده فضایی را انجام میدهند.
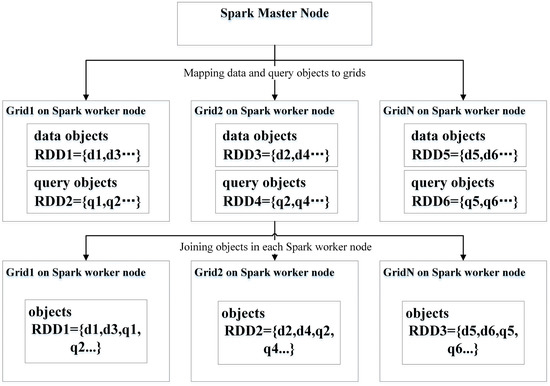
شکل 2. جریان اجرای الگوریتم های اتصال فضایی مبتنی بر Spark (SJQ). داده ها و اشیاء پرس و جو با توجه به موقعیت مکانی آنها در شبکه ها پارتیشن بندی و ذخیره می شوند. مجریان اسپارک در گرههای کارگر اسپارک، پس از دریافت وظایف تبدیل پیوستن از نمونه Spark Master، محاسبات گزارهای همپوشانی فضایی را انجام میدهند.
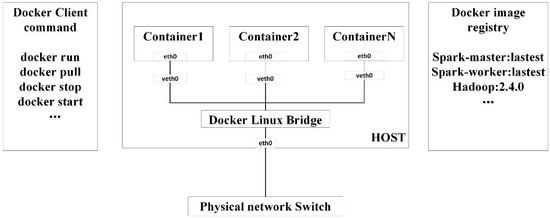
شکل 3. چارچوب داکر برای مدیریت چرخه حیات کانتینرها در یک میزبان. تصاویر داکر در رجیستری های تصویر داکر ذخیره می شوند. هر میزبان یک موتور داکر دارد که طبق درخواست مشتریان داکر این کانتینرها را مستقر و کنترل می کند.
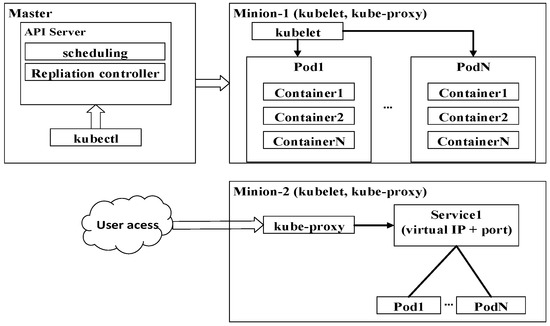
شکل 4. اجزای Kubernetes برای سازماندهی کانتینرهای توزیع شده در گره های مینیون.
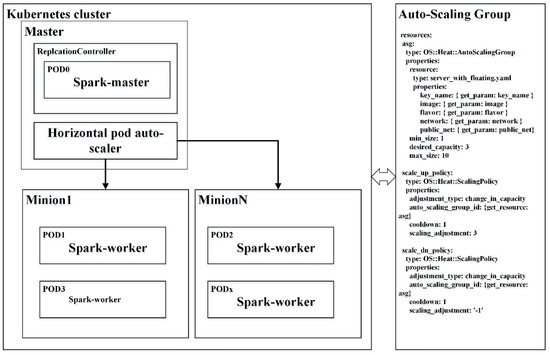
شکل 5. ظروف مقیاس خودکار افقی در OpenStack Cloud برای پردازش پرس و جو فضایی الاستیک داده های فضایی بزرگ. قسمت سمت چپ یک خوشه Kubernetes است و قسمت سمت راست یک گروه مقیاس خودکار است که در آن دیمون های kube-proxy و kubelet بر روی ماشین های مجازی مربوطه اجرا می شوند.
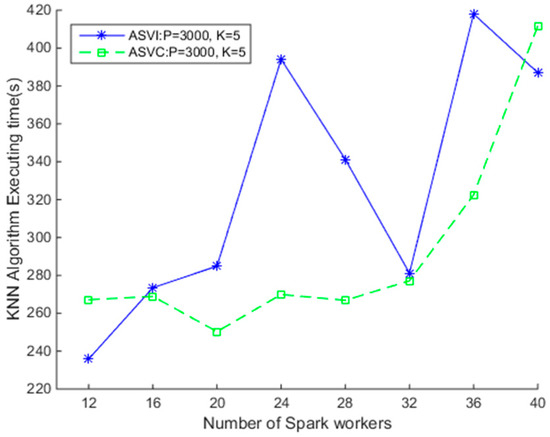
شکل 6. مقایسه الگوریتمهای K Nearest Neighbor (KNN) مبتنی بر Spark با استفاده از نمونههای ماشین مجازی مقیاسپذیر خودکار (VM) (ASVI) و استراتژیهای مقیاس خودکار Docker containers (ASVC).
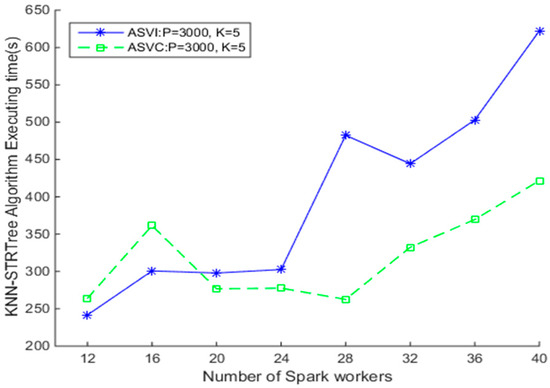
شکل 7. مقایسه الگوریتم های K Nearest Neighbor Sort-Tile-Recursive Tree (KNN-STRtree) مبتنی بر Spark با استفاده از استراتژی های ASVI و ASVC.
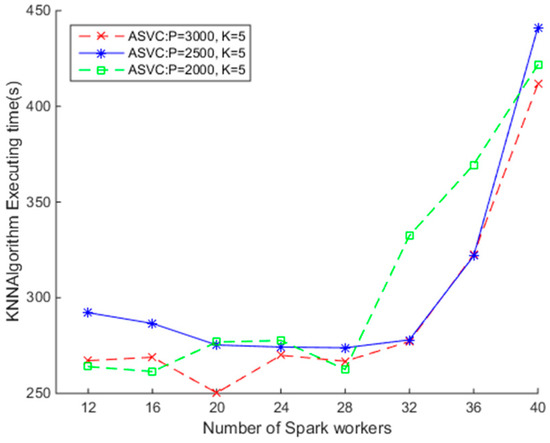
شکل 8. تأثیر پارامتر p بر کارایی الگوریتمهای جستجوی نزدیکترین همسایه مبتنی بر Spark (SNNQAs) با استفاده از ASVC.
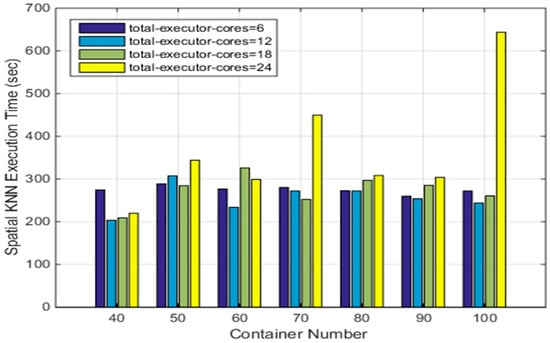
شکل 9. تاثیر کل هسته های اجرایی و تعداد کانتینر بر کارایی SNNQA با استفاده از ASVC.
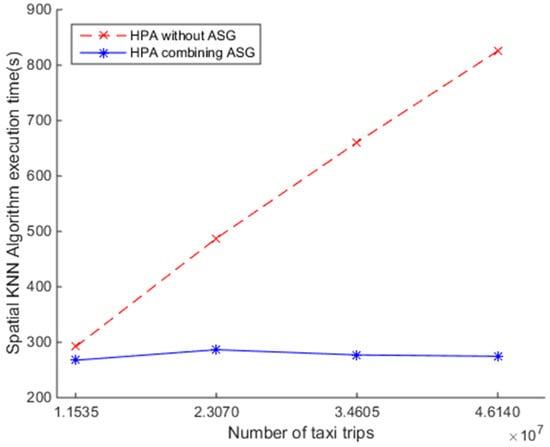
شکل 10. مقایسه کارایی SNNQAها با استفاده از مقیاسکننده خودکار غلاف افقی (HPA) و HPA همراه با گروه مقیاسبندی خودکار (ASG) در ابر OpenStack.

جدول 1. مشخصات محیط رایانش ابری OpenStack.
جدول 2. دو خوشه قابل مقایسه در ابر OpenStack.
جدول 3. جدول خلاصه نرم افزارهای مورد استفاده در آزمون های زیر.
جدول 4. تأثیر شماره کانتینر بر کارایی SNNQA با استفاده از ASVC و تنظیم p = 3000 و k = 5.
جدول 5. تأثیر استراتژی های مختلف مقیاس خودکار بر کارایی SNNQA با استفاده از ASVC.
© 2017 توسط نویسندگان. دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (CC BY) ( http://creativecommons.org/licenses/by/4.0/ ) توزیع شده است.
بدون نظر