2. تقریب تعداد نقاط زیر یک خط
اجازه دهید آر�مجموعه اعداد واقعی را نشان دهید و اجازه دهید آر2�2هواپیمای واقعی باشد در این بخش، ساختار دادههای شاخص را برای مجموعهای P از N نقطه در نظر میگیریمآر2�2که به شما امکان می دهد تقریبی از تعداد نقاط زیر یک خط را به طور موثر پیدا کنید. با چند تعریف شروع می کنیم. یک نقطه (آ1،ب1)(�1,�1) بر نقطه دیگری تسلط دارد(آ2،ب2)(�2,�2)که در آر2�2اگر و تنها اگر آ2≤آ1�2≤�1و ب2≤ب1�2≤�1.
تعریف 1.
در زیر از سه علامت اختصاری زیر استفاده می کنیم:
- (1)
-
# A p r o x ( ℓ , P _)#������(ℓ,�)تعداد تخمینی نقاط در P زیر یک خط ℓ است.
- (2)
-
# B e l o w ( ℓ , P)#�����(ℓ,�)تعداد دقیق نقاط P در زیر یک خط ℓ است.
- (3)
-
# D o m ( p , P)#���(�,�)تعداد نقاطی در S است که نقطه p بر آنها غالب است.
قضیه بعدی بهبود نتیجه پیچیدگی در مورد همان مسئله در [ 17 ] است.
قضیه 1.
# A p r o x ( ℓ , P _)#������(ℓ,�)را می توان در یافت O ( log N)�(log�)زمان و O ( Nورود به سیستم N)�(�log�)فضا، که در آن N تعداد نقاط P است.
اثبات
ما می توانیم یک ساختار داده ای داشته باشیم که مختصات x را مرتب می کند و یک ساختار داده جداگانه که مختصات y نقاط N را مرتب می کند . سپس، حداقل و حداکثر مختصات x ،ایکسدقیقه�minو ایکسحداکثر�maxو حداقل و حداکثر مختصات y ، yدقیقه�minو yحداکثر�max، همیشه می توان در پیدا کرد O ( log N)�(log�)زمان و O ( N)�(�)فضا.
وقتی ℓ یک خط افقی باشد y= a�=�یا یک خط عمودی x = b�=�، سپس مشکل به یافتن کاهش می یابد # D o m ( p , P)#���(�,�)، جایی که p = (ایکسحداکثر، الف )�=(�max,�)یا p = ( b ,yحداکثر)�=(�,�max)، به ترتیب. شماره # D o m ( p , P)#���(�,�)را می توان در یافت O ( log N)�(log�)زمان و O ( Nورود به سیستم N)�(�log�)فضا با استفاده از ساختار داده ECDF-tree شناخته شده [ 18 ]. در اینجا، ECDF به اختصار “تابع توزیع تجمعی تجربی” را بیان می کند.
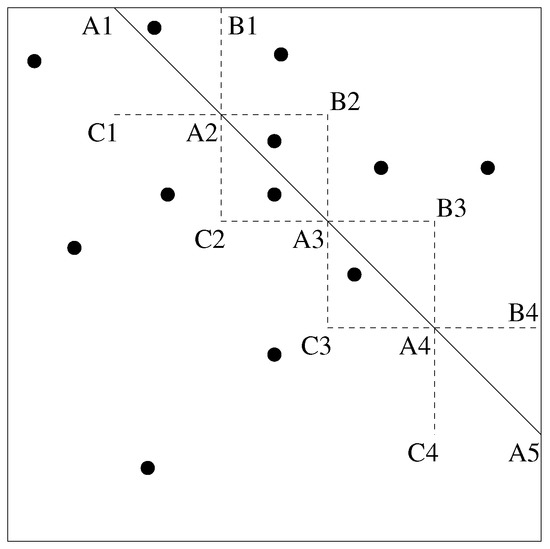
اگر ℓ نه افقی و نه عمودی است، ℓ را بر تقسیم کنیدm – 1�−1افقی و m – 1�−1خطوط عمودی، جایی که متر ≥ 2�≥2هر ثابت است از آنجایی که نقاط N همه در یک کادر با گوشه سمت چپ پایین قرار دارند (ایکسدقیقه،yدقیقه)(�min,�min)و یک گوشه سمت راست بالا (ایکسحداکثر،yحداکثر)(�max,�max)، خطوط عمودی و افقی می توانند آن کادر را به دو قسمت تقسیم کنند متر2�2جعبه های کوچکتر با اندازه مساوی شکل 1 چنین تقسیمی از ℓ را نشان می دهدm = 4�=4. این تقسیم بندی امکان کاهش مشکل یافتن را فراهم می کند # B e l o w ( ℓ , P)#�����(ℓ,�)برای یافتن دنباله ای از # D o m ( p , P)#���(�,�)مقادیر به شرح زیر است:
- (1)
-
مستطیلی را بیابید که شامل تمام نقاط P باشد .
- (2)
-
قسمت ℓ داخل مستطیل را با قطعات خط افقی و عمودی به m تعداد قطعات مساوی ببرید. نقاط جدید ایجاد شده توسط برش ها را به عنوان شماره گذاری کنید آ1, … ,آمتر+ 1�1,…,��+1، ب1, … ,بمتر�1,…,��، و سی1, … ,سیمتر�1,…,��همانطور که در شکل 1 نشان داده شده است .
- (3)
-
تعداد نقاطی که احتمالاً کمتر از ℓ هستند ، بر اساس نقاط B ، یک کران بالایی برای # B e lo w ( ℓ , P)#�����(ℓ,�):
- (4)
-
تعداد نقاطی که مطمئناً زیر ℓ هستند ، بر اساس نقاط C ، یک کران پایین برای #B e l o w ( ℓ , P)#�����(ℓ,�):
- (5)
-
# B e l o w ( ℓ, P)#�����(ℓ,�)می توان به عنوان میانگین کران بالا و پایین بالا تقریب زد:
قضیه از O(Nورود به سیستمN)�(�log�)فضا و ای ( logN)�(log�)زمان مورد نیاز الگوریتم ECDF و این واقعیت که تقریب در (5) فقط نیاز دارد 2 ( m + 1 )2(�+1)فراخوانی به الگوریتم ECDF ☐
مثال 1.
شکل 1 مجموعه ای از نقاط درون یک مستطیل و خطی را نشان می دهد که از مستطیل عبور می کند. خط عبور به داخل قطع می شود m = 4�=4قطعات به صورت افقی توسط بخش های خط اتصال سیمن��و بمن + 1��+1برای 1 ≤ i ≤ 31≤�≤3و به صورت عمودی توسط بخش های خط متصل می شود بj��و سیj + 1��+1برای 1 ≤ j ≤ 31≤�≤3. در شکل 1 کران پایین 5 و کران بالایی 9 است و میانگین اینها 7 است که دقیقاً تعداد نقاط زیر خط است.
در الگوریتم تقریب قضیه 1 از ثابت m استفاده کردیم . می توان ثابت m را که در الگوریتم تقریب استفاده می شود تغییر داد. ما می توانیم به واقعیت زیر توجه کنیم.
نتیجه 1.
مانند m → + ∞�→+∞، # A p r o x ( ℓ , P _) = # B e l o w ( ℓ , P)#������(ℓ,�)=#�����(ℓ,�).
اثبات
با افزایش m ، نواحی مثلثی که مرزهای پایینی و بالایی آن با ناحیه واقعی زیر خط تفاوت دارند، به طور فزاینده ای کوچکتر می شوند. از این رو، دقت تقریب تمایل به افزایش دارد. در حد، مناطق مثلثی ناپدید می شوند و تقریب دقیقاً مقدار را نشان می دهد # B e l o w ( ℓ , P)#�����(ℓ,�). ☐
گاهی اوقات می توان یک شمارش دقیق را برای مقادیر نسبتاً کوچک m تضمین کرد . نمونه ای از چنین تضمینی بر اساس کوتاه ترین فاصله هر نقطه تا خط بعداً در نتیجه 2 مورد بحث قرار می گیرد.
از آنجایی که درختان ECDF در ابعاد بالاتر قابل اجرا هستند، الگوریتم تقریب فوق را می توان به ابعاد بالاتر نیز گسترش داد. به عنوان مثال، در سه بعد، تقریب با استفاده از پرس و جوهای تسلط نقطه تنظیم با استفاده از درختان ECDF، تعداد نقاط زیر یک صفحه را پیدا می کند. در این مورد، هواپیما با استفاده از یک شبکه موازی با محورها بریده می شود.
3. یک جستجوی موقعیت مکانی با توجه به یک خط
در این بخش الگوریتمی را ارائه می کنیم که با توجه به مجموعه ای محدود پ= { (ایکسمن،yمن) ∣ i = 1 ، … ، N}�={(��,��)∣�=1,…,�}از N نقطه در آر2�2، یک ساختار داده می سازد L ( P)�(�)از اندازه ای (ن2)�(�2). ساختار داده L ( P)�(�)می توان برای پاسخ به پرسش زیر استفاده کرد O ( log N)�(log�)زمان: به عنوان ورودی یک خط ℓ در داده می شودآر2�2نقاط P که زیر ℓ هستند ، نقاط P که روی ℓ هستند و نقاط P که بالای ℓ هستند را برگردانید .
الگوریتم دوم یک خط ℓ را به عنوان ورودی به شکل سه گانه دریافت می کند( الف ، ب ، ج )(�,�,�)از اعداد حقیقی که ℓ را با معادله تعیین می کنندa x + b y+ c = 0��+��+�=0. در عمل، این اعداد حقیقی a ، b و c باید به طور محدود قابل نمایش باشند. مثلاً میتوانیم آنها را بهعنوان اعداد واقعی یا گویا قابل محاسبه در نظر بگیریم.
ما دوست داریم بتوانیم مقادیر را سفارش دهیم آایکسمن+ بyمن+ ج���+���+�، برای i = 1 ، … ، N�=1,…,�، به طوری که به راحتی می توان دید که کدامیک از آنها کوچکتر، مساوی یا بزرگتر از 0 هستند. در واقع، آن نقاط (ایکسمن،yمن)(��,��)از P که برای آن آایکسمن+ بyمن+ c > 0���+���+�>0بالای خط ℓ هستند ، آن نقاطی از P که برای آنها آایکسمن+ بyمن+ c = 0���+���+�=0روی خط ℓ و آن نقاط P هستند که برای آنها آایکسمن+ بyمن+ c < 0���+���+�<0زیر خط ℓ هستند . بنابراین، سفارش مقادیر آایکسمن+ بyمن+ ج���+���+�و تعیین شاخص هایی که علامت از − به 0 و سپس به + تغییر می کند، امکان پاسخ دادن به پرسش فوق را در زمان ثابت می دهد (به غیر از نوشتن پاسخ، که لزوماً زمان خطی می برد). به راحتی می توان متوجه شد که ترتیب مقادیر آایکسمن+ بyمن+ ج���+���+�مستقل از c است .
بدیهی است که وجود دارد ن!�!ترتیب احتمالی عناصر P ، یا به طور معادل، شاخص های آنها. در واقع، هر سفارش من1<من2< ⋯ <منن�1<�2<⋯<��از عناصر مجموعه { 1 , 2 , . . . ، ن}{1,2,…,�}را می توان به عنوان جایگشت این مجموعه در نظر گرفت. جایگشت را می نویسیم که 1 به آن نگاشت شده است من1�1; 2 به نقشه برداری شده است من2�2، ….، و N به نگاشت می شود منن��مانند (من1, … ,منن) .(�1,…,��).گروه همه جایگشت های مجموعه را نشان می دهیم { 1 , 2 , . . . ، ن}{1,2,…,�}توسط اسن��. برای (من1, … ,منن) ∈اسن(�1,…,��)∈��، می توانیم زیر مجموعه را در نظر بگیریم الف (من1, … ,منن)�(�1,…,��)از تاپل ها ( الف ، ب ) ∈آر2(�,�)∈�2برای کدام
نابرابری های فوق را می توان به طور معادل، مستقل از c ، as نوشت
مجموعه ها الف (من1, … ,منن)آ(من1،…،منن)که از این طریق تعیین می شود، زیرمجموعه های خطی و نیمه جبری دو بعدی هستند. ( الف ، ب )(آ،ب)-سطح. قبلاً اشاره کردیم که حداکثر وجود دارد ن!ن!چنین مجموعه های ممکن، از آنجایی که وجود دارد ن!ن!عناصر در اسناسن. با این حال، همانطور که به زودی خواهیم دید، تعداد مجموعه های متمایز الف (من1, … ,منن)آ(من1،…،منن)محدود شده است ای (ن2)�(ن2). در واقع، ( † )(†)شامل (حداکثر) ن( ن– 1 )2ن(ن-1)2نابرابری های خطی در a و b . این نابرابری ها را می توان به صورت نوشتاری نوشت یک (ایکسمنj–ایکسمنک) +ب (yمنj–yمنک) ≤0آ(ایکسمن�-ایکسمنک)+ب(�من�-�منک)≤0، 1 ≤ j < k ≤ N1≤�<ک≤ن. بعضی از اینها ن( ن– 1 )2ن(ن-1)2ممکن است منطبق باشند، یعنی زمانی که در مجموعه اصلی P ، جفت نقاطی وجود داشته باشند که پاره خط های موازی را تشکیل می دهند. از نظر هندسی، این نابرابری ها را تقسیم می کنند ( الف ، ب )(آ،ب)هواپیما در (حداکثر) ن( ن– 1 )ن(ن-1)کلاس های پارتیشن تعیین شده توسط خطوط یک (ایکسمنj–ایکسمنک) +ب (yمنj–yمنک) =0آ(ایکسمن�-ایکسمنک)+ب(�من�-�منک)=0، برای 1 ≤ j < k ≤ N1≤�<ک≤ن. این خطوط همه از منشاء می گذرد ( الف ، ب )(آ،ب)هواپیما، و تعیین حداکثر ن( ن– 1 )ن(ن-1)(نامحدود) نیم خط. این نیم خطوط هواپیما را بیشتر به داخل تقسیم می کنند ن( ن– 1 )ن(ن-1)(نامحدود) برش های پای شکل .
متذکر می شویم که در نظر گرفتن مبدأ بی معنی است ( 0 , 0 )(0،0)از ( الف ، ب )(آ،ب)-plane، زیرا هیچ خطی با این نقطه مطابقت ندارد.
ما این را با استفاده از دو مثال افزایش پیچیدگی نشان می دهیم.
مثال 2.
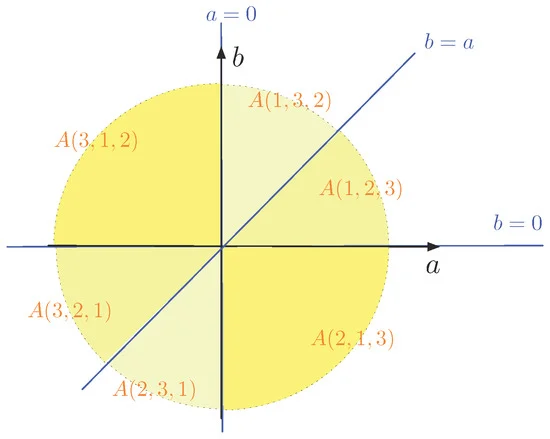
ابتدا می گیریم ن= 3ن=3و نقاط P هستند (ایکس1،y1) = ( 0 , 0 )(ایکس1،�1)=(0،0)، (ایکس2،y2) = ( 0 , 1 )(ایکس2،�2)=(0،1)و (ایکس3،y3) = ( 1 , 0 )(ایکس3،�3)=(1،0). جدول زیر شش ترتیب احتمالی مجموعه شاخص را نشان می دهد { 1 , 2 , 3 }{1،2،3}و معادلات مربوطه که مجموعه ها را توصیف می کنند الف (من1،من2،من3)آ(من1،من2،من3)، برای (من1،من2،من3) ∈اس3(من1،من2،من3)∈اس3.
| (من1،من2،من3)(من1،من2،من3) |
الف (من1،من2،من3)آ(من1،من2،من3) |
| ( 1 , 2 , 3 )(1،2،3) |
0 ≤ b ≤ a0≤ب≤آ |
| ( 1 , 3 , 2 )(1،3،2) |
0 ≤ a ≤ b0≤آ≤ب |
| ( 2 , 1 , 3 )(2،1،3) |
b ≤ 0 ≤ aب≤0≤آ |
| ( 2 , 3 , 1 )(2،3،1) |
b ≤ a ≤ 0ب≤آ≤0 |
| ( 3 , 1 , 2 )(3،1،2) |
a ≤ 0 ≤ bآ≤0≤ب |
| ( 3 , 2 , 1 )(3،2،1) |
a ≤ b ≤ 0آ≤ب≤0 |
مجموعه ها الف (من1،من2،من3)آ(من1،من2،من3)با خطوط مشخص می شوند a = 0آ=0، b = 0ب=0و b = aب=آدر ( الف ، ب )(آ،ب)-سطح. این در شکل 2 نشان داده شده است . ما متذکر می شویم که مجموعه ها الف (من1،من2،من3)آ(من1،من2،من3)از نظر توپولوژیکی بسته هستند و برخی از مجموعه ها الف (من1،من2،من3)آ(من1،من2،من3)یک حاشیه را به اشتراک بگذارید که نیم خط است (همانطور که در شکل 2 مشاهده می شود ). مثلا، A ( 1 , 2 , 3 )آ(1،2،3)و A ( 2 , 1 , 3 )آ(2،1،3)محور a مثبت را به عنوان مرز به اشتراک بگذارید. برای تمام نقاط ( الف ، ب )(آ،ب)با a ≥ 0آ≥0، ما سفارشات را داریم (ایکس1،y1) ≤ (ایکس2،y2) ≤ (ایکس3،y3)(ایکس1،�1)≤(ایکس2،�2)≤(ایکس3،�3)و (ایکس2،y2) ≤ (ایکس1،y1) ≤ (ایکس3،y3)(ایکس2،�2)≤(ایکس1،�1)≤(ایکس3،�3)، که مصادف هستند. در واقع، آایکس1≤ الفایکس2≤ الفایکس3آایکس1≤آایکس2≤آایکس3و آایکس2≤ الفایکس1≤ الفایکس3آایکس2≤آایکس1≤آایکس3هر دو مطابقت دارند 0 ≤ 0 ≤ a0≤0≤آبرای a > 0آ>0.
در مثال قبلی، شش مجموعه داریم الف (من1،من2،من3)آ(من1،من2،من3). استثنایی، برای ن= 3ن=3، ما داریم ن! =ن( ن– 1 )2ن!=ن(ن-1)2. این دیگر برای مقادیر بزرگتر N صادق نیست ، همانطور که مثال بعدی نشان می دهد.
در مثال 2 می بینیم که مجموعه مربوط به ترتیب است 1 ، 3 ، 21،3،2و ترتیب معکوس آن 2 ، 3 ، 12،3،1، برای مثال، A ( 1 , 3 , 2 )آ(1،3،2)و A ( 2 , 3 , 1 )آ(2،3،1)، بازتابی از یکدیگر در امتداد مبدأ هستند ( الف ، ب )(آ،ب)-سطح. این برای همه صدق می کند الف (من1،من2،من3)آ(من1،من2،من3)در مثال 2 (همانطور که با سایه های مربوط به زرد نشان داده شده است) و به طور کلی، همانطور که ویژگی زیر توضیح می دهد:
گزاره 1.
اگر (من1، . . . ،منن) ∈اسن(من1،…،منن)∈اسن، سپس الف (منن، . . . ،من1) = { ( a , b ) ∣ ( − a , − b ) ∈ A (من1، . . . ،منن) }آ(منن،…،من1)={(آ،ب)∣(-آ،-ب)∈آ(من1،…،منن)}.
اثبات
اجازه دهید (من1، . . . ،منن) ∈اسن(من1،…،منن)∈اسن. اگر ( a , b ) ∈ A (من1، . . . ،منن)(آ،ب)∈آ(من1،…،منن)، سپس آایکسمن1+ بyمن1≤ الفایکسمن2+ بyمن2≤ ⋯ ≤ الفایکسمنن+ بyمننآایکسمن1+ب�من1≤آایکسمن2+ب�من2≤⋯≤آایکسمنن+ب�مننو بنابراین – الفایکسمن1– بyمن1≥ – aایکسمن2– بyمن2≥ ⋯ ≥ − aایکسمنن– بyمنن-آایکسمن1-ب�من1≥-آایکسمن2-ب�من2≥⋯≥-آایکسمنن-ب�منن، که دلالت بر آن دارد ( − a , − b ) ∈ A (منن، . . . ،من1)(-آ،-ب)∈آ(منن،…،من1). این یک شمول را ثابت می کند. شمول دیگر نیز همین برهان را دارد. ☐
مثال بعدی پیچیده تر، یک امتیاز به مجموعه P از مثال 2 اضافه می کند.
مثال 3.
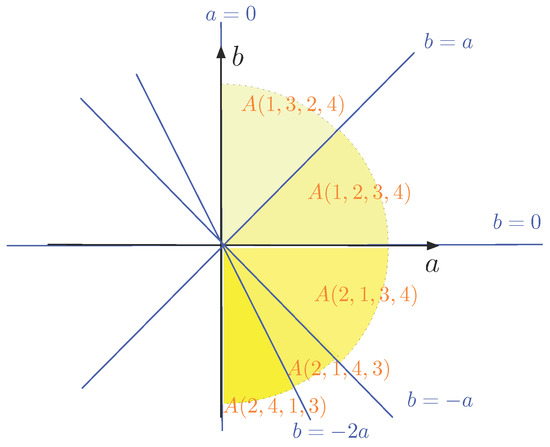
در حال حاضر، ما می گیریم ن= 4ن=4و نقاط P هستند (ایکس1،y1) = ( 0 , 0 )(ایکس1،�1)=(0،0)، (ایکس2،y2) = ( 0 , 1 )(ایکس2،�2)=(0،1)، (ایکس3،y3) = ( 1 , 0 )(ایکس3،�3)=(1،0)و (ایکس4،y4) = ( 2 , 1 )(ایکس4،�4)=(2،1). خاصیت 1 نشان می دهد که ما فقط باید 12 مورد را در نظر بگیریم 4 ! = 244!=24جایگشت های مجموعه { 1 , 2 , 3 , 4 }{1،2،3،4}. جدول زیر این 12 ترتیب مجموعه شاخص را نشان می دهد { 1 , 2 , 3 , 4 }{1،2،3،4}و معادلات مربوطه که مجموعه ها را توصیف می کنند الف (من1،من2،من3،من4)آ(من1،من2،من3،من4).
| (من1،من2،من3،من4)(من1،من2،من3،من4) |
الف (من1،من2،من3،من4)آ(من1،من2،من3،من4) |
| ( 1 , 2 , 3 , 4 )(1،2،3،4) |
0 ≤ b ≤ a ≤ 2 a + b0≤ب≤آ≤2آ+ب |
| ( 1 , 2 , 4 , 3 )(1،2،4،3) |
0 ≤ b ≤ 2 a + b ≤ a0≤ب≤2آ+ب≤آ |
| ( 1 , 3 , 2 , 4 )(1،3،2،4) |
0 ≤ a ≤ b ≤ 2 a + b0≤آ≤ب≤2آ+ب |
| ( 1 , 3 , 4 , 2 )(1،3،4،2) |
0 ≤ a ≤ 2 a + b ≤ b→a = 0 ≤ b0≤آ≤2آ+ب≤ب→آ=0≤ب |
| ( 1 , 4 , 2 , 3 )(1،4،2،3) |
0 ≤ 2 a + b ≤ b ≤ a0≤2آ+ب≤ب≤آ |
| ( 1 , 4 , 3 , 2 )(1،4،3،2) |
0 ≤ 2 a + b ≤ a ≤ b0≤2آ+ب≤آ≤ب |
| ( 2 , 1 , 3 , 4 )(2،1،3،4) |
b ≤ 0 ≤ a ≤ 2 a + bب≤0≤آ≤2آ+ب |
| ( 2 , 1 , 4 , 3 )(2،1،4،3) |
b ≤ 0 ≤ 2 a + b ≤ aب≤0≤2آ+ب≤آ |
| ( 2 , 3 , 1 , 4 )(2،3،1،4) |
b ≤ a ≤ 0 ≤ 2 a + bب≤آ≤0≤2آ+ب |
| ( 2 , 4 , 1 , 3 )(2،4،1،3) |
b ≤ 2 a + b ≤ 0 ≤ aب≤2آ+ب≤0≤آ |
| ( 3 , 1 , 2 , 4 )(3،1،2،4) |
a ≤ 0 ≤ b ≤ 2 a + b→a = 0 ≤ bآ≤0≤ب≤2آ+ب→آ=0≤ب |
| ( 3 , 2 , 1 , 4 )(3،2،1،4) |
a ≤ b ≤ 0 ≤ 2 a + bآ≤ب≤0≤2آ+ب |
از آنجا که خط از طریق (ایکس1،y1) = ( 0 , 0 )(ایکس1،�1)=(0،0)و (ایکس3،y3) = ( 1 , 0 )(ایکس3،�3)=(1،0)و خط از طریق (ایکس2،y2) = ( 0 , 1 )(ایکس2،�2)=(0،1)و (ایکس4،y4) = ( 2 , 1 )(ایکس4،�4)=(2،1)، کمتر از وجود دارد 4 ( 4 – 1 )2= 64(4-1)2=6خطوط در ( الف ، ب )(آ،ب)هواپیما که محدوده مجموعه الف (من1،من2،من3،من4)آ(من1،من2،من3،من4). در واقع، آنها پنج هستند: a = 0آ=0، b = 0ب=0، b = aب=آ، b = – aب=-آو b = – 2 aب=-2آ(همانطور که در جدول نیز مشاهده می شود). بنابراین، در اینجا ( الف ، ب )(آ،ب)همانطور که در شکل 3 نشان داده شده است، صفحه به ده نیم خط و ده برش پای شکل تقسیم شده است . نیمی از برش ها نشان داده نشده اند، اما می توان آنها را از طریق Property 1 به دست آورد. همچنین در شکل 3 حقایقی نشان داده نشده است که A ( 1 , 3 , 4 , 2 ) = A ( 3 , 1 , 2 , 4 )آ(1،3،4،2)=آ(3،1،2،4)محور b غیر منفی است و آن A ( 1 , 2 , 4 , 3 ) = A ( 1 , 4 , 2 , 3 ) = A ( 2 , 3 , 1 , 4 ) = A ( 3 , 2 , 1 , 4 ) = { ( 0 , 0 ) }آ(1،2،4،3)=آ(1،4،2،3)=آ(2،3،1،4)=آ(3،2،1،4)={(0،0)}که با هیچ خطی مطابقت ندارد. بنابراین، ما داریم A ( 1 , 3 , 4 , 2 ) = A ( 3 , 1 , 2 , 4 ) ⊂ A ( 1 , 2 , 3 , 4 )آ(1،3،4،2)=آ(3،1،2،4)⊂آ(1،2،3،4). این مشاهدات نشان می دهد که معمولا نه همه 4 !4!(یا ن!ن!) مجموعه ها به طور جداگانه رخ خواهند داد.
اکنون، ساخت ساختار داده را نشان می دهیم L ( P)�(پ)برای مثال های 2 و 3. ساختار L ( P)�(پ)در اصل یک درخت AVL است. درختان AVL که به نام های Adelson-Velsky و Landis [ 11 ] نامگذاری شده اند، درختان جستجوی دودویی هستند. این بدان معنی است که در هر یک از گره های آن، موارد با مقادیر کلید کمتر از گره در زیردرخت فرزند سمت چپ و مقادیر بزرگتر از مقدار کلید از گره در زیردرخت فرزند سمت راست ذخیره می شوند. درختهای جستجوی دودویی که m مقادیر کلیدی را ذخیره میکنند، در حالت ایدهآل، امکان جستجوی یک مقدار کلیدی معین را در زمان میدهند. O ( log m )�(ورود به سیستممتر). این پیچیدگی زمانی زمانی رخ میدهد که درختهای باینری نسبتاً متعادل باشند. در حالی که بسیاری از روشهای درج و حذف گره ممکن است منجر به درختهای جستجوی باینری نامتعادل شوند (با پیچیدگی جستجو که ممکن است تبدیل شود). O ( m )�(متر)، به جای O ( log m )�(ورود به سیستممتر)روش درختی AVL به صورت پویا درخت AVL را پس از درج یا حذف گره ها با اعمال دنباله ای از چرخش ها یا چرخش های مضاعف متعادل می کند [ 11 ]. تعداد چرخش ها و دو چرخش های مورد نیاز برای متعادل کردن مجدد درخت در ارتفاع درخت خطی است. درختهای AVL «متعادل» باقی میمانند، به این معنا که برای هر گره، ارتفاع زیردرخت سمت چپ و زیردرخت سمت راست حداکثر یک تفاوت دارند. ارتفاع یک درخت را می توان به عنوان طول طولانی ترین مسیر از ریشه تا یک برگ تعریف کرد.
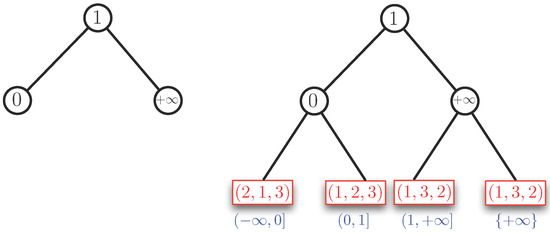
مثال 4.
دو مورد را در نظر می گیریم: a ≥ 0آ≥0و a < 0آ<0. توسط اموال 1، مورد a < 0آ<0را می توان به مورد تقلیل داد a > 0آ>0(با استفاده از ترتیب معکوس). بنابراین، اساسا، مورد a ≥ 0آ≥0، باید حل شود. فرض می کنیم a ≥ 0آ≥0. ابتدا شیب نیم خط هایی را که در نیم صفحه پیدا می کنیم مرتب می کنیم a > 0آ>0در محدوده ( − ∞ , + ∞ ](-∞،+∞]. در اینجا، ما موافق هستیم که محور b مثبت با معادله a = 0آ=0به صورت بیان می شود b / a = + ∞ب/آ=+∞. در مثال 2، شیب ها را داریم b / a = 0ب/آ=0، b / a = 1ب/آ=1و b / a = + ∞ب/آ=+∞، که دستور را می دهند 0 < 1 < + ∞0<1<+∞. ما از این شیب ها به عنوان مقادیر کلیدی برای ساختن درخت AVL استفاده می کنیم. برای مثال 2، این درخت در قسمت سمت چپ شکل 4 نشان داده شده است . ساختار داده مربوطه L ( P)�(پ)در قسمت سمت راست شکل 4 نشان داده شده است . برای این مثال، درخت AVL کاملا متعادل است. فواصل آبی زیر برگ درخت AVL نشان می دهد که کدام قسمت از فاصله است ( − ∞ , + ∞ ](-∞،+∞]مطابق با یک برگ در این مثال، دنبالهای از فواصل باز-بسته در برگها را داریم: ( – ∞ , 0 ](-∞،0]، ( 0 , − 1 ](0،-1]، ( 1 , + ∞ ](1،+∞]و { + ∞ }{+∞}. یک افزونگی کوچک برای پرونده وجود دارد + ∞+∞که توسط دو برگ پوشیده شده است. این فقط زمانی رخ می دهد که b / a = + ∞ب/آ=+∞یک شیب است.
کادرهای قرمز رنگ در برگها ترتیب (شاخص) نقاط را نشان می دهد پ= { (ایکسمن،yمن) ∣ i = 1 ، … ، N}پ={(ایکسمن،�من)∣من=1،…،ن}، برای فاصله شیب ها در هر برگ. هر کادر قرمز نشان دهنده (یا حاوی) یک درخت جستجوی دودویی در ترتیب (یا جایگشت) موجود در آن است.
در مثال 3، دو شیب اضافی داریم، یعنی b / a = – 2ب/آ=-2و b / a = – 1ب/آ=-1. این دستور را می دهد − 2 < 1 < 0 < 1 < + ∞-2<1<0<1<+∞از دامنه ها اگر درج کنیم – 2-2و – 1-1در درخت AVL شکل 4 ، درخت AVL و ساختار را بدست می آوریم L ( P)�(پ)برای مثال 3، همانطور که در شکل 5 نشان داده شده است . در این مثال درخت AVL تقریبا متعادل است. ارتفاع زیردرخت سمت چپ ریشه یک بالاتر از زیردرخت سمت راست است.
ما خاطرنشان می کنیم که ارتفاع AVL از نظر تعداد گره های آن لگاریتمی است. از آنجایی که حداکثر وجود دارد ن( ن– 1 )2ن(ن-1)2دامنه ها، ارتفاع داریم O ( logن( ن– 1 )2) = O ( log N)�(ورود به سیستمن(ن-1)2)=�(ورود به سیستمن). بنابراین، ما نیاز داریم O ( log N)�(ورود به سیستمن)زمان برای یافتن برگ مربوط به شیب یک خط معین.
اکنون قسمت پایینی سازه را توضیح می دهیم L ( P)�(پ)که با کادرهای قرمز رنگ در شکل 4 و شکل 5 نشان داده شده است . برای تعیین جایگشت سمت چپ، یک را انتخاب می کنیم a > 0آ>0و ب طوری که بآبآبه شدت کوچکتر از شیب اول است – 2-2. به عنوان مثال، ما می توانیم b = – 3ب=-3و a = 1آ=1و توجه داشته باشید که هر انتخاب دیگری به گونه ای که بآ< – 2بآ<-2همان جایگشت را خواهد داد. بعد باید سفارش بدیم آایکسمن+ بyمنآایکسمن+ب�من، برای (ایکسمن،yمن) ∈ پ(ایکسمن،�من)∈پ، برای b = – 3ب=-3و a = 1آ=1. این ترتیب (یا جایگشت) را می دهد ( 2 , 1 , 4 , 3 )(2،1،4،3). برای برگه بعدی سمت راست این برگه سمت چپ، نیازی به انجام مجدد فرآیند کامل سفارش نداریم. فقط امتیاز (ایکسمن،yمن)(ایکسمن،�من)و (ایکسj،yj)(ایکس�،��)برای کدام − 2 = −ایکسمن–ایکسjyمن–yj-2=-ایکسمن-ایکس��من-��می تواند هنگام عبور از شیب ترتیب را تغییر دهد – 2-2. در این مثال می بینیم که شیب – 2-2ناشی از (ایکس1،y1) = ( 0 , 0 )(ایکس1،�1)=(0،0)و (ایکس4،y4) = ( 2 , 1 )(ایکس4،�4)=(2،1)و در واقع، جای سوئیچ 1 و 4 در جایگشت ( 2 , 1 , 4 , 3 )(2،1،4،3)دادن ( 2 , 4 , 1 , 3 )(2،4،1،3)برای برگ بعدی ما یادآوری می کنیم که اطلاعات جایگشت در “جعبه های قرمز” را می توان در خود درخت AVL باینری ذخیره کرد.
اکنون می توان از درخت جستجوی شکل 5 برای پاسخ به پرسش محدوده نیم صفحه استفاده کرد. به عنوان مثال، اگر خط ℓ با معادله 2 x − 3 سال+ 1 = 02ایکس-3�+1=0داده می شود، جایگشت را پیدا می کنیم ( 2 , 1 , 4 , 3 )(2،1،4،3)در برگ که با فاصله مطابقت دارد ( − 2 , − 1 ](-2،-1]که در آن شیب – 32-32واقع شده است. برای دیدن کدام یک از (ایکس2،y2) = ( 0 , 1 )(ایکس2،�2)=(0،1)، (ایکس1،y1) = ( 0 , 0 )(ایکس1،�1)=(0،0)، (ایکس4،y4) = ( 2 , 1 )(ایکس4،�4)=(2،1)، (ایکس3،y3) = ( 1 , 0 )(ایکس3،�3)=(1،0)زیر ℓ هستند، ما محاسبه می کنیم 2ایکسمن– 3yمن2ایکسمن-3�منبرای i = 2 ، 1 ، 4 ، 3من=2،1،4،3(به ترتیب) تا زمانی که این مقدار کاملاً پایین باشد − c = − 1-ج=-1. در این مورد فقط (ایکس2،y2) = ( 0 , 1 )(ایکس2،�2)=(0،1)زیر ℓ یافت می شود.
اکنون قضیه زیر را نشان میدهیم که مثالهای 2، 3 و 4 را تعمیم میدهد.
قضیه 2.
یک مجموعه داده شده است پ= { (ایکسمن،yمن) ∣ i = 1 ، … ، N}پ={(ایکسمن،�من)∣من=1،…،ن}از N نقطه در آر2آر2، یک ساختار داده L ( P)�(پ)از اندازه ای (ن3)�(ن3)می تواند در زمان ساخته شود ای (ن3)�(ن3)به طوری که برای هر خط ورودی ℓ در آر2آر2، توسط یک معادله داده می شود a x + b y+ c = 0آایکس+ب�+ج=0، امکان تعیین از L ( P)�(پ)که در O ( log N)�(ورود به سیستمن)زمانی که کدام یک از نقاط N در زیر، بالا و روی خط ℓ قرار دارند.
ساختار داده را می توان به روز کرد ای (ن2ورود به سیستم N)�(ن2ورود به سیستمن)زمانی که نقطه ای به P اضافه می شود یا از P حذف می شود.
قبل از اینکه این قضیه را اثبات کنیم، متذکر می شویم که پیچیدگی تعیین از L ( P)�(پ)، که از N نقطه ها در زیر، بالا و روی خط ℓ قرار دارندO ( log N)�(ورود به سیستمن)زمان. این شامل نوشتن پاسخ در مواقع ضروری نمی شود. بدیهی است که نوشتن این ترتیب لزوما ممکن است زمان خطی داشته باشد. با این حال، اگر به پاسخ اجازه داده شود که یک اشاره گر در درخت جستجو باشد و پاسخ واقعی شامل «همه نکاتی که قبل از این نقطه هستند» باشد، فهرست کردن مؤثر این نکات ممکن است ضروری نباشد. این امکان پذیر است زیرا جایگشت نقاط خود را می توان در یک درخت باینری (AVL) قرار داد. حال به اثبات قضیه می پردازیم.
اثبات
یک مجموعه داده شده است پ= { (ایکسمن،yمن) ∣ i = 1 ، … ، N}پ={(ایکسمن،�من)∣من=1،…،ن}از N نقطه در آر2آر2، ابتدا شیب های موجود در را تعیین می کنیم ( الف ، ب )(آ،ب)-صفحه خطوط یک (ایکسمن–ایکسj) +ب (yمن–yj) =0آ(ایکسمن-ایکس�)+ب(�من-��)=0، برای 1 ≤ i < j ≤ N1≤من<�≤ن. حداکثر وجود دارد ن( ن– 1 )2ن(ن-1)2چنین شیب هایی، که برخی ممکن است همزمان باشند. این طول می کشد ای (ن2)�(ن2)زمان و فضا.
اکنون، همانطور که در مثال 4 نشان دادیم، روی نیم صفحه تمرکز می کنیم که توسط a ≥ 0آ≥0. برای رسیدگی به پرونده a < 0آ<0می توانیم از Property 1 استفاده کنیم. در این مرحله می توانیم قسمت بالایی را بسازیم L ( P)�(پ)با ساختن یک درخت AVL روی شیب ها (به روشی که در مثال 4 نشان داده ایم). از آنجایی که هزینه درج یک گره در درخت AVL با n گره است O ( log n )�(ورود به سیستم�)، هزینه ساخت یک درخت AVL از n گره، با قرار دادن این n گره پشت سر هم، برابر است با O ( n log n )�(�ورود به سیستم�)و درخت می گیرد O ( n )�(�)فضا. اعمال شده به تنظیمات ما، ما حداکثر ن( ن– 1 )2ن(ن-1)2شیب ها، بنابراین ساختن درخت AVL در این شیب ها طول می کشد ای (ن2ورود به سیستم N)�(ن2ورود به سیستمن)زمان و ای (ن2)�(ن2)فضا. اگر به برگ های درخت از چپ به راست نگاه کنیم، ساختن درخت AVL، به عنوان یک اثر جانبی، نظم شیب ها را ایجاد می کند. به این ترتیب، اطلاعات بازهای را نیز بدست میآوریم که با فواصل آبی در شکل 4 و شکل 5 ارائه شده است .
پس از ساخته شدن درخت AVL، باید ترتیب (شاخص های) نقاط P را در هر یک از برگ های درخت تعیین کنیم. این ترتیبات با جایگشت در “جعبه های قرمز” در شکل 4 و شکل 5 نشان داده شده اند . بگذارید شیب هایی که در درخت AVL رخ می دهد باشد س1،س2، . . . ،سکس1،س2،…،سک، با − ∞ <س1<س2< ⋯ <سک≤ + ∞ .-∞<س1<س2<⋯<سک≤+∞.با گرفتن برخی از خودسرانه a > 0آ>0و ب طوری که − ∞ <بآ<س1-∞<بآ<س1و سفارش دادن آایکسمن+ بyمنآایکسمن+ب�من، برای i = 1 , . . . ، نمن=1،…،ن، جایگشتی را بدست می آوریم که در سمت چپ ترین برگ درخت AVL است. ما می توانیم این جایگشت (در کادر قرمز) را به عنوان خود درخت AVL ذخیره کنیم. طول می کشد O ( Nورود به سیستم N)�(نورود به سیستمن)زمان و O ( N)�(ن)فضایی برای ساخت این درخت AVL کوچکتر برای ذخیره سفارش. برای برگهای بعدی (از چپ به راست در درخت میرویم)، همانطور که از مقداری شیب عبور میکنیم سℓسℓ، فقط ترتیب شاخص های i و j در مقایسه با برگ قبلی، اگر
در واقع اگر، برای مثال آایکسمن+ بyمن≤ الفایکسj+ بyjآایکسمن+ب�من≤آایکس�+ب��برای بآ<سℓبآ<سℓ، پس داریم آ“ایکسj+ب“yj≤آ“ایکسمن+ب“yمنآ”ایکس�+ب”��≤آ”ایکسمن+ب”�منبرای سℓ<ب“آ“سℓ<ب”آ”. این بدان معناست که با رفتن از چپ به راست از میان برگهای درخت AVL، میتوانیم جایگشتها را در زمان خطی در N بهروزرسانی کنیم. بهروزرسانی کنیم .
از آنجایی که درخت AVL دارد ای (ن2)�(ن2)برگ، کل زمان ساخت سازه L ( P)�(پ)است ای (ن2ورود به سیستم N) +O ( Nورود به سیستم N) + O (ن2⋅ ن) =O (ن3)�(ن2ورود به سیستمن)+�(نورود به سیستمن)+�(ن2·ن)=�(ن3). ما همان فضای محدود را داریم. اشاره می کنیم که ارتفاع کل سازه L ( P)�(پ)که به دست می آوریم است O ( logن2) +O ( log N) = O ( log N)�(ورود به سیستمن2)+�(ورود به سیستمن)=�(ورود به سیستمن).
پیچیدگی زمان پرس و جو به شرح زیر است. در خط ورودی ℓ که توسط معادله داده می شود a x + b y+ c = 0آایکس+ب�+ج=0، طول می کشد O ( log N)�(ورود به سیستمن)زمان تعیین برگ درخت AVL که شامل فاصله زمانی شیب است بآبآواقع شده است. در واقع، ارتفاع درخت AVL از نظر تعداد گره های آن لگاریتمی است که ای (ن2)�(ن2). اجازه دهید فرض کنیم که این برگ حاوی جایگشت است (من1،من2، . . . ،منن)(من1،من2،…،منن)(در جعبه قرمزش). برای خروجی نقاطی که در زیر ℓ هستند ، می نویسیم (ایکسمنj،yمنj)(ایکسمن�،�من�)به خروجی برای j = 1 , 2 , . . .�=1،2،…تا زمانیکه آایکسمنj+ بyمنj< – جآایکسمن�+ب�من�<-ج. در حالت بدتر، خروجی شامل تمام نقاط P است . بدیهی است که این فرآیند نوشتن در اندازه خروجی زمان خطی می برد.
در نهایت، در مورد به روز رسانی درخت AVL زمانی که یک نقطه به P اضافه می شود یا یک نقطه از P حذف می شود، بحث می کنیم . افزودن یا حذف یک نقطه می تواند باعث معرفی یا حذف حداکثر N شیب شود. افزودن یا حذف N شیب در درخت AVL طول می کشد O ( Nورود به سیستم N)�(نورود به سیستمن)زمان. در نهایت، جایگشت ها در برگ ها باید به روز شوند. یادآور میشویم که از آنجایی که فهرستهای جایگشت خود بهعنوان درختهای AVL ذخیره میشوند، پس حذف یک نقطه از P منجر به حذف یک برگ از درخت AVL در کادرهای قرمز میشود. به طور مشابه، افزودن یک نقطه به P منجر به افزودن یک برگ به درختان کوچک AVL می شود. این هزینه به روز رسانی دارد O ( log N)�(ورود به سیستمن). بنابراین کل زمان به روز رسانی است ای (ن2ورود به سیستم N) .�(ن2ورود به سیستمن).این اثبات را به پایان می رساند. ☐



بدون نظر