1. معرفی
نقاط مورد علاقه (POI) مکانهای مورد علاقه هر کاربر اطلاعات جغرافیایی، مانند مکانهای توریستی، امکانات رفاهی، یا فروشگاهها را توصیف میکنند و میتوانند به راحتی توسط شهروندان جمعسپاری شوند. در نتیجه، آنها اغلب بخش عمده ای از مشارکت پروژه های داوطلبانه اطلاعات جغرافیایی (VGI) هستند. برای مثال OpenStreetMap (OSM) و Wikimapia را ببینید. با این حال، نشان دادن یک مکان جغرافیایی که می تواند وسعتی به اندازه یک ساختمان داشته باشد با استفاده از نقطه ابتدایی، برای مشارکت کنندگان یا حتی برای نقشه برداران حرفه ای فرآیند ساده ای نیست: بهترین مکان برای یک نقطه نشان دهنده مدرسه ای است که ممکن است از چندین مدرسه تشکیل شده باشد. ساختمان ها؟ علاوه بر این، دادههای جمعسپاری شده ممکن است در معرض تغییرات مکرر، جزئی یا عمده باشند تا زمانی که بین داوطلبان به توافق برسند. بنابراین، تنها اندازهگیری فاصله بین این دادههای POI و همتای آنها در یک مجموعه داده مرجع چندان معنیدار نیست. با این حال، مجموعه داده های VGI POI باید ارزیابی شوند تا به طور موثر در برنامه ها مورد استفاده قرار گیرند: به عنوان مثال، زمانی که POI ها روی نقشه نمایش داده می شوند، سازگاری مکان آنها در ناحیه مبهمی که نشان می دهند برای کاهش نقشه خوان بسیار مهم است. بار شناختی
از ابتدا، ارزیابی کیفیت داده ها یکی از موضوعات اصلی تحقیقاتی مربوط به VGI، و به ویژه OSM بود (به عنوان مثال [ 1 ] مراجعه کنید)، و عمدتاً از طریق مقایسه با مجموعه داده های مرجع معتبر [ 2 ، 3 ] انجام می شود. سپس روش های زیادی برای ارزیابی کیفیت VGI پیشنهاد شده است. یک بررسی را می توان در [ 4 ، 5 ، 6 ]، در میان دیگران یافت . ارزیابی کیفیت POI های VGI ضروری است زیرا بسیاری از برنامه ها بر اساس چنین داده هایی هستند و می توانند تحت تأثیر POI های با کیفیت پایین قرار گیرند. POI از OSM، ویکیپدیا، یا شبکههای اجتماعی مانند Facebook یا Swarm میتوانند برای راهیابی کاربر محور [ 7 ]، برای تجزیه و تحلیل جمعیت استفاده شوند [ 8 ،9 ]، برای نقشه برداری کاربری زمین [ 10 ]، برای تحلیل شهری [ 11 ]، یا برای تجزیه و تحلیل ادراک مردم از مکان ها [ 12 ].
علیرغم تحقیقات فوق الذکر و در حال انجام در مورد کیفیت VGI، هیچ چارچوب جامع و جامعی برای ارزیابی کیفیت کلی چنین داده هایی وجود ندارد (تحقیق در این راستا، به عنوان مثال، در [13، 14]) و روش های موجود (به عنوان مثال). , ارزیابی کیفیت مبتنی بر ISO) به اندازه کافی فراگیر یا انعطاف پذیر نیستند تا این نوع جدید از داده ها را در خود جای دهند.
ماهیت جمعسپاری VGI اساساً با اطلاعات جغرافیایی کلاسیک (GI) متفاوت است، به ویژه به این دلیل که اکنون یک عامل اجتماعی قوی پشت مشارکتهای عمومی و ایجاد داده وجود دارد. بنابراین، برای VGI غیرمعمول نیست که از سوگیری های مشارکت در تمام سطوح ریزه کاری رنج می برد. علاوه بر این، از آنجایی که VGI در طعمهای مختلف و از منابع متنوع ارائه میشود، روشهای ارزیابی کیفیت موجود همیشه ابزاری برای ارزیابی آنها فراهم نمیکنند. برای مثال، منابع صریح (مانند OSM، Geograph و غیره) و ضمنی (مثلاً، فلیکر، توییتر و غیره) GI [ 15 ، 16] وجود دارد.]، که با توجه به پیشرفتهای روششناسی بازیابی GI، میتواند برای استخراج دادههای معنادار از انواع محتوای موجود در وب و در نتیجه ایجاد محصولات فضایی نوآورانه (مثلاً از نقشههای دوچرخه گرفته تا نقشههای احساسی) استفاده شود. این محصولات فضایی خارج از محدوده تولیدکنندگان سنتی داده های جغرافیایی مانند آژانس های نقشه برداری ملی (NMA) یا شرکت های بزرگ هستند.
علاوه بر این، VGI به اندازهای بالغ شده است که به عنوان جایگزین یا راهی برای غنیسازی دادههای معتبر با GI در نظر گرفته شود، که تاکنون در پایگاههای داده معتبر وجود نداشته است. بنابراین، همراه با ارزیابی در برابر داده های مرجع معتبر، VGI به یک روش مستقل و جامع برای ارزیابی کیفیت نیاز دارد. در این زمینه، بسیاری از کارهای تحقیقاتی بر کشف، مستندسازی و توسعه شاخصهای کیفیت VGI ذاتی متمرکز شده است [ 4 ]. در چنین مطالعاتی، تلاش ها عمدتاً بر یک بررسی سطح ویژگی متمرکز شده است. بررسی اصل و نسب (مثلاً نسخهها)، توپولوژی یا ویژگیهای هندسی (مثلاً طول، مساحت)، میتواند به درک اساسی از کیفیت کلی مجموعه داده VGI منجر شود.
به دنبال این خط از تحقیقات، این مقاله راه های مختلف برای ارزیابی کیفیت VGI را بررسی می کند. تحقیقات اخیر روش هایی را برای ارزیابی POI های VGI بر اساس تاریخچه [ 17 ] یا مقایسه با مجموعه داده های مرجع [ 18] پیشنهاد کرده است.]، اما هیچکدام برای ارزیابی کیفیت به تنهایی کافی نیستند. به منظور ارزیابی پتانسیل ترکیب چنین روشهایی در POI، روشهای جایگزین را روی همان مجموعه داده مقایسه میکنیم. بنابراین، اولین هدف ما ارزیابی قابلیت استفاده از این روشها برای ارزیابی کیفیت VGI POI و شناسایی جنبههایی از کیفیت دادهها است که هر روش میتواند یا نمیتواند پوشش دهد. هدف دوم ما آزمایش یک رویکرد جامع تر با ترکیب روش های مختلف و شناسایی چیزهایی است که می توانیم در مورد کیفیت از طریق این ترکیب بیاموزیم. به عنوان مثال، مقایسه هر نمونه از یک تاریخچه ویژگی با داده های مرجع می تواند به ما بگوید که آیا نسخه های جدید ویژگی کیفیت آن را بهبود بخشیده است یا خیر.
ساختار باقیمانده این مقاله به شرح زیر است: بخش 2 یک نمای کلی از روش شناسی و داده های مورد استفاده ارائه می دهد. بخش 3 داده های VGI را با استفاده از اصل و نسب آنها ارزیابی می کند. بخش 4 کیفیت VGI را با استفاده از روابط فضایی داخلی ارزیابی می کند. بخش 5 ارزیابی کیفیت را با استفاده از تکنیک های تطبیق داده ها با مقایسه آنها با داده های مرجع معتبر مورد بحث قرار می دهد. بخش 6 ارزیابی کیفیت را با استفاده از داده های سایر منابع VGI مورد بحث قرار می دهد. سپس، بخش 7 احتمالات را هنگام ترکیب روش های قبلی مورد بحث قرار می دهد. در نهایت، در بخش 8 ، این مقاله نتیجهگیری و توصیههایی را برای کار آینده ارائه میکند.
2. روش شناسی و مجموعه داده های مورد استفاده
به منظور ارزیابی کیفیت POI های جمع سپاری، از دو رویکرد کلی استفاده کردیم: (1) استفاده از ویژگی های ذاتی و اندازه گیری های مشتق شده از مجموعه داده های جمع سپاری در دست، و (ب) ارزیابی POI های جمع سپاری با استفاده از یک مجموعه داده خارجی، که می تواند یک مجموعه معتبر باشد. مرجع یا مجموعه داده های جمع سپاری شده دیگر. به طور خاص، داده های مورد ارزیابی، POI های OSM برای منطقه پاریس هستند. برای رویکرد اول، دو روش برای ارزیابی کیفیت پیشنهاد شده است: استفاده از تاریخچه هر ویژگی به تنهایی ( بخش 3 ) و تجزیه و تحلیل روابط فضایی و توپولوژیکی ویژگی های OSM ( بخش 4).). برای مورد دوم، کیفیت نقاط OSM را در مقابل نقاط معتبر از IGN (آژانس نقشهبرداری فرانسه) با استفاده از الگوریتم تطبیق دادهها (به بخش 5 مراجعه کنید) و با استفاده از عکسهای دارای برچسب جغرافیایی از فلیکر (به بخش 6 مراجعه کنید ) بررسی کردیم. در نهایت، تمام این روش های ارزیابی برای بهبود تجزیه و تحلیل کیفیت داده ها و تولید دانش جدید ترکیب شدند (به بخش 7 مراجعه کنید ).
2.1. مجموعه داده OpenStreetMap
پروژه OSM یکی از نمونه های بارز Crowdsourcing GI است. از سال 2004، پروژه OSM مشارکت کنندگان را از سراسر جهان به منظور ایجاد یک پایگاه داده جغرافیایی آزادانه در دسترس بسیج کرده است. امروزه، بیش از سه میلیون مشارکتکننده ثبتشده در OSM وجود دارد و علیرغم این واقعیت که اکثریت قریب به اتفاق مشارکتکنندگان گاه به گاه هستند و بنابراین تنها بخش کوچکی از آنها به طور مداوم مشارکت میکنند، به صورت ماهانه، بیش از 20000 مشارکتکننده فعال وجود دارد. زمان نوشتن)؛ این یک نیروی کار بزرگ را تشکیل می دهد. هدف اولیه این بود که داوطلبان بتوانند از دانش محلی خود برای گرفتن داده های جغرافیایی مناطقی که می شناسند استفاده کنند. این از آن زمان گسترش یافته است و داوطلبان اکنون به دلیل پیشرفت های تکنولوژیکی و در دسترس بودن تصاویر ماهواره ای و هوایی با وضوح بسیار بالا در حال نقشه برداری از مناطق در سراسر جهان هستند. این توسعه گسترش OSM را با این مبادله تقویت کرده است که تأثیر دانش محلی در داده های OSM در حال کاهش است. با این وجود، OSM هنوز هم بهروزترین پایگاه داده جغرافیایی جهانی جمعسپاری شده است و دادهها در برنامههای مختلف از کمک به تلاشهای بشردوستانه استفاده میشوند.19 ] برای استفاده در پروژه های دولتی [ 20 ].
مدل داده OSM از سه نمونه اولیه هندسی مبتنی بر برداری تشکیل شده است. اولی گرههایی هستند که مبتنی بر نقطه هستند و برای گرفتن نقاط منفرد (مثلاً نشانهها) استفاده میشوند یا بخشی از دومین اولیه هستند، یعنی راهی هستند که برای گرفتن موجودیتهای خطی یا چندضلعی استفاده میشود. در نهایت، روابط برای گرفتن مجموعه منطقی از گره ها ، راه ها یا سایر روابط استفاده می شود . برای هر یک از این موارد اولیه، مدل داده OSM اجازه می دهد تا ویژگی ها (که معمولاً به عنوان برچسب ها شناخته می شوند) با استفاده از یک کلید: ارزش پیوست شوند.فرم. در حالی که یک اصل اساسی OSM این است که مشارکتکنندگان در انتخاب هر ویژگی که میخواهند آزادند، در عمل یک مشخصات مبتنی بر ویکی برای پروژه OSM وجود دارد که پیشنهادات و بهترین روشها را در مورد ترکیبهایی که باید در هر مورد استفاده شود ارائه میدهد. یکی دیگر از عناصر مهم مدل داده OSM این است که خود پایگاه داده جغرافیایی به شیوه ای مبتنی بر ویکی ایجاد می شود. این بدان معناست که همه مشارکتکنندگان میتوانند تمام ویژگیهای موجود را ویرایش کنند و تمام نسخههای قبلی یک ویژگی به همراه جزئیات مربوط به هر نسخه در دسترس هستند (به عنوان مثال، زمان ایجاد، توسط کدام کاربر، برچسبهایی که به ویژگی اختصاص داده شده است، و غیره). ). OSM یک رابط برنامه نویسی کاربردی (API) ارائه می دهد که امکان دسترسی به داده های جغرافیایی، داده های مربوط به مشارکت کنندگان و داده های مربوط به ویژگی های فردی و نسخه های قبلی آنها را فراهم می کند.
برای این مطالعه، دادههای OSM برای یک منطقه مورد مطالعه در منطقه پاریس دانلود شد. پوشش منطقه انتخاب شده به دلیل وجود جامعه OSM فعال کاملاً کامل است. برای دانلود داده های OSM از سرویس دانلود شیپ فایل Geofabrik استفاده شد. اگرچه تفاوتهایی بین مخازن OSM و Geofabrik وجود دارد (عمدتاً به دلیل حذف برچسبهای غیر استاندارد)، این تفاوتها تأثیری بر روششناسی ما نخواهد داشت. از آنجایی که موضوع این مقاله ارزیابی کیفی ویژگیهای رمزگذاریشده نقطهای و بهویژه هندسه، نام و انواع نقاط OSM است، تنها لایههای مکانها (4275 ویژگی) و POI (192228 ویژگی) مورد ارزیابی قرار گرفتند. شکل فایل های Geofabrik به عنوان یک ویژگی، OSM_ID اصلی و منحصر به فرد هر ویژگی OSM را شامل می شود. این اطلاعات در ترکیب با OSM API استفاده شد. به عنوان مثال، کل تاریخچه ویژگی OSM با OSM_ID 26691437، با استفاده از درخواست API قابل دسترسی است:http://api.openstreetmap.org/api/0.6/node/26691437/history/ . پاسخ API یک فایل XML است که شامل تمام نسخههای ویژگی با OSM_ID 26691437 است. از طریق یک فرآیند تکراری، تمام نسخههای هر ویژگی OSM در محدوده دانلود و در پایگاه داده PostgreSQL/PostGIS ذخیره شدند. این روش یک جدول زمانی کامل از ویرایش های OSM انجام شده در منطقه برای داده های مورد علاقه ارائه می دهد.
2.2. مجموعه داده مرجع
داده های مرجع از پایگاه داده BD TOPO تولید شده توسط IGN استخراج شد. BD TOPO یک مجموعه داده توپوگرافی با دقت موقعیتی زیر 1 متر است. دامنه آن همه POI هایی را که در OSM ثبت می شوند را پوشش نمی دهد (به عنوان مثال، هیچ مغازه یا رستورانی وجود ندارد)، اما لایه POI شامل آموزش، مدیریت، حمل و نقل، مذهب، بهداشت، ورزش، و هیدروگرافی است که همپوشانی کافی با OSM ایجاد می کند. POI برای مقاصد مقایسه. مقادیر مشخصه، در اصل به زبان فرانسوی، به انگلیسی ترجمه شده اند تا تطبیق معنایی با OSM را فعال کنند. مجموعه داده IGN POI شامل 6202 ویژگی است. تغییر در ویژگیهای IGN به دلیل بهروزرسانیها (مثلاً تغییر در دنیای واقعی، تصحیح خطاها)، تغییرات در مشخصات یا تغییرات ناشی از مشارکتهایی است که دادهها را در اختیار IGN قرار میدهند (به عنوان مثال، وزارت آموزش و پرورش برای موقعیت مدارس،
2.3. مجموعه داده فلیکر
توسعه وب 2.0 [ 21] منجر به ایجاد یک وب دو جهته شده است که در آن هدف بسیاری از برنامه های کاربردی مبتنی بر وب ارائه پلتفرم هایی است که کاربران را قادر می سازد محتوای خود را ایجاد و منتشر کنند و آن را با سایر کاربران به اشتراک بگذارند. این توسعه منجر به ظهور وب سایت های شبکه های اجتماعی شده است. یکی از اولین نمونههای اینگونه وبسایتها، برنامههای اشتراکگذاری عکس، به عنوان مثال، فلیکر، پیکاسا وب یا جدیدتر اینستاگرام است که از کاربران میخواهد عکسهای خود را همراه با عنوان، نظرات، کلمات کلیدی (معروف به برچسبها) و موقعیت مکانی خود به اشتراک بگذارند. (معروف به برچسب گذاری جغرافیایی) و سپس استفاده از آنها به عنوان ابزار شبکه. در حالی که جغرافیا یا مکان محتوا ویژگی اصلی چنین برنامههایی نیست، اما همچنان میتوانند منابع ضمنی GI باشند زیرا روشهای بازیابی GI جدید توسعهیافته میتوانند اطلاعات ضمنی را به محتوای جغرافیایی تبدیل کنند.22 ]. در این مطالعه، عکسهای دارای برچسب جغرافیایی دانلود شده از فلیکر برای ارزیابی اعتبار و کیفیت ویژگیهای مبهم OSM استفاده شدهاند. با استفاده از Flickr API، تمام عکسهای دارای برچسب جغرافیایی که بین آوریل تا دسامبر 2015 در وبسایت فلیکر آپلود شدهاند، بارگیری شدهاند، که در مجموع 79722 عکس دارای برچسب جغرافیایی برای کمک به تعیین وجود و نوع OSM POIهایی که با استفاده از آنها قابل شناسایی نیستند، دریافت شدهاند. تصاویر ماهواره ای (به عنوان مثال، POI واقع در زیر درختان یا نوع ساختمان).
3. ارزیابی با تحلیل تاریخی
تحقیق در مورد شاخص های ارزیابی درونی هندسی بر جنبه های مختلف موقعیت و توپولوژی متمرکز شده است (همچنین به بخش 4 مراجعه کنید ). به عنوان مثال، ون اکسل و همکاران. [ 23 ] منشأ ویژگی های OSM را به عنوان شاخصی از کیفیت آنها بررسی کرد. طول ویژگی و چگالی نقطه توسط Ciepłuch و همکاران استفاده شده است. [ 24 ] برای تجزیه و تحلیل کیفیت داده های OSM. Keßler و de Groot [ 25 ] ویژگیهای سطح ویژگی را که مختص VGI هستند (و برای دادههای معتبر قابل استفاده نیستند) مانند تعداد نسخهها، پایداری در برابر تغییرات سایر مشارکتکنندگان، و تعداد اصلاحات یا بازگشت ویژگیهای OSM بررسی کردند. . بارون و همکاران [ 14] چارچوبی را ارائه میکند که شاخصهای ذاتی متعددی را ارائه میکند که صرفاً بر اساس تاریخچه دادههای OSM است که به ارزیابی کیفیت کمک میکند.
در اینجا، ما نوع، نام و اصل و نسب هندسی ویژگیهای کدگذاری شده با نقطه OSM (یعنی مکانها و POI) را برای منطقه مورد مطالعه بررسی میکنیم. بنابراین، تغییرات احتمالی در یک نقطه OSM که برای این مطالعه مورد توجه است، تغییراتی است که میتواند بر موارد زیر تأثیر بگذارد: (1) نوع آن، برای مثال، ویژگیای که در ابتدا به عنوان شهر مشخص میشود، میتواند بعداً به شهر یا روستا تغییر یابد .; (ii) نام آن، که در آن نام یک ویژگی میتواند دستخوش تغییر دستوری اصلی یا جزئی شود (به عنوان مثال، نام مکان «سنت لوئیس» میتواند به «سنت لوئیس» یا به چیزی کاملاً متفاوت تغییر کند). و (iii) مکان آن، که در آن یک ویژگی می تواند توسط مشارکت کنندگان فقط چند سانتی متر تا صدها متر دورتر جابجا شود. بنابراین، حالت های ممکن یک نقطه OSM یا باید در تمام چرخه عمر آن پایدار باشد یا در یک یا چند عامل از سه عامل فوق الذکر تغییر ایجاد کند. برای ارزیابی POI حاضر با تجزیه و تحلیل تاریخچه، ما فقط مکان ها و POI های نامگذاری شده را انتخاب کردیم (به ترتیب 4273 و 53052 ویژگی).
3.1. روش شناسی و نتایج
برای ارزیابی کیفیت نقاط OSM (که دارای نام هستند) در طول زمان، از تاریخچه (یعنی نسخه های OSM) هر ویژگی استفاده کردیم تا انواع و سطح تغییرات را بررسی کنیم. توانایی تکرار وضعیت یک عنصر در هر نقطه خاص از زمان، امکان ارزیابی کمی و کیفی نوع و بزرگی تغییرات را فراهم میکند.
ابتدا، ویژگیهای تحتتاثیر انواع مختلف یا ترکیبی از تغییرات را برای مکانهای OSM و OSM POI شمارش کردیم. سپس، میزان تغییر را برای موارد منتخب بررسی کردیم. برای مکانهای OSM ما موارد زیر را محاسبه کردیم: (i) درصد ویژگیهای جابجا شده در هر نوع ویژگی (مثلاً چند درصد از شهرها در طول سالها تغییر موقعیت دارند). و (ب) جابجایی کلی (بر حسب متر) در هر نوع ویژگی. برای OSM POI ما محاسبه کردیم: (i) درصد ویژگی های جابجا شده در هر نوع ویژگی. (ب) درصد تغییرات نام و تغییر مکان در هر نوع ویژگی. و (iii) جابجایی (بر حسب متر) ویژگی ها در هر نوع ویژگی.
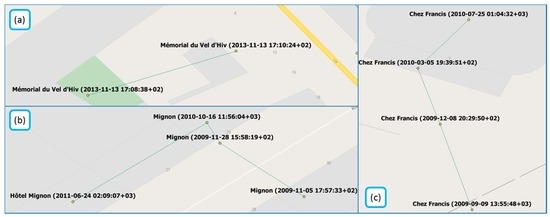
بزرگی جابجایی یک ویژگی با فاصله بین مرکز به دست آمده از تمام موقعیت های شناخته شده مکان (در تمام طول عمر آن) و آخرین موقعیت آن تعریف می شود. شکل 1 نمونه هایی از تغییر موقعیت POI را به همراه نام نهادها و تاریخ ایجاد هر نسخه نقطه نشان می دهد.
با پیروی از این روش، ما سعی کردیم مشخص کنیم که POIهای OSM نامگذاری شده در طول عمر خود چگونه رفتار می کنند. در حالی که این یک تحلیل جامع نیست، با این وجود، زمینه را برای درک چگونگی رفتار انواع ویژگیهای مختلف و بنابراین چه فرضیاتی در رابطه با کیفیت آنها در طول زمان میتوان انجام داد.
3.2. ارزیابی مکان های OSM
مکانها و نامها عنصر ارزشمندی در بسیاری از محصولات مختلف از جمله روزنامهها، نقشهبرداری و برنامههای موبایل، خدمات مبتنی بر مکان و موتورهای جستجو هستند. بنابراین، هر نوع تغییر در داده ها بر ثبات محصولات یا خدماتی که از VGI استفاده می کنند، تأثیر می گذارد.
تجزیه و تحلیل در مورد انواع مختلف یا ترکیبی از تغییرات احتمالی نشان داد که دو سوم از ویژگی ها (66.8٪) بدون تغییر باقی مانده است. شایع ترین تغییر در موقعیت جغرافیایی (12.3٪) از ویژگی ها و به دنبال آن یک تغییر ترکیبی در موقعیت و نام (7.8٪) ثبت شده است. جالب توجه است، تجزیه و تحلیل درصد ویژگی های جابجا شده در هر نوع نشان داد که انواع مکان های OSM رفتارهای متفاوتی دارند. نمونهای از آن شهر ویژگی OSM است که در آن 80٪ (یعنی 198 از 248) در طول زمان از نظر جغرافیایی جابهجا شدهاند در حالی که تنها 8٪ از محل ویژگیهادر موقعیت خود دستخوش تغییر شده است. تجزیه و تحلیل بزرگی جابجایی موقعیت در هر نوع ویژگی نشان داد که ویژگیهایی با وسعت فضایی زیاد در مقایسه با موجودیتهای کوچکتر با تغییرات بزرگی در مکان خود مواجه هستند. به عنوان مثال، 21٪ از ویژگی های دارای نوع حومه کمتر از 100 متر حرکت کردند، در حالی که تنها برای 2٪ از حومه ها تغییر موقعیت بیش از 1000 متر ثبت شد. در مقابل، 14 درصد از تمام ویژگیها در رده شهرها بیش از 1000 متر جابجا شدهاند.
3.3. ارزیابی OSM POI
فقط اخیراً POI ها راه خود را در کاربردهای فضایی پیدا کرده اند. فرآیندهای سنتی تهیه نقشه این نوع اطلاعات را مستثنی میکردند، نه به دلیل اهمیت، بلکه بیشتر به این دلیل که نقشهها، و بهویژه نقشههای کاغذی، بهعنوان محصولات عمومی طولانیمدت با هدف پشتیبانی از برنامههای کاربردی متعدد به دلیل هزینه بالا و دانش گسترده مورد نیاز برای ساخت آنها ساخته شدند. [ 26]. با این حال، ظهور VGI به شهروندان این امکان را داده است که به راحتی اطلاعات محلی را ضبط کرده و روی نقشه قرار دهند. بیشتر این اطلاعات به شکل POI ارائه می شود. معمولاً، جدای از محل POI، مشارکتکنندگان میتوانند ویژگیهای مختلفی مانند نام آن (در صورت وجود) یا نوع آن (مانند بانک، بیمارستان، کافیشاپ و غیره) را اضافه کنند. از POIهای استخراج شده از OSM برای منطقه مورد مطالعه، (یعنی 200000)، تنها 27.6٪ از آنها (یعنی 53052) دارای ویژگی نام بودند. این یک نتیجه مورد انتظار است زیرا POI بخشی از یک لایه فضایی ناهمگن است که میتواند شامل نشانهها و بناهای تاریخی شناختهشده جهان و همچنین تقاطعهای خیابانهای محلی و چراغهای راهنمایی باشد که در آن ویژگی نام قابل اعمال نیست.
همانطور که در روش توضیح داده شد، تغییرات در مکان، نوع، نام و هرگونه ترکیب ممکن نیز برای POI ها بررسی شده است. تجزیه و تحلیل نشان می دهد که حدود 60٪ از ویژگی ها از زمان ایجاد آنها تغییر نکرده اند، در حالی که رایج ترین تغییر برای POI ها تغییر نام (13.2٪) و پس از آن تغییر در مکان (12.7٪) یا در هر دو مکان است. و نام (10.2%). بقیه تغییرات مربوط به هر کدام کمتر از 2.0٪ است.
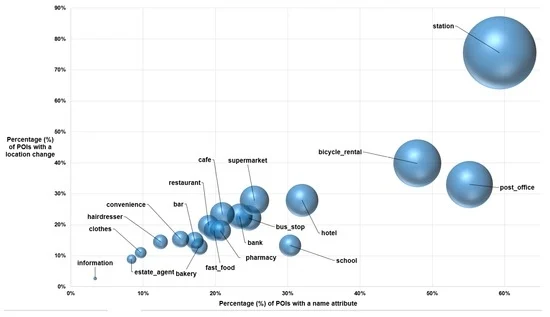
با توجه به اینکه دو تغییر متداول ویژگی ها، تغییر نام و مکان است، و با بررسی این موضوع از دیدگاه دسته بندی های فردی (یعنی انواع OSM)، جالب است که ببینید کدام دسته های POI بیشتر و چقدر تغییر می کنند. در حال تغییر. شکل 2 درصد POI های OSM را نشان می دهد که تحت یک نام و تغییر مکان قرار گرفته اند که بر اساس دسته بندی POI برای 20 دسته بندی محبوب گروه بندی شده اند. این تجسم نوسانات هر دسته را می توان به تناسب مقاصد مقوله های مختلف فراتر از اندازه گیری های دقیق و ملموس عناصر کیفیت (همانطور که در [ 27 ] تعریف شد) مرتبط دانست. مثلاً ایستگاهدسته بندی یک دسته بندی بسیار فرار است زیرا 59٪ از ویژگی ها موقعیت خود را تغییر داده اند و 76٪ تغییر نام داده اند. تجزیه و تحلیل شرح داده شده در بخش 5 نشان می دهد که این دسته بندی پیچیده است و می تواند به توضیح نوسانات بالا در ویژگی این دسته کمک کند. تعداد تغییرات همچنین نشان دهنده محبوبیت ویژگی ها است زیرا ایستگاه ها توسط اکثر کاربران این منطقه استفاده می شود. هر برنامه یا محصولی که قصد دارد این ویژگی ها را در خود جای دهد باید این تغییرات احتمالی را در نظر بگیرد. در مقابل، POI های مرتبط با اطلاعات ثابت می کنند که در برابر تغییر بسیار انعطاف پذیرتر هستند.
جدول 1 و جدول 2 آماری از حرکت موقعیتی ده دسته OSM را نشان می دهد که بر اساس بالاترین حرکت رتبه بندی شده اند. هدف یک بار دیگر درک تناسب برای مقاصد دسته های مختلف برای کاربردهای مختلف است. به عنوان مثال، برای ویژگی های ایستگاه OSM که تغییر مکان خود را تجربه کرده اند، میانگین حرکت تقریباً 40 متر است در حالی که برای نانوایی فقط 4.7 متر است. با این حال، در همه موارد انحراف استاندارد بزرگتر از آستانه (خودسرانه) دقت 10 متری است که دستگاه های GPS دستی می توانند به دست آورند. به موازات آن، حداکثر حرکت موقعیتی ثبت شده نشان می دهد که در برخی موارد (به عنوان مثال، سوپرمارکت یا ایستگاه ها)، مشارکت کنندگان ممکن است در مورد اینکه بهترین مکان برای قرار دادن نقطه ای است که نمایانگر ویژگی های فیزیکی است، اختلاف نظر داشته باشند، زیرا مساحت ویژگی ممکن است بسیار بزرگ باشد (برای بحث بیشتر در مورد این نکته به بخش های بعدی مراجعه کنید). برای موارد دیگر مانند کافه ، نانوایی ، هتل و بانککه با گسترههای جغرافیایی کوچک و دقیق مشخص میشوند، حداکثر فاصله نشان میدهد که برخی از اشتباهات فاحش توسط مشارکتکنندگان صورت گرفته است که در نسخههای بعدی تصحیح شدهاند (یا برعکس). با این حال، مفهوم خطای فاحش به نوعی گریزان است و مطمئناً در این مجموعه داده ها یکنواخت نیست. به عنوان مثال، حداکثر جابجایی 339 متر برای نقطه ای که یک هتل را نشان می دهد، ممکن است یک حرکت معتبر باشد زیرا هر دو نقطه می توانند در ردپای فضایی هتل باشند. حتی در موردی که یکی از دو موقعیت اندازه گیری اشتباه باشد، مجدداً باید یک بازرسی بصری برای تعیین اینکه آیا بزرگی جابجایی زیر “جابجایی خطای ناخالص” قرار می گیرد یا اینکه خطای قابل قبولی است، مورد نیاز است. بدین ترتیب تصمیم گرفته شد که تمامی موقعیت ها در محاسبه آمار توصیفی ارائه شده در آن لحاظ شودجدول 1 و جدول 2 ، که به خواننده امکان می دهد تا میزان نوسان چنین داده هایی را درک کند.
4. ارزیابی با تحلیل روابط فضایی
4.1. روش شناسی
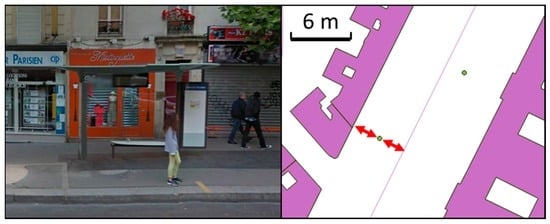
راه دیگر برای انجام ارزیابیهای کیفیت ذاتی VGI تکیه بر ویژگیهای جغرافیایی ویژگیها است [ 28 ]. اگر روابط فضایی مورد انتظار را در ویژگیهای VGI بیابیم، به عنوان مثال، یک تقاطع بزرگراه در تقاطع یک بزرگراه و یک جاده دیگر است، کیفیت خوب است. برعکس، اگر روابط فضایی غیرممکن یا غیرمحتمل را در داخل ویژگی ها پیدا کنیم، به عنوان مثال، یک POI مغازه در خارج از یک ساختمان قرار دارد، آنگاه کیفیت آن ضعیف است. این استفاده از روابط فضایی برای هدایت ارزیابی کیفیت قبلاً در [ 29] اجرا شده است]. با این حال، مشکل اصلی این است که POI ها نقاطی هستند که یک موجودیت جغرافیایی را نشان می دهند که وسعت جغرافیایی آن اغلب بسیار بزرگتر از نقطه است، بنابراین، برای مثال، نقطه ای را که نشان دهنده یک مدرسه است، در کجا قرار دهیم: در محدوده مدرسه، در ورودی مدرسه یا وسط مدرسه؟ هیچ راه حل منحصر به فردی برای این مشکل وجود ندارد ( شکل 3 )، و ما روش های مختلفی را برای انواع مختلف POI در بخش های فرعی بعدی پیشنهاد می کنیم. این امر کیفیت کلی را بهبود می بخشد زیرا ثبات مشارکت ها را بهبود می بخشد.
4.2. POI های رفاهی
انواع مختلفی از امکانات OSM وجود دارد اما همه آنها در داخل ساختمان قرار ندارند. ما امکاناتی را که میتوان خارج از ساختمان قرار داد، مانند کامیونهای حمل غذا ، در نظر نگرفتیم . بنابراین، ما در نظر می گیریم که اگر در داخل ساختمان باشند و در قسمتی از ساختمان که توسط امکانات رفاهی اشغال شده باشد، کیفیت آنها خوب است. دو راه برای جذب چنین امکاناتی وجود دارد: POI را در مرکز امکانات رفاهی یا در ورودی آن قرار دهید. بنابراین، ما پیشنهاد می کنیم سه رابطه فضایی را بررسی کنیم ( شکل 4 ):
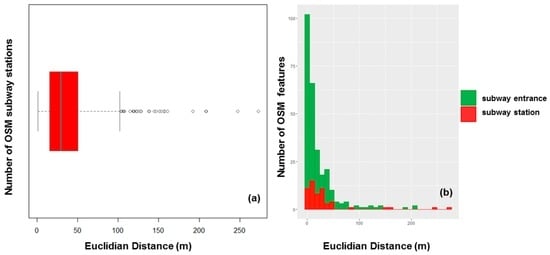
شکل 5 الف نشان می دهد که مرکز ساختمان همیشه تقریب خوبی از مرکز رفاهی نیست، زیرا چندین امکانات رفاهی می توانند در یک ساختمان مشترک باشند. بنابراین، ما همچنین مناطق Voronoï را در اطراف نقاط رفاهی محاسبه کردیم ( شکل 5 b) و ساختمان ها را با مناطق Voronoï ( شکل 5 c) قطع کردیم. سپس، فاصله تا مرکز و مرز این مناطق جدید را نیز محاسبه کردیم. ما چهار نوع امکانات را انتخاب کردیم (حدود 6500 POI در مجموعه داده پاریس):
-
امکانات بسیار کوچک: فروشگاه های هدیه، به عنوان مثال، ویژگی های برچسب گذاری شده با “امکانات = هدایا”.
-
امکانات رفاهی متوسط: بارها (“امکانات = بار”)، کافه ها (“امکانات = کافه”) و رستوران ها (“امکانات = رستوران”).
-
امکانات رفاهی بزرگ: سینما (“امکانات = سینما”)؛
-
امکانات رفاهی بسیار پایدار: آرایشگاه ها (“آمانی = آرایشگران”) که طبق [ 17 ] اغلب جابجا نمی شوند.
نتایج در جدول 3 خلاصه شده است، نشان می دهد که دقت به نوعی به اندازه امکانات رفاهی مرتبط است، که منطقی است زیرا فضای بیشتری برای قرار دادن یک POI در داخل امکانات رفاهی بزرگ وجود دارد. می توان متوجه شد که درصد امکاناتی که در خارج از ساختمان ها قرار دارند از 1.5٪ تا 5٪ متغیر است و بنابراین این POI ها دقت موقعیتی پایینی دارند (فروشگاه های هدیه برای اینکه در اینجا قابل توجه باشند بسیار کم هستند). اعداد در تمام امکانات رفاهی کوچک/متوسط کاملاً مشابه هستند، به عنوان مثال، آنها کاملاً از مرکز دور هستند، حتی در مناطق Voronoï، با تنوع زیاد، و به نظر میرسد الگویی با POI در نزدیکی مرز / ورودی وجود دارد. اما درست در داخل ساختمان ها (حدود دو متر). این را می توان با روشی توضیح داد که نماد رفاه در نقشه OSM نشان داده می شود زیرا نماد درست در ورودی ساختمان با این تغییر 2 متری ظاهر می شود.
منطقی خواهد بود که POIهای داخل ساختمانهای مشابه با یکدیگر همخوانی داشته باشند، یعنی به طور مشابه در مرکز امکانات رفاهی، یا در ورودی قرار داشته باشند (شکل 6)، زیرا یا مشارکت کننده یکسان است یا اولین مشارکت کننده ها مشارکت کنندگان زیر بنابراین، ما این فرض را برای بیش از 4000 ساختمان در پاریس که حاوی بیش از دو POI هستند بررسی کردیم.
نتایج که در جدول 4 خلاصه شده است ، همگنی خوبی را در داخل یک ساختمان نشان می دهد. استانداردسازی وجود دارد: POI ها نزدیک تر به مرزها قرار دارند تا مرکز اما نه در مرز. با این حال، حتی با یک مکان استاندارد شده دقیق، همانطور که در شکل 4 نشان داده شده است، دقت بسیار کم است .
4.3. POI های ATM
در شهر پاریس، بیشتر دستگاه های خودپرداز بر روی دیوار بانک ها قرار دارند و تنها تعداد کمی از آنها در داخل ساختمان بانک قرار دارند. بنابراین، یک موقعیت منطقی از POI های ATM فقط در مرز چند ضلعی های ساختمان خواهد بود. ما از همان روشی که برای امکانات رفاهی برای محاسبه مرکز ساختمان استفاده میشود، استفاده کردیم و فاصله تا مرکز و مرز را اندازهگیری کردیم ( جدول 5)). 347 دستگاه خودپرداز در مجموعه داده وجود دارد و 6.6 درصد از نقاط خارج از هر ساختمانی هستند: این نقاط به وضوح کیفیت پایینی دارند زیرا لایه ساختمان از کامل بودن خوبی برخوردار است که با بازرسی بصری آن نقاط تأیید شد. شصت و پنج درصد از دستگاه های خودپرداز فقط در مرز ساختمان ها قرار دارند، بنابراین اکثریت قریب به اتفاق نقاط با کیفیت خوب وجود دارد. 6٪ اضافی وجود دارد که هم از مرکز و هم از مرز دور هستند، بنابراین به طور تصادفی و بد در نظر گرفته می شوند. ما همچنین آزمایش مشابهی را برای سازگاری در ساختمانهایی که دارای چندین دستگاه خودپرداز هستند انجام دادیم. نتایج نشان میدهد که دستگاههای خودپرداز عمدتاً در داخل یک ساختمان قرار دارند، اما زمانی که یکی از آنها در مرز قرار دارد، همه در آنجا قرار میگیرند، به استثنای بسیار کمی.
4.4. POI های مدرسه
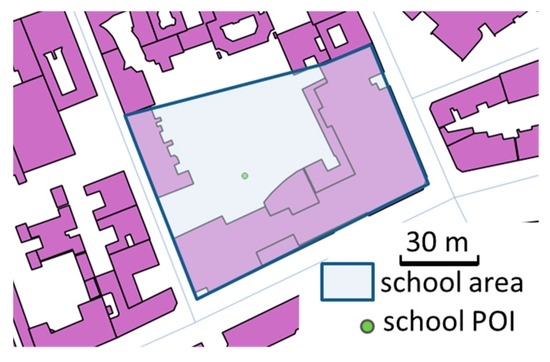
مدارس موجودیت های عملکردی پیچیده ای هستند که از ساختمان ها، حیاط مدرسه، زمین های ورزشی، کتابخانه ها و حتی نمازخانه ها تشکیل شده اند [ 30 ]. در حالت ایدهآل، ما باید وسعت کامل مدرسه و اجزای آن را برای ارزیابی کیفیت موقعیت POI مدرسه بدانیم: در شکل 7 ، POI در حیاط مدرسه قرار دارد، بنابراین در داخل هیچ ساختمانی نیست، اما نزدیک به مدرسه است. وسعت مرکز متأسفانه، چند ضلعی های گستره برای همه POI های مدرسه در این مجموعه داده در دسترس نیستند: تنها 23٪ از 438 مدرسه با هر دو POI و چند ضلعی ثبت شده اند. دشواری ارزیابی کیفیت POI مدرسه به دلیل ساختارهای پیچیده مدارس در [ 31] برجسته شده است.]، نویسندگان آن سعی کردند چندین مجموعه داده POI مدرسه را از VGI مختلف یا مجموعه داده های مرجع مطابقت دهند.
هنگامی که یک وسعت چند ضلعی برای POI در دسترس بود، ما فاصله تا مرکز این چند ضلعی و تا مرز آن را اندازهگیری کردیم. وقتی هیچ کدام در دسترس نبود، از ساختمانی که حاوی POI بود، استفاده کردیم، همانطور که برای امکانات رفاهی و دستگاه های خودپرداز استفاده کردیم. نتایج در جدول 6 خلاصه شده است، نشان می دهد که وقتی چند ضلعی در دسترس است، POI به مرکز مدرسه نزدیک تر است و بنابراین به احتمال زیاد بیرون ساختمان ها. وقتی چند ضلعی در دسترس نباشد، مشارکتکنندگان OSM تمایل دارند POIهای مدرسه را نزدیکتر به دیوارها، در ورودی مدرسه ترسیم کنند. با این حال، با 30٪ از POI در خارج از یک ساختمان، بهتر است از وسعت مدرسه واقعی استفاده شود، که می تواند به صورت هندسی با تجمیع ساختمان ها و موجودات جغرافیایی مجاور، با استفاده از احتمال تعلق آنها به مدرسه (به عنوان مثال، ساختمانی که حاوی POI های فروشگاهی بعید است که بخشی از مدرسه باشد). همین رویکرد با موفقیت در [ 32] استفاده شد] برای تنظیم هندسه چنین وسعت مدرسه برای نقشه کشی. هنگامی که یک چند ضلعی در دسترس است، مشارکت کنندگان تمایل دارند POI را نزدیک تر به مرکز قرار دهند، اما اندازه مدرسه نشان دهنده دقت پایینی است.
4.5. POI های ایستگاه اتوبوس
در پاریس، ایستگاههای اتوبوس را میتوان با یک سرپناه اتوبوس، مانند شکل 8 ، یا با علامت مشخص کرد ، اما آنها همیشه در پیادهرو قرار دارند، بنابراین حداقل فاصله بین ایستگاه اتوبوس و نزدیکترین مرز ساختمان وجود دارد. ایستگاه اتوبوس و خط مرکزی جاده اطلاعات کافی در داده های OSM برای بررسی اینکه آیا ایستگاه اتوبوس روی پیاده رو است وجود ندارد، اما می توانیم بررسی کنیم که به نزدیکترین مرز ساختمان یا خط مرکزی جاده خیلی نزدیک نباشد. ما همچنین می خواهیم اندازه گیری کنیم که آیا جاده ای نزدیک به ایستگاه اتوبوس وجود دارد یا خیر، زیرا هیچ ایستگاه اتوبوسی بدون جاده در نزدیکی آن وجود ندارد.
ما از 1.5 متر به عنوان حداقل فاصله بین نقطه ایستگاه اتوبوس و نزدیکترین مرز ساختمان استفاده کردیم. حداقل فاصله تا خط مرکزی جاده بستگی به نوع جاده دارد اما در اینجا از آستانه 2 متری استفاده می شود. به موازات آن، از آنجایی که جادههای بزرگ با چندین خط در دادههای OSM پاریس ثبت میشوند، ما از 10 متر به عنوان آستانه برای دور بودن بیش از حد از هر جادهای استفاده کردیم. جدول 7نتایج به دست آمده در نقاط ایستگاه اتوبوس 2022 در مجموعه داده را نشان می دهد. از این تعداد، 13.5٪ از ایستگاه های اتوبوس یا خیلی نزدیک به یک جاده یا یک ساختمان هستند (چون نمی توانند هر دو باشند)، و موقعیت بدی در نظر گرفته می شوند. فقط 0.4 درصد از هر جاده ای خیلی دور هستند. نتایج مکانهای ثابتی را در نقاط باقیمانده ایستگاه اتوبوس نشان میدهند، که میتوان با این واقعیت توضیح داد که ایستگاههای اتوبوس موجودیتهایی با وسعت جغرافیایی کمی هستند و به راحتی از تصاویر ماهوارهای با وضوح بالا قابل تشخیص هستند.
5. ارزیابی بر اساس تطبیق داده ها با داده های مرجع
تعدادی از مقالات تحقیقاتی که با ارزیابی کیفیت داده های VGI سروکار دارند، داده های جمع سپاری را با داده های مرجع مقایسه کرده اند تا کیفیت آنها را استنباط کنند [ 2 ، 3 ، 33 ]. مقایسه دو مجموعه داده فرض میکند که ویژگیهای همولوگ (یعنی ویژگیهایی که همان شی را در دنیای واقعی نشان میدهند) ابتدا شناسایی میشوند. این فرآیند به عنوان تطبیق داده ها نامیده می شود. در این مقاله، ما استفاده از یک الگوریتم تطبیق داده تعریف شده توسط [ 34 ] را برای شناسایی خودکار ویژگیهای همولوگ بین OSM و IGN POI پیشنهاد میکنیم. این روش که از نظریه باورها استفاده می کند، معیارهای مختلفی را بر اساس ویژگی های هندسی، موضوعی و معنایی ترکیب می کند.
5.1. روش شناسی
برای مقایسه IGN و OSM POI، ابتدا انواع ویژگی هایی را که در هر دو مجموعه داده نشان داده شده اند شناسایی می کنیم. همانطور که در شکل 2 نشان داده شده است، ایستگاه ها و ورودی های مترو انواعی از اشیاء هستند که تغییرات مربوط به نام یا موقعیت را دارند و در هر دو مجموعه داده نشان داده شده اند. بنابراین، تطبیق دادهها را بر روی ایستگاههایی متمرکز میکنیم که ایستگاههای مترو و ورودیهای مترو را نشان میدهند.
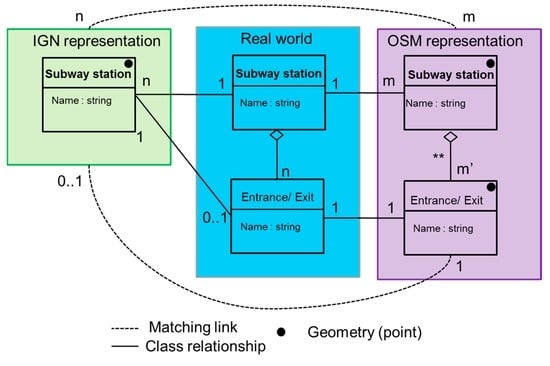
شکل 9 مدل داده ای را برای نمایش ایستگاه مترو نشان می دهد و پیوندهای بین دنیای واقعی و دو نمایش را از IGN و OSM تعریف می کند. بنابراین، یک ایستگاه مترو در دنیای واقعی (که در کادر آبی نشان داده شده است) با یک نام و تعداد معینی ورودی و خروجی مترو مشخص می شود. با توجه به نمایش ایستگاه های مترو در دو مجموعه داده، دو تفاوت عمده قابل مشاهده است. در مجموعه داده IGN (جعبه سبز)، یک ایستگاه مترو از دنیای واقعی با n نشان داده می شودامکانات. بنابراین، با توجه به مشخصات داده IGN، دو نوع نقشه برداری برای هر ایستگاه مترو امکان پذیر است: (i) برای ایستگاه های مترو بدون اتصال بین چندین خط، تنها یک ویژگی نقطه در مجموعه داده نشان داده می شود. (ii) برای ایستگاههای مترو که به حداقل دو خط مترو متصل میشوند، حداقل دو نقطه ویژگی در مجموعه داده نشان داده میشود. حتی اگر مفهوم ورودی/خروجی در مجموعه داده IGN وجود نداشته باشد، ویژگی هایی که ایستگاه مترو را نشان می دهند اغلب نزدیک به ورودی قرار می گیرند.
از سوی دیگر، در OSM (جعبه بنفش)، یک ایستگاه مترو در دنیای واقعی با m ویژگی های متعلق به ایستگاه نوع OSM نشان داده می شود . ایستگاه مترو متشکل از m ‘ ورودی/وجود است که با یک ویژگی نقطه نشان داده شده است، هر ورودی/خروجی یک نام دارد. در شکل 9 ، خطوط نقطه چین پیوندهای منطبق را نشان می دهند (یعنی ویژگی هایی که همان شی را در دنیای واقعی نشان می دهند و اعداد، اصلی بودن پیوندهای منطبق را نشان می دهند (به عنوان مثال، n ایستگاه مترو IGN باید با m تطبیق داده شود.ایستگاه های مترو OSM). با توجه به پیچیدگی نمایش دو مجموعه داده، انواع مختلفی از پیوندهای تطبیق داده ها امکان پذیر است، اما ما در این مطالعه به دو نوع پیوند تطبیق داده علاقه مند هستیم. ابتدا پیوندهای n : m برای مفهوم ایستگاه مترو تعریف می شوند (یعنی n نقطه مترو IGN را می توان با m نقطه مترو OSM که همان ایستگاه مترو را نشان می دهد مطابقت داد ). دوم، m : پیوندهای m برای یک ایستگاه مترو و ورودی/خروجیهای آن تعریف میشوند ( m ایستگاههای مترو OSM با m مطابقت دارند.ورودی/خروجی های OSM). در نهایت، پیوندهای 1:1 برای ورودی/خروجی ها تعریف شده است (1 ایستگاه مترو IGN با 1 ورودی/وجود OSM مطابقت دارد).
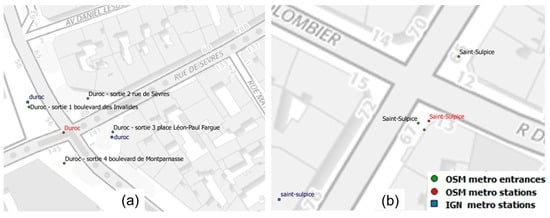
شکل 10 نمونه ای از دو نمایش متفاوت در مجموعه داده های IGN و OSM را نشان می دهد. برای مثال، ایستگاه مترو Duroc ( شکل 10 a) یک نقطه در دادههای OSM و دو نقطه در مجموعه داده IGN دارد که به دو ورودی مترو در OSM نزدیکتر هستند (‘Duroc—sortie 3 place Léon-Paul Fargue and ‘Duroc—sortie 1» بلوار Invalides’). برعکس، برای ایستگاه مترو Saint-Sulpice، یک نقطه در داده های IGN و OSM ترسیم شده است، اما هیچ ارتباطی بین ایستگاه مترو IGN و ورودی مترو OSM وجود ندارد. در شکل 10 ب دو ورودی OSM در نزدیکی ایستگاه متروی OSM دیده می شود. یکی از آنها را می توان ورودی تکراری در نظر گرفت و باید حذف شود.
الگوریتم تطبیق داده ها به صورت زیر عمل می کند: برای هر ویژگی مرجع از یک مجموعه داده، الگوریتم به دنبال کاندیدهایی (از مجموعه داده مقایسه) می گردد تا با استفاده از یک بافر مطابقت داشته باشند. سپس عوامل شباهت مختلف بین ویژگی مرجع و همه نامزدهای انتخاب شده مقایسه میشوند. دانستن ویژگی های مجموعه داده های ما (به بخش 2.1 و بخش 2.2 مراجعه کنید) از سه معیار موقعیت، نام نامی و معنایی استفاده شد. معیار موقعیت بر اساس فاصله بین ویژگی مرجع و نامزد است. معیار نام نامی، نام ویژگی مرجع را با نام نامزد مقایسه می کند. در میان معیارهای مختلف آزمایش شده برای مقایسه نام ها، فاصله نرمال شده Levenshtein استفاده شد زیرا مناسب ترین برای مجموعه داده ما در نظر گرفته شد. در نهایت، معیار معنایی، که انواع ویژگیها را با هم مقایسه میکند، برای انتخاب ویژگیهایی در هر دو مجموعه داده استفاده شد که نوع مشابهی از اشیاء را در دنیای واقعی نشان میدهند، در مورد ما: ایستگاههای مترو، ایستگاهها و ورودیهای مترو .
تطبیق دادههایی که در بالا توضیح داده شد در مجموعه دادههای مختلف اعمال شد: (i) ایستگاههای مترو از IGN با ایستگاههای OSM (پیوند * در شکل 7 ، n : m اصلی) و (ii) ایستگاههای عمومی از OSM با ورودیهای مترو از OSM (پیوند ** در شکل 7 ، m : m ‘ cardinality). در حالت اول، ویژگی مرجع IGN است و ویژگی های کاندید از OSM است، در حالی که برای مورد دوم ویژگی مرجع ورودی های مترو OSM و ویژگی های کاندید ایستگاه های OSM هستند.
آستانه های مورد استفاده در الگوریتم تطبیق با توجه به ویژگی های داده به دست آمده با تجزیه و تحلیل توزیع فاصله ها برای هر معیار تعریف شد. بنابراین، آستانه معیار موقعیت (فاصله اقلیدسی) و معیار تشابه نام (فاصله لونشتاین) که نشان می دهد بعید است که دو ویژگی یک شی را در دنیای واقعی نشان دهند، به ترتیب برابر با 220 متر و 0.6 است. . بافر برای انتخاب نامزد روی 350 متر تنظیم شد.
5.2. نتایج تطبیق داده ها
نتایج تطبیق داده ها و ارزیابی آنها (به صورت دستی بررسی شده) در جدول 8 ارائه شده است . بنابراین، نتایج برای اولین تطبیق (یعنی ایستگاههای مترو IGN و ایستگاههای OSM) بسیار خوب است. از 329 ایستگاه مترو IGN، 328 ایستگاه به درستی با ویژگی های همولوگ خود در ایستگاه های OSM مطابقت داده شدند.
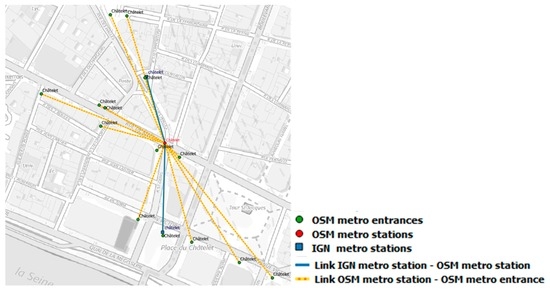
شکل 11 نتیجه تطبیق داده ها را برای ایستگاه های IGN و OSM (پیوند آبی) و ایستگاه های OSM و ورودی ها (پیوند زرد بین ایستگاه مترو و ورودی های آن) نشان می دهد. ایستگاه مترو Châtelet با دو ویژگی در داده های IGN و یک ویژگی در داده های OSM نشان داده می شود. پیوند بین ایستگاههای مترو همولوگ با کاردینالیته 2:1 به رنگ آبی نشان داده شده است. دوازده ورودی OSM با ایستگاه متروی OSM ‘Châtelet’ مطابقت دارد. پیوند، با کاردینالیته 1:12، با خطوط زرد در شکل 11 نشان داده شده است . می بینیم که ایستگاه های متروی همولوگ کاملاً از یکدیگر دور هستند، یعنی 140 متر و 180 متر از ایستگاه مترو IGN فاصله دارند.
در بین ایستگاههای مترو IGN که مطابقت ندارند، هفت تای آنها صحیح هستند (یعنی هیچ ایستگاه متروی همولوگ در OSM وجود ندارد) و دو تای آنها اشتباه هستند (یعنی باید با ایستگاهی از OSM مطابقت داده شوند). ویژگی ها مطابقت ندارند زیرا فاصله بین ویژگی های همولوگ زیاد است و نام ها کاملاً متفاوت هستند. برای مشاهده یکی از ایستگاههای مترو IGN غیر همسان، شکل 12 a را ببینید .
برای 10 ایستگاه مترو IGN هیچ تصمیمی گرفته نشده است. این به این دلیل است که برای ایستگاه متروی IGN بسیاری از نامزدهای OSM با ویژگی های یکسان وجود دارد. به عنوان مثال، در شکل 12 ب، ایستگاه متروی IGN ‘Concorde’ دارای سه نامزد در OSM است که نام یکسانی دارند و نزدیک به ایستگاه مترو IGN هستند. این قطعاً محدودیت داده های مورد استفاده و الگوریتم تطبیق برای هر یک از پیوندهای اصلی n : m است .
از مجموع ایستگاه های OSM، 408 ایستگاه مطابقت نداشتند. این به طور کلی به این دلیل است که دسته ایستگاه های OSM نه تنها ایستگاه های مترو بلکه سایر انواع حمل و نقل عمومی در منطقه پاریس مانند قطار، RER و غیره را نیز شامل می شود.
خط دوم جدول 8نتایج مربوط به تطبیق داده ها بین ورودی های مترو OSM و ایستگاه های مترو OSM را خلاصه می کند. از 794 ورودی مترو OSM، 701 ورودی حداقل به یک ایستگاه OSM مربوط می شود. همه این پیوندها به صورت دستی بررسی و تأیید شده اند (دقت = 100٪). شاخص فراخوان برای این مورد محاسبه نمی شود زیرا هیچ حقیقتی در مورد تعداد ورودی و خروجی هر ایستگاه مترو وجود ندارد. با توجه به نتایج غیر همسان، 19 ورودی مترو OSM با الگوریتم تطبیق داده مطابقت ندارند اما همه آنها حداقل یک ایستگاه OSM متناظر دارند. در این حالت الگوریتم تطبیق داده ها با شکست مواجه می شود زیرا ورودی های مترو از ایستگاه مربوطه دور هستند و اکثر ورودی های مترو OSM غیر منطبق نامی ندارند (حذف ویژگی).
مشابه تطبیق داده ها بین ایستگاه های مترو OSM و IGN، 74 ورودی مترو مطابقت ندارند زیرا هیچ تصمیمی گرفته نشده است. این به دلیل این واقعیت است که برای ورودی مترو OSM بسیاری از ایستگاه های OSM کاندیدهایی وجود دارند که ویژگی های یکسانی دارند.
دو نتیجه تطبیق ویژگیهای همولوگ بین ایستگاههای مترو IGN و OSM را تعریف میکنند و پیوندهایی را تعریف میکنند که ورودیها و خروجیها را به هر ایستگاه متروی OSM اختصاص میدهند. به لطف این دو نتیجه، می توان ارتباط بین ایستگاه های مترو IGN و ورودی/خروجی های مترو OSM را تعریف کرد. این سه لینک برای ارزیابی کیفیت ایستگاههای مترو و ورودیهای مترو از OSM استفاده خواهند شد.
5.3. ارزیابی کیفیت موضعی بر اساس نتایج تطبیق داده ها
برای ارزیابی کیفیت موقعیت، ابتدا فواصل اقلیدسی بین اجسام همولوگ در داده های IGN و OSM محاسبه می شود. شکل 13 الف نشان می دهد که ایستگاه های متروی همولوگ بسیار دور از یکدیگر هستند. فاصله میانه برابر با 35 متر است (50٪ از ویژگی های همولوگ در فاصله کمتر از 35 متر قرار دارند) و برای بسیاری از ایستگاه های مترو OSM این فاصله بالاتر از 100 متر است. دوم، فاصله بین هر ایستگاه مترو IGN و نزدیکترین ورودی مترو OSM آن محاسبه می شود. شکل 13b به وضوح نشان می دهد که ایستگاه های مترو IGN نسبت به ایستگاه های مترو OSM به ورودی های مترو OSM نزدیک تر هستند. این با مشخصات IGN مطابقت دارد (یعنی مکان ایستگاه مترو نشان دهنده یک ورودی است) و پیچیدگی این نوع ویژگی ها را نشان می دهد. هنگامی که ایستگاه مترو IGN به ورودی مترو نزدیکتر است، فاصله آن حدود 80 متر است. در نهایت، زمانی که یک ایستگاه متروی IGN به ایستگاه متروی OSM نزدیکتر است، فواصل به طور مساوی در یک بازه 50 متری توزیع میشوند.
علاوه بر این، تطبیق داده ها و ارزیابی نتایج به ما امکان می دهد موارد زیر را شناسایی کنیم:
-
یک ایستگاه متروی OSM (“Pont de Neuilly”) نقشه برداری نشده است. مهم است که توجه داشته باشید که این ایستگاه در طول سال 2016، پس از استخراج مجموعه داده های OSM اضافه شد.
-
13 ایستگاه مترو OSM هنوز ورودی مترو ندارند.
-
دو ایستگاه مترو OSM دارای مکان های تکراری هستند (دقیقاً همان موقعیت).
5.4. ارزیابی کیفیت موضوعی بر اساس نتایج تطبیق داده ها
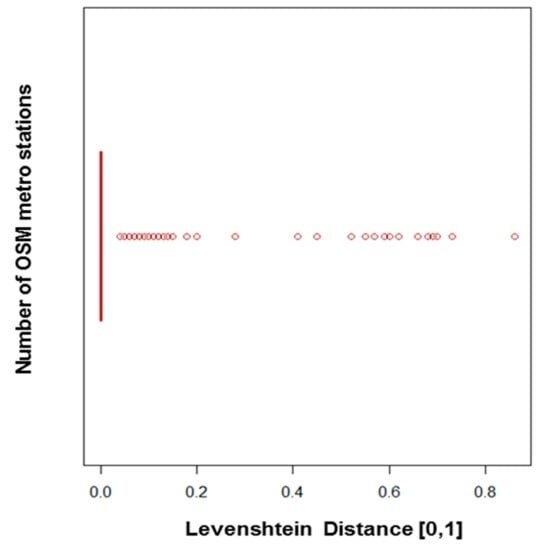
در مقایسه با کیفیت موقعیتی، کیفیت موضوعی بهتر به نظر می رسد همانطور که با مقایسه بین نام ایستگاه های مترو همولوگ آشکار می شود. برای مقایسه اسامی از فاصله لونشتاین استفاده شد. فاصله زمانی که نام ها دقیقاً یکسان باشد صفر و زمانی که کاملاً متفاوت باشند برابر با 1 است. همانطور که در شکل 14 مشاهده می شود ، تقریباً تمام ایستگاه های مترو همولوگ یک نام دارند (میانگین فاصله Levenshtein صفر است). از 329 پیوند منطبق، 257 پیوند دارای فاصله Levenshtein برابر با صفر هستند. هنگامی که این مورد نیست، شرایط زیر را می توان مشاهده کرد:
-
برای 17 ایستگاه مترو، نام IGN بسیار دقیق است، مانند “Goncourt (Hôpital Saint-Louis)” (IGN) در مقابل “Goncourt” (OSM)، “Pont Neuf (la Monnaie)” (IGN) در مقابل “Pont Neuf” .
-
نوع ایستگاه در نام ایستگاه های مترو OSM مانند: “Charles de Gaulle Étoile (RER)”، “Gare de Lyon (métro 1)” یکپارچه شده است.
-
از نامگذاری متفاوتی استفاده می شود: “Palais Royal (Musée du Louvre)” برای IGN در مقابل “Palais Royal – Musée du Louvre” برای OSM.
ما متوجه شدهایم که نامگذاری ورودیهای مترو OSM کم و بیش از یک استاندارد پیروی میکند: نام ایستگاه مترو – خروجی nn – خیابان xxx. بنابراین، ما علاقه مند بودیم که ببینیم این استاندارد تا چه حد رعایت می شود. موارد زیر مشاهده می شود:
-
مورد 1: ورودی های مترو OSM که حاوی نام ایستگاه مترو OSM است.
-
مورد 2: ورودی های مترو OSM با ایستگاه متروی مربوطه OSM که دارای حداقل دو ورودی مترو است، یکسان است. این مورد می تواند به شناسایی ورودی های مترو OSM کمک کند که نام آنها باید از نام ایستگاه مترو OSM متمایز شود (زیرا ایستگاه مترو بیش از دو ورودی مترو دارد) اما اینطور نیست.
-
مورد 3: ورودی های مترو OSM که نام آنها حاوی ” خروج xx ” یا ” -xx ” است.
نتایج برای این سه مورد در جدول 9 آورده شده است .
علاوه بر تجزیه و تحلیل های قبلی، تطبیق داده ها و ارزیابی نتایج به ما امکان می دهد موارد زیر را شناسایی کنیم:
6. ارزیابی با بررسی منابع مکمل VGI
همانطور که در بخش قبل بحث شد، یک رویکرد رایج برای ارزیابی کیفیت داده های VGI، مقایسه آن با مجموعه داده های معتبر است. این روش استفاده از روشهای ارزیابی کیفیت موجود را امکانپذیر میکند و دارای تعدادی مزیت است که میتواند درک جامعی از VGI ارائه دهد، میتواند هر گونه الگو یا سوگیری که ممکن است در دادهها وجود داشته باشد (به عنوان مثال، تعداد مشارکتها و سطح مشارکت در روستاها را آشکار کند. در مقابل مناطق شهری) یا میتواند به شیوهای ملموس، توافق دادههای VGI را با دادههای مکانی معتبر، و در نتیجه ادعا شده و قابل اعتماد، مستند کند.
با این حال، برخی از معایب به همان اندازه مهم وجود دارد. اولاً، دادههای معتبر همیشه آزادانه در دسترس نیستند یا با توافقنامههای مجوز محدود همراه نیستند. ثانیاً، در برخی موارد، مجموعه دادههای VGI نسبت به نمونههای معتبر فعلیتر هستند و بنابراین ارزیابی خطاهای حذف و کمیسیون دشوار است. این مشکل با این واقعیت تشدید می شود که VGI می تواند در مورد ویژگی های خاص (مثلاً نقاط اجاره دوچرخه) یا در مناطق جغرافیایی خاص (مثلاً مناطق محبوب یا توریستی) جزئیات بیشتری داشته باشد. علاوه بر این، در بسیاری از موارد، فقدان مشخصات در محصولات VGI منجر به داده های ناهمگن می شود که مقایسه مستقیم با داده های معتبر را ممنوع می کند. در نهایت، پروژه های VGI، مانند OSM، می توانند دقیق تر و کامل تر از داده های معتبر باشند (به ویژه در کشورهای در حال توسعه).35 ].
همه این دلایل به تدریج مسئولیت ارزیابی کیفیت VGI را به مشارکت کنندگان منتقل می کند. اگرچه این مفهوم بخش اصلی پروژههای VGI است، سوگیریهای مشارکت و مشارکت اجازه ارزیابی یکنواخت کیفیت را نمیدهد (برای مثال [ 1 را ببینید]). علاوه بر این، حتی زمانی که مشارکتکنندگان میخواهند در ارزیابی کیفیت کمک کنند، مواردی وجود دارد که این امر همیشه امکانپذیر نیست، بهویژه زمانی که این کار از راه دور و با استفاده از تصاویر ماهوارهای برای ویژگیها و ویژگیهایی که نمیتوان در تصاویر نشان داده شوند (به عنوان مثال، ویژگیها، نام ها، ویژگی های پنهان یا غیر قابل مشاهده و غیره) و بنابراین نمی توان با تفسیر عکس استخراج کرد. در نهایت، مواردی وجود دارد که برای ویژگی های یکسان یا مجاور، مشارکت هایی وجود دارد که متناقض هستند یا از نظر توپولوژیکی امکان پذیر نیستند. باز هم، در چنین مواردی، مجموعه مشارکت کنندگان و مشارکت های یک پروژه VGI ممکن است برای ارزیابی کیفیت VGI کافی نباشد.
6.1. روش شناسی
به منظور پوشش این شکاف در ارزیابی کیفیت، ما از دادههای سایر منابع محتوای ضمنی VGI برای ارزیابی اعتبار و کیفیت OSM POI استفاده کردیم. برای این نقش، عکسهای دارای برچسب جغرافیایی موجود از فلیکر را انتخاب کردیم. نمای ترکیبی OSM POI و عکسهای دارای برچسب جغرافیایی میتواند به ارزیابی کیفیت OSM POI و رفع ناسازگاریها یا مشارکتهای متناقض کمک کند، بهویژه زمانی که مهر زمانی موجود در هر دو مجموعه داده VGI در نظر گرفته شود. این ارزیابی به صورت دستی برای POI های OSM که مستقیماً از تصاویر ماهواره ای قابل مشاهده نیستند (به عنوان مثال، POI هایی که در زیر مناطق جنگلی هستند) انجام شده است.
6.2. نتایج
ما از مجموعه داده IGN برای مناطق جنگلی پاریس استفاده کردیم تا POI های OSM را که با استفاده از تصاویر ماهواره ای قابل مشاهده نیستند، شناسایی کنیم. آن POI ها را نمی توان توسط مشارکت کنندگان ارزیابی یا تصحیح کرد، مگر اینکه به طور فیزیکی از مکان بازدید کنند. با این حال، با در نظر گرفتن اصل پارتو، که برای مشارکتهای VGI [ 36 ] نیز اعمال میشود و حکم میکند که درصد کمی از داوطلبان اکثریت قریب به اتفاق محتوا، و همچنین مشارکت و سوگیریهای فضایی مشارکتکنندگان را تولید میکنند، قابل درک است که کیفیت ارزیابی یا به روز رسانی عناصر “پنهان” یک مسئله چالش برانگیز است. در این زمینه، ما به صورت دستی بررسی کردیم که آیا استفاده از عکسهای دارای برچسب جغرافیایی میتواند اطلاعات بیشتری را برای POIهایی که مستقیماً از سنجش از راه دور قابل مشاهده نیستند فراهم کند یا خیر. شکل 15a نقشه OSM را برای منطقه ای در پاریس (“باغ موزه رودن”) نشان می دهد که تعدادی از POI در زیر درختان قرار دارند. شکل 15 ب همان ناحیه را با چند ضلعی های IGN نواحی درختی و موقعیت عکس های فلیکر با برچسب جغرافیایی نشان می دهد. عکس فلیکر به عنوان یک پاپ آپ با ویژگی های اضافی ارائه شده توسط عکاس نشان داده می شود.
مثال بالا نشان می دهد که ترکیب منابع مختلف داده های VGI می تواند درک بهتری از واقعیت اساسی ارائه دهد و امکان ارزیابی یا به روز رسانی محتوای داوطلبانه را فراهم کند. با این حال، ارزیابی دستی دست و پا گیر است، و بنابراین، به عنوان گام دوم، ما یک برنامه ویژه توسعه دادیم که از فاصله بین نقاط برای شناسایی ترکیبات احتمالی عکسهای دارای برچسب جغرافیایی و POIهای OSM پنهان استفاده میکند و سپس از کاربر میخواهد پاسخ دهد که آیا یک مورد خاص POI (طبق OSM) را می توان در عکسی که از فاصله نزدیک گرفته شده است شناسایی کرد (مثلاً ” آیا ایستگاه اتوبوس را در فاصله 4 متری در عکس زیر می بینید؟ “) که در آن ویژگی ” ایستگاه اتوبوس ” وجود دارد.‘ از OSM POI می آید و فاصله 4 متری فاصله بین OSM POI و عکس دارای برچسب جغرافیایی است. ما 1000 جفت را به صورت دستی ارزیابی کردیم (یعنی عکس POI-برچسب جغرافیایی) و امکان شناسایی و ارزیابی مثبت 78 POI وجود داشت. در این موارد، POI ها را می توان به طور مثبت شناسایی کرد و بنابراین وجود و اعتبار آنها را ارزیابی کرد.
7. ترکیب روش ها
همه روش های ارائه شده بینشی در مورد ارزیابی کیفیت POI های VGI از دیدگاه متفاوت ارائه می دهند، اما هیچ کدام واقعاً قادر به ارائه یک چارچوب عمومی نیستند. روش های مبتنی بر مرجع به داده های مرجع نیاز دارند که همیشه در دسترس نیستند یا ممکن است اصلا وجود نداشته باشند. روشهای مبتنی بر تاریخ، نمیتوانند بین ویژگیهای با کیفیت بالا ایجاد شده از اولین ویرایش و ویژگیهایی که برای بهبود کیفیت نیاز به ویرایشهای بیشتری دارند، تمایز قائل شوند. ترکیبی از منابع مختلف VGI میتواند موارد مشکلساز را تا سطح معینی ابهامزدایی یا تأیید کند، در حالی که روشهای مبتنی بر روابط فضایی در یافتن موارد پرت مانند امکانات در خارج از ساختمانها خوب هستند، اما به دادههای موجود برای ارائه یک ارزیابی کیفیت دقیقتر وابسته هستند (مثلاً ، اگر چند ضلعی مدرسه در دسترس باشد، POI های مدرسه بهتر ارزیابی می شوند). ارزیابی برخی از POI های دیگر دشوار است زیرا هیچ رابطه فضایی عمومی وجود ندارد که بتوان برای آنها اعمال کرد. به عنوان مثال، در OSM، POI آثار هنری، قطعات هنری هستند که عمدتاً در فضای باز قرار دارند، اما آثار هنری داخلی نیز می توانند اضافه شوند. در این زمینه سعی داریم به بررسی سوالات زیر بپردازیم:
7.1. ترکیب تاریخ با تحلیل روابط فضایی
روش مبتنی بر تاریخچه نسخه های ارائه شده در بخش 3 نشان داد که برخی از انواع ویژگی ها بیشتر از سایرین در معرض جابجایی هستند. یک راه برای درک الگوهای مشارکت در زیر این جابجایی، استفاده از روش مبتنی بر تجزیه و تحلیل روابط فضایی در هر نسخه از ویژگیها است که در آن تغییرات قابل توجهی وجود دارد. ما سه نوع ویژگی را از میان آنهایی که بیشترین جابجایی را انجام میدهند انتخاب کردیم – تقاطعهای بزرگراه ، ایستگاههای مترو ، و ایستگاههای اتوبوس – و بررسی کردیم که آیا کیفیت POI در طول زمان از نظر سازگاری فضایی با ویژگیهای اطراف بهبود یافته است یا خیر.
7.1.1. تقاطع های بزرگراه
بر اساس تحلیل های تاریخی، اتصالات بزرگراه ها ویژگی هایی هستند که بیشترین حرکت را داشته اند. کیفیت آنها را می توان با اندازه گیری روابط توپولوژیکی آنها با جاده ها ارزیابی کرد، به عنوان مثال، POI های تقاطع بزرگراه باید در تقاطع بزرگراه ها و یک رمپ قرار گیرند. مطالعه 76 نقطه از مجموعه داده، سازگاری کامل 100٪ با جاده ها را نشان داد. تاریخچه این نقاط نشان می دهد که اکثر آنها (حدود 70٪) از موقعیت اولیه خود جابجا شده اند، جایی که هیچ سازگاری با جاده ها وجود نداشت، با جابجایی های اغلب بزرگ ( شکل 16 ).
در مطالعه موردی ما، فقط تاریخچه نقاط جمعآوری شد، بنابراین نمیتوانیم مطمئن باشیم که جابجایی سازگاری توپولوژیک تقاطعهای بزرگراه را بهبود بخشیده است، زیرا ممکن است آنها فقط جابجایی جادهها را دنبال کرده باشند. این باید با تجزیه و تحلیل تاریخچه ویژگی های جاده نیز بررسی شود.
7.1.2. ایستگاه های مترو
ایستگاه های مترو در تقاطع دو خط یا به سادگی روی چند خطی که یک خط مترو را نشان می دهد قرار دارند ( شکل 17 a). آنها ورودی/خروجی های مترو را که با مقدار برچسب ” subway_entrance ” گرفته شده اند را نشان نمی دهند. سازگاری توپولوژیکی با خطوط مترو به طور مشابه با اتصالات بزرگراه با جاده ها اندازه گیری می شود و در این مورد، 3.8٪ از 291 نقطه به هیچ خط مترو متصل نیست. یک بازرسی بصری تأیید می کند که مشکل سازگاری به دلیل مکان مشخص شده ضعیف برای نقطه ایستگاه است.
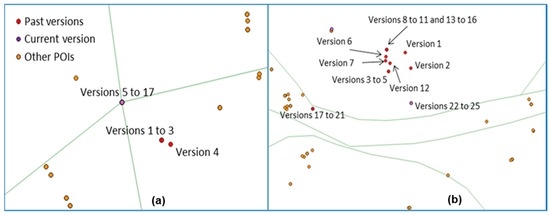
بررسی تاریخچه ایستگاه های مترو نشان می دهد که این کیفیت خوب در طول زمان با ویرایش های فراوان روی ایستگاه ها به دست آمده است. اغلب اوقات، ویرایشهای انجامشده توسط چندین مشارکتکننده با هم نتیجهگیری رضایتبخشی را به همراه داشت ( شکل 17 ب). با این حال، مطالعه مواردی که نسخه فعلی هنوز کیفیت پایینی دارد موارد جالبی از اختلاف نظر بین مشارکت کنندگان در مورد مکان یافتن ویژگی را نشان می دهد. مثال در شکل 17 ب تکامل ایستگاه بزرگ مترو “ملت” را با 17 مشارکت کننده که این ویژگی را ویرایش کرده اند و 9 موقعیت مختلف نشان می دهد.
7.1.3. ایستگاه های اتوبوس
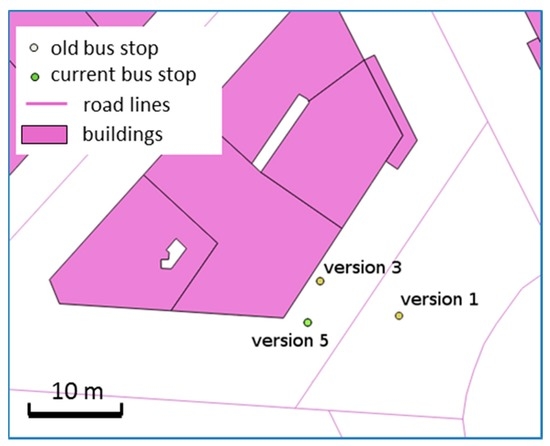
در مورد ایستگاه های اتوبوس، روش توصیف شده در بخش 4.5 در هر نسخه از ایستگاه های اتوبوس استفاده شد. در این حالت، ترکیب روشهای ارتباط تاریخی و فضایی الگوی خاصی را برجسته نمیکند. موارد زیادی وجود دارد که ویرایشهای هندسه نقطهای را از مرز ساختمان یا خط مرکزی جاده منتقل میکند (نسخه 3 به نسخه 5 در شکل 18) .) اما موارد زیادی نیز وجود دارد که ایستگاههای اتوبوس خیلی نزدیک به جاده یا ساختمان قرار میگیرند، و موارد دیگری که این دو رابطه فضایی برای تعیین اینکه آیا ویرایشها باعث بهبود یا کاهش کیفیت شدهاند کافی نیستند. به عنوان مثال، ایستگاه های اتوبوس در پاریس در سال های اخیر به طور قابل توجهی جابجا شده اند، و نسخه های مختلف POI اغلب از این جابجایی ناشی می شوند (به عنوان مثال، نسخه 1 تا نسخه 3 در شکل 18 ).
7.2. ترکیب تاریخچه با تطبیق داده ها
در این بخش، تطبیق داده ها را با تحلیل تاریخی ترکیب می کنیم. هدف ما تجزیه و تحلیل این بود که چگونه ایستگاههای مترو همولوگ و ورودیهای متروی مربوطه آنها در طول زمان تغییر میکنند و الگوهای تغییرات را شناسایی کنیم.
7.2.1. تکامل ایستگاه مترو IGN
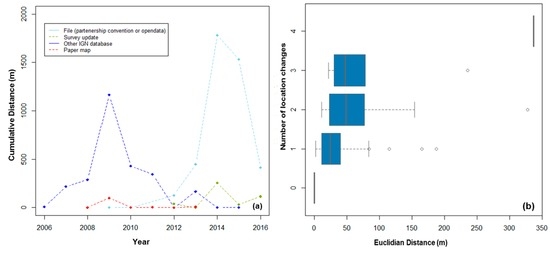
همانطور که در بخش 2.2 ذکر شد، تغییر در دادههای IGN زمانی امکانپذیر است که شرایط زیر رخ دهد: تغییر در دنیای واقعی، تصحیح خطا، تغییر در مشخصات دادهها، یا قراردادهای مشارکت جدید برای اشتراکگذاری دادههای باز برای برخی از لایهها ایجاد میشود. منبع اطلاعات هرچه باشد، همه ویژگیهای مورد استفاده برای بهروزرسانی مجموعه دادههای IGN POI بررسی میشوند و از اعتبارسنجی کیفیت داده پیروی میکنند. شکل 19a تغییرات ایستگاه های مترو در منطقه پاریس را از سال 2006 تا به امروز با توجه به منبع اطلاعات نشان می دهد. میتوانیم ببینیم که از سال 2006 تا 2011، تغییرات موقعیت بیشتر به دلیل بهروزرسانیها بوده و از پایگاه داده IGN دیگری (خط آبی) میآیند. برخی از تغییرات موضوعی (فاصله تجمعی 0) ناشی از نقشه های کاغذی (خط قرمز) را می توان از سال 2010 و 2013 مشاهده کرد. نکته جالب توجه این است که با شروع سال 2012 (خط آبی روشن)، تغییر در مکان ایستگاه مترو زیاد است، فاصله تجمعی بیش از 1600 متر در سال 2014، به دنبال آن 1500 متر در سال 2015، و به سمت ثبات (مثلاً کمتر از 500 متر) تمایل دارد. این به دلیل یک قرارداد مشارکت جدید بین IGN و RATP است. در واقع، ما متوجه شده ایم که 93٪ از ایستگاه های مترو که در سال 2014 تغییر کرده اند از پایگاه داده RATP هستند.شکل 19 ب تغییر فاصله بین تغییرات متوالی را با توجه به تعداد تغییرات نشان میدهد، که نشان میدهد تعداد تغییرات با فاصله متوسط بین تغییرات متوالی همبستگی مثبت دارد. به عنوان مثال، برای ایستگاههای مترو که دو تغییر مکان در طول زمان دارند، فاصله میانه حدود 50 متر و بیش از 300 متر برای ایستگاههای مترو با چهار تغییر مکان است.
7.2.2. تغییر مکان ایستگاه مترو و ورودی مترو
در این بخش، ما علاقه مند به شناسایی الگوهای تغییر مکان در مورد ایستگاههای مترو و ورودیهای مترو با تجزیه و تحلیل پیوندهای تطبیق دادههای شرح داده شده در بخش 5 هستیم . با توجه به ویژگی تعریف شده به عنوان مرجع، تحلیل ها بر روی سه نسخه آخر هر ویژگی انجام می شود: نسخه فعلی (T n )، نسخه قبل (T n-1 ) و نسخه قبل از T n-1 (یعنی ، T n-2 ). جدول 10 تکامل مکان را برای سه نسخه آخر هر ویژگی نشان می دهد.
اول از همه، می بینیم که تمام ایستگاه های مترو IGN حداقل یک تغییر مکان دارند. در مورد ورودی های مترو OSM، 449 مورد از آنها در طول زمان تغییر مکان نمی دهند. الگوهای مختلف در جدول 10 نشان داده شده است. با توجه به فاصله مکان تغییرات، دو نوع الگو را می توان شناسایی کرد: ویژگی به مرجع نزدیکتر می شود (یعنی مکان تغییر ویژگی و فاصله بین ویژگی و مرجع آن در طول زمان کاهش می یابد) و وضعیت برعکس. که در آن ویژگی از مرجع جدا می شود (یعنی مشخصه مکان را تغییر می دهد و فاصله بین ویژگی و مرجع آن در طول زمان افزایش می یابد). برای مثال، 109 ایستگاه مترو OSM به نقاط همولوگ IGN خود نزدیکتر میشوند و 52 ایستگاه واگرا هستند. هنگامی که ایستگاه متروی OSM به عنوان مرجع تعریف می شود، روند متفاوت است، به عنوان مثال، ایستگاه های مترو IGN از OSM (92) دورتر می شوند تا نزدیک تر شوند (61).
الگوی دوم مربوط به تغییرات زمانی است که بین نسخه ها اختلاف نظر وجود دارد. چهار نوع اختلاف مشخص شده است. اول، اختلاف بین نسخههایی که به مرجع نزدیکتر میشوند (مثلاً از مرجع جدا میشوند و سپس به مرجع نزدیکتر میشوند). می بینیم که این الگو به طور خاص به ایستگاه های مترو OSM (35 ویژگی) مربوط می شود. الگوی دوم مربوط به یک اختلاف است که ویژگی ها را از مرجع خود دور می کند (مثلاً به مرجع نزدیک می شوند و سپس از مرجع فاصله می گیرند). این برای هر دو ایستگاه مترو OSM و ورودی برای 69 و 47 ویژگی رخ می دهد. در نهایت، دو نوع الگوی آخر با تغییرات بازگشتی مشخص میشوند: نزدیک شدن و سپس بازگشت به مکان قبلی (17 ایستگاه مترو OSM) و واگرایی و سپس بازگشت به مکان قبلی (14 ایستگاه مترو OSM). این یک بار دیگر پیچیدگی نقشه برداری ایستگاه متروی عمومی را نشان می دهد.
برای بررسی اینکه آیا ارتباطی بین اهمیت ایستگاههای مترو و تعداد تغییرات وجود دارد، این فرضیه را آزمایش کردیم که هر چه ایستگاه مترو اهمیت بیشتری داشته باشد، تعداد تغییرات در مکان باید بیشتر باشد. برای سنجش اهمیت ایستگاه مترو تعداد ورودی های مترو را شمردیم. نتایج نشاندادهشده در شکل 20 کاملاً شگفتانگیز است و نشان میدهد که تعداد تغییرات به اهمیت ایستگاه مترو مرتبط نیست. به عنوان مثال، خط آبی ایستگاه های مترو را با 1-2 تغییر نشان می دهد. متوجه شدیم که 35 ایستگاه مترو با تنها دو تغییر، تنها یک ورودی مترو در OSM دارند.
7.2.3. تغییر نام ایستگاه مترو و ورودی مترو
در مورد نام ایستگاه های مترو، در بخش 5 دیدیم که شباهت زیادی بین IGN و آخرین نسخه ایستگاه های مترو OSM وجود دارد. بر این اساس ما به موارد زیر علاقه مند هستیم: آیا نام ایستگاه های OSM در طول زمان بهبود یافته است یا نام آنها از ابتدا درست بوده است؟
در میان ایستگاههای مترو OSM که با ایستگاههای مترو IGN مطابقت دارند، در مجموع 391 تغییر نام رخ داده است:
-
64 ویژگی در معرض اصلاحات کوچک قرار گرفتند (فاصله Levenshtein کمتر از 2 ویرایش است). به عنوان مثال: ‘Marcadet—Poissonniers’→’Marcadet—Poissoniers’
-
برای 62 ویژگی، این تغییر به نام نسخه قبلی بازگشت. این نشان دهنده اختلاف نظر بین مشارکت کنندگان است.
-
202 ایستگاه مترو در نسخه اول فاقد برچسب نام بودند و نام ها به مرور زمان اضافه شدند.
-
140 ایستگاه مترو OSM در طی دو روز نام خود را تغییر دادند (یعنی 14-05-2008 و 2008-05-15). این مورد میتواند به دلیل فرآیند خودکاری باشد که در ایستگاههای مترو OSM اجرا شده است، یا یک مشارکتکننده یا مشارکتکنندگان تمام این تغییرات را طی چند روز انجام دادهاند تا مجموعه داده را استاندارد کنند.
-
مورد مشابهی در سال 2013 رخ داد که 168 ایستگاه مترو در طول یک روز نام خود را تغییر دادند (یعنی 2013-11-24). در این مورد، یک فرضیه این است که تغییرات جدید از دفتر حمل و نقل است که داده های خود را به عنوان داده های باز در سال 2012 منتشر کرد.
این تحلیل نشان می دهد که تکامل نام ایستگاه های مترو در طول زمان کیفیت موضوعی نام ها را بهبود بخشیده است.
در رابطه با تغییر نام ورودیهای مترو، سعی کردیم با هماهنگ کردن نامها به سمت یک نام استاندارد، ببینیم که آیا این تغییرات باعث بهبود کیفیت موضوعی آنها نیز شده است؟ برای این تحلیل، سه تغییر اخیر در نام در نظر گرفته شد.
از بین 701 ورودی مترو OSM مطابق با ایستگاه های مترو OSM (و به طور غیرمستقیم با IGN)، 365 ورودی مترو بدون تغییر، 256 ورودی مترو دارای دو تغییر و 80 مورد از آنها سه تغییر داشته اند. ما متوجه شدیم که به طور کلی، نام ورودی مترو ” نام ایستگاه مترو – خروجی nn – خیابان ” است. بنابراین، ما سعی میکنیم تشخیص دهیم که آیا نام از این قالب پیروی میکند یا خیر و آیا تغییراتی که رخ داده است تمایل به این قالب دارد یا خیر. بنابراین، سه مورد مرتبط نشان داده شده است ( جدول 11 را ببینید ):
-
مورد 1: نام ورودی مترو OSM حاوی نام ایستگاه مترو OSM است.
-
مورد 2: نام ورودی مترو OSM حاوی نام ایستگاه مترو IGN است.
-
مورد 3: نام ورودی مترو OSM حاوی کلمه “خروج xx ” است.
همانطور که می بینیم، یک بار دیگر، تغییرات باعث بهبود کیفیت نام ایستگاه های مترو OSM می شود.
مثال زیر روند کلی تغییرات در مورد نام ورودی های مترو OSM را نشان می دهد. برای ایستگاه مترویی به نام «Porte de Montreuil»، نام فعلی یکی از ورودیهای متروی آن «Porte de Montreuil—sortie 1 Avenue de la Porte de Montreuil» است. نام این ورودی مترو مورد اشاره قبلاً دو بار تغییر کرده است: در نسخه اول نام ‘Av. de la Porte de Montreuil و در نسخه دوم، درست قبل از نسخه فعلی، نام “Avenue de la Porte de Montreuil” بود.
7.3. بحث
برخی از روش ها، به ویژه آنهایی که مبتنی بر روابط فضایی بین ویژگی ها و تاریخچه هستند، می توانند برای بهبود کیفیت POI در زمان واقعی استفاده شوند. محدودیتهای یکپارچگی را میتوان در یک سیستم مشترک تعریف و پیادهسازی کرد تا مشارکتکننده را برای تولید دادههای ثابت راهنمایی کند تا بررسی شود که تغییر در یک ویژگی باعث ایجاد تناقض یا بدتر شدن کیفیت دادههای موجود نمیشود. اگرچه تحقیقات در این راستا از قبل وجود دارد، در بیشتر موارد روشهایی برای رفع خطای پس از ایجاد پیشنهاد میشوند یا مشارکتکننده را در انتخاب نوع ویژگی جدید راهنمایی میکنند [ 37 ، 38 ]. در مورد ارزیابی کیفیت بلادرنگ، چند مطالعه تحقیقاتی انجام شده است: یکی بر ارزیابی ویژگی تمرکز دارد [ 15]]، یکی دیگر مقایسه زمان واقعی آدرس ها با مراجع را پیشنهاد می کند [ 39 ]، و آخرین مورد خطاهایی را شناسایی می کند که محدودیت های یکپارچگی را رعایت نمی کنند [ 40 ]. در این مطالعه آخر تنها چند محدودیت یکپارچگی تعریف شده است و رویکرد بر روی یک مجموعه داده کوچک آزمایش شد. بنابراین، تحقیقات بیشتری برای تعریف و ترکیب بسیاری از محدودیتهای یکپارچگی مورد نیاز است.
چهار روش ارائه شده در اینجا همگی قابل بهبود هستند. با توجه به رویکرد تطبیق داده ها، تطبیق طرحواره معنایی که در این مقاله به صورت دستی انجام شده است، می تواند با استفاده از تطبیق طرحواره مبتنی بر هستی شناسی بهبود یابد. برای آن، تحقیقات بیشتری به منظور همسویی هستی شناسی توپوگرافی IGN [ 41 ] با هستی شناسی OSM [ 42 ] ضروری است. در رابطه با روش روابط فضایی، مشکل اصلی این است که تعبیر کنیم روابط فضایی از نظر کیفیت به چه معناست. استفاده از تکنیک های یادگیری ماشین برای استنباط کیفیت POI با توجه به مجموعه ای از روابط فضایی مفید خواهد بود.
اگرچه مقاله استفاده از رویکردهای کل نگر برای ارزیابی کیفیت VGI را توصیه می کند، ترکیب روش های ارزیابی آزمایش شده در این مقاله تنها از دو روش از چهار روش ارائه شده استفاده می کند: تاریخچه با روابط فضایی، و تاریخچه با تطبیق با داده های مرجع NMA. ترکیب هر چهار واقعاً دامنه ارزیابی کیفیت را افزایش می دهد. به عنوان مثال، برای یک ویژگی با چندین نسخه، میتوان مطابقت با دادههای مرجع، تحلیل روابط فضایی برای همه نسخهها، و مجموعهای از عکسهای برچسبگذاریشده جغرافیایی مربوط به تاریخ هر نسخه را به دست آورد. سپس میتوانیم بر محدودیتهای هر روش غلبه کنیم (به عنوان مثال، کیفیت دادههای مرجع، یا فازی بودن تحلیل روابط فضایی). با این حال، رویکرد کل نگر نباید به استفاده از چهار روش ارائه شده در اینجا محدود شود.28 ]، یعنی روشهایی که تعاملات اجتماعی بین مشارکتکنندگان یک پروژه جمعسپاری را در نظر میگیرند، به وضوح به ما در درک مواردی که اختلاف نظر بین مشارکتکنندگان رخ میدهد کمک میکنند. البته، اگر تعداد روشهای ترکیبی برای ارزیابی کیفیت دادهها را افزایش دهیم، متعادل کردن سهم هر روش در ارزیابی جهانی دشوار خواهد بود. استفاده از تکنیک های علوم کامپیوتر مانند تصمیم گیری چند معیاره [ 29 ]، مدل سازی فازی و یادگیری ماشین برای اجرای چنین پروتکلی اجباری خواهد شد.
7.4. دستورالعمل برای موارد استفاده معمولی
اولین مورد استفاده معمولی یک NMA است که یک برنامه وب اشتراکگذاری عکس و/یا یک پلتفرم مشارکت بردار (یعنی ویژگی نقطه) را کنترل میکند. چگونه میتوان POIهای جمعسپاری شده را با مجموعه دادههای معتبر NMA ادغام کرد؟ تطبیق دادهها را میتوان در این موقعیت برای پیوند دادن هر دو مجموعه داده به منظور شناسایی ویژگیهای همولوگ یا POIهای جمعسپاری که در مجموعه داده معتبر وجود ندارند، استفاده کرد. در فرآیند تطبیق سه نوع نتیجه می تواند وجود داشته باشد. اولاً، اگر POI جمعسپاری مطابقت نداشته باشد، تجزیه و تحلیل مشترک روابط فضایی آن با مجموعه داده معتبر و نسخههای گذشته آن میتواند به ما کمک کند تا ارزیابی کنیم که آیا میتوان آن را در مجموعه داده معتبر ادغام کرد (یعنی کیفیت خوب است یا خیر). . اگر POI جمعسپاریشده مطابقت داشته باشد و بسیار نزدیک به همتای خود در مجموعه داده معتبر باشد، سپس این دو ویژگی را می توان ادغام کرد، که ممکن است مجموعه داده NMA را از نظر معنایی غنی کند. غنیسازی میتواند یا افزودن ویژگیهای گمشده در POI معتبر یا غنیسازی آن با نام(های) عامیانه باشد. در نهایت، اگر POI جمعسپاری شده با یک POI معتبر متناظر تطبیق داده شود، اما تا حدودی از نظر هندسی یا معنایی متفاوت باشد، هم تاریخچه و هم تحلیل روابط فضایی میتوانند به تصمیمگیری در مورد اینکه کدام باید حفظ شود، یا چگونه میتوان آنها را ادغام کرد (مثلاً استفاده) کمک کند. هندسه یکی و معناشناسی دیگری). بنابراین، در این مورد استفاده، تطبیق داده ها برای رسیدگی به چالش یکپارچه سازی داده های فضایی چند منبعی استفاده می شود. تاریخچه و تجزیه و تحلیل روابط فضایی برای ارزیابی پیوندهای تطبیق داده ها و بهبود مرحله تصمیم گیری استفاده می شود. در همه موارد، اگر عکسهای دارای برچسب جغرافیایی از POI وجود داشته باشد،
دومین مورد استفاده، استخراج نقشهها با پسزمینه نقشهبرداری از یک NMA، و OSM POI در بالا برای ایجاد یک نقشه پیشرفته است. همانطور که در [ 32 ] توضیح داده شد، مشکل در اینجا سازگاری بین POI و پیشینه معتبر است. در این مورد، نیازی به تطبیق نیست زیرا POIها از OSM به عنوان یک مجموعه داده اضافی گرفته می شوند. اولین گام، تجزیه و تحلیل سازگاری در رابطه فضایی بین POI جمعسپاری شده و پسزمینه نقشه است. اگر سازگاری ضعیف یا غیرقطعی است، تجزیه و تحلیل مشترک نسخههای گذشته و تجزیه و تحلیل سازگاری روابط فضایی تنها با دادههای OSM انجام میشود، همانطور که در بخش 7.1 ذکر شده است.، که می تواند ابهامات را برطرف کند و دوباره به فرآیند تصمیم گیری کمک کند. برای مثال، ممکن است موردی وجود داشته باشد که یک POI فروشگاه از طریق نسخههای مختلف به یک موقعیت ثابت در داخل ساختمان در OSM منتقل شده باشد، اما ناسازگاری ناشی از تغییر موقعیت ساختمان باشد. در این مورد، سادهترین راهحل جابهجایی ساختمان نیست، زیرا خوانایی مهمتر از دقت موقعیتی است، بلکه انتقال خودکار POI به یک موقعیت مشابه در ساختمان NMA است (ساختمانها را میتوان با توجه به وجود آنها در هر دو مجموعه داده مطابقت داد). . بنابراین، در این مورد از تاریخچه و تحلیل روابط فضایی برای بهبود کیفیت OSM POI استفاده می شود.
8. نتیجه گیری
در این مقاله ما بر ارزیابی کیفیت POIهای موفق ترین پروژه VGI: OSM تمرکز کردیم. اولین سهم مقاله پیشنهاد چهار روش مختلف برای ارزیابی کیفیت VGI POI بوده است. دو تا از این روش ها شامل مقایسه با رویکرد مجموعه داده مرجع، به عنوان مثال، تطبیق چند معیاره با داده های NMA و استفاده از عکس های فلیکر برای بررسی اعتبار POI است. روش دیگر از رویکرد جمع سپاری Goodchild & Li [ 28 ] با تحلیل تاریخچه ویژگی پیروی می کند. آخرین روش از رویکرد جغرافیایی Goodchild و Li [ 28 ] با تجزیه و تحلیل روابط فضایی POIها با ویژگی های همسایه آنها پیروی می کند.
از یک طرف، استفاده از هر روش بر روی همان مجموعه داده معیار نشان می دهد که نتایج به دست آمده توسط یک روش می تواند یک پدیده را برجسته کند و می تواند به عنوان ورودی برای روش دیگری برای تجزیه و تحلیل بهتر دلایل این پدیده استفاده شود. به عنوان مثال، تجزیه و تحلیل تاریخ نشان داد که برخی از انواع ویژگی ها بیشتر از انواع دیگر تغییر می کنند. برای درک بهتر دلیل، می توان این نوع ویژگی ها را با سایر منابع اطلاعاتی مقایسه کرد. از سوی دیگر، هر روش میتواند بینش منحصربهفردی در مورد کیفیت دادهها ارائه دهد، اما هیچ کدام برای ارزیابی واضح کیفیت POI از VGI کافی نیست. سپس بر اساس درسهایی که از نقاط قوت و ضعف هر روش آموختهایم، سعی کردیم آنها را ترکیب کنیم تا درک بهتری از کیفیت دادهها به دست آوریم. برای مثال، ترکیب تاریخ و روابط فضایی نشان می دهد که ویرایش های متعدد یک ویژگی عمدتاً تمایل به بهبود سازگاری منطقی با سایر ویژگی ها دارد. ترکیب تطبیق با داده ها و تاریخچه NMA، چندین الگوی بهبود یا عدم توافق را هنگامی که چندین مشارکت کننده یک ویژگی را ویرایش می کنند برجسته می کند. این مقاله نشان می دهد که یک رویکرد کل نگر برای ارزیابی کیفیت مورد نیاز است، به طوری که باید راه های کاملا جدیدی در مقایسه با روش های ارزیابی کیفیت داده های مکانی موجود ایجاد شود. بنابراین، این تجزیه و تحلیل به ما کمک کرد تا بفهمیم گامهای بعدی در ایجاد چارچوب ارزیابی کیفیت VGI جامد چیست، چگونه باید رفتار کند و چالشها کجاست. ترکیب تطبیق با داده ها و تاریخچه NMA، چندین الگوی بهبود یا عدم توافق را هنگامی که چندین مشارکت کننده یک ویژگی را ویرایش می کنند برجسته می کند. این مقاله نشان می دهد که یک رویکرد کل نگر برای ارزیابی کیفیت مورد نیاز است، به طوری که باید راه های کاملا جدیدی در مقایسه با روش های ارزیابی کیفیت داده های مکانی موجود ایجاد شود. بنابراین، این تجزیه و تحلیل به ما کمک کرد تا بفهمیم گامهای بعدی در ایجاد چارچوب ارزیابی کیفیت VGI جامد چیست، چگونه باید رفتار کند و چالشها کجاست. ترکیب تطبیق با داده ها و تاریخچه NMA، چندین الگوی بهبود یا عدم توافق را هنگامی که چندین مشارکت کننده یک ویژگی را ویرایش می کنند برجسته می کند. این مقاله نشان می دهد که یک رویکرد کل نگر برای ارزیابی کیفیت مورد نیاز است، به طوری که باید راه های کاملا جدیدی در مقایسه با روش های ارزیابی کیفیت داده های مکانی موجود ایجاد شود. بنابراین، این تجزیه و تحلیل به ما کمک کرد تا بفهمیم گامهای بعدی در ایجاد چارچوب ارزیابی کیفیت VGI جامد چیست، چگونه باید رفتار کند و چالشها کجاست.
به عنوان مثال، وقتی صحبت از استفاده از تصاویر دارای برچسب جغرافیایی می شود، می توان چندین منبع (نه فقط فلیکر) را در فرآیند ارزیابی گنجاند و این روش همچنین می تواند از سایر داده ها مانند عنوان، برچسب یا توضیحات استفاده کند. علاوه بر این، الگوریتمهای جدیدی باید به منظور فیلتر کردن بسیاری از نویزهای موجود در محتوای شبکههای اجتماعی ایجاد شوند. تجزیه و تحلیل و طبقه بندی خودکار تصویر، همانطور که در [ 43 ] ارائه شده است، روند را تا حد زیادی بهبود می بخشد.
با توجه به تکامل مکانهای OSM و POI، تجزیه و تحلیل نشان داد که، حتی اگر در برخی موارد تغییر یک ویژگی OSM به دلیل عدم توافق بین مشارکتکنندگان باشد، معمولاً تغییراتی برای بهبود کیفیت ویژگیها و کاهش ناهمگونی ویژگیهای موضوعی رخ میدهد. به یک معنا گسترش یافته های [ 1]. به موازات آن، روش های جدیدی برای مقایسه تکامل نام ها نیاز است. به طور خاص، متوجه شدیم که معیارهای موجود که امکان مقایسه رشته ها را فراهم می کند، همیشه برای این کار قابل اجرا نیستند. به عنوان مثال، فاصله بین ‘Sully Morland’ و ‘Sully Morland-sortie 4’ بزرگتر از فاصله بین ‘Sully Morland’ و ‘Pont Marie’ است. این بدان معناست که «سالی مورلند» از نظر زبانشناسی به «پونت ماری» نزدیکتر است تا «سالی مورلند-سورتی 4».
در نهایت، ما می خواهیم پیشنهاد کنیم که تمام مجموعه داده های مورد استفاده در اینجا بخشی از یک معیار برای ارزیابی کیفیت VGI باشد. در اینجا، فقط از داده های POI استفاده شد، اما این رویکرد می تواند برای ویژگی های دیگر مانند جاده ها، رودخانه ها، ساختمان ها و کاربری زمین اعمال شود.











بدون نظر