

خلاصه
شاخص آسیب پذیری اجتماعی (SoVI) بیش از یک دهه است که به جامعه خطرات خدمت کرده است. با استفاده از یوتا به عنوان یک مورد آزمایشی، ایالتی با جمعیتی که در معرض خطرات مختلف قرار دارد، این مطالعه به دنبال ایجاد رویکرد SoVI با تقویت آن با یک شبکه عصبی مصنوعی غیرخطی (ANN) بود. یک SoVI برای ایالت یوتا در سطح گروه بلوک سرشماری با استفاده از داده های پنج ساله (2008-2012) از نظرسنجی جامعه آمریکا ایجاد شد. SoVI مجموعه داده ای را برای آموزش شبکه عصبی ارائه کرد. سپس از ANN برای طبقه بندی زیرمجموعه ای از وضعیت استفاده شد تا مشخص شود که آیا می تواند طبقه بندی قابل مقایسه ای از آسیب پذیری ارائه دهد یا خیر. ANN یک طبقه بندی آسیب پذیری ایجاد کرد که تقریباً 26٪ با SoVI ایجاد شده با استفاده از رویکرد سنتی سازگار بود. تفاوتها در طبقهبندیها با استفاده از نمودارهای راداری میانگینهای متغیر گروه بلوک برای بررسی نحوه استفاده از متغیرها در هر طبقهبندی ارزیابی شد. نتایج این مطالعه مستلزم بررسی بیشتر قابلیتهای یک SoVI تقویتشده با ANN است.
کلید واژه ها:
شبکه های عصبی مصنوعی ; آسیب پذیری اجتماعی ؛ شاخص آسیب پذیری اجتماعی ; خطرات زیست محیطی
1. معرفی
تحقیقات معاصر در مورد ابعاد انسانی مخاطرات زیست محیطی معمولاً به سه پارادایم تقسیم می شود: (1) کاوش آسیب پذیری اجتماعی که به طور بالقوه به افزایش تأثیر بلایا کمک می کند. (2) بررسی تاب آوری در برابر بلایا، ظرفیت جوامع و افراد برای بهبود و بازیابی از تأثیر یک فاجعه؛ و (3) کاوش در ادراکات اجتماعی که می تواند تأثیر یک فاجعه را تقویت یا کاهش دهد [ 1 ، 2 ، 3 ، 4 ، 5 ، 6]. در حالی که تلاشها در هر سه زمینه درک ما را از مؤلفه انسانی مخاطرات و بلایای زیستمحیطی ارتقا میدهد، آسیبپذیری اجتماعی طولانیترین سابقه تحقیق در رشته مخاطرات زیستمحیطی سه پارادایم را دارد [ 2 ].
آسیب پذیری اجتماعی، همانطور که توسط Cutter [ 2 ، 3 ] ارائه شده است]، بر شناسایی آسیبپذیری تمرکز دارد، زیرا از طریق سیستمهای اجتماعی از طریق کاوش در دادههای جمعیتی برای ایجاد یک شاخص آسیبپذیری اجتماعی (SoVI) ساخته میشود. کاوش این دادهها برای تعیین عواملی که به آسیبپذیری اجتماعی برای یک منطقه، معمولاً یک واحد سرشماری ایالات متحده، کمک میکنند، با استفاده از تجزیه و تحلیل مؤلفههای اصلی (PCA) انجام میشود، که به دادهها اجازه میدهد تا انتخاب عامل برای آسیبپذیری را هدایت کنند. متغیرهای جمعیتی بارگذاری شده در PCA شناسایی شدهاند تا بر اساس درک موجود ما از نقش نابرابری اجتماعی بر آسیبپذیری اجتماعی، بازنماییهای خاصی از آسیبپذیری داشته باشند، و عوامل شناساییشده توسط PCA برای محاسبه امتیاز SoVI برای هر واحد شمارش استفاده میشوند. SoVI در مقیاس های مختلف نشان داده شده است،3 ، 7 ] و در سطح شهرستان در نروژ [ 8 ]، اگرچه رویکرد PCA فقط در سطح شهرستان نشان داده شده است [ 3 ، 8 ].
در حالی که به نظر می رسد SoVI فراگیرترین ارزیابی آسیب پذیری اجتماعی در ادبیات یک و نیم دهه اخیر باشد، این تنها روشی نیست که ارزیابی آسیب پذیری را می توان انجام داد. Füssel [ 6 ] و Adger [ 9 ] چندین رویکرد را برای آسیبپذیری در طول سالها شناسایی کردهاند که هر کدام دارای تفاوتهای اساسی هستند که رویکردها را به حوزههای تخصصی تحقیقاتی بر اساس مفروضات اولیه، اهداف اولیه و اهداف نقطه پایانی تفکیک کردهاند. علاوه بر این، از Füssel [ 6] که نیاز به پذیرش انواع چارچوب های معتبر برای ارزیابی آسیب پذیری و استفاده مناسب از چارچوب ها برای مشکلات داده شده وجود دارد. هدف این مقاله این نیست که پیشرفت ارزیابی آسیبپذیری را فقط به یک مثال از یک رویکرد به بهای سایر روشها محدود کند یا برتری یک روش را بر روش دیگر پیشنهاد کند. SoVI در این مطالعه به عنوان یک ابزار ارزیابی خطی که ساده ترین آزمون را برای استفاده از یک روش غیر خطی ارائه می دهد، مورد توجه است.
در حالی که روش کنونی ساخت SoVI برای بیش از یک دهه به خوبی به تحلیلگران خدمت کرده است، هنوز مناطقی برای بهبود بالقوه وجود دارد. PCA مورد استفاده در SoVI یک روش آماری خطی است که می تواند مشکلاتی را برای داده های جغرافیایی انسانی اغلب غیرخطی ایجاد کند. یک رویکرد برای رسیدگی به این مشکل ممکن است در استفاده از شبکه عصبی مصنوعی (ANN) باشد. یک ANN یک روش مبتنی بر داده شبیه به PCA است، با این حال این یک روش طبقه بندی است، زمانی که در یک ظرفیت نظارت شده استفاده می شود، که ممکن است عوارض ناشی از داده های غیر خطی را از بین ببرد [ 10 ، 11 ].
این مطالعه رویکرد سنتی SoVI را با رویکرد SoVI اصلاحشده با پسوند طبقهبندی ANN با استفاده از مطالعه موردی برای ایالت یوتا مقایسه کرد. به طور خاص، مقایسه بین روش سنتی SoVI و SoVI طبقه بندی شده توسط ANN، تفاوت این دو را مشخص کرد.
از طریق انجام این تحقیق به دنبال پاسخ به سوالات زیر بودیم:
-
چگونه یک نتیجه ANN SoVI با نتیجه یک SoVI سنتی برای یک منطقه معین مقایسه می شود؟
-
نتایج چگونه و کجا متفاوت است و چرا؟
-
چگونه می توان طبقه بندی ANN را نسبت به روش سنتی با توجه به نقاط قوت و ضعف آن تفسیر کرد؟
یک نقطه نگرانی در این رویکرد استفاده از نتیجه سنتی SoVI برای یک منطقه معین به عنوان یک مرجع معتبر برای ANN SoVI است. نگرانی مشترکی که در بحث استفاده از شاخصها به معنای وسیعتر مطرح میشود، این است که چنین شاخصهایی مستقل از دادههای منبع خود هستند، که یک شاخص معین هیچ رابطه مستقیمی با آنچه که نشان میدهد ندارد. استفاده از شاخص ها علیرغم این چالش ادامه دارد، با این حال، زیرا جایگزین های قوی تر اغلب وجود ندارد. بازگشت به نگرانی استفاده از یک شاخص به عنوان مبنای معتبر برای یک شاخص جدید – مبتنی بر ANN SoVI بر اساس SoVI سنتی – مهم است که توجه داشته باشیم که هدف این مطالعه ادعای اعتبار و مناسب بودن شاخص نیست. در یک مفهوم نظری گسترده تر. چنین بحثی خارج از محدوده این پروژه است. همینطور،2 ، 3 ، 7 ، 8 ]. این امر برای ارزیابی قابلیت استفاده از ANN برای بهبود روش شناسی سنتی، مرکزی است.
2. پس زمینه
مفهوم SoVI جزء مدل خطرات مکان سوزان کاتر (HoP) است که به دنبال ادغام آسیبپذیری فیزیکی و آسیبپذیری اجتماعی به روشی بصری است [ 2 ، 3 ]. این رویکرد دو مفهوم را به شیوهای بدیع ترکیب میکند: آسیبپذیری هم با نزدیکی به خطرات و هم با عوامل سیاسی-اقتصادی مرتبط است. با این حال، کاتر این ترکیب را یک قدم فراتر برد و مفهوم HoP را به عنوان آسیبپذیری توصیف میکند که یک ویژگی مبتنی بر مکان برای جمعیت آسیبپذیر جایی است که در آن زندگی میکنند [ 2 ، 7 ].]. بنابراین آسیبپذیری در مقیاسهای مختلف متفاوت است و اصول تعمیم را در نظر میگیرد: هرچه مقیاس تحلیل کوچکتر باشد، مدل به صورت محلی برای جمعیت آن مکان مرتبطتر خواهد بود. مکان به معنای یک فضای اشغال شده توسط انسان، یک مکان اشغال شده است [ 2 ].
کاتر اولین بار مدل HoP را با ویلیام سولکی در مقاله ای در سال 1989 در مورد الگوهای انتشار سمی در هوا در ایالات متحده معرفی کرد [ 12 ]. کاتر تا دهه 1990 به کار با مفهوم HoP ادامه داد، جایی که این مدل گسترش یافت تا ویژگیهای فیزیکی و اجتماعی گستردهتری را در مورد آسیبپذیری خطر شامل شود [ 2 ]. مدل آسیبپذیری شامل پتانسیل خطر به عنوان ترکیبی از خطر و کاهش شد که خود به بخشهای مرتبط بافت اجتماعی، بافت جغرافیایی، آسیبپذیری بیوفیزیکی (مشابه نزدیکی به مکتب فکری خطر) و آسیبپذیری اجتماعی تقسیم میشود. به جنبه های آسیب پذیری اجتماعی مفاهیم سیاسی-اقتصادی آسیب پذیری اجتماعی) [ 2] (ص 78). بافت اجتماعی در این مدل نشاندهنده پسزمینه اجتماعی و سیاسی مکان و نحوه تأثیرگذاری آن بر آسیبپذیری اجتماعی است، در حالی که بافت جغرافیایی بیشتر ویژگیهای فیزیکی منظر مکان را تطبیق میدهد زیرا آنها همراه با خطرات بیوفیزیکی عمل میکنند. مدل HoP این ویژگیها را ادغام میکند که وقتی برای یک مکان اعمال میشود، منجر به ارزیابی جامع آسیبپذیری آن میشود. پیوستن ریسک فیزیکی به یک SoVI به عنوان جزء آسیب پذیری اجتماعی در چندین کار توسط Cutter و دیگران در سال های پس از ایجاد مدل HoP برای نشان دادن قابلیت های آن انجام شده است [ 2 ، 3 ، 7 ].
کار بیشتر مربوط به SoVI برای کشف اینکه چگونه SoVI از نظر حساسیت و واریانس در مقیاسهای مختلف قوی است، ادامه یافته است [ 3 ، 13 ]. اشمیتلین و همکاران [ 13 ] مشخص کرد که مقیاس و تغییرات جزئی در انتخاب متغیر تأثیر کمی بر کارایی SoVI دارد، نگرانی که در کار کاتر ذکر شده است. با این حال، تیت [ 14 ] به چالش کشید که سوگیری آماری، دقت و عدم قطعیت ذاتاً بخشی از سلسله مراتب کلی SoVI است، بنابراین اصرار داشت که تجزیه و تحلیل حساسیت در ایجاد یک شاخص آسیب پذیری گنجانده شود. هولند و لوجالا [ 8] با رویکردی برای انطباق SoVI با یک زمینه جغرافیایی جدید، در مورد مطالعه آنها، SoVI متمرکز ایالات متحده را برای اعمال در نروژ دنبال کرد. هولند و لوجالا [ 8 ] انتخاب متغیر را برای SoVI تغییر دادند تا بافت فرهنگی، اجتماعی و سیاسی نروژ را بهتر منعکس کند. در مجموع، این ادبیات نشان میدهد که SoVI در ساخت خود انعطافپذیر است و برای نتایج قابل دوام است، به شرطی که در ساخت شاخصها دقت شود.
با عنصر تطبیقی شناسایی شده توسط Holand و Lujala [ 8 ] همراه با تجزیه و تحلیل حساسیت شاخص توسط Schmidtlein و همکاران. و Tate [ 13 , 14 ]، امکانات جدیدی برای پیشبرد قدرت SoVI باز شده است. زمانی که ارزیابی استفن و داونینگ [ 15 ] از آسیب پذیری در برابر قحطی و ناامنی غذایی در اتیوپی در مقایسه بین سه روش، یکی از این فرصت ها آشکار می شود. نویسندگان روشهای متداول استفاده از روشهای اقتصاد غذایی خانگی و نقشه ریسک (HFE) و طبقهبندی و درخت رگرسیون (CART) را مقایسه کردند و سپس آن دو را با یک رویکرد جدید با استفاده از ANN مقایسه کردند.
ANN یک روش محاسباتی یادگیری ماشینی است که قادر به انجام کاوش داده ها (در حالت بدون نظارت) و طبقه بندی داده ها (در حالت نظارت شده)، در میان سایر کاربردها است [ 16 ، 17 ]. این روش دارای ساختار اصلی از سه لایه گره است: یک لایه ورودی با یک گره در هر ورودی متغیر. یک لایه پنهان از گره ها که تجزیه و تحلیل را در مدل انجام می دهند، معمولاً یک به اضافه تعداد گره های ورودی. و یک لایه خروجی، با تعداد گره ها برابر با تعداد خروجی های کلاس مورد نظر [ 10 ، 11 ، 16]. گرههای ورودی مقادیر خود را به هر یک از گرههای پنهان ارسال میکنند، که سپس تحلیل رابطه ورودیها را انجام میدهند و سپس طبقهبندی را به گرههای خروجی منتقل میکنند [ 10 ، 11 ، 16 ]. یک اصلاح رایج در این ساختار اساسی در مطالعات مدرن با استفاده از شبکههای عصبی مصنوعی، گنجاندن پس انتشار است، که به موجب آن، نتیجه تجزیه و تحلیل در گرههای پنهان به پیوندهای شبکه بین لایههای ورودی و مخفی بازگردانده میشود تا وزنی با تنظیم خودکار اعمال شود. به پیوندهای شبکه برای افزایش عملکرد ANN [ 10 ، 16 ]. ساختار شبکه عصبی مصنوعی و الگوریتم ارتباط آن به گونه ای تعیین شده است که به طور ضمنی روابط غیرخطی را در داده های اعمال شده بر روی یک شبکه عصبی مصنوعی ثبت کند [ 10 ،11 ، 16 ]. این روش با توجه به کاربردهای اجتماعی یک اشکال قابل توجه دارد. آموزش یک ANN میتواند به مقدار قابلتوجهی از دادههای نمونه نیاز داشته باشد، که، زمانی که یک مدل تک موردی را در نظر میگیریم که به طور مکرر SoVI استفاده میشود، میتواند به دلیل کاهش اندازه مجموعه داده برای طبقهبندی از آموزش مشکلساز باشد [ 17 ]. این مشکل را می توان با استفاده از یک ANN آموزش دیده برای مطالعات موردی دیگر با استفاده از پارامترهای ورودی مشابه کاهش داد، که به موجب آن داده ها فقط باید برای اعتبارسنجی مدل ذخیره شوند تا برای آموزش. کنوانسیون ارائه شده توسط شاهین و همکاران. [ 17 ] یک مجموعه آموزشی بهینه را توصیه میکند که 70 درصد دادهها و 30 درصد آن برای آزمایش استفاده شود.
کاربرد مستقیم شبکه های عصبی مصنوعی در مشکلات اجتماعی حضور کمی در ادبیات دارد. با این حال، استفاده از شبکه های عصبی مصنوعی در مدل سازی سیستم های فیزیکی بسیار گسترده است. نمونههایی در جغرافیا شامل، اما محدود به این نمیشوند: تخمین بارندگی [ 18 ]، حساسیت زمین لغزش [ 19 ]، کیفیت آب [ 20 ]، و پتانسیل انرژی خورشیدی [ 21 ]]. این برنامهها از پتانسیل طبقهبندی یک ANN در توسعه مدلهای پیشبینی برای ارزیابی پدیدههای فیزیکی با استفاده از متغیرهای ورودی که به عنوان کلید درک آن پدیدهها شناسایی شدهاند، استفاده کردهاند. SoVI محصول تلاش برای پارامترسازی آسیبپذیری اجتماعی با دادههای کمی اجتماعی است، که باعث میشود SoVI از نظر شکل با پدیدههای فیزیکی بیتفاوت نباشد. این شباهت بین SoVI و دیگر تحلیلهای پدیدههای فیزیکی، که با نشان دادن استفن و داونینگ [ 15 ] از یک ANN در یک برنامه آسیبپذیری گرفته شده است، نشان میدهد که یک ANN ممکن است برای ارزیابی آسیبپذیری مفید باشد.
استفن و داونینگ [ 15 ] دریافتند که ANN میتواند نتایج قابل مقایسه با روشهای HFE و CART که معمولاً مورد استفاده قرار میگیرند تولید کند، اما مهمتر از آن برخی از تشخیصها را بر روی عملکرد ANN در زمینه آسیبپذیری انجام دادند. آنها دریافتند که ANN آنها به مقیاس فضایی حساس نیست و بیشتر تعیین کردند که ANN آنها می تواند مجموعه های داده با مقیاس های مختلف را در خود جای دهد، که می تواند راه ممکنی را برای رسیدگی به مشکل واحد منطقه ای قابل تغییر در ساخت SoVI پیشنهاد کند [ 15 ، 22 ، 23 ]. ANN همچنین به عنوان دارای روابط غیرخطی در دادههای خود شناسایی شد، حتی زمانی که دادهها همبستگی خودکار داشتند [ 15 ]، مطابق با اظهارات فیشر و آبراهارت در مورد عملکرد ANN [15].16 ]. همانطور که استفن و داونینگ [ 15 ] و فیشر و آبراهارت [ 16 ] اشاره کردند، توپولوژی بین مشاهدات نیز می تواند در برخی از کاربردهای ANN حفظ شود. در نهایت، استفن و داونینگ [ 15 ] مسیر جدیدی را برای آسیبپذیری اجتماعی و SoVI از طریق یکپارچهسازی ANN باز کردند.
3. بخش تجربی
برای بررسی اصلاح روش SoVI، آزمایشی برای ارزیابی آسیبپذیری یوتا با استفاده از روش سنتی ایجاد کردیم. از آن نقطه یک ANN برای گسترش SoVI با یک روش غیر خطی برای افزایش نتایج ساخته شد. بخشهای زیر با جزئیات بیشتری روش مورد استفاده برای بررسی این کاربرد ANN در گسترش SoVI را شرح میدهند. ما روش SoVI را برای آزمایش یک ANN انتخاب کردیم زیرا ادبیات موجود در SoVI [ 3 ، 4 ، 6 ، 8 ، 13 ، 14 ، 15 ] به نظر می رسد که یک راه روشن برای کاوش فراهم می کند.
3.1. منطقه مطالعه
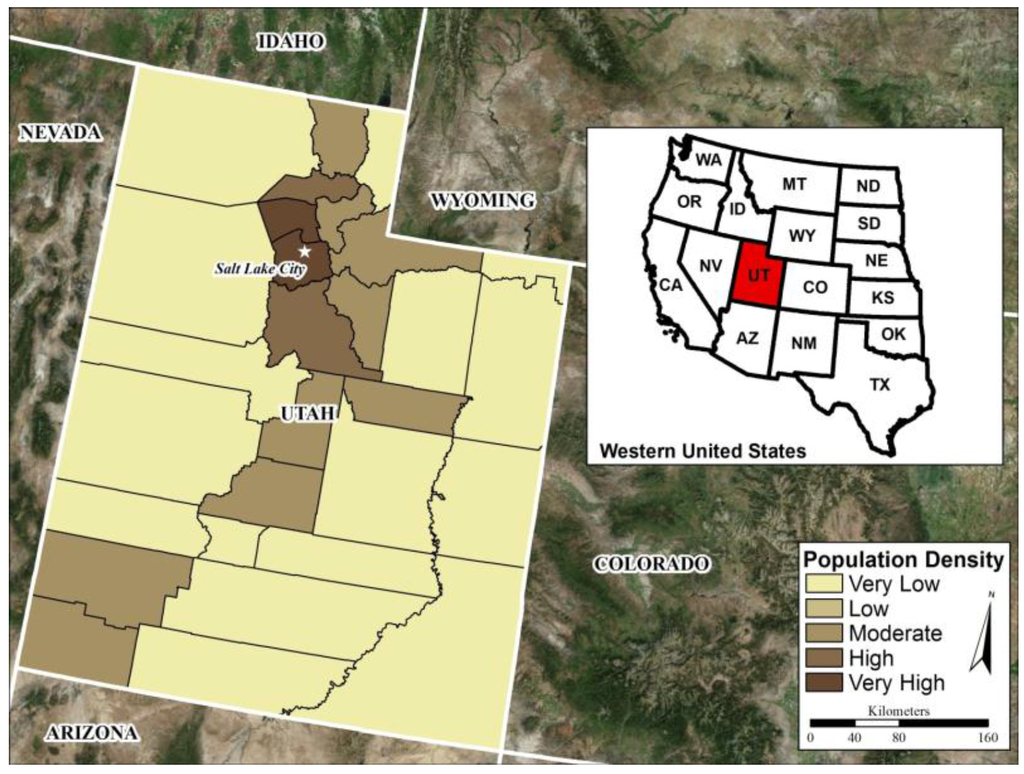
یوتا ایالتی واقع در کوهستان راکی غرب با جمعیتی بالغ بر 2763885 نفر در سال 2010 است ( شکل 1 ) [ 24 ]. این ایالت دارای 29 شهرستان است که 18 شهرستان آن 25000 نفر یا کمتر جمعیت دارند. پایتخت یوتا، سالت لیک سیتی است که در شهرستان سالت لیک واقع شده است، که همچنین بزرگترین شهر این ایالت با جمعیت شهری 186440 نفر بر اساس سرشماری ده ساله 2010 [ 24 ] است. توزیع جمعیت در سراسر ایالت غیریکنواخت است، زیرا بخش بزرگی از جمعیت ایالت در کریدور Ogden-Salt Lake-Provo در جبهه Wasatch متمرکز است و بقیه ایالت عمدتاً روستایی هستند.
شکل 1. ایالت یوتا در غرب ایالات متحده با جمعیت شهرستان بر اساس مساحت زمین نشان داده شده است.
3.2. داده های جمعیت
برای انجام مطالعه خود، زیرمجموعه ای از داده های بررسی جامعه آمریکایی (ACS) اداره سرشماری ایالات متحده را برای ایالت یوتا برای یک دوره پنج ساله انتخاب کردیم تا بیشترین عوامل اجتماعی ممکن را از روش سنتی SoVI در نظر بگیریم [ 3 ]. ACS هر سال نمونه کوچکی از جمعیت را بررسی می کند تا سرشماری ده ساله را تکمیل و گسترش دهد و سایر محصولات آماری مفید برای برنامه ریزان را در زمینه های مختلف ارائه دهد [ 25 ]. ما داده های پنج ساله را برای این مطالعه انتخاب کردیم تا اثرات خطا را کاهش دهیم که از طریق ترکیب نمونه های هر یک از سال ها کاهش می یابد و در نتیجه حجم نمونه افزایش می یابد. دوره داده ما از 2008 تا 2012 است.
داده های ACS در سطوح مختلف برای نیازهای مختلف جمع می شوند. ما کوچکترین سطح تجمعی را که ACS در آن منتشر شده است برای این مطالعه انتخاب کردیم، سطح گروه بلوک سرشماری – دومین واحد کوچک تجمعی که اداره سرشماری در داده های منتشر شده استفاده می کند. این کار برای استفاده از دو مزیت کلیدی انجام شد: مقیاس فضایی نسبتاً خوب برای ارزیابی آسیبپذیری و بیشترین تعداد ممکن واحدهای تجمع برای منطقه مورد مطالعه. کیفیت نسبی ACS نسبت به در دسترس بودن آماده تعداد زیادی از متغیرهای جمعیت شناختی که دیگر در فرم طولانی سرشماری ایالات متحده جمع آوری نشده اند، اهمیت کمتری دارد، به خصوص که سازگاری داخلی داده ها تنها نگرانی اعتبار برای این مطالعه است.
داده های پنج ساله ACS برای یوتا در سطح گروه بلوک سرشماری از 1690 گروه بلوک سرشماری تشکیل شده است و در مجموع شامل 2739 متغیر با حاشیه خطای مربوطه است. زیرمجموعه متغیرهای مورد استفاده در این مطالعه 60 متغیر از ACS و 1 متغیر از هندسه گروه بلوک سرشماری ( جدول 1 ) تشکیل شده است. برخی از متغیرها در صورت لزوم با هم ترکیب شدند تا متغیرهای توصیفی گستردهتری تولید کنند، مانند میزان تحصیلات عمومی. متغیرهای انتخاب شده برای این مطالعه تقریباً یک شاخص اساسی را پوشش می دهد که گسترده ترین مضامین آسیب پذیری اجتماعی را که توسط Cutter و همکاران ارائه شده است، پوشش می دهد. [ 3]. این دادهها یک اسکلت اساسی را فراهم میکنند که به وسیله آن میتوان توانایی یک ANN را برای انجام به عنوان یک روش طبقهبندی، به جای ارزیابی آسیبپذیری کامل و دقیق، آزمایش کرد.

جدول 1. زیرمجموعه ای از متغیرهای بررسی جامعه آمریکایی (ACS) اداره سرشماری ایالات متحده که در مطالعه مورد استفاده قرار گرفت با توضیحات و اینکه آیا متغیر از گروه بزرگتری از متغیرها از داده های ACS مشتق شده است یا خیر.
این داده ها به چند ضلعی گروه های بلوک سرشماری در یک سیستم اطلاعات جغرافیایی (GIS) پیوست و متغیرهای نهایی در پایگاه داده محاسبه شدند. داده های پیوست شده از GIS به بسته نرم افزار آماری R برای انجام تجزیه و تحلیل بیشتر صادر شد.
3.3. ساخت و ساز سنتی SoVI
متغیرهای ACS متصل به گروههای بلوک سرشماری برای یوتا از GIS به یک قالب فایل شکل صادر شده و با استفاده از بسته “maptools” به R خوانده شدند. جدول پایگاه داده حاوی متغیرهای حالت به یک قاب داده در R ترجمه شد. هنگامی که داده ها در فرمت داخلی صحیح در R قرار گرفتند، PCA با استفاده از تابع “prcomp” روی داده ها اجرا شد. دادهها در تابع بهمنظور مرکزیت همه متغیرها و اطمینان از عدم تغییر واریانس توسط تفاوتهای بزرگی متغیر، مقیاسبندی شدند. تجزیه و تحلیل PCA حاصل در مجموع 22 مؤلفه اصلی را تولید کرد که 13 مؤلفه به عنوان عوامل اجتماعی با 87.8 درصد از واریانس توضیح داده شده انتخاب شدند ( جدول 2 ).
جدول 2. عوامل شاخص آسیب پذیری اجتماعی سنتی (SoVI) با کاردینالیته، نام عامل و نسبت واریانس توضیح داده شده (گرد) و متغیرهای اجتماعی غالب با بار عاملی اصلی.
از این انتخاب از عوامل اجتماعی، تابعی برای ترکیب افزودنی عوامل – با استفاده از بارگذاری متغیر – در امتیاز نهایی SoVI ایجاد شد. تابع مورد استفاده برای افزودن بارگذاری ها در زیر نشان داده شده است:
– اف1 + F2 + F3 + F4 + F5 + | اف6 | –اف7 – F8 + F9 + F10 – F11 + F12 + F13–اف1+اف2+اف3+اف4+اف5+|اف6|–اف7–اف8+اف9+اف10–اف11+اف12+اف13
دادهها به GIS برای تجسم آسیبپذیری اجتماعی برای دولت بازگردانده شدند. نمرات SoVI با استفاده از چندک با پنج شکست نمادین شدند. وقفه ها آسیب پذیری طبقه بندی شده را نشان می دهند ( جدول 3 ).
جدول 3. دستههای آسیبپذیری و کمیت مربوطه آنها مقدار کران بالایی را میشکنند.
یک فیلد جدید به جدول پایگاه داده اضافه شد تا دسته بندی های SoVI را شامل شود. داده ها با دسته بندی های موجود در قالب فایل شکل صادر شدند تا یک بار دیگر در R خوانده شوند.
3.4. ساخت و ساز ANN SoVI
داده ها بار دیگر با استفاده از بسته “maptools” در R بارگذاری شدند. جدول پایگاه داده در یک قاب داده در R بارگذاری شد و فیلدهای غیر ضروری از جدول حذف شدند (به عنوان مثال ، جدول امتیازات SoVI، فیلدهای تولید شده توسط GIS و غیره ). سپس داده ها به دو مجموعه، یک مجموعه آموزشی و یک مجموعه پیش بینی تقسیم شدند. مجموعه آموزشی 70 درصد دادهها بود که در مجموع 1183 گروه بلوک سرشماری را شامل میشد و 507 گروه بلوک سرشماری باقیمانده برای طبقهبندی ANN استفاده میشد. این بخش مجموعه آموزش و تست طبق کنوانسیون ایجاد شده توسط شاهین و همکاران مورد استفاده قرار گرفت. [ 17 ].
ANN با استفاده از بسته “nnet” ایجاد شد. شبکه دارای 22 گره ورودی بود که برابر با تعداد متغیرهای ورودی بود. لایه پنهان دارای تعدادی گره برابر با گره های ورودی به اضافه یک یا 23 بود. لایه خروجی دارای پنج گره بود که برابر با تعداد دسته های آسیب پذیری اجتماعی بود ( شکل 2 ).
ANN نهایی پنج بار برای طبقهبندی طبقهبندی اجرا شد تا یک مقدار همگرایی مشترک پیدا شود تا مشخص شود که مدل به طور مداوم اجرا میشود و نتایج ثابتی تولید میکند. یک مقدار دانه ایستا نیز در این فرآیند برای اطمینان از ثبات در خروجی تنظیم شد. همه اجراهای طبقهبندی با یک مقدار همگرا میشوند، حتی زمانی که مدل روی ماشینهای دیگر اجرا میشد. ANN چندین بار با تغییرات جزئی در ساختار اجرا شد، با این حال ساختار ارائه شده در اینجا بهترین موارد آزمایش را انجام داد.
3.5. مقایسه SoVI های سنتی و ANN
مقایسه SoVI مبتنی بر PCA در برابر SoVI توسعهیافته ANN با استفاده از تشخیص تغییر و مقایسه نمودار راداری از نحوه مدیریت هر روش با متغیرهای اجتماعی ورودی انجام شد. برای این مطالعه اساساً بر شباهت بین نتایج PCA و ANN متمرکز شدیم و عملکرد روشها را بر اساس شباهت نسبی نتایج مقایسه کردیم.
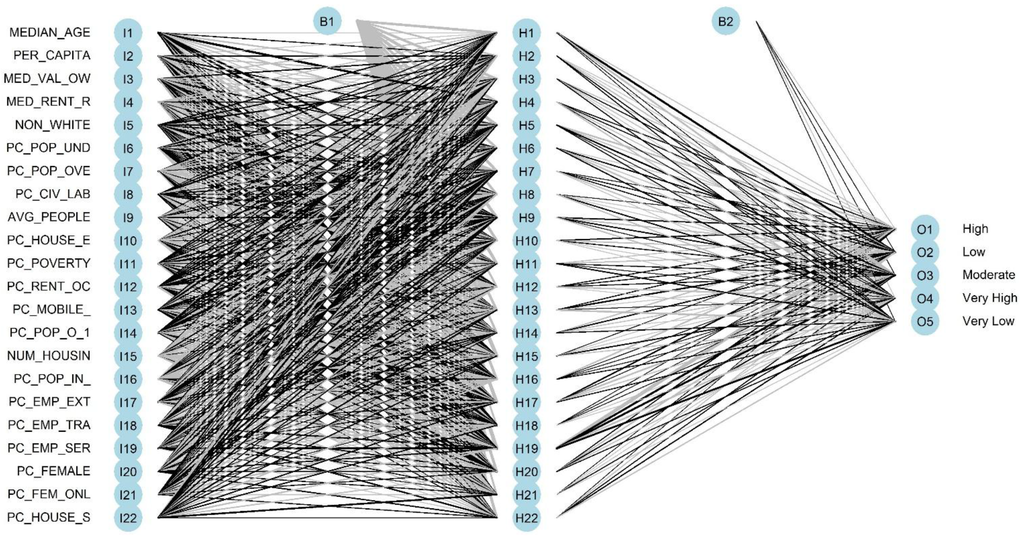
شکل 2. ساختار شبکه عصبی مورد استفاده برای طبقه بندی SoVI برای یوتا. شبکه شامل 22 گره ورودی، 23 گره پنهان و پنج گره خروجی است.
تشخیص تغییر به کار گرفته شده، یک رابطه «از به» را بین SoVI سنتی و SoVI گسترشیافته با ANN شناسایی کرد. یک ماتریس تشخیص تغییر ایجاد شد که نشان میدهد کدام بلوکها بین روشها تغییر میکنند و چگونه بلوکها در SoVI توسعهیافته ANN طبقهبندی میشوند. ماتریس تشخیص تغییر به تعیین ماهیت طبقهبندی بین دو روش کمک کرد و تفاوتهای بین روشها را تجسم کرد.
ساخت نمودارهای راداری به ما این امکان را داد که اهمیت نسبی هر متغیر را در هر کلاس آسیبپذیری برای SoVI سنتی و SoVI توسعهیافته با ANN تجسم کنیم. مقایسه مدیریت متغیرها، اهمیت هر متغیر در هر کلاس آسیبپذیری، به ما این امکان را میدهد تا ارزیابی کنیم که هر دو روش چگونه آسیبپذیری را طبقهبندی میکنند و تعیین کنیم که آیا انحرافات قابل توجهی در مدیریت متغیر وجود دارد یا خیر.
4. نتایج و بحث
4.1. بحث سنتی SoVI
نمرات PCA از SoVI سنتی به کلاس های آسیب پذیری بر اساس چندک طبقه بندی شدند ( شکل 3 ). آسیبپذیری اجتماعی نشاندادهشده برای ایالت یوتا، الگوی تصادفی آسیبپذیری را نشان میدهد. برخی از خوشهبندیها، با استفاده از آمار Local Moran’s I، در مجاورت شهرهای ایالت، اما نه منحصر به شهرها، بهطور تصادفی در اطراف ایالت پیدا شد ( شکل 4 ). با توجه به تمرکز شدید جمعیت روستایی-شهری برای ایالت یوتا همانطور که در شکل 1 مشاهده می شود، این الگو قابل انتظار است .. گروههای بلوک با آسیبپذیری بالا و بسیار بالا عموماً در بخشهای جنوبی و شرقی ایالت یافت میشوند، در حالی که گروههای بلوک با آسیبپذیری کم و بسیار کم در سراسر ایالت پراکنده هستند، با این حال این کلاسها در بخشهای مرکزی و شمال غربی یوتا رایجتر هستند.
جالب است بدانید که روش سنتی چند نمونه از طبقهبندی نادرست بالقوه را ایجاد کرد. این روش گروه های بلوک سرشماری با جمعیت صفر را به عنوان دارای آسیب پذیری بالا طبقه بندی کرد. این گروههای بلوک برای آزمایش اینکه آیا ANN گروههای بلوک را بهطور مناسبتری مجدداً طبقهبندی میکند، استفاده شد، با نتایج PCA به ANN در آزمایشهای مختلف، تصحیح (گروههای بلوک طبقهبندیشده اشتباه مجدداً طبقهبندی شدند) و اصلاح نشده (گروههای بلوک طبقهبندی اشتباه بدون تغییر بودند). شکل 3 نتیجه SoVI سنتی اصلاح نشده را برای مقایسه با نتیجه ANN SoVI با گروه های بلوک اصلاح نشده نشان داده شده در زیر نشان می دهد.
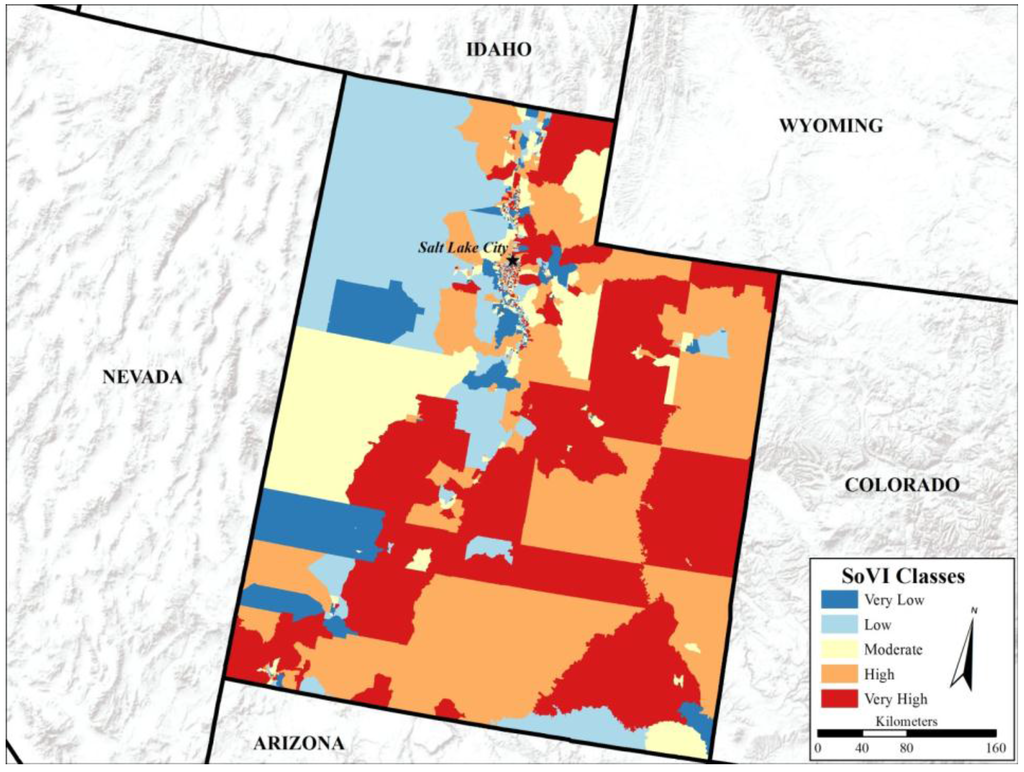
شکل 3. SoVI برای ایالت یوتا با استفاده از رویکرد سنتی ساخته شده است.

شکل 4. خوشه بندی دسته های آسیب پذیری برای یوتا بر اساس SoVI سنتی با استفاده از آمار Local Moran’s I. این الگو برخی از مناطق خوشهبندی را در نزدیکی شهرهای پرجمعیت نشان میدهد.
نتیجه SoVI از رویکرد سنتی تا حد زیادی با درک آسیبپذیری در یوتا بر اساس ارزیابی کیفی توسط نویسندگان سازگار است. علاوه بر این، این الگو مشابه یک مطالعه در مقیاس کوچکتر با استفاده از مجموعه داده های مختلف برای شهرستان سالت لیک در یوتا است [ 26 ]. نویسندگان SoVI سنتی مورد استفاده در این مطالعه را با محدودیتهای ذکر شده در پاراگراف قبل به عنوان یک نتیجه معتبر میپذیرند.
4.2. بحث ANN SoVI
شبکه عصبی مصنوعی با استفاده از 70 درصد داده ها (استفن و داونینگ [ 15 ] نشان داده شد و از فیشر و آبراهارت [ 16 ] پشتیبانی کرد) آموزش داده شد که در مجموع 1183 گروه بلوک سرشماری را تشکیل می دادند. 507 گروه بلوک باقی مانده برای آزمایش قابلیت طبقه بندی شبکه عصبی مصنوعی آموزش دیده استفاده شد ( شکل 5). طبقه بندی توسط ANN یک طبقه بندی تقریباً یکنواخت ایجاد کرد. اندازه هر یک از کلاس ها در یک انحراف استاندارد از میانگین تعداد گروه های بلوک در هر کلاس آسیب پذیری بود. با این حال، طبقه بسیار پایین دارای 129 گروه بلوک بود. ممکن است به نظر برسد که طبقه بسیار پایین کمی مغرضانه است. مقایسه بین SoVI سنتی و SoVI توسعهیافته با ANN، برخی از ماهیت طبقهبندی ANN را نشان داد، همانطور که در بخش زیر بحث شد. همچنین شایان ذکر است که طبقه بندی ANN به طور مداوم نتایج یکسانی را با یک مقدار دانه مشخص در R در چندین مدل اجرا می کند، که نشان دهنده ثبات در طبقه بندی است.
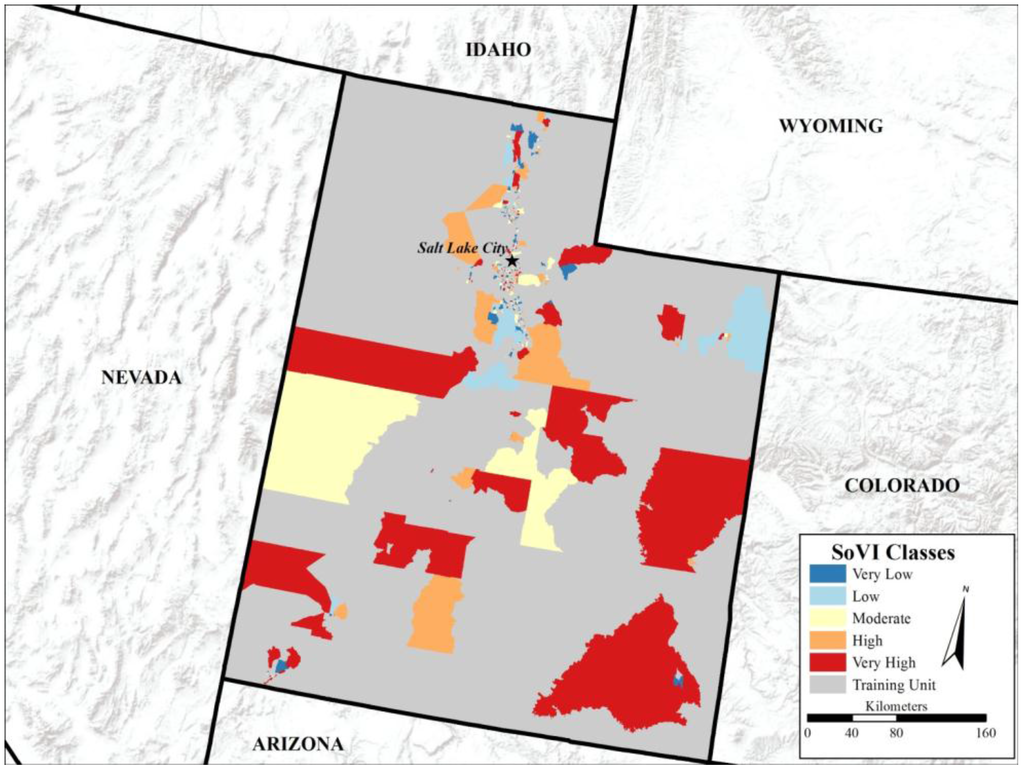
شکل 5. SoVI برای ایالت یوتا با استفاده از روش توسعه یافته شبکه عصبی مصنوعی (ANN) ساخته شده است.
4.3. مقایسه سنتی SoVI و ANN SoVI
مقایسه این دو نتیجه استخراج بارهای PCA و وزن شبکه ANN را ضروری کرد. این دادهها مستقیماً قابل مقایسه نیستند، بنابراین دو روش مقایسه برای ارزیابی هر دو روش ابداع شد: تشخیص تغییر بین نتایج هر دو روش و ارزیابی نمودار راداری مدیریت متغیر در هر روش. برای کمک به مقایسه، از کاردینالیته و مقادیر نسبی داخلی بارگذاریهای PCA و وزن شبکه ANN استفاده کردیم.
بخش اول مقایسه از طریق تجزیه و تحلیل نمودار تشخیص تغییر بین SoVI سنتی و ANN SoVI با ماتریس تغییر همراه انجام شد ( شکل 6 ). اولین نکته ای که باید به آن توجه کرد توافق بین این دو روش است. SoVI توسعهیافته ANN طبقهبندی را تولید کرد که با SoVI سنتی بیش از ۲۶ درصد از گروههای بلوک طبقهبندیشده سازگار بود. اگرچه ممکن است این مقدار کم به نظر برسد، مهم است که توجه داشته باشید که این دو روش باید نتایج متفاوتی ایجاد کنند. بنابراین، یافتن توافق (اما نه کامل) بین روش ها دلگرم کننده است. در جایی که روش ها متفاوت است، فرصت هایی برای بررسی بیشتر در مورد تفاوت ANN با PCA وجود دارد.
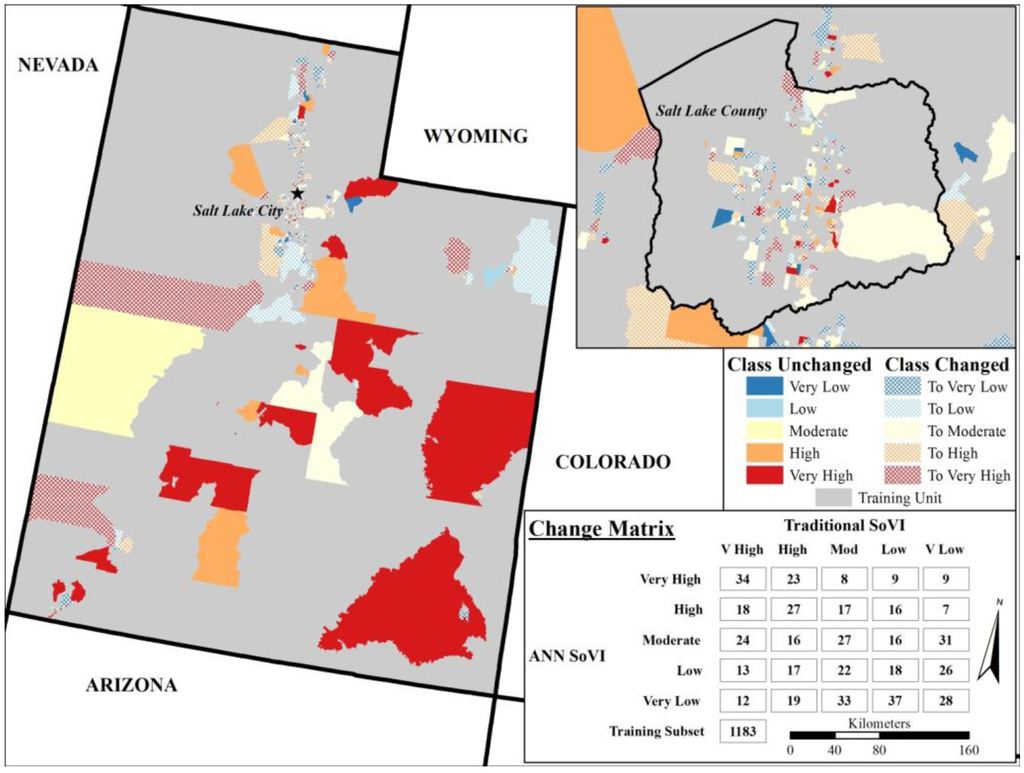
شکل 6. مقایسه کلاسهای SoVI سنتی و کلاسهای SoVI توسعهیافته ANN برای ایالت یوتا. این افسانه شامل یک ماتریس تغییر است که نشان میدهد چگونه SoVI سنتی گروههای بلوک سرشماری را در مقابل نحوه طبقهبندی SoVI با گسترش ANN همان گروههای بلوک سرشماری را برای زیرمجموعه طبقهبندی طبقهبندی میکند. کلاسهای نمادین بلوکهای سرشماری را نشان میدهند که بین روشها بدون تغییر باقی ماندهاند و همچنین نمایش کلی که بلوک سرشماری به هر کلاس آسیبپذیری تغییر کرده است. یک نقشه داخلی از شهرستان سالت لیک برای نشان دادن پرجمعیت ترین بخش منطقه مورد مطالعه گنجانده شده است.
با مراجعه به بخش قبل و نگرانی احتمالی تعصب طبقهبندی در کلاس آسیبپذیری بسیار کم، از ماتریس تغییر میتوان دریافت که این دو روش دومین توافق بالاتر را در کلاس بسیار پایین داشتند. علاوه بر این، بخش عمده ای از طبقه بندی مجدد از گروه های بلوک طبقه بندی شده به عنوان آسیب پذیری متوسط و کم در SoVI سنتی انجام شد. بر اساس این اطلاعات به نظر می رسد که ممکن است یک سوگیری برای کلاس آسیب پذیری بسیار کم وجود داشته باشد. بسیاری از گروههای بلوک از طبقهبندی سنتی SoVI خود از طریق طبقهبندی ANN تغییر کردند، و قابل ذکر است که این امر از هر کلاس به کلاس دیگر رخ میدهد. این ممکن است شواهدی باشد که نشان میدهد ANN قادر به گرفتن روابط غیرخطی در دادهها و بیان آن در طبقهبندی خود بوده است.
با استفاده از گروههای بلوک طبقهبندیشده اشتباه از رویکرد سنتی بهعنوان یک تشخیص اضافی، متوجه شدیم که ANN گروههای بلوک (بالقوه) اشتباه طبقهبندیشده را در همان دستهبندی رویکرد سنتی طبقهبندی میکند. این نتیجه دلگرم کننده است زیرا ANN ممکن است مجبور شده باشد برای تطبیق گروه های بلوک غیرعادی تنظیم شود. این نقطه سازگاری اضافی بین دو روش طبقه بندی نشان می دهد که ANN در حال گرفتن برخی از روابطی است که PCA نیز پیدا کرده است. مجموعه آموزشی شامل نمونههایی از دسته بالا بود که نامعتبر نبودند، و در برخی از آن طبقهبندیها با SoVI سنتی سازگار بود، اما برخی از گروههای بلوک بالا را نیز در کلاسهای آسیبپذیری دیگر طبقهبندی کرد.
همچنین میتوان از ارزیابی تصویری شکل 6 پیشنهاد کرد که نواحی روستایی یوتا بر مجموعه آموزشی ANN تسلط دارند. نگاهی دقیق تر به شهرستان سالت لیک – مرکز پرتراکم ترین منطقه در یوتا – نشان می دهد که گروه های بلوک در این منطقه پرجمعیت به خوبی در داده های آموزشی و همچنین در مجموعه طبقه بندی نشان داده شده اند.
بخش دوم مقایسه با ارزیابی کیفی متغیرهای اجتماعی گروه های بلوکی و نتایج طبقه بندی از هر دو روش انجام شد. با ساختن نمودارهای راداری با هر متغیر – متغیرها برای هر کلاس آسیبپذیری استاندارد و میانگین شدند – که در محور X خودش نشان داده شده بود، ما توانستیم گرایش اهمیت متغیر را در طبقهبندیها تعیین کنیم ( شکل 7 ). نمودارهای رادار سازگاری داخلی نسبی را برای نحوه طبقهبندی گروههای بلوک توسط رویکرد سنتی و ANN نشان میدهد. از شکل 7 (اعداد محورها با متغیرهای جدول 1 مطابقت داردما میتوانیم ببینیم که تمایل برای بسیار زیاد و متوسط بین طبقهبندی سنتی و طبقهبندی ANN به خوبی همخوانی دارد ( شکل 7 a,c). تنوع واضح در مدیریت متغیر بین هر دو روش را می توان در کلاس آسیب پذیری بسیار کم مشاهده کرد ( شکل 7 ج). این تفاوت بین دو روش طبقه بندی ممکن است موردی باشد که ANN روابط متغیر را به روشی غیر خطی مدیریت می کند.
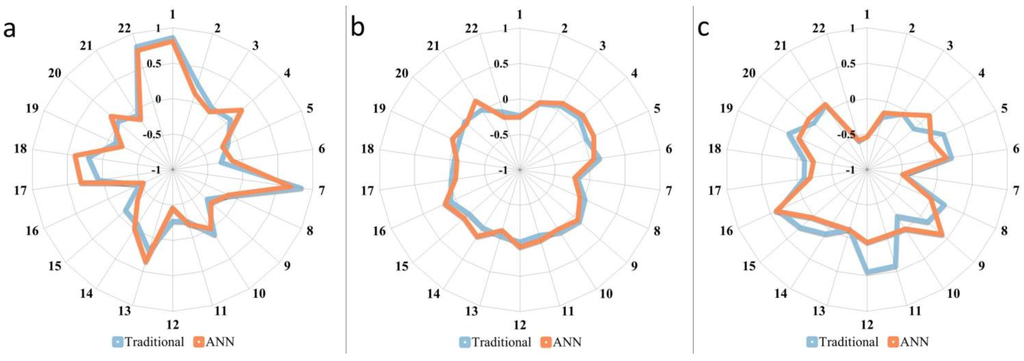
شکل 7. مقایسه میانگین متغیرهای اجتماعی در محدوده بسیار بالا ( a ); متوسط ( b )؛ و کلاسهای آسیبپذیری بسیار کم ( c ) بین SoVI سنتی و SoVI توسعهیافته با ANN.
از طریق تجزیه و تحلیل تفاوتهای بین طبقهبندی SoVI سنتی و طبقهبندی SoVI توسعهیافته با ANN، ما توانستیم تعیین کنیم که نتایج هر دو روش معقول بوده و این دو روش به راحتی قابل مقایسه هستند. مقایسه موقعیتهایی را نشان داد که ماهیت غیرخطی طبقهبندی شبکه عصبی مصنوعی ممکن است سودمند بوده باشد، که منجر به تفاوت مشاهدهشده در شکل 6 شد. پایداری طبقهبندی ANN با رسیدن شبکه به همگرایی به تقویت این یافتهها کمک میکند، علاوه بر این که سازگاری بین روش با استفاده از گروههای بلوک نامعتبر بررسی میشود.
با توجه به ماهیت اکتشافی این مطالعه – برای تعیین اینکه آیا ANN می تواند روش سنتی SoVI را تقویت کند یا خیر – از عبارت حاشیه خطا برای متغیرهای ACS با داده های مطالعه استفاده نشد. در حالی که ما احساس نمی کردیم که این برای این مطالعه ضروری باشد، سایر محققانی که از روش توصیف شده در این مقاله استفاده می کنند تشویق می شوند تا اطمینان حاصل کنند که حاشیه خطا برای ارائه دقیق ترین نتایج گنجانده شده است.
5. نتیجه گیری ها
این مطالعه روش سنتی طبقهبندی آسیبپذیری SoVI را با یک فرم اصلاحشده با استفاده از ANN مقایسه کرد. هر دو رویکرد سنتی و رویکرد ANN طبقهبندی آسیبپذیری معقولی را برای ایالت یوتا با توجه به پارامترهای اساسی مورد استفاده برای این مطالعه ایجاد کردند. روشها برای 26 درصد از گروههای بلوک رایج همخوانی داشتند. این توافق جزئی نشان می دهد که هر دو روش قادر به شناسایی برخی از روابط یکسان بین متغیرهای ورودی هستند. تفاوت در نحوه مدیریت روابط نشان میدهد که ANN روابط غیرخطی را که PCA نمیتوانست به دست آورد. علاوه بر این، توافق بین روشها برای گروههای بلوک نامعتبر، طبقهبندی شده به عنوان آسیبپذیری بالا در هر دو رویکرد،
SoVI توسعهیافته ANN برخی از تعصبات را در طبقهبندی در کلاسهای آسیبپذیری بالا و بسیار پایین نشان داد، با تفاوتهای قابلتوجه در نحوه دستهبندی سنتی و طبقهبندی ANN با متغیرهای آن کلاسها. نمودارهای راداری متغیرهای اجتماعی برای هر کلاس آسیبپذیری نشان میدهد که ANN متغیرهای سه کلاس دیگر را مشابه رویکرد سنتی مدیریت میکند. این سازگاری درونی مدیریت دادهها بین روشها این یافته را تقویت میکند که ANN غیرخطی بودن بین متغیرها را، مطابق با عبارات موجود در ادبیات [ 10 ، 11 ، 16 ]، همانطور که در زیر مشاهده میشود، تقویت میکند ( شکل 8).). سازگاری بین اجرای مدل ANN نتیجه طبقهبندی را بیشتر تقویت میکند، زیرا هیچ گونه تغییری در نتایج بین اجراها وجود نداشت و همگرایی در هر اجرای آزمایشی یکسان بود.
با استفاده از روش شناسی بیان شده در این مقاله، می توانیم یافته های خود را با توجه به سؤالات مطالعه خود خلاصه کنیم. اولاً، SoVI سنتی و SoVI توسعهیافته ANN هر دو نتایج معقولی برای ایالت یوتا ایجاد کردند – طبقهبندی آسیبپذیری از هر دو روش در مقایسه با کار موجود در منطقه برای جمعیت معقول بود [ 26 ، 27 ].]. ثانیا، نتایج بین روشها متفاوت، اما تا حدی سازگار بود. ANN 26 درصد از زیرمجموعه طبقهبندی را به طور سازگار با SoVI سنتی طبقهبندی کرد، که نشان میدهد هر دو روش قادر به گرفتن روابط مشابه بین متغیرهای ورودی بودند. با این حال، ANN زیرمجموعه های باقیمانده را متفاوت طبقه بندی کرد، در برخی موارد به یک کلاس آسیب پذیری دور از اصلی (مثلاً از خیلی زیاد به بالا). تجزیه و تحلیل تمایلات متغیر در کلاسهای آسیبپذیری برای هر دو روش (با استفاده از نمودارهای رادار) نشان میدهد که هر دو روش متغیرها را تا حد زیادی به روشی مشابه، با برخی تفاوتهای قابل توجه، مدیریت میکنند. واگرایی بین دو روش نشان می دهد که ANN قادر به گرفتن روابط غیر خطی در متغیرهایی است که با PCA خطی گرفته نشده اند. سرانجام، از آنجایی که ANN غیرخطی بودن متغیرها را برای طبقهبندی خود دریافت میکند، ANN باید مسیری مناسب برای بهبود روش ساخت SoVI در آینده باشد و میتواند در سایر روشهای ارزیابی آسیبپذیری کمی مفید باشد. سازگاری بین روشها نشان میدهد که ANN قادر است روابط خطی شناسایی شده با PCA را به تصویر بکشد، به این معنی که میتوان نقاط قوت روش PCA را هنگام استفاده از ANN حفظ کرد. با این حال، دادههای نامعتبر، علیرغم قوت سازگاری با استفاده از دادههای نامعتبر، مشکلاتی را برای هر دو روش ایجاد میکند. تحلیلگران باید مراقب باشند تا اطمینان حاصل شود که داده های با کیفیت در هنگام استفاده از ANN استفاده می شود، همانطور که در رویکرد سنتی وجود دارد. و می تواند در سایر روش های ارزیابی کمی آسیب پذیری مفید باشد. سازگاری بین روشها نشان میدهد که ANN قادر است روابط خطی شناسایی شده با PCA را به تصویر بکشد، به این معنی که میتوان نقاط قوت روش PCA را هنگام استفاده از ANN حفظ کرد. با این حال، دادههای نامعتبر، علیرغم قوت سازگاری با استفاده از دادههای نامعتبر، مشکلاتی را برای هر دو روش ایجاد میکند. تحلیلگران باید مراقب باشند تا اطمینان حاصل شود که داده های با کیفیت در هنگام استفاده از ANN استفاده می شود، همانطور که در رویکرد سنتی وجود دارد. و می تواند در سایر روش های ارزیابی کمی آسیب پذیری مفید باشد. سازگاری بین روشها نشان میدهد که ANN قادر است روابط خطی شناسایی شده با PCA را به تصویر بکشد، به این معنی که میتوان نقاط قوت روش PCA را هنگام استفاده از ANN حفظ کرد. با این حال، دادههای نامعتبر، علیرغم قوت سازگاری با استفاده از دادههای نامعتبر، مشکلاتی را برای هر دو روش ایجاد میکند. تحلیلگران باید مراقب باشند تا اطمینان حاصل شود که داده های با کیفیت در هنگام استفاده از ANN استفاده می شود، همانطور که در رویکرد سنتی وجود دارد. با این حال، با وجود قوت سازگاری با استفاده از دادههای نامعتبر، مشکلاتی را برای هر دو روش ارائه میکند. تحلیلگران باید مراقب باشند تا اطمینان حاصل شود که داده های با کیفیت در هنگام استفاده از ANN استفاده می شود، همانطور که در رویکرد سنتی وجود دارد. با این حال، با وجود قوت سازگاری با استفاده از دادههای نامعتبر، مشکلاتی را برای هر دو روش ارائه میکند. تحلیلگران باید مراقب باشند تا اطمینان حاصل شود که داده های با کیفیت در هنگام استفاده از ANN استفاده می شود، همانطور که در رویکرد سنتی وجود دارد.
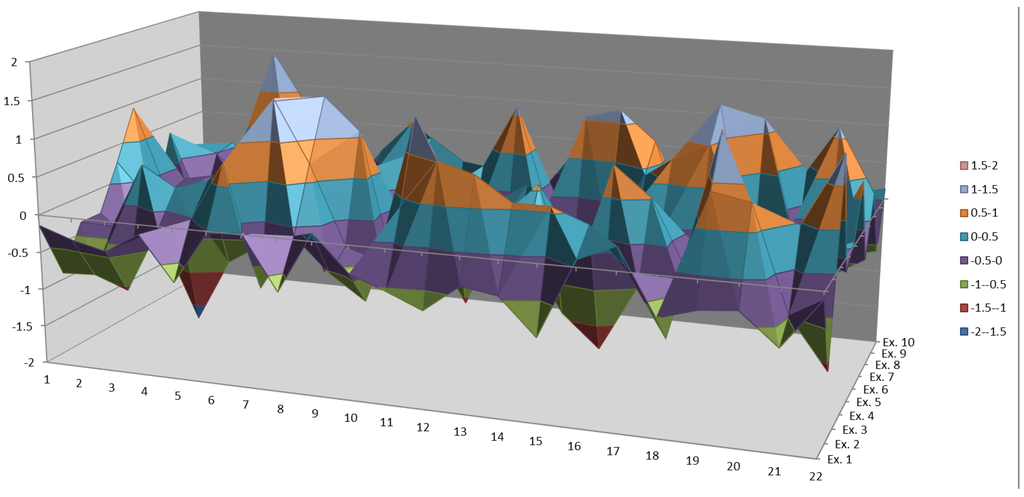
شکل 8. شواهدی از روابط غیر خطی بین متغیرهای ورودی. ده نمونه انتخاب شد: دو تا از هر کلاس از SoVI سنتی که به دو کلاس دورتر در SoVI توسعهیافته ANN تغییر کرد (مثلاً یکی از بالا به پایین، یکی زیاد به خیلی کم، یکی متوسط به خیلی زیاد و غیره ) .
روشهای بررسی استفاده از ANN برای تقویت روش SoVI که در این مطالعه مشخص شد نشان میدهد که این رویکرد میتواند جایگزین مناسبی برای رویکرد به خوبی تثبیت شده برای ایجاد یک SoVI برای یک منطقه باشد. در واقع، ANN نقاط قوت روش موجود را با تعداد کمی از نقاط ضعف خود، علاوه بر نقاط قوت خود، به ویژه مدیریت روابط داده های غیر خطی، حفظ می کند. کاوش بیشتر در مورد این روش نشان خواهد داد که ANN تا چه حد می تواند برای تجزیه و تحلیل SoVI، و همچنین چگونه می تواند به بهترین شکل برای ایجاد یک SoVI پیاده سازی شود. اکتشاف آتی پیادهسازی ANN در سایر روشهای ارزیابی آسیبپذیری، پتانسیل پیشرفت در زمینه ارزیابی آسیبپذیری را در کل دارد.
منابع
- بلیکی، پی. کانن، تی. دیویس، آی. Wisner, B. در معرض خطر: خطرات طبیعی، آسیب پذیری مردم و بلایا . Routledge: لندن، انگلستان، 1994. [ Google Scholar ]
- کاتر، SL آسیب پذیری در برابر خطرات محیطی. Prog. هوم Geogr. 1996 ، 20 ، 529-539. [ Google Scholar ] [ CrossRef ]
- کاتر، SL; بوروف، بی جی؛ شرلی، WL آسیب پذیری اجتماعی در برابر خطرات محیطی. Soc. علمی Q. 2003 , 84 , 242-261. [ Google Scholar ] [ CrossRef ]
- کاتر، SL; بارنز، ال. بری، م. برتون، سی. ایوانز، ای. تیت، ای. Webb, J. مدلی مبتنی بر مکان برای درک تاب آوری جامعه در برابر بلایای طبیعی. گلوب. محیط زیست چانگ. 2008 ، 18 ، 598-606. [ Google Scholar ] [ CrossRef ]
- واچینگر، جی. رن، او. بگ، سی. Kuhlicke, C. پارادوکس ادراک ریسک – پیامدهای حاکمیت و ارتباط مخاطرات طبیعی. ریسک مقعدی 2013 ، 33 ، 1049-1065. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Füssel, H. Vulnerability: یک چارچوب مفهومی به طور کلی قابل اجرا برای تحقیقات تغییرات آب و هوا. گلوب. محیط زیست چانگ. 2007 ، 17 ، 155-167. [ Google Scholar ] [ CrossRef ]
- کاتر، SL; میچل، جی تی; اسکات، ام اس افشای آسیب پذیری افراد و مکان ها: مطالعه موردی شهرستان جورج تاون، کارولینای جنوبی. ان دانشیار صبح. Geogr. 2000 ، 90 ، 713-737. [ Google Scholar ] [ CrossRef ]
- هلند، IS; Lujala، P. تکرار و تطبیق یک شاخص آسیب پذیری اجتماعی با یک زمینه جدید: مطالعه مقایسه ای برای نروژ. پروفسور Geogr. 2013 ، 65 ، 312-328. [ Google Scholar ] [ CrossRef ]
- Adger، آسیب پذیری WN. گلوب. محیط زیست چانگ. 2006 ، 16 ، 268-281. [ Google Scholar ] [ CrossRef ]
- سامرز، ام جی; Casal، JC استفاده از شبکههای عصبی مصنوعی برای مدلسازی غیرخطی: مورد رابطه رضایت شغلی-عملکرد شغلی. عضو. Res. Methods 2009 ، 12 ، 403-417. [ Google Scholar ] [ CrossRef ]
- مائو، جی. شبکههای عصبی مصنوعی جین، AK برای استخراج ویژگی و پیشبینی دادههای چند متغیره. IEEE Trans. شبکه عصبی 1995 ، 6 ، 296-317. [ Google Scholar ]
- کاتر، SL; Solecki, WD الگوی ملی انتشار سموم در هوا. پروفسور Geogr. 1989 ، 41 ، 149-161. [ Google Scholar ] [ CrossRef ]
- اشمیتلین، ام سی; Deutsch، RC; پیگورش، WW; کاتر، SL تجزیه و تحلیل حساسیت شاخص آسیب پذیری اجتماعی. ریسک مقعدی 2008 ، 28 ، 1099-1114. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- تیت، E. تجزیه و تحلیل عدم قطعیت برای یک شاخص آسیب پذیری اجتماعی. ان دانشیار صبح. Geogr. 2013 ، 103 ، 526-543. [ Google Scholar ] [ CrossRef ]
- استفان، ال. داونینگ، TE گرفتن مقیاس درست: مقایسه روشهای تحلیلی برای ارزیابی آسیبپذیری و هدفگیری در سطح خانوار. بلایا 2001 ، 25 ، 113-135. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- فیشر، MM; آبراهارت، RJ Neurocomputing – ابزارهایی برای جغرافیدانان. در ژئومحاسبات ، چاپ اول؛ Openshaw, S., Abrahart, RJ, Eds. تیلور و فرانسیس: لندن، بریتانیا، 2000; ص 187-217. [ Google Scholar ]
- شاهین، م. مایر، اچ. Jaksa، M. بخش داده برای توسعه شبکه های عصبی کاربردی در مهندسی ژئوتکنیک. جی. کامپیوتر. مدنی مهندس 2004 ، 18 ، 105-114. [ Google Scholar ] [ CrossRef ]
- بلربی، تی. تاد، ام. Kniveton، D.; Kidd, C. برآورد بارندگی از ترکیبی از رادار بارش TRMM و تصاویر ماهواره ای چندطیفی GOES با استفاده از یک شبکه عصبی مصنوعی. J. Appl. هواشناسی کلیماتول. 2000 ، 39 ، 2115-2128. [ Google Scholar ] [ CrossRef ]
- بیسواجیت، پ. Saro, L. استفاده از داده های سنجش از دور نوری و ابزارهای GIS برای تجزیه و تحلیل خطر زمین لغزش منطقه ای با استفاده از یک مدل شبکه عصبی مصنوعی. علوم زمین جلو. 2007 ، 14 ، 143-151. [ Google Scholar ] [ CrossRef ]
- سینگ، KP; بسانت، ا. مالک، ع. جین، جی. مدلسازی شبکه عصبی مصنوعی کیفیت آب رودخانه – مطالعه موردی. Ecol. مدل. 2009 ، 220 ، 888-895. [ Google Scholar ] [ CrossRef ]
- ملیت، آ. Pavan، AM پیشبینی 24 ساعته تابش خورشیدی با استفاده از شبکه عصبی مصنوعی: کاربرد برای پیشبینی عملکرد یک نیروگاه PV متصل به شبکه در تریست، ایتالیا. سول انرژی 2010 ، 84 ، 807-821. [ Google Scholar ] [ CrossRef ]
- Openshaw, S. مفاهیم و تکنیک ها در جغرافیای مدرن شماره 38: مسئله واحد مساحتی قابل تغییر . Geo Books: Norwich، UK، 1984. [ Google Scholar ]
- Wong, D. مسئله واحد منطقه ای قابل اصلاح (MAUP). In The SAGE Handbook of Spatial Analysis , 1st ed.; Fotheringham, AS, Rogerson, PA, Eds. SAGE: لندن، انگلستان، 2009; صص 105-124. [ Google Scholar ]
- حقایق جامعه FactFinder آمریکایی. در دسترس آنلاین: http://factfinder.census.gov/faces/nav/jsf/pages/community_facts.xhtml (در 26 مارس 2015 قابل دسترسی است).
- نظرسنجی جامعه آمریکایی در دسترس آنلاین: http://www.census.gov/acs/www/ (در 26 مارس 2015 قابل دسترسی است).
- هیل، آر. Chaney، PL نقشهبرداری آسیبپذیری اجتماعی برای خطرات زلزله در شهرستان سالت لیک، یوتا. Auburn Univ. J. Undergrad. دانش پژوه. 2013 ، 2 ، 48-53. [ Google Scholar ]
- متغیر SoVI 2006–10-30 | نقشه های ایالتی و منطقه ای در دسترس آنلاین: http://webra.cas.sc.edu/hvri/products/sovi2010_maps.aspx (در 26 مارس 2015 قابل دسترسی است).
© 2015 توسط نویسندگان; دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر