

خلاصه
با بهبود سریع تکنیکهای جمعآوری و پردازش دادههای مکانی، انواع پایگاههای اطلاعاتی جغرافیایی از سازمانهای دولتی یا خصوصی در دسترس قرار گرفتهاند. اغلب، یک مجموعه داده ممکن است در یک، اما نه همه جنبه ها، برتر از مجموعه داده های دیگر باشد. به عنوان مثال، در آلمان، سه داده اصلی شبکه جاده ای وجود داشت، یعنی. Tele Atlas (که اکنون “TOMTOM” است)، NAVTEQ (که اکنون “اینجا” است) و ATKIS. با این حال، هیچ یک از آنها برای هدف ناوبری چند وجهی (مثلاً رانندگی + پیاده روی) واجد شرایط نبودند: Tele Atlas و NAVTEQ از اطلاعات جامع مرتبط با مسیریابی تشکیل شدهاند، اما بسیاری از راههای عابر پیاده گم شدهاند. ATKIS مناطق عابر پیاده بیشتری را پوشش می دهد اما اشیاء جاده به طور کامل نسبت داده نمی شوند. برای برآوردن الزامات ناوبری چند وجهی، یک رویکرد خودکار برای ادغام شبکه های جاده های مختلف با هم پیشنهاد شده است که شامل پنج روال است: (الف) تطبیق شبکه جاده بین مجموعه داده ها. ب) شناسایی مسیرهای عابر پیاده. ج) تبدیل هندسی برای از بین بردن ناسازگاری هندسی. (د) بازسازی توپولوژیکی شبکه جاده ای در هم آمیخته. و (ه) بررسی و تصحیح خطا. رویکرد پیشنهادی عملکرد بالایی را در تعدادی از مناطق آزمایشی بزرگ نشان میدهد و بنابراین با موفقیت برای تولید دادههای دنیای واقعی در کل منطقه آلمان مورد استفاده قرار گرفته است. در نتیجه، شبکه جاده ای در هم آمیخته امکان ناوبری چند وجهی “رانندگی + پیاده روی” را فراهم می کند. ج) تبدیل هندسی برای از بین بردن ناسازگاری هندسی. (د) بازسازی توپولوژیکی شبکه جاده ای در هم آمیخته. و (ه) بررسی و تصحیح خطا. رویکرد پیشنهادی عملکرد بالایی را در تعدادی از مناطق آزمایشی بزرگ نشان میدهد و بنابراین با موفقیت برای تولید دادههای دنیای واقعی در کل منطقه آلمان مورد استفاده قرار گرفته است. در نتیجه، شبکه جاده ای در هم آمیخته امکان ناوبری چند وجهی “رانندگی + پیاده روی” را فراهم می کند. ج) تبدیل هندسی برای از بین بردن ناسازگاری هندسی. (د) بازسازی توپولوژیکی شبکه جاده ای در هم آمیخته. و (ه) بررسی و تصحیح خطا. رویکرد پیشنهادی عملکرد بالایی را در تعدادی از مناطق آزمایشی بزرگ نشان میدهد و بنابراین با موفقیت برای تولید دادههای دنیای واقعی در کل منطقه آلمان مورد استفاده قرار گرفته است. در نتیجه، شبکه جاده ای در هم آمیخته امکان ناوبری چند وجهی “رانندگی + پیاده روی” را فراهم می کند.
کلید واژه ها:
ترکیب داده ها ; راه های عابر پیاده ؛ ناوبری چند وجهی
1. معرفی
کلمه “conflation” از کلمه لاتین con flare به معنای “با هم ضربه بزنید” یک کلمه قانونی است که به طور سنتی برای توصیف ادغام دو نسخه خطی در نسخه ترکیبی سوم استفاده می شود. ترکیب داده ها، در محیط GIS، به ترکیب دو مجموعه داده مکانی برای تولید مجموعه داده سومی اشاره دارد که از هر یک از منابع مؤلفه «بهتر» است [ 1 ]. به طور کلی، ترکیب دادههای جغرافیایی یک فرآیند پیچیده است که ممکن است از کارهای طیف گستردهای از رشتهها استفاده کند که شامل GIS، نقشهبرداری، هندسه رایانه، نظریه گراف، پردازش تصویر، تشخیص الگو، و نظریه آماری میشود [2 ] .
در حال حاضر، بسیاری از تولیدکنندگان ناوبری، مانند اپل، گوگل، و بایدو (چین) شروع به رسیدگی به عابران پیاده برای خدمات ناوبری خود به جای رانندگان کردهاند، که میخواهند یک سیستم ناوبری همه نوع جادهها را ادغام کند (مانند راههای عابر پیاده و راههای موتور). اجازه دادن به یک مسیریابی معقول و کارآمد برای ناوبری چند وجهی [ 3 ، 4 ]. با این حال، با توجه به روشهای جمعآوری داده، Tele Atlas (که اکنون «TOMTOM» است) و NAVTEQ (که اکنون «اینجا» است)، بهعنوان شناختهشدهترین پایگاهداده با قابلیت مسیریابی در جهان، چندان واجد شرایط چنین اطلاعاتی نیستند. هنگامی که ما شروع به بررسی کارهای مربوطه برای ناوبری چند وجهی در سال 2011 کردیم. در Tele Atlas یا NAVTEQ، شبکه های جاده عمدتاً توسط تجهیزات پشتیبانی شده از GPS در اتومبیل ها ضبط می شدند .، جاده هایی که تردد وسایل نقلیه موتوری ممنوع است به ندرت تصرف می شوند. در حالی که دادههای ATKIS، از آژانس نقشهبرداری آلمان، از طریق دیجیتالی کردن نقشه در ترکیبی از استخراج شی نیمه خودکار از دادههای تصویر گرفته شد و در نتیجه مناطق عابر پیاده را بهطور گرد پوشش داد. از سوی دیگر، مجموعه داده ATKIS خود قادر به اهداف ناوبری نیست، اگرچه شامل راه های موتور و راه های عابر پیاده می شود، زیرا ویژگی های جاده به طور کامل با مقادیر پوشانده نشده بودند، به خصوص اطلاعات مربوط به مسیریابی به ندرت در این مجموعه داده در نظر گرفته می شد. به منظور ارائه پایه داده حتی ارضای الزامات ناوبری چند وجهی، به عنوان مثال، “رانندگی + پیاده روی”، شبکه های جاده های مختلف باید با هم ترکیب شوند. واضح است که نمیتوان به یک رویکرد دستی برای ترکیب مجموعههای دادههای جغرافیایی مختلف تکیه کرد، زیرا منطقه مورد نظر ممکن است در هر نقطه از جهان باشد و ترکیب دستی یک منطقه بزرگ (مثلاً کل آلمان) بسیار زمانبر و مستعد خطا است. بدین وسیله، این مقاله بر توسعه یک رویکرد تلفیقی خودکار برای ترکیب شبکههای جادهای مختلف NAVTEQ و ATKIS با هم تمرکز میکند. در نتیجه نهایی، شبکه جاده NAVTEQ به عنوان ستون فقرات عمل می کند و در نتیجه به عنوان “داده داده مرجع” نامگذاری می شود. به همین ترتیب، ATKIS راههای عابر پیاده اضافی را ارائه میکند و به عنوان «دادهداده ضمیمه» نامیده میشود. علیرغم پیشرفت های مداوم NAVTEQ و ATKIS در سال های اخیر،
2. کارهای مرتبط
دلیل ادغام مجموعههای دادههای جغرافیایی مختلف را میتوان به اواسط دهه 1980 در پروژهای که توسط سازمان زمینشناسی ایالات متحده (USGS) و اداره سرشماری برای ادغام نقشههای برداری دیجیتالی هر دو سازمان آغاز شد، برمیگردد [1 ] . تمرکز اولیه تلفیق حذف ناسازگاری هندسی بین مجموعه دادههای جغرافیایی فضایی ناهمگن بود. از آن زمان به بعد، بسیاری از ایده ها و فن آوری های جدید در این زمینه پرورش یافته است [ 5 ].
در دهه 1990، Gabay و Doytsher (1994) [ 6 ] روشی را برای تطبیق چند خطوط متناظر بین دو نقشه مختلف تعریف شده در مکان ها و ویژگی های توپولوژیکی مختلف ایجاد کردند. این روش می تواند به عنوان اولین مرحله برای ترکیب نقشه ها از چندین منبع در یک پایگاه داده یکنواخت بدون تضاد هندسی و/یا توپولوژیکی استفاده شود. بر اساس مجموعه شناسایی شده از موجودیت های تطبیق از نقشه های مختلف، گابای و دویتشر (1995) [ 7 ] یک رویکرد خودکار برای تصحیح و تنظیم چندخط ها از یک نقشه به منظور دقیق تر کردن مکان های آنها نسبت به نقشه دیگر ارائه کردند. والتر و فریچ (1999) [ 8] یک استراتژی تطبیقی با هدف تبادل متقابل ویژگیها بین دادههای ناوبری خودرو و دادههای نقشه توپوگرافی آلمانی ارائه کرد. برای دستیابی به نتیجه تطابق رضایت بخش، نویسندگان یک تبدیل افینی را برای حذف خطای کلی قبل از فرآیند تطبیق اجرا کردند.
از زمان ورود به قرن 21، کانگ (2001) [ 9 ] کار تحقیقاتی خود را در مورد ترکیب نقشه انجام شده توسط شهرستان دلاور اوهایو، ایالات متحده گزارش داد. با کمک این کار، مدیران در شهرستان دلاور با موفقیت 2000 بلوک مجموعه شهرستان را به روز کردند، آدرس های نادرست را تصحیح کردند و واحدهای مسکونی گمشده و مکان آنها را شناسایی کردند. این تحقیق به دولتهای محلی اجازه میدهد تا دادههای بستههای دقیق داخلی خود را با دادههای جمعیتی در سطح بلوک مرتبط کنند، که امکان تحلیلهای آماری، جامعهشناختی و فضایی بسیار جالب و پیچیده را در مورد الگوهای رشد و تغییر فراهم میکند. سپس ژانگ و منگ (2007) [ 10] رویکردی برای غنیسازی لایه جاده از مدل چشمانداز دیجیتال «Basis DLM» که توسط آژانسهای نقشهبرداری و نقشهبرداری آلمانی با شمارههای خانه ارجاعشده جغرافیایی آدرسهای پست نگهداری میشود، پیشنهاد کرد.
اخیراً، ژانگ و همکاران. (2012) [ 11 ] یک الگوریتم تطبیق نقطه به خط برای کدگذاری اطلاعات دقیق پل از پایگاه داده فهرست ملی پل به پایگاه داده جاده ای TIGER ایالات متحده ارائه کرد. نتایج ترکیبی به ایجاد یک شبکه جاده ای سه بعدی در ایالات متحده کمک کرده است. او (2013) [ 12 ] با انتزاع اطلاعات مورد نیاز از مجموعه داده های برداری چند منبعی با توجه به کاربردهای مختلف، بحث های مفصلی را در مورد چگونگی تنظیم چارچوب ترکیب داده های مکانی برداری بردار انجام داد. نتایج آزمایشهای تلفیقی نقشه احتمال نشان داد که الگوریتم و مدل ترکیبی پیشنهادی مؤثر بوده و دقت بالایی برای حفظ ویژگیهای اجسام در هم آمیخته دارد. در ژانگ و همکاران.(2014) [ 13 ]، یک رویکرد عمومی برای ادغام خودکار داده های پایگاه داده جاده توپوگرافی DLM De (گرفته شده توسط آژانس نقشه برداری آلمان) با اطلاعات تکمیلی مرتبط با مسیریابی از منبع داده دیگری از Tele Atlas ایجاد شده است. در این تحقیق، مفاهیم جدیدی برای نشان دادن «جفتهای تطبیق با یک رابطه 1:n/m» و «جفتهای تطبیق با یک رابطه شبه 1:1» تعریف شدهاند، که توسط یک فرآیند استانداردسازی برای تبادل ویژگی جامع بین موارد مختلف ضروری است. شبکه های جاده ای
کار در ادبیات علمی بدون شک راه را برای توسعه سیستم های جامع تر از ترکیب خودکار داده ها هموار کرده است. با این حال، با توجه به این واقعیت ها، تحقیقات بیشتر هنوز ضروری است:
اول، بسته به اهداف متنوع، فن آوری های ادغام را می توان به طور کلی به سه گروه دسته بندی کرد: ترکیب هندسی، ادغام معنایی، و ترکیب توپولوژیکی [ 14] .]. مشکل اختلاط هندسی به این صورت تعریف میشود که چگونه ویژگیها را برای کاهش اختلاف هندسی بین مجموعههای داده مختلف تغییر دهیم. ترکیب معنایی برای تبادل ویژگیهای معنایی بین اشیاء همولوگ مجموعه دادههای همتا استفاده میشود. اختلاط توپولوژیکی تکاملی از ترکیب هندسی است: نه تنها ویژگی های یک مجموعه داده را به دیگری تبدیل و منتقل می کند، بلکه توپولوژی ها را در صورت وجود اتصال، تغییر یا ناپدید شدن ویژگی ها مجدداً مرتب می کند. روشهای بهروز موجود عمدتاً بر ترکیب هندسی یا ترکیب معنایی متمرکز هستند. اختلاط توپولوژیکی به دلیل پیچیدگی و دشواری آن در حصول اطمینان از دقت فرآیند خودکار همچنان یک چالش باقی مانده است.
ثانیاً، اکثر تحقیقات قبلی در درجه اول استراتژی کلی و ایده های اساسی را برای کار ترکیب داده ها توصیف کرده اند [ 1 ، 5 ، 9 ]. رویکردهای بتن و همچنین نتایج تلفیقی خودکار آنها به ندرت مورد بحث و ارزیابی قرار می گیرند. بنابراین، اجرای مستقیم آثار گزارش شده برای تولید داده در دنیای واقعی به سختی امکان پذیر است.
سوم، به جای ارائه یک ترکیب کاملاً خودکار داده ها با نرخ تطبیق یا دقت 100٪، روال خودکار اغلب به یک نتیجه دقیق تا درصد معینی منجر می شود، به عنوان مثال، نتایج ترکیب خودکار داده ها باید پس از آن اصلاح شوند. بنابراین، یک فرآیند خودکار برای بررسی خطا برای کاهش نیروی انسانی برای پالایش نتایج اختلاط خودکار مطلوب است. در حوزه تلفیق داده ها، چنین فرآیندی به ندرت توسط ادبیات منتشر شده در نظر گرفته شده است، حتی اگر ضروری باشد، به خصوص زمانی که مجموعه داده های بزرگ باید پردازش شوند.
به این دلایل، این مقاله به توسعه یک رویکرد عمومی برای ترکیب توپولوژیکی دادههای بردار شبکه جادهای مختلف اختصاص دارد که با پردازش پس از تشخیص و تصحیح خطای هوشمند تقویت میشود. در نتیجه، رویکرد پیشنهادی قابلیتهای کاربردهای دنیای واقعی ادغام خودکار راههای عابر پیاده از مجموعه دادههای پیوست شده (مانند ATKIS) به مجموعه داده مرجع (مانند NAVTEQ) را در مناطق مختلف بزرگ نشان میدهد.
3. استراتژی
در سطحی بالاتر از ترکیب هندسی یا معنایی، اختلاط توپولوژیکی مجموعه دادههای جغرافیایی متنوع یک کار چالش برانگیز است زیرا (الف) مجموعه دادههایی که باید ترکیب شوند اغلب از پیشبینیهای متفاوتی استفاده میکنند و بنابراین دقت یا وضوح متفاوتی در برخی مناطق دارند. (ب) اشیاء جاده همولوگ بین مجموعه داده های مختلف انحرافات غیر سیستماتیک را نشان می دهند و هیچ مکانیسم خودکاری برای پیش بینی میزان انحرافات فردی وجود ندارد. (ج) یکی از مجموعه داده ها حاوی اطلاعات معنایی کمی با ارزش است، به عنوان مثال، ویژگی “نام خیابان” که برای محاسبه ترکیبی بسیار مهم است در مجموعه داده ATKIS موجود نبود. و (د) مجموعه دادههای مختلف به روشهای متفاوت و برای اهداف مختلف استفاده-مقصد جمعآوری شدهاند، که منجر به ساختارهای توپولوژیکی متمایز برای سازماندهی داده های مکانی می شود. با این وجود، اگر شرکتها بخواهند برنامههای کاربردی جدیدی راهاندازی کنند یا اطلاعات موجود را برای سودآوری بهتر سازماندهی مجدد کنند، امروزه با آن مواجه میشوند.15 ].
با در نظر گرفتن این شرایط، این مقاله یک رویکرد عمومی و قوی برای ترکیب خودکار شبکههای جادهای متنوع پیشنهاد میکند که شامل پنج فرآیند است که در شکل 1 نشان داده شده است: (1) تطبیق شبکه جاده بین مجموعه دادههای شرکتکننده. (ii) شناسایی مسیرهای عابر پیاده که باید ترکیب شوند (PWs-tbc) در مجموعه داده ضمیمه. (iii) تبدیل PWs-tbc برای از بین بردن ناسازگاری هندسی. (IV) بازسازی شبکه جاده ای در هم آمیخته. و (v) بررسی و تصحیح خطا. از بخش 3.1 تا بخش 3.5 ، پنج فرآیند به ترتیب معرفی خواهند شد.
3.1. تطبیق جاده-شبکه بین مجموعه داده های شرکت کننده
یک ادغام کامل و دقیق شبکه جاده ای مستلزم شناسایی اشیاء جاده مربوطه، یعنی تطبیق داده ها بین مجموعه داده های مختلف شرکت کننده است [ 16 ]. با توجه به ادبیات منتشر شده تاکنون، الگوریتم های مختلفی را می توان برای دستیابی به تطابق شبکه های جاده ای استفاده کرد [ 8 ، 17 ، 18]. در اینجا بافر در حال رشد (BG)، نزدیکترین نقطه تکراری (ICP) و امتداد مرزی (DSO) سه مورد از محبوب ترین و شناخته شده ترین الگوریتم های تطبیق هستند. با الگوریتم DSO، لبه های به هم پیوسته را می توان به راحتی کنار هم قرار داد تا یک سکته مغزی محدود ایجاد شود. سپس شبکه مربوطه به عنوان یک واحد جدایی ناپذیر در فرآیند تطبیق در نظر گرفته می شود که می تواند منجر به تطابق مبتنی بر شبکه شود. در مقایسه با تطبیق مبتنی بر خط یا نقطه، تطبیق مبتنی بر شبکه قادر است اطلاعات توپولوژیکی مرتبط با زمینه و سایر اطلاعات را راحتتر و کافیتر پیادهسازی کند – هر چه اطلاعات زمینه بیشتر در نظر گرفته شود، نتایج تطبیق بهتری خواهد داشت [19 ]]. در رویکرد پیشنهادی، الگوریتم DSO برای شناسایی جفتهای تطبیق جاده – شی بین مجموعه دادههای شرکتکننده NAVTEQ و ATKIS استفاده شده است.
قابل ذکر است که با کمک “مقوله ساختار” [ 20 ]، رویکرد تطبیق متنی DSO نه تنها می تواند جفت های تطبیق با m : nمتر:�( m ≥ 1، n ≥ 1، m، n ∈∈ N )، رابطه (مراجعه به شکل 2 a)، بلکه جفت های تطبیق با روابط متناظر معادل (رجوع کنید به شکل 2 b,c). با بهره گیری از نرخ تطابق بالا و دقت الگوریتم متنی DSO، اکنون اجازه می دهد تا مسیرهای عابر پیاده را به صورت خودکار از ATKIS (مجموعه داده ضمیمه شده) به NAVTEQ (داده داده مرجع) به دنبال فرآیندهای 3.2 تا 3.5 ترکیب کند.
3.2. شناسایی PWs-Tbc در ATKIS
ما شبکه جاده ای ATKIS را به عنوان نشان می دهیم ندبلیوA Tندبلیوآتی، و شبکه راه های NAVTEQ به عنوان ندبلیونآندبلیونآ. هدف این فرآیند شناسایی تمام راههای عابر پیاده است که هنوز در NAVTEQ ثبت نشدهاند اما در ATKIS وجود دارند، به عنوان مثال ، محاسبه مجموعه PWs-tbc (یعنی راههای عابر پیاده که باید با هم ترکیب شوند) تعریف شده توسط عبارت اسe t ( P دبلیواس − t c b ) ={P دبلیومن | پ دبلیومن ∈ ن دبلیوA T، پ دبلیومن ∉ N دبلیونآ}اسهتی (پدبلیواس – تیجب)= {پدبلیومن | پدبلیومن ∈ ندبلیوآتی، پدبلیومن ∉ ندبلیونآ}، جایی که پدبلیوپدبلیونشان دهنده “راه عابر پیاده” است.
پس از تطبیق خودکار داده ها، جاده به داخل اشیاء وارد می شود ندبلیوA Tندبلیوآتی(ATKIS) را می توان به دو گروه طبقه بندی کرد: (الف) همسان. و (ب) بی همتا. “همسان” می تواند نشان دهد که اشیاء جاده در داخل است ندبلیوA Tندبلیوآتی(ATKIS) با موفقیت همتایان خود را در ندبلیونآندبلیونآ(NAVTEQ) که شرط را می شکند پدبلیومن ∉ N دبلیونآپدبلیومن ∉ ندبلیونآ. بنابراین، فقط اشیاء منطبق با هم در ندبلیوA Tندبلیوآتیبه عنوان راههای بالقوه عابر پیاده برای ترکیب با مجموعه داده NAVTEQ (یعنی PWs-tbc بالقوه) در نظر گرفته میشود، نمونههایی از خط چین خاکستری را در شکل 3 ببینید .
با این حال، همه PWs-tbc بالقوه نباید با مجموعه داده NAVTEQ ترکیب شوند به این دلایل که: (الف) علیرغم پیشرفتهای ظاهری، رویکرد تطبیق استفاده شده هنوز نمیتواند تطبیق دادههای کاملاً خودکار بین مجموعههای داده مختلف را تضمین کند. نشان می دهد که برخی از اشیاء جاده ای در ATKIS و شرکای مربوطه آنها در NAVTEQ نمی توانند با هم تطبیق داده شوند، به عنوان مثال ، تعداد معینی از اشیاء بدون توجه به وجود همتایان آنها به عنوان “بی همتا” شناسایی می شوند. و (ب) در مجموعه داده ATKIS، چندین شی جاده در NAVTEQ همتای ندارند، اگرچه آنها مسیرهای عابر پیاده نیستند. واضح است که این جاده ها نیز به مجموعه PWs-tbc تعلق ندارند.
برای دستیابی به شناسایی دقیق تر PWs-tbc، اطلاعات معنایی را می توان برای حذف چندین شی جاده که به راه های عابر پیاده تعلق ندارند، در نظر گرفت.
3.3. تبدیل PWs-tbc برای از بین بردن ناسازگاری هندسی
PWs-tbc شناساییشده را نمیتوان مستقیماً برای ترکیب دادهها پیادهسازی کرد زیرا هندسههای آنها ممکن است در برخی موارد با شبکه جادهای مجموعه داده مرجع در تضاد باشد. به عنوان مثال، در شکل 3 مسیر عابر پیاده p 2 ← p 1 ′ از ATKIS باید به خیابان P 1 → P 2 در NAVTEQ متصل شود، اما در واقع آنها در اینجا جدا شده اند. و به جای تقاطع با یکدیگر، جاده p 3 ” ← p 4 ” جدا از جاده P 3 → P 4 قرار می گیرد.. چنین موردی نیاز به یک تبدیل تطبیقی برای هماهنگ کردن شکل و مکان PWs-tbc به شبکه جاده NAVTEQ دارد. این فرآیند تبدیل را می توان با دو مرحله مشخص کرد:
مرحله 1: ایجاد جفت نقطه کنترل
یک جفت نقطه کنترل (به اختصار CPP) از یک نقطه در یک مجموعه داده و یک نقطه متناظر در مجموعه داده دیگر تشکیل شده است. یافتن جفت نقاط کنترل مناسب گام مهمی در فرآیند تبدیل است زیرا تمام نقاط دیگر بر اساس آنها تراز می شوند (چن 2005). اساساً، بر اساس جفت های تطبیق شناسایی شده، جفت های نقطه کنترل را می توان با استفاده از درون یابی (مراجعه به مرحله 2) تولید کرد. مختصات متناظر شناسایی شده (نمونه فلش های سبز را در شکل 3 ببینید) در حافظه فیزیکی ذخیره می شوند و به عنوان جفت نقاط کنترل در مرحله بعدی «تراز بر اساس جفت نقاط کنترل» عمل می کنند. در اینجا، جفت نقطه کنترل توسط fromPoint در ATKIS (مجموعه داده ضمیمه) و toPoint در NAVTEQ (مجموعه داده مرجع) ساخته می شود که تمایل دارند همان موقعیت را در دنیای واقعی نشان دهند.
مرحله 2: تراز بر اساس جفت نقطه کنترل
تبدیل کلی PWs-tbc از ATKIS باید چندین محدودیت نقشهبرداری مانند حفظ جهت، موقعیت فضایی نسبی و تداوم بین اشیاء مجاور را برآورده کند. این بدان معناست که نقاط عطف PWs-tbc باید به درستی بر اساس جفتهای نقطه کنترل (CPPs) تراز شوند. با توجه به ویژگی های توپولوژیکی و ارتباط آنها با CPP ها، این نقاط عطف را می توان به سه گروه طبقه بندی کرد: (الف) نقاط عطف که به از نقاط CPP کپی می شوند. (ب) گذرگاههای جادهای (ظرفیت ≥3) یا بنبستها (ظرفیت = 1) که در fromPoint هیچ CPP کپی نشدهاند. و (ج) سایر نقاط شکل در امتداد PWs-tbc. دسته بندی های مختلف از روش های مختلفی برای تراز نقطه استفاده می کنند.
-
(الف) نقاط عطفی که به نقاط از CPP کپی می شوند
برای این نوع نقطه عطف، هم ترازی با جابجایی نقطه عطف بین جفت نقطه کنترل، به عنوان مثال، از نقطه A’ به A در شکل 3 انجام می شود . چنین همترازی تداوم توپولوژیکی را حفظ میکند و تضمین میکند که تبدیل میتواند اشیاء جادهای متصل را بین مجموعه دادههای متنوع به هم بچسباند.
-
(ب) گذرگاههای جادهای یا بنبستهایی که در fromPoint هیچ CPP کپی نشدهاند
جفت های نقطه کنترل ایجاد شده در مرحله 1 یک نقشه اعوجاج را برای کل منطقه تلفیقی تشکیل می دهند. به منظور تنظیم صحیح موقعیت تقاطع ها (والانس ≥ 3) و بن بست ها ( ظرفیت = 1) PWs-tbc که در fromPoint هیچ CPP کپی نشده اند، به عنوان مثال، گره های p 2 ” و p 4 ” در شکل 3 ، تبدیل محلی اعمال شده است، که از تقسیم فضایی کل منطقه تلفیقی به مناطق بسیار کوچکتر استفاده می کند و بنابراین می تواند اعوجاج های محلی را در هر منطقه بهتر کنترل کند.
در یک شبکه جاده، ساختار توپولوژیک خطی یک راه طبیعی برای تقسیم فضایی مجموعه داده ها، به عنوان مثال ، پارتیشن مبتنی بر مش [ 21 ] فراهم می کند. یک مش که صورت نیز نامیده می شود، می تواند به عنوان یک منطقه بسته در نظر گرفته شود که شامل هیچ منطقه دیگری نیست. مش ها، به عنوان مثال، { m e sساعتمن | i = 1 , 2 , 3 , … , 13 } {مترهسساعتمن | من=1، 2، 3، …، 13}بر اساس شبکه جاده ای NAVTEQ که در شکل 4 الف نشان داده شده است، مرزها را به صورت طبیعی تعریف کنید و همچنین مناطقی را تشکیل دهید که اجسام داخل زون ها را از خارج جدا می کند. با توجه به اینکه هدف این فرآیند تبدیل PWs-tbc از ATKIS است، مش های { m e sساعتمن | i = 1 , 2 , 3 , … , 13 } {مترهسساعتمن | من=1، 2، 3، …، 13}بر اساس NAVTEQ باید در اطراف CCP ها تحریف شود. در نتیجه، مجموعه ای از مش های جدید { مe sساعتمن ‘ | i = 1 , 2 , 3 , … , 13 } {مهسساعتمن ‘| من=1، 2، 3، …، 13}(نگاه کنید به شکل 4 ب) ایجاد خواهد شد که متناسب با هندسه مجموعه داده ATKIS باشد.
با هر مش تحریف شده (نمونه هایی را در شکل 4 ب ببینید)، CCP ها می توانند یک نقشه اعوجاج محلی ایجاد کنند، که بر تراز کردن نقاط داخل یا روی مرز این مش تأثیر می گذارد. اجازه دهید CPP را به عنوان بردار تعریف کنیم، جایی که پمن=(ایکسمن،Yمن)تیپمن=(ایکسمن،�من)تیfromPoint و است پمن‘ =(ایکسمن‘ ،Yمن‘ )تیپمن‘=(ایکسمن‘،�من‘)تینقطه پایان است. همسایه از پمنپمنبه عنوان مشخص می شود پمن ، جپمن،�. مفهوم “همسایه” را می توان با مثال در شکل 5 نشان داد ، جایی که نقطه پ2پ2دارای سه همسایه از {پ2 ، 1،پ2 ، 2،پ2 ، 3| پ2 ، 1=پ3،پ2 ، 2=پ1،پ2 ، 3=پ11}{پ2،1،پ2،2،پ2،3| پ2،1=پ3،پ2،2=پ1،پ2،3=پ11}; نقطه پ1پ1دو همسایه دارد پ1 ، 1=پ2پ1،1=پ2و پ1 ، 2=پ10پ1،2=پ10; و اشاره کنید پ11پ11فقط یک همسایه دارد پ2پ2.
بنابراین، با توجه به گذرگاه های جاده و یا بن بست پ0=(ایکس0،Y0)تیپ0=(ایکس0،�0)تیافتادن در داخل مش تحریف شده (نمونه چند ضلعی p 1 p 2 … p 10 p 1 در شکل 5 ، موقعیت جدید آن را ببینیدپ0‘ =(ایکس0‘ ،Y0‘ )تیپ0‘=(ایکس0‘،�0‘)تیدر مجموعه داده ترکیبی را می توان با رابطه (1) محاسبه کرد.
پ0‘ =پ0+∑i = 1n[∑j = 1متر(پمن ، ج–پمن)تی⋅ (پمن ، ج–پمن) ]α⋅[(پ0–پمن)تی⋅ (پ0–پمن) ]– β⋅ (پمن‘ –پمن)∑i = 1n[∑j = 1متر(پمن ، ج–پمن)تی⋅ (پمن ، ج–پمن) ]α⋅[(پ0–پمن)تی⋅ (پ0–پمن) ]– βپ0‘=پ0+∑من=1�[∑�=1متر(پمن،�–پمن)�⋅(پمن،�–پمن)]�⋅[(پ0–پمن)�⋅(پ0–پمن)]–�⋅(پمن‘–پمن)∑من=1�[∑�=1متر(پمن،�–پمن)�⋅(پمن،�–پمن)]�⋅[(پ0–پمن)�⋅(پ0–پمن)]–�
جایی که،
-
m – تعداد همسایگان p i ;
-
n – تعداد CPP ها.
-
α، β – دو ضریب تجربی بزرگتر از 0.
معادله (1) نشان می دهد که وقتی یک نقطه داده شده به یکی از رئوس مرجع کپی می شود، وزن این راس [ (پ0–پمن) ]تی⋅ (پ0–پمن)]– β[(پ0–پمن)]تی⋅(پ0–پمن)]–�به بی نهایت نزدیک می شود این نشان می دهد که تبدیل نقطه داده شده تنها با توجه به جابجایی خود راس محاسبه می شود که مطابق با تراز نقاط عطف در گروه (a) است و بنابراین می تواند یک مدل تبدیل متوالی را برای ما ارائه دهد.
در عمل، مجموعه CPP ها شامل نقاط بیشتری نسبت به آنهایی است که مش های بسته را تشکیل می دهند. معمولاً با لبههای باز یا لبههایی مواجه میشویم که مشها را به هم متصل میکنند، که نشان میدهد چندین محل عبور یا بنبست PWs-tbc میتواند خارج از تمام مشهای بسته باشد (نقطه p 0′ را در شکل 3 ببینید ) . برای چنین مواردی، مدل تبدیل محلی پیشنهادی یک بافر کاملاً تعریف شده در اطراف نقطه داده شده ایجاد می کند. سپس تمام CPP هایی که در این بافر قرار می گیرند برای تبدیل در نظر گرفته می شوند. با این حال، اگر CPP در داخل نباشد، نقطه موقعیت اولیه خود را پس از ادغام داده ها حفظ می کند.
به منظور افزایش کارایی محاسباتی، اگر انحراف هندسی کلی بین مجموعه دادههای مختلف به اندازه کافی کوچک باشد (مثلاً <3 متر) میتوان از همترازی گذرگاهها و بنبستها در این گروه چشمپوشی کرد.
-
(ج) سایر نقاط عطف PWs-tbc.
نقاط عطف این گروه عبارتند از: (1) نه گذرگاه های جاده ای و نه بن بست. و (ii) در fromPoint هیچ CPP کپی نشده است. به منظور حفظ جهت گیری اولیه و شکل PWs-tbc، این نقاط عطف بر اساس تبدیل های نقطه ای در گروه (a) و گروه (b) تراز می شوند. به عنوان مثال، PWs-tbc p 1 p 2 … p n – 1 p n توسط p 1 و p n محدود شده است ، که در آن پ1=(ایکس1،y1)تیپ1=(ایکس1،�1)تییک نقطه عطف در گروه (الف) با تبدیل است △تیص 1=( △ایکس1، △ y1)تی △تیپ1=(△ایکس1، △�1)تی و پn=(ایکسn،yn)تیپ�=(ایکسn،�n)تییک گذرگاه جاده ای در گروه (ب) با تغییر شکل است △تیp n=( △ایکسn، △ yn)تی△تیپ�=(△ایکس�، △��)تی. سپس، تبدیل نقطه عطف پمن ( 2 ≤ i ≤ n − 1 )پمن (2≤من≤�–1)را می توان با معادله (2) محاسبه کرد، جایی که △تیp i△تیپمننشان دهنده تبدیل نقطه عطف است پمنپمنو γ ضریب تجربی بین (0،1) است.
Δتیp i=( Δایکسمن، Δyمن)تی=Δتیp n⋅[(پمن–پ1)تی⋅ (پمن–پ1) ]γ+ Δتیص 1⋅[(پمن–پn)تی⋅ (پمن–پn) ]γ[(پمن–پ1)تی⋅ (پمن–پ1) ]γ+[(پمن–پn)تی⋅ (پمن–پn) ]γ( 2 ≤ i ≤ n − 1 )Δتیپمن=(Δایکسمن،Δ�من)تی=Δتیپ�⋅[(پمن–پ1)تی⋅(پمن–پ1)]�+Δتیپ1⋅[(پمن–پ�)تی⋅(پمن–پ�)]�[(پمن–پ1)تی⋅(پمن–پ1)]�+[(پمن–پ�)تی⋅(پمن–پ�)]�(2≤من≤�–1)
پس از تراز کردن تمام نقاط عطف در گروه (a)، (b) و (c)، PWs-tbc شکلها و موقعیتهای جدید خود را در شبکه جادهای بهم پیوسته خواهند داشت (شکل 6 ) .
3.4. بازسازی مجموعه داده ترکیبی
در مجموعه داده ترکیبی، PWs-tbc جدید الحاق شده و شبکه راه اولیه NAVTEQ باید از منظر توپولوژیکی و معنایی به خوبی سازماندهی شوند. برای نشان دادن این موضوع، چندین نمایش تغییر یافته در مجموعه داده تلفیقی در بخشهای فرعی زیر مورد بحث قرار میگیرند.
3.4.1. ایجاد تقاطع های جدید (گره ها)
پس از تبدیل هندسی تطبیقی، یک PW-tbc میتواند با موقعیت همزمان جدید در شبکه جادهای درهم تراز شود. از نظر توپولوژیکی، PW-tbc در صورتی که کاملاً از شبکه راه های اولیه NAVTEQ جدا باشد یا نقطه تماس آن با شبکه جاده NAVTEQ یک گره موجود باشد، هیچ ارتباطی با شبکه جاده های در هم آمیخته ندارد . 1 ← p 2 در شکل 6. با این حال، شرایط زمانی پیچیده تر می شود که PW-tbc یک شی جاده را از شبکه جاده NAVTEQ لمس کند و نقطه تماس نه از گره و نه به گره این شی باشد. در چنین مواردی، شبکه جادهای در هم آمیخته نیاز به تقاطعها (گرهها) جدید برای تنظیم مجدد توپولوژیهای شبکه جادهای درهم دارد. به عنوان مثال در شکل 6 ، ادغام PW-tbc p 1 ” → p 3 ” یک تقاطع جدید p 3 ” را ضروری می کند تا جسم P 5 → P 6 را به دو قسمت تقسیم کند، که اتصال بین PWs-tbc و ذخیره می شود. شبکه جاده از NAVTEQ.
3.4.2. تجزیه و انتقال اطلاعات معنایی
تجزیه و انتقال ویژگی ها از مجموعه داده مرجع به مجموعه جدید یک تابع مهم برای ترکیب نقشه است. این یک کار ساده برای اشیاء جاده ای بدون تغییر توپولوژیکی است زیرا این اشیاء منجر به انتقال ویژگی 1:1 می شود. با این حال، ممکن است برای کسانی که توسط تقاطعهای ایجاد شده جدید تقسیم شدهاند، مشکلاتی پیش بیاید، به عنوان مثال، در شکل 6 ، شی جاده P 5 → P 6 از شبکه راه اولیه NAVTEQ به دو شیء P 5 → p 3 ‘ و تقسیم شده است. p 3 ← P 6در مجموعه داده تلفیقی در این حالت ابتدا باید ویژگی اولیه شیء تجزیه شود و سپس به قسمت های تقسیم شده منتقل شود. ویژگیهای غیرمکانی شی اصلی، مانند نام خیابان، کلاس جاده عملکردی، شکل مسیر و غیره را میتوان مستقیماً به اشیاء ایجاد شده جدید نسبت داد، در حالی که ویژگیهای فضایی، مانند طول خیابان و زمان سفر، باید با استفاده از درونیابی نسبتاً به موارد جدید اختصاص داده شود.
3.4.3. مسائل مربوط به شناسه نهاد
در پایگاه داده جغرافیایی با قابلیت مسیریابی، هر موجودیت جغرافیایی باید یک شناسه (ID) منحصر به فرد داشته باشد تا آن را از همه موجودیت های جغرافیایی دیگر متمایز کند. به طور کلی، شناسه شی یا شناسه گره می تواند برای اهداف مسیریابی مورد توجه قرار گیرد.
برای اشیاء ترکیب شده، به عنوان مثال، p 1 ← p 2 ” و p 1 ← p 3 ” در شکل 6 ، باید شناسه های شی جدید را برای آنها اختصاص دهیم. در همین حال، شناسه گره P 4 در NAVTEQ به گره شیء p 1 ← p 2 ” (یعنی p 2 “) منتقل می شود. در حالی که شناسه گره های جدید توسط گره هایی مورد نیاز است که یا از ATKIS اولیه هستند (مثلاً p 1 ‘ در شکل 6 ) یا تقاطع های تازه ایجاد شده (مثلاً p 3 ‘ درشکل 6 ).
برای اشیاء بدون تغییر از مجموعه داده مرجع NAVTEQ، به عنوان مثال، P 4 → P 5 در شکل 6 ، ما همه شناسه های مربوط به شی جاده، از گره و به گره را نگه می داریم. با این حال، اگر یک شی جاده از مجموعه داده مرجع NAVTEQ پس از ادغام داده ها به قسمت های مختلف تقسیم شود (به عنوان مثال، P 5 → P 6 در شکل 6 )، سپس هر قسمت (به P 5 → p 3 ‘ و p 3 ‘ → مراجعه کنید. P 6 در شکل 6) باید یک شناسه شی جدید به آن اختصاص داده شود زیرا به عنوان یک شی جاده منفرد در مجموعه داده ترکیبی عمل می کند.
علاوه بر این، همه شناسههای شی اصلی باید رزرو شوند تا ارتباطات بین مجموعه داده ترکیبی نهایی و منابع حفظ شود.
3.5. تشخیص و تصحیح خطا
روال خودکار تعریف شده در بخش 3.1 تا بخش 3.4 ، به جای ارائه ادغام کامل داده های دقیق بین مجموعه داده های مختلف، اغلب به یک نتیجه دقیق تا درصد معینی منجر می شود، که نشان می دهد پس از ادغام خودکار داده ها، یک پس پردازش برای بهبود وضعیت ضروری است. کیفیت داده. بنابراین، بررسی و تصحیح خطا برای کمک به اپراتورها برای شناسایی و حذف/تصحیح راههای عابر پیاده که به اشتباه ترکیب شدهاند، مورد نیاز است. در مقایسه با شبکه راه های اولیه NAVTEQ، راه های عابر پیاده در هم آمیخته از ATKIS را می توان به چهار دسته طبقه بندی کرد:
دسته 1 : مسیرهای عابر پیاده در هم آمیخته تکراری.
در رویکرد پیشنهادی، راههای عابر پیاده ترکیبی، که با هم تداخل دارند یا بسیار نزدیک به جادهها از مجموعه داده مرجع قرار دارند، به عنوان موارد تکراری در نظر گرفته میشوند و میتوانند به طور خودکار از مجموعه دادههای ترکیبی حذف شوند.
دسته 2: تکرارهای جزئی.
شکل 7 یک نمونه بسیار معمولی از تکرار جزئی را نشان می دهد که می تواند توسط روال خودکار تصحیح شود: A → C (نگاه کنید به شکل 7 b) یک مسیر عابر پیاده در هم آمیخته است که در ابتدا از شبکه جاده ای ATKIS می آید (به A’ → C’ در نگاه کنید). شکل 7 الف) و A → B یک کلش جاده از مجموعه داده NAVTEQ است. از آنجایی که A → B هندسه های کاملاً متفاوتی را برای A’ → C’ نشان می دهد ، به عنوان مثال، A → B بسیار کوتاه تر از A’ → C’ است ، این دو جاده با روال خودکار با هم مطابقت ندارند، حتی اگر تا حدی با هم مطابقت داشته باشند. واقعیت با توجه به اینکه مسیر عابر پیاده A → Cو جاده A → B در نقطه A و زاویه قطع می شود∠ B A C∠بآسیبه اندازه کافی کوچک است، مسیر عابر پیاده A → C باید به طور خودکار به B → C در مجموعه داده ترکیبی نهایی تبدیل شود تا از تکرارهای جزئی جلوگیری شود ( شکل 7 ج را ببینید).
دسته 3: مسیرهای عابر پیاده درهم که احتمالاً اشتباه هستند.
ترکیب اشتباه احتمالی به مسیرهای عابر پیاده در هم آمیخته اشاره دارد که (i) نزدیک به جاده ها از مجموعه داده NAVTEQ قرار دارند. یا (ii) عبور از یک جاده از مجموعه داده NAVTEQ بدون هیچ تقاطع. یا (iii) با انتهای باز در هر دو گره از گره و گره مسیرهای عابر پیاده درهم و غیره .در رویکرد پیشنهادی، ابزارهای تعاملی برای مقابله با این راههای احتمالاً اشتباه عابر پیاده توسعه یافتهاند. در ابتدا، این ابزارها یک به یک بر روی مسیرهای عابر پیاده که احتمالاً اشتباه هستند تمرکز می کنند. سپس لیست تمام راه حل های ممکن برای آنها محاسبه می شود. بنابراین، کاری که اپراتورهای انسانی باید انجام دهند این است که بهترین راه حل را برای تصحیح خطا انتخاب کنند. به این ترتیب، فرآیندهای تعامل انسانی به طور قابل ملاحظه ای ساده می شود که منجر به افزایش کارایی کار می شود.
رده 4: راه های عابر پیاده قابل اعتماد.
مواردی که به رده (1) – (3) تعلق ندارند را می توان به عنوان ترکیبات قابل اعتماد در نظر گرفت که نتایج بسیار دقیقی را ارائه می دهد.
4. بحث در مورد نتایج تلفیق
همانطور که قبلا ذکر شد، مجموعه داده ATKIS بسیاری از مسیرهای عابر پیاده را پوشش می دهد که در NAVTEQ ثبت نشده بودند. به دنبال فرآیندهای تلفیقی تعریف شده در این مقاله، راههای عابر پیاده ATKIS که در NAVTEQ وجود ندارند را میتوان شناسایی، تغییر شکل داد، بازسازی کرد و سپس به شبکه جاده NAVTEQ اضافه کرد.
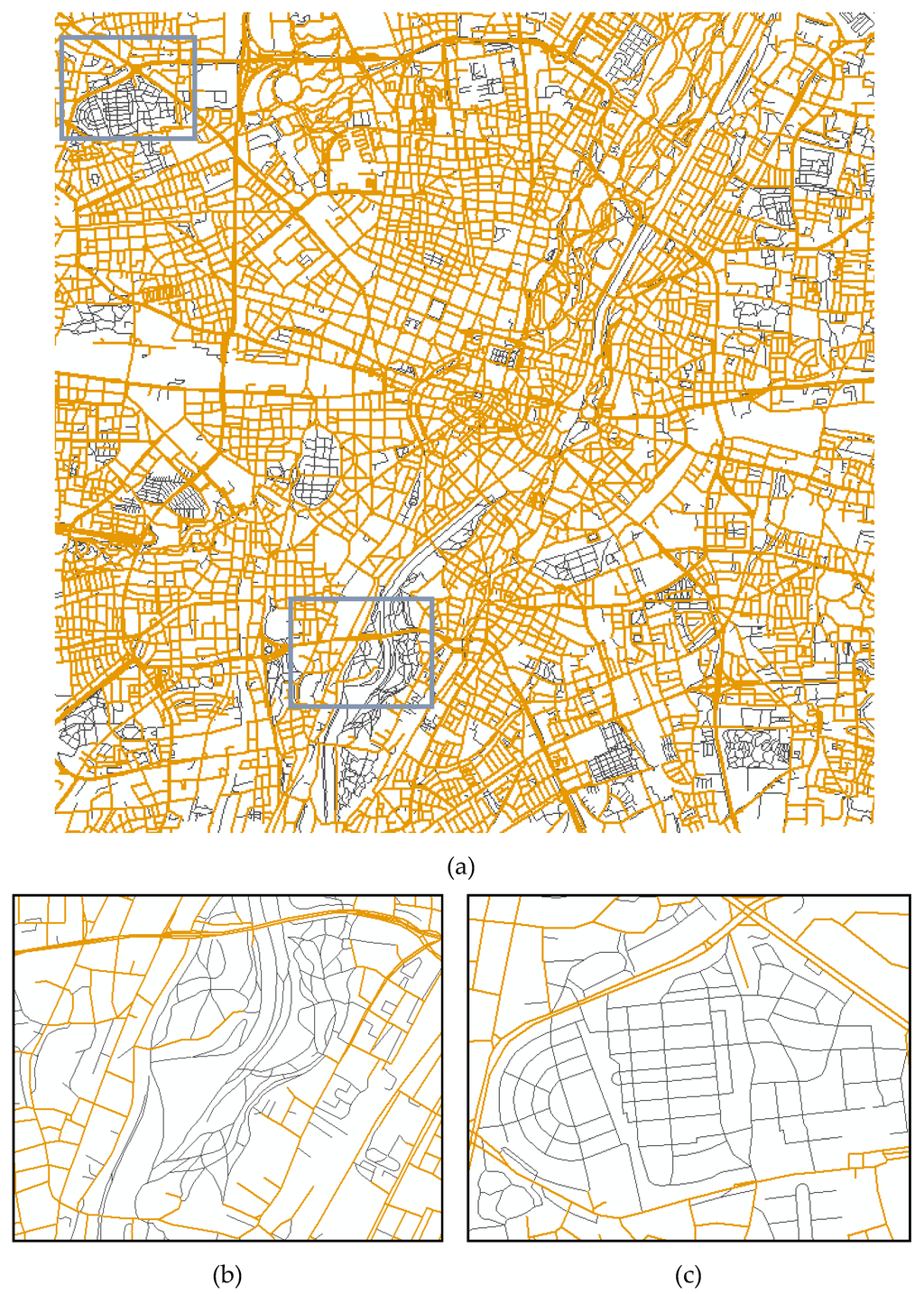
برای ارزیابی عملکرد رویکرد اختلاط خودکار، سه نمونه از NAVTEQ غنیشده با راههای عابر پیاده اضافی ATKIS به طور تصادفی در جمهوری فدرال آلمان انتخاب شدهاند. در اینجا، یکی در منطقه ساخته شده مونیخ، بقیه به ترتیب در منطقه روستایی گارمیش و حومه هامبورگ هستند. همانطور که در شکل 8 ، شکل 9 و شکل 10 نشان داده شده است، جاده های NAVTEQ اولیه و راه های عابر پیاده ضمیمه شده از ATKIS موقعیت و اتصال توپولوژیکی نسبتاً ثابتی در شبکه های جاده ای در هم آمیخته دارند، که برای محاسبات مسیریابی بسیار مهم است.
پس از مقایسه نتایج اختلاط خودکار با نتایج دستی تولید شده، عملکرد روش پیشنهادی با توجه به اندازهگیریهای سرعت محاسبات و صحت ارزیابی میشود. همانطور که در جدول 1 نشان داده شده است ، 20285 ویژگی NAVTEQ (مرجع) و 31112 ویژگی ATKIS وجود دارد. پس از ادغام خودکار، بیش از 10000 ویژگی ATKIS با موفقیت با مجموعه داده مرجع NAVTEQ ترکیب شده است، که در آن تنها 65 ویژگی به صورت نادرست یا غیرضروری ترکیب شده اند، به عنوان مثال، این رویکرد “صحت” خودکار رضایت بخش را در آزمایش های انجام شده نشان داد. در همین حال، چنین محاسباتی بسیار سریع است: برای انجام سه کار ترکیبی با مساحت کل حدود. 300 کیلومتر 2، در یک کامپیوتر شخصی معمولی (Intel Core i7 2.80 گیگاهرتز) فقط 39 ثانیه طول کشیده است.
بدیهی است که شبکه جادهای در هم آمیخته اکنون به ناوبری چند وجهی «رانندگی + پیادهروی» اجازه میدهد، زیرا (i) هم جادههای موتوری و هم راههای عابر پیاده را شامل میشود. (ii) جادههای موتوری به طور کامل با اطلاعات مربوط به مسیریابی از NAVTEQ نسبت داده میشوند. و (iii) جادههای الحاقی به بسیاری از ویژگیهای مرتبط با مسیریابی برای اهداف ناوبری نیاز ندارند زیرا به هر حال برای وسایل نقلیه موتوری ممنوع هستند. معمولاً سرعت متوسط سفر در مسیرهای عابر پیاده را می توان تقریباً 4 کیلومتر در ساعت تعیین کرد.
علاوه بر آزمایش های نشان داده شده در شکل 8 ، شکل 9 و شکل 10 ، رویکرد ترکیبی پیشنهادی قبلاً برای تولید داده های دنیای واقعی در بسیاری از مناطق بزرگ دیگر در آلمان استفاده شده است. نتایج تلفیقی کلی بسیار رضایت بخش است و در نتیجه توسط شرکت های GIS و ITS (سیستم حمل و نقل هوشمند) در آلمان و اتریش (به عنوان مثال، Alpstein، GeoCOM، Prisma، و غیره ) به عنوان “پایه داده” برای توسعه چند مورد استفاده قرار گرفته است. خدمات ناوبری معین
همانطور که شناخته شده است، دو دلیل وجود دارد که می تواند منجر به نقص در ترکیب خودکار داده ها شود – محدودیت های الگوریتم و ابهام داده ها. در زمینه ترکیب دادهها، «ابهام دادهها» به موقعیتهایی اشاره دارد که دادههای مجموعه دادههای مختلف با شرایط هندسی/توپولوژیکی مشخص میشوند که بسیار پیچیده و/یا متمایز هستند که حتی اپراتورهای انسانی باتجربه نیز برای شناسایی صحیح متناظر مشکل خواهند داشت. همتایان برای اختلاط های مناسب، به نمونه هایی در شکل 11 مراجعه کنید . در آزمایشهای ما، «ابهام دادهها» به عنوان محرک اولیه برای بسیاری از نتایج اختلاط نامطلوب تأیید شده است.
5. نتیجه گیری ها
در این تحقیق، نویسندگان یک رویکرد تلفیقی خودکار جاده-شبکه را به منظور انتقال مسیرهای عابر پیاده از ATKIS به NAVTEQ توسعه دادهاند. با وجود 99.79% صحت کلی و 99.35% صحت ترکیبی علیرغم پیچیدگی و ابهام داده ها، رویکرد ترکیب خودکار پیشنهادی بسیار موفق است. این ممکن است ناشی از (الف) عملکرد بالای الگوریتم تطبیق DSO به کار گرفته شده باشد. (ب) تبدیل سلسله مراتبی PW-tbc در دسته بندی های مختلف. و (ج) فرآیند تشخیص و تصحیح خطا. علاوه بر آزمایش های انجام شده، رویکرد تلفیقی پیشنهادی در کل آلمان با مساحت کل اجرا شده است. 360000 کیلومتر 2و بیش از 15388000 شی ATKIS و 6690000 شی NAVTEQ. در نتیجه، شبکه جادهای NAVTEQ توسط راههای عابر پیاده ضمیمه شده از ATKIS غنی شده است و بنابراین قابلیتهای لازم برای توسعه خدمات ناوبری چندوجهی را به دست آورده است که قبلاً در برخی از پلتفرمهای باز (مثلاً نقشههای گوگل) به قابلیتهای اساسی تبدیل شدهاند. . همین روش اکنون با داده های بسیاری از کشورهای اروپایی دیگر مانند اتریش، سوئیس، فرانسه، بلژیک، هلند، لوکزامبورگ، دانمارک، لهستان، جمهوری چک و غیره در حال آزمایش است .
همچنین ماهیت عمومی رویکرد ترکیبی پیشنهادی قابل ذکر است: میتواند با بدترین حالت کار کند – یک یا هر دو مجموعه دادهای که باید مطابقت داده شوند، اطلاعات معنایی ندارند یا اطلاعات معنایی کمی دارند، یعنی اصولاً نسبت به مقدار اطلاعات معنایی حساس نیست و بنابراین می توان به همان روش برای سایر مدل های داده شبکه جاده ای استفاده کرد. در واقع، رویکرد پیشنهادی قبلاً برای چندین برنامه تجاری برای دستیابی به ترکیب دادههای جامع در میان مجموعههای داده مختلف Tele Atlas، OpenStreetMap، Swiss Topo و غیره پیادهسازی شده است.با محیط های کاربردی مختلف نتایج آزمایش مربوطه در مطالعات بعدی ما گزارش خواهد شد. رویکرد پیشنهادی به جای یک نمونه اولیه تحقیقاتی قابل توجه، قابلیتهایی برای تبدیل شدن به یک محصول تجاری به دست آورده است.
منابع
- Saalfeld, A. Conflation: Automated map Compilation. بین المللی جی. جئوگر. Inf. سیستم 1988 ، 2 ، 217-228. [ Google Scholar ] [ CrossRef ]
- چن، سی.-سی. ادغام خودکار و دقیق دادههای بردار جاده، نقشههای خیابان و تصوّرهای راست. دکتری پایان نامه، دانشگاه کالیفرنیای جنوبی، لس آنجلس، کالیفرنیا، ایالات متحده آمریکا، 2005. [ Google Scholar ]
- لوزانو، آ. Storchi، G. کوتاه ترین هایپرمسی قابل دوام در شبکه های چندوجهی. ترانسپ Res. روش B. 2002 ، 36 ، 853-874. [ Google Scholar ] [ CrossRef ]
- لیو، ال. Meng, L. الگوریتم های برنامه ریزی مسیر چندوجهی بر اساس مفهوم نقطه سوئیچ. فتوگرام فرنرکوند. اطلاعات جغرافیایی 2009 ، 5 ، 431-444. [ Google Scholar ] [ CrossRef ]
- رویز، جی جی؛ آریزا، FJ; Ureña، MA; Blázquez، EB ترکیب نقشه دیجیتال: بررسی فرآیند و پیشنهادی برای طبقه بندی. بین المللی جی. جئوگر. Inf. علمی 2011 ، 25 ، 1439-1466. [ Google Scholar ] [ CrossRef ]
- گابای، ی. Doytsher, Y. تنظیم خودکار نقشه های خط. در مجموعه مقالات کنوانسیون سالانه GIS/LIS’94، فینیکس، آریزونا، ایالات متحده آمریکا، 25-27 اکتبر 1994. صص 333-341.
- گابای، ی. Doytsher, Y. تصحیح خودکار ویژگی در ادغام نقشه های خط. در مجموعه مقالات کنوانسیون سالانه ACSM-ASPRS 1995، شارلوت، کارولینای شمالی، 27 فوریه تا 2 مارس 1995. صص 404-410.
- والتر، وی. Fritsch، D. تطبیق مجموعه داده های مکانی: یک رویکرد آماری. بین المللی جی. جئوگر. Inf. علمی 1999 ، 13 ، 445-473. [ Google Scholar ] [ CrossRef ]
- کانگ، اچ. ادغام داده های مکانی: مطالعه موردی تلفیق نقشه با داده های اداره سرشماری و دولت محلی . دانشگاه ایالتی اوهایو: کلمبوس، OH، ایالات متحده آمریکا، 2001. [ Google Scholar ]
- ژانگ، ام. منگ، ال. یک رویکرد تطبیق جاده ای تکراری برای ادغام داده های پستی. محاسبه کنید. محیط زیست سیستم شهری 2007 ، 31 ، 598-616. [ Google Scholar ] [ CrossRef ]
- ژانگ، Q. گریفیتس، اس. ولرشیم، ام. Tighe، ML; Xu, C. ترکیب پایگاه داده موجودی پل ملی با بردارهای جاده مبتنی بر ببر. در مجموعه مقالات کنگره XXII ISPRS: ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences، ملبورن، استرالیا، 25 اوت تا 1 سپتامبر 2012.
- او، دی. مطالعه ای در مورد نظریه و روش ترکیب داده های برداری فضایی. Res. J. Appl. علمی مهندس تکنولوژی 2013 ، 5 ، 563-567. [ Google Scholar ]
- ژانگ، ام. یائو، دبلیو. Meng, L. غنی سازی پایگاه داده توپوگرافی جاده به منظور مسیریابی و ناوبری. بین المللی جی دیجیت. زمین 2014 ، 7 ، 411-431. [ Google Scholar ] [ CrossRef ]
- Casado، ML برخی از قیودهای ریاضی اساسی برای مسئله اختلاط هندسی. در مجموعه مقالات هفتمین سمپوزیوم بین المللی ارزیابی دقت فضایی در منابع طبیعی و علوم محیطی، لیسبون، پرتغال، 5-7 ژوئیه 2006.
- پدر و مادر، سی. Spaccapietra، S. یکپارچه سازی پایگاه داده: کلید تعامل پذیری داده ها، پیشرفت در مدل سازی داده های شی گرا . پاپازوگلو، نماینده مجلس، اسپکاکاپیترا، س.، تاری، ز.، ویرایش. انتشارات MIT: کمبریج، MA، ایالات متحده آمریکا، 2000. [ Google Scholar ]
- لی، ال. Goodchild، MF یک مدل بهینه سازی برای تطبیق ویژگی های خطی در ترکیب داده های جغرافیایی. بین المللی J. Image Data Fusion 2011 ، 2 ، 309-328. [ Google Scholar ] [ CrossRef ]
- ولز، اس. یک رویکرد تکراری برای تطبیق نمایش های متعدد داده های خیابانی. در مجموعه مقالات کارگاه ISPRS در مورد بازنمایی چندگانه و قابلیت همکاری داده های فضایی، هانوفر، آلمان، 22-24 فوریه 2006.
- یانگ، بی. ژانگ، ی. Luan، X. یک رویکرد آرامش احتمالی برای تطبیق شبکه های جاده ای. بین المللی جی. جئوگر. Inf. علمی 2013 ، 27 ، 319-338. [ Google Scholar ] [ CrossRef ]
- ژانگ، ام. منگ، ال. الگوریتم محوری سکته مغزی محدود – اصل کار و پیاده سازی برای تطبیق شبکه های جاده ای. جی. جئوگر. Inf. علمی 2008 ، 14 ، 44-53. [ Google Scholar ] [ CrossRef ]
- ژانگ، ام. منگ، ال. Bobrich, J. رویکرد تطبیق جاده-شبکه که توسط “ساختار” هدایت می شود. ان Geogr. Inf. سیستم 2010 ، 16 ، 165-176. [ Google Scholar ] [ CrossRef ]
- چن، جی. هو، ی. لی، ز. ژائو، آر. منگ، L. حذف انتخابی ویژگی های جاده بر اساس تراکم مش برای تعمیم خودکار نقشه. بین المللی جی. جئوگر. Inf. علمی 2009 ، 23 ، 1013-1032. [ Google Scholar ] [ CrossRef ]
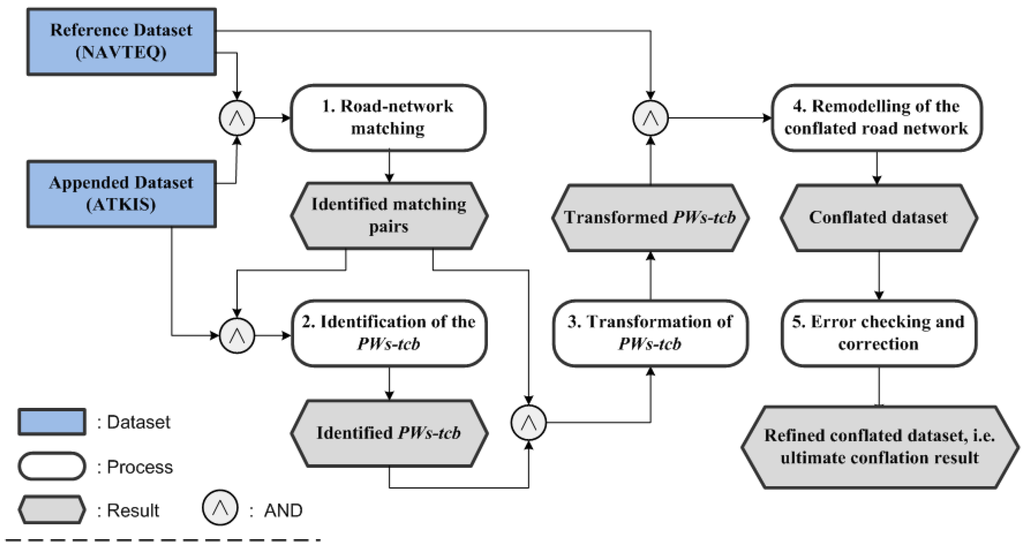
شکل 1. استراتژی برای دستیابی به ترکیب شبکه های جاده ای مختلف.

شکل 2. جفت های تطبیقی با روابط تطبیق متفاوت شناسایی شد: ( a ) m:n تطبیق; ( ب ) تطبیق معادل (خطوط موازی با خط منفرد). ( ج ) تطبیق معادل (چند ضلعی به نقطه). خطوط سیاه: شبکه جاده 1; خطوط قرمز: شبکه جاده ای 2; فلش سبز: پیوندها.

شکل 3. تطبیق بین NAVTEQ و ATKIS. خطوط نارنجی: NAVTEQ; خطوط خاکستری: ATKIS; خطوط چین: راه های عابر پیاده که باید با هم ترکیب شوند (PWs-tbc). فلش سبز: پیوندها.

شکل 4. پارتیشن فضایی بر اساس مش: ( الف ) مش های اولیه بر اساس NAVTEQ. و ( ب ) مش های تحریف شده که متناسب با هندسه ATKIS است. خطوط جامد نارنجی: NAVTEQ اولیه. خطوط خط تیره خاکستری: NAVTEQ تحریف شده؛ فلش سبز: پیوندها.
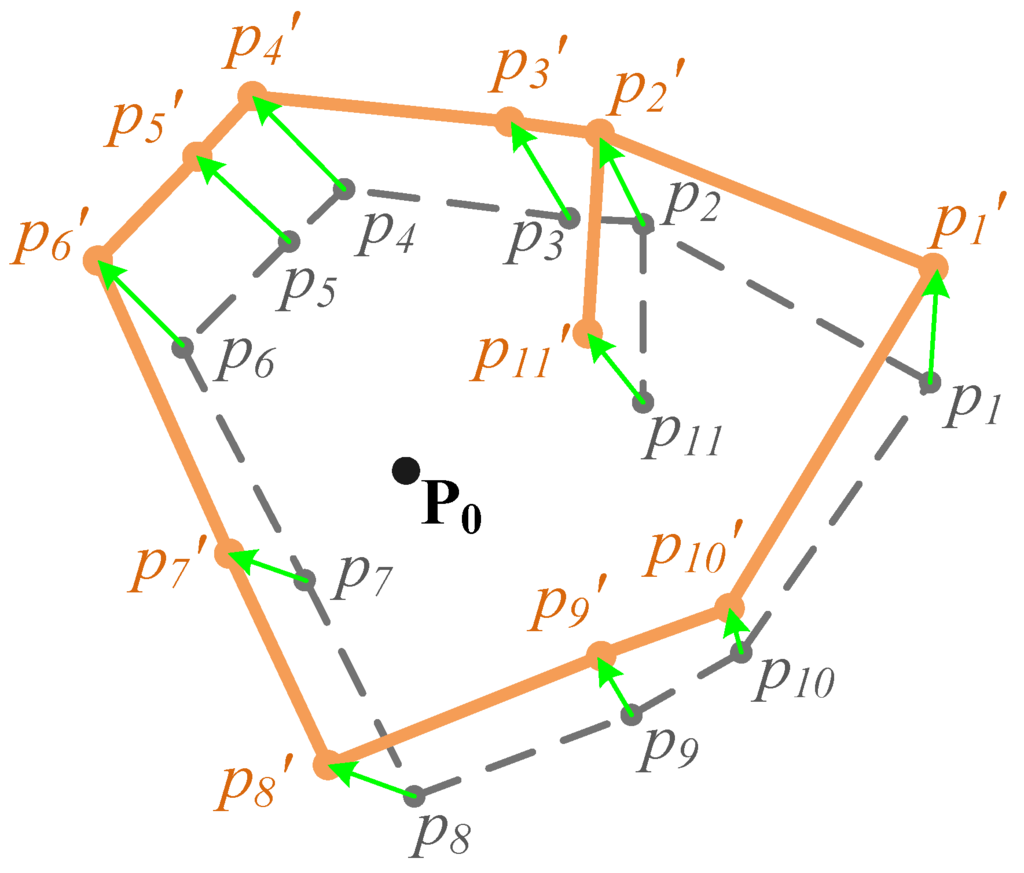
شکل 5. نقشه اعوجاج محلی بر اساس پارتیشن مش. خطوط جامد نارنجی: NAVTEQ اولیه. خطوط خط تیره خاکستری: NAVTEQ تحریف شده؛ فلش سبز: پیوندها.
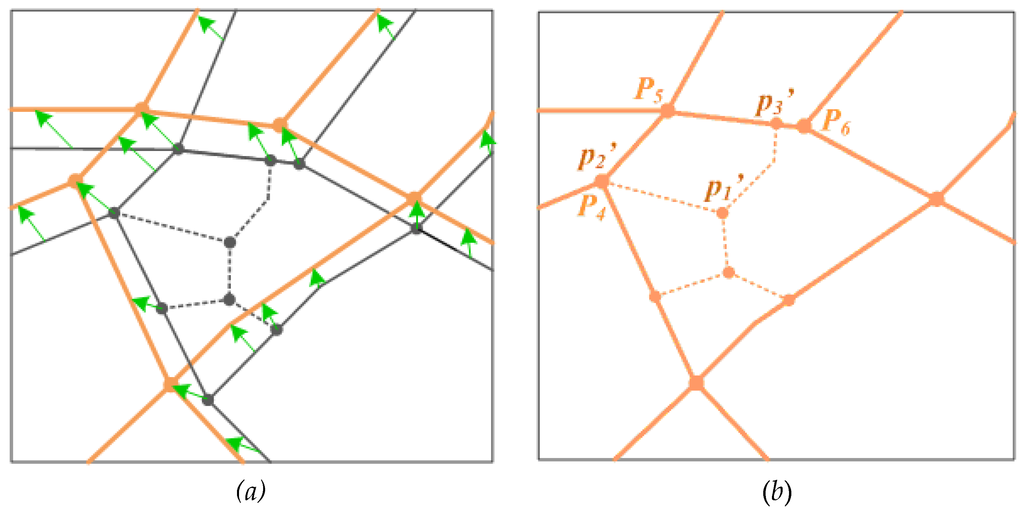
شکل 6. تبدیل PWs-tbc از یک شبکه جاده ای به شبکه دیگر: ( الف ) PWs-tbc قبل از تبدیل. ( ب ) PWs-tbc پس از تبدیل. خطوط نارنجی: NAVTEQ; خطوط خاکستری: ATKIS; خطوط چین: راه های عابر پیاده درهم. فلش سبز: پیوندها (جفت نقطه کنترل).

شکل 7. فرآیند حل مشکلات تکرارهای جزئی: ( الف ) تطبیق داده ها. ( ب ) ترکیب داده ها. ( ج ) تصحیح خطا. خطوط نارنجی: NAVTEQ; خطوط خاکستری: ATKIS; خطوط چین: راه های عابر پیاده درهم. خطوط چین: راه های عابر پیاده درهم. فلش سبز: پیوندها.
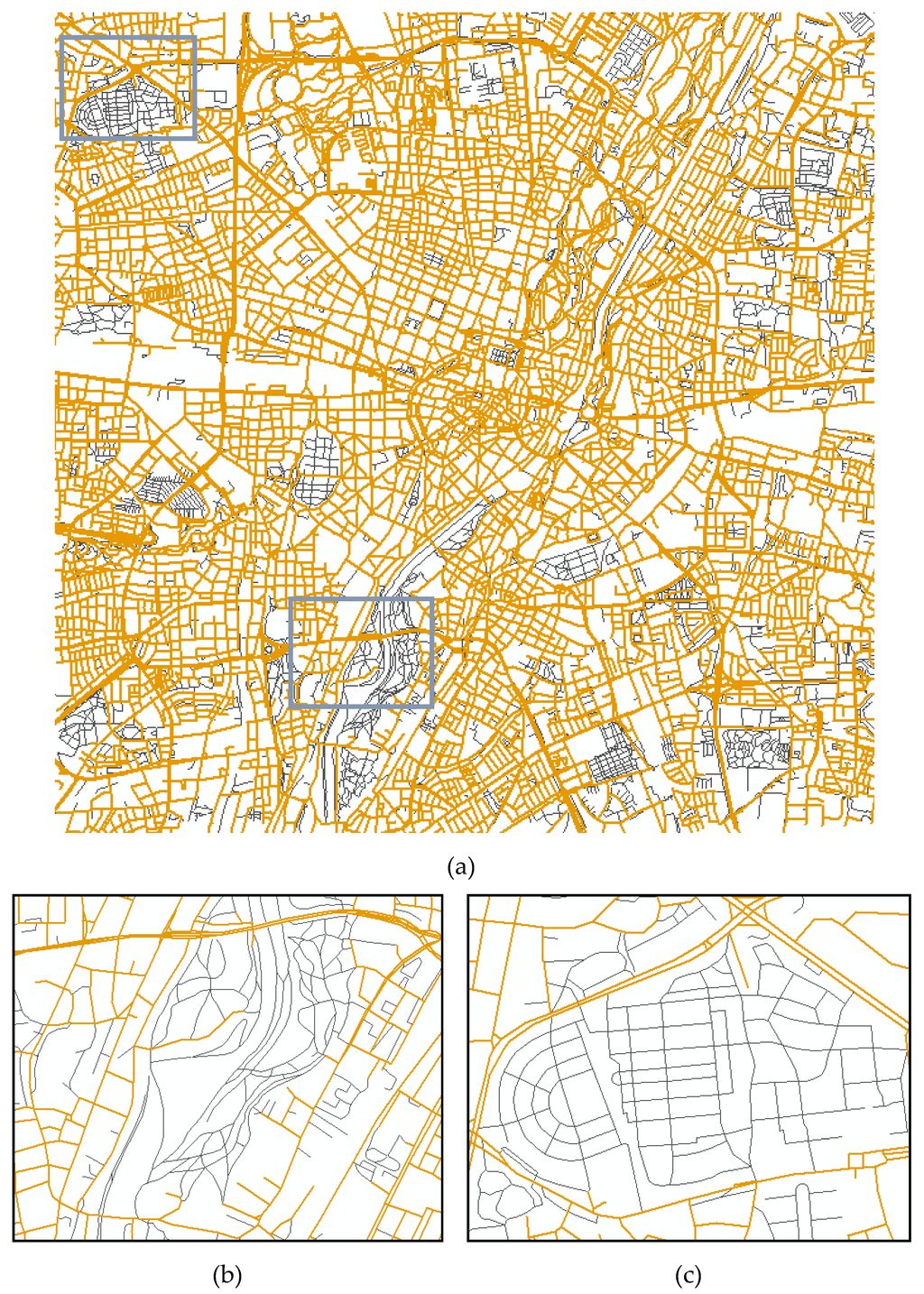
شکل 8. نمونه ای از شبکه جاده ای در هم آمیخته در یک منطقه ساخته شده: ( الف ) منطقه ای به ابعاد 10×10 کیلومتر مربع به طور تصادفی انتخاب شده در مونیخ، آلمان. ( ب ) نمای بزرگ شده جزئی (الف)؛ ( ج ) نمای بزرگ شده جزئی (الف). نارنجی: شبکه راه های اولیه NAVTEQ; خاکستری: جاده های آمیخته از ATKIS.
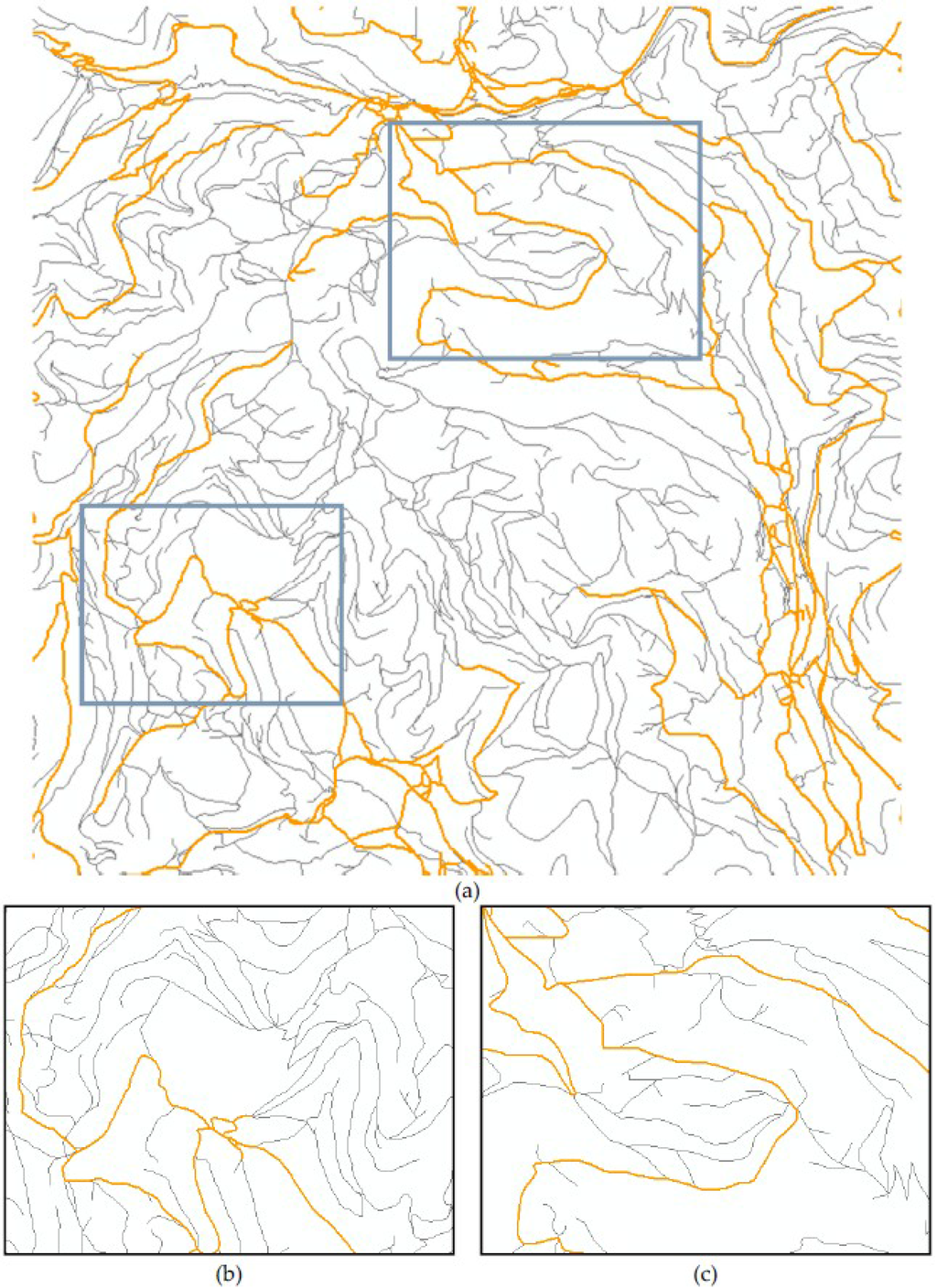
شکل 9. نمونه ای از شبکه جاده ای در هم آمیخته در یک منطقه روستایی: ( الف ) منطقه ای به ابعاد 7 × 7 کیلومتر مربع به طور تصادفی انتخاب شده در گارمیش، آلمان. ( ب ) نمای بزرگ شده جزئی (الف)؛ ( ج ) نمای بزرگ شده جزئی (الف). نارنجی: شبکه راه های اولیه NAVTEQ; خاکستری: جاده های آمیخته از ATKIS.
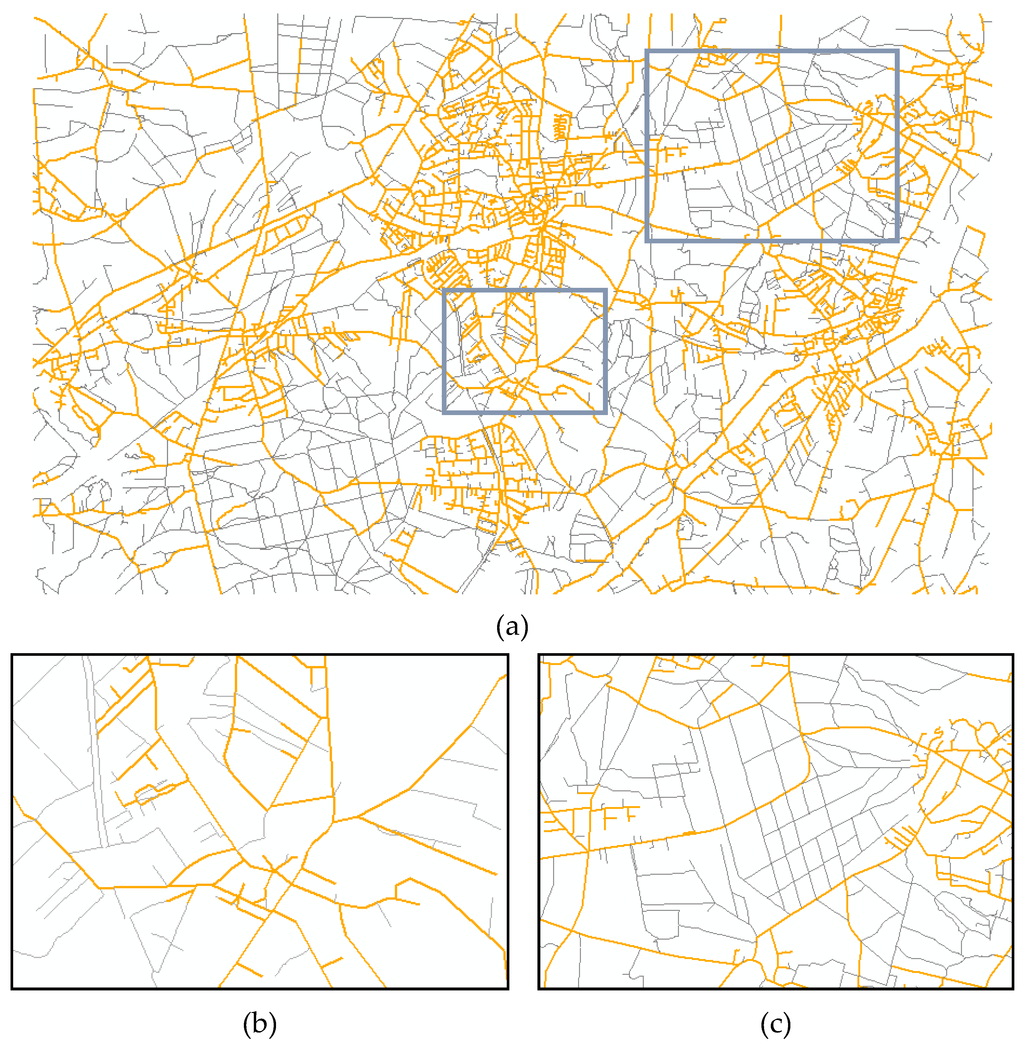
شکل 10. نمونه ای از شبکه جاده ای در هم آمیخته در یک منطقه حومه شهر: ( الف ) منطقه ای به ابعاد 15×10 کیلومتر مربع به طور تصادفی انتخاب شده در هامبورگ، آلمان. ( ب ) نمای بزرگ شده جزئی (الف)؛ ( ج ) نمای بزرگ شده جزئی (الف). نارنجی: شبکه راه های اولیه NAVTEQ; خاکستری: جاده های آمیخته از ATKIS.

شکل 11. نمونه هایی از “ابهام داده ها”: ( الف ) ناحیه ای که در آن شرایط هندسی/توپولوژیکی بسیار پیچیده است. ( ب ) ناحیه ای که در آن شرایط هندسی/توپولوژیک متمایز از یکدیگر هستند. خطوط قرمز: NAVTEQ; خطوط خاکستری: ATKIS.

جدول 1. نتایج آماری تراکم جاده-شبکه.
© 2016 توسط نویسندگان؛ دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (CC-BY) (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر