

چکیده
ما کاربرد تحلیل معنایی پنهان (LSA) را در ترکیب با سیستمهای توصیهگر ارائه میکنیم تا کشف در ژئوپورتالها را افزایش دهیم. به عنوان مبنایی برای کشف، ابرداده های داده ها و خدمات مکانی و همچنین منابع غیرمکانی مانند اسناد و مقالات علمی ایجاد و به صورت (نیمه) خودکار در کاتالوگ ژئوپورتال ثبت می شود. پیوندهایی که در خود داده ها ذاتی نیستند بر اساس شباهت معنایی محتوای متنی آن با استفاده از LSA ایجاد می شوند. این منجر به گذار از داده های بدون ساختار به اطلاعات ساخت یافته (فراداده) می شود که به عنوان پایه ای برای تولید دانش عمل می کند. اطلاعات فراداده در یک سیستم توصیه ادغام می شود که یک لیست رتبه بندی را ارائه می دهد که (1) آنچه سایر کاربران مشاهده کرده اند و (2) منابع مرتبط کشف شده توسط گردش کار LSA در نتیجه را نشان می دهد. بر اساس این فرض که متون مشابه دارای وجوه مشترکی هستند و کاربران احتمالاً به آنچه سایر کاربران مشاهده کردهاند علاقه مند هستند، توصیهها یک نتیجه جستجوی گستردهتر، اما همچنین دقیقتر ارائه میدهند. از یک طرف ، موتور توصیه کننده اطلاعات اضافی را در نظر می گیرد. از سوی دیگر، منابع را بر اساس تجربه کشف سایر کاربران و احتمال مرتبط بودن اسناد با یکدیگر رتبه بندی می کند. بلکه دقیق تر، نتیجه جستجو. از یک طرف ، موتور توصیه کننده اطلاعات اضافی را در نظر می گیرد. از سوی دیگر، منابع را بر اساس تجربه کشف سایر کاربران و احتمال مرتبط بودن اسناد با یکدیگر رتبه بندی می کند. بلکه دقیق تر، نتیجه جستجو. از یک طرف ، موتور توصیه کننده اطلاعات اضافی را در نظر می گیرد. از سوی دیگر، منابع را بر اساس تجربه کشف سایر کاربران و احتمال مرتبط بودن اسناد با یکدیگر رتبه بندی می کند.
کلید واژه ها:
تحلیل معنایی پنهان ; LSA ; توصیه کننده ; تطبیق ; شباهت
1. مقدمه
با ظهور دستگاه های هوشمند، محاسبات توزیع شده و سیار، و همچنین گسترش حوزه های کاربردی برای سیستم های اطلاعاتی، انتقال جامعه ما به یک جامعه اطلاعاتی مدت هاست کامل شده است. در سال 1997، IBM یک جامعه اطلاعاتی را به عنوان «جامعهای که با سطح بالایی از شدت اطلاعات در زندگی روزمره اکثر شهروندان، در اکثر سازمانها و محلهای کاری مشخص میشود» با قابلیت «انتقال، دریافت و تبادل سریع دادههای دیجیتال بین مکانها بدون در نظر گرفتن موقعیتها» پیشبینی کرد. فاصله» [ 1]. در جامعه ما، ایجاد، توزیع، دستکاری و تفسیر اطلاعات تا حد زیادی بر محیط های کاری و زندگی روزمره ما تأثیر می گذارد. نیازها و ایده های جدید منجر به توسعه سریع فناوری شده است که به ما کمک می کند تا سرعت، مقدار و دقت به دست آوردن آنچه که به خاک اقتصاد و زندگی ما تبدیل شده است را بهبود بخشیم: داده ها.
در این زمینه، یافتن دادههای مرتبط در آن جهان دیجیتالی گسترده و روزافزون که در سال 2011 بیش از 1.8 زتابایت (1.8 × 1012 گیگابایت) موجود در 500 کوادریلیون فایل بود، به یک چالش بزرگ تبدیل شده است [ 2 ] . اگرچه تأیید نشده است، اما استفاده گسترده در ادبیات، و همچنین انواع فنآوریهای جریان اصلی با استفاده از اطلاعات مکان، ثابت میکند که بیش از 80 درصد از کل دادهها دارای یک جزء فضایی هستند.
با این حال، این حجم زیاد داده تا زمانی که اطلاعات معنیداری از آن استخراج نشود، ارزش کمی دارد. همانطور که بلینگر [ 3 ] بیان میکند، دادهها به تنهایی «فقط یک نقطه بیمعنی در فضا و زمان هستند، بدون اشاره به فضا یا زمان». برای به دست آوردن اطلاعات از موجودیت های داده های مسطح، لازم است آنها را در بافت یا روابط قرار دهیم ( شکل 1 را رجوع کنید ). اگر نه تنها روابط بین داده ها شناسایی شود، بلکه الگوها نیز بتوانند استخراج شوند و به طور مستقل مجدداً اعمال شوند، دانش تولید می شود. این امر از یک سو منجر به افزایش پیچیدگی و همچنین افزایش درک از سوی دیگر می شود.

شکل 1. از داده تا دانش.
در نظر گرفتن ابزار تبدیل موثر داده ها به اطلاعات و دانش به عنوان مبنایی برای تصمیم گیری برای بهینه سازی استفاده از داده ها [ 4 ]، به دلیل افزایش سریع مقادیر داده های تولید شده توسط انسان و همچنین سیستم های خودکار، مانند حسگرها، تبدیل به طور موثر داده ها به اطلاعات امروزه به یک چالش بزرگ برای افراد و مشاغل تبدیل شده است. با این حال، مشکل تنها استخراج ارزش مفید از داده ها و اطلاعات نیست، بلکه یافتن قطعاتی از اطلاعات است که در وهله اول مرتبط به نظر می رسد [ 4 ]. برای چالش برانگیزتر کردن همه چیز، 70 درصد از کل داده ها در جهان دیجیتال ساختاری ندارند [ 5 ]] و اغلب بدون یک زمینه هنوز مهم که امکان کشف معنادار را فراهم می کند. مثالهایی برای چنین دادههای بدون ساختار عبارتند از ایمیلها، اسناد متنی، ارائهها، تصاویر، ویدئوها و هر داده دیگری که همراه با ابرداده ارائه نشده است، اما برای دادههای مکانی نیز صادق است.
بنابراین، رشد مقادیر دادههای بدون ساختار، مکانیسمها و الگوریتمهای جستجو را به چالش میکشد، که برای تخلیه کاربران در جستجوی اطلاعات مرتبط طراحی شدهاند. طبق نظر کروزیه [ 6 ]، اضافه بار اطلاعات، روشهای فیلتر متنی از دست رفته در استخرهای اطلاعات غیرمرتبط، و همچنین موتورهای جستجویی که فهرست نتایج مسطح را بر اساس جستارهای ساده کلیدواژه ایجاد میکنند، اثرات منفی بر کارایی و بهرهوری دارند.
در این زمینه، یک وظیفه مهم کاهش درصد داده های بدون ساختار با توسعه روش های جدید برای کشف است که چالش ساختاردهی موجودیت های داده های مسطح را برطرف می کند. به گفته کروزیه [ 6 ]، دو رویکرد متفاوت برای توسعه ظرفیت معنایی در سیستمهای اطلاعاتی وجود دارد: «اول، رویکرد پایین به بالا مشکلساز است، زیرا فرض میکند ابردادهها به هر بخش از محتوا اضافه میشود تا اطلاعات بیشتری در مورد آن درج شود. متن نوشته. […] دوم، رویکرد از بالا به پایین ممکن است موفقیت بیشتری برای بقیه داده ها داشته باشد، زیرا بر توسعه قابلیت های خودکار حاشیه نویسی متن مبتنی بر زبان طبیعی تمرکز دارد.
ما تطبیق متن معنایی را در ترکیب با توصیهها به عنوان راهحلی برای غلبه بر چالشها در کشف اطلاعات در حوزه زیرساختهای دادههای مکانی (SDI) در نظر میگیریم. در ساده ترین شکل، تطبیق متن معنایی به ارتباط دو نهاد یا متن می پردازد. در حالی که تطبیق متن معنایی برای اسناد حاوی متن به خوبی کار میکند، میتوان آن را برای ابردادههای ساختیافته نیز اعمال کرد، در نتیجه رویکردهای از پایین به بالا و از بالا به پایین کروزیه را مخلوط کرد [ 6 ]]، ضمن افزایش قابلیت های بازیابی اطلاعات از طریق استخراج اطلاعات و ترویج کشف دانش محتوای ساختاریافته. این تکنیکها نه تنها در فرآیندهای کشف فعال (“چه میخواهم بدانم؟”)، بلکه در فرآیندهای توصیه غیرفعال نیز استفاده میشوند (“بر اساس آنچه میخواهم بدانم، احتمالاً من نیز میخواهم بدانم که…”) . این امر با چالش عمده موتورهای جستجو که بر روی حجم وسیعی از داده ها کار می کنند، مواجه می شود، و اغلب انجام جستجو در مورد چیزهایی که هنوز از وجود آنها اطلاعی ندارند را برای کاربران دشوار می کند.
2. پورتال های فضایی
در بسیاری از محیطهای اطلاعاتی، مانند زیرساختهای دادههای مکانی (SDI)، به اصطلاح پورتالها به دروازههای مهمی بهعنوان نقاط واحد برای دسترسی به مجموعههای اطلاعاتی شرکتها، سازمانها یا سرمایهگذاریهای مشترک تبدیل شدهاند. پورتال وب سایتی است که به عنوان پل نهایی و مهمی عمل می کند که کاربران و محتوا را گرد هم می آورد [ 7 ]. این یک پلت فرم مرکزی برای کشف، انتشار، دسترسی و به اشتراک گذاری اطلاعات و دانش است [ 8 ]. در حالی که نمونه های رایج مانند گوگل یا بینگ نیز ممکن است به عنوان پورتال در نظر گرفته شوند، در حوزه جغرافیایی، اصطلاحات “پرتال فضایی” یا “ژئوپورتال” وجود داشت. بنابراین، یک ژئوپورتال واسطه اطلاعاتی بین منابع مکانی و کاربران بالقوه آنها است [ 8]. با این حال، عامل حیاتی برای سودمندی و پذیرش نهایی یک پورتال، تهیه منابع مرتبط است که بتوان آن را به صورت ساختاریافته و مستند جستجو کرد. در هر محیطی، پورتالی که منابع مستند کمی ارائه میکند یا بدون آن است، هیچ مزیتی از نظر بازیابی اطلاعات و استخراج دانش ارائه نمیکند [ 4 ].
SDIهای جدید از ابرداده های قابل خواندن توسط کامپیوتر و ساختار XML برای اهداف کشف استفاده می کنند. متادیتا – که اغلب از استانداردهای تایید شده پیروی می کند تا از قابلیت همکاری و مقایسه اطمینان حاصل شود – باید توسط صاحبان منابع به صورت دستی وارد شود. عناصر تا حدی از اطلاعات ساختاریافته تشکیل شده اند، اما برخی از عناصر، مانند چکیده ها یا اصل و نسب، متن آزاد بدون ساختار هستند [ 9 ]. خود سوابق فراداده در پایگاه داده های مرکزی یا توزیع شده نگهداری می شوند که به اصطلاح کاتالوگ ها را تشکیل می دهند [ 10 ]. به عنوان ثبت منابع، آنها به عنوان واسطه بین کاربران و ارائه دهندگان عمل می کنند. در یک مکانیسم اکتشاف اساسی، جستجوهای مبتنی بر کلیدواژه کاربران به صورت نحوی با کلمات موجود در فایلهای فراداده مطابقت داده میشوند [ 9 ]]. فقط ابردادههایی که دقیقاً حاوی کلمات کلیدی وارد شده توسط کاربر هستند بازگردانده میشوند. در کنار جستجوی مبتنی بر کلمه کلیدی، ابرهای برچسب، لیست های تکمیل خودکار محتوا، و همچنین فیلترهای مکانی (جعبه محدود) و زمانی بیشتر در رابط های جستجوی امروزی در SDI اعمال می شوند [ 11 ]. با این حال، روشهای جستجوی مبتنی بر کلمه کلیدی، چالشهایی را نشان میدهند که سعی میشود از طریق در نظر گرفتن اصطلاحنامهها، طبقهبندیها و هستیشناسیها برطرف شوند [ 12 ، 13 ]. در مقابل این رویکردها، ما از توصیههایی در ترکیب با روشهای تطبیق متن معنایی برای غلبه بر این چالشها استفاده میکنیم.
از آنجایی که یک ژئوپورتال باید نیازهای کاربران را برآورده کند، ما ساختار اساسی ژئوپورتال را برای پروژه FP7 اتحادیه اروپا EnerGEO (ر.ک. شکل 2 ) بر اساس پارادایم طراحی وظیفه محور، همانطور که توسط Scholz و Mittlböck [ 14 ] توضیح داده شد، ساختیم. بنابراین برای کاربردها و همچنین برای کشف با اصل “یک سوال-یک پاسخ” مطابقت دارد. این به این معنی است که استفاده از یک پورتال باید آسان باشد و اطلاعات معنادار و نه فقط داده های ساده را در اختیار کاربران قرار دهد. علاوه بر این، به عنوان نشان دهنده مفهوم تطبیق متن معنایی و توصیه های ارائه شده در این مقاله است.
شکل 2. ژئوپورتال EnerGEO.
در این زمینه، روشهای جستجو با ابزارهای تطبیق معنایی که به بهرهبرداری از مقادیر زیادی از دادههای بدون ساختار با آشکار ساختن ساختارهای معنایی [ 6 ] کمک میکنند و راه را از پورتالهای داده تطبیق کلمه کلیدی ساده به پورتالهای دانش زمینهای هدایت میکنند، تقویت شدند. روشهای جستجوی هوشمند، روابط پنهان بین ساختارهای معنایی با معنای مشابه را مطابقت داده و کشف میکنند و محتوای خام را با دادهها و منابع اطلاعاتی قابل اعتماد پیوند میدهند [ 6 ]. چنین «سرویسهای غنیسازی محتوا» [ 6 ] قادر به پیشنهاد کلمات کلیدی، استخراج موضوعات و موجودیتها و انجام سایر اشکال طبقهبندی خودکار، مانند تجزیه و تحلیل احساسات هستند.
3. روشهای تطبیق معنایی متن
به منظور ایجاد پیوند بین منابع در یک ژئوپورتال، الگوریتم های تشابه معنایی باید اعمال شود. در ادامه تنها زیرمجموعه کوچکی از رایج ترین و برجسته ترین روش های تطبیق معنایی متن در ادبیات ارائه و ارزیابی می شود. برای مرور کاملتر الگوریتمهای تطبیق متن معنایی، به اسلام و Inkpen و Mihalcea و همکاران مراجعه میکنیم. [ 15 ، 16 ].
3.1. بررسی اجمالی روش
مدل فضای برداری (VSM) یکی از ساده ترین روش ها برای محاسبه شباهت معنایی است. VSM به طور خودکار دانش را استخراج می کند و بنابراین، در مقایسه با سایر رویکردهای معنایی، مانند هستی شناسی، به کار دستی کمتری نیاز دارد [ 17 ]. VSM بر اساس تطابق دقیق عباراتی است که در اسناد یافت می شود. متن ها را برای اندازه گیری فواصل بین آنها به بردارهای n بعدی تبدیل می کند. به عنوان اندازه گیری فاصله، کسینوس زاویه بین دو بردار در بیشتر موارد استفاده می شود. نتیجه یک مقدار شباهت از 0 تا 1 است، که در آن 1 نشان دهنده تطابق دقیق/بالا بین عبارت ها و 0 نشان دهنده عدم وجود تطابق است. این بدان معناست که هر چه مقدار کسینوس بالاتر باشد، احتمال برابری دو جمله بیشتر است.
با این حال، این واقعیت که این روش صرفاً مبتنی بر تطابق دقیق کلمات است، مشکلاتی مانند مترادف و چند معنایی را ایجاد می کند. مترادف با کلمات مختلف با معنی یکسان سروکار دارد. به عنوان مثال، ماشین و خودرو مترادف هستند که در VSM برابر نیستند. این می تواند منجر به یادآوری ضعیف شود، به این معنی که همه منابع اطلاعاتی مرتبط کشف نمی شوند. چند معنایی به کلماتی اطلاق می شود که بیش از یک معنی متمایز داشته باشند. به عنوان مثال، اصطلاح «مدل» میتواند نمایشی مقیاسبندی شده از یک شی دنیای واقعی، شخصی که برای نمایش کالاهای لباس یا یک نوع طراحی از یک ماشین به کار میرود. این می تواند منجر به دقت ضعیف شود، به این معنی که “دقت” بازیابی برای کاربر کافی نیست، زیرا تعداد زیادی از نتایج جستجو را دریافت می کند که به سوالاتی که مطرح کرده مربوط نمی شود.
برای کاهش اشکالات VSM، دومایس و همکاران. [ 18 ] تجزیه و تحلیل معنایی پنهان (LSA)، یک روش مقایسه متنی آماری مبتنی بر پیکره را ارائه کرد. در سراسر ادبیات، گاهی اوقات به عنوان نمایه سازی معنایی پنهان (LSI) نیز شناخته می شود، که عمدتاً در زمینه بازیابی اطلاعات استفاده می شود، در حالی که LSA در سایر حوزه های کاربردی استفاده می شود [ 19 ]. فرآیند یادگیری کلماتی که به یکدیگر مرتبط هستند بر اساس همروی آماری آنها با هم در یک زمینه است [ 20 ].
LSA روشی برای تجزیه و تحلیل اسناد بدون نظارت است. بدون نظارت به این معنی است که هیچ ورودی مستقیم انسانی برای انجام تجزیه و تحلیل مورد نیاز نیست. Wiemer-Hastings [ 21 ] ادعا می کند که LSA حتی قادر به یادگیری کلمات با سرعتی مشابه انسان است. لاندوئر و همکاران [ 22 ] ثابت کرد که LSA قادر است سطح دانش دانش آموزان را با بررسی مقالات کوتاهی که آنها نوشته اند تخمین بزند. نتایج نشان می دهد که تفاوت کمی بین قضات انسانی و مدل وجود دارد. این به این واقعیت مربوط می شود که معنای متن را فقط می توان با کلمات حمل کرد [ 22]. بر خلاف انسان، LSA برای استخراج معنای اساسی ذخیره شده در اسناد نیازی به ترتیب کلمات یا نحو ندارد. اصل کلیدی LSA این است که از هیچ منبع ایجاد شده دستی مانند اصطلاحنامه یا فرهنگ لغت استفاده نمی کند. القای دانش در مورد معانی اسناد و کلمات تنها به مقادیر زیادی از متون بستگی دارد [ 23 ]. LSA فرض می کند که معنای یک متن را می توان به عنوان مجموع معنای کلمات آن استخراج کرد [ 24 ].
LSA از یک ماتریس سند مدت وزنی استفاده می کند که از مجموعه بزرگی از اسناد ایجاد می شود. برای اهداف وزن دهی یا تبدیل، می توان از چندین صورت فلکی استفاده کرد. اگرچه tf-idf (فرکانس معکوس فرکانس سند) و log-entropy رایج ترین روش ها هستند. به طور کلی. 20 ترکیب مختلف از طرح های وزن دهی محلی و جهانی وجود دارد [ 25 ]. در روش وزندهی tf-idf، عباراتی که کمتر اتفاق میافتند، برای منعکسکننده اهمیت نسبی آنها، وزن بالایی دارند [ 24 ]. استفاده از وزن لگ آنتروپی تأثیر کلماتی را که در طیف گسترده ای از زمینه ها رخ می دهند کاهش می دهد [ 21 ]. هدف از تحول، کشف روابط بین کلمات و استفاده از چنین روابطی برای توصیف اسناد است.
LSA از تجزیه ارزش واحد برای کاهش ابعاد استفاده می کند. در طول فشرده سازی، اطلاعات معنایی نهفته (~”پنهان”) در خود پیکره ضبط می شود. در مقابل VSM، مفاهیم را به جای کلمات استخراج می کند.
به طور خلاصه، LSA شامل چهار مرحله است: (1) ایجاد یک ماتریس سند اصطلاح از مجموعه متون، (2) استفاده از یک تبدیل (به عنوان مثال، tf-idf، log-انتروپی)، (3) کاهش ابعاد. با استفاده از تجزیه ارزش منفرد (SVD) و (4) بازیابی در فضای کاهش یافته توسط شباهت کسینوس.
اگرچه برای مجموعه های بزرگی از متون ایجاد شد، ترزی و همکاران. [ 26 ] LSA را یک معیار تشابه پیشرفته برای مقایسه متون کوتاه، مانند نظرات یا چکیدههای کاربر، در نظر میگیرند که هر دوی آنها را میتوان در ژئوپورتالها نیز یافت. با این حال ترزی و همکاران. [ 26 ] فکر می کنم که LSA در مورد بررسی های کوتاه تولید شده توسط کاربر در سیستم های توصیه کننده عملکرد ضعیفی دارد. از آنجایی که LSA از هیچ اطلاعات نحوی استفاده نمی کند، برای متون طولانی تر از چکیده های بسیار کوتاه که فقط از دو یا سه جمله تشکیل شده اند مناسب تر است [ 15 ]. این به ویژه برای اطلاعات پر سر و صدا و بدون ساختار که حاوی اشتباهات املایی است صادق است [ 26]. این نقص همچنین به این واقعیت مربوط می شود که ممکن است همزمانی کلمه در متون کوتاه نادر باشد [ 27 ]. برخلاف منابع مکانی، اسناد حاوی URL فایل یک نسخه چکیده کوتاه و همچنین متن کامل سند را ارائه می دهند. بنابراین، یک چالش این است که اطلاعات با طول های مختلف با استفاده از LSA در تحقیقات ما مقایسه می شود.
در کنار LSA، اطلاعات متقابل نقطهای در ترکیب با تکنیکهای بازیابی اطلاعات (PMI-IR) [ 28 ] یک روش تطبیق متن معنایی رایج است. این یک معیار نظارت نشده است که مبتنی بر تکرار همزمان کلمات است، مانند LSA [ 16 ]. از مجموعه بزرگی از داده های آماری جمع آوری شده توسط فرآیندهای بازیابی اطلاعات (IR) از وب استفاده می کند [ 16 ، 28 ].
علاوه بر LSA و PMI-IR، گابریلوویچ و مارکوویچ [ 29 ] تحلیل معنایی صریح (ESA) را به عنوان روشی برای تحلیل شباهت در متون پیشنهاد کردند. از ویکیپدیا به عنوان پایگاه دانش برای استخراج مجموعههای از پیش تعیینشده مفاهیم طبیعی استفاده میکند [ 29 ]. ESA برای هر متن یک بردار ویژگی ایجاد می کند. هر ویژگی مربوط به یک مقاله ویکی پدیا است. میزان ارتباط هر کلمه با کلمات استفاده شده در ویکی پدیا را تعیین می کند. ESA را می توان به عنوان “صریح” در نظر گرفت، زیرا از دسته بندی های خارجی که از ویکی پدیا می آیند استفاده می کند، برخلاف LSA که از موضوعات پنهان استفاده می کند [ 30 ]. گابریلوویچ و مارکوویچ [ 29 ] بیان می کنند که مزیت ESA این است که می تواند از “دانش انسانی رمزگذاری شده در ویکی پدیا” استفاده کند.
تخصیص دیریکله پنهان (LDA) [ 31 ] فرض می کند که هر سند ترکیبی از موضوعات پنهان است [ 20 ]. L’Huillier و همکاران. [ 32 ] بیان می کند که “[…] هر موضوع به عنوان توزیع احتمال بر روی مجموعه ای از کلمات نشان داده شده توسط واژگان و هر سند به عنوان توزیع احتمال بر روی مجموعه ای از موضوعات مدل سازی می شود.” همانطور که از این بیانیه مشاهده می شود، تمرکز LDA بر مدل سازی موضوع است تا معنای کلمات [ 20 ]. برخلاف LSA، LDA از یک پسزمینه احتمالی به جای SVD استفاده میکند [ 33 ]. بلی و همکاران [ 31] LDA را یک مدل ساده و بنابراین رقیبی برای LSA در آینده در نظر بگیرید.
رویکردهای جدیدتر روش های تطبیق متن معنایی شامل STASIS، STS و OMIOTIS است. STASIS [ 27 ] اطلاعات پایگاه داده واژگانی، WordNet را به منظور محاسبه شباهت بین متون [ 26 ] می گیرد. STS [ 15 ] از شباهت رشته در ترکیب با شباهت کلمه مبتنی بر پیکره در متون کوتاهتر استفاده می کند [ 26 ]. این یک نسخه اصلاح شده از الگوریتم تطبیق رشته طولانی ترین زیر دنباله مشترک (LCS) است [ 15 ]، که با یافتن طولانی ترین زیر دنباله مشترک از دو دنباله سر و کار دارد. تفاوت اصلی با سایر رویکردها این است که اسلام و اینکپن [ 15 ] بر شباهت بین دو جمله یا پاراگراف کوتاه تمرکز دارند، اما نه متون کامل. OMIOTIS [ 34] یک معیار کلمه به کلمه را گسترش می دهد تا بتواند با متون برخورد کند و پیوندهایی بین مفاهیم از WordNet برقرار کند [ 26 ]. برای اهداف وزن دهی، از طول مسیر معنایی، عمق گره در سلسله مراتب اصطلاحنامه و انواع یال های معنایی که مسیر را تشکیل می دهند استفاده می کند [ 35 ].
3.2. مقایسه روشهای تطبیق معنایی متن
در سرتاسر ادبیات، ما از هیچ گونه ارزیابی همه جانبه ای از همه روش های ارائه شده قبلی آگاه نیستیم. با این حال، چند مقاله علمی وجود دارد که برخی از این روش ها را در زمینه های خاص مقایسه می کند. به عنوان مثال، Ramage و همکاران. [ 36 ] توانایی یک روش فضای برداری n گرم مبتنی بر کلمه کلیدی و LSA را برای مدلسازی قضاوتهای انسانی ارزیابی کرد. مدل LSA با قضاوت های انسانی با همبستگی 0.6 مطابقت داشت [ 36 ]. PMI-IR، به عنوان یکی دیگر از اعضای تکنیک های مبتنی بر پیکره، تقریباً همان نتایج LSA را ایجاد می کند [ 16 ، 37 ]. در برخی موارد، مانند آزمون انگلیسی به عنوان یک زبان خارجی (TOEFL)، PMI-IR 10 درصد نتایج بهتری نسبت به LSA به دست آورد [ 28 ].]. با این حال، Turney [ 28 ] بیان می کند که این ممکن است به دلیل این واقعیت باشد که مقادیر متفاوتی از داده ها در تجزیه و تحلیل ها استفاده شده است. تسارونیس و همکاران [ 35 ] نشان داد که روش آنها، OMIOTIS، بهترین عملکرد را با مایکروسافت Paraphrase Corpus [ 38 ] داشت. OMIOTIS [ 34 ] در مقایسه با LSA، STASIS [ 27 ] و STS [ 15 ] بالاترین همبستگی اسپیرمن (0.8905 = p ) را داشت، با LSA دارای دومین همبستگی اسپیرمن ( 0.8714 = p ) در مقایسه با انسان [ 35 ].
Mohler و Mihalcea [ 39 ] کشف کردند که یک پیکره کوچک و دامنه خاص بهتر از یک مجموعه عمومی، مانند نمونه ای که از ویکی پدیا آمده است، عمل می کند. در آن صورت، LSA ( r = 0.4628) همبستگی پیرسون را بالاتر از ESA نشان می دهد ( r = 0.4385). بنابراین، برای LSA، کیفیت متون مهمتر از کمیت آنها است [ 39 ]. برای اطلاعات مربوط به دامنه، LSA بهتر از ESA عمل می کند، در حالی که ESA برای مجموعه های عمومی مناسب تر است [ 39 ]. Cimiano و همکاران [ 33 ] نشان داد که LSA بهتر از LDA عمل می کند، مهم نیست که LSA بر روی اسناد دامنه خاص یا یک منبع عمومی مانند ویکی پدیا آموزش دیده باشد.
از آنجایی که ما عمدتاً با اطلاعات مرتبط با انرژی در EnerGEO سروکار داریم، و تمام نتایج دیگری که در ادبیات کشف کردیم نشان داد که LSA در مقایسه با انسانها یکی از بهترین الگوریتمها است، ما LSA را به عنوان مناسبترین روش برای محاسبه شباهت معنایی متون انتخاب کردیم.
4. رویکردهای توصیه
فروشگاههای آنلاین، مانند Amazon.com، توصیههایی را در WWW ایجاد کردهاند تا «اقلام» مرتبطی را ارائه دهند، که ممکن است مشتریان آنها هنگام جستجوی یک کالای خاص به آن فکر نکرده باشند. خود توصیه ها بر اساس محاسبات تعاملات کاربر در فرآیندهای پس زمینه است. به طور کلی، یک موتور توصیه، آنچه را که سایر کاربران مشاهده کرده اند، خریداری کرده یا با «ردیابی» کلیک های کاربر رتبه بندی می کنند، در نظر می گیرد. در زمینه فروشگاه های آنلاین، “اقلام” کتاب یا سی دی هستند. در حوزه SDI، ما محتوای مکانی (بردار، شطرنجی و سرویس) و همچنین محتوای غیرمکانی مانند مقالات علمی یا گزارشهای پروژه را پیشنهاد میکنیم تا بخشی از یک موتور توصیهگر باشند و اطلاعاتی را برای پایان کاربران به منظور کمک به آنها در کسب دانش خود.
سیستم های توصیه گر از انواع مختلفی از الگوریتم ها برای محاسبه توصیه ها استفاده می کنند. برای مثال، رویکردهای فیلتر مشارکتی [ 40 ] از تعاملات قبلی کاربر با موارد برای ارائه توصیههایی به کاربر استفاده میکنند. آنها به مقدار زیادی اطلاعات و کاربران نیاز دارند تا بتوانند ترجیحات کاربر را در مقایسه با سایر کاربران پیش بینی کنند. فیلتر مبتنی بر محتوا [ 41 ] بر اساس جلسات قبلی یک کاربر و نمایه کاربر است. بنابراین، برای ارائه توصیه های مفید به تعداد کمتری از کاربران نیاز دارد.
برای ادغام موتورهای توصیه در ژئوپورتال ها، ما یک قیاس ایجاد کردیم تا مفاهیم مختلف را به هم مرتبط کنیم. شکل 3گردش کار یک تعامل معمولی کاربر در ژئوپورتال را نشان می دهد. کاربر یک جستجو را انجام می دهد، لیستی از نتایج را بازیابی می کند و با آنها تعامل دارد. بنابراین، وظیفه “یافتن” اطلاعات و نگاه کردن به یک نتیجه واحد در یک ژئوپورتال را می توان یک اقدام “نما” در نظر گرفت، در حالی که “استفاده از” یک منبع (مانند نگاهی به پیش نمایش) با یک “مشاهده” مرتبط است. اقدام خرید» در موتور توصیهگر. «رتبهبندی» هم در دنیای SDI و هم در فروشگاههای آنلاین وجود دارد. یکی دیگر از جنبههای مهم در سیستمهای توصیهگر، به اصطلاح قابلیت عقبنشینی است. این بدان معناست که اگر کاربر روی نتایج توصیه کلیک کند، این تعامل به موتور توصیهگر نیز ارسال میشود و نشان میدهد که توصیههای ارائه شده واقعا مفید بودهاند.

شکل 3. گردش کار پیشنهاد تعامل کاربر.
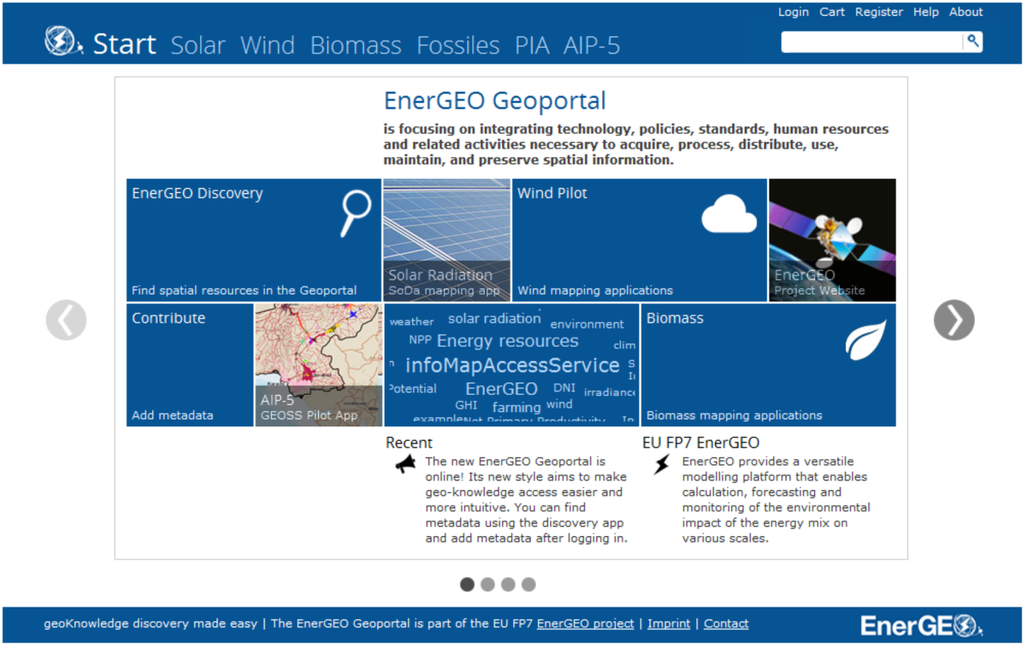
از آنجایی که با وضعیتی روبرو هستیم که دامنه فضایی و ژئوپورتالها به اندازه فروشگاههای آنلاین دارای تعداد کاربران نیستند، پیشنهاد میکنیم مفهوم توصیهها را بر اساس تعاملات کاربر با نتایج تطبیق متن معنایی به عنوان ورودی اضافی برای محاسبه توصیهها گسترش دهیم. بنابراین، معماری پیشنهادی شامل دو جزء متقابل برای ارائه توصیههای معنادار است: (1) “ردیابی” تعاملات کاربر در ژئوپورتال و (2) “تطبیق متن معنایی” (همچنین به شکل 4 مراجعه کنید ).
شکل 4. دو مؤلفه متقابل برای ارائه توصیه ها.
5. اجرا
ما مفاهیم یکپارچه سازی ابزارهای استخراج خودکار فراداده، الگوریتم های تطبیق متن معنایی و سیستم های توصیه گر را در ژئوپورتال EnerGEO پیاده سازی کردیم. ژئوپورتال EnerGEO یک پورتال فضایی است که حاوی منابع اطلاعاتی از حوزه انرژی است. بخش های اصلی سیستم پیشنهادی در زیر ارائه شده است.
5.1. چارچوب ژئوپورتال
یک ژئوپورتال به عنوان چارچوبی برای رویکرد یکپارچه سازی ابزارهای تطبیق متن معنایی و همچنین توصیه ها عمل می کند. یک مثال برای چنین چارچوبی، سرور جغرافیایی ESRI [ 42 ] است، یک پیادهسازی منبع باز از یک سرویس کاتالوگ با یک رابط کاربری بسیار قابل تنظیم. پورتال ESRI مدیریت منابع فضایی و غیر مکانی و همچنین مکانیسم های اکتشاف اساسی بر اساس شاخص لوسن را امکان پذیر می کند. با استفاده از چارچوب JavaServer Faces (JSF)، ژئوپورتال ESRI امکان ادغام مکانیسمهای کشف پیشرفته را با استفاده از جاوا اسکریپت فراهم میکند. طرحبندی سرور ژئوپورتال استاندارد را میتوان با استفاده از چارچوب Apache Struts Tiles تطبیق داد، جایی که یک صفحه برنامه وب به قطعاتی تقسیم میشود که در زمان اجرا در صفحه کامل مونتاژ میشوند [ 43 ]]. سرور ژئوپورتال مبنای تکنولوژیکی برای ژئوپورتال EnerGEO و افزونه های بعدی است که در این مقاله ارائه شده است.
5.2. ابزار استخراج متادیتا (نیمه) خودکار
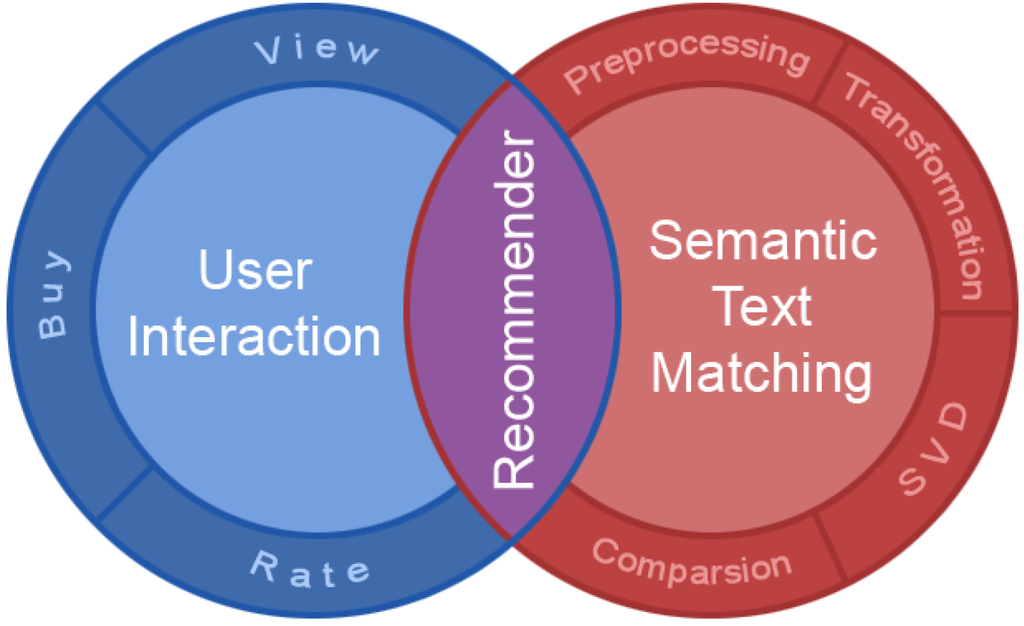
به عنوان مبنایی برای تطبیق شباهت معنایی متون، محتوای فراداده استاندارد و ساختاریافته مورد نیاز است. از آنجایی که کاربران در ژئوپورتالها معمولاً تمایل داشتند تنها چند مجموعه داده یا خدمات را وارد کنند، اگر مجبور بودند ورودیهای خود را به صورت دستی ایجاد کنند، یک ابزار استخراج ابرداده (نیمه) خودکار ایجاد شد. این ابزار اطلاعات مربوطه را نه تنها از منابع مکانی، بلکه از اسنادی مانند مقالات علمی استخراج می کند. بنابراین، داده های بدون ساختار را به عنوان مبنایی برای تولید دانش به محتوای ساختاریافته تبدیل می کند ( شکل 5 ).
شکل 5. دایره دانش.
ابزار فعلی به زبان برنامه نویسی پایتون نوشته شده است و استخراج اطلاعات از فرمت های اسناد قابل حمل (pdf)، اسناد Microsoft Word (doc، docx) و اسناد متنی (txt) را ممکن می سازد. برای پشتیبانی از اسناد pdf، از کتابخانه اضافی پایتون، gfx [ 44 ] استفاده می کنیم. برای سایر انواع اسناد، ما از ماژول های استاندارد پایتون به همراه win32com [ 45 ] استفاده می کنیم. اگر اسناد قبلاً با ابرداده (مانند نویسنده، چکیده یا تاریخ ایجاد) برچسب گذاری شده باشند، این اطلاعات استخراج شده و در یک سند XML استاندارد Dublin Core (DC) ادغام می شود.
برای منابع مکانی، از استانداردهای ابرداده زیر استفاده می شود: ISO 19110 (کاتالوگ ویژگی)، ISO 19115، ISO 19119 و ISO 19139. در حال حاضر، ابرداده از همه فرمت های داده های برداری و شطرنجی، و همچنین خدمات ESRI ArcGIS، به صورت خودکار قابل استخراج است. توسط ماژول ArcGIS Python، ArcPy. این بر اساس ابرداده مدیریت شده در ESRI ArcCatalog است. از جمله این پوشهها میتوان به پوشههایی اشاره کرد که حاوی Shapefiles، کلاسهای ویژگی (File Geodatabase، Personal Geodatabase)، کلاسهای ویژگی SDE، فایلهای GRID و TIFF هستند. این ابزار امکان کسر خودکار جعبههای محدود، فهرستهای ویژگی ویژگیها (ISO 19110)، پیوند خودکار اسناد ISO 19115 و ISO 19110، خلاصهها (در صورت وجود در توضیحات مورد ArcGIS)، کلمات کلیدی (در صورت وجود) و مسیر یا پیوند به مجموعه داده یا سرویس فضایی واقعی.
پس از استخراج فراداده، اطلاعات ساختاریافته به طور خودکار در ژئوپورتال ثبت می شود (همچنین به شکل 6 مراجعه کنید ). ما از رابط استاندارد OGC CSW (Catalogue Service Web 2.0.2) برای آپلود/ثبت خودکار اطلاعات استفاده می کنیم. کل فرآیند بهعنوان نیمه خودکار در نظر گرفته میشود، زیرا نمیتواند تمام اطلاعاتی را که برای اجرای استانداردهای ISO و همچنین نمایه فراداده کامل EnerGEO بهطور خودکار مورد نیاز است، استخراج کند. در مورد اطلاعات با کیفیت، کاربر باید داده ها را به صورت دستی وارد کند. در مورد اطلاعات متنی غیر مکانی، برخی از محتواها (مثلاً اصطلاحات) ممکن است با مشاهده فراوانی کلمات در ترکیب با فرهنگ لغات کلمات رایج استخراج شوند. در ابزار استخراج ابرداده ژئوپورتال EnerGEO، ماژول پایتون، Topia Termextract [46 ]، بنابراین استفاده می شود.

شکل 6. گردش کار استخراج ابرداده (نیمه) خودکار.
قرار دادن منابع در قالب های استاندارد شده مزایای زیادی را ارائه می دهد. از یک طرف، محتوا را شفاف و قابل تعویض بین مجموعه های مختلف ابرداده می کند. از سوی دیگر، بخش هایی را ارائه می دهد که می توانند با یکدیگر مقایسه شوند. به عنوان مثال، چکیده اسناد را می توان با چکیده منابع مکانی یا اطلاعات کیفیت داده یک مورد با همان نوع اطلاعات مورد دیگر مطابقت داد. این می تواند برای پیوند دادن منابع مختلف استفاده شود.
5.3. ابزار تطبیق متن معنایی
برای ابزار نرم افزار تطبیق متن معنایی، ما از ماژول های پایتون gensim و simserver [ 47 ] استفاده می کنیم. دلیل انتخاب این دو ماژول عمدتاً به دلیل عملکرد رویکرد است. بیشتر محاسبات در RAM کامپیوتر انجام می شود. [ 48 ] بیان می کند که ایجاد مدل LSA برای ویکی پدیای انگلیسی کامل تقریباً چهار ساعت در مک بوک پرو (Intel Core i7 2.3 گیگاهرتز، 16 گیگابایت رم DDR3، OS X) طول کشید. بنابراین، gensim قادر است حدود 16000 سند در دقیقه (شامل تمام ورودی/خروجی) را پردازش کند [ 48 ]. شکل 7اجرای کلی روش تطبیق متن شباهت معنایی را نشان می دهد. با مجموعه ای از اسناد (به اصطلاح پیکره) شروع می شود که باید به یک نمایش برداری تبدیل شوند. اسناد هم شامل اطلاعات ساختاری (مثلاً ابرداده های مکانی برای سرویس های وب) و هم اطلاعات غیرساختار یافته (مثلاً مقالات علمی) می شوند. در کار ما، فرآیندهای بعدی که باید اعمال شوند برای همه نوع اطلاعات یکسان هستند.

شکل 7. گردش کار تطبیق شباهت معنایی متون.
قبل از این، فرآیندی به نام توکن سازی مورد نیاز است. این بدان معنی است که یک متن کامل به کلمات واحد یا مفاهیم معنی دار تقسیم می شود. همچنین برای حذف کلمات متداول مانند مقالات یا حروف اضافه با استفاده از لیستی از کلمات توقف مفید است. خود بردار از طریق تکنیک های مختلف ایجاد می شود. یکی از ساده ترین آنها روش به اصطلاح “کیف کلمات” است. از جفت پرسش و پاسخ تشکیل شده است. به عنوان مثال، سؤال: “کلمه … چند بار در سند ظاهر می شود؟” می توان با “دو بار” پاسخ داد. پس از آن، به هر کلمه یک شناسه و همچنین شمارش اختصاص داده می شود. می توان فرض کرد که اگر اعداد در دو بردار مشابه باشند، اسناد نیز احتمالاً مشابه هستند، زیرا سؤالات برای هر مدرک یکسان است.
نتیجه مرحله قبل یک فضای برداری n بعدی است. برای انتقال یک بردار به بردار دیگر، تبدیلی مانند tf-idf یا log-entropy باید اعمال شود. بر اساس مقدار اسناد در نظر گرفته شده برای محاسبه، از tf-idf یا log-entropy توسط ابزار استفاده می شود. همانطور که قبلاً بیان شد، هدف از تبدیل، کشف روابط معنایی بین کلمات و استفاده از آنها برای توصیف اسناد است. تبدیل گاهی اوقات به عنوان “آموزش اسناد” نیز شناخته می شود. برای اهداف آموزشی، می توان از اسنادی که نیاز به مقایسه با یکدیگر دارند یا مجموعه ای از اسناد رایج که مثلاً از ویکی پدیا آمده است استفاده کرد. در محدوده این کار، فقط از مدارک ثبت شده در ژئوپورتال برای آموزش استفاده شد. این به این دلیل است که منابع مورد استفاده محدود به حوزه انرژی است،33 ].
تجزیه مقدار منفرد (SVD) پس از آن فضای برداری n بعدی را به ابعاد کمتر کاهش می دهد. این امر برای کشف ساختار معنایی اسناد با بررسی الگوهای آماری همروی کلمات، در مجموعهای از اسناد آموزشی ضروری است [ 47 ]. این منجر به افتادن اصطلاحات مشابه در یک بعد می شود. به عنوان آخرین مرحله قبل از اعمال معیار تشابه کسینوس، اسنادی که از کاتالوگ می آیند نمایه می شوند. در نهایت، مقدار تشابه کسینوس نشان میدهد که آیا تطابق دقیق/بالا (1) بین دو بردار وجود دارد یا اصلاً مطابقت (0) وجود دارد، با درجات احتمالی در بین.
5.4. سیستم توصیه کننده
به عنوان یک سیستم توصیهکننده، ما محصول نرمافزار منبع باز، easyrec [ 49 ] را پیادهسازی کردیم. Easyrec مانند سرور جئوپورتال ESRI یک سرور جاوا است. easyrec عمدتا بر دو الگوریتم استوار است: الگوریتم Apriori R [ 50 ] و SlopeOne [ 51 ]. هر دو مبنای تحلیلگر سبد خرید به نام “Association Rule Miner (ARM)” هستند. Apriori یک الگوریتم یادگیری برای ارتباط قوانین بین موارد خاص است. SlopeOne عضوی از تکنیک های فیلتر مشارکتی مبتنی بر آیتم است. روشهای فیلتر مشارکتی ترجیحات کاربران را بر اساس رفتار سایر کاربران پیشبینی میکنند.
easyrec بین سه روش مختلف تعامل با کاربر تمایز قائل میشود: «مشاهده»، «خرید» و «نرخ». در اجرای easyrec در سرور جغرافیایی ESRI، کلیکها بر روی لیست نتایج جستجو مبتنی بر آپاچی لوسن (عملیات “یافتن” در دامنه SDI) به عنوان اقدامات مشاهده در نظر گرفته میشوند ( شکل 3 ) . نگاه دقیقتر به سند فراداده کامل، و همچنین هرگونه پیشنمایش یا دانلود («استفاده») از یک منبع، اقدام خرید در نظر گرفته میشود. با کلیک بر روی دکمه های “شست بالا” یا “شست پایین”، فرض می شود که اقدامات رتبه بندی هستند. شرح دقیقتری از الگوریتمهای استفاده شده توسط easyrec و پیادهسازی آن برای ثبت کلیکهای کاربر در قالب اقدامات «مشاهده»، «خرید» و «نرخ» در سرور ژئوپورتال ESRI در Vockner et al.[ 11 ].
مزیت اصلی استفاده از easyrec در زمینه الگوریتم های تطبیق متن معنایی این است که API را ارائه می دهد که قادر به دریافت ورودی اضافی برای تولید قانون است. مقادیر تطبیق متن دو منبع محاسبه شده توسط ابزار ما به مقادیر درصد تبدیل شده و به سرور easyrec ارسال می شود. در آنجا از آنها برای محاسبه توصیه ها استفاده می شود.
6. نتایج
نتیجه اجرای نهایی ترکیبی از دو بخش ارائه شده در فصل های قبلی است. شکل 8لیست نتایج موتور توصیه یکپارچه شده در صفحه جستجوی ژئوپورتال EnerGEO را در قالب یک چرخ فلک تصویر نشان می دهد. اگر کاربر روی یک مورد در لیست نتایج در سمت راست (1) کلیک کند، توصیه های مرتبط با این مورد در بخش زیر (2) ارائه شده است. همانطور که قبلاً ذکر شد، توصیه ها بر محاسبات تعاملات کاربر و همچنین درصد انطباق بین منابع به دست آمده از ابزار تطبیق متن معنایی متکی هستند. پیوندهای بین منابع مختلف فضایی و غیرمکانی حوزه انرژی مبتنی بر اطلاعات فراداده ساختاری است که به صورت دستی وارد شده یا به طور خودکار استخراج می شود. ابزار استخراج خودکار محتوا به مسئله داشتن حجم عظیمی از داده ها در فرم های بدون ساختار که حاوی اطلاعات ارزشمند است، می پردازد.
از آنجایی که درصد تطابق بین بخشهای فراداده متنی (مثلاً چکیدهها) برای ایجاد پیوند بین منابع غیرمرتبط استفاده میشود، روش جدیدی برای کشف منابع به ژئوپورتال EnerGEO اضافه شد.
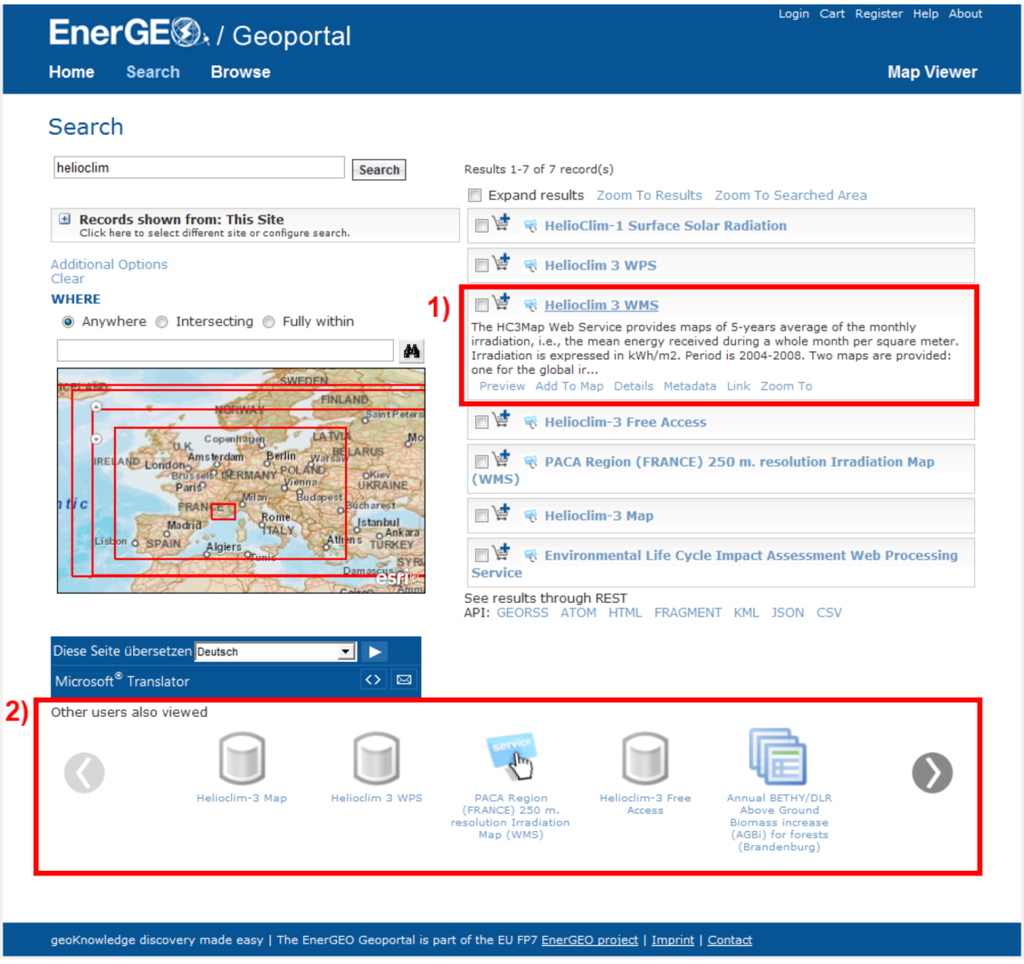
شکل 8. اکتشاف پیشرفته با توصیه در ژئوپورتال EnerGEO.
7. چشم انداز و بحث
فعالیت های تحقیقاتی مداوم به بهبود کشف اطلاعات در پورتال های جغرافیایی اختصاص یافته است [ 9 ، 13 ، 52 ، 53]. رویکردهای مختلف از اصطلاحنامه ها و هستی شناسی ها استفاده می کنند. در رویکرد ما، ما استفاده از الگوریتمهای تطبیق متن معنایی را در ترکیب با سیستمهای توصیهکننده برای غلبه بر مشکلات ناشی از معانی و کاربردهای مختلف اصطلاحات، بهویژه به دلیل پیشزمینههای علمی ناهمگون گروههای کاربری در حوزه انرژی، پیشنهاد میکنیم. ابزار تطبیق متن معنایی در ترکیب با سیستم توصیهکننده، easyrec، یک راهحل مستقل برای جایگزینی یک جستجوی کلی مبتنی بر کلیدواژه نیست، بلکه رویکردی برای ارائه نتایج مرتبشده اضافی بر اساس شباهت آنها و زمینههای دیگر کاربران است. برای اعتبارسنجی رویکرد خود، این مؤلفهها را در ژئوپورتال EnerGEO پیادهسازی کردیم. داده های ورودی حاوی منابع انرژی در قالب های مکانی و غیر مکانی است.
تمام کارهای مرتبطی که کشف کردیم یا بر توسعه الگوریتمهای جدید یا کاربرد این الگوریتمها در سایر حوزههای علمی متمرکز بود. در حوزه زیرساختهای دادههای مکانی و ژئوپورتالها، ما هیچ پیادهسازی از روش تطبیق متن مبتنی بر برداری برای بهبود کشف اطلاعات نمیشناسیم. بنابراین، ما کارهای مرتبطی را که در رشته های مختلف علمی یافت می شود در ادامه ارائه می دهیم.
کارهای مرتبط، مانند Omiotis [ 34 ] که از حوزه کتابشناسی آمده است، از معیاری مبتنی بر اصطلاحنامه برای ارتباط متن استفاده می کند. این در درجه اول توسعه VSM با اصطلاحنامه WordNet است. با این حال، در مورد این مقاله، WordNet ممکن است VSM را چندان بهبود نبخشد، زیرا اساساً برای دادههای مرتبط با انرژی ساخته نشده است. بنابراین، ترجیح ما LSA است.
با این وجود، ما رویکرد فعلی را با اصطلاحنامه ها یا هستی شناسی ها گسترش می دهیم. برای دومی، Ankolekar و همکاران. [ 54 ] بیان می کند که بسط معیارهای تشابه متن با هستی شناسی ها ممکن است به مسائلی منجر شود، به عنوان مثال، دانش معنایی رمزگذاری شده در هستی شناسی ها با مفاهیم مهم برای طبقه بندی متن مطابقت ندارد. سوال دیگر این است که چگونه می توان مفهوم نسبتاً دقیق هستی شناسی ها را در رویکرد تطبیق متن معنایی فازی که توسط ما استفاده می شود، ادغام کرد.
Mihalcea و همکاران [ 16 ] روشی را برای معیارهای پیکره محور و دانش محور تشابه متن معنایی ارائه می دهد. مخصوصاً برای متون کوتاه مناسب است. در مقایسه با معیارهای تشابه مبتنی بر برداری، آزمایشها نشان میدهند که روش آنها میزان خطا را تا 13 درصد کاهش میدهد [ 16 ]]. تمرکز این مقاله بر توسعه یا بهبود خود الگوریتمهای تطبیق متن معنایی نیست، بلکه بر روی کاربرد الگوریتمها به منظور نشان دادن امکانات تطبیق متن معنایی به عنوان ابزاری برای تولید دانش از اطلاعات از طریق پیوند دادن منابع است. بنابراین، مناسب ترین راه حل برای استفاده ما، یعنی LSA، انتخاب شد تا در ژئوپورتال EnerGEO به عنوان اولین گام پیاده سازی شود. در مراحل بعدی پیادهسازی، الگوریتمهایی که برای متون نسبتاً کوتاه مناسبتر هستند، استفاده و ارزیابی خواهند شد.
مزیت اصلی کاربرد LSA این است که مشکل بازیابی اطلاعات بین زبانی را که در صورتی رخ می دهد که عبارت های جستجو به زبانی متفاوت از زبان منبع باشد، برطرف می کند. از آنجایی که تمام اسناد و ترجمهها به بردار تبدیل میشوند، میتوان آنها را با استفاده از پسوند تخصصی به نام Cross-Language LSA (CL-LSA) مقایسه کرد [ 23 ]. Cimiano و همکاران [ 33 ] الگوریتم های تطبیق متن بین زبانی را در زبان انگلیسی و فرانسوی ارزیابی کرده اند. همانطور که قبلاً ارائه شد، نتایج آنها نشان می دهد که ESA بهتر از LSA یا LDA عمل می کند، به جز برای اسناد آموزشی خاص دامنه، مانند مورد ما [ 33 ]]. LSA به وضوح نسبت به LDA و ESA برتری دارد زمانی که بر روی خود اسناد بازیابی آموزش داده شود [ 33 ].
یک اشکال احتمالی روش پیشنهادی این است که توصیهها ممکن است با انتظارات کاربران مطابقت نداشته باشند. مسائلی که باعث این امر می شود معمولاً تعداد کمی از کاربران یا مقادیر کمی از منابع ثبت شده در کاتالوگ است. اولین مسئله به این واقعیت مربوط می شود که یک سیستم توصیه گر بر اساس اقدامات کاربر برای محاسبه قوانین توصیه ها است. اگر فقط مقدار کمی از منابع وجود داشته باشد، موارد بسیار کمی برای ارائه توصیه به کاربران وجود دارد. در آن صورت، لیست توصیه ها خالی می ماند که منجر به نارضایتی کاربر می شود.
علاوه بر این، کاربران ممکن است توصیههای نامناسبی را دریافت کنند که از دامنههایی غیر از پورتال اختصاصی دامنه ایجاد شده باشد. از آنجایی که توصیهها بر اساس مواردی که سایر کاربران کلیک کردهاند محاسبه میشوند، علایق ممکن است متفاوت باشد.
مسئله دیگری ممکن است در هنگام داشتن متون با طول های مختلف ایجاد شود. در متون بسیار کوتاه تطبیق فقط بر اساس چند کلمه امکان پذیر است. هرچه متون طولانی تر باشند، الگوریتم ها بهتر می توانند برای استخراج اسناد مرتبط استفاده شوند.
برای تأیید کیفیت تطابق متن در توصیهها، از مکانیسمهای عقبگرد تعاملات کاربر در فهرست توصیهها در نگاه اول استفاده میکنیم. بر اساس تجربه [ 16 ، 33 ، 35 ، 37 ، 39 ]، ما مناسب بودن الگوریتم LSA را در مورد نیازهای خاص خود برای مقایسه محتوای معنایی فراداده کشف کردیم. علاوه بر این، آزمایشهای مختلف کاربر را برای ارزیابی کیفیت کشف و توصیهها انجام دادیم. توصیه ها نتایج امیدوارکننده ای را برای گروه کارشناسان داخلی ما نشان داد. این نتیجه ما را تشویق میکند تا با آزمایشهای تجربه کاربری پیشرفته به عنوان گام تحقیقاتی بعدی شروع کنیم.
از این رو، یک نظرسنجی انجام خواهد شد، که در آن تجربه کاربران با ترکیب LSA و سیستمهای توصیهکننده در Geoportals به صورت کمی ارزیابی میشود و از ابزارهای تجزیه و تحلیل وب پیشرفته، مانند Piwik [ 55 ] و تجزیه و تحلیل ردیابی ماوس (مثلا ایجاد ماوس) استفاده میکند. -نقشه حرارتی اشاره گر). این آزمون با یک نظرسنجی آنلاین همراه خواهد بود که تجربه کیفی کاربران را جویا می شود.
8. نتیجه گیری
به عنوان نتیجه اصلی کار ارائه شده، ما ادغام الگوریتمهای تطبیق متن معنایی و سیستمهای توصیهکننده را برای افزایش کیفیت کشف ابرداده و تجربه کاربر در ژئوپورتالها پیشنهاد میکنیم. بنابراین، ما ابزاری را برای استخراج ابرداده (نیمه) خودکار از محتوای مکانی و غیر مکانی برای تولید دانش آگاه از مکان توسعه دادیم. فراداده ساختاریافته و استاندارد شده به عنوان ورودی برای تطبیق متن معنایی محتوا با استفاده از LSA عمل می کند. با این رویکرد جدید، میتوان به طور خودکار پیوندهایی بین منابعی ایجاد کرد که قبلاً به یکدیگر مرتبط نبودند. این پیوندهای ایجاد شده از نظر کمی با استفاده از توصیه هایی در مورد شباهت متنی متون ارائه شده اند. علاوه بر این، تعاملات کاربر در رابط اکتشاف geoportal تجزیه و تحلیل شده، رتبهبندی توصیهها را بیشتر میکند. بدین ترتیب، ژئوپورتال FP7 اتحادیه اروپا EnerGEO نتایج تحقیقات ما را به عنوان اثبات مفهوم نشان می دهد. این نتایج کشفی را ارائه میکند که ذاتی خود داده نیستند، بلکه به شکل شباهت متنی و آنچه سایر کاربران مشاهده کردهاند، از زمینه مشتق شدهاند.
منابع
- Rouse, M. جامعه اطلاعاتی. واژه نامه استانداردهای فناوری اطلاعات و سازمان ها . در دسترس آنلاین: http://whatis.techtarget.com/definition/Information-Society (در 19 ژانویه 2013 قابل دسترسی است).
- گانتز، جی. Reinsel, D. استخراج ارزش از آشوب . در دسترس آنلاین: http://www.emc.com/collateral/analyst-reports/idc-extracting-value-from-chaos-ar.pdf (در تاریخ 17 ژانویه 2011 قابل دسترسی است).
- بلینگر، جی. مدیریت دانش – دیدگاه های نوظهور . در دسترس آنلاین: http://www.systems-thinking.org/kmgmt/kmgmt.htm (در 11 ژانویه 2013 قابل دسترسی است).
- ریشتر، الف. زیرساختهای اطلاعات فضایی و دانش سازمانی – مفاهیم و فناوریها برای تجارت نفت و گاز با استفاده از مثال OMV. پایان نامه کارشناسی ارشد، دانشگاه سالزبورگ، سالزبورگ، اتریش، 2012. [ Google Scholar ]
- SAS. تجزیه و تحلیل متن – هوش متنی . در دسترس آنلاین: http://www.eu.gov.hk/sc_chi/cmps/files/cmps_20100125_1210_sas.pdf (در 1 مه 2012 قابل دسترسی است).
- Croisier, S. ظهور کاربردهای معنایی آگاه. در فن آوری های معنایی در سیستم های مدیریت محتوا ; Maass, W., Kowatsch, T., Eds. Springer: برلین، آلمان، 2012; صص 23-33. [ Google Scholar ]
- تانگ، دبلیو. سلوود، جی . پورتال های فضایی. دروازه های اطلاعات جغرافیایی ; ESRI Press: Redlands، CA، USA، 2005. [ Google Scholar ]
- تانگ، دبلیو. سلوود، جی . پورتال های فضایی. افزودن ارزش به زیرساخت های داده های مکانی در دسترس به صورت آنلاین: http://www.isprs.org/proceedings/XXXVI/4-W6/papers/35-40WinnieTang-A022.pdf (در 21 ژوئیه 2012 قابل دسترسی است).
- فوگازا، سی. لوراشی، گ. نمایهسازی معناشناسی منابع جغرافیایی بر اساس اصطلاحنامههای چندزبانه: روششناسی و نتایج اولیه. بین المللی جی. اسپات. زیرساخت داده Res. 2012 ، 7 ، 16-37. [ Google Scholar ]
- اسمیت، کامپیوتر; فریس کریستنسن، الف. کشف منبع در زیرساخت داده های فضایی اروپا. IEEE Trans. بدانید. مهندسی داده 2007 ، 19 ، 85-95. [ Google Scholar ] [ CrossRef ]
- وکنر، بی. بلژیک، م. Mittlböck، M. افزایش کشف مبتنی بر توصیه در Geoportals. بین المللی جی. اسپات. زیرساخت داده Res. 2012 ، 7 ، 441-463. [ Google Scholar ]
- Latre، MA; هوفر، بی. لاکاستا، جی. Nogueras-Iso، J. توسعه و پیوند واژگان خشکسالی در زیرساخت کاتالوگ قابل همکاری EuroGEOSS. بین المللی جی. اسپات. زیرساخت داده Res. 2012 ، 7 ، 225-248. [ Google Scholar ]
- یانوویچ، ک. شوارتز، ام. Wilkes, M. پیادهسازی و ارزیابی یک رابط کاربری مبتنی بر معناشناسی برای روزنامههای وب. در مجموعه مقالات رابط های بصری به وب اجتماعی و معنایی (VISSW 2009) کارگاه در ارتباط با کنفرانس بین المللی رابط های کاربری هوشمند (IUI 2009)، جزیره Sanibel، FL، ایالات متحده، 8-11 فوریه 2009.
- شولز، جی. Mittlböck، M. تجسم فضایی-زمانی نتایج شبیهسازی با استفاده از استعاره طراحی مبتنی بر کاشی مبتنی بر وظیفه. در نقشه برداری خدمات گرا 2012 ; جابست، ام.، اد. Jobsstmedia Management Verlag: وین، اتریش، 2012; صص 369-382. [ Google Scholar ]
- اسلام، ع. Inkpen، D. شباهت متن معنایی با استفاده از شباهت کلمه مبتنی بر پیکره و شباهت رشته. ACM Trans. بدانید. کشف کنید. داده 2008 ، 2 ، 1-25. [ Google Scholar ] [ CrossRef ]
- Mihalcea، R. کورلی، سی. Strapparava، C. معیارهای مبتنی بر پیکره و دانش مبتنی بر تشابه معنایی متن. در مجموعه مقالات بیست و یکمین کنفرانس ملی هوش مصنوعی، بوستون، MA، ایالات متحده آمریکا، 16-20 ژوئیه 2006; جلد 1، ص 775–780.
- Turney، PD; پانتل، پ. از فرکانس تا معنا: مدلهای فضای برداری معناشناسی. جی آرتیف. بین المللی Res. 2010 ، 37 ، 141-188. [ Google Scholar ]
- دومایس، ST; Furnas، GW; Landauer، TK; دیروستر، اس. هارشمن، آر. استفاده از تحلیل معنایی پنهان برای بهبود دسترسی به اطلاعات متنی. در مجموعه مقالات کنفرانس SIGCHI در مورد عوامل انسانی در سیستم های محاسباتی، واشنگتن، دی سی، ایالات متحده آمریکا، 15-19 مه 1988; ص 281-285.
- دیروستر، اس. دومایس، اس. لاندوئر، تی. فرناس، جی. هارشمن، آر. نمایه سازی با تحلیل معنایی نهفته. مربا. Soc. Inf. علمی 1990 ، 41 ، 391-407. [ Google Scholar ] [ CrossRef ]
- ماس، ا. دالی، آر. فام، پی. هوانگ، دی. نگ، ا. پاتس، سی. یادگیری بردارهای کلمه برای تحلیل احساسات. در مجموعه مقالات چهل و نهمین نشست سالانه انجمن زبانشناسی محاسباتی: فناوریهای زبان انسانی، پورتلند، OR، ایالات متحده آمریکا، 19 تا 24 ژوئن 2011. صص 142-150.
- Wiemer-Hastings، P. تحلیل معنایی پنهان چقدر پنهان است؟ در مجموعه مقالات شانزدهمین کنفرانس مشترک بین المللی هوش مصنوعی، استکهلم، سوئد، 31 ژوئیه تا 6 اوت 1999. جلد 2، ص 932–937.
- لاندوئر، تی. لهام، دی. رهدر، بی. Schreiner, ME چقدر خوب میتوان بدون استفاده از ترتیب کلمات، معنای گذر را استخراج کرد. در مجموعه مقالات نوزدهمین نشست سالانه انجمن علوم شناختی، پالو آلتو، کالیفرنیا، ایالات متحده آمریکا، 7 تا 10 اوت 1997.
- دومایس، اس. تحلیل معنایی پنهان. آنو. Rev. Inf. علمی تکنولوژی 2004 ، 38 ، 188-230. [ Google Scholar ] [ CrossRef ]
- ویسیجوسکی، جی. زیولکو، بی. استخراج دانش معنایی از ویکی پدیا. در سیستم های اطلاعاتی هوشمند: رویکردهای جدید . کلوپوتک، MA، ویرایش. انتشارات دانشگاه Podlasie: Podlasie، لهستان، 2011; ص 91-98. [ Google Scholar ]
- ناکوف، پ. پوپووا، آ. Mateev، P. تاثیر توابع وزن بر عملکرد LSA. در مجموعه مقالات کنفرانس یورو پیشرفت های اخیر در پردازش زبان طبیعی (RANLP’01)، Tzigov Chark، بلغارستان، 5-7 سپتامبر 2001. ص 187-193.
- ترزی، م. فراریو، M.-A. Whittle, J. متن رایگان در نظرات کاربران: نقش آنها در سیستم های توصیه کننده. در مجموعه مقالات سومین کارگاه ACM RecSys’10 در مورد سیستم های توصیه کننده و وب اجتماعی، شیکاگو، IL، ایالات متحده، 23-27 اکتبر 2011. ص 45-48.
- لی، ی. مک لین، دی. بندر، ز. اوشی، جی. Crockett, K. شباهت جمله بر اساس شبکه های معنایی و آمار پیکره. IEEE Trans. بدانید. مهندسی داده 2006 ، 18 ، 1138-1150. [ Google Scholar ] [ CrossRef ]
- Turney، PD Mining the Web for Synonyms: PMI-IR در مقابل LSA در تافل. در مجموعه مقالات دوازدهمین کنفرانس اروپایی در مورد یادگیری ماشین، فرایبورگ، آلمان، 5-7 سپتامبر 2001. صص 491-502.
- گابریلوویچ، ای. مارکوویچ، اس. محاسبه رابطه معنایی با استفاده از تحلیل معنایی صریح مبتنی بر ویکیپدیا. در مجموعه مقالات بیستمین کنفرانس مشترک بین المللی در زمینه هوش مصنوعی، هیدرآباد، هند، 6 تا 12 ژانویه 2007. صفحات 1606-1611.
- سورگ، پ. Cimiano، P. بازیابی اطلاعات بین زبانی با تحلیل معنایی صریح. در مجموعه مقالات یادداشت های کاری برای کارگاه آموزشی CLEF 2008، آرهوس، دانمارک، 17-19 سپتامبر 2008.
- Blei، DM; Ng، AY؛ جردن، MI تخصیص دیریکله نهفته. جی. ماخ. فرا گرفتن. Res. 2003 ، 3 ، 993-1022. [ Google Scholar ]
- L’Huillier، G. هیویا، ا. وبر، آر. Ríos، SA تحلیل معنایی پنهان و استخراج کلمات کلیدی برای طبقهبندی فیشینگ. در مجموعه مقالات کنفرانس بین المللی IEEE در سال 2010 در زمینه اطلاعات و انفورماتیک امنیتی (ISI)، ونکوور، BC، کانادا، 23-26 مه 2010. صص 129-131.
- Cimiano، P. شولتز، آ. سیزوف، اس. سورگ، پ. Staab، S. مدل های مفهومی آشکار در مقابل پنهان برای بازیابی اطلاعات بین زبانی. در مجموعه مقالات بیست و یکمین کنفرانس مشترک بین المللی در زمینه هوش مصنوعی، پاسادنا، کالیفرنیا، ایالات متحده آمریکا، 11 تا 17 ژوئیه 2009; صص 1513-1518.
- تساتسارونیس، جی. وارلامیس، آی. وزیرگیانیس، م. Norvag، K. Omiotis: سنجشی مبتنی بر اصطلاحنامه برای ارتباط متن. در مجموعه مقالات کنفرانس اروپایی یادگیری ماشین و کشف دانش در پایگاههای داده: بخش دوم، بلد، اسلوونی، 7 تا 11 سپتامبر 2009. صص 742-745.
- تساتسارونیس، جی. وارلامیس، آی. وزیرگیانیس، م. ارتباط متن بر اساس اصطلاحنامه واژه. جی آرتیف. بین المللی Res. 2010 ، 37 ، 1-40. [ Google Scholar ]
- لی، دکتر Pincombe، BM; ولز، MB ارزیابی تجربی مدلهای تشابه سند متنی. در مجموعه مقالات کنفرانس سالانه XXVII انجمن علوم شناختی، Stresa، ایتالیا، 21-23 ژوئیه 2005. صص 1254-1259.
- راماژ، دی. رافرتی، AN; منینگ، سی دی پیاده روی تصادفی برای تشابه معنایی متن. در مجموعه مقالات کارگاه 2009 در مورد روشهای مبتنی بر نمودار برای پردازش زبان طبیعی، Suntec، سنگاپور، 7 اوت 2009; ص 23-31.
- دولان، بی. کویرک، سی. Brockett, C. ساخت و ساز بدون نظارت مجموعه های پارافراسی بزرگ: بهره برداری گسترده از منابع خبری موازی. در مجموعه مقالات بیستمین کنفرانس بین المللی زبان شناسی محاسباتی، ژنو، سوئیس، 23 تا 27 اوت 2004. پ. 350.
- مولر، ام. Mihalcea, R. تشابه معنایی متن به متن برای درجه بندی خودکار پاسخ های کوتاه. در مجموعه مقالات دوازدهمین کنفرانس فصل اروپایی انجمن زبانشناسی محاسباتی، آتن، یونان، 20 مارس تا 3 آوریل 2009. صص 567-575.
- رسنیک، پی. یاکوو، ن. سوچاک، م. برگستروم، پی. Riedl, J. GroupLens: یک معماری باز برای فیلتر مشارکتی نت نیوز. در مجموعه مقالات کنفرانس ACM 1994 در مورد کار تعاونی با پشتیبانی رایانه، چپل هیل، NC، ایالات متحده، 22 تا 26 اکتبر 1994. صص 175-186.
- Pazzani, MJ چارچوبی برای فیلتر مشارکتی، مبتنی بر محتوا و جمعیت شناختی. آرتیف. هوشمند Rev. 1999 , 13 , 393-408. [ Google Scholar ] [ CrossRef ]
- سرور ژئوپورتال ESRI . در دسترس آنلاین: http://www.esri.com/software/arcgis/geoportal (در 16 مارس 2013 قابل دسترسی است).
- بنیاد نرم افزار آپاچی کاشی آپاچی در دسترس آنلاین: http://tiles.apache.org (در 20 اوت 2012 قابل دسترسی است).
- gfx . در دسترس آنلاین: http://www.swftools.org/gfx_tutorial.html (دسترسی در 10 سپتامبر 2012).
- Win32com . در دسترس آنلاین: http://starship.python.net/~skippy/win32/Downloads.html (در 10 سپتامبر 2012 قابل دسترسی است).
- Topia Termextract . در دسترس آنلاین: http://pypi.python.org/pypi/topia.termextract/ (در 12 سپتامبر 2012 قابل دسترسی است).
- ریورک، آر. Sojka، P. چارچوب نرم افزاری برای مدل سازی موضوع با شرکت های بزرگ. در مجموعه مقالات کارگاه آموزشی LREC 2010 در مورد چالش های جدید برای چارچوب های NLP، والتا، مالت، 17-23 می 2010. صص 45-50.
- Rehurek, R. آزمایشهایی با ویکیپدیای انگلیسی . در دسترس آنلاین: http://radimrehurek.com/gensim/wiki.html (دسترسی در 15 فوریه 2013).
- آسان رک . در دسترس آنلاین: http://www.easyrec.org (دسترسی در 15 مارس 2012).
- آگراوال، آر. Srikant، R. الگوریتم های سریع برای قوانین انجمن معدن در پایگاه های داده بزرگ. در مجموعه مقالات بیستمین کنفرانس بین المللی پایگاه های داده بسیار بزرگ، سانتیاگو دی شیلی، شیلی، 12 تا 15 سپتامبر 1994. ص 487-499.
- لمیر، دی. Maclachlan، A. Slope One Predictors برای فیلترینگ مشارکتی مبتنی بر رتبه بندی آنلاین. در مجموعه مقالات کنفرانس بین المللی SIAM 2005 در مورد داده کاوی (SDM’05)، نیوپورت بیچ، کالیفرنیا، ایالات متحده آمریکا، 21-23 آوریل 2007.
- آبرگوز، سی. گرانل، سی. دیاز، ال. هوئرتا، جی. Beltran، A. کشف داده های جغرافیایی تولید شده توسط کاربر با استفاده از موتورهای جستجوی وب. در پیشرفت در علوم زمین و سنجش از دور ؛ Jedlovec, G., Ed. InTech: Rijeka، کرواسی، 2009. [ Google Scholar ]
- پرلمن، جی. کراگلیا، ام. برتراند، اف. ناتیوی، س. گیگالاس، جی. دوبوا، جی. نیمایر، اس. فریتز، S. EuroGEOSS: یک رویکرد بین رشته ای به تحقیقات و کاربردها برای جنگلداری، تنوع زیستی و خشکسالی. در مجموعه مقالات سی و چهارمین سمپوزیوم بین المللی سنجش از دور محیط زیست، سیدنی، استرالیا، 10-15 آوریل 2011; صص 1-4.
- آنکوله کار، ا. Seo, YW; Sycara، K. بررسی دانش معنایی برای یادگیری متن. در مجموعه مقالات کارگاه ACM SIGIR در وب معنایی، تورنتو، ON، کانادا، 28 ژوئیه تا 1 اوت 2003.
- پیویک . در دسترس آنلاین: http://piwik.org/ (دسترسی در 10 فوریه 2013).
© 2013 توسط نویسندگان; دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (http://creativecommons.org/licenses/by/3.0/) توزیع شده است.
بدون نظر