

خلاصه
مسیرهای GPS ; روش بهینه سازی چگالی تطبیقی ; طبقه بندی کننده ساده بیزی ; اطلاعات سطح خط ؛ اطلاعات بزرگ
1. معرفی
- (1)
-
ما یک روش جدید، روش بهینهسازی چگالی تطبیقی، برای بهینهسازی مسیر GPS خودرو بر اساس روش خوشهبندی چگالی و توزیع فضایی نقاط ردیابی پیشنهاد میکنیم. نقاط پرت مخلوط شده در داده های خام به طور خودکار با استفاده از روش بهینه سازی چگالی تطبیقی حذف می شوند.
- (2)
-
ما روش جدیدی را برای استنتاج اطلاعات سطح خط از مسیرهای GPS خودروهای مکانی-زمانی با دقت پایین (MLIT) بررسی میکنیم.
- (3)
-
ما قوانین دور هر خط را با ردیابی مسیرهای وسیله نقلیه در رابطه با میزان رانندگی بی احتیاطی تشخیص می دهیم.
2. کارهای مرتبط
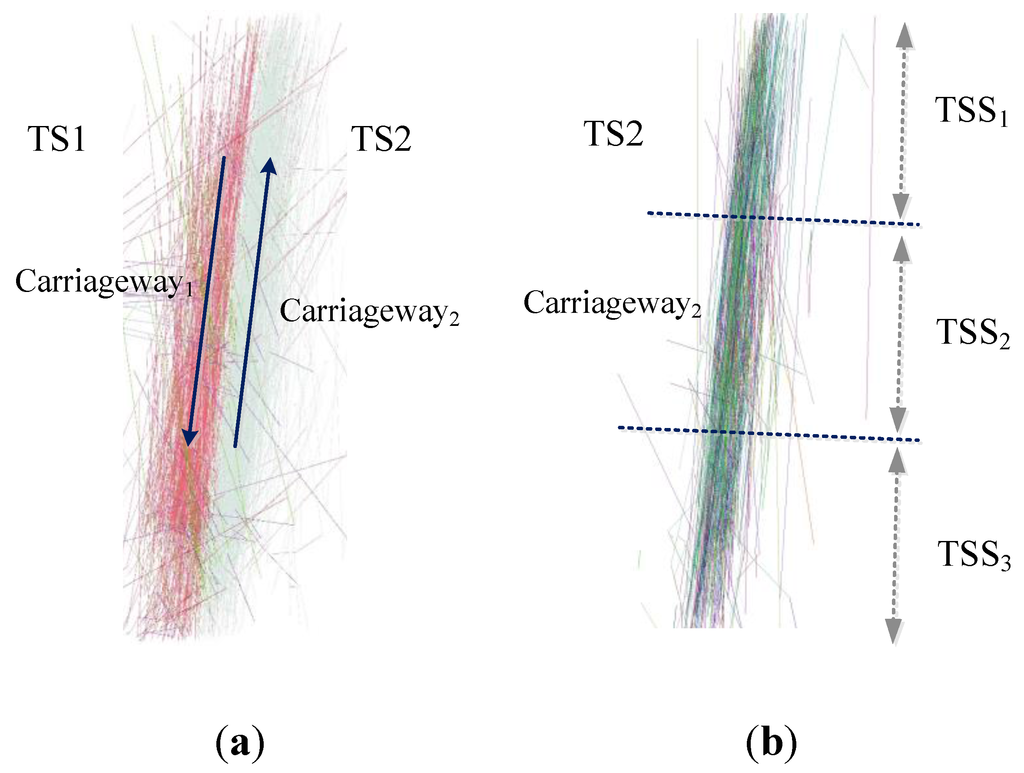
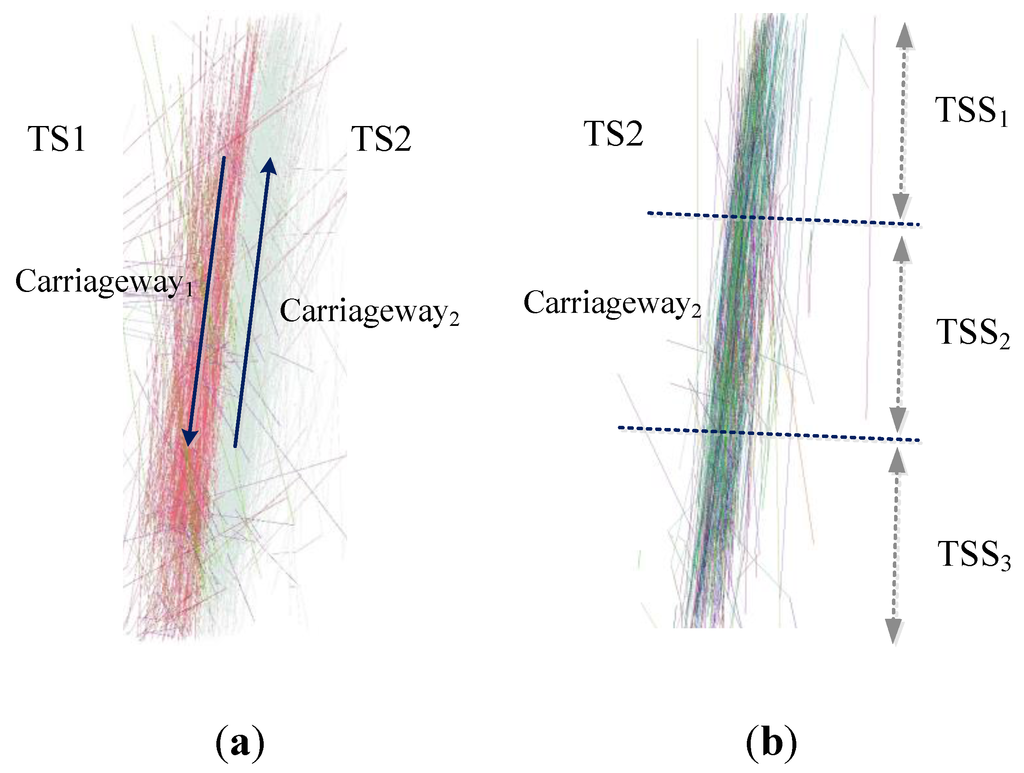
3. استخراج اطلاعات شبکه جاده در سطح خط از مسیرهای GPS خودرو
3.1. بهینه سازی مسیر GPS خودرو

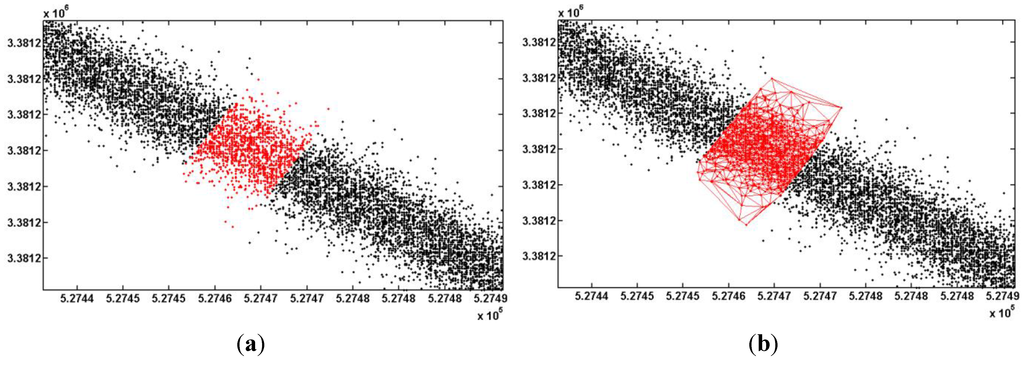
3.1.1. روش بهینه سازی چگالی تطبیقی
که در آن N(A) تعداد نقاط هر زیرمجموعه ای است که با A نشان داده شده است (به عنوان مثال، شکل 2 ب)، k = 1،2، …، N(A) ، | A | مساحت زیر مجموعه A است ، λ شدت توزیع صفر است و می توان آن را به صورت زیر تخمین زد:
که در آن x هر نقطه ای از زیرمجموعه A را نشان می دهد ، P( x ≥ n i ) اهمیت x ، n i تعداد نقاط همسایگی x است ، | نی | مساحت همسایگی x است ، r شعاع همسایگی x است .
که در آن meanDE میانگین طول تمام لبههای مثلث دلونی است و variationDE انحراف استاندارد طول تمام یالها در مثلث دلونی است ( شکل 2 ج را ببینید). مساحت A به صورت زیر محاسبه می شود:
که در آن M تعداد مثلث ها در مثلث دلونی است ( شکل 2 ج را ببینید)، AT i مساحت مثلث i است . هر چگالی نقطه ردیابی با استفاده از فرمول های 1-7 محاسبه می شود. سپس روش پیشنهادی چگالی را با اهمیت η مقایسه میکند (معمولا η = 0.05 یا η = 0.01 تنظیم میشود)، و x به عنوان یک نقطه ردیابی واقعی تعریف میشود اگر اهمیت آن کمتر از η باشد. در غیر این صورت نقطه x به عنوان نقطه پرت تعریف می شود و از مجموعه داده حذف می شود.
3.1.2. بهينه سازي
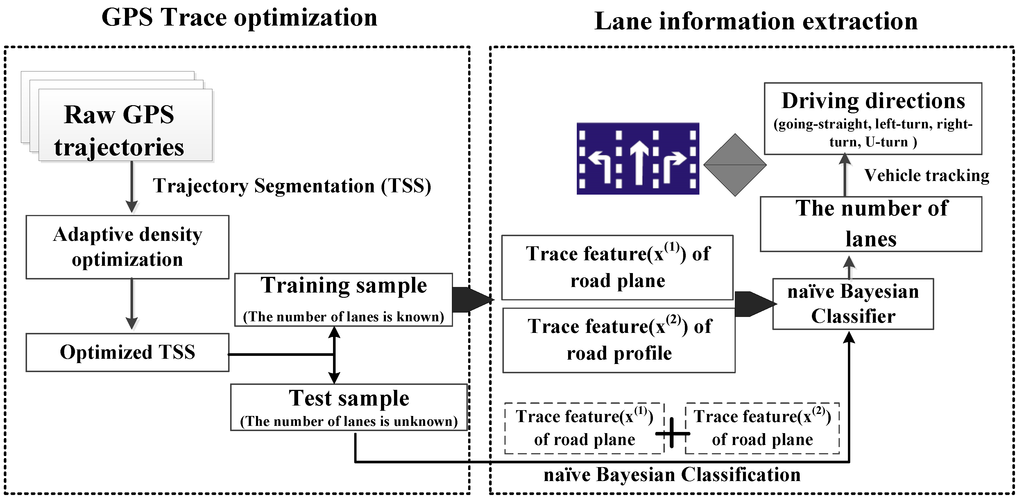
3.2. استخراج شماره خطوط بر اساس طبقه بندی ساده بیزی
3.2.1. روش پایه
در جایی که I تابع نشان داده شده است، I y (c) = 1 اگر c ε y و 0 در غیر این صورت، i = 1,2, …, N , j = 1, 2, l = 1, 2, …, sj , k = 1، 2، …، ک .
که در آن y تعداد خطوط در نمونه آزمایشی x و y ε ( c 1 , c 2 , …, c K ) است.
3.2.2. طبقه بندی کننده ساده بیزی
| /*مقداردهی اولیه*/ |
| مبدا مختصات: n 1 ; |
| محور افقی: جهت TSS فعلی . |
| محور طولی: UY i = 0; DY i = 0; |
| پنجره کشویی: طول = l ; عرض = w ; نسبت = 0; |
| /*وظیفه*/ |
| برای هر TSS i ، انجام دهید |
| تکرار |
| حرکت پنجره کشویی در جهت مثبت و جهت منفی محور طولی و جمع آوری نسبت (نسبت = تعداد نقاط فعلی در پنجره کشویی/همه نقاط در TSS فعلی ) |
| تا نسبت = 100% |
| تنظیم Dw i = ∑ (حداکثر | UY j | + | حداکثر | DY j |)/( h / l ); j = 1،2،…، ( h / l ). |
| تنظیم مبدا مختصات به n i+1 تغییر کرد . UY i+1 = 0; DY i+1 = 0; i = 1،2،…، m . |
| پایان برای |

که در آن ln تعداد مؤلفههای گاوسی را نشان میدهد، و هر مؤلفه مربوط به هر خط است، در حالی که w 1 ، …، w ln وزن هر مؤلفه، مربوط به حجم ترافیک نسبی در هر خط و ∑l nj = 1wj= 1∑�=1ل���=1. μ 1 ، …، μln میانگین مسیرهای هر جزء و برابر با خط مرکزی هر خط است . σ واریانس استاندارد مسیرها برای هر جزء است و مقدار یکسانی را تنظیم می کند زیرا عرض خط خطوط مجاور معمولاً یکسان است. تعداد اجزای یک CGMM برابر است با تعداد خوشه مسیرهای یک TSS و توسط مدل ریسک ساختاری (به حداقل رساندن ریسک ساختاری، SRM) تعیین می شود. برای تخمین w i ، u i و σ برای مجموعه ای از ln و سپس ln را انتخاب کنیدکه مدل ریسک ساختاری را به حداقل می رساند. روش محاسبه و استخراج تعداد خوشه ها را می توان با توجه به [ 7 ] به دست آورد.
3.3. قوانین تشخیص چرخش هر خط

4. آزمایش ها و نتایج

4.1. بهینه سازی مسیر
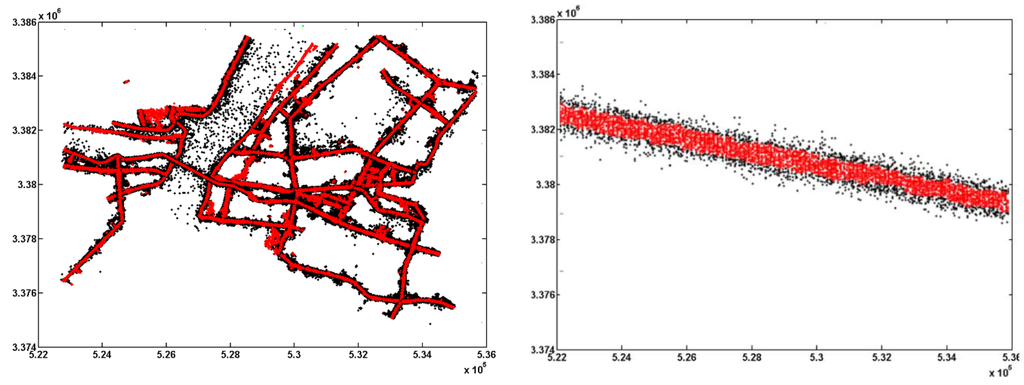
4.2. ساخت طبقه بندی کننده ساده بیزی
4.3. استخراج اطلاعات خطوط


 . در عین حال، دقت قوانین پیچ در تشخیص خطوط تا حد زیادی به نتایج تعداد خطوط بستگی دارد. در جدول 2 ، قوانین دور از خطوط در نمونه های آزمایشی نیز به دلیل تخمین نادرست تعداد خطوط، طبقه بندی نادرستی دریافت می کنند.
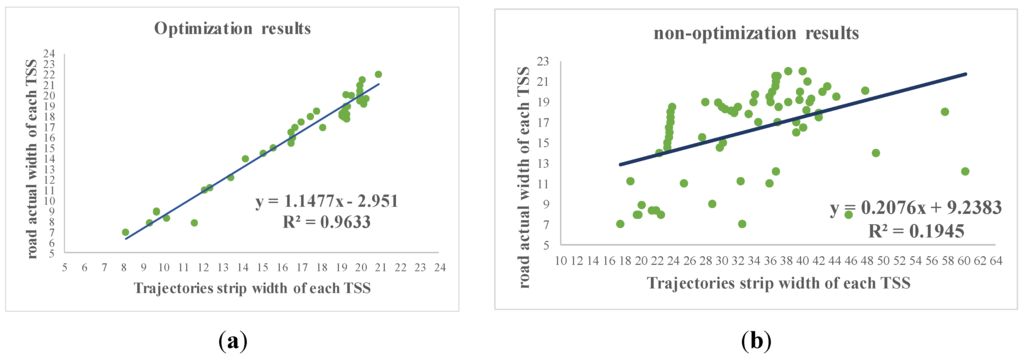
. در عین حال، دقت قوانین پیچ در تشخیص خطوط تا حد زیادی به نتایج تعداد خطوط بستگی دارد. در جدول 2 ، قوانین دور از خطوط در نمونه های آزمایشی نیز به دلیل تخمین نادرست تعداد خطوط، طبقه بندی نادرستی دریافت می کنند.4.4. ارزیابی کمی
4.4.1. ارزیابی کمی برای شماره شناسایی خط
4.4.2. ارزیابی کمی برای تشخیص قوانین چرخش
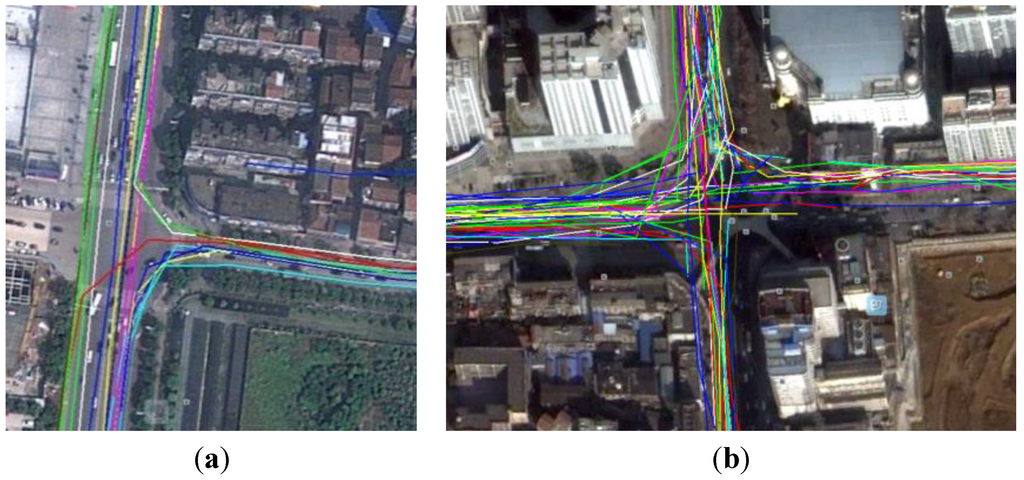
5. نتیجه گیری ها
منابع
- گونزالس، جی پی؛ اوزگونر، تشخیص خط U. با استفاده از تقسیمبندی و درخت تصمیم مبتنی بر هیستوگرام. در مجموعه مقالات 2000 IEEE Intelligent Transportation Systems، دیربورن، MI، ایالات متحده آمریکا، 1-3 اکتبر 2000.
- وانگ، ی. Teoh، EK; شن، دی. تشخیص لین با استفاده از مار B. در مجموعه مقالات کنفرانس بین المللی 1999 در زمینه هوش اطلاعاتی و سیستم ها، Bethesda، MD، ایالات متحده آمریکا، 3 اکتبر 1999.
- هیلل، AB; لرنر، آر. لوی، دی. راز، جی. پیشرفت اخیر در تشخیص جاده و خط: یک بررسی. ماخ Vis. Appl. 2014 ، 25 ، 727-745. [ Google Scholar ] [ CrossRef ]
- کامل، اس. پیتزر، بی. تشخیص و نقشه برداری نشانگر خط مبتنی بر لیدار. در مجموعه مقالات سمپوزیوم وسایل نقلیه هوشمند، آیندهوون، هلند، 4 تا 6 ژوئن 2008.
- Thuy، M. León, F. Lane تشخیص و ردیابی بر اساس دادههای Lidar. مترو Meas. سیستم 2010 ، 17 ، 311-321. [ Google Scholar ] [ CrossRef ]
- یانگ، BS; دونگ، ز. ژائو، جی. Dai، WX استخراج سلسله مراتبی اشیاء شهری از دادههای اسکن لیزری سیار. ISPRS J. Photogr. Remote Sens. 2015 ، 99 ، 45-57. [ Google Scholar ] [ CrossRef ]
- چن، YH; Krumm, J. مدلسازی احتمالی خطوط ترافیک از ردیابی GPS. در مجموعه مقالات هجدهمین کنفرانس بین المللی SIGSPATIAL در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، سن خوزه، کالیفرنیا، ایالات متحده آمریکا، 2 تا 5 نوامبر 2010.
- بله، پیش از این؛ ژونگ، تی. Yue, Y. چندضلعیسازی سلسله مراتبی برای تولید و بهروزرسانی اطلاعات شبکه جادهای مبتنی بر خط برای پیمایش از علامتگذاری جادهها. بین المللی جی. جئوگر. Inf. علمی 2015 ، 29 ، 1509-1533. [ Google Scholar ] [ CrossRef ]
- لیو، XT; Ban، YF کشف الگوهای خوشهای مکانی-زمانی با استفاده از دادههای عظیم خودروهای شناور. ISPRS Int. J. Geo-Inf. 2013 ، 2 ، 371-384. [ Google Scholar ] [ CrossRef ]
- ساینیو، جی. وسترهولم، جی. Oksanen, J. با رعایت حریم خصوصی، نقشههای حرارتی مسیرهای پرطرفدار را بهصورت آنلاین از دادههای برنامه ردیابی ورزشی تلفن همراه عظیم در میلیثانیه ایجاد میکند. ISPRS Int. J. Geo-Inf. 2015 ، 4 ، 1813-1826. [ Google Scholar ] [ CrossRef ]
- ژنگ، ی. ژانگ، ال. Xie، X. Ma، WY Mining مکان های جالب و توالی سفر از مسیرهای GPS. در مجموعه مقالات هجدهمین کنفرانس بین المللی وب جهانی، مادرید، اسپانیا، 20-24 آوریل 2009.
- جیانوتی، اف. نانی، م. پینلی، اف. Pedreschi، D. استخراج الگوی مسیر. در مجموعه مقالات سیزدهمین کنفرانس بین المللی ACM SIGKDD در مورد کشف دانش و داده کاوی، سن خوزه، کالیفرنیا، ایالات متحده آمریکا، 12 تا 15 اوت 2007.
- یین، پی. بله، م. لی، WC; Li، Z. استخراج داده های GPS برای توصیه مسیر. در پیشرفت در کشف دانش و داده کاوی ؛ Springer: Cham, Switzerland, 2014; صص 50-61. [ Google Scholar ]
- تانگ، LL; چانگ، XM; Li، QQ بهینه سازی مسیر سفر عمومی بر اساس الگوریتم بهینه سازی کلونی مورچه ها و داده های GPS تاکسی. چین جی هایو. ترانسپ 2011 ، 24 ، 89-95. [ Google Scholar ]
- وانگ، جی. روئی، ایکس. آهنگ، X. Tan, X. یک رویکرد جدید برای تولید نقشههای جاده قابل مسیریابی از مسیرهای GPS خودرو. بین المللی جی. جئوگر. Inf. علمی 2014 ، 29 ، 69-91. [ Google Scholar ] [ CrossRef ]
- تانگ، LL; هوانگ، FZH؛ ژانگ، XY; تشخیص تغییر شبکه جاده ای لی، QQ بر اساس داده های شناور خودرو. J. Netw. 2012 ، 7 ، 1063-1070. [ Google Scholar ] [ CrossRef ]
- ژو، BD; لی، QQ; مائو، QZH; تو، دبلیو. ژانگ، ایکس. Chen, L. ALIMC: نقشه برداری فضای داخلی مبتنی بر نقطه عطف فعالیت از طریق جمع سپاری. IEEE Trans. هوشمند ترانسپ سیستم 2015 ، 16 ، 2774-2785. [ Google Scholar ] [ CrossRef ]
- دی فابریتیس، سی. راگونا، آر. Valenti، G. برآورد و پیشبینی ترافیک بر اساس دادههای شناور خودرو در زمان واقعی. در مجموعه مقالات یازدهمین کنفرانس بین المللی IEEE در مورد سیستم های حمل و نقل هوشمند (ITSC)، پکن، چین، 12 تا 15 اکتبر 2008.
- سان، دی. ژانگ، سی. ژانگ، ال. چن، اف. تحلیل رفتار سفر شهری Peng، ZR و پیشبینی مسیر بر اساس دادههای شناور خودرو. ترانس. Lett. بین المللی J. Trans. Res. 2014 ، 6 ، 118-125. [ Google Scholar ] [ CrossRef ]
- لی، WC; Krumm, J. پیش پردازش مسیر. در محاسبات با مسیرهای فضایی ; Zheng, Y., Zhou, X., Eds. Springer: نیویورک، نیویورک، ایالات متحده آمریکا، 2011; صص 3-33. [ Google Scholar ]
- برکاتسولاس، اس. Pfoser، D.; سالاس، آر. Wenk, C. در مورد داده های ردیابی وسیله نقلیه مطابق با نقشه. در مجموعه مقالات سی و یکمین کنفرانس بین المللی پایگاه های داده بسیار بزرگ، تروندهایم، نروژ، 30 اوت تا 2 سپتامبر 2005.
- هاکلی، م. Weber, P. OpenStreetMap: نقشه های خیابانی تولید شده توسط کاربر. IEEE Perv. محاسبه کنید. 2008 ، 7 ، 12-18. [ Google Scholar ] [ CrossRef ]
- یاناگیساوا، ی. آکاهانی، ج. Satoh، T. پرس و جوی تشابه مبتنی بر شکل برای مسیر اشیاء متحرک. در مجموعه مقالات چهارمین کنفرانس بین المللی مدیریت داده های تلفن همراه، ملبورن، استرالیا، 21 تا 24 ژانویه 2003.
- برونتروپ، آر. ادلکمپ، اس. جبار، اس. تولید نقشه افزایشی با ردیابی GPS. در مجموعه مقالات سیستم های حمل و نقل هوشمند IEEE 2005، وین، اتریش، 13 تا 15 سپتامبر 2005.
- لی، جی. Qin، Q. زی، سی. ژائو، ی. لی، جی. Qin، Q. استفاده یکپارچه از روابط مکانی و معنایی برای استخراج شبکههای جادهای از دادههای شناور خودرو. بین المللی J. Appl. زمین Obs. Geoinf. 2012 ، 19 ، 238-247. [ Google Scholar ] [ CrossRef ]
- لیو، CHY; شیونگ، ال. هو، XY; Shan, J. یک روش بافر پیشرو برای به روز رسانی نقشه راه با استفاده از داده های OpenStreetMap. ISPRS Int. J. Geo-Inf. 2015 ، 4 ، 1246-1264. [ Google Scholar ] [ CrossRef ]
- لی، QQ; تانگ، LL; زو، XQ؛ مدلسازی و تجسم سه بعدی جاده مبتنی بر ترانسکت لی، HW. ژئو اسپات. Inf. علمی 2004 ، 7 ، 14-17. [ Google Scholar ]
- پولاک، ک. پلد، ا. مدلهای آماری مبتنی بر ژئو برای پیشبینی آسیبپذیری بخشهای شبکه بزرگراهی هاکرت، اس. ISPRS Int. J. Geo-Inf. 2014 ، 3 ، 619-637. [ Google Scholar ] [ CrossRef ]
- واگستاف، ک. کاردی، سی. راجرز، اس. Schroedl, S. K-محدود به معنی خوشه بندی با دانش پس زمینه است. در مجموعه مقالات هجدهمین کنفرانس بین المللی یادگیری ماشین (ICML)، ویلیامزتاون، MA، ایالات متحده آمریکا، 28 ژوئن تا 1 ژوئیه 2001.
- ادلکمپ، اس. Schrödl، S. برنامه ریزی مسیر و استنتاج نقشه با مسیرهای موقعیت یابی جهانی. محاسبه کنید. علمی چشم انداز 2003 ، 2598 ، 128-151. [ Google Scholar ]
- اودوواراگودا، ا. پررا، ع. Dias، SAD تولید داده های جاده سطح خط از مسیرهای خودرو با استفاده از تخمین چگالی هسته. در مجموعه مقالات شانزدهمین کنفرانس بین المللی سالانه IEEE در مورد سیستم های حمل و نقل هوشمند (ITSC)، لاهه، هلند، 6 تا 9 اکتبر 2013.
- هان، جی. Kamber، M. جریان معدن، سری زمانی، و داده های توالی. در داده کاوی: مفاهیم و تکنیک ها . اسما، س.، اد. الزویر: ایالات متحده آمریکا، 2011; صص 467-531. [ Google Scholar ]
- شکر، س. ایوانز، ام آر. کانگ، جی.ام. پرادیپ، ام. شناسایی الگوها در اطلاعات مکانی: بررسی روشها. حداقل داده سیم بدانید. کشف کنید. 2011 ، 1 ، 193-214. [ Google Scholar ] [ CrossRef ]
- لیو، کیو. تانگ، جی. دنگ، م. Shi، Y. یک روش تشخیص و حذف تکراری برای تشخیص خوشههای فضایی با چگالیهای مختلف. ترانس. در GIS 2015 ، 19 ، 82-106. [ Google Scholar ] [ CrossRef ]
- لی، جی جی; Han, J. خوشهبندی مسیر: یک چارچوب پارتیشن و گروهی. در مجموعه مقالات کنفرانس بین المللی ACM SIGMOD 2007 در مورد مدیریت داده ها، پکن، چین، 11-14 ژوئن 2007.
© 2015 توسط نویسندگان; دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر