

خلاصه
جغرافیای اقتصادی شروع به بررسی گزینه های موجود در داده های خرد کرده است. پایگاههای اطلاعاتی جدیدی در دسترس قرار گرفتهاند و تکنیکهای جدید و افزایش قدرت رایانه امکان درمان آنها را فراهم میکند. با این حال، دو موضوع عمده مانع استفاده از این مجموعه دادهها میشود: فقدان موقعیت مکانی مکانی کدگذاریشده جغرافیایی و عدم جامعیت در پوشش. در این مقاله، من به بررسی امکانات استفاده از پایگاههای اطلاعاتی شرکت در مقیاس خرد برای جغرافیای اقتصادی در اروپا میپردازم. من نشان میدهم که تکامل کنونی در انتشار رسمی دادههای مکانی اروپایی، امکان کدگذاری جغرافیایی چنین پایگاههایی را با استفاده از ابزارهایی فراهم میکند که برای محققانی با حداقل دانش برنامهنویسی قابل دسترسی است. برای مورد خاص پایگاه داده آمادئوس از Bureau Van Dijk، نشان میدهم که محدودیتهای آن از نظر پوشش باید در نظر گرفته شود، اما مانع استفاده از آن برای تجزیه و تحلیل نمیشود.
کلید واژه ها:
داده های خرد ؛ شرکت ها ؛ جغرافیای اقتصادی ; اروپا ؛ آمادئوس ; ژئوکدینگ ; الهام بخشیدن
1. معرفی
جغرافیای اقتصادی تجربی از طریق داده ها، داده ها برای مشاهده و داده ها برای تلاش برای توضیح تمایزات فضایی در توسعه اقتصادی زندگی می کند. عموماً چنین دادههایی به صورت مجموع برای تقسیمات سرزمینی خاص در دسترس هستند، یا به این دلیل که دادهها فقط به این شکل جمعآوری میشوند، یا به این دلیل که جمعآوری در زمان انتشار به دلایل محدودیت منابع، قوانین محرمانگی یا صرفاً سنت اتفاق میافتد (به [ 1 ] مراجعه کنید.] برای مروری انتخابی از وضعیت در اروپا). با این حال، سالهای اخیر شاهد ورود بیشتر و بیشتر مجموعه دادههای حاوی دادههای خرد بودهایم. برای اکثر مجموعههای دادههای رسمی، اطلاعات مکانی هنوز فقط در قالب مقیاسهای خاص تقسیمبندیهای سرزمینی در دسترس است، یا به این دلیل که فقط یک سطح سرزمینی خاص در طول بررسی ثبت میشود یا به این دلیل که قوانین محرمانگی انتشار اطلاعات مکان دقیق را ممنوع میکند (برای مثال رجوع کنید به [ 2]). با این حال، در برخی از مجموعههای داده، عمدتاً تجاری، اطلاعات مکانی به شکل آدرسهای پستی در دسترس است، بنابراین امکان محلیسازی بسیار دقیق موضوع دادهها را فراهم میکند. با این حال، برای اینکه این آدرس ها برای تجزیه و تحلیل جغرافیایی قابل استفاده باشند، باید از طریق فرآیند geocoding به مختصات جغرافیایی ترجمه شوند که کلاس جدیدی از مشکلات را برای محققانی که با مجموعه داده های بزرگ سروکار دارند ایجاد می کند.
در عین حال، این مجموعه داده های خصوصی همیشه دارای همان سطح جزئیات مجموعه داده های عمومی نیستند. پایگاه داده آمادئوس دفتر ون دایک، برای مثال، حاوی اطلاعاتی در مورد واحدهای تولید محلی نیست، بلکه فقط در مورد دفتر مرکزی (حداقل برای اکثر کشورها) اطلاعاتی را در بر می گیرد، در حالی که ثبت رسمی کسب و کار که مبنایی برای آمارهای ساختاری کسب و کار یورواستات است، حاوی اطلاعاتی است. اطلاعات مربوط به واحدهای تولید محلی در مجموعه داده های منطقه ای. بنابراین، محققان باید مراقب باشند تا بررسی کنند که آیا داده ها هنوز برای کار تعیین شده قابل استفاده هستند یا خیر.
این مقاله تحلیلی از قابلیت استفاده پایگاه داده آمادئوس برای مطالعه بومی سازی و تمرکز شرکت در چندین کشور اروپایی ارائه می دهد. این بر دو سؤال اصلی تمرکز دارد: چگونه مجموعه دادههای بزرگی از چنین دادههای خرد را به صورت جغرافیایی کدگذاری کنیم و اینکه آیا دادهها واقعاً برای جغرافیای اقتصادی قابل استفاده هستند، جایی که هم تمایز مکانی و هم بخشی مهم است. ساختار مقاله به شرح زیر است: من با مرور مختصر برخی بحثها در مورد استفاده از دادههای خرد، از جمله نمونههایی از این کاربردها در جغرافیای اقتصادی، شروع میکنم. سپس به ارائه داده های مورد استفاده برای این مطالعه، پایگاه داده آمادئوس از Bureau Van Dijck می پردازم. سپس دو بخش اصلی به جزئیات بیشتری در مورد اول، فرآیند کدگذاری جغرافیایی با استفاده از دادههای عمومی و سرویسهای وب میپردازند و دوم، تجزیه و تحلیل دقیق در مورد قابلیت استفاده از داده ها با توجه به برخی از محدودیت های آن. در بخش پایانی، نقشههایی را ارائه میکنم که از دادهها بیرون میآیند و سپس نتیجهگیری خود را در مورد استفاده از چنین پایگاههای اطلاعاتی و مسائلی که محققان در استفاده از آنها با آن مواجه هستند، ارائه میکنم.
2. داده های خرد در جغرافیای اقتصادی
اخیراً، استفاده از داده های خرد در جغرافیای اقتصادی (و اقتصاد، به طور کلی) افزایش یافته است. این را میتوان با افزایش دسترسی به چنین مجموعههای دادهای و نیز با ظهور فناوریهایی که امکان درمان مجموعههای داده بزرگتر را فراهم میکند، توضیح داد. یکی از استدلالهای اصلی برای استفاده از دادههای خرد، توانایی آن برای جلوگیری از مشکلات مربوط به واحد منطقهای قابل تغییر است. مورد دیگر این است که ریز داده ها بینش های جدیدی را ارائه می دهند که در مجموعه داده های انباشته نامرئی هستند.
2.1. مسئله واحد مساحتی قابل اصلاح
در جغرافیای اقتصادی، الگوها و روابط فضایی پایههای تحلیل هستند. علاوه بر این، بر کسی پوشیده نیست که محتوای این آجرها بسیار وابسته به مقیاس است. نتیجهگیریهای گرفتهشده در سطح NUTS 2 در اروپا، با ترکیب مناطق روستایی و شهری، بسیار متفاوت از نتیجهگیریهای حاصل از مشاهدات جمعآوریشده در سطح شهرداری خواهد بود. این میتواند شامل سؤال ساده تمایز فضایی داخلی محلیسازیها باشد، اما بر نتایج تحلیلهای آماری روابط بین متغیرها نیز تأثیر میگذارد. مسئله واحد منطقه ای قابل اصلاح (MAUP) مفهومی فراگیر است که با این مسائل سروکار دارد.
MAUP برای مدت طولانی شناخته شده است [ 3 ]، اما به عنوان Briant و همکاران. [ 4 ]، “به طرز شگفت انگیزی، اقتصاددانان تا همین اواخر توجه کمی به این مشکل داشتند.” با این حال، جغرافی دانان در مورد این موضوع بسیار نوشته اند. بحثها از تأثیر واقعی MAUP تا بهترین راههای «حل» مشکل تا این تصور که MAUP بهعنوان یک مشکل نیست، بلکه بخشی درونگرایانه از تحلیل جغرافیایی است (برای یک مرور کلی به [ 5 ] مراجعه کنید) را شامل میشود. . برایانت و همکاران [ 4] همچنین نشان می دهد که برای مثال، حداقل در بیشتر موارد، حداقل در سلسله مراتب فضایی اداری و آماری فرانسه، مشخصات مدل یا تعاریف متغیر در واقع تأثیر بسیار قوی تری بر نتایج نسبت به MAUP دارند، اگرچه این بستگی به نحوه تجمیع متغیرها در واحدهای فضایی
با این حال، ایده این نیست که در اینجا در مورد این بحث ها وارد جزئیات شویم، بلکه دنبال کردن یک رشته است که از آن بیرون می آید و فرض می کند که بهترین پاسخ به این سؤالات استفاده از داده های خرد است. همانطور که توسط Grasland و Madelin [ 5 ] بیان شده است، «البته دسترسی به دادههای فردی وضعیت ایدهآل است، نه به این دلیل که سطح فردی در همه موارد مناسبترین سطح برای مشاهده یا مدلسازی یک پدیده است، بلکه عمدتاً به این دلیل که انتخاب میکند. برای مشاهده اطلاعات در تمام سطوح ممکن و برای همه اشکال پارتیشن های فضایی.” طرفداران برجسته استفاده از داده های خرد عبارتند از Tobler [ 6 ، 7 ]، Grasland [ 8 ] و همچنین، و به طور خاص در زمینه جغرافیای اقتصادی، Arbia [ 9 ]., 10 , 11 ]. آنها استفاده از فضای پیوسته را به منظور فراتر رفتن از مسائل مطرح شده توسط مرزهای گسسته یا استفاده از انعطاف پذیری تجمع ارائه شده توسط داده های خرد در نقطه پیشنهاد می کنند.
2.2. بینش جدید از طریق داده های خرد
همانطور که قبلاً ذکر شد، دادههای خرد روز به روز در دسترس محققان قرار میگیرند، و قدرت محاسباتی و آمار بهبود یافته اکنون امکان پردازش این دادهها را با روشهای پیچیدهتر و بیشتر میدهد. چندین نمونه از تحقیقات موجود وجود دارد که نشان می دهد استفاده از داده های خرد در جغرافیای اقتصادی مسیر امیدوارکننده ای به نظر می رسد.
آربیا چندین مثال از کاربردهای مدلسازی پیوسته فضایی، به ویژه در تحلیل تولد، بقا و رشد شرکتها ارائه میکند [ 9 ، 11 ، 12 ] که کاربردهای نوآورانهای از مدلسازی فرآیندهای فضایی را پیشنهاد میکنند. با این حال، او اذعان میکند که یکی از ضعفهای موجود در وضعیت کنونی این است که مجموعههای دادهها اغلب در محتوای خود محدود هستند و «لازم است به مجموعه اطلاعات بزرگتری در مورد متغیرهای ساختاری غیر از صرفاً موقعیت جغرافیایی شرکتها، مانند، برای مثال، ویژگیهای تقاضای محلی، مهارت نیروی کار و ساختار شهری» [ 11 ]]. همانطور که در ادامه خواهیم دید، پایگاه داده آمادئوس در حال حاضر دامنه اطلاعات موجود را گسترش می دهد، اگرچه هنوز به ویژگی های خود شرکت ها محدود است.
یکی دیگر از کاربردهای خرد داده ها در سال های اخیر در مطالعه انباشتگی یا خوشه بندی شرکت ها بوده است. بوکس و همکاران [ 13 ] با استفاده از نمونهای از تقریباً 600000 شرکت از پایگاه داده آمادئوس، با استفاده از خوشهبندی سلسله مراتبی نزدیکترین همسایه فضایی برای شناسایی خوشهها در هر صنعت، خوشههای خلاق را در اروپا کاوش کنید. آنها نتیجه میگیرند که استفاده از دادههای خرد، نتایج بسیار غنیتر و دقیقتری را نسبت به روشهای کلاسیک با دادههای انبوه میدهد. از نظر روش شناسی، مارکون و پوچ، و همچنین دورانتون و اورمن [ 14 ، 15 ، 16 ]] یک خط بازتاب را در مورد بهترین راه برای اندازه گیری الگوهای محلی سازی و تمرکز بر اساس داده های خرد، عمدتاً در راستای یا به صراحت بر اساس تابع K ریپلی، آغاز کرده اند.
در اقتصاد، یک زمینه تحقیقاتی اخیر که وابسته به داده های خرد است، ناهمگونی شرکت است [ 17 ، 18 ، 19 ، 20 ]]. اگرچه، در این مرحله، پژوهش یک فضایی است، به این معنا که الگوهای فضایی را به عنوان عاملی در تحلیل لحاظ نمیکند، اما استفاده از دادههای خرد برای درک بهتر محرکهای واقعی اقتصاد منطقهای، مورد جالبی است. توسعه. یک نتیجه تحریک آمیز از این تحقیق این است که صادرات به خارج از مناطق محدود به چند شرکت صادرکننده با بهره وری بالا است، در حالی که بیشتر شرکت ها فقط به بازارهای محلی می پردازند. اگرچه این نتیجهگیریها بر اساس نظرسنجیهایی است که تعداد زیادی متغیر را ارائه میکند، اما آنها تنها نمونه محدودی از شرکتها را نشان میدهند، و بنابراین اغلب از نظر الگوهای فضایی چندان نماینده نیستند. بنابراین، استفاده از دادههای خرد جامعتر، اگرچه از نظر متغیرها محدودتر است، ممکن است مسیر جالب دیگری را برای کاوش در آن زمینه فراهم کند.21 ، 22 ]. همراه با کار فوق الذکر در مورد مکان و تمرکز در فضای پیوسته، این ادبیات اخیر در مورد پیوندهای بین تجمع و صادرات مطمئناً موضوع جالبی برای آینده است.
3. داده ها
داده های شرکت مورد استفاده از پایگاه داده آمادئوس تولید شده توسط Bureau Van Dijck و حاوی داده های خرد در مورد شرکت های همه کشورهای اروپایی است [ 23 ]. در مجموع شامل حدود 17 میلیون شرکت در سراسر قاره است. این بر اساس حساب های تجاری است که در ثبت ملی ثبت شده و قبل از وارد شدن به پایگاه داده توسط نقاط تماس ملی جمع آوری شده است. منشا داده ها توضیح می دهد که عمدتاً حاوی اطلاعات مالی است و تعداد زیادی متغیر برای ارزیابی ترازنامه هر شرکت در دسترس است. همچنین حاوی اطلاعات مالکیت است که امکان مطالعه شبکه های شرکت را فراهم می کند [ 24]، اگرچه این داده ها برای مطالعه حاضر در دسترس نبود. در نهایت، این شامل آدرس پستی رسمی کامل دفتر مرکزی است (اگرچه برای برخی از کشورها این داده ها باید با هزینه اضافی خریداری شوند)، یک موقعیت جغرافیایی در سطح NUTS2 (سطح جغرافیایی که مستقیماً در پایگاه داده AMADEUS موجود است در واقع به طور قابل توجهی بهبود یافته است. در طول نگارش و بازنگری این مقاله از سطح NUTS2 به NUTS3 یا حتی وضوح بهتر – تا شهرداریها در برخی کشورها – پایگاه داده را مستقیماً برای انواع خاصی از تحلیلها در جغرافیای اقتصادی قابل استفاده میکند.) و ویژگیهای اساسی مانند NACE 4 رقمی کدها و شکل قانونی اطلاعات اندازه در قالب تعداد کارمندان و گردش مالی موجود است، اگرچه این داده ها در بسیاری از کشورها کامل نیست.
یکی از اهداف این مطالعه ارزیابی این بود که چه دادهها یا خدمات عمومی در حال حاضر برای امکان رمزگذاری جغرافیایی چنین ریز دادهها بدون نیاز به توسل به راهحلهای تجاری گران قیمت موجود است. تلاشی برای شناسایی دادههای موجود در هر کشور در اروپا انجام شد، اگرچه هیچ ادعایی مبنی بر جامع بودن نمیتوان داشت، زیرا یافتن دادهها اغلب آسان نیست، اگرچه این مسئله باید به زودی با زیرساختهایی که در زمینه ایجاد شده حل شود. دستورالعمل INSPIRE (به زیر مراجعه کنید).
با ترکیب دادههای آدرسی که در پایگاه داده آمادئوس به آنها دسترسی داشتم و دادههای آدرس یا خدمات رمزگذاری جغرافیایی که پیدا کردم، در نهایت با دادههای کشورهای زیر کار کردم: بلژیک، دانمارک، فرانسه، هلند، اسپانیا و بریتانیا، در مجموع 5232318 شرکت.
4. منابع عمومی برای کدگذاری جغرافیایی
در هر تحلیل فضایی، قرار دادن داده ها در مکان مناسب ضروری است. در بسیاری از کاربردها، مکان در ابتدا داده می شود، چه برای داده های جمع آوری شده در واحدهای اداری شناخته شده یا برای داده های جمع آوری شده در میدان با GPS، ماهواره یا سایر ابزارها. با این حال، مجموعهای از دادهها در حال افزایش است که مکان آنها با آدرسهای پستی داده میشود، و هر گونه تحلیلی را غیرممکن میکند، زیرا آدرسها اجازه درمان کمی را نمیدهند، و به صراحت اطلاعاتی درباره فواصل و سایر روابط فضایی بین مشاهدات ارائه نمیدهند.
برای به دست آوردن موقعیت جغرافیایی قابل استفاده از این داده ها، آدرس های پستی باید از طریق کدگذاری جغرافیایی به مختصات نقطه ای تبدیل شوند. راهحلهای تجاری وجود دارند، اما اغلب برای کاربران در حوزه دانشگاهی بسیار گران هستند. خدمات رمزگذاری جغرافیایی آنلاین تجاری رایگان مانند APIهای Google، Yahoo و Bing به شدت استفاده از نتایج کدگذاری جغرافیایی را به مشاهده ساده بر روی نقشه های مربوطه محدود می کند. هر گونه رفتار تحلیلی از نظر قانونی مستثنی است، بنابراین این خدمات به قرار دادن ساده نشانگرها بر روی نقشه ها کاهش می یابد. دلیل اصلی این محدودیت ها در واقع خود سرویس نیست، بلکه داده های پشت سرویس است. ارائه دهندگان داده های خصوصی منابع مهمی را برای نگهداری پایگاه داده های خود سرمایه گذاری می کنند که آدرس ها را به مختصات جغرافیایی پیوند می دهد. همانطور که APIهای فوق یا سایر راه حل های تجاری از این پایگاه داده ها استفاده می کنند، محدودیتهایی که با هدف حفاظت از این دادهها انجام میشود، خدمات رمزگذاری جغرافیایی مرتبط را نیز مختل میکند (ارتباط شخصی از سرویسهای پشتیبانی Google با نویسنده). در یک محیط دانشگاهی که در آن استفاده انعطاف پذیر از داده ها اولیه است، چنین محدودیت هایی نتایج کدگذاری جغرافیایی را تقریباً بی فایده می کند. در ایالات متحده آمریکا، یک جایگزین به شکل داده های اداره سرشماری ببر وجود دارد و راه حل های رایگان بر اساس این داده ها وجود دارد. در اروپا دسترسی به چنین داده هایی در گذشته بسیار دشوارتر بود. یک جایگزین در قالب داده های اداره سرشماری ببر وجود دارد و راه حل های رایگان بر اساس این داده ها وجود دارد. در اروپا دسترسی به چنین داده هایی در گذشته بسیار دشوارتر بود. یک جایگزین در قالب داده های اداره سرشماری ببر وجود دارد و راه حل های رایگان بر اساس این داده ها وجود دارد. در اروپا دسترسی به چنین داده هایی در گذشته بسیار دشوارتر بود.
در نهایت، یک راهحل جمعسپاری در سالهای گذشته به وجود آمده است (اغلب دادههای عمومی را در صورتی که تحت شرایط مجوز کافی در دسترس باشد، یکپارچه میکند)، در قالب OpenStreetMap. بسته به کشورها، داده ها در حال حاضر کاملاً کامل است، اگرچه در برخی مناطق شماره خانه هنوز در دسترس نیست. برای مطالعه استفاده از این داده ها برای کدگذاری جغرافیایی به [ 25 ] مراجعه کنید.
با این حال، زمان در حال تغییر است و در حال حاضر تحولات اساسی در دیدگاه و سیاست دولت های اروپایی در مورد داده های تولید شده توسط دولت رخ می دهد. جنبش OpenData در حال شتاب گرفتن است [ 26 ]، که توسط اصلاح عمومی دسترسی به داده های مکانی عمومی که توسط دستورالعمل اتحادیه اروپا INSPIRE حمایت می شود، پشتیبانی می شود، و بنابراین چندین کشور داده های آدرس رسمی خود را به صورت عمومی و رایگان در دسترس قرار داده اند، بنابراین امکان بسط راه حل های کدگذاری جغرافیایی مبتنی بر آن را فراهم کرده اند. روی آن داده ها برخی کشورها و مناطق از این هم فراتر رفته اند و خدمات وب ژئوکدینگ را ارائه می دهند.
4.1. نقش دستورالعمل INSPIRE
انتشار داده های مکانی در اروپا به شدت تحت تأثیر دستورالعمل INSPIRE اروپا در سال 2007 است که قوانین و زیرساخت های یک سیستم داده مکانی اروپایی را ایجاد می کند [ 27 ]. این یک سری موضوعات را مشخص می کند که کشورهای عضو باید داده ها را در قالب انواع خدمات، از کشف تا دانلود، در دسترس قرار دهند. طبق ماده 14 این دستورالعمل، تنها خدمات کشف و مشاهده باید رایگان باشد، زیرا سایر کشورهای عضو می توانند هزینه دریافت کنند. دادههای آدرس بخشی از پیوست I است که مهمترین دادهها را فهرست میکند. کلیه خدمات از جمله خدمات دانلود باید از دسامبر 2012 توسط کشورهای عضو اجرا شود [ 28]. علاوه بر این، کشورهای عضو همچنین می توانند خدمات داده های مکانی را همانطور که در قوانین اجرایی مربوطه تنظیم شده است ارائه دهند که در حال حاضر در مراحل نهایی سازی است.
کشورهای عضو مسیرهای بسیار متفاوتی را در اجرای دستورالعمل و مقررات INSPIRE انتخاب کرده اند. بسیاری محدودیت های دسترسی را از نظر هزینه و مجوز تغییر نداده اند، بلکه فقط شکل دسترسی را مطابق با INSPIRE ساخته اند. با این حال، در برخی کشورها، دستورالعمل INSPIRE الهام بخش یک حرکت اساسی تر به سمت باز کردن مجموعه داده های عمومی برای دسترسی و استفاده عمومی است.
محتوای مجموعه داده ها نیز در فرآیند INSPIRE تعیین می شود. به عنوان مثال، دستورالعمل INSPIRE در ضمیمه I خود، داده های آدرس را به عنوان “موقعیت دارایی ها بر اساس شناسه های آدرس، معمولاً بر اساس نام جاده، شماره خانه، کد پستی” تعریف می کند [ 27 ]. مشخصات دادههای INSPIRE برای آدرسها با توضیح اینکه «یک آدرس دارای یک شناسه است، به عنوان مثال، یک شماره آدرس یا یک نام ساختمان، که کاربر را قادر میسازد آن را از آدرسهای همسایه متمایز کند، و همچنین موقعیت جغرافیایی، که این امکان را فراهم میکند. برنامه برای مکان یابی آدرس به صورت مکانی. شناسه قابل خواندن توسط انسان در طرحواره برنامه به عنوان آدرس “مکان یاب” تعریف شده است. موقعیت جغرافیایی به عنوان یک نقطه جغرافیایی نشان داده می شود» [ 27]. بنابراین، کشورها باید دادههای خود را ساختاربندی کنند تا با این مشخصات مطابقت داشته باشند و استفاده از دادهها هنگام کار در بین کشورها آسانتر شود.
4.2. مروری بر اشکال مختلف انتشار داده ها
حتی اگر دستورالعمل INSPIRE سطح مشخصی از هماهنگی را فراهم می کند، کشورها در مورد شکلی که در آن داده های خود را منتشر می کنند، آزادی عمل دارند. میز 1نمای کلی از اشکال مختلفی که کشورها داده های خود را عمومی می کنند ارائه می دهد. این یک موجودی جامع نیست، به ویژه از آنجایی که هدف موجودی در حال حاضر یک هدف متحرک است، با دادههای جدید و سرویسهای جدید که اغلب ظاهر میشوند. در عوض، جدول مجموعه داده هایی را که من در زمینه تحقیق خود استفاده کردم را ارائه می دهد، اما حتی در این انتخاب محدود، بسیاری از اشکال مختلف انتشار داده ها نشان داده شده است. هدف نشان دادن این موارد به عنوان نمونههایی از نحوه رسیدگی کشورها به تعهدات INSPIRE و خطمشی کلی دادههایشان، با استفاده از دادههای آدرس به عنوان مطالعه موردی است، اما همچنین ارائه اطلاعات دقیق در مورد مشکلاتی که ممکن است در تلاش برای استفاده از چنین دادههای آدرسی برای آنها پیش بیاید، ارائه شود. ژئوکدینگ به طور خاص، جدول نمای کلی از اشکال انتشار از نظر دسترسی به داده ها و انواع مجوزهای مورد استفاده را ارائه می دهد.مبنای موردی برای تحقیق در بسیاری از کشورهای دیگر، دادهها وجود دارد، اما فقط در ازای هزینهای در دسترس هستند که میتواند به سطوح بسیار چشمگیر برسد (برای مثال، در آلمان، دسترسی به مجموعه دادههای تمام آدرسهای آلمانی با مختصات جغرافیایی به قیمت بیش از 100000 یورو فروخته میشود، از جمله برای استفاده تحقیقاتی و تا لحظه نگارش این مقاله، هیچ سرویس آنلاینی برای کاربران غیر از ادارات دولتی در دسترس نبود، که باعث می شود در اکثر زمینه های دانشگاهی غیر قابل دسترس باشد.

جدول 1. مروری بر اشکال انتشار داده های آدرس.
4.3. خصوصیات ملی در قالب ها و محتوای داده ها
در هر کشوری، آدرس ها به گونه ای متفاوت مدیریت می شوند. مسائل اصلی که ساده بودن ژئوکدینگ را تعیین می کند عبارتند از:
-
جزئیات مکانی کدهای پستی که میتواند هر چیزی را از ساختمانها و خیابانها تا مجموعهای از شهرداریها نشان دهد: از آنجایی که کدهای پستی عنصری نسبتاً آسان برای تطبیق هستند، هر چه منطقه کد پستی کوچکتر باشد، پیدا کردن یک خیابان خاص در آن آسانتر است. حوزه.
-
(در ترکیب با قبلی) وجود یا نبودن بیش از یک خیابان با همان نام در یک منطقه کدپستی واحد.
-
تمایل در کشور به استفاده از نام مکان های غیررسمی (“lieux-dits”)، نام ساختمان ها و غیره به عنوان آدرس های قابل قبول برای تحویل پست.
-
وجود آدرسهای قدیمی و متروکه با تاریخ اعتبار در مجموعه دادههای مرجع: این امکان را میدهد تا دادهها را حتی اگر تغییر نام خیابان، شمارهگذاری مجدد یا تغییر کدپستی صورت گرفته باشد، ژئوکدگذاری شود.
-
انتشار آدرسها بر خلاف دادههای GIS (خیابانها، بستهها و غیره ) که نیاز به استفاده از نرمافزار تخصصی دارند و اغلب قبل از بهدستآوردن آدرسهای واقعی نیاز به پیشپرداخت دارند.
جدول 2 برخی از ویژگی های مجموعه داده های مورد استفاده واقع در تحقیق را از نظر محتوا و سهولت استفاده فهرست می کند. باز هم وضعیت متفاوت است. برخی از کشورها داده های نوع صفحه گسترده ساده را با آدرس های تجزیه شده و مختصات مربوطه ارائه می دهند. برخی دیگر داده های پیچیده XML را ارائه می دهند که استفاده مستقیم از آنها آسان نیست.
جدول 2. محتوا، قالب و مشخصات مجموعه داده آدرس ملی.
5. مسائل کاربردی در ژئوکدینگ
5.1. معرفی
فرآیند geocoding در واقع ترکیبی از دو فرآیند است: (الف) رمزگشایی آدرس به بخشهای تشکیلدهنده آن (خیابان، شماره خانه، کد پستی و شهر) و (ب) تطبیق هر یک از این بخشها با دادههای مربوطه در پایگاه داده مرجع. نحوه اعمال این موارد به داده ها یا خدمات ارائه شده در هر کشور بستگی دارد.
اکثر کشورهای ارائه دهنده خدمات وب، خدمات تجزیه آدرس را نیز ارائه می دهند که گاهی در یک سرویس ادغام می شود، گاهی اوقات به عنوان یک سرویس جداگانه. در مورد دوم، بنابراین ابتدا باید سرویس تجزیه آدرس را برای یافتن بهترین تطابق و سپس سرویس کدگذاری جغرافیایی برای بازیابی مختصات آدرس یافت شده فراخوانی کرد.
هنگام استفاده از داده های مرجع مکانی برای رمزگذاری جغرافیایی، یا زمانی که هیچ سرویس تجزیه ای ارائه نمی شود، یا زمانی که استفاده از سرویس تجزیه تا حدودی چالش برانگیزتر است، می توان آدرس ها را قبل از ارسال به یک سرویس یا تطبیق آنها با آدرس های موجود در داده های مرجع، به صورت دستی تجزیه کرد. .
هدف در این بخش بررسی تئوری geocoding در تمام جنبه های آن نیست (برای یک نمای کلی به [ 30 ] مراجعه کنید)، بلکه بیشتر به بررسی مسائل عملی در زمینه داده های عمومی فعلی و در دسترس بودن خدمات است.
5.2. خدمات وب یکپارچه
در تئوری، آن دسته از کشورهایی که خدمات وب یکپارچه تجزیه و کدگذاری جغرافیایی را ارائه میدهند، سادهترین روش برای کاربر هستند: فقط آدرس «همانطور که هست» را به سرویس ارسال کنید و مختصات بهترین تطابقی را که سرویس میتواند پیدا کند، بازیابی کنید. این شبیه حالت استفاده عمومی از خدمات آنلاین تجاری مانند Google Maps یا API مربوطه است. در این مورد نیازی به تجزیه آدرس دستی نیست. با این حال، گاهی اوقات آدرس ها در وضعیت بدی قرار می گیرند یا حاوی اطلاعات بسیار بیشتر از حد لازم هستند، در نتیجه وب سرویس را گیج می کند. در این صورت، برخی از تجزیه و تمیز کردن دستی ممکن است برای افزایش قابل توجه نرخ تطابق ضروری باشد. یک سری آزمایش با یک نمونه محدود و تصادفی از آدرسها اغلب برای شناسایی مشکلات رایج و مداخلات ضروری ضروری است.
بنابراین چالش اصلی این سرویس ها هنگام کار با پایگاه داده های بزرگ، خودکارسازی فرآیند است. در بیشتر مواقع، این سرویس به درخواستها برای یک آدرس در یک زمان اجازه میدهد، بنابراین نیاز به حلقهای دارد که از همه آدرسها عبور میکند، آنها را یک به یک بررسی میکند و نتایج را ذخیره میکند. خدمات به صورت REST [ 31 ] یا به صورت SOAP [ 32 ] ارائه می شود] خدمات. در مورد اول، استفاده از سرویس یک موضوع ساده فراخوانی یک URL HTTP حاوی آدرس به عنوان پارامتر و بازیابی نتیجه در فرم ارائه شده (JSON، XML و CSV) است. در مورد دوم، ارسال اطلاعات در فرم XML کمی پیچیده تر است. در هر دو مورد، مطالعه مستندات مربوط به API برای درک محتوای بازگردانده شده توسط سرویس مهم است. یک اطلاعات ضروری که توسط اکثر سرویس ها ارائه می شود، معیاری برای سنجش کیفیت مسابقه است. اگرچه مقادیر مطلق این معیارها لزوماً معنای روشنی ندارند، می توان از آنها برای مقایسه بین مسابقات و برای دریافت احساس کیفیت بالقوه مسابقه استفاده کرد. در تکمیل،
حداقل دانش یک زبان سازگار با اسکریپت مانند Python، Ruby یا سایرین برای ارائه حلقه و مدیریت خطای اساسی ضروری است. در مورد سرویس SOAP، کتابخانه های تخصصی برای اکثر زبان های برنامه نویسی وجود دارد که دسترسی به چنین خدماتی را تسهیل می کند. در مورد ارائه شده در این مقاله، من از زبان Python استفاده کردم، با کتابخانه suds [ 33 ] که یک رابط برای پروتکل SOAP فراهم می کند.
5.3. تجزیه آدرس
برای همه کشورهایی که برای آنها ضروری بود، تجزیه آدرس در سیستم مدیریت پایگاه داده رابطهای PostgreSQL (با پسوند آن PostGIS برای مدیریت مجموعههای دادهای که به شکل هندسه برداری هستند) انجام شد. زبان مورد استفاده SQL خالص بود.
به دلیل اشکال بسیار متفاوت آدرسها در هر کشور، و این واقعیت که آدرسهای پایگاه داده آمادئوس توسط خبرنگاران ملی به سبک خاص کشور ارائه میشد، من قوانین خاص کشور به کشور را برای جداسازی نام خیابانها و شماره خانهها ایجاد کردم. در پایگاه داده آمادئوس، آدرس شامل یک خیابان یا نام مکان و به طور کلی یک شماره خانه است، گاهی اوقات با اصلاح کننده ها. نام شهرها و کدهای پستی قبلاً در فیلدهای جداگانه پایگاه داده هستند. به طور کلی، سبکهای آدرس در هر کشور با شماره خانه قبل یا بعد از نام خیابان، استفاده احتمالی از کاما بین شماره خانه و نام خیابان و غیره سازگار است.با این حال، هنوز هم تمیز کردن زیادی برای سازگاری نام خیابانها و شهرها بین پایگاههای داده (جایگزینی کاراکترهای برجسته، گسترش اختصارات و غیره ) ضروری بود. به طور کلی، قوانین ad hoc برای رمزگشایی آدرس ها شامل قطع کردن آدرس طبق قوانین خاص است. کد SQL در فایل های اضافی جزئیاتی را که قوانین در مورد آنها اعمال شده است را ارائه می دهد.
یک سوال مهم در این مرحله این است که آیا شماره خانه ضروری است، و اگر بله، آیا اصلاح کننده ها و ترکیبات شماره خانه (به عنوان مثال، 7A 115-117، 234 جعبه 10A) باید حفظ شوند یا می توان آنها را حذف کرد. از آنجایی که در برخی کشورها خیابانها طولانی هستند، تصمیم گرفتم شماره خانهها را حفظ کنم. تلاش برای حفظ اصلاحکنندهها بهطور قابلتوجهی دشواری رمزگشایی آدرس را افزایش میدهد، بدون اینکه دقت موقعیت مکانی بهبود یابد، بنابراین تصمیم گرفتم بدون اصلاحکننده کار کنم، به جز کشورهایی که استخراج این اصلاحکنندهها آسان بود. باید توجه داشت که همه پایگاههای داده آدرس حاوی اصلاحکنندهها نیستند، یا حداقل همیشه به شیوهای ثابت نیستند.
هنگامی که شماره خانه و اصلاح کننده ها شناسایی و استخراج شدند، بقیه را می توان به طور کلی به عنوان نام خیابان در نظر گرفت. با این حال، استثنائات زیادی برای این قاعده وجود دارد، با نام مکانها، نام ساختمانها، نام پارکهای صنعتی و ترکیبهای متعددی از این موارد. به منظور شناسایی نام واقعی خیابان، در این مرحله، توصیه میشود که از پایگاه داده مرجع به عنوان منبع نامهای احتمالی خیابانها استفاده کنید و بنابراین نام خیابان رسمی را که احتمالاً با آدرس موجود در پایگاه داده آمادئوس مطابقت دارد، شناسایی کنید. این جستجو مستلزم استفاده از الگوریتمهای تطبیق رشتههای فازی است که معیاری از شباهت بین دو رشته را ارائه میدهد، بنابراین امکان انتخاب شبیهترین نام خیابان را فراهم میکند. الگوریتم های زیادی در ادبیات وجود دارند و با گذشت زمان الگوریتم های بیشتری توسعه می یابند.و غیره ترکیبی از تکنیک های مختلف می تواند برای ایجاد الگوریتم های تطبیق پیچیده تر، مانند درخت تصمیم [ 34 ] استفاده شود. پرداختن به جزئیات این تحقیق از حوصله این مقاله خارج است، اما برای تطبیق متون کوتاه مانند نام خیابان و شهر، دو الگوریتم به عنوان پرکاربردترین الگوریتم برجسته هستند: n-gram و فاصله Levenshtein. اولی همه زیررشتههای ممکن n حرف را شناسایی میکند (من از n = 3 استفاده کردم) در هر رشته کاراکتری و سپس شباهت استاندارد شده بین دو رشته را به عنوان تعداد زیررشتههای منطبق تقسیم بر اندازهگیری طول کل رشتهها محاسبه میکند. دومی فاصله ویرایش است که به عنوان تعداد ویرایشها (حذف، درج و جایگزینی) لازم برای رسیدن از یک رشته به رشته دیگر تعریف میشود [ 35 ,36 ، 37 ]. برای انتخاب بین این دو، چند تست مختصر با الگوریتم های ارائه شده توسط PostgreSQL انجام دادم. هر دو نتایج تقریباً مشابهی را نشان دادند، با یک مزیت جزئی نسبت به تریگرام ها، بنابراین تصمیم گرفتم از آنها برای تطبیق الگو، با استفاده از پسوند pg_trgm استفاده کنم [ 38 ]. این به اندازه کافی خوب عمل کرد تا عدم ساخت موتور تطبیق الگوی پیچیده تر را توجیه کند.
در نتیجه، تجزیه آدرس، از جمله تطبیق فازی نام خیابانها و شهرها، چالشبرانگیزترین بخش فرآیند است که بسته به وضعیت آدرسها، به راهحلهای موقت زیادی نیاز دارد. با این حال، راه حل ها وجود دارند و می توانند در SQL خالص اعمال شوند، بنابراین به مهارت های برنامه نویسی زیادی نیاز ندارند. یکی از تلاشهای توسعه تکنیکهای تجزیه آدرس رایگان در دسترس که شایان ذکر است، geocoder PostGIS [ 39 ] است. در ابتدا برای داده های ببر ایالات متحده توسعه داده شد، بنابراین به فرمت های آدرس ایالات متحده محدود شد، اکنون تلاش ها برای توسعه ماژول های خاص برای هر کشور ادامه دارد که باید تجزیه آدرس را با استفاده از این نرم افزار رایگان تسهیل کند (سرویس آنلاین اسپانیایی بر اساس چنین ماژول سفارشی سازی شده است).
5.4. تکنیک های مورد استفاده برای ژئوکدینگ
هنگامی که آدرس رمزگشایی شد و نام خیابان و شهر مناسب یافت شد، کد جغرافیایی واقعی، یعنی ترجمه داده های آدرس به مختصات جغرافیایی در یک پایگاه داده نسبتاً آسان است و صرفاً شامل بازیابی مختصات مربوط به خیابان و شهر پیدا شده است. و شماره خانه خاص
با این حال، گاهی اوقات، شماره خانه در پایگاه داده شرکت در پایگاه داده مرجع وجود ندارد، یا به سادگی شماره خانه در آدرس وجود ندارد. در حالت اول، می توان مکان شماره خانه را بر اساس شماره خانه های همسایه در پایگاه مرجع درون یابی کرد. در مورد دوم، یا باید از یک نقطه مرجع که خیابان را نشان میدهد استفاده کرد (مثلاً نقطه مرکزی آن)، یا میتوان یک مکان مرکزی را بر اساس شماره خانههای موجود در آن خیابان درون یابی کرد. این رویکرد اخیر بهویژه برای مناطق روستایی مفید است، جایی که خیابانها میتوانند بسیار طولانی باشند و ساختمانهایی که فقط در نقاط خاصی متمرکز شدهاند، و بهویژه در کشورهایی که شهرداریها کوچک هستند، مؤثر است، و بهعنوان پایهای برای درونیابی تنها از آن دسته از شمارههای خانه استفاده میشود که در محدوده قرار میگیرند. همان شهرداری که آدرس جستجو شده است.
برای خدمات آنلاین، همه چیز به اجرای خاص سرویس پیشنهادی بستگی دارد. برخی از سرویسها بهطور خودکار آدرسهای «مشابه» از جمله نزدیکترین شماره خانه، نزدیکترین نام خیابان یا مختصات کوچکترین واحد فضایی بالاتری را که میتوان شناسایی کرد (خیابان، منطقه پستی و غیره ) پیشنهاد میکند. در سرویس دسته ای فلاندری، در صورت عدم وجود شماره خانه، هیچ مختصاتی ارائه نمی شود. در این صورت، باید از وب سرویس دیگری برای دریافت مختصات در سطح خیابان استفاده شود.
از آنجایی که درون یابی اعداد خانه به یک سری آزمایش و محاسبات نیاز دارد، من تصمیم گرفتم از زبان برنامه نویسی داخلی PL/PGSQL برای این کار هنگام کدگذاری جغرافیایی در پایگاه داده استفاده کنم یا الگوریتم های درون یابی را در اسکریپت های پایتون که سرویس های وب را فراخوانی می کنند، پیاده سازی کردم. دور زدن نزدیکترین شماره خانه تا زمانی که مطابقت پیدا شود. الگوریتم اساسی پیاده سازی شده برای درون یابی عبارت است از:
-
نزدیکترین اعداد را در بالا و پایین شماره خانه داده شده جستجو کنید (احتمالاً فقط اعداد زوج یا فرد را در نظر بگیرید اگر سیستم محلی این اعداد را در طرفین خیابان های مخالف داشته باشد)
-
اگر عددی فقط در بالا یا پایین یافت شود

-
از نزدیکترین عدد یافت شده استفاده کنید و مختصات آن را بازیابی کنید (احتمالاً شعاع جستجوی اعداد نزدیک را محدود کنید)
-
اگر اعداد بالا و پایین یافت شوند،
-
تفاوت بین شماره خانه داده شده و نزدیکترین شماره خانه زیر و نسبت آن اختلاف در تفاوت بین نزدیکترین شماره خانه بالا و نزدیکترین شماره خانه زیر را محاسبه کنید.
-
مختصات x (y) را به عنوان نسبت معادل تفاوت بین مختصات x (y) عدد بالا و عدد زیر اضافه شده به کمترین مقدار x(y) محاسبه کنید.

جزئیات پیاده سازی های فردی را می توان در فایل های اضافی یافت. به منظور اطمینان از هماهنگی در اطلاعات محلی سازی، تمام مختصات در مجموعه داده های مرجع با تابع PostGIS ST_Transform به مختصات طولانی در درجه با استفاده از WGS84 مبدأ (کد EPSG 4326) قبل از کدگذاری جغرافیایی تبدیل شدند.
6. قابلیت استفاده
در حالی که geocoding یک موضوع مهم در ارزیابی قابلیت استفاده از پایگاه های داده میکرو مانند پایگاه داده آمادئوس است، مهم ترین سوال بدیهی است که اطلاعات واقعی موجود در پایگاه داده چقدر مفید است. اغلب پاسخ به سؤال تحقیقی خاص بستگی دارد، اما چند عنصر اساسی در اکثر اهداف تأثیرگذار است.
6.1. کامل بودن
پایگاه داده آمادئوس در نسخه فوریه 2012 خود که برای این مطالعه مورد استفاده قرار گرفت، شامل حدود 17 میلیون شرکت فعال در سراسر اروپا است. وقتی محدود به شرکتهای درون اتحادیه اروپا باشد، این تعداد به حدود 14 میلیون کاهش مییابد. پایگاه داده آمار ساختاری کسب و کار (SBS) Eurostat، بر اساس ثبت ملی کسب و کار، در مجموع حدود 22 میلیون شرکت را در سال 2011 (سال گذشته که پوشش جامع برای EU28 در دسترس است) در NACE Rev. 2 بخش های B تا N و بخش 95 ارائه می دهد. این نشان میدهد که آمادئوس تمام مشاغل ثبتشده در ثبتهای تجاری در سراسر اتحادیه اروپا را پوشش نمیدهد، اما همچنان دارای سهم عادلانهای از شرکتها است.
در مقایسه کشور به کشور ( جدول 3 )، مشخص می شود که وضعیت بین کشورها بسیار نابرابر است، مطابق با مشاهدات Boix و همکاران در مورد صنایع خلاق [ 12 ]. توجه داشته باشید که مجموعها در اینجا فقط برای بخشهایی است که تحت پوشش پایگاه داده SBS هستند، بنابراین فقط زیر مجموعهای از بخشهای تحت پوشش پایگاه داده آمادئوس است.
جدول 3. تعداد شرکت ها در پایگاه داده آمادئوس و در آمارهای ساختاری تجاری Eurostat در بخش های تحت پوشش SBS.
تفاوتهای بزرگ ناشی از قوانین مربوط به شرکتهایی است که باید حسابها را ثبت کنند، زیرا پایگاه داده آمادئوس بر اساس این حسابهای بایگانی است در حالی که ثبت کسب و کار بر اساس دادههای اداری و نظرسنجی است، و همچنین میتواند شامل اشکال مختلف شرکتهای عمومی، از جمله شرکتهایی باشد که به دولتهای محلی مرتبط است و احتمالاً باید از تحلیلهای بومیسازی حذف شود زیرا آزادی حرکت آنها محدود است. برای فرانسه، آمادئوس در واقع شرکتهای بیشتری از آنچه در جدول نشان داده شده است، پیشنهاد میکند، اما نیمی از شرکتها از منبع متفاوتی برای دسترسی به پایگاهداده میآیند که دسترسی به آن مشمول هزینههای اضافی است و بنابراین برای این مطالعه در دسترس نبودند. با این حال، به طور کلی، داده های پایگاه داده آمادئوس را می توان به عنوان نمونه ای به اندازه کافی بزرگ برای تجزیه و تحلیل محلی سازی سازمانی در نظر گرفت.
بومی سازی ساده شرکت ها بر اساس بخش در حال حاضر یک متغیر جالب برای مطالعه است، اما پایگاه داده آمادئوس تعداد زیادی متغیر دیگر را ارائه می دهد که می تواند برای جغرافیای اقتصادی جالب باشد. کلیه متغیرهای حسابهایی که شرکتها موظف به تشکیل پرونده هستند و همچنین اطلاعات موجود در بازار سهام و مالکیت در بانک اطلاعاتی ثبت میشوند. اطلاعات شامل اطلاعات حقوقی مانند فرم حقوقی و داده های شرکت، کل ترازنامه و حساب سود و زیان شامل اطلاعات دارایی ها، کارکنان و بهره وری مبتنی بر کارمندان، و فروش، داده های سهام، اطلاعات مربوط به سهامداران و شرکت های تابعه است. بنابراین تحلیلهای بالقوه شامل تولدهای شرکت، جغرافیای سود، جغرافیای روابط مالکیت در مقیاسهای بسیار خوب، تحلیلهای بهرهوری و غیره است.. با این حال، اینکه کدام متغیرها برای کدام نوع شرکت ها اجباری هستند به هر کشوری بستگی دارد. با تغییر قوانین حسابداری و تکامل کیفیت گزارشدهی، پایگاه داده آمادئوس نیز در طول زمان تغییر میکند، و بنابراین نشانهها در اینجا فقط یک عکس فوری در تاریخ دادههای مورد استفاده (فوریه 2012) هستند. به محض در دسترس قرار گرفتن اطلاعات جدید، داده ها به روز می شوند. بنابراین برای ایجاد سری های زمانی، باید عکس های فوری معمولی گرفته شود. جدول 4نسبت داده های از دست رفته را برای انتخاب کوچکی از این متغیرها نشان می دهد. این به وضوح نشان می دهد که محققان باید در انتخاب متغیرها و قلمرو مطالعه دقت زیادی داشته باشند تا با یک نمونه به شدت محدود کار نکنند. با این حال، وقتی فقط به شرکتهای بزرگ و بسیار بزرگ نگاه میکنیم (طبق تعریف آمادئوس)، وضعیت در حال حاضر بسیار دلگرمکنندهتر است، زیرا این شرکتها عموماً تابع قوانین حسابداری گستردهتری نسبت به شرکتهای کوچک و متوسط هستند.
جدول 4. نسبت بر اساس کشور داده های از دست رفته برای مجموعه ای از متغیرها در پایگاه داده آمادئوس (EBIT = سود قبل از بهره و مالیات، ROE = بازده حقوق صاحبان سهام، L&VL = فقط شرکت های بزرگ و بسیار بزرگ، به عنوان مثال ، درآمد عملیاتی ≥ 10 میلیون یورو یا کل دارایی ها ≥ 20 میلیون یورو یا کارکنان ≥ 150).
از آنجایی که ما نه تنها به مجموع شرکتها علاقهمندیم، بلکه به تمایز این شرکتها از نظر بخش فعالیت نیز علاقهمندیم، من همبستگیهای کشور به کشور را بین تعداد مطلق شرکتها در هر بخش NACE2 بر اساس SBS و با توجه به آمادئوس ( جدول 5 – در کل مقاله، تمام همبستگی های اعداد مطلق با تابع corr() در PostgreSQL محاسبه شد، همبستگی های وزنی با تابع cov.wt() در R [ 40 ] محاسبه شد. وضعیت مجدداً بین کشورها با برخی از کشورها با همبستگی بسیار بالا متفاوت است، اما برخی دیگر، به ویژه بریتانیا، اسپانیا و هلند با مقادیر پایینتر متفاوت است. تصویر مشابه است اما هنگام استفاده از همبستگی های وزنی نسبت ها به همبستگی های پایین تر تغییر می کند (به عنوان مثال ، نسبت بخش NACE در کل کشور وزن شده با تعداد مطلق شرکت ها در NACE). جالب توجه است که به نظر نمی رسد هیچ رابطه ای بین نسبت بین شرکت های آمادئوس و SBS و این همبستگی ها وجود داشته باشد.
جدول 5. همبستگی در هر کشور بین تعداد شرکت ها در هر NACE2 در آمادئوس و SBS (وزن = تعداد متوسط شرکت ها بین آمادئوس و SBS).
بررسی وضعیت کمی بیشتر برای کشورهایی که همبستگی پایین است نشان می دهد که چند بخش دورتر تعیین کننده هستند. به عنوان مثال، در مورد انگلستان، حذف یک بخش، NACE 82 (اداره اداری، پشتیبانی اداری و سایر فعالیت های پشتیبانی تجاری)، همبستگی را از 0.69 به 0.89 افزایش می دهد (با ضریب وزنی از 0.27 به 0.75). این نشان میدهد که باید دقت ویژهای انجام شود، و در هر کشور آداب و رسوم خاص مربوط به انتساب شرکتها به بخشها و محیط قانونی و نظارتی که شرکتها در آن فعال هستند، تجزیه و تحلیل شود. برای نشان دادن این نکته، جدول 6همبستگی ها را برای بخش های تولیدی تنها نشان می دهد (حرف C). در اینجا، ما 80 درصد واریانس را در همه کشورها توضیح داده ایم (اما برای تعداد بسیار کمتری از شرکت ها).
جدول 6. همبستگی در هر کشور بین تعداد شرکت ها در هر NACE2 در آمادئوس و SBS (فقط تولید، وزن = میانگین تعداد شرکت ها بین آمادئوس و SBS).
6.2. استفاده از ستاد به جای تأسیسات
برای قضاوت واقعی درباره سودمندی پایگاه داده آمادئوس برای جغرافیای اقتصادی، فقط ارزیابی تعداد کل شرکت ها در هر کشور کافی نیست. ما باید ارزیابی کنیم که آیا الگوی جغرافیایی شرکت ها در پایگاه داده با الگوهای جغرافیایی که ما می خواهیم تجزیه و تحلیل کنیم مطابقت دارد یا خیر. یکی از عواملی که ممکن است قابلیت استفاده پایگاه داده آمادئوس را محدود کند این است که (به طور کلی) فقط اطلاعات مربوط به دفتر مرکزی شرکت و نه واحدهای تولیدی را ارائه می دهد. اگر بخواهیم تولید را در مقیاس منطقه ای تجزیه و تحلیل کنیم، در شرایطی که این تولید ممکن است توسط دفاتر مرکزی مستقر در مناطق دیگر کنترل شود، این می تواند یک سوگیری جدی باشد. با این حال، تجزیه و تحلیل نشان می دهد که این سوگیری آنقدر قوی نیست که می توان انتظار داشت.جدول 7 ). با این حال، توجه داشته باشید که تعداد کم موارد، محدود به تعداد مناطق NUTS2 در هر کشور است (حتی با چنین تعداد موارد کم، مقادیر p برای همه همبستگیهای اندازهگیری شده در این مقاله کمتر از 0.001 است، حتی اکثر آنها بسیار کمتر است).
جدول 7. همبستگی در هر کشور بین تعداد شرکت ها در آمادئوس و تعداد واحدهای محلی در SBS توسط NUTS2.
وقتی به ترکیب NUTS2 و NACE2، یعنی تمایز فضایی و بخشی نگاه میکنیم، وضعیت کمتر واضح است، اما باید تعداد بسیار بالاتر موارد ناشی از عبور از مناطق NUTS2 با کدهای NACE2 را در نظر گرفت ( جدول 8). ). نتیجه زمانی که به همبستگی وزنی نسبت ها نگاه می کنیم دلسرد کننده تر است. با این حال، این تنها تاییدی است بر مشاهدات انجام شده در بالا در سطح ملی که تنها بر اساس بخش متمایز شده است. باز هم، حذف برخی از بخشها بلافاصله همبستگیها را افزایش میدهد (به استثنای NACE 82 در انگلستان، همبستگی را به 0.82 و همبستگی وزنی نسبتها را به 0.64 افزایش میدهد).
جدول 8. همبستگی بر اساس کشور بین تعداد شرکتها در آمادئوس و تعداد واحدهای محلی در SBS توسط NUTS2 و NACE2 (برای ترکیبهایی که تعداد شرکتها در هر NUTS2 و NACE2 > 5- وزن = میانگین تعداد شرکتها بین Amadeus و SBS).
به منظور ارزیابی تأثیر بخشهای مختلف، من همبستگیهای هر کشور را بین تعداد شرکتهای آمادئوس و واحدهای محلی SBS به ازای کدهای تک حرفی NUTS2 و NACE محاسبه کردم. همانطور که در جدول 9 مشاهده می شود ، برخی از بخش ها با همبستگی بسیار کم وجود دارد، اما 10 بخش از 13 بالاتر از 0.8 هستند. این نتایج با حذف شرکت های بزرگ و بسیار بزرگ تغییر قابل توجهی نمی کند. با این حال، استفاده از همبستگیهای وزنی نسبتها، تمایز بیشتری را در بین بخشها نشان میدهد، با برخی از بخشها، بهویژه شرکتهای برق، اما همچنین مجموعهای از بخشهای دیگر، همبستگیهای کمتری را نشان میدهند.
6.3. نتیجه گیری در مورد قابلیت استفاده از پایگاه داده آمادئوس
از تحلیلهای مقایسهای فوق، مشخص میشود که محققان همیشه باید مراقب باشند که دادههایی که استفاده میکنند در واقع چه چیزی را نشان میدهند. با این حال، به طور کلی، به نظر میرسد که حداقل برای برخی کشورها و برای بیشتر بخشهای اقتصادی، دادههای خرد مبتنی بر دفتر مرکزی مانند پایگاه داده آمادئوس را میتوان برای تجزیه و تحلیل در جغرافیای اقتصادی بدون ریسک نتایج کاملاً متفاوت از نتایج محلی استفاده کرد. داده های مبتنی بر واحد به طور خاص، متغیرهای اضافی موجود در پایگاههای داده مبتنی بر ترازنامه ارزش تلاش برای هدایت مشکلات ذاتی در دادهها را دارند تا از این انبوه اطلاعات استفاده کنند. در برخی موارد، به ویژه برای برخی از انواع متغیرها، ممکن است لازم باشد که تجزیه و تحلیل به شرکت های بزرگتر محدود شود تا بتوان به مجموعه بزرگتری از متغیرها دسترسی داشت.
جدول 9. همبستگی با کد NACE بین تعداد شرکت ها در آمادئوس و تعداد واحدهای محلی بر اساس NUTS2 و NACE2.
7. برخی از نقشه ها به عنوان نتایج
این مقاله بیشتر در مورد سوال قابلیت استفاده از پایگاه داده آمادئوس و در مورد امکان کدگذاری جغرافیایی با داده های عمومی باز است. با این حال، ناامید کننده خواهد بود که حداقل چند نتیجه از پایگاه داده بیرون نیاید. بنابراین، در این بخش، چند نقشه ارائه می کنم که به احتمالاتی که استفاده از چنین داده های خرد عظیمی ارائه می دهد اشاره می کند. این نقشهها به ویژه انعطافپذیری را در نقشهبرداری دادهها در مقیاسهای مختلف نشان میدهند، اما همچنین وضوح بخشی بالاتری را که این دادهها ارائه میدهند در مقایسه با آمارهای تجاری ساختاری Eurostat نشان میدهند.
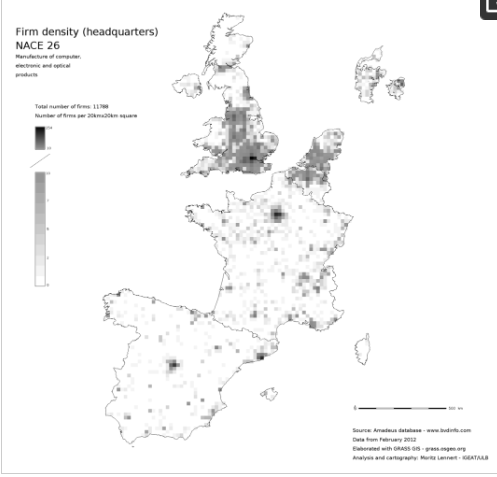
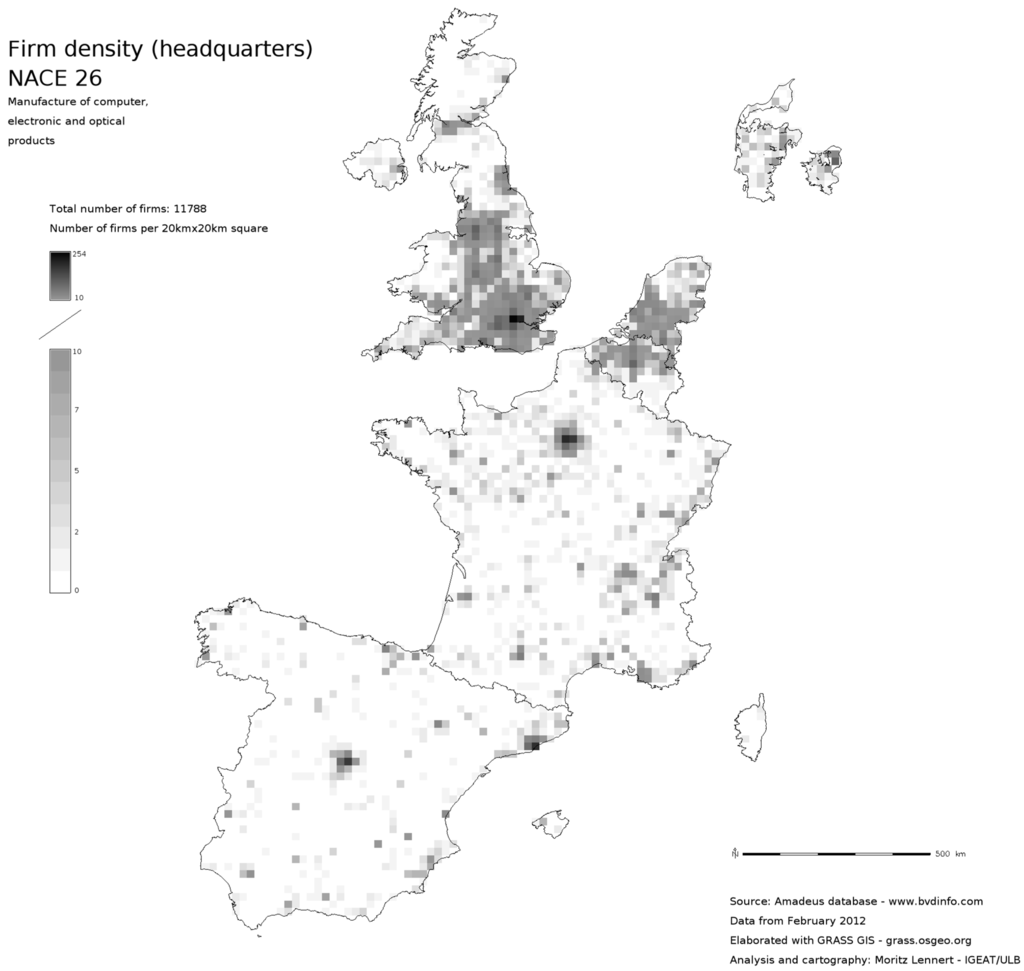
شکل 1 ، شکل 2 و شکل 3 محلی سازی شرکت ها را در بخش NACE 26 (تولید محصولات کامپیوتری، الکترونیکی و نوری) در سه مقیاس مختلف نشان می دهد: نقشه نقطه ای که در آن هر شرکت با یک نقطه نشان داده می شود، یک 5 کیلومتر مربع . و نقشه تراکم 20 کیلومتر مربعی. به عنوان مقایسه شکل 4 تراکم شرکت ها در هر کیلومتر مربع را بر اساس واحد NUTS2 بر اساس داده های SBS نشان می دهد. می توان دید که الگوی کلی یکسان است، اما تمایز داخلی در NUTS2 به وضوح کاملاً از بین رفته است. در نهایت، شکل 5 و شکل 6به زیربخش های NACE 26 نشان می دهد تا امکان تجزیه و تحلیل محلی سازی با وضوح بخشی بهتر از SBS را نشان دهد.
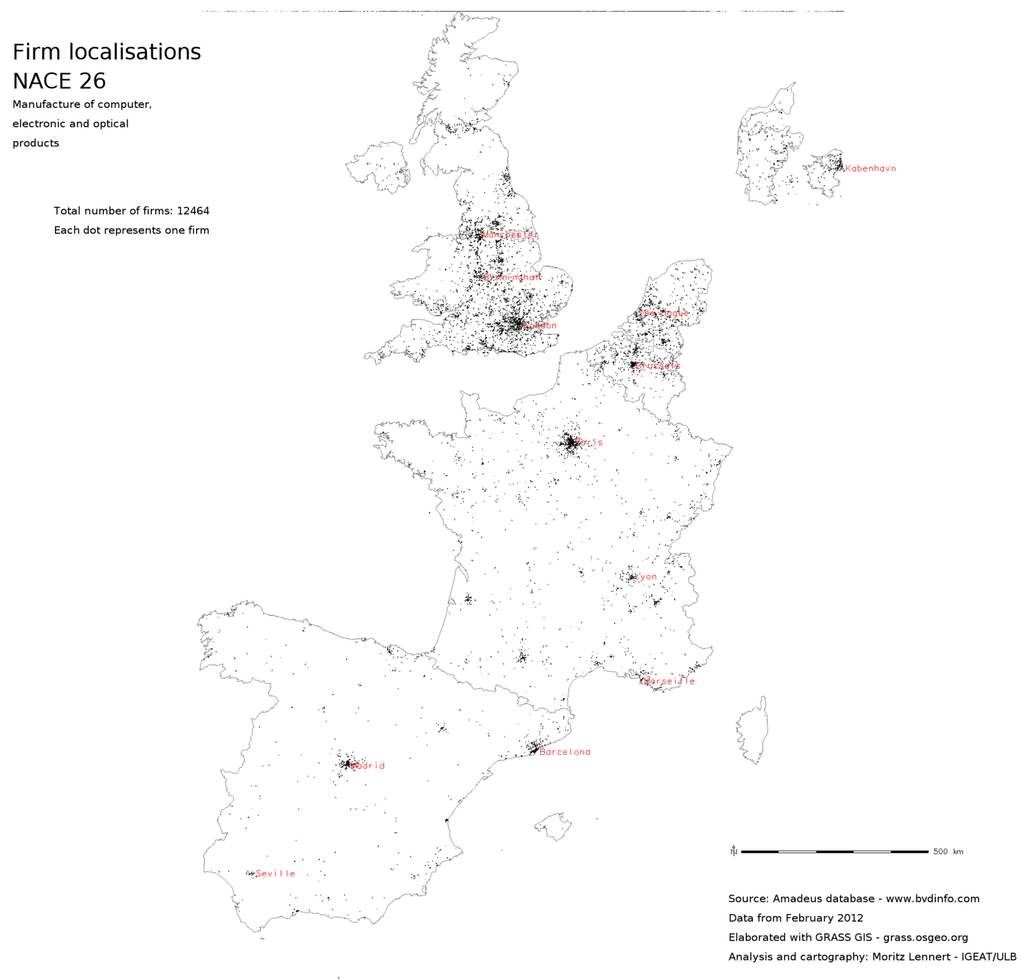
شکل 1. نقشه نقطه ای محلی سازی شرکت در بخش NACE 26.

شکل 2. نقشه تراکم 20 × 20 کیلومتری محلی سازی شرکت در بخش NACE 26.
شکل 3. تراکم محلی سازی شرکت توسط NUTS2 در بخش NACE 26.
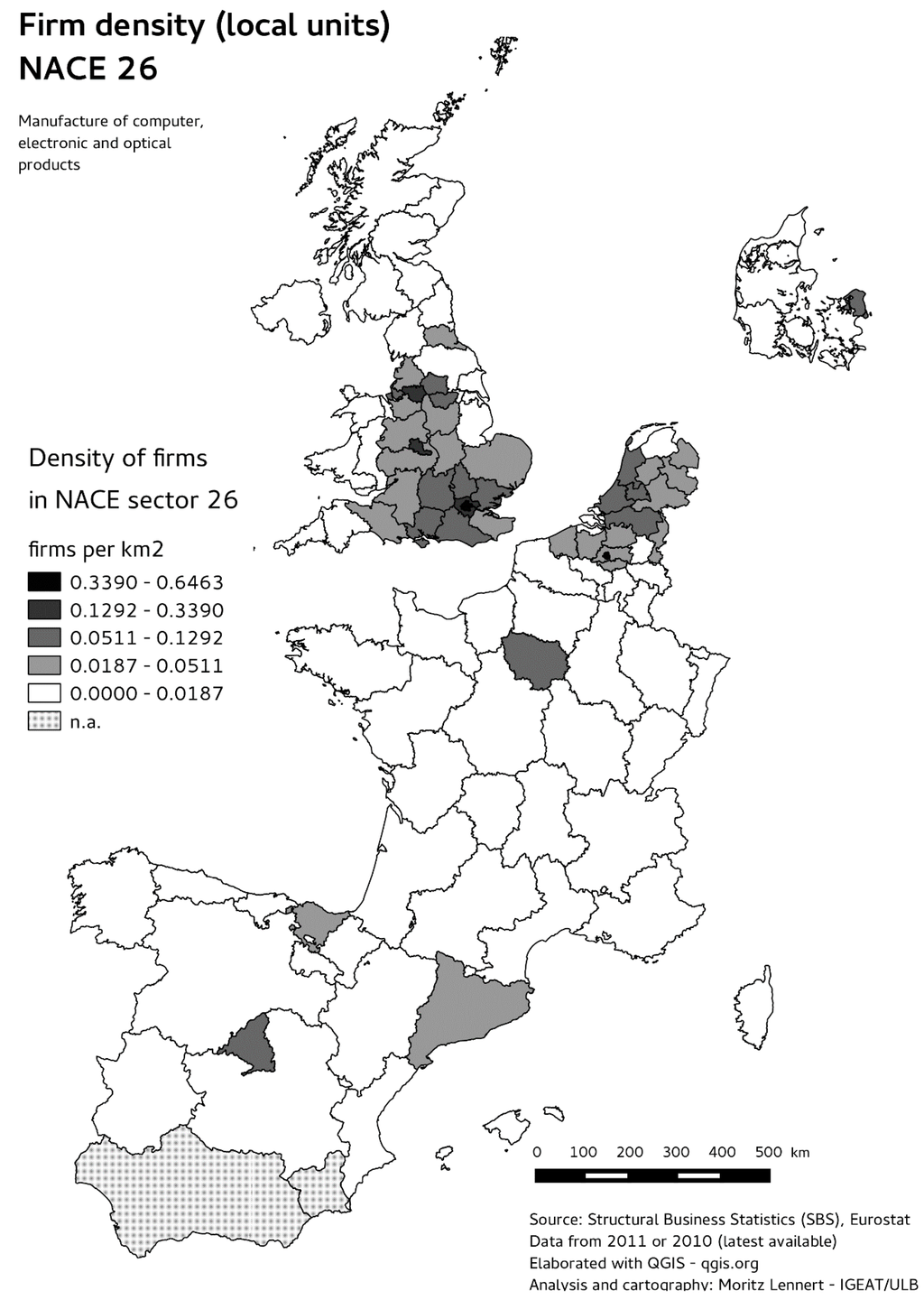
شکل 4. تراکم شرکت ها در هر کیلومتر مربع بر اساس واحد NUTS2 بر اساس داده های SBS
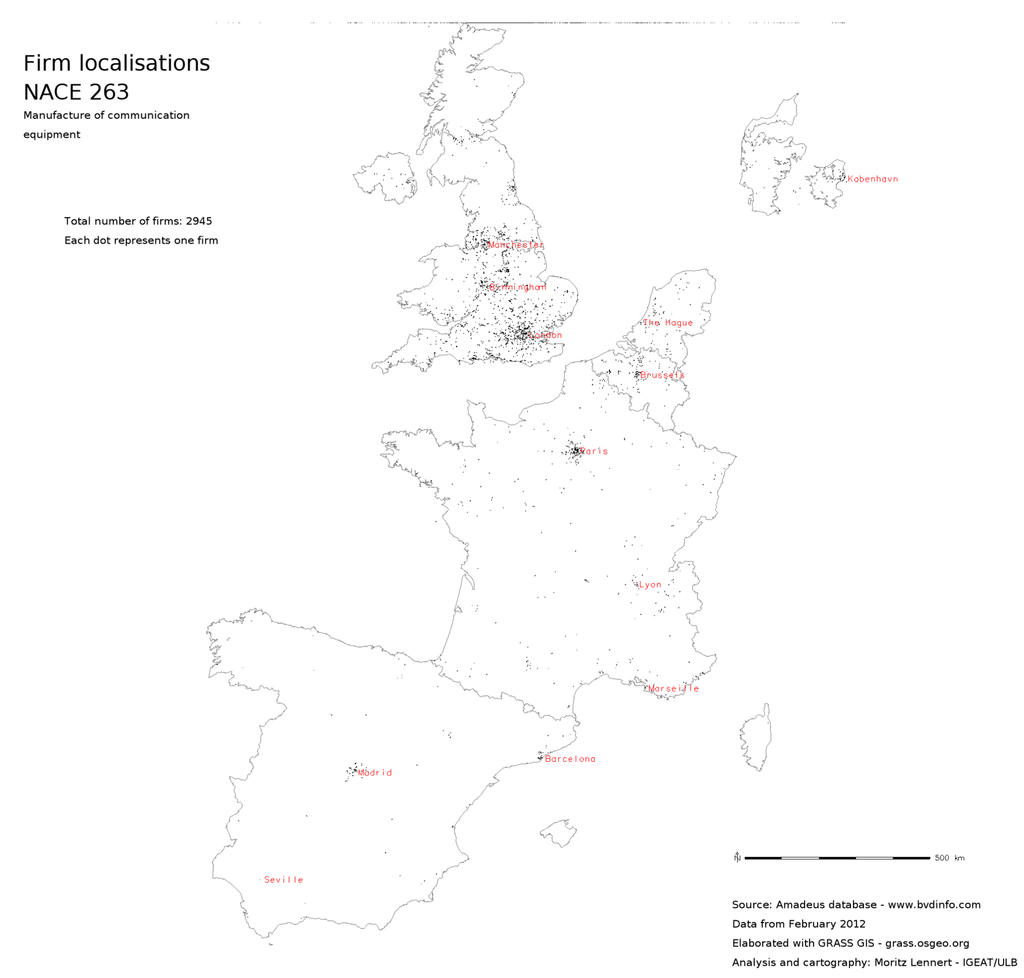
شکل 5. نقشه نقطه ای محلی سازی شرکت در بخش NACE 263.
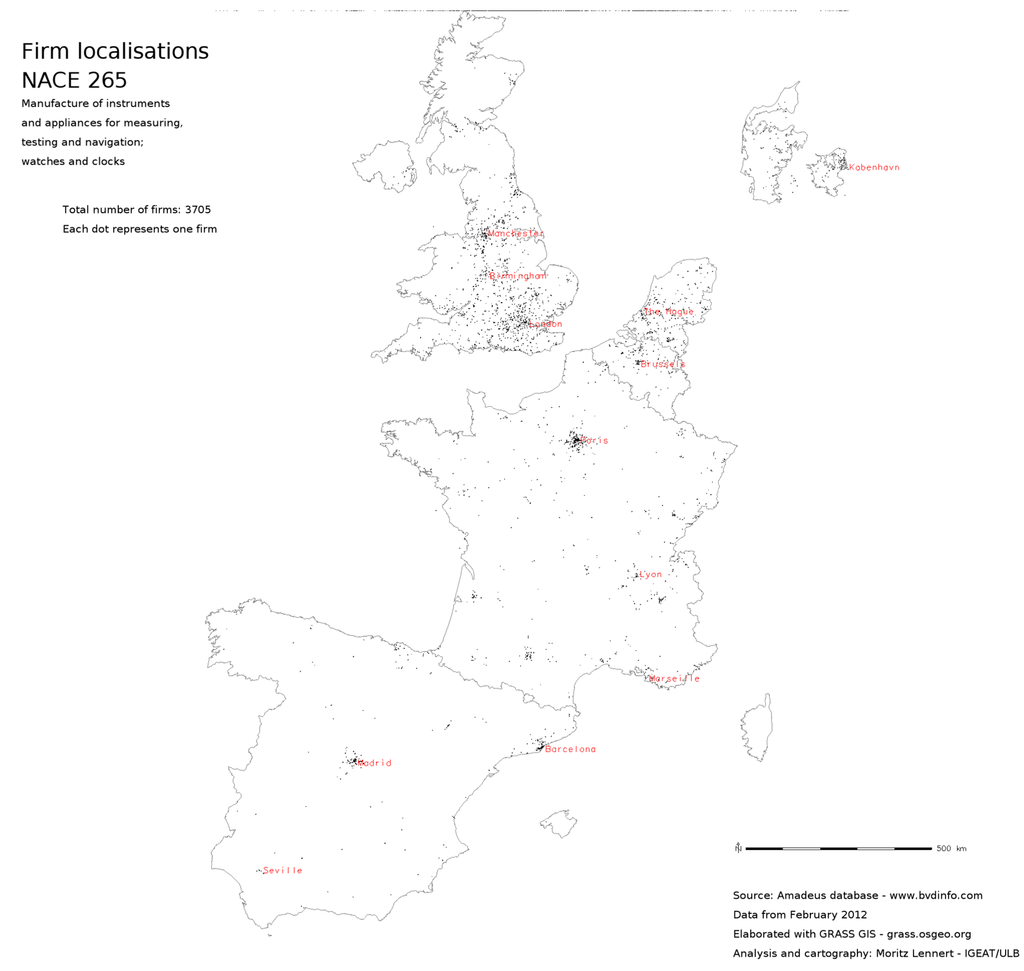
شکل 6. نقشه نقطه ای محلی سازی شرکت در بخش NACE 265.
8. نتیجه گیری
در این مقاله، من قابلیت استفاده از یک پایگاه داده خرد شرکت بزرگ برای جغرافیای اقتصادی را بررسی کردهام، و هم به امکانات کدگذاری جغرافیایی دادهها به روشی مقرونبهصرفه با استفاده از دادههای آدرس عمومی یا خدمات کدگذاری جغرافیایی و هم به قابلیت استفاده دادهها در نور نگاه میکنم. از محدودیت های آن حتی اگر این محدودیتها را نباید خیلی ساده تلقی کرد، و حتی اگر کدگذاری جغرافیایی به حداقل سطح دانش در دستکاری پایگاه داده و/یا اسکریپتنویسی سرویسهای وب نیاز دارد، نتیجه کلی این است که دادهها قابل استفاده هستند و زمینه جدیدی را به روی آن باز میکنند. برای جغرافیدانان اقتصادی، هم از نظر (انعطاف پذیری) مقیاس تحلیل و هم از نظر محتوای داده ها، کاوش کنید، اگرچه نتایج باید با دقت مورد بررسی قرار گیرند.
پایگاه داده آمادئوس مورد استفاده در این آزمایش یک پایگاه داده خصوصی است که مشمول هزینه اشتراک می باشد. با این حال، پایگاه های داده عمومی به شکل ثبت کسب و کار وجود دارد. دومی ها اغلب از نظر پوشش شرکت ها جامع تر هستند، اما دارای متغیرهای کمتری هستند. علاوه بر این، محدودیتهای محرمانگی کنونی دسترسی به اطلاعات محلیسازی دقیق را محدود میکند، اگرچه درک اینکه چرا دادههایی که به صورت عمومی در پایگاههای اطلاعاتی حسابها در دسترس هستند باید مشمول نگرانیهای محرمانه باشند، بهویژه زمانی که این دادهها فقط به شرکتها مربوط میشوند، و نه افراد یا خانوادهها، دشوار است. داده های اساسی مانند بخش دقیق فعالیت، گردش مالی و تعداد کارکنان باید بدون محدودیت در ارتباط با مکان یابی دقیق بر اساس آدرس جغرافیایی در دسترس باشد.
منابع
- Rouault، D. L’accès aux micro-données et la gestion de la confidentialité dans quelques INS Européens. در دسترس آنلاین: http://www.insee.fr/fr/ffc/docs_ffc/cs121h.pdf (دسترسی در 15 اکتبر 2014).
- مقررات (EC) شماره 223/2009 پارلمان اروپا و شورای 11 مارس 2009. در دسترس آنلاین: http://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX:32009R0223 (دسترسی در 15 اکتبر 2014).
- Gehlke، CE; Biehl, K. برخی از اثرات گروه بندی بر اندازه ضریب همبستگی در مواد دستگاه سرشماری. مربا. آمار دانشیار 1934 ، 29 . [ Google Scholar ] [ CrossRef ]
- برایانت، آ. Combes، P.-P.; Lafourcade، M. Dots to box: آیا اندازه و شکل واحدهای فضایی تخمین های جغرافیای اقتصادی را به خطر می اندازد؟ J. شهری اقتصاد. 2010 ، 67 ، 287-302. [ Google Scholar ] [ CrossRef ]
- گراسلند، کلود؛ Madelin, M. مسئله واحد مساحت قابل تغییر. در دسترس آنلاین: http://www.espon.eu/export/sites/default/Documents/Projects/ESPON2006Projects/StudiesScientificSupportProjects/MAUP/tender_3.4.3-web.pdf (در 15 اکتبر 2014 قابل دسترسی است).
- Tobler، WR درونیابی پیکنوفیلاکتیک صاف برای مناطق جغرافیایی. مربا. آمار دانشیار 1979 ، 74 ، 519-530. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- تحلیل فضایی مستقل Tobler، WR Frame. در پایگاه داده های مکانی دقت ; Goodchild, M., Sucharita, G., Eds. تیلور و فرانسیس: لندن، بریتانیا، 1989; صص 115-122. [ Google Scholar ]
- گرسلند، سی. ماتیان، اچ. وینسنت، جی.-ام. تحلیل چند مقیاسی و تعمیم نقشه پدیدههای اجتماعی گسسته: مشکلات آماری و پیامدهای سیاسی آمار JUN Econ. Comm. یورو 2000 ، 17 ، 157-188. [ Google Scholar ]
- آربیا، جی. مدلسازی جغرافیای فعالیتهای اقتصادی در فضایی پیوسته. پاپ Reg. علمی 2001 ، 80 ، 411-424. [ Google Scholar ] [ CrossRef ]
- آربیا، جی. کوپتی، ام. دیگل، پی. مدلسازی رفتار فردی شرکتها در مطالعه تمرکز فضایی. در رشد و نوآوری مناطق رقابتی ; Fratesi, DU, Senn, PL, Eds. Springer Berlin Heidelberg: Heidelberg, Germay, 2009; صص 297-327. [ Google Scholar ]
- آربیا، جی. سلا، پی. اسپا، جی. جولیانی، دی. تحلیل فضایی خرد جمعیت شناسی شرکت: مورد فروشگاه های مواد غذایی در منطقه ترنتو (ایتالیا). امپراتور اقتصاد 2014 ، 7 . [ Google Scholar ] [ CrossRef ]
- آربیا، جی. اسپا، جی. جولیانی، دی. Dickson، MM خوشه بندی فضایی-زمانی در صنعت تولید تجهیزات دارویی و پزشکی: یک تجزیه و تحلیل در سطح خرد جغرافیایی. Reg. علمی شهری. اقتصاد 2014 ، 49 ، 298-304. [ Google Scholar ] [ CrossRef ]
- بوکس، آر. لازرتی، ال. هرواس، جی ال. de Miguel, B. Creative Clusters in Europe: A Microdata Approach. در دسترس آنلاین: http://www.uv.es/~raboixdo/references/2011/11006.pdf (دسترسی در 15 اکتبر 2014).
- مارکون، ای. Puech, F. ارزیابی تمرکز جغرافیایی صنایع با استفاده از روش های مبتنی بر فاصله. جی. اکون. Geogr. 2003 ، 3 ، 409-428. [ Google Scholar ] [ CrossRef ]
- مارکون، ای. Puech, F. اندازه گیری های تمرکز جغرافیایی صنایع: بهبود روش های مبتنی بر فاصله. جی. اکون. Geogr. 2010 ، 10 ، 745-762. [ Google Scholar ] [ CrossRef ]
- مارکون، ای. Puech, F. A Tipology of Distance-based Measures of Spatial Concentration. در دسترس آنلاین: http://hal.cirad.fr/halshs-00679993v2/document (دسترسی در 15 اکتبر 2014).
- گرینوی، دی. Kneller، R. ناهمگونی شرکت، صادرات و سرمایه گذاری مستقیم خارجی. اقتصاد J. 2007 , 117 , F134–F161. [ Google Scholar ] [ CrossRef ]
- Redding، SJ نظریه های شرکت های ناهمگن و تجارت. ان کشیش Econ. 2010 ، 3 ، 77-105. [ Google Scholar ] [ CrossRef ]
- برنارد، AB; جنسن، جی بی. ردینگ، اس جی. Schott, PK تجربیات ناهمگونی شرکت و تجارت بینالملل. ان کشیش Econ. 2011 ، 4 ، 283-313. [ Google Scholar ] [ CrossRef ]
- ملیتز، ام جی. ردینگ، SJ فصل 1 – شرکتها و تجارت ناهمگن. در کتابچه راهنمای اقتصاد بین الملل ; الزویر: آمستردام، هلند، 2015; صص 1-54. [ Google Scholar ]
- کونیگ، پ. تراکم و تصمیمات صادراتی شرکت های فرانسوی. J. Urban. اقتصاد 2009 ، 66 ، 186-195. [ Google Scholar ] [ CrossRef ]
- فارول، تی. وینکلر، دی. موقعیت شرکت و عوامل تعیین کننده صادرات در کشورهای با درآمد کم و متوسط. جی. اکون. Geogr. 2014 ، 14 ، 395-420. [ Google Scholar ] [ CrossRef ]
- پایگاه داده آمادئوس در دسترس آنلاین: http://www.library.hbs.edu/go/amadeus.html (در 15 اکتبر 2014 قابل دسترسی است).
- Rozenblat، C. باز کردن جعبه سیاه اقتصادهای تراکم برای اندازه گیری رقابت شهرها از طریق شبکه های شرکت بین المللی. شهری. گل میخ. 2010 ، 47 ، 2841-2865. [ Google Scholar ] [ CrossRef ]
- Amelunxen، C. رویکردی به کدگذاری بر اساس دادههای فضایی داوطلبانه. در دسترس آنلاین: http://koenigstuhl.geog.uni-heidelberg.de/publications/2010/Amelunxen/amelunxen-geocodingOSM.pdf (دسترسی در 15 اکتبر 2014).
- هویجبوم، ن. ون دن بروک، تی. داده های باز: مقایسه بین المللی استراتژی ها. یورو J. EPractice 2011 ، 12 ، 1-13. [ Google Scholar ]
- دستورالعمل 2007/2/EC پارلمان اروپا و شورای 14 مارس 2007 برای ایجاد زیرساخت برای اطلاعات فضایی در جامعه اروپایی (INSPIRE). در دسترس آنلاین: http://eur-lex.europa.eu/legal-content/EN/ALL/?uri=CELEX:32007L0002 (در 15 اکتبر 2014 قابل دسترسی است).
- مقررات کمیسیون (EC) شماره 976/2009 مورخ 19 اکتبر 2009 برای اجرای دستورالعمل 2007/2/EC پارلمان اروپا و شورا در رابطه با خدمات شبکه. در دسترس آنلاین: http://eur-lex.europa.eu/legal-content/EN/ALL/?uri=CELEX:32009R0976 (در 15 اکتبر 2014 قابل دسترسی است).
- ویکیپدیا. کد پستی در بریتانیا در دسترس آنلاین: http://en.wikipedia.org/wiki/Postcodes_in_the_United_Kingdom (دسترسی در 15 اکتبر 2014).
- گلدبرگ، DW; ویلسون، جی پی؛ Knoblock، CA از متن تا مختصات جغرافیایی: وضعیت فعلی کدگذاری جغرافیایی. اوریسا. J. 2007 ، 19 ، 33-46. [ Google Scholar ]
- فیلدینگ، RT; تیلور، RN طراحی اصولی معماری مدرن وب. ACM Trans. بین المللی تکنولوژی 2002 ، 2 ، 115-150. [ Google Scholar ] [ CrossRef ]
- پروتکل دسترسی به اشیاء ساده W3C. در دسترس آنلاین: http://www.w3.org/TR/2000/NOTE-SOAP-20000508/ (دسترسی در 15 اکتبر 2014).
- اورتل، جی. نوهر، ج. Van Gheem، N. Python suds Library. در دسترس آنلاین: https://fedorahosted.org/suds/ (دسترسی در 15 اکتبر 2014).
- دوشاتو، اف. بلاسن، ز. کولتا، آر. یک رویکرد انعطاف پذیر برای برنامه ریزی الگوریتم های تطبیق طرحواره. در حرکت به سوی سیستم های اینترنتی معنادار: OTM 2008 ; Meersman, R., Tari, Z., Eds. Springer Berlin Heidelberg: Heidelberg, Germany, 2008; صص 249-264. [ Google Scholar ]
- کدهای باینری Levenshtein، VI که قادر به تصحیح حذف، درج و معکوس هستند. Sov. فیزیک دوکل. 1966 ، 10 ، 707-710. [ Google Scholar ]
- Ukkonen، E. تطبیق تقریبی رشته با q-گرم و حداکثر مطابقت. نظریه. محاسبه کنید. علمی 1992 ، 92 ، 191-211. [ Google Scholar ] [ CrossRef ]
- Ranzijn، B. الگوریتم ژئوکدینگ مبتنی بر مطالعه مقایسه ای تکنیک های تطبیق آدرس. پایان نامه کارشناسی ارشد، دانشگاه اراسموس، روتردام، هلند، 2013. [ Google Scholar ]
- بارتونوف، او. Sigaev, T. PostgreSQL 9.3.5 Documentation. در دسترس آنلاین: http://www.postgresql.org/docs/9.3/static/pgtrgm.html (دسترسی در 15 اکتبر 2014).
- فصل 12. اضافی PostGIS. در دسترس آنلاین: http://postgis.net/docs/manual-2.1/Extras.html#Tiger_Geocoder (در 15 اکتبر 2014 قابل دسترسی است).
- تیم اصلی R. R: زبان و محیطی برای محاسبات آماری . بنیاد R برای محاسبات آماری: وین، اتریش، 2014. [ Google Scholar ]
© 2015 توسط نویسندگان; دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر