

چکیده
زیرساخت ملی دادههای مکانی (NSDI) به عنوان فناوریها، سیاستها و افراد لازم برای ترویج اشتراکگذاری دادههای مکانی در تمام سطوح دولتی، بخشهای خصوصی و غیرانتفاعی و جامعه دانشگاهی تعریف میشود. اداره سرشماری ایالات متحده رهبری آژانس فدرال برای داده های واحدهای اداری، یکی از هفت موضوع داده ای است که توسط چارچوب NSDI شناسایی شده است. واحد اداری واحدی است با وظایف اداری. این واحدها بهعنوان دادههای ویژگی گرهها/خطوط/منطقه سازماندهی میشوند. زبان نشانه گذاری جغرافیایی OpenGIS (GML) گرامر XML برای بیان ویژگی های جغرافیایی است. این مطالعه در اداره سرشماری ایالات متحده بررسی میکند که چگونه استاندارد GML همه منظوره میتواند برای توصیف جامعترین مجموعه داده جغرافیایی با پوشش ملی در ایالات متحده به کار گرفته شود و گسترش یابد. چالشها و مشکلات در برخورد با حجم دادهها، ساختار سند GML، طراحی طرحواره GML و نامگذاری سند GML تجزیه و تحلیل میشوند و به دنبال آن راهحلهای پیشنهادی برای امکانسنجی اثبات شدهاند. نتایج ما نشان میدهد که یک نکته کلیدی در ایجاد موفقیت آمیز استقرار GML برای NSDI، منعکس کردن ویژگیهای دادههای جغرافیایی از طریق طرح، ساختار و سازمان GML است. درس های آموخته شده ممکن است برای دیگران مفید باشد که داده های چارچوب NSDI و دیگر مجموعه داده های بزرگ جغرافیایی را به ساختارهای GML تبدیل می کنند. نتایج ما نشان میدهد که یک نکته کلیدی در ایجاد موفقیت آمیز استقرار GML برای NSDI، منعکس کردن ویژگیهای دادههای جغرافیایی از طریق طرح، ساختار و سازمان GML است. درس های آموخته شده ممکن است برای دیگران مفید باشد که داده های چارچوب NSDI و دیگر مجموعه داده های بزرگ جغرافیایی را به ساختارهای GML تبدیل می کنند. نتایج ما نشان میدهد که یک نکته کلیدی در ایجاد موفقیت آمیز استقرار GML برای NSDI، منعکس کردن ویژگیهای دادههای جغرافیایی از طریق طرح، ساختار و سازمان GML است. درس های آموخته شده ممکن است برای دیگران مفید باشد که داده های چارچوب NSDI و دیگر مجموعه داده های بزرگ جغرافیایی را به ساختارهای GML تبدیل می کنند.
کلید واژه ها:
زیرساخت ملی داده های مکانی (NSDI) ; OpenGIS Geography Markup Language (GML) ; سیستم رمزگذاری و مرجع جغرافیایی یکپارچه توپولوژیکی (TIGER)
1. مقدمه
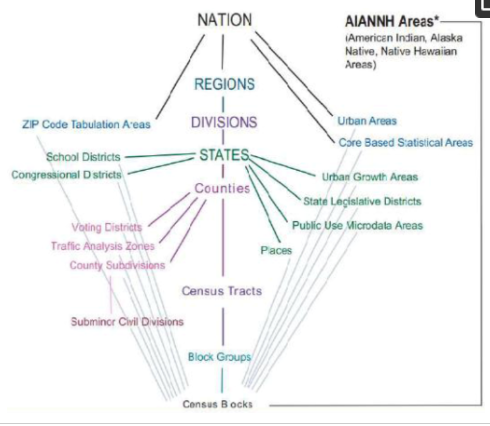
مفهوم زیرساخت ملی داده های فضایی (NSDI) در ایالات متحده آغاز شد و اکنون به طور گسترده توسط بسیاری از کشورهای دیگر از جمله استرالیا، کانادا، شیلی، چین، بریتانیا و فنلاند پذیرفته شده است. این به عنوان فناوریها، سیاستها و افراد لازم برای ترویج اشتراکگذاری دادههای مکانی در تمام سطوح دولتی، بخشهای خصوصی و غیرانتفاعی و جامعه دانشگاهی تعریف میشود [ 1 ]. کنترل ژئودتیک، کاداستر، تصوير راستا، ارتفاع، هيدروگرافي، واحدهاي اداري و حمل و نقل هفت موضوع داده اي هستند که توسط چارچوب NSDI شناسايي شده اند [ 2 ، 3 ].] که ستون فقرات داده NSDI را تشکیل می دهد. اداره سرشماری ایالات متحده یک آژانس فدرال است که با واحدهای اداری ایالات متحده کار می کند. واحد اداری یک نهاد جغرافیایی است که با اقدام قانونی و به منظور اجرای وظایف اداری یا دولتی ایجاد می شود. اکثر واحدهای اداری مرزها را به رسمیت شناخته اند. همه مناطق و جمعیت ایالات متحده بخشی از یک یا چند واحد قانونی هستند. این واحدها شامل ملت، ایالتها و مناطق از نظر آماری معادل، شهرستانها و مناطق از نظر آماری معادل، مکانهای ادغامشده و شهرهای ادغامشده، بخشهای مدنی جزئی فعال و قانونی، رزرواسیون سرخپوستان آمریکایی به رسمیت شناختهشده توسط فدرال و ایالت و سرزمینهای امانی خارج از رزرو و منطقه بومی آلاسکا هستند. شرکت ها همانطور که در شکل 1 نشان داده شده است، داده های واحدهای اداری ایالات متحده یک ساختار داخلی پیچیده را ارائه می دهد. این ارائه جغرافیایی سلسله مراتبی موجودیت های جغرافیایی را در یک ساختار برتر/فرع نشان می دهد. این ساختار برگرفته از روابط حقوقی، اداری یا منطقه ای نهادها است. نمونه ای از ارائه سلسله مراتبی، سلسله مراتب جغرافیایی سرشماری است که از یک بلوک سرشماری، در گروه بلوک، در مسیر سرشماری، داخل مکان، در زیربخش شهرستان، در داخل شهرستان و در داخل ایالت تشکیل شده است. این اطلاعات به عنوان یک سری روابط تودرتو ارائه می شود.

شکل 1. سلسله مراتب واحدهای جغرافیایی سرشماری.
بخش جغرافیا در اداره سرشماری ایالات متحده، سیستم رمزگذاری و ارجاع جغرافیایی یکپارچه توپولوژیکی (TIGER) و پایگاه داده دیجیتال را برای پشتیبانی از برنامه های سرشماری ده ساله و نمونه برنامه های بررسی اداره سرشماری، که با سرشماری ده ساله 1990 شروع می شود، مدیریت می کند. داده های TIGER جامع ترین مجموعه داده جغرافیایی با پوشش ملی در ایالات متحده است. برای در دسترس قرار دادن آن برای عموم، اداره سرشماری چندین نوع فایل و یک برنامه کاربردی برای نقشه برداری داده های جغرافیایی سرشماری به عنوان فایل های TIGER/Line، TIGER/Line Shapefiles یا فایل های نمونه اولیه KML ارائه می دهد. به عنوان مثال TIGER/Line Shapefiles را در نظر بگیرید: آنها عصاره های فضایی از پایگاه داده TIGER اداره سرشماری هستند که شامل ویژگی هایی مانند جاده ها، راه آهن، رودخانه ها و همچنین مناطق جغرافیایی قانونی و آماری است. برای همکاری نزدیک با زیرساخت های NSDI ایالات متحده،4 ] برای سازماندهی و انتشار داده های مکانی TIGER.
GML یک دستور زبان XML است که در XML Schema برای مدلسازی، انتقال و ذخیرهسازی دادههای ویژگیهای جغرافیایی نوشته شده است [ 5 ]. تحقیقات زیادی در مورد چگونگی ذخیره موثر اسناد GML [ 6 ، 7 ، 8 ، 9 ]، تکنیک های فشرده سازی داده ها برای اسناد GML [ 10 ]، تحلیل نحوی و واژگانی اسناد GML، پشتیبانی بومی از پایگاه های داده مکانی برای اسناد GML [ 11 ] انجام شده است. ]، چگونه اسناد GML می توانند به طور موثر در محیط های سیستم اطلاعات جغرافیایی وب (GIS) استفاده شوند [ 12 ، 13 ، 14 ، 15 ]، زبان پرس و جو فضایی موثر بر GML [ 16 ]] و تبدیل GML به سایر فرمت های داده باز، از جمله گرافیک برداری مقیاس پذیر (SVG) [ 17 ]. Ahn پسوندهای GML، یک زبان Spatial XQuery و ماژولهای پردازش آن را برای برنامههای تلفن همراه و مبتنی بر مکان معرفی کرد [ 18 ]. باردت یک نقشه برداری از اجسام هندسی پایه در داده های ژئوتکنیکی تا ویژگی های هندسی اساسی GML ارائه کرد [ 19 ]. Corcoles یک رویکرد مبتنی بر هستی شناسی را برای ادغام منابع غیر مکانی با اسناد GML تعریف کرد [ 20 ]، و Ferri روشی را برای ارزیابی شباهت معنایی عناصر GML [ 21 ] پیشنهاد کرد. هوانگ یک مدل داده شبکه حمل و نقل را با طرحواره های GML برای رمزگذاری و اشتراک گذاری داده ها معرفی کرد [ 22]. لیک ویژگی های استانداردهای GML 3.0 را بررسی کرد و کاربرد آن را در علوم زمین شناسی از طریق چندین مطالعه موردی ارائه کرد [ 23 ]. Nativi ساختارهای مبتنی بر GML را برای دادههای netCDF تعریف کرد که یکی از روشهای اولیه ذخیرهسازی دادهها و دسترسی به خود مستندسازی در جامعه تحقیقاتی و آموزشی بینالمللی علوم زمین است [ 24 ]. ژانگ یک موتور جستجوی اطلاعات جغرافیایی مبتنی بر GML را از طریق اینترنت ارائه کرد [ 25 ].
کار مشابه دیگر INSPIRE است، یک ابتکار اتحادیه اروپا برای ایجاد زیرساختی برای اطلاعات مکانی در اروپا که کمک می کند تا اطلاعات مکانی یا جغرافیایی برای طیف گسترده ای از اهداف حمایت از توسعه پایدار قابل دسترس تر و قابل همکاری تر شود. مطابق با دستورالعمل INSPIRE، سه نوع یا سطح مختلف ابرداده متمایز می شود: ابرداده «برای کشف»، ابرداده «برای ارزیابی» و ابرداده «برای استفاده». به دلیل توسعه پذیری و انعطاف پذیری آن، GML یک رمزگذاری توصیه شده برای ابرداده ها برای استفاده است (زیرا این نوع ابرداده می تواند کاملاً غنی و متفاوت از ابرداده برای کشف یا ارزیابی باشد، که در INSPIRE، غنی تر و رایج تر است) . برای دیگر رمزگذاری ابرداده، استانداردهای ISO/TS 19139 (و مدل های اطلاعاتی ISO 19115/19119) و دوبلین کور (ISO 15836) استفاده می شود. لازم به ذکر است که با توجه به الزامات هماهنگ سازی INSPIRE، ایجاد طرحواره های ابرداده یکی از بالاترین اولویت ها می باشد. از نقطه نظر NSDI، بسیار مطلوب است که کاربرد استانداردهای عمومی GML برای داده های ویژگی های جغرافیایی پیچیده با پوشش ملی، مانند داده های واحدهای اداری ایالات متحده که در اداره سرشماری نگهداری می شوند، به طور کامل بررسی شود. تحقیقات کمی برای استقرار GML برای داده های جغرافیایی در مقیاس ملی انجام شده است.
بقیه این مقاله به شرح زیر سازماندهی شده است. سناریوی مطالعه موردی معرفی میشود و پس از آن خلاصهای از چالشها در استفاده از استانداردهای عمومی GML برای دادههای جامع TIGER ارائه میشود. بخش بعدی بر روی راهحلهای پیشنهادی و پیادهسازی با جزئیات تمرکز دارد و به دنبال آن محصولات تولید شده TIGER/GML ارائه میشود. مزایا و محدودیت های راه حل پیشنهادی قبل از نتیجه گیری مورد بحث قرار می گیرد.
2. سناریو
2.1. داده های ببر ایالات متحده
داده های TIGER از اواسط دهه 1980 در اداره سرشماری ایالات متحده نگهداری می شد. این شامل نهادهای جغرافیایی حقوقی و آماری، و همچنین شبکه های حمل و نقل و هیدروگرافی است که ایالات متحده، پورتوریکو و مناطق جزیره (ساموآی آمریکا، جزایر مشترک المنافع ماریانای شمالی، گوام و جزایر ویرجین ایالات متحده) را پوشش می دهد. دادههای نقشهبرداری TIGER/Line و TIGER/Line Shapefile به طور گسترده توسط تمام سطوح دولتی، بخشهای خصوصی و غیرانتفاعی و جامعه دانشگاهی بهعنوان یکی از منابع داده اولیه GIS در سراسر ایالات متحده مورد استفاده قرار گرفتهاند.
2.2. TIGER GML
اداره سرشماری یک تحقیق آزمایشی و اجرای TIGER/GML انجام داد. این پروژه امکان تولید ساختارهای GML را از پایگاه داده عظیم TIGER در محیط تولید آزمایشی در دفتر مرکزی اداره سرشماری ارزیابی کرد.
2.3. سیستم مورد نیاز
یک برنامه اختصاصی برای تولید اسناد GML برای داده های TIGER در مقیاس ملی به طور مستقیم از پایگاه داده TIGER مورد نیاز است. انتظار می رود این یک برنامه خط فرمان مستقل باشد که می تواند تولید داده های GML بدون نظارت را برای کل مجموعه داده TIGER در محیط تولید یونیکس انجام دهد.
3. چالش ها در به کارگیری استاندارد GML برای داده های TIGER
تجزیه و تحلیل انجام شده در بخش جغرافیای اداره سرشماری ایالات متحده، مسائل مهم زیر را هنگام طراحی، پیاده سازی و بسته بندی اسناد GML برای داده های TIGER در مقیاس ملی نشان داده است.
3.1. حجم داده ها
GML بر اساس XML، یک فرمت رمزگذاری مبتنی بر متن است. اسناد GML از نظر اندازه بسیار بزرگتر از سایر فرمت های حاوی اطلاعات مشابه هستند. در پایگاه داده TIGER، حتی پارتیشنهای مبتنی بر شهرستان اغلب بیش از 250 مگابایت برای شهرستانها در مناطق بزرگ شهری خواهند بود. اکثر ابزارهای XML برای باز کردن فایلهای GML با این اندازه، بسیار کمتر پردازش میکنند، بدون ذکر اندازه فایل برای سطوح بالاتر موجودیتهای جغرافیایی.
3.2. سازمان جامع TIGER
داده های TIGER سازماندهی بسیار جامعی از مناطق جغرافیایی سرشماری دارد.
یک مجموعه سلسله مراتبی از مناطق جغرافیایی سرشماری – کشور / منطقه / بخش / ایالت / شهرستان / تراکت / گروه بلوک / بلوک – یک ساختار کاملا تودرتو است، که در آن مناطق تودرتو در هر سطح زیر کشور متقابلاً منحصر به فرد و مجموعاً منطقه بالا را کامل می کند. که حاوی آنهاست.
مجموعه دیگری از مناطق جغرافیایی – حوزههای رایگیری، مناطق تحلیل ترافیک (TAZ)، زیرمجموعههای شهرستان و بخش مدنی فرعی – در داخل شهرستانها لانه دارند.
مجموعه سوم از مناطق جغرافیایی – مناطق کنگره، مناطق مدرسه، مکانها، شرکتهای محلی بومی آلاسکا (ANRCs) و ناحیههای قانونی ایالتی (SLDs) – بالا و پایین، مناطق رشد شهری (UGA)، مناطق دادههای خرد استفاده عمومی (PUMA) و ادغامشده شهرها (CONC) – در داخل ایالت ها لانه می کنند.
مجموعه چهارم از مناطق جغرافیایی – مناطق جدولبندی کد پستی (ZCTAs)، مناطق شهری و مناطق آماری کلانشهری و مناطق بومی هندی آمریکا/آلاسکا/بومی هاوایی (AIANNH) – در داخل کشور لانه دارند.
3.3. نامگذاری سند GML
ارائه داده های TIGER در یک سند GML یک راه حل عملی نیست. بنابراین، TIGER/GML باید مجموعه ای از اسناد GML مرتبط با هم باشد. نحوه نامگذاری این اسناد GML منفرد برای منعکس کردن ارتباطات درونی آنها مشکل دیگری است زمانی که تعداد اسناد GML تولید شده نسبتاً زیاد است.
3.4. تعریف شناسه عنصر GML
داده های TIGER دارای بسیاری از انواع ویژگی های یک بعدی (1D) و دو بعدی (2D) هستند. هنگام تولید یک نمایش GML برای داده های TIGER، باید از مقادیر منحصر به فرد برای هر شناسه GML استفاده شود. با این حال، مقدار منحصر به فرد باید به شخص اجازه دهد تا به طور مستقیم به موجودیت در خود پایگاه داده ارجاع دهد، در غیر این صورت شناسه بی معنی می شود. بنابراین تصمیم گرفته شد که شناسه GML را با ترکیب چنین اطلاعاتی که موفقیت استقرار نهایی GML را تضمین می کند ساخته شود.
4. راه حل پیشنهادی
یک رویکرد تقسیم کن برای مقابله با چالشهای فوقالذکر طراحی شده است: اسناد GML عمدتاً در سطح شهرستان تولید میشوند. چندین نوع سند GML طراحی شده اند که هر نوع با ویژگی های خاص TIGER سروکار دارد. نام اسناد شامل چندین بخش است که با نوع سند GML و سطح واحد جغرافیایی مطابقت دارد. و شناسه عنصر GML با در نظر گرفتن هر دو نوع ویژگی و سطح مربوط به موجودیت های جغرافیایی توسعه می یابد.
4.1. انواع سند TIGER/GML
داده های TIGER/GML بین 9 نوع مختلف سند توزیع می شود:
-
فهرست مطالب
-
فراداده
-
ویژگی های منطقه (موجودات جغرافیایی)
-
بلوک ها
-
مناطق ریز داده استفاده عمومی (PUMA)
-
ویژگی های خطی (جاده، راه آهن و غیره )
-
نشانه ها (نقطه، خط و منطقه)
-
تاریخچه TIGER/Line ID (TLID).
-
محدوده های شناسایی
ساختار اسناد همه اسناد یکسان است. همانطور که در جدول 1 نشان داده شده است، انواع اسناد از نظر عناصر اختیاری در سطوح ملی، ایالتی و شهرستانی متفاوت است . برخی از اسناد ممکن است برای برخی از سطوح قابل اجرا نباشند. به عنوان مثال، از آنجایی که دادههای Tiger/GML از پارتیشنهای شهرستانی پایگاه داده TIGER استخراج میشوند، همه ویژگیهای خطی و بیشتر نشانهها در یک شهرستان قرار دارند. آنها در هیچ سطح دولتی یا ملی نیستند.

جدول 1. سیستم رمزگذاری و ارجاع جغرافیایی یکپارچه توپولوژیکی (TIGER)/ زبان نشانه گذاری جغرافیایی (GML) نوع سند/فایل.
4.2. طرحواره TIGER/GML
طرح Census TIGER/GML یک طرح کاربردی OGC GML است که در پنج سند XML/Schema موجود است. این طرحواره ها بر اساس مشخصات GML نسخه 3.1.1 و طرحواره هایی که در سند OGC 03-105r1 توضیح داده شده است.
-
CensusTiger.xsd: ویژگی های سرشماری و مجموعه ویژگی ها را تعریف می کند.
-
CensusTiger123.xsd: انواع انتزاعی و پایه 1، 2 و 3 بعدی را تعریف می کند.
-
CensusTigerSpatialTypes.xsd: انواع هندسه تخصصی را تعریف می کند.
-
CensusTigerBasicTypes.xsd: کدهای جغرافیایی و ابرداده سرشماری را تعریف می کند.
-
CensusTigerMetadata.xsd: انواع و عناصر فراداده سرشماری TIGER را تعریف می کند.
انواع سرشماری TIGER/GML، الحاقات و محدودیت های انواع پایه GML هستند، همانطور که در مشخصات GML توضیح داده شده است. این طرحوارهها ساختار سند XML را برای اسناد TIGER/GML، مدل اطلاعاتی برای ویژگیهای Census TIGER/GML و مقادیر معتبر برای کدها و سایر موارد داده اتمی ساده را تعریف میکنند.
طرحواره های Census TIGER/GML از قرارداد رمزگذاری XML “2-step” GML <Class><property><Class> پیروی می کنند. عنصر کلاس یک شی GML با هویت ارائه شده توسط ویژگی gml:id است که یک شناسه XML است. عنصر ویژگی در واقع یک نام محلی برای استفاده از عنصر کلاسی است که حاوی آن است یا به یک xlink:href ارجاع می دهد. هر عنصر خاصیت ممکن است حاوی یک عنصر کلاس باشد یا به آن ارجاع دهد، اما ممکن است هر دو را انجام ندهد. یک مقدار xlink:href اگر به عنصری در یک سند XML دیگر، شناسه قطعه “#” یا شناسه XML اشاره داشته باشد، حاوی یک پیشوند URI است.
نام عناصر ویژگی در LowCamelCase و نام عناصر Class در UpperCamelCase هستند. به عنوان مثال، نام عنصر ویژگی gml:boundedBy در قالب LowCamelCase است، در حالی که عنصر Class آن، gml:Envelope، در قالب UpperCamelCase است. یک عنصر ویژگی ممکن است شناسه XML نداشته باشد.
طرحواره های Census TIGER/GML تعاریف XLink مورد استفاده در GML را از xlinks.xsd وارد می کنند. این اجازه می دهد تا آن اطلاعات در داخل و در اسناد XML ارجاع داده شود و همچنین به صورت خطی گنجانده شود. آنها انواع ابرداده کمیته داده های جغرافیایی فدرال ایالات متحده (FGDC) را از طریق fgdc-std-001-1998.xsd وارد می کنند. استفاده از فراداده FGDC برای همه اشیاء TIGER/GML از طریق عنصر gml:metadataProperty اختیاری است.
4.3. نامگذاری سند TIGER/GML
بر اساس معماری سازمان GML فوق الذکر، قرارداد نامگذاری زیر برای این انواع اسناد استفاده می شود:
“tgr” + ssccc + docTypeName + “.xml”
که در آن “ssccc” کدهای ایالت و شهرستان فدرال (کدهای FIPS) برای یک شهرستان یا کد ایالت FIPS است که با “000” برای یک ایالت یا “00000” برای کشور اضافه شده است، و “docTypeName” “Index” است، ” AreaEntities، “LinearFeatures”، و غیره ، همانطور که در ستون Document در بالا ذکر شده است.
4.4. تعریف شناسه عنصر TIGER/GML
شی GML عناصر XML که مجموعهها را نشان میدهند، یک شناسه (شناسه جغرافیایی) را در خود جای میدهند که ترکیبی از کدهای موجودیت منطقه است که بهطور منحصربهفرد منطقه را شناسایی میکند. طرح نوع های پایه سرشماری شامل مجموعه کدهای <name of area>EntityCodesType برای همه نهادهای منطقه سرشماری است، که در آن <نام منطقه> “ایالت”، “شهرستان” و غیره است. همه عناصر فرزند، به جز سال و تولید داده استخراج شده، در شناسه (geo-id) برای آن نوع منطقه گنجانده شده است. شناسههای مجموعههای ویژه در سطوح ملی و ایالتی به درستی با صفر پر شده است.
ویژگیهای ID در عناصر XML شی GML (gml:id) در دادههای Census TIGER/GML برای حفظ منحصربهفرد بودن جهانی اختصاص داده میشوند.
5. تولید اسناد TIGER/GML
در این پروژه آزمایشی، محصولات TIGER/GML در محیط تولید آزمایشی در بخش جغرافیای اداره سرشماری ایالات متحده در حدود سه هفته اجرای مداوم تولید شده است. همانطور که در فایل های آرشیو ZIP ذخیره می شود، داده های TIGER/GML برای سال 2005 تقریباً 11 گیگابایت است. از حالت فشرده خارج شده، نزدیک به 400 گیگابایت است. این پروژه تولید TIGER/GML یک آزمایش داخلی در اداره سرشماری ایالات متحده است که برای آزمایش فناوری انتقال داده های جغرافیایی با حجم بالا در سراسر کشور به فرمت GML طراحی شده است. GML حاصل آنلاین قرار نخواهد گرفت. با این حال، اسناد و طرحواره های GML را می توان با تماس با بخش جغرافیایی اداره سرشماری ایالات متحده به دست آورد.
6. بحث
6.1. مدیریت ویژگی های مرزی
داده های TIGER/GML بر اساس شهرستان به شهرستان از پایگاه داده TIGER استخراج می شود. همه ویژگیهای خطی و بیشتر نشانهها در یک شهرستان قرار دارند. با این حال، برخی از ویژگی های منطقه جغرافیایی ممکن است از مرزهای شهرستان عبور کنند، و برخی دیگر نیز ممکن است از مرزهای ایالت عبور کنند. نسبت ویژگی هایی که از مرزهای شهرستان و ایالت عبور می کنند با نوع نهاد/ویژگی متفاوت است و همچنین در ایالت ها و مناطق مختلف متفاوت است. ویژگیهای چند حالته در فایلهای GML در سطح کشور قرار میگیرند. ویژگی های منطقه چند شهرستانی در فایل های GML سطح ایالت هستند. ویژگی های تک شهرستان در فایل های GML در سطح شهرستان هستند. همه نهادهای چند ایالتی و چند شهرستانی نیاز به پردازش ویژه دارند، زیرا همه فایلهای GML پایه به صورت شهرستانی ایجاد شدهاند. برای انجام این کار، مشخص شد که همه فایلهای TIGER/GML مستقر در شهرستان در پایگاه داده Oracle خوانده میشوند. سپس ترکیبی از SQL و یک اسکریپت XSLT برای ایجاد یک فایل GML حاوی موجودیت های چند ایالتی و چند شهرستانی استفاده شد. با ارزیابی دادهها، اسکریپتها هر موجودیتی را که از مرز شهرستان یا ایالت عبور میکند ترکیب میکنند و رکوردی برای قرار دادن در فایل ملی GML ایجاد میکنند. این موجودیت در شهرستان ها یافت می شود، در حالی که در پرونده ایالتی وجود ندارد.
6.2. مختصات در TIGER/GML
همانطور که از سیستم پایگاه داده TIGER استخراج شده است، داده های مختصات TIGER/GML در داده آمریکای شمالی 1983 (NAD 83) با مختصات به ترتیب طول و عرض جغرافیایی است. TIGER پیش بینی نشده است و مختصات آن در درجه اعشار است. TIGER/GML با استفاده از Oracle Spatial تولید شد و به شناسه سیستم مرجع فضایی آن (SRID) برای NAD83 که 8265 است اشاره دارد.
داده های مختصات TIGER/GML ممکن است به سیستم های مرجع مختصات مختلف برای نمایش کارتوگرافی تبدیل شوند. چنین تبدیل هایی ممکن است ترتیب مختصات و/یا انواع مختصات را تغییر دهند، به عنوان مثال، به سمت شرق یا شمال، در بسیاری از سیستم های مرجع مختصات پیش بینی شده.
6.3. gml:boundedBy Element در TIGER/GML
عنصر gml:boundedBy در هر عنصر مجموعه ویژگی های CensusGeographyCollections گنجانده شده است تا گستره فضایی همه ویژگی های موجود در مجموعه را نشان دهد. مختصات موجود در gml:Envelope موجود در یک عنصر gml:boundedBy مانند سایر مختصات TIGER/GML نشان داده می شود. عناصر gml:boundedBy مجموعههای ویژگیهای حاوی ممکن است گسترههای فضایی کوچکتری را نسبت به موارد موجود در CensusGeographyCollections نشان دهد. عنصر gml:boundedBy نیز در هر ویژگی TIGER/GML گنجانده شده است.
6.4. اسامی در TIGER/GML
همه ویژگیها و مجموعههای ویژگی در TIGER/GML ممکن است یک یا چند عنصر اختیاری gml:name داشته باشند که از دسترسی و نمایش دادههای TIGER/GML توسط نرمافزار GML عمومی پشتیبانی میکنند. برای ویژگیهای ناحیه جداگانه، ویژگیهای خطی و ویژگیهای شاخص، gml:name عناصر نام را در ساختارهای تخصصی TIGER/GML تکرار میکند. عنصر نام منطقه برای مناطقی که به طور کلی نامی ندارند، مانند Blocks، مانند gml:id خواهد بود، به عنوان مثال، نام عنصر به اضافه کدهای منطقه که به طور منحصر به فرد آن را شناسایی می کنند.
ویژگیهای خطی در TIGER/GML توسط یک یا چند عنصر CensusFeatureName توصیف میشوند که حاوی یک عنصر نام ویژگی مورد نیاز و جهت پیشوند ویژگی اختیاری، نوع ویژگی و عناصر جهت پسوند ویژگی هستند. محتویات عنصر نام ویژگی در هر CensusFeatureName در یک عنصر gml:name جداگانه برای ویژگی خطی تکرار خواهد شد. ویژگیهای شاخص در TIGER/GML توسط یک عنصر LandmarkName توصیف میشوند. در هر نقطه عطف تنها یک نام نشانه وجود دارد. محتویات آن در یک عنصر gml:name جداگانه برای علامت مشخصه تکرار خواهد شد.
6.5. gml:توضیحات در TIGER/GML
نرم افزار GML با هدف عمومی اغلب به عنصر اختیاری gml:description برای توصیف داده های GML برای کاربر متکی است. برای پشتیبانی از این استفاده، هر مجموعه ویژگی و ویژگی در یک سند داده TIGER/GML یک عنصر gml:description خواهد داشت. شرح عنصر سطح بالای CensusGeographyCollections محتویات سند، وسعت مکانی، پوشش محتویات آن، سال داده، تولید داده و تاریخ استخراج آن از پایگاه داده TIGER را نشان می دهد. توضیحات مربوط به هر مجموعه ویژگی، انواع و وسعت ویژگی های مجموعه را توضیح می دهد. به عنوان مثال، برای ایالات، توصیف «ایالت ها و ایالت های معادل (منطقه کلمبیا، پورتوریکو، ساموآی آمریکایی، گوام، مشترک المنافع جزایر ماریانای شمالی، جزایر ویرجین ایالات متحده و جزایر کوچک دورافتاده ایالات متحده) ایالات متحده است. این توصیفات ممکن است توصیفات موجود در مستندات فنی TIGER/Line را تکرار کنند. توضیحات برای یک ویژگی فردی آن و زمینه جغرافیایی آن را توصیف می کند. به عنوان مثال، “گروه بلوک سرشماری 490039601001 در شهرستان باکس الدر، یوتا”.
6.6. CensusMetaData در Census TIGER/GML
CensusMetaData برای TIGER/GML دارای همان محتوای اساسی با متادیتا برای TIGER/Line 2005 است که برای منعکس کردن تفاوتها در ساختار داده اصلاح شده است. CensusMetaData کامل جهانی از هر مجموعه ویژگی و ویژگی در مجموعه داده فعلی TIGER/GML ارجاع داده می شود. CensusMetaData محلی جزئی که برای ویژگیها یا عناصر مجموعه ویژگیهای انتخاب شده در یک سند یا ذخیره داده اعمال میشود و تنها برای آن عناصر انتخابشده با CensusMetaData جهانی متفاوت است، ممکن است به صورت خطی در یکی از آن عناصر در مجموعههای داده TIGER/GML آینده گنجانده شود. سایر عناصری که همه CensusMetaData محلی جزئی را به اشتراک می گذارند ممکن است دارای یک سرشماریMetaDataProperty با xlink:href باشند که به CensusMetaData درون خطی اشاره دارد. به عنوان مثال، عناصری با دقت مکانی کمتر یا بالاتر از حد متوسط (که 7 بود.
7. نتیجه گیری
این مقاله تحقیقات انجام شده در بخش جغرافیای اداره سرشماری ایالات متحده را در مورد نحوه استفاده از استاندارد GML برای سازماندهی و ارائه داده های TIGER در مقیاس ملی ارائه می دهد. ما مسائل تحقیقاتی را خلاصه کردیم، راهحلهای پیشنهادی را ارائه کردیم و نتایج تجربی TIGER/GML تولید شده را معرفی کردیم. نتایج زیر حاصل شد:
-
حجم داده، سازماندهی جامع داده ها، نامگذاری سند GML و تعریف شناسه GMLelement مسائل اصلی هنگام تولید یک سند GML برای مجموعه داده های NSDIframework هستند.
-
رویکرد تفرقه بینداز و حکومت کن یک راه حل عملی برای غلبه بر مسائل فوق الذکر است.
-
طرحواره، ساختار و سازمان GML با دقت طراحی شده که منعکس کننده ویژگی های مجموعه داده های جغرافیایی هدفمند است، کلید ایجاد موفقیت آمیز استقرار GML برای NSDI است.
منابع
- FGDC. هماهنگی اکتساب و دسترسی به داده های جغرافیایی: زیرساخت ملی داده های مکانی (دستور اجرایی 12906). در دسترس آنلاین: http://www.fgdc.gov/policyandplanning/executive_order (در 17 فوریه 2013 قابل دسترسی است).
- FGDC. مقدمه و راهنمای چارچوب. در دسترس آنلاین: http://www.fgdc.gov/framework/frameworkintroguide (در 17 فوریه 2013 قابل دسترسی است).
- FGDC. استاندارد داده های چارچوب اطلاعات جغرافیایی. در دسترس آنلاین: http://www.fgdc.gov/standards/projects/FGDC-standardsprojects/framework-data-standard/framework-data-standard (در 17 فوریه 2013 قابل دسترسی است).
- Clemens, P. OpenGIS Geography Markup Language (GML) استانداردهای رمزگذاری. در دسترس آنلاین: http://www.opengeospatial.org/standards/gml (در 17 فوریه 2013 قابل دسترسی است).
- اسکوکس، وی. استورر، سی. مروری بر استفاده از GML در زیرساختهای دادههای مکانی مدرن. مجله علمی علوم کامپیوتر دانشگاه فنی ریگا 2011 ، 42 ، 60-67. [ Google Scholar ]
- کورکولز، جی. گونزالس، پی. تجزیه و تحلیل رویکردهای مختلف برای ذخیره سازی اسناد GML. در مجموعه مقالات دهمین سمپوزیوم بین المللی ACM در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، مک لین، VA، ایالات متحده آمریکا، 4-9 نوامبر 2002; صص 11-16.
- زو، اف. گوان، جی. ژو، جی. ژو، اس. ذخیره سازی و پرس و جوی GML در پایگاه داده های شی – رابطه ای. در مجموعه مقالات دهمین سمپوزیوم بین المللی ACM در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، مک لین، VA، ایالات متحده آمریکا، 4-9 نوامبر 2002; صص 107-114.
- کیم، YK; جانگ، YJ; Chang، JW طراحی و پیادهسازی طرحوارههای ذخیرهسازی کارآمد و مدیر ذخیرهسازی سطح پایین برای اسناد GML. در مجموعه مقالات سومین کنفرانس بین المللی چالش های پژوهشی در علم اطلاعات، نیویورک، نیویورک، ایالات متحده آمریکا، 22-24 آوریل 2009.
- زو، اف. گوان، جی. ژو، S. محدودیتها-حفظ ذخیرهسازی GML در پایگاههای داده رابطهای شی. در مجموعه مقالات پانزدهمین سمپوزیوم بین المللی سالانه ACM در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، 2007; صص 1-4.
- لی، ی. ایمایزومی، تی. Guan، J. تکنیک های فشرده سازی داده های فضایی برای GML. در مجموعه مقالات کارگاه مشترک ژاپن و چین در مرز علوم و فناوری کامپیوتر، ناکازاکی، ژاپن، 27-28 دسامبر 2008; صص 79-84.
- سریپادا، ال. لو، سی. Wu, W. ارزیابی پشتیبانی GML برای پایگاههای داده فضایی. در مجموعه مقالات بیست و هشتمین کنفرانس بین المللی نرم افزار و برنامه های کامپیوتری سالانه، هنگ کنگ، چین، 28-30 سپتامبر 2004. صص 74-77.
- هوانگ، CH; چوانگ، TR; دنگ، DP; لی، HM Eficient GML-Native Processors for Web-based GIS: Techniques and Tools. ص 91-98.
- شکر، س. وتساوایی، ر.ر. ساهای، ن. بورک، تی. سیستم نقشه برداری وب تعاملی مبتنی بر Lime، S. WMS و GML. در مجموعه مقالات نهمین سمپوزیوم بین المللی ACM در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، آتلانتا، GA، ایالات متحده آمریکا، 9-10 نوامبر 2001; صص 106-111.
- پل، م. Ghosh, SK رویکردی برای مدیریت داده های مکانی برای بازیابی کارآمد وب. در مجموعه مقالات ششمین کنفرانس بین المللی IEEE در زمینه کامپیوتر و فناوری اطلاعات، سئول، کره، 20-22 سپتامبر 2006. IEEE 28.
- کیم، ام جی؛ کیم، ام. جو، آی اچ. جانگ، سیستم خدمات وب اطلاعات ترافیک رمزگذاری شده BT GML. در مجموعه مقالات شصتمین کنفرانس فناوری وسایل نقلیه IEEE 2004، نیویورک، نیویورک، ایالات متحده آمریکا، 26-29 سپتامبر 2004.
- کورکولز، جی. گونزالس، پی. مشخصات یک زبان پرس و جو فضایی بر روی GML. در مجموعه مقالات نهمین سمپوزیوم بین المللی ACM در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، آتلانتا، GA، ایالات متحده آمریکا، 9-10 نوامبر 2001; صص 112-117.
- گوا، ز. ژو، اس. خو، ز. Zhou، A. G2ST: روشی جدید برای تبدیل GML به SVG. در مجموعه مقالات یازدهمین سمپوزیوم بین المللی ACM در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، نیواورلئان، لس آنجلس، ایالات متحده آمریکا، 3-8 نوامبر 2003. صص 161-168.
- Ahn، YS; پارک، SY; یو، اس بی. Bae، HY Extension of Geography Markup Language (GML) برای موبایل و برنامه های مبتنی بر مکان. در علوم محاسباتی و کاربردهای آن: ICCSA 2004 ; Springer: برلین/هایدلبرگ، آلمان، 2004. [ Google Scholar ]
- Bardet، JP; زند، الف. مدلسازی فضایی اطلاعات ژئوتکنیکی با استفاده از GML. ترانس. GIS 2009 ، 13 ، 125-165. [ Google Scholar ] [ CrossRef ]
- کورکولز، جی. گونزالس، پی. یکپارچه سازی منابع GML و سایر منابع وب. در مجموعه مقالات پانزدهمین کارگاه بین المللی در مورد پایگاه داده و کاربردهای سیستم های خبره (DEXA’04)، ساراگوزا، اسپانیا، 30 اوت تا 3 سپتامبر 2004.
- فری، اف. فرمیکا، ا. گریفونی، پ. Rafanelli, M. ارزیابی تشابه معنایی با استفاده از GML در سیستم های اطلاعات جغرافیایی. در حرکت به سوی سیستم های اینترنتی معنادار 2005: کارگاه های آموزشی OTM 2005 ; Springer: برلین/هایدلبرگ، آلمان، 2005; جلد 3762، ص 1009–1019. [ Google Scholar ]
- Huang, R. مدل سازی شبکه های حمل و نقل توسط GML برای برنامه ریزان سفرهای حمل و نقل توزیع شده. جی. اسپات. علمی 2008 ، 53 ، 1-15. [ Google Scholar ] [ CrossRef ]
- Lake, R. کاربرد زبان نشانه گذاری جغرافیا (GML) در علوم زمین شناسی. محاسبه کنید. Geosci. 2005 ، 31 ، 1081-1094. [ Google Scholar ] [ CrossRef ]
- ناتیوی، س. کارون، جی. دیویس، ای. Domenico، B. طراحی و پیاده سازی زبان نشانه گذاری netCDF (NcML) و پسوند مبتنی بر GML آن (NcML-G(ML)). محاسبه کنید. Geosci. 2005 ، 31 ، 1104-1118. [ Google Scholar ] [ CrossRef ]
- ژانگ، جی تی. Gruenwald, L. یک معماری باز مبتنی بر GML برای ساخت موتور جستجوی اطلاعات جغرافیایی از طریق اینترنت. در مجموعه مقالات دومین کنفرانس بین المللی مهندسی سیستم های اطلاعات وب، کیوتو، ژاپن، 3-6 دسامبر 2001; 2، صص 25-32.
© 2013 توسط نویسندگان; دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (http://creativecommons.org/licenses/by/3.0/) توزیع شده است.
بدون نظر