

خلاصه
ما یک چارچوب تقسیم بندی و گروه بندی جدید برای استنتاج نقشه راه از ردیابی GPS پیشنهاد می کنیم. ما ابتدا یک الگوریتم کلاستربندی فضایی مبتنی بر تراکم پیشرونده از کاربرد با نویز (DBSCAN) با یک محدودیت جهتگیری برای تقسیم کل مجموعه نقطهای از آثار به خوشههایی ارائه میکنیم که بخشهای جاده را نشان میدهند. سپس یک الگوریتم گروهبندی خوشه نقطهای جدید، با توجه به رابطه توپولوژیکی و مجاورت فضایی خوشههای نقطهای برای بازیابی شبکه راه، توسعه مییابد. پس از تولید خوشههای نقطهای، از روش قوی محلی وزن پراکنده صاف (پایین) برای استخراج خطوط مرکزی آنها استفاده میشود. سپس پیشنهاد میکنیم که رابطه توپولوژیکی خطوط مرکزی را توسط الگوریتم تطبیق نقشه مبتنی بر مدل مارکوف پنهان (HMM) بسازیم. و برای ارزیابی اینکه آیا نزدیکی فضایی بین خوشههای نقطهای با فرض فاصله از نقاط تا خط مرکزی با توزیع گاوسی مطابقت دارد یا خیر. در نهایت، خوشههای نقطهای بر اساس رابطه توپولوژیکی و مجاورت فضایی گروهبندی میشوند تا سکتههایی را برای بازیابی نقشه راه تشکیل دهند. نتایج تجربی نشان میدهد که الگوریتم ما نسبت به نویز و نرخهای نمونهگیری متفاوت قوی است. نقشه های راه تولید شده دقت هندسی بالایی را نشان می دهد.
کلید واژه ها:
استنتاج نقشه ؛ DBSCAN _ تطبیق نقشه HMM ; تقسیم بندی ابر نقطه ای 2 بعدی گروه بندی خوشه نقطه ای
1. معرفی
نقشه شبکه راه یکی از اساسی ترین ویژگی های اطلاعات مکانی است که کاربردهای متنوعی مانند مدیریت عمومی، برنامه ریزی شهری و ناوبری دارد. با این حال، بهروزرسانی سریع و مداوم نقشههای راه موجود [ 1 ]، بهویژه در کشورهای در حال توسعه که شبکههای جادهای به سرعت در حال تغییر هستند، چالش برانگیز است . تکنیک های مرسوم به روز رسانی نقشه عمدتاً شامل بررسی های زمینی و هوایی است [ 2 ]. بررسیهای زمینی به یک چرخه طولانی کسب اطلاعات محدود میشوند، در حالی که بررسیهای هوایی میتوانند دادههای مقیاس بزرگی را در مورد سطح زمین در مدت زمان کوتاهی به دست آورند. اگرچه بسیاری از الگوریتمها برای استخراج شبکههای جادهای از تصاویر ماهوارهای با وضوح بالا پیشنهاد شدهاند [ 3 ، 4]]، به دلیل پیچیدگی شبکه های جاده ای و انسداد ناشی از درختان و ساختمان ها، تولید شبکه های جاده ای در مقیاس بزرگ با این الگوریتم ها هنوز دشوار است.
به منظور غلبه بر کاستی های نقشه برداری سنتی نقشه راه، محتوای تولید شده توسط کاربر (UGC) [ 5 ] در حال حاضر برای تولید نقشه راه به دو صورت استفاده می شود: (1) برنامه های نقشه برداری مشترک، مانند OpenStreetMap، که بسیار وابسته به کار دستی؛ و (2) تولید جاده خودکار از مسیرهای سیستم موقعیت یاب جهانی (GPS) [ 6 ] که به عنوان استنتاج نقشه از آن یاد می شود و اکنون یک روش رایج و کارآمد برای به روز رسانی شبکه های جاده ای است. مسیرهای GPS توسط وسایل نقلیه مجهز به GPS، دوچرخه ها یا عابران پیاده جمع آوری می شوند و می توانند به صراحت هندسه و توپولوژی جدیدترین شبکه های جاده ای را نشان دهند.
هدف از استنتاج نقشه استخراج موقعیت های هندسی جاده ها، اتصالات توپولوژیکی، و همچنین برخی از اطلاعات ویژگی ها، مانند تعداد خطوط [ 7 ] و نام راه ها [ 6 ] است. بیشتر روشهای استنتاج نقشه موجود با هدف برخورد با ردیابیهای GPS کم نویز، نمونهبرداری متراکم و توزیع یکنواخت انجام میشوند [ 1 ]. با این حال، در بسیاری از موارد، کاوشگرهای GPS ممکن است نرخ نمونه برداری را به دلیل هزینه های انرژی و ارتباطات کاهش دهند [ 8 ]. به طور معمول، این نوع داده ها بخش اصلی ردیابی GPS را تشکیل می دهند. بنابراین، استنباط نقشههای راه با کیفیت بالا از ردیابیهای GPS کم نمونه و پر سر و صدا یک موضوع تحقیقاتی مهم و چالش برانگیز است.
به منظور غلبه بر محدودیت نرخ نمونهگیری پایین GPS، ما یک چارچوب تقسیمبندی و گروهبندی جدید برای تولید نقشههای راه پیشنهاد میکنیم. مشارکت های اولیه روش ما را می توان به صورت زیر خلاصه کرد:
-
یک چارچوب تقسیمبندی و گروهبندی انعطافپذیر برای استنتاج نقشه که در برابر نویز و نرخهای نمونهگیری متغیر ردیابی GPS مقاوم است.
-
یک الگوریتم خوشهبندی فضایی مبتنی بر چگالی پیشرفته توسعهیافته برنامه با نویز (DBSCAN) با یک محدودیت جهتگیری برای تقسیمبندی ابر نقطهای دو بعدی (2 بعدی).
-
الگوریتم تطبیق نقشه مبتنی بر مدل مارکوف پنهان (HMM) برای ساخت رابطه توپولوژیکی خوشه نقطه ای.
-
یک الگوریتم گروه بندی خوشه نقطه مترقی برای بازیابی نقشه راه طبق اصل سکته مغزی [ 9 ].
بقیه مقاله به شرح زیر سازماندهی شده است: بخش 2 مروری بر کار مرتبط ارائه می کند. بخش 3 روند الگوریتم استنتاج نقشه ما را تشریح می کند. بخش 4 آزمایشات روی دو مجموعه داده ردیابی GPS را شرح می دهد. بخش 5 نقشه های راه تولید شده را ارزیابی می کند. و بخش 6 کار آینده روش ما را مورد بحث قرار می دهد.
2. کارهای مرتبط
روشهای استنتاج نقشه کنونی را میتوان تقریباً به چهار دسته طبقهبندی کرد: روشهای مبتنی بر خوشه، روشهای مبتنی بر ادغام ردیابی، روشهای مبتنی بر تخمین تراکم هسته (KDE) و رویکردهای مبتنی بر پیوند تقاطع [10 ، 11 ] .
رویکردهای مبتنی بر خوشهبندی با تعیین مجموعهای از دانههای خوشهای بر اساس مکان، باربری و سرفصل آثار آغاز میشوند. سپس دانه ها به هم متصل می شوند تا بخش های جاده را با توجه به آثار خام تشکیل دهند. روشهای معمولی موجود شامل روشهایی است که توسط Edelkamp و Schrödl [ 12 ]، Schrödl و همکاران پیشنهاد شدهاند. [ 7 ] و آگامنونی و همکاران. [ 13 ، 14 ]. این روش ها می توانند نقشه های راه را با دقت هندسی بالا، یعنی اطلاعات خطوط دقیق و مدل های تقاطع استنباط کنند. با این حال، این روشها برای ردیابیهای GPS با نمونهبرداری متراکم طراحی شدهاند. اطلاعات هندسی دقیق را فقط می توان از ردیابی های دقیق GPS استنباط کرد. آنها در برابر نویز ردیابی GPS مقاوم نیستند.
رویکردهای مبتنی بر ادغام ردیابی شامل ادغام بخشهای ردیابی بر اساس روابط هندسی و شباهت شکل آنها است. سپس خطوط مرکزی جاده ها توسط ردیابی های ادغام شده ایجاد می شود. کائو و کروم [ 15 ] یک تکنیک تجمیع را برای کنار هم کشیدن آثار در یک جاده پیشنهاد کردند. آنها دو نوع نیرو را با هر اثر مرتبط می کنند. نیروی اول باعث می شود که هر ردی توسط ردهای مجاور جذب یا کشیده شود و نیروی دیگر باعث می شود هر ردی توسط موقعیت اصلی محدود شود. برای اصلاح تقاطع شبکه جاده استنباط شده، وانگ و همکاران. [ 16 ] یک رویکرد جدید برای تولید نقشه های راه قابل مسیریابی از ردیابی GPS بر اساس تحقیقات [ 15 ] ارائه کرد. آنها مرزهای دایره ای را برای جداسازی نقاط نزدیک تقاطع ها معرفی کردند و از a استفاده کردندk – به معنای روش خوشهبندی برای اصلاح تقاطعها است. روشهای آنها روی دادههای ردیابی GPS با نمونهبرداری متراکم خوب عمل میکنند، اما در برابر نویز مقاوم نیستند. به منظور بهبود عملکرد روش مبتنی بر ادغام ردیابی، از برخی تکنیکهای ریاضی استفاده میشود. نیهوفر و همکاران [ 17 ] یک مکانیسم فیلتر را برای کاهش نویز ردیابی GPS که توسط تلفن همراه گرفته شده است، اعمال کرد. چن و همکاران [ 18 ] از نظر تئوری دقت هندسی نقشه راه استنباط شده را بر اساس این فرض که آثار به طور متراکم نمونه برداری شده و در سطح جاده باقی می مانند، تضمین می کند. وانگ و همکاران [ 1 ] فاصله Hausdorff را برای اندازه گیری فاصله بین ردیابی GPS برای فیلتر کردن نویز اعمال کرد. رویکرد ادغام ردیابی نوعی روش مبتنی بر خط است [ 19]، و عملکرد آن به شدت به نرخ نمونه گیری بستگی دارد. اگر دو نقطه ردیابی متوالی از یکدیگر دور باشند، به ویژه هنگامی که وسیله نقلیه در یک تقاطع می چرخد، بخش های ردیابی GPS نمی توانند با جاده ها هماهنگ شوند. در این حالت، بخش های جاده ای جعلی تولید می شود.
روشهای مبتنی بر KDE، استنتاج نقشه را به عنوان یک روش پردازش تصویر دیجیتال در نظر میگیرند. ردیابیهای جیپیاس خام به یک تصویر خاکستری دوبعدی تبدیل میشوند و سپس یک آستانه جهانی برای فیلتر کردن تصویر اعمال میشود. در نهایت، رویکردهای اسکلت سازی، مانند نمودار ورونوی و عملیات مورفولوژیکی، برای استخراج خطوط مرکزی بخش های جاده استفاده می شود [ 20 ، 21 ، 22 ]. این نوع روش به توزیع چگالی حساس است و انتخاب یک آستانه جهانی مناسب دشوار است. به منظور غلبه بر محدودیت KDE، Biagioni و Erikson [ 23] یک روش پیشرو مبتنی بر KDE را پیشنهاد کرد. آنها یک خط لوله استنتاج نقشه ترکیبی، از جمله تولید نقشه اولیه با اسکلت بندی در مقیاس خاکستری، هرس نقشه با الگوریتم تطبیق نقشه Viterbi و اصلاح توپولوژی و هندسه جاده ها را توسعه دادند. روش آنها در برابر نویز و نابرابری قوی است. با این حال، از آنجایی که این یک رویکرد مبتنی بر خط است، ردیابیهای نمونهبرداری پراکنده را نمیتوان مدیریت کرد.
رویکردهای پیوند تقاطع شامل دو مرحله اصلی است. اولین قدم تشخیص تقاطع های نقشه راه است. مرحله دوم، پیوند دادن تقاطع ها با توجه به ردیابی های خام است. فتحی و کروم [ 24 ] یک توصیفگر شکل محلی برای نشان دادن توزیع ردپای GPS طراحی کردند و یک طبقهبندی بر روی توصیفگر برای یافتن تقاطعها از ردیابی GPS آموزش دادند. Karagiorgou و Pfoser [ 25 ] الگوریتم مشابهی را پیشنهاد کردند. آنها از آستانه سرعت و تغییر جهت به عنوان شاخص برای شناسایی تقاطع ها استفاده کردند. این روشها برای شبکههای جادهای با تقاطعهای ساده و آثار نمونهبرداری متراکم به خوبی کار میکنند. با این حال، آنها همچنین به نرخ نمونه برداری از ردیابی GPS حساس هستند.
اکثر روشهایی که در بالا توضیح داده شد از ردیابیهای GPS نمونهبرداری متراکم استفاده میکنند و برخی از روشها نویز و نابرابری را در نظر میگیرند [ 23 ]. با این حال، در برخی موارد، ردیابی GPS جمعآوریشده به اندازه کافی برای این الگوریتمها متراکم نیست. اگرچه مقدار کل ردیابی ها بسیار زیاد است، نرخ نمونه برداری برای یک اثر منفرد کم است. روش KDE مبتنی بر نقطه [ 19 ] میتواند با ردیابیهای GPS با نمونهبرداری پراکنده مقابله کند، اما به تفاوتها حساس است.
بررسی بالا نشان می دهد که یک الگوریتم عمومی تر برای استنتاج نقشه باید توسعه یابد. الگوریتم باید توانایی مقابله با ردیابی متراکم و پراکنده را داشته باشد. اخیراً کیو و همکاران. [ 26 ] روشی را برای بخشبندی ردیابیهای GPS با نمونهگیری پراکنده به خوشههای نقطهای برای تولید خطوط مرکزی بخشهای جاده پیشنهاد کرد. بر اساس این کار، ما یک چارچوب تقسیم بندی و گروه بندی جدید برای استنتاج نقشه پیشنهاد می کنیم. تا جایی که ما می دانیم، این اولین بار است که چنین چارچوبی برای استنتاج نقشه از ردیابی GPS ارائه شده است. این روش برای هر دو ردیابی GPS با نمونه متراکم و پراکنده به خوبی کار می کند.
3. روش
مجموعه داده ردیابی GPS تیrبرای روش ما توسط وسایل نقلیه مجهز به GPS جمع آوری شد: تیr={تیrمن|من=1،2،…،ن}، که در آن N تعداد ردیابی ها است. ردیابی GPS تیrمنتوسط یک وسیله نقلیه در یک بازه زمانی مشخص جمع آوری می شود و متشکل از دنباله ای از نقاط GPS است پمن،r، با هر نقطه ای که موقعیت وسیله نقلیه را در یک زمان خاص ثبت می کند که با نشان داده شده است تیrمن={پمن،r|r=1،2،…،n}با پمن،r=(لonمن،r،لآتیمن،r،تیمن،r)، جایی که لonمن،r∈[–180، 180]و لآتیمن،r∈[–90، 90]طول و عرض جغرافیایی نقطه هستند. تیمن،r∈آر+زمانی است که نقطه جمع آوری شده است. n تعداد نقاط است. و زمان تیمن،1<تیمن،2<…<تیمن،n. با مقدار زیادی ردیابی GPS که توسط وسایل نقلیه در مکان و زمان جمعآوری میشود، میتوانیم شبکه جادهای را با آثار انباشته شده ایجاد کنیم. در آزمایش، طول و عرض جغرافیایی تمام نقاط به یک سیستم مختصات پیش بینی شده تبدیل می شود که با نشان داده می شود. (ایکس،y).
روش ما برای استنتاج نقشه از ردیابی های GPS شامل دو جزء است: تقسیم بندی ابر نقطه و گروه بندی خوشه نقطه. برای تقسیم بندی، جهت گیری نقاط را با استفاده از دو نقطه متوالی به عنوان بردار محاسبه می کنیم. سپس تمام نقاط GPS را با یک الگوریتم توسعهیافته DBSCAN پیشرونده با یک محدودیت جهتگیری به خوشههایی تقسیم میکنیم، جایی که هر خوشه نشان دهنده یک منحنی کوتاه و تقریبا مستقیم از جاده است.
در مولفه گروهبندی، خطوط مرکزی خوشههای نقطهای را با الگوریتم قوی Scatterplot Smooth (Lowess) [ 27 ] با وزن محلی ایجاد میکنیم . سپس یک الگوریتم تطبیق نقشه مبتنی بر HMM [ 28 ] برای تطبیق ردیابیهای GPS خام با خطوط مرکزی خوشهها برای ایجاد رابطه توپولوژیکی بین خوشهها استفاده میشود. نزدیکی بین خوشه ها با این فرض ارزیابی می شود که فاصله نقاط تا خط مرکزی با توزیع گاوسی مطابقت دارد. در نهایت، ما خوشه ها را بر اساس رابطه توپولوژیکی و مجاورت گروه بندی می کنیم تا سکته مغزی را برای بازیابی نقشه راه تشکیل دهیم.
قبل از تقسیم بندی، ردیابی ها از قبل پردازش می شوند. اگر فاصله بین دو نقطه متوالی در یک اثر خام بیشتر از یک آستانه (یعنی 300 متر) باشد، رد به دو رد تقسیم می شود. اگر دو نقطه از یکدیگر خیلی دور باشند، پاره خط بین این دو نقطه به درستی با جاده واقعی همسو نخواهد شد.
3.1. الگوریتم DBSCAN با یک محدودیت جهت
الگوریتم DBSCAN [ 29 ] یک الگوریتم خوشه بندی فضایی برای نقاط است. این برای کشف خوشه هایی با اشکال دلخواه با استفاده از یک محدودیت چگالی طراحی شده است که بر اساس تعداد نقاط در یک منطقه خاص تخمین زده می شود. این الگوریتم در برابر نویز مقاوم است و برای تعیین تعداد خوشه ها به کمک کاربران نیازی ندارد. در الگوریتم کلاسیک DBSCAN، ε–nهمنgساعتبoتوrساعتooدبرای نشان دادن چگالی استفاده می شود که با تعریف 1 تعریف شده است. ورودی الگوریتم DBSCAN شامل ε و ممنnپتیس، جایی که ε شعاع جستجو برای یافتن همسایگان یک نقطه است و ممنnپتیسآستانه تعیین اینکه آیا یک نقطه یک نقطه هسته است (تعریف 2) است یا خیر. تولید خوشه نقطه جمتریک روش افزایشی است اول، یک نقطه اصلی یافت می شود. و همسایه های آن برای مقداردهی اولیه استفاده می شود جمتر. سپس، جمتربا افزودن همسایگان نقاط اصلی در گسترش می یابد جمترتا زمانی که هیچ امتیازی اضافه نشود.
تعریف 1.
ε–nهمنgساعتبoتوrساعتooداز نقطه p ، نشان داده شده با نپ، توسط تعریف شده است نپ={q∈پ|دمنس(پ،q)≤ε}، که در آن P مجموعه نقاط و دمنس(پ،q)فاصله اقلیدسی نقاط p و q است .
تعریف 2.
سیorهپoمنnتی. نقطه p را اگر نقطه هسته می گویند ε–nهمنgساعتبoتوrساعتooدنپحداقل شامل ممنnپتیسامتیاز (حداقل تعداد امتیاز).
در زمینه تقسیمبندی ابر نقطهای، ما قصد داریم خوشههای نقطهای را تعیین کنیم که منحنیهای تقریباً مستقیم را نشان میدهند. محدوده مقادیر مختصات x و y ( ایکس،y∈آر) با دامنه جهت گیری نقاط متفاوت است ( [0درجه، 360درجه]یا [0،2π]). بنابراین، همسایگی یک نقطه را با دو جزء دوباره تعریف می کنیم: شعاع جستجو ε و تفاوت جهت α بین دو نقطه (تعریف 3). همچنین نقطه مرکزی را با چگالی ردیابی ها دوباره تعریف می کنیم (تعریف 4.) جهت گیری از 0 درجه شروع می شود که با محور x منطبق است و در جهت خلاف جهت عقربه های ساعت افزایش می یابد.
تعریف 3.
ε،α–nهمنgساعتبoتوrساعتooداز نقطه p که با مجموعه نقطه نشان داده می شود نپ، توسط تعریف شده است نپ={q∈پ|دمنس(پ،q)≤ε∧دمنffOrمن(پ،q)≤α}، که در آن P مجموعه ای از نقاط است، دمنس(پ،q)فاصله اقلیدسی نقاط p و q و استدمنffOrمن(پ،q)تفاوت در جهت گیری نقاط p و q است .
تعریف 4.
سیorهپoمنnتی. نقطه p در صورتی نقطه مرکزی نامیده می شود که مجموعه نقطه آن باشد ε،α–nهمنgساعتبoتوrساعتooدنپمتعلق به کمتر از ممنnLnسردیابی GPS (حداقل تعداد ردیابی GPS).
رویه الگوریتم DBSCAN ما با یک محدودیت جهت گیری به صورت الگوریتم 1 نشان داده شده است.
در مرحله اول از ε , α و استفاده می کنیمممنnLnسبرای تولید خوشه های نقطه ای (خطوط 1 تا 15)، که در آن ε و α شعاع جستجو و تفاوت جهت گیری بین نقاط برای تعیین همسایگی هستند، و ممنnLnستعداد ردیابی های GPS برای تعیین اینکه آیا یک نقطه یک نقطه هسته است یا خیر. در مرحله دوم، از تجزیه و تحلیل مؤلفه اصلی (PCA) برای ایجاد یک پاره خط متناسب با خوشه نقطه استفاده می کنیم و خوشه نقطه را بر اساس طول و جهت قطعه خط فیلتر می کنیم (خطوط 16 تا 21). اگر طول پاره خط کوچکتر از آستانه باشد ممنnLهn(حداقل طول)، خوشه نقطه را دور می اندازیم. اگر جهت پاره خط (محدوده [ 0درجه، 180درجه]) با جهت گیری میانگین نقاط در خوشه (مدول 180 درجه) مطابقت ندارد، یعنی اگر اختلاف جهت ها از آستانه بزرگتر باشد. مآایکسدیoOس(حداکثر اختلاف جهت ها)، سپس خوشه نقطه را نیز کنار می گذاریم. مولفه های ممنnLهnو مآایکسدیoOسهدف آنها ایجاد یک بخش نسبتا طولانی است و همچنین به حذف خوشه های ایجاد شده توسط نویز کمک می کند. متغیر nاستیآrتیمندهویت اولین خوشه نقطه تولید شده است.
 |
پارامترهای مختلف برای یافتن همسایگان منجر به خوشههای نقطهای متفاوت میشود. از بین پارامترهای ε , α و ممنnLnسحساس ترین α است . شکل 1 حساسیت α را نشان می دهد . شکل 1 a مجموعه نقطه ای از ردیابی خام GPS است. ما خوشه های نقطه ای را با α=1درجهو α=5درجه. شکل 1 b,c دو تا از خوشه های نقطه ای را نشان می دهد α=1درجهو α=5درجه، به ترتیب. سپس دو خوشه نقطه با قطعات خط محاسبه شده با PCA (خطوط قرمز در شکل 1 ) متناسب می شوند. در مقایسه شکل 1 b,c، می توانیم مشاهده کنیم که خوشه نقطه ای ایجاد شده با یک α کوچک را می توان به خوبی با یک پاره خط نشان داد. با این حال، در همان زمان، یک محدودیت قوی ( α کوچک ) منجر به نقاط زیادی می شود که نمی توان آنها را خوشه بندی کرد.
به منظور متعادل کردن این مبادله، ما یک الگوریتم پیشرونده DBSCAN با یک محدودیت جهتگیری برای تولید خوشههای نقطهای پیادهسازی میکنیم که به صورت الگوریتم 2 نشان داده شده است. ابتدا، خوشههای نقطهای را با α کوچک تولید میکنیم . سپس α را بزرگ می کنیم و از نقاطی که به عنوان ورودی طبقه بندی نمی شوند برای تولید خوشه های جدید استفاده می کنیم. این مرحله دوم تا زمانی تکرار می شود که محدودیت α به آستانه از پیش تعریف شده برسد.
 |
الگوریتم پیشرو DBSCAN ما با یک محدودیت جهت گیری به سه پارامتر برای تولید خوشه و دو پارامتر برای فیلتر خوشه نیاز دارد. در روش تولید خوشه، شعاع جستجو ε در 15 متر ثابت شد. این مقدار بر اساس عرض خط و تعداد جاده های شهری واقعی برآورد شد. عرض خط در شهرها حدود 3.75 ~ 4.0 متر است و ما فرض می کنیم که جاده هایی که وسایل نقلیه از آنها بازدید کردند حداقل دارای 4 خط بودند. پارامتر α در محدوده [ 1درجه، 30درجه]. تنظیم کران پایین بر این واقعیت استوار بود که نقاط نزدیک به یکدیگر در یک جاده دارای جهت گیری های مشابه هستند. و تنظیم کران بالایی نویز و نرخ نمونه برداری از ردیابی GPS را در نظر گرفت. پارامتر سوم ممنnLnس2 تعیین شد، به این معنی که بخش واقعی جاده در مناطقی که کمتر از دو بار توسط وسایل نقلیه بازدید شده است، قرار نمی گیرد.
در فیلتر خوشه ای، فرض می کنیم که طول قطعه جاده تولید شده بزرگتر از عرض جاده واقعی (15 متر) است. بنابراین، ما رفع شد ممنnLهnتا 15 متر پارامتر مآایکسدیoOسبا توجه به آزمایشات تجربی روی 5 درجه تنظیم شد.
3.2. گروه بندی خوشه های نقطه
بخشهای جادهای که توسط الگوریتم DBSCAN مترقی ما با یک محدودیت جهتگیری تولید میشوند، شامل بخشهای کوتاه بسیاری با جهتگیریهای مشابه هستند. برای کاهش افزونگی، باید آنها را گروه بندی کرد تا منحنی های طولانی تشکیل شود. برای هر خوشه نقطه ای، فرض می کنیم که فاصله نقاط تا خط مرکزی خوشه با توزیع گاوسی مطابقت دارد. جی∼(μ،σ2)، جایی که μ=0نشان دهنده خط مرکزی و σ انحراف استاندارد است. بر اساس این فرض، ما رابطه توپولوژیکی را ایجاد می کنیم و نزدیکی بین خوشه های نقطه ای را برای گروه بندی آنها ارزیابی می کنیم.
در این بخش، از الگوریتم Lowess قوی برای تولید خط مرکزی استفاده میکنیم لمناز خوشه نقطه جمنو از فرمول انحراف مطلق میانه (MAD) برای تخمین مربوطه استفاده کنید σمنتوزیع گاوسی سپس یک الگوریتم تطبیق نقشه مبتنی بر HMM را برای تطبیق ردپای GPS خام با خطوط مرکزی تولید شده برای ایجاد یک رابطه توپولوژیکی بین خوشههای نقطه اعمال میکنیم. در نهایت، خوشههای نقطهای را به روشی پیشرونده بر اساس مجاورت فضایی آنها گروهبندی میکنیم.
3.2.1. ایجاد خط مرکزی از خوشه نقطه
انواع بسیاری از الگوریتم های تولید خط مرکزی برای ابرهای نقطه سازمان نیافته در جامعه علوم کامپیوتر [ 30 ] وجود دارد. خوشه های نقطه ای تولید شده توسط الگوریتم ما منحنی های تقریبا مستقیم را نشان می دهند. منحنی خود تلاقی نمی کند، بلکه توسط نویز و نقاط پرت منحرف می شود. بنابراین، ما از روش لاوس قوی برای ایجاد خط مرکزی خوشه نقطه استفاده می کنیم. این روش از تجزیه و تحلیل باقیمانده برای غلبه بر مشکل ناشی از نویز و نقاط پرت استفاده می کند.
شکل 2 a یک خوشه نقطه معمولی است که با روش استنتاج نقشه ما ایجاد شده است. برای اعمال الگوریتم لاوس قوی، باید خوشه نقطه را از قبل پردازش کنیم. ابتدا نقاط را به سیستم مختصات جدید محاسبه شده توسط PCA می چرخانیم. آبسیسا به صورت خط در شکل 2 الف نشان داده شده است. سپس نقاط را بر اساس مقادیر x آنها در سیستم مختصات جدید به ترتیب صعودی مرتب می کنیم و آنها را به هم وصل می کنیم تا یک منحنی ناهموار ایجاد کنیم که در شکل 2 ب نشان داده شده است. پس از این دو مرحله، همانطور که در شکل 2 ج نشان داده شده است، می توانیم از Lowess قوی برای ایجاد یک منحنی صاف استفاده کنیم . در نهایت، منحنی را به سیستم مختصات اولیه برمیگردانیم.
روش کلی روش لاوس قوی را می توان به صورت زیر خلاصه کرد:
-
برای هموار کردن منحنی، یک رگرسیون حداقل مربعات خطی با وزن محلی برای هر نقطه اعمال کنید.
-
باقیمانده هر نقطه را با توجه به منحنی صاف شده محاسبه کنید.
-
برای حذف مقادیر پرت و به روز رسانی وزن های محلی، مقدار MAD را محاسبه کنید. باقیمانده های پرت بیش از 6 برابر ارزش MAD است.
-
منحنی را همانطور که در مرحله 1 توضیح داده شد، دوباره با استفاده از وزنه های جدید صاف کنید.
-
مراحل 2 تا 4 را در مجموع پنج بار تکرار کنید تا یک منحنی صاف به دست آورید.
در الگوریتم، رگرسیون خطی محلی برای هر نقطه بر روی k نزدیکترین همسایه آن انجام می شود که با مقادیر x آنها در سیستم مختصات چرخشی محاسبه می شود. برای هر خوشه باید k را به صورت دستی تعیین کنیم . از آنجایی که چگالی (تعداد نقاط در یک منطقه ثابت) نقاط GPS خام در فضا متفاوت است، ما از میانگین تعداد نقاط موجود در یک بازه مشخص استفاده می کنیم. داسپآnبرای تخمین k : ک=داسپآn/ل×n، که در آن l طول پاره خط تولید شده از خوشه نقطه با PCA و n تعداد نقاط خوشه است. را تعمیر کردیم داسپآnطبق آزمایشات تجربی تا 10 متر.
برای هر خوشه نقطه جمن={پمن،r|r=1،2،…،متر}، خط مرکزی آن را تولید می کنیم لمن: لمن={vمن،r“|r“=1،2،…،متر“∧متر“≤متر}، جایی که vمن،r“گره هایی است که خط مرکزی را تشکیل می دهند. با توجه به نقاط پرت، تعداد گره ها ( متر“) که خط مرکزی را تشکیل می دهند لمنکمتر یا مساوی تعداد نقاط ( m ) در خوشه استجمن. سپس می توانیم مربوطه را تخمین بزنیم σمنبا فرمول MAD، همانطور که در معادله ( 1 ) نشان داده شده است.
σمن=1.4826×میانه|دمنس(پمن،r،لمن)–میانه(دمنس(پمن،r،لمن))|
جایی که دمنس(پمن،r،لمن)=دقیقه{دمنس(پمن،r،vمن،r“)}،(r“=1،2،…،متر“)فاصله از نقطه است پمن،rبه خط مرکزی لمن، دمنس(پمن،r،vمن،r“)فاصله اقلیدسی از نقطه است پمن،rبه گره vمن،r“و 1.4826 ضریب مقیاس برای داده های توزیع نرمال است. اگرچه توزیع خوشههای نقطهای دقیقاً با توزیع گاوسی مطابقت ندارد، میتوانیم با فرمول MAD یک تخمین معقول به دست آوریم.
3.2.2. ساخت رابطه توپولوژیکی بین خوشه ها
طبق نیوسون و کروم [ 28 ]، تطبیق ردیابی GPS با نقشه راه واقعی (یعنی تطبیق نقشه) از طریق یافتن محتمل ترین مسیری که وسیله نقلیه بازدید کرده بر اساس موقعیت وسیله نقلیه اندازه گیری شده توسط GPS به دست می آید. آنها مشکل تطبیق نقشه را به عنوان یک HMM مدل کردند که یک فرآیند مارکوف با مجموعه ای از حالت ها و مشاهدات پنهان است. انتقال از حالت به حالت با احتمالات انتقال تعریف می شود. هر حالت دارای یک توزیع احتمال به نام توزیع احتمال انتشار بر روی مشاهدات ممکن است. با توجه به دنباله ای از مشاهدات، می توان با به حداکثر رساندن احتمال کلی، دنباله ای از حالت های پنهان تولید کرد.
در زمینه تطبیق نقشه، حالت های پنهان بخش های جاده هستند. و مشاهدات نقاطی هستند که توسط GPS اندازه گیری می شوند. احتمالات انتقال احتمالات انتقال وسیله نقلیه از یک بخش به بخش دیگر را فراهم می کند. و احتمال انتشار برای یک حالت در یک مشاهده نشان دهنده احتمال این است که وسیله نقلیه واقعاً از بخش بازدید کرده است با توجه به نقطه (موقعیت وسیله نقلیه) اندازه گیری شده توسط GPS.
در الگوریتم تطبیق نقشه مبتنی بر HMM که توسط کروم و همکاران ارائه شده است. [ 28 ، 31]، آنها هر نقطه اندازهگیری شده توسط GPS را به بخشهای جادهای نزدیک آن نشان دادند تا مجموعهای از نامزدها را برای تطبیق ایجاد کنند و احتمال انتشار را بر اساس فاصله نقطه تا نقطه پیشبینیشده هر نامزد محاسبه کردند. برای وسیله نقلیه ای که از یک نقطه به نقطه دیگر حرکت می کند (اندازه گیری شده توسط GPS)، مجموعه ای از انتقال های احتمالی از یک بخش جاده به قسمت دیگر می تواند ایجاد شود. احتمالات انتقال برای بخش ها با توجه به تفاوت دو فاصله محاسبه می شود: (1) فاصله اقلیدسی دو نقطه GPS. و (2) کوتاه ترین طول مسیر دو نقطه پیش بینی شده در بخش های جاده. در نهایت، آنها از الگوریتم Viterbi برای تطبیق ردیابی GPS تولید شده توسط یک وسیله نقلیه با مسیری که بیشترین احتمال را در بین تمام مسیرهای ممکن دارد، استفاده می کنند. الگوریتم به طور همزمان مکان نقاط GPS و رابطه توپولوژیکی نقشه راه واقعی را در نظر گرفت. این روش در برابر نویز مقاوم است.
روش پیشنهادی ردیابیهای خام GPS را با خطوط مرکزی تولید شده توسط خوشههای نقطهای برای ایجاد روابط توپولوژیکی بین خوشههای نقطه مطابقت میدهد. حالت پنهان خط مرکزی است و مشاهده نقطه ای است که توسط GPS اندازه گیری می شود. نتیجه تطبیق همچنین می تواند برای حذف خوشه های نقطه اضافی که در اثر نویز ایجاد می شوند استفاده شود.
احتمالات انتقال در روش ما احتمال حرکت یک وسیله نقلیه از یک خط مرکزی را فراهم می کند لمن(تولید شده توسط جمن) به خط مرکزی دیگر لj(تولید شده توسط جj). از دو خوشه نقطه ای مشتق شده است جمنو جj، جایی که جمن={پمن،r|r=1،2،…،متر}، جj={پj،س|س=1،2،…،n}و m و n اندازه خوشه ها هستند. توالی نقاط با ردیابی خام GPS نشان داده می شود. به طور شهودی، اگر وجود داشته باشد مترمن،j( مترمن،j≤متر) امتیاز در جمنکه نکات بعدی خود را در جj، احتمال انتقال را برای انتقال از حالت تعریف می کنیم لمنبه لjمانند Pr(لمن،لj)=مترمن،j/متر. بر اساس این تعریف، مجموع احتمالات انتقال غیر صفر است Pr(لمن،لj)برای انتقال از لمنبه همه موارد ممکن دیگر لjبرابر با 1 است؛ و با شماره ممکن تماس می گیریم لjفارغ التحصیل د(لمن)از لمن.
در آزمایشات با داده های واقعی GPS، ما دو واقعیت را برای برخی از خطوط مرکزی مشاهده کردیم: (1) Pr(لمن،لمن)≫Pr(لمن،لj)، جایی که من≠j، که به این معنی است که احتمال انتقال برای انتقال از خط مرکزی لمنبه خود بسیار بزرگتر از انتقال از لمنبه دیگران؛ و (2) Pr(لمن،لj)≫Pr(لr،لس)، جایی که د(لمن)≪د(لr)و من≠j، r≠س، که بیانگر این است که احتمالات انتقال برای انتقال از خطوط مرکزی خارج درجه پایین بسیار بزرگتر از احتمالات انتقال برای انتقال از خطوط مرکزی خارج درجه بالاتر است. به منظور اجتناب از اولویت برای تطبیق ردیابی GPS با خطوط مرکزی خارج از درجه پایین، ما احتمالات انتقال را اصلاح کردیم. Pr(لمن،لj)مستقل بودن از درجه خارج از خطوط مرکزی با معرفی ضریب وزن ω . فاکتور وزن از درجه خارج از خطوط مرکزی به دست می آید. نتایج بر اساس این تنظیم معقول تر است. مراحل پالایش به شرح زیر است:
-
برای یک خوشه نقطه جمن∈سی، شماره را بدست آورید متر“از نکات گنجانده شده در جمنکه نقاط متوالی آنها در آن گنجانده نشده است جمن.
-
برای یک خوشه نقطه جj∈سی، شماره را بدست آورید مترمن،jاز نکات گنجانده شده در جمنکه نقاط متوالی خود را در خود دارند جj( من≠j).
-
محاسبه احتمال انتقال برای انتقال از خط مرکزی لمنبه لj، Pr(لمن،لj)=مترمن،j/متر“.
-
مراحل 2 و 3 را تکرار کنید، محاسبات احتمالات انتقال برای انتقال از لمنبه همه ممکن لj.
-
تعريف كردن Pr(لمن،لمن)=حداکثر(Pr(لمن،لj))، ( من≠j).
-
مراحل 1 تا 5 را تکرار کنید و احتمالات انتقال غیر صفر را در تمام خطوط مرکزی محاسبه کنید لمن∈L.
-
حداقل مدرک تحصیلی را پیدا کنید دمترمنnدر میان تمام درجات خارج از تمام خطوط مرکزی لمن∈L.
-
به روز رسانی احتمالات انتقال به عنوان Pr(لمن،لj)=ωمن×Pr(لمن،لj)، جایی که لمن∈L، لj∈L ωمنفاکتور وزن است و ωمن=د(لمن)/دمترمنn.
احتمال انتشار برای یک نقطه خاص پتیتوسط GPS در زمان t مرتبط با خط مرکزی نزدیک اندازه گیری می شودلمن، نشان داده شده با Pr(لمن|پتی)، این احتمال را می دهد که پتیاز مشاهده شد لمن. این احتمال را نشان می دهد که وسیله نقلیه از خط مرکزی بازدید کرده است لمندر زمان t با توجه به اندازه گیری پتی. ما احتمال انتشار را بر اساس این فرض محاسبه می کنیم که توزیع فاصله نقاط تا خط مرکزی با توزیع گاوسی مطابقت دارد. جی∼(μ،σ2). برای هر نقطه از ردیابی خام GPS، احتمالات با معادله ( 2 ) تخمین زده می شود:
Pr(لمن|پتی)=12πσه–0.5دمنس(پتی،لمن)σ2
جایی که دمنس(پتی،لمن)=دقیقه{دمنس(پتی،vمن،r“)|vمن،r“∈لمن}فاصله از نقطه است پتیبه خط مرکزی لمن.
واریانس σ در روش تولید خط مرکزی تخمین زده می شود. پس از محاسبه σمنبرای هر خوشه نقطه جمن، ما استفاده می کنیم حداکثرمنσمنبه عنوان σ برای تخمین احتمالات انتشار. در عمل، ما تا 10 کاندید خط مرکزی همسان برای هر نقطه را پیدا می کنیم. اگر دمنس(پتی،لمن)بزرگتر است از 6×σ، احتمال انتشار نزدیک به 0 است و ما در نظر نمی گیریم لمنبه عنوان کاندیدای تطبیق با پتی. احتمال انتشار Pr(لمن|پتی)از نقطه پتیبا مقیاس بندی به [0، 1] نرمال می شود.
پس از مقداردهی اولیه احتمالات انتقال و احتمالات انتشار، از الگوریتم تطبیق نقشه ویتربی [ 28 ، 32 ] برای تطبیق ردپای GPS خام با خطوط مرکزی تولید شده برای یافتن احتمالی ترین مسیری که وسایل نقلیه بازدید کرده اند استفاده می کنیم. مسیر با بالاترین احتمال، ارتباط بین خوشه ها را نشان می دهد. خوشه هایی که با هیچ اثر خام مطابقت ندارند به عنوان نویز در نظر گرفته می شوند.
3.2.3. گروه بندی خوشه نقطه
مجموعه ای از مسیرها O={oمن|من=1،2،…،ن}با تطبیق ردیابی های خام GPS با خطوط مرکزی، که در آن N تعداد مسیرها است که با تعداد ردیابی ها مطابقت دارد، به دست می آید. هر مسیر oمنبا تطبیق یک ردیابی تولید می شود تیrمن={پمن،r|r=1،2،…،n}با خطوط مرکزی بدین ترتیب، oمنشامل مجموعه ای از خطوط مرکزی، oمن={لمن1،لمن2،…،لمنn}، جایی که لمنrبا نقطه مطابقت دارد پمن،rاز ردیابی تیrمن. از آنجایی که می دانیم یک وسیله نقلیه از نقطه حرکت می کند پمن،rبه نقطه بعدی، پمن،r+1، می توانیم استنباط کنیم که خطوط مرکزی لمنrو لمنr+1از نظر توپولوژیکی به هم متصل هستند. در مرحله بعد، از موقعیت های هندسی این دو خط مرکزی استفاده می کنیم تا مشخص کنیم که آیا می توان آنها را گروه بندی کرد یا خیر.
مفهوم ضربه این است که یک منحنی را می توان در یک حرکت صاف رسم کرد [ 9 ]. از اصل تداوم خوب گرفته شده است، که نشان می دهد عناصری که از جهت های مشابه پیروی می کنند تمایل دارند با هم گروه شوند. با استفاده از مفهوم stroke، ما خوشه های نقطه را گروه بندی می کنیم تا منحنی های صاف را تا دورترین حد ممکن ایجاد کنیم. برای خوشه های دو نقطه ای جمنو جjکه دو منحنی مرتبط با توپولوژی را ایجاد می کند لمنو لj، به ترتیب، ما به طور موقت گروه جمنو جjبرای به دست آوردن یک خوشه نقطه جدید جgو یک خط مرکزی جدید ایجاد کنید لgتوسط جg. اگر لgاز نظر مکانی نزدیک به لمنو لj، گروه بندی را دائمی می کنیم. در غیر این صورت حفظ می کنیم جمنو جj. بر اساس این ایده، ما یک الگوریتم گروه بندی خوشه نقطه ای جدید را پیشنهاد می کنیم، همانطور که در الگوریتم 3 نشان داده شده است.
| الگوریتم 3: الگوریتم گروه بندی خوشه های نقطه ای. | |
| ورودی : TwoPointClusters جمن، و جj، β | |
| خروجی : NewPointClusters | |
| 1 | تفاوت جهت گیری های میانگین را محاسبه کنید دیoOستوسط نقاط در جمنو جj; |
| 2 | اگر دیoOس>β سپس |
| 3 | ⌊ دو خوشه را برگردانیدجمنو جj; |
| 4 | خطوط مرکزی را ایجاد کنید لمنو لjبرای خوشه نقطه جمنو جjتوسط Lowess قوی; |
| 5 | خطاها را برآورد کنید σمنو σjتوسط MAD برای جمنو جj; |
| 6 | یک خط مرکزی جدید ایجاد کنید لgتوسط جg=جمن∪جj; |
| 7 | ∀vمن،r“∈لمنپیدا کن دمنس(vمن،r“،لg)=مترمنn{دمنس(vمن،r“،vg،تی)|vg،تی∈لg}به عنوان فاصله تعیین شده دیمنس(لمن،لg); |
| 8 | ∀vj،س“∈لjپیدا کن دمنس(vj،س“،لg)=مترمنn{دمنس(vj،س“،vg،تی)|vg،تی∈لg}به عنوان فاصله تعیین شده دیمنس(لj،لg); |
| 9 | مرتب سازی فواصل در دیمنس(لمن،لg)و دیمنس(لj،لg)مانند دیمنسس(لمن،لg)و دیمنسس(لj،لg)به ترتیب نزولی؛ |
| 10 | میانگین فاصله فواصل از ابتدا تا چندک α در مجموعه را محاسبه کنیددیمنسس(لمن،لg)و دیمنسس(لj،لg)مانند دمنسα(لمن،لg)و دمنسα(لj،لg); |
| 11 | اگر دمنسα(لمن،لg)+ دمنسα(لj،لg)>6×(σمن+σj) سپس |
| 12 | ⌊ دو خوشه را برگردانیدجمنو جj; |
| 13 | دیگر |
| 14 | ⌊ خوشه گروه بندی شده جدید را برگردانیدجg; |
ابتدا از اختلاف میانگین جهت گیری های دو خوشه نقطه ای استفاده می کنیم جمنو جjبرای تعیین اینکه آیا خطوط مرکزی لمنو لjتولید شده توسط جمنو جjبه هم متصل شوند (خطوط 1 تا 3). به گفته جیانگ و همکاران. [ 33 ]، آستانه زاویه انحراف برای ایجاد ضربه از بخش های جاده با دامنه [30 درجه، 75 درجه] نتایج پایدار ایجاد می کند. زاویه انحراف زاویه بین دو بخش جاده متصل است.
در روش خود، ما قصد داریم یک منحنی تقریبا مستقیم طولانیتر ایجاد کنیم، لg، از خوشه نقطه جgتولید شده توسط گروه بندی خوشه های نقطه جمنو جj. مشابه ایده تولید سکته مغزی، اگر تفاوت میانگین جهت گیری از جمنو جjبزرگتر از آستانه از پیش تعریف شده β است ، ما فرض می کنیم جمنو جjنمی توان گروه بندی کرد ما β را بر اساس آزمایش تجربی روی 60 درجه تنظیم کردیم. با این حال، برای گروه بندی خوشه های نقطه ای با تفاوت جهت گیری های کوچکتر به خوبی جلوتر از خوشه های نقطه ای با تفاوت جهت گیری های بزرگتر، از یک روش پیش رونده استفاده می کنیم: الگوریتم 3 را به مجموعه ای از خوشه نقطه C که با یک β کوچک شروع می شود اعمال می کنیم ( یعنی ، 10 درجه) و به طور مکرر الگوریتم 3 را با افزایش β در اندازه گام (یعنی 10 درجه) اجرا کنید تا به 60 درجه برسد.
اگر تفاوت جهت گیری های میانگین از جمنو جjکوچکتر از β است ، از موقعیت هندسی نقاط در استفاده می کنیم جمنو جjبرای تعیین اینکه آیا دو خوشه نقطه را می توان گروه بندی کرد یا خیر. شکل 3 تصویری از گروه بندی دو خوشه نقطه ای را ارائه می دهد. خطوط چین دار سیاه در شکل 3 مناطق بافر را نشان می دهد لمنو لjبا شعاع 6σمنو 6σj، به ترتیب. با این فرض جمنو جjرا می توان گروه بندی کرد، خوشه نقطه را به دست می آوریم جgو خط مرکزی تولید کنید لgبه عنوان خط قرمز قرمز در شکل 3 . اگر لgدر اتحاد از مناطق بافر از لمنو لj، می توانیم گروه بندی کنیم جمنو جjدائمی با توجه به معادله ( 1 ) σمنو σjبر اساس برآورد می شوند جمن، لمنو جj، لj. ما گروه بندی را اجرا می کنیم جمنو جjبا استفاده از فواصل از نقاط لمنو لjبه نقاط لgبه عنوان یک متریک این روش به صورت خطوط 4 تا 14 در الگوریتم 3 نشان داده شده است.
برای هر گره vمن،r“∈لمن، نزدیکترین گره را پیدا می کنیم vg،تی∈لgبا توجه به فاصله اقلیدسی آنها دمنس(vمن،r“،vg،تی)به عنوان فاصله دمنس(vمن،r“،لg)از گره vمن،r“به خط مرکزی لg. مجموعه ای از راه دور دیمنس(لمن،لg)={دمنس(vمن،r“،لg)|r“=1،2،…،متر“}سپس می توان با محاسبه فاصله از تمام گره های به دست آورد لمنبه خط مرکزی لg، جایی که متر“تعداد گره های موجود در آن است لمن. فاصله ها را مرتب می کنیم دیمنس(لمن،لg)مانند دیمنسس(لمن،لg)به ترتیب نزولی و میانگین فاصله از ابتدا تا چندک α -in را بدست آوریددیمنسس(لمن،لg)به عنوان فاصله میانگین چندک αدمنسα(لمن،لg)از خط مرکزی لمنبه لg. میانگین فاصله چندک αدمنسα(لj،لg)از جانب لjبه لgرا نیز می توان با همین روش به دست آورد. در نهایت، اگر مجموع دو فاصله میانگین چندک α کوچکتر یا مساوی باشد 6×(σمن+σj)، دو خوشه نقطه را گروه بندی می کنیم جمنو جjبدست آوردن جg. میانگین فاصله چندک α نشان دهنده انحراف از دو خط مرکزی اصلی به خط مرکزی جدید است که توسط دو خوشه گروهبندی شده تولید میشود. دمنسα(لمن،لg)+دمنسα(لj،لg)≤6×(σمن+σj)به این معنی که خط مرکزی جدید در اتحاد دو منطقه بافر قرار دارد لمنو لj. با توجه به آزمایش تجربی، α را روی یک مقدار کوچک (یعنی 0.02) قرار دادیم.
موضوع دیگر این است که نرخ نمونهبرداری از ردیابیهای خام GPS یکسان نیست. دو خوشه که از نظر توپولوژیکی به هم متصل هستند ممکن است از نظر مکانی به یکدیگر نزدیک نباشند. ما فاصله بین دو خوشه را مانند رابطه ( 3 ) تعریف می کنیم. اگر فاصله بین دو خوشه دمنس(جمن،جj)بزرگتر از یک آستانه است (یعنی 100 متر)، آنها را نمی توان گروه بندی کرد. در آزمایش ردیابی های GPS با نمونه های پراکنده، متوجه شدیم که احتمالی ترین مسیر نمی تواند رابطه بین دو خوشه مجاور را کشف کند. بنابراین، به عنوان آخرین مرحله از گروه بندی خوشه، ما خوشه ها را برای گروه بندی با توجه به فاصله بین آنها پیدا می کنیم. اگر فاصله بین دو خوشه کمتر یا مساوی یک آستانه (یعنی 100 متر) باشد، الگوریتم گروه بندی را با آستانه زاویه β معادل 60 درجه برای این دو خوشه اعمال می کنیم.
دمنس(جمن،جj)=دقیقهپمن،r∈جمن(دقیقهپj،س∈جjدمنس(پمن،r،پj،س))
4. آزمایشات
ما از دو مجموعه داده برای آزمایش الگوریتم خود استفاده کردیم. مجموعه داده جمعآوریشده در شیکاگو، ایالات متحده آمریکا (مجموعه داده 1)، شامل آثار نمونهبرداری متراکم است. و دیگر مجموعه داده جمع آوری شده در ووهان، چین (مجموعه داده 2)، از ردپای نمونه برداری پراکنده تشکیل شده است. ویژگی های دو مجموعه داده در زیر توضیح داده شده است:
-
مجموعه داده شیکاگو ردیابی GPS از اتوبوسی بود که به دانشگاه ایلینویز در پردیس شیکاگو خدمت می کرد [ 23 ]. مجموعه دادهها منطقهای به ابعاد 3.8 کیلومتر × 2.4 کیلومتر را پوشش میدهند، با نرخهای نمونهگیری از 1 تا 29 ثانیه (با میانگین 3.61 ثانیه و انحراف استاندارد 3.67 ثانیه). فاصله بین دو نقطه متوالی از 19.97 متر تا 96.6 متر (با میانگین 24.4 متر و انحراف معیار 3.31 متر) متغیر بود. حدود 118000 نقطه وجود داشت.
-
مجموعه داده ووهان ردیابی GPS بود که توسط تاکسی ها جمع آوری شده بود. مجموعه داده منطقه ای به ابعاد 4.8 کیلومتر × 5.5 کیلومتر را پوشش می دهد، با نرخ های نمونه برداری از 1 ثانیه تا 81 ثانیه (با میانگین 37.42 ثانیه و انحراف استاندارد 17.66 ثانیه). فاصله بین دو نقطه متوالی از 0 متر تا 496.255 متر (با میانگین 218.84 متر و انحراف معیار 140.38 متر) متغیر بود. حدود 350000 نقطه وجود داشت.
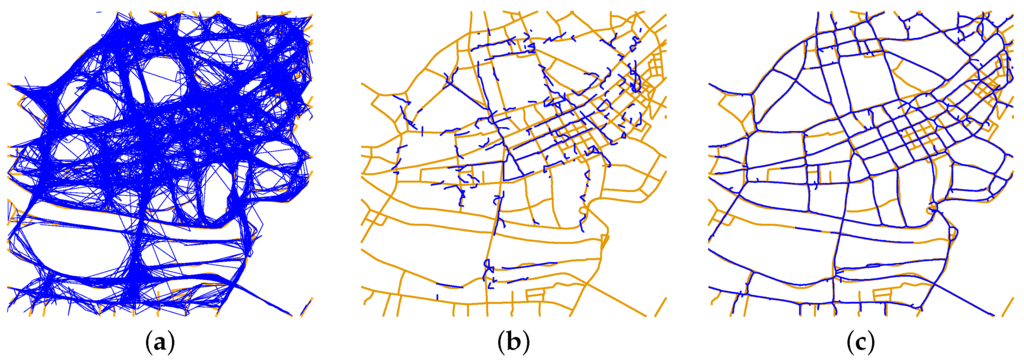
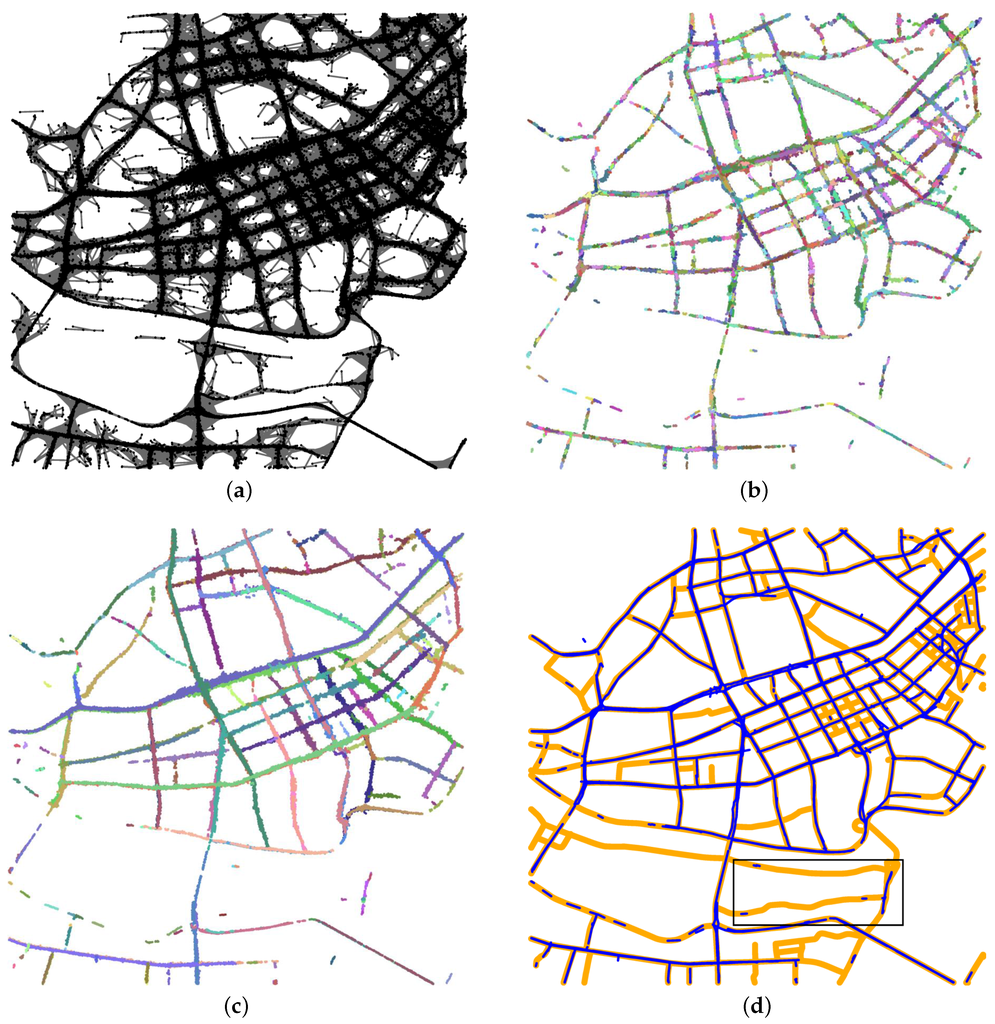
شکل 4 a ردیابی خام GPS مجموعه داده شیکاگو را نشان می دهد که به عنوان نقاط نمایش داده شده است. ما الگوریتم پیشروی DBSCAN خود را با یک محدودیت جهتگیری به مجموعه داده اعمال کردیم و نتایج تقسیمبندی نقاط GPS دوبعدی را به دست آوردیم، همانطور که در شکل 4 ب نشان داده شده است. در مجموع 1099 خوشه نقطه به دست آمد و آنهایی که از نظر فضایی مجاور یکدیگر بودند در رنگ های مختلف نشان داده شده اند. در شکل 4 ب، ما میتوانیم به صورت بصری تشخیص دهیم که خوشههای مستطیل را میتوان برای ایجاد یک منحنی تقریباً مستقیم، به دلیل جهتگیریهای مشابه و مجاورت فضایی، گروهبندی کرد. دلیل تولید خوشههایی با جهتگیریهای مشابه به شرح زیر است: (1) ما الگوریتم تقسیمبندی را با یک محدودیت قوی شروع کردیم ( α)برای یافتن همسایگان یک نقطه 1 درجه است). و (2) جهت گیری های محاسبه شده توسط دو نقطه متوالی به دلیل نویز نقاط GPS و نرخ نمونه برداری نادرست بود.
سپس ردیابیهای خام GPS را با خطوط مرکزی که توسط خوشههای نقطهای ایجاد شدهاند تطبیق دادیم تا رابطه توپولوژیکی بین خوشهها را ایجاد کنیم. خوشه هایی که از نظر توپولوژیکی به هم متصل بودند بر اساس موقعیت هندسی خود گروه بندی شدند. به عنوان آخرین مرحله از روش گروهبندی پیشرونده خوشههای نقطه، ما همچنین از روش تطبیق نقشه مبتنی بر HMM برای فیلتر کردن خوشهها استفاده کردیم. اگر خط مرکزی لمنما در نظر گرفتیم که تنها با دو (یا کمتر) ردیابی GPS خام مطابقت داشت لمنتوسط نویز ایجاد می شود و خوشه نقطه مربوطه را حذف می کند جمن.
شکل 4 ج نتایج گروه بندی خوشه نقطه ای را نشان می دهد. پنجاه و پنج خوشه به دست آمد. مقایسه شکل 4 b,c نشان می دهد که خوشه های نقطه ای مستطیل توسط الگوریتم ما گروه بندی شده اند. در واقع، خوشه های فضایی مجاور با جهت گیری های مشابه به درستی گروه بندی شدند.
به عنوان آخرین مرحله، ما از الگوریتم Lowess قوی برای تولید خطوط مرکزی از خوشههای نقطه گروهبندی شده استفاده کردیم. نقشه راه استنباط شده (خطوط آبی) با نقشه حقیقت زمینی (خطوط زرد روشن) در شکل 4 d همپوشانی داشت. مطابق شکل 4 d، بخشهای جاده استنباطشده در مستطیل نقشه حقیقت زمین را به خوبی نشان نمیدهند: جادهها اغلب توسط وسایل نقلیه مجهز به GPS بازدید نمیشدند. بنابراین، کمبود نقاط کافی برای بازیابی جاده ها با الگوریتم ما وجود داشت. در بیضی نشان داده شده در شکل 4 d، برخی از بخش های جاده جعلی ایجاد شد. همانطور که در a مشاهده می شود همانطور که در شکل 4، نقاط GPS در این منطقه پر سر و صدا بوده و انباشته شدن نویز باعث ایجاد بخش های جعلی جاده می شود.
ما همین رویه را برای مجموعه داده ووهان اعمال کردیم. شکل 5 a ردیابی های GPS از پیش پردازش شده (خطوط خاکستری) را نشان می دهد که با نقاط مربوطه (نقاط سیاه) همپوشانی دارند. بر اساس این رقم، ردیابی پراکنده جیپیاس بهخوبی با موقعیت واقعی خودروها، بهویژه برای ردیابیهای نزدیک تقاطعهای شبکه جادهای، مطابقت ندارد. سپس از الگوریتم تقسیم بندی خود برای تولید خوشه های نقطه استفاده کردیم، همانطور که در شکل 5 ب نشان داده شده است. به دلیل عدم دقت جهت گیری نقاط GPS، 4970 خوشه تولید شد. پس از گروه بندی، 216 خوشه نشان داده شده در شکل 5 ج به دست آمد. در نهایت، خطوط مرکزی شبکه جادهها را با الگوریتم لاوس قوی تولید کردیم. خطوط مرکزی به صورت خطوط آبی در شکل 5 نشان داده شده استd، و خطوط زرد نشان دهنده نقشه حقیقت زمین است. شکل 5 d نشان می دهد که برخی از بخش های جاده (به عنوان مثال، بخش های جاده در ناحیه مستطیل شکل) به دلیل تعداد ناکافی نقاط GPS قابل بازیابی نیستند.
ما روش استنتاج نقشه خود را با چهار روش معمولی، از جمله خط لوله استنتاج نقشه ترکیبی [ 23 ]، روش مبتنی بر خوشه بندی [ 12 ]، روش مبتنی بر KDE [ 20 ] و روش مبتنی بر ادغام ردیابی [ 15 ] با استفاده از مجموعه داده ووهان نتایج در شکل 6 نشان داده شده است . شکل 6 a جاده های تولید شده توسط روش Edelkamp و Schrödl را نشان می دهد. روش آنها نمی تواند خطوط مرکزی جاده را برای این آثار ایجاد کند. دلیل آن این است که جهت گیری نقاط ردیابی GPS کم نمونه برداری شده دقیق نیست، و از این رو، دانه های خوشه را نمی توان با هم گروه بندی کرد. ما از 3000 ردیابی برای روش استفاده کردیم (تعداد کل ردیابی ها در مجموعه داده ووهان 12832 است). مطابق باشکل 6 الف، 3000 ردیابی شبکه جاده را بر روی نقشه حقیقت زمینی پوشش می دهد. شکل 6 ب شبکه جاده ای را نشان می دهد که با روش بیاجیونی و اریکسون ایجاد شده است. ما تعداد کامل ردیابی را در این روش اعمال کردیم. با این حال، الگوریتم در مرحله فروپاشی گره ها در تقاطع ها شکست خورد. سپس روش را روی 3000 ردیابی اعمال کردیم، همانطور که در شکل 6 ب. با توجه به نرخ نمونه برداری پراکنده، بسیاری از جاده ها نمی توانند توسط الگوریتم بازیابی شوند. شکل 6c شبکه جاده تولید شده با روش دیویس را با تعداد کامل آثار در مجموعه داده ووهان نشان می دهد. این روش نسبت به نرخ نمونه گیری قوی است و ما روش خود را با این روش در بخش بعدی مقایسه می کنیم. ما همچنین روش کائو و کروم را با استفاده از مجموعه داده ووهان ارزیابی کردیم. با این حال، به دلیل نرخ نمونه برداری پراکنده، الگوریتم همگرا نشد و آثار مجاور ادغام نشدند.
تا کنون، ما فقط خطوط مرکزی راه استنباط شده را با نقشه های حقیقت زمینی مقایسه کرده ایم تا الگوریتم استنتاج نقشه خود را به صورت کیفی ارزیابی کنیم. در بخش بعدی، یک ارزیابی کمی برای دقت هندسی الگوریتم استنتاج نقشه خود ارائه میکنیم.
5. ارزشیابی
چندین روش ارزیابی کمی برای دقت هندسه و توپولوژی نقشه های راه استنباط شده اخیرا پیشنهاد شده است. لیو و همکاران [ 19 ] ارزیابی کمی خود را با اندازهگیری یادآوری و دقت جادهها روی نقشه استنتاج شده ( M ) با توجه به جادههای روی نقشه حقیقت زمینی انجام دادند. تیrتوتیساعت). فراخوان نشاندهنده کسری از جادهها در نقشه حقیقت زمینی است که بازیابی شدهاند، و دقت، کسری از جادهها در نقشه استنباطشده مربوطه بود. آنها از فاصله و جهت گیری به عنوان محدودیت برای تطبیق جاده های دو نقشه با یکدیگر با نزدیکترین فاصله و تعیین طول مثبت واقعی استفاده کردند. تیپ=م∩تیrتوتیساعتبا نسبت منطبق سپس فراخوان، دقت و اندازه گیری F به شرح زیر محاسبه شد: rهجآلل=تیپ/||تیrتوتیساعت||، پrهجمنسمنon=تیپ/||م||، و اف–مترهآستوrه=(2×پrهجمنسمنon×rهجآلل)/(پrهجمنسمنon+rهجآلل)، جایی که ||.||طول کل بخش های جاده را در مجموعه مربوطه اندازه گیری می کند. روش آنها دقت هندسی نقشه استنباط شده را ارزیابی کرد.
Biagioni و Eriksson [ 23 ] روش جدیدی را برای اندازه گیری شباهت های هندسی و توپولوژیکی نقشه های حقیقت استنباط شده و زمینی به طور همزمان معرفی کردند. آنها دو نوع نقشه را مجدداً نمونهبرداری کردند و حفرههایی را روی نقشه حقیقت زمین و تیلهها را روی نقشه استنباطشده قرار دادند. سپس تیلهها را با حفرهها با فواصل بین آنها مطابقت دادند و تیلههای بیهمتا و سوراخهای خالی را شمارش کردند. دقت نقشه استنباط شده با توجه به نقشه حقیقت زمینی با تیله های جعلی و سوراخ های خالی اندازه گیری شد.
Karagiorgou و Pfoser [ 25 ] از کوتاه ترین مسیر برای اندازه گیری شباهت نقشه های حقیقت استنباط شده و زمینی استفاده کردند. آنها به طور همزمان مبدا و مقصد را روی دو نقشه قرار دادند و کوتاه ترین مسیر را بین آنها محاسبه کردند تا دو مجموعه از کوتاه ترین مسیرها را به دست آورند. آنها فاصله فرچه گسسته و فاصله عمودی متوسط را برای مقایسه شباهت دو مجموعه از کوتاه ترین مسیرها برای اندازه گیری کمی نقشه استنتاج شده اعمال کردند. روش آنها بر اتصال بخش های جاده متمرکز است.
احمد و همکاران [ 11 ] یک اندازه گیری فاصله مبتنی بر مسیر برای مقایسه نقشه راه پیشنهاد کرد. آنها از فواصل بین دو مسیر (یعنی نقشه ها) که بر اساس فاصله Hausdorff محاسبه شده بود برای اندازه گیری فواصل بین دو شبکه جاده استفاده کردند. روش آنها ویژگی های ساختاری و مکانی نقشه راه را در نظر گرفت.
ما از روش پیشنهادی لیو و همکاران استفاده می کنیم. [ 19 ] برای ارزیابی دقت هندسی نقشه های راه استنباط شده. جزئیات روش ارزیابی هندسه را می توان به شرح زیر توصیف کرد:
-
نقاطی را در جاده های حقیقت زمین و نقشه های استنباط شده با فواصل مساوی (یعنی 1 متر) قرار دهید.
-
جهت گیری همه نقاط را با اتصالات آنها محاسبه کنید (مدول 180 درجه).
-
نقاط نمونه بر روی نقشه استنباط شده را با نقشه حقیقت زمینی با نزدیکترین تطبیق فاصله تحت محدودیت جهت مطابقت دهید. اختلاف جهت دو نقطه ای که با یکدیگر تطبیق داده شده اند بیش از 60 درجه نیست.
-
از آستانه های فاصله متفاوت برای تعیین بهترین نسبت تطابق استفاده کنید.
نقشه حقیقت زمینی (خطوط زرد) و نقشه استنباط شده (خطوط آبی) مجموعه داده شیکاگو، همانطور که در شکل 7 نشان داده شده است، همپوشانی داشتند . شکل 7 a نقشه راه تولید شده توسط الگوریتم بیاجیونی و اریکسون [ 23 ] را نشان می دهد. ما به صورت دستی جاده های نقشه حقیقت زمینی را که در واقع توسط وسایل نقلیه بازدید شده است، با توجه به ردیابی خام GPS انتخاب کردیم. هر جاده با یک خط مرکزی نشان داده می شد، زیرا الگوریتم آنها خطوط مرکزی را با جهت مخالف برای یک جاده دو طرفه جدا نمی کرد. شکل 7b نقشه راه تولید شده توسط روش ما است. همانطور که در جزئیات نشان داده شده است، ما دو خط مرکزی برای جهات مخالف یک جاده دو طرفه ایجاد کردیم. جاده های مربوط به نقشه حقیقت زمینی نیز دارای دو خط مرکزی بودند.
طول کل جاده ها در نقشه حقیقت زمینی در شکل 7 a,b به ترتیب 32.89 کیلومتر و 41.1 کیلومتر است. طول کل نقشه راه استنباط شده در شکل 7 الف (روش بیاجیونی و اریکسون) و شکل 7 ب (روش ما) به ترتیب 50/24 کیلومتر و 9/30 کیلومتر بود. در شکل 7 ب، دو خط مرکزی را برای جاده های دو جهته استنباط می کنیم که با دو خط مرکزی در نقشه حقیقت زمینی نیز نمایش داده می شوند. با این حال، تمام جاده ها در شکل 7 a با خطوط مرکزی منفرد نشان داده شده اند. به همین دلیل است که طول کل جاده ها در نقشه حقیقت زمینی و نقشه راه استنباط شده در شکل 7 ب از جاده های شکل 7 بیشتر است.آ. ما دو نقشه راه استنباطشده را با آستانههای تطبیق متفاوت فاصله ارزیابی میکنیم، جایی که نتایج در جدول 1 و جدول 2 نشان داده شده است . در جدول 1 و جدول 2 ، طول جاده هایی که به خوبی تطبیق داده شده اند، طول کل جاده هایی است که روی نقشه حقیقت زمینی (یا نقشه استنباط شده) با جاده هایی در نقشه استنتاج شده (یا نقشه حقیقت زمینی) مطابقت داده شده اند. آستانه تطبیق فاصله
شکل 8 نمودارهای فراخوان، دقت و اندازه گیری F دو روش را نشان می دهد. شکل 8 a نشان می دهد که مقادیر فراخوان، دقت و معیارهای اندازه گیری F روش بیاجیونی و اریکسون [ 23 ] با افزایش آستانه تطبیق از 5 متر به 20 متر افزایش می یابد و پس از رسیدن آستانه به 20 متر ثابت می شود. شکل 8b نشان می دهد که مقادیر این سه معیار پس از رسیدن به آستانه تطبیق 10 متر با روش ما تغییر چندانی نکرده است. مقادیر معیارهای روش ما بزرگتر از مقادیر روش بیاجیونی و اریکسون بود که آستانه تطبیق کمتر از 20 متر بود. این نتایج نشان میدهد که نقشه راه استنباطشده با روش ما از نظر هندسه از دقت بهتری برخوردار است. بعلاوه، Biagioni و Eriksson با استفاده از همان مجموعه داده [ 23 ] نشان دادند که از نظر هندسه، روش آنها بهتر از روشهای استنتاج نقشه موجود، یعنی روشهای مبتنی بر خوشهبندی، روشهای مبتنی بر ادغام ردیابی و روشهای مبتنی بر KDE عمل میکند.
حقیقت زمین و نقشه های استنتاج شده برای مجموعه داده 2 (مجموعه داده ووهان) در شکل 5 د نمایش داده شده است. ما خطوط مرکزی را با جهت مخالف برای جاده های دو طرفه جدا کردیم. با این حال، نقشه حقیقت زمینی فقط یک خط مرکزی برای هر بخش جاده داشت. بنابراین، تمام نقاط نمونه برداری شده از نقشه حقیقت زمینی را می توان با دو نقطه از جاده های استنباط شده مطابقت داد. طول کل جاده ها در نقشه حقیقت زمینی در شکل 5 d 117.67 کیلومتر است و طول کل جاده های استنباط شده با روش ما 148.38 کیلومتر است. نتایج تطبیق در جدول 3 نشان داده شده است. طول جادههای منطبقشده نشاندهنده طول کل جادهها در نقشه حقیقت زمینی است که با جادههای روی نقشه استنباطشده مطابقت دارد، با توجه به آستانه تطبیق فاصله. طول جادههایی که به درستی استنباط شدهاند، کل طول جادههایی است که در نقشه استنباطشده با جادههای روی نقشه حقیقت زمین مطابقت دارند، با توجه به آستانه تطبیق فاصله. از آنجایی که طول کل جاده ها در نقشه راه استنباط شده بزرگتر از طول کل جاده ها در نقشه حقیقت زمینی بود، ما فرمول استاندارد یادآوری و دقت را به صورت زیر اصلاح کردیم: rهجآلل=||wهللمترآتیجساعتهدroآدس||/||تیrتوتیساعت||، و پrهجمنسمنon=||جorrهجتیلyمنnfهrrهدroآدس||/||م||. جدول 4 نتایج تطبیق شبکه جاده تولید شده با روش دیویس را نشان می دهد ( شکل 6 ج). طول کل جاده های استنباط شده در شکل 6 ج 97.97 کیلومتر است.
شکل 9 نمودارهای گرافیکی یادآوری، دقت و اندازه گیری F را برای مجموعه داده ووهان نمونه برداری شده پراکنده (مجموعه داده 2) نشان می دهد. شکل 9 a نمودار روش ما است. و شکل 9 ب نمودار روش دیویس است. مطابق شکل 9 الف، زمانی که آستانه تطبیق فاصله بزرگتر از 15 متر باشد، دقت بیشتر از 0.9 است. بنابراین، نتیجه میگیریم که روش ما میتواند یک نقشه راه را از ردیابیهای GPS پراکنده با دقت هندسی بالا استنتاج کند. وقتی آستانه برابر با 5 متر است، دقت کمتر از 0.5 است، زیرا ما دو خط مرکزی برای جادههای دو طرفه ایجاد کردیم و نقشه حقیقت زمینی فقط از یک خط مرکزی برای نشان دادن جادههای دو طرفه استفاده میکرد. در مقایسه شکل 9a،b، نتیجه می گیریم که شبکه جاده ای که با روش ما تولید می شود، دقت هندسی بهتری نسبت به شبکه جاده استنباط شده با روش دیویس دارد.
6. نتیجه گیری
ما یک چارچوب تقسیم بندی و گروه بندی جدید برای استنتاج نقشه راه از ردیابی GPS پیشنهاد کرده ایم. جنبه کلیدی پارتیشن بندی کل نقاط ردیابی GPS به خوشه هایی است که منحنی های تقریباً مستقیم را برای بازیابی نقشه راه نشان می دهند. به طور خلاصه، روش ما این قابلیت را دارد که با ردیابی های GPS پراکنده و پراکنده برخورد کند. با توجه به نتایج تجربی و ارزیابی، میتوان نتیجه گرفت که روش ما از نظر دقت هندسی عملکرد خوبی دارد. چارچوبی که ما پیشنهاد کردیم باز و منعطف است. ما میتوانیم الگوریتم تقسیمبندی ابر نقطهای دوبعدی پیچیدهتری را برای جایگزینی الگوریتم فعلی ایجاد کنیم، در نتیجه عملکرد کلی روش پیشنهادی را بیشتر بهبود میبخشیم.
در این تحقیق از دو نقطه متوالی برای تخمین جهت گیری نقاط استفاده شده است. با این حال، نویز و نمونه برداری پراکنده به طور قابل توجهی بر دقت تخمین جهت گیری تأثیر می گذارد. در کار آینده، ما قصد داریم تا ارتباط بین نقاط و توزیع ابر نقطه را برای تخمین جهتگیریها برای بهبود عملکرد الگوریتم ادغام کنیم. این روش برای ایجاد منحنی های تقریبا مستقیم برای بازیابی شبکه جاده طراحی شده است. با این حال، همه جاده ها مستقیم نیستند. در کار آینده، منحنیها را با دنبالهای از بخشهای خط شبیهسازی میکنیم تا جادههای پرپیچپیچ را از ردیابی GPS استنتاج کنیم. علاوه بر این، ما نیاز به پردازش تقاطع خطوط مرکزی برای تولید مدل نمودار شبکه جاده داریم.
اختصارات
در این نسخه از اختصارات زیر استفاده شده است:
| DBSCAN |
خوشه بندی فضایی مبتنی بر چگالی کاربرد با نویز
|
| لوس |
Scatterplot هموار با وزن محلی
|
| HMM |
مدل مارکوف پنهان
|
| UGC |
محتوای ایجاد شده توسط کاربر
|
| جی پی اس |
سیستم موقعیت یاب جهانی
|
| 2 بعدی |
دو بعدی
|
| KDE |
تخمین چگالی هسته
|
| PCA |
تجزیه و تحلیل مؤلفه های اصلی
|
| دیوانه |
انحراف مطلق میانه
|
منابع
- وانگ، ی. لیو، ایکس. وی، اچ. فورمن، جی. چن، سی. Zhu, Y. CrowdAtlas: نقشههای خودبهروزرسانی برای ابر و استفاده شخصی. در مجموعه مقالات یازدهمین کنفرانس بین المللی سالانه سیستم های تلفن همراه، برنامه ها و خدمات، تایپه، تایوان، 25-28 ژوئن 2013. ص 27-40.
- گوا، تی. ایوامورا، ک. Koga, M. به سمت تولید نقشه های جاده با دقت بالا از داده های ردیابی عظیم GPS. در مجموعه مقالات سمپوزیوم بین المللی زمین شناسی و سنجش از دور IEEE 2007، بارسلون، اسپانیا، 23 تا 28 ژوئیه 2007.
- فرناندز، آر. پریمبیدا، سی. پیکسوتو، پی. ولف، دی. Nunes، U. تشخیص جاده با استفاده از LiDAR با وضوح بالا. در مجموعه مقالات کنفرانس قدرت و محرکه خودرو (VPPC)، کویمبرا، پرتغال، 27 تا 30 اکتبر 2014. صص 1-6.
- هیلل، AB; لرنر، آر. لوی، دی. راز، جی. پیشرفت اخیر در تشخیص جاده و خط: یک بررسی. ماخ Vis. Appl. 2014 ، 25 ، 727-745. [ Google Scholar ] [ CrossRef ]
- کروم، جی. دیویس، ن. Narayanaswami، C. محتوای تولید شده توسط کاربر. محاسبات فراگیر IEEE 2008 ، 7 ، 10-11. [ Google Scholar ] [ CrossRef ]
- لی، جی. Qin، Q. هان، جی. تانگ، L.-A.; دادههای مسیر معدن لی، KH و دادههای برچسبگذاری شده جغرافیایی در رسانههای اجتماعی برای استنتاج نقشه راه. ترانس. GIS 2015 ، 19 ، 1-18. [ Google Scholar ] [ CrossRef ]
- شرودل، اس. واگستاف، ک. راجرز، اس. لنگلی، پی. Wilson, C. استخراج ردیابی GPS برای اصلاح نقشه. حداقل داده بدانید. کشف کنید. 2004 ، 9 ، 59-87. [ Google Scholar ] [ CrossRef ]
- لو، ی. ژانگ، سی. ژنگ، ی. Xie، X. وانگ، دبلیو. Huang, Y. تطبیق نقشه برای مسیرهای GPS با نرخ نمونه برداری پایین. در مجموعه مقالات هفدهمین کنفرانس بین المللی ACM SIGSPATIAL در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، سیاتل، دی سی، ایالات متحده آمریکا، 4-6 نوامبر 2009. صص 352-361.
- تامسون، آرسی بروکس، آر. بهرهبرداری از گروهبندی ادراکی برای تحلیل، درک و تعمیم نقشه: مورد شبکههای جاده و رودخانه. در الگوریتم ها و برنامه های تشخیص گرافیک ; Springer: برلین، آلمان، 2002; صص 148-157. [ Google Scholar ]
- بیاجیونی، جی. اریکسون، جی. استنتاج نقشه های راه از ردیابی سیستم موقعیت یابی جهانی: بررسی و ارزیابی مقایسه ای. ترانسپ Res. سابقه: J. Transp. Res. هیئت 2012 . [ Google Scholar ] [ CrossRef ]
- احمد، م. کاراگیورگو، اس. Pfoser، D.; Wenk, C. مقایسه و ارزیابی الگوریتمهای ساخت نقشه با استفاده از دادههای ردیابی خودرو. GeoInformatica 2015 ، 19 ، 601-632. [ Google Scholar ] [ CrossRef ]
- ادلکمپ، اس. Schrödl, S. برنامه ریزی مسیر و استنتاج نقشه با ردیابی موقعیت یابی جهانی. در علوم کامپیوتر از دیدگاه ; Springer: برلین، آلمان، 2003; صص 128-151. [ Google Scholar ]
- آگامنونی، جی. نیتو، جی. Nebot، گزارش فنی EM : استنتاج مسیرهای اصلی جاده با استفاده از داده های GPS . دانشگاه سیدنی، مرکز استرالیا برای رباتیک میدانی: سیدنی، استرالیا، 2010. [ Google Scholar ]
- آگامنونی، جی. نیتو، جی. Nebot، EM استنباط قوی از مسیرهای جاده اصلی برای سیستم های حمل و نقل هوشمند. IEEE Trans. هوشمند ترانسپ سیستم 2011 ، 12 ، 298-308. [ Google Scholar ] [ CrossRef ]
- کائو، ال. Krumm, J. از ردیابی GPS تا نقشه راه قابل مسیریابی. در مجموعه مقالات هفدهمین کنفرانس بین المللی ACM SIGSPATIAL در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، سیاتل، دی سی، ایالات متحده آمریکا، 4-6 نوامبر 2009. صص 3-12.
- وانگ، جی. روئی، ایکس. آهنگ، X. تان، ایکس. وانگ، سی. Raghavan, V. رویکردی جدید برای تولید نقشههای جاده قابل مسیریابی از ردیابی GPS خودرو. بین المللی جی. جئوگر. Inf. علمی 2015 ، 29 ، 69-91. [ Google Scholar ] [ CrossRef ]
- نیهوفر، بی. بردا، ر. ویتفلد، سی. بائر، اف. Lueert، O. تولید نقشه جامعه GPS برای روش های مسیریابی پیشرفته بر اساس جمع آوری ردیابی توسط تلفن های همراه. در مجموعه مقالات اولین کنفرانس بین المللی 2009 در زمینه پیشرفت در ارتباطات ماهواره ای و فضایی (SPACOMM 2009)، کولمار، فرانسه، 20-25 ژوئیه 2009; صص 156-161.
- چن، دی. Guibas، LJ; هرشبرگر، جی. Sun, J. بازسازی شبکه جاده برای سازماندهی مسیرها. در مجموعه مقالات بیست و یکمین سمپوزیوم سالانه ACM-SIAM در مورد الگوریتم های گسسته. انجمن ریاضیات صنعتی و کاربردی، فیلادلفیا، PA، ایالات متحده آمریکا، 17-19 ژانویه 2010. ص 1309–1320.
- لیو، ایکس. بیاجیونی، جی. اریکسون، جی. وانگ، ی. فورمن، جی. ژو، ی. ردیابی GPS پراکنده در مقیاس بزرگ معدن برای استنتاج نقشه: مقایسه رویکردها. در مجموعه مقالات هجدهمین کنفرانس بین المللی ACM SIGKDD در مورد کشف دانش و داده کاوی، پکن، چین، 12 تا 16 اوت 2012. صص 669-677.
- دیویس، جی جی. برسفورد، آر. Hopper، A. مقیاس پذیر، توزیع شده، تولید نقشه بلادرنگ. محاسبات فراگیر IEEE 2006 ، 5 ، 47-54. [ Google Scholar ] [ CrossRef ]
- چن، سی. Cheng، Y. تولید نقشه دیجیتال جاده ها با داده های GPS چند مسیره. در مجموعه مقالات کارگاه بین المللی 2008 در زمینه فناوری آموزشی و آموزش و کارگاه بین المللی 2008 در زمینه علوم زمین و سنجش از دور (ETT و GRS)، شانگهای، چین، 21-22 دسامبر 2008. ص 508-511.
- شی، دبلیو. شن، اس. Liu, Y. تولید خودکار نقشه شبکه جاده از GPS عظیم، مسیرهای خودرو. در مجموعه مقالات دوازدهمین کنفرانس بین المللی IEEE در مورد سیستم های حمل و نقل هوشمند، لوئیس، MO، ایالات متحده آمریکا، 4 تا 7 اکتبر 2009. صص 1-6.
- بیاجیونی، جی. اریکسون، جی. استنتاج نقشه در مواجهه با نویز و نابرابری. در مجموعه مقالات بیستمین کنفرانس بین المللی پیشرفت در سیستم های اطلاعات جغرافیایی، ردوندو بیچ، کالیفرنیا، ایالات متحده آمریکا، 6-9 نوامبر 2012. صص 79-88.
- فتحی، ع. Krumm, J. تشخیص تقاطع جاده ها از ردیابی GPS. در علم اطلاعات جغرافیایی ; Springer: برلین، آلمان، 2010; صص 56-69. [ Google Scholar ]
- کاراگیورگو، اس. Pfoser، D. در مورد ردیابی وسایل نقلیه مبتنی بر داده تولید شبکه جاده ای. در مجموعه مقالات بیستمین کنفرانس بین المللی پیشرفت در سیستم های اطلاعات جغرافیایی، ردوندو بیچ، کالیفرنیا، ایالات متحده آمریکا، 6-9 نوامبر 2012. صص 89-98.
- کیو، جی. وانگ، آر. Wang, X. استنباط نقشههای راه از ردیابی GPS با نمونههای پراکنده. در پیشرفت در هوش مصنوعی ؛ Springer: برلین، آلمان، 2014; صص 339-344. [ Google Scholar ]
- کلیولند، WS قوی رگرسیون وزن محلی و هموار کردن نمودارهای پراکنده. مربا. آمار دانشیار 1979 ، 74 ، 829-836. [ Google Scholar ] [ CrossRef ]
- نیوزون، پی. Krumm, J. Hidden Markov نقشه مطابق با نویز و پراکندگی. در مجموعه مقالات هفدهمین کنفرانس بین المللی ACM SIGSPATIAL در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، سیاتل، دی سی، ایالات متحده آمریکا، 4-6 نوامبر 2009. صص 336-343.
- استر، ام. کریگل، اچ.-پی. ساندر، جی. Xu, X. یک الگوریتم مبتنی بر چگالی برای کشف خوشه ها در پایگاه داده های فضایی بزرگ با نویز. KDD 1996 ، 96 ، 226-231. [ Google Scholar ]
- وانگ، جی. یو، ز. ژانگ، دبلیو. وید، م. تانا، سی. دایا، ن. Zhange، X. بازسازی قوی منحنیهای دوبعدی از دادههای نقاط پر سر و صدا پراکنده. Comput.-Aided Des. 2014 ، 50 ، 27-40. [ Google Scholar ] [ CrossRef ]
- کروم، جی. هورویتز، ای. Letchner, J. تطبیق نقشه با محدودیت های زمان سفر . کنگره جهانی SAE: دیترویت، MI، ایالات متحده آمریکا، 2007. [ Google Scholar ]
- تیاگاراجان، ع. راویندرانات، ال. لاکورتس، ک. مدن، اس. Balakrishnan, H. VTrack: برآورد تاخیر ترافیک جاده ای دقیق و آگاه از انرژی با استفاده از تلفن همراه. در مجموعه مقالات هفتمین کنفرانس ACM در مورد سیستم های حسگر شبکه جاسازی شده، برکلی، کالیفرنیا، ایالات متحده آمریکا، 4 تا 6 نوامبر 2009.
- جیانگ، بی. ژائو، اس. یین، جی. جاده های طبیعی خود سازمان یافته برای پیش بینی جریان ترافیک: مطالعه حساسیت. J. Stat. Mech.: Theory Exp. 2008 ، 2008 ، P07008. [ Google Scholar ] [ CrossRef ]
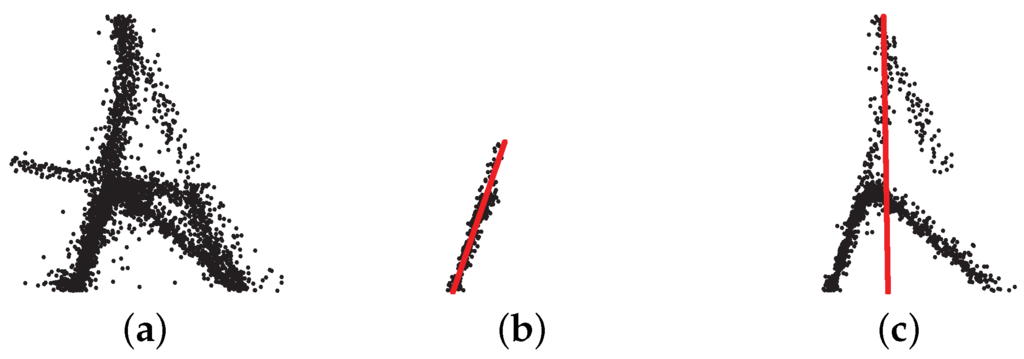
شکل 1. تصویری از حساسیت α . ( الف ) مجموعه نقطه ای از ردیابی خام GPS. ( ب ) یکی از خوشه های نقطه تولید شده با α=1درجه; ( ج ) یکی از خوشه های نقطه تولید شده با α=5درجه.

شکل 2. روند تولید خط مرکزی از نقاط توسط الگوریتم قوی Scatterplot Smooth (Lowess) با وزن محلی. ( الف ) نقاط و آبسیسا ( محور x ) محاسبه شده توسط PCA. ( ب ) نقاط به ترتیب صعودی با توجه به مقادیر x آنها مرتب شده اند. ( ج ) خط تولید شده توسط الگوریتم قوی Lowess.
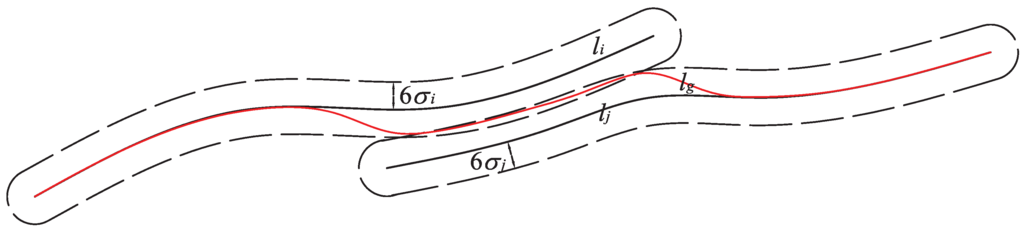
شکل 3. تصویر گروه بندی خوشه نقطه ای. خطوط جامد سیاه هستند لمنو لjکه از خوشه های نقطه ای تولید می شوند جمنو جj; خطوط تیره سیاه نشان می دهد 6σمناطق بافر؛ و خط قرمز قرمز لgتولید می شود توسط جg، که با گروه بندی تولید می شود جمنو جj.

شکل 4. نتیجه آزمایش مجموعه داده شیکاگو. ( الف ) ردیابی خام GPS از مجموعه داده شیکاگو به عنوان نقاط نمایش داده می شود. ( ب ) خوشههای نقطهای تولید شده توسط الگوریتم خوشهبندی فضایی مبتنی بر تراکم پیشرونده کاربرد با نویز (DBSCAN) با یک محدودیت جهتگیری. ( ج ) خوشه های نقطه ای پس از گروه بندی مترقی. ( د ) نقشه راه تولید شده (خطوط آبی) با نقشه حقیقت زمینی (خطوط زرد) شیکاگو همپوشانی دارد.
شکل 5. نتیجه آزمایش مجموعه داده ووهان. ( الف ) ردیابی های GPS خام با نقاط GPS جمع آوری شده در ووهان همپوشانی دارند. ( ب ) خوشههای نقطهای تولید شده توسط الگوریتم پیشرونده DBSCAN با یک محدودیت جهتگیری. ( ج ) خوشه های نقطه ای پس از گروه بندی مترقی. ( د ) نقشه راه تولید شده (خطوط آبی) با نقشه حقیقت زمینی (خطوط زرد) ووهان همپوشانی دارد.
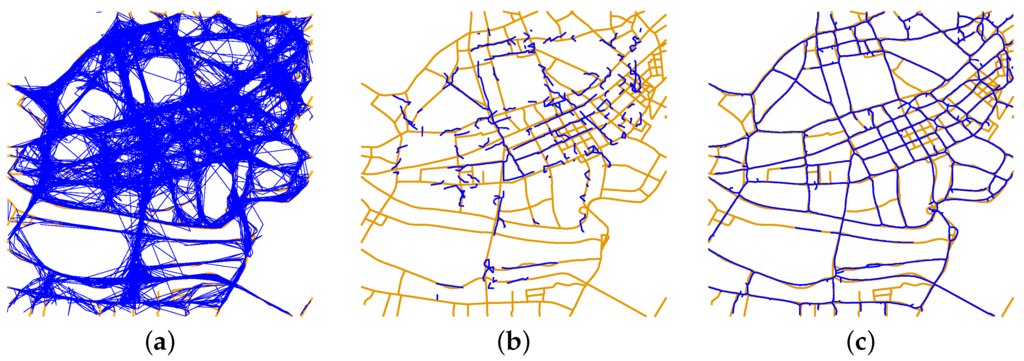
شکل 6. شبکه های جاده استنباط شده با نقشه حقیقت زمینی مجموعه داده ووهان همپوشانی دارند. ( الف ) شبکه جاده ای ایجاد شده با روش ادلکمپ و شرودل. ( ب ) شبکه جاده ای که با روش بیاجیونی و اریکسون تولید می شود. ( ج ) شبکه جاده ای که به روش دیویس ایجاد شده است.

شکل 7. مقایسه روش بیاجیونی و اریکسون و روش ما در مجموعه داده شیکاگو. ( الف ) نقشه راه (خطوط آبی) با روش Biagioni و Erikson و شبکه جاده ای که واقعاً توسط وسایل نقلیه بازدید می شود (خطوط زرد) ایجاد شده است. ( ب ) تهیه نقشه راه (خطوط آبی) با روش پیشنهادی و شبکه جاده مورد بازدید واقعی وسایل نقلیه (خطوط زرد).
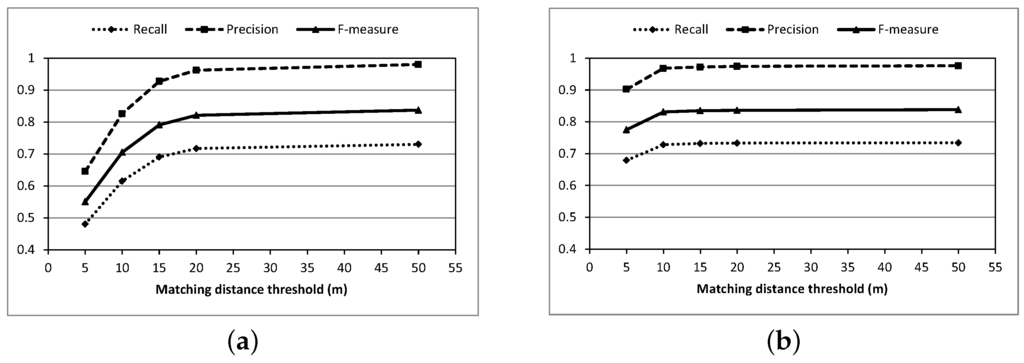
شکل 8. اندازه گیری F روش بیاجیونی و اریکسون و روش ما. ( الف ) یادآوری، دقت و اندازه گیری F از روش Biagioni و Eriksson برای مجموعه داده 1. ( ب ) یادآوری، دقت و اندازه گیری F روش ما برای مجموعه داده 1.

شکل 9. مقایسه روش ما و روش دیویس برای مجموعه داده ووهان. ( الف ) یادآوری، دقت و اندازه گیری F روش ما برای مجموعه داده ووهان؛ ( ب ) یادآوری، دقت و اندازه گیری F روش دیویس برای مجموعه داده ووهان.

جدول 1. نتایج تطبیق روش بیاجیونی و اریکسون در مجموعه داده شیکاگو.
جدول 2. نتایج تطبیق روش ما در مجموعه داده شیکاگو.
جدول 3. نتایج تطبیق روش ما برای مجموعه داده ووهان.
جدول 4. نتایج تطبیق روش دیویس برای مجموعه داده ووهان.
© 2016 توسط نویسندگان؛ دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (CC-BY) (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر