

خلاصه
:
پایگاه داده های چند بازنمایی (MRDBs) در چندین برنامه کاربردی سیستم اطلاعات جغرافیایی برای اهداف مختلف استفاده می شود. MRDB ها عمدتاً از طریق تعمیم مدل و نقشه برداری به دست می آیند. سادهسازی عامل اساسی تعمیم نقشهبرداری است و نهرها و دریاچهها ویژگیهای ضروری در هیدروگرافی هستند. در این مطالعه، الگوریتم جدیدی برای سادهسازی نهرها و دریاچهها توسعه داده شد. در این الگوریتم از زوایای انحراف و باندهای خطا به ترتیب برای تعیین رئوس مشخصه و دقت پلانیمتری ویژگی ها استفاده می شود. این الگوریتم با استفاده از مجموعه داده ملی هیدروگرافی با وضوح بالا Pomme de Terre، یک زیرحوضه در ایالات متحده آزمایش شد. برای ارزیابی عملکرد الگوریتم جدید، الگوریتمهای Bend Simplify و Douglas-Peucker، مجموعه داده هیدروگرافی با وضوح متوسط زیرحوضه، و قانون رادیکال تاپفر استفاده شد. برای تجزیه و تحلیل کمی، اعداد رأس، طول ها و مقادیر سینوسی محاسبه شدند. در نتیجه، نشان داده شد که الگوریتم جدید قادر به برآوردن الزامات اصلی (یعنی دقت، خوانایی و زیبایی شناسی و ذخیره سازی).
کلید واژه ها:
نقشه کشی ; تعمیم ; ساده سازی ؛ الگوریتم ; زاویه انحراف ؛ باند خطا
1. معرفی
این ایده که ما میتوانیم اطلاعات جغرافیایی را در مقیاسهای چندگانه به شکل نقشه انتزاعی و به تصویر بکشیم، هزاران سال است که وجود داشته است. آژانسهای ملی نقشهبرداری (NMA) پایگاههای اطلاعاتی مکانی را در سطوح مختلف جزئیات نگهداری میکنند – پایگاههایی که نمایشهای متعددی از پدیدههای جغرافیایی یکسان را ذخیره میکنند. پایگاههای داده چند بازنمایی (MRDB) میتوانند با اتصال اشیاء بین پایگاههای داده موجود یا با تولید نمایشهای مقیاس کوچکتر از یک پایگاه داده در مقیاس بزرگ از طریق تعمیم خودکار ایجاد شوند [ 1 ]]. در بسیاری از برنامه های کاربردی سیستم اطلاعات جغرافیایی (GIS)، کاربران نیاز به تجسم و بازرسی داده ها در مقیاس های مختلف دارند، که نیاز به نمایش های متفاوتی برای ذخیره در سطوح مختلف جزئیات دارد. انعطاف پذیری MRDB ها در توانایی آن در استخراج انواع مختلف نقشه ها، با استفاده از مدل ها و روش های تعمیم نقشه برداری نهفته است. از این نظر، تکنیکهای تعمیم خودکار دادههای مکانی به اندازه مدلسازی، مدیریت و توزیع دادهها اهمیت دارند. برنامه های نقشه برداری وب یا تلفن همراه معمولاً برخی از داده های موضوعی پیش زمینه را در برابر مرجع فضایی ارائه شده توسط برخی از داده های پس زمینه (مثلاً نقشه توپوگرافی یا تصویر راستا) نمایش می دهند. معمولاً فرض میشود که دادههای پسزمینه از نظر محتوا ثابت هستند و بنابراین میتوانند توسط یک سرویس کاشی از پیش تعمیمیافته ارائه شوند (خدمات نقشه مبتنی بر خیابان باز، نقشههای گوگل، Bing Maps) برای ارائه تعامل نقشه یکپارچه. از سوی دیگر، داده های پیش زمینه بسته به درخواست کاربر از نظر محتوا متفاوت خواهد بود. بنابراین، تعمیم نقشهکشی دادههای پیشزمینه باید در زمان واقعی به دست آید، که به الگوریتمهای تعمیمپذیر انعطافپذیر و در حال پرواز نیاز دارد.2 ].
تقریباً همه نقشهبرداران حرفهای و دانشگاهی، فرآیند تعمیم نقشهکشی را یکی از چالشبرانگیزترین مؤلفههای فکری و فنی نقشهسازی میدانند. با شروع نوشتههای ماکس اکرت، نقشهبردار آلمانی در اوایل قرن بیستم، مشکلات مربوط به تعمیم توسط بسیاری از محققان بزرگ در نقشهبرداری به دقت بیان شده است. در در نظر گرفتن فرآیند تعمیم کارتوگرافی دیجیتال، تقریباً تمام کاربردهای این فرآیند به عنوان اولین گام خود انتخاب اشیا و ویژگی ها از پایگاه داده اولیه برای نمایش را دارند. هنگامی که یک شی یا ویژگی در ابتدا انتخاب شد، فرآیندهای تعمیم به ترتیب با استفاده از تبدیل فضایی یا ویژگی ادامه می یابد. دگرگونی های فضایی آن دسته از عملگرهایی هستند که نمایش داده ها را از منظر جغرافیایی یا توپولوژیکی تغییر می دهند. ساده سازی و هموارسازی دو عملگر اول از ده یا چند عملگر هستند. عملگرهای سادهسازی نقاط مشخصه، بحرانی یا توصیفکننده شکل را برای حفظ انتخاب میکنند، یا نقاط اضافی را که برای نمایش کاراکتر خط غیرضروری در نظر گرفته میشوند، رد میکنند. اپراتورهای صاف کننده خطی با کاریکاتور زیبایی شناختی تر تولید می کنند [3 ]. توضیحات و انتقادات مفصلی در مورد سادهسازی خطوط و الگوریتمهای هموارسازی را میتوان از مقالات مروری متعددی که توسط White [ 4 ]، Weibel [ 5 ]، McMaster [ 6 ]، Brassel and Weibel [ 7 ]، Thapa [ 8 ] تولید شدهاند به دست آورد. ، لی [ 9 ، 10 ] و ویسوالینگام و ویلیامسون [ 11 ].
همانطور که در شکل 1 نشان داده شده است ، لی [ 10 ] الگوریتم های تشخیص نقطه بحرانی را به سه گروه اصلی طبقه بندی کرد: تشخیص گوشه، تقریب چند ضلعی، و یک تکنیک ترکیبی که ترکیبی از دو مورد اول است.
دو روش متداول مورد استفاده، روشهای متوالی و روشهای تکراری در تقریب چند ضلعی هستند. اکثر الگوریتمها برای تشخیص نقاط بحرانی که در ادبیات نقشهکشی/GIS ظاهر میشوند به تقریب چند ضلعی تعلق دارند.
روشهای متوالی از نقطهای شروع میشوند تا طولانیترین بخش مجاز را پیدا کنند، که در آن تمام نقاط در امتداد خط اصلی با یک معیار یا تلورانس یا آستانه نادیده گرفته میشوند. آخرین نقطه در طولانی ترین قطعه مجاز به عنوان نقطه بحرانی در نظر گرفته می شود.

شکل 1. طبقه بندی الگوریتم ها برای تشخیص نقاط بحرانی.
دو رویکرد متداول در روش های تکرار شونده وجود دارد، یعنی تقسیم پیش رونده و تقسیم و ادغام. روشهای تقسیم پیشرونده، بخش منحنی بین دو نقطه اولیه را با یک نقطه تقسیم بین آنها به دو قسمت تقسیم میکنند. این نقطه پارتیشن به عنوان نقطه بحرانی انتخاب می شود. در روش تقسیم و ادغام، تعداد دلخواه نقاط در امتداد خط به عنوان نقاط بحرانی اولیه تخصیص داده می شود. برای هر جفت از نقاط بحرانی، فواصل عمود همه نقاط تا خطی که این دو نقطه بحرانی را به هم میپیوندد محاسبه میشود. اگر هر یک از فواصل عمود بر معیار بزرگتر باشد، نقطه با بیشترین فاصله عمود به عنوان نقطه بحرانی انتخاب می شود.
مراحل متداول برای تکنیکهای تشخیص گوشه، تخمین انحنا برای هر نقطه روی منحنی، و مکانیابی نقاطی است که دارای حداکثر انحنای محلی (هم مثبت و هم منفی) به عنوان گوشهها مطابق با آستانه و فرآیندی از سرکوب غیر حداکثری هستند. گوشه های شناسایی شده به عنوان نقاط بحرانی منحنی در نظر گرفته می شوند. الگوریتمهای تشخیص گوشه به دو گروه روشهای پارامتریک و روشهای ناپارامتریک طبقهبندی میشوند . روشهای پارامتریک به یک یا چند پارامتر ورودی مانند تشخیص زاویه نیاز دارند، در حالی که روشهای ناپارامتریک یک رویکرد تطبیقی برای تعیین منطقه پشتیبانی برای هر نقطه از یک منحنی بدون هیچ پارامتر ورودی طراحی میکنند.
هیدروگرافی نمایش ویژگی های آبی مانند نهرها/رودخانه ها، دریاچه ها/برکه ها، رپیدها، مخازن، باتلاق ها/مرداب ها و سدها/سرریزها بر روی نقشه ها است [ 12 ]. هیدروگرافی یک عنصر مهم در تعریف شکل و تقسیمات طبیعی سطح زمین است [ 13 ]. نقشه نگاران مرکز عالی علوم اطلاعات مکانی (CEGIS) سازمان زمین شناسی ایالات متحده (USGS)، دانشگاه کلرادو بولدر و دانشگاه ایالتی پنسیلوانیا از ابزار ArcGIS Simplify Line استفاده کردند که بر اساس الگوریتم Bend Simplify توسعه یافته توسط وانگ و مولر [ 14] برای ساده کردن جریان های انتخاب شده (هرس شده). در این الگوریتم، حساس ترین ویژگی موثر بر انتخاب/حذف خم، اندازه است. اندازه یک خم به عنوان مساحت چند ضلعی محصور شده توسط خم و خط پایه آن تعریف می شود. شکل یک چند ضلعی خمشی را می توان با یک شاخص فشردگی (cmp) توصیف کرد، که به نوبه خود به عنوان نسبت مساحت چند ضلعی به دایره ای که طول محیط آن با طول محیط یکسان است تعریف می شود. چند ضلعی. برای انتخاب/حذف خم، معکوس cmp برای تنظیم اندازه خم و به عنوان معیار اصلی برای انتخاب خم استفاده می شود [ 14 ]:
a dj u s t e d s i ze = a r e a × ( 0.75c m p)آد�توستیهد سمن�ه=آ�هآ ×(0.75جمترپ)
برای انجام تعمیم خمیدگی، کاربر باید حداقل قطر را برای یک خم نیم دایره تعیین کند و این حداقل به عنوان تلورانس و مرجع برای حذف خم استفاده می شود. عمل برش به صورت تکراری [ 14 ] اجرا می شود.
الگوریتم Bend Simplify به یک مقدار آستانه تعریف شده توسط کاربر نیاز دارد. نتیجه الگوریتم Bend Simplify مستقیماً به مقدار آستانه ( یعنی کاربر) بستگی دارد. هیچ نتیجه منحصر به فردی برای مجموعه داده منبع وجود ندارد. مقدار آستانه از طریق آزمون و خطا تعیین می شود. بنابراین ارزیابی هر نتیجه زمان زیادی می برد. علاوه بر این، هیچ شی یا معیاری مربوط به ارزیابی دقت در الگوریتم Bend Simplify وجود ندارد. بر این اساس، برخی (بخشهایی) از نهرها یا دریاچهها نمیتوانند نیاز دقت را برآورده کنند.
وانگ و مولر (1998) ساختار کلی را با خمیدگی های خطی حفظ کردند که از نظر ریاضی بر اساس اندازه، شکل و زمینه تعریف می شوند. آنها ادعا کردند که هیچ خمشی توسط الگوریتم معروف داگلاس-پیکر [ 15 ] شناسایی نمیشود، که فواصل عمود بر هر نقطه میانی را به عنوان معیاری منحصر به فرد برای انتخاب نقطه اندازهگیری میکند. آنها خم را به عنوان بخشی از یک خط تعریف کردند که شامل تعدادی رئوس بعدی است، با زوایای خمش در همه رئوس موجود در خم مثبت یا منفی و خمش دو راس انتهایی خم علائم مخالف هستند.
شهریاری و تائو [ 16 ] به جای ارائه یک مقدار تلورانس در الگوریتم داگلاس-پوکر برای ساده سازی خطوط جریان با پیچیدگی های مختلف، دقت موقعیتی تعریف شده توسط کاربر را پیشنهاد کردند. بنابراین، آنها قصد داشتند مقادیر تحمل را برای هر ویژگی جریان به طور خودکار مشخص کنند.
سینها و همکاران [ 17 ] یک روش سادهسازی خط چند معیاره را برای خودکارسازی سادهسازی ویژگیهای هیدروگرافی خطی بر اساس محدودیتهای فضایی، توپولوژیکی و هیدروژئولوژیکی توسعه داد. سه معیار برای سادهسازی خط چند معیاره، فاصله داگلاس-پوکر، تغییر در شیب توپوگرافی، و فاصله معکوس ورود به سیستم به نزدیکترین چاه بود. آنها از امتیاز چند معیاره استفاده کردند که احتمال انتخاب یک نقطه را تعیین می کند.
گری و همکاران [ 18 ] جریانها را در مقیاس 1:100,000 مجموعه داده ملی هیدروگرافی (NHD) برای ایجاد مجموعه دادههای هیدروگرافی ملی در مقیاس 1:1,000,000 با استفاده از الگوریتم Bend Simplify با مقدار تحمل 500 متر ساده کرد. به طور مشابه، بدنه های آبی با استفاده از این الگوریتم با مقدار تحمل 500 متر ساده شدند.
بروور و همکاران [ 19 ] خطوط جریان ساده، مسیرهای مصنوعی و مسیرهای مصنوعی ثانویه (بی نام) با استفاده از الگوریتم Bend Simplify. مقدار تلرانس 75 متر برای خطوط جریان و مسیرهای مصنوعی ثانویه و 100 متر برای مسیرهای مصنوعی استفاده شد. بنابراین، آنها نقشههای 1:50000 را از نقشههای مقیاس 1:24000 برای رژیمهای مرطوب صاف، خشک صاف، تپهای مرطوب و مرطوب کوهستانی تولید کردند. مسیرهای مصنوعی خطوط مرکزی نواحی آبی هستند که شامل کانالهای رودخانهای وسیع با دو کرانه کشیده شده است. مسیرهای مصنوعی ثانویه متعلق به کانال های جریانی هستند که نام آنها مشخص نیست.
Wilmer و Brewer [ 20 ] جریانهای هرس شده را در داده های مقیاس 1:5000 با استفاده از الگوریتم Bend Simplify با مقادیر تحمل 24، 100، و 2000 متر به ترتیب برای 1:24000، 1:100،000، و مقیاس 1:00، و 1:000 ساده کردند. علاوه بر این، آنها جریان ها را در مقیاس های 1:100000 و 1:2000000 از داده های مقیاس 1:24000 به ترتیب با استفاده از مقادیر تحمل 100 و 2000 متر استخراج کردند.
استانیسلاوسکی و باتنفیلد [ 21 ] یک حوضه زیرحوضه کوهستانی خشک از NHD را مطالعه کردند که از مقیاس 1:24000 تعمیم داده شد که برای نقشه برداری نقشه برداری در مقیاس های بین 1:50000 و 1:200000 مناسب است. آنها همچنین از الگوریتم Bend Simplify برای ساده کردن مرزهای چند ضلعی و خطوط جریان (خطوط جریان) با مقادیر تحمل به ترتیب 200 و 150 متر استفاده کردند.
به طور مشابه استانیسلاوسکی و همکاران. [ 22 ] از الگوریتم Bend Simplify برای سادهسازی جریانها در زیرحوضههای NHD که از مواد منبع در مقیاس 1:24000 گردآوری شدهاند، استفاده کرد. ویژگی های هندسی ویژگی های توپوگرافی های مسطح، تپه ای و کوهستانی مناطق مرطوب قبل و بعد از استفاده از پنج مقدار تحمل ساده سازی (15، 25، 50، 100 و 200 متر) که در خط پایه خم ها به آنها اشاره شده است، اندازه گیری می شود. و با استفاده از چندین معیار ارزیابی شد.
در این مقاله، الگوریتم جدیدی که از این پس Segment Simplify نامیده می شود، برای ساده سازی نهرها و دریاچه ها پیشنهاد شده است. الگوریتم Segment Simplify بر اساس الگوریتمی است که توسط Gökgöz [ 23 ] برای ساده سازی کانتور توسعه داده شده است که از این پس Contour Simplify نامیده می شود. در هر دو الگوریتم، هدف آن به دست آوردن ویژگی های دقیق و صاف است ( به عنوان مثال، خطوط، نهرها و دریاچه ها) با حداقل تعداد نقاط مشخصه در مقیاس هدف به تصویر کشیده شوند. طبق الگوریتم Contour Simplify، سادهسازی یک کانتور عبارت است از انتخاب و اتصال متوالی تعداد کافی از نقاط مشخصه به نوبه خود، از مشخصترین نقطه علاوه بر اولین و آخرین نقطه کانتور تا سقوط به داخل ناحیه باند خطای آن. . نقاط مشخصه مطابق با زوایای انحراف مرتب می شوند. نقطه کانتوری که در آن مقدار زاویه انحراف حداکثر است مشخصه ترین نقطه کانتور می شود. نقاط مرزی یک باند خطا، نقاط انتهایی شیب ترین خطوط در هر دو طرف هر نقطه خطوط هستند. طول هر خط شیب تند به میانگین خطای پلان متری مربع در هر نقطه کانتور محدود می شود. از آنجایی که کانتورها همیشه به صورت منحنی های صاف روی نقشه ها نشان داده می شوند، یک کانتور ساده شده با قرار دادن یک اسپلاین مکعبی روی نقاط کانتور ساده شده هموار می شود. الگوریتم Segment Simplify عمدتاً از دو جنبه با الگوریتم Contour Simplify متفاوت است. اولاً مشخصترین نقاط رودخانهها و دریاچهها در خمهای تیزشان قرار گرفتهاند و عموماً تصاویر صافی را ارائه نمیدهند. از سوی دیگر، نیازی به نمایش نهرها و دریاچه ها به همواری خطوط وجود ندارد. بنابراین در الگوریتم Segment Simplify برخی از مشخص ترین نقاط حذف می شوند و از اسپلاین های مکعبی برای هموارسازی استفاده نمی شود. ثانیاً، تندترین خطوط شیب را نمی توان در ساخت باندهای خطا در الگوریتم Segment Simplify استفاده کرد. باندهای خطا به عنوان بافرهای عرض ثابت با استفاده از خطای پلانی متری نهرها و دریاچه ها گزارش شده توسط آژانس نقشه ملی ساخته می شوند. طبق طبقه بندی Li که در بالا ذکر شد، الگوریتم Segment Simplify می تواند به عنوان یک الگوریتم تشخیص گوشه پارامتری در نظر گرفته شود.
الگوریتم Segment Simplify با استفاده از دادههای NHD با وضوح بالا در مقیاس 1:24000 از یک زیرحوضه، Pomme de Terre، آزمایش میشود تا دادههای با وضوح متوسط مربوطه در مقیاس 1:100،000 به دست آید. نتایج با دادههای NHD با وضوح متوسط متناظر و نتایج بهدستآمده با استفاده از هر دو الگوریتم Bend Simplify و Douglas-Peucker و چندین معیار مقایسه میشوند.
2. روش شناسی
ویژگی های خطی که باید در مقیاس هدف (1:100000) نشان داده شوند در مطالعه قبلی [ 24 ] به دست آمده بودند . این مرحله مربوط به قسمت زرد فلوچارت در شکل 2 است . بنابراین، فرآیند انتخاب/حذف تنها بر روی ویژگیهای چند ضلعی در مجموعه داده با در نظر گرفتن استانداردهای USGS NHD انجام شد. این مرحله مربوط به قسمت آبی فلوچارت در شکل 2 است. در این مرحله ویژگی های چند ضلعی با هندسه هایی که باید به خطوط تبدیل شوند مشخص شد. چند ضلعی های حذف شده که باعث قطع شدن شبکه شده بودند نیز مشخص شدند. در نتیجه، هم چند ضلعی ها و هم مسیرهای مصنوعی که قرار است ساده شوند، در پایان این مرحله به دست آمدند. مرحله ساده سازی مربوط به قسمت سبز فلوچارت در شکل 2 است. به منظور حفظ ارتباط بین ویژگیها پس از سادهسازی، تمام ویژگیهای خط و چند ضلعی انتخاب شده در اتصالات شکسته شدند. در نتیجه، تمام ویژگی های خط و چند ضلعی انتخاب شده به ویژگی های خطی متشکل از دو یا چند نقطه بدون هیچ گونه اتصالی، به جز نقاط انتهایی آنها، تغییر یافتند. از این به بعد قطعه نامیده می شوند. چند ضلعی های بافر در اطراف بخش ها به عنوان باندهای خطای آنها مطابق با استانداردهای دقت نقشه ملی ایالات متحده ایجاد شد. همه بخش ها با الگوریتم Segment Simplify ساده شدند. در نهایت، مجموعه داده هدف به دست آمد و بخش های ساده شده با توجه به ویژگی هایشان، از جمله انواع و سطوح جریان، ادغام شدند. در زیر هر مرحله به تفصیل توضیح داده شده است. با هدف مقایسه، تمامی بخشها با استفاده از الگوریتمهای Bend Simplify و Douglas-Peucker سادهسازی شدند.

شکل 2. نمودار جریان مطالعه.
فرآیندهای شکستن، بافر کردن و ادغام توسط ابزار ArcGIS انجام شد. الگوریتم Segment Simplify به طور خودکار در اتوکد با استفاده از برنامه ای که توسط AutoLISP نوشته شده بود انجام شد. الگوریتم Bend Simplify و Douglas-Peucker توسط ابزار ArcGIS انجام شد.
2.1. منبع اطلاعات
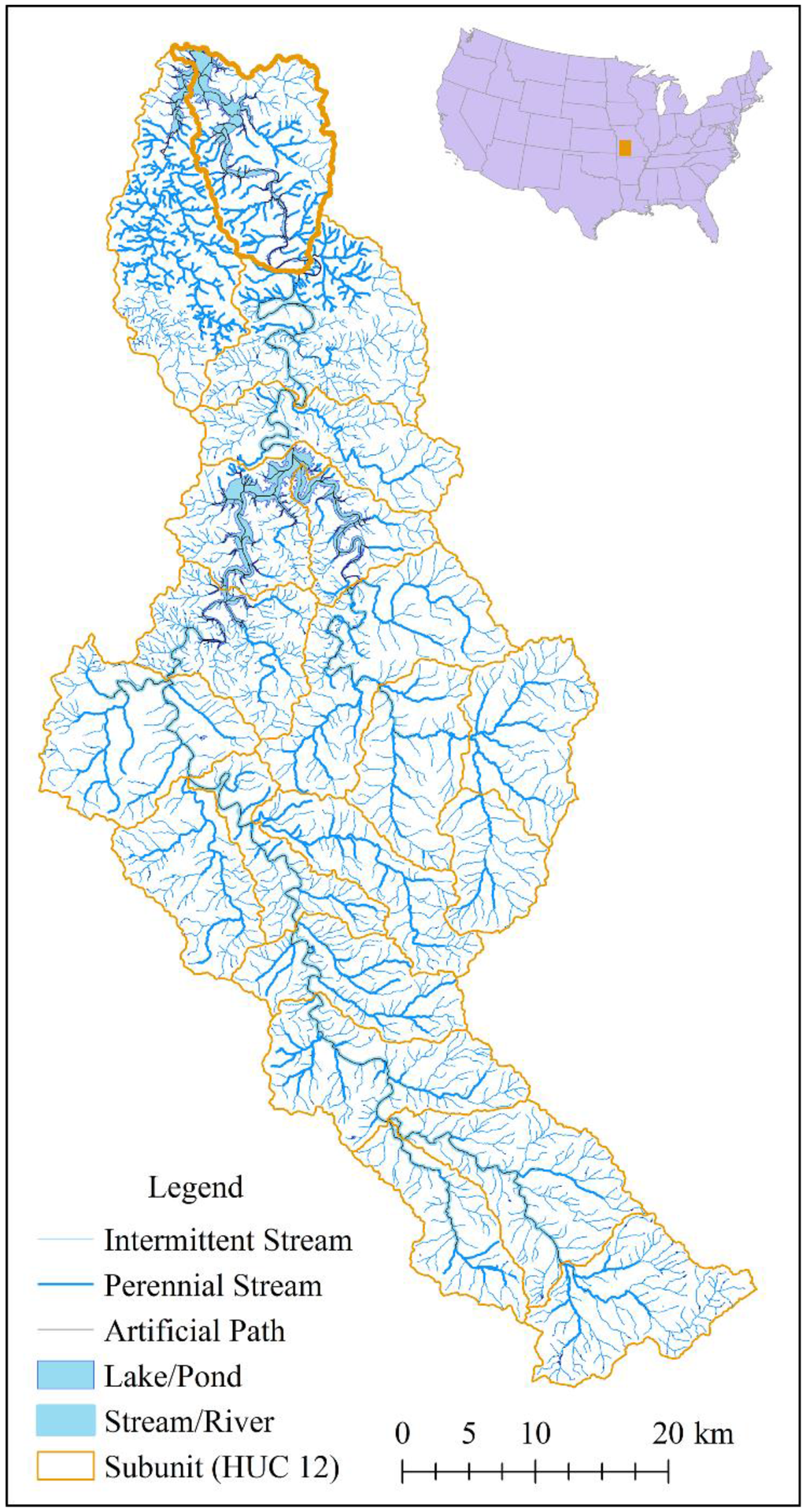
دادههای مورد استفاده در این مطالعه، یک NHD با وضوح بالا (NHDH1029)، و NHD با وضوح متوسط (NHDM1029) مربوط به یک زیرحوضه Pomme de Terre (PT)، در ژوئن 2011 دانلود شد. PT دارای یک الگوی دندریتی است. شرایط زمین بر ویژگی های هندسی ویژگی های خطی برای چندین نوع ویژگی تأثیر می گذارد. در این زمینه، PT در یک منطقه آب و هوای مرطوب است. PT در یک مکان تپه ای در فلات Ozark در ارتفاعات داخلی است [ 25 ]. داده ها حاوی ویژگی های چند ضلعی و خطی مانند دریاچه ها / برکه ها، نهرها / رودخانه ها و مسیرهای مصنوعی هستند. مجموعه داده منبع در شکل 3 نشان داده شده است .

شکل 3. مجموعه داده منبع مطالعه.
2.2. انتخاب/حذف ویژگی های خط
ما ویژگی های خط را مطابق با روش پیشنهاد شده توسط Sen و همکاران انتخاب کردیم. [ 24 ]. در این روش از نقشه های خودسازماندهی (SOM)، یک روش بدون نظارت شبکه های عصبی مصنوعی استفاده می شود. مناسب ترین ویژگی اشیاء جریان ( یعنی طول، سینوسیته، درجه، بین، نزدیکی، سطح جریان، و نوع) به عنوان متغیرهای ورودی استفاده شد. وزن صفات با استفاده از آزمون استقلال کای دو انجام شد. قانون رادیکال تاپفر [ 26 ] برای تعیین اینکه چند ویژگی باید انتخاب شوند استفاده شد. یک رویکرد افزایشی برای تعیین اینکه کدام خوشه ها باید از SOM انتخاب شوند استفاده شد.
2.3. انتخاب/حذف ویژگی های چند ضلعی
ما ویژگی های چند ضلعی را طبق استانداردهای NHD [ 27 ] حذف کردیم. دو پارامتر اصلی برای نمایش و انتخاب استفاده می شود: طول و عرض که به ترتیب به صورت l و w در جدول 1 نشان داده شده اند .

جدول 1. بازنمایی و قوانین انتخاب استانداردهای مجموعه داده ملی هیدروگرافی برای ویژگی های نشان داده شده در منطقه مورد مطالعه.
برای تعیین طول و عرض یک مشخصه که ممکن است یک چند ضلعی منظم یا نامنظم باشد، به استثنای چندضلعی های جریان مانند دراز خطی، به ترتیب از مستطیل های مناسب جهت دار یا غیر جهت دار استفاده شد (شکل 4 ) . مستطیل گرا با بهترین برازش کوچکترین ناحیه ای است که یک چند ضلعی را در بر می گیرد و مستطیل غیر جهت دار بهترین برازش، پوشش یک چند ضلعی با لبه هایی است که با محورهای X و Y موازی هستند. ما از ابزار ArcGIS Minimum Bounding Geometry برای به دست آوردن بهترین مستطیل های متناسب استفاده کردیم.

شکل 4. مستطیل های مناسب. ( الف ) جهت یک چندضلعی منظم. ( ب ) غیر جهت دار برای چند ضلعی نامنظم.
با توجه به روش توسعهیافته در این مطالعه، عرض یک چندضلعی جریانمانند دراز خطی به شرح زیر تعیین شد. نیمسازها در رئوس مسیر مصنوعی، به جز نقاط انتهایی، به صورت خطوط یک سانتی متری در دو طرف رسم شدند. پس از آن، آنها به لبه های چند ضلعی کشیده شدند ( شکل 5 ). عرض یک چند ضلعی جریان مانند دراز خطی با تقسیم طول کل تمام خطوط بر تعداد رئوس هایی که نیمسازها در آنها رسم شده بودند محاسبه شد. این فرآیند به طور خودکار با استفاده از یک اسکریپت نوشته شده توسط AutoLISP مدیریت شد.

شکل 5. نیمسازها در رئوس مسیر مصنوعی یک چندضلعی جریان مانند دراز خطی.
2.4. ساده سازی
الگوریتم Segment Simplify در این مطالعه با الزامات زیر توسعه داده شد. اولاً، بخش های ساده شده باید در داخل باندهای خطا قرار گیرند (نیاز به دقت). ثانیا، بخش های ساده شده باید به اندازه کافی صاف باشند (خوانا بودن و الزامات زیبایی شناختی). ثالثاً، بخش های ساده شده باید با حداقل تعداد امتیاز به تصویر کشیده شوند (نیاز به ذخیره سازی). در اینجا، بخش ها به تمام ویژگی های موجود در پایان مرحله شکست اشاره می کنند.
اولین نیاز مربوط به دقت پلانیمتری قطعات است. از آنجایی که زمین توپوگرافی کاملاً نامنظم است، بدون هیچ گونه انطباق ریاضی، موقعیت های جغرافیایی بخش ها روی نقشه ها “مشخص” است اما “درست” نیست. به عبارت دیگر، بخش ها همیشه دارای خطاهای پلانیمتری هستند. بنابراین، موقعیت جغرافیایی واقعی یک بخش در هر نقطه از یک منطقه خاص از نقشه است. این مناطق به عنوان باندهای خطای بخش ها در نظر گرفته می شوند. در این مطالعه، چند ضلعی های بافر در اطراف قطعات ایجاد می شوند تا به عنوان باندهای خطا عمل کنند. فاصله بافر مطابق با استانداردهای دقت نقشه ملی ایالات متحده تعیین می شود. گزارش شده است که 90 درصد از جریان های به خوبی تعریف شده در 167 فوت (0.02 اینچ در مقیاس نقشه) از موقعیت جغرافیایی واقعی خود در مقیاس 1:100000 قرار دارند [28 ]]. در نتیجه فاصله بافر 50.80 متر است.
الزامات دوم و سوم مربوط به نقاط مشخصه قطعات است. از آنجایی که این نقاط در خم های تیز یک قطعه قرار می گیرند، معمولاً تصویر صافی از بخش را ارائه نمی دهند. بنابراین، هنگام انتخاب نقاط برای به دست آوردن بخش های خوانا و زیبایی شناختی، نباید آنها را در اولویت قرار داد. از سوی دیگر، ذخیره نقاط اضافی گزینه مطلوبی نیست. بنابراین، حداقل تعداد نقاط مشخصه باید انتخاب شود تا نیاز ذخیره سازی برآورده شود. واضح است که این یک مشکل پیچیده است و ابتدا باید نقاط مشخصه یک بخش را تعریف کرد.
نقاط با حداکثر انحنا را می توان نقاط مشخصه بخش ها فرض کرد. بر اساس این فرض، نقاط مشخصه قطعات به طور مستقیم تعیین می شوند، اما استفاده از انحناها در نقاط قطعه دشوار است. می توان از روش های مختلفی مانند اسپلین مکعبی یا ترکیب سهموی استفاده کرد، اما هر کدام نتیجه متفاوتی را به همراه دارد. بنابراین، مقادیر متفاوتی برای هر انحنا در یک نقطه قطعه می توان به دست آورد. علاوه بر این، نقاط مشخصه و ترتیب آنها، که توسط انحناها مشخص می شود، می تواند هر بار متفاوت باشد. به این دلایل، در این الگوریتم، زوایای انحراف به جای انحناها در نقاط قطعه محاسبه میشود. زاویه بین دو قسمت متوالی یک قطعه، زاویه انحراف در یک نقطه در نظر گرفته می شود ( شکل 6)).

شکل 6. زوایای انحراف در نقاط قطعه.

شکل 7. نمودار جریان الگوریتم Segment Simplify.
همانطور که در نمودار جریان الگوریتم نشان داده شده است ( شکل 7، یک بخش در سه مرحله متوالی ساده می شود. در مرحله اول، زوایای انحراف یک قطعه محاسبه می شود. مرحله دوم بر دو الزام اول متمرکز است. بنابراین مرحله دوم با مرتبسازی نقاط قطعه به ترتیب صعودی نسبت به زوایای انحراف آغاز میشود. علاوه بر نقاط پایانی بخش، اولین نقطه در لیست، کمترین نقطه مشخصه بخش، انتخاب می شود. نقاط انتخاب شده به طور متوالی به هم متصل می شوند و بنابراین، یک بخش ساده به دست می آید. برای تعیین اینکه آیا قطعه ساده شده در باند خطا قرار می گیرد یا خیر، لازم است کشف کنیم که آیا هیچ تقاطعی بین بخش ساده شده و مرز باند خطا وجود دارد یا خیر. اگر تقاطع وجود داشته باشد، بخش ساده شده به طور کامل داخل باند خطا نیست. در این مورد، نقطه بعدی در لیست، کمترین مشخصه بعدی بخش، انتخاب شده و در مجموعه نقاط انتخاب شده قرار می گیرد. پس از این، فرد به مرحله اتصال باز می گردد. این مراحل تا زمانی تکرار می شوند که بخش ساده شده به طور کامل در محدوده باند خطا قرار گیرد. بخش ساده شده به دست آمده از این طریق (یعنی خروجی مرحله دوم) ورودی مرحله سوم به همراه باند خطا است. مرحله سوم بر الزامات اول و سوم تمرکز دارد. بنابراین، مرحله سوم با مرتبسازی نقاط قطعه ساده شده به ترتیب نزولی زوایای انحراف آغاز میشود. این تنها تفاوت بین مرحله دوم و سوم است. مراحل باقی مانده از مرحله سوم به همان ترتیب مرحله دوم با استفاده از لیست جدیدی از نقاط اجرا می شود. در نتیجه، یک بخش ساده شده با تمام الزامات ذکر شده در بالا به دست می آید.
در شکل 8 الف، یک قطعه اصلی (قرمز) متشکل از 92 نقطه و نوار خطای آن (خاکستری) نشان داده شده است. پس از مرحله دوم و سوم الگوریتم، تعداد نقاط به ترتیب به 53 و 29 کاهش می یابد. به عبارت دیگر 42.4 درصد از امتیاز بخش اصلی در مرحله دوم حذف شد و 45.3 درصد از امتیاز بخش ساده شده در پایان مرحله دوم در مرحله سوم حذف شد. در مجموع 68.5 درصد از نقاط بخش اصلی توسط الگوریتم حذف شدند. نتایج مرحله دوم و سوم در شکل 8 b-d نشان داده شده است.

شکل 8. مراحل الگوریتم Segment Simplify. ( الف ) یک قطعه اصلی و باند خطای آن. ( ب ) نتیجه مرحله دوم. ج ) نتیجه مرحله سوم. ( د ) خروجی الگوریتم.
3. نتایج و بحث
این روش برای انجام یک تجربه محاسباتی استفاده شد که عمدتاً در شکل 9 نشان داده شده است . شبکه در شکل 9 a با استفاده از الگوریتم Bend Simplify به دست آمد که به ترتیب 100 و 200 متر را به عنوان مقادیر تحمل برای نهرها و دریاچه ها تعیین کرد. شبکه در شکل 9 b نیز با الگوریتم Bend Simplify به دست آمد، اما مقادیر تحمل برای نهرها و دریاچه ها به ترتیب 150 و 200 متر تعیین شد. مقادیر تحمل برای الگوریتم Bend Simplify توسط Wilmer and Brewer [ 20 ]، Stanislawski و Buttenfield [ 21 ] و Stanislawski و همکاران پیشنهاد شده است. [ 22 ]. شبکه در شکل 9c با الگوریتم داگلاس-پوکر به دست آمد و مقدار تلورانس را 25.4 متر تعیین کرد که نصف فاصله بافر است، یعنی باند خطا استفاده شده در الگوریتم Segment Simplify. شبکه به دست آمده توسط الگوریتم Segment Simplify در شکل 9 d نشان داده شده است. مجموعه داده USGS در مقیاس 100K در شکل 10 نشان داده شده است .
اعداد ویژگیها در شبکهها در مقیاسهای 24K و 100K، علاوه بر مقادیر محاسبهشده توسط فرمولهای تاپفر، در شکل 11 الف آورده شدهاند. از آنجایی که تمام شبکههای بهدستآمده در این مطالعه از ویژگیهای یکسانی تشکیل شدهاند، تعداد ویژگیها با نوار «مطالعه» نشان داده میشوند. تمام جریانهایی که بهعنوان ویژگیهای چند ضلعی در شبکه USGS در مقیاس 24K نشان داده شدهاند، مطابق با مشخصات USGS در مرحله انتخاب/حذف به ویژگیهای خط تغییر کردند. همه جریانها قبلاً به عنوان ویژگیهای خطی در شبکه USGS در مقیاس 100K نشان داده شدهاند. در نتیجه هیچ تضادی بین شبکه ها از نظر نوع ویژگی جریان ها وجود ندارد. با این حال، تعداد بخشهای جریان در شبکهها ( به عنوان مثال، شبکه USGS در مقیاس 100K و شبکه های به دست آمده در این مطالعه) یکسان نیستند. تعداد بخش جریان در شبکه USGS در مقیاس 100K کمتر از این مطالعه است. در حالی که نقشهبر 20 درصد از بخشها را در شبکه USGS در مقیاس 24K انتخاب کرد، ما 22 درصد از آنها را انتخاب کردیم. دلیل این امر این است که از روش های مختلفی برای انتخاب/حذف استفاده می شود. برخلاف USGS، یک روش بدون نظارت از شبکههای عصبی مصنوعی ( به عنوان مثال ، SOM) برای انتخاب/حذف جریانها در این مطالعه استفاده شد. تعداد بخشهای جریانهای محاسبهشده با فرمول تاپفر بزرگتر از تعداد بخشهای جریان برای هر دو شبکه در مقیاس 100K است. فرمول تاپفر که برای استریم ها استفاده می شود این است:
nf=nآ(مآ/مf)2–––––––––√��=�آ(مآ/م�)2
جایی که nf��تعداد ویژگی ها در مقیاس هدف است، nآ�آتعداد ویژگی ها در مقیاس منبع است، مآمآمخرج مقیاس نقشه منبع است و مfم�مخرج مقیاس نقشه هدف است.
تفاوت قابل توجهی بین اعداد دریاچه در هر دو شبکه در مقیاس 100K وجود دارد. در حالی که نقشه نگار 8 درصد از دریاچه ها را در شبکه USGS در مقیاس 24K انتخاب کرد، ما فقط 1 درصد از آنها را انتخاب کردیم. تعداد دریاچه ها در هر دو شبکه در مقیاس 100K به طور قابل توجهی کوچکتر از مقدار محاسبه شده توسط فرمول تاپفر زیر است:
nf=nآ(مآ/مf)3–––––––––√��=�آ(مآ/م�)3
نتایج تجزیه و تحلیل کمی برای ارزیابی عملکرد الگوریتم Segment Simplify در شکل 11 b-d آورده شده است. در حالی که تعداد راس جریانها در شبکه بهدستآمده توسط الگوریتم Bend Simplify با استفاده از 100 متر به عنوان مقدار آستانه بزرگتر از شبکه USGS در مقیاس 100K است، تعداد راس جریانها در شبکه توسط الگوریتم Bend Simplify بهدست میآید. استفاده از 150 متر به عنوان مقدار آستانه کوچکتر از شبکه USGS در مقیاس 100K است ( شکل 11ب). علاوه بر این، الگوریتم داگلاس-پیکر کمترین تعداد رئوس جریان را حفظ کرد. تعداد رأس جریانهای شبکه که توسط الگوریتم Segment Simplify به دست میآید بین مقادیر الگوریتم Bend Simplify و Douglas-Peucker است. با توجه به مقدار محاسبه شده توسط فرمول تاپفر زیر، تمامی نتایج قابل قبول هستند. با این حال، از نظر ارزیابی دقت، نتایج به دست آمده توسط هر دو الگوریتم Segment Simplify و Douglas-Peucker قابل قبول است. تمام جریانهای سادهشده بهدستآمده توسط الگوریتمهای Segment Simplify و Douglas-Peucker کاملاً در داخل باندهای خطا قرار دارند، در حالی که برخی از جریانهای سادهشده بهدستآمده توسط نقشهنگار یا الگوریتم Bend Simplify نیستند (شکل 12 ) .
nf=nآ(مآ/مf)––––––––√��=�آ(مآ/م�)
دریاچه ها با الگوریتم Bend Simplify با استفاده از 200 متر به عنوان مقدار آستانه ساده شدند [ 20 ]. همانطور که در شکل 11 ب مشاهده می شود، تعداد رأس دریاچه های ساده شده توسط الگوریتم داگلاس-پوکر کوچکتر از آن است که توسط نقشه نگار USGS، الگوریتم های Bend Simplify و Segment Simplify به دست آمده است. هنگامی که توسط الگوریتم Segment Simplify ساده می شود، تعداد راس دریاچه ها کوچکتر از نقشه نگار USGS است اما بزرگتر از آن با استفاده از الگوریتم Bend Simplify و Douglas-Peucker است. اعداد رأس دریاچه ها در همه شبکه ها کوچکتر از مقدار محاسبه شده توسط معادله تاپفر (4) است. در نتیجه همه شبکهها از نظر تعداد رأس دریاچههای ساده شده رضایتبخش هستند. با این حال، نتایج ( به عنوان مثالدریاچه های ساده شده) به دست آمده توسط الگوریتم های Segment Simplify و Douglas-Peucker از نقطه نظر ارزیابی دقت قابل قبول هستند. تمام دریاچههای سادهشده بهدستآمده با الگوریتمهای Segment Simplify و Douglas-Peucker کاملاً در داخل باندهای خطا قرار دارند، در حالی که برخی از دریاچههای سادهشده بهدستآمده توسط نقشهنگار یا الگوریتم Bend Simplify نیستند.
طول کل جریان های ساده شده به دست آمده توسط الگوریتم Bend Simplify با استفاده از 100 متر به عنوان مقدار آستانه نزدیک به جریان های USGS در مقیاس 100K است، در حالی که طول کل دریاچه های ساده شده به دست آمده توسط الگوریتم داگلاس-پیکر نزدیک تر است. جریان های USGS در مقیاس 100K ( شکل 11 ج). علاوه بر این، طول کل دریاچه های ساده شده به دست آمده توسط الگوریتم Segment Simplify بین مقادیر الگوریتم Bend Simplify و Douglas-Peucker است.
همانطور که در شکل 11 d مشاهده می شود، مقدار سینوسی بخش های ساده شده به دست آمده توسط الگوریتم Segment Simplify به بخش های USGS در مقیاس 24K نزدیک تر است، اگرچه تفاوت قابل توجهی بین هیچ یک از آنها وجود ندارد. در نتیجه، الگوریتم Segment Simplify نیز رضایتبخشترین نتیجه را در رابطه با معیار سینوسی تولید کرد. شخصیت بخش های اصلی را حفظ کرد.
به طور خلاصه، الگوریتم داگلاس-پوکر کمترین تعداد رئوس جریان و دریاچه را حفظ کرد. علاوه بر این، جریانهای سادهشده بهدستآمده توسط الگوریتم Segment Simplify حداقل در طول کل بودند، در حالی که دریاچههای سادهشده بهدستآمده توسط الگوریتم Bend Simplify حداقل در طول کل بودند. تعداد رأس جریان های ساده شده به دست آمده توسط الگوریتم Bend Simplify با استفاده از 150 متر به عنوان مقدار آستانه، نزدیک تر به جریان های USGS در مقیاس 100K است، در حالی که تعداد رأس دریاچه های ساده شده به دست آمده توسط الگوریتم Segment Simplify به آن نزدیک تر است. جریان USGS در مقیاس 100K. مقادیر محاسبهشده توسط فرمولهای تاپفر برای اعداد رأس نهرها و دریاچهها در مقیاس 100K به طور گستردهای از تمام مقادیر مرتبط در این مطالعه منحرف میشوند. از این رو،

شکل 9. خروجی های الگوریتم ها. ( الف ) Bend Simplify (تلرانس: 100 متر و 200 متر برای نهرها و دریاچه ها، به ترتیب). ( ب ) Bend Simplify (تلرانس ها: 150 متر و 200 متر برای نهرها و دریاچه ها، به ترتیب). ( ج ) داگلاس-پوکر (تلرانس: 25.4 متر). ( د ) ساده سازی بخش (باند خطا: 50.8 متر).

شکل 10. مجموعه داده USGS در مقیاس 100K.
از آنجایی که الگوریتم داگلاس-پوکر دورترین نقاط را در هر مورد انتخاب می کند، فضاهای میانی بین دو طرف برخی از خم ها به ادغام در مقیاس هدف نزدیک می شوند. به عبارت دیگر، از آنجایی که فضاهای میانی بین دو طرف برخی از خم ها کمتر از 0.25 میلی متر است که حد گرافیکی برای فضای بین دو خط در مقیاس هدف است [29]، الگوریتم داگلاس-پوکر خم های تیز ایجاد می کند که در مقیاس هدف ناخوانا هستند. به عنوان مثال، خم با فضای میانی 0.13 میلی متر، که کمتر از حد گرافیکی است، در شکل 13 a در مقیاس هدف توسط الگوریتم داگلاس-پوکر ارائه شده است ( شکل 13) .ج). در نتیجه، الگوریتم داگلاس-پوکر باعث ایجاد مشکل خوانایی در برخی از خمها در مقیاس هدف در این مطالعه شد. بر این اساس، الگوریتم داگلاس-پوکر کیفیت زیبایی شناختی آن ویژگی ها را حفظ نکرد. اینها نقاط ضعف اصلی الگوریتم داگلاس-پوکر بودند. با این حال، الگوریتم Segment Simplify دورترین نقاط را انتخاب نمی کند و در نتیجه چنین مشکلاتی را در این مطالعه ایجاد نمی کند.
الگوریتم Bend Simplify ویژگیهای سادهشدهای را ایجاد کرد که نسبت به الگوریتمهای Douglas-Peucker و Segment Simplify با حذف برخی از خمها که قبلاً در مقیاس هدف خوانا بودند، صافتر بودند. به عنوان مثال، خم با فضای میانی 1.11 میلی متر، که بزرگتر از حد گرافیکی است، در شکل 13 a در مقیاس هدف توسط الگوریتم Bend Simplify ارائه نشده است ( شکل 13 ب). از سوی دیگر، الگوریتم Bend Simplify رئوس بسیار بیشتری را حفظ کرد. در این زمینه، به نظر می رسد که برخی از رئوس حفظ شده توسط الگوریتم Bend Simplify می توانند کمتر مشخصه، بحرانی یا توصیف کننده شکل باشند.

شکل 11. آمار آزمایش. ( الف ) اعداد ویژگی. ( ب ) اعداد رأس. ( ج ) طول (کیلومتر). ( د ) مقادیر سینوسیتی.

شکل 12. نسخه های اصلی و خروجی الگوریتم ها.

شکل 13. رفتار الگوریتم ها در چندین خم. ( الف ) یک جریان اصلی. ( ب ) Bend Simplify (تحمل: 150 متر). ( ج ) داگلاس-پوکر (تلرانس: 25.4 متر). ( د ) ساده سازی بخش (باند خطا: 50.8 متر).
4. نتیجه گیری
ما یک الگوریتم جدید به نام Segment Simplify برای ساده سازی رودخانه ها و دریاچه ها ارائه کرده ایم. نوارهای خطای جریان ها یا دریاچه ها اشیایی هستند که برای ارزیابی دقت در الگوریتم Segment Simplify استفاده می شوند. الگوریتم Segment Simplify اجازه نمی دهد یک جریان یا دریاچه ساده شده از باند خطای خود خارج شود. بنابراین، تمام جریان ها یا دریاچه های ساده شده به دست آمده توسط الگوریتم Segment Simplify همیشه در داخل باندهای خطا قرار دارند و در صحت آنها تردیدی وجود ندارد. در الگوریتم Segment Simplify مشخصه ترین نقاط از کم مشخصه ترین نقاط یک رودخانه یا دریاچه تا حدی انتخاب می شوند. به عبارت دیگر مشخص ترین نقاط یک نهر یا دریاچه تا حدودی از بین می رود. از این رو، خم های یک رودخانه یا دریاچه ساده شده به اندازه الگوریتم های دیگر تیز یا صاف نیستند. در این زمینه، الگوریتم Segment Simplify ویژگی های خوانا و زیبایی شناختی را تولید می کند. الگوریتم Segment Simplify مقدار قابل توجهی از نقاط را حذف می کند. الگوریتم Segment Simplify به طور خودکار اجرا می شود، هیچ پارامتر تعریف شده توسط کاربر ندارد و یک نتیجه منحصر به فرد برای مجموعه داده منبع ایجاد می کند.
به عنوان یک مطالعه آینده، الگوریتم Segment Simplify ممکن است بر روی داده های دیگری که به عنوان مثال به یک منطقه آب و هوای خشک با الگوی تریلی تعلق دارند، انجام شود. علاوه بر این، یک مطالعه باید برای تعیین عرض باندهای خطای مورد استفاده توسط الگوریتم Segment Simplify هنگام استفاده از مختصات جغرافیایی به جای مختصات پیش بینی شده در مقیاس معین طراحی شود.
منابع
- چودری، او. Mackaness، WA شناسایی خودکار مرزهای سکونتگاههای شهری برای پایگاههای اطلاعاتی چندگانه. محاسبه کنید. محیط زیست سیستم شهری 2008 ، 32 ، 95-109. [ Google Scholar ] [ CrossRef ]
- بروتر، پی. الگوریتمهای Weibel، R. برای تعمیم در جریان دادههای نقطهای با استفاده از چهار درخت. در مجموعه مقالات AutoCarto 2012، کلمبوس، OH، ایالات متحده آمریکا، 16-18 سپتامبر 2012.
- مک مستر، آر.بی. شی، تعمیم KS در کارتوگرافی دیجیتال . انجمن جغرافیدانان آمریکایی: واشنگتن، دی سی، ایالات متحده آمریکا، 1992. [ Google Scholar ]
- وایت، ارزیابی ER الگوریتم های تعمیم خط با استفاده از نقاط مشخصه. صبح. کارتوگر. 1985 ، 12 ، 17-27. [ Google Scholar ] [ CrossRef ]
- Weibel, R. تعمیم نقشه برداری خودکار. در کتابشناسی منتخب در مورد مدیریت داده های مکانی: ساختارهای داده، تعمیم و نقشه برداری سه بعدی . Sieber, R., Brassel, KE, Eds. Geographisches Institut der Universitӓt Zürich: Zürich, Switzerland, 1986; ص 20-35. [ Google Scholar ]
- مک مستر، RB تعمیم خودکار خط. Cartographica 1987 ، 24 ، 74-111. [ Google Scholar ] [ CrossRef ]
- براسل، KE; Weibel, R. یک بررسی و چارچوب مفهومی تعمیم خودکار نقشه. بین المللی جی. جئوگر. Inf. سیستم 1988 ، 2 ، 229-244. [ Google Scholar ] [ CrossRef ]
- تاپا، ک. بررسی الگوریتمهای تشخیص نقاط بحرانی و تعمیم خط. Surv. نقشه 1988 ، 48 ، 185-205. [ Google Scholar ]
- Li، Z. الگوریتمی برای فشرده سازی داده های کانتور دیجیتال. کارتوگر. J. 1988 , 25 , 143-146. [ Google Scholar ] [ CrossRef ]
- Li، Z. بررسی الگوریتمهایی برای تشخیص نقطه بحرانی در خطوط کارتوگرافی دیجیتال. کارتوگر. J. 1995 , 32 , 121-125. [ Google Scholar ] [ CrossRef ]
- Visvalingam، M. ویلیامسون، PJ ساده سازی و تعمیم داده های مقیاس بزرگ برای جاده ها: مقایسه دو الگوریتم فیلترینگ. کارتوگر. Geogr. Inf. علمی 1995 ، 22 ، 264-275. [ Google Scholar ] [ CrossRef ]
- Raisz, E. Principles of Cartography ; McGraw-Hill: توکیو، ژاپن، 1962. [ Google Scholar ]
- Loon, JC Cartographic Generalization of Digital Terrain Models. Ph.D. پایان نامه، دانشگاه ایالتی اوهایو، کلمبوس، OH، ایالات متحده آمریکا، 1978. [ Google Scholar ]
- وانگ، ز. تعمیم خط مولر، JC بر اساس تجزیه و تحلیل ویژگی های شکل. کارتوگر. Geogr. Inf. علمی 1998 ، 25 ، 3-15. [ Google Scholar ] [ CrossRef ]
- داگلاس، دی اچ. الگوریتم های Peucker، TK برای کاهش تعداد نقاط مورد نیاز برای نمایش یک خط دیجیتالی یا کاریکاتور آن. می توان. کارتوگر. 1973 ، 10 ، 112-122. [ Google Scholar ] [ CrossRef ]
- شهریاری، ن. تائو، CV به حداقل رساندن خطاهای موقعیتی در ساده سازی خط با استفاده از مقادیر تحمل تطبیقی. در پیشرفت در مدیریت داده های مکانی ; Richardson, DE, Oosterom, PV, Eds. Springer: برلین، آلمان، 2002; صص 153-166. [ Google Scholar ]
- سینها، جی. سیلویسسریت، دبلیو. کریگ، جی آر. Flewelling، سادهسازی خط چند معیاره DM (MCLS) برای مدلسازی آبهای زیرزمینی AEM. در مجموعه مقالات ششمین سمپوزیوم بین المللی ارزیابی دقت فضایی در منابع طبیعی و علوم محیطی، پورتلند، ME، ایالات متحده آمریکا، 28 ژوئن تا 1 ژوئیه 2004.
- گری، RH; ویلسون، زد. Archuleta، CM; تامپسون، FE; Vrabel, J. تولید مجموعه داده های هیدروگرافی ملی با مقیاس 1:1,000,000 برای ایالات متحده – انتخاب ویژگی، ساده سازی و اصلاح . سازمان زمین شناسی ایالات متحده: Reston، VA، ایالات متحده آمریکا، 2009; پ. 22.
- برویر، کالیفرنیا؛ باتنفیلد، BP; Usery، EL ارزیابی تعمیم های هیدروگرافی در زمین های مختلف برای نقشه ملی ایالات متحده. در مجموعه مقالات بیست و چهارمین کنفرانس بین المللی کارتوگرافی (ICC 2009)، سانتیاگو، شیلی، 15 تا 21 نوامبر 2009.
- ویلمر، جی.ام. بروور، کالیفرنیا استفاده از قانون رادیکال در تعمیم داده های هیدروگرافی ملی برای نقشه برداری چند مقیاسی. در مجموعه مقالات سمپوزیوم مشترک ویژه کمیسیون فنی ISPRS IV و AutoCarto در ارتباط با کنفرانس تخصصی پاییز 2010 ASPRS/CaGIS، اورلاندو، FL، ایالات متحده آمریکا، 15-19 نوامبر 2010.
- استانیسلاوسکی، LV; تعمیم ویژگی هیدروگرافی باتنفیلد، BP در زمین های کوهستانی خشک. در مجموعه مقالات سمپوزیوم مشترک ویژه کمیسیون فنی ISPRS IV و AutoCarto در ارتباط با کنفرانس تخصصی پاییز 2010 ASPRS/CaGIS، اورلاندو، FL، ایالات متحده آمریکا، 15-19 نوامبر 2010.
- استانیسلاوسکی، LV; راپوسو، پی. هوارد، ام. باتنفیلد، BP ارزیابی متریک خودکار ساده سازی خط در مناظر مرطوب. در مجموعه مقالات AutoCarto 2012، کلمبوس، OH، ایالات متحده آمریکا، 16-18 سپتامبر 2012.
- Gökgöz، T. تعمیم خطوط با استفاده از زوایای انحراف و باندهای خطا. کارتوگر. J. 2005 ، 42 ، 145-156. [ Google Scholar ] [ CrossRef ]
- سن، ا. گوکگز، تی. Sester، M. مدل تعمیم دو الگوی زهکشی مختلف توسط نقشه های خودسازماندهی. کارتوگر. Geogr. Inf. علمی 2014 ، 41 ، 151-165. [ Google Scholar ] [ CrossRef ]
- استانیسلاوسکی، LV; فین، ام. بارنز، ام. کاربر، ارزیابی EL از یک رویکرد سریع برای تخمین حوزه های آبریز برای خطوط زهکشی سطحی. در مجموعه مقالات 2007 ACSM-IPLSA-MSPS، سنت لوئیس، MO، ایالات متحده آمریکا، 9 تا 12 مارس 2007.
- تاپفر، اف. Pillewiser, W. اصول انتخاب. کارتوگر. J. 1966 ، 3 ، 10-16. [ Google Scholar ] [ CrossRef ]
- سازمان زمین شناسی ایالات متحده (USGS). مجموعه داده های هیدروگرافی ملی: مفاهیم و محتوا. در دسترس آنلاین: http://nhd.usgs.gov/chapter1/chp1_data_users_guide.pdf (دسترسی در 17 ژوئن 2015).
- سازمان زمین شناسی ایالات متحده (USGS). مجموعه داده های هیدروگرافی ملی: سوالات متداول. در دسترس آنلاین: http://nhd.usgs.gov/nhd_faq.html#q108 (در 17 ژوئن 2015 قابل دسترسی است).
- رایتز، ا. بانتل، ای. هوینکس، سی. مرکل، جی. شلینگ، G. Kartographische Generalisierung: Topographische Karten ; Schweizerische Gesellschaft für Kartographie: Bern, Switzerland, 1975. (به آلمانی) [ Google Scholar ]
© 2015 توسط نویسندگان; دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر