1. مقدمه
در مقاله قبلی ما برای اولین بار یک رویکرد ریاضی جدید (الگوریتم H-PST) برای شناسایی مکان احتمالی یک منبع شیوع همه گیر معرفی کردیم [ 1] نشان می دهد که توزیع رویدادهای تولید شده توسط یک فرآیند در یک فضای دو بعدی دارای اطلاعات پنهان زیادی است. ما این روش جدید هوش مصنوعی را با سایر الگوریتمهای معروف مقایسه کردیم تا منبع سه نمونه از شیوع بیماریهای عفونی را که از ادبیات به دست آمده است شناسایی کنیم. الگوریتم H-PST سیستمی است که قادر است یک ماتریس فاصله از نقاط (رویدادها) را در یک فضای دوبعدی با تولید یک نقطه جدید که واحد پنهان نامیده شده است، طرح کند. این واحد پنهان جدید فضای اولیه اقلیدسی را تغییر شکل داده و آن را به فضای جدیدی (فضای شناختی) تبدیل می کند. تابع هزینه این تبدیل، به حداقل رساندن تفاوت بین ماتریس فاصله اصلی بین نقاط اختصاص داده شده و ماتریس فاصله همان نقاط پیش بینی شده در نقشه دو بعدی است. ثابت شد که موقعیت واحد پنهان به طور موثر منبع شیوع بیماری را در بسیاری از اپیدمی ها بسیار بهتر از سایر الگوریتم های کلاسیک که به طور خاص برای این کار هدف قرار داده اند، هدف قرار می دهد. این مطالعه به وضوح نشان میدهد که یکی از اطلاعات پنهان احتمالی که میتوان فاش کرد، مکانی است که رویداد از آن سرچشمه گرفته است. برای درک کافی تاریخچه این روش، خواننده به [1 ، 2 ].
با این حال، از همان ابتدا، ما از برخی محدودیتهای این تکنیک آگاه بودیم. در واقع، الگوریتم H-PST زمانی بسیار کارآمد است که فواصل نقطهای از معیارهای اقلیدسی یا منهتن پیروی نمیکنند (فاصلههای زمانی، فواصل منحنیخطی، و غیره )، اما زمانی که فواصل نقطهای با یک نقشه دو بعدی مطابقت دارند، کارایی کمتری دارد. علاوه بر این، H-PST منطقه جستجو را به عنوان یک نقطه و نه به عنوان یک منطقه احتمال تعریف می کند. این ما را بر آن داشت تا الگوریتم دقیق تری با عملکرد چند ظرفیتی ایجاد کنیم. الگوریتم ارائه شده در اینجا مرکز وزنی توپولوژیکی (TWC) نامیده می شود و در سال 2008 طراحی شده است [ 3 ، 4 ]] در مرکز تحقیقات Semeion. آنتروپی جهانی را در بین موقعیتهای نقاطی که رویدادها در آنها رخ دادهاند، بدون استفاده از اطلاعات اضافی، به حداقل میرساند، اما میتواند موقعیت یک «نقطه صفر» پنهان (منبع فرآیند) را نشان دهد، و اطلاعات تاریخی را فقط از اطلاعات دقیق از قبل آشکار میگیرد. موقعیت سایر رویدادها همراه با سایر موجودات ریاضی جالب. این کشف نشان می دهد که هر توزیع ایستا از نقاط در یک فضای دو بعدی می تواند اطلاعات جدیدی در مورد دینامیک آنها دخیل باشد.
این مقاله در بخش های زیر سازماندهی شده است:
در بخش 2 ما یک سری از موجودیت های ریاضی را ارائه می کنیم که الگوریتم TWC ایجاد کرده است:
-
یک نقطه جدید، TWC Alfa، و یک میدان اسکالر جدید، نقشه TWC Alfa: این دو موجودیت تخمینی از شیوع اپیدمی اختصاص داده شده را تشکیل میدهند.
-
یک میدان اسکالر، TWC Beta، که هدف آن نشان دادن نقشه انتشار احتمالی اپیدمی است.
-
یک میدان اسکالر دیگر، TWC Gamma، و دیگر موجودیت های ریاضی تخمینی از انتشار آینده همه گیری را نشان می دهد.
در بخش 3 ما چهار مورد مختلف و شناخته شده اپیدمی را ارائه می کنیم که شیوع آنها به خوبی شناخته شده است:
-
مورد 1: اپیدمی تب چیکونگونیا در سال 2007.
-
مورد 2: اپیدمی بیماری تب برفکی 1967 در بریتانیای کبیر.
-
مورد 3: اپیدمی وبا در میدان طلایی 1854 در لندن.
-
مورد 4: آنفولانزای روسی در سوئد در 1889-1890.
در بخش 4 اثربخشی الگوریتم TWC- α را با سایر الگوریتم های شناخته شده در زمینه پروفایل جغرافیایی ارائه و مقایسه خواهیم کرد:
-
-
الگوریتم جمع نمایی منفی (NES) [ 1 ];
-
الگوریتم حداکثرسازی واریانس احتمال (LVM) [ 1 ];
-
الگوریتم احتمال مکزیکی (Mex Prob) [ 4 ].
ما تصمیم گرفتهایم برخی از الگوریتمهای بیاهمیت مانند گرایش مرکزی فضایی را در نظر نگیریم، زیرا قبلاً نشان داده شده است که بیش از حد سادهلوحانه و رقابتی نیستند (Le Comber [ 6 ]، Stevenson [ 7 ]).
ما همچنین تصمیم گرفتهایم که برخی از رویکردهای دیگر از جمله اطلاعات زمانی و فرکانسها را در پویایی اپیدمی در نظر نگیریم. ما قبلاً الگوریتمهای جدیدی را برای مقابله با این مجموعه دادههای غنیتر پیشنهاد کردهایم (به Buscema [ 8 ] مراجعه کنید). در این مقاله می خواهیم تنها امکان به دست آوردن حداکثر اطلاعات را از توزیع فضایی خام مجموعه ای از رویدادها (نقاط با طول و عرض جغرافیایی) در فضای دو بعدی نشان دهیم.
در بخش 5 ، ما نتایج مقایسه را ارائه خواهیم داد و روشی متشکل از چهار شاخص برای ارزیابی عملکرد هر الگوریتم در پروفایل جغرافیایی پیشنهاد می کنیم:
-
فاصله قله نقشه از هدف (شیوع)؛
-
حساسیت مکان هدف روی نقشه؛
-
ویژگی مکان هدف روی نقشه؛
-
درصد منطقه جستجوی پیشنهاد شده توسط هر الگوریتم.
در بخش 6 ، ما اولین اعتبارسنجی از قابلیت پیشبینی روش TWC را با استفاده از 12 ماه جمعآوری دادهها در مورد یک اپیدمی غذایی در OAHU (هاوایی) در سال 2010 ارائه میکنیم.
در نهایت، در بخش 7 ما کارایی TWC را در شیوع همهگیری که در آلمان در سال 2010 رخ داد، نشان میدهیم، اپیدمی سندرم اورمیک همولیتیک (HUS) که در آن بیش از 40 مرگ در یک دوره دو ماهه رخ داده است. بخش 7 نیز به نتیجه گیری می پردازد.
2. الگوریتم مرکز وزنی توپولوژیکی
2.1. برخی از جزئیات ریاضی در مورد روش TWC-α
به نقاطی که یک رویداد مورد علاقه در آن رخ می دهد، نقاط اختصاص داده شده می گویند. مرکز جرم نقاط اختصاص داده شده نشان دهنده نقطه ای است که حداکثر آنتروپی در آن رخ می دهد.
فرض کنید N = تعداد نقاط تخصیص داده شده و K = تعداد تمام نقاط صفحه دو بعدی در یک شبکه انتخاب شده/ثابت. سپس مختصات مرکز جرم با معادله زیر تعریف می شود:
که در آن Px r و Py r و y از نقطه اختصاص داده شده هستند . 
حال، اگر معادله (1) را دوباره بنویسیم که به هر یک از نقاط اختصاص داده شده یک وزن خاص بدهد و همچنین فاصله بین دو نقطه را با میانگین فاصله (اصلاح شده) هر نقطه از نقاط دیگر وزن کنیم، معادله (4) را ایجاد می کنیم. ):
جایی که
و جایی که D = حداکثر فاصله بین نقاط اختصاص داده شده، فاصله تغییر یافته بین دو نقطه اختصاص داده شده، d i ، j ، d i ، k = فاصله اقلیدسی بین دو نقطه اختصاص داده شده، و .
وزن با رابطه (5) تعریف می شود. معادله (4) همان معادله (1) است اما با معادله (5) وزن می شود.
معادله (5a) جذب کننده نهایی TWC (αn ) را به صورت n∞∞ به یک جاذبه غیر پیش پا افتاده تغییر می دهد. با معادله (5a) برای هر فاصله ( d i,j ) میانگین فاصله های دیگر را در نظر می گیریم ( d i,k , با k ≠ i و k ≠ j ). در واقع، بدون معادله (5a)، نقطه همگرایی TWC(αn ) ، به صورت n∞، مربوط به میانگین دو نقطه ای است که حداقل فاصله اقلیدسی را دارند (به اثبات پیوست A مراجعه کنید)، در حالی که در رابطه (5a) جاذبه نهایی نقطه ای در فضا است که فاصله متوسط آن از سایر نقاط حداقل است. این نقطه نباید منحصر به فرد باشد زیرا ماتریس فواصل ایجاد شده توسط معادله (5a) متقارن نیست (به پیوست B مراجعه کنید).
اکنون، بردار اوزان بهینه (معادله (5)) را مییابیم که دارای ویژگیهای زیر است:
ما یک الگوریتم برای بهینه سازی معادله (6) به شرح زیر ایجاد کرده ایم:
-
مقدار اولیه α (0 ) = 0 در چرخه اول. تمام اجزای بردار w ( α n ) در این نقطه برابر با 1 خواهند بود و TWC ( α n ) مختصات مرکز جرم یکسانی خواهد داشت.
-
در چرخه بعدی α را با یک مقدار مثبت کوچک افزایش دهید:
-
معادلات (7) و (8) کاهش آنتروپی و افزایش انرژی آزاد را نشان خواهند داد (به پیوست C مراجعه کنید)، و سپس TWC (αn ) در جهت خاصی از صفحه حرکت خواهد کرد (معادله (4)). .
-
هنگامی که انرژی آزاد (معادله (7)) به حداکثر جهانی می رسد، فرآیند در α * = α n خاتمه می یابد .
شرایط وجود یک نقطه همگرا، یعنی همگرایی به یک نقطه (یکتا)، با شرایط همگرایی به نقطه (یکتا) روش نیوتن همراه است. روش دیگر، می توان این الگوریتم را از نقطه نظر الگوریتم نقطه ثابت تحلیل کرد (به پیوست D مراجعه کنید). مسیر توصیف شده توسط تکامل TWC (αn ) نیز بسیار آموزنده است و حداقل به دو دلیل می توان آن را حفظ کرد:
-
همه نقاط TWC ( α n ) بهترین مسیری را نشان می دهند که با آن می توان به حداکثر انرژی آزاد میانگین وزنی نقاط اختصاص داده شده، از مرکز جرم شروع کرد. این مسیر معمولاً غیرخطی و منحنی غیر یکنواخت است.
-
مجموعه نقاط متعلق به مسیر TWC ( αn ) می تواند برای تبدیل صفحه به یک میدان اسکالر، TWSF (αn ) استفاده شود ، جایی که نزدیکی هر نقطه هندسی به این مسیر قابل اندازه گیری است.
بنابراین TWC ( α * ) نشان دهنده نقطه ای است که در آن میانگین وزنی نقاط تخصیص داده شده حداکثر انرژی آزاد را نشان می دهد. در بسیاری از کاربردها، این نقطه قابل توجه میتواند منبع فرآیند را نشان دهد یا به آن اشاره کند، زیرا این نقطه همچنین نقطهای است که آنتروپی در آن حداقل است، بنابراین نقطهای است که (اگر بخواهید خودتان را آنجا قرار دهید) نقاط دیگر تولید میشوند. حداکثر اطلاعات؛ به عبارت دیگر این نقطه ی نگنتروپی است. از طرف دیگر، مرکز جرم نقطهای است که آنتروپی حداکثر است، بنابراین نقطهای است که (اگر بخواهید خود را در آنجا قرار دهید) توزیع نقاط اختصاص داده شده کمترین اطلاعات را دارد. ما همچنین می توانیم α * را پیدا کنیمبا استفاده از روش نیوتن یا الگوریتم نقطه ثابت (به پیوست D مراجعه کنید). شرایط مرتبط با روش نیوتن یا الگوریتم نقطه ثابت بیانگر وجود و منحصر به فرد بودن روشی است که همگرایی به یک راه حل منحصر به فرد است.
2.2. جزئیات روش TWC-β
حال معادله (5) را به شکل زیر تغییر می دهیم:
معادله (10) دینامیکی متفاوت با معادله (5) ارائه می دهد. به طور خاص، هنگامی که پارامتر β هنوز کوچک است، آنتروپی سیستم کاهش می یابد، اما برای مقادیر بزرگتر β ، فاصله هر نقطه از خود (که در معادله (10) گنجانده شده است) غالب خواهد شد و مسیر نقاط TWC خواهد بود. با افزایش آنتروپی به مرکز جرم بازگردید. بنابراین، با معادله (10) جهت دیگری را هدف قرار می دهیم: مسیر از مرکز جرم خارج می شود و سپس به نقطه مورد نظر باز می گردد. این بدان معنی است که ما می توانیم سعی کنیم مقدار بهینه β را تعریف کنیمزمانی که آنتروپی میانگین وزنی نقاط تخصیص داده شده را در محاسبه وزن ها و شبه فاصله هر نقطه از خود لحاظ کنیم، حداقل است. این β * است که نقطه TWC ( β * ) مسیر شروع به برگشت به عقب می کند. این به این دلیل است که v i ( β * ) بردار اوزان است که با مقدار خاصی از β تعریف می شود ، که در آن آنتروپی کوچکترین ( β * ) است که توسط موارد زیر محاسبه می شود:
مولفه های x و y داده شده است:
همچنین، الگوریتم تکراری که در آن پارامتر β افزایش یافته است، طبق رابطه (14) ضروری است، زیرا ما نمی دانیم که کدام مقدار β عبارت موجود در رابطه (11) را برآورده می کند و β = β * را می دهد (پیوست A را ببینید. معادله (A16) به معادله (A22)).
پارامتر β * اکنون برای تعریف نزدیکی هر نقطه هندسی (تمام نقاط شبکه ای که فضا را تعریف می کنند) به نقاط اختصاص داده شده استفاده می شود:
N ; {تعداد امتیازات اختصاص داده شده}
M ; {تعداد نقاط فضای گسسته}
i , j {1,2,…,N}; {شاخص امتیازهای اختصاص یافته}
k {1,2,…,M}; {شاخص نقاط هندسی}
{فاصله اقلیدسی بین هر دو نقطه اختصاص داده شده}
{حداکثر فاصله بین نقطه تعیین شده}
{فاصله اقلیدسی بین هر نقطه هندسی و هر نقطه تعیین شده}
توجه: p k به TWSF ( β * ) تغییر یافته است.
{نزدیک بودن هر نقطه هندسی به تمام نقاط اختصاص داده شده، با پارامتر β * به حداقل رساندن آنتروپی}
معادله (19) میدان اسکالر TWC- β ، TWSF ( β * ) را می دهد که از پارامتر β * تولید می شود.
2.3. برخی از جزئیات ریاضی روش TWC-γ
TWC ( γi ) فواصل وزنی هر یک از نقاط تخصیص یافته از دیگری را تجزیه و تحلیل می کند . در واقع، TWC ( γi ) مجموعه ای از نقاط است که مرکز جرم را به هر یک از نقاط اختصاص داده شده متصل می کند. در نتیجه، هر یک از نقاط اختصاص داده شده توسط یک بردار، z ، از وزن توصیف می شود.
اجزای هر بردار مجموعه ای از نقاط TWC ( γi ) را برای هر یک از نقاط اختصاص داده شده تعریف می کنند. بنابراین، هر جزء از این مجموعه از نقاط، میانگین وزنی تمام نقاط را با توجه به مقدار فزاینده پارامتر γ ، در رابطه با هر یک از نقاط اختصاص داده شده، نشان می دهد. نقطه شروع هر TWC ( γi ) در مرکز جرم قرار دارد. اکنون آخرین TWC ( γi ) در نقطه ای خاتمه می یابد که برای هر یک از نقاط اختصاص داده شده، آنتروپی میانگین وزنی طبق رابطه (29) به حداقل برسد.
معادلات زیر الگوریتمی را نشان می دهد که TWC ( γi ) را محاسبه می کند :
{فاصله اقلیدسی بین i ام و j ام موجودیت}
{حداکثر فاصله بین نقطه تعیین شده}
{ γ- مجاورت وابسته بین i ام و j ام موجودیت}
{مختصات مرکز وزنی i-ام در مرحله t }
{آنتروپی نقطه i در مرحله t }
{نرمال سازی وزنه ها}
بنابراین TWC ( γi ) مجموعهای از مسیرها را تعریف میکند که دینامیک آنها خروجی برهمکنشهای چند به چند در میان فواصل تمام نقاط تخصیصیافته است. نقشه TWC- γ میدان اسکالر، TWSF ( β * ( γi )) است، که نزدیکی کلی هر نقطه هندسی فضای دو بعدی را به تمام این مسیرهای TWC ( γi ) اندازه میگیرد.
معادلات زیر جزئیات الگوریتم تولید میدان اسکالر TWC- γ ، TWSF ( β * ( γi ) ) را نشان می دهد:
افسانه:
N= تعداد نقاطی که تمام نقاط مسیر را تشکیل میدهند، TWC ( γi ) ، در فضای گسسته.
M= تعداد نقاط هندسی فضای گسسته.
i , j {1,2,…, N }; {شاخص برای نقاط مسیر}
k {1,2,…, M }; {شاخص نقاط هندسی}.
{فاصله اقلیدسی بین هر نقطه هندسی و هر نقطه مسیر}
{نزدیک بودن یک نقطه به نقاط مسیر، با پارامتر β * }
معادله (31) میدان اسکالر TWC- γ ، TWSF ( β * ( γi )) را می دهد که به پارامتر β * بستگی دارد.
2.4. سنتز کوتاه روش TWC
TWC ( α * ) نقطه جدیدی از فضا است که سایر نقاط تخصیص یافته (نقاط داده ورودی مورد علاقه) دارای حداقل آنتروپی با حداکثر انرژی آزاد هستند. نشان داده شده است که این نقطه منبع فرآیند پویا را نشان می دهد که زمینه وقوع نقاط مورد علاقه را فراهم می کند. این ابزار پیش بینی دارای تعدادی الگوریتم معیار است که در بخش 4 توضیح داده شده است. مجموعه نقاط متعلق به مسیر TWC ( α k )، k = 0،1،… صفحه را به یک میدان اسکالر تبدیل می کند که در آن نزدیکی هر نقطه هندسی (نقاط روی شبکه نقشه) به این مسیر قابل اندازه گیری است. . پارامتر β * مقدار بحرانی β استکه در آن آنتروپی میانگین وزنی نقاط اختصاص داده شده حداقل است و برای تعریف میدان اسکالر TWC -β ، TWSF ( β * ) استفاده می شود. احتمال انتشار را می توان با اندازه گیری شدت میدان اسکالر محاسبه کرد. احتمال انتشار احتمال وقوع یک رویداد جدید را در یک نقطه هندسی نقشه تعیین می کند. یک میدان اسکالر در فیزیک اساساً برای مرتبط کردن یک مقدار اسکالر (مانند دما یا انرژی پتانسیل الکتریکی) به هر نقطه از فضا استفاده میشود. گرادیان (یا منهای گرادیان) یک میدان اسکالر یک میدان برداری است، برای مثال، گرادیان منفی پتانسیل الکتریکی، میدان الکتریکی است. بنابراین TWSF ( β *) خاصیتی از فضا را نشان می دهد که شبیه پتانسیل الکتریکی است. ما این نقاط، مسیرها، و میدانهای اسکالر را به عنوان منابع احتمالی بیماری یا شاخصهایی برای گسترش بعدی بیماری تفسیر خواهیم کرد.
مجموعه نقاط، TWC ( γi ) ، اطلاعاتی در مورد فواصل وزنی هر یک از نقاط اختصاص داده شده از نقاط دیگر ارائه می دهد. TWC ( γi ) مجموعه ای از نقاط است که مرکز جرم را به هر یک از نقاط اختصاص داده شده متصل می کند. TWC ( γi ) را می توان برای ایجاد ماتریسی از مسیرهای غیرخطی که نقاط مورد نظر را به هم متصل می کند، استفاده کرد، که ممکن است به عنوان حرکت پویا شیوع بیماری تفسیر شود. نقاط TWC ( β * ( γi ) ) به نقشه ای تبدیل می شوند که میدان اسکالر TWSF ( β * ( γi ) است .)) اندازه گیری مجاورت کلی هر نقطه هندسی فضای دو بعدی به تمام مسیرهای TWC ( γi ) با استفاده از پارامتر β * . نقطه با حداقل آنتروپی و حداکثر انرژی آزاد ممکن است در زمینه بسیاری از کاربردها به عنوان یک نقطه قابل توجه تفسیر شود که نشان دهنده، یا می تواند به منبع یک پدیده در حال گسترش مانند یک شیوع همه گیر اشاره کند. مجموعه نقاط TWC -β و TWC- γ هنوز هیچ الگوریتم معیاری ندارند.
3. چهار بیماری همه گیر از قبل شناخته شده است
3.1. اپیدمی تب چیکونگونیا در سال 2007
تب چیکونگونیا یک بیماری ویروسی توگا است که از طریق نیش پشههای آلوده پشههای Aedes Aegypti منتشر میشود. پشه ها در آب های سطحی راکد یا ایستاده، گودال ها یا طبل های نفتی تولید مثل می کنند و با تغذیه از یک فرد بیمار آلوده می شوند. تب چیکونگونیا با درد مفاصل (آرتریت) شدید، گاهی اوقات مداوم و همچنین تب و بثورات پوستی مشخص می شود. این بیماری ناتوان کننده است اما به ندرت تهدید کننده زندگی است. این ویروس برای اولین بار بین سالهای 1952 تا 1953 از انسان و پشه در طی یک اپیدمی تب که از نظر بالینی از تب دنگی قابل تشخیص نبود در تانزانیا جدا شد.
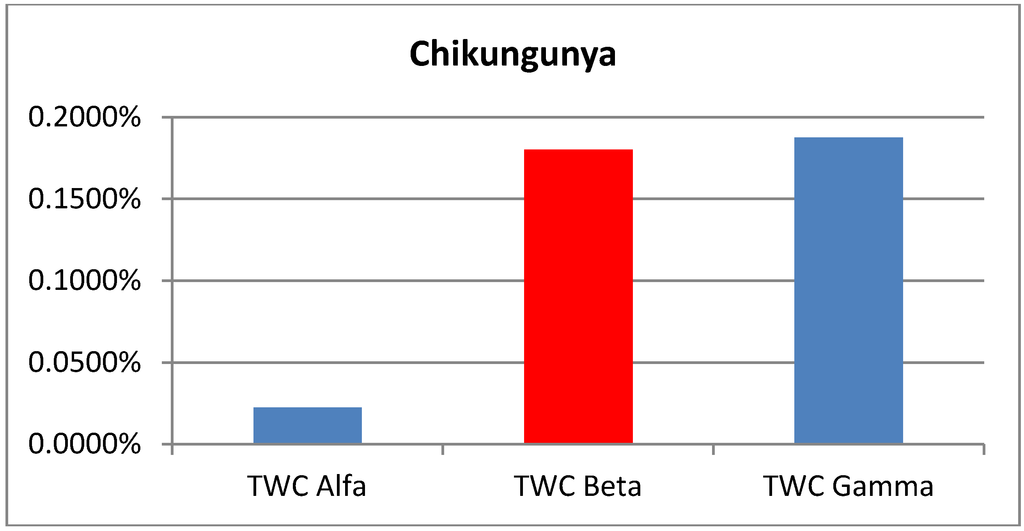
تا سال 2007، هیچ موردی در خارج از این مناطق رخ نداده بود، اما بین ژوئیه و اوت 2007، 205 مورد تب Chickungunya در اطراف دو روستای شمالی Castiglione di Cervia و Castiglione di Ravenna در شمال ایتالیا رخ داد. توپوگرافی فضایی اپیدمی شیب متحدالمرکز رو به کاهشی داشت و موارد کمتری در دورتر از کانون زلزله اتفاق افتاد. مورد احتمالی شاخص به عنوان مسافری از منطقه ای از هند شناسایی شد که در آن اپیدمی تب Chickungunya در جریان بود و بیشترین غلظت موارد به عنوان روستای Castiglione di Cervia شناسایی شد [ 9 ]. ما از مختصات نقاط مربوط به وضعیت شیوع در مرحله پایانی توسعه استفاده کرده ایم.
3.3. اپیدمی وبا میدان طلایی در سال 1854
جان اسنو (1813-1858)، یک پزشک لندنی بود که به عنوان بخشی از یک مطالعه گسترده تر به بررسی اپیدمی وبا در سال 1854 در اطراف منطقه خیابان Berwick در سوهو پرداخت تا فرضیه خود را آزمایش کند که وبا به جای آنطور که اکثراً معتقد بودند در هوا منتقل می شود، از طریق آب منتقل می شود. اسنو همچنین بر این باور بود که ناقل انتقال یا تماس شخصی با یک فرد آلوده یا نوشیدن آب آلوده است که در آن مقداری “سم بیمارگونه” منتقل شده است. او دو مطالعه جداگانه انجام داد. یکی ارتباط بین منابع آب و بروز وبا در جنوب لندن را در نظر گرفت و دیگری شیوع محلی در منطقه سوهو لندن را بررسی کرد.11 ].
این اپیدمی منبع نقطه ای معروف (بخشی از یک اپیدمی منبع منتشر شده در حال انجام) توسط اسنو که با ساکنان محلی صحبت کرد و تحقیقات خانه به خانه انجام داد، به طور مفصل مورد بررسی قرار گرفت، بنابراین داده ها را برای ایجاد نقشه نقطه ای برای نشان دادن چگونگی موارد وبا جمع آوری کرد. در مرکز پمپ او از میلهها برای نشان دادن مرگهای رخ داده در خانوارهای مشخص شده استفاده کرد و با وزندهی به تراکم این میلهها و ربط دادن آنها به فاصله پمپهای محله، توانست پمپ خیابان براد را به عنوان منشأ شیوع شیوع وبا تأیید کند. استفاده اسنو از نقشه معروفش به جای اثبات تاییدی بود، زیرا او نظریه اساسی متمرکز را برای توضیح گسترش وبا که در آب به وجود آمده بود توضیح داده بود [ 12 ].
تأیید تصویری کامل ارتباط بین آبریز نزدیک شماره 40 و چاه پمپ مجاور در آوریل 1855، چهار ماه پس از انتشار کتاب کلاسیک اسنو در مورد نحوه ارتباط وبا، پس از حفاری کامل حوضچه توسط محله ارائه شد. شورا. به نظر میرسد که مورد شاخص با والدینش در شماره 40 زندگی میکرده و مادرش (سارا لوئیس) پوشک کودک بیمار را در حفره آب میشوید و اجازه میداد ویبریوها از طریق ارتباط بین مخزن و چاه پمپ وارد منبع آب شوند. . علیرغم تلاش های مذبوحانه اسنو، در بازه زمانی 19 مرداد تا 31 اوت (آغاز اپیدمی میدان طلایی)، 73 مورد وبا و 12 مورد مرگ به ثبت رسید.
کشف هوشمندانه شیوع اپیدمی وبا قبلاً با ریاضیات و آمار مدرن درمان شده است [ 1 ، 6 ].
نقشه دیجیتال از 578 مکان (ساختمان) و سه تکرار تشکیل شده است که ما تصمیم گرفته ایم آنها را از مجموعه داده حذف نکنیم. مجموعه داده ها وضعیت نهایی تکامل اپیدمی های وبا را منعکس می کند.
3.4. آنفولانزای روسی در سوئد در 1889-1890
در سال 1890، بلافاصله پس از شیوع آنفولانزای روسی، از همه پزشکان سوئدی خواسته شد تا اطلاعاتی در مورد شروع و اوج همه گیری و تعداد کل موارد در منطقه خود ارائه دهند و پرسشنامه ای در مورد تعداد، جنسیت و جنسیت پر کنند. سن افراد مبتلا در خانواده هایی که از آنها بازدید کردند.
پاسخ های کلی در مورد همه گیری از 398 پزشک دریافت شد و داده های مربوط به بیماران فردی برای بیش از 32600 نفر در دسترس بود. از پاسخها، جدولی جمعآوری شد و نقشهای در سال 1890 ترسیم شد که نشان میدهد اولین بار چه زمانی آنفولانزا در مکانهای مختلف ظاهر شد. برای حمایت از نظریه سرایت، تحلیلی از شبکه راه آهن در رابطه با شروع شیوع انجام شد. در هفته اول دسامبر 1889، 12 مکان از 13 مکان تحت تأثیر خارج از استکهلم دارای ایستگاه راه آهن بودند. لینروث نشان داد که تا 20 دسامبر، 82 درصد از مکانهای گزارشدهنده دارای ایستگاه راهآهن و 47 درصد بدون ایستگاه تحت تأثیر قرار گرفتهاند [ 13 ].
انتشار بسیار سریع بود و اپیدمی های محلی با سرعتی توسعه یافتند که در برخی موارد انفجاری توصیف می شد. با توجه به حساسیت عمومی، زمان کم نهفتگی و دشواری تشخیص اولین موارد، برای تأیید علمی اینکه آنفلوآنزا واقعاً مسری است، به شواهد بیشتری نیاز بود.
با این حال، لینروث بر این عقیده بود که بسیاری از شواهد فردی که چگونگی انتقال مستقیم عفونت از افراد آلوده را توضیح میدهند، این فرضیه را توجیه میکنند: آنفولانزا یک بیماری مسری است.
در یک مطالعه اخیر GIS [ 13 ]، جداول اصلی Linroth به فرمت Excel و نقشه های نقطه ای تبدیل شدند.
ما روی نقاط هفته سوم با استفاده از مختصات نقاط مربوط به 44 مکان مورد علاقه با شیوع در هفته سوم کار کرده ایم، مرحله اولیه تکامل در شرایط زمانی (تعداد موارد در هر مکان) اما نه از نظر توپولوژیکی ( تعداد مکان هایی با حداقل یک مورد).
4. الگوریتم های مورد استفاده برای مقایسه با TWC- α
این دسته از الگوریتمها تنها بر متریک فضا، DN و شکل تابع فاصله فروپاشی، F ( DN ) و مجموع به عنوان تابع ترکیب، S ، بدون فرضیات خاص در مورد عوامل دیگر تمرکز میکنند. به دنبال این رویکرد، نقطه لنگر، Y * ، در منطقه ای با “امتیاز ضربه” بالا قرار دارد [ 14 ]:
این رویکردها تمایل دارند که احتمال شیوع هر نقطه از شبکه – در داخل بدنه محدب مکانهای مشاهدات – را مشخص کنند. در نتیجه، استراتژی توزیع احتمال، ناحیه جستجویی را تعریف میکند که نقاط آن احتمال بالایی دارند که نقطه شیوع باشند [ 1 ، 14 ].
4.1. الگوریتم Rossmo
الگوریتم Rossmo [ 5 ، 6 ] از فاصله بلوک (منهتن) استفاده می کند. از چهار پارامتر رایگان استفاده می کند که هر کدام باید به صورت تجربی با توجه به موقعیت کالیبره شوند. این الگوریتم مخصوص یافتن نقطه لنگر در جنایات سریالی است. ما چهار پارامتر و معیارهای آن را برای اعمال آن در زمینه ردیابی بیماری های همه گیر تطبیق دادیم. معادلات Rossmo به شرح زیر است:
جایی که: d = فاصله بین نقاط، در هر متریک. B = قطر منطقه حفاظتی، در صورت وجود. g و h = توانهای حاکم بر رقابت بین فاصله فروپاشی بین نقاط و منطقه حفاظتی.
جمله اول معادله از گرانش نیوتنی الهام گرفته است. کل معادله فرمولبندی مدل منطقه جستجوی Brantingham و Brantingham [ 15 ، 16 ] را نشان میدهد که در آن رفتار جستجوی مجرم بهعنوان تابع کاهش فاصله با کاهش فعالیت در نزدیکی پایگاه اصلی مجرم دیده میشود. Rossmo نمونه هایی تولید کرده است که نشان می دهد چگونه می توان این مدل را برای مجرمان زنجیره ای اعمال کرد [ 17 ]. برای هر دو تابع “درون منطقه بافر” (نزدیک به پایه اصلی، کنترل شده توسط پارامتر ” B “) و “منطقه بافر خارج” (دور از پایه اصلی)، پارامتر ” k ” و توانگرهای ” h ” و ” g “” به صورت تجربی تعیین می شوند.
4.2. الگوریتم جمع نمایی منفی (NES)
الگوریتم NES [ 1 ] از مفهوم بافر مدل Rossmo و نمایی منفی کانتر [ 18 , 19 , 20 , 21 , 22 ] استفاده می کند و آنها را در معادلات زیر ترکیب می کند:
جایی که: φ = قدرت اتصال بین نقاط. d = فاصله بین نقاط، در هر متریک. ب = قطر منطقه حفاظتی در صورت وجود. g و h = نماهای حاکم بر رقابت بین فاصله فروپاشی بین نقاط و منطقه حفاظتی.
هنگامی که ” h ” و ” g ” به درستی تنظیم شوند ( h = 0.05 و g = 0.01)، الگوریتم NES ثابت کرده است که نسبت به توزیع مکان های مشاهده شده بسیار حساس است [ 23 ، 24 ].
4.3. الگوریتم حداکثرسازی واریانس احتمال (LVM)
الگوریتم LVM [ 1 ] از تکنیک حداکثر احتمال الهام گرفته شده است که اولری به عنوان یک مدل ضعیف به نفع رویکرد بیزی ارائه و رد می کند [ 25 ]. اما نقطه قوت این تکنیک ساده تابع هزینه است: ما سعی می کنیم واریانس احتمال را در بین تمام نقاط عملیاتی کاندید با استفاده از یک فرآیند تکرار شونده به حداکثر برسانیم:
σ و σ * = عرض (و عرض بهینه) زنگ تابع واپاشی و σ * = عرض (و عرض بهینه) زنگ تابع واپاشی.
الگوریتم LVM دو مزیت اصلی دارد: نیازی به تنظیم پارامترهای خارجی ندارد و بر اساس نظریه بیزی است.
4.4. الگوریتم احتمال مکزیکی (Mex Prob)
الگوریتم MexProb [ 4 ] برای مدیریت تنها در یک معادله تمام پارامترهای معمولاً در الگوریتمهای تئوری مکان ایجاد شد:
φ = قدرت اتصال بین نقاط.
d = فاصله بین نقاط، در هر متریک.
ب = قطر منطقه حفاظتی در صورت وجود.
σ و σ * = عرض (و عرض بهینه) زنگ تابع واپاشی.
علاوه بر این، الگوریتم MexProb، تمام این پارامترها را به خودی خود، با به حداکثر رساندن واریانس میدان اسکالر خود، به طور مکرر کالیبره میکند:
5. نتایج
5.1. نتایج مقایسه چهار الگوریتم با TWC
TWC ( α * ) و به ویژه TWFS (αn ) در این مقایسه در نظر گرفته شدهاند، زیرا برای تخمین شیوع یک توزیع نقطه بسیار مفید هستند .
همانطور که اشاره کردیم سایر الگوریتم هایی که در این بنچمارک در نظر گرفته شده اند عبارتند از:
-
الگوریتم Rossmo [ 5 , 6 ]
-
-
-
این آزمایش با استفاده از همان بسته نرم افزاری [ 26 ] انجام شد.
علاوه بر این، ما چهار شاخص مختلف را برای مقایسه این چهار الگوریتم با TWC در نظر گرفتهایم:
-
فاصله پیک هر الگوریتم تا شیوع واقعی به صورت زیر محاسبه شده است: اساساً فاصله نسبی است و نسبت به قطر اصلی شبکه پنجره تولید شده توسط نرم افزار به صورت درصد محاسبه می شود. برای هر توزیع داده (مجموعه داده) نرم افزار ما یک نقشه شبکه ای با ابعاد 600 × 600 پیکسل ترسیم می کند که در آن همه نقاط در یک پنجره فرعی 500 × 500 پیکسل جاسازی شده اند.
-
حساسیت به عنوان مقدار نقطه میدان اسکالر هر الگوریتم (هر مقدار پیکسل میدان اسکالر تولید شده توسط هر الگوریتم بین 0 و 1 مقیاس بندی می شود) در محلی که شیوع واقعی در آن قرار دارد، تعریف می شود. ویژگی به عنوان مقدار درصد تعداد نقاط کل پنجره تعریف می شود که مقدار آن کوچکترین مقادیر حساسیت هر الگوریتم است.
-
ناحیه جستجویی که در آن شیوع واقعی در میدان اسکالر هر الگوریتم یافت می شود به صورت زیر تعریف می شود: ما میدان اسکالر تولید شده توسط هر الگوریتم را در 20 سطل با طول مساوی تقسیم کرده ایم و سپس وسعت ناحیه ای را که در آن قرار دارد محاسبه می کنیم. شیوع واقعی را شامل می شود. در نهایت مقدار این bin area را در رابطه با مساحت پنجره جهانی بیان می کنیم.
-
جدول 1 ، جدول 2 ، جدول 3 ، جدول 4 نتایج تحلیلی مقایسه را نشان می دهد در حالی که جدول 5 میانگین رتبه ای را که هر الگوریتم در هر آزمون انجام داد را نشان می دهد. پیوست E نقشه های پیش بینی شده توسط هر الگوریتم برای هر بیماری همه گیر را نشان می دهد.
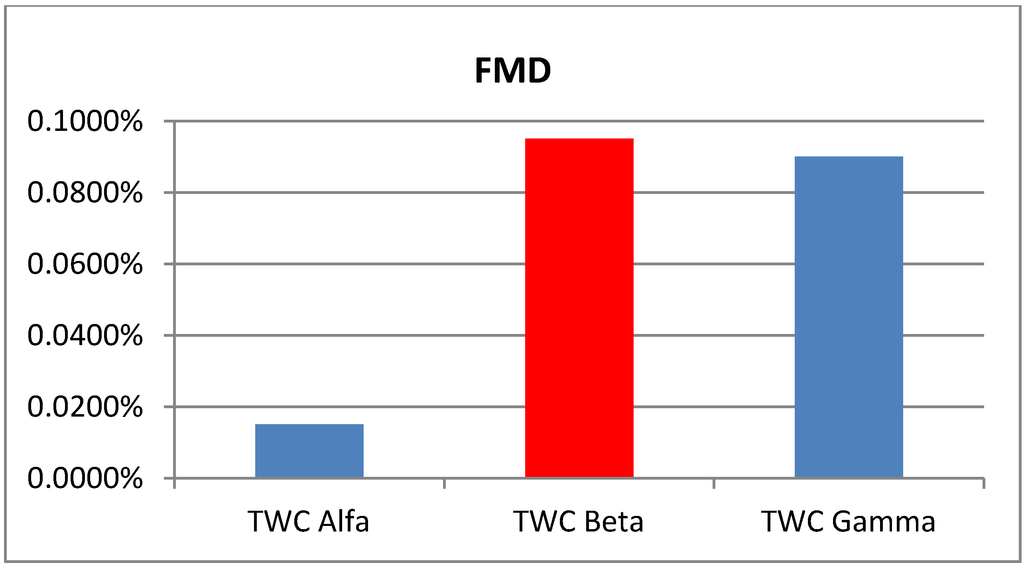
جدول 1. نتایج بیماری پا و دهان.
جدول 2. نتایج تب چیکونگونیا.
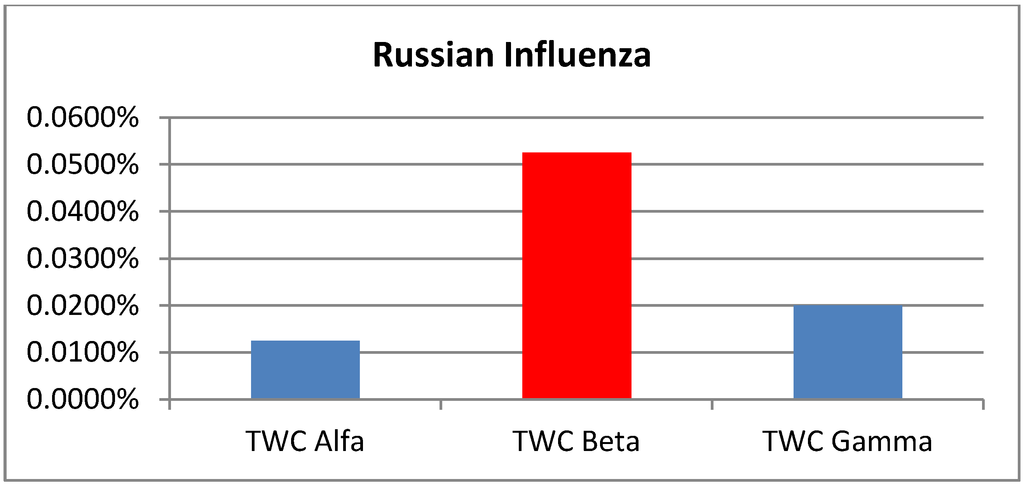
جدول 4. نتایج آنفولانزای روسی.
جدول 5. میانگین رتبه هر الگوریتم در چهار آزمون.
این نتایج مقایسه با توجه به “منطقه جستجو” به عنوان شاخص کلیدی برای رتبه بندی عملکرد الگوریتم ها، همانطور که اخیراً توسط برخی از نویسندگان توصیه شده است، ارائه شده است [ 19 ]. استفاده از این معیار TWC بهتر از هر چهار الگوریتم دیگر به خصوص در 3 مورد از 4 تست عمل می کند. اما همچنین سایر شاخصهایی که معرفی کردهایم مرتبط هستند و همیشه با «منطقه جستجو» همبستگی ندارند.
فاصله از شیوع (r) یک معیار معیوب نیست [ 6 ]. این دایرهای به شعاع «r» را توصیف میکند که ناحیه آن یک « منطقه جستجو » معنیدار را توصیف میکند و پیوند دلخواه به «استراتژی binning» انتخاب شده توسط محققان ندارد. منطقه جستجو در واقع ممکن است اندازه های متفاوتی را در رابطه با تقسیم بندی باینینگ میدان اسکالر داشته باشد.
“حساسیت” نشان می دهد که هر الگوریتم چقدر موقعیت شیوع واقعی را “محل داغ” در نظر می گیرد. به عبارت دیگر، منطقه جستجو می تواند کوچک باشد اما موقعیت واقعی شیوع واقعی مکانی با مقدار احتمال بالا در نظر گرفته نمی شود. نگاهی به مورد “بیماری پا و دهان”، که در آن همه الگوریتم های آزمایش شده، به جز TWC ( α )، عدم وجود مقادیر بسیار بالا را در محلی که شیوع واقعاً در آن قرار دارد، نشان می دهد.
“ویژگی” یک شاخص اساسی برای درک صدکی است که در آن شیوع واقعی واقع شده است. در مورد “آنفولانزای روسی”، الگوریتم Rossmo در رابطه با روشهای دیگر کاملاً عمومی است: حساسیت خوب، اما کمترین ویژگی.
در پایان این مقایسه می توان مشاهدات زیر را اضافه کرد:
-
همه الگوریتم ها در هر یک از پنج تست (این چهار مورد به اضافه E-coli) نسبتاً خوب عمل کرده اند. این بدان معناست که پایه آنها مستحکم و محکم است.
-
نتایج TWC ( α ) به طور قابل توجهی نشان داده است که این روش نسبت به سایر الگوریتمها مؤثرتر است (در بیشتر موارد منطقه جستجوی آن یک مرتبه قدر کوچکتر از ناحیه جستجوی سایر الگوریتمها است).
-
بدیهی است که برای ارزیابی عملکرد هر الگوریتمی که به نمایه جغرافیایی اختصاص داده شده است، نیاز به ایجاد بیش از یک شاخص داریم. در این زمینه تحقیقات روششناختی همچنان باز است و امیدواریم بتوانیم در آینده نزدیک سهمی را ارائه دهیم.
-
فقط TWC ( α ) در این مقایسه مورد آزمایش قرار گرفت. سایر کمیت های تولید شده توسط الگوریتم TWC – TWC ( β ) و TWC ( γi ) – انواع مختلفی از اطلاعات کلیدی را در مورد پویایی فرآیند ارائه می دهند که هیچ یک از الگوریتم های موجود در این لحظه نمی تواند ادعا کند.
6. یک مورد خاص از شیوع همه گیر: اپیدمی های HUS آلمان در ماه مه تا ژوئن 2011
6.1. مجموعه داده آلمانی
از اوایل ماه مه 2011 تعداد بسیار زیادی از موارد سندرم اورمیک همولیتیک (HUS) در آلمان مشاهده شده است. HUS یک عارضه جدی و گاه کشنده است که می تواند در عفونت های روده ای باکتریایی با شیگا توکسین (Syn. verotoxin) ایجاد کننده اشریشیا کلی رخ دهد. STEC/VTEC). تصویر بالینی کامل HUS با نارسایی حاد کلیه، کم خونی همولیتیک و کاهش تعداد پلاکت های در گردش (ترومبوسیتوپنی) مشخص می شود. معمولاً قبل از آن اسهال وجود دارد که اغلب خونی است. طبق آماری که هر ساله توسط موسسه رابرت کخ ایجاد می شود، به طور متوسط هزار مورد عفونت STEC علامت دار و تقریباً شصت مورد HUS در آلمان گزارش می شود که بیشتر کودکان خردسال زیر پنج سال را تحت تاثیر قرار می دهد [ 27 ].]. در سال 2010 دو مورد مرگبار HUS وجود داشت [ 28 ]. STEC منشاء مشترک بین انسان و دام است و می تواند به طور مستقیم یا غیر مستقیم از حیوانات به انسان منتقل شود.
نشخوارکنندگان به ویژه گاو، گوسفند و بز مخزن آن محسوب می شوند. انتقال از طریق مدفوع-دهانی از طریق تماس با حیوانات (یا مدفوع آنها)، مصرف غذا یا آب آلوده یا از طریق تماس مستقیم از فردی به فرد دیگر (عفونت اسمیر) صورت می گیرد. دوره نهفتگی STEC بین دو تا ده روز با دوره نهفتگی از شروع علائم گوارشی تا HUS انتروپاتیک تقریباً یک هفته است.
جدول 7 تعداد موارد HUS یا HUS مشکوک را فهرست می کند که به ادارات بهداشت محلی اطلاع داده شده و توسط ایالت های فدرال به موسسه رابرت کخ (RKI) تا 26 مه 2011 ابلاغ شده است.
جدول 7. فهرست تعداد موارد HUS یا سندرم همولیتیک اورمیک مشکوک (HUS) [ 27 ، 28 ].
HUS مشکوک شامل می شود زیرا سندرم یک فرآیند است و HUS مشکوک معمولاً در طی چند روز به تصویر بالینی کامل تبدیل می شود. شروع بیماری (به ویژه اسهال) در 214 بیمار بین 2 و 24 می 2011 شناسایی شد. در مجموع 119 (56٪) از موارد گزارش شده از چهار ایالت فدرال شمالی (هامبورگ، شلزویگ-هولشتاین، نیدرزاکسن و برمن) بودند. بیشترین میزان بروز تجمعی در دو ایالت شمالی هامبورگ و برمن ثبت شد. 31 مورد دیگر در هسن رخ داده است. موارد ابتلا به این بیماری از ابتدای ماه مه شروع شد و شیوع این بیماری در سه هفته بعد به سطح بحران رسید و شهر هامبورگ در مرکز آن قرار داشت. آنها در ابتدا به یک شرکت پذیرایی متصل بودند که کافه تریاهای یک شرکت و یک موسسه مسکونی را تامین می کرد. علاوه بر خوشه بندی جغرافیایی، توزیع سنی و جنسیتی موارد مشهود است: از 214 مورد، 186 مورد (87%) 18 سال یا بیشتر (عمدتا بزرگسالان جوان تا میانسال) و 146 (68%) زن هستند. . در داده های اطلاع رسانی برای موارد HUS از سال 2006 تا 2010، نسبت بزرگسالان بین 1.5٪ تا 10٪ سالانه بود و جنسیت ها به همان اندازه تحت تأثیر قرار گرفتند.
موارد مرتبط با این شیوع از دیگر کشورهای اروپایی نیز بود: در 25 مه 2011، سوئد از طریق سیستم هشدار و پاسخ اروپایی (EWRS) 9 مورد HUS را گزارش کرد که چهار نفر از آنها در یک مهمانی 30 نفره به شمال آلمان از 8 تا 8 سفر کرده بودند. 10 می. دانمارک چهار مورد عفونت STEC را گزارش کرد که دو مورد از آنها با HUS بودند. همه موارد سابقه سفر اخیر به شمال آلمان داشتند. دو مورد دیگر HUS با سابقه سفر به شمال آلمان در دوره مربوطه، هر کدام توسط هلند و بریتانیا ارسال شد.
در طول شیوع، توضیحات و فرضیههای مختلفی در مورد منبع شیوع بیماری همهگیر گزارش شد که تأثیر شدیدی بر افکار عمومی داشت. نتایج اولیه یک مطالعه مورد-شاهدی که توسط مقامات بهداشتی هامبورگ انجام شد، ارتباط معنیداری بین بیماری و مصرف گوجهفرنگی خام، خیار و سالاد برگدار را نشان میدهد و توجه در منطقه هامبورگ به دلیل تراکم بیشتر موارد معطوف شد. دو هفته بعد، جوانه های آلوده سویا مشکل اصلی در نظر گرفته شد و یک شرکت در Uelzen، شهری واقع در 100 کیلومتری جنوب هامبورگ، منبع اصلی مشکوک عفونت شد. این شرکت محصولات خود را بیشتر در آلمان به فروش می رساند اما محصولات خود را به سایر کشورهای اروپایی و برخی کشورهای آسیایی نیز صادر می کند.
در 18 ژوئن 2011 منبع شیوع بیماری همه گیر پیدا شد. سویه مرگبار 0104:H4 E. coli که جان نزدیک به 40 آلمانی را گرفت در شامگاه 17 ژوئن 2011 در شمال شرقی فرانکفورت در رودخانه ارلنباخ پیدا شد. وزارت محیط زیست ایالت هسن گفت که نظریه های مختلفی وجود دارد. در مورد چگونگی ورود E. coli به رودخانه، اگرچه یک نمونه آزمایشی از یک کارخانه فاضلاب مجاور گرفته شد. در حالی که چنین گیاهانی به طور کلی استانداردهای بهداشتی بسیار بالایی دارند، مقامات گفتند که نمی توان این را به عنوان یک منبع احتمالی رد کرد.
لازم به ذکر است که در ماه می 2011 اطلاعات مربوط به موقعیت جغرافیایی پرونده های ثبت شده به طور رسمی در دامنه های وب سایت عمومی در دسترس نبود. نویسندگان اطلاعات محرمانه ای را در مورد داده های GPS 13 مکان اول با حداقل یک مورد اثبات شده HUS در 30 مه از شخصی که در آن زمان در یک کنگره اپیدمیولوژی سمیت زیست محیطی در اروپا شرکت می کرد و با اپیدمیولوژیست های آلمانی در تماس بود دریافت کردند. شیوع. جدول 8 فهرست مکان ها را نشان می دهد.
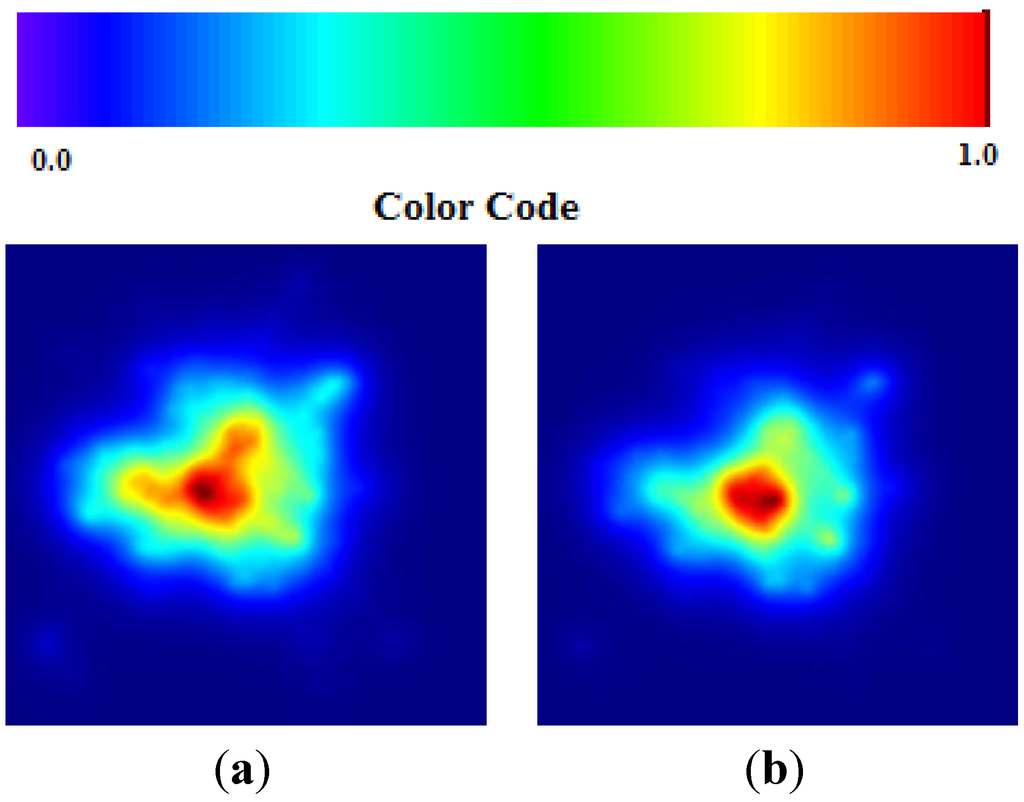
لازم به ذکر است که مختصات جغرافیایی به طور خاص به یک شهر درگیر اشاره نمی کند، بلکه به مرکز منطقه درگیر اشاره دارد. تنها 3 مکان از 13 مکان مطابقت دقیق با رویدادهای واقعی است. شکل 9 (الف) 13 مکان را در نقشه مصنوعی ما نشان می دهد. تنها داده هایی که برای هر مکان در نظر می گیریم، طول و عرض جغرافیایی است، 26 عدد برای کل مطالعه. شکل 9 (ب) در عوض، همان نقشه را با در نظر گرفتن فراوانی موارد مشکوک در 13 شهر در زمان جمع آوری این داده ها نشان می دهد.
جدول 8. موقعیت جغرافیایی 13 شهر/منطقه اول با حداقل یک مورد HUS.
شکل 9. ( الف ) طول و عرض جغرافیایی 13 شهر اول آلمان. ( ب ) تعداد موارد مشکوک در 13 شهر اول آلمان.
6.2. روش TWC-α و شیوع واقعی
نقاط TWC ( α ) از مرکز جرم شروع می شود و به مجاورت فرانکفورت ختم می شود، که ما آن را به عنوان منبع شیوع در نظر گرفتیم ( شکل 10 (الف، ب) را ببینید). به خواننده یادآوری می کنیم که تعداد موارد (فرکانس) در هر مکان به هیچ وجه توسط الگوریتم در نظر گرفته نمی شود. الگوریتم TWC تنها با در نظر گرفتن هندسه توزیع 13 مکان کار می کند.
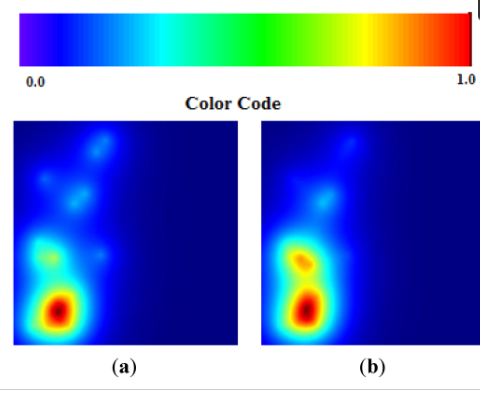
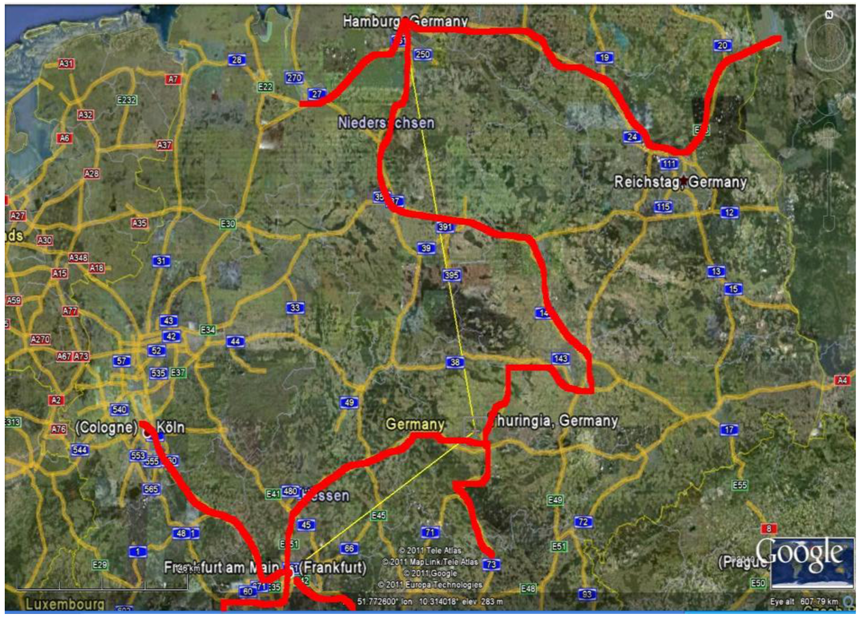
شکل 10. ( الف ) TWC ( α * ) به شیوع نزدیک به فرانکفورت اشاره می کند. ( ب ) میدان اسکالر αn ، TWSF ( αn ) .
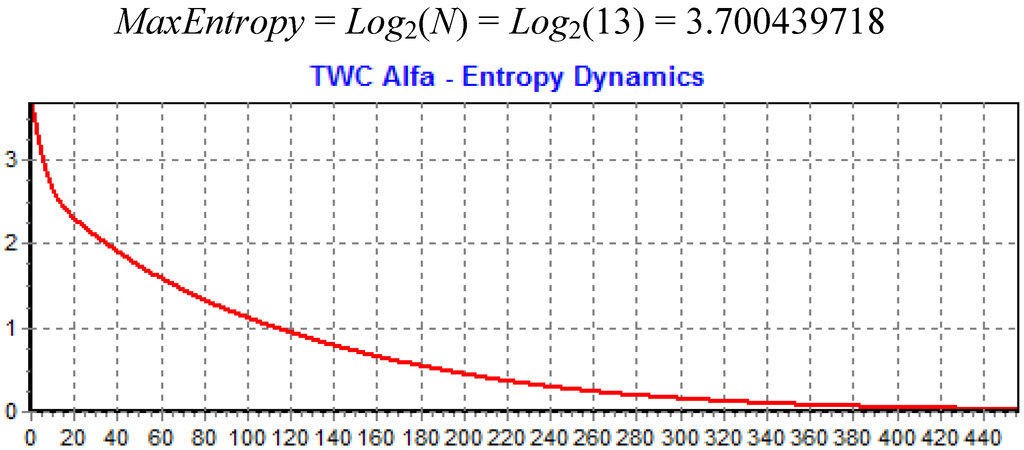
مرکز جرم نقطهای است که مجذور فواصل آن از سایر مکانهای شیوع حداقل است و همچنین نقطه تعادل نقشه است. به عبارت دیگر، مرکز جرم، موقعیت نقشه است که از آن آنتروپی توزیع سایر مکان ها بالاتر است. بنابراین با نگاه کردن به نقشه از این موقعیت، مکان های دیگر به عنوان بی نظم ترین توزیع ممکن ظاهر می شوند. با این حال، TWC ( α ) نقطه ای را در نقشه مشخص می کند که آنتروپی توزیع نقطه در آن کمترین است. یعنی از موقعیت TWC ( α ) 13 مکان دیگر بالاترین مقدار قابل پیش بینی را دارند، بیشترین مرتبه را. به عبارت دیگر، اگر خود را در TWC قرار دهیم ( α) طول و عرض جغرافیایی، هر مکان دیگر از نقشه قابل پیش بینی است. شکل 10 (الف) همچنین مسیر یافت شده توسط الگوریتم را از مرکز جرم تا نقطه شروع تخمینی اپیدمی نشان میدهد، شکل 10 (ب) میدان اسکالر نقاط αn ایجاد شده با روش TWC ( α ) را نشان میدهد. در حالی که شکل 11 پویایی کاهش آنتروپی سیستم را در طول این فرآیند جستجو نشان می دهد.
شکل 11. کاهش آنتروپی در طول جستجوی TWC ( α ).
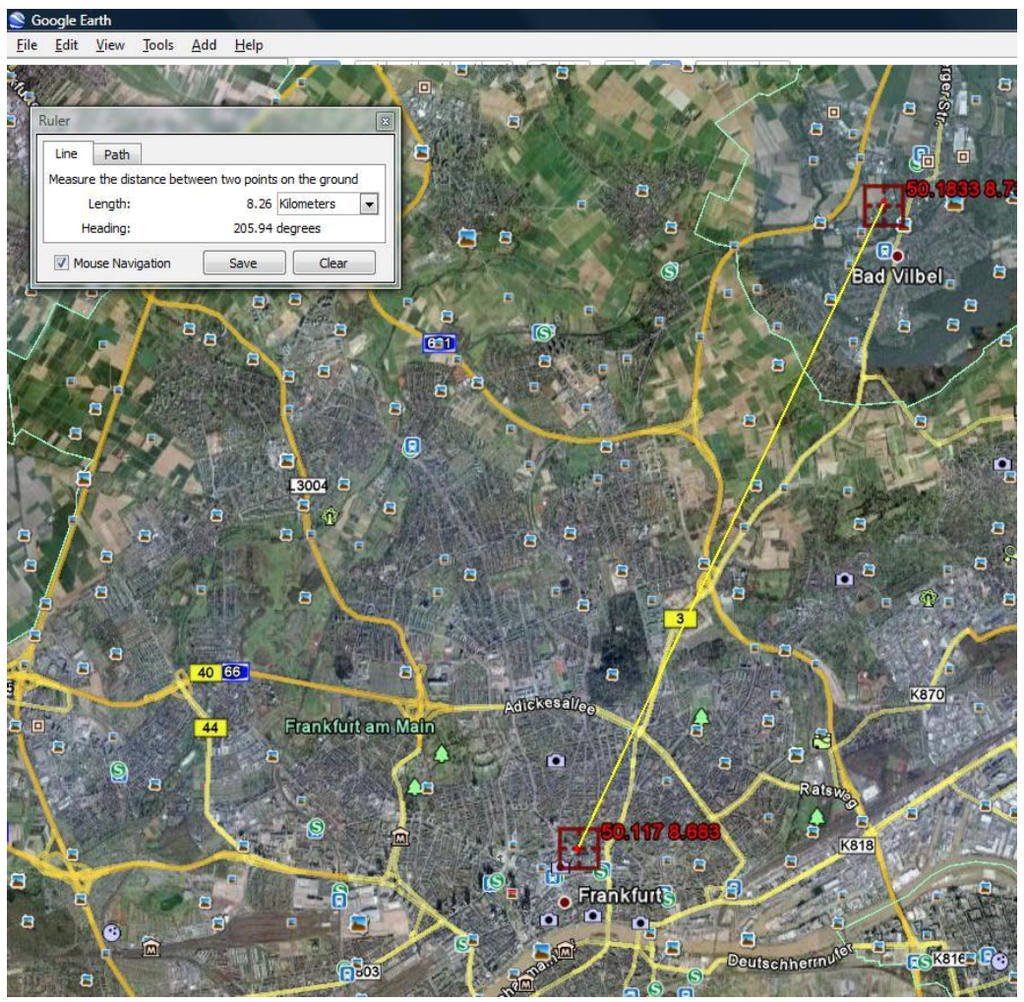
با استفاده از Google Earth، مکان های فیزیکی نقطه TWC ( α ) را پیدا کردیم. شکل 12 فاصله آن را از ارلنباخ نشان می دهد.
شکل 12. TWC ( α )، منبع شیوع احتمالی، در Google Earth در Long 8.683 و Lat 50.117 و فاصله آن از جریان Erlenbach.
الگوریتم TWC- α در 29 می 2011 در دانشگاه کلرادو-دنور پیدا شد، در حالی که شیوع اپیدمی HUS به طور عمومی توسط مقامات آلمانی در فرانکفورت در نظر گرفته نشد. تنها در 18 ژوئن 2011 مقامات آلمانی فرانکفورت را به عنوان دومین منبع شیوع بیماری معرفی کردند. اگر نتایج این الگوریتم توسط اپیدمیولوژیست های آلمانی در 29 مه “یک نظر دوم احتمالی” در نظر گرفته می شد، ممکن بود یک استراتژی پیشگیری 20 روز قبل از اعلام رسمی آغاز شود.
6.3. نقشه TWC-β
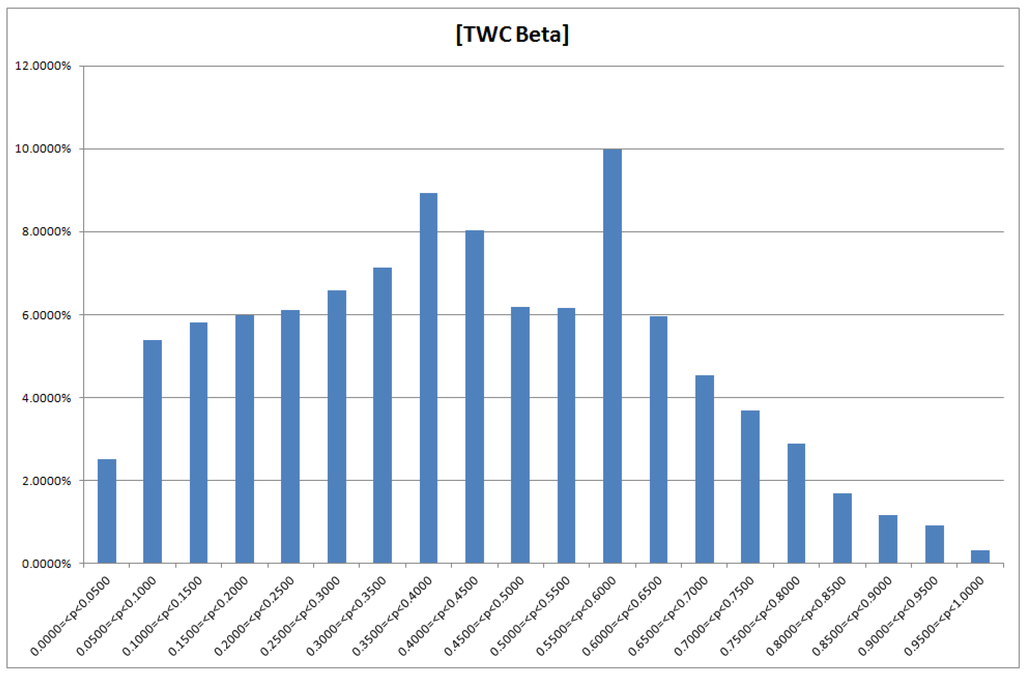
الگوریتم TWC -β احتمال توزیع فرآیند اپیدمی را در زمان جمع آوری داده ها نشان می دهد. شکل 13 نقشه اپیدمی ها را نشان می دهد که به دو خوشه تقسیم شده اند. خوشه هامبورگ، در شمال آلمان، و خوشه فرانکفورت، در مرکز آلمان. هر خوشه از چندین ناحیه تشکیل شده است که هر چه رنگ قرمز تیره تر و شدیدتر روی نقشه باشد، احتمال انتشار بیشتر است.
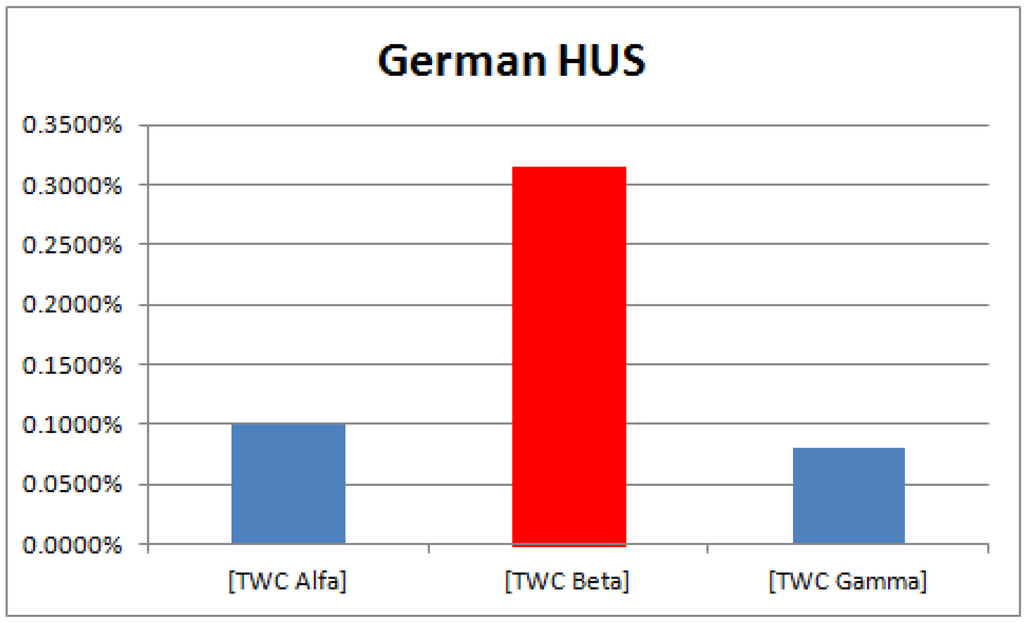
شکل 13. میدان اسکالر TWC -β ، TWSF ( β * ) – هر چه قرمز عمیق تر باشد، غلظت اپیدمی ها بیشتر است (منطقه قرمز عمیق حدود 3/1000 کل منطقه را نشان می دهد).
الگوریتم TWC -β اطلاعات بسیار جالبی را ارائه می دهد:
-
احتمال بیشتر انتشار اپیدمی ها (p > 0.95) ناحیه ای است که 0.32٪ از کل مساحت نقشه را نشان می دهد ( شکل 14 را ببینید ). 66 درصد از این منطقه در اطراف فرانکفورت است، در حالی که 34 درصد در خوشه هامبورگ است. شدت میدان اسکالر به 20 سطح تقسیم شد. بیستمین ناحیه ای است که شدت آن در آن بیشتر است، بنابراین احتمال رویدادهای جدید باید بیشتر باشد (p> 0.95).
شکل 14. احتمال اپیدمی در نقشه TWC -β ، در رابطه با مناطق جهانی نقشه (20 سطل).
این بدان معناست که طبق الگوریتم TWC -β ، انتشار سریع و شدید اپیدمی در خوشه فرانکفورت اتفاق میافتد، در حالی که انتشار وسیع و گسترده همان اپیدمی در خوشه هامبورگ اتفاق میافتد. این پیشبینی «غیر زمانی» معنیدار است زیرا نقشه رنگی TWC -β (نگاه کنید به شکل 13 ) دقیقاً تعداد موارد را در لحظه جمعآوری دادهها منعکس میکند ( جدول 7 را ببینید ، و ما توجه میکنیم که الگوریتم اینطور نیست و فراوانی موارد را برای ایجاد نقشه در نظر نگرفت).
با استفاده از روششناسی متفاوت و دادههای متفاوت، در فضا و زمان، یک مقاله تحقیقاتی اخیر [ 29 ] شبکه انتشار اپیدمی HUS را نشان میدهد. این شبکه همچنین به دو مرکز مستقل تقسیم شده است که از زمان شیوع تخمینی شروع می شود. حتی اگر کسی فکر کند که پیشبینیهای شیوع در این مورد اشتباه بوده است، فرضیه دو خوشه مستقل برای توضیح پویایی HUS با روشهای ما به درستی به دست آمد. به عبارت دیگر، الگوریتم TWC -β تنها با استفاده از طول و عرض جغرافیایی 13 مکان اولی که اپیدمی HUS مشاهده شد، یک نقشه احتمال مناسب از انتشار HUS را چند روز قبل از اعلام دو مکان شیوع، بازسازی کرد.
6.4. نقشه TWC-γ
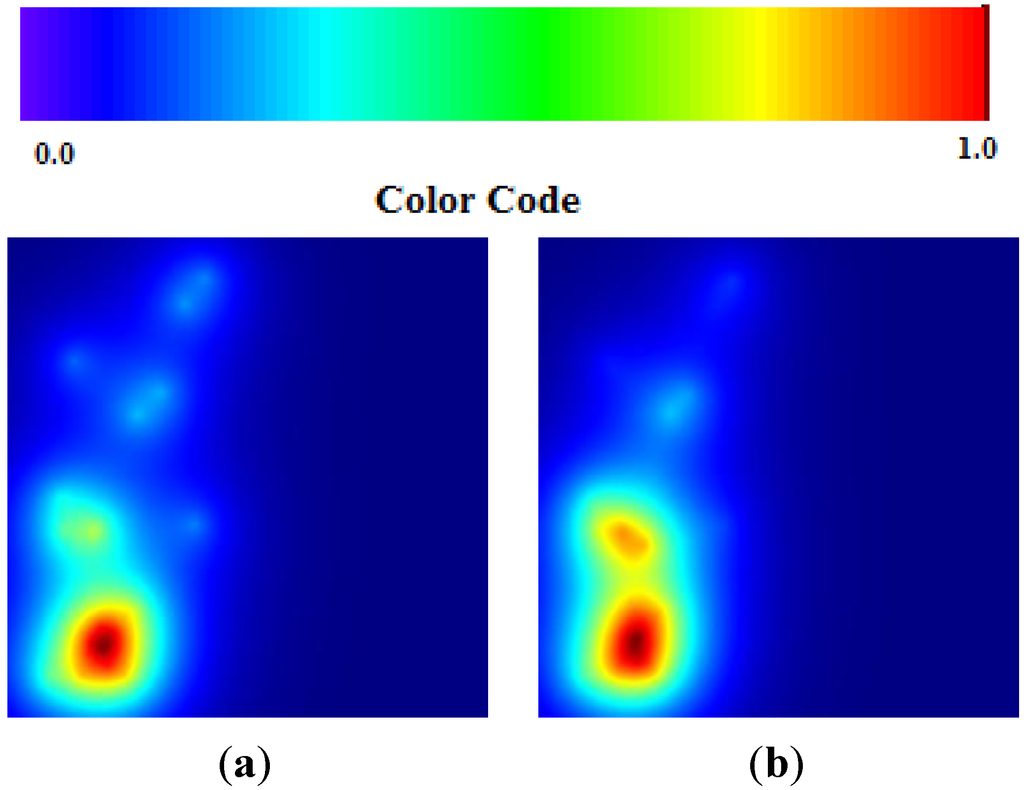
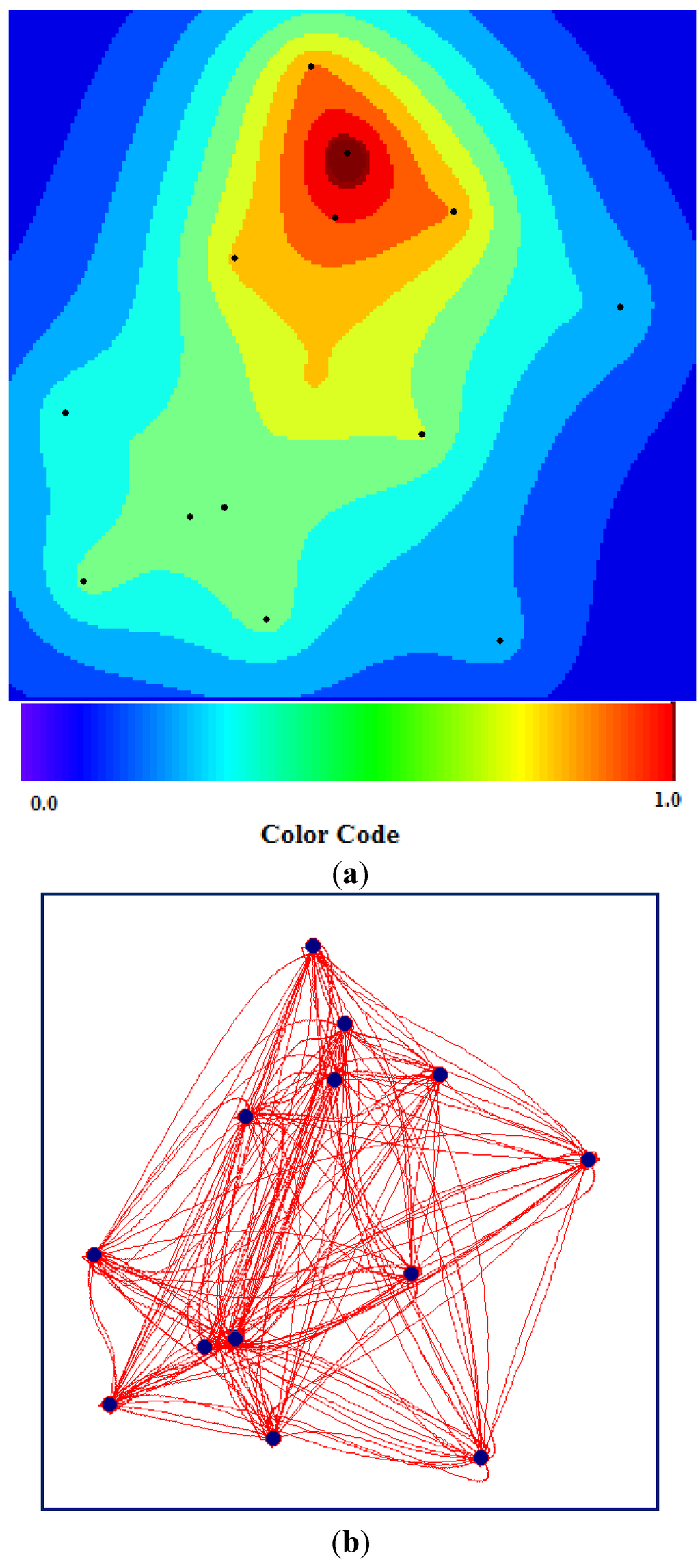
نقشه TWC- γ با در نظر گرفتن مسیرهای انتشار احتمالی بازسازی شده توسط الگوریتم TWC، توزیع اپیدمی ها را تقریبی نشان می دهد ( شکل 15 (الف) را ببینید). شکل 15 (الف) توسط شکل 15 (ب) ایجاد شده است. هر چه یک نقطه عمومی روی نقشه به مسیرها نزدیکتر باشد، احتمال انتشار اپیدمیها در آن نقطه بیشتر میشود. شکل 15 (الف، ب)، در واقع، شدت انتشار اپیدمی HUS را در اطراف خوشه هامبورگ توضیح می دهد (و پیش بینی می کند). و این همان چیزی بود که واقعاً از 29 مه تا 18 ژوئن 2011 اتفاق افتاد.
شکل 15. ( الف ) نقشه TWC- γ که در آن هر چه قرمز تیره تر باشد، غلظت اپیدمی ها بیشتر است (تیره ترین منطقه قرمز تقریباً 1/1000 کل منطقه را نشان می دهد). ( ب ) TWC- γ تمام مسیرهای ممکن را در میان 13 مکان بازسازی کرد.
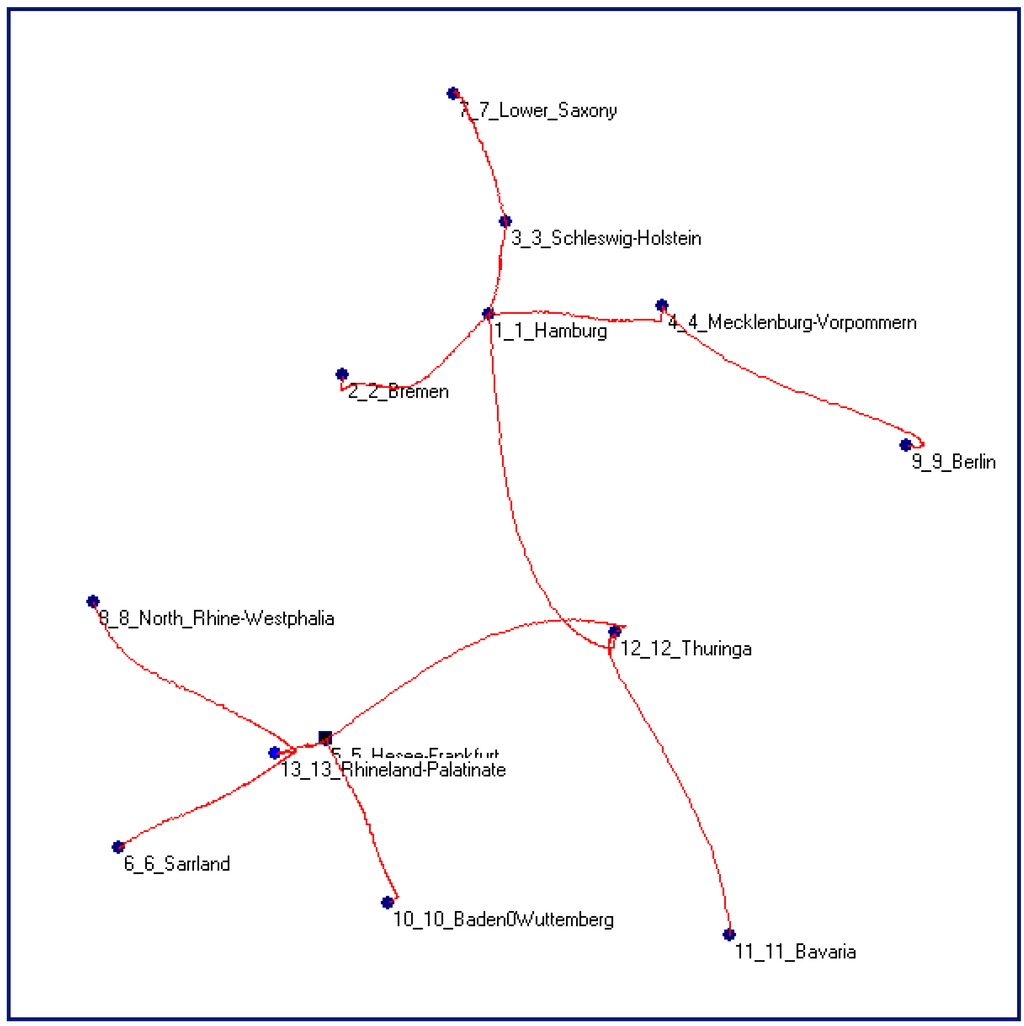
شکل 16 حداقل درخت پوشا (MST) نمودار کامل و منظم ارائه شده در شکل 6 (ب) یا محتمل ترین مسیر انتشار اپیدمی را نشان می دهد که از فرانکفورت (نقطه مربع سیاه) شروع می شود. اگر MST شکل 16 را با شبکه جاده واقعی آلمان در همان مناطق مقایسه کنیم ( شکل 17 ، خط قرمز را ببینید)، شباهت بین دو شبکه شگفت آور است، به ویژه اگر در نظر بگیریم که MST غیرخطی تولید شده توسط TWC – γ هیچ اطلاعی از هیچ گونه اطلاعات جغرافیایی در مورد سیستم جاده ای آلمان ندارد.
شکل 18 نیز پیامد شکل 16 است. این یک نمایش توپولوژیکی از نمودار حداکثر منظم (MRG) مسیرهای TWC- γ است. MRG نوع خاصی از گراف است که میتواند بنیادیترین مدارهای درگیر در ماتریس اصلی فواصل غیر اقلیدسی را که MST غیرخطی از آن تولید میشود، به MST اصلی اضافه کند (به [ 30 ] مراجعه کنید).
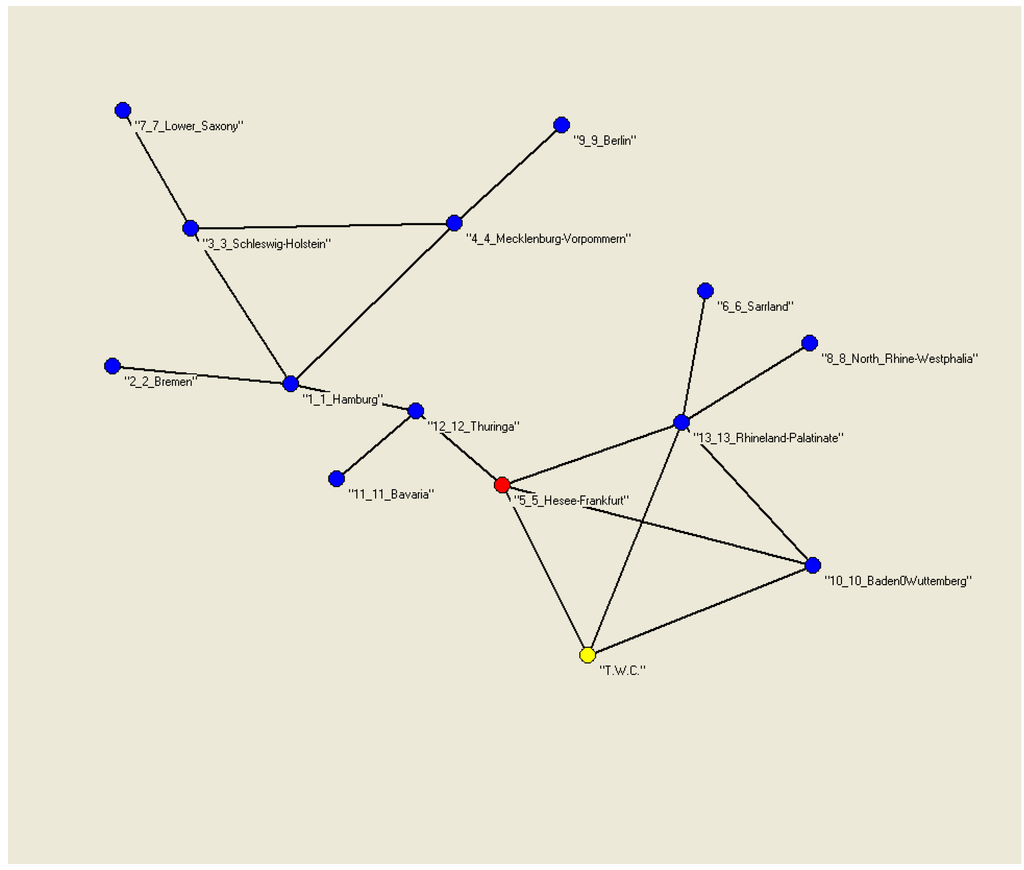
نمودار شکل 18 حداقل به سه دلیل جالب توجه است:
-
دو مدار مستقل (کلیک) را نشان می دهد. اولی شامل هامبورگ، شلزویگ-هولشتاین و مکلنبورگ-فورپومرن و دومی شامل فرانکفورت، نقطه TWC ( α ) و راینلند-فالتز و بادن است. طبق TWC- γ ، این دو مدار، با استفاده از یک حلقه بازخورد، باید موتورهای اصلی اپیدمی های HUS باشند .
-
فرانکفورت، در این مورد، مرکز نمودار است ( شکل 18 ، نقطه قرمز را ببینید).
-
هامبورگ، تورینگا و فرانکفورت گره هایی هستند که حداکثر “بین” دارند.
این مثال دنیای واقعی نشان می دهد که الگوریتم TWC قادر است با دقت بالا، مکان پویایی شیوع E. coli آلمانی را با مقدار محدودی از اطلاعات، حتی زمانی که اطلاعات دقیق نیست، ردیابی کند.
شکل 16. مسیرهای انتشار توسط الگوریتم TWC- γ بازسازی شده است.
شکل 17. جاده های واقعی، به رنگ قرمز، شهرهای آلمانی را که درگیر اپیدمی شده اند به هم وصل می کنند.
شکل 18. MRG مسیرهای یافت شده با استفاده از الگوریتم TWC- γ .
6.5. مقایسه با سایر الگوریتم ها
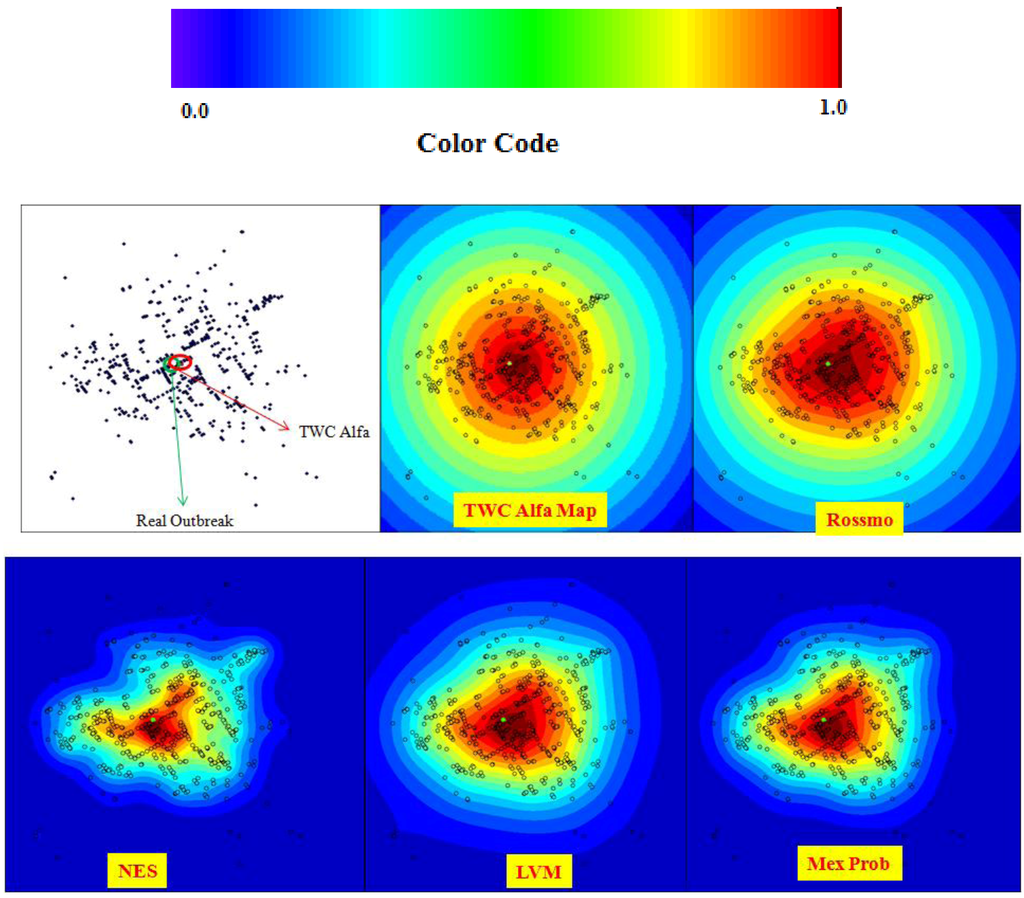
در زمان نگارش این مقاله می دانیم که شیوع واقعی HUS آلمان در نزدیکی فرانکفورت قرار دارد. در نتیجه، ما راه حل های ارائه شده توسط TWC را با تخمین سایر الگوریتم های در نظر گرفته شده در این مقاله مقایسه کرده ایم.
جدول 9 نتایج مقایسه را با توجه به شاخص های معمول نشان می دهد. TWC ( α ) دوباره از سایر الگوریتم ها بهتر عمل می کند.
جدول 10 میانگین به روز شده رتبه عملکرد الگوریتم ها را نشان می دهد. این ترکیب عملکرد کلی همه الگوریتمها در پنج آزمون کاملاً شبیه به نتایجی است که قبلاً نشان داده شد.
جدول 9. مقایسه الگوریتم ها در مورد اشریشیا کلی آلمانی .
جدول 10. میانگین به روز شده رتبه هر الگوریتم در پنج آزمون.
6.6. TWC (γ) و آلمانی HUS Dynamics
هنگامی که اندازه نواحی گرم را با توجه به تخمینهای TWC α ، β و γ مقایسه میکنیم (به شکل 19 مراجعه کنید )، متوجه میشویم که HUS آلمان در پایان ماه مه 2011 در اوج انتشار خود قرار گرفت. TWC β بزرگترین منطقه را نشان می دهد)، پس از انتشار سریع و بزرگ از شیوع اولیه (منطقه TWC α کوچک نیست). از آنجایی که منطقه TWC ( γ ) بسیار کوچکتر از سایرین است، باید نتیجه بگیریم که این اپیدمی در ابتدای ژوئن تأثیر خود را کاهش داده است.
این برآوردها نشان داده است که مطابق با توسعه واقعی این همه گیری است.
شکل 19. HUS آلمانی: تخمین مناطق داغ انتشار اپیدمی بر اساس TWC α ، β و γ .
7. اوآهو (هاوایی): نحوه پیشبینی 3 ماه قبل از شدت اپیدمی غذایی
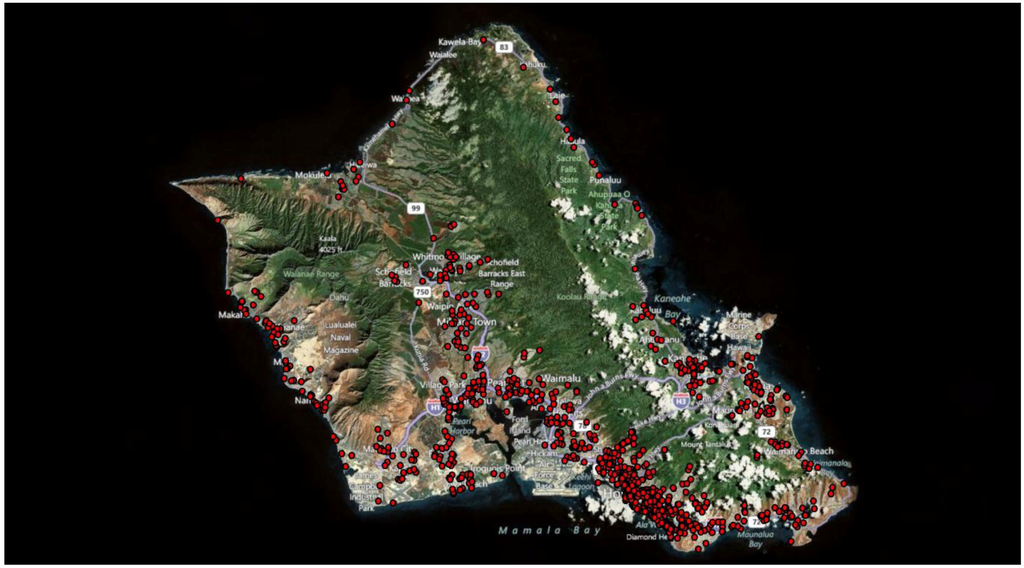
در سال 2010، داده های اوآهو (هاوایی) از یک اپیدمی غذایی (1245 مورد) به مدت 12 ماه به طور سیستماتیک جمع آوری شد. ما این مجموعه داده را از آل برونشتاین، مدیر مرکز سموم کوه راکی دریافت کرده ایم. شکل 20 توزیع جغرافیایی موارد اپیدمی اوآهو و جدول 11 توزیع موارد جدید را در هر ماه از سال 2010 نشان می دهد.
شکل 20. توزیع جغرافیایی 1245 مورد اپیدمی غذایی در اوآهو (سال 2010).
جدول 11. 1245 مورد اپیدمی غذایی در سال 2010 در اوآهو (هاوایی).
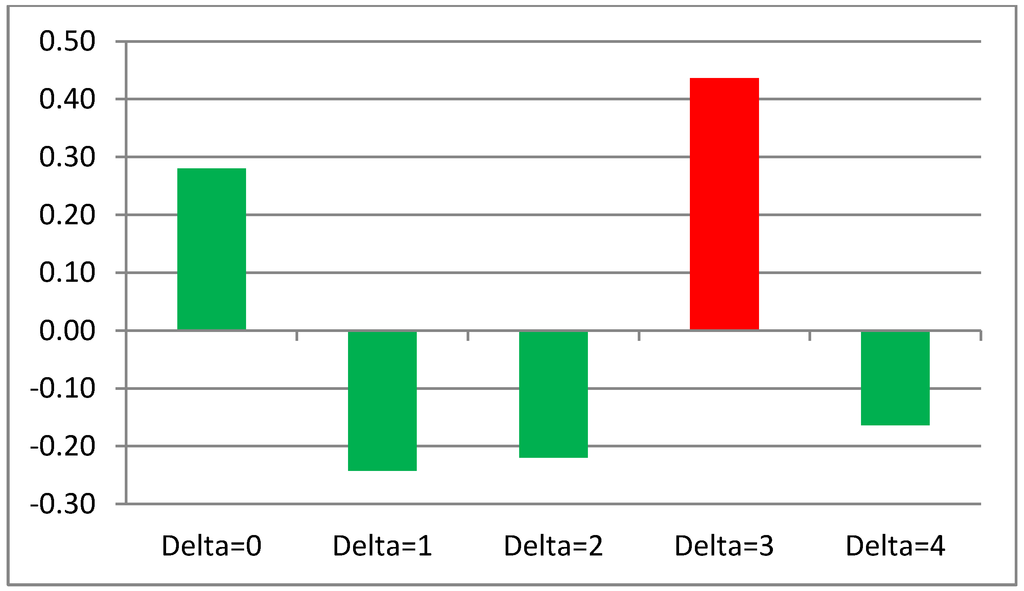
جدول 12. همبستگی پیش بینی بین TWC (گاما) و TWC (بتا) با دلتاهای مختلف.
ما اولین آزمون اعتبار سنجی را در مورد قابلیت پیشبینی TWC Gamma همانطور که در فصل 6 فرض کردیم تنظیم کردیم و به طور مستقل TWC بتا و TWC گاما را برای دادههای هر ماه اعمال کردیم. سپس، ما همبستگی خطی بین حساسیت میدان اسکالر فشرده تر TWC بتا و TWC گاما را اندازه گیری کردیم (s( x )> 0.9، که در آن x بین 0 و 1 است. اگر فرض کنیم که TWC گاما به عنوان یک تخمین فازی از چگونگی شدت اپیدمی در مراحل بعدی بعدی کار می کند، باید بالاترین حساسیت TWC بتا را در ماه مقایسه کنیم (n + دلتا، دلتا = {0،1،2). ,…,11}) با بالاترین حساسیتی که TWC Gamma در آن زمان (n) تخمین زده است.
جدول 12 پنج مقایسه را با مقادیر مختلف دلتا نشان می دهد (0، 1، 2، 3، 4).
کاملاً مشهود است که TWC (گاما) قادر است شدت بالای انتشار اپیدمی غذایی را سه ماه قبل به روش قابل قبولی تخمین بزند ( شکل 21 را ببینید ).
شکل 21. همبستگی خطی بین بیشترین شدت اپیدمی در میدان های اسکالر گاما TWC بتا و TWC، با مراحل زمانی مختلف.
بدیهی است که ما این آزمایش را به عنوان اعتبار سنجی کامل قابلیت پیش بینی TWC Gamma در نظر نمی گیریم. ما باید یک پروتکل اعتبار سنجی گسترده تر و عمیق تر برنامه ریزی کنیم تا قابل قبول بودن آنچه را که فرض می کنیم تأیید کنیم. این آزمون کوتاه و غیرنماینده تنها اولین مرحله مثبت فرآیند است که باید در کارهای آینده بهبود یابد.
8. بحث
بیماری های انتشاری عفونی ممکن است خود را با الگوهای پیچیده زمانی و مکانی نشان دهند که تشخیص آنها دشوار است. این بیماریها برخلاف بیماریهای مزمن، تا حدودی منحصربهفرد هستند، زیرا مواجهه و پیامد آن یکسان است، یعنی فرد یا حیوان آلوده. این منجر به پویایی غیر خطی می شود که تجزیه و تحلیل و پیش بینی عفونت ها در یک جمعیت را بسیار چالش برانگیز می کند.
سالانه میلیونها نفر در سراسر جهان بر اثر بیماریهای عفونی منتشر مانند مالاریا، سل، تب دنگی، ویروس نیل غربی و غیره جان خود را از دست میدهند. سازمانهای دولتی به دنبال مدلهای ریاضی کارآمدی هستند که بتوانند بینشی در مورد پویایی اپیدمیهای بیماری ارائه دهند و به مقامات در تصمیمگیری کمک کنند. در مورد سیاست بهداشت عمومی
فرض اصلی در بررسی شیوع این است که فرآیند به طور تصادفی رخ نمی دهد. گاهی اوقات الگوهای خاص به خودی خود سرنخ هایی در مورد روش انتقال در محل ارائه می دهند. به عنوان مثال، افزایش سریع تعداد موارد در یک دوره زمانی بسیار کوتاه، یک اپیدمی نقطهای را نشان میدهد که در آن تعداد زیادی از افراد به طور همزمان در معرض منبع مشترک عامل بیماریزا قرار میگیرند. چنین الگوی اغلب با بیماری های منتقله از غذا یا آب یا یک عامل عفونی بسیار خطرناک دیده می شود. یک یا دو مورد و به دنبال آن افزایش تدریجی فراوانی بیماری نشان دهنده یک اپیدمی منتشر شده است که در آن یک عامل عفونی مستقیماً از حیوان به حیوان منتقل می شود، از طریق فومیت ها یا حشرات ناقل.
از نظر تئوری، با توجه به توزیع نقاط در یک محیط خاص و تعداد معینی از محدودیتهای مربوط به انواع ویژگیهای فیزیکی قلمرو، مانند انواع مختلف سفرهای ممکن و معیارها (زمان سفر، تلاش یا هزینه)، یک بهینه وجود دارد. راه حلی که فاصله بین نقاط و منبع آنها را به حداقل می رساند. با این حال، از نظر محاسباتی، تعریف آن تقریباً غیرممکن است، که نیازمند شمارش هر ترکیب ممکن است، که به عنوان یک مسئله NP-hard شناخته میشود. در نتیجه در عمل، راه حل های تقریبی، هرچند احتمالاً کمتر از حد بهینه، از طریق روش های مختلف به دست می آیند. «نظریه مکان» تلاش میکند تا مکان بهینه را برای هر توزیع خاصی از فعالیتها، جمعیت یا رویدادها در یک منطقه با توجه به یک معیار خاص پیدا کند. و از این رو یکی از موضوعات محوری در جغرافیا است. در مورد شناسایی منبع شیوع، می توان منطق را معکوس کرد. با توجه به توزیع نقاط مورد علاقه، این تئوری می تواند برای تخمین یک مکان مرکزی که مسافت یا زمان سفر از آن به حداقل می رسد، اعمال شود. مدلهای اپیدمی سعی در توصیف شیوع بیماریهای عفونی در جمعیت دارند. بیشتر و بیشتر از این مدل ها برای پیش بینی، درک و توسعه استراتژی های کنترل استفاده می شود. در مدلهای اپیدمی واقعی، یک مسئله کلیدی که باید در نظر گرفته شود، نمایش فرآیند تماس است که از طریق آن یک بیماری گسترش مییابد، و مدلهای شبکهای به عنوان نامزدهای خوبی به وجود آمدهاند که پیشبینی میکنند کدام شهرها منابع همهگیری هستند و درک مسیر امواج مسافرتی مکرر ممکن است کمک کند. ما برای طراحی استراتژی های نظارت و کنترل بهینه. در مورد شناسایی منبع شیوع، می توان منطق را معکوس کرد. با توجه به توزیع نقاط مورد علاقه، این تئوری می تواند برای تخمین یک مکان مرکزی که مسافت یا زمان سفر از آن به حداقل می رسد، اعمال شود. مدلهای اپیدمی سعی در توصیف شیوع بیماریهای عفونی در جمعیت دارند. بیشتر و بیشتر از این مدل ها برای پیش بینی، درک و توسعه استراتژی های کنترل استفاده می شود. در مدلهای اپیدمی واقعی، یک مسئله کلیدی که باید در نظر گرفته شود، نمایش فرآیند تماس است که از طریق آن یک بیماری گسترش مییابد، و مدلهای شبکهای به عنوان نامزدهای خوبی به وجود آمدهاند که پیشبینی میکنند کدام شهرها منابع همهگیری هستند و درک مسیر امواج مسافرتی مکرر ممکن است کمک کند. ما برای طراحی استراتژی های نظارت و کنترل بهینه. در مورد شناسایی منبع شیوع، می توان منطق را معکوس کرد. با توجه به توزیع نقاط مورد علاقه، این تئوری می تواند برای تخمین یک مکان مرکزی که مسافت یا زمان سفر از آن به حداقل می رسد، اعمال شود. مدلهای اپیدمی سعی در توصیف شیوع بیماریهای عفونی در جمعیت دارند. بیشتر و بیشتر از این مدل ها برای پیش بینی، درک و توسعه استراتژی های کنترل استفاده می شود. در مدلهای اپیدمی واقعی، یک مسئله کلیدی که باید در نظر گرفته شود، نمایش فرآیند تماس است که از طریق آن یک بیماری گسترش مییابد، و مدلهای شبکهای به عنوان نامزدهای خوبی به وجود آمدهاند که پیشبینی میکنند کدام شهرها منابع همهگیری هستند و درک مسیر امواج مسافرتی مکرر ممکن است کمک کند. ما برای طراحی استراتژی های نظارت و کنترل بهینه. با توجه به توزیع نقاط مورد علاقه، این تئوری می تواند برای تخمین یک مکان مرکزی که مسافت یا زمان سفر از آن به حداقل می رسد، استفاده شود. مدلهای اپیدمی سعی در توصیف شیوع بیماریهای عفونی در جمعیت دارند. بیشتر و بیشتر، این مدل ها برای پیش بینی، درک و توسعه استراتژی های کنترلی مورد استفاده قرار می گیرند. در مدلهای اپیدمی واقعی، یک موضوع کلیدی که باید در نظر گرفته شود، نمایش فرآیند تماسی است که از طریق آن یک بیماری گسترش مییابد، و مدلهای شبکه به عنوان نامزدهای مناسبی به وجود آمدهاند که پیشبینی میکنند کدام شهرها منابع اپیدمی هستند و درک مسیر امواج مسافرتی مکرر ممکن است کمک کند. ما برای طراحی استراتژی های نظارت و کنترل بهینه. با توجه به توزیع نقاط مورد علاقه، این تئوری می تواند برای تخمین یک مکان مرکزی که مسافت یا زمان سفر از آن به حداقل می رسد، اعمال شود. مدلهای اپیدمی سعی در توصیف شیوع بیماریهای عفونی در جمعیت دارند. بیشتر و بیشتر از این مدل ها برای پیش بینی، درک و توسعه استراتژی های کنترل استفاده می شود. در مدلهای اپیدمی واقعی، یک مسئله کلیدی که باید در نظر گرفته شود، نمایش فرآیند تماس است که از طریق آن یک بیماری گسترش مییابد، و مدلهای شبکهای به عنوان نامزدهای خوبی به وجود آمدهاند که پیشبینی میکنند کدام شهرها منابع همهگیری هستند و درک مسیر امواج مسافرتی مکرر ممکن است کمک کند. ما برای طراحی استراتژی های نظارت و کنترل بهینه. این تئوری می تواند برای تخمین یک مکان مرکزی که از آن مسافت یا زمان سفر به حداقل می رسد، استفاده شود. مدلهای اپیدمی سعی در توصیف شیوع بیماریهای عفونی در جمعیت دارند. بیشتر و بیشتر از این مدل ها برای پیش بینی، درک و توسعه استراتژی های کنترل استفاده می شود. در مدلهای اپیدمی واقعی، یک مسئله کلیدی که باید در نظر گرفته شود، نمایش فرآیند تماس است که از طریق آن یک بیماری گسترش مییابد، و مدلهای شبکهای به عنوان نامزدهای خوبی به وجود آمدهاند که پیشبینی میکنند کدام شهرها منابع همهگیری هستند و درک مسیر امواج مسافرتی مکرر ممکن است کمک کند. ما برای طراحی استراتژی های نظارت و کنترل بهینه. این تئوری می تواند برای تخمین یک مکان مرکزی که از آن مسافت یا زمان سفر به حداقل می رسد، استفاده شود. مدلهای اپیدمی سعی در توصیف شیوع بیماریهای عفونی در جمعیت دارند. بیشتر و بیشتر از این مدل ها برای پیش بینی، درک و توسعه استراتژی های کنترل استفاده می شود. در مدلهای اپیدمی واقعی، یک مسئله کلیدی که باید در نظر گرفته شود، نمایش فرآیند تماس است که از طریق آن یک بیماری گسترش مییابد، و مدلهای شبکهای به عنوان نامزدهای خوبی به وجود آمدهاند که پیشبینی میکنند کدام شهرها منابع همهگیری هستند و درک مسیر امواج مسافرتی مکرر ممکن است کمک کند. ما برای طراحی استراتژی های نظارت و کنترل بهینه. درک و توسعه استراتژی های کنترل در مدلهای اپیدمی واقعی، یک مسئله کلیدی که باید در نظر گرفته شود، نمایش فرآیند تماس است که از طریق آن یک بیماری گسترش مییابد، و مدلهای شبکهای به عنوان نامزدهای خوبی به وجود آمدهاند که پیشبینی میکنند کدام شهرها منابع همهگیری هستند و درک مسیر امواج مسافرتی مکرر ممکن است کمک کند. ما برای طراحی استراتژی های نظارت و کنترل بهینه. درک و توسعه استراتژی های کنترل در مدلهای اپیدمی واقعی، یک مسئله کلیدی که باید در نظر گرفته شود، نمایش فرآیند تماس است که از طریق آن یک بیماری گسترش مییابد، و مدلهای شبکهای به عنوان نامزدهای خوبی به وجود آمدهاند که پیشبینی میکنند کدام شهرها منابع همهگیری هستند و درک مسیر امواج مسافرتی مکرر ممکن است کمک کند. ما برای طراحی استراتژی های نظارت و کنترل بهینه.
اصلی که ما رویکرد خود را بر اساس آن استوار کردیم، جداسازی عنصر توپوگرافی از فراوانی (بروز) رویداد است. این به خودی خود یک تغییر پارادایم در اپیدمیولوژی مدرن را تشکیل می دهد. مزیت اصلی این رویکرد این است که الگوریتم هایی مانند TWC را می توان در مرحله اولیه یک اپیدمی استفاده کرد، حتی زمانی که همه موارد شناخته شده نیستند. پس از آن، میتوانیم توزیع توپوگرافی را با فرکانس در یک نزول گرادیان مطابقت دهیم تا مکانی را که فاصله و فرکانس رویداد در آن کوتاهترین است، شناسایی کنیم. این ممکن است به کمک قابل توجهی در بهبود کیفیت کنترل عفونت منجر شود.
کاملاً واضح است که نتایج حاصل از نقشهبرداری جغرافیایی به دقت و اعتبار مجموعه دادهها بستگی دارد و برای فعال کردن تکرار تحلیل ما استفاده از دادههای معتبر و با کیفیت بالا را توصیه میکنیم. با این حال، قابل توجه است که الگوریتم TWC علیرغم اطلاعات نادرست در مورد محلی سازی دقیق موارد در مراحل اولیه اپیدمی HUS بسیار قوی به نظر می رسد. این توسط دقت TWC ( α *) پیش بینی “عقب” یا به طور گذشته، منبع اپیدمی، علیرغم عدم اطلاع برنامه (و همچنین نویسندگان) از ماهیت یا مکان آن (هامبورگ)، که در زمان تجزیه و تحلیل، ناشناخته بود و در ششم قرار داشت. -صد کیلومتر از منبع دوم (فرانکفورت) فاصله دارد. بنابراین غیرمنطقی نیست که باور کنیم این رویکرد میتواند در موقعیتهای دنیای واقعی در طول شیوع بیماریهای همهگیر آینده برای توصیف و درک بهتر ویژگیهای مکانی-زمانی خطر عفونت و گسترش استفاده شود.
تعدادی از نقاط قوت در این مقاله وجود دارد: اول از همه، الگوریتم TWC از نظر منطقی دقیق است و مفروضات صریحی در مورد منبع فرآیند پویا ارائه میدهد. ثانیاً اعتبار سنجی بر پنج مجموعه داده بدنام با تعداد زیادی موارد متکی است که همه در ادبیات منتشر شده است که در آنها منبع شیوع بیماری همه گیر به طور واضح ثابت شده است. ثالثاً عملکرد الگوریتم در زمینه سایر الگوریتمهای مورد استفاده برای پروفایل جغرافیایی مورد استفاده قرار گرفته است. مقایسه با این سیستم های معیار مستلزم توسعه یک روش شناسی صحیح بر اساس پارامترهای متعدد است. این به خودی خود نشان دهنده یک پیشرفت واقعی در این زمینه است.
آلفای TWC حاصل از بین چهار الگوریتم انتخاب شده برای مقایسه، بهترین عملکرد را دارد، که از نظر ما بهترین الگوریتم های موجود امروز در هر چهار آزمایش با توجه به فاصله از شیوع در سه مورد از چهار، و دوم در یکی از آنها هستند. چهار آزمایش (آنفولانزای روسی) با توجه به منطقه جستجو.
علاوه بر این، الگوریتم TWC پارامترهای بسیار مفید دیگری را در مدیریت اطلاعات شیوع همهگیری فراهم میکند: بتا TWC شدت واقعی همهگیریها را نشان میدهد و TWC گاما نشاندهنده مسیر دینامیکی آینده اپیدمیها است.
علیرغم یافته های ثابت ما، ما از یک محدودیت اصلی این مطالعه آگاه هستیم. چهار بیماری همه گیر نشان دهنده اثبات خوبی از مفهوم هستند اما ممکن است نماینده همه اپیدمی ها نباشند. بنابراین روش ما به تأیید و اعتبارسنجی دقیق هم از سایر شیوع های مستند و هم در مراحل اولیه شیوع جدید، هم در محیط های انسانی و هم در حیوانات نیاز دارد.
یافتههای ما همچنین باید توجه به سهم مدلسازی ریاضی در بهبود دقت علوم زیستی پزشکی را برانگیزد. تجزیه و تحلیل ما نشان می دهد که چگونه یک سیستم با ریاضیات سیستم های پیچیده می تواند جایگزین هایی برای روش های کلاسیک ارائه دهد. علاوه بر این، این ابزار قدرتمندی برای بررسی مراحل اولیه یک اپیدمی است و ممکن است مبنای روشهای شبیهسازی جدید برای درک فرآیند انتشار یک بیماری عفونی باشد.
9. نتیجه گیری
الگوریتم های TWC، همانطور که در این مقاله ارائه شده است، اولین گام از یک نظریه جدید از معنای شناسی فضا را نشان می دهد. ما می دانیم که بسیاری از مراحل دیگر برای طراحی مناسب یک نظریه کامل مورد نیاز است.
این کار امکان خواندن اطلاعات معنایی توزیع رویدادها را در یک فضای دو بعدی در شرایط توپولوژیکی نشان می دهد. در نتیجه، رویکردهای احتمالی و رویکردهای گرانشی نه بهترین راه حل هستند و نه تنها راه حل ها هستند.
ما به دنبال ادغام الگوریتمهای TWC در ابتکارات تحقیقاتی آینده به دنبال این دستور کار هستیم:
-
گنجاندن یک الگوریتم جدید (بر اساس فلسفه TWC) که قادر به شناسایی مجموعه ای از شیوع های احتمالی و متفاوت با توجه به توزیع فضایی رویدادها باشد.
-
گنجاندن بعد سوم فضایی در تحلیل فضا، و در نتیجه یک متریک جدید که بتواند انرژی مورد نیاز برای تکمیل یک مسیر (و نه تنها فاصله) را در نظر بگیرد.
-
افزودن طول و عرض جغرافیایی فهرستی از ویژگیهای کیفی معنادار برای هر رویداد، و یافتن راهی برای پردازش جمعی همه این ویژگیها.
-
ادغام جریان زمانی با رویکرد TWC به گونهای که توضیح دهد که چگونه نقشهها با تغییر برخی ویژگیهای رویدادهای فضایی تغییر میکنند و کدام یک از آن ویژگیها احتمالاً میتواند پیوند علت و معلولی بین این تغییرات باشد.
الگوریتم های TWC باید در یک نظریه کلی از معنای شناسی رویدادها واقع در فضای خاص و تحت محدودیت های زمانی خاص ادغام شوند.














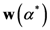




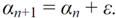





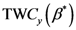





























































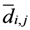


















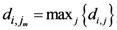















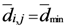
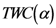


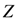
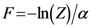
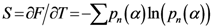
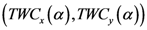
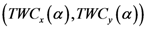
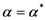

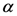

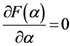
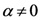


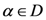
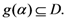


بدون نظر