1. معرفی
داده های سری زمانی در دنیای واقعی بسیار رایج هستند و عموماً ناهمگونی فضایی آشکاری را نشان می دهند. استخراج ویژگیهای خوشهبندی فضایی دادههای سری زمانی برای کشف مکانیسم توزیع بالقوه زیربنایی این نوع دادهها ضروری است.
بسیاری از روش های خوشه بندی سری های زمانی برای تحقق خوشه بندی فضایی داده های سری زمانی پیشنهاد شده اند. این روشها را میتوان بر اساس مکانیسم خوشهبندی به پنج نوع زیر دستهبندی کرد: الگوریتمهای خوشهبندی سریهای زمانی مبتنی بر پارتیشن بندی [ 1 ، 2 ، 3 ]، الگوریتمهای خوشهبندی سریهای زمانی سلسله مراتبی [ 4 ]، الگوریتمهای خوشهبندی سریهای زمانی مبتنی بر چگالی [ 5 ، 6 ، الگوریتمهای خوشهبندی سریهای زمانی مبتنی بر نمودار [ 7 ] و الگوریتمهای همخوشهبندی سریهای زمانی [ 8 ، 9]]. اگرچه این الگوریتمها میتوانند کاربردهای خاصی را مدیریت کنند، اما همچنان از کاستیهای متعددی رنج میبرند و نیاز به بهبود دارند. برای مثال، اکثر الگوریتمهای موجود نمیتوانند بهطور تطبیقی خوشهها را شناسایی کنند، زیرا به چندین پارامتر از پیش تعریفشده نیاز دارند که به شدت به دانش قبلی بستگی دارد. با این حال، دانش قبلی همیشه در کاربردهای واقعی محدود است. به عنوان مثالی دیگر، الگوریتم های فعلی ناهمگونی فضایی را نادیده می گیرند و به ندرت ویژگی های فضایی را در نظر می گیرند. در کاربردهای واقعی، بسیاری از پدیده های جغرافیایی، مانند تغییر شکل سطح، بارندگی و محتوای ذهنی سنگین خاک، تحت تأثیر محیط اطراف قرار می گیرند. اشیاء این پدیده ها به طور کلی با فاصله مکانی کوتاه مشابه هستند. در همین حال، اگر ویژگیهای مکانی نادیده گرفته شوند، خوشههایی با ویژگیهای غیرمکانی مشابه همپوشانی خواهند داشت. و اشیاء در خوشه ها به طور پراکنده در حوزه فضایی توزیع می شوند. این پدیده تا حدی شرایط واقعی را نقض می کند و بر اثر تجسم تأثیر می گذارد. از این رو، ویژگی های مکانی باید در نظر گرفته شود تا به درستی ویژگی های خوشه بندی فضایی داده های سری زمانی به دست آید. علاوه بر این، یا شباهت مقادیر ویژگی سری زمانی غیر مکانی یا شباهت روندهای ویژگی سری زمانی غیر مکانی در اندازه گیری شباهت ویژگی بین اشیا در نظر گرفته می شود. با این حال، اشیاء با روند ویژگیهای سریهای زمانی غیرمکانی مشابه اما مقادیر مشخصه سری زمانی غیرمکانی به طور قابلتوجهی متفاوت، به اشتباه بهعنوان اشیاء مشابه در حوزه غیرمکانی شناسایی میشوند، زمانی که فقط شباهت روندهای ویژگی سریهای زمانی غیرمکانی در نظر گرفته شود. اندازه گیری شباهت ویژگی غیر فضایی به طور مشابه، اگر روندهای ویژگی سری زمانی غیرمکانی بین اشیا به طور قابل توجهی متفاوت باشد و مقادیر ویژگی سری زمانی غیرمکانی بین آنها مشابه باشد، در این صورت اشیاء نیز به اشتباه به عنوان اشیاء مشابه در حوزه غیر مکانی تشخیص داده می شوند. شباهت مقادیر ویژگی سری زمانی غیر مکانی در اندازه گیری شباهت ویژگی غیر مکانی در نظر گرفته می شود. علاوه بر این، دادههای سری زمانی با روندهای ویژگی مشابه و مقادیر مشخصه متفاوت یا مقادیر مشخصه مشابه و روندهای مشخصه متفاوت در برنامههای کاربردی واقعی وجود دارند. به عنوان مثال، مناطقی با آب و هوای موسمی با عرض های جغرافیایی متوسط در تابستان بارانی و در زمستان خشک هستند. روند بارندگی در این مناطق مشابه است. با این حال، ظرفیت بارندگی بستگی به مکان دارد. از این رو، روند بارش و ظرفیت بارندگی باید به طور همزمان در مناطق معدنی با بارش مشابه در نظر گرفته شود. بنابراین، شباهت مقادیر ویژگی سری زمانی غیر مکانی و شباهت روندهای ویژگی سری زمانی غیرمکانی باید به طور همزمان در نظر گرفته شود تا ویژگی های توزیع خوشه بندی اشیاء به درستی استخراج شود.
برای غلبه بر کمبودهای ذکر شده در بالا، یک الگوریتم جدید خوشهبندی سریهای زمانی مبتنی بر چگالی (DTSC) بر اساس الگوریتم خوشهبندی فضایی مبتنی بر چگالی (DBSC) پیشنهاد شده است [10 ] . الگوریتم DTSC پیشنهادی میتواند بهطور تطبیقی خوشههایی را با ویژگیهای مکانی مشابه، مقادیر ویژگی سری زمانی غیرمکانی و روند ویژگیهای سری زمانی غیرمکانی شناسایی کند. علاوه بر این، خوشه های مربوطه برای تجسم واضح با هم تداخل ندارند. مهمتر از آن، برنامه های مربوط به سری های زمانی پیچیده با طول های نابرابر (فواصل زمانی در سری های زمانی نابرابر هستند) و نویزها همه جا حاضر هستند. فواصل زمانی و نویزهای نابرابر در روش پیشنهادی برای شبیهسازی برنامههای پیچیده دنیای واقعی در نظر گرفته میشوند.
ادامه مقاله به شرح زیر تدوین شده است. بخش 2 به طور خلاصه استراتژی خوشه بندی فضایی سری های زمانی تطبیقی را شرح می دهد. الگوریتم پیشنهادی معرفی شده و روشهای تحلیل دقت مربوطه در بخش 3 مورد بحث قرار گرفتهاند . در بخش 4 ، آزمایشهایی بر روی مجموعه دادههای شبیهسازیشده و کاربردهای واقعی برای تأیید امکانسنجی الگوریتم پیشنهادی انجام میشود. در نهایت، نتایج بیشتر در بخش 5 مورد بحث قرار می گیرد .
2. روش های خوشه بندی سری های زمانی
انجام خوشه بندی سری های زمانی تطبیقی به دو جنبه دشوار بستگی دارد. یکی اندازه گیری شباهت بین اشیاء سری زمانی است و دیگری شامل استراتژی تطبیقی خوشه بندی سری های زمانی است.
2.1. اندازه گیری شباهت بین اشیاء
شباهتهای فضایی و غیرمکانی بهطور وابسته به یکدیگر در نظر گرفته میشوند تا نیازی به تعیین وزنهای مناسب برای شباهت بین اشیاء در حوزههای فضایی و غیرمکانی نداشته باشند. فاصله اقلیدسی، که برای اندازه گیری شباهت ویژگی فضایی مفید است، برای حوزه فضایی در این مطالعه استفاده شده است. از سوی دیگر، فاصله اقلیدسی (اندازهگیری شباهت مقادیر ویژگیهای سری زمانی غیرمکانی) یا ضریب همبستگی پیرسون (اندازهگیری شباهت روندهای ویژگی سریهای زمانی غیرمکانی) معمولاً برای اندازهگیری شباهتهای ویژگیهای غیرمکانی استفاده میشود، اما همانطور که در شکل 1 و شکل 2 نشان داده شده است، این روش ها نمی توانند به طور موثر پدیده های خاصی را از هم جدا کنند .
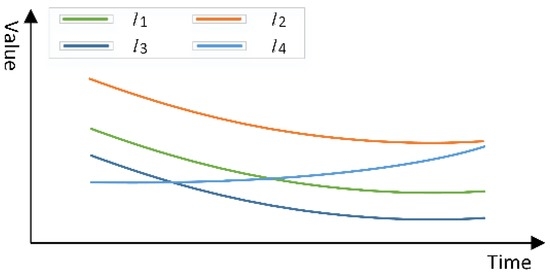
شکل 1 نشان می دهد که شی سری زمانی ل1�1با شی بیشتر شبیه است ل3�3نسبت به اشیاء ل2�2و ل4�4. با این حال، فاصله اقلیدسی بین اشیاء ل1�1و ل3�3برابر بین اجسام است ل1�1و ل4�4. ضریب همبستگی پیرسون بین ل1�1و ل2�2برابر است با بین ل1�1و ل3�3. استفاده از تنها یکی از دو روش اندازه گیری شباهت، بدیهی است که قضاوت نادرستی در مورد درجه شباهت بین اشیاء سری زمانی ایجاد می کند. با این حال، اگر فاصله اقلیدسی و ضریب همبستگی پیرسون به صورت ترکیبی برای اندازهگیری درجه تشابه بین اجسام استفاده شود، نتیجه نشان میدهد که درجه شباهت بین ل1�1و ل3�3بالاترین در بین تمام جفت ها است. بنابراین، معیار قضاوت در مورد درجه تشابه باید بر اساس فاصله اقلیدسی و ضریب همبستگی پیرسون باشد – هر چه مقدار ضریب همبستگی پیرسون بزرگتر و مقدار فاصله اقلیدسی کوچکتر باشد، درجه تشابه غیر بالاتر خواهد بود. ویژگی فضایی دو شی خواهد بود.
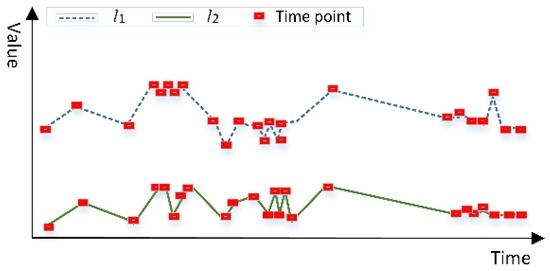
علاوه بر این، فاصله اقلیدسی موجود و ضریب همبستگی پیرسون، پدیده سری های زمانی نامساوی را نادیده می گیرند، همانطور که در اشیاء سری زمانی در شکل 2 نشان داده شده است . شکل 2 نشان می دهد که پدیده بازه زمانی نامساوی مانع از روش های اندازه گیری شباهت موجود می شود. روند ویژگی غیر مکانی بین اشیاء سری زمانی ل1�1و ل2�2ظاهراً از نظر تجسم مشابه هستند، در حالی که ضریب همبستگی پیرسون بین ل1�1و ل2�20.423 با سطح معنی داری 0.029 است و نمی تواند درجه شباهت بین اشیاء سری زمانی با فواصل زمانی نامساوی را نشان دهد. یک روش اندازهگیری شباهت بهبودیافته که سریهای زمانی نابرابر را در نظر میگیرد برای افزایش دقت اندازهگیری درجه شباهت ویژگیهای غیرمکانی بین اشیاء سری زمانی پیشنهاد شدهاست. این روش از فاصله اقلیدسی وزنی (معادله (1)) برای اندازهگیری شباهت مقادیر ویژگی غیرمکانی و ضریب همبستگی پیرسون وزندار (معادله (2)) برای اندازهگیری شباهت روندهای ویژگی غیرمکانی استفاده میکند. به گفته رامیرز-لوپز و همکاران. [ 11]، اگر ضریب همبستگی پیرسون بین دو شی سری زمانی بزرگتر از 0.6 و سطح معنی داری کمتر از 0.1 باشد، آنگاه اشیاء سری زمانی یک روند مشخصه مشابه را نشان می دهند. ضریب همبستگی پیرسون وزنی بین ل1�1و ل2�20.786 با سطح معنی داری 0.001 است که نشان می دهد که روند صفت بین ل1�1و ل2�2به طور قابل توجهی مشابه است.
جایی که لt ( من )1�1�(�)ارزش در است من هفتم�thنقطه زمانی شی سری زمانی ل1�1، و w ( t ( i ) ) =( t ( i ) − t ( i − 1 ) )( t ( T) – t ( 0 ) )/�(تی(من))=(تی(من)–تی(من–1))(تی(تی)–تی(0)).
2.2. یک استراتژی تطبیقی جدید برای خوشه بندی سری های زمانی
استراتژی تشخیص جداگانه خوشهها در حوزههای فضایی و غیرمکانی در این مطالعه برای شناسایی سازگارانه خوشهها با ویژگیهای فضایی و غیرمکانی مشابه پیشنهاد شدهاست. فاصله اقلیدسی در حوزه فضایی پذیرفته شده است. با در نظر گرفتن رابطه همسایگی بین اشیاء [ 10 ]، روابط مجاورت فضایی بین اشیاء سری زمانی به طور تطبیقی با حذف لبه های ناسازگار در مثلث سازی Delaunay ساخته شده از اشیاء با ادغام الگوریتم بهینه سازی ازدحام ذرات (PSO) به دست می آید [12] .]. سپس، بر اساس روابط مجاورت فضایی، خوشهها با اشیاء همسایه که ویژگیهای سری زمانی غیرمکانی مشابهی دارند، با استفاده از روش خوشهبندی سریهای زمانی مبتنی بر چگالی بهبودیافته در حوزه غیرمکانی، بهصورت تطبیقی خوشهبندی میشوند. روش خوشهبندی سریهای زمانی مبتنی بر چگالی با ادغام اندازهگیریهای شباهت پیشنهادی (شرح شده در بخش 2.1 ) و استراتژی شاخص چگالی یک روش خوشهبندی مبتنی بر چگالی دوگانه (DBSC) [ 10 ]، که در بخش 3 معرفی میشود، بهبود مییابد .
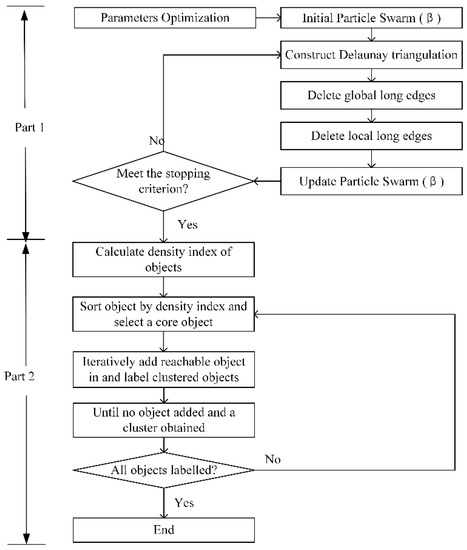
3. الگوریتم DTSC
الگوریتم DTSC شامل دو فاز است. در فاز 1، روابط مجاورت فضایی با حذف لبه های ناسازگار که در سطوح جهانی و محلی بیش از حد طولانی هستند، ایجاد می شود. این مرحله به طور تطبیقی توسط PSO کنترل می شود، همانطور که در بخش 3.1 نشان داده شده است . سپس فاز 2 بر اساس روابط مجاورت فضایی انجام میشود، و یک روش خوشهبندی مبتنی بر چگالی بهبودیافته برای شناسایی تطبیقی خوشههایی با ویژگیهای سری زمانی مشابه، که در بخش 3.2 مورد بحث قرار خواهد گرفت، استفاده میشود . رویه های اصلی DTSC به صورت شماتیک در شکل 3 نشان داده شده است . در نهایت، برای ارزیابی نتیجه الگوریتم DTSC، شاخصهای ارزیابی معرفی و در بخش 3.3 توضیح داده میشوند .
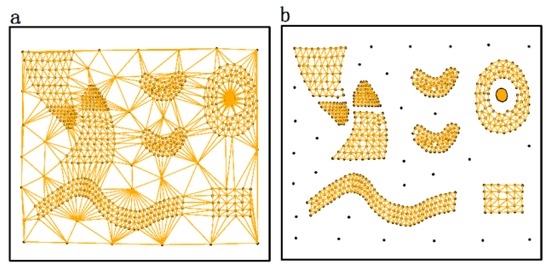
3.1. ساخت روابط مجاورت فضایی
مثلث سازی Delaunay ابزار مفیدی برای ساخت روابط همسایه فضایی [ 13 ] است، اما به طور کلی برخی از لبه های ناسازگار در مثلث سازی Delaunay ساخته شده وجود دارد. از این رو، روابط مجاورت فضایی با حذف لبه های ناسازگار ساخته می شوند، که از رویه ساخت مجاورت فضایی DBSC [ 10 ] مشتق شده است. مراحل اصلی به شرح زیر معرفی می شوند:
مرحله 1: مثلث سازی دلونه جیجیساخته شده است.
مرحله 2: محدودیت فاصله جهانی با معادله زیر محاسبه می شود:
جایی که G l o b a l _ m e a n ( G )جیل�بآل_مترهآ�(جی)و G l o b a l _ v a r i a t i o n ( G )جیل�بآل_�آ�منآتیمن��(جی)مقدار متوسط و انحراف استاندارد طول لبه ها در است جیجی، به ترتیب؛ و من یک نفر ( _پمن)مترهآ�(پمن)مقدار میانگین طول لبه ها نسبت به پمنپمن.
مرحله 3: لبه های بلند در سطح جهانی حذف می شوند جیجی. لبه متصل به پمنپمن، که فاصله ای بزرگتر از G l o b a l _ c u t _ c o n s t a i n t (پمن)جیل�بآل_جتوتی_ج��ستیآمن�تی(پمن)، باید حذف شود تا لبه های ناسازگار سراسری حذف شوند.
مرحله 4: محدودیت فاصله محلی با معادله زیر محاسبه می شود:
جایی که مe an2جیمنمهآ�جیمن2میانگین طول یال ها توسط نقاط برابر با کمتر از همسایه های مرتبه دوم است پمنپمن; مe a n _ v a r i a t i o n ( G )مهآ�_�آ�منآتیمن��(جی)مقدار میانگین تغییرات محلی نقاط در نمودار است جی جی; و β�پارامتر تنظیمی است که حساسیت ویژگی های فضایی را کنترل می کند. در عمل، β�از 1 تا 2 تنظیم شده است [ 10 ]. هر چه ارزش آن کمتر باشد β�یعنی حذف لبه های بلند آسان تر است.
مرحله 5 : لبه های بلند در سطح محلی حذف می شوند. لبه متصل به پمنپمن، که فاصله آن بزرگتر از L o c a l _ c u t _ v a l u e (پمن)��جآل_جتوتی_�آلتوه(پمن)، برای حذف لبه های ناسازگار محلی باید حذف شود. اشیاء متصل همسایه در نظر گرفته می شوند و نمودارهای فرعی با اشیاء متصل به دست می آیند.
β�تا حد زیادی بر نتیجه روابط نزدیکی تأثیر می گذارد. ارزیابی و بهینه سازی β�ضروری هستند و بنابراین در این مطالعه برای به دست آوردن نتایج رضایت بخش تحت مقدار مناسب استفاده می شوند β�. ساخت روابط مجاورتی یک روش خوشهبندی مبتنی بر نمودار است [ 14 ]. از این رو، یک تابع ارزیابی مبتنی بر نمودار [ 15 ] که اثربخشی پرت فضایی را در نظر می گیرد در این مرحله استفاده می شود. این روش می تواند به طور دقیق امکان سنجی نتایج ساخت مجاورت فضایی را ارزیابی کند. تابع ارزیابی به صورت زیر تعریف می شود:
جایی که پپو سسبه ترتیب تعداد خوشه ها و نویزها هستند. ز زارزش ارزیابی است. افE(جیمن)اف�(جیمن)شباهت بین گراف گراف فرعی است جیمنجیمن; افE(Oj)اف�(��)شباهت بین پرت است Oj��و نمودارهای فرعی و افمن(جیمن)افمن(جیمن)شباهت درون خوشه ای است جیمنجیمن.
با توجه به تابع ارزیابی ، اگر شباهت بین گراف زیاد باشد و اگر شباهت درون گراف و شباهت نمودار و نویز کم باشد، مقدار Z بزرگ خواهد بود. PSO [ 12 ] برای جستجوی تطبیقی برای نتیجه خوب با بزرگترین استفاده می شود ززو مناسب β�بطور خودکار. روند بهینه سازی تا زمانی که مقدار Z به حداکثر جهانی همگرا شود پایان می یابد. زمان اجرا به صورت برچسب گذاری شده است کک. هزینه زمانی فرآیند بهینه سازی عمدتاً به اندازه داده ها و کک. راندمان محاسباتی فاز 1 است O ( k × ( Nlog ( N ) ) _�(ک×(Nlog (ن))). ککرا می توان با استفاده از مهارت موازی به طور قابل توجهی کاهش داد [ 16 ].
3.2. خوشه بندی اشیاء با ویژگی های سری زمانی مشابه
در حوزه غیر مکانی، یک روش خوشه بندی سری زمانی بهبود یافته بر اساس استراتژی شاخص چگالی الگوریتم DBSC [ 10 ] پیشنهاد شده است. روش را می توان به دو بخش تقسیم کرد. قسمت 1 درجه تشابه را بر اساس روابط مجاورت فضایی محاسبه می کند. درجه تشابه بین اشیاء بدون رابطه مجاورتی نزدیک به صفر در نظر گرفته می شود [ 10 ]. قسمت 2 اشیاء با ویژگی های سری زمانی مشابه را جمع می کند. ابتدا چندین اصل اساسی برای روشن شدن روش پیشنهادی معرفی میشوند.
- (1)
-
همسایگان فضایی: اشیایی که با لبه هایی در مثلث دلونی اصلاح شده به هم متصل شده اند.
- (2)
-
ویژگی مستقیم قابل دسترسی: اشیایی با مقادیر مشخصه سری زمانی مشابه و روندهای ویژگی به عنوان ویژگی مستقیماً قابل دسترسی در نظر گرفته می شوند. شی پ1پ1و پ2پ2ویژگی مستقیماً قابل دسترسی هستند، اگر
- (من)
-
p c w (پ1، پ2) > 0.6 پج�(پ1، پ2)> 0.6و s i g(پ1، پ2) < 0.1 سمن�(پ1، پ2)< 0.1; و
- (II)
-
د (پ1، پ2) < تیاس�(پ1، پ2)<تیاس
جایی که تیاستیاسآستانه صفات غیر مکانی است که به صورت زیر قابل محاسبه است. اول، فاصله های صفت D�بین اشیاء مجاور محاسبه می شود. ثانیا، اشیاء و اشیاء حداقل ویژگی فاصله جستجو و برچسب گذاری می شوند. میانگین حداقل فواصل ویژگی محاسبه و به آن اختصاص داده می شود تیاس تیاس. اثربخشی این روش به صورت تجربی ثابت شده است [ 10 ].
- (3)
-
ویژگی قابل دسترسی: ویژگی قابل دسترسی شباهت بین یک شی و اشیاء همسایه اش را اندازه گیری می کند. برای مجموعه ای از اشیاء S، شی مجاور آن پ1پ1در صورت فاصله صفت بین صفت قابل دسترسی از S در نظر گرفته می شود پ1پ1و مقدار میانگین S کمتر از TS است.
- (4)
-
شاخص چگالی: نشانگر چگالی نشان دهنده چگالی اجسام با ویژگی های مشابه در حوزه فضایی است. برای یک شی پ1پ1، شاخص چگالی با معادله زیر محاسبه می شود:
جایی که نs dr(پ1)نسد�(پ1)تعداد اشیایی است که ویژگی مستقیماً از آنها قابل دسترسی است پ1پ1. n _ Nد (پ1)�_ن�(پ1)تعداد همسایگان است پ1پ1.
بر اساس مفاهیم اولیه، روند الگوریتم DTSC به شرح زیر است:
مرحله 1: فاصله ویژگی را محاسبه کنید D�و ضریب همبستگی p c wپج�از اشیاء مجاور مقدار پیش فرض آستانه مشخصه تیاستیاسرا می توان در این مرحله تعیین کرد. این محاسبه نیاز دارد O ( 2 N* تی)O(2ن*تی)پیچیدگی زمانی
مرحله 2: شاخص چگالی را با دو قسمت زیر محاسبه کنید. بخش 1 محاسبه ویژگی اشیاء مستقیماً قابل دسترسی است. قسمت 2 محاسبه شاخص چگالی هر جسم با استفاده از رابطه (6) است. روش محاسبه تقریباً هزینه دارد O ( Nl o g( ن) )�(نل��(ن)).
مرحله 3: یک شیء طبقه بندی نشده را انتخاب کنید پمنپمنبا بزرگترین شاخص تراکم اگر چندین شی با مقدار یکسان بزرگترین نشانگر چگالی وجود داشته باشد، آنگاه شیء با حداقل فاصله صفت با شی مجاور خود انتخاب می شود.
مرحله 4: یک شی طبقه بندی نشده که یک ویژگی است که مستقیماً از آن قابل دسترسی است پمنپمنبه ترتیب نزولی بر اساس نشانگر چگالی اضافه می شود و اشیاء خوشه ای به عنوان یک خوشه برچسب گذاری می شوند. سیمنسیمن. اشیاء طبقه بندی نشده به طور مکرر به آن اضافه می شود سیمن سیمنویژگی هایی هستند که مستقیماً از اشیاء موجود در آن قابل دسترسی هستند سیمنسیمنو صفت قابل دستیابی از سیمنسیمن.
مرحله 5: سیمنسیمنتا زمانی که هیچ شیء طبقه بندی نشده دیگری نمی تواند اضافه شود به دست می آید.
مرحله 6: مراحل 3-5 را به طور مکرر اجرا کنید. هنگامی که همه اشیا مورد قضاوت قرار می گیرند، روند خوشه بندی متوقف می شود. اشیایی که به هیچ خوشه ای تعلق ندارند به عنوان نویز شناخته می شوند.
پیچیدگی زمانی فرآیند خوشه بندی شامل سه بخش اصلی است: مرحله 1 ( O ( 2 N* تی)�(2ن*تی))، گام 2 ( O ( Nl o gن)�(نل��ن)، و مراحل 3-6 ( O ( N)�(ن)). ساخت روابط مجاورت فضایی استفاده می کند O ( k × ( Nl o g ن) )�(ک×(نل�� ن)). از این رو، کل روش محاسباتی الگوریتم DTSC تقریباً هزینه دارد O ( ( k N+ ن) l o g ن+ ( 2 T+ 1 ) N)�((کن+ن)ل�� ن+(2تی+1)ن).
3.3. ارزیابی دقت نتایج خوشه بندی
ادبیات چندین شاخص ارائه می دهد که برای ارزیابی نتایج خوشه بندی مفید هستند [ 17 و 18 ]. این شاخصها میتوانند نتایج الگوریتمهای مختلف خوشهبندی را برای یک مجموعه داده ارزیابی کنند. روش های محاسبه دقیق به شرح زیر است.
شاخص رند توانایی یک رویکرد تشخیص خوشه خاص برای یافتن خوشه ها و نویزهای شناخته شده را ارزیابی می کند. شاخص به صورت زیر بیان می شود:
جایی که تیپتیپیک تصمیم مثبت واقعی است (یعنی شمارش نقاط در خوشه های به درستی شناسایی شده بر اساس توابع نگاشت [ 19 ])، افپافپیک تصمیم مثبت کاذب است (یعنی شمارش نقاط در خوشه های نادرست شناسایی شده)، تینتینیک تصمیم مثبت واقعی است (یعنی تعداد کل صداهای به درستی شناسایی شده)، و افنافنیک تصمیم منفی کاذب است (یعنی تعداد کل صداهای نادرست شناسایی شده). موضوع شاخص دقت شامل در نظر گرفتن همزمان مثبت کاذب و منفی کاذب است. برای پرداختن به این موضوع، دو شاخص دیگر، دقت و یادآوری بیشتر برای ارزیابی دقت اعمال میشوند [ 18 ].
Recall توانایی الگوریتم خوشه بندی را برای شناسایی موفقیت تشخیص مثبت ارزیابی می کند و به صورت زیر تعریف می شود:
دقت ظرافت های الگوریتم خوشه بندی را به تصویر می کشد و به صورت زیر تعریف می شود:
قابل ذکر است که صحت نتایج توسط هر سه شاخص مورد قضاوت قرار می گیرد. برای دو نتیجه خوشه بندی r 1�1و r 2�2از همان مجموعه داده، نتایج ارزیابی نهایی به عنوان نشان داده می شود { R a n d ( r 1 ) , r e c a l l ( r 1 ) , p r e c i s i o n ( r 1 ) }{ آرآ�د(�1)، �هجآلل(�1)، پ�هجمنسمن��(�1) }و { R a n d ( ر 2 ) ، r e c a l l ( r 2 ) , p r e c i s i o n ( r 2 ) }{ آرآ�د(�2)، �هجآلل(�2)، پ�هجمنسمن��(�2)}، به ترتیب. r 1�1اگر شاخص های آن یکی از معیارهای زیر را داشته باشند، به عنوان نتیجه بهتر در نظر گرفته می شود.
معیار 1:
r e c a l l ( r 1 ) > r e c a l l ( r 2 ) �هجآلل(�1)> �هجآلل(�2)و p r e c i s i o n ( r 1 ) > p r e c i s i o n ( r 2 ) پ�هجمنسمن��(�1)> پ�هجمنسمن��(�2).
معیار 2:
r e c a l l ( r 1 ) > r e c a l l ( r 2 )�هجآلل(�1)> �هجآلل(�2)، p r e c i s i o n ( r 1 ) < p r e c i s i o n ( r 2 ) پ�هجمنسمن��(�1)< پ�هجمنسمن��(�2)و R a n d( r 1 ) > R a n d ( ر 2 )آرآ�د(�1)> آرآ�د(�2).
4. نتایج
مجموعه داده های شبیه سازی شده و برنامه های کاربردی واقعی برای تایید اثربخشی و دقت DTSC طراحی و مورد استفاده قرار می گیرند. مجموعه داده های شبیه سازی شده بر اساس چندین مطالعه قبلی در مورد تعیین مجموعه داده های شبیه سازی شده [ 20 ] و ویژگی های برنامه های واقعی تنظیم شده اند. اعتبار سنجی دقیق الگوریتم DTSC در مجموعه داده های شبیه سازی شده در بخش 4.1 آورده شده است . داده های بارندگی در سرزمین اصلی چین از سال 1960 تا 2009 با استفاده از DTSC پیشنهادی برای استخراج ویژگی های توزیع بارندگی برای اعتبارسنجی بیشتر مزایای DTSC مورد بررسی قرار می گیرد. مطالعه موردی داده های بارش با استفاده از DTSC به طور کامل در بخش 4.2 توضیح داده شده است .
4.1. اعتبار سنجی الگوریتم DTSC بر روی مجموعه داده های شبیه سازی شده
این بخش سه آزمایش را بر اساس مجموعه داده های شبیه سازی شده برای اعتبارسنجی اثربخشی و دقت الگوریتم DTSC انجام می دهد. مجموعه داده های شبیه سازی شده برای تأیید امکان سنجی و دقت DTSC طراحی شده اند، همانطور که در بخش 4.1.1 نشان داده شده است . در بخش 4.1.2 ، کارایی الگوریتم DTSC پیشنهادی سپس با مقایسه DTSC با یک الگوریتم معمولی (الگوریتم خوشه بندی سری های زمانی مبتنی بر چگالی) [ 6 ] نشان داده شده است. آزمایش 2 در بخش 4.1.3 برای ارزیابی اثربخشی روش بهینهسازی پارامتر پیشنهادی که در بخش 3.1 پیشنهاد شده بود انجام میشود. . نتایج با یک پارامتر بهینه و پارامترهای غیربهینه با استفاده از توابع ارزیابی دقت فوق الذکر با یکدیگر مقایسه می شوند (به بخش 3.3 مراجعه کنید ). آزمایش 3 در بخش 4.1.4برای اعتبارسنجی امکانسنجی اندازهگیریهای شباهت پیشنهادی که در بخش 2.1 توضیح داده شدهاند، استفاده میشود، که با مقایسه نتایج خوشهبندی بر اساس اندازهگیریهای شباهت پیشنهادی با نتایج بهدستآمده بر اساس اندازهگیریهای شباهت معمولی به دست میآید.
4.1.1. اعتبار سنجی الگوریتم DTSC بر اساس مجموعه داده های شبیه سازی شده
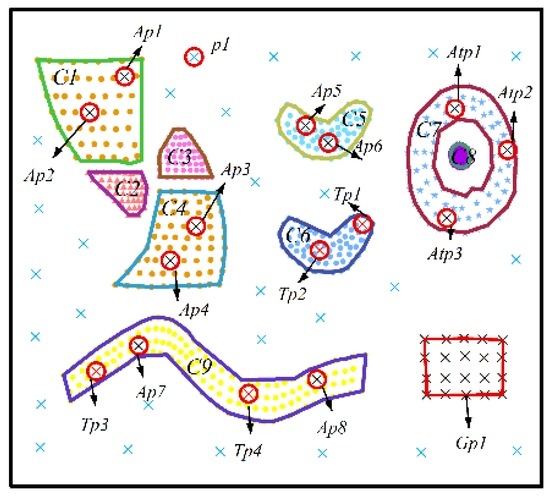
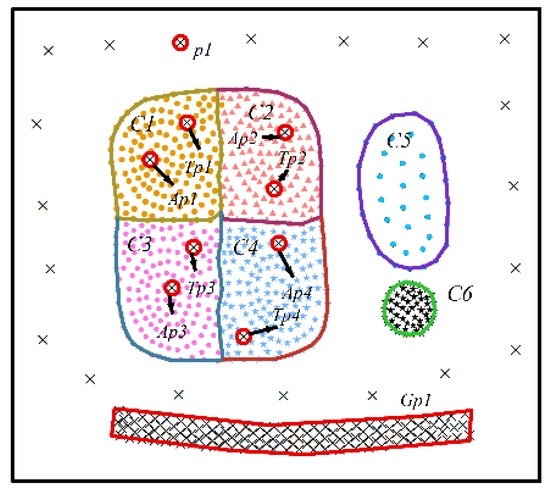
برای ارائه یک مجموعه داده شبیه سازی شده معقول برای ارزیابی عملکرد الگوریتم DTSC، مجموعه داده های شبیه سازی شده اس1اس1(نگاه کنید به شکل 4 و شکل 5 ) و اس2اس2(نگاه کنید به شکل 6 و شکل 7 ) بر اساس ویژگی های کاربردهای واقعی و با مراجعه به مطالعات قبلی [ 20 ] طراحی شده اند.
ویژگی های اس1اس1و اس2اس2در زیر شرح داده شده است.
- (1)
-
اس1اس1و اس2اس2دارای 759 و 806 شیء به ترتیب
- (2)
-
بعد زمانی 20 است و فواصل زمانی مجاور برابر است،
- (3)
-
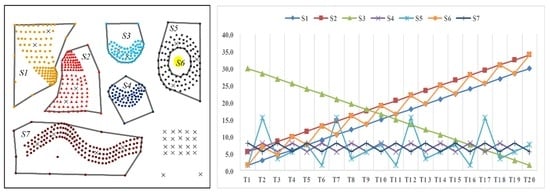
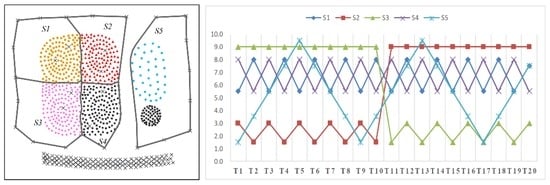
نه خوشه از پیش تعریف شده با عنوان سی1سی1به سی9سی9که در اس1اس1(در شکل 4 ) و پنج خوشه از پیش تعریف شده با عنوان سی1سی1به سی5سی5که در اس2اس2(در شکل 6 ) وجود دارد. این خوشه ها دارای اشکال هندسی دلخواه و چگالی متفاوت هستند. ویژگیهای غیرمکانی خوشه در هر نقطه زمانی بهطور تصادفی در یک محدوده توزیع میشوند، و مقدار میانگین ویژگیها در هر خوشه در شکل 5 و شکل 7 نشان داده شده است .
- (4)
-
برای حفظ سازگاری با برنامه های واقعی، نویزها در مجموعه داده های شبیه سازی شده تنظیم می شوند و به پنج نوع طبقه بندی می شوند. نوع 1 شامل نویزهای فضایی است که معنایی مشابه با نقاط پرت فضایی دارند که مقادیر ویژگی مکانی آنها به طور قابل توجهی با سایر اشیاء در همسایگی فضایی آنها متفاوت است. اینها به عنوان برچسب گذاری شده اند پپ(مانند ص 1پ1). ویژگیهای غیرمکانی نویزهای فضایی شبیه به نزدیکترین خوشههای مجموعه داده است اس1اس1. نوع 2 و 3 به ترتیب نویزهای ویژگی غیرمکانی و نویزهای روند ویژگی غیرمکانی هستند که با عنوان یک صفحهآپ(مانند A p 1 آپ1به ص 8پ8) و تیپتیپ(مانند تیص 1تیپ1به تیپ 4تیپ4)، به ترتیب. ویژگی های این نوع نویزها به طور قابل توجهی با اجسام مجاورشان متفاوت است. نوع 4 شامل نویزهایی است که مقادیر مشخصهها و روند ویژگیها هر دو بهطور قابلتوجهی با اشیاء همسایه متفاوت هستند. این صداها به عنوان برچسب گذاری شده اند A t pآتیپ(مانند A t p 1آتیپ1به A t p 3آتیپ3). نوع 5 شامل نویزهای در حال تغییر تدریجی است که مقادیر مشخصه آنها به صورت نزولی یا صعودی در امتداد موقعیت مکانی تغییر می کند، اگرچه روند ویژگی آنها مشابه است. به عنوان مثال، با افزایش ارتفاع، دما کاهش می یابد و روند دما در ارتفاعات مختلف با تغییرات فصلی مشابه است. این صداهای در حال تغییر تدریجی به عنوان برچسب گذاری شده اند ج صجیپ(مانند G p 1جیپ1).
4.1.2. مقایسه بین DTSC و الگوریتم های معمولی
آزمایشها بر روی مجموعه دادههای شبیهسازیشده برای تأیید کارآمدی و دقت الگوریتم DTSC در مقایسه با الگوریتم خوشهبندی سریهای زمانی مبتنی بر چگالی، که ویژگیهای مکانی و غیر مکانی را نیز در نظر میگیرد، انجام میشود. الگوریتم خوشهبندی سریهای زمانی مبتنی بر چگالی بر اساس روش اندازهگیری شباهت مبتنی بر فاصله اقلیدسی است. پارامترها در الگوریتم خوشهبندی سریهای زمانی مبتنی بر چگالی پیچیده هستند و شامل شعاعهای فضایی و آستانه ویژگیها میشوند. در الگوریتم سری زمانی مبتنی بر چگالی، زمانی که اشیاء در شعاع یک جسم p که فاصله صفت آنها از p کمتر از آستانه صفات باشد، به صورت تکراری جمع می شوند. بدست آوردن مقادیر بهینه این پارامترها دشوار است. از این رو، برای به دست آوردن مناسب ترین نتیجه، یک مطالعه پارامتری انجام می دهیم.
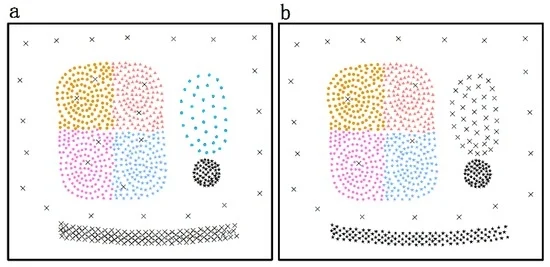
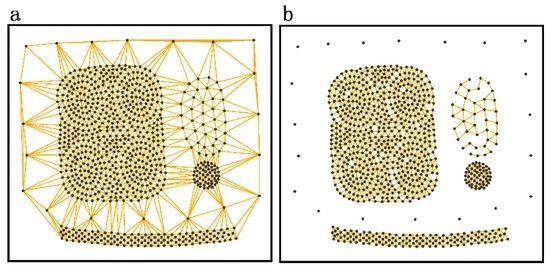
نتایج الگوریتم DTSC در اس1اس1و اس2اس2با توجه به مراحل بخش 3 به شرح زیر به دست می آیند: ابتدا، روابط مجاورت فضایی بر اساس مثلث سازی Delaunay با استفاده از استراتژی در بخش 3.1 به دست آمده و در شکل 8 و شکل 9 نشان داده شده است . دوم، خوشههایی با ویژگیهای مکانی و غیرمکانی مشابه (در شکل 10 a و شکل 11 a) با اتخاذ روش پیشنهادی در بخش 3.2 شناسایی میشوند . در نهایت، مقادیر ارزیابی دقت نتایج در جدول 1 نشان داده شده است .
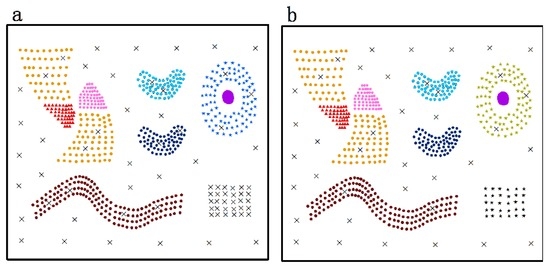
برای مقایسه، نتایج خوشه بندی الگوریتم خوشه بندی سری های زمانی مبتنی بر چگالی در شکل 10 ب و شکل 11 ب نشان داده شده است. یک خوشه به عنوان همان نماد با همان رنگ، و نویزها با یک “x” سیاه برچسب گذاری می شوند. شکلها نشان میدهند که الگوریتم خوشهبندی سریهای زمانی مبتنی بر چگالی به نویزها حساس است. مثلاً صداها تیص 1تیپ1به تیص 4تیپ4(که در اس1اس1و اس2اس2) به اشتباه به عنوان بخشی از خوشه های همسایه و نویزهای به تدریج در حال تغییر شناخته می شوند. جیp 1جیپ1(که در اس1اس1و اس2اس2) به اشتباه به عنوان یک خوشه شناسایی می شوند. علاوه بر این، الگوریتم خوشهبندی سریهای زمانی مبتنی بر چگالی برای خوشههایی با چگالیهای مختلف نامناسب است. سی4سی4(که در اس2اس2، با چگالی نسبتا کم، به اشتباه به عنوان نویز تشخیص داده می شود. هزینه محاسباتی روش های جدول 1 نشان می دهد که هر دو روش بسیار کارآمد هستند. با ترکیب شاخصهای ارزیابی دقت، میتوانیم ببینیم که الگوریتم DTSC پیشنهادی میتواند به طور مؤثر و دقیق خوشههای غیر همپوشانی با اشکال دلخواه و توزیع ناهموار ویژگیهای سری زمانی مکانی و غیر مکانی را تشخیص دهد.
4.1.3. مقایسه الگوریتم DTSC با پارامترهای بهینه و غیربهینه در حوزه فضایی
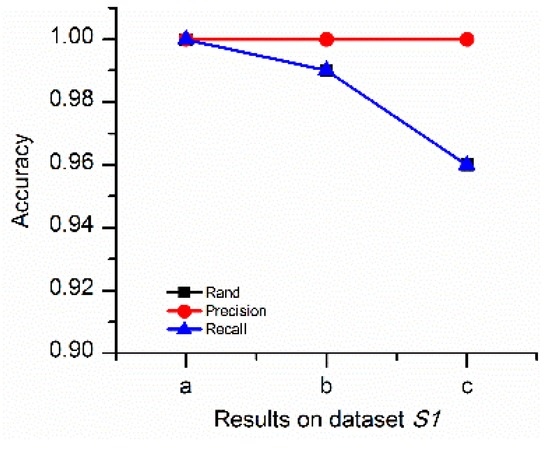
این بخش کاربرد روش بهینه سازی پارامتر شرح داده شده در بخش 3.1 را ارزیابی می کند . نتایج خوشه بندی از اس1اس1به دست آمده توسط الگوریتم DTSC با پارامترهای بهینه و غیر بهینه مقایسه شده است. مقدار بهینه پارامتر β�(در معادله (4)) با بزرگترین تابع ارزیابی پارامتر زز(در شکل 12 ) به طور خودکار با استفاده از روش بهینه سازی پارامتر به دست می آید. پارامتر غیر بهینه β�که به طور قابل توجهی با یکدیگر متفاوت است و پارامتر بهینه در بین محدوده های پارامتر تنظیم می شود.
نتایج خوشه بندی در اس1اس1(در شکل 13 ) نشان می دهد که مقدار پارامتر به شدت بر نتیجه تأثیر می گذارد. هنگامی که پارامتر کوچک است، چندین خوشه، مانند سی1سی1و سی7سی7، بیش از حد قطعه بندی شده اند و چندین شی در این خوشه ها به اشتباه به عنوان نویز تشخیص داده می شوند. هنگامی که پارامتر بزرگ است، خوشه های همسایه با چگالی متفاوت به عنوان یک خوشه شناسایی می شوند. به عنوان مثال، خوشه های همسایه سی1سی1و سی2سی2با چگالی های مختلف به عنوان یک خوشه شناخته می شوند. از طریق مقادیر ارزیابی دقت در شکل 14 ، می بینیم که نتیجه با پارامتر بهینه می تواند خوشه ها و نویزها را با بالاترین دقت نسبت به نتایج پارامترهای غیربهینه تشخیص دهد.
4.1.4. مقایسه الگوریتم DTSC با اندازهگیریهای شباهت پیشنهادی و اندازهگیریهای تشابه معمول در دامنه غیرمکانی
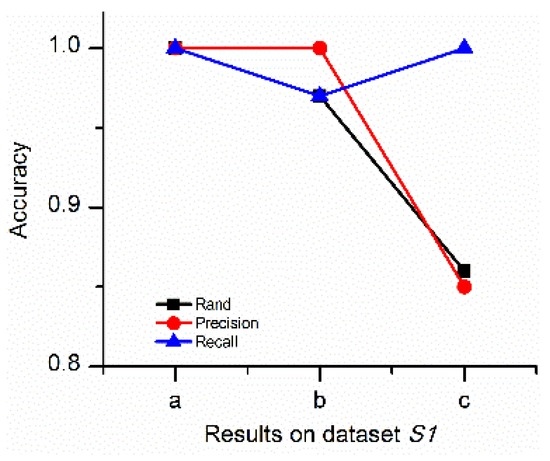
همانطور که در بخش 2.1 نشان داده شده است ، روش اندازه گیری شباهت جزء کلیدی الگوریتم خوشه بندی است. آزمایشها بر اساس اندازهگیریهای شباهت پیشنهادی، اندازهگیری شباهت فاصله اقلیدسی و اندازهگیری شباهت ضریب همبستگی پیرسون برای تأیید اندازهگیریهای شباهت پیشنهادی انجام میشوند. نتایج در اس1اس1در شکل 15 نشان داده شده است . نتایج DTSC بر اساس فاصله اقلیدسی ( شکل 15 ب) نشان می دهد که نویزهای نوع 3 قابل تشخیص نیستند. مثلاً صداها تیص 1تیپ1به تیپ 4تیپ4( شکل 15 ب) با روندهای مشخصه به طور قابل توجهی متفاوت از همسایگان خود به اشتباه به عنوان بخشی از خوشه همسایه شناسایی می شوند. نتایج DTSC بر اساس ضریب همبستگی پیرسون ( شکل 15 ب) نشان می دهد که نویزهای ویژگی های نوع 2 و 4 را نمی توان به درستی با این روش تشخیص داد. مثلاً صداها آ p 1آپ1به یک صفحه 8آپ8( شکل 15 ج) به اشتباه به عنوان بخشی از خوشه های همسایه و نویزهای به تدریج در حال تغییر شناخته می شوند. ج ص1جیپ1( شکل 15 ج) نیز به اشتباه به عنوان یک خوشه شناسایی شده اند. هم نتیجه DTSC بر اساس اندازهگیریهای شباهت پیشنهادی ( شکل 15 الف) و هم نتیجه دقت ( شکل 16 ) نشان میدهد که دقت DTSC با اندازهگیریهای شباهت پیشنهادی بالاترین است. بنابراین، اندازهگیریهای شباهت پیشنهادی موثر هستند.
4.2. مطالعه موردی DTSC بر روی داده های بارندگی
توزیع بارندگی به طور قابل توجهی تحت تأثیر موقعیت جغرافیایی، توپوگرافی، دما و فاصله تا اقیانوس ها، دریاچه ها و عوامل دیگر است، که بنابراین نشان می دهد که توزیع بارندگی به طور کلی ناهمگونی فضایی قوی دارد. ویژگی های توزیع خوشه ای بارندگی، زمینه را برای استخراج بیشتر مکانیسم بارش فراهم می کند. این خوشهبندی تلاشهای پیشبینی بارندگی آینده را بهبود میبخشد. روشهای خوشهبندی سریهای زمانی میتوانند با دقت ویژگیهای توزیع خوشهبندی پدیدهها را بدون به خطر انداختن کلیت تشخیص دهند. بنابراین الگوریتم DTSC پیشنهادی برای دادههای بارندگی سالانه برای استخراج الگوی خوشهبندی بارندگی اعمال میشود.شکل 17 .
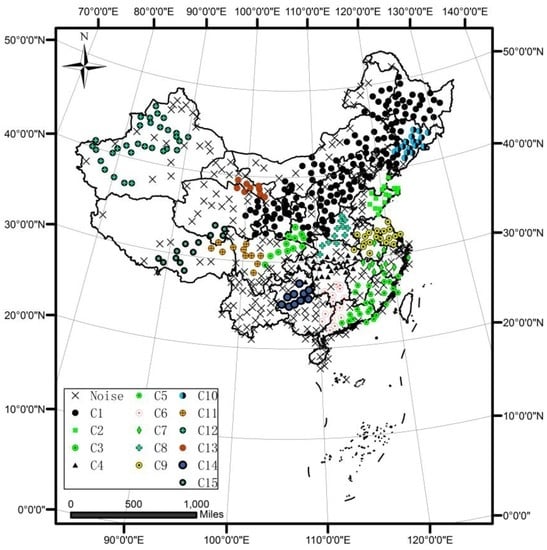
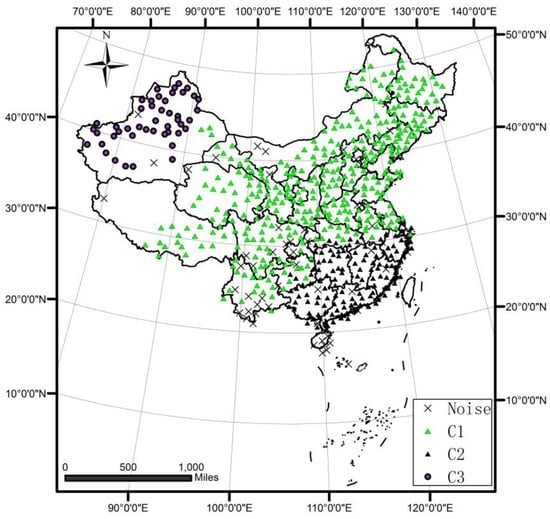
روند توزیع بارندگی در چین در طول دوره مورد مطالعه به تدریج از جنوب شرقی به شمال غربی کاهش می یابد. نتیجه خوشه بندی در شکل 18 و شکل 19 نشان داده شده است . چندین الگوی جالب که در پاراگراف بعدی به تفصیل توضیح داده خواهد شد، در نتایج کشف شده است. برای مقایسه، الگوریتم خوشه بندی سری های زمانی مبتنی بر چگالی نیز در مجموعه داده استفاده می شود و نتیجه آن در شکل 20 نشان داده شده است .
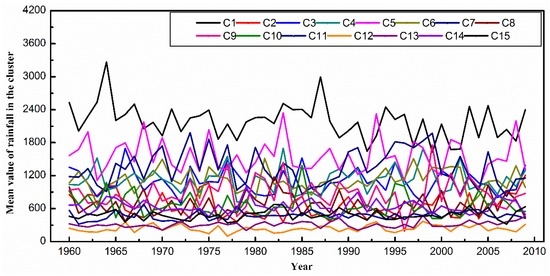
شکل 18 نشان می دهد که 15 خوشه جالب به دست آمد. میانگین و انحراف معیار خوشه ها در هر نقطه زمانی در شکل 19 و جدول 2 ذکر شده است.. خوشه های همسایه از نظر مقادیر و روندهای ویژگی سری زمانی غیرمکانی به طور قابل توجهی متفاوت هستند. پراکندگی و آمار خوشهها نشان میدهد که بارندگی از نواحی شمال غربی به جنوب شرقی به تدریج افزایش یافته است. خوشه های C1، C12، C13 و C15 در نواحی شمالی و شرقی دارای بارندگی کم و نسبتاً پایدار هستند. با این حال، خوشههای دیگر در بخشهای شرقی و جنوبی بارندگی فراوانی را تجربه میکنند و در طول زمان به شدت در نوسان هستند. در این مناطق، خوشههایی با مقادیر مشخصه سری زمانی و روندهای متفاوت یا که توسط نویزها از هم جدا شدهاند، توسط الگوریتم DTSC پیشنهادی به درستی شناسایی میشوند. علاوه بر این، هو و همکاران. [ 21] بیان کرد که خط جداکننده بین C1 و C2، C3، C8 و C10 با خط مناطق نیمه مرطوب و نیمه خشک سازگار است. این نتایج با شرایط واقعی سازگار است. مناطقی که به عنوان نویز شناخته می شوند ناپایدار هستند و در حوزه فضایی بسیار متفاوت هستند. این مناطق می توانند به عنوان پایه ای برای رویدادهای دورتر و پدیده های شدید آب و هوایی عمل کنند.
در مقایسه با نتایج الگوریتم خوشهبندی سریهای زمانی مبتنی بر چگالی در شکل 20 ، خوشههایی با مقادیر مشخصه سری زمانی و روندهای متفاوت بهعنوان خوشههای یکسان شناسایی میشوند. با ترکیب آمار در جدول 2 ، می بینیم که انحراف استاندارد خوشه ها به طور جدی بزرگتر از نتیجه به دست آمده توسط الگوریتم DTSC است.
به طور خلاصه، دو یافته مهم از کاربرد DTSC برای داده های بارندگی به دست می آید. ابتدا، خوشههایی با مقادیر مشخصه سری زمانی و روند مشابه با استفاده از الگوریتم DTSC شناسایی میشوند. دوم، ویژگی های خوشه ها با ترکیب آمار آنها و مطالعات موجود تجزیه و تحلیل می شود. این ترکیب یک مرجع مهم برای تجزیه و تحلیل مکانیسم بارش و پیش بینی فراهم می کند.
5. بحث و کار بیشتر
در این مقاله، یک الگوریتم DTSC برای تشخیص تطبیقی خوشههای اشیاء با مجاورت فضایی و مقادیر و روندهای ویژگی سری زمانی مشابه پیشنهاد شد. الگوریتم پیشنهادی از دو تکنیک مهم برای تحقق یک روش خودکار برای تشخیص خوشهها استفاده میکند. اولین تکنیک استفاده ترکیبی از عملیات ساخت مجاورت فضایی در DBSC و PSO است که به طور قابل توجهی به کشف خودکار مجموعههای اشیاء همگن فضایی با مجاورت فضایی، چگالیهای مشابه و اشکال دلخواه کمک میکند. روش دیگر ترکیب استراتژی خوشهبندی غیرمکانی در DBSC با اندازهگیریهای شباهت پیشنهادی است که بر اساس آن DTSC میتواند خوشههای غیر همپوشانی را با مقادیر و روندهای ویژگی سری زمانی مشابه به درستی تشخیص دهد.
آزمایشها روی مجموعه دادههای شبیهسازیشده و یک کاربرد واقعی، کارایی الگوریتم DTSC را تأیید کردهاند. بنابراین چند نتیجه به شرح زیر خلاصه می شود. ابتدا الگوریتم DTSC می تواند اشیاء با چگالی های مختلف را جدا کرده و با استفاده از PSO از تقسیم بندی بیش از حد و کم تقسیم بندی جلوگیری کند. دوم، الگوریتم DTSC به طور خودکار خوشههایی را با ویژگیهای مکانی مشابه و مقادیر و روند ویژگیهای سری زمانی غیرمکانی شناسایی میکند. سوم، در مقایسه با الگوریتمهای سنتی که خوشهها را شناسایی میکنند اما به چندین پارامتر از پیش تعریفشده نیاز دارند، الگوریتم DTSC میتواند ویژگیهای توزیع دادهها را بدون دانش قبلی کافی استخراج کند. چهارم، صداهایی با ویژگیهای قابل توجهی متفاوت از همسایگان را میتوان به راحتی با دقت معقولی تشخیص داد. در آخر،
بر اساس مطالعه فعلی، مطالعات آتی باید بر روی موارد زیر تمرکز کنند: (1) افزایش کارایی محاسباتی DTSC با استفاده از استراتژیهای پیشرفتهتر مانند روش کاهش ابعاد [ 22 ]. (2) گسترش DTSC به برنامه های کاربردی با متغیرهای متعدد. و (3) ترکیب قوانین ارتباط با DTSC برای استخراج ارتباط خوشه ها با سایر عوامل همزیستی که می تواند اطلاعات اساسی را برای تجزیه و تحلیل مکانیسم بیشتر فراهم کند.








بدون نظر