

خلاصه
پیشرفت تلفنهای هوشمند مجهز به GPS امکان جمعآوری دادههای مسیر حرکت انسان را در مقیاسهای وسیع فراهم کرده است که میتوان از آنها در توصیه مسیر، برنامهریزی شهری و مدیریت ترافیک استفاده کرد. در این کار ما یک سرور نقشه سریع ارائه میکنیم که میتواند نقشههای حرارتی مسیرهای محبوب را بهصورت آنلاین از دادههای مسیرهای ورزشی عظیم بر اساس ترجیحات مشتری، به عنوان مثال، مسیرهای در حال اجرا کمتر از یک ساعت، تولید و تجسم کند. نقشه های حرارتی نشان داده شده با نشان ندادن مسیرهایی با تعداد کمتر از پیش تعریف شده کاربر مختلف، به عنوان مثال پنج، به حریم خصوصی کاربر احترام می گذارد. نتایج با استفاده از یک لایه کاشی پویا به مشتری نشان داده می شود. اجرای فعلی از داده های جمع آوری شده توسط برنامه موبایل Sports Tracker با بیش از 800000 مسیر مختلف و 2.8 میلیارد نقطه داده GPS استفاده می کند.
کلید واژه ها:
کلان داده ؛ نقشه حرارتی ؛ حریم خصوصی داده ها
1. معرفی
تلفن های همراه در دو دهه اخیر تقریباً به طور کامل در جامعه نفوذ کرده اند. تخمین زده می شود که تعداد کل اشتراک های تلفن همراه تا پایان سال 2015 به 97 درصد از جمعیت جهان می رسد [ 1 ]. این تحول نحوه ارتباط افراد و دسترسی به اطلاعات را به شدت تغییر داده است. در این دوره زمانی خود گوشی های موبایل نیز به طور قابل توجهی تغییر کرده اند. از نظر فناوری اوایل دهه 1990، یک تلفن مدرن دارای عملکردهایی از رایانه، پخش کننده سی دی، تلفن، رادیو و دوربین فیلمبرداری است. علاوه بر این ویژگیها، تلفنهای هوشمند ممکن است دارای حسگرهای پیشرفتهای مانند شتابدهندهها و گیرندههای GPS باشند که امکان جمعآوری دادهها را در مقیاس بزرگ فراهم کردهاند. اندازه گیری ها را می توان به عنوان مثال برای پیش بینی رفتار کاربر بر اساس میزان استفاده از تلفن استفاده کرد [2 ، برای ردیابی تحرک انسان با داده های مکان از تلفن ها [ 3 ]، برای نظارت بر ترافیک در زمان واقعی [ 4 ] یا استفاده از تلفن همراه برای اندازه گیری سطح زمین و فرآیندهای آن [ 5 ].
تلفن های همراه همچنین نحوه پیگیری فعالیت های ورزشی کاربران را تغییر داده اند. انواع جدید برنامه های ورزشی موبایل، از جمله Nike+ [ 6 ]، Sports Tracker [ 7 ] و Strava [ 8 ]]، به کاربران این امکان را می دهد که داده های دقیقی را در مورد مسیرهای خود جمع آوری کنند و پیشرفت خود را دنبال کنند. یک ضبط ورزشی شامل دادههای مکان است که در فواصل زمانی تقریباً یکسان نمونهبرداری میشود، به عنوان مثال، هر ثانیه، همراه با برخی دادههای دیگر وابسته به برنامه و نوع تلفن، برای مثال، ضربان قلب یا مصرف انرژی در طول فعالیت. یک فعالیت ورزشی می تواند از چند دقیقه تا ساعت طول بکشد که منجر به هزاران نقطه داده در هر مسیر شود. برای یک برنامه ورزشی محبوب با صدها هزار کاربر فعال، داده های تولید شده را می توان در صدها گیگابایت در روز اندازه گیری کرد. جنبههای اجتماعی این برنامهها نیز قابل توجه است: کاربران میتوانند برای مثال مسیرهایی را که طی کردهاند توصیه کنند یا نتایج خود را برای تشویق رقابت دوستانه به اشتراک بگذارند.
دادههای فعالیت جمعآوریشده را میتوان به روشهای بسیاری برای درک بهتر تحرک انسان مورد استفاده و مطالعه قرار داد. یکی از راه ها یافتن مسیرهایی در میان داده هایی است که محبوب هستند. این اطلاعات می تواند برای ارائه توصیه های مسیر به کاربران [ 9 ] یا برای کمک به بهبود شبکه جاده ها و برنامه ریزی شهری استفاده شود [ 10 ، 11 ]. این سرویس را میتوان در قالب نرمافزار بهعنوان سرویس (SaaS) به مشتریان ارائه کرد، که در آن کاربران میتوانند به دنبال مسیرهای محبوب مطابق با علایق خود در نزدیکی مکانشان بگردند، بهعنوان مثال، مسیرهایی که حداقل 30 دقیقه طول میکشید، بیشتر از 5 بودند. کیلومتر و در خرداد ماه ثبت شد. Strava نقشه گرمای جهانی را منتشر کرده است [ 12] که مسیرهای محبوب جهانی را از تقریباً 80 میلیون مسیر دوچرخه سواری و 20 میلیون مسیر دویدن از طریق Google Maps نشان می دهد [ 13 ]. با این حال، این سرویس به نقشههای حرارتی ساکن بدون گزینه فیلتر کردن دادههای مسیر محدود میشود. برای نقشه های ایستا، کاشی ها از قبل محاسبه شده و در صورت درخواست به راحتی بازیابی می شوند. با این حال، زمانی که تعداد انتخاب های مختلف فیلتر توسط کاربر بسیار زیاد است، امکان محاسبه از پیش تجسم ها وجود نخواهد داشت و در عوض باید در زمان درخواست ایجاد شوند.
یکی از مشکلات در نمایش مسیرهای محبوب این است که مردم تمایل دارند در مسیرهای مشابه حرکت کنند، به عنوان مثال، هنگام خروج از خانه یا رفت و آمد. این بدیهی است که می تواند باعث مشکلات حریم خصوصی [ 14 ، 15 ] در یک نقشه حرارتی شود که در آن مکان خانه کاربران به وضوح قابل مشاهده است. یکی از راهحلها این است که نقشههای حرارتی تولید شده را با شمارش تعداد کاربران جداگانه برای هر پیکسل ناشناس کنید. اجرای این در مقایسه با یک جمعبندی ساده روی مسیرها، پیچیدگی را به تولید نقشه حرارتی میافزاید. برای تعداد زیادی از مسیرها و کاربران خدمات، این نوع تولید نقشه حرارتی تعاملی به عملکرد محاسباتی بالایی نیاز دارد.
در این مطالعه ما یک سرور نقشه حرارتی طراحی و پیادهسازی میکنیم که نقشههای حرارتی را به صورت تعاملی از بیش از نیم میلیون آهنگ ناشناس ارائه شده توسط Sports Tracking Technologies Ltd (هلسینکی، فنلاند) تولید میکند. نتایج در یک صفحه وب با استفاده از یک لایه کاشی پویا به کاربر ارائه می شود. با استفاده از یک سرور گره می توانیم صدها درخواست شبیه سازی شده در ثانیه را با تاخیر بسیار کمی پشتیبانی کنیم. از این نوع خدمات می توان برای یافتن و نمایش مسیرهای محبوب برای ورزشکاران یا برنامه ریزان شهری که خواهان بهبود زیرساخت های شهری هستند استفاده کرد.
مقاله بصورت زیر مرتب شده است. کارهای مرتبط قبلی در بخش 2 ارائه شده است . بخش 3 داده های ردیابی ارائه شده توسط Sports Tracking Technologies Ltd (فنلاند) را شرح می دهد. در بخش 4 ما مراحل انجام شده برای پیش پردازش داده ها و نحوه عملکرد واقعی نقشه حرارتی را ارائه می دهیم. نتایج حاصل از تست استرس که با Apache JMeter [ 16 ] انجام شد در بخش 5 آورده شده است. در نهایت، ما در بخش 6 با بحث در مورد چگونگی توسعه بیشتر سرور نقشه حرارتی نتیجه گیری می کنیم.
2. کارهای مرتبط
راه های زیادی برای یافتن مسیرهای محبوب از داده های GPS وجود دارد. یک روش خاص از تکنیک های خوشه بندی استفاده می کند. برای بررسی روش های مختلف خوشه بندی، [ 17 ] را ببینید. برای مثال می توان این کار را با استفاده از روش های هسته انجام داد [ 18]، که در آن تجسم بر اساس تعداد کل آهنگ ها در یک مکان مشخص است. با این حال، استفاده از این روش در دادههای GPS میتواند الزام حریم خصوصی پنهان کردن ردیابیهای یک کاربر را نقض کند. نقشههای حرارتی که محاسبه میکنیم بهعنوان تعداد کاربران مختلف در یک پیکسل از نقشه تعریف میشوند. اگر این عدد کمتر از یک مقدار از پیش تعریف شده باشد، مثلاً پنج، پس از شمارش همه کاربران، پیکسل شفاف تنظیم می شود. به عنوان مثال، اگر تنها یک کاربر یک مسیر را چندین بار طی کند، روی نقشه حرارتی نشان داده نمی شود. روشهای جایگزین برای محاسبه نقشههای حرارتی آگاه از حریم خصوصی در [ 19 ] ارائه شدهاند]. تعداد کاربران همچنین می تواند به عنوان یک فیلتر برای روش های دیگر استفاده شود. به عنوان مثال، ما یک آهنگ شمار را پیاده سازی کرده ایم که تعداد کل آهنگ ها را در یک پیکسل می شمارد و اگر تعداد کاربران خیلی کم باشد شفاف می شود. با این حال، در اینجا تاکید بر ارائه فنآوریهای مختلف افزایش حریم خصوصی نیست، بلکه نشان میدهد که حداقل برخی از تکنیکهای ساده آگاه از حریم خصوصی را میتوان با موفقیت به کار برد، حتی زمانی که کل زمان صرف شده برای تولید نقشههای حرارتی دهها میلیثانیه باشد.
مطالعات قبلی در مورد تولید سریع نقشه حرارتی با معیارهای جستجوی قابل انتخاب توسط کاربر، از نقاط تک بعدی در فضا و زمان، به عنوان مثال، [ 20 ]، یا از اجسام گسترش یافته فضایی برای تخمین چگالی استفاده کرده است [ 21 ]. همچنین تا جایی که می دانیم این روش ها حریم خصوصی را رعایت نمی کنند. بر خلاف این بخشهای قبلی، برنامه ما آهنگهای گسترشیافته فضایی را که به صورت محلی به یکدیگر متصل میشوند، دستکاری میکند. علاوه بر این، روش ما با نمایش تنها آن دسته از معیارهای کاربر که مسیرهایی را که حداقل تعداد از پیش تعیین شده ای از ورزشکاران مجزا در آنها مشارکت داشته اند، به حریم خصوصی احترام می گذارد.
3. داده ها
داده های اصلی برای نقشه های حرارتی توسط Sports Tracking Technologies Ltd. (هلسینکی، فنلاند) ارائه شده است و شامل ضبط های مسیر است که توسط ورزشکار به صورت عمومی علامت گذاری شده است. داده ها از اطلاعات کاربر توسط Sports Tracker ناشناس شده است. اطلاعات موجود در یک فایل عبارتند از شناسه هش شده کاربر، نوع فعالیت مسیر و داده های ردیابی واقعی (مهر زمانی، طول جغرافیایی، عرض جغرافیایی و ارتفاع) که در فاصله زمانی نزدیک به ثابت ثبت شده است. مهر زمانی بر حسب میلی ثانیه از زمان یونیکس در 1 ژانویه 1970، ساعت 0:00:00 UTC نشان داده شده است. محبوب ترین انواع فعالیت ها دوچرخه سواری و دویدن هستند و نتایج مربوط به آنها در اینجا ارائه خواهد شد.
پس از بررسی دقیقتر، مشاهده شد که دادههای GPS کاملاً نویز دارند و بسیاری از مسیرها حداقل یک بار سیگنال ردیابی را از دست داده بودند. برای حذف پر سر و صداترین مسیرها، داده ها با نیاز به اینکه فاصله بین دو نقطه متوالی باید کمتر از یک کیلومتر باشد فیلتر شد. این با فرمول هارسین [ 22 ] برای یک زمین کروی محاسبه شد. همچنین تصمیم گرفتیم تراکهایی را که دارای مهر زمانی نامعتبر هستند، به عنوان مثال، حذف کنیم. معیار مربوط به زمان دلیل در بیش از 90 درصد از مسیرهایی بود که حذف شدند. آهنگهای فیلتر شده در فایلهای فرمت داده سلسله مراتبی (HDF5) نوشته شدند [ 23] با فعالیت های مختلف کاربر ذخیره شده در فایل های منحصر به فرد. حجم کل این فایل ها با داده های فعلی تقریباً 37 گیگابایت است، تقریباً 2.8 میلیارد نقطه داده GPS در بیش از 800000 مسیر شمال اروپا از جمله هلند و بلژیک را پوشش می دهد، با تمرکز آشکار در شهرهای بزرگ و مناطق پرجمعیت.
برای نشان دادن تنوع دادههای ورودی ما با توجه به میانگین سرعت و طول مسیرها، که طول کل مسیر را میتوان تخمین زد، هیستوگرامهای فیلتر شده دادههای دویدن و دوچرخهسواری را در شکل 1 و شکل 2 ترسیم کردهایم. ، به ترتیب. در هر دوی اینها، مسیرها را از نظر مدت زمان و سرعت متوسط جمع می کنیم vخیابان�خیابانفضا و نمایش آنها به صورت نمودارهای چگالی با هیستوگرام های حاشیه ای. تعریف می کنیم vخیابان= Δ l / Δ t�خیابان=Δل/Δتی، جایی که Δ lΔلو Δ tΔتیبه ترتیب طول و مدت زمان کل مسیر هستند. یک پیست با سرعت و مدت متوسط بالا نشان دهنده ورزش استقامتی است.
در شکل 1 ، هیستوگرام تمام 246390 مسیر دویدن را توسط 23343 دونده رسم کرده ایم. یکی از ویژگی های طرح، خطوط کانتور به وضوح قابل تشخیص است. آنها به دلیل دویدن یک مسافت ثابت با مدت زمان های مختلف، به عنوان مثال، در یک مسابقه ایجاد می شوند. ماراتن های شهری محبوب نمونه های خوبی از این نوع اجراها هستند که در داده ها قابل مشاهده هستند. در نمودار این منحنی ها مطابقت دارند vخیابانΔ t = C�خیابانΔتی=سیکه در آن C فاصله کل ثابت است. از نظر کیفی، توزیع سرعت گوسی به نظر می رسد، در حالی که هیستوگرام طول مدت شبیه یک توزیع اساسا log-normal است.
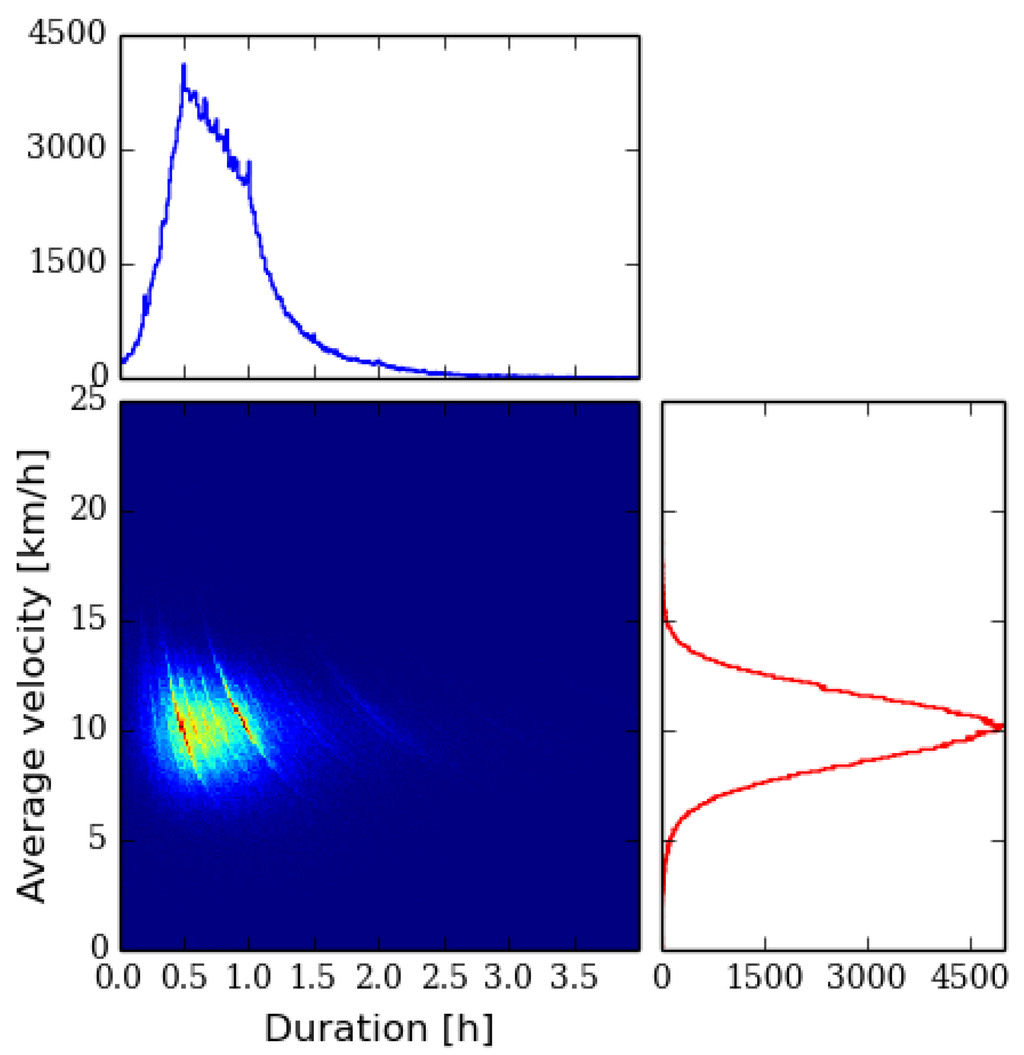
شکل 1. هیستوگرام مسیرهای در حال اجرا از نظر مدت زمان و سرعت متوسط با هیستوگرام های حاشیه ای.

شکل 2. هیستوگرام مسیرهای دوچرخه سواری از نظر مدت زمان و سرعت متوسط با هیستوگرام های حاشیه ای.
برای 149784 پیست دوچرخه سواری توسط 18163 دوچرخه سوار، توزیع در شکل 2 دارای ویژگی هایی شبیه توزیع مسیر دویدن است. تفاوت اصلی این است که توزیع مدت زمان طولانی تری دارد و برخی از اجراها چندین ساعت طول می کشند. وجود خطوط کانتور به اندازه داده های در حال اجرا متمایز نیست.
یک سوال جداگانه این است که آیا مجموعه داده ما به عنوان نمونه ای از ترجیحات دویدن و دوچرخه سواری کل جمعیت، مغرضانه است یا غیر مغرضانه. ما استدلال می کنیم که سرور نقشه حرارتی طراحی و پیاده سازی شده در این کار به هیچ وجه به این ویژگی متکی نیست. در عوض، سرور نقشه حرارتی بدون توجه به نقشه های حرارتی، نقشه های حرارتی را تولید می کند، و این بر عهده کاربر خواهد بود که تصمیم بگیرد چگونه نقشه حرارتی باید تفسیر و استفاده شود.
4. تولید نقشه حرارتی
هدف تولید نقشه های حرارتی است که با استفاده از یک سرور نقشه به کاربر نهایی نمایش داده می شود. ما فرض میکنیم که نقشه پسزمینه توسط سرور دیگری میزبانی میشود یا از قبل تولید شده است و از طرح Mercator [ 24 ] با یک زمین کروی استفاده میکند. از هرم کاشی برای ذخیره و نمایش نقشه حرارتی ایجاد شده با سایز کاشی ۲۵۶ در ۲۵۶ پیکسل استفاده می کنیم. این برنامه به زبان C++ با استفاده از کتابخانه fastCGI برای ارتباط با سرور HTTP آپاچی نوشته شده است. ما از یک صف کار و رشته های C++11 در برنامه و mpm-worker در آپاچی برای بارگذاری تعادل در رسیدگی به درخواست سرویس استفاده می کنیم.
تولید کارآمد نقشه های حرارتی به پیش پردازش داده های زیادی نیاز دارد تا میزان محاسبات در زمان درخواست کاهش یابد. پیش بینی Mercator به توابع ماورایی بستگی دارد که از نظر محاسباتی گران هستند. برای 2.8 میلیارد نقطه GPS، این منجر به صرف زمان قابل توجهی در تولید نقشه حرارتی و تاخیر قابل توجه در وب سرویس می شود. بعلاوه، نقاط داده GPS مجاور اغلب به همان پیکسل نگاشت می شوند که منجر به محاسبات اضافی برای نقشه حرارتی می شود. ما تصمیم گرفتیم ابتدا تمام داده ها را با شطرنجی کردن آهنگ ها، تقسیم آنها به کاشی های سطح زوم و مرتب سازی داده ها در کاشی ها، از قبل پردازش کنیم. سپس داده های از پیش پردازش شده را می توان به طور موثرتری برای ایجاد نقشه های حرارتی بازیابی کرد.
4.1. پیش پردازش داده ها
داده های مکانی با شطرنجی کردن هر مسیر پیش پردازش شده و شطرنجی سازی با استفاده از پیکسل های کاشی ها انجام می شود. مزایای اصلی این است که پیش بینی های گران قیمت Mercator به صورت آفلاین محاسبه می شوند و اندازه داده ها به میزان قابل توجهی کاهش می یابد. نقطه ضعف این فرآیند این است که اطلاعات مربوط به ترتیب بازدید از پیکسل ها از بین می رود. با این حال، برای این سرویس نقشه حرارتی، این غیر مهم است. برای بهینهسازی محاسبه نقشه حرارتی، یک مسیر شطرنجی لزوماً در یک کاشی نگهداری نمیشود، بلکه بر اساس کاشیهایی که روی آنها همپوشانی دارند به بخشهایی تقسیم میشود. در طول تولید نقشه حرارتی، برنامه به سرعت تمام بخشهای مسیر را در یک کاشی مطابق با عبارت جستجو پیدا میکند و نقشه حرارتی را از نتایج محاسبه میکند.
کلید یافتن سریع بخشهای آهنگ منطبق با پرس و جوی کاربر نهایی، فهرستبندی کارآمد دادههای مسیر است. این کار را با استفاده از تاپل ( z, a c t i v i t y، مo r t o nمن n de x�،آجتیمن�منتی�،م��تی��من�دهایکس) به عنوان شاخص، جایی که مo r t o nمن n de xم��تی��من�دهایکسمرتبه Z یا مقدار مورتون [ 25 ] مختصات کاشی در سطح زوم z است. این با درهم کردن نمایش های دودویی مختصات محاسبه می شود. داده ها با توجه به شاخص مرتب می شوند و بنابراین بخش های ردیابی در یک کاشی خاص مطابق با یک فعالیت را می توان به راحتی پیدا کرد. در مرحله پیش پردازش، بخشهای آهنگ را از کاربران فردی با همان مقدار شاخص جمعآوری میکنیم.
مسیرهای کاربر به صورت متوالی پردازش می شوند. یک آهنگ ابتدا در سطح بزرگنمایی اولیه شطرنجی می شود و سپس بر اساس کاشی هایی که در این سطح بزرگنمایی با آن تلاقی می کنند به بخش هایی تقسیم می شود. سطح زوم اولیه 14 تنظیم شده است که منجر به وضوح پیکسل 9.55 در 9.55 متر می شود. نقاط GPS یک مسیر نمونه همراه با پایین ترین سطح شبکه Mercator آن در شکل 3 a و مسیر شطرنجی مربوطه در شکل 3 b نشان داده شده است. اگر یک مسیر شطرنجی پیوسته نباشد، یعنی پیکسل های گم شده در یک مسیر وجود داشته باشد، الگوریتم برسنهام [ 26 ]] برای پر کردن پیکسل های از دست رفته استفاده می شود. پیکسل های داخل کاشی های 256 در 256 با استفاده از اعداد صحیح 16 بیتی ایندکس می شوند و مقادیر منحصر به فرد در یک بردار کتابخانه قالب استاندارد C++ (STL) ذخیره می شوند. برای این برنامه ما از شاخص های مورتون برای مختصات پیکسل در یک کاشی استفاده می کنیم، اگرچه می توان از یک نمایه سازی خطی با گامی برابر با 256 استفاده کرد. استفاده از اعداد صحیح 16 بیتی به ما اجازه می دهد تا ردپای حافظه را کاهش دهیم. آهنگهایی با مقدار شاخص تاپل یکسان به همان بردار اضافه میشوند. سپس سطح زوم یک بار کاهش می یابد و همان روش شطرنجی سازی روی مسیر انجام می شود. این روند تا رسیدن به کمترین سطح زوم برای نقشه حرارتی که ما انتخاب کرده ایم ادامه می یابد zm i n= 3�مترمن�=3. نتیجه نهایی این است که مسیرهای کاربر در تمام سطوح زوم مورد استفاده در سرویس نقشه حرارتی پیکسل شده است. برای تخمین تعداد نقاط شطرنجی برای یک مسیر معمولی در سطح زوم 14، یک مسیر معمولی را از شکل 2 انتخاب می کنیم که یک مسیر دوچرخه سواری با سرعت متوسط 20 کیلومتر در ساعت و مدت زمان 1 ساعت به دست می آید. با فرض اینکه نیمی از این مسیر در یک جهت قطب نما اصلی تولید می شود 10 000 / 9 . _ 55 ≈ 105010،000/9.55≈1050پیکسل ها در حالی که نیمه دیگر در جهت قطب نمای جزئی قرار دارد 10 000 / ( 9. 55 × _ _2–√) ≈ 74010،000/(9.55×2)≈740پیکسل، در مجموع 1800 پیکسل داریم.
در طول فرآیند شطرنجی، ما برخی از ابردادههای مربوط به یک مسیر را محاسبه میکنیم که میتوان از آن برای فیلتر کردن مسیرها استفاده کرد. اینها شامل طول مسیر، مدت زمان و سرعت متوسط است. ما همچنین تعداد شاخصهای کاشی محلی نوشته شده در بردار STL را برای هر بخش آهنگ ذخیره میکنیم. هنگامی که مسیرهای کاربر پردازش شد، بردارهای STL با اندیسهای چندگانه مختلف در یک بردار STL طولانی ترکیب میشوند، که ما آن را در قالب باینری روی دیسک مینویسیم. ایندکس تاپلی همراه با ابرداده برای یک قطعه آهنگ در سرور PostgreSQL نوشته میشود، که به عنوان یک ذخیرهسازی طولانی مدت برای دادهها کار میکند. PostgreSQL همچنین برای توزیع داده ها به سروری که نقشه های حرارتی را محاسبه می کند استفاده می شود. از آنجایی که سرورهای PostgreSQL را می توان ادغام کرد، می توان از آنها برای ذخیره مقادیر بسیار بیشتری از داده ها از آنچه در حال حاضر داریم استفاده کرد.

شکل 3. ( الف ) آهنگ اصلی به رنگ آبی همراه با شبکه شطرنجی ارائه شده توسط طرح مرکاتور در سطح زوم 14 با اندازه کاشی 256 در 256 پیکسل نمایش داده می شود. ( ب ) مسیر شطرنجی شده که با الگوریتم رسم خط برزنهام [ 26 ] تکمیل شده است تا پیکسل های از دست رفته را پر کند.
4.2. ایجاد نقشه
نتیجه نهایی مرحله پیش پردازش این است که تمام مسیرهای فیلتر شده شطرنجی شده و در سطوح بزرگنمایی جداگانه به کاشی ها تقسیم شده اند. ابرداده مربوط به آهنگ ها با شاخص های فضایی کاشی ها در یک جدول PostgreSQL ذخیره می شود. تولید نقشه حرارتی اساساً پرس و جوهای سریعی را در پایگاه داده ایجاد می کند و نتایج را در لحظه تجسم می کند. با این حال، بازیابی نتایج از PostgreSQL به C++ یک گلوگاه عملکرد در طول توسعه برنامه بود. برای بهبود عملکرد، فراداده و دادههای شاخص مکانی را از PostgreSQL در حافظه محلی میخوانیم و از آن به عنوان پایگاه داده استفاده میکنیم. ما از کتابخانه CUDA Thrust [ 27 ] برای ذخیره و دسترسی سریع به داده ها استفاده می کنیم. بردارهای STL نیز از روی دیسک در حافظه خوانده می شوند.
ستونهای پایگاه داده برای جدا کردن بردارهای میزبان Thrust ذخیره میشوند که برای ایجاد یک بردار کلید و یک بردار مقدار به یکدیگر فشرده میشوند. ما استفاده می کنیم ( z, a c t i v i t y، مo r t o nمن n de x ، u s e r _ i d, t r a c k _ s t a r t�،آجتیمن�منتی�،م��تی��من�دهایکس،توسه�_مند،تی�آجک_ستیآ�تی) تاپل ها به عنوان کلید با مقادیر داده شده توسط ( m o n t h , t r a c k _ s i zهمتر��تیساعت،تی�آجک_سمن�ه) تاپل ها در اجرای فعلی. اینجا u s e r _ i dتوسه�_مندمتغیر یک شناسه عدد صحیح منحصر به فرد است که به همه شناسه های کاربر هش شده اختصاص داده شده است در حالی که t r a c k _ s t a r tتی�آجک_ستیآ�تیو t r a c k _ s i zهتی�آجک_سمن�هاصطلاحات مربوط به فایل های باینری هستند که در مرحله پیش پردازش نوشته شده اند: t r a c k _ s t a r tتی�آجک_ستیآ�تیافست را از ابتدای فایل و t r a c k _ s i zهتی�آجک_سمن�هبه برنامه می گوید که چند عنصر را بخواند. مقادیر بر اساس کلید مرتب شده اند تا امکان استفاده از t h r u s t : : l o w e r _ b o u n dتیساعت�توستی::ل��ه�_ب�تو�دو t h r u s t : : u p e r _ b o u n d _تیساعت�توستی::توپپه�_ب�تو�دتوابع برای یافتن بخش های آهنگ با مقادیر خاص z ، a c t i v i t yآجتیمن�منتی�و مo r t o nمن n de xم��تی��من�دهایکس.
ایجاد نقشه با درخواستی از مشتری وب شروع می شود که منطقه جغرافیایی مورد علاقه، سطح بزرگنمایی، نوع فعالیت و احتمالاً برخی معیارهای جستجوی دیگر مانند ماه سال و/یا زمان روز را مشخص می کند. این کار توسط سرور HTTP (در مورد ما سرور HTTP Apache) انجام می شود که درخواست را به نقشه ایجاد شبح ارسال می کند. ابتدا بررسی می کند که آیا کاشی نقشه حرارتی درخواستی از قبل وجود دارد یا باید ایجاد شود. یک درخواست پایگاه داده بر اساس کلید تاپل ( z, a c t i v i t y، مo r t o nمن n de x ، u s e r _ i d, t r a c k _ s t a r t�،آجتیمن�منتی�،م��تی��من�دهایکس،توسه�_مند،تی�آجک_ستیآ�تی). سپس بخشهای آهنگ با مقادیر منطبق با the یافت میشوند t h r u s t : : l o w e r _ b o u n dتیساعت�توستی::ل��ه�_ب�تو�دو t h r u s t : : u p e r _ b o u n d _تیساعت�توستی::توپپه�_ب�تو�دکارکرد. سپس آنها را اسکن می کنیم و نتایج را بر اساس بقیه معیارهای جستجو فیلتر می کنیم (در حال حاضر ماه سال است، اما به راحتی می توان آن را گسترش داد). از آن عناصر بردار زیپ شده که از فیلتر عبور می کنند ما کپی می کنیم u s e r _ i dتوسه�_مند، t r a c k _ s t a r tتی�آجک_ستیآ�تیو t r a c k _ s i zهتی�آجک_سمن�هبه بردارهای جدید تعداد شطرنجی کاربر از اینها با الگوریتم 1 محاسبه میشود، جایی که اساساً تمام پیکسلهای منحصربهفردی که کاربر بازدید کرده است را در یک کاشی مییابیم و مقادیر مربوطه را در یک آرایه تعداد کاربر افزایش میدهیم. وقتی همه کاربران پردازش شدند، برای حفظ حریم خصوصی، اکنون پیکسلها را با تعداد کاربران کمتر از مثلاً پنج عدد صفر میکنیم. سپس نتیجه به صورت یک تصویر PNG در حافظه پنهان کاشی نوشته می شود و در نهایت برای سرویس گیرنده وب ارسال می شود. بزرگترین مقادیر تعداد کاربر به احتمال زیاد در شهرهایی یافت می شود که اندازه جمعیت معمولاً از قانون Zipf یا قانون قدرت پیروی می کند [ 28 ]]. ما در حال حاضر از یک مقیاس لگاریتمی برای رنگهای پیکسل استفاده میکنیم تا مرتبههای مختلف بزرگی تعداد کاربران را به طور یکنواختتر پوشش دهیم. امکان دیگر استفاده از معیارهای محلی برای برجسته کردن مسیرهای محبوب است، به عنوان مثال، با محاسبه توزیع تعداد کاربران در یک کاشی و هشت کاشی همسایه آن و استفاده از یک مقدار آستانه برای رنگ آمیزی پیکسل ها، به عنوان مثال، نقشه حرارتی Strava در حال حاضر از یک محلی استفاده می کند. رنگ آمیزی نکته مثبت این رنگ آمیزی محلی این است که مسیرهای محبوب محلی را واضح تر نشان می دهد و به وسعت جمعیت شهر حساس نیست.
| الگوریتم 1: محاسبه شطرنجی شماره کاربر |
|
5. نتایج
این سرور از یک سیستم لینوکس اوبونتو با پردازنده شش هسته ای Intel Core i7-980 و 24 گیگابایت حافظه اصلی تشکیل شده است. سیستم دیسک از یک درایو SSD RAID-0 برای خواندن و نوشتن سریع استفاده می کند. برنامه ایجاد نقشه از 9.6 گیگابایت حافظه استفاده می کند که 8.8 گیگابایت آن توسط داده های شاخص کاشی استفاده می شود. بقیه با طرح جدول بسیار ساده پایگاه داده ای که ما استفاده می کنیم استفاده می شود: قرار دادن همه داده ها در یک جدول بزرگ انجام پرس و جوها را آسان می کند، اما ابرداده آهنگ چندین بار برای بخش های یک آهنگ تکرار می شود.
مهمترین پارامترها برای عملکرد سرور، تنظیمات سرور Apache HTTP و اندازه thread pool است که درخواستهای کاشی را مدیریت میکند. سرور آپاچی از mpm-worker استفاده می کند که قرار است تا 6400 مشتری را مدیریت کند. تنظیمات برای برنامه ما بهینه شده است. برای استخر نخ ما 32 نخ اختصاص می دهیم. تعداد کمتر، عملکرد را در تعداد کمتری از کاربران افزایش میدهد، اما ممکن است زمانی که هزاران مشتری به طور همزمان کاشیها را درخواست میکنند، خطاهای مهلت زمانی ایجاد کند.
ما از برنامه Apache JMeter برای تست استرس سرور نقشه حرارتی استفاده کرده ایم. ما رفتار کاربر را با انتخاب تصادفی یک کاشی شبیه سازی می کنیم ( x ، y)(ایکس،�)در سطح زوم z و سپس همسایه را درخواست کنید 5 × 55×5کاشی هایی با استفاده از حلقه های تو در تو. پس از بازگشت سرور، کاربر برای زمان تصادفی بین 0 تا 4 ثانیه منتظر می ماند که از توزیع یکنواخت نمونه برداری می شود و سپس مجموعه دیگری از کاشی ها را درخواست می کند. این رفتار برای تقلید از یک کاربر نهایی است که درخواست یک صفحه کاشی را در یک شبکه 5 در 5 می دهد و مدتی را صرف مشاهده نقشه حرارتی برگشتی می کند. همه کاربران این کار را 25 بار در طول یک شبیه سازی تکرار می کنند. مختصات کاشی به سطح زوم محدود شد z= 14�=14و در جنوب فنلاند که در آن تراکم کاربران فعال Sports Tracker زیاد است. ما تست استرس را روی یک پردازنده چهار هسته ای Intel Core i7-3770K با 16 گیگابایت حافظه اصلی اجرا کردیم. کاربران با استفاده از thread ها در برنامه JMeter شبیه سازی شدند و تعداد آنها در قدرت افزایش یافت 2–√2(به نزدیکترین عدد صحیح گرد شده) در طول اجرای آزمایشی. ما همچنین تأثیر کش کاشی را با فعال کردن آن در اجرای دوم و نگه داشتن کاشیهای ایجاد شده در اجرای غیر کش روی آرایه RAID مطالعه میکنیم.
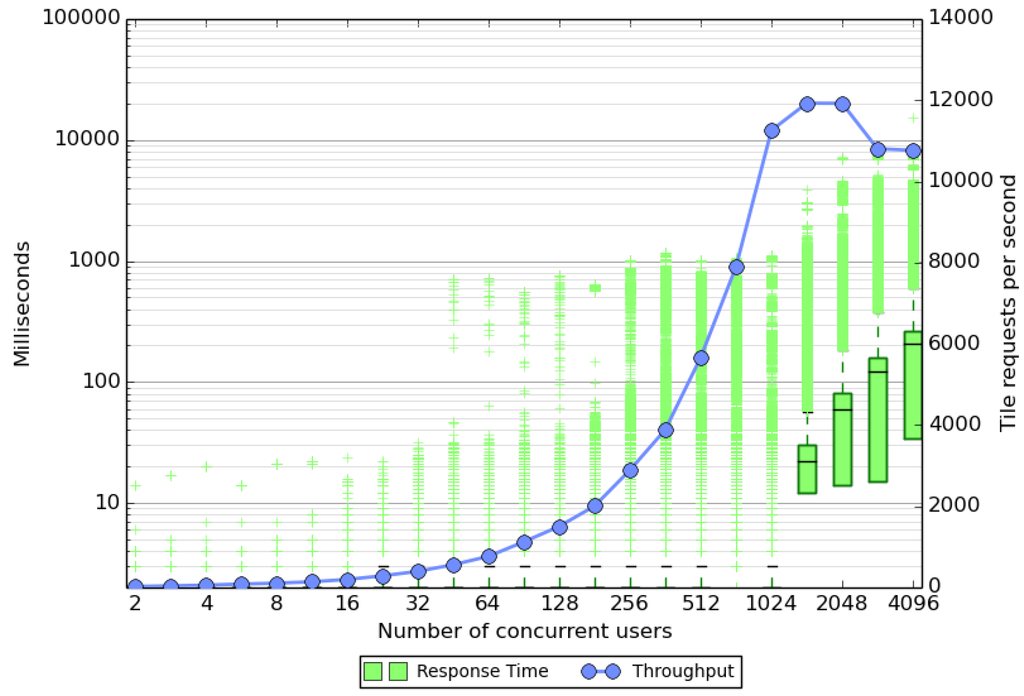
نتایج تست استرس با فعال کردن کش کاشی در شکل 4 نشان داده شده است. عملکرد سرور بر حسب زمان پاسخگویی و توان عملیاتی سرور نشان داده می شود. از نمودارها می توان دریافت که سرور می تواند تا حدود 2000 کاربر شبیه سازی شده به خوبی با درخواست ها هماهنگ باشد. در 1448 کاربر، تنها تعداد کمی از درخواستها بیش از دو ثانیه طول میکشد تا تکمیل شوند. با این حال، پس از این، تعداد موارد پرت افزایش مییابد، از این رو کاربران ممکن است مجبور شوند در بدترین حالت چندین ثانیه برای پاسخ منتظر بمانند. این رفتار به طور طبیعی تعاملی بودن سرویس را حداقل برای برخی از کاربران از بین می برد. با این حال، میانگین زمان پاسخگویی حتی در 4096 کاربر زیر 200 میلیثانیه باقی میماند. این رفتار به احتمال زیاد ناشی از پراکندگی داده ها است. بسیاری از کاشی ها هیچ داده GPS در دسترس ندارند و می توان آنها را در چند میلی ثانیه بدون نیاز به استفاده از الگوریتم 1 پردازش کرد. کاشیهای دارای اطلاعات کاربر زمانی که هیچ کاشی دیگری درخواست نمیشود، تقریباً 25 تا 40 میلیثانیه طول میکشد تا پردازش شوند. هنگامی که بسیاری از درخواست ها در این کاشی ها هستند، این می تواند منجر به صف و زمان پاسخ طولانی شود. نتایج منحنی توان عملیاتی، داستان مشابهی را بیان می کند. در تعداد کم کاربر، سرور به حد مجاز نمی رسد و سرور می تواند کاشی های بیشتری از درخواستی ارائه دهد. اشباع پس از 1024 کاربر رخ می دهد که سرور می تواند تا 12000 کاشی در ثانیه ارائه دهد.
نتایج بدون ذخیره کاشی در شکل 5 نشان داده شده است. زمان پاسخ کاملاً شبیه به حالت حافظه پنهان است، با بزرگترین تفاوت افزایش جزئی در زمانهای دورافتاده در تعداد کاربران کم و در زمان پاسخ متوسط در تعداد کاربران بالا. با این حال، دسترسی به سرور نقشه حرارتی در طول تست استرس، بدون ذخیرهسازی کاشی، به طور ذهنی کندتر به نظر میرسید.

شکل 4. نتایج تست استرس برای سرور با کاشی کاشی. به مقیاس لگاریتمی در محور چپ توجه کنید. کادر سبز رنگ زمان پاسخ، زمان میانه را به عنوان یک خط سیاه نشان می دهد که پایین و بالای کادر به ترتیب توسط چارک های اول و سوم داده شده است. نقاط پرت با استفاده از علامت مثبت نشان داده می شوند. توان با استفاده از یک مقیاس خطی در سمت راست نشان داده شده است. تست استرس هیچ پاسخ ناموفقی توسط سرور نقشه ایجاد نکرد. این نمودار با استفاده از نسخه اصلاح شده یک اسکریپت پایتون [ 29 ] ایجاد شد.
شکل 5. نتایج تست استرس برای سرور بدون کش. برای توضیح نمودار به شکل 4 مراجعه کنید .
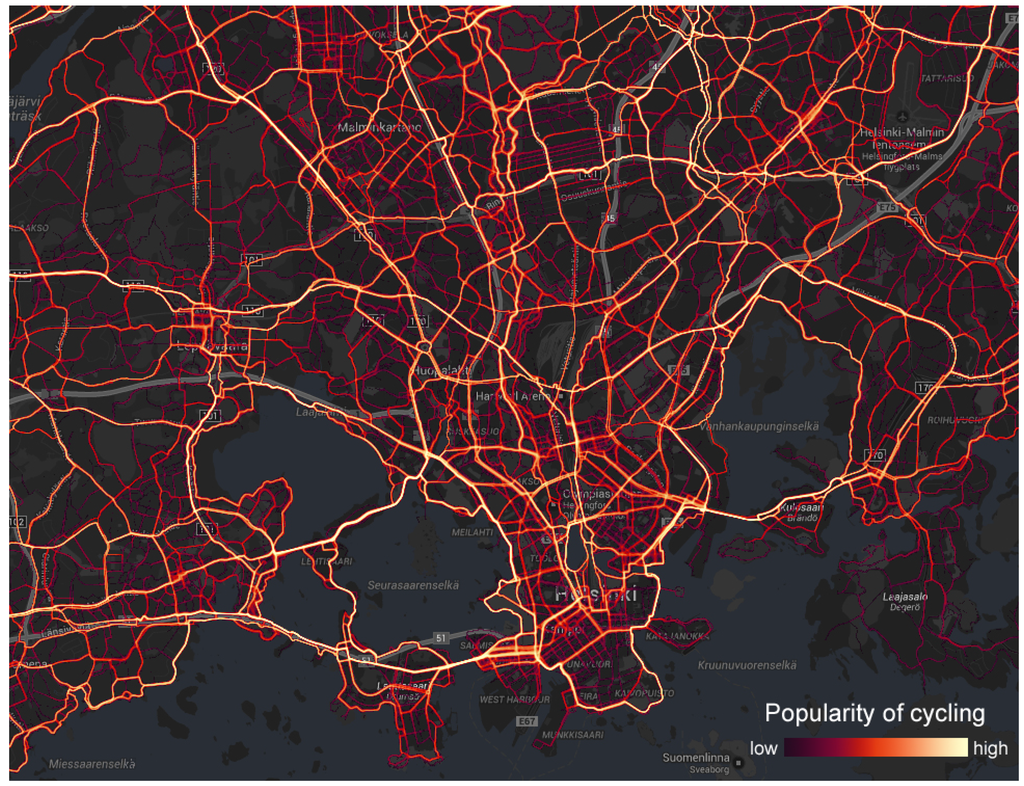
یک نمونه نقشه حرارتی در شکل 6 نشان داده شده است که در آن مسیرهای دوچرخه سواری محبوب در منطقه هلسینکی را با استفاده از مقیاس لگاریتمی نشان می دهیم. مسیرهای زرد روشن محبوب ترین مسیرها هستند، در حالی که مسیرهای بنفش کمتر محبوب هستند. ما حداقل به پنج کاربر مختلف در هر پیکسل نیاز داریم. اگر این معیار رعایت نشود، پیکسل شفاف تنظیم می شود.
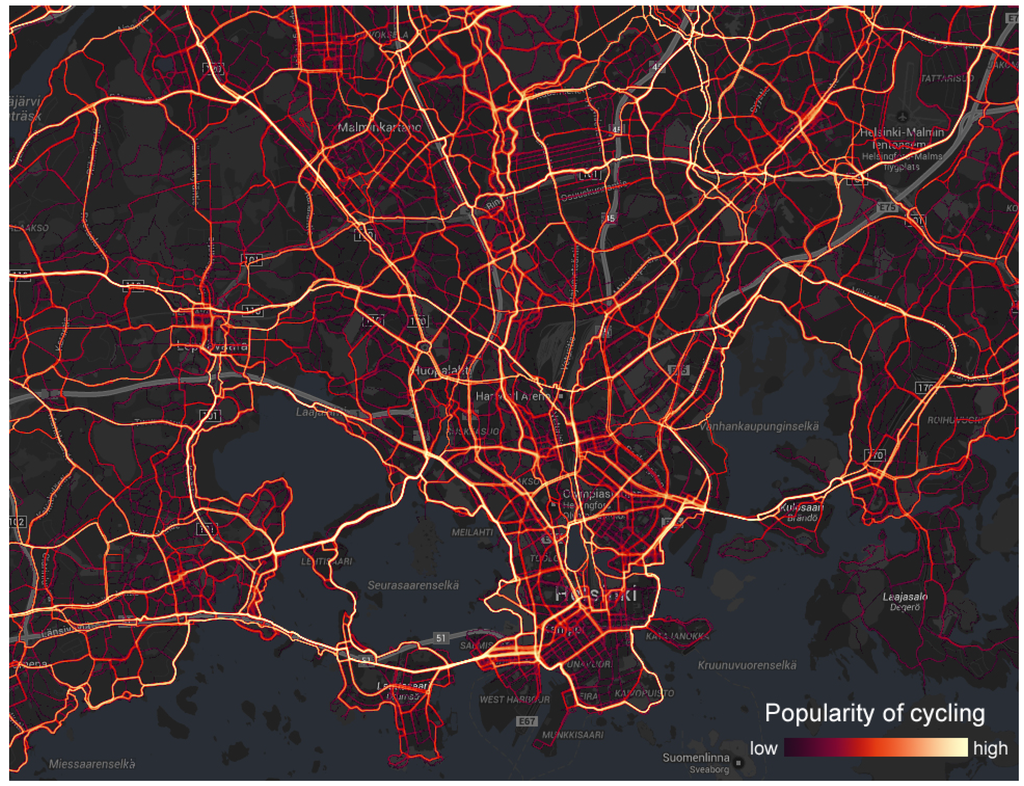
شکل 6. نقشه گرمایی مسیرهای محبوب دوچرخه سواری در هلسینکی.
6. نتیجه گیری و کار آینده
ما یک نمای کلی از یک سرور تعاملی ارائه کرده ایم که اطلاعات نقشه حرارتی را در مسیرهای محبوب در ورزش ارائه می دهد. طراحی کلی برای ایجاد هرچه سریعتر کاشی و به حداکثر رساندن تعداد کاربرانی که می توانند به طور همزمان به سرور دسترسی داشته باشند برنامه ریزی شده است. تست های عملکرد نشان می دهد که حتی سرور تک نود فعلی می تواند بیش از 1000 کاربر همزمان را بدون تأثیر قابل توجهی بر زمان پاسخگویی برای مشتریان پشتیبانی کند. فراتر از این محدودیت، نیاز تعاملی سرویس میتواند برای برخی از مشتریان از بین برود، اما حتی در این حالت میانگین زمان پاسخ کمتر از 200 میلیثانیه است.
برای اندازههای داده بزرگتر و تعداد بیشتر کلاینتهای وب، سرور را میتوان با یک گره بزرگتر جایگزین کرد، بهعنوان مثال یک سوکت دو سوکت Intel Xeon با هستهها و حافظه بیشتر، یا مقیاسبندی آن به پیکربندی گرههای چندگانه. ابرداده قبلاً با ذخیره آن در سرور PostgreSQL که می تواند به چندین گره مقیاس شود، برای این کار آماده شده است. الگوریتم ایجاد نقشه حرارتی را می توان با رابط عبور پیام [ 30 ] مقیاس بندی کرد] به چندین گره که در آن داده ها بین گره ها تقسیم می شود. طراحی باید با دقت انجام شود زیرا تاخیر بین گره ها ممکن است به یک گلوگاه تبدیل شود. داده های مکان را می توان از نظر فضایی به مناطق مختلفی که به صورت موازی پردازش می شوند تقسیم کرد. سرور HTTP می تواند بر روی یک گره متفاوت باشد یا به چندین ماشین توزیع شود تا عملکرد را افزایش دهد.
گزارش های دسترسی از سرور نقشه حرارتی را می توان در برنامه های دیگر داده کاوی استفاده کرد تا بفهمد کدام مناطق و فعالیت ها برای کاربران سرویس جالب تر هستند. نتایج همچنین میتوانند بر حسب نقشههای حرارتی [ 31 ] تجسم شوند و برای مثال هنگام متعادلسازی بار سرویس مورد استفاده قرار گیرند.
منابع
- ITU. آمار و ارقام فناوری اطلاعات و ارتباطات ; اتحادیه بینالمللی مخابرات: ژنو، سوئیس، اکتبر 2014. [ Google Scholar ]
- چیترنجان، گ. بلوم، جی. Gatica-Perez, D. استخراج داده های گوشی هوشمند در مقیاس بزرگ برای مطالعات شخصیت. پارس محاسبات همه جا حاضر. 2013 ، 17 ، 433-450. [ Google Scholar ] [ CrossRef ]
- گونزالس، ام سی؛ هیدالگو، کالیفرنیا؛ Barabasi, AL درک الگوهای حرکتی فردی انسان. طبیعت 2008 ، 453 ، 779-782. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- هررا، جی سی. کار، DB; شاه ماهی، آر. Ban، X. جیکوبسون، کیو. Bayen، AM ارزیابی داده های ترافیکی به دست آمده از طریق تلفن های همراه مجهز به GPS: آزمایش میدانی قرن موبایل. ترانسپ Res. قسمت C Emerg. تکنولوژی 2010 ، 18 ، 568-583. [ Google Scholar ] [ CrossRef ]
- فرستر، سی جی; Coops، NC مروری بر رصد زمین با استفاده از دستگاه های ارتباطی شخصی سیار. محاسبه کنید. Geosci. 2013 ، 51 ، 339-349. [ Google Scholar ] [ CrossRef ]
- Nike Inc. موجود آنلاین: http://nikeplus.nike.com/ (در 15 سپتامبر 2015 قابل دسترسی است).
- Sports Tracking Technologies Ltd. موجود آنلاین: http://www.sports-tracker.com/ (در 15 سپتامبر 2015 قابل دسترسی است).
- Strava, Inc. موجود به صورت آنلاین: http://www.strava.com/ (دسترسی در 15 سپتامبر 2015).
- چن، ز. شن، HT; Zhou، XF کشف مسیرهای محبوب از مسیرها. در مجموعه مقالات بیست و هفتمین کنفرانس بین المللی IEEE در مهندسی داده (ICDE)، هانوفر، آلمان، 11-16 آوریل 2011. ص 900-911.
- هود، جی. سال، ای. چارلتون، بی. مدل انتخاب مسیر دوچرخه مبتنی بر GPS برای سانفرانسیسکو، کالیفرنیا. ترانسپ Lett. بین المللی J. Transp. Res. 2011 ، 3 ، 63-75. [ Google Scholar ] [ CrossRef ]
- لیو، ی. وانگ، اف. شیائو، ی. گائو، جنوب. استفاده از زمین شهری و ترافیک “مناطق منبع غرق”: شواهد از داده های تاکسی مجهز به GPS در شانگهای. Landsc. طرح شهری. 2012 ، 106 ، 73-87. [ Google Scholar ] [ CrossRef ]
- نقشه حرارتی Strava Inc. در دسترس آنلاین: http://labs.strava.com/heatmap (دسترسی در 15 سپتامبر 2015).
- Strava Inc. و Google Maps. در دسترس آنلاین: http://engineering.strava.com/global-heatmap/ (دسترسی در 15 سپتامبر 2015).
- بارخوس، ال. Dey, A. خدمات مبتنی بر مکان برای تلفن همراه: مطالعه نگرانی های حریم خصوصی کاربران. در مجموعه مقالات نهمین کنفرانس بین المللی IFIP TC13 در مورد تعامل انسان و کامپیوتر، زوریخ، سوئیس، 3 تا 24 ژوئیه 2003. ص 709-712.
- بونچی، اف. Lakshmanan، LVS; وانگ، اچ. ناشناس بودن مسیر در انتشار داده های تحرک شخصی. SIGKDD کاوش. 2011 ، 13 ، 30-42. [ Google Scholar ] [ CrossRef ]
- آپاچی جی متر در دسترس آنلاین: http://jmeter.apache.org/ (دسترسی در 15 سپتامبر 2015).
- لانگ، ج.ا. نلسون، TA مروری بر روشهای کمی برای دادههای حرکتی. بین المللی جی. جئوگر. Inf. علمی 2013 ، 27 ، 292-318. [ Google Scholar ] [ CrossRef ]
- سیلورمن، تخمین چگالی BW برای آمار و تجزیه و تحلیل داده ها . چپمن و هال: لندن، بریتانیا، 1986. [ Google Scholar ]
- اوکسانن، جی. برگمن، سی. ساینیو، جی. Westerholm, J. روشهایی برای استخراج و کالیبره کردن نقشههای حرارتی حفظ حریم خصوصی از دادههای برنامه ردیابی ورزشی موبایل. J. Transp. Geogr. 2014 . [ Google Scholar ] [ CrossRef ]
- لینز، ال. کلوسوفسکی، جی تی. Scheidegger, C. Nanocubes برای اکتشاف بلادرنگ مجموعه داده های مکانی-زمانی. IEEE Trans. Vis. محاسبه کنید. نمودار. 2013 ، 19 ، 2456-2465. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Bär, HR; Hurni، L. برآورد تراکم بهبود یافته برای تجسم فضاهای ادبی. کارتوگر. J. 2011 , 48 , 309-316. [ Google Scholar ] [ CrossRef ]
- Sinnott، RW Virtues of the Haversine. Sky Telesc. 1984 ، 68 ، 159-163. [ Google Scholar ]
- گروه HDF قالب داده سلسله مراتبی نسخه 5. موجود به صورت آنلاین: http://www.hdfgroup.org/HDF5 (در 4 مارس 2014 قابل دسترسی است).
- Maling، سیستم های مختصات DH و پیش بینی نقشه ; Elsevier Science & Technology Books: Amsterdam, The Netherlands, 1992. [ Google Scholar ]
- مورتون، GM یک پایگاه داده های ژئودتیک کامپیوتر گرا و یک تکنیک جدید در توالی یابی فایل ها . International Business Machines Company Ltd.: Ottawa, ON, Canada, 1966. [ Google Scholar ]
- الگوریتم برسنهام، JE برای کنترل کامپیوتری پلاتر دیجیتال. سیستم آی بی ام J. 1965 , 4 , 25-30. [ Google Scholar ] [ CrossRef ]
- هوبروک، جی. Bell, N. Thrust: A Parallel Template Library. در دسترس آنلاین: http://thrust.github.io/ (دسترسی در 4 مارس 2014).
- Gabaix، قانون X. Zipf برای شهرها: توضیح. QJ Econ. 1999 ، 114 ، 739-767. [ Google Scholar ] [ CrossRef ]
- تستر بار Metaltoad. در دسترس آنلاین: http://www.metaltoad.com/blog/plotting-your-load-test-jmeter/ (در 15 سپتامبر 2015 قابل دسترسی است).
- انجمن MPI. MPI: رابط عبور پیام. در دسترس آنلاین: http://www.mpi-forum.org/ (دسترسی در 4 مارس 2014).
- فیشر، دی. هات مپ: نگاهی به توجه جغرافیایی. IEEE Trans. Vis. محاسبه کنید. نمودار. 2007 ، 13 ، 1184-1191. [ Google Scholar ] [ CrossRef ] [ PubMed ]
© 2015 توسط نویسندگان; دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر