

خلاصه
داده های بزرگ مکانی بایگانی می شوند و از طریق کشف وب و دسترسی آنلاین در دسترس قرار می گیرند. با این حال، یافتن داده های مناسب برای تحقیق علمی و توسعه برنامه هنوز یک چالش است. هدف این مقاله بهبود کشف دادهها با استخراج دانش کاربر از فایلهای گزارش است. به طور خاص، بازسازی جلسه وب کاربر در این مقاله به عنوان یک گام مهم برای استخراج الگوهای استفاده متمرکز شده است. با این حال، بازسازی جلسات کاربر از لاگ های وب خام همیشه دشوار بوده است، زیرا یک شناسه جلسه در اکثر پورتال های داده وجود ندارد. برای پرداختن به این مشکل، ما دو روش شناسایی جلسه، از جمله روشهای مبتنی بر خوشهبندی زمان و مبتنی بر ارجاع زمان را پیشنهاد میکنیم. ما همچنین گردش کار بازسازی جلسه را ارائه می کنیم و رویکرد انتخاب آستانه های مناسب برای مراحل مربوطه در گردش کار را مورد بحث قرار می دهیم. روشهای شناسایی جلسه پیشنهادی و گردش کار ثابت شدهاند که میتوانند الگوهای دسترسی به دادهها را برای تجزیه و تحلیل الگوی بیشتر رفتار کاربر و بهبود کشف دادهها برای رتبهبندی دادهها، پیشنهادها و ناوبری بیشتر استخراج کنند.
کلید واژه ها:
استخراج استفاده از وب ; شناسایی و بازسازی جلسه ; تشخیص خزنده ؛ جستجوی معنایی ; کشف داده ها
1. مقدمه و بررسی ادبیات
ما در عصر “داده های بزرگ” هستیم. دادههای مکانی و زمانی، که حاوی اطلاعات مکانی و زمانی هستند، مانند تصاویر ماهوارهای گرفتهشده از طریق حسگرهای راه دور، پیشبینیهای اقلیمی ایجاد شده از شبیهسازیهای مقیاس بزرگ و دادههای رسانههای اجتماعی برچسبگذاری شده جغرافیایی، روز به روز در حال افزایش هستند [1 ] . با این حال، پیشرفتهای اخیر در ماهوارههای سنجش از دور و سایر حسگرها باعث شده است که دادههای مکانی-زمانی حتی سریعتر رشد کنند. همه این پیشرفتها منجر به افزایش حجم، سرعت و تنوع دادههای مکانی-زمانی میشود و چالش بزرگی برای محققان برای کشف و دسترسی به چنین دادههایی برای تحقیقات و برنامههای کاربردی پشتیبانی تصمیمگیری ایجاد میکند. در پاسخ، تعدادی از اجزای زیرساخت داده های مکانی (SDI) (به عنوان مثال، کاتالوگ ها و پورتال ها) توسعه یافته اند [ 2]، 3 ]. به عنوان مثال، Common Metadata Repository (CMR) توسط ناسا توسعه داده شده است تا جامعه علمی را قادر سازد تا به راحتی از داده ها و خدمات ناسا استفاده و تبادل کنند. در واقع، اکثر SDI ها هنوز از جستجوی مبتنی بر کلیدواژه استفاده می کنند، یکی از ابتدایی ترین روش های بازیابی اطلاعات، که از مفهوم تطبیق دقیق برای تطبیق اسناد با درخواست کاربر استفاده می کند. جستجوی مبتنی بر کلمه کلیدی متداول ترین مشکلات بازیابی اطلاعات را به ارث می برد: مترادف و چندمعنی [ 4 ].
جستجوی معنایی راه حلی را برای غلبه بر مشکلات با درک هدف کاربران و معنای متنی اصطلاحات با استفاده از پایگاه دانش ارائه می دهد که هستی شناسی نیز نامیده می شود [ 5 ]. ایجاد یک پایگاه دانش معنایی موثر و قوی دشوار است زیرا به روز نگه داشتن آن با تغییر دامنه ها بسیار هزینه بر است. در همین حال، موفقیت چشمگیر کاوی استفاده از وب در شخصیسازی وبسایت، بهبود سیستم و هوش تجاری [ 6 ، 7 ]، الگوهای ارزشمندی (به عنوان مثال، روابط کلمات کلیدی و مجموعه دادهها) را در زیر رفتار مرور کاربران در پورتالهای داده ارائه میدهد. در این راستا، ما رویکردی را برای استخراج این الگوها برای ایجاد یک پایگاه معنایی به شیوهای مؤثرتر و کارآمدتر پیشنهاد میکنیم.
هدف ما استخراج الگوهای جستجو و استفاده کاربران برای بهبود فرآیند کشف داده است که شامل استخراج دانش و به کارگیری این دانش کاربر در کشف داده است. این مقاله بر مرحله قبلی یک تکنیک جدید برای آشکار کردن هدف جستجوهای کاربر تمرکز دارد. قبل از استخراج دانش کاربر (به عنوان مثال، رابطه معنایی پنهان بین عبارات جستجو) از حجم عظیمی از گزارش های دسترسی به داده، یک گام ضروری و حیاتی بازسازی رفتارهای جستجو و مرور کاربران با حذف نویز، شناسایی کاربران انسانی در مقایسه با کاربران ماشینی است. یا خزنده ها، و همچنین اتصالات بین هر درخواست فردی. به عنوان یک گام مهم، بازسازی جلسه وب تمرکز اصلی این مقاله برای ایجاد زمینه برای تجزیه و تحلیل بیشتر است.بخش 6 .
ابتدا تمام فعالیت هایی که توسط یک فرد انجام می شود باید با هم گروه بندی شوند. دوم، تمام فعالیت های مربوط به یک بازدید باید در یک گروه قرار گیرند [ 8]. طبق W3C (W3C Web Usage Characterization Activity 1999)، جلسه کاربر به مجموعه فعالیت هایی اطلاق می شود که کاربر از لحظه ورود به سایت تا لحظه خروج از سایت انجام می دهد. برای پیگیری فعالیتهای کاربر، بسیاری از وبسایتها شناسه جلسه را در ارتباطات شبکه خود میپذیرند تا اطمینان حاصل کنند که هنگام استفاده از پروتکل بدون حالت مانند HTTP، وضعیت فعلی کاربر از بین نمیرود. با این حال، در بیشتر موارد، این بخش از اطلاعات در دسترس نیست. چندین رویکرد شناسایی کاربر برای رسیدگی به این مشکل ابداع شده است و آنها به طور کلی در دو دسته اکتشافی مبتنی بر زمان و اکتشافی مبتنی بر ارجاع قرار می گیرند. دو نوع اکتشافی مبتنی بر زمان و یک اکتشافی مبتنی بر ارجاع اولیه در زیر آورده شده است:
-
h1: مدت زمان کل جلسه ممکن است از آستانه α تجاوز نکند. با توجه به t0، مهر زمانی برای اولین درخواست در یک جلسه ساخته شده S، درخواست با مهر زمانی t به S اختصاص داده می شود، اگر t – t0 ≤ α.
-
h2: کل زمان صرف شده در یک صفحه ممکن است از آستانه α تجاوز نکند. با توجه به t1، مهر زمانی برای درخواست اختصاص داده شده به جلسه ساخته شده S، درخواست بعدی با مهر زمانی t2 به S اختصاص داده می شود، اگر t2 – t1 ≤ α.
-
href: با توجه به دو درخواست متوالی p و q، با p متعلق به جلسه ساخته شده S. سپس q به S اختصاص داده می شود، اگر ارجاع دهنده برای q قبلاً در S فراخوانی شده باشد.
اکتشافی سنتی مبتنی بر زمان مبتنی بر یک بازه زمانی تجربی و ثابت [ 9 ] موضوع مهمی است. آستانه های زمانی که معمولا برای h1 و h2 استفاده می شود به ترتیب 30 و 10 دقیقه است [ 10 ]. بحث اصلی این است که آستانه زمانی باید مختص سایت باشد و به ساختار وب سایت و گروه های کاربری بستگی دارد. به عنوان مثال، جونز و کلیننر دریافتند که آستانه 30 دقیقه در زمینه شناسایی وظایف جستجو “بهتر از تصادفی” انجام نمی شود [ 11 ]. برخی از مقالات ذکر کردند که آستانه را می توان با استفاده از آمار استفاده از وب سایت تعیین کرد [ 12]، اما هیچ یک از آنها به صراحت به این موضوع اشاره نکرده اند. برای پر کردن این شکاف، هم تئوری و هم عمل انتخاب یک آستانه مناسب برای روش اکتشافی مبتنی بر زمان را در این مقاله ارائه میکنیم.
استدلال شده است که (1) سرعت مرور کاربران مختلف از یکی به دیگری متفاوت است. (2) حتی برای یک کاربر، او می تواند زمان های مختلفی را در صفحات مختلف بگذراند. برخی اکتشافی پویا برای مقابله با این مشکل با محدودیتهای خاص معرفی شدهاند [ 9 ]. ایده پشت اکتشافی مبتنی بر خوشه این است که شناسایی جلسه اساساً می تواند به عنوان یک مشکل خوشه بندی در یک بعد در نظر گرفته شود .، زمان. بر اساس این مفهوم، ما تجزیه و تحلیل خوشهبندی را برای تشخیص خودکار وقفه جلسه، به جای استفاده از یک آستانه ثابت، اتخاذ کردیم. با این حال، تعداد خوشهها معمولاً قبل از فرآیند خوشهبندی ناشناخته است، که استفاده از الگوریتمهای خوشهبندی رایج مانند روش خوشهبندی k-means را دشوار میکند. برای جلوگیری از تخصیص شماره خوشه در ابتدا، ما یک روش خوشهبندی سلسله مراتبی، که به عنوان اکتشافی مبتنی بر خوشه نیز شناخته میشود، توسعه دادیم تا سلسله مراتبی از خوشهها را در بعد زمان بسازیم.
یک اکتشافی مبتنی بر ارجاع، عملکرد ضعیفی را در سایتهای دارای مجموعه فریم به دلیل فرضیات ضمنی در مورد معماری وب نشان میدهد [ 8 ]. پیچیدگی محض این استراتژی و تمرکز توسعهای آن بر روی جلسه، آن را به عنوان جایگزینی برای روشهای اکتشافی زمانمحور در تحلیلهای وب عملی جلسات کاربر نامناسب میکند [13 ]]. به طور خاص، اولین مشکل مهم این است که فقط بر روی کار تمرکز می کند تا جلسه و تمایل دارد در برخی موارد جلسات کوتاه زیادی ایجاد کند، جایی که کاربر چندین کار را در یک جلسه خاص انجام می دهد اما برای هر کار جداگانه از صفحه اول شروع می کند. از سوی دیگر، زمانی که رویدادهای تصادفی مانند برقراری تماس تلفنی یا وقفههای ناهار اتفاق میافتد و صفحه وب در غیاب آنها باز میماند، این احتمال وجود دارد که چندین جلسه کوتاه در یک جلسه طولانی غیرمنطقی ادغام شوند. برای پرداختن به این چالش، یک اکتشافی مبتنی بر ارجاع زمان را با معرفی یک آستانه زمانی در اکتشافی مبتنی بر ارجاع دهنده موجود ایجاد کردیم.
اکثر کارها در این زمینه نتیجه بازسازی جلسه خود را با یک جدول ساده ارائه می دهند [ 14 ، 15 ، 16 ]. این روش ارائه، تحلیل ساختار جلسه را برای کاربران و محققین دشوار می کند. همچنین در بکارگیری و ادغام هر تکنیک فردی مشکل وجود دارد زیرا در واقعیت برخی از تکنیک ها در مراحل مختلف پردازش انجام می شوند. به عنوان مثال، شناسایی خزنده تا حدی قبل از شناسایی جلسه انجام می شود و بقیه پس از شناسایی جلسه انجام می شود. علاوه بر این، معمول است که محتوای ارائه شده به کاربران از چندین سرور در یک سیستم وب در مقیاس بزرگ می آید [ 17]]. به منظور پیگیری رفتار مرور «بین سایتی» کاربران، انجام همگام سازی جهانی در سرورهای مختلف ضروری است [ 18 ]. در غیاب شناسههای کاربر و جلسه، اکتشافی مبتنی بر ارجاع معمولاً برای ایجاد ارتباط بین گزارشهای HTTP مختلف استفاده میشود [ 19 ]. با این حال، هیچ یک از آنها به موضوع ارتباط بین HTTP log و FTP log که حاوی اطلاعات ارجاع دهنده و کاربر-عامل نیست، نمی پردازد. بنابراین، ما گردش کار بازسازی جلسه را از وارد کردن داده تا تجسم نتیجه توصیف میکنیم و همگامسازی گزارشها از چندین سرور را برجسته میکنیم.
2. فرمت داده ها و آماده سازی
2.1. فرمت لاگ وب
فرمت Common Log پرکاربردترین فرمت گزارش است که توسط W3C نگهداری می شود. دارای تعدادی فیلد از جمله آدرس IP مشتری، تاریخ/زمان درخواست، صفحه درخواستی، کد HTTP، و بایت های ارائه شده (فرمت فایل Log توسعه یافته W3C، جدول 1 ). یکی دیگر از فرمت های محبوب، فرمت گزارش ترکیبی است که همان قالب گزارش مشترک است، به جز با اضافه کردن دو فیلد دیگر: عامل کاربر و ارجاع دهنده ( جدول 1 ). عامل کاربر اطلاعات شناسایی است که مرورگر مشتری خودش گزارش می دهد. ارجاع دهنده می گوید که درخواست از کجا شروع شده است [ 20]. به طور مشابه، ویژگی های موجود در فرمت گزارش FTP عبارتند از: تاریخ، زمان انتقال، میزبان راه دور، اندازه فایل، نام فایل، نوع انتقال، پرچم عمل ویژه، جهت، حالت دسترسی، نام کاربری، نام سرویس، روش احراز هویت. ، authenticated-user-id و completion-status [ 21 ] ( جدول 2 ). آنچه Log FTP را از HTTP log متفاوت می کند این است که گزارش FTP حاوی اطلاعات ارجاع دهنده و عامل کاربر نیست.
2.2. منبع اطلاعات
برای نشان دادن روشهای پیشنهادی بازسازی جلسه، گزارشهای وب از وبسایت مرکز آرشیو فعال توزیعشده اقیانوسشناسی فیزیکی (PO.DAAC؛ http://podaac.jpl.nasa.gov ) استفاده میشود. PO.DAAC یک مرکز داده ناسا است که عمدتاً مسئول بایگانی و توزیع مجموعه داده های اقیانوس شناسی است. تاسیسات آن در آزمایشگاه پیشرانش جت ناسا (JPL) در پاسادنا، کالیفرنیا مدیریت و واقع شده است. PO.DAAC حداقل دو نوع سرور در سیستم خود دارد که سرور HTTP ظرفیت جستجو را فراهم می کند و سرور FTP از درخواست دانلود پشتیبانی می کند. در این آزمایش، ما از گزارشهای وب از فوریه 2015 استفاده میکنیم که شامل 4،191،741 گزارش دسترسی وب PO.DAAC و 3،174،458 گزارش FTP است.
2.3. شناسایی کاربر
شناسایی کاربر اولین مرحله در بازسازی جلسه برای تمایز بین کاربران مختلف برای مرحله بعدی و داده کاوی بیشتر است. در غیاب شناسه کاربر و کوکی سمت سرویس گیرنده، رویکرد رایج برای شناسایی کاربران منحصر به فرد از طریق ترکیبی از آدرس های IP و عوامل کاربر است [ 22] .]. آدرسهای IP به تنهایی برای نگاشت ورودیهای گزارش به مجموعه بازدیدکنندگان منحصربهفرد کافی نیستند، عمدتاً به این دلیل که یک سرور پراکسی ممکن است چندین کاربر به یک وبسایت دسترسی داشته باشند، احتمالاً در یک دوره زمانی یکسان. با توجه به منشور مرکز داده برای ارائه رایگان داده ها در دسترس عموم، دانلود داده ها به صورت ناشناس انجام می شود. این به معنای کمبود اطلاعات عامل کاربر در گزارش های FTP است. برای وارد کردن اطلاعات سایت FTP به تجزیه و تحلیل ما، اطلاعات عامل کاربر در شناسایی کاربر در نظر گرفته نمی شود.
2.4. پاک کردن داده
هدف از پاکسازی داده ها حذف گزارش های اضافی و داده های تولید شده توسط خزنده ها است. در بیشتر موارد، فقط ورودی گزارش درخواست فایل HTML باید برای تجزیه و تحلیل بیشتر نگه داشته شود، زیرا کاربر به صراحت تمام درخواستها را انجام نمیدهد، که بیشتر آنها تصاویر دانلود شده خودکار، جاوا اسکریپت و فایلهای CSS هستند که در یک صفحه وب جاسازی شدهاند. یکی دیگر از مشکلات رایج این است که یک فایل گزارش معمولی معمولاً حاوی درصد قابل توجهی (گاهی تا 50٪) از مراجع ناشی از موتورهای جستجو یا سایر خزنده ها است [ 17 ]. به منظور متمایز کردن رفتار خزندههای وب از کاربران واقعی، روشی را برای شناسایی خزندهها از جنبههای مختلف توسعه دادیم [ 17 ، 23 ]:
-
خزنده های معروف موتورهای جستجو راحت ترین تشخیص هستند، زیرا آنها معمولاً هویت خود را در قسمت عامل کاربر می نویسند. بنابراین، آنها را می توان با حفظ لیستی از خزنده های شناخته شده شناسایی و حذف کرد.
-
سایر خزندههای «خوش رفتار» که از پروتکلهای استاندارد حذف ربات پیروی میکنند، خزیدن سایت خود را ابتدا با دسترسی به فایل حذف «robots.txt» در فهرست اصلی سرور آغاز میکنند. بنابراین، چنین خزندههایی را میتوان با بررسی اینکه آیا درخواستی برای فایل robots.txt انجام شده است شناسایی کرد.
-
متأسفانه بسیاری از خزنده ها خود را به صراحت شناسایی نمی کنند. و نه عمداً خود را به عنوان کاربران قانونی معرفی کنید. در این مورد، دو ویژگی مهم دیگر را بررسی می کنیم: حداکثر نرخ درخواست پایدار و تعداد انواع درخواست. دلیل این امر این است که یک حد بالایی برای حداکثر تعداد کلیک هایی که یک انسان می تواند در یک بازه زمانی خاص انجام دهد وجود دارد. همچنین، پس از بررسی بسیاری از درخواستهای خزنده، متوجه شدیم که درخواستهایی که توسط انسانها ایجاد میشوند، در طول بازدید تکی آنها متنوعتر هستند.
3. روش شناسایی جلسه
شناسایی جلسه فرآیند تقسیمبندی سوابق فعالیت کاربر هر کاربر به جلسات است که هر رکورد یک بازدید از سایت را نشان میدهد. این بخش نحوه انتخاب آستانه های مناسب برای اکتشافی مبتنی بر زمان را مورد بحث قرار می دهد. ما همچنین دو اکتشافی جدید مبتنی بر خوشهبندی و اکتشافی مبتنی بر ارجاع زمان را معرفی میکنیم.
3.1. انتخاب آستانه در اکتشافی مبتنی بر زمان
بنابراین ما روشی را برای انتخاب آستانه های مناسب بر اساس آمار استفاده ارائه می کنیم. هنگامی که شناسایی کاربر و پاکسازی داده ها تکمیل شد، زمان های تعاملی را برای هر کاربر ایجاد می کنیم. زمان بین فعالیت، فاصله زمانی بین درخواست داده شده و آخرین درخواست آن است. بر اساس یک تحقیق مرتبط اخیر [ 13 ]، اگر ما هیستوگرام و مدل مخلوط گاوسی مؤلفه را با استفاده از بیشینه سازی انتظار ترسیم کنیم، الگوهای آماری معنی داری در زمان تعامل وجود دارد [ 24 ]. همانطور که در [ 13 ، 24 توضیح داده شد]، چهار نوع الگو وجود دارد که با بازرسی بصری شناسایی می شوند: تناسب دو وجهی ساده، تناسب با وقفه های طولانی، تناسب با مولفه فرکانس بالا و تناسب غیر معمول. رایج ترین الگوی برازش دو وجهی است: منحنی اول خوشه نظری درون جلسه را با مقدار مورد انتظار چند دقیقه (<10 دقیقه) نشان می دهد، و منحنی دوم به خوشه نظری بین جلسه با مقدار مورد انتظار چند اشاره دارد. روزها. با الهام از این نتیجه، ابتدا زمانهای بینفعالیتی را با انتخاب یک برش تخمینی نسبتاً بزرگ (مثلاً 3 ساعت) به دو بخش تقسیم میکنیم و مقدار تعامل را در سطح اطمینان 97.5٪ محاسبه میکنیم. سپس این مقدار می تواند به عنوان α در اکتشافی مبتنی بر زمان استفاده شود.
3.2. اکتشافی مبتنی بر خوشه
برای جلوگیری از تخصیص شماره خوشه در ابتدا، ما یک روش خوشهبندی سلسله مراتبی (یعنی یک اکتشافی مبتنی بر خوشه)، برای ایجاد سلسله مراتبی از خوشهها در بعد زمان ایجاد کردیم. به طور خاص، این استراتژی یک رویکرد تقسیمکننده یا «بالا به پایین» است: همه مشاهدات بهعنوان یک خوشه کامل دیده میشوند و تقسیمها به صورت بازگشتی با پایین رفتن سلسله مراتب انجام میشوند. این روش شامل سه مرحله است ( شکل 1 ):
-
برای یک کاربر معین، بازدید او به عنوان کل خوشه L در نظر گرفته می شود . اگر طول بازدید او بیشتر از T باشد ، همه گزارش های دسترسی (مرتب شده بر اساس زمان، از جمله HTTP و FTP) به دو خوشه تقسیم می شوند: l 1 و l 2 . آستانه T را می توان به عنوان مقیاس مطالعه در نظر گرفت.
-
اگر طول l 1 یا l 2 بیشتر از T باشد ، دوباره به دو خوشه تقسیم می شوند.
-
فرآیند تقسیم به صورت بازگشتی انجام می شود تا زمانی که تمام طول خوشه از T کوتاهتر شود .
به منظور تصمیمگیری در جایی که یک خوشه باید تقسیم شود، روشی به نام بهینهسازی شکستهای طبیعی Jenks [ 25 ]، که در اصل برای نقشهبرداری آماری استفاده میشد، در رویکرد ما ادغام شده است. بهینهسازی شکستهای طبیعی Jenks یک فرآیند تکراری است که به دنبال یافتن بهترین شکست با کاهش واریانس در کلاسها و به حداکثر رساندن واریانس بین کلاسها است. این فرآیند با تقسیم دادههای مرتب شده به گروهها آغاز میشود و اجازه میدهد که تقسیمبندی گروه اولیه دلخواه باشد. چهار مرحله وجود دارد که باید تکرار شوند [ 26 ]:
-
مجموع مجذور انحرافات بین کلاس ها را محاسبه کنید (SDBC).
-
مجموع مجذور انحرافات از میانگین آرایه (SDAM) را محاسبه کنید.
-
SDBC را از SDAM کم کنید (SDAM-SDBC). این برابر با مجذور انحرافات از میانگین کلاس (SDCM) است.
-
پس از بازرسی هر یک از SDBC، تصمیم گرفته می شود که یک واحد از کلاس دارای بزرگترین SDBC به کلاس با کمترین SDBC منتقل شود.
-
سپس انحرافات کلاس جدید محاسبه می شود و این فرآیند تا زمانی تکرار می شود که مجموع انحرافات کلاس به حداقل مقدار برسد. بر اساس بهینهسازی شکستهای طبیعی Jenks، بهترین شکست در مرحله دو اکتشافی مبتنی بر خوشهبندی ما قابل شناسایی است.
3.3. اکتشافی مبتنی بر ارجاع زمان
با در نظر گرفتن صفحه وب ارجاع دهنده (که قبلاً قبلاً به آن دسترسی داشتید) در گزارش وب به عنوان یک اطلاعات مهم برای پیگیری رفتار کاربر، ما همچنین یک اکتشافی مبتنی بر ارجاع زمان ایجاد کردیم تا مشکلات موجود در اکتشافی مبتنی بر ارجاع دهنده را برطرف کنیم. اکتشافی مبتنی بر ارجاع زمان این دو مشکل را با معرفی یک آستانه زمانی که قبلاً در بخش 3.1 تعیین شده است، برطرف می کند . با مرتبسازی گزارشهای هر کاربر بر اساس زمان دسترسی شروع میشود و سپس چهار مرحله زیر را طی میکند:
برای گزارش های HTTP،
-
اگر ارجاعدهنده log q «-» باشد، آدرس وبسایتهای دیگر (مثلاً موتور جستجوی تجاری) یا صفحه اول وبسایت، جلسه S جدید شروع میشود.
-
اگر ارجاع دهنده r هیچ یک از سه مورد در مرحله 1 نباشد، ما به دنبال آخرین صفحه p که درخواست آن با r یکسان است، می گردیم . به جای اینکه به سادگی log q را به جلسه S اختصاص دهیم ، همانطور که در اکتشافی مبتنی بر ارجاع دهنده سنتی انجام می دهند، فاصله زمانی T pq بین p و q را محاسبه می کنیم . سپس فاصله زمانی با T * N مقایسه می شود . توجه داشته باشید که N تعداد لاگهای بین p و q و T آستانه زمانی در بخش اول است.
-
اگر T pq < T * N ، log q به جلسه S اختصاص داده می شود . در غیر این صورت، اگر T pq > T * N ، یا صفحه قبلی یافت نشد، یک جلسه جدید شروع می شود.
-
پس از بازدید همه گزارشها، اگر فاصله زمانی بین زمان پایان یک جلسه و زمان شروع جلسه دیگر کمتر از T باشد، جلسات بسته با هم ادغام میشوند .
از آنجایی که لاگ های FTP اطلاعات ارجاع دهنده ندارند:
- 5.
-
اگر فاصله زمانی آخرین گزارش، HTTP یا FTP، کمتر از T باشد ، گزارش FTP به همان جلسه و آخرین گزارش اختصاص داده میشود. در غیر این صورت یک جلسه جدید شروع می شود.
جدول 3 نمونه ای است که مزیت روش پیشنهادی را نشان می دهد. عدد در جدول نشان دهنده تعداد جلسات است. از روش سنتی تا نتیجه میانی روش پیشنهادی، جلسه 1 از یک جلسه طولانی که 14 ساعت طول می کشد به چندین جلسه کوتاه تغییر می کند. پس از آن، جلسات بسته (به عنوان مثال، جلسات 2 و 3) با هم ادغام می شوند.
4. پیاده سازی و گردش کار
4.1. پیاده سازی
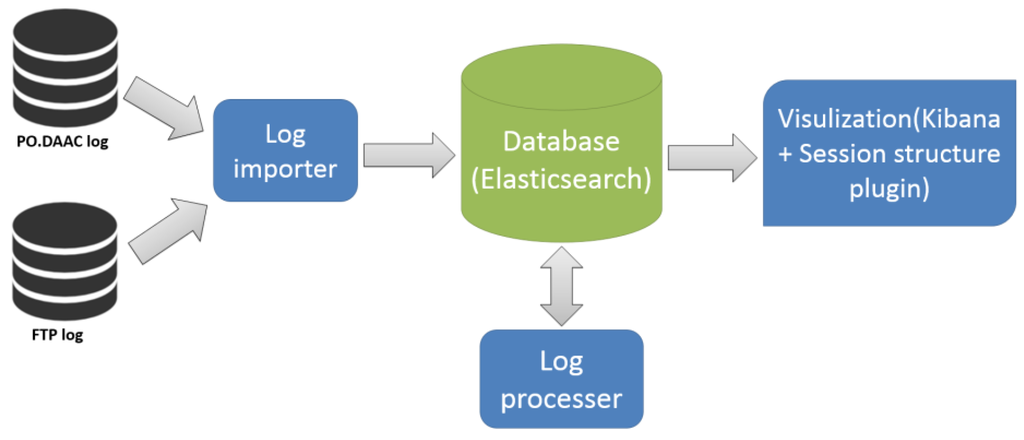
این سیستم از چهار جزء تشکیل شده است: واردکننده گزارش، پایگاه داده، پردازشگر گزارش و ابزار تجسم ( شکل 2)). واردکننده گزارش برای تجزیه، تمیز کردن (فقط شناسایی بخشی از خزنده) و وارد کردن لاگ های HTTP و FTP خام به پایگاه داده استفاده می شود. پردازشگر گزارش در درجه اول مسئول شناسایی کاربر، تشخیص خزنده و شناسایی جلسه است. پایگاه داده مورد استفاده در سیستم بر اساس یک راه حل پایگاه داده منبع باز به نام Elasticsearch ساخته شده است. اگرچه این یک فناوری پایگاه داده نسبتاً جدید است، اما یک موتور جستجوی متن کامل، مقیاس پذیر و توزیع شده با رابط وب HTTP ارائه می دهد و از اسناد JSON بدون طرحواره پشتیبانی می کند. دلیل دیگری که ما Elasticsearch را انتخاب می کنیم این است که با یک افزونه تجسم داده منبع باز به نام Kibana ارائه می شود. Kibana با ارائه قابلیتهای داشبورد تجسم در بالای محتوای نمایهشده در کلاستر Elasticsearch، در بسیاری از تلاشهای توسعه صرفهجویی میکند. به دلیل نیازهای خاص ما، ما همچنین یک ابزار تجسم برای درخت ساختار جلسه در Kibana توسعه دادیم. در آزمایش ما، پردازش یک ماه فایل های گزارش (6 هسته، حافظه 12G و سیستم عامل Win 7) 20 دقیقه طول کشید. این قابل قبول است وقتی با داده های کوچک سروکار داریم، ما قصد داریم از محاسبات خوشه ای و ابری استفاده کنیم [27 ] برای سرعت بخشیدن به روند داده های گزارش بزرگ (مثلاً 10 سال فایل گزارش).
4.2. جریان کار
به طور کلی، بازسازی جلسه شامل هفت مرحله است:
-
وارد کردن گزارشهای HTTP: اولین قدم این است که گزارشهای HTTP وبسایت PO.DAAC را به Elasticsearch وارد کنید. تمام درخواستهای اضافی (img.، .js، و غیره ) و بخشی از درخواستهای خزنده بر اساس لیست خزنده شناخته شده حذف میشوند. فقط درخواست های HTML تجزیه و برای پردازش بیشتر به پایگاه داده وارد می شوند. ورودی 4، 191، 741 گزارش HTTP خام، و خروجی 297، 569 درخواست HTML در قالب JSON است.
-
وارد کردن گزارش های FTP: از آنجایی که هیچ اطلاعات عامل کاربر برای مقایسه با لیست خزنده وجود ندارد، همه گزارش های FTP (3، 174، 458 گزارش) به Elasticsearch وارد می شوند.
-
همگامسازی گزارشهای HTTP و FTP: اگرچه ترکیبی از user-agent و آدرس IP ترجیح داده میشود، کاربر منحصربهفرد تنها از طریق آدرس IP شناسایی میشود زیرا هیچ عامل کاربر در گزارش FTP وجود ندارد. IP هایی با حداکثر نرخ درخواست پایدار بیشتر از دو درخواست از پایگاه داده حذف می شوند. پس از این مرحله، ما 7536 کاربر منحصر به فرد را با 901، 945 گزارش پیدا کردیم.
-
انتخاب آستانه زمانی: پس از شناسایی کاربر، هیستوگرام تعاملی را بر اساس آنچه در بخش روش شناسی توضیح دادیم رسم می کنیم. از آنجایی که مقدار مورد انتظار منحنی دوم چند روز است، آن را کنار گذاشتیم و فقط روی اولین منحنی توزیع نرمال تمرکز کردیم. پس از محاسبه، دریافتیم که مقدار بحرانی در سطح اطمینان 97.5% حدود 10 دقیقه (596.73 ثانیه) است ( شکل 3 ).
-
شناسایی جلسه: هر دو روش شناسایی جلسه در این مرحله آزمایش می شوند. 15783 جلسه کاربر پیدا شد. بر اساس این نتیجه، ما جلسه را با استفاده از تعداد انواع درخواست فیلتر می کنیم. به طور خاص، تعداد درخواستهای جستجو، مشاهده و دانلود باید کمتر از 1 نباشد. هنگامی که یکی از درخواستها گم شده باشد (کمتر از 1)، جلسه دانش معتبری را که برای کشف دادهها لازم است ارائه نمیکند. به این ترتیب، جلسه کاربر واقعی که فقط شامل یک یا دو مورد از آنها است و سایر جلساتی که توسط خزنده ها ایجاد شده اند، در نهایت حذف می شوند. در نهایت 414 جلسه پس از این مرحله مشخص می شود.
-
به طور مشابه، 34604 جلسه کاربر با اکتشافی مبتنی بر خوشهبندی زمانی شناسایی میشوند که T برای 30 دقیقه تنظیم شود، و آنها به 471 جلسه کاربر که شامل هر سه نوع درخواست هستند، محدود میشوند.
-
بازسازی ساختار: آخرین مرحله بازسازی جلسه بر اساس ارجاع است. توجه داشته باشید که گزارشهای FTP در این فرآیند به نزدیکترین درخواست مشاهده پیوست میشوند.
5. نتایج
5.1. مقایسه اکتشافی شناسایی جلسه
جدول 4نمونه ای از این دو نتیجه شناسایی جلسه را نشان می دهد. در حالی که نتیجه اکتشافی مبتنی بر ارجاع زمان تمام این درخواست های متوالی را به صورت یک جلسه نشان می دهد، اکتشافی مبتنی بر خوشه بندی زمان آنها را به دو جلسه تقسیم می کند. هر دوی آنها موافقند که چند لاگ اول متعلق به یک جلسه است، زیرا فاصله زمانی متوالی بین آنها بسیار کوتاه است (همه آنها در 2 دقیقه اتفاق افتادند). با این حال، اکتشافی مبتنی بر خوشهبندی زمان در آخرین ثبت ثانیه شکست میخورد، زیرا فاصله زمانی بزرگتر از 30 دقیقه است. برای اکتشافی مبتنی بر ارجاع زمان، چون ارجاع دهنده دومین درخواست آخر با درخواست اول یکسان است و فاصله زمانی نیز معقول است، باید با تفسیر انسانی به همان جلسه اختصاص داده شوند. اگرچه میتوان آنها را با تنظیم مقیاس بزرگ در اکتشافی مبتنی بر خوشهبندی زمان به یک جلسه کشید، اما برخی از جلسات کوچک نادیده گرفته میشوند زیرا فرآیند تقسیم زودتر متوقف میشود. برای مثال، اگر آستانه زمانی را روی 40 دقیقه تنظیم کنیم، تشخیص جلسات با طول بین 30 تا 40 دقیقه دشوار خواهد بود. از آنجایی که ارجاعدهنده اطلاعات ارزشمندی برای ردیابی رفتار جستجوی کاربر است، اکتشافی مبتنی بر زمان ارجاعشده از خوشهبندی زمانی بهتر عمل میکند.
5.2. ساختار جلسه
بر اساس گردش کار شرح داده شده، ساختار را برای هر جلسه بازسازی می کنیم. شکل 4 a نمونه ای از مجموعه 414 جلسه را نشان می دهد. کاربر در این جلسه دو کار را انجام داد که هر کدام مربوط به یک شاخه در درخت ساختار است. این ساختار جلسه نقش مهمی در تحلیل الگوی بعدی خواهد داشت. هم کلمات کلیدی و هم فاصله بین آنها اطلاعات حیاتی برای ایجاد پایگاه دانش هستند. علاوه بر این، جدول 5کلمات کلیدی جستجو شده در چندین جلسه نمونه را نشان می دهد. ستون اول شماره جلسه را نشان می دهد. فقط با تفسیر بصری، «ghrsst» و «pathfinder» (جلسات 3 و 4)، و «qscat» و «ascat» (جلسات 1، 5 و 12) بیشتر از جفتهای کلیدواژه دیگر جستجو میشوند. علاوه بر این، مجموعه پرس و جو که شامل رفتار جستجو، مشاهده و دانلود کاربر است، می تواند بر اساس درخت ساختار جلسه استخراج شود. شکل 4 ب نمونه ای از هزاران پرس و جو را نشان می دهد. در این مثال، کاربر “quickscat” را جستجو کرد، همان مجموعه داده “qscat_level_2b_owv_comp_12” را مشاهده و دانلود کرد. این دانش برای ایجاد روابط بین پرس و جو و مجموعه داده مفید است و می تواند برای بهبود کشف داده ها یکپارچه شود.
5.3. هیستوگرام طول جلسه و محبوبیت کلمات کلیدی
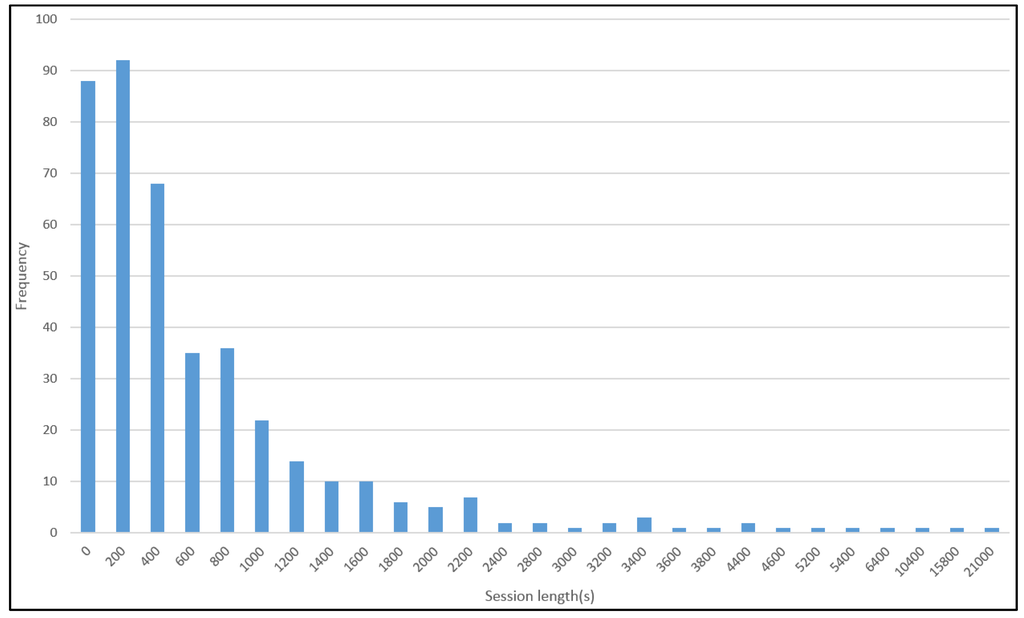
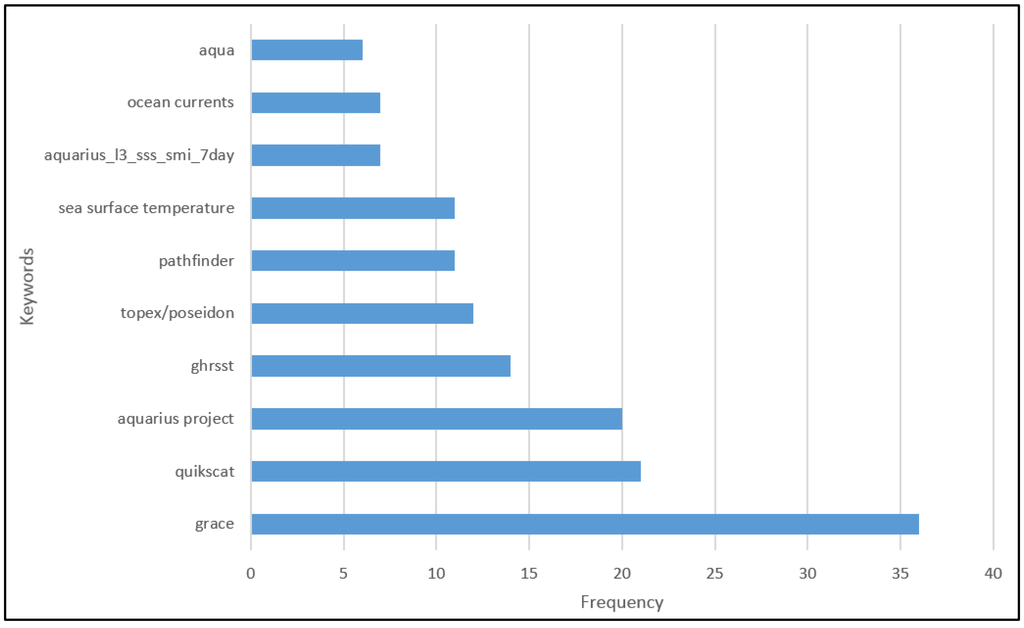
با مشاهده هیستوگرام طول جلسه، متوجه شدیم که بیشتر جلسات در یک ساعت و حداکثر طول حدود پنج ساعت است ( شکل 5 ). همچنین محبوبیت کلمات کلیدی از نتیجه جلسه نهایی خلاصه می شود. 10 کلمه کلیدی برتر عبارتند از “فضل”، “جریان های اقیانوسی” و غیره ( شکل 6 ).
5.4. ترافیک وب سایت و مکان کاربر (هیت مپ)
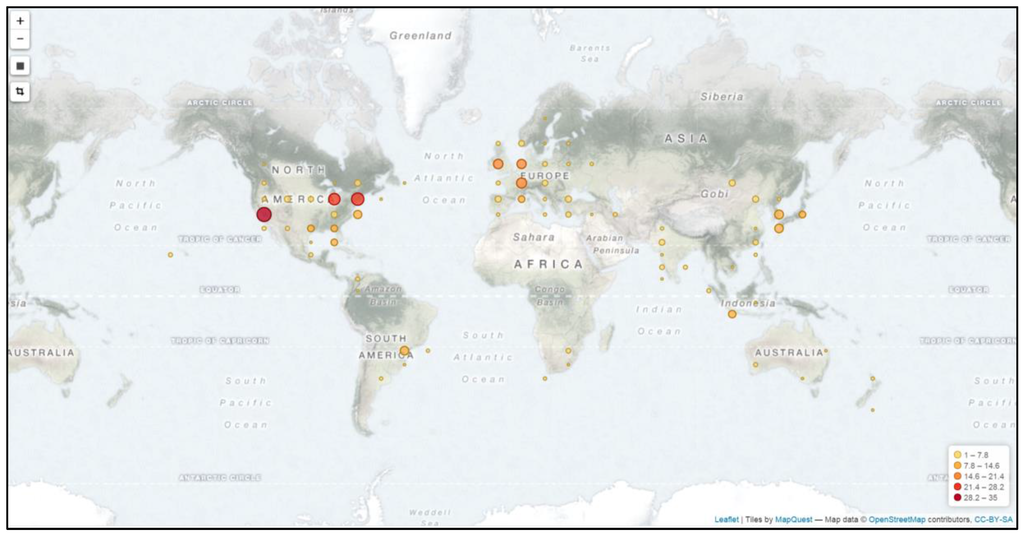
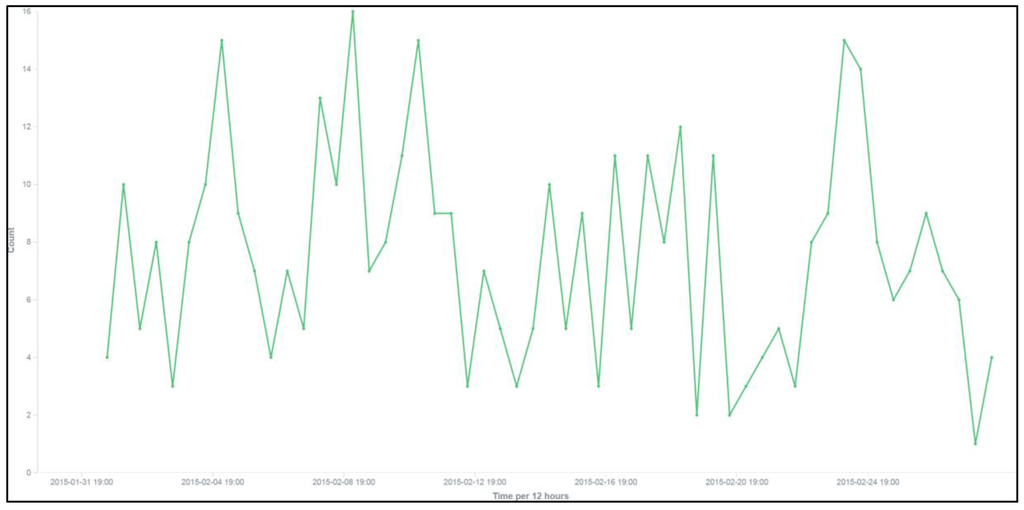
افراد از مکان های مختلف ممکن است به موضوعات مختلف علاقه مند شوند و این موضوعات نیز ممکن است در طول زمان تغییر کنند. ترافیک وب سایت و مکان کاربران برای ایجاد اطلاعات مکانی-زمانی در پایگاه دانش مفید است. برای انجام این کار، آدرسهای IP به مکانهای جغرافیایی تبدیل میشوند و با OpenStreetMap تجسم میشوند. همانطور که از شکل 7 مشاهده می شود ، کاربران تقریباً از سراسر جهان آمده اند. سه خوشه در ایالات متحده وجود دارد، یکی از کالیفرنیا، و دو گروه دیگر از شمال شرقی ایالات متحده برای تجسم ترافیک وب سایت، یک نمودار خطی ایجاد می شود تا نشان دهد که چگونه تعداد جلسات کاربر (نه کاربران) در طول زمان تغییر می کند (UTC) ( شکل 8). کمی تعجب آور است که یک الگوی روزانه در نمودار یافت نمی شود. یک توضیح احتمالی این است که کاربران از مناطق زمانی مختلف می آیند. در اینجا باید تحلیل های بیشتری انجام شود.
6. بحث و نتیجه گیری
این مقاله تحقیقات ما را در مورد بازسازی جلسه از لاگهای وب خام گزارش میکند و دو روش شناسایی جلسه شامل روشهای مبتنی بر خوشهبندی زمان و روشهای مبتنی بر ارجاع زمان را پیشنهاد میکند.
-
روش انتخاب پیشنهادی بر اساس آستانه آماری تعاملی، در مقایسه با آستانه زمانی تجربی، اطمینان بیشتری را برای تحلیل بیشتر فراهم میکند.
-
در مقایسه با اکتشافی مبتنی بر ارجاعدهنده استاندارد، اکتشافی مبتنی بر ارجاعدهنده زمان عملکرد را از دو جنبه با معرفی یک مؤلفه زمانی بهبود میبخشد: اول، وظایف مبتنی بر ارجاع نزدیک برای تشکیل یک جلسه واقعی به هم متصل میشوند، که به معنای ارتباطات بین این موارد است. وظایف نزدیک به این ترتیب حفظ می شوند. دوم، یک مؤلفه زمانی یک چارچوب زمانی پویا را به عنوان محدودیتی برای جستجوی صفحه قبلی اضافه می کند، که از ایجاد یک جلسه طولانی غیرمنطقی جلوگیری می کند.
-
هنگامی که با اکتشافی مبتنی بر زمان استاندارد مقایسه میشود، اکتشافی مبتنی بر خوشهبندی با ایجاد سلسله مراتبی از خوشهها در بعد زمان، به محدودیت آستانه ثابت میپردازد.
-
گردش کار بازسازی جلسه از چندین سرور ثابت کرده است که میتواند اطلاعات ارزشمندی را از دادههای گزارش خام استخراج و تجسم کند، که اساس کشف روابط کلیدواژه و مجموعه داده را پایهگذاری کرده است. علاوه بر این، تعمیم و استفاده مجدد از این اطلاعات در سایر تحقیقات کاوی استفاده از وب آسان است.
چندین جهت وجود دارد که این تحقیق می تواند بیشتر بهبود یابد. از نظر بازسازی خود جلسه، ما قصد داریم با استفاده از گزارشهای وب که حاوی اطلاعات شناسه جلسه هستند، ارزیابی دقت انجام دهیم. اگرچه یک اکتشافی مبتنی بر ارجاع زمان در مورد ما انتخاب شده است، زیرا ارجاع دهنده بخش مهمی از اطلاعات برای ردیابی رفتار جستجوی کاربر است، ما معتقدیم که اکتشافی خوشه بندی زمان از اکتشافی مبتنی بر زمان سنتی با یک آستانه ثابت، به ویژه برای سایت های بدون فریم که اطلاعات ارجاع دهنده در آنها چندان مهم نیست. مقایسه دقت کمی بین اکتشافی مبتنی بر ارجاع زمان و خوشهبندی زمانی تحت ساختارهای مختلف سایت، به عنوان مثال ، سایتهای مبتنی بر فریم و بدون فریم [ 8] انجام خواهد شد.]. به صورت افقی، گردش کار و روش های شناسایی جلسه را می توان برای سایر سیستم های داده مانند داده های قطبی و بیولوژیکی اعمال کرد. دانش استخراج شده از حوزه های مختلف می تواند برای ایجاد پایگاه دانش قوی تر و جامع تر ادغام شود. بر اساس جفت کلمات کلیدی استخراج شده، ما جستجوی معنایی را به صورت عمودی با ایجاد یک پایگاه دانش ساختاریافته ادغام خواهیم کرد [ 28]]. به طور خاص، تلاشهای بیشتری برای کشف روابط معنایی پنهان در میان پرس و جوهای مختلف باید انجام شود. به عنوان مثال، می توانیم احتمال را محاسبه کنیم و قوانینی را که برای آنها دو کلمه کلیدی همراه با یکدیگر جستجو می شود، شناسایی کنیم. برخلاف استخراج قوانین انجمن سنتی، فواصل پرسوجوهای مختلف در درخت ساختار جلسه، مزیت منحصربهفردی را برای کاوش بهتر روابط آنها در اختیار ما قرار میدهد. تکنیکهای بالقوهای که میتوان از آنها استفاده کرد عبارتند از قانون تداعی، یادگیری توالی و زنجیرههای مارکوف. علاوه بر این، ما قصد داریم نتایج تجزیه و تحلیل تاریخچه پرس و جو کاربران، رفتار کلیک کردن، ابرداده ها و هستی شناسی موجود را برای تقویت پرس و جوهای کاربر با عبور از پایگاه دانش یکپارچه، ادغام کنیم و هدف واقعی جستجوهای کاربر را آشکار کنیم.27 ]. هنگامی که پایگاه دانش معنایی با موفقیت ساخته شد، هدف نهایی بهبود کشف دادهها با نتایج رتبهبندی بهتر، توصیه دادههای مرتبط، و ناوبری هستیشناسی است [ 29 ].
منابع
- وتساوایی، ر.ر. گانگولی، ا. چاندولا، وی. استفانیدیس، ا. کلاسکی، اس. Shekhar, S. داده کاوی فضایی و زمانی در عصر داده های مکانی بزرگ: الگوریتم ها و کاربردها. در مجموعه مقالات اولین کارگاه بین المللی ACM SIGSPATIAL در مورد تجزیه و تحلیل برای داده های مکانی بزرگ، ردوندو بیچ، کالیفرنیا، ایالات متحده آمریکا، 7 تا 9 نوامبر 2012.
- گی، ز. یانگ، سی. شیا، جی. لیو، ک. خو، سی. لی، جی. Lostritto، P. یک موتور جستجوی توزیع شده با عملکرد، معنایی و بهبود کیفیت خدمات برای بهبود کشف منابع جغرافیایی. بین المللی جی. جغرافی. Inf. علمی 2013 ، 27 ، 1109-1132. [ Google Scholar ] [ CrossRef ]
- یانگ، سی. سان، م. لیو، ک. هوانگ، Q. لی، ز. گی، ز. جیانگ، ی. شیا، جی. یو، م. خو، سی. Lostritto، P. فن آوری های محاسباتی معاصر برای پردازش داده های بزرگ مکانی-زمانی. در ادغام فضا-زمان در جغرافیا و علم GIS ; اسپرینگر هلند، 2015; صص 327-351. [ Google Scholar ]
- Langille، AN; Meyer، CD Google’s PageRank و فراتر از آن: علم رتبه بندی موتورهای جستجو. در دسترس آنلاین: http://geza.kzoo.edu/~erdi/patent/langvillebook.pdf (دسترسی در 3 ژانویه 2016).
- لی، ی. اورن، وی. Motta، E. Semsearch: یک موتور جستجو برای وب معنایی. در دسترس آنلاین: http://kmi.open.ac.uk/publications/pdf/semsearch_paper.pdf (در 3 ژانویه 2016 قابل دسترسی است).
- سریواستاوا، جی. کولی، آر. دشپنده، م. تان، P.-N. کاوی استفاده از وب: کشف و کاربردهای الگوهای استفاده از داده های وب. در دسترس آنلاین: http://nlp.uned.es/WebMining/Tema5.Uso/srivastava2000.pdf (در 3 ژانویه 2016 قابل دسترسی است).
- رومرو، سی. اسپژو، پی.جی. ظفره، ع. Romeroand، JR; Ventura, S. استفاده از وب برای پیش بینی نمرات نهایی دانش آموزانی که از دوره های Moodle استفاده می کنند. محاسبه کنید. Appl. مهندس آموزش. 2013 ، 21 ، 135-146. [ Google Scholar ] [ CrossRef ]
- برنت، بی. مبشر، ب. ناکاگاوا، م. Spiliopoulou، M. تاثیر ساختار سایت و محیط کاربر بر بازسازی جلسه در تجزیه و تحلیل استفاده از وب. در WEBKDD 2002-Mining Web Data for Discovering Usage Patterns and Profiles ; Springer: برلین، آلمان، 2003; صص 159-179. [ Google Scholar ]
- ژانگ، جی. قربانی، ع. بازسازی جلسات کاربر از لاگ سرور با استفاده از اکتشافی زمان گرا بهبود یافته. در مجموعه مقالات دومین کنفرانس سالانه تحقیقات شبکه های ارتباطی و خدمات، فردریکتون، NB، کانادا، 19-21 مه 2004.
- شارما، ن. ماخیجا، ص. کاوی استفاده از وب: یک رویکرد جدید برای ساخت جلسه کاربر وب. گلوب. جی. کامپیوتر. علمی تکنولوژی 2015 ، 15 ، 23-27. [ Google Scholar ]
- جونز، آر. Klinkner، KL Beyond the session: تقسیم بندی سلسله مراتبی خودکار موضوعات جستجو در گزارش های جستجو. در مجموعه مقالات هفدهمین کنفرانس ACM در مدیریت اطلاعات و دانش، دره ناپا، کالیفرنیا، ایالات متحده آمریکا، 26 تا 30 اکتبر 2008.
- کولی، آر. مبشر، ب. Srivastava, J. آماده سازی داده ها برای استخراج الگوهای مرور وب در سراسر جهان. بدانید. Inf. سیستم 1999 ، 1 ، 5-32. [ Google Scholar ] [ CrossRef ]
- هالفاکر، ا. کییز، او. کلوور، دی. Thebault-Spieker، J. نگوین، تی. سواحل، ک. Uduwage، A.; Warncke-Wang، M. شناسایی جلسه کاربر بر اساس قوانین قوی در زمان بین فعالیت. در مجموعه مقالات بیست و چهارمین کنفرانس بین المللی وب جهانی، فلورانس، ایتالیا، 18 تا 22 مه 2015.
- پی، جی. هان، جی. مرتضوی اصل، ب. Zhu, H. الگوهای دسترسی کارآمد استخراج از لاگ های وب. در دسترس آنلاین: http://www.cse.msu.edu/~cse960/Papers/usagemining/pei00mining.pdf (در 3 ژانویه 2016 قابل دسترسی است).
- Zaiane، OR; شین، ام. Han, J. کشف الگوها و روندهای دسترسی به وب با استفاده از فناوری OLAP و داده کاوی در لاگ های وب. در مجموعه مقالات انجمن بین المللی IEEE در زمینه پیشرفت های تحقیقاتی و فناوری در کتابخانه های دیجیتال، ADL 98، سانتا باربارا، CA، ایالات متحده آمریکا، 22-24 آوریل 1998.
- اسپیلیوپولو، م. مبشر، ب. برنت، بی. ناکاگاوا، M. چارچوبی برای ارزیابی اکتشافات بازسازی جلسه در تجزیه و تحلیل استفاده از وب. Inf. جی. کامپیوتر. 2003 ، 15 ، 171-190. [ Google Scholar ] [ CrossRef ]
- لیو، بی. داده کاوی وب: کاوش پیوندها، محتویات و داده های استفاده ؛ Springer Science & Business Media: برلین، آلمان، 2007. [ Google Scholar ]
- تاناسا، دی. Trousse, B. پیش پردازش داده های پیشرفته برای استخراج استفاده از وب بین سایتی. IEEE Intell. سیستم 2004 ، 19 ، 59-65. [ Google Scholar ] [ CrossRef ]
- Tanasa, D. Web Usage Mining: کمک به پیش پردازش لاگ بین سایت ها و استخراج الگوی متوالی با پشتیبانی کم. در دسترس آنلاین: https://tel.archives-ouvertes.fr/tel-00178870/document (در 1 ژانویه 2016 قابل دسترسی است).
- آپاچی Apache HTTP Server نسخه 2.4. در دسترس آنلاین: http://httpd.apache.org/docs/current/logs.html#combined (در 1 ژانویه 2016 قابل دسترسی است).
- کاستالیا فایل لاگ سرور ProFTPD. 2009. در دسترس آنلاین: http://www.castaglia.org/proftpd/doc/xferlog.html (در 1 ژانویه 2016 قابل دسترسی است).
- رومرو، سی. ونتورا، اس. گارسیا، ای. داده کاوی در سیستم های مدیریت دوره: مطالعه موردی مودل و آموزش. محاسبه کنید. آموزش. 2008 ، 51 ، 368-384. [ Google Scholar ] [ CrossRef ]
- دوران، دی. تکنیک های تشخیص ربات وب SS Gokhale: نمای کلی و محدودیت ها حداقل داده بدانید. کشف کنید. 2011 ، 22 ، 183-210. [ Google Scholar ] [ CrossRef ]
- بنگلیا، تی. شوو، دی. هانتر، DR. Young، DS Mixtools: یک بسته R برای تجزیه و تحلیل مدل های مخلوط محدود. J. Stat. نرم افزار 2009 ، 32 ، 1-29. [ Google Scholar ] [ CrossRef ]
- جنکس، GF مفهوم مدل داده در نقشه برداری آماری. بین المللی سالب. کارتوگر. 1967 ، 7 ، 186-190. [ Google Scholar ]
- ESRI. روش بهینه سازی JENKS چیست؟ 2012. در دسترس آنلاین: http://support.esri.com/en/knowledgebase/techarticles/detail/26442 (در 3 ژانویه 2016 قابل دسترسی است).
- یانگ، سی. خو، ی. Nebert, D. تعریف مجدد امکان زمین دیجیتال و علوم زمین با محاسبات ابری فضایی. بین المللی جی دیجیت. زمین 2013 ، 6 ، 297-312. [ Google Scholar ] [ CrossRef ]
- لیو، ک. یانگ، سی. لی، دبلیو. گی، ز. خو، سی. Xia, J. استفاده از جستجوی معنایی و استدلال دانش برای بهبود کشف سوابق علوم زمین: مثالی با بستر آزمایش معنایی ESIP. بین المللی J. Appl. Geos. Res. 2014 ، 5 ، 44-58. [ Google Scholar ] [ CrossRef ]
- یانگ، سی. لی، دبلیو. زی، جی. Zhou، B. پردازش اطلاعات مکانی توزیع شده: به اشتراک گذاری منابع جغرافیایی توزیع شده برای پشتیبانی از زمین دیجیتال. بین المللی جی دیجیت. زمین 2008 ، 1 ، 259-278. [ Google Scholar ] [ CrossRef ]
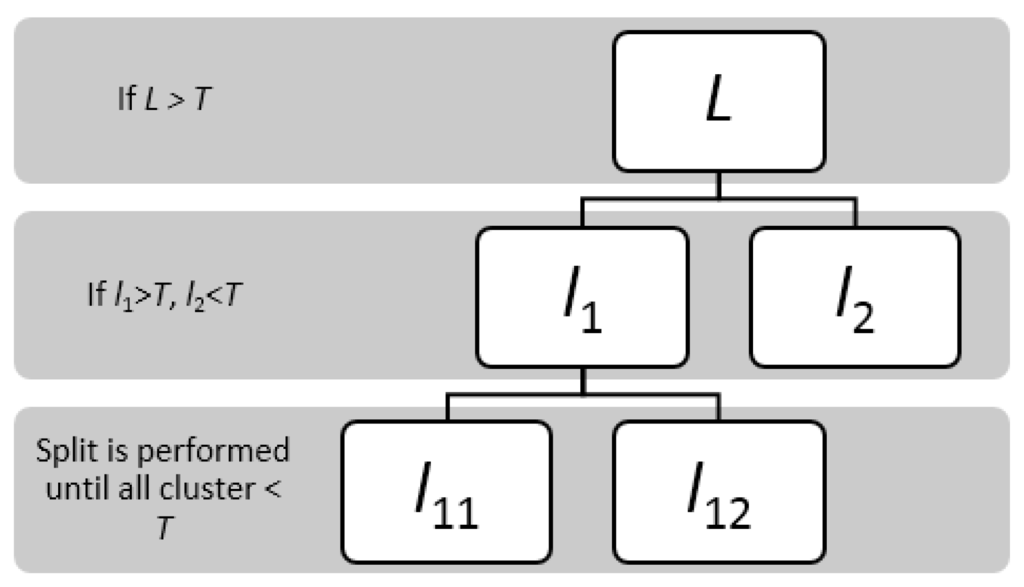
شکل 1. نمونه ای از اکتشافی مبتنی بر خوشه بندی.

شکل 2. معماری سیستم بازسازی جلسه.
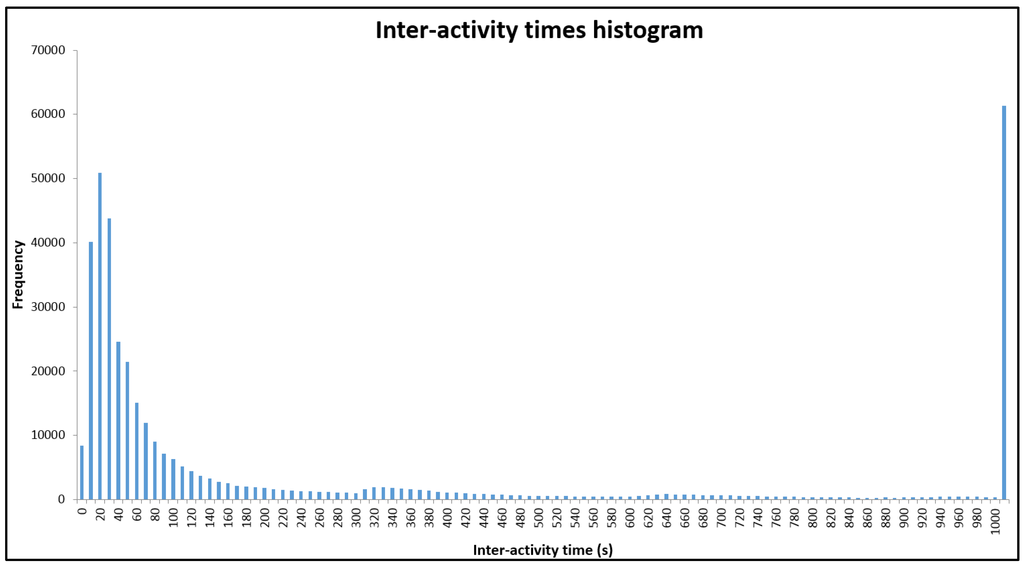
شکل 3. هیستوگرام زمان های بین فعالیت.
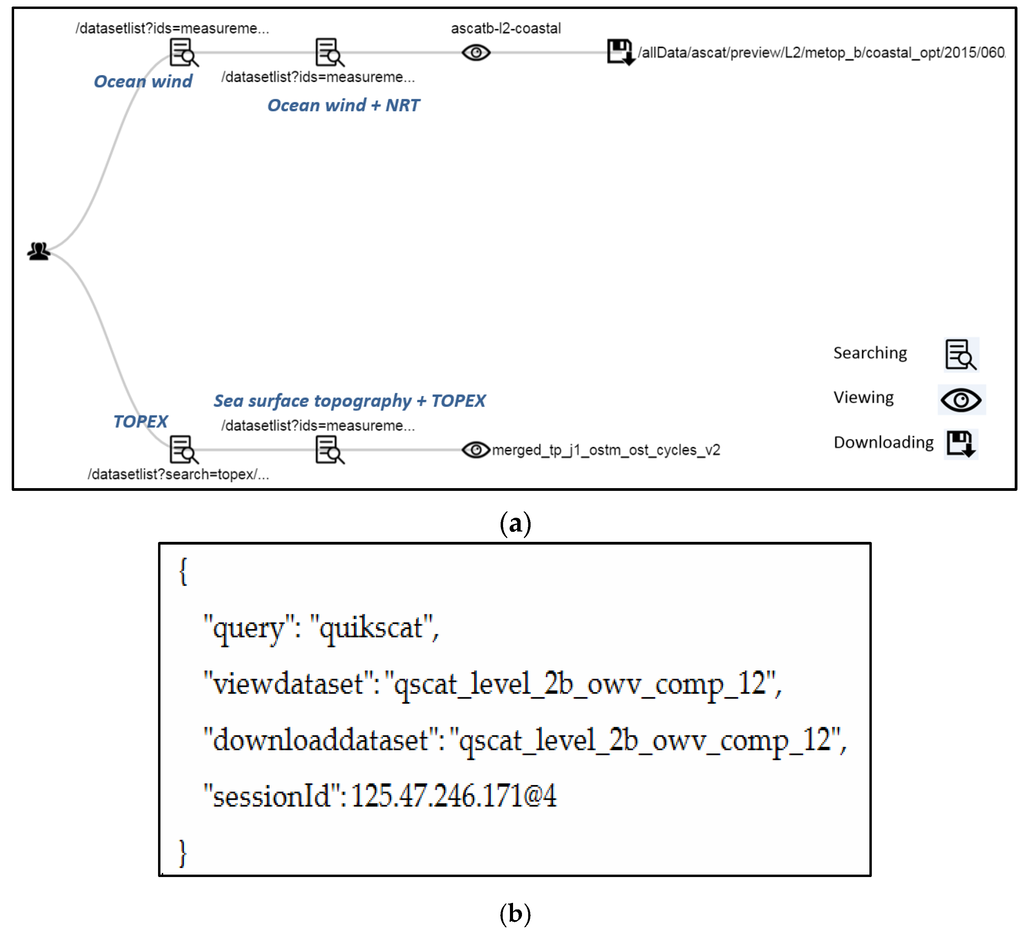
شکل 4. نمونه ای از نتایج ساختار جلسه. ( الف ) درخت ساختار جلسه. ( ب ) مجموعه پرس و جو.
شکل 5. هیستوگرام طول جلسه.
شکل 6. محبوبیت کلمات کلیدی.
شکل 7. نقشه حرارتی محل ورود کاربران.
شکل 8. ترافیک وب سایت.

جدول 1. نمونه داده های گزارش HTTP در قالب Log ترکیبی.
جدول 2. نمونه داده های گزارش FTP در قالب FTP Log.
جدول 3. مقایسه نتیجه با روش سنتی ارجاع دهنده، نتیجه میانی و نهایی اکتشافی مبتنی بر ارجاع زمان.
جدول 4. مقایسه اکتشافی مبتنی بر ارجاع زمان و مبتنی بر خوشه بندی زمان.
جدول 5. کلمات کلیدی جستجو شده در جلسات نمونه.
© 2016 توسط نویسندگان؛ دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (CC-BY) (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر