

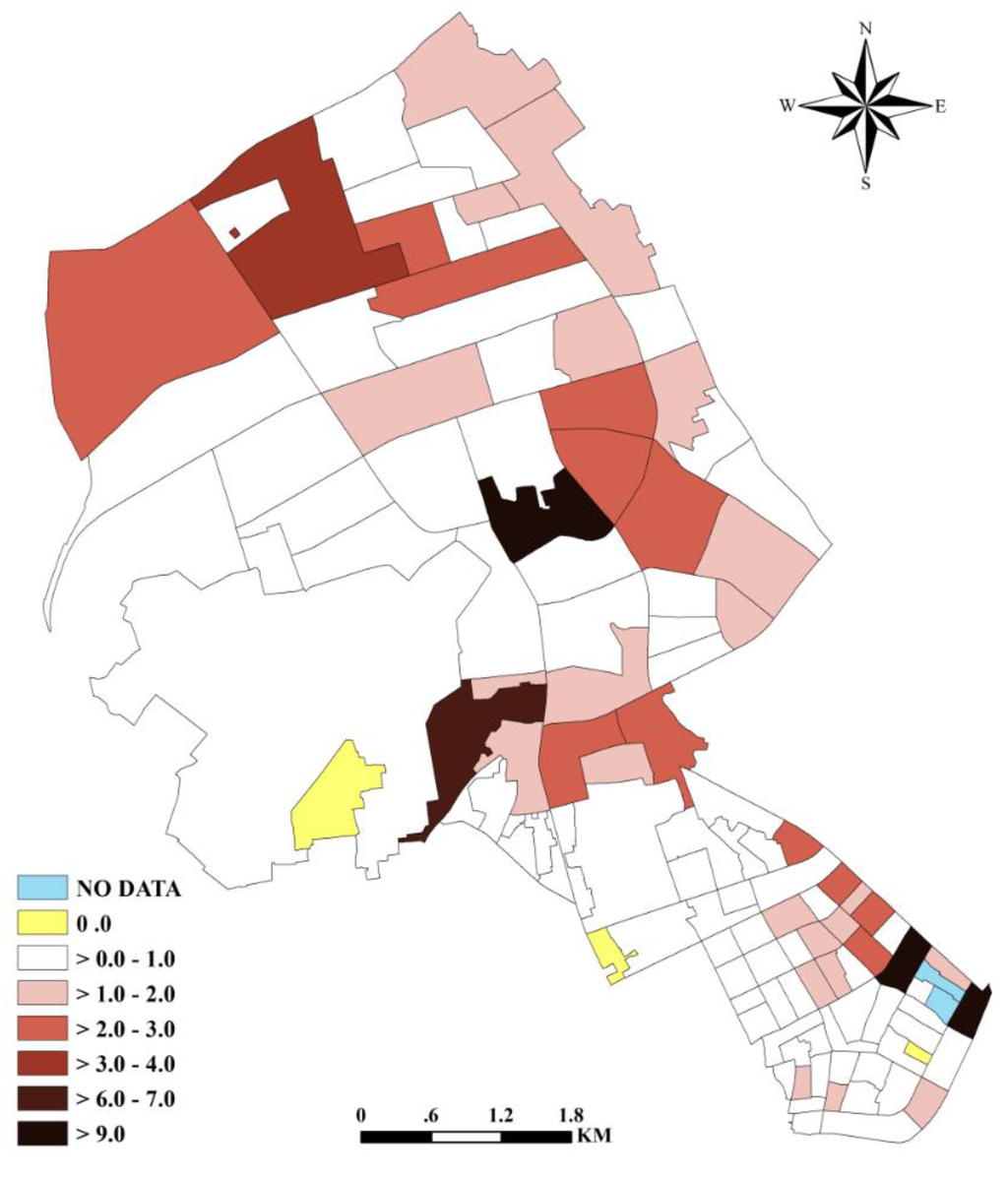
خلاصه
خطر سرقت ؛ مدل سازی اثرات تصادفی بیزی رگرسیون پواسون فضایی ; WinBUGS ; زنجیره مارکوف مونت کارلو
1. معرفی
2. مطالعه منطقه و داده ها
2.1. منطقه مطالعه
2.2. داده ها
3. روش ها
3.1. استراتژی مدلسازی
جایی که E( i ) r ( i )�(من)�(من)مقدار مورد انتظار توزیع پواسون است، E( من )�(من)تعداد موارد سرقت در محله i است که در صورت توزیع تصادفی رویدادها در منطقه مورد مطالعه به گونه ای که تعداد مورد انتظار در هر محله با جمعیت آن نسبت مستقیم داشته باشد، می توان انتظار داشت. r ( i )�(من)خطر سرقت مربوط به منطقه خاص است. مدل رگرسیون پواسون سنتی به شرح زیر است:
جایی که l o g[ E( من ) ]ل��[�(من)]یک عبارت افست با ضریب رگرسیون یک است، β0�0رهگیری است، ایکس1ایکس1، ⋯ ⋯ ، ایکسکایکسکمشاهدات متغیرهای کمکی هستند، β1�1، ⋯ ⋯ ، βک�کضرایب رگرسیون مربوطه هستند و ککتعداد متغیرهای کمکی، پنج در این مطالعه است. این مدل فرض می کند که همه متغیرهای کمکی مربوطه به درستی مشخص شده اند. علاوه بر این، غیر فضایی است و پراکندگی بیش از حد یا هیچ ساختار فضایی بین محله ها را در نظر نمی گیرد. برای مقابله با این مشکلات، از رویکرد مدلسازی اثرات تصادفی بیزی استفاده شد. مدل اثرات تصادفی بیزی به صورت زیر مشخص می شود:
جایی که U( من )�(من)یک اصطلاح اثرات تصادفی بدون ساختار برای محاسبه بیش از حد پراکندگی است، و اس( من ) اس(من) یک اصطلاح اثرات تصادفی فضایی برای توضیح خودهمبستگی فضایی است. به طور خاص، اصطلاح اثرات تصادفی فضایی اس( من )اس(من)به عنوان یک پروکسی برای متغیرهای کمکی گمشده یا اندازهگیری نشده عمل میکند که از نظر مکانی همبستگی خودکار دارند، در غیر این صورت ساختار فضایی را در باقیماندهها ثبت میکند. این مدل اثرات تصادفی در واقع بسط مدل غیر فضایی است که با گنجاندن عبارت اثرات تصادفی فضایی، آن را به یک مدل پواسون فضایی تبدیل می کند. اگر متغیرهای کمکی از دست رفته یا اندازهگیری نشده از نظر مکانی همبستگی خودکار نداشته باشند، عبارت اثرات تصادفی ساختار نیافته در نظر گرفته شود. U( من ) �(من) ممکن است کافی باشد و اصطلاح اثرات تصادفی فضایی باشد اس( من )اس(من)را می توان از معادله (4) حذف کرد. بنابراین، مدل دیگری را نیز در تحلیل اجرا کردیم:
3.2. مشخصات قبلی
جایی که ωمن ، ج= 1�من،�=1اگر i و j مجاور باشند و ωمن ، ج= 0�من،�=0در غیر این صورت (با ωمن ، من�من،منهمچنین روی 0) و nمن�منتعداد محله های مجاور محله i است . محله هایی که مرز مشترک دارند به عنوان همسایه تعریف می شوند. همانطور که گلمن [ 59 ] توصیه می کند، ما از یک توزیع یکنواخت قبلی dunif(0، 100) برای پارامترهای انحراف استاندارد، به جای گاما استفاده کردیم. ϵ�، ϵ�) خانواده توزیع غیر اطلاعاتی که در آن ϵ�مقدار کمی برای پارامترهای دقیق تنظیم شده است U( من )�(من)و اس( من )اس(من); اگر پارامتر انحراف معیار نزدیک به صفر تخمین زده شود، استنباط های حاصل حساس به ϵ .�.
جایی که s d( اس)سد(اس)و s d( U)سد(�)انحرافات استاندارد حاشیه ای تجربی هستند اساسو U،�،به ترتیب [ 60 ]. ψ �برای اندازه گیری تغییرپذیری در اثرات تصادفی ناشی از وابستگی فضایی استفاده می شود. مقادیر بزرگ از ψ �(یعنی نزدیک به 1) یک جزء واریانس همبسته فضایی غالب را نشان می دهد، در حالی که مقادیر کوچک (یعنی نزدیک به صفر) یک جزء ناچیز را نشان می دهد.
3.3. پیاده سازی
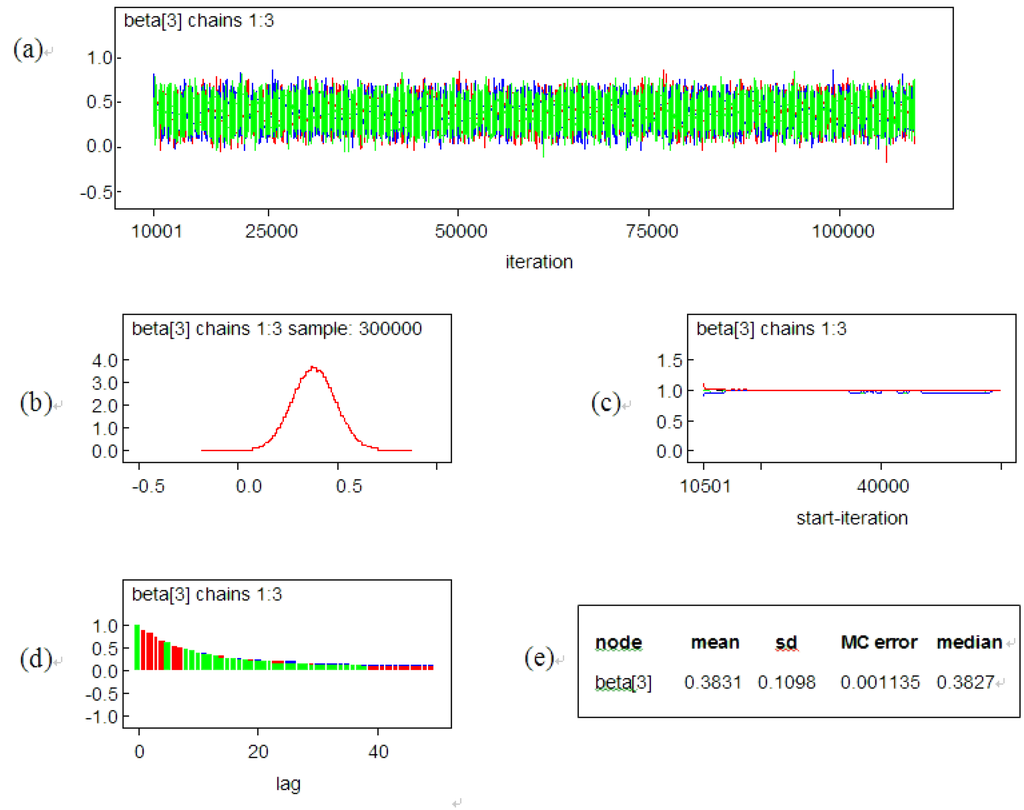
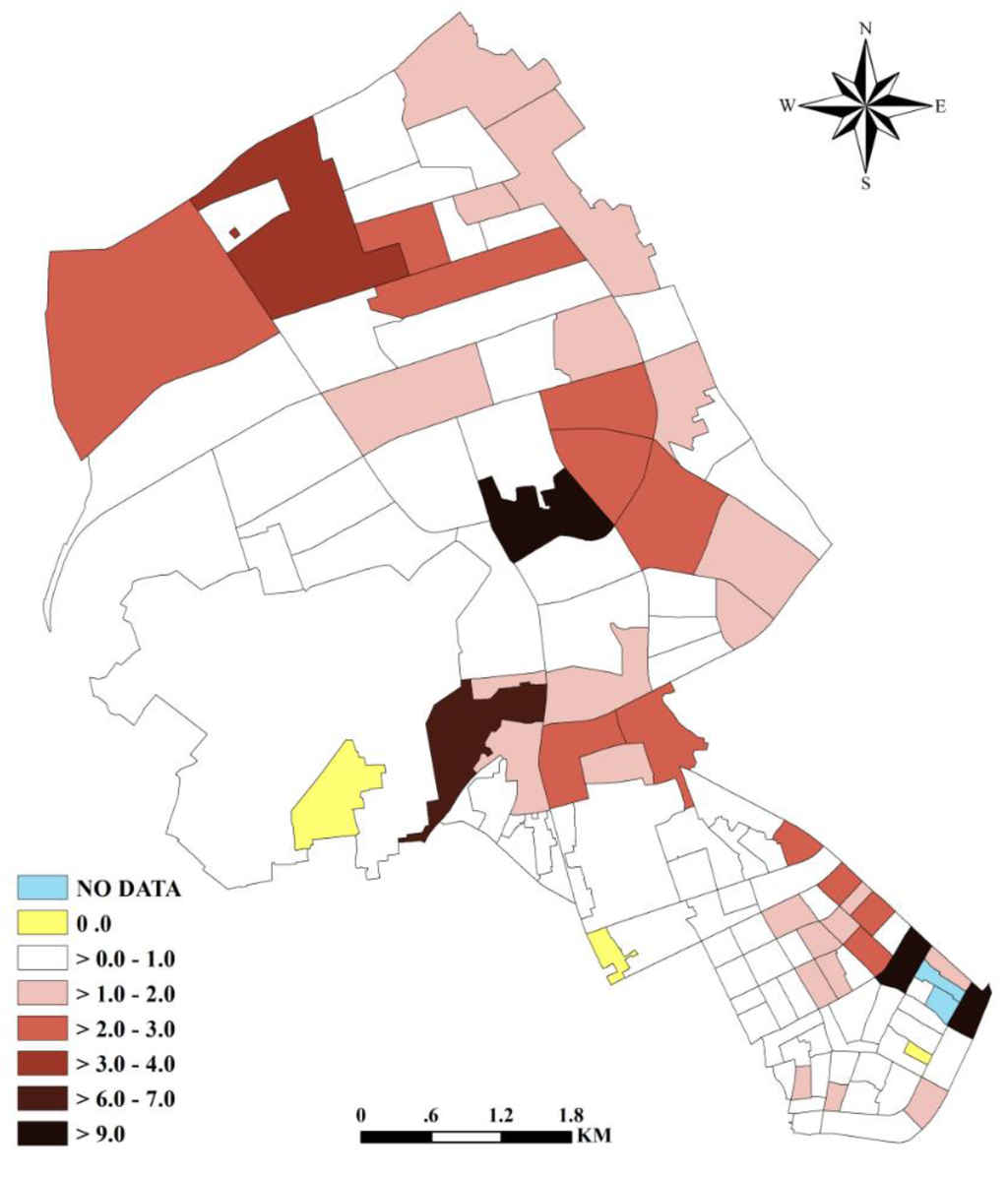
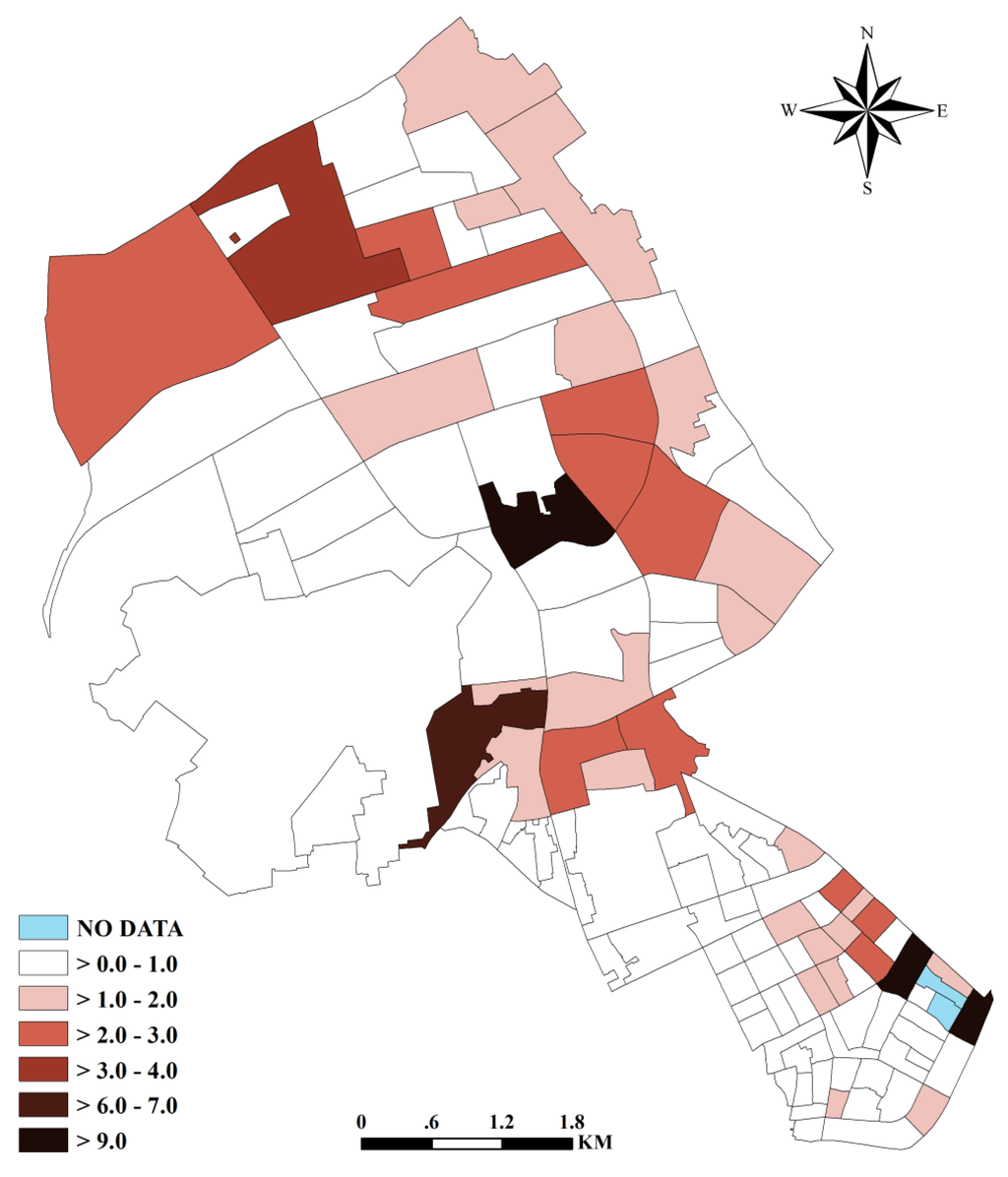
4. نتایج
5. بحث
6. نتیجه گیری
منابع
- ویزبرد، دی. بروینسما، جی جی; برناسکو، دبلیو. واحدهای تحلیل در جرم شناسی جغرافیایی: توسعه تاریخی، مسائل بحرانی و سؤالات باز. در قرار دادن جنایت در جای خود ; Springer: برلین، آلمان، 2009; صص 3-31. [ Google Scholar ]
- ویر، آر. بنگس، م. بریتانیا، جی. استفاده از سیستم های اطلاعات جغرافیایی توسط تحلیلگران جرم و جنایت در انگلستان و ولز . دفتر خانه: لندن، بریتانیا، 2007. [ Google Scholar ]
- آرچر، دی. گارتنر، آر. خشونت و جنایت در دیدگاه فراملی . انتشارات دانشگاه ییل: نیوهیون، CT، ایالات متحده آمریکا، 1987. [ Google Scholar ]
- فگیانی، د. بیبل، دی. برنسیلبر، دی. حل مشکل منطقه ای با استفاده از سیستم گزارش دهی مبتنی بر حادثه. در حل مشکلات جرم و بی نظمی ; انجمن تحقیقات اجرایی پلیس: واشنگتن، دی سی، ایالات متحده آمریکا، 2001; صص 155-174. [ Google Scholar ]
- Baller، RD; آنسلین، ال. مسنر، اس.اف. دین، جی. هاوکینز، DF متغیرهای ساختاری نرخ قتل شهرستانی ما: ترکیب اثرات فضایی. جرم شناسی 2001 ، 39 ، 561-588. [ Google Scholar ] [ CrossRef ]
- کورک، دی. بررسی تعامل فضا-زمان در دادههای قتل در سطح شهر: بازارهای شکاف و انتشار اسلحه در بین جوانان. جی. کوانت. Criminol. 1999 ، 15 ، 379-406. [ Google Scholar ] [ CrossRef ]
- بامر، ای. Lauritsen، JL; روزنفلد، آر. رایت، آر. تأثیر کوکائین کراک بر میزان سرقت، سرقت، و قتل: یک تجزیه و تحلیل بین شهری، طولی. J. Res. Crime Delinquency 1998 , 35 , 316-340. [ Google Scholar ] [ CrossRef ]
- تیلور، RB نظم اجتماعی و بی نظمی بلوک های خیابان و محله ها: بوم شناسی، میکرواکولوژی، و مدل سیستمی بی سازمانی اجتماعی. J. Res. Crime Delinquency 1997 , 34 , 113-155. [ Google Scholar ] [ CrossRef ]
- مارتین، دی. الگوهای فضایی در سرقت مسکونی ارزیابی اثر سرمایه اجتماعی محله. J. Contemp. عدالت کیفری 2002 ، 18 ، 132-146. [ Google Scholar ] [ CrossRef ]
- گراف، ای آر. ویزبرد، دی. یانگ، اس.-م. آیا بررسی روندهای جرم و جنایت در سطح “خرد” محلی مهم است؟: تحلیل طولی تغییرپذیری خیابان به خیابان در مسیرهای جرم و جنایت. جی. کوانت. Criminol. 2010 ، 26 ، 7-32. [ Google Scholar ] [ CrossRef ]
- اسمیت، WR; Frazee, SG; دیویسون، EL تداوم ادغام فعالیت های معمول و نظریه های بی نظمی اجتماعی: واحدهای کوچک تحلیل و مطالعه سرقت خیابانی به عنوان یک فرآیند انتشار. جرم شناسی 2000 ، 38 ، 489-524. [ Google Scholar ] [ CrossRef ]
- قانون، ج. هاینینگ، آر. رویکرد بیزی برای مدلسازی دادههای باینری: مورد مناطق جرم و جنایت با شدت بالا. Geogr. مقعدی 2004 ، 36 ، 197-216. [ Google Scholar ] [ CrossRef ]
- مورنوف، جی دی. سامپسون، RJ; Raudenbush، SW محله نابرابری، اثربخشی جمعی، و پویایی فضایی خشونت شهری. جرم شناسی 2001 ، 39 ، 517-558. [ Google Scholar ] [ CrossRef ]
- آندرسن، MA تحلیل فضایی جرم در ونکوور، کلمبیا بریتانیا: ترکیبی از بیسازمانی اجتماعی و نظریه فعالیت معمول. می توان. Geogr./Le Géographe canadien 2006 ، 50 ، 487–502. [ Google Scholar ] [ CrossRef ]
- Malczewski، J. Poetz، A. سرقت های مسکونی و زمینه اجتماعی-اقتصادی محله در لندن، انتاریو: تحلیل رگرسیون جهانی و محلی. پروفسور Geogr. 2005 ، 57 ، 516-529. [ Google Scholar ] [ CrossRef ]
- استین، RE; کانلی، جی اف. دیویس، سی. تأثیر متمایز اختلال جسمانی و اثربخشی جمعی: یک رگرسیون وزندار جغرافیایی بر جنایت خشونتآمیز. GeoJournal 2015 ، 81 ، 1-15. [ Google Scholar ] [ CrossRef ]
- Anselin, L. اقتصاد سنجی فضایی: روش ها و مدل ها . Kulwer Academic: Dordrecht، هلند، 1988. [ Google Scholar ]
- کارلین، BP; Louis, TA Bayes and Empirical Bayes Methods for Data Analysis , 2nd ed.; چپمن و هال: لندن، بریتانیا، 2000. [ Google Scholar ]
- Spiegelhalter، دی جی; توماس، ا. بهترین، NG; گیلکس، اشکالات WR: استنتاج بیزی با استفاده از نمونه گیری گیبس ، نسخه 0.50; دانشگاه کمبریج، واحد آمار زیستی MRC: کمبریج، بریتانیا، 1995. [ Google Scholar ]
- کلیتون، دی. کالدور، جی. بیز تجربی خطرات نسبی استاندارد شده با سن را برای استفاده در نقشه برداری بیماری تخمین می زند. بیومتریک 1987 ، 43 ، 671-681. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- برناردینلی، ال. کلیتون، دی. پاسکوتو، سی. مونتومولی، سی. غسلندی، م. Songini، M. Bayesian تجزیه و تحلیل تغییرات فضا-زمان در خطر بیماری. آمار پزشکی 1995 ، 14 ، 2433-2443. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- لاوسون، نقشه برداری بیماری بیزی AB : مدلسازی سلسله مراتبی در اپیدمیولوژی فضایی . CRC Press: Boca Raton، FL، USA، 2013. [ Google Scholar ]
- کیم، اچ. اولسون، جی جی مدل تعامل پویای مکانی-زمانی بیزی: کاربرد برای بروز سرطان پروستات. Geogr. مقعدی 2008 ، 40 ، 77-96. [ Google Scholar ] [ CrossRef ]
- هاینینگ، آر. قانون، جی. ترکیب ادراک پلیس با سوابق پلیس از مناطق جرم و جنایت جدی: یک رویکرد مدل سازی. JR Stat. Soc. سر. A (Stat. Soc.) 2007 ، 170 ، 1019-1034. [ Google Scholar ] [ CrossRef ]
- فریستلر، بی. Weiss, RE استفاده از مدلهای فضا-زمان بیزی برای درک محیط مصرف مواد و خطر ارجاع به خدمات محافظت از کودک. فرعی استفاده از سوء استفاده 2008 ، 43 ، 239-251. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- ویلر، دی سی؛ والر، لس آنجلس مقایسه مدلهای ضریب متغیر فضایی: یک مطالعه موردی که نرخ جرم خشونتآمیز و روابط آنها با فروشگاههای الکل و دستگیریهای غیرقانونی مواد مخدر را بررسی میکند. جی. جئوگر. سیستم 2009 ، 11 ، 1-22. [ Google Scholar ] [ CrossRef ]
- لوین، ن. تخمین سفر به جرم بلاک، R. Bayesian: یک بهبود در روش شناسی پروفایل جغرافیایی. پروفسور Geogr. 2011 ، 63 ، 213-229. [ Google Scholar ] [ CrossRef ]
- یو، کیو. اسکریبنر، آر. کارلین، بی. تال، ک. سیمونسن، ن. قوش دستیدار، ب. کوهن، دی. میسون، کی. مدلهای نقطه تغییر دوگانه فضایی-زمانی چند سطحی برای ارتباط تخریب خروجی الکل و تغییرات در نرخ خشونتهای تهاجمی در محله. Geosp. سلامت 2008 ، 2 ، 161-172. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Cunradi، CB; مایر، سی. پونیکی، دبلیو. Remer، L. فروشگاه های الکل، ویژگی های محله، و خشونت شریک صمیمی: تجزیه و تحلیل زیست محیطی یک شهر کالیفرنیا. J. Urban Health 2011 ، 88 ، 191-200. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- قانون، ج. مدلسازی اثر تصادفی فضایی چان، PW بیزی برای تجزیه و تحلیل خطرات سرقت با کنترل عوامل خطر متخلف، اجتماعی-اقتصادی و ناشناخته. Appl. تف کردن مقعدی سیاست 2012 ، 5 ، 73-96. [ Google Scholar ] [ CrossRef ]
- قانون، ج. کوئیک، ام. بررسی پیوندهای بین مجرمان نوجوان و بیسازمانی اجتماعی در مقیاس بزرگ نقشه: رویکرد مدلسازی فضایی بیزی. جی. جئوگر. سیستم 2013 ، 15 ، 89-113. [ Google Scholar ] [ CrossRef ]
- گراسیا، ای. لوپز-کوئیلز، آ. مارکو، ام. لادوسا، اس. لیلا، ام. بررسی تأثیرات همسایگی بر تغییرات منطقه کوچک در خطر خشونت شریک صمیمی: رویکرد مدلسازی اثرات تصادفی بیزی. بین المللی جی. محیط زیست. Res. بهداشت عمومی 2014 ، 11 ، 866-882. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- قانون، ج. کوئیک، م. چان، پ. بیزی مدل سازی فضایی-زمانی برای تحلیل الگوهای محلی جرم در طول زمان در سطح منطقه کوچک. جی. کوانت. Criminol. 2014 ، 30 ، 57-78. [ Google Scholar ] [ CrossRef ]
- قانون، ج. کوئیک، م. چان، PW تجزیه و تحلیل نقاط داغ جنایت با استفاده از رویکرد مدلسازی فضایی-زمانی بیزی: مطالعه موردی جنایات خشونتآمیز در ناحیه بزرگتر تورنتو. Geogr. مقعدی 2015 ، 47 ، 1-19. [ Google Scholar ] [ CrossRef ]
- گراسیا، ای. لوپز-کوئیلز، آ. مارکو، ام. لادوسا، اس. لیلا، ام. اپیدمیولوژی فضایی خشونت شریک جنسی: آیا محله ها اهمیت دارند؟ صبح. J. Epidemiol. 2015 ، 182 ، 58-66. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Knorr-Held، L. Bayesian مدلسازی تغییرات تفکیک ناپذیر فضا-زمان در خطر بیماری. آمار پزشکی 1999 ، 19 ، 2555-2567. [ Google Scholar ] [ CrossRef ]
- مولیه، آ. گیلکس، دبلیو. ریچاردسون، اس. Spiegelhalter، D. نقشه برداری بیزی بیماری. تمرین زنجیره ای مارکوف مونت کارلو. 1996 ، 1 ، 359-379. [ Google Scholar ]
- ویکفیلد، جی. بهترین، ن. رویکردهای Waller، L. Bayesian به نقشه برداری بیماری. تف کردن اپیدمیول. Methods Appl. 2000 . [ Google Scholar ] [ CrossRef ]
- اداره آمار شهرداری ووهان سالنامه آماری ووهان 2014 ; انتشارات آمار چین: پکن، چین، 2014.
- شاو، CR; مک کی، HD بزهکاری نوجوانان و مناطق شهری ؛ انتشارات دانشگاه شیکاگو: شیکاگو، IL، ایالات متحده آمریکا، 1942. [ Google Scholar ]
- کوهن، LE; فلسون، ام. تغییرات اجتماعی و روند نرخ جرم و جنایت: رویکرد فعالیت معمول. صبح. اجتماعی Rev. 1979 , 44 , 588-608. [ Google Scholar ] [ CrossRef ]
- Bursik، RJ بیسازمانی اجتماعی و نظریههای جرم و بزهکاری: مشکلات و چشماندازها. جرم شناسی 1988 ، 26 ، 519-552. [ Google Scholar ] [ CrossRef ]
- آکرمن، WV همبستگی اجتماعی و اقتصادی افزایش نرخ جرم و جنایت در جوامع کوچکتر. پروفسور Geogr. 1998 ، 50 ، 372-387. [ Google Scholar ] [ CrossRef ]
- فلسون، ام. کوهن، LE اکولوژی انسانی و جرم: رویکرد فعالیت معمول. هوم Ecol. 1980 ، 8 ، 389-406. [ Google Scholar ] [ CrossRef ]
- شرمن، LW; گارتین، روابط عمومی؛ Buerger, ME نقاط داغ جنایات غارتگرانه: فعالیت های معمول و جرم شناسی مکان. جرم شناسی 1989 ، 27 ، 27-56. [ Google Scholar ] [ CrossRef ]
- جیکوبز، جی. مرگ و زندگی شهرهای بزرگ آمریکا . Random House: نیویورک، نیویورک، ایالات متحده آمریکا، 1961. [ Google Scholar ]
- بیزلی، RW; Antunes, G. علت شناسی جرم شهری یک تحلیل بوم شناختی. جرم شناسی 1974 ، 11 ، 439-461. [ Google Scholar ] [ CrossRef ]
- روتولو، تی. عنوان، CR اندازه جمعیت، تغییر، و جرم و جنایت در شهرهای ایالات متحده. جی. کوانت. Criminol. 2006 ، 22 ، 341-367. [ Google Scholar ] [ CrossRef ]
- Roncek, DW مکان های خطرناک: جرم و محیط مسکونی. Soc. نیروها 1981 ، 60 ، 74-96. [ Google Scholar ] [ CrossRef ]
- استارک، آر. مکان های انحرافی: نظریه ای از بوم شناسی جرم. جرم شناسی 1987 ، 25 ، 893-910. [ Google Scholar ] [ CrossRef ]
- Roncek، DW; مایر، بارها، بلوکها و جنایات PA مورد بازبینی مجدد: پیوند نظریه فعالیتهای معمول با تجربهگرایی «نقاط داغ». جرم شناسی 1991 ، 29 ، 725-753. [ Google Scholar ] [ CrossRef ]
- Evans، JD Straightforward Statistics for the Behavioral Sciences . Brooks/Cole Publishing: Pacific Grove, CA, USA, 1996. [ Google Scholar ]
- Dormann، CF; الیت، جی. باچر، اس. بوخمن، سی. کارل، جی. کاره، جی. مارکوز، جی آر جی؛ گروبر، بی. لافورکید، بی. Leitão، PJ Colinearity: مروری بر روشهای مقابله با آن و یک مطالعه شبیهسازی که عملکرد آنها را ارزیابی میکند. اکوگرافی 2013 ، 36 ، 27-46. [ Google Scholar ] [ CrossRef ]
- مونتگومری، دی سی؛ پک، EA؛ Vining، GG مقدمه ای بر تحلیل رگرسیون خطی . جان وایلی و پسران: نیویورک، نیویورک، ایالات متحده آمریکا، 2015. [ Google Scholar ]
- بیزتی، اچ اس. د کاروالیو، CGP; د سوزا، JRP; Destro، D. تجزیه و تحلیل مسیر تحت چند خطی در سویا. براز قوس. Biol. تکنولوژی 2004 ، 47 ، 669-676. [ Google Scholar ] [ CrossRef ]
- توماس، ا. بهترین، ن. لون، دی. آرنولد، آر. راهنمای کاربر Spiegelhalter, D. Geobugs . واحد آمار زیستی شورای تحقیقات پزشکی: کمبریج، انگلستان، 2004. [ Google Scholar ]
- بساج، ج. یورک، جی. Mollié، A. بازیابی تصویر بیزی، با دو کاربرد در آمار فضایی. ان Inst. آمار ریاضی. 1991 ، 43 ، 1-20. [ Google Scholar ] [ CrossRef ]
- بساج، ج. Kooperberg, C. در مورد خودرگرسیون های شرطی و ذاتی. Biometrika 1995 ، 82 ، 733-746. [ Google Scholar ]
- Gelman, A. توزیع های قبلی برای پارامترهای واریانس در مدل های سلسله مراتبی. مقعد بیزی. 2006 ، 1 ، 515-534. [ Google Scholar ]
- بهترین، NG; آرنولد، RA؛ توماس، ا. والر، لس آنجلس; مدلهای Conlon، EM Bayesian برای دادههای بیماری و مواجهه با همبستگی فضایی. در مجموعه مقالات ششمین نشست بین المللی والنسیا در مورد آمار بیزی، Alcossebre، اسپانیا، 6-10 ژوئن 1999. صص 131-156.
- Spiegelhalter، دی جی; بهترین، NG; کارلین، BP; Van der Linde، A. Bayesian Deviance، تعداد موثر پارامترها، و مقایسه مدلهای پیچیده دلخواه. در دسترس آنلاین: http://www.sph.umn.edu/faculty1/wp-content/uploads/2012/11/rr98-009.pdf (دسترسی در 10 ژانویه 2016).
- Spiegelhalter، دی جی; بهترین، NG; کارلین، BP; اندازهگیریهای پیچیدگی و تناسب مدل ون در لیند، A. بیزی. JR Stat. Soc. سر. B (Stat. Methodol.) 2002 ، 64 ، 583-639. [ Google Scholar ] [ CrossRef ]
- آکایک، اچ. نظریه اطلاعات و بسط اصل احتمال حداکثری. در منتخب مقالات هیروتوگو آکایکه ; Springer: برلین، آلمان، 1998; صص 199-213. [ Google Scholar ]
- گلمن، ا. استنتاج روبین، DB از شبیه سازی تکراری با استفاده از توالی های متعدد. آمار علمی 1992 ، 7 ، 457-472. [ Google Scholar ] [ CrossRef ]
- ریچاردسون، اس. تامسون، ا. بهترین، ن. الیوت، پی. تفسیر تخمین خطر نسبی خلفی در مطالعات نقشه برداری بیماری. محیط زیست چشم انداز سلامتی 2004 ، 112 ، 1016-1025. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Roncek، DW; بل، آر. میلهها، بلوکها و جنایات. جی. محیط زیست. سیستم 1981 ، 11 ، 35-47. [ Google Scholar ] [ CrossRef ]
- گراف، ای آر. La Vigne, NG نقشه برداری از یک سطح فرصت سرقت مسکونی. J. Res. جنایت دلینق. 2001 ، 38 ، 257-278. [ Google Scholar ] [ CrossRef ]
- رابینسون، MB; Mullen، KL Crime در محوطه دانشگاه: نظرسنجی از کاربران فضا. جنایت قبلی جامعه ایمن 2001 ، 3 ، 33-46. [ Google Scholar ] [ CrossRef ]


© 2016 توسط نویسندگان؛ دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (CC-BY) (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر