

خلاصه
با نگاهی به چهار دهه گذشته، فناوریهایی که برای رصد و نقشهبرداری زمین ایجاد شدهاند، میتوانند فناوریهایی را که امروزه در حال پیشرفت هستند و چالشهای آنها را روشن کند. چهل سال پیش، اولین تصاویر دیجیتالی سرنوشت سنجش از دور، مهندسی فتوگرامتری، GIS یا به طور خلاصه: ژئوماتیک را رقم زدند. این موج ناگهانی حجم دادهها باعث آغاز تحقیقات در زمینههایی شد که امروزه Big Data در حال شخم زدن است: این مقاله این انتقال را بررسی خواهد کرد. اول، بررسی سریع فناوری از طریق متوالی اصطلاحات انتخاب شده، به شناسایی دو دوره اصلی در چهار دهه گذشته کمک خواهد کرد. اطلاعات مکانی در سال 1970 با تهیه Landsat و Big Data در سال 2010 ظاهر شد. بررسی هر یک از “Vs”هایی است که امروزه برای مشخص کردن دومی استفاده می شود: حجم، سرعت، تنوع، تجسم، ارزش، صحت، اعتبار و تغییرپذیری. ژئوماتیک در طول این دوره با هر یک از این جنبه ها مواجه بوده است. این بحث، پاسخهای اولیه ارائه شده توسط geomatics را با وضعیت امروز در Big Data مقایسه میکند. در طیف وسیعی از مسائل، از پردازش سیگنال گرفته تا معناشناسی اطلاعات، ژئوماتیک به بسیاری از مدلها و الگوریتمهای داده کمک کرده است. Big Data اکنون به اطلاعات جغرافیایی امکان می دهد تا بسیار گسترده تر منتشر شود و از منابع اطلاعاتی جدید بهره مند شود و از طریق اینترنت اشیا به سمت زمین دیجیتالی آینده گسترش یابد. برخی از درس های آموخته شده در طول چهار دهه ژئوماتیک نیز می تواند درس هایی برای داده های بزرگ امروزی و برای آینده ژئوماتیک باشد. سرعت، تنوع، تجسم، ارزش، صحت، اعتبار و تنوع. ژئوماتیک در طول این دوره با هر یک از این جنبه ها مواجه بوده است. این بحث، پاسخهای اولیه ارائه شده توسط geomatics را با وضعیت امروز در Big Data مقایسه میکند. در طیف وسیعی از مسائل، از پردازش سیگنال گرفته تا معناشناسی اطلاعات، ژئوماتیک به بسیاری از مدلها و الگوریتمهای داده کمک کرده است. Big Data اکنون به اطلاعات جغرافیایی امکان می دهد تا بسیار گسترده تر منتشر شود و از منابع اطلاعاتی جدید بهره مند شود و از طریق اینترنت اشیا به سمت زمین دیجیتالی آینده گسترش یابد. برخی از درس های آموخته شده در طول چهار دهه ژئوماتیک نیز می تواند درس هایی برای داده های بزرگ امروزی و برای آینده ژئوماتیک باشد. سرعت، تنوع، تجسم، ارزش، صحت، اعتبار و تنوع. ژئوماتیک در طول این دوره با هر یک از این جنبه ها مواجه بوده است. این بحث، پاسخهای اولیه ارائه شده توسط geomatics را با وضعیت امروز در Big Data مقایسه میکند. در طیف وسیعی از مسائل، از پردازش سیگنال گرفته تا معناشناسی اطلاعات، ژئوماتیک به بسیاری از مدلها و الگوریتمهای داده کمک کرده است. Big Data اکنون به اطلاعات جغرافیایی امکان می دهد تا بسیار گسترده تر منتشر شود و از منابع اطلاعاتی جدید بهره مند شود و از طریق اینترنت اشیا به سمت زمین دیجیتالی آینده گسترش یابد. برخی از درس های آموخته شده در طول چهار دهه ژئوماتیک نیز می تواند درس هایی برای داده های بزرگ امروزی و برای آینده ژئوماتیک باشد. ژئوماتیک در طول این دوره با هر یک از این جنبه ها مواجه بوده است. این بحث، پاسخهای اولیه ارائه شده توسط geomatics را با وضعیت امروز در Big Data مقایسه میکند. در طیف وسیعی از مسائل، از پردازش سیگنال گرفته تا معناشناسی اطلاعات، ژئوماتیک به بسیاری از مدلها و الگوریتمهای داده کمک کرده است. Big Data اکنون به اطلاعات جغرافیایی امکان می دهد تا بسیار گسترده تر منتشر شود و از منابع اطلاعاتی جدید بهره مند شود و از طریق اینترنت اشیا به سمت زمین دیجیتالی آینده گسترش یابد. برخی از درس های آموخته شده در طول چهار دهه ژئوماتیک نیز می تواند درس هایی برای داده های بزرگ امروزی و برای آینده ژئوماتیک باشد. ژئوماتیک در طول این دوره با هر یک از این جنبه ها مواجه بوده است. این بحث، پاسخهای اولیه ارائه شده توسط geomatics را با وضعیت امروز در Big Data مقایسه میکند. در طیف وسیعی از مسائل، از پردازش سیگنال گرفته تا معناشناسی اطلاعات، ژئوماتیک به بسیاری از مدلها و الگوریتمهای داده کمک کرده است. Big Data اکنون به اطلاعات جغرافیایی امکان می دهد تا بسیار گسترده تر منتشر شود و از منابع اطلاعاتی جدید بهره مند شود و از طریق اینترنت اشیا به سمت زمین دیجیتالی آینده گسترش یابد. برخی از درس های آموخته شده در طول چهار دهه ژئوماتیک نیز می تواند درس هایی برای داده های بزرگ امروزی و برای آینده ژئوماتیک باشد. در طیف وسیعی از مسائل، از پردازش سیگنال گرفته تا معناشناسی اطلاعات، ژئوماتیک به بسیاری از مدلها و الگوریتمهای داده کمک کرده است. Big Data اکنون به اطلاعات جغرافیایی امکان می دهد تا بسیار گسترده تر منتشر شود و از منابع اطلاعاتی جدید بهره مند شود و از طریق اینترنت اشیا به سمت زمین دیجیتالی آینده گسترش یابد. برخی از درس های آموخته شده در طول چهار دهه ژئوماتیک نیز می تواند درس هایی برای داده های بزرگ امروزی و برای آینده ژئوماتیک باشد. در طیف وسیعی از مسائل، از پردازش سیگنال گرفته تا معناشناسی اطلاعات، ژئوماتیک به بسیاری از مدلها و الگوریتمهای داده کمک کرده است. Big Data اکنون به اطلاعات جغرافیایی امکان می دهد تا بسیار گسترده تر منتشر شود و از منابع اطلاعاتی جدید بهره مند شود و از طریق اینترنت اشیا به سمت زمین دیجیتالی آینده گسترش یابد. برخی از درس های آموخته شده در طول چهار دهه ژئوماتیک نیز می تواند درس هایی برای داده های بزرگ امروزی و برای آینده ژئوماتیک باشد. گسترش از طریق اینترنت اشیا به سمت زمین دیجیتال آینده. برخی از درس های آموخته شده در طول چهار دهه ژئوماتیک نیز می تواند درس هایی برای داده های بزرگ امروزی و برای آینده ژئوماتیک باشد. گسترش از طریق اینترنت اشیا به سمت زمین دیجیتال آینده. برخی از درس های آموخته شده در طول چهار دهه ژئوماتیک نیز می تواند درس هایی برای داده های بزرگ امروزی و برای آینده ژئوماتیک باشد.
کلید واژه ها:
ژئوماتیک ; کلان داده ؛ سنجش از دور ؛ انبار داده ; داده کاوی ; تاریخچه فناوری
1. معرفی
بیگ دیتا علاوه بر اینکه یک کلمه کلیدی است، راه ظهور، تکامل، ادغام با هم، جایگزینی با قدیمیترها، یا آوردن زندگی جدید به فناوریهای فراموش شده را نشان میدهد. علاوه بر این، زمینه جدیدی را که در آن این تغییرات در حال ظهور هستند روشن می کند. اجازه دهید به آنچه حرفه ای ها از Big Data انتظار دارند گوش دهیم: وب سایت IBM (مه 2016) بیان می کند که ” فناوری داده های بزرگ باید از خدمات جستجو، توسعه، حاکمیت و تجزیه و تحلیل برای همه انواع داده ها – از داده های تراکنش و برنامه گرفته تا داده های ماشین و حسگر پشتیبانی کند. به داده های اجتماعی، تصویری و جغرافیایی و موارد دیگر. ”
با این حال، زندگی قبل از کلان داده چگونه بود؟
این مقاله به بررسی مسائل اصلی میپردازد که علم اطلاعات جغرافیایی (از جمله ژئواطلاعات ، علم دادههای مکانی ، ژئوماتیک و غیره (همه ± 1990)، ترجیحاً از دومی استفاده میکنیم.) از مراحل اولیه خود با آنها مواجه بوده است. این گذشتهنگر تحت نوری که واژگان کلان دادهها میریزد انجام میشود: ما از سه V محبوب (حجم، سرعت و تنوع) و Vهای اضافی که اغلب پیشنهاد میشوند (مقدار، اعتبار، صحت، تغییرپذیری، و گاهی اوقات، آسیبپذیری و تجسم) استفاده میکنیم.
با تصاویر لندست در سال 1972، “چالش های مدیریت داده” به وجود آمد: چگونه می توان با چنین حجم عظیمی از داده ها مقابله کرد. چگونه می توان ساختار را به یک سیگنال نمونه برداری شده دوبعدی رساند و آن را با اطلاعات زمین مرتبط کرد. و چگونه می توان چنین مجموعه داده های عظیمی را در زمان واقعی پردازش کرد؟ بلافاصله پس از ورود به چالش تجزیه و تحلیل داده ها. اطلاعات جغرافیایی مربوط به “دنیای واقعی” است. واقعا چیه؟ چه چیزی با رادیومتری پیکسلی اندازه گیری می شود، یا چه چیزی با لیست مختصات مشخص می شود؟ نتایج ارائه شده توسط الگوریتمهای طبقهبندی تصویر، یا مدلهای تجمیع/تجزیه فضایی، از اواخر دهه 1970، ارزش افزوده زیادی برای دادههای جمعآوریشده (ارزش) به ارمغان آورد، اما ارزشی که توسط یک عدم قطعیت ذاتی فراگرفته شده بود، مانع استفاده مستقیم از آنها در تصمیمگیری شد. صحت). علاوه بر این، هنگام ادغام منابع مختلف داده، که بیشتر و بیشتر اتفاق می افتد، سوالات جدیدی وجود دارد. آیا ادغام از نظر معنایی مرتبط است؟ با رسیدن به اعتبار، آیا از نظر نحوی سازگار است؟ در نهایت، استفاده از دادههای جغرافیایی بسیار، که برای چندین دهه در سرتاسر جهان انباشته شدهاند، نیاز به شفافسازیهایی دارد که تنوع را بررسی میکند. این داده ها چه داده هایی هستند؟ آنها چه تکامل یا تفاوت های واقعی را اندازه گیری می کنند؟ چه نوع تصمیمی می توانیم بر آنها بنا کنیم؟
در زمینه دادههای جدید، این پرسشهای دیرینه همچنان مطرح میشوند، به علاوه برخی مسائل جدید نیز (به عنوان مثال، موقعیت جغرافیایی و حریم خصوصی، اعتماد به دادهها، و مسئولیت قانونی). توسط ژئوماتیک، که نادیده گرفته شده است، و اگر چه درس هایی می توان از این چهار دهه آموخت.
2. چهار دهه ژئوماتیک بازبینی شده از طریق داده های بزرگ
2.1. حجم: ذخیره سازی و نیازهای پردازش عددی
2.1.1. داده ها، داده های مکانی، ذخیره سازی، دسترسی و تجزیه و تحلیل: یک گذشته نگر
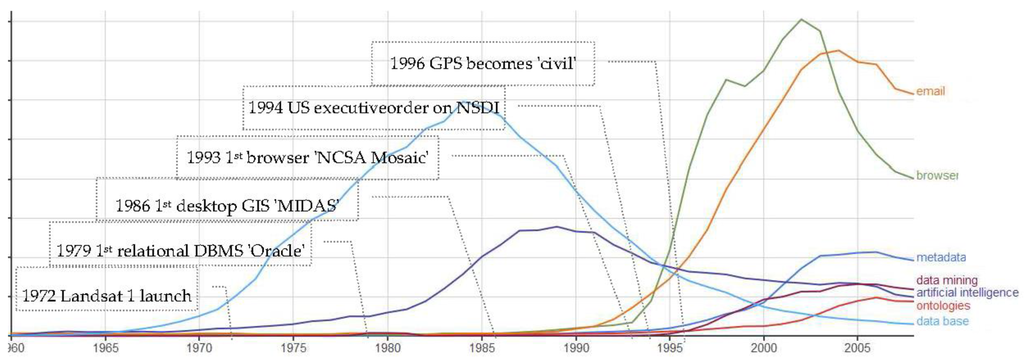
اجازه دهید ۴۰ سال پیش را با نگاهی زبانشناختی، با استفاده از ابزار Google Ngram Viewer [ 1 ] نگاه کنیم: این ابزار تعداد اصطلاحات را در ادبیات عمومی شمارش میکند و کاملاً دقیق نشان میدهد که چه زمانی یک اصطلاح رایج شد. علم پشت این اصطلاح عموماً دو تا پنج سال قبل در مقالات علمی منتشر شده است، اما Ngram نشانگر ارتباط فناوری توصیف شده توسط این اصطلاح است. ما چندین گروه از اصطلاحات را با این ابزار محک زده ایم ( شکل 1 ):
-
ابزارهای پیشرو برای استدلال و پردازش تصویر: تجزیه و تحلیل داده ها 1958، تشخیص الگوی 1958، هوش مصنوعی 1961، تجزیه و تحلیل اجزای اصلی 1960، تجزیه و تحلیل مکاتبات 1975، پردازش تصویر 1965، درک تصویر 1970، و یادگیری ماشینی 1981.
-
داده ها و دانش شرکتی: پایگاه های داده 1965-1970، انبار داده 1988-1992، ابرداده 1991، OLAP 1994، داده کاوی 1995، هوش تجاری 1996، و تجزیه و تحلیل 2004.
-
دادهها، دستگاهها و ابزارهای اطلاعات مکانی: تصاویر ماهوارهای یا سنجش از دور 1970، Landsat 1972، GPS 1975، و کیفیت دادههای مکانی 1990. و
-
ابزارهای اینترنتی: اینترنت 1990، ایمیل 1992، مرورگر 1992، وب و وب سایت 1994 (توجه داشته باشید: “وب” و اینترنت، نشان داده نمی شوند – خارج از مقیاس در مقایسه با اصطلاحات دیگر – “مرورگر” یک پروکسی خوب است).متأسفانه، در حالی که Ngram هنوز در دسترس بود، در سال 2008 از گنجاندن کتاب ها خودداری کرد، بنابراین اصطلاحات “رایانش ابری” و “داده های بزرگ” بسیار “جوان” هستند و در Ngram وجود ندارند.
چه درس هایی می توانیم از این مرور تاریخی بیاموزیم؟
-
سال تولد Big Data حدود 2010 است، در حالی که داده های مکانی به سال 1970، قبل از داده های Landsat باز می گردد.
-
پایگاه داده و ابزارهای هوش مصنوعی بین سالهای 1975 و 1985 در اوج خود قرار داشتند و به طور گسترده برای پردازش حجم خارقالعاده دادههای جمعآوریشده توسط ماهوارهها استفاده میشدند: یک پتابایت در طول دهه، در زمانی که حافظه مرکزی رایانههای بزرگ به چند مگابایت محدود بود.
-
1995 به عنوان یک نقطه اوج ظاهر می شودبا استفاده گسترده از ابزارهای اینترنتی، و با داده کاوی، تجزیه و تحلیل، هستی شناسی ها که پایگاه های داده و هوش مصنوعی را در اختیار گرفته اند، که وزوز آن تا حدودی محو می شود. این نقطه عطف نشان دهنده یک تغییر پارادایم مهم، به دنبال «ساختار انقلاب های علمی» توماس کوهن است. این یک کشف (مثلاً ترانزیستور در سال 1947) یا یک موفقیت تکنولوژیکی (مثلاً پرتاب لندست در سال 1972) نیست، بلکه یک آگاهی جمعی است (اصطلاحی که توسط نظریه پردازان اجتماعی مانند دورکیم، آلتوسر و یونگ برای توضیح چگونگی ظهور الگوهای مشترک استفاده می شود. در میان گروههای بزرگی از افراد مستقل.) که همه فناوریهای مربوط به محاسبات (الگوریتمها، دستگاههای شخصی، شبکه و غیره) و اطلاعات (مجموعههای داده، نظرسنجی، ادبیات، اخبار و غیره) باید با هم ادغام شوند.
2.1.2. داده های مکانی = داده های عظیم قبل از داده های بزرگ
چهل سال پیش نه گوشی هوشمند، نه جی پی اس و نه ایمیل وجود داشت. رایانهها کنسولهای الفبایی عددی بودند، اما ماهوارهها شروع به پر کردن تصاویر زمینی ما کردند. ناگهان، دادهها وجود داشتند، مجموعههای عظیمی از پیکسلها، که به سختی تبدیل به عکس میشد (بدون صفحه نمایش، فقط کنسولهای الفبایی عددی، و تصاویر باید روی دستگاههای گران قیمت چاپ میشد): دانشمندان آن زمان را مجبور کرد که دادهها را بدون فرصت خرد کنند. برای مشاهده آنها! مقدار داده برای یک پوشش سیاره توسط Landsat خارق العاده است: یک ترابایت. یک پتابایت، فقط از داده های جغرافیایی، در حدود سال 1980 به دست آمد. در سال 2010، مقدار داده های ذخیره شده برای کل سیاره به یک زتابایت رسید [ 2]]. این بهمن پیکسل ها با دیجیتالی شدن بسیاری از داده های دیگر همراه شد که همان ویژگی اساسی را به اشتراک می گذاشتند: آنها مربوط به زمین بودند. اطلاعات جغرافیایی متولد شد. در آوریل 1994، رئیس جمهور ایالات متحده کلینتون فرمان اجرایی را امضا کرد: ” هماهنگی جمع آوری و دسترسی به داده های جغرافیایی: زیرساخت ملی داده های مکانی” (NSDI) . این NSDI به جمع آوری داده های جغرافیایی در سراسر کشور، کاهش هزینه های عملیاتی، و بهبود خدمات داده و تصمیم گیری کمک کرد.
2.2. تنوع و سرعت: ساختار داده قبل از داده های بدون ساختار
2.2.1. از داده های جانبی تا فراداده
ماهواره های مخابراتی فضا را برای بهره برداری اقتصادی باز کردند. بلافاصله پس از آن، ماهواره های آب و هوا و رصد زمین فرصت بعدی بود. سنجش از دور، در ابتدا یک پردازش سیگنال صرف (نمونهبرداری و کالیبراسیون)، به دلیل گسترش سریع حسگرهای جدید، با لزوم پیوند تصاویر با مختصات زمین یا با تصاویر دیگر مواجه شد: بنابراین استفاده از ابرداده آغاز شد، حتی اگر اولین اصطلاح “داده های جانبی” بود. کتابخانه ها که در دهه 1960 با مشکلات فهرست نویسی مواجه شدند، زبان نشانه گذاری MARC را توسعه دادند که HTML مدیون آن است. سپس، از زمان هسته دوبلیندر سال 1995، پیشوند “meta” نشاندهنده بررسی بهتر این است که اولین روش فنی برای ترجمه روابط دادهها در زبان کامپیوتر چیست. این کار با اولین پیکسل لندست در سال 1972 آغاز شد: یک سلول تصویری (پیکسل) تقریبی از سطح زمین است که ما سیگنال نمونه برداری منعکس شده (یا گسیل شده) را در محدوده طول موج اندازه گیری می کنیم، اثرات پراش، جذب و غیره را یکپارچه می کنیم. هدف بهبود داده ها از وضعیت «خام» به وضعیت «داده های تصحیح شده» بود. پیکسلها یک به یک پردازش نمیشوند، بلکه بهعنوان یک متغیر آماری که به یک کلاس اختصاص داده میشود، به ویژگیها (مثلاً یک پیکسل حاشیه)، که باید در برخی اطلاعات اضافی توضیح داده شود، پردازش میشوند. یک “تصویر پردازش شده” چنین اطلاعات زیادی دارد. در اینجا دو نمونه وجود دارد:
-
رصد زمین: برنامه ” CORINE ” ( “هماهنگی اطلاعات در مورد محیط زیست “: برنامه ای که در سال 1985 توسط کمیسیون اروپا آغاز شد.) که تغییر کاربری زمین در اروپا را با به روز رسانی داده ها از طبقات استخراج شده از تصاویر ماهواره ای نظارت می کند. از فراداده به طور گسترده استفاده می کند [ 3 ].
-
نقشه کشی خودکار: چگونه توپولوژی را در نمایش بردار داده مشخص می کنید؟ توپولوژی در یک هندسه صحیح، ضمنی است، اما بار محاسبه مجدد آن در هر بار بسیار سنگین است. بنابراین، در دهه 1990، چندین NGI در حال کار بر روی چیزی بودند که در نهایت به ISO 19101 تبدیل شد : مدل مرجع GI (مفهوم زیربنایی مدل چند ضلعی-قوس-گره، با تمام روابط توپولوژیکی است)، مانند جدول 1 ، که می گوید بسته ها ” 2″ و “3” مجاور هستند و اتحاد آنها یک سوراخ واحد را در بسته “1” تشکیل می دهد. مضامین و قوانین را می توان اضافه کرد: ابرداده برای رمزگشایی همه آن اطلاعات اجباری است.
بنابراین، پایگاههای اطلاعاتی و پردازش سیگنال باید در هر نقطهای به یکدیگر ملحق شوند.
2.2.2. از ستون های داده تا مکعب های داده
مدل رابطهای یکی از پیشرفتهای مهم در مهندسی داده بود. بر اساس یک پسزمینه ریاضی محکم، به ساختن سیستمهای «معاملهای» قابل اعتماد کمک کرد، که تجارت الکترونیک را شعلهور کرد. کهن الگوی مدل رابطه ای صفحه گسترده است که هنوز در دفاتر بسیار محبوب است.
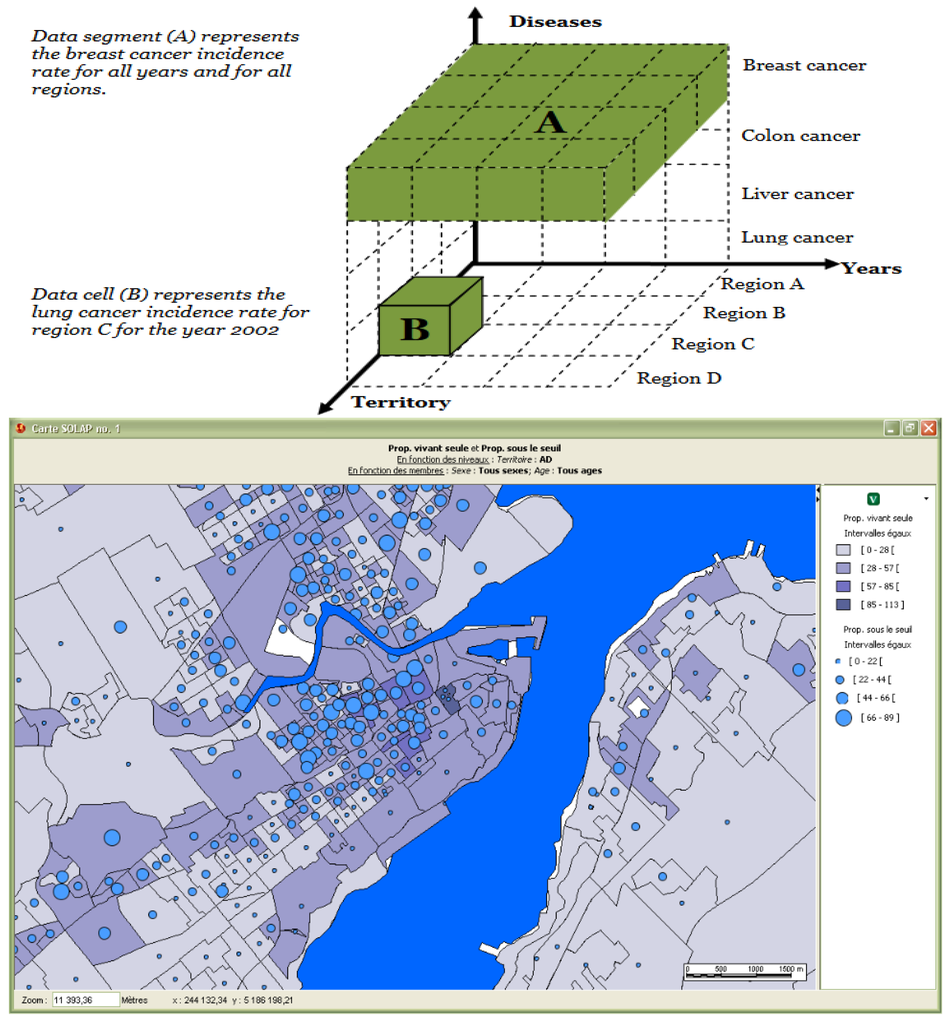
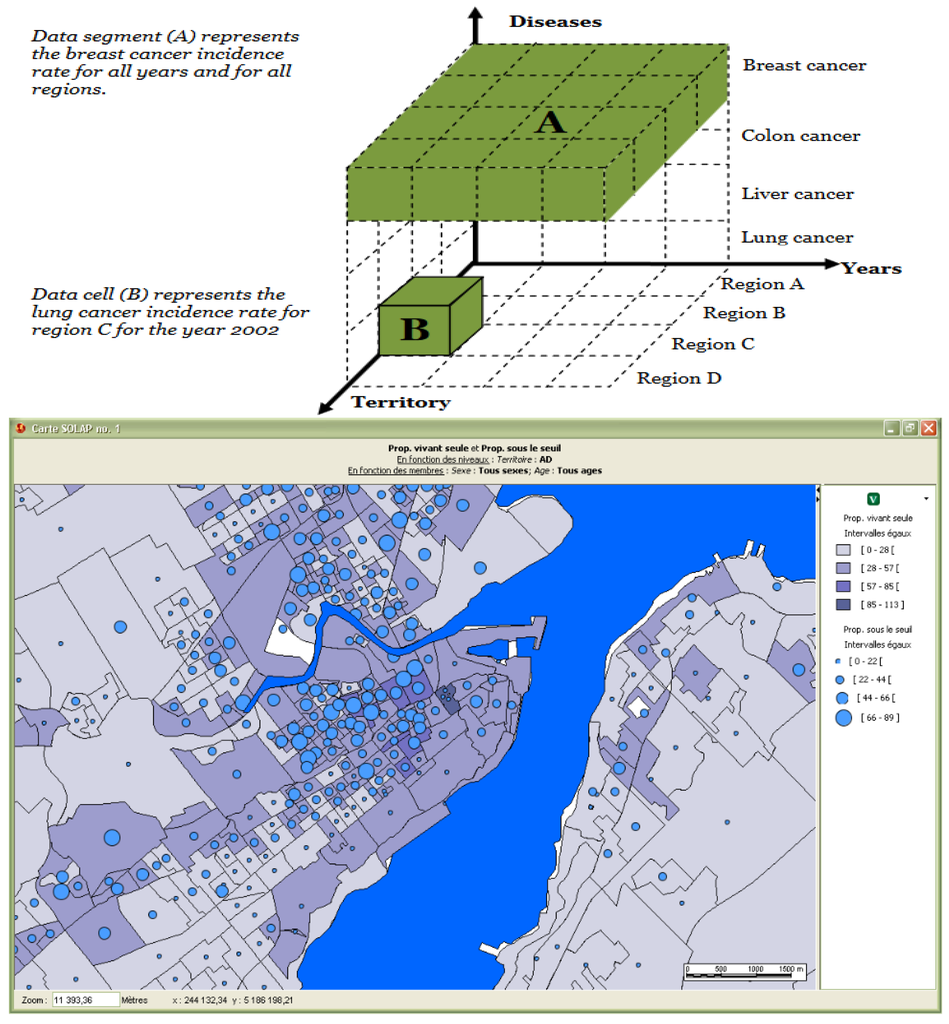
روند جدیدی برای اهداف «تحلیلی» پدیدار شد که در اوایل دهه 1990 سیستمهای OLAP مورد استفاده در «انبار دادهها» توسط اکثر شرکتهای بزرگ را با وعده کشف رفتار پنهان مشتریان به وجود آورد. کهن الگو «مکعب» است ( شکل 2 را ببینید )، بر اساس مفاهیم: ( الف ) «ابعاد»، در امتداد یک سلسله مراتب خاص (به عنوان مثال، سال، ماه، روز)، که می تواند یک نظم جزئی باشد (به عنوان مثال، هفته ها و ماه ها)؛ ( ب ) “معیارها”، مقادیر ثبت شده برای ابعاد مختلف (به عنوان مثال، نرخ سرطان). و ( ج ) “حقایق”، هر ترکیبی از ابعاد و معیارها. تجمع آنها یک مکعب داده را تشکیل می دهد [ 4 ]. دو بعد (ماتریس) یا سه (مکعب) را می توان به راحتی مشاهده کرد، اما بیشتر (هیپر مکعب) را نمی توان مشاهده کرد.
ماهیت جغرافیایی بیشتر دادهها مدتهاست که مورد توجه قرار گرفته است: « […] تقریباً 80 درصد از نیازهای اطلاعاتی یک سیاستگذار دولت محلی به یک موقعیت جغرافیایی مربوط میشود. (“80٪” از آن زمان تا حد زیادی مورد استناد قرار گرفته و به ندرت مورد مناقشه قرار گرفته است). این بیانیه به مقاله ای در سال 1987 توسط ویلیامز برمی گردد [ 5 ]. انبارهای داده با موضوع مدیریت دادههای مکانی مواجه بودند و ابعاد جدیدی به ابعاد «موضوعی» اضافه میکردند: ابعاد توصیفی (مثلاً «کبک»)، یا ابعاد مکانی هندسی (مثلاً خطوط برداری کبک)، که دوباره با مسئله اختلاط مواجه شدند. دو یا چند نمایش بسیار متفاوت از فضا [ 6 ].
هندسه به خوبی با جداول مطابقت ندارد: اگر بخش اطلاعات جغرافیایی اطلاعات جغرافیایی را بتوان در RDBMS ذخیره کرد، بخش “قوس” (مختصات) نه تصاویر (پیکسل) نمی تواند. در طی دو دهه، اطلاعات جغرافیایی به بازار نسبتاً بسته GIS محدود شد. (چند شرکتی GIS را می فروختند: ESRI، Intergraph، MapInfo، و غیره اغلب به عنوان بسته های سخت افزاری-نرم افزاری). در پایان دهه 1990، چندین پیشگام پیشنهاد کردند که OLAP و پایگاههای داده فضایی را ترکیب کنند: نمونه اولیه GeoMiner در Simon Fraser [ 7 ]، ترکیبی از GIS–OLAP، که منجر به SOLAP شد (اصطلاح OLAP فضایی یا SOLAP توسط Bédard (1997) معرفی شد. با اشاره به اصطلاح پایگاه داده فضایی) سیستم ها، در دانشگاه لاوال [ 8 ].
آزمایشها بر روی کاربردهای پیچیده، در حملونقل عمومی یا بهداشت عمومی به صورت آزمایشی انجام شد. به عنوان مثال، ادغام شاخص های ارجاع جغرافیایی ، برای نظارت بر اثرات تغییرات آب و هوایی [ 9 ]، ابزار جدیدی برای کاوش داده ها در مقیاس های مختلف، مناطق و دوره های مختلف و برای تجسم نتایج در نقشه ها، جداول همگام شده فراهم کرد. ، و نمودارها ارتباط آن توسط کاربران نهایی پروژه در جامعه نظارت تایید شد. شکل 2 نحوه ترکیب نسبت (طبقه) جمعیتی که به تنهایی زندگی می کنند (نقشه choropleth)، و نسبت جمعیت با درآمد کم (نمادها) را نشان می دهد که در همان سطح فضایی ترجمه شده است.
2.2.3. جریان، موازی سازی، و پیش پردازش در ژئوماتیک
جنبه سرعت این دوره چندشکل بود. اندازه عظیم تصاویر سنجش از دور آنها را محدود به نوارهای مغناطیسی می کرد. بارگذاری آنها در حافظه اصلی غیرممکن بود: الگوریتم های توسعه یافته بر اساس مفاهیم تقسیم، جریان، و موازی سازی، به محض در دسترس قرار گرفتن اولین پردازنده های به اصطلاح برداری (اواخر دهه 1970) بودند. در سیستمهای OLAP، گلوگاه، عملیات «پیوستن» زمانبر است، در DBMS رابطهای: پاسخ این است که همه اتصالهای ممکن را از قبل محاسبه کنیم – یا تا آنجا که ممکن است – به منظور ارائه پاسخ سریع برای تجسم تعاملی. یک اشکال این است که پیش محاسباتی باید پس از هر درج/حذف در پایگاه داده، که مستلزم توسعه روشهای کارآمد برای تحقق مکعبهای فضایی است، دوباره انجام شود [ 10 ].
با این حال، جنبه سرعت هرگز در ژئوماتیک تحت محدودیتهای یکسانی مانند Big Data امروز مورد توجه قرار نگرفته است. سرعت در ژئوماتیک یک مسئله بود: (الف) در پردازش حجم بالای داده. و (ب) برای تجسم تعاملی، همانطور که در بالا با مکعب داده مشاهده شد. در آن زمان، AOL-Mapquest نقشه برداری اینترنتی را افتتاح کرد و نقشه های گوگل برای اولین بار در سال 2004 برای ایالات متحده منتشر شد. سپس، بزرگترین آژانس های نقشه برداری ملی پورتال های دسترسی عمومی خود را راه اندازی کردند: Ordnance Survey، IGN، USGS، Geomatics Canada، محیط مبتنی بر شبکه برای این آژانسها محیطی آشنا یا دوستانه نبود و آنها باید با مشکلاتی مواجه میشدند که برای آنها آماده نبودند، مانند تأخیر زمانی و خروج بستههای داده [11] .]. حل این مشکلات بیرونی بود. در نتیجه، انتشار و در نهایت بازار اطلاعات جغرافیایی به دست بازیگران اصلی Big Data افتاد.
علاوه بر این، امروزه استفاده گسترده از ویدئو در اینترنت باعث توسعه الگوریتمهای جریان بسیار کارآمدتر شده است، که بعداً میتواند استفاده از ابزارهای جدید در ژئوماتیک (مثلاً دوربینهای نظارتی و ویدئویی پهپادها) را امکانپذیر کند.
2.3. ارزش، اعتبار، صحت و تغییرپذیری: تبدیل داده ها به دانش
2.3.1. ارزش افزوده شده توسط پردازش داده: از تجزیه و تحلیل داده تا داده کاوی
از اوایل قرن بیستم (Nyquist (1928) و Shannon (1949) از نویسندگان مشهور در تئوری انتقال هستند)، پردازش سیگنال زمینه تحقیقاتی در رویکردهای آماری، تصادفی یا تبدیل دادهها و همچنین برای روشهای محاسباتی فشرده بوده است. الگوریتم های کارآمد الگوریتم Cooley-Tukey برای FFT در سال 1965 منتشر شد. تجزیه و تحلیل داده های اکتشافی (EDA)، منتشر شده در سال 1977 [ 12 ]، به تحلیل فوریه مرتبط است. این اصطلاح ممکن است قدیمی به نظر برسد، اما EDA به ترویج تحقیقات در محاسبات پیشرفته کمک کرد. به عنوان مثال، اجازه دهید الگوریتمهای سلسله مراتبی را برای طبقهبندی پیکسلها، که با تصاویر Landsat استفاده میشوند [ 13 ]، یا رویکردهای پیچیدهتر برای طبقهبندی بدون نظارت، مانند «خوشههای پویا» [ 14] به یاد بیاوریم.].
Alpilles-ReSeDA (همسان سازی داده های سنجش از دور)، کنسرسیومی متشکل از 10 شریک اروپایی طی دوره 1995-1998، با تمرکز بر پایش خاک و پوشش گیاهی در مقیاس های مختلف [15]، یکی از اولین تلاش های بین المللی برای دستیابی به ادغام چندگانه در مقیاس بزرگ بود. داده های حسگرها (مانند شکل 3 ): تصاویر ماهواره ای (مرئی، مادون قرمز، رادار)، نمونه های خاک، سوابق آب و هوا، بررسی های کشاورزی. حداکثر شش تاریخ و 14 طول موج در کل سایت آزمایش (25 کیلومتر مربع ) جمع آوری شد.، و پس از ثبت پیکسل، albedo و سایر کالیبراسیون ها قابل بهره برداری می شود. LAI (شاخص سطح برگ)، نسبت نرمال شده بین طول موج سبز و نزدیک به مادون قرمز، برای پوشش گیاهی، در هر تاریخ، و بین انواع پوشش گیاهی در تاریخ های مختلف بسیار متمایز است [16 ] . این قدرت تمایز با تجزیه و تحلیل مؤلفه اصلی 6 تاریخ LAI نشان داده شده است.
ساختن کلاسها از دادههای شطرنجی (خوشهبندی)، در فضای برداری چند تاریخ LAI (یک دوجین کیلو هشتت) محاسبه میشود. اختصاص یک کلاس به صدها هزار پیکسل توسط یک جدول جستجوی ساده انجام می شود. این عدم تقارن در کاردینالیته باعث شد متخصصان سنجش از دور به جای خوشهبندی «سلسله مراتبی تجمعی» از «تقسیمکننده» استفاده کنند. با کل مجموعه شروع می شود، سپس با دوگانگی های متوالی از بالا به پایین کار می کند. خوشهبندی از بالا به پایین عموماً پیچیدهتر از خوشهبندی از پایین به بالا است: O(2 n )، به جای O(n2 ) برای اکثر روشهای انباشته. با این حال، اگر ما یک سلسله مراتب کامل ایجاد نکنیم، این مزیت را دارد که کارآمدتر باشد [ 17]]. این فرآیند دوگانگیهای متوالی را با یک الگوریتم k-means (k=2) ایجاد میکند، که با دو مرکز اولیه شروع میشود: در هر مرحله، مرکز اول از مقدار پیک هیستوگرامهای کمترین خوشه منسجم (سانتروید دوم) مقداردهی اولیه میشود. می تواند حالت دوم هیستوگرام یا هر مقدار بسیار متفاوتی باشد). بهترین عدم تشابه با به حداکثر رساندن “عدم تشابه بین خوشه ای” یا به حداکثر رساندن “شباهت درون خوشه ای” به دست می آید. دندروگرام ( شکل 4 ، سمت چپ) از بالا به پایین ساخته می شود، تا زمانی که به تعداد مناسبی از کلاس ها (چند ده) برسد. ارتفاع دندروگرام متناسب با شباهت درون خوشه ای است: می توان از آن برای مشخص کردن “کیفیت” خوشه های به دست آمده برای یک سطح خاص استفاده کرد (نسخه ای از این الگوریتم، DIANA–Divisive Analysis Clustering-، اکنون بخشی از بسته R است.
در نهایت، تمام پیکسلهای یک قطعه زمین بر اساس کلاس میانگین ارزش پیکسل آن قطعه طبقهبندی میشوند، که امکان ترسیم آنها را بر روی نقشه فراهم میکند ( شکل 4 ، سمت راست: سه سایه سبز برای سه کلاس).
جالب است بدانید که در سال 1990، کافمن و روسو در حال نوشتن « در ادبیات، روش های تفرقه افکنی تا حد زیادی نادیده گرفته شده است. (در واقع، وقتی مردم در مورد خوشهبندی سلسله مراتبی صحبت میکنند، اغلب منظورشان خوشهبندی تجمعی است.) » [ 17 ]. علاوه بر این، برای یادآوری احیای اخیر (2008): « شواهدی وجود دارد که الگوریتمهای تقسیمکننده سلسله مراتب دقیقتری نسبت به الگوریتمهای پایین به بالا در برخی شرایط ایجاد میکنند. روشهای پایین به بالا تصمیمات خوشهبندی را بر اساس الگوهای محلی بدون در نظر گرفتن اولیه توزیع جهانی میگیرند. این تصمیمات اولیه قابل لغو نیستند. خوشهبندی از بالا به پایین از اطلاعات کامل در مورد توزیع جهانی هنگام تصمیمگیری پارتیشنبندی سطح بالا سود میبرد .» [ 18].
اکنون میتوانیم انتظار داشته باشیم که برای چندین موقعیت، کاردینالیته فضای متغیر بسیار بیشتر از کاردینالیته فضای ارزش افزایش یابد و وضعیت مطلوب خوشهبندی در سنجش از دور را بازتولید کند: خوشهبندی از بالا به پایین ممکن است در دادههای بزرگ احیا شود.
اصطلاح مهم دیگر، “داده کاوی” به اواسط دهه 1990 باز می گردد و برای دانشمندان پایگاه داده به عنوان یک رویکرد عملیاتی “یادگیری ماشینی” آشنا است. یادگیری ماشین، که پایه های آن ماشین تورینگ است، بیشتر نظری است: بر اساس منطق و حساب لامبدا. ماشینهای بردار پشتیبان (SVM) – کهنالگوریتمهای یادگیری ماشین – بهعنوان طبقهبندیکنندههای خطی باینری غیراحتمالی [ 19 ] توسعه یافتند، و مانند ابزارهای مشابه، ارزش غیرقابل انکاری به تجزیه و تحلیل بسیاری از دادههای جغرافیایی اضافه کردند. امروزه، این اصطلاحات کم و بیش در کلمات متوالی هوش تجاری، تجزیه و تحلیل داده ها و داده های بزرگ پیچیده شده اند. با وجود تفاوتهای دیگر، واقعیت این است که جریان اصلی از پردازش سیگنال به تجارت الکترونیکی تغییر کرده است.
2.3.2. صحت، عدم قطعیت داده: از دقت تا شاخص های کیفیت
اطلاعات جغرافیایی با «دنیای واقعی» سروکار دارد. از نظر فنی، بیان میکند که جهان واحدی وجود دارد که میتوان آن را با ابزارهای مختلف، در مقیاسهای مختلف، از دیدگاههای متعدد اندازهگیری کرد، اما در نهایت همه چیز باید قابل مکانیابی و سازگار ( منطقی ) باشد، زیرا یک جهان واحد وجود دارد.
در ابتدا، کیفیت اندازهگیریها به دقت محدود بود: یک پیکسل خاص چه نقطه خاصی را در زمین نشان میدهد؟ سهم رادیومتری این نقطه در مقدار پیکسل چقدر است؟ ثبت تصویر و ادغام حسگرها سخت ترین کارها در دهه 1970 بودند. کمی بعد، اعتماد به طبقه بندی داده ها مسئله بزرگی بود. اتحاد جماهیر شوروی واقعا چقدر گندم دارد؟ بزرگترین رایانههای ایالات متحده در آن زمان، در طول هفتهها، روز و شب، پیکسلها را برای پاسخ به چنین سؤالی در هم میکوبیدند (اکنون، ابررایانههای NSA در حال پردازش تریلیونها ایمیل هستند).
هنگامی که ادغام تصاویر سنجش از دور و پایگاههای اطلاعاتی جغرافیایی آسانتر شد، سؤالات پیچیدهتری در دسترس بود. افزایش وضوح زمین زمینه های جدیدی را برای ما باز می کند: از محصولات مستطیلی بزرگ غرب میانه در اولین تصاویر Landsat تا باغ های پشت بام شهری. در حال حاضر ژئوماتیک می تواند علم را با جامعه شناسی صحبت کند، همانطور که با کشاورزی در دهه 1980 انجام داد.
چالش در مورد کیفیت دیگر صرفاً در مورد دقت داده ها نیست. چندین شاخص کیفیت طراحی شده است و حوزه کیفیت بر اساس اجماع بین المللی ساختار یافته است. (کمیته فنی ISO TC211 برای انتشار استانداردهای اطلاعات جغرافیایی ایجاد شد). استانداردهای ISO 19101: “مدل مرجع” و ISO 19113: “اصول کیفیت” در سال 2002 صادر شدند که منعکس کننده یک زمینه مشترک هستند ( جدول 2 را ببینید).) بین سازمان های مختلف نشنال جئوگرافیک. دفاتر ملی آمار، و نهادهای بین المللی، مانند سازمان ملل متحد، OECD (سازمان همکاری اقتصادی و توسعه) و یورواستات. یکی از نتایج مهم دقیقاً تمایز بین علل عدم اطمینان (دقت، سازگاری و نامگذاری) بود که به نحوی منعکس کننده تفاوت بین صحت، اعتبار و تنوع بود.
2.3.3. روایی، سازگاری داده ها: دانش منطقی از دانش نامطمئن
درک بسیاری از علل عدم قطعیت داده ها، تقریب های زیادی را که در طول فرآیند جمع آوری و اندازه گیری داده ها، حتی ساده ترین داده ها (به عنوان مثال، دمای زمین) انجام می شود، روشن می کند.
با توجه به اینکه داده ها همیشه تا حدودی نادرست هستند و همیشه به یک مدل بستگی دارند که به طور ناقص جنبه ای از واقعیت را نشان می دهد، ارائه دستورالعمل ها مهم است. هر بار که میتوانیم یک محدودیت وارد کنیم، میتوانیم با دادهها مقابله کنیم و برای هر درگیری شناسایی شده یک هشدار صادر کنیم. شکل 5 زیر یک تصویر فوری از آزمایشی است که در طول پروژه اروپایی REV!GIS (بازبینی در GIS: پروژه برنامه چارچوب پنجم، شامل دانشگاههای Keele، Laval، Leicester، Marseilles، Pisa، TUW Vienna، Twente ITC) توسعه یافته است . داده های سیل نامشخص با استفاده از جهت های جریان به عنوان محدودیت [ 20]. نمودارهای بالا-چپ و پایین-چپ نشان می دهند که چگونه دو مدل، برای دو ناحیه فضایی مجاور، می توانند به طور مستقل از نظر منطقی سازگار باشند، اما در صورت ادغام می توانند به یک مدل ناسازگار منجر شوند. با استفاده از جهت جریان و محدودیت ها، حداقل و حداکثر برآورد ارتفاع آب را می توان بهبود بخشید (کوچک کردن فواصل)، یا گاهی اوقات برای ایجاد مجدد سازگاری جهانی، بزرگتر شد. این فرآیند از نظر محاسباتی گران است: چنین الگوریتمهای هوش مصنوعی NP-hard (برای غیر چند جملهای) نامیده میشوند: هوش مصنوعی ممکن است راهحلهایی به همراه داشته باشد و همچنین ممکن است مشکلات جدیدی را ایجاد کند.
این مثال شرایطی را نشان می دهد که در آن نیاز به ادغام (یا برای “تلفیقی”: این اصطلاح در جامعه بازنمایی دانش و استدلال رایج تر است) اطلاعات کمی (مثلاً اندازه گیری مستقیم یا تجزیه و تحلیل پیکسل) و اطلاعات کیفی (مثلاً دامنه) وجود دارد. قوانین خاص یا متخصص، محدودیت ها، غیرممکن های شناخته شده یا استثنائات). این احتمالا یکی از چالش های بعدی برای تجزیه و تحلیل داده های بزرگ است.
در سال 2008، انتشار “گرایش های آنفولانزا” توسط گوگل به دنبال جستجوهای اینترنتی مورد توجه رسانه ها قرار گرفت. در سال 2011، کامپیوتر IBM Watson دو قهرمان “Jeopardy” را شکست داد: پروژه DeepQA پشت سر واتسون از استدلال اطلاعات جغرافیایی برای پاسخ دادن به سوالاتی مانند ” این دو ایالت هستند که در صورت عبور از فلوریدا می توانید دوباره وارد آن شوید.” مرز شمالی » [ 21 ]. جبر بازهای آلن، جبرهای RCC «Mereotopology» یا «حساب اتصال منطقه» [ 22 ، 23 ] که در دهه 1980 توسعه یافت، دقیقاً توسط IBM Watson برای محدود کردن پرس و جوها و محدود کردن و کارآمدتر کردن پاسخها استفاده میشود.
استدلال تحت محدودیت ها به خوبی با استدلال تصادفی هماهنگ است و الگوریتم های شبکه بیز با موفقیت برای توسعه شبیه سازی فضایی استفاده شده است [ 24]]. به عنوان مثال، پیروی از یک رویکرد سه مرحلهای: (الف) یک نمودار اولیه – یک شبکه بیز – از مجموعهای از پارامترها مشتق شده است که احتمالاً با روابط علی همبستگی دارند و در یک قلمرو در دو سال متوالی مشاهده میشوند. (ب) محدودیت های اضافی (مثلاً قوانین ژئوفیزیک) برای “بهبود” نمودار محاسبه شده با دانش پیشینی متخصص استفاده می شود. و در نهایت، (ج) این نمودار بهبودیافته که با مقادیر جمعآوریشده در تاریخ جدید تغذیه میشود، یک پیشبینی از آنچه باید در سال آینده اتفاق بیفتد ارائه میدهد. این رویکرد، که میتواند «سیستمهای خبره» دهه 1970 را به ما یادآوری کند، با ظهور تحلیلهای تجاری محبوبیت زیادی پیدا میکند. مایکروسافت رویکردهای مشابهی را در الگوریتم MS Naive Bayes خود پیادهسازی کرده است، که این شرکت آن را برای تولید سریع مدلهای استخراج برای کشف روابط بین ستونهای ورودی و ستونهای قابل پیشبینی مفید توصیف میکند.
2.4. هستی شناسی ها و تنوع: داده ها اعمال هستند نه واقعیت
جغرافی دانان هنوز ویژگی های زمین را طبقه بندی می کنند، هنوز زمین را منطقه بندی می کنند، اما توجه بسیار بیشتری به معنای فرآیند، تفسیرپذیری یک نتیجه، و مناسب بودن برای تصمیم گیری معطوف شده است. Geomatics همچنین این سوال را مطرح کرد که در داده ها چه چیزی وجود دارد. توافق مشترک، کیفیت داده ها و قابلیت استفاده تنها برخی از جنبه های مختلف چیزی است که اغلب به عنوان “هستی شناسی شما چیست؟” خلاصه می شود. و مشکل بعدی “همسویی هستی شناسی” [ 25 ، 26 ].
اصطلاح “هستی شناسی” با معرفی مفهوم وب معنایی (استفاده از نشانه گذاری به عنوان کمکی برای روبات های اینترنتی برای ایجاد روابط بهتر بین قطعات وب) مورد توجه عموم قرار گرفته است. در ژئوماتیک، تحقیقات در مورد هستی شناسی ها به دلیل تنوع شدید نامگذاری و نمایش اشیاء جغرافیایی توسعه یافت. سوال “جنگل چیست؟” یک نمونه علامتی از تنوع است که می تواند بسته به کشورها و کاربران معرفی شود [ 27 ، 28 ]. این نشان میدهد که نه «استفاده از زمین» و نه «پوشش زمین» واژههای خنثی نیستند، بلکه همیشه انتخابهایی هستند که در یک زمینه خاص در زمان و هدف انجام میشوند. یک سوال کلی تر که توسط فیلسوف کواین پرسیده شده است: « آنجا چیستاست؟»، «هستیشناسیها» (علم اطلاعات) و هستیشناسی (فلسفه) [ 29 ] را از طریق فرض یک جهان جغرافیایی واحد نزدیکتر میکند.
بافت فضایی که توسط «آنجا» به ارمغان میآید، ماهیت اطلاعات جغرافیایی است و اگر دو مشاهده در یک مکان انجام شود، رابطهای بین آنها وجود دارد ، هر چه که باشند، حتی اگر متعلق به دو متفاوت باشند. هستی شناسی ها علاوه بر این، میتوان پرسید که آیا «همسویی هستیشناسی» به نحوی امکانپذیر است. مشکل ادغام سلسله مراتب مفهومی با استفاده از اتصالات Galois، در اواخر دهه 1990 مورد بررسی قرار گرفت [ 30 ].
پروژه CLC اروپایی پوشش CORINE-Land که قبلاً ذکر شد [ 5 ]، با این مسئله هم ترازی مواجه شد، زمانی که چندین کشور مجبور بودند با بررسیهای قبلی پوشش زمین خود، با لزوم هماهنگی با اروپا مقابله کنند. به طور خاص، LCMGB بریتانیا (نقشه برداری پوشش زمین بریتانیای کبیر) بر اساس طبقه بندی تقسیم شده به 27 کلاس و 72 نوع، در مقابل 44 کلاس برای CLC ساخته شد [31 ] .
شکل 6 نمودارهای (ساده شده) حاصل از دو بررسی مختلف از یک منطقه را نشان می دهد. هر قطعه زمین یک ارزش کلاسی از هر دو بررسی دریافت می کند، و ما می توانیم دو شبکه گالویز را استخراج کنیم ( شکل 6 ): نظم جزئی (به عنوان مثال، جنگل > نیمه طبیعی) این واقعیت را منعکس می کند که هر قطعه مشاهده شده و طبقه بندی شده به عنوان “جنگل” ، به عنوان “نیمه طبیعی” نیز گفته می شود . هدف این نیست که یک طبقهبندی را مجبور کنیم که در طبقهبندی دوم قرار گیرد، بلکه بهتر درک کنیم که کدام کلاسها میتوانند هنگام مقایسه هستیشناسیها مشکلساز باشند [ 32]]. ما دو فرض را می پذیریم: (1) قطعات زمین متعلق به یک جهان جغرافیایی هستند و می توانند مستقیماً شناسایی شوند، مشروط بر اینکه اشتباهات هندسی به درستی تصحیح شده باشد. و (2) طبقات “گیاهی” دو شبکه قرار است همان جهان مشترک باشند. جغرافیا اجازه می دهد تا چنین فرضیه هایی را ایجاد کنید، چیزی که لزوماً برای سایر منابع اطلاعاتی در داده های بزرگ، مانند پروفایل های مشتری، صادق نیست.
روش به دست آوردن نمودار شکل 7 مراحل زیر را دنبال می کند:
-
با استفاده از همان مجموعه بسته ها به عنوان کلید یکتا، یک رابطه جدید ساخته می شود، به عنوان اتحاد دو رابطه اصلی: این یک رابطه عملکردی است.
-
یک شبکه Galois مشتق شده است: گره های جدید پدیدار می شوند، و نظم جزئی جدید مستقیماً از مشاهدات مشتق می شود، نه از دو مرتبه جزئی اصلی.
-
گره های جدید باید بر حسب ترکیبی از دو طبقه بندی اصلی تفسیر شوند: اشاره می کند که برخی از کلاس های اصلی مشکل سازتر هستند، به عنوان مثال، یک قطعه چمنزار از دنیای واقعی می تواند در طبقه بندی 2 به عنوان علفی (زرد) طبقه بندی شود. اما یا علفزار، سپس نیمه طبیعی، یا کشاورزی، در طبقه بندی 1 (سبز).
-
شاخصهای کیفیت را میتوان به طبقهبندیهای اصلی، سنجیده با مناطق انباشته بستههای مرتبط، یا با هر داده زمینهای، برای تعیین کمیت عدم قطعیت متصل به هر گره جدید، پیوست کرد.
فرآیند کلی، نشانههای مفیدی در مورد چگونگی تصمیمگیری ارائه میدهد، برای مثال اگر منطقه مورد نظارت بسیار بزرگتر از منطقه آزمایشی بالا باشد، و هدف این است که هر بسته طبقهبندیشده در یک طبقهبندی را مجبور کنیم تا به دیگری ترجمه شود. این مشکل ترجمه LCMGB به CLC بود.
این یک تراز هستی شناسی پسینی تحت محدودیت های فضایی است. محدودیتهای قبلی اضافی (ترتیب جزئی) ممکن است مانند مثال خالص Bayes در بخش قبل معرفی شده باشند.
بدیهی است که تصمیم گیرندگان به طور فزاینده ای برای تهیه و تصمیم گیری خود به داده ها تکیه می کنند، اما تعداد کمی از آنها از آنچه در پس این داده ها نهفته است آگاه هستند و این که آنها از بسیاری از انتخاب های غیرمستند و فرآیندهای کوچک تصمیم گیری در همه مراحل ناشی می شوند. . از این رو، دادهها از مجموعهای از تصمیمگیریها، در زمینه خاصی که میتواند توسط هستیشناسیها نمایش داده شود، حاصل میشود.
توجه: آژانس محیط زیست اروپا مجموعه داده های CORINE-Land-Cover را از سال های 1990، 2000، 2006 و 2012 ارائه می دهد. برخی از تغییرات در روش طبقه بندی در طول زمان ارائه شده است. مجموعه داده های 1990 اصلاح شده است تا با سال 2000 “سازگارتر” باشد، اما تغییرات جدیدی بعداً ارائه شد و مجموعه داده اصلی 1990 دیگر در دسترس نیست. از این رو بخشی از معناشناسی از بین رفته است. این میتواند درسی برای Big Data باشد: چندین نسخه تاریخی از مجموعه دادههای مشابه را میتوان بهجای نگهداشتن آخرین نسخهها، در لحظه پردازش کرد.
در یک زمینه علمی متفاوت، آموختن اینکه چگونه باستان شناسان داده های مربوط به مصنوعات را جمع آوری می کنند، و چگونه فرآیند جمع آوری را مستند می کنند، آموزنده است: “داده ها حقایق نیستند، بلکه اعمال هستند”، پایان نامه اصلی [33] است که بیان می کند که اطلاعات جغرافیایی باید با مجموعه ای از فعالیت ها نشان داده شود، نه با مجموعه داده ها. موضوع کیفیت دادههای مکانی از هستیشناسیها استفاده میکند، بهویژه برای تمایز مفهوم کیفیت خارجی (کیفیت برای کاربر، یا کیفیت «فعالشده»)، در مقابل کیفیت (داخلی یا غیرفعال) اعلامشده توسط ارائهدهندگان داده. 34 ].
3. بحث
آیا می توانیم بگوییم که ژئوماتیک قبل از ابداع این اصطلاح با داده های بزرگ سروکار داشت؟
بیایید سعی کنیم موانعی را که ژئوماتیک طی چهار دهه بر آن ها غلبه کرده است، خلاصه کنیم، و اجازه دهید آنها را از طریق منشور هفت V که برای مشخص کردن داده های بزرگ فراخوانی می کنند، دوباره مرور کنیم. برخی از درس های آموخته شده توسط ژئوماتیک ممکن است هنوز برای Big Data مفید باشد. متقابلا، اهمیت Big Data به عنوان تبدیل شدن به مخزن منحصر به فرد برای هر روش جمعآوری و انتشار اطلاعات، و برای همه روشها و الگوریتمهای پردازش اطلاعات، دانشمندان و مهندسان ژئوماتیک را وادار میکند تا خود را در این زمینه جدید تغییر مکان دهند.
3.1. جلد
از سال 1972، حجم دادهها بسیار زیاد بوده است، بیش از ظرفیتهای محاسباتی معمول آن زمان، که توسعه ابزارهای خاصی را برای کاهش زمان محاسبات تا حد قابل قبول ضروری میکند. اکنون، تفاوت اصلی در استفاده بسیار گستردهتر از این دادهها، توسط افراد بسیار بیشتر است. ذخیره سازی کارآمد دیروز یک مشکل برای سنجش از راه دور بود، همانطور که امروز برای Big Data، احتمالاً با ریسک های مشابه بالا، مشکلی بود. ارتباط از طریق شبکه ها در آن زمان وجود نداشت و ضرورت دسترسی سریع به داده ها اکنون یک چالش است. مفهوم ” MapReduce ” پیشرفت عمده سیستمی است که “داده های بزرگ برای همه” را امکان پذیر می کند، اگرچه محاسبات موازی 40 سال پیش لکنت داشتند.
3.2. سرعت
نوع داده ها و همچنین نوع کاربرانی که در ژئوماتیک می توانستیم ببینیم تا اواسط دهه 2000 به مسائل مربوط به انتشار داده ها وابسته نبود. بیشتر تصاویر، تصاویر ثابت بودند. نقشه ها هر روز به روز نمی شوند. برخی استثناها، مانند پردازش تصاویر آب و هوا، به متخصصان خاصی محدود می شد. انتشار نقشه های آنلاین، از جمله نماهای هوایی و خیابانی، بازار را عمیقاً تغییر داده است. استفاده اخیر و به سرعت رو به رشد از پهپادها برای تصاویر هوایی نزدیک، تغییری عمیق را ایجاد می کند، مانند معرفی گسترده حسگرهای محیطی (اینترنت اشیا) – بدون فراموش کردن دوربین های نظارتی. اکنون این فرصتی برای بازیکنان Big Data است تا دامنه فعالیتهای خود را به تقریباً همه بخشهای Geomatics گسترش دهند.
3.3. تنوع (و تجسم)
داده های ژئوماتیک در ابتدا عمدتاً اندازه گیری، سیگنال، هندسه، سری زمانی بودند. پیوند با اطلاعات زبان ساده محدود به نوع متن کمیاب بود که میتوانیم روی نقشهها چاپ کنیم. چالش با دادههایی که بهطور همزمان بزرگ و متنوع هستند، با آوردن ساختاری برطرف شد: از حداقل دادههای جانبی، برای تصاویر، تا منطقهای مرتبه اول (مدل رابطهای) برای دادهها با پایگاههای داده. در دهه 1990، رویکرد تحلیلی، پیش پردازشگرهای دیگری را معرفی کرد که به بازسازی (به عنوان مثال، ETL، استخراج-تبدیل-بار) اطلاعات اولیه، در امتداد چندین بعد انتخاب شده اختصاص داده شده بودند.
از سوی دیگر، قلمرو دادههای بزرگ سرزمین «verbum» را در بر میگیرد، مانند انجیل یوحنا: « In principio erat Verbum ». Verbum استخراج شده از وب سایت ها، از شبکه های اجتماعی شامل تریلیون ها سند پراکنده، پراکنده و نامرتبط (بدون ساختار) در هر نقطه از اینترنت است. به اصطلاح «رباتها» سعی میکنند پاسخها را به هر درخواست مرتبط و رتبهبندی کنند (یعنی فهرستبندی اینترنت)، از جمله درخواستهای پیچیده و چند شکلی (تحلیل دادهها). این پیش پردازش “در حال پرواز” گسترش قابل توجهی از کاری است که “انبار داده ها” انجام می دهند، اگرچه تا همین اواخر ساختار بسیار کمتری داشتند. XML و هستیشناسی ابزارهای کلیدی برای ساختاردهی این قلمرو بدون ساختار از verbum هستند.
مفهوم داده های بدون ساختار 30 سال پیش مورد استفاده قرار نمی گرفت: پایگاه های داده رابطه ای در حال افزایش بودند. اصطلاح داده های نیمه ساختار یافته در سال 1995 ظاهر شد و XML برای اولین بار در سال 1997 ایجاد شد. با این حال، NoSQL SQL را پاک نمی کند: برای مثال، سرویس Big Query توسط Google از SQL استفاده می کند. در این میان، ظهور محاسبات ابری توسعه جهانی “داده های بزرگ به عنوان یک سرویس” (BDaaS) را بسیار تسهیل می کند. Teich میگوید [ 35 ]: « زبان برنامهنویسی SQL بهترین وسیله برای دسترسی و جستجوی دادهها است، چه در پایگاههای داده رابطهای، چه سیستمهای NoSQL یا خوشههای Hadoop ».
3.4. ارزش، صحت، اعتبار و تغییرپذیری
سه V – حجم، سرعت و تنوع – کار خوبی برای تعریف داده های بزرگ انجام می دهند. […] تغییرپذیری، صحت، اعتبار و ارزش از ویژگیهای کلان داده تعریف ذاتی نیستند. آنها مطلق نیستند. در مقابل، آنها منعکس کننده کاربردهایی هستند که شما برای داده های خود در نظر دارید. آنها به نیازهای تجاری خاص شما مربوط می شوند » [ 36 ]. اگر داده های بزرگ را نه تنها به عنوان یک پلت فرم، بلکه به عنوان یک سرویس (BDaaS) در نظر بگیریم، این بیانیه اهمیت این مجموعه اضافی از “Vs” را آشکار می کند.
در دهه 1970، زرادخانه کامل ابزارهای ریاضی (تقریبا) آنجا بود. تجزیه و تحلیل اجزای اصلی، تشخیص الگو، پرس و جوهای فضایی پیچیده، تصمیم گیری، تجزیه و تحلیل داده های اکتشافی و غیره، پایه های یادگیری ماشین و تجزیه و تحلیل داده ها هستند. اگر عمیقاً به الگوریتم های امروزی نگاه کنید، می توانید میراث پردازش جغرافیایی را بیابید: از IBM Watson بخواهید که شهادت دهد!
صحت نزدیک به چیزی است که geomatics آن را “کیفیت داده” می نامد. این جنبه به طور گسترده توسط ارائه دهندگان داده های مکانی (به عنوان مثال، سازمان های غیر دولتی)، از جمله به دلایل قانونی، مورد مطالعه قرار گرفته است. این هنوز در مورد کلان داده صادق نیست، زیرا روابط و همبستگی ها بر روی اطلاعات متنی به جای اندازه گیری های فیزیکی محاسبه می شوند. با این حال، روند این است که به این جنبه و همچنین دو جنبه دیگر عدم قطعیت، که اعتبار و متغیر بودن است، توجه بیشتری شود. این عبارت بعدی به عنوان یک “V” دیگر برای داده های بزرگ اضافه شد: “[ بر اساس تغییرپذیری ]منظورم تنوع در معنا، در فرهنگ لغت است. بهترین مثال برای آن مشکل تغییرپذیری است که [ابر رایانه] واتسون در IBM در تلاش برای حل آن بود. [واتسون] پاسخی میگرفت و باید آن پاسخ را به معنای آن تشریح میکرد و سپس تلاش میکرد تا در آن زمان پاسخ سه ثانیهای بفهمد که سؤال درست چیست » [ 37 ]. این چشم انداز کاملاً شبیه مفاهیمی است که با هستی شناسی ها و همسویی آنها بررسی شده است.
3.5. نتیجه گیری
حدود 40 سال پیش، تکثیر تصاویر سنجش از دور، نقشهبرداری خودکار، و افزایش سریع قدرت محاسباتی فرصتی برای ادغام و پردازش حجم عظیمی از دادهها فراهم کرد. ژئوماتیک مانند زیست شناسی در آن لبه بود، زیرا توالی یابی DNA در دهه 1990 به الگوریتم های یادگیری ماشین کمک زیادی کرد، به ویژه برای پردازش متن. با این حال، ویژگی ژئوماتیک تنوع زیاد منابع اطلاعاتی آن است و بنابراین، تنوع زیادی از چالش ها برای غلبه بر آن است.
این یافته به این پرسش که چه درس هایی می توان از این چهار دهه گرفت، مشروعیت بخشید. ظهور ژئوماتیک، به عنوان یک سیستم جامع از فن آوری ها، شیوه ها و محصولات، و سپس با محو شدن نسبی فعلی آن، نشانه تغییرات بزرگتری است که در آن دوره رخ داده است. شکل 1 نشان می دهد که هوش مصنوعی و پایگاه های داده سرنوشت مشابهی را دنبال کرده اند. شکل 1 همچنین نشان می دهد که این تغییر در سال 1995 رخ داده است، زمانی که استفاده از اینترنت بردار اصلی تقریباً هر توسعه فناوری عددی دیگری شد.
درس 1: در ژئوماتیک، موضوع نمایش اطلاعات بالاترین چالش بوده است: (الف) غلبه بر فرمت های بسیاری برای داده های شطرنجی یا داده های برداری. (ب) برای نمایش ابرداده های پیچیده، تا هستی شناسی ها. و (ج) سپس برای کمک به فرآیندها برای تبدیل شدن به یکپارچه با یکدیگر، تا ادغام اطلاعات. Big Data میتواند بر اساس XML یا JSON ایجاد شود و برخی منطقها را با RDF و OWL اضافه کند، اما چالش ادغام اطلاعات همچنان زیاد است.
درس 2: عدم قطعیت در همه جا وجود دارد، و مشاهدات دنیای واقعی با سطوح مختلف کیفیت متفاوت، که هر فرآیند ترکیب اطلاعاتی باید همراه با داده ها باشد، مانع مشاهدات دنیای واقعی می شود، چیزی که پیچیدگی را به صورت تصاعدی افزایش می دهد. حدود دو دهه طول کشید تا مسائل کیفیت به یک دغدغه اصلی در ژئوماتیک تبدیل شود. در Big Data که عمدتاً توسط اتوماسیون بازاریابی هدایت می شود، آگاهی از کیفیت هنوز یک نگرانی عمده نیست، اما باید به زودی رخ دهد، به عنوان مثال برای تجزیه و تحلیل شکست Google به [ 38 ] مراجعه کنید.
درس 3: کوهن نوشت [ 39 ]: «تصمیم به رد یک پارادایم همیشه تصمیم به پذیرش پارادایم دیگر است». انتشار نقشه های AOL و Google و به دنبال آن گسترش گسترده ناوبرهای GPS همراه با تلفن های هوشمند، در نهایت تصمیم گرفت که ژئوماتیک اکنون بخشی از داده های بزرگ است. اگرچه همه آگاه نیستند. تأثیر آن برای شرکتها، برنامههای درسی دانشگاهها و برای نوع مشاغلی که ارائه خواهد شد، مهم خواهد بود. آینده احتمالاً برای نسل گستردهای از «دانشمندان داده» است که به مدارک تحصیلی جزئی در علوم اجتماعی یا طبیعی یا مطالعات حقوق مجهز هستند.
چالشهای بزرگی پیش روی ما هستند، از جمله برای ژئوماتیک: جمعسپاری و اطلاعات جغرافیایی داوطلبانه، استفاده گسترده از تصاویر پهپاد، دوربینهای نظارتی، اینترنت اشیا در فضاهای شهری و طبیعی، برای ذکر واضحترین آنها.
اختصارات
در این نسخه از اختصارات زیر استفاده شده است:
| هوش مصنوعی | هوش مصنوعی |
| BDaaS | کلان داده به عنوان یک سرویس |
| DBMS | سیستم مدیریت پایگاه داده (RDBMS: Relational DBMS) |
| GIS | سیستم اطلاعات جغرافیایی |
| ISO | سازمان بین المللی استاندارد |
| LAI | شاخص سطح برگ (پایش پوشش گیاهی) |
| NGO | سازمان نشنال جئوگرافیک |
| OECD | سازمان همکاری اقتصادی و توسعه |
| OLAP | فرآیند تحلیل آنلاین (SOLAP: Spatial OLAP) |
| PCA | تجزیه و تحلیل مؤلفه های اصلی |
| یونسکو | سازمان آموزشی، علمی، فرهنگی ملل متحد |
منابع
- میشل، جی بی. شن، YK; آیدن، AP; ورس، ا. خاکستری، MK; پیکت، جی پی؛ هویبرگ، دی. کلنسی، دی. نورویگ، پی. Orwant, J. تحلیل کمی فرهنگ با استفاده از میلیون ها کتاب دیجیتالی شده. Science 2011 ، 331 ، 176-182. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- تامسون رویترز. در دسترس آنلاین: http://blog.thomsonreuters.com/index.php/Big%20Data-graphic-of-the-day (در 24 اوت 2016 قابل دسترسی است).
- کیمبال، آر. Ross, M. The Data Warehouse Toolkit: The Complete Guide to Dimensional Modeling , 2nd ed.; John Wiley & Sons, Inc.: New York, NY, USA, 2002. [ Google Scholar ]
- دمپسی، سی. عبارت “80% داده ها جغرافیایی هستند” کجاست. در دسترس آنلاین: https://www.gislounge.com/80-percent-data-is-geographic/ (در 24 آگوست 2016 قابل دسترسی است).
- آژانس محیط زیست اروپا پوشش زمین CORINE—بخش 1: روش شناسی. در دسترس آنلاین: http://www.eea.europa.eu/publications/COR0-part1 (در 24 اوت 2016 قابل دسترسی است).
- Bédard، Y.; لام، اس. پرولکس، ام.-جی. کارون، P.-Y. Létourneau, F. انبار داده برای داده های مکانی: مسائل تحقیق. در مجموعه مقالات سمپوزیوم بین المللی: ژئوماتیک در عصر رادارست (GER’97)، اتاوا، ON، کانادا، 25 تا 30 مه 1997.
- استفانوویچ، ن. طراحی و پیاده سازی پردازش تحلیلی آنلاین (OLAP) داده های مکانی. دکتری پایان نامه، دانشکده علوم محاسباتی، دانشگاه سایمون فریزر، ونکوور، BC، کانادا، ژانویه 1997. [ Google Scholar ]
- ریست، اس. Bédard، Y.; Proulx، MJ; نادو، م. هوبرت، اف. پاستور، J. SOLAP: ادغام هوش تجاری با فناوری مکانی برای اکتشاف و تجزیه و تحلیل فضایی-زمانی تعاملی داده ها. ISPRS J. Photogramm. Remote Sens. 2005 ، 60 ، 17-33. [ Google Scholar ] [ CrossRef ]
- برنیر، ای. گوسلین، پی. بدارد، ت. Bédard، Y. نظارت آسان تر از آسیب پذیری های بهداشتی مرتبط با آب و هوا از طریق یک برنامه کاربردی OLAP فضایی مبتنی بر وب. بین المللی ج. جغرافی بهداشت. آوریل 2009 ، 8 ، 18. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- هان، جی. استفانوویچ، ن. Koperski، K. متریال سازی انتخابی: یک روش کارآمد برای ساخت مکعب داده های مکانی. در تحقیق و توسعه در کشف دانش و داده کاوی ; Springer: برلین/هایدلبرگ، آلمان، 1998; صص 144-158. [ Google Scholar ]
- کیو، جی. گائو، اچ. Ding، SX پیشرفتهای اخیر در سیستمهای کنترل غیرخطی شبکهای مبتنی بر مدل فازی: یک بررسی. IEEE Trans. الکترون صنعتی 2016 ، 63 ، 1207-1217. [ Google Scholar ] [ CrossRef ]
- Tukey، JW تجزیه و تحلیل داده های اکتشافی ; Addison-Wesley: Reading، MA، ایالات متحده آمریکا، 1977. [ Google Scholar ]
- ژانسولین، آر. فونتین، ی. فری، دبلیو. تقسیم بندی چند زمانی با استفاده از مجموعه های فازی. در مجموعه مقالات هفتمین سمپوزیوم LARS در مورد پردازش ماشینی داده های سنجش از دور، با تاکید ویژه بر ارزیابی محدوده، جنگل و تالاب ها، دانشگاه پردو، لافایت غربی، IN، ایالات متحده، 23-26 ژوئن 1981. صص 336-340.
- دیدی، ای. روش خوشههای پویا در خوشهبندی غیر سلسله مراتبی. بین المللی جی. کامپیوتر. Inf. علمی 1973 ، 2 ، 61-88. [ Google Scholar ] [ CrossRef ]
- اولیوسو، ا. پریوت، ال. بارت، اف. Vlevers، JGPW جنبه های فضایی در پروژه Alpilles-ReSeDA. در مجموعه مقالات مقیاس گذاری و مدل سازی کارگاهی در جنگلداری: کاربردها در سنجش از دور و GIS، مونترال، QC، کانادا، 19-21 مارس 1998.
- Jonckheere، I. فلک، اس. Nackaerts، K. مییز، بی. کاپین، پی. ویس، م. Baret, F. بررسی روشهای تعیین شاخص سطح برگ در محل. کشاورزی برای. هواشناسی 2004 ، 121 ، 19-35. [ Google Scholar ] [ CrossRef ]
- کافمن، ال. Rousseeuw, PJ یافتن گروهها در دادهها: مقدمهای بر تحلیل خوشهای . جان وایلی و پسران: نیویورک، نیویورک، ایالات متحده آمریکا، 1990. [ Google Scholar ]
- منینگ، سی دی; رغوان، پ. Schütze, H. Introduction to Information Retrieval ; انتشارات دانشگاه کمبریج: نیویورک، نیویورک، ایالات متحده آمریکا، 2008. [ Google Scholar ]
- کورتس، سی. Vapnik، VN پشتیبانی شبکه های بردار. ماخ فرا گرفتن. 1995 ، 20 ، 273-297. [ Google Scholar ] [ CrossRef ]
- ژانسولین، آر. ویلسون، ن. کیفیت اطلاعات جغرافیایی: رویکرد هستیشناختی و ابزارهای هوش مصنوعی در پروژه Revigis. در مجموعه مقالات هشتمین کارگاه آموزشی EC-GI&GIS، دوبلین، ایرلند، 3 تا 5 ژوئیه 2002.
- فروچی، دی. براون، ای. چو-کارول، جی. فن، جی. گوندک، دی. Kalyanpur، AA; لالی، ا. مرداک، جی دبلیو. نایبرگ، ای. پراگر، جی. ساختمان واتسون: مروری بر پروژه DeepQA. AI Mag. 2010 ، 31 ، 59-79. [ Google Scholar ]
- راندل، دی. کوی، ز. Cohn, AG یک منطق فضایی مبتنی بر مناطق و اتصال. در مجموعه مقالات سومین کنفرانس بین المللی اصول بازنمایی و استدلال دانش، سن متئو، کالیفرنیا، ایالات متحده آمریکا، اکتبر 1992; صص 165-176.
- اوزنات، ج. بسیر، سی. ژانسولین، آر. Revault، J. Schwer, S. Dossier Raisonnement spatial et temporel. گاو نر de l’Assoc. Fr. de l’Intell. آرتیف. 1997 ، 29 ، 2-13. [ Google Scholar ]
- کاواروک، M.-A. بنفرهات، اس. Jeansoulin، R. مدل سازی تغییرات کاربری اراضی با استفاده از شبکه های بیزی. در مجموعه مقالات بیست و دومین کنفرانس بین المللی IASTED در زمینه هوش مصنوعی و کاربردها، اینسبروک، اتریش، 16 فوریه 2004.
- گروبر، تی. اولسن، جی. هستی شناسی برای ریاضیات مهندسی. در مجموعه مقالات چهارمین کنفرانس بین المللی اصول بازنمایی و استدلال دانش، بن، آلمان، 24-27 مه 1994; صص 258-269.
- Halevy، A. چرا داده های شما با هم ترکیب نمی شوند؟ صف ACM: نیویورک، نیویورک، ایالات متحده آمریکا، 2005. [ Google Scholar ]
- کامبر، ای جی. فیشر، پی. Wadsworth، R. جنبههای هستیشناختی پوشش زمین را در معرض خطر نادیده بگیرید: درخواستی برای فراداده گسترده. در مجموعه مقالات کنفرانس انجمن سنجش از دور و فتوگرامتری، آبردین، بریتانیا، 6 سپتامبر 2004.
- Lund، HG تعاریف جنگل، جنگل زدایی، جنگل کاری و احیای جنگل ; خدمات اطلاعات جنگل: Gainesville، VA، ایالات متحده آمریکا، 2007. [ Google Scholar ]
- Quine، WV در مورد آنچه وجود دارد . انتشارات دانشگاه هاروارد: کمبریج، TN، ایالات متحده آمریکا، 1948. [ Google Scholar ]
- گانتر، بی. ویل، آر. تحلیل مفهومی رسمی: مبانی ریاضی . Springer: برلین، آلمان، 1999. [ Google Scholar ]
- اسمیت، جنرال موتورز; براون، نیوجرسی؛ Thomson, AG CORINE Land Cover 2000: به روز رسانی نیمه خودکار پوشش زمین CORINE در بریتانیا . مرکز اکولوژی و هیدرولوژی، شورای تحقیقات محیط طبیعی بریتانیا: Monks Wood، UK، 2005. [ Google Scholar ]
- فام، TT; Phan-Luong، V. Jeansoulin، R. همجوشی مبتنی بر کیفیت داده: کاربرد در پوشش زمین. در مجموعه مقالات هفتمین کنفرانس بین المللی در همجوشی اطلاعات (FUSION’04)، استکهلم، سوئد، 28 ژوئن تا 1 ژوئیه 2004.
- ژانسولین، آر. کوره، او. احمد، ع. گادمر، ا. رودانت، ج.-پی. اطلاعات جغرافیایی یک عمل است نه یک واقعیت. در مجموعه مقالات دوازدهمین کنفرانس بین المللی AGILE در علم اطلاعات جغرافیایی، دانشگاه لایبنیتس، هانوفر، آلمان، 2 تا 5 ژوئن 2009.
- واسور، بی. ژانسولین، آر. دیویلر، آر. فرانک، ای. ارزیابی کیفیت خارجی کاربردهای جغرافیایی: یک رویکرد هستی شناختی. در مبانی کیفیت داده های مکانی ; Devillers, R., Jeansoulin, R., Eds. انتشارات ISTE: لندن، انگلستان، 2006; صص 255-270. [ Google Scholar ]
- Teich, DA SQL -vs- NoSQL: بحث طراحی پایگاه داده حتی یک مبارزه واقعی نیست. فوریه 2016. در دسترس آنلاین: http://searchdatamanagement.techtarget.com/tip/SQL-vs-NoSQL-database-design-debate-isnt-even-a-real-fight (در 24 اوت 2016 قابل دسترسی است).
- Grimes، S. Big Data: اجتناب از سردرگمی “Wanna V”. در دسترس آنلاین: http://www.informationweek.com/big-data/big-data-analytics/big-data-avoid-wanna-v-confusion/d/d-id/1111077 (در 24 آگوست 2016 قابل دسترسی است).
- هاپکینز، بی. فارستر، تحلیلگر اصلی، در مصاحبه TechTarget، توسط مارک برونلی. در دسترس آنلاین: http://searchdatamanagement.techtarget.com/news/2240036228/Will-your-organization-benefit-from-big-data-processing-technology (در 24 آگوست 2016 قابل دسترسی است).
- لازر، دی. کندی، آر. آنچه می توانیم از شکست حماسی روند آنفولانزای گوگل بیاموزیم. در دسترس آنلاین: http://www.wired.com/2015/10/can-learn-epic-failure-google-flu-trends/ (در 24 آگوست 2016 قابل دسترسی است).
- کوهن، ساختار انقلاب های علمی TS ; انتشارات دانشگاه شیکاگو: شیکاگو، IL، ایالات متحده آمریکا، 1962. [ Google Scholar ]
شکل 1. مهندسی داده: رویدادهای مهم و کلیدواژه های اصلی در 50 سال گذشته.
شکل 2. ( بالا ) مکعب چند بعدی: دو نمونه از میزان بروز بر اساس قلمرو، زمان و بیماری ها. ( پایین ) ترکیب حقایق: افرادی که به تنهایی زندگی می کنند (نقشه رنگی) و افراد با درآمد پایین (نمادها).

شکل 3. بسیاری از موضوعات شناسایی شده توسط کمیته داده های جغرافیایی فدرال، جمع آوری شده توسط آژانس های ایالات متحده.
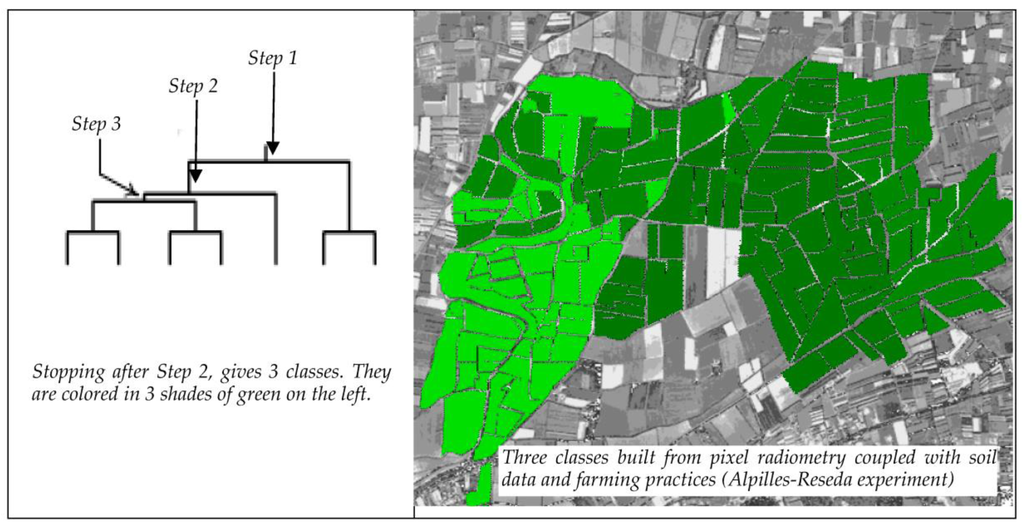
شکل 4. مثال خوشه بندی سلسله مراتبی (گاهی اوقات به عنوان درخت فیلوژنتیک نیز شناخته می شود).
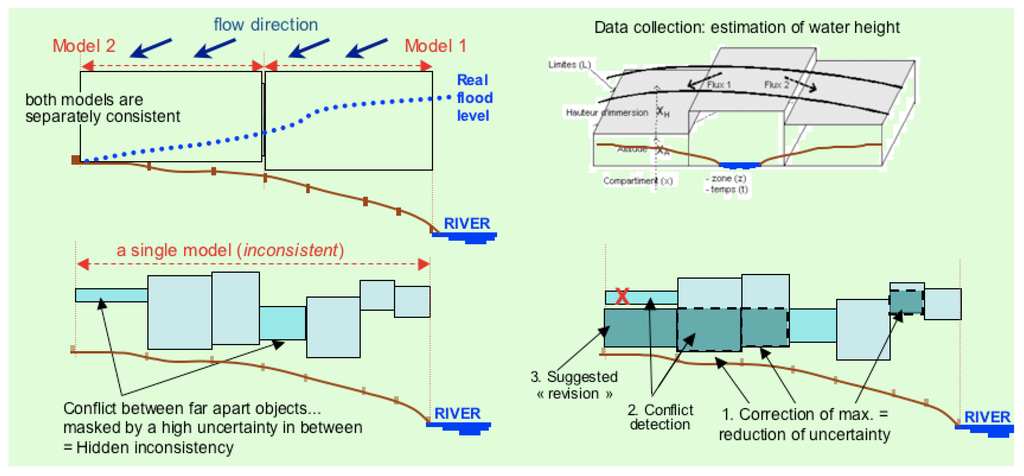
شکل 5. برآورد یک رویداد سیل، با ترکیب دو منبع داده: جهت جریان ( بالا سمت چپ ) و ارتفاع (تخمین تکهای: بالا سمت راست ). خط پایین طرح میکند که چگونه میتوان ناسازگاریها را بین مدلهای محلی شناسایی کرد ( پایین سمت چپ )، و سپس در یک مدل یکپارچه ( پایین سمت راست ) تصحیح کرد.
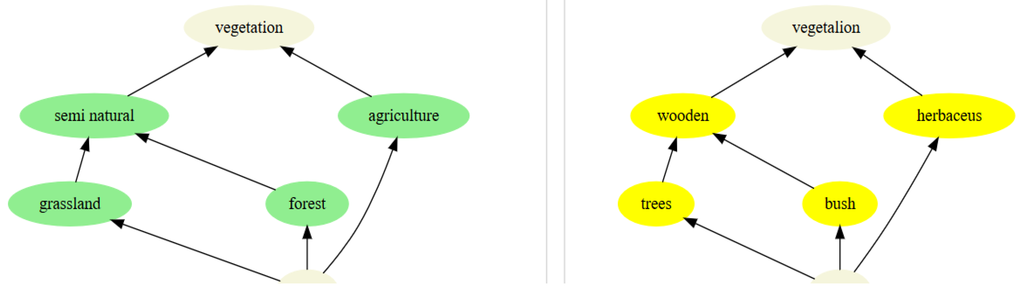
شکل 6. دو هستی شناسی که به صورت شبکه های گالویز محاسبه شده اند که از دو مجموعه مشاهده به دست آمده اند.

شکل 7. تراز هستی شناسی: ترکیب دو شبکه Galois و نامگذاری گره های اضافی.

جدول 1. رمزگذاری هندسه و توپولوژی مجموعه ای از قطعات زمین.
جدول 2. فراداده برای نمایش کیفیت داده های مکانی (ISO 2002).
© 2016 توسط نویسنده; دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (CC-BY) (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر