


خلاصه
تایپیکاسیون یک اپراتور کاملاً تثبیت شده برای تعمیم نقشه است. اگرچه به طور گسترده در بسیاری از زمینه های تحقیقاتی موجود استفاده می شود، بحث کمتری به کیفیت نوع بندی اختصاص داده شده است. این مقاله یک نظرسنجی کاربر را برای ارزیابی نتایج تیپسازی مختلف سازههای نما تحت محدودیتهای مختلف ارائه میکند. بررسی نشان میدهد که حفظ شکل ویژگیها مهمترین محدودیت برای یک فرآیند تایپسازی معقول است، که از نظر کمی نیز با محاسبه شباهتهای بین نماهای مشخص شده و نمای اصلی با استفاده از نمودار رابطهای نسبتدادهشده (ARG) و زمین تودرتو تأیید شده است. الگوریتم های فاصله متحرک (NEMD) بر این اساس، الگوریتمی برای تولید نمایش معقول قابل درک از نمای اصلی با کاهش مقیاس نقشه توسعه یافته است. الگوریتم بر روی تعدادی نما پیاده سازی و آزمایش شده است. آزمایشها نشان میدهند که تایپسازی میتواند به طور خودکار انجام شود و نتایجی ایجاد کند که به خوبی با نماهای اصلی مرتبط است.
کلید واژه ها:
تعمیم ; تایپ سازی ; نظرسنجی کاربران ; نمودار رابطه ای نسبت داده شده (ARG)
1. معرفی
تعمیم اشیاء ساختمانی در سالهای اخیر موضوعی بوده است زیرا (1) ارائه کارآمد اشیاء ساختمانی مستلزم نمایش ساختمانها در سطوح مختلف جزئیات (LoDs) است. و (2) برای تجسم ساختمان ها بر روی دستگاه های نمایشگر کوچک مانند تلفن های همراه، PDA ها و غیره، مدل های ساختمان های انتزاعی باید تولید شوند.
از آنجایی که Staufenbiel [ 1 ] یک رویکرد مبتنی بر قانون را برای سادهسازی پلان زمین ساختمان دوبعدی پیشنهاد کرد، تعدادی الگوریتم برای تعمیم مدلهای ساختمان در دسترس قرار گرفتهاند. کارهای اولیه بر توسعه تکنیکهایی برای تعمیم نقشههای زمین ساختمان به صورت دو بعدی تمرکز داشتند [ 2 ، 3 ، 4 ، 5 ]. با استفاده از این تکنیکها، میتوان با حذف بخشهای خط با برخی معیارها، یعنی حداقل طول نما، میزان جزئیات در پلان زمین را کاهش داد. به عنوان مثال، سستر [ 6] یک روش دو مرحله ای را پیشنهاد کرد: (1) حذف حداقل فرم ها توسط قوانین. و (2) تنظیم فرم ساختمان ساده شده به شکل اصلی با استفاده از تنظیم حداقل مربعات. در این مرحله دوم، ویژگیهای خاصی از ساختمانها را میتوان حفظ یا حتی بر آن تأکید کرد، مثلاً مستطیل بودن و موازی بودن یا اندازه. روشهای دیگر روشهای تشخیص الگو را برای جایگزینی طرح زمین اصلی با یک شکل استاندارد اعمال میکنند [ 7 ].
در سال های اخیر، تعدادی الگوریتم به طور خاص برای تعمیم مدل های ساختمان سه بعدی پیشنهاد شده است. لال و منگ [ 8 ] قوانین و محدودیت هایی را برای تعمیم سه بعدی تعریف کردند. با این حال، تعمیم در یک عملیات، یعنی تجمیع، محدود شده است. کادا [ 9 ] رویکرد سستر را گسترش داد [ 6 ]. او قوانینی را برای حذف ساختارهایی که در چند وجهی سه بعدی خیلی کوچک بودند، در ابتدا ایجاد کرد و سپس ساختمان ساده شده را به شکل اصلی خود تنظیم کرد.
بر اساس تقسیم بندی چند وجهی پیشنهاد شده توسط Ribelles و همکاران. [ 10 ]، Thiemann و همکارانش پیشنهاد کردند که یک ساختمان را به اولیههای سه بعدی اولیه تجزیه کنند و آنهایی را با حجمهای کوچک حذف کنند [ 11 ، 12 ]. کادا [ 13 ، 14 ] یک رویکرد ساختاری مشابه را پیشنهاد کرد. او بخشهایی از ساختمانهای سادهشده را بهعنوان تقاطعهای نیمصفحهها تعریف کرد که بر اساس آنها تجزیه سلولی و نمونهسازی اولیه اعمال میشود. تحقیقات مرتبط بیشتر را می توان در [ 15 ، 16 ] یافت .
مطالعات ذکر شده در بالا عمدتاً بر ساده سازی ساختمان ها با حذف عناصر دیواری کوچکتر متمرکز است. ویژگی های نمای ساختمان به ندرت مورد توجه قرار می گیرند، اما آنها همچنین نیاز به تعمیم دارند، به عنوان مثال، پنجره ها باید بزرگ شوند تا در فضای نمایشی کاهش یافته خوانا باشند. با این حال، بزرگ شدن ممکن است باعث همپوشانی ویژگی ها شود. برای دور زدن این مشکل میتوان از تایپسازی استفاده کرد. از سوی دیگر، با کوچک شدن بیشتر فضای نمایش، ساختمان ها باید به صورت گروهی تعمیم داده شوند. برای این مورد، عملیات typification زمانی ترجیح داده می شود که ساختمان ها به طور منظم توزیع شوند [ 15 ].
عملگر تایپ سازی به عنوان فرآیندی برای جایگزینی تعداد زیادی از اشیاء با تعداد کمتری از اشیاء یکنواخت با حفظ ویژگی های مناسب الگو تعریف می شود. با توجه به رویکرد تایپ سازی، در [ 17 ]، هر چهار چند ضلعی همسایه یکدیگر با یک چند ضلعی جدید ایجاد شده با اتصال نقاط مرکزی چهار چند ضلعی جایگزین شدند. الگوریتم گونهبندی Regnauld [ 4 ] بر اساس حداقل درخت پوشا در نظریه گراف بود. در [ 18] روند تیپ سازی به دو مرحله تقسیم شد: موقعیت یابی و نمایش، در حالی که مرحله موقعیت یابی تعداد و موقعیت ساختمان ها را بر اساس مثلث سازی دلونی تعیین می کند، در مرحله نمایش اندازه و جهت جایگزینی محاسبه می شود. علاوه بر این، اکثر کارهای قبلی مانند [ 19 ، 20 ، 21 ، 22 ] چگالی اجسام را با استفاده از قانون رادیکال تروپفر تعیین کردند [ 23 ]. علاوه بر این، این نوع عملیات در بسیاری از متون برای تعمیم استفاده شد و نتایج مختلفی در [ 5 ، 11 ، 14 ، 24 ارائه شد.]. با این حال، بحث نمی شود که چرا نتایج آنها معقول است. در همین حال، مشکل مشابهی در زمینه علوم کامپیوتر وجود دارد. برای مدیریت چیدمان رابط کاربری گرافیکی (GUI) در گرافیک، از تایپ برای تنظیم مجدد دکمه ها (یا نمادها) با تغییر اندازه رابط کاربری گرافیکی برای دستگاه ها یا مقیاس های مختلف استفاده می شود. تعدادی الگوریتم در حال حاضر برای این موضوع موجود است. به عنوان مثال، لویتن و همکاران. [ 25 ] روشی را برای ترکیب توصیفات رابط کاربری انتزاعی (UI) و سیستم مدیریت چیدمان مبتنی بر محدودیت برای دستگاه های مختلف توصیف کرد. متأسفانه، هیچ تحقیقی برای یافتن یک نتیجه معقول از تایپ سازی نیز وجود ندارد.
در کار ما یک نظرسنجی از کاربران انجام شده است تا مشخص شود که چه نوع نمایشی پس از تایپ سازی با توجه به ادراک بصری انسان به بهترین وجه با مجموعه داده اصلی مرتبط است. به منظور تأیید نتایج نظرسنجی کاربر، نمودارهای ارتباطی نسبت داده شده (ARGs) از مجموعه داده اصلی و نمایش نامزد پس از تایپ سازی تولید می شوند. سپس ساختار تودرتو فاصله حرکت دهنده زمین (NEMD) [ 26 ] بین این ARG ها محاسبه می شود. مقادیر NEMD شباهتهای بین نماهای مشخص شده و نماهای اصلی را نشان میدهد و میتواند به عنوان یک معیار کمی برای هدایت رویکرد خودکار نوعسازی در نظر گرفته شود.
مابقی مقاله به صورت زیر ساختار یافته است: ابتدا نظرسنجی کاربر برای نوعیابی در بخش 2 ارائه شده است. در بخش 3 ، الگوریتمهای ARG و NEMD به منظور تأیید نتایج نظرسنجی کاربر توضیح داده شدهاند. رویکرد خودکار نوعسازی بر اساس نتایج نظرسنجی کاربر ما در بخش 4 با نتایج تجربی نشان داده شده در بخش 5 بیان شده است . در نهایت، نتیجه گیری و کاری که در آینده باید انجام شود در بخش 6 آورده شده است .
2. نظرسنجی کاربر برای تایپ
2.1. محدودیت های تایپ سازی
نظرسنجی کاربران بر تجزیه و تحلیل نمای ساختمان با پنجره متمرکز است، زیرا پنجره ها رایج ترین سازه ها در نما هستند. علاوه بر این، پنجره های روی نما در بیشتر موارد از نظر شکل و اندازه یکنواخت هستند و به طور منظم توزیع می شوند. در نظرسنجی کاربر، محدودیتهای مختلفی شناسایی میشوند که به حفظ شباهت بین نمای نمونهسازی شده و نمای اصلی کمک میکنند:
-
پوشاندن منطقه توسط پنجره ها،
-
حفظ نسبت بین ارتفاع و عرض پنجره ها،
-
حفظ فاصله بین پنجره ها،
-
حفظ فاصله بین پنجره ها و طرح کلی نما،
-
توزیع پنجره ها در جهت تمایل.
با ترکیب محدودیتهای فوق، گزینههای مختلفی را برای تایپسازی ایجاد کردیم که پایهای را برای آزمون کاربر با هدف شناسایی معقولترین نوعنویسی ایجاد میکند. شکل 1 یک نمای نمونه با پنجره های توزیع منظم را نشان می دهد و گزینه های مختلف تایپ سازی در شکل 2 نشان داده شده است .
2.2. نظرسنجی کاربر و نتایج
شش گزینه در سه نمای مختلف ( شکل 3 ) از جمله نمای (ب) ارائه شده در شکل 1 اعمال می شود . این نماها جهت گرایش متفاوتی دارند یا جهتی ندارند که در پیش زمینه باقی بمانند. نما (الف) جهت گرایشی ندارد. فاصله بین پنجره ها در جهت افقی و عمودی تقریباً برابر است. نما (ب) دارای تمایل به جهت افقی است زیرا فاصله بین پنجره ها در جهت افقی کمتر از جهت عمودی است. نما (ج) تمایل خود را در جهت عمودی دارد. فاصله بین پنجره ها در جهت عمودی کمتر از جهت افقی است.
هر سه نما دارای توزیع منظم الگوی شبکه ای هستند. ما آنها را به یک نمایش مبتنی بر برداری استخراج کردیم و آنها را به شش نامزد مربوط به شش گزینه در بخش 2.1 تایپ کردیم.. ما همچنین چندین تصویرسازی با سوالات مناسب برای شرکت کنندگان طراحی کردیم تا آزمون کاربر را انجام دهند. این تجسمها به صورت بصری کدگذاری میشوند و شرکتکنندگان از محدودیتهایی که در طول تایپسازی استفاده میشوند بیاطلاع هستند. نمونه ای از یک سوال این است: لطفاً تصاویر را به ترتیبی که شبیه تصویر اصلی هستند رتبه بندی کنید. برای هر سوال دو یا سه گزینه با یکدیگر مقایسه می شود. شرکت کنندگان باید نماها را به ترتیب (از بهترین به بدترین) رتبه بندی کنند. به عبارت دیگر آنها باید بگویند که کدام نوع نگارش با نمای اصلی استخراج شده مرتبط است و انتخاب دوم و سوم آنها کدام است.
نظرسنجی کاربران طی یک سخنرانی در 12 نوامبر 2008 در دانشگاه فنی مونیخ انجام شد. آزمودنی ها شامل 9 دانشجوی دختر و 12 پسر در مقطع کارشناسی در رشته ژئودزی می باشد. سن آنها بین 19 تا 26 سال بود. به هر آزمودنی 15 ثانیه داده شد تا به پنجره های استخراج شده و گزینه های تایپ آنها نگاه کند. سپس آنها باید تصمیم خود را بگیرند.
نتایج نظرسنجی کاربران برای سه نما خلاصه و میانگین شده است ( جدول 1 ). این مقادیر نشان می دهد که در چه درجه ای شش گزینه ( شکل 2 ) می توانند به نمای اصلی مرتبط شوند.
جدول 1 شباهت های شش گزینه را با نمای اصلی نشان می دهد. ما فرض می کنیم که هر چه گزینه مشابه با نمای اصلی باشد، محدودیت های اعمال شده برای گزینه مربوطه مهم تر است ( شکل 2 را مقایسه کنید). درجه اهمیت محدودیتها ( بخش 2.1 ) برای نوعبندی محاسبه میشود. آنها با 10 وزن و نرمال می شوند تا نتایج را قابل مقایسه تر کنند.
جدول 2 مقادیر اهمیت رو به کاهش گزینه ها را نشان می دهد. این ممکن است این فرض را تقویت کند که حفظ شکل عناصر نما (شکل منسجم) مهم ترین است. دومین محدودیت مهم حفظ فاصله بین پنجره ها و حفظ فاصله بین پنجره ها و طرح کلی نما در همان زمان است. این یافته در کوانتیشن شباهت با ARG و NEMD در بخش بعدی استفاده خواهد شد.
3. تأیید نظرسنجی کاربر با استفاده از الگوریتم ARG و NEMD
برای تعیین کمیت شباهت بصری بین نماها، از روشهای تشخیص الگو استفاده میشود. نمودار رابطه ای نسبت داده شده (ARG) به طور گسترده برای نشان دادن اشیاء یا ساختارهایی که باید در بینایی کامپیوتری و تشخیص الگوی شناسایی شوند استفاده شده است [ 27 ]. در این مقاله از ARG برای نمایش پنجره های نما استفاده شده است. بنابراین ارزیابی شباهت بصری بین نمای مشخص شده و نمای اصلی را می توان با تطبیق ARGهای آنها کمیت کرد. الگوریتمهای زیادی برای تطبیق ARG مانند تطبیق نمودار تخصیص مدرج (GAGM) [ 28 ] و تطبیق نمودار حداقل مربعات (LSGM) [ 29 ] پیشنهاد شدهاند. الگوریتم Nested Earth Mover’s Distance (NEMD) انتخاب شده است زیرا عملکرد بهتری در تطبیق ARG با توجه به نتایج در [26 ].
یک ARG G به صورت G = { V,R } تعریف می شود که در آن V = { v i |1 ≤ I ≤ n } و R = { r ij |1 ≤ I ≤ n , 1 ≤ j ≤ n }. V مجموعه ای از n گره است و هر v i نمایانگر یک پنجره در نما است. R یک است n × n�×�ماتریس و هر r ij رابطه بین پنجره v i و v j است . در این نرم افزار گره دارای ویژگی هایی در مورد پنجره مانند عرض و ارتفاع است و رابطه بین گره ها نشان دهنده روابط فضایی و توپولوژیکی بین پنجره ها در نما خواهد بود.
تطبیق ARG را می توان به عنوان یک روش دو مرحله ای، ساخت یک ماتریس فاصله و ایجاد مطابقت بر اساس ماتریس فاصله، اجرا کرد. به طور خاص، NEMD از EMD داخلی (فاصله حرکت دهنده زمین) و EMD بیرونی تشکیل شده است. EMD داخلی تفاوت بین گره های مربوطه از دو ARG را منعکس می کند. EMD خارجی از فواصل EMD داخلی همه جفت گره ها تشکیل شده است و می توانیم مطابقت بین گره ها را در دو ARG برقرار کنیم و با انتخاب و اضافه کردن حداقل عنصر در هر ستون یا ردیف EMD بیرونی، فاصله دو ARG را بدست آوریم. جزئیات در مورد محاسبه NEMD در [ 26 ، 30 ] آورده شده است.
یک مثال ساده از محاسبه NEMD 2 ARG نشان داده شده در شکل 4 توسط کیم و همکاران ارائه شده است. 2004. تفاوت بین مثال در شکل 4 و روش پیشنهادی برای ارزیابی تعمیم، تعریف فاصله بین گره ها و روابط است. برای سادهتر کردن محاسبه، ویژگی گره فقط یک شکل را شامل میشود و فاصله بین گرهها، مقدار تفاوت ارقام آنها است. برای روابط در شکل 4 نیز همینطور است . برای ارزیابی کیفیت، ما فقط توابع فاصله گره Δ و رابطه Δ در معادله (1) را با توابع تعریف شده در بخش 3.2 جایگزین می کنیم .
Δمن n n e r( j , j ‘ ) = ( 1 − α ) ×Δگره(vj،v“j“) + α ×Δرابطه(rمن ج،r“من“j“)Δمن��ه�(�،�“)=(1–�)×Δگره(��،�“�“)+�×Δرابطه(�من�،�“من“�“)
در شکل 4 ، G’ نمودار فرعی G با گره های 1، 2، 3 در G’ مربوط به گره های 4، 2، 1 در G است . فاصله بین گره ها و فاصله بین روابط تفاوت مقادیر آنها در شکل 4 است .
ابتدا، EMD داخلی بین هر جفت گره در G و G’ از ماتریس داخلی D inner محاسبه میشود که در آن هر عنصر از معادله (1) تولید میشود. به عنوان مثال، D داخلی گره v 1 در G و v’ 1 در G’ ( v i و v’ i’ ) در رابطه (3) آورده شده است، که در آن ردیف 1 و ستون دوم ماتریس داخلی D inner ، Δ درونی (1، 2) را می توان با رابطه (2) محاسبه کرد.
Δمن n n e r( 1 , 2 ) = ( 1 − α ) ×Δگره(v1،v“2) + α ×Δرابطه(r11،r“12)Δمن��ه�(1،2)=(1–�)×Δگره(�1،�“2)+�×Δرابطه(�11،�“12)
که در آن، I = 1، I’ = 1، j = 1، j’ = 2، گره Δ ( v 1 , v’ 2 ) = |0.8 − 0.3| = 0.5، رابطه Δ ( r 11 ,r’ 12 ) = |0 − 0.2| = 0.2، α = 0.5. بنابراین، Δ داخلی (1، 2) = 0.35. به طور مشابه، میتوانیم تمام Δ درونی ( j, j’ ) را محاسبه کنیم و D درونی را برای جفت گره v 1 و v’ 1 بسازیم همانطور که در رابطه (3) نشان داده شده است. بر این اساس، EMD داخلی گره v 1در G و v’ 1 در G’ 0.1 + 0.3 + 0.35 = 0.75 است (حداقل مجموع حداقل مقدار در هر ستون یا سطر).
D بیرونی G و G’ نیز در رابطه (3) آورده شده است، که در آن عنصر اول طبق محاسبات قبلی 0.75 است. EMD بین G و G بر اساس D بیرونی 0 است ، زیرا G’ نمودار فرعی G است. اما در برنامه ما، نه تنها تفاوت جزئی بلکه کلی بین ARGها باید در نظر گرفته شود. بنابراین، تفاوت بین دو ARG حداکثر مجموع مقدار حداقل در هر ستون یا ردیف D بیرونی است ، به عنوان مثال، 0.05 برای G و G’ در شکل 4 .
Dمن n n e r(v1،v“1) =⎡⎣⎢⎢⎢⎢0.350.50.70.350.350.30.50.350.350.30.10.35⎤⎦⎥⎥⎥⎥،Do u t e r=⎡⎣⎢⎢⎢⎢0.750.250.6500.6500.550.2500.750.050.95⎤⎦⎥⎥⎥⎥�من��ه�(�1،�“1)=[0.350.350.350.50.30.30.70.50.10.350.350.35]،��توتیه�=[0.750.6500.2500.750.650.550.0500.250.95]
این بقیه بخش بر ایجاد ARG نما و ساخت ماتریس فاصله گره ها و روابط متمرکز است.
3.1. نسل ARG
از آنجایی که پنجره ها در داده های نمای آزمایشی ما همه مستطیل هستند، عرض و ارتفاع پنجره به عنوان ویژگی های گره ذخیره می شود. v i = ( w i , h i ) که در آن v i نمایانگر i-امین پنجره در نما است. w i و h iعرض و ارتفاع پنجره هستند. رابطه بین دو پنجره به نسبت فاصله بین دو چند ضلعی پنجره و مجموع مساحت آنها تنظیم می شود. با این حال، فاصله مطلق به تنهایی برای انعکاس رابطه بصری بین دو پنجره در نما کافی نیست زیرا دو پنجره بزرگ بیشتر شبیه به یکدیگر هستند تا دو پنجره کوچکتر حتی اگر فاصله یکسانی داشته باشند.
3.2. تعریف فاصله
سه نوع فاصله توسط NEMD مورد نیاز است و آنها (1) فاصله بین گره ها هستند. (2) فاصله بین روابط. و (3) فاصله با ترکیب دو نوع قبلی. فاصله گره نشان دهنده تفاوت بین اشکال هر جفت پنجره است. فاصله رابطه نشان دهنده توزیع فضایی و تفاوت توپولوژیکی گروه پنجره است. فاصله ترکیبی مجموع وزنی فاصله گره و فاصله رابطه است. همه این مقادیر فاصله از 0 تا 1 نرمال شده اند که 0 دقیقاً یکسان و 1 نشان دهنده کاملاً متفاوت است.
گره Δ فاصله گره از دو قسمت تشکیل شده است: فاصله شکل Δ شکل و فاصله مساحت Δ ناحیه . با فرض اینکه v i و v j دو گره هستند، گره Δ را می توان به صورت زیر محاسبه کرد:
vمن= (wمن،ساعتمن) ،vj= (wj،ساعتj)�من=(�من،ساعتمن)،��=(��،ساعت�)
مترایکسمن= حداکثر {wمن،ساعتمن} ، مایکسj= حداکثر {wj،ساعتj}مترایکسمن=حداکثر{�من،ساعتمن}،مترایکس�=حداکثر{��،ساعت�}
wm i n= دقیقه {wمنمترایکسمن،wjمترایکسj} ،ساعتm i n= دقیقه {ساعتمنمترایکسمن،ساعتjمترایکسj}�مترمن�=دقیقه{�منمترایکسمن،��مترایکس�}،ساعتمترمن�=دقیقه{ساعتمنمترایکسمن،ساعت�مترایکس�}
Δs h a p e=∣∣∣wمنمترایکسمن–wjمترایکسj∣∣∣⋅ساعتm i n+∣∣∣ساعتمنمترایکسمن–ساعتjمترایکسj∣∣∣⋅wm i nΔسساعتآپه=|�منمترایکسمن–��مترایکس�|·ساعتمترمن�+|ساعتمنمترایکسمن–ساعت�مترایکس�|·�مترمن�
a r eآمن=wمن⋅ساعتمندبلیومن.اچمن، a r eآj=wj⋅ساعتjدبلیوj.اچjآ�هآمن=�من·ساعتمندبلیومن.اچمن،آ�هآ�=��·ساعت�دبلیو�.اچ�
Δa r e a=| a r eآمن– a r eآj|حداکثر { a r eآمن، a r eآj}Δآ�هآ=|آ�هآمن–آ�هآ�|حداکثر{آ�هآمن،آ�هآ�}
Δn o dه= α ⋅Δs h a p e+ ( 1 − α ) ⋅Δa r e aΔ��ده=�·Δسساعتآپه+(1–�)·Δآ�هآ
همانطور که در شکل 5 نشان داده شده است، شکل Δ برابر است با مجموع مساحت D 1 و D 2 (قسمت سایه دار در شکل 5 ج). از آنجایی که مستطیل P 1 و P 2 به مستطیل با 1 به عنوان طولانی ترین لبه نرمال می شوند، شکل Δ مقداری بین 0 (یعنی دقیقاً یکسان است) و 1 (کاملاً متفاوت) است. در معادله (8) دبلیومندبلیومنو اچمناچمنعرض و طول کل نما هستند که شامل vمن�من، همینطور هستند دبلیومندبلیومنو اچمناچمن. مساحت Δ اختلاف سطح نرمال شده است. α عددی بین 0 و 1 است که وزن شکل و فاصله مساحت در فاصله گره نهایی را نشان می دهد.
فاصله رابطه Δr e l a t i o n s h i pΔ�هلآتیمن��سساعتمنپتفاوت نرمال شده بین دو فاصله نسبی است. فرض rمن ج= (vمن،vj)�من�=(�من،��)رابطه بین دو چند ضلعی است vمن�منو vj��، همینطور است rp q= (vپ،vq)�پ�=(�پ،��). سپس فاصله رابطه بین rمن ج�من�و rp q�پ�را می توان به صورت زیر محاسبه کرد:
آمن ج= a r e a (vمن) + a r e a (vj) ،آp q= a r e a (vپ) + a r e a (vq)آمن�=آ�هآ(�من)+آ�هآ(��)،آپ�=آ�هآ(�پ)+آ�هآ(��)
Δr e l a t i o n s h i p=∣∣∣Δمن جآمن ج–Δp qآp q∣∣∣/ حداکثر {Δمن جآمن ج،Δp qآp q}Δ�هلآتیمن��سساعتمنپ=|Δمن�آمن�–Δپ�آپ�|/حداکثر{Δمن�آمن�،Δپ�آپ�}
در معادله (11) a r e a (vمن)آ�هآ(�من)مساحت چند ضلعی است. Δ ij و Δ pq به ترتیب فاصله گره بین آنها را نشان می دهند vمن�منو vj��و فاصله گره بین v p و v q . فاصله ترکیبی معادل معادله (1) است. Δمن n n e r= α ⋅Δn o dه+ ( 1 − α ) ⋅Δr e l a t i o n s h i pΔمن��ه�=�·Δ��ده+(1–�)·Δ�هلآتیمن��سساعتمنپ، که α عددی بین 0 و 1 است و وزن گره و فاصله رابطه را نشان می دهد. در اجرای ما، α در معادله (10) 0.5 تنظیم شده است، زیرا اهمیت شکل و مساحت یکسان در نظر گرفته می شود. برای فاصله ترکیبی در معادله (1)، α مطابق با مقدار جدول 2 برابر با 10/17 تنظیم می شود که در آن مقدار اهمیت برای پنجره ها 10 و برای رابطه بین پنجره ها 7 است. بنابراین، وزن برای گره 10/(10 + 7) و وزن برای رابطه روی 7/(10 + 7) تنظیم شده است. اگر وزن از پیش تعریف شده وجود نداشته باشد، وزن های پیش فرض برای محاسبه NEMD در فرآیند یکسان هستند، به عنوان مثال، α = 0.5 در معادله (10). در غیر این صورت، وزن ها برای انعکاس منطقی تولید می شوند، به عنوان مثال، α = 10/17 در رابطه (1).
3.3. ارزش شباهت
مقادیر NEMD بین نمای اصلی و نمای نمونه بر اساس تعاریف فاصله در بخش 3.2 محاسبه می شود . ما مقادیر NEMD را با نتایج نظرسنجی کاربر تأیید می کنیم. جدول 3 مقادیر NEMD محاسبه شده برای شش گزینه نمونهسازی نقشههای زمین آزمایشی را در مقایسه با نتایج نظرسنجی کاربر نشان میدهد.
مقادیر NEMD در جدول 3 نشان دهنده تفاوت های شش گزینه با توزیع اصلی است، در حالی که مقادیر نظرسنجی کاربر شباهت هایی را نشان می دهد. به منظور مقایسه این دو مجموعه از مقادیر، مقادیر NEMD به صورت خطی تبدیل شده و مقادیر نظرسنجی کاربر به تفاوتها تبدیل میشوند. فرض کنید یک مقدار NEMD a است و یک مقدار نظرسنجی کاربر b است. فرض کنید a’ = a/5 − 7.5 و b’ = 10 − b. این تبدیل خطی برای ترسیم مقدار NEMD و نظرسنجی کاربر در یک محدوده و نشان دادن همبستگی آنها استفاده می شود. a’ و b’ از هر شش گزینه در شکل 6 آورده شده است ، که از آن نشان داده شده است که روش NEMD پیشنهادی می تواند به درستی درک بصری کاربر از شباهت را در مورد ما منعکس کند. در شکل 6NEMD پایین تر ارتباط بهتری را بین نمای اصلی و نمای نمونه نشان می دهد، در حالی که مقدار نظرسنجی کاربر (b) به (10-b) تبدیل می شود که به این معنی است که نظرسنجی کاربر بالاتر (b) ارتباط بهتری را نشان می دهد.
4. رویکرد خودکار تایپ سازی
همانطور که در نظرسنجی کاربران نشان داده شد، مهمترین محدودیت برای تیپسازی نما، حفظ شکل عناصر آن، یعنی پنجرهها در مورد ما (شکل منسجم) است. بر این اساس یک رویکرد خودکار توسعه یافته است.
4.1. توزیع معمولی ویندوز در نما
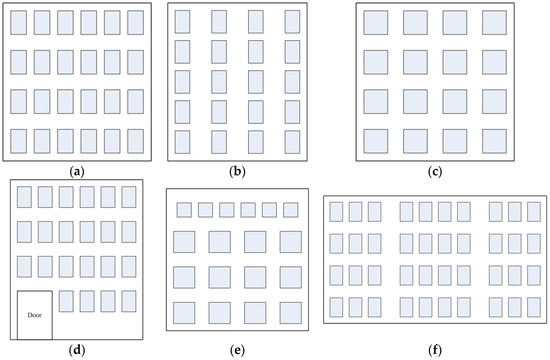
اگرچه پنجرهها تنوع گستردهای را در ساختار و توزیع نشان میدهند، اما اکثر آنها دارای نظم هستند. شکل 7 مجموعه ای از توزیع پنجره ها را در نماها نشان می دهد. شکل 7 الف دارای تمایل در جهت افقی است. به عبارت دیگر فاصله بین پنجره ها در جهت افقی کمتر از فاصله پنجره ها در جهت عمودی است. برعکس، شکل 7 ب تمایلی در جهت عمودی دارد. علاوه بر این، اگر فواصل بین پنجره ها در هر دو جهت یکسان باشد، توزیع بدون تمایل در نظر گرفته می شود ( شکل 7 ج). با این حال، گاهی اوقات نظم ممکن است به صورت محلی به دلیل سبک های مختلف معماری شکسته شود ( شکل 7d-f). در چنین مواردی، برخی از پیش پردازش ها مانند پارتیشن بندی جدید را می توان قبل از فرآیند خودکار تایپ سازی به کار گرفت. در این مقاله، پنجره های روی نما، داده های برداری هستند و تقسیم بندی گروه پنجره با آزمایش اندازه پنجره و فاصله بین پنجره ها اجرا می شود. برای یک نما در قالب شطرنجی، به عنوان مثال، تصاویر بافت، روش های بازسازی پنجره ها توسط Ripperda و Brenner [ 31 ] و Becker [ 32 ] پیشنهاد شده است.
4.2. فرآیند تایپ سازی
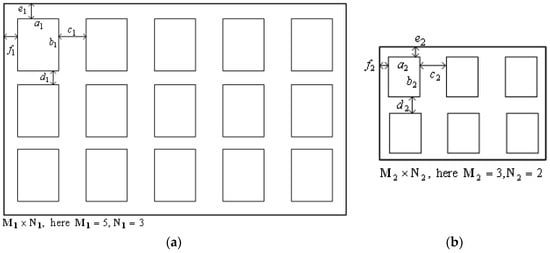
قبل از مشخص کردن پنجرهها در نما، الگوی کلی به تعدادی زیر الگو تقسیم میشود که حاوی پنجرههایی است که به طور منظم توزیع شدهاند. اگر پنجره ها به طور نامنظم در یک نما توزیع شوند (به عنوان مثال، شکل 7 d-f)، در ابتدا به چندین بخش با توزیع منظم تقسیم می شوند و فرآیند خودکار برای هر بخش به طور جداگانه انجام می شود. شکل 8 a پارامترسازی توزیع ویندوز را قبل از فرآیند تایپسازی نشان میدهد: آ1،ب1آ1،ب1برای کناره های پنجره ها به ترتیب در جهت افقی و عمودی قرار بگیرید. ج1،د1ج1،د1فاصله بین پنجره ها را به ترتیب در جهت افقی و عمودی قرار دهید. ه1،f1ه1،�1فواصل بین بلوک پنجره ها و طرح کلی نما به ترتیب در جهت افقی و عمودی است. همچنین تعداد پنجره ها در جهت افقی برابر است م1م1، و تعداد پنجره ها در جهت عمودی برابر است با ن1ن1. سپس طول نما در جهت افقی و عمودی Lh 1�ساعت1و Lv 1��1را می توان به صورت زیر محاسبه کرد:
Lh 1= 2f1+م1⋅آ1+ (م1− 1 ) ⋅ج1�ساعت1=2�1+م1·آ1+(م1–1)·ج1
Lv 1= 2ه1+ن1⋅ب1+ (ن1− 1 ) ⋅د1��1=2ه1+ن1·ب1+(ن1–1)·د1
فرآیند تایپ سازی زمانی آغاز می شود که فاصله بین پنجره ها در جهت افقی یا عمودی کمتر از مقدار حداقل باشد. ε�. ما فرض می کنیم که نتیجه نوع یابی در شکل 8 ب نشان داده شده است. سپس برخی از روابط بین این دو توزیع وجود دارد:
Lh 2= (مترمن/مترf) ⋅Lh 1�ساعت2=(مترمن/متر�)·�ساعت1
Lv 2= (مترمن/مترf) ⋅Lv 1��2=(مترمن/متر�)·��1
جایی که Lh 2�ساعت2و Lv 2��2برای طول های نما در جهت افقی و عمودی پس از تایپ سازی ایستاده، در حالی که مترمنمترمنو مترfمتر�مخفف مقیاس اصلی و هدف. مانند توزیع اصلی، طول نما پس از تایپ سازی را می توان به صورت زیر بیان کرد:
Lh 2= 2f2+م2⋅آ2+ (م2− 1 ) ⋅ج2�ساعت2=2�2+م2·آ2+(م2–1)·ج2
Lv 2= 2ه2+ن2⋅ب2+ (ن2− 1 ) ⋅د2��2=2ه2+ن2·ب2+(ن2–1)·د2
طبق نظرسنجی کاربران ما، روابط بین پارامترهای توزیع اصلی و پارامترهای پس از تایپسازی را میتوان به صورت زیر ایجاد کرد:
آ1/ب1=آ2/ب2آ1/ب1=آ2/ب2
ه2= τ⋅ه1⋅ (مترمن/مترf)ه2=�·ه1·(مترمن/متر�)
f2= τ⋅f1⋅ (مترمن/مترf)�2=�·�1·(مترمن/متر�)
دقیقه {ج2،د2} =κ1⋅ εدقیقه{ج2،د2}=�1·�
حداکثر {ج2،د2}حداکثر {ج1،د1}=κ2⋅دقیقه {ج2،د2}دقیقه {ج1،د1}حداکثر{ج2،د2}حداکثر{ج1،د1}=�2·دقیقه{ج2،د2}دقیقه{ج1،د1}
(م2⋅ن2) ⋅ (آ2⋅ب2) = γ⋅ ( (م1⋅ن1) ⋅ (آ1⋅ب1) )⋅(مترمن/مترf)(م2·ن2)·(آ2·ب2)=�·((م1·ن1)·(آ1·ب1))·(مترمن/متر�)
از آنجایی که «شکل منسجم» به عنوان مهمترین محدودیت برای نوعبندی شناسایی میشود، نسبت ارتفاع و عرض پنجرهها باید حفظ شود. با ترتیبی رو به کاهش از اهمیت، τ�، κ1�1، κ2�2، γ�به ترتیب سفتی نسبی ارضای محدودیتهای «حفظ فاصله بین پنجرهها و طرح کلی نما»، «پنجرهها باید در جهت تمایل ادغام شوند»، «حفظ فواصل بین پنجرهها» و محدودیت «منطقه منطبق» هستند.
اکنون هشت معادله وجود دارد (معادلات (17) – (24))، 12 مجهول که باید حل شوند، یعنی، م2م2، ن2ن2، آ2آ2، ب2ب2، ج2ج2، د2د2، ه2ه2، f2�2; و τ،κ1،κ2، γ�،�1،�2،�. یعنی این سیستم معادله تعریف نشده است. در اجرای عملی ما، معادله (24) در طول محاسبه در نظر گرفته نشد، زیرا (1) “منطقه منطبق” کمترین محدودیت برای نوع بندی است و (2) در دسترس بودن این معادله هیچ تاثیری بر مجهولات به جز عامل ندارد. γ�. سیستم معادله باقیمانده را می توان با تنظیم مقدار اولیه برای محدودیت اهمیت مطابق با نتایج نظرسنجی کاربر به صورت بازگشتی حل کرد:
- (1)
-
مرحله اولیه: بگذارید اهمیت محدودیت برابر با یک باشد. سپس دو طرف پنجره را می توان در ابتدا با توجه به تغییر فاصله بین پنجره ها تنظیم کرد: آ2=آ1⋅دقیقه {ج2،د2}دقیقه {ج1،د1}آ2=آ1·دقیقه{ج2،د2}دقیقه{ج1،د1}، و ب2=ب1⋅دقیقه {ج2،د2}دقیقه {ج1،د1}ب2=ب1·دقیقه{ج2،د2}دقیقه{ج1،د1}.
- (2)
-
مقادیر اولیه را در معادلات (17) و (18) قرار دهید، سپس تعداد پنجرههای ردیف و ستون را میتوان به صورت زیر محاسبه کرد:م2= (ج2+Lh 2– 2f2) / (آ2+ج2)م2=(ج2+�ساعت2–2�2)/(آ2+ج2)ن2= (د2+Lv 2– 2ه2) / (آ2+د2)ن2=(د2+��2–2ه2)/(آ2+د2)
- (3)
-
م2م2و ن2ن2به نزدیکترین عدد صحیح گرد می شوند. تفاوت بین مقادیر محاسبه شده م2م2، ن2ن2و نزدیکترین عدد صحیح آنها را می توان برای قضاوت در مورد اینکه آیا فرآیند باید خاتمه یابد یا خیر استفاده شود. در کار ما | آروم نیستی ( _ _ _م2) –م2| <0.25|��تو�د(م2)–م2|<0.25و | آروم نیستی ( _ _ _ن2) –ن2| <0.25|��تو�د(ن2)–ن2|<0.25بهعنوان آستانههایی تعیین شدند که در زیر آنها فرآیند خاتمه مییابد.
- (4)
-
اگر هنوز به آستانه نرسیده باشد، κ1�10.01 افزایش می یابد، به عنوان مثال، κ1=κ1+ 0.01�1=�1+0.01. سپس جدید م2م2و ن2ن2محاسبه خواهد شد. در صورت رسیدن به آستانه، فرآیند خاتمه خواهد یافت. در غیر این صورت به مرحله بعدی می رود.
- (5)
-
κ2�20.01 افزایش می یابد، به عنوان مثال، κ2=κ2+ 0.01�2=�2+0.01. سپس جدید م2م2و ن2ن2محاسبه خواهد شد. در صورت رسیدن به آستانه، فرآیند خاتمه می یابد، در غیر این صورت به مرحله بعدی می رود.
- (6)
-
τ�0.01 افزایش می یابد، به عنوان مثال، τ= τ+ 0.01�=�+0.01. سپس جدید م2م2و ن2ن2محاسبه خواهد شد. در صورت رسیدن به آستانه، فرآیند خاتمه می یابد، در غیر این صورت به مرحله 4 برمی گردد.
وقتی تکرار پایان می یابد، م2= آریا تو دی ( _ _م2)م2=��تو�د(م2)و ن2= آریا تو دی ( _ _ن2)ن2=��تو�د(ن2). فاصله های جدید بین پنجره ها ج2ج2و د2د2قابل محاسبه است:
ج2=Lh 2– 2f2–م2⋅آ2م2– 1ج2=�ساعت2–2�2–م2·آ2م2–1
د2=Lv 2– 2ه2–ن2⋅ب2ن2– 1د2=��2–2ه2–ن2·ب2ن2–1
با این پارامترهای محاسبه شده می توان موقعیت پنجره های جدید را تعیین کرد. بنابراین نتیجه تیپ سازی به دست می آید.
همانطور که در ابتدای این بخش گفته شد، الگوریتم طراحی شده برای نماهایی که پنجره ها به طور منظم در بیش از یک ردیف و ستون توزیع شده اند، طراحی شده است. با این حال، گاهی اوقات تنها یک ردیف (یا ستون) از پنجره ها در یک نما وجود دارد، یا یک ردیف (یا ستون) از پنجره ها علاوه بر توزیع ماتریسی پنجره ها وجود دارد، به عنوان مثال، شکل 7 e . در اینجا، پنجرههای یک ستون (یا یک ردیف) با نادیده گرفتن محاسبات برای ستونها (یا ردیفها) به عنوان یک مورد خاص در فرآیند تایپ خودکار در نظر گرفته میشوند.
5. آزمایش ها و ارزیابی
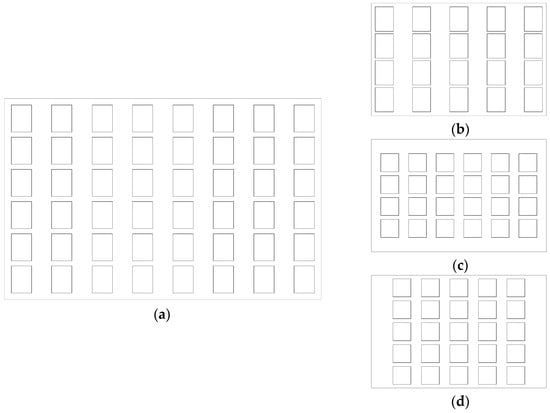
الگوریتم تایپ سازی خودکار با استفاده از Matlab (نسخه Matlab 7.4) بر روی تعدادی از نماها پیاده سازی شده است. گزیده ای از نمونه ها در این بخش ارائه شده است. شکل 9 نتیجه تیپ سازی را برای نما نشان می دهد که در آن تمام پنجره ها به طور منظم در ردیف ها و ستون ها توزیع شده اند. شکل 9 ب توزیع جدید پنجره ها را پس از تایپ سازی برای کاهش مقیاس به میزان دو برابر نشان می دهد.
به منظور ارزیابی رویکرد پیشنهادی، دو نتیجه جایگزین برای نمونهسازی شکل 9 a به صورت دستی تولید میشوند ( شکل 9 c,d). سپس شباهت های 9b، 9c و 9d با توزیع اصلی ( شکل 9 a) با استفاده از الگوریتم ارائه شده در بخش 3.2 محاسبه می شود . مقادیر NEMD شکل 9 b، 9c و 9d تا 9a به ترتیب 42.41، 75.82 و 76.83 است. این به وضوح نشان می دهد که نتیجه رویکرد ما بهتر از سایر راه حل های تایپ سازی است.
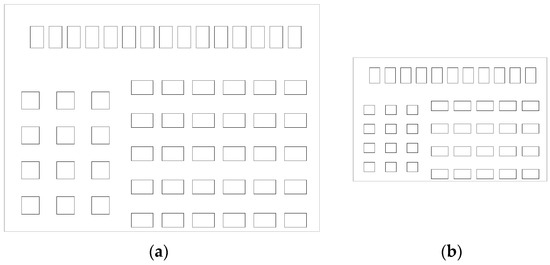
نوع دیگری از نمای کاملاً رایج با پنجره ها ممکن است زمانی باشد که پنجره ها به طور مساوی در یک جهت توزیع شده باشند، اما در جهت دیگر نه، اگرچه آنها به خوبی تراز شده اند. یک مثال در شکل 10 الف نشان داده شده است. در این مورد، ابتدا باید کل نما را با مقایسه اندازه پنجره ها و فواصل بین پنجره ها به چندین بخش تقسیم کرد. سپس فرآیند تایپ سازی برای هر بخش انجام می شود. در عین حال، فرآیند باید نتایج نمونهسازی بخشهای همسایه را در نظر بگیرد. به عبارت دیگر، پنجره های بعد از تایپ سازی باید منعکس کننده کاراکتر توزیع اصلی باشد. در اجرای خود، ابتدا توزیع پنجره ها را برای قسمتی که در آن پنجره های بیشتری نسبت به سایر بخش ها وجود دارد محاسبه می کنیم (در مورد شکل 10) .الف، ابتدا قسمت میانی مشخص می شود). سپس تعداد پنجره های ستون برای تمام بخش های دیگر تعیین می شود. این بدان معنی است که پارامتر ن2ن2به عنوان شناخته شده در طول فرآیند تایپ سازی برای بخش های دیگر رفتار می شود. شکل 10b نتیجه نوع بندی را برای توزیع اصلی شکل 10 a با در نظر گرفتن زمینه بین بخش ها نشان می دهد.
شکل 11 الف نمایی را با پنجره های خوب تراز اما نامنظم نشان می دهد. مشابه نما در شکل 10 ، پنجرهها باید به سه بخش تقسیم میشد و بخش پس از آن مشخص میشد ( شکل 11 ب).
6. نتیجه گیری و کارهای بعدی
این مقاله یک نظرسنجی از کاربران را برای یافتن اینکه کدام نوع نمایش پس از تایپسازی از نظر بصری با مجموعه داده اصلی مرتبط است، ارائه کرد. نتایج آزمایش کاربر نشان داد که «نسبت بین ارتفاع و عرض پنجرهها» و «الگوی توزیع عناصر پنجره» مهمترین سرنخها برای حفظ ویژگیهای گرافیکی نما هستند.
به منظور تأیید نتایج نظرسنجی کاربران، الگوریتمهای ARG و NEMD برای تعیین کمیت شباهت بین نمای اصلی و نمای نمونهسازی شده معرفی شدهاند. مقادیر شباهت به خوبی با نتایج نظرسنجی کاربران ما مطابقت دارد.
بر اساس آزمون کاربر، که مقادیر معنیداری متفاوتی از محدودیتها را نشان میدهد، یک رویکرد خودکار برای تایپسازی توسعه داده میشود که میتواند به طور مکرر محدودیتهای داده شده را برآورده کند. این الگوریتم بر روی تعدادی نما پیاده سازی و آزمایش شده است. آزمایشها نشان میدهند که نتایج تیپسازی میتواند به طور موثری منعکس کننده شخصیت توزیع نماهای اصلی باشد.
سهم اصلی این کار این است که این رویکرد می تواند برای اولین بار، اشیاء چند ضلعی توزیع شده منظم را در نمای ساختمان به صورت کمی مشخص کند. از آنجایی که روش تیپسازی پیشنهادی به طور کامل عوامل و وزنهای آنها را برای ثبات تأثیر بصری در نظر میگیرد و در عین حال، تعداد اشیاء نما و تغییر موقعیت آنها را کاهش میدهد، نتایج حاصل از رویکرد پیشنهادی میتواند ویژگیهای گرافیکی نما را تا حد امکان حفظ کند. . این را می توان برای ساده سازی اشیاء نما در فرآیند تعمیم سه بعدی اعمال کرد. در یک مفهوم گسترده، روش پیشنهادی در این مقاله میتواند برای نمونهسازی اشیاء چند ضلعی (یعنی ردپای ساختمان یا بلوکهای شهری) بر روی یک نقشه دوبعدی در صورتی که اشیاء الگوهایی را تشکیل دهند که شرایط تیپسازی را برآورده میکنند، استفاده شود.
با این حال، رویکرد ما فقط برای مشخص کردن نماهایی با پنجرههای مستطیلی استفاده میشود. برای پنجره هایی با ساختار پیچیده، پارامترهای بیشتری باید معرفی شوند. در آینده نزدیک، یک نوعسازی زمینهای بررسی خواهد شد، به این معنی که نوعبندی برای پنجرههای نما باید توزیع پنجرهها را در نماهای مجاور آن در نظر بگیرد. علاوه بر این، رویکرد توسعهیافته بر روی پلانهای زمینی گسترده ساختمانهای با توزیع متراکم آزمایش خواهد شد. الگوریتم تایپ سازی خودکار با استفاده از Matlab (نسخه Matlab 7.4) بر روی تعدادی از نماها پیاده سازی شده است. گزیده ای از نمونه ها در این بخش ارائه شده است. شکل 9 نتیجه تیپ سازی را برای نما نشان می دهد که در آن تمام پنجره ها به طور منظم در ردیف ها و ستون ها توزیع شده اند. شکل 9b نشان دهنده توزیع جدید پنجره ها پس از تایپ برای کاهش مقیاس به میزان دو برابر است.
منابع
- Staufenbiel، W. Zur Automation der Generalisierung Topographischer Karten Mit Besonderer Berücksichtigung Großmaßstäbiger Gebäudedarstellungen. دکتری Thesis, Wissenschaftliche Arbeiten der Fachrichtung Vermessungswesen der Universität Hannover (51), Hannover, Gemany, 1973. [ Google Scholar ]
- لامی، اس. رواس، ع. دمازو، ی. جکسون، ام. Mackaness، W. Weibel, R. کاربرد عوامل در تعمیم خودکار نقشه. در مجموعه مقالات نوزدهمین کنفرانس بین المللی کارتوگرافی ICA، اتاوا، ON، کانادا، 14 تا 21 اوت 1999.
- رینفورد، دی. Mackaness، W. تطبیق الگو در حمایت از تعمیم ساختمان های روستایی. در مجموعه مقالات سمپوزیوم بینالمللی مشترک درباره «نظریه، پردازش و کاربردهای جغرافیایی» (ISPRS کمیسیون IV SDH2002)، اتاوا، ON، کانادا، 8 تا 12 ژوئیه 2002.
- Regnauld، N. نوع سازی ساختمان متنی در تعمیم خودکار نقشه. الگوریتمیکا 2001 ، 30 ، 312-333. [ Google Scholar ] [ CrossRef ]
- ون کرولد، ام. تعمیم صاف برای بزرگنمایی مداوم. در مجموعه مقالات ICC، پکن، چین، 6 تا 10 اوت 2001.
- Sester, M. تعمیم بر اساس تعدیل حداقل مربعات. در آرشیو بین المللی فتوگرامتری و سنجش از دور ; ISPRS: آمستردام، هلند، 2000; ص 931-938. [ Google Scholar ]
- Meyer, U. Generalisierung der Siedlungsdarstellung in Digitalen Situationsmodellen. دکتری Thesis, Wissenschaftliche Arbeiten der Fachrichtung Vermessungswesen der Universität Hannover, Hannover, Gemany, 1989. [ Google Scholar ]
- لعل، ج. Meng, L. قوانین و محدودیتها برای تعمیم سه بعدی منطقه شهری. جی. جئوگر. علمی 2001 ، 11 ، 17-28. [ Google Scholar ] [ CrossRef ]
- Kada, M. تعمیم خودکار مدل های ساختمان سه بعدی. در مجموعه مقالات سمپوزیوم بین المللی مشترک در نظریه زمین فضایی، پردازش و کاربردها، اتاوا، ON، کانادا، 9-12 ژوئیه 2002.
- ریبلز، جی. Hechbert، PS; گارلند، ام. Stahovich، TF یافتن و حذف ویژگی ها از چند وجهی. در مجموعه مقالات DETC’01، کنفرانس فنی مهندسی طراحی ASME، پیتسبورگ، PA، ایالات متحده آمریکا، 9-12 سپتامبر 2001.
- Thiemann, F. تعمیم داده های ساختمان سه بعدی. در آرشیو بین المللی فتوگرامتری، سنجش از دور و علم اطلاعات مکانی ؛ آرشیو بین المللی فتوگرامتری سنجش از دور و علوم اطلاعات فضایی: گوتینگن، آلمان، 2002; ص 286-290. [ Google Scholar ]
- تیمن، اف. Sester, M. بخش بندی ساختمان ها برای تعمیم سه بعدی. در مجموعه مقالات کارگاه ICA در مورد تعمیم و بازنمایی چندگانه، لستر، بریتانیا، 20-21 اوت 2004.
- Kada, M. تعمیم ساختمان سه بعدی بر اساس مدل سازی نیمه فضا. در مجموعه مقالات کارگاه ISPRS در مورد بازنمایی چندگانه و قابلیت همکاری داده های فضایی، هانوفر، آلمان، 22-24 فوریه 2006.
- Kada, M. تعمیم ساختمان سه بعدی با ساده سازی و تیپ سازی سقف. در مجموعه مقالات بیست و سومین کنفرانس بین المللی کارتوگرافی، مسکو، روسیه، 4 تا 10 اوت 2007.
- Sester, M. تجسم سه بعدی و تعمیم. در فتوگرامتری هفته 07 ; Wichmann: اشتوتگارت، آلمان، 2007; ص 285-295. [ Google Scholar ]
- منگ، ال. فوربرگ، A. تعمیم ساختمان سه بعدی. در چالش های به تصویر کشیدن اطلاعات جغرافیایی: مسئله تعمیم و بازنمایی چند مقیاسی ; Mackaness, W., Ruas, A., Sarjakoski, T., Eds.; Elsevier Science Ltd.: آمستردام، هلند، 2007; ص 211-232. [ Google Scholar ]
- سستر، ام. برنر، سی. تعمیم مداوم برای تجسم در دستگاه های تلفن همراه کوچک. در تحولات در مدیریت داده های مکانی ; Springer: برلین/هایدلبرگ، آلمان، 2004; صص 469-480. [ Google Scholar ]
- بورگاردت، دی. Cecconi، A. ساده سازی مش برای نمونه سازی ساختمان. بین المللی جی. جئوگر. Inf. علمی 2007 ، 21 ، 283-298. [ Google Scholar ] [ CrossRef ]
- فولین، جی.ام. بوجو، ا. برتراند، اف. Boursier, P. تجسم داده های فضایی با وضوح چندگانه در سیستم تلفن همراه. در مجموعه مقالات اولین کارگاه بین المللی GIS همه جا حاضر، Gävle، سوئد، 7-9 ژوئن 2004.
- لی، ز. یان، اچ. آی، تی. چن، جی. تعمیم خودکار ساختمان بر اساس مورفولوژی شهری و نظریه گشتالت. بین المللی جی. جئوگر. Inf. علمی 2004 ، 18 ، 513-534. [ Google Scholar ] [ CrossRef ]
- لی، اچ. گوا، کیو. لیو، جی. الگوریتم سریع نمونهسازی ساختمان در نقشهبرداری وب. در مجموعه مقالات سمپوزیوم بینالمللی مدلسازی فضایی-زمانی، استدلال فضایی، تحلیل، دادهکاوی و تلفیق داده، پکن، چین، 27-29 اوت 2005.
- لی، زی. بنیاد الگوریتم بازنمایی فضایی چند مقیاسی ; CRC Press of Taylor & Francis Group: Boca Raton، FL، USA; لندن، انگلستان؛ نیویورک، نیویورک، ایالات متحده آمریکا، 2007. [ Google Scholar ]
- تاپفر، اف. Pillewizer, W. اصول انتخاب. کارتوگر. J. 1966 ، 3 ، 10-16. [ Google Scholar ] [ CrossRef ]
- Anders، KH سطح تولید جزئیات گروه های ساختمانی سه بعدی با تجمیع و نوع بندی. در مجموعه مقالات XXII کنفرانس بین المللی کارتوگرافی 2005، A Coruňa، اسپانیا، 11-16 ژوئیه 2005.
- لویتن، ک. کریمرز، بی. Coninx، K. مدیریت طرحبندی چند دستگاهی برای دستگاههای محاسباتی سیار . گزارش فنی TR-LUC-EDM-0301; Limburgs Univeristair Centrum-Expertise Center for Digital Media: Hasselt، بلژیک، 2003. [ Google Scholar ]
- کیم، دی اچ. یون، شناسه; Uk Lee, S. الگوریتم تطبیق گراف رابطه ای نسبت داده شده جدید با استفاده از ساختار تودرتو فاصله حرکت دهنده زمین. در مجموعه مقالات هفدهمین کنفرانس بین المللی شناخت الگو (ICPR’04)، کمبریج انگلستان، 23 تا 26 اوت 2004.
- بارو، HG; Popplestone، RJ توضیحات رابطه ای در پردازش تصویر. ماخ هوشمند 1971 ، 6 ، 377-396. [ Google Scholar ]
- طلا، اس. Rangarajan, A. الگوریتم انتساب درجه بندی شده برای تطبیق نمودار. IEEE Trans. الگوی مقعدی ماخ هوشمند 1996 ، 18 ، 377-388. [ Google Scholar ] [ CrossRef ]
- Wyk، MA; کلارک، جی. الگوریتمی برای تطبیق نمودارهای نسبت داده شده با حداقل مربعات تقریبی. در مسائل ریاضی کاربردی و هوش محاسباتی ; انتشارات انجمن علمی و مهندسی جهانی: لندن، انگلستان، 2000; صص 67-72. [ Google Scholar ]
- مائو، بی. فن، اچ. هری، ال. بان، ی. ارزیابی کیفیت تعمیم مدل منگ، ال سیتی با استفاده از ساختار تودرتو فاصله حرکتدهنده زمین. در مجموعه مقالات سیزدهمین کارگاه کمیسیون ICA در مورد تعمیم و نمایندگی چندگانه، زوریخ، سوئیس، 12-13 سپتامبر 2010.
- ریپردا، ن. Brenner, C. بازسازی سازه های نما با استفاده از گرامر رسمی و RjMCMC. در مجموعه مقالات بیست و هشتمین سمپوزیوم سالانه انجمن Geman-for-Pattern-Recognition، برلین، آلمان، 12-14 سپتامبر 2006.
- Becker, S. تولید و کاربرد قوانین برای بازسازی نما وابسته به کیفیت. ISPRS J. Photogramm. Remote Sens. 2009 , 64 , 640-653. [ Google Scholar ] [ CrossRef ]

شکل 1. نمونه نما و نمایش برداری آن: ( الف ) نمای نمونه ساختمان واقع در خیابان آرنولف استراس 53، مونیخ. ( ب ) ویندوز استخراج شده از تصویر.
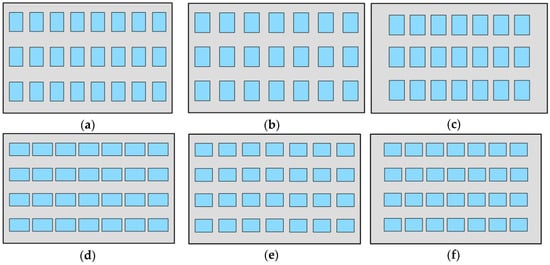
شکل 2. شش گزینه مختلف برای نمونه سازی نمای نمونه در شکل 1 : ( الف ) گزینه 1: محدودیت های 2، 3 و 4. ( ب ) گزینه 2: محدودیت های 1، 2 و 4. ( ج ) گزینه 3: محدودیت های 1، 2 و 3. ( د ) گزینه 4: محدودیت های 3، 4 و 5. ( ه ) گزینه 5: محدودیت های 1، 4 و 5. ( f ) گزینه 6: محدودیت های 1، 3 و 5.

شکل 3. سه نمای مختلف با پنجره های منظم توزیع شده. با ( a ) نمای هتل NH در مونیخ است، ( b ) و ( c ) نمای دو ساختمان معمولی در خیابان Nymphenburg در مونیخ هستند.
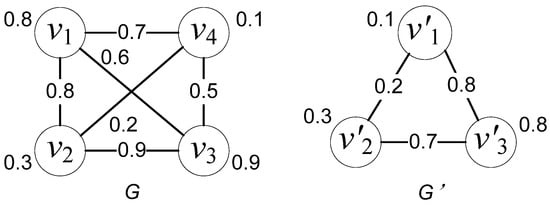
شکل 4. نمونه ای از تطبیق ARG ([ 26 ]).
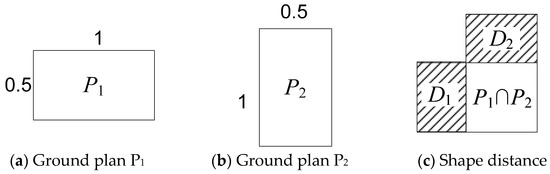
شکل 5. نمونه ای از فاصله بین دو پلان زمین.
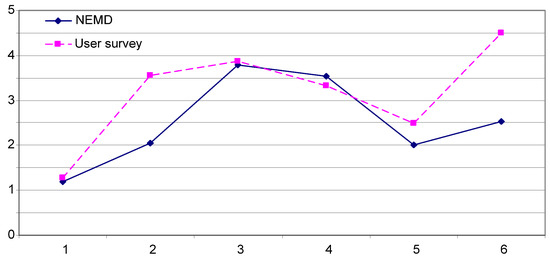
شکل 6. همبستگی بین NEMD و نظرسنجی کاربر.
شکل 7. توزیع معمولی پنجره ها در یک نما: ( الف ) تمایل در جهت افقی است. ( ب ) تمایل در جهت عمودی است. ج ) عدم تمایل ( د ) نظم توسط یک در به هم می خورد. ( ه ) پنجره ها به اندازه یکسان نیستند. ( و ) نما از سه الگوی منظم تشکیل شده است.
شکل 8. توزیع پنجره ها: ( الف ) توزیع اصلی. ( ب ) توزیع ممکن پس از تایپ سازی.
شکل 9. نمونهسازی برای نمای پراکنده منظم در دو مقیاس مختلف: ( الف ) توزیع اصلی. ( ب ) برای مقیاس کاهش 2×; ( ج ) تایپ دستی؛ ( د ) تایپ دستی.

شکل 10. نشان دادن نمای ظاهری که پنجره های آن به طور مساوی در هر دو جهت توزیع نشده اند: ( الف ) نمای اصلی که می تواند از چند بخش تشکیل شده باشد. ( ب ) برای مقیاس کاهش 2× مشخص شده است.
شکل 11. مشخص کردن یک نما، که در آن پنجره ها به طور نامنظم توزیع شده اند: ( الف ) نمای اصلی که می تواند از چندین بخش تشکیل شده باشد. ( ب ) برای مقیاس کاهش 2×.

جدول 1. مقادیر متوسط برای شش گزینه.
جدول 2. نتایج آزمون کاربر برای تایپ سازی به ترتیب کاهش اهمیت.
جدول 3. NEMD و نتایج نظرسنجی کاربران.
© 2016 توسط نویسندگان؛ دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (CC-BY) (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر