1. معرفی
مجموعه داده NDVI با وضوح زمانی و مکانی بالا (HTSN) برای استخراج فنولوژی پوشش گیاهی یا محصولات در مناطق با سطح زمین پیچیده مهم است. با این حال، به دلیل محدودیتهای مالی و تکنولوژیکی، بسیاری از سنسورهای سنتی ( مانند نقشهبردار موضوعی لندست (TM)/نقشهنگار موضوعی پیشرفته (ETM+) یا طیفسنج تصویربرداری با وضوح متوسط Terra/Aqua (MODIS)) قادر به دریافت دادههای سنجش از راه دور با وضوح زمانی و مکانی بالا به طور همزمان. بنابراین، سنتز HTSN با استفاده از داده های بازتاب سطحی ارائه شده توسط یک حسگر منفرد، هنوز دشوار است. به دست آوردن HTSN با توسعه الگوریتمهای همجوشی دادههای مربوطه برای ترکیب دادهها با ویژگیهای مختلف ارائهشده توسط حسگرهای مختلف، یک ایده عملی است.1 ، 2 ، 3 ، 4 ].
برخی از محققان HTSN را از طریق عدم اختلاط پیکسل های با وضوح فضایی پایین در حوزه فضایی بر اساس نظریه حداقل مربعات [ 5 ، 6 ] به دست آوردند، به دلیل این واقعیت که NDVI اساساً با مدل اختلاط طیفی خطی مطابقت دارد [ 7 ، 8 ]. برخی دیگر از محققان مجموعه داده نوار قرمز و باند مادون قرمز نزدیک (NIR) را با وضوح زمانی و مکانی بالا، ابتدا بر اساس مدل همجوشی بازتابی (به عنوان مثال، مدل همجوشی بازتابی تطبیقی مکانی و زمانی، STARFM [ 9 ]) سنتز کردند و سپس محاسبه کردند. HTSN مربوطه مدل همجوشی مبتنی بر تئوری عدم اختلاط اغلب به یک نقشه کاربری/پوشش زمین با وضوح فضایی بالا به عنوان داده کمکی نیاز دارد [ 6 ,10 ]، در حالی که الگوریتم STARFM به داده های کمکی دیگری نیاز ندارد و بنابراین کاربردی تر است و به پرکاربردترین الگوریتم برای سنتز بازتاب یا مجموعه داده NDVI با وضوح مکانی و زمانی بالا تبدیل شده است [ 11 ، 12 ، 13 ]. درک آسانتر است [ 14 ]. به عنوان مثال، هیلکر و همکاران. [ 15 ] ثابت کرد که HTSN سنتز شده توسط الگوریتم STARFM می تواند قانون نوسانات پوشش گیاهی مختلف را در یک دوره یک ساله به خوبی منعکس کند. بنداری و همکاران [ 16] مجموعه داده بازتاب را در یک بازه زمانی هشت روزه و با تفکیک مکانی 30 متر با ترکیب داده های Landsat TM و MODIS Nadir BRDF Adjusted Reflectance (NBAR) همراه با استفاده از الگوریتم STARFM به دست آورد و سپس HTSN را ساخت.
الگوریتم STARFM در اصل برای سنتز داده های بازتاب سطحی با وضوح زمانی و مکانی بالا با ترکیب داده ها با ویژگی های مختلف (مثلاً بازتاب سطح Landsat و MODIS) استفاده شد [ 9 ]. با در نظر گرفتن رابطه گذار بین باند NDVI، نوار قرمز و باند NIR، الگوریتم همچنین می تواند به طور غیرمستقیم برای سنتز HTSN استفاده شود [ 15 ، 16 ] (شکل 1). متناوبا، الگوریتم را می توان مستقیماً برای سنتز HTSN نیز استفاده کرد که NDVI را تنها به عنوان یک باند از داده های ورودی [ 17 ] می گیرد (شکل 2). تحقیقات کمی روی تفاوت بین این دو طرح متمرکز شده است. با این حال، رابطه انتقال غیرخطی بین باند NDVI، نوار قرمز و باند NIR وجود دارد [18 ]. آیا چنین رابطه ای باعث ایجاد تفاوت بین HTSN های سنتز شده بر اساس دو طرح مختلف می شود؟ علاوه بر این، آیا HTSN های سنتز شده باعث تفاوت قابل توجهی در کاربردهای عملی، مانند استخراج اطلاعات فنولوژیکی محصول می شوند؟ پاسخ به این سوالات برای انتخاب یک طرح مناسب برای تولید HTSN برای برنامه های مختلف مفید خواهد بود. اگر تفاوت معنی داری بین دو HTSN سنتز شده یا بین اثرات یک برنامه کاربردی در استفاده از دو HTSN سنتز شده وجود نداشته باشد، انتخاب طرح 2 منطقی تر خواهد بود. زیرا تنها یک باند (به عنوان مثال ، NDVI) برای اجرای طرح مورد نیاز است. 2، در زمان و فضای حافظه بسیار صرفه جویی می کند.
در این مقاله، با در نظر گرفتن نواحی تپه ای در استان سیچوان شرقی در چین به عنوان منطقه موردی که با پوشش اراضی ناهمگن فضایی بالا مشخص می شود، سوالات فوق با انتخاب داده های Landsat و MODIS به عنوان منبع داده مورد بررسی قرار گرفت. بقیه این مقاله به شرح زیر سازماندهی شده است. بخش 2 پیشینه منطقه مورد مطالعه را مرور می کند. داده ها و پیش پردازش آن در بخش 3 معرفی شده است. روش ها در بخش 4 توضیح داده شده است. نتایج تجربی و تجزیه و تحلیل در بخش 5 نشان داده شده است و در بخش 6 مورد بحث قرار گرفته است. نتیجه گیری در بخش 7 پیشنهاد شده است.
2. منطقه مطالعه
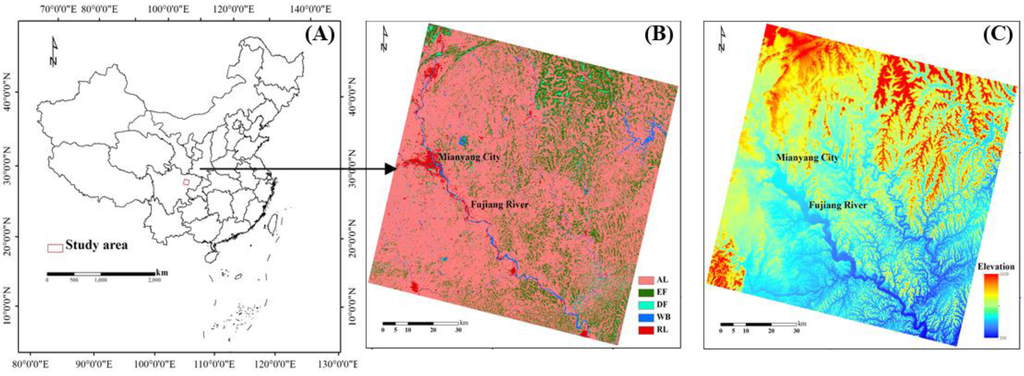
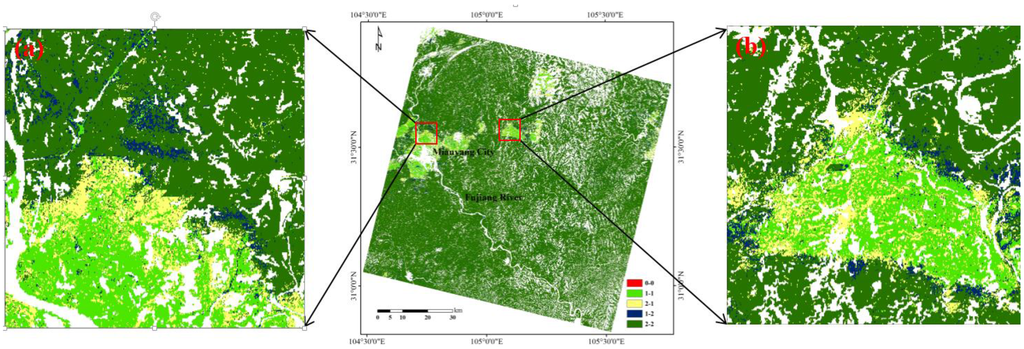
منطقه ای به مساحت 8100 کیلومتر مربع ( 90 × 90 کیلومتر) در استان سیچوان شرقی به عنوان منطقه مورد انتخاب شد ( شکل 1 الف). این منطقه یک منطقه تپه ای معمولی با ناهمگونی فضایی بالا از پوشش زمین ( شکل 1 C) و بسیاری از انواع ویژگی های سطحی است، که در میان آنها زمین های کشاورزی و جنگلی بیشترین توزیع را دارند ( شکل 1 B). میان یانگ، دومین شهر بزرگ سیچوان، در وسط سمت چپ این منطقه قرار دارد. رودخانه فوجیانگ از شمال غربی به جنوب شرقی در این منطقه می گذرد ( شکل 1 B).
شکل 1. ( الف ) موقعیت منطقه مورد مطالعه. ( ب ) نقشه پوشش اراضی منطقه مورد مطالعه. مخفف در افسانه به صورت AL (زمینهای قابل کشت)، EF (جنگلهای همیشه سبز)، DF (جنگلهای برگریز)، WB (آبها)، و RL (زمینهای مسکونی) تعریف شده است. ( C ) DEM منطقه مورد مطالعه که توپوگرافی زمین را نشان می دهد.
این منطقه در منطقه آب و هوای موسمی مرطوب نیمه گرمسیری حوضه سیچوان واقع شده است. میزان بارندگی در فصل خشک و فصل مرطوب متفاوت است. بیش از 80 درصد ظرفیت بارندگی سالانه در فصل مرطوب (تقریباً از ماه می تا اکتبر) را می گیرد [ 19 ]. درجه حرارت به وضوح در چهار فصل متفاوت است: بالاترین درجه حرارت در تابستان، حدود 25 درجه سانتیگراد، معتدل در بهار و پاییز، حدود 16-17 درجه سانتیگراد، و کمترین آن در زمستان، تنها حدود 6 درجه سانتیگراد است [ 20 ]]. آب و هوای مطبوع امکان یک سیستم کشت چندگانه را فراهم می کند. فصل کشت تابستانه تقریباً از اردیبهشت تا مهر و فصل کشت زمستانه تقریباً از نوامبر تا اردیبهشت سال بعد است. انواع پوشش گیاهی پیچیده، مناظر تکه تکه، و زمین های کشاورزی به طور گسترده پراکنده هستند و کشت های متعدد در منطقه مورد مطالعه رایج است. با این ویژگی ها، منطقه برای تحلیل مقایسه ای تفاوت بین دو طرح سنتز متفاوت بسیار مناسب است.
3. داده ها و پیش پردازش
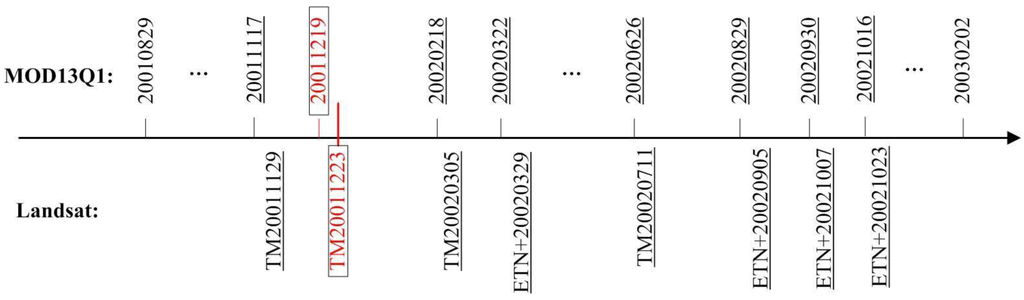
تصاویر Landsat با کیفیت بالا برای ارزیابی دقت پیشبینی دو طرح در این مقاله مورد نیاز است. در حالی که تصاویر Landsat ETM+ از می 2003 به دلیل خطوط بد اسکن شده برای اعتبار سنجی مناسب نیستند، هفت صحنه Landsat TM یا ETM+ با ابر کم یا بدون ابر در طول سال های 2001 و 2002 به عنوان داده های آزمایش استفاده شد ( شکل 2 را ببینید ). به منظور به حداقل رساندن تأثیر منفی ابر و سایه، کامپوزیت های مشاهده بهینه 16 روزه MODIS ( به عنوان مثال ، MOD13Q1) به عنوان داده با وضوح زمانی بالا انتخاب شدند. مجموعه داده در مجموع شامل 12 لایه است. تنها لایههای قرمز، NIR، NDVI و قابلیت اطمینان پیکسل در مطالعه ما انتخاب شدند. همانطور که در شکل 2 مشاهده می شود، تصویر Landsat TM در 23 دسامبر 2001 و ترکیب 23 از داده های MOD13Q1 در سال 2001، مربوط به تصویر TM، به عنوان تصاویر پایه در الگوریتم STARFM انتخاب شدند. 33 کامپوزیت دیگر MOD13Q1، از ترکیب 16 2001 تا کامپوزیت سوم 2003، به عنوان داده ورودی با وضوح زمانی 16 روزه استفاده شد. زیرا برای حذف “اثر لبه” [ 21 ]، هفت ترکیب آخر سال 2001 ( یعنی 16 تا 22 سال 2001) و سه ترکیب اول سال 2003 ( یعنی اولین تا سوم سال 2003) به داده های مجاور اضافی نیاز دارد. همچنین در کنار تمام کامپوزیت های سال 2002 (نشان داده شده در شکل 2 ) انتخاب شدند. تمام داده های Landsat و MODIS از وب سایت پورتال USGS GLOVIS [ 22 ] دانلود شد].
شکل 2. تاریخ اکتساب صحنه های Landsat و MODIS مورد استفاده برای این مطالعه. تصویر Landsat در تاریخ پایه (23 دسامبر 2001) و تصویر MOD13Q1 مربوطه در تاریخ پایه (بیست و سومین ترکیب در سال 2001) با مربع های قرمز مشخص شده اند. تصاویر مرجع Landsat برای اعتبارسنجی و تصاویر MOD13Q1 مربوط به آنها با خطوط زیر مشخص شده اند. توجه داشته باشید که داده های MODIS به عنوان ترکیبات 16 روزه به دست آمد. تاریخ های ارائه شده در شکل به ترتیب اولین روز از دوره کسب 16 روزه است.
پیش بینی ها و اندازه پیکسل های داده های Landsat و MODIS ورودی باید در الگوریتم STARFM یکسان باشد. تبدیل طرح ریزی، نمونه برداری مجدد، و برش برای محصولات MOD13Q1 توسط MRT (ابزار بازپروری MODIS) برای به دست آوردن 30 متر داده با طرح UTM انجام شد. روش LEDAPS ( به عنوان مثال ، سیستم پردازش تطبیقی اختلال اکوسیستم Landsat) [ 23 ] برای اولین بار برای کالیبراسیون رادیومتری و تصحیح جو برای داده های Landsat استفاده شد. علاوه بر این، بازتاب سطح و دادههای NDVI در نهایت از دادههای لندست از پیش پردازش شده بهدست آمد.
نقشه پوشش زمین از سال 2000 نیز برای پوشاندن زمین های کشاورزی در حین استخراج اطلاعات محصول اعمال شد. اعتبار میدانی مستقل نشان داد که دقت محصول پوشش زمین از 85 درصد فراتر رفت که می تواند نیاز این مطالعه را برآورده کند [ 24 ].
4. روش ها
4.1. الگوریتم STARFM
از آنجایی که بازتاب سطح MODIS و بازتاب سطح Landsat با هم تطابق زیادی دارند [ 25 ]، اگر بازتاب سطح MODIS در تاریخ t 0 که بازتاب سطح Landsat ناشناخته است شناخته شود، بازتاب سطح Landsat در t 0 را می توان به صورت زیر بیان کرد:
که در آن ( xi ، yj ) یک مکان پیکسل معین را برای تصاویر Landsat و MODIS نشان می دهد. ε 0 تفاوت بین بازتاب سطح MODIS و بازتاب سطح Landsat را نشان می دهد که توسط پهنای باند و هندسه خورشیدی مختلف ایجاد می شود.
اگر هر دو بازتاب سطح MODIS و Landsat در تاریخ دیگری t k شناخته شده باشند، تحت پیش شرط فرض شده که پوشش زمین و خطای سیستم از t 0 به t k تغییر نکند ( یعنی ε0 = ε k ) ، Landsat ناشناخته بازتاب سطح در t 0 را می توان با معادله زیر ارزیابی کرد [ 9 ]:
با در نظر گرفتن اثر پیکسل مختلط، پوشش زمین یا تغییر فنولوژیکی، و تابع توزیع بازتاب دو طرفه هندسه خورشیدی (BRDF)، با معرفی اطلاعات پیکسل های همسایه مشابه در یک پنجره جستجو، بازتاب ناشناخته Landsat پیکسل مرکزی ( x ) ω / 2 ، y ω / 2 ) در t 0 را می توان به صورت زیر بیان کرد:
جایی که ω اندازه پنجره جستجو را نشان می دهد. و W ijk وزن پیکسل های همسایه مشابه را در یک پنجره نشان می دهد که توسط سه عامل زیر تعیین می شود: (1) فاصله طیفی ( S ijk ) بین داده های Landsat و MODIS در یک مکان معین در t k . (2) فاصله فضایی ( d ijk ) بین یک پیکسل همسایه و پیکسل مرکزی. و (3) فاصله زمانی ( Tijk ) بین ورودی و داده های MODIS پیش بینی شده.
شرط فیلتر کردن پیکسل های همسایه مشابه در یک پنجره این است که باید اطلاعات طیفی و فضایی بیشتری نسبت به پیکسل مرکزی ارائه دهد. یک پارامتر عدم قطعیت با در نظر گرفتن عدم قطعیت در طی مراحل پیش پردازش برای بازتاب سطح Landsat و MODIS به شرایط فیلتر اضافه می شود. می توان به ادبیات اصلی برای توصیف دقیق تر روش های محاسبه همه پارامترها و نظریه الگوریتم مراجعه کرد [ 9 ].
4.2. دو طرح قابل مقایسه
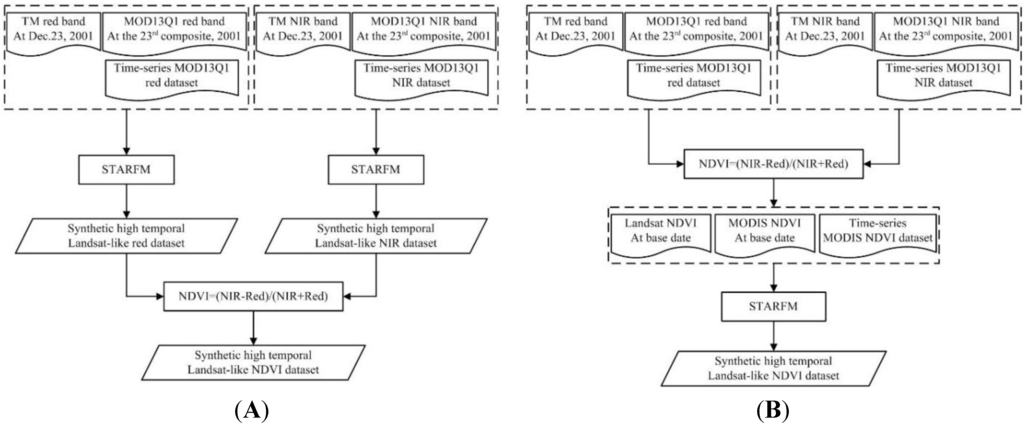
از نظر تئوری، دو طرح مختلف برای سنتز HTSN بر اساس الگوریتم STARFM وجود دارد. آنها به شرح زیر توصیف می شوند.
طرح 1 : با در نظر گرفتن داده های آزمایشی معرفی شده در بخش 3 به عنوان مثال، تصاویر بازتابی قرمز و NIR مانند Landsat زمانی بالا را می توان با استفاده از تصویر TM از مجموعه داده 23 دسامبر 2001 و سری زمانی مجموعه داده MOD13Q1 توسط الگوریتم STARFM تولید کرد، و سپس داده های NDVI مانند Landsat زمانی بالا را می توان به طور غیر مستقیم از طریق عملیات جبری به دست آورد ( شکل 3 A).
شکل 3. نمودار جریان طرح 1 ( A ) و طرح 2 ( B ) برای سنتز HTSN ها.
طرح 2 : ابتدا، تمام تصاویر بازتابی، از جمله تصاویر موجود در TM و MOD13Q1، برای تعیین تصاویر NDVI استفاده میشوند و سپس دادههای NDVI مانند Landsat زمانی بالا را میتوان مستقیماً با ترکیب تصاویر NDVI مشتقشده از طریق الگوریتم STARFM سنتز کرد. ( شکل 3 ب).
4.3. تنظیمات پارامتر
برای الگوریتم STARFM، توصیه می شود که ترکیبات پارامترهای مختلف برای مناطق با ناهمگنی فضایی متفاوت استفاده شود. اندازه پنجره کشویی باید بزرگتر تنظیم شود، و یک فرمول لگاریتمی که به فاصله طیفی حساس نیست باید برای محاسبه وزن پیکسل های همسایه مشابه برای مناطق با ناهمگنی بالا اعمال شود [ 9 ]. به طور همزمان، پارامتر عدم قطعیت نیز باید با توجه به ناهمگنی فضایی و محدوده نوسان یک مقدار باند تنظیم شود. برای مناطق با ناهمگونی فضایی بالا، عدم قطعیت نوار قرمز معمولاً 0.01 و نوار NIR برابر 0.015 تعیین می شود [ 9 ]]. در این تحقیق با توجه به اینکه منطقه مورد مطالعه یک منطقه تپه ماهور با ناهمگونی فضایی بالا است، اندازه پنجره کشویی 3000 متر × 3000 متر تعیین شد. از آنجایی که باند NDVI گسترده تر از باند NIR نوسان می کند، پارامتر عدم قطعیت باند NDVI برابر 0.025 تنظیم شد.
4.4. پروتکل مقایسه و ارزیابی
4.4.1. ارزیابی دقت پیش بینی
با گرفتن تصاویر Landsat TM یا ETM+ به عنوان داده های اعتبارسنجی، می توان دقت پیش بینی کلی طرح های مختلف را با یکدیگر مقایسه کرد. تصاویر Landsat مشاهده شده و تصاویر مشابه Landsat پیش بینی شده مربوط به آنها برای تعیین ضریب تعیین استفاده شد ( R2) و RMSE (ریشه میانگین مربعات خطا)، که به عنوان شاخص های ارزیابی برای ارزیابی دقت پیش بینی طرح های مختلف در نظر گرفته شد. از آنجایی که دادههای MOD13Q1 در یک دوره 16 روزه تشکیل شدهاند، تصاویر Landsat مشاهدهشده نمیتوانند دقیقاً از نظر زمانی با تصاویر مشابه Landsat پیشبینیشده منطبق باشند. گستره تاریخ دادههای MOD13Q1 و تصویر مشابه Landsat پیشبینیشده مربوطه باید تاریخ مشاهده را پوشش دهد که تصویر واقعی Landsat به دست آمده است. برای مثال، تصویر لندستمانند پیشبینیشده مربوط به بیست و یکمین کامپوزیت MOD13Q1 در سال 2001 انتخاب و با تصویر TM بدستآمده از 29 نوامبر 2001 مقایسه شد، زیرا تاریخهای ترکیبی MOD13Q1 ( یعنی از 17 نوامبر تا 2 دسامبر 2001) شامل میشود. تاریخ مشاهده تصویر واقعی TM (به عنوان مثال، 29 نوامبر 2001). علاوه بر این، دقت پیشبینی باند قرمز و باند NIR نیز همراه با باند NDVI برای طرح 1 محاسبه شد، در حالی که فقط دقت پیشبینی باند NDVI برای طرح 2 محاسبه شد.
4.4.2. مقایسه سازگاری
دو HTSN سنتز شده توسط دو طرح مختلف از حوزه زمانی و مکانی با یکدیگر مقایسه شدند:
سازگاری زمانی : ضریب همبستگی R بین دو تصویر NDVI زمانی یکسان از دو HTSN سنتز شده محاسبه شد و سپس یک منحنی زمانی R برای ارائه سازگاری زمانی بین دو HTSN (نشان داده شده در شکل 4 A) تعیین شد.
سازگاری فضایی : ضریب همبستگی R بین دو NDVI سری زمانی استخراج شده از دو HTSN سنتز شده برای هر پیکسل محاسبه شد. سپس یک نقشه فضایی از R برای همه پیکسل ها مشخص شد و برای توصیف سازگاری فضایی بین دو HTSN استفاده شد (نمونه شده در شکل 4 B).
4.4.3. مقایسه های کاربردی
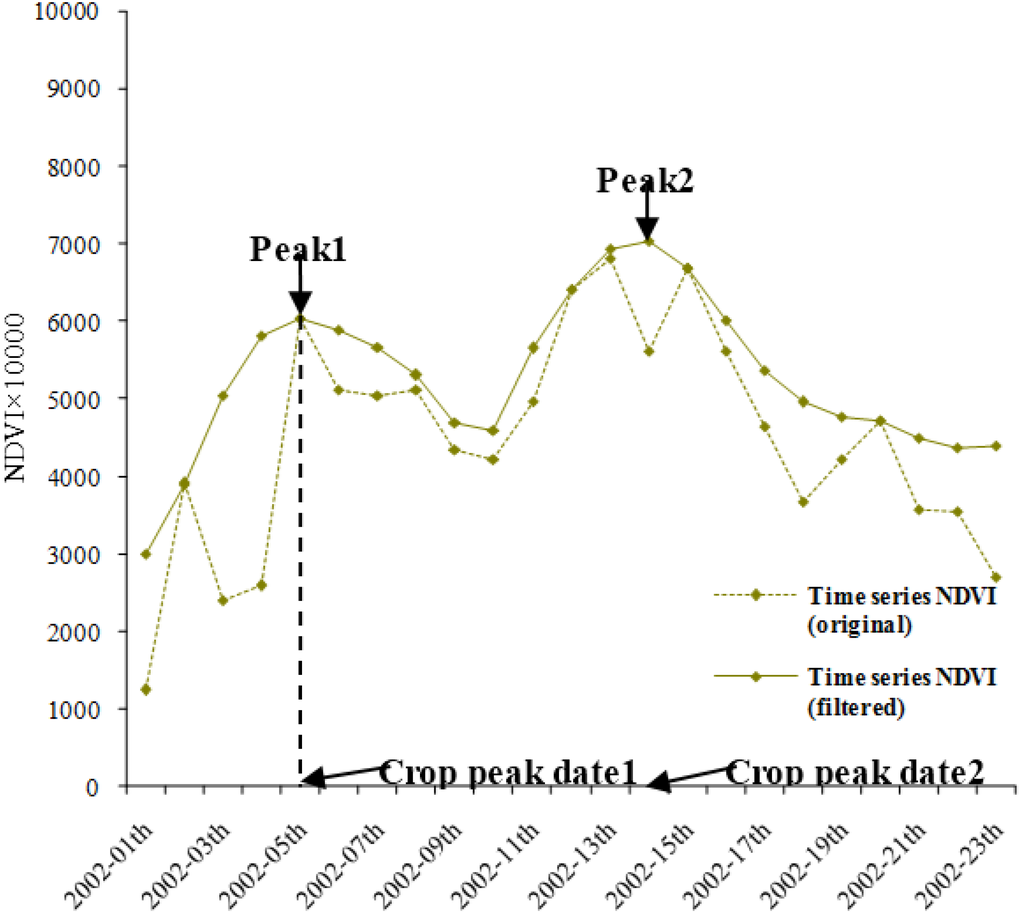
داده های سری زمانی NDVI اغلب برای استخراج اطلاعات مهم کشاورزی مانند شدت کشت و فنولوژی محصول استفاده می شود [ 26 ، 27 ]. مشخص شد که اوج منحنی NDVI سری زمانی نشان میدهد که زیست توده زمینی محصولات به حداکثر رسیده و با فرآیندهای رشد محصول مانند کاشت، بذر، سنبلهدهی، رسیدن و برداشت طی یک سال در نوسان است [ 28 ]. به همین ترتیب، شدت کشت به عنوان تعداد پیک ها و تاریخ پیک محصول به عنوان زمانی تعریف می شود که “اوج” ظهور در منحنی NDVI سری زمانی است ( شکل 5).). در این مقاله، مقایسههای کاربردی برای استخراج شدت کشت و تاریخهای پیک محصول در منطقه مورد مطالعه بر اساس دو HTSN سنتز شده توسط دو طرح مختلف انجام شد. دو نتیجه برای یک برنامه مشابه پیکسل به پیکسل با یکدیگر مقایسه شدند. نرخ انطباق، درصد پیکسل هایی که نتایج آنها بر اساس هر دو HTSN دقیقاً یکسان است، برای ارائه تفاوت بین آنها محاسبه شد. سپس تجزیه و تحلیلی برای تعیین اینکه آیا تفاوت بین دو HTSN می تواند تأثیر قابل توجهی بر چنین برنامه هایی داشته باشد انجام شد.
شکل 4. تصاویر برای توصیف سازگاری زمانی و سازگاری فضایی بین دو HTSN که توسط دو طرح متفاوت سنتز شدهاند. ( الف ) همبستگی زمانی: با در نظر گرفتن کامپوزیت شانزدهم در سال 2001 به عنوان مثال، ضریب همبستگی R بین دو تصویر NDVI سنتز شده در کامپوزیت محاسبه شد. مقدار یک نقطه از منحنی زمانی R بین دو HTSN سنتز شده بود. ( ب ) همبستگی فضایی: با در نظر گرفتن یک پیکسل به عنوان مثال، دو مقدار NDVI سری زمانی برای پیکسل استخراج شد و ضریب همبستگی R بین آنها محاسبه شد. مقدار یک نقطه از نقشه فضایی R بین دو HTSN سنتز شده برای همه پیکسل ها بود.
دو HTSN سنتز شده ابتدا توسط فیلتر SG [ 21 و 29 ] به منظور از بین بردن اثر منفی ابرها و سایه ها فیلتر شدند ( شکل 5 را ببینید ). سپس پیکهای احتمالی توسط الگوریتم تفاوت مرتبه دوم [ 30 ، 31 ] استخراج شدند و «قلههای جعلی» با شرایط آزمون تاریخ ظهور پیک و آستانه مقدار پیک حذف شدند. شرایط آزمایش بهعنوان تاریخ پیکهای محصول که باید در فصول رشد بالقوه محصول ظاهر شوند، تعیین شد (به بخش 2 بالا مراجعه کنید.، و مقدار NDVI پیک ها باید بیشتر از 0.4 باشد. پس از آن، شدت کشت از طریق شمارش تعداد پیک ها به دست آمد و تاریخ هر قله به طور همزمان ثبت شد. در حین استخراج شدت کشت و تاریخ پیک محصول، نتایج برای زمین کشاورزی با استفاده از محصول پوشش زمین پوشانده شد.
شکل 5. تصویری برای ارائه شدت کشت و تاریخ اوج کشت در مطالعه. 2002-01th در محور افقی نشان دهنده اولین ترکیب در سال 2002 و غیره است.
5. نتایج و تجزیه و تحلیل
5.1. مقایسه دقت پیش بینی
برای هفت تصویر Landsat به دست آمده (ذکر شده در شکل 2 ) ، R2 و RMSE بین تصاویر واقعی Landsat و تصاویر پیش بینی شده توسط دو طرح مختلف در جدول 1 توضیح داده شده است. دقت پیشبینی هر دو طرح مشابه است. طرح 2 کمی برتر از طرح 1 است. در مقایسه، دقت پیش بینی NDVI هر دو طرح با هم مطابقت دارد (R 2: 0.14 < طرح 1 < 0.53; 0.15 < طرح 2 < 0.53)، در حالی که پیش بینی تاریخ در 5 مارس 2002 و در 5 سپتامبر 2002 نسبتا ضعیف است. عموماً کلزا در اوایل اسفند شکوفا می شود و ذرت و برنج به تدریج در اوایل شهریور بالغ می شوند. بنابراین، ناهمگونی بالایی در فضا در دو لحظه وجود دارد، که ممکن است منجر به پیشبینی بدتری با توجه به ویژگیهای الگوریتم STARFM شود [ 9 ]. به طور مشابه، پیشبینی تاریخها در 29 نوامبر 2001 و 29 مارس 2002 نسبتاً خوب است ( جدول 1 )، احتمالاً به این دلیل که تجاوز به عنف در پایان نوامبر چند برگ رشد میکند یا نزدیک به اوج فصل رشد در پایان مارس است. زمانی که همگنی بالایی وجود دارد. برای طرح 1، دقت پیشبینی در سه باند ( یعنیقرمز، NIR و NDVI) با یکدیگر متفاوت هستند.
5.2. مقایسه سازگاری
5.2.1. سازگاری زمانی
منحنی زمانی R بین دو HTSN سنتز شده در شکل 6 ارائه شده است . دو HTSN به طور کلی سازگاری زمانی نسبتاً بالایی را نشان میدهند و بیشتر ضرایب همبستگی بالای 0.8 و برخی حتی بالای 0.9 هستند. کامپوزیت های با ضریب همبستگی بالا در تمام فصول به جز تابستان غیرمتمرکز هستند. علاوه بر این، بالاترین ضرایب همبستگی به ترتیب مربوط به ترکیب 21 سال 2001 (زمستان، R = 0.92)، ترکیب دوم سال 2003 (زمستان، R = 0.91)، و ترکیب ششم سال 2002 (بهار، R = 0.90) است. (فلش های سیاه را در شکل 6 ببینید). کامپوزیت ها با همبستگی نسبتاً پایین تر، عمدتاً از 12 تا 17، در تابستان 2002 متمرکز شده اند (0.66 < R < 0.72، تاریخ اکتساب از 26 ژوئن تا 29 سپتامبر 2002 است؛ فلش های قرمز را در شکل 6 ببینید).
جدول 1. نتایج رگرسیون مبتنی بر پیکسل تصاویر Landsat مرجع در مقابل تصاویر پیش بینی شده توسط دو طرح برای هفت تاریخ دریافت. نتیجه بهتر برای هر تاریخ به صورت پررنگ نشان داده شده است.
5.2.2. سازگاری فضایی
شکل 7 نقشه فضایی R را بین دو HTSN سنتز شده نشان می دهد. سازگاری فضایی بین آنها نسبتاً زیاد است، با R در بیشتر مناطق بالاتر از 0.8 است ( شکل 7 A را ببینید)، اما هنوز تفاوت هایی را در فضا نشان می دهد. برخلاف نقشه پوشش زمین، نقشه فضایی ظاهراً با انواع پوشش زمین مرتبط است ( شکل 7 الف در مقابل شکل 7 ب). همبستگی فضایی در زمین های کشاورزی نسبتاً بالا است، با میانگین R 0.91. همبستگی در اراضی جنگلی در جایگاه دوم قرار دارد (b 1 و b 2 در شکل 7 )، با میانگین R 0.86. در حالی که Rدر مناطق آب (مثلاً α و β در شکل 7 ) نسبتاً کم است و حتی در مناطق مسکونی منفی است (به a 1 در مقابل b 1 در شکل 7 مراجعه کنید).
رابطه غیر خطی بین باند NDVI، نوار قرمز و نوار NIR ممکن است ویژگیهای مکانی-زمانی ذکر شده در بالا را توضیح دهد. هر چه رابطه غیرخطی آشکاری که وجود دارد بزرگتر باشد، تفاوت بین دو HTSN بیشتر خواهد بود و نتایج همبستگی کمتری خواهند داشت. منحنی زمانی R در تابستان پایین است (در شکل 6 نشان داده شده است )، احتمالاً به این دلیل که محصولات یا پوشش گیاهی در تابستان رشد رونقی دارند، زمانی که NDVI می تواند به مقادیر نسبتاً بالایی برسد و رابطه غیرخطی آشکاری بین نوار NDVI، نوار قرمز وجود دارد. و باند NIR [ 18 ]. به طور مشابه، نقشه فضایی R مقادیر کم را در بدنه آبی و مناطق مسکونی نشان می دهد ( شکل 7 را ببینید.)، احتمالاً به این دلیل که مقادیر NDVI در آن مناطق نسبتاً پایین است و رابطه غیرخطی آشکار نیز وجود دارد [ 18 ]. علاوه بر این، به دنبال ویژگیهای مکانی-زمانی، دو نتیجه مبتنی بر دو HTSN در کاربرد یکسان در زمینهای کشاورزی یا جنگلها ممکن است تفاوت کمی با هم داشته باشند، زیرا دو HTSN در آن مناطق سازگاری فضایی بالاتری را نشان میدهند. با این حال، زمانی که فصل تابستان برای مقایسه این دو نتیجه در نظر گرفته می شود، باید توجه بیشتری شود، فقط به این دلیل که دو HTSN سازگاری زمانی کمتری را در تابستان نشان می دهند.
شکل 6. منحنی زمانی R بین دو HTSN سنتز شده توسط دو طرح متفاوت. سه کامپوزیت با ضریب همبستگی بالا در تمام فصول به جز تابستان غیرمتمرکز هستند. بالاترین ضرایب همبستگی مشخص شده با فلش های سیاه بالای 0.9 به ترتیب مربوط به ترکیب 21 سال 2001 (زمستان، R = 0.92)، ترکیب دوم 2003 (زمستان، R = 0.91)، و ترکیب ششم سال 2002 (بهار، R ) است. = 0.90). ضرایب همبستگی پایینتر که با فلشهای قرمز مشخص شدهاند، مربوط به کامپوزیتهای 12 تا 17 در تابستان 2002 است.
شکل 7. نقشه فضایی R بین دو HTSN سنتز شده توسط دو طرح مختلف، ( A ) برای نقشه فضایی R و ( B ) برای نقشه پوشش زمین. افسانه در (B) مانند شکل 1 B است.
5.3. مقایسه های کاربردی
5.3.1. شدت کشت
آمار مربوط به مقایسه شدت کشت استخراج شده از دو HTSN در جدول 2 فهرست شده است. پیکسل های آیش همخوانی کمی دارند و تنها 20.57 درصد هستند. با این حال، نتیجه هیچ اهمیت آماری ندارد، زیرا تعداد پیکسل های آیش استخراج شده در هر دو طرح کوچک است (1810 پیکسل در طرح 2 و تنها 1118 پیکسل در طرح 1). بنابراین، تجزیه و تحلیل بیشتری در مورد آیش انجام نمی شود. برای پیکسل های استخراج شده در سیستم تک برش، میزان تصادف کم است و تنها به 56.81٪ می رسد. از نقشه مقایسه پیکسل به پیکسل ( شکل 8 )، می توان کشف کرد که عدم انطباق عمدتاً در بخشی از منطقه انتقالی بین سیستم تک کشت و سیستم دوبرش یافت می شود ( شکل 8).). دلیل اصلی این عدم انطباق این است که قضاوت در مورد “آیا اولین محصول کشت شده است” بر اساس دو طرح پیشنهادی پس از بازرسی بیشتر متفاوت است. ممکن است به توزیع فضایی پیچیده محصولات در دوره مربوط باشد. از اراضی زراعی تک زراعی بیشتر برای کاشت غلات پاییزه در منطقه استفاده می شود. علف های هرز در زمین های زراعی رشد می کنند وقتی که کاشت وجود نداشته باشد. در همان زمان، محصولات غلات تابستانی در زمین های کشاورزی دوبل رشد می کنند. HTSN ها در منطقه انتقالی ممکن است تحت تأثیر علف های هرز در زمین های زراعی تک زراعی یا محصولات غلات تابستانی در زمین های کشاورزی دو کشت برای زمین های کشاورزی در منطقه انتقالی قرار گیرند. بنابراین، قضاوت های مبتنی بر HTSN ها این است که “اولین محصول کشت نشده است” بر روی اولی تأثیر می گذارد. یا “اولین محصول کشت شده است” بر دومی تأثیر می گذارد، در نهایت منجر به این می شود که نتایج شدت کشت معمولاً متفاوت است. با این حال، نتیجه برای پیکسل های سیستم برش دوبل بسیار بالا است و به 96.12٪ می رسد که آشکارا با نقشه مقایسه مطابقت دارد.شکل 8 ). به طور کلی، نتایج شدت کشت دو طرح عموماً به خوبی با یکدیگر منطبق است و به 93.86٪ می رسد.
جدول 2. آمار مقایسه در نتایج شدت کشت و تاریخ اوج محصول بر اساس دو HTSN سنتز شده توسط دو طرح مختلف. اعداد جدول تعداد پیکسل های 30 متری را نشان می دهد.
شکل 8. نقشه مقایسه بین نتایج شدت کشت بر اساس دو HTSN سنتز شده توسط دو طرح مختلف. اولی “xx” در افسانه نقشه، نتیجه طرح 1 را نشان می دهد، و دومی نتیجه طرح 2 را نشان می دهد. برای مثال، 2-1 نشان می دهد که نتیجه طرح 1 2 است، در حالی که برای طرح 2 این است. 1.
5.3.2. تاریخ اوج محصول
نتایج آماری نرخ همزمانی تاریخ های پیک محصول استخراج شده از دو HTSN در جدول 2 نشان داده شده است.. در مقایسه با نتایج شدت کشت، هر دو نرخ همزمانی تاریخ اوج محصول نسبتاً پایین است. به خصوص برای سیستم تک کشت، نرخ تصادفی تنها 35.26٪ است. این ممکن است به این دلیل باشد که توزیع فضایی زمینهای کشاورزی تککشت تکهتکه است و فصل رشد آنها به مرور زمان با زمینهای زراعی دو کشت جایگزین میشود. چنین جانشینی ممکن است باعث شود که تاریخ اوج محصول در سیستم تک کشت از قبل تحت تأثیر اولین محصول در سیستم کشت دوبل به نظر برسد، یا ممکن است تحت تأثیر کشت دوم در سیستم کشت دوبل به تأخیر بیفتد. برای سیستم کشت مضاعف، نرخ تصادفی نیز خیلی بالا نیست، حدود 72.03%. به طور کلی، نرخ تصادفی برای استخراج تاریخ پیک محصول حدود 70.95 درصد است که به مراتب کمتر از شدت برداشت است.
6. بحث و گفتگو
6.1. تنظیمات پارامتر
طبق الگوریتم STARFM، سه پارامتر (شامل اندازه پنجره کشویی، عدم قطعیت و استراتژی وزندهی) برای پیشبینیها تعیینکننده هستند. دو پارامتر اول تعیین میکنند که چند و کدام پیکسل باید به عنوان پیکسلهای همسایه مشابه در روند پیشبینی درگیر شوند، و آخرین پارامتر سهم پیکسلهای کاندید را در پیکسل مرکزی در پنجره تعیین میکند. اگرچه اندازه پنجره کشویی در اکثر مطالعات 1500 متر تعیین شد، یافته ها نشان داد که چنین تنظیمی همیشه پیش بینی های خوبی در مناطق مختلف به دست نمی آورد. اگر اندازه پنجره خیلی بزرگ تنظیم شود، پیکسل های همسایه بیشتری در روند پیش بینی شرکت می کنند و در نتیجه تصاویر پیش بینی شده مبهم هستند [ 17 ]]؛ با این حال، اگر اندازه پنجره خیلی کوچک تنظیم شده باشد، ممکن است یافتن پیکسل های “خالص” کافی دشوار باشد، که باعث می شود دقت پیش بینی پایین باشد [ 9 ]. تنظیم عدم قطعیت نیز با چنین مشکلی مواجه می شود. یکی از راه حل ها مشاهده برخی از نتایج پیش بینی با ترکیب پارامترهای مختلف توسط آزمایش های سری است تا بتوان یک ترکیب پارامتر مناسب برای یک منطقه به دست آورد. استراتژیهای وزندهی مختلف برای پیکسلهای همسایه نیز تأثیری بر نتایج پیشبینیشده دارد [ 17 ]. تنظیم استراتژی های وزن دهی نسبتاً ساده بود و مکانیسم آن به طور کامل در الگوریتم اصلی در نظر گرفته نشده بود. بهبود در محاسبه وزن طیفی از طریق روش آماری طبقه بندی شده ساده [ 32 ] انجام شده است.]. اگر بتوان روابط داخلی بین پیکسل های همسایه مشابه در منطقه مورد مطالعه را از طریق روش های زمین آماری یافت، ممکن است برای بهینه سازی استراتژی های وزن دهی مفیدتر باشد. در حالی که کاربردهای الگوریتم STARFM به تدریج در زمینههای دیگر توسعه مییابد، تغییر روش فیلتر و استراتژی وزندهی برای پیکسلهای همسایه مشابه، با توجه به ویژگیهای خود مکانیزم در کاربردهای خاص، استراتژی معقولتری است [ 33 ، 34 ]. .
6.2. دقت پیش بینی
مشابه تحقیقات قبلی در مورد ساخت داده های با وضوح زمانی و مکانی بالا بر اساس الگوریتم STARFM، با در نظر گرفتن زمین های کشاورزی به عنوان منطقه اصلی [ 11 ، 35 ]، همبستگی بین تصاویر پیش بینی شده و تصاویر مشاهده شده در نوار قرمز و باند NIR هر دو است. تأیید شده در سمت پایین (R 2: 0.01-0.72) در این مقاله. برای منطقه تپه ای در شرق سیچوان که در آن زمین نسبتاً پیچیده است، ساختار محصول در زمین های کشاورزی به راحتی توسط فعالیت های انسانی مختل می شود و ناهمگونی فضایی نسبتاً زیاد است. ممکن است به طور بالقوه باعث شود که همبستگی بین مقادیر پیش بینی و مقادیر واقعی کمتر شود. در مقایسه، در برخی تحقیقات که جنگل ها یا درختچه ها را به عنوان منطقه اصلی در نظر گرفته بودند، همبستگی بهتری بین تصاویر پیش بینی شده و تصاویر مشاهده شده وجود داشت [ 12 ، 15 ، 16 ، 36 ، 37 .]، به دلیل ناهمگونی فضایی کم ویژگی های سطح. بنابراین، ترکیب برنامههای کاربردی خاص مانند پایش فنولوژی محصول، هنوز نیاز به ارزیابی دقیق و مفید بودن دادههای NDVI مشابه سری زمانی Landsat در کاربردهای عملی دارد. از آنجایی که این هدف اصلی این مقاله نیست، بحث بیشتری در مورد این موضوع انجام نمی شود.
از آنجایی که باندهای طول موج کوتاهتر به راحتی تحت تأثیر شرایط جو قرار می گیرند [ 38 ]، همبستگی تأیید شده باند NIR به طور کلی برتر از نوار قرمز است ( جدول 1 ). این همان نتایج برخی تحقیقات مرتبط است [ 11 ، 15 ، 35 ]. با این حال، برخی از محققان دیگر نتایج کاملاً مخالفی را نشان دادند [ 16 ، 36 ]. دلیل احتمالی در Walker et al. [ 36] که نشان داد تصاویر Landsat در تحقیقات خود برای جلوه های زاویه دید تصحیح نشدند در حالی که تصاویر MODIS با داده های NBAR برای زاویه دید خورشیدی و دید تصحیح شدند. چنین تفاوت هایی را می توان در مناطقی که چندین لایه پوشش گیاهی بلند وجود دارد تقویت کرد زیرا این مناطق باعث پراکندگی بیشتر نوار NIR می شوند. بنابراین، در مناطقی که تعداد لایههای پوشش گیاهی کم است یا ارتفاع پوشش گیاهی کم است (مثلاً زمینهای کشاورزی)، همبستگی نوار NIR همچنان نسبت به نوار قرمز برتری دارد.
در پیشبینی سه باند (قرمز، NIR و NDVI) در طرح 1، همبستگیهای تایید شده باند NDVI کمتر از باندهای قرمز و NIR است ( جدول 1 ). کشف شد که همبستگی باند NDVI کمی کمتر از باندهای قرمز و NIR در مناطق خشک و جنگلی است [ 12 ]، در حالی که نتیجه در مناطق جنگلی در مناطق معتدل کاملاً مخالف است [ 15 ]. اگر بتوان NDVI را به عنوان باندی با طول موج بلندتر از باند NIR در نظر گرفت، دلیل این تفاوت ممکن است شرایط جوی متفاوت در مناطق تحقیقاتی باشد. در منطقه تحقیقاتی Hilke et al. [ 15]، در مقایسه با NDVI، باندهای قرمز و NIR با طول موج کوتاهتر به راحتی تحت تأثیر شرایط جوی قرار میگیرند [ 12 ]. مقایسه نتایج پیشبینیشده دو طرح روی باندهای NDVI با یکدیگر، تیان و همکاران. [ 37 ] اعلام کرد که همبستگی تأیید شده طرح 2 به وضوح برتر از طرح 1 است. توضیح محتمل این است که پس از استفاده از نوار قرمز و نوار NIR برای محاسبه باند NDVI، تأثیر جو بیشتر کاهش می یابد. با این حال، شایان ذکر است که نتایج در این مقاله نشان می دهد که طرح 2 تنها کمی برتر از طرح 1 است. پوشش سطح اصلی بوته ها در Tian et al.منطقه تحقیقاتی، جایی که مقدار بالای NDVI در فصل رشد ممکن است اغلب اشباع شود. بنابراین، تفاوت بین دو طرح به دلیل رابطه غیرخطی واضح تر در مقادیر بالا تقویت می شود. با این حال، NDVI اغلب حتی در فصل رشد محصولات در مقادیر متوسط است و رابطه غیرخطی در چنین مناطقی آشکار نیست [ 18 ]. در نتیجه، تفاوت کمی بین نتایج پیشبینیشده طرح 1 و طرح 2 در این مقاله وجود دارد.
6.3. برنامه های کاربردی
تفاوتهای کوچکی بین دو HTSN وجود دارد، اگرچه آنها به طور کلی مطابقت خوبی دارند ( جدول 1 ، شکل 6 و شکل 7 ). با این حال، چنین تفاوت هایی تأثیرات بسیار متفاوتی بر کاربردهای خاص مختلف دارند. نتایج آزمایش نشان میدهد که کاربرد استخراج شدت کشت به چنین تفاوتهایی حساس نیست. نرخ همزمانی چنین برنامه ای بین دو HTSN سنتز شده حدود 93.86٪ است. از آنجایی که نرخ تصادفی بالا به این معنی است که تقریباً نتایج یکسانی را از استخراج شدت کشت بر اساس دو طرح مختلف دریافت می کند، طرح 2 می تواند طرحی جایگزین برای طرح 1 در نظر گرفته شود، به طوری که زمان و فضای حافظه بیشتری را می توان ذخیره کرد، زیرا تنها یک طرح باند ( یعنی، NDVI) در طرح 2 استفاده می شود. به خصوص برای مناطق تپه ای، تحقیقات موجود نشان داد که NDVI سری زمانی با وضوح فضایی درشت (به عنوان مثال، MODIS) نمی تواند دقت رضایت بخشی برای بازیابی شدت کشت بدست آورد [ 30 ، 39 ]. چنین طراحی (به عنوان مثال، طرح 2 به جای طرح 1) برای تولید HTSN ها بسیار مفید خواهد بود که ممکن است دقت را بهبود بخشد. با این حال، استفاده از ثبت تاریخ اوج محصول بسیار حساس به تفاوت است. نرخ همزمانی آن برنامه بین دو طرح تنها حدود 70.95٪ است. لازم به ذکر است که داده های MODIS سنتز شده به HTSN ترکیبی از مشاهدات بهینه 16 روزه است، به این معنی که در واقع، تفاوت ممکن است بین 0 تا 32 روز بین دو نتیجه تاریخ اوج محصول برای یک باشد. پیکسل بنابراین، اگر مقیاس زمانی به هشت روز یا کمتر کاهش یابد، ممکن است میزان تصادف کمتر باشد. بنابراین، برای کاربردهای کمی بیشتر مانند استخراج تاریخهای پیک محصول، طرح 2 را نمیتوان جایگزین طرح 1 کرد زیرا نرخ تصادفی پایینی دارد.
علاوه بر این، از آنجایی که سازگاری فضایی بین دو HTSN در زمینهای بوتهای کمتر از زمینهای کشاورزی است، هنگام انتخاب طرحی برای این مناطق به اجرای دقیق نیاز است. اگرچه تحقیقات موجود نشان میدهد که دقت پیشبینی طرح 2 نسبت به طرح 1 در مناطق بوتهای [ 37 ] برتر است، نمیتوان استنباط کرد که طرح 2 همچنان نسبت به طرح 1 در کاربردهای خاص برتر است. در تحقیقات بعدی، دادههای راستیآزمایی مطمئنتری (مثلاً دادههای اندازهگیری زمین) برای مقایسه اثر کاربرد دو طرح مورد نیاز است.
7. نتیجه گیری
الگوریتم STARFM به طور رایج برای سنتز بازتاب سطح و همچنین NDVI با وضوح زمانی و مکانی بالا استفاده شد. همانطور که در مقاله ذکر شد، دو طرح مختلف برای سنتز مجموعه داده NDVI با وضوح زمانی و زمانی بالا (HTSN) از طریق الگوریتم STARFM وجود دارد. دو HTSN بر اساس دو طرح در این مقاله با یکدیگر مقایسه شدند. با انتخاب منطقه تپه ای در شرق استان سیچوان چین به عنوان منطقه تحقیقاتی، هفت صحنه از تصاویر Landsat و سری زمانی MOD13Q1 از اکتبر 2001 تا فوریه 2003 به عنوان داده های آزمایشی انتخاب شدند. نتایج مقایسه نشان داد که رویههای مختلف در دو طرح تأثیر زیادی بر مجموعهدادههای NDVI مشابه Landsat ساختهشده با سری زمانی ندارد. به طور کلی، دقت پیشبینی هر دو HTSN تقریباً یکسان است (R2 : 0.14 < طرح 1 < 0.53; 0.15 < طرح 2 < 0.53)، و دو HTSN از لحاظ زمانی و مکانی سازگاری بالایی دارند. با این حال، برنامههای مختلف حساسیتهای متفاوتی را نسبت به تفاوت فضایی و زمانی کوچک بین آنها نشان دادند، با قضاوت از این واقعیت که نتایج بهطور قابلتوجهی متفاوت بود زمانی که دو HTSN در کاربردهای استخراج شدت کشت و تاریخهای اوج محصول به کار رفتند. در مورد شدت برداشت، نرخ تصادفی نسبتاً بالایی وجود داشت که به 93.86٪ رسید. با این حال، در مورد استخراج تاریخ اوج محصول، نرخ تصادف پایین و تنها 70.95٪ بود. بنابراین، در این مقاله اعتقاد بر این است که طرح 2 ( یعنی، باند NDVI مستقیماً به STARFM وارد می شود) می تواند جایگزین طرح 1 در کاربرد استخراج شدت برش به منظور صرفه جویی در زمان و فضای حافظه بیشتر شود زیرا طرح 2 فقط به یک ورودی باند (به عنوان مثال NDVI) نیاز دارد.
HTSN برای به دست آوردن اطلاعات کشاورزی در مناطقی با سطح زمین پیچیده نیاز فوری دارد. علاوه بر انتخاب الگوریتمهای مناسب برای سنتز HTSN، مقایسه طرحهای مختلف بر اساس یک الگوریتم نیز ضروری است. برای الگوریتم STARFM، با توجه به اینکه طرح 2 به زمان کوتاهتر و فضای حافظه کمتری نیاز دارد و به دست آوردن مجموعه داده NDVI با آن در مقایسه با دادههای بازتاب سطحی آسانتر است، نتیجه تحقیق این مقاله شواهدی را برای سنتز HTSN در سطوح پیچیده ارائه میکند. مناطق به روشی ساده تر و برای استخراج بیشتر اطلاعات شدت کشت زمین های کشاورزی. با این حال، برای کاربردهای کمی بیشتر مانند استخراج تاریخهای پیک محصول، نرخ تصادف عمومی پایین به این معنی است که نتایج نسبتاً متفاوتی ممکن است بر اساس دو HTSN به دست آید.






بدون نظر