1. معرفی
1.1. SAR و استخراج شبکه جاده ای
تصاویر رادار دیافراگم مصنوعی (SAR) کاربردهای قابل توجهی در دنیای واقعی دارند، مانند نقشه برداری، سنجش از دور، برنامه ریزی شهری، کشاورزی و پیشگیری از بلایا [ 1 ]. در میان این کاربردها، استخراج جاده از علاقه تحقیقاتی قابل توجهی برخوردار است زیرا اهداف خطی (شامل جاده ها، پل ها، خطوط خط الراس و خطوط ساحلی) با تاریکی قابل توجهی در تصاویر SAR به دلیل پراکندگی عجیب ظاهر می شوند [2 ] .
دو مرحله کلی استخراج جاده از تصاویر SAR عبارتند از: تشخیص بخش محلی نامزد جاده و بهینه سازی شبکه جهانی جاده. عملگرهای تشخیص مختلف، مانند آشکارسازهای لبه معمولی [ 3 ] و عملگرهای مورفولوژیکی [ 4 ]، می توانند برای به دست آوردن بخش های نامزد از پیکسل ها یا سایت های محلی طراحی شوند. الگوریتم تشخیص نسبت بر اساس ویژگی های آماری توسعه یافته توسط توزی و همکاران. [ 5 ] تأثیر لکه را بسیار کاهش می دهد. برای بهینهسازی شبکه جاده، اطلاعات قبلی محدودیتهایی را برای تکنیکهای انتخاب جهانی فراهم میکند [ 6 ، 7 ]. توپین و همکاران [ 8] یک تکنیک دو مرحله ای با اپراتورهای آشکارساز 1 (D1) و D2 برای استخراج نامزدهای اصلی پیشنهاد کرد. سپس، یک میدان تصادفی مارکوف (MRF) بر اساس نمودار متشکل از بخشهای محلی برای بهینهسازی ساخت جاده ساخته شد. مدل MRF متغیرهای تصادفی باینری را بدون توجه به اینکه آیا بخشها جادههای واقعی بودند، ارزیابی کرد و احتمال اتصال دو نامزد محلی را ارزیابی کرد. فرآیند بهینهسازی با به حداقل رساندن یک تابع انرژی با استفاده از آنیل شبیهسازی شده اجرا شد.
اکثر روشهای سنتی تشخیص خط مبتنی بر اپراتور، بخشهایی را بر اساس ویژگیهای محلی تصاویر SAR بدست میآورند. به دلیل نویز لکه ای در تصاویر SAR، برای به دست آوردن نتایج محلی به یک بهینه سازی جهانی نیاز است. انتخاب سراسری بخشهای نامزد جاده اساساً یک فرآیند برچسبگذاری دستهبندی است که از اطلاعات زمینهای استفاده میکند، به عنوان مثال، هر نامزد جاده به عنوان جاده یا نویز برچسبگذاری میشود. در [ 7 ، 8]، مدلهای MRF برای شناسایی شبکههای جادهای واقعی ساخته شدند. پیشرفته ترین MRF رویکردی است که از اطلاعات زمینه ای برای به حداقل رساندن تابع هزینه جهانی استفاده می کند که تأثیر مثبتی بر نتیجه طبقه بندی دارد. با این حال، MRF توزیع مشترک برچسبها و دادهها را تخمین میزند و شامل توزیع دادههایی است که دستیابی به آن همیشه دشوار است. علاوه بر این، احتمال در یک سایت فقط از یک سایت به دست می آید، اما نه همه سایت ها، و عبارت قبلی فقط سایت های مجاور را مقایسه می کند [ 9 ، 10 ]. در مقابل، اطلاعات متنی جهانی در CRF برای مدلسازی احتمال عقبی برچسبها در نظر گرفته میشود [ 11 ، 12]. CRF بر اساس حداکثر آنتروپی است و مزیت دستیابی به نتایج برچسب گذاری شده دقیق و قوی را دارد. وگنر و همکاران [ 13 ] یک فرمول جدید CRF برای برچسبگذاری جادهها ایجاد کرد، که در آن موارد قبلی توسط گروههای درجه بالاتر با هدف توصیف اتصالات و تقاطعها در ساختار جادهها نشان داده میشد.
1.2. مشکلات و انگیزه
روشهای سنتی دو مرحلهای مکمل یکدیگر نیستند و بخشهای جاده معمولاً در روند بهینهسازی کاهش مییابند. در مطالعات قبلی ما، تجزیه و تحلیل هندسی چند مقیاسی برای تشخیص بخش [ 14 ] و بهینه سازی شبکه [ 15 ] استفاده شد. این دو مطالعه بر چالشهای سنتی اصلی استخراج جاده از تصاویر SAR غلبه کردند، یعنی: (1) ویژگیهای هندسی، مانند عرض و انحنای جادههای مختلف، در یک تصویر متغیر هستند. (2) تنوع دانش زمینه ای بخش. و (3) وجود نویز ضربی وابسته به سیگنال معروف به لکه. در [ 14 ]، یک آشکارساز ویژگی خطی چند مقیاسی (MLFD) ارائه شد که عملگر همبستگی نسبت را گسترش داد [ 7]] و تجزیه و تحلیل گوه [ 16 ]، و می تواند مستقیماً یک هدف خطی را شناسایی کرده و اندازه ماسک را به صورت تطبیقی تنظیم کند. الگوریتم بهینه سازی ارائه شده در [ 15 ]، که بر اساس یک چارچوب تجزیه و تحلیل تصویر چند مقیاسی بود، نمایشی از ویژگی های منحنی در فضا ارائه می دهد. تحقیقات بیشتر در مورد این دو روش شامل اجرای مستقل استخراج بخش و فرآیند بهینهسازی در این الگوریتمها بوده است. کاهش نویز در بهینهسازی نیازمند محدودیتهای قبلی است، در حالی که دانش قبلی تعاملات فضایی را منعکس میکند و با اطلاعات احتمالی نامزدهای جاده مرتبط است. بهینه سازی انجمن از بهترین ویژگی های هر دو استفاده می کند. بنابراین، ممکن است منجر به نتایج بهتر در برچسب گذاری جاده ها و سر و صدا واقعی شود.
انتخاب جهانی بخشهای نامزد جاده اساساً یک فرآیند برچسبگذاری دستهبندی است. اعمال محدودیتهای زمینهای برای نامزدهای شناساییشده میتواند تا حد زیادی اثربخشی تحلیل محلی را بهبود بخشد. در [ 7 ، 8 ]، مدل های MRF برای شناسایی شبکه های جاده ای واقعی ساخته شد. با این حال، MRF نمی تواند به طور کامل از اطلاعات زمینه ای جهانی در طول فرآیند برچسب گذاری استفاده کند. علاوه بر این، دستیابی به توزیع مشترک درگیر در MRF همیشه دشوار است. بنابراین، ما از CRF برای پیاده سازی استدلال مشترک در این مقاله استفاده می کنیم. CRF از مزایای دستیابی به نتایج برچسب گذاری شده دقیق و قوی و ارائه یک طبقه بندی نهایی با تخصیص احتمالات برخوردار است.
در این مقاله، ما یک چارچوب بیزی برای استخراج جاده می سازیم تا تعامل و یادگیری متقابل اطلاعات قبلی و احتمالی را انجام دهیم. در این کار: (1) یک چارچوب بیزی برای انتقال استخراج شبکه جادهای به استدلال مشترک احتمال استخراج کسری و اولویت بهینهسازی شبکه استفاده میشود. (2) آشکارساز ویژگی خطی چند مقیاسی (MLFD) و پرتو بهینه سازی شبکه معرفی شده است. و (3) یک میدان تصادفی شرطی (CRF) برای استدلال مشترک استفاده می شود. استخراج کسری و بهینهسازی شبکه در یک روش پیادهسازی میشوند، بنابراین یک بهینه جهانی به دست میآید.
1.3. مشارکت و ساختار
سهم اصلی این مقاله معرفی یک تحلیل چند مقیاسی یکنواخت تحت چارچوب بیزی است که دو روش تشخیص هندسی مجزا و همچنین گسترش الگوریتم یادگیری و استنتاج در CRF را به هم مرتبط میکند:
- (1)
-
تجزیه و تحلیل چند مقیاسی برای ساخت هرم های تصویری بر روی داده های هر نگاه، که در آن هر تصویر به دنباله ای از مربع های دوتایی در هر سطح تقسیم می شود، معرفی شده است.
- (2)
-
بر اساس کار قبلی ما، از عملگرهای چند مقیاسی برای به دست آوردن احتمال و محدودیت های قبلی در CRF استفاده می شود: برای پتانسیل یکنواخت، یک آشکارساز به نام آشکارساز ویژگی خطی چند مقیاسی (MLFD) حداکثر پاسخ بخش های جاده را در مربع های دوتایی محاسبه می کند. در مقیاس های مختلف
- (3)
-
برای پتانسیل زوجی در CRF، پنج رابطه محدود، از جمله فواصل و زوایای متقاطع بین بخشهای مجاور، تحت یک چارچوب پرتو بهدست میآیند، و چندین تابع خطی کوتاه بهطور دقیق طراحی شدهاند تا از هموار شدن بیش از حد جلوگیری شود.
ساختار باقیمانده این مقاله به شرح زیر است. جزئیات چارچوب بیزی در بخش 2 ارائه شده است . بخش 3 پتانسیل یکنواخت در مدل CRF را شرح می دهد و بخش 4 پتانسیل جفتی در مدل CRF را شرح می دهد. بخش 5 خلاصه ای از جمله فلوچارت چارچوب بیزی را ارائه می دهد. در نهایت، بخش 6 آزمایشی را بر اساس داده های SAR هوابرد و فضابرد ارائه می کند و بخش 7 نتیجه گیری این مقاله را ارائه می دهد.
2. چارچوب بیزی
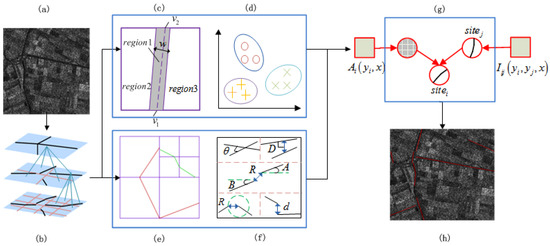
استخراج جاده را می توان به عنوان یک مشکل برچسب گذاری باینری در نظر گرفت و بسیاری از فرضیات قبلی در مورد جاده ها ممکن است در مدل ها کدگذاری شوند. در این مقاله، یک چارچوب بیزی برای انتقال استخراج شبکه جادهای به استدلال مشترک احتمال استخراج کسری و اولویت بهینهسازی شبکه استفاده میشود. ما یک مدل CRF با شرایط قبلی دقیق طراحی شده برای استخراج جاده از تصاویر SAR میسازیم: (1) یک آشکارساز ویژگی خطی چند مقیاسی (MLFD) [14] این احتمال را برای بخشهای جاده فراهم میکند تا نمایش پراکنده سازههای جاده را در چندگانه به دست آورند . داده های نگاه. (2) پیشین های محلی با چندین محدودیت از پرتو توصیف می شوند. تجزیه و تحلیل پرتو [ 15 ، 17] یک چارچوب چند مقیاسی برای تشخیص اجسام هندسی است که از طیفی از مقیاس، محلیسازی و بخشهای خط جهت برای نمایش تصویر استفاده میکند. در اینجا، ما فلوچارت را برای ارائه چارچوب خود در شکل 1 ارائه می کنیم . ابتدا، چارچوب MLFD برای استخراج احتمال بخشهای جاده با استفاده از هرم چند مقیاسی مورد سوء استفاده قرار میگیرد. سپس، تجزیه و تحلیل بیملت و محدودیتهای فاصله قبلی برای تشکیل عبارتهای واحد و زوجی در مدل CRF گنجانده شدهاند. در نهایت، رویکرد بیزی مبتنی بر بهینه سازی حداکثر پسینی (MAP) [ 18 ] برای به دست آوردن نتایج استخراج جاده انجام می شود.
2.1. مدل CRF
به عنوان یک مدل گراف، CRF می تواند تصمیمات دقیقی را در مورد نتایج طبقه بندی ارائه دهد و توزیع احتمال دامنه برچسب گذاری شده را از نمونه های ورودی محاسبه کند. در مقایسه با MRF، که توزیع احتمال مشترک را برای بهینهسازی اطلاعات کلی مدل میکند، CRF مستقیماً توزیع احتمال خلفی فیلد برچسب را برای ارائه بهینهسازی ارتباط اطلاعات قبلی و احتمال ایجاد میکند.
اجازه دهید x نشان دهنده داده های مشاهده شده و y مجموعه برچسب باشد (دودویی، – 1–1یا یکی در این مقاله)؛ احتمال پسین را می توان به صورت نمایی به صورت زیر نشان داد:
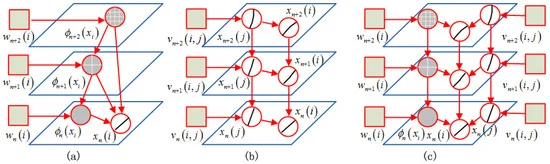
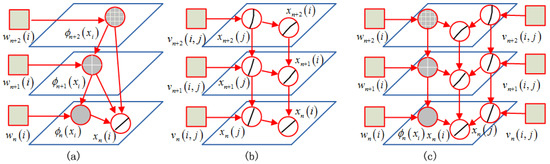
من= {ایکس1،ایکس2, … ,ایکسم}من=ایکس1،ایکس2،…،ایکسمیعنی تصویر I از M پیکسل یا سوپرپیکسل تشکیل شده استایکسمنایکسمن(مجموعه ای از چند پیکسل)، که در آن i یک بخش را نشان می دهد اس= { 1 , 2 , … , M}اس=1،2،…،ماز تمام بخش های تصویر و j یک قطعه در مجموعه همسایه است نمننمناز بخش i در فرمول (1) آمنآمنو منمن جمنمن�به ترتیب پتانسیل های واحد و جفتی هستند. آمنآمناحتمال برچسب گرفتن بخش i را اندازه گیری می کندyمن�من، در حالی که منمن جمنمن�تعامل بین بخش های i و j را توصیف می کند .
2.2. استدلال CRF برای استخراج جاده
علاوه بر مدلسازی مستقیم توزیع شرطی برچسبها، یکی دیگر از جنبههای کلیدی CRF از نظر ما این است که نمونههای مشاهدهشده، به عنوان مثال، بخشهای جاده، در هر بخش دوتایی لازم نیست بهطور مشروط مستقل باشند. رویکردهای چند مقیاسی برای CRF به طور گسترده در تشخیص هدف خطی [ 14 ، 15 ، 19 ] استفاده می شود، که در آن ویژگی ها در هر مقیاس متفاوت است. با استخراج ویژگیها برای هر مقیاس هدف خطی احتمالی و یادگیری پارامترها به طور مشترک در مقیاسها، مقیاس مدل را ثابت میکنیم.
برای کاربردهای استخراج جاده، ما به طور انعطاف پذیر دو شکل از توابع ویژگی را در CRF پیکربندی می کنیم: تابع ویژگی حالت ϕمن( x )�منایکساز برچسب در بخش i در عبارت واحد و تابع ویژگی انتقال μ (ϕمن( x ) ،ϕj( x ) )��منایکس،��ایکساز برچسبها در بخش i و یک قطعه j مجاور به صورت زوجی. پتانسیل یکنواخت و پتانسیل زوجی با طبقهبندیکنندههای مربوطه طراحی شدهاند. ویژگی حالت برای تفسیر ویژگیهای جاده به صورت پراکنده در نظر گرفته شده است، جایی که حداکثر پاسخهای بخشهای دوتایی چند مقیاسی در MLFD به عنوان عناصر ویژگی عمل میکنند. ویژگی انتقال نشان دهنده روابط هندسی محلی بین بخش های همسایه، مانند فواصل زاویه ای و نقطه پایانی است. بنابراین، احتمال مشروط پ( y| ϕ ( x ) )پ�|�ایکسمی تواند توسط:
جایی که ز( ϕ ( x ) )ز�ایکستابع پارتیشن است و توسط:
در ساختار گراف CRF مشروط به بخش مشاهده است ایکسn( من )ایکس�من( شکل 2 را ببینید )، ایکسn( من )ایکس�منقطعه نامزد در بخش i در مقیاس k است ، ایکسn( j )ایکس��بخشی است که با آن در تعامل است ایکسn( من )ایکس�منو ϕn(ایکسمن)��ایکسمنویژگی احتمال ایجاد شده توسط یک درجه پارتیشن مشخص در مقیاس n است . متغیر تصادفی را می گیریم ایکسهایکسهیک راس در نمودار CRF باشد. برچسب آن yه�هزمانی خواهد بود که در واقع روی خطوط جاده قرار گیرد.
3. پتانسیل واحد در مدل CRF ما
آشکارساز ویژگی خطی چند مقیاسی (MLFD) پتانسیل یکپارچه را ضبط می کند، که در آن حداکثر پاسخ های بخش های دوتایی چند مقیاسی به عنوان عناصر ویژگی عمل می کنند.
تابع پتانسیل واحد آمن(yمن،ϕمن( x ) )آمن�من،�منایکساطلاعات را در یک بخش توصیف می کند و احتمال اینکه برچسب بخش i باشد را اندازه گیری می کندyمن�منبرای داده های مشاهده شده x . CRFهای مختلف ممکن است طبقهبندیکنندههای مختلفی را به عنوان پتانسیلهای یکپارچه در نظر بگیرند، مانند پتانسیل تقویتی [ 17 ] و CRF هسته [ 15 ]. در این CRF، پتانسیل واحد ما توسط طبقهبندی کننده لجستیک عمومی [ 20 ] تعریف میشود و ویژگیهای احتمال توسط MLFD ارائه میشود.
3.1. اطلاعات احتمال از MLFD
در [ 8 ]، آشکارساز ویژگی خطی چند مقیاسی یک فیلتر ماسکی طراحی می کند که یک تصویر را به چندین منطقه مختلف برای تشخیص بخش های منطقه محلی تقسیم می کند. محدوده اندازه ماسک با استفاده از روش چند وضوح انتخاب می شود. اپراتور می تواند اندازه ماسک را به صورت تطبیقی تنظیم کند و عرض و جهت ناحیه مرکزی را تغییر دهد. علاوه بر این، ویژگی های آماری و هندسی منطقه محلی در نظر گرفته شده است.
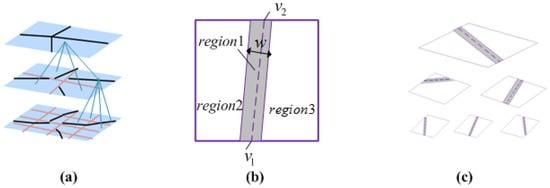
MLFD از ادغام آشکارساز خط نسبت (D1) و آشکارساز خط همبستگی متقابل (D2) [ 7 ] مشتق شده است. در طول روش MLFD، یک تصویر ورودی به طور مکرر به دو در دو مربع تقسیم می شود، و سپس، همانطور که در شکل 3 نشان داده شده است، یک چهار درخت برای هرم تصویر ساخته می شود . در هر سطح، MLFD پاسخ های تمام بخش های قبلی را محاسبه می کند. پاسخ ها به عنوان ویژگی در نظر گرفته می شوند و ارتباط ویژگی ها در سطوح مختلف به عنوان بردار ویژگی در اصطلاح احتمال چارچوب CRF در نظر گرفته می شود. در جزئیات، ماسک یک بخش محلی را به سه ناحیه مجاور تقسیم می کند ( شکل 3 ب را ببینید). سپس، پاسخ بخش محلی را می توان به صورت بیان کرد r (v1،v2, w ,μ1،μ2،μ3)��1،�2،�،�1،�2،�3، جایی که v1،v2�1،�2نقاط انتهایی خط مرکزی در ناحیه مرکزی، w عرض ناحیه مرکزی و μ1،μ2،μ3�1،�2،�3مقادیر میانگین سه ناحیه در ماسک هستند که با استفاده از معادله زیر محاسبه می شوند:
که در آن s یک پیکسل با دامنه است آسآسو nمن�منتعداد پیکسل های تک بخش i را می شمارد .
با l نشان دهنده طول ناحیه مرکزی و α بیانگر ضریب یکنواختی، پاسخ MLFD را می توان به صورت زیر تعریف کرد:
جایی که m خط مرکزی ماسک در ناحیه ای است که باید تشخیص داده شود و r و ρ به ترتیب پاسخ عملگرهای D1 و D2 هستند که در رابطه ( 6 ) ارائه شده است. α تداوم ناحیه مرکزی را که با r مرتبط است ارزیابی می کند .
جایی که rمن ج�من�نشان دهنده پاسخ نسبت مناطق i و j است ، جمن ج=μمن/μjجمن�=�من/��و γمن�منواریانس دامنه ها در منطقه i است .
در این مقاله، با داده های SAR، می توانیم سه پاسخ MLFD مختلف را به دست آوریم تیک( متر )تیک(متر)در مورد ظاهرهای مختلف، به عنوان مثال، ک∈ { h h , h v , v v }ک∈{ساعتساعت،ساعت�،��}. تیک( متر )تیک(متر)یک بردار به هم پیوسته است که از پاسخهایی بر روی سه عنصر پراکنده تشکیل شده است آساعت ساعتسآسساعتساعتدامنه عنصر پراکنده است اسساعت ساعتاسساعتساعت. پاسخ ها تیک( متر )تیک(متر)در تابع ویژگی حالت و تابع ویژگی انتقال در CRF طراحی خواهد شد.
3.2. اصطلاح بالقوه Unary
در این مقاله، ما یک طبقهبندی کننده لجستیک کلی برای توصیف پتانسیل یکنواخت در CRF میگیریم، به عنوان مثال،
جایی که ساعتمن( x )ساعتمنایکسماتریس ویژگی های چند مقیاسی بخش دوتایی i است که از پاسخ های MLFD تشکیل شده است. تیn(مترمن)تی�مترمننشان دهنده حداکثر پاسخ MLFD در بخش i در مقیاس n است . بردار پارامتر مدل ω =[ω1،ω2, … ,ωک،α1]تی�=�1،�2،…،�ک،�1تیشامل وزنی برای هر آیتم در ماتریس است ساعتمن( x )ساعتمنایکسو در طی فرآیند آموزشی یاد گرفته می شود و α1�1یک پارامتر مبادله است.
4. پتانسیل زوجی در مدل CRF ما
تابع پتانسیل زوجی منمن ج(yمن،yj، μ (ϕمن( x ) ،ϕj( x ) ) )منمن��من،��،��منایکس،��ایکستعامل فضایی بین دو بخش i و j را با توجه به کل داده های مشاهده شده x منعکس می کند . تفاوت با پتانسیل های دسته در MRF ها این است که قطعه j لزوماً نباید در همسایگی قطعه i باشد.، اما ممکن است یک بخش دلخواه از همه داده ها باشد. در چارچوب استخراج جاده، اطلاعات قبلی در پتانسیل زوجی تحت تجزیه و تحلیل بیملت مورد بهرهبرداری قرار میگیرد. ما به طور کامل از انعطافپذیری طراحی ماتریس ویژگی در پتانسیل زوجی استفاده میکنیم و چندین محدودیت را بین بخشهای همسایه محلی معرفی میکنیم. تابع پتانسیل زوجی با محدودیت های قبلی، از جمله طول قطعه، انحنا و فاصله تقاطع طراحی شده است.
4.1. محدودیت های قبلی تحت تجزیه و تحلیل بیملت
تجزیه و تحلیل Beamlet [ 21 ] یک چارچوب درک تصویر با وضوح چندگانه است که توسط Donoho و Hou در سال 2000 ایجاد شد. مقیاس، مکان و جهتگیری را بر اساس بخشهای خطی سازمانیافته دوگانه بومیسازی میکند. در این چارچوب، یک تبدیل beamlet بر اساس فرهنگ لغت beamlet انجام میشود که از انواع بخشهای خط در طیف وسیعی از مقیاسها، مکانها و جهتها تشکیل شده است. سپس، هرم پرتو و نمودار را می توان برای الگوریتم بیملت ساخت.
تبدیل Beamlet از طریق تجزیه چند مقیاسی مشابه MLFD انجام می شود که به طور مکرر یک تصویر را به یک سری از بخش های دوتایی تقسیم می کند. در هر بخش، اتصال دو راس دلخواه یک قطعه پرتو را تشکیل می دهد. مجموع مقادیر سطح خاکستری پیکسل ها روی یک پرتو به عنوان تبدیل پرتو تعریف می شود، و پاسخ تبدیل پرتو گسسته در این مقاله به صورت زیر ارائه می شود:
جایی که g( ص )�پمقدار سطح خاکستری پیکسل p و طول استل ( ب )لبتعداد پیکسل های قطعه b را می شمارد .
علاوه بر این، در طول تجزیه و تحلیل بیملت، از یک پارتیشن چند مقیاسی برای به دست آوردن دنباله ای از بخش های دوتایی استفاده می شود. پپدر سطوح مختلف هر مربع با یک پرتو نشان داده می شود و تجزیه پرتو برای نشان دادن بهترین پارتیشن به صورت زیر است:
جایی که b ~ sب∼سماسک پرتو b در قطعه دوتایی s و است# ص#پتعداد واحدهای مجموعه p را در یک سطح معین می شمارد. پارامتر λ ضریب جریمه پیچیدگی است که درجه تجزیه را اندازه می گیرد. λ کوچکتر بخش های بیشتری را به دست می آورد و جزئیات تصویر بیشتری را نشان می دهد، در حالی که یک λ بزرگ ممکن است خطوط کلی تصویر را با بخش های نویز کمتر تعیین کند.
برای به دست آوردن جواب بهینه برای معادله ( 9 )، یک فرآیند هرس از پایین به بالا برای چهار درخت ساخته شده استفاده می شود. برای یک بخش در مقیاس های مختلف، تنها بخش های حداکثر پاسخ ها در یک سطح حفظ می شوند:
که در آن بخشهای چهار زیرمربع ذخیره میشوند و پاسخ والد آنها به مجموع چهار پاسخ فرعی بهروزرسانی میشود. در غیر این صورت، مربع های فرعی کنار گذاشته می شوند و والد آنها دیگر تقسیم نمی شوند. در معادله ( 10 ) تی(بمن)تیبمنپاسخ پرتوی مربع فرعی i است وتی(بپ)تیبپمربع والد مربوطه آنهاست. در این مرحله هرس، نتایج نهایی جاده بیملت ارائه می شود.
سازمان ادراکی، که برای ارزیابی روابط ساختاری عناصر اولیه مختلف شناخته شده است، به طور گسترده در بینایی کامپیوتر استفاده شده است [ 22 ، 23 ]. در این مطالعه، روابط متنی بین بخشهای جاده، مانند زوایای تقاطع، انحناها، فواصل نقطه پایانی و مجاورتها، بهینهسازی جهانی را با محدودیتهای قبلی موثر برای استخراج جاده از تصاویر SAR ارائه میدهد. همانطور که در شکل 4 نشان داده شده است، از چندین قید رابطه ای برای گروه بندی و برچسب گذاری بخش ها استفاده می کنیم .
فاصله زاویه ای: این مورد زاویه عبور دو خط را اندازه گیری می کند ( شکل 4 a را ببینید) و به صورت زیر تعریف می شود:
جایی که θ1�1و θ2�2زوایای مماس دو بخش با محدوده مقدار هستند ( – π/ 2 ، π/ 2 ]–�/2،�/2.
فاصله جانبی: فاصله جانبی قطعات در یک منطقه محلی باید کوچک باشد و به عنوان فاصله عمود از نقطه میانی خط کوتاهتر به خط بلندتر محاسبه می شود. همانطور که در شکل 4 ب نشان داده شده است، اگر L نشان دهنده طول پاره بلندتر و D فاصله عمودی این دو خط باشد، فاصله جانبی با:
فاصله نقطه پایانی: این شبیه به فاصله جانبی است، به طوری که d نشان دهنده حداقل فاصله تقاطع چهار نقطه انتهایی در دو خط و L نشان دهنده طول قطعه طولانی تر است، همانطور که در شکل 4 c نشان داده شده است. فاصله نقطه پایانی را می توان به صورت زیر نوشت:
مجاورت: نزدیکی دو بخش، میزان احتمال نزدیک بودن بخشهای مجاور به یکدیگر را اندازهگیری میکند و اهمیت ادراکی آنها را منعکس میکند، همانطور که در شکل 4 د نشان داده شده است. مجاورت به صورت زیر محاسبه می شود:
که در آن L طول خط کوتاهتر و R حداقل فاصله تقاطع مشابه d در معادله ( 13 ) است.
پیوستگی: پیوستگی [ 23 ] رابطه ساختاری بین بخشها را توصیف میکند و وزنی را که بخشهای جاده باید به آن متصل شوند، همانطور که در شکل 4 نشان داده شده است، تعیین میکند . تداوم به صورت زیر تعریف می شود:
که در آن α و β زوایای تقاطع خطوط با خطوط افقی در نقاط انتهایی متصل هستند و w1�1و w2�2وزن صافی را در نقطه پایانی متصل و فاصله بین نقاط انتهایی اتصال را تعیین کنید. مشابه پاسخ های MLFD تیک( متر )تیک(متر)در دادههای SAR، پنج محدودیت بالا بر روی مجموعه داده SAR K محاسبه شده و در پنج بردار با سه عنصر ترکیب میشوند. بردارها به صورت نوشته می شوند Dآک�کآ، Dتیک�کتی، Dهک�که، پکپکو سیکسیک. در پتانسیل زوجی نهایی، سه بردار اول یکنواختی قبلی را تشکیل میدهند و دو بردار آخر پیشین وابسته به کنتراست را تشکیل میدهند.
4.2. اصطلاح پتانسیل زوجی
پتانسیل زوجی ما شامل یک قبل صافی و قبل وابسته به کنتراست است. با توجه به تعریض و صاف بودن معابر، Dآ�آ، Dتی�تیو Dه�هبین بخشها در منطقه محلی بسیار کوچک هستند، به این معنی که مقدار کمتری از این صافی قبل انرژی بالاتری را اعمال میکند و ما باید به شدت فاصله بزرگتری را جریمه کنیم. Dآ�آ، Dتی�تیو Dه�ه. ما یک تابع سیگموئید را برای صافی قبل به صورت زیر معرفی می کنیم:
جایی که μسمن ج( x ) = [Dآک،Dتیک،Dهک]�من�س(ایکس)=[�کآ،�کتی،�که]بردار ویژگی مربوط به بخش های i و j در مجموعه داده SAR K است . ϑ�و κ�بردارهای خمش منحنی هستند Dآ�آ، Dتی�تیو Dه�ه; ⊙ نشان دهنده محصول هادامارد است. vs i j�سمن�تأثیر هر فاصله بر همواری قبل را اندازه گیری می کند.
در امتداد جادههای نسبتاً پیوسته، بخشهای مجاور فواصل زاویهای و نقطه پایانی مشابهی دارند، و این پارامترهای بخشهای جاده واقعی نزدیک به میانگین بردار مجموعه نامزدهای محلی خواهند بود. ما یک مجموعه محلی به دست می آوریم که شامل حداقل ده بخش در ناحیه همسایه قطعه است ایکسمنایکسمن، و سپس، بردار ویژگی میانگین را محاسبه می کنیم μ¯من�¯منو انحراف معیار σمن�من. با فاصله اقلیدسی، دمن ج=μمن ج–μ¯مندمن�=�من�–�¯منانحراف بردار را اندازه گیری می کند μمن ج�من�از جانب μ¯من�¯من، و وزن vs i j�سمن�به عنوان … تعریف شده است:
تابع خطی کوتاه [ 13 ] وزن کامل را برای بخش های زوجی در داخل تضمین می کند σمن�من، کاهش خطی وزن به بخش های بین σمن�منو 4σمن4�من(آستانه تجربی) و بخش های زوجی بالاتر از چهار انحراف استاندارد را حذف می کند. عملکرد وزن دهی به طور قابل توجهی به جلوگیری از صاف شدن بیش از حد کمک می کند.
سپس، پیشین وابسته به کنتراست در مدل Ising [ 24 ] شکل زیر را به خود می گیرد:
جایی که μپمن ج( x ) = [fمن ج( x ) ،پمن ج،سیمن ج]�من�پ(ایکس)=[�من�(ایکس)،پمن�،سیمن�]بردار ویژگی مرتبط است، fمن ج= [ساعتمن( x ) ،ساعتj( x ) ]�من�=[ساعتمن(ایکس)،ساعت�(ایکس)]یکی از ویژگی های الحاق بخش های منفرد i و j است . پمن جپمن�و سیمن جسیمن�به ترتیب اولویت های مجاورت و تداوم را نشان می دهد. و vتیp i j�پمن�تینشان دهنده وزن برای μپمن ج( x )�من�پ(ایکس)، که در طول فرآیند آموزش CRF تنظیم می شوند.
در نهایت، پتانسیل زوجی در این مدل CRF به صورت زیر تعریف میشود:
که در آن ε و η نقاط قوت عبارتهای زوجی را با عبارت واحد در مدل مبادله میکنند و از طریق یافتن مقدار بهینه در مجموعه آموزشی تنظیم میشوند. فرآیند بهینه سازی معادله (2) با نسخه بهبود یافته روش شبه نیوتن بر اساس نسخه ارائه شده توسط گولد و همکاران به کار گرفته شده است. [ 25 ].
5. پردازش پست
5.1. توزیع کامل خلفی CRF
با استفاده از تعاریف عینی پتانسیل یکنواخت در رابطه ( 7 ) و پتانسیل زوجی در معادله ( 19 )، احتمال پسین p ( y| ϕ ( x ) )پ�|�ایکسدر رابطه (1) می توان به صورت زیر بازنویسی کرد:
جایی که Θ = { ω , v }Θ=�،�مجموعه ای از پارامترها در مدل است.
5.2. روش های عادی سازی
در قسمت های بالا ویژگی های مختلف و محدودیت های قبلی را تعریف کرده ایم. اینها می توانند برای تفسیر خواص مختلف و ارائه توصیفی یکسان از ویژگی های جاده ها استفاده شوند. برای جلوگیری از بی ثباتی عددی در دوره آموزش CRF، روش های عادی سازی باید در مدیریت ماتریس های ویژگی معرفی شوند.
دوتایی سازی: برای فاصله زاویه ای از روش باینریزه سازی استفاده می شود Dآ�آ، فاصله جانبی Dتی�تیو فاصله نقطه پایانی Dه�هدر این مطالعه. باینریزه کردن با مقایسه مقادیر ویژگی بخش با همسایگی چهار اتصال آن انجام می شود. گرفتن فاصله زاویه ای Dآمن ج�من�آاز قطعات در بخش i و j به عنوان مثال، Dآمن ج�من�آبا استفاده از رابطه ( 11 ) و میانگین فاصله زاویه ای محاسبه می شودD¯آمن�¯منآبین بخش i و همسایگی آن به صورت زیر تعریف می شود:
جایی که نمننمنمجموعه همسایگی بخش i است ، Dآمن ک�منکآفاصله زاویه ای قطعات در پاره های i و k و استn u m (نمن)�تومترنمنمقدار مجموعه را می شمارد نمننمن.
با توجه به تعریض و صاف بودن معابر، Dآ�آ، Dتی�تیو Dه�هبین بخش ها در مناطق محلی باید مقادیر کمی داشته باشند. بنابراین، ما آستانه تعیین می کنیم تیآتیآبا استفاده از چندین مجموعه از نتایج تجربی. به طور خاص، فاصله زاویه ای Dآمن ج�من�آدر صورت اختلاف مطلق از میانگین محلی حفظ خواهد شد D¯آمن�¯منآکوچکتر از آستانه است تیآتیآ; در غیر این صورت دور ریخته می شود. بنابراین، باینری سازی به صورت زیر نوشته می شود:
شبیه به معادله ( 22 )، دوتایی ها برای فاصله جانبی Dتیمن ج�من�تیو فاصله نقطه پایانی Dهمن ج�من�هرا می توان با جایگزینی اختلاف مطلق با نسبت بین مقدار ویژگی و میانگین محلی بدست آورد. برای آستانه ها، این دو باینری سازی را به صورت زیر تعریف می کنیم:
برای نزدیکی پمن جپمن�و تداوم سیمن جسیمن�، پس پردازش به عنوان نسبت مقدار فعلی و میانگین محلی نرمال می شود، اما نه دوتایی ها، و می تواند به صورت زیر بیان شود:
جایی که میانگین های محلی پ¯من جپ¯من�و سی¯من جسی¯من�با استفاده از روش مشابه برای محاسبه می شوند D¯آمن�¯منآدر معادله ( 21 ).
در نهایت، ماتریس ویژگی انجمن μمن ج( x )�من�ایکسدر پتانسیل زوجی را می توان با استفاده از پنج محدودیت قبلی دودویی ارائه شده در بالا و ویژگی های بخش i و j تعیین کرد . سپس شکل قطعی به صورت زیر است:
جایی که fn i j= [ساعتn من( x ) ،ساعتn j( x ) ]��من�=ساعت�منایکس،ساعت��ایکسترکیب ساده ای از ویژگی های بخش های منفرد i و j در یک مقیاس خاص n است .
6. آزمایش ها و نتایج
6.1. داده ها و تنظیمات تجربی
برای ارزیابی روش استخراج جاده پیشنهادی، هر دو تصاویر SAR فضابرد و هوابرد برای آزمایش روش استفاده میشوند. دو داده اول، دادههای واقعی TerraSAR هستند که در آلمان ( شکل 5 الف را ببینید) و ووهان، چین (نگاه کنید به شکل 6 الف) به دست آمدهاند. اندازه تصویر اول است 1000 × 10001000×1000پیکسل و وضوح مکانی آن است 3.03.0متر × 2.2×2.2متر تصویر دوم یک صحنه گسترده با اندازه است 1152 × 6441152×644پیکسل ها حقایق زمین مربوطه تصاویر دو بعدی هستند که به صورت دستی برچسب گذاری شده اند ( شکل 5 ب و شکل 6 ب). ما همچنین از دادههای SAR هوابرد، که با استفاده از تجهیزات توسعهیافته توسط چین و مشتق شده از SAR باند X هوابرد ارائه شده توسط مؤسسه 38 چین، شرکت فناوری الکترونیک، به دست آمدهاند، برای ارزیابی روش پیشنهادی استفاده کردیم. منطقه آزمایش در نزدیکی شهرستان لینگشوی، استان هاینان، چین است. تصاویر دهانه در شکل 7 الف و شکل 8 الف ارائه شده اند و اندازه آنها هر دو است. 1000 × 10001000×1000پیکسل ها پارامترهای هر آزمایش که در طول فرآیند آموزش آموخته شده است، به شرح زیر فهرست شده است: در شکل 5 ، درجه تجزیه λ تیرچه به صورت 4.4 تنظیم شده است، و بردارهای خمش منحنی عبارتند از ϑ�= [ 1 ، 5 ، 7 ] و κ�= [30، 0.8، 0.5]، در حالی که در شکل 6 ، λ 2.3 است، ϑ�= [ 1 ، 6 ، 5 ] و κ�= [20، 0.8، 0.7]. برای صحنه های SAR هوابرد در شکل 7 a و شکل 8 a، روش های مقایسه ای MLFD و beamlet بر روی تصاویر دهانه پیاده سازی شده اند و درجه تجزیه λ به ترتیب 4.6 و 5.3 است. پارامترهای CRF، بردارهای خمش منحنی ϑ�و κ�توسط پارامترهایی از مجموعه داده اصلی SAR به هم متصل می شوند. در شکل 7 ، ϑ�= [1.2، 4، 6، 1.8، 4.5، 6.3، 1.5، 4.2، 6.5] و κ�= [22، 0.7، 0.75، 26، 0.74، 0.8، 24، 0.71، 0.78]، در حالی که در شکل 8 ، ϑ�= [1.5، 5.1، 7.5، 2.1، 5.8، 8، 1.7، 5.3، 7.7] و κ�= [32، 1، 1.2، 36، 1.4، 1.7، 33، 1.2، 1.4].
چندین معیار برای ارزیابی کیفی عملکرد استخراج جاده پیشنهاد شده است. به طور کلی، سه معیار برای ارزیابی وجود دارد [ 23 ] که به صورت زیر تعریف می شوند:
که در آن کامل بودن به معنای نسبت طول حقیقت زمین است ( Lgتی��تی) که دقیقا استخراج شده است، Lr��طول تطبیق بین جاده های استخراج شده و حقیقت و صحت زمین است ( Lr/Lن��/�ن) کسری از کل طول جاده استخراج شده را نشان می دهد ( Lن�ن) که با جاده های واقعی مطابقت دارد. کیفیت توسط Lr/ (Lن+Lu gتی)��/(�ن+�تو�تی)، با Lu gتی�تو�تیطول جاده های واقعی است که با جاده های استخراج شده مطابقت ندارند. اگر فاصله نقطه میانی بین جادههای استخراجشده و جادههای مرجع کمتر از تحمل معین باشد، در نظر میگیریم که جادههای استخراجشده با جادههای واقعی مطابقت دارند. تلورانس ها در این چهار تصویر به صورت 13، 8، 11 و 13 پیکسل تنظیم شده است.
6.2. نتایج تجربی
آزمایشهای روش پیشنهادی و چندین آزمایش مقایسهای با استفاده از تصاویر SAR فضایی واقعی و تصاویر SAR هوابرد انجام میشوند. برای داده های فضایی Terra-SAR، شکل 5 c و شکل 6 c بخش های جاده شناسایی شده را با استفاده از MLFD نشان می دهد. این روش در درجه اول خطوط کلی جاده را با تولید نویز نسبتا کمی پیدا می کند، اما MLFD نمی تواند تقاطع های جاده پیچیده را به خوبی اداره کند، همانطور که در تصویر اول واضح است. شکل 5 d و شکل 6 d نتایج تجزیه تیرآهن هستند که شامل جزئیات بیشتر جاده و بخش های پیچیده حتی در مناطق و تقاطع های پیچیده است. با این حال، این بخش های غیر جاده ای بیشتری را در مناطق همسایه محلی ایجاد می کند. شکل 5 e و شکل 6e شبکههای جادهای هستند که پس از بهینهسازی سراسری توسط MRF از Tupin [ 8 ]، که بخشهای طولانی مجاور را در هنگام نادیده گرفتن قطعات کوتاه با تعیین طول معین به خطوط متصل میکند. با این حال، در مناطق شهری متراکم که جادهها دارای طول کوتاه و محیط پیچیده هستند، نمیتواند چنین خطوطی را استخراج کند، و بهویژه در مجموعه داده دوم که شامل بخشهای کوچک جاده است، MRF به اشتباه برخی از بخشهای کوتاه مثبت را کنار میگذارد. نتایج مدل CRF در شکل 5 f و شکل 6 ارائه شده است f ارائه شده است که از کل طرح استخراج شده توسط MLFD پیروی می کند و جزئیات دقیق را در صحنه های پیچیده استخراج شده توسط پرتوهای زمانی که نویز تا حد زیادی حذف می شود حفظ می کند. در مقایسه با MRF، بخشهای جدید زیادی ایجاد میشود و خطوط جادهها بسیار هموار هستند.
برای داده های SAR هوابرد، نتایج مقایسه ای روی تصاویر دهانه به دست می آید. شکل 7 c و شکل 8 ج جاده های MLFD را نشان می دهد که در آن بخش ها قطعات ناپیوسته هستند. با این حال، زمانی که تعداد کمتری غیرجاده رزرو شده است، روش MLFD بخشهای مؤثر را در امتداد خطوط واقعی بهدست میآورد. نتایج بیملت در شکل 7 d و شکل 8 d نشان داده شده است که در آنها قطعات کامل تری به عنوان یک کل و بخش های تصفیه شده تری در امتداد منحنی ها و چهارراه ها نسبت به MLFD به دست می آیند. جاده های بهینه سازی شده MRF در شکل 7 e و شکل 8 آورده شده استe، جایی که ما می توانیم مشاهده کنیم که بیشتر خطوط جاده با جاده های واقعی مطابقت دارند و به خصوص در امتداد چهارراه به هم متصل می شوند، اما برخی از بخش ها در اطراف مناطق پیچیده ساختمان گمراه کننده هستند. نتایج همجوشی الگوریتم CRF پیشنهادی در شکل 7 f و شکل 8 f ارائه شده است، جایی که بخشهای جدید انتخاب میشوند، و سپس، جادههای مجاور بهطور هموار به هم متصل میشوند. علاوه بر این، نویز بسیار کوچک تا حد زیادی کاهش می یابد. هر دو MRF و CRF برخی از شبه جاده ها مانند سقف ها و خطوط شکاف بین زمین های کشاورزی را حفظ می کنند.
برای ارزیابی اثر پتانسیل واحد و پتانسیل زوجی در روش پیشنهادی، دادههای TerraSAR به عنوان مثال برای مقایسه در نظر گرفته شدهاند. همانطور که در شکل 9c نشان داده شده است ، حضور آشکار نویز در نتایج پتانسیل یکنواخت به تنهایی وجود دارد. به عبارت دیگر، برچسب های پیکسل های همسایه با یکدیگر سازگار نیستند. این به این دلیل است که روابط فضایی، یعنی محدودیت های قبلی، در این مدل در نظر گرفته نشده است. در مقابل، نتایج بهتری با مدل CRF فیوژن، که در شکل 9 d نشان داده شده است، به دست میآید، زیرا از اطلاعات زمینهای بیشتر برای تسهیل استخراج جادهای قوی و مؤثر استفاده میشود.
میز 1مقایسه ارزیابی های کیفیت برای هر روش بر روی تصاویر آزمایشی را ارائه می دهد. همانطور که در این جدول نشان داده شده است، MLFD دارای صحت قابل قبول، اما کامل بودن و کیفیت نامطلوب است، در حالی که بیملت به دلیل نمایش جزئیات بیشتر استخراج شده، از کاملیت و کیفیت بالاتری برخوردار است. سه شاخص CRF به طور قابل توجهی در هر دو تصویر افزایش می یابد. همچنین آشکار است که شاخصهای کیفیت، که ارزیابی کلی و شاخص صحت را نشان میدهند، هر دو برای CRF بالاترین هستند. از آنجایی که پیامهای اعتقادی در بین تمام سایتهای تصویر ارسال میشوند و محدودیتهای متعددی در آن دخیل هستند، هزینه زمانی CRF گرانتر از MRF است، اما در همان مقیاس است. از آنجایی که MRF بخش های کوتاه جدا شده را حذف می کند و بخش های مجاور را بر اساس چندین قانون به خطوط الحاق می کند، شاخص های ارزیابی قابل قبولی برای همه تصاویر دارد.
7. نتیجه گیری
در این مقاله، یک چارچوب بیزی که عملگرهای تشخیص هندسی چند مقیاسی و کاربرد آن برای استخراج جاده از تصاویر SAR را ترکیب میکند، ارائه میشود. (1) سهم اصلی این مقاله معرفی دو روش تشخیص جاده برای تجزیه و تحلیل چند مقیاسی و ترکیب آنها با استفاده از چارچوب بیزی برای استفاده کامل از نقاط قوت تجزیه و تحلیل چند مقیاسی است. بهینه سازی ارتباط CRF منجر به شبکه جاده ای بهتر در مقایسه با روش های تشخیص جداگانه می شود. شبکه راه های گروه بندی شده از CRF بهترین ویژگی های هر روش را در خود جای داده است. به طور خاص، MLFD خطوط کلی جاده را هدایت می کند و صدای نسبتا کمی تولید می کند، در حالی که beamlet بخش های پیچیده ای را حتی در مناطق پیچیده و تقاطع ها ارائه می دهد. (2) در مدل CRF، MLFD ویژگیهای احتمال چند مقیاسی را برای هر بخش دوتایی فراهم میکند، و محدودیتهای قبلی تحت تجزیه و تحلیل پرتو به دست میآیند. الگوریتم یادگیری و استنتاج در یک ساختار هرمی یکنواخت، یافتن نتایج بهینه جهانی مشترک را تضمین می کند. (3) نتایج تجربی نشان می دهد که روش همجوشی پیشنهادی برای استخراج جاده در تصاویر SAR به طور قابل توجهی در صحت و کیفیت در مقایسه با هر اپراتور مستقل و رویکرد بهینه سازی مبتنی بر MRF بهبود یافته است، که کارایی روش همجوشی ما را با استفاده از CRF تأیید می کند.









بدون نظر