

خلاصه
تقاطع ها اجزای مهم شبکه های جاده ای هستند که هم برای برنامه ریزی مسیر و هم برای بهینه سازی مسیر حیاتی هستند. اکثر روشهای موجود تقاطعها را به عنوان مکانهایی تعریف میکنند که کاربران جاده جهت حرکت خود را تغییر میدهند و از طریق تجزیه و تحلیل رفتارهای چرخشی کاربران جاده، تقاطعها را از روی ردیابی GPS شناسایی میکنند. با این حال، این روشها از یافتن آستانه مناسب برای تغییر جهت متحرک رنج میبرند، که منجر به شناسایی نشدن تقاطعهای واقعی یا تشخیص نادرست تقاطعهای جعلی میشود. در این مقاله، تقاطع ها به عنوان مکان هایی تعریف می شوند که سه یا چند بخش جاده را در جهات مختلف به هم متصل می کنند. ما پیشنهاد میکنیم که تقاطعها را در این تعریف با یافتن زیرمجموعههای مشترک ردیابی GPS شناسایی کنیم. ما ابتدا با استفاده از رویکرد برنامهنویسی پویا، طولانیترین دنبالههای متداول (LCSS) را بین هر جفت ردیابی GPS شناسایی میکنیم. دوم، ما طولانی ترین دنباله های غیر متوالی را به زیر آهنگ های متوالی تقسیم می کنیم. نقاط شروع و پایان مسیرهای فرعی مشترک به عنوان نقاط اتصال جمع آوری می شوند. در نهایت، تقاطع ها از طریق تخمین تراکم هسته (KDE) از نقاط اتصال شناسایی می شوند. نتایج تجربی نشان میدهد که روش پیشنهادی ما از نظر امتیاز F از روشهای مبتنی بر نقطه عطف بهتر عمل میکند. تقاطع ها از طریق تخمین تراکم هسته (KDE) از نقاط اتصال شناسایی می شوند. نتایج تجربی نشان میدهد که روش پیشنهادی ما از نظر امتیاز F از روشهای مبتنی بر نقطه عطف بهتر عمل میکند. تقاطع ها از طریق تخمین تراکم هسته (KDE) از نقاط اتصال شناسایی می شوند. نتایج تجربی نشان میدهد که روش پیشنهادی ما از نظر امتیاز F از روشهای مبتنی بر نقطه عطف بهتر عمل میکند.
کلید واژه ها:
تشخیص تقاطع ; استنباط نقشه راه ; KDE ; LCSS ; ردیابی GPS
1. معرفی
شبکه جاده ای سیستمی از خطوط به هم پیوسته است که نشان دهنده راه های به هم پیوسته در یک منطقه معین است [ 1 ، 2 ، 3 ]. به طور سنتی، شبکههای جادهای از نقشهبرداری جغرافیایی از طریق دستگاههایی مانند تلسکوپ و سکسنت ساخته میشوند. این دستگاه های نقشه برداری بسیار گران هستند و انجام چنین بررسی هایی به زمان و تلاش زیادی نیاز دارد. در نتیجه، چنین نقشه هایی را نمی توان به طور مکرر به روز کرد [ 4]. با توسعه فناوری سیستم موقعیت یاب جهانی (GPS) در چند دهه اخیر، کمپین های نقشه برداری سیار با دستگاه های GPS جایگزین دستگاه های نقشه برداری در مناطق شهری شده و هزینه نیروی کار برای تولید نقشه راه را کاهش داده است. اگرچه، هنوز هم زمان بر است تا کمپین ها تمام خیابان های روی نقشه را پوشش دهند. بنابراین، به روز رسانی نقشه به طور قابل توجهی از ساخت و ساز جاده عقب است. به لطف استفاده همه جانبه از واحدهای GPS دستی، اکنون میتوانیم به راحتی دادههای ردیابی GPS عظیم را از انواع کاربران جاده مانند رانندگان وسایل نقلیه، دوچرخهسواران و عابران پیاده بهدست آوریم. این توسعه استنتاج شبکه جاده ای خودکار را شبیه سازی کرده است [ 5 , 6 , 7 , 8 , 9 , 10 , 11 .، 12 ].
تقاطع های جاده ای نقش مهمی در شبکه های جاده ای ایفا می کنند. آنها می توانند اطلاعات بسیار مفیدی مانند اتصال، توپولوژی و جهت حرکت مجاز را ارائه دهند که نه تنها برای ساخت توپولوژی شبکه جاده ها مفید است، بلکه برای تولید نمایش هندسی بخش های جاده در شبکه نیز مفید است. بر اساس شبکه جادهای تولید شده، میتوانیم ترجیحات مسافران در انتخاب مسیر [ 13 ]، انتقال بین حالتهای مختلف حملونقل [ 14 ]، تراکم ترافیک در جادهها [ 15 ، 16 ، 17 ]، تأخیرهای ناشی از ترافیک [ 9 ، 14 ، 18 ، 19]، و غیره.
در ادبیات، برخی از روشهای غیرمستقیم برای تشخیص تقاطعها با بررسی تغییرات جهت حرکت کاربران جاده در مسیرشان پیشنهاد شدهاند. Karagiorgou و Pfoser نمونه های چرخشی را از ردیابی GPS با آستانه گذاری سرعت حرکت و تغییر جهت حرکت شناسایی کردند [ 10 ]. بردار از نقطه فعلی به نقطه مجاور بعدی برای توصیف جهت حرکت در این نقطه استفاده شد. یک روش خوشهبندی سلسله مراتبی تجمعی برای خوشهبندی نمونههای چرخشی به گرههای تقاطع Wu و همکاران استفاده شد. برای اولین بار نقاط عطف را از ردیابی درشت GPS با آستانه گذاری در تغییر جهت حرکت پیدا کرد [ 20]]. برای بهبود غلظت نقاط عطف، آنها نقاط متقاطع را جمع آوری کردند، جایی که نقاط عطف همگرا شدند. الگوریتم X-means در کار آنها برای خوشه بندی نقاط همگرا به تقاطع ها استفاده شد [ 21 ]. وانگ و همکاران ابتدا نقاط درگیری را شناسایی کرد، جایی که دو یا چند اثر از طریق آستانه تغییر جهت حرکت کاربران جاده از هم متقاطع، واگرا یا همگرا می شوند [ 22 ]. آنها سپس موقعیت مکانی و دایره مرزی هر تقاطع جاده را از نقاط درگیری محاسبه کردند. در کار قبلی ما [ 23]، جهت حرکت را در هر نقطه GPS با استفاده از نقطه جلوتر از آن با فاصله ثابت تا آن، به جای نقطه بعدی محاسبه کردیم و نقاط عطف را با تغییر جهت حرکت در نامزدهای تقاطع دسته بندی کردیم. ما در نهایت الگوهای چرخش را بررسی کردیم تا خم های نادرست شناسایی شده را حذف کنیم.
اگرچه محققین ذکر شده در بالا تکنیک های مختلفی را برای تشخیص تقاطع ها اعمال کرده اند، اما اساس الگوریتمی آنها یکسان است: تقاطع به عنوان مکان یا منطقه ای تعریف می شود که کاربران جاده اغلب جهت حرکت خود را تغییر می دهند. محدودیت این رویکردها این است که تعیین آستانه مناسب برای تغییر جهت حرکت دشوار است. آستانه پایین منجر به شناسایی نادرست تقاطع های جعلی بیشتر می شود و آستانه بالا منجر به شناسایی نشدن تقاطع های واقعی بیشتر می شود.
متفاوت از روش های بالا، فتحی و کروم یک توصیفگر شکل طراحی کردند که نشان دهنده توزیع ردپای GPS در اطراف یک نقطه است و یک طبقه بندی بر روی توصیفگر آموزش دادند تا نقاط تقاطع را از نقاط غیرتقاطع متمایز کند [24 ] . نتایج آنها نشان داد که تقاطع های شناسایی شده با حقیقت زمینی آنها مطابقت نزدیکی دارد. با این حال، آنها باید برای هر نوع جدید تقاطع یک توصیفگر شکل جدید آموزش دهند که برای به روز رسانی خودکار نقشه راه مناسب نیست.
در این اثر، یک تقاطع با ویژگی خاص خود به عنوان مکانی که سه یا چند بخش جاده را در جهات مختلف به هم متصل می کند، تعریف می شود. بر اساس این تعریف، یک روش جدید برای تشخیص تقاطعها از ردیابی GPS بر اساس الگوریتم طولانیترین دنباله مشترک (LCSS) پیشنهاد شدهاست. ابتدا، ردیابیهای GPS جفتی برای یافتن طولانیترین دنبالههای مشترک بین آنها تراز میشوند. سپس دنباله های غیر متوالی به زیر آهنگ های متوالی تقسیم می شوند. دوم، نقاط شروع و پایان مسیرهای فرعی مشترک به عنوان نقاط اتصال جمع آوری می شوند، در صورتی که هیچ یک از ردیابی های GPS در آنجا شروع یا ختم نمی شوند. چگالی نقاط اتصال تخمین زده می شود و حداکثرهای محلی در نقشه چگالی به عنوان تقاطع شناسایی می شوند. در آخر،
نتایج اولیه در یک مقاله چهار صفحه ای نوشته شد و در سال 2016 در سمپوزیوم بین المللی علوم زمین و سنجش از دور IEEE [ 25] منتشر شد.]. در این مقاله، الگوریتم تشخیص تقاطع خود را با عمق بیشتری شرح می دهیم. به جز مسیرهای فرعی رایج در یک جهت، با معکوس کردن یکی از ردیابیهای GPS و اعمال الگوریتم LCSS بر روی آنها، زیر مسیرهای رایج را در جهت مخالف نیز مییابیم. ما استحکام الگوریتم خود را در برابر خطاهای GPS با بررسی الگوهای ملاقات ردیابی GPS در تقاطع ها و حذف تقاطع هایی که از یک ردیابی GPS منفرد شناسایی می شوند که با همه ردیابی های دیگر همگرا یا واگرا شده اند، بهبود می دهیم. علاوه بر این، ما دقت تقاطع های شناسایی شده را به طور کامل با استفاده از معیار F-score ارزیابی می کنیم که هم دقت و هم یادآوری را در نظر می گیرد.
ساختار باقی مانده این مقاله به شرح زیر است. در بخش بعدی، مشکل تشخیص تقاطع از ردیابی GPS را با توجه به تعریف تقاطع جدید ارائه میکنیم، سپس بخش 3 را توضیح میدهیم که چگونه میتوان مسیرهای فرعی مشترک بین ردیابیهای جفتی را شناسایی کرد و از نقاط شروع و پایان این موارد فرعی استفاده کرد. مسیرهایی برای شناسایی تقاطع ها بخش 4 نتایج تجربی ما را نشان می دهد. در نهایت، نتیجه در بخش 5 ترسیم شده است .
2. بیان مشکل
در این کار، ما یک قطعه جاده را به عنوان دنباله ای از مکان های جغرافیایی غیر تقاطع تعریف می کنیم که دو تقاطع را به هم متصل می کند. کاربران جاده اغلب به جای یک بخش جاده، دنباله ای از بخش های جاده را طی می کنند تا به مقصد خود برسند. در سفرهای خود، آنها ممکن است یک بخش جاده را طی کنند و سپس به بخش های مختلف جاده تقسیم شوند. یا ممکن است از بخش های مختلف جاده به یک بخش جاده تردد کنند. در نتیجه، ردیابی GPS تولید شده ممکن است از بخش های مختلف جاده به بخش جاده مشترک همگرا شود یا از بخش جاده مشترک به بخش های مختلف جاده منحرف شود. نقاط همگرا و واگرا در ردیابی GPS در تقاطع ها قرار دارند. بنابراین، تقاطع ها را می توان از طریق یافتن مسیرهای فرعی مشترک ردیابی GPS ثبت شده در همان بخش های جاده شناسایی کرد. یک مسیر فرعی مشترک، دنباله ای از نقاط است که به ترتیب نسبی یکسان ظاهر می شود و موقعیت های متوالی را در هر دو ردیابی GPS اشغال می کند. هر مسیر فرعی مشترک مربوط به یک بخش جاده مشترک است.
شکل 1نمونه ای از دو رد GPS را نشان می دهد که در یک تقاطع واگرا شده و سپس در تقاطع دیگر همگرا می شوند. اولین ردیابی GPS که شامل 16 نقطه است، با استفاده از خطوط آبی با نقاط آبی نشان داده می شود که مکان های نقطه را نشان می دهد. 12 نقطه در رد دوم وجود دارد که با خطوط قرمز با نقطه نشان داده شده است. فلش ها نشان می دهد که کاربران جاده در هر دو مسیر از یک منطقه عرض جغرافیایی بالاتر به یک منطقه عرض جغرافیایی پایین تر حرکت می کنند. هر دو کاربر جاده سفر خود را در یک بخش جاده شروع می کنند، در اولین تقاطع که با استفاده از ستاره سیاه نشان داده شده است، به بخش های مختلف جاده تقسیم می شوند، در تقاطع دوم که با استفاده از یک مثلث سیاه نشان داده شده است، به بخش دیگری از جاده می آیند و سفر خود را در این پایان می دهند. بخش جاده ردیابی GPS تولید شده در تقاطع اول از هم جدا می شود و در تقاطع دوم همگرا می شود.
3. روش پیشنهادی
در این بخش ابتدا طولانیترین دنبالههای مشترک بین ردیابیهای GPS زوجی را پیدا میکنیم، سپس آنها را به زیر آهنگهای مشترک تقسیم میکنیم. نقاط شروع و پایان مسیرهای فرعی مشترک، یعنی نقاط همگرا و واگرای ردیابی ها، به عنوان نقاط اتصال جمع آوری می شوند. سپس تقاطع ها را از نقاط اتصال از طریق KDE شناسایی می کنیم. در نهایت، ما الگوهای ملاقات ردیابی GPS در تقاطع ها را بررسی می کنیم، به طوری که تقاطع های مثبت کاذب شناسایی شده از یک رد منفرد همگرا یا واگرا با همه ردیابی های دیگر را حذف می کنیم.
3.1. طولانی ترین دنباله متداول
دنباله ردیابی دنباله ای از نقاط داده است که به همان ترتیب نسبی در ردیابی اصلی ظاهر می شود که یک مسیر فرعی نشان می دهد، اما لزوماً موقعیت های متوالی را مانند یک مسیر فرعی اشغال نمی کند. دنباله مشترک دو ردیابی GPS، دنباله ای است که در هر دوی آنها وجود دارد. طولانی ترین زیر دنباله مشترک یک زیر دنباله مشترک از طول حداکثر است. سادهلوحانهترین رویکرد برای یافتن طولانیترین دنباله، برشمردن همه دنبالههای مشترک برای هر دو ردیابی GPS و انتخاب یکی با طول حداکثر است. با این حال، استفاده از این رویکرد بسیار زمان بر است. برای غلبه بر این چالش، از برنامه نویسی پویا برای یافتن طولانی ترین دنباله به طور موثر استفاده می شود [ 26 ].
برنامه نویسی پویا الگوریتمی است برای شکستن یک مسئله پیچیده به مجموعه ای از مسائل فرعی ساده تر، ابتدا هر یک از آن مسائل فرعی را حل می کند و سپس از آنها برای یافتن راه حل مسئله پیچیده استفاده می کند [ 27 ، 28 ، 29 ]. در مورد ما، به جای یافتن LCSS بین دو ردیابی کامل، ابتدا LCSS را بین پیشوندهای کوچکتر ردیابی ها پیدا کرده و از آنها برای یافتن LCSS بین پیشوندهای بزرگتر استفاده می کنیم، تا زمانی که LCSS را بین کل ردیابی ها پیدا کنیم.
نمادهای زیر را اتخاذ می کنیم. فرض کنید دو رد GPS داریم r( 1 )�(1)و r( 2 )�(2). اجازه دهید r( 1 )(تی1)�(1)(�1)، تی1= 1 ، … ،تی1�1=1,…,�1و r( 2 )(تی2)�(2)(تی2)، تی2= 1 ، … ،تی2تی2=1،…،تی2نقاط از r( 1 )�(1)و r( 2 )�(2)، جایی که تی1تی1و تی2تی2به ترتیب تعداد نقاط در هر ردیابی است. اولین مرحله اجرای برنامه نویسی پویا، ایجاد یک دو بعدی (2 بعدی) است. تی1×تی2تی1×تی2ماتریس طول L. مقدار در هر سلول، L (تی1،تی2)�(�1,�2)، نشان دهنده طول طولانی ترین دنباله های مشترک بین پیشوندهای ردیابی های داده شده است، r( 1 )( من )�(1)(�)، i = 1 ، … ،تی1من=1،…،تی1و r( 2 )( j )�(2)(�)، j = 1 ، … ،تی2�=1،…،تی2. بستگی به شباهت نقاط دارد r( 1 )(تی1)�(1)(تی1)و r( 2 )(تی2)�(2)(تی2)و مقادیر سلول های مجاور آن { L (تی1،تی2− 1 , L ( _تی1− 1 ،تی2) ، L (تی1− 1 ،تی2− 1 ) }{�(�1,�2−1),�(�1−1,�2),�(�1−1,�2−1)}. ما همچنین یک 2 بعدی ایجاد می کنیم تی1×تی2�1×�2ماتریس فلش B فلش در هر سلول، ب (تی1،تی2)�(�1,�2)، نشان می دهد کدام یک از سلول های مجاور L (تی1،تی2)�(�1,�2)مطابق با معادله ( 2 ) محاسبه می شود.
L (تی1،تی2)=△⎧⎩⎨⎪⎪0 ,L (تی1− 1 ،تی2− 1 ) + 1 ,m a x ( L (تی1،تی2− 1 , L ( _تی1− 1 ،تی2) ) ،اگرتی1= 0یاتی2= 0اگرتی1،تی2> 0ود(r1(تی1) ،r2(تی2) ) ≤دt h r eاگرتی1،تی2> 0ود(r1(تی1) ،r2(تی2) ) >دt h r e�(تی1،تی2)=▵{0،اگرتی1=0یاتی2=0�(تی1–1،تی2–1)+1،اگرتی1،تی2>0ود(�1(تی1)،�2(تی2))≤دتیساعت�همترآایکس(�(تی1،تی2–1)،�(تی1–1،تی2))،اگرتی1،تی2>0ود(�1(تی1)،�2(تی2))>دتیساعت�ه
جایی که تی1∈ [ 0 ,تی1]تی1∈[0،تی1]و تی2∈ [ 0 ,تی2]تی2∈[0،تی2]. فاصله جغرافیایی بین دو نقطه، د(r( 1 )(تی1) ،r( 2 )(تی2) )د(�(1)(تی1)،�(2)(تی2))، برای اندازه گیری عدم تشابه محلی آنها استفاده می شود. آستانه فاصله دt h r eدتیساعت�هباید بر اساس عرض جاده و خطای مورد انتظار GPS انتخاب شود.
ب (تی1،تی2)=△⎧⎩⎨⎪⎪↑ ،← ،↖ ،اگرL (تی1،تی2) = L (تی1− 1 ،تی2)وL (تی1− 1 ،تی2) ≤ L (تی1،تی2– 1 )اگرL (تی1،تی2) = L (تی1،تی2– 1 )وL (تی1− 1 ،تی2) < L (تی1،تی2– 1 )اگرL (تی1،تی2) = L (تی1− 1 ،تی2− 1 ) + 1 ,ب(تی1،تی2)=▵{↑،اگر�(تی1،تی2)=�(تی1–1،تی2)و�(تی1–1،تی2)≤�(تی1،تی2–1)←،اگر�(تی1،تی2)=�(تی1،تی2–1)و�(تی1–1،تی2)<�(تی1،تی2–1)↖،اگر�(تی1،تی2)=�(تی1–1،تی2–1)+1،
جایی که تی1∈ [ 1 ،تی1]تی1∈[1،تی1]و تی2∈ [ 1 ،تی2]تی2∈[1،تی2].
| الگوریتم 1 FindPath. |
| ورودی: L , B |
| خروجی: g1( ک )�1(ک)، g2( ک )�2(ک)، w2( ک )�2(ک)، w2( ک )�2(ک)، k = 1 … Kک=1…ک |
| مقداردهی اولیه تی1←تی1تی1←تی1، تی2←تی2تی2←تی2، k ← 1ک←1 |
| 2: در حالی که تی1+تی2> 2تی1+تی2>2 انجام دادن |
| اگر تی1= 1تی1=1 سپس |
| 4: تی2←تی2– 1تی2←تی2–1 |
| دیگر اگر تی2= 1تی2=1 سپس |
| 6: تی1←تی1– 1تی1←تی1–1 |
| دیگر |
| 8: سوئیچ ب (تی1،تی2)ب(تی1،تی2) انجام دادن |
| مورد ” ↖ ““↖” |
| 10: g1( k ) =r( 1 )(تی1)�1(ک)=�(1)(تی1)، g2( k ) =r( 2 )(تی2)�2(ک)=�(2)(تی2) |
| w1( k ) =تی1�1(ک)=تی1، w2( k ) =تی2�2(ک)=تی2 |
| 12: k ← k + 1ک←ک+1 |
| تی1←تی2– 1تی1←تی2–1، تی2←تی2– 1تی2←تی2–1 |
| 14: مورد ” ↑ ““↑” |
| تی1←تی1– 1تی1←تی1–1 |
| 16: مورد ” ← ““←” |
| تی2←تی2– 1تی2←تی2–1 |
| 18: پایان اگر |
| 20: پایان در حالی که |
| اگر L ( 1 , 1 ) = L (تی1،تی2) – 1�(1،1)=�(تی1،تی2)–1 سپس |
| 22: g1( k ) =r( 1 )( 1 )�1(ک)=�(1)(1)، g2( k ) =r( 2 )( 1 )�2(ک)=�(2)(1) |
| w1( k ) = 1�1(ک)=1، w2( k ) = 1�2(ک)=1 |
| 24: پایان اگر |
| g1← معکوس (g1)�1←معکوس(�1)، g2← معکوس (g2)�2←معکوس(�2) |
| 26: w1← معکوس (w1)�1←معکوس(�1)، w2← معکوس (w2)�2←معکوس(�2) |
هنگامی که ماتریس طول L و ماتریس جهت B ساخته شد، طولانیترین دنبالههای متداول با دنبال کردن فلشها به سمت عقب از طریق ماتریس B استنتاج میشوند . از آخرین سلول شروع می شود (تی1،تی2)(تی1،تی2)و به سلول اول ختم می شود ( 1 , 1 )(1،1). اگر طول کاهش یابد، ردیابی ها باید نقاط داده مشابهی داشته باشند. این دو نقطه داده به طولانی ترین دنباله ها اضافه می شوند، g1�1و g2�2، به ترتیب برای هر ردیابی و شاخص های زمانی آنها در ردیابی های اصلی به آن اضافه می شود w1�1و w2�2، یعنی g1( k ) =r( 1 )(w1( ک ) )�1(ک)=�(1)(�1(ک))و g2( k ) =r( 2 )(w2( ک ) )�2(ک)=�(2)(�2(ک)). الگوریتم 1 روش را توضیح می دهد.
شکل 2 روش یافتن LCSS ها بین دو ردیابی GPS را نشان می دهد. شکل 2 a LCSS را برای هر ردیابی GPS به ترتیب با استفاده از خطوط آبی با نقاط سیاه و خطوط قرمز با نقاط سیاه نشان می دهد. در مجموع، 9 نقطه در LCSS برای هر ردیابی وجود دارد. LCSS برای اولین ردیابی به صورت بیان می شود r( 1 )(تی1)�(1)(تی1)، تی1= 1 , 2 , 3 , 4 , 5 , 13 , 14 , 15 , 16تی1=1،2،3،4،5،13،14،15،16، و r( 2 )(تی2)�(2)(تی2)، تی2= 1 , 2 , 3 , 4 , 5 , 9 , 10 , 11 , 12تی2=1،2،3،4،5،9،10،11،12برای دومی است
شکل 2 b طول ماتریس L و ماتریس فلش B را در شبکه ها نشان می دهد. روال “بازگشت” از سلول شروع می شود ( 16 , 12 )(16،12)و جهت فلش ها را به سمت سلول اول دنبال می کند ( 1 , 1 )(1،1). مسیر عبور از ماتریس با استفاده از سلول هایی با پس زمینه خاکستری نشان داده می شود. فقط نقاط مربوط به سلولهای با طول رو به کاهش برای LCSS ذخیره میشوند. طول این سلول ها با اعداد سبز نشان داده شده است.
3.2. مجموعه نقاط اتصال
دنبالهای دنبالهای از نقاطی است که به ترتیب نسبی یکسان ظاهر میشوند و نیازی به اشغال موقعیتهای متوالی در ردیابی اولیه ندارند. طولانی ترین دنباله متداول ممکن است با بیش از یک بخش جاده مطابقت داشته باشد. با این حال، ما بیشتر علاقه مند به زیر مسیرهای مشترک برای هر دو ردیابی GPS هستیم، که نقاط آنها موقعیت های متوالی را در ردیابی های اصلی اشغال می کنند. هر مسیر فرعی مشترک مربوط به یک بخش جاده است که کاربران جاده در هر دو مسیر از آن عبور می کنند. بنابراین، نقطه شروع و پایان مسیر فرعی منطبق بر دو انتهای قطعه جاده، یعنی تقاطع ها است. مسیرهای فرعی مشترک بین دو ردیابی GPS را می توان با پارتیشن بندی طولانی ترین دنباله های مشترک بدست آورد.
ابتدا متوالی بودن نقاط طولانی ترین دنباله های مشترک را بررسی می کنیم. با توجه به k- امین نقاط LCSS برای هر دو ردیابی، g1( ک )�1(ک)و g2( ک )�2(ک)، و زمان آنها را در ردیابی اصلی نمایه می کند w1( ک )�1(ک)و w2( ک )�2(ک)، آنها نقاط غیر متوالی در صورت نقاط بعدی هستند g1( k + 1 )�1(ک+1)و g2( k + 1 )�2(ک+1)موقعیت هایی بسیار جلوتر از آنها در آثار اولیه اشغال می کنند، به عنوان مثال، w1( k + 1 ) –w1( k ) > ξ�1(ک+1)–�1(ک)>�و w2( k + 1 ) –w2( k ) > ξ�2(ک+1)–�2(ک)>�، جایی که ξ یک آستانه از پیش تعریف شده است. در این کار، ما ξ را بزرگتر از یک تنظیم می کنیم تا نقاط انحرافی روی ردیابی، که به دلیل خطاهای GPS ایجاد می شوند، به اشتباه به عنوان نقاط غیر متوالی شناسایی شوند.
طولانی ترین دنباله مشترک توسط این نقاط غیر متوالی به زیر آهنگ های مشترک تقسیم می شود. اگر تمام نقاط LCSS ها متوالی باشند، اگر نقطه شروع و پایان این دو رد GPS نباشند، مستقیماً نقطه شروع و پایان LCSS ها را به عنوان نقاط اتصال می گیریم.
همانطور که در شکل 2 نشان داده شده است ، نقاط پنجم LCSS ها در ردیابی های اصلی متوالی نیستند. برای ردیابی r( 1 )�(1)، ششمین نقطه LCSS آن در جایگاه سیزدهم قرار دارد r( 1 )�(1). نقاط پنجم و ششم LCSS با هفت نقطه آبی از هم جدا شده اند. برای ردیابی r( 2 )�(2)، ششمین نقطه LCSS آن جایگاه هشتم را به خود اختصاص داده است r( 2 )�(2). نقاط پنجم و ششم LCSS با دو نقطه قرمز از هم جدا شده اند. بنابراین، هر LCSS توسط نقطه پنجم به دو تراک فرعی تقسیم میشود: آهنگ فرعی اول شامل پنج نقطه و دومی شامل چهار نقطه. برای اولین ردیابی، زیر آهنگ های رایج شناسایی شده هستند r( 1 )(تی1)�(1)(تی1)، تی1= 1 ، 2 ، 3 ، 4 ، 5تی1=1،2،3،4،5و r( 1 )(تی1)�(1)(تی1)، تی1= 13 ، 14 ، 15 ، 16تی1=13،14،15،16. آهنگ های فرعی رایج برای ردیابی دوم هستند r( 2 )(تی2)�(2)(تی2)، تی2= 1 ، 2 ، 3 ، 4 ، 5تی2=1،2،3،4،5و r( 2 )(تی2)�(2)(تی2)، تی2= 8 ، 9 ، 10 ، 11تی2=8،9،10،11. نقاط پایانی اولین آهنگ فرعی مشترک برای هر ردیابی، r( 1 )( 5 )�(1)(5)و r( 2 )( 5 )�(2)(5)، نقاط اتصال هستند و نقاط شروع آهنگ فرعی دوم برای هر ردیابی، r( 1 )( 13 )�(1)(13)و r( 2 )( 8 )�(2)(8)، همچنین نقاط اتصال هستند. نقاط شروع اولین آهنگ فرعی مشترک برای هر ردیابی، r( 1 )( 1 )�(1)(1)و r( 2 )( 1 )�(2)(1)، نقاط اتصال نیستند زیرا آنها همچنین نقاط شروع ردیابی GPS هستند. نقاط پایانی آهنگ فرعی دوم برای هر ردیابی، r( 1 )( 16 )�(1)(16)و r( 2 )( 11 )�(2)(11)، نقاط اتصال نیستند زیرا r( 1 )( 16 )�(1)(16)نقطه پایان ردیابی است r( 1 )�(1).
روش شناسایی LCSS ها دو رد GPS را به صورت جهت دار پردازش می کند که از ابتدای هر دو ردیابی شروع می شود و در انتهای هر دو ردیابی خاتمه می یابد. بنابراین، تنها مسیرهای فرعی مشترک در یک جهت قابل شناسایی هستند. اگر کاربران جاده از همان بخش جاده عبور کنند و دو اثر ایجاد کنند، اما در جهت مخالف، هیچ مسیر فرعی مشترکی بین آنها یافت نمی شود. همانطور که در شکل 3 نشان داده شده است، همه ردیابی های GPS یک بخش جاده را بین دو تقاطع مشترک دارند که با دایره های قرمز نشان داده می شوند. در این بخش جاده، کاربران جاده در مسیرهای آبی از چپ به راست، اما در مسیرهای سیاه از راست به چپ حرکت میکنند. هیچ مسیر فرعی مشترکی بین مسیرهای آبی و سیاه یافت نمیشود، اگرچه آنها در یک بخش جاده مشترک هستند. بنابراین، نقاط اتصال در انتهای مسیرهای فرعی مشترک در جهات مخالف تشخیص داده نمی شود و منجر به نادرست بودن تشخیص تقاطع می شود. این را می توان با معکوس کردن نقاط داده ردیابی سیاه حل کرد.
با توجه به مجموعه داده ای از N ردیابی GPS، ابتدا ردهای فرعی مشترک بین هر جفت ردیابی GPS را همانطور که در بالا توضیح داده شد پیدا می کنیم و نقاط شروع و پایان مسیرهای فرعی مشترک را به عنوان نقاط اتصال جمع می کنیم، اگر آنها شروع و پایان نباشند. نقاط این دو رد GPS. سپس یک ردیابی را در هر جفت ردیابی GPS معکوس می کنیم و این روش را دوباره تکرار می کنیم تا نقاط اتصال بیشتری پیدا کنیم.
3.3. استخراج تقاطع از نقاط اتصال
در این بخش، تقاطع ها با استفاده از نقاط اتصال با تخمین تراکم آنها در منطقه تحت پوشش ردیابی GPS شناسایی می شوند. ابتدا منطقه جغرافیایی را به یک شبکه دو بعدی (2 بعدی) از سلول ها گسسته می کنیم و تعداد نقاط اتصال را در هر سلول می شماریم و یک هیستوگرام دو بعدی تولید می کنیم [ 5 ، 30 ]. سپس این هیستوگرام دوبعدی را با یک تابع هموارسازی گاوسی در هم میکشیم ن( 0 ,σ2)ن(0،�2)، که منجر به تقریبی از تخمین تراکم هسته (KDE) می شود. پارامتر σ تأثیر قوی بر تخمین حاصل از خود نشان می دهد. یک σ کوچک می تواند باعث شود که هیستوگرام دوبعدی زیر هموار شود و در نتیجه بیش از یک تقاطع در محل یک تقاطع واقعی شناسایی شود. یک σ بزرگ ممکن است منجر به هموار شدن بیش از حد شود، سپس دو تقاطع مجاور در نقشه چگالی با هم ادغام می شوند. بنابراین، انتخاب σ باید بسته به اندازه تقاطع و حداقل فاصله بین تقاطع های مجاور انجام شود.
حداکثرهای محلی در نقشه چگالی، به عنوان مثال، سلول هایی که مقادیر بیشتری نسبت به همسایگان خود دارند، به عنوان تقاطع تشخیص داده می شوند. خروجی های این مرحله موقعیت های جغرافیایی تقاطع های شناسایی شده و نقاط اتصالی است که به هر تقاطع تعلق دارد.
نقاط اتصال از تراز ردیابی GPS با استفاده از الگوریتم LCSS شناسایی می شوند. یک جلسه ردیابی منفرد با بسیاری دیگر از ردیابیهای GPS مشابه در یک مکان میتواند تعداد زیادی نقطه اتصال ایجاد کند که منجر به حداکثر محلی در نقشه چگالی میشود. با این حال، این ردیابی GPS می تواند یک رد غیر طبیعی باشد که به دلیل خطاهای GPS از جاده منحرف می شود. یک مثال در شکل 4 نشان داده شده است . این منجر به تشخیص نادرست تقاطع می شود. بنابراین، ما باید الگوهای ملاقات ردیابی GPS را در یک تقاطع بررسی کنیم و این نوع تقاطع شناسایی شده را حذف کنیم تا الگوریتم خود را در برابر خطاهای GPS قوی تر کنیم.
با توجه به نامزد تقاطع q�، M نقاط اتصال متعلق به این تقاطع وجود داردr( من ( م ) )(تیمن ( م ))�(من(متر))(تیمن(متر))و r( j ( m ) )(تیj ( m ))�(�(متر))(تی�(متر))، i ( m ) ∈ [ 1 ، N]من(متر)∈[1،ن]، j ( m ) ∈ [ 1 ، N]�(متر)∈[1،ن]، تیمن ( م )∈ [ 1 ،تیمن ( م )]تیمن(متر)∈[1،تیمن(متر)]، تیj ( m )∈ [ 1 ،تیj ( m )]تی�(متر)∈[1،تی�(متر)]، m = 1 ، … ، Mمتر=1،…،م، که در آن N تعداد ردیابی های GPS در مجموعه داده است و من ( م )من(متر)و j ( m )�(متر)شاخص های ردپایی هستند که نقاط اتصال را ایجاد می کنند r( من ( م ) )(تیمن ( م ))�(من(متر))(تیمن(متر))و r( j ( m ) )(تیj ( m ))�(�(متر))(تی�(متر)). اجازه دهید پnپ�تعداد نقاط اتصالی باشد که با تراز کردن ردیابی شناسایی می شوند r( n )(تیn)�(�)(تی�)با سایر ردیابی ها با استفاده از LCSS، پn=∑مm = 11 { i ( m ) = n } +∑مm = 11 { j ( m ) = n }پ�=∑متر=1م1{من(متر)=�}+∑متر=1م1{�(متر)=�}. نقاط اتصال به صورت جفت شناسایی می شوند، یکی از r( n )(تیn)�(�)(تی�)و دیگری از رد دیگری. هر نقطه اتصال با تراز کردن دو ردیابی شناسایی می شود. از این رو ∑نn = 1پn= 2 M∑�=1نپ�=2م، جایی که پn≤ مپ�≤م. اگر تمام نقاط اتصال از ردیابی تراز شناسایی شوند r( n )(تیn)�(�)(تی�)با هر اثر دیگری، پn= مپ�=م. در این حالت، در صورت ردیابی، یک تقاطع به اشتباه از این نقاط اتصال تشخیص داده می شود r( n )(تیn)�(�)(تی�)یک اثر غیر طبیعی است برای هر ردیابی GPS محاسبه می کنیم پnپ�، n = 1 ، … ، N�=1،…،ن، و این نامزد تقاطع را در صورت وجود حذف کنید پnپ�برابر با M است .
همانطور که در شکل 4 نشان داده شده است، نامزد تقاطع نشان داده شده در دایره قرمز از تقاطع های واقعی حذف می شود زیرا تمام نقاط اتصال آن که با نقاط سبز نشان داده شده اند از تراز کردن ردیابی GPS که با استفاده از خطوط آبی با نقاط نشان داده شده است، با هر یک از نقاط دیگر شناسایی می شوند. 152 رد GPS با خطوط مشکی با نقطه نشان داده شده است. ما اعتراف میکنیم که تقاطعهای واقعی را نیز حذف خواهیم کرد که سه بخش جاده را به هم متصل میکنند، که در آن کاربران جاده دو بخش از جاده را بسیار مکرر طی میکنند، اما از بخش سوم جاده فقط یک بار عبور میکنند. این نامزد تقاطع شناسایی شده حذف خواهد شد تا زمانی که ردیابی GPS بیشتری برای تأیید وجود این بخش سوم جاده داشته باشیم.
3.4. اندازه گیری دقت
به دلیل دقت محدود ردیابیهای GPS، ممکن است تقاطعهای «جعلی» را شناسایی کنیم که با هیچ تقاطعی در نقشه حقیقت زمین مطابقت ندارند. به دلیل پوشش کم ردیابی GPS در برخی از مناطق، ممکن است همه تقاطع های زمین-حقیقت را شناسایی نکنیم. یک روش کارآمد تشخیص تقاطع قرار است تا حد امکان تقاطعهای واقعی زمین و تا حد امکان تقاطعهای «جعلی» و «گمشده» را شناسایی کند. بنابراین، ما یادآوری، دقت و امتیاز F روشهای تشخیص تقاطع را اندازهگیری میکنیم. فراخوان نشان دهنده نسبت تقاطع های “همسان” در بین تقاطع های “همسان” و تقاطع های “فقدان” است، به عنوان مثال، یادآوری =منج/ (منمتر+منج)به خاطر آوردن=منج/(منمتر+منج)، جایی که منمترمنمترو منجمنجبه ترتیب تعداد تقاطع های “فقدان” و تعداد تقاطع های “همسان” هستند. دقت، نسبت تقاطعهای «همسان» را در بین تمام تقاطعهای شناساییشده مشخص میکند، به عنوان مثال، دقت =منج/ (منس+منج)دقت، درستی=منج/(منس+منج)، جایی که منسمنستعداد تقاطع های “جعلی” است. ما از امتیاز F شناخته شده [ 31 ، 32 ] که با استفاده از دقت و یادآوری محاسبه می شود، به عنوان یک اندازه گیری دقت کلی استفاده می کنیم:
اف − امتیاز =2 × فراخوان × دقتفراخوانی + دقتاف–نمره=2×به خاطر آوردن×دقت، درستیبه خاطر آوردن+دقت، درستی
4. نتایج تجربی
برای ارزیابی عملکرد روش پیشنهادی ما، آن را بر روی مجموعه داده ای از 889 ردیابی GPS از شاتل های دانشگاه ایلینویز [ 33 ] اعمال کرده ایم. این مجموعه داده شامل 889 ردیابی GPS است و مساحتی از آن را پوشش می دهد 7 × 4 . 57×4.5کیلومتر 22. ردیابی ها با نرخ نمونه برداری از 1 تا 29 ثانیه (میانگین: 3.61 ثانیه) ثبت می شوند. شکل 5 ردیابی GPS را با استفاده از خطوط سیاه با نقاط نشان دهنده مکان های نقطه نشان می دهد. OpenStreetMap به عنوان حقیقت زمینی برای اندازه گیری دقت تقاطع های شناسایی شده استفاده می شود. در خیابانهایی که شاتلها از آنها عبور میکردند، 33 تقاطع زمین-حقیقت وجود دارد، همانطور که با استفاده از دایرههای آبی در شکل 5 نشان داده شده است .
4.1. نتایج روش پیشنهادی
به دلیل خطاهای GPS، برخی نقاط از ردیابی اصلی منحرف می شوند. این نقاط، دنبالههای فرعی رایج را با یک کوچک به تراکهای فرعی بیشتری تقسیم میکنند دt h r eدتیساعت�هدر معادله ( 1 )، منجر به نقاط اتصال نادرست در جاده می شود. با یک بزرگ دتیh r eدتیساعت�ه، نقاط اتصال برای تقاطع های مجاور ممکن است با هم همپوشانی داشته باشند و در نتیجه این تقاطع های مجاور قابل تشخیص نیستند. با در نظر گرفتن حداکثر عرض جاده 20 متر و خطاهای GPS، انتخاب کردیم دt h r eدتیساعت�هبه عنوان 40 متر برای این مجموعه داده.
شکل 6 نقاط اتصال را در نقاط سبز نشان می دهد. بیشتر نقاط اتصال در تقاطع ها جمع شده اند. در گوشه سمت راست بالای نقشه، به دلیل پوشش ناکافی شاتل، تنها چند نقطه اتصال شناسایی شده است. برخی از نقاط اتصال به دلیل خطاهای GPS به جای تقاطع ها در بخش های جاده یافت می شوند. یک مثال در مستطیل قرمز نشان داده شده است. یک رد GPS از جاده اصلی منحرف می شود. مسیرهای فرعی مشترک بین این ردیابی GPS و سایر ردیابی ها در وسط جاده شروع می شود، نه در یک انتهای بخش جاده، که منجر به نقاط اتصال مثبت کاذب می شود.
شکل 7 تخمین چگالی هسته نقاط اتصال را نشان می دهد. نقشه به گسسته شده است 1 × 11×1سلول های متر مربع یک هیستوگرام دوبعدی از نقاط اتصال تولید می شود و با یک تابع توزیع نرمال درگیر می شود ن( 0 ,σ2)ن(0،�2). ما انتخاب میکنیم σ= 15�=15متر بسته به اندازه تقاطع ها و حداقل فاصله بین دو تقاطع مجاور. برآورد تراکم قله های واضح در تقاطع ها را روی نقشه نشان می دهد.
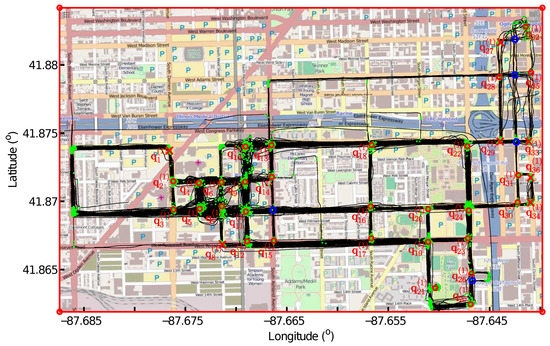
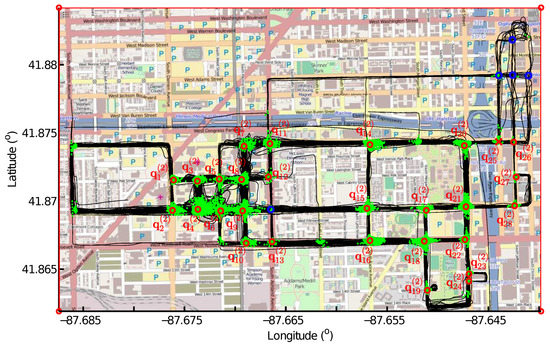
شکل 8 41 نامزد تقاطع را در دایره های قرمز نشان می دهد که حداکثرهای محلی در نقشه چگالی هستند. شکل 9 تقاطع های واقعی را پس از بررسی الگوهای ردیابی در کاندیداهای تقاطع نشان می دهد. اگر تمام نقاط اتصال در اطراف یک نامزد تقاطع توسط یک ردیابی GPS که با تعدادی رد دیگر تلاقی می کند به دست آید، حذف می شود زیرا وجود یک بخش جاده باید با ردیابی های بیشتری تأیید شود. در مجموع، 13 نامزد حذف شدند، و 28 تقاطع، از جمله 27 تقاطع واقعی که با دایره های قرمز نشان داده شده اند و یک تقاطع کاذب حفظ شدند. q(2 )25�25(2)در صلیب قرمز نشان داده شده است. q( 2 )25�25(2)با هیچ تقاطعی در نقشه زمین-حقیقت مطابقت ندارد. دایرههای آبی نشاندهنده تقاطعهایی است که نتوانستیم شناسایی کنیم.
اگرچه هیچ تقاطعی در محل یافت نشد q( 2)25�25(2)در نقشه زمین-حقیقت، شاتل ها از سه بخش جاده در جهات مختلف از کنار این مکان عبور می کنند. از آنجایی که OpenStreetMap در آگوست 2014 به عنوان نقشه واقعی زمین بارگیری شد، اما این مجموعه داده در آوریل 2011 ثبت شد، تقاطع گمشده q( 2 )25�25(2)بر روی نقشه حقیقت روی زمین می تواند ناشی از کنترل موقت ترافیک یا ساخت و ساز جاده باشد. برای تأیید این موضوع، نمای خیابان Google این مکان را در نزدیکترین تاریخها به تاریخ دسترسی بررسی کردیم و متوجه شدیم که بخش جاده بین تقاطع q( 2 )20�20(2)و q( 2 )25�25(2)در مهر 1393 در دست ساخت و صعب العبور بود. بنابراین، یک پیچ اتصال دو بخش جاده ای موجود در محل وجود دارد. q( 2 )25�25(2)در نقشه حقیقت زمینی، اما تقاطع سه بخش جاده که به هم متصل می شوند با استفاده از روش ما شناسایی می شود.
4.2. مقایسه ها
در این بخش، روش پیشنهادی خود را با روش مبتنی بر نقطه عطف در کار قبلی خود به طور مستقیم مقایسه می کنیم [ 23 ]. شکل 10 نقاط عطف را در نقاط سبز رنگ و تقاطع های شناسایی شده از نقاط عطف را در نشانگرهای قرمز نشان می دهد. پیچ ها، که فقط دو بخش جاده را به هم متصل می کنند، با بررسی الگوهای چرخش شاتل ها در این مکان ها حذف می شوند. در مجموع، 36 تقاطع پس از برداشتن خم، شامل 29 تقاطع واقعی که با دایره های قرمز نشان داده شده اند و هفت تقاطع کاذب که در صلیب های قرمز نشان داده شده اند، شناسایی می شوند. پنج تا از تقاطع های حقیقت زمین، که با استفاده از دایره های آبی نشان داده شده اند، با استفاده از روش مبتنی بر نقطه عطف شناسایی نمی شوند.
شکل 11 a,b دقت تقاطع های شناسایی شده از دو روش مختلف را به طور جداگانه نشان می دهد: شکل 11 a برای روش مبتنی بر نقطه چرخش و شکل 11 است.b برای روش پیشنهادی. آستانه تطبیق به عنوان فاصله مجاز بین تقاطع های شناسایی شده و موقعیت آنها در نقشه زمین-حقیقت تعریف می شود. تقاطع در صورتی که تقاطع زمین-حقیقت در فاصله مجاز وجود نداشته باشد جعلی محسوب می شود. با کمترین آستانه تطبیق پنج متری، هیچ تقاطع واقعی در نقشه زمین-حقیقت مطابق با تقاطع های شناسایی شده با استفاده از روش مبتنی بر نقطه عطف، و نه با استفاده از روش پیشنهادی، وجود ندارد. با بزرگتر شدن آستانه تطابق، تقاطع های بیشتری به درستی شناسایی می شوند. بنابراین، نسبت تقاطع های گم شده کمتر می شود و نسبت تقاطع های کاذب نیز کاهش می یابد و در نتیجه امتیاز F بالاتری به دست می آید. اف( 1 )منافمن(1)و اف( 2 )منافمن(2).
روش مبتنی بر نقطه عطف، تقاطعهای جعلی بیشتری را نسبت به روش پیشنهادی ما تشخیص میدهد، که در نتیجه بالاتر است. من(1 )سمنس(1)، اما پایین تر اف( 1 )منافمن(1)در شکل 11 الف، در مقایسه با من( 2)سمنس(2)و اف( 2 )منافمن(2)در شکل 11 ب. شکل 11 a نشان می دهد که روش مبتنی بر نقطه عطف به یک امتیاز F در حدود می رسد 0 . 80.8با آستانه منطبق 40 متر. با این حال، مقدار F-score روش پیشنهادی ما به آن می رسد 0 . 850.85با آستانه 30 متر این نشان میدهد که روش پیشنهادی ما در مقایسه با روشهای مبتنی بر تغییر جهت حرکت، دقت تشخیص بالاتری دارد. میانگین فاصله بین تقاطع های شناسایی شده و موقعیت زمین-حقیقت آنها است 14 . 9014.90m برای روش پیشنهادی ما و 22 . 6922.69m برای روش مبتنی بر نقطه عطف. این نیز تایید می کند که روش پیشنهادی بهتر از روش دیگر عمل می کند.
5. نتیجه گیری ها
ما یک رویکرد جدید برای شناسایی تقاطعها از ردیابیهای GPS با شناسایی زیر مسیرهای مشترک بین ردیابیهای زوجی با استفاده از LCSS ارائه کردهایم. نقاط شروع و پایان این مسیرهای فرعی متوالی به عنوان نقاط اتصال جمع آوری شده و برای یافتن تقاطع ها از طریق KDE استفاده می شود. الگوهای ملاقات ردیابی GPS در تقاطع ها بررسی می شوند تا تشخیص های مثبت کاذب حذف شوند. نتایج تجربی نشان می دهد که روش پیشنهادی ما به دقت بالاتری نسبت به روش مبتنی بر نقطه عطف دست می یابد. به خصوص، ما با موفقیت تقاطع های واقعی را از خم ها متمایز می کنیم.
یک اشکال روش پیشنهادی ما هزینه محاسباتی است. با توجه به ردیابی N GPS، ( ن− 1 ) ن2(ن–1)ن2ردیابیهای دوتایی برای شناسایی ردهای فرعی رایج با استفاده از روش ما پردازش میشوند، در حالی که N ردیابی بهطور جداگانه پردازش میشوند تا نقاط عطف را با استفاده از روش مبتنی بر نقطه عطف پیدا کنند. بنابراین هزینه محاسباتی ما گرانتر است. در آینده، ما ردیابی GPS را برای کاهش هزینه محاسباتی از قبل پردازش خواهیم کرد. به عنوان مثال، اگر نقاط همپوشانی بین آنها وجود نداشته باشد، ردیابی های GPS جفتی به رویه LCSS نمی روند. علاوه بر این، به جای منطق دو ارزشی در روش فعلی، روی استنباط آماری وجود و پوشش تقاطع ها با استفاده از روش احتمالی کار خواهیم کرد. ما همچنین الگوریتم خود را در شبکههای جادهای با بخشهای جاده غیرمتعامد آزمایش خواهیم کرد.
منابع
- شی، دبلیو. شن، اس. Liu, Y. تولید خودکار نقشه شبکه جاده از GPS عظیم، مسیرهای خودرو. در مجموعه مقالات دوازدهمین کنفرانس بین المللی IEEE در مورد سیستم های حمل و نقل هوشمند، سنت لوئیس، MO، ایالات متحده، 4 تا 7 اکتبر 2009.
- احمد، م. کاراگیورگو، اس. Pfoser، D.; Wenk, C. مقایسه و ارزیابی الگوریتمهای ساخت نقشه با استفاده از دادههای ردیابی خودرو. GeoInformatica 2014 ، 19 ، 601-632. [ Google Scholar ] [ CrossRef ]
- آگامنونی، جی. نیتو، جی. Nebot، EM استنباط قوی از مسیرهای جاده اصلی برای سیستم های حمل و نقل هوشمند. IEEE Trans. هوشمند ترانسپ سیستم 2011 ، 12 ، 298-308. [ Google Scholar ] [ CrossRef ]
- شرودل، اس. واگستاف، ک. راجرز، اس. لنگلی، پی. Wilson, C. استخراج ردیابی GPS برای اصلاح نقشه. حداقل داده بدانید. کشف کنید. 2004 ، 9 ، 59-87. [ Google Scholar ] [ CrossRef ]
- بیاجیونی، جی. اریکسون، جی. استنباط نقشه های راه از ردیابی سیستم موقعیت یابی جهانی. ترانسپ Res. ضبط 2012 ، 2291 ، 61-71. [ Google Scholar ] [ CrossRef ]
- ادلکمپ، اس. Schrödl, S. برنامه ریزی مسیر و استنتاج نقشه با ردیابی موقعیت یابی جهانی. در علوم کامپیوتر از دیدگاه ; Springer: برلین/هایدلبرگ، آلمان، 2003; صص 128-151. [ Google Scholar ]
- کائو، ال. Krumm, J. از ردیابی GPS تا نقشه راه قابل مسیریابی. در مجموعه مقالات هفدهمین کنفرانس بین المللی ACM SIGSPATIAL در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، واشنگتن، دی سی، ایالات متحده آمریکا، 4 تا 6 نوامبر 2009.
- ورال، اس. Nebot، E. فرآیند خودکار برای تولید نقشه های دیجیتالی از طریق فشرده سازی داده های GPS. در مجموعه مقالات کنفرانس استرالیایی در مورد رباتیک و اتوماسیون، بریزبن، استرالیا، 10-12 دسامبر 2007.
- نیهوفر، بی. بردا، ر. ویتفلد، سی. بائر، اف. Lueert، O. تولید نقشه جامعه GPS برای روش های مسیریابی پیشرفته بر اساس جمع آوری ردیابی توسط تلفن های همراه. در مجموعه مقالات اولین کنفرانس بین المللی پیشرفت در ارتباطات ماهواره ای و فضایی، کولمار، فرانسه، 20 تا 25 ژوئیه 2009.
- کاراگیورگو، اس. Pfoser، D. در مورد ردیابی وسایل نقلیه مبتنی بر داده تولید شبکه جاده ای. در مجموعه مقالات بیستمین کنفرانس بین المللی پیشرفت در سیستم های اطلاعات جغرافیایی، ردوندو بیچ، کالیفرنیا، ایالات متحده آمریکا، 7 تا 9 نوامبر 2012.
- داویکس، جی. برسفورد، آر. Hopper، A. مقیاس پذیر، توزیع شده، تولید نقشه بلادرنگ. محاسبات فراگیر IEEE 2006 ، 5 ، 47-54. [ Google Scholar ]
- Xie، X. فیلیپس، دبلیو. ویلارت، پی. آقاجان، ح. استنتاج شبکه راه از ردیابی GPS با استفاده از الگوریتم DTW. در مجموعه مقالات هفدهمین کنفرانس بین المللی IEEE در مورد سیستم های حمل و نقل هوشمند، چینگدائو، چین، 8 تا 11 اکتبر 2014.
- ژنگ، ی. ژانگ، ال. Xie، X. Ma، WY Mining مکان های جالب و توالی سفر از مسیرهای GPS. در مجموعه مقالات هجدهمین کنفرانس بین المللی وب جهانی، مادرید، اسپانیا، 20-24 آوریل 2009.
- شما، س. کروم، جی. توموگرافی ترانزیت با استفاده از جغرافیای زمان احتمالی: برنامه ریزی مسیرها بدون نقشه راه. J. Locat. سرویس مبتنی بر 2014 ، 8 ، 211-228. [ Google Scholar ] [ CrossRef ]
- ولاهوگیانی، EI; Karlaftis، MG; Golias، JC شبکه های عصبی بهینه شده و فرا بهینه شده برای پیش بینی جریان ترافیک کوتاه مدت: یک رویکرد ژنتیکی. ترانسپ Res. قسمت C 2005 ، 13 ، 211-234. [ Google Scholar ] [ CrossRef ]
- هررا، جی سی. کار، DB; شاه ماهی، آر. Ban، XJ; جیکوبسون، کیو. Bayen، AM ارزیابی داده های ترافیکی به دست آمده از طریق تلفن های همراه مجهز به GPS: آزمایش میدانی قرن موبایل. ترانسپ Res. قسمت C 2010 ، 18 ، 568-583. [ Google Scholar ] [ CrossRef ]
- Xie، X. وونگ، ک. آقاجان، ح. فیلیپس، دبلیو. تجزیه و تحلیل رفتار دوچرخه سواران و کاوش در محیط از مسیرهای دوچرخه سواری. در کارگاه آموزشی مجموعه مقالات چالش داده دوچرخه سواری 2013، لوون، بلژیک، 14 مه 2013.
- Syberfeldt، A. Person, L. استفاده از جستجوی اکتشافی برای شروع جمعیت ژنتیکی در بهینه سازی مبتنی بر شبیه سازی مسائل مسیریابی خودرو. در مجموعه مقالات کنفرانس شبیه سازی صنعتی 2009، Loughborough، UK، 1-3 ژوئن 2009.
- Xie، X. وونگ، ک. آقاجان، ح. فیلیپس، دبلیو. توصیه های مسیر هوشمند بر اساس مسیرهای GPS تاریخی و اطلاعات آب و هوا. در مجموعه مقالات موبایل گنت، 2013، گنت، بلژیک، 23 تا 25 اکتبر 2013.
- وو، جی. زو، ی. کو، تی. Wang, L. تشخیص تقاطعهای جادهای از ردیابی درشت GPS بر اساس خوشهبندی. جی. کامپیوتر. 2013 ، 8 ، 2959-2965. [ Google Scholar ] [ CrossRef ]
- پلگ، دی. Moore، AW X-means: گسترش K-means با تخمین کارآمد تعداد خوشه ها. در مجموعه مقالات هفدهمین کنفرانس بین المللی یادگیری ماشین (ICML ’00)، استنفورد، کالیفرنیا، ایالات متحده آمریکا، 29 ژوئن تا 2 ژوئیه 2000.
- وانگ، جی. روئی، ایکس. آهنگ، X. تان، ایکس. وانگ، سی. Raghavan, V. رویکردی جدید برای تولید نقشههای جاده قابل مسیریابی از ردیابی GPS خودرو. بین المللی جی. جئوگر. Inf. علمی 2015 ، 29 ، 69-91. [ Google Scholar ] [ CrossRef ]
- Xie، X. وونگ، ک. آقاجان، ح. ویلارت، پی. فیلیپس، دبلیو. استنتاج شبکههای جادهای هدایتشده از ردیابی GPS توسط Track Alignment. بین المللی J. Geo-Inf. 2015 ، 4 ، 2446-2471. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- فتحی، ع. Krumm, J. تشخیص تقاطع جاده ها از ردیابی GPS. در مجموعه مقالات علم اطلاعات جغرافیایی، زوریخ، سوئیس، 14-17 سپتامبر 2010.
- Xie، X. لیائو، دبلیو. آقاجان، ح. ویلارت، پی. فیلیپس، دبلیو. یک رویکرد جدید برای استنباط تقاطع ها از ردیابی GPS. در مجموعه مقالات سمپوزیوم بین المللی IEEE 2016 در زمینه علوم زمین و سنجش از دور، پکن، چین، 10 تا 15 ژوئیه 2016.
- هیرشبرگ، الگوریتمهای DS برای طولانیترین مسئله متداول متوالی. J. ACM 1977 ، 24 ، 664-675. [ Google Scholar ] [ CrossRef ]
- Denardo، EV Dynamic Programming: Models and Applications ; شرکت پیک: نورث چلمسفورد، MA، ایالات متحده آمریکا، 2012. [ Google Scholar ]
- اسنیدویچ، ام. برنامه نویسی پویا: مبانی و اصول . CRC Press: Boca Raton، FL، USA، 2010. [ Google Scholar ]
- کیوگ، ای جی. Pazzani، MJ مشتق دینامیک زمان تاب. در مجموعه مقالات اولین کنفرانس بین المللی SIAM در مورد داده کاوی (SDM’2001)، شیکاگو، IL، ایالات متحده آمریکا، 5-7 آوریل 2001.
- اسکات، DW برآورد چگالی چند متغیره: تئوری، عمل، و تجسم . جان وایلی و پسران: هوبوکن، نیوجرسی، ایالات متحده آمریکا، 2015. [ Google Scholar ]
- یانگ، ی. ارزیابی رویکردهای آماری برای طبقهبندی متن. Inf. Retr. 1999 ، 1 ، 69-90. [ Google Scholar ] [ CrossRef ]
- لیو، بی. داده کاوی وب . Springer: برلین/هایدلبرگ، آلمان، 2007. [ Google Scholar ]
- آزمایشگاه، BNS در دسترس آنلاین: http://bits.cs.uic.edu/ (در 21 دسامبر 2016 قابل دسترسی است).
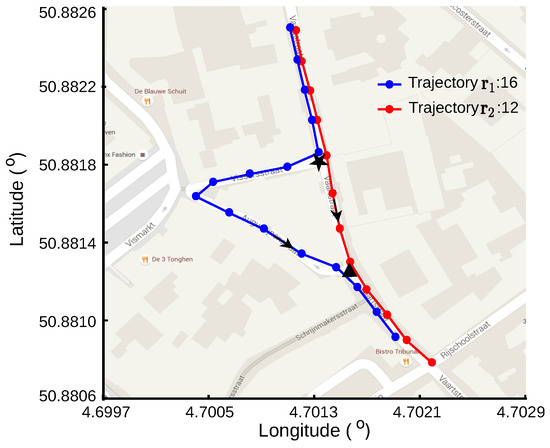
شکل 1. نمونه ای از دو ردیابی GPS که جاده ها را به اشتراک می گذارند. دو اثر GPS از یک بخش جاده مشترک به بخش های مختلف جاده در تقاطع اول، که با استفاده از یک ستاره سیاه نشان داده شده است، واگرا می شوند و سپس در تقاطع دوم که با استفاده از یک مثلث سیاه نشان داده شده است، به یک بخش جاده مشترک دیگر همگرا می شوند.

شکل 2. مشکل LCSS دو ردیابی GPS. ( الف ) طولانی ترین دنباله های مشترک بین ردیابی r1�1و r2�2با استفاده از نشانگرهای سیاه برای هر ردیابی 9 نقطه در طولانی ترین دنباله مشترک وجود دارد. ( ب ) رویه «بازگشت» برای یافتن مسیر تاب بهینه این دو ردیابی با دنبال کردن فلشها. طولانی ترین دنباله های متداول با استفاده از سلول هایی با اعداد سبز نشان داده می شوند.
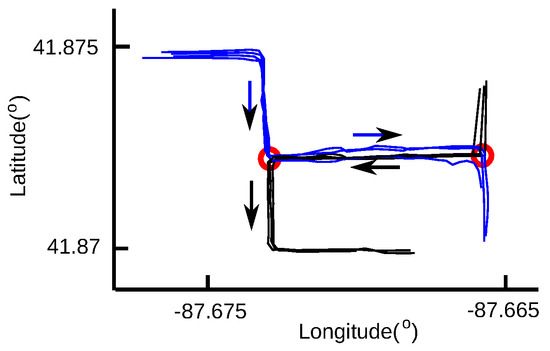
شکل 3. ردیابی GPS در جهت مخالف. در بخش جاده بین دو تقاطع که با دایرههای قرمز مشخص شدهاند، هیچ مسیر فرعی مشترکی بین خطوط آبی و سیاه یافت نمیشود، زیرا کاربران جاده در مسیرهای آبی از چپ به راست و در مسیرهای سیاه از راست به چپ عبور میکنند. .
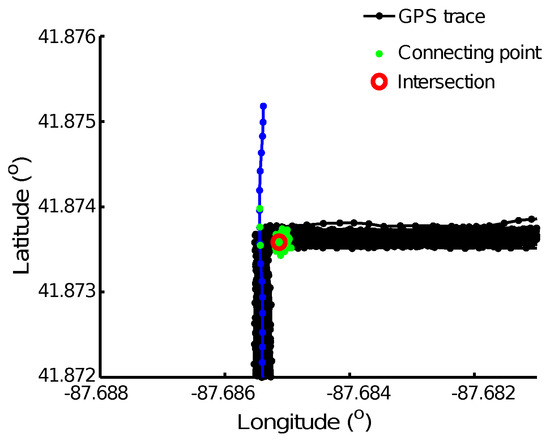
شکل 4. تقاطع مثبت کاذب. یک نامزد تقاطع در دایره قرمز از نقاط اتصال در نقاط سبز تشخیص داده می شود. این یک مثبت کاذب است زیرا تمام نقاط اتصال از 152 اثری که با یک ردی به هم متصل می شوند تولید می شوند.

شکل 5. ردیابی GPS شیکاگو و تقاطع های حقیقت زمین. هشتصد و هشتاد و نه ردیابی GPS در طول 118 ساعت در خطوط سیاه با نقاط نشان داده شده است که موقعیت های ضبط شده GPS را نشان می دهد. سی و سه تقاطع حقیقت زمین با استفاده از دایره های آبی نشان داده شده است.

شکل 6. نقاط اتصال. نقاط اتصال با نقاط سبز نشان داده شده است.

شکل 7. KDE نقاط اتصال. قله های KDE در تقاطع ها قرار دارند.

شکل 8. نامزدهای تقاطع. نامزدهای تقاطع از نقاط اتصال با یافتن حداکثرهای محلی در نقشه چگالی استخراج می شوند. در مجموع 41 نامزد شناسایی شدند.
شکل 9. تقاطع های شناسایی شده از نقاط اتصال. با بررسی الگوهای ملاقات ردیابی در تقاطع ها، 13 نامزد تقاطع حذف می شوند که در نتیجه 28 تقاطع واقعی با دایره های قرمز نشان داده شده است.

شکل 10. تقاطع های شناسایی شده از نقاط عطف. 36 تقاطع شامل 29 تقاطع واقعی در دایره های قرمز و هفت تقاطع کاذب در صلیب های قرمز شناسایی شده است. پنج تقاطع در نقشه زمین-حقیقت شناسایی نشده اند که با استفاده از دایره های آبی نشان داده شده اند.

شکل 11. تجزیه و تحلیل دقت تقاطع ها. ( الف ) دقت تقاطع های شناسایی شده از نقاط عطف. ( ب ) روش پیشنهادی مبتنی بر تشخیص نقطه اتصال.
© 2016 توسط نویسندگان؛ دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (CC-BY) (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر