1. معرفی
هنگام بازدید از یک شهر جدید، گردشگران اغلب به کمک نیاز دارند تا مکانهای شخصی جالب را از میان مجموعهای از انتخابهای بالقوه بسیار زیاد شناسایی کنند. برنامه ریزی سفر یک کار وقت گیر است. این کار به دلیل محیط فیزیکی پیچیده تر می شود، زیرا مکان های توریستی شخصی جالب ممکن است در سراسر یک شهر پراکنده باشند. از سوی دیگر، با پیشرفت های سریع در رسانه های اجتماعی دارای برچسب جغرافیایی، سال های اخیر شاهد بوده ایم که بسیاری از افراد اطلاعات و تجربیات سفر خود را از طریق رسانه های اجتماعی مانند چک-این های چهار ضلعی و عکس های فلیکر منتشر می کنند. تحقیقات نشان داده است که تجربیات کاربران گذشته در زمینه های مشابه می تواند به کاربران فعلی کمک کند تا مشکلات خود را به طور موثر حل کنند [ 1 ، 2]]، به عنوان مثال، انتخاب محل بازدید. بنابراین، جمعآوری دادههای رسانههای اجتماعی دارای برچسب جغرافیایی پتانسیل بالایی برای کمک به گردشگران در شناسایی مکانهای مورد علاقه هنگام بازدید از یک شهر جدید دارد.
اخیرا، تجزیه و تحلیل داده های رسانه های اجتماعی با برچسب جغرافیایی توجه قابل توجهی را به خود جلب کرده است. تحقیقات در مورد این جنبه، به عنوان مثال، بر روی کشف نقطه عطف و نقطه مهم [ 3 ، 4 ] استخراج معناشناسی مکان [ 5 ، 6 ]، مدل سازی رفتار [ 7 ، 8 ] و طبقه بندی جامعه (مثلا، [ 9 ]) متمرکز شد. همچنین تحقیقی با استفاده از دادههای رسانههای اجتماعی برچسبگذاریشده جغرافیایی برای مکان و توصیه برنامه سفر انجام شد [ 10 ، 11 ، 12 ، 13 ، 14]. این مطالعات مکانها یا برنامههای سفری را توصیه میکنند که با ترجیحات سفر گردشگران و زمان در دسترس مطابقت داشته باشند، در حالی که زمینه بازدید، مانند آب و هوا و فصل را نادیده میگیرند. با این حال، ترجیحات گردشگران با توجه به بازدید از یک مکان اغلب تحت تأثیر زمینه ای است که در آن قرار دارند [ 2 ]. به عنوان مثال، ممکن است ترجیح دهیم در یک روز آفتابی از یک پارک دیدن کنیم، در حالی که وقتی بارانی است از موزه بازدید می کنیم. بنابراین، عدم توجه به این نوع اطلاعات زمینه منجر به توصیه های نامربوط و نامناسب می شود.
هدف این مقاله بررسی روشهای آگاه از زمینه برای ارائه توصیههای مکان منطبق با علایق سفر گردشگران و زمینه بازدید (به عنوان مثال، آب و هوا، فصل و زمان روز) بر اساس عکسهای دارای برچسب جغرافیایی است. به طور خاص، ما تاریخچه سفر هر گردشگر را از عکس های فلیکر استخراج می کنیم که ترجیحات سفر او را نشان می دهد. سپس یک معیار تشابه بافت جدید را برای تعیین کمیت شباهت بین هر دو زمینه و توسعه سه روش فیلتر مشارکتی آگاه از زمینه (CaCF) برای تولید توصیههای مکان، به عنوان مثال، پیش فیلتر زمینه، پس از فیلتر کردن و مدلسازی پیشنهاد میکنیم. با استفاده از مجموعه دادههای فلیکر در دسترس عموم، روشهای پیشنهادی در مقایسه با سایر روشهای پیشرفته ارزیابی میشوند تا مزایایی را که با در نظر گرفتن اطلاعات زمینه در فرآیند توصیه به دست میآیند، نشان دهند.
بقیه مقاله به شرح زیر سازماندهی شده است. بخش 2 تحقیقات مرتبط را ارائه می کند. در بخش 3 ، روش شناسی را به تفصیل شرح می دهیم. بخش 4 در مورد ارزیابی گزارش می دهد و نتایج را مورد بحث قرار می دهد. ما نتیجه گیری می کنیم و کارهای آینده را در بخش 5 ارائه می کنیم .
2. کارهای مرتبط
2.1. تکنیک های توصیه و آگاهی از زمینه
سیستم های توصیه یک لیست شخصی از آیتم ها (به عنوان مثال، فیلم ها، آهنگ ها و محصولات) را به کاربر ارائه می دهند که علایق و نیازهای او را برآورده می کند. آنها اغلب در دستههای زیر طبقهبندی میشوند: فیلترهای مشارکتی (توصیه مواردی که افراد دیگر با ترجیحات مشابه در گذشته دوست داشتند)، توصیه مبتنی بر محتوا (ارائه مواردی مشابه مواردی که قبلاً به کاربر ترجیح میداد) و رویکردهای ترکیبی. در میان آنها، فیلتر مشارکتی (CF) محبوب ترین روش توصیه است [ 15 ]. توصیه هایی را بر اساس نظرات کاربران (به عنوان مثال، رتبه بندی) در مورد موارد مختلف ارائه می دهد. رتبه یک تاپل است ( تو ای آر ، من ، من ، آر آ تی ان گ _ _ _)(توسه�،منتیهمتر،�آتیمن��). رتبهبندیها را میتوان به صراحت توسط کاربران بیان کرد یا به طور ضمنی استنباط کرد، به عنوان مثال، از تاریخچه خرید یا مسیرهای سفر. به دلیل سادگی و شهودی بودن آن، CF مبتنی بر کاربر (UCF) اغلب استفاده می شود. با توجه به رتبهبندی ناشناخته (از یک مورد توسط کاربر فعلی) که باید تخمین زده شود، UCF ابتدا شباهتهای کاربر فعلی و سایر کاربران را اندازهگیری میکند. سپس رتبهبندی مجهول با جمعآوری رتبهبندیهای شناخته شده مورد توسط کاربران مشابه پیشبینی میشود.
اخیراً، محققان شروع به بررسی چگونگی بهبود CF با در نظر گرفتن اطلاعات زمینه، به عنوان مثال، اهداف خرید و فصلها کردهاند [ 16 ، 17 ، 18 ]. Adomavicius و Tuzhilin (2011) [ 19 ] برای طبقهبندی رویکردهای CF آگاه از زمینه (CaCF) به شرح زیر پیشنهاد کردند: (1) پیش فیلتر کردن متنی از اطلاعات زمینه برای فیلتر کردن رتبهبندیهای نامربوط استفاده میکند و سپس از CF کلاسیک برای تولید توصیهها استفاده میکند. (2) پس فیلترینگ متنی از CF کلاسیک برای تولید توصیهها استفاده میکند و سپس نتایج را بر اساس اطلاعات زمینه فیلتر یا رتبهبندی مجدد میکند. (3) مدلسازی زمینهای از اطلاعات زمینه مستقیماً در فرآیند CF برای تولید توصیهها استفاده میکند.
توجه داشته باشید که بیشتر روشهای CF و CaCF فوق برای حوزه فیلم، موسیقی و محصول طراحی شدهاند و از رتبهبندی صریح استفاده میکنند. همچنین مطالعاتی در مورد اعمال CF برای توصیه رستوران [ 20 ]، توصیه فروشگاه [ 21 ]، توصیه رویداد [ 22 ] توصیه نمایشگاه در موزه ها [ 23 ] و توصیه مکان با استفاده از مسیرهای GPS [ 24 ] وجود داشت. با این حال، بسیاری از آنها از کاربران خواستند که علایق خود را به صراحت بیان کنند یا رتبه بندی ارائه کنند، به عنوان مثال، Horozov و همکاران. (2006) [ 20 ] و لی و همکاران. (2009) [ 22]. برای دیگرانی که از رفتار کاربران یاد میگیرند، توصیهها اغلب فقط با علایق کاربران تطبیق داده میشوند، در حالی که بسیاری از عوامل زمینهای، مانند آب و هوا و فصل، که ممکن است برای ایجاد توصیهها نیز مرتبط باشند، نادیده گرفته میشوند.
این مقاله سه روش CaCF را پیشنهاد میکند تا توصیههای مکانی شخصیشده و آگاه از زمینه را از دادههای رسانههای اجتماعی دارای برچسب جغرافیایی در دسترس، بهویژه عکسهای فلیکر، استخراج کند. کار ما از دو جنبه با تکنیک های ذکر شده در بالا متفاوت است. در مرحله اول، ما توصیه های مکان را بر اساس تاریخچه ضمنی سفر در دنیای واقعی کاربران، همانطور که از عکس های Flickr استنباط می شود، استخراج می کنیم. ثانیا، ما یک معیار تشابه را برای تعیین کمیت شباهت بین هر دو زمینه و توسعه سه روش توصیه آگاه از زمینه (به عنوان مثال، پیش فیلتر کردن، پس از فیلتر کردن و مدل سازی) پیشنهاد می کنیم.
2.2. تجزیه و تحلیل داده های رسانه های اجتماعی دارای برچسب جغرافیایی
اخیرا، افزایش دسترسی به رسانه های اجتماعی آنلاین (به عنوان مثال، Foursquare و Flickr) منجر به انباشت حجم عظیمی از داده های رسانه های اجتماعی شده است. این داده ها، به ویژه آنهایی که با موقعیت جغرافیایی برچسب گذاری شده اند (به عنوان مثال، طول و عرض جغرافیایی)، حاوی اطلاعات زیادی در مورد سفر، فعالیت ها و رفتار افراد در محیط های مختلف است. در سال های اخیر، استخراج داده های رسانه های اجتماعی با برچسب جغرافیایی توجه قابل توجهی را به خود جلب کرده است.
تحقیقاتی در مورد شناسایی نقاط دیدنی و نقاط توریستی (به عنوان مثال، مکانهای با عکسبرداری بالا) از دادههای رسانههای اجتماعی دارای برچسب جغرافیایی [ 3 ، 4 ، 25 ، 26 ] انجام شد. روشهای خوشهبندی مختلفی مانند K-means، خوشهبندی میانگین تغییر، خوشهبندی مبتنی بر چگالی (به عنوان مثال، DBSCAN (خوشهبندی فضایی مبتنی بر چگالی برنامههای کاربردی با نویز) و انواع آن) و خوشهبندی طیفی استفاده شدهاند. این مطالعات اغلب برای خلاصه کردن مجموعههای عکس دارای برچسب جغرافیایی و استخراج برچسبها یا عکسها و معناشناسی برای مکانهای خاص گسترش مییابد [ 5 ، 6 ، 27 ].
علاوه بر شناسایی نقطه عطف و استخراج معنایی مکان، مطالعاتی نیز با تمرکز بر مدلسازی رفتار سفر افراد با استفاده از دادههای رسانههای اجتماعی برچسبگذاریشده جغرافیایی انجام شد [ 7 ، 8 ، 28 ]. این رویکردها اغلب یک پایگاه داده از مسیرهای سفر و تکنیک های داده کاوی را برای شناسایی مکان های جاذبه و توالی سفرهای مکرر ایجاد می کنند. در حالی که مطالعات فوق از عکسهای دارای برچسب جغرافیایی استفاده میکردند، توجه پژوهشی به سایر دادههای رسانههای اجتماعی (به عنوان مثال، توییتها) نیز معطوف شده است [ 29 ، 30 ]. این رویکردها برای کاربردهای دیگر، مانند تعیین کاربری های زمین [ 31 ] و درک پویایی شهر [ 30 ] گسترش یافته اند.
2.3. توصیه مکان با استفاده از داده های رسانه اجتماعی دارای برچسب جغرافیایی
در سالهای اخیر، روشهای زیادی برای استخراج توصیههای مکان و سفر بر اساس دادههای رسانههای اجتماعی (مثلاً عکسهای فلیکر و چکهای چهار ضلعی) پیشنهاد شدهاند [ 32 ، 33 ]. برای مثال، De Choudhury و همکاران. (2010) [ 34 ] عکس های فلیکر گردشگران را استخراج کرد، آنها را در یک نمودار مکان جمع کرد و با در نظر گرفتن زمان در دسترس کاربران، برنامه های سفر را ساخت. به طور مشابه، سان و همکاران. (2015) [ 14 ] یک سیستم توصیه برای ارائه محبوب ترین نقاط عطف به کاربران و همچنین بهترین مسیری که آنها را به هم متصل می کند، ساخته است. این روشها عمدتاً محبوبیت مکان را در نظر میگرفت و ترجیحات سفر گردشگر را نادیده میگرفت و بنابراین توصیههای غیرشخصی به او ارائه میکرد.
بسیاری از مطالعات دیگر با تمرکز بر توصیه های شخصی وجود دارد. برای مثال، چنگ و همکاران. (2011) [ 11 ] یک الگوریتم توصیه سفر شخصی را با در نظر گرفتن نمایه های کاربر خاص (به عنوان مثال، جنسیت، سن) که از عکس های فلیکر شناسایی شدند، پیشنهاد کرد. بر اساس CF، کلمنتز و همکاران. (2010) [ 10 ] مکان های مورد علاقه کاربر را با استفاده از عکس های Flickr پیش بینی کرد. آنها شباهت بین کاربر فعلی و سایر کاربران را با مقایسه تاریخچه سفر آنها اندازه گیری کردند و از مقادیر شباهت برای رتبه بندی مکان ها استفاده کردند. به طور مشابه، یین و همکاران. (2014) [ 13 ] و گائو و همکاران. (2015) [ 35] روشهای توصیه شخصی مبتنی بر CF را توسعه داد و عمدتاً به مشکل شروع سرد (یعنی «کاربر جدید» و «مورد جدید») پرداخت. شی و همکاران (2013) [ 12 ] یک روش شخصی سازی شده را برای توصیه نشانه های غیر ضروری که مکان های معمولی نیستند و یافتن آنها در راهنمای سفر دشوار است، پیشنهاد کرد. جیانگ و همکاران (2016) [ 36 ] روشی را برای توصیه توالی سفر شخصی (سفر) بر اساس داده های رسانه های اجتماعی بزرگ چند منبعی ایجاد کرد. ژانگ و همکاران (2016) [ 37] توصیه های شخصی سفر را با توجه به در دسترس بودن POI، تنوع و عدم قطعیت زمان سفر ارائه کرد. توجه داشته باشید که روشهای فوق بر توصیه مکانها یا سفرهایی که با علایق و محدودیتهای گردشگران مطابقت دارند، تمرکز میکنند، در حالی که زمینه بازدید را نادیده میگیرند، به عنوان مثال، آب و هوا و فصل، که ممکن است به طور بالقوه برای ایجاد توصیهها مرتبط باشند.
برخلاف روشهای فوق که توصیههای غیرمتنآگاهی را ارائه میکردند، این مقاله روشهای فیلتر مشارکتی آگاه از زمینه را برای ارائه توصیههای مکان مطابق با علایق سفر گردشگر و همچنین زمینه بازدید او بر اساس عکسهای دارای برچسب جغرافیایی بررسی میکند. ما نه تنها محبوبیت مکانها و علایق سفر یک گردشگر را که از تاریخچه سفر او به دست میآید، در نظر میگیریم، بلکه همچنین زمینه بازدید از او را نیز در نظر میگیریم (به عنوان مثال، آب و هوا، فصل و زمان روز). کار تحقیقی مشابهی توسط مجید و همکاران ارائه شده است. (2013) [ 38]، که در آن یک روش پیش فیلترسازی متنی پیشنهاد شد. آنها ابتدا زمینه بازدید محبوب هر مکان را شناسایی کردند و مکان هایی را که زمینه محبوب آنها با زمینه فعلی متفاوت است فیلتر کردند. یک تطابق دقیق به کار گرفته شد: برای مثال، اگر زمینه بازدید کنونی «روز هفته-صبح و گرم-آفتاب» باشد، فقط مکانهایی که بافت محبوب «صبح روز هفته و گرم-آفتابی» را دارند حفظ میشوند. سپس CF برای رتبهبندی مجموعههای فیلتر شده مکانها اعمال شد و توصیههای مکان آگاه از زمینه ارائه شد. به طور خلاصه، روش آنها را می توان به عنوان یک روش CF پیش فیلترسازی متنی با “تطابق دقیق” در نظر گرفت. کار ما با مجید و همکاران فرق دارد. (2013) [ 38] از دو جنبه. اولا، به جای استفاده از “تطابق دقیق”، ما یک معیار شباهت را برای کمی کردن شباهت بین هر دو زمینه پیشنهاد می کنیم. در مرحله دوم، بر اساس اندازه گیری شباهت، ما سه روش CaCF (یعنی پیش فیلتر کردن، پس از فیلتر کردن و مدل سازی) را توسعه می دهیم. نتایج ارزیابی نشان میدهد که روشهای پیشنهادی به طور قابلتوجهی بهتر از روشهای پیشرفته هستند. به عبارت دیگر، در مقایسه با “تطابق دقیق”، استفاده از معیار تشابه زمینه پیشنهادی به طور قابل توجهی عملکرد توصیه را بهبود می بخشد.
3. روش شناسی
3.1. تعریف مسئله و بررسی اجمالی روش
تعریف 1
(عکس دارای برچسب جغرافیایی). یک عکس دارای برچسب جغرافیایی پپبه عنوان یک تاپل تعریف شده است ( من د, u , l o c , t )(مند،تو،ل�ج،تی)، حاوی یک شناسه عکس من dمند، شناسه کاربر کمک کننده توتو، مکان عکس گرفته شده است l o cل�ج(به عنوان یک جفت طول و عرض جغرافیایی نشان داده می شود) و زمان صرف شده است تیتی.
ما استفاده می کنیم پتوپتوبرای نشان دادن مجموعه ای از عکس های ارائه شده توسط کاربر توتو، U�به عنوان مجموعه همه کاربران و پپبه عنوان مجموعه ای از عکس های ارائه شده توسط همه کاربران.
تعریف 2
(موقعیت گردشگری). یک مکان توریستی للیک منطقه جغرافیایی در یک شهر، مانند یک میدان، یک پارک یا یک موزه است که گردشگران زیادی را برای بازدید و گرفتن عکس جذب می کند.
ما استفاده می کنیم L�برای نشان دادن مجموعه ای از همه مکان ها و Lتو�توبه عنوان زیر مجموعه مکان های بازدید شده توسط کاربر توتو.
تعریف 3
(مدل زمینه بازدیدها). مدل زمینه بازدیدها سیمسیمشامل فهرستی منظم از پارامترهای زمینه (ابعاد) مربوطه است. بدین ترتیب، سیم= ( Cپ1، سیپ2، … ، سیپn)سیم=(سیپ1،سیپ2،…،سیپ�)، کجا n�تعداد پارامترهای زمینه مربوطه است. هر پارامتر سیپمنسیپمنیک تاپل است ( n a m e , r a n gه )(�آمتره،�آ��ه)، جایی که سیپمن. n a m eسیپمن.�آمترهیک برچسب منحصر به فرد برای نشان دادن نام پارامتر است (به عنوان مثال، “آب و هوا”) و سیپمن. r a n gهسیپمن.�آ��همجموعه مقادیر معتبری است که می توان به آن نسبت داد (به عنوان مثال، تمام شرایط آب و هوایی موجود، “آفتابی” و “بارانی”). سیمˆسیم^فضای مدل زمینه را نشان می دهد و مجموعه ای از تمام موقعیت های ممکن است که تحت آن یک بازدید می تواند رخ دهد.
نمونه ای از سیمسیماست (“آب و هوا: آفتابی، بارانی”، “فصل: بهار، تابستان، پاییز، زمستان”) ، که در آن “آب و هوا” و “فصل” پارامترهای زمینه مرتبط هستند. یک عنصر نمونه از سیمˆسیم^می تواند (“آفتابی”، “پاییز”) باشد .
تعریف 4
(زمینه بازدید). زمینه بازدید c x ∈سیمˆجایکس∈سیم^نمونه ای از سیمسیم. c x = ( c pv1، ج صv2, … , c pvمن, … , c pvn)جایکس=(جپ�1،جپ�2،…،جپ�من،…،جپ��)، کجا ج صvمن∈ سیپمن. r a n gهجپ�من∈سیپمن.�آ��ه. به عنوان مثال، (“آفتابی”، “بهار”) زمینه نمونه ای از بازدید است.
وظیفه توصیه را می توان به صورت زیر تعریف کرد: مجموعه ای از عکس های دارای برچسب جغرافیایی پپ، یک کاربر خاص توتوو زمینه بازدید او c xجایکس، مجموعه ای از مکان ها را پیدا کنید Lآر⊆ L −Lتو�آر⊆�–�توکه توتوبه احتمال زیاد بازدید می شود.
ما با جمعآوری تاریخچه سفر سایر گردشگران (که از عکسهای دارای برچسب جغرافیایی استخراج میشود) مشکل را برطرف میکنیم تا کاربر فعلی را ارائه دهیم. توتوبا توصیه های مکان مطابق با ترجیحات سفر و زمینه بازدید. به ویژه، CF، که مواردی را به کاربر توصیه میکند که سایر کاربران با اولویتهای مشابه قبلاً استفاده میکردند یا از آنها بازدید میکردند.
شکل 1 یک نمای کلی از روش شناسی را نشان می دهد. بر اساس مجموعه عکس های بازیابی شده از فلیکر، ابتدا مکان های گردشگری را با استفاده از روش های خوشه بندی مبتنی بر تراکم شناسایی می کنیم ( بخش 3.2 ). با مکانهای کشفشده، مکانهای بازدید شده هر گردشگر در هر شهر استخراج و با بافت بازدید غنیسازی میشوند ( بخش 3.2 ). ما اطلاعات «تاریخ گرفتهشده» عکسها را برای استخراج بافت زمانی (یعنی زمان روز و فصل) تجزیه و تحلیل میکنیم و از Weather Underground API [ 39 ] برای بازیابی شرایط آب و هوایی استفاده میکنیم. ما از این تاریخچه سفر برای مدل سازی ترجیحات گردشگران استفاده می کنیم. سپس از آنها برای تخمین شباهت های بین گردشگران و شباهت های بین زمینه ها استفاده می شود ( بخش 3.3). برای ایجاد توصیههای مکان، ما سه روش آگاه از زمینه را توسعه میدهیم، یعنی پیش فیلتر کردن متنی، پس فیلتر کردن و مدلسازی ( بخش 3.4 ). این روش ها در نحوه و زمان استفاده از اطلاعات زمینه متفاوت هستند.
3.2. شناسایی موقعیت مکانی توریستی و استخراج تاریخچه سفر
3.2.1. تشخیص موقعیت مکانی توریستی
قبل از شناسایی مکان های گردشگری از مجموعه عکس های دارای برچسب جغرافیایی، باید عکس های ارائه شده توسط ساکنان محلی را فیلتر کنیم. به دلیل فقدان اطلاعات خانه در پروفایل بسیاری از کاربران فلیکر، چندین الگوریتم اکتشافی برای تمایز بین ساکنان محلی و گردشگران پیشنهاد شده است [ 14 ، 34 ، 40 ]. به دلیل سادگی و شهودی بودن آن، قاعده اکتشافی به کار رفته در De Choudhury و همکارانش. (2010) [ 34 ] و Kadar and Gede (2013) [ 40] استفاده می شود. فرض بر این است که در حالی که بیشتر گردشگران بازدیدهای خود را در یک بازه زمانی کوتاه چند روزه متمرکز می کنند، ساکنان محلی یک شهر تمایل دارند از شهر در مدت زمان بسیار طولانی تری عکس بگیرند. بنابراین، گردشگران و ساکنان محلی را می توان با بررسی بازه زمان گرفته شده بین اولین و آخرین عکس آنها متمایز کرد. به دنبال Kadar و Gede (2013) [ 40 ]، آستانه بازه زمانی را 5 روز تعیین کردیم.
پس از فیلتر کردن عکسهای ارائهشده توسط ساکنان محلی، میتوانیم مکانهای گردشگری را از عکسهای باقیمانده شناسایی کنیم. یافتن مکانهای توریستی از مجموعه عکسهای دارای برچسب جغرافیایی را میتوان به عنوان یک مشکل خوشهبندی در شناسایی مکانهای با عکسبرداری بالا در نظر گرفت. همانطور که قبلا ذکر شد، الگوریتمهای خوشهبندی مختلفی مانند K-means، خوشهبندی طیفی و خوشهبندی مبتنی بر چگالی (به عنوان مثال، DBSCAN) پیشنهاد شدهاند. با توجه به توانایی آن در کشف خوشه هایی با اشکال دلخواه و عدم حساسیت به نویز، DBSCAN برای شناسایی مکان های بسیار عکاسی شده (یعنی مکان های توریستی) برای هر شهر استفاده می شود. این به دو پارامتر نیاز دارد: شعاع (Eps) و حداقل تعداد نقاط در یک خوشه (MinPts). خروجی DBSCAN مجموعه ای از خوشه های عکس (مکان ها) است. Lج= {ل1،ل2, … ,لn}�ج={ل1،ل2،…،ل�}برای هر شهر هر عنصر l = ( i d،پل)�=(��,��)یک مکان توریستی است، که در آن پل��گروه عکس های درون خوشه است. پل��می توان برای محاسبه مرز جغرافیایی خوشه (موقعیت گردشگری)، و همچنین برای شناسایی معنایی (به عنوان مثال، دسته بندی ها) یا نام این مکان توریستی استفاده کرد، که هر دو از حوصله این مقاله خارج هستند. در این مقاله، ما به سادگی هر مکان گردشگری را به عنوان یک برچسب منحصر به فرد (مثلاً مکان A) نشان می دهیم.
3.2.2. استخراج تاریخچه سفر
هنگامی که مکان های گردشگری برای هر شهر شناسایی شد، می توانیم مکان های بازدید شده توسط هر گردشگر را استخراج کنیم.
تعریف 5
(بازدید). یک دیدار v�به عنوان یک تاپل تعریف شده است ( u , l , t , c x )(�,�,�,��)، جایی که تو�کاربری است که بازدید کرده است v�به مکان ل�در زمان تی�و در چارچوب c x��.
برای استخراج بازدیدهای هر گردشگر، ابتدا عکس های او را بر اساس زمان گرفته شده مرتب می کنیم. اگر یک عکس p = ( i d, u , l o c , t )�=(��,�,���,�)در یک خوشه عکس خاص موجود است ل�(یعنی مکان توریستی)، بازدیدی که توسط تو�به مکان ل�در زمان تی�تشخیص داده می شود. توجه داشته باشید که یک توریست تو�ممکن است در بازدید از یک مکان بیش از یک عکس بگیرد. بنابراین، اگر مجموعهای از عکسهای متوالی گرفتهشده توسط یک کاربر در یک خوشه عکس وجود داشته باشد و اختلاف زمانی بین اولین و آخرین عکس در مجموعه کمتر از آستانه مدت زمان باشد. δدتو آر����، این مجموعه عکس ها را متعلق به همان بازدید می دانیم و از میانگین زمان گرفته شده از این عکس ها به عنوان زمان بازدید استفاده می کنیم. تی�.
برای شناسایی زمینه بازدید cxcxبرای هر بازدید شناسایی شده v�، ما عمدتا از مکان استفاده می کنیم ل�و زمان تی�. در این مقاله به دلیل در دسترس بودن آنها، بر ابعاد (پارامترهای) زیر تمرکز می کنیم: «فصل»، «زمان روز» و «آب و هوا». ما استفاده می کنیم تی�برای استخراج دو بعد اول مشابه لی و همکاران. (2010) [ 41 ]، انتزاع از مهر زمانی خام اعمال می شود: (1) “فصل”: بهار (مارس-مه)، تابستان (ژوئن تا آگوست)، پاییز (سپتامبر-نوامبر) و زمستان (دسامبر-فوریه) ) (2) “زمان روز”: صبح (6:00-12:00)، بعد از ظهر (12:00-18:00)، شب (18:00-6:00). برای استخراج وضعیت آب و هوا، اطلاعات آب و هوا را برای مکان بازیابی می کنیم ل�در زمان تی�با استفاده از Weather Underground API و طبقه بندی اطلاعات خام آب و هوا در سه حالت زیر: “بارانی_یا_برفی”، “روشن” (به عنوان مثال، آفتابی) و “ابری”. به عبارت دیگر، سیم�م= («فصل: بهار، تابستان، پاییز، زمستان»، «زمان روز: صبح، بعد از ظهر، شب»، «آب و هوا: بارانی_یا_برفی، صاف، ابری»).
با اینها، مکان های بازدید شده توسط هر گردشگر به همراه زمینه های بازدید از مجموعه عکس قابل شناسایی است. این مجموعه از بازدیدها را می توان به عنوان مشخصات گردشگر در نظر گرفت و ترجیحات و علایق سفر او را منعکس می کند.
3.3. شباهت کاربر و کاوش شباهت زمینه
3.3.1. شباهت کاربر
برای شناسایی سایر گردشگرانی که از «تجربههای سفر» آنها میتوان برای ایجاد توصیههایی برای کاربر فعلی (گردشگر) استفاده کرد، یک معیار شباهت کاربر (بر اساس ضریب سورنسن-دایس) با مقایسه مکانهای بازدید شده توسط گردشگران ایجاد میشود.
|Lآ||�آ|و ∣∣Lب∣∣|�ب|تعداد مکان های بازدید شده توسط گردشگران است آآو بب، و ∣∣Lآ∩Lب∣∣|�آ∩�ب|تعداد مکان هایی است که معمولاً توسط آنها بازدید می شود.
بدیهی است که دو گردشگر که مجموعهای از مکانهای بازدید شده توسط چند نفر را به اشتراک میگذارند ممکن است نسبت به دیگرانی که مجموعهای از مکانهای بازدید شده توسط افراد زیادی را به اشتراک گذاشتهاند، همبستگی بیشتری داشته باشند [ 24 ]. به عنوان مثال، بسیاری از مردم از بیگ بن و پل تاور، دو مکان دیدنی معروف لندن دیدن کردهاند. شاید اینطور نباشد که همه این افراد شبیه یکدیگر باشند. با این حال، اگر دو کاربر از مکانی بازدید کنند که چندان محبوب نیست، ممکن است در واقع ترجیحات سفر مشابهی داشته باشند. بنابراین، محبوبیت مکان هنگام اندازه گیری شباهت کاربر در نظر گرفته می شود. به دلیل سادگی، فرکانس معکوس سند (IDF)، که اغلب در بازیابی اطلاعات برای سنجش اینکه یک اصطلاح (مثلاً کلمه) رایج است یا نادر در همه اسناد استفاده می شود [42 ]]، برای اندازه گیری محبوبیت یک مکان استفاده می شود لل.
ننتعداد تمام گردشگران است و نلنلتعداد گردشگرانی است که بازدید کردند لل. ارزش های منD Fمن�افمحدوده 0-1. بزرگتر منD Fمن�اف، هر چه یک مکان محبوبیت کمتری داشته باشد. بنابراین، معادله (1) به صورت زیر بسط مییابد:
مقادیر شباهت از 0 تا 1 متغیر است. صفر به این معنی است که هر دو گردشگر تاریخچه مکان مشترکی نداشتند و 1 به این معنی است که آنها از یک مجموعه مکان بازدید کرده اند. با اعمال اندازه گیری، می توانیم یک ماتریس شباهت کاربر USim_M UU بسازیم . هر عنصر در آن نشان دهنده شباهت بین دو کاربر است.
3.3.2. شباهت زمینه
به طور کلی، «تجربههایی» (یعنی بازدیدهای موجود در این مقاله) که در زمینههای مشابه با شرایط فعلی اتفاق میافتند، برای ایجاد توصیههای مکان مفیدتر از تجربیاتی هستند که در زمینههای غیرمشابه اتفاق میافتند. بنابراین، ما یک رویکرد مبتنی بر اکتشافی برای اندازهگیری شباهت بین هر دو زمینه پیشنهاد میکنیم.
ما فرض می کنیم که اگر بازدیدهایی که در یک زمینه (موقعیت) اتفاق می افتد مشابه بازدیدهایی باشد که در زمینه دیگری اتفاق می افتد، این دو زمینه (موقعیت) را می توان مشابه در نظر گرفت. توجه داشته باشید که برای “بازدید”، منظور ما هر بازدید جداگانه نیست، بلکه مجموعه ای از تمام بازدیدهایی است که در زمینه اتفاق می افتد. بر اساس این فرض، شباهت بین هر دو زمینه را با دو مرحله زیر اندازه گیری می کنیم:
-
نمایه هر زمینه (موقعیت) به عنوان یک بردار نشان داده می شود ایکسآ= ⟨wآ1،wآ2, … ,wآل, … ,wآn⟩ایکسآ=〈�1آ،�2آ،…،�لآ،…،��آ〉، جایی که آآنشان دهنده زمینه، و A∈ _سیمˆآ∈سیم^(به تعاریف 3 و 4 مراجعه کنید). هر یک از اعضای بردار wآل�لآمربوط به استفاده از یک مکان در این شرایط است آآ، و بنابراین، n�برابر است با تعداد مکان ها در سناریوی برنامه (مثلاً در یک شهر معین). ما از اصطلاح اندازه گیری فرکانس سند معکوس فرکانس (TF-IDF) برای محاسبه مقدار هر یک استفاده می کنیم wآل�لآ. TF-IDF در زمینه بازیابی اطلاعات برای اندازه گیری اهمیت یک کلمه برای یک سند در یک مجموعه یا مجموعه استفاده می شود. متناسب با تعداد دفعاتی که یک کلمه در سند ظاهر می شود، افزایش می یابد، اما با فراوانی کلمه در مجموعه جبران می شود [ 42 ]. بخش دوم این واقعیت را کنترل می کند که برخی از کلمات به طور کلی رایج تر از دیگران هستند. از این رو، wآل�لآبه صورت زیر محاسبه می شود:
نالف ، لنآ،لتعداد بازدیدها در زمینه است آآکه مکان بازدید شده است لل; نالف ،. _نآ،.تعداد بازدیدها را نشان می دهد آآ; ن. ، لن.،لنشان دهنده تعداد بازدیدها در تمام زمینه هایی است که بازدید شده است لل; و ن. ، .ن.،.تعداد کل بازدیدها در همه زمینه ها است. بخش اول معادله (4) تعداد دفعات را نشان می دهد للدر بازدید شد آآ، در حالی که بخش دوم اندازه گیری می کند که آیا للمعمولاً یا به ندرت در همه زمینه ها بازدید می شد.
نمایه یک بافت را می توان به عنوان یک نمای تلفیقی از استفاده از مکان های مختلف در این زمینه (موقعیت) در نظر گرفت که می تواند برای توصیف بافت مورد استفاده قرار گیرد.
-
سپس شباهت بین دو زمینه با استفاده از معیار تشابه کسینوس محاسبه می شود. این عمدتا به این دلیل است که شباهت کسینوس اغلب برای اندازه گیری شباهت بین اشیایی که به عنوان بردار نشان داده می شوند استفاده می شود و کسینوس زاویه بین این دو بردار را اندازه گیری می کند [43 ] . بنابراین، شباهت بین دو زمینه (که با A و B مشخص می شود ) را می توان به عنوان شباهت کسینوس بین بردارهای نمایه متناظر آنها اندازه گیری کرد.
مقادیر شباهت از 0 تا 1 متغیر است. لطفاً توجه داشته باشید که اندازه گیری بر اساس رفتار بازدید گردشگران محاسبه می شود که برای کار توصیه مکان مناسب است. ممکن است مستقیماً در سناریوهای برنامه دیگر استفاده نشود. با این حال، ما استدلال می کنیم که ایده های کلیدی پشت آن هنوز قابل اجرا هستند.
در ارزیابی ( بخش 4 )، با توجه به ویژگی های متنوع شهرهای مختلف (که به طور بالقوه بر رفتار بازدید گردشگران در زمینه های مختلف تأثیر می گذارد)، فرض می کنیم که شباهت بافت وابسته به شهر است. بنابراین، ما یک ماتریس شباهت زمینه CSim_M CC برای هر شهر می سازیم. هر عنصر در CSim_M CC نشان دهنده شباهت بین دو زمینه در شهر است.
3.4. توصیه موقعیت مکانی آگاه از زمینه
همانطور که قبلا ذکر شد، Adomavicius و Tuzhilin (2011) [ 19 ] پیشنهاد کردند که اطلاعات زمینه را می توان با پیش فیلتر کردن متنی، پس از فیلتر کردن و مدل سازی در CF گنجاند. با این حال، این طبقه بندی برای توصیه های مکان در حوزه گردشگری اعمال نشده است. در این بخش، ما این طبقهبندی را اعمال میکنیم و سه روش را برای استخراج توصیههای مکان شخصیشده و آگاه از زمینه ایجاد میکنیم.
3.4.1. پیش فیلتر کردن متنی
ایده اصلی پیش فیلتر کردن متنی فیلتر کردن مکان های نامربوط قبل از استفاده از CF کلاسیک (یعنی CF غیر متنی) است. بنابراین، ما رویکرد پیشفیلترسازی متنی زیر را توسعه میدهیم (CaCF_Pre):
3.4.2. پس-فیلترسازی متنی
متفاوت از پیش فیلتر متنی، پس فیلترینگ متنی (CaCF_Post) ابتدا از CF کلاسیک استفاده می کند و سپس نتایج را بر اساس اطلاعات زمینه تنظیم می کند.
با اینها، میتوانیم مکانهای نامزد را مجدداً رتبهبندی کنیم و k تعداد مکانهای برتر را به عنوان نتایج توصیهها به کاربر فعلی برگردانیم.
3.4.3. مدلسازی متنی
در مقایسه با رویکردهای فوق، مدلسازی زمینهای از اطلاعات زمینه مستقیماً در فرآیند CF استفاده میکند. توجه داشته باشید که فرآیند CF را می توان به عنوان “شناسایی نظرات مفید” و “تجمیع نظرات” در نظر گرفت. بنابراین، ما رویکرد مدلسازی زمینهای زیر (CaCF_Mdl) را طراحی میکنیم.
4. ارزیابی و بحث
این بخش روشهای CaCF پیشنهادی را در برابر برخی روشهای معیار ارزیابی میکند. ارزیابی با استفاده از Python و PostgreSQL اجرا شد. بخش 4.1 مجموعه داده را توصیف می کند. بخش 4.2 نحوه پردازش مجموعه داده ها را برای شناسایی مکان های گردشگری و استخراج تاریخچه سفر هر گردشگر ارائه می دهد. ما تنظیمات آزمایشی را در بخش 4.3 توضیح می دهیم . نتایج در بخش 4.4 ارائه و مورد بحث قرار گرفته است .
4.1. مجموعه داده
ما از API عمومی Flickr (به ویژه flickr.photos.search) برای بازیابی عکس های دارای برچسب جغرافیایی برای شش شهر در اروپا بین 1 ژانویه 2008 تا 31 دسامبر 2013 استفاده کردیم. فقط ابرداده های هر عکس نگهداری می شد که حاوی “photoid”، “مالک” بود. ، “عنوان”، “تاریخ آپلود”، “تاریخ گرفته شده”، “برچسب ها”، “لات”، “lon” و غیره. در مجموع، ما 2,627,139 عکس دارای برچسب جغرافیایی از 79,951 کاربر جمع آوری کردیم ( جدول 1 ).
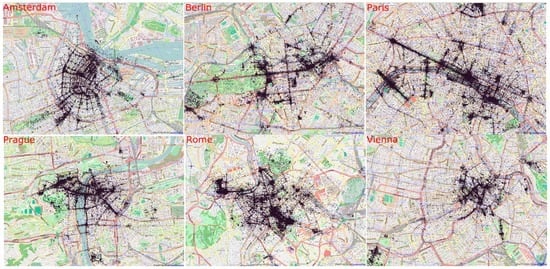
ما ابتدا ابرداده عکسهایی را حذف کردیم که زمان بارگذاری آنها (“تاریخ آپلود”) با زمان گرفته شده (“تاریخ گرفته شده”) یکسان است. برای پاکسازی بیشتر مجموعه داده ها، عکس ها را بر اساس شهرهایی که در آن گرفته شده اند جدا کردیم. برای عکسهای هر شهر، عکسهای ارائهشده توسط ساکنان محلی آن شهر را با استفاده از قانون اکتشافی معرفیشده در بخش 3.2.1 فیلتر کردیم . شکل 2 توزیع فضایی عکس های باقی مانده را در شهرهای مختلف نشان می دهد.
4.2. شناسایی موقعیت مکانی توریستی و استخراج تاریخچه سفر
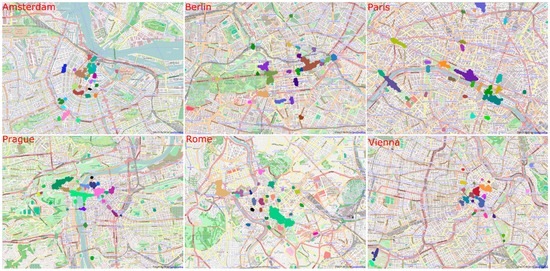
همانطور که در بخش 3.2 معرفی شد ، ما از DBSCAN برای خوشهبندی عکسها و شناسایی مکانهای توریستی استفاده کردیم. DBSCAN دارای دو پارامتر MinPts و Eps است. ما تجزیه و تحلیل حساسیت این دو پارامتر را انجام دادیم. شکل 3 نشان می دهد که چگونه تعداد خوشه های شناسایی شده در MinPts و Eps مختلف تغییر می کند. به غیر از منحنی برای MinPts = 60، منحنی های دیگر به طور مشابه تغییر می کنند. هنگامی که مقدار Eps حدود 30 متر است، تعداد خوشه ها به حداکثر مقدار می رسد. تعداد خوشههای شناساییشده همیشه با افزایش MinPt کاهش مییابد، و زمانی که MinPts بیش از 100 باشد، کاهش آهسته میشود. شکل 4 مکان های گردشگری شناسایی شده در شهرهای مختلف را نشان می دهد.
بر اساس فهرست مکانهای گردشگری، تاریخچه سفر هر گردشگر را استخراج کردیم. برای شناسایی بازدیدها از عکسها، آستانه مدت بازدید را تنظیم میکنیم δدتو آر�دتو�به عنوان هشت ساعت، که با مدت زمان افتتاح بسیاری از مکان های دیدنی در اروپا قابل مقایسه است. برای هر بازدید، از مهر زمانی آن برای استخراج «فصل» و «زمان روز» استفاده کردیم و از Weather Underground API برای بازیابی «آب و هوا» استفاده کردیم. در مجموع 21541 بازدید از 1257 گردشگر استخراج کردیم. جدول 2 تعداد گردشگران و توزیع آن در تعداد مکان های بازدید شده در هر شهر را خلاصه می کند.
4.3. راه اندازی آزمایشی
اهداف: برای ارزیابی تجربی، ما عمدتاً علاقه مند به مقایسه روشهای CaCF پیشنهادی با روش CF کلاسیک (یعنی CF غیر متنی) و سایر روشهای مدرن آگاه از زمینه بودیم. ما می خواهیم به سؤالات زیر پاسخ دهیم: (1) آیا در نظر گرفتن اطلاعات زمینه در CF عملکرد توصیه را بهبود می بخشد؟ (2) آیا روشهای آگاه از زمینه پیشنهادی بهتر از روشهای پیشرفته عمل میکنند؟ آیا استفاده از معیار تشابه زمینه پیشنهادی عملکرد توصیه را بهبود می بخشد؟
روش های محک زنی: به منظور رفع اهداف فوق، روش های محک گذاری زیر را اجرا کردیم:
-
CF کلاسیک (“nonCaCF”): این یک CF غیر متنی است که مکان هایی را به کاربر توصیه می کند که سایر کاربران با ترجیحات مشابه در گذشته از آنها بازدید کرده اند. تنها با استفاده از مرحله دوم CaCF_Pre می توان آن را پیاده سازی کرد (به بخش 3.4.1 مراجعه کنید ).
-
پیش فیلتر متنی با “تطابق دقیق” (“CaCF_Pre_EM”): این یک روش پیشرفته است که در مجید و همکاران ارائه شده است. (2013) [ 38 ]. برای اجرای آن، هر مکان را شناسایی کردیم للزمینه بازدید محبوب (یعنی زمینه ای که بیشترین بازدیدها در آن است للاتفاق افتاد) و سپس مکانهایی را فیلتر کرد که زمینه بازدید محبوب آنها با بافت فعلی متفاوت است با استفاده از تطابق دقیق ( برای جزئیات بیشتر به بخش 2.3 مراجعه کنید ). سپس CF کلاسیک برای رتبهبندی مجدد مجموعه فیلتر شده مکانها توسعه یافت.
چارچوب ارزیابی: برای ارزیابی، تنها گردشگرانی انتخاب شدند که حداقل از دو شهر بازدید کرده باشند. برای هر توریست توتو، از یکی از شهرهای بازدید شده وی به عنوان شهر آزمایش استفاده کردیم سیتیتوسیتوتیو سایر شهرها به عنوان شهرهای آموزشی سیoتوسیتو�. به عبارت دیگر، ما مکانهایی را که واقعاً بازدید شدهاند پیشبینی کردیم توتودر شهر سیتیتوسیتوتی، بر اساس سابقه سفر او در سیoتوسیتو�. بازدیدهای انجام شده توسط توتودر شهر سیتیتوسیتوتیبرای به دست آوردن: تعداد (که با k نشان داده می شود ) مکان هایی که واقعاً توسط آنها بازدید شده است استفاده شدتوتوو مجموعه زمینه های مرتبط با بازدید از این مکان ها. این مجموعه از زمینه ها به عنوان ورودی برای الگوریتم های توصیه زمینه آگاه (CaCF) استفاده شد. برای هر الگوریتم، k مکان را برای کاربر آزمایشی توصیه کردیمتوتوبرای بازدید در شهر سیتیتوسیتوتی.
برای اندازهگیری عملکرد روشهای پیشنهادی و روشهای معیار، ما لیست توصیهها را با فهرست واقعی مکانهای بازدید شده توسط توتودر شهر سیتیتوسیتوتی. دقت و یادآوری محبوب ترین معیارها برای ارزیابی سیستم های بازیابی اطلاعات هستند [ 44 ]. هرلوکر و همکاران (2004) [ 45 ] استدلال کردند که یادآوری برای ارزیابی کیفیت توصیه غیرعملی است. بنابراین، در این مطالعه از دقت برای ارزیابی کیفیت توصیه استفاده شد و به عنوان کسری از مکانهای پیشنهادی که واقعاً توسط آنها بازدید شده بود، تعریف شد. توتو. علاوه بر این، ما از میانگین دقت متوسط (MAP) نیز استفاده کردیم، که نشان داده شده است که تمایز و ثبات خوبی برای اندازهگیری اثربخشی رتبهبندی دارد [ 44 ]. بهعنوان میانگین مقادیر میانگین دقت (AP) همه پرسوجوها محاسبه شد، و AP هر پرسوجو بهعنوان میانگین مقادیر دقت در هر توصیه درست محاسبه میشود (یعنی مکان پیشنهادی در واقع توسط کاربر تست توتو).
4.4. نتایج ارزیابی و بحث
4.4.1. تجزیه و تحلیل میزان حساسیت
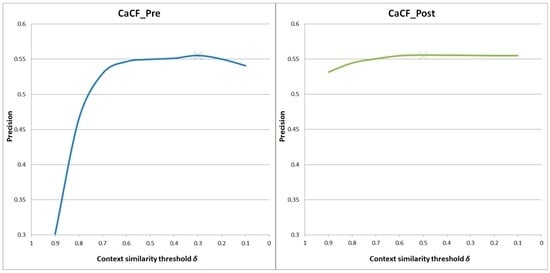
قبل از مقایسه روشها، ما یک تحلیل حساسیت را برای مطالعه تأثیر آستانه تشابه زمینه اجرا کردیم. δ�در CaCF_Pre و CaCF_Post. ما آزمایش هایی را با تغییر مقادیر آستانه انجام دادیم. نتایج در شکل 5 نشان داده شده است .
شکل 5 نشان می دهد که آستانه بر کیفیت توصیه CaCF_Pre و CaCF_Post تاثیر می گذارد. در مقایسه با CaCF_Post، آستانه تأثیر بیشتری بر نتایج توصیههای CaCF_Pre دارد. این را میتوان با روشهایی که آنها اطلاعات زمینه را ترکیب میکنند توضیح داد: CaCF_Pre مکانهایی را فیلتر میکند که برای بازدید در شرایط فعلی مناسب نیستند. CaCF_Post مجموعه ای از مکان های نامزد را با استفاده از CF غیر متنی ایجاد می کند و نتایج را بر اساس اطلاعات زمینه تنظیم می کند.
عملکرد توصیه هر دو روش با کاهش آستانه افزایش می یابد. با این حال، کیفیت پس از یک نقطه خاص بدتر می شود، یعنی δ�= 0.3 برای CaCF_Pre و δ�= 0.5 برای CaCF_Post. برای آزمایشهای زیر تنظیم کردیم δ�= 0.3 برای CaCF_Pre و δ�= 0.5 برای CaCF_Post.
4.4.2. مقایسه الگوریتم
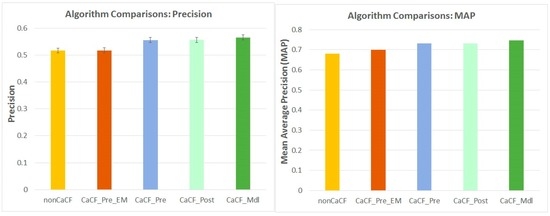
در ادامه، عملکرد پیشنهادی روشهای CaCF پیشنهادی و روشهای محکگذاری را با هم مقایسه میکنیم. شکل 6 نتایج را نشان می دهد.
CF غیر متنی (nonCaCF) در مقابل CF آگاه از زمینه (CaCF): از نظر عملکرد توصیه، همه روشهای CaCF پیشنهادی (به عنوان مثال، CaCF_Pre، CaCF_Post، CaCF_Mdl) به نتایج قابلتوجهی بهتر از nonCaCF (با همه p <0.001) دست مییابند . با پیشرفت های 7.65%، 7.72% و 9.47% برای دقت و با پیشرفت های 7.58%، 7.75% و 9.81% برای MAP. این با آنچه ما انتظار داشتیم مطابقت دارد: از آنجایی که روشهای CaCF پیشنهادی از زمینهای که کاربر در آن قرار دارد آگاه هستند، ممکن است توصیههایی ایجاد کنند که برای بازدید مناسبتر هستند.
CaCF_Pre_EM در مقابل CF آگاه از متن (CaCF_Pre، CaCF_Post، CaCF_Mdl): از نظر عملکرد توصیه، همه روشهای CaCF پیشنهادی به نتایج قابلتوجهی بهتر از CaCF_Pre_EM (یعنی پیشفیلترسازی متنی با تطبیق دقیق) میرسند (با همه p < 0.0 ) با بهبودهای 7.45%، 7.53% و 9.27% برای دقت و با بهبودهای 4.48%، 4.64% و 6.64% برای MAP. CaCF_Pre_EM حتی کمی بهتر از nonCaCF عمل می کند. دلیل عملکرد ضعیف آن این است که از تطابق دقیق برای فیلتر کردن مکانهایی استفاده میکند که زمینه بازدید محبوب آنها با بافت فعلی یکسان نیست، که واقعاً بسیاری از مکانهای مرتبط را فیلتر میکند.
CaCF_Pre در مقابل CaCF_Post در مقابل CaCF_Mdl : در بین همه روش ها، CaCF_Mdl بهترین عملکرد را دارد، سپس CaCF_Post و در نهایت CaCF_Pre. تفاوت بین CaCF_Mdl و دو مورد دیگر قابل توجه است (با همه p <0.001). CaCF_Pre و CaCF_Post به طور مشابه عمل می کنند و تفاوت معنی داری از مقایسه ها به دست نمی آید (دقت: p = 0.76؛ MAP: p= 0.39). عملکرد متنوع این روشها را میتوان با روشهایی که آنها اطلاعات زمینه را ترکیب میکنند توضیح داد: CaCF_Pre مکانهایی را فیلتر میکند که برای بازدید در شرایط فعلی مناسب نیستند. CaCF_Post مجموعه ای از مکان های نامزد را با استفاده از CF غیر متنی ایجاد می کند و نتایج را بر اساس اطلاعات زمینه تنظیم می کند. CaCF_Mdl از شباهت زمینه و شباهت کاربر برای اندازه گیری ابزار توصیه هر بازدید به کاربر فعلی استفاده می کند و سپس همه بازدیدها را با در نظر گرفتن مقادیر مفید آنها برای ایجاد توصیه های مکان جمع می کند.
4.4.3. توصیه هایی با تعداد مکان های آموزشی متفاوت
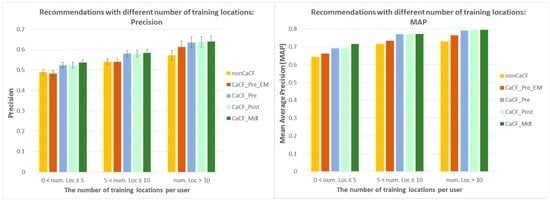
تعداد مکانهای آموزشی (یعنی مکانهایی که یک توریست قبل از درخواست توصیهها بازدید کرده است) میزان اطلاعات (به عنوان مثال، تاریخچه سفر) موجود در مورد یک گردشگر را منعکس میکند. در ادامه، چگونگی تغییر عملکرد هنگام ایجاد توصیهها برای گردشگران با تعداد مکانهای آموزشی متفاوت را بررسی میکنیم ( شکل 7 ).
شکل 7 یک روند صعودی را برای عملکرد توصیه برای همه روش های توصیه نشان می دهد که تعداد مکان های آموزشی افزایش می یابد. این با انتظارات ما مطابقت دارد: با افزایش تعداد مکان های آموزشی، اطلاعات بیشتری در مورد یک گردشگر برای روش های توصیه در دسترس است و بنابراین، عملکرد توصیه بهبود می یابد.
4.4.4. خلاصه نتایج و بحث ها
به طور خلاصه، یافته های اصلی آزمایش ها به شرح زیر است:
-
همه روش های CaCF پیشنهادی به طور قابل توجهی بهتر از CF کلاسیک (یعنی CF غیر متنی، nonCaCF) عمل می کنند.
-
روشهای پیشنهادی (به عنوان مثال، CaCF_Pre، CaCF_Post و CaCF_Mdl) به طور قابلتوجهی بهتر از روش توصیه مکان آگاه از زمینههای پیشرفته (یعنی CaCF_Pre_EM) عمل میکنند.
-
در میان همه روشهای پیشنهادی پیشنهادی موقعیت مکانی آگاه از زمینه، CaCF_Mdl بهترین عملکرد را دارد، سپس CaCF_Post و در نهایت CaCF_Pre.
-
با افزایش تعداد مکان های آموزشی، عملکرد پیشنهادی همه روش های پیشنهادی بهبود می یابد.
به طور کلی، این یافته ها با آنچه ما انتظار داشتیم مطابقت دارد.
-
نتایج آزمایش نشان میدهد که با جمعآوری تاریخچه سفر سایر گردشگران (به عنوان مثال، همانطور که از عکسهای دارای برچسب جغرافیایی استخراج میشود)، میتوانیم توصیههای مکان مطابق با اولویتهای سفر و زمینه بازدید را به کاربر فعلی ارائه کنیم. نتایج، یافته های Wexelblat (1999) [ 1 ] و ژنگ و همکاران را تایید می کند. (2011) [ 24 ] و پیشنهاد می کند که تجربیات کاربران گذشته (به ویژه آن دسته از کاربرانی که مشابه کاربر فعلی هستند) می تواند به کاربر فعلی کمک کند تا مشکلات خود را به طور موثر حل کند، به عنوان مثال، انتخاب مکان بعدی برای بازدید.
-
ما انتظار داریم که از آنجایی که روشهای پیشنهادی (یعنی CaCF_Pre، CaCF_Post و CaCF_Mdl) از زمینهای که کاربر در آن قرار دارد آگاه هستند، ممکن است توصیههایی برای مکان ایجاد کنند که برای بازدید مناسبتر هستند. این آزمایشها این انتظار را تأیید میکنند و نشان میدهند که گنجاندن اطلاعات زمینه در فرآیند توصیه میتواند به بهبود کیفیت توصیه کمک کند.
-
همانطور که از شکل 6 و شکل 7 مشاهده می شود ، روش های پیشنهادی به طور قابل توجهی بهتر از روش های پیشرفته زمینه آگاه عمل می کنند. این نشان می دهد که روشی که اطلاعات زمینه در CF ادغام می شود تا حد زیادی بر عملکرد توصیه تأثیر می گذارد. به طور خاص، آزمایشها نشان میدهند که در مقایسه با «تطابق دقیق»، استفاده از معیار تشابه زمینه پیشنهادی به طور قابلتوجهی عملکرد توصیه را بهبود میبخشد.
-
نتایج بالا نشان میدهد که در بین تمام روشهای CaCF پیشنهادی، روش مدلسازی زمینهای (CaCF_Mdl) ممکن است برای ایجاد توصیههای مکان مطابق با ترجیحات سفر کاربر و زمینه بازدید مناسبتر باشد. از آنجایی که هر دو روش پیش فیلتر متنی (CaCF_Pre) و پس فیلترینگ متنی (CaCF_Post) یک پارامتر برای کالیبره کردن دارند (یعنی آستانه تشابه زمینه δ�، بنابراین توصیه می شود از CaCF_Mdl برای توصیه های مکان آگاه از متن استفاده کنید.
همچنین باید به چند محدودیت اصلی این کار اشاره کرد. در مرحله اول، این تحقیق از DBSCAN برای شناسایی مکان های توریستی استفاده می کند و از CF برای ارائه توصیه ها استفاده می کند. برای ارزیابی، از مجموعه دادههای چندین شهر بزرگ در اروپا استفاده میکنیم که هر کدام حاوی عکسهای دارای برچسب جغرافیایی بسیاری از کاربران مختلف است. از آنجایی که هم DBSCAN و هم CF با مجموعه داده های بزرگ (مانند مجموعه داده های مورد استفاده در این مقاله) به خوبی کار می کنند، روش های پیشنهادی ممکن است هنگام استفاده از مجموعه داده های کوچک با تعداد کم کاربر، به عنوان مثال، مجموعه داده های عکس دارای برچسب جغرافیایی از شهرهای کوچک و مناطق روستایی، عملکرد خوبی نداشته باشند. برای ارائه توصیه هایی بر اساس این مجموعه داده های کوچک، روش های CaCF پیشنهادی را می توان با رویکردهای مبتنی بر محتوا یا مبتنی بر دانش ترکیب کرد. ثانیا، این کار مقادیر هر پارامتر زمینه را به عنوان مجموعه ای از مقوله ها نشان می دهد (به عنوان مثال، پارامتر زمینه “زمان روز” مقادیری مانند “صبح”، “بعد از ظهر” و “شب” دارد). در حالی که مقادیر طبقه بندی شده ممکن است پیچیدگی مدل را ساده کند، گاهی اوقات ممکن است انتقال داده های زمینه خام به دسته های مربوطه آسان نباشد. منطق فازی یا مقیاس های تدریجی (به عنوان مثال، [46]) ممکن است برای رفع این مشکل به کار گرفته شود. ثالثاً، این مقاله نشان می دهد که در نظر گرفتن اطلاعات زمینه (یعنی مجموعه “فصل”، “زمان روز” و “آب و هوا” در این مقاله) می تواند به طور قابل توجهی عملکرد توصیه را بهبود بخشد. این تحقیق را می توان با بررسی اینکه چگونه هر پارامتر زمینه به بهبود عملکرد کمک می کند، افزایش داد. ما این را به عنوان یک کار آینده در نظر میگیریم و میخواهیم آن را بیشتر گسترش دهیم تا یک روش محاسباتی برای شناسایی پارامترهای زمینه مرتبط حتی قبل از اعمال روشهای پیشنهادی پیشنهادی آگاه از زمینه ایجاد کنیم. در نهایت، در تحقیق حاضر، مجموعه دادهها را به دادههای آموزشی و آزمایشی برای ارزیابی روشهای پیشنهادی تقسیم میکنیم. در حالی که این رویکرد ارزیابی به مقایسه عملکرد توصیه ها کمک می کند، می توان آن را با استفاده از آزمایشات با شرکت کنندگان انسانی (مثلاً گردشگران) بهبود بخشید. برای مثال، میتوانیم از هر شرکتکننده بخواهیم در مورد نتایج توصیههای تولید شده توسط روشهای پیشنهادی اظهار نظر کند. این نوع آزمایشات انسانی همچنین به بررسی بیشتر اینکه آیا بهبود عملکرد قابل توجه هنگام در نظر گرفتن اطلاعات زمینه (همانطور که در این مقاله نشان داده شده است) واقعاً نتایج توصیه های بسیار بهتری را برای گردشگران به ارمغان می آورد کمک خواهد کرد. ما انتظار داریم که نتایج ارزیابی مشابهی را بتوان در این آزمایش ها به دست آورد.
5. نتیجه گیری و کار آینده
این مقاله بررسی میکند که چگونه عکسهای دارای برچسب جغرافیایی در رسانههای اجتماعی را میتوان جمعآوری کرد تا توصیههای مکان مطابق با اولویتهای سفر گردشگران و زمینه بازدید (مانند آب و هوا، فصل و زمان روز) را استخراج کند. به طور خاص، ما روشهای خوشهبندی را برای شناسایی مکانهای گردشگری به کار بردیم و تاریخچه سفر را از عکسهای فلیکر دارای برچسب جغرافیایی استخراج کردیم. سپس یک معیار شباهت جدید را برای تعیین کمیت شباهت بین هر دو زمینه پیشنهاد کردیم و سه روش فیلتر مشارکتی آگاه از زمینه (CaCF) را توسعه دادیم، به عنوان مثال، پیش فیلتر زمینه، پس از فیلتر کردن و مدلسازی. این روشها میتوانند «توصیههای اجتماعی» را برای انتخاب مکان بازدید به گردشگران ارائه دهند، به عنوان مثال، توصیههای مکان مانند «در زمینههای مشابه، سایر گردشگران مشابه شما اغلب بازدید میکردند…»
ما روشهای پیشنهادی را در مقابل سایر روشهای پیشرفته پیشنهاد مکان با استفاده از یک مجموعه عکس فلیکر در دسترس عموم، که حاوی عکسهای دارای برچسب جغرافیایی در شش شهر اروپایی بود، ارزیابی کردیم. نتایج ارزیابی نشان میدهد که: (1) روشهای پیشنهادی میتوانند به یک گردشگر توصیههای مکان منطبق با ترجیحات او و زمینه بازدید فعلی ارائه کنند. (2) مهمتر از همه، در مقایسه با سایر روشهای پیشرفته، روشهای پیشنهادی، که از معیار تشابه زمینه استفاده میکنند، میتوانند به طور قابل توجهی توصیههای مکان یابی بهتری را در اختیار گردشگران قرار دهند. به عبارت دیگر، در مقایسه با تطبیق دقیق، استفاده از معیار تشابه زمینه پیشنهادی به طور قابل توجهی عملکرد توصیه را بهبود می بخشد.
در نتیجه، با جمعآوری تاریخچه سفر سایر گردشگران (به عنوان مثال، همانطور که از عکسهای دارای برچسب جغرافیایی استخراج میشود)، میتوان توصیههای مکانی شخصی و آگاه از زمینه را برای کاربر فعلی ارائه کرد. در حالی که دادههای فلیکر در این مطالعه استفاده شدهاند، روشهای CaCF پیشنهادی را میتوان برای انواع دیگر تاریخچههای موقعیت مکانی، مانند مسیرهای GPS و بررسی چهار ضلعی، برای ارائه توصیههای آگاه از زمینه گسترش داد. این روشها همچنین میتوانند برای در نظر گرفتن اطلاعات زمینه بیشتر، مانند اهداف بازدید و همراه (با چه کسی) استفاده شوند.
به عنوان گام بعدی، به مسائل کیفی (مثلاً نمایندگی، ناقص بودن، خطاهای برچسبگذاری و سوگیری) دادههای رسانههای اجتماعی خواهیم پرداخت و روشهایی را برای پاکسازی آنها توسعه خواهیم داد. در عین حال، ما می خواهیم الگوریتم های پیشنهادی را از توصیه مکان به توصیه های توالی و برنامه سفر گسترش دهیم (به عنوان مثال، توصیه به دنباله ای از مکان ها برای بازدید). توصیه دنباله باید نه تنها مسافت سفر، بلکه تنوع اقلام، اثرات متقابل همزمان موارد و سایر محدودیت ها را نیز در نظر بگیرد. ما همچنین علاقه مند به توسعه روش های CaCF جامع تر، با استفاده از تعاریف فازی و مقیاس های تدریجی در مدل زمینه هستیم. علاوه بر این، تحقیق فعلی از CF برای استخراج توصیههای مکان از عکسهای دارای برچسب جغرافیایی استفاده کرد. در حالی که CF یک تکنیک توصیه موثر است که به دانش کمی از دامنه نیاز دارد، از مشکل “شروع سرد” (“کاربر جدید” و “مورد جدید”) رنج می برد. ما با ادغام سایر تکنیکهای توصیه، به عنوان مثال، توصیههای مبتنی بر محتوا یا مبتنی بر دانش، به این مسائل خواهیم پرداخت. ما انتظار داریم که تکنیک های ترکیبی عملکرد توصیه را بیشتر بهبود بخشد. ما همچنین میخواهیم یک آزمایش انسانی برای بررسی بیشتر مزایای در نظر گرفتن اطلاعات زمینه در توصیه مکان برای گردشگران طراحی کنیم. علاوه بر این، ما همچنین علاقه مند به گسترش روش های خود هستیم تا نه تنها توصیه های مکان، بلکه توضیحاتی در مورد اینکه چرا این مکان ها توصیه می شوند نیز ایجاد کنیم. ما با ادغام سایر تکنیکهای توصیه، به عنوان مثال، توصیههای مبتنی بر محتوا یا مبتنی بر دانش، به این مسائل خواهیم پرداخت. ما انتظار داریم که تکنیک های ترکیبی عملکرد توصیه را بیشتر بهبود بخشد. ما همچنین میخواهیم یک آزمایش انسانی برای بررسی بیشتر مزایای در نظر گرفتن اطلاعات زمینه در توصیه مکان برای گردشگران طراحی کنیم. علاوه بر این، ما همچنین علاقه مند به گسترش روش های خود هستیم تا نه تنها توصیه های مکان، بلکه توضیحاتی در مورد اینکه چرا این مکان ها توصیه می شوند نیز ایجاد کنیم. ما با ادغام سایر تکنیکهای توصیه، به عنوان مثال، توصیههای مبتنی بر محتوا یا مبتنی بر دانش، به این مسائل خواهیم پرداخت. ما انتظار داریم که تکنیک های ترکیبی عملکرد توصیه را بیشتر بهبود بخشد. ما همچنین میخواهیم یک آزمایش انسانی برای بررسی بیشتر مزایای در نظر گرفتن اطلاعات زمینه در توصیه مکان برای گردشگران طراحی کنیم. علاوه بر این، ما همچنین علاقه مند به گسترش روش های خود هستیم تا نه تنها توصیه های مکان، بلکه توضیحاتی در مورد اینکه چرا این مکان ها توصیه می شوند نیز ایجاد کنیم. ما همچنین میخواهیم یک آزمایش انسانی برای بررسی بیشتر مزایای در نظر گرفتن اطلاعات زمینه در توصیه مکان برای گردشگران طراحی کنیم. علاوه بر این، ما همچنین علاقه مند به گسترش روش های خود هستیم تا نه تنها توصیه های مکان، بلکه توضیحاتی در مورد اینکه چرا این مکان ها توصیه می شوند نیز ایجاد کنیم. ما همچنین میخواهیم یک آزمایش انسانی برای بررسی بیشتر مزایای در نظر گرفتن اطلاعات زمینه در توصیه مکان برای گردشگران طراحی کنیم. علاوه بر این، ما همچنین علاقه مند به گسترش روش های خود هستیم تا نه تنها توصیه های مکان، بلکه توضیحاتی در مورد اینکه چرا این مکان ها توصیه می شوند نیز ایجاد کنیم.





بدون نظر