1. معرفی
اهمیت معناشناسی در GIS (سیستمهای اطلاعات جغرافیایی) توجه فزایندهای را در زمینه کاربردهای مختلف از جمله یکپارچهسازی دادههای جغرافیایی، بازیابی دادهها، سیستمهای راهیابی و کشف دانش جغرافیایی به خود جلب کرده است. خوشه بندی جغرافیایی، که الگوریتم های خوشه بندی استاندارد را با ترکیب دانش پس زمینه بهبود می بخشد، نمی تواند به صراحت در برنامه های GIS مستثنی شود. چنین خوشه بندی باید به دانش قبلی دامنه GIS و زمینه کاربر GIS بستگی داشته باشد. استفاده بهتر از دانش مکانی و خوشهبندی برای انتخاب محدودیتها و پارامترهای مناسب، احتمالاً خوشههای بهتر و معنیداری را به همراه خواهد داشت.
داده کاوی جغرافیایی [ 1 ] استخراج دانش ضمنی، روابط مکانی، و ویژگی ها و الگوهای جالبی است که به صراحت در یک پایگاه داده جغرافیایی نشان داده نمی شوند. در حال حاضر، کاربرد اصلی داده کاوی جغرافیایی، تجزیه و تحلیل داده های جغرافیایی با هدف استخراج و انتقال اطلاعات مکانی است. تجزیه و تحلیل جغرافیایی جوهر GIS است که امکان به دست آوردن اطلاعات و دانش پنهان از داده های جغرافیایی را فراهم می کند. از داده کاوی جغرافیایی می توان در نقشه برداری و نقشه برداری استفاده کرد، اما به این زمینه ها محدود نمی شود.
خوشه بندی جغرافیایی یک حوزه مهم تحقیق در داده کاوی مکانی است. الگوریتم های خوشه بندی نقش کلیدی در تکنیک های تجزیه و تحلیل فضایی GIS مانند همپوشانی چند ضلعی دارند [ 2 ]. نیاز به راه حل های عملی در انواع کاربردهای خوشه بندی محدود وجود دارد. بنابراین، برای بهبود سودمندی خوشهبندی، مطالعه آنالیز خوشهبندی جغرافیایی مبتنی بر محدودیت حیاتی است. مفهوم معرفی یک رویکرد مبتنی بر پیشینه جغرافیایی در فرآیند حل مسئله جغرافیایی جدید نیست، همانطور که آثار متعدد نشان می دهد. به طور خاص، نمودارهای معنایی جغرافیایی برای نمایش و تجزیه و تحلیل داده های سنجش از دور استفاده شده است [ 3 ]. علاوه بر این، چندین مطالعه دیگر به محدودیتهای خوشهبندی پرداختهاند [ 4، 5 ، 6 ]، اما اینها اغلب قیود معنایی را نادیده گرفته اند. به خصوص توجه کمی به معناشناسی محدودیت های جغرافیایی شده است.
الگوریتم خوشهبندی معروف DBSCAN (خوشهبندی مبتنی بر چگالی مکانی برنامهها با نویز) [ 7 ] دارای چندین نقص است. به طور خاص، کمبود دانش پس زمینه جغرافیایی (محدودیت های خوشه بندی جغرافیایی) وجود دارد و مشکلات قابل توجهی در کسب و نمایش روابط بین دانش مکانی وجود دارد. اکثر روشهای خوشهبندی موجود صرفاً بر روی خود دادهها تمرکز میکنند، بدون در نظر گرفتن عوامل محدودکننده (مانند شهرهای مختلف، موانع رودخانهای و موانع کوهستانی و غیره) .). بنابراین، خوشهبندی در سطح دادهها به جای سطح دانش انجام میشود، که مانع از درک کامل نتایج خوشهبندی توسط کاربران میشود. با وجود این، مطالعات کمی در مورد خوشهبندی مبتنی بر دانش حوزه با محدودیتها انجام شده است. پیشرفتها در زمینه مهندسی دانش، از جمله مهندسی هستیشناسی، توانایی ما را برای مدلسازی دادهها و استنتاج روابط بسیار بهبود بخشیده است. با این حال، این روش دارای کاستی های بسیاری در پشتیبانی از استفاده از دانش پیشینه جغرافیایی برای فرمول بندی محدودیت ها است. رویز و همکاران C-DBSCAN (خوشه بندی مبتنی بر چگالی با محدودیت ها) [ 8روش ]، که عملکرد بهبود یافته ای را نسبت به DBSCAN با تعداد کمی از محدودیت ها ارائه می دهد. با این حال، C-DBSCAN نمی تواند محدودیت های جغرافیایی واقعی را مدیریت کند، و فاقد معناشناسی است.
برای حل مسائل فوق، این مقاله روش جدیدی را پیشنهاد میکند که مبتنی بر دانش پیشینه جغرافیایی است. هستی شناسی DBSCAN (DBSCANO) مطابق با فرآیند DBSCAN و ویژگی های داده های اطلاعات جغرافیایی توسعه یافته است. الگوریتم C-DBSCANO با معرفی DBSCANO به DBSCAN تحقق یافته است. این باعث میشود که فرآیند عملیات خوشهبندی در DBSCAN تحت محدودیتهای دانش معنایی پسزمینه جغرافیایی و نتایج خوشهبندی معقولتر باشد.
برای حل این مشکلات، این مقاله روش جدیدی را برای بهرهبرداری از دانش پیشینه جغرافیایی پیشنهاد میکند. هستی شناسی DBSCAN ( DBSCANO ) برای سازگاری با فرآیند DBSCAN و ویژگی های داده های جغرافیایی توسعه یافته است. الگوریتم C-DBSCANO با ترکیب DBSCANO با DBSCAN توسعه یافت. این ابزارها، خوشهبندی را در DBSCAN تحت محدودیتهای مبتنی بر دانش معنایی پسزمینه جغرافیایی، امکانپذیر میسازند که منجر به نتایج خوشهبندی معقولتری میشود.
ادامه مقاله به شرح زیر تدوین شده است. بخش 2 مطالعات قبلی خوشه بندی و هستی شناسی های جغرافیایی را معرفی می کند. بخش 3 چارچوب DBSCAN را با یک هستی شناسی توصیف می کند. بخش 4 یک استدلال مبتنی بر dotNetRDF را توصیف می کند. بخش 5 نتایج به دست آمده با استفاده از اجرای الگوریتم C-DBSCANO را شرح می دهد. ما نتیجهگیریها را ارائه میکنیم و در مورد مطالعات احتمالی آینده در بخش 6 بحث میکنیم .
2. کار قبلی: خوشه بندی جغرافیایی و هستی شناسی
2.1. DBSCAN
DBSCAN از چگالی فضایی اتصال کلاس یک شی برای تعیین سریع کلاس های شکل انباشته شده استفاده می کند. ایده اصلی این است که هر شی دارای یک کلاس است و در دامنه خود در حداقل شعاع قرار دارد. الگوریتم های خوشه بندی را می توان به طور کلی به عنوان سلسله مراتبی یا پارتیشن بندی طبقه بندی کرد [ 9 ]. بسته به تعریفی که فرد از یک خوشه دارد، هر دسته میتواند به عنوان روش مبتنی بر فاصله، مدلمحور یا مبتنی بر چگالی طبقهبندی شود، و خوشهبندی مبتنی بر چگالی میتواند از استراتژی مبتنی بر شبکه یا محلهمحور استفاده کند [10] . ]. الگوریتم DBSCAN یک استراتژی مبتنی بر همسایگی برای پارتیشن بندی مبتنی بر چگالی است.
در بیشتر موارد عملی، نتایج دادهکاوی جغرافیایی باید هنگام حل یک مشکل خوشهبندی تحت محدودیتهای مختلف برای بهبود سودمندی خوشهبندی اعمال شود. کارلوس رویز و همکاران [ 10] برای به دست آوردن الگوریتم جدید C-DBSCAN، خوشه بندی نیمه نظارت شده مبتنی بر چگالی از نقاط داده را توسعه داد. C-DBSCAN عملکرد بهتری را در مقایسه با DBSCAN حتی با تعداد کمی از محدودیت ها نشان می دهد. C-DBSCAN مفهوم “Cannot-Link” را معرفی می کند (بر اساس دانش پس زمینه، دو شی باید مستقیماً به عنوان یک خوشه طبقه بندی شوند) و “Must-Link” (طبق دانش پس زمینه، این دو شی نمی توانند مستقیماً باشند. به عنوان محدودیت های خوشه ای مشابه در DBSCAN طبقه بندی می شوند. با این حال، این روش هیچ محدودیت جغرافیایی واقعی ندارد. علاوه بر این، C-DBSCAN دارای اثر جانبی ایجاد بسیاری از خوشه های تک تنه است. چارچوب C-DBSCAN توجه چندانی به معناشناسی زمینه محدودیتهای مرتبط با دادههای GIS در محیطهای جغرافیایی واقعی ندارد. که اغلب منجر به نتایج تحلیلی می شود که با وضعیت واقعی ناسازگار است. می توان گفت که C-DBSCAN به جای محدودیت های معنایی پس زمینه جغرافیایی، بر محدودیت های سخت تکیه دارد.
در مجموع، الگوریتم DBSCAN و الگوریتم DBSCAN و الگوریتم C-DBSCAN به ندرت در محدودیت های محیط جغرافیایی واقعی در نظر گرفته می شوند. چند نمونه از مدل های خوشه بندی مشکل ساز در زیر ارائه شده است.
1. بیان محدودیتهای خوشهبندی محدود است، و در نتیجه خوشهبندی میشود که میتواند روابط را در برخی سناریوها به اشتباه نشان دهد.
مثال نشان داده شده در شکل 1 یک نتیجه خوشه بندی را نشان می دهد که در برخی سناریوها نمی تواند معقول باشد. نتیجه خوشه بندی مرزهای ناحیه را نادیده می گیرد زیرا خوشه بندی کاملاً بر اساس معیارهای هندسی انجام شده است. اگر عضویت منطقه مهم باشد، مثلاً در مشکلات تخصیص مدرسه، یک محدودیت مربوطه لازم است. در غیاب هرگونه محدودیت بر اساس مناطق اداری، نقاط مورد علاقه از مناطق اداری مختلف صرفاً بر اساس مجاورت آنها خوشه بندی می شوند.
2. Eps و MinPts انعطاف ناپذیر و نامعقول هستند که منجر به خوشه بندی نامناسب می شود.
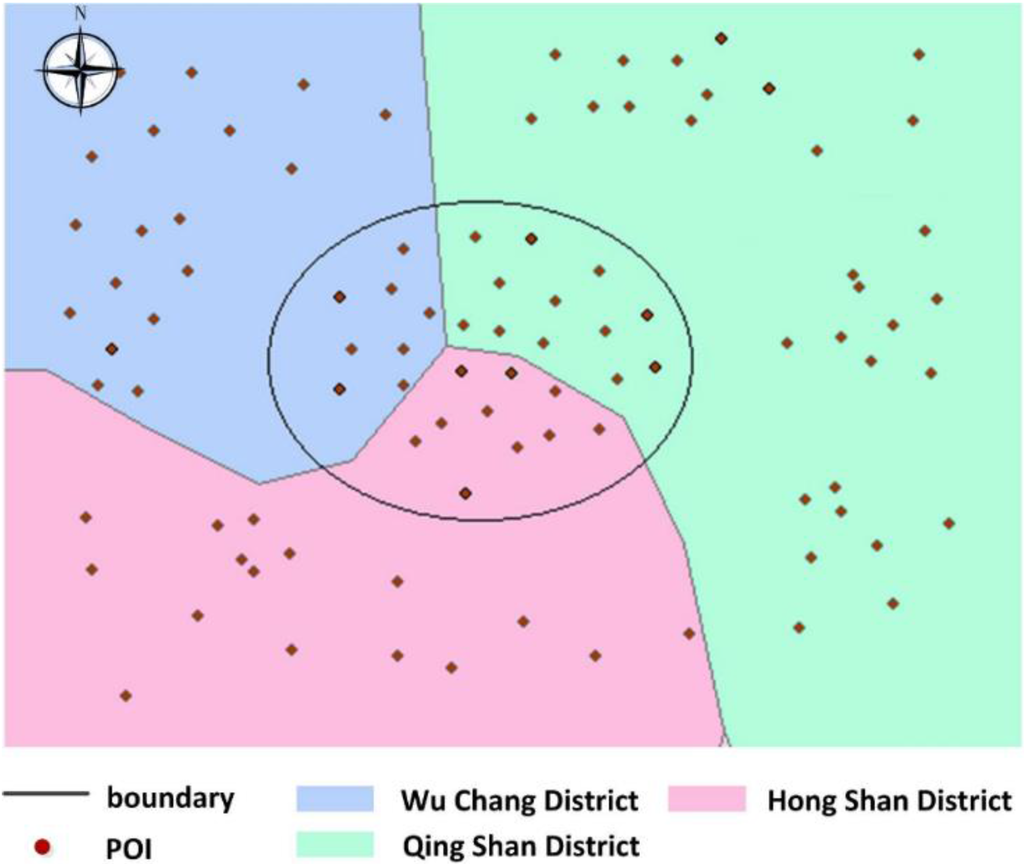
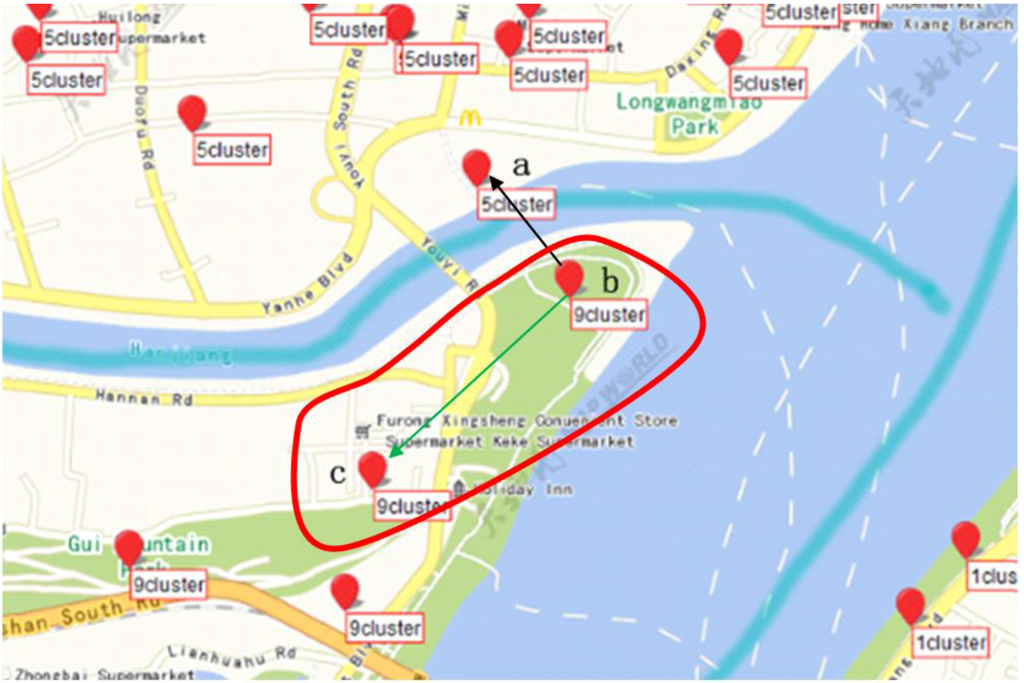
نمونه ای از نتایج خوشه بندی به دست آمده در چنین موردی در شکل 2 نشان داده شده است .
در مثال بالا، Eps (پارامتر فاصله) و MinPts (پارامتری از حداقل اندازه خوشه) بر اساس یک نوع منطقه تنظیم شدند: پارامترهای Eps1 و MinPts1 به خوبی برای مناطق شهری مناسب هستند اما برای مناطق مناسب نیستند. با سکونت پراکنده تر با این حال، هر دو منطقه شهری و حومه شهر در این منطقه وجود دارد. بنابراین، هنگام تجزیه و تحلیل حومهها، Eps و MinPts باید بر این اساس تنظیم شوند تا نتایج خوشهبندی بهتری به دست آید.
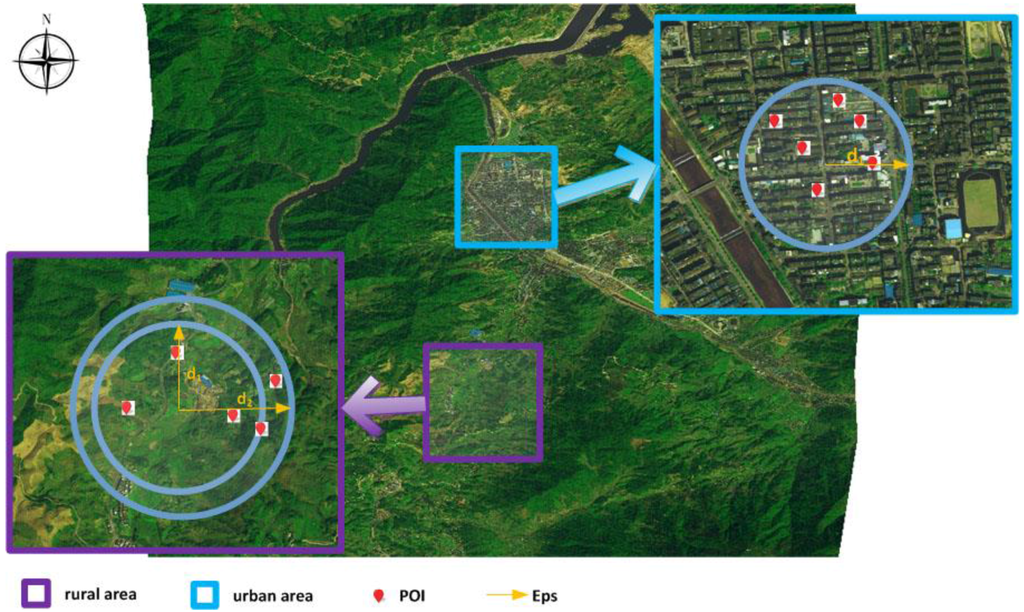
همانطور که اشاره کردیم، الگوریتمهای خوشهبندی مکانی سنتی تمایل دارند با الگوریتمهایی که در کاربردهای واقعی اعمال میشوند، متفاوت باشند، زیرا مشکلات خاص محیط فضایی اغلب با آن مواجه میشوند. به عنوان مثال، یک گروه تجاری را در نظر بگیرید که آماده است تا فعالیت های خود را در ووهان (استان هوبی، مرکز چین) با ساخت تعدادی سوپرمارکت گسترش دهد. بخش تصمیمگیری منطقی مایل است مغازههایی را در مکانهایی ایجاد کند که مرکز آدرسهای مسکونی مشتریانشان باشد. با این حال، در ووهان، محیط در معرض محدودیت های جغرافیایی است، مانند رودخانه یانگ تسه و رودخانه هانجیانگ، همانطور که در شکل 3 الف نشان داده شده است. اگر این محدودیت ها نادیده گرفته شوند، داده کاوی جغرافیایی منجر به خوشه های نشان داده شده در شکل 3 می شود.ب اینها به وضوح کمتر از حد مطلوب هستند زیرا این خوشه ها نیاز مشتریان خاص به سفر مسافت های طولانی را برای عبور از رودخانه ها نادیده می گیرند. بنابراین، این تحلیل در سناریو غیر منطقی است. نتایج خوشه بندی به دست آمده با در نظر گرفتن محدودیت های رودخانه در شکل 3 ج نشان داده شده است. بنابراین واضح است که برای کاربردهای عملی، DBSCAN باید محدودیتهای مانع را در نظر بگیرد. زمانی که در فرآیند خوشهبندی جغرافیایی استفاده میشود، محدودیتهای پسزمینه جغرافیایی در درجه اول برای غلبه بر عدم آگاهی از دادههای مکانی مربوطه در نظر گرفته شده است.
پس از در نظر گرفتن مشکلات بالا، ما تعیین کردیم که محدودیتهای پارامترهای الگوریتم (همانطور که در شکل 2 نشان داده شده است ) و محدودیتهای روی دادههای مکانی (همانطور که در شکل 1 نشان داده شده است ) باید هر دو توسط هستیشناسی ما در زمینه DBSCAN توصیف شوند.
2.2. هستی شناسی
یکی از پراستنادترین تعاریف اصطلاح “هستی شناسی” توسط گروبر [ 11 ] ارائه شد: ” هستی شناسی یک مشخصه رسمی و صریح از یک مفهوم سازی مشترک است .” هدف یک هستی شناسی به دست آوردن دانشی است که مجموعه ای مشترک از مفاهیم و بدیهیات را برای استدلال در زمینه های مرتبط فراهم می کند. برای خوشهبندی مبتنی بر چگالی، یک هستیشناسی دانش پسزمینه جغرافیایی مناسب از انواع مفاهیم و روابط مربوط به ویژگیهای مکانی و خوشهبندی ساخته میشود.
مسائل معنایی وجود دارد که به ایجاد، استفاده و بحث از اطلاعات جغرافیایی مربوط می شود. هنگام حل یک مشکل خوشه بندی مکانی، کاربران ممکن است داده های مکانی و دانش پس زمینه را با استفاده از روش های مختلف و از منابع مختلف جمع آوری کنند. زمانی که معنایی دادهها بهطور مناسبی در طول فرآیند تحلیل مکانی جمعآوری نشده باشد، دادههای جغرافیایی و نتایج تجزیه و تحلیل ممکن است دچار سوء تفاهم و استفاده نامناسب شوند. هدف اصلی این مقاله تعریف مفاهیم و روابط کلی برای همه تحلیلهای جغرافیایی نیست. در عوض، یک هستی شناسی به طور خاص برای الگوریتم DBSCAN ارائه می کند. ما این کار را برای کاهش مشکلاتی که در تعریف معناشناسی جغرافیایی وجود دارد انجام می دهیم.
3. چارچوب برای DBSCAN با هستی شناسی
بر اساس الگوریتم DBSCAN، این مقاله یک هستیشناسی را برای روابط محدودیت معنایی جغرافیایی معرفی میکند و این هستیشناسی را با استفاده از نمایشهای معنایی اندازهگیریهای فاصله جغرافیایی چندگانه برای تحلیل خوشهای در حوزه دادههای مکانی غنی میکند. انتخاب محدودیتهای معنایی جغرافیایی به دلیل اهمیت اطلاعات ساختاری در تفسیر DBSCAN مجموعههای داده با چنین محدودیتهایی و با ماهیت ذاتی بیشتر معناشناسی فاصله چندمکانی انجام میشود. در این مقاله، ما بر روی محدودیت های مربوط به قوانین مبتنی بر هستی شناسی تمرکز می کنیم.
3.1. ساختار هستی شناسی DBSCAN
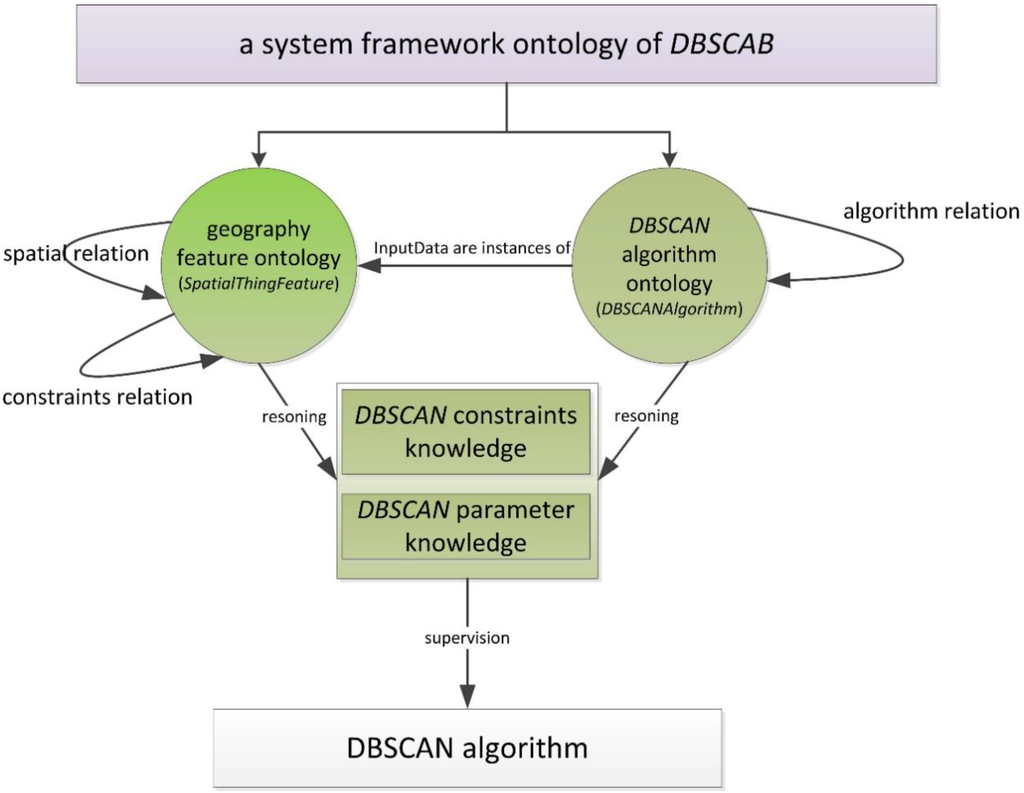
هستی شناسی ها، به عنوان شکلی از نمایش دانش، در کاربردهای مختلف اطلاعات جغرافیایی استفاده شده است. بنابراین یک هستی شناسی کاربردی در حوزه DBSCAN می تواند به عنوان یک نمایش خوب از دانش خوشه بندی در نظر گرفته شود. با توجه به نمایش الگوریتم DBSCAN، هستی شناسی شامل دانش ویژگی های مکانی، روابط جغرافیایی و خود الگوریتم DBSCAN است. ما می توانیم این دانش را به عنوان مجموعه ای از کلاس ها در نظر بگیریم.
در این مقاله، معناشناسی عملیاتی را برای بیان این هستی شناسی با استفاده از Notation3 (N3)، به صورت O 4 تایی = <C, R, P, I> ارائه می کنیم که در آن C مجموعه مفاهیم است، R مجموعه روابط است. ، I مجموعه ای از نمونه ها است و P مجموعه ای از خصوصیات است که C را توصیف می کند. هستی شناسی DBSCAN برای بیان دانش معنایی DBSCAN توسعه یافته است.
مثال 1. اجازه دهید یک هستی شناسی مثال ساده شده برای DBSCAN در نظر بگیریم. شناسه دامنه DBSCANontology است . چهار مفهوم (GeospatialFeature، BaseFeature، POIFeature و DBSCANAlgorithm) و چهار نوع رابطه (فاصله، جهت، توپولوژیک و محدودیت) وجود دارد. مجموعه ویژگی P {Belong، Location، hasInput، hasOutput، IsReferenceFeature، DataType} است و مجموعه نمونههای I {ATM1، bankA، river1، scale1، eps1، …} است.
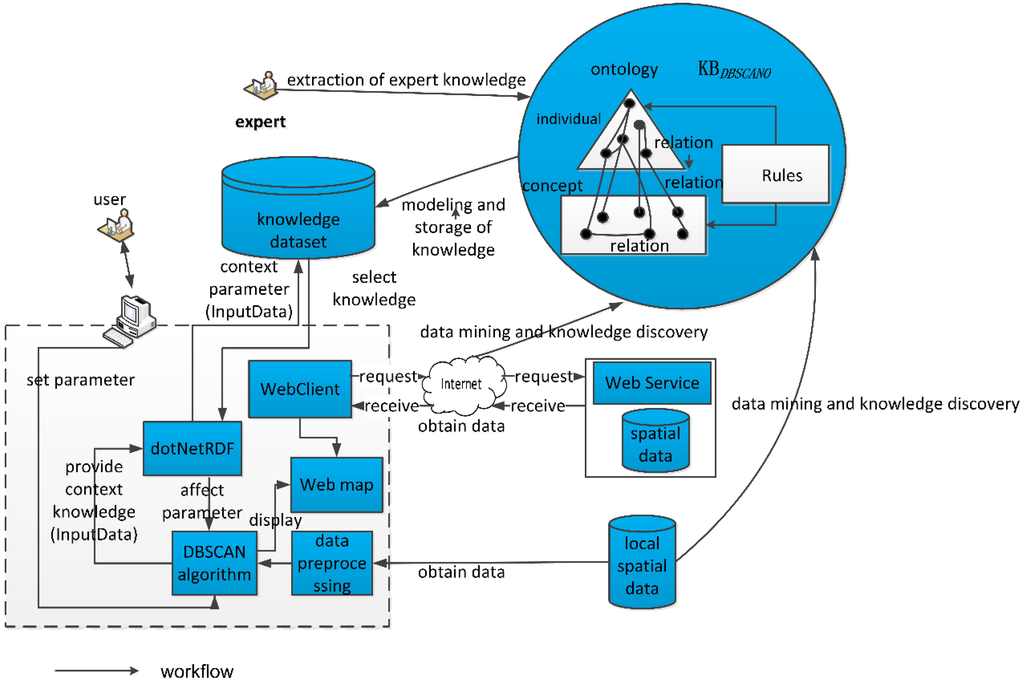
روابط مکانی در هستی شناسی کاربرد DBSCAN مهم هستند. چارچوب DBSCAN با این هستی شناسی در شکل 4 نشان داده شده است .
3.2. شرح هستی شناسی DBSCAN
ما هستی شناسی DBSCAN را طراحی کرده ایم که آن را DBSCANO می نامیم . این یک هستی شناسی ویژه برنامه برای DBSCAN است. هستی شناسی شامل دانش ویژگی های جغرافیایی و الگوریتم DBSCAN است. DBSCANO را می توان برای الگوریتم DBSCAN همانطور که در بالا معرفی شد اعمال کرد. هدف از معرفی DBSCANO این است که نشان دهد چگونه تصمیمات مدل سازی که در چارچوب گرفته می شود با هستی شناسی ها مرتبط است.
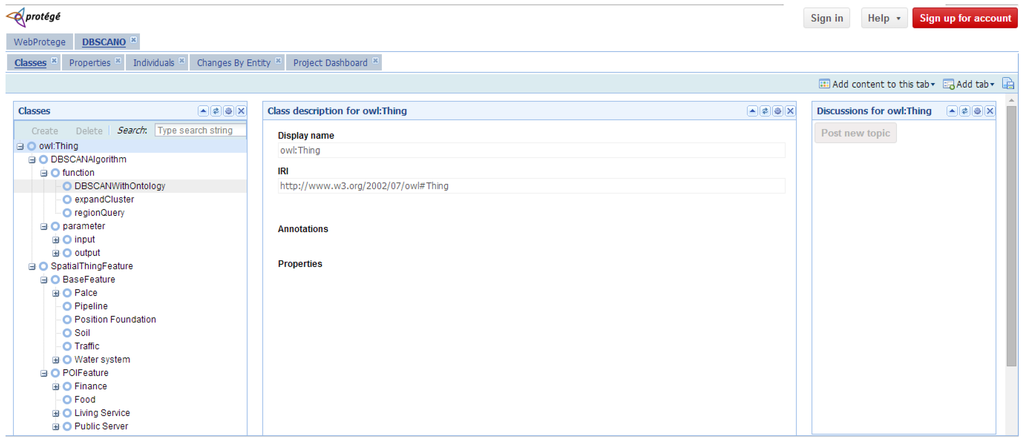
در این مقاله از روش بالا به پایین برای ساخت DBSCANO استفاده می کنیم . ابتدا تجزیه و تحلیل می کنیم که DBSCAN شامل داده های مکانی و الگوریتم است، سپس سیستم مفهومی داده های مکانی و الگوریتم ها را به ترتیب ایجاد می کنیم، سپس ساختار هستی شناسی را گسترش می دهیم و رابطه بین داده ها و الگوریتم را ایجاد می کنیم. ساختار DBSCANO در شکل 5 نشان داده شده است . عکس فوری بخشی از سلسله مراتب DBSCANO در WebProtégé در شکل 6 نشان داده شده است ( http://webprotege.stanford.edu/#Edit:projectId=bbfed2b3-fb75-4cec-8148-6f798c86619f 20 آوریل 20 مشاهده شده).
اکنون هر جزء DBSCANO را به تفصیل مورد بحث قرار می دهیم.
(1) مجموعه مفاهیم C شامل دو کلاس اصلی SpatialThingFeature و DBSCANAlgorithm است .
SpatialThingFeature یک کلاس سطح بالا برای اشیاء اطلاعات جغرافیایی است. کلاس های نسل آن برای نشان دادن مفاهیم یا اشیاء مربوط به اشیاء اطلاعات جغرافیایی در DBSCANO خدمت می کنند . هر ویژگی یا رکوردی از مجموعه داده مورد استفاده در DBSCAN نمونه ای از SpatialThingFeature است .
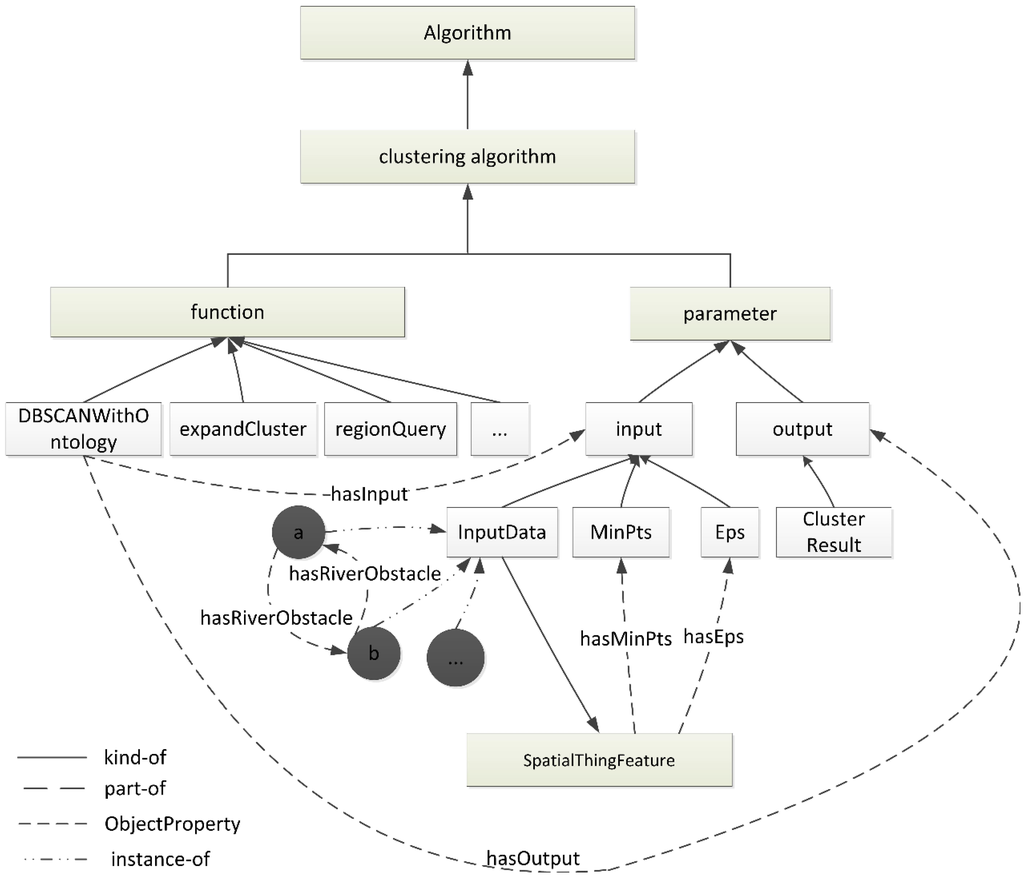
الگوریتم DBSCANA مجموعه ای از روش های خوشه بندی DBSCAN موجود و ویژگی های رابط های آنها را نشان می دهد. این یک کلاس اصلی از DBSCANO است . الگوریتم DBSCANA از طریق روابط DBSCAN به SpatialThingFeature مربوط می شود . برای مثال، الگوریتم DBSCANA از طریق ترکیبی از روابط «مثلاً» و «بخشی از» به SpatialThingFeature مرتبط است. ویژگی های الگوریتم DBSCANA شامل پارامترهای مورد نیاز برای DBSCAN مانند ” Eps ” و ” MinPts ” است. InputDataclass پارامترهای ورودی مجموعه داده POI در DBSCAN را نشان می دهد. نمونه ای از کلاس InputData مربوط به SpatialThingFeature استاز طریق ویژگی “نوع”.
(2) مجموعه R از روابط بین دو کلاس فوق، از جمله DataRelation و AlgorithmRation تشکیل شده است .
DataRelation روابط جغرافیایی بین نمونه های SpatialThingFeature را تعریف می کند . اشیاء DataRelation به دو نوع “روابط فضایی” و “روابط محدودیت” تقسیم می شوند. روابط فضایی در تحقیقات قبلی [ 12 ] مورد بررسی قرار گرفته است. DBSCANO شامل سه نوع اساسی از روابط فضایی است: روابط جهت، روابط فاصله، و روابط توپولوژیکی. اینها انتخاب و گسترش یافتند زیرا ظرفیت آنها برای بیان روابط فضایی به خوبی درک شده است. یک رابطه محدودیت یک نوع کلیدی از رابطه در DBSCANO است. یک رابطه محدودیت منطق زیربنای محدودیت ها یا شرایط موجود در بین اشیاء مکانی DBSCANO را توصیف می کند.. روابط محدودیت ممکن است شامل مناطق و/یا موانع مختلف باشد، و این روابط شامل تمام محدودیتهای احتمالی DBSCAN و محدودیتهای فرعی تولید شده توسط کاربر، مانند ConstraintsOfRiver و ConstraintsOfDifferentCity است.
AlgorithmRelation روابط اثر را بین نمونه های DBSCANAالگوریتم تعریف می کند . در DBSCANO ، یک رابطه تعاملی کنترل الگوریتم DBSCANA یا تغییر در پارامترهای آن را توصیف می کند. نمونههایی از این روابط اثر عبارتند از ” Eps ” و ” MinPts ” که از طریق ویژگی “hasChangeWith” در InputData انتخاب میشوند. در DBSCANO ، روابط DBSCANRelation ممکن است استدلال را برای به دست آوردن محدودیت های پارامتر برای DBSCAN تسهیل کند.
در DBSCANO ، میتوانیم روابط بین ویژگیهای اشیاء بیان شده با استفاده از SpatialThingFeature را تعریف کنیم که بر اساس هستیشناسی برای دانش پسزمینه جغرافیایی استنتاج میشوند. سازگاری روابط موجود در DBSCANO قابل ارزیابی است. به عنوان مثال، یک رابطه متضاد بین روابط “حاوی” و “تعلق” وجود دارد. تعریف این روابط امکان استدلال در مورد محدودیت های خاص در DBSCANO را فراهم می کند . به عنوان مثال، چپ و راست روابط جهت معکوس هستند. اگر واقعیتی در هستی شناسی بیان کند که شی a در سمت چپ شی m (کوه) است، در آن صورت وقتی واقعیتی که آن شی را بیان می کند، می توان یک محدودیت را از طریق استدلال استنباط کرد.b در سمت راست m است به هستی شناسی اضافه می شود.
(3) مجموعه P ویژگی های ویژگی کلاس های فوق و زیر کلاس های آنها را تعریف می کند. در DBSCANO ، یک ویژگی به صورت یک رابطه 2 تایی بر اساس SpatialThingFeature و DBSCANAالگوریتم نمایش داده می شود . ویژگی یک داده تحت اللفظی یا پیوندهایی به نمونه دیگری است. ویژگیهای SpatialThingFeature و DBSCANAlgorithm و ویژگیهایی که آنها را به هم پیوند میدهند، دو نوع اصلی از ویژگیها (ویژگیهای داده و الگوریتم) را نشان میدهند. این ویژگی ها نشان دهنده ارتباط متقابل بین SpatialThingFeature و DBSCANAالگوریتم همانطور که در SpatialThingFeature و DBSCANAlgorithm تعریف شده است.. به عنوان مثال، ویژگی های یک نمونه از زیر کلاس “حومه” SpatialThingFeature شامل hasEps (ویژگی شی). ویژگی های یک نمونه از کلاس InputDatasub از الگوریتم DBSCANA شامل نوع (ویژگی شی). نمونه ای از کلاس InputDatasub از الگوریتم DBSCANA به زیر کلاس مربوطه از SpatialThingFeature از طریق ترکیبی از روابط “type” و “subClassOf” مربوط می شود.
(4) مجموعه I اشیاء SpatialThingFeature و DBSCANAlgorithm را تعریف می کند . اینها با منطق توصیف فردی مطابقت دارند. برای مثال، { Yangtze ، Amazon ، Thames …} مجموعهای از نمونههای «رودخانه» در DBSCANO است .
3.3. طبقه بندی هستی شناختی ویژگی های جغرافیایی
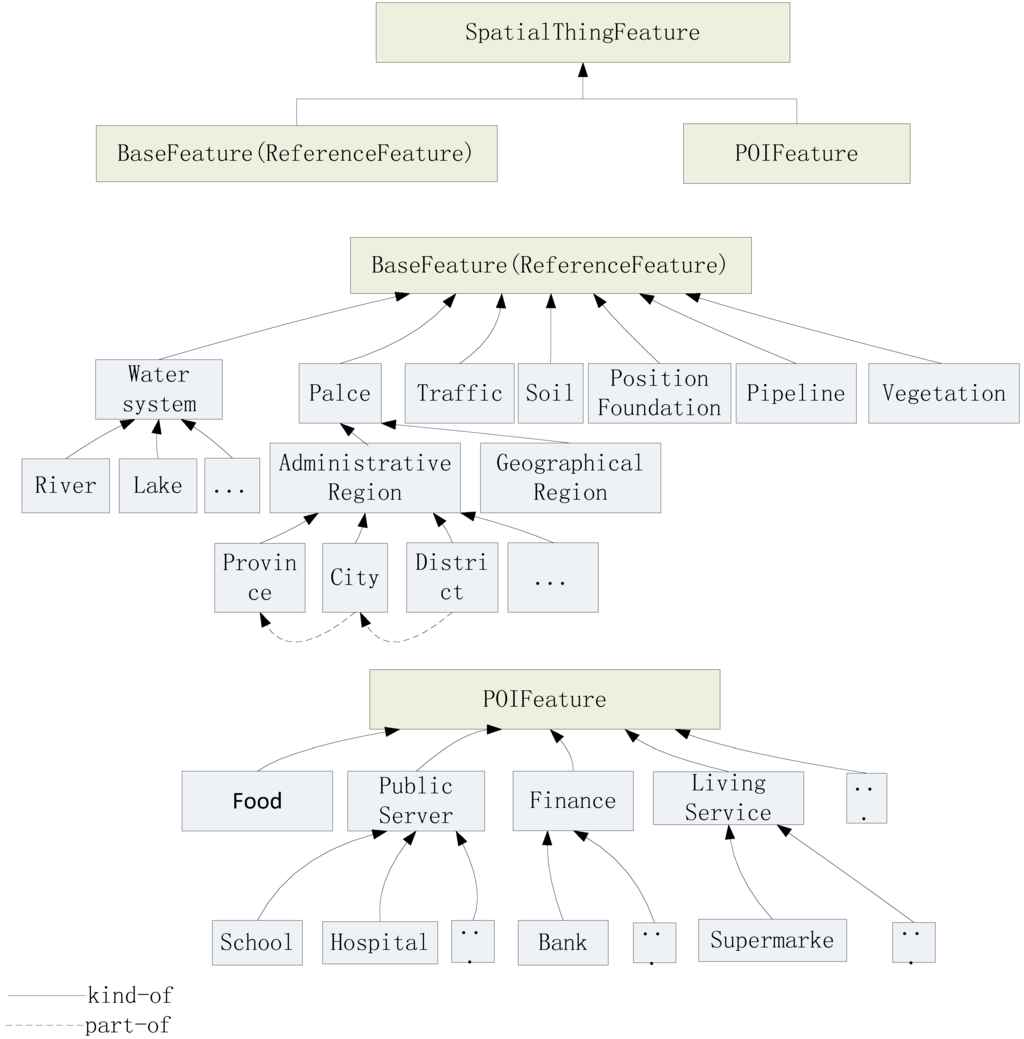
کلاس SpatialThingFeature جزء پایه DBSCANO است . SpatialThingFeature را می توان به صورت سلسله مراتبی به BaseFeature ( ReferenceFeature ) و POIFeature طبقه بندی کرد. این بدان معنی است که SpatialThingFeature یک مفهوم فوق العاده از BaseFeature و POIFeature است . روابط خاصی (مانند جهت ها) بین یک شی مرجع ثابت و یک شی اولیه (مانند ” a در سمت چپ تیمز است “، ” b در سمت راست تیمز است” تعریف می شود.”). اشیاء اصلی و مرجع به تعریف این روابط DBSCAN کمک می کنند. اشیاء مرجع با هم یک چارچوب مرجع ایجاد می کنند که به ما کمک می کند روابط فضایی شی اولیه را نسبت به شی مرجع تعیین کنیم. اشیاء مرجع با ارجاع به مجموعه ” BaseFeature ” تعریف می شوند. برای مثال، در عبارت «ATM1 در سمت چپ تیمز است»، ATM1 شی اصلی و تیمز شی مرجع است. شی مرجع نمونه ای از کلاس “river” است که زیرمفهوم BaseFeature است . به دلیل این تابع مرجع، BaseFeature نیز ReferenceFeature نامیده می شود . سلسله مراتب کلاس را می توان همانطور که در شکل 7 نشان داده شده است نشان داد .
بگذارید “منطقه” نوعی “نام مکان” باشد. روابط در DBSCANO همبستگی های خاصی را بین ویژگی های جغرافیایی و غیرمکانی عناصر جغرافیایی نشان می دهد (به عنوان مثال، یک بانک ممکن است در داخل یک بلوک باشد، جایی که “بانک” و “بلوک” مفاهیم هستند و “درون” یک رابطه جغرافیایی است). افراد جغرافیایی نمونه هایی از مفاهیم در DBSCANO هستند . در این مقاله، افراد جغرافیایی معمولاً اشیاء جغرافیایی مهمی هستند، مانند رودخانههای یانگ تسه و هانجیانگ. روابط هستی شناسی DBSCAN عمدتاً روابط طبقه بندی و انجمنی هستند. طبقه بندی ساختاری SpatialThingFeatureیک درخت طبقه بندی سلسله مراتبی است (مثلاً یک نهر یا اقیانوس نوعی سیستم آبی است) و روابط فضایی و غیر فضایی بین مفاهیم موجود در درخت (مثلاً سمت چپ، نزدیک به، بخشی از، و نوع) ساختار درخت را تشکیل می دهد. .
3.4. طبقه بندی هستی شناختی الگوریتم DBSCAN
ساختار هستی شناسی DBSCAN با انگیزه نیاز به ارائه دانش اساسی در مورد DBSCAN است . این اطلاعات برای محدود کردن فرآیند DBSCAN و معنادارتر کردن خوشه های حاصل استفاده می شود. در چارچوب DBSCANO ، کلاس DBSCANAlgorithm وسیله ای برای توصیف توابع ارائه شده توسط الگوریتم فراهم می کند. الگوریتم DBSCANA تابعی از انواع اطلاعات پایه، یعنی تابع محاسبه شده توسط سرویس را توصیف می کند.
یکی از اجزای ضروری DBSCANO مشخصات DBSCAN است. الگوریتم DBSCANA دو جنبه از عملکرد الگوریتم را نشان می دهد: تبدیل اطلاعات (نمایش داده شده توسط ورودی ها و خروجی ها) و تغییر حالت (نمایش داده شده توسط مقادیر پارامتر) که با اعمال محدودیت ها ایجاد می شود. برای تکمیل خوشه بندی، هم به یک مجموعه داده جغرافیایی به عنوان ورودی و هم به پیش شرطی نیاز داریم که هستی شناسی مجموعه داده واقعاً وجود داشته باشد. نتیجه خوشه بندی خروجی محدودیت های مشخص شده است و اجرای صحیح تراکنش خوشه بندی را تایید می کند.
کلاس های هستی شناسی اصلی، توابع و پارامترهای موجود در الگوریتم DBSCAN را نشان می دهند. این کلاس ها بیشتر از طریق روابط “is-a” یا “بخشی از” به زیر کلاس ها تقسیم می شوند . سلسله مراتب کلاسی که بدین ترتیب ایجاد شده است را می توان همانطور که در شکل 8 نشان داده شده است نشان داد .
3.5. طبقه بندی هستی شناختی روابط DBSCAN
در هستی شناسی کلی، روابط معنایی اغلب به صورت روابط «جزئی»، «نوع»، «ویژگی-از» و «مثلا» بیان می شوند. در هستی شناسی جغرافیایی، به استثنای روابط عمومی غیرمکانی، مهمترین روابط، روابط جغرافیایی مکانی هستند. روابط جغرافیایی پیشنهادی موجود در هستیشناسی ویژگی جغرافیایی که در بالا معرفی شد، بر حسب هستیشناسی 3 تایی به شکل SR-Ontology = {< فضا، اشیاء، روابط >} تعریف میشوند [ 12 ]. مجموعه Space جغرافیای دامنه و مجموعه اشیاء را توصیف می کندشامل موجودیتهای مکانی مورد علاقه و ویژگیهای مرتبط با آنها است که در هستیشناسی ویژگیهای مکانی تعریف شدهاند.
نمونه های جغرافیایی و اشیاء تابع خاص DBSCAN نمونه هایی از مفاهیم ترکیب شده با روابط و قوانینی هستند که دانش دامنه DBSCAN را بیان می کنند . به عنوان مثال، یک نمونه جغرافیایی معتبر به عنوان (دانشگاه ووهان، منطقه Wuchang) نشان داده می شود. قوانین و روابط برای بیان دانش پسزمینه جغرافیایی و محدود کردن دستهبندی کلاسها یا نمونهها استفاده میشوند (مثلاً، یک ناحیه خاص ممکن است در نزدیکی رودخانه یانگ تسه باشد، و یک POI خاص ممکن است در سمت چپ یک شی مرجع تعریف شود، که سپس باید POI دیگری را که در سمت راست همان شی مرجع است محدود کند). هستیشناسی ویژگی جغرافیایی برای خوشهبندی با استفاده از یک زبان نمایش خوشهبندی رسمی با معنایی روشن بیان میشود.
در DBSCANO ، “روابط محدودیت” و “روابط الگوریتم” نقش مهمی در خوشه بندی دارند. روابط محدودیت، روابط گذرا هستند، در حالی که روابط الگوریتم نامتقارن هستند. ادغام چنین محدودیتها و روابط الگوریتمی در الگوریتمهای خوشهبندی هنوز به خوبی بررسی نشده است. کار ما در این مقاله نشان خواهد داد که مشکلات واقعی زمین فضایی به روابط غنی تری برای بیان دانش حوزه مربوطه نیاز دارند.
روابط محدودیت اغلب به اطلاعات رابطه ای نیاز دارد که برای زیر مجموعه ای از اشیاء مکانی اعمال می شود. روابط محدودیت می تواند روابط متناظر با “بدون محدودیت”، “محدودیت ها”، “محدودیت های نمی تواند پیوند” یا “محدودیت های باید پیوند” باشد. اگر دو شی دارای روابط “بدون محدودیت” با توجه به یک مانع باشند، DBSCANO به فاصله بین آنها به طور مستقیم محاسبه شود.اگر دو جسم دارای روابط “محدودیت” با توجه به یک مانع باشند، DBSCANO مقداری جریمه برای انعکاس این محدودیت ها اضافه می کند، به عنوان مثال، زمان لازم برای عبور از رودخانه در هنگام حرکت از یک طرف به سمت دیگر ، هنگام تعیین اینکه آیا اشیاء را در یک خوشه قرار دهید یا خیر. سپس DBSCANO اجازه نخواهد داد که آنها در یک خوشه قرار گیرند. اگر دو شیء دارای «محدودیتهای پیوند ضروری» در رابطه با یکدیگر باشند، DBSCANO اطمینان حاصل میکند که آنها در یک خوشه قرار میگیرند.
روابط الگوریتم بیانگر اطلاعات رابطه ای است که برای الگوریتم DBSCAN اعمال می شود. چنین اطلاعاتی در درجه اول به روابط بین پارامترها در DBSCAN مربوط می شود. نقش “پارامترها” فعال کردن تنظیم انعطاف پذیر Eps و MinPts در DBSCAN است. روابط الگوریتم روابط بین مجموعه داده ها را در DBSCAN، Eps و MinPts توصیف می کند . بر اساس زمینه مجموعه داده هایی که با استفاده از DBSCAN تجزیه و تحلیل می شوند، می توان مقادیر مناسب را برای Eps و MinPts استنتاج کرد . دانش پس زمینه در مورد این مجموعه داده ها می تواند به طور چشمگیری بر مقادیر Eps و MinPts تأثیر بگذارد. نوع دیگری از رابطه، “فرآیند”، هستی شناسی فرآیندهای الگوریتم را توصیف می کند که برای گسترش آینده مدل مناسب خواهد بود.
ساختار هستی شناسی روابط جغرافیایی در شکل 9 نشان داده شده است . این روابط را می توان به صورت پویا ویرایش و گسترش داد. نمونه ای از محدودیت های مانع بین نقاط a و b در شکل 10 نشان داده شده است .
چندین ویژگی و روابط از اشیاء در DBSCANO وجود دارد که میتوان از آنها برای استدلال استفاده کرد، مانند خواص معکوس، گذرا، و عدم تقارن و روابط نوع، قسمت از، نمونه و صفت.
به عنوان مثال، یک مثال از ویژگی transitivity به شرح زیر است:
اجازه دهید بگوییم که یک ویژگی transitivity شی left_Of وجود دارد که با علامت TransitivityProperty نشان داده شده است. یعنی اگر a در سمت چپ b و b در سمت چپ c باشد، a در سمت چپ c قرار دارد.
بدیهیات زیر را در نظر بگیرید:
سپس، ادعای leftOf (a, c) معتبر است.
بگذارید بگوییم leftOf نیز یک ویژگی عدم تقارن شی است که با علامت AsymmetryProperty نشان داده می شود. یعنی اگر a در سمت چپ b باشد، b در سمت چپ a نیست.
بدیهیات زیر را در نظر بگیرید:
سپس، ادعای leftOf (b, a) نامعتبر است.
اولویت ها برای روابط قیود موجود در DBSCANO می توانند برای استدلال استفاده شوند. این مکانیسم تعیین اولویت برای روابط محدودیتها اولویت (“محدودیتهای نمیتوان پیوند”) > اولویت (“محدودیتها”) > اولویت (“بدون محدودیت”) > اولویت (“محدودیتهای باید پیوند”) باشد. سیستم قاعدهای که تولید میکند ممکن است روابط محدودیتها را با بالاترین اولویت بهعنوان روابط محدودیتها برای یک جفت ویژگی انتخاب کند، زمانی که برخی از روابط محدودیت چند جانبه وجود دارد.
4. پردازش: استدلال در DBSCANO
4.1. استدلال در DBSCANO
در چارچوب هستی شناسی DBSCAN، یک استدلال مبتنی بر dotNetRDF [ 13 ] برای استنتاج دانش ارائه شده در DBSCANO استفاده می شود . dotNetRDF نوعی کتابخانه API برای کار با RDF (N3) و SPARQL بر اساس C#/.NET است. dotNetRDF شامل یک API قدرتمند برای کار با Apache Jena است. محدودیتهای کاربر بهعنوان ورودی برای استدلال عمل میکنند و خروجی مجموعهای از خوشهها و مجموعه دادههای مکانی معنیدار است.
استدلالگر DBSCANO ابتدا تمام نمونههای SpatialThingFeature را میسازد ، بنابراین استدلال را با هستیشناسی خوشهبندی جغرافیایی و هدف کاربر مرتبط میکند. برای مثال 1 ارائه شده در بخش 3.1 ، نمونه SpatialThingFeature “مدارس در ووهان” با استفاده از یک سرویس ویژگی وب ایجاد شده است. سپس استدلال کننده نمونه ای از الگوریتم DBSCANA می سازد که شامل چندین نمونه ورودی است. به عنوان مثال، دو نمونه “پارامتر منطقه شهری ( Eps : 2000 m)” و “پارامتر منطقه حومه شهر ( Eps : 5000 m)” توسط متخصصان دامنه ایجاد شده اند.
در مرحله بعد، استدلال کننده DBSCANO قوانین محدودیت را با استفاده از قوانین Jena ایجاد می کند. این قوانین Jena به عنوان پلی بین مجموعه داده های جغرافیایی و الگوریتم DBSCAN عمل می کنند و برای کمک به استدلال در ترکیب با DBSCANO طراحی شده اند . محدودیتهای DBSCAN قوانین Jena هستند که وابستگیهای بین روابط و ویژگیها را در DBSCANO نشان میدهند . ما از یک مدل قانون مدار برای به اشتراک گذاشتن دانش مبتنی بر محدودیت در DBSCAN با کارشناسان استفاده می کنیم. قوانین تعبیه شده در DBSCAN محدودیت های قابل درک و صریح در استدلال را در اختیار کاربر قرار می دهد. DBSCAN می تواند محدودیت های توصیف شده توسط مجموعه خاصی از ورودی ها و استراتژی مورد استفاده برای ساخت مجموعه داده های مکانی را مدل کند.
در نهایت، استدلال کننده دانش محدودیت حاصل را در DBSCAN وارد می کند. این نتایج را می توان به مدل ها یا زبان های دیگر استنتاج ترجمه کرد.
4.2. قوانین برای تولید محدودیت بر اساس DBSCANO
تولید محدودیت ها در DBSCANO به کمک هستی شناسی ماالگوریتم به صورت زیر پیش می رود. دانش پیشینه قبلی به محدودیتهای DBSCAN که در کار خوشهبندی مبتنی بر چگالی ادغام شدهاند، تزریق میشود. اینها با استفاده از قواعد استدلالی به دست می آیند که معمولاً توسط متخصصان زمین فضایی ایجاد می شوند (به عنوان مثال، با استفاده از ادبیات خوشه بندی GIS). بنابراین، تجزیه و تحلیل دستی و استخراج داده های مکانی (مانند قوانین تداعی فضایی) به صورت نیمه خودکار انجام می شود. وظیفه تولید قوانینی که دانش ما را محدود می کند در اینجا به تفصیل مورد بحث قرار نمی گیرد. در این مقاله، ما فرض میکنیم که این قوانین محدودیت جغرافیایی قبلاً تولید شدهاند و قوانین محدودیت تولید شده بر اساس قوانین Jena، محدودیتهایی را تعیین میکنند که بر نتایج خوشهبندی بهدستآمده با استفاده از الگوریتم DBSCAN تأثیر میگذارند.
تعریف 1:
اجازه دهید KB دانش منطق توصیف (DL) از DBSCAN با محدودیتهایی از جمله محدودیتهای دادههای جغرافیایی برای خوشهبندی باشد. ما از تعاریف استاندارد برای قوانین محدودیت استفاده می کنیم. یک قانون مبتنی بر DBSCANO به شکل زیر است:
که در آن A DBSCANO و B DBSCANO پیوندهای اتم های قانون Jena بر اساس DBSCANO هستند . مجموعه اتم های B DBSCANO سر قاعده و مجموعه اتم های A DBSCANO بدنه قانون نامیده می شود. اتمهای موجود در A DBSCANO میتوانند به شکل C(x)، P(x، y)، یا ساخته شده(r، x…)، که در آن C یک توصیف N3 یا محدوده دادهای از DBSCANO است . P یک ویژگی DBSCANO است. r یک رابطه داخلی است. و x و y یا متغیرها، افراد یا مقادیر داده هستند. اتم های موجود در B DBSCANOهمچنین ممکن است به افراد، دادهها، متغیرهای فردی یا متغیرهای داده اشاره داشته باشد. با این حال، B DBSCANO به شکل P(x، y) محدود می شود، که در آن P خاصیت یک محدودیت یا پارامتر در DBSCANO است و x و y متغیرها، افراد یا مقادیر داده هستند.
بر اساس مشکلاتی که در بالا باید حل شوند، خلاصه می کنیم که 2 نوع قاعده استدلالی در این مقاله استفاده می شود:
1. استدلال رابطه قیود با دانش پیشینه جغرافیایی:
تعریف 2:
محدودیتهای قانون ::= مستلزم (مقدم (A SpatialThingFeature )، نتیجه ( محدودیتهای B ))
SpatialThingFeature مجموعه ای از اتم ها بر اساس SpatialThingFeature است . محدودیتهای B عبارتی از این شکل است: { محدودیتهای اتم } که در آن حداقل یکی از { محدودیتهای اتم } یک اتمهای خاصیت محدودیت است.
2. استدلال مقادیر مناسب Eps و MinPts
تعریف 3:
قاعده Eps&MinPts ::= مستلزم (مقدم (A Eps&MinPts )، نتیجه (B Eps & MinPts ))
یک Eps&MinPts مجموعهای از اتمها است که بر اساس SpatialThingFeature و DBSCANAالگوریتم است. B Eps&MinPts بیانی از این شکل است: {atom Eps&MinPts } که در آن {atom Eps&MinPts }”hasparameter” (“hasEps” یا “hasMinPs) هستند.
4.3. پایگاه دانش DBSCAN با محدودیت ها
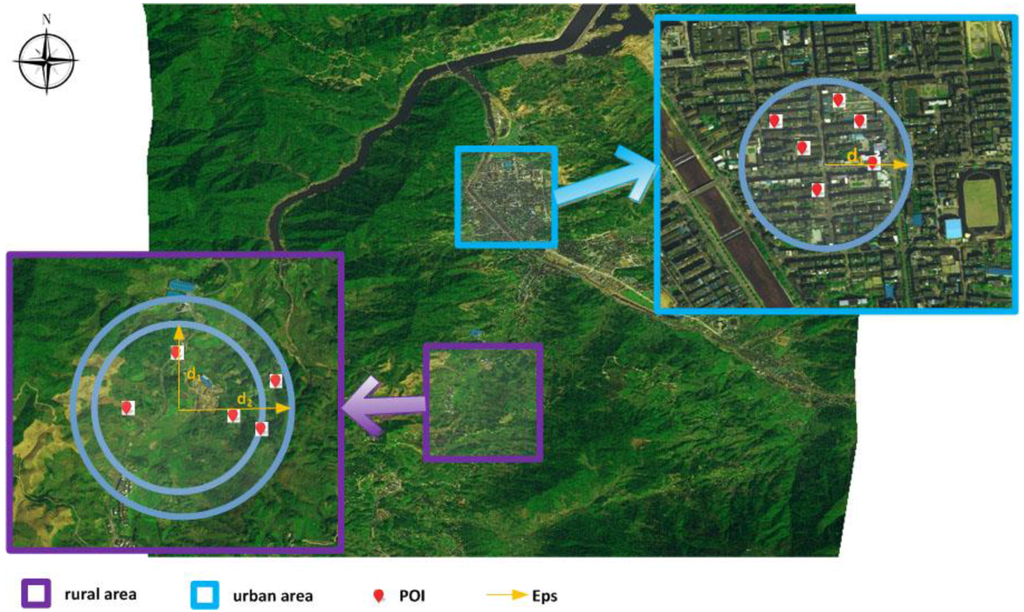
اجازه دهید KB DBSCANO پایگاه دانش DBSCAN با محدودیت ها باشد. دارای فرم زیر است:
که در آن ∑ DBSCANO و ∏ قانون DBSCANO است که یک پایه قانون برای DBSCANO است . مجموعه ای از قوانین در ∑ می تواند برای استنتاج دانش محدودیت های جدید از DBSCANO استفاده شود . محتویات هستی شناسی در ∏ و قوانین در ∑ را می توان به صورت پویا گسترش داد، اصلاح کرد و حذف کرد.
4.4. نمونه ای از استدلال
نقطه a را در سمت راست رودخانه یانگ تسه و نقطه b را در سمت چپ تعریف می کنیم ( شکل 10 محدودیت مانع). ما نقطه a متعلق به ناحیه wuchang و نقطه c متعلق به ناحیه wuchang را تعریف می کنیم ( شکل 10 Must-Link). ما نقطه d را متعلق به منطقه هونگشان تعریف می کنیم ( شکل 10نمی توان-پیوند کرد). با استدلال قاعده ینا، دو نقطه ab به عنوان یک خوشه جغرافیایی با محدودیت مانع در نظر گرفته می شود. a و c به عنوان یک خوشه جغرافیایی با یک محدودیت Must-Link در نظر گرفته می شوند. به طور مشابه، a و d به عنوان یک خوشه جغرافیایی با یک محدودیت Cannot-Link در نظر گرفته می شوند. در زیر تعاریف نقاط a ، b ، c و d ، ویژگی ” hasRiverObstacle “، ” hasMustLink ” و ” hasCannotLink ” و قوانین مربوطه آمده است.
| الگوریتم 1. تعاریف نقاط a ، b ، c و d، ویژگی « hasRiverObstacle »، « hasMustLink » و « hasCannotLink » و قوانین مربوطه. |
| 1: :a rdf:type:ATM, |
| 2: :POIFeature; |
| 3: :rightTo:YangtzeRiver; |
| 4: :hasBelongDistrict:wuchang. |
| 5: :b rdf:type:ATM, |
| 6: : POIFeature; |
| 7: :leftTo:YangtzeRiver. |
| 8: :c rdf:type:ATM, |
| 9: :POIFeature; |
| 10: hasBelongDistrict:wuchang. |
| 11: :d rdf:type:ATM, |
| 12: :POIFeature; |
| 13: hasBelongDistrict:hongshan. |
| 14: :YangtzeRiver a:River, :RiverObstacle; |
| 15: :name “YangtzeRiver”. |
| 16: :leftTo rdf:type:Direction; |
| 17: owl:inverseOf:rightTo. |
| 18: :rightTo rdf:type:Direction; |
| 19: owl:inverseOf:leftTo. |
| 20: hasRiverObstacle rdf:type:ObjectProperty; |
| 21: rdfs:domain:POIFeature; |
| 22: rdfs:range:POIFeature; |
| 23: rdfs:subPropertyOf:hasConstraint. |
| 24: hasMustLink rdf:type :ObjectProperty; |
| 25: rdfs:domain:POIFeature; |
| 26: rdfs:range:POIFeature. |
| 27: has CannotLink rdf:type:ObjectProperty; |
| 28: rdfs:domain:POIFeature; |
| 29: rdfs:range:POIFeature. |
| [قانون1-1 🙁 (?ویژگی1 : راست به ?ویژگی3) (?ویژگی2 : چپبه ?ویژگی3) (?ویژگی3 a :River) -> (?ویژگی1 : دارایRiverObstacle ?feature2) (?ویژگی3 a :RiverObstacle) (?feature3: نام ?نام))] |
| [قانون1-2 :(?feature1 :hasBelongDistrict ?a) (?feature2 :hasBelongDistrict ?b) notEqual (?feature1,?feature2) برابر(?a,?b)-> (?feature1 :hasMustLink ?feature2)] |
| [قانون1-3 :(?feature1 :hasBelongDistrict ?a) (?feature2 :hasBelongDistrict ?b) notEqual (?feature1,?feature2) notEqual(?a,?b)-> (?feature1 :hasCannotLink ?feature2)] |
طبق قانون 1-1 بالا، محدودیت ها را می توان با استدلال تحت این الگوریتم نشان داده شده در شکل 11 به دست آورد .
تعاریف نقطه e و مقادیر مناسب برای Eps و MinPts در شکل 2 در زیر آورده شده است.
| الگوریتم 2. تعاریف نقطه e و مقادیر مناسب برای Eps و MinPts. |
| 1: :e rdf:type :ATM, |
| 2: : POIFeature; |
| 3: :location : hedong. |
| 4: : hedong rdf:type :placeName, |
| 5: : حومه 1. |
| 6: : حومه1 rdf:نوع : ناحیهType; |
| 7: : hasEps : EpsA; |
| 8: : hasMinPts : MinPtsA. |
| 9: : EpsA rdf:type : Eps; |
| 10: :hasValue 5000. |
| 11: : MinPtsA rdf:نوع : MinPts; |
| 12: :hasValue 3. |
| [قانون2 :(?p : مکان :?a) (?a : نوع ?b) (?b : hasEps ?c)-> (?p : hasEps ?c) (?p : hasMinPts ?c)] |
4.5. بهبود عملکرد فاصله در حضور موانع
بهبود عملکرد فاصله یکی از مهمترین مراحل DBSCAN است. در این مقاله، فاصله موانع را در الگوریتم DBSCAN با استفاده از محدودیتهای به کمک هستیشناسی بازتعریف میکنیم. تابع فاصله جدید dist ‘( p , q ) است که نشاندهنده کوتاهترین فاصله از شی p تا شی q با در نظر گرفتن هر مانعی است. قسمتی از مسیر که توسط هر گونه مانع بین دو جسم قطع می شود، فاصله مانع نامیده می شود. تعریف می کنیم
که در آن dist ( a , b ) تابع فاصله است که کوتاهترین مسیر بین نقاط a و b را با استفاده از فاصله Mahalanobis، فاصله اقلیدسی یا سایر اندازه گیری های فاصله محاسبه می کند. اجازه دهید Vertex(obstacle) = { v 1, v 2,…, v n } مجموعه تمام نقاط مرزی مانع باشد و مسیر اطراف مرز مانع را در نظر بگیرید.
تابع dist'( p , q ) در الگوریتم پیشنهادی استفاده می شود. این تابع معنای معنایی جغرافیایی را به صورت زیر بیان می کند:
- (1)
-
برخی از اشیاء جغرافیایی به عنوان موانع در تجزیه و تحلیل خوشهبندی در نظر گرفته نمیشوند، مانند مسیرهای هوایی یا خطوط ولتاژ بالا بین POI.
- (2)
-
برخی از اشیاء جغرافیایی، موانعی را نشان میدهند که نمیتوان آنها را نادیده گرفت، مانند رودخانهای که بین دو نقطه به هم متصل شدهاند.
- (3)
-
برخی از اشیاء جغرافیایی باید به دلیل محدودیتهای کلاسی از خوشهبندی منع شوند، مانند دو نقطه در مناطق اداری مختلف زمانی که وظیفه گروهبندی اشیاء در مناطق اداری است.
- (4)
-
با این حال، برخی از اشیاء جغرافیایی باید به یک خوشه اختصاص داده شوند، زیرا محدودیتهای کلاسی خاص، حتی در مورد محدودیتهای متضاد، مانند دو نقطه در مناطق اداری مختلف که به یک شرکت تعلق دارند، زمانی که اولویت اول در کار خوشهبندی قرار میگیرد. وابستگی شرکت
4.6. تعیین مقادیر مناسب برای Eps و MinPts
تعیین مقادیر مناسب برای Eps و MinPts یکی دیگر از وظایف مهم است. در این مرحله از فرآیند، الگوریتم از استدلال برای به دست آوردن مقادیر مناسب بر اساس مجموعه داده ای که قرار است خوشه بندی شود، استفاده می کند. الگوریتم DBSCAN با محدودیت ها مقادیر Eps و MinPts را به صورت زیر بدست می آورد:
- (1)
-
کاربر مقادیر پیش فرض خاصی از Eps و MinPts را تنظیم می کند . این برنامه هستی شناسی را از DBSCANO و قوانین را از Rule DBSCANO می خواند .
- (2)
-
در حالی که برنامه در حال اجرا است، استدلال هستیشناختی مقادیر مناسبی از Eps و MinPts را برای مجموعه دادهها به دست میدهد. این مجموعه داده برای تعیین مقادیر Eps و MinPts استفاده می شود. استدلال انجام شده برای این منظور در حال حاضر مبتنی بر dotNetRDF است که از استدلالگرهای ایستا و پویا پشتیبانی می کند، به عنوان مثال ، آنهایی که از مجموعه قوانین ثابتی برای Eps و MinPts استفاده می کنند و آنهایی که قوانین خود را به صورت پویا بر اساس داده های مکانی ورودی ایجاد می کنند.
- (3)
-
اگر فرآیند به طور خودکار مقادیر مناسب Eps و MinPts را ایجاد نکند، این پارامترها به مقادیر پیش فرض خود باز می گردند.
جریان کلی فرآیند استدلال برای تعیین Eps و MinPts در شکل 12 نشان داده شده است .
4.7. موتور استنتاج
الگوریتم DBSCAN به کمک هستی شناسی با محدودیت ها شامل چندین توابع اضافی در مقایسه با الگوریتم استاندارد DBSCAN است که فراخوانی موتور استدلال را نشان می دهد. بسته به ویژگیهای زمینه مسئله (ورودیهای داده)، واحدهای عملکردی مختلفی برای حل یک مشکل خوشهبندی با محدودیتها فراخوانی میشوند.
ما الگوریتم DBSCAN را مطابق با سیستم هستی شناسی مورد بحث در بالا تطبیق دادیم. الگوریتم اقتباس شده مشابه الگوریتم اصلی است، با اضافه کردن محدودیت های معنایی. توابع اضافی اصلی در الگوریتم 3 توضیح داده شده اند. موتور استنتاج در الگوریتم 1 برای محاسبه روابط محدودیت بین نمونه ها در هستی شناسی ” SpatialThingFeature ” و برای به دست آوردن پارامترهای متعدد برای کاربرد در فرآیند خوشه بندی استفاده می شود.
| الگوریتم 3. الگوریتم DBSCAN با دانش پس زمینه مبتنی بر هستی شناسی. |
| 1: DBSCANWithOntology (InputData، Eps، MinPts) |
| 2: D = داده های ورودی |
| 3: خوشه = پوچ |
| 4: clusterID = 0 |
| 5: برای هر نقطه P از D |
| 6: وضعیت P. را به عنوان بازدید نشده تنظیم کنید |
| 7: برای i = 0 تا D.count-1 |
| 8: P = D.get(i) |
| 9: اگر (P.status بازدید نشده است) |
| 10: newEps = testParameterOf Eps(p) |
| 11: if (newEps != Eps) |
| 12: Eps = NewEps |
| 13: MinPts = testParameterOf MinPts (MinPts) |
| 14: وضعیت P. را به عنوان بازدید شده تنظیم کنید |
| 15: NeighborPoints = SearchNeighborPoints (P، Eps) |
| 16: if (NeighborPoints.length < MinPts) |
| 17: P را به عنوان NOISE برچسب بزنید |
| 18: دیگری |
| 19: P را به خوشه اضافه کنید[clusterID++] |
| 20: برای هر نقطه P’ در NeighborPoints |
| 21: اگر (P’.status بازدید شده است) |
| 22: وضعیت P’.status را به عنوان بازدید شده علامت بزنید |
| 23: NeighborPoints’ = searchNeighborPoints (P’، Eps) |
| 24: if (NeighborPoints’.length >= MinPts) |
| 25: NeighborPoints = NeighborPoints با NeighborPoints ترکیب شده است |
| 26: اگر (P به هیچ خوشه ای تعلق ندارد) |
| 27: P’ را به خوشه [clusterID] اضافه کنید |
| 28: خوشه بازگشت |
| 29: جستجوی NeighborPoints (P، Eps) |
| 30: pAll = همه نقاط در همسایگی Eps P (از جمله P) |
| 31: PNewSet = null |
| 32: برای هر نقطه P’ در pAll |
| 33: اگر (dist'(P, P’) <= Eps) |
| 34: P’ را به PNewSet خوشه اضافه کنید |
| 35: PNewSet را برگردانید |
| 36: dist'(p, q) |
| 37: فاصله = 0 |
| 38: محدودیت = testIsConstraint(p, q) |
| 39: اگر (محدودیت ==null|| محدودیت = noHasConstraint) |
| 40: فاصله = dist (p, q) |
| 41: اگر (محدودیت == دارای محدودیت) |
| 42: v midStart = getMidStart(p,q) |
| 43: v midEnd = getMidEnd(p,q) |
| 44: فاصله = dist(p، v midStart ) + dist(v midStart ، v midEnd ) + dist(v midEnd ، q) |
| 45: اگر (محدودیت ==hasCannotLink) |
| 46: فاصله = Eps + ثابت (> 0) |
| 47: if (محدودیت ==hasMustLink) |
| 48: فاصله = 0 |
| 49: فاصله برگشت |
| 50: testParameterOf Eps(p) |
| 51: Eps را از طریق استدلال بر اساس p |
| 52: testParameterOf MinPts(p) |
| 53: برگرداندن MinPts از طریق استدلال بر اساس p |
| 54: testIsConstraint(p1, p2) |
| 55: نوع بازگشتی برای وجود یک رابطه محدودیت بین p1 و p2 |
نمای ساختار هستی شناسی الگوریتم DBSCAN در نشان داده شده است شکل 13 نشان داده شده است .
DBSCAN تقریباً به زمان O (N 2 ) نیاز دارد که در آن N تعداد نقاط در مجموعه داده ها است. برای تجزیه و تحلیل یک تابع عملیات محدودیت اضافی با محدودیتهای پسزمینه جغرافیایی با استفاده از یک عبارت معنایی در DBSCANWithOntology، پیچیدگی زمانی برای {testParameterOfEps, testParameterOfMinPts, testIsConstraint} حداکثر مربع تعداد نقاط n است.


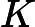
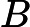
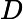
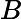
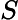
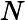


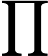
 ���������::==(�,∏)
���������::==(�,∏)









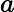
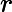

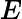
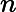
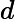
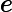
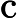
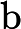

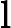
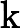
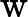
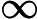


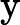










بدون نظر