1. معرفی
تحت اصطلاح عمومی جمعسپاری، دادههای جمعآوریشده از مردم بهعنوان اطلاعات جغرافیایی داوطلبانه (VGI) در حال تبدیل شدن به یک موضوع مهم در بسیاری از رشتههای علمی است. رسانههای اجتماعی و پلتفرمهای کلان داده اغلب اطلاعات جغرافیایی جمعآوریشده از وب را با استفاده از APIهای اختصاصی (مانند دادههای توییتر) ارائه میکنند. سایر تکنیکهای جمعآوری دادههای مشارکتیتر که بهعنوان علم شهروندی شناسایی شدهاند، مانند خدمات وب سفارشی و استفاده از برنامههای تلفن همراه به شهروندان این امکان را میدهند که در مشاهدات محیطی (مانند www.ispotnature.org ، www.brc.ac.uk/irecord ) مشارکت کنند و رویدادها را گزارش کنند. که می تواند در تحقیقات علمی و سیاست گذاری استفاده شود [ 1 ، 2 ، 3 ].
VGI از ارائه اطلاعات به موقع و مشاهدات ارزان و متراکم، فرصت هایی را برای درک بهتر و نظارت بر پدیده های مختلف اجتماعی و طبیعی به ارمغان می آورد. این ارزش افزوده پس از ادغام، ادغام و ترکیب داده های VGI در یک نمای واحد، در حالی که احتمالاً از منابع داده دیگر استفاده مجدد می شود، به دست می آید. در این مقاله، ما این فرآیند دوم را ترکیب دادهها یا ترکیب دادهها (DCDF) میگوییم، با این ایده که طیف وسیعی از روشها را با توجه به ناهمگونی مجموعه دادههای مورد استفاده و نتیجه مورد نظر نشان دهیم. مجموعه قابل توجهی از ادبیات، مسائل کیفیت داده مرتبط با داده های VGI، همراه با ویژگی های فضایی و فضایی آنها را مورد بحث قرار داده است [ 4 ، 5]]. ویژگی های تضمین کیفیت (QA) هنگام جمع آوری داده های جمع سپاری یا علم شهروندی [ 6 ، 7 ، 8 ، 9 ، 10] به طراحی های بهتر در مورد چگونگی واجد شرایط بودن داده ها به عنوان یک مشاهده منفرد یا به عنوان بخشی از یک مجموعه داده کمک می کنند. تضمین کیفیت (QA) به عنوان مجموعهای از خطمشی دادهها، کنترلها و آزمایشهایی تعریف میشود که به منظور برآوردن نیازهای خاص انجام میشود. در زمینه ما، کنترلهای کیفیت (QC) عملیاتهای محاسباتی (جغرافیایی) هستند که مقادیر کیفیت را بر اساس معیارها و استانداردهای مشخص شده تولید میکنند. آنچه همه رویکردهای مختلف بر آن توافق دارند، جنبه چند بعدی کیفیت است که در جمع سپاری و علم شهروندی ضروری است. ذاتاً این باعث میشود که فرآیندهای QA و DCDF درهمتنیده شوند، زیرا معیار قابلیت استفاده ISO19157 فرآیند تنظیم داده (DCP) را هدایت میکند. قابلیت استفاده در استاندارد ISO19157 به عنوان میزان پایبندی یک مجموعه داده به مجموعه ای از الزامات تعریف شده است که شامل سایر عناصر کیفیت می شود یا خیر. و از یک ارزیابی کلی کیفیت به دست آمده است. مدیریت داده (DCP) به عنوان مجموعه ای از تنظیمات و اقدامات سازمان یافته در یک سیستم تعریف می شود که در طول چرخه عمر داده از ضبط تا ذخیره سازی و مدیریت آن، از جمله در طول استفاده از آن، وجود دارد. بر اساس دو هدف به خوبی تعریف شده برگرفته از ادبیات با چند رویکرد روش شناختی (نگاه کنید بهبخش 1.1 و بخش 1.2 )، این مقاله به بررسی چیستی این درهمتنیدگی میپردازد و اگر بتوانیم علت و محل درهمتنیدگی این دو فرآیند را شناسایی کنیم، میتوان راهحلهایی برای آن پیشنهاد کرد یا نه. ما بحث خود را با استفاده از چارچوب توضیح داده شده در پروژه COBWEB (شبکه رصدخانه شهروندان) و تجربه به دست آمده از آن [ 11 ] چارچوب بندی می کنیم. پروژه اروپایی FP7 COBWEB ( www.cobwebproject.eu ) یک ابزار طراحی نظرسنجی شامل یک ابزار تألیف برای ترکیب کنترلهای کیفیت مختلف (QC) در یک گردش کار پیشنهاد کرد که به عنوان QA برای هر مطالعه موردی خاص عمل میکند [ 9 ، 10 ، 11 ، 12]؛ دادههای جمعآوریشده و سپس واجد شرایط از طریق گردش کار QA در نهایت برای یک DCDF در یک فرآیند تکمیل دادهسازی در دسترس قرار میگیرد [ 12 ، 13 ، 14 ، 15 ].
QA و DCDF دو فرآیند اساسی هستند که بخشی از DCP را تشکیل می دهند که می تواند توسط یک انسان یا یک کامپیوتر یا ترکیبی از این دو از طریق یک سری مراحل انجام شود، بنابراین هر یک از آنها می تواند توسط یک گردش کار نمایش داده شود. در چارچوب COBWEB، این گردشهای کاری با استفاده از استاندارد نشانگذاری مدلسازی فرآیند کسبوکار (BPMN) نشان داده میشوند و از فرآیندهای خودکار تشکیل شدهاند [ 9 ، 11 ، 15 ، 16.]. QA به تضمین کیفیت داده اختصاص داده شده است و اطلاعات فراداده را در سطح تک رکورد یا سطح مجموعه داده کامل تولید می کند. به عنوان مثال، یک QA می تواند یک مقدار صحت طبقه بندی (ISO1957) (به عنوان مثال، درصد توافق) برای یک نوع پوشش زمین ارائه شده توسط یک داوطلب پس از مشاهده تصویر منطقه یا مقداری برای دقت مطلق (ISO1957) ارائه دهد (به عنوان مثال، به عنوان مثال، درصد توافق) ، 68٪ خطای دایره ای) برای وسعت طغیان ناشی از جمع آوری داده های محدودیت سیل از یک شهروند با استفاده از یک برنامه تلفن همراه خاص. DCDF به استفاده از داده های VGI برای استخراج یک محصول داده ثانویه اختصاص دارد. برای دو مثال مورد مطالعه، این مربوط به تعیین نقشه پوشش زمین از داده های تاریخی و تغییرات مشاهده شده توسط داوطلبان یا احتمال آبگرفتگی یک مکان در زمان انتخابی با استفاده از شواهد شهروندان و تصاویر ماهواره ای موجود است. هر دو در این زمان انتخاب شده. درهم تنیدگی QA و DCDF منبع خود را از رویکرد مفهومی ذینفعان به مطالعه میگیرد که تحت تأثیر چندین همپوشانی معنایی در مورد کیفیت، اعتبار، اهداف مطالعه و غیره است که در مقاله بررسی میکنیم. در عمل، حتی اگر QCهای عمومی منطق و استدلال پیوستن کیفیتی را ارائه میدهند که عدم قطعیت در دادههای گرفتهشده را روشن میکند، ترکیب گردش کار QA عمدتاً ناشی از استفاده آینده از دادهها است. همچنین ممکن است عناصر کیفیت در خود الگوریتم DCDF ارزیابی شوند، یا در QA گنجانده شده اند (داده های تلفیقی یک محصول جانبی هستند) یا کاملاً از هم جدا شوند (کیفیت داده ها یک محصول جانبی است). این یادآور یک رویکرد مدلسازی آماری است که در آن، پس یا در طول برازش مدل،
این مقاله با تصدیق و تلاش برای شناسایی منابع این درهم تنیدگی، مزایا یا معایبی را که ممکن است در هنگام ادغام یا جداسازی فرآیندهای QA و DCDF ایجاد شود، مورد بحث قرار میدهد و توصیههایی را پیشنهاد میکند. با یادآوری اینکه DCDFهای بالقوه قوی تر از اطلاعات کیفی ایجاد شده برای داده های VGI استفاده شده استفاده خواهند کرد، می توان درک کرد که درهم تنیدگی (فرایندهای QA و DCDF) ممکن است مشکل ساز شود (هدف این مقاله توصیف این موارد نیست. عواقب). دو نمونه از جمعآوری و استفاده از دادههای VGI، که در زیر توضیح داده شده است، به عنوان پایهای برای کشف این درهمتنیدگیهای احتمالی عمل میکنند. علاقه به نتایج مثالها یا تشخیص بهتر بودن یکی از روشها نیست، بلکه بیشتر به طرحها و رویکردهای مورد استفاده و چگونگی تبدیل آنها به درهمتنیدگی بالقوه است.
1.1. مثال اعتبار سنجی پوشش زمین
این مثال از مطالعه اخیر VGI برای اعتبارسنجی پوشش زمین [ 17 ، 18 ، 19 ، 20 ] گرفته شده است که در آن، با استفاده از پلت فرم Geo-Wiki [ 21 ]، داوطلبان رتبه بندی های متعددی از تصاویر ماهواره ای را به عنوان کلاس های پوشش زمین انجام می دادند. برای این مطالعه بر روی کیفیت داده ها [ 19]، 65 داوطلب، 269 سایت را از یک سری تصاویر برچسب گذاری کردند و، هنگام نسبت دادن یک نوع پوشش زمین، داوطلبان همچنین میزان اطمینان خود را اعلام کردند (ورودی با استفاده از یک نوار لغزنده با یک برچسب، به عنوان مثال، “حتما”). استخراج دقت طبقه خاص پوشش زمین به ازای هر داوطلب (دقت های تولیدکننده) و تخمین طبقات پوشش زمین از احتمالات پسین با استفاده از تخمین مدل تحلیل کلاس پنهان (LCA) امکان پذیر بود (برای بررسی اخیر در مورد استفاده، به [22] مراجعه کنید . LCA برای ارزیابی دقت “تست های تشخیصی” جدید بدون استاندارد طلایی در زمینه کاربردهای پزشکی).
1.2. مثال تخمین میزان سیلاب
این مثال به سه رویکرد مختلف برای تخمین میزان طغیان سیل با استفاده از داده های VGI مربوط می شود. دو روش از جمع سپاری از رسانه های اجتماعی استفاده کردند، توییتر [ 23 ] و فلیکر [ 24 ، 25 ]. سومین مورد از یک رویکرد علمی شهروندی برای گزارش داوطلبانه طغیان سیل از طریق یک برنامه کاربردی تلفن همراه استفاده کرد که از مطالعه موردی پروژه COBWEB نشات می گرفت. برای مثال توییتر رسانههای اجتماعی، توییتهای دارای برچسب جغرافیایی برای استخراج اطلاعات سیل احتمالی و جستجوی مناطق آبگرفته، به عنوان مثال، «جاده لندن سیلزده!»، احتمالاً با موقعیت جغرافیایی توییتها ترکیب شده است، تجزیه و تحلیل شدند. سپس، یک مدل سیل (شبیهسازیهای هیدرودینامیکی شوکگیر، به اختصار hydroDyn در بخش 4با استفاده از مدل زمین (DEM) از منطقه برای برآورد وسعت طغیان اجرا شد. در مثال رسانههای اجتماعی فلیکر [ 25 ]، یک نمای تجمعی از مکانهای عکس به عنوان شواهدی برای وسعت سیل در کنار شواهدی از دادههای مشاهده زمین (EO)، شاخص تغییر نرمال شده آب تغییر یافته (MNDWI) و توپوگرافی (شیب و ارتفاع) استفاده شد. برای ارائه نقشه سیل احتمال پسین.
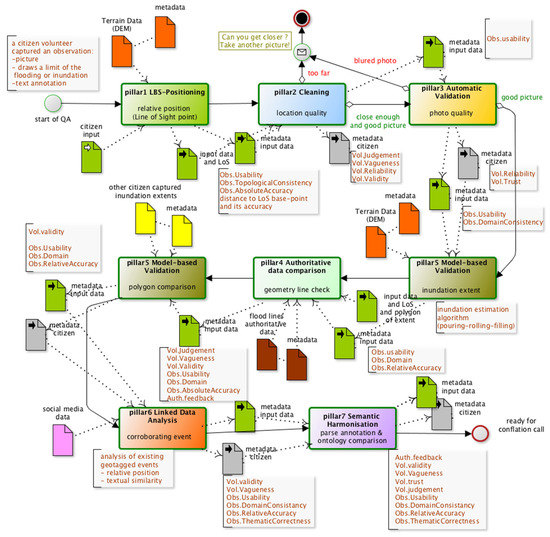
برای رویکرد علمی شهروندی COBWEB، یک برنامه تلفن همراه طراحی شده است تا با استفاده از نقاشی شهروند بر روی عکس گرفته شده و خط دید (LoS) یک تخمین موقعیت جغرافیایی یک خط محدودیت جزئی سیل/آب گرفتگی (Swipe-line) را امکان پذیر کند. ) موقعیت نقطه پایه برگرفته از DEM و جهت گیری تلفن همراه شهروندان [ 16 ، 26 ]. این حد طغیان جزئی (با دقت آن حاصل از دقت LoS) در یک الگوریتم ریختن-غلت-حوض استفاده شد [ 26 ، 27] تا زمانی که سطح آب به آن خط تند وشدید برسد، بنابراین تخمینی از وسعت آبگرفتگی از آن مشاهده منفرد با عدم قطعیت ناشی از انتشار خطا (با استفاده از DEM و عدم قطعیت های حد جزئی) ارائه می دهد. گردش کار QA که پس از هر جمع آوری داده انجام می شود در بخش 4 آورده شده است ، جایی که پس از هر QC (یک “وظیفه” در گردش کار)، ابرداده های مربوط به کیفیت ایجاد یا به روز شدند [ 10 ، 13 ].
2. گفتمان معنایی
زمانی که معمولاً در مورد کیفیت و اعتبار صحبت می شود، درهم تنیدگی در زبان آشکار می شود. خود کلمه «کیفیت» اغلب به سطحی از کیفیت اشاره دارد، یعنی کیفیت خوب یا کیفیت بد در رابطه با این که کالا برای چه چیزی استفاده میشود یا چقدر مفید است. “این لاستیک ها کیفیت خوبی دارند زیرا 40000 کیلومتر را طی می کنند” یا “این لاستیک ها کیفیت خوبی دارند زیرا فاصله ترمز را 20٪ کاهش می دهند”. سپس یک QA طراحی میشود تا آن ویژگیها را آزمایش کند و مقادیری را برای شاخصهای کیفیت تنظیم کند، که در اینجا کاملاً با عملکرد در استفاده آینده مرتبط هستند. همچنین توجه داشته باشید که طی کردن 40000 کیلومتر ممکن است کاملاً با کاهش 20 درصدی فاصله ترمز سازگار نباشد، بنابراین کیفیت خوب می تواند یک مفهوم نسبی باشد. برای استاندارد کیفیت داده های مکانی ISO19157، معیار قابلیت استفاده به تعریف و کمی کردن سطح کیفیت بر اساس الزامات خاص اعلام شده برای برآورده کردن درجه خاصی کمک می کند. با این وجود، این الزامات ممکن است در گزارشهای قابلیت استفاده جداگانه ظاهر شوند و از تمام عناصر کیفیت به خودی خود استفاده نکنند. بنابراین، DCDF، که استفاده آینده از داده ها را در نظر می گیرد، به نظر می رسد تعیین کننده در ارزیابی عناصر کیفیت خاص باشد، اما همه در گزارش های کیفیت قابلیت استفاده دخیل نیستند.
نگاهی به دادههای مکانی مانند دادههای نقشه خیابان باز (OSM) ( www.openstreetmap.org) برای یک منطقه معین، میتوان OSM را با کیفیت خوب اعلام کرد اگر هنگام استفاده از نقشه، فردی مثلاً بین خانهاش و مکان دیگری گم نشود، مثلاً برای قرار ملاقات با دندانپزشک. بنابراین کیفیت بدون در نظر گرفتن (1) کامل بودن OSM برای شبکه جادهای که مستقیماً در طول مسیریابی استفاده نمیشود (به عنوان DCDF خط پرواز و شبکه جادهای در نظر گرفته میشود) یا (ii) مطلق آن ارزیابی میشود. دقت فضایی (به ISO19157 مراجعه کنید) و «از دست نرفته» به عنوان کیفیت یا اعتبار در هنگام استفاده از DCDF در نظر گرفته می شود. فقط یک دقت نسبی (به ISO19157 مراجعه کنید) و یک ثبات توپولوژیکی (نگاه کنید به ISO19157) برای “گم نشدن” مورد نیاز است، و کامل بودن برای یافتن یک مسیر (البته نه لزوما کوتاهترین) کافی است.
2.1. کیفیت داده نتیجه نهایی
QA باید بر ارزیابی کیفیت اندازه گیری های متصل به آن تایر متمرکز شود. نتیجهگیری مانند «این تایر خوبی است» از تخمین ارزش یک ویژگی خاص پس از آزمایش به دست میآید، مثلاً اینکه لاستیک چقدر نرم است. مقدار ثبت شده می تواند به معنای خوب یا بد برای ترمز یا مسافت پیموده شده باشد. در اینجا توجه داشته باشید که گفتمان در خطر لغزش است، زیرا ترکیبی بین (الف) ارزش خود ویژگی وجود دارد که ممکن است به معنای کیفیت خوب یا کیفیت بد باشد. (ب) دقت آن مقدار که برای آزمایش خود لطافت لازم است. و (ج) ارزش آن آزمون آماری. دادهها، ویژگی یا مشخصهای از ویژگی ممکن است حاکی از انطباق یا قابلیت استفاده باشد (یا خیر)، اما تنها با دانستن دقت پیوست میتوان تصمیم گرفت که آیا الزامات کیفیت برآورده شده است (یا خیر).
هدف QA عمدتاً این ارزیابی پسینی از دقت داده ها است. این جنبه کنترلی تضمین کیفیت (جریان کاری QCها) است. در مورد QA، زبان رایج و رویه در تولید، هر دو به مجموعه ای از رویه های پیشینی اشاره می کنند که سطح کیفیت را تضمین می کنند و مجموعه ای پسینی از کنترل ها و آزمایش ها، و اطمینان می دهند که مقادیر هدف در سطح قابل قبولی از تنوع برآورده شده اند. یعنی عدم قطعیت. این مقادیر هدف، اعتبار را با یک سطح اطمینان تعریف شده، به عنوان مثال، با سطح حاشیه ای عدم قطعیت تعریف می کنند. کیفیت خوب یا بد باید فقط در معیار قابلیت استفاده به عنوان درجه ای از انطباق با مجموعه ای از الزامات باشد و به هر دو حالت پیشینی وانواع پسینی تنظیمات تضمین کیفیت
بنابراین هنگام در نظر گرفتن تناسب به منظور شرطی کردن QA، باید این را در میان طیف وسیعی از اهداف قابل قبول به صورت جمع قرار داد. با این وجود، گفتمان میتواند این باشد: «من به ارزیابی این عنصر کیفیت نیاز دارم تا کیفیت نتیجه نهایی را بدانم»، یعنی مسیریابی DCDF تا قرار ملاقات دندانپزشک، که به زمان سفر نیاز دارد، که حداقل مسافت و آن دقت نیز مورد نیاز خواهد بود. در اینجاست که میتوان احساسی از مزیت تفکیک پیدا کرد، جایی که کیفیت ورودی خوب یا بد به هدف خاصی از تخمین انتشار خطا مرتبط میشود. بهطور دقیقتر، کیفیت داده، «خطای اندازهگیری» و «عدم اطمینان در مورد دادهها» بر این ارزیابی قابلیت استفاده (تحلیل عدم قطعیت) تأثیر میگذارد.
تجزیه و تحلیل عدم قطعیت و تجزیه و تحلیل حساسیت به تصمیم گیری در مورد اینکه آیا کیفیت داده های VGI عامل مهمی در اطمینان از نتیجه نهایی DCDF است و بنابراین آیا نگران بودن در مورد هر گونه درهم تنیدگی مهم است یا خیر کمک می کند. بنابراین فرض میشود که یا یک QA جداگانه میتواند کیفیت دادههای دادههای VGI را از قبل تخمین بزند، یا یک تخمین تقریبی از این کیفیت، تست حساسیت را ممکن میسازد. سپس، تجزیه و تحلیل عدم قطعیت، با تمرکز بر تخمین عدم قطعیت خروجی با دانستن عدم قطعیت ورودی و تحلیل حساسیت، تمرکز بر تخمین بخشی از عدم قطعیت خروجی به دلیل عدم قطعیت ورودی خاص، میتواند انجام شود (همچنین به بخش 3.2 مراجعه کنید .). هر دو، تحلیل حساسیت و تحلیل عدم قطعیت را می توان به عنوان پارادایم های انتشار خطا در نظر گرفت.
2.2. کیفیت خوب و بد در جمع سپاری برای داده های فضایی محیطی چیست؟
“لاستیک های خوب و بد وجود دارند”. برای دادههای مکانی، چه برای دادههای پوشش زمین یا نمونههای گستردگی طغیان سیل، هر مشاهده دادههای VGI منفرد باید با یک حقیقت زمینی بالقوه (فعالی یا تاریخی) مقایسه شود که عدم قطعیت خاص خود را دارد. بنابراین، دقت (عدم) ممکن است به دلیل یک اندازه گیری بد و/یا به دلیل یک اندازه گیری نادقیق باشد. طبقهبندی که توسط یک داوطلب برای هر پوشش زمین انجام شده بود با یک ارزیابی خود از «دقت» انتساب پیوست شد. در مورد برنامه طغیان سیل، شهروند ممکن است کمی بیش از حد از لبه خط آب هدف بگیرد یا هنگام عکس گرفتن دستگاه را حرکت دهد، مثلاً به دلیل باد سرد تکان بخورد. اینها انواعی از عدم دقت را نشان می دهند که می توانند با استفاده از دقت موضوعی یا عناصر دقت موقعیت نسبی استاندارد ISO19157 رمزگذاری شوند.بخش 4 این جنبه را بیشتر مورد بحث قرار می دهد.
توجه داشته باشید که هنگام استفاده از یک DEM، دقت موقعیت برای یک ارتفاع خاص با دقت آن ارتفاع کاهش می یابد. با این حال، در عمل فقط از دقت عمودی برای وضوح مشخص استفاده می شود. این می تواند هم بر DCDF و هم بر QA برای وسعت طغیان تأثیر بگذارد، اما این موضوع در اینجا به طور مستقیم مورد توجه نیست.
برای طبقهبندی نوع پوشش زمین، سردرگمی احتمالی داوطلب در درک توضیحات نوشتاری مختلف انواع پوشش زمین به نوع دیگری از عدم قطعیت، یعنی کیفیت دادههای ناشی از داوطلب (حسگر شهروند) اشاره دارد. «اعتماد» اغلب کیفیت دادههای یک داوطلب را در بر میگیرد. برای مثال اعتبار سنجی پوشش زمین، خود ارزیابی، به عنوان مثال، “مطمئنا”، بخشی از ارزیابی اعتماد است. در COBWEB QA، سه نوع کیفیت مختلف به دنبال میگردند: (1) مدل کیفیت تولیدکننده (کیفیت ISO1957). (2) مدل کیفیت مصرف کننده ( http://www.opengeospatial.org/projects/groups/gufswg )، به عنوان مثال، کیفیت بازخورد [ 28 ]. و (iii) مدل کیفیت سهامداران ( جدول 1 ).
این عناصر اخیر را می توان به عنوان معیارهای یک شهروند به عنوان یک حسگر در “عملکرد” درک کرد و بر مشاهدات ثبت شده توسط این شهروند در حال حاضر و بعد تأثیر خواهد گذاشت. آنها همچنین بر سایر ارزیابیهای کیفیت تأثیر میگذارند، به عنوان مثال، وابستگی گاهی اوقات مانع از ارزیابی میشود [ 6 ]. در سیستم QA COBWEB، یک شهروند داوطلب می تواند ثبت نام شود (به صورت ناشناس)، و ارزش های کیفی آن را می توان از مشارکت در نظرسنجی او با جریان های کاری مختلف QA استفاده شده به روز کرد.
به طور بالقوه، یک متخصص مورد اعتماد با عدم اطمینان کمتری نسبت داده می شود، مثلاً در اعلام حضور یک گونه گیاهی در یک منطقه غیرمنتظره. با این حال، اگر قابلیت اطمینان آن پایین باشد، این عدم قطعیت را افزایش می دهد. هنگامی که نگرانیهایی را در یک QC معین در مورد دریافت مقادیر کیفیت پایین مشاهدهای برای طیفی از عناصر با کیفیت مطرح میکنید، مقادیر CSQ در نتیجه بهروزرسانی میشوند و به طور مشابه زمانی که یک QC اطمینان بیشتری را در مشاهده ثبتشده نشان میدهد.
همچنین عقل سلیم این است که عدم قطعیت موقعیت بزرگ (“بد”) در مورد نقطه ای که یک داوطلب در آن ایستاده است ممکن است هنگام ارزیابی نوع پوشش زمین در طول یک جلسه بررسی میدانی برای یک مطالعه علمی شهروندی مشکلی ایجاد نکند (متفاوت با مثال در بخش 1.1 ) اگر منطقه به صورت گذشته نگر همگن در نظر گرفته شود (مثلاً پس از تقسیم تصویر). برای میزان طغیان برنامه سیل، مبهم بودن حاشیه نویسی مرتبط با تصویر خط آب ممکن است از خود خط اهمیت کمتری داشته باشد. در مقابل، اگر همان شهروند در حال گرفتن طبقات پوشش زمین باشد، مقادیر ابهام گذشته او ممکن است این داده ها را نامطمئن تر کند. بنابراین ممکن است به دلیل وابستگی در ابعاد کیفیت با توجه به داده های گرفته شده، درهم تنیدگی نیز وجود داشته باشد.
2.3. قابلیت اطمینان و کیفیت داده ها
در ادبیات توافق وجود دارد که کیفیت داده های VGI معمولاً فاقد کیفیت تعریف شده است و این استفاده از داده های علوم شهروندی را محدود می کند [ 2 ، 4 ، 5 ، 8 ، 29 ، 30 ]. از این رو، اغلب تلاشی برای دور زدن کیفیت داده ها از قابلیت اعتماد وجود دارد. این گویی اعتماد تمام قابلیت های کیفیت را در بر می گیرد. همانطور که کارشناسان مورد اعتماد هستند، داوطلب مورد اعتماد ممکن است وضعیت خود را تغییر دهد و به یک “متخصص” تبدیل شود، و باعث می شود که ذینفعان دیدگاه جدیدی در مورد داده های VGI داشته باشند، همانطور که همه اکنون از متخصصان می آیند. این با وجود یافته هایی است که حتی زمانی که اعتماد مهم است، متخصصان نیز اشتباه می کنند [ 20]. در پروژه های علمی شهروندی، شرکت کنندگان همتا و شرکت کنندگان قابل اعتماد اغلب در شناسایی و اعتبار بخشیدن به مشاهدات ارائه شده توسط داوطلبان جدید کمک می کنند [ 31 ، 32 ]. این تأیید همتا کنترلی را ممکن میسازد و با جمعسپاری [ 8 ] دادهها و بهطور غیرمستقیم داوطلبی که دادهها را جمعآوری کرده است، نوعی QA را تشکیل میدهد . تأیید همتا و تأیید تخصصی، به عنوان مکانیزم های بالقوه برای ایجاد یا افزایش اعتماد، بدون مشکل نیستند [ 20 ، 33]]. وقتی حجم دادههایی که باید تأیید شوند بسیار زیاد میشود، تأیید همتا یا تأیید کارشناسی احتمالاً خطاهای انسانی را ایجاد میکند. میتوان موازی با ویکیپدیا ایجاد کرد، که امکان ویرایش متوالی یک مقاله را با هدف اطمینان از همگرایی با یک دیدگاه مشترک فراهم میکند. در این مکانیسم اخیر، خود “داده” در معرض بهبود است و اطلاعات مربوط به کیفیت به نحوی در یک سری ویرایش های متعدد باقی می ماند [ 33 ، 34]]. برای علم شهروندی، در بیشتر مواقع دادهها به اندازه ویکیپدیا قابل تغییر نیستند، دارای کیفیت قابل شناسایی از QA استفاده شده خواهند بود و سپس، بسته به سطوح کیفیت و قابلیت اطمینان منتسب، دادهها مجدداً استفاده میشوند. یا نه و تایید شده یا نه. حتی مشاهدات علمی چندگانه شهروندی در مورد یک قلمرو (موقعیت جغرافیایی و مهر زمانی) میتواند فرآیندی مشابه با ویرایش پی در پی ویکیپدیا را امکانپذیر کند و سپس اعتبار دادهها را این بار افزایش دهد (دادههای OSM از این اصل پیروی میکنند [29] ) . بنابراین، در طول این فرآیند خاص پردازش داده، یک فرآیند تضمین کیفیت ضمنی وجود دارد [ 10 ، 35]]. توجه داشته باشید که مدل کیفیت مصرفکننده، بر اساس بازخورد (عمدی یا غیرعمدی)، میتواند به ایجاد یا اصلاح اعتماد به دادهها و در نتیجه قابل اعتماد بودن داوطلبانی که به دادهها کمک کردهاند کمک کند.
بنابراین اعتماد و قابل اعتماد بودن کیفیت هایی هستند که به شدت با سایر عناصر کیفیت داده مرتبط هستند. هنگامی که به یک متخصص یا یک داوطلب اعتماد می شود، داده های جمع آوری شده توسط این شخص معتمد نیز قابل اعتماد است، و برعکس، اعتماد انباشته شده بر روی داده ها، کیفیت جمع سپاری، یا سایر شواهد، به اعتماد به داوطلبانی که کمک کرده اند بازخورد می دهد [ 6 ، 30 ، 36 ، 37 ].
2.4. شواهد، منشأ و اطمینان
این سه عبارت بازتاب فرآیند تصمیم گیری و عناصر لازم برای اجرای آن هستند [ 6 ، 28 ، 38]]. ارائه شواهد را می توان با DCDF به عنوان زمینه سازی منابع مختلف اطلاعات به اطلاعات جدید قانع کننده، قابل درک و یکپارچه مقایسه کرد. به طور ضمنی شواهد کیفیت بهبود یافته ای را منتقل می کند زیرا فرآیند جمع آوری این شواهد حاوی ایده اعتبار سنجی اطلاعات در طول تلفیق (DCDF) است. یکی دیگر از DCDF ممکن است در واقع در هنگام «مقابله با شواهد متعدد» دخالت داشته باشد، که مستلزم آگاهی از کیفیت هر شواهد مرتبط با منشأ آنها یا کیفیت هدفمندی است که اطمینان را افزایش میدهد. از این منظر، DCDF نیاز به اجرای QA دارد، و برعکس، ممکن است یک DCDF در خود فرآیند QA مورد نیاز باشد. با این حال، مواجهه با قطعات مختلف اطلاعات، ممکن است متمایز از فرآیند تصمیم گیری و همچنین از یک DCDF به نظر برسد.
این موقعیت های مختلف با رویکرد کلی انتخاب شده در COBWEB [ 19 ، 24 ، 25 ، 27 ]، با ترکیب گردش کار QA از مخزن QCهای متعلق به هفت ستون کنترل کیفیت مطابقت دارد ( جدول 2 را ببینید ). هر مشاهده ای که ثبت می شود، به منظور بررسی و بهبود ابعاد مختلف کیفیت داده ها، به طور متوالی با سایر اطلاعات روبرو می شود. گردش کار QA را می توان یک فراکیفیت اطلاعات در نظر گرفت، که منشأ ابرداده در مورد کیفیت داده داده های VGI را تشکیل می دهد. حتی اگر زنجیرهبندی QCها میتواند با ترتیب جدول 2 متفاوت باشد(و میتوان از گردشهای کاری پیچیدهتری استفاده کرد)، این ایده اصلاح عناصر کیفیت و بنابراین افزایش اطمینان در سراسر گردش کار را منتقل میکند، به عنوان مثال، گردش کار QA در بخش 4 برای مطالعه موردی وسعت طغیان سیل علم شهروندی.
به عنوان مثال، در ستون 3، “اعتبارسنجی خودکار”، یک مقدار مشخصه را می توان با “محدوده ای از مقادیر” ارائه شده توسط یک متخصص مقایسه کرد، و سپس، در ستون 4، “مقایسه داده های معتبر” را می توان با یک مقدار مشاهده شده قبلی مطابقت داد. توزیع علاوه بر این، رد یا پذیرش اندازه گیری به عنوان معتبر (تخصیص یک دقت)، انجام شده در آخرین QC، ارزیابی قبلی را در نظر می گیرد.
ذینفعی که QA را تهیه می کند تصمیم خواهد گرفت که آیا این QCهای خاص را از ستون 3 به ستون 4 یا بالعکس و همچنین هر QC موجود دیگر از همه ستون ها را زنجیره ای کند. به عنوان بخشی از کل فرآیند پردازش داده، گردش کار QA انتخاب شده طراحی شده را می توان به مجموعه ای از QCها در این ستون ها ردیابی کرد.
فرآیند ارائه و انتخاب شواهد به شدت با ارزیابی کیفیت مرتبط است، اما درهم تنیدگی با یک DCDF را نیز نشان میدهد، زیرا این QA به عنوان پشتیبانی از شواهد (برای DCDF) طراحی شده است. این مرحله تنظیم داده ها تنها یک درهم تنیدگی ضعیف است، زیرا شواهد از هم جدا هستند (هنوز ادغام صورت نمی گیرد). بنابراین، ثبت کل منشأ دادههای بهدستآمده پس از DCDF، مستلزم فهرست شواهد دادهها و کیفیت دادههای آنها، فرآیند گردش کار QA را نیز در بر میگیرد. در این فرآیند پردازش داده ها، داده های VGI بخشی از شواهد هستند، به عنوان مثال، نظرسنجی های مختلف علوم شهروندی در یک منطقه.
همانطور که در بخش قبل بحث شد، QA پیشینی و بنابراین “طراحی آزمایش” نیز بخشی از منشأ است. هم QA پیشینی و هم QA پسینی منشأ را درک میکنند و به این ترتیب، در متاکیفیت ثبت میشوند (ISO 19157). گردش کار QA مقادیری را برای عناصر کیفیت از هر سه مدل کیفیت تولید می کند (به بخش 2.2 مراجعه کنید ) اما خود را به یک فراکیفیت از دیدگاه تولید کننده مرتبط می کند.
بدیهی است که استفاده مجدد از دادههای جمعسپاری شده برای یک DCDF یا استفاده مجدد از دادههای تولید شده توسط این DCDF، منشأ و اطمینان به شواهد جدید، شواهد ترکیبی را با تداوم زنجیره فراداده و بنابراین درهمتنیدگی اطلاعات با کیفیت به صورت گذشتهنگر، یعنی انتشار هرگونه درهمتنیدگی قبلی، همراه خواهد داشت. به استفاده جدید این مهم است زیرا ما فرض می کنیم که هر DCDF از کیفیت تثبیت شده داده ها برای اجرای الگوریتم خود (“بهترین تخمین”) استفاده می کند. ردیابی کیفیت با استفاده از منشأ کدگذاری شده با استفاده از گردش کار QA و گردش کار DCDF ممکن است با درهم تنیدگی های متعدد بسیار پیچیده شود، در حالی که هنوز اطلاعات لازم را ارائه می دهد.
3. پردازش داده ها
هر چقدر که فرآیندهای QA و DCDF درهم تنیده باشند، آنها به عنوان بخشی از فرآیند بررسی داده ها (DCP) انجام می شوند. چرخه عمر داده ها بسته به مطالعه جمع سپاری و استفاده مجدد بالقوه از داده ها در کوتاه مدت و بلند مدت می تواند بسیار متفاوت باشد. بنابراین، امکان دسترسی آسان به داده ها و ابرداده ها در مراحل مختلف بسیار مهم است. در این مرحله برخی از سوالات در مورد وضعیت یک نقطه داده واحد گرفته شده توسط یک شهروند و مجموعه ای از داده های جمع آوری شده توسط شهروندان به عنوان بخشی از همان نظرسنجی یا یک نظرسنجی مشابه، به عنوان مثال، یک مجموعه داده مطرح می شود. به عنوان نمونه ای از تضمین کیفیت که در پایش بیولوژیکی استفاده می شود، شبکه ملی بیولوژیکی (NBN) در انگلستان ( www.nbn.org.uk ) «پاک کننده رکورد NBN» ( http://www.nbn.org) را در اختیار دارد . uk/Tools-Resources/Recording-Resources/NBN-Record-Cleaner.aspx). این با برخی از جنبه های تمیز کردن (ستون 2 در جدول 2 ) و انطباق (ستون 7 در جدول 2 ) مطابقت دارد. ممکن است تعدادی از این «کنترلها» به عنوان بخشی از ابزار جمعآوری دادهها بهتر دیده شوند، به عنوان مثال، یک برنامه تلفن همراه، مانند قالب تاریخ. این نوع از QCها اغلب نسبتاً مستقل از استفاده در آینده از داده ها هستند، زیرا هدف آنها “اصلاح” اشتباهات یا استفاده از استانداردهای رمزگذاری است (به عنوان مثال، هستی شناسی دامنه و اصطلاحنامه گونه ها).
3.1. طراحی آزمایش
نظرسنجی های جمع سپاری برای اهداف خاصی انجام می شود. بنابراین، اطلاعات جمع آوری شده اغلب با در نظر گرفتن آن اهداف طراحی می شود. یک پروتکل از یک آزمایش به شناسایی منابع تنوع و کیفیت با چندین محدودیت و الزام کمک می کند. این منجر به نیاز به پیاده سازی QA می شود: (1) در سطح جمع آوری داده ، به عنوان مثال، در برنامه تلفن همراه. (2) به عنوان یک QA پیشینی ، کنترل در یک روش پیشگیرانه. یا (3) در یک QA به صورت پسینی ، در نتیجه کنترل و ارزیابی تحت یک روش اصلاح و مقایسه. برای جمع سپاری رسانه های اجتماعی، بخشی از طرح آزمایشی به صورت پیشینی ظاهر می شودQA خزیدن و استخراج مورد نیاز برای استخراج داده ها بر اساس معیارهای مرتبط انتخاب شده، به عنوان مثال، تطبیق کلمه کلیدی و جستجوهای جعبه محدود است. این مورد برای نمونه های طغیان سیل با استفاده از توییتر [ 23 ] و فلیکر [ 25 ] است. بسته به کامل بودن تطابق معنایی موجود، این QA پیشینی ممکن است از نظر مفهومی از یک DCDF جدایی ناپذیر باشد. توجه داشته باشید که در اینجا عدم کنترل طراحی آزمایش با نفوذ این DCDF و با تعداد بیشتری از مشاهدات مورد انتظار نسبت به مطالعه علوم شهروندی جبران می شود (همچنین به بخش 4.1 مراجعه کنید)، یعنی انتظار برای دریافت کیفیت بهتر . سطح از مثلاً «میانگین» بیش از یک نمونه بزرگ.
برای مطالعات علوم شهروندی، یک محرک برای کیفیت داده ها نیز در سادگی یا پیچیدگی طراحی مطالعه و طراحی رابط مورد استفاده منعکس می شود [ 3 ، 39 ]. یک عامل انسانی در اینجا باید در نظر گرفته شود و همچنین با استفاده از عناصر کیفیت در جدول 1 به تصویر کشیده می شود . یک مطالعه آزمایشی طراحی شده برای جمع آوری این عناصر به حداقل رساندن آنها در مطالعه واقعی، یعنی بهبود کیفیت از QA پیشینی کمک می کند.
نوع سوم QA در بین مراحل پیشینی و پسینی رخ می دهد : hic et nunc یا QA تعاملی [ 40 ، 41 ]. دو QC ساده که تعامل را ارائه می دهند در شکل 3 برای علم شهروندی نشان داده شده است. یک QC یا فاصله تا نزدیکترین رودخانه را تجزیه و تحلیل میکند یا تکهای بزرگ از آب را روی عکس گرفته شده تشخیص میدهد (ستون 2 “تمیز کردن” برای کیفیت مکان) و از داوطلب میخواهد در صورت لزوم نزدیکتر شود (در صورت امن بودن). سپس یک QC دوم سطح کنتراست را در تصویر آزمایش میکند (ستون 3 ‘تأیید اعتبار خودکار’ برای کیفیت عکس) و ممکن است از شهروند بخواهد عکس دیگری بگیرد. برخی از این hic و nuncQC همچنین ممکن است به دلیل منابع محاسباتی مورد نیاز یا برای دسترسی به اطلاعات به موقع از منابع دیگر (که از استفاده از آن در مناطق اتصال ضعیف جلوگیری می کند) به طور انحصاری روی سرور اجرا شود [40 ] .
از آنجایی که اهداف تعریف شده در یک طراحی آزمایش ممکن است شامل محدوده ای از DCDF از قبل برنامه ریزی شده باشد، QA های مختلف نیز می توانند با آنها درگیر شوند، همانطور که در بخش 2 توضیح داده شد . با مثال طبقه بندی پوشش زمین، LCA را می توان در یک QA پسینی پس از پایان مطالعه انجام داد، به عنوان مثال، با استفاده از یک قانون توقف اندازه نمونه. همچنین میتوان آن را به صورت پسینی انجام داد ، هر بار که داوطلب فعلی نظرسنجی را به پایان رساند، اما با استفاده از نمونهای از فوق رتبهدهندههای موجود برای مقایسه، به عنوان مثال، با استفاده از ده رتبهدهنده برتر که بر اساس دقت میانگین بهدستآمده آنها رتبهبندی شدهاند (یعنی دقت تولیدکنندهشان) بخش 4.1، [ 18 ]) که برای همین مطالعه به دست آمده است را ببینید.
3.2. ذخیره سازی، استفاده، استفاده مجدد
دسترسی به داده ها در مراحل مختلف DCP همراه با تکامل فراداده، از جمله کیفیت داده های مکانی، مطلوب خواهد بود. همانطور که در بخش 2 ذکر شد ، این امر هنگام استفاده مجدد از داده ها با عوامل تعیین کننده کیفیت آن در زمینه های مختلف اهمیت دارد. آگاهی از عناصر کیفیت و فراکیفیت مرتبط که قبلاً مشتق شدهاند به این معنی است که آنها پس از آن دوباره ارزیابی میشوند یا تحت شرایط جدید مورد استفاده قرار میگیرند. یک مدیریت منشأ ممکن است این انعطافپذیری را تسهیل کند که از طریق آن میتوان درهمتنیدگی بالقوه QA و DCDF را شناسایی کرد. برای علم شهروندی، ارزیابی و دسترسی به عناصر کیفی فهرست شده در جدول 1 مفید خواهد بود.، که در سطح رکورد برای هر فرد ارزیابی می شوند. این عناصر ممکن است یک QA را برای داده های تازه گرفته شده شرطی کنند یا در هنگام تلفیق با داده های شهروندی استفاده شوند (به عنوان مثال، در ستون 5 یا ستون 6) اما همچنین اطمینان به داده های مشتق شده از DCDF را فراهم می کنند.
در شیوهای مشابه، DCDF و انتشار خطا از طیفی از عناصر کیفیت دادههای مکانی استفاده میکنند، اما DCDF بیشتر علاقهمند به ارائه یک نتیجه نهایی، یک تخمین است، در حالی که انتشار خطا بر دقت به دست آمده از این نتیجه نهایی تخمین زده تمرکز میکند. . هر دو از ارزیابی اولیه کیفیت ارائه شده توسط فرآیند QA استفاده می کنند. بنابراین، اگر DCP از هم گسسته شود، یک استعاره بیزی میتواند برای ایجاد تغییرات کیفیت قبلی از QA اولیه دادههای VGI استفاده شود که سپس در یک DCDF برای ارائه مجموعهای از مجموعه دادههای نتیجه نهایی شرطی با خطای مرتبط منتشر شده استفاده میشود. سپس، دو DCP بعدی ممکن را می توان انجام داد: (1) تحت یک فرض ارگودیسیته (تغییر فضایی تخمینی از تغییرات نقطهای را ارائه میکند)، که در آن بهترین مطابقت دارد.عدم قطعیت پسینی منجر به به روز رسانی کیفیت اولیه برای داده های VGI برای DCP به روز شده می شود. و (2) انتخاب فضایی داده های VGI با کمترین عدم قطعیت از نتیجه (اما با ارائه سوگیری بالقوه)، به عنوان مثال، دادن قابلیت استفاده شبه تهی برای رکوردهای انتخاب نشده، و سپس تکرار مجدد DCP. این دو موقعیت نشاندهنده درهمتنیدگی مجدد کنترلشده QA و DCDF است که امیدواریم با هم همگرا شوند.
تکرار اول یک تحلیل حساسیت را نشان می دهد (به بحث اولیه در بخش 2.1 مراجعه کنید )، به عنوان مثال، نگاهی به عدم قطعیت منتشر شده برای طیف وسیعی از سطوح کیفیت ورودی. به عنوان مثال، در سناریوی وسعت طغیان فلیکر، به نظر می رسد برخی از نتایج در تحلیل حساسیت چندراهی نشان می دهد که دقت موقعیت به تنهایی می تواند عامل مهمی در تصمیم گیری باشد [ 23 ]. بنابراین، یک QA اولیه مناسب میتواند برای هر DCDF واحدی که قرار است انجام شود یا هر فرآیند تکراری DCP انجام شود، مهم باشد (به بخش 4 مراجعه کنید ).
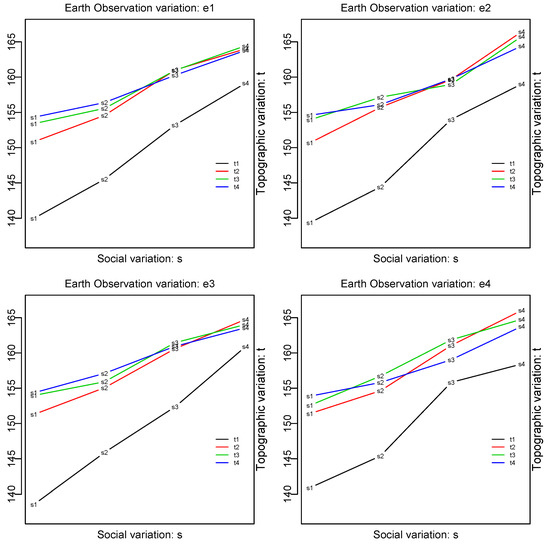
شکل 1 تغییرات خروجی بهدستآمده برای هر ترکیبی از سطوح عدم قطعیت تنظیمشده برای تجزیه و تحلیل حساسیت چندراهی [ 23 ] جریان کار وسعت غرقاب فلیکر DCDF [ 31 ] را نشان میدهد. یک عدم قطعیت مونت کارلو برای هر ترکیبی از عدم قطعیت ورودی اجرا شد. یعنی برای هر یک از سه بعد مشاهده زمین (MNDWI)، ویژگیهای توپولوژیکی (شیب و ارتفاع)، و دادههای اجتماعی (موقعیت فلیکر)، چهار سطح عدم قطعیت انتخاب شدند. سطح 1 0.5 × sd ، سطح 2 1 × sd ، سطح 3 2 × sd و سطح 4 3 × sd بود که sdتخمین اولیه انحراف استاندارد برای متغیر فعلی مورد نظر است.
از یک بررسی بصری، عدم قطعیت مشاهده زمین ( e ) الگوهای بسیار مشابهی را در چهار سطح انتخابی خود نشان می دهد. به نظر می رسد عامل توپولوژیکی ( t ) t1 را از سایرین (اثر اصلی) با یک تعامل جزئی با تنوع اجتماعی (تندترین تغییرات برای t1 ) و تنوع اجتماعی ( s) جدا می کند.) اثر گرادیان را نشان می دهد. این مثال گویا نقش تنوع اجتماعی (دقت موقعیت فلیکر) را در ارزیابی عدم قطعیت نتیجه نهایی DCDF برآورد وسعت طغیان سیل نشان میدهد. تجزیه و تحلیل چند بعدی چند بعدی تغییرات فضایی در نتایج حساسیت نشان داد که نمای تجمعی فقط در لبههای آستانه دید دارای عدم قطعیت بالایی است اما بیشتر برای عدم قطعیت موقعیت بالا [24 ] . به طور گذشته نگر، این تا حد زیادی به مقدار محلی داده های فلیکر (متاکالیته) با دقت موقعیت قابل قبول ( 1× sd ) وابسته بود.
با در نظر گرفتن یک DCDF با ارزیابی عدم قطعیت نتایج به عنوان یک عمل خوب، هر چه بهتر بتوانیم QA را برای تخمین عدم قطعیت ورودی انجام دهیم، اطمینان بیشتری به عدم قطعیت خروجی خواهیم داشت. بنابراین، یا یک موقعیت از هم گسیخته یا در نهایت یک فرآیند تکراری درهم تنیدگی، همانطور که در بالا توضیح داده شد، مطلوب است.
4. آیا گسستگی امکان پذیر است؟
در بخشهای قبلی، موقعیتهای درهمتنیدگی بهعنوان منبعی از معناشناسی زیرزمینشده در هنگام توصیف و طراحی مطالعه موردی یا هنگام اجرای مطالعه موردی و تمرکز در درجه اول بر هدف و کاربرد آن شناسایی شدهاند. در حالی که اصول QA و استفاده از داده ها در یک DCDF به این معنی است که این دو مرحله تنظیم به صورت پشت سر هم عمل می کنند، ابعاد چندگانه کیفیت و زمان ارزیابی ( QA پیشینی ، QA پسینی ، و hic et nuncQA) انعطافپذیریهایی را به متصدی ارائه دهید. او ممکن است انتخاب کند که دادههای علمی شهروندی جمعسپاری شده را با استفاده محدود بسازد، یعنی کیفیت آن را فقط برای یک تمرکز محدود مشخص کند، یا زمانی که به دنبال طیف کیفیت بزرگتری در هنگام توصیف دادهها (از جمله تناسب آن برای هدف) است، تمرکز بیشتری داشته باشد. تحت تمرکز محدود، درهم تنیدگی ممکن است کمتر مشکل ساز باشد، و کیفیت QA را به چند کیفیت با الزامات بسیار خاص کاهش می دهد (قابلیت استفاده در این استفاده محدود)، اگرچه قابلیت استفاده را کاهش می دهد (به بخش 3.2 مراجعه کنید).مثال). با این حال، محدود کردن استفاده آینده از دادههای VGI در این تمرکز محدود ممکن است ما را به بیانیه اولیه «عدم اعتبار برای دادههای VGI»، به معنای فقدان ابرداده در مورد کیفیت داده، بازگرداند. تلاش برای واجد شرایط بودن داده ها با طیف وسیعی از کیفیت ممکن است به طور طبیعی QA و DCDF را از هم جدا کند، زیرا برخی ارزیابی های کیفیت بدون استفاده در آینده انجام می شود.
با بازگشت به استفاده از داده ها و ابرداده های آن بر روی کیفیت داده، دو نوع مثال انتخاب شده (با تمرکز نسبتاً محدود) ظاهراً از جهات مختلف هدایت می شوند: (1) طبقه بندی پوشش زمین (بخش 1.1)، با استفاده از LCA به عنوان وسیله ای برای ایجاد دقت برای هر ارزیاب (یک داوطلب) اما در عین حال برآورد طبقات پوشش زمین برای هر عکس از الگوی مشاهده شده آن از توافقات و حداکثر احتمالات پسینی (MAP). و (2) وسعت طغیان سیل ( بخش 1.2) پس از ارزیابی عدم قطعیت ورودی تخمین زده می شود که منجر به عدم قطعیت مرتبط با میزان غرقاب با استفاده از انتشار خطا می شود. توجه داشته باشید که به تک تک دادههای جمعآوریشده (نوع پوشش زمین دادهشده به ازای هر داوطلب برای پوشش زمین) میتوان به صورت گذشتهنگر یک عدم قطعیت داد، و دقت برای آن داوطلب با اجماع بهدستآمده از مدل LCA برای آن پوشش زمین (MAP) است. . توضیحات برای این دو نوع مثال مشابه به نظر می رسد، اما چرخه های عمر داده ها موقعیت های متفاوتی را ارائه می دهند ( شکل 2 را ببینید ). مثال توییتر به صراحت به عدم قطعیت منتشر شده اشاره نمی کند، اما الگوی مشابهی با مثال فلیکر به دست آمد.
در شکل 2 ، برای طبقه بندی پوشش زمین، مدل LCA QA پسینی از کل مجموعه بررسی VGI را ارائه می دهد و، به دنبال طبقه بندی ما در جدول 2 ، می تواند یک QC متعلق به ستون 5 (“اعتبارسنجی مبتنی بر مدل”) باشد. با این حال، به نظر میرسد رویکرد LCA به شدت QA و DCDF را در هم میگیرد، زیرا هم دقت و هم کلاسهای پوشش زمین توافقی در یک الگوریتم تولید میشوند. با این حال، از خود-QA در حال انجام، بخشی از QA را می توان جدا کرد، به عنوان مثال، “انتخاب” داده ها فقط با برچسب “مطمئن”. همانطور که قبلاً در بخش 3.1 بحث شدیک فرآیند نظارت دیگر (DCP) به طور بالقوه می تواند یک QA را برای هر داوطلب پس از اتمام نظرسنجی او انجام دهد، به عنوان مثال، اجرای LCA با انتخابی از فوق رتبهدهندگان قبلی و او به عنوان رتبهدهنده جدید. با این وجود، نمیتوان از آن برای ارائه عدم قطعیت مشاهده منفرد جدید (طبقه زمین منتسب در آن مکان) که از این داوطلب گرفته شده است استفاده کرد، مگر در صورت استفاده از عدم قطعیت پسین ناشی از «مطالعه مرجع قبلی» (دقتهای مشتقشده LCA را ببینید [18 ] ، 19]). این «مطالعه مرجع قبلی»، که یک داده شبه معتبر (برای یک Pillar4 QC) یا دادههای مرجع مدلشده (برای یک Pillar5 QC) را نشان میدهد، میتواند مشاهدات گذشته آن مطالعه فعلی باشد، بنابراین از احتمال پسین (گذشته) برای کلاس استفاده میکند. توسط این رتبهدهنده جدید در آن مکان نسبت داده شده است. این مطالعه مرجع همچنین میتواند مطالعهای باشد که مشابه مطالعه حاضر قضاوت میشود، این بار با استفاده از نوعی عدم قطعیت مدلسازیشده مشاهده آن طبقه از اکثر رتبهدهندگان موافق با آن.
وسعت غرقابی از مثال علم شهروندی، DCP معمولی تری را با یک QA از پیش تعیین شده، مانند شکل 3 نشان می دهد . ارزیابی عدم قطعیت از QC های مستقیم (ستون 1، ستون 2، و ستون 4) استفاده می شود، و به دنبال آن یک QC در ستون 5 بر اساس یک مدل فرآیند فیزیکی انجام می شود. دومی را می توان به عنوان یک DCDF تک مشاهده ای داخلی با استفاده از یک DEM با عدم قطعیت آن تا خروجی به عنوان میزان غرقابی با عدم قطعیت مشاهده کرد. این تک مشاهدات دقیق (میزان طغیان) یک DCDF واقعی نیست، زیرا فقط از یک رکورد استفاده میکند و آن را برای استخراج عدم قطعیت با استفاده از انتشار خطا از دقت موقعیت، که به وسعت تخمین زده شده برای این مشاهده منفرد متصل است، میگیرد. در DCP، DCDF “واقعی” هنگام “تجمیع” n می آیدتخمین گستردگی طغیان زمانی که QA شکل 3 برای هر یک از n داده های گرفته شده از شهروند انجام شود . این کار با تخمین مجموعه انجام شد، که N برابر n وسعت طغیان سیل داوطلب تخمین زده شده (هر بار با عدم قطعیت خود تعدیل میشود) تقاطع میکند [ 26 ]. برای این گردش کار DCP، QA و DCDF به خوبی از هم جدا شده و از هم جدا شده اند.
مثال توییتر بیشتر یک DCP است که به یک DCDF کاهش مییابد، زیرا QA عملشده عمدتاً یک QA پیشینی است، که در اینجا به مجموعه گستردهای از توییتها (ستون 2) پیوند داده شده است. به صورت پسینیتصحیح QA این انتخاب (توئیتهایی با خواندن بالقوه اشتباه GPS و تحلیل معنایی که در ستون 7 و ستون 2 قرار میگیرد) نیز میتواند انجام شود. این منجر به یک QA مبتنی بر “تمیز کردن” می شود، به عنوان مثال، داخل یا خارج از مجموعه داده. سپس تخمین وسعت طغیان پس از تلفیقی گستره های جزئی حاصل از توییت های انتخابی انجام می شود. بنابراین هیچ درهم تنیدگی واقعی و یک رویکرد سنتی تر برای انتخاب داده های مرتبط برای تجزیه و تحلیل بدون بازگشت به واجد شرایط بودن داده های اولیه انجام نمی شود. این مطالعه بر بررسی گذشتهنگر اعتبار بالقوه روش تخمین میزان غرقاب از توییتها و مدل هیدرودینامیکی [ 23 ] متمرکز بود. در شکل 2QA موجود برای مثال دادههای توییتر، انتخاب دومی از توییتها از آزمایش خوانشهای اشتباه GPS و تحلیل معنایی برای دستهبندی/حذف برخی توییتها است [ 23 ]. چرخه عمر داده برای مثال داده فلیکر از نظر رویکرد QA شبیه به دومی است.
دیدگاه تحلیل آماری
هنگام انجام یک تجزیه و تحلیل آماری، تنظیمات بیشتر شبیه یک DCDF است زیرا ما تخمینها را با برازش توابع بر اساس مجموعهای از اطلاعات میسازیم. QA پیشینی به عنوان بخشی از پروتکل برای جمعآوری دادهها انجام میشود، اما برخلاف مرحله پاکسازی دادهها که کیفیت یک رکورد را حفظ نمیکند، اما آن را میپذیرد، تصحیح میکند یا رد میکند، هیچ مشاهده یا رکوردی واجد شرایط نیست. پسینی . یک فرضیه در مورد توزیع (های) مشاهدات ممکن است به محیط QA تعلق داشته باشد، اما فرضیه کلاسیک مستقل به طور یکسان توزیع شده است ( iid) در QA برای جمع سپاری «علاقه» ندارد، با فرض وجود داده های با کیفیت «خوب» و «بد». این وضعیت ممکن است بیشتر شبیه یک مدل اندازه گیری خطا با واریانس های نابرابر و تشخیص پرت باشد. با این حال، روشهای تشخیص دورافتاده و تشخیص تغییر متعلق به حوزه آماری ممکن است برای طیفی از QCها در ستون 4 و ستون 5 مناسب باشند. این QCها میتوانند یک مشاهده منفرد (و اعتبارسنجی را کمیسازی کنند) به عنوان متعلق به برخی از انتظارات دادههای معتبر بدون انجام تأیید کنند. یک DCDF فی نفسه ، در نتیجه هیچ درهم تنیدگی ایجاد نمی کند.
روش شناسی عمومی متاآنالیز در آمار پزشکی [ 42 ] شبیه QA است که با رویکرد DCDF دنبال می شود. هدف از یک متاآنالیز ترکیب نتایج حاصل از طیف وسیعی از مطالعات در مورد یک موضوع است. در اینجا، با افزودن کیفیتی بر اساس طرحهای مورد استفاده، همراه با اطمینان از یک نتیجه خاص برآورد شده در هر مطالعه، متاآنالیز یک تخمین محدود جدید از آن نتیجه را با قدرت بهتر محاسبه میکند (یعنی «شاخص حساسیت» یا دقت تولیدکننده). .
به طور کلی، در یک رویکرد آماری DCP، گفتمان معنایی در مورد درهمتنیدگی QA و DCDF را میتوان با این واقعیت نشان داد که هنگام اندازهگیری داوطلبان به عنوان تخمین «حقیقت»، میانگین مجذور خطای زیر است:
جایی که معادله مخفف هر دو است yتیˆ�تی^مشاهده ثبت شده توسط یک داوطلب یا اختلاط حاصل از n داوطلب. E (.) عملگر انتظار است. بهینه سازی یا ارزیابی دقت، هم سوگیری و هم دقت را در نظر می گیرد، به طوری که:
که در آن (in)accuracy ریشه میانگین مربعات خطا و دقت خطای استاندارد است. تعصب چیزی است که DCDF بیشتر به آن توجه دارد، و دقت در درجه اول وقتی به کیفیت نگاه می کنیم، اما هر دو جنبه در این معادله درگیر می شوند. جمع سپاری بر یک ویژگی آماری متکی است که تضمین می کند معادلات (1) یا (2) به خوبی متعادل هستند (در صورت استفاده از یک آمار به اصطلاح کافی)، طبق قانون اعداد بزرگ (با افزایش حجم نمونه، تعصب مشاهده شده کاهش می یابد. و دقت تقسیم بر n––√ n). زمانی که تمام مفروضات نمونه برداری برآورده شوند، این یک وضعیت ایده آل است ( iid .). در دنیای VGI، [ 19نتیجه گیری می شود که برای مدل LCA که برای داوطلبان به عنوان ارزیاب اعمال می شود، افزایش حجم نمونه آنها ممکن است بهترین راه حل برای دستیابی به دقت بالا در تخمین طبقات پوشش زمین (جنبه DCDF) نباشد، زیرا چند داوطلب به خوبی انتخاب شده با توجه به عدم قطعیت آنها (دقت سازنده) می تواند بهتر باشد. این، یک مسئله درهم تنیدگی ذاتی بالقوه را به دلیل فرض استقلال مشروط در مدل LCA ایجاد می کند. این محدودیت، استقلال ارزیابها به صورت مشروط به طبقات پوشش زمین، تأیید نمیشود، برای مثال زمانی که «نوع پوشش زمین آسان» به درستی توسط همه برچسبگذاری میشود، اما «سختها» تنها توسط تعداد کمی به درستی برچسبگذاری میشوند. توجه داشته باشید که در علوم شهروندی حجم نمونه کوچکتر از جمع سپاری انتظار می رود اما معمولاً با کیفیت بهتر (تأثیر پیشینیQA) و/یا با اطلاعات بسیار بیشتر به عنوان اندازه گیری، به عنوان مثال، جمع آوری متغیرهای بیشتری که می تواند به کاهش عدم قطعیت کمک کند.
5. نظرات و نتیجه گیری نهایی
طراحان مطالعات علمی که از شهروندان داوطلب برای جمعآوری دادهها استفاده میکنند با چالش دشواری روبرو هستند. اعتبار با توانایی شناسایی انتقادی ویژگیهای کل فرآیند پردازش داده به دست میآید. در این زمینه، تضمین کیفیت (QA) و تلفیق داده ها یا ترکیب داده ها (DCDF) دو فرآیندی هستند که با توجه به تعریف نقش خود و تجزیه و تحلیل استفاده ترکیبی از آنها به توجه بیشتری نیاز دارند. QA به این موضوع مربوط می شود که چگونه داده ها مجموعه ای از الزامات را برآورده می کنند، در حالی که DCDF وظیفه مدل سازی است که محصول یا نتیجه جدیدی را استخراج می کند. این مقاله از طریق بررسی شرایطی که اغلب میتواند این دو فرآیند را در هم تنیده کند، از جداسازی آنها به عنوان هدف هر طراحی دادهها حمایت میکند. حتی اگر قابلیت استفاده، یک یا چند گزارش در فراداده، نیاز به ارزیابی چندین عنصر کیفی دیگر را برانگیزد، این عناصر کیفیت باید، تا حد امکان، بدون «درهمتنیدگی» با DCDF (به عنوان کاربرد آینده) ارزیابی شوند. تلاش برای دستیابی به این هدف، درک محدودیت های هر یک از این فرآیندها را در کسب شواهد و اطمینان به داده های مطالعه طراحی شده افزایش می دهد.
هنگام طراحی کل فرآیند مدیریت، یک رویکرد مفهومی که جنبههای مختلف درهم تنیدگی را در مدلسازی و نگارش گردشهای کاری مربوطه در نظر میگیرد، کنترل قابلیت استفاده مجدد را افزایش میدهد. با افزایش انعطافپذیری، میتوان به پیچیدگی بیشتری دست یافت و در نتیجه امکان استفاده مؤثرتر از جمعسپاری و اطلاعات جغرافیایی داوطلبانه یا مشتق از شهروندان را فراهم کرد. برای این منظور، یک سرویس فراکیفیت که ارتباط متقابل QA و جریانهای کاری DCDF را تنظیم میکند، میتواند یک رابط بازخورد برای دانشمند و تصمیمگیرنده باشد که الزامات مدیریت دادهها و بررسیهای جدید جمعآوری دادهها را سازماندهی میکند.
درهمتنیدگی QA و DCDF با استفاده از دو مثال مصور از اعتبارسنجی پوشش زمین و تخمین گستره سیل، بر مبنای بلاغت سودمند به نظر میرسد، اما این میتواند به ویژه زمانی مفید باشد که جریان دادهها پیوستهتر میشوند و به روز رسانی منظم در کیفیت دادهها را وادار میکنند. در داده های تلفیقی از آنجایی که داده های علم شهروندی ممکن است به عنوان شواهد به موقع برای تصمیم گیری های مختلف، از جمله سیاست های زیست محیطی عمل کنند، تنها با مدیریت خوب داده ها و ابرداده ها، و به ویژه کیفیت داده ها، است که داده های علم شهروندی می توانند نقش خود در توانمندسازی شهروندان را ایفا کنند [2، 43 ] .]. با ظهور اینترنت اشیا و حسگرهای تعبیه شده، علم شهروندی تنها در صورتی میتواند تأثیر خود را از بعد انسانی خود به حداکثر برساند که بررسی دادههای آن مشکوک نباشد و حداقل شفاف باشد.





بدون نظر