

خلاصه
مقادیر زیادی از داده های سنجش مکان از خدمات شبکه اجتماعی مبتنی بر مکان تولید می شود. این داده ها به عنوان ویژگی های نقطه با مختصات مکان به دست آمده از یک سیستم موقعیت یابی جهانی یا سیگنال Wi-Fi ارائه می شوند. برای نشان دادن دادههای نقطهای در سرویسهای نقشه چند مقیاسی، دادهها باید توسط خوشههایی به دنبال روش خوشهبندی مبتنی بر شبکه نمایش داده شوند که در آن اندازه شبکه مناسب باید تعیین شود. در حال حاضر هیچ معیاری برای تعیین اندازه شبکه مناسب وجود ندارد و مسئله واحد سطحی قابل تغییر به منظور پرداختن به این موضوع فرموله شده است. روش پیشنهادی در این مقاله این است که یک شبکه شش ضلعی را برای دادههای نقطه توییتر برچسبگذاری شده جغرافیایی اعمال میکند، با در نظر گرفتن اندازه شبکه از نظر کمیت و کیفیت برای به حداقل رساندن محدودیتهای مرتبط با مشکل واحد منطقهای قابل تغییر. از نظر کمی، دادههای اصلی توییتر را با استفاده از قانون رادیکال تاپفر به مقدار مناسب کاهش دادیم. از نظر کیفی، ما ویژگی های توزیع اصلی را با استفاده از موران حفظ کردیممن _ در نهایت، با تجزیه و تحلیل توزیع دادهها روی نمودارها، اندازههای مناسب خوشهها را از سطوح بزرگنمایی 9 تا 13 تعیین کردیم. بر اساس نتایج خوشهبندی تجسمی، تأیید میکنیم که الگوی توزیع اصلی به طور موثر با استفاده از روش پیشنهادی حفظ میشود.
کلید واژه ها:
خوشه بندی ; LBSN ; توییتر ؛ MAUP ; من موران _ قانون رادیکال تاپفر
1. معرفی
تعمیم نقشه به فرآیند بیان ویژگی های نقطه به صورت خوشه ها با ادغام نقاط روی یک نقشه چند مقیاسی اشاره دارد. تعمیم نقشه معمولاً از نظر کمیت و کیفیت در نظر گرفته می شود. از نظر کمی، دادههای نقطهای باید هنگام بزرگنمایی روی نقشه به مقدار صحیح کاهش یابد، در حالی که، از نظر کیفی، دادهها باید ویژگیهای توزیع اصلی خود را حفظ کنند [ 1 ].
در این مطالعه، فرآیند خوشهبندی نقطهای را از منظر فرآیند تعمیم ویژگیهای نقطه نقشه در نظر میگیریم. در زمینه تعمیم نقشه، مطالعاتی در مورد تعمیم خط [ 2 ، 3 ، 4 ، 5 ، 6 ، 7 ] یا تعمیم چندضلعی [ 8 ، 9 ، 10 ، 11 ] برای مدتی انجام شده است. با این حال، مطالعات در مورد تعمیم نقطه به حداقل انجام شده است [ 1]، زیرا اکثر اجزای نقشه وب ویژگی های خطی هستند، مانند جاده ها و نهرها، یا ویژگی های چند ضلعی، مانند ساختمان ها و قطعات. از سوی دیگر، ویژگیهای نقطهای تمایل دارند حداقل اهمیت را در نظر بگیرند.
در این راستا، یو [ 1 ] بر روی الگوی توزیع ویژگی های نقطه تمرکز کرد و ویژگی های توزیع داده های نقطه اصلی را از طریق تحلیل ربع، تحلیل نزدیکترین همسایه و تابع K یافت. ویژگیهای نقطه اضافی با استفاده از یک آستانه تعمیم حذف شدند که میتوانست الگوی توزیع اصلی را حفظ کند. یک روش انتخاب و حذف به داده های نقطه ای برای تعمیم یک نقشه مقیاس کوچک از یک نقشه در مقیاس بزرگ استفاده شد. بنابراین، تنها الگوی توزیع دادههای نقطهای مورد تجزیه و تحلیل قرار گرفت، در حالی که بر خلاف روششناسی پیشنهادی در اینجا، شبکهها در نمایش ویژگیهای نقطهای در نظر گرفته نشدند.
با توسعه سیستم موقعیتیابی جهانی، افزایش قابل توجهی در فناوریهای تعیین مکان و دستگاههای هوشمند، و همچنین افزایش استفاده از دادههای مختلف سنجش موقعیت که از خدمات شبکههای اجتماعی مبتنی بر مکان (LBSN) مانند توییتر تولید میشوند، افزایش یافته است. ، فیس بوک و اینستاگرام. چنین داده های سنجش مکان به صورت نقاطی با x ، y منفرد ارائه می شوندمختصات به دست آمده از یک سیستم موقعیت یاب جهانی یا سیگنال Wi-Fi که مکان تولید داده ها را توصیف می کند. هنگام تجسم این دادههای نقطهای در سرویسهای نقشه چند مقیاسی، خوانایی اطلاعات توسط کاربران در طول اقدامات کوچکنمایی نقشه به دلیل همپوشانی دادهها کاهش مییابد. بنابراین، دادههای نقطهای باید توسط خوشههایی نمایش داده شوند تا خوانایی و قابلیت ارتباط اطلاعات بهبود یابد.
دادههای LBSN شکل نسبتاً جدیدی از دادهها با ویژگیهای منحصربهفرد در مقایسه با دادههای مکانی عمومی موجود، مانند دادههای آب و هوا، آلودگی و جمعیت است. دادههای LBSN احتمالاً در مناطق پرجمعیت یا مراکز شهری که احتمال زیادی وجود دارد که کاربران زیادی جمعآوری شوند، تولید میشوند. بنابراین، این دادهها در مقایسه با سایر دادهها در مناطق خاص بیشتر خوشهبندی میشوند و به طور قابلتوجهی در زمان واقعی انباشته میشوند. بنابراین، یک روش خوشهبندی که برای این ویژگیهای داده سفارشی شده است برای نمایش این دادهها در خدمات نقشه مورد نیاز است.
خوشهبندی k -means و الگوریتمهای خوشهبندی مبتنی بر شبکه معمولاً برای خوشهبندی دادههای نقطهای استفاده میشوند. با پیروی از روش k -means، محققین تعداد خوشهها ( k ) را از قبل مشخص میکنند و بنابراین، اعمال این روش برای اشکال غیر محدب یا اندازههای بسیار متفاوت خوشهها دشوار است. با پیروی از رویکرد خوشهبندی مبتنی بر شبکه، یک فضای شی در تعداد محدودی از فضاهای شامل یک ساختار شبکه ایجاد میشود و تمام فرآیندهای خوشهبندی در ساختار اجرا میشوند. این روش خوشه بندی مستقل از تعداد اشیاء داده است، فقط به تعداد سلول ها بستگی دارد و از مرکز هر کاشی استفاده می کند [ 12]]. با این حال، روش مبتنی بر شبکه نمی تواند ویژگی های توزیع داده های اصلی را حفظ کند زیرا از یک اندازه شبکه از پیش تعیین شده برای هر سطح بزرگنمایی استفاده می کند.
بنابراین، در این مقاله، ما روشی را پیشنهاد میکنیم که الگوی توزیع دادههای اصلی را با تغییر اندازه شبکه بر اساس سطح بزرگنمایی حفظ میکند. برای انجام خوشهبندی مبتنی بر شبکه دادههای LBSN، باید یک اندازه شبکه مناسب برای هر سطح بزرگنمایی تعیین شود. با این حال، هنوز هیچ معیاری برای تعیین اندازه شبکه مناسب ارائه نشده است. علاوه بر این، از آنجایی که اندازه به ویژگی ها و هدف داده ها بستگی دارد، تعیین اندازه به طور ذاتی شامل ذهنیت محقق می شود. در چنین حالتی، مشکل واحد منطقه ای قابل اصلاح (MAUP) با احتمال زیاد تأثیرگذاری بر نتیجه تجزیه و تحلیل رخ می دهد، همانطور که در بخش 2 با جزئیات بیشتر مورد بحث قرار خواهد گرفت .
هدف از این مطالعه تعیین اندازههای مناسب خوشهها برای سطوح مختلف زوم با در نظر گرفتن جنبههای کمی و کیفی و در عین حال به حداقل رساندن اثر MAUP است. ما روشی را پیشنهاد میکنیم که اندازههای مناسب خوشههای داده نقطهای توییتر با برچسب جغرافیایی را از طول یک طرف ششضلعیها ( h) در شبکه های مشبکی که برای این منظور ایجاد می شود. به دنبال روش پیشنهادی، اصطلاحات “خوشه” و “شش ضلعی” معنای یکسانی را در این مطالعه نشان می دهند. برای در نظر گرفتن ویژگیهای دادههای کمی، روش پیشنهادی با استفاده از قانون رادیکال تاپفر، که یک مدل ریاضی برای محاسبه تعداد مناسب اشیاء نقشه است، تعداد مناسب خوشهها را برای سطوح بزرگنمایی مختلف تعیین میکند. علاوه بر این، ویژگیهای دادههای کیفی با استفاده از Moran’s I به عنوان معیار همبستگی مکانی برای شناسایی ویژگیهای توزیع دادههای خوشهای در نظر گرفته میشوند.
بقیه این مقاله به شرح زیر سازماندهی شده است: بخش 2 به تفصیل MAUP، و بخش 3 مبانی نظری روش شناسی های اصلی – قانون رادیکال تاپفر و I موران – را که در این مطالعه استفاده شده اند، تشریح می کند. بخش 4 تکنیک مورد استفاده برای تعیین اندازه مناسب خوشه ها را با توجه به سطوح بزرگنمایی و همچنین نتایج در هنگام اعمال بر یک مجموعه داده واقعی مورد بحث قرار می دهد و بخش 5 نتیجه گیری و معنای این مطالعه را استخراج می کند.
2. مشکل واحد منطقه ای قابل تغییر (MAUP)
مطالعه ارائه شده در این مقاله بر روی اثر مقیاس MAUP متمرکز است، که به موجب آن ویژگیهای توزیع ناشی از تغییرات در اندازههای شبکه را تجزیه و تحلیل میکنیم. در این رابطه، او و همکاران. [ 13 ] از اثر مقیاس MAUP برای جستجوی مقیاس بهینه استفاده کرد که بیشتر از همه نشان دهنده الگوی توزیع فضایی واقعی جوامع گیاهی است. علاوه بر این، ویگاس و همکاران. [ 14 ] اثر مقیاس MAUP را برای متغیرهای مربوط به به حداقل رساندن تأثیر MAUP در هنگام ایجاد یک منطقه تجزیه و تحلیل ترافیک تجزیه و تحلیل کرد، و Swift و همکاران. [ 15] تلاش کرد تا تأثیر تجمع فضایی و MAUP را بر همبستگی بین کیفیت آب آشامیدنی و مشکلات معده تعیین کند و نه واحد فضایی مختلف را برای تجزیه و تحلیل اثرات مقیاس و منطقهبندی توسعه داد.
چنین مطالعاتی در مورد تأثیر مکانیسم عملیات MAUP بر تحلیل های فضایی و آماری مدتی است که در زمینه های مختلف انجام شده است. با این وجود، این عمل هنوز برای داده های LBSN اعمال نشده است، زیرا علیرغم پیشرفت مداوم مطالعات مرتبط با MAUP از دهه 1980، خدمات LBSN تا اوایل دهه 2000 پس از معرفی دستگاه های هوشمند و رسانه های اجتماعی ایجاد نشد. در نتیجه، سهم قابل توجه این مطالعه بررسی اثر MAUP بر انواع جدید داده ها از منظر اثر مقیاس است. علاوه بر این، ما نشان میدهیم که هنگام تجزیه و تحلیل دادههای سنجش مکان مبتنی بر منطقه، باید اثر MAUP در نظر گرفته شود.
برای پرداختن به هدف بیان شده، داده های نقطه اصلی باید با چند ضلعی ها برای تجزیه و تحلیل بر اساس واحدهای فضایی که با یک مشخصه خاص، مانند اندازه جمعیت منطقه ای یا نرخ اشتغال، تعریف می شوند، ترکیب شوند. محققان باید اندازه و شکل مناسب واحدهای فضایی را برای تجزیه و تحلیل انتخاب کنند یا با تنظیم واحدهای موجود، واحدهای فضایی جدیدی ایجاد کنند [ 16 ]. اما معیار خاصی برای تعیین اندازه و شکل مناسب واحدهای فضایی وجود ندارد.
مشکل ساخت یک واحد فضایی جدید ارتباط نزدیکی با موضوع تجمیع فضایی مقیاس های کوچک در رابطه با مقیاس های بزرگ دارد. به عنوان مثال، همان منطقه را می توان به روش های مختلف با توجه به طرح تجمیع تقسیم کرد. به این معنا که یک منطقه را می توان در مقیاس های مختلف نشان داد، و مناطق متشکل از مناطق مختلف را می توان در یک مقیاس تولید کرد [ 16 ].
به این مشکل MAUP گفته می شود. به گفته اوپنشاو، «انتخاب واحدهای منطقهای، یا سیستمهای منطقهبندی، نمیتواند جدا یا مستقل از هدف و فرآیند یک تحلیل فضایی خاص باشد» [17 ] . MAUP نشان می دهد که انتخاب واحد فضایی بر نتایج تأثیر می گذارد.
MAUP به این دلیل به وجود می آید که اکثر واحدهای فضایی در حالت های دلخواه و محدود متغیر هستند. بنابراین، واحدهای فضایی را می توان برای ایجاد مقیاس ها یا مناطق مختلف تجمیع یا تبدیل کرد [ 18 ]. یعنی MAUP دو دیدگاه دارد: اثر مقیاس و اثر منطقهبندی. با اثر مقیاس، زمانی که تجزیه و تحلیل برای مقیاسهای فضایی مختلف انجام میشود، نتیجه تغییر میکند. با اثر منطقه بندی، نتایج متفاوتی با گروه بندی مجدد واحدهای فضایی تولید می شود [ 19 ]. نمونه ای از دو اثر MAUP در شکل 1 نشان داده شده است . شکل 1 a تعداد جمعیت در هر واحد فضایی را نشان می دهد و شکل 1 b تعداد افراد بیکار را نشان می دهد. شکل 1c,d هر دو نشان دهنده اثرات MAUP در تعیین نرخ بیکاری هستند که در آن مقادیر در یک مکان به ترتیب به دلیل مقیاس و اثرات منطقه بندی متفاوت است. با اثر مقیاس، تعداد کل واحدهای فضایی متفاوت است و اندازه واحدهای فضایی یکسان است. از سوی دیگر، با اثر پهنه بندی، تعداد کل واحدهای فضایی یکسان است و اندازه واحدهای فضایی متفاوت است.
بحرانیترین دلیل برای وقوع MAUP، واریانس و کوواریانس متغیرها زمانی است که واحدهای فضایی بر اساس مقیاس و اثرات منطقهبندی تجمیع میشوند. به این معنا که، واریانس متغیرها به دلیل اثر هموارسازی، زمانی که واحدهای فضایی تجمیع میشوند، عموماً کاهش مییابد. به عنوان مثال، نقاط پرت عددی تمایل دارند در طول تجمع به سمت مقادیر متوسط همگرا شوند، زیرا آنها با سایر واحدهای فضایی ترکیب می شوند [ 16 ].
3. روش شناسی
هدف از این مطالعه ارائه روشی برای تعیین معیارهای خوشه بندی مناسب داده های نقطه سنج مکان با استفاده از سطوح زوم برای تجسم داده ها بر روی یک سرویس نقشه چند مقیاسی است. در این رویکرد، ما پیامهای توئیتر دارای برچسب جغرافیایی را با استفاده از رابط برنامهنویسی برنامه باز توییتر (API) جمعآوری میکنیم. سپس یک مشخصه توزیع دادههای اصلی توییتر با استفاده از تحلیل ربع (QA) و تحلیل نزدیکترین همسایه (NNA) تجزیه و تحلیل میشود. این نتیجه بعداً به عنوان مرجعی برای ارزیابی محاسبات موران I مورد استفاده قرار می گیرد ، همانطور که در بخش 4.2 با جزئیات بیشتر مورد بحث قرار خواهد گرفت.. سپس تعداد مناسب نقاط برای هر سطح بزرگنمایی با استفاده از قانون رادیکال تاپفر محاسبه می شود. تعداد نقاط را به عنوان تعداد مناسب خوشه در نظر می گیریم. پس از آن، محدوده طول ضلع شش ضلعی h محاسبه می شود و اندازه های مختلفی از شبکه های شش ضلعی ایجاد می شود. این دادههای شبکهای و دادههای نقطه توئیتر دارای برچسب جغرافیایی به صورت مکانی با سطوح بزرگنمایی به هم میپیوندند. پس از آن، I موران از نتایج بهم پیوسته فضایی برای تجزیه و تحلیل ویژگی های توزیع برای هر محدوده محاسبه می شود. در نهایت، مقدار مناسب h با حفظ ویژگی های توزیع اصلی داده های نقطه توییتر محاسبه شده قبلی تعیین می شود. این فرآیند در شکل 2 نشان داده شده است .
3.1. تعیین تعداد مناسب خوشه ها با استفاده از قانون رادیکال تاپفر
عملگر انتخاب و حذف فیلد تعمیم نقشه به فرآیندی اشاره دارد که برای انتخاب و حذف اشیایی که نیازی به بیان روی نقشه در سطح خاصی ندارند، استفاده می شود. مهمترین وظیفه این است که تعیین کنید چند شی باقی می ماند. هنگام انتخاب و حذف برخی از اشیا، باید درجه اهمیت اشیاء مانند هندسه، معناشناسی و توزیع آنها را در نظر بگیریم [ 21 ].
تعیین تعداد اشیایی که انتخاب و حذف خواهند شد به هدف نقشه، سطح مقیاس هدف و قصد محقق بستگی دارد. قانون رادیکال تاپفر در این مورد استفاده می شود زیرا این مدل ریاضی است که برای محاسبه تعداد اشیا یا ویژگی هایی که باید بر اساس منبع و مقیاس مشتق شده انتخاب شوند استفاده می شود. یعنی محاسبه می کند که در فرآیند تعمیم نقشه چه تعداد شی باید در مقیاس های کوچکتر باقی بمانند. قانون رادیکال تاپفر را می توان با استفاده از رابطه (1) [ 22 ] محاسبه کرد:
nf=nآ×مآمf––––√��=��×����
اینجا، nf��تعداد خوشه هایی است که می توان در مقیاس مشتق شده نشان داد، nآ��تعداد خوشه هایی است که از منبع منبع نشان داده شده است، مآ��مخرج مقیاس نقشه منبع است و مf��مخرج مقیاس نقشه مشتق شده برای بیان بسیار اغراق آمیز [ 22 ] است.
در این مطالعه، ما تعداد مناسب نقاط را برای هر سطح بزرگنمایی با اعمال قانون رادیکال تاپفر برای دادههای نقطه توئیتر دارای برچسب جغرافیایی محاسبه میکنیم. نتایج محاسبات تعداد خوشه هایی را که برای هر سطح بزرگنمایی نمایش داده می شود، مطابق فرآیند زیر نشان می دهد. ابتدا، دادههای نقطه توییتر به صورت فضایی با شبکههای شش ضلعی برای تجزیه و تحلیل مبتنی بر ناحیه به هم متصل میشوند. تعداد امتیازهای موجود در هر شبکه محاسبه می شود. هنگام شمارش تعداد خوشهها با استفاده از قانون رادیکال تاپفر، شبکههایی با مقدار پیوستن صفر حذف میشوند و تنها شبکههایی که باید با خوشهبندی بیان شوند، شمارش میشوند.
از رابطه (2) برای تعیین مقدار مناسب طول ضلع شش ضلعی h استفاده می کنیم . این به این دلیل است که وقتی محدوده مقدار h مشخص نشده باشد، میتوان یک جزء همپوشانی از مقدار ایجاد کرد که میتواند به طور مداوم با توجه به سطوح بزرگنمایی تغییر کند:
ساعتمن + 1<ساعتمن<ساعتمن – 1ℎ�+1<ℎ�<ℎ�−1
اینجا، ساعتمنℎ�طول یک طرف شبکه شش ضلعی است من�مرحله، ساعتمن + 1ℎ�+1طول یک طرف شبکه شش ضلعی است من + 1�+1سطح، و ساعتمن – 1ℎ�−1طول یک طرف شبکه شش ضلعی است من – 1�−1مرحله.
3.2. تحلیل ویژگیهای الگوی فضایی با I موران
به گفته لی [ 23 ]، داده های مکانی حاوی اطلاعات مکان نمی توانند مستقل از سایر داده های مکانی وجود داشته باشند. مطابق با Doreian [ 24 ]، وابستگی ها و تعاملات فضایی در بسیاری از پدیده های اجتماعی-اقتصادی، مبتنی بر جمعیت و طبیعی را نمی توان در هنگام تجزیه و تحلیل داده های مکانی با روش های تحلیل خطی سنتی کنترل کرد. مشابه قانون اول جغرافیای توبلر، “همه چیز به هر چیز دیگری مربوط است، اما چیزهای نزدیک بیشتر از چیزهای دور مرتبط هستند” [ 25 ]. خودهمبستگی فضایی برهمکنش فضایی بین واحدهای فضایی مجاور [ 26 ] است و I موران معیاری برای این خودهمبستگی فضایی است. من مورانمقداری در محدوده تقریباً 1- تا 1 دارد. مقدار 1 نشاندهنده همبستگی کامل، مقدار -1 نشاندهنده پراکندگی کامل، و مقدار صفر نشاندهنده یک الگوی فضایی تصادفی است. من موران را می توان همانطور که در رابطه (3) نشان داده شده است محاسبه کرد [ 27 ]:
من=n∑من∑jwمن ج×∑من∑jwمن ج(ایکسمن–ایکس¯) (ایکسj–ایکس¯)∑من(ایکسمن–ایکس¯)2�=�∑�∑����×∑�∑����(�i−�¯)(�j−�¯)∑�(�i−�¯)2
اینجا، n�تعداد واحدهای مکانی است که توسط من�و j�، wمن ج���عنصر یک ماتریس وزن های فضایی است، ایکسمن��متغیر مورد علاقه است و ایکس¯�¯میانگین است ایکس�.
Moran’s I برای مقایسه و تجزیه و تحلیل ویژگی های توزیع فضایی چند ضلعی هایی که به صورت مکانی با نقاط متصل شده اند استفاده می شود. به عنوان مثال، اگر مشخصه توزیع داده های نقطه ای اصلی تصادفی باشد، این توزیع تصادفی باید هنگام نمایش داده های نقطه ای به صورت خوشه حفظ شود. علاوه بر این، Moran’s I به عنوان یک شاخص مهم برای استخراج اندازه خوشه مناسب عمل می کند. این به این دلیل است که درجه خودهمبستگی فضایی محاسبه شده توسط موران I می تواند مرجع خوبی برای اندازه گیری و به حداقل رساندن اثر MAUP باشد [ 16 ].
4. نتایج تجربی و بحث
4.1. داده های مورد استفاده
برای ارزیابی اثربخشی روش پیشنهادی، آزمایشی را با استفاده از 188627 نقطه داده توییتر با برچسب جغرافیایی جمعآوریشده در سئول، کره، با استفاده از API باز توییتر انجام دادیم. ما شبکه های شش ضلعی تولید شده برای هر سطح بزرگنمایی در سئول را به عنوان واحد تحلیل در نظر گرفتیم. شش ضلعی ها به این دلیل مورد استفاده قرار گرفتند که طبق نظریه مکان مرکزی کریستالر [ 28 ]، شش ضلعی ها تقسیم فضایی همگن بیشتری را در مقایسه با شبکه های دایره ای یا مربعی امکان پذیر می کنند. فاصله بین مرکز شش ضلعی ها بر خلاف فواصل عمود بر مرکز مستطیل ها همیشه یکسان است.
سطوح بزرگنمایی با توجه به مقیاس نقشه های گوگل تعیین شد. Google Maps یک نقشه کاشی با سطوح از 0 تا 20 ارائه می دهد. ما محدوده های مناسب را برای خوشه بندی از سطح 9، جایی که کل شهر سئول می توان مشاهده کرد، تا سطح 13، که در آن ساختمان های جداگانه به صورت ترکیبی نشان داده شده اند، تعیین کردیم (جدول 1) . ).
برای استفاده از قانون رادیکال تاپفر، از سطح 19 (حداکثر سطح بزرگنمایی) هنگام محاسبه مخرج مقیاس نقشه منبع استفاده شد. مآ��). مخرج مقیاس نقشه مشتق شده ( مf��) با استفاده از سطوح 9 تا 13 محاسبه شد.
4.2. شناسایی ویژگی های توزیع داده های اصلی
دو روش برای تعیین ویژگی های توزیع داده های اصلی توییتر مورد استفاده قرار گرفت. از آنجایی که داده ها اساسا دارای ویژگی های نقطه ای هستند، از QA و NNA استفاده کردیم. QA برای تشخیص چگالی توزیع نقطه و NNA برای تجزیه و تحلیل رابطه فضایی بین نقاط استفاده شد. ما به دقت در نظر گرفتیم که ویژگی های توزیع اصلی داده های خام را با تجزیه و تحلیل الگوهای توزیع اصلی آنها حفظ کنیم.
QA کل منطقه را به سلول های شبکه تقسیم می کند و تعداد نقاط موجود در هر سلول شبکه را محاسبه می کند و سپس این فرضیه با استفاده از نسبت میانگین واریانس (VMR) آزمایش می شود. نتیجه QA نشان می دهد که وقتی اندازه شبکه 50 متر است، VMR 27.80712 است، که نشان می دهد که توزیع نقاط بسیار خوشه ای است.
NNA برای اندازه گیری فاصله بین دو نزدیکترین نقطه در منطقه جغرافیایی و برای توصیف الگوهای توزیع استفاده شد. نسبت فاصله از میانگین نزدیکترین همسایه مورد انتظار به میانگین نزدیکترین همسایه مشاهده شده R است . نتیجه محاسبه برای الگوهای نقطه ای نشان می دهد که R 0.216184 است، به این معنی که توزیع آن به طور معنی داری از نظر آماری خوشه بندی شده است. نتایج دو تجزیه و تحلیل نشان می دهد که ویژگی های توزیع اصلی به شدت خوشه ای هستند.
4.3. تعیین اندازه خوشه مناسب با توجه به سطوح بزرگنمایی
تعیین اندازه مناسب خوشه ها از تعداد مناسب خوشه های محاسبه شده توسط قانون رادیکال تاپفر یک موضوع جایگزین ساده نیست. از آنجایی که شبکه ها باید به عنوان یک خوشه عمل کنند، شبکه هایی که نیازی به نمایش ندارند باید حذف شوند. به طور خاص، فرآیند تعیین اندازه مناسب خوشه ها شامل شش مرحله است که در شکل 3 نشان داده شده است.: (1) محاسبه تعداد مناسب خوشه از سطح 9 تا سطح 13 با استفاده از قانون رادیکال تاپفر. (2) محاسبه اندازه خوشه ها که با تعداد محاسبه شده خوشه ها مطابقت دارد و ایجاد شبکه های شش ضلعی مطابق با اندازه محاسبه شده. (3) پیوستن فضایی به شش ضلعی ها و داده های توئیتر دارای برچسب جغرافیایی؛ (4) محاسبه تعداد شبکههای شش ضلعی که از نظر مکانی به هم متصل شدهاند، به استثنای شبکههایی با تعداد اتصال صفر. (5) تکرار مراحل بالا تا زمانی که نتیجه محاسبه حذف شده با تعداد مناسب خوشه مطابقت داشته باشد. و (6) تعیین اندازه مناسب خوشه ها ( h ) که با نتیجه در هنگام محاسبه تعداد مناسب خوشه ها مطابقت دارد.
نتایج محاسبه تعداد مناسب خوشه ها، تعداد کل خوشه ها، تعداد خوشه های با تعداد اتصال صفر و یکی از طول های ضلع شبکه های شش ضلعی در جدول 2 نشان داده شده است .
در اولین فرآیند برای تعیین مناسب ترین اندازه خوشه ها برای هر سطح بزرگنمایی، محدوده اندازه خوشه را با استفاده از رابطه (2) محاسبه کردیم. ما محدوده را به ده سطح با نسبت های یکسان برای هر سطح بزرگنمایی تقسیم کردیم و Moran’s I را برای هر مقدار در محدوده محاسبه کردیم. بنابراین، هر نسبت برای هر سطح بزرگنمایی متفاوت است.
هنگام محاسبه I موران ، از روش رابطه تداوم فضایی استفاده شد. ماتریس وزن فضایی با یک روش وزن دهی باینری ساده استفاده شد، که مقدار 1 را برای یک جفت واحد فضایی مجاور و مقدار 0 را در غیر این صورت، که در آن هر مقدار به صورت ردیفی استاندارد شده بود، به دست آورد. نتایج محاسبات Moran’s I به ترتیب در جدول 3 ، جدول 4 ، جدول 5 ، جدول 6 و جدول 7 و شکل 4 ، شکل 5 ، شکل 6 ، شکل 7 و شکل 8 نشان داده شده است . با توجه به نتایج، تمام مورانمقادیر I بزرگتر از صفر هستند، که نشان می دهد همه توزیع ها با احتمال معناداری 99٪ خوشه بندی شده اند.
به طور دقیق تر، مقادیر تا نقطه سوم کاهش می یابد و در نقطه ششم در سطح 9 به طور قابل توجهی افزایش می یابد. سپس مقدار دوباره در نقطه هفتم با نسبت مشابه کاهش می یابد. مقادیر باقی مانده به طور مداوم افزایش می یابد ( جدول 3 ، شکل 4 ). نتیجه سطح 10 مشابه سطح 9 است. در سطح 10 مقادیر تا نقطه چهارم افزایش می یابد و سپس تا نقطه ششم کاهش می یابد و در نقطه هفتم به میزان قابل توجهی افزایش می یابد. سپس مقدار دوباره در نقطه هشتم با نسبتی مشابه کاهش مییابد، و مقادیر باقیمانده به طور پیوسته افزایش مییابند، مشابه سطح 9 ( جدول 4 ، شکل 5) .). در سطح 11، مقدار در نقطه سوم به شدت افزایش می یابد، سپس به طور مکرر کاهش می یابد و افزایش می یابد، با کاهش قابل توجه در نقطه هفتم. سپس مقدار دوباره با نسبت مشابه به طور قابل توجهی افزایش می یابد و به تدریج افزایش می یابد ( جدول 5 ، شکل 6 ). نتیجه سطح 11 مشابه سطح 13 است. در سطح 12 مقادیر تا نقطه هفتم افزایش می یابد و سپس اندکی کاهش می یابد. سپس به طور مکرر افزایش و کاهش می یابند ( جدول 6 ، شکل 7 ). در سطح 13، مقادیر به طور مداوم تا نقطه پنجم افزایش می یابد و سپس در نقطه ششم به طور قابل توجهی کاهش می یابد و در نقطه هفتم دوباره به طور قابل توجهی افزایش می یابد. سپس مقادیر باقی مانده به طور مکرر افزایش و کاهش می یابد ( جدول 7 ,شکل 8 ).
در این آزمایش، مقدار Moran’s I به طور کلی برای هر سطح زوم به طور مکرر افزایش و کاهش می یابد. طبق مطالعات قبلی [ 16 ، 26 ، 29 ]، با افزایش اندازه واحدهای فضایی، ارزش Moran’s I تمایل به کاهش دارد. با این حال، این یک حقیقت مطلق نیست; علاوه بر این، نمی توان آن را برای همه انواع داده اعمال کرد. در واقع، طبق مطالعه Fotheringham [ 30 ]، با افزایش اندازه واحدهای فضایی، Moran’s I نیز افزایش مییابد و سپس در نقطهای کاهش مییابد. در همین مطالعه، ارزش Moran’s I به طور مداوم با افزایش اندازه واحدها افزایش می یابد.
در بخش 4.1 ، ما نشان دادیم که توزیع دادههای نقطه اصلی توییتر به شدت خوشهبندی شده است. بر این اساس، ما اندازههای خوشههای مورد نیاز برای حفظ تا حد امکان الگوهای توزیع خوشهای را در طول خوشهبندی برای هر سطح بزرگنمایی تعیین کردیم. با افزایش مقدار Moran’s I ، توزیع فضایی دادهها خوشهبندی میشود و خودهمبستگی مکانی قویتر میشود. اثر MAUP را می توان با خوشه بندی در زمانی که درجه خودهمبستگی فضایی زیاد است به حداقل رساند. با MAUP حداقل شده، واحدهای فضایی با ویژگی های مشابه به طور پیوسته جمع آوری می شوند که نتیجه مطلوب فرآیند خوشه بندی است. ما ارزش I موران را در نظر گرفتیمو واریانس آن، به ویژه نقطه منفردی که در آن مقدار به طور قابل توجهی افزایش یا کاهش می یابد، برای تعیین اندازه خوشه مناسب. به طور خاص، اولین تفاوت ارزش Moran’s I ( Δمنتی=منt + 1–منتی∆��=��+1−��) برای هر سطح بزرگنمایی نقطه منفردی را تعیین می کند که نشان دهنده مقدار مناسب h است . نقاط شکست هر جا که مقدار آن باشد رخ می دهد Δمنتی∆��منفی است و حداکثر مقدار مطلق در بین نقاط شکست به عنوان نقطه منفرد تعیین شد. این فرآیند به این دلیل اجرا شد که مقدار مورد نظر آن چیزی بود که قبل از کاهش نسبتاً زیاد Moran’s I در الگوی افزایش و کاهش آن رخ داده بود. افزایش مداوم بعد از نقطه مفرد را می توان ساختاری در نظر گرفت زیرا I موران با افزایش مقدار h تمایل به افزایش دارد .
در نتایج تجربی، مقدار Moran’s I تمایلی به افزایش زمانی که مقدار h افزایش مییابد، نشان میدهد، همانطور که در مطالعه فاثرینگهام و ونگ [ 30 ] نشان داده شد. سطوح 9 و 10 دارای سه امتیاز استراحت هستند. نقاط شکست در سطح 9 در جایی که h 167.9840 متر، 171.5718 متر و 185.9231 متر است، و نقاط شکست در سطح 10 در جایی که h 142.4684 متر، 145.6578 متر و 152.0367 متر است، رخ داده است. در بین این نقاط، نقطه مفرد نقطه ای است که حداکثر قدر مطلق را دارد Δمنتی∆��، و در جایی مشاهده می شود که مقادیر به شدت افزایش یافته و بلافاصله پس از نقطه منفرد کاهش می یابد. ما مقدار را در این نقطه خاص به عنوان اندازه مناسب h در نظر گرفتیم زیرا این نقطه نشان میدهد که درجه خودهمبستگی فضایی به ویژه در آن توزیع در محدوده افزایشی عمومی بالا است. بنابراین، اندازه مناسب h در سطح 9 185.9231 متر است، که در آن Moran’s I 0.351418 است، و اندازه مناسب h در سطح 10 152.0367 m است، که در آن Moran’s I 0.318932 است ( جدول 3 و جدول 4 ، به ترتیب، شکل 4 و ; شکل 5 به ترتیب).
سطوح 11 و 13 نیز دارای سه امتیاز شکست هستند. نقاط شکست در سطح 11 در جایی که h برابر با 108.6273 متر، 116.7182 متر و 122.1121 متر است، و نقاط شکست در سطح 13 در جایی که h برابر با 62.3591 متر، 66.5336 متر و 68.6209 متر است، رخ داده است. در بین این مقادیر، نقطه منفرد بلافاصله قبل از کاهش شدید مقدار مشاهده می شود. بر این اساس، ما مقدار را در این نقطه خاص به عنوان اندازه مناسب h در نظر گرفتیم . بنابراین، اندازه مناسب h در سطح 11 116.7182 متر است که در آن I موران 0.265357 است و اندازه مناسب h در سطح 13 62.35914 متر است که در آن موران I 0.171634 است ( جدول 5 وجدول 7 به ترتیب؛ به ترتیب شکل 6 و شکل 8 ).
در سطح 12 الگوی مقادیر به طور کلی افزایش می یابد و تنها یک نقطه شکست مشاهده شد که h برابر 91.2955 متر است و این مقدار را به عنوان نقطه منفرد در نظر گرفتیم. بنابراین، اندازه مناسب h در سطح 12 91.2955 متر است که در آن I موران 0.22293 است ( جدول 6 ، شکل 7 ).
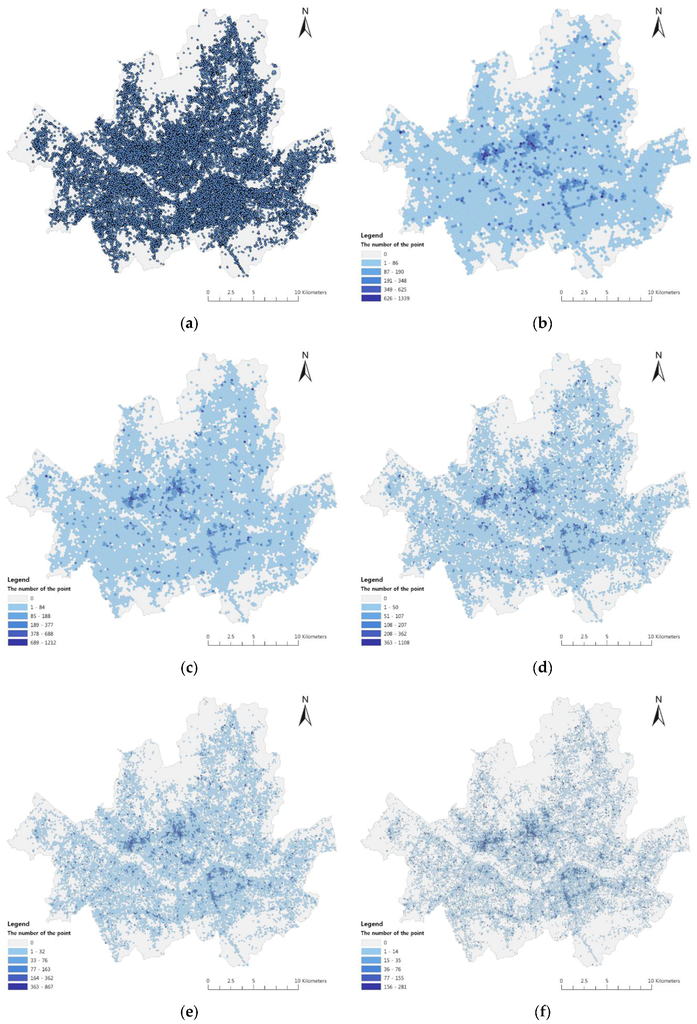
نتیجه خوشه بندی برای h مناسب مشتق شده در شکل 9 نشان داده شده است که در آن با تیره شدن رنگ، مقدار افزایش می یابد. نتایج خوشه بندی از شکل 9 ب تا شکل 9 f نشان می دهد که الگوی توزیع خوشه ای داده های اصلی ( شکل 9 الف) به خوبی در طول خوشه بندی برای هر یک از سطوح بزرگنمایی حفظ می شود. بنابراین، نتیجه می گیریم که روش ما برای حفظ ویژگی های توزیع اصلی، که همان بینش بصری توزیع اصلی را منتقل می کند، موثر است.
5. نتیجه گیری ها
هنگام نمایش دادههای نقطهای استخراجشده از سرویسهای LBSN بر روی نقشههای چند مقیاسی، دادهها باید با استفاده از خوشهها برای انتقال مناسب اطلاعات مربوطه بیان شوند. تعداد خوشه های تجسم شده باید کاهش یابد تا مناسب باشد و ویژگی های توزیع اصلی باید حفظ شود. با این حال، هیچ معیار مشخصی برای این منظور وجود ندارد. علاوه بر این، MAUP با توجه به اندازه شبکه ها در طول خوشه بندی مبتنی بر شبکه رخ می دهد.
بنابراین، در این مطالعه، ما روشی را برای تعیین اندازههای مناسب خوشهها برای هر سطح بزرگنمایی هنگام تجسم دادههای نقطهای بهدستآمده از خدمات LBSN بر روی نقشه، با در نظر گرفتن جنبههای کمی و کیفی پیشنهاد کردیم. ما از داده های نقطه توئیتر دارای برچسب جغرافیایی و داده های شبکه شش ضلعی تولید شده برای سطوح مختلف بزرگنمایی استفاده کردیم. برای این منظور، ویژگیهای توزیع دادههای اصلی را تحلیل کردیم که توزیع خوشهای را نشان داد. ما از قانون رادیکال تاپفر برای محاسبه تعداد مناسب خوشه برای سطوح بزرگنمایی استفاده کردیم. اندازه مناسب خوشه هایی که می توانند الگوی توزیع اصلی را حفظ کرده و اثر MAUP را به حداقل برسانند با استفاده از Moran’s I تعیین شد.. از این نتایج محاسباتی، اولین و مهمترین تفاوت مقدار Moran’s I بهعنوان مکانی استفاده شد که در آن، اندازه مناسب شبکه ششضلعی برای هر یک از سطوح بزرگنمایی تعیین شد. در نهایت، الگوهای توزیع برای هر سطح بزرگنمایی روی نقشه تجسم شد.
سهم قابل توجه مطالعه ما این است که هنگام تجزیه و تحلیل داده های سنجش مکان مبتنی بر منطقه، باید اثر MAUP در نظر گرفته شود. علاوه بر این، ما تعیین کردیم که نتیجه آماری به انتخاب واحدهای فضایی بستگی دارد. روش ما ممکن است به عنوان معیاری برای تعیین اندازه مناسب خوشهها مورد استفاده قرار گیرد که اثر MAUP میتواند هنگام نمایش دادههای سنجش مکان بر روی نقشه به حداقل برسد. اگرچه دادههای توئیتر دارای برچسب جغرافیایی در این مطالعه استفاده شد، روش پیشنهادی میتواند برای انواع دیگر دادههای نقطهسنجی مکانیابی اعمال شود.
اختصارات
در این نسخه از اختصارات زیر استفاده شده است:
| LBSN | شبکه اجتماعی مبتنی بر مکان |
| MAUP | مشکل واحد مساحتی قابل تغییر |
| API | رابط برنامه نویسی کاربردی |
| QA | تحلیل ربع |
| NNA | تحلیل نزدیکترین همسایه |
| VMR | میانگین واریانس نسبت |
منابع
- Yu, KB تعمیم ویژگی نقطه در نقشه دیجیتال از طریق تجزیه و تحلیل الگوی نقطه. J. GIS Assoc. کره 1998 ، 6 ، 11-23. [ Google Scholar ]
- داگلاس، دی اچ. الگوریتم های Peucker، TK برای کاهش تعداد نقاط مورد نیاز برای نمایش یک خط دیجیتالی یا کاریکاتور آن. کارتوگر. بین المللی جی. جئوگر. Inf. جئوویس. 1973 ، 10 ، 112-122. [ Google Scholar ] [ CrossRef ]
- ژائو، ز. Saalfeld، A. الگوریتمهای سادهسازی چند خط آستین با زمان خطی. در مجموعه مقالات AutoCarto 13، سیاتل، WA، ایالات متحده آمریکا، 7-10 آوریل 1997; ص 214-223.
- Lang, T. قوانین برای طراحان روبات. Geogr. Mag. 1969 ، 42 ، 50-51. [ Google Scholar ]
- رومان، ک. ویتکام، الف. بهینه سازی تقسیم بندی منحنی در گرافیک کامپیوتری. در مجموعه مقالات سمپوزیوم محاسباتی بین المللی، داووس، سوئیس، 4 تا 7 سپتامبر 1973; صص 467-472.
- Visvalingam، M. وایات، جی. تعمیم خط با حذف مکرر نقاط. کارتوگر. J. 1993 ، 30 ، 46-51. [ Google Scholar ] [ CrossRef ]
- Rangayan, RM; گولیاتو، دی. د کاروالیو، جی دی. Santiago, SA تقریب چند ضلعی خطوط بر اساس تابع زاویه چرخش. جی الکتر. Imaging 2008 , 17 , 023016. [ Google Scholar ]
- لی، ز. یان، اچ. آی، تی. چن، جی. تعمیم خودکار ساختمان بر اساس مورفولوژی شهری و نظریه گشتالت. بین المللی جی. جئوگر. Inf. علمی 2004 ، 18 ، 513-534. [ Google Scholar ] [ CrossRef ]
- چن، جی. هو، ی. لی، ز. ژائو، آر. منگ، L. حذف انتخابی ویژگی های جاده بر اساس تراکم مش برای تعمیم خودکار نقشه. بین المللی جی. جئوگر. Inf. علمی 2009 ، 23 ، 1013-1032. [ Google Scholar ] [ CrossRef ]
- تیمن، اف. سستر، ام. بوبریچ، جی. استخراج خودکار استفاده از زمین از داده های توپوگرافی. بین المللی قوس. فتوگرام حسگر از راه دور اسپات. Inf. علمی 2010 ، 38 ، 558-563. [ Google Scholar ]
- Haunert، JH; ولف، الف. تجمیع مساحت در تعمیم نقشه با برنامه نویسی عدد صحیح مختلط. بین المللی جی. جئوگر. Inf. علمی 2010 ، 24 ، 1871-1897. [ Google Scholar ] [ CrossRef ]
- هان، جی. پی، جی. کامبر، ام. داده کاوی: مفاهیم و تکنیک ها . Elsevier Science: نیویورک، نیویورک، ایالات متحده آمریکا، 2011. [ Google Scholar ]
- او، ز. ژائو، دبلیو. چانگ، X. مشکل واحد مساحتی قابل اصلاح ناهمگونی فضایی جامعه گیاهی در منطقه انتقالی بین واحه و بیابان با استفاده از تحلیل نیمه واریانس. Landsc. Ecol. 2007 ، 22 ، 95-104. [ Google Scholar ] [ CrossRef ]
- ویگاس، جی.ام. مارتینز، LM; سیلوا، EA اثرات مسئله واحد منطقه ای قابل تغییر بر ترسیم مناطق تحلیل ترافیک. محیط زیست طرح. B طرح. دس 2009 ، 36 ، 625-643. [ Google Scholar ] [ CrossRef ]
- سویفت، آ. لیو، ال. Uber, J. کاهش سوگیری MAUP از آمار همبستگی بین کیفیت آب و بیماری GI. محاسبه کنید. محیط زیست سیستم شهری 2008 ، 32 ، 134-148. [ Google Scholar ] [ CrossRef ]
- لی، SI ترسیم مناطق تابع و مسئله واحد منطقه ای قابل تغییر (MAUP). جی. جئوگر. محیط زیست آموزش. 1999 ، 7 ، 757-783. [ Google Scholar ]
- Openshaw, S. مسئله واحد مساحتی قابل تغییر . Geobooks: Norwich، UK، 1984. [ Google Scholar ]
- Jelinski، DE; Wu, J. مسئله واحد منطقه ای قابل اصلاح و پیامدهای آن برای بوم شناسی چشم انداز. Landsc. Ecol. 1996 ، 11 ، 129-140. [ Google Scholar ] [ CrossRef ]
- کوان، نماینده مجلس؛ وبر، جی. مقیاس و دسترسی: مفاهیم برای تجزیه و تحلیل استفاده از زمین – تعامل سفر. Appl. Geogr. 2008 ، 28 ، 110-123. [ Google Scholar ] [ CrossRef ]
- حمید، اس ام. بل، ن. Schuurman, N. تجزیه و تحلیل اثرات مکان بر آسیب: آیا انتخاب مقیاس جغرافیایی و منطقه اهمیت دارد؟ Med را باز کنید. 2010 ، 4 ، 171-180. [ Google Scholar ]
- پارک، دبلیو. یو، ک. ساده سازی خط ترکیبی برای تعمیم نقشه برداری. تشخیص الگو Lett. 2011 ، 32 ، 1267-1273. [ Google Scholar ] [ CrossRef ]
- تاپفر، اف. Pillewizer, W. اصول انتخاب. کارتوگر. J. 1966 ، 3 ، 10-16. [ Google Scholar ] [ CrossRef ]
- لی، SI توسعه یک معیار تداعی فضایی دو متغیره: ادغام r پیرسون و I موران . جی. جئوگر. سیستم 2001 ، 3 ، 369-385. [ Google Scholar ] [ CrossRef ]
- دوریان، ص. برآورد مدل های خطی با داده های توزیع شده فضایی. اجتماعی روش. 1981 ، 12 ، 359-388. [ Google Scholar ] [ CrossRef ]
- Tobler, WR یک فیلم کامپیوتری شبیه سازی رشد شهری در منطقه دیترویت. اقتصاد Geogr. 1970 ، 46 ، 234-240. [ Google Scholar ] [ CrossRef ]
- Getis, A. Handbook of Applied Spatial Analysis: Software Tools, Methods and Applications ; Springer Science & Business Media: نیویورک، نیویورک، ایالات متحده آمریکا، 2009. [ Google Scholar ]
- موران، PA یادداشت هایی در مورد پدیده های تصادفی پیوسته. Biometrika 1950 ، 37 ، 17-23. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Christaller, W. Central Places در جنوب آلمان Prentice Hall: Upper Saddle River، نیوجرسی، ایالات متحده آمریکا، 1966. [ Google Scholar ]
- Can، A. ماتریس های وزن و آمار همبستگی فضایی با استفاده از مدل داده های برداری توپولوژیکی. بین المللی جی. جئوگر. Inf. سیستم 1996 ، 10 ، 1009-1017. [ Google Scholar ] [ CrossRef ]
- Fotheringham، AS; Wong، DW مسئله واحد سطحی قابل اصلاح در تحلیل آماری چند متغیره. محیط زیست طرح. A 1991 , 23 , 1025-1044. [ Google Scholar ] [ CrossRef ]
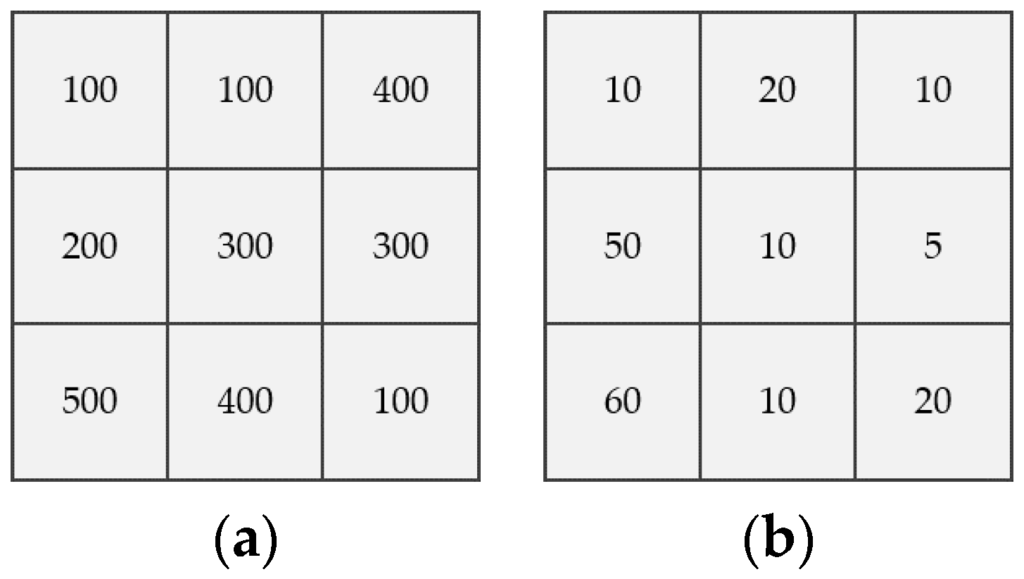

شکل 1. نمونه ای از اثر مقیاس MAUP و اثر منطقه بندی: ( الف ) جمعیت پایه. ( ب ) تعداد بیکاران؛ ( ج ) اثر مقیاس. و ( د ) اثر منطقه بندی [ 20 ].
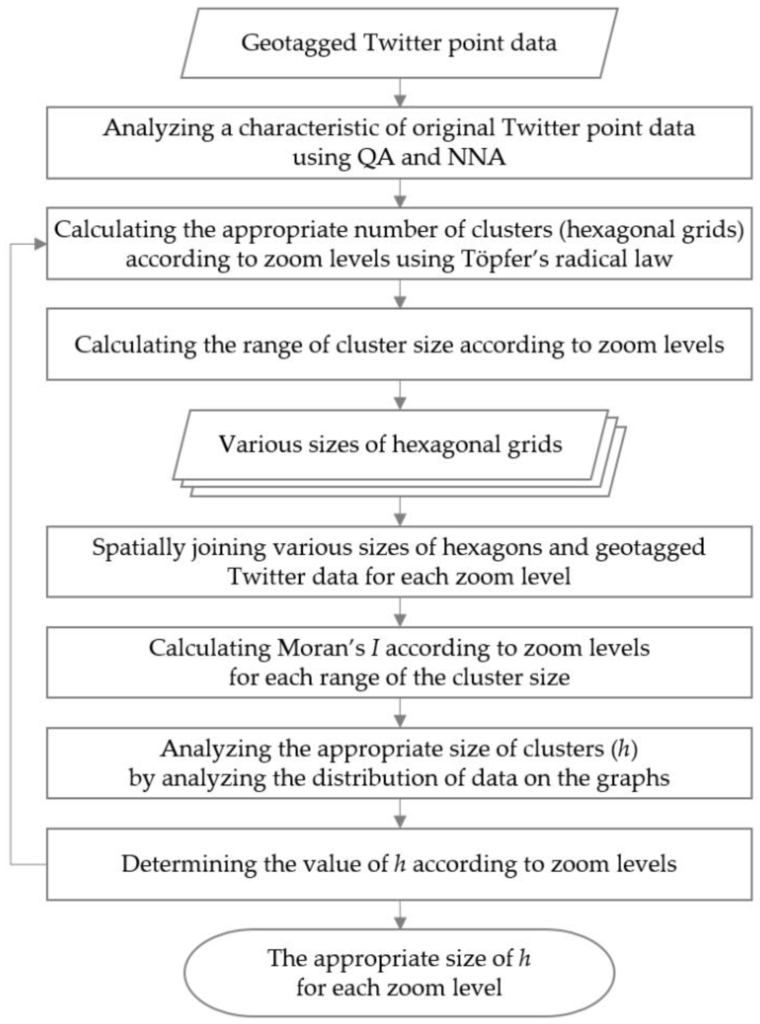
شکل 2. فلوچارت فرآیند تعیین اندازه مناسب خوشه ها.
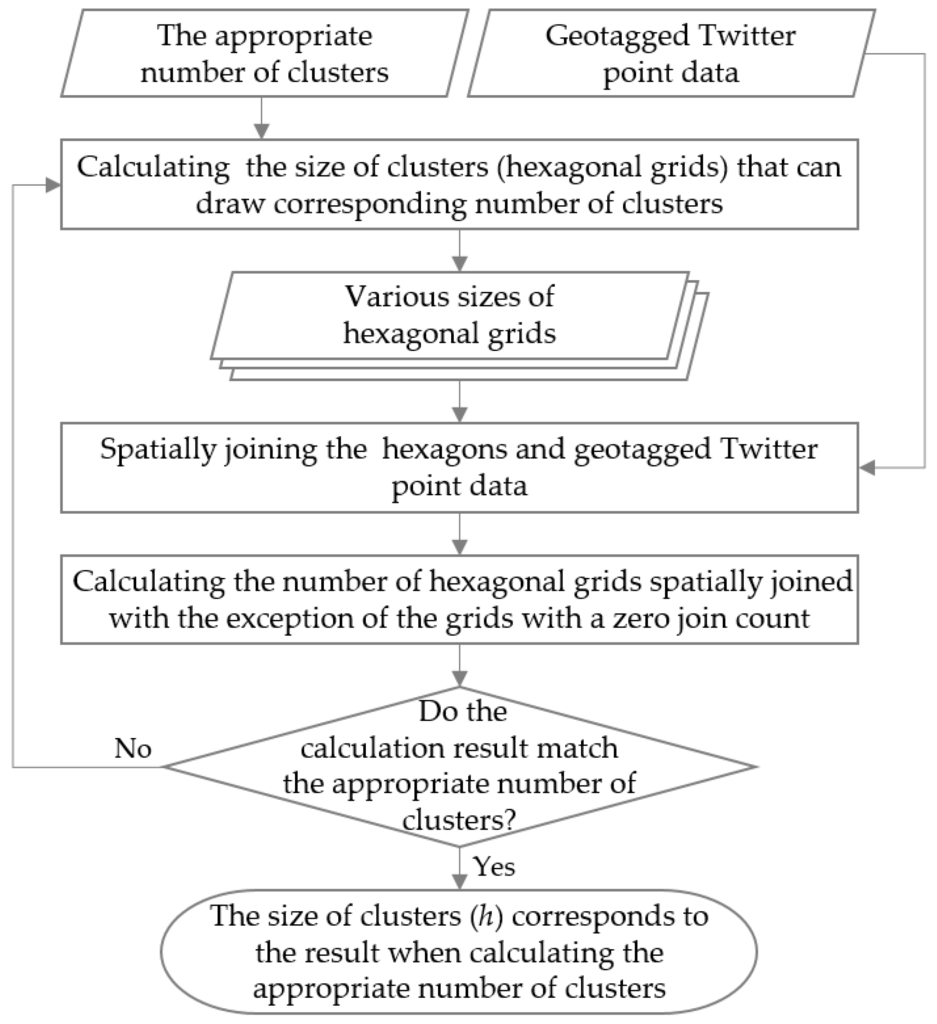
شکل 3. فرآیند تفصیلی تعیین اندازه مناسب خوشه ها.
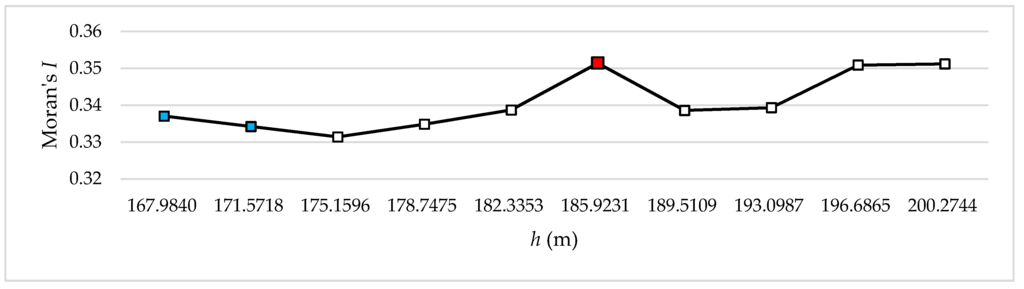
شکل 4. تغییرات Moran’s I با توجه به اندازه خوشه در سطح 9.
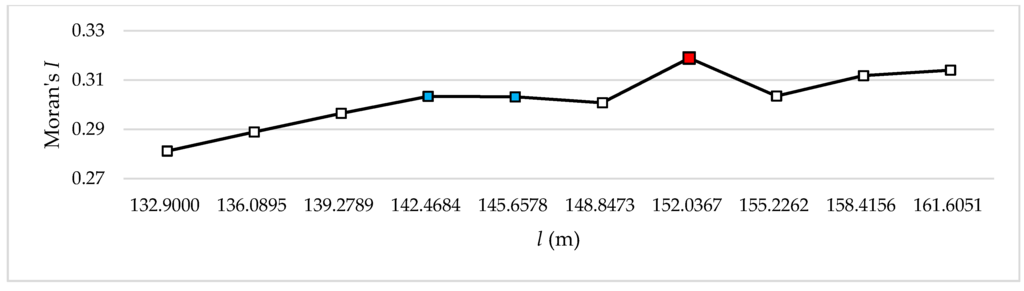
شکل 5. تغییرات Moran’s I با توجه به اندازه خوشه در سطح 10.
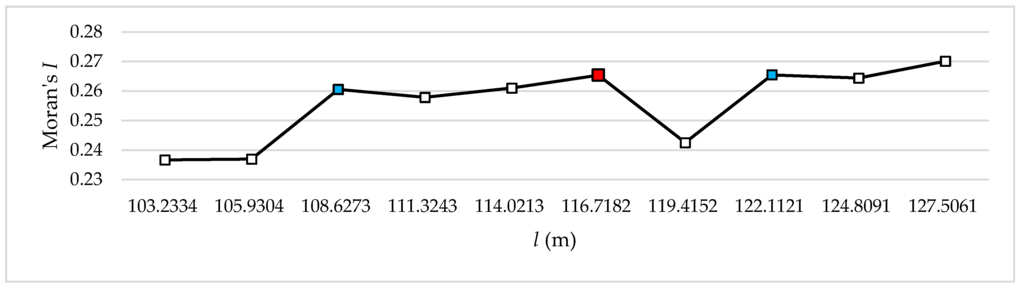
شکل 6. تغییرات Moran’s I با توجه به اندازه خوشه در سطح 11.

شکل 7. تغییرات Moran’s I با توجه به اندازه خوشه در سطح 12.
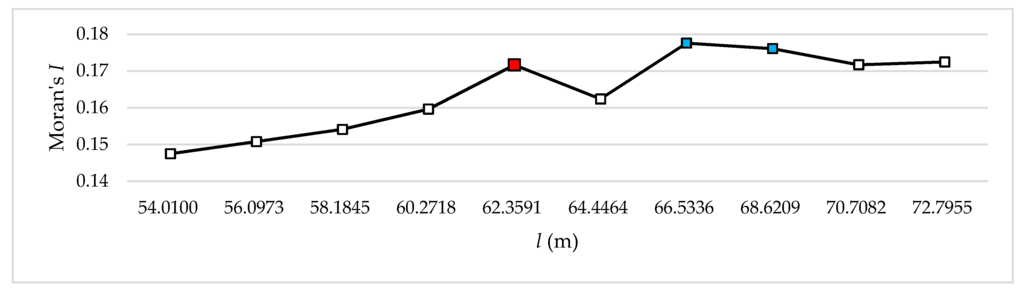
شکل 8. تغییرات Moran’s I با توجه به اندازه خوشه در سطح 13.

شکل 9. نتیجه خوشهبندی با استفاده از اندازههای مناسب خوشهها: توزیع ( a ) دادههای توئیتر دارای برچسب جغرافیایی. ( ب ) سطح 9; ( ج ) سطح 10; ( د ) سطح 11; ( ه ) سطح 12; و ( f ) سطح 13.

جدول 1. مقیاس نقشه های گوگل بر اساس سطوح بزرگنمایی.
جدول 2. نتیجه تعداد و اندازه خوشه مناسب.
جدول 3. نتیجه محاسبه موران I با توجه به اندازه خوشه در سطح 9.
جدول 4. نتیجه محاسبه موران I با توجه به اندازه خوشه در سطح 10.
جدول 5. نتیجه محاسبه موران I با توجه به اندازه خوشه در سطح 11.
جدول 6. نتیجه محاسبه موران I با توجه به اندازه خوشه در سطح 12.
جدول 7. نتیجه محاسبه موران I با توجه به اندازه خوشه در سطح 13.
© 2016 توسط نویسندگان؛ دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (CC-BY) (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر