

چکیده
وب حسگر پدیده ای رو به رشد است که در آن تعداد فزاینده ای از حسگرها در حال جمع آوری داده ها در دنیای فیزیکی هستند تا از طریق اینترنت در دسترس قرار گیرند. برای کمک به تحقق وب حسگر، کنسرسیوم فضایی باز (OGC) استانداردهای باز را برای استاندارد کردن پروتکل های ارتباطی برای به اشتراک گذاری داده های حسگر ایجاد کرده است. زیرساختهای دادههای مکانی (SDIs) سیستمهایی هستند که برای دسترسی، پردازش و تجسم دادههای مکانی از منابع ناهمگن توسعه یافتهاند و SDIها را میتوان به طور خاص برای وب حسگر طراحی کرد. با این حال، مشکلاتی با قابلیت همکاری مرتبط با عدم نامگذاری استاندارد وجود دارد، حتی با داده های جمع آوری شده با استفاده از همان استاندارد باز. هدف از این تحقیق گروه بندی خودکار لایه های داده حسگر مشابه است. ما یک روش برای گروهبندی خودکار لایههای داده حسگر مشابه بر اساس پدیدهای که اندازهگیری میکنند، پیشنهاد میکنیم. روش شناسی ما مبتنی بر یک رویکرد منحصر به فرد از پایین به بالا است که از پردازش متن، تطبیق رشته های تقریبی، و تطبیق رشته معنایی لایه های داده استفاده می کند. ما از WordNet بهعنوان یک پایگاه داده واژگانی برای محاسبه شباهتهای جفت کلمه و استخراج تابع عدم تشابه مبتنی بر مجموعه با استفاده از آن امتیازها استفاده میکنیم. دو رویکرد برای گروهبندی لایههای داده اتخاذ میشود: نقشهبرداری بین تمام لایههای داده تعریف میشود و خوشهبندی برای گروهبندی لایههای داده مشابه انجام میشود. ما نتایج روش شناسی خود را ارزیابی می کنیم. ما از WordNet بهعنوان یک پایگاه داده واژگانی برای محاسبه شباهتهای جفت کلمه و استخراج تابع عدم تشابه مبتنی بر مجموعه با استفاده از آن امتیازها استفاده میکنیم. دو رویکرد برای گروهبندی لایههای داده اتخاذ میشود: نقشهبرداری بین تمام لایههای داده تعریف میشود و خوشهبندی برای گروهبندی لایههای داده مشابه انجام میشود. ما نتایج روش شناسی خود را ارزیابی می کنیم. ما از WordNet بهعنوان یک پایگاه داده واژگانی برای محاسبه شباهتهای جفت کلمه و استخراج تابع عدم تشابه مبتنی بر مجموعه با استفاده از آن امتیازها استفاده میکنیم. دو رویکرد برای گروهبندی لایههای داده اتخاذ میشود: نقشهبرداری بین تمام لایههای داده تعریف میشود و خوشهبندی برای گروهبندی لایههای داده مشابه انجام میشود. ما نتایج روش شناسی خود را ارزیابی می کنیم.
GIS ; داده کاوی ; بازیابی اطلاعات ؛ قابلیت همکاری داده ها OGC ; SOS
1. مقدمه
شبکه جهانی وب (WWW) تقریباً بر تمام جنبه های زندگی تأثیر عمیقی داشته است. در طول 20 سال گذشته از گمنامی به وجدان عموم مردم آمد و به درستی هم همینطور است. WWW ارتباطات را متحول کرده است. اگرچه اینترنت برای چندین دهه وجود داشت، اما وب در اوایل دهه 1990 به وجود آمد. تیم برنرز لی زبان نشانه گذاری فرامتن (HTML) را توسعه داد که به اسناد متنی اجازه می داد از طریق لینک ها به اشتراک گذاشته شوند. او همچنین پروتکل هایی را برای به اشتراک گذاری HTML توسعه داد، یعنی پروتکل انتقال متن بیش از حد (HTTP). این فناوریها اساس WWW بودند و با در دسترس بودن یک مرورگر کاربر پسند، WWW در سال 1993 منفجر شد. به همین ترتیب، تحقق وب حسگر به سرعت در حال نزدیک شدن است و یک عامل مهم و تعیینکننده در نسل بعدی اینترنت
واژه Sensor Web اولین بار توسط ناسا استفاده شد [ 1 ]، که به این صورت توصیف شد: «Web Sensor شامل سیستمی از غلاف های حسگر بی سیم، درون ارتباطی و توزیع شده در فضایی است که می تواند به راحتی برای نظارت و کاوش محیط های جدید مستقر شود.» لیانگ و همکاران [ 2] تعریف وب حسگر را گسترش داد تا طیف گسترده ای از برنامه ها و حسگرها را در بر گیرد. آنها در مورد طیف گسترده ای از حسگرهای ممکن، مانند شبکه های حسگر بی سیم، سیل سنج ها، برج های آب و هوا، مانیتورهای آلودگی هوا، سنجنده های استرس بر روی پل ها، حسگرهای زیستی موبایل، وب کم ها و دستگاه های تصویربرداری زمینی ماهواره ای بحث می کنند. همچنین، آنها استدلال می کنند که وب حسگر را می توان به عنوان یک “حسگر جهانی” در نظر گرفت که به همه حسگرها و مشاهدات آن متصل می شود. ما از این مفهوم از وب حسگر در بقیه این مقاله استفاده می کنیم.
برای اینکه ماشینها بتوانند از طریق وب حسگر ارتباط برقرار کنند، به یک زبان مشترک نیاز است. همانطور که WWW به دلیل انطباق HTML و HTTP موفق بوده است، وب حسگر دارای مجموعه ای از استانداردهای رایج است. کنسرسیوم فضایی باز (OGC)، یک سازمان استاندارد، سالهاست در توسعه این استانداردهای باز مشارکت داشته است. آنها استانداردهای Sensor Web Enablement (SWE) را توسعه داده اند. این استانداردها مدلهای اطلاعاتی و پروتکلهای ارتباطی را تعریف میکنند تا حسگرها را در اینترنت قابل دسترس و قابل استفاده کنند. بوتس و همکاران [ 3] تأثیر تحقق وب حسگر از طریق SWE را توصیف می کند، “این امر برای علم، نظارت بر محیط زیست، مدیریت حمل و نقل، ایمنی عمومی، امنیت تاسیسات، مدیریت بلایا، کنترل نظارتی و عملیات جمع آوری داده های شرکت ها (SCADA) اهمیت فوق العاده ای دارد. کنترلهای صنعتی، مدیریت تأسیسات و بسیاری از حوزههای فعالیت دیگر».
استاندارد سرویس مشاهده حسگر (SOS) از اهمیت ویژه ای برخوردار است [ 4]. این سرویسی است برای برقراری ارتباط مشاهدات ایجاد شده از رویه ها. یک رویه اغلب یک حسگر است، زیرا یک مشاهده بر اساس برخی پدیده های فیزیکی تولید می کند، اما یک رویه کلی تر است و می تواند یک معادله یا سیستمی باشد که یک مشاهده را ایجاد می کند. برای اختصار، ما از عبارت سنسور در سراسر این مقاله استفاده خواهیم کرد. استاندارد SOS یک استاندارد اصلی برای به اشتراک گذاری داده های حسگر است. در این مقاله، بحث لایه های داده حسگر به داده های استخراج شده از SOS ها اشاره دارد. در این مقاله، ما فقط نسخه استاندارد SOS 1.0 را در نظر می گیریم. از اینجا به بعد، هر ذکری از SOS شکل اختصاری SOS نسخه 1.0 است. از سال 2012، OGC نسخه 2.0 SOS را منتشر کرده است. با این حال، از آنجایی که ابزارهای کمی از نسخه جدید پشتیبانی میکنند، برای آزمایش روششناسی خود به دادههای موجود و نرمافزار سازگار با نسخه 1.0 تکیه میکنیم.
ماهیت وب حسگر بسیار زمانی- مکانی است. همه حسگرهای فیزیکی دارای موقعیت فیزیکی هستند که همه دادههای حسگر را به شدت به مدلسازی و درک صحیح مکان وابسته میکند. همچنین، یک مشاهده شامل یک مقدار است، محاسبه شده، تولید شده یا جمع آوری شده در نقطه ای از زمان، به تمام مشاهدات حسگر یک مهر زمانی می دهد. مشاهدات و اندازهگیریها (O&M) یک استاندارد OGC SWE برای رمزگذاری دادههای حسگر است [ 5 ]، و مدل O&M این دیدگاه مکانی-زمانی دادههای حسگر را تقویت میکند. عنصر OM_Observation دارای چندین ویژگی زمان، resultTime، validTime و fenomenTime است و مکان را از GF_FeatureType به ارث می برد.
در واکنش به حجم عظیمی از داده های تولید شده از وب حسگر، بسیاری از گروه های تحقیقاتی از سراسر جهان در حال طراحی و تحقیق سیستم هایی برای مدیریت و پردازش این داده های جدید هستند. سیستم اطلاعات جغرافیایی (GIS) اصطلاحی است که معمولاً برای اشاره به بستههای نرمافزاری استفاده میشود که قادر به ادغام دادههای مکانی و غیر مکانی برای بدست آوردن اطلاعات مکانی است که برای تصمیمگیری استفاده میشود. نبرت [ 6 ] توضیح می دهد که اصطلاح زیرساخت داده های مکانی (SDI) “اغلب برای نشان دادن مجموعه پایه مربوطه از فن آوری ها، سیاست ها و ترتیبات سازمانی استفاده می شود که در دسترس بودن و دسترسی به داده های مکانی را تسهیل می کند.” کلمن و نبرت [ 7] استدلال می کند که اجزای اصلی SDI شامل ارائه دهندگان داده، پایگاه های داده و ابرداده، شبکه های داده، فناوری ها، ترتیبات سازمانی، سیاست ها و استانداردها، و کاربران نهایی است. Nogueras-Iso و همکاران. [ 8 ] توضیح میدهد، «باید توجه داشت که زیرساختهای دادههای مکانی درست مانند سایر اشکال زیرساختهای شناختهشدهتر، مانند جادهها، خطوط برق یا راهآهن هستند. کل مفهوم زیرساختهای دادههای مکانی و سایر اشکال زیرساخت این است که به اعضای مجاز و/یا مشارکتکننده جامعه اجازه استفاده از آنها را میدهند.» می بینیم که مفهوم SDI شامل فناوری های مورد نیاز برای مهار قدرت حسگر وب می شود.
یک SDI که قادر به تعامل با Sensor Web است، یک سیستم پیچیده است، با بسیاری از اجزای نرم افزاری مهم. هدف نهایی چنین سیستمی این است که به کاربران اجازه دهد داده های حسگر مربوط به نیازهای خود را جمع آوری کنند. توانایی های معمولی عبارتند از توانایی تجسم داده ها، اتصال به ارائه دهندگان مختلف داده، جستجو بر اساس موقعیت جغرافیایی و دوره زمانی. یکی از موارد استفاده مهم این است که به کاربران اجازه داده شود تا داده های حسگر را بر اساس پدیده دنیای واقعی که سنسور اندازه گیری می کند، جستجو کنند. این به عنوان فیلتر موضوعی شناخته می شود: به جای حذف داده های خارج از مکان مورد علاقه یا محدوده زمانی مورد علاقه، داده هایی را حذف می کنیم که با درخواست موضوعی کاربر مطابقت ندارند. پدیده تنها یک مقوله موضوعی ممکن است.
هدف از این تحقیق ارائه عملکرد فیلتر کردن دادههای حسگر بر اساس پدیدهای است که اندازهگیری میکند، که با گروهبندی دادههای حسگر مشابه انجام میشود. مفهوم لایه برای کمک به تعریف هدف معرفی شده است. یک لایه حسگر به عنوان یک موجودیت گسسته متشکل از مجموعه ای از داده های حسگر از یک منبع، بر اساس یک پدیده واحد تعریف می شود. همچنین، ما میخواهیم فرآیند گروهبندی دادههای حسگر مشابه را خودکار کنیم، زیرا حجم بالای دادهها، روشهای دستی یا نیمه دستی را برای انجام بسیار پرهزینه میکند. بنابراین، ممکن است هدف خود را به عنوان تعریف روشی برای گروهبندی خودکار لایههای داده حسگر مشابه بازنویسی کنیم.
1.1. چالش ها و مسائل
دو مشکل اساسی مرتبط با گروه بندی لایه های داده بر اساس ویژگی مشاهده شده آنها از منابع داده های مختلف وجود دارد: قابلیت همکاری نحوی و قابلیت همکاری معنایی. اگرچه استفاده از استانداردهای باز بسیاری از مشکلات مربوط به انتقال داده را برطرف می کند، اما این دو مشکل باید تعریف و برطرف شوند.
قابلیت همکاری نحوی اولین مشکل گروه بندی خودکار لایه های داده است. بیشر [ 9 ] این ایده را هنگام بحث در مورد ناهمگونی در یک محیط چند GIS معرفی کرد. “تحقیق نحوی به رسمیت بخشیدن به دستور زبان طرحواره ها و عبارات معنایی، بدون هیچ اشاره ای به معنای واقعی آنها می پردازد. ممکن است دستور زبان متفاوتی وجود داشته باشد که منجر به ناهمگونی نحوی شود.» به عبارت دیگر، قابلیت همکاری نحوی به این دلیل به وجود میآید که ویژگیهای مشاهدهشده به صورت رشتههای متنی نمایش داده میشوند، و مگر اینکه دو دنباله کاراکتر دقیقاً مطابقت داشته باشند، رایانه آنها را متفاوت در نظر میگیرد.
بیشر [ 9 ] همچنین ایده قابلیت همکاری معنایی را به عنوان هدف تعامل GIS تعریف کرد. قابلیت همکاری معنایی به این صورت توصیف میشود: «…برای ایجاد ارتباط یکپارچه بین GIS از راه دور بدون داشتن دانش قبلی از معناشناسی اساسی». آنها در ادامه خاطرنشان می کنند که ناهمگونی معنایی زمانی است که یک واقعیت دنیای واقعی ممکن است بیش از یک توصیف اساسی داشته باشد. کوهن [ 10] ایده یک سیستم مرجع معنایی را ذکر می کند و قابلیت همکاری معنایی را به عنوان ظرفیت سیستم های اطلاعاتی یا خدمات برای کار با یکدیگر بدون نیاز به دخالت انسانی توصیف می کند. مشکل قابلیت همکاری معنایی از کلمات یا توصیف های مختلف برای نشان دادن یک مفهوم ناشی می شود. به عنوان مثال، دو رشته “باران” و “باران” را در نظر بگیرید. از آنجایی که بارندگی نوعی بارندگی است، کاربر علاقهمند به دادههای بارش میتواند به میزان بارندگی و همچنین بارش برف، تگرگ، شدت بارندگی و سایر ویژگیهای مشاهدهشده مرتبط علاقهمند باشد. اگرچه این مفاهیم به طور شهودی با هر انسانی مرتبط است، برای هر رایانه ای اینها به سادگی دنباله های متفاوتی از شخصیت ها هستند.
این مشکلات تطبیق رشته اصلی را برای گروه بندی خودکار لایه های داده حسگر با هم بی اثر می کند. به عنوان مثال، با استفاده از استاندارد SOS [ 11 ]، انواع نام های اختصاص داده شده به ویژگی های مشاهده شده را در لایه های داده حسگر توصیف می کنیم. جدول 1 خواص مختلف مشاهده شده را نشان می دهد که همگی با مفهوم یکسانی از سرعت باد مطابقت دارند. با این حال، ارائه دهندگان داده های مختلف داده های خود را متفاوت برچسب گذاری می کنند. این امر طراحی سیستمها را برای بازگرداندن تمام لایههای داده حسگر که سرعت باد را اندازهگیری میکنند، دشوار میسازد.
1.2. راه حل های قبلی
رویکردهای مختلفی برای حل مسائل قابلیت همکاری، به ویژه قابلیت همکاری معنایی وجود داشته است. ما راه حل های قابل توجه و جدید برای این مشکل را در زمینه وب حسگر بیان می کنیم.
یکی از روشهای پیشنهادی برای یافتن و گروهبندی لایههای دادههای حسگر مشابه، استفاده از رجیستری قابل مشاهده حسگر (SOR) و حاشیهنویسی معنایی [ 12 ] است. SOR شامل فرهنگ لغت URN هایی است که ویژگی های مشاهده شده را شناسایی می کند، همچنین تعاریف ویژگی های مشاهده شده و ارجاع به مفاهیم برای آن ویژگی های مشاهده شده در یک هستی شناسی. این یک روش عملی برای مدیریت لایه های داده حسگر است، اما به سطح خاصی از کار دستی نیاز دارد. ویژگی های مشاهده شده جدید باید به صورت دستی به برخی از هستی شناسی های مورد توافق مرتبط شوند. همچنین، اگر چندین هستی شناسی استفاده شود، باید روشی برای تطبیق هستی شناسی های مختلف پیاده سازی شود. این راه حل با کار شرح داده شده در [ 13]. آنها یک زیرساخت سنسور Plug and Play را توصیف میکنند، از جمله توضیحی در مورد همسانسازی با قابلیت معنایی. اگرچه آنها در مورد استفاده از معیارهای نحوی برای تطبیق بحث می کنند، اما تأکید آنها بر معماری وب حسگر در مقیاس بزرگ است. تمرکز این تحقیق بر گروهبندی لایههای داده حسگر از سرویسهای SOS موجود و با حداقل کمک از ارائهدهنده داده است. این بر این فرض استوار است که بسیاری از ارائه دهندگان داده های حسگر سنسورهای خود را ثبت یا حاشیه نویسی نمی کنند بلکه به سادگی داده ها را مطابق با مشخصات SOS ارائه می دهند.
Bermudez [ 14 ] دسته بندی هایی را برای جستجوی داده های حسگر در پورتال تعریف کرد. سپس، یک هستی شناسی برای نمایش مفاهیم مورد استفاده توسط ارائه دهندگان خدمات ایجاد شد. نقشه برداری بین دسته های پورتال و شرایط ارائه دهنده خدمات با استفاده از ابزار نقشه برداری هستی شناختی به دست آمد. این به کاربر اجازه داد تا یک دسته پورتال را انتخاب کند، و سیستم نیز به نوبه خود می تواند نتایج را بر اساس ویژگی مشاهده شده مورد علاقه کاربر فیلتر کند. ثابت شد که این یک راه حل موثر است، اما به ارائه دهندگان داده یا ادغام کننده داده نیاز دارد تا ایجاد و نگهداری کنند. هستی شناسی و همچنین اعتماد به اینکه فرآیند نقشه برداری موثر بوده است.
یک سیستم توصیه مبتنی بر folksonomy برای مدیریت حجم زیادی از دادههای حسگر پیشنهاد شده است [ 15 ]. اگرچه این سیستم ها بسیار موثر هستند، اما این سیستم ها اغلب از مشکلات شروع سرد رنج می برند. یک مزیت بالقوه در ساختن سیستم های ترکیبی وجود دارد که از منابع دانش خارجی و حاشیه نویسی های تعریف شده توسط کاربر استفاده می کنند، اما این کار خارج از محدوده این مقاله است.
ما یک فرض کلیدی داریم که همه ارائه دهندگان داده هستی شناسی های قابل استفاده را ارائه نمی دهند و همچنین همه ارائه دهندگان داده از قراردادهای نامگذاری توصیه شده پیروی نمی کنند. بر اساس بسیاری از داده های موجود، این فرض تا جایی که می دانیم درست است. به جای تکیه بر ارائه دهندگان داده برای ارائه نشانه های معنایی، ما روشی پیشنهاد می کنیم که اطلاعات متنی را مستقیماً از سرویس های داده مبتنی بر استاندارد باز مصرف می کند و از آن داده ها، همراه با برخی پایگاه داده واژگانی همه منظوره، برای استنتاج معنایی بین لایه های داده استفاده می کند.
فرض کلیدی دیگر این است که “عنوان” لایه داده حسگر یک کلمه یا عبارت مختصر برای توصیف داده است. این فرض موجه است زیرا استفاده از استانداردهای باز این اطمینان را ایجاد می کند که می توانیم انتظار سازگاری خاصی با عنوان داشته باشیم، حتی اگر ارائه دهنده داده از یک ثبت نام استفاده نکند یا از آن اطلاعی نداشته باشد.
1.3. مشارکت ها
این مقاله به جامعه SDI کمک می کند. اولین و مهمترین سهم ما ارزیابی توابع رشته های نحوی و معنایی مختلف به منظور گروه بندی لایه های داده حسگر مشابه است. این کار اولیه را در مورد استفاده از یک رویکرد تطبیق رشته از پایین به بالا برای قابلیت همکاری داده ها برای جامعه فراهم می کند. پردازش رشتهها و تطبیق رشتهها را میتوان بهطور کلی در سایر جنبههای قابلیت همکاری دادهها در SDI اعمال کرد، و ارزیابی ما نشان میدهد که چگونه این تکنیکها برای مجموعه دادههای ما انجام میشوند.
سهم مهم دیگر این کار این است که پیشرفت فعلی SWE OGC، یعنی SOS را برجسته می کند. این مقاله SOS را به تفصیل مورد بحث قرار می دهد، از جمله داده های نمونه از ارائه دهندگان داده SOS در حال حاضر مستقر شده است. کار ما بر مشکل فعلی SOS در مورد نامگذاری ناسازگار متمرکز است و به عنوان رکوردی از پیشرفت فعلی استاندارد OGC عمل میکند. این احتمالاً می تواند برای کسانی که مایل به طراحی استانداردهای باز دیگر برای به اشتراک گذاری اطلاعات هستند، چه در داخل و چه خارج از جامعه GIS مفید باشد.
سهم عمده این کار مجموعه داده های منحصر به فردی است که ما برای خوشه بندی و طبقه بندی استفاده می کنیم. تا آنجا که ما می دانیم، هیچ تحقیق دیگری که سعی در خوشه بندی یا طبقه بندی لایه های داده داشته باشد، وجود ندارد. این شبیه به برخی از کارهای انجام شده در تگ های خوشه بندی است، با این تفاوت که این مجموعه داده اساساً با برچسب ها متفاوت است. این یک مورد منحصر به فرد برای کسانی که علاقه مند به بازیابی اطلاعات یا داده کاوی هستند، در مورد اینکه چگونه تکنیک ها ممکن است از مجموعه داده به مجموعه داده متفاوت باشد، ارائه می دهد.
2. کارهای مرتبط
ما در مورد کار مربوط به گروه بندی خودکار لایه های داده حسگر مشابه بحث می کنیم. ابتدا بازیابی اطلاعات را به عنوان یک مجموعه کلی از کار معرفی می کنیم. سپس بحث می کنیم که چگونه WordNet می تواند به عنوان یک منبع معنایی استفاده شود. در نهایت، ما به روشهای دیگر برای قابلیت همکاری مبتنی بر هستیشناسی در SDI نگاه میکنیم.
2.1. بازیابی اطلاعات
بازیابی اطلاعات (IR) یافتن مواد (معمولا اسناد) با ماهیت بدون ساختار (معمولاً متن) است که نیاز اطلاعاتی را از درون مجموعه های بزرگ (معمولاً در رایانه ها ذخیره می شود) برآورده می کند [ 16 ]. ما از یک رویکرد IR برای گروه بندی لایه های داده حسگر مشابه، با رفتار لایه های داده مانند اسناد استفاده می کنیم. شهاتا و همکاران پیاده سازی یک مدل کاوی مبتنی بر مفهوم برای خوشه بندی اسناد مبتنی بر متن [ 17 ]. ما رویکرد آنها را با اعمال پیش پردازش متن بر روی ویژگیهای مشاهده شده، استفاده از توابع رشتهای برای تعیین شباهتهای لایه داده، و سپس خوشهبندی لایههای داده در گروههای مشابه دنبال میکنیم.
برای تعیین رابطه بین دو لایه داده، ما به داده های متنی برای نشانه هایی در مورد نزدیک بودن دو لایه داده تکیه می کنیم. این نیاز به الگوریتم های تطبیق رشته های پیچیده تری نسبت به تطبیق دقیق رشته ها دارد. کوهن و همکاران [ 18] معیارهای فاصله رشته را برای کارهای تطبیق نام مقایسه کنید. نویسندگان سه دسته از معیارهای فاصله را ارزیابی کردند: توابع مانند فاصله ویرایش، توابع فاصله مبتنی بر رمز و توابع ترکیبی. توابع ویرایش فاصله شامل فاصله لونشتاین، تابع فاصله مونگر-الکان، متریک جارو و متریک جارو-وینکلر هستند. برای توابع مبتنی بر توکن، آنها شباهت جاکارد، شباهت کسینوس، فاصله جنسن-شانون، و همچنین روشی را که توسط Fellegi و Sunter ارائه شده است، در نظر می گیرند. به طور کلی، آنها بهترین عملکرد را از یک طرح ترکیبی با ترکیب وزنهای tf-idf با طرح فاصله رشتهای Jaro-Winkler پیدا کردند.
کروز و همکاران [ 19 ] روشی را برای همسویی هستیشناختی پیشنهاد میکنیم که به عنوان مبنای روششناسی خود استفاده میکنیم. آنها بر اساس تکنیکهای مختلف برای مقایسه متن در عناصر کلاس هستیشناختی، سیستم AgreementMake را برای همترازی هستیشناختی طراحی و توسعه میدهند. همترازی هستیشناختی بر اساس یافتن کلاسهای منطبق بین دو هستیشناسی است. آنها یک تطابق مبتنی بر رشته پارامتریک (PSM) پیشنهاد می کنند، که در آن عناصر فرعی عنصر کلاس هستی شناسی (نام محلی، برچسب، نظرات و غیره ) را می گیرند..)، آنها را عادی کنید، معیارهای رشته ای را برای ایجاد مقادیر شباهت اعمال کنید، که سپس در یک معیار تشابه نهایی وزن می شوند. تطبیقکنندههای رشته شامل فاصله ویرایش، جارو-وینکلر، و اندازهگیری مبتنی بر رشته فرعی است که توسط آنها ابداع شده است. آنها همچنین از یک تطبیق چند کلمه ای مبتنی بر برداری (VMM) استفاده می کنند که کلاس های هستی شناسی را نشانه گذاری می کند، بردارهای tf-idf را می سازد و شباهت کسینوس را اعمال می کند.
2.2. WordNet به عنوان یک منبع معنایی
به منظور تعریف توابع تطبیق رشته ها که از معنای کلمات بهره می برند، از WordNet [ 20 ] به عنوان یک منبع معنایی استفاده می کنیم. ما از کار ارائه شده در [ 21 ، 22 ] استفاده می کنیم، جایی که چندین رویکرد مختلف برای ایجاد شباهت بین کلمات با استفاده از WordNet استفاده می شود. هنگامی که مقادیر شباهت برای جفت کلمات ایجاد شد، سپس میتوانیم یک تابع عدم تشابه معنایی برای تعیین اینکه چگونه دو لایه داده مشابه بر اساس روابط کلمه هستند تعریف کنیم.
WordNet یک شبکه واژگانی از کلمات انگلیسی است. اسم ها، افعال، صفت ها و قیدها در مجموعه ای از مترادف ها یا synset ها سازماندهی می شوند. WordNet معمولاً برای ساختار گسترده اسامی استفاده می شود. ستون فقرات شبکه اسمی سلسله مراتب فرعی است که از روابط والد-فرزند تشکیل شده است. سینست ها با روابط مختلفی از جمله هیپونیمی (is-a)، ابرنام معکوس، شش رابطه مرویمی (بخشی از) و متضاد (مکمل-از) به هم متصل می شوند. برای استفاده از WordNet، ما یک عنصر ریشه جهانی تعریف می کنیم به طوری که تمام synset ها در یک نمودار قرار می گیرند.
بسیاری از رویکردهای تشابه کلمه نام رسمی ندارند، و بنابراین ما قرارداد نامگذاری را از [ 22 ] تطبیق می دهیم. جدول 2 خلاصه ای از اختصارات و رویکردهای مورد استفاده در این مقاله است. نویسندگان [ 22 ] یک ابزار رایگان برای محاسبه شباهت های کلمه ارائه می دهند که توسط گروه ما برای محاسبه همه شباهت های جفت کلمه استفاده می شود. همچنین، ما الگوریتم اصلی تشابه جفت کلمه خود را با نام kno معرفی میکنیم . همه این رویکردها بر اساس رویکرد کلی آنها به طور جداگانه مورد بحث قرار می گیرند.
سه رویکرد مبتنی بر محتوای اطلاعاتی، res [ 23 ]، lin [ 24 ] و jcn [ 25 ] وجود دارد. این رویکردها از یک پیکره برای تولید فرکانس یک کلمه خاص استفاده می کنند و آن اطلاعات را با طول بین کمترین والد مشترک دو مفهوم ترکیب می کنند. ایده اصلی این است که وقتی فرد از طریق یک طبقه بندی به سمت بالا حرکت می کند، احتمال مواجهه با یک مفهوم افزایش می یابد. بنابراین محتوای اطلاعاتی مفاهیم عمومی سطح بالا بسیار پایین است، زیرا آنها با بسیاری از مفاهیم دیگر مرتبط هستند.
دو رویکرد بر اساس طول مسیر بین مفاهیم وجود دارد، lch [ 21 ] و wup [ 21 ]. این دو معیار بر اساس طول مسیر بین دو مفهوم هستند.
سه رویکرد بر اساس معیارهای مربوط به کلمه وجود دارد، hso [ 26 ]، lesk [ 27 ] و برداری . رویکرد هیرست و سنت اونگ یا hso بر اساس طول مسیر و همچنین مسیرهایی است که بر اساس ماهیت رابطه بین دو مفهوم جهت دارند. لسک یک معیار ارتباط معنایی است که بر اساس تعداد کلمات مشترک در واژگان آنها است [ 27 ]. در اینجا gloss به عنوان یک کلمه جایگزین برای توصیف یا تعریف یک کلمه تعریف می شود. بردار _اندازه گیری یک ماتریس همزمانی را از پیکره ای متشکل از براق های WordNet ایجاد می کند و هر مفهوم را به عنوان یک بردار براق تعریف می کند. ارتباط بین مفاهیم با محاسبه کسینوس بین یک جفت بردار براق پیدا می شود.
رویکرد kno با یک استراتژی ساده ابداع شد. یک شباهت جفت کلمه یک به روابط والد-فرزند و صفر به همه جفتهای کلمه دیگر اختصاص میدهد. این مفید است زیرا به تعریف روابط واضح و مفید کمک می کند و همه روابط دیگر بین کلمات را نادیده می گیرد. این یک نمره شباهت جفت کلمه بسیار ساده شده است تا به ارزیابی اثربخشی استراتژیهای دیگر کمک کند.
WordNet یک پایگاه داده گسترده از کلمات انگلیسی است، اما در تحقیقات ما نشانه هایی وجود دارد که WordNet آنها را نمی شناسد. اینها اغلب اختصارات، کلمات اختصاری یا عامیانه هستند (به عنوان مثال، “tempc” به عنوان مخفف “دمای سانتیگراد”). اگر نشانه ای طبق WordNet به عنوان یک کلمه شناسایی نشود، به هر جفت کلمه ای که حاوی این نشانه ناشناخته باشد، نمره شباهت صفر تعلق می گیرد.
2.3. SDI های مبتنی بر هستی شناسی
ما به سایر محققانی که از هستی شناسی ها در SDI خود استفاده می کنند نگاه می کنیم، زیرا این روش ترجیحی برای دستیابی به قابلیت همکاری معنایی بوده است. ما مرتبط ترین مقالات را با سیستم های نزدیک به کارمان انتخاب می کنیم.
هنسون و همکاران سیستمی برای افزودن هوش به داده های حسگر طراحی کرد [ 28 ]. آنها از نظر معنایی SOS را با افزودن حاشیهنویسی معنایی به دادههای حسگر و استفاده از مدلهای هستیشناسی برای استدلال بر مشاهدات، فعال میکنند. معماری سیستم آنها دارای یک بخش جلویی SOS است که به موتور جستجوی SPARQL متصل است و به پایگاه دانش آنها مرتبط است. برای اینکه سیستم خود را تا حد امکان قابل استفاده و عملی کنیم، روی رویکردی از پایین به بالا تمرکز می کنیم که نیازی به هستی شناسی های بزرگ و پیچیده از متخصصان حوزه ندارد. ما فقط از معناشناسی کلمات برای ارائه گروه هایی از لایه های داده مرتبط استفاده می کنیم.
یانوویچ و همکاران [ 29] معناشناسی شباهت را در زمینه بازیابی اطلاعات جغرافیایی مورد بحث قرار می دهد. چارچوب آنها را می توان برای مشخص کردن معناشناسی شباهت استفاده کرد. آنها استدلال می کنند که شباهت معنایی را فقط می توان بین مفاهیم محاسبه کرد که اغلب از یک هستی شناسی به دست می آیند. در این زمینه، یک رویکرد از پایین به بالا یک معیار تشابه نحوی پیچیده خواهد بود. با این حال، از آنجایی که هستی شناسی ها از یک سرویس SOS در دسترس نیستند، استفاده از هستی شناسی های غنی از نظر معنایی برای سنجش تشابه معنایی غیرممکن است. روش پیشنهادی در این مقاله شامل نمرات شباهت جفت کلمه مشتق شده از WordNet است که روابط بین مفاهیم را مشخص می کند. استفاده از نمره شباهت جفت کلمه در یک الگوریتم مشکل قابلیت همکاری معنایی را در زمینه گروه بندی ویژگی های مشاهده شده حل می کند.
لوتز و همکاران [ 30 ] درباره غلبه بر ناهمگونی معنایی در SDI بحث می کنند. سیستم آنها مبتنی بر یک رویکرد هستی شناسی ترکیبی است، که در آن هر سیستم اطلاعاتی هستی شناسی کاربردی خاص خود را دارد، و هر یک از این هستی شناسی ها بر اساس یک واژگان مشترک، یک هستی شناسی سطح بالا است. برای اتصال منابع داده به هستی شناسی های سطح برنامه، از نگاشت ثبت استفاده می شود. هستیشناسی برنامهها و نگاشتهای ثبت به آسانی تولید نمیشوند و مطمئناً توسط همه ارائهدهندگان داده ارائه نمیشوند. اگرچه یک چارچوب محکم است، اما تا زمانی که ارائه دهندگان خدمات استفاده از هستی شناسی ها را ادغام کنند، این سیستم از بسیاری از منابع داده واقعی که ما می خواهیم به آنها متصل شویم، جدا است.
ما از هیچ هستی شناسی سطح بالا دیگری در روش شناسی خود استفاده نمی کنیم. ما بر یک رویکرد قوی از پایین به بالا تنها با استفاده از شباهتهای جفت کلمه تأکید میکنیم، و در نتیجه رویکرد ما بسیار انعطافپذیر است و میتوان آن را در زمینههای مختلف SDI دوباره به کار برد. با عضویت در یک هستیشناسی، باید نقشهبرداری یا ترجمههایی را از همه منابع داده خارجی به هستیشناسی خود تعریف کنیم، که حل آن با یک راهحل کاملا خودکار مشکلی است.
3. روش شناسی
برای این مقاله، ما یک رویکرد از پایین به بالا برای گروهبندی خودکار لایههای داده حسگر مشابه را توصیف میکنیم. ابتدا، دادههای مورد استفاده برای نمایش لایههای داده را مورد بحث قرار میدهیم. در مرحله بعد، توابع عدم تشابه را برای تولید مقادیر عددی از ناهمسانی دو لایه داده توصیف می کنیم. سپس از توابع عدم تشابه برای انجام هر دو نگاشت لایه ویژگی و خوشه بندی استفاده می کنیم.
3.1. داده ها
ابتدا باید تعریف کنیم که لایه داده در زمینه تحقیق ما چیست. تمام دادههای حسگر که در تحقیقات خود استفاده میکنیم از طریق استاندارد SOS دانلود میشوند. استاندارد SOS باید برای توصیف تعریف لایه داده حسگر توضیح داده شود.
SOS از طریق معماری سرویس گیرنده-سرور از طریق HTTP اجرا می شود. محتوا از طریق اسناد XML مذاکره می شود. برخی از اصطلاحات مهم از استاندارد SOS در سراسر این مقاله استفاده خواهد شد و در اینجا تعریف شده است.
- پیشنهاد مشاهده – گروه بندی منطقی از منابع داده.
- پدیده – یک رویداد طبیعی در دنیای واقعی که می تواند اندازه گیری شود (به عنوان مثال ، سرعت باد، دمای هوا).
- ویژگی مشاهده شده – اصطلاح دیگری برای پدیده.
- رویه – رویه یک اصطلاح دیگر برای حسگر است، با این تفاوت که رویه برای شامل هر فرآیندی که یک مقدار مشاهده ای ایجاد می کند، کلی تر است.
- ویژگی مورد علاقه (FOI) – یک شی مرتبط با یک مشاهده، مانند دریاچه ای که در آن اندازه گیری دما انجام شده است.
رابطه SOS در شکل 1 ارائه شده است . یک SOS یک یا چند پیشنهاد مشاهده خواهد داشت. هر پیشنهاد مشاهده فهرستی از یک یا چند ویژگی مشاهده شده، اطلاعات اطلاعاتی و رویه ها را خواهد داشت. گروه تحقیقاتی ما یک لایه ویژگی (PL) را به عنوان یک لایه داده حسگر استخراج شده از یک SOS تعریف کرده است. اصطلاحات لایه داده، لایه داده حسگر و PL به جای یکدیگر در بقیه این مقاله استفاده خواهند شد. یک PL یک لایه داده منحصر به فرد است که توسط یک URL سرویس SOS، یک پیشنهاد مشاهده و یک ویژگی مشاهده شده تعریف شده است [ 11 ]. از آنجایی که یک SOS، یا حتی یک پیشنهاد مشاهده منفرد در یک SOS، ممکن است منابع داده مختلفی را ارائه دهد، یک PL تنها لایه اتمی داده موجود از یک SOS است.
برای این مقاله، ما فقط از ویژگی مشاهده شده یک PL به منظور تعیین شباهت استفاده خواهیم کرد. این به این دلیل است که شباهت بر اساس شباهت پدیده دو لایه داده است و ویژگی مشاهده شده سازگارترین، مفیدترین و مستقیم ترین قطعه اطلاعات برای تعیین اینکه یک حسگر چه پدیده دنیای واقعی را اندازه گیری می کند است.
برای این مقاله، داده ها را از 27 SOS مختلف استخراج خواهیم کرد. خدمات SOS با استفاده از یک سیستم کشف منابع Peer-to-Peer (P2P) کشف شد [ 31 ]. 212 PL در مجموعه داده ما وجود دارد. نمونه کوچکی از مجموعه داده در جدول 3 نشان داده شده است . لازم به ذکر است که بسیاری از خدمات SOS موجود صرفاً به دلیل توسعه تدریجی و استقرار استاندارد SOS در مرحله آزمایش هستند. همچنین، بسیاری از سرویسهای SOS فعلی بهصورت آنلاین توسط آزمایشگاه GeoSensorweb، گروه تحقیقاتی خود ما، اجرا میشوند. این ممکن است باعث سوگیری در منبع داده شود که ممکن است بر ارزیابی تأثیر بگذارد. با این حال، روش ارائه شده تحت تأثیر این قرار نمیگیرد و برای دادههای جمعآوریشده توسط سرویسهای SOS آینده کاملاً معتبر است. لیست کامل خدمات SOS در جدول 4 ارائه شده است.
3.2. پردازش متن
پردازش متن یک گام اساسی در روش شناسی ما است. ما دو نوع پردازش متن را در نظر می گیریم، عادی سازی و توکن سازی . عادی سازی فرآیندی است که رشته ها را متعارف می کند به طوری که تفاوت های سطحی بین رشته ها حذف می شود و نشانه سازی فرآیند تبدیل متن به نشانه های متمایز است. برای عادی سازی، پیشوند OGC URI را حذف می کنیم، به طوری که فقط متن ویژگی مشاهده شده باقی می ماند. ما همچنین همه نویسههای بزرگ را به نویسههای کوچک تبدیل میکنیم و فضای خالی و سایر کاراکترهای جداکننده مانند زیرخط را حذف میکنیم.
توکن سازی به عنوان مرحله دوم پس از عادی سازی انجام می شود. همانطور که در بالا توضیح داده شد، ابتدا خواص مشاهده شده را عادی می کنیم. در مرحله بعد، از WordNet به عنوان یک فرهنگ لغت استفاده می کنیم و ویژگی مشاهده شده را به کلمات متمایز تقسیم می کنیم. در نتیجه، فهرستی از رشتهها باقی میماند که هر رشته یک کلمه مجزا است. به عنوان مثال، ویژگی مشاهده شده “urn:ogc:def:property:geocens:rocky_view_groundwater:groundwater” را در نظر بگیرید. پس از عادی سازی، ما با “آب های زیرزمینی” باقی می مانیم و پس از توکن سازی، فهرستی از دو رشته (“زمین”، “آب”) باقی می ماند. یک تابع رشته مبتنی بر ویرایش فقط از یک رشته استفاده می کند که از نرمال سازی تولید می شود. یک تابع رشته مبتنی بر مجموعه از لیست نشانه ها به عنوان ورودی استفاده می کند که از توکن سازی تولید می شود.
3.3. توابع عدم تشابه
شباهت بین دو شی یک اندازه گیری عددی از درجه یکسانی دو جسم است [ 32 ]. با این حال، ما از مفهوم عدم تشابه برای این مقاله استفاده خواهیم کرد، که معیاری عددی برای درجه تفاوت این دو شی است. ما از اصطلاح عدم تشابه در فاصله استفاده می کنیم زیرا همه این توابع نابرابری مثلث را برآورده نمی کنند، که معتقدیم برای استفاده مناسب از عبارت فاصله باید ارضا شود.
ما برای این کار از سه تابع عدم تشابه تعریف و استفاده می کنیم، یک تابع عدم تشابه Length Adjusted Levenshtein، یک تابع عدم تشابه مبتنی بر ژاکارد و یک تابع عدم تشابه معنایی. تابع عدم تشابه Length Adjusted Levenshtein یک تابع مبتنی بر ویرایش است، در حالی که دو مورد آخر توابع مبتنی بر مجموعه هستند.
3.3.1. عدم تشابه Levenshtein تنظیم شده با طول
عدم تشابه Length Adjusted Levenshtein (LALD) اصلاحی از فاصله Levenshtein [ 33 ] است. برای (1) کاهش تأثیر طول رشته بر عدم تشابه بین رشته ها و (2) عادی سازی تمام مقادیر عدم تشابه بین 0 و 1 از آن در فاصله ویرایش اولیه استفاده می شود.
فاصله لونشتاین تعداد اضافهها، تفریقها و تعویضهای مورد نیاز برای عبور از یک رشته به رشته دیگر را میشمارد. اصلاح ما این است که طول رشته تقسیم بر حداکثر طول رشته بین هر دو کلمه است.
3.3.2. عدم شباهت ژاکارد
ضریب جاکارد اندازه گیری شباهت بین دو شی داده است. با توجه به دو شی، ضریب ژاکارد تعداد ویژگی های باینری مشترک تقسیم بر تعداد کل ویژگی های باینری هر دو شی داده است. بنابراین، این تابع به ورودی آرایه ای از نشانه ها نیاز دارد که در آن هر نشانه یک رشته است. برای استفاده از این تابع به عنوان یک تابع عدم تشابه، به سادگی یکی را با ضریب جاکارد تفاوت می کنیم.
m 11 تعداد کلماتی است که در هر دو رشته وجود دارد، m 10 تعداد کلماتی است که فقط در رشته 1 وجود دارند و m 01 تعداد کلماتی است که فقط در رشته 2 وجود دارند. ما از جاکارد روی کسینوس به عنوان عدم تشابه استفاده می کنیم. زیرا کلمات در خواص مشاهده شده تکرار نمی شوند. بنابراین ما از یک معیار بولی برای عدم تشابه استفاده می کنیم.
3.3.3. تابع عدم تشابه معنایی
این تابع عدم تشابه معنایی، با استفاده از رویکرد عدم تشابه مبتنی بر مجموعه، بین نشانهها اعمال خواهد شد. شباهت های جفت کلمه ایجاد شده از WordNet، که در بخش قبل توضیح داده شد، در این تابع عدم تشابه استفاده می شود. ما تابع عدم تشابه خود را بر اساس معیار عدم تشابه جاکارد، ارائه شده در بالا، قرار می دهیم.
مخرج شامل تعداد کل نشانه های متمایز در هر دو لیست نشانه در جدول 5 است. برای مثال، اگر دو آرایه از نشانههای A داشته باشیم: [“X”، “Y”، “Z”] و B: [“X”، “W”، “V”]، میگوییم 5 نشانه مجزا وجود دارد. ، و یک نشانه تطبیق واحد، به طوری که عدم تشابه خواهد بود دj a c c a r d= 1 –15= 0.8د�آججآ�د=1–15=0.8. اما اجازه دهید فرض کنیم شباهت های جفت کلمه ای در دسترس ماست. ما از این اطلاعات برای ترکیب توکن ها به جفت توکن های مشابه استفاده می کنیم. برای ادامه مثال برای عدم تشابه معنایی، می بینیم که “X” از A همان نشانه “X” از B است. اکنون با چهار نشانه متمایز “Y”، “Z”، “W” باقی مانده ایم. و “V”. ماتریسی از شباهتهای جفت کلمه ایجاد میکنیم و آن را از شبیهترین به کممشابهترین رتبهبندی میکنیم.
می بینیم که Y و W بیشترین شباهت را دارند. ما فرض می کنیم که این دو توکن به هم مرتبط هستند و این دو نشانه یک جفت توکن واحد، “YW” را تشکیل می دهند. دو نشانه دیگر، “Z” و “V” نیز مرتبط فرض می شوند و یک جفت نشانه، “ZV” را تشکیل می دهند. تعداد کل توکن های متمایز اکنون 3 است و آنها [“X”، “YW”، “ZV”] هستند.
با این حال، A حاوی “YW” نیست، بلکه فقط حاوی “Y” است که تنها 0.8 از جفت “YW” است. ما تابع عدم تشابه خود را به صورت بودن تغییر می دهیم
که در آن m 11 مجموع شباهت های جفت نشانه است. به نظر می رسد m 11 = 1.0 + 0.8 + 0.1 = 0.9 باشد. بنابراین، عدم تشابه معنایی کلی است دs e m a n t i c= 1 –1.93 + 3 − 1.9= 0.54دسهمترآ�تیمنج=1–1.93+3–1.9=0.54.
3.4. مثالی از محاسبه عدم تشابه
برای کمک به توضیح روش، دو PL معرفی شده و عدم تشابه بین آنها با استفاده از توابع عدم تشابه مختلف محاسبه میشود. جدول 6 دو PL مختلف از دو سرویس SOS مختلف، از جمله نتیجه عادی سازی و توکن سازی را نشان می دهد. جدول 7 مقادیر شباهت جفت کلمه برای توکن ها و همچنین تمام مقادیر عدم تشابه بین دو PL را نشان می دهد.
3.5. نگاشت لایه خواص
اولین بخش از روش ما استفاده از توابع رشته برای تعریف نقشه ها بین PL ها است. نقشه یک پیوند نمادین بین دو PL است و وجود نقشه بین دو PL نشان می دهد که آن PL ها مشابه هستند. برای اهداف ما، دو لایه داده مشابه هستند اگر خصوصیات مشاهده شده آنها رابطه مستقیم داشته باشند. در نهایت، اگر دانشمندی آن دو لایه داده را منبع داده یکسانی در نظر بگیرد، میخواهیم PLها را با هم گروه کنیم.
مجموعه ای از نقشه ها در مجموع به عنوان نقشه برداری شناخته می شوند. بنابراین، تعریف نگاشت بین PL ها مهم است. یک PL نمی تواند برای خودش نقشه برداری کند. یک نقشه دو طرفه است. ارزشی ندارد، یا هست یا نیست.
متدولوژی برای تعریف نگاشت لایه خاصیت به دو چیز نیاز دارد، یک تابع عدم تشابه و یک آستانه. فرآیند بسیار سرراست است. هر PL با هر PL دیگری که خودش نیست مقایسه می شود. اگر مقدار تابع عدم تشابه کمتر از مقدار آستانه باشد، نقشه ای بین دو PL تعریف می شود. در غیر این صورت نقشه ای بین دو PL تعریف نشده است.
3.6. خوشه بندی
خوشهبندی برای گروهبندی خودکار PLها به خوشههای مجزای غیر همپوشانی انجام میشود. ورودی برای خوشه بندی یک الگوریتم خوشه بندی، یک تابع عدم تشابه و یک آستانه است. هر الگوریتم خوشه بندی از آستانه و تابع عدم تشابه استفاده می کند، البته به روش های مختلف. بنابراین، روش واقعی خوشه بندی به الگوریتم خوشه بندی بستگی دارد.
برای این روش، ما سه الگوریتم خوشهبندی مختلف، K-medoids، DBSCAN و HAC را پیادهسازی کردیم. K-medoids یک تغییر شناخته شده از الگوریتم خوشه بندی K-means است. DBSCAN یک الگوریتم خوشهبندی مبتنی بر چگالی است که اساساً نوع متفاوتی از الگوریتم خوشهبندی است. در نهایت، HAC یک تکنیک استاندارد خوشهبندی اسناد در نظر گرفته میشود. شهاتا و همکاران [ 17] از HAC، خوشهبندی تک گذر و k-نزدیکترین همسایه (k-NN) به عنوان تکنیکهای خوشهبندی در تحقیقات خود برای خوشهبندی متن استفاده کردند. انتخاب الگوریتم خوشه بندی ما بر اساس الگوریتم های اساسا متفاوت است. از آنجایی که این یک نوع داده جدید است که در خوشه بندی استفاده می شود، ما با انواع الگوریتم ها آزمایش می کنیم. ما این سه تکنیک مختلف خوشهبندی را ارزیابی میکنیم تا ببینیم کدام الگوریتم با مجموعه دادههای ما بهترین کار را دارد. هر الگوریتم خوشه بندی به تفصیل در این بخش مورد بحث قرار گرفته است.
K-medoids، همچنین به عنوان Partitioning Around Medoids (PAM) شناخته می شود، یک الگوریتم خوشه بندی مشابه با K-means [ 34 ] است. K-means یک الگوریتم خوشه بندی متداول است. این شامل انتخاب نقاط شروع به عنوان دانه، و مرتبط کردن هر نقطه داده یا شی به هر دانه، تشکیل خوشه ها است. مرکز هر خوشه محاسبه میشود و هر شیء دادهای بر اساس مرکزهای جدید مجدداً به یک خوشه اختصاص مییابد. این کار به صورت بازگشتی انجام می شود تا زمانی که خوشه ها دیگر تغییر نکنند یا تغییر در بین تکرارها ناچیز باشد.
با این حال، با نمایشهای مبتنی بر رشته از اشیاء داده، محاسبه مرکزهای خوشهها غیرممکن است. این به راحتی با داده های عددی امکان پذیر است، اما با داده های اسمی غیرممکن است. استفاده از K-means با ورودی های نشانه گذاری شده امکان پذیر است، اما برای توابع عدم تشابه مبتنی بر ویرایش، این کار نمی کند. در عوض، از مفهوم مدوید استفاده می کنیم. یک medoid به سادگی یک شی داده در یک خوشه است که نزدیک به مرکز است و به جای یک مرکز استفاده می شود.
خوشه بندی فضایی مبتنی بر چگالی برنامه های کاربردی با نویز (DBSCAN) یک الگوریتم خوشه بندی مبتنی بر چگالی است [ 35 ]]. DBSCAN اساساً با K-medoids متفاوت است زیرا می تواند خوشه های هندسی نامنظم یا غیرعادی را ثبت کند. دو پارامتر ورودی عبارتند از حداقل تعداد نقاط و مقداری که شعاع را مشخص می کند که اغلب به آن اپسیلون می گویند. DBSCAN با عبور از تمام اشیاء داده کار می کند، و اگر یک شی داده ای داده شده به اندازه کافی اشیاء داده دیگر در همسایگی خود داشته باشد که توسط پارامترهای ورودی تعریف شده است، آن اشیاء داده یک خوشه را تشکیل می دهند. در مرحله بعد، خوشه با پیوستن به اشیاء داده نزدیک گسترش می یابد. این الگوریتم تمام اشیاء داده ای را که به یک خوشه تعلق ندارند به عنوان نویز در نظر می گیرد. با این حال، از آنجایی که همه PL ها لایه های داده معتبر هستند، نمی توان آنها را نویز در نظر گرفت، بنابراین پارامتر ورودی برای حداقل تعداد اشیاء داده متعلق به یک خوشه یک است.
خوشهبندی سلسله مراتبی انباشتهای (HAC) یک الگوریتم خوشهبندی [ 32 ] است که با تقسیم مکرر یک خوشه بزرگ یا ترکیب خوشههای منفرد، با شروع هر شی داده به عنوان یک خوشه، کار میکند. دومی، یک رویکرد از پایین به بالا، اجرا شد. این به این معنی است که برای هر شی داده ای یک خوشه ایجاد می شود و خوشه ها یکی یکی ادغام می شوند. برای تعیین اینکه کدام دو خوشه باید ادغام شوند، به یک متریک فاصله درون خوشه ای نیاز است. برای این پروژه از مفهوم پیوند کامل استفاده کردیم.
پیوند کامل دو خوشه به عنوان حداکثر فاصله تمام فاصله های شی ممکن از یکی از اشیاء در یک خوشه به همه اشیاء در خوشه دیگر تعریف می شود.
کمترین پیوند کامل دو خوشه برای همه جفتهای خوشه محاسبه میشود. اگر مقدار پیوند کامل کمتر از مقدار آستانه بین دو خوشه باشد، آنگاه دو خوشه ادغام شده و فرآیند تکرار می شود.
4. ارزیابی و نتایج
این فصل روشهای مختلفی را که در روششناسی گروهبندی خودکار لایههای ویژگی (PL) مورد بحث قرار گرفتهاند، ارزیابی میکند. ابتدا معیارهای ارزیابی مورد استفاده برای ارزیابی معرفی می شوند. در مرحله بعد، مفهوم آزمایش داده ها و نحوه جمع آوری آنها را معرفی می کنیم. سه بخش آخر این فصل به ترتیب ارزیابی توابع عدم تشابه، خوشهبندی و تطبیق است.
4.1. داده های آزمایشی
هدف این روش شناسایی گروههایی از لایههای داده حسگر مرتبط، بر اساس ویژگیهای مشاهدهشده آنهاست. برای آزمایش اثربخشی روش، گروه های PL باید تجزیه و تحلیل شوند تا ببینیم آیا PL ها در همان گروه واقعا مشابه هستند یا خیر. برای انجام این ارزیابی، مقداری از شباهت “واقعی” بین PL ها مورد نیاز است. برای انجام این کار، از چهار اپراتور انسانی خواسته شد تا به روابط بین PL ها امتیاز دهند. هر فرد فهرستی از جفتهای PL داشت، بهعنوان مثال، «بارش» و «آبهای زیرزمینی». سپس، از آنها خواسته شد که برای آن رابطه نمره بدهند و آن را به عنوان مشابه یا غیر مشابه رتبه بندی کنند.
روابط رتبه بندی شده انسانی بین PL ها را می توان با روابط محاسبه شده ماشینی بین PL ها مقایسه کرد. روابط رتبهبندی شده انسانی برای بررسی این که چه روابطی توسط روششناسی ثبت شدهاند و چه روابطی نادیده گرفته شدهاند یا به اشتباه طبقهبندی شدهاند استفاده میشوند.
از آنجایی که 212 PL وجود دارد، این بدان معناست که 22366 رابطه PL-PL متمایز وجود دارد. اینکه فردی هر رابطه را رتبه بندی کند بسیار زمان بر است. بنابراین، ما 8 PL متمایز را انتخاب می کنیم و روابط بین هر PL هدف و هر PL دیگر را طبقه بندی می کنیم. این PL ها در جدول 8 نشان داده شده است. به عنوان مثال، یک PL از جدول 8 ، مانند “urn:ogc:def:property:noaa:ndbc:نقطه شبنم” در برابر هر PL دیگر رتبه بندی می شود و 211 رابطه جفت PL-PL را ارائه می دهد. از هر اپراتور انسانی خواسته شد تا کار مشابهی را بر روی مجموعه داده های یکسان انجام دهد و از میانگین شباهت در ارزیابی استفاده شد. این افزونگی به ما اجازه میدهد تا تأثیر تفاوتها در دادههای آزمایشی را نفی کنیم.
4.2. ارزیابی نگاشت لایه خواص
ارزیابی نقشه برداری PL-PL مورد بحث قرار گرفته است. هر جفت PL از بخش داده های آزمایشی بر اساس روش ما آزمایش می شود. برای اینکه سیستم یک جفت PL را به عنوان مشابه یا غیر مشابه طبقه بندی کند، به دو ورودی، یک تابع عدم تشابه و یک آستانه نیاز دارد. اولین ورودی یکی از توابع عدم تشابه است که در بخش قبل توضیح داده شد. با استفاده از خصوصیات مشاهده شده دو PL به عنوان ورودی، مقداری از صفر تا یک برای یک جفت PL ایجاد می کند. بعد، یک مقدار آستانه مورد نیاز است. این مقدار قطع است. هر چیزی که زیر این مقدار باشد به عنوان مشابه طبقه بندی می شود و هر چیزی در بالا به عنوان غیر مشابه طبقه بندی می شود.
به عنوان یک مثال ساده، یک جفت PL با ویژگی های مشاهده شده به عنوان “سرعت باد” و “وزش باد” را در نظر بگیرید. توجه داشته باشید که این ویژگی های مشاهده شده نرمال شده اند و ورودی برای یک تابع مبتنی بر ویرایش هستند. ما LALD را به عنوان تابع عدم تشابه انتخاب می کنیم و عدم تشابه بین آنها را محاسبه می کنیم که 0.56 است. ما به یک آستانه نیاز داریم تا تصمیم بگیریم که آیا 0.56 باید به عنوان مشابه طبقه بندی شود یا خیر. اگر آستانه 0.60 را انتخاب کنیم، این جفت PL به عنوان مشابه طبقه بندی می شود.
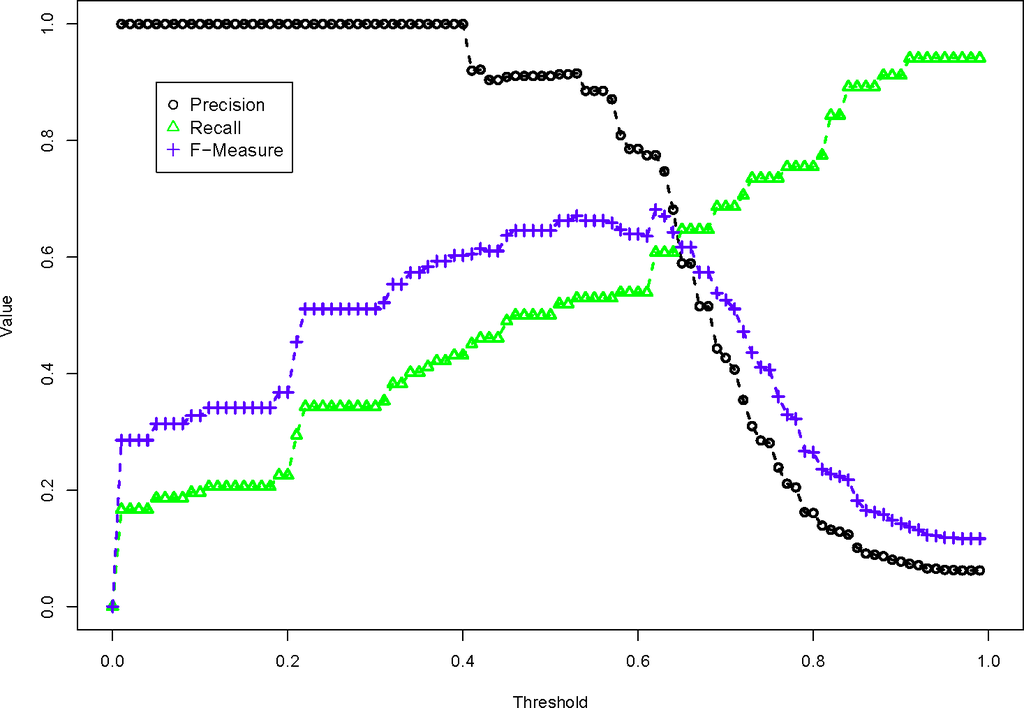
آستانه یک عدد کاملا دلخواه است و انتخاب آستانه مناسب کاملاً به تابع عدم تشابه استفاده شده بستگی دارد. جفتهای PL با طیف وسیعی از مقادیر آستانه ارزیابی میشوند تا به یافتن آستانه ایدهآل کمک کنند که مثبتهای کاذب و منفیهای کاذب را به حداقل برساند. شکل 2 را در نظر بگیرید، که نشان می دهد که چگونه تابع عدم تشابه LALD در مقادیر آستانه متفاوت عمل می کند. در این شکل، هر مقدار آستانه متمایز، یک نگاشت PL منحصر به فرد است. یک مقدار آستانه پایین فقط بین PLهایی که مقادیر ناهمسانی بسیار پایینی دارند، یا برای الگوریتم LALD، رشتههایی که بسیار شبیه هستند، نگاشت میشود. به همین دلیل است که دقت بسیار بالا است، تنها ویژگی های مشاهده شده با همین نام نقشه برداری می شوند. با این حال، فراخوانی با آستانه پایین بسیار کم است، زیرا ویژگی های مشابه مشاهده شده با تفاوت های جزئی کاراکتر به عنوان غیر مشابه طبقه بندی می شوند. هنگامی که آستانه بالا است، فیلتر به اندازه کافی محدود نمی شود و نقشه هایی بین PL ایجاد می شود که مطلقاً هیچ ارتباطی ندارند. این منجر به دقت بسیار پایین، اما فراخوانی بالاتر می شود.
برای تفسیر این ارقام، به آستانه ای که بالاترین F-Measure را تولید می کند نگاه می کنیم. از آنجایی که F-Measure تعادلی از دقت و یادآوری است، به طور کلی با افزایش آستانه شاهد افزایش و کاهش هستیم. با توقف در بالاترین F-Measure، آستانه ایده آل را برای آن تابع عدم تشابه انتخاب کرده ایم.
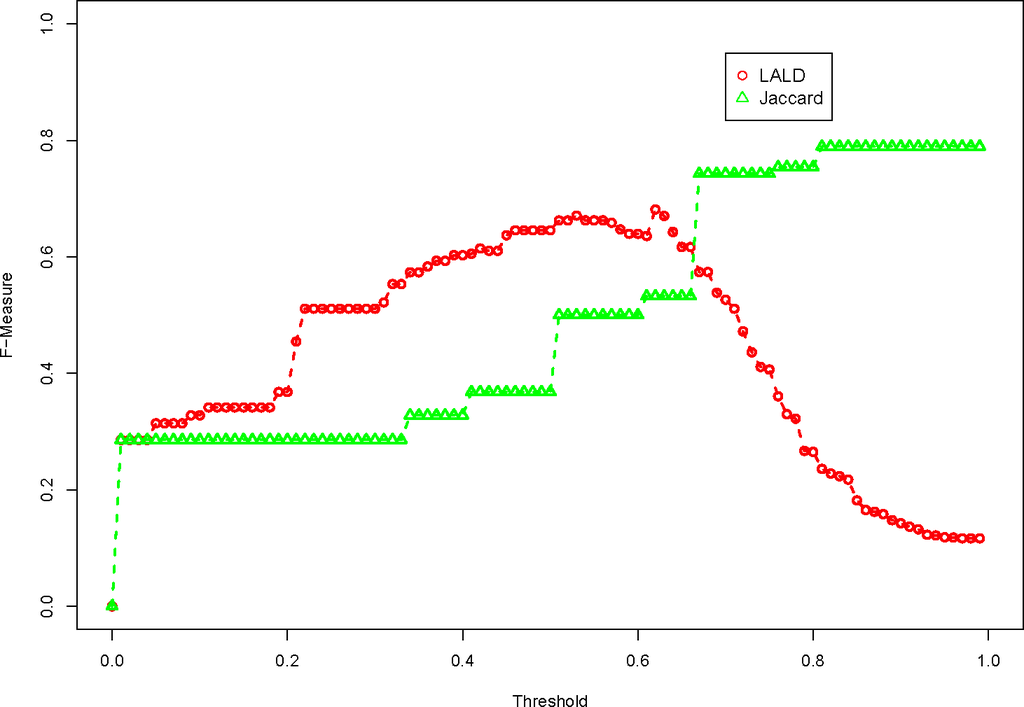
شکل 3 نشان می دهد که چگونه توابع عدم تشابه LALD و Jaccard با یکدیگر مقایسه می شوند. جالب است بدانید که تابع عدم تشابه جاکارد با حداکثر مقدار آستانه بهترین عملکرد را دارد. به این دلیل که اگر دو ویژگی مشاهده شده هیچ نشانه مطابقی نداشته باشند، تفاوت آنها 1.0 است. از آنجایی که آستانه هرگز از 1.0 تجاوز نمی کند، همه ویژگی های مشاهده شده بدون نشانه های منطبق هرگز مطابقت نخواهند داشت. توجه داشته باشید که تابع عدم تشابه جاکارد گام به گام است، به این دلیل که عدم تشابه بر اساس تعداد توکنهای منطبق و تعداد توکنهای غیر منطبق است. از آنجایی که هر ویژگی مشاهده شده فقط حاوی حداکثر چندین نشانه است، تنها تعداد کمی از مقادیر ممکن وجود دارد که تابع آنها را برمی گرداند.
عدم تشابه جاکارد بسیار بهتر از LALD عمل می کند، بنابراین ما از آن به عنوان مبنایی برای ارزیابی تابع عدم تشابه معنایی استفاده خواهیم کرد. ما نمرات مختلف شباهت جفت کلمه ایجاد شده از WordNet را ارزیابی خواهیم کرد.
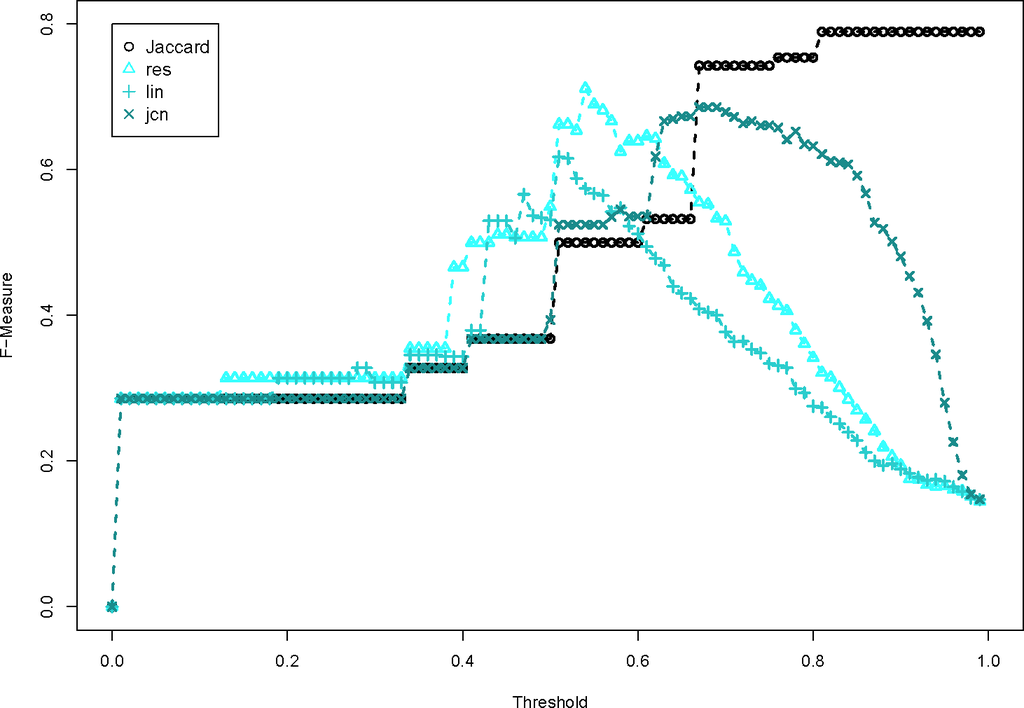
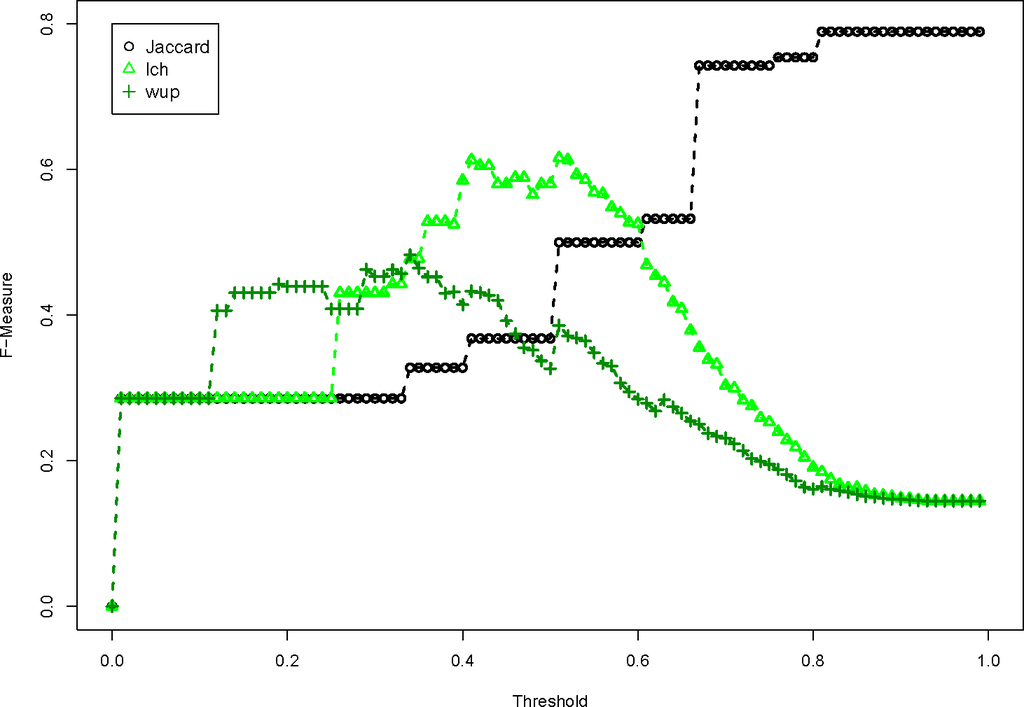
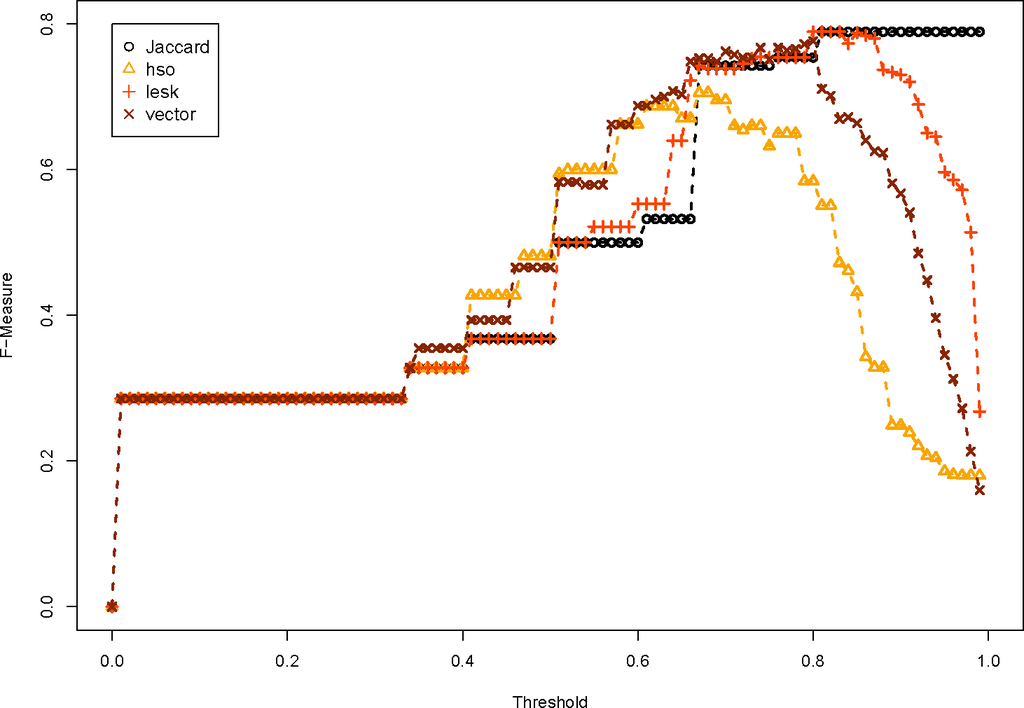
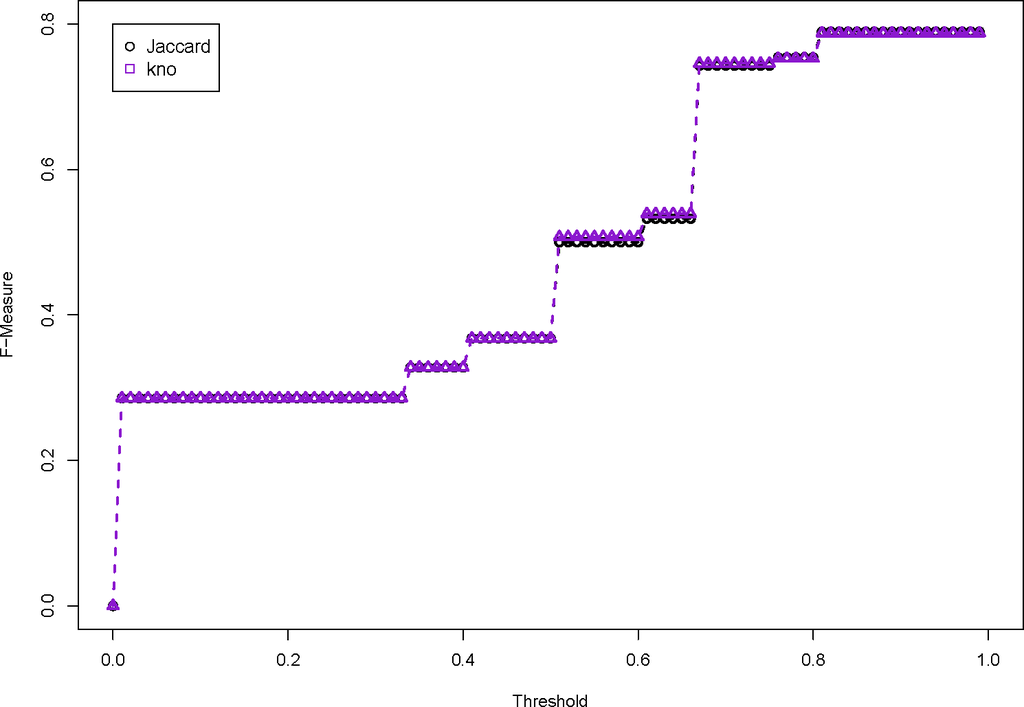
ما به شکل های 4-7 مراجعه می کنیم . بسیاری از اقدامات WordNet مختلف اجرا شده است. شکل 4 معیارهای تشابه کلمه را بر اساس محتوای اطلاعاتی نشان می دهد. آنها به سادگی به خوبی اندازه گیری جاکارد خط پایه عمل نمی کنند، زیرا F-Measure به طور مداوم پایین تر است، مهم نیست که آستانه چقدر است. شکل 5 طول مسیر بین کلمات WordNet است و همچنین عملکرد خوبی ندارد. این گروه از الگوریتم های جفت کلمه بدترین عملکرد را دارند زیرا شباهت های بسیار بالایی را بین کلماتی که به هم مرتبط نیستند تعریف می کنند. شکل 6 از سه معیار ارتباط استفاده می کند و این معیارها بسیار نزدیک به مقدار عدم تشابه جاکارد هستند. این به این دلیل است که نمرات شباهت جفت کلمه به طور کلی بسیار پایین است. لسک _اندازه گیری تنها موردی است که به خوبی خط پایه عمل می کند. در نهایت، شکل 7 امتیاز شباهت جفت کلمه kno پیشنهادی را نشان میدهد که کمی از خط پایه بهتر عمل میکند. در این شرایط یک الگوریتم جفت کلمه بسیار ساده برای تعریف روابط مشابه موثر است.
ارزیابی توابع عدم تشابه معنایی نشان می دهد که تابع عدم تشابه معنایی به طور مداوم در پشت تابع عدم تشابه اصلی جاکارد انجام می شود. این به این دلیل است که نمرات شباهت جفت کلمه WordNet، روابط بین کلماتی را که به طور شهودی به هم مرتبط نیستند، مشخص می کند.
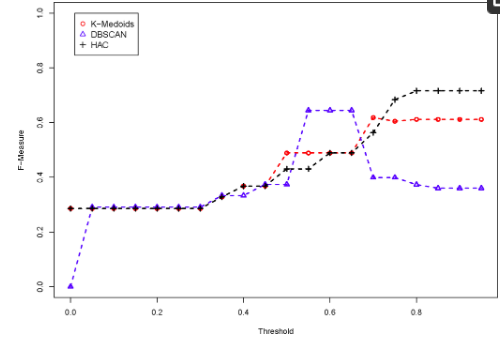
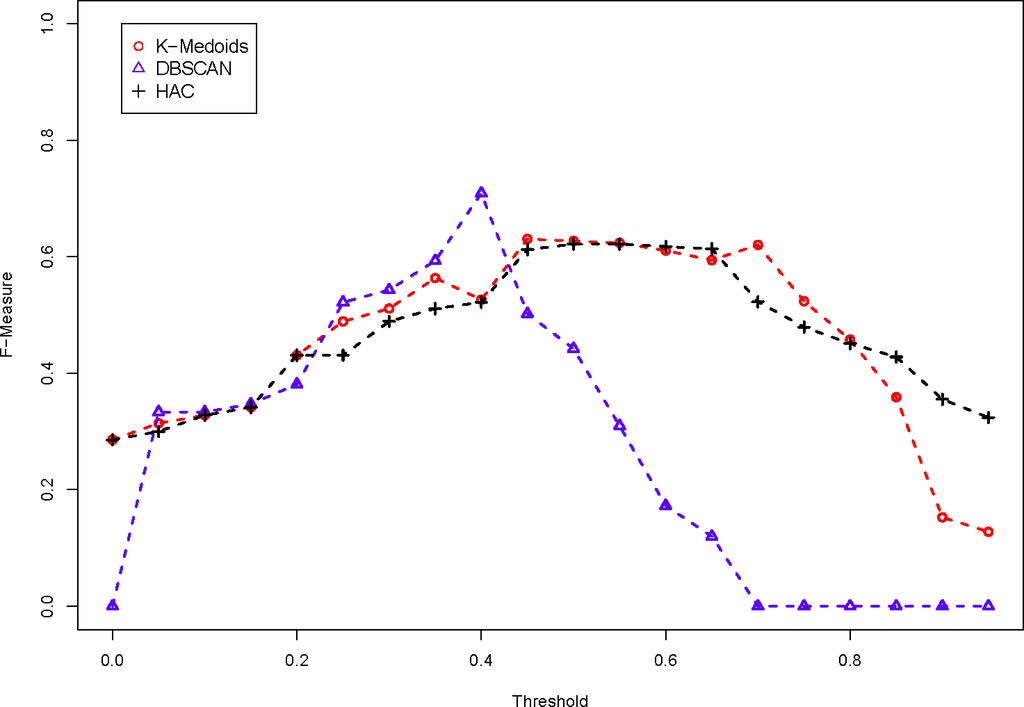
نتایج خوشه بندی مشابه است، همانطور که در شکل 8 و 9 می بینیم .
مطابق جدول 9 ، الگوریتم جفت کلمه با بالاترین F-Measure بردار است که در شکل 10 نشان داده شده است. برای این ارقام، آستانه به الگوریتم خوشه بندی بستگی دارد. برای K-Medoids، از آن برای شناسایی یک مدوید بیرونی در یک خوشه استفاده می شود که یک خوشه جدید ایجاد می کند. برای DBSCAN، آستانه به عنوان ورودی اپسیلون استفاده می شود. برای HAC، آستانه حداکثر پیوند را تعریف می کند، که اگر حداکثر عدم تشابه بین تمام اشیاء بیشتر از آستانه باشد، دو خوشه را ترکیب می کند. ما آستانه را تغییر میدهیم، مانند نقشهبرداری PL-PL، تا ببینیم کدام دسته از خوشهها بالاترین F-Measure را تولید میکنند. بنابراین، امتیاز شباهت جفت کلمه برداری با روش خوشهبندی K-Medoids یا HAC بهترین عملکرد را داشت. این بخاطر این است کهنمره شباهت جفت کلمه برداری یک نمره شباهت جفت کلمه محافظه کارانه است، بنابراین به شدت به نحو کلمات متکی است، اما هنوز روابط لازم بین مفاهیم را مشخص می کند.
5. نتیجه گیری ها
ما این مقاله را با مقایسه ظهور وب جهانی (WWW) در اوایل دهه 1990 با وب حسگر رو به رشد امروزی شروع می کنیم. وب حسگر از طریق استفاده از استانداردهای باز در بالای اینترنت اجرا می شود، اما حتی با استفاده از استانداردهای باز برای به اشتراک گذاری اطلاعات، هنوز مشکلات قابلیت همکاری وجود دارد. بسیاری از SDI ها متکی به دسترسی به داده ها از منابع متعدد و ادغام آنها به صورت یکپارچه در یک ارائه منطقی برای کاربر هستند. تمرکز ما بر روی کار گروه بندی لایه های داده حسگر مشابه معنایی است. این کار با صرفهجویی در زمان مرتبسازی دستی بین لایههای داده، قابلیت استفاده SDI را افزایش میدهد.
با این حال، مشکلات زیادی در ارتباط با این کار وجود دارد. تعداد زیاد حسگرهای منحصر به فرد نیاز به یک رویکرد خودکار دارد، زیرا دسته بندی دستی با افزایش تعداد سنسورها امکان پذیر نخواهد بود. همچنین، نامگذاری ناهمگون لایههای داده حسگر، انجام تطبیق دقیق رشتهها را دشوار میکند. یکی از راه حل های خوب تحقیق شده برای این مشکل، فهرست معنایی بوده است. این کاتالوگ ها به طور خودکار منابع داده ناهمگن را با هم گروه بندی می کنند. با این حال، این رویکرد مستلزم ایجاد و نگهداری هستی شناسی ها است که فرآیندی بسیار زمان بر است. همچنین، ارائه دهندگان داده های دنیای واقعی اغلب هستی شناسی با داده های خود ارائه نمی دهند، که استفاده از آن داده ها را در فهرست معنایی بسیار دشوار می کند.
گروه بندی خودکار لایه های داده حسگر دو چالش اصلی را در قالب تفاوت بین نام ها ارائه می دهد. اینها تفاوت های نحوی و معنایی است. تفاوت های نحوی تا حدی با استانداردهای باز حل می شود، اما همان نام را می توان با استفاده از کاراکترهای مختلف نشان داد. بهترین مثال از تفاوت های نحوی استفاده از حروف بزرگ و کوچک برای نشان دادن یک نام است. حل تفاوتهای معنایی دشوارتر است و برای نشان دادن مفهوم دنیای واقعی یکسان به دو نام متفاوت اشاره میشود. مقاله ما یک چارچوب روش شناختی جدید و مفید را به جامعه GIS ارائه می دهد. ما در اینجا ارزیابی الگوریتمهای تطبیق رشتههای نحوی و معنایی را برای اهداف گروهبندی خودکار لایههای داده حسگر مشابه ارائه میکنیم. ما استاندارد SOS را با جزئیات بررسی می کنیم،
روش ما یک رویکرد محکم از پایین به بالا است. ما ابتدا داده ها را از سرویس های مختلف OGC SOS جمع آوری می کنیم. سپس آن را به لایه های داده اتمی معروف به لایه های خاصیت (PL) تقسیم می کنیم. متن PLها که اطلاعات مربوط به پدیدهای را که اندازهگیری میکنند منتقل میکنند، از طریق عادیسازی و توکنسازی پردازش میشوند. در مرحله بعد، WordNet را به عنوان یک پایگاه داده واژگانی برای ایجاد امتیاز شباهت زوج کلمه معرفی می کنیم. بسیاری از توابع عدم تشابه بر اساس تطبیق رشته تقریبی معرفی شده اند. با استفاده از این توابع عدم تشابه، نگاشت PL-PL و خوشه بندی PL را انجام می دهیم.
ما یک ارزیابی از نحوه عملکرد این توابع عدم تشابه در گروهبندی لایههای داده حسگر مشابه ارائه میکنیم. به طور کلی، ما شاهد نتایج قابل مقایسه با استفاده از توابع عدم تشابه مبتنی بر ویرایش و مجموعه هستیم. تابع عدم تشابه معنایی آنطور که انتظار می رفت عمل نکرد و اغلب خیلی خوب عمل نمی کرد. بهترین تابع عدم تشابه معنایی تابعی بود که فقط روابط بسیار مستقیم و ساده بین نشانه ها را در نظر گرفت.
6. کار آینده
این تحقیق نشان میدهد که چگونه لایههای داده حسگر ممکن است با ویژگیهای مشاهدهشدهشان گروهبندی یا مرتبط شوند. این گروه از PL های تولید شده از روش می تواند در یک SDI وب سنسور گنجانده شود. این قبلاً توسط گروه تحقیقاتی ما از طریق نمونه اولیه VirtualSOS [ 11 ] انجام شده است. نگاشت PL به PL می تواند برای یک سیستم توصیه استفاده شود، برای مثال، زمانی که کاربر یک ویژگی مشاهده شده را دانلود می کند، ما می توانیم تمام PL های مرتبط را که کاربر ممکن است به آنها علاقه مند باشد بازیابی کنیم. در VirtualSOS، کلاس ها مانند لایه های داده حسگر مجازی رفتار می شوند. و هنگامی که کاربر یک کلاس را انتخاب می کند، تمام PL های مرتبط بازیابی می شوند.
ما میتوانیم این رویکرد را با یک رویکرد از بالا به پایین ادغام کنیم و زمانی که اطلاعات هستیشناختی گم یا ناقصی وجود دارد از رویکرد پایین به بالا استفاده کنیم.
همچنین، یکی از کارهای بسیار مهم آینده، ادامه بررسی الگوریتمها یا تکنیکهایی برای ایجاد شباهت معنایی خواهد بود. نمرات شباهت جفت کلمه از نظر کاربرد محدود است و فرض میکنیم که تمام اطلاعات معنایی در هر کلمه مستقل است. علاوه بر این، ممکن است اطلاعات معنایی دیگری در استاندارد SOS وجود داشته باشد که میتواند برای استنباط ویژگیهای مشاهدهشده دادههای حسگر، مانند واحد اندازهگیری مشاهدات یا توصیف حسگر استفاده شود.
منابع
- دلین، کالیفرنیا؛ جکسون، وب سنسور SP: مفهوم ابزار جدید. Proc. SPIE 2001 ، 4282 ، 1-9. [ Google Scholar ]
- لیانگ، SH. کرویتورو، آ. تائو، CV یک زیرساخت جغرافیایی توزیع شده برای حسگر وب. محاسبه کنید. Geosci. 2005 ، 31 ، 221-231. [ Google Scholar ]
- بوتس، ام. پرسیوال، جی. رید، سی. فعال سازی وب حسگر دیویدسون، J. OGC : نمای کلی و معماری سطح بالا. شبکه های ژئوسنسور 2008 ، 4540 ، 175-190. [ Google Scholar ]
- Na، A. Priest, M. Sensor Observation Service نسخه 1.0.0. ; DocNr. OGC 06-009r6; Open Geospatial Consortium Inc.: Wayland, MA, USA, 2007. [ Google Scholar ]
- Cox, S. اطلاعات جغرافیایی: مشاهدات و اندازه گیری ها ; سند OGC 10-004r3/ISO 19156. Open Geospatial Consortium Inc.: Wayland، MA، ایالات متحده آمریکا، 2010. [ Google Scholar ]
- Nebert، DD Developing Spatial Data Infrastructures: The SDI Cookbook، 2004 ، در دسترس آنلاین: http://www.gsdi.org/gsdicookbookindex در 25 اکتبر 2012 قابل دسترسی است.
- کلمن، دی جی; Nebert، DD ساخت زیرساخت داده های مکانی آمریکای شمالی. کارتوگر. Geogr. Inf. علمی 1998 ، 25 ، 151-160. [ Google Scholar ]
- نوگراس-ایسو، جی. Zarazaga-Soria، FJ; Muro-Medrano، PR فراداده های اطلاعات جغرافیایی برای زیرساخت های داده های مکانی ; Springer: برلین، آلمان، 2005. [ Google Scholar ]
- بیشر، ی. غلبه بر موانع معنایی و دیگر قابلیت همکاری GIS. بین المللی جی. جئوگر. اطلاعات علمی 1998 ، 12 ، 299-314. [ Google Scholar ]
- کوهن، دبلیو. سیستم های مرجع معنایی. بین المللی جی. جئوگر. اطلاعات علمی 2003 ، 17 ، 405-409. [ Google Scholar ]
- Knoechel، B. هوانگ، سی. لیانگ، اس. طراحی و پیادهسازی سیستمی برای جستجوی بهبودیافته و دسترسی به خدمات SOS در دنیای واقعی، مجموعه مقالات کارگاه بینالمللی در زمینه فعالسازی حسگر وب 2011، Banff، AB، کانادا، 6-7 اکتبر 2011.
- جیرکا، س. برورینگ، ا. Foerster، T. Handling Semantics of Sensor Observables در SWE Discovery Solutions، مجموعه مقالات سمپوزیوم بین المللی 2010 در زمینه فن آوری ها و سیستم های مشارکتی (CTS)، شیکاگو، IL، ایالات متحده، 17-21 مه 2010. صص 322-329.
- برورینگ، ا. مائو، پی. یانوویچ، ک. نوست، دی. Malewski، C. اتصال و پخش حسگر با قابلیت معنایی برای وب حسگر. Sensors 2011 , 11 , 7568-7605. [ Google Scholar ]
- Bermudez, L. OGC Ocean Science Interoperability Experiment Phase 1 Report (08-124r1) ; کنسرسیوم فضایی باز، 2011. [ Google Scholar ]
- رزل، ر. لیانگ، اس. یک سیستم توصیه مبتنی بر فولکسونومی برای وب حسگر، مجموعه مقالات دهمین سمپوزیوم بین المللی در وب و سیستم های اطلاعات جغرافیایی بی سیم (W2GIS 2011)، کیوتو، ژاپن، 3-4 مارس 2011. صص 64-67.
- منینگ، سی دی; رغوان، پ. Schtze, H. Introduction to Information Retrieval ; انتشارات دانشگاه کمبریج: نیویورک، نیویورک، ایالات متحده آمریکا، 2008. [ Google Scholar ]
- شهاتا، س. کارای، اف. کامل، ام. یک مدل کاوی مبتنی بر مفهوم کارآمد برای افزایش خوشهبندی متن. IEEE Trans. بدانید. مهندسی داده 2010 ، 22 ، 1360-1371. [ Google Scholar ]
- کوهن، WW; راویکومار، پی. Fienberg، SE مقایسهای از متریکهای فاصله رشتهای برای وظایف تطبیق نام، مجموعه مقالات کارگاه آموزشی IJCAI-2003 در مورد یکپارچهسازی اطلاعات در وب (IIWeb-03)، آکاپولکو، مکزیک، 9-10 اوت 2003. صص 73-78.
- کروز، آی. پال، اف. آنتونلی، آر. استرو، سی. انتخاب کارآمد نگاشتها و ترکیب خودکار مبتنی بر کیفیت از روشهای تطبیق، مجموعه مقالات کارگاه بینالمللی ISWC در مورد تطبیق هستیشناسی (OM 2009)، مکزیکو سیتی، مکزیک، 3-4 دسامبر 2009.
- Fellbaum, C. WordNet: An Electronic Lexical Database ; کتاب های برادفورد: برادفورد، MA، ایالات متحده آمریکا، 1998. [ Google Scholar ]
- بودانیتسکی، آ. هرست، جی. ارزیابی معیارهای مبتنی بر وردنت ارتباط معنایی واژگانی. جی. کامپیوتر. لینگ. 2006 ، 32 ، 13-47. [ Google Scholar ]
- پدرسن، تی. پاتواردان، اس. Michelizzi, J. WordNet::Similarity: Measuring the Related of Concepts, HLT-NAACL—Demonstrations ’04 مقاله های نمایشی در HLT-NAACL 2004; انجمن زبانشناسی محاسباتی: استرودزبورگ، PA، ایالات متحده آمریکا، 2004; صص 38-41.
- Resnik، P. استفاده از محتوای اطلاعاتی برای ارزیابی تشابه معنایی در یک طبقهبندی، مجموعه مقالات IJCAI’95 از چهاردهمین کنفرانس مشترک بینالمللی در زمینه هوش مصنوعی. Morgan Kaufmann Publishers Inc: San Francisco, CA, USA, 1995; 1، ص 448-453.
- Lin, D. An Information-Toretic Definition of Simarity، مجموعه مقالات پانزدهمین کنفرانس بین المللی یادگیری ماشین، مدیسون، WI، ایالات متحده آمریکا، 24-27 ژوئیه 1998. 1، ص 296-304.
- جیانگ، جی جی. Conrath، شباهت معنایی DW بر اساس آمار بدنه و طبقهبندی واژگانی . مخزن تحقیقات محاسباتی: cmp-lg/9709008; 1997. [ Google Scholar ]
- هرست، جی. St-Onge، E. زنجیره های واژگانی به عنوان بازنمایی زمینه برای تشخیص و تصحیح نارسایی ها. در WordNet: یک پایگاه داده الکترونیکی واژگانی . Fellbaum, C., Ed. انتشارات MIT: کمبریج، MA، ایالات متحده آمریکا، 1995; صص 305-332. [ Google Scholar ]
- بانرجی، اس. Pedersen, T. Extended Gloss overlaps as a Meaure of Semantic Relatedness, Proceeding IJCAI’03 مجموعه مقالات هجدهمین کنفرانس مشترک بین المللی در زمینه هوش مصنوعی. Morgan Kaufmann Publishers Inc: San Francisco, CA, USA, 2003; 18، ص 805-810.
- هنسون، سی. پسکور، جی. شث، ا. Thirunarayan، K. SemSOS: خدمات مشاهده حسگر معنایی، مجموعه مقالات سمپوزیوم بین المللی در زمینه فن آوری ها و سیستم های مشارکتی (CTS’09)، بالتیمور، MD، ایالات متحده آمریکا، 18-22 مه 2009. صص 44-53.
- یانوویچ، ک. راوبال، م. کوهن، دبلیو. معناشناسی شباهت در بازیابی اطلاعات جغرافیایی. جی. اسپات. Inf. علمی 2011 ، 2 ، 29-57. [ Google Scholar ]
- لوتز، ام. اسپرادو، جی. کلین، ای. شوبرت، سی. مسیح، I. غلبه بر ناهمگونی معنایی در زیرساخت های داده های مکانی. محاسبه کنید. Geosci. 2009 ، 35 ، 739-752. [ Google Scholar ]
- چن، اس. لیانگ، اس. یک معماری ترکیبی همتا به همتا برای کشف خدمات وب جغرافیایی جهانی، مجموعه مقالات دانش و اطلاعات فضایی-کانادا، فرنی، پیش از میلاد، کانادا، 20 تا 22 فوریه 2011.
- قهوهای مایل به زرد، PN; مایکل، اس. Vipin, K. مقدمه ای بر داده کاوی ; Pearson Education Inc.: Boston, MA, USA, 2006. [ Google Scholar ]
- Levenshtein، V. کدهای باینری که قادر به تصحیح حذف، درج و معکوس هستند. فیزیک شوروی-دوکلادی. 1966 ، 10 ، 707-710. [ Google Scholar ]
- کافمن، ال. Rousseeuw, P. Clustering by Means of Medoids. در تجزیه و تحلیل داده های آماری بر اساس هنجار L1 ; Dodge, Y., Ed. هلند شمالی: آمستردام، هلند، 1987; ص 405-416. [ Google Scholar ]
- استر، ام. کریگل، اچ پی؛ ساندر، جی. Xu, X. الگوریتم مبتنی بر چگالی برای کشف خوشهها در پایگاههای داده فضایی بزرگ با نویز، مجموعه مقالات دومین کنفرانس بینالمللی کشف دانش و دادهکاوی KDD-96، پورتلند، OR، ایالات متحده آمریکا، 2-4 اوت 1996. ص 226-231.




© 2013 توسط نویسندگان; دارنده مجوز MDPI، بازل، سوئیس این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (http://creativecommons.org/licenses/by/3.0/) توزیع شده است.
بدون نظر