

خلاصه
توییتر از زمان آغاز به کار خود نقش مهمی در رویدادهای دنیای واقعی ایفا کرده است – به ویژه در پس از بلایا و حوادث فاجعه بار، و به طور فزاینده ای تبدیل به اولین نقطه تماس برای کاربرانی شده است که مایل به ارائه یا جستجوی اطلاعات در مورد چنین موقعیت هایی هستند. استفاده از توییتر در مدیریت واکنش اضطراری و بلایای طبیعی راههایی برای تحقیق در مورد جنبههای مختلف کیفیت، سودمندی و اعتبار دادههای توییتر باز میکند. یک چالش واقعی که توجه قابل توجهی را در جامعه تحقیقاتی توییتر به خود جلب کرده است، در استنتاج مکان دادههای توییتر وجود دارد. با توجه به اینکه کمتر از ۲ درصد توییتها دارای برچسب جغرافیایی هستند، یافتن روشهای استنتاج موقعیت مکانی که میتواند فراتر از قابلیت برچسبگذاری جغرافیایی باشد، بدون شک حوزه تحقیقاتی اولویت دارد. این امر به ویژه در مورد واکنش اضطراری صادق است، که در آن جنبه های فضایی اطلاعات نقش مهمی ایفا می کنند. این مقاله یک روش استنتاج مکان چند عنصری را معرفی میکند که برچسبگذاری جغرافیایی را کنار میگذارد و سعی میکند مکان توییتها را با بهرهبرداری از دیگر عناصر داده ذاتی پیوست شده پیشبینی کند. در این راستا محتوای متنی، موقعیت مکانی پروفایل کاربران و برچسب گذاری مکان به عنوان عناصر اصلی مرتبط با مکان مورد توجه قرار می گیرد. کلاس های مکان-نام در سه سطح دانه بندی تعریف شده و برای جستجوی مراجع مکان از عناصر مرتبط با مکان استفاده می شود. مکان استنباطشده بهترین سطح دانهبندی، بر اساس قانون تخصیص مکان جدید، به یک توییت اختصاص داده میشود. مکان اختصاص داده شده توسط فرآیند استنتاج مکان به عنوان مکان استنباط شده یک توییت در نظر گرفته می شود و با مختصات برچسب جغرافیایی به عنوان حقیقت اصلی مطالعه مقایسه می شود.
کلید واژه ها:
استنتاج مکان ; رسانه های اجتماعی ؛ توییتر ; پاسخ اضطرار ی
1. معرفی
رسانه های اجتماعی که همه جا حاضر و همه جا حضور دارند، در حال تبدیل شدن به کانال های مهمی برای انتشار اطلاعات و ارتباط در میان جمعیت عمومی هستند. چنین پلتفرمهایی سرعت و ماهیت درک و واکنش مردم به رویدادهای اضطراری یا پیشبینی نشده را نیز تغییر میدهند. اکنون احتمالاً اولین خبر در مورد وضعیت اضطراری در کانال های رسانه های اجتماعی مانند توییتر به جای منابع خبری معمولی ظاهر می شود. جدیدترین نمونه از چنین رویدادی، حملات پاریس است که در 13 نوامبر 2015 رخ داد، پس از آن شاهدان عینی در حساب های شبکه های اجتماعی خود، که عمدتاً توییتر بودند، پست کردند تا به دیگران در مورد آنچه اتفاق می افتد هشدار دهند [1 ]]. کاربرد عملی توییتر در شرایط اضطراری، راههای جدیدی را برای بررسی در مورد استفاده مؤثر از پلتفرمهای رسانههای اجتماعی، مانند توییتر، در رویدادهای فاجعهبار و متناسب کردن آنها با الزامات واکنش اضطراری پیشنهاد میکند. رسانههای اجتماعی، در این زمینه، میتوانند شکافی را که در سیستمهای واکنش اضطراری کنونی در رابطه با آنچه که South [ 2 ] بهعنوان فقدان جریان اطلاعات فوری از افراد حاضر در صحنه به مقامات یا کسانی که میتوانند کمک کنند، توصیف میکند، پر کنند. پشتیبانی شده توسط تعدادی از مطالعات [ 3 ، 4]، توییتر، در میان پلتفرمهای رسانههای اجتماعی، نشان داده است که توانایی تقویت با ارزشی برای سیستمهای واکنش اضطراری فعلی را دارد. با این حال، این اضافه کردن ساده نیست، زیرا چالش های مهمی وجود دارد که ابتدا باید بر آنها غلبه کرد.
اطلاعات بحران به روز و مرجع مکانی نقش حیاتی در واکنش اضطراری دارد [ 5 ، 6 ، 7 ]. به عبارت دیگر، واکنش اضطراری نیازمند اطلاعاتی است که به موقع و از یک مکان قابل شناسایی باشد. در حالی که توییتر از یک جدول زمانی قابل اعتماد بهره می برد که نیاز به موقع بودن واکنش اضطراری را برآورده می کند و توییتر را برای زمینه های حساس به زمان مناسب می کند، شناسایی مکانی که اطلاعات از آنجا در حال انتشار است هنوز یک مسئله غیر ضروری است. توجه به این نکته مهم است که اطلاعات به موقع از یک مکان ناشناخته ارزش زیادی برای واکنش اضطراری ندارد. از سال 2009، زمانی که توییتر شروع به تطبیق برچسبگذاری جغرافیایی کرد [ 8]، توییتها میتوانند حاوی مختصات جغرافیایی باشند که توسط دستگاههای دارای GPS متصل شدهاند. با این حال، علیرغم ماهیت ذاتی توییتها در زمان واقعی، برچسبگذاری جغرافیایی یک سرویس «انتخاب» است که به صلاحدید کاربر فعال میشود. نتایج تجزیه و تحلیل تجربی انجام شده بر روی بیش از 300 هزار توییت جمع آوری شده به طور تصادفی در مرکز مدیریت بلایای طبیعی و ایمنی عمومی (CDMPS) در آوریل 2015 نشان می دهد که حدود 2٪ از همه توییت ها دارای برچسب جغرافیایی هستند و دارای مکان دقیق هستند. در ادبیات مرتبط، این نرخ از 0.42٪ [ 9 ] تا 3.17٪ [ 10] متغیر است.]. سیستمها یا ابزارهایی که مکان توییتها را تنها با در نظر گرفتن برچسبگذاری جغرافیایی استخراج میکنند، میتوانند از بخش کوچکی از دادههای توییتر بهره ببرند، حتی اگر اطلاعات ارزشمندی در بخش بدون برچسب جغرافیایی باقیمانده وجود داشته باشد. بنابراین، یافتن روشهایی برای استنتاج اطلاعات مکان از دیگر قابلیتهای ذاتی توییتها، مانند محتوای متنی یا مکان نمایه کاربر، میتواند یک جایگزین ضروری باشد.
علاقه تحقیقاتی فزاینده ای به موضوعات حول محور استنتاج موقعیت مکانی توییتر همراه با روش های پیشنهادی برای رسیدگی به آنها وجود دارد که در بخش 2 مورد بحث قرار می گیرد . با این حال، شکاف های قابل توجهی در وضعیت فعلی دانش وجود دارد. اولاً، روشهای فعلی تنها از یکی از عناصر موجود دادههای توییتر برای استنباط مکان استفاده میکنند، در حالی که چندین عنصر بالقوه برای استنتاج مکان (مثلاً محتوای متنی، مکان نمایه و برچسبگذاری مکان) وجود دارد که میتوانند برای بهبود عملکرد مکان ترکیب شوند. الگوریتم های استنتاج علاوه بر این، روشهای فعلی میتوانند در بهترین حالت به دقت موقعیت جغرافیایی تا سطح شهر دست یابند، که به نظر نمیرسد سطح تفکیک مناسبی برای واکنش اضطراری باشد.
این مقاله روش جدیدی را معرفی میکند که با بهترین دانش نویسندگان، برای اولین بار از تمام منابع بالقوه اطلاعات مکان در یک رویکرد چند عنصری بهرهبرداری میکند و میانگین و میانگین خطای فاصله را به ترتیب 12.2 کیلومتر و 4.5 کیلومتر به دست میآورد. ، برای 87 درصد از توییت های نمونه. روش معرفیشده از تمام حاملهای اطلاعات موقعیت مکانی بالقوه برای استنتاج مکان دادههای توییتر در غیاب برچسبگذاری جغرافیایی استفاده میکند. برخی از آزمایشها که روش پیشنهادی را تأیید میکنند انجام میشوند. این آزمایشها از مجموعه دادههایی از توییتها استفاده میکنند که بین ۲۱ و ۲۶ آوریل ۲۰۱۵ جمعآوری شدهاند، زمانی که شرایط آب و هوایی شدید منطقه سیدنی را تحت تأثیر قرار داد و باعث فروریختن تعدادی از انبارها در غرب سیدنی شد [11 ]]. سهم اصلی این تحقیق را می توان در زمینه های زیر خلاصه کرد:
-
آشنایی با دادههای توییتر، عناصر بالقوه اطلاعات مکان در یک توییت، و همچنین برخورد با جمعآوری و نمونهگیری دادههای توییتر
-
پیشنهاد یک رویکرد ترکیبی و چند عنصری نسبت به استنتاج مکان در توییتر، که به طور قابل توجهی دقت مکان روش های فعلی را بهبود می بخشد.
بقیه مقاله به شرح زیر سازماندهی شده است. بخش 2 کار مرتبط را تشریح و خلاصه می کند. بخش 3 مقدمه کوتاهی بر داده های توییتر ارائه می دهد و عناصر بالقوه مرتبط با مکان را بررسی می کند. بخش 4 طراحی روش را توضیح می دهد و مقدمات اساسی کار، از جمله فرآیندهای جمع آوری داده ها و نمونه گیری را توضیح می دهد. اجرا و ارزیابی روش پیشنهادی در بخش 5 مورد بحث قرار گرفته است . این مقاله در بخش 6 ، با دیدگاههایی برای تحقیقات آتی مورد بحث و نتیجهگیری قرار میگیرد.
2. رویکردهای موجود برای استنتاج مکان
بازیابی اطلاعات مکان دادههای توییتر، که به عنوان «استنتاج مکان» شناخته میشود، توجه نسبتاً قابلتوجهی را در ادبیات به خود جلب کرده است. استنتاج مکان، به طور کلی، می تواند به عنوان فرآیند بازیابی اطلاعات مکان از هر یک از محتوای متنی، عناصر خاص مکان، یا شبکه اجتماعی کاربر توضیح داده شود. تعدادی از مطالعات فقط بر ماهیت توییتهای دارای برچسب جغرافیایی متمرکز شدهاند و اینکه چگونه میتوان از این قابلیت برای ردیابی و تجزیه و تحلیل موضوعات مختلف در حوزههایی مانند سلامت عمومی [12]، رویدادهای اجتماعی [13]، انتخابات سیاسی [ 14 ] استفاده کرد . نقاط توریستی [ 15 ] و زمین لرزه ها [ 16]. با این حال، همانطور که قبلا ذکر شد، توییت های دارای برچسب جغرافیایی حدود 2٪ از تمام توییت های عمومی منتشر شده توسط کاربران توییتر را تشکیل می دهند. این امر نیاز به روشهایی را ایجاد میکند که میتوانند از اجزای دیگر توییتها برای استخراج اطلاعات مکان و افزایش قابلیت اطمینان مکان کلی دادههای توییتر برای واکنش اضطراری استفاده کنند. روشهای مختلفی از زمینههای مختلف مانند یادگیری ماشین، آمار، احتمال و پردازش زبان طبیعی برای رفع نیاز به روشهای استنتاج مکان دقیقتر و دقیقتر اتخاذ شده است [17 ] .
مطالعات مربوط به محتوای متنی توییتها برای تعیین مکان در غیاب برچسبگذاری جغرافیایی، عمدتاً بر شناسایی و استخراج منابع جغرافیایی ذکر شده در محتوای متنی تمرکز دارند. این ارجاعات ممکن است به شکل “کلمات نشان دهنده مکان” (LIWs) یا اصطلاحات روزنامه باشند که می توانند با استفاده از یک پایگاه داده فضایی کدگذاری شوند. آیزنشتاین و همکاران [ 18 ] مدلی به نام «مدل موضوع جغرافیایی» را توصیف میکند و این مدل را بر روی کاربران مستقر در ایالات متحده پیادهسازی میکند تا آنها را بر اساس محتوای آنها مکانیابی کند. مدل آنها میانه خطای مسافت 494 کیلومتر را به دست می آورد. این میزان خطا توسط وینگ و بالدریج [ 19 ] کاهش مییابد که خطای متوسط 479 کیلومتر را برای مدل خود دریافت میکنند. چنگ، کاورلی و لی [ 9] رویکردی را ارائه می دهد که محتوای توییت های دارای برچسب جغرافیایی را تجزیه و تحلیل می کند و آمار پرتکرارترین کلمات را در هر شهر ارائه می دهد. با روش آنها، 51 درصد از کاربران توییتر به طور تصادفی در فاصله 100 مایلی از مکان واقعی خود قرار می گیرند. واتانابه و همکاران [ 20 ] سیستمی به نام “یاس” را برای تشخیص رویدادها در مقیاس محلی از طریق استخراج و تجزیه و تحلیل اصطلاحات همزمان در محتوای توییت ها پیشنهاد می کند. در رویکردی که توسط دالوی و همکاران انجام شد. [ 21 ]، کاربران بر اساس ارجاعات فضایی غیرمستقیم موجود در محتوا، با در نظر گرفتن رستوران ها به عنوان هدف مطالعه، مکان یابی می شوند. هان و همکاران [ 22] با شناسایی و تجزیه و تحلیل “کلمات نشان دهنده مکان” یک پلت فرم پیش بینی موقعیت جغرافیایی را معرفی کنید. روش آنها فاصله خطای پیش بینی میانه را 209 کیلومتر کاهش می دهد. در روشی که توسط Minot و همکاران انجام شد. [ 23 ]، ترکیبی از تجزیه و تحلیل محتوا و ارزیابی تعاملات اجتماعی کاربران (اشاره به کاربر در محتوا) استفاده شده است و دقت سطح شهر برای 60 درصد از کاربران نمونه آنها مشاهده شده است.
رویکردهایی نیز وجود دارد که از محتوای متنی توییتها برای اهداف استنتاج موقعیت مکانی فراتر میرود. به عنوان مثال، Hecht و همکاران. [ 24 ] مکانهای نمایه کاربران را از طریق استفاده از یک مدل چندجملهای ساده بیز برای طبقهبندی مکان کاربر با تمرکز منطقهای و تخصیص کاربران به ایالتهای خود با دقت تا 30% مطالعه کنید. Hecht و همکاران متوجه می شوند که کاربران، آگاهانه یا سهوا، اطلاعات مکان را در توییت های خود افشا می کنند. هیروتا و همکاران [ 25] روشی را برای شناسایی و طبقهبندی توییتها بر اساس همبستگی احتمالی مکانهای نمایه کاربران با محتوای متنی و برچسبگذاری جغرافیایی در دستههای مختلف انجام میدهد. شواهد مشخصی مبنی بر دانه بندی جغرافیایی به دست آمده در مطالعه آنها وجود ندارد، اما به نظر می رسد که تفکیک جغرافیایی به دست آمده از کار آنها دقیق تر از سطح شهر نیست.
در یک کار مرتبط تر، شولز و همکاران. [ 26 ] یک روش استنتاج مکان را از طریق ترکیب منابع بالقوه شاخصهای فضایی، مانند پیامهای توییت، اطلاعات مکان نمایه، پیوندهای اینترنتی و مناطق زمانی با استفاده از تکنیک نقشهبرداری چند ضلعی که مکان 54 درصد توییتها را در شعاع 50 کیلومتری تخمین میزند، پیشنهاد میکند. . به طور کلی، روش آنها قادر است با بهرهبرداری از منابع خارجی متعدد مانند Geonames، DBPedia Spotlight، IPinfoDB و غیره، تخمین مکان 92 درصد از توییتها را با میانگین خطای مسافت 1408 کیلومتر و خطای فاصله متوسط 30 کیلومتر ایجاد کند .، برای استنباط مکان توییت ها. اگرچه، در مقایسه با سایر مطالعات، این روش خطای فاصله میانه را افزایش می دهد، میانگین خطای فاصله هنوز خیلی درشت است که در زمینه پاسخ اضطراری مفید در نظر گرفته شود. علاوه بر این، استفاده از منابع خارجی متعدد برای تخمین مکان توییتها برای استفاده در سناریوهای حساس به زمان بسیار زمانبر، پیچیده و کار فشرده به نظر میرسد.
بسیاری از کارهای انجام شده بر روی استنتاج مکان دادههای توییتر از محتوای توییت یا یکی از عناصر خاص مکان برای استنتاج مکان استفاده میکنند. هدف از این مطالعه بررسی ترکیب احتمالی عناصر مختلف برای پیشبینی مکان توییتهایی است که در یک مجموعه داده وجود دارد. روش پیشنهادی یک توییت را در برابر هر عنصر بالقوه مکان خاص ارزیابی می کند تا سطح پاسخگویی توییت به هر عنصر را بررسی کند. این روش در نهایت مکان توییت را بر اساس بهترین عنصر مناسب پیش بینی می کند. علاوه بر این، از نظر میانگین خطای فاصله، آثار موجود در بهترین حالت به سطح شهر یا خطای میانگین مسافت بیش از 200 کیلومتر دست مییابند که برای حوزه واکنش اضطراری بسیار درشت هستند و به اندازه کافی جزئیات ندارند. بدین ترتیب، برای رسیدن به یک سطح دانه ای دقیق تر و دقیق تر، باید روش هایی ایجاد شود. روش پیشنهادی در این تحقیق، مکان 87 درصد توئیتهای نمونه را با میانگین خطای مسافت 12.2 کیلومتر و خطای میانگین مسافت 4.5 کیلومتر برآورد میکند که نسبت به روشهای فعلی پیشرفت قابلتوجهی محسوب میشود.
3. داده های توییتر و عناصر خاص مکان
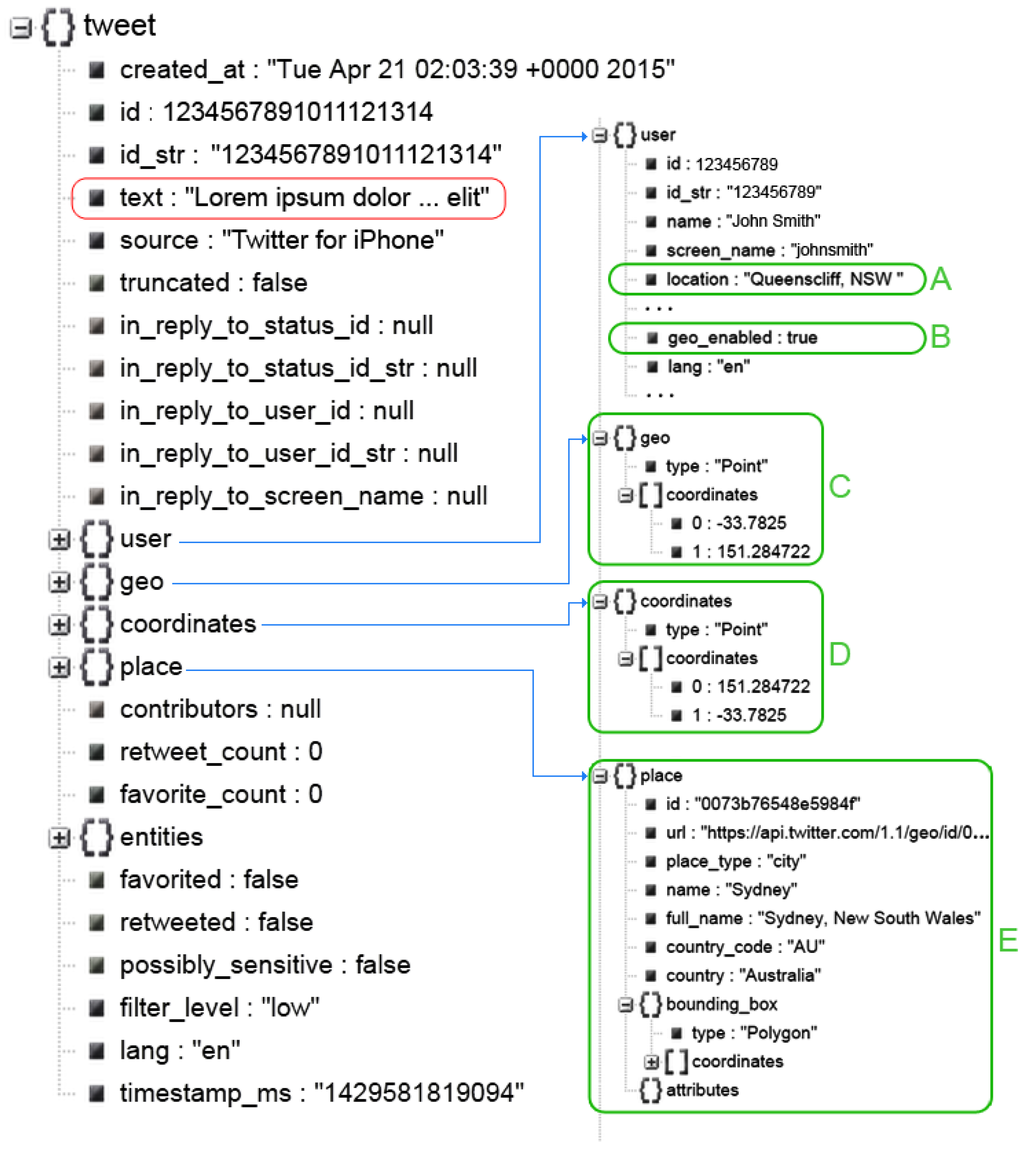
توییتر که در سال 2006 راه اندازی شد، یک شبکه اجتماعی رایگان و سرویس میکروبلاگینگ است که به کاربران اجازه می دهد پیام هایی به نام توییت ارسال کنند. توییت ها پیام های کوتاهی هستند که به 140 کاراکتر محدود می شوند. با این حال، یک توییت بیشتر از یک پیام کوتاه است. توییتها همراه با مجموعهای از ابردادههای نسبتاً غنی هستند. از طریق API جریان، زیرمجموعههای توصیف وضعیت عمومی را میتوان بر اساس معیارهای تعریفشده توسط کاربر در دادههای قالببندی شده جاوا اسکریپت Object Notation (JSON) که یک فرمت تبادل داده سبک و مبتنی بر متن است، بازیابی کرد. شکل 1 یک فید خام توییتر را نشان می دهد که در قالب JSON تورفتگی ارائه شده است تا خواندن و همچنین درک آن را تسهیل کند.
آنچه عموماً به عنوان یک توییت شناخته می شود، تنها بخشی از یک فید کامل را تشکیل می دهد و در عنصر “متن” قرار می گیرد. این عنصر در کادر قرمز در شکل 1 نشان داده شده است. همانطور که در شکل به وضوح مشاهده می شود، عناصر مختلفی با عنصر “متن” در فید توییتر همراه هستند. توصیف همه عناصر از محدوده این مقاله خارج است، با این حال، عناصر مرتبط با مکان برای پرداختن به تمرکز اصلی مطالعه معرفی و مورد بحث قرار میگیرند. بر اساس آنچه در شکل بالا نشان داده شده است، به غیر از عنصر “متن”، که ممکن است حاوی ارجاعات مکان باشد، عناصر خاص مکان وجود دارند که می توانند مقادیر متفاوتی داشته باشند. این عناصر در کادرهای سبز با برچسب از A تا E مشخص شده اند. عناصر مربوط به مکان و توضیح مختصری از هر کدام در جدول 1 فهرست شده است .
در میان فیلدهای مربوط به مکان در جدول 1 ، “geo” و “coordinates” مربوط به برچسب گذاری جغرافیایی هستند و هر دو حاوی اطلاعات یکسانی هستند [ 27 ]. از آنجایی که فیلد «مختصات» رسمی است و توسط توییتر توصیه می شود، این مطالعه در صورت نیاز از فیلد «مختصات» استفاده می کند. همچنین چند اصطلاح در جدول 1 وجود دارد که نیاز به توضیح بیشتر دارد. “Nullable” به این معنی است که یک فیلد لزوماً حاوی مقدار نیست و می توان آن را خالی گذاشت. بیشتر فیلدهایی که با تنظیمات کاربر سروکار دارند، فیلدهای باطل شدنی هستند که کاربران را قادر می سازد تا سطحی از ناشناس بودن و حریم خصوصی را حفظ کنند. علاوه بر این، یک فیلد “غیرقابل تجزیه” مانند user\location، معمولاً به این معنی است که ممکن است ورودی های غیرمنتظره ای در فیلد وجود داشته باشد که با نوع داده مورد انتظار فیلد سازگار نباشد. این به این دلیل است که هیچ قالب دقیقی برای user\location وجود ندارد و میتواند هر چیزی باشد که کاربر یادداشت میکند، به عنوان مثال “somewhere” یا ممکن است null باشد. بنابراین، اگر ورودی وجود داشته باشد، لزوماً نام مکان نیست.
همچنین فیلد دیگری در عنصر “user” به نام “geo_enabled” وجود دارد. این فیلد نشان می دهد که آیا کاربر تا به حال اطلاعات مکانی را به اشتراک گذاشته است یا خیر. اگر فیلد “geo_enabled” درست باشد، به این معنی است که کاربر موافقت کرده است که سرویس مکان را حداقل یک بار روشن کند، اما لزوماً نشان دهنده این نیست که فیلدهای “مختصات” و “مکان” دارای مقادیر هستند. این فیلد در مطالعات مربوط به مکان کاملاً مفید است و میتواند برای انجام فیلتر اولیه توییتها استفاده شود، حتی اگر نمیتواند اطلاعات مکانی را برای اهداف استنتاج ارائه کند.
کاربران همچنین میتوانند با ضربه زدن بر روی نشانگر مکان و انتخاب مکانی که میخواهند به توئیت، یک نام مکانی (مانند شهر یا محله) دلخواه خود را به صورت انتخابی پیوست کنند. از دیدگاه دادههای توییتر، «مکانها» مکانهای مشخص و نامگذاری شدهای هستند که دارای چند ویژگی هستند که در مجموع به فیلد «مکان» و زیرفیلدهای فوری آن منتقل میشوند. توییتهایی که با مکانها بسته میشوند لزوماً از آن مکان صادر نمیشوند، اما احتمالاً از داخل یا اطراف آن مکان هستند [ 27 ]. برای بررسی وضعیت فعلی دادههای توییتر در رابطه با هر یک از عناصر مربوط به مکان، یک مطالعه تجربی با استفاده از یک نمونه تصادفی از بیش از 300 هزار توییت جمعآوری شده در سراسر جهان در آوریل 2015 انجام شد. شکل 2نتیجه تجزیه و تحلیل عناصر مرتبط با مکان را نشان می دهد.
شکل 2 نشان می دهد که تنها 41 درصد از کاربران با حداقل یک بار اشتراک گذاری موقعیت مکانی خود موافقت کرده اند و 59 درصد از کاربران هرگز با اشتراک گذاری اطلاعات مکان به هیچ وجه موافقت نکرده اند یا رضایت نداده اند. مشخص شده است که تنها 35 درصد از کاربران اطلاعات مکانی معتبر از انواع، قالبها، مقیاسهای جغرافیایی و زبانهای مختلف را در پروفایل خود دارند. علاوه بر این، 2.5٪ از همه توییت ها دارای برچسب مکان هستند که از این تعداد 89٪ در سطح شهر هستند. در نهایت، همانطور که در بخش قبلی ذکر شد، تنها 2٪ از توییت ها دارای برچسب جغرافیایی همراه با مختصات مکان دقیق هستند. به نظر می رسد نیازی به ذکر نیست که آمار ارائه شده در اینجا در مقیاس متوسط جهانی است و نتایج ممکن است بسته به وضوح جغرافیایی، زمان و نحوه جمع آوری داده ها متفاوت باشد.
4. طراحی و توسعه روش
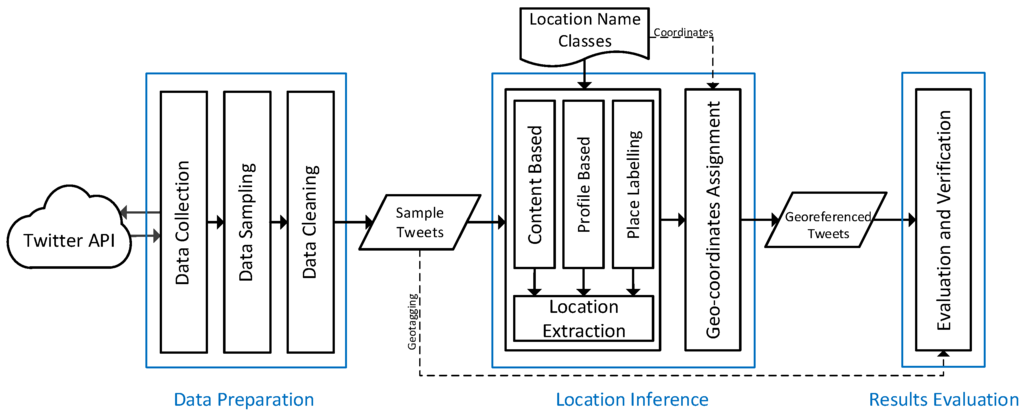
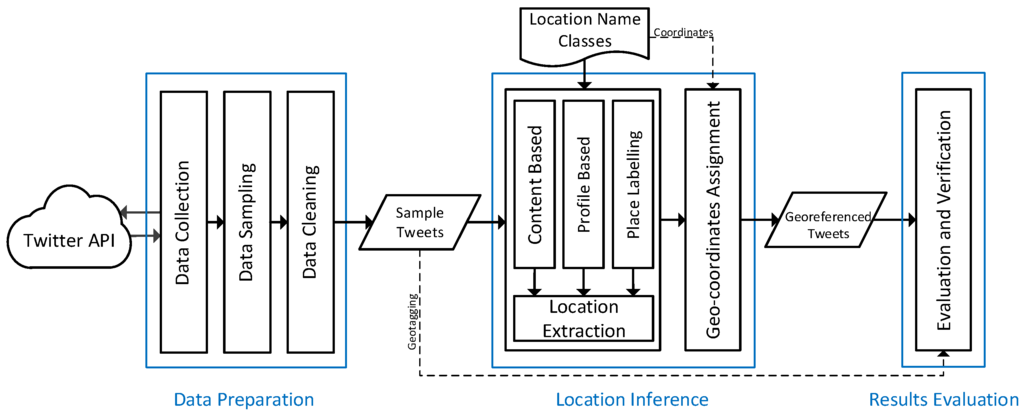
شکل 3طرح و معماری روش پیشنهادی را تشریح می کند. در شکل زیر مشاهده می شود که این روش از سه جزء اصلی تشکیل شده است. جزء آماده سازی داده ها عمدتاً با فرآیندهای جمع آوری داده ها و نمونه گیری سروکار دارد. پس از مرحله آمادهسازی دادهها، توییتهای نمونه مرتبط با رویداد به سمت مؤلفه استنتاج مکان میروند که سعی میکند مکان را از منابع بالقوه مرتبط با مکان، که در بخش قبل توضیح داده شد، پیشبینی کند. جزء به کلاس های نام مکان به عنوان ورودی مورد نیاز برای استنتاج مکان نیاز دارد. تابع اصلی این روش، تابع امتیازدهی و استخراج مکان است که به هر توییت بهترین مکان دانه ای استخراج شده از منابع بالقوه را اختصاص می دهد. تخصیص مختصات جغرافیایی آخرین مرحله ای است که در فرآیندهای استنتاج مکان انجام می شود. سرانجام،بخش 5 ، مکان استنباط شده را با مکان واقعی توییتهای نمونه مقایسه میکند و خطای فاصله روش را محاسبه میکند. بقیه این بخش اجزای آمادهسازی داده و استنتاج مکان را به تفصیل شرح میدهد.
4.1. آماده سازی داده ها
قبل از پرداختن به جزئیات مؤلفه استنتاج مکان، بخشهای اساسی مؤلفه آمادهسازی داده در اینجا توضیح داده میشود. این شامل فرآیندهای جمعآوری دادهها و نمونهبرداری به همراه تکنیکهای پاکسازی دادهها و پیش فرآیندهایی است که برای اجرای روان آزمایش مهم هستند.
4.1.1. جمع آوری داده ها
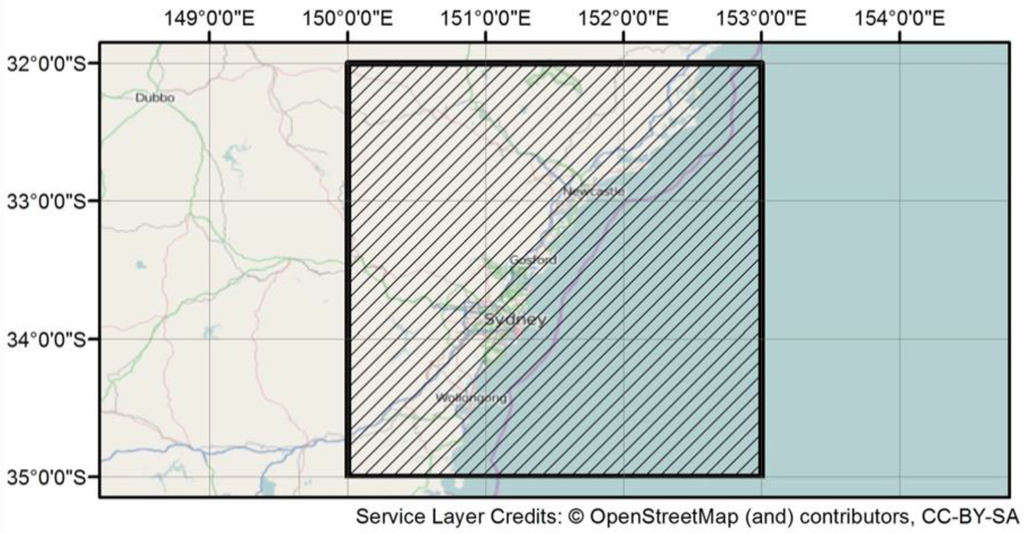
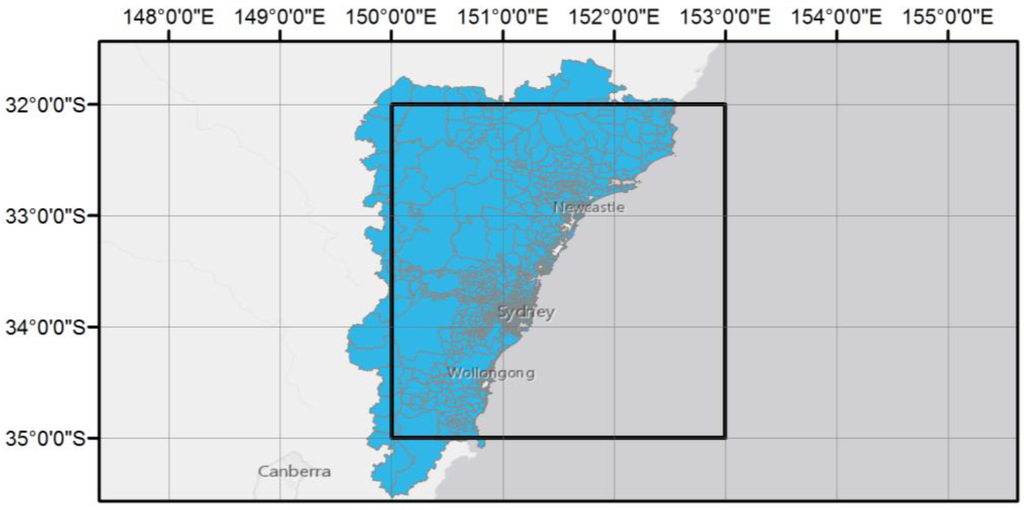
در تحقیقات توییتر، که میتوان آن را بهعنوان دادهمحور توصیف کرد، دسترسی به مجموعه دادههای مناسب توییتر به منظور اعتبارسنجی نظریهها و روشها بسیار مهم است. دادههای توییتر را میتوان با خرید از فروشندگان دادههای تجاری که توییتر با آنها شریک است بهدست آورد (به عنوان مثال، Dataminr [ 28 ]، Gnip [ 29 ] و Datasift [ 30 ]]، یا مجموعه ای بدون هزینه از طریق رابط برنامه نویسی برنامه کاربردی توییتر (API) که هر کدام مزایا و معایب خاص خود را دارند. با این حال، استفاده از APIهای رایگان توییتر برای اهداف تحقیقاتی مناسبتر به نظر میرسد، جایی که بودجه به شدت محدود است و ممکن است برای جمعآوری مجموعه دادههای مناسب به تلاشهای جمعآوری دادههای متعدد نیاز باشد. در میان APIهای توییتر، API جریان، که دسترسی با تاخیر کم به زیرمجموعههای توییتهای عمومی را فراهم میکند، برای جمعآوری دادهها از ناحیهای استفاده میشود که توسط یک کادر محصور شده با گوشه پایین سمت چپ در (35.00 درجه جنوبی، 150.00 درجه شرقی) و گوشه بالا سمت راست در (32.00 درجه جنوبی، 153.00 درجه شرقی)، همانطور که در شکل 4 نشان داده شده است .
این منطقه شامل سیدنی و همچنین مراکز مهم منطقه ای نیو ساوت ولز است. جمعآوری دادهها از ساعت 12:00 سهشنبه 21 آوریل 2015 تا ساعت 23:59 یکشنبه، 26 آوریل 2015 انجام شد که طی آن بارشهای شدید و تگرگ گاه به گاه سیدنی و مناطق اطراف آن را درنوردید و دهها سیل را در سراسر منطقه ایجاد کرد. . در این مدت، 90078 توییت منحصر به فرد و بازتوییت نشده جمع آوری و در یک پایگاه داده محلی ذخیره شد. این شرایط آب و هوایی شدید در دفتر هواشناسی [ 11 ]، شماره آوریل 2015 هواشناسی ماهانه استرالیا منعکس شده است.
4.1.2. نمونه گیری داده ها
به منظور ایجاد یک مجموعه داده با اندازه معقول برای بررسی عملکرد روش پیشنهادی، روشی برای به دست آوردن نمونه ای از توییت ها از مجموعه داده حدود 90 کیلو تویت جمع آوری شده استفاده می شود. در اولین قدم، توییت های غیر انگلیسی از پایگاه داده محلی فیلتر می شوند. زیرا این روش برای یافتن مراجع موقعیت مکانی انگلیسی در عناصر مربوط به مکان توییت طراحی شده است و حضور توییتها به زبانهای دیگر (مثلاً عربی یا چینی) ممکن است منجر به غیرعملی بودن روش شود. مرحله دوم نمونه برداری، یافتن توییت هایی است که فرض می شود مربوط به شرایط آب و هوایی شدید مشاهده شده است. برای دستیابی به این هدف، جستجوی کلمه کلیدی در محتوای توییت ها با استفاده از طوفان تگرگ و اصطلاحات مرتبط با سیل مانند “طوفان”، “تگرگ” و “سیل” انجام می شود.
حسابهای زیادی از «رباتهای» توییتهای خودکار با دهها توییت ساعتی وجود دارد که اکثر آنها یکسان هستند و احتمالاً برای اهداف تجاری یا بازاریابی هستند که باید از دادههای نمونه برداشته شوند. بدین ترتیب در مرحله بعدی توییت هایی که احتمال ارسال آنها توسط کاربران واقعی کمتر است، هدف قرار می گیرند. برای انجام این کار، فیلد «منبع» توییتها در نظر گرفته میشود و تنها توییتهای ارسال شده از دستگاههای تلفن همراه دستی (تلفنهای همراه و تبلت) و مشتریان وب استخراج میشوند. فرضیه پشت این موضوع این است که تلفنها و تبلتها معمولاً به عنوان دستگاههای شخصی استفاده میشوند و برای انتشار انبوه توییتها مناسب نیستند. علاوه بر این، بر اساس اطلاعات ارائه شده توسط توییتر، ارزش منبع “وب” برای توییت هایی استفاده می شود که مستقیماً از وب سایت توییتر ارسال می شوند [ 27] .]، که فقط به کاربران اجازه می دهد از طریق مرورگر وب، توییت ها را بخوانند و بنویسند. بنابراین، استفاده از آن به عنوان یک ربات توییت بسیار بعید به نظر می رسد.
در مرحله آخر، توییتهای باقیمانده که فیلد «مختصات» در آنها غیر تهی است و دارای یک مقدار است، به مجموعه دادههای نمونه نهایی ارسال میشوند. “مختصات” ثبت شده، همانطور که در بخش 3 بحث شد ، اطلاعات برچسب گذاری جغرافیایی را نشان می دهد و برای ارزیابی و ارزیابی دقت روش پیشنهادی در بخش 6 استفاده می شود . انجام روش نمونه گیری منجر به ایجاد نمونه ای از این مطالعه می شود که حاوی 2409 توییت منحصر به فرد و دارای برچسب جغرافیایی به زبان انگلیسی است که احتمالاً مربوط به شرایط آب و هوایی شدید بوده و توسط کاربران واقعی ارسال شده است. شکل 5 کل روش نمونه گیری را نشان می دهد.
4.1.3. پاکسازی داده ها
برخی از عناصر دادههای توییتر اطلاعات ایجاد شده توسط کاربر (مثلاً متن و مکان نمایه کاربر) را نشان میدهند و به شدت مستعد انواع مختلف نویز و افزونگی هستند. به عنوان مثال، تعداد زیادی شکلک، نام کاربری و پیوندهای اینترنتی در قسمت متن وجود دارد که ممکن است منجر به عملکرد کند و ناکارآمد روش شود. یک فرآیند تمیز کردن، به عنوان مرحله پیش پردازش، باید برای دستیابی به محتوای متنی یکنواخت در زمینه های ایجاد شده توسط کاربر انجام شود. برای پاک کردن قسمت های متن و مکان نمایه کاربر، ابتدا تمام عناصر زیر حذف می شوند:
-
چندین نقطه «…» که افراد در موقعیتهای مختلف استفاده میکنند (با یک فضای واحد جایگزین میشوند).
-
نام کاربر (@somebody).
-
علامت هشتگ (#) از ابتدای همه کلمات هشتگ.
-
همه علائم نگارشی، اعداد و پیوندهای اینترنتی (با “http://” شروع می شوند).
پس از حذف عناصر ذکر شده، تمامی کاراکترها به حروف کوچک تبدیل می شوند. تبدیل حروف کوچک به ارزیابی ارجاعات مکان که دارای همان مقدار با حروف بزرگ یا کوچک هستند کمک می کند. پس از تبدیل حروف کوچک، همه چند فاصله های احتمالی در یک فضای واحد ادغام می شوند. فرآیند پاکسازی از طریق استاندارد کردن متن، با حذف کاراکترهای غیرASCII (مانند ä، £، 質) تکمیل میشود. فرآیند تمیز کردن در هر دو قسمت متن و مکان نمایه کاربر در مجموعه داده نمونه اعمال می شود.
4.2. استنتاج مکان
مولفه استنتاج مکان با استخراج مراجع مکان از پیش تعریف شده از هر یک از سه منبع ممکن سروکار دارد: محتوای متنی، مکان نمایه کاربر و برچسبهای مکان. مجموعههای از پیش تعریفشده ارجاعهای نام مکان «کلاسهای نام مکان» نامیده میشوند و در زیر بخش زیر توضیح داده شدهاند.
4.2.1. نام مکان کلاس
برای تعریف کلاسهای نام مکان، این مطالعه تا حدی از شکلفایلهای GIS ارائهشده توسط اداره آمار استرالیا (ABS) [ 31 ] استفاده میکند که رایگان و در دسترس عموم هستند. با توجه به در دسترس بودن داده های قابل اعتماد، نام مکان ها به سه سطح مختلف از جزئیات تقسیم می شوند. این سطوح که هر یک نشان دهنده یک کلاس هستند به سه گروه تقسیم می شوند:
-
سطح حومه: حومه هایی که به طور جزئی یا کامل در محدوده جمع آوری داده ها قرار دارند انتخاب می شوند. برای شناسایی حومهها، شکل فایل چند ضلعی حومه شهر که از وبسایت ABS دانلود شده است با منطقه جمعآوری دادهها تقاطع مییابد ( شکل 6 ). 1381 حومه انتخاب شده و فیلد نام این حومه ها نشان دهنده کلاس نام در سطح حومه است ( L1�1). مرکز جغرافیایی حومه انتخاب شده در یک محیط GIS محاسبه می شود. مختصات مرکز به عنوان محل حومه مربوطه در نظر گرفته می شود.
-
سطح شهر: شهرهای اصلی در منطقه جمع آوری داده ها برای تشکیل کلاس نام در سطح شهر شناسایی می شوند. L2�2). مختصات این شهرها از نقشه گوگل استخراج شده و به کلاس نام مربوطه پیوست می شود.
-
سطح اداری: نام مناطق اداری بزرگ (ایالت یا کشور) به هر شکل ممکن (NSW، New South Wales، استرالیا، Aus و OZ) در اطراف منطقه جمع آوری داده ها برای شکل دادن به کلاس نام اداری در نظر گرفته می شود. L3�3). از آنجایی که آنها بیش از حد بزرگ هستند که نمیتوان آنها را به عنوان یک نقطه مکان نشان داد، مختصات جغرافیایی در این سطح محاسبه نمیشود.
4.2.2. امتیازدهی و انتساب مکان
همانطور که در شکل 3 مشهود است ، مؤلفه استنتاج مکان از سه منبع اصلی بهره برداری می کند: محتوای متنی، مکان نمایه و برچسب های مکان. هر یک از منابع ذکر شده در برابر کلاس های نام مکان بررسی می شود تا بررسی شود که آیا با نام مکانی در یکی از کلاس های مکان-نام مطابقت دارد یا خیر. برای فرمول بندی این:
اجازه دهید،
-
t e x t .دمنتیهایکستی.دمنمحتوای متنی یک توییت باشد دمندمن
-
p r o fمن من _ _دمنپ���منله.دمنفیلد مکان نمایه یک توییت باشد دمندمن
-
p l a c مکان .دمنپلآجمحل.دمنفیلد برچسب مکان یک توییت باشد دمندمن
-
Lj��یک کلاس مکان-نام باشد
سپس، یک نمایش ماتریسی از هر رابطه بین محتوای یک توییت t e x t .دمنتیهایکستی.دمنو کلاس Lj��را می توان به صورت زیر نشان داد:
مc o n= t e x t .د1t e x t .د2⋮t e x t .دمنL1 L2 L3⎡⎣⎢⎢⎢⎢⎢f1 ، 1f2 ، 1⋮fمن ، 1f1 ، 2f2 ، 2⋮fمن ، 2f1 ، 3f2 ، 3⋮fمن ، 3⎤⎦⎥⎥⎥⎥⎥مج��= �1 �2 �3تیهایکستی.د1تیهایکستی.د2⋮تیهایکستی.دمن[�1،1�2،1⋮�من،1�1،2�2،2⋮�من،2�1،3�2،3⋮�من،3]
جایی که fمن ، ج�من،�یک نام مکان است که در هر دو مشاهده می شود t e x t .دمنتیهایکستی.دمنو Lj��و به صورت زیر قابل تعریف است:
fمن ، ج= {x ، i f ∃ x ∈ t e x t . دمن | x∈ _ Ljn u l l ، o t h e r w i s e �من،�={ایکس، من� ∃ ایکس∈تیهایکستی.دمن | ایکس∈���تولل، �تیساعته��منسه
در معادله بالا، زمانی که چندین نمونه از نام مکانها در آن وجود دارد t e x t .دمنتیهایکستی.دمن، که به یک کلاس نام مکان تعلق دارند (مثلاً نام چندین حومه)، فقط اولین نمونه به آن اختصاص داده می شود. ایکسایکس.
داشتن مc o nمج��استخراج مکان مبتنی بر محتوا بر اساس عبارت IF زیر انجام می شود که نام مکان بهترین جزئیات را به عنوان مکان مبتنی بر محتوا توییت اختصاص می دهد. دمندمناز طریق تابع F.
مناف (fمن ، 1≠ n u l l ) T اچEناف( t e x t .دمن) =fمن ، 1Eال اسE مناف (fمن ، 2 ≠ n u l l ) T اچEناف( t e x t .دمن) =fمن ، 2Eال اسE مناف (fمن ، 3 ≠ n u l l ) T اچEناف( t e x t .دمن) =fمن ، 3Eال اسEاف( t e x t .دمن) = n u l lEنD I افمناف (�من،1≠�تولل) تیاچ�ناف(تیهایکستی.دمن)=�من،1��اس� مناف (�من،2 ≠�تولل) تیاچ�ناف(تیهایکستی.دمن)=�من،2��اس� مناف (�من،3 ≠�تولل) تیاچ�ناف(تیهایکستی.دمن)=�من،3��اس�اف(تیهایکستی.دمن)=�تولل�ن� مناف
اف( t e x t .دمن)اف(تیهایکستی.دمن)اگر نام مکان منطبقی در محتوا مشاهده نشود، می تواند مقدار تهی داشته باشد. دقیقاً همین فرآیند در فیلد مکان نمایه انجام می شود ( p r o fمن من _ _دمنپ���منله.دمن، و همچنین فیلد برچسب مکان ( p l a c e .دمنپلآجه.دمن) و در نتیجه، اف( صفحه _ _ _من من _ _ دمن )اف(پ���منله.دمن)و اف ( p l a c e . dمن )اف (پلآجه.دمن)، که بهترین سطح دانه بندی هر فیلد را نشان می دهد، برای همه توییت های نمونه مشخص می شود. به عنوان خروجی این مرحله، به هر توییت فیلدهای جدیدی اختصاص داده می شود که حاوی مقادیر استخراج شده برای آن است ( t e xt .دمن)(تیهایکستی.دمن)، اف( صفحه _ _ _من من _ _دمن)اف(پ���منله.دمن)و اف( p l a c e .دمن)اف(پلآجه.دمن)به همراه شناسه کلاسی که مقدار به آن تعلق دارد. پس از این مرحله، به هر توییت باید فقط یک مکان اختصاص داده شود و باید تصمیم گرفت که کدام فیلد استخراجشده برای استفاده به عنوان مکان نهایی توییت مناسبتر است. برای این منظور یک قانون به شرح زیر تعریف شده است:
-
مکان نهایی یک توییت، فیلد استخراج شده است که به بهترین سطح دانه بندی تعلق دارد.
-
اگر بیش از یک فیلد متعلق به یک سطح دانه ای وجود داشته باشد، مکان نهایی بر اساس ترتیب اهمیت زیر تعیین می شود:
-
مکان مبتنی بر محتوا اف( t e x t .دمن)اف(تیهایکستی.دمن)
-
مکان مبتنی بر برچسب مکان اف( صl a c e .دمن)اف(پلآجه.دمن)
-
موقعیت مکانی مبتنی بر نمایه اف( صفحه _ _ _من من _ _دمن)اف(پ���منله.دمن)
-
دلیل قانون دوم این است که مراجع مکان در متن و برچسب مکان در زمان ایجاد یک توییت ایجاد می شوند و احتمالاً در ارتباط با موضوع توییت هستند. آنها همچنین بسیار جدیدتر از موقعیت مکانی پروفایل کاربر هستند، که احتمالاً در زمان باز کردن حساب توییتر ایجاد می شود. علاوه بر این، مکان مبتنی بر محتوا نسبت به برچسبگذاری مکان مرتبطتر و دقیقتر در نظر گرفته میشود که بیشتر برای اختصاص نامهای مکان (شهرها) گسترده و عمومی استفاده میشود. به هر حال، اگر متد نتواند هیچ مرجع مکانی را پیدا کند که با کلاسهای نام مکان مطابقت داشته باشد، یا اگر هیچ مرجع مکانی در عناصر مربوط به مکان یافت نشد، به سادگی NA (ناکاربرد) را برمیگرداند تا نشان دهد که روش قادر نیست. برای پی بردن به مکان آن توییت خاص. طبق قانون بالا، به هر توییت یک نام مکان از کلاس نام مکان مربوطه اختصاص داده می شود. پس از اختصاص هر توییت نمونه با نام مکان، مختصات مرکز مکان استنباط شده (محاسبه شده دربخش 4.2.1 ) به آن توییت اختصاص داده شده است. بخش بعدی نتایج اجرای روش را گزارش می کند.
5. نتایج و ارزیابی
روشی که در بخش قبل توضیح داده شد برای 2409 توییت نمونه اعمال می شود. جدول 2 چند نمونه از توییت های نمونه را پس از اجرای متد نشان می دهد.
در جدول بالا، فیلد “Tweet ID” شناسه منحصربهفرد یک توییت است که توسط توییتر اختصاص داده شده است. فیلد “منبع” عنصر مربوط به مکان را نشان می دهد که به عنوان عنصر مناسب برای استنتاج مکان توسط روش تعیین می شود. قسمت “Location Name Class” کلاس نام مکان مربوطه را نشان می دهد که از آن یک نام مکان به هر توییت نمونه اختصاص داده می شود. فیلد “مکان استنتاج” و زیرفیلدهای آن (“نام مکان”، “طول و عرض جغرافیایی” و “طول جغرافیایی”) نام و مختصات جغرافیایی مکان استنباط شده را نشان می دهد. علاوه بر این، همانطور که در بخش 4.1.2 ذکر شد، فقط توییت های دارای برچسب جغرافیایی برای قرار گرفتن در مجموعه داده نمونه انتخاب می شوند. این به این معنی است که هر توییت نمونه دارای اطلاعات برچسبگذاری جغرافیایی (به شکل طول و عرض جغرافیایی) است که در عنصر «مختصات» توییت تودرتو است. مختصات برچسبگذاری شده جغرافیایی توییتهای نمونه به عنوان مکان واقعی توییتها در نظر گرفته میشوند و در قسمت “موقعیت واقعی” نشان داده میشوند. فیلد «خطای فاصله» که بعداً در این بخش مورد بحث قرار می گیرد، فاصله بین مکان واقعی و مکان استنباط شده یک توییت را نشان می دهد. این فیلد به عنوان معیار ارزیابی برای اندازه گیری دقت نتایج استفاده می شود.
همانطور که در جدول بالا مشاهده می شود، رکوردهایی که با رنگ زرد مشخص شده اند، نمونه هایی از رکوردهایی را نشان می دهند که در آنها زیرفیلدهای “Location Name”، “Latitude” و “Longitude” به عنوان NA (غیر قابل اجرا) علامت گذاری شده اند. این به این معنی است که این روش قادر به اختصاص مختصات جغرافیایی به آن توییتها نبود، یا به این دلیل که نام مکان منطبقی در کلاسهای نام مکان وجود نداشت یا هیچ مرجع مکانی در منابع بالقوه ذکر نشده بود. علاوه بر این، همانطور که در جدول 2 با رنگ فیروزه ای مشخص شده است، اگر مکان استنباط شده متعلق به سطح اداری باشد، روش ممکن است NA را فقط برای زیرفیلدهای “Latitude” و “Longitude” برگرداند. (L3)(�3)، که در نظر گرفته می شود بسیار بزرگ و بنابراین نامناسب برای نشان دادن با مختصات نقطه اختصاص داده شده است. تجزیه و تحلیل دقیق نتایج نشان می دهد که این روش قادر به استنباط و اختصاص مختصات جغرافیایی به 312 توییت نمونه نیست. این نشان میدهد که این روش در استنباط مختصات مکان 312 (از 2409) نمونه توییت به دلایل مورد بحث شکست خورد. برای بقیه مجموعه داده نمونه، که شامل 2097 توییت است، روش پیشنهادی توانست نام مکان را با موفقیت استنتاج کند و مختصات جغرافیایی منطبق را به هر توییت اختصاص دهد. این نشان دهنده میزان موفقیت 87٪ برای روش پیشنهادی از نظر استنباط مکان توییت های نمونه است.
به منظور ارزیابی بیشتر عملکرد روش در توییت های استنباط شده مکان (87٪)، یک معیار ارزیابی برای اندازه گیری دقت نتایج تعریف شده است. دقت در زمینه استنتاج مکان به عنوان فاصله بین مکان استنتاج به دست آمده از تلاش محلی سازی و مکان واقعی در فضای فیزیکی تعریف می شود [ 32 ]. دقت، از منظر تکنیک های استنتاج مکان، می تواند به عنوان خطای فاصله نامیده شود. زکاوات و بوهرر [ 32 ] استدلال می کنند که میانگین خطای فاصله می تواند به عنوان معیار عملکرد برای ارزیابی تکنیک های استنتاج مکان و مکان یابی استفاده شود.
برای ارزیابی دقت روش، فاصله بین مختصات جغرافیایی استنباط شده و ژئو مختصات مکان واقعی توییت ها با استفاده از فرمول “Haversine” [33 ] محاسبه می شود . این فرمول فاصله دایره بزرگ را به عنوان کوتاهترین فاصله بین دو نقطه بر اساس مختصات داده شده محاسبه می کند. به عنوان مثال، بیایید فرض کنیم که دو نقطه وجود دارد پ1= (ϕ1،λ1)پ1=(�1،�1)و پ2= (ϕ2،λ2)پ2=(�2،�2)، سپس فاصله بین این دو نقطه را می توان با استفاده از فرمول زیر محاسبه کرد:
د= 2 r arcsin (من _n2(ϕ2–ϕ12) +cos (ϕ1) × cos (ϕ1) × s in2(λ2–λ12)––––––––––––––––––––––––––––––––––––––––––––√)د=2�آرکسین(سمن�2(�2–�12)+cos(�1)×cos(�1)×سمن�2(�2–�12))
جایی که r�شعاع کره است که تقریباً برابر با 6372 کیلومتر است.
با استفاده از رابطه (4)، فاصله بین مکان های استنباط شده و واقعی توییت های نمونه محاسبه شده و در قسمت “خطای فاصله” در جدول 2 نشان داده شده است . تابعی که فرمول را اعمال می کند NA را برمی گرداند که در آن مختصات جغرافیایی استنباط شده به دلیل ذکر شده مقادیر معتبری ندارند. نتایج نشان می دهد که خطای مسافت از 0.11 کیلومتر تا 177.6 کیلومتر متغیر است. شکل 7 خطای فاصله توییت های نمونه را در فواصل 10 کیلومتری نشان می دهد. توییت های نمونه ای که خطای فاصله برای آنها غیرقابل تعیین است در شکل NA مشخص شده اند.
از شکل 7 مشخص است که برای 1435 توییت (60٪) از 2409 توییت نمونه، مکان استنباط شده در فاصله ای برابر یا کمتر از 10 کیلومتر از مکان واقعی آنها بوده است. علاوه بر این، می توان مشاهده کرد که 569 توییت در مجاورت 10 تا 50 کیلومتری مکان واقعی خود قرار داشتند. از میان توییتهای باقیمانده، مکان 93 توییت با دقت 50 تا 180 کیلومتر استنباط شد و در نهایت خطای فاصله 312 توییت به دلیل عدم توانایی روش در استنباط مکان آنها غیرقابل تعیین باقی مانده است. شکل 8 دقت روش را بر اساس درصد توییت های نمونه در محدوده های مختلف متریک خطای فاصله (DE) نشان می دهد.
برای ارزیابی عملکرد کلی روش، میانگین خطای فاصله را می توان به عنوان مقدار میانگین خطاهای فاصله محاسبه شده برای 2097 توییت محاسبه کرد، که روش توانست استنتاج مکان را با موفقیت انجام دهد. با کنار گذاشتن توییتهای نامشخص، این روش مکان 87 درصد از توییتهای نمونه را با میانگین خطای مسافت 12.2 کیلومتر استنباط میکند که در مقایسه با روشهای پیشرفته کنونی، میتوان به عنوان یک پیشرفت قابل توجه در نظر گرفت. بیش از روش های استنتاج مکان فعلی
6. بحث، نتیجه گیری و کار آینده
توییتر نشان داده است که ابزاری موثر در انتشار و به دست آوردن اطلاعات به روز در مورد حوادث دنیای واقعی است. با این حال، مسائل و مشکلات قابل توجهی در حصول اطمینان از کیفیت و قابلیت اطمینان داده های توییتر برای واکنش اضطراری وجود دارد. در حال حاضر، با داشتن کمتر از 2٪ برچسب جغرافیایی، استنتاج مکان داده های توییتر یکی از چالش های قابل توجه است. برای ارائه بینش به دادههای توییتر و پیشنهاد راهحلهای ممکن، این مطالعه بررسی دقیقی در مورد عناصر مرتبط با مکان دادههای توییتر ارائه میکند. شناخت ماهیت دادههای توییتر و استفاده از روشهای مقابله با آن، به خودی خود، یک حوزه دانش ضروری است. بنابراین، توصیفی پیشرفته از عناصر مرتبط با مکان و همچنین ارائه وضعیت کلی فعلی هر عنصر از طریق مطالعات عملی،
این مطالعه همچنین یک روش استنتاج مکان چند عنصری را پیشنهاد میکند که از سه منبع احتمالی اطلاعات مکان استفاده میکند و تلاش میکند تا مکان توییتها را بر اساس این عناصر استنتاج کند. تا آنجا که نویسندگان آگاه هستند، روش استنتاج مکان پیشنهادی اولین روش در نوع خود است که تمام عناصر ممکن یک توییت را از طریق الگوریتمهای امتیازدهی و رتبهبندی برای دستیابی و پیشبینی بهترین سطح جزئیات مکان در نظر میگیرد. علاوه بر این، از نظر کارایی و دقت روش پیشنهادی، توانسته است موقعیت 87 درصد از توییت های نمونه را با میانگین خطای فاصله 12.2 کیلومتر و خطای میانگین فاصله 4.5 کیلومتر با موفقیت استنباط کند. این یک پیشرفت قابل توجه در مقایسه با روش های فعلی در ادبیات است، که می تواند مکان را یا با خطای پیش بینی فاصله بسیار بزرگتر و میانگین فاصله 200 کیلومتر و 30 کیلومتری پیش بینی کند. با این حال، این مطالعه محدودیت هایی را ارائه می دهد که باید اذعان کرد. این محدودیتها، در مرحله کنونی، شامل موارد زیر است، اما ممکن است محدود به آنها نباشد:
-
هنگامی که چندین مرجع مکان متعلق به یک کلاس نام مکان در یک عنصر مرتبط با مکان وجود دارد (مثلاً، متن توییت)، این روش فقط اولین نمونه را شناسایی می کند و بقیه را نادیده می گیرد. بررسی دقیقتر تعداد منتخبی از توییتها نشان میدهد که حدود 1٪ از توییتها ممکن است چندین مرجع مکان از یک کلاس (مثلاً نامهای چند حومه) داشته باشند، که به احتمال زیاد همسایه و مجاور هستند. حتی اگر این مقدار را می توان بدون تأثیر قابل توجهی بر عملکرد و دقت روش ناچیز در نظر گرفت، پیشرفت های آتی روش باید شامل رسیدگی پیچیده تری به چنین مواردی باشد.
-
این روش قادر به مقابله مناسب با ارجاعات مکانی نیست که ممکن است در عنصر مربوط به مکان در یک توییت یافت شود اما در کلاس های نام مکان وجود ندارد. حل این مشکل در آینده می تواند میزان موفقیت کلی روش را افزایش دهد.
-
این روش به گونهای برنامهریزی شده است که روی توییتهای انگلیسی اعمال شود و ممکن است در زبانهای غیرانگلیسی، بهویژه زبانهایی که از کاراکترهای غیرASCII استفاده میکنند (مانند عربی و چینی) قابل اجرا نباشد.
مطالعه به اینجا ختم نمی شود. اجرای روش برای انواع مختلف مجموعه داده های مرتبط با انواع حوادث (مانند آتش سوزی، زلزله و حملات تروریستی)، همراه با مراحل مورد نیاز برای غلبه بر محدودیت های ذکر شده در بالا، جهت گیری تحقیقاتی آینده را شکل می دهد که نویسندگان می خواهند. پيگيري كردن. علاوه بر این، بررسی عمیقتر نتایج، با تمرکز بر عناصر مرتبط با مکان با هدف تنظیم دقیق روش، میتواند به عنوان دیگر کارهای آینده در این خط در نظر گرفته شود.
اختصارات
در این نسخه از اختصارات زیر استفاده شده است:
| API | رابط برنامه نویسی کاربردی |
| ASCII | کد استاندارد آمریکایی برای تبادل اطلاعات |
| CDMPS | مرکز مدیریت بلایای طبیعی و ایمنی عمومی |
| جی پی اس | سیستم موقعیت یاب جهانی |
| JSON | نشانه گذاری شی جاوا اسکریپت |
منابع
- بی بی سی چگونه حملات پاریس در شبکه های اجتماعی آشکار شد. در دسترس آنلاین: http://www.bbc.com/news/blogs-trending-348 36214 (در 23 نوامبر 2015 قابل دسترسی است).
- South, JA اطلاعات اضطراری تعاملی و سیستمها و روشهای شناسایی. پتنت ایالات متحده 20,150,111,524, 23 آوریل 2015. [ Google Scholar ]
- استایگر، ای. آلبوکرک، JP; Zipf، A. مروری بر ادبیات سیستماتیک پیشرفته در مورد تجزیه و تحلیل مکانی-زمانی داده های توییتر. در معاملات در GIS ; کتابخانه آنلاین وایلی: هوبوکن، نیوجرسی، ایالات متحده آمریکا، 2015. صص 809-834. [ Google Scholar ]
- ویلیامز، SA; Terras, MM; وارویک، سی. مردم هنگام مطالعه توییتر چه چیزی را مطالعه می کنند؟ طبقه بندی مقالات دانشگاهی مرتبط با توییتر J. Doc. 2013 ، 69 ، 384-410. [ Google Scholar ] [ CrossRef ]
- هاینزلمن، جی. Waters, C. Crowdsourcing اطلاعات بحران در هائیتی آسیب دیده از بلایای طبیعی ; انتشارات موسسه صلح ایالات متحده: واشنگتن، دی سی، ایالات متحده آمریکا، 2010. [ Google Scholar ]
- منصوریان، ع. رجبی فرد، ع. Valadan Zoej، MJ; Williamson, I. استفاده از SDI و سیستم مبتنی بر وب برای تسهیل مدیریت بلایا. محاسبه کنید. Geosci. 2006 ، 32 ، 303-315. [ Google Scholar ] [ CrossRef ]
- پوزر، ک. Dransch، D. اطلاعات جغرافیایی داوطلبانه برای مدیریت بلایا با کاربرد برای برآورد سریع خسارت سیل. Geomatica 2010 ، 64 ، 89-98. [ Google Scholar ]
- توییتر. وبلاگ توییتر: مکان، موقعیت مکانی، مکان. در دسترس آنلاین: https://blog.twitter.com/2009/location-location-location (در 12 اکتبر 2015 قابل دسترسی است).
- چنگ، ز. کاورلی، جی. لی، کی. شما جایی هستید که توییت می کنید: رویکردی مبتنی بر محتوا برای مکان یابی کاربران توییتر. در مجموعه مقالات نوزدهمین کنفرانس بین المللی ACM در مدیریت اطلاعات و دانش، تورنتو، ON، کانادا، 26 تا 30 اکتبر 2010. صص 759-768.
- مورستاتر، اف. پففر، جی. لیو، اچ. Carley، KM آیا نمونه به اندازه کافی خوب است؟ مقایسه دادههای API جریان توییتر با Firehose توییتر ؛ دانشگاه کرنل arXiv: ایتاکا، نیویورک، ایالات متحده آمریکا، 2013. [ Google Scholar ]
- اداره هواشناسی. بررسی ماهانه آب و هوا استرالیا آوریل 2015. در دسترس آنلاین: http://www.bom.gov.au/climat e/mwr/aus/mwr-aus-201504.pdf (در 21 اکتبر 2015 قابل دسترسی است).
- پل، ام جی. Dredze، M. شما همان چیزی هستید که توییت می کنید: تحلیل توییتر برای سلامت عمومی. در مجموعه مقالات پنجمین کنفرانس بین المللی AAAI در وبلاگ ها و رسانه های اجتماعی، بارسلون، اسپانیا، 17 تا 21 ژوئیه 2011.
- سیولا، اف. موکانو، دی. بارونچلی، آ. گونسالوز، بی. پرا، ن. Vespignani، A. ضرب و شتم اخبار با استفاده از رسانه های اجتماعی: مطالعه موردی American Idol. EPJ Data Sci. 2012 ، 1 ، 1-11. [ Google Scholar ] [ CrossRef ]
- اسکوریچ، م. پور، ن. آچانانوپارپ، پ. لیم، ای.-پی. جیانگ، جی. توییتها و رایها: بررسی انتخابات عمومی سال 2011 سنگاپور. در مجموعه مقالات چهل و پنجمین کنفرانس بین المللی هاوایی در علم سیستم (HICSS)، مائوئی، HI، ایالات متحده آمریکا، 4 تا 7 ژانویه 2012. صص 2583-2591.
- اوکو، ک. اوئنو، ک. هاتوری، اف. نقشه برداری از توییت های دارای برچسب جغرافیایی به نقاط توریستی برای سیستم های توصیه کننده. در مجموعه مقالات سومین کنفرانس بین المللی IIAI در زمینه انفورماتیک کاربردی پیشرفته (IIAIAAI)، کیتاکیوشو، ژاپن، 31 اوت تا 4 سپتامبر 2014. صص 789-794.
- ساکاکی، ت. اوکازاکی، م. Matsuo, Y. زلزله کاربران توییتر را تکان داد: تشخیص رویداد در زمان واقعی توسط حسگرهای اجتماعی. در مجموعه مقالات نوزدهمین کنفرانس بین المللی وب جهانی، رالی، NC، ایالات متحده، 26-30 آوریل 2010; صص 851-860.
- آجائو، او. هونگ، جی. لیو، دبلیو. بررسی تکنیکهای استنتاج مکان در توییتر. J. Inf. علمی 2015 ، 41 ، 855-864. [ Google Scholar ] [ CrossRef ]
- آیزنشتاین، جی. اوکانر، بی. اسمیت، NA; Xing، EP یک مدل متغیر پنهان برای تنوع واژگانی جغرافیایی. در مجموعه مقالات کنفرانس 2010 در مورد روشهای تجربی در پردازش زبان طبیعی، استرودزبورگ، PA، ایالات متحده آمریکا، 27-29 ژوئیه 2010; ص 1277–1287.
- بال، BP; بالدریج، جی. مکان یابی اسناد نظارت شده ساده با شبکه های ژئودزیکی. در مجموعه مقالات چهل و نهمین نشست سالانه انجمن زبانشناسی محاسباتی: فناوریهای زبان انسانی، پورتلند، OR، ایالات متحده آمریکا، 19 تا 24 ژوئن 2011. ص 955-964.
- واتانابه، ک. اوچی، م. اوکابه، م. Onai, R. Jasmine: یک سیستم تشخیص رویداد محلی در زمان واقعی بر اساس اطلاعات موقعیت جغرافیایی منتشر شده در میکروبلاگ ها. در مجموعه مقالات بیستمین کنفرانس بین المللی ACM در مدیریت اطلاعات و دانش، گلاسکو، اسکاتلند، 24 تا 28 اکتبر 2011. صص 2541-2544.
- دالوی، ن. کومار، آر. Pang، B. تطبیق اشیاء در توییتها با مدلهای فضایی. در مجموعه مقالات پنجمین کنفرانس بین المللی ACM در جستجوی وب و داده کاوی، سیاتل، WA، ایالات متحده، 8-12 فوریه 2012; صص 43-52.
- هان، بی. کوک، پی. بالدوین، تی. پیشبینی موقعیت جغرافیایی کاربر توییتر مبتنی بر متن. جی آرتیف. هوشمند Res. 2014 ، 49 ، 451-500. [ Google Scholar ]
- مینوت، ع. هییر، ا. کینگ، دی. سیمک، او. استانیشا، ن. جستجوی پستهای توییتر بر اساس مکان. در مجموعه مقالات کنفرانس بین المللی 2015 در نظریه بازیابی اطلاعات، نورث همپتون، MA، ایالات متحده، 27-30 سپتامبر 2015. صص 357-360.
- هچت، بی. هونگ، ال. سو، بی. توییتهای چی، EH از قلب جاستین بیبر: پویایی فیلد مکان در پروفایلهای کاربر. در مجموعه مقالات کنفرانس SIGCHI در مورد عوامل انسانی در سیستم های محاسباتی، ونکوور، BC، کانادا، 7-12 مه 2011. صص 237-246.
- هیروتا، اس. یونزاوا، تی. جورمو، م. توکودا، اچ. تشخیص، طبقهبندی و تجسم توییتهای دارای برچسب جغرافیایی ایجاد شده در مکان. در مجموعه مقالات کنفرانس ACM 2012 در محاسبات همه جا حاضر، پیتسبورگ، PA، ایالات متحده آمریکا، 5-8 سپتامبر 2012. ص 956-963.
- شولز، آ. هاجاکوس، ا. پاولهایم، اچ. ناچتوی، جی. Mühlhäuser، M. یک رویکرد چند شاخص برای مکانیابی جغرافیایی توییتها. در مجموعه مقالات هفتمین کنفرانس بین المللی AAAI در وبلاگ ها و رسانه های اجتماعی، کمبریج، MA، ایالات متحده آمریکا، 8 تا 11 ژوئیه 2013.
- توییتر. مستندات توسعه دهندگان توییتر. در دسترس آنلاین: https://dev.twitter.com/overview/documentation (در 21 اکتبر 2015 قابل دسترسی است).
- Dataminr. در دسترس آنلاین: https://www.dataminr.com/ (در 16 ژانویه 2016 قابل دسترسی است).
- GNIP. در دسترس آنلاین: https://www.gnip.com/ (در 16 ژانویه 2016 قابل دسترسی است).
- DATASIFT. در دسترس آنلاین: http://www.datasift.com/ (در 16 ژانویه 2016 قابل دسترسی است).
- اداره آمار استرالیا در دسترس آنلاین: http://www.abs.gov.au/ (در 16 ژانویه 2016 قابل دسترسی است).
- ذکاوت، ر. Buehrer, RM Handbook of Position Location: Theory, Practice and Advances ; جان وایلی و پسران: هوبوکن، نیوجرسی، ایالات متحده آمریکا، 2011. [ Google Scholar ]
- ریک، دی. استخراج فرمول هاورسین. در دسترس آنلاین: http://mathforum.org/ library/drmath /view/51879.html (در 16 ژانویه 2016 قابل دسترسی است).
شکل 1. یک توییت با فرمت JSON تورفتگی.

شکل 2. وضعیت فعلی عناصر مرتبط با مکان داده های توییتر.
شکل 3. نمای کلی روش و اجزای آن.
شکل 4. منطقه جمع آوری داده ها.

شکل 5. روش نمونه گیری داده ها.
شکل 6. حومه شهر با منطقه جمع آوری داده ها تقاطع یافته است.

شکل 7. توزیع مبتنی بر خطای فاصله توئیت های استنباط شده مکان.
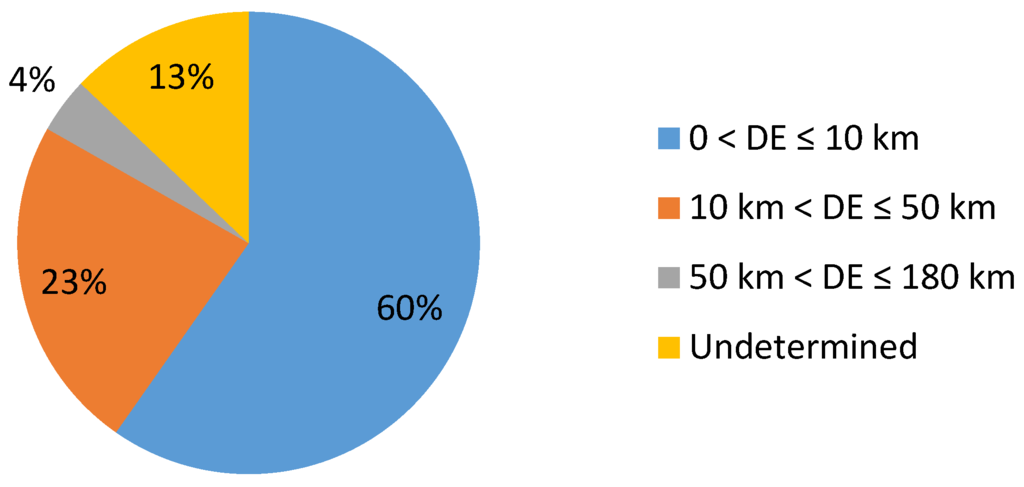
شکل 8. دقت روش استنتاج مکان بر اساس خطای فاصله (DE).

جدول 1. فهرست عناصر مرتبط با مکان در یک توییت.
جدول 2. نتایج کاربرد روش در توییت های نمونه.
© 2016 توسط نویسندگان؛ دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (CC-BY) (http://creativecommons.org/licenses/by/4.0/) توزیع شده است
بدون نظر