

خلاصه
شبکه های اجتماعی مبتنی بر مکان ؛ رسانه های دارای برچسب جغرافیایی ; خدمات مبتنی بر مکان ؛ علایق کاربر ؛ سیستم توصیه گر
1. معرفی
-
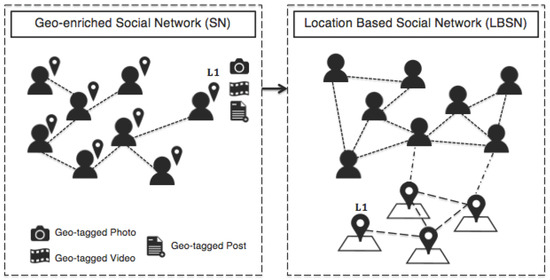
غنیسازی جغرافیایی SNها، کاربران را قادر میسازد تا محتوای دارای برچسب جغرافیایی را در قالب اعلام حضور، عکسهای دارای برچسب جغرافیایی یا یادداشت به اشتراک بگذارند.
-
نسل جدیدی از شبکه های اجتماعی به نام شبکه های اجتماعی مبتنی بر مکان (LBSNs) ظاهر شد که مکان ها عناصر اصلی ساختار شبکه هستند. از این رو، یک مکان می تواند یک موجودیت مستقل از شبکه باشد که با سایر مکان ها و کاربران ارتباط دارد.
-
SN ها، به دلیل پایگاه کاربر بزرگ، دارای مقادیر وسیعی از محتوای برچسب گذاری شده جغرافیایی هستند که به دلیل فقدان قابلیت های پردازش فضایی، کمتر مورد استفاده قرار می گیرد. دقیقاً، رسانه های دارای برچسب جغرافیایی در SN های اشتراک گذاری عکس (به عنوان مثال، اینستاگرام) همیشه با حاشیه نویسی برچسب همراه هستند که در صورت سوء استفاده، محتوای مکان به میزان قابل توجهی غنی می شود. آنها همچنین چیزی را ارائه می دهند که می توان آن را “خرد جمعی” نامید، یعنی شناسایی اقلام / فعالیت های جالب در یک مکان بر اساس تجربیات قبلی افراد در آن مکان.
-
LBSN ها، علیرغم قابلیت های پردازش فضایی خود، نمی توانند پایگاه کاربری بزرگی را جذب کنند، زیرا ارزش کمتری را برای کاربران غیرفعال فراهم می کنند. آنها همچنین برای ارائه توصیه ها به شدت به نمایه های کاربر، تاریخچه موقعیت مکانی کاربر و مسیرهای کاربر متکی هستند که بر شدت مشکل شروع سرد می افزاید. بنابراین، کیفیت توصیههای شخصیشده تنها به فناوری وابسته نیست، بلکه به فعالیتها و ویژگیهای کاربر نیز بستگی دارد.
-
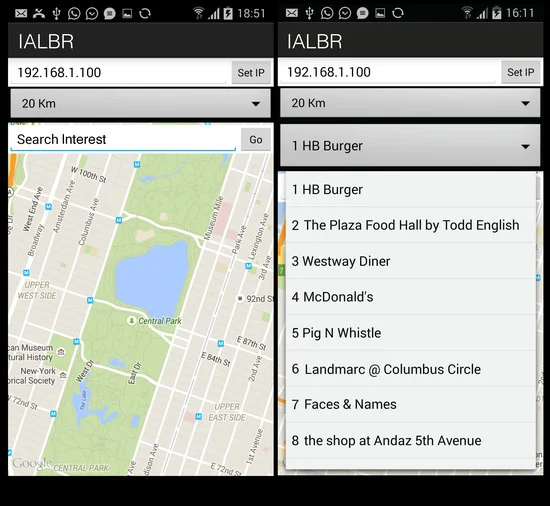
در تمام کارهای مرتبط قبلی، عوامل مؤثر بر توصیه مکان شخصیشده به جمعیتشناسی کاربر، نزدیکی به مکان، تحرک کاربر و سابقه موقعیت مکانی محدود میشود. با این حال، علاقه خاص کاربر در هر مقطع زمانی قبلاً مورد توجه قرار نگرفت. برای مثال، کاربر فهرستی از رستورانهایی را میخواهد که بهترین برگر شهر را سرو میکنند، به شرطی که در محدوده جغرافیایی مشخصی قرار داشته باشند. برای برآورده کردن این درخواست، نمایه کاربر و تاریخچه موقعیت مکانی کاربر به اندازه تشخیص اینکه کدام رستوران بهترین همبرگر را سرو می کند مهم نخواهد بود. به عبارت دیگر، نه تنها در مورد رتبه بندی مکان ها، بلکه در مورد رتبه بندی اقلام / فعالیت های جالب در مکان ها است.
-
پیوند SN و LBSN برای توصیه آگاهانه از علاقه: پیوستن حاشیهنویسیهای رسانه با برچسب جغرافیایی در SNها به مکانهای مربوطه آنها در LBSN.
-
توصیه و امتیازدهی آگاه به علاقه: IALBR از توصیه هایی (به عنوان مثال، رستوران ها) مطابق با علاقه بسیار خاص کاربر (مانند سیب زمینی سرخ کرده) پشتیبانی می کند. این توصیه بر اساس یک روش امتیازدهی جدید انجام می شود که هم محبوبیت یک علاقه در مکان و هم محبوبیت مکان را در نظر می گیرد.
2. کارهای مرتبط
-
مبتنی بر نمایه کاربر: اینها توصیهکنندگانی هستند که مکانها را با تطبیق معنای مکان یا ابرداده با نمایههای کاربر پیشنهاد میکنند. برای مثال، [ 11 ] داده های نمایه کاربر (به عنوان مثال، جنسیت، درآمد و سن) را با قیمت و دسته یک رستوران با استفاده از مدل شبکه بیزی مطابقت می دهد. دیگران نزدیکی مکان نامزد [ 12 ] را در نظر گرفتند یا از دستگاه های ارزان قیمت [ 13 ] با تمرکز بر استفاده از آدرس کاربر و وابستگی اجتماعی پشتیبانی کردند. در [ 14 ، 15 ، 16]، نویسندگان سعی کردند با استخراج ویژگیها و شناسایی همبستگیها و زیر دنبالههای مرتبط با فعالیتهای ترجیحی کاربر، روابط مکانی و زمانی بین مکانهای درون مسیرها را کشف کنند.
-
مبتنی بر سابقه موقعیت مکانی کاربر: اینها توصیهکنندگانی هستند که از تاریخچه موقعیت مکانی کاربر از طریق رتبهبندیهایی که به مکانهایی که بازدید کردهاند یا از طریق سابقه اعلام حضور خود استفاده میکنند. برای مثال [ 17 , 18 , 19 , 20 , 21 , 22] با در نظر گرفتن رتبهبندی سایر کاربران با استفاده از مدلهای فیلتر مشارکتی (CF)، توصیههای شخصیسازی شده برای مکانها ارائه کرد. از این رو، این امر با نادیده گرفتن مکانهایی که بازبینی ضعیفی دارند و میتوانند با نمایه کاربر در توصیهکنندگان مبتنی بر نمایه کاربر مطابقت داشته باشند، کیفیت توصیه را بهبود بخشید. توصیه مبتنی بر CF ابتدا با شناسایی کاربران مشابه، با استفاده از تاریخچه رتبه بندی آنها، و سپس انتخاب زیرمجموعه ای از مکان های نامزد بر اساس موقعیت مکانی کاربر و در نهایت، پیش بینی رتبه ای که کاربر به این مکان می دهد، انجام شد. کار در [ 23 ] همچنین یک مدل تصادفی مبتنی بر پیادهروی ایجاد کرد که مکانهای جدید را با یادگیری همزمان از روابط اجتماعی و ورود به جلسه توصیه میکرد. علاوه بر این، نویسندگان در [ 24] از دادههای ورود برای مدلسازی احتمال ورود کاربر در مکانی به عنوان مدل گاوسی چند مرکزی (MGM) استفاده کرد. این امر از طریق ادغام فاکتورسازی ماتریس با نفوذ جغرافیایی و اجتماعی انجام شد. نویسندگان در [ 25 ] همچنین از طریق استفاده از فاکتورسازی ماتریس وزن دار که شامل خوشه بندی فضایی است، از داده های ورود به سیستم برای توصیه مکان استفاده کردند. اخیراً، [ 26 ] یک رویکرد توصیه مکان شخصیشده را معرفی کرده است که مبتنی بر شناسایی همبستگیهای بین POI از طریق سرمایهگذاری بر دادههای ثبتنام تاریخی کاربران است.
-
مبتنی بر مسیر کاربر: اینها توصیهکنندگانی هستند که اولویتهای کاربر را بر اساس ترتیب مکانهای بازدید شده، مسیر طی شده و زمان اقامت در مکانها تخمین میزنند. سیستمهای نمونه شامل [ 27 ، 28 ، 29 ، 30 ، 31 ، 32 ، 33 ] است که چارچوبهای توصیهای را پیشنهاد میکنند که مکانهای جالبی را با استخراج دادههای مسیر GPS پیشنهاد میکنند. نویسندگان در [ 34 ] GTAG را پیشنهاد کردند، یک توصیهکننده مکان آگاه از زمان که تأثیرات جغرافیایی و زمانی را از طریق بهرهبرداری از حجم زیادی از دادههای مسیر مکانی-زمانی کاربر در نظر میگرفت. اخیراً [ 26] یک مدل جدید برای توصیه مکان به نام LORE ایجاد کرد که الگوهای متوالی را از دادههای ثبتنام تاریخی همه کاربران استخراج میکرد تا از آنها در پیشبینی مکانی که کاربران علاقهمند به بازدید از آن هستند استفاده کند.
-
مبتنی بر اطلاعات مکان: اینها توصیهکنندگانی هستند که POI را بر اساس اطلاعات مکان نشاندادهشده در ویژگیهای POI (مثلاً مکان مکانی)، محتوای تولید شده توسط کاربر (مثلاً نکات)، رسانههای برچسبگذاریشده جغرافیایی کاربر، و غیره توصیه میکنند. در میان این توصیهکنندگان، Orec [ 35 ]، یک چارچوب توصیه مبتنی بر نظر است که POI را بر اساس نظرات کاربران موجود در نکات محل برگزاری توصیه می کند. در [ 36 ]، نویسندگان از فیلتر مشارکتی آگاهانه محتوا با بازخورد ضمنی (ICFF) برای توصیه مکان برای ترکیب محتوای معنایی (به عنوان مثال، توییتهای دارای برچسب جغرافیایی) بدون نمونهگیری منفی (یعنی ترجیحات منفی کاربر) استفاده کردند. علاوه بر این، نویسندگان در [ 37] Geo-SAGE را پیشنهاد کرد، یک مدل مولد افزودنی پراکنده جغرافیایی برای توصیه POI، که از نفوذ جغرافیایی و اجتماعی یکپارچه، اثر زمانی و اطلاعات محتوایی POI برای توصیه بهرهبرداری کرد. علاوه بر این، [ 38 ، 39 ] سیستمهایی پیشنهاد کرد که از رسانههای برچسبگذاریشده جغرافیایی در برنامههای اشتراکگذاری عکس برای شناسایی مکانهای گردشگری معنادار از نظر معنایی بهرهبرداری میکنند. آنها فیلتر مشترک را برای به دست آوردن ترجیحات گردشگران در یک شهر، از عکس های برچسب جغرافیایی عمومی خود، اعمال کردند و از آن برای توصیه سفر شخصی در شهر دیگر استفاده کردند.
-
ترکیبی: اینها توصیهکنندههایی هستند که دستههای منابع داده بالا را برای توصیه مکان ادغام میکنند. برای مثال، نویسندگان در [ 40 ] از یک مدل عامل احتمالی استفاده کردند که ترجیحات کاربر را با شمارش ورود کاربر (سابقه مکان کاربر)، تأثیر جغرافیایی (اطلاعات مکان) و رفتارهای تحرک کاربر (مسیر کاربر) برای ارائه توصیههای شخصی در نظر میگیرد. از مکان ها نویسندگان در [ 41 ] چارچوب توصیهای را توسعه دادند که بر روی اطلاعات POI، به عنوان ویژگیهای مکان، علایق کاربر و تشخیص احساسات، برای بهبود توصیههای POI در LBSNها، سرمایهگذاری کرد. مثال دیگری را می توان در [ 42]، که یک سیستم توصیهکننده را پیشنهاد میکند که مجموعههای بزرگی از رسانههای برچسبگذاریشده جغرافیایی (اطلاعات مکان) را برای شناسایی محبوبترین نشانهها، و همچنین بهترین مسیر سفر بین نشانهها (مسیر کاربر) را برای استفاده در جادهها استخراج میکند. توصیه سفر یک چارچوب مشابه، اما شخصیشدهتر در [ 43 ] پیشنهاد شد که در آن مجموعههای مقیاس بزرگی از رسانههای برچسبگذاری شده جغرافیایی عکاس (اطلاعات مکان) برای شناسایی مسیرها (مسیر کاربر) در نقاط دیدنی جالب استخراج شدند، و از آنها برای توسعه مدلهای رفتار عکاس احتمالی استفاده کردند . توصیه مسیر سفر شخصی
3. طراحی سیستم IALBR
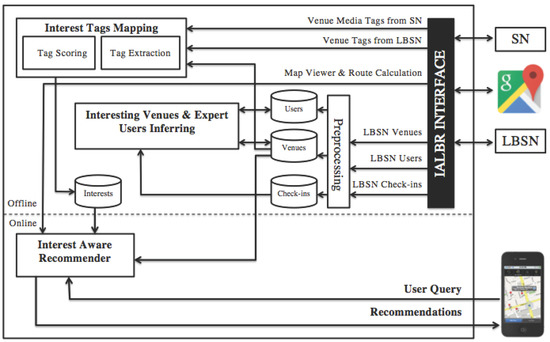
3.1. معماری سیستم
-
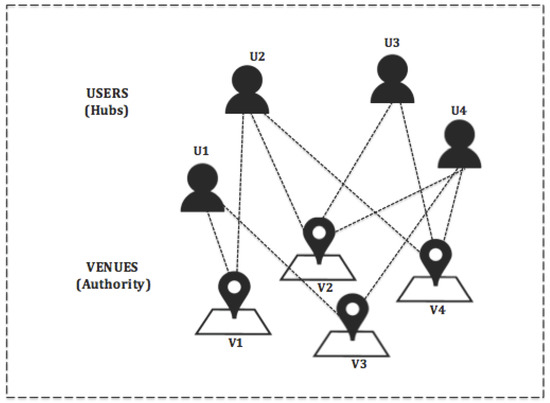
مدلسازی آفلاین: این کار با خزیدن رسانههای برچسبگذاری شده جغرافیایی اینستاگرام مربوط به مکانهای Foursquare با استفاده از توابع API اینستاگرام و کلیدهای منحصربهفرد مکان، مشترک در Foursquare و Instagram شروع میشود. سپس تگهای رسانهای با برچسب جغرافیایی که نشان دهنده علایق هستند را استخراج میکند تا امتیازات علاقه را بر اساس فراوانی وقوع آن برچسبها محاسبه کند. همچنین برچسب های علاقه مندرج در این مکان را در Foursquare استخراج می کند. در نهایت، یک امتیاز میانگین وزنی برای هر برچسب بهره بر اساس فراوانی وقوع آن در هر دو LBSN و SN محاسبه میشود. شکل 4رسانههای دارای برچسب جغرافیایی را نشان میدهد که از مکانی به نام «تدز» در اینستاگرام استخراج شدهاند. هر عکس حاوی برچسب هایی است که آن را حاشیه نویسی می کند. در این مثال، برچسبهای علاقهای شبیه به این عکسها عبارتند از: #توت فرنگی، #موهیتو، #مولتنکک، #شکلاتسوفل، #ماکنشیز، #ماکرونی و #پنیر.یکی دیگر از فرآیندهای آفلاین مهم در مکانهای جالب و ماژول استنباط کاربر متخصص انجام میشود، جایی که کاربران امتیازات مرکز و مکانها با استفاده از اطلاعات اعلام حضور امتیازات مرجع را دریافت میکنند. کاربری با امتیاز هاب بالا، کاربری است که از مکانهای جالب زیادی بازدید میکند (یعنی مکانهایی که امتیاز اتوریتی بالایی دارند)، و مکانی که امتیاز اتوریتی بالایی دارد، مکانی است که توسط بسیاری از کاربران متخصص بازدید میشود (یعنی کاربرانی که امتیازات هاب بالایی دارند) .
-
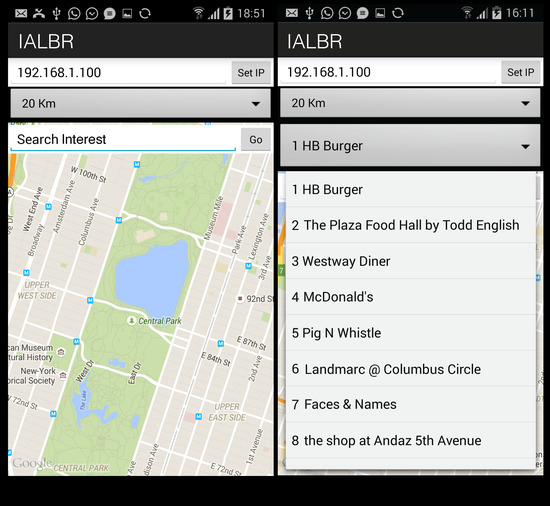
توصیه آنلاین: این زمانی شروع میشود که IALBR یک درخواست کاربر را دریافت میکند که از مکانهایی مطابق با یک علاقه (مثلاً برگر) در محدوده جغرافیایی خاص (مثلاً 10 کیلومتر) درخواست میکند. امتیاز توان p برای مکان هایی که با این علاقه مطابقت دارند محاسبه می شود و در محدوده جغرافیایی از پیش تعیین شده قرار دارند. این امتیاز قدرت بر اساس امتیاز برچسب علاقه حاصل از ماژول نگاشت برچسبهای علاقه و امتیاز اعتبار مکان ناشی از مکانهای جالب و ماژول استنباط کاربر متخصص محاسبه میشود. در نهایت، فهرستی رتبهبندی شده از توصیههای مکان را برمیگرداند.
3.2. مدل داده
جایی که یک کاربر تومنتومندارای نام n و شهر خانه hc است . ما ورودی کاربر را با یک امتیاز مرکز محاسبه شده غنی می کنیم ساعت (تومن)ساعت(تومن). این امتیاز با استفاده از روش [ 32 ] نیز محاسبه می شود. امتیاز هاب بالاتر نشان می دهد که کاربر با تجربه است و برچسب های او بیشتر مورد اعتماد هستند. نمونه ای از یک کاربر به صورت زیر ارائه می شود: (“توماس روسی”، “واشنگتن، دی سی”، 2.97).
به معنی کاربر تومن∈ Uتومن∈�دارای لیستی از جفت های مرتب شده است ( v , t )(�،تی)، جایی که v ∈ V�∈�محل برگزاری و t∈ T _تی∈تییک مهر زمان است. نمونه ای از اعلام حضور برای یک کاربر به صورت زیر ارائه می شود: (“توماس روسی”، < (“Amrit”، 17 ژانویه 2013 9:02:30)، (“TUM”، 17 ژانویه 2013 9:05:51) ، (“Marineplatz”, 17 ژانویه 2013 9:05:51)>). اجازه دهید C مجموعه ای از این ورودی ها برای همه کاربران در U باشد .
3.3. ماژول نقشه برداری برچسب های علاقه
3.4. مکان های جالب و ماژول استنباط کاربر متخصص
جایی که σ تعداد ورود کاربر است تومنتومنکه در vj��و λ تعداد ورود کاربر است توjتو�که در vمن�من.
3.5. ماژول پیشنهاد دهنده علاقه مند
جایی که سمنjسمن�میانگین وزنی نمره یک است من n t e r e sتیمنمن�تیه�هستیمندر یک مکان vj��. مقدار آن کمتر از یک است. در حالی که یک (vj)آ(��)امتیاز اعتبار محل برگزاری است vj��با استفاده از HITS محاسبه می شود. به این ترتیب، امتیاز توان p از an من n t e r e sتیمنمن�تیه�هستیمنکسری از اختیارات کل محل برگزاری خواهد بود vj��تعیین شده توسط محبوبیت من n t e r e sتیمنمن�تیه�هستیمندر آن، یعنی، هر چه مقدار p بیشتر باشد ، محبوبیت آن بیشتر است من n t e r e sتیمنمن�تیه�هستیمنکه در vj��.
| الگوریتم 1: توصیه کننده آگاه از علاقه. |
| ورودی : (1) مکان جغرافیایی کاربر ; (2) توصیه محدوده جغرافیایی r ; (3) علاقه کاربر i |
| خروجی : یک لیست مرتب شده L از توصیه های مکان. |
 |
4. پیاده سازی سیستم
5. ارزیابی تجربی
5.1. تنظیمات آزمایشی
-
کاربرد توصیه ها
-
رتبه بندی توصیه ها
5.2. نتایج تجربی
5.2.1. کاربرد توصیه ها
5.2.2. رتبه بندی توصیه ها
که در آن rel ارتباط درجه بندی شده نتیجه در موقعیت i است. برای اینکه بتوانیم این مقایسه را انجام دهیم، باید امتیازهای P IALBR را به یک مقیاس پنج ستاره شبیه به مقیاس Yelp تبدیل کنیم. ما مقیاس را طوری تنظیم کردیم که به مکانی که بالاترین p را برای برچسب علاقه “برگر” در کل مجموعه داده ما دارد، امتیاز پنج می دهد و به مکانی که کمترین p را برای همان برچسب علاقه دارد، امتیاز یک می دهد. .
6. بحث
-
سناریو 1، LBSN ها:اجازه دهید فرض کنیم که کاربر Foursquare به دنبال مکانی برای خوردن “برگر” در محدوده جغرافیایی 20 کیلومتری است. تنها راهی که Foursquare می تواند به این پرس و جو پاسخ دهد، جستجوی کلمه “برگر” در برچسب های مکان های این محدوده جغرافیایی است. در آزمایش ما، چهار توصیه بازگردانده شد، که نشان میدهد LBSN به تنهایی توصیههای کمتری را ارائه میدهد. برای همان پرس و جو، IALBR گزینه های مرتبط جدیدی با نمرات p حتی بهتر (مثلاً Nature Works و The Plaza Food Hall) کشف کرد.
-
سناریو 2، LBSN ها و SN ها:یک کاربر از یک LBSN استفاده می کند که از رسانه های برچسب گذاری شده جغرافیایی SN برای ترسیم علایق به مکان ها استفاده می کند. این سناریو از روش HITS برای استنباط کاربران خبره و مکان های جالب استفاده نمی کند. کاربر به دنبال مکانی برای خوردن “برگر” در محدوده جغرافیایی 20 کیلومتری است. مکانهایی را توصیه میکند که اغلب موارد پرس و جو را در رسانههای دارای برچسب جغرافیایی و نکات و برچسبهای LBSN دارند. با اجرای این پرس و جو، توانستیم 10 مکان را توصیه کنیم که با استفاده از میانگین امتیازات وزنی توضیح داده شده در بخش 3.2 مرتب شده اند .، اما بدون در نظر گرفتن اینکه آیا آن مکان ها “مکان های جالب” هستند یا معمولا توسط کاربران “متخصص” بازدید می شوند. با مقایسه این نتایج با نتایج IALBR، متوجه میشویم که IALBR نه تنها مکانهایی را توصیه میکند که دارای علاقه پرس و جو در میان علایق برتر هستند، بلکه باید مکانهایی با کیفیت باشند (یعنی اغلب توسط کاربران متخصص بازدید میشوند). به عنوان مثال: مک دونالد به برگر معروف است، بنابراین احتمالاً در این سناریو با رتبه بالایی ظاهر می شود. با این حال، به دلیل کیفیت غذای متوسط شناخته شده است و معمولاً توسط کاربران متخصص بازدید نمی شود، که به آن نمره اعتبار پایینی می دهد. از آنجایی که رویکرد IALBR امتیاز اعتبار محل برگزاری را در نظر می گیرد، مک دونالد رتبه پایین تری را کسب می کند. این نشان می دهد که IALBR بین نظر متخصص و افکار عمومی در مورد علاقه پرس و جو، مبادله درستی انجام می دهد.
-
سناریو 3، آمار:این کاربری است که از یک LBSN استفاده میکند که از رسانههای برچسبگذاریشده جغرافیایی SN برای ترسیم علایق به مکانها استفاده میکند. از مدل HITS برای استنتاج کاربران خبره و مکان های جالب استفاده می کند. اگر کاربر به دنبال مکانی برای خوردن “برگر” در محدوده جغرافیایی 20 کیلومتری است، این سیستم “مکان های” جالبی را توصیه می کند که حاوی “برگر” مورد علاقه کاربر نیز می باشد. با شبیه سازی این سیستم، ما توانستیم 10 مکان را با استفاده از امتیاز مرجع محل برگزاری a ( v ) که در بخش 3.3 توضیح داده شده است، مرتب کنیم.. با مقایسه نتایج این سناریو با نتایج IALBR، متوجه شدیم که HITS به تنهایی مکانهایی را ارائه میکند که امتیازات بسیار بالایی به عنوان مکانهای “جالب” دارند که توسط “متخصصان” بازدید میشوند و آیتم پرس و جو را در بین برچسبهای خود قرار میدهند. با این حال، نتیجه شامل مکان هایی است که چندان مرتبط نیستند. به عنوان مثال: استفاده از HITS به تنهایی “New York Hilton Midtown” را به عنوان اولین گزینه برای برگر آورده است. درست است که می توانید یک همبرگر عالی را در آنجا میل کنید، اما این توصیه بر اساس محبوبیت محل برگزاری بود، نه بر اساس محبوبیت کالای مورد علاقه (یعنی برگر) در محل برگزاری.
7. نتیجه گیری
منابع
- رادیکتی، س. Hoang، Q. گزارش آمار ایمیل، 2011–2015 ; The Radicati Group, Inc.: Palo Alto, CA, USA, 2011. [ Google Scholar ]
- بائو، جی. ژنگ، ی. ویلکی، دی. Mokbel، MF نظرسنجی در مورد توصیهها در شبکههای اجتماعی مبتنی بر مکان. ACM Trans. هوشمند سیستم تکنولوژی 2013 ، 19 ، 525-565. [ Google Scholar ] [ CrossRef ]
- Zheng, Y. آموزش در مورد شبکه های اجتماعی مبتنی بر مکان. در مجموعه مقالات بیست و یکمین کنفرانس بین المللی وب جهانی (WWW)، لیون، فرانسه، 16 تا 20 آوریل 2012.
- Constine, J. اینستاگرام برای پیشی گرفتن از توییتر به 300 میلیون کاربر ماهانه می رسد و با نشان های تایید شده آن را واقعی نگه می دارد. 2014. موجود به صورت آنلاین: http://techcrunch.com/2014/12/10/not-a-fad/ (دسترسی در 6 دسامبر 2016).
- D’Onfro, J. این نمودار نشان می دهد که چگونه اینستاگرام در نیمی از زمان توییتر به 150 میلیون کاربر رسیده است. 2014. در دسترس آنلاین: http://www.businessinsider.com/instagram-growth-chart-2014-2 (دسترسی در 6 دسامبر 2016).
- ابتکار جدید داده های بزرگ اسمیت، سی. فورسکوئر به پیشرفت آن کمک می کند، حتی با پایان یافتن ورود. 2014. موجود آنلاین: http://www.businessinsider.com/foursquare-surpasses-45-million-registered-users-and-begins-collecting-data-in-new-ways-2-2014-1 (دسترسی در 6 دسامبر 2016).
- تعداد کاربران فعال ماهانه اینستاگرام از ژانویه 2013 تا ژوئن 2016 (به میلیون). 2016. موجود به صورت آنلاین: https://www.statista.com/statistics/253577/number-of-monthly-active-instagram-users/ (دسترسی در 6 دسامبر 2016).
- Weber، JNH Foursquare بر اساس اعداد: 60 متر کاربران ثبت نام شده، 50 متر Maus، و 75 متر نکات تا به امروز. 2015. موجود آنلاین: http://venturebeat.com/2015/08/18/foursquare-by-the-numbers-60m-registered-users-50m-maus-and-75m-tips-to-date/ (دسترسی در 6 دسامبر 2016).
- Wilhelm, A. خرید دیوانه کننده فیس بوک اینستاگرام در مورد ارزش Foursquare به ما چه می گوید. 2012. موجود به صورت آنلاین: http://thenextweb.com/insider/2012/04/13/what-instagrams-crazy-facebook-buyout-tells-us-about-the-value-of-foursquare/ (دسترسی در 6 دسامبر 2016).
- خلاصه نام تجاری GWI q1 2014. در دسترس آنلاین: http://www.media2000.it/wp-content/uploads/2014/04/GWI_Brand_Summary.pdf (در 6 دسامبر 2016 قابل دسترسی است).
- پارک، MH; هنگ، جی اچ. Cho, SB سیستم توصیه مبتنی بر مکان با استفاده از مدل ترجیحی کاربر بیزی در دستگاه های تلفن همراه. در هوش و محاسبات همه جا حاضر ؛ Springer: برلین/هایدلبرگ، آلمان، 2007; صص 1130–1139. [ Google Scholar ]
- برزسونی، اس. کوسمن، دی. Stocker, K. اپراتور افق. در مجموعه مقالات هفدهمین کنفرانس بین المللی IEEE در مهندسی داده، واشنگتن، دی سی، ایالات متحده آمریکا، 2 تا 6 آوریل 2001.
- راماسوامی، ال. دیپک، پی. پولواراپو، آر. گوناسکرا، ک. گارگ، دی. Visweswariah، K. Kalyanaraman، S. Caesar: یک سیستم توصیهکننده اجتماعی آگاه از زمینه برای دستگاههای تلفن همراه ارزان قیمت. در مجموعه مقالات دهمین کنفرانس بینالمللی مدیریت دادههای تلفن همراه: سیستمها، خدمات و میانافزار (MDM’09)، تایپه، تایوان، 18–21 مه 2009. صص 338-347.
- لو، CT; لی، روابط عمومی؛ پنگ، WC; سو، ج. چارچوبی از استخراج مناطق معنایی از مسیرها. در سیستم های پایگاه داده برای برنامه های کاربردی پیشرفته ; Springer: برلین/هایدلبرگ، آلمان، 2011; ص 193-207. [ Google Scholar ]
- بله، م. یانوویچ، ک. مولیگان، سی. لی، دبلیو. آنچه شما هستید زمانی است که هستید: بعد زمانی انواع ویژگی ها در شبکه های اجتماعی مبتنی بر مکان. در مجموعه مقالات نوزدهمین کنفرانس بینالمللی ACM SIGSPATIAL در مورد پیشرفتها در سیستمهای اطلاعات جغرافیایی، شیکاگو، IL، ایالات متحده آمریکا، 1–4 نوامبر 2011. صص 102-111.
- بله، م. شو، دی. لی، دبلیو. یین، پی. Janowicz، K. در حاشیه نویسی معنایی مکان ها در شبکه های اجتماعی مبتنی بر مکان. در مجموعه مقالات هفدهمین کنفرانس بین المللی ACM SIGKDD در مورد کشف دانش و داده کاوی (KDD’11)، سن دیگو، کالیفرنیا، ایالات متحده آمریکا، 21 تا 24 اوت 2011.
- Chow، CY; بائو، جی. Mokbel، MF به سمت خدمات شبکه اجتماعی مبتنی بر مکان. در مجموعه مقالات دومین کارگاه بین المللی ACM SIGSPATIAL درباره شبکه های اجتماعی مبتنی بر مکان، سن خوزه، کالیفرنیا، ایالات متحده آمریکا، 3 تا 5 نوامبر 2010. صص 31-38.
- هوروزوف، تی. نراسیمهان، ن. Vasudevan، V. استفاده از موقعیت مکانی برای توصیه های شخصی سازی شده در محیط های تلفن همراه. در مجموعه مقالات سمپوزیوم بین المللی برنامه ها و اینترنت در سال 2006 (SAINT 2006)، فینیکس، AZ، ایالات متحده آمریکا، 23 تا 27 ژانویه 2006.
- دل پریت، ال. Capra, L. differs: یک سرویس توصیهکننده تلفن همراه. در مجموعه مقالات یازدهمین کنفرانس بین المللی مدیریت داده های تلفن همراه (MDM) در سال 2010، کانزاس سیتی، MO، ایالات متحده آمریکا، 23 تا 26 مه 2010. ص 21-26.
- بله، م. یین، پی. لی، دبلیو.-سی. توصیه مکان برای شبکه های اجتماعی مبتنی بر مکان. در مجموعه مقالات هجدهمین کنفرانس بین المللی SIGSPATIAL در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، سن خوزه، کالیفرنیا، ایالات متحده آمریکا، 3 تا 5 نوامبر 2010. ACM: نیویورک، نیویورک، ایالات متحده آمریکا، 2010; ص 458-461. [ Google Scholar ]
- بائو، جی. ژنگ، ی. Mokbel، MF توصیه مبتنی بر موقعیت و اولویت آگاه با استفاده از داده های شبکه های جغرافیایی-اجتماعی پراکنده. در مجموعه مقالات بیستمین کنفرانس بین المللی پیشرفت در سیستم های اطلاعات جغرافیایی، ردوندو بیچ، کالیفرنیا، ایالات متحده آمریکا، 7-9 نوامبر 2012. ص 199-208.
- سروات، م. بائو، جی. الدوی، ا. لواندوسکی، جی جی. مجدی، ا. Mokbel، MF Sindbad: یک سیستم شبکه اجتماعی مبتنی بر مکان. در مجموعه مقالات کنفرانس بین المللی ACM SIGMOD 2012 در مدیریت داده ها، اسکاتسدیل، AZ، ایالات متحده آمریکا، 20-24 مه 2012. صص 649-652.
- نولاس، ا. اسکلاتو، اس. لاتیا، ن. Mascolo، C. یک پیاده روی تصادفی در اطراف شهر: توصیه مکان جدید در شبکه های اجتماعی مبتنی بر مکان. در مجموعه مقالات کنفرانس بینالمللی حریم خصوصی، امنیت، ریسک و اعتماد (PASSAT) و کنفرانس بینالمللی محاسبات اجتماعی (SocialCom) در سال 2012، آمستردام، هلند، 3 تا 5 سپتامبر 2012. صص 144-153.
- چنگ، سی. یانگ، اچ. کینگ، آی. لیو، MR فاکتورسازی ماتریس ذوب شده با نفوذ جغرافیایی و اجتماعی در شبکه های اجتماعی مبتنی بر مکان. در مجموعه مقالات بیست و ششمین کنفرانس AAAI در مورد هوش مصنوعی (AAAI’12)، تورنتو، ON، کانادا، 22 تا 26 ژوئیه 2012; جلد 12، ص 17-23.
- لیان، دی. ژائو، سی. Xie، X. سان، جی. چن، ای. Rui، Y. GeoMF: مدلسازی جغرافیایی مشترک و فاکتورسازی ماتریسی برای توصیه نقطهنظر. در مجموعه مقالات بیستمین کنفرانس بین المللی ACM SIGKDD در مورد کشف دانش و داده کاوی، نیویورک، نیویورک، ایالات متحده آمریکا، 24 تا 27 اوت 2014. صص 831-840.
- ژانگ، J.-D. چاو، سی.-ای. مدلسازی تأثیر متوالی مکانی-زمانی برای توصیههای مکان: یک رویکرد مبتنی بر گرانش ACM Trans. هوشمند سیستم تکنولوژی (TIST) 2015 ، 7 ، 11. [ Google Scholar ] [ CrossRef ]
- لئونگ، KW-T. لی، دی ال. لی، دبلیو.-سی. CLR: یک چارچوب توصیه مکان مشارکتی مبتنی بر همخوشهبندی. در مجموعه مقالات سی و چهارمین کنفرانس بین المللی ACM SIGIR در مورد تحقیق و توسعه در بازیابی اطلاعات، پکن، چین، 24 تا 28 ژوئیه 2011.
- تاکوچی، ی. Sugimoto، M. CityVoyager: یک سیستم توصیه در فضای باز بر اساس تاریخچه مکان کاربر. در هوش همه جا حاضر و محاسبات SE-64 ; Ma, J., Jin, H., Yang, L., Tsai, JJ-P., Eds.; Springer: برلین/هایدلبرگ، آلمان، 2006; صص 625-636. [ Google Scholar ]
- ژنگ، ی. ژانگ، ال. Xie، X. ما، W.-Y. استخراج مکان های جالب و توالی سفر از مسیرهای GPS. در مجموعه مقالات هجدهمین کنفرانس بین المللی وب جهانی، مادرید، اسپانیا، 20-24 آوریل 2009; صص 791-800.
- ژنگ، ی. ژانگ، ال. Xie، X. ما، W.-Y. ارتباط معدنی بین مکانها با استفاده از تاریخچه موقعیت مکانی انسانی. در مجموعه مقالات هفدهمین کنفرانس بین المللی ACM SIGSPATIAL در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، سیاتل، WA، ایالات متحده آمریکا، 4-6 نوامبر 2009. ACM: نیویورک، نیویورک، ایالات متحده آمریکا؛ صص 472-475.
- لیان، دی. Xie, X. یادگیری نامگذاری مکان از تاریخچه ورود کاربر. در مجموعه مقالات نوزدهمین کنفرانس بینالمللی ACM SIGSPATIAL در مورد پیشرفتها در سیستمهای اطلاعات جغرافیایی، شیکاگو، IL، ایالات متحده آمریکا، 1-4 نوامبر 2011.
- ژنگ، ی. Xie, X. یادگیری توصیههای سفر از طریق ردیابی GPS تولید شده توسط کاربر. ACM Trans. هوشمند سیستم تکنولوژی 2011 ، 2 ، 1-29. [ Google Scholar ] [ CrossRef ]
- ژنگ، فولکس واگن؛ ژنگ، ی. Xie، X. Yang, Q. توصیههای مکان و فعالیت مشترک با دادههای سابقه GPS. در مجموعه مقالات نوزدهمین کنفرانس بین المللی وب جهانی، رالی، NC، ایالات متحده، 26-30 آوریل 2010; صص 1029–1038.
- یوان، Q. کنگ، جی. Sun، A. توصیه نقطه مورد علاقه مبتنی بر نمودار با تأثیرات جغرافیایی و زمانی. در مجموعه مقالات بیست و سومین کنفرانس بین المللی ACM در کنفرانس مدیریت اطلاعات و دانش، شانگهای، چین، 3 تا 7 نوامبر 2014. صص 659-668.
- ژانگ، J.-D. Chow, C.-Y.; Zheng, Y. ORec: یک چارچوب توصیه مبتنی بر نقطه نظر. در مجموعه مقالات بیست و چهارمین کنفرانس بین المللی ACM در مورد مدیریت اطلاعات و دانش، ملبورن، استرالیا، 19 تا 23 اکتبر 2015. صفحات 1641-1650.
- لیان، دی. Ge، Y. ژانگ، اف. یوان، نیوجرسی؛ Xie، X. ژو، تی. Rui، A. فیلتر مشارکتی آگاه از محتوا برای توصیه مکان براساس دادههای تحرک انسان. در مجموعه مقالات کنفرانس بین المللی IEEE در سال 2015 در مورد داده کاوی (ICDM)، آتلانتیک سیتی، نیوجرسی، ایالات متحده آمریکا، 14 تا 17 نوامبر 2015. ص 261-270.
- وانگ، دبلیو. یین، اچ. چن، ال. سان، ی. صادق، س. Zhou، X. Geo-SAGE: یک مدل مولد افزودنی پراکنده جغرافیایی برای توصیه اقلام فضایی. در مجموعه مقالات بیست و یکمین کنفرانس بین المللی ACM SIGKDD در مورد کشف دانش و داده کاوی، سیدنی، استرالیا، 10 تا 13 اوت 2015. ص 1255-1264.
- مجید، ع. چن، ال. چن، جی. میرزا، ح.ت. حسین، من. Woodward, J. یک سیستم توصیه مسافرتی شخصیشده آگاه از زمینه مبتنی بر دادهکاوی رسانههای اجتماعی دارای برچسب جغرافیایی. بین المللی جی. جئوگر. آگاه کردن. علمی 2013 ، 27 ، 662-684. [ Google Scholar ] [ CrossRef ]
- ممون، آی. چن، ال. مجید، ع. Lv، M. حسین، من. چن، جی. توصیه سفر با استفاده از عکسهای دارای برچسب جغرافیایی در رسانههای اجتماعی برای گردشگران. سیم. پارس اشتراک. 2015 ، 80 ، 1347–1362. [ Google Scholar ] [ CrossRef ]
- لیو، بی. فو، ی. یائو، ز. Xiong, H. یادگیری ترجیحات جغرافیایی برای توصیه نقطه مورد علاقه. در مجموعه مقالات نوزدهمین کنفرانس بین المللی ACM SIGKDD در مورد کشف دانش و داده کاوی، شیکاگو، IL، ایالات متحده، 11-14 اوت 2013. صص 1043-1051.
- گائو، اچ. تانگ، جی. هو، ایکس. لیو، اچ. توصیههای مورد علاقه آگاه از محتوا در شبکههای اجتماعی مبتنی بر مکان. در مجموعه مقالات بیست و نهمین کنفرانس AAAI در مورد هوش مصنوعی (AAAI’15)، آستین، TX، ایالات متحده آمریکا، 25 تا 30 ژانویه 2015. صفحات 1721-1727.
- سان، ی. فن، اچ. باکیالله، م. Zipf، A. توصیه سفر مبتنی بر جاده با استفاده از تصاویر دارای برچسب جغرافیایی. محاسبه کنید. محیط زیست سیستم شهری 2015 ، 53 ، 110-122. [ Google Scholar ] [ CrossRef ]
- کوراشیما، تی. ایواتا، تی. آیری، جی. فوجیمورا، ک. توصیه مسیر سفر با استفاده از عکسهای دارای برچسب جغرافیایی. دانستن آگاه کردن. سیستم 2013 ، 37 ، 37-60. [ Google Scholar ] [ CrossRef ]
- حسینمردی، ح. لی، اس. یانگ، ز. Lv، Q. رفیق، ری. هان، آر. Mishra, S. مقایسه کاربران رایج در سراسر اینستاگرام و پرسش. fm برای درک بهتر آزار و اذیت سایبری. در مجموعه مقالات چهارمین کنفرانس بین المللی IEEE در سال 2014 درباره داده های بزرگ و محاسبات ابری (BdCloud)، سیدنی، استرالیا، 3 تا 5 دسامبر 2014؛ صص 355-362.
- یانگ، دی. ژانگ، دی. Q، B. نقشه برداری فرهنگی مشارکتی بر اساس داده های رفتار جمعی در شبکه های اجتماعی مبتنی بر مکان. ACM Trans. هوشمند سیستم تکنولوژی 2015 ، 7 ، 30. [ Google Scholar ] [ CrossRef ]
- یانگ، دی. ژانگ، دی. چن، ال. Qu, B. Nationtelescope: نظارت و تجسم رفتار جمعی در مقیاس بزرگ در lbsns. J. Netw. محاسبه کنید. Appl. 2015 ، 55 ، 170-180. [ Google Scholar ] [ CrossRef ]




© 2016 توسط نویسندگان؛ دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (CC-BY) (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر