

چکیده
:
ژئوپورتال ها به عنوان دروازه های اصلی برای یافتن، ارزیابی و شروع استفاده از اطلاعات جغرافیایی ایجاد شده اند. با این حال، پیادهسازیهای ژئوپورتال فعلی به دلیل مسائل ناهمگونی معنایی در بهینهسازی فرآیند کشف با مشکلاتی مواجه هستند که منجر به یادآوری کم و دقت پایین در انجام جستجوهای مبتنی بر متن میشود. بنابراین، ما یک رویکرد کشف معنایی پیشرفته را پیشنهاد میکنیم که از چندزبانگی و زمینه حوزه اطلاعات پشتیبانی میکند. بنابراین، ما جریان کاری را ارائه میکنیم که ابردادههای ساختاریافته موجود را با مترادفها، نامها، و اصطلاحات ترجمهشده مشتقشده از کلمات کلیدی تعریفشده توسط کاربر بر اساس اصطلاحنامهها و هستیشناسیهای چندزبانه غنی میکند. برای اینکه نتایج آسانتر و قابل درک باشد، ما همچنین قابلیتهای ترجمه خودکار را برای ابرداده منبع ارائه میکنیم تا از کاربر در درک محتوای موضوعی فراداده توصیفی پشتیبانی کند، حتی اگر با استفاده از زبانی که کاربر با آن آشنا نیست مستند شده باشد. علاوه بر این، برای فعال کردن قابلیتهای فیلتر فضایی، کلمات کلیدی نام مکان اضافی را به مجموعههای ابرداده اضافه میکنیم. اینها بر اساس کادر محدود موجود هستند و هنگام انجام پرس و جوهای تک خط متنی، امتیازهای کشف را تغییر می دهند. به منظور بهبود تجربه جستجوی کاربر، ما استراتژیهای جستجوی وجهی را طراحی میکنیم که یک رابط جستجوی پیشرفته برای کشف فرادادههای جغرافیایی ارائه میکند که به طور شفاف از اصطلاحنامهها و هستیشناسیهای زیربنایی استفاده میکنند. برای فعال کردن قابلیتهای فیلتر فضایی، کلمات کلیدی نام مکان اضافی را به مجموعههای ابرداده اضافه میکنیم. اینها بر اساس کادر محدود موجود هستند و هنگام انجام پرس و جوهای تک خط متنی، امتیازهای کشف را تغییر می دهند. به منظور بهبود تجربه جستجوی کاربر، ما استراتژیهای جستجوی وجهی را طراحی میکنیم که یک رابط جستجوی پیشرفته برای کشف فرادادههای جغرافیایی ارائه میکند که به طور شفاف از اصطلاحنامهها و هستیشناسیهای زیربنایی استفاده میکنند. برای فعال کردن قابلیتهای فیلتر فضایی، کلمات کلیدی نام مکان اضافی را به مجموعههای ابرداده اضافه میکنیم. اینها بر اساس کادر محدود موجود هستند و هنگام انجام پرس و جوهای تک خط متنی، امتیازهای کشف را تغییر می دهند. به منظور بهبود تجربه جستجوی کاربر، ما استراتژیهای جستجوی وجهی را طراحی میکنیم که یک رابط جستجوی پیشرفته برای کشف فرادادههای جغرافیایی ارائه میکند که به طور شفاف از اصطلاحنامهها و هستیشناسیهای زیربنایی استفاده میکنند.
کلید واژه ها:
مترادف ; ترجمه ؛ SKOS ; اصطلاحنامه ; هستی شناسی ; ویکی واژه نامه ; ژئوپلتفرم ؛ کاتالوگ ; SDI
1. مقدمه
ژئوپورتال ها به عنوان نقاط ورودی اصلی اطلاعات جغرافیایی به خوبی تثبیت شده اند. آنها به عنوان واسطه بین ارائه دهندگان داده های مکانی و کاربران عمل می کنند. با این حال، ما در کار با پورتالهای جغرافیایی که زیرساختهای دادههای مکانی (SDI) را باز میکنند، با دو اشکال بزرگ روبرو هستیم: اول، همه منابع دادههای جغرافیایی موجود مستند نیستند و بنابراین برای یک جامعه گستردهتر در دسترس نیستند. ثانیاً، اگر مجموعه دادهها به شیوهای مبتنی بر استاندارد مستند شوند، ابردادههای آن معمولاً در مؤلفههای کاتالوگ ژئوپورتالها ذخیره میشوند. رابط های آنها در حال حاضر فاقد مکانیسم های کشف کارآمد هستند.
برای غلبه بر مسئله اول، باید تلاش هایی برای انتقال مزایای اشتراک گذاری اطلاعات به ارائه دهندگان منابع و همچنین مصرف کنندگان انجام شود. این یک موضوع سازمانی است، نه فنی، و بنابراین، باید زمان برترین فرآیند در هنگام ایجاد یک پورتال SDI در نظر گرفته شود، زیرا مردم باید از مزایای همکاری کاربر و ارائه دهنده منابع متقاعد شوند [ 1 ].
اشکال دوم با ترکیبی از پیادهسازیهای فنی، مشکلات ناهمگونی معنایی، و استراتژیها و اولویتهای جستجوی تثبیتشده کاربر سر و کار دارد. در سالهای گذشته، ابتکاراتی مانند کوپرنیک (که قبلاً به عنوان GMES – نظارت جهانی برای محیط و امنیت شناخته میشد)، GEOSS (سیستمهای جهانی مشاهده زمین) و SEIS (سیستم اطلاعات محیطی مشترک) با هدف پیشرفت قابلیت همکاری فنی یا نحوی انجام شدهاند. تعامل معنایی که با معنای اصطلاحات سروکار دارد کمتر مورد توجه قرار گرفته است. حداقل، در تمام این ابتکارات، قابلیت همکاری معنایی یک نگرانی مهم است. به عنوان مثال، در پروژههایی که به GEOSS کمک میکنند، مانند EuroGEOSS، رویکردی را در مورد نحوه رسیدگی به مشکلات قابلیت همکاری معنایی بهویژه در کارگزار اکتشاف به پیش میبرد.2 ].
در این مقاله، ما عمدتاً بر راهبردهایی برای غلبه بر موضوع دوم تمرکز می کنیم.
در حال حاضر، جستجوی اطلاعات جغرافیایی در پیادهسازیهای ژئوپورتال بر اساس پرسوجو بخشهای ابرداده عنوان، چکیده و کلمه کلیدی در ترکیب با فیلترهای مکانی و زمانی است. از آنجایی که کلمات کلیدی ذاتاً توسط ابهامات زبانهای طبیعی محدود میشوند، مشکلات ناهمگونی معنایی به وجود میآیند [ 3 ]. به خصوص هنگام برخورد با چند زبان، تعارضات به دلیل تفاسیر مختلف از ویژگی ها بسته به زمینه اجتماعی و فرهنگی ایجاد می شود [ 4 ].
همانطور که در بسیاری از موارد، جوامع SDI نمی توانند منابع را به همه زبان ها به اشتراک بگذارند و انگلیسی به دلیل پایین ترین مخرج مشترک ممکن است کافی نباشد، نیاز به توسعه یک استراتژی برای بازیابی اطلاعات بین زبانی در ژئوپورتال ها قبلا توسط Nogueras-Iso و همکاران ذکر شده بود. [ 5 ] و نواک و همکاران. [ 4 ]. این رویکردها شامل ترجمه اصطلاحات پرس و جو به چندین زبان و ترجمه محتوای نتایج است.
علاوه بر زبان، تکینگی های حوزه اطلاعاتی مشکلات قابلیت همکاری معنایی را افزایش می دهد. جوامع جغرافیایی حتی ممکن است دیدگاه های متفاوتی داشته باشند و بر اساس آن، ممکن است از اصطلاحات مختلفی برای توصیف یک نوع اطلاعات استفاده کنند. در بسیاری از موارد مترادف وجود دارد.
در نتیجه، ما باید با یادآوری کم و دقت کم در کشف اطلاعات کنار بیاییم. یادآوری کم زمانی ایجاد می شود که اصطلاحات استفاده شده توسط کاربر با ارائه دهنده متفاوت باشد. بنابراین، یادآوری کامل بودن بازیابی را مشخص می کند. این بدان معناست که کاربران نمی توانند تمام اطلاعات مرتبط موجود را که به دنبال آن بودند، کشف کنند [ 6 ]. دقت پایین به این معنی است که همه اطلاعات کشف شده مربوط به کاربر نیست. اغلب با یک لیست طولانی از نتایج جستجو ترکیب می شود.
واچه و همکاران [ 7 ] و بوسلا و همکاران. [ 8 ] اصطلاحنامه ها و هستی شناسی ها (چند زبانه) را به عنوان رویکردهایی برای آشتی دادن ناهمگونی معنایی پیشنهاد می کنند. با این حال، مزیت اصلی اصطلاحنامه ها و هستی شناسی ها این است که ” آنها معنایی یک حوزه کاربردی را هم برای انسان و هم برای ماشین ها قابل درک می کنند ” [ 9 ]. به این ترتیب آنها ابزاری برای برقراری ارتباط و ترجمه معنای اصطلاحات پیشنهادی توسط کاربر به ماشین و بالعکس هستند.
هدف این مقاله پژوهشی توسعه هستی شناسی یا اصطلاحنامه چندزبانه جدید دیگری نیست، بلکه در عوض استفاده از واژگان کنترل شده و هستی شناسی های موجود به خوبی تثبیت شده برای تقویت اسناد فراداده با مترادف ها و اصطلاحات ترجمه شده و همچنین نام مکان ها برای بهبود یافته است. کشف و واجد شرایط بودن داده های مرتبط عبارات پرس و جو اضافی در چندین زبان روند کشف فراداده را بهبود می بخشد. مکان مشتق شده از کادر محدود مجموعه های فراداده و تبدیل به یک عبارت توصیفی این امکان را برای کاربران فراهم می کند تا بر اساس مکان به روشی مبتنی بر متن جستجو کنند [ 10 ].
2. نقش ژئوپورتال ها در SDI
ژئوپورتال ها به عنوان دروازه های استاندارد و نقاط دسترسی اصلی اطلاعات مکانی و غیر مکانی برای SDI ها تکامل یافته اند. رابط کاتالوگ یک ژئوپورتال به عنوان جزء اصلی برای بازیابی اطلاعات عمل می کند. استانداردهای بین المللی، اروپایی و ملی، قابلیت همکاری فنی کاتالوگ های فراداده را تضمین می کنند، در حالی که قابلیت همکاری معنایی فقط برای تعاریف عناصر فراداده پوشش داده می شود، نه محتوای آن. پرکاربردترین استاندارد در حوزه جغرافیایی، استاندارد وب سرویس کاتالوگ (CSW 2.0.2) کنسرسیوم فضایی باز (OGC) است. CSW ساختار و عملیات XML (زبان نشانهگذاری توسعهیافته) را تعریف میکند که ثبت فراداده و جستجوی منابع را به روشی استاندارد امکانپذیر میسازد. مشتریان سازگار با CSW می توانند خدمات کاتالوگ مبتنی بر CSW را جستجو کنند.
طراحی ژئوپورتال ها عمدتاً تحت تأثیر اصول OGC و مفهوم معماری سرویس گرا (SOA) است. مرکز این مفهوم معماری بر پارادایم «انتشار-پیدا-پیوند» استوار است. این پارادایم بیان می کند که یک ارائه دهنده خدمات یک سرویس را در یک کاتالوگ یا مخزن ثبت یا منتشر می کند (“انتشار”) و کاربران متعاقبا می توانند این منابع را جستجو و پیدا کنند (“یافتن”). کاربر همچنین تمام اطلاعات مورد نیاز برای مصرف اطلاعات را هنگامی که به عنوان یک سرویس ارائه می شود (“bind”) دریافت می کند. در این رویکرد کلی، قابلیت کشف منابع نقش اصلی را ایفا می کند: تنها زمانی که کاربران بتوانند منابع را کشف کنند، می توانند از آن استفاده کنند.
یکی از عناصر اصلی در مفهوم کاتالوگ های جغرافیایی این است که آنها اساسا خود داده ها را شامل نمی شوند، بلکه اطلاعات فراداده توصیفی در مورد مجموعه داده ها یا خدمات را شامل می شوند. در حالت ایده آل، ابرداده همچنین حاوی پیوندی به داده یا سرویس واقعی است.
ابرداده در حوزه جغرافیایی امروزه معمولاً بر اساس استانداردهای ابرداده توسعه یافته توسط سازمان بین المللی استاندارد (ISO) و OGC ذخیره و نگهداری می شود. سری ISO 191xx شامل استانداردهایی برای توصیف ابرداده منابع مکانی است. مهمترین این استانداردها ISO 19115 است که چارچوبی را برای توسعه هماهنگ رابط های تعاملی برای خدمات فراداده و کاتالوگ فراهم می کند. ISO 19139 یک کدگذاری XML برای استاندارد ISO 19115 ارائه می کند.
علاوه بر این استانداردهای مناسب برای مجموعه دادههای فضایی، در بسیاری از موارد، استاندارد ابردادههای جغرافیایی آگنوستیک Dublin Core (DC) به دلیل مسائل قابلیت همکاری بهعنوان «کمترین مخرج مشترک» برای به اشتراک گذاشتن ابرداده بین حوزههای ناهمگن استفاده میشود. Dublin Core از حوزه کتابخانهای سرچشمه میگیرد و در اولین مرحله برای فهرستنویسی کتابها مورد استفاده قرار میگرفت. نمایه ساده از مجموعه استانداردی از 15 عنصر فراداده اجباری مانند عنوان یا چکیده یک آیتم تشکیل شده است. بنابراین، برای فهرست نویسی انواع مختلف منابع اطلاعاتی مفید است [ 11 ].
به طور خلاصه، با توجه به تحول رویکردها در چند سال اخیر، مبنای فنی برای راهحلهای ژئوپورتال آینده آماده شده است. به عنوان یک دستاورد بزرگ، قابلیت همکاری نحوی تضمین شده است. هنگام تجزیه و تحلیل نتایج پرس و جوهای ژئوپورتال، باید بیان کنیم که باید تلاش، کار و تحقیق بیشتری برای کاهش و غلبه بر ناهمگونی معنایی، که مبتنی بر ناهمگونی جوامع کاربر، زبان ابرداده های مختلف و زمینه دامنه است، انجام دهیم.
ما پیشنهاد می کنیم با ارائه راه حل هایی برای تکنیک های بازیابی اطلاعات بین زبانی همراه با هستی شناسی ها و اصطلاحنامه ها، چالش های ناهمگونی معنایی را به حداقل برسانیم و بر آن غلبه کنیم.
3. قابلیت همکاری معنایی و مسائل ناهمگونی معنایی
نویسندگان مختلف [ 3 ، 12 ، 13 ] به چالش های مربوط به قابلیت همکاری معنایی و ناهمگونی معنایی اشاره کرده اند. در این معنا، ناهمگونی معنایی به ” اختلاف در مورد معنا، تفسیر یا استفاده مورد نظر از داده های مشابه یا مرتبط ” اشاره دارد [ 14 ].
ناهمگونی معنایی مسئله اصلی است که از قابلیت همکاری کامل بین سیستم ها جلوگیری می کند [ 13 ]. در مقابل قابلیت همکاری نحوی، قابلیت همکاری معنایی با معنای واقعی عناصر سروکار دارد [ 3 ]. به دلیل اینکه افراد اطلاعات یکسانی را به روشی متفاوت تفسیر می کنند، « تشخیص و حل ناهمگونی معنایی مسائل دشواری است » [ 12 ]. این امر مخصوصاً برای مجموعههای فراداده صادق است اگر اطلاعات کافی در مورد نحوه تفسیر منابعی که توصیف میکنند به درستی در اختیار کاربران قرار ندهند [ 15 ].
لوتز و همکاران [ 3 ] تمایز بین سه سطح ناهمگونی معنایی. ناهمگونی معنایی در سطح فراداده (در رابطه با ” کشف اطلاعات جغرافیایی “)، در سطح طرحواره (در مورد “بازیابی اطلاعات جغرافیایی “) و در سطح محتوای داده ها (” تفسیر، یکپارچه سازی و تبادل اطلاعات جغرافیایی ” رخ می دهد.”). در این مقاله، ما بر ناهمگونی معنایی در سطح ابرداده تمرکز میکنیم. به عنوان مثال، زمانی که ارائه دهندگان منابع و کاربران درک مشترکی از اصطلاحات ندارند، این سطح به وجود می آید. این از داشتن پیشینه های علمی، اجتماعی یا فرهنگی متفاوت سرچشمه می گیرد. هنگامی که افراد با یکدیگر (به صورت شفاهی یا نوشتاری) ارتباط برقرار می کنند، دانش خود را هنگام ارسال و درک کلمات به کار می برند. با این حال، هنگامی که ما با رایانهها تعامل داریم، توانایی انتقال آن «دانش» پیچیدهتر است: سیستم رایانهای ممکن است نتواند آنچه را که میخواهیم در یک زمینه خاص به آن دست پیدا کنیم، به روشی که احتمالاً یک انسان انجام میدهد، تفسیر کند. بنابراین، دانش حوزه باید در این سیستمها گنجانده شود تا امکان تبادل دقیق معنا فراهم شود [ 14 ].
مشکلات قابلیت همکاری معنایی زمانی که مجبور به کنار آمدن با چندین زبان هستید افزایش می یابد. همانطور که قبلا ذکر شد، بازیابی اطلاعات بین زبانی ابزاری کارآمد برای غلبه بر ناهمگونی معنایی در نظر گرفته می شود.
4. بازیابی اطلاعات بین زبانی در SDI
بازیابی اطلاعات بین زبانی زیرشاخه ای از بازیابی اطلاعات است. ” بازیابی اطلاعات (IR) به یافتن و بازگرداندن اطلاعات ذخیره شده در رایانه ها مربوط به نیازهای کاربر ( که در یک درخواست یا پرس و جو مادی شده است) مربوط می شود ” [ 16 ]. چالش اصلی آن حوزه تحقیقاتی این است که « ما از رایانه میخواهیم اطلاعاتی را که میخواهیم ارائه کند، به جای اطلاعاتی که درخواست کردیم » [ 17 ].
در کار ما، بازیابی اطلاعات بین زبانی (گاهی اوقات به عنوان بازیابی اطلاعات چند زبانه نیز نامیده می شود) با دو جنبه سروکار دارد: منابعی که می توانند به زبان های مختلف مستند شوند و اینکه اصطلاح درخواست کاربر ممکن است با زبان مورد استفاده برای توصیف منبع متفاوت باشد. 6 ]. بازیابی اطلاعات بین زبانی را می توان به عنوان ” بازیابی اطلاعات نوشته شده به زبانی متفاوت از زبان درخواست کاربر “ [ 18 ] تعریف کرد.
در سراسر ادبیات در حوزه جغرافیایی، بیشتر رویکردها در بازیابی اطلاعات، چندزبانگی را در نظر نمی گیرند. در عوض، آنها عمدتاً بر روی الگوریتمهای شباهت جدید تمرکز میکنند، مانند de Andrade و de Baptista [ 9 ] و Janowicz و همکاران. [ 19 ] که با بهبود عملکرد پرس و جوها سروکار دارند. با این حال، نتایج جستجو بر اساس مناسب بودن برای سؤالات خاص مرتب نمیشوند، زیرا تخمین میزنند که نتایج مربوط به کاربر یکسان است، در حالی که تطبیق دقیق ممکن است مرتبطتر از تطبیق عبارات مرتبط در نظر گرفته شود [ 9 ].
تحقیقات فعلی مفهوم بازیابی اطلاعات را با افزودن زمینه کاربر گسترش میدهد [ 20 ]. زمینه ممکن است به عنوان ” هر اطلاعاتی که می تواند برای توصیف و تفسیر موقعیتی که در آن یک کاربر در یک زمان معین با یک برنامه کاربردی تعامل دارد ” [ 21 ] تعریف شود. اطلاعات زمینه ای که می تواند در اکتشاف گنجانده شود، به عنوان مثال مکان (مثلاً بر اساس مکان مبتنی بر IP) و زبان (به عنوان مثال، بر اساس تنظیمات زبان مرورگر وب یا زبان عبارت جستجوی وارد شده) است.
در پیادهسازیهای فعلی ژئوپورتال، فرآیند کشف معمولاً به جستجوی عنوان، چکیده و کلمه کلیدی با استفاده از جستجوی متنی محدود میشود. این بدان معناست که فرآیند بازیابی اطلاعات محدود به تطبیق الگوهای نوشتاری ساده است بدون در نظر گرفتن مترادفها (نامهای مختلف برای مفاهیم یکسان)، متجانس (همان نامی که برای مفاهیم مختلف استفاده میشود)، یا اشکال مختلف املا (مثلاً آمریکایی). در مقابل انگلیسی بریتانیایی).
در حوزه بازیابی اطلاعات بین زبانی، مشکلات دیگری رخ می دهد: اینها – در میان دیگران – نامگذاری ناهمگونی هایی است که با عبارات مختلف برای یک مفهوم سروکار دارند (مانند “see” در آلمانی، “lac” در فرانسوی، “lago” در پرتغالی ، برای مفهوم دریاچه) و ناهمگونی های شناختی که در آن مفاهیم مختلف با اصطلاحات یکسان بیان می شود (مانند “سبز روستا” برای “چمنزار”، “علفزار”، “lea”، “مید” و “hayfield”) [ 4 ]. در مورد دوم، مشکل برای هر سیستم کامپیوتری این است که تعیین کند کدام یک از چندین حواس به بهترین وجه با پرس و جو و نتایجی که کاربر تخمین می زند که می تواند یک کار کاملا چالش برانگیز باشد، مطابقت دارد [ 5 ].
مشکلات دیگر این است که برای مثال در یک زبان دو اصطلاح ممکن است تنها با یک عبارت در زبان دیگر نشان داده شود (مثلاً “آفریقای جنوبی” در انگلیسی و “Südafrika” در آلمانی) یا هیچ مشابه مستقیمی وجود ندارد (مثلاً در زبان روسی آنجا وجود ندارد. هیچ تمایزی بین “دست” و “بازو” وجود ندارد).
موضوع قابل توجه دیگری که گاهی از آن به عنوان ناهمگونی ساختاری یاد می شود، مبهم بودن تعریف مفاهیم جغرافیایی است [ 7 ]. به عنوان مثال تعریف رودخانه کوچک و بزرگ – که در بیشتر زبان های طبیعی نام های مختلفی مانند کلمه انگلیسی “creek” یا آلمانی “bach” برای رودخانه های کوچک دارند – در مورد عرض رودخانه به عنوان روشی برای تمایز بین این دو. مفاهیم ممکن است بین کشورهای مختلف یا نمایش های مختلف پایگاه داده متفاوت باشد.
5. نقش SKOS، اصطلاحنامه ها و هستی شناسی ها در کاهش مشکلات ناهمگونی معنایی
به منظور غلبه بر مشکلات ناهمگونی معنایی، استفاده از اصطلاحنامه ها و هستی شناسی ها (چند زبانه) به طور گسترده به عنوان راه حل ممکن پیشنهاد شده است [ 3 ، 13 ]. به گفته گروبر [ 22 ]، اصطلاح هستی شناسی به عنوان « مشخصات رسمی و صریح یک مفهوم سازی مشترک » تعریف شده است. این بدان معنی است که هستی شناسی ها را می توان نوعی بازنمایی از اشیاء (جهان واقعی) یا مفهوم سازی ما از این اشیاء در نظر گرفت [ 23 ]. اصطلاحنامه ها واژگان کنترل شده حاوی روابط هستند [ 24 ].
از آنجایی که هدف این تحقیق ساخت یک هستی شناسی جدید نیست، ترکیبی از اصطلاحنامه ها و هستی شناسی های شناخته شده و پرکاربرد انجام شده است. این همچنین می تواند به عنوان یک رویکرد ترکیبی برای غلبه بر مشکلات ناهمگونی معنایی [ 7 ] در نظر گرفته شود.
این بخش شامل نمونه هایی از هستی شناسی ها و اصطلاحنامه هایی است که در نظر گرفتیم در رویکرد خود از آن استفاده کنیم. به خصوص در اروپا، مشکل چند زبانه به دلیل تفاوتهای فرهنگی، تاریخی و اجتماعی بین یا حتی بین دولتهایی که گاهی با زبانهای مختلف در یک کشور (مانند اسپانیا، لوکزامبورگ، بلژیک) نشان داده میشوند، چالش بزرگی است. در نتیجه، پایگاههای اطلاعاتی جغرافیایی که دیدگاههای مختلف جهان را با استفاده از زبانهای مختلف و توصیف اصطلاحات نشان میدهند، وجود دارد که مانع از فرآیند اشتراکگذاری دادهها در کشورها میشود [ 4 ].
اصطلاحنامه GEMET (General Multilingual Environmental Thesaurus؛ [ 25 ]) ابزار ارزشمندی برای مقابله با این مشکل در ارائه فهرستی از اصطلاحات در همه زبانهای رسمی است. این توسط اتحادیه اروپا نگهداری می شود و به 29 زبان موجود است. نسخه SKOS (سیستم سازماندهی دانش ساده) از بیش از 5000 مفهوم تشکیل شده است. مزیت دیگر استفاده از اصطلاحنامه GEMET برای کشف این است که طبق قانون پیاده سازی INSPIRE برای فراداده (MD IR) ارائه حداقل یک کلمه کلیدی از GEMET الزامی است. در نتیجه، می توان تخمین زد که حداقل یک کلمه کلیدی از GEMET در منابع قابل کشف وجود دارد.
هستی شناسی شیرین ناسا (وب معنایی زمین و اصطلاحات محیطی؛ [ 26 ]) از حدود 6000 مفهوم تشکیل شده است و در قالب OWL (زبان هستی شناسی وب) قابل دانلود است. این فقط به زبان انگلیسی موجود است و بنابراین برای رویکرد بین زبانی ما مناسب نیست.
Wordnet [ 27 ] یک پایگاه داده انگلیسی از مترادف ها است. این شبیه یک اصطلاحنامه است، زیرا کلمات بر اساس معانی آنها در کنار هم قرار می گیرند. این شامل 207000 جفت کلمه-حس به زبان انگلیسی است.
Openthesaurus [ 28 ] یک فرهنگ لغت آلمانی رایگان برای مترادف ها است. این یک رویکرد مبتنی بر جامعه است و از 106000 کلمه تشکیل شده است.
اصطلاحنامه یونسکو [ 29 ] فهرستی ساختاریافته از مفاهیم است که شامل زمینه های آموزش، فرهنگ، علوم طبیعی، علوم اجتماعی و انسانی، ارتباطات و اطلاعات است. این شامل حدود 7000 اصطلاح به زبان های انگلیسی، روسی، فرانسوی و اسپانیایی است.
AGROVOC [ 30 ] توسط سازمان غذا و کشاورزی سازمان ملل متحد نگهداری می شود. این شامل نزدیک به 40000 مفهوم در بیش از 20 زبان است. می توان آن را در چندین فرمت از جمله SKOS و OWL بارگیری کرد و برای اهداف آموزشی یا سایر اهداف غیرتجاری رایگان است.
EuroVoc [ 31 ] توسط اتحادیه اروپا نگهداری می شود و از 22 زبان اتحادیه اروپا تشکیل شده است. این شامل تقریباً 6000 اصطلاح است و برای دانلود در قالب SKOS/RDF- (Resource Description Framework) یا XML در دسترس است.
ویکیواژه [ 32 ] پروژهای است که برای ارائه یک فرهنگ لغت چند زبانه رایگان در نظر گرفته شده است. هدف کلی بلندپروازانه این پروژه ایجاد این فرهنگ لغت برای همه اصطلاحات همه زبان ها است. در حال حاضر، اصطلاحنامه ویکیواژه شامل بیش از 347200 کلمه آلمانی و 3559616 اصطلاح انگلیسی است ( شکل 1 ). برخلاف دیگر اصطلاحنامه ها، این مزیت را دارد که به طور منظم توسط یک جامعه کاربری بزرگ نگهداری و به روز می شود و همچنین دارای بیشترین تعداد اصطلاحات در مقایسه با سایر اصطلاحنامه ها است.
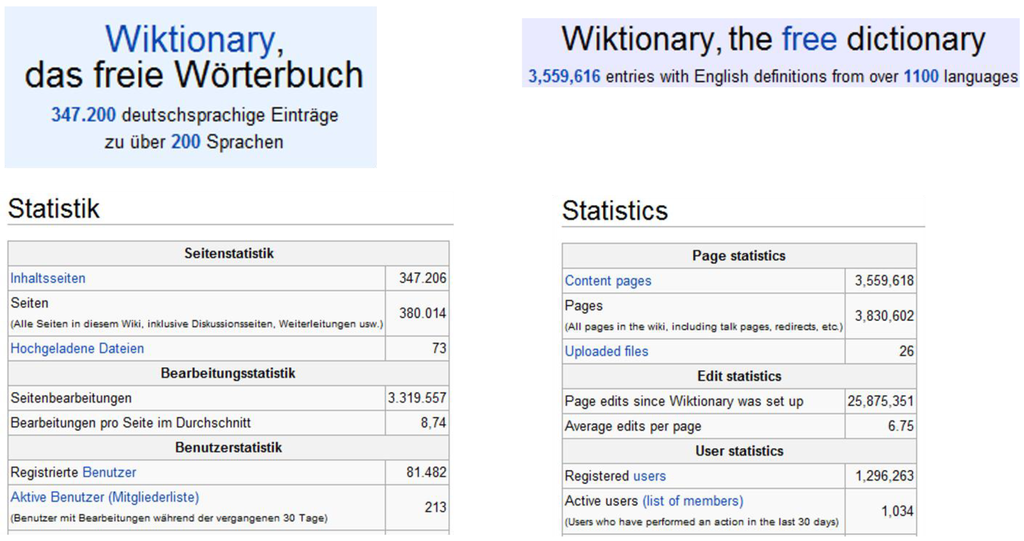
شکل 1. آمار استفاده از ویکیواژه.
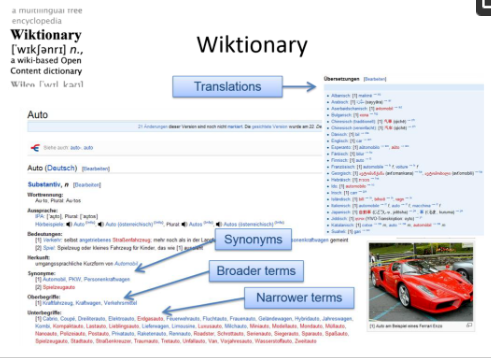
ویکیواژهنامه در قالب SKOS در دسترس نیست، اما از آنجایی که اصول یکسانی با SKOS دارد (مترادفها، اصطلاحات گستردهتر و محدودتر)، میتواند مانند SKOS هنگام تجزیه صفحه ویکی از طریق Wiki API استفاده شود. شکل 2 نمونه ای از ویکیواژه آلمانی و پرس و جوی “Auto” (“ماشین” در انگلیسی) را نشان می دهد که مترادف هایی مانند “Automobil” (“خودرو” در انگلیسی) و گسترده تر (“PKW” که کوتاه است را نشان می دهد. برای “ماشین مسافربری”)، و همچنین اصطلاحات محدودتر، مانند “cabrio” (“تبدیل” در انگلیسی).

شکل 2. صفحه ویکیواژهای که مترادفها، اصطلاحات گستردهتر/ محدودتر و ترجمهها را ارائه میکند.
6. Geoplatform.at – کاتالوگ فراداده برای تقویت معنایی غنیسازی جغرافیایی
در حوزه اطلاعات جغرافیایی، منابع اطلاعاتی ارزشمند زیادی وجود دارد. در اتریش، چندین سازمان و مؤسسه ابرداده منابع جغرافیایی خود را ارائه می دهند. اکثر این ارائه دهندگان داده های مکانی از پورتال های جغرافیایی مانند سرور جغرافیایی و شبکه جغرافیایی بر اساس استاندارد وب سرویس کاتالوگ کنسرسیوم فضایی باز (OGC CSW 2.0.2) برای اشتراک گذاری اطلاعات استفاده می کنند. به عنوان یکی از مزایای رویکردهای استانداردسازی در زیرساخت داده های مکانی (SDI)، امکان برداشت منابع از یک فهرست ابرداده به فهرست دیگر وجود دارد.
در چند سال گذشته، مفهوم موازی کاتالوگ های ابرداده از حوزه داده های دولت باز (OGD) تکامل یافته است. ایده اصلی OGD این است که منابع (مانند مجموعه داده ها، اسناد و خدمات وب) مورد علاقه مشترک را بدون هیچ محدودیتی در دسترس عموم قرار دهد. از آنجایی که هشتاد درصد اطلاعات کلی به لحاظ مکانی مرتبط هستند [ 33 ]، OGD همچنین ابرداده هایی را در مورد اطلاعات جغرافیایی ارائه می دهد. OGD از CKAN (شبکه آرشیو دانش جامع؛ [ 34 ]) به عنوان رابطی برای به اشتراک گذاری محتوای خود استفاده می کند. به دلیل تلاشهای هماهنگسازی، نمایه ابرداده اتریشی ON A 2270:2010 (مشخصات AT) و نمایه OGD اتریشی [ 35] با یکدیگر همسو هستند. بنابراین، منابع را می توان بین این دو حوزه مبادله کرد.
یکی از این رویکردهای نمونه اولیه که از فراداده این منابع ناهمگن استفاده می کند geoplatform.at است ( شکل 3 ). این به عنوان مبنایی برای رویکرد تحقیقی که در این مقاله ارائه میکنیم عمل میکند. این شامل منابعی است که از «دفتر فدرال اندازهشناسی و نقشهبرداری» (BEV)، «Land-, forst- und wasserwirtschaftliches Rechenzentrum» (LfRZ)، «Geoland»، «Cooperation OGD Österreich» و پورتال ایالتهای فدرال اتریش میآیند. (GIS-Steiermark).
شکل 3. geoplatform.at: بستری برای به اشتراک گذاری دانش [ 36 ].
همه کاتالوگ های ذکر شده در بالا از یکی از پایه های فنی زیر استفاده می کنند.
6.1. سرور ژئوپورتال
Geoportal Server [ 37 ] یک راه حل مبتنی بر استاندارد منبع باز برای ذخیره سازی و کشف منابع مکانی و غیر مکانی است. این متادیتای ISO، FGDC و DC را پشتیبانی می کند و می تواند با پروفایل های سفارشی یا ملی گسترش یابد.
6.2. زمین شبکه
Geonetwork [ 38 ] یک رابط کاربری برای ویرایش ابرداده و همچنین یک رابط کشف برای جستجوی دادههای مکانی در کاتالوگهای متعدد فراهم میکند. مانند Geoportal Server، همچنین قادر به استفاده از متادیتای ISO، FGDC و DC است.
6.3. CKAN
CKAN (شبکه بایگانی دانش جامع؛ [ 34 ]) یک سیستم ثبت یا فهرست برای مجموعه داده ها یا سایر منابع «دانش» است که توسط «بنیاد دانش باز» (OKFN) توسعه یافته است. هدف CKAN یافتن، اشتراکگذاری و استفاده مجدد از محتوا و دادههای باز است، بهویژه به روشهایی که ماشینی خودکار هستند [ 39 ].
CKAN یک کاتالوگ داده باز است که به طور گسترده توسط موسسات دولتی در چارچوب داده های دولت باز (OGD) استفاده می شود، که – در کنار دیگران – به طور گسترده در بریتانیا (data.gov.uk)، نروژ (data.norge.no) استفاده می شود. ) و عمدتاً توسط شهرهای بزرگتر اتریش. در CKAN، همه انواع منابع در قالبی شبیه به Dublin Core مستند شده اند. این “کمترین مخرج مشترک” ابرداده را برای بسته های خود می دهد: نویسنده، شناسه، مجوز، برچسب های تولید شده توسط کاربر، و پیوندها، که می تواند توسط کاربر در بخش به اصطلاح “اضافی” گسترش داده شود یا توسط ارائه دهنده از پیش تعریف شده باشد. از پورتال CKAN به دلیل نیازهای خاص دامنه [ 40 ].
Geonetwork و Geoportal Server از پروتکل CSW استفاده می کنند و بنابراین می توان برعکس آن را برداشت کرد. از آنجایی که هیچ ارتباط مستقیمی بین OGC’s CSW و CKAN’s REST API وجود ندارد، ما یک ابزار Python را برای فرآیند برداشت بین مؤلفه کاتالوگ ژئوپورتال ها و CKAN ایجاد کردیم. ما REST API CKAN را با کتابخانه ای به نام “ckanclient” جستجو می کنیم [ 41] و رابط CSW ژئوپورتال، یک تبدیل عناصر را برای مطابقت با هسته فراداده ISO و ثبت منابع با سرور جغرافیایی با استفاده از تراکنش درج CSW انجام دهید. خود فرآیند برداشت در حال حاضر یک بار در روز انجام می شود، اما فرکانس به روز رسانی را می توان در صورت تقاضا افزایش یا کاهش داد. یکی دیگر از گزینههای ممکن برای برداشت ابرداده از CKAN، پسوند «ckanext-spatial» است. با این حال، از آنجایی که ابرداده در geoplatform.at بر اساس نمایه اتریشی ON A 2270:2010 (profil.AT) است، ما یک فرآیند برداشت سفارشی با REST را ترجیح می دهیم زیرا استاندارد ckanext-spatial extension تمام عناصر موجود در را در نظر نمی گیرد. نمایه ابرداده اتریش.
در حال حاضر، geoplatform.at [ 36 ] شامل بیش از 2200 مجموعه ابرداده است که مجموعه داده ها، خدمات و اسناد حوزه جغرافیایی را توصیف می کند. ابرداده کاملاً به زبان آلمانی است. از آنجایی که در مرحله اولیه geoplatform.at کاربران از نتایج اکتشاف هم از نظر کمبود قابلیت جستجوی مترادف یا کشف ناکارآمد نام مکانها راضی نبودند، ما یک گردش کار بهبود معنایی و غنیسازی جغرافیایی غیرمکانی ایجاد و اجرا کردیم. در geoplatform.at.
7. گردش کار افزایش معنایی غیر فضایی
گردش کار افزایش معنایی غیر فضایی ما به اصطلاحنامه ها، هستی شناسی ها و SKOS متکی است. خود گردش کار با ابرداده ذخیره شده در مؤلفه کاتالوگ ژئوپورتال شروع می شود ( شکل 4). در اجرای نمونه اولیه خود، از Geoportal Server 1.2.4 به عنوان کاتالوگ ابرداده و از Python 2.7 برای استخراج کلمات کلیدی اسناد فراداده استفاده می کنیم. ما ابزارهای مختلف پایتون را برای یافتن مترادف ها، اصطلاحات گسترده تر و محدودتر، و ترجمه کلمات کلیدی تعریف شده توسط کاربر توسعه دادیم. در نمونه اولیه خود، میتوانیم از منابع مختلفی به عنوان ورودی استفاده کنیم، اما اصطلاحنامههای چندزبانه را ترجیح میدهیم، زیرا آنها با رویکرد کشف چندزبانی ما سازگاری بیشتری دارند. میتوانیم از هستیشناسی SWEET (انگلیسی)، Wordnet (انگلیسی)، Openthesaurus (آلمانی)، اصطلاحنامه یونسکو (چند زبان)، AGROVOC (چند زبانه)، و ویکیواژه (چند زبانه) استفاده کنیم. از نقطه نظر فنی، نمونه اولیه ما بر اساس چندین ماژول پایتون است. آنها شامل «ztfy.theasaurus» [ 42 ]، «python-skos» [ 43 ]، «NLTK» [ 44 ] هستند.]، و «درخواستها» [ 45 ]. ما آنها را با یکدیگر ترکیب کردیم و تعدادی کد اضافی را برای پاسخگویی به نیازهای خود اضافه کردیم. پیادهسازی اصطلاحنامههایی که بهعنوان یک سرویس وب ارائه میشد و یک API ارائه میکرد (مانند مورد Openthesaurus) ساده بود. در مورد ویکیواژه، ما مجبور بودیم سایت پاسخ را برای هر کلمه کلیدی در اسکریپت پایتون خود پرس و جو و تجزیه کنیم. بنابراین، ما پیشنهاد میکنیم که یک رابط REST (انتقال حالت نمایندگی) برای ویکیواژه با یک تعریف API واضح ایجاد کنیم تا ترجمهها و مترادفها و همچنین اصطلاحات گستردهتر و محدودتر را برای نمونه اولیه و سایر موارد استفاده سریعتر و آسانتر در دسترس قرار دهیم.
نمونه اولیه ما از SKOS نیز استفاده می کند. چالش اصلی برای تجزیه فایلهای SKOS مقابله با فایلهایی است که الزامات استاندارد SKOS را برآورده نمیکنند. در این صورت، تطبیقهای دستی کد ضروری است و منجر به یک مرحله توسعه طولانیتر میشود.
در حال حاضر، نمونه اولیه پایتون به صورت روزانه اجرا می شود تا مجموعه های ابرداده را با پیشرفت های معنایی ما افزایش دهد. با این حال، این فاصله می تواند عمداً کاهش یابد یا کاهش یابد.
همانطور که در نمونه اولیه تحقیق ما geoplatform.at فقط مجموعههای فراداده آلمانی وجود دارد، ما اصطلاحنامههای موجود به زبان آلمانی را ترجیح میدهیم. از آنجایی که ویکیواژه گستردهترین تعداد اصطلاحات را ارائه میدهد، منبع ایدهآلی برای رویکرد ما است و ما از نتایج آن بسیار راضی بودیم. بنابراین، ویکیواژه برای استفاده در بیشتر موارد انتخاب شد.
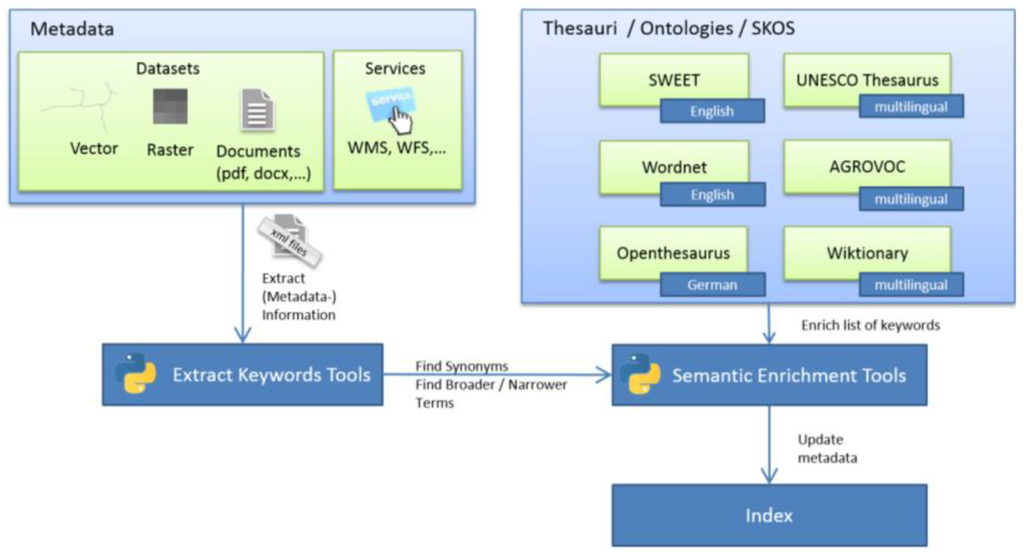
شکل 4. گردش کار افزایش معنایی غیر فضایی.
ما یک مورد استفاده برای نشان دادن مزایای رویکرد خود ایجاد کردیم. در مورد استفاده ما، عبارت آلمانی “تبدیل پذیر”، یعنی “cabrio” را در geoplatform.at جستجو می کنیم ( شکل 5 ). فهرست نتایج، ورودیهایی مانند «Kraftfahrzeugbestand» («انواع خودروها») را نشان میدهد. در این ورودی ابرداده، اصطلاح “cabrio” قبلا وجود نداشت، اما توسط ابزار افزایش معنایی غیر مکانی ما اضافه شد.
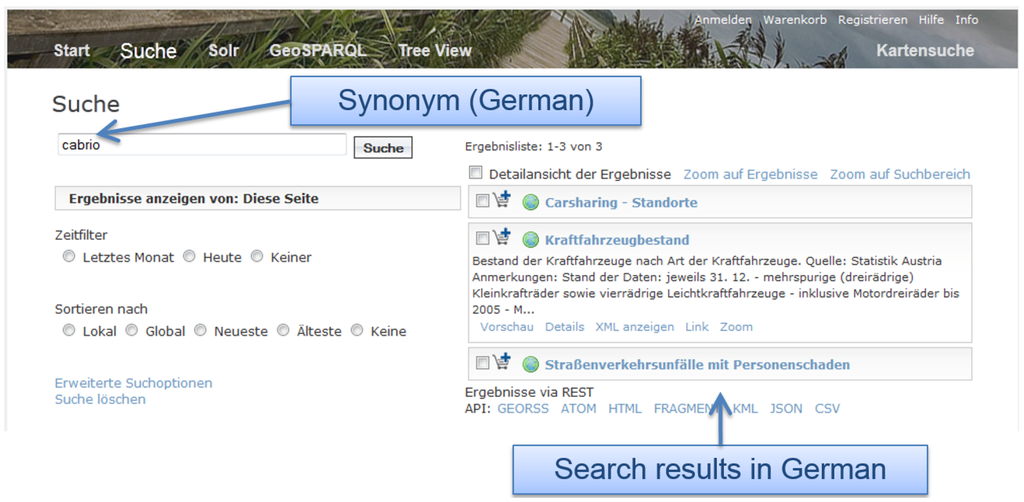
شکل 5. جستجوی مترادف.
همانطور که رویکرد ما ترجمههای اصطلاحات را نیز در نظر میگیرد، میتوانیم به دنبال “ماشین” نیز بگردیم تا اسناد فراداده مشابه مورد استفاده قبلی را کشف کنیم ( شکل 6 ). برای اینکه کاربر حداقل ایده ای در مورد محتوای داده های کشف شده داشته باشد، ترجمه خودکار نتایج را ارائه می دهیم ( شکل 7 ). در نمونه اولیه خود، از “مترجم مایکروسافت” [ 46 ] استفاده می کنیم که در حال حاضر به 42 زبان موجود است. در نگاه اول، ما فقط ترجمه های انگلیسی را به اسناد فراداده اضافه کردیم، اما زبان های دیگر را می توان به همین روش اضافه کرد.
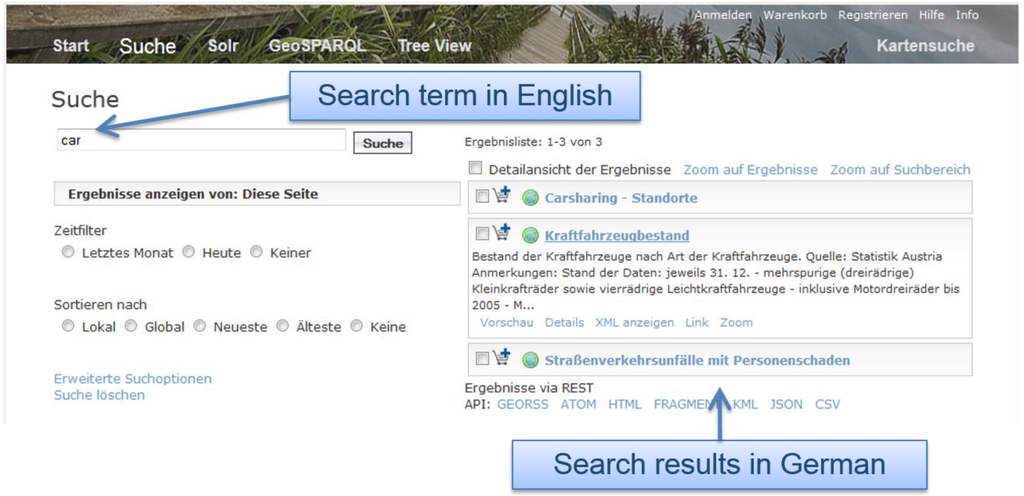
شکل 6. جستجوی چند زبانه.
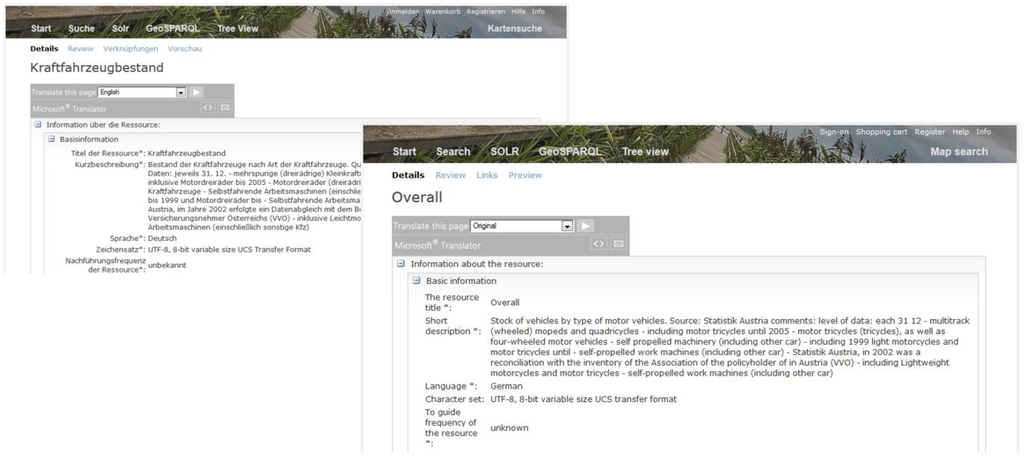
شکل 7. ترجمه خودکار نتایج جستجو.
8. گردش کار غنی سازی جغرافیایی
علاوه بر امکان جستجو برای کلمات مترادف، کاربران باید بتوانند مکان ها را نه تنها بر اساس انتخاب نقشه، بلکه به عنوان ورودی های متنی نیز جستجو کنند. در نمونه اولیه ما، کلمات کلیدی مکان به صورت روزانه با یک اسکریپت پایتون پر میشوند که از مناطق NUTS («نامگذاری آمار واحدهای سرزمینی»، «نامگذاری واحدهای سرزمینی برای آمار») و LAU 2 («واحد اداری محلی») استفاده میکند. اتحادیه اروپا ( شکل 8). ما از گستره مکانی منابع استفاده می کنیم و آنها را با نام مکان هایی که در کادر محدود منبع هستند به طور خودکار حاشیه نویسی می کنیم. ابرداده از مولفه کاتالوگ پیاده سازی ژئوپورتال ما می آید. در مواردی که فقط یک نام مکان (که مخصوصاً برای اسناد صادق است، مانند pdfهایی که حاوی اطلاعات توصیفی درباره یک مجموعه داده یا پروژه هستند) در فراداده وجود دارد، نام مکان با Python و کتابخانه جغرافیایی اضافی [ 47 ] کدگذاری می شود. با geopy، Google Maps، Yahoo! Maps، Windows Local Live (Virtual Earth)، geocoder.us، GeoNames، صفحات MediaWiki و صفحات Semantic MediaWiki را می توان استفاده کرد. برای متون کامل، از شناسایی موجودیت نامگذاری شده (NER)، مانند جعبه ابزار زبان طبیعی (NLTK؛ [ 44 ) استفاده می کنیم.]) و یک نسخه اقتباس شده از کتابخانه geodict [ 48 ] برای استخراج کلمات کلیدی مکان.
به عنوان مثال، اگر کاربران برای “Hallein” (شهر کوچکی در اتریش) جستجو کنند، نتایج “سالزبورگ” را نیز دریافت می کنند، زیرا “Hallein” در ایالت فدرال “سالزبورگ” واقع شده است. چالشها زمانی به وجود میآیند که از همین اصطلاح برای یک شهر و یک ایالت فدرال استفاده شود. این در مورد سالزبورگ صادق است، که می تواند شهر سالزبورگ یا ایالت فدرال سالزبورگ باشد. در این صورت می توان از زمینه برای رسیدگی به این موضوع استفاده کرد. به عنوان مثال، اگر اصطلاحات “سالزبورگ” و “شهر” به صورت ترکیبی استفاده شوند، سیستم ممکن است در مورد شهر سالزبورگ اختلال ایجاد کند.
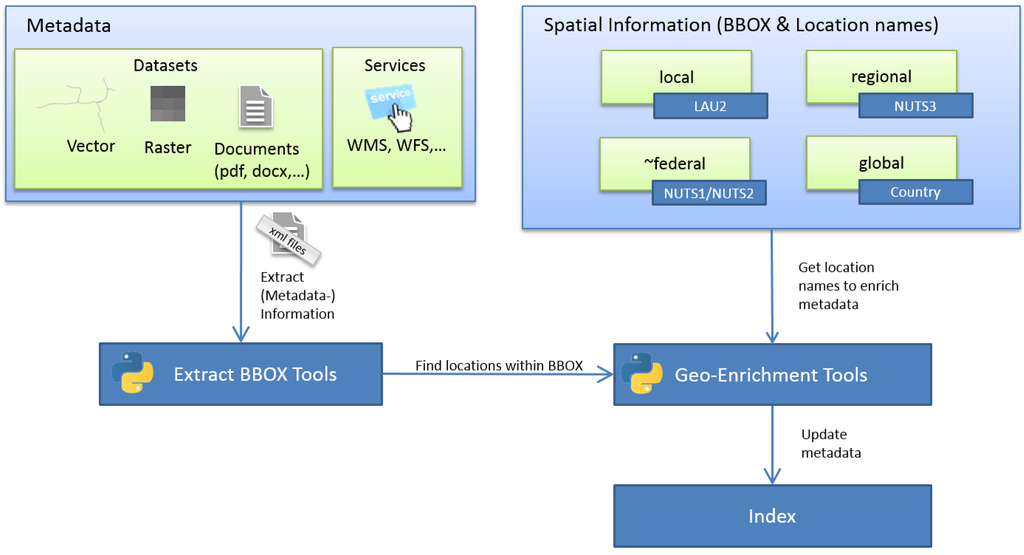
شکل 8. گردش کار غنی سازی جغرافیایی.
9. تقویت رابط های کاربری Discovery در SDI
برای اهداف کشف، ما سه رویکرد مختلف برای پرس و جو از کاتالوگ ارائه می دهیم. دو نفر به Apache Lucene (سفارشیسازی جنبههای جغرافیایی با Apache Solr و GeoSPARQL) متکی هستند. یک رویکرد از الگوریتم های تطبیق متن معنایی در ترکیب با سیستم های توصیه کننده استفاده می کند که به طور گسترده در فروشگاه های آنلاین مانند Amazon.com استفاده می شود.
9.1. قابلیت جستجوی گسترده با استفاده از Apache Solr
Apache Solr این امکان را برای کاربران نهایی فراهم می کند تا جستجوهای خود را بر اساس کلمات کلیدی و/یا پارامترهای مکانی-زمانی فیلتر کنند. مزیت اصلی استفاده از Apache Solr عملکرد آن است زیرا از مکانیسم های نمایه سازی بسیار پیشرفته استفاده می کند. Apache Solr یک سرور جاوا است که می تواند در یک کانتینر مانند Apache Tomcat مستقر شود. فهرست بندی و جستجوی متن کامل بر اساس کتابخانه جستجوی جاوا Lucene [ 49 ] است. برای ادغام و استفاده از آن در geoplatform.at، یک API شبیه REST ارائه می کند. سفارشیسازی جنبههای جغرافیایی (GFC) از شاخص Apache Solr 4.1.0 سرور جغرافیایی استفاده میکند و بنابراین، آن را گسترش میدهد تا بتواند از Solr برای کشف استفاده کند [ 50 ].
شکل 9 رابط کاربری صفحه جستجو را بر اساس Apache Solr نشان می دهد. فیلترهایی مانند گستره مکانی و زمانی، آخرین تاریخ اصلاح، کلمات کلیدی و سازمانها را میتوان به صورت ترکیبی برای محدود کردن نتایج جستجو استفاده کرد.
Solr امکان ادغام سایر سیستمها مانند سایر ژئوپورتالها را در فهرست ارائه میدهد، بنابراین مکانیسمهای جستجوی توزیع شده را فراهم میکند. این به ویژه برای نمونه اولیه ما که از منابعی استفاده می کند که از سیستم های مختلف نشات می گیرند مفید است. جستجوی فضایی را میتوان با استفاده از نقشه یا جستجوی مکانها بر اساس کلمات کلیدی که با گردش کار غنیسازی جغرافیایی معرفی شده است، انجام داد.

شکل 9. جستجوی Solr.
9.2. قابلیت های جستجوی معنایی توسعه یافته بر اساس GeoSPARQL برای کارشناسان
هنگام تلاش برای ایجاد پیوند بین اطلاعات غیر مرتبط، RDF به عنوان مبنایی برای مفهوم داده های پیوندی به ویژه در زمینه کتابخانه های (آنلاین) استفاده می شود. از سال 2010، این مفهوم در حوزه جغرافیایی نیز به کار گرفته شده است، جایی که دادههای بیشتر و بیشتری از منابع ناهمگن، مانند پایگاههای داده، صفحات گسترده، XML، اندازهگیریها یا دادههای جمعآوریشده به دلیل تلاشهای داده باز در دسترس است. تبدیل ابرداده این منابع به RDF میتواند برای جستجوی معنایی و در نتیجه کشف آسانتر در کاتالوگهای زیربنایی استفاده شود. معناشناسی همچنین به مسئله ناهمگونی اشاره دارد، زمانی که چندین اصطلاح مترادف برای یک شی وجود دارد.
پیوند داده ها به ویژه برای پاسخگویی به سؤالات پیچیده ای ضروری است: “اگر سطح آب بیش از پنج متر افزایش یابد، کدام مدارها برای تغییر منبع برق از یک طرف یک رودخانه خاص به سمت دیگر ضروری هستند؟”
برای فرمول بندی چنین پرس و جوی، SPARQL را می توان برای سه گانه RDF، متشکل از موضوعات، محمول ها و اشیا اعمال کرد. خود جستجو بر اساس کشف الگوهایی است که معیارهای پرس و جو را مطابق فیلترها برآورده می کنند [ 51 ]. نحو پرس و جو شبیه به زبان پرس و جو ساخت یافته (SQL) است که به طور گسترده در دامنه پایگاه های داده استفاده می شود. گسترش فضایی SPARQL GeoSPARQL نامیده می شود و فرمول بندی پرس و جوهای فضایی را با استفاده از مفاهیم شناخته شده Egenhofer، مانند شامل، درون، بیرون و درون [ 51 ] تسهیل می کند.
ما یک پسوند GeoSPARQL را در سرور جئوپورتال منبع باز ادغام کردیم. بنابراین، یک کاربر متخصص که با GeoSPARQL آشناست میتواند مستقیماً از آن برای پرسوجو از فهرست فراداده استفاده کند. مثالی برای نحو جستجوی نمونه اولیه ما در شکل 10 ارائه شده است . نتیجه جستجو در شکل 11 نشان داده شده است .
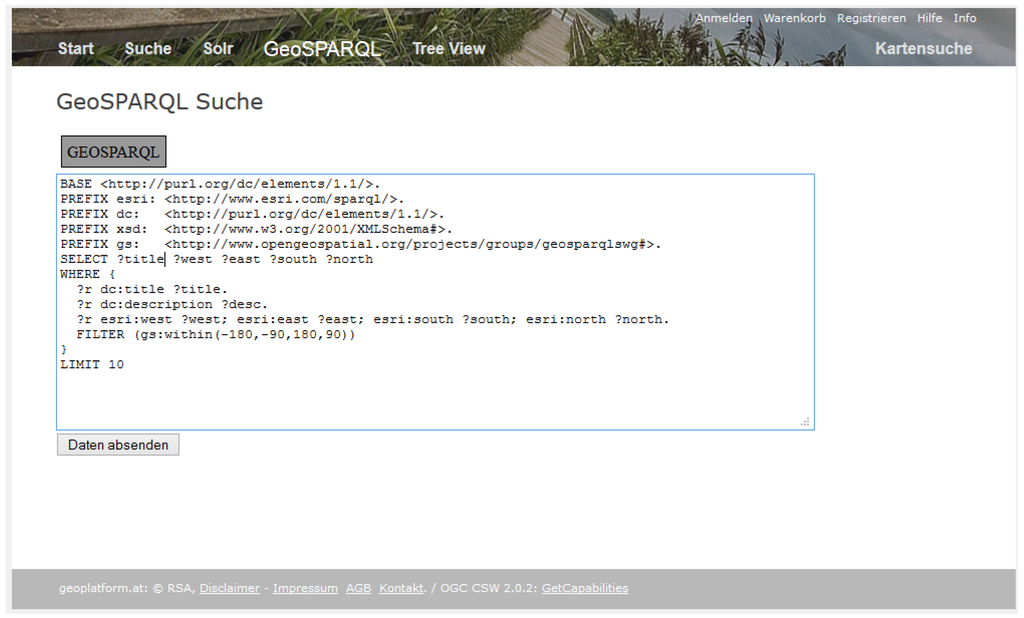
شکل 10. جستجوی GeoSPARQL.

شکل 11. نتیجه جستجوی GeoSPARQL.
9.3. قابلیت های جستجوی معنایی گسترده برای کاربران معمولی
همانطور که قبلا توسط Vockner و همکاران ارائه شده است. [ 52 ]، ما قابلیتهای جستجوی استاندارد جزء کاتالوگ geoplatform.at را با مفهوم توصیهها در ترکیب با رویکرد تطبیق متن معنایی که موارد مرتبط با یکدیگر را شناسایی میکند، گسترش دادیم. توصیهها بر اساس منابعی که سایر کاربران با هم مشاهده کردهاند، بر اساس رتبهبندی اقلام و ابزاری که شباهت معنایی چکیدههای منابع را با الگوریتمی به نام تحلیل معنایی پنهان (LSA; [ 53 ) محاسبه میکند، محاسبه میشوند.]). LSA ساده شده، متون را به بردارهای n بعدی تبدیل می کند، ابعاد آنها را کاهش می دهد و با بررسی الگوی هم رخدادی آماری، ساختار معنایی متون را کشف می کند. LSA از شباهت کسینوس برای تعیین شباهت دو بردار یا متن استفاده می کند. مقدار 1 مطابقت دقیق را نشان می دهد، مقدار 0 نشان می دهد که هیچ تطابقی وجود ندارد.
رابط کاربری که فهرستی از پیشنهادات قابل پیمایش را نشان می دهد در شکل 12 مشخص شده است.
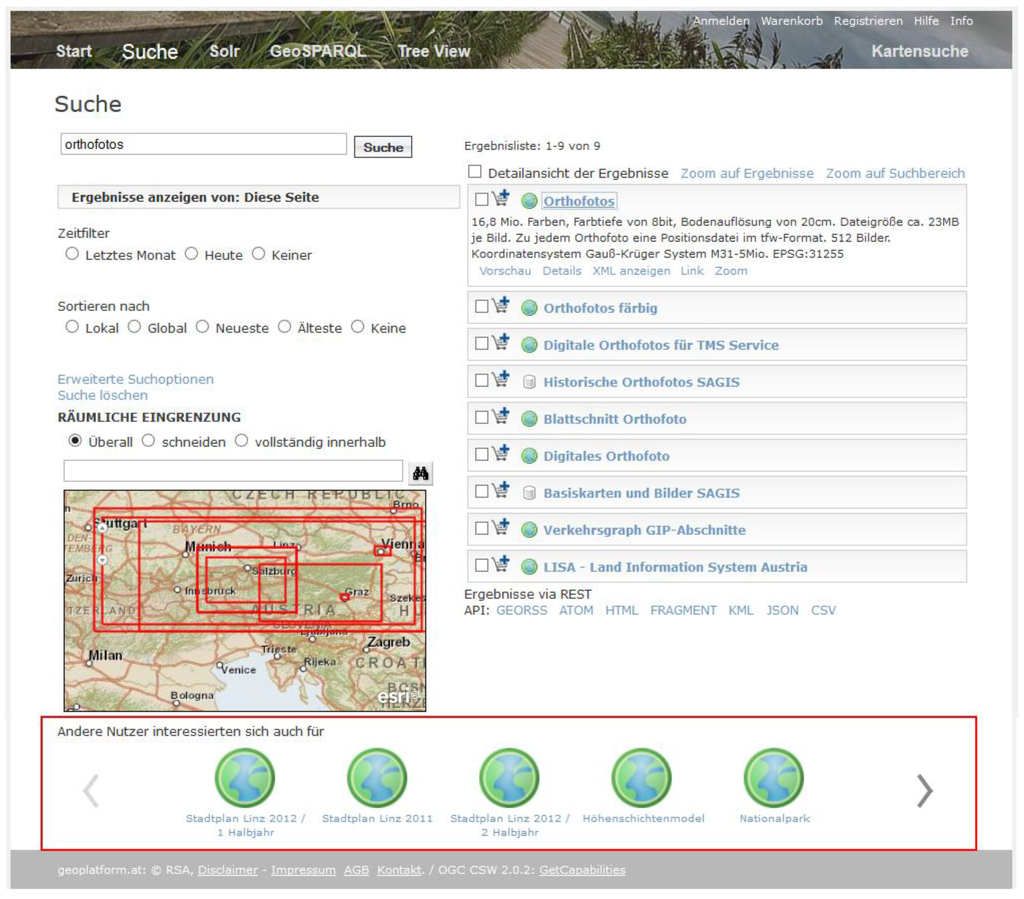
شکل 12. کشف افزایش یافته توسط توصیه کننده.
10. نتایج
برای مقابله با حجم عظیمی از منابع در SDI، ما خواستار یک استراتژی کارآمد و مؤثر برای کشف شدیم. به منظور قابل کشف کردن منابع، مفاهیم غنیسازی جغرافیایی و افزایش معنایی مجموعههای ابرداده را معرفی کردیم. بنابراین، کاربران می توانند ابرداده را کشف کنند، اگرچه ممکن است از اصطلاح متفاوتی نسبت به ارائه دهنده ابرداده استفاده شده برای توصیف منبع استفاده کنند. رویکرد ما همچنین امکان کشف اطلاعات به زبانی دیگر را فراهم می کند. ترجمههای خودکار به کاربر کمک میکند تا درباره محتوای منابعی که به زبان دیگری مستند شدهاند، اطلاعات کسب کند. رویکرد کلی به کاربران در انجام وظایف اکتشافی خود کمک می کند. آنها می توانند (فرا-)داده هایی را که نمی توانستند مستقیماً با عبارت جستجو یا زبان جستجویی که وارد کرده اند، بازیابی کنند.
در مورد کشف مجموعه داده های فضایی، کاربران معمولاً به دلیل تجربه روزمره در انجام جستجوهای وب، به یک رابط جستجوی مبتنی بر متن به جای انتخاب کادر محدود در نقشه عادت دارند. بنابراین، گردش کار بهبود جغرافیایی ما به کاربران اجازه میدهد تا پرسشهای خود را به صورت متنی فرموله کنند.
ما رویکرد خود را در نمونه اولیه geoplatform.at آزمایش کردیم. برای این منظور، قبل از اعمال بهبود معنایی و گردش کار غنیسازی جغرافیایی، عباراتی مانند “cabrio”، “convertible” و “auto” را جستجو کردیم. پرس و جو هیچ نتیجه ای نداشت. پس از آن، مجموعههای فرادادهها را با مترادفها، ترجمهها، اصطلاحات وسیعتر/محدودتر، و نامهای نامی اصطلاحات موجود در اسناد فراداده تقویت کردیم. در نتیجه، جستجو اکنون مواردی را برگرداند (مثلاً “انواع ماشینها”) که قبلاً قادر به کشف آنها نبودیم.
با این حال، آزمایش ما نشان داد که در برخی موارد نتایج مبتنی بر کلمات کلیدی بهبود یافته از نظر معنایی، نتایج رضایتبخشی را نشان نمیدهند: به عنوان مثال، اگر فردی برای جستجوی “kokain” (کلمه آلمانی برای “کوکائین”) به دنبال اطلاعاتی در مورد میزان جرایم مواد مخدر باشد، نتیجه اطلاعاتی مانند “پوشش برفی” را نشان می دهد. این به این واقعیت مربوط می شود که “برف” کلمه عامیانه کوکائین است. این نشان میدهد که اجرای ما از ویکیواژه حداقل باید از در نظر گرفتن کلمات عامیانه در نسخه بعدی اجتناب کند.
ما سه نوع رابط کاربری برای کشف منابع ثبت شده در geoplatform.at ایجاد کردیم. در ادبیات، (Geo-)SPARQL به عنوان یک ابزار کارآمد برای پرسوجو از رابطهای کاتالوگ پیشنهاد شد، که امکان فرمولبندی پرس و جوهای نسبتاً دشوار را فراهم میکند، که در کاتالوگ مطرح میشوند. این رویکرد به ویژه برای کاربران متخصص مناسب است. برای کسانی که با نحو و زبان GeoSPARQL آشنایی ندارند، یک رابط کاربری گرافیکی ایجاد خواهیم کرد که پیچیدگی ساختار پرس و جو را از کاربر نهایی پنهان می کند. با این حال، این همچنین منجر به کاهش آزادی در جستجو می شود زیرا در این صورت می توان پرس و جوهای از پیش فرموله شده را مطرح کرد.
کاربران معمولی ممکن است رویکرد توصیه ما را ترجیح دهند که موارد مرتبط را به مواردی که جستجوی مبتنی بر کلمه کلیدی برگردانده است نشان دهد. این مفهوم در حوزه فروشگاههای آنلاین کاملاً موفق است و بنابراین در رویکرد geoplatform.at که در این مقاله استفاده میکنیم، ادغام شد. به عنوان یک روش اضافی برای جستجوی اطلاعات، Apache Lucene و Apache Solr را می توان مستقیماً از مؤلفه رابط کاربری کاتالوگ استفاده کرد. آنها امکان جستجوی متن کامل، جستجوی وجهی، مدیریت اسناد غنی (به عنوان مثال، Word، PDF) و جستجوی مکانی را فراهم می کنند [ 49 ].
11. چشم انداز و بحث
ما از هستی شناسی ها و اصطلاحنامه ها برای تقویت ابرداده استفاده کردیم و سه نوع رابط کاربری برای جستجوی داده ها ارائه کردیم. با این حال، برای اینکه به کاربران امکان “تنظیم دقیق” جستجو را بدهیم، قصد داریم یک رابط کاربری به ویژه برای جستجوهای مشابه ایجاد کنیم.
یانوویچ و همکاران [ 54 ] یک رابط جستجو ارائه کرد که به کاربر اجازه میدهد با فهرستهای مترادف تعامل داشته باشد. به نظر می رسد این رویکرد برای گسترش رویکرد ما ارزشمند باشد، زیرا در حال حاضر فقط سیستم، اما نه کاربر می تواند تصمیم بگیرد که از کدام سلسله مراتب عبارات در فرآیند جستجو استفاده کند. رابط کاربری آنها نوارهای اسکرول را برای افزایش/کاهش کلیت و تشابه عبارات جستجوی وارد شده توسط کاربران فراهم می کند ( شکل 13 ). اندازه فونت و رنگی که آنها استفاده می کنند مقادیر شباهت را نشان می دهد. برخلاف رویکرد ما، Janowicz و همکاران. [ 54 ] چند زبان را در نظر نگیرید. بنابراین، چنین رابط کاربری باید در مورد ما متفاوت به نظر برسد.

شکل 13. رابط کاربری برای افزایش/کاهش عمومیت و تشابه عبارات جستجو [ 54 ].
علاوه بر این، Janowicz و همکاران. [ 54 ] یک رابط جستجوی ایستا را فراهم می کند، جایی که آنها انواع مکان های مشابه را بر اساس هستی شناسی به کاربر نشان می دهند ( شکل 14 ). این به کاربر اجازه نمی دهد که مستقیماً با جزئیات عبارات تعامل داشته باشد، بلکه یک نمایش بصری از آنچه ممکن است برای آنها مفید باشد را ارائه می دهد.

شکل 14. رابط کاربری مبتنی بر شباهت برای روزنامه نگاران وب [ 54 ].
سینککیلا و همکاران [ 55 ] یک مفهوم ترکیبی از تکمیل خودکار (شکلی از ورودی متنی که سعی میکند کلمهای را که کاربر وارد میکند کامل کند) از عبارات جستجو و ناوبری بافت هستیشناختی (که روشی برای انتخاب عبارات است) ارائه کرد. در رویکرد خود، آنها سلسله مراتب و رابطه مفاهیم را برای برقراری ارتباط هستی شناسی ها به کاربر ارائه می دهند. این مفهوم را می توان در ابزار تکمیل خودکار که در geoplatform.at پیاده سازی کرده ایم نیز استفاده کرد، اما ما آن را به موارد کمتری نسبت به Sinkkilä و همکاران محدود می کنیم. [ 55 ] استفاده کنید تا حواس کاربر را پرت نکنید. این مطابق با Hyvönen و Mäkelä [ 56 ] و Hildebrand و همکاران است. [ 57] که همچنین سعی کرد رویکرد تکمیل خودکار را با هستی شناسی ها بهبود بخشد، و به این نتیجه رسید که تکمیل خودکار یک ویژگی پیچیده است به جای یک رویکرد آسان که در نگاه اول به نظر می رسد.
امکان دیگر برای بهبود رابط کاربری ما استفاده از نمایش ابر برچسب از اصطلاحات مشابه است. Ostländer و Lutz [ 58 ] مفهوم چنین نمایش ابری برچسب ها را به شیوه ای کمی متفاوت ارائه کردند. در آنجا، اندازه هر مفهوم بستگی به این دارد که چقدر به عنوان یک کلمه کلیدی برای حاشیه نویسی یک منبع به جای شباهت عبارت جستجو و اصطلاحنامه چند زبانه وارد شده توسط کاربر استفاده شده است.
ما همچنین با کتابخانه jOWL JavaScript [ 59 ] برای تعامل با هستی شناسی ها آزمایش کردیم. این به کاربر امکان می دهد یک هستی شناسی را بر اساس متن جستجوی وارد شده مرور کند تا نتایج جستجوی خاص یا عمومی تری ارائه دهد ( شکل 15 ).

شکل 15. کتابخانه جاوا اسکریپت jOWL برای مرور هستی شناسی ها.
مزیت های پشت رویکرد کمک به کاربر در ارائه عبارات گسترده تر یا محدودتر قبلاً توسط کرافت و داس [ 60 ] نشان داده شده است، که هنگامی که از کاربران برای عبارات اضافی خواسته می شود (مثلاً در قالب مرور سلسله مراتب) پیشرفت های قابل توجهی را در پرس و جو گزارش کردند. یک هستی شناسی) که می تواند برای جستجو استفاده شود [ 6 ].
می خواهیم مفهومی از مترادف وزن و اصطلاحات ترجمه شده را معرفی کنیم. در حال حاضر، ما در مقایسه با کلمات کلیدی تعریف شده توسط کاربر، وزن کمتری به مترادف ها قائل نیستیم. این برای مورد آزمایشی ما کافی است، اما باید برای مقادیر بیشتری از داده ها گسترش یابد.
همچنین قصد داریم گردشهای کاری غنیسازی جغرافیایی و بهبود معنایی را مستقیماً در سیستم توصیهگر خود ادغام کنیم تا این گردشها با تنظیم رتبهبندی موارد، توصیههایی را که به کاربر ارائه میشود، بهبود بخشند.
برای نشان دادن مزایای رویکرد ما، تستهای معیار و قابلیت استفاده برای ارزیابی رویکرد ما انجام خواهد شد. این یک وظیفه حیاتی است زیرا همانطور که ون اوسنبروگن و همکارانش. [ 61 ]، ایجاد و ارزیابی یک رابط کاربری حاوی معناشناسی بسیار دشوار است، زیرا جزء رابط کاربر را نمی توان به وضوح از موتور جستجو و کیفیت منابع استفاده شده جدا کرد.
12. نتیجه گیری
ما ادغام غنیسازی جغرافیایی و افزایش معنایی مجموعههای فراداده در ژئوپورتالها را برای غلبه بر مشکلات ناهمگونی معنایی به عنوان نتیجه اصلی تحقیق خود پیشنهاد میکنیم. برای نشان دادن مزایای چنین رویکردی، ابزارهای پایتون را توسعه دادیم که به صورت روزانه برای استخراج کلمات کلیدی تعریف شده توسط کاربر از مجموعههای ابرداده و غنیسازی آنها با مترادفها و ترجمهها به زبانهای دیگر اجرا میشوند. این امکان بازیابی اطلاعات بین زبانی را فراهم می کند که در آن کاربر در کار کشف با ترجمه خودکار نتایج جستجو کمک می کند. علاوه بر این، ما یک گردش کار در مورد نحوه حاشیه نویسی ابرداده ها به صورت جغرافیایی پیشنهاد و اجرا کردیم، زیرا کاربران ترجیح می دهند مکانی را بر اساس ورودی های متنی به جای جعبه های مرزی جستجو کنند. ما نتایج تحقیق خود را به عنوان اثبات مفهوم در geoplatform.at نشان دادیم.
منابع
- مرد، ED درک SDI; پیچیدگی و نهادینه شدن بین المللی جی. جئوگر. Inf. علمی 2006 ، 20 ، 329-343. [ Google Scholar ] [ CrossRef ]
- بستر کارگزاری EuroGEOSS. در دسترس آنلاین: http://www.eurogeoss.eu/broker/Pages/TheEuroGEOSSBrokeringPlatform.aspx (در 11 فوریه 2014 قابل دسترسی است).
- لوتز، ام. اسپرادو، جی. کلین، ای. شوبرت، سی. مسیح، I. غلبه بر ناهمگونی معنایی در زیرساخت های داده های مکانی. محاسبه کنید. Geosci. 2009 ، 35 ، 739-752. [ Google Scholar ] [ CrossRef ]
- نواک، ج. نوگراس-ایسو، جی. Peedell, S. مسائل چندزبانگی در ایجاد SDI اروپایی – چشم انداز قابلیت همکاری داده های مکانی. در مجموعه مقالات یازدهمین کارگاه EC GI&GIS، ESDI تنظیم چارچوب، آلگرو، ایتالیا، 29 ژوئن تا 1 ژوئیه 2005.
- نوگراس-ایسو، جی. Zarazaga-Soria، FJ; لاکاستا، جی. تولوسانا، ر. Muro-Medrano، روابط عمومی بهبود خدمات جستجوی کاتالوگ چند زبانه با استفاده از ابهامزدایی اصطلاحنامه چند زبانه. در مجموعه مقالات دهمین کارگاه EC GI & GIS، ESDI State of the Art، ورشو، لهستان، 23-25 ژوئن 2004.
- اسمیت، کامپیوتر; فریس کریستنسن، الف. کشف منبع در زیرساخت داده های فضایی اروپا. IEEE Trans. بدانید. مهندسی داده 2007 ، 19 ، 85-95. [ Google Scholar ] [ CrossRef ]
- واچه، اچ. وگله، تی. ویسر، یو. استاکنشمیت، اچ. شوستر، جی. نویمان، اچ. Hübner, S. یکپارچه سازی اطلاعات مبتنی بر هستی شناسی – بررسی رویکردهای موجود. در مجموعه مقالات کارگاه آموزشی IJCAI-01: هستی شناسی ها و به اشتراک گذاری اطلاعات، سیاتل، WA، ایالات متحده آمریکا، 4-5 آوریل 2001. صص 108-117.
- بوچلا، آ. چکیچ، آ. فیلوترانی، P. یکپارچه سازی اطلاعات جغرافیایی مبتنی بر هستی شناسی: بررسی رویکردهای فعلی. محاسبه کنید. Geosci. 2009 ، 35 ، 710-723. [ Google Scholar ] [ CrossRef ]
- Andrade، FGD; سوزا باپتیستا، سی دی استفاده از شباهت معنایی برای بهبود کشف اطلاعات در زیرساخت های داده های مکانی. J. Inf. داده 2011 ، 2 ، 181-194. [ Google Scholar ]
- Renteria-Agualimpia، W. لوپز-پلیسر، FJ; لاکاستا، جی. Zarazaga-Soria، FJ; Muro-Medrano، PR شناسایی منابع جغرافیایی پنهان در کاتالوگ ها. در مجموعه مقالات سومین کنفرانس بین المللی هوش وب، کاوی و معناشناسی (WIMS)، مادرید، اسپانیا، 12 تا 14 ژوئن 2013; صص 1-7.
- Nebert، D. GEOSS AIP-2 اکوسیستم قطبی تنوع زیستی SBA گزارش مهندسی. 2009. در دسترس آنلاین: http://www.ogcnetwork.net/system/files/Final_090721_Polar_ER_ecosystems_v1.pdf (دسترسی در 14 فوریه 2014).
- Fileto, R. مسائلی در مورد قابلیت همکاری و یکپارچگی داده های جغرافیایی ناهمگن. در دسترس آنلاین: http://www.geoinfo.info/proceedings_geoinfo2001.split/paper6.pdf (در 13 فوریه 2014 قابل دسترسی است).
- کاشیاپ، وی. Sheth، A. ناهمگونی معنایی در سیستم های اطلاعات جهانی: نقش فراداده، زمینه و هستی شناسی ها. در سیستمهای اطلاعات تعاونی: روندها و جهتها . پاپازوگلو، م.، شلاژتر، جی.، ویرایش. انتشارات دانشگاهی: Waltham, MA, USA, 1997; صص 139-178. [ Google Scholar ]
- خو، ز. لی، ناهمگونی معنایی ژئوداده YC. در دسترس آنلاین: http://www.isprs.org/proceedings/XXXIV/part4/pdfpapers/499.pdf (دسترسی در 11 دسامبر 2013).
- Sheth، AP; لارسون، JA سیستم های پایگاه داده فدرال برای مدیریت پایگاه های داده توزیع شده، ناهمگن و مستقل. کامپیوتر ACM. Surv. 1990 ، 22 ، 183-236. [ Google Scholar ]
- دومینیچ، اس . جبر مدرن بازیابی اطلاعات . Springer Publishing Company: New York, NY, USA, 2008; پ. 330. [ Google Scholar ]
- بری، مگاوات؛ براون، ام. درک موتورهای جستجو: مدلسازی ریاضی و متن. بازیابی (نرم افزار، محیط، ابزار) ، ویرایش دوم. Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2005. [ Google Scholar ]
- مانیکندان، بی. Shrira, R. A Novel Approach for Cross Language Retrieval. در مجموعه مقالات سومین کنفرانس بین المللی فناوری کامپیوتر الکترونیک (ICECT)، کانیاکوماری، هند، 8 تا 10 آوریل 2011; صص 34-38.
- یانوویچ، ک. ویلکس، ام. لوتز، ام. بازیابی اطلاعات مبتنی بر شباهت و نقش آن در زیرساخت های داده های مکانی. در مجموعه مقالات پنجمین کنفرانس بین المللی علم اطلاعات جغرافیایی; Springer-Verlag: Park City, UT, USA, 2008; جلد 5266، صص 151–167. [ Google Scholar ]
- کسلر، سی. راوبال، م. Wosniok، C. قواعد معنایی برای بازیابی اطلاعات جغرافیایی آگاه از زمینه. در مجموعه مقالات چهارمین کنفرانس اروپایی در زمینه حس هوشمند و زمینه؛ Springer-Verlag: Guildford، UK، 2009; صص 77-92. [ Google Scholar ]
- بازیره، م. Brézillon, P. درک زمینه قبل از استفاده از آن. در مدل سازی و استفاده از زمینه ; Dey, A., Kokinov, B., Leake, D., Turner, R., Eds. Springer Berlin Heidelberg: برلین، آلمان، 2005; جلد 3554، ص 29–40. [ Google Scholar ]
- گروبر، TR به سمت اصولی برای طراحی هستی شناسی های مورد استفاده برای اشتراک دانش. بین المللی J. Hum.-Comput. گل میخ. 1995 ، 43 ، 907-928. [ Google Scholar ]
- تریپاتی، ا. بابایی، HA در حال توسعه هستی شناسی هیدروژئولوژی مدولار با گسترش هستی شناسی های سطح بالایی SWEET. محاسبه کنید. Geosci. 2008 ، 34 ، 1022-1033. [ Google Scholar ] [ CrossRef ]
- Society, IC Thesaurus سوالات متداول. در دسترس آنلاین: http://www.computer.org/portal/web/tandc/Thesaurus-FAQ (در 23 دسامبر 2013 قابل دسترسی است).
- EIONET. اصطلاحنامه GEMET. در دسترس آنلاین: http://www.eionet.europa.eu/gemet (در 11 دسامبر 2013 قابل دسترسی است).
- هستی شناسی شیرین. در دسترس آنلاین: http://sweet.jpl.nasa.gov/ (دسترسی در 12 دسامبر 2013).
- Wordnet چیست؟ در دسترس آنلاین: http://wordnet.princeton.edu/ (دسترسی در 22 دسامبر 2013).
- Openthesaurus.de-Synonyme und Assoziationen. در دسترس آنلاین: http://www.openthesaurus.de/ (در 22 دسامبر 2013 قابل دسترسی است).
- اصطلاحنامه یونسکو در دسترس آنلاین: http://databases.unesco.org/thesaurus/ (دسترسی در 12 دسامبر 2013).
- AGROVOC. در دسترس آنلاین: http://aims.fao.org/standards/agrovoc/ (دسترسی در 12 دسامبر 2013).
- EuroVoc، اصطلاحنامه چند زبانه اتحادیه اروپا. در دسترس آنلاین: http://eurovoc.europa.eu/ . (دسترسی (دسترسی در 12 دسامبر 2013).
- ویکیواژه در دسترس آنلاین: http://www.wiktionary.org/. (دسترسی (دسترسی در 12 دسامبر 2013).
- رایترزگارد، جی. زیرساخت داده های فضایی، روندها و چالش ها در حال توسعه. در مجموعه مقالات کنفرانس بین المللی اطلاعات فضایی برای توسعه پایدار، نایروبی، کنیا، 2 تا 5 اکتبر 2001. پ. 8.
- CKAN، پلتفرم پیشرو درگاه داده منبع باز در جهان. در دسترس آنلاین: http://ckan.org/ (دسترسی در 20 دسامبر 2013).
- OGD Metadata-2.2. در دسترس آنلاین: http://reference.e-government.gv.at/Veroeffentlichte-Informationen.2774.0.html (در تاریخ 16 ژانویه 2014 قابل دسترسی است).
- Geoplatform.at. در دسترس آنلاین: http://www.geoplatform.at(دسترسی (دسترسی در 11 دسامبر 2013).
- سرور ژئوپورتال ESRI. در دسترس آنلاین: http://www.esri.com/software/arcgis/geoportal (در 11 دسامبر 2013 قابل دسترسی است).
- منبع باز GeoNetwork. در دسترس آنلاین: http://geonetwork-opensource.org/ (دسترسی در 20 دسامبر 2013).
- شبکه آرشیو دانش جامع (CKAN). در دسترس آنلاین: http://lod2.eu/Project/CKAN.html (در 15 دسامبر 2013 قابل دسترسی است).
- CKAN: Apt-Get برای Debian of Data. در دسترس آنلاین: http://events.ccc.de/congress/2009/Fahrplan/events/3647.en.html (دسترسی (دسترسی در 18 دسامبر 2013).
- Ckanclient. در دسترس آنلاین: https://github.com/okfn/ckanclient (در 12 اکتبر 2013 قابل دسترسی است).
- Ztfy.Thesaurus. در دسترس آنلاین: https://pypi.python.org/pypi/ztfy.thesaurus (در 13 فوریه 2013 قابل دسترسی است).
- Python-Skos. در دسترس آنلاین: https://pypi.python.org/pypi/python-skos (در 13 فوریه 2014 قابل دسترسی است).
- جعبه ابزار زبان طبیعی. در دسترس آنلاین: http://www.nltk.org (در 23 دسامبر 2013 قابل دسترسی است).
- درخواست ها. در دسترس آنلاین: https://pypi.python.org/pypi/requests/2.2.1 (در تاریخ 13 فوریه 2014 قابل دسترسی است).
- مترجم مایکروسافت. در دسترس آنلاین: http://www.microsoft.com/en-us/translator/ (دسترسی در 10 اکتبر 2013).
- Geopy – جعبه ابزار ژئوکدینگ برای پایتون. در دسترس آنلاین: http://code.google.com/p/geopy/ (در 12 دسامبر 2013 قابل دسترسی است).
- Geodict – ابزاری منبع باز برای استخراج مکان ها از متن. در دسترس آنلاین: http://petewarden.com/2010/10/03/geodict-an-open-source-tool-for-extracting-locations-from-text/ (دسترسی در 12 دسامبر 2013).
- آپاچی سولر. در دسترس آنلاین: http://lucene.apache.org/solr/ (دسترسی در 11 دسامبر 2013).
- جنبه های ژئوپورتال. در دسترس آنلاین: https://github.com/Esri/geoportal-server/wiki/Geoportal-Facets (دسترسی در 15 دسامبر 2013).
- OGC GeoSPARQL – یک زبان پرس و جو جغرافیایی برای داده های RDF. در دسترس آنلاین: http://www.opengeospatial.org/standards/geosparql (در 12 دسامبر 2013 قابل دسترسی است).
- وکنر، بی. ریشتر، آ. Mittlböck، M. از geoportals تا پورتال دانش جغرافیایی. ISPRS Int. J. Geo-Inf. 2013 ، 2 ، 256-275. [ Google Scholar ] [ CrossRef ]
- دومایس، ST; Furnas، GW; Landauer، TK; دیروستر، اس. هارشمن، آر. استفاده از تحلیل معنایی پنهان برای بهبود دسترسی به اطلاعات متنی. در مجموعه مقالات کنفرانس SIGCHI در مورد عوامل انسانی در سیستم های محاسباتی، واشنگتن، دی سی، ایالات متحده آمریکا، 15-19 مه 1988; ص 281-285.
- یانوویچ، ک. شوارتز، ام. Wilkes, M. پیادهسازی و ارزیابی یک رابط کاربری مبتنی بر معناشناسی برای روزنامههای وب. در مجموعه مقالات رابط های بصری به وب اجتماعی و معنایی (VISSW 2009) کارگاه در ارتباط با کنفرانس بین المللی رابط های کاربری هوشمند (IUI 2009)، جزیره Sanibel، FL، ایالات متحده، 8-11 فوریه 2009.
- سینککیلا، آر. ماکلا، ای. کاوپینن، تی. Hyvönen، E. ترکیب پیمایش متن با تکمیل خودکار معنایی برای حل مسائل در انتخاب مفهوم. در مجموعه مقالات کارگاه آموزشی SEMMA 2008، پنجمین کنفرانس وب معنایی اروپایی 2008، تنریف، جزایر قناری، اسپانیا، 1 تا 5 ژوئن 2008.
- هیونن، ای. مکلا، ای. تکمیل خودکار معنایی. در مجموعه مقالات اولین کنفرانس آسیایی در وب معنایی، پکن، چین، 3-7 سپتامبر 2006. صص 739-751.
- هیلدبراند، ام. Ossenbruggen، JRV; امین، ع.ک. آریو، LM؛ ویلر میکر، جی. هاردمن، L. فضای طراحی یک جزء تکمیل خودکار قابل تنظیم ؛ Stichting Centrum voor Wiskunde en Informatica: آمستردام، هلند، 2007. [ Google Scholar ]
- اوستلندر، ن. Lutz، M. الهام بخش GEMET-افزایش ایجاد و کشف فراداده. در مجموعه مقالات انفورماتیک محیطی و بوم شناسی صنعتی لونبورگ، 2008، لونبورگ، آلمان، 10-12 سپتامبر 2008; Moeller, A., Page, B., Schreiber, M., Eds. Shaker Verlag: آخن، آلمان؛ صص 212-214.
- مرورگر هستی شناسی jOWL. در دسترس آنلاین: http://jowl.ontologyonline.org/ (دسترسی در 23 دسامبر 2013).
- کرافت، WB; Das, R. آزمایشهایی با پرس و جو و استفاده در سیستمهای بازیابی اسناد. در مجموعه مقالات سیزدهمین کنفرانس بین المللی سالانه Acm Sigir در مورد تحقیق و توسعه در بازیابی اطلاعات، بروکسل، بلژیک، 5-7 سپتامبر 1990. صص 349-368.
- Ossenbruggen, JV; هیلدبراند، AAM چرا ارزیابی برنامه های کاربردی وب معنایی دشوار است؟ در مجموعه مقالات تعامل کاربر وب معنایی در CHI 2008: بررسی چالش های HCI، فلورانس، ایتالیا، 5-10 آوریل 2008. صص 1-4.
© 2014 توسط نویسندگان; دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (http://creativecommons.org/licenses/by/3.0/) توزیع شده است.
بدون نظر