1. معرفی
در حال حاضر، با محبوبیت تلفن های هوشمند و توسعه اینترنت تلفن همراه، تعداد زیادی از خدمات مبتنی بر مکان (LBS) پدیدار می شود، مانند تبلیغات الکترونیکی برای مشتریانی که در مراکز خرید قدم می زنند و برای اتومبیل هایی که خدمات مکان یابی در پارکینگ های زیرزمینی را انجام می دهند. واحد سنجش موقعیت کاربر، جزء اساسی LBS، نقش کلیدی در کل برنامه ایفا کرده است. نیاز فوری به رویکردی وجود دارد که بتواند موقعیت کاربران متحرک را در مدت زمان کوتاهی به طور دقیق جمع آوری کند. به عنوان یک فناوری بالغ، GPS به طور گسترده در موقعیت یابی در فضای باز استفاده شده است، اما نمی توان از آن در موقعیت یابی داخلی استفاده کرد زیرا سیگنال توسط ساختمان مسدود می شود [ 1 ، 2 ، 3 ، 4]]. در حال حاضر، به دلیل پیچیدگی محلی سازی داخلی، هنوز یک استراتژی به طور گسترده شناخته شده ای وجود ندارد که برای انواع محیط های داخلی منحصر به فرد مناسب باشد. از این رو، بومی سازی فضای داخلی به یک مرکز تحقیقاتی تبدیل شده و توجه بیش از پیش محققین را به خود جلب کرده است.
روش های تعیین موقعیت داخلی زیادی پیشنهاد شده است که با توجه به اصول اندازه گیری و موقعیت یابی به دو دسته تقسیم می شوند. دسته اول روش های هندسی شامل سه لایه و مثلث بندی است. روشهای سهلایهبندی موقعیت یک شی متحرک را با اندازهگیری فاصله آن بین چندین مکان مرجع تخمین میزنند. فاصله معمولاً با استفاده از مدل تضعیف سیگنال یا حاصل ضرب سرعت نور و زمان انتشار بر اساس اندازهگیری قبلی زمان رسیدن (TOA) یا اختلاف زمانی رسیدن (TDOA) محاسبه میشود. به عنوان یک روش معمولی تریلاتراسیون، فناوری باند فوق العاده (UWB) موقعیت یابی داخلی اخیراً بسیار محبوب شده است. روشهایی که از TOA استفاده میکنند نیاز به همگامسازی زمانی دقیق بین فرستنده و گیرنده دارند. تکنیک مثلث بندی، همچنین به عنوان زاویه ورود (AOA) نامیده می شود، از زوایای مشاهده جسم متحرک برای دو موقعیت شناخته شده برای تخمین موقعیت هدف استفاده می کند. فناوری AOA دو مزیت دارد: نیازی به همگام سازی زمانی ندارد و به مشاهدات کمتری نیاز دارد. با این حال، AOA دو نقطه ضعف نیز دارد. به سخت افزار اضافی مانند آرایه آنتن نیاز دارد که گران است. علاوه بر این، با دورتر شدن جسم متحرک، دقت موقعیت یابی کاهش می یابد [5 ، 6 ، 7 ].
محلیسازی اثر انگشت، دسته دوم روشهای موقعیتیابی داخلی، به دلیل مزایای زیر به عنوان یک جهت تحقیقاتی اصلی شناخته میشود: انعطافپذیر است و به راحتی قابل درک است. نیازی به دانستن دقیق مکان فیزیکی APها نیست. و به سخت افزار اضافی متکی نیست. این روش شامل دو مرحله است: مراحل آفلاین و آنلاین. در مرحله آفلاین، پایگاه داده اثر انگشت با استفاده از کالیبراسیون سایت ساخته می شود. ابتدا، در منطقه مورد نظر، تعدادی از نقاط مرجع با توجه به یک فضای خاص مستقر می شود. در مرحله دوم، برای هر مکان مرجع، قدرت سیگنال دریافتی (RSS) از همه AP در منطقه جمع آوری می شود. در نهایت، اثر انگشت، رکوردی متشکل از بردار RSS و مختصات مکان مربوطه آن، برای ایجاد پایگاه داده اثر انگشت ذخیره می شود. در مرحله آنلاین، روش تخمین مکان، بردار RSS مشاهده شده در زمان واقعی را با سوابق پایگاه داده اثر انگشت مقایسه میکند و پس از آن، موقعیت بهترین رکورد اثر انگشت را به عنوان نتیجه برآورد شده انتخاب میکند. با توجه به انواع داده های اثر انگشت، الگوریتم های اثر انگشت را می توان به الگوریتم های قطعی و احتمالی تقسیم کرد.8 ، 9 ، 10 ، 11 ]. الگوریتم قطعی مقدار RSS را از هر AP در پایگاه داده اثر انگشت ذخیره می کند، در حالی که الگوریتم احتمالی مدل توزیع احتمال RSS را ذخیره می کند. به طور کلی اعتقاد بر این است که الگوریتم های احتمالی به دلیل توانایی آنها در مقابله با تغییرات زمانی RSS موثرتر هستند [ 12 ، 13 ، 14 ].
با استفاده گسترده از LAN بی سیم، تعداد بیشتری از APهای قابل شناسایی در محیط وجود دارند. با این حال، برخی از این AP ها برای موقعیت یابی مفید نیستند. در همین حال، برخی از AP ها به عنوان مرجع موقعیت یابی اضافی هستند. بنابراین، نیاز فوری به یافتن یک استراتژی خوب برای یافتن مجموعه ای از مفیدترین APها و در عین حال بهره برداری موثر از تعامل بین APها است. ما یک روش جدید انتخاب AP، LocalReliefF-C (روشی جدید بر اساس ReliefF و ضریب همبستگی) پیشنهاد کردهایم، که میتواند مجموعه بهترین APهای متمایزکننده را برای هر مکان مرجع از طریق حذف APهای بیفایده و زائد به دست آورد. فرآیند انتخاب AP بعد بردار ورودی مورد استفاده برای موقعیتیابی را کاهش میدهد و از این رو، پیچیدگی محاسباتی کمتری را به همراه دارد. به منظور بهبود سرعت موقعیت یابی، ما یک روش خوشه بندی موثر را برای تقسیم مکان های مرجع به چندین خوشه اتخاذ می کنیم. در طول فرآیند تخمین مکان، ابتدا خوشه هدف را از طریق مقایسه کلید هر خوشه با مجموعه ای از بهترین APهای متمایز کننده دنباله مشاهده RSS در این مکان تعیین می کنیم و سپس مدل بیز پنهان پنهان را برای تکمیل کار درونی وارد می کنیم. موقعیت یابی خوشه ای
سهم اصلی این مقاله به شرح زیر است:
-
یک روش جدید انتخاب AP LocalReliefF-C برای به دست آوردن مجموعه ای از بهترین APهای متمایز برای هر مکان مرجع ارائه شده است، که می تواند سربار محاسباتی موقعیت یابی را کاهش دهد و در عین حال، عملکرد موقعیت یابی قابل مقایسه با استراتژی را با استفاده از مجموعه کامل AP ها به دست آورد. . مجموعهای از بهترین APهای متمایزکننده سپس با روش خوشهبندی مؤثر دادههای اثر انگشت استفاده میشوند.
-
یک روش خوشهبندی سریع و مؤثر دادههای اثر انگشت برای محدود کردن فضای جستجو و بهبود عملکرد موقعیتیابی پیشنهاد شده است، که سوابق اثرانگشت را دارای زیرمجموعهای مشترک از بهترین APهای متمایزکننده در یک خوشه قرار میدهد. کارآمدتر و اجرا آسان تر است.
-
مدل بیز پنهان پنهان برای تخمین مکان اعمال می شود، که فرض استقلال شرطی AP را از بین می برد و به طور موثر از وابستگی APها استفاده می کند.
بقیه این مقاله به شرح زیر سازماندهی شده است: بخش 2 کار مرتبط در انتخاب AP را معرفی می کند و روش انتخاب AP پیشنهادی، LocalReliefF-C، را به تفصیل نشان می دهد. بخش 3 فرآیند خوشهبندی سریع سوابق اثر انگشت را بر اساس مجموعهای از APهای متمایزکننده نشان میدهد. بخش 4 روش تخمین مکان را بر اساس مدل پنهان بیز ساده توضیح می دهد. بخش 5 طرح آزمایشی و تجزیه و تحلیل نتایج را ارائه می دهد. و بخش 6 مقاله را به پایان می رساند و پیشنهادهایی برای تحقیقات آتی ارائه می دهد.
2. انتخاب نقاط دسترسی با استفاده از LocalReliefF-C
2.1. کار مرتبط در انتخاب AP
امکانات فراگیر LAN بیسیم، فناوری موقعیتیابی WLAN را در محیط داخلی امکانپذیر میسازد. با این حال، گاهی اوقات، تعداد زیاد AP ها نیز پیچیدگی محاسباتی و دشواری موقعیت یابی را افزایش می دهند. تعداد APهای قابل شناسایی اغلب می تواند تا 20 در انواع محیط های داخلی مانند مراکز خرید، پردیس ها، دفاتر یا خانه ها باشد. به عنوان مثال، جدول 1میانگین تعداد APهای قابل شناسایی را در یک مکان خاص در محیط های داخلی مختلف پردیس دانشگاه معدن و فناوری چین (CUMT) به ترتیب در ساعات کاری و غیر کاری نشان می دهد. علاوه بر این، به دلیل تأثیر شدید چند مسیری انتشار سیگنال داخلی، مجموعه AP قابل تشخیص با زمان و موقعیت مشاهده متفاوت است. اشاره شده است که همه APهای قابل تشخیص را نمی توان برای موقعیت یابی استفاده کرد [ 15 ]. چنین APهایی وجود دارند که یا به عنوان یک عامل نویز عمل می کنند یا نقش اضافی در موقعیت یابی دارند. این الهام بخش محققان است تا بر روی استراتژی انتخاب AP برای غربالگری زیرمجموعه های APهایی که برای موقعیت یابی و دور انداختن موارد پر سر و صدا و اضافی لازم و کافی هستند، تمرکز کنند.
یوسف و همکاران [ 16 ، 17 ، 18 ] روش MaxMean را پیشنهاد کرده اند که اولین k را انتخاب می کند.قوی ترین AP ها در واقع، آنها به طور شهودی معتقدند که APهایی که اغلب در نمونه ها ظاهر می شوند مورد نیاز هستند. بر اساس تجزیه و تحلیل آنها، APهایی با بالاترین میانگین قدرت سیگنال آنهایی هستند که اغلب ظاهر می شوند. این روش ساده و موثر است. با این حال، ممکن است در برخی شرایط کامل نباشد. به طور خاص، از آنجایی که سخت افزار LAN بی سیم در یک محیط واقعی معمولاً توسط چندین سازنده مختلف ارائه می شود، میانگین سطوح قدرت سیگنال دریافتی از آنها می تواند کاملاً متفاوت باشد. روش MaxMean برای دور انداختن این APها با قدرت سیگنال متوسط کم، که ممکن است اغلب ظاهر شوند و به موقعیتیابی کمک کنند، مناسب است. چن و همکاران [ 19] روش InfoGain را بر اساس معیار تئوری اطلاعات ارائه کرده اند. به دست آوردن اطلاعات، به عنوان معیاری از قابلیت های متمایز در نظر گرفته می شود، برای هر AP محاسبه می شود و سپس به ترتیب نزولی رتبه بندی می شود. اولین k AP مربوط به بالاترین بهره اطلاعات در نهایت انتخاب می شوند. لین و همکاران [ 20 ] یک روش انتخاب AP مبتنی بر تبعیض گروهی ارائه کردهاند که از تابع ریسک از ماشینهای بردار پشتیبان (SVM) برای تخمین قابلیتهای موقعیتیابی برای گروه AP استفاده میکند.
2.2. روش انتخاب AP پیشنهادی LocalReliefF-C
با ترکیب الگوریتم انتخاب ویژگی مورد قبول ReliefF با اندازه گیری ضریب همبستگی پیرسون، ما یک روش انتخاب AP جدید به نام LocalReliefF-C ارائه کرده ایم که می تواند به طور موثر قابلیت موقعیت یابی را برای هر AP تخمین بزند و همبستگی معنادار بین هر دو را تعیین کند. AP ها، که به طور بالقوه اضافی هستند. این می تواند دقت موقعیت یابی را بهبود بخشد و سربار محاسباتی سیستم های موقعیت یابی را با دور انداختن AP های اضافی و به دست آوردن مجموعه ای از بهترین AP های متمایز کننده کاهش دهد.
تا به حال، چندین مدل یادگیری ماشین برای موقعیتیابی داخلی استفاده شده است، مانند Bayes ساده، SVM، القای درخت تصمیم و شبکههای عصبی [ 20 ، 21 ]. موقعیت یابی اثر انگشت در فضای داخلی را می توان به عنوان یک مشکل طبقه بندی چند طبقه در زمینه یادگیری ماشین مشاهده کرد. سوابق پایگاه داده اثر انگشت مربوط به نمونه های آموزشی است، در حالی که مکان های مرجع با برچسب های کلاس مطابقت دارند. در روش یادگیری ماشینی، تخمین مکان در واقع برای تعیین کلاس برای نمونه جدید داده شده است. انتخاب ویژگی در تکیه ماشین، فرآیند انتخاب یک زیرمجموعه حاوی ویژگیهای مرتبط برای استفاده در ساخت مدل است [ 22]]. هم شباهت ها و هم تفاوت هایی بین انتخاب AP و انتخاب ویژگی وجود دارد. با این حال، ما هنوز معتقدیم که با توجه به هر AP به عنوان یک ویژگی، معقول است که یک روش انتخاب ویژگی کلاسیک را برای موقعیت یابی در انتخاب AP معرفی کنیم.
امداد یک روش انتخاب ویژگی به خوبی پذیرفته شده برای مسئله طبقه بندی دو کلاسه است. این مزیت این است که پیاده سازی آن ساده است و راندمان اجرایی بالایی دارد [ 23 ، 24 ]. ایده اصلی آن انتخاب زیر مجموعه ای از ویژگی ها با بهترین قابلیت تشخیص است. قابلیت تمایز هر ویژگی با وزنی نشان داده می شود که بر اساس میزان خوبی که مقادیر ویژگی می توانند نمونه های مشابه یکدیگر را جدا کنند محاسبه می شود. به طور مشخص، از بین تمام موارد آموزشی، Relief به طور تصادفی یک نمونه را انتخاب می کند آرمنآرمنو دو تا از نزدیکترین همسایگان خود را پیدا می کند: یکی از همان کلاس، به نام نزدیکترین ضربه H ، و دیگری از کلاس متفاوت، به نام نزدیکترین miss M. فرآیند انتخاب یک نمونه تصادفی m بار تکرار می شود. در هر تکرار، با توجه به مقادیر آرمنآرمن، ممو H ، الگوریتم وزن را به روز می کند دبلیو[ الف ]دبلیو[آ]برای هر ویژگی آآبه شرح زیر است:
جایی که:
در معادله (2)، تابع diff تفاوت مقدار در ویژگی A نمونه ها را محاسبه می کندآرمنآرمنو اچ�. نتیجه تقسیم بر m a x ( A ) – m i n ( A )مترآایکس(آ)–مترمن�(آ)به دلیل عادی شدن الگوریتم در نظر میگیرد که ویژگیهای خوب باید نمونههای یک کلاس را نزدیک و نمونههای کلاسهای مختلف را دور کند. همانطور که در رابطه (1) نشان داده شده است آرمنآرمنو H دارای مقادیر متفاوتی هستند آآ، این به معنای آن ویژگی است آآدو نمونه از یک کلاس را جدا می کند. این مطلوب نیست: از این رو، وزن را کاهش می دهیم دبلیو[ الف ]دبلیو[آ]. از سوی دیگر، زمانی که آرمنآرمنو M مقادیر متفاوتی دارند آآ، این بدان معنی است که آآدو نمونه را با مقادیر کلاس متفاوت جدا می کند. که مطلوب است، بنابراین وزن را افزایش می دهیم دبلیو[ الف ]دبلیو[آ].
ReliefF، یک الگوریتم بهبود یافته از Relief، میتواند با مشکل انتخاب ویژگی برای طبقهبندی چند کلاسه مقابله کند [ 24 ]. ما از آن برای ارزیابی قابلیت تمایز هر AP استفاده می کنیم. از چند جهت با Relief تفاوت دارد. اول از همه، k نزدیکترین ضربه از یک کلاس و همچنین k نزدیکترین خطا از هر یک از کلاسهای مختلف را جستجو می کند . بعد، هر کلاس متفاوت را در نظر می گیرد سیسیو از نسبت نمونه استفاده می کند p r o p ( C) / ( 1 − p r o p ( c l a s s ( R _ i ) ))پ��پ(سی)/(1–پ��پ(جلآسس(آر_من )))به عنوان عامل مشارکت آن، که در آن p r o p ( C)پ��پ(سی)تعداد نمونه های کلاس را نشان می دهد سیسیتقسیم بر تعداد کل همه نمونه ها در نهایت، وزنهای ویژگی را بسته به سهم وزنی همه نزدیکترین ضربهها و نزدیکترین موارد بهروزرسانی میکند. روند دقیق ReliefF در شکل 1 (خطوط 3-14) آورده شده است.
یکی از معایب ReliefF این است که همه AP ها را با قابلیت موقعیت یابی بالا انتخاب می کند، حتی اگر برخی از آنها برای یکدیگر اضافی هستند. با هدف حذف APهای اضافی و به دست آوردن مجموعهای از بهترین APهای متمایز که فقط برای موقعیتیابی کافی است، از ضریب همبستگی پیرسون استفاده کردهایم که معیاری از درجه وابستگی خطی بین دو متغیر تصادفی است [22 ] . به عنوان کوواریانس دو متغیر تقسیم بر حاصل ضرب انحراف معیار آنها تعریف می شود. فرمول به شرح زیر است:
ضریب همبستگی پیرسون بین -1 و 1 است. با توجه به دو AP، ما محاسبه می کنیم r�، که ضریب همبستگی بردارهای RSS آنها است و قدر مطلق را با هم مقایسه کنید r�با θ�، آستانه ای که تعیین کردیم. اگر | r ||�|بزرگتر است از θ�، فرض بر این است که دو AP به طور قابل توجهی همبستگی دارند، یعنی برای یکدیگر زائد هستند. مقادیر معمولی برای θ�در بخش 5 آورده شده است .
به منظور ارائه شرح مفصلی از LocalReliefF-C، تعریف پایگاه داده ابتدا به شرح زیر است:
جایی که ( ل ، آر )( من )(ل،آر)(من)نشان دهنده i-امین نمونه و U نشان دهنده تعداد تمام نمونه ها است. للبه مکان مرجع، یعنی برچسب کلاس نمونه ها اشاره دارد. R = [ R Sاس1، آر اساس2… آر اساسn]آر=[آراساس1،آراساس2…آراساس�]، که یک n�-بردار بعدی متشکل از قدرت سیگنال دریافتی از هر AP در محل مرجع لل; و n�به تعداد APهای موجود اشاره دارد. در روش یادگیری ماشین، هر AP به عنوان یک ویژگی در نظر گرفته می شود. یک وزن W به هر AP اختصاص داده می شود که توانایی تشخیص آن، یعنی ظرفیت موقعیت یابی را می سنجد. شبه کد LocalReliefF-C در شکل 1 نمایش داده شده است . این روش ابتدا وزن هر AP (خطوط 1-12) را محاسبه می کند، سپس وزن ها را به ترتیب نزولی مرتب می کند و در نهایت، N از APهای مجموعه Sb را که با N بالاترین وزن مطابقت دارد، حفظ می کند (خطوط 13-14). ). پس از آن، مجموعه Sb را طی می کندبرای محاسبه ضرایب همبستگی برای هر دو AP و مجموعه نهایی از بهترین APهای متمایز کننده پس از حذف موارد اضافی (خطوط 15-22).
در شکل 1 ، پارامتر k تعداد نزدیکترین همسایگان را نشان می دهد، در حالی که m تعداد تکرارها را نشان می دهد. معمولاً زمانی که k در محدوده مناسبی قرار دارد ، وزنهای تخمینی به حداکثر مقادیر بالا میروند و سپس با افزایش k کاهش مییابند . در اصل m نشان دهنده درجه پوشش فضای نمونه برای الگوریتم است. هرچه m بزرگتر باشد، عملکرد بهتر است. با این حال، پیچیدگی محاسباتی الگوریتم با افزایش پارامتر m افزایش می یابد. هر دو پارامتر m و k باید به درستی تنظیم شوند. مقادیر معمولی آنها در آورده شده استبخش 5 . پارامتر N تعداد APهای انتخابی را نشان می دهد که ارتباط نزدیکی با دقت موقعیت یابی دارد. بخش 5.4 مقدار پیشنهادی N را ارائه می دهد و دقت موقعیت یابی بین سیستم ها را با استفاده از روش های مختلف انتخاب AP مقایسه می کند. علاوه بر این، توجه داشته باشید که برای یافتن k نزدیکترین همسایه، فاصله منهتن را برای اندازه گیری فاصله بین دو نمونه انتخاب می کنیم. این به عنوان مجموع تفاوت هر ویژگی تعریف می شود. با توجه به دو مورد آر1 و آر2آر1 و آر2، فاصله منهتن آنها به صورت زیر محاسبه می شود:
علاوه بر این، ما همچنین از فاصله شناخته شده اقلیدسی به جای فاصله منهتن استفاده کرده ایم. نتیجه نشان می دهد که تفاوت معنی داری برای نتیجه مرتب سازی وزن APها ایجاد نمی کند. علاوه بر این، نکته دیگری که شایان ذکر است این است که مجموعههای APهای متمایزکننده با مکانهای مرجع متفاوت است، که دقیقاً مشابه وضعیت قویترین AP تنظیم شده در [16] است . برای به دست آوردن مجموعههای مختلف از APهای متمایز مکانهای مرجع، LocalReliefF-C روند نمونهبرداری از ReliefF را بهبود میبخشد. همانطور که در خطوط 2-4 شکل 1 نشان داده شده است، به طور تصادفی نمونه ها را در یک فضای نمونه محلی مطابق با مکان مرجع داده شده به جای کل فضای نمونه انتخاب می کند.. به همین دلیل است که اصطلاح “محلی” به نام روش پیشنهادی ما اضافه شده است. پس از آن، تمام مجموعههای بهدستآمده از APهای متمایزکننده بهعنوان مبنایی برای فرآیند خوشهبندی زیر مکانهای مرجع استفاده میشوند.
3. خوشهبندی مکانهای مرجع بر اساس زیرمجموعههای رایج APهای متمایزکننده
3.1. روش خوشهبندی پیشنهادی مکانهای مرجع
همانطور که همه ما می دانیم، جستجوی مکان مطابق از تعداد زیادی اثر انگشت در پایگاه داده بسیار زمان بر است. لازم است که مکان های مرجع مشابه در خوشه ها گروه بندی شوند. سرعت جستجو را می توان ابتدا از طریق فرآیند تعیین خوشه هدف برای نمونه RSS جدید و سپس تخمین مکان دقیق در خوشه بهبود بخشید. در [ 19]، چن و همکاران. کار مشابهی را با استفاده از الگوریتم کلاسیک کلاسیک K-means انجام داده اند. آنها بیشتر بر روی شباهت داده های نمونه های RSS تمرکز کرده اند. به نظر ما، مکانهای مرجع مشابه آنهایی هستند که دارای مجموعه مشترک بهترین APهای متمایز هستند. بنابراین، بر اساس بهدستآوردن مجموعهای از APهای متمایزکننده برای هر مکان مرجع، یک روش خوشهبندی همپوشانی جدید را برای گروهبندی مکانهای مرجع معرفی کردهایم که زیرمجموعه مشترکی از بهترین APهای متمایز را در یک خوشه به اشتراک میگذارند. هر زمان که یک خوشه جدید تولید می شود، جستجو می کند که آیا خوشه موجودی وجود دارد که بتواند با آن ادغام شود یا خیر. تا زمانی که خوشه جدیدی تولید نشود متوقف می شود. همیشه به یک نتیجه همگرا می شود،
توجه داشته باشید که به دلیل پیچیدگی مجموعه داده واقعی، مجموعه ای از APهای متمایزکننده هر مکان مرجع متفاوت است. بنابراین، در عمل، یک زیرمجموعه مشترک به جای کل مجموعه یکسان از APهای متمایزکننده به عنوان شرایط خوشهبندی انتخاب میشود. در اینجا، ما یک پارامتر S را تعریف می کنیم که نشان دهنده حداقل اندازه زیر مجموعه مشترکی است که استفاده می کنیم. به طور مشخص، مکانهای مرجع در یک خوشه گروهبندی میشوند اگر مجموعههای متناظر از APهای متمایزکننده آنها کمتر از S نباشد.عناصر مشترک در این روش ساختار داده یک خوشه از دو فیلد تشکیل شده است. یکی “کلید” است که زیرمجموعه این APهای رایج مربوط به خود را ثبت می کند و دیگری “لیست اعضا” است که نام مکان های مرجع را در آن ذخیره می کند. شکل 2 شبه کد روش را نشان می دهد. این روش مجموعه داده محل مرجع D را طی می کند و مقایسه بین هر دو مکان را انجام می دهد. اگر اندازه زیرمجموعه مشترک APهای دارای بهترین تمایز دو مکان برابر یا بزرگتر از S باشد.، هر دوی آنها در یک خوشه جدید گروه بندی می شوند. متعاقباً، جستجو می کند که آیا مجموعه نتایج شامل خوشه ای است که می تواند با خوشه جدید ادغام شود یا خیر. در صورت یافتن، فیلدهای لیست اعضا و کلید خوشه یافت شده به ترتیب به روز می شوند تا ترکیب خوشه تکمیل شود. در غیر این صورت، خوشه جدید به مجموعه نتیجه اضافه می شود. در نهایت، تمام مکانهای مرجع که خوشهبندی نشدهاند به مجموعه نتایج اضافه میشوند. در مقایسه با الگوریتم K-means، روش پیشنهادی دارای مزایایی است. اولاً، به هیچ عملیات محاسباتی پیچیده ای نیاز ندارد. تنها کاری که باید انجام دهد این است که تعداد عناصر متداول مجموعه APهای متمایزکننده را شمارش و مقایسه کند. K-means باید فواصل اقلیدسی بین هر نمونه و مرکز را محاسبه کند، که چندین بار تکرار می شود و شامل بسیاری از عملیات ضرب می شود. دوم، نتیجه خوشهبندی برای پردازش به رکوردهای اولیه متکی نیست. در مورد الگوریتم K-Means، نتیجه خوشه بندی با انتخاب مرکز اولیه تغییر می کند. علاوه بر این، شماره خوشه بندیk از K-means باید در ابتدا تنظیم شود، که تعیین آن همیشه مشکل است. تجزیه و تحلیل فرآیند خوشه بندی در بخش 5.3 بر اساس یک مثال تجربی ارائه شده است، در حالی که تاثیر پارامتر S بر عملکرد خوشه بندی نیز مورد بحث قرار گرفته است.
3.2. تعیین خوشه هدف در مرحله آنلاین
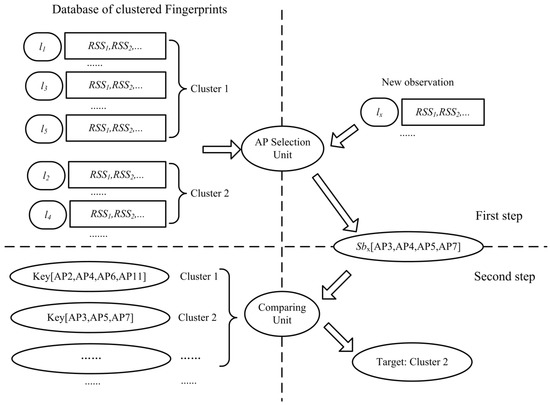
در مرحله آفلاین، پایگاه داده اثر انگشت ساخته شده است. بهترین مجموعه های APهای متمایز برای مکان های مرجع به دست می آیند. و خوشه بندی مکان ها نیز قبلاً تکمیل شده است. اکنون، در مرحله آنلاین، در یک مکان ناشناخته خاص لایکسلایکسهنگامی که یک نمونه RSS، یا دنباله ای از آنها داده می شود، اولین گام تعیین خوشه هدف است. شایان ذکر است که مکان مرجع در واقع توسط شبکه ای به ابعاد 2 متر × 2 متر مربع پوشیده شده است، همانطور که در بخش 5 ذکر شد ، جایی که تنظیمات آزمایشی معرفی شده است. یعنی، تمام نمونههای RSS که با ماندن ناظر در این شبکه به دست میآیند، میتوانند به عنوان اعضای دنباله نمونه این مکان مرجع استفاده شوند. این فرآیند از دو مرحله تشکیل شده است: محاسبه بهترین مکان AP متمایزکننده لایکسلایکسو مقایسه بین این مجموعه و هر کلید خوشه ای در پایگاه داده اثر انگشت.
به طور مشخص، ما تعریف می کنیم Dایکس�ایکسبه عنوان مجموعه ای از نمونه های RSS مکان لایکسلایکس، اسبایکساسبایکسبه عنوان بهترین مجموعه مکان AP متمایز للو سیL = <سیمن> , i ∈ { 1 , 2 , … }سی�=<سیمن>،من∈{1،2،…}به عنوان خوشه های مکان مرجع در پایگاه داده اثر انگشت تنظیم شده است که از جمله آنهاست Dایکس�ایکسو سیLسی�داده می شود. در مرحله اول به منظور محاسبه اسبایکساسبایکس، ما روش انتخاب AP پیشنهادی LocalReliefF-C را به کار می بریم Dایکس�ایکس. همه عملیات مشابه هستند، اما هنوز تفاوت هایی وجود دارد که ارزش توضیح دارد. ابتدا در طی فرآیند محاسبه وزن AP ها را می گیریم Dایکس�ایکسبه عنوان یک کلاس و هر خوشه از سیLسی�به جای هر مکان مرجع به عنوان یک کلاس متفاوت. همانطور که در بالا ذکر شد، لازم است نزدیکترین همسایگان را در هر کلاس مختلف پیدا کنید. از آنجایی که تعداد خوشه ها معمولاً بسیار کمتر از تعداد نقاط مرجع است، این فرآیند می تواند زمان کمتری نسبت به مرحله آفلاین داشته باشد. دوم، اگر اندازه یک داده شده است Dایکس�ایکسکوچک یا حتی برابر با یک است، فرآیند محاسبه هنوز هم زمانی قابل انجام است که نزدیکترین همسایگان طبقات مختلف سهم بیشتری در محاسبه وزن داشته باشند. اگر فقط یک نمونه در آن وجود داشته باشد Dایکس�ایکس، فرآیند یافتن نزدیکترین همسایگان در همان کلاس حذف شده است و فرمول محاسبه در خط 10 شکل 1 به:
در مرحله دوم مقایسه می کنیم اسبایکساسبایکسبا کلید هر خوشه سیمنسیمنو تعداد APهای مشترکی را که دارند ثبت کنند. در نهایت، خوشه مربوط به بزرگترین تعداد، هدف است. یعنی ما می خواهیم سیسی، که می تواند به حداکثر برسد اندازه ( Comm (سیمن، اسبایکس) )اندازه(کام(سیمن،اسبایکس)). به عنوان مثال، با فرض اینکه محاسبه شده به ما داده شود اسبایکساسبایکس= [AP3، AP4، AP5، AP7]، سی1. کلید = [ AP 2 , AP 4 , AP 6 , AP 11 ]سی1.کلید=[AP2، AP4، AP6، AP11]و سی2. کلید = [ AP 3 , AP 5 , AP 7 ]سی2.کلید=[AP3، AP5، AP7]، سپس تعداد AP رایج آنها به ترتیب یک و سه است. در این موقعیت، سی2سی2خوشه هدف است. فرآیند تعیین خوشه هدف در شکل 3 نشان داده شده است . هنگامی که خوشه هدف شناسایی شد، کار زیر برای تخمین مکان در خوشه است.
4. تخمین مکان با بهره برداری از تأثیرات متقابل نقاط دسترسی
4.1. روش کلاسیک تخمین موقعیت مکانی ساده بیز
به منظور تخمین مکان هدف در خوشه داده شده، محققان اخیر از طبقهبندیکننده ساده بیز استفاده میکنند که همچنین به طور گسترده در زمینههای داده کاوی و یادگیری ماشین استفاده شده است. بر اساس یک نظریه ریاضی جامد، بیز ساده برای پیاده سازی ساده است و می تواند در بیشتر موارد عملکرد خوبی داشته باشد [ 25 ، 26 ]. ساختار آن در شکل 4 نشان داده شده است که در آن گره کلاس l والد همه گره های ویژگی است. به عنوان سادهترین شکل طبقهبندی شبکه بیز، بیز ساده لوحانه فرض میکند که همه ویژگیها مستقل از یکدیگر هستند. از نظر مشکل موقعیت یابی داخلی، گره کلاس l مکان را نشان می دهد و گره ویژگی RSSi مربوط به قدرت سیگنال دریافتی از هر AP است.
ایده اصلی حداکثر تخمین پسینی است. به طور مشخص، برای یک جسم متحرک در یک مکان ناشناخته خاص، با توجه به مشاهده بردار قدرت سیگنال R = [ R Sاس1، آر اس اس2… آر اساسn]آر=[آراساس1، آراساس2…آراساس�]، موقعیت للکه احتمال خلفی را به حداکثر می رساند پ( l | R )پ(ل|آر)موقعیت هدف مورد نظر ما است. یعنی به دست آوردن:
در این موقعیت، پ( R )پ(آر)و پ( ل )پ(ل)ثابت هستند. همانطور که در [ 16 ] توضیح داده شد، معادله (6) به صورت زیر تبدیل می شود:
در عمل، هر کدام پ( آر اساسمن| ل )پ(آراساسمن|ل)می توان با کمک تابع توزیع قدرت سیگنال، که از نمونه های پایگاه داده انگشت نگاری تخمین زده می شود، محاسبه کرد.
4.2. روش تخمین موقعیت مکانی پیشنهادی بیزهای ساده لوح پنهان
فرض اساسی روش تخمین مکان بیز ساده این است که APها به طور مشروط مستقل هستند و هیچ تأثیری بر یکدیگر ندارند [ 27 ، 28 ]. چنین فرضی بیش از حد ایده آل و ناسازگار با محیط واقعی است. همانطور که همه ما می دانیم، در یک محیط WLAN واقعی، سیگنال های دریافتی از AP های مختلف به دلیل همپوشانی کانال های انتقال، ناگزیر با یکدیگر تداخل دارند.
بیز ساده پنهان (HNB) یک طبقه بندی بهبود یافته برای بیز ساده است، که نیازی به فرض استقلال شرطی بین ویژگی ها ندارد و تأثیر بین ویژگی ها را برای بهبود دقت طبقه بندی در نظر می گیرد [29 ، 30 ] . این مقاله HNB را به میدان موقعیتیابی داخلی معرفی میکند، که میتواند محیط WLAN واقعی را با دقت بیشتری به تصویر بکشد و دقت موقعیتیابی را از طریق بهرهبرداری از تعامل بین APها بهبود بخشد.
HNB یک گره والد مخفی برای هر ویژگی تعریف می کند تا تاثیر سایر ویژگی ها را ترکیب کند. همانطور که در شکل 5 نشان داده شده است ، هر گره ویژگی آر اساسمنآراساسمنیک گره والد پنهان دارد آر اساسh p iآراساسساعتپمن، i ∈ { 1 , 2 , … , n }من∈{1،2،…،�}، که به صورت دایره ای بریده به تصویر کشیده شده است. فلش از آر اساسh p iآراساسساعتپمنبه آر اساسمنآراساسمنهمچنین یک خط چین است که نشان دهنده رابطه پنهان والدین و فرزند است.
به رابطه (7) نگاه کنید، برای تعیین موقعیت هدف، می خواهیم:
در اینجا نکته کلیدی است: در مدل HNB، توزیع احتمال مشترک در رابطه (8) به صورت زیر تعریف می شود:
جایی که:
در معادله (10) وجود دارد ∑nj = 1 ، j ≠ iدبلیومن ، ج= 1∑�=1،�≠من�دبلیومن،�=1. در واقع، گره والد RSSh p iRSSساعتپمنمجموع وزنی تأثیر بر است RSSمنRSSمناز بقیه گره های ویژگی. وزن دبلیومن ، جدبلیومن،�به عنوان … تعریف شده است:
جایی که:
من( آر اساسمن; آر اساسj| ل )من(آراساسمن;آراساس�|ل)اطلاعات متقابل مشروط بین ویژگی است آر اساسمنآراساسمنو آر اساسjآراساس�. با این فرض که l شناخته شده است، میزان عدم قطعیت را اندازه می گیرد آر اساسمنآراساسمنزمانی که ارزش کاهش می یابد آر اساسjآراساس�شناخته شده است. تمام احتمالات موجود در معادله را می توان با تابع توزیع مربوطه محاسبه کرد که از نمونه های آموزشی در پایگاه داده اثر انگشت از طریق یک تخمینگر هیستوگرام تخمین زده می شود. این توابع توزیع را می توان از طریق تکنیک های ناپارامتریک دیگر مانند تخمین چگالی هسته نیز به دست آورد. در نهایت، از طریق محاسبه و مقایسه، مکانی که احتمال مشترک را در رابطه (8) به حداکثر می رساند، نتیجه ای است که ما می خواهیم.
5. آزمایش ها و تجزیه و تحلیل
5.1. راه اندازی آزمایشی
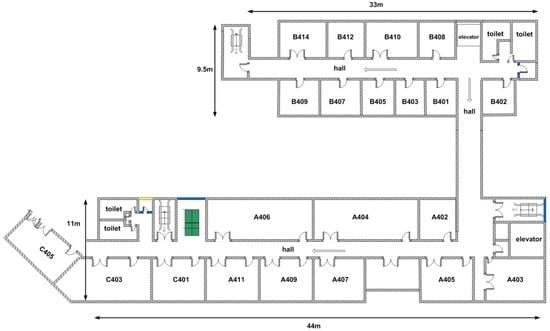
به منظور ارزیابی استراتژیهای پیشنهادی، آزمایشها را در طبقه چهارم دانشکده علوم محیطی و انفورماتیک فضایی در دانشگاه معدن و فناوری چین (CUMT) انجام دادهایم. این یک محیط اداری معمولی با مساحت کلی حدود 800 متر مربع، شامل چند دفتر، اتاق کنفرانس و چندین سالن است. شکل 6طرح محیط آزمایشی را به تصویر می کشد. نزدیک به 50 AP را می توان در کل محیط شناسایی کرد، که شامل APهای موجود برای سرویس های شبکه واقع در طبقات مختلف و برخی دیگر که ما مخصوصاً برای تأیید اثربخشی روش انتخاب AP مستقر کرده ایم، می شود. کل طبقه به عنوان فضایی از 180 مکان مرجع مدل سازی شده است که هر یک از آنها یک سلول شبکه 2 متری را پوشش می دهد. به طور متوسط، هر موقعیت توسط 25 AP پوشش داده می شود.
با استفاده از برنامه خودساخته ای که بر روی تلفن هوشمند هواوی (شنژن، گوانگدونگ، چین) مجهز به اندروید 4.4 اجرا می شود، که مجهز به چهار هسته 1.3 گیگاهرتز و 1 گیگابایت رم است، ما 160 نمونه RSS از همه APهای اطراف جمع آوری کرده ایم. در هر مکان مرجع با توجه به اینکه قدرت سیگنال نمونه متغیر زمانی است و به راحتی تحت تأثیر محیط های اطراف قرار می گیرد، نمونه برداری در زمان های مختلف، به ترتیب 9 صبح و 3:00 بعد از ظهر در دو روز مختلف انجام می شود. در هر زمان از فرآیند نمونه برداری، ناظری که تلفن هوشمند را در دست دارد، به نوبه خود به چهار جهت شرق، جنوب، غرب و شمال رو به رو می شود و 10 نمونه را در هر جهت جمع آوری می کند. دادههای خام در یک فایل متنی جمعآوری میشوند که از چندین فیلد مانند مکان مرجع، SSID (شناسه مجموعه خدمات) AP تشکیل شده است. آدرس MAC (کنترل دسترسی متوسط) AP و قدرت سیگنال. قبل از هر عملیاتی، واحد پیش پردازشی که ما توسعه داده ایم، وظیفه تبدیل داده های خام به سوابق اثر انگشت در پایگاه داده را تکمیل می کند. برای سادگی، AP ها با اعداد مشترک شناسایی می شوند که از ترکیب آدرس SSID و MAC تبدیل می شوند. بخشهای جزئی دادههای خام و سوابق اثر انگشت به ترتیب در نمایش داده میشوندجدول 2 و جدول 3 .
5.2. تنظیم پارامتر روش انتخاب AP LocalReliefF-C
همانطور که در بخش 2.2 ذکر شد ، پارامتر m زمان های تکرار را هنگام محاسبه وزن های طبقه بندی APهای LocalReliefF-C نشان می دهد. می توان دریافت که با افزایش m، قابلیت اطمینان نتیجه وزن قوی تر است، اما پیچیدگی محاسبات نیز افزایش می یابد. بنابراین، باید بین عملکرد موقعیت یابی و سربار محاسبات یک معاوضه ایجاد شود. به طور مشخص، امید است که مقدار بهینه m تا حد امکان پایین باشد و در عین حال، می تواند نتایج تخمینی خوب وزن AP را تضمین کند. این وابسته به مشکل است و مربوط به مجموعه داده ای است که ما با آن سروکار داریم. فرآیند تنظیم پارامتر به شرح زیر انجام می شود.
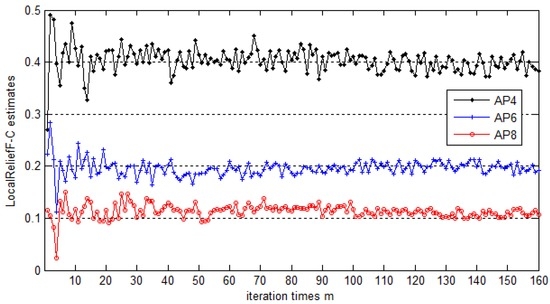
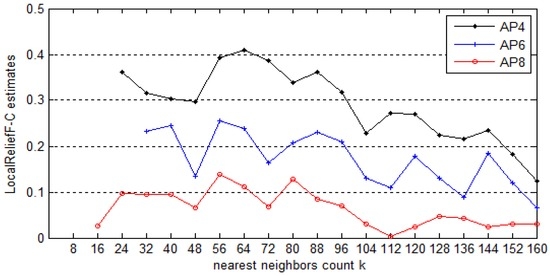
ما به طور تصادفی چندین مکان مرجع را انتخاب می کنیم و وزن AP های مختلف را زمانی که مقادیر متفاوت m اتخاذ می شود محاسبه می کنیم. شکل 7 نمونه ای نماینده را نشان می دهد که در آن نتیجه بر اساس مکان مرجع 1 و AP4، AP6 و AP8 است. شکل 8نشان می دهد که وزن تخمینی این APها با زمان تکرار m تغییر می کند. می توان دریافت که وزن تخمینی AP4، AP6 و AP8 زمانی که از 1 تا 30 تکرار استفاده می شود، به طور جدی در نوسان است. پس از 40-60 تکرار، وزن ها تقریباً ثابت می شوند. علاوه بر این، با وجود تکرارهای بیشتر، نمی توان نتیجه بهتری به دست آورد. بنابراین، 40 انتخاب ایده آل ما برای m است که به مراتب کمتر از 160، حداکثر مقدار برای m است. این همچنین نشان می دهد که روش پیشنهادی مقیاس پذیری خوبی دارد و می تواند مجموعه داده های بزرگی را مدیریت کند. علاوه بر این، نتایج ثابت در تجزیه و تحلیل تجربی در مکان مرجع 12 دیگر به دست میآیند، همانطور که در شکل 8 نشان داده شده است، که در آن سه AP، AP10، AP14 و AP16 بهطور تصادفی انتخاب شدهاند.
پارامتر k نشاندهنده تعداد نزدیکترین نمونههای همسایه هنگام محاسبه وزن طبقهبندی APها در LocalReliefF-C است. توجه داشته باشید که در الگوریتم اصلی Relief تنها از نزدیکترین همسایه استفاده شده است. به ناچار، ویژگیهای اضافی و پر سر و صدا در مجموعه دادههای واقعی وجود دارد که در یافتن نزدیکترین همسایه اختلال ایجاد میکند و باعث نتایج تخمین غیرقابل اعتماد میشود. به منظور مقابله با این مشکل، Kononenko تعداد نزدیکترین همسایگان را به k گسترش می دهد و پیشنهاد می کند که مقدار پیش فرض k 10 است [ 23 ]. با این حال، فرض بر این است که انتخاب kهمچنین ارتباط نزدیکی با پیچیدگی مشکل دارد. با فرض اینکه m برابر با 40 است، آزمایش را انجام دادیم و دریافتیم که برای مجموعه داده ما، وزن ها معمولاً زمانی که k در محدوده 55-65 قرار دارد به حداکثر مقادیر می رسند و سپس با افزایش k کاهش می یابند . شکل 9 نمونه ای از تغییر وزن تخمینی AP4، AP6 و AP8 را با مقادیر k در محل مرجع 1 نشان می دهد. دلیل کاهش وزن به عنوان kبالاتر می شود این است که احتمال به روز رسانی های مثبت و منفی در فرمول محاسبه وزن زمانی که نزدیک ترین همسایگان بیشتر به دست می آیند به احتمال زیاد برابر است. معمولاً برای یک AP خاص، وزن بالاتری مورد نظر است که احتمال نادیده گرفتن یک AP مهم را کاهش می دهد. بنابراین، برای مجموعه داده ما، 60 به عنوان مقدار بهینه k انتخاب می شود که تضمین می کند که وزن های AP بالاتری به دست می آید.
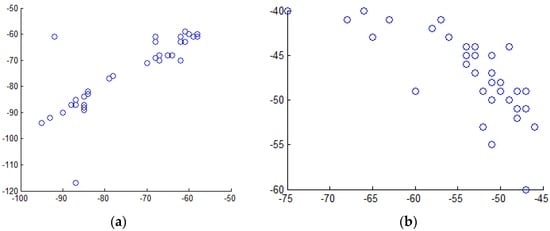
پارامتر θ�آستانه ضریب همبستگی پیرسون است که برای حذف AP های اضافی در LocalReliefF-C استفاده می شود. مقدار محاسبه شده ضریب همبستگی پیرسون، نشان داده شده است r�، همبستگی خطی بین دو AP را توصیف می کند. ارزش r�نهفته در [ – 1 ، 1 ][–1،1]. 0 < r < 10<�<1دلالت بر همبستگی مثبت دارد و − 1 < r < 0–1<�<0دلالت بر یک همبستگی منفی دارد. به عنوان یک ابزار کمکی برای تجزیه و تحلیل همبستگی، نمودارهای پراکنده می توانند به طور شهودی همبستگی دو ویژگی را منعکس کنند. شکل 10 نمودارهای پراکندگی گرفته شده از داده های تجربی ما را نشان می دهد که در آن (الف) همبستگی مثبت و (ب) همبستگی منفی را نشان می دهد. شکل 10 a نمودارهای پراکندگی AP8 و AP9 را در محل مرجع 1 با r = 0.89 نشان می دهد. شکل 10b نمودارهای پراکندگی AP3 و AP17 را در محل مرجع 2 با r = 0.75 نشان می دهد. معمولاً ترسیم نمودارهای پراکندگی برای یافتن روند همبستگی دو AP مفید است. توجه داشته باشید که نمودارهای پراکنده تنها در مرحله تجزیه و تحلیل داده ها مهم و ترسیم شده اند. هنگامی که رتبه همبستگی APها پیدا شد، نیازی به رسم نمودارهای پراکندگی در مرحله محاسبه مقدار ضریب همبستگی نیست.
اشاره شده است که درجه همبستگی دو AP با افزایش قدر مطلق افزایش می یابد | r ||�|[ 22 ]. از طریق تجزیه و تحلیل همبستگی و آزمون فرضیه در مجموعه داده ما، به این نتیجه رسیدیم که درجه همبستگی به طور کلی پایین یا متوسط است زمانی که | r ||�|بین 0 و 0.59 قرار دارد. چه زمانی | r ||�|بزرگتر از 0.6، درجه همبستگی معنی دار است. ما 0.6 را به عنوان مقدار آستانه انتخاب می کنیم θ�. اگر مقدار مطلق ضریب همبستگی پیرسون از دو AP بیشتر باشد θ�، فرض بر این است که آنها به طور قابل توجهی همبستگی دارند، یعنی برای یکدیگر زائد هستند. به طور کلی، برای حفظ اطلاعات مفیدتر، AP ضعیف تر از آنها حذف می شود و قوی تر ذخیره می شود. به عنوان مثال، مجموعه AP در محل مرجع 1 {AP2، AP9، AP11، AP4، AP6، AP17، AP13، AP10، AP7، AP19} است که بر اساس وزن طبقه بندی به ترتیب نزولی مرتب شده است. ضرایب همبستگی پیرسون APهای مختلف در مجموعه به ترتیب محاسبه شده است که در جدول 4 نشان داده شده است.. می توان دریافت که چهار جفت AP با همبستگی بالا وجود دارد: AP9 و AP13، با r = 0.79. AP11 و AP10، با r = 0.88. AP10 و AP7، با r = 0.89. و AP11 و AP7، با r = 0.80. پس از حذف همه APهای اضافی، مجموعه نهایی از بهترین APهای متمایز کننده {AP2، AP4، AP6، AP9، AP11، AP17، AP19} است. به روشی مشابه، مجموعه ای از APهای متمایزکننده در هر مکان مرجع را می توان به دست آورد.
5.3. تجزیه و تحلیل تجربی خوشهبندی مکانهای مرجع بر اساس زیرمجموعههای مشترک بهترین اپلیکیشنهای متمایزکننده
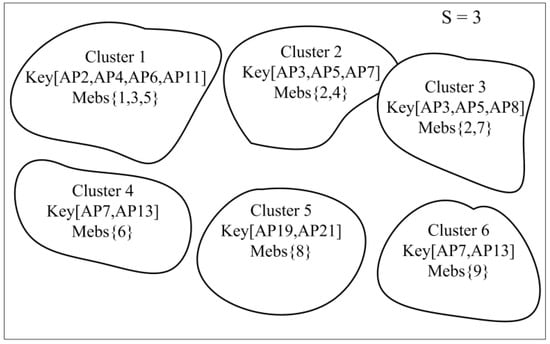
پارامتر S برای عملکرد خوشهبندی مکان مرجع بر اساس زیرمجموعههای مشترک Aps با بهترین تمایز بسیار مهم است. برای واضح تر شدن، یک تصویر تجربی ارائه شده است. جدول 5 مجموعه دادههای خوشهبندی استخراجشده از مجموعه داده تجربی ما را نشان میدهد که شامل نه مکان مرجع با مجموعههای متناظر از بهترین APهای متمایزکننده است. رکوردها از @1–@9 پردازش می شوند و نتایج خوشه بندی در شکل 11 و شکل 12 نشان داده شده است . دو فیلد داده برای هر خوشه وجود دارد: “Key” و “Mebs”. فیلد Key زیرمجموعه مشترک AP ها را ثبت می کند، در حالی که فیلد Mebs همه اعضای مکان های مرجع را در خوشه ثبت می کند. شش و چهار خوشه به دست آمده، زمانی که پارامتر وجود داردS به ترتیب روی سه و دو تنظیم شده است. توجه داشته باشید که در شکل 11 ، خوشه های شماره 2 و شماره 3 را نمی توان در یک خوشه ترکیب کرد، حتی اگر یک زیر مجموعه مشترک {AP3، AP5} داشته باشند. دلیل آن این است که اندازه زیرمجموعه مشترک برابر با دو است که کمتر از سه است، مقدار S. با این حال، در شکل 12 ، زمانی که S روی دو تنظیم شود، این دو خوشه ادغام می شوند .
علاوه بر این، مشخص شد که وقتی مکانها به ترتیب متفاوتی اسکن میشوند، بهعنوان مثال، از Locations @9–@1، خوشههای یکسانی را به دست میآوریم. دلیل آن این است که، برای روش پیشنهادی، شباهت مکانها فقط با زیرمجموعه مشترک بهترین Apsهای متمایز اندازهگیری میشود، و شرط گروهبندی مکانها در یک خوشه، تعداد زیرمجموعه مشترک آنها از بهترین APهای متمایزکننده است که بیش از آن است. پارامتر S . فرآیند خوشهبندی تنها توسط خود مجموعه داده و پارامتر S تعیین میشود، که تحت تأثیر انتخاب اولین اثر انگشت برای پردازش یا ترتیب پردازش اثر انگشت قرار نمیگیرد. بنابراین، همانطور که برای یک مجموعه داده معین، پس از تنظیم پارامتر S، همیشه به همان نتیجه همگرا می شود.
جدول 6 اثر S را بر تعداد و اندازه متوسط خوشه ها نشان می دهد. می توان دریافت که با افزایش S ، تعداد خوشه ها افزایش می یابد، در حالی که اندازه متوسط خوشه ها کاهش می یابد. مقدار خیلی زیاد یا خیلی کم اندازه و تعداد نامطلوب است، که می تواند عملکرد خوشه بندی را کاهش دهد. در واقع، انتخاب S وابسته به مسئله است و توسط مجموعه داده ای که با آن سروکار داریم تعیین می شود. مقدار بهینه S باید تضمین کند که اندازه متوسط و تعداد کل خوشه ها نسبت به مقیاس مسئله مناسب است. در مورد مجموعه داده آزمایشی ما، S = 6 را تنظیم کرده ایم و 10 خوشه به دست آورده ایم.
5.4. مقایسه دقت و دقت روشهای مختلف انتخاب AP
این بخش بر تأثیر روش انتخاب AP پیشنهادی بر عملکرد موقعیتیابی متمرکز است. LocalReliefF-C با سایر روش های موجود انتخاب AP، مانند GD (تبعیض گروهی)، InfoGain و MaxMean مقایسه می شود. مقدار مناسب پارامتر N در LocalReliefF-C، که تعداد APهای مورد استفاده است، نیز داده شده است. همانطور که در بخش 2 توضیح داده شد ، روش GD قابلیت های موقعیت یابی گروه های AP را با استفاده از تابع ریسک از ماشین های بردار پشتیبان (SVM) اندازه گیری می کند. علاوه بر این، روش InfoGain انتخاب AP را با محاسبه بهره اطلاعات برای هر AP انجام می دهد، در حالی که روش MaxMean APهایی را با بالاترین میانگین قدرت سیگنال انتخاب می کند.
همه این روشها در پایگاه داده اثر انگشت از پیش جمعآوریشده ما برای تکمیل انتخاب AP پیادهسازی شدهاند. از بین 180 مکان مرجع، 120 مورد از آنها را به عنوان مکان های آزمایشی انتخاب کرده ایم که تقریباً می تواند هر قسمت از منطقه آزمایشی را پوشش دهد. ما 80 نمونه مشاهده شده را در هر مکان مرجع برای برآوردگر مکان آنلاین جمع آوری کرده ایم. برای هر یک از روش ها، تنها قدرت سیگنال AP های انتخابی مربوطه به عنوان ورودی تخمینگر مکان در نظر گرفته می شود. با توجه به اینکه سیگنال متغیر زمانی است، نمونه ها و نمونه های آموزشی در روزهای مختلف جمع آوری می شود. برای سادگی، طبقهبندیکننده ساده بیز را به عنوان تخمینگر مکان در مرحله آنلاین انتخاب میکنیم. به منظور مقایسه عملکرد روشهای مختلف، از سه معیار فاصله خطا، دقت و دقت استفاده کردهایم. فاصله خطا، فاصله اقلیدسی بین نتیجه برآورد شده و مختصات واقعی آن است. با فرض اینکه، در یک مکان آزمایشی خاص، مختصات مربوطه آن است (ایکسمن،yمن)(ایکسمن،�من)و نتیجه برآورد شده است ( X، ی)(ایکس،�)، سپس فاصله خطا به صورت تعریف می شود (ایکسمن– X)2+(yمن– Y)2––––––––––––––––––√(ایکسمن–ایکس)2+(�من–�)2. دقت یکی از مهم ترین معیارهای عملکرد برای یک سیستم موقعیت یابی است که به عنوان میانگین فاصله خطای همه مکان های تست توصیف می شود. هرچه میانگین فاصله خطا کمتر باشد، دقت روش بالاتر است. دقت یکی دیگر از معیارهای عملکرد موقعیت یابی است که معمولاً به عنوان تابع توزیع تجمعی (CDF) فاصله خطا توصیف می شود. به منظور مقایسه دقت، تعداد APهای انتخاب شده از 3 تا 25 تنظیم شده است و مقادیر میانگین فاصله خطا در 180 مکان آزمایشی به ترتیب محاسبه و رزرو شده است. نتیجه در شکل 13 نشان داده شده است . نتیجه مقایسه دقت در شکل 14 نشان داده شده است .
شکل 13میانگین فاصله خطا در مقابل تعداد APها را برای آن روشهای انتخاب AP نشان میدهد. می توان دریافت که میانگین فاصله خطای هر روش با افزایش تعداد AP ها کاهش می یابد. با این حال، در مقایسه با روشهای دیگر، منحنی LocalReliefF-C نسبتاً مسطح است و تمام مقادیر میانگین فاصله خطا پایین میمانند. این به این دلیل است که LocalReliefF-C AP ها را با بهترین قابلیت تشخیص انتخاب می کند و علاوه بر این موارد اضافی را حذف می کند. آن APهای انتخاب شده حاوی اطلاعات ارزشمندتری برای تخمین مکان هستند. از این رو، LocalReliefF-C می تواند عملکرد قابل مقایسه با آن روش ها را با استفاده از AP های بیشتر به دست آورد. از آنجایی که این روش از AP های کمتری استفاده می کند، هزینه محاسباتی سیستم کاهش می یابد و کارایی بهبود می یابد. این امر نیز ضرورت و اهمیت تحقیق در مورد روش انتخاب AP را اثبات می کند. علاوه بر این، توجه داشته باشید که برای LocalReliefF-C، زمانی که تعداد APها بیشتر از 12 باشد، میانگین فاصله خطا تقریباً کاهش مییابد و مقدار ثابتی در حدود 1.8 متر حفظ میکند. حتی اگر تعداد بیشتری از AP استفاده می شود، دقت نمی تواند بهبود یابد. بنابراین، با توجه به داده های واقعی که با آنها سروکار داریم، مقدار بهینه پارامتر استN در LocalRelief-C می تواند 12 باشد. علاوه بر تعداد AP ها، دقت سیستم های موقعیت یابی نیز ارتباط نزدیکی با روش تخمین مکان دارد. بخش بعدی تجزیه و تحلیل تجربی در مورد بهبود دقت یک روش جدید تخمین مکان را توصیف می کند که از مدل HNB به جای مدل NB استفاده می کند.
علاوه بر سه روش انتخاب AP در بالا، در طول فرآیند مقایسه دقیق، ما یک روش دیگر به نام “APs کامل” اضافه کردهایم. در مورد مجموعه داده ما، از مجموعه کامل 25 AP قابل تشخیص در تخمین مکان استفاده می کند. سایر روش های انتخاب AP به ترتیب 12 بهترین AP را برای استفاده با توجه به اصول انتخاب خود انتخاب می کنند. منحنی های CDF از فواصل خطای بین آنها ترسیم و در شکل 14 مقایسه شده است. می توان دریافت که LocalReliefF-C از سه روش دیگر انتخاب AP عملکرد بهتری دارد و اساساً به عملکردی قابل مقایسه با روش با استفاده از مجموعه کامل AP ها دست می یابد. منحنی LocalReliefF-C با سرعت بیشتری به بالا صعود می کند، که نشان می دهد فاصله خطا در محدوده کوچکتری متمرکز است. به طور مشخص، برای LocalReliefF-C، احتمال فاصله خطا در چهار متر 82٪ است، در حالی که نتایج مربوط به سه روش دیگر به ترتیب 73٪، 70٪ و 59٪ است. به ترتیب 9٪، 12٪ و 24٪ بهبود یافته است. این کارایی روش انتخاب AP پیشنهادی را تایید می کند.
5.5. مقایسه دقیق روش های مختلف تخمین مکان
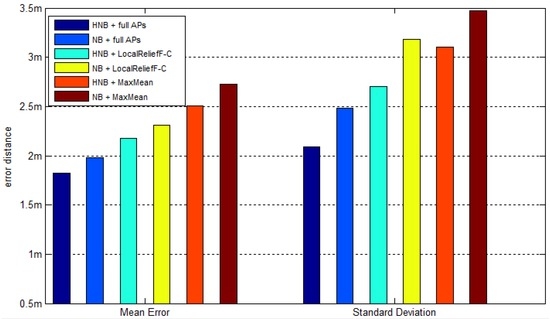
به منظور ارزیابی عملکرد روش تخمین مکان پیشنهادی بیز ساده پنهان، دو مدل تخمین مکان، HNB و NB، و دو روش انتخاب AP، LocalReliefF-C و MaxMean، به ترتیب در سیستم های موقعیت یابی ترکیب می شوند. برای به دست آوردن بهترین عملکرد، تعداد APهای انتخابی 12 تنظیم شده است. برای مقایسه، دو مدل با استفاده از APهای کامل نیز گنجانده شده است. در نهایت، در مجموع شش نوع سیستم موقعیتیابی روی یک مجموعه داده آزمایشی آزمایش میشوند که عبارتند از HNB + APهای کامل، NB + APهای کامل، HNB + LocalReliefF-C، NB + LocalReliefF-C، HNB + MaxMean و NB + MaxMean. CDFهای فاصله خطای همه سیستمها در شکل 15 نشان داده شده است .
بدون توجه به اینکه کدام روش انتخاب AP استفاده می شود، می توان دریافت که HNB از NB بهتر عمل می کند. با استفاده از روش انتخاب AP از LocalReliefF-C، احتمال فاصله خطا در سه متر و پنج متر 7٪ و 6٪ نسبت به NB بهبود می یابد. نتیجه ثابت زمانی به دست می آید که از روش انتخاب AP MaxMean استفاده شود. احتمال فاصله خطا در سه متر و پنج متر به ترتیب 8 و 10 درصد نسبت به NB بهبود یافته است. هنگامی که از APهای کامل استفاده می شود، به ترتیب 4% و 3% بهبود می یابد. چنین بهبودی ناشی از مکانیسمهای خوب مدل HNB است: یعنی شکستن فرض غیرواقعی استقلال مشروط APها و بهرهبرداری از تأثیر متقابل APها در فرآیند تخمین مکان.جدول 7 . نوارهای خطای مربوطه در شکل 16 نشان داده شده است . این نیز گواهی بر اعتبار مدل HNB است.
5.6. مقایسه هزینه محاسباتی در مرحله آنلاین
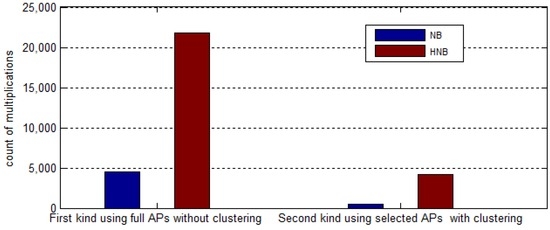
همانطور که همه ما می دانیم، کاهش هزینه محاسباتی تخمین مکان آنلاین بسیار مهم است، که می تواند سرعت پاسخگویی سیستم را بهبود بخشد و تجربیات کاربران را افزایش دهد. به منظور آزمایش اثربخشی استراتژی پیشنهادی انتخاب AP و خوشهبندی مکان بر کاهش هزینههای محاسباتی آنلاین، ما دو نوع روش موقعیتیابی آنلاین را انجام دادهایم: نوع اول از مجموعه کامل APها بدون خوشهبندی استفاده میکند و نوع دوم از مجموعه کامل APها بدون خوشهبندی استفاده میکند. از AP های انتخاب شده توسط LocalReliefF-C با خوشه بندی مکان استفاده می کند. برای مقایسه، هر نوع رویه به ترتیب از هر دو مدل تخمین NB و HNB استفاده میکند. هزینه محاسباتی به عنوان میانگین تعداد عملیات ضرب استفاده شده توسط هر تخمین مکان آزمون اندازه گیری می شود. بطور مشخص، ما مکان های تمام 120 نقطه آزمایش را برای محاسبه مجموع عملیات ضرب استفاده شده تخمین زده ایم و سپس آن را بر 120 تقسیم می کنیم تا مقدار متوسط را بدست آوریم. تعداد مجموعه کامل AP ها 25 است که میانگین تعداد APهای قابل شناسایی در همه مکان ها است. برای LocalReliefF-C، تعداد APهای انتخاب شدهN 12 است که می تواند عملکرد موقعیت یابی رقابتی را با استفاده از APهای کامل تضمین کند. در مجموع، 10 خوشه در مجموعه داده اثر انگشت وجود دارد، و اندازه متوسط یک خوشه منفرد 18 است. شکل 17 نتیجه مقایسه هزینه محاسباتی دو نوع روش را نشان می دهد. می توان دریافت که صرف نظر از مدل تخمینی که استفاده می شود، هزینه محاسباتی روش موقعیت یابی تقریباً با یک مرتبه بزرگی هنگام استفاده از AP های انتخاب شده با خوشه بندی کاهش می یابد.
این به این دلیل است که استراتژی خوشهبندی باعث میشود محدوده جستجوی کل پایگاهداده اثر انگشت به یک خوشه خاص کوچک شود، که تعداد عملیات مقایسه و تطبیق را کاهش میدهد. علاوه بر این، انتخاب AP تعداد APهای استفاده شده را کاهش می دهد، که می تواند تعداد ضرب در هر تطابق رکورد را کاهش دهد. به طور خاص، برای یک مکان آزمایشی، نوع اول باید 180 مقایسه مربوط به تمام اثرانگشت ها را انجام دهد و نوع دوم فقط، کم و بیش، 20 مقایسه را در یک خوشه بر اساس چندین عملیات تطبیق کلیدی برای تعیین خوشه هدف انجام می دهد. علاوه بر این، در طول هر تطابق رکورد، نوع اول نیاز به محاسبه حاصل ضرب احتمال توزیع 25 Aps دارد، در حالی که نوع دوم به حدود 12 AP نیاز دارد. علاوه بر این،
6. نتیجه گیری و کار آینده
در این مقاله، ما یک روش جدید انتخاب AP برای موقعیتیابی اثر انگشت WLAN، LocalRelief-C ارائه کردهایم که از ایده تکنیک انتخاب ویژگی و ضریب همبستگی پیرسون الهام گرفته شده است. اول از همه، اهمیت AP ها با توجه به قابلیت طبقه بندی آنها رتبه بندی می شود. سپس APهای اضافی تعیین و از طریق محاسبه ضریب همبستگی پیرسون بین آنها حذف می شوند. در نهایت، مجموعه ای از بهترین APهای متمایز کننده به دست می آید که حاوی موثرترین AP برای تشخیص مکان ها است. نتایج تجربی نشان میدهد که روش پیشنهادی LocalRelief-C میتواند اطمینان حاصل کند که سیستم موقعیتیابی به عنوان روشی که از APهای بیشتری استفاده میکند، عملکرد قابل مقایسهای را به دست میآورد. متعاقبا، مکان های مرجع بر اساس زیرمجموعه مشترک APهای متمایز کننده هر مکان مرجع، به منظور محدود کردن فضای جستجو و بهبود سرعت موقعیت یابی، خوشه بندی می شوند. در مرحله آنلاین، خوشه هدف از طریق مقایسه کلید هر خوشه با مجموعه ای از بهترین APهای متمایز کننده دنباله مشاهده RSS در این مکان تعیین می شود. در مرحله تخمین مکان، مدل بیز پنهان (HNB) برای در نظر گرفتن تأثیر بین APها اتخاذ میشود. اعتقاد بر این است که این مدل بیشتر با محیط WLAN واقعی مطابقت دارد و از این رو، دقت موقعیت یابی بالاتری نسبت به Bayes ساده لوح به دست می آورد. از طریق آزمایشها با استفاده از دادههای واقعی جمعآوریشده در یک محیط اداری، مقادیر پیشنهادی بهینه پارامترها مورد بحث قرار میگیرد و اثربخشی روشهای پیشنهادی تایید میشود.
یکی از تلاشهای مداوم ما این است که از نمونههای آموزشی کمتری برای ساختن یک مدل جدید برای موقعیتیابی استفاده کنیم، که بتواند سیگنالهای بیسیم را با دقت بیشتری به تصویر بکشد. علاوه بر این، نحوه ادغام سیگنالهای Wi-Fi با سایر سیگنالهای حسگر موجود، مانند شتابسنج، ژیروسکوپ و مغناطیسسنج، برای بهبود عملکرد موقعیتیابی نیز در حال مطالعه است.













بدون نظر