

خلاصه
در عصر دادههای بزرگ اخیر، دادههای مرتبط فضایی عظیم به طور مداوم از منابع مختلف تولید و درهم میشوند. کسب اطلاعات دقیق جغرافیایی نیز به فوریت مورد نیاز است. نحوه بازیابی دقیق اطلاعات جغرافیایی مورد نظر به موضوع مهمی تبدیل شده است که باید در اولویت بالایی حل شود. فناوریهای کلیدی در بازیابی اطلاعات جغرافیایی، مدلسازی ردپای اسناد و رتبهبندی اسناد بر اساس ارزیابی شباهت آنهاست. روشهای سنتی ارزیابی شباهت فضایی عمدتاً با استفاده از مدل ردپای MBR (مستطیل محدودکننده حداقل) انجام میشود. با این حال، به دلیل ماهیت ساده و ناهمواری آن، نتایج روش های سنتی تمایل به همسانگردی و فضای اضافی دارند. در این مقاله، یک مدل جدید که ردپاها را در قالب مجموعههای نقطهای میسازد، ارائه میشود. ردپای مبتنی بر مجموعه نقطه با ماهیت نام مکان ها در صفحات وب منطبق است، بنابراین برای توصیف گستره مکانی اسناد بدون افزونگی، سازگار، دقیق و ناهمسانگرد است و می تواند اطلاعات جغرافیایی چند مقیاسی را مدیریت کند. روش رتبه بندی فضایی مربوطه نیز بر اساس مدل مبتنی بر مجموعه نقطه ارائه شده است. الگوریتم ارزیابی شباهت جدید این روش ابتدا فواصل چندگانه را برای مجاورت فضایی در مقیاسهای مختلف اندازهگیری میکند و سپس فراوانی نام مکانها را برای بهبود دقت و دقت ترکیب میکند. نتایج تجربی نشان میدهد که روش پیشنهادی در سناریوهای مختلف جستجو از روشهای سنتی با دقت بالاتر بهتر عمل میکند. و ناهمسانگرد برای توصیف گستره فضایی اسناد، و می تواند اطلاعات جغرافیایی چند مقیاسی را مدیریت کند. روش رتبه بندی فضایی مربوطه نیز بر اساس مدل مبتنی بر مجموعه نقطه ارائه شده است. الگوریتم ارزیابی شباهت جدید این روش ابتدا فواصل چندگانه را برای مجاورت فضایی در مقیاسهای مختلف اندازهگیری میکند و سپس فراوانی نام مکانها را برای بهبود دقت و دقت ترکیب میکند. نتایج تجربی نشان میدهد که روش پیشنهادی در سناریوهای مختلف جستجو از روشهای سنتی با دقت بالاتر بهتر عمل میکند. و ناهمسانگرد برای توصیف گستره فضایی اسناد، و می تواند اطلاعات جغرافیایی چند مقیاسی را مدیریت کند. روش رتبه بندی فضایی مربوطه نیز بر اساس مدل مبتنی بر مجموعه نقطه ارائه شده است. الگوریتم ارزیابی شباهت جدید این روش ابتدا فواصل چندگانه را برای مجاورت فضایی در مقیاسهای مختلف اندازهگیری میکند و سپس فراوانی نام مکانها را برای بهبود دقت و دقت ترکیب میکند. نتایج تجربی نشان میدهد که روش پیشنهادی در سناریوهای مختلف جستجو از روشهای سنتی با دقت بالاتر بهتر عمل میکند. الگوریتم ارزیابی شباهت جدید این روش ابتدا فواصل چندگانه را برای مجاورت فضایی در مقیاسهای مختلف اندازهگیری میکند و سپس فراوانی نام مکانها را برای بهبود دقت و دقت ترکیب میکند. نتایج تجربی نشان میدهد که روش پیشنهادی در سناریوهای مختلف جستجو از روشهای سنتی با دقت بالاتر بهتر عمل میکند. الگوریتم ارزیابی شباهت جدید این روش ابتدا فواصل چندگانه را برای مجاورت فضایی در مقیاسهای مختلف اندازهگیری میکند و سپس فراوانی نام مکانها را برای بهبود دقت و دقت ترکیب میکند. نتایج تجربی نشان میدهد که روش پیشنهادی در سناریوهای مختلف جستجو از روشهای سنتی با دقت بالاتر بهتر عمل میکند.
کلید واژه ها:
بازیابی اطلاعات جغرافیایی ; رد پا ; ارزیابی شباهت ; نقطه مجموعه ; چند مقیاسی
1. معرفی
در عصر دادههای بزرگ اخیر، توسعه سریع فناوریهای مبتنی بر وب و مکان، و همچنین کاربردهای گسترده رسانههای اجتماعی با برچسبگذاری اطلاعات مکان، به تنوع و بزرگواری دادههای جغرافیایی، همراه با تقاضای فوری کسب کمک کرده است. اطلاعات دقیق جغرافیایی گزارش شده است که 20 درصد از جستجوها در گوگل مربوط به مکان ها است [ 1 ]. یک گزارش سالانه از comScore/TMPDM که به رفتار جستجوی محلی در سال 2013 اشاره می کند همچنین بیان می کند که تا سال 2013، نزدیک به 86 میلیون نفر در ایالات متحده به دنبال اطلاعات کسب و کار محلی در دستگاه های تلفن همراه خود بودند که افزایش 63 درصدی از سال 2010 را نشان می دهد [2] .]. همه این ارقام نشان میدهند که اطلاعات جغرافیایی در وب فراگیر است و موجودیتهای جغرافیایی در پرسشهای کاربران مکرر هستند. کسب و پردازش اطلاعات جغرافیایی، به ویژه بازیابی اطلاعات جغرافیایی، از ارزش مطالعاتی حیاتی و یک چشم انداز کاربردی امیدوارکننده است.
اولین بار توسط لارسون [ 3 ] پیشنهاد شد، بازیابی اطلاعات جغرافیایی (GIR) به عنوان یک فرآیند مربوط به فراهم کردن دسترسی به منابع اطلاعاتی مرجع جغرافیایی تعریف می شود. GIR شامل تمام حوزههایی است که به طور سنتی هسته تحقیقات بازیابی اطلاعات (IR) را تشکیل میدهند، با تأکید یا اضافه بر نمایهسازی و بازیابی مکانی و جغرافیایی.
زمینه های اصلی تحقیقاتی GIR توسط جونز [ 4 ] به هفت چالش تعمیم داده شده است: تشخیص، ابهام زدایی، تفسیر، نمایه سازی، رتبه بندی، طراحی رابط های کاربری و ارزیابی. به دلیل منابع متعدد و انواع رسانه های داده های جغرافیایی، اطلاعات ضمنی همیشه مبهم است. این منجر به اشکال متنوعی از ردپاها میشود که الگوریتمهای رتبهبندی فضایی را تعیین میکنند. پیترز و همکاران [ 5] ردپای اسناد را با نام مکان ها ساخت و تفاوت های نحوی بین عبارات را برای ارزیابی شباهت ها مقایسه کرد. با این حال، ارزیابی شباهت فضایی بر اساس معناشناسی است: دو عبارت مختلف که نشان دهنده یک منطقه فضایی یکسان هستند به عنوان یک نام مکان در نظر گرفته می شوند. در این مورد، معیار شباهت دیگر تحت اللفظی نیست، بلکه «مجاورت» ضمنی موجودیت ها است.
برای ارضای معناشناسی جغرافیایی، برخی از محققین [ 6 ، 7 ، 8 ] ردپاها را به عنوان MBRs (مستطیل محدود حداقل) یا بدنه های محدب که شامل فضایی است که نام مکان ها در اسناد به آن اشاره دارد، و ارزیابی شباهت فضایی برای رتبه بندی نامیده اند. به رابطه توپولوژیکی بین دو چند ضلعی، منظم یا نامنظم بستگی دارد [ 9 ]. با توجه به GeoCLEF، یک مسیر بازیابی جغرافیایی بین زبانی از انجمن ارزیابی بین زبانی (CLEF) که هدف آن ارزیابی سیستم های GIR برای کارهای جستجوی فضایی و چند زبانه است [ 10 ، 11] .]، MBR و بدنه محدب رایج ترین مدل های مورد استفاده در حال حاضر هستند. با این حال، مدل بدنه محدب به دلیل پیچیدگی مدل بدنه محدب به اندازه مدل MBR فراگیر نیست. تولید و ذخیره بدنه محدب یک سند، و همچنین محاسبه رابطه توپولوژیکی بین بدنه های محدب، زمان و فضا وقت گیر است.
اگرچه مدل های چند ضلعی ساده و سرراست هستند، هر دو MBR و بدنه محدب از نقایص ذاتی رنج می برند که از ماهیت چند ضلعی ها و ارزیابی توپولوژی ناشی می شود. معایب خاص مدل های فوق به شرح زیر است:
- (آ)
-
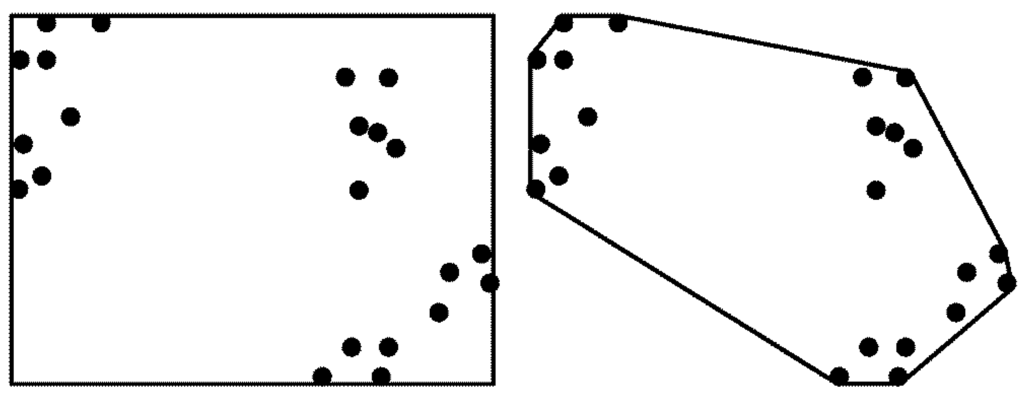
افزونگی فضا آشکارترین ضعف زمانی اتفاق می افتد که مدل های چند ضلعی نواحی مورب، نامنظم، غیر محدب یا چند قسمتی را نشان می دهند [ 12 ]. چند ضلعی ها فضای بیشتری را نسبت به اسنادی که به آن اشاره می کنند پوشش می دهند ( شکل 1 )، و اگر پرس و جو در فضای اضافی قرار گیرد، اسناد نامربوط بازیابی خواهند شد.
- (ب)
-
باتلاقی محل. اسناد ممکن است شامل مکان هایی در مقیاس های مختلف باشد، به عنوان مثال، پکن، منطقه هایدیان، و دانشگاه پکن ( شکل 2 ). با این حال، چند ضلعی نهایی فقط ناحیه کلی را نشان می دهد و مکان های داخلی پوشانده می شوند که منجر به از دست رفتن اطلاعات می شود. به عنوان مثال، اگر پرس و جو دانشگاه پکن باشد، و دو سند وجود داشته باشد که هر دو به پکن اشاره می کنند، اما یک سند به دانشگاه پکن اشاره می کند و دیگری نه، در این صورت مدل چند ضلعی نمی تواند بین این دو سند تمایز قائل شود و هدف قرار نمی دهد. مرتبط ترین سند، زیرا ردپای این دو سند به صورت چند ضلعی یکسان ارائه شده است.
- (ج)
-
عدم دقت ارزیابی شباهت بر اساس مدلهای چند ضلعی برای بررسی رابطه توپولوژیکی است، یعنی اینکه آیا آنها یکدیگر را لمس/تقاطع/حاوی یکدیگر هستند یا خیر. از آنجایی که این رابطه باینری است (0 برای جداسازی و 1 برای تقاطع)، نتیجه ناهموار است. این روش ارزیابی بین شناخت «دور» یا «نزدیک» که از نظر شناخت فضایی انسان مهم است، تبعیض قائل نمی شود و باید بر فاصله دو موجود تأکید کرد. برخی از بهبودها برای غلبه بر عدم دقت ارزیابی باینری با بررسی مجاورت در سه سناریو انجام شده است: حاوی، همپوشانی، و مجاورت [ 11]. به همین ترتیب، تابع ارزیابی از باینری به نسبت مساحت تنظیم میشود که دقت را بهبود میبخشد، اما نتیجه ممکن است همیشه با عقل سلیم مطابقت نداشته باشد. به عنوان مثال، اگر پرس و جو “Beijing” باشد و این پرس و جو را از دو سند A و B بازیابی کنیم ، و ردپای سند A “Dongcheng District” و ردپای سند B “Haidian District” باشد ( شکل 2 ). سپس هنگام استفاده از تابع ارزیابی نسبت مساحت، سند B بالاتر از A قرار می گیرد زیرا مساحت ناحیه Haidian بزرگتر از مساحت ناحیه Dongcheng است. اما چون سند الف و سند بهر دو به مناطق فرعی پکن اشاره می کنند و اطلاعات بیشتری برای تشخیص ارتباط وجود ندارد، هنگام بازیابی پکن، هر دو منطقه فرعی باید رتبه یکسانی داشته باشند.
- (د)
-
همگنی. فضای درون یک MBR واحد به طور مساوی در نظر گرفته میشود، حتی اگر برخی از مکانها به دلیل فرکانسهای بالاتر مهمتر باشند. به عنوان مثال، اگر یک سند 50 بار به منطقه هایدیان اشاره کند و در سند دیگر فقط یک بار به منطقه هایدیان اشاره شود، ممکن است ردپای چند ضلعی برای این دو سند یکسان باشد. با این حال، در بازیابی متن سنتی، با توجه به مدل TF-IDF [ 13 ]، موجودیتهای با بسامد بالاتر تمایل به امتیازهای رتبهبندی بالاتری دارند. به همین ترتیب، ما سند اول را قطعاً بیشتر مربوط به ولسوالی حیدیان می دانیم تا سند دوم، زیرا در سند اول مکان را بیشتر ذکر کرده است.
تلاش هایی برای رفع مشکلات فوق صورت گرفته است. مدل های ردپای هندسی بهبود یافته، از جمله چند ضلعی [ 14 ، 15 ] و مجموعه MBR [ 16 ، 17 ]، به عنوان یک نوع راه حل ارائه می شوند. De Andrade [ 18 ] بیشتر درجه همپوشانی MBR ها را با ارتباط فضایی، که توسط فرکانس های همپوشانی MBR ها تعریف می شود، برای محاسبه رتبه بندی های فضایی ادغام می کند. دی ساباتا و رایشنباخر [ 19 ، 20] پنج معیار دقیق (شامل موضوعی بودن، مجاورت مکانی-زمانی، جهت، خوشه، و هممکانی) را برای محاسبه امتیاز مربوط به فضایی ارائه میکند. اگرچه این روشها از مشکل افزونگی جلوگیری میکنند، مسائل مربوط به باتلاقی مکان و همگنی هنوز وجود دارد. مدلهای غنی از نظر معنایی نیز به عنوان راهحل برای چنین مسائلی ارائه شدهاند. مجموعهای از نام مکانها ابتدا برای نشان دادن گسترههای سند استفاده میشوند و ارتباط با روابط سلسله مراتبی آنها محاسبه میشود [ 21 ، 22 ]. علاوه بر این، هستیشناسیهای جغرافیایی یا نمودارهای دانش، بهجای ردپای، برای اندازهگیری شباهتهای معنایی برای رتبهبندیهای فضایی [ 23 ، 24 ، 25 ، 26] ساخته میشوند.]. آخرین مدلهای موضوعی نیز در بازیابی اطلاعات جغرافیایی برای یافتن اسناد مرتبط با مکان مشابه بر اساس معناشناسی پنهان استفاده میشوند [ 23 ، 27 ]. اگرچه این روشهای مبتنی بر معنایی میتوانند ارتباط فضایی و موضوعی را با هم در رتبهبندی ادغام کنند، هستیشناسیها و دانش مختص حوزه هستند و معمولاً ساختن آنها دشوار است. در مقایسه با فاصله مکانی، فاصله معنایی ممکن است منجر به عدم دقت و اطلاعات از دست رفته شود. در سالهای اخیر، جمعسپاری، شبکههای اجتماعی و دیگر منابع کلان داده در مدلهای ردپای معنایی و هندسی برای محاسبات مجاورت فضایی و رتبهبندی گنجانده شدهاند [ 28 ، 29]]. با این حال، همه روشهای فوق فرکانس مکانها را در نظر نمیگیرند، که عامل مهمی برای توصیف تمرکز اسناد است.
در مطالعه حاضر، ما یک مدل جدید ردپای مبتنی بر مجموعه نقطه از اسناد ایجاد میکنیم که بر معایب مدلهای چندضلعی فائق میآید. در همان زمان، ما یک روش ارزیابی شباهت مبتنی بر فاصله و فرکانس متناظر را برای رتبهبندی فضایی برای دستیابی به دقت بالاتر در بازیابی مکانهای جغرافیایی مرتبط ارائه کردیم.
2. مدل ردپای اسناد
به جای MBR کلی یا بدنه محدب، مدل ردپاها را از چند ضلعی به مجموعه نقطه ای تغییر می دهیم.
معقول است که نقاط را به عنوان رد پا تعیین کنیم زیرا بیشتر اطلاعات جغرافیایی آشکار شده در متون به شکل نام مکان ها است [ 30 ]. با توسعه LBS (سرویس مبتنی بر مکان)، روزنامهها اکنون حاوی مقادیر زیادی داده POI (نقطه مورد علاقه) هستند. این روزنامهنگارها میتوانند هر نام مکان را به یک جفت طول و عرض جغرافیایی، یعنی یک نقطه مکانی، نشان دهند.
از این رو، مدل مجموعه نقطهای با معادلات (1) و (2) نشان داده میشود، که در آن F I نشاندهنده ردپای سند I با N نقطه I است ، و نقطه مکانی متناظر یک نام مکان و نامهای مستعار آن به صورت fp i نشان داده میشود . و φ , λ , f و S به ترتیب عرض جغرافیایی، طول جغرافیایی، فرکانس و سطح زمین را نشان می دهند.
F I = { fp 1 , fp 2 , fp 3 , …, fp NI }
fp i = { φ , λ , f , S }
مدل نقطه گسسته دارای مزایای خاصی نسبت به مدل های سنتی چند ضلعی است. اولاً، علیرغم توزیع مکانها، ردپا بدون افزونگی است. از آنجایی که هر نام مکان به یک نقطه نمایش داده می شود، ردپای تنها حاوی نقاط توصیه شده در متن است و الگوریتم ارزیابی شباهت مستقیماً نقاط را بررسی می کند. باید تاکید کرد که این فرافکنی یک فرافکنی چند به یک است. بسیاری از نام مکان ها ممکن است به دلیل نام مستعار با یک نقطه نشان داده شوند. دوم، مدل مجموعه نقطه، هر مکانی را که در سند ظاهر می شود، حفظ می کند و هیچ اطلاعاتی از دست نمی رود. سوم، الگوریتم شباهت مشتق شده با ویژگی های یک مجموعه نقطه مطابقت دارد و نتیجه دقیق تر است. در نهایت چون فرکانس ظاهری یک نقطه فضایی را با پارامتر f ثبت می کنیم، این مدل ناهمسانگرد است. رد پای یک سند دیگر دامنه جهانی ندارد. از آنجایی که شمارش فراوانی ظاهر نام مکانها آسان است، میتوانیم وزنهای مختلفی را با توجه به فراوانی آنها به نقاط مختلف اختصاص دهیم تا اهمیت هر نقطه را متمایز کنیم. هرچه نام مکان بیشتر ظاهر شود، سند مربوط به مکان مربوطه بیشتر است. فاکتور فراوانی ارزیابی ما را دقیق و قابل اعتماد می کند.
یک مشکل این است که رابطه بین نام مکان ها در یک سطح سلسله مراتبی نیست. برای مثال، فضایی که «چین» به آن اشاره میکند، حاوی فضایی است که «پکن» به آن اشاره میکند. رابطه واقعی بین این دو نام مکان، گنجاندن فضایی است. با این حال، اگر این دو نام مکان را به سادگی در دو نقطه مجزا قرار دهیم، رابطه شمول گم شده است زیرا نقطه یک ویژگی بعد صفر است. نتیجه رابطه ای که ما از دو نقطه به دست می آوریم ممکن است با واقعیت متفاوت باشد، به عنوان مثال، نام مکان ها دانه بندی های متفاوتی دارند، بنابراین روش های ارزیابی شباهت باید بر اساس دانه بندی تنظیم شوند. ما این وضعیت را با افزودن ضریب بعد S و تنظیم الگوریتم ارزیابی در سطوح مختلف، همانطور که به طور مفصل دربخش 3.1 .
3. روش رتبه بندی فضایی
پس از استخراج ردپای یک سند، باید از رتبه بندی مکانی برای استخراج اسناد مربوطه استفاده شود. رتبه بندی فضایی بر اساس نمرات ارزیابی شباهت فضایی است و از این رو در پیشنهاد یک الگوریتم ارزیابی شباهت فضایی کارآمد از اهمیت بالایی برخوردار است. فاصله یک راه مستقیم برای توصیف شباهت فضایی است و مهمترین عامل در الگوریتم ارزیابی شباهت فضایی ما است. تابع فاصله خاص که در بخش 3.1 بحث خواهیم کردروش سنتی برای اندازه گیری مجاورت فضایی بین موجودیت ها است. علاوه بر این، از آنجایی که سند مربوط به مکانی است که بیشتر ذکر شده است، تأثیر فرکانس به عنوان پارامتر وزن در تابع فاصله ادغام می شود که باعث می شود خلاصه و ارزیابی اطلاعات جغرافیایی یک سند دقیق و دقیق تر شود. ما ترکیب فاصله و فرکانس را به تفصیل در بخش 3.2 مورد بحث قرار خواهیم داد .
3.1. مجاورت فضایی
به طور کلی، هر نام مکانی دلالت بر ناحیه ای دارد که می تواند با مرکز آن نشان داده شود. در نتیجه، نام مکان ها در اسناد را می توان به نقاط فضایی پیش بینی کرد و فاصله مختصرترین و مؤثرترین راه برای بررسی نزدیکی بین نقاط جدا شده است. همانطور که قاعده کلی جغرافیا می گوید: “همه چیز به هر چیز دیگری مربوط است، اما چیزهای نزدیک بیشتر از چیزهای دور مرتبط هستند” [ 31 ]. بر اساس این قانون می توان یک پارامتر ارزیابی مربوطه ساخت که با فاصله اقلیدسی همبستگی منفی دارد. در مورد ما، ما اسناد را جستجو می کنیم تا همبستگی آنها را با یک پرس و جو Q تعیین کنیم . ردپای پرس و جو شامل M نقطه است و برای هر سند I، دارای یک ردپای مجموعه نقطه با N نقطه I است . مجاورت مکانی نقطه i در ردپای سند I به نقطه m در ردپای پرس و جو Q که با g i نشان داده می شود | m را می توان با معادله (3) محاسبه کرد که از آن به عنوان “مدل گرانشی” یاد می شود. پارامتر r یک پارامتر کاهش فاصله است که تأثیرات فاصله را بر رفتار تعامل نشان می دهد. r بزرگتر به معنی اثر پوسیدگی سریعتر است و فعل و انفعالات بیشتر تحت تأثیر فاصله قرار می گیرند. مقدار تجربی r معمولاً به عنوان کسری از 1 تا 2 نسبت داده می شود [ 32 ]. سمبلd نشان دهنده فاصله زمین (معادله (4)) یا فاصله اقلیدسی (معادله (5)) بین دو نقطه جغرافیایی است، جایی که R نشان دهنده شعاع زمین است. طول و عرض جغرافیایی نقطه i و نقطه m به ترتیب به صورت φ i , λ i , φ m و λ m نشان داده می شوند . مختصات طرح ریزی به ترتیب x 1 ، y 1 ، x 2 و y 2 نشان داده می شود .
gمن | متر=1دrمن | متر�من|متر=1دمن|متر�
دمن | متر= R × a r c c o s [ c o sϕمنج _ _ϕمترسس ( _ _λمن–λمتر) + s i nϕمنs i nϕمتر]دمن|متر=آر×آ�جج�س[ج�س🝓منج�س🝓مترج�س(�من–�متر)+سمن�🝓منسمن�🝓متر]
دمن |متر=(ایکس1–ایکس2)2+(y1–y2)2––––––––––––––––––√دمن|متر=(ایکس1–ایکس2)2+(�1–�2)2
با این حال، انتزاع هیچ تبعیضی با توجه به “اندازه” منطقه ای که نام مکان به آن اشاره دارد، ایجاد نمی کند. یک ایستگاه اتوبوس یا یک شهر هر دو به یک نقطه بعد صفر ختم میشوند و ابعاد آن نادیده گرفته میشود. فرض کنید ایستگاه اتوبوس در داخل شهر باشد، انتزاع ممکن است منجر به دو نقطه جداگانه شود که اطلاعات مربوط به رابطه بین شهر و ایستگاه اتوبوس را از دست می دهد. این محدودیت مدل مجموعه نقطه با تابع فاصله معمولی به دلیل ماهیت یک نقطه است که یک نقطه فقط حاوی مکان است و اطلاعات ابعاد را از دست می دهد. در چنین شرایطی، مشکل چند مقیاسی رخ می دهد که ناشی از تفاوت ابعاد و مساحت بین مکان های مورد بررسی است. به عنوان مثال، دو مکان “دانشگاه پکن” و “موزه ملی” (شکل 2 ) نزدیکی فضایی یکسانی با پرس و جو «پکن» خواهد داشت، زیرا هر دو در داخل شهر هستند و اطلاعات بیشتری برای ایجاد تبعیض وجود ندارد. با این حال، نتیجه ارتباط بر اساس اندازهگیری فاصله این است که «موزه ملی» بیشتر با «پکن» مرتبط است، زیرا «موزه ملی» به مرکز شهر نزدیکتر است، که نقطه فضایی مربوط به نام مکان «پکن» است. . این یک مثال معمولی از یک مسئله چند مقیاسی است که باید بر آن غلبه کنیم تا ارزیابی های معقولی بر اساس مدل مجموعه نقطه انجام دهیم.
قبل از بحث در مورد مسئله چند مقیاسی ذکر شده در بالا، باید مشخص شود که فرآیند بازیابی جهت دار و غیر قابل برگشت است. ما ترجیح میدهیم زیرمنطقههای پرس و جو را به جای نواحی بالایی بازیابی کنیم. این محدودیت به دلیل هدف بازیابی اطلاعات است. مردم تمایل دارند به جای اطلاعات عمومی تر، اطلاعات دقیق تری از پرس و جوها دریافت کنند. به عنوان مثال، اگر منطقه پرس و جو “پکن” است، اسنادی که به “دانشگاه پکن” اشاره می کنند باید بالاتر از اسنادی با ردپایی که به “چین” اشاره می کنند، رتبه بندی شوند. برعکس، برای پرسش “دانشگاه پکن”، سند با ردپای “پکن” در اولویت اول نیست.
قبل از شروع، ما سه فاصله (معادلات (6) – (8)) بین نقطه m در ردپای پرس و جو Q و نقطه i در ردپای سند I تعریف می کنیم . فاصله زمین بین این دو نقطه را نشان می دهند د1د1. تمام نشانه های دیگر با معادله (4) یکسان است. شعاع نقطه پرس و جو m به صورت نشان داده می شود د2د2، با مساحت آن S m بر حسب کیلومتر محاسبه می شود که می توان آن را از پایگاه دانش گوگل یا روزنامه روزنامه ها بدست آورد ( شکل 3 ). شعاع نقطه سند i را نشان می دهند د3د3، با مساحت آن S i بر حسب کیلومتر محاسبه می شود. ما از شعاع یک منطقه به عنوان یک اندازه گیری ساده برای پوشش استفاده می کنیم.
د1= R × a r c c o s [ c o sϕمنج _ _ϕمترسس ( _ _λمن–λمتر) + s i nϕمنs i nϕمتر]د1=آر×آ�جج�س[ج�س🝓منج�س🝓مترج�س(�من–�متر)+سمن�🝓منسمن�🝓متر]
د2=اسمترπ–––√د2=اسمتر�
د3=اسمنπ–––√د3=اسمن�
علاوه بر این، موارد بازیابی را به سه سناریو تعمیم می دهیم ( شکل 4 ).
- (آ)
-
سناریوی 1: نقطه m و نقطه i کاملاً حاوی یکدیگر نیستند ( شکل 4 a)، از جمله موارد همپوشانی و قطع شدن. در این حالت فاصله ای که برای ارزیابی شباهت این دو نقطه استفاده می شود را به صورت تعریف می کنیم د1د1.
- (ب)
-
سناریوی 2: مساحت پیشنهاد شده توسط نقطه m شامل مساحت نقطه i است . به عنوان مثال، پرس و جو “Beijing” است و اسنادی وجود دارد که به “دانشگاه پکن”، “PKU DaXing” و “Tianjin” اشاره دارد ( شکل 4 ب). برای این سه مکان، “دانشگاه پکن” و “PKU Daxing” در پکن گنجانده شده است. تیانجین و پکن شهرهای همسایه هستند و هیچ منطقه همپوشانی ندارند. ما هر دو فاصله را تعریف می کنیم، فاصله بین پکن و دانشگاه پکن و فاصله بین پکن و PKU Daxing، د2د2، زیرا دانشگاه پکن و PKU Daxing در یک سطح هستند (بدون حاوی) و هر دو در داخل پکن هستند. نزدیکی آنها به پکن را نمی توان بیشتر از این متمایز کرد. رابطه بین پکن و تیانجین با سناریوی 1 مطابقت دارد، بنابراین فاصله بیشتر از د2د2که در نهایت منجر به نمره پایین تری در مقایسه با دانشگاه پکن/PKU Daxing می شود. به طور خلاصه، برای هر مکان در منطقه پرس و جو، فاصله یکسانی ( د2د2) برای کسب همان امتیاز رتبه بندی.
- (ج)
-
سناریوی 3: محدوده جغرافیایی نقطه m در محدوده نقطه i قرار دارد . به عنوان مثال، پرس و جو “دانشگاه پکن” است و دو سند به ترتیب به پکن و منطقه هایدیان اشاره دارند ( شکل 4 ج). ما تصمیم گرفتیم که اگرچه این دو ناحیه هر دو شامل ناحیه پرس و جو هستند، اما ناحیه Haidian مرتبط تر است زیرا جزئیات آن دقیق تر است. برای درک این موضوع، فاصله ها به این صورت تعریف می شوند نوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونتنوع گره ناشناخته: فونت. از آنجایی که شعاع ناحیه ریزدانه کوتاهتر از ناحیه درشت دانه است، رتبه ناحیه ریزدانه بالاتر خواهد بود.
در فرآیند ارزیابی نزدیکی، حالت واقعی همیشه مخلوطی از سه موقعیت فوق است ( شکل 5 ). دایره Q ناحیه پرس و جو را نشان می دهد و دایره های P 1 تا P 6 مساحت هر نقطه در ردپای را نشان می دهد. دایرههای P 1 و P 2 توسط Q قرار میگیرند که با سناریوی 2 مطابقت دارد، بهعنوان مثال، ناحیه ذکر شده در سند توسط ناحیه پرسوجو شامل میشود. بنابراین، فاصله به عنوان Rq برای هر دو P 1 وبنابراین ، P2، زیرا اطلاعات دیگری برای تفکیک ارتباط این دو مکان وجود ندارد. دایرههای P 3 و P 4 با سناریوی 3 مطابقت دارند زیرا دایرههای P 3 و P 4 هر دو حاوی Q هستند و فواصل بهعنوان شعاع مکانهایی که ناحیه پرس و جو را شامل میشوند، تعریف میشوند که به ترتیب R 3 و R 4 هستند. دایره های P 5 و P 6 با سناریوی مناسب (1). زیرا دایره های P 5 و P 6از ناحیه پرس و جو جدا می شوند، فواصل به عنوان فواصل مرکزی تعریف می شوند که 3د 5 و د 6 . با توجه به تصویر، نتایج رتبه بندی بازیابی برای منطقه پرس و جو Q ، رتبه ( P 1 ) = Rank ( P 2 ) > Rank ( P 3 ) > Rank ( P 4 ) > Rank ( P 5 ) > Rank ( P 6 ) خواهد بود . ، زیرا R q < R < R 4 < D 5 < D 6. این نتیجه با عقل سلیم مطابقت دارد.
با این حال، در مراحل فوق تصمیم می گیریم که کدام فاصله ( د1،د2،د3د1،د2،د3) بر اساس آگاهی از روابط توپولوژیکی انتخاب خواهد شد. اگر از قبل توپولوژی را نمی دانیم چگونه می توانیم فاصله را انتخاب کنیم؟
-
در سناریوی (2)، به عنوان مثال، P 1 و Q , d 3 < d 1 < d 2 و فاصله تعیین شده نهایی d 2 (یا Rq ) است.
-
در سناریوی (3)، به عنوان مثال، P 3 و Q , d 2 < d 1 < d 3 و فاصله تعیین شده نهایی d 3 (یا R 3 ) است.
-
در سناریوی (1)، به عنوان مثال، P 5 و Q ، d 3 < d 2 < d 1 و فاصله تعیین شده نهایی d 1 است .
به طور خلاصه، فاصله نهایی d i|m که در ارزیابی شباهت در همه سناریوها استفاده می کنیم را می توان به صورت معادله (9) تعمیم داد. بنابراین در فرآیند بازیابی دیگر نیازی به بررسی روابط توپولوژیکی نیست. در عوض، ما فقط باید d 1 ، d 2 و d 3 را محاسبه کنیم و فاصله نهایی را به عنوان حداکثر بین آنها تعیین کنیم که حجم کار را به شدت کاهش می دهد.
d i | m = حداکثر ( d 1 , d 2 , d 3 )
از آنجایی که اغلب بیش از یک نقطه در رد پای یک سند یا پرس و جو وجود دارد، تأثیرات همه نکات خلاصه می شود. تابع کلی با معادله (10) نشان داده می شود، که در آن معانی نمادها با نمادهای قبلی یکسان است. این روش می تواند مشکل چند مقیاسی را برطرف کند و از اشتباهات ناشی از عیوب مدل ساده نقطه ای جلوگیری کند. از آنجایی که این روش ارزیابی سناریوی جستجوی واقعی را دقیقتر توصیف میکند، نتایج رتبهبندی مربوطه دقیقتر خواهد بود.
جیمن| س=∑m = 1م∑i = 1نمن1دrمن | مترجیمن|س=∑متر=1م∑من=1نمن1دمن|متر�
3.2. پارامتر وزن فرکانس
ما تابع مدل گرانش را در بالا برای ارزیابی نزدیکی فضایی بر اساس فاصله نشان میدهیم. با این حال، نزدیکی و شباهت دقیقاً معادل نیستند. تشابه نه تنها نزدیکی، بلکه تأکید اسناد را نیز ارزیابی می کند. ما می دانیم که فرکانس بالاتر ظاهر شدن یک کلمه در سند نشان دهنده احتمال ارتباط بیشتر است. این مشخصه به طور گسترده و با موفقیت در IR برای فیلتر کردن کلمات توقف در زمینه های موضوعی مختلف از جمله خلاصه سازی متن و طبقه بندی، مانند ضریب وزنی TF-IDF استفاده می شود. 13] .]. برخلاف MBR ها که با هر نقطه در مستطیل به طور مساوی رفتار می کنند، در نظر گرفتن فرکانس در این مقاله، چگالی نقاط را منعکس می کند و نتیجه می تواند دقیق تر و صحیح تر باشد. به عنوان مثال، فرض کنید دو سند با ظرفیت و ردپای کلمه یکسان داریم. کلمه ظرفیت برای هر مدرک 1000 می باشد و هر دو سند مربوط به پکن است. سند A 100 بار پکن را توصیه می کند، در حالی که B فقط 10 بار پکن را توصیه می کند. نتیجه گیری از تجزیه و تحلیل MBR می تواند این باشد که A و B برای پرس و جو “Beijing” امتیاز یکسانی دارند زیرا MBR های آنها یکسان است. با این حال، به معنای رایج مرتبط بودن، سند A احتمالاً بیشتر مربوط به پکن است تا سندب _ با معرفی ضریب فرکانس، ممکن است از چنین کمبودهایی جلوگیری شود.
فراوانی موقعیت مکانی i به صورت f i در معادله (11) تعریف میشود ، که در آن n i تعداد وقوع نام مکانهایی است که به هر مکان اشاره میکنند و N I کل وقوع نام مکانها در سند مربوطه است. لازم به ذکر است که بسامد بر اساس معناشناسی جغرافیایی به جای املایی محاسبه میشود، بنابراین شمارش رخداد نام مستعار مربوط به یک مکان جغرافیایی یکسان را میتوان انباشته کرد، حتی اگر عبارات ممکن است کاملاً متفاوت باشند. f i بالاتر نشان دهنده ارتباط بیشتر سند با مکان مکانی است.
fمن=nمن∑نمنj = 1nj�من=�من∑�=1نمن��
برای ترکیب اثرات فرکانس و فاصله، وزن فاصله بین نقاط پرس و جو و نقاط ردپای سند را به نسبت مستقیم با فراوانی وقوع نام مکان مربوطه در یک سند اختصاص می دهیم. بنابراین، مدل جاذبه در رابطه (3) را می توان با معادله (12) تنظیم کرد. پارامتر r در معادله یک مقدار تجربی برای هماهنگ کردن تأثیر فرکانس و فاصله مکانی است. با افزایش r ، فاصله مکانی تعیین کننده تر می شود.
gمن | متر=fمن×1دrمن | متر�من|متر=�من×1دمن|متر�
تابع ارزیابی نرمال شده کل سند به صورت معادله (13) محاسبه خواهد شد. با توجه به اینکه مکان مکانی m در یک پرس و جو ممکن است بیش از یک بار ظاهر شود، پارامتر f m فراوانی آن در پرس و جو است. معادله (14) یک نسخه ساده شده است که فراوانی نقاط در پرس و جو را نادیده می گیرد. | D | تعداد اسناد موجود در مجموعه است و بقیه نشانه ها با معادلات قبلی یکسان است.
جیمن| س=∑مm = 1fمتر∑نمنi = 1fمن1دrمن | متر∑| D |من= 1∑مm = 1fمتر∑نمنi = 1fمن1دrمن | مترجیمن|س=∑متر=1م�متر∑من=1نمن�من1دمن|متر�∑من=1|�|∑متر=1م�متر∑من=1نمن�من1دمن|متر�
جیمن| س=∑مm = 1∑نمنi = 1fمن1دrمن | متر∑| D |من= 1∑مm = 1∑نمنi = 1fمن1دrمن | مترجیمن|س=∑متر=1م∑من=1نمن�من1دمن|متر�∑من=1|�|∑متر=1م∑من=1نمن�من1دمن|متر�
الگوریتم اثر فرکانس و فاصله را ترکیب می کند. با رتبه G I | با امتیازات Q به ترتیب نزولی، فهرستی به دست میآوریم که آیتمهای برتر آن نسبیترین نتایج برای پرس و جو هستند.
3.3. روش رتبه بندی
3.3.1. پیش فیلترینگ و شاخص فضایی
یک نقص در الگوریتم ارزیابی مبتنی بر فاصله فرکانس وجود دارد. اگر سندی حاوی مکانهایی باشد که بسیار نزدیک به نقطه پرس و جو هستند، اما فرکانس این مکانها پایین باشد، ممکن است امتیاز ترکیبی سند به اندازهای بالا نباشد که اجازه بازیابی سند را بدهد. برای غلبه بر این غیرمنطقی بودن، قانونی تعیین می کنیم که اگر سند دارای مکان هایی باشد که به اندازه کافی به نقطه پرس و جو نزدیک هستند، سند باید در نتیجه برگردانده شود و سپس رتبه بندی شود. ما این اصل را با افزودن یک مرحله فیلتر در زمان اجرا متوجه می شویم.
قبل از محاسبه امتیازهای شباهت، برای هر سند، حداقل فاصله بین نقطه پرس و جو m و نقاط ردپای سند را محاسبه می کنیم، سپس اسناد را با حداقل فاصله های W -کوتاه ترین بازیابی می کنیم تا یک مجموعه نامزد برای پرس و جو ایجاد شود. ارزیابی شباهت فقط بر روی داوطلب انجام می شود. این مرحله تضمین می کند که اصل ذکر شده در بالا اعمال می شود و همچنین بار کاری را کاهش می دهد. در عمل، مقدار W با در نظر گرفتن مجموع اسناد موجود در مجموعه تصمیم گیری می شود.
یک شاخص فضایی بر اساس geohash ساخته شده است تا فیلتر را تسریع کند. اختراع شده توسط Niemeyer [ 33 ]، geohash یک سیستم ژئوکد طول و عرض جغرافیایی است و برای نمایه سازی نقاط مکانی مناسب است. Geohash فضا را به سطل های شبکه ای به نام geohash تقسیم می کند و هر سطل دارای یک کد رشته منحصر به فرد است. از آنجا که مدل ردپای ما مبتنی بر نقطه است و مناطق را به طور همزمان در نظر می گیرد، geohash مناسب است و در کار ما به کار می رود. ما از هفت رقم برای کدگذاری نقاط در ردپای اسناد استفاده می کنیم که به دقت 0.076 ± کیلومتر می رسد. ایندکس رشته کد و شناسه های اسنادی را که ردپای آنها حاوی این کد است را ثبت می کند.
این یک مزیت بزرگ است که شاخص geohash اطلاعات مکانی را به رشته تبدیل می کند. بنابراین جستجوی همسایگی با مقایسه کدهای ژئوهش از طریق فیلتر فضایی به جای محاسبه فاصله انجام می شود. علاوه بر این، با به کارگیری ایده الگوریتم پر کردن دانه، میتوانیم به سرعت اسناد W بالای حاوی نزدیکترین مکانها به نقطه پرس و جو را به دست آوریم.
روش پیش فیلتر کردن مانند شکل 6 نشان داده شده است . هنگامی که درخواست فضایی ارسال شد، ردپای آن در geohash کدگذاری میشود و به فهرست هدف منتقل میشود. اسنادی را که ردپای آنها حاوی رشته geohash هدف است به عنوان نامزد انتخاب کنید. اگر تعداد کاندیداها کمتر از آستانه ای باشد که ما تعیین کرده ایم، باید تعداد بیشتری کاندید انتخاب شوند. برای بدست آوردن نامزدهای بیشتر، کدهای geohash هشت همسایه شبکه هدف را در لیست هدف قرار می دهیم. مراحل بالا را تکرار کنید، و با رسیدن تعداد نامزدها به آستانه، روند پیش فیلتر کردن به پایان می رسد.
3.3.2. روش رتبه بندی
روش کلی رتبه بندی فضایی در شکل 7 نشان داده شده است . پس از ارسال یک پرس و جو، ما یک پیش فیلترینگ geohash برای ایجاد یک لیست نامزد انجام می دهیم. با استفاده از الگوریتم ارزیابی پیشنهادی در بخش 3 ، امتیاز رتبه بندی را برای هر سند در لیست محاسبه کنید . و مدارک را بر اساس نمرات رتبه بندی به ترتیب نزولی مرتب کنید و نتیجه را برگردانید. لازم به ذکر است که پس از محاسبه فراوانی امتیازات در یک سند کاندید، می توانیم امتیازها را به ترتیب نزولی f i مرتب کنیم و K بالا را استخراج کنیم.نقاطی برای نشان دادن ردپای سند. این مرحله تعداد امتیازهایی را که در محاسبه فاصله درگیر می شود کاهش می دهد و مقدار محاسبه را به طور چشمگیری کاهش می دهد.
پیچیدگی زمانی الگوریتم ما O(M×K×W) است. در بین سه عامل مؤثر بر کارایی، تعداد مکانهای مکانی ذکر شده توسط یک پرس و جو ( M ) کوچک است، معمولاً کمتر از 5، و پارامتر K یک ثابت تجربی است. از این رو، پارامتر W عامل تعیین کننده کارایی است. مقدار W متناسب با تعداد کل سند مجموعه است. بنابراین، پیچیدگی زمانی را می توان به صورت O(n) ساده کرد .
4. آزمایش ها و نتایج
4.1. منبع اطلاعات
مجموعه ای که ما در آزمایش خود استفاده کردیم شامل اخبار داخلی چین است که از ژوئن تا دسامبر 2014 از سینا نیوز [ 34 ] خزیده شده است. 700 سند در مجموعه وجود دارد و هر سند شامل 1 تا 29 نام مکان است. مقیاس مکان های فضایی اشاره شده از یک نقطه به استان متفاوت است.
دو مدل ردپای در پیش پردازش بر اساس این پیکره ساخته شده است. یکی از آن ها مدل کلی MBR سند سنتی است که با مختصات نام مکان های موجود که از gazetteer مشتق می شوند و به عنوان مرجع استفاده می شود، محاسبه می شود. مدل ردپای دیگر مدل مبتنی بر مجموعه نقطه است که ما پیشنهاد کردیم. برای آزمایش استحکام مدل ما در برخورد با سناریوهای مختلف، 50 پرس و جو از مقیاس های مختلف به طور خاص انتخاب شده اند که همه موقعیت های ممکن را در نظر می گیرند. برخی از پرس و جوها در جدول 1 فهرست شده اند .
4.2. شاخص
ما دقت، یادآوری، دقت متوسط ( AP )، میانگین دقت متوسط ( MAP ) و دقت R را انتخاب میکنیم که به عنوان معادلات (15)-(19) تعریف میشوند تا عملکرد مدل خود را ارزیابی کنیم. آزمایشهای مبتنی بر مدل باینری MBR و مدل نسبت مساحت MBR به عنوان یک مقایسه عمل میکنند.
پr e c i s i o n =آرآآپ�هجمنسمن��=آرآآ
R e c a l l =آرآآرآرهجآلل=آرآآر
A P=⎛⎝⎜∑i = 1آرمنr a nکمن⎞⎠⎟/ رآپ=(∑من=1آرمن�آ�کمن)/آر
مA P=⎛⎝⎜∑i = 1سآپمن⎞⎠⎟/ سمآپ=(∑من=1سآپمن)/س
R – Pr e c i s i o n =⎛⎝⎜∑i = 1سپمن@ R⎞⎠⎟/ سآر–پ�هجمنسمن��=(∑من=1سپمن@آر)/س
در معادله (15) تا معادله (19)، R a نشان دهنده اسنادی است که بازیابی شده و مرتبط هستند. A نشان دهنده اسنادی است که بازیابی می شوند. R نشان دهنده اسنادی است که مرتبط هستند. رتبه i نشان دهنده رتبه سند مربوطه i در لیست نتایج است. Q تعداد پرس و جوها در یک دسته را نشان می دهد. و P i @R نشان دهنده دقت زمانی است که تعداد اسناد بازیابی شده R باشد . معیارهایی با مقادیر بالاتر نشان دهنده عملکرد بهتر بازیابی ها هستند.
4.3. مقایسه عملکرد
با اعمال فرآیند نشان داده شده در شکل 7 ، ما نتایج بازیابی را به دست آوردیم که از آن منحنی Recall دقیق (PR) ( شکل 8 )، APs ( شکل 9 )، MAPs ( جدول 2 )، و هیستوگرام پرس و جو ( شکل 10 ) هستند. نشات گرفته.
منحنی PR مدل نقطهای بالاترین است، که نشان میدهد مدل ردپای ما و الگوریتم ارزیابی به دقت بالاتری نسبت به مدلهای MBR تحت نرخهای فراخوان یکسان دست مییابند. علاوه بر این، نرخ نزولی دقت مدل نقطهای کم است، که نشان میدهد دقت متوسط بازدههای عظیم قابل قبول است.
برای شکل 9 ، عملکرد الگوریتم ما برای اکثر پرس و جوها، مانند جستارهای 6-9 یا 24-28، که بر روی یک منطقه نسبتاً ریزدانه تمرکز دارند، مانند ناحیه لیچنگ در شهر کوانژو، استان فوجیان، بسیار بهتر است. پرس و جو 6) و دانشگاه نانچانگ (پرسمان 27) و به احتمال زیاد همراه با واحدهای اداری بالاتر مانند شهرها و استان ها ذکر می شوند. در آن صورت، برای این پرسوجوها، مکانهای هدف در مدل سنتی MBR قرار خواهند گرفت. علاوه بر این، جستارهایی مانند جستارهای 9 (استان گوانگدونگ)، 16 (شهر مائومینگ استان گوانگژو)، 23 (منطقه خودمختار نینگ شیا)، و 29 (شهر لوئویانگ) مکان های درشتی هستند و از باتلاق موقعیت در MBR سنتی زنده خواهند ماند. مدل.
میانگین دقت الگوریتم ما برای 92.0٪ از پرس و جوها ظاهراً بالاتر از دو مدل دیگر است و MAP الگوریتم ما به 84.79٪ می رسد.
هیستوگرام های پرس و جو به عنوان دیفرانسیل R-Precision بین روش های مختلف تولید می شوند. هرچه ستون بالاتر باشد، الگوریتم ما در مقایسه با مدل های MBR عملکرد بهتری به دست می آورد. برای 84 درصد پرس و جوها، دقت R روش ما بسیار بالاتر است.
در نتیجه، همه این ارقام این ادعا را تایید میکنند که مدل و الگوریتم رتبهبندی که در این مقاله پیشنهاد کردیم، بهتر از مدلهای MBR عمل میکند، بهویژه در برخورد با اسنادی که ردپای آنها شامل مکانهای ریز دانه یا مکانهای سطوح سلسله مراتبی مختلف است. این ویژگی برای بازیابی اطلاعات جغرافیایی مبتنی بر وب با توجه به چند منبعی و کاراکترهای بدون ساختار اطلاعات آنلاین بسیار مناسب است. علاوه بر این، POI یک فرمت بسیار محبوب از اطلاعات جغرافیایی در منابع آنلاین است و ماهیت نقطهای دارد.
5. نتیجه گیری ها
در این مقاله، ما یک روش جدید مبتنی بر مجموعه نقطه برای ایجاد ردپای برای اسناد و یک روش رتبهبندی فضایی بر اساس آن ساختار پیشنهاد میکنیم. مدل مبتنی بر مجموعه نقطه پیشنهاد شده، بدون افزونگی است و باتلاق مکان را غلبه می کند. با توجه به خاصیت پراکندگی نقاط مکانی، فراوانی نام مکان در یک سند را می توان به عنوان یک عامل وزن در نظر گرفت و ارزیابی را ناهمسانگرد و در نتیجه دقیق تر می کند. یکی از ارزشهای کلیدی مدل این است که مدل میتواند دادههای مقیاس مختلط را بدون بررسی رابطه توپولوژیکی، که به ندرت در کارهای مرتبط مورد مطالعه قرار میگیرد، نه توسط مدل کلی MBR و نه مدل مجموعه MBR، مورد بررسی قرار دهد. علاوه بر این، یک روش اجرایی کامل و همچنین بهینه سازی طرح ها بر اساس نمایه سازی geohash ارائه شده است. آزمایش ها انجام می شود، و نتایج نشان میدهد که (1) الگوریتم ما به دقت بالاتری نسبت به مدلهای MBR تحت نرخهای فراخوان یکسان دست مییابد، و نرخ نزولی دقت آن بسیار پایینتر است، و اطمینان میدهد که دقت بازدههای عظیم تضمین میشود. (2) دقت الگوریتم ما بسیار بالاتر از روشهای MBR در هنگام برخورد با پرس و جوهای دقیق است، به این معنی که الگوریتم ما برای به دست آوردن اطلاعات دقیق مناسبتر خواهد بود. و (3)MAP الگوریتم ما به 84.79٪ می رسد، در حالی که MAP برای مدل های MBR به ترتیب 47.8٪ و 13.9٪ است. همه این ارقام نشان می دهد که الگوریتم ما در بیشتر موارد از روش های سنتی بهتر عمل می کند.
منابع
- آمار و حقایق Google Places. در دسترس آنلاین: https://sites.google.com/a/pressatgoogle.com/googleplaces/metrics (در 7 ژوئیه 2014 قابل دسترسی است).
- Neustar Localeze. مطالعه استفاده از جستجوی محلی در دسترس آنلاین: http://www.localsearchstudy.com/ (دسترسی در 7 ژوئیه 2014).
- لارسون، RR بازیابی اطلاعات جغرافیایی و مرور فضایی. در GIS و کتابخانه ها: مراجعین، نقشه ها و اطلاعات مکانی . Smith, L., Gluck, M., Eds. Urbana-Champaign، دانشگاه ایلینوی: Champaign، IL، ایالات متحده آمریکا، 1995; صص 81-124. [ Google Scholar ]
- جونز، CB; آلانی، ح. تودوپ، دی. بازیابی اطلاعات جغرافیایی با هستی شناسی مکان. در مجموعه مقالات کنفرانس در نظریه اطلاعات فضایی، Morro Bay، CA، ایالات متحده آمریکا، 19-23 سپتامبر 2001; صص 322-335.
- پیترز، سی. کلاف، پی. Gey، FC ارزیابی بازیابی اطلاعات چند زبانه و چندوجهی ; Springer Science & Business Media: Medford، MA، ایالات متحده آمریکا، 2007. [ Google Scholar ]
- گی، اف. لارسون، آر. ساندرسون، ام. جوهو، اچ. کلاف، پی. Petras, V. GeoCLEF: مروری بر مسیر بازیابی اطلاعات جغرافیایی بین زبانی CLEF 2005. در دسترسی به مخازن اطلاعات چند زبانه ؛ Perters, C., Gey, F., Gonzalo, J., Müller, H., Jones, GJF, Kluck, M., Magnini, B., de Rijke, M., Eds. Springer: برلین، آلمان، 2006; ص 908-919. [ Google Scholar ]
- آزمایشهای Guillén، R. CSUSM در GeoCLEF2005: وظایف یکزبانه و دو زبانه. در دسترسی به مخازن اطلاعات چند زبانه ؛ Perters, C., Gey, F., Gonzalo, J., Müller, H., Jones, GJF, Kluck, M., Magnini, B., de Rijke, M., Eds. Springer: برلین، آلمان، 2006; ص 956-962. [ Google Scholar ]
- Kornai, A. ارزیابی بازیابی اطلاعات جغرافیایی ; Springer: برلین، آلمان، 2006. [ Google Scholar ]
- لارسون، آر.آر. Frontiera, P. روش های رتبه بندی فضایی برای بازیابی اطلاعات جغرافیایی (GIR) در کتابخانه های دیجیتال. در نکات سخنرانی در علوم کامپیوتر 3232 ; Heery, R., Lyon, L., Eds.; Springer: برلین، آلمان، 2004; صص 45-57. [ Google Scholar ]
- پیتر، سی. دیزلرز، تی. فرو، ن. گونزالو، جی. جونز، GJF; کوریمو، ام. ماندل، تی. نخود، A.; پتراس، وی. سیستم های ارزیابی برای دسترسی به اطلاعات چند زبانه و چندوجهی . Springer: برلین، آلمان، 2009. [ Google Scholar ]
- مارتینز، بی. Calado, P. یادگیری رتبه بندی برای بازیابی اطلاعات جغرافیایی. در مجموعه مقالات ششمین کارگاه در مورد بازیابی اطلاعات جغرافیایی، زوریخ، سوئیس، 28-29 ژانویه 2010. ACM: نیویورک، نیویورک، ایالات متحده آمریکا، 2010. [ Google Scholar ]
- پاپادیاس، دی. تئودوریدیس، ی. سلیس، تی. Egenhofer، MJ روابط توپولوژیکی در دنیای حداقل مستطیل های مرزی: مطالعه ای با درختان R. Acm Sigmod Rec. 2010 ، 24 ، 92-103. [ Google Scholar ] [ CrossRef ]
- سالتون، جی. باکلی، سی. رویکردهای وزن دهی در بازیابی خودکار متن. Inf. روند. & مدیریت. 1988 ، 24 ، 513-523. [ Google Scholar ]
- جونز، CB; عبدالموتی، هوش مصنوعی؛ فینچ، دی. فو، جی. Vaid, S. موتور جستجوی فضایی SPIRIT: معماری، هستی شناسی ها و نمایه سازی فضایی. لکت. یادداشت ها محاسبه. علمی 2004 ، 3234 ، 125-139. [ Google Scholar ]
- Purves، RS; کلاف، پی. جونز، CB; آرامپاتزیس، ا. بوچر، بی. فینچ، دی. فو، جی. جوهو، اچ. سید، ع.ک. واید، اس. و همکاران طراحی و اجرای SPIRIT: یک موتور جستجوی فضایی برای بازیابی اطلاعات در اینترنت. بین المللی جی. جئوگر. Inf. علمی 2007 ، 21 ، 717-745. [ Google Scholar ] [ CrossRef ]
- ژو، ی. Xie، X. وانگ، سی. گونگ، ی. Ma, W. ساختارهای فهرست ترکیبی برای جستجوی وب مبتنی بر مکان. در مجموعه مقالات چهاردهمین کنفرانس بین المللی ACM در مدیریت اطلاعات و دانش، برمن، آلمان، 31 اکتبر تا 5 نوامبر 2005. صص 155-162.
- چن، ی. سوئل، تی. Markowetz، A. پردازش پرس و جو کارآمد در موتورهای جستجوی وب جغرافیایی. در مجموعه مقالات کنفرانس بین المللی ACM SIGMOD در مدیریت داده ها، شیکاگو، IL، ایالات متحده آمریکا، 27-29 ژوئن 2006. ص 277-288.
- De Andrade، FG; باپتیستا، سی اس; دیویس، کالیفرنیا بهبود بازیابی اطلاعات جغرافیایی در زیرساخت های داده های مکانی. Geoinformatica 2014 ، 18 ، 793-818. [ Google Scholar ] [ CrossRef ]
- دی ساباتا، اس. Reichenbacher, T. معیارهای ارتباط جغرافیایی: یک مطالعه تجربی. بین المللی جی. جئوگر. Inf. علمی 2013 ، 26 ، 1495-1520. [ Google Scholar ] [ CrossRef ]
- رایشنباخر، تی. دی ساباتا، اس. Purves، RS; Fabrikant، SI ارزیابی ارتباط جغرافیایی برای جستجوی تلفن همراه: یک مدل محاسباتی و اعتبار سنجی آن از طریق جمع سپاری. J. Assoc. Inf. علمی تکنولوژی 2016 . [ Google Scholar ] [ CrossRef ]
- دینگ، جی. گراوانو، ال. Shivakumar، N. محاسبات دامنه جغرافیایی منبع وب. در مجموعه مقالات بیست و ششمین کنفرانس بین المللی پایگاه های داده بسیار بزرگ، قاهره، مصر، 10-14 سپتامبر 2000.
- آمیتای، ای. هارئل، ن. سیوان، ر. Soffer، A. Web-a-where: برچسب گذاری جغرافیایی محتوای وب. در مجموعه مقالات بیست و هفتمین کنفرانس بین المللی سالانه ACM SIGIR در مورد تحقیق و توسعه در بازیابی اطلاعات، شفیلد، انگلستان، 25-29 ژوئیه 2004.
- آدامز، بی. Janowicz، K. امضاهای موضوعی برای پاکسازی و غنیسازی دادههای مرتبط مرتبط با مکان. بین المللی جی. جئوگر. Inf. علمی 2015 ، 29 ، 556-579. [ Google Scholar ] [ CrossRef ]
- فرس، دی. رودریگز، اچ. ارزیابی رتبهبندی مجدد دانش جغرافیایی، پردازش زبانی و تکنیکهای بسط پرس و جو برای بازیابی اطلاعات جغرافیایی. در پردازش رشته و بازیابی اطلاعات ، مجموعه مقالات بیست و دومین سمپوزیوم بین المللی، لندن، انگلستان، 1 تا 4 سپتامبر 2015. Iliopoulos, C., Puglisi, S., Yilmaz, E., Eds. صص 311-323.
- نگوین، تی تی. Jung, JJ بهره برداری از منابع دارای برچسب جغرافیایی برای رتبه بندی فضایی با گسترش الگوریتم HITS. محاسبه کنید. علمی Inf. سیستم 2014 ، 12 ، 185-201. [ Google Scholar ]
- آدامز، ب. یافتن مکان های مشابه با استفاده از مدل مکان مشاهده به تعمیم. جی. جئوگر. سیستم 2015 ، 17 ، 137-156. [ Google Scholar ] [ CrossRef ]
- جیانگ، دی. ووسکی، جی. Leung، KW; یانگ، ال. Ng, W. SG-WSTD: چارچوبی برای کشف موضوع جستجوی وب جغرافیایی مقیاس پذیر. سیستم مبتنی بر دانش 2015 ، 84 ، 18-33. [ Google Scholar ] [ CrossRef ]
- ریورا، اف ام؛ رویز، ام تی; گوزمام، جی. ایبارا، MM یک رویکرد یادگیری مشارکتی برای بازیابی اطلاعات جغرافیایی بر اساس شبکه های اجتماعی. محاسبه کنید. هوم رفتار 2015 ، 51 ، 829-842. [ Google Scholar ] [ CrossRef ]
- موراتیدیس، ک. لی، جی. تانگ، ی. Mamoulis, N. جستجوی مشترک بر اساس مجاورت اجتماعی و فضایی. IEEE Trans. بدانید. مهندسی داده 2015 ، 27 ، 781-793. [ Google Scholar ] [ CrossRef ]
- لیو، ی. یوان، ی. شیائو، دی. ژانگ، ی. Hu, J. تقریب مبتنی بر مجموعه نقطه برای اشیاء منطقه: مطالعه موردی نشان دادن محلات. محاسبه کنید. محیط زیست سیستم شهری 2010 ، 34 ، 28-39. [ Google Scholar ] [ CrossRef ]
- Tobler, WR یک فیلم کامپیوتری شبیه سازی رشد شهری در منطقه دیترویت. اقتصاد Geogr. 1970 ، 46 ، 234-240. [ Google Scholar ] [ CrossRef ]
- لیو، ی. سویی، ز. کانگ، سی. گائو، ی. کشف الگوهای سفر بین شهری و تعامل فضایی از داده های ورود به شبکه های اجتماعی. PLoS ONE 2014 ، 9 ، e86026. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- نکات و ترفندهای Neimeyer، G. Geohash. در دسترس آنلاین: http://geohash.org/site/tips.html (در 1 ژوئن 2016 قابل دسترسی است).
- سینا نیوز. در دسترس آنلاین: http://roll.news.sina.com.cn/news/gnxw/gdxw1/index.shtml (در 1 ژانویه 2015 قابل دسترسی است).
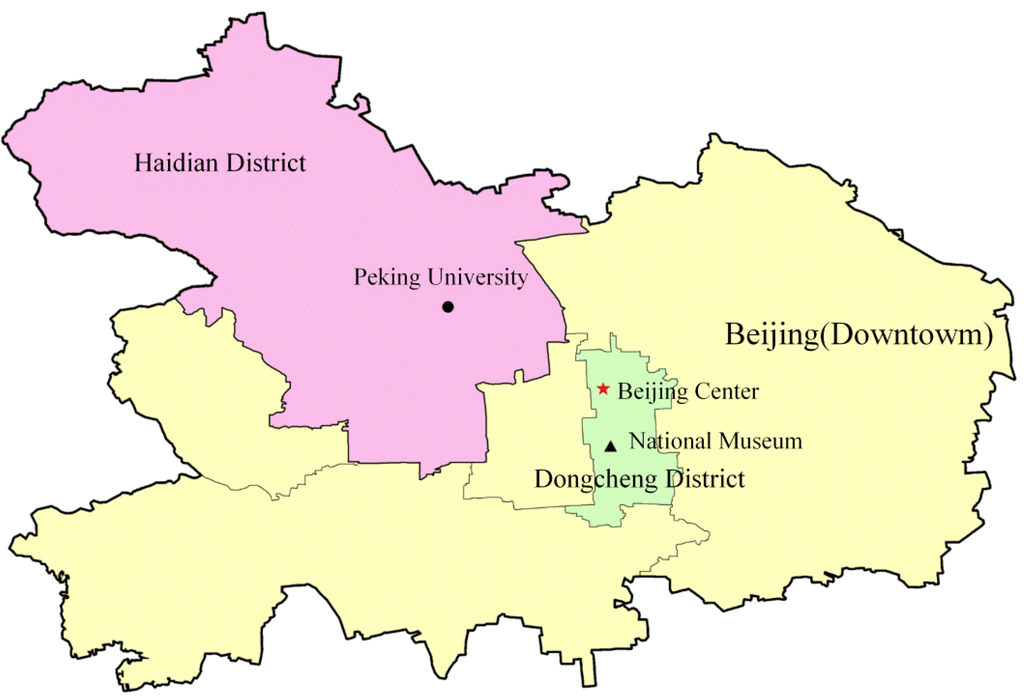
شکل 1. افزونگی های فضایی ناشی از مدل MBR و مدل بدنه محدب. نقاط سیاه نشان دهنده مکان ها یا مناطق مربوطه است که با نام مکان ها در یک سند به آنها اشاره می شود.
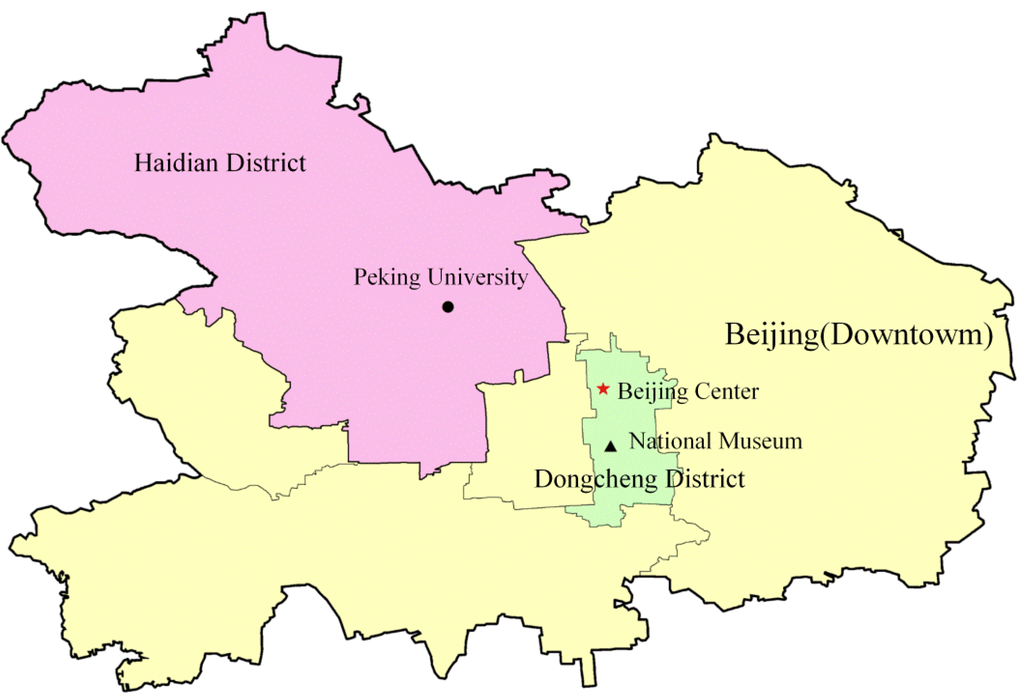
شکل 2. نقشه طرح روابط فضایی بین پکن (مرکز شهر)، ناحیه هایدیان، ناحیه دونگ چنگ، دانشگاه پکن، موزه ملی و مرکز پکن.

شکل 3. نمونه ای از نام مکانی که اطلاعات منطقه آن را می توان از روزنامه ها بدست آورد.

شکل 4. ترسیم نقشه های سه سناریوی روابط منطقه ای. ( الف ) سناریوی 1: نقطه m و نقطه i به طور کامل حاوی یکدیگر نیستند. ( ب ) سناریوی 2: مساحت پیشنهاد شده توسط نقطه m شامل مساحت نقطه I است . ( ج ) سناریوی 3: محدوده جغرافیایی نقطه m در محدوده نقطه i قرار دارد .
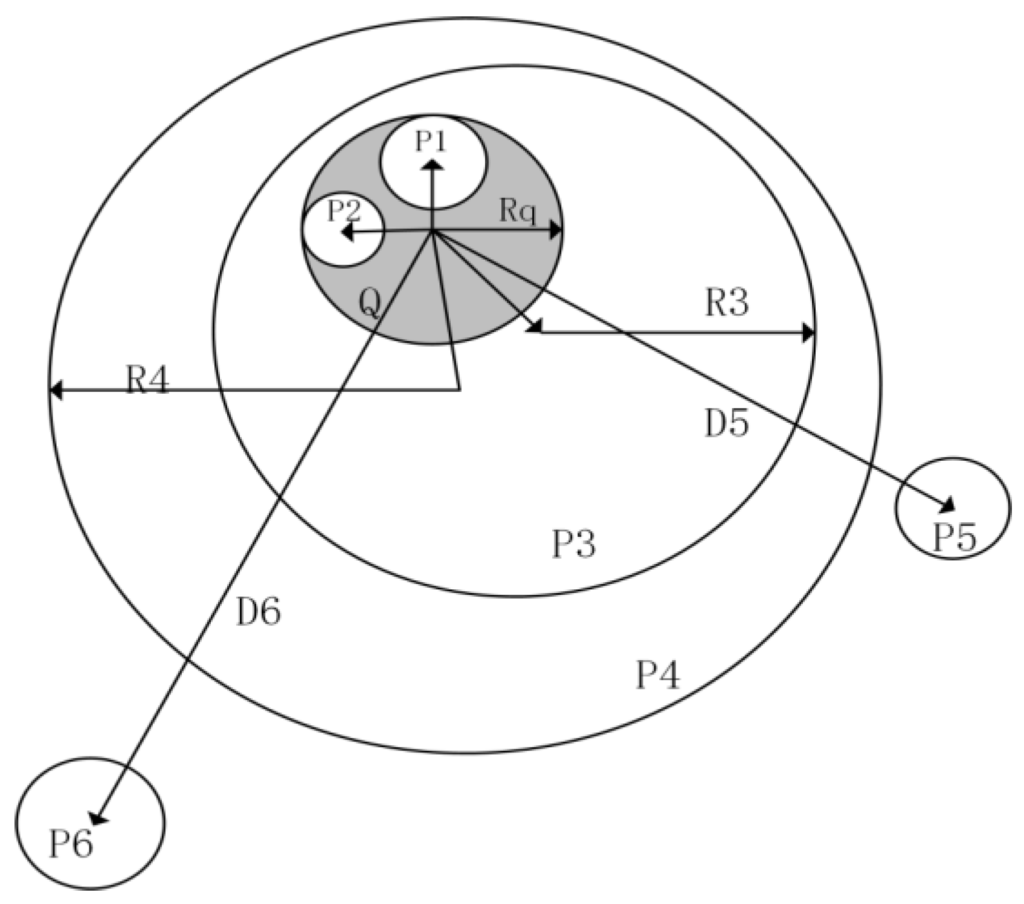
شکل 5. رابطه بین حوزه های پرس و جو و سند با توجه به سه سناریو.
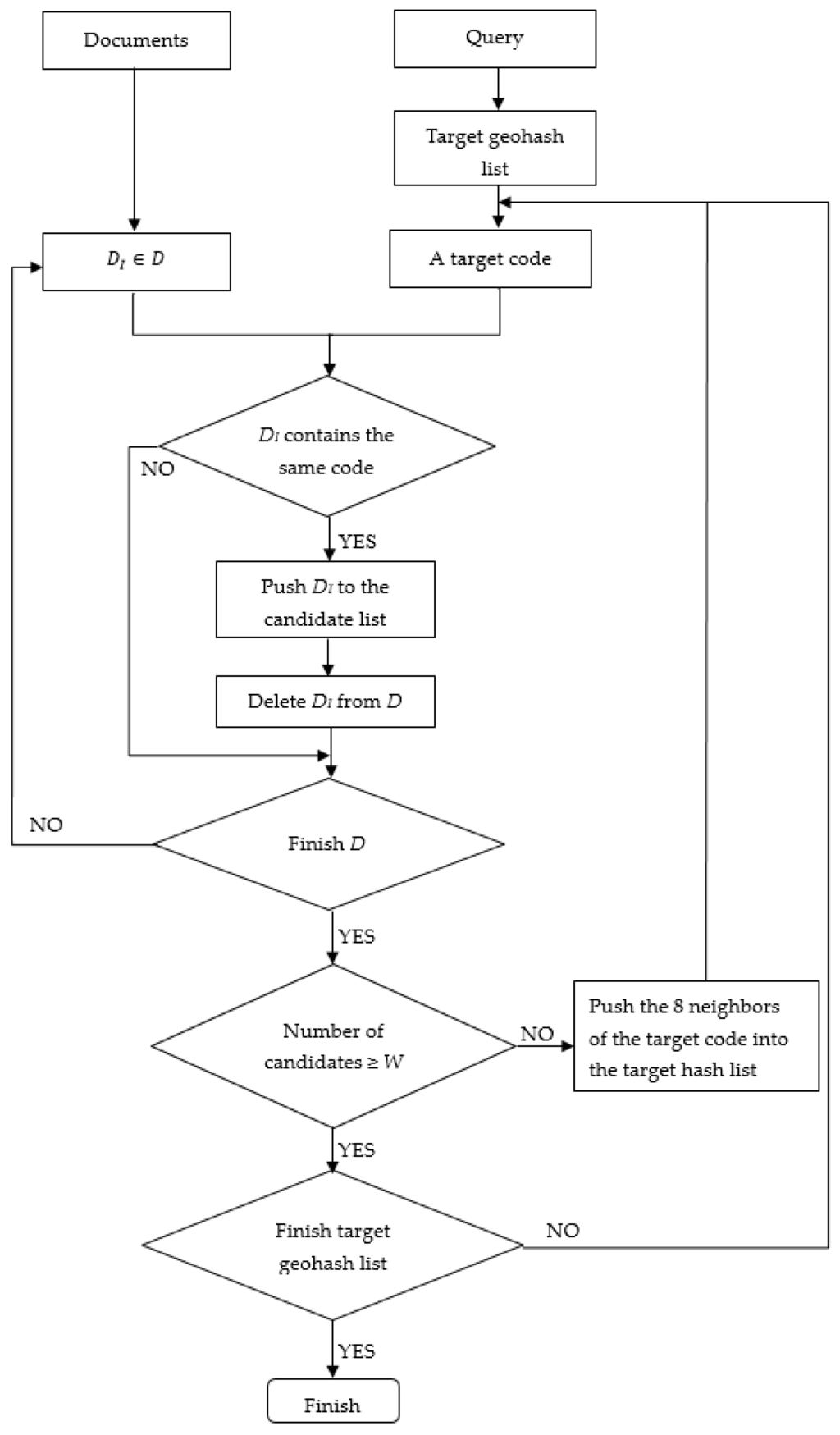
شکل 6. روش پیش فیلترینگ ژئوهش.

شکل 7. فرآیند کلی رتبه بندی فضایی مدل ردپای مبتنی بر مجموعه نقطه.
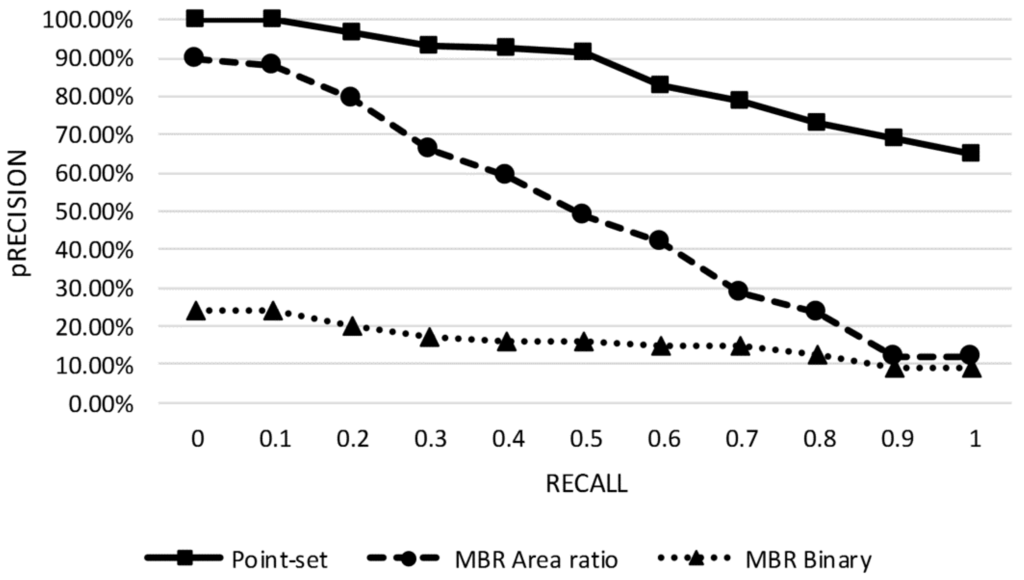
شکل 8. منحنی دقیق یادآوری سه مدل ردپای.

شکل 9. Aps سه مدل ردپای.

شکل 10. هیستوگرام پرس و جو از سه مدل ردپای.

جدول 1. نمونه هایی از پرس و جو.
جدول 2. نقشه های سه مدل ردپای.
© 2016 توسط نویسندگان؛ دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (CC-BY) (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر