1. معرفی
در سالهای اخیر، آرایههای حسگر در مقیاس بزرگ و مجموعه دادههای گسترده تولید شده در سراسر جهان توسط تعداد فزایندهای از ارائهدهندگان داده مورد استفاده، اشتراکگذاری و منتشر شدهاند. با استانداردهای باز که طرحوارههای داده و رابطهای خدمات وب را تعریف میکنند، مانند کنسرسیوم فضایی باز (OGC) سنسور فعالسازی وب (SWE) استانداردها، حسگرها و دادههای آنها را میتوان به شیوهای متقابل ادغام کرد، که به ایده اصلی در پس زمینه جهانی تبدیل شده است. وب سنسور [ 1 ، 2 ، 3 ]. این سنسور جهانی قادر به نظارت بر دنیای فیزیکی با مقیاس های مکانی و زمانی است که قبلا غیرممکن بود.
قابلیتهای نظارت قدرتمند فنآوریهای وب حسگر به طور فزایندهای توجه محققان را برای طیف گستردهای از کاربردها، از جمله نظارت بر محیطزیست در مقیاس بزرگ [ 4 ، 5 ، 6 ]، سازههای عمرانی [ 7 ]، جادهها [ 8 ، 9 ] جلب میکند. و زیستگاه حیوانات [ 10 ، 11 ]. برخی از برنامه ها از نظر زمانی بسیار مهم هستند و برای تصمیم گیری و اطلاع رسانی به موقع نیاز به پردازش داده های کارآمد دارند، مانند سیستم های واکنش اضطراری [ 12] .]. این برنامههای کاربردی حساس زمانی ممکن است برای حمایت از تصمیمگیری هنگام مدیریت رویدادهای مهم زمان، مانند فروریختن پل بین ایالتی 35W مینیاپولیس در سال 2007 و زلزله و سونامی ژاپن در سال 2011 استفاده شوند.
از آنجایی که چشم انداز شبکه جهانی حسگر این است که انواع مختلفی از حسگرها را به هم متصل کند که در سرتاسر جهان قرار دارند و مشاهدات با فرکانس بالا را انجام می دهند، می تواند این توانایی را داشته باشد که این رویدادهای مهم زمانی را ثبت کند و اطلاعات به روز را برای حمایت از تصمیم گیری ارائه دهد. ما معتقدیم که با تبدیل کارآمد جریانهای دادههای وب حسگر به اطلاعات و ارائه اعلانهای بهموقع، میتوانیم آسیبهای ناشی از بلایای بحرانی را کاهش دهیم یا حتی از آن جلوگیری کنیم.
به غیر از سیستم مدیریت بلایا، بسیاری از برنامهها همچنین به پردازش جریان دادههای حسگر کارآمد و اعلانهای به موقع نیاز دارند، مانند امنیت خانه و انسان، تشخیص فعالیت غیرقانونی، سیستم هشدار اولیه، خدمات مبتنی بر مکان، نظارت بر سلامت، و غیره. پرس و جوها عبارتند از (1) “اگر دمای آشپزخانه من بالاتر از 50 درجه سانتیگراد است، برای من اعلان ارسال کنید”؛ (2) “اگر موقعیت مکانی GPS فرزندم منطقه مدرسه را ترک کرد، یک اعلان برای من ارسال کنید”. (3) “اگر هر سنسور سطح آب در شعاع 1 کیلومتری خانه من، میزان بالاتر از 1 متر را گزارش کرد، برای من اعلان ارسال کنید” و (4) “اگر مشتریان در شعاع 1 کیلومتری فروشگاهها هستند اعلانهای تخفیفها را ارسال کنید”. همه این پرس و جوها نیاز به پردازش کارآمد دارند تا کاربران را برای انجام اقدامات متناسب و به موقع آگاه کند.
با این حال، مدل ارتباط درخواست/پاسخ سنتی برای پردازش جریانهای داده پیوسته مناسب نیست، زیرا بر اساس تعامل کشش نقطه به نقطه است و برای جریانهای داده سریع و پیوسته طراحی نشده است [13 ] . در سیستمی که از مدل درخواست/پاسخ پیروی می کند (یعنی سیستم مبتنی بر کشش)، پاسخ با یک عکس فوری از سیستم ارزیابی می شود. با این حال، هیچ پیشبینی درباره زمان وقوع یک رویداد نمیتوان انجام داد (مثلاً شروع آتشسوزی، فروریختن یک پل، یا صرفاً هر مشاهدهای). یک ارتباط را نمی توان از قبل برنامه ریزی کرد. زمانی که کاربر درخواستهایی را ارسال میکند، رویدادها ممکن است قدیمی باشند.
یک مدل ارتباطی جایگزین به عنوان مدل انتشار/اشتراک (یا مدل پردازش پرس و جو مستمر) شناخته می شود. مدل انتشار/اشتراک به کاربران این امکان را می دهد که ابتدا پرس و جوها را در یک سیستم ثبت کنند (یعنی پرس و جوهای از پیش تعریف شده). هر زمان که سیستم داده های جدیدی دریافت می کند، کوئری های از پیش تعریف شده را اجرا می کند و نتایج را به عنوان اعلان برای کاربران ارسال می کند. به این ترتیب، مدل انتشار/اشتراک میتواند اعلانها را سریعتر از مدل درخواست/پاسخ ارائه کند.
در سیستمی که از مدل انتشار/اشتراک پیروی میکند (یعنی سیستمهای مبتنی بر فشار)، یک رویکرد معمولی برای انجام یک پرس و جو پیوسته، ابتدا ایجاد یک طرح اجرای پرسوجو [13] است که متشکل از عملگرها و صفها است. تمام داده های جدید از طریق طرح پرس و جو عبور می کنند. در حالی که برخی از رویکردها برای بهینه سازی ساختار کلی طرح های پرس و جو [ 14 ، 15 ] پیشنهاد شده است ، بحث زیادی در مورد چگونگی بهبود کارایی اپراتورهای مکانی محاسباتی فشرده در یک سیستم مبتنی بر فشار وجود ندارد.
در حالی که بسیاری از اپراتورهای همه منظوره به اندازه کافی ساده و کارآمد هستند تا مستقیماً در طرح های اجرای پرس و جو مورد استفاده قرار گیرند (به عنوان مثال، حساب ابتدایی، میانگین، شمارش، جمع)، برخی از عملگرهای مکانی پیچیده و زمان بر هستند. از آنجایی که دادههای وب حسگر ماهیت جغرافیایی دارند، عملگرهای مکانی در بسیاری از برنامههای نظارتی، مانند پرس و جوهای مثال فوق، رایج هستند. برای این تحقیق، ما بر روی عملگرهای توپولوژیکی تمرکز می کنیم که برای تعیین روابط مکانی تعریف شده در مشخصات دسترسی ویژگی ساده OGC [ 16 ] استفاده می شود.
اگر چه پاسخ به پرس و جوهای مثال فوق را می توان با پرس و جوهای توپولوژیکی پایگاه داده به دست آورد، عملگرهای توپولوژیکی معمولاً زمان بر هستند و می توانند در هنگام پردازش تعداد زیادی از هندسه ها یک گلوگاه عملکرد ایجاد کنند [17 ] . در زمینه سیستم انتشار/اشتراک وب حسگر، ما با چالشها و فرصتهای اصلی دادههای وب حسگر روبرو هستیم [ 3 ]: حجم زیاد و سرعت تولید زیاد دادههای حسگر، مدیریت آن را دشوار میکند، اما قابلیت نظارت قدرتمند وب حسگر میتواند در کاربردهای مختلف بسیار ارزشمند باشد. بنابراین، ما انتظار داریم که پردازش پرس و جوهای توپولوژیکی با داده های وب حسگر بزرگ و تعداد زیادی اشتراک، یک گلوگاه عملکرد ایجاد کند.
از این رو، هدف این مقاله پیشنهاد یک رویکرد جدید برای پردازش موثر عملگرهای توپولوژیکی در یک سیستم انتشار/اشتراک وب حسگر است. مدل فضایی سلسله مراتبی انبوه (مدل AHS) را برای پردازش پرس و جوهای توپولوژیکی بر اساس ماهیت پردازش پرس و جو پیوسته ارائه می دهد. مدل AHS شامل دو ایده کلیدی است. اولاً، از آنجایی که پرسوجوها در یک سیستم انتشار/اشتراک از پیش تعریف شده و پیوسته هستند، مدل AHS شاخصهای لازم را برای هندسه اشتراکها از قبل تولید میکند و هر زمان که دادههای جدید وارد میشود، مجدداً از آنها استفاده میکند. ثانیاً، با نمایه سازی هندسه اشتراک ها با ساختار نمایه سازی یکسان، می توانیم شاخص های اشتراک را تجمیع کنیم. در این حالت، ما نه تنها میتوانیم فضای ذخیرهسازی شاخصهای از پیش تولید شده را کاهش دهیم، بلکه میتوانیم دادههای جدید را با همه اشتراکها در یک فرآیند واحد تلاقی کنیم.
علاوه بر این، ما همچنین یک نسخه محاسباتی توزیع شده از مدل AHS (یعنی یک مدل AHS توزیع شده) را پیشنهاد می کنیم. با پیشرفت در محاسبات توزیع شده [ 18 ] و تکنیک های محاسبات ابری (به عنوان مثال، Amazon Elastic Compute Cloud)، ما مدل AHS توزیع شده را برای مقیاس افقی برای محاسبات و منابع ذخیره سازی بیشتر طراحی کردیم.
به طور خلاصه، این مقاله موارد زیر را ارائه می دهد:
-
مدل AHS – مدلی که می تواند به طور موثر رابطه توپولوژیکی بین هندسه ها را در یک سیستم انتشار/اشتراک وب حسگر تعیین کند. از آنجایی که هدف یک سیستم انتشار/اشتراک وب حسگر شناسایی و مدیریت رویدادهای مهم زمانی به موقع است، مدل AHS می تواند یک جزء حیاتی در چنین سیستمی باشد.
-
ادغام یک چارچوب فضایی سلسله مراتبی از پیش تعریفشده برای نمایهسازی و جمعآوری هندسههای اشتراک، که به مدل AHS اجازه میدهد یک نشریه را با همه اشتراکها در یک فرآیند واحد قطع کند. علاوه بر این، تمام شاخص های اشتراک لازم از قبل تولید شده و برای کاهش هزینه پردازش زمان اجرا مجدداً استفاده می شوند.
-
یک مدل AHS توزیع شده که می تواند به صورت افقی برای ذخیره شاخص های از پیش تولید شده و بهبود عملکرد پرس و جو مقیاس شود. با اتصال ماشینهای بیشتر، مدل AHS توزیعشده میتواند ذخیرهسازی فهرست را توزیع کند و همچنین درخواستها را به صورت موازی پردازش کند.
-
ارزیابی مدل AHS از نظر مقیاس پذیری، عملکرد نمایه سازی، عملکرد تطبیق و تأخیر پرس و جوی پایان به انتها. نتایج ارزیابی نشان میدهد که مدل AHS مقیاسپذیرتر از PostGIS است و مدل AHS توزیعشده میتواند با مجموعه دادههای نسبتاً واقعی، عملکرد رضایتبخشی را بهدست آورد.
قبل از ارائه جزئیات، ابتدا اشتراک ها و انتشارات را در یک سیستم انتشار/اشتراک وب حسگر تعریف می کنیم. به طور کلی، اشتراک ها درخواست های پیوسته ای هستند که توسط کاربران ثبت می شوند و انتشارات داده های حسگر تولید شده توسط حسگرها هستند. از آنجایی که دادههای حسگر ماهیت جغرافیایی دارند، هم اشتراکها و هم انتشارات دارای اجزای مکانی هستند. یک اشتراک ( SUB ) می تواند محمولات مختلفی به عنوان معیار/فیلترهای پرس و جو داشته باشد، که در میان آنها گزاره فضایی در یک اشتراک ( SUB SP ) دارای دو پارامتر است: یک هندسه پایه ( SUB SP_GEO ) و یک عملگر توپولوژیکی ( SUB SP_OPER ). کاربران این دو پارامتر را برای انتخاب انتشارات با هندسه ( PUBGEO ) که با رابطه توپولوژیکی (یعنی SUB SP_OPER ) با SUB SP_GEO مطابقت دارد . به عنوان مثال، در رابطه با وب حسگر، یک PUB GEO میتواند مکان یک حسگر یا هندسه یک ویژگی باشد که سنسور مشاهده کرده است (به عنوان مثال، پوشش رودخانه یا تقاطع جاده).
رابطه بین PUB GEO ، SUB SP_OPER و SUB SP_GEO از ساختار فاعل-فعل-مفعول پیروی می کند که در آن PUB GEO ، SUB SP_OPER و SUB SP_GEO به ترتیب فاعل، فعل و مفعول هستند. برای مثال، اگر « point_1 » PUB GEO باشد ، « WITHIN » SUB SP_OPER ، و « polygon_1 » SUB SP_GEO باشد ، محمول فضایی (یعنی SUB SP) ارزیابی می کند که آیا رابطه ” point_1 WITHIN_1 ” درست است یا خیر. به طور دقیقتر، در مثال «اگر سنسور سطح آب در شعاع 1 کیلومتری خانه من اعلان بالاتر از 1 متر گزارش دهد، برای من اعلان ارسال کنید»، SUB SP_GEO « شعاع 1 کیلومتری خانه من» است ، SUB SP_OPER “در داخل” و PUB GEO محل هر سنسور سطح آب است.
این مقاله به شرح زیر سازماندهی شده است: بخش 2 ادبیات مربوط به این تحقیق را مرور می کند و عملگرهای توپولوژیکی را تعریف می کند. بخش 3 و بخش 4 به ترتیب جزئیات مدل AHS پیشنهادی و مدل AHS توزیع شده را معرفی می کنند. بخش 5 نتایج ارزیابی را توضیح می دهد. در نهایت، بخش 6 نتیجه گیری و کار آینده را ارائه می دهد.
2. کارهای مرتبط
مدل AHS برای پردازش کارآمد عملگرهای توپولوژیکی در یک سیستم انتشار/اشتراک وب حسگر جغرافیایی پیشنهاد شده است. انواع مختلفی از سیستمها وجود داشته است که از مدل انتشار/اشتراک برای مدیریت و پردازش جریانهای داده پیوسته استفاده میکنند، مانند سیستمهای انتشار/اشتراک [19 ] ، سیستمهای پردازش رویداد ساده [ 20 ]، سیستمهای مدیریت جریان داده (DSMS) [ 13 ، 21] . ، 22 ] و سیستم های پردازش رویداد پیچیده (CEP) [ 23 ]. علاوه بر این، برخی از پلتفرمهای منبع باز جدید وجود دارند که به کاربران اجازه میدهند یک سیستم انتشار/اشتراک ایجاد کنند، مانند Apache Spark و RethinkDB.
با این حال، سیستم های انتشار/اشتراک جغرافیایی در مقایسه با سیستم های همه منظوره به ندرت مورد بحث قرار می گیرند. اگرچه برخی کارها در مورد موضوع حمایت از اپراتورهای مکانی در یک سیستم انتشار/اشتراک بحث شده است، اکثر آنها عملیات پیوستن پایگاه داده فضایی را برای اثبات این مفهوم اعمال کردند، مانند [12 ، 15 ، 24 ] . هیچ یک از این مطالعات در مورد بهبود کارایی الگوریتم های جغرافیایی برای سیستم های انتشار/اشتراک بحث نکردند. بنابراین، ما این بحث را مطرح می کنیم که الگوریتم های مکانی را می توان بر اساس ماهیت مدل پردازش پرس و جو پیوسته بهبود بخشید.
به طور خاص، یکی از رویکردهای مهم بهینهسازی پرس و جو پیوسته، اشتراکگذاری عملگرها در طرحهای پرس و جوی مشابه است [ 14 ، 25 ، 26 ، 27 ]، که به هر عملگر ضروری اجازه میدهد فقط یک بار اجرا شود و از افزونگی پردازش جلوگیری میکند. با این حال، عملگرهای توپولوژیکی موجود این مفهوم اجرای اشتراک را در نظر نمی گیرند. حتی با استفاده از حداقل جعبه های مرزی هندسه برای محدود کردن تعداد اجرای اپراتورهای توپولوژیکی [ 17]]، مدیریت تعداد زیادی از هندسه ها همچنان به تعداد زیادی عملگر توپولوژیکی نیاز دارد و به یک گلوگاه عملکرد تبدیل می شود. از این رو، هدف این تحقیق کشف فرآیندهای قابل اشتراک گذاری در عملگرهای توپولوژیکی و پیشنهاد یک رویکرد جدید برای به اشتراک گذاشتن آنها در پرس و جوها است.
همانطور که قبلاً ذکر شد، این تحقیق بر روی هشت رابطه توپولوژیکی تعریف شده در مشخصات دسترسی به ویژگی ساده OGC [ 16 ] تمرکز دارد: EQUALS ، DisjoINT ، Intersects ، Touches ، OVERLAPS ، Crosses ، WITHIN و COTAINS . این مشخصات به طور گسترده در بسیاری از پایگاه های داده فضایی مانند PostGIS، Oracle و Microsoft SQL Server مورد استفاده قرار گرفته است. رویکرد معمولی برای تعیین روابط توپولوژیکی، مدل تقاطع 9 بعدی (DE-9IM) [ 28 ] است.
DE-9IM دارای سه مرحله اصلی است. در مرحله اول، DE-9IM مناطق داخلی، مرزی و بیرونی دو هندسه را تولید می کند. مرحله دوم DE-9IM این است که این مناطق داخلی، مرزی و بیرونی دو هندسه را قطع کرده و یک ماتریس تقاطع سه در سه (معادله (1)) بسازید. در نهایت، اگر ماتریس تقاطع با ماتریس های از پیش تعریف شده مطابقت داشته باشد (یعنی جدول 1 )، روابط توپولوژیکی بین دو هندسه را می توان بر این اساس تعیین کرد. جدول 1 روابط توپولوژیکی، تعریف روابط، و ماتریس های تقاطع مربوطه را نشان می دهد که در آنها نماد عام ( ∗∗) به معنی “هر ارزشی کار می کند” [ 16 ] است.
جایی که دمن _دمنمترتابع حداکثر بعد (یعنی 0 برای نقاط، 1 برای خطوط و 2 برای چند ضلعی) تقاطع را برمی گرداند ( ∩∩) داخلی ( منمن)، مرز ( بب، و بیرونی ( E�) از هندسه ها آآو بب. هندسه آآو بببه ترتیب هندسه اولیه و ثانویه نامیده می شوند. اگر یک تقاطع یک مجموعه خالی باشد ( ∅∅)، دمن _دمنمترتابع مقدار -1 را برمی گرداند. اگر یک تقاطع یک مجموعه خالی نباشد، دمن _دمنمترتابع 0، 1 یا 2 را برمی گرداند. یکی از راه های ساده سازی ماتریس ذخیره سازی فقط True است (اگر دمن _دمنمترتابع 0، 1 یا 2) و False (اگر دمن _دمنمترتابع-1) را در ماتریس برمی گرداند که در جدول 1 نیز نشان داده شده است .
توجه داشته باشید که برای رابطه CROSSES ، تعریف OGC نشان داده شده در جدول 1 ممکن است رایج ترین تعریف مورد استفاده نباشد. در عوض، رابطه CROSSES معمولاً به صورت «تعریف میشود. ( دمن ( من _( الف ) ∩ I( ب ) )<max( dمن ( من _( الف ) )،د من ( من _( ب ) )))∧(a ∩ b≠a)∧(a ∩ b≠b) (دمنمتر(من(آ)∩من(ب))<مترآایکس(دمنمتر(من(آ))، دمنمتر(من(ب)))) ∧ (آ ∩ ب ≠آ) ∧ (آ ∩ ب ≠ب)“. از این رو، ماتریس DE-9IM به صورت تعریف شده است دمن ( من _( الف ) ∩ I( ب ) )=0دمنمتر(من(آ)∩من(ب))=0برای رابطه خط/خط در این تحقیق راه حل پیشنهادی از تعریف رایج پیروی می کند.
با این حال، DE-9IM یک فرآیند زمانبر است و میتواند در هنگام پردازش تعداد زیادی از هندسهها یک گلوگاه عملکردی ایجاد کند [ 17 ]. به منظور پرداختن به این موضوع، یک راه حل رایج کاهش تعداد فرآیندهای غیر ضروری DE-9IM است. به عنوان مثال، یک رویکرد معمولی شامل دو مرحله است: فیلتر و پالایش [ 17 ]. مرحله فیلتر، هندسه های نامزد را با مستطیل های تقریبی هندسی (مثلاً حداقل مستطیل های مرزی (MBRs)) پیدا می کند. سپس مرحله پالایش، فرآیند واقعی DE-9IM را بر روی نامزدهای موجود در مرحله فیلتر انجام می دهد. در حالی که این رویکرد به طور گسترده در بسیاری از سیستمهای DBMS (به عنوان مثال، PostGIS) به کار گرفته شده است، ما استدلال میکنیم که میتوان آن را برای یک سیستم انتشار/اشتراک برای مدیریت تعداد بیشتری از هندسهها، بیشتر بهبود بخشید.
اگرچه تحقیقات موجود حمایت از اپراتورهای فضایی را در یک سیستم انتشار/اشتراک مورد بحث قرار میدهد، اکثر آنها تنها رویکرد پیوند فضایی فیلتر و پالایش را برای اثبات این مفهوم اعمال کردند. ما معتقدیم که الگوریتمهای زمانبر جغرافیایی را میتوان با به اشتراک گذاشتن اجراها بهبود بخشید. در نتیجه، این تحقیق مدل AHS را به عنوان یک رویکرد جدید برای بهبود کارایی عملگرهای توپولوژیکی در یک سیستم انتشار/اشتراک وب حسگر پیشنهاد میکند.
3. مدل AHS
ما مدل AHS را برای بهبود کارایی پرس و جو و مقیاس پذیری عملگرهای توپولوژیکی در یک سیستم انتشار/اشتراک وب حسگر پیشنهاد می کنیم. مدل AHS از تعریف هشت رابطه توپولوژیکی در مشخصات دسترسی به ویژگی ساده OGC پیروی می کند. به این ترتیب، از همان چارچوب مفهومی استفاده شده در رویکردهای سنتی مانند DE-9IM پیروی می کند.
تفاوت بین مدل AHS و رویکردهای سنتی این است که مدل AHS فعلی چند نقطه، چند خط و چند ضلعی را در نظر نمی گیرد. گسترش الگوریتم برای پشتیبانی از این نوع هندسه ها، ایده اصلی مدل AHS را تغییر نمی دهد، اما یکی از جهت گیری های آینده است که دنبال خواهد شد.
از آنجایی که اهداف هدف DBMS سنتی و سیستمهای انتشار/اشتراک اساساً متفاوت است، الگوریتمهای بهینهسازی شده برای DBMS ممکن است برای سیستمهای انتشار/اشتراک مناسب نباشند. به عنوان مثال، از آنجایی که پرس و جوها در DBMS اتمی و مستقل هستند، الگوریتم ها برای هر پرس و جو بهینه شده اند. با این حال، از آنجایی که پرسوجوها در سیستمهای انتشار/اشتراک از پیش تعریفشده و پیوسته هستند، الگوریتمهای آنها باید تجمیع پرسشها/اشتراکهای متعدد را در نظر بگیرند.
با توجه به ماهیت پرس و جوهای مداوم، ما استدلال می کنیم که صرف تلاش بیشتر (مثلاً ایجاد شاخص ها) در مرحله آماده سازی راه اندازی برای اجرای کارآمدتر پرس و جوهای مداوم قابل قبول است. اگرچه این رویکرد ممکن است در آغاز باعث تاخیر شود، اما با توجه به ماهیت طولانی مدت پرس و جوهای پیوسته، می تواند توان عملیاتی بزرگ تری ایجاد کند. دو ایده کلیدی در مدل AHS وجود دارد که مبتنی بر این مفاهیم است. ابتدا، مدل AHS شاخص های لازم را از هندسه اشتراک ها از قبل تولید می کند و سپس در صورت نیاز مجدداً از شاخص ها در پرس و جوهای پیوسته استفاده می کند. ثانیاً، با نمایه سازی هندسه اشتراک ها با ساختار نمایه سازی یکسان، می توانیم شاخص های همه اشتراک ها را برای صرفه جویی در فضای ذخیره سازی جمع آوری کنیم و PUB GEO را با همه قطع کنیم.SUB SP_GEO در یک فرآیند واحد.
AHS-Model از سه مرحله اصلی تشکیل شده است: (1) مرحله آماده سازی اطلاعات لازم را از هندسه اشتراک ها تولید می کند. (2) مرحله تقاطع هندسه اشتراک ها را با هندسه انتشار قطع می کند. و (3) مرحله تعیین روابط جغرافیایی را تعیین می کند. جزئیات این سه مرحله در قسمت های بعدی معرفی می شود.
3.1. مرحله آماده سازی: اطلاعات لازم را از هندسه اشتراک ها تولید کنید
مشابه روشی که DE-9IM کار می کند، مدل AHS نیز روابط توپولوژیکی را با تقاطع مناطق داخلی، مرزی و بیرونی دو هندسه تعیین می کند. با این حال، به جای رویکرد معمولی دو مرحله ای (یعنی فیلتر و پالایش)، مدل AHS یافتن نامزد و تقاطع ها را همزمان انجام می دهد. این کار در یک سیستم انتشار/اشتراک وب حسگر قابل انجام است زیرا پرس و جوها از پیش تعریف شده اند و PUB GEO معمولاً کوچک است (مثلاً مکان سنسور، تقاطع جاده یا زمین فوتبال). شاخصهای هندسه در اشتراکها (یعنی SUB SP_GEO ) ابتدا ایجاد شده و تا SUB SP_GEO دوباره استفاده میشوند.تغییر کرده است. با انجام این کار، میتوانیم از تولید شاخصهای اضافی جلوگیری کنیم، که در نتیجه میتواند پردازش پرس و جو را سرعت بخشد.
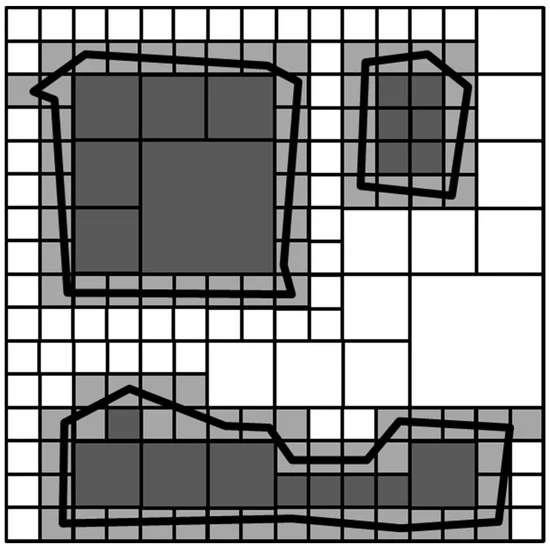
با این حال، هر ساختار نمایه سازی برای مدل AHS مناسب نیست. در مرحله اول، ساختار نمایه سازی باید فضا محور باشد، به طوری که شاخص های SUB SP_GEO می توانند جمع شوند. ثانیاً، ساختار نمایه سازی مبتنی بر فضا باید چندین سطح داشته باشد تا ذخیره سازی را کاهش دهد. بنابراین، مدل AHS به یک ساختار نمایهسازی سلسله مراتبی مبتنی بر فضا و چند سطحی، شبیه به ایده ارائه شده توسط [ 29 ] نیاز دارد. ساختار نمایه سازی سلسله مراتبی اجازه می دهد تا چندین گره در سطح پایین تر به عنوان یک گره در سطح بالاتر تجمیع شوند. در این تحقیق یک سیستم کاشی چهاردرخت [ 30] به عنوان ساختار سلسله مراتبی استفاده می شود. با تعریف پایین ترین سطح چهاردرخت به عنوان بهترین دانه بندی، هر هندسه ای را می توان در فهرستی از گره های چهاردرخت (یعنی چهار کلید) نمایه کرد (یا تقریب زد).
نمونههایی را میتوان در شکل 1 مشاهده کرد ، که در آن حداکثر سطح چهار درخت 4 است و فضای داخلی، مرزها، و بیرونی به ترتیب در رنگهای خاکستری تیره، خاکستری روشن و سفید نشان داده شدهاند. از آنجایی که شاخصهای سطح پایینتر را میتوان در شاخصهای سطح بالاتر جمع کرد، اگر یک هندسه چند کلید چهارگانه را پوشش دهد، میتوان تعداد شاخصها را کاهش داد. از دو چند ضلعی بالایی در شکل 1 به عنوان مثال استفاده شده است. چند ضلعی بالا سمت چپ حدود چهار برابر بزرگتر از چند ضلعی بالا سمت راست است. با استفاده از یک ساختار سلسله مراتبی، میتوانیم شاخصهای داخلی چند ضلعی بالا سمت چپ را از 72 شاخص سطح چهارم به شش شاخص (یعنی پنج شاخص سطح سوم و یک شاخص سطح دوم) تجمیع کنیم که همان تعداد شاخصهای داخلی است. چند ضلعی بالا سمت راست
علاوه بر این، تعیین یک رابطه توپولوژیکی به هر سه قسمت داخلی، مرزی و بیرونی SUB SP_GEO نیاز ندارد . در عوض، مدل AHS فقط نیاز به تولید اطلاعات لازم بر اساس محمول فضایی SUB SP دارد . به این ترتیب، ما می توانیم تعداد شاخص ها را بیشتر کاهش دهیم و پردازش پرس و جو را سرعت بخشیم. بر اساس تعریف روابط توپولوژیکی در OGC Simple Feature Access Specification ( جدول 1 ) و روابط توپولوژیکی احتمالی بین انواع هندسه مختلف، میتوانیم اطلاعات لازم را برای تعیین هر رابطه جغرافیایی تحلیل و پیشنهاد کنیم.
با این حال، در طول آزمایش اولیه نسخه اول مدل AHS، مشخص شد که عملکرد نمایه سازی و پرس و جو با استفاده از شاخص های بیرونی ضعیف تر از زمانی است که فقط از شاخص های داخلی و مرزی استفاده می شود. این به این دلیل است که تعداد شاخص های بیرونی معمولاً بیشتر از تعداد شاخص های داخلی و مرزی است. در نتیجه، مدل AHS را دوباره طراحی کردیم تا از شاخصهای بیرونی جلوگیری کنیم. تحلیل نهایی ما در زیر ذکر شده است:
-
EQUALS : از آنجایی که میتوانیم داخل و مرز دو هندسه را برای تعیین رابطه EQUALS با هم مقایسه کنیم ، فقط داخلی و مرز مورد نیاز است.
-
DISJOINT : از آنجایی که رابطه DISJOINT را می توان به عنوان “عدم تقاطع بین فضاهای داخلی و مرزها” مشاهده کرد، برای تعیین رابطه DISJOINT فقط به داخل و مرز نیاز است.
-
Intersects : از آنجایی که رابطه INTERSECTS به این معنی است که دو هندسه حداقل یک نقطه داخلی یا مرز مشترک دارند، برای این رابطه فقط داخلی و مرز مورد نیاز است.
-
TOUCHES : رابطه TOUCHES به این معنی است که دو هندسه متقاطع هستند اما فضای داخلی آنها با یکدیگر تلاقی ندارد. بنابراین، مشابه رابطه INTERSECTS ، فقط داخلی و مرز برای رابطه TOUCHES مورد نیاز است .
-
OVERLAPS : رابطه OVERLAPS به این معنی است که فضای داخلی هر دو هندسه، داخلی و خارجی هندسه را قطع می کند. اگر هر دو هندسه هندسه خطی هستند، محل تلاقی فضاهای داخلی باید یک خط برای رابطه OVERLAPS باشد . به منظور اجتناب از پردازش شاخصهای بیرونی، از این ایده پیروی میکنیم که « اگر تلاقی فضاهای داخلی و مرزها با هیچ یک از هندسهها برابر نباشد، هر یک از هندسهها با نمای خارجی دیگر علاقهمند است ». ( یک ∩ E ( ب ) ≠ ∅ )∧( E ( a ) ∩ b ≠ ∅ )iif ( a ∩ b ≠ a ) ∧ ( a ∩ b ≠ b ) (آ ∩ �(ب) ≠ ∅) ∧ (�(آ)∩ ب ≠ ∅) منمن� (آ ∩ ب ≠ آ) ∧ (آ ∩ ب ≠ ب). بنابراین برای این رابطه فقط ظاهر داخلی و خارجی لازم است. علاوه بر این، از آنجایی که چند نقطه در محدوده نیست، یک نقطه واحد با نقطه دیگر همپوشانی ندارد.
-
CROSSES: رابطه CROSSES به این معنی است که داخل هندسه اولیه است آآداخلی و خارجی هندسه ثانویه را قطع می کند بب. مشابه رابطه OVERLAPS ، ما نیاز بیرونی را با تقاطع های داخلی و مرزها جایگزین می کنیم. بعلاوه، برای هندسه خطوط، اگر و فقط اگر قسمت داخلی آنها در یک نقطه تلاقی داشته باشد، آنها متقاطع هستند. از آنجایی که ما فقط هندسه های تک نقطه ای را در نظر می گیریم، هیچ هندسه ای نمی تواند بر اساس تعریف OGC از یک نقطه عبور کند. در نتیجه، تعیین رابطه CROSSES فقط به داخل برای هندسه خط نیاز دارد و برای هندسه های چندضلعی هم به داخلی و هم مرز نیاز دارد.
-
درون :” آآ در داخل بب” یعنی داخل و مرز آآبه طور کامل در داخل و مرز بب. این بدان معناست که برای تعیین رابطه WITHIN فقط داخل و مرز مورد نیاز است .
-
CONTAINS : رابطه COTAINS معکوس رابطه WITHIN است که به معنی ” آآ حاوی بب” و ” بب در داخل آآ” برابر هستند. بنابراین، داخل و مرز نیز اطلاعات لازم برای CONTAINS هستند .
پس از تولید اطلاعات لازم از SUB SP ، مدل AHS شاخص های لازم را از همه اشتراک ها در یک ساختار داده واحد جمع می کند. در ساختار داده، هر چهار کلید (که توسط حداقل یک اشتراک مشترک است) فهرستی از شناسههای اشتراک ( SUB ID ) و نوع منطقه مربوطه ( TYPE SUB ) (یعنی داخلی یا مرز) را حفظ میکند. در این مورد، مدل AHS میتواند مستقیماً چهار کلید دادههای جدید را با چهار کلید در ساختار داده مطابقت دهد تا دادههای جدید را با همه اشتراکها در یک فرآیند واحد قطع کند. بدترین حالت این است که هیچ چهار کلیدی توسط هیچ اشتراک دیگری به اشتراک گذاشته نمی شود (یعنی هر چهار کلید فقط به یک شناسه SUB متصل می شود.) به این معنی است که تجمیع نه از ذخیره سازی و نه پردازش پرس و جو سود می برد. از سوی دیگر، تا زمانی که بیش از یک اشتراک وجود داشته باشد که یک چهار کلید مشترک را به اشتراک میگذارد، تجمیع میتواند هم اندازه ذخیرهسازی و هم تأخیر پرس و جو را کاهش دهد. در ادامه این مقاله، این ساختار چهاردرختی انباشته شده به عنوان AHS SUB برای اهداف وضوح نامیده می شود.
سهم مهمتر این است که با جمع کردن چهار کلید از همه SUB SP_GEO در AHS SUB ، مدل AHS می تواند به سادگی PUB GEO را با چهار کلید در AHS SUB مطابقت دهد و به مجموعه ای از SUB ID پیوند دهد . این بدان معنی است که مدل AHS چهار کلید و SUB ID را جدا می کند و به خود اجازه می دهد از نظر تعداد اشتراک ها مقیاس پذیرتر باشد.
3.2. مرحله تقاطع: تلاقی با هندسه انتشار
سه مرحله برای تلاقی هندسه انتشار (یعنی PUB GEO ) با شاخص AHS SUB وجود دارد : (1) ; (2) مطابقت؛ و (3) ایجاد ماتریس. این گردش کار در شکل 2 نشان داده شده است . به منظور تلاقی موثر PUB GEO با AHS SUB ، مدل AHS ابتدا داخل و مرز PUB GEO را با همان ساختار سلسله مراتبی (یعنی سیستم کاشی چهاردرخت) نمایه می کند. نتیجه این نمایه سازی به منظور شفافیت به عنوان AHS PUB نامگذاری شده است.
همانطور که در بخش قبل توضیح داده شد، مدل AHS الگوریتم تعیین را اصلاح می کند تا از پردازش شاخص های بیرونی جلوگیری کند. بنابراین، در این مرحله فقط باید داخل و مرز هندسه نشریه تولید شود.
این مرحله تطبیق از استفاده از همان ساختار نمایه سازی سود می برد. از آنجایی که هر دو AHS PUB و AHS SUB توسط یک سیستم کاشی چهاردرخت نمایه می شوند، می توانیم پیشوندهای چهار کلید را برای یافتن تقاطع مطابقت دهیم. به طور خاص، هر چهار کلید q دارای یک جعبه مرزی جغرافیایی مربوطه bbox است . با توجه به دو چهار کلید q A و q B ، bbox A ⊆ bbox B if، و فقط اگر، q A با q B شروع می شود. جعبه مرزی چهار کلید ‘0’ شامل تمام جعبه های مرزی چهار کلید است که رقم اول آنها ‘0’ است. اگر یک چهار کلید در AHS PUB با یک چهار کلید در AHS SUB تقاطع پیدا کند، این تقاطع به عنوان تطابق نامیده می شود .
هر مسابقه شامل پنج ویژگی زیر است: (1) چهار کلید متقاطع از AHS PUB . (2) چهار کلید متقاطع از AHS SUB . (3) شناسه اشتراک ( SUB ID )؛ (4) نوع منطقه AHS PUB ( TYPE PUB ؛ یعنی داخلی یا مرزی). و (5) نوع منطقه AHS SUB ( TYPE SUB ؛ یعنی داخلی یا مرز). پس از یافتن همه موارد مطابق، آنها توسط SUB ID گروه بندی می شوندو یک ماتریس برای هر گروه ایجاد می شود. این ماتریس به عنوان ماتریس مساحت نامیده می شود زیرا اندازه ناحیه متقاطع را ثبت می کند. به روشی مشابه ماتریس های تقاطع سه در سه DE-9IM، ماتریس های ناحیه برای تعیین رابطه توپولوژیکی بین هندسه ها هستند. ماتریس مساحت یک ماتریس دو در دو است و شکل آن در رابطه (2) نشان داده شده است:
جایی که A r e aآ�هآتابع مجموع تعداد واحد مساحت را برمیگرداند (در اینجا تعریف میکنیم که هر چهار کلید پایینترین سطح یک واحد مساحت دارد و چهار کلید در سطح n دارای 4 (پایینترین سطح- n ) واحد مساحت است). منمن( مثلاً ) _ _ _ _ _ _منمن(مترآتیجساعتهس)چهار کلیدهای متقاطع را برمی گرداند که TYPE PUB و TYPE SUB هر دو داخلی هستند، منب ( m a t c h e s )منب(مترآتیجساعتهس)چهار کلیدهای متقاطع را برمیگرداند که TYPE PUB داخلی و TYPE SUB مرز است، B I( مثلاً ) _ _ _ _ _ _بمن(مترآتیجساعتهس)چهار کلیدهای متقاطع را برمی گرداند که TYPE PUB آنها مرز و TYPE SUB داخلی است، و B B ( m a t c h e s )بب(مترآتیجساعتهس)چهار کلیدهای متقاطع را برمیگرداند که TYPE PUB و TYPE SUB هر دو مرز هستند.
3.3. مرحله تعیین: تعیین رابطه توپولوژیکی
با ماتریس های ناحیه تولید شده در مرحله قبل، روابط توپولوژیکی بین PUB GEO و SUB SP_GEO را می توان تعیین کرد. مانند DE-9IM، هر رابطه دارای یک الگوی ماتریسی خاص است. جدول 2 روابط توپولوژیکی و ماتریس های ناحیه متناظر آنها ( AMAtrix ) را فهرست می کند که در آن A r e aآ�هآتابع عدد واحد مساحت را برمیگرداند در حالی که توابع I و B به ترتیب قسمت داخلی و مرز SUB SP_GEO یا PUB GEO را برمیگردانند . علاوه بر این، AMatrix II ، AMatrix IB ، AMatrix BI ، و AMatrix BB به ترتیب نشان دهنده سلول (0، 0)، (0، 1)، (1، 0)، و (1، 1) در یک ماتریس ناحیه هستند. در نهایت، Sum ( AMatrix ) نشان دهنده AMatrix II + AMatrix IB + AMatrix BI + AMatrix است.بی بی .
توجه داشته باشید که بیشتر اطلاعات مورد استفاده در فرآیند تعیین را می توان از قبل محاسبه کرد. برای مثال، A r e a ( SUباسپ_ جی ایO)����(�����_���)، A r e a ( I( اسUباسپ_ جی ایO) )����(�(�����_���))، A r e a ( B ( SUباسپ_ جی ایO) )����(�(�����_���))، A r e a ( PUبجی ایO)����(������)، A r e a ( I( صUبجی ایO) )����(�(������))، و A r e a ( B ( PUبجی ایO) )����(�(������))می تواند در زمانی که اشتراک ها و نشریات وارد سیستم می شوند ایجاد شود.
توضیح مفهوم هر تعین:
-
EQUALS : اگر PUB GEO EQUALS SUB SP_GEO باشد، فضای داخلی و مرزهای آنها باید یکسان باشد، به این معنی که فضای داخلی آنها کاملاً با یکدیگر تلاقی می کنند و مرزهای آنها نیز همینطور است. در نتیجه، AMatrix II برابر است با مساحت هر دو فضای داخلی، و AMatrix BB برابر با مساحت هر دو مرز است.
-
DISJOINTS : اگر PUB GEO DISJOINTS SUB SP_GEO ، هر دو قسمت داخلی و مرز PUB GEO کاملاً در قسمت بیرونی SUB SP_GEO قرار دارند . هیچ تقاطعی بین فضای داخلی و مرزهای PUB GEO و SUB SP_GEO وجود ندارد . بنابراین، AMatrix II ، AMatrix IB ، AMatrix BI و AMatrix BB همگی صفر هستند.
-
INTERSECTS : PUB GEO INTERSECTS SUB SP_GEO اگر هر قسمت داخلی یا مرزی قطع شود، به این معنی است که یکی از سلول های AMatrix صفر نیست.
-
TOUCHES : اگر PUB GEO INTERSECTS SUB SP_GEO و فضای داخلی آن ها قطع نمی شود (یعنی AMatrix II برابر با صفر است)، PUB GEO TOUCHES SUB SP_GEO .
-
همپوشانی : همانطور که در بخش 3.1 ذکر شد ، پردازش شاخصهای بیرونی با تقاطع فضاهای داخلی و مرزها جایگزین میشود به این صورت که « اگر تلاقی فضاهای داخلی و مرزها با هر دو هندسه برابر نباشد، هر هندسه با نمای خارجی هندسه تلاقی میکند ». بنابراین، برای روابط غیر خط/خط، الگوریتم تعیین میشود: «اگر AMatrix II صفر نباشد و مجموع ( AMAtrix ) مساوی با مساحت ( PUB GEO ) و مساحت ( SUB SP_GEO )، PUB GEO OVERLAPS SUB SP_GEO باشد.“.
-
علاوه بر این، همانطور که مشخصات OGC تعریف می کند، رابطه OVERLAPS مستلزم آن است که بعد منطقه تقاطع با ابعاد هر دو هندسه برابر باشد. محل تقاطع رابطه “خط OVERLAPS خط” باید به جای نقطه، یک خط باشد. بنابراین، برای یک رابطه خط/خط، مدل AHS همچنین بررسی میکند که آیا AMatrix II بزرگتر از یک واحد منطقه است یا نه تا مطمئن شود که PUB GEO با SUB SP_GEO در یک نقطه تلاقی نمیکند .
-
CROSSES : برای روابط غیر خط/خط، الگوریتم تعیین برای رابطه PUB GEO CROSSES SUB SP_GEO مانند رابطه OVERLAPS است . برای روابط خط/خط، همانطور که مدل AHS از تعریف رایج ذکر شده در بخش 2 پیروی می کند ، اگر فضاهای داخلی در یک نقطه (یعنی یک واحد مساحت) تلاقی کنند، PUB GEO CROSSES SUB SP_GEO است.
-
WITHIN : رابطه PUB GEO WITHIN SUB SP_GEO به این معنی است که AMatrix II ، AMatrix IB ، AMatrix BI ، و AMatrix BB شامل کل منطقه PUB GEO (یعنی داخل و مرز PUB GEO ) است.
-
حاوی : PUB GEO حاوی SUB SP_GEO است اگر AMatrix II ، AMatrix IB ، AMatrix BI ، و AMatrix BB کل منطقه SUB SP_GEO را شامل شود (یعنی داخل و مرز SUB SP_GEO ).
4. مدل AHS توزیع شده
همانطور که قبلاً بحث شد، روشهای محاسبات توزیعشده و محاسبات ابری در مدل AHS برای فراهم کردن منابع ذخیرهسازی و محاسباتی بیشتر اعمال میشوند. به عنوان مثال، ما میتوانیم AHS SUB را به قطعات تقسیم کرده و در ماشینهای مختلف ذخیره کنیم تا به طور موثر مشکل ذخیرهسازی بالقوه را برطرف کنیم. همچنین میتوانیم از تکنیکهای محاسباتی توزیعی برای بهبود عملکرد پردازش پرس و جو، بهویژه برای مراحل نمایهسازی و تطبیق استفاده کنیم. برای دقیق تر بودن، ما چارچوب MapReduce [ 18 ] را دنبال می کنیم و یک جریان پردازش مدل AHS توزیع شده را پیشنهاد می کنیم.
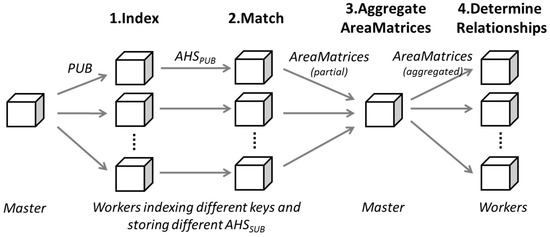
شکل 3 معماری سطح بالا و گردش کار مدل AHS توزیع شده را نشان می دهد. چهار مرحله در مدل AHS توزیع شده، یعنی (1) شاخص وجود دارد. (2) مطابقت؛ (3) ماتریس های مساحت کل. و (4) روابط را تعیین می کند. همانطور که فرآیندهای موجود در شاخص (1)؛ (2) مطابقت؛ و (4) تعیین مراحل روابط مانند مدل AHS مستقل است، (3) مرحله ماتریس های مساحت کل عمدتاً ماتریس های منطقه را بر اساس SUB ID گروه بندی و ادغام می کند .
همانطور که در شکل 3 نشان داده شده است ، مدل AHS توزیع شده دارای یک گره اصلی و مجموعه ای از گره های کارگر است. گره اصلی مسئول دریافت اشتراک ها و انتشارات و همچنین ارسال اشتراک ها و نشریات به کارگران مناسب است. هر کارگر وظیفه ایجاد و تطبیق شاخص ها را بر اساس مجموعه چهار کلید اختصاص داده شده به آن بر عهده دارد. به این معنی که اگر یک کارگر مسئول چهار کلید q A باشد ، تمام شاخص هایی که q A را به عنوان پیشوند دارند، توسط این کارگر ایجاد و حفظ می شود. گره اصلی یک جدول جستجو دارد که مجموعه ای از چهار کلید را که هر کارگر مسئول آن است ذخیره می کند. در ادامه این مقاله، این مجموعه از چهار کلید به عنوان WorkerQ نامیده می شودو جدول جستجو به عنوان LUT برای اهداف وضوح. از این رو، Worker Worker i WorkerQ i را به عنوان مجموعه چهار کلیدی که مسئول آن است دارد .
الگوریتم 1 الگوریتم انتخاب کارگر را نشان می دهد. هنگامی که یک گره اصلی یک SUB اشتراک یا یک PUB انتشار دریافت می کند، از LUT و SUB SP_GEO یا PUB GEO برای تعیین کارگرانی که مسئول پردازش SUB یا PUB هستند استفاده می کند . اگر WorkerQ آنها با SUB SP_GEO یا PUB GEO همپوشانی داشته باشد، بازگردانده می شوند . به منظور کاهش بار محاسباتی روی گره اصلی، از یک تخمین درشت روی SUB SP_GEO و PUB GEO استفاده کردیم.. یعنی ابتدا با تابع GetLowestQuadkeyLevel (خط 2 از الگوریتم 1) پایین ترین سطح چهار کلید (یعنی LowestLevel ) را در LUT پیدا می کنیم و چهار کلیدهای SUB SP_GEO یا PUB GEO (یعنی qs ) را در پایین ترین سطح (خط ) تولید می کنیم. 3 از الگوریتم 1). سپس رابطه حاوی با تطبیق پیشوند چهار کلید از qs و WorkerQ i تعیین می شود (خط 6 از الگوریتم 1). در نهایت، اگر چهار کلید از qs و WorkerQ i با یکدیگر همپوشانی داشته باشند، الگوریتم Worker i را برمیگرداند..
| الگوریتم 1. الگوریتم انتخاب کارگر. |
| تابع SelectWorkers (LUT، Geo) : کارگران |
| 1: |
کارگران ← {} |
| 2: |
LowestLevel ← GetLowestQuadkeyLevel(LUT) |
| 3: |
qs ← GetQuadkeysByLevel (جغرافیایی، پایین ترین سطح) |
| 4: |
FOREACH WorkerQ i ∈ LUT |
| 5: |
FOREACH q ∈ qs |
| 6: |
اگر q توسط WorkerQ i یا q حاوی WorkerQ i THEN باشد |
| 7: |
IF Workers شامل Worker i نیست |
| 8: |
کارگران ← کارگران + کارگر آی |
| 9: |
زنگ تفريح |
| 10: |
END IF |
| 11: |
پایان FOREACH |
| 12: |
پایان FOREACH |
| 13: |
بازگشت کارگران |
برای تطبیق یک نشریه، هنگامی که گره اصلی یک انتشارات PUB دریافت می کند ، ابتدا از الگوریتم 1 برای انتخاب یک یا چند کارگر استفاده می کند و سپس PUB را به کارگران انتخاب شده ارسال می کند. وقتی کارگری PUB را دریافت میکند، شاخصهایی را با PUB GEO براساس چهار کلیدهایی که مسئول آن است ایجاد میکند ، AHS PUB را با AHS SUB محلی تطبیق میدهد و ماتریسهای ناحیه را بر اساس تطابقهای محلی ایجاد میکند، قبل از اینکه در نهایت ماتریسهای ناحیه ایجاد شده را به آن برگرداند. ارباب. از آنجایی که هر کارگر فقط بخشی از AHS SUB را دارد(بر اساس چهار کلیدی که مسئول آن است)، ماتریس های ناحیه ایجاد شده تنها بخشی از ماتریس های ناحیه کامل را نشان می دهند. بنابراین، پس از اینکه کارگران ماتریسهای مساحت جزئی را برای Master ارسال میکنند، Master گروهبندی میکند و آنها را بر اساس SUB ID در ماتریسهای مساحت کامل جمعآوری میکند . در نهایت، گره اصلی به طور مساوی ماتریس های منطقه انبوه را بین کارگران توزیع می کند تا روابط توپولوژیکی را به صورت موازی تعیین کند.
با توجه به تعادل بار در مدل AHS توزیع شده، تعداد چهار کلید در AHS SUB عملکرد پردازش را نشان می دهد. این به این دلیل است که تعداد چهار کلید در AHS SUB ، ذخیره سازی مورد نیاز و منابع CPU را در یک گره کارگر تعیین می کند. بنابراین، یک رویکرد متعادل کننده بار ساده، یک آستانه θ را بر روی تعداد کلیدهای چهارگانه ای که هر کارگر کنترل می کند، اختصاص می دهد. پس از هر فرآیند ثبت اشتراک، اگر تعداد چهار کلید در AHS SUB کارگر بزرگتر از آستانه θ باشد ، کارگر AHS SUB اصلی را به چند AHS SUB تقسیم می کند.بر اساس چهار کلیدی که مسئول آن است. این AHS SUB های تقسیم شده سپس به سایر کارگران موجود یا تازه ایجاد شده اختصاص داده می شوند. در نهایت، Master جدول جستجوی خود را مطابق با آن به روز می کند.
به طور خلاصه، مدل AHS با استفاده از مفاهیم محاسبات توزیع شده بهبود یافته است. مدل AHS توزیع شده پیشنهادی میتواند منابع ذخیرهسازی و CPU را از چندین ماشین برای رسیدگی به مشکلات ذخیرهسازی بالقوه و بهبود عملکرد نمایهسازی و تطبیق مهار کند. مدل توزیعشده AHS، چهار کلید را به کارگران (یعنی WorkerQ ) برای توزیع بار پردازش اختصاص میدهد. این رویکرد به مدل توزیعشده AHS اجازه میدهد تا توانایی تطبیق یک نشریه با همه اشتراکها را در یک فرآیند واحد حفظ کند. این به این دلیل است که چهار کلید مشترک توسط چندین اشتراک در یک AHS SUB جمع میشوند .
5. نتایج ارزیابی
ما مدل AHS پیشنهادی را از چهار منظر ارزیابی می کنیم. اولا، از آنجایی که هدف اصلی مدل AHS پردازش کارآمد عملگرهای توپولوژیکی در هنگام مدیریت تعداد زیادی هندسه است، ما مقیاس پذیری مدل AHS را بر حسب تعداد پرس و جوها/اشتراک ها با مقایسه آن با PostGIS، که مورد استفاده قرار می گیرد، تجزیه و تحلیل می کنیم. برای نشان دادن عملگرهای توپولوژیکی سنتی.
ارزیابی دوم برای اندازه گیری تاخیر نمایه سازی است. از آنجایی که مدل AHS هندسهها را با یک سیستم کاشی چهاردرخت تقریب میکند، نمایهسازی برای هندسههای بزرگ ممکن است زمانبر باشد. اگرچه ما استدلال میکنیم که اشتراکها و دادهها در زمینه وب حسگر پوشش جغرافیایی زیادی ندارند، ما تأخیر نمایهسازی مدل AHS را با شبیهسازی هندسهها در اندازههای مختلف برای جامعیت ارزیابی میکنیم.
ارزیابی سوم تأخیر تطبیق مدل AHS را تحلیل میکند. به طور خاص، این ارزیابی تأخیر تطبیق AHS PUB و AHS SUB را اندازه گیری می کند . مانند ارزیابی دوم، هندسه های شبیه سازی شده در اندازه های مختلف را برای ارائه یک ارزیابی جامع بررسی می کنیم.
در نهایت، چهارمین ارزیابی، تجزیه و تحلیل عملکرد پایان به انتها برای مدل AHS توزیع شده است. ما تاخیرهای سربار را اندازه گیری می کنیم و هر یک از مراحل زیر را انجام می دهیم: (1) انتشار فهرست. (2) مطابقت AHS PUB با AHS SUB . و (3) رابطه را تعیین کنید. این ارزیابی تمام روابط ممکن بین دو هندسه را بررسی می کند. دادههای آزمایشی برای این ارزیابی، اشتراکها و نشریات سطح شهر به صورت دستی شبیهسازی شدهاند که فکر میکنیم نسبتاً واقعی هستند و عملکرد مدل AHS مورد انتظار را در یک برنامه کاربردی دنیای واقعی ارائه میدهند.
5.1. ارزیابی مقیاس پذیری مدل AHS
یکی از مهمترین عملکردهای مدل AHS اجرای عملگرهای توپولوژیکی به صورت تجمیع شده است. با تجمیع شاخصها از همه اشتراکها در یک ساختار واحد (یعنی AHS SUB ) و جداسازی شاخصها و اشتراکها، مدل AHS میتواند دادههای جدید را با همه اشتراکها در یک فرآیند واحد تطبیق دهد. در انجام این کار، اشتراک هایی که دارای چهار کلید مشترک هستند می توانند از این طراحی بهره مند شوند.
به منظور نشان دادن این سهم، مقیاسپذیری مدل AHS را در این بخش ارزیابی میکنیم. عملکرد پرس و جو همزمان با ثبت تعداد اشتراک های مختلف در مدل AHS اندازه گیری می شود. پرس و جو نقطه در چند ضلعی به عنوان مورد آزمایشی ما انتخاب می شود، زیرا یکی از رایج ترین پرس و جوها است. اشتراکی با پوشش یک شهر (یعنی یک چند ضلعی) شبیه سازی شد و به عنوان عملگر توپولوژیکی در محمول فضایی WITHIN اختصاص داده شد. این امر با شبیه سازی یک نشریه با هندسه نقطه ای واقع در شهر دنبال شد. با اشتراک و انتشار شبیه سازی شده، تعداد اشتراک های مختلف در مدل AHS (با شناسه اشتراک SUB ID متفاوت) ثبت شد.) و تأخیر پرس و جو هر 500 اشتراک اضافی را با ارسال نشریه به مدل AHS اندازه گیری کرد. همین آزمایش بر روی پایگاه داده PostGIS خارج از قفسه برای مقایسه انجام شد.
PostGIS عمدتا از کتابخانه GEOS استفاده می کند که جاوا توپولوژی سوئیت (JTS) را به C++ پورت می کند. JTS در بسیاری از محصولات از جمله GDAL/OGR، QGIS، MapServer و GeoTools استفاده شده است. برای هندسه های ذخیره شده در PostGIS، حداقل مستطیل های مرزی (MBRs) آنها نمایه می شوند. در مرحله فیلتر، MBR ها با هندسه های ورودی قطع می شوند و هندسه های متقاطع پیدا می شوند. سپس در مرحله اصلاح، PostGIS از هر جفت هندسه پایگاه داده و هندسه ورودی برای ساخت یک ماتریس تقاطع استفاده می کند، که برای مقایسه با الگوهای از پیش تعریف شده DE-9IM برای تصمیم گیری در مورد روابط توپولوژیکی استفاده می شود [31 ] .
از آنجایی که این ارزیابی عمدتاً در مورد مقیاس پذیری از نظر تعداد اشتراک ها بود، این ارزیابی بر روی یک ماشین با یک مدل AHS مستقل انجام شد تا از سربار ارتباط و ناهمگنی ماشین جلوگیری شود. این ارزیابی بر روی یک دستگاه رومیزی انجام شد که روی یک Intel® Core™ i5-650 @ 3.20GHz، 6GB RAM و Western Digital WD10EARS-22Y5B1 اجرا میشود .
تأخیرهای پرس و جو در تعداد اشتراک های مختلف در شکل 4 نشان داده شده است . بر اساس این نتایج تجربی، مشاهده کردیم که تأخیر پرس و جو با تعداد اشتراکها برای پایگاه داده PostGIS و مدل AHS افزایش مییابد. با این حال، از آنجایی که تاخیر پرس و جو مدل AHS 2.5 برابر کندتر از PostGIS افزایش می یابد، نشان می دهد که مدل AHS از نظر تعداد اشتراک ها مقیاس پذیرتر از راه حل سنتی است.
5.2. ارزیابی عملکرد شاخصسازی مدل AHS
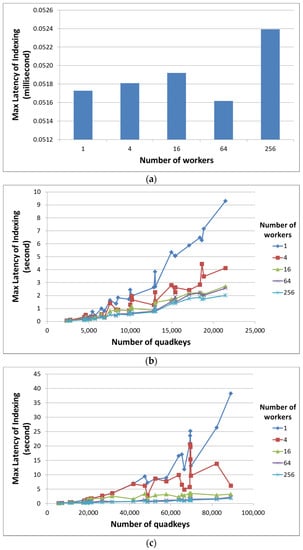
این بخش تأخیر تولید کوادکیهای ضروری را از هندسه اشتراکها اندازهگیری میکند. از آنجایی که هزینه زمانی نمایهسازی ممکن است بر اساس اندازه هندسه متفاوت باشد، ما بهطور تصادفی هندسههایی را در اندازههای مختلف تولید کردیم و تأخیرهای نمایهسازی آنها را اندازهگیری کردیم. علاوه بر این، همانطور که قبلا ذکر شد، کمترین سطح کاشی چهاردرخت به عنوان دانه بندی در تقریب هندسی مورد نیاز است. سیستم کاشی چهاردرختی مورد استفاده در این ارزیابی دارای 14 سطح بود.
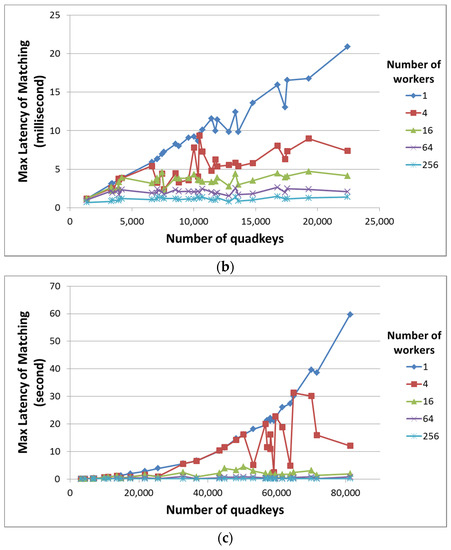
علاوه بر این، از آنجایی که مدل AHS توزیعشده میتواند وظایف نمایهسازی را به صورت موازی اجرا کند، ما همچنین تأخیر نمایهسازی را هنگام استفاده از تعداد کارگران مختلف اندازهگیری میکنیم. با این حال، برای جلوگیری از ناهمگونی ماشین، ما از یک ماشین واحد برای شبیهسازی هر کارگر در مدل AHS توزیع شده با اجرای وظایف کارگران بهطور مستقل استفاده کردیم. ما سناریوهای مدل های AHS توزیع شده را با یک، چهار، 16، 64 و 256 کارگر شبیه سازی کردیم. در حالی که سناریوی تک کارگری اساساً مدل AHS مستقل است، هر کارگر در سناریوهای چهار، 16، 64 و 256 کارگری به ترتیب در سطوح اول، دوم، سوم و چهارم درخت چهارگانه یک چهار کلید را کنترل میکند. . به عنوان مثال، برای سناریوی چهار کارگر، ما چهار کارگر را شبیه سازی کردیم که چهار کلیدهای ‘0’، ‘1’، ‘2’ و ‘3’ را کنترل می کنند. با فرآیندهای محاسباتی توزیع شده، کل فرآیند در زمانی که آخرین کارگر وظیفه خود را تمام می کند، به عنوان تمام شده در نظر گرفته می شود. در اینجا ما حداکثر (به جای متوسط) تاخیر نمایه سازی را از کارگران در هر سناریو ارائه می کنیم.
تأخیر نمایه سازی هندسه نقطه، خط و چند ضلعی در شکل 5 نشان داده شده است . از آنجایی که اندازه هندسه نقطه یکسان است (یعنی یک واحد مساحت = یک چهار کلید)، میانگین را برای هر سناریو می گیریم. از شکل 5 ، میتوانیم مشاهده کنیم که تأخیر نمایهسازی برای هندسه نقطهای بسیار کمتر از سایر انواع هندسه است، و تأخیر نمایهسازی برای هندسه خط کمتر از هندسه چند ضلعی است. ما معتقدیم این به دلیل تعداد متفاوتی از چهار کلید در حال نمایه سازی است که به اندازه و مکان هندسه ها مربوط می شود.
با مقایسه تأخیرهای نمایه سازی بر اساس تعداد کارگران مختلف، می توان مشاهده کرد که عملکرد را می توان با استفاده از کارگران بیشتر در مدل AHS توزیع شده به طور قابل توجهی بهبود بخشید. علاوه بر این، گاهی اوقات استفاده از چهار کارگر عملکردی مشابه با استفاده از یک کارگر دارد. دلیل آن این است که کارگران در مدل AHS توزیع شده، مناطق مختلف جغرافیایی را مدیریت می کنند. اگر داده های آزمایشی شبیه سازی شده تصادفی فقط در یک منطقه قرار داشته باشند، تنها یک کارگر کل فرآیند را انجام خواهد داد. از این رو، با کارگران بیشتری که مناطق مختلف را اداره می کنند، فرصت های بیشتری برای توزیع بار پردازش خواهیم داشت. نتایج ارزیابی ما نشان می دهد که فرآیند نمایه سازی استفاده از 256 کارگر می تواند 5 تا 10 برابر سریعتر از فرآیند نمایه سازی مستقل باشد.
در نهایت، در حالی که این ارزیابی هندسه های شبیه سازی شده را در اندازه های مختلف برای جامعیت بررسی می کند، برخی از این هندسه ها در زمینه شبکه حسگر بسیار بزرگ هستند. در میان این هندسه های شبیه سازی شده، طولانی ترین هندسه خط تولید شده 7112 کیلومتر طول داشت. بزرگترین هندسه چند ضلعی حدود 37 درصد از زمین را پوشانده است. در واقع، یک بزرگراه اصلی شهر معمولاً حدود 100 کیلومتر است. و یک شهر معمولا کمتر از 1 درصد از زمین را پوشش می دهد.
به طور خلاصه، در حالی که برخی از هندسه های شبیه سازی شده واقعی نیستند، مدل AHS قادر است مرحله نمایه سازی را به موقع با کمک پردازش توزیع شده به پایان برساند. برای نمایه سازی اشتراک ها، با توجه به ماهیت طولانی مدت پرس و جو پیوسته، ما استدلال می کنیم که سربار نمایه سازی اندازه گیری شده قابل قبول است. علاوه بر این، از آنجایی که دادههای وب حسگر دنیای واقعی معمولاً پوشش جغرافیایی بسیار کمتری نسبت به هندسههای شبیهسازی شده دارند، ما معتقدیم که نمایهسازی برای انتشارات بسیار سریعتر از اشتراکها خواهد بود.
5.3. ارزیابی عملکرد تطبیق مدل AHS
این بخش تأخیر تطبیق AHS PUB با AHS SUB را اندازه گیری می کند . از آنجایی که هزینه زمان برای تطبیق ممکن است بر اساس تعداد چهار کلید متفاوت باشد، ما به طور تصادفی هندسههایی را در اندازههای مختلف تولید میکنیم تا یک ارزیابی جامع ارائه کنیم. برای اینکه مطمئن شویم که چهار کلید این هندسه ها پردازش می شوند، ابتدا هندسه یکسانی را برای انتشار و اشتراک اعمال کردیم و سپس EQUALS را به عنوان عملگر توپولوژیک اختصاص دادیم. در این ارزیابی، سیستم کاشی چهاردرخت دارای 14 سطح بود.
علاوه بر این، مانند ارزیابی قبلی، ما همچنین تأخیر تطبیق را هنگام اعمال تعداد مختلف کارگر اندازهگیری کردیم. در این ارزیابی، ما از یک ماشین برای شبیهسازی هر کارگری که چهار کلیدهای مختلف را در مدل AHS توزیعشده کنترل میکند، استفاده کردیم. سناریوهای مدل های AHS توزیع شده با یک، چهار، 16، 64 و 256 کارگر شبیه سازی شد. حداکثر (به جای میانگین) تأخیر تطبیق از کارگران در هر سناریو نیز ارائه شد.
تأخیر تطبیق هندسه نقطه، خط و چند ضلعی در شکل 6 نشان داده شده است . از آنجایی که اندازه هندسه نقطه یکسان است (یعنی یک واحد سطح)، ما تأخیر متوسط را برای هر سناریو در نظر گرفتیم. از شکل 6 ، میتوان مشاهده کرد که تأخیر تطبیق برای هندسه نقطهای بسیار کمتر از سایر انواع هندسه است، و تأخیر تطبیق برای هندسه خط کمتر از هندسه چند ضلعی است. همانطور که در مورد عملکرد نمایه سازی، ما معتقدیم که این به دلیل تعداد متفاوتی از چهار کلید در حال پردازش است.
با مقایسه تأخیرهای نمایه سازی بر اساس تعداد کارگران مختلف، می توان مشاهده کرد که عملکرد را می توان به طور قابل توجهی با استفاده از کارگران بیشتر در مدل AHS توزیع شده بهبود بخشید. علاوه بر این، گاهی اوقات استفاده از چهار کارگر عملکردی مشابه با استفاده از یک کارگر دارد. دلیل آن این است که کارگران در مدل AHS توزیع شده، مناطق مختلف جغرافیایی را مدیریت می کنند. اگر دادههای آزمایشی شبیهسازیشده تصادفی فقط در یک منطقه قرار داشته باشند، تنها یک کارگر کل فرآیند را انجام میدهد. از این رو، با کارگران بیشتری که مناطق مختلف را اداره می کنند، فرصت های بیشتری برای توزیع بار پردازش خواهیم داشت. نتایج ارزیابی ما نشان میدهد که فرآیند تطبیق استفاده از 256 کارگر میتواند 20 تا 300 برابر سریعتر از فرآیند تطبیق مستقل باشد.
در نهایت، مانند ارزیابی قبلی، این ارزیابی هندسه های شبیه سازی شده در اندازه های مختلف را برای جامعیت بررسی می کند. با این حال، برخی از این هندسه ها ممکن است در زمینه شبکه حسگر بسیار بزرگ باشند. به عنوان مثال، در میان این هندسه های شبیه سازی شده، طولانی ترین هندسه خطی که ما ایجاد کردیم 7778 کیلومتر طول داشت. بزرگترین هندسه چند ضلعی حدود 20 درصد از زمین را پوشانده است. با این حال، در حالی که برخی از هندسه های شبیه سازی شده واقعی نیستند، مدل AHS قادر است با کمک پردازش توزیع شده، AHS PUB و AHS SUB را به موقع تطبیق دهد.
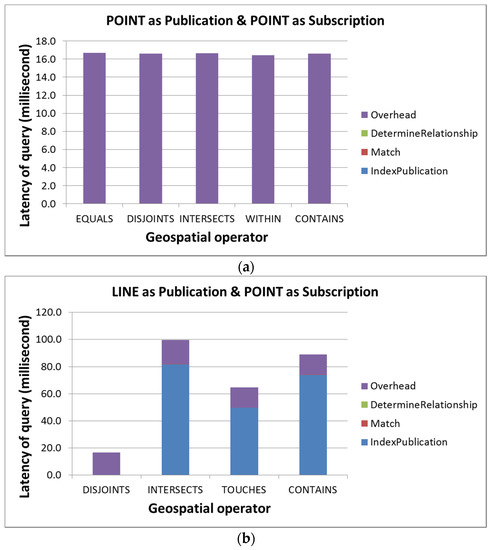
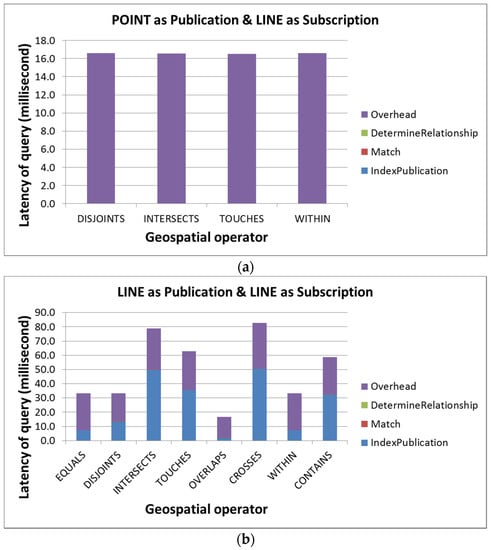
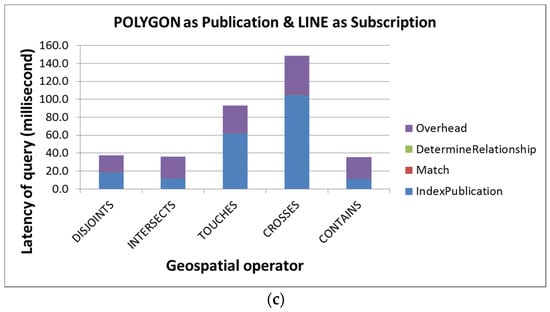
5.4. ارزیابی عملکرد پرس و جوی پایان به انتها مدل AHS
در این بخش، عملکرد پرس و جوی سرتاسر مدل AHS را ارزیابی می کنیم. ما تأخیر انتشار نمایه سازی، مطابقت AHS PUB و AHS SUB را اندازه گیری می کنیم.و تعیین روابط و همچنین سربار. علاوه بر این، این ارزیابی بر روی تمام روابط ممکن انجام می شود. ما یک جفت اشتراک/انتشار را برای هر رابطه ممکن شبیهسازی کردیم و سعی کردیم هندسههایی با اندازههای مشترک برای برنامههای سطح شهر ایجاد کنیم. به عنوان مثال، ما نقطه، خط و چند ضلعی اشتراک را بر اساس ایده های یک نقطه در یک شهر (به عنوان مثال، نقطه عطف شهر)، جاده ای که از یک شهر عبور می کند (به عنوان مثال، یک بزرگراه اصلی) و پوشش شهر ایجاد کردیم. به ترتیب. انتشاراتی که اشتراکها را برای هر رابطه توپولوژیکی ممکن مطابقت میدهند نیز به صورت دستی ایجاد شدند (به عنوان مثال، یک حسگر واقع در یک تقاطع جاده).
به منظور آزمایش سربار محاسبات توزیع شده، این ارزیابی از دو ماشین واقع در یک شبکه محلی استفاده کرد. مجموعهای از چهار کلیدها که هر کارگر مسئول آن است بهصورت دستی پیکربندی شدهاند تا کارگران مقدار مشابهی از کار را انجام دهند. هر دو دستگاه رومیزی هستند. یکی از آنها روی Intel® Core ™ i5-650 @ 3.20 گیگاهرتز و 6 گیگابایت رم و دیگری بر روی Intel® Core ™ i7-3770 @ 3.40 گیگاهرتز و 10 گیگابایت رم اجرا می شود. با در نظر گرفتن ناهمگونی ماشین و مقدار احتمالاً نابرابر کار اختصاص داده شده، به جای ارائه حداکثر تأخیر، این ارزیابی میانگین تأخیرها را برای ارائه عملکرد مدل AHS مورد انتظار در یک برنامه دنیای واقعی محاسبه می کند. هر سناریو 10 بار تست شده و میانگین برای هر سناریو گرفته شده است.
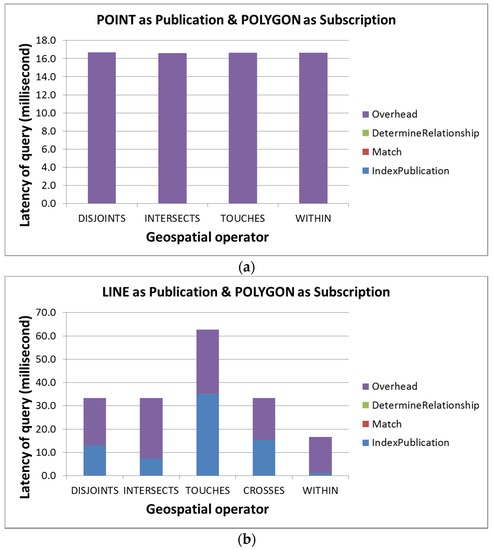
عملکردهای جستجوی سرتاسر استفاده از هندسه نقطه، خط و چند ضلعی به عنوان اشتراک در شکل 7 ، شکل 8 و شکل 9 نشان داده شده است.، به ترتیب. بر اساس این نتایج ارزیابی، ما دریافتیم که شبیهسازی مجموعههای دادهای که به اندازه کافی برابر هستند تا در مقایسه عملگرهای توپولوژیکی مختلف مورد استفاده قرار گیرند، دشوار است. ما استدلال میکنیم که تفاوتهای عملکردی بین عملگرهای توپولوژیکی معنی زیادی ندارد زیرا این تفاوتها ممکن است از ناهمگونی ماشین یا مجموعه دادههای شبیهسازیشده، مانند اندازه هندسه ناشی شود. با این حال، این ارزیابی همچنان ارزشمند است زیرا هزینه های محاسبات توزیع شده را اندازه گیری می کند، تأخیر هر مرحله را ارائه می دهد و عملکرد بالقوه مدل AHS را در یک برنامه کاربردی وب حسگر دنیای واقعی نشان می دهد.
بنابراین، بر اساس نتایج تجربی، اولین مشاهدات ما این است که نمایه سازی و سربار بیش از 99 درصد از تأخیر انتها به انتها را به خود اختصاص می دهند. در حالی که هزینه های سربار اعمال فرآیند محاسبات توزیع شده نسبتاً پایدار است (بین 10 تا 30 میلی ثانیه)، تأخیر نمایه سازی بسته به اندازه هندسه انتشار به طور گسترده ای متفاوت است. علاوه بر این، در زمینه یک سیستم انتشار/اشتراک وب حسگر، از آنجایی که هندسه انتشار معمولاً کوچک است (مثلاً مکانهای حسگر یا ویژگیهای مشاهده شده)، ما معتقدیم که تأخیر نمایهسازی نیز کم خواهد ماند.
مشاهده دوم ما این است که تأخیرها برای تعیین روابط بسیار اندک است زیرا هر تعیین فقط یک ماتریس دو به دو را کنترل می کند. در نهایت، از آنجایی که این ارزیابی مبتنی بر مجموعه دادههای واقعیتر است، عملکرد اندازهگیری شده میتواند عملکرد مدل AHS ممکن را در یک برنامه دنیای واقعی به ما ارائه دهد. همانطور که از نتایج ارزیابی می بینیم، اکثر تست ها را می توان در 100 میلی ثانیه به پایان رساند، در حالی که بیش از 70٪ از آنها را می توان در 50 میلی ثانیه تکمیل کرد. بنابراین، ما معتقدیم که مدل AHS میتواند هر عملگر توپولوژیکی ممکن را برای دادههای وب حسگر، که برای برنامههای حساس به زمان حیاتی است، به طور موثر پردازش کند.
6. نتیجه گیری و کار آینده
ما مدل AHS را ارائه کردهایم که میتواند به طور موثر روابط توپولوژیکی بین هندسهها را در یک سیستم انتشار/اشتراک وب حسگر تعیین کند. با توجه به حجم بالقوه زیاد داده های وب حسگر، مدل پردازش پرس و جو پیوسته به طور فزاینده ای توجه بسیاری از برنامه های کاربردی حساس به زمان را به خود جلب می کند. با این حال، اپراتورهای جغرافیایی زمان بر برای برنامه هایی که نیاز به پردازش و اطلاع رسانی به موقع دارند، مناسب نیستند. مدل AHS نمونهای است که نشان میدهد عملگرهای مکانی سنتی را میتوان به عنوان اپراتورهای جستجوی پیوسته کارآمد در زمینه سیستمهای انتشار/اشتراک مجدد طراحی کرد.
نتایج ارزیابی ما نشان میدهد که مدل AHS پیشنهادی 2.5 برابر سریعتر از PostGIS هنگام پردازش تعداد زیادی از هندسهها است، که نشان میدهد راهحل پیشنهادی مقیاسپذیرتر از راهحل سنتی است. ما همچنین عملکردهای نمایه سازی و تطبیق مدل AHS توزیع شده را ارزیابی کردیم. ارزیابی نشان میدهد که با کمک پردازش توزیعشده، مدل AHS توزیعشده میتواند به طور قابلتوجهی عملکردهای نمایهسازی و تطبیق را بهبود بخشد و وظایف را به موقع به پایان برساند، حتی برای هندسههایی با اندازههای بزرگ.
در نهایت، ما همچنین تأخیر پرس و جوی سرتاسری را با مجموعه دادههای نسبتاً واقعی ارزیابی کردیم. مشاهده کردیم که نمایه سازی و سربار بیش از 99 درصد از تأخیر انتها به انتها را تشکیل می دهند. در حالی که سربار استفاده از فرآیند محاسبات توزیع شده نسبتاً پایدار است (بین 10 تا 30 میلی ثانیه)، تأخیر نمایه سازی بسته به اندازه هندسه انتشارات به طور گسترده ای متفاوت است. همانطور که قبلا نشان داده شد، مدل AHS می تواند اکثر پرس و جوهای شبیه سازی شده را در 100 میلی ثانیه به پایان برساند، بنابراین ما معتقدیم که مدل AHS قادر است عملگرهای توپولوژیکی را در یک سیستم انتشار/اشتراک وب حسگر جغرافیایی پردازش کند.
با توجه به جهت های آینده، رویکرد تعادل بار فعلی یک راه حل ساده و ساده است. عوامل دیگری نیز وجود دارد که در آینده می توان آنها را در نظر گرفت. به عنوان مثال، به منظور بهبود در دسترس بودن سرویس و جلوگیری از مشکل بالقوه خرابی ماشین، مدل AHS توزیع شده میتواند چندین کارگر را به کار با چهار کلید یکسان (یعنی کپی) اختصاص دهد. علاوه بر این، از آنجایی که رویکرد متعادلسازی بار فعلی فقط توزیع جغرافیایی اشتراکها را در نظر میگیرد، نظارت بر هندسه نشریات ممکن است توزیع تطبیقی بارهای پردازش را امکان پذیر کند. در نهایت، ما همچنین سعی خواهیم کرد مدل AHS را به منظور پشتیبانی از هندسه های چند نقطه ای، چند خطی و چند ضلعی بهبود دهیم.








بدون نظر