

خلاصه
نیاز به یکپارچهسازی دادههای اطلاعات مکانی (GI) از منابع مختلف ناهمگن اهمیت بیشتری برای قابلیت همکاری سیستم اطلاعات جغرافیایی (GIS) داشته است. استفاده از هستی شناسی های دامنه برای شفاف سازی و ادغام معنایی داده ها به عنوان یک گام مهم برای ادغام معنایی موفقیت آمیز در حوزه GI در نظر گرفته می شود. با این وجود، مکانیسمهایی برای تسهیل نگاشت معنایی بین هستیشناسیهای GI که در زبانهای طبیعی مختلف توصیف شدهاند، هنوز مورد نیاز است. این تحقیق یک مدل هستی شناسی رسمی را برای نقشه برداری هستی شناسی اطلاعات مکانی بین زبانی ایجاد می کند. با استخراج ابتدایی های معنایی از یک تعریف متن آزاد مقوله ها در دو استاندارد طبقه بندی GI با زبان های طبیعی مختلف، یک رویکرد هستی شناسی محور استفاده می شود. و یک مدل هستی شناسی رسمی ایجاد می شود تا به طور رسمی این مفاهیم ابتدایی معنایی را در گزاره های معنایی نشان دهد، که در آن ویژگی ها و روابط مربوط به فضایی به عنوان گزاره های حیاتی برای نمایش و شناسایی معناشناسی مقوله های GI در نظر گرفته می شوند. سپس، الگوریتمی برای مقایسه این عبارات معنایی در یک محیط بین زبانی پیشنهاد شده است. ما بیشتر یک الگوریتم محاسبه شباهت را بر اساس مدل هستیشناسی رسمی پیشنهادی طراحی میکنیم تا از شباهتهای معنایی فاصله بگیرد و روابط نگاشت بین دستهها را شناسایی کنیم. به طور خاص، ما با دو استاندارد طبقه بندی GI برای نقشه های توپوگرافی چینی و آمریکایی کار می کنیم. نتایج تجربی امکانسنجی و قابلیت اطمینان مدل پیشنهادی را برای نقشهبرداری هستیشناسی اطلاعات مکانی بین زبانی نشان میدهد. که در آن ویژگی ها و روابط مرتبط با فضایی به عنوان گزاره های حیاتی برای نمایش و شناسایی معناشناسی مقوله های GI در نظر گرفته می شوند. سپس، الگوریتمی برای مقایسه این عبارات معنایی در یک محیط بین زبانی پیشنهاد شده است. ما بیشتر یک الگوریتم محاسبه شباهت را بر اساس مدل هستیشناسی رسمی پیشنهادی طراحی میکنیم تا از شباهتهای معنایی فاصله بگیرد و روابط نگاشت بین دستهها را شناسایی کنیم. به طور خاص، ما با دو استاندارد طبقه بندی GI برای نقشه های توپوگرافی چینی و آمریکایی کار می کنیم. نتایج تجربی امکانسنجی و قابلیت اطمینان مدل پیشنهادی را برای نقشهبرداری هستیشناسی اطلاعات مکانی بین زبانی نشان میدهد. که در آن ویژگی ها و روابط مرتبط با فضایی به عنوان گزاره های حیاتی برای نمایش و شناسایی معناشناسی مقوله های GI در نظر گرفته می شوند. سپس، الگوریتمی برای مقایسه این عبارات معنایی در یک محیط بین زبانی پیشنهاد شده است. ما بیشتر یک الگوریتم محاسبه شباهت را بر اساس مدل هستیشناسی رسمی پیشنهادی طراحی میکنیم تا از شباهتهای معنایی فاصله بگیرد و روابط نگاشت بین دستهها را شناسایی کنیم. به طور خاص، ما با دو استاندارد طبقه بندی GI برای نقشه های توپوگرافی چینی و آمریکایی کار می کنیم. نتایج تجربی امکانسنجی و قابلیت اطمینان مدل پیشنهادی را برای نقشهبرداری هستیشناسی اطلاعات جغرافیایی بین زبانی نشان میدهد. الگوریتمی برای مقایسه این عبارات معنایی در یک محیط بین زبانی پیشنهاد شده است. ما بیشتر یک الگوریتم محاسبه شباهت را بر اساس مدل هستیشناسی رسمی پیشنهادی طراحی میکنیم تا از شباهتهای معنایی فاصله بگیرد و روابط نگاشت بین دستهها را شناسایی کنیم. به طور خاص، ما با دو استاندارد طبقه بندی GI برای نقشه های توپوگرافی چینی و آمریکایی کار می کنیم. نتایج تجربی امکانسنجی و قابلیت اطمینان مدل پیشنهادی را برای نقشهبرداری هستیشناسی اطلاعات جغرافیایی بین زبانی نشان میدهد. الگوریتمی برای مقایسه این عبارات معنایی در یک محیط بین زبانی پیشنهاد شده است. ما بیشتر یک الگوریتم محاسبه شباهت را بر اساس مدل هستیشناسی رسمی پیشنهادی طراحی میکنیم تا از شباهتهای معنایی فاصله بگیرد و روابط نگاشت بین دستهها را شناسایی کنیم. به طور خاص، ما با دو استاندارد طبقه بندی GI برای نقشه های توپوگرافی چینی و آمریکایی کار می کنیم. نتایج تجربی امکانسنجی و قابلیت اطمینان مدل پیشنهادی را برای نقشهبرداری هستیشناسی اطلاعات جغرافیایی بین زبانی نشان میدهد. ما با دو استاندارد طبقه بندی GI برای نقشه های توپوگرافی چینی و آمریکایی کار می کنیم. نتایج تجربی امکانسنجی و قابلیت اطمینان مدل پیشنهادی را برای نقشهبرداری هستیشناسی اطلاعات جغرافیایی بین زبانی نشان میدهد. ما با دو استاندارد طبقه بندی GI برای نقشه های توپوگرافی چینی و آمریکایی کار می کنیم. نتایج تجربی امکانسنجی و قابلیت اطمینان مدل پیشنهادی را برای نقشهبرداری هستیشناسی اطلاعات جغرافیایی بین زبانی نشان میدهد.
کلید واژه ها:
سیستم های اطلاعات جغرافیایی ; قابلیت همکاری معنایی ; متقابل زبانی ; هستی شناسی سبک ؛ نقشه توپوگرافی
1. معرفی
چشم انداز “زمین دیجیتال” بیان شده توسط معاون رئیس جمهور ایالات متحده، ال گور [ 1 ، 2 ، 3 ] کمک قابل توجهی به رشد اطلاعات جغرافیایی جهانی (GI) در محیط های فیزیکی و اجتماعی کرده است. با این حال، نحوه پرس و جو، بازیابی و دستکاری آن داده ها از منابع ناهمگن، جامعه GI را به چالش کشیده است [ 2 ، 3 ، 4 ، 5 ]. بنابراین، رویکرد یکپارچه سازی داده های GI از منابع مختلف ناهمگن اهمیت بیشتری پیدا کرده است [ 6 ].
فرآیند یکپارچه سازی داده ها به سادگی پیوستن به چندین سیستم نیست، زیرا هر تلاشی برای به اشتراک گذاری اطلاعات با مشکل ناهمگونی معنایی مواجه می شود [ 7 ]. ناهمگونی معنایی زمانی رخ میدهد که قابلیت همکاری بین سیستمهای اطلاعات جغرافیایی (GIS) را فراهم میکند [ 8 ، 9 ، 10 ، 11 ]، زیرا GIS اغلب برای رسیدگی به دادهها از منابع داده بسیار پراکنده، چند رشتهای و بین زبانی با تقاضاهای کاربردی متفاوت طراحی شده است [12 ] . بنابراین شفاف سازی معنایی داده ها گامی حیاتی به سوی یکپارچه سازی موفق داده ها است [ 13]]. برای دستیابی به این هدف، هستی شناسی های دامنه به عنوان واسطه ای برای تبادل اطلاعات ساخته می شوند به گونه ای که معنای دقیق داده ها ( به عنوان مثال ، معناشناسی) به راحتی فراتر از تطبیق کلمات کلیدی ساده از طریق زبان های بازنمایی دانش و استدلال قابل بازیابی باشد [ 7 ، 13 ، 14 ، 15 ]. بنابراین، مهندسی هستیشناسی بهعنوان وسیلهای مؤثر برای ایجاد ارتباط یکپارچه بین مؤلفههای GIS در سطح معنایی در نظر گرفته شده است [ 8 ، 12 ، 16 ].
در حالی که جامعه GI کاربرد فناوری های هستی شناسی را به طور گسترده تایید می کند، دو مشکل اصلی برای مهندسی هستی شناسی GI و به اشتراک گذاری باید حل شود به شرح زیر است: (1) تحقیقات هستی شناسی سنتی و فناوری های متمرکز بر اصطلاحات و طرح واره نمی توانند به این سوال در مورد چگونگی مهندسی پاسخ دهند. هستی شناسی های GI و ادغام آنها با GIS یا زیرساخت های داده های مکانی (SDI) [ 6 ]. و (2) مکانیسمها هنوز باید برای نقشهبرداری هستیشناسی GI در محیطهای بین زبانی برای تسهیل ادغام معنایی بین هستیشناسیهای GI که در زبانهای طبیعی مختلف توصیف شدهاند، بررسی شوند [ 17 ، 18 ، 19 ، 20 ].
دلیل مشکل اول این است که ویژگی ها و مقوله های GI محصول شناخت فضایی و قرارداد اجتماعی است. بنابراین، کارهای مهندسی هستیشناسی در حوزههای GI با سایر حوزهها متفاوت است، که در آن مکان، توپولوژی، صرفاشناسی و سایر روابط فضایی نقش عمدهای در شناسایی و نمایش معناشناسی GI ایفا میکنند [14 ] . به عنوان مثال، از دیدگاه هستی شناسی ویژگی محور، دسته های جغرافیایی «رودخانه» و «کرانه» باید در طبقات مختلف مشخص شوند و به طور معمول، رابطه فضایی «مجاور به» بین این دو دسته وجود ندارد. علاوه بر این، موجودیتهای جغرافیایی و غیرجغرافیایی از جنبههای مختلفی از نظر هستیشناختی متمایز هستند [ 21]]. برای تقویت بیان معنایی و غلبه بر مسئله ناهمگونی معنایی در طول فرآیند مهندسی هستیشناسی GI، ویژگیهای مرتبط با فضای مقولههای GI باید برای غنیسازی معناشناسی مرتبط با فضای هستیشناسی دادهشده در نظر گرفته شود.
اگرچه اکثر هستیشناسیهای فعلی GI به زبان انگلیسی با واژگان انگلیسی توسعه یافتهاند، مقدار محتوای چند زبانه در وب معنایی و بنابراین تعداد واژگان/هستیشناسی در چندین زبان همچنان در حال رشد است [22 ] . بنابراین، روشهای تطبیق واژگان بین زبانها برای ارتقای دسترسی به دادهها در چندین زبان توسط کاربران نهایی اهمیت فزایندهتری پیدا کردهاند [ 23] .]. به عنوان یک سناریوی انگیزشی، اگر کاربری بخواهد داده های سطح آب را در امتداد رودخانه مکونگ (هفتمین رودخانه طولانی جهان که شش کشور مختلف را پوشش می دهد – کامبوج، لائوس، میانمار، تایلند، ویتنام و چین- و زبان های رسمی را جستجو کند. هر کشور متفاوت است)، چندین ارائه دهنده داده وجود دارد که داده های GI مرتبط را از طریق GIS ملی خود به زبان های طبیعی مادری خود ارائه می دهند. این وضعیت چالشی اساسی برای ادغام داده های GI بسیار ناهمگن در میان موانع زبان طبیعی ایجاد کرده است.
هدف از این مطالعه ایجاد یک مدل هستی شناسی رسمی برای نقشه برداری هستی شناسی اطلاعات مکانی بین زبانی است. با شروع از دو استاندارد طبقهبندی GI با زبانهای طبیعی مختلف – چینی و انگلیسی (برای سادگی و وضوح، این مطالعه به مقولههای «آبهای سطحی» از این دو استاندارد محدود شد) – مجموعهای از ابتداییهای معنایی از رایگان استخراج میشوند. -تعریف متنی دسته بندی ها در استانداردها با استفاده از تکنیک های پردازش زبان طبیعی (NLP). سپس، یک رویکرد مبتنی بر هستی شناسی استفاده می شود، و مدل هستی شناسی رسمی ایجاد می شود تا به طور رسمی این مفاهیم ابتدایی معنایی را با استفاده از عبارات معنایی نشان دهد. که در آن ویژگی ها و روابط مرتبط با فضایی به عنوان گزاره های حیاتی برای نمایش و شناسایی معناشناسی مقوله های GI در نظر گرفته می شوند. برای غلبه بر مانع زبان طبیعی، عبارات به زبان چینی با استفاده از ابزارهای ترجمه ماشینی به انگلیسی ترجمه میشوند و روابط نگاشت بین عبارات در یک زمینه انگلیسی تعیین میشود، که سپس به عنوان مبنایی برای محاسبه شباهت بین دستهها در هستیشناسیهای مختلف GI عمل میکند. . در نهایت، یک الگوریتم محاسبه شباهت طراحی شده است تا از شباهت معنایی بین دستههای GI در هستیشناسیهای مختلف فاصله بگیرد و روابط نگاشت نهایی بین جفت مقولهها بر اساس مقادیر شباهت محاسبهشده تعیین میشود.
ادامه این مقاله به شرح زیر سازماندهی شده است. بخش 2 آثار مرتبط را در ادبیات ارائه می کند. سپس، رویه اصلی روش شناسی ما در بخش 3 ارائه شده است . در مرحله بعد، یک مطالعه موردی که کاربرد روش ما را نشان می دهد در بخش 4 نشان داده شده است . در نهایت، نتیجه گیری شده و کارهای آتی ذکر شده است.
2. آثار مرتبط
2.1. تفسیر معنایی
کسب دانش (KA) یک زمینه وسیع است که فرآیندهای استخراج، ایجاد و ساختاردهی دانش از منابع ناهمگن را در بر می گیرد [ 24 ]. تفسیر معنایی (SI) برای KA به عنوان ترکیب دو فرآیند فرعی تعریف میشود: استخراج ابتداییهای معنایی از تعریف متن آزاد در هستیشناسیها و غنیسازی معنایی بر اساس اولیههای معنایی استخراجشده.
تحقیق در مورد استخراج ابتدایی معنایی بر روی مجموعه وسیعی از آثار در زمینههای پردازش زبان طبیعی (NLP) [ 25 ] استوار است. NLP و متن کاوی زمینه های تحقیقاتی با هدف بهره برداری از منابع غنی دانش با هدف درک، استخراج و بازیابی اطلاعات معنایی از متن نوشته شده بدون ساختار هستند. منابع دانشی که برای این اهداف مورد استفاده قرار گرفتهاند شامل طیف وسیعی از اصطلاحات، از جمله واژگان، واژگان کنترلشده، اصطلاحنامهها و هستیشناسیها میشود [ 26 ، 27 ]. اگرچه اخیراً روشها و الگوریتمهای متعددی (مانند رویکردهای نمادین، آماری و ترکیبی) توسعه یافتهاند [ 26]]، یک الگوریتم کاملاً خودکار برای استخراج معنایی با استفاده از تکنیکهای NLP دست نیافتنی به نظر میرسد و فرآیند دستی به عنوان دستیار معمولاً اجتنابناپذیر است.
برای غنیسازی معنایی، نویسندگان در [ 28 ، 29 ] یک روش سیستماتیک برای کشف و شناسایی اطلاعات معنایی ارائه شده توسط دستهها در هستیشناسیهای جغرافیایی پیشنهاد کردند، که در آن بازنمایی معنایی مقولهها با مجموعهای از ویژگیها و روابط معنایی برای آشکار کردن شباهتها و ناهمگونیها غنی میشود. بین این دسته ها نویسندگان [ 30] یک رسمیت بدیهی از یک نظریه روابط سطح بالا (روابط جدایی، روابط فرعی، و روابط بین مقوله ای) بین سه دسته از موجودیت های مرتبط با فضای مکانی، یعنی افراد، کلیات و مجموعه ها ارائه کرد. علاوه بر این، آنها نشان دادند که چگونه درک دقیق تر به غلبه بر مشکلات ناهمگن معنایی در فرآیند یکپارچه سازی اطلاعات کمک می کند. که در [ 13]، معناشناسی یک مفهوم در هستی شناسی های GI با استفاده از یک چارچوب تعریف توسعه پذیر و ساختاری متشکل از تعدادی گزاره سه گانه RDF ارائه شد و یک الگوریتم مقایسه برای تعیین روابط معنایی مفاهیم بین حوزه های مختلف طراحی شد. هدف اولیه این مطالعات استخراج و بازنمایی معناشناسی مفاهیم/موجودات بر اساس واژگان رایج ساختاری بود که معناشناسی مفاهیم/موجودات را قابل مقایسه میکند. با این حال، واژگان رایج ساختاری در این آثار توسط کارشناسان حوزه به صورت دستی تعیین می شود. بنابراین، عینیت و اتوماسیون الگوریتمها (جلوگیری از روشهای دستی موقت و دانش کارشناسان ذهنی) کاملاً محدود است.
2.2. نقشه برداری هستی شناسی
کشف رابطه نقشه برداری برای هستی شناسی ها در سال های اخیر توجه قابل توجهی را به خود جلب کرده است. رویکردهای مختلفی مبتنی بر فرآیندها برای یافتن شباهتها بین هستیشناسیهای مختلف اما مرتبط پدید آمده است [ 31 ]. با توجه به ادبیات مربوط به هستی شناسی اطلاعات مکانی (GI)، نویسندگان در [ 32 ] تحلیلی از مدل های مختلف اندازه گیری تشابه معنایی انجام دادند و این مدل ها را با توجه به الزامات خاص داده های مکانی ارزیابی کردند. نویسندگان در [ 7 ، 33] به طور سیستماتیک چندین اثر اخیر و اغلب ارجاع شده را در مورد ادغام نقشه هستی شناسی GI و GI با استفاده از معیارهای مقایسه، مانند استنتاج منطقی، رویکردهای نقشه برداری، درجه اتوماسیون و نسبیت جغرافیایی بررسی کرد. علاوه بر این، یک نتیجهگیری کلی پیشنهاد میشود که برای کار نگاشت هستیشناسی، استفاده از هستیشناسیهای رسمی و در نتیجه، استفاده از استدلالها باید اجباری باشد.
در سال های اخیر، اطلاعات جغرافیایی داوطلبانه (VGI) برای نقشه برداری هستی شناسی GI در یک محیط وب پیشنهاد شده است. نویسندگان در [ 34 ، 35 ] مکانیزمی برای محاسبه شباهت معنایی کلاس های جغرافیایی نقشه خیابان باز (OSM) با استفاده از تعاریف واژگانی داوطلبانه برای کاهش شکاف معنایی بین تولیدکنندگان مختلف VGI ابداع کردند. مجموعه دیگری از مطالعات بر معرفی یک رویکرد شبکه عصبی مصنوعی برای شبیهسازی ادراک انسانی و اندازهگیری شباهت معنایی بین موجودات فضایی به منظور بهبود خودکار بودن فرآیند نقشهبرداری هستیشناسی متمرکز بود [36 ، 37 ] .
همه این پیشنهادها، ترکیبی از استفاده از مدلهای مختلف اندازهگیری تشابه معنایی، برای ارائه راهحلهایی برای مشکلات نقشهبرداری هستیشناسی GI موجود در محیطهای انگلیسی پدید آمدهاند. با این حال، وب معنایی و مهندسی هستی شناسی پیشرفت های قابل توجهی را در استانداردها و تکنیک ها تجربه کرده اند، و هستی شناسی های دامنه و محتوای محلی سازی بیشتری در وب معنایی با استفاده از زبان های طبیعی بومی توصیف می شوند [23 ] . نیاز مبرمی به مکانیسمهای نقشهبرداری هستیشناسی بین زبانی در جامعه GI وجود دارد که برای تطبیق معنایی هستیشناسیهای مختلف در محیطهای چندزبانه و بهبود دسترسی به هستیشناسیهای مختلف GI در میان موانع زبان طراحی شدهاند [38 ] .
نویسنده در [ 39 ] الگوریتمهای نگاشت هستیشناسی متقابل زبانی (CLOM) موجود را به دستههای زیر گروهبندی میکند: پردازش دستی [ 40 ، 41 ، 42 ]، رویکرد مبتنی بر پیکره [ 43 ]، غنیسازی زبانی [ 44 ]، ترکیب همترازی غیرمستقیم [ 45 ] و رویکرد مبتنی بر ترجمه [ 39 ، 46 ]. در مقایسه با این رویکردهای CLOM، CLOM مبتنی بر ترجمه در حال حاضر یک رویکرد بسیار محبوب است که توسط چندین محقق اعمال می شود [ 47 ، 48 ، 49 ، 50]]، که با ترجمه های به دست آمده از طریق استفاده از ابزارهای ترجمه ماشینی (MT)، اصطلاحنامه های دوزبانه/چندزبانه، لغت نامه ها و غیره فعال می شود. به طور معمول، این رویکردها تنها بر مقایسه واژگانی مبتنی بر رشته نام ها و توضیحات موجودیت ها متکی هستند [ 51 ، 52 ، 53 ، 54 ]، در حالی که مقایسه بین تفسیر معنایی، به عنوان مثال، معناشناسی مدل-نظری موجودیت ها وجود ندارد.
3. روش شناسی
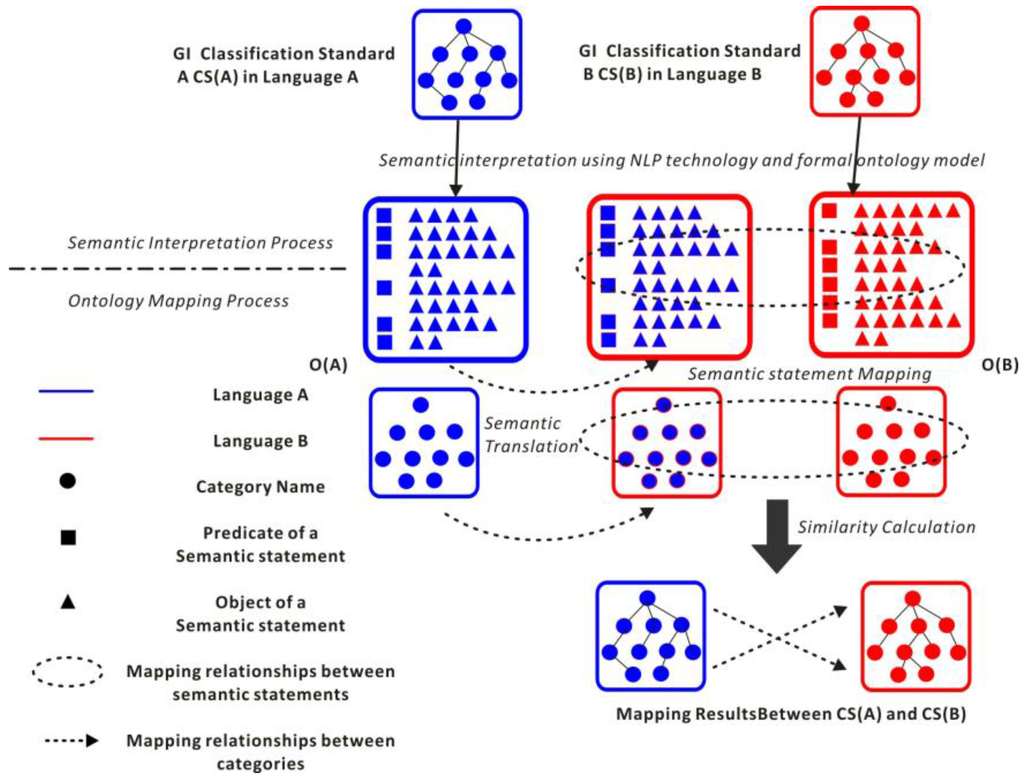
همانطور که در شکل 1 نشان داده شده است، رویه اصلی روش شناسی ما به دو فرآیند فرعی تقسیم می شود . در فرآیند تفسیر معنایی، دو هستیشناسی رسمی GI، یعنی O A و O B ، از تعریف متن آزاد استانداردهای طبقهبندی متناظر با زبانهای طبیعی مختلف ایجاد میشوند. در فرآیند نقشه برداری هستی شناسی، تمام نام های دسته ها و عبارات معنایی در O A از L A به L B ترجمه می شوند.و روابط نگاشت بین نام دسته ها و عبارات معنایی در بافت زبانی یکسان تعیین می شود، که سپس به عنوان مبنایی برای محاسبه شباهت بین دسته ها در هستی شناسی های مختلف GI عمل می کند. در نهایت، یک الگوریتم محاسبه شباهت طراحی شده و نتایج نگاشت نهایی بین جفت دستهها در استانداردهای طبقهبندی مختلف تعیین میشود.
3.1. تفسیر معنایی
3.1.1. استخراج ابتدایی معنایی
در مخازن اطلاعات مکانی، تعاریف متن آزاد اغلب اولین و تنها توضیحات عینی موجود مقوله ها هستند. ابتدایی های معنایی الگوهای نحوی و واژگانی در تعریف متن آزاد هستند و می توانند با استفاده از ابزار NLP استخراج شوند [ 55 ]. حوزههای مطالعاتی NLP روشها و الگوریتمهایی را برای بازیابی اطلاعات و استخراج از منابع دانش متن آزاد توسعه دادهاند. روشی که در اینجا برای تجزیه و تحلیل تعاریف و استخراج مفاهیم ابتدایی معنایی اتخاذ شد توسط [ 56 ] معرفی شد. در این تحقیق، الگوهای واژگانی عبارات اسمی و عبارات فعل به عنوان بدوی معنایی در نظر گرفته شده است. یک مثال در شکل 2 نشان داده شده است و مراحل اصلی فرآیند به شرح زیر است:
-
یک تعریف دسته بندی در قالب متن آزاد به عنوان ورودی مواد زبان طبیعی انتخاب می شود.
-
تقسیم بندی کلمات برای تقسیم کل جمله به کلمات جداگانه انجام می شود.
-
کلمات دستهبندی میشوند و در مجموعههای برچسب قسمتهای گفتار خود برچسبگذاری میشوند ( جدول 1 و جدول 2 را ببینید ) و بر این اساس برچسبگذاری میشوند.
-
عبارات اسمی و عبارات فعل تکه تکه می شوند و ساختار جمله برای استخراج الگوهای واژگانی به عنوان ابتدایی های معنایی تجزیه و تحلیل می شود.
3.1.2. ساخت مدل هستی شناسی رسمی
از ویکیپدیا، «هستیشناسی در علم اطلاعات» نامگذاری و تعریف رسمی انواع، ویژگیها و روابط متقابل مفاهیمی است که واقعاً یا اساساً برای یک حوزه خاص از گفتمان وجود دارد. بنابراین این یک کاربرد عملی از هستی شناسی فلسفی با طبقه بندی است. علاوه بر این، هستی شناسی دامنه (یا هستی شناسی خاص دامنه) مفاهیمی را نشان می دهد که به یک حوزه عمومی تعلق دارند. بنابراین، برای یک نمایش رسمی [ 57 ، 58 ]، هستی شناسی دامنه (که با O Domain مشخص می شود )، و مفاهیم موجود در حوزه را می توان با معادلات (1)-(3) خلاصه کرد.
ODomain={S(CDomain),S(RC),S(HC),S(PC)}�������={�(�������),�(��),�(��),�(��)}
CDomain={TC,DC}�������={��,��}
DC={RC,HC,PC},RC∈S(RC),HC∈S(HC),PC∈S(PC)��={��,��,��},��∈�(��),��∈�(��),��∈�(��)
در معادله (1)، S ( C Domain ) مجموعه ای از مفاهیم را در یک حوزه نشان می دهد و معنایی هر مفهوم در حوزه به گروه های مختلفی طبقه بندی می شود، یعنی S(H C )، S(R C )، و S(P C ) ; S(H C ) مجموعه روابط سلسله مراتبی در مورد اطلاعات طبقه بندی در O Domain را نشان می دهد ، S(R C ) مجموعه دیگر روابط متقابل بین این مفاهیم را نشان می دهد و S(P C )مجموعه ای از ویژگی های معنایی متعلق به مفاهیم این حوزه را نشان می دهد.
در معادله (2)، معنای شناسی یک مفهوم در حوزه به عنوان ترکیب اصطلاحات این مفهوم (که با T C نشان داده می شود ) و تعریف ساختاری این مفهوم (با نشان دادن D C ) در نظر گرفته شده است. برخلاف قالب متن آزاد تعریف، DC معمولاً شامل ویژگیهای معنایی مفهوم ( P C )، رابطه سلسله مراتبی ( H C ) و سایر روابط متقابل ( R C ) بین این مفهوم و سایر مفاهیم در حوزه است. بنابراین، از معادلات (2) و (3)، یک مفهوم خاص در حوزه، C Domain را می توان به عنوان تابعی از C استنباط کرد. T استنباط کرد., R C , H C , و P C در معادله (4)
CDomain={TC,RC,HC,PC},RC∈S(RC),HC∈S(HC),PC∈S(PC)�������={��,��,��,��},��∈�(��),��∈�(��),��∈�(��)
که در آن از R C , H C , P C برای نمایش معنایی این مفهوم استفاده می شود و به ترتیب متعلق به S(R C ) ، S(H C ) ، S(P C ) می باشد .
با توجه به وضعیت حوزه GI، به جای مفهوم از کلمه «رده» استفاده می کنیم. از آنجایی که ویژگیهای معنایی دسته GI در مکان و زمان بسیار همبستگی دارند [ 59 ]، ویژگیها و روابط معنایی مربوط به مکانی و زمانی باید به عنوان واژگان مهم برای نمایش و شناسایی معنایی GI در مدل گنجانده شوند. دسته بندی ها. بنابراین، هستی شناسی GI O GI و معناشناسی یک دسته خاص C GI در O GI را می توان به صورت معادلات (5) و (6) نشان داد:
OGI={S(TC),S(RS),S(RT),S(RC),S(HC),S(PS),S(PT),S(PC)}���={�(��),�(��),�(��),�(��),�(��),�(��),�(��),�(��)}
CGI={(TC=VTC)∩(RS=VRS)∩(RT=VRT)∩(RC=VRC)∩(HC=VHC) ∩(PS=VPS)∩(PT=VPT)∩(PC=VPC)}���={(��=���)∩(��=���)∩(��=���)∩(��=���)∩(��=���) ∩(��=���)∩(��=���)∩(��=���)}
در معادله (5)، S(T C ) مجموعه ای از نام دسته ها را در O GI نشان می دهد . S(R S ) ، S(RT ) مجموعه روابط معنایی مربوط به مکانی و زمانی را بین مقوله ها نشان می دهد. S(H C ) مجموعه ای از روابط سلسله مراتبی را نشان می دهد. S(P S ) ، S(P T ) مجموعه ای از ویژگی های معنایی مرتبط با مکانی و زمانی را نشان می دهد که متعلق به دسته های موجود در O GI است . و S(R C ) ، S(Pج ) مجموعه ای از خصوصیات و روابط معنایی دیگر را در O GI نشان می دهد . و در معادله (6)، V x مقادیر برخی از خصوصیات/روابط معنایی C GI را نشان می دهد . T C , R S , R T , R C , H C , P S , P T , P C برای نمایش معنایی C GI استفاده می شود و متعلق به S(T C , S ) است . S(Rبه ترتیب ، S(R T ) ، S(R C ) ، S(H C ) ، S(P S ) ، S(P T ) ، S(P C ) .
به منظور حل مسائل بازنمایی جغرافیایی، نویسندگان در [ 60 ] سه ابزار نظری اصلی را که برای اهداف توسعه یک نظریه رسمی کلی از بازنمایی فضایی، یعنی صرفاشناسی، مکان و توپولوژی مورد نیاز است، متمایز کردند، این ابزارهای نظری انتخاب شدهاند. به عنوان مبنایی برای تعریف معناشناسی مرتبط با فضایی در مدل هستی شناسی رسمی ما. علاوه بر این، موجودات جغرافیایی در واقعیت اساسا پویا هستند، نویسندگان در [ 61] اشاره کرد که یک هستی شناسی خوب باید بتواند واقعیت فضایی را هم به صورت همزمان (همانطور که در یک زمان وجود دارد) و هم به صورت دیاکرونیک (همانطور که در طول زمان آشکار می شود) محاسبه کند، بنابراین باید از ویژگی های “نقطه زمانی” و “دوره زمانی” استفاده شود. برای توصیف ویژگی های دینامیکی موجودیت های جغرافیایی در مدل ما. علاوه بر این، به منظور مشخص کردن روابط معنایی و ویژگی های مورد استفاده در تعاریف جغرافیایی، نویسندگان در [ 28 ] چندین هستی شناسی جغرافیایی را تجزیه و تحلیل کردند و الگوهایی را شناسایی کردند که به طور سیستماتیک برای بیان روابط و ویژگی های معنایی خاص، از جمله روابط سلسله مراتبی، روابط جزئی کل و روابط همسایگی استفاده می شدند. و خصوصیات معنایی مانند هدف، ماهیت، ماده، اندازه و غیره.
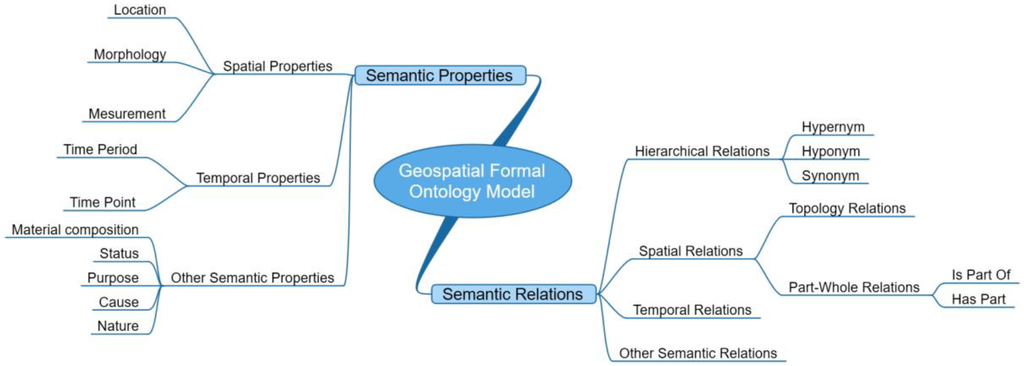
بر اساس تحقیقات قبلی و مدل هستیشناسی رسمی ما در معادله (5)، ویژگیهای معنایی و انواع روابط در مدل ما تقسیمبندی شدهاند و در شکل 3 نشان داده شدهاند .
3.1.3. تبدیل از مفاهیم اولیه معنایی به مدل هستی شناسی رسمی
به منظور ساختاری و قابل مقایسه اولیههای معنایی، متخصصان حوزه مسئول تجزیه و تحلیل این ابتداییهای معنایی و تبدیل آنها به گروههای مختلف خصوصیات/روابط معنایی در مدل هستیشناسی رسمی مکانی ما هستند. عبارت سه گانه معروف Subject-Predicate-Object و زبان هستی شناسی وب (OWL) به عنوان مبنایی برای ارائه خصوصیات/روابط معنایی و مقادیر آنها به شیوه ای قابل خواندن توسط ماشین انتخاب شده اند. موضوع نشان دهنده یک GI در O GI است . محمول یک ویژگی معنایی خاص یا نوع رابطه معنایی است که در شکل 3 نشان داده شده است .، که در آن همه روابط معنایی با ویژگی شی ارائه می شوند و Object در این روابط معنایی یک GI دیگر در O GI یا یک نوع شی “جغد:کلاس” است، در حالی که بیشتر خصوصیات معنایی با ویژگی شی نیز ارائه می شوند. و تعدادی از آنها با ویژگی datatype در نحو OWL ارائه میشوند، و Object در این ویژگیهای معنایی یک نوع داده “rdfs:literal” است. قوانین زیر برای رسیدگی به فرآیند رسمی سازی اتخاذ می شود:
- (1)
-
دسته GI را می توان با تعدادی از روابط/ویژگی های معنایی نشان داد. با این حال، تعداد روابط/ویژگی های معنایی درگیر باید به حداقل برسد تا از افزونگی جلوگیری شود.
- (2)
-
هر دسته GI نباید همه روابط/ویژگی های معنایی مدل را پوشش دهد. وضعیتی که در آن دو مقوله مختلف از مجموعه ای از روابط/ویژگی های معنایی یکسان برای نمایش معنایی خود استفاده می کنند، نمی تواند تضمین شود.
- (3)
-
اطلاعات معنایی یک دسته خاص در مدل ما ترکیبی از روابط معنایی-خواص و مقادیر آنهاست. این ترکیب باید تمام اطلاعات معنایی دسته را نشان دهد و بتواند دسته بندی های مختلف مکانی را در درون و فراتر از هستی شناسی های حوزه تشخیص دهد تا از ابهام جلوگیری شود.
- (4)
-
روابط hypernym، hyponym و مترادف باید در گروه روابط سلسله مراتبی قرار گیرند. اگر مقوله A مترادف مقوله B باشد، A باید تمام خصوصیات/روابط معنایی B را برای حفظ ثبات معنایی ذاتی داشته باشد.
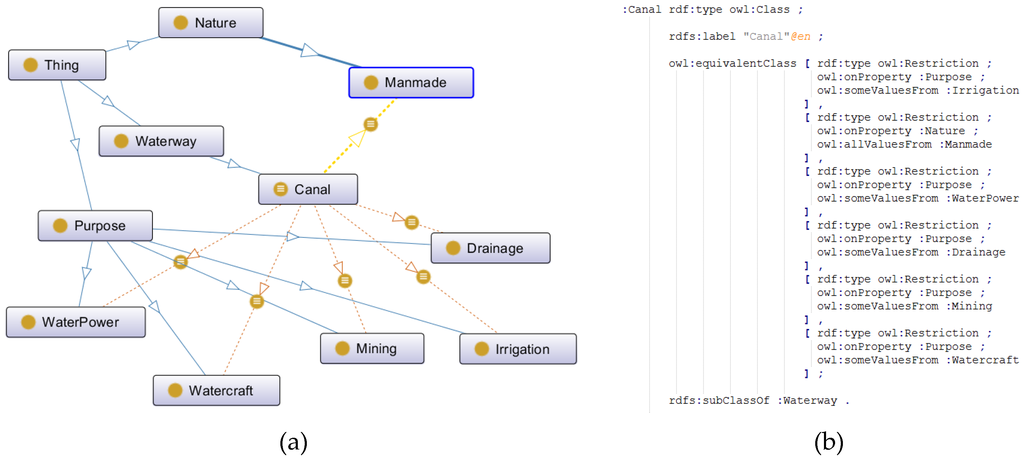
با توجه به قوانین فوق الذکر، ابتدایی های معنایی را می توان در این نوع خصوصیات/روابط به عنوان عبارات ساختاری برای شناسایی و نمایش مقوله های GI مشخص کرد. برای مثال، تعریف متن آزاد مقوله «کانال» در زبان انگلیسی، «آبهای ساختهشده توسط کشتیها یا برای زهکشی، آبیاری، معدن، یا نیروی آب استفاده میشود». علاوه بر این، ابتداییهای معنایی مقوله «کانال» با استفاده از ابزار NLP در مجموعه عباراتی از جمله «آبراه مصنوعی»، «استفادهشده»، «آبراه»، «زهکشی»، «آبیاری»، «معدنسازی» و “نیروی آب”. سپس، با تبدیل این مفاهیم اولیه معنایی به مدل هستیشناسی رسمی پیشنهادی، معناشناسی مقوله «کانال» را میتوان به صورت مجموعهای از چندین گزاره معنایی به شرح زیر نشان داد:
سیسیa n a l= {تیسی= ‘ ‘ c a n a l ‘ ‘ ∩اچسی= ” H _yp e r n ym : w a t e r w a y‘ ∩ _پسی= ” “ ( صu r p o s e : w a t e r c r a ft ) ∪( صتو : د _ _ _ _ _r a i n a gه ) ∪ ( صu r p o s e : i r r i ga t i o n ) ∪ ( صu r p o s e : m i n i n g) ∪( صurpose:waterpower)”∩PC=”Nature:Manmade”}������={��=″�����″∩��=″��������:��������″∩��=″(�������:����������)∪(�������:��������)∪(�������:����������)∪(�������:������)∪(�������:����������)″∩��=″������:�������″}
علاوه بر این، نمایش در قالب OWL در شکل 4 نشان داده شده است .
3.2. الگوریتم های نقشه برداری هستی شناسی
3.2.1. ترجمه معناشناسی
فرض کنید که ما هستی شناسی های رسمی O A , O B را داریم که به ترتیب به زبان های طبیعی مختلف، یعنی زبان A ( L A ) و B ( L B ) ارائه شده اند. با توجه به مدل هستی شناسی رسمی جغرافیایی معرفی شده در بخش 3.1.2 ، معناشناسی هستی شناسی های O A و O B شامل مجموعه نام های دسته S (CN A ) و S (CN B ) و مجموعه های دستور معنایی S (SS A ) و S است. (SS B )برچسبگذاری شده در زبانهای طبیعی مختلف، که در آن عبارت معنایی از انواع ویژگی/رابطه معنایی (همانطور که در شکل 3 در بخش 3.1.2 نشان داده شده است ) و مقادیر متناظر آنها تشکیل شده است. به منظور عبور از مانع زبان طبیعی بین O A و O B ، الگوریتم 1 روند ترجمه معنایی بین L A و L B را نشان می دهد :
| الگوریتم 1. ترجمه معناشناسی. |
| 1: ورودی: هستی شناسی های رسمی O A (S(CN A )، S(SS A )) در L A |
| 2 : خروجی: مجموعه نتایج نامزد ترجمه از معناشناسی در O A , O ‘ A (S(TC(CN A ))، S(TC(SS A -object))) در |
| 3 : L B. |
| 4: نمادها: |
| 5: S(TC(CN A ) )- مجموعه نتایج کاندید ترجمه S(CN A ) در L B. |
| 6: S(TC(SS A ) )- مجموعه نتایج کاندید ترجمه S(SS A ) در L B. |
| 7 : ss A – object— قسمت Object عبارت معنایی ss A . |
| 8 : 1: برای نام هر دسته cn A در S (CN A ) ، با استفاده از خدمات وب مختلف ترجمه ماشینی (MT) ( Google Translator API در ” http : // translate.google.cn/ ، Bing Translator API در” http://www.bing.com/translator/?ref=SALL&mkt=zh-CN ، و Baidu Translator API در ” http://fanyi.baidu.com /?aldtype=16047#zh/en/ ”)، تمام نتایج ترجمه را در مورد cn A در نتایج کاندید ترجمه جمع آوری کنید ( TC جمع آوری کنید.cn A )، و تمام نتایج نامزد ترجمه نام دسته را در مجموعه نامزد ترجمه S(TC(CN A )) ذخیره کنید . |
| 9: 2: برای هر عبارت معنایی ss A در S(SS A ) ، با توجه به نحو دستور سه گانه OWL، می توان آن را به سه قسمت Subject ، Predicate و Object تقسیم کرد، ss A – شی در L A را به ss ترجمه کرد. یک شیء در L B با استفاده از خدمات وب مختلف ترجمه ماشینی (MT)، همه نتایج ترجمه را در مورد ss A-object جمع آوری کنید ، در نتایج کاندید ترجمه TC ( ss جمع آوری کنید. A -object )، و تمام عبارات معنایی نتایج کاندید ترجمه را در مجموعه کاندید ترجمه S(TC(SS A -object)) ذخیره کنید . |
| 10: دسته “运河” را به عنوان مثال در زبان چینی در نظر بگیرید، ابتدایی های معنایی دسته “运河” با استفاده از ابزار NLP در مجموعه عباراتی از جمله “跨流域”، “开凿”، “供调水” استخراج می شوند. “航运”، “人工水道”. سپس، با تبدیل این مفاهیم اولیه معنایی به مدل هستی شناسی رسمی پیشنهادی، معناشناسی مقوله “运河” را می توان به عنوان مجموعه ای از چندین گزاره معنایی به شرح زیر نشان داد: |
| 11:
سی运河= {تیسی= ‘ ‘运河‘ ‘ ∩اچسی= ” H _yp e r n ym :水道‘ ‘ ∩پسی= ” “ ( صu r p o s e :调水) ∪( صu r p o s e :航运) ‘ ‘ ∩پسی= ‘ ‘ Na t u r e :人工‘ ‘ ∩آراس= ” “ تیo p o l o gy:跨流域‘ ‘ ‘ }سی运河={تیسی=“运河“∩اچسی=“اچ�په���متر:水道“∩پسی=“(پتو�پ�سه:调水)∪(پتو�پ�سه:航运)“∩پسی=“نآتیتو�ه:人工“∩آراس=“تی�پ�ل���:跨流域“}
|
| 12: و نتیجه ترجمه معنایی C运河در انگلیسی به شرح زیر است: |
| 13:
سی运河= {تیسی= ‘ ‘ ( کانال) ‘ ‘ ∩اچسی= ” H _yp e r n yم : ( آبراه , قنات ) ‘ ‘ ∩پسی= ” “ ( صu r p o s e : ( انتقال آب , انحراف ) ) ∪( صu r p o s e : ( ارسال ) ) ‘ ‘ ∩پسی= ‘ ‘ Na t u r e : ( دستی، مصنوعی ) ‘ ‘ ∩آراس= ” “ تیo p o l o gy: ( بین حوضه ای ، در سراسر حوضه های رودخانه ای ) ‘ ‘ }سی运河={تیسی=“(کانال)“∩اچسی=“اچ�په���متر:(آبراه،قنات)“∩پسی=“(پتو�پ�سه:(انتقال آب،انحراف))∪(پتو�پ�سه:(حمل دریایی))“∩پسی=“نآتیتو�ه:(دستی، مصنوعی)“∩آراس=“تی�پ�ل���:(بین حوضه ای،در سراسر حوضه های رودخانه)“}
|
3.2.2. نگاشت بیان معنایی
برای تعیین روابط نگاشت بین مقولهها در هستیشناسیهای GI مختلف، ابتدا باید روابط نگاشت در سطح عبارت معنایی تعیین شود زیرا عبارت معنایی جزئیترین ویژگیهای معنایی مقولههای مقایسه شده را ارائه میدهد. هنگامی که روابط آنها مشخص شد، شباهت بین دسته ها را می توان به صورت کمی تعیین کرد. الگوریتم 2 روند مقایسه نام دسته ها و عبارات معنایی بین O A و O B را نشان می دهد . علاوه بر این، تمام نتایج نگاشت M(O A , O B ) به عنوان مبنایی برای محاسبه شباهت بین مفاهیم در هستی شناسی های مختلف GI ذخیره می شوند.
| الگوریتم 2. نگاشت بیان معنایی. |
| 1: ورودی: O ‘ A (S(TC(CN A ))، S(TC(SS A -object))) در L B ، هستی شناسی های رسمی O B (S(CN B )، S(SS B )) در L B |
| 2: خروجی: مجموعه نتایج نگاشت M(O A , O B ) در مورد نام دسته ها و عبارات معنایی بین 3: O A و O B . |
| 4: نمادها: |
| 5: T(ss) – انواع خاصیت/رابطه معنایی برای یک عبارت معنایی خاص ss . |
| 6: M(O A ‘ , O B ) – نگاشت روابط در مورد نام دسته ها و عبارات معنایی بین O A ‘ |
| 7: و O B. |
| 8: 1: برای نام هر دسته cn A در S(CN A ) ، نتایج کاندید ترجمه cn A ، TC ( cn A ) را بیابید. |
| 9: 2: برای هر کاندید ترجمه tc(cn A ) در TC ( cn A ) ، S(CN B ) را در O B جستجو کنید ، مطابق را پیدا کنید |
| 10: نام دسته cn B در S(CN B ) با اعمال رابطه (10)، |
| 11: 3: اگر نامزد ترجمه وجود داشته باشد tc(cn A ) رابطه نگاشت “تطابق دقیق” دارد. |
| 12: با cn B ، نتیجه نگاشت m ( cn A , cn B ، ‘تطابق دقیق’) را در M(O A , O B ) ذخیره کنید . |
| 13: 4: else اگر کاندیدای ترجمه وجود داشته باشد tc(cn A ) رابطه نگاشت را دارد |
| 14: “تطبیق نزدیک” با cn B ، نتیجه نگاشت m ( cn A , cn B , ‘close match’) را در M(O A , O B ) ذخیره کنید . |
| 15: 5: برای هر عبارت معنایی ss A در S(SS A ) ، نتایج کاندید ترجمه ss A -object t را بیابید، |
| 16: TC ( ss A -object )، |
| 17: 6: برای هر کاندید ترجمه tc(ss A -object) در TC ( ss A -object )، S(SS B -object) را در O B جستجو کنید ، |
| 18: با استفاده از معادله (10)، عبارت معنایی تطبیق Object ، ss B -object را در S(SS B ) پیدا کنید. |
| 19: 7: اگر یک نامزد ترجمه وجود داشته باشد tc(ss A -object) رابطه نگاشت «دقیق دارد. |
| 20: مطابقت» با ss B -object ، و T(ss A ) برابر T(ss B ) است ، نتیجه نگاشت را ذخیره کنید ( ss A , ss B , ‘exact |
| 21: match’) در M(O A , O B ) ; |
| 22: 8: else اگر یک نامزد ترجمه وجود داشته باشد tc(ss A -object) رابطه نگاشت “close” دارد. |
| 23: مطابقت» با ss B -object ، و T(ss A ) برابر T(ss B ) است ، نتیجه نگاشت m ( ss A ، ss B ، «close» را ذخیره کنید. |
| 24: مسابقه’) در M(O A , O B ) . |
| 25:
m ( A , B ) =⎧⎩⎨⎪⎪e x a c t l y m a t c h , A i s t h es a m e w o r d _ o r s yn o nym o f بc l o s e m a t c h , A i s t h e n e a r s y n o n ym o f بn o t m a t c h , o t h e r w i s e متر(آ،ب)={هایکسآجتیل� مترآتیجساعت، آ منس تیساعته سآمتره ���د �� س�����متر �� بجل�سه مترآتیجساعت، آ منس تیساعته �هآ� س�����متر �� ب��تی مترآتیجساعت، �تیساعته��منسه
|
3.2.3. محاسبه شباهت
با توجه به دو دسته C a و C b در هستی شناسی های رسمی O A و O B به ترتیب بر اساس M(O A , O B ) می توان شباهت معنایی C a و C b را با استفاده از الگوریتم 3 محاسبه کرد.
| الگوریتم 3. محاسبه شباهت. |
| 1: ورودی: دسته های C a (CN a , SS a ) در O A , C b (CN b , SS b ) در O B و مجموعه روابط نگاشت M(O A , O B ) |
| 2: در مورد نام دسته ها و عبارات معنایی بین O A و O B. |
| 3: خروجی: مقدار شباهت معنایی بین C a و C b , Sim(a, b) . |
| 4: نمادها: |
| 5: Cot(SS a )- تعداد عبارات معنایی در SS a . |
| 6: Cot(SS b ) – تعداد عبارات معنایی در SS b . |
| 7: m ( CN a , CN b ) – رابطه نقشه برداری بین CN a و CN b . |
| 8: m ( SS a ( i) , SS b (j) ) – رابطه نگاشت بین SS a (i) در C a و SS b (j) در Cb . |
| 9: Pt ( SS ab ) – مجموع مقدار نقطه تطابق بین SS a و SS b . |
| 10: Pt ( CN ab ) – مقدار نقطه تطابق بین CN a و CN b . |
| 11: 1: برای هر عبارت معنایی SS a (i) در SS a ، عبارت معنایی منطبق SS b (j) را در SS b پیدا کنید. |
| 12: بر اساس رابطه نگاشت مجموعه M(O A , O B ) ; |
| 13: اگر m ( SS a (i) , SS b (j) ) = “تطابق دقیق”، آنگاه مقدار نقطه تطابق بین SS a (i) و SS b (j) 1 اختصاص داده می شود. |
| 14: در غیر این صورت اگر m ( SS a (i) , SS b (j) ) = “تطابق نزدیک”، آنگاه مقدار نقطه تطابق بین SS a (i) و SS b (j) است . |
| 15: اختصاص داده شده 0.5; |
| 16: 2: مجموع مقادیر نقطه تطابق بین SS a و SS b را به عنوان Pt ( SS ab ) و تعداد |
| 17: عبارات مطابقت بین SS a و SS b به عنوان Cot ( SS ab ); |
| 18: 3: رابطه نگاشت بین CN a و CN b را بر اساس M(O A , O B ) پیدا کنید ، |
| 19: اگر m( CN a , CN b ) = “تطابق دقیق”، آنگاه مقدار نقطه تطابق بین CN a و CN b 1 اختصاص داده می شود. |
| 20: در غیر این صورت اگر m( CN a , CN b ) = “تطابق نزدیک” باشد، آنگاه مقدار نقطه تطابق بین CN a و CN b است |
| 21: اختصاص داده شده 0.5; |
| 22: 4: مقدار نقطه تطابق بین CN a و CN b را به عنوان Pt ( CN ab ) ثبت کنید. |
| 23: 5: شباهت دسته های C a و C b را می توان با استفاده از رابطه زیر محاسبه کرد: |
| 24:
اسi m ( a , b ) =⎧⎩⎨⎪⎪12*پt ( Sاسa ب)سیo t ( Sاسآ)+12*پt ( Sاسa ب)سیo t ( Sاسب)، من f m ( Cنآ، سینب) = ‘ ‘ n o t m a t c h ‘ ‘ 13*پt ( Sاسa ب)سیo t ( Sاسآ)+13*پt ( Sاسa ب)سیo t ( Sاسب)+پt ( Cنa ب)3، من f m ( Cنآ، سینب) = ‘ ‘ e x a c t m a t c h ‘ ‘ / ‘ ‘ c l o s e m a t c h ‘ ‘ اسمنمتر(آ،ب)={12*پتی(اساسآب)سی�تی(اساسآ)+12*پتی(اساسآب)سی�تی(اساسب)، من� متر(سینآ،سینب)= “��تی مترآتیجساعت“13*پتی(اساسآب)سی�تی(اساسآ)+13*پتی(اساسآب)سی�تی(اساسب)+پتی(سینآب)3، من� متر(سینآ،سینب)= “هایکسآجتی مترآتیجساعت“/“جل�سه مترآتیجساعت“
|
| 25: علاوه بر این، روابط نگاشت بین جفت های دسته C a و C b ، یعنی MR(a, b) می تواند |
| 26: با استفاده از رابطه زیر تعیین می شود: |
| 27:
مR ( a , b ) =⎧⎩⎨⎪⎪⎪⎪⎪⎪⎪⎪e x a c t m a t c h , i f اسi m ( a , b ) = 1c l o s e m a t c h , i f 0.5 < = Si m ( a , b ) < 1r e l a t e d، من f 0 < Si m ( a , b ) < 0.5n o t m a t c h , i f اسi m ( a , b ) = 0مآر(آ،ب)={هایکسآجتی مترآتیجساعت، من� اسمنمتر(آ،ب)=1جل�سه مترآتیجساعت، من� 0.5<=���(�,�)<1�������, �� 0<���(�,�)<0.5��� ����ℎ, �� ���(�,�)=0
|
4. مطالعه موردی
4.1. مواد مطالعه
برای نشان دادن روشها، دو استاندارد طبقهبندی مختلف در دو زبان طبیعی متناظر برای استفاده در فرآیند نقشهبرداری انتخاب شدهاند. CS C بر اساس استانداردهای نقشه توپوگرافی ملی در چین (استانداردهای “نمادهای نقشه برداری برای نقشه های مقیاس اساسی ملی” و “مشخصات طبقه بندی ویژگی ها و کدهای اطلاعات جغرافیایی اساسی”) توسعه یافته است. CS A توسط سازمان زمین شناسی ایالات متحده در آمریکا ( http://cegis.usgs.gov/ttl/USTopographic.ttl ) توسعه یافته است.). هر دو استاندارد مواد ادبیات دیجیتال هستند. نام دسته ها و تعاریف متن آزاد آنها به عنوان اطلاعات منبع برای آزمایش ما ارائه شده است. علاوه بر این، برای سادگی و وضوح، مطالعه ما به دستههای «آبهای سطحی» از این دو استاندارد طبقهبندی محدود شد. جدول 3 به طور خلاصه ویژگی های این دو مجموعه داده انتخاب شده را با توضیحات مفصل به شرح زیر فهرست می کند:
- (1)
-
هر دو استاندارد سیستم طبقه بندی خود را برای رسیدگی به مقوله های “آب های سطحی” دارند. دسته بندی ها در CS C با استفاده از یک سلسله مراتب چهار سطحی با شش دسته اصلی سازماندهی می شوند. در مقابل، دستهها در CS A توسط یک سلسله مراتب چهار سطحی با 81 دسته اصلی سازماندهی میشوند، به این معنی که ساختار سلسله مراتبی CS A با CS C مطابقت ندارد .
- (2)
-
تعاریف متن آزاد در هر دو استاندارد به عنوان تعاریف دسته استفاده می شود.
- (3)
-
تعداد دسته ها در CS C 74 و تعداد مفاهیم در CS A 92 است. بنابراین، CS A انواع دسته بندی بیشتری را نسبت به CS C پوشش می دهد .
- (4)
-
زبان طبیعی در CS C چینی است، در حالی که زبان طبیعی در CS A انگلیسی است، به این معنی که یک مانع زبان طبیعی بین این دو استاندارد طبقهبندی GI وجود دارد.
4.2. نتایج
تعاریف دسته بندی به خوبی تعریف شده در هر دو CS C و CS A به عنوان پایه ای برای مطالعه ما عمل می کند. API زبان هستی شناسی وب (OWL) برای تسهیل اجرای الگوریتم پیشنهادی در Eclipse با زبان JAVA یکپارچه شده است و نتایج آزمایش به شرح زیر است.
4.2.1. نگاشت عبارات معنایی
ابتدایی های معنایی با استفاده از ابزارهای پردازش زبان طبیعی استانفورد ( http://nlp.stanford.edu/software/ ) استخراج می شوند و به هستی شناسی های رسمی O C و O A با مجموعه ای از نام های دسته ها و عبارات معنایی توسط متخصصان حوزه تبدیل می شوند. و توسط OWL از طریق Protégé کدگذاری شده است. با استفاده از الگوریتم نگاشت عبارات معنایی معرفی شده در بخش 3.2.2 ، تعداد روابط نگاشت بین عبارات در O C و O A ثبت می شود و نتایج نگاشت برای انواع مختلف ویژگی/رابطه معنایی در جدول 4 نشان داده شده است .
تعداد کل گزاره های معنایی در O C 142 و تعداد کل این گزاره ها در O A 181 است. علاوه بر این، نرخ کل نگاشت گزاره های معنایی بین O C و O A 28.69٪ است. جزئیات روابط نگاشت بین عبارات معنایی در هر نوع را می توان در ضمیمه یافت .
برای بیان معنایی در مورد انواع ویژگی های معنایی، منطبق ترین نوع “هدف” است. این به این دلیل است که نوع خاصیت معنایی “هدف” برای نشان دادن مقوله دست ساز استفاده می شود که شامل “خندق”، “کانال” و “سد” و تعاریف متن آزاد در استانداردهای طبقه بندی چینی و آمریکایی برای این موارد است. انواع دسته ها بسیار مشابه هستند. اطلاعات معنایی در مورد هدف و کارکرد به عنوان مشخصه های حیاتی مقوله ها در نظر گرفته می شود. به راحتی می توان فهمید که نوع خاصیت معنایی “nature” دارای بالاترین نرخ نگاشت یعنی 100٪ است، زیرا تنها دو مقدار برای این نوع گزاره معنایی، یعنی “natural” و “manmade” در هر دو O وجود دارد. C و O A. با در نظر گرفتن نوع ویژگی معنایی “مکان”، هفت عبارت معنایی در O C و هشت عبارت در O A وجود دارد ، اما نرخ نگاشت این نوع بسیار پایین است (تنها یک عبارت معنایی با نرخ نگاشت 7.14٪ نگاشت شده است). دلیل آن این است که نوع خاصیت معنایی “موقعیت” برای توصیف محیط منطقه ای استفاده می شود که در آن دسته جغرافیایی خاصی قرار دارد، و بسیاری از دسته بندی ها در O A مربوط به خلیج یا یخچال هستند، مانند “یخچال”، “کلاهک یخی”. » و «زبان کوه یخ» به ترتیب با ارزش ویژگی معنایی «موقعیت»، «منطقه کوهستانی»، «مناطق یخبندان چند ساله» و «ساحل» و چنین دستههایی در O وجود ندارد. » و «زبان کوه یخ» به ترتیب با ارزش ویژگی معنایی «موقعیت»، «منطقه کوهستانی»، «مناطق یخبندان چند ساله» و «ساحل» و در OC. برای بیان معنایی در مورد انواع رابطه، بیشترین نوع مطابقت، “رابطه فضایی” است، که همچنین نوع با بالاترین نرخ نگاشت است، که نشان می دهد روابط مرتبط با فضایی نقش عمده ای در شناسایی و نمایش معناشناسی GI ایفا می کند.
4.2.2. محاسبه شباهت و نگاشت طبقه بندی
شباهت های بین مفاهیم با استفاده از روابط نگاشت گزاره های معنایی و الگوریتم 3 ارائه شده در بخش 3.2.3 محاسبه می شود . سه نمونه معمولی از نتایج نگاشت بین دستهها برای بحث بیشتر انتخاب میشوند. جدول 5 اسامی و تعاریف متن آزاد جفت های مقوله مقایسه شده را نشان می دهد. علاوه بر این، گزاره های معنایی متناظر، مقادیر شباهت محاسبه شده و روابط نگاشت نهایی بین این جفت های دسته در جدول 6 ارائه شده است .
مثال 1: جفت مفهومی “سرریز” در O C و “سرریز” در O A
این دو مفهوم قابل مقایسه هستند زیرا رابطه نگاشت بین نام مفهوم آنها “تطابق دقیق” است. از آنجا که نام مفهومی و چهار عبارت معنایی آنها مطابقت دارند (روابط نگاشت تفصیلی در جدول 6 ، خط 1 و 2 نشان داده شده است )، شرط دوم در معادله (9) برای محاسبه شباهت نهایی بین “سرریز” در O C و ” استفاده می شود. سرریز» در O A . مقدار شباهت بین این دو مفهوم 0.78 محاسبه شده است. بنابراین، رابطه نگاشت بین این دو مفهوم “تطابق نزدیک” است. این مثال ساده ترین حالت را برای محاسبه شباهت معنایی بین مفاهیم نشان می دهد.
مثال 2: جفت مفهومی “آرویو (رودخانه خشک)” در O C و “شستن” در O A
در این مثال، رابطه نقشه برداری بین نام مفهوم “آرویو (رودخانه خشک)” و “شستن” را نمی توان بر اساس الگوریتم نقشه برداری در بخش 3.2.1 تعیین کرد . با این حال، مقدار شباهت بین این دو مفهوم بیشتر از مقدار در مثال (1) است. این به این دلیل است که تمام عبارات معنایی مورد استفاده برای نشان دادن معنای معنایی این دو مفهوم به ترتیب مطابقت دارند (روابط نگاشت تفصیلی در جدول 6 ، خط 3 و 4 نشان داده شده است)، و همه روابط نگاشت بین آنها “تطابق دقیق” است. شرط اول در معادله 9 برای محاسبه شباهت نهایی بین مفاهیم “آرویو (رودخانه خشک)” در O C و “شستن” در O A استفاده می شود.. مقدار شباهت بین این دو مفهوم 1.0 محاسبه می شود. بنابراین، رابطه نگاشت بین این دو مفهوم “تطابق دقیق” است. این مثال وضعیت مشترکی را در محیط بین زبانی نشان می دهد که دو مفهوم معنای معنایی یکسانی دارند در حالی که نام آنها قطعاً متفاوت است. علاوه بر این، سودمندی استفاده از روشهای ما برای کاربرد پیچیده ادغام هستیشناسی GI بین زبانی ثابت شده است.
مثال 3: جفت مفهومی مفهوم 3 “سیستم آب” در O C و مفهوم 3 “آب سطحی” در O A
در نگاه اول، گزاره های معنایی بین مفهوم «سیستم آب» و «آب سطحی» چندان با هم تطبیق ندارند و نام مفهومی این دو مفهوم نیز قابل تطبیق نیست.
این به این دلیل است که این دو مفهوم، هر دو مفهوم برتر در طبقه بندی های خود هستند، و این دو مفهوم مفاهیم انتزاعی هستند، زیرا آنها اشیاء دنیای واقعی را با موجودیت های مشخصه دقیق، به عنوان مثال، رودخانه ها، دریاچه ها، و اقیانوس ها نشان نمی دهند. بنابراین، تعاریف این مقوله در زبان های مختلف ممکن است بسیار متفاوت باشد، حتی زمانی که آنها معنای یکسانی را منتقل می کنند. بنابراین، راه حل برای نمایش معنای معنایی این نوع مفهوم، با راه حل استفاده شده در مثال های (1) و (2) یکسان نیست. برای استنباط معنای معنایی یکپارچه این مفهوم انتزاعی، باید معنای معنایی مفاهیم مرتبط با همنام را در نظر گرفت. پس از استنباط عبارات معنایی ضمنی (روابط نگاشت تفصیلی در نشان داده شده است جدول 6 نشان داده شده است.، خط 5 و 6)، شرط اول در معادله (9) برای محاسبه شباهت نهایی بین مفاهیم “سیستم آب” در O C و “آب سطحی” در O A استفاده می شود . مقدار شباهت بین این دو مفهوم 0.92 محاسبه شده است. بنابراین، رابطه نگاشت بین این دو مفهوم “تطابق نزدیک” است.
5. نتیجه گیری و کار آینده
پژوهش ارائه شده بر تعیین روابط نگاشت معنایی بین مقولهها در هستیشناسیهای مختلف GI با موانع زبان طبیعی تمرکز دارد. مدل هستیشناسی رسمی پیشنهادی در این مطالعه برای نشان دادن و شناسایی ویژگیهای معنایی دستههای GI با عبارات معنایی مبتنی بر OWL که از تعاریف متن آزاد دو استاندارد طبقهبندی GI تبدیل شدهاند، استفاده میشود. یک الگوریتم محاسبه شباهت جدید بر اساس این مدل هستی شناسی رسمی برای فاصله انداختن شباهت های معنایی و شناسایی روابط نگاشت بین دسته ها ارائه شده است.
به طور خاص، ما با دو استاندارد طبقه بندی نقشه های توپوگرافی به زبان چینی و انگلیسی آمریکایی کار می کنیم. آزمایش انجامشده نشان میدهد که رویکرد پیشنهادی با موفقیت روابط نگاشت بین دستهها را در هستیشناسیهای GI مختلف تعیین میکند و ادغام هستیشناسی را در یک محیط بین زبانی تسهیل میکند. با توجه به استفاده از ابزارهای چندزبانه NLP در آزمایش ما، تکرار مدل ما برای تعیین روابط نگاشت بین دیگر هستیشناسیهای GI، که ممکن است با استفاده از زبانهای طبیعی بومی دیگر، علاوه بر زبان چینی، توصیف شوند، آسان است. با این حال، این مدل فقط برای ادغام اطلاعات مکانی (GI) در سطح دسته اعمال شده است و تحقیقات در مورد یکپارچه سازی GI در سطح داده انجام نشده است. که مبنایی برای مطالعات آینده خواهد بود. علاوه بر این،
پیوست: جزئیات بیانیه های نگاشت بین O C و O A

جدول A1. جزئیات بیانیه های نگاشت بین O C و O A.
منابع
- Gore, A. زمین دیجیتال: درک سیاره ما در قرن بیست و یکم. فتوگرام مهندس Remote Sens. 1999 , 65 . [ Google Scholar ] [ CrossRef ]
- کراگلیا، ام. Goodchild، MF; آنونی، ا. کامارا، جی. گولد، ام. کوهن، دبلیو. مارک، دی. ماسر، آی. مگوایر، دی. لیانگ، اس. و همکاران نسل بعدی زمین دیجیتال: مقاله موضعی از ابتکار vespucci برای پیشرفت علم اطلاعات جغرافیایی. بین المللی جی. اسپات. زیرساخت داده Res. 2008 ، 3 ، 146-167. [ Google Scholar ]
- کراگلیا، ام. دی بی، ک. جکسون، دی. پسری، م. Remetey-Fülöpp، G. وانگ، سی. آنونی، ا. بیان، ال. کمبل، اف. اهلرز، ام. و همکاران Digital Earth 2020: به سوی چشم انداز دهه آینده. بین المللی جی دیجیت. زمین 2012 ، 5 ، 4-21. [ Google Scholar ] [ CrossRef ]
- یو، پی. دی، ال. یانگ، دبلیو. یو، جی. ژائو، پی. ترکیب خودکار زنجیرههای خدمات وب جغرافیایی مبتنی بر معناشناسی. محاسبه کنید. Geosci. 2007 ، 33 ، 649-665. [ Google Scholar ] [ CrossRef ]
- یانوویچ، ک. هیتزلر، پی. زمین دیجیتال به عنوان موتور دانش. سمنت. وب 2012 ، 3 ، 213-221. [ Google Scholar ]
- Janowicz، K. مهندسی ژئوآنتولوژی مبتنی بر مشاهدات. ترانس. GIS 2012 ، 16 ، 351-374. [ Google Scholar ] [ CrossRef ]
- بوچلا، آ. چکیچ، آ. ژاندارمی، د. لانوبیل، اف. سمرارو، جی. کولاگروسی، A. ساخت یک هستی شناسی عادی جهانی برای یکپارچه سازی منابع داده های جغرافیایی. محاسبه کنید. Geosci. 2011 ، 37 ، 893-916. [ Google Scholar ] [ CrossRef ]
- بیشر، ی. غلبه بر موانع معنایی و دیگر قابلیت همکاری GIS. بین المللی جی. جئوگر. Inf. علمی 1998 ، 12 ، 299-314. [ Google Scholar ] [ CrossRef ]
- Lemmens، RL قابلیت همکاری معنایی ژئوسرویس های توزیع شده. Ph.D. پایان نامه، دانشگاه صنعتی دلفت، دلفت، هلند، 2006. [ Google Scholar ]
- فلاحی، GR; فرانک، AU; مسگری، ام اس; رجبی فرد، ع. ساختار هستیشناختی برای تعامل معنایی GIS و مدلسازی محیطی. بین المللی J. Appl. زمین Obs. Geoinf. 2008 ، 10 ، 342-357. [ Google Scholar ] [ CrossRef ]
- ما، ایکس. وو، سی. Carranza، EJM; Schetselaar، EM; ون در میر، FD; لیو، جی. Wange، X. Zhang، X. توسعه واژگان کنترل شده برای قابلیت همکاری معنایی داده های زمین اکتشاف معدنی برای پروژه های معدن. محاسبه کنید. Geosci. 2010 ، 36 ، 1512-1522. [ Google Scholar ]
- کوهن، دبلیو. معناشناسی جغرافیایی: چرا، از چه، و چگونه؟ J. داده سمنت. III 2005 ، 3534 ، 1-24. [ Google Scholar ]
- هانگ، جی.-اچ. کو، سی.-ال. یک پل هستی شناسی سبک وزن نیمه خودکار برای ادغام معنایی اطلاعات مکانی متقابل دامنه. بین المللی جی. جئوگر. Inf. علمی 2015 ، 29 ، 1-25. [ Google Scholar ] [ CrossRef ]
- Fonseca، FT; Egenhofer، MJ; دیویس، کالیفرنیا، جونیور؛ بورخس، هستی شناسی های KAV و اشتراک دانش در GIS شهری. محاسبه کنید. محیط زیست سیستم شهری 2000 ، 24 ، 251-272. [ Google Scholar ] [ CrossRef ]
- پوندت، اچ. Bishr, Y. هستی شناسی های دامنه برای به اشتراک گذاری داده ها – نمونه ای از پایش محیطی با استفاده از GIS میدانی. محاسبه کنید. Geosci. 2002 ، 28 ، 95-102. [ Google Scholar ] [ CrossRef ]
- یانگ، سی. راسکین، آر. گودچایلد، م. گاهگان، م. زیرساخت سایبری زمین فضایی: گذشته، حال و آینده. محاسبه کنید. محیط زیست سیستم شهری 2010 ، 34 ، 264-277. [ Google Scholar ] [ CrossRef ]
- استویمنوف، ال. استانیمیروویچ، آ. Djordjevic-Kajan, S. کشف نگاشت بین هستی شناسی ها در فرآیند ادغام معنایی. در مجموعه مقالات نهمین کنفرانس AGILE در علم اطلاعات جغرافیایی، ویسگراد، مجارستان، 20-22 آوریل 2006.
- یانوویچ، ک. راوبال، م. کوهن، دبلیو. معناشناسی شباهت در بازیابی اطلاعات جغرافیایی. جی. اسپات. Inf. علمی 2011 ، 2 ، 29-57. [ Google Scholar ] [ CrossRef ]
- شورینگ، آ. Raubal, M. روابط فضایی برای سنجش تشابه معنایی. در دیدگاه های مدل سازی مفهومی ; Springer-Verlag: هایدلبرگ، آلمان، 2005; صص 259-269. [ Google Scholar ]
- حکیم پور، ف. استفاده از هستی شناسی ها برای حل ناهمگونی معنایی برای یکپارچه سازی طرحواره های پایگاه داده فضایی . دانشگاه زوریخ: زوریخ، سوئیس، 2003. [ Google Scholar ]
- مارک، DM; اسکوپین، ا. اسمیت، ب. ویژگی ها، اشیاء و چیزهای دیگر: تمایزات هستی شناختی در حوزه جغرافیایی. در نظریه اطلاعات مکانی ; Springer: New York, NY, USA, 2001; صص 489-502. [ Google Scholar ]
- استدلر، سی. جنز، ال. کنراد، اچ. Sören، A. Linkedgeodata: هسته ای برای شبکه ای از داده های باز فضایی. وب معنایی 2012 ، 3 ، 333-354. [ Google Scholar ]
- تروجان، سی. فو، بی. زمازال، او. Ritze, D. آخرین هنر در تطبیق هستی شناسی چند زبانه و چند زبانه . Springer: هایدلبرگ، آلمان، 2014. [ Google Scholar ]
- لیو، ک. هوگان، WR; کراولی، RS روشها و سیستمهای پردازش زبان طبیعی برای یادگیری هستیشناسی زیستپزشکی. جی. بیومد. آگاه کردن. 2011 ، 44 ، 163-179. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Buitelaar، P. Cimiano، P. Magnini، B. یادگیری هستی شناسی از متن: روش ها، ارزیابی و کاربردها. محاسبه کنید. زبانشناس. 2006 ، 32 ، 569-572. [ Google Scholar ]
- پرنده ها.؛ کلاین، ای. Loper، E. پردازش زبان طبیعی با پایتون . O’Reilly Vlg. GmbH & Co.: Sebastopol, CA, USA, 2009. [ Google Scholar ]
- ژورافسکی، دی. مارتین، JH پردازش گفتار و زبان: مقدمه ای بر پردازش زبان طبیعی، زبان شناسی محاسباتی، و تشخیص گفتار . Prentice Hall: Upper Saddle River، نیوجرسی، ایالات متحده آمریکا، 2000. [ Google Scholar ]
- کاووراس، م. کوکلا، م. Tomai, E. مقایسه مقوله ها در میان هستی شناسی های جغرافیایی. محاسبه کنید. Geosci. 2005 ، 31 ، 145-154. [ Google Scholar ] [ CrossRef ]
- کاووراس، م. کوکلا، ام. نظریه های مفاهیم جغرافیایی: رویکردهای هستی شناختی به ادغام معنایی . CRC Press: Boca Raton، FL، USA، 2008. [ Google Scholar ]
- بیتنر، تی. دانلی، ام. اسمیت، بی. هستی شناسی مکانی-زمانی برای ادغام اطلاعات جغرافیایی. بین المللی جی. جئوگر. Inf. علمی 2009 ، 23 ، 765-798. [ Google Scholar ] [ CrossRef ]
- ژنگ، جی جی. فو، LY; ما، XG; Fox, P. SEM+: ابزاری برای کشف نقشه مفهومی در حوزه مرتبط با علم زمین. علوم زمین آگاه کردن. 2015 ، 8 ، 1-8. [ Google Scholar ] [ CrossRef ]
- Schwering، A. رویکردهایی به اندازه گیری تشابه معنایی برای داده های جغرافیایی- فضایی: یک بررسی. ترانس. GIS 2008 ، 12 ، 5-29. [ Google Scholar ] [ CrossRef ]
- بوچلا، آ. چکیچ، آ. فیلوترانی، P. یکپارچه سازی اطلاعات جغرافیایی مبتنی بر هستی شناسی: بررسی رویکردهای فعلی. محاسبه کنید. Geosci. 2009 ، 35 ، 710-723. [ Google Scholar ] [ CrossRef ]
- بالاتوره، آ. برتولتو، ام. استخراج دانش جغرافیایی ویلسون، دی سی و تشابه معنایی در OpenStreetMap. بدانید. Inf. سیستم 2013 ، 37 ، 61-81. [ Google Scholar ] [ CrossRef ]
- بالاتوره، آ. ویلسون، دی سی؛ برتولتو، ام. محاسبه شباهت معنایی اصطلاحات جغرافیایی با استفاده از تعاریف واژگانی داوطلبانه. بین المللی جی. جئوگر. Inf. علمی 2013 ، 27 ، 2099-2118. [ Google Scholar ] [ CrossRef ]
- لی، دبلیو. راسکین، آر. Goodchild، MF اندازهگیری شباهت معنایی مبتنی بر دانش کاوی: یک رویکرد شبکه عصبی مصنوعی. بین المللی جی. جئوگر. Inf. علمی 2012 ، 26 ، 1415-1435. [ Google Scholar ] [ CrossRef ]
- خو، ی. زی، ز. Chen, Z. تحقیق در مورد معناشناسی اندازه گیری شباهت فضای موجودیت بر اساس شبکه های عصبی مصنوعی. در مجموعه مقالات بیست و سومین کنفرانس بین المللی ژئوانفورماتیک، ووهان، چین، 19 تا 21 ژوئن 2015.
- لاورینی، آر. هستی شناسی های جغرافیایی، روزنامه نگاران و چندزبانگی. اینترنت آینده 2015 ، 7 ، 1-23. [ Google Scholar ] [ CrossRef ]
- فو، بی. برنان، آر. O’Sullivan، D. یک سیستم نقشه برداری هستی شناسی بین زبانی مبتنی بر ترجمه قابل تنظیم برای تنظیم نتایج نگاشت. وب سمنت علمی خدمت Agents World Wide Web 2012 ، 15 ، 15-36. [ Google Scholar ] [ CrossRef ]
- سینی، ع. Sini، M. نقشه برداری AGROVOC و اصطلاحنامه کشاورزی چین: تعاریف، ابزارها، رویه ها. جدید Rev. Hypermedia Multimed. 2006 ، 12 ، 51-62. [ Google Scholar ]
- وانگ، اس. اسحاق، ا. شوپمن، بی. اشلوباخ، اس. van der Meij, L. تطبیق واژگان موضوعی چند زبانه. در تحقیق و فناوری پیشرفته برای کتابخانه های دیجیتال ; Springer: برلین، آلمان، 2009; صص 125-137. [ Google Scholar ]
- میلیکه، سی. گارسیا کاسترود، آر. فریتاس، اف. ون هاگ، WR; مونتیل-پونسودا، ای. د آزودو، RR; استاکنشمیت، اچ. شواب-زامازال، او. سواتک، وی. تامیلین، آ. و همکاران MultiFarm: معیاری برای تطبیق هستی شناسی چند زبانه. J. وب سمنت. 2012 ، 15 ، 62-68. [ Google Scholar ] [ CrossRef ]
- نگای، جی. کارپوات، م. Fung، P. شناسایی مفاهیم در سراسر زبان: اولین گام به سمت یک رویکرد مبتنی بر پیکره برای همترازی هستیشناسی خودکار. در مجموعه مقالات نوزدهمین کنفرانس بین المللی زبانشناسی محاسباتی، استرودزبورگ، PA، ایالات متحده آمریکا، آگوست 2002.
- Pazienza، MT; Stellato، A. نقشه برداری هستی شناسی با انگیزه زبانی برای وب معنایی. در مجموعه مقالات دومین کارگاه آموزشی وب معنایی ایتالیایی، ترنتو، ایتالیا، 14-16 دسامبر 2005; صص 14-16.
- یونگ، جی جی. هاکانسون، ا. هارتانگ، آر. همسویی غیرمستقیم بین هستی شناسی های چند زبانه. در سیستمهای عامل و چند عامل: فناوریها و کاربردها . Springer: برلین، آلمان، 2009; جلد 5559، ص 233–241. [ Google Scholar ]
- تروجان، سی. کوارشما، پ. Vieira, R. چارچوبی برای نگاشت هستی شناسی چند زبانه. در مجموعه مقالات کنفرانس بین المللی منابع و ارزشیابی زبان، مراکش، مراکش، 28 تا 30 مه 2008. صص 1034–1037.
- وانگ، اس. انگلبین، جی. Schlobach, S. یادگیری نگاشت مفهومی از شباهت نمونه. در وب معنایی-ISWC 2008 ; Springer: برلین، آلمان، 2008; صص 339-355. [ Google Scholar ]
- ژنگ، کیو. شائو، سی. لی، جی. وانگ، ز. نتایج Hu، L. RiMOM2013 برای OAEI 2013. در مجموعه مقالات هشتمین کنفرانس بین المللی کارگاه در مورد تطبیق هستی شناسی، سیدنی، استرالیا، 21 اکتبر 2013.
- ژانگ، ایکس. ژونگ، کیو. شی، اف. لی، جی. Tang, J. RiMOM نتایج برای OAEI 2009. در مجموعه مقالات چهارمین کنفرانس بین المللی کارگاه در مورد تطبیق هستی شناسی، واشنگتن، دی سی، ایالات متحده آمریکا، 25 اکتبر 2009.
- وانگ، ز. ژانگ، ایکس. هو، ال. ژائو، ی. لی، جی. چی، ی. نتایج Tang, J. RiMOM برای OAEI 2010. در مجموعه مقالات پنجمین کنفرانس بین المللی تطبیق هستی شناسی، شانگهای، چین، 7 نوامبر 2010.
- اوزنات، ج. شوایکو، پی. تطبیق هستی شناسی ؛ Springer: برلین، آلمان، 2007. [ Google Scholar ]
- اهریگ، م. مطمئنا، Y. نقشه برداری هستی شناسی – یک رویکرد یکپارچه. در وب معنایی: تحقیقات و کاربردها ; Springer: برلین، هایدلبرگ، آلمان، 2004; صص 76-91. [ Google Scholar ]
- کلفوگلو، ی. Schorlemmer, M. نقشه برداری هستی شناسی: وضعیت هنر. بدانید. مهندس Rev. 2003 , 18 , 1-31. [ Google Scholar ] [ CrossRef ]
- دوان، ق. مدهاوان، ج. دومینگوس، پی. Halevy، A. تطبیق هستی شناسی: رویکرد یادگیری ماشین. در کتاب های راهنمای بین المللی در مورد سیستم های اطلاعاتی ; Springer: برلین، آلمان، 2004; صص 397-416. [ Google Scholar ]
- کانتور، پی. مبانی پردازش زبان طبیعی آماری. نات. لنگ مهندس 1999 ، 26 ، 91-92. [ Google Scholar ]
- مک کارتنی، بی. گروه پردازش زبان طبیعی استانفورد. در دسترس آنلاین: http://nlp.stanford.edu/ (دسترسی در 18 دسامبر 2015).
- Guarino، N. هستی شناسی رسمی، تحلیل مفهومی و بازنمایی دانش. بین المللی جی. هوم. محاسبه کنید. گل میخ. 1995 ، 43 ، 625-640. [ Google Scholar ] [ CrossRef ]
- هستی شناسی رسمی عمومی (GFO): هستی شناسی بنیادی برای مدل سازی مفهومی. در نظریه و کاربردهای هستی شناسی کاربردهای کامپیوتری ; Springer Netherlands: Dordrecht, The Netherlands, 2010; صص 297-345. [ Google Scholar ]
- فرانک، هستی شناسی AU برای پایگاه های داده مکانی-زمانی. در پایگاه داده های مکانی-زمانی ؛ Springer: برلین، آلمان، 2003; ص 9-77. [ Google Scholar ]
- کازاتی، ر. اسمیت، بی. ورزی، ابزار هستیشناسی AC برای بازنمایی جغرافیایی. در هستی شناسی رسمی در سیستم های اطلاعاتی ; IOS Press: آمستردام، هلند، 1998; صص 77-85. [ Google Scholar ]
- گرنون، پی. اسمیت، بی. اسنپ و SPAN: به سوی هستی شناسی فضایی پویا. تف کردن شناخت. محاسبه کنید. 2004 ، 4 ، 69-104. [ Google Scholar ] [ CrossRef ]
شکل 1. روش اصلی روش شناسی ما.

شکل 2. با استفاده از ابزارهای NLP به زبان های چینی و انگلیسی، مفاهیم ابتدایی معنایی را از تعاریف متن آزاد استخراج کنید.

شکل 3. ویژگی های معنایی و گروه های رابطه در مدل هستی شناسی رسمی جغرافیایی.
شکل 4. نمایش دسته “کانال” در قالب OWL: ( الف ) نمای OntoGraf در Protégé و ( ب ) ارائه عبارت معنایی در قالب فایل لاک پشت.
جدول 1. خلاصه مجموعه های برچسب بخشی از گفتار Penn Treebank به زبان انگلیسی.
جدول 2. خلاصه مجموعه های برچسب بخشی از گفتار Penn Treebank به زبان چینی.
جدول 3. ویژگی های CS C و CS A.
جدول 4. وضعیت عبارات نگاشت بین O C و O A.
جدول 5. نام ها و تعاریف متن آزاد جفت های مفهومی مقایسه شده.
جدول 6. نمونه ای از تعاریف دسته ها و محاسبه شباهت.
© 2016 توسط نویسندگان؛ دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (CC-BY) (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر