

خلاصه
پرس و جوهای اولویت فضایی Top- k اشیاء را بر اساس امتیاز اشیاء ویژگی در همسایگی فضایی آنها رتبه بندی می کنند. پرس و جوهای اولویت برتر برای طیف وسیعی از خدمات مبتنی بر مکان مانند جستجوی هتل و جستجوی آپارتمان بسیار مهم هستند. در سالهای اخیر، تحقیقات زیادی در مورد پردازش پرسوجوهای ترجیحی فضایی برتر در فضای اقلیدسی انجام شده است . در حالی که تعداد کمی از الگوریتمها پرس و جوهای ترجیحی برتر را در شبکههای جادهای مطالعه میکنند ، همه آنها بر روی شبکههای جادهای بدون جهت تمرکز میکنند. در این مقاله، مشکل پردازش top- k را بررسی می کنیمجستارهای ترجیحی فضایی در شبکه های جاده هدایت شده که در آن هر بخش جاده دارای جهت گیری خاصی است. محاسبه امتیازات شی داده ای مستلزم بررسی امتیازات هر شیء ویژگی در همسایگی فضایی آن است. این ممکن است باعث تاخیر محاسباتی شود و در نتیجه زمان پردازش پرس و جو زیاد شود. در این مقاله، ما این مشکل را با پیشنهاد هرس و گروه بندی اشیاء ویژگی برای کاهش تعداد اشیاء ویژگی حل می کنیم. علاوه بر این، ما یک الگوریتم کارآمد به نام TOPS ارائه میکنیم که میتواند پرسوجوهای ترجیحی فضایی بالا را در شبکههای جادهای هدایتشده پردازش کند . نتایج تجربی نشان می دهد که الگوریتم ما به طور قابل توجهی زمان پردازش پرس و جو را در مقایسه با حل دوره برای طیف گسترده ای از تنظیمات مشکل کاهش می دهد.
کلید واژه ها:
top- k پرس و جو ترجیح فضایی ; شبکه های جاده ای هدایت شده ; پایگاه داده های فضایی ; خدمات مبتنی بر مکان ؛ رتبه بندی اشیاء داده
1. معرفی
با توجه به رشد تصاعدی دستگاه های دستی، در دسترس بودن گسترده نقشه ها و پهنای باند شبکه ارزان قیمت، خدمات مبتنی بر مکان را متداول کرده است. طبق گفته Skyhook، تعداد برنامه های مبتنی بر مکان که هر ماه توسعه می یابند به طور تصاعدی در حال افزایش است. بنابراین، پرس و جوهای فضایی مانند نوع گره ناشناخته: فونتنزدیکترین همسایه، پرس و جوهای محدوده و معکوس نزدیکترین همسایه [ 1 ، 2 ، 3 ، 4 ، 5 ] توجه قابل توجهی را از سوی جامعه پژوهشی به خود جلب کرده است. با این حال، بیشتر برنامههای کاربردی موجود به پرسوجوهای فضایی سنتی محدود میشوند، که اشیاء را بر اساس فاصلهشان از نقطه پرس و جو برمیگردانند.
در این مقاله، ما پرس و جو ترجیح فضایی top- k را مطالعه میکنیم که فهرست رتبهبندی شدهای را برمیگرداند کبهترین اشیاء فضایی بر اساس امکانات محله. با توجه به مجموعه ای از اشیاء داده {د1،د2،…،د�}∈دی، یک پرس و جو ترجیح فضایی top- k مجموعه ای از را بازیابی می کند کاشیاء در D بر اساس کیفیت امکانات (کیفیت با تجمیع امتیاز فاصله و امتیاز غیر مکانی محاسبه می شود) در همسایگی خود. بسیاری از سناریوهای واقعی برای نشان دادن مفید بودن پرس و جوهای ترجیحی وجود دارد. بنابراین، اگر سناریویی را در نظر بگیریم که در آن یک دفتر آژانس املاک بانک اطلاعاتی از آپارتمانهای موجود را نگهداری میکند، ممکن است مشتری بخواهد آپارتمانها را بر اساس امکانات همسایه (مثلاً بازار، بیمارستانها و مدرسه) رتبهبندی کند.
در مثالی دیگر، یک گردشگر ممکن است به دنبال هتلهایی باشد، جایی که ممکن است به هتلهای واقع در نزدیکی برخی رستورانها، کافهها یا نقاط توریستی با کیفیت خوب علاقه داشته باشد. شکل 1 اشیاء داده (یعنی هتل ها) را به صورت مثلث و دو مجموعه داده مشخصه نشان می دهد: مستطیل های جامد نشان دهنده کافه ها هستند در حالی که مستطیل های توخالی نشان دهنده رستوران ها هستند. عدد روی هر لبه نشاندهنده هزینه سفر در آن لبه است، جایی که هزینه یک یال را میتوان به عنوان مقدار زمان لازم برای سفر در طول آن در نظر گرفت، به عنوان مثال، دمنستی(د1،آ1→)=2، دمنستی(د3،ب2¯)=1. اعداد داخل پرانتز روی اشیاء ویژگی نشان دهنده امتیاز آن شی ویژگی خاص است، به عنوان مثال، امتیاز شی ویژگی ب20.5 است. حال اجازه دهید توریستی را در نظر بگیریم که به دنبال هتلی در نزدیکی کافه ها و رستوران ها است. گردشگر می تواند محدوده پرس و جو را محدود کند، بنابراین ما فرض می کنیم که محدوده 3 باشد (یعنی، �=3) در این مثال. امتیاز هتل ها را می توان با توجه به معیارهای زیر تعیین کرد (1) حداکثر کیفیت برای هر ویژگی در منطقه محله. و (2) مجموع این کیفیت ها. به عنوان مثال، اگر هتل ها فقط بر اساس نمرات کافه ها رتبه بندی شوند، هتل برتر خواهد بود. د1چون نمره از د1،د2و د3به ترتیب 0.7، 0 و 0.5 هستند. لازم به ذکر است که امتیاز از د20 است اگرچه آ1در محدوده خود قرار دارد، زیرا یک شبکه جاده هدایت شده است و هیچ مسیری به هم متصل نمی شود د2به آ1. برعکس، اگر هتل ها تنها بر اساس امتیاز رستوران ها رتبه بندی شوند، هتل برتر خواهد بود د2چون نمره از د1،د2و د3به ترتیب 0، 0.8 و 0.5 هستند. در نهایت، اگر هتل ها بر اساس نمرات مجموع رستوران ها و کافه ها رتبه بندی شوند، هتل برتر خواهد بود. د3چون نمره از د1،د2و د3به ترتیب 0.7، 0.8 و 1 هستند.
هنگام رتبه بندی اشیا دو عامل اساسی در نظر گرفته می شود: (1) رتبه بندی فضایی که فاصله است و (2) رتبه بندی غیرمکانی که اشیا را بر اساس کیفیت اشیاء ویژگی رتبه بندی می کند. الگوریتم پرس و جو ترجیح مکانی top- k ما به طور موثر این دو عامل را برای بازیابی لیستی از اشیاء داده با بالاترین امتیاز یکپارچه می کند.
بر خلاف پرس و جوهای top- k سنتی [ 6 ، 7 ]، پرس و جوهای ترجیحی فضایی top- k مستلزم آن است که امتیاز یک شی داده توسط اشیاء ویژگی که شرایط همسایگی فضایی مانند محدوده، نزدیکترین همسایه یا تأثیر [8] را برآورده می کند، تعریف شود . , 9 , 10 , 11 ]. بنابراین، یک جفت شامل یک شی داده و یک شیء ویژگی باید مورد بررسی قرار گیرد تا امتیاز شی داده مربوطه مشخص شود. علاوه بر این، پردازش بالا- kجستارهای ترجیحی فضایی در شبکههای جادهای پیچیدهتر از فضای اقلیدسی است، زیرا اولی نیاز به کاوش در همسایگی فضایی در امتداد شبکه جادهای معین دارد.
بالا- کپرس و جوهای ترجیحی فضایی بصری هستند و چندین برنامه کاربردی مانند مرور هتل دارند. متأسفانه اکثر الگوریتم های موجود بر روی فضای اقلیدسی متمرکز شده اند و توجه کمی به شبکه های جاده ای شده است. در واقع، اگرچه الگوریتمهای کمی برای پرس و جوهای ترجیحی در شبکههای جادهای وجود دارد، اما همه آنها شبکههای جادهای بدون جهت را در نظر میگیرند. با انگیزه دلایل ذکر شده، ما یک رویکرد جدید برای پردازش برتر پیشنهاد می کنیم. کجستارهای ترجیحی فضایی در شبکههای جادهای هدایتشده، که در آن هر بخش جاده دارای جهتگیری خاصی است (یعنی جهتدار یا بدون جهت). در روش ما، اشیاء ویژگی در شبکه جاده ها با هم گروه بندی می شوند تا تعداد جفت هایی را که باید برای یافتن بالاترین مورد بررسی قرار گیرند، کاهش دهند. کاشیاء داده ما روشی را برای گروه بندی اشیاء ویژگی بر اساس گره های محوری پیشنهاد می کنیم. همانطور که در بخش 4.2.1 به تفصیل توضیح داده شده است . همه جفتهای اشیاء داده و گروههای ویژگی بر روی یک فضای امتیاز فاصله نگاشت میشوند و زیر مجموعهای از جفتها شناسایی میشوند که برای پاسخ به پرس و جوهای ترجیحی فضایی کافی است. به منظور ترسیم جفت ها، یک فرمول ریاضی برای محاسبه حداقل و حداکثر فاصله در شبکه های جاده هدایت شده بین اشیاء داده و گروه های ویژگی توصیف می کنیم. در نهایت، ما الگوریتم پرس و جو ترجیحی فضایی Top- k خود را (TOPS) ارائه می کنیم، که می تواند به طور موثر اشیاء داده top- k را با استفاده از این جفت ها محاسبه کند.
این مطالعه یک نسخه توسعهیافته از تحقیقات قبلی ما از پرسوجوهای ترجیحی فضایی top- k در شبکههای جادهای هدایتشده است [ 12 ]. با این حال، ما چهار پسوند جدید را ارائه می کنیم که در مطالعه اولیه خود در نظر نگرفتیم [ 12 ]. اولین فرمت یک تکنیک گروهبندی پیشرفته است که میتواند به طور موثر گروههای ویژگی مرتبط با یک گره محوری را به دست آورد ( بخش 4.2.1 ). توسعه دوم، سازگاری های الگوریتم های پیشنهادی را برای مقابله با شرایط همسایگی به غیر از امتیاز دامنه، به عنوان مثال، امتیاز نزدیکترین همسایه و امتیاز تأثیر ( بخش 5 ) مورد مطالعه قرار می دهد. در گسترش سوم، ما یک روش تعمیر و نگهداری افزایشی کارآمد را برای مجموعههای افق مادی ارائه میکنیم (بخش 5 ). در پسوند چهارم، ما یک مطالعه تجربی گسترده انجام می دهیم که در آن تعداد پارامترها را برای ارزیابی عملکرد TOPS افزایش می دهیم. و همچنین پیاده سازی دو نسخه TOPS: برترین ها��و برترین هامن�که در آن عملکرد آنها را با رویکرد دوره مقایسه کردیم ( بخش 6 ). علاوه بر این پسوندهای اصلی، ما همچنین یک لم را ارائه می کنیم تا ثابت کنیم که مجموعه افق تحقق یافته برای تعیین امتیاز جزئی یک شی داده کافی است. د∈دی. علاوه بر این، ما همچنین محدودیتهای الگوریتمهای مبتنی بر شبکههای جادهای هدایتنشده را در شبکههای جاده هدایتشده مورد بحث قرار میدهیم ( بخش 4.4 ).
مشارکت های این مقاله به شرح زیر خلاصه می شود:
-
ما یک الگوریتم کارآمد به نام TOPS را برای پردازش پرس و جوهای اولویت برتر در شبکه های جاده هدایت شده پیشنهاد می کنیم. تا جایی که ما می دانیم، این اولین مطالعه ای است که به این مشکل پرداخته است.
-
ما روشی را برای گروه بندی اشیاء ویژگی بر اساس گره محوری ارائه می کنیم. ما نگاشت اشیاء داده و گروههای ویژگی را در یک فضای امتیاز فاصله نشان میدهیم تا یک مجموعه افق ایجاد کنیم.
-
ما لم هایی را برای محاسبه حداقل و حداکثر فاصله بین شی داده و گروه ویژگی بیان می کنیم.
-
علاوه بر این، ما یک روش مقرونبهصرفه برای نگهداری تدریجی مجموعههای افق مادی پیشنهاد میکنیم.
-
بر اساس ارزیابیهای تجربی، ما اثرات اعمال الگوریتم پیشنهادی خود را با پارامترهای مختلف با استفاده از مجموعه دادههای جاده واقعی مطالعه میکنیم.
ادامه این مقاله به شرح زیر سازماندهی شده است. ما تحقیقات مرتبط را در بخش 2 مورد بحث قرار می دهیم . در بخش 3 ، اصطلاحات و نمادهای اولیه مورد استفاده در این مطالعه و همچنین فرمول بندی مسئله را تعریف می کنیم. در بخش 4 ، هرس و گروه بندی اشیاء ویژگی، و همچنین نگاشت جفت اشیاء داده و گروه های ویژگی را در یک فضای امتیاز فاصله توضیح می دهیم. بخش 5 الگوریتم پیشنهادی ما را برای پردازش پرسوجوهای ترجیحی فضایی بالا در شبکههای جادهای هدایتشده ارائه میکند . ارزیابی های تجربی گسترده ما در بخش 6 ارائه شده است . در نهایت، ما نتیجه گیری خود را در بخش 7 ارائه می کنیم .
2. کارهای مرتبط
در این بخش، الگوریتمهای قبلی پیشنهادی برای رتبهبندی اشیاء دادههای مکانی را بررسی میکنیم. رتبه بندی اشیا یک کار بازیابی محبوب در برنامه های مختلف است. همانطور که در اکثر برنامه های کاربردی پایگاه داده رابطه ای مشاهده می شود، ما اغلب می خواهیم تاپل ها را با استفاده از یک امتیاز مجموع مقادیر مشخصه رتبه بندی کنیم. به عنوان مثال، یک آژانس خودروی کرایه ای پایگاه داده ای را نگهداری می کند که حاوی اطلاعاتی درباره خودروهای موجود برای اجاره است. یک مشتری بالقوه مایل است 10 گزینه برتر را در میان جدیدترین مدل ها با کمترین قیمت مشاهده کند. در این حالت امتیاز هر خودرو با مجموع دو کیفیت مدل و قیمت بیان می شود. در پایگاه داده های فضایی، رتبه بندی ها اغلب با پرس و جوهای نزدیکترین همسایه مرتبط هستند. بنابراین، با توجه به یک نقطه پرس و جو q، ما عمدتاً علاقه مند به یافتن مجموعه ای از نزدیکترین اشیاء به آن هستیم که شرایط خاصی را دارند. الگوریتم های زیادی [ 1 ، 13 ، 14 ، 15 ] برای بازیابی نزدیک ترین اشیاء همسایه هم در فضای اقلیدسی و هم در شبکه های جاده ای پیشنهاد شده اند.
در بخشهای فرعی زیر، پرسوجوهای خط آسمان را در بخش 2.1 بررسی میکنیم ، و همچنین به طور خلاصه پرسوجوهای فضایی مبتنی بر ویژگی در بخش 2.2 ، و پرسوجوهای ترجیحی فضایی top- k در بخش 2.3 را بررسی میکنیم .
2.1. پرس و جوهای خط افق
در سالهای اخیر، پردازش پرس و جو در آسمان [ 16 ، 17 ، 18 ، 19 ، 20 ، 21 ] به دلیل مناسب بودن آن برای برنامههای تصمیمگیری مانند پرسوجوهای ترجیحی فضایی top- k ، توجه زیادی را به خود جلب کرده است . لین و همکاران [ 16 ] مسئله خط افق فضایی عمومی (GSSKY) را مورد مطالعه قرار داد، که یک مجموعه نامزد حداقلی را ایجاد میکند که شامل راهحلهای بهینه برای هر پرس و جو ترجیحی فضایی مبتنی بر فاصله یکنواخت است. آنها یک الگوریتم پیشرونده کارآمد به نام P-GSSKY پیشنهاد کردند که به طور قابل توجهی تعداد اشیاء غیر امیدوارکننده را در طول محاسبات کاهش می دهد. لی و همکاران [ 17] دو رویکرد مبتنی بر شاخص را پیشنهاد کرد، به نام درخت R و نمودار تسلط تقویت شده برای پرس و جوهای مختلف خط افق در فضای اقلیدسی، به عنوان مثال، پرس و جوهای خط افق وابسته به مکان و پرس و جوهای خط افق وابسته به مکان معکوس. لیو و همکاران [ 18 ] الگوریتمی را برای پرسوجوهای top- k سنتی در شبکههای جادهای ارائه کرد که ویژگیهای چندگانه اشیاء داده، از جمله مکان شی داده را در نظر میگیرد. به عنوان مثال، زمانی که کاربر می خواهد هتلی را پیدا کند، اغلب فاکتورهای مختلفی مانند فاصله تا هتل، رتبه هتل و کیفیت خدمات را در نظر می گیرد. با این حال، روش آنها رابطه بین یک شی داده و یک شی ویژگی را در نظر نمی گیرد. بنابراین، نمی توان آن را برای جستجوهای ترجیحی فضایی بالا در شبکه های جاده ای اعمال کرد . دنگ و همکاران [19 ] اولین کسی بود که مشکل پرس و جوهای خط آسمان چند منبعی را در شبکه های جاده ای در نظر گرفت. اخیراً Cheema و همکاران. [ 22 ] به پرس و جوهای خط آسمان برای پرس و جوهای متحرک پرداختند، جایی که آنها یک الگوریتم مبتنی بر منطقه امن را برای نظارت مستمر یک پرس و جو خط آسمان پیشنهاد کردند.
2.2. پرس و جوهای فضایی مبتنی بر ویژگی
شیا و همکاران [ 23 ] یک الگوریتم جدید برای بازیابی تأثیرگذارترین مکانهای فضایی (مثلاً آپارتمانهای مسکونی) بر اساس تأثیر آنها بر نقاط مشخصه (مثلاً بازار) پیشنهاد کرد. تأثیر هر سایت p توسط مجموع امتیازات همه اشیاء ویژگی با p به عنوان نزدیکترین مکان آنها تعیین می شود. یانگ و همکاران [ 24 ، 25 ] مسئله یافتن پرس و جوهای مکان بهینه را مورد مطالعه قرار داد، با این حال، برخلاف [ 23 ] پرس و جو مکان بهینه هر نقطه در فضای داده را بازیابی می کند و لزوماً یک شی در مجموعه داده نیست. اگرچه روش محاسبه امتیاز مشابه است [ 23 ]. این الگوریتم ها [23 ، 24 ، 25 ] مخصوص انواع پرس و جوی خاصی هستند که در بالا ذکر شد و نمی توان آنها را برای پرس و جوهای اولویت فضایی top- k اعمال کرد . علاوه بر این، آنها فقط با مجموعه داده تک ویژگی سروکار دارند در حالی که پرس و جو ترجیحی یک مجموعه داده چند ویژگی را در نظر می گیرد.
2.3. جستجوهای ترجیحی فضایی Top-k
چندین الگوریتم برای پرس و جوهای اولویت فضایی top -k در فضای اقلیدسی پیشنهاد شده است . ییو ال ال. [ 8 ، 9 ] ابتدا محاسبه امتیاز شی دادهای p را بر اساس مجموعه اشیاء ویژگی چندگانه در همسایگی فضایی آن به جای یک مجموعه شی ویژگی منفرد همانطور که قبلاً مطالعه شد، در نظر گرفت [ 21 ، 22 ، 23 ]. می دانیم که امتیاز یک شی داده را می توان با سه امتیاز فضایی مختلف، یعنی محدوده، نزدیکترین همسایه و نزدیکترین امتیاز تعریف کرد. بنابراین، ییو و همکاران. [ 8 ، 9] چندین الگوریتم را با توجه به سه دسته (الگوریتمهای کاوشگر، الگوریتمهای شاخه و کران، و الگوریتمهای پیوستن ویژگی) برای ارزیابی پرسوجوهای اولویت فضایی بالا برای این امتیازها طراحی کرد . در مقابل ییو و همکاران. [ 8 ، 9 ]، Rocha-Junior و همکاران. [ 10 ] یک تکنیک تحقق را پیشنهاد کرد که باعث صرفه جویی قابل توجهی در هزینه محاسباتی و I/O در طول پردازش پرس و جو می شود. آنها نقشه برداری از جفت شی داده و شی ویژگی را در یک فضای امتیاز فاصله معرفی کردند. حداقل زیرمجموعه جفت ها تحقق می یابد و کافی است به هر پرس و جو ترجیح مکانی به شیوه ای کارآمد پاسخ دهیم. با این حال، این الگوریتم های مبتنی بر فضای اقلیدسی [ 8 ، 9 ،10 ] برای ارزیابی پرسوجوهای اولویت فضایی بالا در شبکههای جادهای مناسب نیستند ، زیرا فاصله بین اشیاء توسط کوتاهترین مسیری که آنها را در شبکههای جادهای به هم وصل میکند، تعیین میشود.
چو و همکاران [ 11 ] یک الگوریتم جدید به نام ALPS برای پردازش پرس و جوهای ترجیحی برتر در شبکه های جاده ای پیشنهاد کردند ، جایی که آنها تکنیک تحقق [ 10 ] را بر اساس فضای امتیاز فاصله برای شبکه های جاده ای گسترش دادند. برای به حداقل رساندن تعداد اشیاء داده، روش آنها مجموعه ای از اشیاء داده را در یک بخش جاده گروه بندی می کند و سپس اشیاء داده گروه بندی شده را به یک بخش داده تبدیل می کند. ALPS [ 11 ] می تواند به طور موثر پرس و جوهای اولویت مکانی top- k را در شبکه های جاده ای پردازش کند، اما فقط برای شبکه های جاده های هدایت نشده کار می کند.
این مطالعه از چندین جنبه خود را از مطالعات موجود متمایز می کند. اولاً، ما پرس و جوهای ترجیحی فضایی top-k را در یک شبکه جاده هدایتشده مطالعه میکنیم که در آن هر بخش جاده دارای جهتگیری خاصی است در حالی که مطالعات قبلی آنها یا بر فضای اقلیدسی [ 8 ، 9 ، 10 ] یا یک شبکه جادهای بدون جهت [ 11 ] تمرکز دارند. ثانیا، رویکرد ما بر اساس گروه بندی اشیاء ویژگی است که هزینه محاسبات را کاهش می دهد. در نهایت، یک فرمول ریاضی برای محاسبه سریع حداقل و حداکثر فواصل بین شی داده و گروه ویژگی در شبکه جاده ایجاد می کنیم. در سالهای اخیر، انواع مختلفی از پرس و جوهای ترجیحی در شبکههای جادهای فضایی مورد مطالعه قرار گرفتهاند. موراتیدیس و همکاران [ 26] پرس و جوهای ترجیحی را در شبکه حمل و نقل چند هزینه ای مورد مطالعه قرار می دهد که در آن هر بخش جاده با مقادیر هزینه های متعدد مرتبط است. لین و همکاران [ 27 ] k پرس و جوهای چند ترجیحی را برای بازیابی گروه های بالای امکاناتی که مسافت طی شده در شبکه جاده را به حداقل می رساند، مطالعه می کند. این مطالعات سناریوهای مشکل متفاوتی با موارد موجود در مطالعه ما دارند و راه حل آنها در حوزه مشکل ما مناسب نیست. علاوه بر این، محدودیتهای دقیق الگوریتمهای مبتنی بر هدایت نشده در شبکههای جادهای هدایتشده را در بخش 4.4 ارائه میکنیم .
3. مقدمات
بخش 3.1 اصطلاحات و نشانه های استفاده شده در این مقاله را تعریف می کند. بخش 3.2 مسئله را با استفاده از یک مثال برای نشان دادن نتایج بهدستآمده از پرسوجوهای اولویت فضایی top- k فرمولبندی میکند .
3.1. تعریف اصطلاحات و نمادها
شبکه راه :
یک شبکه جاده با یک نمودار جهت دار وزنی نشان داده می شود ( G = N، E، W ) که در آن N ، E ، و W به ترتیب مجموعه گره، مجموعه یال و ماتریس فاصله لبه را نشان می دهند. به هر یال نیز جهتی اختصاص داده شده است که یا جهت دار یا جهت دار است. یک یال غیر جهت دار با نشان داده می شود ه=�من��¯، جایی که �منو ��گره های مجاور هستند، در حالی که یک لبه جهت دار به صورت نمایش داده می شود �من��→یا �من��←. به طور طبیعی، فلش های بالای لبه ها، جهت های مرتبط با آنها را نشان می دهند.
قطعه s ( p i ، pj ) بخشی از یک یال بین دو نقطه p 1 و p 2 در لبه است . یک لبه شامل یک یا چند بخش است. یک یال نیز بخشی در نظر گرفته می شود که در آن گره ها نقاط انتهایی لبه هستند. برای ساده کردن ارائه، جدول 1 نمادهای استفاده شده در این مطالعه را فهرست می کند.
3.2. فرمول مسأله
با توجه به مجموعه ای از اشیاء داده دی= {د1، د2، …، د�}و مجموعه ای از مجموعه داده ویژگی mافمن= {�1، �2، …، �متر} (1 ≤من ≤متر)پرس و جو ترجیح مکانی top- k اشیاء داده k را با بالاترین امتیاز برمی گرداند. امتیاز یک شی داده د∈دیبا امتیازات اشیاء ویژگی تعریف می شود �∈افمندر همسایگی فضایی شی داده. هر شیء ویژگی f دارای امتیاز غیر مکانی است که با s ( f ) نشان داده می شود، که کیفیت (خوبی) f را نشان می دهد و در محدوده [0,1] درجه بندی می شود.
نمره ��(د)یک شی داده d با تجمیع امتیازهای جزئی تعیین می شود �من�(د) (1 ≤من ≤متر)با توجه به یک شرط همسایگی θ و مجموعه داده ویژگی ith F i . تابع تجمع ‘ agg ‘ می تواند هر تابع یکنواختی باشد ( جمع ، حداکثر ، حداقل )، اما در این مطالعه از مجموع برای ساده کردن بحث استفاده می کنیم. محدودیت های محدوده ( rng )، نزدیکترین همسایه ( nn ) و تأثیر ( inf ) را به عنوان شرط همسایگی θ در نظر می گیریم . به طور خاص، نمره ��(د)به عنوان … تعریف شده است، ��(د) =آ��{�من�(د)| 1 ≤من ≤متر}، جایی که � ∈ {���،��،من��}و آ��∈ {ستومتر، مترآایکس،مترمن�}.
نمره جزئی �من�توسط اشیاء مشخصه ای که فقط به مجموعه داده های ویژگی F i تعلق دارند و شرط همسایگی θ را برآورده می کنند تعیین می شود . به عبارت دیگر �من�با بالاترین امتیاز s(f) برای یک شیء مشخصه تعریف می شود�∈افمنکه محدودیت فضایی θ را برآورده می کند . مشابه مطالعات قبلی [ 9 ، 10 ، 11 ]، نمرات جزئی �من�برای شرایط همسایگی مختلف θ به صورت زیر تعریف می شود:
-
محدوده ( rng ) امتیاز d : �من���(د)=مترآایکس{س(�)|� ∈ افمن : دمنستی(د،�)≤�}
-
نزدیکترین همسایه ( nn ) امتیاز d :�من��(د)=مترآایکس{س(�)|� � افمن، ∀��∈ افمن : دمنستی(د،�)≤دمنستی(د،��)}
-
نمره تأثیر ( inf ) از d : �منمن��(د)=مترآایکس{س(�)×2-دمنستی(د،�)� | � ∈ افمن}
سپس، امتیازات اشیاء داده d 1 ، d 2 و d 3 را در شکل 1 ارزیابی می کنیم . ما مقدار محدودیت محدوده r = 3 را در نظر می گیریم. جدول 2 امتیازهای بدست آمده از d 1 , d 2 و d 3 را با استفاده از تعاریف فوق الذکر از شرایط همسایگی { rng , nn , inf } خلاصه می کند.
امتیاز شی داده d مجموع امتیاز جزئی هر مجموعه ویژگی است. امتیاز دامنه d 1 به صورت محاسبه می شود ����(د1)= �1���(د1) + �2���(د1) =0.7. امتیاز محدوده جزئی یک شی داده d حداکثر امتیاز غیر مکانی اشیاء ویژگی است �∈افمنکه در محدوده r هستند . بنابراین، اولین نمره جزئی �1���(د1) =0.7، زیرا س(آ1)=0.7و دمنستی(د1، آ1) ≤�. با این حال، �2���(د1) =0زیرا هیچ رستورانی در محدوده تعریف شده r وجود ندارد . به طور مشابه، نمرات دامنه d 2 و d 3 هستند ����(د2)=0+0.8 =0.8و ����(د3)=0.5+0.5 =1.0، به ترتیب.
نمره نزدیکترین همسایه d 1 به صورت محاسبه می شود ���(د1)= �1��(د1) + �2��(د1) =1.5. من امتیاز جزئی نزدیکترین همسایه شی داده d امتیاز نزدیکترین شیء ویژگی است �∈افمنبه د . بنابراین، اولین نمره جزئی �1nn(د1) =0.7، زیرا a 1 نزدیکترین شیء ویژگی d 1 و استس(آ1)=0.7، در حالیکه �2��(د1) =0.8زیرا b 1 نزدیکترین شیء ویژگی d 1 و استس(ب1)=0.8. به طور مشابه، نمره نزدیکترین همسایه d 2 و d 3 هستند ���(د2)=0.5+0.8 =1.3و ���(د3)=0.5+0.5 =1.0، به ترتیب.
امتیاز تأثیر d 1 به صورت محاسبه می شود �من��(د1)= �1من��(د1) + �2من��(د1) =0.64. امتیاز تأثیر جزئی یک شیء داده d با استفاده از امتیاز شی ویژگی محاسبه می شود �∈افمنو فاصله آن تا شی داده. به طور خاص، امتیاز تأثیر با فاصله بین d و f نسبت معکوس دارد . بنابراین، با افزایش فاصله بین شی ویژگی f و شی داده d ، امتیاز تأثیر به سرعت کاهش می یابد . اولین امتیاز جزئی �1من��(د1) =حداکثر{0.7×2-23،0.5×2-93}= 0.44، زیرا س(آ1)=0.7، دمنستی(د1،آ1)=2، س(آ2)=0.5، و دمنستی(د1،آ2)=9، در حالیکه �2من��(د1) =حداکثر{0.8×2-63،0.5×2-103}= 0.2، زیرا س(ب1)=0.8، دمنستی(د1،ب1)=6، س(ب2)=0.5، و دمنستی(د1،آ2)=10. به طور مشابه، امتیاز تأثیر d 2 و d 3 است �من��(د2)=0.198+0.4 =0.598و �من��(د3)=0.396+0.315 =0.711، به ترتیب.
3.3. یافتن گره های محوری
اکنون روش مورد استفاده برای محاسبه گره های محوری را مورد بحث قرار می دهیم. در رویکردمان، اشیاء ویژگی را بر اساس گرههای محوری گروهبندی میکنیم. هر شیء ویژگی با یک گره محوری مرتبط است، و بنابراین اشیاء ویژگی که گره محوری یکسانی را به اشتراک می گذارند می توانند با هم گروه بندی شوند. بدیهی است که اگر تعداد گروه های ویژگی کم باشد، عملکرد طرح پیشنهادی بهبود می یابد. بنابراین، هدف اصلی بازیابی حداقل تعداد گره های محوری است. محاسبه حداقل تعداد گره های محوری یک مسئله پوشش حداقل راس است. پوشش حداقل راس شامل مجموعه ای از گره ها است که می تواند تمام لبه های نمودار را با حداقل تعداد گره به هم متصل کند.
تعریف 1:
پوشش راس یک نمودار جی=(�،�) یک زیر مجموعه است اس⊂� به گونه ای که اگر (تو،�)∈� سپس یا تو∈اس یا �∈اس یا هر دو. به عبارت دیگر، پوشش راس زیرمجموعه ای از گره ها است که حداقل یک گره در هر لبه دارد.
پوشش حداقل راس یک مسئله NP-complete است و همچنین ارتباط نزدیکی با بسیاری از مشکلات گراف سخت دیگر دارد. بنابراین، مطالعات متعددی برای طراحی تکنیکهای بهینهسازی و تقریب بر اساس الگوریتم شاخه و کران، الگوریتم حریص و الگوریتم ژنتیک انجام شده است. ما تکنیک ارائه شده توسط هارتمن [ 28 ] را بر اساس الگوریتم شاخه و کران به کار می گیریم زیرا یک الگوریتم کامل است، در نتیجه اطمینان حاصل می کنیم که بهترین راه حل یا راه حل بهینه مسائل مختلف بهینه سازی، از جمله پوشش حداقل راس را پیدا می کنیم. با این حال، تنها سود هنگام استفاده از الگوریتم Branch و Bound این است که زمان اجرا با نمودارهای بزرگ افزایش مییابد.
الگوریتم Branch and Bound به صورت بازگشتی نمودار کامل را با تعیین وجود یا عدم وجود یک گره در پوشش در طول هر مرحله از فرآیند بازگشتی بررسی می کند و سپس به صورت بازگشتی مشکل را برای گره های باقی مانده حل می کند. فضای جستجوی کامل را می توان به عنوان یک درخت در نظر گرفت که در آن هر سطح وجود یا عدم وجود یک گره را تعیین می کند و دو شاخه ممکن برای هر گره وجود دارد. یکی مربوط به انتخاب گره برای پوشش است در حالی که دیگری مربوط به نادیده گرفتن گره است. تقریباً یک گره که پوشیده شده است و تمام لبه های مجاور آن از نمودار حذف می شوند. وقتی پوششی پیدا شد، یعنی وقتی همه لبه ها پوشانده شدند، الگوریتم نیازی به فرود بیشتر به داخل درخت ندارد. بعد، فرآیند عقبگرد شروع می شود و جستجو در سطوح بالاتر درخت برای شناسایی پوششی با پوشش احتمالاً رأس کوچکتر ادامه می یابد. در طول عقبگرد، تمام گره های تحت پوشش مجدداً در نمودار درج می شوند. زیرمجموعههای گرهها مشخص میشوند که پوششهای راس قانونی تولید میکنند و کوچکترین اندازه، حداقل پوشش راس است.
اجازه دهید مثالی را در شکل 2 در نظر بگیریم ، جایی که متوجه شدیم مجموعه گره ها {�2،�6،�7}حداقل پوشش راس را ایجاد می کند که تمام لبه ها را در یک شبکه جاده معین به هم متصل می کند.
4. هرس و گروه بندی
پرسوجوهای ترجیحی مکانی Top- k مجموعهای رتبهبندی شده از اشیاء دادههای مکانی را برمیگردانند. برخلاف پرس و جوهای top- k سنتی، رتبه هر شی داده با کیفیت اشیاء ویژگی در همسایگی فضایی آن تعیین می شود. بنابراین، محاسبه امتیاز جزئی یک شی داده d بر اساس مجموعه ویژگی F i مستلزم بررسی هر جفت شی ( d ، f ) است. بنابراین، برای تعداد زیادی از اشیاء، فضای جستجویی که برای تعیین امتیاز جزئی باید کاوش شود نیز به میزان قابل توجهی بالا است و در نتیجه چالشهای پردازش کارآمد بالا را افزایش میدهد .پرس و جوهای فضایی در شبکه های راه هدایت شده
در بخش 4.1 ، ما در مورد رابطه برتری بحث می کنیم و سپس لم هرس را توضیح می دهیم. بخش 4.2 الگوریتم گروه بندی و محاسبه امتیاز گروه ویژگی را ارائه می دهد س(�)، و همچنین بحث در مورد محاسبه حداقل و حداکثر فاصله بین اشیاء داده و گروه های ویژگی. بخش 4.3 نگاشت جفت اشیاء داده و گروه های ویژگی را در فضای امتیاز فاصله توضیح می دهد. در نهایت، محدودیتهای الگوریتمهای مبتنی بر هدایت نشده در شبکههای جادهای هدایتشده را در بخش 4.4 مورد بحث قرار میدهیم .
4.1. هرس
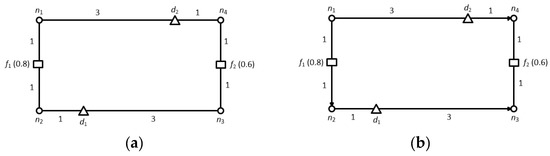
در این بخش، روشی را برای یافتن اشیاء ویژگی غالب که فقط به امتیاز یک شی داده کمک می کنند، ارائه می دهیم. اشیاء ویژگی که به امتیاز یک شی داده کمک نمی کنند به طور خودکار هرس می شوند. این به طور چشمگیری فضای جستجو را کاهش می دهد و در نتیجه هزینه محاسباتی را به میزان قابل توجهی کاهش می دهد. به منظور کارآمدتر کردن مرحله هرس، از فواصل از پیش محاسبه شده ذخیره شده در جدول حداقل فاصله MDT استفاده می کنیم. MDT فواصل از پیش محاسبه شده بین جفت گره n i و n j را در یک شبکه جاده هدایت شده ذخیره می کند. هر تاپل در MDT به شکلی است {(�من،��)،دمنستی(�من،��)}، جایی که (�من،��)به عنوان کلید جستجو برای بازیابی مقدار استفاده می شود دمنستی(�من،��). لازم به ذکر است که فاصله شبکه بین دو گره، n i و n j ، در یک شبکه راه هدایت شده متقارن نیست (یعنی دمنستی(�من،��) ≠دمنستی(��،�من)). بنابراین، باید یک ورودی جداگانه برای بازیابی فاصله n j تا n i وارد کنیم . شکل 2 نمونه ای از یک شبکه جاده هدایت شده را نشان می دهد که ما در سراسر این بخش از آن استفاده می کنیم.
قبل از ارائه لم هرس، اجازه دهید چند اصطلاح مفید را تعریف کنیم:
ابعاد استاتیک :
ابعاد استاتیک i (یعنی 1 ≤من ≤�) معیارهای ثابتی هستند که با حرکت پرس و جو تغییر نمی کنند، مانند رتبه هر رستوران یا قیمت.
برابری استاتیک :
یک شی o از نظر استاتیکی با شی برابر است �”اگر برای هر بعد ثابت i ، �[من]=�”[من]. برابری ایستا را به عنوان نشان می دهیم �”=س�.
تسلط استاتیک :
یک شی o به طور ایستا تحت تسلط شی دیگری است �”اگر �”در هر بعد ایستا بهتر از o است. ما استفاده می کنیم �”⊏س �برای نشان دادن آن شی �”به طور ایستا بر شی o تسلط دارد . ما استفاده می کنیم �” ⊑س�برای نشان دادن آن �”یا از نظر استاتیکی بر o غالب است یا از نظر استاتیکی معادل o است . در شکل 2 ، �1 ⊏س�2زیرا نمره غیر مکانی f 1 بهتر از f 2 است ، یعنی، [س(�1)=0.9]>[س(�2)=0.7].
تسلط کامل :
برای توضیح لم هرس باید تسلط کامل را تعریف کنیم. یک شی o کاملاً تحت تسلط شی دیگری است �”با توجه به شی داده d، اگر �”⊏س �همچنین دمنستی(د،�”)<دمنستی(د،�). به عبارت دیگر، �”به طور کامل بر روی اگر �”از نظر ابعاد استاتیک به همان اندازه خوب است و همچنین به شی داده d نزدیکتر است . در شکل 2 ، شی مشخصه f 1 به طور کامل بر f 2 نسبت به د1زیرا �1⊏س �2و دمنستی(د1، �1)<دمنستی(د1،�2). از سوی دیگر، f 4 به طور کامل تحت سلطه f 1 نیست ، اگرچه �1⊏س �4ولی دمنستی(د1، �1)≮دمنستی(د1،�4).
جفت غالب (DP):
دو جفت داده شده است د⊗�آو د⊗�ب، د⊗�آگفته می شود مسلط است د⊗�ب، اگر دمنستی(د،�آ)<دمنستی(د،�ب)و �آ⊏س �ب. مجموعه جفت هایی که تحت سلطه هیچ جفت دیگری نیستند د⊗افمنبه عنوان مجموعه غالب معرفی می شوند دیپ(د،افمن).
لم 1:
یک شیء ویژگی �” یک شی غالب است اگر و فقط اگر برای هر شیء ویژگی دیگری f برای آن �”⊑س �، دمنستی(د، �”)< دمنستی(د،�).
اثبات:
برهان مستقیم است و بنابراین حذف می شود. به طور شهودی، لمای 1 بیان می کند که �”یک شی غالب است اگر �”از هر جسم دیگر f به d نزدیکتر است و از نظر ابعاد استاتیک حداقل به خوبی f است (یعنی،�”⊑س �).
در شکل 2 ، f 2 یک شی غالب d 1 نیست زیرا یک شیء ویژگی f 1 به گونه ای وجود دارد که �1⊏س �2و دمنستی(د1،�1)<دمنستی(د1،�2). از این رو، f 2 کاملاً تحت تسلط f 1 است ، و بنابراین هرس می شود، در حالی که، f 4 یک شی غالب است زیرا به d 1 نزدیکتر است . در اینجا، توجه داشته باشید که f 3 نمی تواند یک شی غالب برای آبجکت داده d 1 باشد زیرا ما یک شبکه جاده هدایت شده را در نظر می گیریم و هیچ مسیری به f 3 از d 1 وجود ندارد .
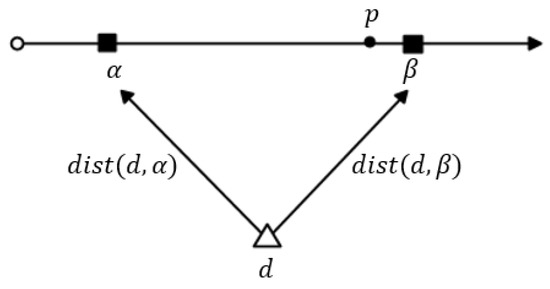
شکل 3 نقشه برداری را نشان می دهد دی⊗افمنبه فضای امتیاز فاصله M . ما به طور رسمی فضای امتیاز فاصله را در بخش 4.3 تعریف می کنیم . مربع سیاه نگاشت جفت ها را نشان می دهد د⊗�جایی که د∈دیو �∈افمن. حال، با اعمال رابطه تسلط بر روی نقشه برداری در شکل 3 a، آن جفت را پیدا می کنیم د1⊗�2کاملا تحت سلطه است د1⊗�1. از این رو، دیپ(د1،افمن)= د1⊗�4، د1⊗�1. شکل 3 ب نشان می دهد که د2⊗�5، د2⊗�7، د2⊗�3و د2⊗�1جفت تحت سلطه هستند. به طور مشابه، شکل 3 ج نگاشت را نشان می دهد د3⊗افمن، و مشخص است که هر دو جفت د3⊗�10و د3⊗�9تحت سلطه هیچ جفت دیگری نیستند.
4.2. گروه بندی
در این بخش، رویکرد خود را برای گروه بندی اشیاء ویژگی شرح می دهیم. مرحله هرس تعداد اشیاء ویژگی را کاهش می دهد، اما می توان با ادغام آنها در یک گروه، این میزان را بیشتر کاهش داد. علاوه بر این، تکنیک گروهبندی اندازه مجموعه خط آسمان و ورودیهای R-tree [ 29 ] را کاهش میدهد و در نتیجه کارایی الگوریتم را با به حداقل رساندن مصرف حافظه مورد نیاز افزایش میدهد. همانطور که قبلا ذکر شد، امتیاز برای شی داده d از امتیاز اشیاء ویژگی محاسبه می شود �∈افمنکه مستلزم آن است که هر جفت شی ( d, f ) را بررسی کنیم. اگر تعداد اشیاء ویژگی بیش از حد زیاد باشد، عملکرد الگوریتم به شدت کاهش می یابد. بنابراین، هدف اصلی از گروه بندی کاهش بیشتر تعداد اشیاء ویژگی با گروه بندی آنها است که در نتیجه تعداد جفت ها کاهش می یابد. بنابراین، به جای ارزیابی جفت های فردی د⊗�، الگوریتم ما ارزیابی می کند د⊗�، که در آن g یک گروه ویژگی را نشان می دهد و مجموعه ای از گروه های ویژگی به صورت G i نشان داده می شود . گروه بندی اشیاء ویژگی دو مزیت اصلی به شرح زیر دارد.
-
محاسبه بالاترین امتیاز یک شی داده آسان است.
-
هزینه محاسباتی و مصرف حافظه با کاهش تعداد جفت ها کاهش می یابد.
4.2.1. روش گروه بندی
اکنون روش گروه بندی اشیاء ویژگی بر اساس گره های محوری را مورد بحث قرار می دهیم. ما تکنیک یافتن حداقل گره های محوری را در بخش 3.3 شرح داده ایم . برای گروه بندی، هر شیء ویژگی با یکی از گره های محوری مرتبط است. در مرحله هرس، اشیاء ویژگی غالب برای هر شی داده را پیدا می کنیم. اشیاء ویژگی غالب هر شی داده با هم گروه بندی می شوند اگر با گره محوری یکسانی مرتبط باشند. در مطالعه قبلی خود [ 12 ]، ما تمام اشیاء ویژگی متصل به یک گره محوری را گروه بندی کردیم، در نتیجه یک گروه ویژگی در هر گره محوری ایجاد شد. با این حال، در برخی موارد، بیش از یک گروه ویژگی ممکن است با یک گره محوری منفرد مرتبط شود، اگر اشیاء ویژگی غالب چندین شی داده، گره محوری یکسانی را به اشتراک بگذارند.
اجازه دهید همان مثال نشان داده شده در شکل 2 را در نظر بگیریم ، جایی که گره �2گره محوری است و اشیاء ویژگی f 1 , f 2 , f 3 و f 4 به آن متصل هستند. همانطور که در بخش 4.1 ذکر شد ، برای شی داده d 1 اشیاء غالب f 1 و f 4 هستند در حالی که شیء ویژگی f 2 و f 3 هرس می شوند. با این حال، برای شی داده d 2 ; f 1 و f 3 غالب است در حالی که f 2 و f 4هرس می شوند. بنابراین دو گروه تشکیل می شود {�1،�4} ∈�1و {�1،�3} ∈�2،که با گره محوری مرتبط هستند �2. جدول 3 گروه بندی اشیاء ویژگی را خلاصه می کند.
4.2.2. محاسبه امتیاز گروه س(�)
با توجه به امتیاز جداگانه هر شیء ویژگی، محاسبه امتیاز جزئی �من�(د)برای تعداد زیادی از اشیاء ویژگی پرهزینه می شود. ما یک روش جدید برای محاسبه نمرات جزئی بر اساس امتیاز گروه نشان داده شده ابداع کردیم س(�). امتیاز گروه بالاترین امتیاز برای هر شیء ویژگی است که به یک گروه تعلق دارد به طوری که شرایط محله را واجد شرایط می کند. جدول 3 نشان می دهد که {�1،�4} ∈�1، س(�1)=0.9و س(�4)=0.5. از این رو، س(�1)=0.9که بالاترین امتیاز شی ویژگی متعلق به آن است �1. امتیاز سایر گروه ها را می توان به روشی مشابه محاسبه کرد.
نمره جزئی �من�با استفاده از س(�)را می توان به صورت زیر تعریف کرد:
-
محدوده ( rng ) امتیاز d : �من���(د)=مترآایکس{س(�)|� ∈ جیمن :مترآایکسدمنستی(د،�)≤�}
-
نزدیکترین همسایه ( nn ) امتیاز d :�من��(د)=مترآایکس{س(�)|� ∈ جیمن، ∀جی�∈ جیمن :مترمن�دمنستی(د،�)≤مترمن�دمنستی(د،��)}
-
نمره تأثیر ( inf ) از d : �منمن��(د)=مترآایکس{س(�)×2-مترآایکسدمنستی(د،�)� | �∈جیمن}
ما فرمول های ارائه شده در بخش 3.2 را برای محاسبه امتیاز جزئی اصلاح می کنیم�من�با استفاده از امتیاز گروه س(�)به جای امتیاز ویژگی س(�). تنها تفاوت این است مترآایکسدمنستی(د،�)به جای استفاده می شود دمنستی(د،�)برای دامنه و نمره نفوذ در حالی که مترمن�دمنستی(د،�)به جای استفاده می شود دمنستی(د،�)برای نمره نزدیکترین همسایه
4.2.3. محاسبه فاصله بین شی داده و گروه ویژگی
در این بخش، لم ها را برای محاسبه حداقل و حداکثر فاصله بین یک شی داده و گروه ویژگی ارائه می کنیم. زیر مجموعه جفت ها د⊗�بازیابی شده در مرحله گروه بندی در یک درخت R [ 17 ] نمایه می شود، جایی که لازم است حداقل و حداکثر فاصله بین یک شی داده و گروه ویژگی محاسبه شود. لم 2 محاسبات را ارائه می دهد مترمن�دمنستی(د،�)، در حالی که لمای 3 و 4 محاسبه را توصیف می کنند مترآایکسدمنستی(د،�)برای د∈��→و د∉��→، به ترتیب.
لم 2:
با توجه به یک شی داده و یک گروه ویژگی g ، مترمن�دمنستی(د،�)به شرح زیر است:
مترمن�دمنستی(د،�)= {0 من� د ∈�ممنن{دمنستی(د،�)|∀�∈�} �تیساعته��منسه }
اثبات:
این لم بدیهی است، بنابراین اثبات حذف شده است. اینجا، �نقطه مرزی گروه ویژگی را نشان می دهد. برای �2، {�1،�3} ∈�، مترمن�دمنستی(د2،�2)=ممنن{دمنستی(د2،�1)،دمنستی(د2،�3)}.
ما یک شبکه جاده هدایت شده را در نظر می گیریم و در نتیجه تعیین می کنیم مترآایکسدمنستی(د، �)، ارزیابی لازم است مترآایکسدمنستی(د،��→ )و مترآایکسدمنستی(د،��¯ )،جایی که، ��→و ��¯به ترتیب به بخش های جهت دار و غیر جهت دار مراجعه کنید. برای محاسبه مترآایکسدمنستی(د،��→ )، ما این دو مورد را جداگانه بررسی می کنیم: (1) د∈��→و (2) د∉��→. برای مترآایکسدمنستی(د،��¯ )ما از روش ارائه شده توسط چو و همکاران استفاده می کنیم. در [ 11 ].
لم 3:
اگر د∈��→، پس دو مورد زیر وجود دارد:
(مورد 3 الف):
اگر مسیری از �به �وجود دارد، مترآایکسدمنستی(د،��→ )= له�(د،�)+دمنستی(�،�)+له�(�،د)
مترآایکسدمنستی(د،��→ )=له�(�،�)+دمنستی(�،�)
اثبات:
اجازه دهید فرض کنیم که �و β نقاط مرزی در بخش جاده هستند که به یک گروه ویژگی تعلق دارند و شی داده d بین آنها قرار دارد ��→.همانطور که در شکل 4 نشان داده شده است، یک نقطه p وجود دارد که مترآایکسدمنستی(د، ��→)=مآایکس{دمنستی(د، پ)|∀پ∈��→}. با توجه به شکل 4 ، بدیهی است که دمنستی(د،پ)=له�(د،�)+دمنستی(�،�)+له�(�،پ). از معادله بالا مشاهده می کنیم که مقدار فاصله با مقدار افزایش می یابد له�(�،پ)بنابراین برای به دست آوردن حداکثر مقدار فاصله، نقطه p باید بسیار نزدیک به d باشد و بنابراین می توان گفت که د≅پ. بنابراین، می توانیم معادله بالا را به صورت بازنویسی کنیم مترآایکسدمنستی(د،��→ )= له�(د،�)+دمنستی(�،�)+له�(�،د)که برابر است با مترآایکسدمنستی(د،��→ )=له�(�،�)+دمنستی(�،�).
(مورد 3 ب):
اگر هیچ مسیری وجود نداشته باشد �به �، مترآایکسدمنستی(د،��→ )=له�(د،�)
اثبات:
این لم بدیهی است، بنابراین اثبات حذف شده است.
لم 4:
اگر د∉��→، سپس مترآایکسدمنستی(د،��→ )به شرح زیر است:
مترآایکسدمنستی(د،��→ )=مآایکس{دمنستی(د،�)+له�(�،�)،دمنستی(د،�)}
اثبات:
طبق تعریف مترآایکسدمنستی(د، ��→)=مآایکس{دمنستی(د، پ)|∀پ∈��→}. همانطور که در شکل 5 نشان داده شده است ، واضح است که ما حداکثر فاصله d تا p را زمانی به دست می آوریم که نقطه p بسیار نزدیک به �، و بنابراین می توانیم بگوییم �≅پ. دو مسیر از d به وجود دارد�: د→�→�و د→�، و بنابراین دمنستی(د،� )=دمنستی(د،�)+له�(�،�)یا دمنستی(د،� )=دمنستی(د،�).بنابراین، می توان گفت که مترآایکسدمنستی(د،��→ )=مآایکس{دمنستی(د،�)+له�(�،�)،دمنستی(د،�)}.
جدول 4 حداقل و حداکثر فاصله را به همراه امتیاز برای آن خلاصه می کند د⊗�در شکل 2 .
4.3. نقشه برداری به فضای امتیاز فاصله
در این بخش، ما به طور رسمی فضای جستجوی پرس و جوهای ترجیحی فضایی top- k را با تعریف نگاشت اشیاء داده d و هر گروه ویژگی g به فضای امتیاز فاصله تعریف می کنیم. اجازه دهید د⊗�یک جفت شامل شی داده را نشان می دهد د∈دیو یک گروه ویژگی �∈جیمن، سپس د⊗�به عنوان نشان داده شده است {[مترمن�دمنستی(د،�)،مترآایکسدمنستی(د،�)]،س(�)}. هر یک د⊗�جفت به یک نقطه یا یک پاره خط در فضای امتیاز فاصله M که توسط محورها تعریف شده است نگاشت می شود.دمنستی(د،�)و س(�)، جایی که دمنستی(د،�)مربوط به فاصله بین شی داده d و گروه ویژگی g و استس(�)مربوط به امتیاز از �.
تعریف 2:
(نقشه برداری از دی⊗جیمن به M): نگاشت جفت ها د⊗� شامل یک شی داده د∈دی و یک گروه ویژگی � ∈جیمن به فضای 2 بعدی M (به نام فضای امتیاز فاصله) است دی⊗جیمن= {د ⊗� | د∈دی، �∈جیمن}.
در ادامه، رابطه تسلط را تعریف می کنیم که زیرمجموعه جفت های M است که مجموعه خط آسمان M را تشکیل می دهد که به صورت نشان داده می شود. اس=اسک�(م). مجموعه افق S مجموعه ای از جفت است (د⊗�)∈مکه تحت سلطه هیچ جفت دیگری نیستند د⊗�”∈م .
تعریف 3:
(سلطه ⊏م): دو جفت داده می شود (د⊗�)∈م گفته می شود که بر یک جفت دیگر تسلط دارد (د⊗�”)∈م، نشان داده شده است (د⊗�) ⊏م (د⊗�”)، اگر مترآایکسدمنستی(د، �)≤ مترمن�دمنستی(د،�”) و س(�)>س(�”) یا اگر مترآایکسدمنستی(د، �)< مترمن�دمنستی(د،�”) و س(�)≥س(�”).
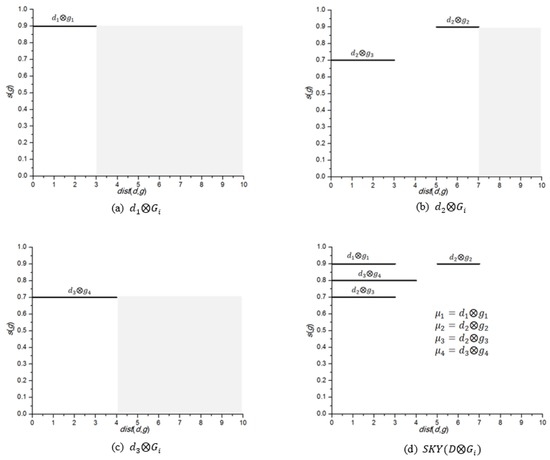
اجازه دهید اسک�(د⊗جیمن)مجموعه ای از تمام جفت هایی باشد که تحت سلطه هیچ جفت دیگری نیستند د⊗جیمن. شکل 6 نقشه برداری را نشان می دهد دی⊗جیمندر جدول 4 به فاصله امتیاز فاصله M . شکل 6 a نقشه برداری از د1⊗جیمن، شکل 6 ب نگاشت را نشان می دهد د2⊗جیمنو شکل 6 ج نگاشت را نشان می دهد د3⊗جیمن. مجموعه افق از د1⊗جیمن، د2⊗جیمنو د3⊗جیمنهستند اسک�(د1،جیمن)={د1⊗�1}، اسک�(د2،جیمن)={د2⊗�2،د2⊗�3}و اسک�(د3،جیمن)={د3⊗�4}، به ترتیب. جفت های مربوط به اشیاء داده های مختلف (به عنوان مثال، د1⊗جیمنو د2⊗جیمن) قطعا غیر قابل مقایسه هستند. سرانجام، خط افق تعیین شد دی⊗جیمناتحاد مجموعه های خط آسمان همه اشیاء داده است د∈دی. بنابراین، شکل 6 d مجموعه افق را نشان می دهد، اسک�(دی⊗جیمن) = اسک�(د1،جیمن)∪را اسک�(د2،جیمن)∪را اسک�(د3،جیمن) = {د1⊗�1، د2⊗�2،د2⊗�3،د3⊗�4}.
توجه کنید که در شکل 6 الف، د1⊗�1در 0.9 ترسیم شده است زیرا س(�1)=0.9. لازم به ذکر است که س(�)با توجه به شرایط محله قابل تغییر است. همانطور که قبلا توضیح داده شد، س(�1)=0.9زیرا {�1،�4} ∈�1و س(�1)=0.9. حال اگر شرط محدوده را در نظر بگیریم �=2، س(�1)≠0.9، زیرا دمنستی(د1،�1)=3، که شرایط محله را برآورده نمی کند. در این سناریو، س(�1)به 0.5 تغییر می کند که امتیاز آن است �4. بدین ترتیب، د1⊗�1در 0.5 نقشه برداری شده است.
شکل 7 a نقشه برداری از اسک�(دی⊗جیمن)به م . شکل 7 ب، از سوی دیگر، یک درخت R را نشان می دهد که چهار جفت را نمایه می کند. اسک�(دی⊗جیمن)با فرض اینکه ظرفیت گره R-tree روی 3 تنظیم شده است. بنابراین، گره شاخص R 2 را در بر می گیرد .د1⊗�1و د2⊗�2، در حالی که گره شاخص R 3 را در بر می گیرد د3⊗�4و د2⊗�3. در نهایت، Lemma 5 را ارائه می کنیم که این را ثابت می کند اسک�(د⊗جیمن)برای تعیین امتیاز جزئی هر شی داده کافی است د∈دی.قبل از ارائه Lemma 5، به یاد بیاورید که هر ویژگی شی است �∈�یک شیء ویژگی غالب است و هیچ شیء ویژگی دیگری بر آن مسلط نیست �”.
لم 5:
برای هر درخواست اولویت مکانی، اسک�(د⊗جیمن) برای تعیین نمره جزئی کافی است �من�(د) از یک شی داده د∈دی.
اثبات:
این را فرض کنیم اسک�(د⊗جیمن)برای کسب نمره جزئی کافی نیست �من�(د)از یک شی داده د∈دی. این به این معنی است که یک گروه ویژگی وجود دارد �بکه به �من�(د). اگر الان �=���یا �=��، سپس �من�(د)=س(�ب)، و اگر �=من��، سپس �من�(د)=س(�ب)×2-مترآایکسدمنستی(د،�ب)�. با این حال، یک جفت (د⊗�ب)∉اسک�(د⊗جیمن)به طوری که یک جفت دیگر وجود دارد د⊗�آ⊏د⊗�بو (د⊗�آ)∈اسک�(د⊗جیمن)،که معادل هر دو است مترآایکسدمنستی(د، �آ)≤ مترمن�دمنستی(د،�ب)و س(�آ)>س(�ب)یا اگر مترآایکسدمنستی(د، �آ)< مترمن�دمنستی(د،�ب)و س(�آ)≥س(�ب). بنابراین، نمره جزئی d است �من�(د)=س(�آ)اگر �=���یا �=��، و �من�(د)=س(�آ)×2-مترآایکسدمنستی(د،�آ)�اگر �=من��. این با فرض ما در تضاد است �بکمک می کند �من�(د). از این رو، اسک�(د⊗جیمن)برای بدست آوردن امتیاز جزء یک شی داده کافی است د∈دی.
4.4. محدودیت های الگوریتم های غیر جهت دار در شبکه های راه هدایت شده
بر خلاف شبکه های جاده ای بدون جهت، فاصله شبکه بین دو گره در شبکه های راه هدایت شده متقارن نیست، به عنوان مثال، دمنستی(�من،��) ≠دمنستی(��،�من). شکل 8 a یک شبکه جاده بدون جهت را نشان می دهد که در آن دو شی داده d 1 و d 2 و دو شیء مشخصه f 1 و f 2 وجود دارد . برای ساده کردن ارائه، ما یک مجموعه داده ویژگی را در نظر می گیریم افمن={�1،0.6،�2،0.8}.
اجازه دهید اکنون امتیازات اشیاء داده را ارزیابی کنیم. فرض کنید که شرط همسایگی محدوده و مقدار محدودیت محدوده r = 3 باشد. امتیاز دامنه d 1 0.8 است زیرا س(�2)=0.8و دمنستی(د1، �2) ≤�. به طور مشابه، امتیاز دامنه d 2 0.6 است زیرا س(�1)=0.6و دمنستی(د2، �1) ≤�. بنابراین، d 1 نتیجه اول با است ����(د1)=0.8.
حال، شبکه راه هدایت شده را همانطور که در شکل 8 ب نشان داده شده است، فرض کنید. در این مورد، امتیاز دامنه d 1 0 است زیرا هیچ شیء ویژگی در فاصله r وجود ندارد. با این حال، امتیاز دامنه d 2 ثابت می ماند زیرا f 1 هنوز در فاصله r وجود دارد . بنابراین، در شبکه راه هدایت شده، d 2 نتیجه برتر 1 است ����(د2)=0.6. این مثال به وضوح نشان می دهد که یک الگوریتم مبتنی بر یک شبکه جاده های هدایت نشده را نمی توان برای شبکه های جاده های هدایت شده اعمال کرد.
مطالعه تحقیقاتی نزدیک به کار حاضر توسط چو و همکاران ارائه شده است. [ 11 ]. آنها الگوریتمی به نام ALPS برای پردازش پرس و جوهای ترجیحی در شبکههای جادهای بدون جهت ارائه کردند، جایی که اشیاء داده در یک دنباله جاده گروهبندی میشوند تا یک بخش داده را در رویکرد خود تشکیل دهند. انگیزه پشت گروه بندی اشیاء داده این است که اشیاء داده در یک دنباله به یکدیگر نزدیک هستند، بنابراین پردازش آنها با هم کارآمدتر است تا اینکه هر شی داده به طور جداگانه مدیریت شود. با این حال، ALPS در پاسخ به سؤالات ترجیحی در شبکههای جادهای هدایتشده کوتاهی میکند.
اکنون، ما ارائه می دهیم که چرا ALPS نمی تواند پرس و جوهای ترجیحی را در شبکه های جاده هدایت شده پردازش کند. یک جاده جهت دار را در شکل 9 در نظر بگیرید که در آن چهار شی داده d 1 , d 2 , d 3 و d 4 و دو شی مشخص f 1 و f 2 وجود دارد که به ترتیب به صورت مثلث و مستطیل نشان داده می شوند. اشیاء داده d 1 و d 2 که در یک دنباله قرار دارند، گروه بندی شده و به بخش داده تبدیل می شوند. د1د2¯و اشیاء داده d 3 و d 4 به تبدیل می شوند د3د4¯. مشاهده کنید که، گروه بندی از د3د4¯معتبر نیست زیرا هیچ مسیری برای اتصال d 3 به d 4 وجود ندارد ، همانطور که در شکل 9 نشان داده شده است .
موضوع دیگر نمایه سازی بخش های داده و جفت اشیاء ویژگی در R-tree برای شبکه های جاده هدایت شده است. اجازه دهید دسه�⊗�جفتی را نشان میدهد که از یک بخش داده dseg و شیء f تشکیل شده است . برای ایندکس کردن یک جفت در درخت R، لازم است حداقل و حداکثر فاصله بین بخش داده dseg و یک شی ویژگی f محاسبه شود . در شکل 9 ، مطابق با محاسبه ALPS مترمن�دمنستی(د1د2¯،�1)=2و مترآایکسدمنستی(د1د2¯،�1)=4. برعکس، واقعی مترآایکسدمنستی(د1د2¯،�1)=6. ALPS حداقل و حداکثر فاصله بین بخش داده و شی ویژگی را بر اساس این فرض محاسبه می کند که دمنستی(د1،د2)=دمنستی(د2،د1)، اما این فرض در یک شبکه راه هدایت شده قابل اجرا نیست که در آن دمنستی(د1،د2)≠دمنستی(د2،د1). بنابراین، ALPS یک درخت R اشتباه ایجاد می کند که منجر به نتایج نادرست می شود. مثال بالا نشان می دهد که ALPS برای شبکه های جاده هدایت شده کار نمی کند. برای ALPS، برای پاسخ به سوالات ترجیحی در یک شبکه جاده هدایت شده، روش گروه بندی و محاسبه مترمن�دمنستی(دسه�،�)و مترآایکسدمنستی(دسه�،�)باید برای در نظر گرفتن جهت خاص هر بخش جاده اصلاح شود.
با مقایسه مفهومی ALPS و TOPS، ALPS گروه بندی اشیاء داده را در بخش های داده اتخاذ می کند در حالی که TOPS اشیاء ویژگی را گروه بندی می کند. ALPS ابتدا اشیاء داده را در بخشهای داده گروهبندی میکند و سپس جفتهای غالب را که ممکن است جفتهای اضافی در درخت R را اجازه دهد، هرس میکند. با این حال، TOPS ابتدا جفت ها را هرس می کند تا از هر جفت اضافی جلوگیری شود و سپس آنها را بر اساس گره های محوری گروه بندی می کند. بنابراین، زمان پردازش پرس و جو می تواند در ALPS زیاد باشد. به طور مشابه، به دلیل تعداد بیشتر جفتهای اضافی، ALPS ممکن است از اندازه دیسک بیشتری برای نمایهسازی مجموعههای افق استفاده کند. با این حال، زمان ساخت شاخص ALPS میتواند بهتر از TOPS باشد، زیرا به دلیل گروهبندی اشیاء داده، باید تعداد مجموعههای خط افق کمتری تولید شود.
5. الگوریتم پرس و جو ترجیح مکانی Top- k
در این بخش، ما الگوریتم پرس و جو ترجیح فضایی Top – k (TOPS) را برای پرس و جوهای اولویت مکانی top- k ارائه می کنیم . TOPS برای هر سه شرایط همسایگی (محدوده، نزدیکترین همسایه و نفوذ) مناسب است، اما ما محدودیت محدوده را برای ساده کردن توضیح مورد بحث قرار می دهیم. سپس اصلاحات لازم را برای حمایت از نزدیکترین همسایه و نمرات تأثیرگذاری ارائه می کنیم. الگوریتم ما پرس و جو ترجیحی top- k را با دسترسی متوالی به اشیاء داده به ترتیب نزولی امتیاز جزئی آنها پردازش می کند. برای دستیابی به این هدف، TOPS اشیاء دادهای واجد شرایط را یک به یک در طول پردازش پرس و جو به ترتیب نزولی بر اساس امتیازات جزئی آنها بازیابی میکند، که میتواند به سرعت مجموعهای از k را تولید کند.اشیاء داده برتر با بالاترین امتیاز.
الگوریتم 1 با جمع کردن امتیازهای جزئی اشیاء دادهای که از هر پشته حداکثری H i به دست میآید، شیء دادهای top- k را با بالاترین امتیاز محاسبه میکند . برای هر مجموعه افق، اسک�(دی⊗جیمن)، ما از یک max heap H i برای پیمایش اشیاء داده به ترتیب نزولی امتیاز جزء آنها استفاده می کنیم. هر زمان که نهایکستیاچمن�ساعتهستیآرآ��هاسج��ه�ب�هجتی(اچمن،�)روش نامیده می شود، شی داده d high با بالاترین امتیاز جزء �من�(دساعتمن�ساعت)از حداکثر پشته H i بیرون آمده است . فرض کنید D k مجموعه k بالای فعلی باشد و R i امتیاز مؤلفه اخیر در H i باشد . علاوه بر این، TOPS فهرستی از اشیاء داده کاندید Dc را نگهداری می کند که ممکن است به اشیاء داده top- k تبدیل شوند . R i تنظیم شده است �من�(دساعتمن�ساعت)(خط 6) و نمره کران پایین �لب�(دساعتمن�ساعت)همچنین با استفاده از تابع جمع (خط 7) به روز می شود. اگر تعداد اشیاء داده در D k کمتر از k یا باشد�لب�(دساعتمن�ساعت)از k- امین بالاترین امتیاز شی داده در D k بیشتر است ، سپس d high به D k اضافه می شود . اگر d high از قبل در D c باشد، از لیست D c حذف خواهد شد . اگر تعداد اشیاء داده در D k = k + 1، شی داده با کمترین �لب�از D k به D c منتقل می شود (خط 8-12). سپس t روی کمترین مقدار تنظیم می شود �لب�از اشیاء داده در D k (خط 13). نمره کران بالا �توب�(د)برای هر شی داده محاسبه می شود د∈دیج.
| الگوریتم 1: TOPS ( H i ، k ، r ) | |||||
| ورودی: H i : یک پشته حداکثر با ورودیها به ترتیب نزولی امتیاز محدوده جزئی، k : تعداد دادههای درخواستی با بالاترین امتیاز، r : محدودیت محدوده | |||||
| خروجی: Top- k اشیاء داده با بالاترین امتیاز | |||||
| 1: | دیج←∅/* مجموعه ای از اشیاء داده کاندید */ | ||||
| 2: | دیک←∅/* مجموعه Top-k فعلی */ | ||||
| 3: | آرمن←o/* امتیاز جزئی اخیر که در H i دیده می شود | ||||
| 4: | در حالی که ∃ H i طوری که اچمن≠∅ انجام دادن | ||||
| 5: | دساعتمن�ساعت،|�من�(دساعتمن�ساعت)←نهایکستیاچمن�ساعتهستیآرآ��هاسج��ه�ب�هجتی(اچمن،�) | ||||
| 6: | آرمن←�من�(دساعتمن�ساعت)/* شی داده پاپ با بالاترین امتیاز از H i */ | ||||
| 7: | �لب�(دساعتمن�ساعت)← �لب�(دساعتمن�ساعت)+�من�(دساعتمن�ساعت) | ||||
| 8: | اگر تعداد اشیاء داده در دیک<ک یا �لب�(دساعتمن�ساعت)>تی سپس | ||||
| 9: | دیک←دیک∪رادساعتمن�ساعت | ||||
| 10: | اگر دساعتمن�ساعت∈دیج سپس دیج←دیج-دساعتمن�ساعت | ||||
| 11: | اگر تعداد اشیاء داده در دیک=ک+1سپس | ||||
| 12: | دیک←دیک-دک+1 و دیج←دیج∪رادک+1 | ||||
| 13: | تی←مترمن�{�لب�(د)|د∈دیک} | ||||
| 14: | دیگر | ||||
| 15: | دیج←دیج∪رادساعتمن�ساعت/* اگر دساعتمن�ساعت∉دیکسپس آن را در D c */ اضافه کنید | ||||
| 16: | برای هر شی داده د∈دیج انجام دادن | ||||
| 17: | �توب�(د)← �لب�(د)+ستومتر{آرمن|من=1،….،متر} | ||||
| 18: | اگر �توب�(د)<تی سپس دیج←دیج-د | ||||
| 19: | تو←مترآایکس{�توب�(د)|د∈دیج} | ||||
| 20: | اگر تی≥توو تعداد اشیاء داده در دیک=ک سپس | ||||
| 21: | عبارت break while | ||||
| 22: | بازگشت D k | ||||
در نهایت، برای هر شیء کاندید در Dc ، امتیاز کران بالایی �توب�(د)محاسبه می شود �توب�(د)←�لب�(د)+ستومتر{آرمن|من=1،…،متر س.تی �من�(د)ساعتآس ��تی بهه� سهه� س� �آ�}. حداکثر �توب�(د)سپس روی u تنظیم می شود (خطوط 16-19). اگر تی≥توآنگاه هیچ شیء داده ای تازه مشاهده شده به D k ختم نمی شود . بنابراین ، الگوریتم خاتمه یافته و D k را برمی گرداندتی≥توو تعداد اشیاء داده در دیک=ک، یا اگر تمام پشته ها تمام شده باشند (خطوط 20-22).
به منظور نشان دادن الگوریتم پیشنهادی خود، اجازه دهید مثال ارائه شده در شکل 7 را در نظر بگیریم ، جایی که درخت R برای نمایه سازی مجموعه خط آسمان نشان داده شده است. اسک�(دی⊗جیمن)که با استفاده از مثال در شکل 2 ساخته شده اند . به یاد می آوریم که هتل ها با اشیاء داده مطابقت دارند دی={د1،د2،د3}و کافه ها با اشیاء ویژگی مطابقت دارند اف={�1،�2،…،�10}. بیایید در نظر بگیریم که مشتری پرس و جوی زیر را از پرس و جو ترجیح فضایی top-k درخواست کرده است: “دو هتل را پیدا کنید که با یک کافه درجه یک مرتبط هستند که در فاصله 4 قرار دارند”. به یاد می آوریم که در این پرس و جو، ک=2و �=4. پس از هرس و گروه بندی، مجموعه افق تولید نهایی در شکل 7 الف نشان داده شده است. اسک�(دی⊗جی)={د1⊗�1،د2⊗�2،د2⊗�3،د3⊗�4}. الگوریتم تمام جفت های واجد شرایط را بر اساس شرایط همسایگی بررسی می کند �=4.سه جفت �1،�3و �4یکی یکی از R بازیابی می شوند و روی یک پشته حداکثر H قرار می گیرند . بدین ترتیب، اچ={�1،�3،�4}={د،����(د)|د1،0.9د3،0.8د2،0.7}. در نهایت، d 1 و d 3 به عنوان نتیجه جستجوی Top-2 انتخاب می شوند زیرا به ترتیب دارای امتیاز 0.9 و 0.8 هستند.
الگوریتم 2 اشیاء داده را برمی گرداند د∈اچمنیکی یکی به ترتیب نزولی بر اساس امتیاز جزئی آنها �من���(د). در ابتدا، پشته H i حاوی گره ریشه یک درخت R است. H i شامل رکوردهای rc است که می تواند شی داده یا گره درخت R باشد. هر بار رکورد rc با بالاترین امتیاز جزئی از H i ظاهر می شود . اگر rc یک گره درخت R را نشان دهد (خط 3)، آنگاه الگوریتم بررسی می کند که آیا گروه ویژگی شرایط همسایگی را برآورده می کند یا خیر. مترآایکسدمنستی(د،�)≤�. اگر ورودی s شرایط همسایگی را برآورده کند، به آن اضافه می شود اچمن(خط 4 و 5). اگر شرایط همسایگی را برآورده نمی کند، که به معنای یک شیء ویژگی است �∈�به گونه ای وجود دارد که دمنستی(د،�)>�. بنابراین، هر شیء ویژگی �∈�برای تایید آن باید بررسی شود دمنستی(د،�)≤�(خط 8). تمام رکوردهای واجد شرایط در Heap H i درج می شوند و بالاترین امتیاز از هر شیء ویژگی به عنوان امتیاز گروهی s(g) اختصاص داده می شود (خطوط 9، 10). در نهایت، هنگامی که شی داده d یافت شد، به عنوان برگردانده می شود دساعتمن�ساعتبا بالاترین امتیاز جزئی (خطوط 15، 17).
الگوریتم 2 را می توان با تغییرات جزئی به نزدیکترین همسایه تطبیق داد و نمرات را تحت تأثیر قرار داد. برای امتیاز نزدیکترین همسایه، جفت ها د⊗�طوری هرس می شوند که f نزدیک ترین همسایه d نباشد . بنابراین، در طول ساخت و ساز از اسک�(د⊗جیمن)، اشیاء داده پرچم گذاری می شوند تا نشان دهند که f نزدیک ترین همسایه d است یا نه (اگر f نزدیک ترین همسایه باشد بیت 1 و در غیر این صورت بیت 0). برای امتیاز تأثیر، شعاع r فقط برای محاسبه امتیاز استفاده می شود و امتیاز شی ویژگی به نسبت فاصله تا یک شی داده کاهش می یابد. بنابراین، شرایط تأیید از الگوریتم 2 (خط 4 و 8) برای امتیاز تأثیر از الگوریتم حذف می شود. بنابراین، برای هر شیء ویژگی �∈�، امتیاز تأثیر مؤلفه با توجه به شی ویژگی محاسبه می شود و ورودی مربوطه به آن اضافه می شود اچمن.
| الگوریتم 2: امتیاز بعدی بالاترین دامنه ( H i , r ) | ||
| ورودی: H i : یک پشته حداکثر با ورودی ها به ترتیب نزولی امتیاز محدوده جزئی، r : محدودیت محدوده | ||
| خروجی: شی داده بعدی در H i با بالاترین امتیاز جزئی | ||
| 1: | �هج��د �ج ←پ�پ �هج��د ���متر اچمن | |
| 2: | در حالی که �ج∉دآتیآ �ب�هجتی انجام دادن | |
| 3: | برای هر رکورد س∈کودک از rج انجام دهید | |
| 4: | اگر مترآایکسدمنستی(د،�)≤� سپس | |
| 5: | رکورد s را به H i فشار دهید | |
| 6: | دیگر | |
| 7: | برای هر شیء ویژگی �∈�انجام دادن | |
| 8: | اگر دمنستی(د،�)≤� سپس | |
| 9: | رکورد s را به H i فشار دهید | |
| 10: | محاسبه س(�) | |
| 11: | پایان اگر | |
| 12: | پایان برای | |
| 13: | پایان اگر | |
| 14: | پایان برای | |
| 15: | �ج ←پ�پ �هج��د ���متر اچمن | |
| 16: | پایان در حالی که | |
| 17: | بازگشت rc | |
تعمیر و نگهداری افزایشی
در این بخش، ما در مورد حفظ تدریجی مجموعه افق در طی فرآیندهای درج، حذف و به روز رسانی داده ها و اشیاء ویژگی بحث می کنیم. ما از انطباق خط افق شاخه و کران (BBS) الگوریتم خط افق پویا برای نگهداری تدریجی مجموعه افق استفاده می کنیم. ابتدا دیپ(دی،افمن)که در مرحله هرس و مجموعه Skyline بازیابی می شود اسک�(دی⊗جیمن)سپس بر اساس به روز رسانی شده دیپ(دی،افمن)تنظیم. هنگامی که مجموعه غالب به روز شد، به روز رسانی گروه و اسک�(دی⊗جیمن)ساده و مستقیم است. درج و حذف اشیاء داده د∈دینسبتا ساده و مقرون به صرفه هستند. هنگامی که یک شی داده جدید d new در D وارد می شود ، همه جفت های غالب د�ه�⊗�به دیپ(د،افمن)مجموعه و اشیاء ویژگی با گره محوری یکسان یک گروه ویژگی را تشکیل می دهند ��ه�.بعد، جفت ها (د�ه�⊗��ه�)در مجموعه افق درج می شوند اسک�(دی⊗جیمن). اگر یک شی داده d حذف شده حذف شود، جفت (ددهلهتیهد⊗جیمن)از مجموعه افق حذف می شوند اسک�(دی⊗جیمن)و همه جفت ها ددهلهتیهد⊗�از دیپ(د،افمن)تنظیم. به روز رسانی های مکان مکانی یک شی داده d به عنوان یک حذف و سپس یک درج پردازش می شود.
در مرحله بعد، در مورد فرآیندهای درج، حذف و به روز رسانی اشیاء ویژگی بحث می کنیم. نمرات اشیاء ویژگی معمولاً در مقایسه با موقعیت مکانی بیشتر به روز می شوند. بنابراین، متداول ترین عملیات تعمیر و نگهداری، به روز رسانی امتیاز یک شی ویژگی است. به روز رسانی امتیاز یک شی ویژگی �∈افمنمی تواند به طور بالقوه بر امتیاز یک گروه تأثیر بگذارد �∈جیمنکه ممکن است مجموعه افق تحقق یافته را تحت تاثیر قرار دهد اسک�(د⊗جیمن). با این حال، هزینه به روز رسانی به دلیل رابطه تسلط زیاد نیست. فرض کنید امتیاز یک شیء ویژگی f به روز شده به روز شده است. در نتیجه، دو مورد زیر ممکن است رخ دهد: (1) مجموعه غالب هنوز معتبر است، (2) مجموعه غالب دیگر معتبر نیست. در حالت اول، اگر دیپ(د،افمن)مجموعه معتبر است، این بدان معناست که مجموعههای افق مادیشده نیز معتبر هستند، بنابراین نیازی به تعمیر و نگهداری نیست و امتیاز f بهروزرسانی شده به سادگی بهروزرسانی میشود. اگر f updated بالاترین امتیاز را در گروه داشته باشد، امتیاز گروه نیز به روز می شود. در حالت دوم، رابطه تسلط را بررسی می کنیم. فقط امتیاز شی ویژگی بهروزرسانی میشود، بنابراین الگوریتم نگهداری به سادگی یک رابطه غالب استاتیک برای بهروزرسانی دیپ(د،افمن)تنظیم. ابتدا بررسی می کنیم که آیا � ⊏س�توپدآتیهدو جفت ها د⊗�توپدآتیهدسپس از دیپ(د،افمن)تنظیم. در مرحله بعد، بررسی می کنیم که آیا شیء ویژگی تحت سلطه f updated است یا خیر . اگر �توپدآتیهد ⊏س�”، سپس جفت ها د⊗�”از دیپ(د،افمن)مجموعه ها در نهایت، اطلاعات مربوط به گروهها (یعنی حداکثر/دقیقه فاصله و s(g) ) بر اساس بهروزرسانی شده دیپ(دی،افمن)مجموعه و اسک�(دی⊗جیمن)تولید می شود.
اجازه دهید اضافه شدن یک شیء ویژگی جدید f new به مجموعه شیء ویژگی F i را در نظر بگیریم . ابتدا باید چک تسلط را اجرا کنیم. اگر یک جفت د⊗��ه�تحت سلطه هر جفت دیگری در دیپ(د،افمن)مجموعه، این بر مجموعه غالب تأثیر نمی گذارد، بنابراین به سادگی کنار گذاشته می شود. با این حال، اگر تحت سلطه هیچ جفت دیگری نباشد، الگوریتم تعمیر و نگهداری یک پرس و جو برای بازیابی همه جفت هایی که تحت تسلط [ د⊗��ه�. اگر هیچ جفتی بازیابی نشد، د⊗��ه�به سادگی به دیپ(د،افمن)تنظیم کنید، در غیر این صورت، الگوریتم نگهداری تمام جفتهای موجود را از دیپ(د،افمن)که تحت تسلط د⊗��ه�. به طور مشابه، اطلاعات مربوط به گروه ها بر اساس به روز شده دیپ(دی،افمن)مجموعه و اسک�(دی⊗جیمن)تولید می شود.
در مرحله بعد، نگهداری از مجموعه افق پس از حذف اشیاء ویژگی را توضیح می دهیم. ابتدا باید بررسی کنیم که آیا د⊗�دهلهتیهد∈دیپ(د،افمن). اگر د⊗�دهلهتیهد∉دیپ(د،افمن)، پس نیازی به پردازش بیشتر نیست. در غیر این صورت، الگوریتم تعمیر و نگهداری نامیده می شود. برای نگهداری افزایشی، باید مجموعه جفت ها را تعیین کنیم د⊗�که به طور انحصاری تحت تسلط د⊗�دهلهتیهد. اگر چنین جفتهایی وجود داشته باشند، جفتهای غالب برای این جفتها محاسبه میشوند و به دیپ(د،افمن)تنظیم؛ در غیر این صورت، د⊗�دهلهتیهدبه سادگی از دیپ(د،افمن)تنظیم. در نهایت، همانطور که قبلا ذکر شد، اطلاعات مربوط به گروه ها بر اساس به روز شده دیپ(دی،افمن)مجموعه و اسک�(دی⊗جیمن)تولید می شود.
در نهایت، ما پیچیدگی های زمانی اضافه کردن، حذف و به روز رسانی یک شی داده و یک شی ویژگی را تجزیه و تحلیل می کنیم. همانطور که قبلا ذکر شد، تعمیر و نگهداری افزایشی در د⊗�به جای د⊗�; بنابراین، ما پیچیدگی زمانی را از نظر بهروزرسانی و حفظ دیپ(دی،افمن). پیچیدگی زمانی اضافه کردن یک شی داده دآ است �(متر|دیپ(دآ،افمن)||دآ⊗افمن|+متر|دیپ(دآ،افمن)|ورود به سیستم|دیپ(دی،افمن)|)، که m تعداد مجموعه داده های ویژگی است. به طور خاص، مجموعه غالب دآ برای هر مجموعه داده ویژگی m که دارای پیچیدگی زمانی �(|دیپ(دآ،افمن)||دآ⊗افمن|). سپس، مجموعه غالب دیپ(دی،افمن)به روز شده است که دارای پیچیدگی زمانی �(|دیپ(دآ،افمن)|ورود به سیستم|دیپ(دی،افمن)|). پیچیدگی زمانی حذف یک شی داده دد است متر|دیپ(دآ،افمن)|ورود به سیستم|دیپ(دی،افمن)|. بنابراین، پیچیدگی زمانی بهروزرسانی یک شی داده دتو است �(متر|دیپ(دتو،افمن)||دتو⊗افمن|+متر|دیپ(دتو،افمن)|ورود به سیستم|دیپ(دی،افمن)|)زیرا در حال به روز رسانی یک شی داده دتومی توان با حذف شی داده ها دتوبه دنبال آن درج.
پیچیدگی زمانی افزودن یک شیء ویژگی �آ است �|دیپ(دی،افمن)|. این به این دلیل است که برای هر جفت د⊗�د�مترمن�آ�تی∈دیپ(دی،افمن)), بررسی تسلط برای بررسی اینکه آیا د⊗�آغالب د⊗�د�مترمن�آ�تییا اینکه د⊗�آتحت سلطه د⊗�د�مترمن�آ�تی. سپس، پیچیدگی زمانی حذف یک شی ویژگی �د. اجازه دهید د⊗افمندمجموعه د⊗�جفت هایی که به طور انحصاری تحت تسلط د⊗�د∈دیپ(دی،افمن)). برای هر شی داده د∈دی, منطقه تسلط انحصاری برای د⊗�دمشخص می شود که پیچیدگی زمانی �(|دیپ(د،افمن)|). سپس، مجموعه غالب برای جفت هایی که به طور انحصاری تحت تسلط د⊗�دمشخص می شود که پیچیدگی زمانی O(|دیپ(د،افمند)||د⊗افمند|). بنابراین، پیچیدگی زمانی حذف یک شی ویژگی �د است �(|دی||دیپ(د،افمن)|+|دیپ(د،افمند)||د⊗افمند|+|دیپ(د،افمند)|ورود به سیستم|دیپ(دی،افمن)|). در نهایت، پیچیدگی زمانی بهروزرسانی یک شی ویژگی �تو است �(|دی||دیپ(د،افمن)|+|دیپ(د،افمنتو)||د⊗افمنتو|+|دیپ(د،افمنتو)|ورود به سیستم|دیپ(دی،افمن)|)زیرا بهروزرسانی (یعنی بهروزرسانی مکان یا امتیاز) یک شی ویژگی �تورا می توان به عنوان یک حذف و به دنبال آن درج در نظر گرفت.
6. ارزیابی عملکرد
در این بخش، ارزیابی عملکرد الگوریتم پیشنهادی TOPS خود را بر اساس آزمایشهای شبیهسازی توصیف میکنیم. در بخش 6.1 ، تنظیمات آزمایشی خود را شرح می دهیم. بخش 6.2 نتایج تجربی را برای زمان پردازش پرس و جو ارائه می کند. بخش 6.3 ارزیابی عملکرد هزینه های تحقق و نگهداری را مطالعه می کند. در نهایت، در بخش 6.4 ، مقایسه عملکرد TOPS و آلپ+.
6.1. تنظیمات آزمایشی
همه آزمایشهای ما با استفاده از یک شبکه جاده واقعی [ 30 ] انجام میشوند که شامل جادههای اصلی آمریکای شمالی، با 175812 گره و 179178 یال است. با توجه به انجمن هتلها و اقامتگاههای آمریکا [ 31 ]، در پایان سال 2014، 53432 هتل در ایالات متحده وجود داشت که با دادههای موجود در این مطالعه مطابقت دارد. همه الگوریتمها در جاوا پیادهسازی شدند و بر روی یک رایانه رومیزی با پردازنده Pentium 2.8 گیگاهرتز و حافظه 4 گیگابایتی اجرا شدند. مجموعه داده ها توسط R-trees با اندازه صفحه 4 کیلوبایت نمایه شدند. نتایج ما شامل مقادیر متوسط به دست آمده از 20 آزمایش است. در تمام آزمایشها، کل زمان پردازش پرس و جو را با توجه به پارامترهای مختلف اندازهگیری کردیم، همانطور که در جدول 5 نشان داده شده است.. در هر آزمایش، ما فقط یک پارامتر را تغییر دادیم در حالی که بقیه در مقادیر پیشفرض پررنگ ثابت ماندند.
ما دو نسخه TOPS را پیاده سازی و ارزیابی می کنیم: برترین ها��و برترین هامن�. برترین ها��اشیاء ویژگی را گروه بندی می کند و سپس مجموعه افق را تولید و ذخیره می کند اسک�(دی⊗جیمن)، در حالی که، برترین هامن�اشیاء ویژگی را گروه بندی نمی کند، اما در عوض مجموعه افق را برای هر جفت شی داده و ویژگی تولید و ذخیره می کند اسک�(دی⊗افمن). ما هر دو نسخه TOPS را با رویکرد Period مقایسه میکنیم، که امتیاز را برای هر شی داده با استفاده از الگوریتمهای گسترش شبکه افزایشی (INE) و گسترش شبکه محدوده (RNE) [32] برای محاسبه امتیازهای نزدیکترین همسایه و محدوده محاسبه میکند . الگوریتم INE با استفاده از الگوریتم Dijkstra، k نزدیکترین همسایه را در شبکه های جاده ای پیدا می کند [ 33 ]. الگوریتم RNE مشابه الگوریتم INE است، با این تفاوت که شبکه را در فاصله r از یک نقطه پرس و جو کاوش می کند. ما کمی الگوریتم RNE را تغییر دادیم تا نمرات تأثیر اشیاء داده را محاسبه کنیم. روش Period از هیچ طرح تحقق استفاده نمی کند.
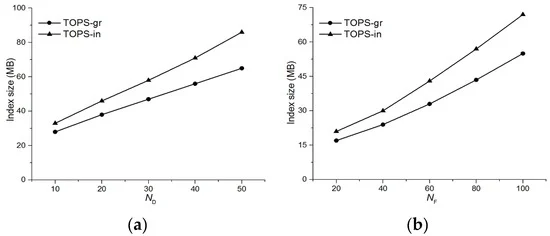
6.2. نتایج تجربی برای زمان پردازش پرس و جو
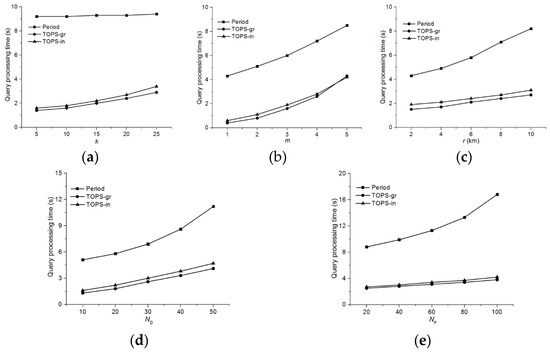
شکل 10 زمان های پردازش پرس و جو را برای برترین ها��, برترین هامن�و روش Period برای شرایط محدوده. شکل 10 a زمان پردازش پرس و جو را به عنوان تابعی از تعداد k اشیاء داده درخواستی با بالاترین امتیاز نشان می دهد. زمان پردازش پرس و جو از روش period یک زمان پردازش پرس و جو را بدون توجه به مقدار k متحمل می شود زیرا تمام اشیاء ویژگی را در محدوده query r شی داده بررسی می کند. با این حال، زمان پردازش پرس و جو برترین ها��و برترین هامن�با مقدار k کمی افزایش می یابد . با این وجود، برترین ها��و برترین هامن�عملکرد بهتر از الگوریتم دوره شکل 10 ب زمان پردازش پرس و جو را به عنوان تابعی از تعداد m مجموعه داده های ویژگی نشان می دهد. زمان پردازش پرس و جو همه الگوریتم ها با مقدار m افزایش می یابد ، اما زمان پردازش پرس و جو روش دوره با مقدار m سریعتر از برترین ها��و برترین هامن�. دلیل اصلی آن برترین ها��و برترین هامن�از مجموعههای خط افق تحقق یافته استفاده کنید، در نتیجه هزینههای سربار محاسباتی را کاهش داده و کارایی عملکرد را افزایش دهید.
شکل 10 ج مقایسه زمان پردازش پرس و جو دوره، برترین ها��و برترین هامن�با مقادیر مختلف r. نتایج تجربی نشان میدهد که زمان محاسبات تحت همه الگوریتمها با افزایش دامنه r افزایش مییابد . این عمدتا به این دلیل است که فضای جستجو به نسبت r افزایش می یابد . شکل 10 d، e عملکرد دوره، برترین ها��و برترین هامن�با مقادیر مختلف N D و N F به ترتیب، که نشان می دهد زمان پردازش پرس و جو Period با مقدار N D و N F افزایش می یابد زیرا روش Period تمام اشیاء ویژگی را در محدوده پرس و جو هر شی داده بررسی می کند. برترین ها��و برترین هامن�روندهای مشابهی را نشان دادند زیرا هر دو الگوریتم جفت ها را به ترتیب در مجموعه های خط آسمان به ترتیب نزولی بر اساس امتیاز دامنه بررسی می کنند. با این حال، برترین ها��مقیاس بهتر از برترین هامن�به دلیل گروه بندی، که به جفت های کمتری اجازه می دهد تا بررسی کنند. لازم به ذکر است که مطابق شکل 10 e، افزایش N F تأثیر کمی بر عملکرد برترین ها��و برترین هامن�زیرا هر دو برترین ها��و برترین هامن�جفتهایی را که غالب هستند تحقق میبخشد ، و بنابراین تعداد جفتها بهطور قابلتوجهی با افزایش NF تحت تأثیر قرار نمیگیرد .
شکل 11 زمان پردازش پرس و جو را برای برترین ها��، برترین هامن�و روش Period برای شرایط نزدیکترین همسایه. شکل 11 a اثر مقادیر مختلف k را بر زمان پردازش پرس و جو توسط همه الگوریتم ها نشان می دهد، که نشان می دهد هر دو برترین ها��و برترین هامن�به وضوح از روش Period بهتر عمل می کند، اگرچه زمان پردازش پرس و جو Period بدون توجه به مقدار k پایدار است . این عمدتاً به این دلیل است که روش Period گسترش شبکه را تا زمانی که نزدیکترین شی ویژگی برای هر شی داده پیدا شود ادامه می دهد. شکل 11b زمان پردازش پرس و جو را به عنوان تابعی از مقدار m نشان می دهد . زمان پردازش پرس و جو برای همه روش های دارای مقدار m به سرعت افزایش می یابد . با این حال، برترین ها��و برترین هامن�در همه موارد بهتر از Period عمل می کند. شکل 11 ج تأثیر تعداد اشیاء داده را بر زمان پردازش پرس و جو دوره، برترین ها��و برترین هامن�. توجه داشته باشید که هر سه الگوریتم نسبت به تعداد اشیاء داده حساس هستند، اما برترین ها��عملکرد قابل توجهی از دوره دارد، در حالی که برترین هامن�قابل مقایسه با برترین ها��. شکل 11 د زمان پردازش پرس و جو دوره، برترین ها��و برترین هامن�با مقادیر مختلف N F ، که نشان می دهد که هر دو برترین ها��و برترین هامن�مقیاس بهتر از دوره
شکل 12 زمان های پردازش پرس و جو را برای برترین ها��،برترین هامن�و روش Period برای شرایط نفوذ. شکل 12 a زمان پردازش پرس و جو را به عنوان تابعی از مقدار k نشان می دهد . مطابق شکل 11 الف، برترین ها��و برترین هامن�بدون در نظر گرفتن مقدار k به وضوح از Period بهتر عمل می کند . همانطور که در شکل 12 ب نشان داده شده است، ما تعداد مجموعه ویژگی های m را تغییر دادیم و نتایج تجربی نشان می دهد که زمان پردازش پرس و جو برای هر سه روش با افزایش مقدار m افزایش می یابد . برترین ها��به وضوح عملکرد بهتری دارد برترین هامن�در هر مورد. شکل 12 c تأثیر r را بر زمان پردازش پرس و جو نشان می دهد. توجه داشته باشید که زمان پردازش پرس و جو هر سه الگوریتم به افزایش محدوده r حساس است ، زیرا فضای جستجو افزایش یافته است. در شکل 12 d,e، اثرات روی زمان پردازش پرس و جو را به ترتیب با تغییر N D و N F نشان می دهیم که نشان می دهد برترین ها��و برترین هامن�همیشه سریعتر از Period هستند، صرف نظر از مقادیر N D و N F زیرا هر دو الگوریتم از مجموعه های خط افق مادی شده استفاده می کنند.
6.3. نتایج تجربی برای تحقق و هزینههای نگهداری افزایشی
در این بخش، ما فقط مقایسه عملکرد تی�پاس��و تی�پاسمن�زیرا در روش پایه از هیچ طرح مادیت سازی و نگهداری افزایشی استفاده نمی شود. شکل 13 زمان ساخت شاخص را برای برترین ها��و برترین هامن�برای کاردینالیته های مختلف داده ها و اشیاء ویژگی. زمان ساخت شاخص هر دو روش با مقادیر ندیو ناف. این عمدتا به این دلیل است که تعداد جفت هایی که باید نمایه شوند با ندیو ناف. اما به دلیل تکنیک گروه بندی برترین ها��برای همه موارد بهتر عمل می کند.
در شکل 14 ، ما تأثیر تعداد اشیاء داده و اشیاء ویژگی را بر اندازه شاخص برترین ها��و برترین هامن�.همانطور که در شکل 14 a,b نشان داده شده است، اندازه شاخص به ترتیب با افزایش تعداد داده ها و اشیاء ویژگی افزایش یافت. با این حال، برترین ها��در مقایسه با برترین هامن�به دلیل تکنیک گروه بندی که تعداد جفت ها را برای نمایه سازی کاهش می دهد.
شکل 15 مقایسه میانگین زمان های سپری شده برای درج یک شی داده و حذف یک شیء ویژگی را نشان می دهد. به منظور اندازه گیری این زمان ها، هم درج اشیاء داده و هم حذف اشیاء ویژگی 500 بار انجام شده است که در طی آن تمام پارامترهای دیگر ثابت می مانند. همانطور که در شکل 15 نشان داده شده است ، زمان نگهداری برای برترین ها��کمی بیشتر از برترین هامن�زیرا همانطور که در بخش 5 ذکر شد ، ابتدا دیپ(دی،افمن)به روز می شود و سپس اسک�(دی⊗جیمن)بر این اساس به روز می شود. نتایج تجربی در شکل 15 نشان می دهد که زمان درج برای یک شی داده به طور قابل توجهی تحت تأثیر تعداد اشیاء داده قرار نمی گیرد. این به این دلیل است که عامل اصلی برای زمان درج، تولید یک جفت غالب از اشیاء داده جدید است که بدون توجه به تعداد اشیاء داده یکسان هستند. تنها عاملی که باعث افزایش جزئی در زمان درج می شود، به روز رسانی مجموعه غالب تحقق یافته است که با مقدار ندی. شکل 15 ب نشان می دهد که حذف اشیاء ویژگی گران تر از درج اشیاء داده است و میانگین زمان حذف یک شی ویژگی به تعداد اشیاء ویژگی حساس است. این عمدتاً به این دلیل است که تعداد جفتهایی که منحصراً تحت سلطه جفتهای شیء ویژگی حذف شده هستند با ناف. بنابراین، مجموعه های تسلط برای جفت های جدید بیشتر تعیین می شود که منجر به افزایش زمان می شود.
6.4. مقایسه TOPS و ALPS +
در این بخش، مقایسه عملکرد TOPS و ALPS + را ارائه می دهیم . توجه داشته باشید که در این قسمت TOPS gr به عنوان TOPS معرفی شده است. همانطور که قبلاً گفته شد ALPS در اصل برای پردازش پرس و جوهای ترجیحی در شبکه های جاده ای بدون جهت طراحی شده است. برای مقایسه منصفانه، ما ALPS را برای پردازش پرسوجوهای اولویت مکانی بالا در شبکههای جادهای هدایتشده که ALPS + مینامیم، اصلاح کردیم . به طور خاص، ما دو تغییر عمده را انجام می دهیم. اولاً، فرض میکنیم که فقط اشیاء دادهای که در لبههای مجاور دو طرفه قرار دارند میتوانند با هم گروهبندی شوند تا یک بخش داده ایجاد کنند، و ثانیاً، تکنیک محاسبه فاصله بین بخشهای داده و اشیاء ویژگی را اصلاح کردیم.
شکل 16 عملکرد زمان های پردازش پرس و جو TOPS و آلپ+برای شرایط محدوده شکل 16 اثر k بر زمان پردازش پرس و جو TOPS و آلپ+در حالی که شکل 16 ب تأثیر r را بر عملکرد هر دو الگوریتم نشان می دهد. نتایج تجربی نشان می دهد که زمان پردازش پرس و جو هر دو روش با مقدار k و r افزایش می یابد. با این حال، TOPS به وضوح عملکرد بهتری از آلپ+در هر مورد چون تعداد داده ها و اشیاء ویژگی در آلپ+بالاتر از TOPS است. دلیل اصلی این است که آلپ+ابتدا اشیاء داده را گروه بندی می کند سپس جفت ها را بر اساس رابطه غالب که ممکن است شامل جفت های اضافی باشد، هرس می کند. در حالی که، روش پیشنهادی ما ابتدا جفت های غالب را هرس می کند و سپس آنها را برای حذف هر جفت اضافی گروه بندی می کند.
7. نتیجه گیری
در این مقاله، ما پرس و جوهای اولویت فضایی بالا را در شبکه های جاده هدایت شده مورد مطالعه قرار دادیم . ما یک رویکرد جدید به نام TOPS را برای بهبود عملکرد جستجوهای ترجیحی فضایی بالا در شبکههای جادهای هدایتشده پیشنهاد کردیم . رویکرد ما بر اساس هرس و گروه بندی اشیاء ویژگی است، در نتیجه تعداد زیر مجموعه های جفت مورد نیاز برای رتبه بندی اشیاء داده را به حداقل می رساند. جفتهای خط آسمان که توسط جفتهای دیگر تسلط ندارند، بر روی فضای امتیاز فاصله نگاشت میشوند و سپس یک مجموعه خط افق تولید و در یک درخت R نمایه میشود. برای رسیدن به این هدف، فرمولهای ریاضی را برای تعیین حداقل و حداکثر فاصله بین یک شی داده و یک گروه ویژگی ارائه کردیم. علاوه بر این، ما یک الگوریتم کارآمد برای پردازش بالا پیشنهاد کردیم. k پیشنهاد کردیمجستارهای ترجیحی فضایی در حالی که اطمینان حاصل می شود اطلاعات تحقق یافته به روز می شوند.
برای ارزیابی تجربی، ما دو نسخه از TOPS را اجرا کردیم: برترین ها��و برترین هامن�و آنها را با رویکرد دوره مقایسه کرد. به طور دقیق، برترین ها��از داده های تحقق یافته و جفت گروه ویژگی استفاده می کند در حالی که برترین هامن�از داده های تحقق یافته و مجموعه اشیاء ویژگی استفاده می کند. بر اساس یافته های تجربی ما، هر دو برترین ها��و برترین هامن�عملکرد قابل توجهی از رویکرد Period از نظر زمان پردازش پرس و جو برای پارامترهای مختلف بهتر است. با این حال، هر دو برترین ها��و برترین هامن�از نظر زمان پردازش پرس و جو قابل مقایسه هستند. اما تی�پاس��از نظر هزینه های تحقق برتری دارد.
منابع
- بائو، جی. چاو، سی. موکبل، م. Ku, W. ارزیابی کارآمد پرسشهای نزدیکترین همسایه در محدوده k در شبکههای جادهای. در مجموعه مقالات یازدهمین کنفرانس بین المللی مدیریت داده های تلفن همراه (MDM)، کانزاس سیتی، MO، ایالات متحده آمریکا، 23-26 مه 2010; صص 115-124.
- چو، اچ.-جی. ریو، K.-Y. چانگ، T.-S. یک الگوریتم کارآمد برای محاسبه نقاط خروج ایمن پرس و جوهای محدوده متحرک در شبکه های جاده هدایت شده. Inf. سیستم 2014 ، 41 ، 1-19. [ Google Scholar ] [ CrossRef ]
- چیما، م. لین، ایکس. ژانگ، ی. ژانگ، دبلیو. Li، X. جستارهای معکوس پیوسته k نزدیکترین همسایگان در فضای اقلیدسی و در شبکه های فضایی. VLDB J. 2012 ، 21 ، 69-95. [ Google Scholar ] [ CrossRef ]
- آتیک، م. هایلو، ی. گودتا، اس. چو، اچ.-جی. چانگ، T.-S. یک رویکرد خروج ایمن برای نظارت مستمر k نزدیکترین همسایگان معکوس در شبکه های جاده ای بین المللی عرب J. Inf. تکنولوژی 2015 ، 12 ، 540-549. [ Google Scholar ]
- وانگ، اچ. Zimmermann, R. پردازش پرس و جوهای محدوده مبتنی بر مکان پیوسته بر روی اجسام متحرک در شبکه های جاده ای. IEEE Trans. بدانید. مهندسی داده 2011 ، 23 ، 1065-1078. [ Google Scholar ] [ CrossRef ]
- الیاس، آی. بسکالس، جی. Soliman, M. بررسی تکنیک های پردازش پرس و جو Top-k در سیستم های پایگاه داده رابطه ای. کامپیوتر ACM. Surv. 2008 , 40 . [ Google Scholar ] [ CrossRef ]
- مامولیس، ن. ییو، م. چنگ، ک. Cheung، D. کارآمد Top-k تجمع ورودی های رتبه بندی شده. ACM Trans. سیستم پایگاه داده 2007 ، 32 . [ Google Scholar ] [ CrossRef ]
- ییو، م. لو، اچ. مامولیس، ن. Vaitis، M. رتبه بندی داده های مکانی بر اساس اولویت های کیفیت. IEEE Trans. بدانید. مهندسی داده 2011 ، 23 ، 433-446. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ییو، م. دای، ایکس. مامولیس، ن. Vaitis، M. جستجوهای ترجیحی فضایی Top-k. در مجموعه مقالات بیست و سومین کنفرانس بین المللی IEEE در مهندسی داده (ICDE 2007)، استانبول، ترکیه، 15-20 آوریل 2007.
- روشا جونیور، جی. ولاچو، ع. دولکریدیس، سی. Nørvag، K. پردازش کارآمد پرس و جوهای ترجیحی فضایی top-k. PVLDB 2010 ، 4 ، 93-104. [ Google Scholar ] [ CrossRef ]
- چو، اچ.-جی. کوون، اس.-جی. چانگ، T.-S. ALPS: یک الگوریتم کارآمد برای جستجوی اولویت مکانی top-k در شبکه های جاده ای. بدانید. Inf. سیستم 2015 ، 42 ، 599-631. [ Google Scholar ] [ CrossRef ]
- آتیک، م. قمر، ر. چو، اچ.-جی. چانگ، T.-S. رویکردی جدید برای پردازش پرسوجوهای ترجیحی فضایی بالا در یک شبکه جادهای هدایتشده. در مجموعه مقالات سومین کارگاه بین المللی ACM SIGSPATIAL در سیستم های اطلاعات جغرافیایی سیار، دالاس، تگزاس، ایالات متحده آمریکا، 4 تا 7 نوامبر 2014.
- کلاهدوزان، م. شهابی، سی. ورونوی مبتنی بر k نزدیکترین همسایه جستجو برای پایگاه داده شبکه فضایی. در مجموعه مقالات سی امین کنفرانس بین المللی در مورد پایگاه های داده بسیار بزرگ، تورنتو، ON، کانادا، 31 اوت تا 3 سپتامبر 2004.
- آهنگ، ز. Roussopoulos, N. k -نزدیکترین همسایه جستجو برای نقطه جستجوی متحرک. در مجموعه مقالات هفتمین سمپوزیوم بین المللی پیشرفت در پایگاه های داده مکانی و زمانی، ردوندو بیچ، کالیفرنیا، ایالات متحده آمریکا، 12 تا 15 ژوئیه 2001.
- سان، ی. یو، ایکس. بی، آر. آهنگ، H. کشف کوتاهترین مسیر وابسته به زمان در نمودار ترافیک برای رانندگان به سمت رانندگی سبز. J. Netw. محاسبه کنید. Appl. 2016 ، در دست چاپ. [ Google Scholar ] [ CrossRef ]
- لین، کیو. ژانگ، ی. ژانگ، دبلیو. Lin, X. محاسبه افق فضایی عمومی کارآمد. وب جهانی 2013 ، 16 ، 247-270. [ Google Scholar ] [ CrossRef ]
- تره فرنگی.؛ ژنگ، بی. چن، سی. Chow, C. رویکردهای مبتنی بر شاخص کارآمد برای پرس و جوهای خط افق در برنامه های کاربردی مبتنی بر مکان. IEEE Trans. بدانید. مهندسی داده 2013 ، 25 ، 2507-2520. [ Google Scholar ] [ CrossRef ]
- لیو، دبلیو. جینگ، ی. چن، ک. Sun، W. ترکیب پرس و جو top-k در شبکه های جاده ای. در مدیریت اطلاعات عصر وب ; Springer: برلین، آلمان، 2012; صص 63-75. [ Google Scholar ]
- دنگ، ک. ژو، ایکس. شن، اچ. پردازش پرس و جو خط افق چند منبعی در شبکههای جادهای. در مجموعه مقالات بیست و سومین کنفرانس بین المللی مهندسی داده IEEE، استانبول، ترکیه، 15 تا 20 آوریل 2007.
- چن، جی. هوانگ، جی. جیانگ، بی. پی، جی. یین، جی. توصیه هایی برای انتخاب دو طرفه با استفاده از نمایش داده های نمای افق. بدانید. Inf. سیستم 2013 ، 34 ، 397-424. [ Google Scholar ] [ CrossRef ]
- وانگ، ی. وی، دبلیو. دنگ، س. لیو، دبلیو. Song, H. یک پرس و جو خط افق انرژی کارآمد برای داده های حسی بسیار چند بعدی. Sensors 2016 , 16 . [ Google Scholar ] [ CrossRef ] [ PubMed ]
- چیما، م. لین، ایکس. ژانگ، دبلیو. Zhang، Y. یک رویکرد مبتنی بر منطقه امن برای نظارت بر پرس و جوهای متحرک خط افق. در مجموعه مقالات شانزدهمین کنفرانس بین المللی گسترش فناوری پایگاه داده، جنوا، ایتالیا، 18 تا 22 مارس 2013. ص 275-286.
- شیا، تی. ژانگ، دی. کانولاس، ای. Du, Y. در محاسبات تاپ ترین سایت های فضایی تاثیرگذار. در مجموعه مقالات سی و یکمین کنفرانس بین المللی پایگاه های داده بسیار بزرگ، تروندهایم، نروژ، 30 اوت تا 2 سپتامبر 2005.
- دو، ی. ژانگ، دی. Xia, T. جستجوی مکان بهینه. در پیشرفت در پایگاه داده های مکانی و زمانی ; Springer: برلین، آلمان، 2005; صص 163-180. [ Google Scholar ]
- ژانگ، دی. دو، ی. شیا، تی. تائو، ی. محاسبات پیش رونده پرس و جوی مکان بهینه فاصله کوچک. در مجموعه مقالات سی و دومین کنفرانس بین المللی پایگاه های داده بسیار بزرگ، سئول، کره، 12 تا 15 سپتامبر 2006.
- موراتیدیس، ک. لین، ی. Yiu, M. پرس و جوهای ترجیحی در شبکه های حمل و نقل چند هزینه ای بزرگ. در مجموعه مقالات بیست و ششمین کنفرانس بین المللی مهندسی داده IEEE 2010 (ICDE 2010)، لانگ بیچ، کالیفرنیا، ایالات متحده آمریکا، 1 تا 6 مارس 2010.
- لین، پی. یین، ی. Nie, P. K-پرس و جوی چند اولویتی بر روی شبکه های جاده ای. پارس محاسبات همه جا حاضر. 2016 ، 20 ، 413-429. [ Google Scholar ] [ CrossRef ]
- هارتمن، الف. انتقال فاز و ویژگیهای خوشهبندی مسائل بهینهسازی . سخنرانی ارائه شده در مدرسه فیزیک DPG: Bad Honnef، آلمان، 2012. [ Google Scholar ]
- گاتمن، A. R-Trees: ساختار شاخص پویا برای جستجوی فضایی. در مجموعه مقالات کنفرانس بین المللی ACM SIGMOD 1984 در مورد مدیریت داده ها، بوستون، MA، ایالات متحده آمریکا، 18-21 ژوئن 1984.
- مجموعه داده های واقعی برای پایگاه های داده فضایی. در دسترس آنلاین: http://www.cs.fsu.edu/~lifeifei/SpatialDataset.htm (در 13 اکتبر 2014 قابل دسترسی است).
- انجمن هتل ها و اقامتگاه های آمریکا در دسترس آنلاین: http://www.ahla.com/ (در 4 اوت 2015 قابل دسترسی است).
- پاپادیاس، دی. ژانگ، جی. مامولیس، ن. Tao, Y. پردازش پرس و جو در پایگاه های داده شبکه فضایی. در مجموعه مقالات بیست و نهمین کنفرانس بین المللی پایگاه های داده بسیار بزرگ، برلین، آلمان، 9 تا 12 سپتامبر 2003. ص 802-813.
- Dijkstra, E. یادداشتی در مورد دو مشکل در ارتباط با نمودارها. عدد. ریاضی. 1959 ، 1 ، 269-271. [ Google Scholar ] [ CrossRef ]
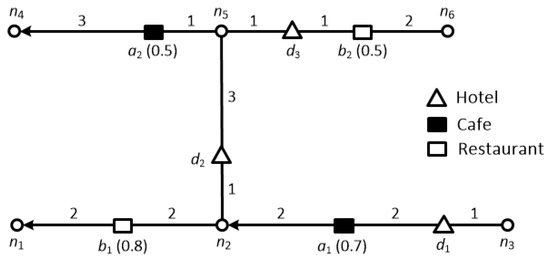
شکل 1. نمونه ای از پرس و جوهای اولویت مکانی top- k در یک شبکه راه هدایت شده.
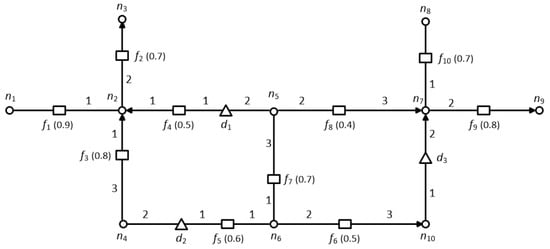
شکل 2. نمونه هرس و گروه بندی.
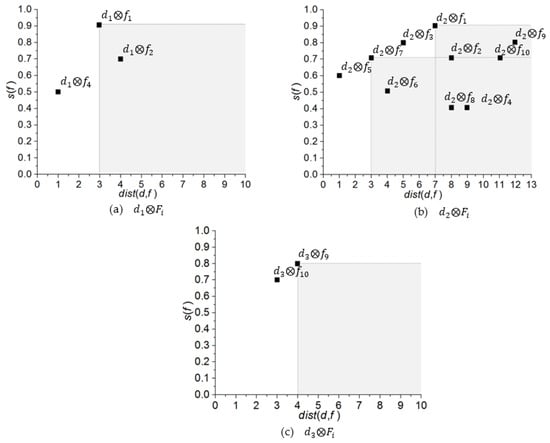
شکل 3. نقشه برداری دی⊗افمنبه فضای امتیاز فاصله. ( الف ) د1⊗افمن; ( ب ) د2⊗افمن; ( ج ) د3⊗افمن.

شکل 4. تعیین مترآایکسدمنستی(د،��→)وقتی د∈��→.
شکل 5. تعیین مترآایکسدمنستی(د،��→)وقتی د∉��→.
شکل 6. نقشه برداری دی⊗جیمنبه فضای امتیاز فاصله. ( الف ) د1⊗جیمن; ( ب ) د2⊗جیمن; ( ج ) د3⊗جیمن; ( د ) اسک�(دی⊗جیمن).

شکل 7. نقشه برداری دی⊗جیمنبه فضای امتیاز فاصله. ( الف ) اسک�(دی⊗جیمن); ( ب ) نمایش درخت R برای اسک�(دی⊗جیمن).
شکل 8. مثال های ( الف ) شبکه جاده های بدون جهت. ( ب ) شبکه راه هدایت شده.

شکل 9. نمونه ای از ALPS در شبکه راه های هدایت شده.

شکل 10. مقایسه زمان پردازش پرس و جو برای �=���. ( الف ) اثر k ; ( ب ) اثر m ; ( ج ) اثر r ; ( د ) اثر ندی; ( ه ) اثر ناف.

شکل 11. مقایسه زمان پردازش پرس و جو برای �=��. ( الف ) اثر k ; ( ب ) اثر m ; ( ج ) اثر ندی; ( د ) اثر ناف.
شکل 12. مقایسه زمان پردازش پرس و جو برای �=من��. ( الف ) اثر k ; ( ب ) اثر m ; ( ج ) اثر r ; ( د ) اثر ندی; ( ه ) اثر ناف.

شکل 13. زمان ساخت شاخص. ( الف ) اثر ندی; ( ب ) اثر ناف.

شکل 14. اندازه شاخص. ( الف ) اثر ندی; ( ب ) اثر ناف.
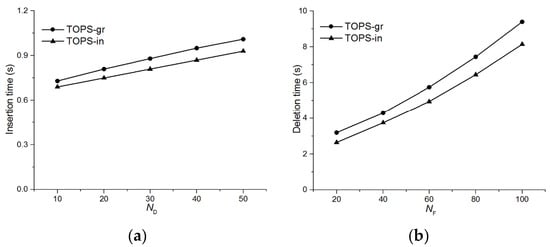
شکل 15. هزینه نگهداری افزایشی. ( الف ) اثر ندیدر زمان درج شی داده. ( ب ) اثر نافدر زمان حذف شیء ویژگی
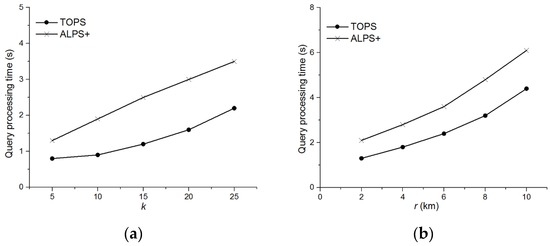
شکل 16. مقایسه TOPS و آ�پاس+برای �=���.( الف ) اثر k بر زمان پردازش پرس و جو. ( ب ) اثر r بر زمان پردازش پرس و جو.

جدول 1. خلاصه نمادهای مورد استفاده در این مطالعه.
جدول 2. محاسبه امتیازات اشیاء داده d 1 , d 2 , و d 3 .
جدول 3. خلاصه گروه بندی اشیاء ویژگی.
جدول 4. خلاصه د⊗�در شکل 2 .
جدول 5. تنظیمات پارامترهای آزمایشی.
© 2016 توسط نویسندگان؛ دارنده مجوز MDPI، بازل، سوئیس. این مقاله یک مقاله با دسترسی آزاد است که تحت شرایط و ضوابط مجوز Creative Commons Attribution (CC-BY) (http://creativecommons.org/licenses/by/4.0/) توزیع شده است.
بدون نظر